читать 2 мин
Одна ошибка, с которой вы можете столкнуться при использовании pandas:
KeyError : 'column_name'
Эта ошибка возникает, когда вы пытаетесь получить доступ к несуществующему столбцу в pandas DataFrame.
Обычно эта ошибка возникает, когда вы просто неправильно пишете имена столбцов или случайно включаете пробел до или после имени столбца.
В следующем примере показано, как исправить эту ошибку на практике.
Как воспроизвести ошибку
Предположим, мы создаем следующие Pandas DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'points': [25, 12, 15, 14, 19, 23, 25, 29],
'assists': [5, 7, 7, 9, 12, 9, 9, 4],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]})
#view DataFrame
df
points assists rebounds
0 25 5 11
1 12 7 8
2 15 7 10
3 14 9 6
4 19 12 6
5 23 9 5
6 25 9 9
7 29 4 12
Затем предположим, что мы пытаемся напечатать значения в столбце с именем «точка»:
#attempt to print values in 'point' column
print(df['point'])
KeyError Traceback (most recent call last)
/srv/conda/envs/notebook/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3360 try:
-> 3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
/srv/conda/envs/notebook/lib/python3.7/site-packages/pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
/srv/conda/envs/notebook/lib/python3.7/site-packages/pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError : 'point'
Поскольку в нашем DataFrame нет столбца «точка», мы получаем KeyError .
Как исправить ошибку
Чтобы исправить эту ошибку, просто убедитесь, что мы правильно написали имя столбца.
Если мы не уверены во всех именах столбцов в DataFrame, мы можем использовать следующий синтаксис для печати каждого имени столбца:
#display all column names of DataFrame
print(df.columns.tolist ())
['points', 'assists', 'rebounds']
Мы видим, что есть столбец с именем «точки», поэтому мы можем исправить нашу ошибку, правильно написав имя столбца:
#print values in 'points' column
print(df['points'])
0 25
1 12
2 15
3 14
4 19
5 23
6 25
7 29
Name: points, dtype: int64
Мы избегаем ошибки, потому что правильно написали имя столбца.
Дополнительные ресурсы
В следующих руководствах объясняется, как исправить другие распространенные ошибки в Python:
Как исправить: столбцы перекрываются, но суффикс не указан
Как исправить: объект «numpy.ndarray» не имеет атрибута «добавлять»
Как исправить: при использовании всех скалярных значений необходимо передать индекс
In this article, we will discuss how to fix the KeyError in pandas. Pandas KeyError occurs when we try to access some column/row label in our DataFrame that doesn’t exist. Usually, this error occurs when you misspell a column/row name or include an unwanted space before or after the column/row name.
The link to dataset used is here
Example
Python3
import pandas as pd
df = pd.read_csv('data.csv')
Output:
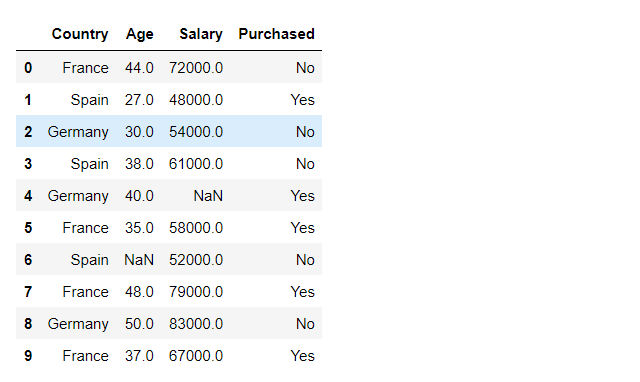
Reproducing keyError :
Python3
output:
KeyError: 'country'
Since there is no column with the name country we get a KeyError.
How to Fix the KeyError?
We can simply fix the error by correcting the spelling of the key. If we are not sure about the spelling we can simply print the list of all column names and crosscheck.
Python3
print(df.columns.tolist())
Output:
['Country', 'Age', 'Salary', 'Purchased']
Using the Correct Spelling of the Column
Python3
Output:
0 France 1 Spain 2 Germany 3 Spain 4 Germany 5 France 6 Spain 7 France 8 Germany 9 France Name: Country, dtype: object
If we want to avoid errors raised by the compiler when an invalid key is passed, we can use df.get(‘your column’) to print column value. No error is raised if the key is invalid.
Syntax : DataFrame.get( ‘column_name’ , default = default_value_if_column_is_not_present)
Python3
df.get('country', default="no_country")
Output:
'no_country'
But when we will use correct spelling we will get the value of the column instead of the default value.
Python3
df.get('Country', default="no_country")
Output:
0 France 1 Spain 2 Germany 3 Spain 4 Germany 5 France 6 Spain 7 France 8 Germany 9 France Name: Country, dtype: object
Last Updated :
28 Nov, 2021
Like Article
Save Article
Pandas KeyError is frustrating. This error happens because Pandas cannot find what you’re looking for.
To fix this either:
- Preferred Option: Make sure that your column label (or row label) is in your dataframe!
- Error catch option: Use df.get(‘your column’) to look for your column value. No error will be thrown if it is not found.
1. df.get('your_column', default=value_if_no_column)Pseudo code: Check to see if a column is in your dataframe, if not, return the default value.
In most cases, think of ‘key’ as the same as ‘name.’ Pandas is telling you that it can not find your column name. The preferred method is to *make sure your column name is in your dataframe.*
OR if you want to try and catch your error, you can use df.get(‘your_column’). However, if you don’t know what columns are in your dataframe…do you really know your data?
It’s best to head back upstream with your code and debug where your expectations and dataframe columns mismatch.
For a general solution, you can use the Try Except convention to catch errors in your code. However, beware. Using a blanket Try/Except clause is dangerous and poor code practice if you do not know what you are doing.
If you are ‘catching’ general errors with try/except, this means that anything can slip through your code. This could result in unexpected errors getting through and a web of complexity.
Goal: Try to never let the reality of your code get too far away from the expectations of your code.
Let’s take a look at a sample:
One error you may encounter when using pandas is:
KeyError: 'column_name'
This error occurs when you attempt to access some column in a pandas DataFrame that does not exist.
Typically this error occurs when you simply misspell a column names or include an accidental space before or after the column name.
The following example shows how to fix this error in practice.
How to Reproduce the Error
Suppose we create the following pandas DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame({'points': [25, 12, 15, 14, 19, 23, 25, 29], 'assists': [5, 7, 7, 9, 12, 9, 9, 4], 'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]}) #view DataFrame df points assists rebounds 0 25 5 11 1 12 7 8 2 15 7 10 3 14 9 6 4 19 12 6 5 23 9 5 6 25 9 9 7 29 4 12
Then suppose we attempt to print the values in a column called ‘point’:
#attempt to print values in 'point' column print(df['point']) KeyError Traceback (most recent call last) /srv/conda/envs/notebook/lib/python3.7/site-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance) 3360 try: -> 3361 return self._engine.get_loc(casted_key) 3362 except KeyError as err: /srv/conda/envs/notebook/lib/python3.7/site-packages/pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc() /srv/conda/envs/notebook/lib/python3.7/site-packages/pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc() pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item() pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item() KeyError: 'point'
Since there is no ‘point’ column in our DataFrame, we receive a KeyError.
How to Fix the Error
The way to fix this error is to simply make sure we spell the column name correctly.
If we’re unsure of all of the column names in the DataFrame, we can use the following syntax to print each column name:
#display all column names of DataFrame print(df.columns.tolist()) ['points', 'assists', 'rebounds']
We can see that there is a column called ‘points’, so we can fix our error by spelling the column name correctly:
#print values in 'points' column print(df['points']) 0 25 1 12 2 15 3 14 4 19 5 23 6 25 7 29 Name: points, dtype: int64
We avoid an error because we spelled the column name correctly.
Additional Resources
The following tutorials explain how to fix other common errors in Python:
How to Fix: columns overlap but no suffix specified
How to Fix: ‘numpy.ndarray’ object has no attribute ‘append’
How to Fix: if using all scalar values, you must pass an index
Python KeyError: How to fix and avoid key errors
A KeyError occurs when a Python attempts to fetch a non-existent key from a dictionary.
This error commonly occurs in dict operations and when accessing Pandas Series or DataFrame values.
In the example below, we made a dictionary with keys 1–3 mapped to different fruit. We get a KeyError: 0 because the 0 key doesn’t exist.
fruit = {
1: 'apple',
2: 'banana',
3: 'orange'
}
print(fruit[1])
print(fruit[0])Out:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[4], line 8
1 fruit = {
2 1: 'apple',
3 2: 'banana',
4 3: 'orange'
5 }
7 print(fruit[1])
----> 8 print(fruit[0])
KeyError: 0There is a handful of other places where we might see the KeyError (the os and zipfile modules, for example). Yet, the main reason for the error stays the same: the searched key is not there.
The easiest, immediate, all-fitting solution to the key error would be wrapping the value-fetching portion of the code in a try-except block. Like the code below does:
fruit = {
1: 'apple',
2: 'banana',
3: 'orange'
}
for key in range(5):
try:
print(fruit[key])
except KeyError:
print("Couldn't find a match for the key:", key)Out:
Couldn't find a match for the key: 0
apple
banana
orange
Couldn't find a match for the key: 4The try-except construct saved our program from terminating, allowing us to avoid the keys that have no match.
In the next section, we’ll use more nuanced solutions, one of which is the _proper_ way of adding and removing dictionary elements.
While working with dictionaries, Series and DataFrames, we can use the in keyword to check whether a key exists.
Below you can see how we can use in with a conditional statement to check the existence of a dictionary key.
info = {
"name": "John",
"surname": "Doe"
}
if "email" in info:
print(info["email"])
else:
print("No e-mail recorded.")This method does not change in the slightest when applying to a Pandas Series, as you can see below:
import pandas as pd
info_series = pd.Series(data=info) # parsed the previous dict to Series
if 'name' in info_series:
print(info_series['name'])We can use the same if key in collection structure when verifying DataFrame column names. However, we have to add a bit more if we want to check a row name.
Let’s start by building a DataFrame to work with:
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d, index=['row1', 'row2'])
print(df)Now we can check whether a column name is in df or a row name is in df.index:
if 'col1' in df:
print('Found col1')
if 'row2' in df.index:
print('Found row2')Out:
Found col1
Found row2We can use the get() method to fetch dictionary elements, Series values, and DataFrame columns (only _columns_, unfortunately).
The get() method does not raise a KeyError when it fails to find the key given. Instead, it returns None, which is more desirable since it doesn’t crash your program.
Take a look at the code below, where fetching the non-existent key3 returns None:
d = {'key1': 111, 'key2': 222}
print(d.get('key3'))get() also allows us to define our own default values by specifying a second parameter.
For example, say we have a website with a few URLs and want to fall back to a 404 page:
urls = {
'home': '/index.html',
'about': '/about.html',
'contact': '/contact.html'
}
print(urls.get('/blog.html', '404.html'))The get() method also works on Pandas DataFrames.
Let’s define one like so:
data = {
'Name': ['John', 'Jane'],
'Age':[34, 19],
'Job':['Engineer','Engineer']
}
df = pd.DataFrame(data)
print(df)We can try and grab two columns by name and provide a default value if one doesn’t exist:
df.get(['Name', 'School'], 'Non-Existent')Since not all the keys match, get() returned 'Non-Existent'.
Programmers learning Pandas often mistake loc for iloc, and while they both fetch items, there is a slight difference in mechanics:
locuses row and column names as identifiersilocuses integer location, hence the name
Let’s create a Series to work with:
data = ['John', 'Peter', 'Gabriel', 'Riley', 'Roland']
index = list('abcde')
names = pd.Series(data, index)
namesOut:
a John
b Peter
c Gabriel
d Riley
e Roland
dtype: objectHow would we retrieve the name «John» from this Series?
We can see John lies in the «a» row, which we can target using loc, like so:
If we were to use iloc for the same purpose, we’d have to use the row’s integer index. Since it’s the first row, and Series are 0-indexed, we need to do the following:
If we used an integer for loc we would get a KeyError, as you can see below:
Out:
Traceback (most recent call last):
File ~\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexes\base.py:3802 in get_loc
return self._engine.get_loc(casted_key)
File pandas\_libs\index.pyx:138 in pandas._libs.index.IndexEngine.get_loc
File pandas\_libs\index.pyx:165 in pandas._libs.index.IndexEngine.get_loc
File pandas\_libs\hashtable_class_helper.pxi:5745 in pandas._libs.hashtable.PyObjectHashTable.get_item
File pandas\_libs\hashtable_class_helper.pxi:5753 in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 0
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
Cell In[36], line 1
names.loc[0]
File ~\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexing.py:1073 in __getitem__
return self._getitem_axis(maybe_callable, axis=axis)
File ~\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexing.py:1312 in _getitem_axis
return self._get_label(key, axis=axis)
File ~\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexing.py:1260 in _get_label
return self.obj.xs(label, axis=axis)
File ~\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\generic.py:4056 in xs
loc = index.get_loc(key)
File ~\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexes\base.py:3804 in get_loc
raise KeyError(key) from err
KeyError: 0Note that this is only true for the cases where the row labels have different values than the indexes.
Now we’ll look closer at the operations that may cause KeyError and offer good practices to help us avoid it.
Let’s give an example of how this may go wrong:
fruit_list = ['apple', 'berries', 'apple', 'pear', 'berries']
fruit_dict = {}
for item in fruit_list:
fruit_dict[item] += 1Out:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[15], line 5
2 fruit_dict = {}
4 for item in fruit_list:
----> 5 fruit_dict[item] += 1
KeyError: 'apple'It’s clear this is a mistake since the code is trying to fetch items from an empty dictionary, but this example demonstrates the problem of wanting to use a dictionary as if it already had the keys present.
We could write another loop at the start that initializes each value to zero, but Python offers defaultdicts for such situations. They are type-specific dictionaries with defaults for handling new keys.
Take a look:
from collections import defaultdict
fruit_list = ['apple', 'berries', 'apple', 'pear', 'berries']
fruit_dict = defaultdict(int) # instead of {}
for item in fruit_list:
fruit_dict[item] += 1
print(fruit_dict)Out:
defaultdict(<class 'int'>, {'apple': 2, 'berries': 2, 'pear': 1})The only change needed is swapping in defaultdict for the empty brackets. The defaultdict is of type int, meaning that the access of any new key will auto-create that key with an initial value of 0.
This also works for more complex scenarios, like if you want a default value to be a list. In the following example, we generate ten random numbers and store them as either even or odd:
from collections import defaultdict
import random
numbers = defaultdict(list)
for i in range(10):
r = random.randint(1, 5)
if r % 2 == 0:
numbers['even'].append(r)
else:
numbers['odd'].append(r)
print(numbers)Out:
defaultdict(<class 'list'>, {'odd': [1, 1, 1, 3, 1, 1], 'even': [4, 4, 2, 4]})Using defaultdict(list) we’re able to immediately append to the «even» or «odd» keys without needing to inialized lists beforehand.
Deleting dictionary keys runs into the same problem as accessing keys: first we need to get the key using \[\] to delete it.
We can always check whether the key exists before attempting to delete the value assigned to it, like so:
babies = {
'cat':'kitten',
'dog':'pup',
'bear':'cub'
}
if 'bear' in babies:
del babies['bear']
babiesOut:
{'cat': 'kitten', 'dog': 'pup'}A quicker way, however, would be to pop() the value out of the dictionary, effectively deleting it if we don’t assign it to a variable.
pop() takes the desired key as its first parameter and, similar to get(), allows us to assign a fall-back value as the second parameter.
Take a look:
babies = {'cat':'kitten', 'dog':'pup', 'bear':'cub'}
baby = babies.pop('lion', 'nope, no lion')
print(baby)Since Python couldn’t find the key, pop() returned the default value we assigned.
If the key exists, Python will remove it. Let’s run pop() one more time with a key we know exists:
babies.pop('cat')
print(babies)Out:
{'dog': 'pup', 'bear': 'cub'}The 'cat' was found and removed.
KeyError occurs when searching for a key that does not exist. Dictionaries, Pandas Series, and DataFrames can trigger this error.
Wrapping the key-fetching code in a try-except block or simply checking whether the key exists with the in keyword before using it are common solutions to this error. One can also employ get() to access elements from a dictionary, Series or DataFrame without risking a KeyError.