В своей прошлой статье «Как использовать Монитор ресурсов Windows 7 для эффективной диагностики» я рассказал о возможностях Монитора ресурсов Windows 7 (Resource Monitor), объяснил, как с его помощью наблюдать за распределением системных ресурсов между процессами и службами, а также упомянул, что его можно использовать для решения конкретных задач — например, для анализа расходования памяти. Именно об этом и пойдет речь в данной статье.Немного о памяти
Прежде чем приступать к анализу, коротко расскажу о том, как Microsoft Windows 7 управляет памятью. После этого вам будет проще понять, какая информация представлена в Мониторе ресурсов Windows 7.
Диспетчер памяти Windows 7 создает виртуальную систему памяти, которая состоит из доступной физической RAM и файла подкачки на жестком диске. Это позволяет операционной системе выделять блоки памяти фиксированной длины (страницы) с последовательными адресами в физической и виртуальной памяти.
Запуск Монитора ресурсов Windows 7
Чтобы запустить Монитор ресурсов Windows 7, откройте меню «Пуск» (Start), введите в строке поиска «Resmon.exe» и нажмите [Enter]. В открывшемся окне выберите вкладку «Память» (Memory, рис. A).

Рисунок A. На вкладке «Память» в Мониторе ресурсов Windows 7 приводятся подробные сведения о распределении памяти.
Таблица «Процессы»
На вкладке «Память» есть таблица «Процессы» (Processes, рис. B), в которой перечислены все запущенные процессы, а сведения об используемой памяти разбиты на несколько категорий.

Рисунок B. Сведения об используемой памяти для каждого процесса разбиты на несколько категорий.
Графа «Образ»
В колонке «Образ» (Image) указывается имя исполняемого файла процесса. Процессы, запущенные приложениями, узнать очень легко — например, процесс «notepad.exe» со всей очевидностью принадлежит Блокноту (Notepad). Процессы с именем «svchost.exe» представляют различные службы операционной системы. Название службы указывается в скобках рядом с именем процесса.
Графа «ИД процесса»
В колонке «ИД процесса» (PID) указывается номер процесса — уникальное сочетание цифр, позволяющее идентифицировать запущенный процесс.
Графа «Завершено»
В столбце «Завершено» (Commit) указывается объем виртуальной памяти в килобайтах, зарезервированный системой для данного процесса. Сюда входит и используемая физическая память, и сохраненные в файле подкачки страницы.
Графа «Рабочий набор»
В графе «Рабочий набор» (Working Set) указывается объем физической памяти в килобайтах, используемой процессом в данный момент времени. Рабочий набор складывается из общей и частной памяти.
Графа «Общий»
В колонке «Общий» (Shareable) указан объем физической памяти в килобайтах, которую данный процесс использует совместно с другими. Использование одного сегмента памяти или страницы подкачки для родственных процессов позволяет сэкономить место в памяти. При этом физически сохраняется только одна копия страницы, которая затем сопоставляется с виртуальным адресным пространством других процессов, которые к ней обращаются. Например, все процессы, инициированные системными библиотеками DLL — Ntdll, Kernel32, Gdi32 и User32 — используют общую память.
Графа «Частный»
В столбце «Частный» (Private) указывается объем физической памяти в килобайтах, используемой исключительно данным процессом. Именно это значение позволяет определить, сколько памяти нужно тому или иному приложению для работы.
Графа «Ошибок отсутствия страницы в памяти/сек.»
В графе «Ошибок отсутствия страницы в памяти/сек.» (Hard Faults/sec) указано среднее за последнюю минуту количество ошибок отсутствия страницы в памяти в секунду. Если процесс пытается использовать больше физической памяти, чем доступно в данный момент времени, система записывает часть данных из памяти на диск — в файл подкачки. Последующее обращение к данным, сохраненным на диск, и называется ошибкой отсутствия страницы в памяти.
О чем говорят ошибки отсутствия страницы в памяти
Теперь, когда вы представляете, какие сведения собраны в таблице «Процессы», давайте посмотрим, как с их помощью следить за распределением памяти. При запуске приложений и работе с файлами диспетчер памяти отслеживает объем рабочего набора для каждого процесса и фиксирует запросы на дополнительные ресурсы памяти. По мере увеличения рабочего набора процесса, диспетчер соотносит эти запросы с потребностями ядра и других процессов. Если доступного адресного пространства недостаточно, диспетчер уменьшает объем рабочего набора, сохраняя данные из памяти на диск.
В дальнейшем при чтении этих данных с диска возникает ошибка отсутствия страницы в памяти. Это вполне нормально, но если ошибки происходят одновременно для разных процессов, системе требуется дополнительное время для чтения данных с диска. Слишком частые ошибки отсутствия страницы в памяти, соответственно, снижают быстродействие системы. Вам наверняка доводилось наблюдать неожиданное замедление работы всех приложений, которое затем также неожиданно прекращалось. Почти наверняка это замедление было связано с активным перераспределением данных между физической памятью и подкачкой.
Отсюда следует вывод: если ошибки отсутствия страницы в памяти для того или иного процесса происходят слишком часто и притом регулярно, компьютеру не хватает физической памяти.
Чтобы было удобнее наблюдать за процессами, вызывающими частые ошибки отсутствия страницы в памяти, можно отметить их флажками. При этом выбранные процессы переместятся наверх списка, а в графике ошибок отсутствия страницы в памяти будут представлены оранжевой кривой.
Стоит учитывать, что распределение памяти зависит от целого ряда других факторов, и мониторинг ошибок отсутствия страницы в памяти — не лучший и не единственный способ выявления проблем. Тем не менее, он может послужить неплохой отправной точкой для наблюдения.
Таблица «Физическая память»
В таблице «Процессы» приводятся детальные сведения о распределении памяти между отдельными процессами, а таблица «Физическая память» (Physical Memory) дает общую картину использования RAM. Ее ключевой компонент — уникальная гистограмма, показанная на рис. C.

Рисунок C. Гистограмма в таблице «Физическая память» позволяет составить общее представление о распределении памяти в Windows 7.
Каждая секция гистограммы обозначена собственным цветом и представляет определенную группу страниц памяти. По мере использования системы, диспетчер памяти в фоновом режиме перемещает данные между этими группами, поддерживая тонкий баланс между физической и виртуальной памятью для обеспечения эффективной работы всех приложений. Давайте рассмотрим гистограмму поподробнее.
Секция «Зарезервированное оборудование»
Слева расположена секция «Зарезервированное оборудование» (Hardware Reserved), обозначенная серым цветом: это память, выделенная на нужды подключенного оборудования, которую оно использует для взаимодействия с операционной системой. Зарезервированная для оборудования память заблокирована и недоступна диспетчеру памяти.
Обычно объем памяти, выделенной оборудованию, составляет от 10 до 70 Мбайт, однако этот показатель зависит от конкретной конфигурации системы и в некоторых случаях может достигать нескольких сотен мегабайт. К компонентам, влияющим на объем зарезервированной памяти, относятся:
• BIOS;
• компоненты материнской платы — например, усовершенствованный программируемый контроллер прерываний ввода/вывода (APIC);
• звуковые карты и другие устройства, осуществляющие ввод/вывод с отображением на память;
• шина PCI Express (PCIe);
• видеокарты;
• различные наборы микросхем;
• флеш-накопители.
Некоторые пользователи жалуются, что в их системах для оборудования зарезервировано ненормально много памяти. Мне с такой ситуацией сталкиваться не приходилось и потому я не могу ручаться за действенность предложенного решения, но многие отмечают, что обновление версии BIOS позволяет решить проблему.
Секция «Используется»
Секция «Используется» (In Use, рис C), обозначенная зеленым цветом, представляет количество памяти, используемой системой, драйверами и запущенными процессами. Количество используемой памяти рассчитывается, как значение «Всего» (Total) за вычетом суммы показателей «Изменено» (Modified), «Ожидание» (Standby) и «Свободно» (Free). В свою очередь, значение «Всего» — это показатель «Установлено» (Installed RAM) за вычетом показателя «Зарезервированное оборудование».
Секция «Изменено»
Оранжевым цветом выделена секция «Изменено» (Modified), в которой представлена измененная, но не задействованная память. Фактически она не используется, но может быть в любой момент задействована, если снова понадобится. Если память не используется достаточно давно, данные переносятся в файл подкачки, а память переходит в категорию «Ожидание».
Секция «Ожидание»
Секция «Ожидание», обозначенная синим цветом, представляет страницы памяти, удаленные из рабочих наборов, но по-прежнему с ними связанные. Другими словами, категория «Ожидание» — это фактически кэш. Страницам памяти в этой категории присваивается приоритет от 0 до 7 (максимум). Страницы, связанные с высокоприоритетными процессами, получают максимальный приоритет. Например, совместно используемые процессы обладают высоким приоритетом, поэтому связанным с ними страницам присваивается наивысший приоритет в категории «Ожидание».
Если процессу требуются данные с ожидающей страницы, диспетчер памяти сразу же возвращает эту страницу в рабочий набор. Тем не менее, все страницы в категории «Ожидание» доступны для записи данных от других процессов. Когда процессу требуется дополнительная память, а свободной памяти недостаточно, диспетчер памяти выбирает ожидающую страницу с наименьшим приоритетом, инициализирует ее и выделяет запросившему процессу.
Секция «Свободно»
В категории «Свободно», обозначенной голубым цветом, представлены страницы памяти, еще не выделенные ни одному процессу или освободившиеся после завершения процесса. В этой секции отображается как еще не задействованная, так и уже освобожденная память, но на самом деле, еще не задействованная память относится к другой категории — «Нулевые страницы» (Zero Page), которая так называется, потому что эти страницы инициализированы нулевым значением и готовы для использования.
О проблеме свободной памяти
Теперь, когда вы в общих чертах представляете, как работает диспетчер памяти, ненадолго остановимся на распространенном заблуждении, связанном с системой управления памятью в Windows 7. Как видно из рис. C, секция свободной памяти — одна из самых маленьких в гистограмме. Тем не менее, ошибочно на этом основании полагать, будто Windows 7 потребляет чересчур много памяти и что система не может нормально работать, если свободной памяти так мало.
На самом деле, все совсем наоборот. В контексте принятого в Windows 7 подхода к управлению памятью, свободная память бесполезна. Чем больше памяти задействовано, тем лучше. Заполняя память до максимума и постоянно перемещая страницы из одной категории в другую с использованием системы приоритетов, Windows 7 повышает эффективность работы и предотвращает попадание данных в файл подкачки, не давая ошибкам отсутствия страницы в памяти замедлить быстродействие.
Мониторинг памяти
Хотите понаблюдать систему управления памятью Windows 7 в действии? Перезагрузите компьютер и сразу же после запуска откройте Монитор ресурсов Windows 7. Перейдите на вкладку «Память» и обратите внимание на соотношение секций в гистограмме физической памяти.
Затем начните запускать приложения. По мере запуска следите за изменением гистограммы. Запустив как можно больше приложений, начните закрывать их по одному и наблюдайте, как изменяется соотношение секций в гистограмме физической памяти.
Проделав этот экстремальный эксперимент, вы поймете, как Windows 7 управляет памятью на вашем конкретном компьютере, и сможете использовать Монитор ресурсов Windows 7 для наблюдения за распределением памяти в нормальных условиях повседневной работы.
А что думаете вы?
Нравится ли вам идея использовать Монитор ресурсов Windows 7 для наблюдения за распределением памяти? Поделитесь своим мнением в комментариях!
Автор: Greg Shultz
Перевод
SVET
Оцените статью: Голосов
При работе с любой системой необходимо понимать качество ее работы. Для этого необходимо собирать, контролировать и анализировать определенные показатели этой системы. В данной статье мы рассмотрим «экспресс» настройку инструмента «Системный монитор» (performance monitor, perfmon), входящий в поставку операционной системы Windows, а так же рассмотрим какие показатели нас интересуют в первую очередь при мониторинге системы на базе Windows и MS SQL Server.
Создание группы сборщиков данных
Во-первых, нам необходимо открыть «Системный монитор». Для этого можно воспользоваться командной Win+R, в строке ввести команду perfmon.exe и нажать ОК. Альтернативой способ: перейти в «Панель управления» (Control panel) → «Администрирование» (Administrative tools) → «Системный монитор» (Performance monitor). После этого необходимо в дереве (в окне системного монитора) перейти в «Группы сборщиков данных» (Data Collector Sets), далее «Особый» (User Defined), сделать клик правой клавишей мыши, в контекстном меню выбрать «Создать» (New) → Группа сборщиков данных (Data Collector Set)».
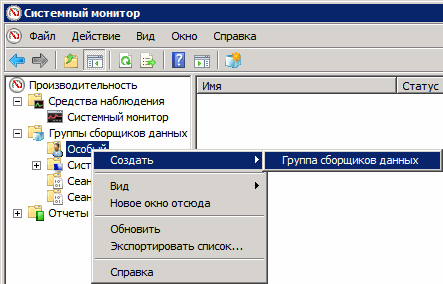
В открывшемся окне зададим пользовательское имя для группы и выберем «Создать вручную (для опытных)» (Create manually (advanced)) и кнопку «Далее» (Next).
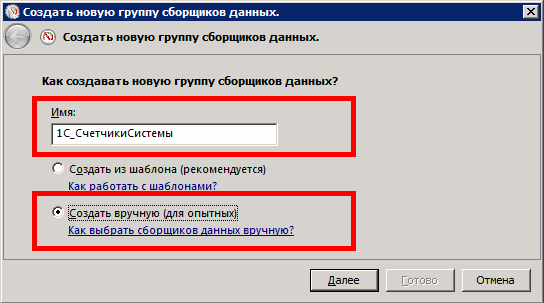
На следующем шаге укажем «Создать журналы данных» (Create data logs) и выберем «Счетчик производительности» (Performance counter).
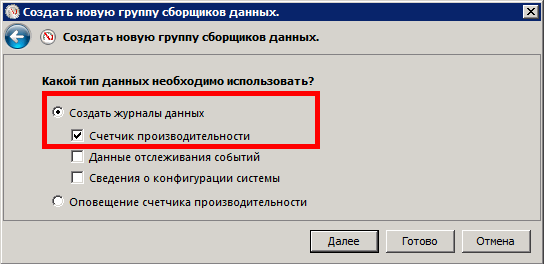
Далее установим интервал выборки (sample interval) в значение 5 секунд и нажмем «Добавить» (Add).
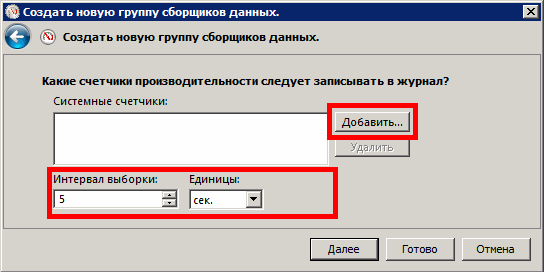
В новом окне в списке «Имеющиеся счетчики» (Available counters) найдем интересующий нас счетчик, например, «% загруженности процессора» (% processor time), из списка «Экземпляры выбранного объекта» (Instances of selected object) выберем интересующий нас, например, «_Total» и нажмем «Добавить» (Add), после чего счетчик появится в правом окне «Добавленные счетчики» (Added counters). Если Вы плохо знакомы с назначением счетчиков, тогда стоит установить флажок «Отображать описание» (Show description), при включении которого будет выведено окошко с описанием счетчика. Нажмем «ОК» и вернемся к предыдущему окну, в котором нажмем «Далее» (Next). Список наиболее интересных счетчиков, их назначение и рекомендуемые интервалы значений будут приведены ниже в этой статье.
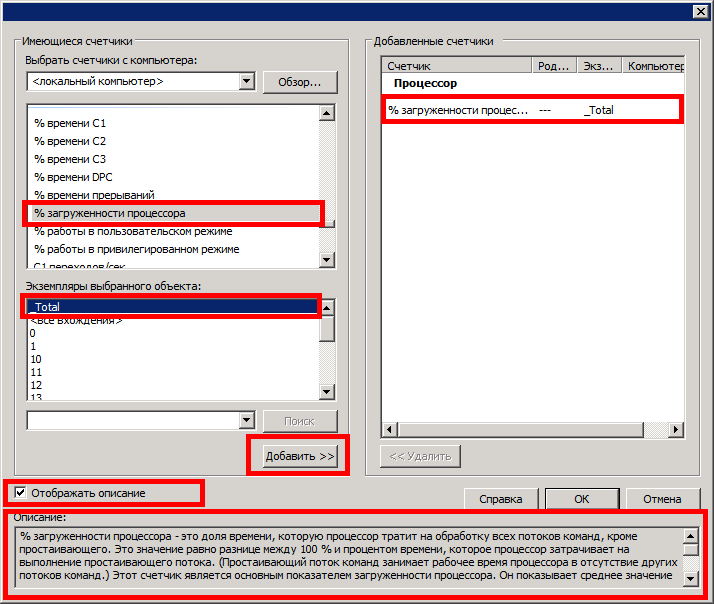
На следующем этапе необходимо указать системе в каком каталоге будут сохраняться данные группы сборщиков и нажать «Далее» (Next)
И, наконец, на последней странице мастера создания группы сборщиков данных необходимо выбрать одно из завершающих действий: «Открыть свойства группы сборщиков данных» (Open properties for this data collector set) — для более тонкой настройки группы, которую можно выполнить и в любой момент позднее; «Запустить группу сборщиков данных сейчас» (Start this data collector set now) — для того чтобы сохранить и начать замер немедленно; «Сохранить и закрыть» (Save and close) — только для того чтобы сохранить.
На этом «экспресс» создание группы сборщиков данных завершено, теперь давайте же вернемся к вопросу о том какие счетчики нас интересуют.
Счетчики производительности
В таблицах ниже приведены наиболее интересные счетчики производительности для ОС Windows и MS SQL Server. Там же можно найти описания счетчиков и рекомендуемые значения показателей.
Счетчики производительности системы на операционной системе Windows
| Показатель | Группа | Описание | Значение |
|---|---|---|---|
| Free Megabytes | Logical Disk | Показывает объем незанятого пространства на диске в мегабайтах | Много больше 0 Мбайт для системного диска, дисков файлов БД и служебных файлов 1С |
| Available MBytes | Memory | Объем физической памяти в мегабайтах, немедленно доступной для выделения процессу или для использования системой. Эта величина равна сумме памяти, выделенной для кэша, свободной памяти и обнуленных страниц памяти | Много больше 0 Мбайт |
| Page Reads/sec | Memory | Число операций чтения диска при получении страниц виртуальной памяти для разрешения ошибок страницы. При выполнении одной операции чтения могут быть получены одновременно несколько страниц. Ошибка чтения страницы возникает при обращении процесса к виртуальной памяти, не принадлежащей рабочему множеству или физической памяти, и должна быть извлечена с диска | |
| Page Writes/sec | Memory | Счетчик записи страниц на диск, выполняемой для освобождения места в оперативной памяти. Страницы записываются на диск только в том случае, если они были изменены в оперативной памяти, поэтому они вероятнее всего содержат данные, а не программный код. Этот счетчик отображает число операций записи, без учета числа страниц, записываемых при каждой операции. Этот счетчик показывает разницу значений между двумя последними снятыми показаниями, деленную на длительность интервала измерения. | |
| Bytes Total/sec | Network Interface | Скорость, с которой происходит получение или посылка байт через сетевые адаптеры, включая символы обрамления (framing characters) | Не более 65% от пропускной способности сетевого интерфейса |
| Avg. Disk Queue Length | Physical Disk | Среднее общее количество запросов на чтение и на запись, которые были поставлены в очередь для соответствующего диска в течение интервала измерения | Не более 2 на каждый из параллельно работающих дисков |
| Avg. Disk sec/Transfer | Physical Disk | Время в секундах, затрачиваемое в среднем на один обмен данными с диском | В среднем 10 мс; В пиках не более 300 мс |
| % Processor Time | Processor(_Total) | Доля времени, которую процессор тратит на обработку всех потоков команд, кроме простаивающего. Этот счетчик является основным показателем загруженности процессора. Он показывает среднее значение занятости процессора в течение интервала измерения | Не более 70% в течении длительного времени |
| Processor Queue Length | System | Текущая длина очереди процессора, измеряемая числом ожидающих потоков. Все процессоры используют одну общую очередь, в которой потоки ожидают получения циклов процессора. Этот счетчик не включает потоки, которые выполняются в настоящий момент. Этот счетчик отражает текущее значение, и не является средним значением по некоторому интервалу времени | Не более 2 на каждое ядро процессора |
Соответствие наименований счетчиков по-английски и по-русски (Windows 7)
| По-английски | По-русски |
|---|---|
| Logical DiskFree Megabytes | Логический дискСвободно мегабайт |
| MemoryAvailable MBytes | ПамятьДоступно МБ |
| MemoryPage Reads/sec | ПамятьЧтений страниц/с |
| MemoryPage Writes/sec | ПамятьОпераций вывода страниц/с |
| Network InterfaceBytes Total/sec | Сетевой интерфейсВсего байт/с |
| Physical DiskAvg. Disk Queue Length | Физический дискСредняя длина очереди диска |
| Physical DiskAvg. Disk sec/Transfer | Физический дискСреднее время обращения к диску (с) |
| Processor% Processor Time | Процессор% загруженности процессора |
| SystemProcessor Queue Length | СистемаДлина очереди процессора |
Счетчики производительности для MS SQL Server
| Показатель | Группа | Описание | Значение |
|---|---|---|---|
| Table Lock Escalations/sec | Access Methods | Количество раз, когда блокировки таблицы были укрупнены | Стремящееся к 0 |
| Page life expectancy | Buffer Manager | Количество секунд, в течение которых страница остается в буферном пуле без ссылок на нее | Не менее 300 с |
| Buffer cache hit ratio | Buffer Manager | Процент найденных в буферном пуле страниц, что исключило необходимость чтения с диска | Стремящееся к 100% |
| Average Latch Wait Time (ms) | Latches | Среднее время ожидания (мс) для запросов кратковременной блокировки | Стремящееся к 0 мс |
| Average Wait Time (ms) | Locks | Среднее время ожидания (в миллисекундах) для всех ждавших запросов блокировки | Стремящееся к 0 мс |
| Lock Waits/sec | Locks | Количество запросов блокировки, которые не были выполнены немедленно и ожидали предоставления блокировки | Стремящееся к 0 |
| Lock Timeouts/sec | Locks | Количество запросов блокировки, время ожидания которых истекло, включая запросы блокировок NOWAIT. | Стремящееся к 0 |
| Number of Deadlocks/sec | Locks | Количество запросов блокировки, приведших к взаимоблокировкам | Стремящееся к 0 |
| Cache Hit Ratio | Plan Cache | Соотношение между попаданиями в кэш и обращениями к кэшу | Стремящееся к 100% |
| Longest Transaction Running Time | Transactions | Наиболее продолжительное время выполнения какой-либо транзакции в секундах | Для OLTP систем не должно быть высоким |
| Transactions | Transactions | Общее количество активных транзакций. | — |
Cлужебную программу Windows 98 под названием Системный монитор можно рассматривать как своего рода приборную панель ПК. Подобно панели приборов в автомобиле, он оперативно оповещает о состоянии машины и может своевременно сообщить о том, что под кожухом ПК назревает какая-либо неприятность.
На графиках, выстраиваемых Системным монитором в реальном времени отображены основные статистические данные, характеризующие работу ПК. Кроме того, в реальном времени можно наблюдать за изменением различных настроек системы, в том числе относящихся к памяти и влияющих на работу центрального процессора, а также многих других, что очень удобно для оптимизации работы ПК или поиска неисправностей.
Системный монитор можно найти, выбрав опции «Пуск?Программы?Стандартные?Служебные?Системный монитор». Если программы там не окажется, то проинсталлируйте ее с помощью утилиты «Установка и удаление программ», находящейся на Панели управления. Для этого выберите закладку «Установка Windows» и щелкните на строке «Служебные».

|
Рис. 1. Графики программы Системный монитор отображают полезные сведения о работе ПК |
Когда Системный монитор заработает, следует задать наилучшую форму представления выбранных статистических показателей. Для вывода того или иного показателя в окно Системного монитора откройте меню «Правка» и сначала выберите опцию «Добавить показатель», а затем и сам этот показатель среди семи различных категорий, список которых отображается в одном подокне, а список показателей — в другом.
Однако перед тем как добавлять показатели для просмотра, вы, возможно, захотите настроить окно Системного монитора. Надо сделать так, чтобы статистические данные Системного монитора были доступны для ознакомления во время повседневной работы. Простейший способ добиться этого — запускать Системный монитор в маленьком удобном окошке, к тому же расположенном так, чтобы оно, если возможно, не мешало выполнению других задач.
|
|
Рис. 2. Для удобства просмотра выберите в меню «Вид» Системного монитора опцию «Поверх других окон» |
Чтобы придать окну Системного монитора примерно такой же вид, как на рис. 2, откройте меню «Вид» этой программы и выберите опцию «Числовое представление». Линейные и столбчатые диаграммы многоцветны и привлекательны на вид, однако числовое представление правильнее и легче воспринимается. Включите также опции «Поверх остальных окон» и «Скрыть заголовок».
Теперь установите желаемый размер окна Системного монитора и поместите его на краю экрана, где он ничему не помешает. Если вы готовы использовать для идентификации показателей цвет рамочек вместо подписей, то окно можно сделать весьма небольшим.
Что стоит за цифрами
В принципе для просмотра доступно гораздо больше всяческих статистических показателей, чем вам когда-либо захочется увидеть на одном экране. Большинство из них покажутся неискушенным пользователям излишне «техническими» (и, увы, объяснения сути этих показателей, выдаваемые при щелчке на кнопке «Сведения» в окне «Добавить показатель», сложно воспринимать всерьез). Но все же знакомство с некоторыми показателями будет небесполезно.
Ядро: использование процессора. Это отменный индикатор суммарной вычислительной нагрузки, приходящейся на ПК. Если ЦП постоянно загружен более чем на 75%, то ПК явно переутомляется. Причинами столь высокой нагрузки могут быть нехватка памяти, слишком большое число одновременно работающих программ или же какой-нибудь испорченный продукт, не желающий освобождать процессор от своего присутствия. В отдельных случаях можно разрешить эту проблему, увеличив объем ОЗУ, а иногда требуется более мощная система.
Если ваш ЦП функционирует с большой нагрузкой, скажем, потому, что вы вынуждены запускать на старом ПК обновленное и требовательное к аппаратной части ПО, то убедитесь, что вентиляторы процессора и блока питания работают исправно, и проверьте, нет ли препятствий для прохождения воздуха через корпус компьютера. Ведь вы должны помнить, что сильно загруженный ЦП разогревается, и без надлежащего охлаждения микросхема может выйти из строя.
Ядро: потоки команд. Активные потоки команд (threads, букв. «нити») — небольшие порции ПО, занимающие собой ОЗУ. То, какое их количество в ОЗУ считается оптимальным, зависит от используемых программ. В ОЗУ моей настольной системы, не подсоединенной к сети, при работе Windows 98 и отсутствии открытых приложений обычно находится от 50 до 70 цепочек выполняемых команд.
Прочувствовав, что является нормой для вашего ПК, следите за внезапными изменениями параметров. Если какая-нибудь программа увеличивает при своем запуске число потоков команд, но не освобождает от них ОЗУ после своего закрытия, то она может «пожирать» память, что по-английски называется memory leak — утечка памяти.
Такая утечка часто возникала при работе ПК в среде Windows 3.x, и единственным способом справиться с нею был перезапуск системы. В Windows 9x подобное хотя и бывает гораздо реже, но все же случается, особенно при использовании более старых 16-разрядных приложений; для освобождения памяти при этом обычно бывает достаточно закрыть приложение, вызвавшее путаницу.
Если какая-либо новая 32-разрядная программа (написанная для Windows 9x) упорно «пожирает» память, оставляя «застрявшие» последовательности команд, то источником проблем может оказаться какой-нибудь испорченный файл. Когда дело обстоит именно так, вам следует переустановить содержащее такой файл приложение.
Диспетчер памяти: свободная физическая память. Как вы, должно быть, и ожидали, этот параметр характеризует объем физической оперативной памяти, которая остается свободной. Удивить же вас может то, как мало ее бывает при работе в среде Windows даже в том случае, когда запущено совсем немного приложений. Дело обстоит так потому, что Windows непрерывно перемещает данные между ОЗУ и расположенным на жестком диске файлом подкачки. Параметр «Свободная физическая память» будет особенно информативен, если рассматривать его совместно со следующими шестью статистическими показателями употребления памяти.
Диспетчер памяти: размер файла подкачки. Система Windows использует файл подкачки (называемый также виртуальной памятью) в качестве временного хранилища тех данных из ОЗУ, которые не требуются в тот же момент. Благодаря этому ОС поддерживает одновременную работу большего количества программ, чем может поместиться на одном лишь физически установленном ОЗУ.
Размер файла подкачки равен размеру файла, создаваемого Windows на жестком диске. Если объем дискового пространства в системе ограничен, то с помощью данного статистического показателя можно сбалансировать свои потребности в пространстве для хранения данных на жестком диске с потребностями Windows в виртуальной памяти.
Диспетчер памяти: занято в файле подкачки. Этот параметр показывает, каков объем данных из ОЗУ, реально хранящихся в файле подкачки в каждый конкретный момент.
Диспетчер памяти: ошибки страниц; очищенные страницы. Если какой-либо из этих двух показателей внезапно подскакивает выше нормы, то это может означать, что работа Windows слишком сильно зависит от применения файла подкачки. А если рост значения данных параметров сопровождается замедлением работы системы, то нужно увеличить объем ОЗУ.
Диспетчер памяти: выделено памяти. Данный параметр указывает общий объем данных, с которыми Windows манипулирует в памяти. Чтобы точно определить, в каком объеме оперативной памяти нуждается та или другая конкретная программа, вычтите один раз значение показателя «Диспетчер памяти: кэш-память диска» (см. ниже) из значения показателя «Выделено памяти», когда интересующая вас программа работает, и еще раз, когда не работает. Разница между полученными значениями и будет равняться объему ОЗУ, используемому программой.
Диспетчер памяти: заблокированная память. Заблокированной памятью называют такой объем данных, который должен оставаться в физическом ОЗУ и который не может копироваться на жесткий диск. Если какое-либо приложение держит значительную часть данных «запертой» в ОЗУ, то работа других приложений может замедлиться, поскольку увеличивается объем относящихся к ним данных, а последние должны переписываться между диском и ОЗУ.
Диспетчер памяти: кэш-память диска. Этот показатель сообщает, какая часть ОЗУ выделена под кэширование данных с жесткого диска. В системах, работающих в среде первоначальной версии Windows 95 с файловой системой FAT 16, вы, возможно, сумеете сэкономить несколько мегабайт оперативной памяти, уменьшив значение этого параметра.
Понаблюдайте за значением показателя кэш-памяти диска, чтобы определить максимальные потребности системы в кэшировании. Если вы обнаружите более чем мегабайтную разницу между объемом используемой диском кэш-памяти и ее фиксированным максимальным значением, определяемым настройкой параметра MaxFileCache= в разделе [vcache] файла system.ini, то сумеете сохранить часть напрасно расходуемой оперативной памяти, уменьшив значение этого параметра. Конечно, объем памяти, который вы таким образом сбережете, может и не стоить таких хлопот, если объем ОЗУ системы превосходит 32 Мбайт. Но если вы работаете с 32-Мбайт или менее вместительным ОЗУ, то ваши приложения от прибавки оперативной памяти только выиграют.
Dial-Up Adapter: получено байт/с. Это удобный индикатор для проверки скорости телефонного соединения. Помимо него Системный монитор отслеживает еще и значение показателя «Передано байт/с».
Погашенный экран — лучше
? Я каждый день постоянно отхожу от своего рабочего стола то на несколько минут, а то и на несколько часов, оставляя ПК и монитор работающими. Мне сказали, что если я хочу продлить срок службы монитора, то должен пользоваться программой — хранителем экрана. Следовать ли мне такому совету?
Алан Холперн, Чикаго
|
|
Рис. 3. Для автоматического отключения монитора используйте утилиту «Управление электропитанием», расположенную на Панели управления |
!Скорее всего, нет. В ранний юрский период развития вычислительной техники, когда в ландшафте настольных систем преобладали монохромные мониторы, хранители экрана действительно были необходимой частью ПО. Если монохромные мониторы оставались включенными и воспроизводящими при этом в течение длительного времени одно и то же изображение, то оно могло оказаться в результате выжженным на поверхности экрана. Однако фосфорное покрытие современных цветных мониторов подвержено выгоранию в гораздо меньшей степени, так что нынешние программы — хранители экрана служат главным образом для развлечения, а также являются удобным инструментом для защиты ПК паролем при долгой отлучке.
На самом деле использование хранителя экрана может даже укоротить срок службы монитора. Наиболее уязвимый компонент цветных дисплеев — электронная пушка, которая управляет пучками лучей, вызывающих свечение экрана. И лучший способ продлить срок ее жизни — просто отключать неработающий монитор. А если вам лень делать это вручную всякий раз, когда вы отходите от стола, то предоставьте Windows 98 отключать монитор. Для этого надо открыть утилиту «Управление электропитанием», расположенную на Панели управления, и щелкнуть на закладке «Схемы управления электропитанием».
Даже при применении схемы «Включен постоянно» можно задать настройку, в соответствии с которой монитор будет автоматически отключаться по истечении заданного времени. Любое нажатие на клавишу немедленно вернет его в активное состояние.
Проблемы при работе с кэшем и способы их решения
Время на прочтение
12 мин
Количество просмотров 36K
Привет, Хабр!
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Самый очевидный способ разбивки данных — вычисление номера сервера псевдослучайным образом в зависимости от ключа кэширования.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
$cache_server_index = crc32($cache_key) % count($cache_servers_list);Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.
Обычно идею согласованного хеширования визуализируют с помощью колец, точки на окружностях которых показывают слоты или границы диапазонов слотов (в случае если этих слотов очень много). Вот простой пример перераспределения для ситуации с небольшим количеством слотов (60), которые изначально распределены по четырём серверам:
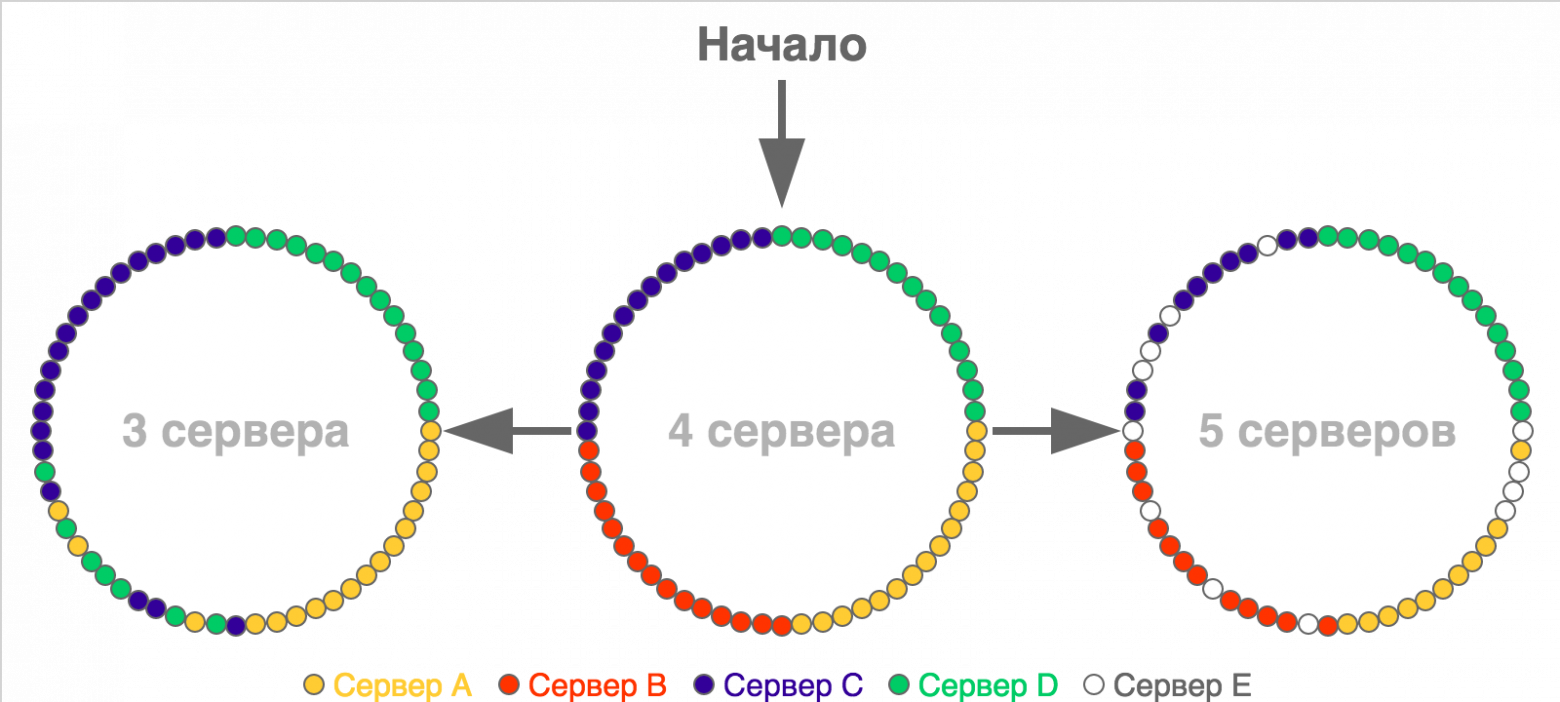
На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей (k / N, где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть масса реализаций на самых разных языках.
Наряду с согласованным хешированием есть и другие способы решения этой проблемы (например, rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
См. также:
- Статья «Distributed hash table» в Wikipedia
- Статья «Consistent hashing» в Wikipedia
- A Guide to Consistent Hashing
- Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web
- Building a Consistent Hashing Ring
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
public function getContactsCountCached(int $user_id) : ?int
{
$contacts_count = \Contacts\Cache::getContactsCount($user_id);
if ($contacts_count !== false) {
return $contacts_count;
}
$contacts_count = $this->getContactsCount($user_id);
if (is_null($contacts_count)) {
return null;
}
\Contacts\Cache::setContactsCount($user_id, $contacts_count);
return $contacts_count;
}
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:
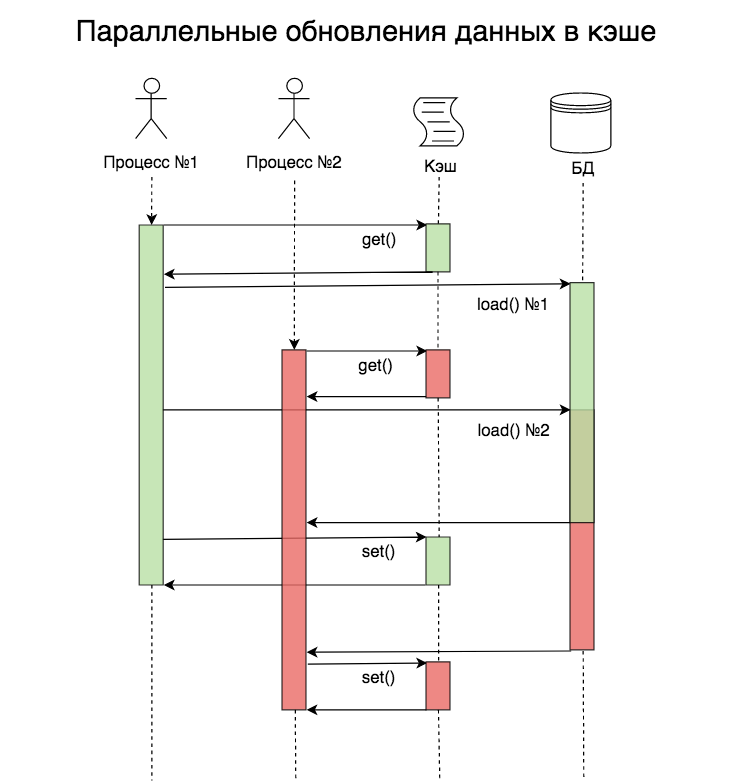
На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
function xFetch($key, $ttl, $beta = 1)
{
[$value, $delta, $expiry] = cacheRead($key);
if (!$value || (time() − $delta * $beta * log(rand())) > $expiry) {
$start = time();
$value = recomputeValue($key);
$delta = time() – $start;
$expiry = time() + $ttl;
cacheWrite(key, [$value, $delta, $expiry], $ttl);
}
return $value;
}
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
См. также:
- Статья «Cache stampede» в Wikipedia
- Optimal Probabilistic Cache Stampede Prevention
- Репозиторий на GitHub с описанием и тестами разных способов
- Статья «Кэши для “чайников”»
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
public function getNewSnapshotTTL()
{
$random_factor = rand(950, 1050) / 1000;
return intval($this->getSnapshotTTL() * $random_factor);
}
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:
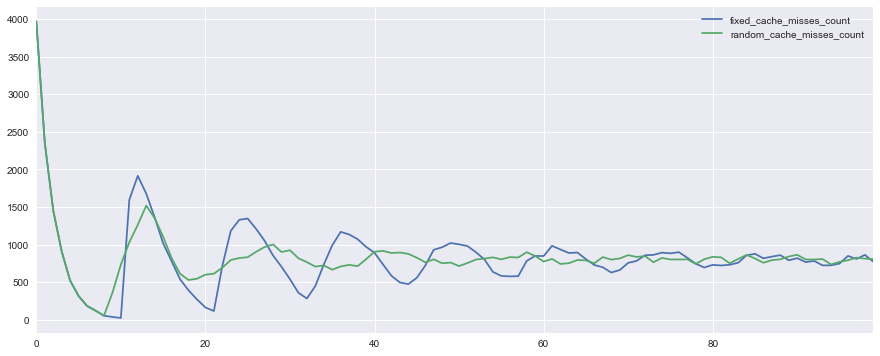
Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.
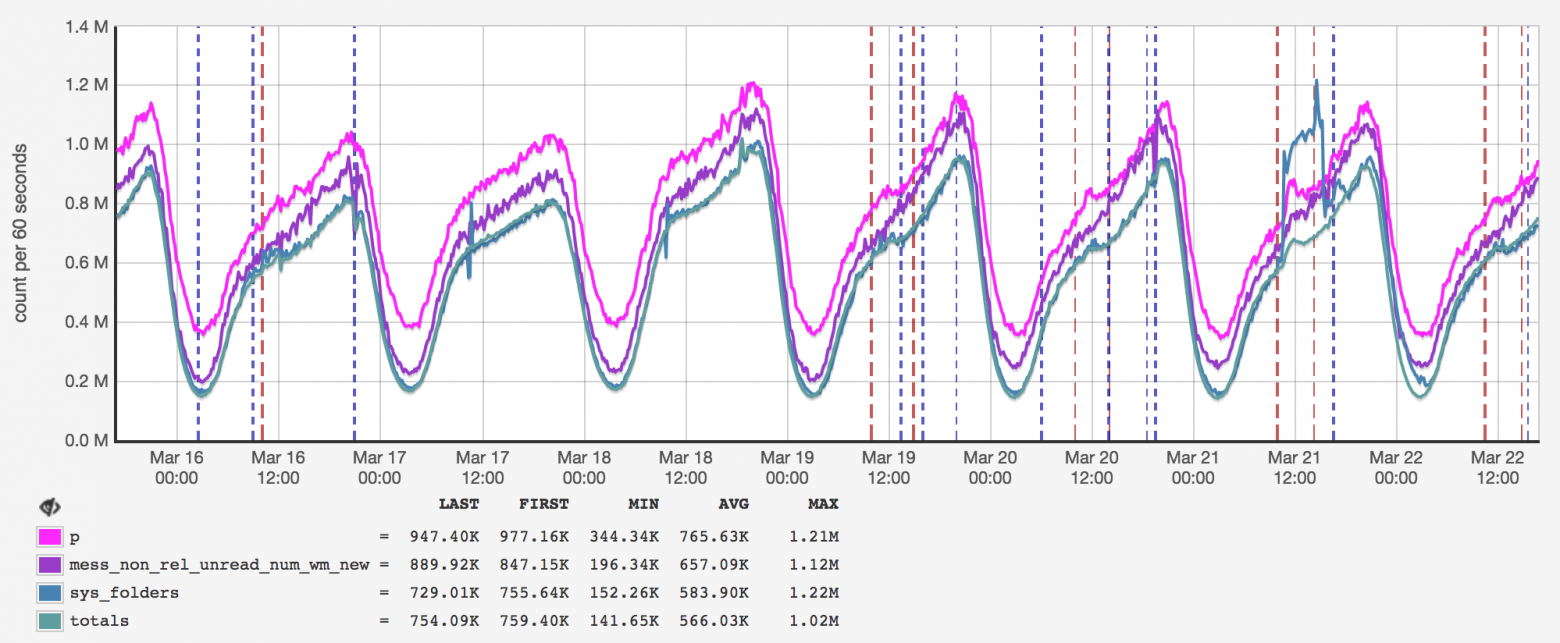
Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде total_users_count_1, total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
См. также:
- How Etsy caches: hashing, Ketama, and cache smearing
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
Про сбои в работе кэша я уже рассказывал в предыдущих разделах. Единственное, что можно добавить, — хорошо было бы предусмотреть возможность отключения части функционала на работающей системе. Это полезно, когда система не в состоянии справиться с пиком нагрузки.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.
Заключение
В статье я затронул основные проблемы при работе с кэшем, но уверен, что, кроме них, есть множество других, и продолжать этот разговор можно очень долго. Надеюсь, что после прочтения моей статьи ваш кэш станет более эффективным.
Оперативная память
Устранение ошибок памяти
- Подробности
- Родительская категория: Оперативная память
- Категория: Прочая информация про оперативную память
Устранить ошибки памяти довольно сложно, поскольку не всегда удается идентифициро
вать вызвавшую их проблему. Чаще всего пользователи винят во всех сбоях программное обеспечение, хотя на самом деле во всем виновата память. В этом разделе речь пойдет о выявлении ошибок памяти и способах их устранения.
Для устранения ошибок памяти необходимо иметь под рукой несколько диагностических программ. Следует отметить, что некоторые ошибки памяти могут быть выявлены одной программой и остаться невидимыми для другой. При включении компьютера системная BIOS проверяет память. В большинстве случаев к компьютеру прилагается компакт-диск, содержащий специальные программы диагностики. Также на рынке можно встретить множество других диагностических утилит, практически каждая из которых содержит свои тесты памяти.
При запуске компьютера тест POST не только проверяет память, но и вычисляет ее объем. Затем этот объем памяти сравнивается с записанным в параметрах BIOS и в случае несоответствия генерируется сообщение об ошибке. При проверке памяти тест POST записывает в каждый из блоков памяти некоторый шаблон, а затем считывает его и сверяет с оригиналом. При обнаружении ошибок выводится соответствующее сообщение или генерируется звуковой сигнал. Звуковой сигнал, как правило, используется для индикации критических ошибок в областях, важных для выполнения системных операций. Если система может получить доступ к объему памяти, достаточному для запуска видеосистемы, вместо звукового сигнала будет отображено сообщение об ошибке.
На прилагаемом к книге компакт-диске содержится подробный перечень звуковых сигналов BIOS и кодов ошибок, характерных для той или иной BIOS, в формате PDF. К примеру, в большинстве материнских плат Intel используется Phoenix BIOS, которая для индикации критических ошибок использует несколько звуковых кодов.
Если процедура POST не обнаружила ошибок памяти, следовательно, причина возникновения ошибок лежит не в аппаратной среде, или программа POST не справилась со своей задачей. Нерегулярные ошибки зачастую не обнаруживаются POST, что справедливо и для других аппаратных дефектов. Данная процедура проводится достаточно быстро и не претендует на тщательный анализ. Поэтому для доскональной проверки применяется загрузка DOS, режим консоли восстановления в Windows XP или диагностический диск. Тесты такого рода могут в случае необходимости проводиться в течение нескольких дней для определения неуловимого дефекта.
В Интернете доступно множество хороших бесплатных программ тестирования памяти.
- Microsoft Windows Memory Diagnostic (http://oca.microsoft.com/en/windiag)
- DocMemory Diagnostic (http://www.simmtester.com/page/products/doc/docinfo.asp)
- Memtest86 (http://www.memtest86.com)
Следует отметить, что все эти утилиты имеют загружаемый формат, т.е. их не нужно устанавливать в тестируемой системе, а достаточно записать на загрузочный компакт-диск. Это связано с тем, что многие операционные системы, работающие в защищенном режиме, в частности Windows, пресекают прямой доступ к памяти и другим устройствам. По этой причине загрузку системы нужно выполнять с компакт-диска. Все эти программы используют алгоритмы, записывающие определенные шаблоны в различные области системной памяти, после чего считывают их и проверяют на совпадение каждый бит. При этом они отключают системный кэш, чтобы результат операции отражал поведение модулей памяти, без каких-либо посредников. Некоторые утилиты, в частности Windows Memory Diagnostic, даже способны указать на конкретный модуль памяти, в котором произошла ошибка.
Однако эти программы могут только записать данные и проверить при считывании их соответствие, не более того. Они не определяют, насколько близка память к критической точке сбоя. Повышенный уровень диагностики памяти обеспечивают только специальные аппаратные тестеры модулей SIMM/DIMM. Эти устройства позволяют вставить в них модуль памяти и проверить ее на множестве скоростей, при разных напряжениях питания и таймингах, в результате чего выдать свой вердикт относительно пригодности модуля. Существуют версии таких тестеров, позволяющие проверять модули памяти практически всех типов, начиная от ранних версий SIMM и заканчивая самыми современными модулями DDR DIMM и RIMM. К примеру, я сталкивался с модулями, которые отлично работали в одних компьютерах и выдавали ошибки в других. Это значит, что одни и те же программы диагностики, запущенные на разных компьютерах, выдавали для одних и тех же модулей памяти противоположные результаты. В аппаратных тестерах источник ошибки можно выявить с точностью до конкретного бита, при этом узнать реальное быстродействие памяти, а не номинальное, указанное на маркировке. К числу компаний, которые занимаются реализацией тестеров модулей памяти, относятся Tanisys (www.tanisys.com), CST (www.simmtester.com) и Aristo (www.memorytester.com). Предлагаемые тестеры довольно дорого стоят, но для специалистов, занимающихся ремонтом ПК на профессиональном уровне, тестеры SIMM/DIMM просто необходимы.
Чаще всего память служит причиной следующих ошибок:
- ошибки четности, генерируемые системной платой;
- общие ошибки защиты, вызванные повреждением данных запущенной программы в памяти, что приводит к остановке приложения (часто они вызваны ошибками программ);
- критические ошибки исключений, возникающие при выполнении программой недопустимых инструкций, при доступе к некорректным данным или некорректном уровне привилегий операции;
- ошибки деления, вызванные попыткой деления на нуль, которая приводит к невозможности записи результата в регистр памяти.
Некоторые из приведенных типов ошибок могут быть следствием аппаратных (сбои в цепи питания, статические заряды и т.д.) или программных (некорректно написанные драйверы устройств, ошибки в программах и т.д.) сбоев.
Если причиной возникновения ошибок является оперативная память, следует воспользоваться помощью либо одной программы тестирования, либо нескольких диагностических приложений.
Многие допускают существенную ошибку в использовании диагностических программ,например выполняют диагностику с включенным системным кэшированием. Это затрудняет тестирование, поскольку в большинстве систем используется так называемый кэш с обратной записью. Принцип его работы состоит в том, что данные, записываемые в основную память, в первую очередь записываются в кэш. Поскольку диагностическая программа изначально записывает данные и затем сразу же их считывает, данные считываются из кэша, а не из основной памяти. При этом тестирование проводится очень быстро, но проверке подвергается лишь сам кэш. Таким образом, обязательно отключайте кэширование перед тестированием оперативной памяти. Компьютер будет работать довольно медленно, диагностика отнимет на порядок больше времени, однако проверяться будет именно оперативная память, а не кэш.
При проверке памяти придерживайтесь алгоритма, схематически показанного на рисунке ниже.
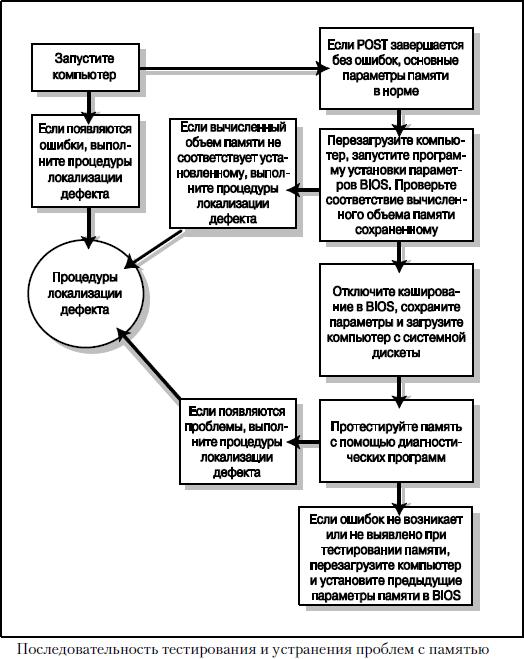
Теперь ознакомимся с процедурой проверки и устранения ошибок памяти.
- Включите систему и проследите за выполнением процедуры POST. Если этот тест завершается без ошибок, следовательно, основные параметры памяти успешно проверены. При обнаружении ошибок перейдите к выполнению процедуры локализации дефектов.
- Перезапустите систему и войдите в программу настройки BIOS. Для этого во время выполнения POST (но до начала процесса загрузки) нажмите клавишу <F2>. Проверьте в параметрах BIOS, совпадает ли объем обнаруженной и установленной памяти. В том случае, если вычисленный объем памяти не соответствует установленному, обратитесь к процедуре локализации дефектов.
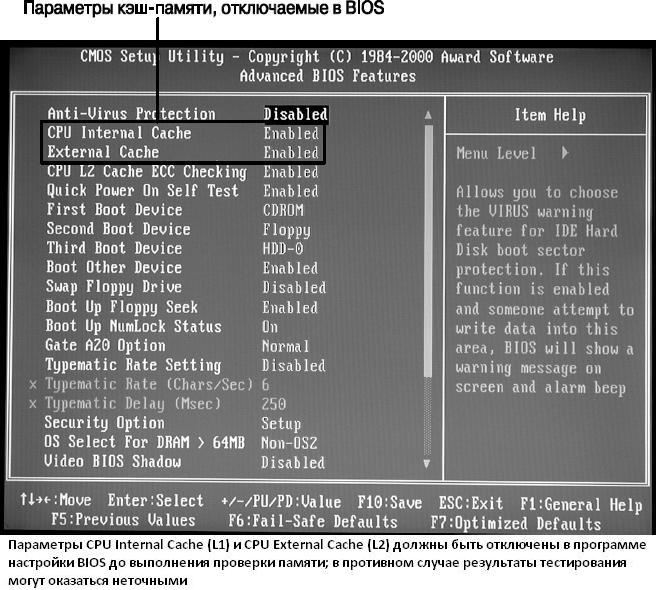
- В программе настройки BIOS отключите параметры кэширования. На рисунке ниже представлено типичное меню Advanced BIOS Features, в котором выделены параметры кэш-памяти. Сохраните выполненные изменения и загрузите компьютер с отформатированной системной дискеты, содержащей выбранные диагностические программы. Если в комплект поставки компьютера входил компакт-диск с программами диагностики, можете воспользоваться им. К тому же на рынке доступно множество коммерческих программ диагностики, таких как PC-Technician от Windsor Technologies, Norton System Works от Symantec и Doc Memory от SIMMTester.
- Следуя инструкциям, появляющимся при выполнении диагностической программы, протестируйте основную и дополнительную (XMS) память. Обычно в таких программах существует специальный режим, допускающий непрерывное циклическое выполнение диагностических процедур. Это позволяет обнаружить периодические ошибки. При выявлении ошибок памяти перейдите к выполнению процедуры локализации дефектов.
- Отсутствие ошибок при выполнении POST или во время более полного тестирования памяти говорит о ее нормальном функционировании на аппаратном уровне. Перезагрузите компьютер и установите предыдущие параметры памяти в настройках BIOS, в частности включите параметр использования кэш-памяти.
- Отсутствие выявленных ошибок при наличии каких#либо проблем говорит о том, что существующие ошибки памяти не могут быть обнаружены стандартными методами или же их причина, вероятно, связана с программным обеспечением. Для более полной проверки модулей SIMM/DIMM на аппаратном тестере обратитесь в сервисный центр. Я бы обратил внимание и на программное обеспечение (в частности, на версии драйверов), блок питания, а также на системное окружение, особенно на источники статического электричества, радиопередатчики и т.п.
Выбирайте на страницах сайта услуги разных индивидуалок. Все индивидуалки Пятигорска доступны к взятию в способное для потребителей время. В качестве их услуг затруднений нет!
Панель управления Система и безопасность Администрирование Системный монитор
5000–100000 ошибок кеша в секунду
что это значит?
Привет,
Укажите код, название и описание ошибки
http://gayevoy.spaces.live.com/
Источник: https://answers.microsoft.com/ru-ru/windows/forum/all/system/5a51c58d-8757-4e9f-8b01-ca92c4b3de3d

Современные операционные системы ветки Виндовс оснащены функцией кэширования данных. Это ускоряет загрузку программ и упрощает работу ПК. Но когда кэш забит, начинаются проблемы: виснет браузер, игры и приложения долго запускаются и могут вылетать. Чтобы такого не случалось, нужно знать, как отключить кэширование оперативной памяти или очистить кэш в Windows 10.
Как убрать кэширование оперативной памяти Windows 10
Чем шире объем запоминающего устройства, там резвее работает компьютер. И, соответственно, тем больше программ в фоновом режиме могут функционировать без каких-либо проблем.
Тем не менее, при работе с некоторыми их них кэш нужно отключать или обнулять. В противном случае возможна потеря информации, сбои системы или оборудования. Забитый кэш негативно сказывается на производительности ПК, особенно когда места уже нет, а процесс сжатия продолжается. Чтобы не рисковать программным обеспечением, нужно своевременно решать данную проблему.

Средствами ОС
Самый простой способ — это использовать специальные системные утилиты, которые очистят кэш ОЗУ.
- При помощи комбинации клавиш «Win+R» вызвать окно «Выполнить».
- Ввести в поле окна адрес C:\windowssystem32rundll32.exe.
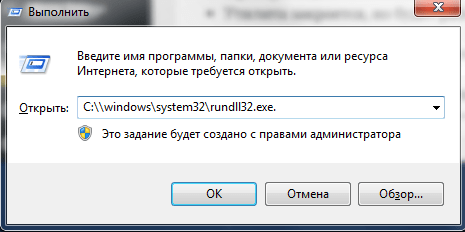
- Если Виндовс имеет битность х64, то адрес меняется: C:\windowsSysWOW64rundll32.exe.
- Проверить данные и кликнуть «ОК».
- Утилита закроется, но будет работать на фоне, то есть без каких-либо окон и полей. Спустя 10-15 минут кэш будет обнулен.
Чтобы полностью отключить функцию сжатия данных на диск, нужно будет произвести другую операцию:
- Кликнуть на значок моего компьютера правой кнопкой мышки, далее выбрать пункт «Свойства».
- Открыть вкладку с оборудованием, отыскать Диспетчер устройств.
- Открыть папку «Дисковые накопители».
- Выбрать необходимый накопитель, щелкнуть правой кнопкой на него опять, выбрать также «Свойства».
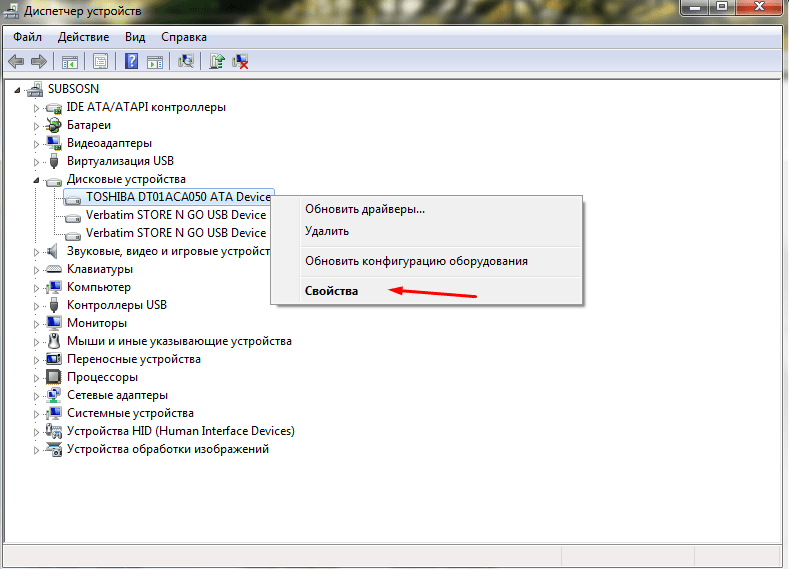
- Переключиться в раздел политики.
- Убрать галочку в поле «Включить кэширование записи», нажать «ОК».

Перезагрузка ПК
Этот вариант для тех, кто не хочет копаться во внутренних алгоритмах и заморачиваться с поиском необходимых функций. Элементарная перезагрузка компьютера спасет положение. Во время нее на некоторое время обесточивается модуль RAM, что стирает сжатые данные из ОЗУ. Тем не менее, злоупотреблять им не стоит, поскольку частая перезагрузка в полном функционале негативно сказывается не только на скорости работы системы, но и на «железной начинке».
ATM
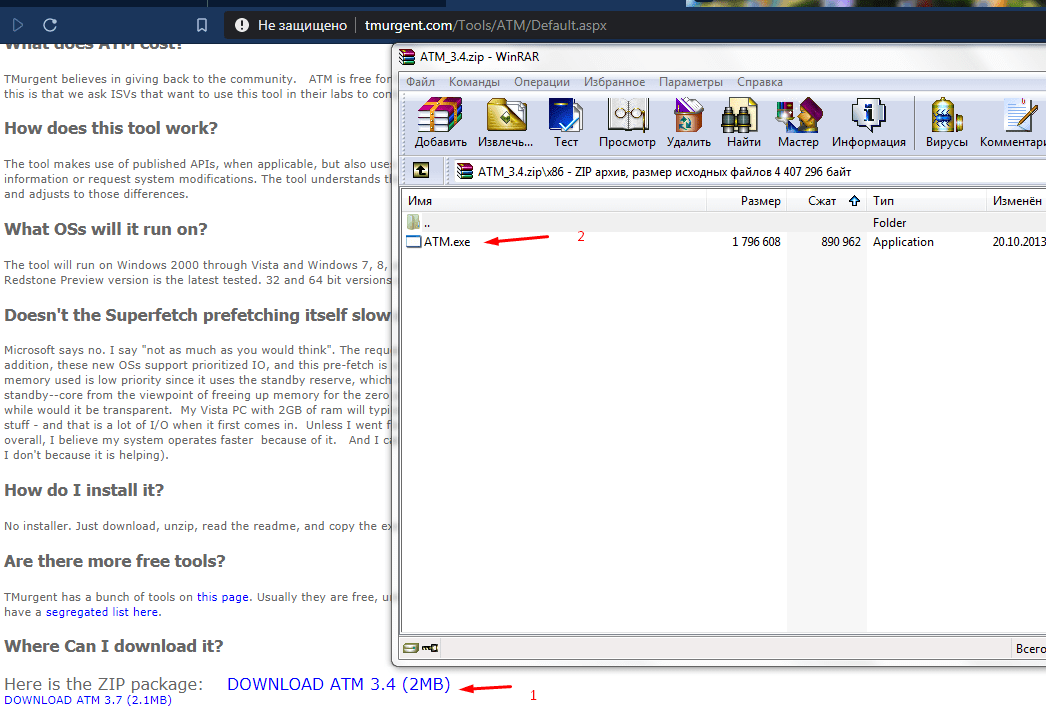
Когда стандартные методы не помогают, остается прибегнуть к стороннему решению, например, к программе ATM:
- Скачать приложение по ссылке http://www.tmurgent.com/Tools/ATM/Default.aspx.
- Распаковать архив и открыть папку со значением х86(х32).
- 2 раза щелкнуть на файл exe.
- Откроется окно с программным кодом. В самом низу окна найти 2 кнопки – «Flush Cache WS» и «Flush All Standby» – и нажать их именно в такой последовательности.
RAMMap
Другая программа выступает детищем самого «Майкрософта», который борется с проблемой утечки данных ОЗУ в кэш.
- Скачать приложение https://docs.microsoft.com/en-us/sysinternals/downloads/rammap.
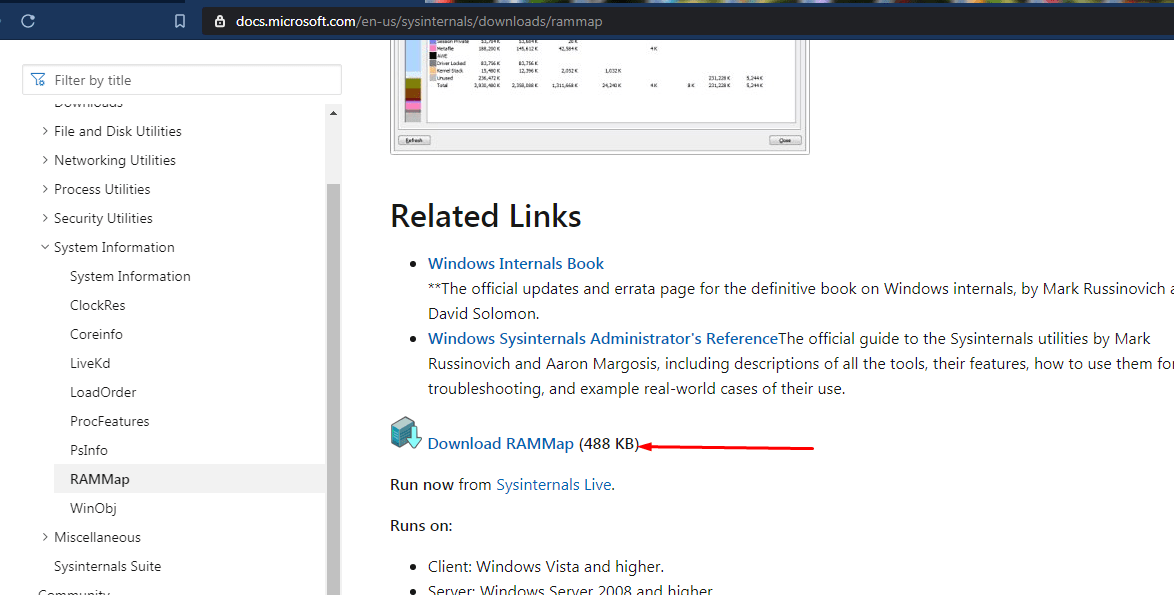
- Установка не требуется, нужно открыть один из корневых файлов.
- В открывшемся окне вверху открыть вкладку «Empty» и выбрать «Empty Standby List».

- Результат можно проверить через вкладку «Производительность», открыв Диспетчер задач.
Возможные проблемы
Во время отключения или очистки кэша можно столкнуться с:
- Ошибками, когда программа не может найди диск, на котором следует отключить эту функцию. Решение: переустановить ее из другого источника.
Кэш не очищается по причине открытых программ. Решение: закрыть все лишнее и попробовать снова.

Вам помогло? Поделитесь с друзьями — помогите и нам!