Problem
Diagnosing problems with the IBM eServer xSeries 130, 135, 330, and IntelliStation R Pro
Resolving The Problem
Affected configurations
- IBM eServer xSeries 130, 135, 330, and IBM IntelliStation R Pro
This document is intended for trained servicers who are familiar with IBM server and workstation products. Use this document along with advanced diagnostic tests to troubleshoot problems effectively. Before servicing an IBM product, be sure to review the safety information. Click here to review the safety information.
- SCSI error messages
- Temperature error messages
- Fan error messages
- Voltage related system shutdown
- DASD error messages
- Bus fault messages
SCSI error mesages
| Error Code | FRU/Action |
|---|---|
|
One or more of the following might be causing the problem:
|
|
Temperature error messages
| Message | Action |
|---|---|
| DASD over recommended temperature (sensor X) (level-warning; DASD bay «X» had over temperature condition) |
|
| DASD under recommended temperature (sensor X) (level-warning;direct access storage device bay «X» had under temperature condition) |
|
| DASD 1 over temperature (level-critical; sensor for DASD1 reported temperature over recommended range) |
|
| Power supply «X» temperature Fault (level-critical; power supply «x» had over temperature condition) |
|
| System board is over recommended temperature (level-warning; system board is over recommended temperature) |
|
| System board is under recommended temperature (level-warning; system board is under recommended temperature) |
|
| System over temperature for CPU «X» (level-warning; CPU «X» reporting over temperature condition) |
|
| System under recommended CPU «X»temperature (level-warning; system reporting under temperature condition for CPU «X») |
|
Fan error messages
|
Message |
Action |
|---|---|
|
Fan «X» failure (level-critical; fan «X» had a failure) |
|
|
Fan «X» fault (level-critical; fan «X» beyond recommended RPM range) |
|
|
Fan «X» Outside Recommended Speed Action |
|
Voltage related system shutdown
|
Message |
Action |
|---|---|
|
System shutoff due to «X» current over maximum value (level-critical; system drawing too much current on voltage «X» bus) |
|
|
System shutoff due to «X» current under minimum. value (level-critical; current on voltage bus «X» under minimum value) |
|
|
System shutoff due to «X» V over voltage (level-critical; system shutoff due to «X» supply over voltage) |
|
|
System shutoff due to «X» V under voltage (level-critical system shutoff due to «X» supply under voltage) |
|
|
System shutoff due to VRM «X»over voltage |
|
DASD error messages
|
Message |
Action |
|---|---|
|
Hard drive «X» removal detected (level-critical; hard drive «X» has been removed) |
|
Bus fault messages
|
Message |
Action |
|---|---|
|
Failure reading I2C device. Check devices on bus 0. |
|
|
Failure reading I2C device. Check devices on bus 1. |
|
|
Failure reading I2C device. Check devices on bus 2. |
|
|
Failure reading I2C device. Check devices on bus 3. |
|
|
Failure reading I2C device. Check devices on bus 4. |
|
|
Need more help? |
|---|
Please select one of the the following options for further assistance:
Document Location
Worldwide
Operating System
IntelliStation Pro:All operating systems listed
Older System x:Operating system independent / None
[{«Type»:»HW»,»Business Unit»:{«code»:»BU016″,»label»:»Multiple Vendor Support»},»Product»:{«code»:»HW18E»,»label»:»Older System x->xSeries 135″},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»»,»label»:»»}},{«Type»:»HW»,»Business Unit»:{«code»:»BU016″,»label»:»Multiple Vendor Support»},»Product»:{«code»:»HW18L»,»label»:»Older System x->xSeries 330″},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»»,»label»:»»}},{«Type»:»HW»,»Business Unit»:{«code»:»BU054″,»label»:»Systems w/TPS»},»Product»:{«code»:»HWP99″,»label»:»IntelliStation Pro->IntelliStation R Pro»},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»»,»label»:»»}}]

Today, one of our IBM system3650X series server encountered an DASD error.
An orange Exclamation light turned ON and the server was not booting properly. This server have 2 HDD running in RAID mode. both HDD green lights were flashing properly which was showing that the HDD are in good condition. So I applied the Power Recycling solution and it worked like a charm 🙂 .
Howto do Power Recycling / Cold Restart
# Shutdown the Server
# Remove Power cables (both) from power supply.
# Wait for 10 Minutes,
# Now plugin the power cables and turn ON the servers and you won’t see orange light 🙂
More information can be found here
http://www.google.com.pk/search?q=ibm+system+x3650+dasd+error&ie=utf-8&oe=utf-8&aq=t&rls=org.mozilla:en-US:official&client=firefox-a
Regard’s
Syed Jahanzaib
5 Replies
-

pure capsaicin
Windows Server Expert
-
check
242
Best Answers -
thumb_up
532
Helpful Votes
DASD and LPD are code to those who might not understand.
What RAID level are you using, your card may remember the fault and take it through with it, there is a word for this but I can’t remember it off the top of my head, but the card marks the slot as bad, not the disk.
Was this post helpful?
thumb_up
thumb_down
-
check
-
Hi Rod, How can I clear the memory of the card so it will forget the error? I am using Raid 5 on my existing SAS disk.
Was this post helpful?
thumb_up
thumb_down
-
Just additional info. I have a M1015 controller connected to my SAS Expander card. Is this okay?
Was this post helpful?
thumb_up
thumb_down
-
Additional Information:
I just notice something while reading
the system documentation of System X3650 M3 on http://systemx.lenovofiles.com/help/index.jsp?topic=%2Fcom.lenovo.sysx.7945.doc%2Ft_installing_sas_s… Opens a new windowI notice here that when there is a two
option for us to expand the SAS 8 PAC HDD. One is to install a SAS/SATA 8Pac
HDD Option where we needs to have ServeRaid controller and SAS expander
card and the second option is to install a SAS/SATA
8Pac HDD for 2 RAID kit with 2 M5015 adapters option where we will need to
have 2 M5015 adapter.Where in our currently setup we do have one M5015 adapter and a SAS
expander card. Just thinking that this might be the
reason why we are encountering the issue we had. need your thoughts on this.
Was this post helpful?
thumb_up
thumb_down
-
All fixed, We did replace all the parts including the M. Board and find out that it is just a firmware issue of the SAS expander.
Was this post helpful?
thumb_up
thumb_down


Содержание
- Ошибка dasd что значит
- Русские Блоги
- Описание аварийного сигнала светового индикатора сервера IBM
- Ошибки и проблемы серверов большой тройки: часть третья. IBM
- Оперативная память
- Накопители
- Обновление прошивок и ПО
- Другие проблемы
- Преимущества серверов IBM
Сообщения: 90
Благодарности: 0
Установлен IBM xSeries 346. Внутри — 3 диска по 70гиг (IBM 90P1309) и два по 140 (IBM 90P1310).
Насколько я вижу (т.к. досталось это хозяйство в наследство) 3 по 70 собраны в Raid 5, а два по 140 — в Raid 1.
Не так давно на одном из 70 начала гореть оранжевая лампочка, что по цветовой идентификации распознается как DASD (A hard disk drive rror has occured) с предложением исправить ошибку как «Check the LEDs on the hard disk drives and replace the indicated drive»
Сначала лампочка помигивала, а сейчас уже горит ровным цветом  . Соответственно при перезагрузке компьютера я вижу две очень непряитные для меня строчки:
. Соответственно при перезагрузке компьютера я вижу две очень непряитные для меня строчки:
1. Logical drive is critical
2. Defunct drive
Сервер работает, что не может не радовать потому как это — главный домен-контроллер. Новые диски (а я заказал весь комплект: 3 по 70 и два по 140) в дороге. Но дорога длинная.
Утилита, идущая в комплекте, ServeRAID Manager, выдает такую картинку:

Собственно, проблемный диск как бы виден. При вызове контекстного меню на нем мне предлагается Rebuild. Теперь собственно вопросы.
1. Могу ли я провести этот «ребилдинг» в нормальном рабочем состоянии, т.е. из-под Windows, домен-контроллер работает,и в это самый момент я провожу операцию. Или же лучше приостановить работу?
2. Попадался на глаза пост, что во время проведения «ребилдинга» данные восстановились, но с откатом на две недели назад. Меня такой вариант не очень устраивает
3. Да и вообще — насколько опасна эта операция?
Источник
Русские Блоги
Описание аварийного сигнала светового индикатора сервера IBM
IBM Описание тревоги индикатора сервера
1. Панель диагностики светового тракта
Кнопка напоминания: Эта кнопка устанавливает индикатор системной ошибки на передней панели как режим напоминания. В режиме напоминания загорается индикатор системной ошибки. 2 Мигает раз в секунду, Пока проблема не будет исправлена, система перезапустится или возникнет новая проблема. Установив индикатор системной ошибки в режим напоминания, вы можете подтвердить, что знаете о предыдущем сбое, но не принимаете немедленных мер для устранения проблемы. Функция напоминания контролируется IMM контроль.
NMI Кнопка: Нажмите эту кнопку, чтобы микропроцессор сгенерировал немаскируемое прерывание. Это позволяет сделать синий экран сервера и выполнить дамп памяти (только если IBM Эту кнопку можно использовать только по указанию обслуживающего персонала).
Экран кода контрольной точки: На этом экране отображается код контрольной точки, указывающий, что система остановится в этой точке во время блока загрузки и POST.
Код контрольной точки — это значение байта или слово, сгенерированное UEFI. На этом экране не отображаются коды ошибок или рекомендуемые компоненты для замены.
кнопка сброса: Нажмите эту кнопку, чтобы перезагрузить сервер и запустить самотестирование при включении (POST). Для нажатия кнопки может потребоваться кончик ручки или конец выпрямленной канцелярской скрепки. Кнопка сброса расположена в правом нижнем углу панели диагностики светового тракта.
over spec Индикатор: Когда этот световой индикатор горит, это означает, что потребность в мощности превышает указанный источник питания.
log Индикатор: Когда этот индикатор горит, это означает, что в журнале событий есть ошибка, и вам следует проверить журнал событий.
link Индикатор : Когда этот индикатор горит, сетевая карта неисправна.
ps Индикатор:Когда этот световой индикатор горит, это указывает на отказ источника питания.
pci Индикатор:Если этот индикатор горит, это означает, что на шине PCI возникла ошибка.
sp Индикатор:Когда этот индикатор горит, это указывает на то, что потоковый процессор обнаружил ошибку (роль sp заключается в обработке данных, переданных ЦП, и преобразовании их в цифровой сигнал, который может быть распознан дисплеем после обработки)
fan : Когда этот индикатор горит, это означает, что охлаждающий вентилятор или вентилятор блока питания вышел из строя или работает слишком медленно. Отказ вентилятора также может вызвать temp Световой индикатор горит.
temp Индикатор : Когда этот индикатор горит, это означает, что температура системы слишком высока.
mem Индикатор : Когда этот индикатор горит, это означает, что произошла ошибка памяти.
nmi Индикатор:Когда этот индикатор горит, это означает, что произошло немаскируемое прерывание ( nmi )。
cnfg Индикатор: Когда этот индикатор горит, это означает BIOS Ошибка конфигурации.
cpu Индикатор:Когда этот индикатор горит, это означает, что микропроцессор вышел из строя.
vrm Индикатор:Когда этот индикатор горит, это означает, что vrm произошла ошибка.
dasd Индикатор:Когда этот индикатор горит, это означает, что произошел сбой жесткого диска с возможностью горячей замены.
raid Индикатор:Когда этот индикатор горит, это означает, что карта массива неисправна.
brd Индикатор:Когда этот индикатор горит, это означает, что подключенный i/o Блок расширения неисправен.
2. Информационная панель оператора
Крышка кнопки управления питанием: Сдвиньте крышку на кнопку управления питанием, чтобы предотвратить случайное выключение сервера.
Кнопка управления питанием: Нажмите эту кнопку, чтобы вручную включить и выключить сервер.
Источник питания Индикатор: Если индикатор горит и не мигает, это означает, что сервер включен; если индикатор мигает, это означает, что сервер выключен и все еще подключен к источнику переменного тока; если индикатор не горит, это означает, что нет питания переменного тока или источника питания, или сам индикатор неисправен . Заметка : Если этот индикатор не горит, это не означает, что на сервере нет питания. Световой индикатор может перегореть. Чтобы полностью отключить питание сервера, необходимо вынуть шнур питания из розетки.
Индикатор значка Ethernet: Этот индикатор загорается значком Ethernet.
Индикатор активности Ethernet: Если эти индикаторы мигают, это означает, что между сервером и сетью существует активность на указанном ими порте.
Индикатор локатора: Используйте этот индикатор, чтобы найти целевой сервер среди множества серверов невооруженным глазом. можно использовать IBM Director Световой индикатор можно включить дистанционно или вручную, нажав кнопку локатора. Этот индикатор также загорится при запуске. Если в многоузловой конфигурации этот индикатор мигает, это означает, что соответствующий ему сервер является главным узлом. Если индикатор продолжает гореть, это означает, что соответствующий ему сервер является вторичным узлом.
Кнопка локатора: Нажмите эту кнопку, чтобы вручную включить или выключить индикатор локатора. В многоузловой конфигурации нажмите эту кнопку, чтобы включить или выключить индикаторы локатора всех узлов в конфигурации.
Информационный индикатор: Если этот индикатор горит, это означает, что какой-то аспект сервера находится не в оптимальном состоянии, и при диагностике светового пути загорится еще один индикатор, помогающий определить проблему. Только после того, как проблема будет решена или будет нажата кнопка напоминания, световой индикатор и световой индикатор на диагностической панели светового тракта погаснут.
Индикатор системной ошибки: Если этот индикатор горит, это означает, что произошла системная ошибка. Индикатор на диагностической панели светового тракта также загорится, чтобы помочь найти эту ошибку.
Источник
Ошибки и проблемы серверов большой тройки: часть третья. IBM

Привет, Хабр! В прошлых статьях мы касались ошибок и проблем с серверами Dell и HP, и наш рассказ об ошибках refurbished-серверов был бы неполон без упоминания продукции третьего вендора «большой тройки» — IBM. Хотя эта славная корпорация уже отошла от производства серверов, её продукция ещё активно используется. Поэтому спешим поделиться с вами накопленным опытом «укрощения» серверов IBM. Это не исчерпывающий список проблем, но всё же он может оказаться кому-то полезен.
Оперативная память
Серверы IBM чувствительны по отношению к конфигурации модулей памяти. Зачастую после самостоятельного апгрейда — добавления памяти или её замены — сервер не загружается, либо видит меньше памяти, чем установлено на самом деле. К счастью, в подобных ситуациях не приходится долго гадать о причинах сбоя: на диагностической панели (если таковая имеется) загораются два индикатора Config и Memory.
Поэтому, прежде чем апгрейдить память обязательно изучите спецификацию, память какого типа и объёма поддерживается вашим сервером. Также большое значение имеет количество процессоров в сервере — от этого зависит порядок размещения модулей в слотах. Это тоже необходимо уточнить в спецификации.
Вообще, с памятью ровно такая же ситуация, как описано в статье про HP, например. Вкратце:
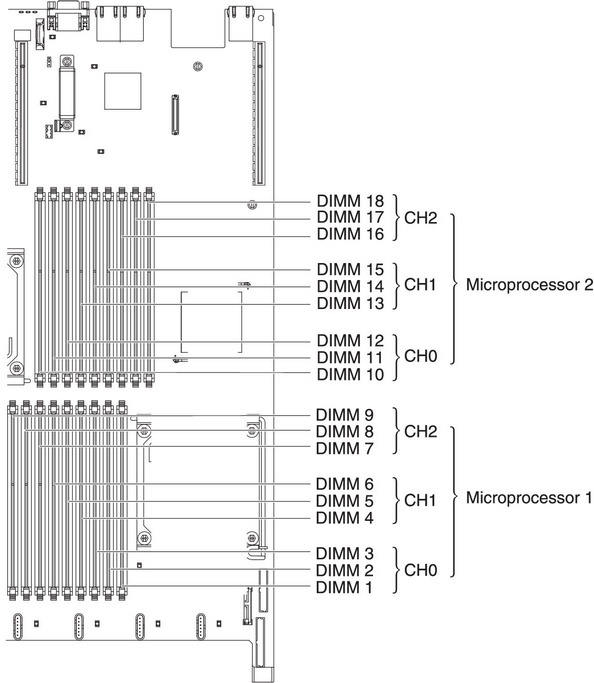
- Соблюдайте канальность памяти.
- Ставьте ECC REG 1(2)Rx4 память в двухпроцессорные системы и UDIMM — в однопроцессорные.
- Ставьте одинаковый объём памяти на каждый процессор.
А что делать, если вы вставили память в соответствии с инструкциями, а сервер всё равно не работает и предательски горит индикатор Memory? В этом случае придётся проверять разные варианты:
- Этот тип памяти не поддерживается сервером. Внимательно сверьтесь со спецификациями.
- Память оказалась «битой». Замените линейку на точно такую же и проверьте, заведётся ли сервер.
- Засорился пылью слот на материнской плате. Это довольно популярная причина, если сервер трудится уже несколько лет, а тем более если вы его не первый владелец. Продуйте слоты сжатым воздухом.
- Загнутый контакт в сокете. Такое бывает очень редко, но всё же бывает: память отказывается работать из-за загнутого контакта в сокете процессора. Если предыдущие варианты не помогли найти причину сбоя, снимите процессор и внимательно осмотрите сокет. Если вы оказались в числе немногочисленных «счастливчиков», то можете попробовать осторожно выпрямить погнутый контакт, но это исключительно на ваш страх и риск.
Многие сисадмины сталкиваются с тем, что при проверке оперативной памяти с помощью MemTest86 получают сообщения об ошибках даже в заведомо рабочих модулях, либо на одних и тех же дорожках. Особенно часто это встречается у серверов поколения M4. Это вовсе не вина машин или памяти: MemTest86 не рекомендуется использовать для проверки серверной памяти. Если же память начнёт сбоить, то сервер сообщит об этом через диагностическую панель. Проверять память на серверах IBM лучше стандартными средствами самодиагностики.
Накопители
Мы уже неоднократно упоминали о том, что совсем не обязательно устанавливать в серверах «родные» накопители. Ни IBM, ни другие вендоры их не производят, они лишь приобретают их у всем известных производителей, перепрошивают и клеят свои логотипы. Поэтому вы можете без труда сэкономить на апгрейде или восстановлении дисковых массивов, выбрав аналоги вместо «родных» накопителей. Двух-трёхкратная разница в цене это оправдывает, особенно если речь идёт о refurbished-серверах. В сети можно легко найти таблицы соответствия моделей, например:
| Модель IBM | Оригинал |
|---|---|
| IBM 49Y2003 | Seagate ST9600204SS |
| IBM 90Y8872 | Seagate ST9600205SS |
| IBM 90Y8908 | Seagate ST9600105SS |
| IBM 81Y9650 | Seagate ST900MM0006 |
Тем не менее, ещё возможны ситуации несовместимости «неродных» накопителей с сервером. В этом случае сервер не грузится штатно, либо не видит накопитель. Обычно это решается с помощью установки свежей прошивки RAID-контроллера. К слову, рекомендуется обновить прошивку и бэкплейна/экспандера, в этом вам поможет приложение IBM Bootable Media Creator (BoMC).
При включении сервера и прохождении POST-проверки возможно появление ошибки:
A discovery error has occurred, please powercycle the system and all the enclosures attached to this system.
Это сигнализирует о проблеме с одним из накопителей. Вычислить его просто: индикаторы на его салазках постоянно мигают, даже когда все остальные носители прошли проверку и перестали мигать.
С дисковой подсистемой бывают и более экзотические проблемы. Например, при использовании RAID-1 в фирменном приложении MegaRAID Storage Manager могут появиться ошибки вида:
ID = 63
SEQUENCE NUMBER = 48442
TIME = 24-01-2016 17:03:59
LOCALIZED MESSAGE = Controller ID: 0 Consistency Check found inconsistent parity on VD strip: ( VD = 0, strip = 637679)
Чаще всего это говорит не об умирании диска, а об ошибке контроля чётности — несовпадении данных на основном и вторичном дисках. Возможные причины:
- Нередко такие ошибки появляются сразу после конфигурирования нового массива или после замены одного из дисков.
- Во время сеанса диагностики поверхности блинов происходит инициализация диска и выполнение операций ввода/вывода. На RAID-1 это может привести к временному несоответствию томов, которое автоматически исправляется при следующей проверке на соответствие. Такое возникает не при любом сеансе диагностики, а когда сходятся звёзды:
- o Используется RAID-контроллер без кэширования, либо активирован режим Write Through.
- o Нехватка оперативной памяти, при которой с диска осуществляется активная подкачка страниц.
- o Просто очень интенсивное использование дисков.
Для решения этой проблемы рекомендуется снизить активность подкачки с диска: используйте RAID-контроллер с кэшированием и увеличьте объём оперативной памяти.
Обновление прошивок и ПО
Любопытная проблема может подстерегать при установке с нуля Windows 2012 или Windows 2012 R2 — свежеустановленная операционка не видит ни одного накопителя. Причём такое бывает не только с серверами IBM. Дело в том, что все накопители в сервере подключены через RAID, а упомянутые версии ОС не имеют вшитых драйверов для работы с RAID. И поэтому они их просто игнорируют. Как быть? Самый надёжный способ: использовать утилиту IBM ServerGuide. При установке ОС она принудительно подсовывает все необходимые драйвера для данной модели и версии операционной системы. Обратите внимание, что образ ОС должен устанавливаться с диска, а не с флэшки: ServerGuide не будет работать с образом на том же USB-носителе, с которого запущен сам.
При покупке серверов бывают ситуации, когда нужно сначала обновить все прошивки, а потом уже накатывать систему. Сделать это можно с помощью вышеупомянутой IBM Bootable Media Creator:
- Загрузитесь с загрузочной флешки или диска.
- Запустите BoMC от имени Администратора.
- Выберите, что вы хотите сделать: обновить и/или провести диагностику.
- Программа спросит, где ей взять драйверы: скачать самой или вытащить из указанного вами архива.
- Выберите носитель для записи загрузочного образа: флэшку или диск. Запись может идти несколько часов, не волнуйтесь, программа не зависла.
- По окончании записи загрузитесь с этого носителя, и далее по инструкции.
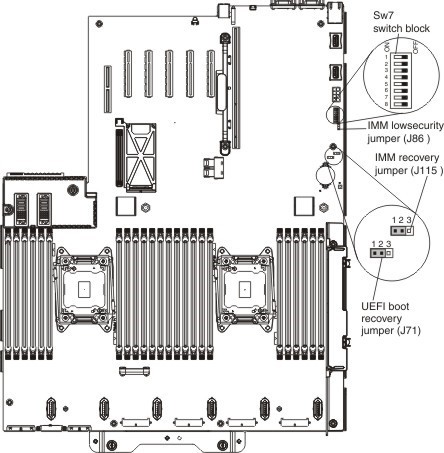
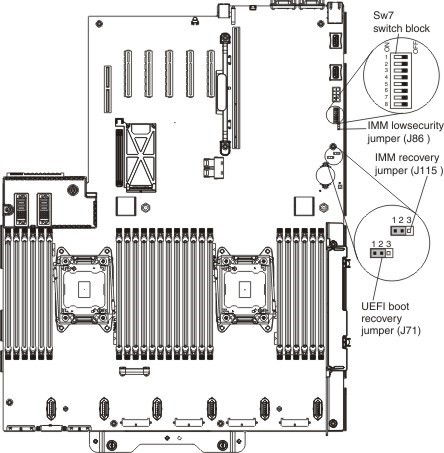
Эта процедура помогает и в ряде проблемных ситуаций. Например, если вы не дождались завершения обновления Integrated Management Module и нажали кнопку «отмена», то при следующих загрузках сервер может не суметь загрузить IMM и использует настройки по умолчанию. Можно сначала попытаться восстановить с помощью джампера “UEFI & IMM recovery jumper” на материнской плате, благодаря которому загружается прошитый образ IMM.
Но если не поможет, то воспользуйтесь процедурой обновления через BoMC.
Бывают и более неприятные ситуации, когда по закону подлости в ходе установки более свежей версии BIOS’а происходит сбой питания.

После этого сервер уже не может загрузить основную прошивку, и использует резервную. Если штатная процедура восстановления BIOS’а не помогает, то сделайте… даунгрейд: установите более старую прошивку, чем та, что была до сбоя питания. Обычно это помогает. После этого уже можно попытаться снова поставить свежую версию BIOS’а. Как говорится, шаг назад — два вперёд.
Другие проблемы
Иногда при попытке удалённого управления сервером возникает ошибка “Login failed with an access denied error.”, причём в любых браузерах. Если перезагрузка сервера и клиента не помогает, то рекомендуется сбросить IMM до заводских настроек.
В статье про ошибки серверов HP мы упоминали о проблемах с системой охлаждения: сразу после запуска сервера вентиляторы выходили на высокие обороты и уже не снижали их. Случается такой недуг и в серверах IBM. Сервер воет, как реактивный лайнер на взлёте. Нам не удалось выяснить причину таких сбоев, но посоветовать можно следующее:
- Проверьте плотность подключения разъёмов питания.
- Отключите все вентиляторы и снимите корзину.
- Проверьте каждый вентилятор на других серверах.
- Соберите корзину снова, поменяв вентиляторы местами. Либо совсем их замените.
Встречался в нашей практике и такой интересный сбой: при загрузке сервера штатно инициализируется IMM, затем начинается инициализация UEFI, и… всё. Дальше сервер не грузится без объяснения причин. Не помогали никакие манипуляции: отключение от сети, полное обесточивание, отключение разных компонентов. Загрузка бэкапа UEFI с помощью джампера на материнской плате тоже не помогла. Опытным путём выяснилось, что если подождать около 20 минут, то всё же можно дождаться загрузки сервера. Так он и работает с тех пор — каждый раз грузится по 20 минут. Выяснить причину сбоя не удалось.
Преимущества серверов IBM
Серверы IBM заслуженно пользуются большой популярностью:
- Это простые и очень надёжные машины.
- Отличная расширяемость даже на начальных моделях и богатый комплект поставки.
- Серверы IBM обычно дешевле конкурентов и не уступают в производительности. Например, поколения M3 и M4 дешевле, чем аналоги у HP (Gen7 и Gen8) и Dell (11G и 12G).
- Самые недорогие расходники. Легко найти в России.
- Удобная диагностическая панель на многих моделях.
Главное, в чём серверы IBM уступают конкурентам — у них очень долгий «холодный» старт.
Источник
IBMОписание тревоги индикатора сервера
1. Панель диагностики светового тракта


Кнопка напоминания:Эта кнопка устанавливает индикатор системной ошибки на передней панели как режим напоминания. В режиме напоминания загорается индикатор системной ошибки.2 Мигает раз в секунду,Пока проблема не будет исправлена, система перезапустится или возникнет новая проблема. Установив индикатор системной ошибки в режим напоминания, вы можете подтвердить, что знаете о предыдущем сбое, но не принимаете немедленных мер для устранения проблемы. Функция напоминания контролируетсяIMM контроль.
NMI Кнопка:Нажмите эту кнопку, чтобы микропроцессор сгенерировал немаскируемое прерывание. Это позволяет сделать синий экран сервера и выполнить дамп памяти (только еслиIBM Эту кнопку можно использовать только по указанию обслуживающего персонала).
Экран кода контрольной точки:На этом экране отображается код контрольной точки, указывающий, что система остановится в этой точке во время блока загрузки и POST.
Код контрольной точки — это значение байта или слово, сгенерированное UEFI. На этом экране не отображаются коды ошибок или рекомендуемые компоненты для замены.
кнопка сброса:Нажмите эту кнопку, чтобы перезагрузить сервер и запустить самотестирование при включении (POST). Для нажатия кнопки может потребоваться кончик ручки или конец выпрямленной канцелярской скрепки. Кнопка сброса расположена в правом нижнем углу панели диагностики светового тракта.
over spec Индикатор:Когда этот световой индикатор горит, это означает, что потребность в мощности превышает указанный источник питания.
log Индикатор:Когда этот индикатор горит, это означает, что в журнале событий есть ошибка, и вам следует проверить журнал событий.
linkИндикатор: Когда этот индикатор горит, сетевая карта неисправна.
psИндикатор:Когда этот световой индикатор горит, это указывает на отказ источника питания.
pci Индикатор:Если этот индикатор горит, это означает, что на шине PCI возникла ошибка.
sp Индикатор:Когда этот индикатор горит, это указывает на то, что потоковый процессор обнаружил ошибку (роль sp заключается в обработке данных, переданных ЦП, и преобразовании их в цифровой сигнал, который может быть распознан дисплеем после обработки)
fan: Когда этот индикатор горит, это означает, что охлаждающий вентилятор или вентилятор блока питания вышел из строя или работает слишком медленно. Отказ вентилятора также может вызватьtemp Световой индикатор горит.
temp Индикатор: Когда этот индикатор горит, это означает, что температура системы слишком высока.
mem Индикатор: Когда этот индикатор горит, это означает, что произошла ошибка памяти.
nmi Индикатор:Когда этот индикатор горит, это означает, что произошло немаскируемое прерывание (nmi)。
cnfgИндикатор: Когда этот индикатор горит, это означаетBIOSОшибка конфигурации.
cpu Индикатор:Когда этот индикатор горит, это означает, что микропроцессор вышел из строя.
vrm Индикатор:Когда этот индикатор горит, это означает, чтоvrm произошла ошибка.
dasd Индикатор:Когда этот индикатор горит, это означает, что произошел сбой жесткого диска с возможностью горячей замены.
raid Индикатор:Когда этот индикатор горит, это означает, что карта массива неисправна.
brd Индикатор:Когда этот индикатор горит, это означает, что подключенныйi/o Блок расширения неисправен.
2. Информационная панель оператора

Крышка кнопки управления питанием:Сдвиньте крышку на кнопку управления питанием, чтобы предотвратить случайное выключение сервера.
Кнопка управления питанием:Нажмите эту кнопку, чтобы вручную включить и выключить сервер.
Источник питанияИндикатор:Если индикатор горит и не мигает, это означает, что сервер включен; если индикатор мигает, это означает, что сервер выключен и все еще подключен к источнику переменного тока; если индикатор не горит, это означает, что нет питания переменного тока или источника питания, или сам индикатор неисправен . Заметка:Если этот индикатор не горит, это не означает, что на сервере нет питания. Световой индикатор может перегореть. Чтобы полностью отключить питание сервера, необходимо вынуть шнур питания из розетки.
Индикатор значка Ethernet:Этот индикатор загорается значком Ethernet.
Индикатор активности Ethernet:Если эти индикаторы мигают, это означает, что между сервером и сетью существует активность на указанном ими порте.
Индикатор локатора:Используйте этот индикатор, чтобы найти целевой сервер среди множества серверов невооруженным глазом. можно использоватьIBM Director Световой индикатор можно включить дистанционно или вручную, нажав кнопку локатора. Этот индикатор также загорится при запуске. Если в многоузловой конфигурации этот индикатор мигает, это означает, что соответствующий ему сервер является главным узлом. Если индикатор продолжает гореть, это означает, что соответствующий ему сервер является вторичным узлом.
Кнопка локатора:Нажмите эту кнопку, чтобы вручную включить или выключить индикатор локатора. В многоузловой конфигурации нажмите эту кнопку, чтобы включить или выключить индикаторы локатора всех узлов в конфигурации.
Информационный индикатор:Если этот индикатор горит, это означает, что какой-то аспект сервера находится не в оптимальном состоянии, и при диагностике светового пути загорится еще один индикатор, помогающий определить проблему. Только после того, как проблема будет решена или будет нажата кнопка напоминания, световой индикатор и световой индикатор на диагностической панели светового тракта погаснут.
Индикатор системной ошибки:Если этот индикатор горит, это означает, что произошла системная ошибка. Индикатор на диагностической панели светового тракта также загорится, чтобы помочь найти эту ошибку.
Эта статья перенесена из блога easy80851CTO, исходная ссылка:http://blog.51cto.com/68240021/1970874Если вам нужно перепечатать, пожалуйста, свяжитесь с первоначальным автором
Здраствуйте !
Пришел новый сервак от IBM X Series 226
ServeRAID 4 hdd по 74 Gb Вместе вышло 210 Gb
Я решил сделать эксперимент
Выдернул на ходу 1 hdd — Система продолжала работать !
Я Вставляю обратно этот 1 hdd — на нем мигает оранжевый индикатор !
2 минуты мигал — я недождался и вытащил 2 hdd
ServeRAID-6i The system has an error due to one or more Blocked logic all drives
Press: F4 to correct the problem
press: F5 Continue on whith no change
хммм — нажал F4 — reset
Warning 1 logic driver(s) offline
Warning 1 Online driver(s) defunct
Пытался сбросить настройки RAID контроллера ! все одинаково
P.S в настройках RAID level 5
при загрузке мигают оранжевые индикаторы 2 и 3 дисков
Это нравится: 0Да / 0Нет
08.04.2008 08:52:10
modwheel, эксперименты к хорошему не приводят.
Это нравится: 0Да / 0Нет
08.04.2008 10:05:59
0 ONL (ONLINE)
1 ONL (ONLINE)
2 DDD (Defunct)
3 RBL (Rebuilding)
Старый, но не бесполезный /Сервер IBM X3200 /Это, просто, @#енно
Что делать ?
Сервер новый там тока винда была !
Я даже согласен убить и заново рейд собрать ?
но как ?
Это нравится: 0Да / 0Нет
08.04.2008 13:28:09
Шарик, поздравляю, ты балбес (с) Матроскин.
Начнем с того, что ты натворил.
Телепатически догадываемся, что стоит raid 5.
Дернул винт — перевел массив в состояние degraded. Воткнул. Должен был запуститься ребилд, причем это надо было проверить из софта для управления контроллером или из его биоса. До того, как массив отребилдится, дергать другие винты нельзя. Ты жахнул свой второй винт.
Массив закономерно развалился. ССЗБ, стену ищи. Перед тем, как что-то дергать изучи матчасть по принципам работы рейдов и изучи доку на контроллер. У меня за такую глупость ты пробкой бы вылетел с работы.
Есть шанс, что принудительно подняв в онлайн второй дернутый тобой винт массив придет в degrated, а потом сможешь доребилдить его. Ребилд 5-го рейда процесс небыстрый. Хоть поднимать упавший рейд научишься, горе луковое.
Это нравится: 0Да / 0Нет
08.04.2008 18:19:10
да лоханулся сильно согласен , сейчас читаю что такое RAID .
В настройках RAID Контроллера при загрузке
облазил все что было , ненашел ничего интересного что
можно поправить жизненно важное !
Есть ли утилиты невшитые в плату ? для работы,воостановления RAID ?
5 часов он так просидел толку пока 0
оставил на ночь !
P.S судя по флагам :
2 DDD (Defunct)
3 RBL (Rebuilding)
Он что нибудь делает ?( пытается воостановить ) ?
ни одна лампочка не мигает !
Источник: www.securitylab.ru
Привет, Хабр! В прошлых статьях мы касались ошибок и проблем с серверами Dell и HP, и наш рассказ об ошибках refurbished-серверов был бы неполон без упоминания продукции третьего вендора «большой тройки» — IBM. Хотя эта славная корпорация уже отошла от производства серверов, её продукция ещё активно используется. Поэтому спешим поделиться с вами накопленным опытом «укрощения» серверов IBM. Это не исчерпывающий список проблем, но всё же он может оказаться кому-то полезен.
IBM System X3650 M4 boot failed
Оперативная память
Серверы IBM чувствительны по отношению к конфигурации модулей памяти. Зачастую после самостоятельного апгрейда — добавления памяти или её замены — сервер не загружается, либо видит меньше памяти, чем установлено на самом деле. К счастью, в подобных ситуациях не приходится долго гадать о причинах сбоя: на диагностической панели (если таковая имеется) загораются два индикатора Config и Memory.
Поэтому, прежде чем апгрейдить память обязательно изучите спецификацию, память какого типа и объёма поддерживается вашим сервером. Также большое значение имеет количество процессоров в сервере — от этого зависит порядок размещения модулей в слотах. Это тоже необходимо уточнить в спецификации.
Вообще, с памятью ровно такая же ситуация, как описано в статье про HP, например. Вкратце:
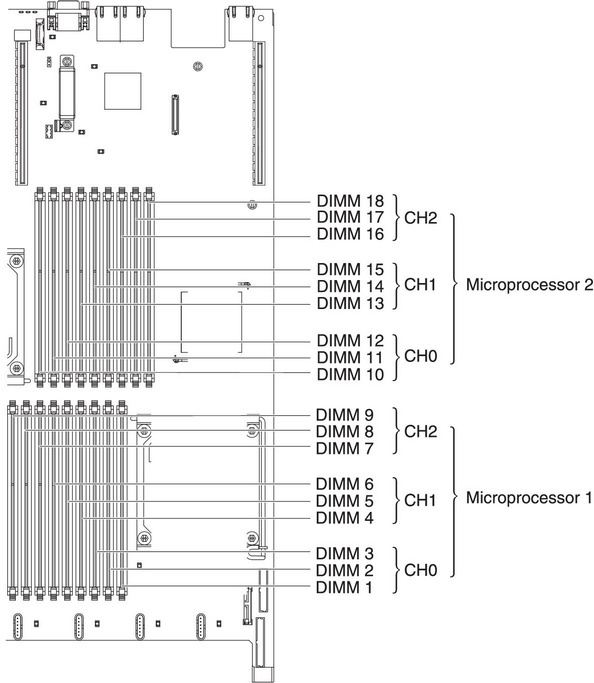
- Соблюдайте канальность памяти.
- Ставьте ECC REG 1(2)Rx4 память в двухпроцессорные системы и UDIMM — в однопроцессорные.
- Ставьте одинаковый объём памяти на каждый процессор.
А что делать, если вы вставили память в соответствии с инструкциями, а сервер всё равно не работает и предательски горит индикатор Memory? В этом случае придётся проверять разные варианты:
- Этот тип памяти не поддерживается сервером. Внимательно сверьтесь со спецификациями.
- Память оказалась «битой». Замените линейку на точно такую же и проверьте, заведётся ли сервер.
- Засорился пылью слот на материнской плате. Это довольно популярная причина, если сервер трудится уже несколько лет, а тем более если вы его не первый владелец. Продуйте слоты сжатым воздухом.
- Загнутый контакт в сокете. Такое бывает очень редко, но всё же бывает: память отказывается работать из-за загнутого контакта в сокете процессора. Если предыдущие варианты не помогли найти причину сбоя, снимите процессор и внимательно осмотрите сокет. Если вы оказались в числе немногочисленных «счастливчиков», то можете попробовать осторожно выпрямить погнутый контакт, но это исключительно на ваш страх и риск.
Накопители
Мы уже неоднократно упоминали о том, что совсем не обязательно устанавливать в серверах «родные» накопители. Ни IBM, ни другие вендоры их не производят, они лишь приобретают их у всем известных производителей, перепрошивают и клеят свои логотипы. Поэтому вы можете без труда сэкономить на апгрейде или восстановлении дисковых массивов, выбрав аналоги вместо «родных» накопителей. Двух-трёхкратная разница в цене это оправдывает, особенно если речь идёт о refurbished-серверах. В сети можно легко найти таблицы соответствия моделей, например:
| IBM 49Y2003 | Seagate ST9600204SS |
| IBM 90Y8872 | Seagate ST9600205SS |
| IBM 90Y8908 | Seagate ST9600105SS |
| IBM 81Y9650 | Seagate ST900MM0006 |
Модель IBM Оригинал
Тем не менее, ещё возможны ситуации несовместимости «неродных» накопителей с сервером. В этом случае сервер не грузится штатно, либо не видит накопитель. Обычно это решается с помощью установки свежей прошивки RAID-контроллера. К слову, рекомендуется обновить прошивку и бэкплейна/экспандера, в этом вам поможет приложение IBM Bootable Media Creator (BoMC).
При включении сервера и прохождении POST-проверки возможно появление ошибки:
A discovery error has occurred, please powercycle the system and all the enclosures attached to this system.
Это сигнализирует о проблеме с одним из накопителей. Вычислить его просто: индикаторы на его салазках постоянно мигают, даже когда все остальные носители прошли проверку и перестали мигать.
С дисковой подсистемой бывают и более экзотические проблемы. Например, при использовании RAID-1 в фирменном приложении MegaRAID Storage Manager могут появиться ошибки вида:
ID = 63
SEQUENCE NUMBER = 48442
TIME = 24-01-2016 17:03:59
LOCALIZED MESSAGE = Controller ID: 0 Consistency Check found inconsistent parity on VD strip: ( VD = 0, strip = 637679)
Чаще всего это говорит не об умирании диска, а об ошибке контроля чётности — несовпадении данных на основном и вторичном дисках. Возможные причины:
- Нередко такие ошибки появляются сразу после конфигурирования нового массива или после замены одного из дисков.
- Во время сеанса диагностики поверхности блинов происходит инициализация диска и выполнение операций ввода/вывода. На RAID-1 это может привести к временному несоответствию томов, которое автоматически исправляется при следующей проверке на соответствие. Такое возникает не при любом сеансе диагностики, а когда сходятся звёзды:
- o Используется RAID-контроллер без кэширования, либо активирован режим Write Through.
- o Нехватка оперативной памяти, при которой с диска осуществляется активная подкачка страниц.
- o Просто очень интенсивное использование дисков.
Обновление прошивок и ПО
Любопытная проблема может подстерегать при установке с нуля Windows 2012 или Windows 2012 R2 — свежеустановленная операционка не видит ни одного накопителя. Причём такое бывает не только с серверами IBM. Дело в том, что все накопители в сервере подключены через RAID, а упомянутые версии ОС не имеют вшитых драйверов для работы с RAID. И поэтому они их просто игнорируют. Как быть?
Самый надёжный способ: использовать утилиту IBM ServerGuide. При установке ОС она принудительно подсовывает все необходимые драйвера для данной модели и версии операционной системы. Обратите внимание, что образ ОС должен устанавливаться с диска, а не с флэшки: ServerGuide не будет работать с образом на том же USB-носителе, с которого запущен сам.

При покупке серверов бывают ситуации, когда нужно сначала обновить все прошивки, а потом уже накатывать систему. Сделать это можно с помощью вышеупомянутой IBM Bootable Media Creator:
- Загрузитесь с загрузочной флешки или диска.
- Запустите BoMC от имени Администратора.
- Выберите, что вы хотите сделать: обновить и/или провести диагностику.
- Программа спросит, где ей взять драйверы: скачать самой или вытащить из указанного вами архива.
- Выберите носитель для записи загрузочного образа: флэшку или диск. Запись может идти несколько часов, не волнуйтесь, программа не зависла.
- По окончании записи загрузитесь с этого носителя, и далее по инструкции.
Но если не поможет, то воспользуйтесь процедурой обновления через BoMC.
Бывают и более неприятные ситуации, когда по закону подлости в ходе установки более свежей версии BIOS’а происходит сбой питания.

После этого сервер уже не может загрузить основную прошивку, и использует резервную. Если штатная процедура восстановления BIOS’а не помогает, то сделайте… даунгрейд: установите более старую прошивку, чем та, что была до сбоя питания. Обычно это помогает. После этого уже можно попытаться снова поставить свежую версию BIOS’а. Как говорится, шаг назад — два вперёд.
Другие проблемы
Иногда при попытке удалённого управления сервером возникает ошибка “Login failed with an access denied error.”, причём в любых браузерах. Если перезагрузка сервера и клиента не помогает, то рекомендуется сбросить IMM до заводских настроек.
В статье про ошибки серверов HP мы упоминали о проблемах с системой охлаждения: сразу после запуска сервера вентиляторы выходили на высокие обороты и уже не снижали их. Случается такой недуг и в серверах IBM. Сервер воет, как реактивный лайнер на взлёте. Нам не удалось выяснить причину таких сбоев, но посоветовать можно следующее:
- Проверьте плотность подключения разъёмов питания.
- Отключите все вентиляторы и снимите корзину.
- Проверьте каждый вентилятор на других серверах.
- Соберите корзину снова, поменяв вентиляторы местами. Либо совсем их замените.
Преимущества серверов IBM
Серверы IBM заслуженно пользуются большой популярностью:
- Это простые и очень надёжные машины.
- Отличная расширяемость даже на начальных моделях и богатый комплект поставки.
- Серверы IBM обычно дешевле конкурентов и не уступают в производительности. Например, поколения M3 и M4 дешевле, чем аналоги у HP (Gen7 и Gen8) и Dell (11G и 12G).
- Самые недорогие расходники. Легко найти в России.
- Удобная диагностическая панель на многих моделях.
Источник: habr.com
Как можно исправить ошибки, связанные с DASD.WPK?
Повреждение, отсутствие или удаление файлов DASD.WPK может привести к ошибкам WATCOM FORTRAN 77.32. Как правило, решить проблему можно заменой файла WPK. Кроме того, некоторые ошибки DASD.WPK могут возникать по причине наличия неправильных ссылок на реестр. По этой причине для очистки недействительных записей рекомендуется выполнить сканирование реестра.
Мы подготовили для вас несколько версий файлов DASD.WPK, которые походят для %%os%% и нескольких выпусков Windows. Данные файлы можно посмотреть и скачать ниже. Для скачивания доступны не все версии DASD.WPK, однако вы можете запросить необходимых файл, нажав на кнопку Request (Запрос) ниже. В редких случаях, если вы не можете найти версию необходимого вам файла ниже, мы рекомендуем вам обратиться за дополнительной помощью к WATCOM International Corp..
Несмотря на то, что размещение соответствующего файла в надлежащем месте позволяет устранить большинство проблем, возникающих в результате ошибок, связанных с DASD.WPK, вам следует выполнить быструю проверку, чтобы однозначно в этом убедиться. Чтобы убедиться в том, что удалось решить проблему, попробуйте запустить WATCOM FORTRAN 77.32, и посмотреть выведется ли ошибка.
Источник: www.solvusoft.com
Ошибка dasd сервер ibm

Добрый день! Уважаемые читатели и гости блога pyatilistnik.org, сегодня я решил с вами поделиться опытом, восстановления RAID массива, на базе LSI контроллера. При загрузке сервера, на этапе старта VDs дисков на контроллере, вы видите ошибку: «The following VDs are missing». В данной статье, я постараюсь описать подробный метод восстановления работоспособности сервера, без потери данных. Надеюсь, что эта информация окажется полезной и сможет кому-то помочь выйти из не приятной ситуации.
Описание проблемы с развалившимся RAID
И так, есть сервер IBM System x3650 M3 в котором установлен RAID контроллер M5015, на контроллере 4 SAS диска, из которых собраны два независимых массива RAID 1. В момент загрузки сервера выскакивает ошибка:
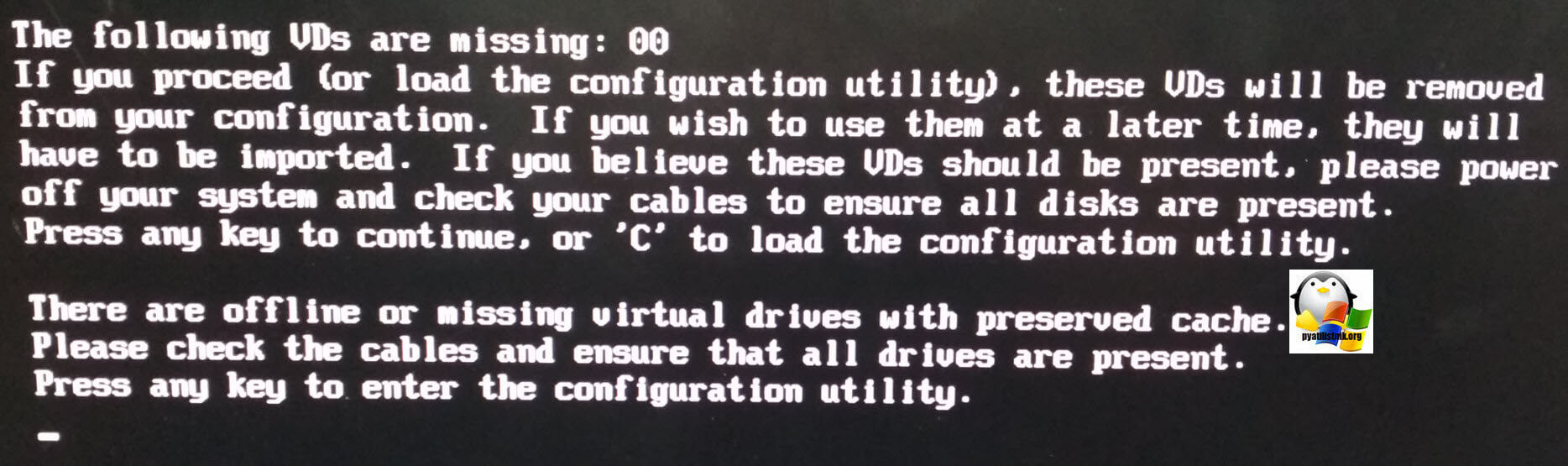
The following VDs are missing: 00. If you proceed (or load the configuration utility), these VDs will be removed from your configuration. If you wish to use them at a later time, they will have to be imported. If you believe these VDs should be present, please power off your system and check your cables to ensure all disks are present. Press any key to continue, or ‘C’ to load the configuration utility.
В сообщении вам говорят, что у вас нет дисков с которых можно было бы загрузиться и предлагают, проверить физически жесткие диски, кабели и все в этом дело. Для попадания в утилиту конфигурации нажмите C или другую клавишу.
Нажмите пробел или ESC.

После чег оу вас появится второе сообщение:
There are offline or missing virtual drives with preserved cache. Please check the cables and ensure that all drives are present. Press any key to the configuration utility.
Тут вам еще раз говорят, что ваши виртуальные диски с кэшем потеряны, проверьте их физически и посмотрите в специальной конфигурационной утилите. Нажимаем ESC.
Как исправить ошибку The following VDs are missing
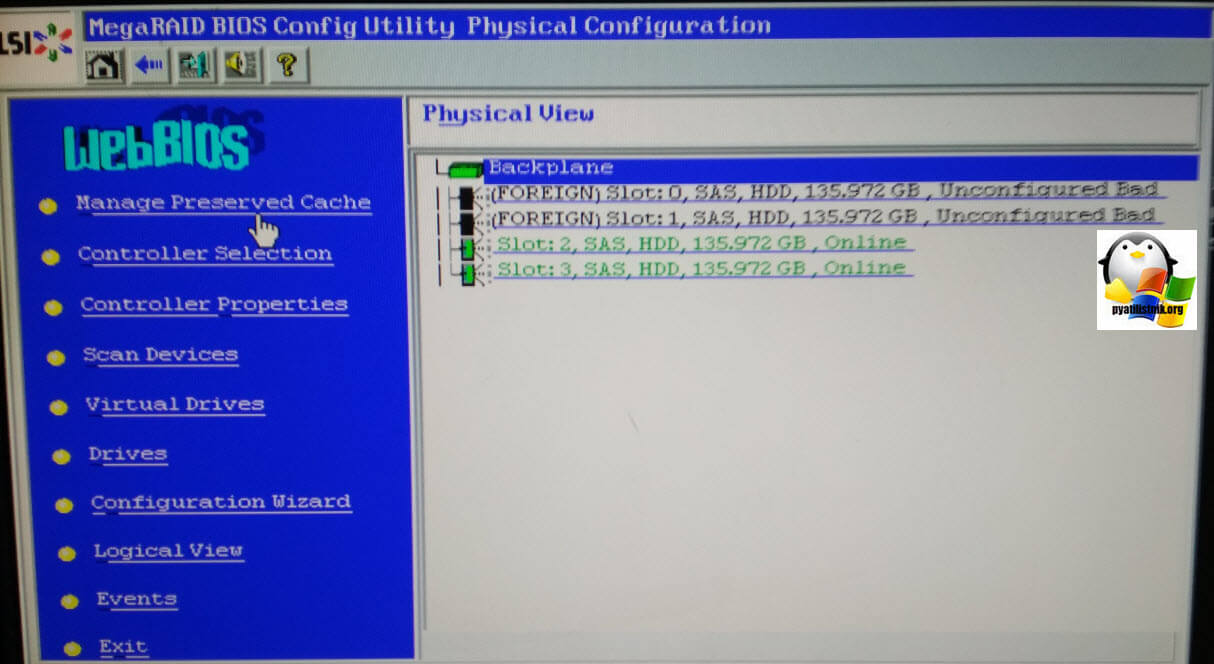
Сразу хочу отметить, что все действия вы делаете на свой страх и риск и автор не несет никакую ответственность за последствия
Первым делом нам необходимо перевести жесткие диски в состояние Foreign disks. Unconfigured good. Для этого, по очереди щелкаете по нужным дискам. Вы попадете в меню с манипуляцией над его параметрами. Выставите у каждого из них значение Unconfigured good и нажмите Go.
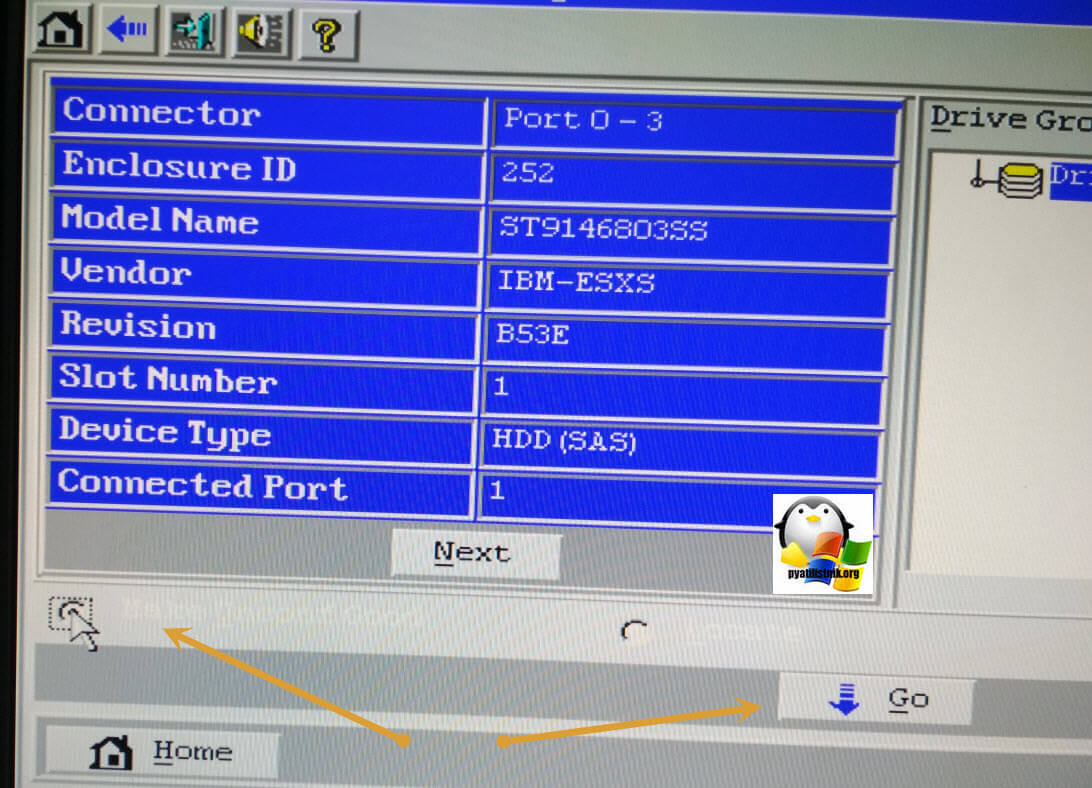
После чего нажмите Next, в следующем меню установите значение Locate и нажмите Go. После чего можно нажать кнопку Home и перейти в главное меню.
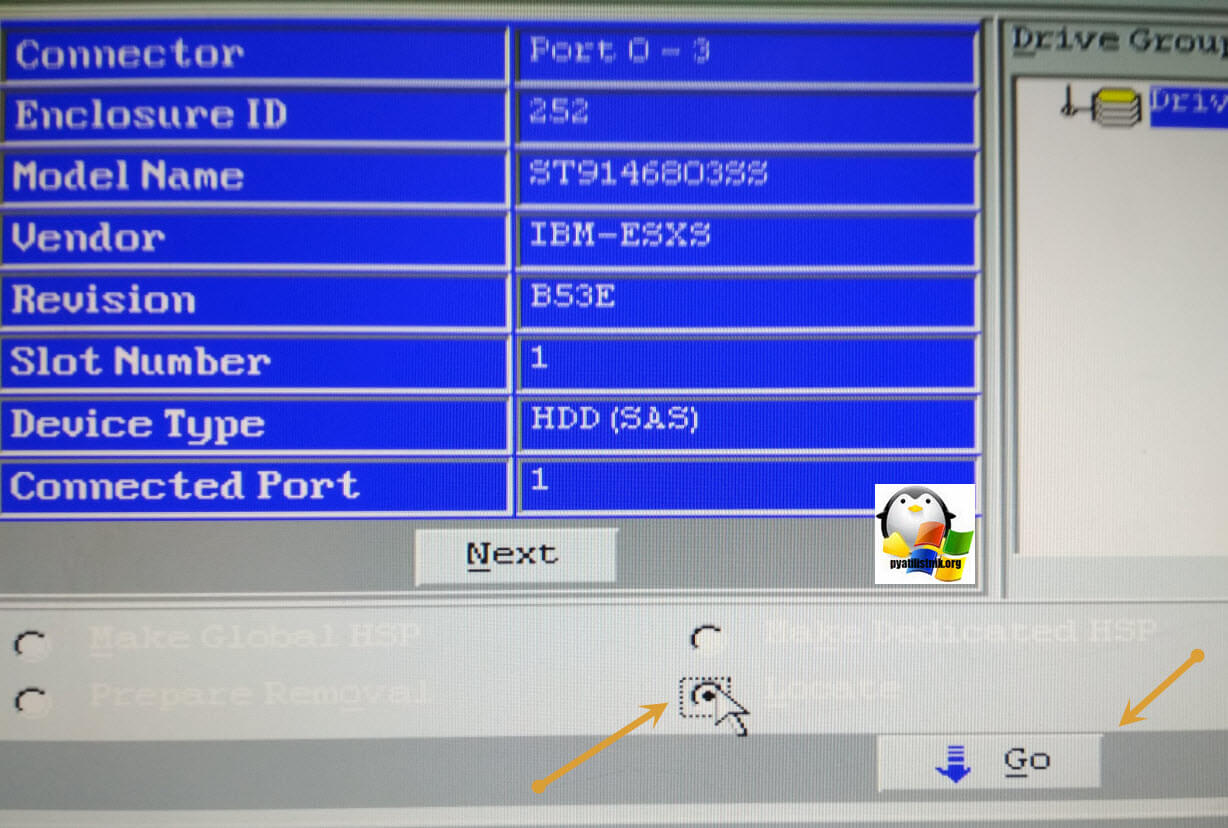
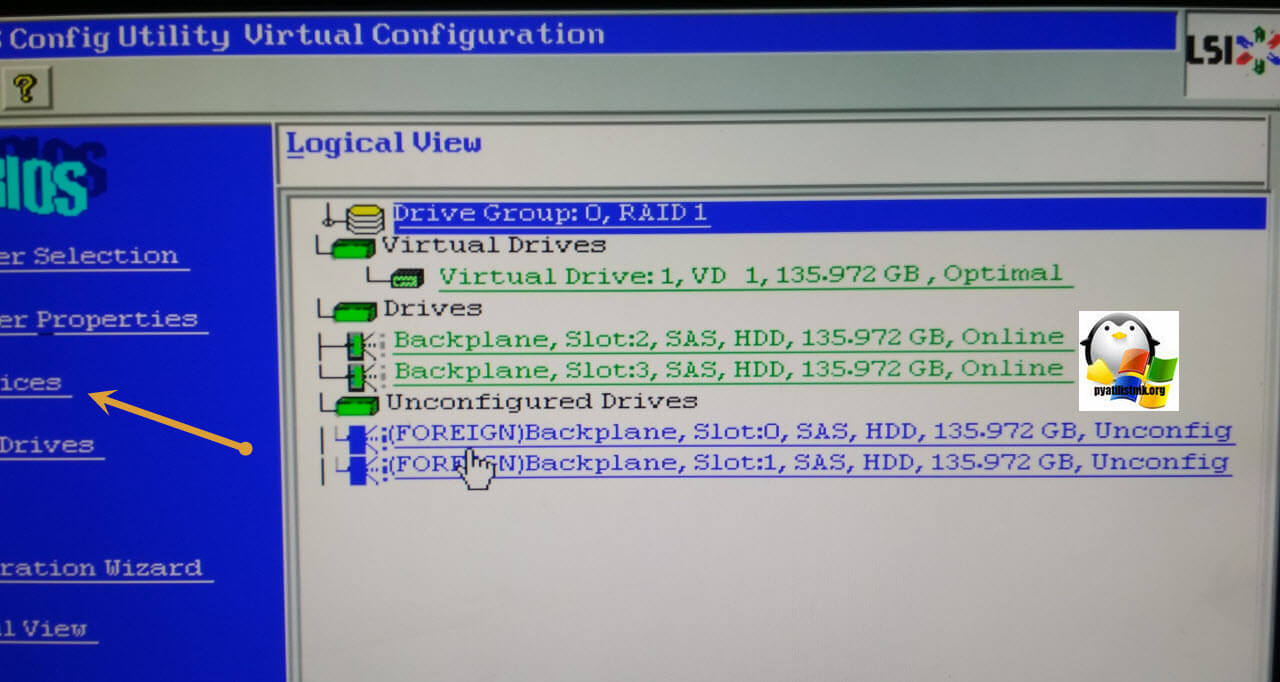
В результате у вас появится вот такая картина, что ваши диски перестанут быть красными и сменят статус Foreign. Unconfigured bad на Foreign. Unconfigured Good. Двигаемся дальше к восстановлению нашего RAID массива. Переходим в меню Scan Devices.
Тут мы постараемся отыскать и импортировать предыдущую конфигурацию.
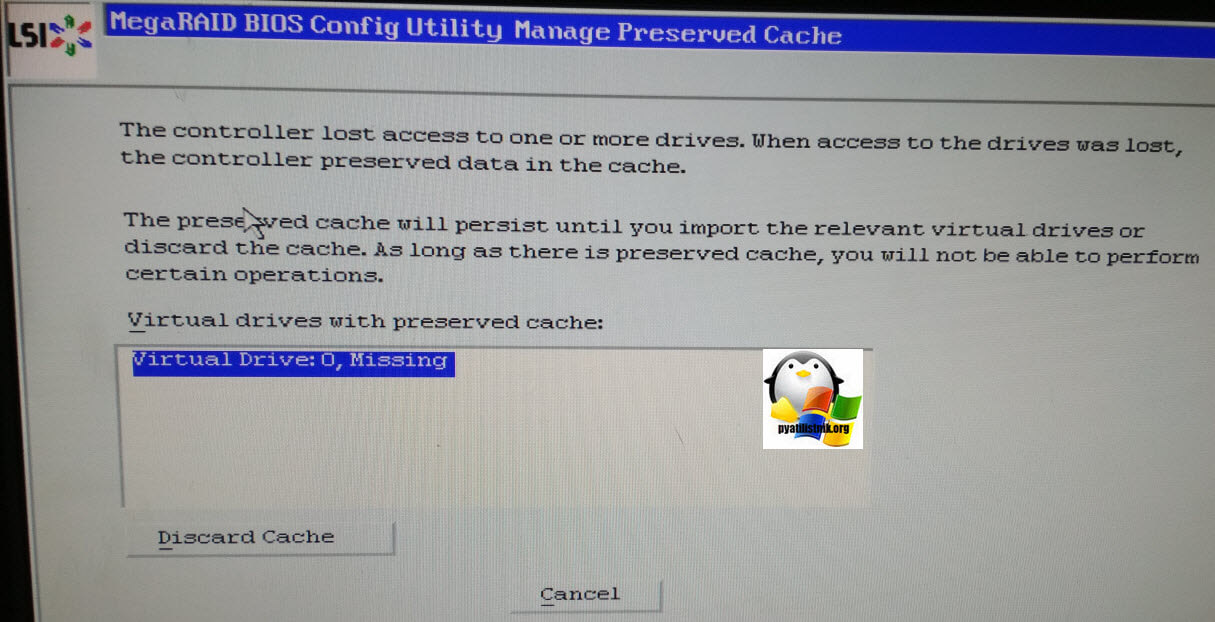
У вас может появиться окно, в котором нужно нажать кнопку Discard Cache, тут мы по сути забываем про кэш.
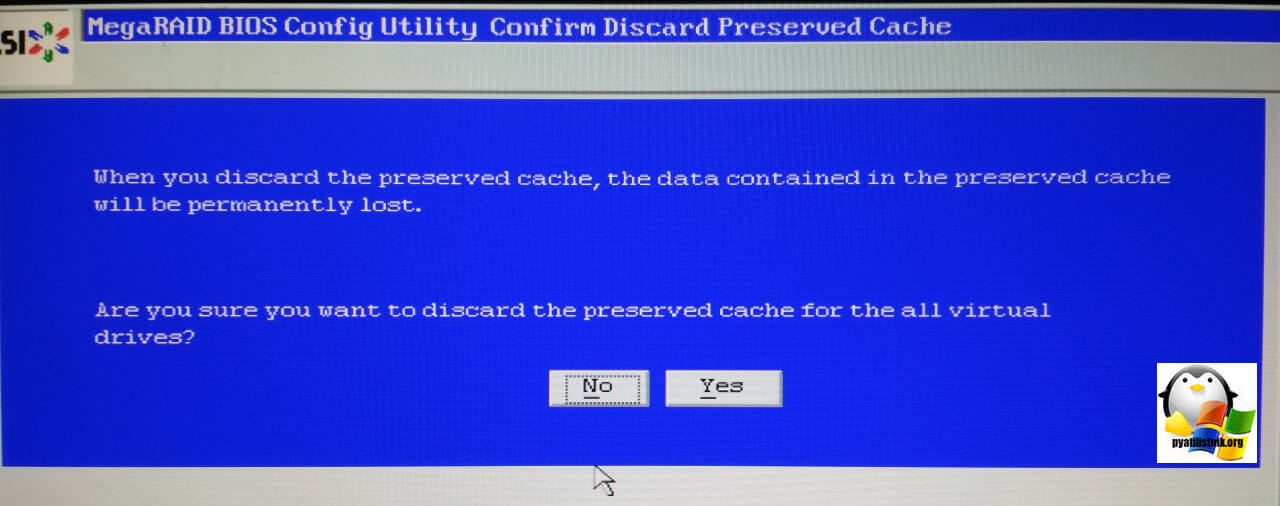
Соглашаемся с сообщением:
When you discard the preserved cache, the data contained in the preserved cache will be permanently lost
Теперь вам необходимо просканировать ваши диски на наличие старых конфигураций, для этого оставьте All Configuration в пункте Select Configuration и нажмите Preview.
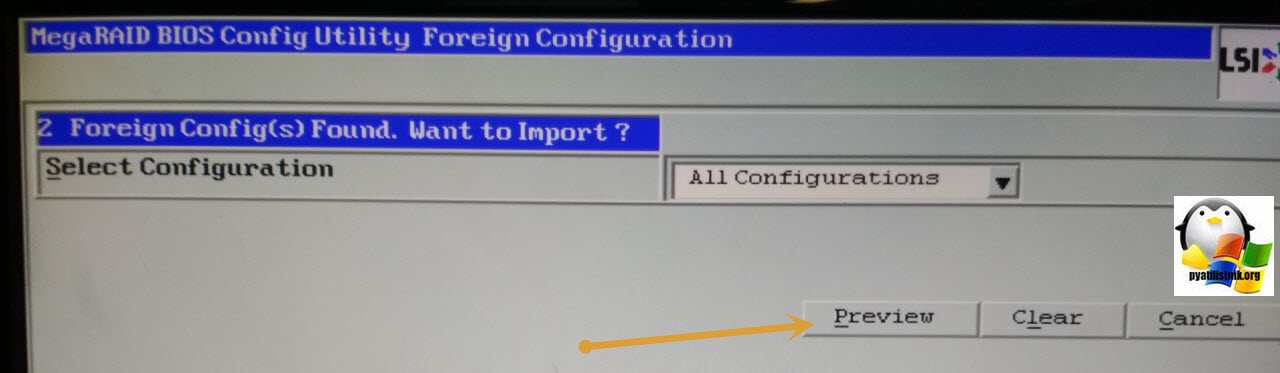
В итоге ваша утилита посмотрит все доступные для импорта конфигурации, проверьте их, если вас все устраивает, нажмите кнопку Import, для восстановления VD, процесс может занимать некоторое время.
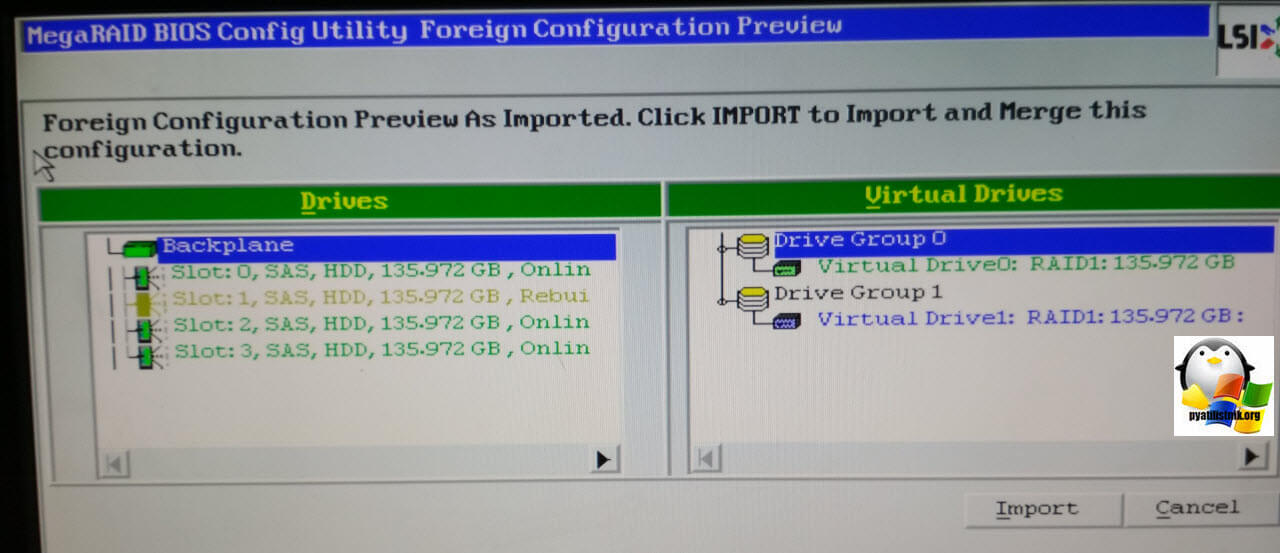
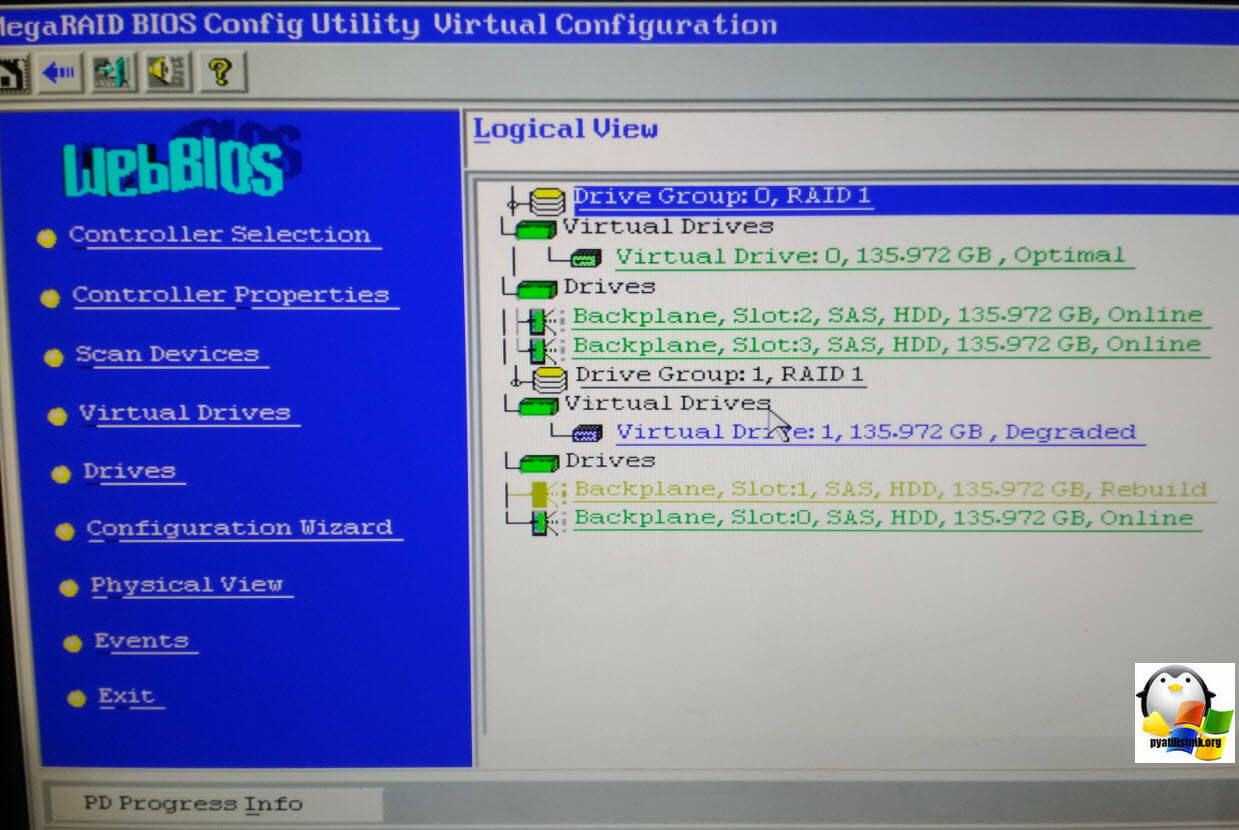
Если у вас с одним из дисков будут проблемы и он будет в состоянии Failed, то вы все равно сможете запустить систему, если оба красных диска переведете в режим Online. Для этого щелкните по каждому и перейдите во внутреннее меню.
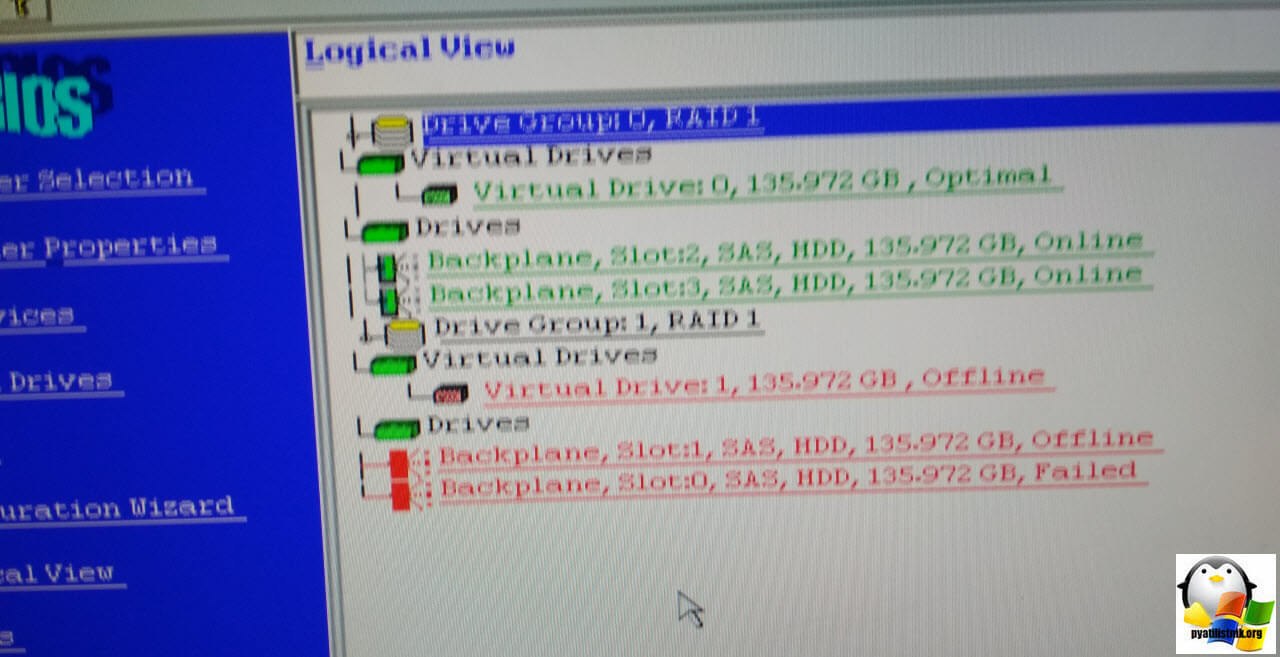

Надеюсь, что данная заметка оказалась для вас полезной и вы смогли восстановить работу сервера и избавиться от ошибки: The following VDs are missing: 00. If you proceed (or load the configuration utility), these VDs will be removed from your configuration. If you wish to use them at a later time, they will have to be imported. If you believe these VDs should be present, please power off your system and check your cables to ensure all disks are present. Press any key to continue, or ‘C’ to load the configuration utility
Популярные Похожие записи:
- Не видятся диски на сервере Dell
- Как создать RAID на Dell PERC H330 Adapter
- Отличия Global Hot Spare и Dedicated Hot Spare
- Ошибка JCP024 Lifecycle Controller in use
- Как установить операционную систему на Dell PowerEdge R740
- Ошибка Missing nameservers reported by parent
Источник: pyatilistnik.org
Войти или зарегистрироваться
Проблема с жестким на серваке ibm
Тема в разделе «Любые вопросы от новичков», создана пользователем Kilwat, 12 авг 2010.
-
Kilwat
Junior User
Доброго времени суток! Сталкнулся с такой проблемой. На работе есть сервер IBM x 3650 m2 c 4мя SAS хардами по 500 гб с поддержкай горячей замены. На время был удалён один из жёских дисков во время работающего сервака. После того как хард был установлен обратно на нём загорелся янтарный индикатор сигнализирующий о неиспрвности а на панели диагности сервера dasd ошибка. Подскажите как можно исправить эту ошибку?
-
oleg
Expert
Вирусоборец
Это нормально, он должен автоматичесски начать делать re-building данных.
У вас раид аппаратный ? (на этапе загрузки нажмите соответстую клавишу) после чего вы должны попасть в панель управления массивом, где вам нужно принудительно запустить ребилд. -
Kilwat
Junior User
Спс за совет, сделал ребилд удалённого харда, и теперь жоский робит как надо
(Вы должны войти или зарегистрироваться, чтобы ответить.)
Показать игнорируемое содержимое
Поделиться этой страницей
- Ваше имя или e-mail:
- У Вас уже есть учётная запись?
-
- Нет, зарегистрироваться сейчас.
- Да, мой пароль:
-
Забыли пароль?
-
Запомнить меня
Поиск
-
- Искать только в заголовках
- Сообщения пользователя:
-
Имена участников (разделяйте запятой).
- Новее чем:
-
- Искать только в этой теме
- Искать только в этом разделе
- Отображать результаты в виде тем
-
Быстрый поиск
- Последние сообщения
Больше…
Войти или зарегистрироваться
Проблема с жестким на серваке ibm
Тема в разделе «Любые вопросы от новичков», создана пользователем Kilwat, 12 авг 2010.
-

Kilwat
Junior UserДоброго времени суток! Сталкнулся с такой проблемой. На работе есть сервер IBM x 3650 m2 c 4мя SAS хардами по 500 гб с поддержкай горячей замены. На время был удалён один из жёских дисков во время работающего сервака. После того как хард был установлен обратно на нём загорелся янтарный индикатор сигнализирующий о неиспрвности а на панели диагности сервера dasd ошибка. Подскажите как можно исправить эту ошибку?
Kilwat,
12 авг 2010
#1 -
oleg
Expert
ВирусоборецЭто нормально, он должен автоматичесски начать делать re-building данных.
У вас раид аппаратный ? (на этапе загрузки нажмите соответстую клавишу) после чего вы должны попасть в панель управления массивом, где вам нужно принудительно запустить ребилд.
oleg,
12 авг 2010
#2 -
Kilwat
Junior UserСпс за совет, сделал ребилд удалённого харда, и теперь жоский робит как надо
Kilwat,
13 авг 2010
#3

(Вы должны войти или зарегистрироваться, чтобы ответить.)
Поделиться этой страницей
- Ваше имя или e-mail:
- У Вас уже есть учётная запись?
-
- Нет, зарегистрироваться сейчас.
- Да, мой пароль:
-
Забыли пароль?
-
Запомнить меня
Поиск
-
- Искать только в заголовках
- Сообщения пользователя:
-
Имена участников (разделяйте запятой).
- Новее чем:
-
- Искать только в этой теме
- Искать только в этом разделе
- Отображать результаты в виде тем
-
Быстрый поиск
- Последние сообщения
Больше…
IBMОписание тревоги индикатора сервера
1. Панель диагностики светового тракта
Кнопка напоминания:Эта кнопка устанавливает индикатор системной ошибки на передней панели как режим напоминания. В режиме напоминания загорается индикатор системной ошибки.2 Мигает раз в секунду,Пока проблема не будет исправлена, система перезапустится или возникнет новая проблема. Установив индикатор системной ошибки в режим напоминания, вы можете подтвердить, что знаете о предыдущем сбое, но не принимаете немедленных мер для устранения проблемы. Функция напоминания контролируетсяIMM контроль.
NMI Кнопка:Нажмите эту кнопку, чтобы микропроцессор сгенерировал немаскируемое прерывание. Это позволяет сделать синий экран сервера и выполнить дамп памяти (только еслиIBM Эту кнопку можно использовать только по указанию обслуживающего персонала).
Экран кода контрольной точки:На этом экране отображается код контрольной точки, указывающий, что система остановится в этой точке во время блока загрузки и POST.
Код контрольной точки — это значение байта или слово, сгенерированное UEFI. На этом экране не отображаются коды ошибок или рекомендуемые компоненты для замены.
кнопка сброса:Нажмите эту кнопку, чтобы перезагрузить сервер и запустить самотестирование при включении (POST). Для нажатия кнопки может потребоваться кончик ручки или конец выпрямленной канцелярской скрепки. Кнопка сброса расположена в правом нижнем углу панели диагностики светового тракта.
over spec Индикатор:Когда этот световой индикатор горит, это означает, что потребность в мощности превышает указанный источник питания.
log Индикатор:Когда этот индикатор горит, это означает, что в журнале событий есть ошибка, и вам следует проверить журнал событий.
linkИндикатор: Когда этот индикатор горит, сетевая карта неисправна.
psИндикатор:Когда этот световой индикатор горит, это указывает на отказ источника питания.
pci Индикатор:Если этот индикатор горит, это означает, что на шине PCI возникла ошибка.
sp Индикатор:Когда этот индикатор горит, это указывает на то, что потоковый процессор обнаружил ошибку (роль sp заключается в обработке данных, переданных ЦП, и преобразовании их в цифровой сигнал, который может быть распознан дисплеем после обработки)
fan: Когда этот индикатор горит, это означает, что охлаждающий вентилятор или вентилятор блока питания вышел из строя или работает слишком медленно. Отказ вентилятора также может вызватьtemp Световой индикатор горит.
temp Индикатор: Когда этот индикатор горит, это означает, что температура системы слишком высока.
mem Индикатор: Когда этот индикатор горит, это означает, что произошла ошибка памяти.
nmi Индикатор:Когда этот индикатор горит, это означает, что произошло немаскируемое прерывание (nmi)。
cnfgИндикатор: Когда этот индикатор горит, это означаетBIOSОшибка конфигурации.
cpu Индикатор:Когда этот индикатор горит, это означает, что микропроцессор вышел из строя.
vrm Индикатор:Когда этот индикатор горит, это означает, чтоvrm произошла ошибка.
dasd Индикатор:Когда этот индикатор горит, это означает, что произошел сбой жесткого диска с возможностью горячей замены.
raid Индикатор:Когда этот индикатор горит, это означает, что карта массива неисправна.
brd Индикатор:Когда этот индикатор горит, это означает, что подключенныйi/o Блок расширения неисправен.
2. Информационная панель оператора
Крышка кнопки управления питанием:Сдвиньте крышку на кнопку управления питанием, чтобы предотвратить случайное выключение сервера.
Кнопка управления питанием:Нажмите эту кнопку, чтобы вручную включить и выключить сервер.
Источник питанияИндикатор:Если индикатор горит и не мигает, это означает, что сервер включен; если индикатор мигает, это означает, что сервер выключен и все еще подключен к источнику переменного тока; если индикатор не горит, это означает, что нет питания переменного тока или источника питания, или сам индикатор неисправен . Заметка:Если этот индикатор не горит, это не означает, что на сервере нет питания. Световой индикатор может перегореть. Чтобы полностью отключить питание сервера, необходимо вынуть шнур питания из розетки.
Индикатор значка Ethernet:Этот индикатор загорается значком Ethernet.
Индикатор активности Ethernet:Если эти индикаторы мигают, это означает, что между сервером и сетью существует активность на указанном ими порте.
Индикатор локатора:Используйте этот индикатор, чтобы найти целевой сервер среди множества серверов невооруженным глазом. можно использоватьIBM Director Световой индикатор можно включить дистанционно или вручную, нажав кнопку локатора. Этот индикатор также загорится при запуске. Если в многоузловой конфигурации этот индикатор мигает, это означает, что соответствующий ему сервер является главным узлом. Если индикатор продолжает гореть, это означает, что соответствующий ему сервер является вторичным узлом.
Кнопка локатора:Нажмите эту кнопку, чтобы вручную включить или выключить индикатор локатора. В многоузловой конфигурации нажмите эту кнопку, чтобы включить или выключить индикаторы локатора всех узлов в конфигурации.
Информационный индикатор:Если этот индикатор горит, это означает, что какой-то аспект сервера находится не в оптимальном состоянии, и при диагностике светового пути загорится еще один индикатор, помогающий определить проблему. Только после того, как проблема будет решена или будет нажата кнопка напоминания, световой индикатор и световой индикатор на диагностической панели светового тракта погаснут.
Индикатор системной ошибки:Если этот индикатор горит, это означает, что произошла системная ошибка. Индикатор на диагностической панели светового тракта также загорится, чтобы помочь найти эту ошибку.
Эта статья перенесена из блога easy80851CTO, исходная ссылка:http://blog.51cto.com/68240021/1970874Если вам нужно перепечатать, пожалуйста, свяжитесь с первоначальным автором
Problem
Diagnosing problems with the IBM eServer xSeries 130, 135, 330, and IntelliStation R Pro
Resolving The Problem
Affected configurations
- IBM eServer xSeries 130, 135, 330, and IBM IntelliStation R Pro
This document is intended for trained servicers who are familiar with IBM server and workstation products. Use this document along with advanced diagnostic tests to troubleshoot problems effectively. Before servicing an IBM product, be sure to review the safety information. Click here to review the safety information.
- SCSI error messages
- Temperature error messages
- Fan error messages
- Voltage related system shutdown
- DASD error messages
- Bus fault messages
SCSI error mesages
| Error Code | FRU/Action |
|---|---|
|
One or more of the following might be causing the problem:
|
|
Temperature error messages
| Message | Action |
|---|---|
| DASD over recommended temperature (sensor X) (level-warning; DASD bay «X» had over temperature condition) |
|
| DASD under recommended temperature (sensor X) (level-warning;direct access storage device bay «X» had under temperature condition) |
|
| DASD 1 over temperature (level-critical; sensor for DASD1 reported temperature over recommended range) |
|
| Power supply «X» temperature Fault (level-critical; power supply «x» had over temperature condition) |
|
| System board is over recommended temperature (level-warning; system board is over recommended temperature) |
|
| System board is under recommended temperature (level-warning; system board is under recommended temperature) |
|
| System over temperature for CPU «X» (level-warning; CPU «X» reporting over temperature condition) |
|
| System under recommended CPU «X»temperature (level-warning; system reporting under temperature condition for CPU «X») |
|
Fan error messages
|
Message |
Action |
|---|---|
|
Fan «X» failure (level-critical; fan «X» had a failure) |
|
|
Fan «X» fault (level-critical; fan «X» beyond recommended RPM range) |
|
|
Fan «X» Outside Recommended Speed Action |
|
Voltage related system shutdown
|
Message |
Action |
|---|---|
|
System shutoff due to «X» current over maximum value (level-critical; system drawing too much current on voltage «X» bus) |
|
|
System shutoff due to «X» current under minimum. value (level-critical; current on voltage bus «X» under minimum value) |
|
|
System shutoff due to «X» V over voltage (level-critical; system shutoff due to «X» supply over voltage) |
|
|
System shutoff due to «X» V under voltage (level-critical system shutoff due to «X» supply under voltage) |
|
|
System shutoff due to VRM «X»over voltage |
|
DASD error messages
|
Message |
Action |
|---|---|
|
Hard drive «X» removal detected (level-critical; hard drive «X» has been removed) |
|
Bus fault messages
|
Message |
Action |
|---|---|
|
Failure reading I2C device. Check devices on bus 0. |
|
|
Failure reading I2C device. Check devices on bus 1. |
|
|
Failure reading I2C device. Check devices on bus 2. |
|
|
Failure reading I2C device. Check devices on bus 3. |
|
|
Failure reading I2C device. Check devices on bus 4. |
|
|
Need more help? |
|---|
Please select one of the the following options for further assistance:
Document Location
Worldwide
Operating System
IntelliStation Pro:All operating systems listed
Older System x:Operating system independent / None
[{«Type»:»HW»,»Business Unit»:{«code»:»BU016″,»label»:»Multiple Vendor Support»},»Product»:{«code»:»HW18E»,»label»:»Older System x->xSeries 135″},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»»,»label»:»»}},{«Type»:»HW»,»Business Unit»:{«code»:»BU016″,»label»:»Multiple Vendor Support»},»Product»:{«code»:»HW18L»,»label»:»Older System x->xSeries 330″},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»»,»label»:»»}},{«Type»:»HW»,»Business Unit»:{«code»:»BU054″,»label»:»Systems w/TPS»},»Product»:{«code»:»HWP99″,»label»:»IntelliStation Pro->IntelliStation R Pro»},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Line of Business»:{«code»:»»,»label»:»»}}]
Today, one of our IBM system3650X series server encountered an DASD error.
An orange Exclamation light turned ON and the server was not booting properly. This server have 2 HDD running in RAID mode. both HDD green lights were flashing properly which was showing that the HDD are in good condition. So I applied the Power Recycling solution and it worked like a charm 🙂 .
Howto do Power Recycling / Cold Restart
# Shutdown the Server
# Remove Power cables (both) from power supply.
# Wait for 10 Minutes,
# Now plugin the power cables and turn ON the servers and you won’t see orange light 🙂
More information can be found here
http://www.google.com.pk/search?q=ibm+system+x3650+dasd+error&ie=utf-8&oe=utf-8&aq=t&rls=org.mozilla:en-US:official&client=firefox-a
Regard’s
Syed Jahanzaib
Войти или зарегистрироваться
Тема в разделе «Любые вопросы от новичков», создана пользователем Kilwat, 12 авг 2010.
-
Kilwat
Junior User
Доброго времени суток! Сталкнулся с такой проблемой. На работе есть сервер IBM x 3650 m2 c 4мя SAS хардами по 500 гб с поддержкай горячей замены. На время был удалён один из жёских дисков во время работающего сервака. После того как хард был установлен обратно на нём загорелся янтарный индикатор сигнализирующий о неиспрвности а на панели диагности сервера dasd ошибка. Подскажите как можно исправить эту ошибку?
-
oleg
Expert
Вирусоборец
Это нормально, он должен автоматичесски начать делать re-building данных.
У вас раид аппаратный ? (на этапе загрузки нажмите соответстую клавишу) после чего вы должны попасть в панель управления массивом, где вам нужно принудительно запустить ребилд. -
Kilwat
Junior User
Спс за совет, сделал ребилд удалённого харда, и теперь жоский робит как надо
(Вы должны войти или зарегистрироваться, чтобы ответить.)
Показать игнорируемое содержимое
Поделиться этой страницей
- Ваше имя или e-mail:
- У Вас уже есть учётная запись?
-
- Нет, зарегистрироваться сейчас.
- Да, мой пароль:
-
Забыли пароль?
-
Запомнить меня
Поиск
-
- Искать только в заголовках
- Сообщения пользователя:
-
Имена участников (разделяйте запятой).
- Новее чем:
-
- Искать только в этой теме
- Искать только в этом разделе
- Отображать результаты в виде тем
-
Быстрый поиск
- Последние сообщения
Больше…
5 Replies
-
pure capsaicin
Windows Server Expert
-
check
243
Best Answers -
thumb_up
534
Helpful Votes
DASD and LPD are code to those who might not understand.
What RAID level are you using, your card may remember the fault and take it through with it, there is a word for this but I can’t remember it off the top of my head, but the card marks the slot as bad, not the disk.
Was this post helpful?
thumb_up
thumb_down
-
check
-
Hi Rod, How can I clear the memory of the card so it will forget the error? I am using Raid 5 on my existing SAS disk.
Was this post helpful?
thumb_up
thumb_down
-
Just additional info. I have a M1015 controller connected to my SAS Expander card. Is this okay?
Was this post helpful?
thumb_up
thumb_down
-
Additional Information:
I just notice something while reading
the system documentation of System X3650 M3 on http://systemx.lenovofiles.com/help/index.jsp?topic=%2Fcom.lenovo.sysx.7945.doc%2Ft_installing_sas_s… Opens a new windowI notice here that when there is a two
option for us to expand the SAS 8 PAC HDD. One is to install a SAS/SATA 8Pac
HDD Option where we needs to have ServeRaid controller and SAS expander
card and the second option is to install a SAS/SATA
8Pac HDD for 2 RAID kit with 2 M5015 adapters option where we will need to
have 2 M5015 adapter.Where in our currently setup we do have one M5015 adapter and a SAS
expander card. Just thinking that this might be the
reason why we are encountering the issue we had. need your thoughts on this.
Was this post helpful?
thumb_up
thumb_down
-
All fixed, We did replace all the parts including the M. Board and find out that it is just a firmware issue of the SAS expander.
Was this post helpful?
thumb_up
thumb_down