I needed to parse a site, but I got a 403 Forbidden error.
Here is the code:
url = 'http://worldagnetwork.com/'
result = requests.get(url)
print(result.content.decode())
The output is:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
What is the problem?
![]()
Gino Mempin
25.7k29 gold badges98 silver badges138 bronze badges
asked Jul 20, 2016 at 19:36
![]()
Толкачёв ИванТолкачёв Иван
1,7593 gold badges12 silver badges13 bronze badges
2
It seems the page rejects GET requests that do not identify a User-Agent. I visited the page with a browser (Chrome) and copied the User-Agent header of the GET request (look in the Network tab of the developer tools):
import requests
url = 'http://worldagnetwork.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
result = requests.get(url, headers=headers)
print(result.content.decode())
# <!doctype html>
# <!--[if lt IE 7 ]><html class="no-js ie ie6" lang="en"> <![endif]-->
# <!--[if IE 7 ]><html class="no-js ie ie7" lang="en"> <![endif]-->
# <!--[if IE 8 ]><html class="no-js ie ie8" lang="en"> <![endif]-->
# <!--[if (gte IE 9)|!(IE)]><!--><html class="no-js" lang="en"> <!--<![endif]-->
# ...
answered Jul 20, 2016 at 19:48
![]()
2
Just adding to Alberto’s answer:
If you still get a 403 Forbidden error after adding a user-agent, you may need to add more headers, such as referer:
headers = {
'User-Agent': '...',
'referer': 'https://...'
}
The headers can be found in the Network > Headers > Request Headers of the Developer Tools. (Press F12 to toggle it.)
![]()
Gino Mempin
25.7k29 gold badges98 silver badges138 bronze badges
answered Jul 9, 2019 at 5:44
![]()
5
If You are the server’s owner/admin, and the accepted solution didn’t work for You, then try disabling CSRF protection (link to an SO answer).
I am using Spring (Java), so the setup requires You to make a SecurityConfig.java file containing:
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure (HttpSecurity http) throws Exception {
http.csrf().disable();
}
// ...
}
answered May 26, 2018 at 11:31
![]()
AleksandarAleksandar
3,5881 gold badge39 silver badges42 bronze badges
HTTP Error 403 is a common error encountered while web scraping using Python 3. It indicates that the server is refusing to fulfill the request made by the client, as the request lacks sufficient authorization or the server considers the request to be invalid. This error can be encountered for a variety of reasons, including the presence of IP blocking, CAPTCHAs, or rate limiting restrictions. In order to resolve the issue, there are several methods that can be implemented, including changing the User Agent, using proxies, and implementing wait time between requests.
Method 1: Changing the User Agent
If you encounter HTTP error 403 while web scraping with Python 3, it means that the server is denying you access to the webpage. One common solution to this problem is to change the user agent of your web scraper. The user agent is a string that identifies the web scraper to the server. By changing the user agent, you can make your web scraper appear as a regular web browser to the server.
Here is an example code that shows how to change the user agent of your web scraper using the requests library:
import requests
url = 'https://example.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content)In this example, we set the User-Agent header to a string that mimics the user agent of the Google Chrome web browser. You can find the user agent string of your favorite web browser by searching for «my user agent» on Google.
By setting the User-Agent header, we can make our web scraper appear as a regular web browser to the server. This can help us bypass HTTP error 403 and access the webpage we want to scrape.
That’s it! By changing the user agent of your web scraper, you should be able to fix the problem of HTTP error 403 in Python 3 web scraping.
Method 2: Using Proxies
If you are encountering HTTP error 403 while web scraping with Python 3, it is likely that the website is blocking your IP address due to frequent requests. One way to solve this problem is by using proxies. Proxies allow you to make requests to the website from different IP addresses, making it difficult for the website to block your requests. Here is how you can fix HTTP error 403 in Python 3 web scraping with proxies:
Step 1: Install Required Libraries
You need to install the requests and bs4 libraries to make HTTP requests and parse HTML respectively. You can install them using pip:
pip install requests
pip install bs4Step 2: Get a List of Proxies
You need to get a list of proxies that you can use to make requests to the website. There are many websites that provide free proxies, such as https://free-proxy-list.net/. You can scrape the website to get a list of proxies:
import requests
from bs4 import BeautifulSoup
url = 'https://free-proxy-list.net/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', {'id': 'proxylisttable'})
rows = table.tbody.find_all('tr')
proxies = []
for row in rows:
cols = row.find_all('td')
if cols[6].text == 'yes':
proxy = cols[0].text + ':' + cols[1].text
proxies.append(proxy)This code scrapes the website and gets a list of HTTP proxies that support HTTPS. The proxies are stored in the proxies list.
Step 3: Make Requests with Proxies
You can use the requests library to make requests to the website with a proxy. Here is an example code that makes a request to https://www.example.com with a random proxy from the proxies list:
import random
url = 'https://www.example.com'
proxy = random.choice(proxies)
response = requests.get(url, proxies={'https': proxy})
if response.status_code == 200:
print(response.text)
else:
print('Request failed with status code:', response.status_code)This code selects a random proxy from the proxies list and makes a request to https://www.example.com with the proxy. If the request is successful, it prints the response text. Otherwise, it prints the status code of the failed request.
Step 4: Handle Exceptions
You need to handle exceptions that may occur while making requests with proxies. Here is an example code that handles exceptions and retries the request with a different proxy:
import requests
import random
from requests.exceptions import ProxyError, ConnectionError, Timeout
url = 'https://www.example.com'
while True:
proxy = random.choice(proxies)
try:
response = requests.get(url, proxies={'https': proxy}, timeout=5)
if response.status_code == 200:
print(response.text)
break
else:
print('Request failed with status code:', response.status_code)
except (ProxyError, ConnectionError, Timeout):
print('Proxy error. Retrying with a different proxy...')This code uses a while loop to keep retrying the request with a different proxy until it succeeds. It handles ProxyError, ConnectionError, and Timeout exceptions that may occur while making requests with proxies.
Method 3: Implementing Wait Time between Requests
When you are scraping a website, you might encounter an HTTP error 403, which means that the server is denying your request. This can happen when the server detects that you are sending too many requests in a short period of time, and it wants to protect itself from being overloaded.
One way to fix this problem is to implement wait time between requests. This means that you will wait a certain amount of time before sending the next request, which will give the server time to process the previous request and prevent it from being overloaded.
Here is an example code that shows how to implement wait time between requests using the time module:
import requests
import time
url = 'https://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
for i in range(5):
response = requests.get(url, headers=headers)
print(response.status_code)
time.sleep(1)In this example, we are sending a request to https://example.com with headers that mimic a browser request. We are then using a for loop to send 5 requests with a 1 second delay between requests using the time.sleep() function.
Another way to implement wait time between requests is to use a random delay. This will make your requests less predictable and less likely to be detected as automated. Here is an example code that shows how to implement a random delay using the random module:
import requests
import random
import time
url = 'https://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
for i in range(5):
response = requests.get(url, headers=headers)
print(response.status_code)
time.sleep(random.randint(1, 5))In this example, we are sending a request to https://example.com with headers that mimic a browser request. We are then using a for loop to send 5 requests with a random delay between 1 and 5 seconds using the random.randint() function.
By implementing wait time between requests, you can prevent HTTP error 403 and ensure that your web scraping code runs smoothly.
Python requests. 403 Forbidden is an error which happens in Python when you do not have a user-agent.
In this article I am going to explain in detail why the error is occurring and how you can go about solving it using multiple solutions which may solve the issue in your particular case.
Explaining The Error : Python requests. 403 Forbidden
First, we should understand that this error is the result of the absence of a user-agent
Second of all, let us try and reproduce the error.
Let us run the Python code bellow.
#
url = 'https://reddit.com/'
result = requests.get(url)
print(result.content.decode())
#
The resulting error is the following
#
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
#
The important line which represents the error is.
#
<head><title>403 Forbidden</title></head>
#
You can clearly see that the webpage is rejecting GET requests which do not have a User-Agent.
Bellow are great solutions which worked for me and will help you to successfully troubleshoot and solve the error.
Solution 1 : Add user-agent with Headers
First of all, you need to understand that it is normal for pages to rejects GET requests that do not have a User-Agent.
The solution is simple, just specify a user-agent with your Get request using headers like in the modified code bellow.
Basically this code represents the code you had before plus the fix which is adding the user-agent in headers.
Your code starts with the following lines.
#
import requests
url = 'https://reddit.com/'
#
Followed by the fix, also known as headers.
#
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)}
result = requests.get(url, headers=headers)
print(result.content.decode())
#
This fix should be enough to solve the error for most developers, if it did not do the job for you, then keep reading, we have more solutions for you.
Solution 2 : Identify the user-agent
This is more like a complementary solution of the solution above, or a fix of a fix if you know what I mean.
Maybe you do not know where to get the user-agent, this is going to solve your problem.
To find the headers, you should navigate to:
Network, in the developer console. Then click on headers then request headers.
This is an example of a user-agent
#
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
#
Solution 3 : Add referer to Headers
Sometimes, none of the above will work, but do not give up, you can try another solution.
In some cases you need to add more elements to headers, like referer for example.
You can modify the code of the first solution, so it can look like this.
#
headers = {
'User-Agent': '...',
'referer': 'https://...'
}
#
You can get the refer by using the developer console like we did before.
If the solutions above helped you, consider supporting us on Kofi, any help is appreciated, writing and working on finding and testing these fixes takes a lot of time.
Summing-up
This is the end of our article, I hope the solutions I presented for the error Python requests 403 Forbidden worked for you, Learning Python is a fun journey, do not let the erros discourage you.
Keep coding and cheers.
If you want to learn more about Python, please check out the Python Documentation : https://docs.python.org/3/
Собственно, проблема следующая:
Postman отрабатывает отлично и возвращает ожидаемый результат
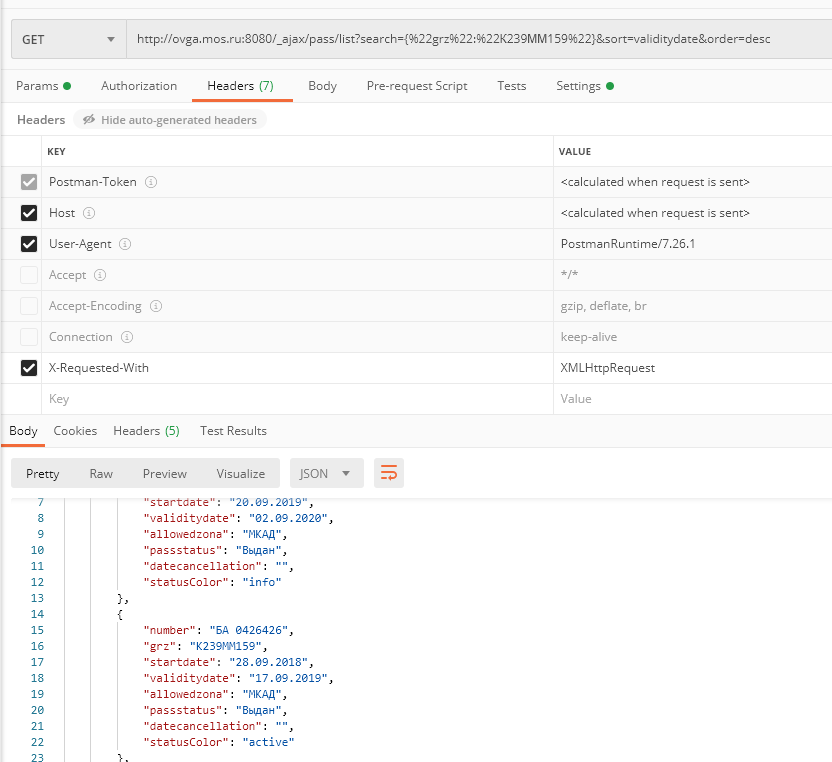
А python на аналогичный запрос выдает 403 код. Хотя вроде как заголовки одинаковые. Что ему, собаке, не хватает?
import requests
from pprint import pprint
url = 'http://ovga.mos.ru:8080/_ajax/pass/list?search={%22grz%22:%22К239ММ159%22}&sort=validitydate&order=desc'
headers = {"X-Requested-With": "XMLHttpRequest",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/54.0.2840.99 Safari/537.36',
}
response = requests.get(url, headers)
pprint(response)
<Response [403]>-
Вопрос задан
-
2822 просмотра
Ты не все заголовки передал. Postman по-умолчанию генерирует некоторые заголовки самостоятельно, вот так подключается нормально:
headers = {
'Host': 'ovga.mos.ru',
'User-Agent': 'Magic User-Agent v999.26 Windows PRO 11',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'http://ovga.mos.ru:8080/_ajax/pass/list?search={"grz":"К239ММ159"}&sort=validitydate&order=desc'
response = requests.get(url, headers=headers)<Response [200]>
Пригласить эксперта
-
Показать ещё
Загружается…
22 сент. 2023, в 11:59
3500 руб./за проект
22 сент. 2023, в 11:34
2500 руб./за проект
22 сент. 2023, в 11:24
30000 руб./за проект
Минуточку внимания
|
olm18 0 / 0 / 0 Регистрация: 15.12.2016 Сообщений: 3 |
||||
|
1 |
||||
|
18.03.2019, 22:28. Показов 20329. Ответов 3 Метки 403, get запрос, requests (Все метки)
Делаю запрос. Статус запроса 403. Через браузер запрос выполнить получается. Везде пишут, что в такой ситуации надо указать User-Agent. Я указал, но никакого результата. Пробовал добавлять различные параметры в headers, но та же ошибка 403. Подскажите, что я делаю не так?
Миниатюры
0 |


|
5412 / 3836 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
18.03.2019, 22:49 |
2 |
|
Сайту нужна кука — поэтому используйте сессию. В requests сессия есть.
0 |
|
olm18 0 / 0 / 0 Регистрация: 15.12.2016 Сообщений: 3 |
||||||||
|
19.03.2019, 00:24 [ТС] |
3 |
|||||||
|
Делаю так. В результате всё равно ошибка 403
Добавлено через 59 минут
0 |
|
Garry Galler
5412 / 3836 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
||||
|
19.03.2019, 00:33 |
4 |
|||
|
Решение
Очень странно, но этот параметр из кук (несмотря на предварительный запрос) почему-то в сессионных куках отсутствует, и поэтому без него ничего не работает.
0 |
 Сообщение было отмечено olm18 как решение
Сообщение было отмечено olm18 как решение
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
19.03.2019, 00:33 |
|
Помогаю со студенческими работами здесь HttpWebRequest любой запрос возвращает 403
import http.client …
Если POST запрос содержит ‘>>’, скрипт отвечает 403 Forbidden Запрос GET idHTTP завершается c ошибкой Запрос HttpWebRequest WebRequest с ошибкой public void Request_Walletone(base_table_test… Ajax запрос выполняется с ошибкой Искать еще темы с ответами Или воспользуйтесь поиском по форуму: 4 |