Этот пост продолжает серию про функции ошибки и функционалы качества в машинном обучении. Сейчас разберёмся с самой простой подтемой — как измерять качество чёткого ответа в задачах бинарной классификации. Уровень для чтения — начальный;)

Предыдущие посты в блоге на эту тему:
- AUC ROC
- Джини
- Логистическая функция ошибки
- Функции ошибок в задачах регрессии
Рассматриваем задачу классификации на два класса (с метками 0 и 1), на рис. 1 показано её графическое представление.

Пусть классификатор выдаёт метку класса. Используем принятые в этом блоге обозначения: yi – метка i-го объекта, ai – ответ на этом объекте нашего алгоритма, m – число объектов в выборке.
Естественным, простым и распространённым функционалом качества является точность (Accuracy или Mean Consequential Error):

т.е. просто доля (процент) объектов, на которых алгоритм выдал правильные ответы. Недостаток такого функционала очевиден: он плох в случае дисбаланса классов, когда представителей одного из класса существенно больше, чем другого. В этом случае, с точки зрения точности, выгодно почти всегда выдавать метку самого популярного класса. Это может не согласовываться с логикой использования решения задачи. Например, в задаче детектирования очень редкой болезни алгоритм, который всех относит к классу «здоровые», на практике не нужен.
Рассмотрим т.н. матрицу несоответствий / ошибок (confusion matrix) – матрицу размера 2×2, ij-я позиция которой равна числу объектов i-го класса, которым алгоритм присвоил метку j-го класса.

На рис. 2 показана такая матрица для решения рис. 1, также показаны названия элементов матрицы. Два класса делятся на положительный (обычно метка 1) и отрицательный (обычно метка 0 или –1). Объекты, которые алгоритм относит к положительному классу, называются положительными (Positive), те из них, которые на самом деле принадлежат к этому классу – истинно положительными (True Positive), остальные – ложно положительными (False Positive). Аналогичная терминология есть для отрицательного (Negative) класса. Дальше используем естественные сокращения:
- TP = True Positive,
- TN = True Negative,
- FP = False Positive,
- FN = False Negative.
Замечание. Иногда матрицу ошибок изображают по-другому: в транспонированном виде (ответы алгоритма соответствуют строкам, а правильные метки – столбцам).
Замечание. Стандартная терминология немного нелогична: естественно называть положительными объектами объекты положительного класса, но здесь – объекты, отнесённые алгоритмом к положительному классу (т.е. это даже не свойство объектов, а алгоритма). Но в контексте употребления терминов «истинно положительный» и «ложно положительный» это уже кажется логичным.


Для точности (Accuracy) справедлива формула:

Ошибки классификатора делятся на две группы: первого и второго рода. В идеале (когда точность равна 100%) матрица несоответствий диагональная, ошибки вызывают отличие от нуля двух недиагональных элементов:
ошибка 1 рода (Type I Error) случается, когда объект ошибочно относится к положительному классу (= FP/m).
ошибка 2 рода (Type II Error) случается, когда объект ошибочно относится к отрицательному классу (= FN/m).
На заглавном рис. поста показаны известные шуточные иллюстрации ошибок 1 и 2 рода: ошибка 1 рода (слева) и ошибка 2 рода (справа). Когда я объясняю студентам, всегда привожу такой пример, который позволяет запомнить отличие ошибок 1 и 2 рода. Пусть студент приходит на экзамен. Если он учил и знает, то принадлежит классу с меткой 1, иначе — имеет метку 0 (вполне логично называть знающего студента «положительным»). Пусть экзаменатор выполняет роль классификатора: ставит зачёт (т.е. метку 1) или отправляет на пересдачу (метку 0). Самое желаемое для студента «не учил, но сдал» соответствует ошибке 1 рода, вторая возможная ошибка «учил, но не сдал» – 2 рода.
Через введённые выше обозначения выражаются следующие функции:
Полнота (Sensitivity, True Positive Rate, Recall, Hit Rate) отражает какой процент объектов положительного класса мы правильно классифицировали:

Здесь и далее показан числитель формулы (тёмно синим) и знаменатель (тёмно и светло синим). Слева это сделано для матрицы несоответствий, справа – для множеств: круглое – объекты положительного класса, квадратное – положительные объекты по мнению классификатора.
Точность (Precision, Positive Predictive Value) отражает какой процент положительных объектов (т.е. тех, что мы считаем положительными) правильно классифицирован:

Точность и полноту можно неформально называть «ортогональными критериями качества». Легко построить алгоритм со 100%-й полнотой: он все объекты относит к классу 1, но при этом точность может быть очень низкой. Нетрудно построить алгоритм с близкой к 100% точностью: он относит к классу 1 только те объекты, в которых уверен, при этом полнота может быть низкая.
Замечание. Отличайте «Accuracy» и «Precision». К сожалению, по-русски их называют одинаково «точность».
F1-мера (F1 score) является средним гармоническим точности и полноты, максимизация этого функционала приводит к одновременной максимизации этих двух «ортогональных критериев»:

Также рассматривают весовое среднее гармоническое точности (P) и полноты (R) – Fβ-меру (Fβ score):

Обратите внимание, что β здесь не вес в среднем гармоническом:

Почему используется среднее гармоническое понятно из рис. 4, на которых показаны линии уровня различных функций усреднения.

Видно, что линии уровня среднего гармонического сильно похожи на «уголки», т.е. на линии функции min, что вынуждает при максимизации функционала сильнее «тянуть вверх» меньшее значение. Если, например, точность очень мала, то увеличение полноты, пусть и в два раза, не сильно меняет значение функционала. Нагляднее это показано на рис. 5: при точности 10% F1-мера не может быть больше 20%.

При использовании Fβ-меры линии уровня «перекашиваются», один из критериев (точность или полнота) становится важнее при оптимизации, см. рис. 6.

Из функционалов качества, которые получаются из матрицы несоответствий, можно также отметить специфичность (Specificity) или TNR – True Negative Rate:

т.е. процент правильно классифицированных объектов негативного класса. Полноту иногда называют чувствительностью (Sensitivity) и используют в паре со специфичностью для оценки качества, также часто их усредняют (об этом поговорим дальше). Оба функционала имеют смысл «процент правильно классифицируемых объектов одного из класса». Можно ввести понятие полноты Rk для k-го класса: это полнота, если считать класс k положительным, тогда

Также запомним False Positive Rate (FPR, fall-out, false alarm rate):

– доля объектов негативного класса, которых мы ошибочно отнесли к положительному (это нужно для понимания функционала AUC ROC).
Коэффициент Мэттьюса (MCC – Matthews correlation coefficient) равен
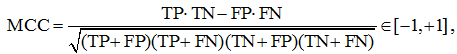
его рекомендуют применять для несбалансированных выборок. Давайте разберёмся, что означает эта «сложная формула». Рассмотрим среднее геометрическое точности и полноты:

Теперь возьмём среднее геометрическое точности и полноты класса 0 (т.е. считая это класс положительным), перемножив эти средние геометрические, получим

Логично полученное выражение максимизировать, по аналогии можно выписать выражение для минимизации. Если теперь внимательно посмотреть на формулу MCC, то становится понятным, что она означает и почему её значение лежит на отрезке [–1, +1] (оставляем это как задание читателю).
Каппа Коэна (Cohen’s Kappa)
В задачах классификации часто используют функционал качества Каппа Коэна (Cohen’s Kappa). Его идея довольно простая: поскольку использование точности (Accuracy) вызывает сомнение в задачах с сильном дисбалансом классов, надо её значения немного перенормировать. Делается это с помощью статистики chance adjusted index: мы точность нашего решения (Accuracy) пронормируем с помощью точности, которую можно было получить случайно (Accuracychance). Под случайной здесь понимаем точность решения, которое получено из нашего случайной перестановкой ответов.

здесь красным выделена вероятность угадать класс 0, а синим – класс 1. Действительно, класс k угадывается, если алгоритм выдаёт метку k и объект действительно принадлежит этому классу. Предполагаем, что это независимые события (мы же хотим вычислить случайную точность). Вероятность принадлежности к классу k можно оценить по матрице несоответствий как долю объектов класса k. Аналогично, вероятность выдать метку оцениваем как долю таких меток в ответах построенного алгоритма.
Сбалансированная точность (Balanced Accuracy)
В случае дисбаланса классов есть специальный аналог точности – сбалансированная точность:

Для простоты запоминания – это среднее полноты всех классов (мы ещё вернёмся к этому определению), ну или в других терминах: среднее чувствительности (Sensitivity) и специфичности (Specificity). Отметим, что чувствительность и специфичность тоже, неформально говоря, «ортогональные критерии». Легко сделать специфичность 100%-й, отнеся все объекты к классу 0, при этом будет 0%-я чувствительность, и наоборот, если отнести все объекты к классу 1, то будет 0%-я специфичность и 100%-я чувствительность.
Если в бинарной задаче классификации представителей двух классов примерно поровну, то TP + FN ≈ TN + FP ≈ m/2 и сбалансированная точность примерно равна точности обычной (Accuracy).
Все указанные функционалы реализованы в библиотеке scikit-learn:

Сравнение функционалов
Рассмотрим модельную задачу, в которой плотности распределения классов на оценках, порождённых алгоритмом, линейные, см. рис. 7 (алгоритм выдаёт оценки принадлежности к классу 1 из отрезка [0, 1], именно на этом отрезке они линейные). На рис. 7 показана конечная небольшая выборка, которая соответствует изображённым плотностям, мы же будем считать, что выборка бесконечная, поскольку плотности простые и позволяют в явном виде вычислить функционалы качества даже в случае такой бесконечной выборки. Будем считать, что классы равновероятны, т.е. наша бесконечная выборка сбалансирована. Выбранная задача очень удобна для исследования и уже использовалась при анализе функционала AUC ROC.

Заметим, что подобные распределения возникают в задаче, показанной на рис. 8 (объекты лежат внутри квадрата [0, 1]×[0, 1], два класса разделяются диагональю квадрата), если алгоритм в качестве оценки выдаст значения первого признака.

Изобразив плотности немного по-другому, мы в явном виде можем вычислить элементы матрицы несоответствий при конкретном пороге бинаризации, см. рис. 9. Все они пропорциональны площадям выделенных зон (обратите внимание на масштаб осей):


Теперь можно вывести формулы для рассмотренных функционалов качества как функции от порога бинаризации:

Попробуйте вывести эти формулы сами, кроме того, попробуйте определить пороги бинаризации при которых указанные функционалы максимальны (здесь будет один сюрприз).
Возникает естественный вопрос: на практике у нас нет бесконечных выборок, что изменится, если мы вычислим значения функционалов на конечной, объекты которой сгенерированы в соответствии с указанными распределениями? Частично ответ на этот вопрос показан на рис. 10. Как видно, кривые довольно близки к теоретическим при m=300, при увеличении выборки в 10 раз практически совпадают.

Рассмотрим теперь графики наших функционалов качества как функций от порога бинаризации, см. рис. 11. Заметим, что кроме F1-меры все они симметричны относительно порога 0.5, но это вполне логично. Теперь рассмотрим ситуацию неравновероятных классов, т.е. когда выборка несбалансированна. На рис. 12 показаны графики функционалов в случае, когда класс 1 в два раза чаще встречается в выборке, чем класс 0. Обратите внимание, что все графики стали несимметричными, кроме графика сбалансированной точности – эта функция не зависит от пропорций классов!


Вопросы для самопроверки
В конце серия вопросов с подвохом… если Вы хотите кого-нибудь «завалить» по простой теме «оценка качества в задачах бинарной классификации», то непременно задайте их:
- у какого функционала качества самый маленький оптимальный порог бинаризации в общем случае, почему? Для справки: ответ «у F1-меры» в общем случае неверный (можно даже простой пример привести).
- какой функционал качества действительно имеет смысл использовать в задачах с сильным дисбалансом классов (заметим, что стандартные советы: BA, MCC, κ, F1 обладают совершенно разными свойствами)?
- какой «самый неустойчивый» из перечисленных функционалов (его значения на небольших выборках сильнее отличаются от вычисленных на достаточно больших)?
- что изменится в примерах выше, если от линейных плотностей перейти к нормальным? Как это сделать корректно (и в чём некорректность описанной модельной задачи)?
- верно ли, что максимальное значение точности (т.е. значение точности при оптимальном выборе порога) всегда не меньше максимального значения сбалансированной точности?
Что дальше…
По задачам классификации осталось рассказать про все скоринговые функции оценки качества в задачах бинарной классификации, про AUC ROC и LogLoss уже было. А потом — как все рассмотренные функционалы обобщаются на случай многих классов. Соответствующие посты скоро будут.
Традиционное в последнее время видео к материалу поста я залью чуть позже.
На правах рекламы
С сентября чему-то научиться у автора блога можно в этом замечательном проекте: Ozon Masters. Кроме курса по машинному обучению, будет много других с потрясающими преподавателями: Андрей Соболевский, Иван Оселедец, Павел Клеменков, Юрий Дорн, Александр Дайняк.
Классификация — одна из наиболее популярных технологий интеллектуального анализа данных. С необходимостью построения классификаторов рано или поздно сталкивается любой аналитик. Но даже построив модель, необходимо прежде всего убедиться в ее работоспособности. Для этого разработано большое количество мер качества. Наиболее популярные из них рассматриваются в данной статье.
Для классификационных моделей, как и для моделей регрессии, актуальна задача оценки их качества для определения работоспособности моделей и их сравнения. Однако решение этой задачи для моделей классификации вообще, и бинарной классификации в частности, сложнее, чем для регрессии. Связано это с тем, что целевая переменная (метка класса) является категориальным (дискретным) значением, и, следовательно, ошибка классификации не может быть выражена числовым значением.
Поэтому в основе оценки качества классификационных моделей лежит статистика результатов классификации обучающих примеров. С ее помощью вычисляются метрики качества — показатели, которые зависят от результатов классификации и не зависят от внутреннего состояния модели.
Среди наиболее популярных методов оценки качества классификаторов можно выделить следующие:
- Матрица ошибок (Сonfusion matrix).
- Меткость (Accuracy).
- Точность (Precision).
- Полнота (Recall).
- Специфичность (Specificity).
- F1-мера (F1-score).
- Метрика P4 .
- Площадь под ROC-кривой (Area under ROC-curve, AUC-ROC).
- Площадь под кривой полнота-точность (Area under precision-recall curve, AUC-PR).
- Коэффициент корреляции Мэтьюса (Matthews correlation coefficient, MCC).
- Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Матрица ошибок
Прежде чем переходить к описанию собственно метрик качества бинарных классификаторов, рассмотрим методику описания этих метрик в терминах ошибок классификации. Пусть заданы два класса y=\left \{ 0,1 \right \} и алгоритм, предсказывающий принадлежность каждого объекта одному из классов. Эта задача анализа известна как бинарная классификация.
Приведем пример. Пусть в страховой компании используется аналитическая платформа для поддержки принятия решений о целесообразности страхования того или иного объекта. Если риск наступления страхового события выше определенного порога, то такие объекты страховать нецелесообразно. Именно выявление таких объектов и является целью анализа. Тогда для объектов, страхование которых целесообразно, система должна установить класс 0, а объектам, в страховании которых отказано, — класс 1.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- класс 0 распознается классификатором как класс 1, что можно интерпретировать как «ложную тревогу»;
- класс 1 распознается как класс 0, что можно трактовать как «пропуск цели».
Очевидно, что приведенные ошибки неравноценны по связанным с ними издержкам классификации. В случае «ложной тревоги» компания потеряет только потенциальную страховую премию, т.е. будет иметь место всего лишь упущенная выгода. В случае «пропуска цели» возможна потеря значительной суммы из-за наступления страхового случая. Поэтому важнее не допустить «пропуск цели», чем «ложную тревогу».
Иными словами, важнее правильно определить объект, нежелательный для страхования из-за высокого риска, чем ошибиться в распознавании желательного. Будем называть соответствующий исход классификации положительным (объект не подлежит страхованию y=1), а противоположный — отрицательным (объект подлежит страхованию y=0). Тогда возможны следующие исходы классификации:
- Объект, нежелательный для страхования, классифицирован как нежелательный, т.е. «положительный» класс распознан как положительный. Такой исход классификации (а также пример, для которого он получен) называют истинноположительным.
- Объект, желательный для страхования, распознан как желательный, т.е. «отрицательный» класс распознан как отрицательный. Такой исход классификации называют истинноотрицательными.
- Объект, желаемый для страхования, классифицирован как не желаемый, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Данный исход классификации называют ложноположительным, а ошибка классификации называется ошибкой I рода.
- Нежелательный объект распознан как желательный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Такой исход классификации называется ложноотрицательным, а ошибка классификации — ошибкой II рода.
Таким образом, ошибка I рода, или ложноположительный исход классификации, имеет место, когда пример, с которым связано отрицательное событие распознан моделью как положительный. Ошибкой II рода, или ложноотрицательным исходом классификации, называют случай, когда пример, с которым связано положительное событие, распознан как отрицательный. Поясним это с помощью матрицы ошибок классификации, называемой также таблицей сопряженности:
| y=0 | y=1 | |
|---|---|---|
| \widehat{y}=0 | Истинноположительный (True Positive — TP) | Ложноположительный (False Positive — FP) |
| \widehat{y}=1 | Ложноотрицательный (False Negative — FN) | Истинноотрицательный (True Negative — TN) |
Здесь \widehat{y} — отклик модели, а y — фактическое значение. Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). В данном случае P означает, что классификатор определяет класс объекта как положительный, а N как — отрицательный. T значит, что класс предсказан правильно, соответственно, F — неправильно. Каждая строка в матрице ошибок представляет предсказанный класс, а каждый столбец — фактически наблюдаемый класс.
Идеальный классификатор, если бы он существовал, выдавал бы только истинноположительные и истинноотрицательные классификации, и его матрица ошибок содержала бы значения, отличные от нуля, только на главной диагонали.
Меткость
Представляет собой долю правильных классификаций модели:
ACC=\frac{TP+TN}{TP+TN+FP+FN}.
Несложно увидеть, что сумма в знаменателе формулы представляет собой общее число классифицируемых примеров. Графически это можно интерпретировать следующим образом:
Рисунок 1. Меткость
В английском языке этот термин обозначается как «accuracy», поэтому в интернете он часто упоминается как «аккуратность», хотя это слово и не передает смыслового значения данной величины.
Несмотря на то, что эта мера хорошо интерпретируется, на практике она используется достаточно редко, поскольку плохо работает в случае дисбаланса классов в обучающей выборке.
Поясним это на примере кредитного скоринга. Пусть требуется классифицировать заемщиков на добросовестных (не допустивших просрочку) и недобросовестных (допустивших просрочку). Целью является выявление недобросовестных заемщиков, поскольку связанные с ними издержки выше. Следовательно, классификация заемщика как недобросовестного является положительным событием, а как добросовестного — отрицательным.
Выборка содержит 1000 добросовестных заемщиков, 900 из которых классификатор предсказал правильно (TN=900, FP=100), и 100 недобросовестных, 50 из которых классификатор также определил верно (TP=50, FN=50).
Несложно вычислить, что:
ACC=\frac{50+900}{50+900+100+50}=0.866.
Однако, если построить «наивную» модель, которая просто будет классифицировать всех клиентов, как добросовестных (на основании того, что таковых большинство), то меткость такой модели окажется:
ACC=\frac{0+1000}{0+1000+0+100}=0.909.
Таким образом, оказалось, что меткость «бесполезной» модели, не имеющей предсказательной силы, выше, чем «рабочей» модели. Это противоречит здравому смыслу. Поэтому на практике стараются использовать альтернативные меры качества.
Точность
Точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение:
Pr=PPV=\frac{TP}{TP+FP}.
Поясним данное выражение с помощью рисунка:
Рисунок 2. Точность
Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту FP и уменьшению значения точности.
Полнота
Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений:
Re=TPR=\frac{TP}{TP+FN}.
Таким образом, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно проиллюстрировать с помощью рисунка:
Рисунок 3. Полнота
Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса.
PPV_{c}=\frac{A_{cc}}{\sum\limits_{i=1}^{n}A_{ci}},
TPR_{c}=\frac{A_{cc}}{\sum\limits_{i=1}^{n}A_{ic}},
где c — класс, n — число элементов столбца (равно числу классов), i — номер элемента в столбце, A — элемент матрицы ошибок.
Специфичность
Специфичность классификатора — это доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций:
Sp=TNR=\frac{TN}{TN+FP}.
TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Поясним это с помощью рисунка.
Рисунок 4. Специфичность
Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
F1-мера
Точность и полнота, в отличие от меткости, не зависят от соотношения классов и, следовательно, могут применяться в условиях несбалансированных выборок. На практике часто встречается задача поиска оптимального баланса между точностью и полнотой. Действительно, улучшая настройку модели на один класс, например, путем изменения дискриминационного порога, мы тем самым ухудшаем настройку на другой.
Чем выше точность и полнота, тем лучше модель. Но на практике их максимальные значения одновременно недостижимы, поэтому приходится искать баланс между ними. Для этого используется метрика, объединяющая в себе информацию о точности и полноте. Она называется F1-мера и вычисляется следующим образом:
F1=\frac{2\cdot PPV\cdot TPR}{PPV+TPR}=\frac{2\cdot TP}{2\cdot TP+FP+FN}.
В данном выражении точность PPV и полнота TPR имеют одинаковый вес, поэтому при их уменьшении F1-мера сокращается пропорционально.
Однако на практике чаще используется сбалансированная F1-мера, в которой точности и полноте присваиваются разные веса с целью найти оптимальный баланс между данными метриками. Для этого в формулу для F1-меры вводится дополнительный балансировочный параметр, обозначаемый β. Сбалансированная F1-мера вычисляется следующим образом:
F1=\frac{(1-\beta ^{2})\cdot PPV\cdot TPR}{\beta ^{2}\cdot PPV+TPR}.
Если параметр принимает значения из диапазона 0< \beta < 1, то приоритет имеет точность, а если \beta> 1, то полнота.
Еще одним источником критики F1-меры является отсутствие симметрии. Это означает, что она может изменить свое значение при инверсии положительного и отрицательного классов.
Метрика P4
Метрика P_{4} была разработана как расширение F1-меры, обладающее симметрией относительно инверсии классов. Вычисляется по формуле:
P_{4}=\frac{4\cdot TP\cdot TN}{4\cdot TP\cdot TN+(TP+TN)\cdot (FP+FN)}.
Метрика P_{4} изменяется в диапазоне от 0 до 1. Чем ближе значение метрики к 1, тем лучше работает модель. Очевидно, что значение меры стремится к 0, если хотя бы один из множителей в числителе становится равным нулю, т.е. когда модель теряет способность правильно распознавать положительные или отрицательные примеры.
AUC-ROC
ROC-кривая, или кривая рабочих характеристик приемника (Receiver Operating Characteristics curve), позволяет не только оценить качество работы классификатора, но и исследовать его поведение при различных значениях дискриминационного порога. Технология оценки качества моделей бинарной классификации с помощью ROC-кривых известна как ROC-анализ.
Рассмотрим совместно TPR и TNR классификатора. TPR показывает, насколько хорошо модель классифицирует положительные примеры. Очевидно, что если все положительные примеры классифицированы правильно (т.е. число ложноотрицательных случаев равно 0), то TPR=1. TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
Таким образом, по отдельности TPR и TNR характеризуют способность модели распознавать только один из классов. Но их совместное использование помогает создать метрику, которая позволяет выбирать значение дискриминационного порога, который оптимально балансирует модель между способностью распознавать положительные и отрицательные примеры. Именно эта задача и решается с помощью ROC-кривой.
Действительно, если изменять дискриминационный порог от 0 до 1 и наносить по оси абсцисс точки 1−TNR, а по оси ординат TPR, то полученный график и будет ROC-кривой. Величину 1−TNR называют долей ложноположительных классификаций (false positive rate) или показателем ложной тревоги. Она вычисляется следующим образом:
1-TNR=FPR=\frac{FP}{FP+TN}.
При пороге, равном 1, все примеры будут классифицированы как отрицательные (FPR=1, TPR=1), а при пороге, равном 0, — как положительные (FPR=0, TPR=0). Поэтому ROC-кривая всегда идет от точки (0,0) до точки (1,1).
Рисунок 5. ROC-кривая
Несложно увидеть, что для идеальной модели ROC-кривая превращается в ломаную, проходящую через точки (0,0), (0,1) и (1,1). При этом площадь под ROC-кривой (AUC — Area Under Curve) окажется равной 1. Площадь под кривой выделена на рисунке светло-серым цветом.
Точка (0,1) соответствует идеальному состоянию модели, в котором и TPR, и TNR одновременно равны 1. Т.е. модель одинаково хорошо «научилась» работать как с положительными, так и с отрицательными примерами при существующем в обучающей выборке балансе классов.
Идеальная модель является скорее гипотетической и на практике, как правило, недостижима. Поэтому обычно приходится иметь дело с ROC-кривыми, которые не проходят через точку (0,1), а приближаются к ней на определенное расстояние. Соответственно и AUC−ROC оказывается меньше 1.
Таким образом показатель AUC−ROC является удобной мерой качества классификатора относительно идеального. Принята следующая шкала оценки качества.
| AUC | Оценка |
|---|---|
| 0.9 — 1 | Отличное |
| 0.8 — 0.9 | Очень хорошее |
| 0.7 — 0.8 | Хорошее |
| 0.6 — 0.7 | Удовлетворительное |
| 0.5 — 0.7 | Плохое |
Если AUC-ROC=0.5, то ROC-кривая превращается в линию, проходящую через точки (0,0) и (1,1), которая соответствует бесполезному классификатору, работающему как случайный предсказатель. Если AUC-ROC< 0.5, то получается модель, которая работает хуже случайного предсказателя и от ее использования следует отказаться.
AUC-PR
PR-кривые определяются аналогично ROC-кривым, но только по оси абсцисс у них откладываются значения полноты, а по оси ординат — точности.
Точность и полнота — две наиболее важные метрики, на которые следует обращать внимание при оценке качества модели бинарной классификации в условиях несбалансированности классов. Они помогают увидеть, какая часть фактически положительных наблюдений была классифицирована правильно, и какие среди классифицированных как положительные, были истинноположительными.
Если точность равна 1, то ложноположительные классификации отсутствуют. Но это ничего не говорит о том, были ли распознаны все положительные примеры. Если полнота равна 1, то все положительные объекты были распознаны правильно, а ложноотрицательные классификации отсутствуют. При этом ничего не говорится о том, сколько было допущено ложноположительных классификаций.
Таким образом, точность и полнота не особенно полезны для оценки качества классификатора, если их использовать по отдельности. В задаче классификации оценка точности, равная 1 для класса C, означает, что каждый элемент, помеченный как принадлежащий классу C, действительно принадлежит к классу C, но ничего не говорит о количестве элементов из класса
C, которые не были правильно классифицированы. Тогда как полнота, равная 1, означает, что каждый элемент из класса C был помечен как принадлежащий к классу C, но ничего не говорит о том, сколько элементов из других классов были также неправильно классифицированы как принадлежащие к классу C.
Обычно показатели точности и полноты не используются по отдельности. Вместо этого либо значения одной меры сравниваются с фиксированным уровнем другой (например, точность на уровне полноты 0.75), либо обе меры объединяются в один показатель. Примерами такой комбинации и является F1-мера — взвешенное гармоническое среднее точности и полноты.
Еще одним способом комбинирования точности и полноты в задаче оценки качества классификации являются так называемые кривые полнота-точность, которые строятся в системе координат, где по оси абсцисс откладывается полнота, а по оси ординат — точность. Кривая точность-полнота показывает, как выбор порога влияет на точность классификатора, а также помогает выбрать лучшее значение дискриминационного порога для определенного баланса классов.
Рисунок 6. Кривая точность-полнота
Каждая точка PR-кривой представляет определенное значение дискриминационного порога, а ее расположение соответствует результирующей точности и полноте, когда этот порог выбран. Точка 1 на рисунке соответствует значению дискриминационного порога, равному 1, а точка 3 — значению порога 0. Точка 2 соответствует идеальному классификатору и совпадает с координатами (1,1), а точка 4 — оптимальному значению порога (точка кривой, наиболее близкая к идеальной точке (1,1)).
Преимущества PR-кривой по сравнению с ROC:
- ROC-кривая, как правило, дает чрезмерно оптимистичную картину в условиях несбалансированности классов.
- При изменении распределения классов ROC-кривая не меняется, а PR-кривая отражает изменение.
Аналогично ROC-кривой, площадь под PR-кривой (для отличия от ROC ее часто называют PR−AUC) отражает качество классификатора и позволяет сравнивать кривые, соответствующие различным балансам классов и значениям порога. Чем выше площадь, тем лучше работает модель.
Пунктирная линия внизу графика соответствует бесполезному классификатору (no-skill model — модель без навыков, или базовая модель), уровень которой изменяется при изменении баланса классов. Такая модель будет присваивать рейтинг 0.5 для любого примера.
На рисунке ниже представлена линия, соответствующая балансу классов, когда положительные примеры составляют 10% от обучающей выборки.
Рисунок 7. Кривая точность-полнота при фиксированном балансе классов
На рисунке точка 1 соответствует порогу 0.5, точка 2 соответствует порогу [0, 0.5). Для порогов (0.5, 1] точность не определена из-за деления на ноль. Можно увидеть, что точность здесь является константой, то есть PPV=0.1 (соответствует доле положительного класса), PR−AUC=0.1.
Таким образом, полнота базовой модели лежит в диапазоне (0.5, 1] независимо от дисбаланса классов, а точность равна доле положительного класса в обучающей выборке.
На следующем рисунке представлена PR-кривая для идеальной модели. На ней точка 1 соответствует порогу (0, 1], точка 2 соответствует порогу 0. Очевидно, что PR−AUC=1.
Рисунок 8. Кривая точность-полнота для идеальной модели
И, наконец, на рисунке ниже отображена PR-кривая (красная линия) для модели, которая работает хуже, чем базовая модель «без навыков» (синяя пунктирная линия). Она расположена ниже линии базовой модели.
Рисунок 9. Кривая точность-полнота для модели хуже бесполезной
Очевидный способ повысить качество «плохой» модели без каких-либо настроек — просто инвертировать классы (класс 0 изменить на класс 1). Это автоматически приведет к повышению точности по сравнению с базовой моделью.
Обычно «плохая» PR-кривая классификатора указывает на то, что в обучающих данных присутствуют проблемы: они содержат шум или классы в них плохо выражены (модель не может выявить закономерность, в соответствии с которой один класс отличается от другого). В этом случае PR−AUC не превышает доли положительных примеров обучающей выборке.
Возможен гибридный случай, когда «плохая» модель работает лучше, чем модель «без навыков», но для определенных пороговых значений.
Коэффициент корреляции Мэтьюса
Коэффициент используется в качестве показателя качества бинарных классификаторов. Он учитывает истинные и ложные классификации и обычно рассматривается как сбалансированная мера, которую можно использовать даже в условиях сильного дисбаланса классов.
MCC, по сути, коэффициент корреляции между фактическими и предсказанными моделью бинарными классификациями. Он изменяется в диапазоне от -1 до 1. MCC=1 указывает на идеальную классификацию, когда фактические и предсказанные классы совпадают для всех обучающих примеров (т.е. ложноположительные и ложноотрицательные классификации отсутствуют). Модель, для которой MCC=0, соответствует случайному предсказателю. MCC=−1 указывает на полное расхождение между фактом и предсказанием (т.е. вместо положительного класса модель всегда предсказывает отрицательный, и наоборот), следовательно, истинноположительные и истинноотрицательные классификации отсутствуют.
Формула для расчета MCC имеет вид:
MCC=\frac{TP\cdot TN-FP\cdot FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}.
Несложно увидеть, что если в этой формуле обнулить все ложные классификации, то MCC=1, что соответствует ранее сделанным заключениям. Если число истинных и ложных классификаций равны, то числитель формулы становится равным 0 и MCC=0. И, наконец, если число истинных классификаций равно нулю, то числитель становится отрицательным, и делает таковым результат формулы.
Если какая-либо из четырех сумм в знаменателе равна нулю, знаменатель можно произвольно установить равным единице, это приводит к нулевому коэффициенту корреляции Мэтьюса.
Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Функция потерь в задачах классификации показывает, какую «цену» придется заплатить за неточность предсказаний классификационной модели. Для логистической регрессии, решающей задачу бинарной классификации, она может быть вычислена следующим образом:
Log Loss=-\frac{1}{l}\sum\limits_{i=1}^{l}(y_{i}\cdot log(\widehat{y_{i}})+(1-y_{i})\cdot log(1-\widehat{y_{i}})),
где l — размер выборки, y_{i}=\left \{ 0,1 \right \} — бинарная метка класса, заданная в примере, \widehat{y_{i}} — предсказание модели.
Несложно увидеть, что функция потерь получается путем суммирования логарифма потерь на каждом примере. Потери на каждом примере определяются следующим образом: если предсказанный класс совпадает с фактическим, то потери равны 0, в противном случае потери равны 1. Очевидно, чем больше будет неправильных классификаций, тем больше будет значение LogLoss и тем хуже будет модель. Таким образом, чтобы получить лучшую модель, нужно минимизировать функцию потерь.
Преимуществом метрики LogLoss является устойчивость к выбросам и аномальным значениям в данных и простота вычисления. Недостатком — сложность интерпретации из-за нелинейного характера.
Сравнение метрик
Подведем итоги, кратко резюмируя преимущества и недостатки рассмотренных мер качества классификационных моделей.
| Мера | Преимущества | Недостатки |
|---|---|---|
| Меткость | Хорошо интерпретируется. | Чувствительна к дисбалансу классов. Неадекватно отражает точность классификации. |
| Точность | Не чувствительна к дисбалансу классов. | Отражает качество классификации только для положительного класса. |
| Полнота | Не чувствительна к дисбалансу классов. | Не учитывает отрицательные классификации. |
| Специфичность | Просто вычисляется и интерпретируется. | Характеризует способность модели распознавать только один класс. |
| F1-мера | Позволяет найти баланс между точностью и полнотой. | Чувствительность к дисбалансу, отсутствие симметрии. |
| P4 | Симметрична относительно инверсии классов. | Чувствительность к дисбалансу классов. |
| AUC-ROC | Наглядна, хорошо интерпретируется. | В условиях дисбаланса классов завышает качество модели. Не отражает изменения баланса классов. |
| AUC-PR | Наглядна, хорошо интерпретируется. | Не учитывает отрицательные классификации. |
| Коэффициент Мэтьюса | Более информативен, поскольку использует все типы результатов классификации. | Не может применяться, если один из множителей в знаменателе обращается в 0. |
| LogLoss | Устойчивость к выбросам в данных, простота вычисления. | Сложность интерпретации из-за нелинейного характера. |
В статье рассмотрены наиболее общие меры оценки качества моделей бинарной классификации, отмечены их преимущества и недостатки. Однако в литературе авторы предлагают и другие подходы, которые показали хорошие результаты при решении конкретных задач и не претендующие на универсальность.
Другие материалы по теме:
Метрики качества линейных регрессионных моделей
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Этот пост продолжает серию про функции ошибки и функционалы качества в машинном обучении. Сейчас разберёмся с самой простой подтемой — как измерять качество чёткого ответа в задачах бинарной классификации. Уровень для чтения — начальный;)
Предыдущие посты в блоге на эту тему:
- AUC ROC
- Джини
- Логистическая функция ошибки
- Функции ошибок в задачах регрессии
Рассматриваем задачу классификации на два класса (с метками 0 и 1), на рис. 1 показано её графическое представление.
Пусть классификатор выдаёт метку класса. Используем принятые в этом блоге обозначения: yi – метка i-го объекта, ai – ответ на этом объекте нашего алгоритма, m – число объектов в выборке.
Естественным, простым и распространённым функционалом качества является точность (Accuracy или Mean Consequential Error):
т.е. просто доля (процент) объектов, на которых алгоритм выдал правильные ответы. Недостаток такого функционала очевиден: он плох в случае дисбаланса классов, когда представителей одного из класса существенно больше, чем другого. В этом случае, с точки зрения точности, выгодно почти всегда выдавать метку самого популярного класса. Это может не согласовываться с логикой использования решения задачи. Например, в задаче детектирования очень редкой болезни алгоритм, который всех относит к классу «здоровые», на практике не нужен.
Рассмотрим т.н. матрицу несоответствий / ошибок (confusion matrix) – матрицу размера 2×2, ij-я позиция которой равна числу объектов i-го класса, которым алгоритм присвоил метку j-го класса.
На рис. 2 показана такая матрица для решения рис. 1, также показаны названия элементов матрицы. Два класса делятся на положительный (обычно метка 1) и отрицательный (обычно метка 0 или –1). Объекты, которые алгоритм относит к положительному классу, называются положительными (Positive), те из них, которые на самом деле принадлежат к этому классу – истинно положительными (True Positive), остальные – ложно положительными (False Positive). Аналогичная терминология есть для отрицательного (Negative) класса. Дальше используем естественные сокращения:
- TP = True Positive,
- TN = True Negative,
- FP = False Positive,
- FN = False Negative.
Замечание. Иногда матрицу ошибок изображают по-другому: в транспонированном виде (ответы алгоритма соответствуют строкам, а правильные метки – столбцам).
Замечание. Стандартная терминология немного нелогична: естественно называть положительными объектами объекты положительного класса, но здесь – объекты, отнесённые алгоритмом к положительному классу (т.е. это даже не свойство объектов, а алгоритма). Но в контексте употребления терминов «истинно положительный» и «ложно положительный» это уже кажется логичным.
Для точности (Accuracy) справедлива формула:
Ошибки классификатора делятся на две группы: первого и второго рода. В идеале (когда точность равна 100%) матрица несоответствий диагональная, ошибки вызывают отличие от нуля двух недиагональных элементов:
ошибка 1 рода (Type I Error) случается, когда объект ошибочно относится к положительному классу (= FP/m).
ошибка 2 рода (Type II Error) случается, когда объект ошибочно относится к отрицательному классу (= FN/m).
На заглавном рис. поста показаны известные шуточные иллюстрации ошибок 1 и 2 рода: ошибка 1 рода (слева) и ошибка 2 рода (справа). Когда я объясняю студентам, всегда привожу такой пример, который позволяет запомнить отличие ошибок 1 и 2 рода. Пусть студент приходит на экзамен. Если он учил и знает, то принадлежит классу с меткой 1, иначе — имеет метку 0 (вполне логично называть знающего студента «положительным»). Пусть экзаменатор выполняет роль классификатора: ставит зачёт (т.е. метку 1) или отправляет на пересдачу (метку 0). Самое желаемое для студента «не учил, но сдал» соответствует ошибке 1 рода, вторая возможная ошибка «учил, но не сдал» – 2 рода.
Через введённые выше обозначения выражаются следующие функции:
Полнота (Sensitivity, True Positive Rate, Recall, Hit Rate) отражает какой процент объектов положительного класса мы правильно классифицировали:
Здесь и далее показан числитель формулы (тёмно синим) и знаменатель (тёмно и светло синим). Слева это сделано для матрицы несоответствий, справа – для множеств: круглое – объекты положительного класса, квадратное – положительные объекты по мнению классификатора.
Точность (Precision, Positive Predictive Value) отражает какой процент положительных объектов (т.е. тех, что мы считаем положительными) правильно классифицирован:
Точность и полноту можно неформально называть «ортогональными критериями качества». Легко построить алгоритм со 100%-й полнотой: он все объекты относит к классу 1, но при этом точность может быть очень низкой. Нетрудно построить алгоритм с близкой к 100% точностью: он относит к классу 1 только те объекты, в которых уверен, при этом полнота может быть низкая.
Замечание. Отличайте «Accuracy» и «Precision». К сожалению, по-русски их называют одинаково «точность».
F1-мера (F1 score) является средним гармоническим точности и полноты, максимизация этого функционала приводит к одновременной максимизации этих двух «ортогональных критериев»:
Также рассматривают весовое среднее гармоническое точности (P) и полноты (R) – Fβ-меру (Fβ score):
Обратите внимание, что β здесь не вес в среднем гармоническом:
Почему используется среднее гармоническое понятно из рис. 4, на которых показаны линии уровня различных функций усреднения.
Видно, что линии уровня среднего гармонического сильно похожи на «уголки», т.е. на линии функции min, что вынуждает при максимизации функционала сильнее «тянуть вверх» меньшее значение. Если, например, точность очень мала, то увеличение полноты, пусть и в два раза, не сильно меняет значение функционала. Нагляднее это показано на рис. 5: при точности 10% F1-мера не может быть больше 20%.
При использовании Fβ-меры линии уровня «перекашиваются», один из критериев (точность или полнота) становится важнее при оптимизации, см. рис. 6.
Из функционалов качества, которые получаются из матрицы несоответствий, можно также отметить специфичность (Specificity) или TNR – True Negative Rate:
т.е. процент правильно классифицированных объектов негативного класса. Полноту иногда называют чувствительностью (Sensitivity) и используют в паре со специфичностью для оценки качества, также часто их усредняют (об этом поговорим дальше). Оба функционала имеют смысл «процент правильно классифицируемых объектов одного из класса». Можно ввести понятие полноты Rk для k-го класса: это полнота, если считать класс k положительным, тогда
Также запомним False Positive Rate (FPR, fall-out, false alarm rate):
– доля объектов негативного класса, которых мы ошибочно отнесли к положительному (это нужно для понимания функционала AUC ROC).
Коэффициент Мэттьюса (MCC – Matthews correlation coefficient) равен
его рекомендуют применять для несбалансированных выборок. Давайте разберёмся, что означает эта «сложная формула». Рассмотрим среднее геометрическое точности и полноты:
Теперь возьмём среднее геометрическое точности и полноты класса 0 (т.е. считая это класс положительным), перемножив эти средние геометрические, получим
Логично полученное выражение максимизировать, по аналогии можно выписать выражение для минимизации. Если теперь внимательно посмотреть на формулу MCC, то становится понятным, что она означает и почему её значение лежит на отрезке [–1, +1] (оставляем это как задание читателю).
Каппа Коэна (Cohen’s Kappa)
В задачах классификации часто используют функционал качества Каппа Коэна (Cohen’s Kappa). Его идея довольно простая: поскольку использование точности (Accuracy) вызывает сомнение в задачах с сильном дисбалансом классов, надо её значения немного перенормировать. Делается это с помощью статистики chance adjusted index: мы точность нашего решения (Accuracy) пронормируем с помощью точности, которую можно было получить случайно (Accuracychance). Под случайной здесь понимаем точность решения, которое получено из нашего случайной перестановкой ответов.
здесь красным выделена вероятность угадать класс 0, а синим – класс 1. Действительно, класс k угадывается, если алгоритм выдаёт метку k и объект действительно принадлежит этому классу. Предполагаем, что это независимые события (мы же хотим вычислить случайную точность). Вероятность принадлежности к классу k можно оценить по матрице несоответствий как долю объектов класса k. Аналогично, вероятность выдать метку оцениваем как долю таких меток в ответах построенного алгоритма.
Сбалансированная точность (Balanced Accuracy)
В случае дисбаланса классов есть специальный аналог точности – сбалансированная точность:
Для простоты запоминания – это среднее полноты всех классов (мы ещё вернёмся к этому определению), ну или в других терминах: среднее чувствительности (Sensitivity) и специфичности (Specificity). Отметим, что чувствительность и специфичность тоже, неформально говоря, «ортогональные критерии». Легко сделать специфичность 100%-й, отнеся все объекты к классу 0, при этом будет 0%-я чувствительность, и наоборот, если отнести все объекты к классу 1, то будет 0%-я специфичность и 100%-я чувствительность.
Если в бинарной задаче классификации представителей двух классов примерно поровну, то TP + FN ≈ TN + FP ≈ m/2 и сбалансированная точность примерно равна точности обычной (Accuracy).
Все указанные функционалы реализованы в библиотеке scikit-learn:
Сравнение функционалов
Рассмотрим модельную задачу, в которой плотности распределения классов на оценках, порождённых алгоритмом, линейные, см. рис. 7 (алгоритм выдаёт оценки принадлежности к классу 1 из отрезка [0, 1], именно на этом отрезке они линейные). На рис. 7 показана конечная небольшая выборка, которая соответствует изображённым плотностям, мы же будем считать, что выборка бесконечная, поскольку плотности простые и позволяют в явном виде вычислить функционалы качества даже в случае такой бесконечной выборки. Будем считать, что классы равновероятны, т.е. наша бесконечная выборка сбалансирована. Выбранная задача очень удобна для исследования и уже использовалась при анализе функционала AUC ROC.
Заметим, что подобные распределения возникают в задаче, показанной на рис. 8 (объекты лежат внутри квадрата [0, 1]×[0, 1], два класса разделяются диагональю квадрата), если алгоритм в качестве оценки выдаст значения первого признака.
Изобразив плотности немного по-другому, мы в явном виде можем вычислить элементы матрицы несоответствий при конкретном пороге бинаризации, см. рис. 9. Все они пропорциональны площадям выделенных зон (обратите внимание на масштаб осей):
Теперь можно вывести формулы для рассмотренных функционалов качества как функции от порога бинаризации:
Попробуйте вывести эти формулы сами, кроме того, попробуйте определить пороги бинаризации при которых указанные функционалы максимальны (здесь будет один сюрприз).
Возникает естественный вопрос: на практике у нас нет бесконечных выборок, что изменится, если мы вычислим значения функционалов на конечной, объекты которой сгенерированы в соответствии с указанными распределениями? Частично ответ на этот вопрос показан на рис. 10. Как видно, кривые довольно близки к теоретическим при m=300, при увеличении выборки в 10 раз практически совпадают.
Рассмотрим теперь графики наших функционалов качества как функций от порога бинаризации, см. рис. 11. Заметим, что кроме F1-меры все они симметричны относительно порога 0.5, но это вполне логично. Теперь рассмотрим ситуацию неравновероятных классов, т.е. когда выборка несбалансированна. На рис. 12 показаны графики функционалов в случае, когда класс 1 в два раза чаще встречается в выборке, чем класс 0. Обратите внимание, что все графики стали несимметричными, кроме графика сбалансированной точности – эта функция не зависит от пропорций классов!
Вопросы для самопроверки
В конце серия вопросов с подвохом… если Вы хотите кого-нибудь «завалить» по простой теме «оценка качества в задачах бинарной классификации», то непременно задайте их:
- у какого функционала качества самый маленький оптимальный порог бинаризации в общем случае, почему? Для справки: ответ «у F1-меры» в общем случае неверный (можно даже простой пример привести).
- какой функционал качества действительно имеет смысл использовать в задачах с сильным дисбалансом классов (заметим, что стандартные советы: BA, MCC, κ, F1 обладают совершенно разными свойствами)?
- какой «самый неустойчивый» из перечисленных функционалов (его значения на небольших выборках сильнее отличаются от вычисленных на достаточно больших)?
- что изменится в примерах выше, если от линейных плотностей перейти к нормальным? Как это сделать корректно (и в чём некорректность описанной модельной задачи)?
- верно ли, что максимальное значение точности (т.е. значение точности при оптимальном выборе порога) всегда не меньше максимального значения сбалансированной точности?
Что дальше…
По задачам классификации осталось рассказать про все скоринговые функции оценки качества в задачах бинарной классификации, про AUC ROC и LogLoss уже было. А потом — как все рассмотренные функционалы обобщаются на случай многих классов. Соответствующие посты скоро будут.
Традиционное в последнее время видео к материалу поста я залью чуть позже.
На правах рекламы
С сентября чему-то научиться у автора блога можно в этом замечательном проекте: Ozon Masters. Кроме курса по машинному обучению, будет много других с потрясающими преподавателями: Андрей Соболевский, Иван Оселедец, Павел Клеменков, Юрий Дорн, Александр Дайняк.
From Wikipedia, the free encyclopedia
Terminology and derivations
- condition positive (P)
- the number of real positive cases in the data
- condition negative (N)
- the number of real negative cases in the data
- true positive (TP)
- A test result that correctly indicates the presence of a condition or characteristic
- true negative (TN)
- A test result that correctly indicates the absence of a condition or characteristic
- false positive (FP)
- A test result which wrongly indicates that a particular condition or attribute is present
- false negative (FN)
- A test result which wrongly indicates that a particular condition or attribute is absent
- sensitivity, recall, hit rate, or true positive rate (TPR)

- specificity, selectivity or true negative rate (TNR)
- precision or positive predictive value (PPV)
- negative predictive value (NPV)
- miss rate or false negative rate (FNR)
- fall-out or false positive rate (FPR)
- false discovery rate (FDR)
- false omission rate (FOR)
- Positive likelihood ratio (LR+)
- Negative likelihood ratio (LR-)
- prevalence threshold (PT)
- threat score (TS) or critical success index (CSI)












- Prevalence
- accuracy (ACC)
- balanced accuracy (BA)
- F1 score
- is the harmonic mean of precision and sensitivity:
- phi coefficient (φ or rφ) or Matthews correlation coefficient (MCC)
- Fowlkes–Mallows index (FM)
- informedness or bookmaker informedness (BM)
- markedness (MK) or deltaP (Δp)
- Diagnostic odds ratio (DOR)









Sources: Fawcett (2006),[1] Piryonesi and El-Diraby (2020),[2]
Powers (2011),[3] Ting (2011),[4] CAWCR,[5] D. Chicco & G. Jurman (2020, 2021),[6][7] Tharwat (2018).[8] Balayla (2020)[9]
from a confusion matrix

The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals. For example, in medicine sensitivity and specificity are often used, while in computer science precision and recall are preferred. An important distinction is between metrics that are independent on the prevalence (how often each category occurs in the population), and metrics that depend on the prevalence – both types are useful, but they have very different properties.
Contingency table[edit]
Given a data set, a classification (the output of a classifier on that set) gives two numbers: the number of positives and the number of negatives, which add up to the total size of the set. To evaluate a classifier, one compares its output to another reference classification – ideally a perfect classification, but in practice the output of another gold standard test – and cross tabulates the data into a 2×2 contingency table, comparing the two classifications. One then evaluates the classifier relative to the gold standard by computing summary statistics of these 4 numbers. Generally these statistics will be scale invariant (scaling all the numbers by the same factor does not change the output), to make them independent of population size, which is achieved by using ratios of homogeneous functions, most simply homogeneous linear or homogeneous quadratic functions.
Say we test some people for the presence of a disease. Some of these people have the disease, and our test correctly says they are positive. They are called true positives (TP). Some have the disease, but the test incorrectly claims they don’t. They are called false negatives (FN). Some don’t have the disease, and the test says they don’t – true negatives (TN). Finally, there might be healthy people who have a positive test result – false positives (FP). These can be arranged into a 2×2 contingency table (confusion matrix), conventionally with the test result on the vertical axis and the actual condition on the horizontal axis.
These numbers can then be totaled, yielding both a grand total and marginal totals. Totaling the entire table, the number of true positives, false negatives, true negatives, and false positives add up to 100% of the set. Totaling the columns (adding vertically) the number of true positives and false positives add up to 100% of the test positives, and likewise for negatives. Totaling the rows (adding horizontally), the number of true positives and false negatives add up to 100% of the condition positives (conversely for negatives). The basic marginal ratio statistics are obtained by dividing the 2×2=4 values in the table by the marginal totals (either rows or columns), yielding 2 auxiliary 2×2 tables, for a total of 8 ratios. These ratios come in 4 complementary pairs, each pair summing to 1, and so each of these derived 2×2 tables can be summarized as a pair of 2 numbers, together with their complements. Further statistics can be obtained by taking ratios of these ratios, ratios of ratios, or more complicated functions.
The contingency table and the most common derived ratios are summarized below; see sequel for details.
| Predicted condition | Sources: [10][11][12][13][14][15][16][17][18]
|
||||
| Total population = P + N |
Positive (PP) | Negative (PN) | Informedness, bookmaker informedness (BM) = TPR + TNR − 1 |
Prevalence threshold (PT) = 
|
|
|
Actual condition |
Positive (P) | True positive (TP), hit |
False negative (FN), type II error, miss, underestimation |
True positive rate (TPR), recall, sensitivity (SEN), probability of detection, hit rate, power = TP/P = 1 − FNR |
False negative rate (FNR), miss rate = FN/P = 1 − TPR |
| Negative (N) | False positive (FP), type I error, false alarm, overestimation |
True negative (TN), correct rejection |
False positive rate (FPR), probability of false alarm, fall-out = FP/N = 1 − TNR |
True negative rate (TNR), specificity (SPC), selectivity = TN/N = 1 − FPR |
|
| Prevalence = P/P + N |
Positive predictive value (PPV), precision = TP/PP = 1 − FDR |
False omission rate (FOR) = FN/PN = 1 − NPV |
Positive likelihood ratio (LR+) = TPR/FPR |
Negative likelihood ratio (LR−) = FNR/TNR |
|
| Accuracy (ACC) = TP + TN/P + N | False discovery rate (FDR) = FP/PP = 1 − PPV |
Negative predictive value (NPV) = TN/PN = 1 − FOR | Markedness (MK), deltaP (Δp) = PPV + NPV − 1 |
Diagnostic odds ratio (DOR) = LR+/LR− | |
| Balanced accuracy (BA) = TPR + TNR/2 | F1 score = 2 PPV × TPR/PPV + TPR = 2 TP/2 TP + FP + FN |
Fowlkes–Mallows index (FM) = 
|
Matthews correlation coefficient (MCC) =  
|
Threat score (TS), critical success index (CSI), Jaccard index = TP/TP + FN + FP |
Note that the rows correspond to the condition actually being positive or negative (or classified as such by the gold standard), as indicated by the color-coding, and the associated statistics are prevalence-independent, while the columns correspond to the test being positive or negative, and the associated statistics are prevalence-dependent. There are analogous likelihood ratios for prediction values, but these are less commonly used, and not depicted above.
Sensitivity and specificity[edit]
The fundamental prevalence-independent statistics are sensitivity and specificity.
Sensitivity or True Positive Rate (TPR), also known as recall, is the proportion of people that tested positive and are positive (True Positive, TP) of all the people that actually are positive (Condition Positive, CP = TP + FN). It can be seen as the probability that the test is positive given that the patient is sick. With higher sensitivity, fewer actual cases of disease go undetected (or, in the case of the factory quality control, fewer faulty products go to the market).
Specificity (SPC) or True Negative Rate (TNR) is the proportion of people that tested negative and are negative (True Negative, TN) of all the people that actually are negative (Condition Negative, CN = TN + FP). As with sensitivity, it can be looked at as the probability that the test result is negative given that the patient is not sick. With higher specificity, fewer healthy people are labeled as sick (or, in the factory case, fewer good products are discarded).
The relationship between sensitivity and specificity, as well as the performance of the classifier, can be visualized and studied using the Receiver Operating Characteristic (ROC) curve.
In theory, sensitivity and specificity are independent in the sense that it is possible to achieve 100% in both (such as in the red/blue ball example given above). In more practical, less contrived instances, however, there is usually a trade-off, such that they are inversely proportional to one another to some extent. This is because we rarely measure the actual thing we would like to classify; rather, we generally measure an indicator of the thing we would like to classify, referred to as a surrogate marker. The reason why 100% is achievable in the ball example is because redness and blueness is determined by directly detecting redness and blueness. However, indicators are sometimes compromised, such as when non-indicators mimic indicators or when indicators are time-dependent, only becoming evident after a certain lag time. The following example of a pregnancy test will make use of such an indicator.
Modern pregnancy tests do not use the pregnancy itself to determine pregnancy status; rather, human chorionic gonadotropin is used, or hCG, present in the urine of gravid females, as a surrogate marker to indicate that a woman is pregnant. Because hCG can also be produced by a tumor, the specificity of modern pregnancy tests cannot be 100% (because false positives are possible). Also, because hCG is present in the urine in such small concentrations after fertilization and early embryogenesis, the sensitivity of modern pregnancy tests cannot be 100% (because false negatives are possible).
Likelihood ratios[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Positive and negative predictive values[edit]
In addition to sensitivity and specificity, the performance of a binary classification test can be measured with positive predictive value (PPV), also known as precision, and negative predictive value (NPV). The positive prediction value answers the question «If the test result is positive, how well does that predict an actual presence of disease?». It is calculated as TP/(TP + FP); that is, it is the proportion of true positives out of all positive results. The negative prediction value is the same, but for negatives, naturally.
Impact of prevalence on prediction values[edit]
Prevalence has a significant impact on prediction values. As an example, suppose there is a test for a disease with 99% sensitivity and 99% specificity. If 2000 people are tested and the prevalence (in the sample) is 50%, 1000 of them are sick and 1000 of them are healthy. Thus about 990 true positives and 990 true negatives are likely, with 10 false positives and 10 false negatives. The positive and negative prediction values would be 99%, so there can be high confidence in the result.
However, if the prevalence is only 5%, so of the 2000 people only 100 are really sick, then the prediction values change significantly. The likely result is 99 true positives, 1 false negative, 1881 true negatives and 19 false positives. Of the 19+99 people tested positive, only 99 really have the disease – that means, intuitively, that given that a patient’s test result is positive, there is only 84% chance that they really have the disease. On the other hand, given that the patient’s test result is negative, there is only 1 chance in 1882, or 0.05% probability, that the patient has the disease despite the test result.
Likelihood ratios[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Precision and recall[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Precision and recall can be interpreted as (estimated) conditional probabilities:
Precision is given by  while recall is given by
while recall is given by  ,[19] where
,[19] where  is the predicted class and
is the predicted class and  is the actual class.
is the actual class.
Both quantities are therefore connected by Bayes’ theorem.
Relationships[edit]
There are various relationships between these ratios.
If the prevalence, sensitivity, and specificity are known, the positive predictive value can be obtained from the following identity:

If the prevalence, sensitivity, and specificity are known, the negative predictive value can be obtained from the following identity:

Single metrics[edit]
In addition to the paired metrics, there are also single metrics that give a single number to evaluate the test.
Perhaps the simplest statistic is accuracy or fraction correct (FC), which measures the fraction of all instances that are correctly categorized; it is the ratio of the number of correct classifications to the total number of correct or incorrect classifications: (TP + TN)/total population = (TP + TN)/(TP + TN + FP + FN). As such, it compares estimates of pre- and post-test probability. This measure is prevalence-dependent. If 90% of people with COVID symptoms don’t have COVID, the prior probability P(-) is 0.9, and the simple rule «Classify all such patients as COVID-free.» would be 90% accurate. Diagnosis should be better than that. One can construct a «One-proportion z-test» with p0 as max(priors) = max(P(-),P(+)) for a diagnostic method hoping to beat a simple rule using the most likely outcome. Here, the hypotheses are «Ho: p ≤ 0.9 vs. Ha: p > 0.9», rejecting Ho for large values of z. One diagnostic rule could be compared to another if the other’s accuracy is known and substituted for p0 in calculating the z statistic. If not known and calculated from data, an accuracy comparison test could be made using «Two-proportion z-test, pooled for Ho: p1 = p2». Not used very much is the complementary statistic, the fraction incorrect (FiC): FC + FiC = 1, or (FP + FN)/(TP + TN + FP + FN) – this is the sum of the antidiagonal, divided by the total population. Cost-weighted fractions incorrect could compare expected costs of misclassification for different methods.
The diagnostic odds ratio (DOR) can be a more useful overall metric, which can be defined directly as (TP×TN)/(FP×FN) = (TP/FN)/(FP/TN), or indirectly as a ratio of ratio of ratios (ratio of likelihood ratios, which are themselves ratios of true rates or prediction values). This has a useful interpretation – as an odds ratio – and is prevalence-independent. Likelihood ratio is generally considered to be prevalence-independent and is easily interpreted as the multiplier to turn prior probabilities into posterior probabilities. Another useful single measure is «area under the ROC curve», AUC.
Alternative metrics[edit]
An F-score is a combination of the precision and the recall, providing a single score. There is a one-parameter family of statistics, with parameter β, which determines the relative weights of precision and recall. The traditional or balanced F-score (F1 score) is the harmonic mean of precision and recall:
- .

F-scores do not take the true negative rate into account and, therefore, are more suited to information retrieval and information extraction evaluation where the true negatives are innumerable. Instead, measures such as the phi coefficient, Matthews correlation coefficient, informedness or Cohen’s kappa may be preferable to assess the performance of a binary classifier.[20][21] As a correlation coefficient, the Matthews correlation coefficient is the geometric mean of the regression coefficients of the problem and its dual. The component regression coefficients of the Matthews correlation coefficient are markedness (deltap) and informedness (Youden’s J statistic or deltap’).[22]
See also[edit]
- Population impact measures
- Attributable risk
- Attributable risk percent
- Scoring rule (for probability predictions)
References[edit]
- ^ Fawcett, Tom (2006). «An Introduction to ROC Analysis» (PDF). Pattern Recognition Letters. 27 (8): 861–874. doi:10.1016/j.patrec.2005.10.010.
- ^ Piryonesi S. Madeh; El-Diraby Tamer E. (2020-03-01). «Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index». Journal of Infrastructure Systems. 26 (1): 04019036. doi:10.1061/(ASCE)IS.1943-555X.0000512.
- ^ Powers, David M. W. (2011). «Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63.
- ^ Ting, Kai Ming (2011). Sammut, Claude; Webb, Geoffrey I. (eds.). Encyclopedia of machine learning. Springer. doi:10.1007/978-0-387-30164-8. ISBN 978-0-387-30164-8.
- ^ Brooks, Harold; Brown, Barb; Ebert, Beth; Ferro, Chris; Jolliffe, Ian; Koh, Tieh-Yong; Roebber, Paul; Stephenson, David (2015-01-26). «WWRP/WGNE Joint Working Group on Forecast Verification Research». Collaboration for Australian Weather and Climate Research. World Meteorological Organisation. Retrieved 2019-07-17.
- ^ Chicco D.; Jurman G. (January 2020). «The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation». BMC Genomics. 21 (1): 6-1–6-13. doi:10.1186/s12864-019-6413-7. PMC 6941312. PMID 31898477.
- ^ Chicco D.; Toetsch N.; Jurman G. (February 2021). «The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation». BioData Mining. 14 (13): 1-22. doi:10.1186/s13040-021-00244-z. PMC 7863449. PMID 33541410.
- ^ Tharwat A. (August 2018). «Classification assessment methods». Applied Computing and Informatics. doi:10.1016/j.aci.2018.08.003.
- ^ Balayla, Jacques (2020). «Prevalence threshold (ϕe) and the geometry of screening curves». PLoS One. 15 (10). doi:10.1371/journal.pone.0240215.
- ^
Balayla, Jacques (2020). «Prevalence threshold (ϕe) and the geometry of screening curves». PLoS One. 15 (10). doi:10.1371/journal.pone.0240215. - ^
Fawcett, Tom (2006). «An Introduction to ROC Analysis» (PDF). Pattern Recognition Letters. 27 (8): 861–874. doi:10.1016/j.patrec.2005.10.010. - ^
Piryonesi S. Madeh; El-Diraby Tamer E. (2020-03-01). «Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index». Journal of Infrastructure Systems. 26 (1): 04019036. doi:10.1061/(ASCE)IS.1943-555X.0000512. - ^
Powers, David M. W. (2011). «Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63. - ^
Ting, Kai Ming (2011). Sammut, Claude; Webb, Geoffrey I. (eds.). Encyclopedia of machine learning. Springer. doi:10.1007/978-0-387-30164-8. ISBN 978-0-387-30164-8. - ^
Brooks, Harold; Brown, Barb; Ebert, Beth; Ferro, Chris; Jolliffe, Ian; Koh, Tieh-Yong; Roebber, Paul; Stephenson, David (2015-01-26). «WWRP/WGNE Joint Working Group on Forecast Verification Research». Collaboration for Australian Weather and Climate Research. World Meteorological Organisation. Retrieved 2019-07-17. - ^
Chicco D, Jurman G (January 2020). «The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation». BMC Genomics. 21 (1): 6-1–6-13. doi:10.1186/s12864-019-6413-7. PMC 6941312. PMID 31898477. - ^
Chicco D, Toetsch N, Jurman G (February 2021). «The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation». BioData Mining. 14 (13): 1-22. doi:10.1186/s13040-021-00244-z. PMC 7863449. PMID 33541410. - ^
Tharwat A. (August 2018). «Classification assessment methods». Applied Computing and Informatics. doi:10.1016/j.aci.2018.08.003. - ^ Information Retrieval Models, Thomas Roelleke, ISBN 9783031023286, page 76, https://www.google.de/books/edition/Information_Retrieval_Models/YX9yEAAAQBAJ?hl=de&gbpv=1&pg=PA76&printsec=frontcover
- ^ Powers, David M W (2011). «Evaluation: From Precision, Recall and F-Score to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63. hdl:2328/27165.
- ^ Powers, David M. W. (2012). «The Problem with Kappa» (PDF). Conference of the European Chapter of the Association for Computational Linguistics (EACL2012) Joint ROBUS-UNSUP Workshop. Archived from the original (PDF) on 2016-05-18. Retrieved 2012-07-20.
- ^ Perruchet, P.; Peereman, R. (2004). «The exploitation of distributional information in syllable processing». J. Neurolinguistics. 17 (2–3): 97–119. doi:10.1016/S0911-6044(03)00059-9. S2CID 17104364.
From Wikipedia, the free encyclopedia
Terminology and derivations
- condition positive (P)
- the number of real positive cases in the data
- condition negative (N)
- the number of real negative cases in the data
- true positive (TP)
- A test result that correctly indicates the presence of a condition or characteristic
- true negative (TN)
- A test result that correctly indicates the absence of a condition or characteristic
- false positive (FP)
- A test result which wrongly indicates that a particular condition or attribute is present
- false negative (FN)
- A test result which wrongly indicates that a particular condition or attribute is absent
- sensitivity, recall, hit rate, or true positive rate (TPR)
- specificity, selectivity or true negative rate (TNR)
- precision or positive predictive value (PPV)
- negative predictive value (NPV)
- miss rate or false negative rate (FNR)
- fall-out or false positive rate (FPR)
- false discovery rate (FDR)
- false omission rate (FOR)
- Positive likelihood ratio (LR+)
- Negative likelihood ratio (LR-)
- prevalence threshold (PT)
- threat score (TS) or critical success index (CSI)
- Prevalence
- accuracy (ACC)
- balanced accuracy (BA)
- F1 score
- is the harmonic mean of precision and sensitivity:
- phi coefficient (φ or rφ) or Matthews correlation coefficient (MCC)
- Fowlkes–Mallows index (FM)
- informedness or bookmaker informedness (BM)
- markedness (MK) or deltaP (Δp)
- Diagnostic odds ratio (DOR)
Sources: Fawcett (2006),[1] Piryonesi and El-Diraby (2020),[2]
Powers (2011),[3] Ting (2011),[4] CAWCR,[5] D. Chicco & G. Jurman (2020, 2021),[6][7] Tharwat (2018).[8] Balayla (2020)[9]
from a confusion matrix
The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals. For example, in medicine sensitivity and specificity are often used, while in computer science precision and recall are preferred. An important distinction is between metrics that are independent on the prevalence (how often each category occurs in the population), and metrics that depend on the prevalence – both types are useful, but they have very different properties.
Contingency table[edit]
Given a data set, a classification (the output of a classifier on that set) gives two numbers: the number of positives and the number of negatives, which add up to the total size of the set. To evaluate a classifier, one compares its output to another reference classification – ideally a perfect classification, but in practice the output of another gold standard test – and cross tabulates the data into a 2×2 contingency table, comparing the two classifications. One then evaluates the classifier relative to the gold standard by computing summary statistics of these 4 numbers. Generally these statistics will be scale invariant (scaling all the numbers by the same factor does not change the output), to make them independent of population size, which is achieved by using ratios of homogeneous functions, most simply homogeneous linear or homogeneous quadratic functions.
Say we test some people for the presence of a disease. Some of these people have the disease, and our test correctly says they are positive. They are called true positives (TP). Some have the disease, but the test incorrectly claims they don’t. They are called false negatives (FN). Some don’t have the disease, and the test says they don’t – true negatives (TN). Finally, there might be healthy people who have a positive test result – false positives (FP). These can be arranged into a 2×2 contingency table (confusion matrix), conventionally with the test result on the vertical axis and the actual condition on the horizontal axis.
These numbers can then be totaled, yielding both a grand total and marginal totals. Totaling the entire table, the number of true positives, false negatives, true negatives, and false positives add up to 100% of the set. Totaling the columns (adding vertically) the number of true positives and false positives add up to 100% of the test positives, and likewise for negatives. Totaling the rows (adding horizontally), the number of true positives and false negatives add up to 100% of the condition positives (conversely for negatives). The basic marginal ratio statistics are obtained by dividing the 2×2=4 values in the table by the marginal totals (either rows or columns), yielding 2 auxiliary 2×2 tables, for a total of 8 ratios. These ratios come in 4 complementary pairs, each pair summing to 1, and so each of these derived 2×2 tables can be summarized as a pair of 2 numbers, together with their complements. Further statistics can be obtained by taking ratios of these ratios, ratios of ratios, or more complicated functions.
The contingency table and the most common derived ratios are summarized below; see sequel for details.
| Predicted condition | Sources: [10][11][12][13][14][15][16][17][18]
|
||||
| Total population = P + N |
Positive (PP) | Negative (PN) | Informedness, bookmaker informedness (BM) = TPR + TNR − 1 |
Prevalence threshold (PT) =
|
|
|
Actual condition |
Positive (P) | True positive (TP), hit |
False negative (FN), type II error, miss, underestimation |
True positive rate (TPR), recall, sensitivity (SEN), probability of detection, hit rate, power = TP/P = 1 − FNR |
False negative rate (FNR), miss rate = FN/P = 1 − TPR |
| Negative (N) | False positive (FP), type I error, false alarm, overestimation |
True negative (TN), correct rejection |
False positive rate (FPR), probability of false alarm, fall-out = FP/N = 1 − TNR |
True negative rate (TNR), specificity (SPC), selectivity = TN/N = 1 − FPR |
|
| Prevalence = P/P + N |
Positive predictive value (PPV), precision = TP/PP = 1 − FDR |
False omission rate (FOR) = FN/PN = 1 − NPV |
Positive likelihood ratio (LR+) = TPR/FPR |
Negative likelihood ratio (LR−) = FNR/TNR |
|
| Accuracy (ACC) = TP + TN/P + N | False discovery rate (FDR) = FP/PP = 1 − PPV |
Negative predictive value (NPV) = TN/PN = 1 − FOR | Markedness (MK), deltaP (Δp) = PPV + NPV − 1 |
Diagnostic odds ratio (DOR) = LR+/LR− | |
| Balanced accuracy (BA) = TPR + TNR/2 | F1 score = 2 PPV × TPR/PPV + TPR = 2 TP/2 TP + FP + FN |
Fowlkes–Mallows index (FM) =
|
Matthews correlation coefficient (MCC) =
|
Threat score (TS), critical success index (CSI), Jaccard index = TP/TP + FN + FP |
Note that the rows correspond to the condition actually being positive or negative (or classified as such by the gold standard), as indicated by the color-coding, and the associated statistics are prevalence-independent, while the columns correspond to the test being positive or negative, and the associated statistics are prevalence-dependent. There are analogous likelihood ratios for prediction values, but these are less commonly used, and not depicted above.
Sensitivity and specificity[edit]
The fundamental prevalence-independent statistics are sensitivity and specificity.
Sensitivity or True Positive Rate (TPR), also known as recall, is the proportion of people that tested positive and are positive (True Positive, TP) of all the people that actually are positive (Condition Positive, CP = TP + FN). It can be seen as the probability that the test is positive given that the patient is sick. With higher sensitivity, fewer actual cases of disease go undetected (or, in the case of the factory quality control, fewer faulty products go to the market).
Specificity (SPC) or True Negative Rate (TNR) is the proportion of people that tested negative and are negative (True Negative, TN) of all the people that actually are negative (Condition Negative, CN = TN + FP). As with sensitivity, it can be looked at as the probability that the test result is negative given that the patient is not sick. With higher specificity, fewer healthy people are labeled as sick (or, in the factory case, fewer good products are discarded).
The relationship between sensitivity and specificity, as well as the performance of the classifier, can be visualized and studied using the Receiver Operating Characteristic (ROC) curve.
In theory, sensitivity and specificity are independent in the sense that it is possible to achieve 100% in both (such as in the red/blue ball example given above). In more practical, less contrived instances, however, there is usually a trade-off, such that they are inversely proportional to one another to some extent. This is because we rarely measure the actual thing we would like to classify; rather, we generally measure an indicator of the thing we would like to classify, referred to as a surrogate marker. The reason why 100% is achievable in the ball example is because redness and blueness is determined by directly detecting redness and blueness. However, indicators are sometimes compromised, such as when non-indicators mimic indicators or when indicators are time-dependent, only becoming evident after a certain lag time. The following example of a pregnancy test will make use of such an indicator.
Modern pregnancy tests do not use the pregnancy itself to determine pregnancy status; rather, human chorionic gonadotropin is used, or hCG, present in the urine of gravid females, as a surrogate marker to indicate that a woman is pregnant. Because hCG can also be produced by a tumor, the specificity of modern pregnancy tests cannot be 100% (because false positives are possible). Also, because hCG is present in the urine in such small concentrations after fertilization and early embryogenesis, the sensitivity of modern pregnancy tests cannot be 100% (because false negatives are possible).
Likelihood ratios[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Positive and negative predictive values[edit]
In addition to sensitivity and specificity, the performance of a binary classification test can be measured with positive predictive value (PPV), also known as precision, and negative predictive value (NPV). The positive prediction value answers the question «If the test result is positive, how well does that predict an actual presence of disease?». It is calculated as TP/(TP + FP); that is, it is the proportion of true positives out of all positive results. The negative prediction value is the same, but for negatives, naturally.
Impact of prevalence on prediction values[edit]
Prevalence has a significant impact on prediction values. As an example, suppose there is a test for a disease with 99% sensitivity and 99% specificity. If 2000 people are tested and the prevalence (in the sample) is 50%, 1000 of them are sick and 1000 of them are healthy. Thus about 990 true positives and 990 true negatives are likely, with 10 false positives and 10 false negatives. The positive and negative prediction values would be 99%, so there can be high confidence in the result.
However, if the prevalence is only 5%, so of the 2000 people only 100 are really sick, then the prediction values change significantly. The likely result is 99 true positives, 1 false negative, 1881 true negatives and 19 false positives. Of the 19+99 people tested positive, only 99 really have the disease – that means, intuitively, that given that a patient’s test result is positive, there is only 84% chance that they really have the disease. On the other hand, given that the patient’s test result is negative, there is only 1 chance in 1882, or 0.05% probability, that the patient has the disease despite the test result.
Likelihood ratios[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Precision and recall[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Precision and recall can be interpreted as (estimated) conditional probabilities:
Precision is given by while recall is given by ,[19] where is the predicted class and is the actual class.
Both quantities are therefore connected by Bayes’ theorem.
Relationships[edit]
There are various relationships between these ratios.
If the prevalence, sensitivity, and specificity are known, the positive predictive value can be obtained from the following identity:
If the prevalence, sensitivity, and specificity are known, the negative predictive value can be obtained from the following identity:
Single metrics[edit]
In addition to the paired metrics, there are also single metrics that give a single number to evaluate the test.
Perhaps the simplest statistic is accuracy or fraction correct (FC), which measures the fraction of all instances that are correctly categorized; it is the ratio of the number of correct classifications to the total number of correct or incorrect classifications: (TP + TN)/total population = (TP + TN)/(TP + TN + FP + FN). As such, it compares estimates of pre- and post-test probability. This measure is prevalence-dependent. If 90% of people with COVID symptoms don’t have COVID, the prior probability P(-) is 0.9, and the simple rule «Classify all such patients as COVID-free.» would be 90% accurate. Diagnosis should be better than that. One can construct a «One-proportion z-test» with p0 as max(priors) = max(P(-),P(+)) for a diagnostic method hoping to beat a simple rule using the most likely outcome. Here, the hypotheses are «Ho: p ≤ 0.9 vs. Ha: p > 0.9», rejecting Ho for large values of z. One diagnostic rule could be compared to another if the other’s accuracy is known and substituted for p0 in calculating the z statistic. If not known and calculated from data, an accuracy comparison test could be made using «Two-proportion z-test, pooled for Ho: p1 = p2». Not used very much is the complementary statistic, the fraction incorrect (FiC): FC + FiC = 1, or (FP + FN)/(TP + TN + FP + FN) – this is the sum of the antidiagonal, divided by the total population. Cost-weighted fractions incorrect could compare expected costs of misclassification for different methods.
The diagnostic odds ratio (DOR) can be a more useful overall metric, which can be defined directly as (TP×TN)/(FP×FN) = (TP/FN)/(FP/TN), or indirectly as a ratio of ratio of ratios (ratio of likelihood ratios, which are themselves ratios of true rates or prediction values). This has a useful interpretation – as an odds ratio – and is prevalence-independent. Likelihood ratio is generally considered to be prevalence-independent and is easily interpreted as the multiplier to turn prior probabilities into posterior probabilities. Another useful single measure is «area under the ROC curve», AUC.
Alternative metrics[edit]
An F-score is a combination of the precision and the recall, providing a single score. There is a one-parameter family of statistics, with parameter β, which determines the relative weights of precision and recall. The traditional or balanced F-score (F1 score) is the harmonic mean of precision and recall:
- .
F-scores do not take the true negative rate into account and, therefore, are more suited to information retrieval and information extraction evaluation where the true negatives are innumerable. Instead, measures such as the phi coefficient, Matthews correlation coefficient, informedness or Cohen’s kappa may be preferable to assess the performance of a binary classifier.[20][21] As a correlation coefficient, the Matthews correlation coefficient is the geometric mean of the regression coefficients of the problem and its dual. The component regression coefficients of the Matthews correlation coefficient are markedness (deltap) and informedness (Youden’s J statistic or deltap’).[22]
See also[edit]
- Population impact measures
- Attributable risk
- Attributable risk percent
- Scoring rule (for probability predictions)
References[edit]
- ^ Fawcett, Tom (2006). «An Introduction to ROC Analysis» (PDF). Pattern Recognition Letters. 27 (8): 861–874. doi:10.1016/j.patrec.2005.10.010.
- ^ Piryonesi S. Madeh; El-Diraby Tamer E. (2020-03-01). «Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index». Journal of Infrastructure Systems. 26 (1): 04019036. doi:10.1061/(ASCE)IS.1943-555X.0000512.
- ^ Powers, David M. W. (2011). «Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63.
- ^ Ting, Kai Ming (2011). Sammut, Claude; Webb, Geoffrey I. (eds.). Encyclopedia of machine learning. Springer. doi:10.1007/978-0-387-30164-8. ISBN 978-0-387-30164-8.
- ^ Brooks, Harold; Brown, Barb; Ebert, Beth; Ferro, Chris; Jolliffe, Ian; Koh, Tieh-Yong; Roebber, Paul; Stephenson, David (2015-01-26). «WWRP/WGNE Joint Working Group on Forecast Verification Research». Collaboration for Australian Weather and Climate Research. World Meteorological Organisation. Retrieved 2019-07-17.
- ^ Chicco D.; Jurman G. (January 2020). «The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation». BMC Genomics. 21 (1): 6-1–6-13. doi:10.1186/s12864-019-6413-7. PMC 6941312. PMID 31898477.
- ^ Chicco D.; Toetsch N.; Jurman G. (February 2021). «The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation». BioData Mining. 14 (13): 1-22. doi:10.1186/s13040-021-00244-z. PMC 7863449. PMID 33541410.
- ^ Tharwat A. (August 2018). «Classification assessment methods». Applied Computing and Informatics. doi:10.1016/j.aci.2018.08.003.
- ^ Balayla, Jacques (2020). «Prevalence threshold (ϕe) and the geometry of screening curves». PLoS One. 15 (10). doi:10.1371/journal.pone.0240215.
- ^
Balayla, Jacques (2020). «Prevalence threshold (ϕe) and the geometry of screening curves». PLoS One. 15 (10). doi:10.1371/journal.pone.0240215. - ^
Fawcett, Tom (2006). «An Introduction to ROC Analysis» (PDF). Pattern Recognition Letters. 27 (8): 861–874. doi:10.1016/j.patrec.2005.10.010. - ^
Piryonesi S. Madeh; El-Diraby Tamer E. (2020-03-01). «Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index». Journal of Infrastructure Systems. 26 (1): 04019036. doi:10.1061/(ASCE)IS.1943-555X.0000512. - ^
Powers, David M. W. (2011). «Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63. - ^
Ting, Kai Ming (2011). Sammut, Claude; Webb, Geoffrey I. (eds.). Encyclopedia of machine learning. Springer. doi:10.1007/978-0-387-30164-8. ISBN 978-0-387-30164-8. - ^
Brooks, Harold; Brown, Barb; Ebert, Beth; Ferro, Chris; Jolliffe, Ian; Koh, Tieh-Yong; Roebber, Paul; Stephenson, David (2015-01-26). «WWRP/WGNE Joint Working Group on Forecast Verification Research». Collaboration for Australian Weather and Climate Research. World Meteorological Organisation. Retrieved 2019-07-17. - ^
Chicco D, Jurman G (January 2020). «The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation». BMC Genomics. 21 (1): 6-1–6-13. doi:10.1186/s12864-019-6413-7. PMC 6941312. PMID 31898477. - ^
Chicco D, Toetsch N, Jurman G (February 2021). «The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation». BioData Mining. 14 (13): 1-22. doi:10.1186/s13040-021-00244-z. PMC 7863449. PMID 33541410. - ^
Tharwat A. (August 2018). «Classification assessment methods». Applied Computing and Informatics. doi:10.1016/j.aci.2018.08.003. - ^ Information Retrieval Models, Thomas Roelleke, ISBN 9783031023286, page 76, https://www.google.de/books/edition/Information_Retrieval_Models/YX9yEAAAQBAJ?hl=de&gbpv=1&pg=PA76&printsec=frontcover
- ^ Powers, David M W (2011). «Evaluation: From Precision, Recall and F-Score to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63. hdl:2328/27165.
- ^ Powers, David M. W. (2012). «The Problem with Kappa» (PDF). Conference of the European Chapter of the Association for Computational Linguistics (EACL2012) Joint ROBUS-UNSUP Workshop. Archived from the original (PDF) on 2016-05-18. Retrieved 2012-07-20.
- ^ Perruchet, P.; Peereman, R. (2004). «The exploitation of distributional information in syllable processing». J. Neurolinguistics. 17 (2–3): 97–119. doi:10.1016/S0911-6044(03)00059-9. S2CID 17104364.
Терминология и выводы
из матрицы неточностей
- положительное состояние (P)
- количество реальных положительных случаев в данных
- условие отрицательное (N)
- количество реальных отрицательных случаев в данных
- истинно положительный (TP)
- экв. с хитом
- истинно отрицательный (TN)
- экв. с правильным отклонением
- ложное срабатывание (FP)
- экв. с ложной тревогой , ошибкой типа I или недооценкой
- ложноотрицательный (FN)
- экв. с промахом, ошибкой II типа или завышением
- чувствительность , отзыв , частота совпадений или истинно положительный показатель (TPR)
- специфичность , селективность или истинно отрицательный показатель (TNR)
- точность или положительная прогностическая ценность (PPV)
- отрицательная прогностическая ценность (NPV)
- коэффициент пропусков или ложноотрицательных результатов (FNR)
- количество выпадений или ложных срабатываний (FPR)
- коэффициент ложного обнаружения (FDR)
- коэффициент ложных пропусков (FOR)
- порог распространенности (ПП)
- оценка угрозы (TS) или индекс критического успеха (CSI)
- точность (ACC)
- сбалансированная точность (BA)
- Оценка F1
- является средним гармоническим из точности и чувствительности :
- Коэффициент корреляции Мэтьюза (MCC)
- Индекс Фаулкса – Маллоуса (FM)
- информированность или информированность букмекеров (BM)
- маркировка (МК) или дельтаП (Δp)
Источники: Fawcett (2006), [1] Piryonesi and El-Diraby (2020), [2]
Powers (2011), [3] Ting (2011), [4] CAWCR, [5] D. Chicco & G. Jurman (2020, 2021) , [6] [7] Тарват (2018). [8]
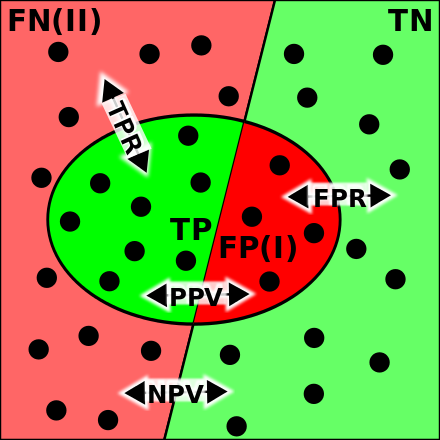
Из матрицы неточностей можно вывести четыре основных показателя
Оценка бинарных классификаторов сравнивает два методы присвоения двоичного атрибута, один из которых, как правило , стандартный метод , а другие расследуются. Есть много показателей, которые можно использовать для измерения производительности классификатора или предиктора; разные поля имеют разные предпочтения для конкретных показателей из-за разных целей. Например, в медицине часто используются чувствительность и специфичность , а в информатике предпочтительны точность и отзыв . Важное различие между метриками, которые не зависят от распространенности (как часто каждая категория встречается в популяции), и метриками, которые зависят от распространенности — оба типа полезны, но имеют очень разные свойства.
Таблица непредвиденных обстоятельств
Для данного набора данных классификация (результат работы классификатора этого набора) дает два числа: количество положительных результатов и количество отрицательных результатов, которые в сумме составляют общий размер набора. Чтобы оценить классификатор, один сравнивает его выходные данные с другой эталонной классификацией — в идеале — идеальной классификацией, но на практике — с результатами другого теста золотого стандарта — и перекрестно табулирует данные в таблицу непредвиденных обстоятельств 2 × 2 , сравнивая две классификации. Затем оценивают классификатор относительно золотого стандарта, вычисляя сводную статистику этих 4 чисел. Как правило, эта статистика не зависит от масштаба.(масштабирование всех чисел одним и тем же коэффициентом не влияет на результат), чтобы сделать их независимыми от размера популяции, что достигается за счет использования соотношений однородных функций , наиболее просто однородных линейных или однородных квадратичных функций.
Допустим, мы проверяем некоторых людей на наличие болезни. Некоторые из этих людей болеют болезнью, и наш тест правильно говорит, что они положительные. Их называют истинно положительными (TP). У некоторых есть болезнь, но тест ошибочно утверждает, что это не так. Их называют ложноотрицательными (ЛО). У некоторых нет болезни, и тест говорит, что нет — истинно отрицательные (TN). Наконец, могут быть здоровые люди с положительным результатом теста — ложноположительными (ЛП). Их можно упорядочить в таблицу непредвиденных обстоятельств 2 × 2 ( матрица неточностей ), условно с результатом теста по вертикальной оси и фактическим состоянием по горизонтальной оси.
Затем эти числа можно суммировать, получая как общий итог, так и предельные итоги.. Суммируя всю таблицу, количество истинных положительных, ложно отрицательных, истинных отрицательных и ложных срабатываний составляет в сумме 100% от набора. Суммируя столбцы (складывая по вертикали), количество истинных положительных и ложных положительных результатов составляет 100% от положительных результатов теста, а также для отрицательных результатов. Суммируя строки (складывая по горизонтали), количество истинных положительных и ложных отрицательных результатов составляет в сумме 100% положительных результатов условия (и наоборот для отрицательных результатов). Базовая статистика предельного отношения получается путем деления значений 2 × 2 = 4 в таблице на предельные итоги (строки или столбцы), что дает 2 вспомогательные таблицы 2 × 2, всего 8 соотношений. Эти отношения представлены в 4 дополнительных парах, каждая пара в сумме равна 1, и поэтому каждую из этих производных таблиц 2 × 2 можно суммировать как пару из 2 чисел вместе с их дополнениями.Дополнительную статистику можно получить, взяв отношения этих отношений, отношения отношений или более сложные функции.
Таблица непредвиденных обстоятельств и наиболее распространенные производные коэффициенты приведены ниже; подробности см. в продолжении.
| Прогнозируемое состояние | Источники: [9] [10] [11] [12] [13] [14] [15] [16] »
|
||||
| Общая численность населения = P + N |
Положительный (PP) | Отрицательный (PN) | Информированность, информированность букмекеров (BM) = TPR + TNR — 1 |
Порог распространенности (PT) =√ TPR × FPR — FPR/TPR — FPR |
|
|
Фактическое состояние |
Положительный (P) | Истинно положительный (TP), хит |
Ложноотрицательный (FN), ошибка типа II , промах, недооценка |
Уровень истинных положительных результатов (TPR), отзыв , чувствительность (SEN), вероятность обнаружения, частота совпадений, мощность =TP/п = 1 — FNR |
Частота ложноотрицательных результатов (FNR), частота промахов =FN/п = 1 — TPR |
| Отрицательный (N) | Ложное срабатывание (FP), ошибка типа I , ложная тревога, завышение |
Истинно отрицательный (TN), правильный отказ |
Частота ложных срабатываний (FPR), вероятность ложной тревоги, выпадение =FP/N = 1 — TNR |
Истинно отрицательная скорость (TNR), специфичность (SPC), селективность =TN/N = 1 — FPR |
|
| Распространенность =п/P + N |
Положительная прогностическая ценность (PPV), точность =TP/ПП = 1 — FDR |
Коэффициент ложных пропусков (FOR) =FN/PN = 1 — ЧПС |
Отношение положительного правдоподобия (LR +) =TPR/FPR |
Отрицательное отношение правдоподобия (LR−) =FNR/TNR |
|
| Точность (ACC) =TP + TN/P + N | Коэффициент ложного обнаружения (FDR) =FP/ПП = 1 — PPV |
Отрицательная прогностическая ценность (NPV) =TN/PN = 1 — ДЛЯ | Маркированность (МК), deltaP (Δp) = PPV + NPV — 1 |
Отношение диагностических шансов (DOR) =LR +/LR− | |
| Сбалансированная точность (BA) =TPR + TNR/2 | F 1 балл =2 PPV × TPR/PPV + TPR знак равно 2 TP/2 TP + FP + FN |
Индекс Фаулкса – Маллоуса (FM) = √ PPV × TPR | Коэффициент корреляции Мэтьюза (MCC) = √ TPR × TNR × PPV × NPV — √ FNR × FPR × FOR × FDR |
Оценка угрозы (TS), индекс критического успеха (CSI), индекс Жаккара =TP/TP + FN + FP |
Обратите внимание , что строки соответствуют условию на самом деле быть положительным или отрицательным (или классифицирован как таковой золотого стандарта), как указано цветокодирующей, и связанные с ними статистические данные распространенности независимые, а столбцы соответствуют тест быть положительным или отрицательный, и соответствующая статистика зависит от распространенности. Существуют аналогичные отношения правдоподобия для значений прогноза, но они используются реже и не показаны выше.
Чувствительность и специфичность
Основными статистическими данными, не зависящими от распространенности, являются чувствительность и специфичность .
Чувствительность или истинно положительный показатель (TPR), также известный как отзыв , — это доля людей, которые дали положительный результат и были положительными (True Positive, TP), от всех людей, которые действительно положительны (положительное состояние, CP = TP + FN). Его можно рассматривать как вероятность того, что тест будет положительным, учитывая, что пациент болен . Чем выше чувствительность, тем меньше фактических случаев заболевания остается незамеченным (или, в случае заводского контроля качества, на рынок поступает меньше бракованной продукции).
Специфичность (SPC) или истинно отрицательный показатель (TNR) — это доля людей, у которых тесты были отрицательными и были отрицательными (True Negative, TN), среди всех людей, которые на самом деле были отрицательными (Condition Negative, CN = TN + FP). Как и в случае с чувствительностью, это можно рассматривать как вероятность того, что результат теста будет отрицательным, при условии, что пациент не болен . Чем выше специфичность, тем меньше здоровых людей маркируются как больные (или, в случае фабрики, меньше хороших продуктов выбрасывается).
Взаимосвязь между чувствительностью и специфичностью, а также производительность классификатора можно визуализировать и изучить с помощью кривой рабочих характеристик приемника (ROC).
Теоретически чувствительность и специфичность независимы в том смысле, что можно достичь 100% в обоих случаях (например, в примере с красным / синим шаром, приведенном выше). Однако в более практичных, менее надуманных случаях обычно приходится идти на компромисс, так что они в некоторой степени обратно пропорциональны друг другу. Это потому, что мы редко измеряем то, что хотим классифицировать; скорее, мы обычно измеряем показатель того, что мы хотели бы классифицировать, называемый суррогатным маркером.. Причина, по которой в примере с мячом достижимо 100%, заключается в том, что покраснение и голубизна определяются путем непосредственного определения покраснения и синевы. Однако индикаторы иногда подвергаются риску, например, когда индикаторы имитируют индикаторы или индикаторы зависят от времени и становятся очевидными только после определенного времени задержки. В следующем примере теста на беременность будет использоваться такой индикатор.
Современные тесты на беременность не используют саму беременность для определения статуса беременности; скорее, используется хорионический гонадотропин человека или ХГЧ, присутствующий в моче беременных женщин, в качестве суррогатного маркера, указывающего на то, что женщина беременна. Поскольку ХГЧ также может вырабатываться опухолью , специфичность современных тестов на беременность не может быть 100% (поскольку возможны ложноположительные результаты). Кроме того, поскольку ХГЧ присутствует в моче в таких небольших концентрациях после оплодотворения и раннего эмбриогенеза , чувствительность современных тестов на беременность не может быть 100% (поскольку возможны ложноотрицательные результаты).
Коэффициенты правдоподобия
Положительные и отрицательные прогнозные значения
Помимо чувствительности и специфичности, эффективность теста бинарной классификации может быть измерена с помощью положительной прогностической ценности (PPV), также известной как точность , и отрицательной прогностической ценности (NPV). Положительное значение прогноза отвечает на вопрос: «Если результат теста положительный , насколько хорошо это предсказывает фактическое наличие болезни?». Рассчитывается как TP / (TP + FP); то есть это доля истинных положительных результатов от всех положительных результатов. Значение отрицательного прогноза такое же, но, естественно, для отрицательных.
Влияние распространенности на значения прогнозов
Распространенность оказывает значительное влияние на значения прогнозов. В качестве примера предположим, что существует тест на заболевание с чувствительностью 99% и специфичностью 99%. Если обследовано 2000 человек и распространенность (в выборке) составляет 50%, то 1000 из них больны и 1000 здоровы. Таким образом, вероятны около 990 истинных положительных результатов и 990 истинно отрицательных результатов, из которых 10 ложноположительных и 10 ложноотрицательных. Положительные и отрицательные значения прогноза будут составлять 99%, поэтому результат может быть высоким.
Однако, если распространенность составляет всего 5%, то есть из 2000 человек действительно болеют только 100, то значения прогнозов значительно изменятся. Вероятный результат — 99 истинных положительных результатов, 1 ложный отрицательный результат, 1881 истинно отрицательный результат и 19 ложных положительных результатов. Из 19 + 99 человек с положительным результатом теста только 99 действительно болеют — это интуитивно означает, что, учитывая положительный результат теста пациента, вероятность того, что он действительно болен, составляет всего 84%. С другой стороны, учитывая, что результат теста пациента отрицательный, существует только 1 шанс из 1882 или 0,05% вероятности, что у пациента есть болезнь, несмотря на результат теста.
Коэффициенты правдоподобия
Точность и отзыв
Отношения
Между этими соотношениями существуют различные отношения.
Если распространенность, чувствительность и специфичность известны, положительная прогностическая ценность может быть получена из следующих данных:
Если распространенность, чувствительность и специфичность известны, отрицательная прогностическая ценность может быть получена из следующих данных:
Единые показатели
Помимо парных показателей, существуют также отдельные показатели, которые дают единое число для оценки теста.
Возможно, самая простая статистика — это точность или правильная доля (FC), которая измеряет долю всех экземпляров, которые правильно классифицированы; это отношение количества правильных классификаций к общему количеству правильных или неправильных классификаций: (TP + TN) / общая популяция = (TP + TN) / (TP + TN + FP + FN). Таким образом, он сравнивает оценки вероятности до и после тестирования . Этот показатель зависит от распространенности . Если 90% людей с симптомами COVID не болеют COVID, априорная вероятность P (-) равна 0,9 и простое правило «Классифицируйте всех таких пациентов как больных без COVID». будет на 90% точным. Диагноз должен быть лучше. Можно построить «однопропорциональный z-тест»с p0 как max (priors) = max (P (-), P (+)) для диагностического метода, который надеется превзойти простое правило, используя наиболее вероятный результат. Здесь гипотезы: «Ho: p ≤ 0,9 против Ha: p> 0,9», отвергая Ho при больших значениях z. Одно диагностическое правило можно сравнить с другим, если точность другого известна и вместо p0 при вычислении статистики z. Если это неизвестно и не рассчитано на основе данных, можно провести сравнительный тест точности с использованием «двухпропорционального z-критерия, объединенного для Ho: p1 = p2» . Не очень часто используется дополнительная статистика, неправильная дробь (FiC): FC + FiC = 1 или (FP + FN) / (TP + TN + FP + FN) — это сумма антидиагонали , деленная на всего населения.Неверные дроби, взвешенные по стоимости, можно сравнить с ожидаемыми затраты на неправильную классификацию для разных методов.
Отношение шансов диагностики (DOR) может быть более полезным общим показателем, который может быть определен непосредственно как (TP × TN) / (FP × FN) = (TP / FN) / (FP / TN) или косвенно как отношение отношения отношений (отношения отношений правдоподобия, которые сами по себе являются отношениями истинных показателей или значений прогноза). Это имеет полезную интерпретацию — как отношение шансов — и не зависит от распространенности. Обычно считается, что отношение правдоподобия не зависит от распространенности и легко интерпретируется как множитель, превращающий априорные вероятности в апостериорные . Еще одна полезная единичная мера — это «площадь под кривой ROC», AUC .
Альтернативные показатели
Оценка F — это комбинация точности и отзывчивости , дающая единую оценку. Существует однопараметрическое семейство статистических данных с параметром β, который определяет относительный вес точности и отзыва. Традиционная или сбалансированная оценка F (оценка F1 ) — это гармоническое среднее значение точности и запоминания:
- .
F-баллы не принимают во внимание истинную отрицательную норму и, следовательно, больше подходят для поиска информации и оценки извлечения информации, где истинные отрицательные значения бесчисленны. Вместо этого, такие меры, как фи коэффициента , коэффициента корреляции Matthews , информированности или каппа Коэна может быть предпочтительным , чтобы оценить производительность бинарного классификатора. [17] [18] В качестве коэффициента корреляции , коэффициент корреляции Мэттьюз является геометрическое среднее из коэффициентов регрессии задачи и ее двойного. Составные коэффициенты регрессии коэффициента корреляции Matthews являются отмеченность (deltap) и информированность ( Youden в J статистики или deltap ‘). [19]
См. Также
- Меры воздействия на население
- Приписываемый риск
- Приписываемый риск в процентах
- Правило подсчета очков (для вероятностных прогнозов)
Ссылки
- ^ Фосетт, Том (2006). «Введение в анализ ROC» (PDF) . Письма о распознавании образов . 27 (8): 861–874. DOI : 10.1016 / j.patrec.2005.10.010 .
- ^ Пирьонеси С. Мадех; Эль-Дираби Тамер Э. (01.03.2020). «Аналитика данных в управлении активами: рентабельное прогнозирование индекса состояния дорожного покрытия». Журнал инфраструктурных систем . 26 (1): 04019036. doi : 10.1061 / (ASCE) IS.1943-555X.0000512 .
- ^ Пауэрс, Дэвид МВ (2011). «Оценка: от точности, отзыва и F-меры к ROC, информированности, значимости и корреляции» . Журнал технологий машинного обучения . 2 (1): 37–63.
- Перейти ↑ Ting, Kai Ming (2011). Саммут, Клод; Уэбб, Джеффри И. (ред.). Энциклопедия машинного обучения . Springer. DOI : 10.1007 / 978-0-387-30164-8 . ISBN 978-0-387-30164-8.
- ^ Брукс, Гарольд; Браун, Барб; Эберт, Бет; Ферро, Крис; Джоллифф, Ян; Ко, Тие-Йонг; Роббер, Пол; Стивенсон, Дэвид (26 января 2015 г.). «Совместная рабочая группа ВПМИ / РГЧЭ по исследованиям для проверки прогнозов» . Сотрудничество в области исследований погоды и климата Австралии . Всемирная метеорологическая организация . Проверено 17 июля 2019 .
- ^ Chicco D .; Юрман Г. (январь 2020 г.). «Преимущества коэффициента корреляции Мэтьюза (MCC) над оценкой F1 и точность оценки бинарной классификации» . BMC Genomics . 21 (1): 6-1–6-13. DOI : 10,1186 / s12864-019-6413-7 . PMC 6941312 . PMID 31898477 .
- ^ Chicco D .; Toetsch N .; Юрман Г. (февраль 2021 г.). «Коэффициент корреляции Мэтьюза (MCC) более надежен, чем сбалансированная точность, информированность букмекеров и заметность при оценке двухклассовой матрицы путаницы» . BioData Mining . 14 (13): 1-22. DOI : 10.1186 / s13040-021-00244-Z . PMC 7863449 . PMID 33541410 .
- ^ Tharwat А. (август 2018). «Классификационные методы оценки» . Прикладные вычисления и информатика . DOI : 10.1016 / j.aci.2018.08.003 .
- ^ Фосетт, Том (2006). «Введение в анализ ROC» (PDF) . Письма о распознавании образов . 27 (8): 861–874. DOI : 10.1016 / j.patrec.2005.10.010 .
- ^ Пирьонеси С. Мадех; Эль-Дираби Тамер Э. (01.03.2020). «Аналитика данных в управлении активами: рентабельное прогнозирование индекса состояния дорожного покрытия». Журнал инфраструктурных систем . 26 (1): 04019036. doi : 10.1061 / (ASCE) IS.1943-555X.0000512 .
- ^ Пауэрс, Дэвид МВ (2011). «Оценка: от точности, отзыва и F-меры к ROC, информированности, значимости и корреляции» . Журнал технологий машинного обучения . 2 (1): 37–63.
- Перейти ↑ Ting, Kai Ming (2011). Саммут, Клод; Уэбб, Джеффри И. (ред.). Энциклопедия машинного обучения . Springer. DOI : 10.1007 / 978-0-387-30164-8 . ISBN
978-0-387-30164-8. - ^ Брукс, Гарольд; Браун, Барб; Эберт, Бет; Ферро, Крис; Джоллифф, Ян; Ко, Тие-Йонг; Роббер, Пол; Стивенсон, Дэвид (26 января 2015 г.). «Совместная рабочая группа ВПМИ / РГЧЭ по исследованиям для проверки прогнозов» . Сотрудничество в области исследований погоды и климата Австралии . Всемирная метеорологическая организация . Проверено 17 июля 2019 .
- ^ Chicco D, Jurman G (январь 2020). «Преимущества коэффициента корреляции Мэтьюза (MCC) над оценкой F1 и точность оценки бинарной классификации» . BMC Genomics . 21 (1): 6-1–6-13. DOI : 10,1186 / s12864-019-6413-7 . PMC 6941312 . PMID 31898477 .
- ^ Chicco D, Toetsch N, Jurman G (февраль 2021 г.). «Коэффициент корреляции Мэтьюза (MCC) более надежен, чем сбалансированная точность, информированность букмекеров и заметность при оценке двухклассовой матрицы путаницы» . BioData Mining . 14 (13): 1-22. DOI : 10.1186 / s13040-021-00244-Z . PMC 7863449 . PMID 33541410 .
- ^ Tharwat А. (август 2018). «Классификационные методы оценки» . Прикладные вычисления и информатика . DOI : 10.1016 / j.aci.2018.08.003 .
- ^ Пауэрс, Дэвид МВ (2011). «Оценка: от точности, запоминания и оценки F до ROC, информированности, значимости и корреляции». Журнал технологий машинного обучения . 2 (1): 37–63. hdl : 2328/27165 .
- ^ Пауэрс, Дэвид МВ (2012). «Проблема с каппой» (PDF) . Конференция Европейского отделения Ассоциации компьютерной лингвистики (EACL2012) Совместный семинар ROBUS-UNSUP . Архивировано из оригинального (PDF) 18 мая 2016 года . Проверено 20 июля 2012 .
- ^ Perruchet, P .; Переман, Р. (2004). «Использование распределительной информации при обработке слогов». J. Нейролингвистика . 17 (2–3): 97–119. DOI : 10.1016 / S0911-6044 (03) 00059-9 . S2CID 17104364 .
Учитывая совокупность, члены которой принадлежат к одному из нескольких различных наборов или классов, a Правило классификации или классификатор — это процедура, с помощью которой каждый элемент совокупности предсказывается как принадлежащий к одному из классов. Совершенная классификация — это такая, при которой каждый элемент в генеральной совокупности отнесен к классу, к которому он действительно принадлежит. Несовершенная классификация — это класс, в котором появляются некоторые ошибки, и затем для анализа классификации должен применяться статистический анализ.
Особый вид правил классификации — это двоичная классификация, для задач, в которых есть только два класса.
Содержание
- 1 Правила классификации тестирования
- 2 Бинарная и мультиклассовая классификация
- 3 Таблица ошибок
- 3.1 Ложные срабатывания
- 3.2 Ложноотрицательные результаты
- 3.3 Рабочий пример
- 4 Измерение a классификатор с чувствительностью и специфичностью
- 5 См. также
- 6 Примечания
- 7 Ссылки
Правила классификации тестирования
Дан набор данных, состоящий из пар x и y, где x обозначает элемент совокупность и y класс, к которому он принадлежит, правило классификации h (x) — это функция, которая присваивает каждому элементу x предсказанный класс y ^ = h (x). { displaystyle { hat {y}} = h (x).} Бинарная классификация такова, что метка y может принимать только одно из двух значений.
Бинарная классификация такова, что метка y может принимать только одно из двух значений.
Истинные метки y i могут быть известны, но не обязательно будут соответствовать их приближениям yi ^ = h (xi) { displaystyle { hat {y_ {i}}} = h (x_ {i})} . В бинарной классификации элементы, которые неправильно классифицированы, называются ложноположительными и ложноотрицательными.
. В бинарной классификации элементы, которые неправильно классифицированы, называются ложноположительными и ложноотрицательными.
Некоторые правила классификации являются статическими функциями. Другие могут быть компьютерными программами. Компьютерный классификатор может изучать или реализовывать правила статической классификации. Для обучающего набора данных истинные метки y j неизвестны, но основной целью для процедуры классификации является то, что приближение yj ^ = h (xj) ≈ yj { displaystyle { hat {y_ {j}}} = h (x_ {j}) приблизительно y_ {j}} настолько хорошо, насколько это возможно, где качество этого приближения должно оцениваться на основе статистические или вероятностные свойства генеральной совокупности, из которой будут проводиться будущие наблюдения.
настолько хорошо, насколько это возможно, где качество этого приближения должно оцениваться на основе статистические или вероятностные свойства генеральной совокупности, из которой будут проводиться будущие наблюдения.
Учитывая правило классификации, тест классификации является результатом применения правила к конечной выборке начального набора данных.
Бинарная и мультиклассовая классификация
Классификация может рассматриваться как две отдельные проблемы — двоичная классификация и мультиклассовая классификация. В бинарной классификации, более понятной задаче, задействованы только два класса, тогда как мультиклассовая классификация включает отнесение объекта к одному из нескольких классов. Поскольку многие методы классификации были разработаны специально для двоичной классификации, многоклассовая классификация часто требует комбинированного использования нескольких двоичных классификаторов. Важным моментом является то, что во многих практических задачах бинарной классификации эти две группы не являются симметричными — интерес представляет не общая точность, а относительная доля различных типов ошибок. Например, при медицинском тестировании ложноположительный результат (обнаружение болезни, когда ее нет) рассматривается иначе, чем ложноотрицательный (не обнаружение болезни, когда она присутствует). В мультиклассовых классификациях классы могут рассматриваться симметрично (все ошибки эквивалентны) или асимметрично, что значительно сложнее.
Методы двоичной классификации включают пробит-регрессию и логистическую регрессию. Методы многоклассовой классификации включают полиномиальный пробит и полиномиальный логит.
Таблица смешения
Левая и правая половины соответственно содержат экземпляры, которые действительно имеют или не имеют условия. Овал содержит экземпляры, которые классифицируются (прогнозируются) как положительные (имеющие условие). Зеленый и красный соответственно содержат экземпляры, которые классифицированы правильно (истинно) и неправильно (ложно).. TP = Истинно Положительный; TN = истинно отрицательный; FP = ложноположительный результат (ошибка типа I); FN = ложноотрицательный (ошибка типа II); TPR = истинно положительная ставка; FPR = ложноположительный показатель; PPV = положительное прогнозное значение; NPV = отрицательное прогнозируемое значение.
Если функция классификации не идеальна, будут отображаться ложные результаты. В приведенном ниже примере матрицы путаницы для 8 настоящих кошек функция предсказала, что три были собаками, а из шести собак она предсказала, что одна была кроликом, а две — кошками. Из матрицы видно, что рассматриваемая система не умеет различать кошек и собак, но может довольно хорошо различать кроликов и других видов животных.
Пример матрицы путаницы
| Прогноз | ||||
|---|---|---|---|---|
| Кот | Собака | Кролик | ||
| Фактический | Кот | 5 | 3 | 0 |
| Собака | 2 | 3 | 1 | |
| Кролик | 0 | 2 | 11 |
Ложные срабатывания
Ложные срабатывания результат, когда тест ложно (неверно) сообщает о положительном результате. Например, медицинский тест на заболевание может дать положительный результат, указывающий на то, что у пациента есть болезнь, даже если у пациента нет болезни. Мы можем использовать теорему Байеса, чтобы определить вероятность того, что положительный результат на самом деле является ложноположительным. Мы обнаружили, что если заболевание встречается редко, то большинство положительных результатов могут быть ложноположительными, даже если тест относительно точен.
Предположим, что тест на болезнь дает следующие результаты:
- Если тестируемый пациент болен, тест дает положительный результат в 99% случаев или с вероятностью 0,99
- Если у протестированного пациента нет заболевания, тест дает положительный результат в 5% случаев или с вероятностью 0,05.
Наивно можно подумать, что только 5% положительных результатов теста являются ложными, но это не так. совершенно неверно, как мы увидим.
Предположим, что только 0,1% населения страдает этим заболеванием, так что случайным образом выбранный пациент имеет априорную вероятность заболевания 0,001.
Мы можем использовать теорему Байеса, чтобы вычислить вероятность того, что положительный результат теста является ложноположительным.
Пусть A представляет состояние, при котором пациент болен, а B представляет свидетельство положительного результата теста. Тогда вероятность того, что у пациента действительно есть заболевание при положительном результате теста, равна
- P (A | B) = P (B | A) P (A) P (B | A) P (A) + P ( B | ¬ A) P (¬ A) = 0,99 × 0,001 0,99 × 0,001 + 0,05 × 0,999 ≈ 0,019. { Displaystyle { begin {align} P (A | B) = { frac {P (B | A) P (A)} {P (B | A) P (A) + P (B | neg A) P ( neg A)}} \\ = { frac {0.99 times 0,001} {0,99 times 0,001 + 0,05 times 0,999}} \ ~ \ приблизительно 0,019. End { выровнено}}}

и, следовательно, вероятность того, что положительный результат будет ложноположительным, составляет примерно 1 — 0,019 = 0,98, или 98%.
Несмотря на кажущуюся высокую точность теста, заболеваемость настолько мала, что подавляющее большинство пациентов с положительным результатом теста не болеют. Тем не менее, доля пациентов с положительным результатом теста, у которых действительно есть заболевание (0,019), в 19 раз превышает долю людей, которые еще не прошли тест и у которых есть болезнь (0,001). Таким образом, тест не бесполезен, а повторное тестирование может повысить надежность результата.
Чтобы уменьшить проблему ложных срабатываний, тест должен очень точно сообщать об отрицательном результате, когда у пациента нет заболевания. Если тест показал отрицательный результат у пациентов без заболевания с вероятностью 0,999, то
- P (A | B) = 0,99 × 0,001 0,99 × 0,001 + 0,001 × 0,999 ≈ 0,5, { displaystyle P (A | B) = { frac {0.99 times 0.001} {0.99 times 0.001 + 0.001 times 0.999}} приблизительно 0,5,}

, так что теперь 1 — 0,5 = 0,5 — это вероятность ложного срабатывания.
Ложноотрицательные
С другой стороны, ложноотрицательные возникают, когда тест ложно или неправильно сообщает об отрицательном результате. Например, медицинский тест на заболевание может дать отрицательный результат, указывающий на то, что у пациента нет болезни, даже если у пациента действительно есть болезнь. Мы также можем использовать теорему Байеса для вычисления вероятности ложноотрицательного результата. В первом примере выше
- P (A | ¬ B) = P (¬ B | A) P (A) P (¬ B | A) P (A) + P (¬ B | ¬ A) P ( ¬ A) = 0,01 × 0,001 0,01 × 0,001 + 0,95 × 0,999 ≈ 0,0000105. { Displaystyle { begin {выровнен} P (A | neg B) = { frac {P ( neg B | A) P (A)} {P ( neg B | A) P (A) + P ( neg B | neg A) P ( neg A)}} \\ = { frac {0,01 times 0,001} {0,01 times 0,001 + 0,95 times 0,999}} \ ~ \ приблизительно 0,0000105. end {align}}}

Вероятность того, что отрицательный результат будет ложноотрицательным, составляет около 0,0000105 или 0,00105%. Если заболевание встречается редко, ложноотрицательные результаты не будут большой проблемой.
Но если бы 60% населения болело, то вероятность ложноотрицательного результата была бы выше. С помощью вышеуказанного теста вероятность ложноотрицательного результата будет
- P (A | ¬ B) = P (¬ B | A) P (A) P (¬ B | A) P (A) + P (¬ B | ¬ A) P (¬ A) = 0,01 × 0,6 0,01 × 0,6 + 0,95 × 0,4 ≈ 0,0155. { Displaystyle { begin {выровнен} P (A | neg B) = { frac {P ( neg B | A) P (A)} {P ( neg B | A) P (A) + P ( neg B | neg A) P ( neg A)}} \\ = { frac {0,01 times 0,6} {0,01 times 0,6 + 0,95 times 0,4}} \ ~ \ приблизительно 0,0155. end {align}}}

Вероятность того, что отрицательный результат является ложноотрицательным, возрастает до 0,0155 или 1,55%.
Рабочий пример
- view
- talk
- Рабочий пример
- Диагностический тест с чувствительностью 67% и специфичностью 91% применяется к 2030 людям для поиска расстройства распространенность в популяции 1,48%
| Пациенты с раком кишечника. (подтверждено эндоскопией ) | |||||
| Положительное состояние | Отрицательное состояние | Распространенность = (TP + FN) / Total_Population. = (20 + 10) / 2030. ≈ 1,48% | Точность (ACC) = (TP + TN) / Total_Population. = (20 + 1820) / 2030. ≈ 90,64% | ||
| Кал. скрытая. кровь. экран. тест. результат | Тест. результат. положительный | Истинно положительный . (TP) = 20. (2030 x 1,48% x 67%) | ложноположительный . (FP) = 180. (2030 x (100 — 1,48%) x (100 — 91%)) | Прогнозное положительное значение (PPV), Точность = TP / (TP + FP). = 20 / (20 + 180). = 10% | Уровень ложного обнаружения (FDR) = FP / (TP + FP). = 180 / (20 + 180). = 90,0% |
| Тест. результат. отрицательный Активный | Ложноотрицательный . (FN) = 10. (2030 x 1,48% x (100-67%)) | Истинно отрицательный . (TN) = 1820. (2030 x (100 -1,48%) x 91%) | Коэффициент ложных пропусков (FOR) = FN / (FN + TN). = 10 / (10 + 1820). ≈ 0,55% | Прогнозируемое отрицательное значение (NPV) = TN / (FN + TN). = 1820 / (10 + 1820). ≈ 99,45 % | |
| TPR, Вызов, Чувствительность = TP / (TP + FN). = 20 / (20 + 10). ≈ 66,7% | Частота ложных срабатываний (FPR), выпадение, вероятность ложной тревоги = FP / (FP + TN). = 180 / ( 180 + 1820). = 9,0% | Отношение положительного правдоподобия (LR +) = TPR / FPR. = (20/30) / (180/2000). ≈ 7,41 | Отношение шансов диагностики (DOR) = LR + / LR−. ≈ 20,2 | F1оценка = 2 · Точность · Отзыв / Точность + Отзыв. ≈ 0,174 | |
| Частота ложных отрицательных результатов (FNR), Частота промахов. = FN / (TP + FN). = 10 / (20 + 10). ≈ 33,3% | Специфичность, Избирательность, Истинно отрицательная скорость (TNR) = TN / ( FP + TN). = 1820 / (180 + 1820). = 91% | Отрицательное отношение правдоподобия (LR-) = FNR / TNR. = (10 /30)/(1820/2000). ≈0.366 |
Связанные вычисления
- Частота ложных срабатываний (α) = ошибка I типа = 1 — специфичность = FP / (FP + TN) = 180 / (180 + 1820) = 9%
- Уровень ложных отрицательных результатов (β) = ошибка типа II = 1 — чувствительность = FN / (TP + FN) = 10 / (20 + 10) = 33%
- Мощность = чувствительность = 1 — β
- Отношение правдоподобия положительное = чувствительность / (1 — специфичность) = 0,67 / (1 — 0,91) = 7,4
- Отрицательное отношение правдоподобия = (1 — чувствительность) / специфичность = (1 — 0,67) / 0,91 = 0,37
- Порог распространенности = PT = TPR (- TNR + 1) + TNR — 1 (TPR + TNR — 1) { displaystyle PT = { frac {{ sqrt {TPR (-TNR + 1)}} + TNR-1} {(TPR + TNR-1)}}}= 0,19 =>19,1%
 = 0,19 =>19,1%
= 0,19 =>19,1%Этот гипотетический скрининговый тест (анализ кала на скрытую кровь) правильно идентифицировал две трети (66,7%) пациентов с колоректальным раком. К сожалению, учет показателей распространенности показывает, что этот гипотетический тест имеет высокий уровень ложноположительных результатов и не позволяет надежно идентифицировать рак прямой кишки в общей популяции бессимптомных людей (PPV = 10%).
С другой стороны, этот гипотетический тест демонстрирует очень точное определение людей, свободных от рака (NPV = 99,5%). Таким образом, при использовании для рутинного скрининга колоректального рака у бессимптомных взрослых отрицательный результат дает важные данные для пациента и врача, такие как исключение рака как причины желудочно-кишечных симптомов или успокаивание пациентов, обеспокоенных развитием колоректального рака.
Измерение чувствительности и специфичности классификатора
При обучении классификатора можно захотеть измерить его производительность, используя общепринятые показатели чувствительности и специфичности. Может быть поучительно сравнить классификатор со случайным классификатором, который подбрасывает монетку в зависимости от распространенности заболевания. Предположим, что вероятность того, что человек болен, равна p { displaystyle p} , а вероятность того, что он не болеет, равна q = 1 — p { displaystyle q = 1-p}.
, а вероятность того, что он не болеет, равна q = 1 — p { displaystyle q = 1-p}. . Предположим, что у нас есть случайный классификатор, который догадывается, что пациент болен с той же вероятностью p { displaystyle p}, и предполагает, что он не болен с такой же вероятностью q { displaystyle q}
. Предположим, что у нас есть случайный классификатор, который догадывается, что пациент болен с той же вероятностью p { displaystyle p}, и предполагает, что он не болен с такой же вероятностью q { displaystyle q} .
.
Вероятность истинно положительного результата — это вероятность того, что у пациента есть заболевание, умноженная на вероятность того, что случайный классификатор угадает это правильно, или p 2 { displaystyle p ^ {2}} . По аналогичным соображениям вероятность ложноотрицательного результата составляет p q { displaystyle pq}
. По аналогичным соображениям вероятность ложноотрицательного результата составляет p q { displaystyle pq} . Из определений выше чувствительность этого классификатора составляет p 2 / (p 2 + pq) = p { displaystyle p ^ {2} / (p ^ {2} + pq) = p}
. Из определений выше чувствительность этого классификатора составляет p 2 / (p 2 + pq) = p { displaystyle p ^ {2} / (p ^ {2} + pq) = p} . С помощью аналогичных рассуждений мы можем вычислить специфичность как q 2 / (q 2 + pq) = q { displaystyle q ^ {2} / (q ^ {2} + pq) = q}
. С помощью аналогичных рассуждений мы можем вычислить специфичность как q 2 / (q 2 + pq) = q { displaystyle q ^ {2} / (q ^ {2} + pq) = q} .
.
Итак, хотя сам показатель не зависит от распространенности заболевания, эффективность этого случайного классификатора зависит от распространенности заболевания. Классификатор может иметь производительность, аналогичную этому случайному классификатору, но с более взвешенной монетой (более высокая чувствительность и специфичность). Таким образом, на эти показатели может влиять распространенность заболевания. Альтернативным показателем эффективности является коэффициент корреляции Мэтьюза, для которого любой случайный классификатор получит средний балл 0.
Распространение этой концепции на небинарные классификации дает матрица путаницы.
См. также
- Байесовский классификатор
- Байесовский вывод
- Двоичная классификация
- Правило принятия решения
- Диагностический тест
- Золотой стандарт (тест)
- Функции потерь для классификации
- Медицинский тест
- Чувствительность и специфичность
- Статистическая классификация
Примечания
Ссылки
From Wikipedia, the free encyclopedia
Sources: Fawcett (2006),[1] Piryonesi and El-Diraby (2020),[2] |
The evaluation of binary classifiers compares two methods of assigning a binary attribute, one of which is usually a standard method and the other is being investigated. There are many metrics that can be used to measure the performance of a classifier or predictor; different fields have different preferences for specific metrics due to different goals. For example, in medicine sensitivity and specificity are often used, while in computer science precision and recall are preferred. An important distinction is between metrics that are independent on the prevalence (how often each category occurs in the population), and metrics that depend on the prevalence – both types are useful, but they have very different properties.
Probabilistic classification models go beyond providing binary outputs and instead produce probability scores for each class. These models are designed to assess the likelihood or probability of an instance belonging to different classes. In the context of evaluating probabilistic classifiers, alternative evaluation metrics have been developed to properly assess the performance of these models. These metrics take into account the probabilistic nature of the classifier’s output and provide a more comprehensive assessment of its effectiveness in assigning accurate probabilities to different classes. These evaluation metrics aim to capture the degree of calibration, discrimination, and overall accuracy of the probabilistic classifier’s predictions.
Contingency table[edit]
Given a data set, a classification (the output of a classifier on that set) gives two numbers: the number of positives and the number of negatives, which add up to the total size of the set. To evaluate a classifier, one compares its output to another reference classification – ideally a perfect classification, but in practice the output of another gold standard test – and cross tabulates the data into a 2×2 contingency table, comparing the two classifications. One then evaluates the classifier relative to the gold standard by computing summary statistics of these 4 numbers. Generally these statistics will be scale invariant (scaling all the numbers by the same factor does not change the output), to make them independent of population size, which is achieved by using ratios of homogeneous functions, most simply homogeneous linear or homogeneous quadratic functions.
Say we test some people for the presence of a disease. Some of these people have the disease, and our test correctly says they are positive. They are called true positives (TP). Some have the disease, but the test incorrectly claims they don’t. They are called false negatives (FN). Some don’t have the disease, and the test says they don’t – true negatives (TN). Finally, there might be healthy people who have a positive test result – false positives (FP). These can be arranged into a 2×2 contingency table (confusion matrix), conventionally with the test result on the vertical axis and the actual condition on the horizontal axis.
These numbers can then be totaled, yielding both a grand total and marginal totals. Totaling the entire table, the number of true positives, false negatives, true negatives, and false positives add up to 100% of the set. Totaling the columns (adding vertically) the number of true positives and false positives add up to 100% of the test positives, and likewise for negatives. Totaling the rows (adding horizontally), the number of true positives and false negatives add up to 100% of the condition positives (conversely for negatives). The basic marginal ratio statistics are obtained by dividing the 2×2=4 values in the table by the marginal totals (either rows or columns), yielding 2 auxiliary 2×2 tables, for a total of 8 ratios. These ratios come in 4 complementary pairs, each pair summing to 1, and so each of these derived 2×2 tables can be summarized as a pair of 2 numbers, together with their complements. Further statistics can be obtained by taking ratios of these ratios, ratios of ratios, or more complicated functions.
The contingency table and the most common derived ratios are summarized below; see sequel for details.
| Predicted condition | Sources: [11][12][13][14][15][16][17][18][19]
|
||||
| Total population = P + N |
Positive (PP) | Negative (PN) | Informedness, bookmaker informedness (BM) = TPR + TNR − 1 |
Prevalence threshold (PT) =
|
|
|
Actual condition |
Positive (P) | True positive (TP), hit |
False negative (FN), type II error, miss, underestimation |
True positive rate (TPR), recall, sensitivity (SEN), probability of detection, hit rate, power = TP/P = 1 − FNR |
False negative rate (FNR), miss rate = FN/P = 1 − TPR |
| Negative (N) | False positive (FP), type I error, false alarm, overestimation |
True negative (TN), correct rejection |
False positive rate (FPR), probability of false alarm, fall-out = FP/N = 1 − TNR |
True negative rate (TNR), specificity (SPC), selectivity = TN/N = 1 − FPR |
|
| Prevalence = P/P + N |
Positive predictive value (PPV), precision = TP/PP = 1 − FDR |
False omission rate (FOR) = FN/PN = 1 − NPV |
Positive likelihood ratio (LR+) = TPR/FPR |
Negative likelihood ratio (LR−) = FNR/TNR |
|
| Accuracy (ACC) = TP + TN/P + N | False discovery rate (FDR) = FP/PP = 1 − PPV |
Negative predictive value (NPV) = TN/PN = 1 − FOR | Markedness (MK), deltaP (Δp) = PPV + NPV − 1 |
Diagnostic odds ratio (DOR) = LR+/LR− | |
| Balanced accuracy (BA) = TPR + TNR/2 | F1 score = 2 PPV × TPR/PPV + TPR = 2 TP/2 TP + FP + FN |
Fowlkes–Mallows index (FM) =
|
Matthews correlation coefficient (MCC) =
|
Threat score (TS), critical success index (CSI), Jaccard index = TP/TP + FN + FP |
Note that the rows correspond to the condition actually being positive or negative (or classified as such by the gold standard), as indicated by the color-coding, and the associated statistics are prevalence-independent, while the columns correspond to the test being positive or negative, and the associated statistics are prevalence-dependent. There are analogous likelihood ratios for prediction values, but these are less commonly used, and not depicted above.
Sensitivity and specificity[edit]
The fundamental prevalence-independent statistics are sensitivity and specificity.
Sensitivity or True Positive Rate (TPR), also known as recall, is the proportion of people that tested positive and are positive (True Positive, TP) of all the people that actually are positive (Condition Positive, CP = TP + FN). It can be seen as the probability that the test is positive given that the patient is sick. With higher sensitivity, fewer actual cases of disease go undetected (or, in the case of the factory quality control, fewer faulty products go to the market).
Specificity (SPC) or True Negative Rate (TNR) is the proportion of people that tested negative and are negative (True Negative, TN) of all the people that actually are negative (Condition Negative, CN = TN + FP). As with sensitivity, it can be looked at as the probability that the test result is negative given that the patient is not sick. With higher specificity, fewer healthy people are labeled as sick (or, in the factory case, fewer good products are discarded).
The relationship between sensitivity and specificity, as well as the performance of the classifier, can be visualized and studied using the Receiver Operating Characteristic (ROC) curve.
In theory, sensitivity and specificity are independent in the sense that it is possible to achieve 100% in both (such as in the red/blue ball example given above). In more practical, less contrived instances, however, there is usually a trade-off, such that they are inversely proportional to one another to some extent. This is because we rarely measure the actual thing we would like to classify; rather, we generally measure an indicator of the thing we would like to classify, referred to as a surrogate marker. The reason why 100% is achievable in the ball example is because redness and blueness is determined by directly detecting redness and blueness. However, indicators are sometimes compromised, such as when non-indicators mimic indicators or when indicators are time-dependent, only becoming evident after a certain lag time. The following example of a pregnancy test will make use of such an indicator.
Modern pregnancy tests do not use the pregnancy itself to determine pregnancy status; rather, human chorionic gonadotropin is used, or hCG, present in the urine of gravid females, as a surrogate marker to indicate that a woman is pregnant. Because hCG can also be produced by a tumor, the specificity of modern pregnancy tests cannot be 100% (because false positives are possible). Also, because hCG is present in the urine in such small concentrations after fertilization and early embryogenesis, the sensitivity of modern pregnancy tests cannot be 100% (because false negatives are possible).
Likelihood ratios[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Positive and negative predictive values[edit]
In addition to sensitivity and specificity, the performance of a binary classification test can be measured with positive predictive value (PPV), also known as precision, and negative predictive value (NPV). The positive prediction value answers the question «If the test result is positive, how well does that predict an actual presence of disease?». It is calculated as TP/(TP + FP); that is, it is the proportion of true positives out of all positive results. The negative prediction value is the same, but for negatives, naturally.
Impact of prevalence on prediction values[edit]
Prevalence has a significant impact on prediction values. As an example, suppose there is a test for a disease with 99% sensitivity and 99% specificity. If 2000 people are tested and the prevalence (in the sample) is 50%, 1000 of them are sick and 1000 of them are healthy. Thus about 990 true positives and 990 true negatives are likely, with 10 false positives and 10 false negatives. The positive and negative prediction values would be 99%, so there can be high confidence in the result.
However, if the prevalence is only 5%, so of the 2000 people only 100 are really sick, then the prediction values change significantly. The likely result is 99 true positives, 1 false negative, 1881 true negatives and 19 false positives. Of the 19+99 people tested positive, only 99 really have the disease – that means, intuitively, that given that a patient’s test result is positive, there is only 84% chance that they really have the disease. On the other hand, given that the patient’s test result is negative, there is only 1 chance in 1882, or 0.05% probability, that the patient has the disease despite the test result.
Likelihood ratios[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Precision and recall[edit]
|
This section is empty. You can help by adding to it. (July 2014) |
Precision and recall can be interpreted as (estimated) conditional probabilities:
Precision is given by while recall is given by ,[20] where is the predicted class and is the actual class.
Both quantities are therefore connected by Bayes’ theorem.
Relationships[edit]
There are various relationships between these ratios.
If the prevalence, sensitivity, and specificity are known, the positive predictive value can be obtained from the following identity:
If the prevalence, sensitivity, and specificity are known, the negative predictive value can be obtained from the following identity:
Single metrics[edit]
In addition to the paired metrics, there are also single metrics that give a single number to evaluate the test.
Perhaps the simplest statistic is accuracy or fraction correct (FC), which measures the fraction of all instances that are correctly categorized; it is the ratio of the number of correct classifications to the total number of correct or incorrect classifications: (TP + TN)/total population = (TP + TN)/(TP + TN + FP + FN). As such, it compares estimates of pre- and post-test probability. This measure is prevalence-dependent. If 90% of people with COVID symptoms don’t have COVID, the prior probability P(-) is 0.9, and the simple rule «Classify all such patients as COVID-free.» would be 90% accurate. Diagnosis should be better than that. One can construct a «One-proportion z-test» with p0 as max(priors) = max(P(-),P(+)) for a diagnostic method hoping to beat a simple rule using the most likely outcome. Here, the hypotheses are «Ho: p ≤ 0.9 vs. Ha: p > 0.9», rejecting Ho for large values of z. One diagnostic rule could be compared to another if the other’s accuracy is known and substituted for p0 in calculating the z statistic. If not known and calculated from data, an accuracy comparison test could be made using «Two-proportion z-test, pooled for Ho: p1 = p2». Not used very much is the complementary statistic, the fraction incorrect (FiC): FC + FiC = 1, or (FP + FN)/(TP + TN + FP + FN) – this is the sum of the antidiagonal, divided by the total population. Cost-weighted fractions incorrect could compare expected costs of misclassification for different methods.
The diagnostic odds ratio (DOR) can be a more useful overall metric, which can be defined directly as (TP×TN)/(FP×FN) = (TP/FN)/(FP/TN), or indirectly as a ratio of ratio of ratios (ratio of likelihood ratios, which are themselves ratios of true rates or prediction values). This has a useful interpretation – as an odds ratio – and is prevalence-independent. Likelihood ratio is generally considered to be prevalence-independent and is easily interpreted as the multiplier to turn prior probabilities into posterior probabilities. Another useful single measure is «area under the ROC curve», AUC.
Alternative metrics[edit]
An F-score is a combination of the precision and the recall, providing a single score. There is a one-parameter family of statistics, with parameter β, which determines the relative weights of precision and recall. The traditional or balanced F-score (F1 score) is the harmonic mean of precision and recall:
- .
F-scores do not take the true negative rate into account and, therefore, are more suited to information retrieval and information extraction evaluation where the true negatives are innumerable. Instead, measures such as the phi coefficient, Matthews correlation coefficient, informedness or Cohen’s kappa may be preferable to assess the performance of a binary classifier.[21][22] As a correlation coefficient, the Matthews correlation coefficient is the geometric mean of the regression coefficients of the problem and its dual. The component regression coefficients of the Matthews correlation coefficient are markedness (deltap) and informedness (Youden’s J statistic or deltap’).[23]
See also[edit]
- Population impact measures
- Attributable risk
- Attributable risk percent
- Scoring rule (for probability predictions)
- Pseudo-R-squared
Weblinks[edit]
- Damage Caused by Classification Accuracy and Other Discontinuous Improper Accuracy Scoring Rules
References[edit]
- ^ Fawcett, Tom (2006). «An Introduction to ROC Analysis» (PDF). Pattern Recognition Letters. 27 (8): 861–874. doi:10.1016/j.patrec.2005.10.010.
- ^ Piryonesi S. Madeh; El-Diraby Tamer E. (2020-03-01). «Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index». Journal of Infrastructure Systems. 26 (1): 04019036. doi:10.1061/(ASCE)IS.1943-555X.0000512.
- ^ Powers, David M. W. (2011). «Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63.
- ^ Ting, Kai Ming (2011). Sammut, Claude; Webb, Geoffrey I. (eds.). Encyclopedia of machine learning. Springer. doi:10.1007/978-0-387-30164-8. ISBN 978-0-387-30164-8.
- ^ Brooks, Harold; Brown, Barb; Ebert, Beth; Ferro, Chris; Jolliffe, Ian; Koh, Tieh-Yong; Roebber, Paul; Stephenson, David (2015-01-26). «WWRP/WGNE Joint Working Group on Forecast Verification Research». Collaboration for Australian Weather and Climate Research. World Meteorological Organisation. Retrieved 2019-07-17.
- ^ Chicco D.; Jurman G. (January 2020). «The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation». BMC Genomics. 21 (1): 6-1–6-13. doi:10.1186/s12864-019-6413-7. PMC 6941312. PMID 31898477.
- ^ Chicco D.; Toetsch N.; Jurman G. (February 2021). «The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation». BioData Mining. 14 (13): 1-22. doi:10.1186/s13040-021-00244-z. PMC 7863449. PMID 33541410.
- ^ Chicco D.; Jurman G. (2023). «The Matthews correlation coefficient (MCC) should replace the ROC AUC as the standard metric for assessing binary classification». BioData Mining. 16 (1). doi:10.1186/s13040-023-00322-4. PMC 9938573.
- ^ Tharwat A. (August 2018). «Classification assessment methods». Applied Computing and Informatics. doi:10.1016/j.aci.2018.08.003.
- ^ Balayla, Jacques (2020). «Prevalence threshold (ϕe) and the geometry of screening curves». PLoS One. 15 (10). doi:10.1371/journal.pone.0240215.
- ^
Balayla, Jacques (2020). «Prevalence threshold (ϕe) and the geometry of screening curves». PLoS One. 15 (10). doi:10.1371/journal.pone.0240215. - ^
Fawcett, Tom (2006). «An Introduction to ROC Analysis» (PDF). Pattern Recognition Letters. 27 (8): 861–874. doi:10.1016/j.patrec.2005.10.010. - ^
Piryonesi S. Madeh; El-Diraby Tamer E. (2020-03-01). «Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index». Journal of Infrastructure Systems. 26 (1): 04019036. doi:10.1061/(ASCE)IS.1943-555X.0000512. - ^
Powers, David M. W. (2011). «Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63. - ^
Ting, Kai Ming (2011). Sammut, Claude; Webb, Geoffrey I. (eds.). Encyclopedia of machine learning. Springer. doi:10.1007/978-0-387-30164-8. ISBN 978-0-387-30164-8. - ^
Brooks, Harold; Brown, Barb; Ebert, Beth; Ferro, Chris; Jolliffe, Ian; Koh, Tieh-Yong; Roebber, Paul; Stephenson, David (2015-01-26). «WWRP/WGNE Joint Working Group on Forecast Verification Research». Collaboration for Australian Weather and Climate Research. World Meteorological Organisation. Retrieved 2019-07-17. - ^
Chicco D, Jurman G (January 2020). «The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation». BMC Genomics. 21 (1): 6-1–6-13. doi:10.1186/s12864-019-6413-7. PMC 6941312. PMID 31898477. - ^
Chicco D, Toetsch N, Jurman G (February 2021). «The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation». BioData Mining. 14 (13): 1-22. doi:10.1186/s13040-021-00244-z. PMC 7863449. PMID 33541410. - ^
Tharwat A. (August 2018). «Classification assessment methods». Applied Computing and Informatics. doi:10.1016/j.aci.2018.08.003. - ^ Information Retrieval Models, Thomas Roelleke, ISBN 9783031023286, page 76, https://books.google.com/books?id=YX9yEAAAQBAJ&pg=PA76
- ^ Powers, David M W (2011). «Evaluation: From Precision, Recall and F-Score to ROC, Informedness, Markedness & Correlation». Journal of Machine Learning Technologies. 2 (1): 37–63. hdl:2328/27165.
- ^ Powers, David M. W. (2012). «The Problem with Kappa» (PDF). Conference of the European Chapter of the Association for Computational Linguistics (EACL2012) Joint ROBUS-UNSUP Workshop. Archived from the original (PDF) on 2016-05-18. Retrieved 2012-07-20.
- ^ Perruchet, P.; Peereman, R. (2004). «The exploitation of distributional information in syllable processing». J. Neurolinguistics. 17 (2–3): 97–119. doi:10.1016/S0911-6044(03)00059-9. S2CID 17104364.
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
- 1 Оценки качества классификации
- 1.1 Матрица ошибок (англ. Сonfusion matrix)
- 1.2 Аккуратность (англ. Accuracy)
- 1.3 Точность (англ. Precision)
- 1.4 Полнота (англ. Recall)
- 1.5 F-мера (англ. F-score)
- 1.6 ROC-кривая
- 1.7 Precison-recall кривая
- 2 Оценки качества регрессии
- 2.1 Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
- 2.2 Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
- 2.3 Коэффициент детерминации
- 2.4 Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
- 2.5 Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
- 2.6 Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
- 2.7 Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
- 3 Кросс-валидация
- 4 Примечания
- 5 См. также
- 6 Источники информации
Оценки качества классификации
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-

Рис.1 Сбалансированная F-мера,
-

Рис.2 F-мера c приоритетом точности,
-

Рис.3 F-мера c приоритетом полноты,
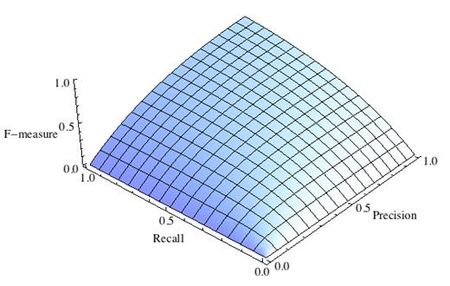
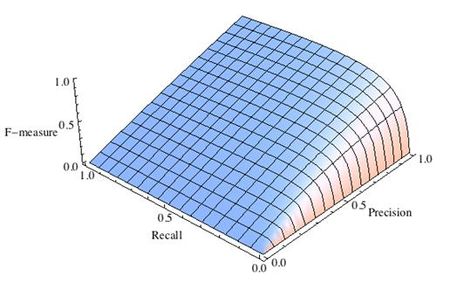
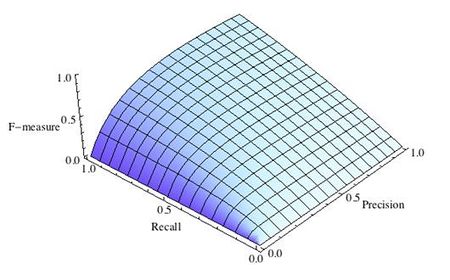
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
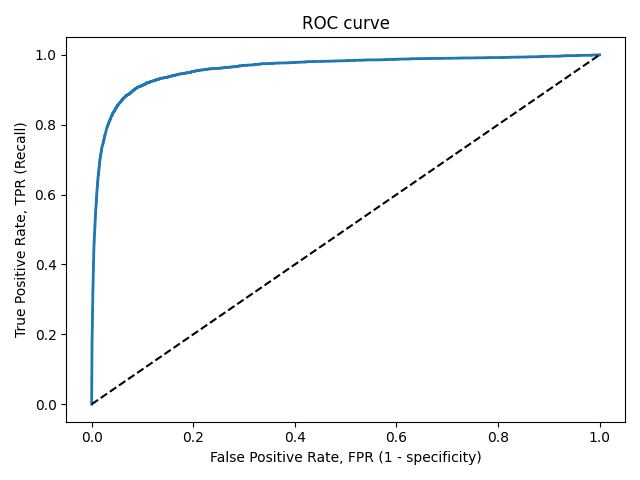
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
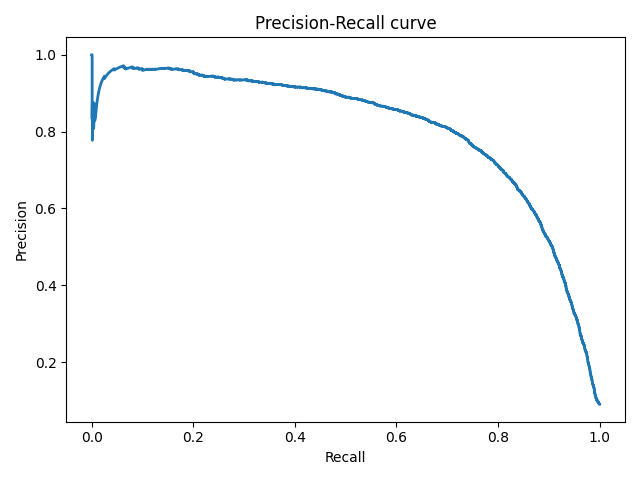
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Оценки качества регрессии
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Кросс-валидация
Хороший способ оценки модели предусматривает применение кросс-валидации (cкользящего контроля или перекрестной проверки).
В этом случае фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Примечания
- [1] Лекция «Оценивание качества» на www.coursera.org
- [2] Лекция на www.stepik.org о кросвалидации
- [3] Лекция на www.stepik.org о метриках качества, Precison и Recall
- [4] Лекция на www.stepik.org о метриках качества, F-мера
- [5] Лекция на www.stepik.org о метриках качества, примеры
См. также
- Оценка качества в задаче кластеризации
- Кросс-валидация
Источники информации
- [6] Соколов Е.А. Лекция линейная регрессия
- [7] — Дьяконов А. Функции ошибки / функционалы качества
- [8] — Оценка качества прогнозных моделей
- [9] — HeinzBr Ошибка прогнозирования: виды, формулы, примеры
- [10] — egor_labintcev Метрики в задачах машинного обучения
- [11] — grossu Методы оценки качества прогноза
- [12] — К.В.Воронцов, Классификация
- [13] — К.В.Воронцов, Скользящий контроль