Время на прочтение
19 мин
Количество просмотров 26K
В этих статьях я попыталась собрать опыт своих ошибок и находок, связанных с малозаметными ловушками в исследованиях. Обычно при обучении исследованиям много внимания уделяется выбору методологии, технике сбора данных и статистической обработке, но почти никто не говорит об организационных нюансах, которые могут извратить результаты, или полностью провалить исследование. Многие из них при прочтении покажутся вам очевидными, но для того, чтобы их подметить и начать учитывать в собственном исследовании, иногда требуются годы. Я провожу лично, преподаю и руковожу исследованиями уже больше 15 лет. Часто встречаясь с бизнес-исследованиями в ИТ-компаниях и видя их изнутри, я уверилась, что эти ловушки редко принимаются в расчет даже опытными исследователями.

А значит, материал будет полезен тем, кто проводит исследование пользователей (клиентов, сотрудников, учеников) с помощью анкетных опросов, кто делает это сам, или заказывает такие исследования. Для профессиональных исследователей эта статья будет представлять меньший интерес, чем для любителей.
Возможно ли исследовать потребности пользователей в опросах?
Иногда у компании возникает необходимость получить мнение пользователя о продукте (или мнение сотрудника о компании), узнать его потребности и скрытые возражения. Обычно выбирается простое решение. Составляется анкета с, казалось бы, логичными и простыми вопросами и рассылается пользователям. Вернувшуюся часть анкет математическими методами обрабатывают и принимают за репрезентативную выборку (отражающую взгляды типичных пользователей), анализируют с помощью статистики, визуализируют и готовят отчет для принятия решений и выработки стратегии. Часто ошибочный и бесполезный отчет.
Одна из самых коварных проблем таких исследований: потребности очень сложно исследовать, но почти всегда кажется, что исследование прошло удачно.
В этой и следующих статьях я расскажу про несколько типичных ошибок в исследовании потребностей пользователей и способах, которыми можно уменьшить их влияние на результаты исследования.
Ошибка 1. Смещение выборки, или кто все эти люди и почему они вам отвечают?
Все, кто когда-либо встречался с анкетными опросами, знают, что из розданных анкет возвращается только малая часть. Иногда – меньше 10%.
Способам уменьшить это зло посвящено много публикаций. В том числе, с советами по статистическому «подгону» выборки. Строго или не строго, но вернувшуюся часть анкет часто признают адеватной выборкой из генеральной совокупности (всей совокупности пользователей, мнения которых исследователь хочет изучить) и работают с тем, что есть. Иногда эта «выборочность» и вовсе незаметна – когда, например, приглашение к опросу рассылается безадресно, и откликнувшиеся пользователи считаются выборкой.
Пример. В крупной ИТ-компании (штатом в несколько тысяч) проводилось исследование удовлетворенности сотрудников работой HR-службы. Нас пригласили помочь только на этапе обработки результатов. До этого сотрудники подразделения сами составили анкету и сами запустили опрос, рассылая работникам приглашения по корпоративной почте. Они не позаботились о мотивации участников опроса и об «административном рычаге» (почти самой важной части любого организационного исследования) и просто рассчитывали на хороший отклик сотрудников. В итоге, анкеты вернулись с 15% отдачей. На анкеты отвечали, в основном, новые или совсем неопытные работники (они еще почти не сталкивались с деятельностью этого подразделения, но анкеты заполняли охотно и, как правило, выставляли завышенные баллы). Самая главная группа – руководители отделов – была представлена всего тремя (из нескольких десятков) самыми лояльными участниками. Возможность привлечь внимание к опросу была упущена, провести опрос повторно тоже было невозможно (организаторов обвинили бы в спаме). В итоге, они выбрали изящное решение – представили руководству результаты в процентном соотношении по каждой группе сотрудников, не указывая количество участников. В отчете получилось, что руководители отделов крайне удовлетворены работой подразделения. Срок жизни такого отчета – до того момента, пока руководитель не узнает, сколько человек из каждой группы реально принимали участие в опросе. Но такие вопросы задаются редко, и организационные исследования, на которые никто из сотрудников не обращает внимания, процветают.
Разберем 3 причины смещения выборки:
1) неправильный выбор канала поиска участников,
2) отзывчивость,
3) меркантильность.
1. Неправильный выбор канала поиска участников
Почти во всех учебниках по статистике вы найдете предостережение о смещении выборки, которое появляется, если вы опрашиваете, скажем, участников только одного Интернет-форума (при условии, что контингент пользователей значительно шире), или если вы проводите опрос сотрудников, находящихся в столовой в рабочее время, или опрашиваете самую доступную вам группу пользователей (например, пришедших на презентацию нового продукта): согласуются ли их мнения с мнениями остальных пользователей, или это все-таки специфическая группа? Эти предостережения – классические советы для исследователей, их наверняка многие учитывают.
Но я хочу обратить внимание на другие опасности смещения выборки – отзывчивость и меркантильность.
2. Отзывчивые враги исследователя
Ответьте честно: когда вы в последний раз были рады заполнению анкеты? Чаще всего, наверное, соглашались из солидарности, пытаясь помочь коллеге. Так вот, ваши ответы стоит исключить из выборки, как нерелевантные (вы отвечали на вопросы, как лояльный друг, или сочувствующий коллега, а не как «наивный» пользователь). В классических маркетинговых исследованиях принято после первичного анализа выборки исключать всех представителей смежных специальностей, в том числе, всех рекламщиков и маркетологов, так как их мнение считается профессионально деформированным. Кто тогда останется?
Кто все эти люди, отвечающие на наши опросы и находящие на них время? Кто в потоке около супермаркета подходит к социологу, кто открывает двери квартиры, или заполняет анкету в Интернет-опросе? Очевидно те, кого опрос волнует лично, или те, у кого полно времени, развит мотив помощи и общения и, возможно, недостаточно других интересных занятий.
Помните, в советском фильме «Самая обаятельная и привлекательная» главная героиня хочет выйти замуж с помощью подруги-социолога, специалиста по семейным отношениям. Вместе они пытаются исследовать потенциальных женихов героини и сталкиваются с их занятостью и нежеланием отвечать на вопросы. Но находится отзывчивый сотрудник, с удовольствием отвечающий на любые вопросы – совершенно не интересный невесте и исследователю респондент. Так и в жизни: в ситуации массового опроса, вероятно, мы можем не заметить, что за многочисленными ответами отзывчивых и нерелевантных пользователей мы не получили ни одного ответа от наших целевых клиентов.
В старом исследовании J.M. Darley, C. D. Batson, 1973 было показано, что даже ученики семинарии, встречая просьбы о помощи, оказывали ее значимо реже, если были заняты и спешили (например, готовились выступить на тему о добром самаритянине).

Источник: Хекхаузен Х. Мотивация и деятельность: В 2 т. Т. 2. М: Педагогика, 1986. С. 234-248 / Darley, J. M., and Batson, C.D., «From Jerusalem to Jericho»: A study of Situational and Dispositional Variables in Helping Behavior». JPSP, 1973, 27, 100-108.
А нужны нам ответы таких отзывчивых и незанятых людей? И будут ли их ответы отражать мнение типичных пользователей о нашем продукте? Они будут хвалить продукт, желая показаться хорошими, или, наоборот, критиковать его, желая привлечь к себе внимание?
Пример. Исследуя несколько лет назад лояльность сотрудников средней по размеру компании, мы обратили внимание на подозрительно позитивные, «монотонные», ответы нескольких ее сотрудников. Они первыми прислали полностью заполненные анкеты, высказывались о компании хорошо и полно, предлагали идеи и, в общем, представляли собой просто идеальных участников опроса. У нас это вызвало подозрения, которые мы смогли прояснить во время глубинных интервью. Оказалось, что сверх-отзывчивость к опросу проявили только продавцы, чувствовавшие свое шаткое положение перед приближающимся отчетным периодом. Они же и давали исключительно положительные отзывы о компании и руководстве (если бы мы взялись анализировать средние, эти отзывы существенно сместили бы общую картину результатов исследования). Один из продавцов и во время интервью расхваливал компанию и искренне признавался, что понимает, что задолжал ей, потому что не показывал результаты в течение года. Когда мы принесли отчет с предостережением для руководства, мы узнали, что «лояльный» сотрудник опередил нас, за день до этого подав заявление об увольнении.
Если портрет вашего пользователя «человек с большим количеством свободного времени, с развитой потребностью в помощи и общении», то да, можно смело использовать результаты таких опросов. Если ваш пользователь – человек занятой и рациональный, нужно дополнительно подумать, как привлечь его к исследованию. Чуть ниже я расскажу про свои находки для такого привлечения.
3. Меркантильные враги исследователя
Вторая проблема смещения выборки и получения ошибочных данных – это участие в опросах «искателей наживы».
Проблема внешней и внутренней мотивации участников опросов тоже обсуждается часто: стоит ли платить за труд, предлагать дополнительные награды и приятные бонусы клиентам, которые ответят на вопросы анкеты? В таких спорах есть четкая позиция: не вводите внешнюю мотивацию (деньги, бесплатный доступ, подарки, отгулы и др.) до тех пор, пока возможно работать с внутренней. И дело тут не в жадности. Внешняя мотивация почти всегда необратима, ее стоит считать последним отчаянным шагом.
Но смещение выборки среди реальных пользователей или потенциальных клиентов в сторону тех, кто заинтересован в оплате своего участия, – это еще малое зло. Большее зло, крайне актуальное сейчас на рынке исследований, – это когда с целью заработка люди выдают себя за ваших реальных или потенциальных клиентов, не являясь таковыми.
Сейчас многие сервисы on-line опросов предлагают услугу доступа к панели платных респондентов. Они привлекают и оплачивают труд участников исследования разными методами и остается догадываться, насколько щепетильно они относятся к таргетингу, и насколько такой удаленный таргетинг вообще выполним.

На рисунке: скриншот одного из сайтов, приглашающих активно участвовать в разных опросах.
Сомнения в чистоте таргетинга подкрепляются параллельно развивающейся волной активности со стороны участников таких опросов, размещающих советы о том, как заработать на онлайн-опросах и повысить вероятность получения приглашения (попадания в выборку). Например, советуют при заполнении анкеты написать, что у вас средний возраст, средний или выше среднего доход, вы состоите в браке, у вас есть водительские права, ребенок, вы являетесь постоянным потребителем определенных продуктов (о каких спросят в анкете – с такими и соглашайтесь) и не являетесь представителем определенной профессии (о какой спросят в анкете – ту и отрицайте). Все эти советы помогают сойти за типичного пользователя, попасть в исследование и получить деньги за участие. Представьте, какие люди зарабатывают на таких исследованиях, и какие ответы они будут давать на ваши вопросы.
На русскоязычных сайтах искателям наживы советуют выдавать себя за средних европейцев или американцев, а дальше – отвечать, как получится, даже без знания иностранного языка. Не нашими ли безработными соотечественниками и их случайными ответами определяются продуктовые стратегии западных брендов?
Мы можем игнорировать смещение выборки только в том редком случае, если для нас совершенно не важно, о каком пользователе идет речь, и нужны, например, какие-то его психофизические показатели, свойственные каждому нормально развивающемуся человеку без учета возраста и пола, или в том случае, если мы только начали тестирование продукта, и на этом этапе нам важны совершенно любые отзывы и идеи, независимо от портрета типичного пользователя. В последнем варианте имеет смысл только сбор «сырых данных» для подготовки более основательного опроса на релевантной выборке.
Как привлечь подходящих?

Чтобы не работать с «хорошей» выборкой неподходящих респондентов, мы время от времени используем такие психологические способы привлечения релевантной выборки.
Способ 1. Нужны деловые и рациональные? Мы находим для них смысл.
Чтобы человек выделил время на заполнение анкеты, ему нужно найти в этом смысл. В таких случаях мы формулируем «легенду», приглашение к исследованию так, чтобы занятой человек, не испытывающий желания нам помогать, проникся идеей важности опроса и согласился, что на него стоит потратить время.
1. Важно для него. Иногда характер исследования позволяет подобрать мотивирующие стимулы, которые касаются лично респондента.
Пример 1. Несколько лет назад нам нужно было апробировать большой психологический опросник. По нему запрещено было сообщать результаты, пока опросник не пройдет проверку. Чтобы привлечь людей, мы присоединили к нему два авторитетных психологических теста, служивших для валидизации опросника. Каждому участнику после опроса давалась подробная индивидуальная расшифровка по этим тестам, что было для них хорошим стимулом участвовать в исследовании. Некоторым региональным участникам мы приносили распечатанные результаты или даже присылали бумажные письма, потому что у них не было e-mail. Однажды на Новый год я даже получила от одной участницы открытку с поздравлением и благодарностью за результаты.
Пример 2. Мы разрабатывали методологию и автоматизировали внутреннюю ежегодную оценку персонала в одной из компаний наших клиентов. Перед тем, как предложить методологию оценки, мы провели краткий опрос и узнали у сотрудников, что больше всего в предыдущих оценках их расстраивало отсутствие обратной связи о результатах. Им сообщался общий рейтинг, или начислялись премии, но развернутый результат никто не предлагал. Автоматизация помогла нам сделать процесс предоставления обратной связи мгновенным, развернутым и направленным на развитие каждого сотрудника.
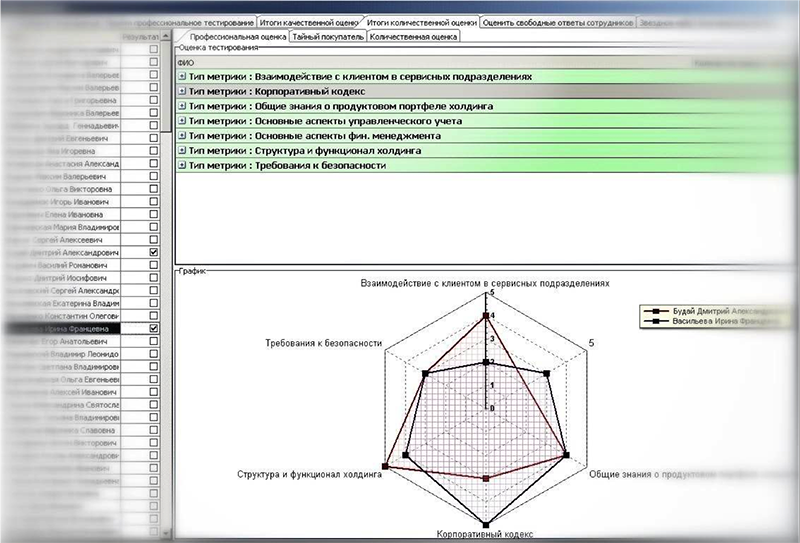
Во-первых, после ответа на вопросы анкеты о себе и о своих сотрудниках (один из этапов оценки по принципу 360 градусов) каждый участник мог посмотреть, как его оценили сотрудники и руководство (оценки были визуализированы в паутинковой диаграмме и представляли вполне наглядные результаты) – см. рисунок.
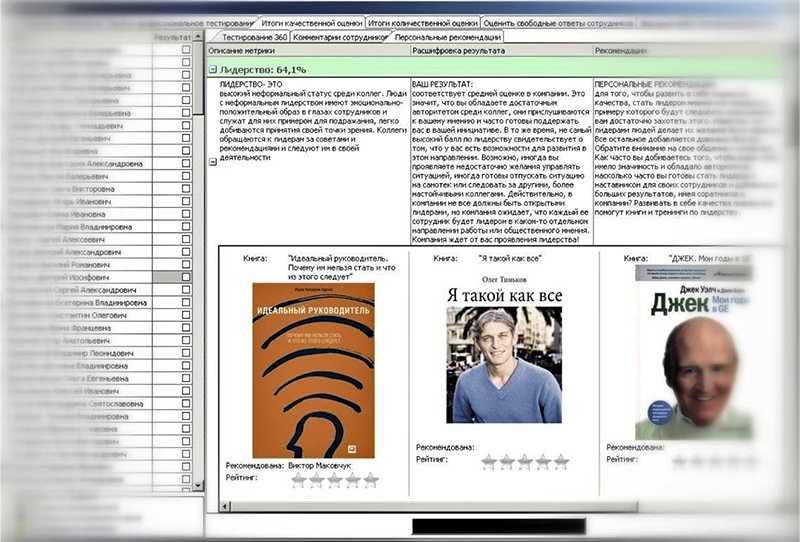
Во-вторых, после получения итоговых баллов оценки личностных качеств сотрудник мог просмотреть расшифровку качества, узнать, что значит именно его оценка, и прочитать личные рекомендации для развития компетенций – в зависимости от полученных баллов, ему предлагались советы по поведению с сотрудниками и руководством, или специальные тренинги и семинары (см. рисунок).
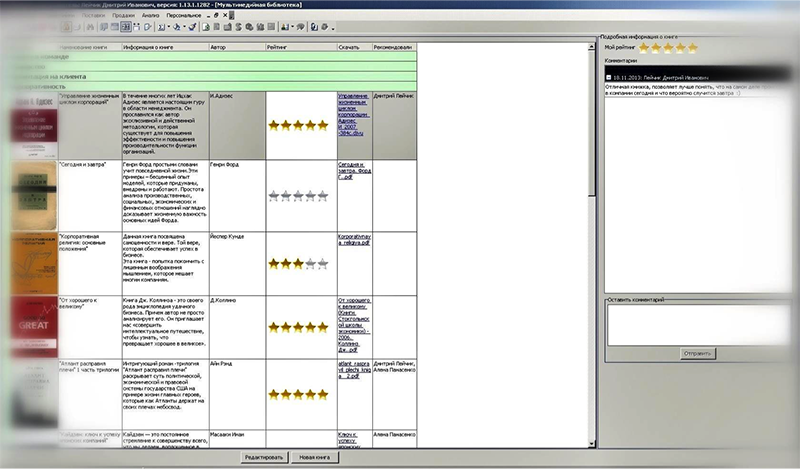
В-третьих, после прочтения рекомендаций участник мог посмотреть, какую литературу он может прочитать для развития тех качеств, которые у него были оценены недостаточно высоко. Ссылки на литературу вели в корпоративную on-line библиотеку, где сотрудники могли оценивать прочитанные книги и оставлять комментарии (см. рисунок).
Так нам удалось вовлечь сотрудников в процесс оценки, добиться быстрого заполнения on-line анкет и существенно расцветить формальный процесс оценки.
2. Важно для общества. Когда лично респондента заинтересовать не получается, мы рассказываем в приглашении, почему возникла необходимость исследования, что угрожает обществу (природе, культуре, науке и др.) и почему важно получить ответы именно такого человека, чтобы понять, как изменить ситуацию. Конечно, такие объяснения подходят только для глобальных исследований, или социально-значимых проектов.
3. Важно для вас. Пожалуй, самый слабый аргумент. Часто эгоизм исследователей вызывает раздражение. Но бывают и удачные примеры, когда исследователь объясняет свое затруднительное положение и вызывает сочувствие.
Пример 1: Я встречала похожие призывы. Обычно они срабатывают: «Я устроился на работу своей мечты. Но могу не пройти испытательный срок, если не проведу хорошее исследование клиентов. (Пишу дипломную работу / Стараюсь выиграть грант на обучение). Я очень стараюсь, чтобы исследование получилось качественным. Только никак не могу собрать нужное количество экспертов для участия в опросе. Пожалуйста, помогите мне получить работу мечты. Вам нужно ответить всего на пару вопросов, а мне это даст огромный шанс сделать что-то стоящее».
Пример 2: Однажды меня по-настоящему подкупил звонок из известной МЛМ-компании, распространяющей косметику. Девушка начала разговор такими словами: «Мы заметили, что в последнее время репутация нашей компании стала падать, и мы решили провести опрос общественного мнения, чтобы понять, что именно не нравится нашим клиентам. Не могли бы вы помочь нам и ответить на несколько вопросов, чтобы мы смогли улучшить свою репутацию и снова радовать клиентов?» Я прониклась их проблемой, готова была подробно ответить на ее вопросы. К сожалению, после этой вводной фразы девушка снова вернулась к обычным шагам телефонных продаж, и я быстро прекратила разговор.
Способ 2. Рассказываем, к чему это приведет.
Одно из самых неприятных переживаний для человека – переживание тщетности усилий. Вероятность заполнения анкет в наших исследованиях обычно повышается, если мы объясняем участникам, как будут использованы их ответы. Иногда мы честно рассказываем, что сейчас выбираем стратегию развития продукта, и будем основывать выбор на решении клиентов. Или сообщаем, что в результате исследования будет опубликован отчет с рекомендациями для всех производителей подобных товаров. Участники исследования имеют право знать, где будут использованы результаты их работы, чтобы решить, стоит ли принимать в этом участие.
Способ 3. Угадываем «внутренний» мотив.
Какие личностные мотивы клиентов могут повлиять на заполнение анкеты? Какую радость мы можем им принести?
Приведу неполный список потребностей, которые можно учитывать в приглашениях и благодарностях для участников опросов. Мы никогда не задействуем все варианты сразу. Тип опроса и особенности целевой аудитории задают и варианты привлечения респондентов. Некоторые ходы требуют от нас дополнительных усилий, но одни из них помогают привлечь участников, а другие помогают сделать их лояльными и возвратить, когда их мнение снова нам понадобится.
Потребность в развитии и самопознании – в этом случае мы гарантируем каждому участнику отчет с результатами исследования, или ссылку на его публикацию в прессе. Если у нас есть ресурсы и участники нам очень дороги, каждому из них мы составляем сравнительный отчет: как его ответы отличались от ответов большинства других участников опроса. Аппаратно организовать это не так сложно, но эффект получается хорошим.
Пример. Однажды такой ход помог нам привлечь к исследованию директоров государственных предприятий. Их желание узнать, как их мнение отличается от мнений других директоров в отрасли, стало единственным мотиватором для участия в нашем опросе. Мы получили богатую специализированную выборку, а затратили на это всего лишь дополнительный день работы недорогого ассистента и немного бумаги для отчета каждому участнику.
Потребность во власти – в этом варианте мы подчеркиваем, что ответы участника будут специально рассматриваться при принятии решения об изменении продукта, или политики компании. И обязательно обещаем выслать отчет о таких изменениях. Самое главное в таких обещаниях – потратить дополнительные усилия, чтобы выдержать их. Так мы повышаем лояльность к продукту и обеспечиваем себе участников для следующего исследования.
Потребность в принадлежности – в этом случае можно создать сообщество тестеров/ друзей / евангелистов продукта, сделать площадку для их общения, давать им привилегии в виде эксклюзивной информации, тестового доступа, тестирования новых функций. Здесь важно выбрать признак, по которому участника можно отнести в небольшую группу подобных ему пользователей: сообщить в приглашении, что этот человек был отобран в группу самых активных (или самых молодых, столичных, владеющих минивэнами, и т.д.) пользователей продукта.
Потребность в получении новых знаний (любопытство) – с этой потребностью работать просто, если в опросе принимают участие эксперты, или фанаты продукта. Опрос можно сделать развивающим, предложить уникальное тестирование новых функций продукта, сообщать в вопросах факты о продукте, или другие важные детали, скомбинировать итоговый отчет с тематической статьей, или пообещать выслать развернутый материал по этой теме, когда закончится исследование. Здесь важно избегать смещения выборки: статья, или обещание эксклюзивного материала привлечет только экспертов в этой области. Если вам нужны мнения неопытных пользователей, нужно обещать им что-то неспециализированное и развлекательное.
Потребность в восхищении (тщеславие) – эту потребность мы задействуем, когда исследуем ограниченное число экспертов. В таких случаях мы обещаем упоминание компании участника, или его имени (если это уместно) в публикации результатов отчета, включение в клуб евангелистов, или клуб рецензентов, и др. Если участников много, мы можем потратить время на именные благодарственные письма каждому из них через несколько дней после исследования, в которых еще раз подчеркиваем, как важно было именно его участие в исследовании.
Потребность оказывать помощь – довольно сильный мотиватор, его можно применять почти во всех опросах. Когда мы его используем, мы подчеркиваем сложное положение, в котором оказались разработчики, рассказываем подробнее о затруднениях (увеличилось число отказов, пользователи недовольны продуктом, но мы не можем понять, что их не устраивает, или не знаем, как сделать лучше, и потому очень нуждаемся в совете). Здесь важно не стесняться показаться в слабой позиции. Иногда компании выдумывают затруднения, чтобы вовлечь в бесплатную работу сочувствующих пользователей. Участникам исследования приятнее чувствовать себя экспертами, чем подопытными, поэтому позиция “просящего о помощи” не ослабит вас, но привлечет более мотивированных участников.
Способ 4. Придумываем нематериальный «внешний» мотив.
Предоставление скидки, эксклюзивных условий использования продукта для пользователей, часа отгула для сотрудников, и т.д. – все еще рискованные стимулы, они могут сместить интерес от заполнения анкеты на получение награды. Нематериальной наградой станет подарок в виде ссылки на интересное видео, анекдот в конце анкеты, неожиданный сувенир.
Если нужно привлечь экспертов для получения профессиональной обратной связи, в таких случаях часто используют предоставление уникального доступа к новой версии продукта, авторы книг и приложений рассылают их бесплатные версии для тестирования и рецензий. Проводятся целые кампании по привлечению ранних тестировщиков продукта. Все это служит еще и маркетинговым целям продвижения.
Способ 5. Стараемся не заигрывать с анонимностью.
Часто я слышу жалобы от сотрудников разных компаний на проводимые внутриорганизационные опросы: «Они заверяют, что опрос анонимный, но просят прислать ответы по e-mail и спрашивают мою должность, пол и возраст! Как только я это увидел, я отказался заполнять их лживый опросник».
Пример:

Источник: pikabu

Часто эта «ложь» у организаторов исследования появляется не со зла, а от желания насытить данные, сегментировать участников и сделать исследование более детальным. Так что, лучше не обещать анонимность, если респондентов можно вычислить по ответам.
В таких случаях мы либо используем максимально защищенные способы сбора ответов (конвертные исследования, анонимный опрос по ссылке), либо обещаем только такую защиту данных, которую можем выполнить сами.
Пример: Наша компания недавно стала партнером в проведении исследования лучших работодателей в Беларуси. Наш партнер, известный Интернет-ресурс о работе в ИТ, проводит это исследование среди ИТ-компаний уже несколько лет. Они выбрали такой вариант обеспечения анонимности: в исследуемую компанию приезжают сотрудницы с коробкой конвертов. Внешне конверты одинаковые, но внутри каждого находится уникальная ссылка на on-line анкету. Конверты раздаются участникам рандомно, имена участников не фиксируются и не сопоставляются с определенными конвертами. Так удается снять тревогу участников по поводу соотнесения ответов с определенным сотрудником. Уникальные ссылки на опрос нужны для того, чтобы защитить исследование от искусственных накруток со стороны руководителей компании-участника и снять подозрения сотрудников на этот счет. Конечно, остается проблема возврата анкет (здесь можно вернуться к вопросу об отзывчивости) и проблема узкого таргетирования, за которым особенно тревожные сотрудники могут заподозрить попытки их вычислить (эта проблема увеличивается по мере уменьшения размера компании, где вычислить сотрудника по полу, возрасту и должности становится просто, и для ее снижения авторы анкеты избегают слишком точных вопросов о возрасте и должности сотрудника).

На фото: коробка с анонимными конвертами для участников исследования.
Когда добиться анонимности совсем сложно, можно гарантировать сохранение данных и доступ к ним только исследовательской команды.
Пример формулировки в приглашении: «Мы гарантируем, что ваши ответы будут анализироваться совокупно с ответами остальных участников исследования, не будут рассматриваться отдельно, разглашаться или передаваться третьим лицам, не участвующим в проведении данного исследования».
Способ 6. По возможности снимаем тревогу по поводу времени.
Анкета становится более привлекательной, если она маленькая, а в введении сразу видна информация о количестве вопросов и ожидаемом времени заполнения. Если присмотреться к анкете придирчиво и переформулировать вопросы, обычно можно сократить ее в 2 раза. И еще треть вопросов – почти всю «паспортичку» – заполнить самостоятельно (если исследование не анонимное, и вы знаете данные об участнике), или дать сразу подготовленную анкету (разделить бланки / ссылки для женщин и мужчин, разных возрастных и статусных групп, и т.д.). Все это уменьшит возражения респондентов против участия в опросе.
1. Обещаем простоту сразу во введении.
Пример: «Анкета содержит 10 простых вопросов, и ее заполнение не займет у вас больше 5 минут».
2. Если вопросы требуют перехода, и участник не видит сразу, где кончается анкета, мы показываем прогресс выполнения – это увеличивает вероятность заполнения анкеты до конца.
Пример: «Вопрос 1 из 19, Вопрос 2 из 19 и т.д.», если анкета моделируется в зависимости от предыдущих ответов, пишите в заглавии вопросов: «Часть 1 из 4, Часть 2 из 4».
3. Маленькая хитрость. Если участник уже заполнил большую часть анкеты, ему жалко потерянного времени, и он, скорее всего, пройдет анкету до конца. Поэтому, в начале анкеты мы обычно помещаем легкие вопросы, которые могут максимально завлечь участника (это вопросы о самом участнике, его вкусах, но не личные вопросы и не сложные сравнения, которые могут сразу отпугнуть).
Способ 7. Устанавливаем временные границы.
Заполнение анкеты люди часто относят «на потом» и вовсе забывают. Мы считаем удачей, если получается сразу вовлечь участников в заполнение анкеты. Это хорошо проходит в организационных исследованиях, когда есть возможность пригласить участников в отдельную комнату для исследования в рабочее время, или когда руководитель выделяет сотрудникам время для заполнения анкеты.
В on-line опросах быстрого заполнения анкеты удается добиться, когда это импульсивное участие в кратком опросе. В других случаях мы дополнительно ограничиваем время и просим прислать заполненную анкету, например, до 22:00 этого дня, или до пятницы, и т.д. Иногда, если участники достаточно лояльны, ближе к истечению срока мы присылаем напоминания.
Способ 8. Развлекаем и удерживаем внимание.
Если анкета все-таки получилась большой (больше 10 вопросов), можно добавить к некоторым вопросам картинки, видео или забавные факты. Мы стараемся чередовать сложные и простые вопросы, убираем по возможности таблицы, сравнения, сложные списки, вопросы с ранжированием: их очень любят исследователи и очень не любят респонденты.
Когда у нас есть больше ресурсов, мы стараемся сделать опрос игровым и максимально визуальным. Это уже отдельная тема геймификации опросов, здесь я приведу только пару примеров из своего опыта.
Пример 1: Сейчас мы заканчиваем проект по внедрению on-line обратной связи для крупной торговой компании. Клиентов обычно очень сложно мотивировать на предоставление обратной связи, особенно, если дело касается быстрой купли-продажи. Для вовлечения клиентов в такой опрос и удержания их лояльности, мы с помощью профессионального иллюстратора визуализировали каждое правило обслуживания клиентов в положительном и негативном ключе. Получился красочный, местами шутливый, комикс с примерами хорошего и плохого обслуживания и приглашением поставить галочку по 6-балльной шкале по каждому пункту. От картинки к картинке в комиксе начинают узнаваться персонажи, поневоле клиент начинает за ними следить, у него усиливается любопытство и ожидание следующей картинки. Это вовлекает участников и страхует нас от не до конца заполненных анкет. Кроме того, для компании это – дополнительная возможность напомнить о своих стандартах обслуживания и показать заботу о клиенте.
Официальный релиз проекта состоится уже совсем скоро, поэтому, я смогу показать примеры и рассказать о результатах внедрения только в следующих статьях.
Пример 2: В компании с автоматизированной оценкой персонала, о которой я писала выше, вопрос первичного вовлечения участников мы также решили за счет визуализации. При опросе сотрудников о том, что они хотели бы поменять в оценке, мы услышали такие мнения: «Вот в Одноклассниках мне интересно ставить оценки, там я сразу вижу, кого оцениваю». Шутка шуткой, а мы решили использовать набиравший тогда силу интерес к Одноклассникам у более взрослых сотрудников компании для вовлечения их в нашу on-line оценку. При оценивании каждого сотрудника перед участником в системе появлялась карточка с его фотографией, возможностью дать быструю, или развернутую оценку, и написать личное пожелание. Эти пожелания никак не учитывались при подведении результатов оценки, но служили для вовлечения сотрудников за счет создания дополнительного канала коммуникации.
Итак, в этой статье я рассказала, какие методы мы применяем в исследованиях, чтобы вовлечь максимально релевантных участников, и не допустить смещения выборки.
Подытожу эту часть в виде краткой памятки по составлению анкеты:
1. Определите портрет целевого респондента и подумайте, что может привлечь такого человека к участию в опросе.
2. В приглашении к исследованию, вводной и заключительной части анкеты сделайте участникам предложение, значимое для их личностных потребностей (потребности во власти, любопытстве, самопознании, принадлежности, помощи, восхищении).
3. Не используйте внешнюю мотивацию на участие в опросе, если можно использовать внутреннюю.
4. Обещайте только тот уровень анонимности, который можете обеспечить.
5. Сократите анкету, насколько это возможно. Оставьте участникам на заполнение только те поля, которые вы не можете заполнить за них.
6. Старайтесь не включать в анкету сложные задания и сравнения. Расскажите участникам про простоту анкеты во введении.
7. Задайте четкие временные рамки.
8. Продумайте развлечение для участников во время и после заполнения анкеты.
В следующих частях:
2 ошибка: формулировка анкеты. 13 случаев непонимания и манипуляций в опросе (1 часть)
2 ошибка: формулировка анкеты. 13 случаев непонимания и манипуляций в опросе (2 часть)
Ошибка 3. Виды лжи в опросах: почему вы верите ответам?
Ошибка 4. Мнение не равно поведению: вы действительно спрашиваете о том, что хотите узнать?
Ошибка 5. Виды опросов: вам нужно узнать, или подтвердить?
Ошибка 6. Разделяйте и насыщайте выборку: среднее ничего не помогает понять.
Ошибка 7. Пресловутый «Net Promouter Score» – это НЕ изящное решение.
From Wikipedia, the free encyclopedia
In statistics, sampling bias is a bias in which a sample is collected in such a way that some members of the intended population have a lower or higher sampling probability than others. It results in a biased sample[1] of a population (or non-human factors) in which all individuals, or instances, were not equally likely to have been selected.[2] If this is not accounted for, results can be erroneously attributed to the phenomenon under study rather than to the method of sampling.
Medical sources sometimes refer to sampling bias as ascertainment bias.[3][4] Ascertainment bias has basically the same definition,[5][6] but is still sometimes classified as a separate type of bias.[5]
Distinction from selection bias[edit]
Sampling bias is usually classified as a subtype of selection bias,[7] sometimes specifically termed sample selection bias,[8][9][10] but some classify it as a separate type of bias.[11]
A distinction, albeit not universally accepted, of sampling bias is that it undermines the external validity of a test (the ability of its results to be generalized to the entire population), while selection bias mainly addresses internal validity for differences or similarities found in the sample at hand. In this sense, errors occurring in the process of gathering the sample or cohort cause sampling bias, while errors in any process thereafter cause selection bias.
However, selection bias and sampling bias are often used synonymously.[12]
Types[edit]
- Selection from a specific real area. For example, a survey of high school students to measure teenage use of illegal drugs will be a biased sample because it does not include home-schooled students or dropouts. A sample is also biased if certain members are underrepresented or overrepresented relative to others in the population. For example, a «man on the street» interview which selects people who walk by a certain location is going to have an overrepresentation of healthy individuals who are more likely to be out of the home than individuals with a chronic illness. This may be an extreme form of biased sampling, because certain members of the population are totally excluded from the sample (that is, they have zero probability of being selected).
- Self-selection bias (see also Non-response bias), which is possible whenever the group of people being studied has any form of control over whether to participate (as current standards of human-subject research ethics require for many real-time and some longitudinal forms of study). Participants’ decision to participate may be correlated with traits that affect the study, making the participants a non-representative sample. For example, people who have strong opinions or substantial knowledge may be more willing to spend time answering a survey than those who do not. Another example is online and phone-in polls, which are biased samples because the respondents are self-selected. Those individuals who are highly motivated to respond, typically individuals who have strong opinions, are overrepresented, and individuals that are indifferent or apathetic are less likely to respond. This often leads to a polarization of responses with extreme perspectives being given a disproportionate weight in the summary. As a result, these types of polls are regarded as unscientific.
- Exclusion bias results from exclusion of particular groups from the sample, e.g. exclusion of subjects who have recently migrated into the study area (this may occur when newcomers are not available in a register used to identify the source population). Excluding subjects who move out of the study area during follow-up is rather equivalent of dropout or nonresponse, a selection bias in that it rather affects the internal validity of the study.
- Healthy user bias, when the study population is likely healthier than the general population. For example, someone in poor health is unlikely to have a job as manual laborer, so if a study is conducted on manual laborers, the health of the general population will likely be overestimated.
- Berkson’s fallacy, when the study population is selected from a hospital and so is less healthy than the general population. This can result in a spurious negative correlation between diseases: a hospital patient without diabetes is more likely to have another given disease such as cholecystitis, since they must have had some reason to enter the hospital in the first place.
- Overmatching, matching for an apparent confounder that actually is a result of the exposure[clarification needed]. The control group becomes more similar to the cases in regard to exposure than does the general population.
- Survivorship bias, in which only «surviving» subjects are selected, ignoring those that fell out of view. For example, using the record of current companies as an indicator of business climate or economy ignores the businesses that failed and no longer exist.
- Malmquist bias, an effect in observational astronomy which leads to the preferential detection of intrinsically bright objects.
Symptom-based sampling[edit]
The study of medical conditions begins with anecdotal reports. By their nature, such reports only include those referred for diagnosis and treatment. A child who can’t function in school is more likely to be diagnosed with dyslexia than a child who struggles but passes. A child examined for one condition is more likely to be tested for and diagnosed with other conditions, skewing comorbidity statistics. As certain diagnoses become associated with behavior problems or intellectual disability, parents try to prevent their children from being stigmatized with those diagnoses, introducing further bias. Studies carefully selected from whole populations are showing that many conditions are much more common and usually much milder than formerly believed.
Truncate selection in pedigree studies[edit]
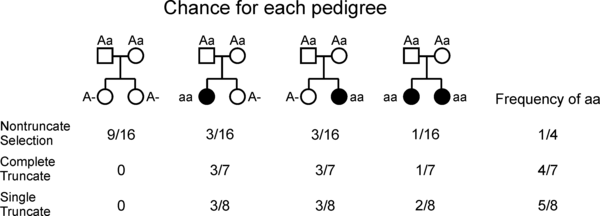
Geneticists are limited in how they can obtain data from human populations. As an example, consider a human characteristic. We are interested in deciding if the characteristic is inherited as a simple Mendelian trait. Following the laws of Mendelian inheritance, if the parents in a family do not have the characteristic, but carry the allele for it, they are carriers (e.g. a non-expressive heterozygote). In this case their children will each have a 25% chance of showing the characteristic. The problem arises because we can’t tell which families have both parents as carriers (heterozygous) unless they have a child who exhibits the characteristic. The description follows the textbook by Sutton.[13]
The figure shows the pedigrees of all the possible families with two children when the parents are carriers (Aa).
- Nontruncate selection. In a perfect world we should be able to discover all such families with a gene including those who are simply carriers. In this situation the analysis would be free from ascertainment bias and the pedigrees would be under «nontruncate selection» In practice, most studies identify, and include, families in a study based upon them having affected individuals.
- Truncate selection. When afflicted individuals have an equal chance of being included in a study this is called truncate selection, signifying the inadvertent exclusion (truncation) of families who are carriers for a gene. Because selection is performed on the individual level, families with two or more affected children would have a higher probability of becoming included in the study.
- Complete truncate selection is a special case where each family with an affected child has an equal chance of being selected for the study.
The probabilities of each of the families being selected is given in the figure, with the sample frequency of affected children also given. In this simple case, the researcher will look for a frequency of 4⁄7 or 5⁄8 for the characteristic, depending on the type of truncate selection used.
The caveman effect[edit]
An example of selection bias is called the «caveman effect». Much of our understanding of prehistoric peoples comes from caves, such as cave paintings made nearly 40,000 years ago. If there had been contemporary paintings on trees, animal skins or hillsides, they would have been washed away long ago. Similarly, evidence of fire pits, middens, burial sites, etc. are most likely to remain intact to the modern era in caves. Prehistoric people are associated with caves because that is where the data still exists, not necessarily because most of them lived in caves for most of their lives.[14]
Problems due to sampling bias[edit]
Sampling bias is problematic because it is possible that a statistic computed of the sample is systematically erroneous. Sampling bias can lead to a systematic over- or under-estimation of the corresponding parameter in the population. Sampling bias occurs in practice as it is practically impossible to ensure perfect randomness in sampling. If the degree of misrepresentation is small, then the sample can be treated as a reasonable approximation to a random sample. Also, if the sample does not differ markedly in the quantity being measured, then a biased sample can still be a reasonable estimate.
The word bias has a strong negative connotation. Indeed, biases sometimes come from deliberate intent to mislead or other scientific fraud. In statistical usage, bias merely represents a mathematical property, no matter if it is deliberate or unconscious or due to imperfections in the instruments used for observation. While some individuals might deliberately use a biased sample to produce misleading results, more often, a biased sample is just a reflection of the difficulty in obtaining a truly representative sample, or ignorance of the bias in their process of measurement or analysis. An example of how ignorance of a bias can exist is in the widespread use of a ratio (a.k.a. fold change) as a measure of difference in biology. Because it is easier to achieve a large ratio with two small numbers with a given difference, and relatively more difficult to achieve a large ratio with two large numbers with a larger difference, large significant differences may be missed when comparing relatively large numeric measurements. Some have called this a ‘demarcation bias’ because the use of a ratio (division) instead of a difference (subtraction) removes the results of the analysis from science into pseudoscience (See Demarcation Problem).
Some samples use a biased statistical design which nevertheless allows the estimation of parameters. The U.S. National Center for Health Statistics, for example, deliberately oversamples from minority populations in many of its nationwide surveys in order to gain sufficient precision for estimates within these groups.[15] These surveys require the use of sample weights (see later on) to produce proper estimates across all ethnic groups. Provided that certain conditions are met (chiefly that the weights are calculated and used correctly) these samples permit accurate estimation of population parameters.
Historical examples[edit]
A classic example of a biased sample and the misleading results it produced occurred in 1936. In the early days of opinion polling, the American Literary Digest magazine collected over two million postal surveys and predicted that the Republican candidate in the U.S. presidential election, Alf Landon, would beat the incumbent president, Franklin Roosevelt, by a large margin. The result was the exact opposite. The Literary Digest survey represented a sample collected from readers of the magazine, supplemented by records of registered automobile owners and telephone users. This sample included an over-representation of wealthy individuals, who, as a group, were more likely to vote for the Republican candidate. In contrast, a poll of only 50 thousand citizens selected by George Gallup’s organization successfully predicted the result, leading to the popularity of the Gallup poll.
Another classic example occurred in the 1948 presidential election. On election night, the Chicago Tribune printed the headline DEWEY DEFEATS TRUMAN, which turned out to be mistaken. In the morning the grinning president-elect, Harry S. Truman, was photographed holding a newspaper bearing this headline. The reason the Tribune was mistaken is that their editor trusted the results of a phone survey. Survey research was then in its infancy, and few academics realized that a sample of telephone users was not representative of the general population. Telephones were not yet widespread, and those who had them tended to be prosperous and have stable addresses. (In many cities, the Bell System telephone directory contained the same names as the Social Register). In addition, the Gallup poll that the Tribune based its headline on was over two weeks old at the time of the printing.[17]
In air quality data, pollutants (such as carbon monoxide, nitrogen monoxide, nitrogen dioxide, or ozone) frequently show high correlations, as they stem from the same chemical process(es). These correlations depend on space (i.e., location) and time (i.e., period). Therefore, a pollutant distribution is not necessarily representative for every location and every period. If a low-cost measurement instrument is calibrated with field data in a multivariate manner, more precisely by collocation next to a reference instrument, the relationships between the different compounds are incorporated into the calibration model. By relocation of the measurement instrument, erroneous results can be produced.[18]
A twenty-first century example is the COVID-19 pandemic, where variations in sampling bias in COVID-19 testing have been shown to account for wide variations in both case fatality rates and the age distribution of cases across countries.[19][20]
Statistical corrections for a biased sample[edit]
If entire segments of the population are excluded from a sample, then there are no adjustments that can produce estimates that are representative of the entire population. But if some groups are underrepresented and the degree of underrepresentation can be quantified, then sample weights can correct the bias. However, the success of the correction is limited to the selection model chosen. If certain variables are missing the methods used to correct the bias could be inaccurate.[21]
For example, a hypothetical population might include 10 million men and 10 million women. Suppose that a biased sample of 100 patients included 20 men and 80 women. A researcher could correct for this imbalance by attaching a weight of 2.5 for each male and 0.625 for each female. This would adjust any estimates to achieve the same expected value as a sample that included exactly 50 men and 50 women, unless men and women differed in their likelihood of taking part in the survey.[citation needed]
See also[edit]
- Censored regression model
- Cherry picking (fallacy)
- File drawer problem
- Friendship paradox
- Reporting bias
- Sampling probability
- Selection bias
- Common source bias
- Spectrum bias
- Truncated regression model
References[edit]
- ^ «Sampling Bias». Medical Dictionary. Archived from the original on 10 March 2016. Retrieved 23 September 2009.
- ^ «Biased sample». TheFreeDictionary. Retrieved 23 September 2009.
Mosby’s Medical Dictionary, 8th edition
- ^ Weising K (2005). DNA fingerprinting in plants: principles, methods, and applications. London: Taylor & Francis Group. p. 180. ISBN 978-0-8493-1488-9.
- ^ Ramírez i Soriano A (29 November 2008). Selection and linkage desequilibrium tests under complex demographies and ascertainment bias (PDF) (Ph.D. thesis). Universitat Pompeu Fabra. p. 34.
- ^ a b Panacek EA (May 2009). «Error and Bias in Clinical Research» (PDF). SAEM Annual Meeting. New Orleans, LA: Society for Academic Emergency Medicine. Archived from the original (PDF) on 17 August 2016. Retrieved 14 November 2009.
- ^ «Ascertainment Bias». Medilexicon Medical Dictionary. Archived from the original on 6 August 2016. Retrieved 14 November 2009.
- ^ «Selection Bias». Dictionary of Cancer Terms. Archived from the original on 9 June 2009. Retrieved 23 September 2009.
- ^ Ards S, Chung C, Myers SL (February 1998). «The effects of sample selection bias on racial differences in child abuse reporting». Child Abuse & Neglect. 22 (2): 103–15. doi:10.1016/S0145-2134(97)00131-2. PMID 9504213.
- ^ Cortes C, Mohri M, Riley M, Rostamizadeh A (2008). «Sample Selection Bias Correction Theory» (PDF). Algorithmic Learning Theory. Lecture Notes in Computer Science. 5254: 38–53. arXiv:0805.2775. CiteSeerX 10.1.1.144.4478. doi:10.1007/978-3-540-87987-9_8. ISBN 978-3-540-87986-2. S2CID 842488.
- ^ Cortes C, Mohri M (2014). «Domain adaptation and sample bias correction theory and algorithm for regression» (PDF). Theoretical Computer Science. 519: 103–126. CiteSeerX 10.1.1.367.6899. doi:10.1016/j.tcs.2013.09.027.
- ^ Fadem B (2009). Behavioral Science. Lippincott Williams & Wilkins. p. 262. ISBN 978-0-7817-8257-9.
- ^ Wallace R (2007). Maxcy-Rosenau-Last Public Health and Preventive Medicine (15th ed.). McGraw Hill Professional. p. 21. ISBN 978-0-07-159318-2.
- ^ Sutton HE (1988). An Introduction to Human Genetics (4th ed.). Harcourt Brace Jovanovich. ISBN 978-0-15-540099-3.
- ^ Berk RA (June 1983). «An Introduction to Sample Selection Bias in Sociological Data». American Sociological Review. 48 (3): 386–398. doi:10.2307/2095230. JSTOR 2095230.
- ^ «Minority Health». National Center for Health Statistics. 2007.
- ^ «Browser Statistics». Refsnes Data. June 2008. Retrieved 2008-07-05.
- ^ Lienhard JH. «Gallup Poll». The Engines of Our Ingenuity. Retrieved 29 September 2007.
- ^ Tancev G, Pascale C (October 2020). «The Relocation Problem of Field Calibrated Low-Cost Sensor Systems in Air Quality Monitoring: A Sampling Bias». Sensors. 20 (21): 6198. Bibcode:2020Senso..20.6198T. doi:10.3390/s20216198. PMC 7662848. PMID 33143233.
- ^ Ward D (20 April 2020). Sampling Bias: Explaining Wide Variations in COVID-19 Case Fatality Rates. Preprint (Report). Bern, Switzerland. doi:10.13140/RG.2.2.24953.62564/1.
- ^ Böttcher L, D’Orsogna MR, Chou T (May 2021). «Using excess deaths and testing statistics to determine COVID-19 mortalities». European Journal of Epidemiology. 36 (5): 545–558. doi:10.1007/s10654-021-00748-2.
- ^ Cuddeback G, Wilson E, Orme JG, Combs-Orme T (2004). «Detecting and Statistically Correcting Sample Selection Bias». Journal of Social Service Research. 30 (3): 19–33. doi:10.1300/J079v30n03_02. S2CID 11685550.
Независимо от используемой методологии или изучаемой дисциплины, исследователи должны убедиться, что они используют репрезентативные выборки, которые отражают характеристики изучаемого населения. В этой статье мы рассмотрим понятие предвзятости выборки, ее различные виды и способы применения, а также лучшие практики по смягчению ее последствий.
Что такое смещение выборки?
Предвзятость выборки относится к ситуации, когда определенные лица или группы населения с большей вероятностью будут включены в выборку, чем другие, что приводит к необъективной или нерепрезентативной выборке. Это может произойти по разным причинам, таким как неслучайные методы выборки, предвзятость самоотбора или предвзятость исследователя.
Другими словами, смещение выборки может подорвать достоверность и обобщаемость результатов исследования за счет перекоса выборки в пользу определенных характеристик или взглядов, которые могут быть нерепрезентативны для более широкой популяции.
В идеале вы должны выбрать всех участников опроса случайным образом. Однако на практике бывает трудно провести случайный отбор участников из-за таких ограничений, как стоимость и доступность респондентов. Даже если вы не проводите случайный сбор данных, очень важно знать о потенциальных погрешностях, которые могут присутствовать в ваших данных.
Некоторые примеры предвзятости выборки включают:
- Предвзятое отношение к добровольцам: Участники, добровольно согласившиеся принять участие в исследовании, могут иметь иные характеристики, чем те, кто не согласился, что приведет к нерепрезентативной выборке.
- Неслучайная выборка: Если исследователь отбирает участников только из определенных мест или только участников с определенными характеристиками, это может привести к необъективной выборке.
- Предвзятое отношение к выживаемости: Это происходит, когда в выборку попадают только те люди, которые выжили или преуспели в определенной ситуации, отбрасывая тех, кто не выжил или потерпел неудачу.
- Удобная выборка: Этот тип выборки предполагает отбор легкодоступных участников, например, тех, кто случайно оказался поблизости, или тех, кто ответил на онлайн-опрос, что может не представлять более широкую популяцию.
- Предвзятость подтверждения: Исследователи могут выбрать — бессознательно или преднамеренно — участников, которые поддерживают их гипотезу или вопрос исследования, что приведет к необъективным результатам.
- Хоторнский эффект: Участники могут изменить свое поведение или ответы, когда они знают, что их изучают или наблюдают, что приведет к нерепрезентативным результатам.
Если вы знаете об этих смещениях, вы можете учесть их в анализе, чтобы провести коррекцию смещения и лучше понять население, которое представляют ваши данные.
Виды смещения выборки
- Предвзятость отбора: возникает, когда выборка не является репрезентативной для населения.
- Ошибка измерения: возникает, когда собранные данные являются неточными или неполными.
- Предвзятость отчетности: возникает, когда респонденты предоставляют неточную или неполную информацию.
- Непредвзятость при ответе: происходит, когда некоторые члены населения не отвечают на опрос, что приводит к нерепрезентативной выборке.
Причины смещения выборки
- Удобная выборка: выборка, основанная на удобстве, а не на использовании научного метода.
- Предвзятость самоотбора: в опрос включены только те, кто добровольно согласился принять участие в опросе, что может быть нерепрезентативным для населения.
- Смещение выборочной совокупности: когда выборочная совокупность, используемая для отбора выборки, не является репрезентативной для населения.
- Предвзятое отношение к выживанию: когда в исследовании участвуют только определенные члены населения, что приводит к нерепрезентативной выборке. Например, если исследователи опрашивают только живых людей, они могут не получить данные от людей, умерших до проведения исследования.
- Предвзятость выборки из-за отсутствия знаний: неспособность признать источники изменчивости, которые могут привести к необъективным оценкам.
- Смещение выборки из-за ошибок в проведении выборки: неиспользование соответствующей или хорошо функционирующей рамки выборки или отказ от участия в исследовании, что приводит к необъективному отбору выборки.
Предвзятость выборки в клинических исследованиях
Клинические испытания проводятся с целью проверки эффективности нового лечения или лекарства на определенной популяции. Они являются важной частью процесса разработки лекарств и определяют, является ли лечение безопасным и эффективным до того, как оно будет представлено широкой публике. Однако клинические испытания также подвержены предвзятости отбора.
Предвзятость отбора возникает, когда выборка, используемая для исследования, не является репрезентативной для представляемого населения. В случае клинических исследований смещение отбора может произойти, когда участники либо избирательно выбираются для участия, либо проходят самоотбор.
Предположим, что фармацевтическая компания проводит клиническое исследование для проверки эффективности нового лекарства от рака. Они решили набрать участников исследования через объявления в больницах, клиниках и группах поддержки больных раком, а также через онлайн-заявки. Однако собранная ими выборка может оказаться предвзятой по отношению к тем, кто более мотивирован на участие в исследовании или имеет определенный тип рака. Это может затруднить обобщение результатов исследования на более широкую популяцию.
Для минимизации смещения отбора в клинических исследованиях исследователи должны применять строгие критерии включения и исключения и процессы случайного отбора. Это гарантирует, что выборка участников, отобранных для исследования, является репрезентативной для более широкой популяции, сводя к минимуму любую предвзятость в собранных данных.
Проблемы из-за смещения выборки
Смещение выборки является проблематичным, поскольку существует вероятность того, что статистика, вычисленная по выборке, систематически ошибочна. Это может привести к систематической завышенной или заниженной оценке соответствующего параметра в популяции. Это происходит на практике, так как практически невозможно обеспечить совершенную случайность выборки.
Если степень искажения мала, то выборку можно рассматривать как разумное приближение к случайной выборке. Кроме того, если выборка не сильно отличается по измеряемой величине, то смещенная выборка все равно может быть разумной оценкой.
Хотя некоторые люди могут намеренно использовать необъективную выборку, чтобы получить недостоверные результаты, чаще необъективная выборка является лишь отражением трудности получения действительно репрезентативной выборки или незнания необъективности в процессе измерения или анализа.
Экстраполяция: выход за пределы диапазона
В статистике вывод о чем-то, выходящем за пределы диапазона данных, называется экстраполяцией. Вывод на основе смещенной выборки является одной из форм экстраполяции: поскольку метод выборки систематически исключает определенные части рассматриваемого населения, выводы применимы только к выборочной подгруппе.
Экстраполяция также имеет место, если, например, вывод, основанный на выборке студентов старших курсов университета, применяется к пожилым людям или к людям с образованием всего восемь классов. Экстраполяция является распространенной ошибкой при применении или интерпретации статистических данных. Иногда, из-за сложности или невозможности получения хороших данных, экстраполяция — это лучшее, что мы можем сделать, но ее всегда нужно воспринимать как минимум с крупицей соли, а часто и с большой дозой неопределенности.
От науки к псевдонауке
Как указано в ВикипедииПримером того, как может существовать незнание о предвзятости, является широко распространенное использование отношения (также известного как fold change) в качестве меры различий в биологии. Поскольку легче добиться большого отношения двух малых чисел с заданной разницей и относительно труднее добиться большого отношения двух больших чисел с большей разницей, при сравнении относительно больших числовых измерений могут быть упущены значительные различия.
Некоторые называют это «смещением демаркации», поскольку использование соотношения (деления) вместо разницы (вычитания) превращает результаты анализа из науки в псевдонауку.
В некоторых выборках используется необъективный статистический дизайн, который, тем не менее, позволяет оценить параметры. Например, Национальный центр статистики здравоохранения США во многих своих общенациональных исследованиях намеренно завышает выборки для представителей меньшинств, чтобы добиться достаточной точности оценок внутри этих групп.
Эти исследования требуют использования весовых коэффициентов выборки для получения правильных оценок по всем этническим группам. При соблюдении определенных условий (главным образом, правильного расчета и использования весов) эти выборки позволяют точно оценить параметры населения.
Лучшие практики по снижению погрешности выборки
Очень важно выбрать подходящий метод выборки, чтобы полученные данные точно отражали исследуемую совокупность.
- Методы случайной выборки: Использование техники случайной выборки повышает вероятность того, что выборка является репрезентативной для населения. Эта техника помогает обеспечить максимальную репрезентативность выборки по отношению к рассматриваемому населению и, следовательно, меньшую вероятность наличия предвзятости.
- Расчет размера выборки: Расчет объема выборки должен быть выполнен таким образом, чтобы обеспечить достаточную мощность для проверки статистически значимых гипотез. Чем больше размер выборки, тем лучше представлено население.
- Анализ тенденций: Поиск альтернативных источников данных и анализ любых наблюдаемых тенденций в данных, которые могут быть невыбранными.
- Проверка на предвзятость: Необходимо отслеживать случаи предвзятости для выявления систематического исключения или чрезмерного включения конкретных точек данных.
Обратите внимание на образцы
Предвзятость выборки является важным моментом при проведении исследований. Независимо от используемой методологии или изучаемой дисциплины, исследователи должны убедиться, что они используют репрезентативные выборки, которые отражают характеристики изучаемого населения.
При создании научных исследований крайне важно уделять пристальное внимание процессу отбора выборки, а также методологии, используемой для сбора данных из выборки. Лучшие практики, такие как методы случайной выборки, расчет размера выборки, анализ тенденций и проверка на предвзятость, должны использоваться для обеспечения валидности и надежности результатов исследования, что повышает вероятность их влияния на политику и практику.
Привлекательные научные инфографики за считанные минуты
Mind the Graph это мощный онлайн-инструмент для ученых, которым необходимо создавать высококачественную научную графику и иллюстрации. Платформа удобна в использовании и доступна для ученых с разным уровнем технической подготовки, что делает ее идеальным решением для исследователей, которым необходимо создавать графику для своих публикаций, презентаций и других материалов для научного общения.
Если вы занимаетесь исследованиями в области наук о жизни, физических или инженерных наук, Mind the Graph предлагает широкий спектр ресурсов, которые помогут вам донести результаты ваших исследований в ясной и наглядной форме.

Подпишитесь на нашу рассылку
Эксклюзивный высококачественный контент об эффективных визуальных
коммуникация в науке.
— Эксклюзивный гид
— Советы по дизайну
— Научные новости и тенденции
— Учебники и шаблоны
Ошибку выборочного
наблюдения называют
ошибкой репрезентативности
(представительности).
Ошибкой
репрезентативности называют
расхождение между выборочной
характеристикой и предполагаемой
характеристикой генеральной совокупности.
Ошибка
репрезентативности может возникнуть
по двум причинам:
1) из-за нарушения
научных принципов отбора (систематическая
ошибка);
2) в результате
случайности отбора (случайная
ошибка).
1) Систематическая
ошибка (ошибка смещения)
возникает как результат смещения
выборки, поскольку при нарушении научных
принципов отбора при отборе каждой
единицы допускается ошибка, всегда
направленная в одну и ту же сторону.
Ее особенность
заключается в том, что, представляя
собой постоянную часть ошибки
репрезентативности, ошибка
смещения
увеличивается
вместе с увеличением объема выборки.
Ошибки смещения
делят на преднамеренные
и
непреднамеренные.
Преднамеренные
ошибки возникают при тенденциозном
подходе к выбору единиц из генеральной
совокупности, и устранить их можно
только путем проведения повторного
отбора с обязательным соблюдением
принципа случайности.
Непреднамеренные
ошибки могут
возникать на стадии подготовки выборочного
наблюдения, формирования выборочной
совокупности и анализа ее данных.
Устранить их можно на стадии подготовки
выборочного наблюдения.
2) Случайная
ошибка
возникает в результате случайных
различий между единицами, попавшими в
выборку и единицами генеральной
совокупности, т.е. связана со случайным
отбором.
Ее особенность
состоит в том, что случайная
ошибка уменьшается с увеличением объема
выборки и ее величину можно определить.
Определение
размера случайной ошибки выборки.
При определении
размера случайной ошибки выборки
различают:
а) среднюю
(стандартную) ошибку выборки
– расхождение между средней выборочной
и генеральной совокупностей, которое
не превышает величины среднего
квадратического отклонения [(![]() )<
)<![]() ];
];
б) предельная
ошибка выборки
– максимально возможное расхождение
между средней выборочной и генеральной
совокупностей при заданной вероятности
ее появления.
На основании
теоремы, доказанной П.Л. Чебышевым,
величину стандартной ошибки
собственно-случайной выборки можно
определить по формуле:
![]() ,
,
(1.1)
где
![]()
— дисперсия выборочной совокупности;
n —
объем выборочной совокупности.
Предельная ошибка
выборки определяется по следующей
формуле:
![]() ,
,
(1.2)
где t
– заданный
коэффициент доверия, величина которого
зависит от заданной вероятности.
-
t
1
2
3
P(t),%
68,3
95,4
99,7
Предельная ошибка
выборки позволяет определить предельные
значения характеристик генеральной
совокупности при заданной вероятности
и их доверительные интервалы:
![]() .
.
(1.3)
Если при выборочном
наблюдении изучению подлежит альтернативный
признак, то случайная ошибка выборки
определяется по формуле:
![]() .
.
(1.4)
Предельная ошибка
при этом определяется по формуле (1.2).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Когда исследователи рассматривают вопросы, представляющие интерес для аналитиков или портфельных менеджеров, они могут исключить из анализа определенные акции, облигации, портфели, или периоды времени, по разным причинам — возможно, из-за недоступности данных.
Когда недоступность данных приводит к исключению из анализа определенных активов, мы называем эту проблему систематической ошибкой или смещением выборки (англ. ‘sample selection bias’ или ‘sampling bias’).
Например, вы можете сделать выборку из базы данных, которая отслеживает только компании, существующие в настоящее время. Например, многие базы данных взаимных фондов предоставляют историческую информацию только о тех фондах, которые существуют в настоящее время.
Базы данных, в которых хранятся балансовые отчеты и отчеты о прибылях и убытках страдают от той же систематической ошибки, что и базы данных фондов: в них нет фондов или компаний, которые прекратили деятельность.
Исследование, которое использует подобные базы данных, подвержено разновидности систематической ошибки выборки, известной как систематическая ошибка выжившего (англ. ‘survivorship bias’).
Исследователи Димсон, Марш и Стонтон (Dimson, Marsh, and Staunton, 2002) подняли вопрос о систематической ошибке выжившего в международных финансовых индексах:
Известной проблемой является влияние выживания рынков на долгосрочную оценку доходности. Рынки могут испытывать не только разочаровывающие результаты, но и полную потерю стоимости за счет конфискации, гиперинфляции, национализации и кризисов.
При оценке результатов рынков, которые выживают в течение длительных интервалов времени, мы сделали выводы о том, чем обусловлено выживание. Тем не менее, как отметили в исследовании Браун, Готцман и Росс (Brown, Goetzmann, и Ross) в 1995 г. и Готцман и Джорион (Goetzmann and Jorion) в 1999 г., человек не способен заранее определить, какие рынки выживут, а какие нет. (стр. 41)
Систематическая ошибка выжившего иногда появляется, когда мы используем совместно цены акций и данные бухгалтерского учета.
Например, многие исследования в области финансов использовали соотношение рыночной стоимости компании к бухгалтерской стоимости компании на одну акцию (т.е. коэффициент котировки акций, англ. P/B, от ‘price-to-book ratio’ или ‘market-to-book ratio’) и обнаружили, что коэффициент P/B обратно пропорционален доходности компании (см. Fama and French 1992, 1993).
Коэффициент P/B также используется для многих популярных индексов стоимости и роста.
Если база данных, которую мы используем для сбора данных бухгалтерского учета, исключает обанкротившиеся компании, это может привести к систематической ошибке выжившего.
Котхари, Шанкен и Слоун (Kothari, Shanken, and Sloan) в 1995 г. исследовали именно этот вопрос, и оспорили то, что акциям обанкротившихся компаний свойственна самая низкая доходность и коэффициент P/B.
Если мы исключаем из выборки акции обанкротившихся компаний, то акции с низким P/B, которые включены в выборку, будут иметь в среднем более высокую доходность, по сравнению со средней доходностью при включении в выборку всех акций с низким P/B. Котхари, Шанкен и Слоун предположили, что эта систематическая ошибка привела к выводу об обратной связи между средней доходностью и P/B.
См. Fama and French (1996, стр. 80) о интеллектуальном анализе данных и систематической ошибке выжившего в их тестах.
Единственный совет, который мы можем предложить в этой ситуации, — это быть в курсе каких-либо смещений, потенциально присущих в выборке. Очевидно, что смещения выборки могут затуманить результаты любого исследования.
Выборка также может быть смещена из-за удаления (или делистинга) акций компании.
Делистинг (англ. ‘delisting’), т.е. исключение акций компании из котировального списка биржи, может происходить по разным причинам: слияние, банкротство, ликвидация, или переход на другую биржу.
Например, Центр исследований котировок ценных бумаг (CRSP, от англ. Center for Research in Security Prices) в Университете Чикаго является основным поставщиком данных о доходности, используемых в научных исследованиях. Когда происходит делистинг, CRSP пытается собрать данные о доходности исключенной компании, но во многих случаях он не может сделать этого из-за связанных с делистингом трудностях. CRSP вынужден просто указать значение доходности исключенной компании как отсутствующее.
Исследование, опубликованное в Финансовом журнале (см. The Journal of Finance) Шумвеем и Вортером (Shumway and Warther) в 1999 году, задокументировало смещение данных доходности NASDAQ в CRSP, вызванное делистингом.
Авторы показали, что делистинг, связанный с плохой работой компании (например, банкротством) исключается из данных чаще, чем делистинг, связанный с хорошей или нейтральной эффективностью компании (например, слиянием или перемещением на другой рынок). Кроме того, делистинг чаще происходит с небольшими компаниями.
Систематическая ошибка выборки встречается даже на рынках, где качество и согласованность данных весьма высоки. Новые классы активов, такие как хедж-фонды могут представлять еще большие проблемы смещения выборки.
Хедж-фонды (англ. ‘hedge funds’) представляют собой гетерогенную группу инвестиционных инструментов, как правило, организованных таким образом, чтобы быть свободными от регулирующего контроля. В целом, хедж-фонды не обязаны публично раскрывать свою эффективность (в отличие, скажем, от взаимных фондов). Хедж-фонды сами решают, нужно ли им включаться в какую-либо базу данных хедж-фондов.
Хедж фонды с плохой репутацией явно не желают, чтобы их результаты публиковались в базе данных, создавая проблему смещения самовыборки (англ. ‘self-selection bias’) в базах данных хедж-фондов.
Кроме того, как отметили Фанг и Хсие (Fung and Hsieh) в исследовании 2002 г., поскольку только хедж-фонды с хорошими показателями добровольно попадают в базу данных, в целом, историческая эффективность отрасли хедж-фондов имеет тенденцию казаться лучше, чем она есть на самом деле.
Кроме того, многие базы данных хедж-фондов исключают фонды, которые выходят из бизнеса, создавая в базе данных систематическую ошибку выжившего. Даже если база данных не удаляет несуществующие хедж-фонды, в попытке устранить ошибку выжившего, остается проблема хедж-фондов, которые перестают отчитываться об эффективности из-за плохих результатов.
См. Fung and Hsieh (2002) и Horst and Verbeek (2007) для более подробной информации о проблемах интерпретации эффективности хедж-фондов.
Обратите внимание, что систематическая ошибка также возможна, когда успешные фонды перестают отчитываться об эффективности, поскольку они больше не нуждаются в новых потоках денежных средств.
Систематическая ошибка опережения.
Процесс тестирования также подвержен систематической ошибке опережения (англ. ‘look-ahead bias’), если он использует информацию, которая не была доступна на момент тестирования.
Например, тесты правил биржевой торговли, которые используют ставки доходности фондового рынка и данные бухгалтерских балансов должны учитывать систематическую ошибку опережения.
В таких тестах, балансовая стоимость компании на акцию обычно используются для расчета коэффициента P/B.
Хотя рыночная цена акции доступна для всех участников рынка на заданный момент времени, балансовая стоимость на акцию на конец финансового года может стать общедоступной только в будущем — когда-то в следующем квартале.
Систематическая ошибка временного периода.
Тесты также подвержены систематической ошибке или смещению временного периода (англ. ‘time-period bias’), если они основаны на временном периоде, для которого результаты тестирования будут специфичными (т.е., характерными только для данного периода).
Ряды коротких временных периодов, скорее всего, дадут результаты, специфичные для определенного периода, которые могут не отражать более длительный период.
Ряды длительных временных периодов могут дать более точную картину истинной эффективности инвестиций. Недостаток длительных периодов заключается в потенциальных структурных изменениях, происходящих в течение периода, что приведет к двум различным распределениям доходности.
В этой ситуации, распределение, отражающее условия до изменений, будет отличаться от распределения, которые описывают условия после изменений.
Пример (7) систематических ошибок в инвестиционных исследованиях.
Финансовый аналитик рассматривает эмпирические данные об исторической доходности акций США.
Она выясняет, что недооцененные акции (то есть, акции с низким P/B) превзошли по эффективности растущие акции (то есть, акции с высоким P/B) в некоторых последних периодах времени.
После изучения американского рынка, аналитик задается вопросом, могут ли недооцененные акции быть привлекательными в Великобритании. Она исследует эффективность недооцененных и растущих акций на британском рынке за 14-летний период с января 2000 года по декабрь 2013 года.
Для проведения этого исследования, аналитик делает следующее:
- Получает текущий состав компаний Индекса всех акций FTSE (Financial Times Stock Exchange All Share Index), который является взвешенным индексом рыночной капитализации;
- Исключает несколько компаний, у которых финансовый год не заканчивается в декабре;
- Использует балансовую и рыночную стоимость компаний на конец года, чтобы ранжировать остальные пространство компаний по коэффициенту P/B на конец года;
- На основе этих рейтингов, она делит пространство ценных бумаг на 10 портфелей, каждый из которых содержит одинаковое количество акций;
- Вычисляет равновзвешенную доходность каждого портфеля и доходность FTSE All Share Index за 12 месяцев после даты расчета каждого рейтинга; а также
- Вычитает доходность FTSE из доходности каждого портфеля, чтобы получить избыточную доходность для каждого портфеля.
Опишите и обсудите каждую из следующих систематических ошибок, которым подвержен план исследований аналитика:
- систематическую ошибку выжившего;
- систематическую ошибку опережения; а также
- систематическую ошибку временного периода.
Систематическая ошибка выжившего.
План тестирования подвержен систематической ошибке выжившего, если он не принимает в расчет обанкротившиеся компании, слившиеся компании, а также компании, иным образом покинувшие базу.
В этом примере, аналитик использовала текущий список акций FTSE, а не фактический список акций на начало каждого года. В той степени, в которой расчет доходности не учитывает компании, исключенные из индекса, эффективность портфелей с наименьшим P/B подвершена систематической ошибке выжившего и, соответственно, может быть завышена.
В какой-то момент периода тестирования, эти ныне не существующие компании, были исключены из тестирования. У них, вероятно, были низкие цены на акции (и низкий P/ B) и плохая доходность.
Систематическая ошибка опережения.
План тестирования подвержен систематической ошибке опережения, если он использует информацию, недоступную на момент тестирования.
В этом примере, аналитик провела тест, сделав допущение о том, что необходимая бухгалтерская информация была доступна в конце финансового года.
Например, аналитик предположила, что балансовая стоимость на акцию за 2 000 финансовый года был известна на 31 декабря 2000 года. Поскольку эта информация, как правило, не публикуется в течение нескольких месяцев после завершения финансового года, тест, возможно, содержал систематическую ошибку опережения.
Эта ошибка может привести к стратегии, которая окажется успешной, но при этом потребуется идеальная способность прогнозировать бухгалтерские результаты.
Систематическая ошибка временного периода.
План тестирования подвержен систематической ошибке временного периода, если он основан на периоде, для которого результаты будут специфичны.
Хотя тестирование охватывает период более 10 лет, этот период может оказаться слишком коротким для тестирования аномалии.
В идеале, аналитик должна протестировать рыночные аномалии в течение нескольких бизнес-циклов, чтобы гарантировать, что результаты не являются специфичными для рассматриваемого периода.
Эта систематическая ошибка может способствовать предлагаемой стратегии, если выбрать временной период, благоприятный для стратегии.