I have solved installing pheonixminer on ethos:
bash <(curl -s https://raw.githubusercontent.com/cynixx3/third-party-miner-installer-for-ethos/master/miner-manager) phoenixminer installI tried your fix, but it didn’t work for me. I was use ethminer before, and have never used phoenixminer.
What does your local.conf file look like?/home/ethos/local.conf
globalminer phoenixminer
maxgputemp 87
stratumproxy enabled
globalfan 80
safevolt enabled
globalpowertune 2
autoreboot 99999
custompanel xxx
loc 4948df rig_name
lockscreen enabled
cor 4948df 1100 1100 1100 1100 1100 1100 1100 1040 1100 1100 1100 1100 1100
mem 4948df 2220 2220 2220 2220 2220 2140 2220 2100 2220 2220 2220 2220 2220
vlt 4948df 850 850 850 850 850 860 850 820 850 850 850 850 850proxywallet 0xXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX/rig_name/youremail@gmail.com
proxypool1 eth-eu1.nanopool.org:9999
proxypool2 eth-eu2.nanopool.org:9999
flags
I tried it with your same local.conf, but I keep getting the same errors below:
Phoenix Miner 5.3b Linux/gcc — Release build
Unknown OpenCL driver version! Hashrate and stale shares may suffer
OpenCL platform: OpenCL 2.0 AMD-APP (1800.11)
Available GPUs for mining:
GPU1: AMD Radeon (TM) R9 390 Series (pcie 1), OpenCL 2.0, 7.9 GB VRAM, 40 CUs
GPU2: AMD Radeon (TM) R9 390 Series (pcie 4), OpenCL 2.0, 7.9 GB VRAM, 40 CUs
GPU3: AMD Radeon (TM) R9 390 Series (pcie 5), OpenCL 2.0, 7.9 GB VRAM, 40 CUs
Unable to initialize AMD hardware monitor
Eth: the pool list contains 2 pools (2 from command-line)
Eth: primary pool: eth-eu1.nanopool.org:9999
Starting GPU mining
Eth: Connecting to ethash pool eth-eu1.nanopool.org:9999 (proto: EthProxy)
Listening for CDM remote manager at port 3333 in read-only mode
Eth: Connected to ethash pool eth-eu1.nanopool.org:9999 (51.15.39.52)
Eth: New job #a825a992 from eth-eu1.nanopool.org:9999; diff: 10000MH
GPU1: Starting up… (0)
GPU1: Generating ethash light cache for epoch #379
GPU2: Starting up… (0)
GPU3: Starting up… (0)
Eth: New job #ab157eab from eth-eu1.nanopool.org:9999; diff: 10000MH
Light cache generated in 2.6 s (24.6 MB/s)
GPU1: Free VRAM: 7.913 GB; used: 0.006 GB
GPU1: Disabling DAG pre-allocation (not enough VRAM)
GPU1: Allocating DAG for epoch #379 (3.96) GB
GPU1: Allocating buffers failed with: clCreateBuffer (-61).
Fatal error detected. Restarting.
GPU2: Free VRAM: 7.921 GB; used: 0.007 GB
GPU2: Disabling DAG pre-allocation (not enough VRAM)
GPU2: Allocating DAG for epoch #379 (3.96) GB
GPU2: Allocating buffers failed with: clCreateBuffer (-61).
GPU3: Free VRAM: 7.921 GB; used: 0.007 GB
GPU3: Disabling DAG pre-allocation (not enough VRAM)
GPU3: Allocating DAG for epoch #379 (3.96) GB
GPU3: Allocating buffers failed with: clCreateBuffer (-61).
Eth speed: 0.000 MH/s, shares: 0/0/0, time: 0:00
GPUs: 1: 0.000 MH/s (0) 2: 0.000 MH/s (0) 3: 0.000 MH/s (0)
Eth: New job #24368525 from eth-eu1.nanopool.org:9999; diff: 10000MH
-
#1
Всем привет! Очень нужна помощь, не могу понять в чем проблема. Ферма все карты 570 8Gb, Dag не создается.
Что не делал, все так же, и проблем не нахожу подобных.
![]()
2020.11.01:14:50:54.433: GPU1 GPU1: Starting up… (0) 2020.11.01:14:50:54.433: GPU1 GPU1: Generating ethash light cache for epoch #384 2020.11.01:14:50:54.433: GPU2 GPU2: Starting up… (0) 2020.11.01:14:50:54.443: GPU3 GPU3: Starting up… (0) 2020.11.01:14:50:54.443: GPU4 GPU4: Starting up… (0) 2020.11.01:14:50:54.443: GPU5 GPU5: Starting up… (0) 2020.11.01:14:50:54.447: GPU6 GPU6: Starting up… (0) 2020.11.01:14:50:54.451: GPU7 GPU7: Starting up… (0) 2020.11.01:14:50:54.451: GPU8 GPU8: Starting up… (0) 2020.11.01:14:50:57.352: GPU1 Light cache generated in 2.9 s (21.9 MB/s) 2020.11.01:14:50:57.701: GPU2 GPU2: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:57.701: GPU2 GPU2: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:57.701: GPU2 GPU2: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:57.701: wdog Fatal error detected. Restarting. 2020.11.01:14:50:57.803: GPU1 GPU1: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:57.811: GPU1 GPU1: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:57.811: GPU1 GPU1: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:57.904: GPU3 GPU3: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:57.915: GPU3 GPU3: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:57.915: GPU3 GPU3: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.006: GPU4 GPU4: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.015: GPU4 GPU4: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.015: GPU4 GPU4: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.110: GPU5 GPU5: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.111: GPU5 GPU5: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.111: GPU5 GPU5: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.211: GPU6 GPU6: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.211: GPU6 GPU6: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.211: GPU6 GPU6: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.310: GPU7 GPU7: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.318: GPU7 GPU7: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.318: GPU7 GPU7: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.411: GPU8 GPU8: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.411: GPU8 GPU8: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.411: GPU8 GPU8: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.698: eths Eth: Received: {«id»:null,»method»:»mining.notify»,»params»:[«000000003a9967e4″,»bf532874eb434842e7a3e4acd113fe454541651872760d9b95d11d7f90ca25dc»,»34170ca940a4cd641f882cb4f8a5fedbcbc5f4fa79ade9174eb6edd1faff60a9″,true]} 2020.11.01:14:50:58.699: eths Eth: New job #34170ca9 from daggerhashimoto.eu-new.nicehash.com:3353; diff: 2664MH 2020.11.01:14:50:59.077: eths Eth: Received: {«id»:null,»method»:»mining.notify»,»params»:[«000000003a99f354″,»bf532874eb434842e7a3e4acd113fe454541651872760d9b95d11d7f90ca25dc»,»0cf2bc70234f576f2e334837364ed1a497b1f90ae0d0aee17a7f468b48362b3f»,true]} 2020.11.01:14:50:59.078: eths Eth: New job #0cf2bc70 from daggerhashimoto.eu-new.nicehash.com:3353; diff: 2664MH 2020.11.01:14:50:59.229: main Eth speed: 0.000 MH/s, shares: 0/0/0, time: 0:00 2020.11.01:14:50:59.229: main GPUs: 1: 0.000 MH/s (0) 2: 0.000 MH/s (0) 3: 0.000 MH/s (0) 4: 0.000 MH/s (0) 5: 0.000 MH/s (0) 6: 0.000 MH/s (0) 7: 0.000 MH/s (0) 8: 0.000 MH/s (0)

cps
Гений мысли
-
#2
Память не слишком до хрена задрана?
Версию хайва обновлял, майнер на TRM менял, холодильник закрывал? )
-
#3
Та нет, ничего необычного не делал.
cps
Гений мысли
-
#4
Та нет, ничего необычного не делал.
А надо ). Обновить хайв, сменить майнер если не вылечится. Холодильник закрыть, если открыт (местный юмор).
-
#5
Ну так поменяй майнер для начала на феникс, клеймор выше 384 эпохи не качает.
-
#6
Всем привет! Очень нужна помощь, не могу понять в чем проблема. Ферма все карты 570 8Gb, Dag не создается.
Что не делал, все так же, и проблем не нахожу подобных.
Посмотреть вложение 151123
2020.11.01:14:50:54.433: GPU1 GPU1: Starting up… (0) 2020.11.01:14:50:54.433: GPU1 GPU1: Generating ethash light cache for epoch #384 2020.11.01:14:50:54.433: GPU2 GPU2: Starting up… (0) 2020.11.01:14:50:54.443: GPU3 GPU3: Starting up… (0) 2020.11.01:14:50:54.443: GPU4 GPU4: Starting up… (0) 2020.11.01:14:50:54.443: GPU5 GPU5: Starting up… (0) 2020.11.01:14:50:54.447: GPU6 GPU6: Starting up… (0) 2020.11.01:14:50:54.451: GPU7 GPU7: Starting up… (0) 2020.11.01:14:50:54.451: GPU8 GPU8: Starting up… (0) 2020.11.01:14:50:57.352: GPU1 Light cache generated in 2.9 s (21.9 MB/s) 2020.11.01:14:50:57.701: GPU2 GPU2: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:57.701: GPU2 GPU2: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:57.701: GPU2 GPU2: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:57.701: wdog Fatal error detected. Restarting. 2020.11.01:14:50:57.803: GPU1 GPU1: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:57.811: GPU1 GPU1: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:57.811: GPU1 GPU1: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:57.904: GPU3 GPU3: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:57.915: GPU3 GPU3: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:57.915: GPU3 GPU3: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.006: GPU4 GPU4: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.015: GPU4 GPU4: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.015: GPU4 GPU4: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.110: GPU5 GPU5: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.111: GPU5 GPU5: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.111: GPU5 GPU5: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.211: GPU6 GPU6: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.211: GPU6 GPU6: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.211: GPU6 GPU6: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.310: GPU7 GPU7: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.318: GPU7 GPU7: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.318: GPU7 GPU7: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.411: GPU8 GPU8: Free VRAM: 7.936 GB; used: 0.051 GB 2020.11.01:14:50:58.411: GPU8 GPU8: Allocating DAG for epoch #384 (4.00) GB 2020.11.01:14:50:58.411: GPU8 GPU8: Allocating buffers failed with: clCreateBuffer (-61). 2020.11.01:14:50:58.698: eths Eth: Received: {«id»:null,»method»:»mining.notify»,»params»:[«000000003a9967e4″,»bf532874eb434842e7a3e4acd113fe454541651872760d9b95d11d7f90ca25dc»,»34170ca940a4cd641f882cb4f8a5fedbcbc5f4fa79ade9174eb6edd1faff60a9″,true]} 2020.11.01:14:50:58.699: eths Eth: New job #34170ca9 from daggerhashimoto.eu-new.nicehash.com:3353; diff: 2664MH 2020.11.01:14:50:59.077: eths Eth: Received: {«id»:null,»method»:»mining.notify»,»params»:[«000000003a99f354″,»bf532874eb434842e7a3e4acd113fe454541651872760d9b95d11d7f90ca25dc»,»0cf2bc70234f576f2e334837364ed1a497b1f90ae0d0aee17a7f468b48362b3f»,true]} 2020.11.01:14:50:59.078: eths Eth: New job #0cf2bc70 from daggerhashimoto.eu-new.nicehash.com:3353; diff: 2664MH 2020.11.01:14:50:59.229: main Eth speed: 0.000 MH/s, shares: 0/0/0, time: 0:00 2020.11.01:14:50:59.229: main GPUs: 1: 0.000 MH/s (0) 2: 0.000 MH/s (0) 3: 0.000 MH/s (0) 4: 0.000 MH/s (0) 5: 0.000 MH/s (0) 6: 0.000 MH/s (0) 7: 0.000 MH/s (0) 8: 0.000 MH/s (0)
Дрова обнови
-
#7
Ну так поменяй майнер для начала на феникс, клеймор выше 384 эпохи не качает.
это и есть феникс
cps
Гений мысли
-
#8
Сколько хайв не обновлял?
(Да, обновлял ). Эпохи идут, на старых драйверах и версиях майнеров начинает глючить.
Последнее редактирование:
-
#9
Сори, но не совсем понятно разве на последней версии hive драйвера не актуальные?
-
#10
Вчера тоже пробовал риг на nicehash настраивать. Hive OS 0.6-170@201029 OpenCL 19.50. Карты 570-580 8Gb. Майнер феникс. Ошибка та же.
На TRM работает.
На нанопуле, с этим же майнером проблем нет.
-
#11
Сколько хайв не обновлял? Эпохи идут, на старых драйверах и версиях майнеров начинает глючить.
Самая последняя версия((

AFR
Друг форума
-
#13
Когда обновляешь хайв, обновляется оболочка, а не драйвера. Вот смотри, у меня версия хайва более старая, а драйвера новее
![]()
Скачай на сайте хайва новую версию и перезалей заново, там уже будут новее драйвера
-
#14
Вчера тоже пробовал риг на nicehash настраивать. Hive OS 0.6-170@201029 OpenCL 19.50. Карты 570-580 8Gb. Майнер феникс. Ошибка та же.
На TRM работает.
На нанопуле, с этим же майнером проблем нет.
Это майнер TRM?
-
#15
Да, TeamRedMiner
Ты тоже на nicehash настраиваешь?
-
#16
Про холодильник не забудь
-
#17
И память по пробуй 2000 и 30рев
AFR
Друг форума
-
#18
Про холодильник не забудь
Стиралки тоже моросят иногда
-
#19
Когда обновляешь хайв, обновляется оболочка а не драйвера. Вот смотри, у меня версия хайва более старая, а драйвера новее
Посмотреть вложение 151127Скачай на сайте хайва новую версию и перезалей заново, там уже будут новее драйвера
Это нельзя сделать удаленно?
Да, TeamRedMiner
Ты тоже на nicehash настраиваешь?
Да, кошмар какой-то) теперь не понятно как его настроить)) В фениксе просто адреса прописываешь. Тут больше всего
-
#20
На фене найс норм работает
Hello Everyone,
I’ve encountered a Problem while updating to oclHashcat-1.33. At first the Error «clCreateBuffer() -61» showed up everytime I tried to start cracking on some Hashes (tried it with the oclExample0.sh). After some Googling I stumbled accross the Command
Code:
export GPU_MAX_HEAP_SIZE=90
Now I am able to run Hashcat fine, except when I am trying to use the tuned performance Profile.
The following Job runs fine
Code:
./oclHashcat64.bin -a 0 -m 2711 -w 2 -o ../outfiles/hashes_out.txt --username --remove ../crackme/hashes_w_u.txt ../wordlist/rockyou.txt --status
But when I try to increase the Performance Profile to 3, I get the above mentioned Error
Code:
./oclHashcat64.bin -a 0 -m 2711 -w 3 -o ../outfiles/hashes_out.txt --username --remove ../crackme/hashes_w_u.txt ../wordlist/rockyou.txt --status
Hashes: 4818 hashes; 4818 unique digests, 4818 unique salts
Bitmaps: 16 bits, 65536 entries, 0x0000ffff mask, 262144 bytes
Rules: 1
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a0.Cypress_1573.4_1573.4.kernel (1053060 bytes)
ERROR: clCreateBuffer() -61
I don’t know if its worth mentioning but I have an old HD5850 that I use to toy around with oclHashcat 
As always thanks in advance for any Help or Suggestions
![]()
Posts: 5,186
Threads: 230
Joined: Apr 2010
clCreateBuffer() -61 basically means «Out of Memory». That means your GPU memory. The number of hashes (plus the fact that they are salted) affects the required memory plus the wordload profile affects the required memory. So it’s perfectly normal to run into this error, sooner or later.
![]()
Posts: 24
Threads: 5
Joined: Oct 2014
03-05-2015, 09:25 AM
(This post was last modified: 03-05-2015, 09:33 AM by TheDarkOne.)
@atom
Thank you for your reply and the Clearification of the Error Message but I’ve done some more tests and the Results don’t seem to Point in that Direction although I am not sure in which Direction the Results point anyway :-\
Let me Explain what I did:
I testet a Single vBulletin hash with oclHashcat 1.33 which returns the clCreateBuffer() -61 Error.
Code:
/oclHashcat/oclHashcat-1.33$ ./oclHashcat64.bin -a 3 -m 2711 -w 3 --username --remove ../crackme/single_hash.txt ?l?l?l?a?a?a?a --status
oclHashcat v1.33 starting...
Device #1: Cypress, 1024MB, 765Mhz, 18MCU
Hashes: 1 hashes; 1 unique digests, 1 unique salts
Bitmaps: 8 bits, 256 entries, 0x000000ff mask, 1024 bytes
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
* Single-Hash
* Single-Salt
* Brute-Force
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a3.Cypress_1573.4_1573.4.kernel (566680 bytes)
Device #1: Kernel ./kernels/4098/markov_le_v4.Cypress_1573.4_1573.4.kernel (71776 bytes)
ERROR: clCreateBuffer() -61
Then I testet the same Hash with oclHahscat 1.31 and everything works fine. So I am a bit out of Ideas here :-\
Code:
/oclHashcat/oclHashcat-1.31$ ./oclHashcat64.bin -a 3 -m 2711 -w 3 --username --remove ../crackme/single_hash.txt ?l?l?l?a?a?a?a --status
oclHashcat v1.31 starting...
Device #1: Cypress, 1024MB, 765Mhz, 18MCU
Hashes: 1 hashes; 1 unique digests, 1 unique salts
Bitmaps: 8 bits, 256 entries, 0x000000ff mask, 1024 bytes
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
* Single-Hash
* Single-Salt
* Brute-Force
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a3.Cypress_1573.4_1573.4.kernel not found in cache! Building may take a while...
Device #1: Kernel ./kernels/4098/m02710_a3.Cypress_1573.4_1573.4.kernel (567944 bytes)
Device #1: Kernel ./kernels/4098/markov_le_v4.Cypress_1573.4_1573.4.kernel (342732 bytes)
Device #1: Kernel ./kernels/4098/bzero.Cypress_1573.4_1573.4.kernel (33848 bytes)
Session.Name...: oclHashcat
Status.........: Running
Input.Mode.....: Mask (?l?l?l?a?a?a?a) [7]
Hash.Target....: <I've removed the Hash and Salt because I read the Rules first ;-) >
Hash.Type......: vBulletin > v3.8.5
Time.Started...: Thu Mar 5 08:17:09 2015 (10 secs)
Time.Estimated.: Thu Mar 5 08:50:32 2015 (33 mins, 9 secs)
Speed.GPU.#1...: 829.6 MH/s
Recovered......: 0/1 (0.00%) Digests, 0/1 (0.00%) Salts
Progress.......: 7247757312/1431576185000 (0.51%)
Skipped........: 0/7247757312 (0.00%)
Rejected.......: 0/7247757312 (0.00%)
HWMon.GPU.#1...: 99% Util, 63c Temp, 41% Fan
Thanks in Advance!
EDIT
When I try the full Hashlist with oclHashcat-1.31 it also works fine :-\ Could it be that my Graphicscard is getting to old for newer Versions of Hashcat?
Code:
/oclHashcat/oclHashcat-1.31$ ./oclHashcat64.bin -a 3 -m 2711 -w 2 -o ../outfiles/hashes_out.txt --username --remove ../crackme/hashes_w_u.txt ?l?l?l?a?a?a?a --status
oclHashcat v1.31 starting...
Device #1: Cypress, 1024MB, 765Mhz, 18MCU
Hashes: 1869 hashes; 1869 unique digests, 1869 unique salts
Bitmaps: 14 bits, 16384 entries, 0x00003fff mask, 65536 bytes
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
* Brute-Force
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a3.Cypress_1573.4_1573.4.kernel (567944 bytes)
Device #1: Kernel ./kernels/4098/markov_le_v4.Cypress_1573.4_1573.4.kernel (342732 bytes)
Device #1: Kernel ./kernels/4098/bzero.Cypress_1573.4_1573.4.kernel (33848 bytes)
Session.Name...: oclHashcat
Status.........: Running
Input.Mode.....: Mask (?l?l?l?a?a?a?a) [7]
Hash.Target....: File (../crackme/hashes_w_u.txt)
Hash.Type......: vBulletin > v3.8.5
Time.Started...: Thu Mar 5 08:30:19 2015 (9 secs)
Time.Estimated.: Wed Apr 22 09:39:57 2015 (48 days, 0 hours)
Speed.GPU.#1...: 357.8 kH/s
Recovered......: 0/1869 (0.00%) Digests, 0/1869 (0.00%) Salts
Progress.......: 6429081600/2675615889765000 (0.00%)
Skipped........: 0/6429081600 (0.00%)
Rejected.......: 0/6429081600 (0.00%)
HWMon.GPU.#1...: 97% Util, 72c Temp, 15% Fan
![]()
Posts: 2,302
Threads: 11
Joined: Jul 2010
03-05-2015, 11:25 AM
(This post was last modified: 03-05-2015, 11:25 AM by undeath.)
The new version probably handles the salts a bit different and hence needs more vram. Split up your hashlist and try again.
![]()
Posts: 24
Threads: 5
Joined: Oct 2014
03-05-2015, 11:48 AM
(This post was last modified: 03-05-2015, 11:50 AM by TheDarkOne.)
@undeath
As I said in the above Post, I have tried this with a single Hash and the Error happens there as well, so I don’t think its a matter of how big the Hashfile is because I don’t believe that a single Hash + Salt need 1GB of vram 
EDIT: At least I don’t think that it matters in this Case how big the Hashfile ist
![]()
Posts: 2,302
Threads: 11
Joined: Jul 2010
Oh, I’m sorry I didn’t read your post properly. Running a mask attack on a single hash should definitely not exhaust your vram.
![]()
Posts: 5,186
Threads: 230
Joined: Apr 2010
It’s as i said, the wordload profile affects the required memory, too. In your above example you used -w 3 with 1.33 and -w 2 with 1.31. That makes no sense unless you test 1.33 with -w 2 as well
![]()
Posts: 24
Threads: 5
Joined: Oct 2014
(03-05-2015, 12:56 PM)atom Wrote: It’s as i said, the wordload profile affects the required memory, too. In your above example you used -w 3 with 1.33 and -w 2 with 1.31. That makes no sense unless you test 1.33 with -w 2 as well
Sorry atom, I didn’t notice the wrong Workload Profile. I’ve done it with -w 3 now and it works with the Full Hashlist under 1.31.
Code:
/oclHashcat/oclHashcat-1.31$ ./oclHashcat64.bin -a 3 -m 2711 -w 3 -o ../outfiles/hashes_out.txt --username --remove ../crackme/hashes_w_u.txt ?l?l?l?a?a?a?a --status
oclHashcat v1.31 starting...
Device #1: Cypress, 1024MB, 765Mhz, 18MCU
Hashes: 1869 hashes; 1869 unique digests, 1869 unique salts
Bitmaps: 14 bits, 16384 entries, 0x00003fff mask, 65536 bytes
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
* Brute-Force
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a3.Cypress_1573.4_1573.4.kernel (567944 bytes)
Device #1: Kernel ./kernels/4098/markov_le_v4.Cypress_1573.4_1573.4.kernel (342732 bytes)
Device #1: Kernel ./kernels/4098/bzero.Cypress_1573.4_1573.4.kernel (33848 bytes)
Session.Name...: oclHashcat
Status.........: Running
Input.Mode.....: Mask (?l?l?l?a?a?a?a) [7]
Hash.Target....: File (../crackme/hashes_w_u.txt)
Hash.Type......: vBulletin > v3.8.5
Time.Started...: Thu Mar 5 12:08:10 2015 (9 secs)
Time.Estimated.: Tue Apr 21 00:21:30 2015 (46 days, 11 hours)
Speed.GPU.#1...: 377.4 kH/s
Recovered......: 0/1869 (0.00%) Digests, 0/1869 (0.00%) Salts
Progress.......: 6643777536/2675615889765000 (0.00%)
Skipped........: 0/6643777536 (0.00%)
Rejected.......: 0/6643777536 (0.00%)
HWMon.GPU.#1...: 99% Util, 62c Temp, 41% Fan
Sorry to keep nagging on about this :-\ I get the Explenation you provided — at least for the full Hashlist. If you look at the Results I got when trying a single Hash the Workload Profile is the same. I just can’t quite grasp that a Single Hash with Workload Profile 3 under 1.31 would work and under 1.33 it would need more then 1GB vram. Or didn’t I get the full Picture here :-\ As I was saying, sorry for nagging on about this…
![]()
Posts: 5,186
Threads: 230
Joined: Apr 2010
I took my oldest card I have, a hd5770, and I tried to reproduce the problem. That card has only 256mb of GPU ram.
Quote:root@sf:~/xy/oclHashcat-1.33# ./oclHashcat64.bin -a 3 -m 2711 -w 3 -o hashes_out.txt —username —remove hashes_w_u.txt ?l?l?l?a?a?a?a —status -d 2
oclHashcat v1.33 starting…Device #1: skipped by user
Device #2: Juniper, 256MB, 1000Mhz, 10MCUHashes: 1 hashes; 1 unique digests, 1 unique salts
Bitmaps: 8 bits, 256 entries, 0x000000ff mask, 1024 bytes
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
* Single-Hash
* Single-Salt
* Brute-Force
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a3.Juniper_1573.4_1573.4.kernel (566680 bytes)
Device #1: Kernel ./kernels/4098/markov_le_v4.Juniper_1573.4_1573.4.kernel (71776 bytes)ERROR: clCreateBuffer() -61
Now this is oclHashcat v1.34 beta which fixed the problem Actually I have no idea what exactly caused the problem but v1.34 fixed many bugs. I think we accidentially fixed the problem you described as well. If you wish to test v1.34 send me an email
Quote:root@sf:~/oclHashcat-1.34# ./oclHashcat64.bin -a 3 -m 2711 -w 3 -o hashes_out.txt —username —remove hashes_w_u.txt ?l?l?l?a?a?a?a —status -d 2
oclHashcat v1.34 starting…Device #1: skipped by user
Device #2: Juniper, 256MB, 1000Mhz, 10MCUHashes: 1 hashes; 1 unique digests, 1 unique salts
Bitmaps: 8 bits, 256 entries, 0x000000ff mask, 1024 bytes
Applicable Optimizers:
* Zero-Byte
* Precompute-Init
* Early-Skip
* Not-Iterated
* Single-Hash
* Single-Salt
* Brute-Force
Watchdog: Temperature abort trigger set to 90c
Watchdog: Temperature retain trigger set to 80c
Device #1: Kernel ./kernels/4098/m02710_a3.Juniper_1573.4_1573.4.kernel (567384 bytes)
Device #1: Kernel ./kernels/4098/markov_le_v4.Juniper_1573.4_1573.4.kernel (71772 bytes)Session.Name…: oclHashcat
Status………: Running
Input.Mode…..: Mask (?l?l?l?a?a?a?a) [7]
Hash.Target….: 98f3c91a605e29e80e9623cc66caff6b:162005066561457267521833088306
Hash.Type……: vBulletin > v3.8.5
Time.Started…: Sun Mar 8 11:55:37 2015 (9 secs)
Time.Estimated.: Sun Mar 8 12:36:29 2015 (40 mins, 42 secs)
Speed.GPU.#1…: 606.6 MH/s
Recovered……: 0/1 (0.00%) Digests, 0/1 (0.00%) Salts
Progress…….: 5704253440/1431576185000 (0.40%)
Skipped……..: 0/5704253440 (0.00%)
Rejected…….: 0/5704253440 (0.00%)
Restore.Point..: 0/81450625 (0.00%)
HWMon.GPU.#1…: 99% Util, 53c Temp, 51% Fan

It seems that owners of video cards with 2GB of video memory has started having issues mining Ethereum (ETH). People are reporting that their cards are not being able to properly allocate the DAG file needed for mining with Ethminer even though it is still well below 2GB in size (a little over 1.3 GB at the moment). The error people with 2GB VRAM GPUs trying to mine Ethereum are getting is the following:
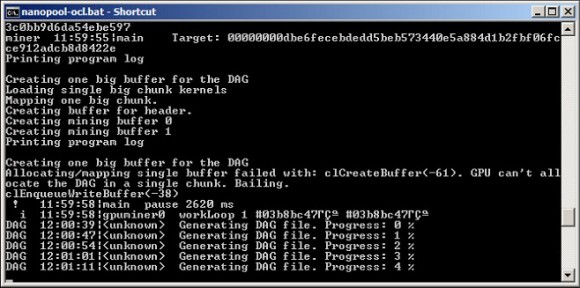
Creating one big buffer for the DAG
Allocating/mapping single buffer failed with: clCreateBuffer(-61). GPU can’t allocate the DAG in a single chunk. Bailing.
clEnqueueWriteBuffer(-38)
There are numerous suggestions on how some people were able to resolve the problem and make their 2GB VRAM video cards able to mine again Ethereum without more problems, but it seems that now all of them work for everyone and in all cases. We have tried different suggestions and have experimented, until we have found out a working solution that works fine on an AMD Radeon R9 285 GPU with 2GB of video memory, so you might want to try and see if it will work for you as well. Try executing the following commands in Windows before running ethminer and see if it will help:
setx GPU_FORCE_64BIT_PTR 0
setx GPU_MAX_HEAP_SIZE 100
setx GPU_USE_SYNC_OBJECTS 1
setx GPU_MAX_ALLOC_PERCENT 100
setx GPU_SINGLE_ALLOC_PERCENT 100
Some people are reporting that they only need to do “setx GPU_MAX_ALLOC_PERCENT 100” and things work fine after that with their 2GB GPUs, but we were not able to make things work only with that variable. So do try and report what works and what does not for you, setting all of the four environment variable listed above did the trick for us. Restarting the computer after applying the environment variable listed above may be required for some users to make them work properly. Using 14.x drivers seems to provide the best success rate for most people, so if you are using newer 15.x drivers and still having issues, you might try going back to 14.x.
Linux users might try this as well, however you need to replace the setx with export and add = before the value you want to set, so the above list of commands needed for Linux users mining Ethereum should look like this:
export GPU_FORCE_64BIT_PTR=0
export GPU_MAX_HEAP_SIZE=100
export GPU_USE_SYNC_OBJECTS=1
export GPU_MAX_ALLOC_PERCENT=100
export GPU_SINGLE_ALLOC_PERCENT=100
Do note that we have not tested if this fixes the issue for Linux users, we can confirm that it worked for us under Windows, so if you test on Linux mining rigs with 2GB video memory GPUs please write in the comments if it helped you or not.
- Publihsed in: General Info
- Related tags: clCreateBuffer 61, clEnqueueWriteBuffer 38, Ethminer 2GB GPU, Ethminer 2GB issue, Ethminer 2GB VRAM, Ethminer error
Check Some More Similar Crypto Related Publications:
- Innosilicon Has Announced Their Terminator 2 Bitcoin ASIC Miner
- New RPi Overclock Image for A2 Innosilicon Miners by Emdje Now Available
- BitGold Now Accepting Multiple Crypto Currencies
- CryptUnit, a Web-based Cryptonote Mining Profitability Calculator
- Merged Mining of Blakecoin (BLC) + PHO + BBLC + XDQ + ELT Now Available
- Bitcoin Price Below $300 USD and Litecoin Under $3.5 USD
- HalleyBTC, a New Service Offering Bitcoin Savings Investment
- What to go for, an ASIC Miner or a Cloud Mining Solution
- More About the New Scrypt Mining Pools on Ghash.io
- A Helpful Ethash DAG Size Calendar and Calculator
- NiceHash Has Added Support for Zhash Algorithm (Equihash 144,5)
- Nicehash Has Also Added Neoscrypt Algorithm Support
- NiceHashBot Tool for Easier Order Management
- Where to Check Alternative Crypto Currency Profitability
- On the Hunt for the Most Profitable Crypto Coins
- Where to Check for the Crypto Currency Market Capitalization
- OnChainFX Cryptoasset Rankings and Metrics Service
- TechPowerUp GPU-Z 2.37.0 With Nvidia GDDR6X Memory Temperature Monitoring
- New Blockchain Lottery Ticket Feature at NiceHash
- PiMP Linux-based Dedicated GPU and ASIC Mining Distribution
- Modify the Bios of Reference Radeon RX 480 For Faster Ethereum Hashrate
- How to Mine Protoshares with CPU and GPU and Where
- Badbitcoin, a List of Bitcoin Websites to Avoid
- New Lyra2RE VertCoin Optimized OpenCL Kernel Crowdfunding Project
- Integrated Intel GPUs that you can Mine Crypto Coins On with OpenCL
- Информация о материале
- Опубликовано: 23.03.2016, 16:19
 Вчера, 23 марта 2016, у владельцев видеокарт с 2Гб видеопамяти начались определенные проблемы при майнинге Ethereum, используя Ethminer. Пользователи сообщают о том, что их 2 Гб видеокарты больше не в состоянии разместить в видеопамяти видеокарты DAG файл, который требуется для майнинга Ethereum по алгоритму Dagger-Hashimoto, даже если тот по-прежнему имеет объем менее 2 Гб (на данный момент DAG файл имеет размер порядка 1.3 Гб).
Вчера, 23 марта 2016, у владельцев видеокарт с 2Гб видеопамяти начались определенные проблемы при майнинге Ethereum, используя Ethminer. Пользователи сообщают о том, что их 2 Гб видеокарты больше не в состоянии разместить в видеопамяти видеокарты DAG файл, который требуется для майнинга Ethereum по алгоритму Dagger-Hashimoto, даже если тот по-прежнему имеет объем менее 2 Гб (на данный момент DAG файл имеет размер порядка 1.3 Гб).
Майнеры с 2Гб видеокартами получают следующие сообщения об ошибках, при попытке запуска майнинга Ethereum:
Creating one big buffer for the DAG
Allocating/mapping single buffer failed with: clCreateBuffer(-61). GPU can’t allocate the DAG in a single chunk. Bailing.
clEnqueueWriteBuffer(-38)
На форумах можно найти множество советов, о том как решить данную проблему, и сделать возможным cнова добывать Эфир на видеокартах с 2 Гб видеопамяти. Мы пробовали различные варианты решения проблемы и экспериментировали, пока не нашли рабочее решение, которое отлично работает на 2GB AMD Radeon R9 285. Поэтому вы можете попробовать это решение и для вашей видеокарты, если столкнулись с подобной проблемой.
Попробуйте выполнить следующие команды в Windows перед запуском Ethminer:
setx GPU_FORCE_64BIT_PTR 0
setx GPU_MAX_HEAP_SIZE 100
setx GPU_USE_SYNC_OBJECTS 1
setx GPU_MAX_ALLOC_PERCENT 100
Некоторые люди утверждают, что достаточно только команды «setx GPU_MAX_ALLOC_PERCENT 100«, после чего все будет нормально работать. Но нам не удалось запустить майнинг только с помощью данной переменной. Некоторые пользователи советуют перезагрузить ваш компьютер после внесения изменений в переменных окружения Windows.
Для пользователей Linux потребуются немного другие команды:
export GPU_FORCE_64BIT_PTR=0
export GPU_MAX_HEAP_SIZE=100
export GPU_USE_SYNC_OBJECTS=1
export GPU_MAX_ALLOC_PERCENT=100
Мы не проверяли данное решение для Linux-пользователей, однако теоретически оно должно работать.