Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Show only
|
Search instead for
Did you mean:
- Home
- Microsoft 365
- Excel
- error message for input range trying to do regression analysis
-
All Discussions -
Previous Discussion -
Next Discussion
4 Replies
Dec 07 2021
05:14 AM
Select your input data. Press F5 and click «Special». Select Constants and ONLY check the Text box. Any cell it now highlights Excel thinks it contains text.
Sep 12 2023
12:31 AM
What if the shortcut key F5 doesn’t work? What can be the alternative?
Sep 12 2023
04:47 AM
@Renj09
Ctrl+G is the other shortcut for the Go To dialog.
Sep 13 2023
05:29 AM
@Renj09 Or click the Home tab, find the looking glass icon (Find & Select) click it and choose Goto Special
Решение проблемы «нечисловых» чисел в таблицах Excel
При импортировании данных из других источников вы, возможно, уже успели обнаружить, что Excel иногда некорректно импортирует значения. В частности, он может принять ваши числа за текст. И тогда, например, при суммировании диапазона значений формула СУММ возвращает 0 — хотя диапазон, по всей видимости, содержит числовые значения.
Часто Excel сообщает вам об этих «нечислах», отображая смарт-тег, который позволяет преобразовать текст в числа. Если смарт-тег не отображается, вы можете использовать следующий метод, чтобы указать Excel изменить эти «нечисловые» числа на их фактические значения. Выполните следующие действия.
- Активизируйте любую пустую ячейку на листе.
- Нажмите Ctrl+C, чтобы скопировать пустую ячейку.
- Выберите диапазон, содержащий проблематичные значения.
- Выберите Главная ► Буфер обмена ► Вставить ► Специальная вставка для открытия диалогового окна Специальная вставка.
- В окне Специальная вставка установите переключатель Операция в положение сложить.
- Нажмите кнопку ОК.
Excel ничего не добавит к значениям, но в процессе укажет этим ячейкам иметь фактические значения.
Числовые характеристики результатов наблюдения
Следующим этапом статистического анализа данных после построения вариационного ряда является характеристика отдельных свойств распределения данных наблюдения. С этой целью в статистике используются специальные числовые параметры, найденные по результатам наблюдения и отражающие в сжатом виде основные, существенные черты распределения данных. Эти числовые параметры называются эмпирическими числовыми характеристиками. Наиболее важными числовыми характеристиками являются характеристики положения, вариации, асимметрии и эксцесса.
Для характеристики положения используются показатели центра распределения данных наблюдения– средняя арифметическая, мода и медиана.
Средняя арифметическая для дискретного ряда распределения рассчитывается по формуле:
–варианты значений признака;
– частота повторения данного варианта.
В интервальном вариационном ряду средняя арифметическая определяется по формуле:
– середина соответствующего интервала;
Мода распределения– это наиболее часто встречающееся значение признака в совокупности. В дискретном ряду определение моды не требует специальных расчётов. Мода соответствует варианту с наибольшей частотой. В интервальном вариационном ряду в отличие от дискретного ряда определение моды требует определённых расчётов на основе специальной формулы.
Модальный интервал (то есть содержащий моду) при интервальном распределении с равными интервалами определяется по наибольшей частоте, а с неравными интервалами– по наибольшей плотности. В первом случае мода рассчитывается по следующей формуле:
– нижняя граница модального интервала;
– величина модального интервала;
– частота модального интервала;
– частота интервала, предшествующего модальному;
– частота интервала, следующего за модальным.
Во втором случае в формуле моды вместо частот используется соответствующая плотность .
Медиана – это значение признака, расположенное в середине (в центре) ранжированного ряда. Медиана делит совокупность на две равные части– со значениями признака меньше медианы и со значениями признака больше медианы.
В дискретном ряду для вычисления медианного значения признака сначала находят его порядковый номер:
– число единиц совокупности.
Полученное значение указывает, что середина приходится на данный номер единицы совокупности. Необходимо определить, к какой группе относится единица с этим порядковым номером. Это можно сделать, рассчитав накопленные частоты.
В интервальном вариационном ряду медиана определяется по формуле:
– нижняя граница медианного интервала;
– величина медианного интервала;
– сумма всех частот ряда;
– накопленная частота интервала, предшествующего медианному;
– частота медианного интервала.
Медианным является интервал, в котором сумма накопленных частот равна или превышает полусумму частот ряда.
Основными характеристики вариации признака являются дисперсия, среднее квадратическое (стандартное) отклонение и коэффициент вариации. Они характеризуют степень рассеивания данных наблюдения относительно центра распределения.
Дисперсия рассчитывается по формуле:
Среднее квадратическое (стандартное) отклонение равно корню квадратному из дисперсии.
Коэффициент вариации равен:
Для оценки степени отклонения распределения исследуемой величины от нормального распределения используется коэффициент асимметрии, основанный на определении центрального момента третьего порядка (в нормальном распределении его величина равна нулю): . В Excel вычисляется несмещённая состоятельная оценка коэффициента асимметрии:
Стандартизированный коэффициент асимметрии имеет приближённое стандартное нормальное распределение.
Эксцесс представляет собой выпад вершины эмпирического распределения вверх или вниз от вершины кривой нормального распределения, имеющей куполообразную форму.
Наиболее точным является коэффициент эксцесса, основанный на использовании центрального момента четвёртого порядка: . Для нормального распределения равен нулю, так как . В Excel вычисляется несмещённая состоятельная оценка коэффициента:
Стандартизированный выборочный коэффициент эксцесса используется при оценке степени отклонения распределения исследуемой случайной величины от нормального распределения.
В Excel числовые характеристики вычисляются с помощью процедуры Описательная статистика, входящей в Пакет анализа, и соответствующих встроенных статистических функций СРЗНАЧ, МЕДИАНА, МОДА, ДИСП, ДИСПР, СТАНДОТКЛОН, СТАНДОТКЛОНП, СРОТКЛ, КВАДРОТКЛ, СКОС и ЭКСЦЕСС.
Для доступа к процедуре Описательная статистика необходимо:
В меню Сервис выделить строку Анализ данных.
В открывшемся окне Анализ данных выделить процедуру Описательная статистика и щёлкнуть на кнопке ОК. На экране появится диалоговое окно Описательная статистика, которое содержит следующие элементы управления:
поле ввода Входной интервал. В это поле вводится ссылка на диапазон ячеек (входной диапазон), содержащий статистические данные, подлежащие обработке. Входной диапазон может быть столбцом или группой смежных столбцов (строкой или группой смежных строк). Если входной диапазон представляет собой группу столбцов (строк), то процедура воспринимает каждый столбец (строку) как отдельную совокупность;
флажок Итоговая статистика. Если этот флажок установлен, процедура вычисляет и помещает в таблицу результатов решения следующие числовые характеристики: среднюю, стандартную ошибку средней, медиану, моду, стандартное отклонение, дисперсию, эксцесс, асимметрию, размах вариации, минимальное и максимальное значение изучаемого признака, сумму всех значений признака и объём совокупности. Если совокупность не имеет повторяющихся значений признака, в строке Мода появляется сообщение # Н/Д!– неопределённые данные;
флажок Уровень надёжности. Флажок устанавливается в том случае, когда необходимо вычислить доверительный интервал для средней, соответствующий заданной доверительной вероятности. При этом справа от флажка открывается поле для ввода доверительной вероятности, выраженной в процентах. Если этот флажок установлен, то в последней строке таблицы результатов решения появляется число, равное половине длины доверительного интервала;
флажки К-й наименьший/К-й наибольший. Если эти флажки установлены. то в таблице результатов решения появляются -й и -й элементы упорядоченной совокупности (то есть единицы совокупности, расположенные на -м месте от её начала и от конца).
Назначение переключателей Группирование по столбцам/по строкам, флажка Метки в первой строке/Метки в первом столбце и группы переключателей Выходной интервал/Новый рабочий лист/Новая книга рассмотрено на стр. 8-9.
Результаты решения выводятся на экран в виде набора таблиц– по одной таблице на каждый столбец входного интервала (на каждую обработанную совокупность). Каждая выходная таблица состоит из двух столбцов. В первом столбце указывается названия числовых характеристик, во втором– их значения. В заголовке указывается номер совокупности, к которой относится данная таблица (например, Столбец 1).
Свой наибольший размер (18×2) таблица принимает при установке всех четырёх флажков, расположенных в нижней части диалогового окна процедуры. В случае возникновения опасности того, что таблица результатов наложится на уже заполненные ячейки, на экран выводится сообщение о такой опасности. В ответ на это сообщение пользователь должен разрешить удаление старых данных и вывод на их место новых (для этого надо щёлкнуть на кнопке ОК).
Формирование выборки
Метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой её части на основе положений случайного отбора, называется выборочным методом.
Подлежащая изучению по определённым признакам статистическая совокупность, из которой производится отбор единиц, называется генеральной. Отобранная из генеральной совокупности в случайном порядке некоторая часть единиц, подвергающаяся обследованию, называется выборочной совокупностью или просто выборкой.
В теории выборочного метода разработаны и в практике статистико-экономических исследований применяются различные способы формирования выборочных совокупностей, обеспечивающие репрезентативность. Организация выборочного наблюдения заключается в определении способа и вида отбора единиц.
Под способом отбора понимают порядок отбора единиц из генеральной совокупности. Различают два способа отбора: повторный и бесповторный.
При повторном способе каждая отобранная в случайном порядке единица после её обследования возвращается в генеральную совокупность и при последующем отборе может снова попасть в выборку. Вероятность попадания любой единицы в выборку равна , и она остаётся той же самой на протяжении всей процедуры отбора.
При бесповторном способе отбора попавшая в выборочную совокупность единица после регистрации значений наблюдаемых признаков не возвращается в совокупность, из которой осуществляется дальнейший отбор. Вероятность попадания единицы в выборку изменяется от – для первой отбираемой единицы до – для последней единицы, то есть по мере производства отбора вероятность попасть в выборку для каждой единицы генеральной совокупности увеличивается, тем самым повышается репрезентативность выборки.
В зависимости от методики формирования выборочной совокупности различают следующие основные виды выборки:
типическая (стратифицированная, расслоенная, районированная);
В Пакете анализа табличного процессора Excel имеется процедура Выборка, реализующая повторную собственно-случайную выборку и механическую выборку с заданным пользователем шагом (периодом) отбора.
Формирование выборки в Excel осуществляется следующим образом:
Единицам генеральной совокупности присваиваются порядковые номера. Для проведения механической выборки генеральная совокупность должна быть каким-либо образом упорядочена, то есть должна быть определённая последовательность в расположении её единиц. Для получения результатов, не содержащих систематическую ошибку выборки, упорядочение необходимо произвести по нейтральному признаку по отношению к изучаемому.
Порядковые номера единиц исходной совокупности вводятся в диапазон ячеек (входной диапазон). Эти номера могут находиться в одном столбце или группе смежных столбцов одинаковой «высоты». При этом число всех ячеек входного диапазона должно равняться числу единиц исходной совокупности. Если среди элементов входного интервала имеются нечисловые данные, то отбор не состоится, а на экране появится сообщение «Выборка– входной интервал содержит нечисловые данные».
В меню Сервис выделяется строка Анализ данных.
В открывшемся диалоговом окне Анализ данных выделяется процедура Выборка и нажимается кнопка ОК. На экране появится диалоговое окно Выборка, которое содержит следующие элементы управления:
поле ввода Входной интервал. В это поле вводится ссылка на диапазон, в котором хранятся номера всех единиц генеральной совокупности, из которой осуществляется выборка.
Метод выборки устанавливается с помощью переключателей Периодический и Случайный. При активизации переключателя Случайный процедура «настраивается» на выполнение случайной выборки с повторением. Нужный объём выборки вводится в поле Число выборок. Единицы генеральной совокупности отбираются случайным образом. Каждая единица исходной совокупности имеет равную со всеми остальными единицами возможность быть включённой в выборку. Любая единица генеральной совокупности может попасть в выборку более одного раза.
При необходимости реализовать механическую выборку активизируется переключатель Периодический. Шаг выборки вводится в поле Период, находящееся справа от переключателя. В выборку войдут элементы исходной совокупности с номерами, кратными заданному периоду. Если входной диапазон состоит из нескольких столбцов, то отбираемые значения будут извлекаться сначала из первого столбца, затем из второго и т.д. Формирование выборки прекращается по достижении конца исходной совокупности.
При формировании случайной выборки выходной интервал представляет собой столбец с числом ячеек, равным заданному объёму выборки. В случае механической выборки число ячеек выходного интервала равно целой части результата деления объёма исходной совокупности на шаг выборки.
Для получения упорядоченной копии номеров единиц совокупности, подлежащих включению в выборку, необходимо щелчком на кнопке Сортировка по возрастанию, расположенной на панели инструментов Стандартная, упорядочить полученный набор номеров.
Корреляционный анализ
В статистике различают две категории зависимостей между признаками:
2) стохастическая, частным случаем которой является корреляционная.
При этом признаки для изучения взаимосвязи по их значению делятся на два класса. Признаки, обуславливающие изменение других, связанных с ними признаков, называются факторными (х). Признаки, изменяющиеся под действием факторных признаков, являются результативными (у).
Функциональной называется связь, при которой каждому значению факторного признака соответствует вполне определённое значение результативного признака. Функциональная связь является строгой, точной, полной зависимостью; проявляется и для каждой единицы совокупности, и во всех случаях наблюдения. Характерной особенностью функциональной связи является то, что в каждом отдельном случае известен полный перечень факторов, влияющих на результативный признак, а также механизм этого влияния, выраженный определённым уравнением.
Стохастическая (вероятностная) связь не проявляется в каждом отдельном случае, а лишь в общем, среднем, при большом числе наблюдений.
Корреляционной называется связь, при которой каждому значению факторного признака может соответствовать несколько значений результативного признака.
Корреляционные связи имеют ряд характеристик:
По форме (аналитическому выражению) корреляционные связи между признаками могут быть линейными (прямолинейными) и нелинейными (криволинейными). При линейной форме равномерное изменение значений одного признака сопровождается более или менее равномерным изменением значений другого признака. Математически она выражается уравнением прямой ух = а + вх, графически — прямой линией. При нелинейной форме равномерному изменению значений одного признака соответствует неравномерное изменение значений другого. Выражается уравнением какой- либо кривой линии: параболы, гиперболы, показательной, степенной, логарифмической, логической функции и др.
По направлению (характеру изменения) корреляционные связи бывают прямыми и обратными. Прямой (положительной) является зависимость, при которой направление изменения значений факторного и результативного признаков совпадает, то есть с увеличением факторного признака, результативный также возрастает, и, наоборот, при уменьшении факторного признака результативный тоже убывает. Обратной (отрицательной) называется связь, при которой изменение значений факторного и результативного признаков осуществляется в разных направлениях, то есть с ростом факторного результативный признак убывает или при убывании факторного признака результативный возрастает.
Степень тесноты корреляционной связи оценивается по специальным шкалам, например, по шкале Чеддока.
Количественный критерий оценки тесноты связи по шкале Чеддока
Величина показателя для измерения тесноты связи
Существуют и другие менее детальные шкалы.
В статистике различают следующие варианты зависимостей:
1) парная корреляция – связь между двумя признаками (результативным и факторным);
2) частная корреляция – зависимость между результативным и одним факторным признаком при фиксированном значении других факторных признаков;
3) множественная корреляция – зависимость результативного от двух или более факторных признаков.
В практике статистических исследований выделяют:
корреляционный анализ, который имеет своей задачей количественное измерение тесноты связи между признаками;
регрессионный анализ, который заключается в определении формы связи, построении одно- или многофакторных моделей (уравнений) регрессии;
корреляционно-регрессионный анализ, который включает в себя установление аналитического выражения (формы) и измерение степени тесноты связи.
Следует также различать собственно-корреляционные (параметрические) и непараметрические методы изучения взаимосвязей между признаками. Основу применения собственно-корреляционных методов составляют однородность и необходимость подчинения распределения совокупности по факторным и результативному признаку закону нормального распределения вероятностей. Несоблюдение этих условий обуславливает необходимость применения при изучении взаимосвязей непараметрических методов.
В связи с этим первым этапом изучения зависимостей является установление подчинения распределения результатов наблюдения по изучаемым признакам закону нормального распределения.
На соответствие изучаемого эмпирического распределения нормальному закону указывает близость значений показателей центра распределения – средней арифметической, моды и медианы. С этой целью производится также расчёт и оценка степени существенности показателей асимметрии и эксцесса. В Excel выборочные числовые характеристики вычисляются с помощью процедуры Описательная статистика, входящей в Пакет анализа, и соответствующих встроенных статистических функций (см. раздел 4).
Для проверки гипотезы о законе распределения изучаемого признака используются также специальные статистические критерии. При этом выдвигается гипотеза о том, что истинной функцией распределения признака является некоторая заданная функция (для нашей задачи– функция нормального распределения). Если гипотеза верна (то есть, если значения признака действительно имеют функцию распределения ), то найденная по данным наблюдения эмпирическая функция распределения не должна сильно отличаться от гипотетической функции распределения , и с увеличением объёма совокупности различие между ними должно уменьшаться. В связи с этим вопрос о принятии или отклонении проверяемой гипотезы решается в зависимости от того, насколько хорошо согласуются эмпирическая и гипотетическая функции распределения. Статистические критерии, базирующиеся на таком подходе, называются критериями согласия или соответствия. В основе этих критериев лежит выбранная статистика, которая служит мерой расхождения между эмпирическим и гипотетическим законами распределения исследуемого признака. Известны критерии К. Пирсона (хи- квадрат), В.И. Романовского, А.Н. Колмогорова, Б.С. Ястремского, омега-квадрат, Крамера-Мизеса-Смирнова и др.
Excel позволяет реализовать проверку статистических гипотез о соответствии эмпирических результатов наблюдения закону нормального распределения на основу вышеуказанных критериев согласия.
Последующий собственно-корреляционный анализ статистических данных, полученных в результате наблюдения, включает в себя:
построение корреляционного поля и корреляционной таблицы;
вычисление выборочных коэффициентов корреляции и корреляционных отношений;
проверка статистических гипотез о значимости корреляционной зависимости.
Корреляционное поле и корреляционная таблица служат для установления наличия и направления зависимости между изучаемыми признаками, дают общее представление об этой зависимости.
В Excel построение поля корреляции (диаграммы рассеивания) между изучаемыми признаками осуществляется при помощи специального средства, служащего для графического изображения статистических данных– Мастера диаграмм (см. 19). Для построения корреляционного поля используется тип Точечная. На палитре Вид выделяется диаграмма в виде изолированных точек, находящаяся в левом верхнем углу палитры.
Расположение точек на графике позволяет в ряде случаев сделать предположение о наличии, направлении и форме взаимосвязи между изучаемыми признаками. Так, линейное расположение точек даёт серьёзное основание для выбора линейной модели, сравнительно небольшой разброс точек относительно воображаемой кривой, проходящей «наилучшим образом» через эти точки, говорит о довольно сильной зависимости между признаками, и наоборот. Расположение точек слева на право свидетельствует о прямой корреляции, а справа налево– об обратной корреляции.
Для подтверждения выводов, сделанных в результате анализа корреляционного поля и в тех случаях, когда корреляция между признаками имеет явно выраженный нелинейный характер и объём выборки велик, данные наблюдения группируют и представляют их в виде корреляционной таблицы, состоящей из строк и столбцов, где –число интервалов группировки по факторному признаку и – число интервалов группировки по результативному признаку. Это обусловлено тем, что при нелинейной зависимости вычисляются корреляционные отношения, которые могут быть определены только по сгруппированным данным.
Построение корреляционной таблицы начинают с группировки значений факторного и результативного признаков. В Excel для группировки данных способом равных интервалов используются процедура Гистограмма, входящая в Пакет анализа (см стр.14).
– середина -го интервала группировки по факторному признаку;
– середина -го интервала группировки по результативному признаку;
– групповая частота «клетки», находящейся на пересечении строки и столбца корреляционной таблицы;
– групповая частота -го интервала группировки по факторному признаку (число наблюдений в -й строке);
–групповая частота -го интервала группировки по результативному признаку (число наблюдений в -м столбце);
–объём изучаемой совокупности (общее число наблюдений).
Заполнение корреляционной таблицы даёт довольно наглядное представление о характере зависимости между изучаемыми признаками.
Для количественного измерения степени тесноты связи служат выборочные коэффициенты корреляции и корреляционные отношения.
Линейный коэффициент корреляции рассчитывается для определения тесноты и направления связи между двумя корреляционными признаками в случае наличия между ними линейной зависимости и распределения значений признаков близкого к нормальному. Линейный коэффициент корреляции может принимать значение от -1 до +1. Чем ближе коэффициент корреляции к 1, тем сильнее (теснее) связь между признаками. Для определения характера связи используют шкалу Чеддока.
В теории разработаны и на практике применяются различные модификации формулы расчёта данного коэффициента:
где –ковариация факторного и результативного признаков;
, – среднее квадратическое (стандартное) отклонение соответственно факторного и результативного признака;
n – число наблюдений.
Квадрат коэффициента корреляции (r 2 ) носит название коэффициента детерминации. Он показывает долю вариации результативного признака, обусловленную влиянием вариации факторного признака.
При наличии нелинейной зависимости используется более универсальный показатель измерения тесноты связи: корреляционное отношение. Различают эмпирическое и теоретическое корреляционное отношение.
Расчет эмпирического корреляционного отношения осуществляется по сгруппированным данным наблюдения и основан на использовании теоремы (правила) сложения дисперсий:
Эмпирическое корреляционное отношение определяется по формуле:
Межгрупповая дисперсия характеризует ту часть колеблемости результативного признака, которая складывается под влиянием изменения факторного признака, положенного в основание группировки:
Средняя из внутригрупповых дисперсий оценивает ту часть вариации результативного признака, которая обусловлена действием других, прочих, «случайных» причин:
-дисперсия результативного признака в соответствующей группе.
Общая дисперсия характеризует вариацию результативного признака, обусловленную влиянием всех факторов:
Расчёт теоретического корреляционного отношения в Excel осуществляется в рамках регрессионного анализа, поэтому будет рассмотрен в следующем разделе.
В Excel вычисление выборочного коэффициента корреляции осуществляется с помощью процедуры Корреляция, входящей в Пакет анализа, и встроенных статистических функций КОРРЕЛ, ПИРСОН и КВПИРСОН.
При применении процедуры Корреляция в поле Входной интервал диалогового окна этой процедуры вводится ссылка на входной диапазон (на диапазон, содержащий данные наблюдения, подлежащие обработке). Входной диапазон должен содержать смежных столбцов по ячеек в каждом столбце или смежных строк по ячеек в каждой строке.
Назначение переключателя Группирование, флажка Метки и группы переключателей Выходной интервал/Новый рабочий лист/ Новая книга рассмотрено в первом разделе на стр.8-9.
Статистические функции КОРРЕЛ и ПИРСОН вычисляют выборочную оценку линейного коэффициента корреляции по первой формуле, представленной на стр. 34, и дублируют друг друга. Синтаксис функции КОРРЕЛ (массив 1; массив 2), где массив 1– диапазон ячеек, в который введены значения факторного признака (например, А1:А25), а массив 2– диапазон ячеек, в который введены значения результативного признака (например, В1:В25). Статистическая функция КВПИРСОН вычисляет квадрат выборочного коэффициента корреляции.
Для вычисление эмпирического корреляционного отношения в Excel не предусмотрено специальных статистических процедур и встроенных функций. Вычисление корреляционного отношения осуществляется по представленным выше формулам и требует предварительного построения корреляционной таблицы и ряда вспомогательных расчётов.
Значимость линейного коэффициента корреляции проверяется на основе t – критерия Стьюдента. При этом выдвигается и проверяется гипотеза ( ) о равенстве коэффициента корреляции в генеральной совокупности нулю (то есть в действительности связь между изучаемыми признаками отсутствует, а эмпирическое значение выборочного коэффициента корреляции обусловлено только случайными совпадениями и в выборке).
Фактическое значение t — критерия рассчитывается по формуле — для совокупностей n<50 по формуле:
при большом числе наблюдений (n>100):
Вычисленное значение t – критерия сравнивается с критическим его значением при принятом уровне занятости α и числе степеней свободы k = n-2. В социально-экономических исследованиях уровень значимости α обычно принимается равным 0,05.
При «ручной» проверке гипотезы критические значения t находятся по таблице распределения Стьюдента. Если расчётное значение t – критерия больше критического, то гипотеза о том, что линейный коэффициент корреляции в генеральной совокупности равен нулю и лишь в силу случайных обстоятельств оказался равен проверяемому значению, отклоняется, то есть коэффициент корреляции признаётся значимым, а связь между признаками – статистически существенной. Если расчётное значение t – критерия меньше критического, то нулевая гипотеза принимается, что означает, что коэффициент корреляции в генеральной совокупности в действительности равен нулю и соответственно эмпирический коэффициент корреляции существенно не отличается от нуля.
В Excel проверка гипотезы об отсутствии корреляции между изучаемыми признаками осуществляется следующим образом:
В ячейку (например, В1) вводится значение выборочного коэффициента корреляции ;
В ячейку В2 для определения расчётного значения t – критерия вводится формула (*): = В1*КОРЕНЬ (115/(1-В1^2)) ( = 117);
В ячейку В3 для нахождения критического значения t – критерия Стьюдента при уровне значимости α= 0,05 и числе степеней свободы k =115 вводится формула: = СТЬЮДРАСПОБР (0.05;115);
Полученные расчётное и критическое значения t – критерия Стьюдента сравниваются, и делается вывод об отклонении или принятии нулевой гипотезы на уровне значимости =0,025 . Если гипотеза противоречит реальным данным наблюдения (отклоняется), то выборочный коэффициент корреляции признаётся значимым и между изучаемыми признаками существует соответствующая по степени тесноты корреляционная зависимость. Если гипотеза принимается, коэффициент корреляции признаётся незначимым.
Для оценки значимости корреляционного отношения используется F – критерий Фишера–Снедекора, вычисленный по формуле:
где n — число наблюдений; m – число интервалов группировки или параметров в уравнении регрессии.
При этом проверяется гипотеза об отсутствии корреляционной зависимости между изучаемыми признаками. Проверяемая гипотеза отклоняется на уровне значимости , если расчётное значение F – критерия превышает его критическое значение для принятого уровня значимости и чисел степеней свободы k1=m-1 и k2=m-n. В этом случае величина корреляционного отношения признаётся значимой, а связь между признаками существенной.
При «ручной» проверке гипотезы используются специальные таблицы F – распределения. В них указывается предельные (критические) значения F – критерия для различных степеней свободы k1 и k2, которые могут быть превзойдены с вероятностью α = 0,05.
В Excel проверка гипотезы об отсутствии корреляции между изучаемыми признаками осуществляется следующим образом:
В ячейку В1 вводится объём совокупности (например, 132) в ячейку В2– число интервалов группировки или параметров в уравнении регрессии (например, 12); в ячейку В3– значение выборочного корреляционного отношения;
В ячейку Е1 для нахождения расчётного значения F – критерий Фишера вводится формула (**): = В3^2*120/(1-В3^2)*11;
В ячейку Е2 для определения критического значения F – критерий Фишера для принятого уровня значимости =0,05 и чисел степеней свободы k1=m-1 (11) и k2=m-n (120) вводится формула: = FРАСПОБР (0.05;11;120).
Полученные расчётное и критическое значения F – критерий Фишера сравниваются, и делается вывод об отклонении или принятии нулевой гипотезы и соответственно о значимости или незначимости корреляционного отношения.
Множественный коэффициент корреляции вычисляется статистической процедурой Регрессия (см. следующий раздел).
Рассмотренные выше вычисления относятся к собственно-корреляционным, параметрическим методам изучения связей.
В случаях, когда анализируется взаимосвязь между количественными признаками, форма распределения которых отличается от нормальной, а также между качественными признаками, используются так называемые непараметрические методы. В основу этих методов положен принцип нумерации значений признаков статистического ряда.
Значения факторного признака записываются в возрастающем или убывающем порядке, а затем ранжируются соответствующие им значения результативного признака. При этом каждой единице в упорядоченном ряду присваивается порядковый номер, который будет её рангом. В случаях наличия одинаковых вариантов каждому из них присваивается среднее арифметическое значение их рангов.
Для определения рангов в Excel предусмотрены статистическая процедура Ранг и персентиль и статистическая функция РАНГ.
Использование процедуры Ранг и персентиль заключается в следующем:
В меню Сервис выделяется строка Анализ данных.
В открывшемся окне Анализ данных выделяется процедура Ранг и персентиль, нажимается кнопка ОК. На экране появляется диалоговое окно Ранг и персентиль.
В поле Входной интервал вводится ссылка на диапазон ячеек, содержащий данные, подлежащие ранжированию. Входной диапазон может быть столбцом или группой смежных столбцов (строкой или группой смежных строк). Если входной диапазон представляет собой группу столбцов (строк), то процедура воспринимает каждый столбец (строку) как отдельную выборку.
Устанавливается переключатель Группирование в нужное положение (по столбцам или строкам).
Флажок Метки устанавливается, если первая строка (столбец) входного диапазона содержит заголовки. Если такие заголовки отсутствуют, флажок не устанавливается.
Щелчком на переключателе Выходной интервал активизируется поле ввода, находящее справа от этого переключателя и вводится в него ссылка на левую верхнюю ячейку таблицы результатов решения. В случае необходимости результаты выводятся на Новый рабочий лист или Новую рабочую книгу. Нажимается кнопка ОК.
Статистическая функция РАНГ имеет следующий синтаксис: РАНГ (число; массив; порядок):
число– номер единицы совокупности, ранг которой надо определить. Если необходимо осуществить ранжирование всей совокупности сразу, то вводится диапазон ячеек, в котором находятся данные, подлежащие обработке;
массив– массив или диапазон ячеек, содержащий единицы исследуемой совокупности (неупорядоченные данные наблюдения);
порядок– величина, определяющая, как упорядочивать (ранжировать) массив:
– если порядок равен 0 или пропущен, массив упорядочивается в порядке убывания;
– если порядок– любое число, не равное нулю, то массив упорядочивается по возрастанию.
Среди непараметрических методов оценки тесноты связи наибольшее значение имеют коэффициенты ранговой корреляции Спирмена и Кендалла.
Коэффициент корреляции рангов (Спирмена) определяется по формуле:
d – разность между рангами соответствующих величин двух признаков;
n – число единиц в ряду (число пар рангов).
Коэффициент корреляции рангов принимает любые значения от -1 до +1. Если все ранги строго изменяются в одном и том же порядке, то d=0, а r=1. Если же ранги изменяются строго в противоположных направлениях, то r= -1. Значение r=0 характеризует отсутствие связи.
В Excel вычисление коэффициента ранговой корреляции Спирмена осуществляется следующим образом:
1. Вводятся заголовки исходных и расчётных данных, необходимых для расчёта коэффициента корреляции рангов: в ячейку А1– названия единиц изучаемой совокупности, в ячейку В1– название факторного признака, в ячейку С1– названия результативного признака, в ячейку D1– символ , обозначающий ранг по факторному признаку, в ячейку Е1– символ , обозначающий ранг по результативному признаку, в ячейку– F– символ , обозначающий квадрат разности между рангами соответствующих величин двух признаков.
2. Производится ввод исходных данных: в диапазон ячеек столбца А вводятся названия или номера единиц изучаемой совокупности; в диапазон ячеек столбца В (например, В2:В11)– значения факторного признака, в диапазон ячеек столбца С (С2:С11)– значения результативного признака.
3. В диапазонах ячеек D2:D11 и Е2:Е11 определяются соответственно ранги по факторному и результативному признаку с помощью описанной выше процедуры Ранг и персентиль или функции РАНГ, для чего вводятся формулы массива = РАНГ (В2:В11; В2:В11;1) и = РАНГ (С2:С11; С2:С11;1).
4. В диапазоне F2:F11 вычислить квадраты разности рангов с помощью формулы массива: = (D2:D11-E2:E11)^2.
5. В ячейках D12, E12 и F12 с помощью кнопки Автосуммирование определить суммы рангов по факторному и результативному признакам и сумму квадрата разности рангов.
6. По формуле рассчитывается выборочная оценка коэффициента ранговой корреляции Спирмена.
Значимость коэффициента корреляции рангов для совокупностей небольшого объёма (n£30) проверяется по таблице предельных значений коэффициента корреляции рангов Спирмена при заданном уровне значимости a и определённом объёме совокупности.
Значимость r может быть проверена также на основе t – критерия Стьюдента. Расчётное значение критерия определяется по формуле:
Значение коэффициента корреляции считается статистически существенным, если расчётное значение t – критерия Стьюдента превосходит его критическое значение при заданном уровне значимости a и числе степеней свободы k=n-2. Критическое значение t – критерия может быть определено по таблице распределения Стьюдента или в Excel по представленному выше в данном разделе порядку.
Коэффициент корреляции рангов Кендалла рассчитывается по формуле:
n – число наблюдений;
S – сумма разностей между числом последовательностей и числом инверсий по результативному признаку.
Расчёт данного коэффициента выполняется в следующей последовательности:
ранги факторного признака располагаются в порядке возрастания;
ранги результативного признака располагаются в порядке, соответствующем рангам признака х;
для каждого ранга результативного признака определяется сколько чисел, находящихся справа от него (следующих за ним) имеют величину ранга, превышающую его величину. Суммируя полученные таким образом числа, получаем слагаемое P, которое можно рассматривать как меру соответствия последовательностей рангов по x и y, и которое учитывается со знаком «+»;
для каждого ранга y определяется число, следующих за ним рангов, меньших его величины. Суммарная величина обозначается через Q и фиксируется со знаком «-»;
определяется сумма баллов S=P+Q
Коэффициент Кендалла также изменяется в пределах от -1 до +1. При достаточно большом числе наблюдений между коэффициентами корреляции рангов Спирмена и Кендалла существует следующее соотношение: r» .
Вычисления, связанные с коэффициентом ранговой корреляции , заметно упрощаются, если результаты ранжировки представить в виде:
где – ранг по результативному признаку той единицы совокупности, которая по факторному признаку имеет ранг .
При таком представлении ранжировки формула коэффициента корреляции рангов Кендалла имеет вид:
где –число единиц совокупности, для которых и одновременно . На практике вычисляют по формуле , где – – число рангов в ранжировке (***), для которых для которых и одновременно .
В Excel вычисление коэффициента ранговой корреляции Кендалла осуществляется по формуле (****) следующим образом:
1. Вводятся заголовки исходных и расчётных данных, необходимых для расчёта коэффициента корреляции рангов: в ячейку А1– названия единиц изучаемой совокупности, в ячейку В1– название факторного признака, в ячейку С1– названия результативного признака, в ячейку D1– символ , обозначающий ранг по факторному признаку, в ячейку Е1– символ , обозначающий ранг по результативному признаку, в ячейку– F– символ , обозначающий квадрат разности между рангами соответствующих величин двух признаков.
2. Производится ввод исходных данных: в диапазон ячеек столбца А вводятся названия или номера единиц изучаемой совокупности; в диапазон ячеек столбца В (например, В2:В11)– значения факторного признака, в диапазон ячеек столбца С (С2:С11)– значения результативного признака.
3. В диапазонах ячеек D2:D11 и Е2:Е11 определяются соответственно ранги по факторному и результативному признаку с помощью описанной выше процедуры Ранг и персентиль или функции РАНГ, для чего вводятся формулы массива = РАНГ (В2:В11; В2:В11;1) и = РАНГ (С2:С11; С2:С11;1).
4. Выделяется диапазон D1:E11, в котором находятся ранги по факторному и результативному признакам, нажимается кнопка Копировать на панели инструментов Стандартная.
5. Выделяется ячейка F1. В меню Правка выделяется команда Специальная вставка.
6. В открывшемся диалоговом окне Специальная вставка в группе переключателей Вставить установливается переключатель Значения и нажимается кнопка ОК. В диапазоне F2:G11 появятся «копии» рангов.
7. Выделяется диапазон F1:G11. В меню Данные выделяется команда Сортировка.
8. В открывшемся окне Сортировка диапазона в раскрывшемся списке Сортировать по выбирается поле , по которому надо выполнить сортировку, и установливается переключатель по возрастанию; в группе переключателей Идентифицировать поля по установливатся переключатель подписям (первая строка диапазона) и нажимается кнопка ОК.
В диапазоне F2:G11 появятся ранги по факторному и результативному признакам, отсортированные в порядке возрастания рангов факторного признака.
9. В ячейку Н2 вводится формула массива = СУММ (ЕСЛИ ($G3:$G11>G2;1;0)), нажимаются клавиши Ctrl+Shift+ Enter и затем эта формула копируется в ячейки Н3:Н11. В диапазоне Н2:Н11 появятся числа .
10. Суммируя эти числа в ячейке Н12, находится выборочное значение .
11. Используя формулу = 4* Н12/(10^2-10)-1 (машинный аналог формулы (****)), находится выборочное значение .
Существенность коэффициента корреляции рангов Кендалла проверяется
–при малом объёме совокупности ( ) с помощью таблиц точного распределения статистики ;
– при больших n для заданного уровня значимости a по формуле:
ta – коэффициент, определяемый по таблице нормального распределения.
Регрессионный анализ
Регрессионным анализом называется раздел статистики, объединяющий практические методы исследования формы корреляционной зависимости между изучаемыми признаками единиц исследуемой совокупности.
В регрессионном анализе различают парную и множественную регрессию. Парная регрессия описывает связь между двумя признаками: факторным и результативным. Множественная регрессия описывает зависимость результативного признака от нескольких факторных признаков.
Регрессионной моделью системы взаимосвязанных признаков принято считать такое уравнение регрессии, которое включает основные факторы, влияющие на вариацию результативного признака, обладает высоким (не ниже 0,5) коэффициентом детерминации и коэффициентами регрессии, интерпретируемыми в соответствии с теоретическим знанием о природе связей в изучаемой системе. Приведённое определение включает достаточно строгие условия: не всякое уравнение регрессии можно считать моделью.
Регрессионный анализ включает в себя следующие основные этапы:
выбор модели регрессии;
оценка параметров выбранной модели регрессии;
проверка значимости параметров модели регрессии и их интерпретация;
проверка адекватности построенной модели регрессии.
Выбор аналитической формы связи осуществляется на основе:
логического теоретического анализа;
графического изображения зависимости в виде эмпирической линии регрессии;
опыта предыдущих исследований, где выбранные формы связи давали удовлетворительные результаты;
различных статистико-математических критериев адекватности конкурирующих уравнений регрессии (остаточных дисперсий, ошибок аппроксимации и др.).
Наиболее разработанной в теории статистики является методология парной регрессии. При этом для изучения связи между изучаемыми признаками применяются различного вида уравнения (типы математических функций) линейной и нелинейной зависимостей.
При анализе линейной связи применяется прямолинейная функция, математическим выражением которой является уравнение прямой линии:
При анализе нелинейных связей используются следующие функции:
параболическая yx=a+bx+cx 2
показательная yx=ab x
логистическая yx= и др.
Решение математических уравнений связи предполагает вычисление по исходным данным их параметров a и b. Это осуществляется способом выравнивания эмпирических (фактических) данных методом наименьших квадратов (МНК). В основу этого метода положено требование минимальности суммы разности квадрата отклонений эмпирических значений результативного признака от его выровненных (теоретических) значений yxi, полученных по выбранному уравнению регрессии:
Параметры b1,… bn в уравнении регрессии называют коэффициентами регрессии. Если связь по направлению прямая – он имеет положительное значение, если обратная – отрицательное. При линейной связи коэффициент регрессии показывает на сколько единиц своего измерения в среднем изменяется величина результативного признака при изменении факторного признака на единицу своего измерения.
В Excel имеется две процедуры и восемь встроенных функций для регрессионного анализа. Они вычисляют не только выборочные параметры регрессии, но и ещё ряд дополнительных выборочных характеристик исследуемой регрессионной зависимости. К числу таких характеристик относятся:
общая сумма квадратов = – сумма квадратов отклонений фактических(эмпирических) значений результативного признака от его среднего значения ;
сумма квадратов, обусловленная регрессией = –сумма квадратов отклонений теоретических (расчётных, выровненных) значений результативного признака от его среднего значения ;
сумма квадратов остатков = –сумма квадратов отклонений фактических значений результативного признака от его теоретических значений ;
числа степеней свободы этих сумм .
средний квадрат регрессии или факторная (систематическая) дисперсия– – характеризует колеблемость результативного признака под влиянием только фактора х, входящего в уравнение регрессии;
средний квадрат остатков или остаточная (случайная) дисперсия– –характеризует колеблемость результативного признака под влиянием прочих факторов, не входящих в уравнение регрессия.
Эти дисперсии связаны между собой равенством, носящим название «правило сложения дисперсий»– ; ;
множественный коэффициент (индекс) корреляции ; в случае парной линейной регрессии этот показатель совпадает с коэффициентом корреляции , а в случае парной нелинейной регрессии носит название теоретического корреляционного отношения;
коэффициент детерминации– ; показывает вариацию результативного признака, обусловленную вариацией факторов, входящих в регрессионную модель;
нормированный (скорректированный) коэффициент детерминации – . где –число факторов, включённых в регрессионную модель. Корректировка не производится при условии, если ;
стандартная ошибка аппроксимации (средняя квадратическая ошибка) уравнения регрессии:
где -число параметров в уравнении регрессии.
стандартное отклонение параметров регрессии– . Наиболее точно эта величина может быть определена по формуле:
где – среднее квадратическое отклонение результативного признака (корень квадратный из общей дисперсии); –среднее квадратическое отклонение — го факторного признака; –величина множественного коэффициента корреляции по фактору с остальными факторами.
Выборочный коэффициент детерминации и выборочные параметры регрессии, вычисленные по ограниченному числу единиц изучаемой совокупности, всегда содержат элемент случайности, в связи, с чем возникает необходимость проверки значимости этих выборочных характеристик.
При проверке значимости параметра регрессии , выдвигается гипотеза о том, что фактор не оказывает заметного влияния на результативный признак. Значимость параметров регрессии проверяется на основе t – критерия Стьюдента:
Параметр признаётся статистически значимым, если расчётное значение t – критерия Стьюдента превосходит его критическое значение, определяемое при заданном уровне значимости α и числе степеней свободы . Критическое значение t – критерия может быть определено по таблице распределения Стьюдента или в Excel по представленному в предыдущем разделе порядку.
При проверке значимости коэффициента детерминации выдвигается гипотеза о том, что коэффициент детерминации генеральной совокупности, из которой извлечена исследуемая выборка, равен нулю. Эта гипотеза равносильна гипотезе о том, что ни один из факторов, включённых в регрессию, не оказывает существенного влияния на результативный признак. Поэтому проверка значимости коэффициента детерминации является проверкой адекватности (соответствия) выбранной модели регрессии реальным данным наблюдения. Значимость коэффициента детерминации осуществляется с помощью F-критерия.
Расчётное значение критерия Фишера–Снедекора, вычисляется по формуле:
Если , то гипотеза о равенстве коэффициента детерминации нулю и несоответствии заложенных в модели связей реально существующим отклоняется на уровне значимости , то есть коэффициент детерминации признаётся статистически значимым, а модель регрессии – адекватной. Величина определяется по специальным таблицам и зависит от заданного уровня значимости и числа степеней свободы: и , где – число наблюдений; – число факторных признаков в модели.
В качестве меры адекватности модели регрессии используется также процентное отношение стандартной ошибки к среднему уровню результативного признака – относительная ошибка аппроксимации:
Если , то точность модели регрессии высокая, если 10-20% – точность модели регрессии хорошая (то есть уравнение достаточно хорошо описывает взаимосвязь между изучаемыми признаками), если 20-50% – точность модели регрессии удовлетворительная.
В Excel для проведения регрессионного анализа существует статистическая процедура Регрессия, позволяющая осуществлять парную линейную, параболическую (полиноминальную) и множественную регрессии. Для выбора формы связи целесообразно построить корреляционное поле, воспользовавшись специальным средством Мастер диаграмм, выбрав тип Точечная (см. предыдущий раздел).
Парная линейная регрессия в Excel осуществляется следующим образом:
Осуществляется ввод исходных данных, т.е. значений факторного и результативного признака.
В меню Сервис выделяется строка Анализ Данных.
В открывшемся окне Анализ данных выделяется процедура Регрессия и нажимается кнопка ОК. Откроется диалоговое окно Регрессия с пульсирующим курсором в поле ввода Входной интервал Y.
С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения результативного признака Y. В поле ввода Входной интервал Y появится соответствующая ссылка.
Нажатием клавиши Tab осуществляется переход в поле ввода Входной интервал Х. С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения факторного признака Х. В поле ввода Входной интервал Х появится соответствующая ссылка.
Устанавливается флажок в группе флажков Остатки. В данную группу входят следующие флажки:
– флажок Остатки. При его установке на экран выводится таблица ВЫВОД ОСТАТКОВ, в состав которой входит столбец Остатки;
– флажок График остатков. При активизации этого флажка на экран выводятся графики зависимости остатков от регрессионных переменных (по одному графику на каждую переменную);
– флажок Стандартизированные остатки. При установке данного флажка в таблицу ВЫВОД ОСТАТКОВ добавляется столбец центрированных нормированных (стандартизированных), которые получаются из остатков делением их на ;
– флажок График подбора. При установке этого флажка на рабочий лист выводятся точечных графиков (по числу контролируемых переменных). На графике, связанном с -й контролируемой переменной , =1, 2…., , каждому значению этой переменной поставлены в соответствие две точки и ;
– флажок График нормальной вероятности. При активизации этого флажка на экран выводятся таблица ВЫВОД ВЕРОЯТНОСТИ и график функции, обратной эмпирической функции распределения результативного признака, выполненный на «вероятностной нормальной бумаге».
Щелчком на кнопке ОК запускается процедура Регрессия.
Помимо этого процедура содержит также следующие элементы управления:
Флажок Константа-ноль. Устанавливается в том случае, когда необходимо, чтобы линия регрессии проходила через начало координат. При этом параметр равен нулю и число параметров регрессии равно числу факторов.
флажок Уровень надёжности. Устанавливается в том случае, когда помимо доверительных интервалов для параметров регрессии, соответствующих используемой по умолчанию «стандартной» доверительной вероятности 95%, необходимо вычислить доверительные интервалы, доверительная вероятность которых отличается от «стандартной». «Нестандартная» вероятность, выраженная в процентах, вводится в поле, расположенное справа от рассматриваемого флажка. Если этот флажок не установлен, то выходной таблице параметров регрессии будут одинаковые пары столбцов, содержащие доверительные границы для параметров регрессии, соответствующие одной и той же доверительной вероятности 95% (при редактировании таблицы их можно убрать).
Назначение флажка Метки и переключателей Выходной интервал/Новый рабочий лист/ Новая книга рассмотрено в 1 разделе.
После запуска процедуры Регрессия на рабочем листе появляются три таблицы результатов этой процедуры. В первой таблице «Регрессионная статистика» содержатся значения множественного коэффициента корреляции, коэффициента детерминации, нормированного коэффициента детерминации, стандартная ошибка уравнения регрессии и число наблюдений. Во второй таблице «Дисперсионный анализ» содержатся значения сумм квадратов и среднего квадрата регрессии, остатков и общие., а также расчётное значение критерия Фишера–Снедекора. В третьей таблице в графе «Коэффициенты» по строке «Y- пересечение» находится значение свободного члена уравнения регрессии , а по строке Х – значение параметра . Далее по графам расположены стандартная ошибка, расчётное значение t – критерия Стьюдента, доверительные интервалы для этих параметров.
Полиноминальная (параболическая) регрессия в Excel осуществляется следующим образом:
1. В ячейки А1, В1 и С1 вводятся метки Y, X и X 2 .
2. В диапазон А2 и далее (например, А2: А15) вводятся значения результативного признака, в диапазон В2 и далее (соответственно В2:В15)– значения факторного признака.
3.В диапазон С2 и далее (С2: С15) вводится формула массива = В2:В15^2 и нажимается комбинация клавиш Ctrl+Shift+ Enter. В диапазоне С2:С15 появится столбец квадратов значений факторного признака.
4. В открывшемся окне Анализ данных выделяется процедура Регрессия и нажимается кнопка ОК. Откроется диалоговое окно Регрессия с пульсирующим курсором в поле ввода Входной интервал Y.
5. С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения результативного признака Y. В поле ввода Входной интервал Y появится соответствующая ссылка.
6. Осуществляется переход в поле ввода Входной интервал Х. С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения факторного признака. В поле ввода Входной интервал Х появится соответствующая ссылка.
7. Устанавливается флажок в группе флажков Остатки.
8. Щелчком на кнопке ОК запускается процедура Регрессия.
После запуска процедуры Регрессия на рабочем листе появляются три таблицы результатов этой процедуры.
Множественная линейная регрессия в Excel осуществляется аналогичным образом. При этом в качестве исходных данных вводятся значения результативного и нескольких ( ) факторных признаков.
К статистическим функциям, предназначенным для регрессионного анализа в Excel, относятся ЛИНЕЙН, НАКЛОН, ОТРЕЗОК, ТЕНДЕНЦИЯ, ПРЕДСКАЗ, СТОШYХ, ЛГРФПРИБЛ, РОСТ.
Из этих функций интерес представляют функции ЛГРФПРИБЛ, ТЕНДЕНЦИЯ и РОСТ, так как другие функции вычисляют некоторые характеристики, определяемые статистической процедурой РЕГРЕССИЯ, а также дублируют друг друга. Эти же три функции производят вычисления, не предусмотренные статистической процедурой РЕГРЕССИЯ.
Функция ЛГРФПРИБЛ вычисляет выборочные оценки параметров показательной (экспоненциальной) регрессии.
Синтаксис данной функции: ЛГРФПРИБЛ (известные значения у; известные значения х;, конст; стат):
известные значения у– множество значений результативного признака. Данный массив представляет собой вектор-столбец размером ;
известные значения х–множество значений факторных признаков.
– Если в случае парной регрессии этот аргумент опущен, то при вычислениях в качестве массива известные значения х используется массив натуральных чисел 1,2…и т.д. такого же размера, как и массив известные значения у;
– В случае множественной регрессии, если массив известные значения у представляет собой вектор-столбец, то массив известные значения х должен иметь строк и столбцов. При этом каждый столбец этого массива содержит значений определённого факторного признака;
– При вводе массива чисел известные значения х с клавиатуры для разделения значений в одной строке используют точку с запятой, а для разделения строк– двоеточие.
конст–логическая переменная, определяющая, следует ли включать в уравнение регрессии свободный член.
– Если конст=1 (ИСТИНА) или опущен, то вычисляются и коэффициенты регрессии, и свободный член.
– Если конст= 0 (ЛОЖЬ), то предполагается, что свободный член равен единице.
стат– логическая переменная, определяющая объём выходной информации.
– Если аргумент стат =0 (ЛОЖЬ) или опущен, то функция выдаёт только параметры уравнения регрессии. При этом для вывода результатов решения надо заранее выделить диапазон ячеек размером , где – число факторов, включённых анализ.
– Если аргумент стат =1 (ИСТИНА), то помимо функция выдаёт дополнительную информацию об исследуемой регрессионной зависимости. В этом случае для вывода результатов решения надо выделить диапазон ячеек размером . В первом столбце выделенного диапазона находятся следующие характеристики коэффициенты регрессии, стандартная ошибка коэффициента регрессии, коэффициент детерминации, расчётное значение F- критерия Фишера, сумма квадратов, обусловленная регрессией. Во втором столбце находятся значения свободного члена, его стандартная ошибка, стандартная ошибка уравнения регрессии, число степеней свободы, сумма квадратов остатков.
Так как результатом реализации функции является массив чисел, содержащий выборочные характеристики исследуемой регрессионной зависимости, то функция вводится как формула массива Ctrl+Shift+ Enter. Например, = ЛГРФПРИБЛ (А1:А6;В1:В6;1;1).
Функции ТЕНДЕНЦИЯ и РОСТ используются для вычисления расчётных значений результативного признака, соответствующих заданным пользователем значениям факторных признаков, хранящимся в массиве новые значения х. При этом функция ТЕНДЕНЦИЯ вычисляет параметры линейной и других видов регрессии, линейных относительно входящих в них коэффициентов, таких, например, как полиноминальная (параболическая) регрессия , а функция РОСТ– параметры экспоненциальной регрессии.
Функции вводится как формула массива Ctrl+Shift+ Enter.
Синтаксис данных функций идентичен: ТЕНДЕНЦИЯ (известные значения у; известные значения х;, новые значения х,; конст) и РОСТ (известные значения у; известные значения х;, новые значения х,; конст):
известные значения у– множество значений результативного признака. Данный массив представляет собой вектор-столбец размером ;
известные значения х–множество значений факторных признаков.
– Если в случае парной регрессии этот аргумент опущен, то при вычислениях в качестве массива известные значения х используется массив натуральных чисел 1,2…и т.д. такого же размера, как и массив известные значения у;
– В случае множественной регрессии, если массив известные значения у представляет собой вектор-столбец, то массив известные значения х должен иметь строк и столбцов. При этом каждый столбец этого массива содержит значений определённого факторного признака;
– При вводе массива чисел известные значения х с клавиатуры для разделения значений в одной строке используют точку с запятой, а для разделения строк– двоеточие.
новые значения х– новые значения факторных признаков, для которых функция должна вычислить расчётные значения результативного признака;
– В случае множественной регрессии, если массив известные значения у представляет собой вектор-столбец, то массив новые значения х должен иметь столбцов и столько строк, сколько расчётных значений у надо вычислить.
–Массив новые значения х, так же как и массив известные значения х, должен содержать столбец для каждого факторного признака. Число столбцов этих массивов должно быть одинаково.
– Если аргумент новые значения х опущен, то предполагается, что он совпадает с аргументом известные значения х.
конст–логическая переменная, определяющая, следует ли включать в уравнение регрессии свободный член.
– Если конст=1 (ИСТИНА) или опущен, то вычисляются и коэффициенты регрессии, и свободный член.
– Если конст= 0 (ЛОЖЬ), то предполагается, что свободный член равен нулю (в случае линейной регрессии) и единице (в случае экспоненциальной регрессии).
Ряды динамики
Ряд динамики– это ряд числовых значений статистических показателей, расположенных в хронологической последовательности и характеризующих изменение явления во времени.
Ряд динамики состоит из двух элементов:
уровней динамического ряда– числовых значений статистических показателей, характеризующих величину изучаемого явления– ;
периодов (или моментов) времени, к которым относятся данные уровни – .
Одной из основных задач в процессе анализа уровней динамического ряда является определение основной закономерности (тенденции) их изменений во времени.
При этом выделяются следующие основные компоненты динамического ряда:
основная тенденция (тренд) (Т);
Первые три компоненты формируют систематическую составляющую динамического ряда.
Тренд характеризует устойчивое систематическое изменение динамического ряда, происходящее в течение длительного времени и обусловленное влиянием медленно развивающихся долговременных факторов.
Сезонная компонента– это колебания, периодически повторяющиеся в некоторое определённое время каждого года, дня месяца или часа дня.
Циклическая (периодическая) компонента проявляется в том, что значение изучаемого показателя в течение какого-то времени возрастает, достигает определённого максимума, затем понижается, достигает определённого минимума, вновь возрастает до прежнего значения и т.д.
Четвёртую компоненту формируют случайные колебания, которые являются результатом действия большого количества относительно слабых второстепенных факторов.
Для выявления и характеристики основной закономерности развития явления необходимо выявить первую компоненту динамического ряда – тренд, и погасить влияние других типов колебаний на изменение уровней ряда.
С этой целью проводят выравнивание динамических рядов. Различают два вида выравнивания: механическое (или сглаживание) и аналитическое.
К приёмам механического выравнивания относятся:
усреднение левой и правой половины ряда;
скользящая средняя: простая, взвешенная;
Выбор приема выравнивания зависит от исходной информации и задач исследования.
В среде Excel для выравнивания динамических рядов используются процедуры Скользящее среднее и Экспоненциальное сглаживание, входящие в Пакет анализа.
Сущность метода скользящей средней заключается в том, что вычисляется средний уровень из определенного числа первых по порядку уровней ряда, затем – средний уровень из такого же числа уровней, начиная со второго, затем, начиная с третьего и т.д. Таким образом, при расчётах среднего уровня как бы «скользят» по ряду динамики от его начала к концу, каждый раз отбрасывая один уровень вначале и добавляя один следующий. Этим объясняется название – скользящая средняя.
Следует отметить, что при использовании метода скользящей средней «теряются» членов в начале и в конце динамического ряда (где –размер интервала (окна) сглаживания). Для восстановления «потерянных» уровней в начале и в конце сглаженного ряда для =3 и =5 могут быть использованы следующие формулы:
Для получения количественной модели, выражающей основную тенденцию изменения уровней динамического ряда во времени, используется приём аналитического выравнивания. Сущность его состоит в том, что основная тенденция развития рассчитывается как функция времени. В этом случае фактические (эмпирические) уровни заменяются теоретическими, вычисленными по соответствующему аналитическому уравнению.
Аналитическое выравнивание производится в следующей последовательности:
1) выделяется этап развития явления и устанавливается характер динамики на этом этапе. Этап развития явления– это период, в течение которого формирование уровней динамического уровня осуществляется под воздействием определённого набора постоянных, периодических и разовых факторов. Решение этой задачи осуществляется не только с помощью статистических методов, а в основном – на базе анализа сущности, природы явлений и общих законов его развития.
2) на основе предположений о той или иной закономерности развития выбирается форма аналитического выражения тренда, то есть вид аппроксимирующей математической функции.
Основанием для выбора уравнения тренда могут служить:
качественный анализ сущности развития данного явления;
результаты предыдущих исследований в данной области;
графическое изображение эмпирических или скользящих уровней ряда динамики;
статистико-математических критериев адекватности.
При анализе рядов динамики используются следующие математические модели:
линейная yt = a0 + a1t,
где и – параметры уравнения;
– начальный уровень тренда в момент или период, принятый за начало отсчёта времени;
– среднее абсолютное изменение за единицу времени;
Параметр определяет направление развития: если , то уровни ряда равномерно возрастают в среднем за единицу времени на величину , если , то происходит их равномерное снижение.
полиноминальная(параболическая) , где –степень полинома. Наиболее применяемой в практике статистических расчётов является уравнение параболы второго порядка yt = a0 + a1t + a2t 2 .
Значение параметров и идентично предыдущему уравнению.
Параметр характеризует изменение интенсивности развития в единицу времени. При происходит ускорение развития, при – замедление развития.
Соответственно при параболической форме тренда возможны следующие варианты развития:
если ; – ускорение роста;
если ; – замедление роста;
если ; – замедление снижения;
если ; – ускорение снижения.
экспоненциальная ,
где – константа ряда, –темп изменения в разах. При >1 экспоненциальный тренд выражает тенденцию ускоренного и всё более ускоряющегося возрастания уровней, при <1 экспоненциальный тренд означает всё более замедляющегося снижения уровней динамического ряда.
логарифмическая . Логарифмическая форма тренда применяется для отображения тенденции замедляющегося роста уровней при отсутствии предельно возможного значения, например, роста спортивных достижений, производительности агрегата, продуктивности скота.
гиперболическая yt = a0 + a1 – применяется для отображения тенденции процессов, ограниченных предельным значением уровня;
степенная – применяется для отображения тенденции явлений с разной мерой пропорциональности изменений во времени;
логистическая и др.
Наиболее точным способом выбора формы тренда является применение статистико-математических критериев, в качестве которых могут выступать остаточное среднее квадратическое отклонение, средняя ошибка аппроксимации ( ), стандартизированная ошибка аппроксимации ( ), относительная ошибка аппроксимации (модифицированный коэффициент вариации):
y и — соответственно фактические и теоретические значения ряда динамики;
n – число уровней ряда;
m – количество параметров в уравнении тренда.
Предпочтение отдаётся той функции, которая имеет наименьшую величину критерия.
Если , то точность модели тренда высокая, если = 10-20% – точность модели тренда хорошая (то есть уравнение достаточно хорошо описывает основную тенденцию развития изучаемого явления), если =20-50% – точность модели тренда удовлетворительная.
3) Вычисляются параметры уравнения тренда, и по ним производится синтезирование трендовой модели.
Расчёт параметров уравнений тренда может быть произведён различными способами:
методом средних значений (или линейных отклонений);
методом конечных разностей;
методом наименьших квадратов.
Наиболее точным является аналитическое выравнивание с помощью способа наименьших квадратов. Суть данного способа состоит в том, что теоретическая линия (прямая или кривая), выравнивающая ряд, должна проходить в максимальной близости к фактическим уровням ряда. Математически это означает, что сумма квадратов отклонений (разность между фактическими и теоретическими уровнями) должна быть минимальной:
å (y – yt) 2 = min.
4) На основе синтезированной модели тренда вычисляются теоретические уровни.
Выявление и характеристика основной тенденции развития дают основание для прогнозирования, то есть для определения возможного варианта размеров явления в будущем. Важное значение при прогнозировании имеют вопросы о базе и сроках прогнозирования.
База прогнозирования – длина или продолжительность базисного периода, закономерность которого будет распространяться на будущее.
Срок прогнозирования (период упреждения) – длина будущего периода, на который распространяется закономерность развития явления.
Однозначного ответа на вопрос об определении допустимого срока прогноза нет. В основном придерживаются следующего правила: срок прогноза не должен превышать третьей части длины базы прогноза. Однако в каждом конкретном случае необходимо учитывать особенности изучаемого явления. При этом необходимо, чтобы продолжительность базисного ряда составляла определенный этап в развитии анализируемого явления в конкретных исторических условий.
Установление сроков прогнозирования зависит от цели исследования. Однако следует иметь в виду, особенности характера изучаемого явления. Например, ограниченные физиологические особенности животных (или растений), делают невозможным увеличение продуктивности животных (или урожайности) до бесконечности. Кроме того, необходимо учитывать неустойчивость экономики в условиях переходного периода. Поэтому чем короче сроки прогнозирования периода, тем надежнее результат прогноза.
Разработка прогнозного уровня динамического ряда может осуществляться на основе использования различных методов, наиболее распространённым из которых является метод экстраполяции.
Метод экстраполяции основывается на предположении о неизменности основных факторов, определяющих тенденцию данного показателя, и заключается в распространении закономерностей развития этого показателя, имевших место в прошлом, на будущее.
Более точным и распространённым методом экстраполяции является применение аналитического выражения тренда, при котором в адекватную трендовую модель подставляются значения в будущие годы. Прогнозирование на основе экстраполяции дает возможность получить точечные значения прогнозируемого уровня исследуемого показателя.
Интерполяция– это приближённый расчёт уровней, находящихся внутри ряда динамики, но почему-либо неизвестных. При интерполяции предполагается, что характер тенденции не претерпел существенных изменений в том промежутке времени, уровень которого нам не известен.
Как и экстраполяция, интерполяция может производится на основе на основе выравнивания динамического ряда по какой-либо аналитической формуле.
В Excel сглаживание динамического ряда методом скользящей средней осуществляется следующим образом:
1. В диапазон ячеек вводятся уровни ряда динамики (числовые значения изучаемого статистического показателя).
2.В меню Сервис выделяется строка Анализ данных.
3. В открывшемся окне Анализ данных выделяется процедура Скользящее среднее и нажимается кнопка ОК. На экране появится диалоговое окно Скользящее среднее.
4. В поле ввода Входной интервал этого окна вводится ссылка на диапазон ячеек, содержащий уровни исследуемого ряда динамики. Входной интервал должен состоять из одного столбца, «высота» которого равна числу уровней данного ряда динамики.
5. В поле Интервал вводится размер окна сглаживания (по умолчанию =3).
6. В поле Выходной интервал вводится ссылка на верхнюю ячейку столбца результатов сглаживания. Выходной интервал всегда располагается на том же самом рабочем листе, на котором находится входной интервал, поэтому в диалоговом окне процедуры нет таких позиций, как Новый рабочий лист и Новая рабочая книга. Выходной интервал состоит по крайней мере из одного столбца, содержащего уровни сглаженного ряда. Высота этого столбца равна высоте входного интервала. При установке флажка Стандартные погрешности в выходном интервале появляется ещё один столбец– столбец стандартных погрешностей. В точках, для которых нельзя вычислить сглаженные значения и стандартные погрешности, процедура выводит сообщение # Н/Д! (Нет данных).
7. Устанавливается флажок Вывод графика. Флажок Стандартные погрешности устанавливается при необходимости получения стандартных погрешностей сглаживания. Назначение флажка Метки рассмотрено в 1 разделе.
8. Нажимается кнопка ОК.
Следует иметь в виду, что процедур Скользящее среднее выдаёт сглаженный ряд так называемых адаптивных скользящих средних. Этот ряд сдвинут на шагов вправо относительно «канонического» ряда скользящих средних. Для сравнения простого и адаптивного скользящих средних в диапазоне ячеек, число которых на -1 меньше числа уровней исходного ряда динамики, свободного столбца, рассчитываются значения скользящих средних, вычисленные по канонической формуле = СРЗНАЧ по диапазону из первых уровней динамического ряда (например, при =3 А1:А3). Данная формула вводится в следующую после по счёту ячейку столбца, предназначенного для расчёта канонических средних (например, при =3–во вторую (С2), при =5 (С3) и т.д.). Затем данная формула копируется в оставшийся диапазон ячеек этого столбца. Адаптивные скользящие средние могут быть вычислены также с помощью статистической процедуры Добавить линию тренда (см. ниже).
При проведении экспоненциального сглаживания использование одноимённой процедуры аналогично выше рассмотренному порядку. Вместо поля Интервал диалогового окна Скользящее среднее в процедуре Экспоненциальное сглаживание заполняется поле Фактор затухания. В это поле вводится фактор затухания , где – параметр сглаживания (вес текущего значения при вычислении экспоненциального среднего, ). Параметр характеризует скорость реакции экспоненциального среднего на изменение текущего значения динамического ряда и одновременно определяет его способность сглаживать случайные колебания. Чем больше , тем быстрее реакция экспоненциального среднего на изменение динамического ряда и тем меньше его сглаживающие возможности. В качестве приемлемого компромисса рекомендуется брать в пределах от 0,1 до 0,3. Следовательно, приемлемыми значениями фактора затухания являются значения из интервала от 0,7 до 0,9. В статистической процедуре Экспоненциальное сглаживание по умолчанию , что противоречит рекомендациям.
При аналитическом выравнивании в Excel используются статистическая процедура Регрессия и статистические функции регрессионного анализа ЛИНЕЙН, ПРЕДСКАЗ, ЛГРФПРИБЛ, ТЕНДЕНЦИЯ и РОСТ, рассмотренные в предыдущем разделе. В этом случае при использовании статистической процедуры Регрессия вместо значений факторного признака вводятся натуральные числа 1,2,…. , обозначающие порядковые номера периодов или моментов времени. При использовании статистических функций натуральные числа можно не вводить, а оставить пропущеным аргумент известные значения х. Тогда при вычислениях в качестве массива известные значения х используется массив натуральных чисел 1,2…и т.д. такого же размера, как и массив известные значения у.
Эффективным средством аналитического выравнивания является процедура Добавить линию тренда, входящая в комплекс графических средств табличного процессора Excel. Она вычисляет параметры выбранной пользователем модели тренда. При вычислениях используется МНК. Модель тренда выбирается из набора, включающего в себя пять наиболее распространённых аналитических моделей: линейную, логарифмическую, полиноминальную (параболическую), степенную, экспоненциальную и модель адаптивной скользящей средней (формулы см. выше данном разделе). Параметры аналитических моделей вычисляются по данным наблюдения, по которым построен график динамического ряда. В результате реализации процедуры в область построения графика выводятся график функции тренда, её аналитическое выражение и значение коэффициента детерминации R 2 . При изменении любых значений исходного ряда динамики процедура автоматически пересчитывает и обновляет параметры линии тренда и её график.
Для доступа к процедуре Добавить линию тренда необходимо:
1. В диапазон ячеек определённого столбца ввести уровни исследуемого динамического ряда.
2. С помощью Мастера Функций построить диаграмму (график) ряда динамики.
3. Щелчком на диаграмме активизировать её. На панели меню на месте пункта Данные появится пункт Диаграмма.
4. В пункте меню Диаграмма выбрать команду Добавить линию тренда. Откроется диалоговое окно Линия тренда.
5. В открывшемся окне Линия тренда раскрыть вкладку Тип.
6. На этой вкладке в разделе Построение линии тренда (аппроксимация и сглаживание) выбрать тип (вид) функции тренда.
7. В списке Построен на ряде выделить ряд данных, для которых строится линия тренда.
8. Раскрыть вкладку Параметры диалогового окна Линия тренда.
Эта вкладка содержит следующие элементы управления:
группу переключателей Название аппроксимирующей (глаженной) кривой, состоящую из двух переключателей. При установке переключателя автоматическое Excel автоматически присваивает линии тренда имя, связанное с типом этой линии и названием данных наблюдения, по которым строится линия тренда, например, Линейный (Урожайность зерновых). При установке переключателя другое пользователь сам устанавливает имя линии регрессии и вводит это имя в поле Линейный (Ряд 1), расположенное справа от переключателя (максимальная длина имени 256 символов);
группу счётчиков Прогноз, в которую входят два счётчика: вперёд на…единиц и назад на…единиц. С помощью этих счётчиков устанавливается срок прогноза и производится экстраполяция и интерполяция ряда динамики. Счётчики недоступны в режиме Скользящее среднее;
флажок пересечение кривой с осью Y в точке. Если этот флажок не установлен, ордината точки пересечения линии тренда с осью Y вычисляется по данным наблюдения. Как правило, этот флажок не устанавливается. Используя этот флажок и расположенное справа от него поле ввода, можно задать нужную ординату точки пересечения (при активном флажке и нуле в поле ввода линия тренда пройдет через начало координат);
флажок показывать уравнение на диаграмме. При установке этого флажка в область построения диаграммы выводится аналитическое выражение (формула) функции тренда;
флажок поместить на диаграмму величину достоверности аппроксимации. При установке этого флажка в область построения диаграммы выводится значение коэффициента детерминации R 2 , который показывает, на сколько процентов выбранная линия тренда объясняет разброс уровней ряда. Чем больше данный показатель, тем более точно выбрана линия тренда. Сравнивая величину R 2 по разным аналитическим моделям можно определить аппроксимирующую функцию. то есть наиболее точно описывающую основную тенденцию развития изучаемого явления.
9. Установить нужные переключатели, счётчики и флажки. Щёлкнуть на кнопке ОК.
Список рекомендуемой литературы
1. Вадзинский Р. Статистические вычисления в среде Еxcel. –СПб.: Питер,2008.
2. Макарова Н.В. Трофимец В.Я. Статистика в Еxcel.– М.: Финансы и статитсика, 2006.
3. Берк К. Кэйри П. Анализ данных с помощью MS Еxcel.–М.: Вильямс, 2005.
4. Васильев А.Н. Научные вычисления в Microsoft Excel.–М.; Спб.; Киев: Диалектика, 2004.
5.Вуколов Э.А. Основы статистического анализа: практикум по статистическим методам и исследованию операций с использованием пакетов STATISTICA и Еxcel.– М.: Форум; Инфра–М, 2004.
6. Минько А.А. Статистический анализ в среде Еxcel.–М., СПб., Киев: Диалектика, 2004.
7. Гайдышев И. Анализ и обработка данных.–СПб; М.: Питер, 2001.
8. Елисеева И.И., Юзбашев М.М. Общая теория статистики: Учебник. М: Финансы и статистика, 2005
9. Ефимова М.Р., Петрова Е.В., Румянцев В.Н. Общая теория статистики: Учебник. – М.: ИНФРА- М, 2006.
10. Теория статистики: Учебник / Под ред. Р.А. Шмойловой .4-е изд., доп. и перераб. — М.: Финансы и статистика, 2005.
Работа с инструментом «Регрессия» в Microsoft Excel
Диалоговое окно «Регрессия». В первое окно «Входной интервал Y» вводим данные объясняемой переменной — у, диапазон должен состоять из одного столбца. Во второе окно «Входной интервал X» вводим данные объясняющих переменных — х. На рис. П.1 представлены у. $С$2:$С$13, х: $В$2:$В$13. Длины интервалов должны быть одинаковы. Если строится уравнение множественной регрессии, то данные объясняющих переменных вводятся в окно «Входной интерват X» соответствующим образом. На рис. П.2 представлены у: $D$2:$D$13, xt—x2: $В2:$С$13. Максималь- ное число независимых объясняющих переменных равно 16.

Рис. П. 1. Задание парной регрессии
Ставим «галочку» в окно «Метки», если в отчете Microsoft Excel требуется знать, к какой из объясняющих переменных относятся результирующие данные.
Если исследователю не требуется константа Ь0, то ставим «галочку» в окно «Константа — ноль». Линия регрессии пройдет через начало координат.

Рис. П.2. Задание множественной регрессии
«Уровень надежности». По умолчанию программа строит уравнение регрессии для доверительной вероятности (уровень надежности) 0,95. Если требуется другая величина, ставим «галочку» в окно «Уровень надежности» и в окно, помеченное символом «%», вводим требуемую величину уровня надежности десятичной дробью.
«Параметры вывода». Указываем, куда вывести результаты регрессионного анализа: на этом листе, как указано на обоих рисунках, на другой рабочий лист или в новую рабочую книгу.
«Остатки». Выбираем то, что требуется исследователю, и ставим «галочку». Можно одновременно пометить несколько окон. Подробная информация дана в справке но инструменту «Регрессия».
Заполнив диалоговое окно «Регрессия», нажимаем кнопку ОК. Программа выводит отчет «Вывод итогов» в виде трех таблиц (рис. П.З, приведено для двух объясняющих переменных).
Приведем описание таблиц (первых двух — в табл. П1.1 и П1.2 соответственно, третьей — в текстовом виде).
Таблица П1.1
Описание первой таблицы
Наименование в отчете
Множественный R
Коэффициент множественной корреляции, индекс корреляции
Коэффициент детерминации, R 2
Скорректированный К 2
Наименование в отчете
Среднее квадратическое отклонение от модели
Рис. П.З. Результаты работы программы
Описание третьей таблицы
Данные первой строки относятся к коэффициенту уравнения регрессии Ь0, данные второй строки — к коэффициенту Ьи третьей — к Ь2 и далее до коэффициента Ьт, но числу объясняющих переменных в уравнении.
Метки, если поставлена галочка в окно «Метки». У-пересечение для коэффициента />0, далее но всем объясняющим переменным.
Значения коэффициентов уравнения регрессии Ь0, Ьь . Ьт.
Стандартная ошибка коэффициента регрессии 5^, 5Л). Sbm.
Статистическая значимость коэффициента регрессии (^-статистика) для а = 0,05 tw . tbm.
P-значение — это значение уровней значимости, соответствующее вычисленным ^статистикам коэффициентов.
Нижние 95% и Верхние 95% — это нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения регрессии. Если в окно «Уровень надежности» не вводилось другое значение доверительной вероятности, то последние два столбца дублируют предыдущие два столбца. Если в окно «Уровень надежности» было введено другое значение доверительной вероятности у, то последние два столбца содержат значения соответственно нижней и верхней границы у-процентных доверительных интервалов.
Корреляция входной интервал содержит нечисловые данные что делать
Входной интервал содержит нечисловые данные что делать?
Работа с инструментом «Регрессия» в Microsoft Excel
Открыв рабочую книгу и введя в нее исходные данные для построения уравнения регрессии, вызываем надстройку «Регрессия»: Данные — Анализ данных — Регрессия.
Рис. П. 1. Задание парной регрессии
Ставим «галочку» в окно «Метки», если в отчете Microsoft Excel требуется знать, к какой из объясняющих переменных относятся результирующие данные.
Рис. П.2. Задание множественной регрессии
«Уровень надежности». По умолчанию программа строит уравнение регрессии для доверительной вероятности (уровень надежности) 0,95. Если требуется другая величина, ставим «галочку» в окно «Уровень надежности» и в окно, помеченное символом «%», вводим требуемую величину уровня надежности десятичной дробью.
«Параметры вывода». Указываем, куда вывести результаты регрессионного анализа: на этом листе, как указано на обоих рисунках, на другой рабочий лист или в новую рабочую книгу.
«Остатки». Выбираем то, что требуется исследователю, и ставим «галочку». Можно одновременно пометить несколько окон. Подробная информация дана в справке но инструменту «Регрессия».
Заполнив диалоговое окно «Регрессия», нажимаем кнопку ОК. Программа выводит отчет «Вывод итогов» в виде трех таблиц (рис. П.З, приведено для двух объясняющих переменных).
Приведем описание таблиц (первых двух — в табл. П1.1 и П1.2 соответственно, третьей — в текстовом виде).
Описание первой таблицы
Наименование в отчете
Коэффициент множественной корреляции, индекс корреляции
Коэффициент детерминации, R 2
Скорректированный К 2
Наименование в отчете
Среднее квадратическое отклонение от модели
Рис. П.З. Результаты работы программы
Описание третьей таблицы
Стандартная ошибка коэффициента регрессии 5^, 5Л). Sbm.
P-значение — это значение уровней значимости, соответствующее вычисленным ^статистикам коэффициентов.
Нижние 95% и Верхние 95% — это нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения регрессии. Если в окно «Уровень надежности» не вводилось другое значение доверительной вероятности, то последние два столбца дублируют предыдущие два столбца. Если в окно «Уровень надежности» было введено другое значение доверительной вероятности у, то последние два столбца содержат значения соответственно нижней и верхней границы у-процентных доверительных интервалов.
Описание второй таблицы
df — число степеней свободы
SS — сумма квадратов
MS = SS/df — дисперсия на одну степень свободы
Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
history 26 января 2019 г.
Проведем простой регрессионный анализ с помощью надстройки MS EXCEL Пакет анализа .
В данной статье решены следующие задачи:
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
В результате вычислений будет заполнен указанный Выходной интервал.
Тот же результат можно получить с помощью формул (см. файл примера лист Надстройка, столбцы I:T ):
Отчет, сформированный надстройкой, состоит из следующих разделов:
Раздел «Регрессионная статистика»:
Раздел « Дисперсионный анализ »:
Регрессия входной интервал содержит нечисловые данные
трюки • приёмы • решения
При импортировании данных из других источников вы, возможно, уже успели обнаружить, что Excel иногда некорректно импортирует значения. В частности, он может принять ваши числа за текст. И тогда, например, при суммировании диапазона значений формула СУММ возвращает 0 — хотя диапазон, по всей видимости, содержит числовые значения.
Часто Excel сообщает вам об этих «нечислах», отображая смарт-тег, который позволяет преобразовать текст в числа. Если смарт-тег не отображается, вы можете использовать следующий метод, чтобы указать Excel изменить эти «нечисловые» числа на их фактические значения. Выполните следующие действия.
Excel ничего не добавит к значениям, но в процессе укажет этим ячейкам иметь фактические значения.
Входной интервал. Нужно ввести ссылку на интервал данных рабочего листа, подлежащих анализу. Excel также прелагает группирование входных данных по строкам или столбцам. Если во входной интервал включаются метки (заголовки строк или столбцов данных), необходимо установит флажок Метки,в противном случае Excel выдаст предупреждающее сообщение.
Метки. Если входной интервал не включает меток, снимите флажок Метки. Excel генерирует соответствующие метки данных для выходной таблицы (Строка 1, Строка 2, или Столбец 1, Столбец 2 и т.д.)
Выходные данные
Выходной интервал. Введите ссылку для верхней левой ячейки интервала, в который вы предполагаете вывести результирующую таблицу.
Новый рабочий лист. Этот параметр вставляет новый лист в рабочую книгу, где располагается текущий рабочий лист, и вставляет результаты в ячейку А1 нового листа. Используйте поле ввода рядом с параметром для задания имени нового листа.
Новая рабочая книга. Этот параметр создает новую рабочую книгу, добавляет новый рабочий лист и вставляет результаты в ячейку А1 нового листа.
Генерация случайных чисел
В имитационных моделях для описания реальных событий используются случайные величины и процессы. Когда имитационная модель рассчитывается на ЭВМ, то возникает необходимость реализации указанных процессов с максимально возможной точностью.
Для генерации случайных величин необходимо иметь возможность получать последовательность равномерно распределенных случайных чисел, т.е. чисел, которые ведут себя как независимые реализации или выборки случайной величины R, равномерно распределенной на единичном интервале [0,1]. Такие числа получают с помощью генераторов случайных чисел.
При помощи последовательности равномерно распределенных случайных чисел можно получить последовательности случайных величин, имеющих другие законы распределения.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Для студента самое главное не сдать экзамен, а вовремя вспомнить про него. 10663 — | 7824 — или читать все.
Встроенные статистические функции используются для проведения статистического анализа данных.
Функция СРЗНАЧ вычисляет среднее арифметическое значение. Она игнорирует пустые, логические и текстовые ячейки и может использоваться вместо длинных формул. Например, для вычисления среднего значения данных в диапазоне ячеек В4:В15 можно использовать формулу:
Очевидно, что проще ввести = СРЗНАЧ(B4:B15).
Функция МЕДИАНА вычисляет медиану множества числовых значений.
Функция МОДА определяет значение, которое чаще других встречается во множестве чисел.
Функция МАКС вычисляет наибольшее значение в диапазоне.
Функция МИН вычисляет наименьшее значение в диапазоне.
Функция СЧЕТ определяет количество ячеек в заданном диапазоне, которые содержат числа, в том числе, даты и формулы, возвращающие числа.
Функции ДИСП и СТАНДОТКЛОН определяют дисперсию и стандартное отклонение чисел, в предположении что они образуют выборку.
Функции ДИСПР и СТАНДОТКЛОНП определяют дисперсию и стандартное отклонение для генеральной совокупности.
Функция НАКЛОН вычисляет коэффициент наклона линии линейной регрессии.
Функция ОТРЕЗОК вычисляет отрезок, отсекаемый на оси линией линейной регрессии.
Функция ПРЕДСКАЗ вычисляет теоретические значения y по линии линейной регрессии.
Чтобы получить доступ к инструментам Пакета анализа необходимо:
· выполнить команду Сервис/Анализ данных;
· для использования инструмента анализа, выбрать его имя в списке и нажать кнопку ОК;
· заполнить открывшееся диалоговое окно (в большинстве случаев это означает задание входного диапазона с данными, которые вы собираетесь анализировать, указание верхней левой ячейки выходного диапазона, в который должны быть помещены результаты, и выбор нужных параметров. Группирование: установить переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне. Установить переключатель в положение Метки в первой строке, если первая строка во входном диапазоне содержит названия столбцов или установить переключатель в положение Метки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически).
Если надстройка Анализ данных отсутствует, то ее можно подключить с помощью команды Сервис/Надстройки/Пакет анализа VBA ( Analysis ToolPak VBA ).
Инструмент Описательная статистика предлагает таблицу основных статистических характеристик для одного или нескольких множеств входных значений ( Рис. 7.1 ):
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю). В диалоговом окне Корреляция ( REF _Ref12174106 h * MERGEFORMAT Рис. 7.2 ) указывается Входной интервал – ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк.
Регрессия используется для подбора графика линии регрессии. Параметры диалогового окна Регрессия ( Рис. 7.3 ):
Входной интервал Y – ссылка на диапазон анализируемых зависимых данных (диапазон должен состоять из одного столбца). Входной интервал X – ссылка на диапазон независимых данных, подлежащих анализу. Уровень надежности – установить флажок, чтобы включить в выходной диапазон дополнительный уровень. В соответствующее поле ввести уровень надежности, который будет использован дополнительно к уровню 95%, применяемому по умолчанию. Константа-ноль – установить флажок, чтобы линия регрессии прошла через начало координат. Остатки – установить флажок, чтобы включить остатки в выходной диапазон. Стандартизированные остатки – установить флажок, чтобы включить стандартизированные остатки в выходной диапазон. График остатков – установить флажок, чтобы построить диаграмму остатков для каждой независимой переменной. График подбора – установить флажок, чтобы построить диаграммы наблюдаемых и предсказанных значений для каждой независимой переменной. График нормальной вероятности – установить флажок, чтобы построить диаграмму нормальной вероятности.
Статистический анализ в excel Назначение и возможности пакета анализа
В состав MicrosoftExcelвходит пакет анализа, который позволяет осуществлять статистическую обработку данных в таблицах. В состав этого пакета входят разнообразные статистические методы. Способы применения их всех аналогичны, поэтому мы рассмотрим лишь некоторые из них: экспоненциальное сглаживание, корреляцию, скользящее среднее, регрессию.
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю).
Скользящее среднее используется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Процедура может использоваться для прогноза сбыта, инвентаризации и других процессов. Мы спрогнозируем курс доллара США на основе данных за июль 1999 года.
Экспоненциальное сглаживание предназначается для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. Использует константу сглаживания, по величине которой определяет, насколько сильно влияют на прогнозы погрешности в предыдущем прогнозе. Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к сдвигу аргумента для предсказанных значений.
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. Мы рассмотрим, как влиял на курс ЕВРО по отношению к рублю курс доллара США в июле 1999 года.
Установка пакета анализа.
Если в Microsoft Excel в меню Сервисотсутствует командаАнализ данных, то необходимо установить статистический пакет анализа данных.
Чтобы установить пакет анализа данных
ВменюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
Установите флажок Пакет анализа,выберите кнопкуOK.
Вызов пакета анализа
Чтобы запустить пакет анализа:
В меню Сервисвыберите командуАнализ данных.
В списке Инструменты анализавыберите нужную строку.
Корреляция
При выборе строки Корреляцияв диалоговом запросеАнализ данныхпоявляется следующее окно.
Входной интервал. Введите ссылку на ячейки, содержащие анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк. (Для этого нужно мышью щелкнуть по кнопке в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
Группирование. Установите переключатель в положениеПо столбцамилиПо строкамв зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Установите переключатель в положениеМетки в первой строке, если первая строка во входном диапазоне содержит названия столбцов. Установите переключатель в положениеМетки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически. (В других видах анализа этот флажок выполняет аналогичную функцию).
Выходной интервал. Введите ссылку на левую верхнюю ячейку выходного диапазона. Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Новый лист. Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая книга. Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Смотри лист Корреляция в примере.
Вернитесь в текущий документ через Панель задач
результате программа сформирует таблицу с коэффициентами корреляции между выбранными совокупностями.
Регрессионный анализ. Построение статических однофакторных моделей
Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
Содержательная постановка задачи. Имеется статистическая информация по центральному федеральному округу, которая представлена в таблице1:
Таблица 1. Число гостиниц и число ночевок в гостиницах
Наименование субъекта Федерации
Число гостиниц и аналогичных средств размещения, ед.
Число ночевок в гостиницах и аналогичных средствах размещения, тыс. ночевок
* — на базе данных Федеральной службы государственной статистики.
Пусть ряд наблюдений X — число гостиниц и аналогичных средств размещения, ряд наблюдений Y — число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Часть I.
Построить точечную диаграмму, предварительно отсортировав таблицу; Выдвинуть гипотезу о виде функции зависимости; Рассчитать параметры модели регрессии, построить тренды; Оценить адекватность построенного уравнения по величине достоверности аппроксимации; Рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Пример. В исходной таблице произведем сортировку по столбцу С (число гостиниц и аналогичных средств размещения) по возрастанию числа гостиниц.
Рис.1. Сортировка по возрастанию числа гостиниц
Отсортированная таблица представлена на рисунке 2:
Рис.2. Отсортированная таблица по возрастанию числа гостиниц
По отсортированным данным, используя мастер диаграмм, построим точечную диаграмму (диапазон ячеек С1:D19) (Рис.3).
Рис. 3. Диаграмма по отсортированной таблице
После построения диаграммы, вызовем контекстовое меню, щелкнув правой кнопкой мыши по одной из точек диаграммы, и выберем в нем команду Добавить линию тренда…(Рис. 4):
Рис. 4. Вкладка Параметры линии тренда
Во вкладке Параметры линии тренда выберем Линейная и отметим флаги показывать уравнение на диаграмме и поместить на диаграмму величину достоверности аппроксимации (R^2). Чем R2 ближе к 1, тем удачнее регрессионная модель. На диаграмме появляется линия тренда (Рис. 5).
Рис.5. Диаграмма с линейной линией тренда
Чаще всего выбор производится среди следующих функций:
у = ах + b — линейная функция;
у = ах2 + bх + с — квадратичная (полиномиальная) функция;
у = аln(х) + b — логарифмическая функция;
у = аеbх — экспоненциальная функция;
у = ахb — степенная функция.
Отобразим на диаграмме все возможные тренды (Рис. 6.).
Рис. 6. Диаграмма с построенными линиями тренда
Часть II.
Требуется: рассчитать основные характеристики случайных величин.
Для расчета основных характеристик случайных величин используются следующие функции: СРЗНАЧ() – возвращает среднее арифметическое своих аргументов, КОРЕНЬ() – возвращает значение квадратного корня, а также ДИСП() и КОРРЕЛ().
ДИСП() — Оценивает дисперсию по выборке (Рис.7).
Число1, число2. — от 1 до 255 числовых аргументов, соответствующих выборке из генеральной совокупности.
Рис. 7. Аргументы функции, оценивающей дисперсию по выборке — Дисп()
КОРРЕЛ() – возвращает коэффициент корреляции между интервалами ячеек «массив1» и «массив2». Коэффициент корреляции используется для определения взаимосвязи между двумя свойствами. Например, можно установить зависимость между средней температурой в помещении и использованием кондиционера (Рис. 8).
Синтаксис функции: КОРРЕЛ(массив1;массив2).
Массив1 — это интервал ячеек со значениями, Массив2 — второй интервал ячеек со значениями.
Рис.8. Аргументы функции, возвращающей коэффициент корреляции Коррел()
Получим следующие результаты (Рис. 9):
Рис. 9. Результаты расчетов с использованием математических функций
Можно сделать вывод о том, что линейная зависимость между числом гостиниц и аналогичных средств размещения (ряд X) и числом ночевок в гостиницах и аналогичных средствах размещения (ряд Y) существует, т. к. коэффициент корреляции равен 0,93729 и .
Коэффициент корреляции значим, т. к. расчетный критерий Стъюдента больше табличного критерия: 10,7566 > 2.1190.
Рассчитаем коэффициент корреляции для исходных данных с помощью функции Корреляция пакета Анализ данных.
Вызвать окно Анализ данных можно с помощью команды Анализ данных меню Данные (Рис. 10).
Рис. 10. Анализ данных
Пакет Корреляция позволяет определить коэффициенты корреляции для n-го количества рядов данных. Выбор команды Корреляция вызывает окно Корреляция (Рис. 11).
Рис. 11. Окно Корреляция
Это окно содержит две панели Входные данные и Параметры вывода. Окно Входной интервал: предназначено для ссылки на диапазон, содержащий анализируемые данные. Эта ссылка должна состоять не менее чем из двух смежных диапазонов данных, расположенных по строкам или столбцам. Флаги Группирование: зависят от расположения данных в диапазоне. Флаг Метки в первой строке (Метки в первом столбце) устанавливается в том случае, если входной интервал включал название диапазонов. Если название диапазонов были включены в интервал, а данный флаг не выставлен, после нажатия кнопки Ок, Excel выдаст сообщение об ошибке «Входной интервал содержит нечисловые данные». Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Если результаты необходимо поместить на имеющемся листе, то нужно установить переключатель рядом с окном Выходной интервал:, а в самом окне следует ввести ссылку на левую верхнюю ячейку выходного диапазона.
Если установить переключатель рядом с окном Новый рабочий лист:, то в книге откроется новый лист и результаты анализа будут вставлены в него, начиная с ячейки A1. При необходимости в окно можно ввести имя нового листа. По умолчанию имя листа будет соответствовать следующему после последнего имеющегося в книге листа.
Если установить переключатель рядом с окном Новая рабочая книга, то откроется новая книга, и результаты анализа будут вставлены в нее, начиная с ячейки A1 на первом листе в этой книге.
Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места.
Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Заполняем все необходимые поля окна Корреляция (Рис. 12).
Входной интервал – это данные, по которым необходимо провести корреляционный анализ, в данном случае это исходные данные по числу гостиниц и аналогичных средств размещения и числу ночевок в гостиницах и аналогичных средствах размещения (С2:D19). Строка 1 также указана во входном интервале, но в ней содержатся заголовки столбцов, поэтому ставим флаг Метки в первой строке.
В выходном интервале ставим Новый рабочий лист, в котором будут вынесены результаты расчета.
Рис. 12. Расчет коэффициента корреляции
Полученные данные абсолютно идентичны коэффициентам полученным с помощью функции КОРРЕЛ() (Рис. 13).
Рис. 13. Результаты расчета коэффициента корреляции
Пакет Описательная статистика предназначен для расчета основных статистических показателей. Окно Описательная статистика (Рис. 14) содержит:
Рис.14. Описательная статистика
панель Входные данные, аналогичную панели в окне Корреляция; панель Параметры вывода содержит указание на выходной интервал, аналогичный окну Корреляция; флаг Итоговая статистика обеспечивает вывод в выходной интервал среднего, стандартную ошибку (среднего), медиану, мода, стандартное отклонение, дисперсию выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумму и количество значений; флаг Уровень надежности, установка которого выводит в выходной интервал строку для уровня надежности. Значение, введенное в поле, соответствует требуемому уровню надежности; флаг К-тый наименьший и К-тый наибольший, установка которых выводит в выходной интервал строки для k-го наибольшего и k-го наименьшего значения для каждого диапазона данных. В соответствующем окне необходимо ввести число k. Если k равно 1, эта строка будет содержать минимум или максимум из набора данных.
Далее вызовем функцию Описательная статистика из пакета Анализ данных (Рис. 15).
Рис. 15. Описательная статистика пакета Анализ данных
Выставив все необходимые флаги, нажимаем кнопку Ок, и получаем таблицу описательных статистик (Рис. 16).
Рис. 16. Таблица описательных статистик
Полученные данные совпадают с данными, рассчитанными с помощью математических функций (математическое ожидание по x и по y, дисперсия по x и по y, среднее квадратическое отклонение по x и по y).
Варианты заданий к практической работе 1.
Содержательная постановка задачи. Исходные данные:
построить точечную диаграмму, предварительно отсортировав таблицу; выдвинуть гипотезу о виде функции зависимости; рассчитать параметры модели регрессии, построить тренды; оценить адекватность построенного уравнения по величине достоверности аппроксимации; рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Вариант 2. Имеется статистическая информация по Северо-Западному федеральному округу*, которая представлена в таблице:
При импортировании данных из других источников вы, возможно, уже успели обнаружить, что Excel иногда некорректно импортирует значения. В частности, он может принять ваши числа за текст. И тогда, например, при суммировании диапазона значений формула СУММ возвращает 0 — хотя диапазон, по всей видимости, содержит числовые значения.
Часто Excel сообщает вам об этих «нечислах», отображая смарт-тег, который позволяет преобразовать текст в числа. Если смарт-тег не отображается, вы можете использовать следующий метод, чтобы указать Excel изменить эти «нечисловые» числа на их фактические значения. Выполните следующие действия.
- Активизируйте любую пустую ячейку на листе.
- Нажмите Ctrl+C, чтобы скопировать пустую ячейку.
- Выберите диапазон, содержащий проблематичные значения.
- Выберите Главная ► Буфер обмена ► Вставить ► Специальная вставка для открытия диалогового окна Специальная вставка.
- В окне Специальная вставка установите переключатель Операция в положение сложить.
- Нажмите кнопку ОК.
Excel ничего не добавит к значениям, но в процессе укажет этим ячейкам иметь фактические значения.
По теме
Новые публикации
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных.
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды.
Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы — руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель — разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию — статистический метод, позволяющий предсказывать значения зависимой переменной Y
по значениям независимой переменной X
. В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y
по значениям нескольких зависимых переменных (Х 1 , Х 2 , …, X k
).
Скачать заметку в формате или , примеры в формате
Виды регрессионных моделей
где ρ
1
– коэффициент автокорреляции; если ρ
1
= 0 (нет автокорреляции), D
≈ 2; если ρ
1
≈ 1 (положительная автокорреляции), D
≈ 0; если ρ
1
= -1 (отрицательная автокорреляции), D
≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D
с критическими теоретическими значениями d L
и d U
для заданного числа наблюдений n
, числа независимых переменных модели k
(для простой линейной регрессии k
= 1) и уровня значимости α. Если D < d L
, гипотеза о независимости случайных отклонений отвергается (следовательно, присутствует положительная автокорреляция); если D > d U
, гипотеза не отвергается (то есть автокорреляция отсутствует); если d L < D < d U
, нет достаточных оснований для принятия решения. Когда расчётное значение D
превышает 2, то с d L
и d U
сравнивается не сам коэффициент D
, а выражение (4 – D
).
Для вычисления статистики Дурбина-Уотсона в Excel обратимся к нижней таблице на рис. 14 Вывод остатка
. Числитель в выражении (10) вычисляется с помощью функции =СУММКВРАЗН(массив1;массив2), а знаменатель =СУММКВ(массив) (рис. 16).

Рис. 16. Формулы расчета статистики Дурбина-Уотсона
В нашем примере D
= 0,883. Основной вопрос заключается в следующем — какое значение статистики Дурбина-Уотсона следует считать достаточно малым, чтобы сделать вывод о существовании положительной автокорреляции? Необходимо соотнести значение D с критическими значениями (d L
и d U
), зависящими от числа наблюдений n
и уровня значимости α (рис. 17).

Рис. 17. Критические значения статистики Дурбина-Уотсона (фрагмент таблицы)
Таким образом, в задаче об объеме продаж в магазине, доставляющем товары на дом, существуют одна независимая переменная (k
= 1), 15 наблюдений (n
= 15) и уровень значимости α = 0,05. Следовательно, d L
= 1,08 и d
U
= 1,36. Поскольку D
= 0,883 < d L
= 1,08, между остатками существует положительная автокорреляция, метод наименьших квадратов применять нельзя.
Проверка гипотез о наклоне и коэффициенте корреляции
Выше регрессия применялась исключительно для прогнозирования. Для определения коэффициентов регрессии и предсказания значения переменной Y
при заданной величине переменной X
использовался метод наименьших квадратов. Кроме того, мы рассмотрели среднеквадратичную ошибку оценки и коэффициент смешанной корреляции. Если анализ остатков подтверждает, что условия применимости метода наименьших квадратов не нарушаются, и модель простой линейной регрессии является адекватной, на основе выборочных данных можно утверждать, что между переменными в генеральной совокупности существует линейная зависимость.
Применение
t
-критерия для наклона.
Проверяя, равен ли наклон генеральной совокупности β 1 нулю, можно определить, существует ли статистически значимая зависимость между переменными X
и Y
. Если эта гипотеза отклоняется, можно утверждать, что между переменными X
и Y
существует линейная зависимость. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0: β 1 = 0 (нет линейной зависимости), Н1: β 1 ≠ 0 (есть линейная зависимость). По определению t
-статистика равна разности между выборочным наклоном и гипотетическим значением наклона генеральной совокупности, деленной на среднеквадратичную ошибку оценки наклона:
(11)
t
= (b
1
–
β
1
) /
S b
1
где b
1
– наклон прямой регрессии по выборочным данным, β1 – гипотетический наклон прямой генеральной совокупности, ![]() , а тестовая статистика t
, а тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
Проверим, существует ли статистически значимая зависимость между размером магазина и годовым объемом продаж при α = 0,05. t
-критерий выводится наряду с другими параметрами при использовании Пакета анализа
(опция Регрессия
). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к t-статистике – на рис. 18.
Рис. 18. Результаты применения t
Поскольку число магазинов n
= 14 (см. рис.3), критическое значение t
-статистики при уровне значимости α = 0,05 можно найти по формуле: t L
=СТЬЮДЕНТ.ОБР(0,025;12) = –2,1788, где 0,025 – половина уровня значимости, а 12 = n
– 2; t U
=СТЬЮДЕНТ.ОБР(0,975;12) = +2,1788.
Поскольку t
-статистика = 10,64 > t U
= 2,1788 (рис. 19), нулевая гипотеза Н 0
отклоняется. С другой стороны, р
-значение для Х
= 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н 0
снова отклоняется. Тот факт, что р
-значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение
F
-критерия для наклона.
Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F
-критерия. Напомним, что F
-критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F
-критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR
, деленной на количество независимых переменных k
), к дисперсии ошибок (MSE = S Y
X
2
).
По определению F
-статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F
=
MSR
/
MSE
, где MSR =
SSR
/
k
, MSE =
SSE
/(n
– k – 1), k
– количество независимых переменных в регрессионной модели. Тестовая статистика F
имеет F
-распределение с k
и n
– k – 1
степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > F
U
, нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t
-критерию F
-критерий выводится в таблицу при использовании Пакета анализа
(опция Регрессия
). Полностью результаты работы Пакета анализа
приведены на рис. 4, фрагмент, относящийся к F
-статистике – на рис. 21.

Рис. 21. Результаты применения F
-критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р
-значение близко к нулю (ячейка Значимость
F
). Если уровень значимости α равен 0,05, определить критическое значение F
-распределения с одной и 12 степенями свободы можно по формуле F U
=F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F
= 113,23 > F U
= 4,7472, причем р
-значение близко к 0 < 0,05, нулевая гипотеза Н 0
отклоняется, т.е. размер магазина тесно связан с его годовым объемом продаж.

Рис. 22. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, с одной и 12 степенями свободы
Доверительный интервал, содержащий наклон β 1 .
Для проверки гипотезы о существовании линейной зависимости между переменными можно построить доверительный интервал, содержащий наклон β 1 и убедиться, что гипотетическое значение β 1 = 0 принадлежит этому интервалу. Центром доверительного интервала, содержащего наклон β 1 , является выборочный наклон b
1
, а его границами — величины b 1 ±
t n
–2
S b
1
Как показано на рис. 18, b
1
= +1,670, n
= 14, S b
1
= 0,157. t
12
=СТЬЮДЕНТ.ОБР(0,975;12) = 2,1788. Следовательно, b 1 ±
t n
–2
S b
1
= +1,670 ± 2,1788 * 0,157 = +1,670 ± 0,342, или + 1,328 ≤ β 1 ≤ +2,012. Таким образом, наклон генеральной совокупности с вероятностью 0,95 лежит в интервале от +1,328 до +2,012 (т.е. от 1 328 000 до 2 012 000 долл.). Поскольку эти величины больше нуля, между годовым объемом продаж и площадью магазина существует статистически значимая линейная зависимость. Если бы доверительный интервал содержал нуль, между переменными не было бы зависимости. Кроме того, доверительный интервал означает, что каждое увеличение площади магазина на 1 000 кв. футов приводит к увеличению среднего объема продаж на величину от 1 328 000 до 2 012 000 долларов.
Использование
t
-критерия для коэффициента корреляции.
был введен коэффициент корреляции r
, представляющий собой меру зависимости между двумя числовыми переменными. С его помощью можно установить, существует ли между двумя переменными статистически значимая связь. Обозначим коэффициент корреляции между генеральными совокупностями обеих переменных символом ρ. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0
: ρ = 0 (нет корреляции), Н 1
: ρ ≠ 0 (есть корреляция). Проверка существования корреляции:

где r
= +
, если b
1
> 0, r
= –
, если b
1
< 0. Тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
В задаче о сети магазинов Sunflowers r 2
= 0,904, а b 1
— +1,670 (см. рис. 4). Поскольку b 1
> 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r
= +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t
-статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t
= 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r
зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y
и предсказания индивидуальных значений Y
при заданных значениях переменной X
.
Построение доверительного интервала.
В примере 2 (см. выше раздел Метод наименьших квадратов
) регрессионное уравнение позволило предсказать значение переменной Y
X
. В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика
при заданном значении переменной X
:
где  , =
, =
b
0
+
b
1
X i
– предсказанное значение переменное Y
при X
= X i
, S YX
– среднеквадратичная ошибка, n
– объем выборки, X
i
— заданное значение переменной X
, µ
Y
| X
=
X
i
– математическое ожидание переменной Y
при Х
= Х i
, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений X
i
. Если значение переменной Y
предсказывается для величин X
, близких к среднему значению
, доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения.
Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X
, часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика Y
X
=
Xi
при конкретном значении переменной X
i
определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел — вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа
(кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, — набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х 8
= 19, Y
8
= 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.

Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X
и Y
всегда начинайте с построения диаграммы разброса. - Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме.
Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t
-критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.

Рис. 27. Структурная схема заметки
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
· линейной (у = а + bx);
· параболической (y = a + bx + cx 2);
· экспоненциальной (y = a * exp(bx));
· степенной (y = a*x^b);
· гиперболической (y = b/x + a);
· логарифмической (y = b * 1n(x) + a);
· показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
1. Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

2. Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
3. Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.

После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
1. Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».

2. Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.

3. После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).

В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Известна тем, что она полезна в разных областях деятельности, включая и такую дисциплину, как эконометрика, где в работе используется данная программная утилита. В основном все действия практических и лабораторных занятий выполняют в Excel, которая существенно облегчает работу, давая подробные объяснения тех или иных действий. Так, один из инструментов анализа «Регрессия» применяется с целью подбора графика для набора наблюдений за счет метода наименьших квадратов. Рассмотрим, что представляет собой данный инструмент программы и в чем заключается его польза для пользователей. Ниже также предоставлена краткая, но понятная инструкция построения регрессионной модели.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных.
К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача:
Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.
Статистическая обработка данных может также проводиться с помощью надстройки ПАКЕТ АНАЛИЗА
(рис. 62).
Из предложенных пунктов выбирает пункт «РЕГРЕССИЯ
» и щелкаем на нем левой кнопкой мыши. Далее нажимаем ОК.
Появится окно, показанное на рис. 63.

Инструмент анализа «РЕГРЕССИЯ
» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию ЛИНЕЙН
.
Диалоговое окно «РЕГРЕССИЯ»
Метки Установите флажок, если первая строка или первый столбец входного диапазона содержит заголовки. Снимите этот флажок, если заголовки отсутствуют. В этом случае подходящие заголовки для данных выходной таблицы будут созданы автоматически.
Уровень надежности Установите флажок, чтобы включить в выходную таблицу итогов дополнительный уровень. В соответствующее поле введите уровень надежности, который следует применить, дополнительно к уровню 95%, применяемому по умолчанию.
Константа — ноль Установите флажок, чтобы линия регрессии прошла через начало координат.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите как минимум семь столбцов для выходной таблицы итогов, которая будет включать в себя: результаты дисперсионного анализа, коэффициенты, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Остатки Установите флажок для включения остатков в выходную таблицу.
Стандартизированные остатки Установите флажок для включения стандартизированных остатков в выходную таблицу.
График остатков Установите флажок для построения графика остатков для каждой независимой переменной.
График подбора Установите флажок для построения графика зависимости предсказанных значений от наблюдаемых.
График нормальной вероятности
Установите флажок, для построения графика нормальной вероятности.
Функция ЛИНЕЙН
Для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем нужную функцию, например СРЗНАЧ
(рис. 22).
Функция ЛИНЕЙН
рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Можно также объединять функцию ЛИНЕЙН
с другими функциями для вычисления других видов моделей, являющихся линейными в неизвестных параметрах (неизвестные параметры которых являются линейными), включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
y=m 1 x 1 +m 2 x 2 +…+b (в случае нескольких диапазонов значений x),
где зависимое значение y — функция независимого значения x, значения m — коэффициенты, соответствующие каждой независимой переменной x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН
возвращает массив{mn;mn-1;…;m 1 ;b}. ЛИНЕЙН
может также возвращать дополнительную регрессионную статистику.
ЛИНЕЙН
(известные_значения_y; известные_значения_x; конст; статистика)
Известные_значения_y — множество значений y, которые уже известны для соотношения y=mx+b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x — необязательное множество значений x, которые уже известны для соотношения y=mx+b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы_известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив_известные_значения_x опущен, то предполагается, что этот массив {1;2;3;…} имеет такой же размер, как и массив_известные_значения_y.
Конст — логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент «конст» имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент «конст» имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y=mx.
Статистика — логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: {mn;mn-1;…;m1;b:sen;sen-1;…;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.(табл.17)
| Величина | Описание |
| se1,se2,…,sen | Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
| seb | Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент «конст» имеет значение ЛОЖЬ). |
| r2 | Коэффициент детерминированности. Сравниваются фактические значения y и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т. е. различия между фактическим и оценочным значениями y не существует. В противоположном случае, если коэффициент детерминированности равен 0, использовать уравнение регрессии для предсказания значений y не имеет смысла. Для получения дополнительных сведений о способах вычисления r2, см. «Замечания» в конце данного раздела. |
| sey | Стандартная ошибка для оценки y. |
| F | F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
| df | Степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Для получения дополнительных сведений о вычислении величины df см. «Замечания» в конце данного раздела. Далее в примере 4 показано использование величин F и df. |
| ssreg | Регрессионная сумма квадратов. |
| ssresid | Остаточная сумма квадратов. Для получения дополнительных сведений о расчете величин ssreg и ssresid см. «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика (рис. 64).

Замечания:
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m): чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять две точки прямой (x 1 ,y 1) и(x 2 ,y 2); наклон будет равен (y 2 -y 1)/(x 2 -x 1).
Y-пересечение (b): Y-пересечением прямой, обычно обозначаемым через b, является значение y для точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид y=mx+b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон: ИНДЕКС (ЛИНЕЙН(известные_значения_y; известные_значения_x); 1)
Y-пересечение: ИНДЕКС (ЛИНЕЙН (известные_значения_y; известные_значения_x); 2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель, используемая функцией ЛИНЕЙН. Функция ЛИНЕЙН использует метод наименьших квадратов для определения наилучшей аппроксимации данных. Когда имеется только одна независимая переменная x, m и b вычисляются по следующим формулам:

где x и y – выборочные средние значения, например x = СРЗНАЧ (известные_значения_x), а y = СРЗНАЧ (известные_значения_y).
Функции аппроксимации ЛИНЕЙН и ЛГРФПРИБЛ могут вычислить прямую или экспоненциальную кривую, наилучшим образом описывающую данные. Однако они не дают ответа на вопрос, какой из двух результатов больше подходит для решения поставленной задачи. Можно также вычислить функцию ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x) для прямой или функцию РОСТ(известные_значения_y; известные_значения_x) для экспоненциальной кривой. Эти функции, если не задавать аргумент новые_значения_x, возвращают массив вычисленных значений y для фактических значений x в соответствии с прямой или кривой. После этого можно сравнить вычисленные значения с фактическими значениями. Можно также построить диаграммы для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов, тем больше значение коэффициента детерминированности r2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Коэффициент r2 равен ssreg/sstotal.
В некоторых случаях один или более столбцов X (пусть значения Y и X находятся в столбцах) не имеет дополнительного предикативного значения в других столбцах X. Другими словами, удаление одного или более столбцов X может привести к значениям Y, вычисленным с одинаковой точностью. В этом случае избыточные столбцы X будут исключены из модели регрессии. Этот феномен называется «коллинеарностью», поскольку избыточные столбцы X могут быть представлены в виде суммы нескольких неизбыточных столбцов. Функция ЛИНЕЙН проверяет на коллинеарность и удаляет из модели регрессии все избыточные столбцы X, если обнаруживает их. Удаленные столбцы X можно определить в выходных данных ЛИНЕЙН по коэффициенту, равному 0, и по значению se, равному 0. Удаление одного или более столбцов как избыточных изменяет величину df, поскольку она зависит от количества столбцов X, в действительности используемых для предикативных целей. Подробнее о вычислении величины df см. ниже в примере 4. При изменении df вследствие удаления избыточных столбцов значения sey и F также изменяются. Часто использовать коллинеарность не рекомендуется. Однако ее следует применять, если некоторые столбцы X содержат 0 или 1 в качестве индикатора указывающего, входит ли предмет эксперимента в отдельную группу. Если конст = ИСТИНА или значение этого аргумента не указано, функция ЛИНЕЙН вставляет дополнительный столбец X для моделирования точки пересечения. Если имеется столбец со значениями 1 для указания мужчин и 0 — для женщин, а также имеется столбец со значениями 1 для указания женщин и 0 — для мужчин, то последний столбец удаляется, поскольку его значения можно получить из столбца с «индикатором мужского пола».
Вычисление df для случаев, когда столбцы X не удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
Формулы, которые возвращают массивы, должны быть введены как формулы массива.
При вводе массива констант в качестве, например, аргумента известные_значения_x следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть различными в зависимости от параметров, заданных в окне «Язык и стандарты» на панели управления.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН
, отличается от основного алгоритма функций НАКЛОН
и ОТРЕЗОК
. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН
возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН
используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Функции НАКЛОН и ОТРЕЗОК возвращают ошибку #ДЕЛ/0!. Алгоритм функций НАКЛОН и ОТРЕЗОК используется для поиска только одного ответа, а в данном случае их может быть несколько.
Помимо вычисления статистики для других типов регрессии функцию ЛИНЕЙН можно использовать при вычислении диапазонов для других типов регрессии, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y=m 1 x+m 2 x 2 +m 3 x 3 +b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
Содержание
- При использовании функции линейная регрессия (ЛИНЕЙН) в Excel возвращается неверный результат
- Проблемы
- Причина
- Обходное решение
- Случай 1: диапазоны x-value и y перекрываются
- Случай 2: количество строк меньше числа столбцов x-Columns.
- Случай 3: указывается нулевая константа
- Дополнительная информация
- Ссылки
- Входной интервал содержит нечисловые данные что делать?
- Работа с инструментом «Регрессия» в Microsoft Excel
- Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
- Регрессия входной интервал содержит нечисловые данные
- Статистический анализ в excel Назначение и возможности пакета анализа
- Установка пакета анализа.
- Вызов пакета анализа
- Корреляция
- Регрессионный анализ. Построение статических однофакторных моделей
- Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
- Часть I.
- Часть II.
- Варианты заданий к практической работе 1.
Проблемы
При использовании функции ЛИНЕЙН на листе в Microsoft Excel результаты статистического вывода могут возвращать неверные значения. Средство регрессия в окне «пакет анализа» может также возвращать неверные значения.
Причина
Результат, возвращаемый функцией ЛИНЕЙН, может быть неправильным, если выполняется одно или несколько из указанных ниже условий.
Диапазон значений x перекрывает диапазон значений y.
Количество строк в диапазоне входных данных меньше числа столбцов в общем диапазоне (x-value + y-Value).
Вы задаете нулевую константу (для третьего аргумента функции ЛИНЕЙН установите значение истина).
Обходное решение
Случай 1: диапазоны x-value и y перекрываются
Если диапазоны x-value и y перекрываются, функция ЛИНЕЙН возвращает неверные значения во всех ячейках результата. Нормальная статистическая вероятность запрещает значения в диапазонах x и y для перекрытия (повторяющиеся друг друга). Не перекрывают диапазоны x и y при ссылке на ячейки в формуле.Примечание. Средство регрессия предупреждает об этой проблеме и не продолжает работу. Вы можете использовать средство регрессия вместо функции ЛИНЕЙН. В Microsoft Office Excel 2007 вы можете найти инструмент регрессия, щелкнув анализ данных в группе анализ на вкладке данные . В Microsoft Office Excel 2003 и более ранних версиях Excel можно найти инструмент регрессия, выбрав пункт анализ данных в меню Сервис .
Случай 2: количество строк меньше числа столбцов x-Columns.
Статистические функции не действительны, так как количество строк должно быть меньше числа столбцов x (переменных). Количество строк данных должно быть больше количества столбцов данных (столбцов x и y).
Случай 3: указывается нулевая константа
Не указывайте нулевые константы (b = 0) в функции.
Дополнительная информация
Средство регрессия входит в пакет анализа. Пакет анализа — это программа надстройки Excel. Оно доступно при установке Microsoft Office или Excel. Прежде чем использовать средство регрессия в Excel, вы должны загрузить анализ ToolPak.To в Excel 2007, выполнив указанные ниже действия.
Нажмите кнопку Microsoft Office, затем нажмите кнопку Параметры Excel.
Выберите пункт надстройки, а затем в поле Управление выберите пункт надстройки Excel .
Нажмите кнопку Перейти.
В окне Доступные надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК.Примечание. Если в списке Доступные надстройки не указан Пакет анализа , нажмите кнопку Обзор , чтобы найти его.
Чтобы сделать это в Excel 2003 и более ранних версиях Excel, выполните указанные ниже действия.
В меню Сервис выберите пунктнадстройки.
В диалоговом окне надстройки выберите Пакет анализаи нажмите кнопку ОК,Обратите внимание на то, что Пакет анализа не указан в поле Доступные надстройки, нажмите кнопку Обзор , чтобы найти его.
Ссылки
Статистические вычисления на цифровом компьютере. Уильям J. Hemmerle. Blaisdell компания публикации: 1967. Глава 3, «вычисления с несколькими регрессиями» и раздел 3.2.1, «теория для предварительной регрессии».
Источник
Входной интервал содержит нечисловые данные что делать?
Работа с инструментом «Регрессия» в Microsoft Excel
Открыв рабочую книгу и введя в нее исходные данные для построения уравнения регрессии, вызываем надстройку «Регрессия»: Данные — Анализ данных — Регрессия.
Диалоговое окно «Регрессия». В первое окно «Входной интервал Y» вводим данные объясняемой переменной — у, диапазон должен состоять из одного столбца. Во второе окно «Входной интервал X» вводим данные объясняющих переменных — х. На рис. П.1 представлены у. $С$2:$С$13, х: $В$2:$В$13. Длины интервалов должны быть одинаковы. Если строится уравнение множественной регрессии, то данные объясняющих переменных вводятся в окно «Входной интерват X» соответствующим образом. На рис. П.2 представлены у: $D$2:$D$13, xt—x2: $В2:$С$13. Максималь- ное число независимых объясняющих переменных равно 16.
![]()
Рис. П. 1. Задание парной регрессии
Ставим «галочку» в окно «Метки», если в отчете Microsoft Excel требуется знать, к какой из объясняющих переменных относятся результирующие данные.
Если исследователю не требуется константа Ь , то ставим «галочку» в окно «Константа — ноль». Линия регрессии пройдет через начало координат.
![]()
Рис. П.2. Задание множественной регрессии
«Уровень надежности». По умолчанию программа строит уравнение регрессии для доверительной вероятности (уровень надежности) 0,95. Если требуется другая величина, ставим «галочку» в окно «Уровень надежности» и в окно, помеченное символом «%», вводим требуемую величину уровня надежности десятичной дробью.
«Параметры вывода». Указываем, куда вывести результаты регрессионного анализа: на этом листе, как указано на обоих рисунках, на другой рабочий лист или в новую рабочую книгу.
«Остатки». Выбираем то, что требуется исследователю, и ставим «галочку». Можно одновременно пометить несколько окон. Подробная информация дана в справке но инструменту «Регрессия».
Заполнив диалоговое окно «Регрессия», нажимаем кнопку ОК. Программа выводит отчет «Вывод итогов» в виде трех таблиц (рис. П.З, приведено для двух объясняющих переменных).
Приведем описание таблиц (первых двух — в табл. П1.1 и П1.2 соответственно, третьей — в текстовом виде).
Описание первой таблицы
Наименование в отчете
Коэффициент множественной корреляции, индекс корреляции
Коэффициент детерминации, R 2
Скорректированный К 2
Наименование в отчете
Среднее квадратическое отклонение от модели
Рис. П.З. Результаты работы программы
Описание третьей таблицы
Данные первой строки относятся к коэффициенту уравнения регрессии Ь , данные второй строки — к коэффициенту Ьи третьей — к Ь2 и далее до коэффициента Ьт, но числу объясняющих переменных в уравнении.
Метки, если поставлена галочка в окно «Метки». У-пересечение для коэффициента/> , далее но всем объясняющим переменным.
Значения коэффициентов уравнения регрессии Ь , Ьь . Ьт.
Стандартная ошибка коэффициента регрессии 5^, 5Л). Sbm.
Статистическая значимость коэффициента регрессии (^-статистика) для а = 0,05 tw . tbm.
P-значение — это значение уровней значимости, соответствующее вычисленным ^статистикам коэффициентов.
Нижние 95% и Верхние 95% — это нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения регрессии. Если в окно «Уровень надежности» не вводилось другое значение доверительной вероятности, то последние два столбца дублируют предыдущие два столбца. Если в окно «Уровень надежности» было введено другое значение доверительной вероятности у, то последние два столбца содержат значения соответственно нижней и верхней границы у-процентных доверительных интервалов.
Описание второй таблицы
df — число степеней свободы
SS — сумма квадратов
MS = SS/df — дисперсия на одну степень свободы
Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем простой регрессионный анализ с помощью надстройки MS EXCEL Пакет анализа .
Эффективно использовать надстройку Пакет анализа для целей регрессионного анализа могут только пользователи знакомые с теорией регрессионного анализа .
В данной статье решены следующие задачи:
- Показано как в MS EXCEL выполнить регрессионный анализ с помощью надстройки Пакет анализа (инструмент Регрессия), т.е. как вызвать надстройку и правильно заполнить входные данные;
- Даны пояснения по разделам отчета, формированного надстройкой.
В надстройке Пакет анализа для построения линейной регрессионной модели (как простой , так и множественной ) имеется специальный инструмент Регрессия .
![]()
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
![]()
- Входной интервалY : ссылка на массив значений переменной Y. Ссылку можно указать с заголовком. В этом случае, при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку Метки );
- Входной интервал Х : ссылка на значения переменной Х. В случае множественной регрессии (несколько переменных Х) нужно указать все столбцы со значениями Х. В случае множественной регрессии ссылку рекомендуется делать на диапазон с заголовками (в окне требуется установить галочку Метки );
- Константа-ноль : если галочка установлена, то надстройка подбирает линию регрессии, проходящую через точку Y=0 ( сдвиг будет равен 0);
- Уровень надежности : Это значение используется для построения доверительных интервалов для наклона и сдвига . Уровень надежности = 1- альфа. Если галочка не установлена или установлена, но уровень значимости = 95%, то надстройка все равно рассчитывает границы доверительных интервалов, причем дублирует их. Если галочка установлена, а уровень надежности отличен от 95%, то рассчитываются 2 доверительных интервала : один для 95%, другой для введенного значения. Для демонстрации вышесказанного введем 90%;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона;
- Остатки : будут вычислены остатки модели , т.е. разница между наблюденными и предсказанными значениями Yi для всех наблюдений n;
- Стандартизированные остатки : Вышеуказанные значения остатков будут поделены на значение их стандартного отклонения ;
- График остатков : Будет построена точечная диаграмма : значения остатков для всех значений Хi;
- График подбора: Будет построена точечная диаграмма: точки данных (X;Y) и линия регрессии ;
- График нормальной вероятности: Будет построена точечная диаграмма с названием График нормального распределения . По сути — это график значений переменной Y, отсортированных по возрастанию .
В результате вычислений будет заполнен указанный Выходной интервал.
![]()
![]()
![]()
Тот же результат можно получить с помощью формул (см. файл примера лист Надстройка, столбцы I:T ):
![]()
Результаты вычислений, выполненных надстройкой, полностью совпадают с вычислениями сделанными нами в статье про простую линейную регрессию с помощью функций ЛИНЕЙН() , НАКЛОН() , ОТРЕЗОК() и др. Использование альтернативных формул помогает разобраться с алгоритмом расчета показателей регрессии.
Отчет, сформированный надстройкой, состоит из следующих разделов:
Раздел «Регрессионная статистика»:
- Множественный R. В случае простой линейной регрессии — это Коэффициент корреляции , функция КОРРЕЛ()
- R-квадрат . В случае простой линейной регрессии – это коэффициент детерминации , функция КВПИРСОН()
- Нормированный R-квадрат . См. про коэффициент детерминации .
- Стандартная ошибка . См. Стандартная ошибка регрессии ;
- Наблюдения . Количество значений Y.
Раздел « Дисперсионный анализ »:
- df – степени свободы (Degrees of Freedom).
- SS – сумма квадратов (Sum of Squares)
- MS – SS/df (MSR и MSE)
- F – значение статистики F (MSR/MSE)
- ЗначимостьF – p-значение, функция F.РАСП.ПХ()
- Коэффициенты : оценка параметров модели а и b. См. Оценка неизвестных параметров .
- Стандартная ошибка : Стандартные ошибки вышеуказанных статистик
- t-статистика : значение тестовой статистики t0. См. Проверка значимости взаимосвязи переменных
- P-Значение : См. Проверка значимости взаимосвязи переменных
- Нижние 95% и Верхние 95%: границы доверительных интервалов для оценок неизвестных параметров модели а и b .
Регрессия входной интервал содержит нечисловые данные
трюки • приёмы • решения
При импортировании данных из других источников вы, возможно, уже успели обнаружить, что Excel иногда некорректно импортирует значения. В частности, он может принять ваши числа за текст. И тогда, например, при суммировании диапазона значений формула СУММ возвращает 0 — хотя диапазон, по всей видимости, содержит числовые значения.
Часто Excel сообщает вам об этих «нечислах», отображая смарт-тег, который позволяет преобразовать текст в числа. Если смарт-тег не отображается, вы можете использовать следующий метод, чтобы указать Excel изменить эти «нечисловые» числа на их фактические значения. Выполните следующие действия.
- Активизируйте любую пустую ячейку на листе.
- Нажмите Ctrl+C, чтобы скопировать пустую ячейку.
- Выберите диапазон, содержащий проблематичные значения.
- Выберите Главная ► Буфер обмена ► Вставить ► Специальная вставка для открытия диалогового окна Специальная вставка.
- В окне Специальная вставка установите переключатель Операция в положение сложить.
- Нажмите кнопку ОК.
Excel ничего не добавит к значениям, но в процессе укажет этим ячейкам иметь фактические значения.
Входной интервал. Нужно ввести ссылку на интервал данных рабочего листа, подлежащих анализу. Excel также прелагает группирование входных данных по строкам или столбцам. Если во входной интервал включаются метки (заголовки строк или столбцов данных), необходимо установит флажок Метки,в противном случае Excel выдаст предупреждающее сообщение.
Метки. Если входной интервал не включает меток, снимите флажок Метки. Excel генерирует соответствующие метки данных для выходной таблицы (Строка 1, Строка 2, или Столбец 1, Столбец 2 и т.д.)
Выходные данные
Выходной интервал. Введите ссылку для верхней левой ячейки интервала, в который вы предполагаете вывести результирующую таблицу.
Новый рабочий лист. Этот параметр вставляет новый лист в рабочую книгу, где располагается текущий рабочий лист, и вставляет результаты в ячейку А1 нового листа. Используйте поле ввода рядом с параметром для задания имени нового листа.
Новая рабочая книга. Этот параметр создает новую рабочую книгу, добавляет новый рабочий лист и вставляет результаты в ячейку А1 нового листа.
Генерация случайных чисел
В имитационных моделях для описания реальных событий используются случайные величины и процессы. Когда имитационная модель рассчитывается на ЭВМ, то возникает необходимость реализации указанных процессов с максимально возможной точностью.
Для генерации случайных величин необходимо иметь возможность получать последовательность равномерно распределенных случайных чисел, т.е. чисел, которые ведут себя как независимые реализации или выборки случайной величины R, равномерно распределенной на единичном интервале [0,1]. Такие числа получают с помощью генераторов случайных чисел.
При помощи последовательности равномерно распределенных случайных чисел можно получить последовательности случайных величин, имеющих другие законы распределения.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Для студента самое главное не сдать экзамен, а вовремя вспомнить про него. 10663 — ![]() | 7824 —
| 7824 — ![]() или читать все.
или читать все.
Встроенные статистические функции используются для проведения статистического анализа данных.
Функция СРЗНАЧ вычисляет среднее арифметическое значение. Она игнорирует пустые, логические и текстовые ячейки и может использоваться вместо длинных формул. Например, для вычисления среднего значения данных в диапазоне ячеек В4:В15 можно использовать формулу:
Очевидно, что проще ввести = СРЗНАЧ(B4:B15).
Функция МЕДИАНА вычисляет медиану множества числовых значений.
Функция МОДА определяет значение, которое чаще других встречается во множестве чисел.
Функция МАКС вычисляет наибольшее значение в диапазоне.
Функция МИН вычисляет наименьшее значение в диапазоне.
Функция СЧЕТ определяет количество ячеек в заданном диапазоне, которые содержат числа, в том числе, даты и формулы, возвращающие числа.
Функции ДИСП и СТАНДОТКЛОН определяют дисперсию и стандартное отклонение чисел, в предположении что они образуют выборку.
Функции ДИСПР и СТАНДОТКЛОНП определяют дисперсию и стандартное отклонение для генеральной совокупности.
Функция НАКЛОН вычисляет коэффициент наклона линии линейной регрессии.
Функция ОТРЕЗОК вычисляет отрезок, отсекаемый на оси линией линейной регрессии.
Функция ПРЕДСКАЗ вычисляет теоретические значения y по линии линейной регрессии.
Если встроенных статистических функций недостаточно, можно обратиться к Пакету анализа .
Чтобы получить доступ к инструментам Пакета анализа необходимо:
· выполнить команду Сервис/Анализ данных;
· для использования инструмента анализа, выбрать его имя в списке и нажать кнопку ОК;
· заполнить открывшееся диалоговое окно (в большинстве случаев это означает задание входного диапазона с данными, которые вы собираетесь анализировать, указание верхней левой ячейки выходного диапазона, в который должны быть помещены результаты, и выбор нужных параметров. Группирование: установить переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне. Установить переключатель в положение Метки в первой строке, если первая строка во входном диапазоне содержит названия столбцов или установить переключатель в положение Метки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически).
Если надстройка Анализ данных отсутствует, то ее можно подключить с помощью команды Сервис/Надстройки/Пакет анализа VBA ( Analysis ToolPak VBA ).
К инструментам Пакета анализа , например, относятся Описательная статистика , Корреляция , Регрессия .
Инструмент Описательная статистика предлагает таблицу основных статистических характеристик для одного или нескольких множеств входных значений ( Рис. 7.1 ):
Выходной интервал этого инструмента содержит следующие статистические характеристики: среднее, стандартная ошибка, медиана, мода, стандартное отклонение, дисперсия, коэффициент эксцесса, коэффициент асимметрии, интервал (размах), минимальное значение, максимальное значение, сумма, число значений, k -е наибольшее и наименьшее значения (для любого заданного значения k ) и уровень значимости для среднего. Установить флажок Итоговая статистика, если нужен полный список характеристик, в противном случае отметить конкретные характеристики, которые должны присутствовать в выходной таблице. Большинство из полученных характеристик, полученных с помощью пакета анализа Описательная статистика можно получить с помощью встроенных статистических формул.
Рис. 7 . 1 Диалоговое окно Описательная статистика
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю). В диалоговом окне Корреляция ( REF _Ref12174106 h * MERGEFORMAT Рис. 7.2 ) указывается Входной интервал – ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк.
Рис. 7 . 2 Диалоговое окно Корреляция
Регрессия используется для подбора графика линии регрессии. Параметры диалогового окна Регрессия ( Рис. 7.3 ):
Входной интервал Y – ссылка на диапазон анализируемых зависимых данных (диапазон должен состоять из одного столбца). Входной интервал X – ссылка на диапазон независимых данных, подлежащих анализу. Уровень надежности – установить флажок, чтобы включить в выходной диапазон дополнительный уровень. В соответствующее поле ввести уровень надежности, который будет использован дополнительно к уровню 95%, применяемому по умолчанию. Константа-ноль – установить флажок, чтобы линия регрессии прошла через начало координат. Остатки – установить флажок, чтобы включить остатки в выходной диапазон. Стандартизированные остатки – установить флажок, чтобы включить стандартизированные остатки в выходной диапазон. График остатков – установить флажок, чтобы построить диаграмму остатков для каждой независимой переменной. График подбора – установить флажок, чтобы построить диаграммы наблюдаемых и предсказанных значений для каждой независимой переменной. График нормальной вероятности – установить флажок, чтобы построить диаграмму нормальной вероятности.
Статистический анализ в excel Назначение и возможности пакета анализа
В состав MicrosoftExcelвходит пакет анализа, который позволяет осуществлять статистическую обработку данных в таблицах. В состав этого пакета входят разнообразные статистические методы. Способы применения их всех аналогичны, поэтому мы рассмотрим лишь некоторые из них: экспоненциальное сглаживание, корреляцию, скользящее среднее, регрессию.
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю).
Скользящее среднее используется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Процедура может использоваться для прогноза сбыта, инвентаризации и других процессов. Мы спрогнозируем курс доллара США на основе данных за июль 1999 года.
Экспоненциальное сглаживание предназначается для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. Использует константу сглаживания, по величине которой определяет, насколько сильно влияют на прогнозы погрешности в предыдущем прогнозе. Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к сдвигу аргумента для предсказанных значений.
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. Мы рассмотрим, как влиял на курс ЕВРО по отношению к рублю курс доллара США в июле 1999 года.
Установка пакета анализа.
Если в Microsoft Excel в меню Сервисотсутствует командаАнализ данных, то необходимо установить статистический пакет анализа данных.
Чтобы установить пакет анализа данных
В![]() менюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
менюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
Установите флажок Пакет анализа,выберите кнопкуOK.
Вызов пакета анализа
Чтобы запустить пакет анализа:
В меню Сервисвыберите командуАнализ данных.
В списке Инструменты анализавыберите нужную строку.
![]()
Корреляция
При выборе строки Корреляцияв диалоговом запросеАнализ данныхпоявляется следующее окно.
![]()
Входной интервал. Введите ссылку на ячейки, содержащие анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк. (Для этого нужно мышью щелкнуть по кнопке ![]() в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
![]()
Группирование. Установите переключатель в положениеПо столбцамилиПо строкамв зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Установите переключатель в положениеМетки в первой строке, если первая строка во входном диапазоне содержит названия столбцов. Установите переключатель в положениеМетки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически. (В других видах анализа этот флажок выполняет аналогичную функцию).
Выходной интервал. Введите ссылку на левую верхнюю ячейку выходного диапазона. Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Новый лист. Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая книга. Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Смотри лист Корреляция в примере.
Вернитесь в текущий документ через Панель задач
результате программа сформирует таблицу с коэффициентами корреляции между выбранными совокупностями.
Регрессионный анализ. Построение статических однофакторных моделей
![]()
Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
Содержательная постановка задачи. Имеется статистическая информация по центральному федеральному округу, которая представлена в таблице1:
Таблица 1. Число гостиниц и число ночевок в гостиницах
Наименование субъекта Федерации
Число гостиниц и аналогичных средств размещения, ед.
Число ночевок в гостиницах и аналогичных средствах размещения, тыс. ночевок
* — на базе данных Федеральной службы государственной статистики.
Пусть ряд наблюдений X — число гостиниц и аналогичных средств размещения, ряд наблюдений Y — число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Часть I.
Построить точечную диаграмму, предварительно отсортировав таблицу; Выдвинуть гипотезу о виде функции зависимости; Рассчитать параметры модели регрессии, построить тренды; Оценить адекватность построенного уравнения по величине достоверности аппроксимации; Рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Пример. В исходной таблице произведем сортировку по столбцу С (число гостиниц и аналогичных средств размещения) по возрастанию числа гостиниц.
![]()
Рис.1. Сортировка по возрастанию числа гостиниц
Отсортированная таблица представлена на рисунке 2:
![]()
Рис.2. Отсортированная таблица по возрастанию числа гостиниц
По отсортированным данным, используя мастер диаграмм, построим точечную диаграмму (диапазон ячеек С1:D19) (Рис.3).
![]()
Рис. 3. Диаграмма по отсортированной таблице
После построения диаграммы, вызовем контекстовое меню, щелкнув правой кнопкой мыши по одной из точек диаграммы, и выберем в нем команду Добавить линию тренда…(Рис. 4):
![]()
Рис. 4. Вкладка Параметры линии тренда
Во вкладке Параметры линии тренда выберем Линейная и отметим флаги показывать уравнение на диаграмме и поместить на диаграмму величину достоверности аппроксимации (R^2). Чем R2 ближе к 1, тем удачнее регрессионная модель. На диаграмме появляется линия тренда (Рис. 5).
![]()
Рис.5. Диаграмма с линейной линией тренда
Чаще всего выбор производится среди следующих функций:
у = ах + b — линейная функция;
у = ах2 + bх + с — квадратичная (полиномиальная) функция;
у = аln(х) + b — логарифмическая функция;
у = аеbх — экспоненциальная функция;
у = ахb — степенная функция.
Отобразим на диаграмме все возможные тренды (Рис. 6.).
![]()
Рис. 6. Диаграмма с построенными линиями тренда
Часть II.
Требуется: рассчитать основные характеристики случайных величин.
Для расчета основных характеристик случайных величин используются следующие функции: СРЗНАЧ() – возвращает среднее арифметическое своих аргументов, КОРЕНЬ() – возвращает значение квадратного корня, а также ДИСП() и КОРРЕЛ().
ДИСП() — Оценивает дисперсию по выборке (Рис.7).
Синтаксис функции: ДИСП(число1;число2; . ).
Число1, число2. — от 1 до 255 числовых аргументов, соответствующих выборке из генеральной совокупности.
![]()
Рис. 7. Аргументы функции, оценивающей дисперсию по выборке — Дисп()
КОРРЕЛ() – возвращает коэффициент корреляции между интервалами ячеек «массив1» и «массив2». Коэффициент корреляции используется для определения взаимосвязи между двумя свойствами. Например, можно установить зависимость между средней температурой в помещении и использованием кондиционера (Рис. 8).
Синтаксис функции: КОРРЕЛ(массив1;массив2).
Массив1 — это интервал ячеек со значениями, Массив2 — второй интервал ячеек со значениями.
![]()
Рис.8. Аргументы функции, возвращающей коэффициент корреляции Коррел()
Получим следующие результаты (Рис. 9):
![]()
Рис. 9. Результаты расчетов с использованием математических функций
Можно сделать вывод о том, что линейная зависимость между числом гостиниц и аналогичных средств размещения (ряд X) и числом ночевок в гостиницах и аналогичных средствах размещения (ряд Y) существует, т. к. коэффициент корреляции равен 0,93729 и ![]() .
.
Коэффициент корреляции значим, т. к. расчетный критерий Стъюдента больше табличного критерия: 10,7566 > 2.1190.
Рассчитаем коэффициент корреляции для исходных данных с помощью функции Корреляция пакета Анализ данных.
Вызвать окно Анализ данных можно с помощью команды Анализ данных меню Данные (Рис. 10).
![]()
Рис. 10. Анализ данных
Пакет Корреляция позволяет определить коэффициенты корреляции для n-го количества рядов данных. Выбор команды Корреляция вызывает окно Корреляция (Рис. 11).
![]()
Рис. 11. Окно Корреляция
Это окно содержит две панели Входные данные и Параметры вывода. Окно Входной интервал: предназначено для ссылки на диапазон, содержащий анализируемые данные. Эта ссылка должна состоять не менее чем из двух смежных диапазонов данных, расположенных по строкам или столбцам. Флаги Группирование: зависят от расположения данных в диапазоне. Флаг Метки в первой строке (Метки в первом столбце) устанавливается в том случае, если входной интервал включал название диапазонов. Если название диапазонов были включены в интервал, а данный флаг не выставлен, после нажатия кнопки Ок, Excel выдаст сообщение об ошибке «Входной интервал содержит нечисловые данные». Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Если результаты необходимо поместить на имеющемся листе, то нужно установить переключатель рядом с окном Выходной интервал:, а в самом окне следует ввести ссылку на левую верхнюю ячейку выходного диапазона.
Если установить переключатель рядом с окном Новый рабочий лист:, то в книге откроется новый лист и результаты анализа будут вставлены в него, начиная с ячейки A1. При необходимости в окно можно ввести имя нового листа. По умолчанию имя листа будет соответствовать следующему после последнего имеющегося в книге листа.
Если установить переключатель рядом с окном Новая рабочая книга, то откроется новая книга, и результаты анализа будут вставлены в нее, начиная с ячейки A1 на первом листе в этой книге.
Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места.
Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Заполняем все необходимые поля окна Корреляция (Рис. 12).
Входной интервал – это данные, по которым необходимо провести корреляционный анализ, в данном случае это исходные данные по числу гостиниц и аналогичных средств размещения и числу ночевок в гостиницах и аналогичных средствах размещения (С2:D19). Строка 1 также указана во входном интервале, но в ней содержатся заголовки столбцов, поэтому ставим флаг Метки в первой строке.
В выходном интервале ставим Новый рабочий лист, в котором будут вынесены результаты расчета.
![]()
Рис. 12. Расчет коэффициента корреляции
Полученные данные абсолютно идентичны коэффициентам полученным с помощью функции КОРРЕЛ() (Рис. 13).
![]()
Рис. 13. Результаты расчета коэффициента корреляции
Пакет Описательная статистика предназначен для расчета основных статистических показателей. Окно Описательная статистика (Рис. 14) содержит:
![]()
Рис.14. Описательная статистика
панель Входные данные, аналогичную панели в окне Корреляция; панель Параметры вывода содержит указание на выходной интервал, аналогичный окну Корреляция; флаг Итоговая статистика обеспечивает вывод в выходной интервал среднего, стандартную ошибку (среднего), медиану, мода, стандартное отклонение, дисперсию выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумму и количество значений; флаг Уровень надежности, установка которого выводит в выходной интервал строку для уровня надежности. Значение, введенное в поле, соответствует требуемому уровню надежности; флаг К-тый наименьший и К-тый наибольший, установка которых выводит в выходной интервал строки для k-го наибольшего и k-го наименьшего значения для каждого диапазона данных. В соответствующем окне необходимо ввести число k. Если k равно 1, эта строка будет содержать минимум или максимум из набора данных.
Далее вызовем функцию Описательная статистика из пакета Анализ данных (Рис. 15).
![]()
Рис. 15. Описательная статистика пакета Анализ данных
Выставив все необходимые флаги, нажимаем кнопку Ок, и получаем таблицу описательных статистик (Рис. 16).
![]()
Рис. 16. Таблица описательных статистик
Полученные данные совпадают с данными, рассчитанными с помощью математических функций (математическое ожидание по x и по y, дисперсия по x и по y, среднее квадратическое отклонение по x и по y).
Варианты заданий к практической работе 1.
Содержательная постановка задачи. Исходные данные:
построить точечную диаграмму, предварительно отсортировав таблицу; выдвинуть гипотезу о виде функции зависимости; рассчитать параметры модели регрессии, построить тренды; оценить адекватность построенного уравнения по величине достоверности аппроксимации; рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Вариант 2. Имеется статистическая информация по Северо-Западному федеральному округу*, которая представлена в таблице:
Число гостиниц и аналогичных средств размещения
Число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Источник
Содержание
- Инструментарий Microsoft Excel 2000 для решения множественной регрессионной задачи
- Числовые характеристики результатов наблюдения
- Формирование выборки
- Корреляционный анализ
- Регрессионный анализ
- Ряды динамики
- Список рекомендуемой литературы
Инструментарий Microsoft Excel 2000 для решения множественной регрессионной задачи
В русифицированной версии EXCEL 97 для корреляционно-регрессионного анализа используются средства специального статистического модуля. Microsoft заказывала разработку этого модуля фирме, специализирующейся на программном обеспечении математико-статистических задач. Модуль включает в себя два вида средств математико-статистического анализа: функции и инструменты. Мы отдаем предпочтение сложным инструментам, обеспечивающим более высокий уровень автоматизации расчетов, комплексности, графического моделирования и организации результатов. Однако некоторые пользователи в определенных случаях вполне обоснованно могут предпочесть функции.
Множественный корреляционно-регрессионный анализ в основном ориентирован на средства дополнительного пакета Анализ данных. Активизация команды Сервис Анализ данных открывает окно Инструменты анализа, предоставляющее 19 статистических инструментальных средств. Среди них — Корреляция и Регрессия, непосредственно и эффективно поддерживающие простой и множественный корреляционно-регрессионный анализ
Эти сложные инструменты доступны в том случае, если они предварительно загружены через команду Сервис / Надстройки. В открывшемся окне дополнений следует пометить флажок слева от позиции пакет анализа, и затем щелкнуть по кнопке ОК. После повторного обращения к команде Сервис, позиция Анализ данных появится в конце меню. Если же команда Анализ данных и в этом случае отсутствует в меню Сервис, то необходимо запустить программу установки Microsoft Excel. После установки пакета анализа его необходимо активизировать с помощью команды Надстройки.
С помощью инструмента Корреляция, можно получить корреляционную матрицу парных коэффициентов за один прием. Для этого, после выбора Сервис/Анализ данных/Корреляция, следует определить в качестве входного все поле имеющихся исходных данных, корреляционные связи которых изучают. Затем следует уточнить с помощью флажков, по столбцам или по строкам размещены переменные. Если поле содержит заголовочную строку (или столбец), то в диалоге активизируют графический флажок Метки (Labels). После выбора графической кнопки выполнения (ОК), корреляционная матрица автоматически выводится на новый лист той же электронной таблицы, начиная с клетки А1. Если матрицу желают вывести на какой-либо конкретный лист и начиная с клетки, определяемой пользователем, то делают соответствующие установки в окне «Выходной интервал» диалогового окна инструмента Корреляция.
Вид корреляционной матрицы, полученной в результате определения входного поля представлен в таблице:
| А | B | C | D | E |
| Х1 | Х2 | Х3 | Х4 | |
| X1 | ||||
| Х2 | k12 | |||
| Х3 | k13 | k21 | ||
| Х4 | k14 | k22 | k34 |
Можно осуществить преобразование корреляционной матрицы копированием в нее формулы для диагностики связей по модулю коэффициента корреляции.
Вспомогательная диагностирующая формула.
Поделиться с друзьями:
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
studopedia.su — Студопедия (2013 — 2023) год. Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав! Последнее добавление
Генерация страницы за: 0.008 сек. —>
Источник
Числовые характеристики результатов наблюдения
Следующим этапом статистического анализа данных после построения вариационного ряда является характеристика отдельных свойств распределения данных наблюдения. С этой целью в статистике используются специальные числовые параметры, найденные по результатам наблюдения и отражающие в сжатом виде основные, существенные черты распределения данных. Эти числовые параметры называются эмпирическими числовыми характеристиками. Наиболее важными числовыми характеристиками являются характеристики положения, вариации, асимметрии и эксцесса.
Для характеристики положения используются показатели центра распределения данных наблюдения– средняя арифметическая, мода и медиана.
Средняя арифметическая для дискретного ряда распределения рассчитывается по формуле:
 , где
, где
 –варианты значений признака;
–варианты значений признака;
– частота повторения данного варианта.
В интервальном вариационном ряду средняя арифметическая определяется по формуле:
 , где
, где
 – середина соответствующего интервала;
– середина соответствующего интервала;
Мода распределения– это наиболее часто встречающееся значение признака в совокупности. В дискретном ряду определение моды не требует специальных расчётов. Мода соответствует варианту с наибольшей частотой. В интервальном вариационном ряду в отличие от дискретного ряда определение моды требует определённых расчётов на основе специальной формулы.
Модальный интервал (то есть содержащий моду) при интервальном распределении с равными интервалами определяется по наибольшей частоте, а с неравными интервалами– по наибольшей плотности. В первом случае мода рассчитывается по следующей формуле:

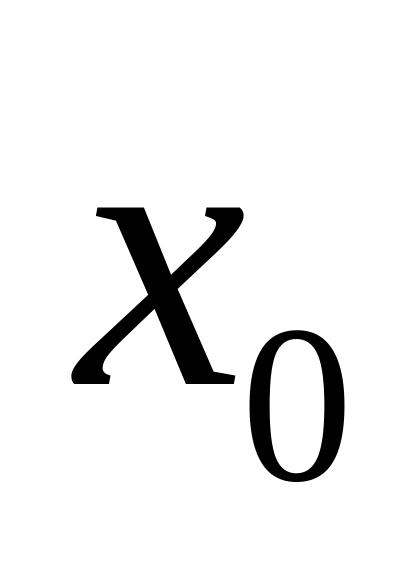 – нижняя граница модального интервала;
– нижняя граница модального интервала;
– величина модального интервала;
 – частота модального интервала;
– частота модального интервала;
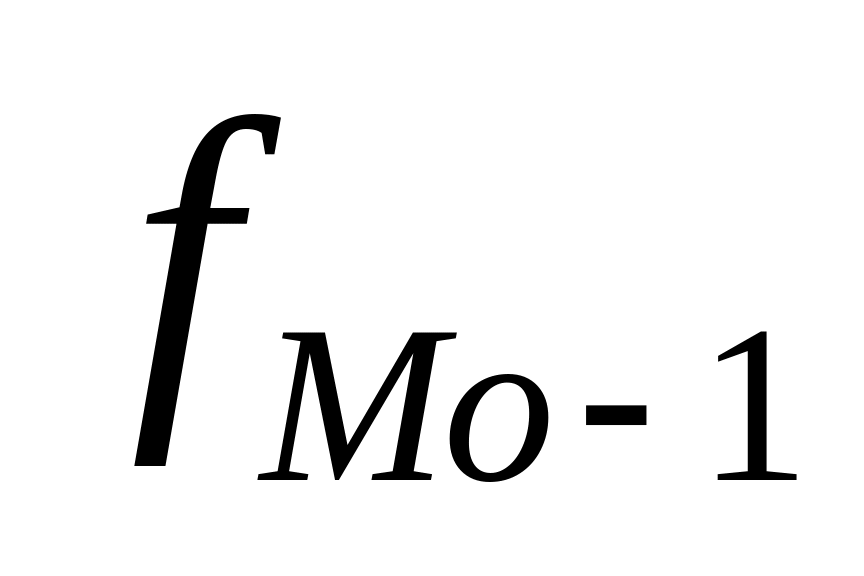 – частота интервала, предшествующего модальному;
– частота интервала, предшествующего модальному;
 – частота интервала, следующего за модальным.
– частота интервала, следующего за модальным.
Во втором случае в формуле моды вместо частот  используется соответствующая плотность
используется соответствующая плотность  .
.
Медиана – это значение признака, расположенное в середине (в центре) ранжированного ряда. Медиана делит совокупность на две равные части– со значениями признака меньше медианы и со значениями признака больше медианы.
В дискретном ряду для вычисления медианного значения признака сначала находят его порядковый номер:
 , где
, где
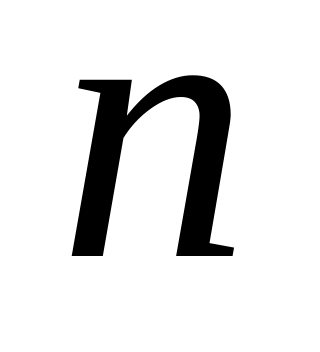 – число единиц совокупности.
– число единиц совокупности.
Полученное значение указывает, что середина приходится на данный номер единицы совокупности. Необходимо определить, к какой группе относится единица с этим порядковым номером. Это можно сделать, рассчитав накопленные частоты.
В интервальном вариационном ряду медиана определяется по формуле:
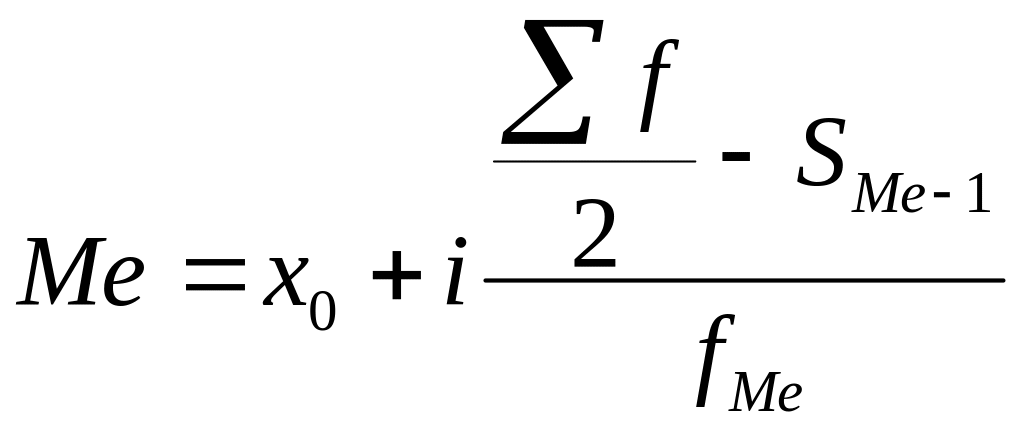 , где
, где
– нижняя граница медианного интервала;
– величина медианного интервала;
 – сумма всех частот ряда;
– сумма всех частот ряда;
 – накопленная частота интервала, предшествующего медианному;
– накопленная частота интервала, предшествующего медианному;
 – частота медианного интервала.
– частота медианного интервала.
Медианным является интервал, в котором сумма накопленных частот равна или превышает полусумму частот ряда.
Основными характеристики вариации признака являются дисперсия, среднее квадратическое (стандартное) отклонение и коэффициент вариации. Они характеризуют степень рассеивания данных наблюдения относительно центра распределения.
Дисперсия рассчитывается по формуле:
 .
.
Среднее квадратическое (стандартное) отклонение равно корню квадратному из дисперсии.
Коэффициент вариации равен:
 .
.
Для оценки степени отклонения распределения исследуемой величины от нормального распределения используется коэффициент асимметрии, основанный на определении центрального момента третьего порядка  (в нормальном распределении его величина равна нулю):
(в нормальном распределении его величина равна нулю):  . В Excel вычисляется несмещённая состоятельная оценка коэффициента асимметрии:
. В Excel вычисляется несмещённая состоятельная оценка коэффициента асимметрии:
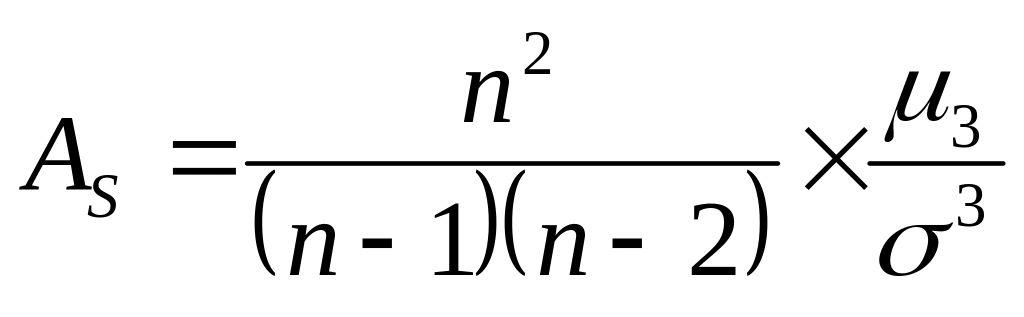 ,
,
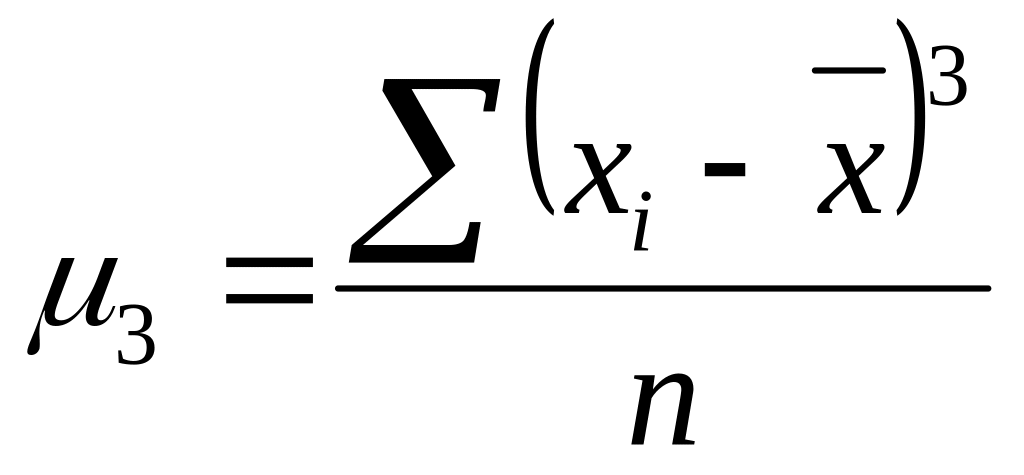 .
.
Стандартизированный коэффициент асимметрии  имеет приближённое стандартное нормальное распределение.
имеет приближённое стандартное нормальное распределение.
Эксцесс представляет собой выпад вершины эмпирического распределения вверх или вниз от вершины кривой нормального распределения, имеющей куполообразную форму.
Наиболее точным является коэффициент эксцесса, основанный на использовании центрального момента четвёртого порядка:  . Для нормального распределения
. Для нормального распределения  равен нулю, так как
равен нулю, так как 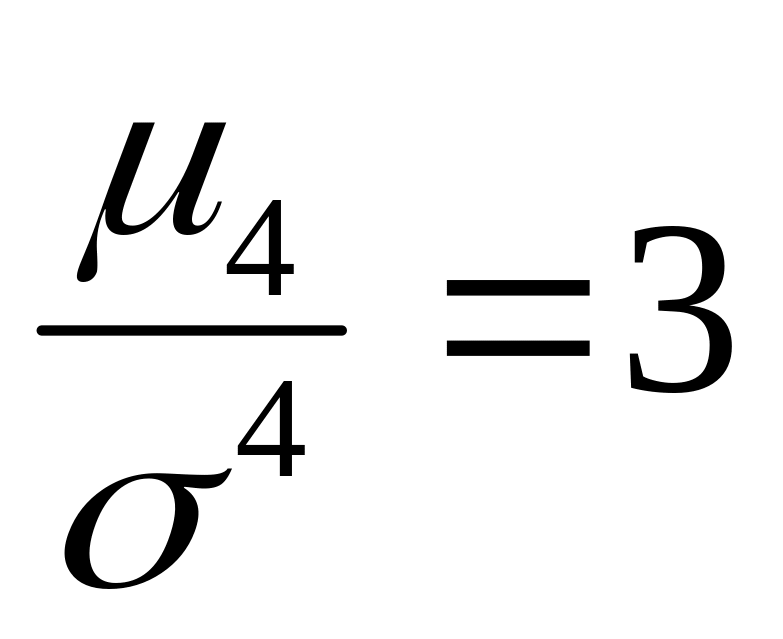 . В Excel вычисляется несмещённая состоятельная оценка коэффициента:
. В Excel вычисляется несмещённая состоятельная оценка коэффициента:
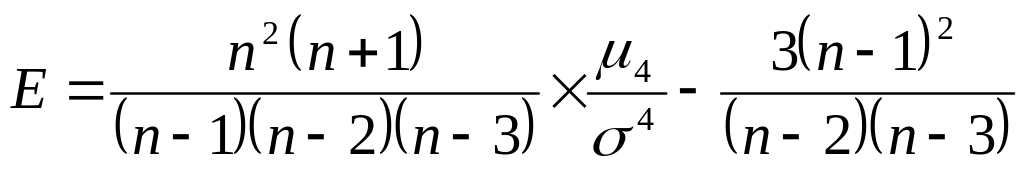 ;
;
 .
.
Стандартизированный выборочный коэффициент эксцесса  используется при оценке степени отклонения распределения исследуемой случайной величины от нормального распределения.
используется при оценке степени отклонения распределения исследуемой случайной величины от нормального распределения.
В Excel числовые характеристики вычисляются с помощью процедуры Описательная статистика, входящей в Пакет анализа, и соответствующих встроенных статистических функций СРЗНАЧ, МЕДИАНА, МОДА, ДИСП, ДИСПР, СТАНДОТКЛОН, СТАНДОТКЛОНП, СРОТКЛ, КВАДРОТКЛ, СКОС и ЭКСЦЕСС.
Для доступа к процедуре Описательная статистика необходимо:
В меню Сервис выделить строку Анализ данных.
В открывшемся окне Анализ данных выделить процедуру Описательная статистика и щёлкнуть на кнопке ОК. На экране появится диалоговое окно Описательная статистика, которое содержит следующие элементы управления:
поле ввода Входной интервал. В это поле вводится ссылка на диапазон ячеек (входной диапазон), содержащий статистические данные, подлежащие обработке. Входной диапазон может быть столбцом или группой смежных столбцов (строкой или группой смежных строк). Если входной диапазон представляет собой группу столбцов (строк), то процедура воспринимает каждый столбец (строку) как отдельную совокупность;
флажок Итоговая статистика. Если этот флажок установлен, процедура вычисляет и помещает в таблицу результатов решения следующие числовые характеристики: среднюю, стандартную ошибку средней, медиану, моду, стандартное отклонение, дисперсию, эксцесс, асимметрию, размах вариации, минимальное и максимальное значение изучаемого признака, сумму всех значений признака и объём совокупности. Если совокупность не имеет повторяющихся значений признака, в строке Мода появляется сообщение # Н/Д!– неопределённые данные;
флажок Уровень надёжности. Флажок устанавливается в том случае, когда необходимо вычислить доверительный интервал для средней, соответствующий заданной доверительной вероятности. При этом справа от флажка открывается поле для ввода доверительной вероятности, выраженной в процентах. Если этот флажок установлен, то в последней строке таблицы результатов решения появляется число, равное половине длины доверительного интервала;
флажки К-й наименьший/К-й наибольший. Если эти флажки установлены. то в таблице результатов решения появляются -й и 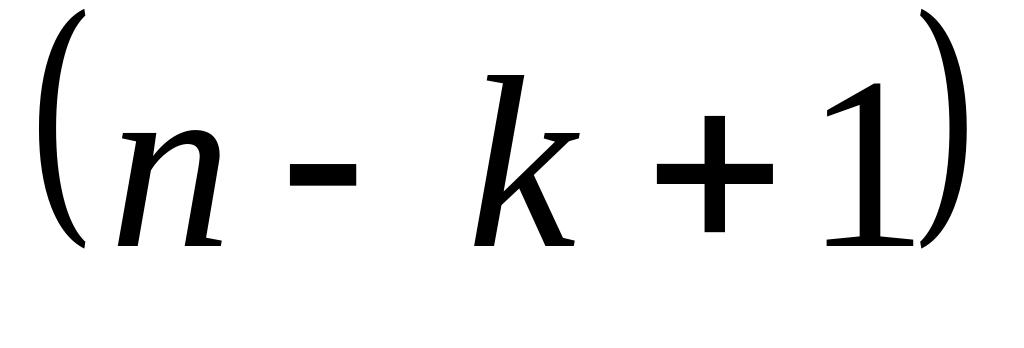 -й элементы упорядоченной совокупности (то есть единицы совокупности, расположенные на -м месте от её начала и от конца).
-й элементы упорядоченной совокупности (то есть единицы совокупности, расположенные на -м месте от её начала и от конца).
Назначение переключателей Группирование по столбцам/по строкам, флажка Метки в первой строке/Метки в первом столбце и группы переключателей Выходной интервал/Новый рабочий лист/Новая книга рассмотрено на стр. 8-9.
Результаты решения выводятся на экран в виде набора таблиц– по одной таблице на каждый столбец входного интервала (на каждую обработанную совокупность). Каждая выходная таблица состоит из двух столбцов. В первом столбце указывается названия числовых характеристик, во втором– их значения. В заголовке указывается номер совокупности, к которой относится данная таблица (например, Столбец 1).
Свой наибольший размер (18×2) таблица принимает при установке всех четырёх флажков, расположенных в нижней части диалогового окна процедуры. В случае возникновения опасности того, что таблица результатов наложится на уже заполненные ячейки, на экран выводится сообщение о такой опасности. В ответ на это сообщение пользователь должен разрешить удаление старых данных и вывод на их место новых (для этого надо щёлкнуть на кнопке ОК).
Формирование выборки
Метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой её части на основе положений случайного отбора, называется выборочным методом.
Подлежащая изучению по определённым признакам статистическая совокупность, из которой производится отбор единиц, называется генеральной. Отобранная из генеральной совокупности в случайном порядке некоторая часть единиц, подвергающаяся обследованию, называется выборочной совокупностью или просто выборкой.
В теории выборочного метода разработаны и в практике статистико-экономических исследований применяются различные способы формирования выборочных совокупностей, обеспечивающие репрезентативность. Организация выборочного наблюдения заключается в определении способа и вида отбора единиц.
Под способом отбора понимают порядок отбора единиц из генеральной совокупности. Различают два способа отбора: повторный и бесповторный.
При повторном способе каждая отобранная в случайном порядке единица после её обследования возвращается в генеральную совокупность и при последующем отборе может снова попасть в выборку. Вероятность попадания любой единицы в выборку равна 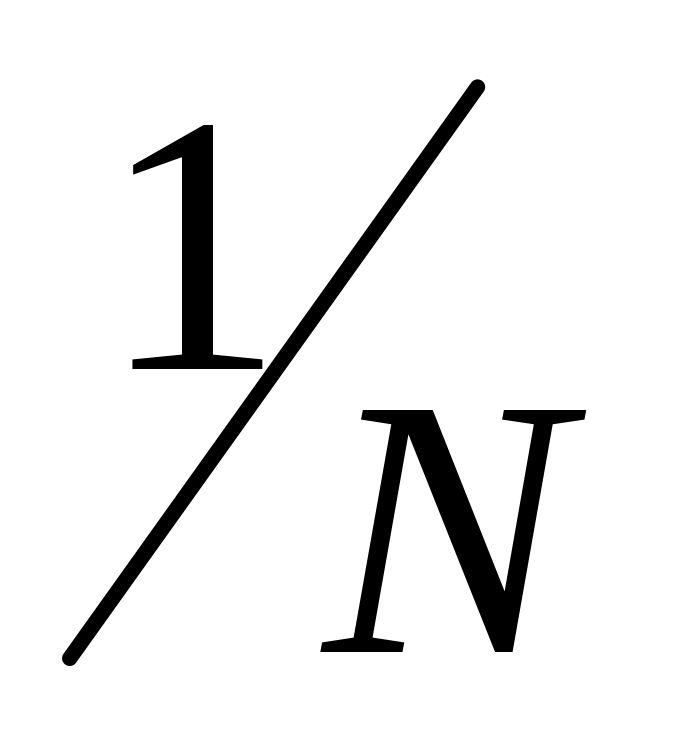 , и она остаётся той же самой на протяжении всей процедуры отбора.
, и она остаётся той же самой на протяжении всей процедуры отбора.
При бесповторном способе отбора попавшая в выборочную совокупность единица после регистрации значений наблюдаемых признаков не возвращается в совокупность, из которой осуществляется дальнейший отбор. Вероятность попадания единицы в выборку изменяется от – для первой отбираемой единицы до  – для последней единицы, то есть по мере производства отбора вероятность попасть в выборку для каждой единицы генеральной совокупности увеличивается, тем самым повышается репрезентативность выборки.
– для последней единицы, то есть по мере производства отбора вероятность попасть в выборку для каждой единицы генеральной совокупности увеличивается, тем самым повышается репрезентативность выборки.
В зависимости от методики формирования выборочной совокупности различают следующие основные виды выборки:
типическая (стратифицированная, расслоенная, районированная);
В Пакете анализа табличного процессора Excel имеется процедура Выборка, реализующая повторную собственно-случайную выборку и механическую выборку с заданным пользователем шагом (периодом) отбора.
Формирование выборки в Excel осуществляется следующим образом:
Единицам генеральной совокупности присваиваются порядковые номера. Для проведения механической выборки генеральная совокупность должна быть каким-либо образом упорядочена, то есть должна быть определённая последовательность в расположении её единиц. Для получения результатов, не содержащих систематическую ошибку выборки, упорядочение необходимо произвести по нейтральному признаку по отношению к изучаемому.
Порядковые номера единиц исходной совокупности вводятся в диапазон ячеек (входной диапазон). Эти номера могут находиться в одном столбце или группе смежных столбцов одинаковой «высоты». При этом число всех ячеек входного диапазона должно равняться числу единиц исходной совокупности. Если среди элементов входного интервала имеются нечисловые данные, то отбор не состоится, а на экране появится сообщение «Выборка– входной интервал содержит нечисловые данные».
В меню Сервис выделяется строка Анализ данных.
В открывшемся диалоговом окне Анализ данных выделяется процедура Выборка и нажимается кнопка ОК. На экране появится диалоговое окно Выборка, которое содержит следующие элементы управления:
поле ввода Входной интервал. В это поле вводится ссылка на диапазон, в котором хранятся номера всех единиц генеральной совокупности, из которой осуществляется выборка.
Метод выборки устанавливается с помощью переключателей Периодический и Случайный. При активизации переключателя Случайный процедура «настраивается» на выполнение случайной выборки с повторением. Нужный объём выборки вводится в поле Число выборок. Единицы генеральной совокупности отбираются случайным образом. Каждая единица исходной совокупности имеет равную со всеми остальными единицами возможность быть включённой в выборку. Любая единица генеральной совокупности может попасть в выборку более одного раза.
При необходимости реализовать механическую выборку активизируется переключатель Периодический. Шаг выборки вводится в поле Период, находящееся справа от переключателя. В выборку войдут элементы исходной совокупности с номерами, кратными заданному периоду. Если входной диапазон состоит из нескольких столбцов, то отбираемые значения будут извлекаться сначала из первого столбца, затем из второго и т.д. Формирование выборки прекращается по достижении конца исходной совокупности.
При формировании случайной выборки выходной интервал представляет собой столбец с числом ячеек, равным заданному объёму выборки. В случае механической выборки число ячеек выходного интервала равно целой части результата деления объёма исходной совокупности на шаг выборки.
Для получения упорядоченной копии номеров единиц совокупности, подлежащих включению в выборку, необходимо щелчком на кнопке Сортировка по возрастанию, расположенной на панели инструментов Стандартная, упорядочить полученный набор номеров.
Корреляционный анализ
В статистике различают две категории зависимостей между признаками:
2) стохастическая, частным случаем которой является корреляционная.
При этом признаки для изучения взаимосвязи по их значению делятся на два класса. Признаки, обуславливающие изменение других, связанных с ними признаков, называются факторными (х). Признаки, изменяющиеся под действием факторных признаков, являются результативными (у).
Функциональной называется связь, при которой каждому значению факторного признака соответствует вполне определённое значение результативного признака. Функциональная связь является строгой, точной, полной зависимостью; проявляется и для каждой единицы совокупности, и во всех случаях наблюдения. Характерной особенностью функциональной связи является то, что в каждом отдельном случае известен полный перечень факторов, влияющих на результативный признак, а также механизм этого влияния, выраженный определённым уравнением.
Стохастическая (вероятностная) связь не проявляется в каждом отдельном случае, а лишь в общем, среднем, при большом числе наблюдений.
Корреляционной называется связь, при которой каждому значению факторного признака может соответствовать несколько значений результативного признака.
Корреляционные связи имеют ряд характеристик:
По форме (аналитическому выражению) корреляционные связи между признаками могут быть линейными (прямолинейными) и нелинейными (криволинейными). При линейной форме равномерное изменение значений одного признака сопровождается более или менее равномерным изменением значений другого признака. Математически она выражается уравнением прямой ух = а + вх, графически — прямой линией. При нелинейной форме равномерному изменению значений одного признака соответствует неравномерное изменение значений другого. Выражается уравнением какой- либо кривой линии: параболы, гиперболы, показательной, степенной, логарифмической, логической функции и др.
По направлению (характеру изменения) корреляционные связи бывают прямыми и обратными. Прямой (положительной) является зависимость, при которой направление изменения значений факторного и результативного признаков совпадает, то есть с увеличением факторного признака, результативный также возрастает, и, наоборот, при уменьшении факторного признака результативный тоже убывает. Обратной (отрицательной) называется связь, при которой изменение значений факторного и результативного признаков осуществляется в разных направлениях, то есть с ростом факторного результативный признак убывает или при убывании факторного признака результативный возрастает.
Степень тесноты корреляционной связи оценивается по специальным шкалам, например, по шкале Чеддока.
Количественный критерий оценки тесноты связи по шкале Чеддока
Величина показателя для измерения тесноты связи
Существуют и другие менее детальные шкалы.
В статистике различают следующие варианты зависимостей:
1) парная корреляция – связь между двумя признаками (результативным и факторным);
2) частная корреляция – зависимость между результативным и одним факторным признаком при фиксированном значении других факторных признаков;
3) множественная корреляция – зависимость результативного от двух или более факторных признаков.
В практике статистических исследований выделяют:
корреляционный анализ, который имеет своей задачей количественное измерение тесноты связи между признаками;
регрессионный анализ, который заключается в определении формы связи, построении одно- или многофакторных моделей (уравнений) регрессии;
корреляционно-регрессионный анализ, который включает в себя установление аналитического выражения (формы) и измерение степени тесноты связи.
Следует также различать собственно-корреляционные (параметрические) и непараметрические методы изучения взаимосвязей между признаками. Основу применения собственно-корреляционных методов составляют однородность и необходимость подчинения распределения совокупности по факторным и результативному признаку закону нормального распределения вероятностей. Несоблюдение этих условий обуславливает необходимость применения при изучении взаимосвязей непараметрических методов.
В связи с этим первым этапом изучения зависимостей является установление подчинения распределения результатов наблюдения по изучаемым признакам закону нормального распределения.
На соответствие изучаемого эмпирического распределения нормальному закону указывает близость значений показателей центра распределения – средней арифметической, моды и медианы. С этой целью производится также расчёт и оценка степени существенности показателей асимметрии и эксцесса. В Excel выборочные числовые характеристики вычисляются с помощью процедуры Описательная статистика, входящей в Пакет анализа, и соответствующих встроенных статистических функций (см. раздел 4).
Для проверки гипотезы о законе распределения изучаемого признака используются также специальные статистические критерии. При этом выдвигается гипотеза  о том, что истинной функцией распределения признака является некоторая заданная функция
о том, что истинной функцией распределения признака является некоторая заданная функция  (для нашей задачи– функция нормального распределения). Если гипотеза верна (то есть, если значения признака действительно имеют функцию распределения ), то найденная по данным наблюдения эмпирическая функция распределения
(для нашей задачи– функция нормального распределения). Если гипотеза верна (то есть, если значения признака действительно имеют функцию распределения ), то найденная по данным наблюдения эмпирическая функция распределения  не должна сильно отличаться от гипотетической функции распределения , и с увеличением объёма совокупности различие между ними должно уменьшаться. В связи с этим вопрос о принятии или отклонении проверяемой гипотезы решается в зависимости от того, насколько хорошо согласуются эмпирическая и гипотетическая функции распределения. Статистические критерии, базирующиеся на таком подходе, называются критериями согласия или соответствия. В основе этих критериев лежит выбранная статистика, которая служит мерой расхождения между эмпирическим и гипотетическим законами распределения исследуемого признака. Известны критерии К. Пирсона (хи- квадрат), В.И. Романовского, А.Н. Колмогорова, Б.С. Ястремского, омега-квадрат, Крамера-Мизеса-Смирнова и др.
не должна сильно отличаться от гипотетической функции распределения , и с увеличением объёма совокупности различие между ними должно уменьшаться. В связи с этим вопрос о принятии или отклонении проверяемой гипотезы решается в зависимости от того, насколько хорошо согласуются эмпирическая и гипотетическая функции распределения. Статистические критерии, базирующиеся на таком подходе, называются критериями согласия или соответствия. В основе этих критериев лежит выбранная статистика, которая служит мерой расхождения между эмпирическим и гипотетическим законами распределения исследуемого признака. Известны критерии К. Пирсона (хи- квадрат), В.И. Романовского, А.Н. Колмогорова, Б.С. Ястремского, омега-квадрат, Крамера-Мизеса-Смирнова и др.
Excel позволяет реализовать проверку статистических гипотез о соответствии эмпирических результатов наблюдения закону нормального распределения на основу вышеуказанных критериев согласия.
Последующий собственно-корреляционный анализ статистических данных, полученных в результате наблюдения, включает в себя:
построение корреляционного поля и корреляционной таблицы;
вычисление выборочных коэффициентов корреляции и корреляционных отношений;
проверка статистических гипотез о значимости корреляционной зависимости.
Корреляционное поле и корреляционная таблица служат для установления наличия и направления зависимости между изучаемыми признаками, дают общее представление об этой зависимости.
В Excel построение поля корреляции (диаграммы рассеивания) между изучаемыми признаками осуществляется при помощи специального средства, служащего для графического изображения статистических данных– Мастера диаграмм (см. 19). Для построения корреляционного поля используется тип Точечная. На палитре Вид выделяется диаграмма в виде изолированных точек, находящаяся в левом верхнем углу палитры.
Расположение точек на графике позволяет в ряде случаев сделать предположение о наличии, направлении и форме взаимосвязи между изучаемыми признаками. Так, линейное расположение точек даёт серьёзное основание для выбора линейной модели, сравнительно небольшой разброс точек относительно воображаемой кривой, проходящей «наилучшим образом» через эти точки, говорит о довольно сильной зависимости между признаками, и наоборот. Расположение точек слева на право свидетельствует о прямой корреляции, а справа налево– об обратной корреляции.
Для подтверждения выводов, сделанных в результате анализа корреляционного поля и в тех случаях, когда корреляция между признаками имеет явно выраженный нелинейный характер и объём выборки велик, данные наблюдения группируют и представляют их в виде корреляционной таблицы, состоящей из  строк и
строк и 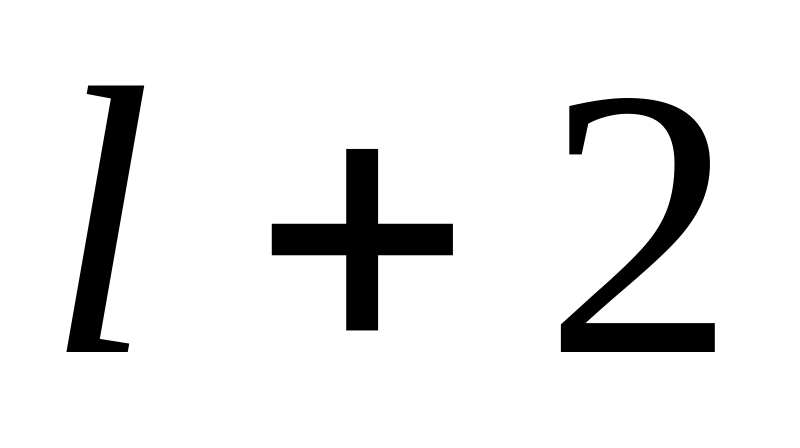 столбцов, где –число интервалов группировки по факторному признаку и
столбцов, где –число интервалов группировки по факторному признаку и  – число интервалов группировки по результативному признаку. Это обусловлено тем, что при нелинейной зависимости вычисляются корреляционные отношения, которые могут быть определены только по сгруппированным данным.
– число интервалов группировки по результативному признаку. Это обусловлено тем, что при нелинейной зависимости вычисляются корреляционные отношения, которые могут быть определены только по сгруппированным данным.
Построение корреляционной таблицы начинают с группировки значений факторного и результативного признаков. В Excel для группировки данных способом равных интервалов используются процедура Гистограмма, входящая в Пакет анализа (см стр.14).
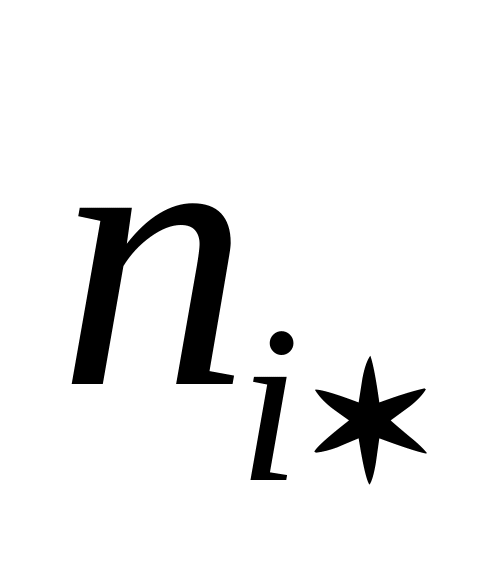






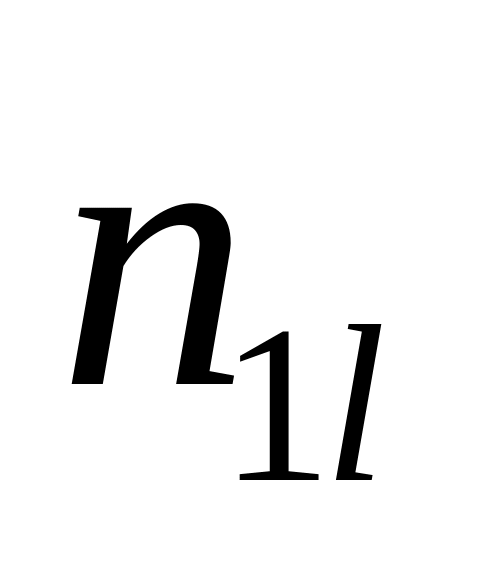

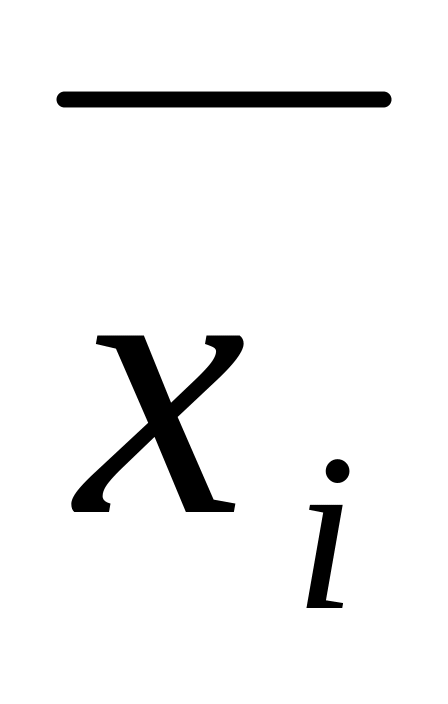


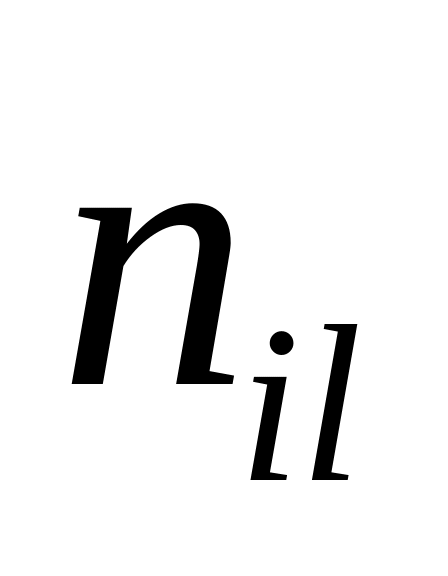
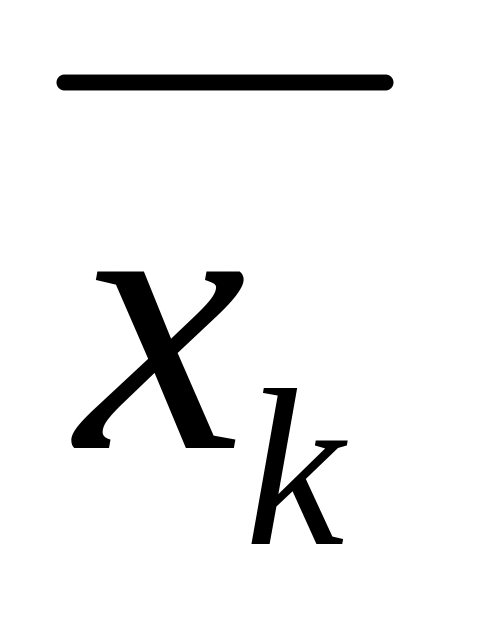







– середина -го интервала группировки по факторному признаку;
– середина  -го интервала группировки по результативному признаку;
-го интервала группировки по результативному признаку;
– групповая частота «клетки», находящейся на пересечении строки и столбца корреляционной таблицы;
– групповая частота -го интервала группировки по факторному признаку (число наблюдений в -й строке);
–групповая частота -го интервала группировки по результативному признаку (число наблюдений в -м столбце);
–объём изучаемой совокупности (общее число наблюдений).
Заполнение корреляционной таблицы даёт довольно наглядное представление о характере зависимости между изучаемыми признаками.
Для количественного измерения степени тесноты связи служат выборочные коэффициенты корреляции и корреляционные отношения.
Линейный коэффициент корреляции рассчитывается для определения тесноты и направления связи между двумя корреляционными признаками в случае наличия между ними линейной зависимости и распределения значений признаков близкого к нормальному. Линейный коэффициент корреляции может принимать значение от -1 до +1. Чем ближе коэффициент корреляции к 1, тем сильнее (теснее) связь между признаками. Для определения характера связи используют шкалу Чеддока.
В теории разработаны и на практике применяются различные модификации формулы расчёта данного коэффициента:
 ;
;
 ;
;
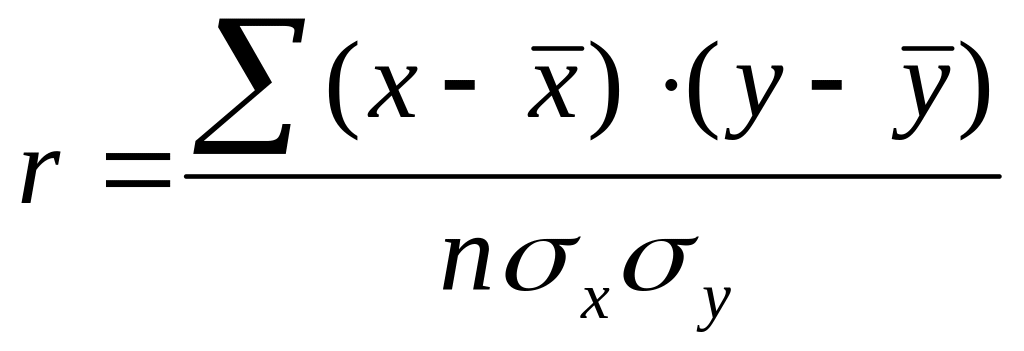 ;
;
 ;
;
 ,
,
где 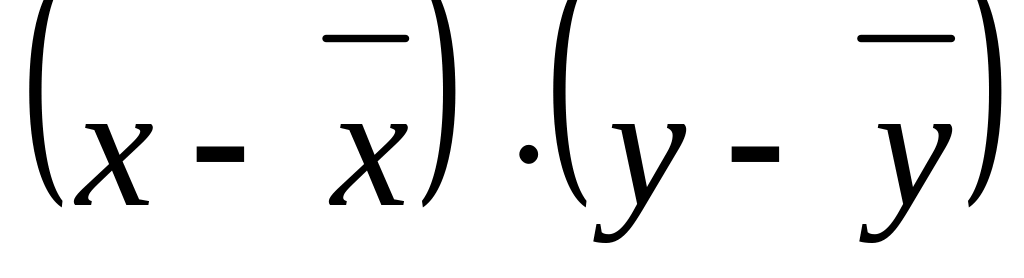 –ковариация факторного и результативного признаков;
–ковариация факторного и результативного признаков;
 ,
,  – среднее квадратическое (стандартное) отклонение соответственно факторного и результативного признака;
– среднее квадратическое (стандартное) отклонение соответственно факторного и результативного признака;
n – число наблюдений.
Квадрат коэффициента корреляции (r 2 ) носит название коэффициента детерминации. Он показывает долю вариации результативного признака, обусловленную влиянием вариации факторного признака.
При наличии нелинейной зависимости используется более универсальный показатель измерения тесноты связи: корреляционное отношение. Различают эмпирическое и теоретическое корреляционное отношение.
Расчет эмпирического корреляционного отношения осуществляется по сгруппированным данным наблюдения и основан на использовании теоремы (правила) сложения дисперсий:
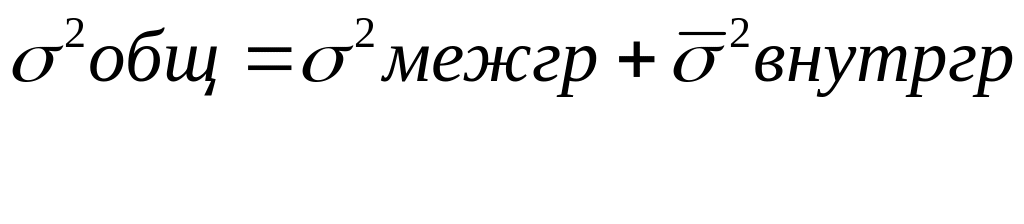
Эмпирическое корреляционное отношение определяется по формуле:

Межгрупповая дисперсия характеризует ту часть колеблемости результативного признака, которая складывается под влиянием изменения факторного признака, положенного в основание группировки:
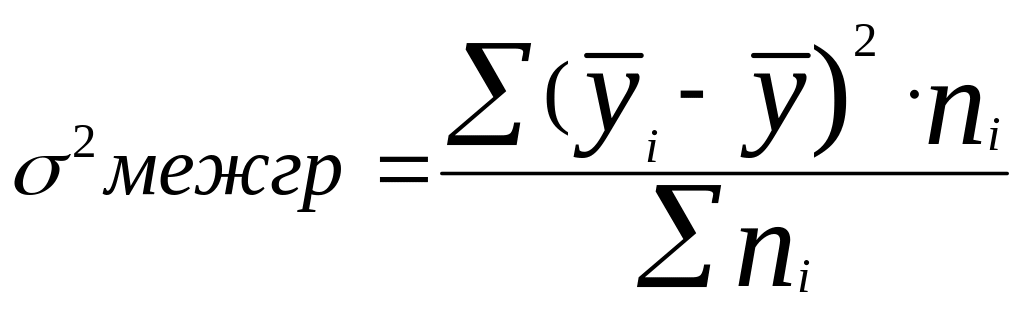
Средняя из внутригрупповых дисперсий оценивает ту часть вариации результативного признака, которая обусловлена действием других, прочих, «случайных» причин:
 , где
, где
 -дисперсия результативного признака в соответствующей группе.
-дисперсия результативного признака в соответствующей группе.

Общая дисперсия характеризует вариацию результативного признака, обусловленную влиянием всех факторов:
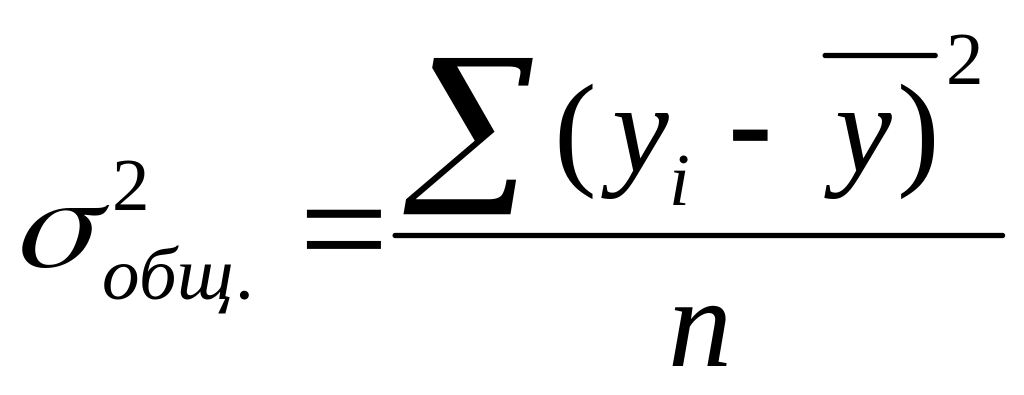
Расчёт теоретического корреляционного отношения в Excel осуществляется в рамках регрессионного анализа, поэтому будет рассмотрен в следующем разделе.
В Excel вычисление выборочного коэффициента корреляции осуществляется с помощью процедуры Корреляция, входящей в Пакет анализа, и встроенных статистических функций КОРРЕЛ, ПИРСОН и КВПИРСОН.
При применении процедуры Корреляция в поле Входной интервал диалогового окна этой процедуры вводится ссылка на входной диапазон (на диапазон, содержащий данные наблюдения, подлежащие обработке). Входной диапазон должен содержать  смежных столбцов по ячеек в каждом столбце или смежных строк по ячеек в каждой строке.
смежных столбцов по ячеек в каждом столбце или смежных строк по ячеек в каждой строке.
Назначение переключателя Группирование, флажка Метки и группы переключателей Выходной интервал/Новый рабочий лист/ Новая книга рассмотрено в первом разделе на стр.8-9.
Статистические функции КОРРЕЛ и ПИРСОН вычисляют выборочную оценку линейного коэффициента корреляции по первой формуле, представленной на стр. 34, и дублируют друг друга. Синтаксис функции КОРРЕЛ (массив 1; массив 2), где массив 1– диапазон ячеек, в который введены значения факторного признака (например, А1:А25), а массив 2– диапазон ячеек, в который введены значения результативного признака (например, В1:В25). Статистическая функция КВПИРСОН вычисляет квадрат выборочного коэффициента корреляции.
Для вычисление эмпирического корреляционного отношения в Excel не предусмотрено специальных статистических процедур и встроенных функций. Вычисление корреляционного отношения осуществляется по представленным выше формулам и требует предварительного построения корреляционной таблицы и ряда вспомогательных расчётов.
Значимость линейного коэффициента корреляции проверяется на основе t – критерия Стьюдента. При этом выдвигается и проверяется гипотеза ( 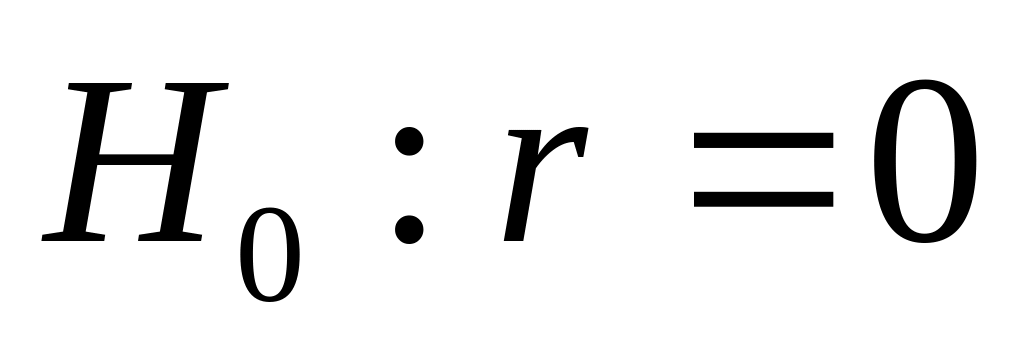 ) о равенстве коэффициента корреляции в генеральной совокупности нулю (то есть в действительности связь между изучаемыми признаками отсутствует, а эмпирическое значение выборочного коэффициента корреляции обусловлено только случайными совпадениями
) о равенстве коэффициента корреляции в генеральной совокупности нулю (то есть в действительности связь между изучаемыми признаками отсутствует, а эмпирическое значение выборочного коэффициента корреляции обусловлено только случайными совпадениями  и
и 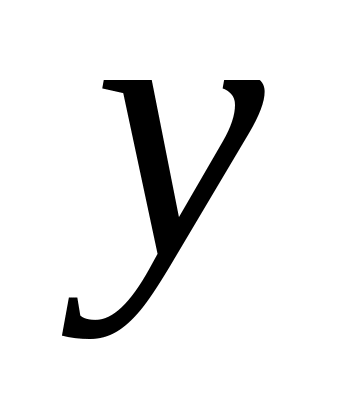 в выборке).
в выборке).
Фактическое значение t — критерия рассчитывается по формуле — для совокупностей n 100):
 .
.
Вычисленное значение t – критерия сравнивается с критическим его значением при принятом уровне занятости α и числе степеней свободы k = n-2. В социально-экономических исследованиях уровень значимости α обычно принимается равным 0,05.
При «ручной» проверке гипотезы критические значения t находятся по таблице распределения Стьюдента. Если расчётное значение t – критерия больше критического, то гипотеза о том, что линейный коэффициент корреляции в генеральной совокупности равен нулю и лишь в силу случайных обстоятельств оказался равен проверяемому значению, отклоняется, то есть коэффициент корреляции признаётся значимым, а связь между признаками – статистически существенной. Если расчётное значение t – критерия меньше критического, то нулевая гипотеза принимается, что означает, что коэффициент корреляции в генеральной совокупности в действительности равен нулю и соответственно эмпирический коэффициент корреляции существенно не отличается от нуля.
В Excel проверка гипотезы об отсутствии корреляции между изучаемыми признаками осуществляется следующим образом:
В ячейку (например, В1) вводится значение выборочного коэффициента корреляции  ;
;
В ячейку В2 для определения расчётного значения t – критерия вводится формула (*): = В1*КОРЕНЬ (115/(1-В1^2)) ( = 117);
В ячейку В3 для нахождения критического значения t – критерия Стьюдента при уровне значимости α= 0,05 и числе степеней свободы k =115 вводится формула: = СТЬЮДРАСПОБР (0.05;115);
Полученные расчётное и критическое значения t – критерия Стьюдента сравниваются, и делается вывод об отклонении или принятии нулевой гипотезы на уровне значимости  =0,025 . Если гипотеза противоречит реальным данным наблюдения (отклоняется), то выборочный коэффициент корреляции признаётся значимым и между изучаемыми признаками существует соответствующая по степени тесноты корреляционная зависимость. Если гипотеза принимается, коэффициент корреляции признаётся незначимым.
=0,025 . Если гипотеза противоречит реальным данным наблюдения (отклоняется), то выборочный коэффициент корреляции признаётся значимым и между изучаемыми признаками существует соответствующая по степени тесноты корреляционная зависимость. Если гипотеза принимается, коэффициент корреляции признаётся незначимым.
Для оценки значимости корреляционного отношения  используется F – критерий Фишера–Снедекора, вычисленный по формуле:
используется F – критерий Фишера–Снедекора, вычисленный по формуле:
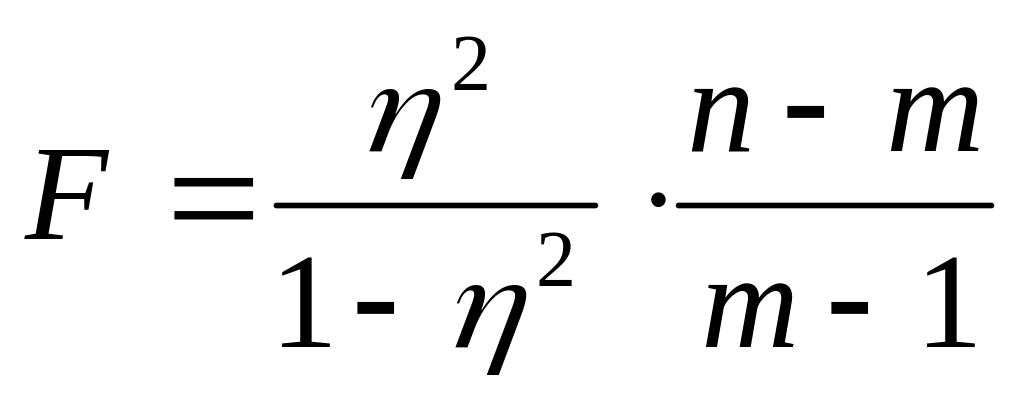 , (**)
, (**)
где n — число наблюдений; m – число интервалов группировки или параметров в уравнении регрессии.
При этом проверяется гипотеза 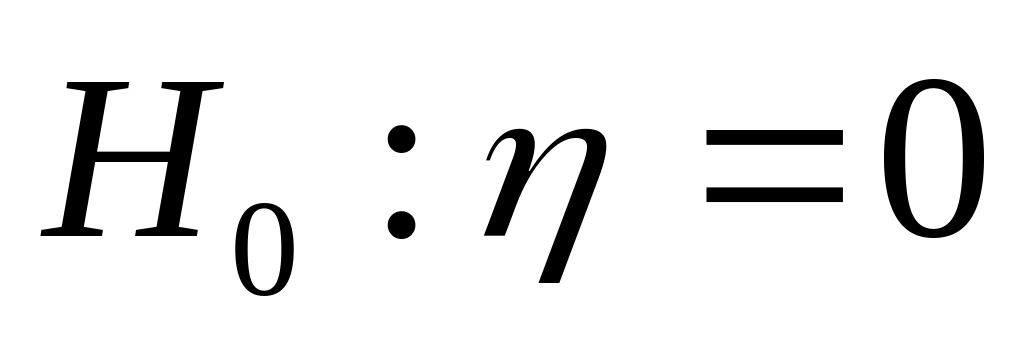 об отсутствии корреляционной зависимости между изучаемыми признаками. Проверяемая гипотеза отклоняется на уровне значимости
об отсутствии корреляционной зависимости между изучаемыми признаками. Проверяемая гипотеза отклоняется на уровне значимости  , если расчётное значение F – критерия превышает его критическое значение для принятого уровня значимости и чисел степеней свободы k1=m-1 и k2=m-n. В этом случае величина корреляционного отношения признаётся значимой, а связь между признаками существенной.
, если расчётное значение F – критерия превышает его критическое значение для принятого уровня значимости и чисел степеней свободы k1=m-1 и k2=m-n. В этом случае величина корреляционного отношения признаётся значимой, а связь между признаками существенной.
При «ручной» проверке гипотезы используются специальные таблицы F – распределения. В них указывается предельные (критические) значения F – критерия для различных степеней свободы k1 и k2, которые могут быть превзойдены с вероятностью α = 0,05.
В Excel проверка гипотезы об отсутствии корреляции между изучаемыми признаками осуществляется следующим образом:
В ячейку В1 вводится объём совокупности (например, 132) в ячейку В2– число интервалов группировки или параметров в уравнении регрессии (например, 12); в ячейку В3– значение выборочного корреляционного отношения;
В ячейку Е1 для нахождения расчётного значения F – критерий Фишера вводится формула (**): = В3^2*120/(1-В3^2)*11;
В ячейку Е2 для определения критического значения F – критерий Фишера для принятого уровня значимости =0,05 и чисел степеней свободы k1=m-1 (11) и k2=m-n (120) вводится формула: = FРАСПОБР (0.05;11;120).
Полученные расчётное и критическое значения F – критерий Фишера сравниваются, и делается вывод об отклонении или принятии нулевой гипотезы и соответственно о значимости или незначимости корреляционного отношения.
Множественный коэффициент корреляции вычисляется статистической процедурой Регрессия (см. следующий раздел).
Рассмотренные выше вычисления относятся к собственно-корреляционным, параметрическим методам изучения связей.
В случаях, когда анализируется взаимосвязь между количественными признаками, форма распределения которых отличается от нормальной, а также между качественными признаками, используются так называемые непараметрические методы. В основу этих методов положен принцип нумерации значений признаков статистического ряда.
Значения факторного признака записываются в возрастающем или убывающем порядке, а затем ранжируются соответствующие им значения результативного признака. При этом каждой единице в упорядоченном ряду присваивается порядковый номер, который будет её рангом. В случаях наличия одинаковых вариантов каждому из них присваивается среднее арифметическое значение их рангов.
Для определения рангов в Excel предусмотрены статистическая процедура Ранг и персентиль и статистическая функция РАНГ.
Использование процедуры Ранг и персентиль заключается в следующем:
В меню Сервис выделяется строка Анализ данных.
В открывшемся окне Анализ данных выделяется процедура Ранг и персентиль, нажимается кнопка ОК. На экране появляется диалоговое окно Ранг и персентиль.
В поле Входной интервал вводится ссылка на диапазон ячеек, содержащий данные, подлежащие ранжированию. Входной диапазон может быть столбцом или группой смежных столбцов (строкой или группой смежных строк). Если входной диапазон представляет собой группу столбцов (строк), то процедура воспринимает каждый столбец (строку) как отдельную выборку.
Устанавливается переключатель Группирование в нужное положение (по столбцам или строкам).
Флажок Метки устанавливается, если первая строка (столбец) входного диапазона содержит заголовки. Если такие заголовки отсутствуют, флажок не устанавливается.
Щелчком на переключателе Выходной интервал активизируется поле ввода, находящее справа от этого переключателя и вводится в него ссылка на левую верхнюю ячейку таблицы результатов решения. В случае необходимости результаты выводятся на Новый рабочий лист или Новую рабочую книгу. Нажимается кнопка ОК.
Статистическая функция РАНГ имеет следующий синтаксис: РАНГ (число; массив; порядок):
число– номер единицы совокупности, ранг которой надо определить. Если необходимо осуществить ранжирование всей совокупности сразу, то вводится диапазон ячеек, в котором находятся данные, подлежащие обработке;
массив– массив или диапазон ячеек, содержащий единицы исследуемой совокупности (неупорядоченные данные наблюдения);
порядок– величина, определяющая, как упорядочивать (ранжировать) массив:
– если порядок равен 0 или пропущен, массив упорядочивается в порядке убывания;
– если порядок– любое число, не равное нулю, то массив упорядочивается по возрастанию.
Среди непараметрических методов оценки тесноты связи наибольшее значение имеют коэффициенты ранговой корреляции Спирмена и Кендалла.
Коэффициент корреляции рангов (Спирмена) определяется по формуле:
r =  , где
, где
d – разность между рангами соответствующих величин двух признаков;
n – число единиц в ряду (число пар рангов).
Коэффициент корреляции рангов принимает любые значения от -1 до +1. Если все ранги строго изменяются в одном и том же порядке, то d=0, а r=1. Если же ранги изменяются строго в противоположных направлениях, то r= -1. Значение r=0 характеризует отсутствие связи.
В Excel вычисление коэффициента ранговой корреляции Спирмена осуществляется следующим образом:
1. Вводятся заголовки исходных и расчётных данных, необходимых для расчёта коэффициента корреляции рангов: в ячейку А1– названия единиц изучаемой совокупности, в ячейку В1– название факторного признака, в ячейку С1– названия результативного признака, в ячейку D1– символ  , обозначающий ранг по факторному признаку, в ячейку Е1– символ
, обозначающий ранг по факторному признаку, в ячейку Е1– символ  , обозначающий ранг по результативному признаку, в ячейку– F– символ
, обозначающий ранг по результативному признаку, в ячейку– F– символ 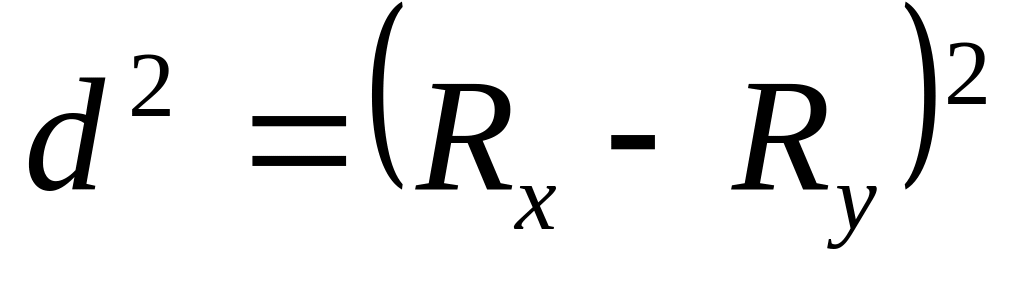 , обозначающий квадрат разности между рангами соответствующих величин двух признаков.
, обозначающий квадрат разности между рангами соответствующих величин двух признаков.
2. Производится ввод исходных данных: в диапазон ячеек столбца А вводятся названия или номера единиц изучаемой совокупности; в диапазон ячеек столбца В (например, В2:В11)– значения факторного признака, в диапазон ячеек столбца С (С2:С11)– значения результативного признака.
3. В диапазонах ячеек D2:D11 и Е2:Е11 определяются соответственно ранги по факторному и результативному признаку с помощью описанной выше процедуры Ранг и персентиль или функции РАНГ, для чего вводятся формулы массива = РАНГ (В2:В11; В2:В11;1) и = РАНГ (С2:С11; С2:С11;1).
4. В диапазоне F2:F11 вычислить квадраты разности рангов с помощью формулы массива: = (D2:D11-E2:E11)^2.
5. В ячейках D12, E12 и F12 с помощью кнопки Автосуммирование определить суммы рангов по факторному и результативному признакам и сумму квадрата разности рангов.
6. По формуле рассчитывается выборочная оценка коэффициента ранговой корреляции Спирмена.
Значимость коэффициента корреляции рангов для совокупностей небольшого объёма (n£30) проверяется по таблице предельных значений коэффициента корреляции рангов Спирмена при заданном уровне значимости a и определённом объёме совокупности.
Значимость r может быть проверена также на основе t – критерия Стьюдента. Расчётное значение критерия определяется по формуле:
tрасч = r× 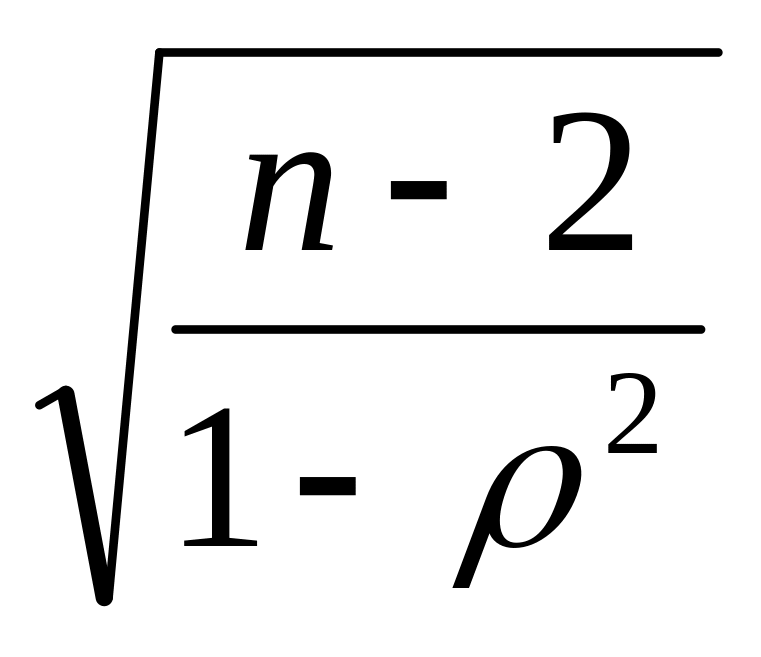
Значение коэффициента корреляции считается статистически существенным, если расчётное значение t – критерия Стьюдента превосходит его критическое значение при заданном уровне значимости a и числе степеней свободы k=n-2. Критическое значение t – критерия может быть определено по таблице распределения Стьюдента или в Excel по представленному выше в данном разделе порядку.
Коэффициент корреляции рангов Кендалла рассчитывается по формуле:
t=  , S=P+Q
, S=P+Q
n – число наблюдений;
S – сумма разностей между числом последовательностей и числом инверсий по результативному признаку.
Расчёт данного коэффициента выполняется в следующей последовательности:
ранги факторного признака располагаются в порядке возрастания;
ранги результативного признака располагаются в порядке, соответствующем рангам признака х;
для каждого ранга результативного признака определяется сколько чисел, находящихся справа от него (следующих за ним) имеют величину ранга, превышающую его величину. Суммируя полученные таким образом числа, получаем слагаемое P, которое можно рассматривать как меру соответствия последовательностей рангов по x и y, и которое учитывается со знаком «+»;
для каждого ранга y определяется число, следующих за ним рангов, меньших его величины. Суммарная величина обозначается через Q и фиксируется со знаком «-»;
определяется сумма баллов S=P+Q
Коэффициент Кендалла также изменяется в пределах от -1 до +1. При достаточно большом числе наблюдений между коэффициентами корреляции рангов Спирмена и Кендалла существует следующее соотношение: r»  .
.
Вычисления, связанные с коэффициентом ранговой корреляции  , заметно упрощаются, если результаты ранжировки представить в виде:
, заметно упрощаются, если результаты ранжировки представить в виде:
 , (***)
, (***)
где  – ранг по результативному признаку той единицы совокупности, которая по факторному признаку имеет ранг .
– ранг по результативному признаку той единицы совокупности, которая по факторному признаку имеет ранг .
При таком представлении ранжировки формула коэффициента корреляции рангов Кендалла имеет вид:
 , (****)
, (****)
где  –число единиц совокупности, для которых
–число единиц совокупности, для которых  и одновременно
и одновременно  . На практике вычисляют по формуле
. На практике вычисляют по формуле  , где –
, где –  – число рангов в ранжировке (***), для которых для которых и одновременно .
– число рангов в ранжировке (***), для которых для которых и одновременно .
В Excel вычисление коэффициента ранговой корреляции Кендалла осуществляется по формуле (****) следующим образом:
1. Вводятся заголовки исходных и расчётных данных, необходимых для расчёта коэффициента корреляции рангов: в ячейку А1– названия единиц изучаемой совокупности, в ячейку В1– название факторного признака, в ячейку С1– названия результативного признака, в ячейку D1– символ , обозначающий ранг по факторному признаку, в ячейку Е1– символ , обозначающий ранг по результативному признаку, в ячейку– F– символ , обозначающий квадрат разности между рангами соответствующих величин двух признаков.
2. Производится ввод исходных данных: в диапазон ячеек столбца А вводятся названия или номера единиц изучаемой совокупности; в диапазон ячеек столбца В (например, В2:В11)– значения факторного признака, в диапазон ячеек столбца С (С2:С11)– значения результативного признака.
3. В диапазонах ячеек D2:D11 и Е2:Е11 определяются соответственно ранги по факторному и результативному признаку с помощью описанной выше процедуры Ранг и персентиль или функции РАНГ, для чего вводятся формулы массива = РАНГ (В2:В11; В2:В11;1) и = РАНГ (С2:С11; С2:С11;1).
4. Выделяется диапазон D1:E11, в котором находятся ранги по факторному и результативному признакам, нажимается кнопка Копировать на панели инструментов Стандартная.
5. Выделяется ячейка F1. В меню Правка выделяется команда Специальная вставка.
6. В открывшемся диалоговом окне Специальная вставка в группе переключателей Вставить установливается переключатель Значения и нажимается кнопка ОК. В диапазоне F2:G11 появятся «копии» рангов.
7. Выделяется диапазон F1:G11. В меню Данные выделяется команда Сортировка.
8. В открывшемся окне Сортировка диапазона в раскрывшемся списке Сортировать по выбирается поле , по которому надо выполнить сортировку, и установливается переключатель по возрастанию; в группе переключателей Идентифицировать поля по установливатся переключатель подписям (первая строка диапазона) и нажимается кнопка ОК.
В диапазоне F2:G11 появятся ранги по факторному и результативному признакам, отсортированные в порядке возрастания рангов факторного признака.
9. В ячейку Н2 вводится формула массива = СУММ (ЕСЛИ ($G3:$G11>G2;1;0)), нажимаются клавиши Ctrl+Shift+ Enter и затем эта формула копируется в ячейки Н3:Н11. В диапазоне Н2:Н11 появятся числа  .
.
10. Суммируя эти числа в ячейке Н12, находится выборочное значение .
11. Используя формулу = 4* Н12/(10^2-10)-1 (машинный аналог формулы (****)), находится выборочное значение .
Существенность коэффициента корреляции рангов Кендалла проверяется
–при малом объёме совокупности ( 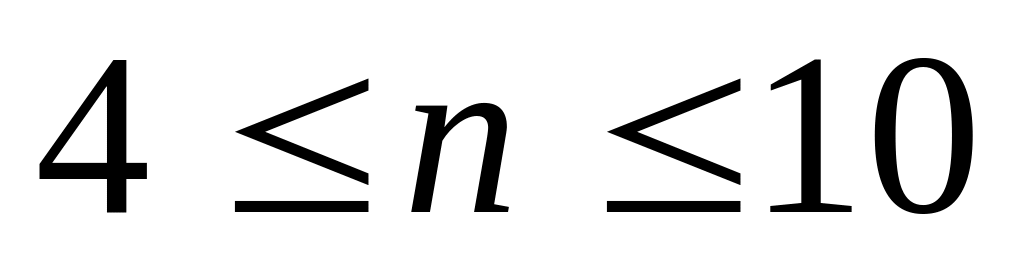 ) с помощью таблиц точного распределения статистики ;
) с помощью таблиц точного распределения статистики ;
– при больших n для заданного уровня значимости a по формуле:
t>ta×  , где
, где
ta – коэффициент, определяемый по таблице нормального распределения.
Регрессионный анализ
Регрессионным анализом называется раздел статистики, объединяющий практические методы исследования формы корреляционной зависимости между изучаемыми признаками единиц исследуемой совокупности.
В регрессионном анализе различают парную и множественную регрессию. Парная регрессия описывает связь между двумя признаками: факторным и результативным. Множественная регрессия описывает зависимость результативного признака от нескольких факторных признаков.
Регрессионной моделью системы взаимосвязанных признаков принято считать такое уравнение регрессии, которое включает основные факторы, влияющие на вариацию результативного признака, обладает высоким (не ниже 0,5) коэффициентом детерминации и коэффициентами регрессии, интерпретируемыми в соответствии с теоретическим знанием о природе связей в изучаемой системе. Приведённое определение включает достаточно строгие условия: не всякое уравнение регрессии можно считать моделью.
Регрессионный анализ включает в себя следующие основные этапы:
выбор модели регрессии;
оценка параметров выбранной модели регрессии;
проверка значимости параметров модели регрессии и их интерпретация;
проверка адекватности построенной модели регрессии.
Выбор аналитической формы связи осуществляется на основе:
логического теоретического анализа;
графического изображения зависимости в виде эмпирической линии регрессии;
опыта предыдущих исследований, где выбранные формы связи давали удовлетворительные результаты;
различных статистико-математических критериев адекватности конкурирующих уравнений регрессии (остаточных дисперсий, ошибок аппроксимации и др.).
Наиболее разработанной в теории статистики является методология парной регрессии. При этом для изучения связи между изучаемыми признаками применяются различного вида уравнения (типы математических функций) линейной и нелинейной зависимостей.
При анализе линейной связи применяется прямолинейная функция, математическим выражением которой является уравнение прямой линии:
При анализе нелинейных связей используются следующие функции:
параболическая yx=a+bx+cx 2
гиперболическая yx=a+ 
показательная yx=ab x
логистическая yx=  и др.
и др.
Решение математических уравнений связи предполагает вычисление по исходным данным их параметров a и b. Это осуществляется способом выравнивания эмпирических (фактических) данных методом наименьших квадратов (МНК). В основу этого метода положено требование минимальности суммы разности квадрата отклонений эмпирических значений результативного признака от его выровненных (теоретических) значений yxi, полученных по выбранному уравнению регрессии:
 .
.
Параметры b1,… bn в уравнении регрессии называют коэффициентами регрессии. Если связь по направлению прямая – он имеет положительное значение, если обратная – отрицательное. При линейной связи коэффициент регрессии показывает на сколько единиц своего измерения в среднем изменяется величина результативного признака при изменении факторного признака на единицу своего измерения.
В Excel имеется две процедуры и восемь встроенных функций для регрессионного анализа. Они вычисляют не только выборочные параметры регрессии, но и ещё ряд дополнительных выборочных характеристик исследуемой регрессионной зависимости. К числу таких характеристик относятся:
общая сумма квадратов  =
=  – сумма квадратов отклонений фактических(эмпирических) значений результативного признака
– сумма квадратов отклонений фактических(эмпирических) значений результативного признака  от его среднего значения
от его среднего значения  ;
;
сумма квадратов, обусловленная регрессией 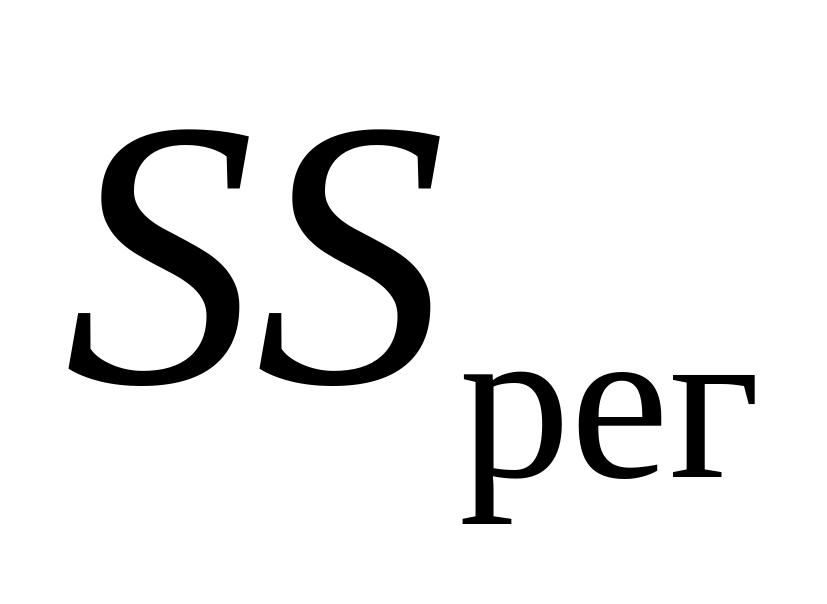 =
=  –сумма квадратов отклонений теоретических (расчётных, выровненных) значений результативного признака
–сумма квадратов отклонений теоретических (расчётных, выровненных) значений результативного признака 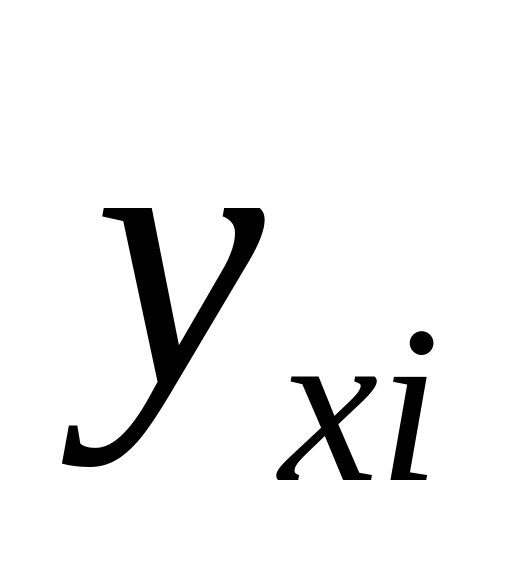 от его среднего значения ;
от его среднего значения ;
сумма квадратов остатков  =
=  –сумма квадратов отклонений фактических значений результативного признака от его теоретических значений ;
–сумма квадратов отклонений фактических значений результативного признака от его теоретических значений ;
числа степеней свободы этих сумм 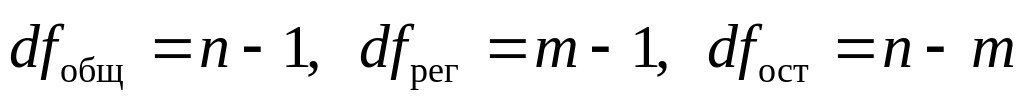 .
.
средний квадрат регрессии или факторная (систематическая) дисперсия–  – характеризует колеблемость результативного признака под влиянием только фактора х, входящего в уравнение регрессии;
– характеризует колеблемость результативного признака под влиянием только фактора х, входящего в уравнение регрессии;
средний квадрат остатков или остаточная (случайная) дисперсия– 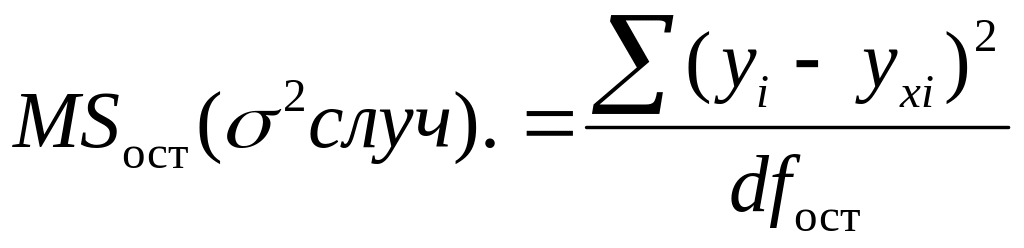 –характеризует колеблемость результативного признака под влиянием прочих факторов, не входящих в уравнение регрессия.
–характеризует колеблемость результативного признака под влиянием прочих факторов, не входящих в уравнение регрессия.
Эти дисперсии связаны между собой равенством, носящим название «правило сложения дисперсий»– 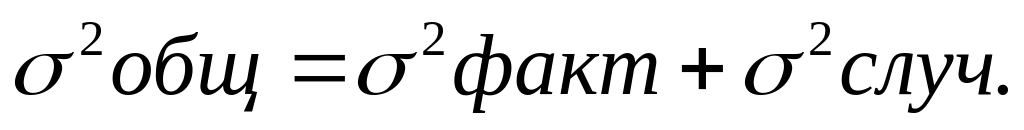 ;
;  ;
;
множественный коэффициент (индекс) корреляции 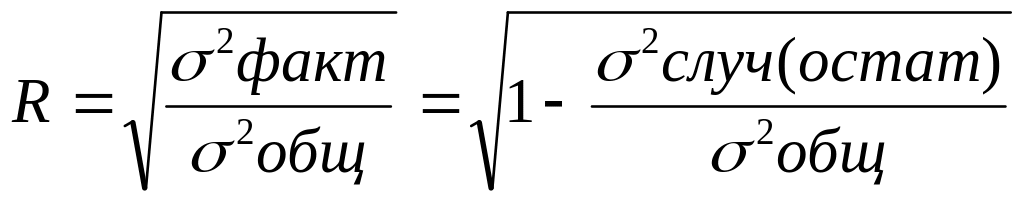 ; в случае парной линейной регрессии этот показатель совпадает с коэффициентом корреляции , а в случае парной нелинейной регрессии носит название теоретического корреляционного отношения;
; в случае парной линейной регрессии этот показатель совпадает с коэффициентом корреляции , а в случае парной нелинейной регрессии носит название теоретического корреляционного отношения;
коэффициент детерминации–  ; показывает вариацию результативного признака, обусловленную вариацией факторов, входящих в регрессионную модель;
; показывает вариацию результативного признака, обусловленную вариацией факторов, входящих в регрессионную модель;
нормированный (скорректированный) коэффициент детерминации –  . где –число факторов, включённых в регрессионную модель. Корректировка не производится при условии, если
. где –число факторов, включённых в регрессионную модель. Корректировка не производится при условии, если  ;
;
стандартная ошибка аппроксимации (средняя квадратическая ошибка) уравнения регрессии:
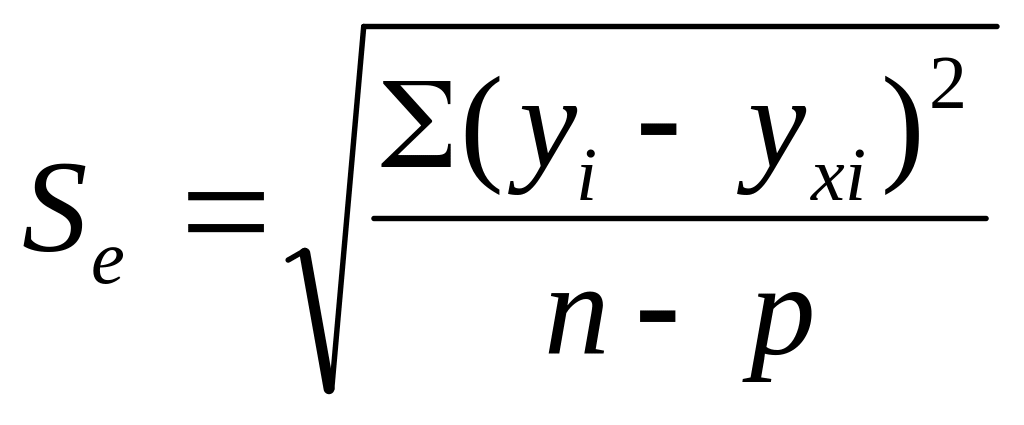 ;
;
где 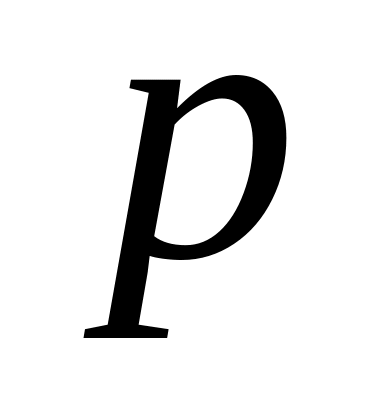 -число параметров в уравнении регрессии.
-число параметров в уравнении регрессии.
стандартное отклонение параметров регрессии–  . Наиболее точно эта величина может быть определена по формуле:
. Наиболее точно эта величина может быть определена по формуле:
 ,
,
где  – среднее квадратическое отклонение результативного признака (корень квадратный из общей дисперсии);
– среднее квадратическое отклонение результативного признака (корень квадратный из общей дисперсии);  –среднее квадратическое отклонение — го факторного признака; –величина множественного коэффициента корреляции по фактору с остальными факторами.
–среднее квадратическое отклонение — го факторного признака; –величина множественного коэффициента корреляции по фактору с остальными факторами.
Выборочный коэффициент детерминации и выборочные параметры регрессии, вычисленные по ограниченному числу единиц изучаемой совокупности, всегда содержат элемент случайности, в связи, с чем возникает необходимость проверки значимости этих выборочных характеристик.
При проверке значимости параметра регрессии  , выдвигается гипотеза
, выдвигается гипотеза  о том, что фактор не оказывает заметного влияния на результативный признак. Значимость параметров регрессии проверяется на основе t – критерия Стьюдента:
о том, что фактор не оказывает заметного влияния на результативный признак. Значимость параметров регрессии проверяется на основе t – критерия Стьюдента:
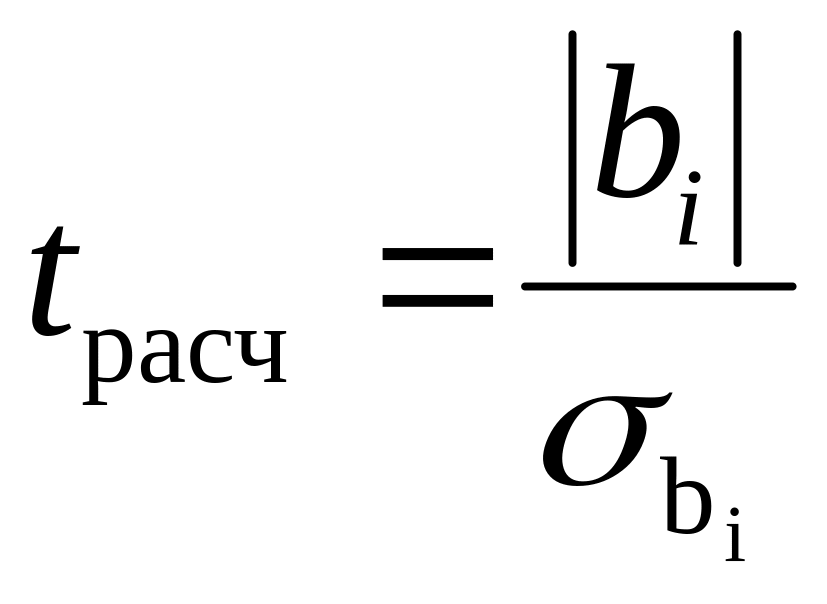 .
.
Параметр признаётся статистически значимым, если расчётное значение t – критерия Стьюдента превосходит его критическое значение, определяемое при заданном уровне значимости α и числе степеней свободы  . Критическое значение t – критерия может быть определено по таблице распределения Стьюдента или в Excel по представленному в предыдущем разделе порядку.
. Критическое значение t – критерия может быть определено по таблице распределения Стьюдента или в Excel по представленному в предыдущем разделе порядку.
При проверке значимости коэффициента детерминации выдвигается гипотеза  о том, что коэффициент детерминации генеральной совокупности, из которой извлечена исследуемая выборка, равен нулю. Эта гипотеза равносильна гипотезе о том, что ни один из факторов, включённых в регрессию, не оказывает существенного влияния на результативный признак. Поэтому проверка значимости коэффициента детерминации является проверкой адекватности (соответствия) выбранной модели регрессии реальным данным наблюдения. Значимость коэффициента детерминации осуществляется с помощью F-критерия.
о том, что коэффициент детерминации генеральной совокупности, из которой извлечена исследуемая выборка, равен нулю. Эта гипотеза равносильна гипотезе о том, что ни один из факторов, включённых в регрессию, не оказывает существенного влияния на результативный признак. Поэтому проверка значимости коэффициента детерминации является проверкой адекватности (соответствия) выбранной модели регрессии реальным данным наблюдения. Значимость коэффициента детерминации осуществляется с помощью F-критерия.
Расчётное значение критерия Фишера–Снедекора, вычисляется по формуле:
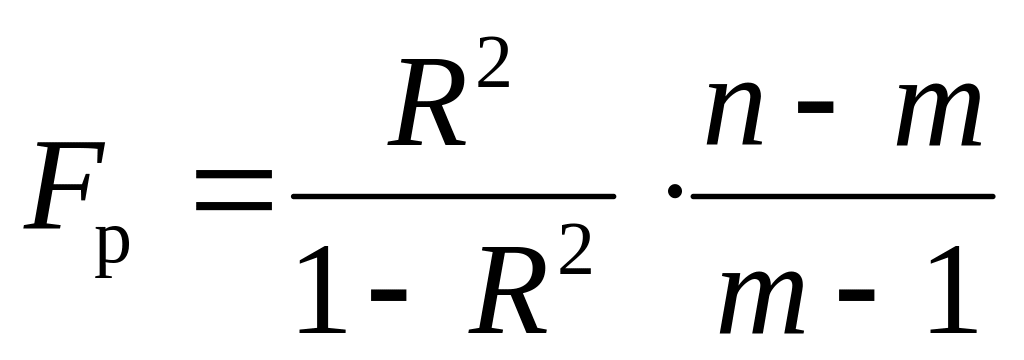 ,
,
Если  , то гипотеза о равенстве коэффициента детерминации нулю и несоответствии заложенных в модели связей реально существующим отклоняется на уровне значимости , то есть коэффициент детерминации признаётся статистически значимым, а модель регрессии – адекватной. Величина
, то гипотеза о равенстве коэффициента детерминации нулю и несоответствии заложенных в модели связей реально существующим отклоняется на уровне значимости , то есть коэффициент детерминации признаётся статистически значимым, а модель регрессии – адекватной. Величина  определяется по специальным таблицам и зависит от заданного уровня значимости и числа степеней свободы:
определяется по специальным таблицам и зависит от заданного уровня значимости и числа степеней свободы:  и
и  , где – число наблюдений; – число факторных признаков в модели.
, где – число наблюдений; – число факторных признаков в модели.
В качестве меры адекватности модели регрессии используется также процентное отношение стандартной ошибки  к среднему уровню результативного признака
к среднему уровню результативного признака  – относительная ошибка аппроксимации:
– относительная ошибка аппроксимации:
 , где
, где
Если  , то точность модели регрессии высокая, если 10-20% – точность модели регрессии хорошая (то есть уравнение достаточно хорошо описывает взаимосвязь между изучаемыми признаками), если 20-50% – точность модели регрессии удовлетворительная.
, то точность модели регрессии высокая, если 10-20% – точность модели регрессии хорошая (то есть уравнение достаточно хорошо описывает взаимосвязь между изучаемыми признаками), если 20-50% – точность модели регрессии удовлетворительная.
В Excel для проведения регрессионного анализа существует статистическая процедура Регрессия, позволяющая осуществлять парную линейную, параболическую (полиноминальную) и множественную регрессии. Для выбора формы связи целесообразно построить корреляционное поле, воспользовавшись специальным средством Мастер диаграмм, выбрав тип Точечная (см. предыдущий раздел).
Парная линейная регрессия в Excel осуществляется следующим образом:
Осуществляется ввод исходных данных, т.е. значений факторного и результативного признака.
В меню Сервис выделяется строка Анализ Данных.
В открывшемся окне Анализ данных выделяется процедура Регрессия и нажимается кнопка ОК. Откроется диалоговое окно Регрессия с пульсирующим курсором в поле ввода Входной интервал Y.
С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения результативного признака Y. В поле ввода Входной интервал Y появится соответствующая ссылка.
Нажатием клавиши Tab осуществляется переход в поле ввода Входной интервал Х. С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения факторного признака Х. В поле ввода Входной интервал Х появится соответствующая ссылка.
Устанавливается флажок в группе флажков Остатки. В данную группу входят следующие флажки:
– флажок Остатки. При его установке на экран выводится таблица ВЫВОД ОСТАТКОВ, в состав которой входит столбец Остатки;
– флажок График остатков. При активизации этого флажка на экран выводятся графики зависимости остатков от регрессионных переменных (по одному графику на каждую переменную);
– флажок Стандартизированные остатки. При установке данного флажка в таблицу ВЫВОД ОСТАТКОВ добавляется столбец центрированных нормированных (стандартизированных), которые получаются из остатков  делением их на
делением их на 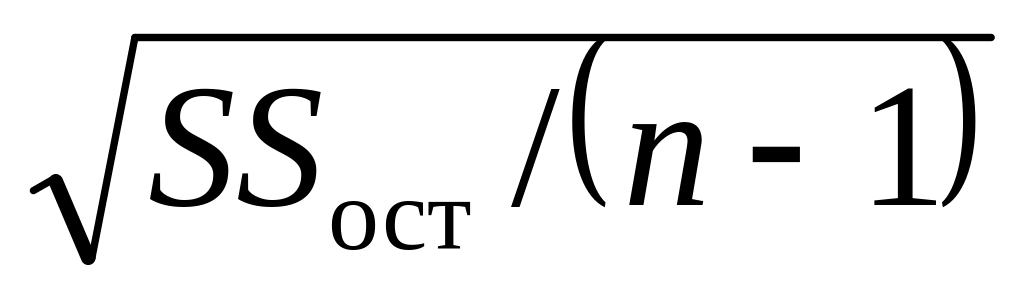 ;
;
– флажок График подбора. При установке этого флажка на рабочий лист выводятся точечных графиков (по числу контролируемых переменных). На графике, связанном с -й контролируемой переменной 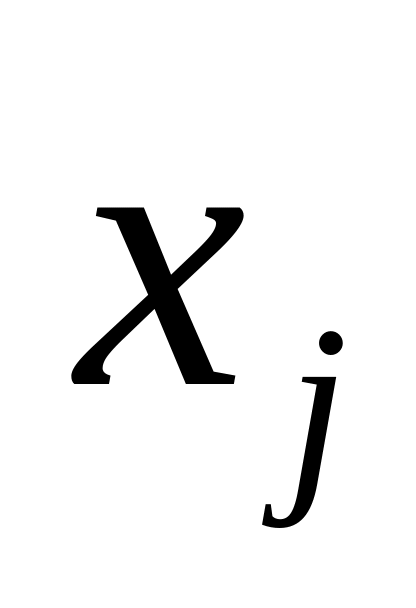 , =1, 2…., , каждому значению
, =1, 2…., , каждому значению  этой переменной поставлены в соответствие две точки и ;
этой переменной поставлены в соответствие две точки и ;
– флажок График нормальной вероятности. При активизации этого флажка на экран выводятся таблица ВЫВОД ВЕРОЯТНОСТИ и график функции, обратной эмпирической функции распределения результативного признака, выполненный на «вероятностной нормальной бумаге».
Щелчком на кнопке ОК запускается процедура Регрессия.
Помимо этого процедура содержит также следующие элементы управления:
Флажок Константа-ноль. Устанавливается в том случае, когда необходимо, чтобы линия регрессии проходила через начало координат. При этом параметр равен нулю и число параметров регрессии равно числу факторов.
флажок Уровень надёжности. Устанавливается в том случае, когда помимо доверительных интервалов для параметров регрессии, соответствующих используемой по умолчанию «стандартной» доверительной вероятности 95%, необходимо вычислить доверительные интервалы, доверительная вероятность которых отличается от «стандартной». «Нестандартная» вероятность, выраженная в процентах, вводится в поле, расположенное справа от рассматриваемого флажка. Если этот флажок не установлен, то выходной таблице параметров регрессии будут одинаковые пары столбцов, содержащие доверительные границы для параметров регрессии, соответствующие одной и той же доверительной вероятности 95% (при редактировании таблицы их можно убрать).
Назначение флажка Метки и переключателей Выходной интервал/Новый рабочий лист/ Новая книга рассмотрено в 1 разделе.
После запуска процедуры Регрессия на рабочем листе появляются три таблицы результатов этой процедуры. В первой таблице «Регрессионная статистика» содержатся значения множественного коэффициента корреляции, коэффициента детерминации, нормированного коэффициента детерминации, стандартная ошибка уравнения регрессии и число наблюдений. Во второй таблице «Дисперсионный анализ» содержатся значения сумм квадратов и среднего квадрата регрессии, остатков и общие., а также расчётное значение критерия Фишера–Снедекора. В третьей таблице в графе «Коэффициенты» по строке «Y- пересечение» находится значение свободного члена уравнения регрессии , а по строке Х – значение параметра  . Далее по графам расположены стандартная ошибка, расчётное значение t – критерия Стьюдента, доверительные интервалы для этих параметров.
. Далее по графам расположены стандартная ошибка, расчётное значение t – критерия Стьюдента, доверительные интервалы для этих параметров.
Полиноминальная (параболическая) регрессия в Excel осуществляется следующим образом:
1. В ячейки А1, В1 и С1 вводятся метки Y, X и X 2 .
2. В диапазон А2 и далее (например, А2: А15) вводятся значения результативного признака, в диапазон В2 и далее (соответственно В2:В15)– значения факторного признака.
3.В диапазон С2 и далее (С2: С15) вводится формула массива = В2:В15^2 и нажимается комбинация клавиш Ctrl+Shift+ Enter. В диапазоне С2:С15 появится столбец квадратов значений факторного признака.
4. В открывшемся окне Анализ данных выделяется процедура Регрессия и нажимается кнопка ОК. Откроется диалоговое окно Регрессия с пульсирующим курсором в поле ввода Входной интервал Y.
5. С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения результативного признака Y. В поле ввода Входной интервал Y появится соответствующая ссылка.
6. Осуществляется переход в поле ввода Входной интервал Х. С помощью мыши выделяется диапазон ячеек, в котором находятся эмпирические значения факторного признака. В поле ввода Входной интервал Х появится соответствующая ссылка.
7. Устанавливается флажок в группе флажков Остатки.
8. Щелчком на кнопке ОК запускается процедура Регрессия.
После запуска процедуры Регрессия на рабочем листе появляются три таблицы результатов этой процедуры.
Множественная линейная регрессия в Excel осуществляется аналогичным образом. При этом в качестве исходных данных вводятся значения результативного и нескольких (  ) факторных признаков.
) факторных признаков.
К статистическим функциям, предназначенным для регрессионного анализа в Excel, относятся ЛИНЕЙН, НАКЛОН, ОТРЕЗОК, ТЕНДЕНЦИЯ, ПРЕДСКАЗ, СТОШYХ, ЛГРФПРИБЛ, РОСТ.
Из этих функций интерес представляют функции ЛГРФПРИБЛ, ТЕНДЕНЦИЯ и РОСТ, так как другие функции вычисляют некоторые характеристики, определяемые статистической процедурой РЕГРЕССИЯ, а также дублируют друг друга. Эти же три функции производят вычисления, не предусмотренные статистической процедурой РЕГРЕССИЯ.
Функция ЛГРФПРИБЛ вычисляет выборочные оценки параметров показательной (экспоненциальной) регрессии.
Синтаксис данной функции: ЛГРФПРИБЛ (известные значения у; известные значения х;, конст; стат):
известные значения у– множество значений результативного признака. Данный массив представляет собой вектор-столбец размером  ;
;
известные значения х–множество значений факторных признаков.
– Если в случае парной регрессии этот аргумент опущен, то при вычислениях в качестве массива известные значения х используется массив натуральных чисел 1,2…и т.д. такого же размера, как и массив известные значения у;
– В случае множественной регрессии, если массив известные значения у представляет собой вектор-столбец, то массив известные значения х должен иметь строк и столбцов. При этом каждый столбец этого массива содержит значений определённого факторного признака;
– При вводе массива чисел известные значения х с клавиатуры для разделения значений в одной строке используют точку с запятой, а для разделения строк– двоеточие.
конст–логическая переменная, определяющая, следует ли включать в уравнение регрессии свободный член.
– Если конст=1 (ИСТИНА) или опущен, то вычисляются и коэффициенты регрессии, и свободный член.
– Если конст= 0 (ЛОЖЬ), то предполагается, что свободный член равен единице.
стат– логическая переменная, определяющая объём выходной информации.
– Если аргумент стат =0 (ЛОЖЬ) или опущен, то функция выдаёт только параметры уравнения регрессии. При этом для вывода результатов решения надо заранее выделить диапазон ячеек размером  , где – число факторов, включённых анализ.
, где – число факторов, включённых анализ.
– Если аргумент стат =1 (ИСТИНА), то помимо функция выдаёт дополнительную информацию об исследуемой регрессионной зависимости. В этом случае для вывода результатов решения надо выделить диапазон ячеек размером  . В первом столбце выделенного диапазона находятся следующие характеристики коэффициенты регрессии, стандартная ошибка коэффициента регрессии, коэффициент детерминации, расчётное значение F- критерия Фишера, сумма квадратов, обусловленная регрессией. Во втором столбце находятся значения свободного члена, его стандартная ошибка, стандартная ошибка уравнения регрессии, число степеней свободы, сумма квадратов остатков.
. В первом столбце выделенного диапазона находятся следующие характеристики коэффициенты регрессии, стандартная ошибка коэффициента регрессии, коэффициент детерминации, расчётное значение F- критерия Фишера, сумма квадратов, обусловленная регрессией. Во втором столбце находятся значения свободного члена, его стандартная ошибка, стандартная ошибка уравнения регрессии, число степеней свободы, сумма квадратов остатков.
Так как результатом реализации функции является массив чисел, содержащий выборочные характеристики исследуемой регрессионной зависимости, то функция вводится как формула массива Ctrl+Shift+ Enter. Например, = ЛГРФПРИБЛ (А1:А6;В1:В6;1;1).
Функции ТЕНДЕНЦИЯ и РОСТ используются для вычисления расчётных значений результативного признака, соответствующих заданным пользователем значениям факторных признаков, хранящимся в массиве новые значения х. При этом функция ТЕНДЕНЦИЯ вычисляет параметры линейной и других видов регрессии, линейных относительно входящих в них коэффициентов, таких, например, как полиноминальная (параболическая) регрессия  , а функция РОСТ– параметры экспоненциальной регрессии.
, а функция РОСТ– параметры экспоненциальной регрессии.
Функции вводится как формула массива Ctrl+Shift+ Enter.
Синтаксис данных функций идентичен: ТЕНДЕНЦИЯ (известные значения у; известные значения х;, новые значения х,; конст) и РОСТ (известные значения у; известные значения х;, новые значения х,; конст):
известные значения у– множество значений результативного признака. Данный массив представляет собой вектор-столбец размером ;
известные значения х–множество значений факторных признаков.
– Если в случае парной регрессии этот аргумент опущен, то при вычислениях в качестве массива известные значения х используется массив натуральных чисел 1,2…и т.д. такого же размера, как и массив известные значения у;
– В случае множественной регрессии, если массив известные значения у представляет собой вектор-столбец, то массив известные значения х должен иметь строк и столбцов. При этом каждый столбец этого массива содержит значений определённого факторного признака;
– При вводе массива чисел известные значения х с клавиатуры для разделения значений в одной строке используют точку с запятой, а для разделения строк– двоеточие.
новые значения х– новые значения факторных признаков, для которых функция должна вычислить расчётные значения результативного признака;
– В случае множественной регрессии, если массив известные значения у представляет собой вектор-столбец, то массив новые значения х должен иметь столбцов и столько строк, сколько расчётных значений у надо вычислить.
–Массив новые значения х, так же как и массив известные значения х, должен содержать столбец для каждого факторного признака. Число столбцов этих массивов должно быть одинаково.
– Если аргумент новые значения х опущен, то предполагается, что он совпадает с аргументом известные значения х.
конст–логическая переменная, определяющая, следует ли включать в уравнение регрессии свободный член.
– Если конст=1 (ИСТИНА) или опущен, то вычисляются и коэффициенты регрессии, и свободный член.
– Если конст= 0 (ЛОЖЬ), то предполагается, что свободный член равен нулю (в случае линейной регрессии) и единице (в случае экспоненциальной регрессии).
Ряды динамики
Ряд динамики– это ряд числовых значений статистических показателей, расположенных в хронологической последовательности и характеризующих изменение явления во времени.
Ряд динамики состоит из двух элементов:
уровней динамического ряда– числовых значений статистических показателей, характеризующих величину изучаемого явления– 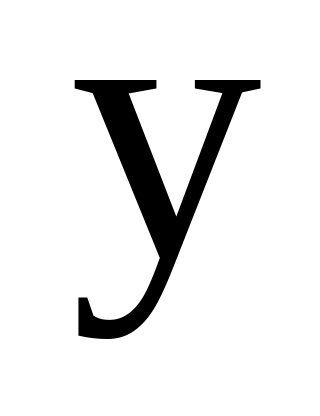 ;
;
периодов (или моментов) времени, к которым относятся данные уровни –  .
.
Одной из основных задач в процессе анализа уровней динамического ряда является определение основной закономерности (тенденции) их изменений во времени.
При этом выделяются следующие основные компоненты динамического ряда:
основная тенденция (тренд) (Т);
Первые три компоненты формируют систематическую составляющую динамического ряда.
Тренд характеризует устойчивое систематическое изменение динамического ряда, происходящее в течение длительного времени и обусловленное влиянием медленно развивающихся долговременных факторов.
Сезонная компонента– это колебания, периодически повторяющиеся в некоторое определённое время каждого года, дня месяца или часа дня.
Циклическая (периодическая) компонента проявляется в том, что значение изучаемого показателя в течение какого-то времени возрастает, достигает определённого максимума, затем понижается, достигает определённого минимума, вновь возрастает до прежнего значения и т.д.
Четвёртую компоненту формируют случайные колебания, которые являются результатом действия большого количества относительно слабых второстепенных факторов.
Для выявления и характеристики основной закономерности развития явления необходимо выявить первую компоненту динамического ряда – тренд, и погасить влияние других типов колебаний на изменение уровней ряда.
С этой целью проводят выравнивание динамических рядов. Различают два вида выравнивания: механическое (или сглаживание) и аналитическое.
К приёмам механического выравнивания относятся:
усреднение левой и правой половины ряда;
скользящая средняя: простая, взвешенная;
Выбор приема выравнивания зависит от исходной информации и задач исследования.
В среде Excel для выравнивания динамических рядов используются процедуры Скользящее среднее и Экспоненциальное сглаживание, входящие в Пакет анализа.
Сущность метода скользящей средней заключается в том, что вычисляется средний уровень из определенного числа первых по порядку уровней ряда, затем – средний уровень из такого же числа уровней, начиная со второго, затем, начиная с третьего и т.д. Таким образом, при расчётах среднего уровня как бы «скользят» по ряду динамики от его начала к концу, каждый раз отбрасывая один уровень вначале и добавляя один следующий. Этим объясняется название – скользящая средняя.
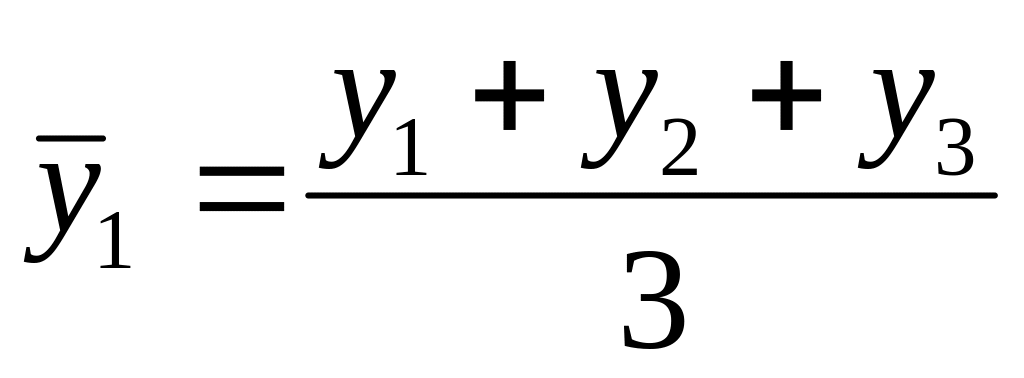 ;
;  ;
;  и т.д.
и т.д.
Следует отметить, что при использовании метода скользящей средней «теряются»  членов в начале и в конце динамического ряда (где –размер интервала (окна) сглаживания). Для восстановления «потерянных» уровней в начале и в конце сглаженного ряда для =3 и =5 могут быть использованы следующие формулы:
членов в начале и в конце динамического ряда (где –размер интервала (окна) сглаживания). Для восстановления «потерянных» уровней в начале и в конце сглаженного ряда для =3 и =5 могут быть использованы следующие формулы:
=3 (  ):
):
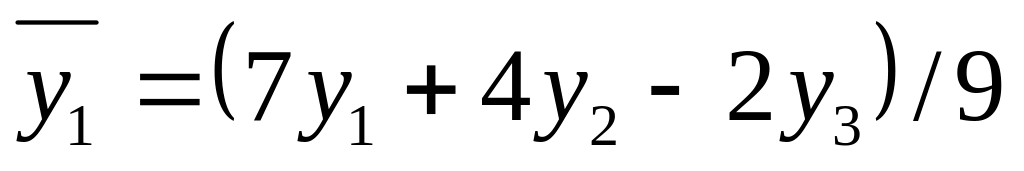 ;
;  ;
;
=5(  ):
):
 ;
;  ;
;
 ;
;  .
.
Для получения количественной модели, выражающей основную тенденцию изменения уровней динамического ряда во времени, используется приём аналитического выравнивания. Сущность его состоит в том, что основная тенденция развития 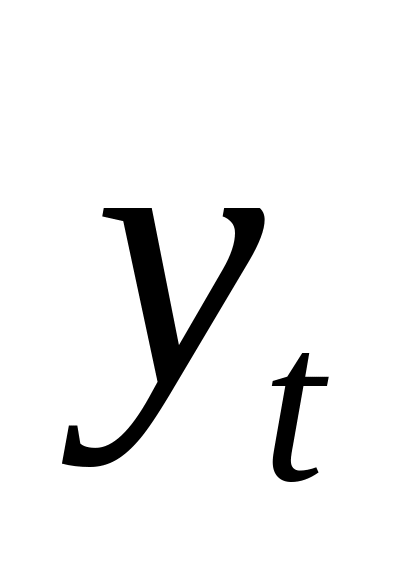 рассчитывается как функция времени. В этом случае фактические (эмпирические) уровни заменяются теоретическими, вычисленными по соответствующему аналитическому уравнению.
рассчитывается как функция времени. В этом случае фактические (эмпирические) уровни заменяются теоретическими, вычисленными по соответствующему аналитическому уравнению.
Аналитическое выравнивание производится в следующей последовательности:
1) выделяется этап развития явления и устанавливается характер динамики на этом этапе. Этап развития явления– это период, в течение которого формирование уровней динамического уровня осуществляется под воздействием определённого набора постоянных, периодических и разовых факторов. Решение этой задачи осуществляется не только с помощью статистических методов, а в основном – на базе анализа сущности, природы явлений и общих законов его развития.
2) на основе предположений о той или иной закономерности развития выбирается форма аналитического выражения тренда, то есть вид аппроксимирующей математической функции.
Основанием для выбора уравнения тренда могут служить:
качественный анализ сущности развития данного явления;
результаты предыдущих исследований в данной области;
графическое изображение эмпирических или скользящих уровней ряда динамики;
статистико-математических критериев адекватности.
При анализе рядов динамики используются следующие математические модели:
где  и
и  – параметры уравнения;
– параметры уравнения;
– начальный уровень тренда в момент или период, принятый за начало отсчёта времени;
– среднее абсолютное изменение за единицу времени;
Параметр определяет направление развития: если 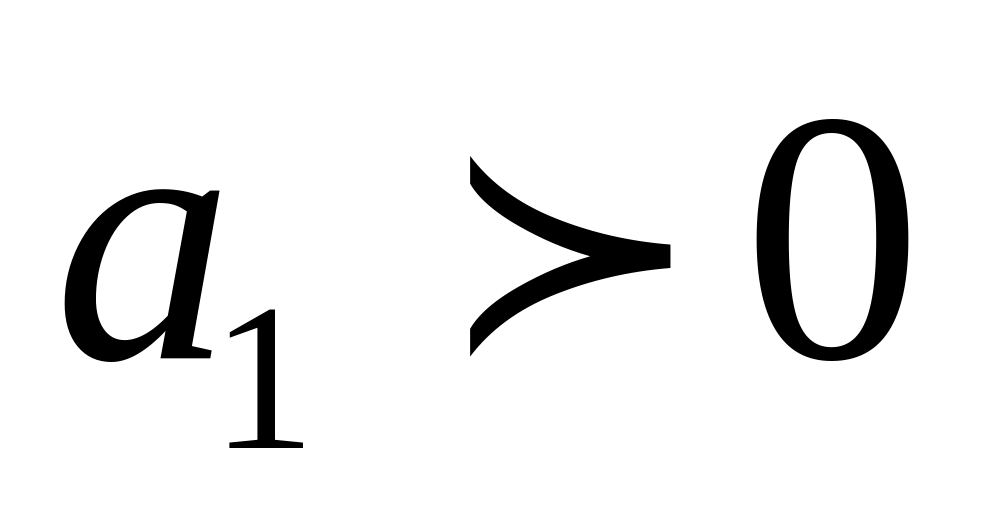 , то уровни ряда равномерно возрастают в среднем за единицу времени на величину , если
, то уровни ряда равномерно возрастают в среднем за единицу времени на величину , если  , то происходит их равномерное снижение.
, то происходит их равномерное снижение.
полиноминальная(параболическая)  , где –степень полинома. Наиболее применяемой в практике статистических расчётов является уравнение параболы второго порядка yt = a0 + a1t + a2t 2 .
, где –степень полинома. Наиболее применяемой в практике статистических расчётов является уравнение параболы второго порядка yt = a0 + a1t + a2t 2 .
Значение параметров и идентично предыдущему уравнению.
Параметр  характеризует изменение интенсивности развития в единицу времени. При
характеризует изменение интенсивности развития в единицу времени. При 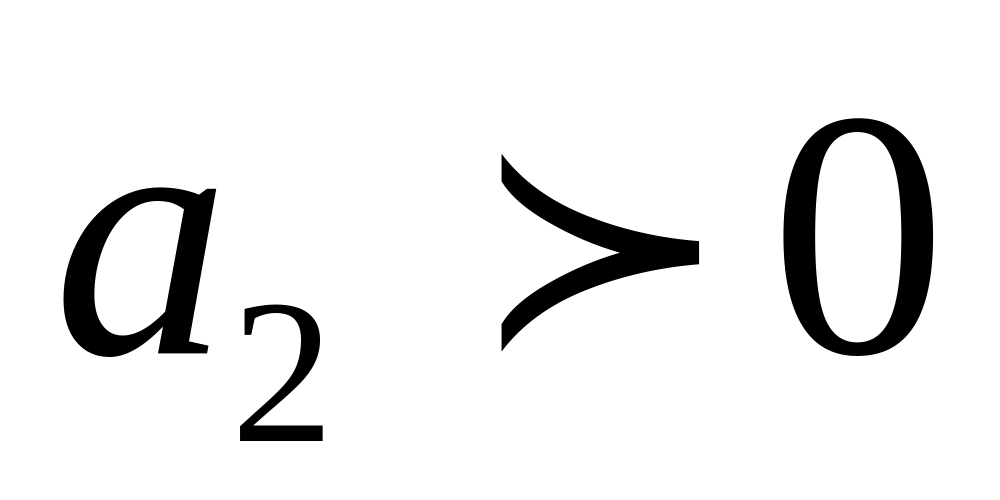 происходит ускорение развития, при
происходит ускорение развития, при 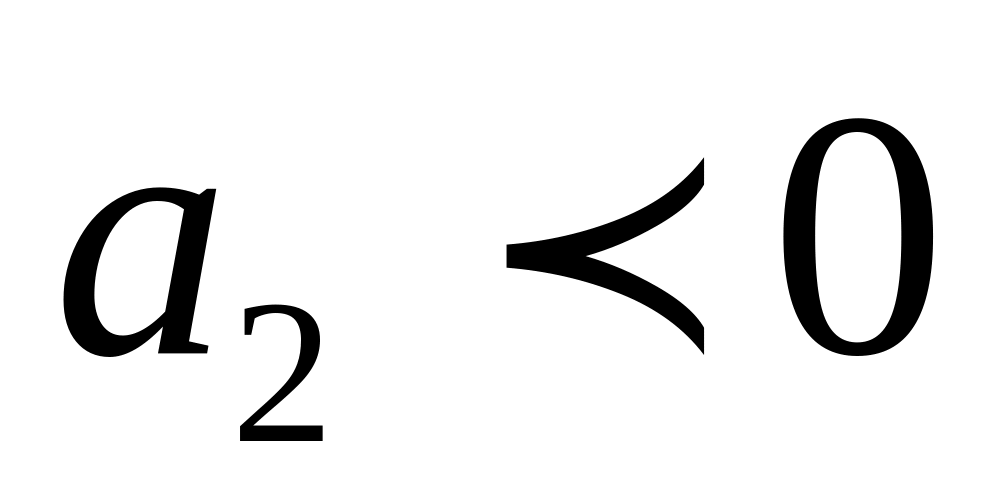 – замедление развития.
– замедление развития.
Соответственно при параболической форме тренда возможны следующие варианты развития:
если ; – ускорение роста;
если ; – замедление роста;
если ; – замедление снижения;
если ; – ускорение снижения.
экспоненциальная 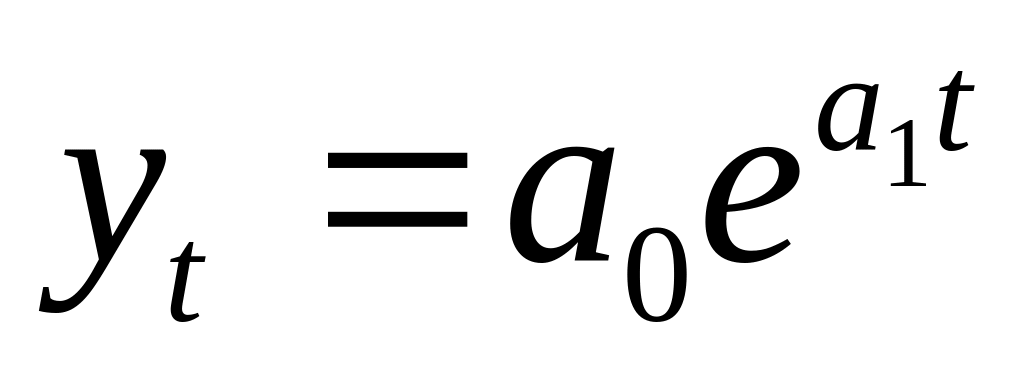 ,
,
где – константа ряда, –темп изменения в разах. При >1 экспоненциальный тренд выражает тенденцию ускоренного и всё более ускоряющегося возрастания уровней, при 2 = min.
4) На основе синтезированной модели тренда вычисляются теоретические уровни.
Выявление и характеристика основной тенденции развития дают основание для прогнозирования, то есть для определения возможного варианта размеров явления в будущем. Важное значение при прогнозировании имеют вопросы о базе и сроках прогнозирования.
База прогнозирования – длина или продолжительность базисного периода, закономерность которого будет распространяться на будущее.
Срок прогнозирования (период упреждения) – длина будущего периода, на который распространяется закономерность развития явления.
Однозначного ответа на вопрос об определении допустимого срока прогноза нет. В основном придерживаются следующего правила: срок прогноза не должен превышать третьей части длины базы прогноза. Однако в каждом конкретном случае необходимо учитывать особенности изучаемого явления. При этом необходимо, чтобы продолжительность базисного ряда составляла определенный этап в развитии анализируемого явления в конкретных исторических условий.
Установление сроков прогнозирования зависит от цели исследования. Однако следует иметь в виду, особенности характера изучаемого явления. Например, ограниченные физиологические особенности животных (или растений), делают невозможным увеличение продуктивности животных (или урожайности) до бесконечности. Кроме того, необходимо учитывать неустойчивость экономики в условиях переходного периода. Поэтому чем короче сроки прогнозирования периода, тем надежнее результат прогноза.
Разработка прогнозного уровня динамического ряда может осуществляться на основе использования различных методов, наиболее распространённым из которых является метод экстраполяции.
Метод экстраполяции основывается на предположении о неизменности основных факторов, определяющих тенденцию данного показателя, и заключается в распространении закономерностей развития этого показателя, имевших место в прошлом, на будущее.
Более точным и распространённым методом экстраполяции является применение аналитического выражения тренда, при котором в адекватную трендовую модель подставляются значения в будущие годы. Прогнозирование на основе экстраполяции дает возможность получить точечные значения прогнозируемого уровня исследуемого показателя.
Интерполяция– это приближённый расчёт уровней, находящихся внутри ряда динамики, но почему-либо неизвестных. При интерполяции предполагается, что характер тенденции не претерпел существенных изменений в том промежутке времени, уровень которого нам не известен.
Как и экстраполяция, интерполяция может производится на основе на основе выравнивания динамического ряда по какой-либо аналитической формуле.
В Excel сглаживание динамического ряда методом скользящей средней осуществляется следующим образом:
1. В диапазон ячеек вводятся уровни ряда динамики (числовые значения изучаемого статистического показателя).
2.В меню Сервис выделяется строка Анализ данных.
3. В открывшемся окне Анализ данных выделяется процедура Скользящее среднее и нажимается кнопка ОК. На экране появится диалоговое окно Скользящее среднее.
4. В поле ввода Входной интервал этого окна вводится ссылка на диапазон ячеек, содержащий уровни исследуемого ряда динамики. Входной интервал должен состоять из одного столбца, «высота» которого равна числу уровней данного ряда динамики.
5. В поле Интервал вводится размер окна сглаживания (по умолчанию =3).
6. В поле Выходной интервал вводится ссылка на верхнюю ячейку столбца результатов сглаживания. Выходной интервал всегда располагается на том же самом рабочем листе, на котором находится входной интервал, поэтому в диалоговом окне процедуры нет таких позиций, как Новый рабочий лист и Новая рабочая книга. Выходной интервал состоит по крайней мере из одного столбца, содержащего уровни сглаженного ряда. Высота этого столбца равна высоте входного интервала. При установке флажка Стандартные погрешности в выходном интервале появляется ещё один столбец– столбец стандартных погрешностей. В точках, для которых нельзя вычислить сглаженные значения и стандартные погрешности, процедура выводит сообщение # Н/Д! (Нет данных).
7. Устанавливается флажок Вывод графика. Флажок Стандартные погрешности устанавливается при необходимости получения стандартных погрешностей сглаживания. Назначение флажка Метки рассмотрено в 1 разделе.
8. Нажимается кнопка ОК.
Следует иметь в виду, что процедур Скользящее среднее выдаёт сглаженный ряд так называемых адаптивных скользящих средних. Этот ряд сдвинут на шагов вправо относительно «канонического» ряда скользящих средних. Для сравнения простого и адаптивного скользящих средних в диапазоне ячеек, число которых на -1 меньше числа уровней исходного ряда динамики, свободного столбца, рассчитываются значения скользящих средних, вычисленные по канонической формуле = СРЗНАЧ по диапазону из первых уровней динамического ряда (например, при =3 А1:А3). Данная формула вводится в следующую после  по счёту ячейку столбца, предназначенного для расчёта канонических средних (например, при =3–во вторую (С2), при =5 (С3) и т.д.). Затем данная формула копируется в оставшийся диапазон ячеек этого столбца. Адаптивные скользящие средние могут быть вычислены также с помощью статистической процедуры Добавить линию тренда (см. ниже).
по счёту ячейку столбца, предназначенного для расчёта канонических средних (например, при =3–во вторую (С2), при =5 (С3) и т.д.). Затем данная формула копируется в оставшийся диапазон ячеек этого столбца. Адаптивные скользящие средние могут быть вычислены также с помощью статистической процедуры Добавить линию тренда (см. ниже).
При проведении экспоненциального сглаживания использование одноимённой процедуры аналогично выше рассмотренному порядку. Вместо поля Интервал диалогового окна Скользящее среднее в процедуре Экспоненциальное сглаживание заполняется поле Фактор затухания. В это поле вводится фактор затухания  , где – параметр сглаживания (вес текущего значения при вычислении экспоненциального среднего,
, где – параметр сглаживания (вес текущего значения при вычислении экспоненциального среднего,  ). Параметр характеризует скорость реакции экспоненциального среднего на изменение текущего значения динамического ряда и одновременно определяет его способность сглаживать случайные колебания. Чем больше , тем быстрее реакция экспоненциального среднего на изменение динамического ряда и тем меньше его сглаживающие возможности. В качестве приемлемого компромисса рекомендуется брать в пределах от 0,1 до 0,3. Следовательно, приемлемыми значениями фактора затухания являются значения из интервала от 0,7 до 0,9. В статистической процедуре Экспоненциальное сглаживание по умолчанию
). Параметр характеризует скорость реакции экспоненциального среднего на изменение текущего значения динамического ряда и одновременно определяет его способность сглаживать случайные колебания. Чем больше , тем быстрее реакция экспоненциального среднего на изменение динамического ряда и тем меньше его сглаживающие возможности. В качестве приемлемого компромисса рекомендуется брать в пределах от 0,1 до 0,3. Следовательно, приемлемыми значениями фактора затухания являются значения из интервала от 0,7 до 0,9. В статистической процедуре Экспоненциальное сглаживание по умолчанию  , что противоречит рекомендациям.
, что противоречит рекомендациям.
При аналитическом выравнивании в Excel используются статистическая процедура Регрессия и статистические функции регрессионного анализа ЛИНЕЙН, ПРЕДСКАЗ, ЛГРФПРИБЛ, ТЕНДЕНЦИЯ и РОСТ, рассмотренные в предыдущем разделе. В этом случае при использовании статистической процедуры Регрессия вместо значений факторного признака вводятся натуральные числа 1,2,…. , обозначающие порядковые номера периодов или моментов времени. При использовании статистических функций натуральные числа можно не вводить, а оставить пропущеным аргумент известные значения х. Тогда при вычислениях в качестве массива известные значения х используется массив натуральных чисел 1,2…и т.д. такого же размера, как и массив известные значения у.
Эффективным средством аналитического выравнивания является процедура Добавить линию тренда, входящая в комплекс графических средств табличного процессора Excel. Она вычисляет параметры выбранной пользователем модели тренда. При вычислениях используется МНК. Модель тренда выбирается из набора, включающего в себя пять наиболее распространённых аналитических моделей: линейную, логарифмическую, полиноминальную (параболическую), степенную, экспоненциальную и модель адаптивной скользящей средней (формулы см. выше данном разделе). Параметры аналитических моделей вычисляются по данным наблюдения, по которым построен график динамического ряда. В результате реализации процедуры в область построения графика выводятся график функции тренда, её аналитическое выражение и значение коэффициента детерминации R 2 . При изменении любых значений исходного ряда динамики процедура автоматически пересчитывает и обновляет параметры линии тренда и её график.
Для доступа к процедуре Добавить линию тренда необходимо:
1. В диапазон ячеек определённого столбца ввести уровни исследуемого динамического ряда.
2. С помощью Мастера Функций построить диаграмму (график) ряда динамики.
3. Щелчком на диаграмме активизировать её. На панели меню на месте пункта Данные появится пункт Диаграмма.
4. В пункте меню Диаграмма выбрать команду Добавить линию тренда. Откроется диалоговое окно Линия тренда.
5. В открывшемся окне Линия тренда раскрыть вкладку Тип.
6. На этой вкладке в разделе Построение линии тренда (аппроксимация и сглаживание) выбрать тип (вид) функции тренда.
7. В списке Построен на ряде выделить ряд данных, для которых строится линия тренда.
8. Раскрыть вкладку Параметры диалогового окна Линия тренда.
Эта вкладка содержит следующие элементы управления:
группу переключателей Название аппроксимирующей (глаженной) кривой, состоящую из двух переключателей. При установке переключателя автоматическое Excel автоматически присваивает линии тренда имя, связанное с типом этой линии и названием данных наблюдения, по которым строится линия тренда, например, Линейный (Урожайность зерновых). При установке переключателя другое пользователь сам устанавливает имя линии регрессии и вводит это имя в поле Линейный (Ряд 1), расположенное справа от переключателя (максимальная длина имени 256 символов);
группу счётчиков Прогноз, в которую входят два счётчика: вперёд на…единиц и назад на…единиц. С помощью этих счётчиков устанавливается срок прогноза и производится экстраполяция и интерполяция ряда динамики. Счётчики недоступны в режиме Скользящее среднее;
флажок пересечение кривой с осью Y в точке. Если этот флажок не установлен, ордината точки пересечения линии тренда с осью Y вычисляется по данным наблюдения. Как правило, этот флажок не устанавливается. Используя этот флажок и расположенное справа от него поле ввода, можно задать нужную ординату точки пересечения (при активном флажке и нуле в поле ввода линия тренда пройдет через начало координат);
флажок показывать уравнение на диаграмме. При установке этого флажка в область построения диаграммы выводится аналитическое выражение (формула) функции тренда;
флажок поместить на диаграмму величину достоверности аппроксимации. При установке этого флажка в область построения диаграммы выводится значение коэффициента детерминации R 2 , который показывает, на сколько процентов выбранная линия тренда объясняет разброс уровней ряда. Чем больше данный показатель, тем более точно выбрана линия тренда. Сравнивая величину R 2 по разным аналитическим моделям можно определить аппроксимирующую функцию. то есть наиболее точно описывающую основную тенденцию развития изучаемого явления.
9. Установить нужные переключатели, счётчики и флажки. Щёлкнуть на кнопке ОК.
Список рекомендуемой литературы
1. Вадзинский Р. Статистические вычисления в среде Еxcel. –СПб.: Питер,2008.
2. Макарова Н.В. Трофимец В.Я. Статистика в Еxcel.– М.: Финансы и статитсика, 2006.
3. Берк К. Кэйри П. Анализ данных с помощью MS Еxcel.–М.: Вильямс, 2005.
4. Васильев А.Н. Научные вычисления в Microsoft Excel.–М.; Спб.; Киев: Диалектика, 2004.
5.Вуколов Э.А. Основы статистического анализа: практикум по статистическим методам и исследованию операций с использованием пакетов STATISTICA и Еxcel.– М.: Форум; Инфра–М, 2004.
6. Минько А.А. Статистический анализ в среде Еxcel.–М., СПб., Киев: Диалектика, 2004.
7. Гайдышев И. Анализ и обработка данных.–СПб; М.: Питер, 2001.
8. Елисеева И.И., Юзбашев М.М. Общая теория статистики: Учебник. М: Финансы и статистика, 2005
9. Ефимова М.Р., Петрова Е.В., Румянцев В.Н. Общая теория статистики: Учебник. – М.: ИНФРА- М, 2006.
10. Теория статистики: Учебник / Под ред. Р.А. Шмойловой .4-е изд., доп. и перераб. — М.: Финансы и статистика, 2005.
11. Теория статистики: Учебник/ Под ред. Г.Л. Громыко.- ИНФРА- М, 2006.
Источник