I needed to parse a site, but I got a 403 Forbidden error.
Here is the code:
url = 'http://worldagnetwork.com/'
result = requests.get(url)
print(result.content.decode())
The output is:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
What is the problem?
![]()
Gino Mempin
25.7k29 gold badges98 silver badges138 bronze badges
asked Jul 20, 2016 at 19:36
![]()
Толкачёв ИванТолкачёв Иван
1,7593 gold badges12 silver badges13 bronze badges
2
It seems the page rejects GET requests that do not identify a User-Agent. I visited the page with a browser (Chrome) and copied the User-Agent header of the GET request (look in the Network tab of the developer tools):
import requests
url = 'http://worldagnetwork.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
result = requests.get(url, headers=headers)
print(result.content.decode())
# <!doctype html>
# <!--[if lt IE 7 ]><html class="no-js ie ie6" lang="en"> <![endif]-->
# <!--[if IE 7 ]><html class="no-js ie ie7" lang="en"> <![endif]-->
# <!--[if IE 8 ]><html class="no-js ie ie8" lang="en"> <![endif]-->
# <!--[if (gte IE 9)|!(IE)]><!--><html class="no-js" lang="en"> <!--<![endif]-->
# ...
answered Jul 20, 2016 at 19:48
![]()
2
Just adding to Alberto’s answer:
If you still get a 403 Forbidden error after adding a user-agent, you may need to add more headers, such as referer:
headers = {
'User-Agent': '...',
'referer': 'https://...'
}
The headers can be found in the Network > Headers > Request Headers of the Developer Tools. (Press F12 to toggle it.)
![]()
Gino Mempin
25.7k29 gold badges98 silver badges138 bronze badges
answered Jul 9, 2019 at 5:44
![]()
5
If You are the server’s owner/admin, and the accepted solution didn’t work for You, then try disabling CSRF protection (link to an SO answer).
I am using Spring (Java), so the setup requires You to make a SecurityConfig.java file containing:
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure (HttpSecurity http) throws Exception {
http.csrf().disable();
}
// ...
}
answered May 26, 2018 at 11:31
![]()
AleksandarAleksandar
3,5881 gold badge39 silver badges42 bronze badges
«Четырёхсотые» коды состояния описывают проблемы на стороне клиента: обычно они возникают, когда браузер отправляет серверу некорректный HTTP-запрос.
Но на практике бывает по-разному. Например, ошибка 403 может появиться из-за неправильной логики на сервере. В этой статье попробуем разобрать все возможные причины.
- Что означает ошибка 403 (Forbidden)
- Что могло пойти не так
- Ошибки на стороне пользователя
- Ошибки на стороне сайта
- Ограничения на стороне хостера или провайдера
- Как исправить ошибку 403
- Что делать владельцу сайта
- Что делать пользователю
Ошибка 403 (Forbidden) — это когда сервер понял запрос, но почему-то отказывается выполнять его и отдавать браузеру HTML-код страницы.
Помимо «Forbidden», сервер может описать ошибку и другими словами: «error access denied» (доступ запрещён), «you don’t have permission to access» (нет разрешения на вход) и так далее. Сообщения разные, но смысл один.
В идеальном мире ошибка с кодом 403 должна возникать, когда доступ к странице пытается получить кто-то, у кого его нет, — например, неавторизованный пользователь.
Но в реальности возможных причин гораздо больше: это и проблемы с устройством пользователя, и неправильно настроенные компоненты сайта, и ограничения со стороны хостера или провайдера, и много что ещё.
Нужна регистрация. Пользователь не авторизован, а для доступа к странице это обязательно. При таком сценарии исправить ошибку просто — залогиниться на сайте.
Неправильный URL-адрес. Возможно, вы случайно постучались на какую-то секретную страничку, а это ни вам, ни серверу не нужно. Банально, но стоит перепроверить ссылку ещё разок.
Проблема в устройстве. Проверить это можно, зайдя на страницу с другого девайса. Если всё откроется, значит, дело в конкретной технике. Причины у этого могут быть разные:
- Неправильные данные в кэше. Тогда можно почистить его или перезагрузить страницу сочетанием Ctrl + F5 (при таком принудительном обновлении кэш игнорируется).
- Устаревшие данные в cookies. Если проблема в этом, то достаточно почистить их, и всё заработает.
- Вы заходите на страницу со смартфона, на котором включён режим экономии трафика. Из-за него браузер может не передавать сайту какие-то нужные ему данные — это и вызывает HTTP-ошибку Forbidden. В этом случае достаточно отключить экономию трафика.
Впрочем, иногда ошибка 403 возникает правомерно. Например, если вы были заблокированы на сайте или пытаетесь получить доступ к служебной странице. В таком случае обратитесь к владельцу сайта, чтобы он снял бан или выдал нужные права.

«Forbidden» может возникнуть, если что-то не так с компонентами сайта. Вот несколько возможных проблем, которые может и должен решить администратор сайта.
Некорректный индексный файл. Это файл, который указывает на главную страницу домена или поддомена. Нужно, чтобы у него были правильное название и формат — а они, в свою очередь, определяются CMS, которой вы пользуетесь. Например, для сайтов на WordPress это может быть index.html, index.htm или index.php.
А ещё индексный файл должен находиться в корневой папке домена или поддомена — смотря к чему он относится.
Неправильно расположены файлы сайта. Как и index, другие файлы сайта тоже должны лежать в корневой директории. Где именно — зависит от CMS и хостинга, которые вы используете.
Неверно настроены права доступа. У каждого файла и папки есть права доступа, которые состоят из трёх цифр от 0 до 7: первая — права владельца, вторая — групповые права, третья — публичные права. Сама цифра означает, какие права предоставлены этой группе.
Если у пользователя нет прав на выполнение действия, то он получит HTTP-ошибку 403 Forbidden. Обычно на папки выставляют доступ 755, на файлы — 644.
Проблемы с плагином. Если вы устанавливали плагины для своей CMS, то вызвать код 403 может какой-то из них. Возможно, он не обновился до последней версии, повреждён или несовместим с конфигурациями сайта.
Вот как это проверить, если у вас WordPress:
- Перейдите в раздел wp-content и найдите папку plugins.
- Переименуйте её — это отключит работу всех плагинов.
- Если проблема уйдёт, значит, дело было в плагинах.
Далее можно включать плагины обратно и искать конкретного виновника. Чтобы это сделать, отключайте их по очереди и обновляйте страницу — где-то по пути точно обнаружите, где с каким плагином проблема.
Некорректные указания в файле .htaccess. Если вы используете Apache Web Server, попробуйте переименовать файл .htaccess. Так же как и с плагинами, это отключит его и позволит понять, виновен ли он в ошибке.
Если дело всё-таки в .htaccess, проверьте и исправьте его директивы. Вот на какие условия стоит обратить внимание:
- deny (запрещает доступ);
- allow (разрешает доступ);
- require (запрещает или разрешает доступ всем, кроме указанных пользователей);
- redirect (перенаправляет запрос на другой URL);
- RewriteRule (преобразует строку с помощью регулярных выражений).
Действия пользователя блокирует брандмауэр. Брандмауэры веб-приложений могут автоматически блокировать действия пользователей, которые считают вредоносными, и возвращать им Forbidden.
Чтобы проверить, в этом ли дело, отключите брандмауэр и повторите запрещённое действие. Если сработает — проблема найдена. Проверьте журнал брандмауэра: там должна быть указана конкретная причина блокировки запроса.
Узнав причину, добавьте её в исключения, и такие запросы будут выполняться корректно.
Тариф хостинга не поддерживает инструменты. Например, вы пишете на PHP 8, а тариф рассчитан только на PHP 7.4. В таком случае придётся либо перейти на другую версию инструмента, либо сменить тариф (а может, и целого хостера).
Бывает так: с логикой на сервере всё в порядке, HTTP-запрос составлен корректно, а ошибка 403 всё равно возникает. Но подождите кричать «Тысяча чертей!» — возможно, шайба на стороне посредника.
Хостер прекратил обслуживание сайта. Просрочка платежа, нарушение условий хостинга, блокировки Роскомнадзора и другие малоприятные истории. Самое время проверить почту — обычно доступ к сайту не отключают без предупреждения.
Не успел обновиться кэш DNS-серверов. Если ваш сайт переезжал на другой адрес, в кэше DNS-серверов могли остаться устаревшие данные. Остаётся только ждать. Обычно кэш обновляется в течение суток, но в редких случаях процесс может занять два-три дня.
Проблемы на стороне провайдера. Возможно, у него неправильно настроена конфигурация оборудования или он заблокировал вас намеренно. Выход один и для пользователя, и для владельца сайта — обратиться к провайдеру.
Да-а, такая маленькая ошибка, а проблем — как с запуском Falcon Heavy на Марс. Держите чек-лист, который поможет не запутаться и быстро всё пофиксить.
Выясните, на чьей стороне проблема. Во-первых, зайдите на сайт самостоятельно — лучше один раз увидеть, чем прочитать тысячу тикетов в техподдержке. Во-вторых, проверьте почту — нет ли там писем счастья от хостера или Роскомнадзора?
Проверьте настройки сайта. Пробегитесь по списку ошибок, о которых мы писали выше. Перебирайте один вариант за другим, пока не поймёте, где собака зарыта.
Если ничего не помогает — обратитесь за помощью к своему хостинг-провайдеру.
- Перепроверьте URL страницы: правильный ли он? Вы могли кликнуть по ошибочной ссылке или сайт переехал на другой адрес, а поисковики этого ещё не поняли.
- Проверьте, авторизованы ли вы на сайте. Залогиньтесь, если есть такая возможность.
- Зайдите на страницу с другого устройства. Если сайт заработал — проблема в устройстве. Попробуйте перезагрузить страницу, почистить кэш и cookies браузера или отключить экономию трафика.
- Включите или выключите VPN. Возможно, доступ к сайту блокируется по IP-адресу для пользователей из определённой страны или региона. Попробуйте использовать IP-адреса разных стран.
- Подключитесь к другой сети. Например, если пользуетесь 4G, перейдите на Wi-Fi. Это поможет понять, есть ли проблемы на стороне поставщика интернета.
Если ничего не помогает, значит, проблема на стороне сайта. Обратитесь в техподдержку и сообщите об ошибке — возможно, о ней ещё никто не знает.
The urllib module can be used to make an HTTP request from a site, unlike the requests library, which is a built-in library. This reduces dependencies. In the following article, we will discuss why urllib.error.httperror: http error 403: forbidden occurs and how to resolve it.
What is a 403 error?
The 403 error pops up when a user tries to access a forbidden page or, in other words, the page they aren’t supposed to access. 403 is the HTTP status code that the webserver uses to denote the kind of problem that has occurred on the user or the server end. For instance, 200 is the status code for – ‘everything has worked as expected, no errors’. You can go through the other HTTP status code from here.
ModSecurity is a module that protects websites from foreign attacks. It checks whether the requests are being made from a user or from an automated bot. It blocks requests from known spider/bot agents who are trying to scrape the site. Since the urllib library uses something like python urllib/3.3.0 hence, it is easily detected as non-human and therefore gets blocked by mod security.
from urllib import request from urllib.request import Request, urlopen url = "https://www.gamefaqs.com" request_site = Request(url) webpage = urlopen(request_site).read() print(webpage[:200])
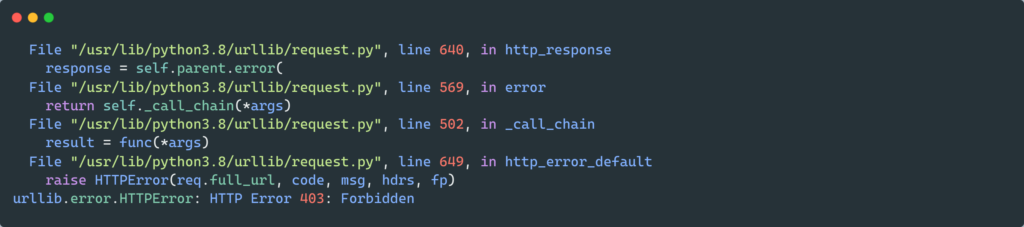
ModSecurity blocks the request and returns an HTTP error 403: forbidden error if the request was made without a valid user agent. A user-agent is a header that permits a specific string which in turn allows network protocol peers to identify the following:
- The Operating System, for instance, Windows, Linux, or macOS.
- Websserver’s browser
Moreover, the browser sends the user agent to each and every website that you get connected to. The user-Agent field is included in the HTTP header when the browser gets connected to a website. The header field data differs for each browser.
Why do sites use security that sends 403 responses?
According to a survey, more than 50% of internet traffic comes from automated sources. Automated sources can be scrapers or bots. Therefore it gets necessary to prevent these attacks. Moreover, scrapers tend to send multiple requests, and sites have some rate limits. The rate limit dictates how many requests a user can make. If the user(here scraper) exceeds it, it gets some kind of error, for instance, urllib.error.httperror: http error 403: forbidden.
Resolving urllib.error.httperror: http error 403: forbidden?
This error is caused due to mod security detecting the scraping bot of the urllib and blocking it. Therefore, in order to resolve it, we have to include user-agent/s in our scraper. This will ensure that we can safely scrape the website without getting blocked and running across an error. Let’s take a look at two ways to avoid urllib.error.httperror: http error 403: forbidden.
Method 1: using user-agent
from urllib import request
from urllib.request import Request, urlopen
url = "https://www.gamefaqs.com"
request_site = Request(url, headers={"User-Agent": "Mozilla/5.0"})
webpage = urlopen(request_site).read()
print(webpage[:500])
- In the code above, we have added a new parameter called headers which has a user-agent Mozilla/5.0. Details about the user’s device, OS, and browser are given by the webserver by the user-agent string. This prevents the bot from being blocked by the site.
- For instance, the user agent string gives information to the server that you are using Brace browser and Linux OS on your computer. Thereafter, the server accordingly sends the information.


Method 2: using Session object
There are times when even using user-agent won’t prevent the urllib.error.httperror: http error 403: forbidden. Then we can use the Session object of the request module. For instance:
from random import seed
import requests
url = "https://www.gamefaqs.com"
session_obj = requests.Session()
response = session_obj.get(url, headers={"User-Agent": "Mozilla/5.0"})
print(response.status_code)
The site could be using cookies as a defense mechanism against scraping. It’s possible the site is setting and requesting cookies to be echoed back as a defense against scraping, which might be against its policy.
The Session object is compatible with cookies.

Catching urllib.error.httperror
urllib.error.httperror can be caught using the try-except method. Try-except block can capture any exception, which can be hard to debug. For instance, it can capture exceptions like SystemExit and KeyboardInterupt. Let’s see how can we do this, for instance:
from urllib.request import Request, urlopen
from urllib.error import HTTPError
url = "https://www.gamefaqs.com"
try:
request_site = Request(url)
webpage = urlopen(request_site).read()
print(webpage[:500])
except HTTPError as e:
print("Error occured!")
print(e)

![[Fixed] io.unsupportedoperation: not Writable in Python](https://www.pythonpool.com/wp-content/uploads/2023/05/io.unsupportedoperation-not-writable-300x157.webp)
FAQs
How to fix the 403 error in the browser?
You can try the following steps in order to resolve the 403 error in the browser try refreshing the page, rechecking the URL, clearing the browser cookies, check your user credentials.
Why do scraping modules often get 403 errors?
Scrapers often don’t use headers while requesting information. This results in their detection by the mod security. Hence, scraping modules often get 403 errors.
Conclusion
In this article, we covered why and when urllib.error.httperror: http error 403: forbidden it can occur. Moreover, we looked at the different ways to resolve the error. We also covered the handling of this error.
Trending Now
-
![[Solved] typeerror: unsupported format string passed to list.__format__](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%200%200'%3E%3C/svg%3E)
[Solved] typeerror: unsupported format string passed to list.__format__
●May 31, 2023
-
Solving ‘Remote End Closed Connection’ in Python!
by Namrata Gulati●May 31, 2023
-
[Fixed] io.unsupportedoperation: not Writable in Python
by Namrata Gulati●May 31, 2023
-
[Fixing] Invalid ISOformat Strings in Python!
by Namrata Gulati●May 31, 2023
![[Solved] typeerror: unsupported format string passed to list.__format__](https://www.pythonpool.com/wp-content/uploads/2023/05/typeerror-unsupported-format-string-passed-to-list.__format__-300x157.webp)
![[Fixing] Invalid ISOformat Strings in Python!](https://www.pythonpool.com/wp-content/uploads/2023/05/invalid-isoformat-string-300x157.webp)
HTTP Error 403 is a common error encountered while web scraping using Python 3. It indicates that the server is refusing to fulfill the request made by the client, as the request lacks sufficient authorization or the server considers the request to be invalid. This error can be encountered for a variety of reasons, including the presence of IP blocking, CAPTCHAs, or rate limiting restrictions. In order to resolve the issue, there are several methods that can be implemented, including changing the User Agent, using proxies, and implementing wait time between requests.
Method 1: Changing the User Agent
If you encounter HTTP error 403 while web scraping with Python 3, it means that the server is denying you access to the webpage. One common solution to this problem is to change the user agent of your web scraper. The user agent is a string that identifies the web scraper to the server. By changing the user agent, you can make your web scraper appear as a regular web browser to the server.
Here is an example code that shows how to change the user agent of your web scraper using the requests library:
import requests
url = 'https://example.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content)In this example, we set the User-Agent header to a string that mimics the user agent of the Google Chrome web browser. You can find the user agent string of your favorite web browser by searching for «my user agent» on Google.
By setting the User-Agent header, we can make our web scraper appear as a regular web browser to the server. This can help us bypass HTTP error 403 and access the webpage we want to scrape.
That’s it! By changing the user agent of your web scraper, you should be able to fix the problem of HTTP error 403 in Python 3 web scraping.
Method 2: Using Proxies
If you are encountering HTTP error 403 while web scraping with Python 3, it is likely that the website is blocking your IP address due to frequent requests. One way to solve this problem is by using proxies. Proxies allow you to make requests to the website from different IP addresses, making it difficult for the website to block your requests. Here is how you can fix HTTP error 403 in Python 3 web scraping with proxies:
Step 1: Install Required Libraries
You need to install the requests and bs4 libraries to make HTTP requests and parse HTML respectively. You can install them using pip:
pip install requests
pip install bs4Step 2: Get a List of Proxies
You need to get a list of proxies that you can use to make requests to the website. There are many websites that provide free proxies, such as https://free-proxy-list.net/. You can scrape the website to get a list of proxies:
import requests
from bs4 import BeautifulSoup
url = 'https://free-proxy-list.net/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', {'id': 'proxylisttable'})
rows = table.tbody.find_all('tr')
proxies = []
for row in rows:
cols = row.find_all('td')
if cols[6].text == 'yes':
proxy = cols[0].text + ':' + cols[1].text
proxies.append(proxy)This code scrapes the website and gets a list of HTTP proxies that support HTTPS. The proxies are stored in the proxies list.
Step 3: Make Requests with Proxies
You can use the requests library to make requests to the website with a proxy. Here is an example code that makes a request to https://www.example.com with a random proxy from the proxies list:
import random
url = 'https://www.example.com'
proxy = random.choice(proxies)
response = requests.get(url, proxies={'https': proxy})
if response.status_code == 200:
print(response.text)
else:
print('Request failed with status code:', response.status_code)This code selects a random proxy from the proxies list and makes a request to https://www.example.com with the proxy. If the request is successful, it prints the response text. Otherwise, it prints the status code of the failed request.
Step 4: Handle Exceptions
You need to handle exceptions that may occur while making requests with proxies. Here is an example code that handles exceptions and retries the request with a different proxy:
import requests
import random
from requests.exceptions import ProxyError, ConnectionError, Timeout
url = 'https://www.example.com'
while True:
proxy = random.choice(proxies)
try:
response = requests.get(url, proxies={'https': proxy}, timeout=5)
if response.status_code == 200:
print(response.text)
break
else:
print('Request failed with status code:', response.status_code)
except (ProxyError, ConnectionError, Timeout):
print('Proxy error. Retrying with a different proxy...')This code uses a while loop to keep retrying the request with a different proxy until it succeeds. It handles ProxyError, ConnectionError, and Timeout exceptions that may occur while making requests with proxies.
Method 3: Implementing Wait Time between Requests
When you are scraping a website, you might encounter an HTTP error 403, which means that the server is denying your request. This can happen when the server detects that you are sending too many requests in a short period of time, and it wants to protect itself from being overloaded.
One way to fix this problem is to implement wait time between requests. This means that you will wait a certain amount of time before sending the next request, which will give the server time to process the previous request and prevent it from being overloaded.
Here is an example code that shows how to implement wait time between requests using the time module:
import requests
import time
url = 'https://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
for i in range(5):
response = requests.get(url, headers=headers)
print(response.status_code)
time.sleep(1)In this example, we are sending a request to https://example.com with headers that mimic a browser request. We are then using a for loop to send 5 requests with a 1 second delay between requests using the time.sleep() function.
Another way to implement wait time between requests is to use a random delay. This will make your requests less predictable and less likely to be detected as automated. Here is an example code that shows how to implement a random delay using the random module:
import requests
import random
import time
url = 'https://example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
for i in range(5):
response = requests.get(url, headers=headers)
print(response.status_code)
time.sleep(random.randint(1, 5))In this example, we are sending a request to https://example.com with headers that mimic a browser request. We are then using a for loop to send 5 requests with a random delay between 1 and 5 seconds using the random.randint() function.
By implementing wait time between requests, you can prevent HTTP error 403 and ensure that your web scraping code runs smoothly.

Receiving any error code while online can be a frustrating experience. While we’ve become accustomed to 404 Not Found pages, even to the extent that it’s become common to see cute placeholder pages to entertain us whenever we get lost, one of the more puzzling errors is the 403: Forbidden response.
What does it mean?
Simply put: the server has determined that you are not allowed access to the thing you’ve requested.
According to RFC 7231:
The 403 (Forbidden) status code indicates that the server understood the request but refuses to authorize it…If authentication credentials were provided in the request, the server considers them insufficient to grant access.
The 403 response belongs to the 4xx range of HTTP responses: Client errors. This means either you, or your browser, did something wrong.
If you encounter this it usually means that you have already authenticated yourself with the server, i.e. you’ve logged in, but the resource you have requested expects someone with higher privileges.
Most commonly, you might be logged in as a standard user, but you are attempting to access an admin page.
How do you fix it?
As a user without access to the server, you really only have a few options:
Authenticate yourself with a more appropriate account
Again, according to RFC 7231:
If authentication credentials were provided in the request, the server considers them insufficient to grant access. The client SHOULD NOT automatically repeat the request with the same credentials. The client MAY repeat the request with new or different credentials.
This is the only one that gives you any immediate power to rectify the issue.
If you have multiple accounts for a site and you are attempting to do something you can usually do, but this time are forbidden from doing, this is the option you should try. Log in with your other account.
You may find that this option also requires clearing your cache or cookies, just in case logging in as another user doesn’t sufficiently flush the previous authentication tokens. But this is usually unnecessary.
As a desperate move, you could also try disabling browser extensions that might be interfering with your use of the site. However, this is unlikely, since a 403 implies you are authenticated, but not authorized.
Notify the site owner that a 403 is being returned when you’d expect otherwise
If you fully expect that you should be able to access the resource in question, but you are still seeing this error, it is wise to let the team behind the site know — this could be an error on their part.
Once more from RFC 7231:
However, a request might be forbidden for reasons unrelated to the credentials.
A common cause for this happening unintentionally can be that a server uses allow- or deny-lists for particular IP addresses or geographical regions.
They might have a good reason for blocking your access outside of their strictly defined parameters, but it could also just be an oversight.
Give up.
Maybe you just aren’t supposed to be able to access that resource. It happens. It’s a big internet and it’s reasonable to expect that there are some areas off limits to you personally.
You could visit http.cat instead while ruminating on why your original request was forbidden.
As a reader of freeCodeCamp News, you are almost certainly not forbidden from following @JacksonBates on Twitter for more tech and programming related content.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started