Ошибки невыполнения перехода
Что такое ошибка «Переход не выполнен»
В этой категории перечислены URL, на которые робот Googlebot не смог перейти, а также указаны возможные причины. Некоторые из этих причин перечислены ниже.
Flash, JavaScript, активное содержание
Некоторые средства, используемые на сайте, такие как JavaScript, файлы cookie, идентификаторы сеансов, фреймы, DHTML или Flash, могут затруднять процесс его сканирования роботами поисковых систем. Выполните следующие проверки:
- Используйте для проверки сайта текстовый браузер (например, Lynx), поскольку большинство поисковых систем видят сайт точно так же, как Lynx. Если вы не сможете просмотреть его целиком из-за таких элементов, как JavaScript, файлы cookie, идентификаторы сеансов, фреймы, DHTML или Flash, то и сканерам поисковых систем тоже будет нелегко его обработать.
- Используйте инструмент Просмотреть как Googlebot, чтобы увидеть свой сайт в точности так, как его видит робот Googlebot.
- Если вы используете динамические страницы (например, если в URL содержится символ «?»), следует иметь в виду, что не все сканеры поисковых систем сканируют динамические страницы так же успешно, как и статические. Мы рекомендуем использовать краткие значения параметров и не злоупотреблять ими. Если вы знаете, как используются параметры на вашем сайте, вы можете сообщить Google, как их следует обрабатывать.
Переадресация
- Если на сайте постоянно используется переадресация с одних страниц на другие, убедитесь, что возвращается правильный код статуса HTTP (301 Окончательно перемещено).
- По возможности используйте абсолютные ссылки вместо относительных. (Например, ссылаясь на другую страницу своего сайта, создавайте ссылку на www.example.ru/mypage.html, а не просто на mypage.html.)
- Рекомендуется, чтобы на каждую страницу сайта вела хотя бы одна статическая текстовая ссылка. Уменьшайте число переадресаций, необходимых для перехода с одной страницы на другую.
- Убедитесь, что переадресация указывает на правильные страницы! Некоторые страницы указывают сами на себя (ошибка циклической переадресации) или на недействительные URL.
- Не включайте URL с переадресацией в файлы Sitemap.
- Длина URL должна быть по возможности минимальной. Убедитесь, что в URL переадресации автоматически не добавляется дополнительная информация (например, идентификатор сеанса).
- Убедитесь, что поисковые роботы могут сканировать ваш сайт без идентификаторов сеансов и без аргументов, которые позволяют отслеживать пути их передвижения по сайту.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Если вы видите сообщение «Страница с переадресацией» в отчете о покрытии, это означает, что Google нашел страницу с переадресацией на вашем сайте и не проиндексировал ее. Google исключает подобные страницы из результатов поиска, чтобы избежать дублирования результатов или ввиду того, что он обнаружил ошибки.

Ошибка страницы с переадресацией может быть вызвана следующими ситуациями:
- Вы перевели свой сайт на премиум-план. Переадресация выполняется с вашего бесплатного URL-адреса Wix на ваш собственный домен.
- Вы настроили 301 редирект страниц в Менеджере переадресации URL.
- Переадресация выполняется с HTTP-версии URL-адреса вашего сайта на HTTPS-версию.
- Переадресация выполняется с https://mydomain.com версии URL вашего сайта на версию https://www.mydomain.com.
В этих случаях это нормально и не повлияет на рейтинг вашего сайта.
Такой вопрос это нужно сделать или стоит переадресация?
# BEGIN WP Rocket v3.8.5
# Use UTF-8 encoding for anything served text/plain or text/html
AddDefaultCharset UTF-8
# Force UTF-8 for a number of file formats
<IfModule mod_mime.c>
AddCharset UTF-8 .atom .css .js .json .rss .vtt .xml
</IfModule>
# FileETag None is not enough for every server.
<IfModule mod_headers.c>
Header unset ETag
</IfModule>
# Since we’re sending far-future expires, we don’t need ETags for static content.
# developer.yahoo.com/performance/rules.html#etags
FileETag None
<IfModule mod_alias.c>
<FilesMatch "\.(html|htm|rtf|rtx|txt|xsd|xsl|xml)$">
<IfModule mod_headers.c>
Header set X-Powered-By "WP Rocket/3.8.5"
Header unset Pragma
Header append Cache-Control "public"
Header unset Last-Modified
</IfModule>
</FilesMatch>
<FilesMatch "\.(css|htc|js|asf|asx|wax|wmv|wmx|avi|bmp|class|divx|doc|docx|eot|exe|gif|gz|gzip|ico|jpg|jpeg|jpe|json|mdb|mid|midi|mov|qt|mp3|m4a|mp4|m4v|mpeg|mpg|mpe|mpp|otf|odb|odc|odf|odg|odp|ods|odt|ogg|pdf|png|pot|pps|ppt|pptx|ra|ram|svg|svgz|swf|tar|tif|tiff|ttf|ttc|wav|wma|wri|xla|xls|xlsx|xlt|xlw|zip)$">
<IfModule mod_headers.c>
Header unset Pragma
Header append Cache-Control "public"
</IfModule>
</FilesMatch>
</IfModule>
# Expires headers (for better cache control)
<IfModule mod_expires.c>
ExpiresActive on
ExpiresDefault "access plus 1 month"
# cache.appcache needs re-requests in FF 3.6 (thanks Remy ~Introducing HTML5)
ExpiresByType text/cache-manifest "access plus 0 seconds"
# Your document html
ExpiresByType text/html "access plus 0 seconds"
# Data
ExpiresByType text/xml "access plus 0 seconds"
ExpiresByType application/xml "access plus 0 seconds"
ExpiresByType application/json "access plus 0 seconds"
# Feed
ExpiresByType application/rss+xml "access plus 1 hour"
ExpiresByType application/atom+xml "access plus 1 hour"
# Favicon (cannot be renamed)
ExpiresByType image/x-icon "access plus 1 week"
# Media: images, video, audio
ExpiresByType image/gif "access plus 4 months"
ExpiresByType image/png "access plus 4 months"
ExpiresByType image/jpeg "access plus 4 months"
ExpiresByType image/webp "access plus 4 months"
ExpiresByType video/ogg "access plus 4 months"
ExpiresByType audio/ogg "access plus 4 months"
ExpiresByType video/mp4 "access plus 4 months"
ExpiresByType video/webm "access plus 4 months"
# HTC files (css3pie)
ExpiresByType text/x-component "access plus 1 month"
# Webfonts
ExpiresByType font/ttf "access plus 4 months"
ExpiresByType font/otf "access plus 4 months"
ExpiresByType font/woff "access plus 4 months"
ExpiresByType font/woff2 "access plus 4 months"
ExpiresByType image/svg+xml "access plus 1 month"
ExpiresByType application/vnd.ms-fontobject "access plus 1 month"
# CSS and JavaScript
ExpiresByType text/css "access plus 1 year"
ExpiresByType application/javascript "access plus 1 year"
</IfModule>
# Gzip compression
<IfModule mod_deflate.c>
# Active compression
SetOutputFilter DEFLATE
# Force deflate for mangled headers
<IfModule mod_setenvif.c>
<IfModule mod_headers.c>
SetEnvIfNoCase ^(Accept-EncodXng|X-cept-Encoding|X{15}|~{15}|-{15})$ ^((gzip|deflate)\s*,?\s*)+|[X~-]{4,13}$ HAVE_Accept-Encoding
RequestHeader append Accept-Encoding "gzip,deflate" env=HAVE_Accept-Encoding
# Don’t compress images and other uncompressible content
SetEnvIfNoCase Request_URI \
\.(?:gif|jpe?g|png|rar|zip|exe|flv|mov|wma|mp3|avi|swf|mp?g|mp4|webm|webp|pdf)$ no-gzip dont-vary
</IfModule>
</IfModule>
# Compress all output labeled with one of the following MIME-types
<IfModule mod_filter.c>
AddOutputFilterByType DEFLATE application/atom+xml \
application/javascript \
application/json \
application/rss+xml \
application/vnd.ms-fontobject \
application/x-font-ttf \
application/xhtml+xml \
application/xml \
font/opentype \
image/svg+xml \
image/x-icon \
text/css \
text/html \
text/plain \
text/x-component \
text/xml
</IfModule>
<IfModule mod_headers.c>
Header append Vary: Accept-Encoding
</IfModule>
</IfModule>
# END WP Rocket
# BEGIN WP Hide & Security Enhancer
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
#WriteCheckString:1614091674_63237
RewriteRule .* - [E=HTTP_MOD_REWRITE:On]
RewriteRule ^usasooju/(.+) /wp-content/themes/houzez/$1 [L,QSA]
RewriteRule ^xuthoalr/(.+) /wp-content/plugins/$1 [L,QSA]
RewriteRule ^oastoops/(.+) /wp-includes/$1 [L,QSA]
RewriteRule ^eglyroat/(.+) /wp-content/uploads/$1 [L,QSA]
RewriteRule ^eceeksyp.php /wp-comments-post.php [L,QSA]
RewriteRule ^fynoomog/(.+) /wp-content/$1 [L,QSA]
</IfModule>
# END WP Hide & Security Enhancer
<IfModule mod_rewrite.c>
RewriteEngine On
# Check if browser supports WebP images
RewriteCond %{HTTP_ACCEPT} image/webp
# Check if WebP replacement image exists
RewriteCond %{DOCUMENT_ROOT}/$1.webp -f
# Serve WebP image instead
RewriteRule (.+)\.(jpe?g|png)$ $1.webp [T=image/webp,E=REQUEST_image]
</IfModule>
<IfModule mod_headers.c>
# Vary: Accept for all the requests to jpeg and png
Header append Vary Accept env=REQUEST_image
</IfModule>
<IfModule mod_mime.c>
AddType image/webp .webp
</IfModule>
# BEGIN WordPress
# Директивы (строки) между `BEGIN WordPress` и `END WordPress`
# созданы автоматически и подлежат изменению только через фильтры WordPress.
# Сделанные вручную изменения между этими маркерами будут перезаписаны.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule .* - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
RewriteBase /
RewriteRule ^index\.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
</IfModule>
# END WordPress
# MalCare WAF
<Files ".user.ini">
<IfModule mod_authz_core.c>
Require all denied
</IfModule>
<IfModule !mod_authz_core.c>
Order deny,allow
Deny from all
</IfModule>
</Files>
# END MalCare WAF
# BEGIN EXPIRES
<IfModule mod_expires.c>
ExpiresActive On
ExpiresDefault "access plus 6 month"
ExpiresByType text/css "access plus 6 month"
ExpiresByType text/plain "access plus 6 month"
ExpiresByType image/gif "access plus 6 month"
ExpiresByType image/png "access plus 6 month"
ExpiresByType image/jpeg "access plus 6 month"
ExpiresByType application/x-javascript "access plus 6 month"
ExpiresByType application/javascript "access plus 6 month"
ExpiresByType application/x-icon "access plus 6 month"
</IfModule>
# END EXPIRESПодробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Даже если Google нашёл и просканировал страницу, это не означает, что она обязательно будет проиндексирована.
Но главное, что вы должны понять и запомнить: нет необходимости в том, чтобы абсолютно все страницы вашего сайты были проиндексированы. Вместо этого убедитесь, что в индекс включены все важные и полезные для пользователей страницы с качественным контентом.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
Как пользоваться Отчётом об индексировании в Google Search Console
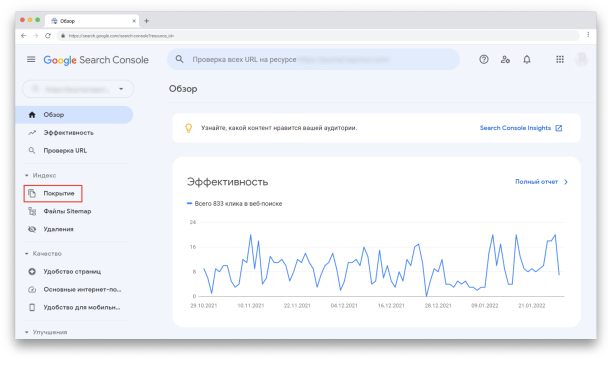
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Перед вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
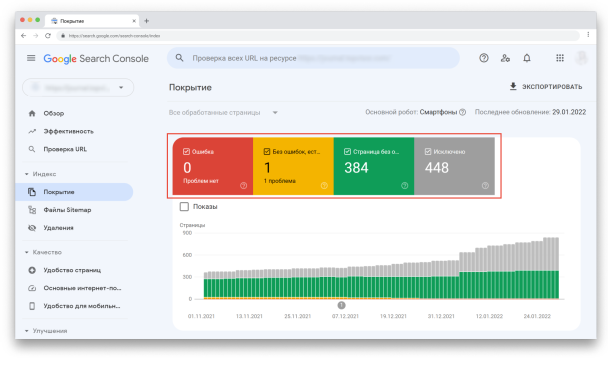
Вы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).
Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
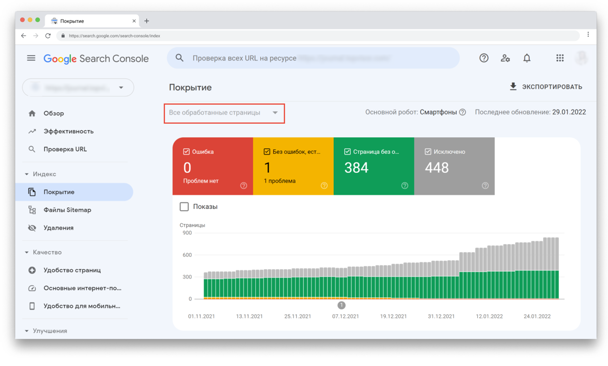
«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
В чём разница?
Первый обычно включает в себя больше URL-адресов и многие из них попадают в секцию «Исключено». Это происходит потому, что карта сайта включает только индексируемые URL, в то время как сайты обычно содержат множество страниц, которые не должны быть проиндексированы.
Как пример — URL с параметрами на сайтах eCommerce. Googlebot может найти их разными способами, но не в карте сайта.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:
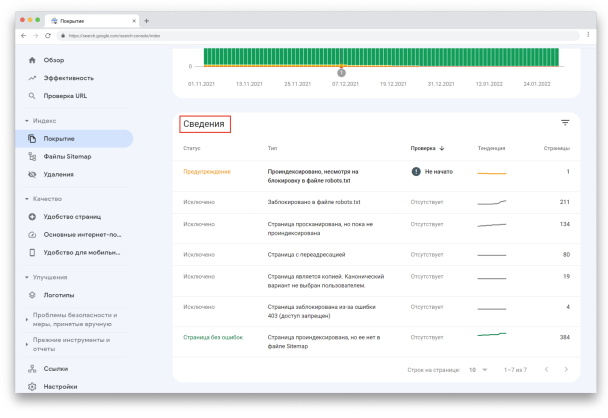
Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
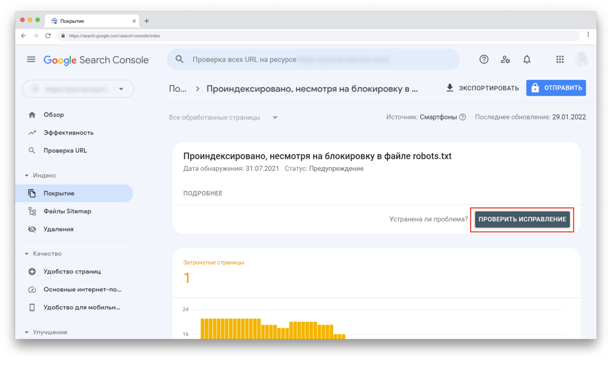
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
Вы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
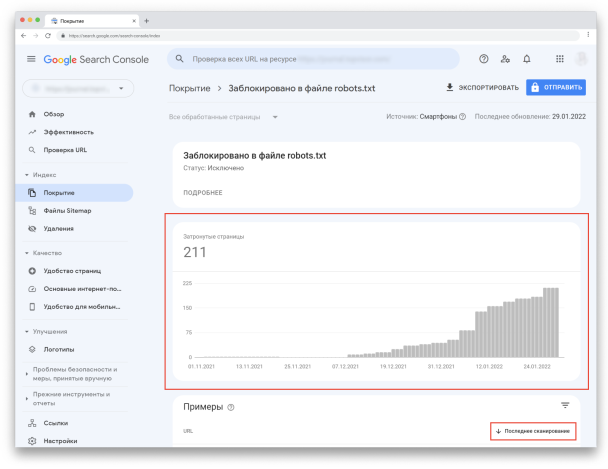
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
Что учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.
Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
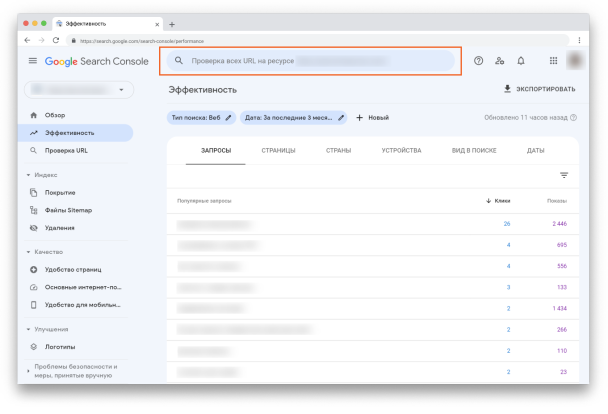
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
Просто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему. Например:
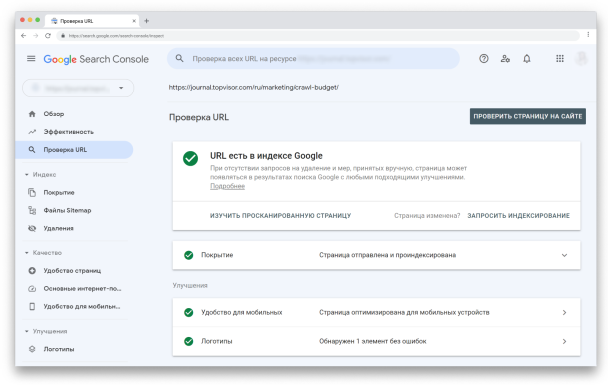
Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту. Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.
Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.
Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её. В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Для постоянного редиректа убедитесь, что вы настроили перенаправление на ближайшую альтернативную страницу, а не на Главную. Редирект страницы с 404 ошибкой на Главную может определять её как soft 404.
@JohnMu what does Google do when a site redirects all its 404s to the homepage? Seeing more and more sites do this and it’s such an anti-pattern.
— Joost de Valk (@jdevalk) January 7, 2019
Yeah, it’s not a great practice (confuses users), and we mostly treat them as 404s anyway (they’re soft-404s), so there’s no upside. It’s not critically broken/bad, but additional complexity for no good reason — make a better 404 page instead.
— ? John ? (@JohnMu) January 8, 2019
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.
На этой странице описывается, как коды статуса HTTP, а также ошибки сети и DNS отражаются на позиции вашего контента в Google Поиске. Мы поговорим о 20 наиболее распространенных кодах статуса, которые обнаруживает на веб-страницах робот Googlebot, а также о самых частых ошибках сети и DNS. Такие редко встречающиеся коды, как 418 (I'm a teapot), в этой статье не рассматриваются. Все перечисленные на этой странице проблемы приводят к появлению ошибки или предупреждения в отчете об индексировании страниц, доступном в Search Console.
Коды статуса HTTP
Когда сервер, на котором размещен сайт, получает запрос клиента (например, браузера или поискового робота), в ответ он отправляет код статуса HTTP. Каждый такой код имеет свое значение, но многие из них предполагают, что запрос будет обрабатываться одинаково. Например, о переадресации могут сигнализировать несколько разных кодов.
Сообщения об ошибке, генерируемые в Search Console, относятся к кодам статуса в диапазоне 4xx–5xx, а также к неудачной переадресации (3xx). Если в ответе сервера указан код статуса 2xx, полученный контент может быть проиндексирован.
В таблице ниже приведены коды статуса HTTP, с которыми чаще всего сталкивается робот Googlebot, и пояснения о том, как обрабатывается каждый такой код.
| Коды статуса HTTP | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Роботы Google проверяют, можно ли проиндексировать контент. Если контент не загружается, например появляется пустая страница или сообщение об ошибке, в Search Console будет зарегистрирована ошибка
|
|||||||||||
|
Робот Googlebot выполняет до 10 переходов в цепочке переадресаций. Если за это время поисковый робот не получает контент, в отчете об индексировании страниц этого сайта в Search Console будет указана ошибка переадресации. Количество переходов робота Googlebot зависит от агента пользователя, например у роботов Googlebot Smartphone и Googlebot Image оно будет отличаться.
Googlebot выполняет пять переходов в цепочке переадресаций согласно спецификации RFC 1945. Затем он прерывает операцию и интерпретирует ситуацию как ошибку Наши роботы игнорируют любой контент, получаемый с URL переадресации. При индексировании используется контент, размещенный по конечному целевому URL.
|
|||||||||||
|
Роботы Google не индексируют URL с кодом статуса
Роботы Googlebot игнорируют любой контент, получаемый с URL, которые возвращают код статуса
|
|||||||||||
|
В случае ошибок сервера Если файл robots.txt выдает ошибку сервера более 30 дней, будут выполняться правила, указанные в последней кешированной копии этого файла. Если такой копии нет, роботы Google будут действовать без ограничений.
Роботы Googlebot игнорируют любой контент, получаемый с URL, которые возвращают код статуса
|
Ошибки soft 404
Ошибкой soft 404 называется ситуация, когда посетитель веб-страницы видит сообщение о том, что ее не существует, при этом браузер получает ответ с кодом статуса 200 (success). Этот код означает «Успешно». В некоторых случаях открывается страница, на которой нет основного или вообще никакого контента.
Такие страницы создаются веб-сервером, где размещен сайт, системой управления контентом или браузером пользователя. Причины могут быть разными. Пример:
- Отсутствие файла SSI
- Ошибка при обращении к базе данных
- Пустая внутренняя страница результатов поиска
- Незагруженный или отсутствующий по другой причине файл JavaScript
Мы не рекомендуем возвращать код статуса 200 (success), а затем выводить сообщение об ошибке или указывать на наличие ошибки на странице. Пользователи могут подумать, что попали на действующую страницу, но после этого увидят сообщение об ошибке. Подобные страницы исключаются из Google Поиска.
Если алгоритмы Google по контенту страницы определяют, что она содержит сообщение об ошибке, то в отчете об индексировании страниц этого сайта в Search Console будет указана ложная ошибка soft 404.
Порядок исправления ошибок soft 404
Есть разные способы устранения ошибок soft 404 в зависимости от состояния сайта и от желаемого результата:
- Страница и ее контент больше не доступны
- Страница или ее контент были перенесены
- Страница и ее контент по-прежнему существуют
Подумайте, какое решение будет оптимальным для ваших пользователей.
Страница и ее контент больше не доступны
Если страница удалена и для нее нет замены на вашем сайте с аналогичным контентом, нужно отправлять ответ с кодом статуса 404 (not found) или 410 (gone). Эти коды статуса сообщают поисковым системам, что страницы не существует, а контент не нужно индексировать.
Если у вас есть доступ к файлам конфигурации вашего сервера, страницы с сообщениями об ошибках можно сделать полезными для пользователей. Например, на такой странице 404 вы можете разместить функции, призванные помогать посетителям в поиске нужной информации, или полезный контент, который удержит их на вашем ресурсе. Вот несколько советов по созданию полезной страницы 404:
- Пользователям должно быть понятно, что запрашиваемая страница недоступна. Текст сообщения должен быть вежливым и привлекающим внимание.
-
Страница
404должна быть выполнена в том же стиле (включая элементы навигации), что и основной сайт. - Разместите на странице ссылки на самые популярные статьи или записи блога, а также на главную страницу.
- Дайте пользователям возможность сообщать о неработающих ссылках.
Полезные страницы 404 создаются исключительно для удобства пользователей. Поисковые системы игнорируют такие страницы, поэтому рекомендуем возвращать для этих страниц код статуса HTTP 404, чтобы они не индексировались.
Страница или ее контент перемещены
Если страница перенесена или у нее есть замена, отправляйте ответ с кодом 301 (permanent redirect), чтобы перенаправлять пользователей. Посетителям сайта это не помешает, а поисковые системы узнают новое расположение страницы. Чтобы узнать, правильный ли код ответа отправляется при открытии страницы, используйте инструмент проверки URL.
Страница и ее контент по-прежнему существуют
Если нормально работающая страница вызвала ошибку soft 404, вероятно, она не была корректно загружена роботом Googlebot, во время отрисовки не были доступны важные ресурсы или показывалось заметное сообщение об ошибке. Проанализируйте отрисованный контент и код ответа HTTP с помощью инструмента проверки URL. Если на обработанной странице нет или очень мало контента или он вызывает ошибку, ошибка soft 404 может быть обусловлена тем, что страница содержит ресурсы (например, изображения, скрипты и прочие нетекстовые элементы), которые не удается загрузить.
Возможные причины проблем с загрузкой – блокировка доступа в файле robots.txt, слишком большое количество ресурсов или слишком большой их размер, а также любые ошибки сервера.
Ошибки сети и DNS
Ошибки сети и DNS отрицательно влияют на показ URL в результатах поиска Google.
Робот Googlebot интерпретирует тайм-ауты сети, факты сброса подключения и ошибки DNS так же, как и ошибки серверов 5xx. В случае сетевых ошибок сканирование начинает постепенно замедляться, поскольку сетевая ошибка означает, что сервер может не справиться с нагрузкой. Так как роботы Googlebot не смогли получить доступ к серверу, на котором размещен сайт, значит, им не удалось извлечь контент. В результате Google не может проиндексировать ранее просканированные URL, а недоступные нашим роботам URL, которые уже были проиндексированы, будут удалены из индекса Google в течение нескольких дней. Search Console может создавать сообщения о каждой возникающей ошибке.
Ошибки отладки сети
Эти ошибки возникают до того, как Google начинает сканирование URL, или во время этого процесса.
Поскольку они зачастую уже присутствуют до того, как сервер возвращает ответ, то из-за отсутствия кода статуса диагностика этих ошибок может вызывать трудности. Чтобы отладить ошибки тайм-аута и сброса подключения, выполните следующие действия:
- Проверьте настройки брандмауэра и записи в журнале. У вас может быть задано слишком общее правило блокировки. Нужно, чтобы ни одно правило брандмауэра не блокировало IP-адреса робота Googlebot.
- Проанализируйте сетевой трафик с помощью таких инструментов как tcpdump и Wireshark. Они помогут вам найти в пакетах TCP аномалии, относящиеся к определенному сетевому компоненту или модулю сервера.
- Если вы не можете найти ничего подозрительного, обратитесь к своему хостинг-провайдеру.
Ошибка может относиться к любому серверному компоненту, который обрабатывает сетевой трафик. Возможно, что перегруженные интерфейсы сети не могут передавать пакеты, что приводит к тайм-аутам (невозможности установить подключение) и сбросу подключений (отправляется пакет RST, поскольку порт был закрыт по ошибке).
Устранение ошибок DNS
Ошибки DNS чаще всего вызваны неправильной конфигурацией, но могут также возникать из-за правил брандмауэра, которые блокируют DNS-запросы робота Googlebot. Чтобы устранить ошибки DNS, выполните следующие действия:
-
Проверьте правила брандмауэра. Нужно, чтобы ни одно правило не блокировало IP-адреса Google и чтобы были разрешены запросы как по протоколу
UDP, так и по протоколуTCP. -
Проверьте записи DNS. Убедитесь, что записи
AиCNAMEведут на правильные IP-адреса и имена хостов. Пример:dig +nocmd example.com a +noall +answer
dig +nocmd www.example.com cname +noall +answer
-
Убедитесь, что все ваши DNS-серверы указывают на правильные IP-адреса вашего сайта. Пример:
dig +nocmd example.com ns +noall +answerexample.com. 86400 IN NS a.iana-servers.net. example.com. 86400 IN NS b.iana-servers.net.dig +nocmd @a.iana-servers.net example.com +noall +answerexample.com. 86400 IN A 93.184.216.34dig +nocmd @b.iana-servers.net example.com +noall +answer... - Если вы внесли изменения в конфигурацию DNS в течение последних 72 часов, на их применение во всей сети DNS может потребоваться некоторое время. Чтобы ускорить внедрение новых настроек, вы можете очистить общедоступный кеш DNS.
- Если вы используете собственный DNS-сервер, убедитесь, что он исправен и не перегружен.