Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)

(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:

(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).

Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом

. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:

(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.

Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n

-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
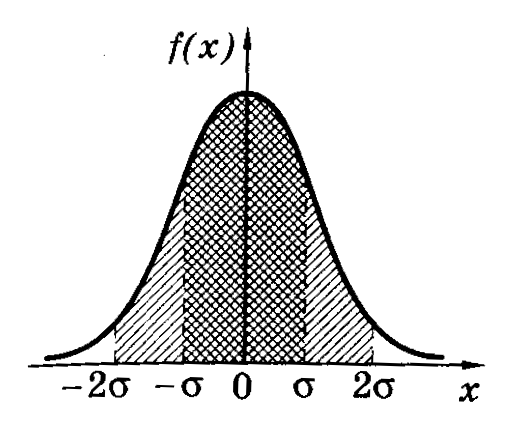
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:

(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:

(26)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
In any quantitative science, the terms relative change and relative difference are used to compare two quantities while taking into account the «sizes» of the things being compared, i.e. dividing by a standard or reference or starting value. The comparison is expressed as a ratio and is a unitless number. By multiplying these ratios by 100 they can be expressed as percentages so the terms percentage change, percent(age) difference, or relative percentage difference are also commonly used. The terms «change» and «difference» are used interchangeably.[1] Relative change is often used as a quantitative indicator of quality assurance and quality control for repeated measurements where the outcomes are expected to be the same. A special case of percent change (relative change expressed as a percentage) called percent error occurs in measuring situations where the reference value is the accepted or actual value (perhaps theoretically determined) and the value being compared to it is experimentally determined (by measurement).
The relative change formula is not well-behaved under many conditions. Various alternative formulas, called indicators of relative difference or change, have been proposed in the literature. Several authors have found log change and log points to be satisfactory indicators, but these have not seen widespread use.[2]
Definition[edit]
Given two numerical quantities, vref and v with vref somereference value. their actual change, actual difference, or absolute change is Δv = v − vref. The term absolute difference is sometimes also used even though the absolute value is not taken; the sign of Δ typically is uniform, e.g. across an increasing data series. If the relationship of the value with respect to the reference value (that is, larger or smaller) does not matter in a particular application, the absolute value may be used in place of the actual change in the above formula to produce a value for the relative change which is always non-negative. The actual difference is not usually a good way to compare the numbers, in particular because it depends on the unit of measurement. For instance, 1 meter is the same as 100 centimeters, but the absolute difference between 2 m and 1 m is 1 while the absolute difference between 200 cm and 100 cm is 100, giving the impression of a larger difference.[3] But even with constant units, the relative change helps judge the importance of the respective change. For example, an increase in price of $100 of a valuable is considered big if changing from $50 to $150 but rather small when changing from $10000 to $10100.
We can adjust the comparison to take into account the «size» of the quantities involved, by defining, for positive values of vref:

The relative change is independent of the unit of measurement employed; for example, the relative change from 2 meters to 1 meter is -50%, the same as for 200 cm to 100 cm. The relative change is not defined if the reference value (vref) is zero, and gives negative values for positive increases if vref is negative, hence it is not usually defined for negative reference values either. For example, we might want to calculate the relative change of −10 to −6. The above formula gives ((−6) − (−10)) / (−10) = 4 / −10 = −0.4, indicating a decrease, yet in fact the reading increased.
Measures of relative difference are unitless numbers expressed as a fraction. Corresponding values of percent difference would be obtained by multiplying these values by 100 (and appending the % sign to indicate that the value is a percentage).
Domain[edit]
The domain restriction of relative change to positive numbers often poses a constraint. To avoid this problem it is common to take the absolute value, so that the relative change formula works correctly for all nonzero values of vref:

This still does not solve the issue when the reference is zero. It is common to instead use an indicator of relative difference, and take the absolute values of both  and
and  . Then the only problematic case is
. Then the only problematic case is  , which can usually be addressed by appropriately extending the indicator. For example, for arithmetic mean this formula may be used:[4]
, which can usually be addressed by appropriately extending the indicator. For example, for arithmetic mean this formula may be used:[4]

Percent error[edit]
The percent error is a special case of the percentage form of relative change calculated from the absolute change between the experimental (measured) and theoretical (accepted) values, and dividing by the theoretical (accepted) value.

The terms «Experimental» and «Theoretical» used in the equation above are commonly replaced with similar terms. Other terms used for experimental could be «measured,» «calculated,» or «actual» and another term used for theoretical could be «accepted.» Experimental value is what has been derived by use of calculation and/or measurement and is having its accuracy tested against the theoretical value, a value that is accepted by the scientific community or a value that could be seen as a goal for a successful result.
Although it is common practice to use the absolute value version of relative change when discussing percent error, in some situations, it can be beneficial to remove the absolute values to provide more information about the result. Thus, if an experimental value is less than the theoretical value, the percent error will be negative. This negative result provides additional information about the experimental result. For example, experimentally calculating the speed of light and coming up with a negative percent error says that the experimental value is a velocity that is less than the speed of light. This is a big difference from getting a positive percent error, which means the experimental value is a velocity that is greater than the speed of light (violating the theory of relativity) and is a newsworthy result.
The percent error equation, when rewritten by removing the absolute values, becomes:

It is important to note that the two values in the numerator do not commute. Therefore, it is vital to preserve the order as above: subtract the theoretical value from the experimental value and not vice versa.
Percentage change[edit]
A percentage change is a way to express a change in a variable. It represents the relative change between the old value and the new one.[5]
For example, if a house is worth $100,000 today and the year after its value goes up to $110,000, the percentage change of its value can be expressed as

It can then be said that the worth of the house went up by 10%.
More generally, if V1 represents the old value and V2 the new one,

Some calculators directly support this via a %CH or Δ% function.
When the variable in question is a percentage itself, it is better to talk about its change by using percentage points, to avoid confusion between relative difference and absolute difference.
Example of percentages of percentages[edit]
If a bank were to raise the interest rate on a savings account from 3% to 4%, the statement that «the interest rate was increased by 1%» would be ambiguous. The absolute change in this situation is 1 percentage point (4% − 3%), but the relative change in the interest rate is:

In general, the term «percentage point(s)» indicates an absolute change or difference of percentages, while the percent sign or the word «percentage» refers to the relative change or difference.[6]
Examples[edit]
Comparisons[edit]
Car M costs $50,000 and car L costs $40,000. We wish to compare these costs.[7] With respect to car L, the absolute difference is $10,000 = $50,000 − $40,000. That is, car M costs $10,000 more than car L. The relative difference is,

and we say that car M costs 25% more than car L. It is also common to express the comparison as a ratio, which in this example is,

and we say that car M costs 125% of the cost of car L.
In this example the cost of car L was considered the reference value, but we could have made the choice the other way and considered the cost of car M as the reference value. The absolute difference is now −$10,000 = $40,000 − $50,000 since car L costs $10,000 less than car M. The relative difference,

is also negative since car L costs 20% less than car M. The ratio form of the comparison,

says that car L costs 80% of what car M costs.
It is the use of the words «of» and «less/more than» that distinguish between ratios and relative differences.[8]
Indicators of relative change[edit]
The (classical) relative change above is but one of the possible measures/indicators of relative change or difference. An indicator of relative change from x (initial or reference value) to y (new value)  is a binary real-valued function defined for the domain of interest which satisfies the following properties:[9]
is a binary real-valued function defined for the domain of interest which satisfies the following properties:[9]
Due to the independence condition, every such function  can be written as a single argument function
can be written as a single argument function  of the ratio
of the ratio  .[10] It is also clear that if
.[10] It is also clear that if  satisfies the other conditions then
satisfies the other conditions then  will as well, for every
will as well, for every  . We thus further restrict indicators to be normalized such that
. We thus further restrict indicators to be normalized such that  . It can be shown that this implies all such indicators behave like the classical one when is close to
. It can be shown that this implies all such indicators behave like the classical one when is close to  .
.
Usually the indicator of relative difference is presented as the actual difference Δ scaled by some function of the values x and y, say f(x, y).[1]

As with classical relative change, the general relative change is undefined if f(x, y) is zero. Various choices for the function f(x, y) have been proposed:[11]
| Name |  where the indicator’s value is where the indicator’s value is  |
|
|---|---|---|
| (Classical) Relative change |  |

|
| Reversed relative change |  |

|
| Arithmetic mean change |  |

|
| Geometric mean change |  |

|
| Harmonic mean change |  |

|
Moment mean change of order  |
 |
![{\displaystyle ((y/x)-1)/[{\frac {1}{2}}(1+(y/x)^{k}))]^{1/k}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/528820ba90e7a0169cb421972c2dfdf8dd66920c)
|
| Maximum mean change |  |

|
| Minimum mean change |  |

|
| Logarithmic (mean) change |  |

|
As can be seen in the table, all but the first two indicators have, as denominator a mean. One of the properties of a mean function  is:[11]
is:[11]  , which means that all such indicators have a «symmetry» property that the classical relative change lacks:
, which means that all such indicators have a «symmetry» property that the classical relative change lacks:  . This agrees with intuition that a relative change from x to y should have the same magnitude as a relative change in the opposite direction, y to x, just like the relation
. This agrees with intuition that a relative change from x to y should have the same magnitude as a relative change in the opposite direction, y to x, just like the relation  suggests.
suggests.
Maximum mean change has been recommended when comparing floating point values in programming languages for equality with a certain tolerance.[12] Another application is in the computation of approximation errors when the relative error of a measurement is required.[citation needed] Minimum mean change has been recommended for use in econometrics.[13][14] Logarithmic change has been recommended as a general-purpose replacement for relative change and is discussed more below.
Tenhunen defines a general relative difference function from L (reference value) to K:[15]

which leads to

In particular for the special cases  ,
,

Logarithmic change[edit]
Of these indicators of relative change, the most natural arguably is the natural logarithm (ln) of the ratio of the two numbers (final and initial), called log change.[1] Indeed, when  , the following approximation holds:
, the following approximation holds:

In the same way that relative change is scaled by 100 to get percentages,  can be scaled by 100 to get what is commonly called log points.[16] Log points are equivalent to the unit centinepers (cNp) when measured for root-power quantities.[17][18] This quantity has also been referred to as a log percentage and denoted L%.[1]
can be scaled by 100 to get what is commonly called log points.[16] Log points are equivalent to the unit centinepers (cNp) when measured for root-power quantities.[17][18] This quantity has also been referred to as a log percentage and denoted L%.[1]
Since the derivative of the natural log at 1 is 1, log points are approximately equal to percentage difference for small differences – for example an increase of 1% equals an increase of 0.995 cNp, and a 5% increase gives a 4.88 cNp increase. This approximation property does not hold for other choices of logarithm base, which introduce a scaling factor due to the derivative not being 1. Log points can thus be used as a replacement for percentage differences.[19][17]
Additivity[edit]
Using log change has the advantages of additivity compared to relative change.[1][17] Specifically, when using log change, the total change after a series of changes equals the sum of the changes. With percent, summing the changes is only an approximation, with larger error for larger changes.[17] For example:
| Log change 0 (cNp) | Log change 1 (cNp) | Total log change (cNp) | Relative change 0 (%) | Relative change 1 (%) | Total relative change (%) |
|---|---|---|---|---|---|
| 10 | 5 | 15 | 10 | 5 | 15.5 |
| 10 | −5 | 5 | 10 | −5 | 4.5 |
| 10 | 10 | 20 | 10 | 10 | 21 |
| 10 | −10 | 0 | 10 | −10 | −1 |
| 50 | 50 | 100 | 50 | 50 | 125 |
| 50 | −50 | 0 | 50 | −50 | −25 |
Note that in the above table, since relative change 0 (respectively relative change 1) has the same numerical value as log change 0 (respectively log change 1), it does not correspond to the same variation. The conversion between relative and log changes may be computed as  .
.
By additivity,  , and therefore additivity implies a sort of symmetry property, namely
, and therefore additivity implies a sort of symmetry property, namely  and thus the magnitude of a change expressed in log change is the same whether V0 or V1 is chosen as the reference.[17] In contrast, for relative change,
and thus the magnitude of a change expressed in log change is the same whether V0 or V1 is chosen as the reference.[17] In contrast, for relative change,  , with the difference
, with the difference  becoming larger as V1 or V0 approaches 0 while the other remains fixed. For example:
becoming larger as V1 or V0 approaches 0 while the other remains fixed. For example:
| V0 | V1 | Log change (cNp) | Relative change (%) |
|---|---|---|---|
| 10 | 9 | −10.5 | −10.0 |
| 9 | 10 | +10.5 | +11.1 |
| 10 | 1 | −230 | −90 |
| 1 | 10 | +230 | +900 |
| 10 | 0+ | −∞ | −100 |
| 0+ | 10 | +∞ | +∞ |
Here 0+ means taking the limit from above towards 0.
Uniqueness and extensions[edit]
The log change is the unique two-variable function that is additive, and whose linearization matches relative change. There is a family of additive difference functions  for any
for any  , such that absolute change is
, such that absolute change is  and log change is
and log change is  .[20]
.[20]
See also[edit]
- Approximation error
- Errors and residuals in statistics
- Relative standard deviation
- Logarithmic scale
Notes[edit]
- ^ a b c d e Törnqvist, Vartia & Vartia 1985.
- ^ Törnqvist, Vartia & Vartia 1985, p. 11: «We suggest that this indicator should be used more extensively.»
- ^ Vartia 1976, p. 9.
- ^ Miller, H. Ronald (29 March 2011). Optimization: Foundations and Applications. New York: John Wiley & Sons. ISBN 978-1-118-03118-6.
- ^ Kazmi, Kumail (March 26, 2021). «Percentage Increase Calculator». Smadent — Best Educational Website of Pakistan. Smadent Publishing. Retrieved March 26, 2021.
- ^ Bennett & Briggs 2005, p. 141
- ^ Bennett & Briggs 2005, pp. 137–139
- ^ Bennett & Briggs 2005, p.140
- ^ Vartia 1976, p. 10.
- ^ Vartia 1976, p. 14.
- ^ a b c Törnqvist, Vartia & Vartia 1985, p. 5.
- ^ What’s a good way to check for close enough floating-point equality
- ^ Rao, Potluri; Miller, Roger LeRoy (1971). Applied econometrics. Belmont, Calif., Wadsworth Pub. Co. p. 17. ISBN 978-0-534-00031-8.
- ^ Vartia 1976, pp. 17–18.
- ^ Tenhunen 1990, p. 20.
- ^ Békés, Gábor; Kézdi, Gábor (6 May 2021). Data Analysis for Business, Economics, and Policy. Cambridge University Press. p. 203. ISBN 978-1-108-48301-8.
- ^ a b c d e Karjus, Andres; Blythe, Richard A.; Kirby, Simon; Smith, Kenny (10 February 2020). «Quantifying the dynamics of topical fluctuations in language». Language Dynamics and Change. 10 (1). Section A.3.1. doi:10.1163/22105832-01001200. S2CID 46928080.
- ^ Roe, John; deForest, Russ; Jamshidi, Sara (26 April 2018). Mathematics for Sustainability. Springer. p. 190. doi:10.1007/978-3-319-76660-7_4. ISBN 978-3-319-76660-7.
- ^ Doyle, Patrick (2016-08-24). «The Case for a Logarithmic Performance Metric». Vena Solutions.
- ^ Brauen, Silvan; Erpf, Philipp; Wasem, Micha (2020). «On Absolute and Relative Change». SSRN Electronic Journal. arXiv:2011.14807. doi:10.2139/ssrn.3739890. S2CID 227228720.
References[edit]
- Bennett, Jeffrey; Briggs, William (2005), Using and Understanding Mathematics: A Quantitative Reasoning Approach (3rd ed.), Boston: Pearson, ISBN 0-321-22773-5
- «Understanding Measurement and Graphing» (PDF). North Carolina State University. 2008-08-20. Archived from the original (PDF) on 2010-06-15. Retrieved 2010-05-05.
- «Percent Difference – Percent Error» (PDF). Illinois State University, Dept of Physics. 2004-07-20. Archived from the original (PDF) on 2019-07-13. Retrieved 2010-05-05.
- Törnqvist, Leo; Vartia, Pentti; Vartia, Yrjö (1985), «How Should Relative Changes Be Measured?» (PDF), The American Statistician, 39 (1): 43–46, doi:10.2307/2683905, JSTOR 2683905
- Tenhunen, Lauri (1990). The CES and par production techniques, income distribution and the neoclassical theory of production (PhD). A. Vol. 290. University of Tampere.
- Vartia, Yrjö O. (1976). Relative changes and index numbers (PDF). ETLA A 4. Helsinki: Research Institute of the Finnish Economy. ISBN 951-9205-24-1. Retrieved 20 November 2022.
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
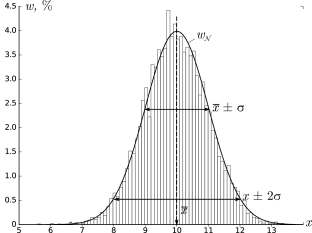
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ и x-x0σ2=2w(x)σ1=1
x-x0σ2=2w(x)σ1=1Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.