- Remove From My Forums
-
Question
-
Hello,
I am running SQL Server 2008 R2 (Microsoft SQL Server Management Studio 10.50.2500.0
Strumenti client di Microsoft Analysis Services 10.50.2500.0
Microsoft Data Access Components (MDAC) 6.1.7601.17514
Microsoft MSXML 3.0 6.0
Microsoft Internet Explorer 9.0.8112.16421
Microsoft .NET Framework 2.0.50727.5456
Sistema operativo 6.1.7601)I have two backup plans, one Daily, with Differential backup, and one Weekly with FULL backup. I keep all files for 30 days.
Since I want to be really really sure of backing up my precious data, I installed Cobian Backup, and created a task to daily zip and transfer the (incremental) files via FTP to some other place in the world.
Since running Cobian Backup, the Daily plan has broken. It complains that it cannot find the backup information any more, and returns a -1073548784 error.
the log files are not very helpful:
«Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.»
Why is the zip and ftp shorting the SQL?
Any help is welcome!
thanks
Answers
-
Hello,
the error detail for -1073548784 suggests that SQL Server is unable to find the latest Full backup, on which to run the Differential.
I tried disabling the Volume Shadow Copy option on Cobian Backup. Now the differential backup on SQL Server works.
Something will not work if one of the two processes try to access the backup files in the same time frame. I will have to find some workaround for this.
My conclusion is:
SQL Server 2008 R2 differential backups are incompatible with Volume Shadow Copy service on Windows Server 2008 R2.
Somehow, somewhere Volume Shadow Copy (or Cobian Backup’s use of it) breaks the ability of SQL Server to find the latest Full backup.
-
Marked as answer by
Friday, September 28, 2012 1:20 PM
-
Marked as answer by
null
MS SQL error 1073548784 access to path … denied
Ошибка с кодом -1073548784
ms sql error 1073548784 access to path ... denied


при выполнении планов обслуживания (maintenance plan) в ms sql server.


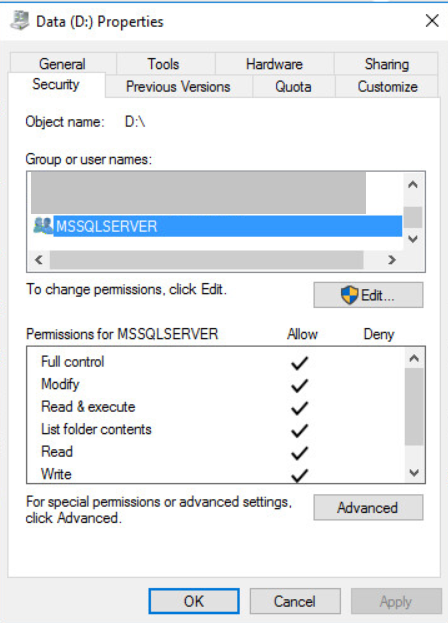
Несмотря на пользователей от которых работают сервисы, необходимо дать разрешения на уровне файловой системы для пользователя NT Service\MSSQLSERVER на уровне rw или full controll

- Remove From My Forums
-
Question
-
Can Someon please Help me!
here the error I’m getting
Microsoft(R) Server Maintenance Utility (Unicode) Version 10.0.1600
Report was generated on «KNTSQL2».
Maintenance Plan: Transaction_Log_Backup
Duration: 00:00:20
Status: Warning: One or more tasks failed.
Details:
Back Up Database (Transaction Log) (KNTSQL2)
Backup Database on Local server connection
Databases: MyDB
Type: Transaction Log
Append existing
Task start: 2010-07-21T07:00:01.
Task end: 2010-07-21T07:00:21.
Failed:(-1073548784) Executing the query «BACKUP LOG [MyDB] TO DISK = N’L:\\\\pat…» failed with the following error: «Exclusive access could not be obtained because the database is in use.
BACKUP LOG is terminating abnormally.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.Command:EXECUTE master.dbo.xp_create_subdir N»L:\\MyDB»
GO
BACKUP LOG [MyDB] TO DISK = N»L:\\MyDB\MyDB_backup_2010_07_21_070001_1384145.trn» WITH NOFORMAT, NOINIT, NAME = N»MyDB_backup_2010_07_21_070001_1384145», SKIP, REWIND, NOUNLOAD, NORECOVERY , STATS = 10
GO
declare @backupSetId as int
select @backupSetId = position from msdb..backupset where database_name=N»MyDB» and backup_set_id=(select max(backup_set_id) from msdb..backupset where database_name=N»MyDB» )
if @backupSetId is null begin raiserror(N»Verify failed. Backup information for database »»MyDB»» not found.», 16, 1) end
RESTORE VERIFYONLY FROM DISK = N»L:\\MyDB\MyDB_backup_2010_07_21_070001_1384145.trn» WITH FILE = @backupSetId, NOUNLOAD, NOREWINDGO
Answers
-
Hello,
Maybe when you created the maintenance plan you selected the option “Backup the tail of the log, and leave the database in the restoring state”. That option requires exclusive access to do the database.
Hope this helps.
Regards,
Alberto Morillo
SQLCoffee.com
-
Proposed as answer by
Wednesday, July 21, 2010 5:20 PM
-
Marked as answer by
Tom Li — MSFT
Sunday, August 1, 2010 6:39 AM
-
Proposed as answer by
-
Alberto,
You hit the nail on the head. Proposing as answer

BACKUP LOG [MyDB] TO DISK = N»L:\\MyDB\MyDB_backup_2010_07_21_070001_1384145.trn» WITH NOFORMAT, NOINIT, NAME = N»MyDB_backup_2010_07_21_070001_1384145», SKIP, REWIND, NOUNLOAD,
NORECOVERY , STATS = 10NORECOVERY is the key here..
Balmukund Lakhani | Please mark solved if I’ve answered your question Personal Blog — http://blogs.msdn.com/blakhani Our Team Blog — http://blogs.msdn.com/sqlserverfaq
-
Proposed as answer by
Alberto MorilloMVP
Wednesday, July 21, 2010 8:22 PM -
Marked as answer by
Tom Li — MSFT
Sunday, August 1, 2010 6:39 AM
-
Proposed as answer by

(9) Вот. Скопировал из нашей базы. Только MYDB поменяй на имя базы.
declare @minRows int
set @minRows = 10000
declare @reindexQuery nvarchar(max)
set @reindexQuery =
REPLACE(REPLACE(
cast(
(
select
‘BEGIN TRY ALTER INDEX ‘+idx.name+’ ON ‘+ sc.name+’.’+ t.name+
CASE
WHEN st.avg_fragmentation_in_percent > 30 THEN ‘ REBUILD WITH (ONLINE=OFF) END TRY BEGIN CATCH ALTER INDEX ‘+idx.name+’ ON ‘+ sc.name+’.’+ t.name+ ‘ REBUILD WITH (ONLINE=OFF) END CATCH;’
ELSE ‘ REORGANIZE END TRY BEGIN CATCH END CATCH;’
END as query
from sys.dm_db_index_physical_stats( DB_ID(),NULL,NULL,NULL,NULL) st
join sys.tables t on (st.object_id=t.object_id)
join sys.schemas sc on (sc.schema_id=t.schema_id)
join sys.indexes idx on (t.object_id=idx.object_id and st.index_id=idx.index_id)
join sys.partitions p on (p.index_id=idx.index_id and p.object_id=idx.object_id)
where p.rows > @minRows and st.avg_fragmentation_in_percent > 30
order by st.avg_fragmentation_in_percent desc
FOR XML PATH(»), TYPE
) as nvarchar(max))
,'</query>’,’;
‘),'<query>’,»)
print @reindexQuery
exec (@reindexQuery)
Автор Bkmzat, 12 фев 2019, 11:30
0 Пользователей и 1 гость просматривают эту тему.
Добрый день.
Исходные данные:
1. 1с 8.3 база размером боле 500 Гб на баз MS SQL 2012
2. Кол-во одновременно работающих круглосуточно пользователей — от 200 до 450.
3. Ресурсы сервера на котором лежит база:
Xeon-E5*2
Оперативная память LRDIMM 256 ГБ
Жёсткий диск — M2 — 2 Tb
Задание:
Раз в неделю запускается регламентное задание по реиндексации базы, но к сожалению постоянно, на разных этапах задание вываливается в ошибки:
«-1073548784» с сообщением об ошибке «Сбой выполнения запроса «sp_msforeachtable N’DBCC DBREINDEX (»?»)’» со следующей ошибкой: «Транзакция (идентификатор процесса 122) вызвала взаимоблокировку ресурсов блокировка с другим процессом и стала жертвой взаимоблокировки. Запустите транзакцию повторно.»
«-1073548784» с сообщением об ошибке «Сбой выполнения запроса «ALTER INDEX [_AccumRg14146_ByDims14584_TR] ON [dbo…» со следующей ошибкой: «Транзакция (идентификатор процесса 104) вызвала взаимоблокировку ресурсов блокировка с другим процессом и стала жертвой взаимоблокировки. Запустите транзакцию повторно.». Возможные причины сбоя: проблемы с этим запросом, свойство «ResultSet» установлено неправильно, параметры установлены неправильно или соединение было установлено неправильно.»
Для примера даны две ошики двух задач (первая ошибка задачи реиндексации командой «sp_msforeachtable N’DBCC DBREINDEX (»?»)’» , вторая ошибка задачи реиндексация стандарная «Задача перестроение индекса»» которая формируется автоматом)
И так далее в разных таблицах разные идентификаторы процесса
Вопрос:
Что можно предпринять для того, чтобы все же реиндексация проводилась?
Пользователей выгонять на время реиндексации нельзя.
Цитата: Bkmzat от 12 фев 2019, 11:30
Добрый день.
Исходные данные:
1. 1с 8.3 база размером боле 500 Гб на баз MS SQL 2012
2. Кол-во одновременно работающих круглосуточно пользователей — от 200 до 450.
3. Ресурсы сервера на котором лежит база:
Xeon-E5*2
Оперативная память LRDIMM 256 ГБ
Жёсткий диск — M2 — 2 Tb
Задание:
Раз в неделю запускается регламентное задание по реиндексации базы, но к сожалению постоянно, на разных этапах задание вываливается в ошибки:
«-1073548784» с сообщением об ошибке «Сбой выполнения запроса «sp_msforeachtable N’DBCC DBREINDEX (»?»)’» со следующей ошибкой: «Транзакция (идентификатор процесса 122) вызвала взаимоблокировку ресурсов блокировка с другим процессом и стала жертвой взаимоблокировки. Запустите транзакцию повторно.»«-1073548784» с сообщением об ошибке «Сбой выполнения запроса «ALTER INDEX [_AccumRg14146_ByDims14584_TR] ON [dbo…» со следующей ошибкой: «Транзакция (идентификатор процесса 104) вызвала взаимоблокировку ресурсов блокировка с другим процессом и стала жертвой взаимоблокировки. Запустите транзакцию повторно.». Возможные причины сбоя: проблемы с этим запросом, свойство «ResultSet» установлено неправильно, параметры установлены неправильно или соединение было установлено неправильно.»
Для примера даны две ошики двух задач (первая ошибка задачи реиндексации командой «sp_msforeachtable N’DBCC DBREINDEX (»?»)’» , вторая ошибка задачи реиндексация стандарная «Задача перестроение индекса»» которая формируется автоматом)
И так далее в разных таблицах разные идентификаторы процесса
Вопрос:
Что можно предпринять для того, чтобы все же реиндексация проводилась?
Пользователей выгонять на время реиндексации нельзя.
https://infostart.ru/public/803209/
Попробуй отсюда
Спасибо, попробую, в пятницу отпишусь.
Добрый день. Все вроде работает. Спасибо за помощь.
- Форум 1С
-
►
Форум 1С — ПРЕДПРИЯТИЕ 8.0 8.1 8.2 8.3 8.4 -
►
Установка и администрирование 1С Предприятие 8 -
►
Реиндексация 1С 8.3 на SQL
Похожие темы (1)

![]()
![]()
Поиск
(9) Вот. Скопировал из нашей базы. Только MYDB поменяй на имя базы.
declare @minRows int
set @minRows = 10000
declare @reindexQuery nvarchar(max)
set @reindexQuery =
REPLACE(REPLACE(
cast(
(
select
‘BEGIN TRY ALTER INDEX ‘+idx.name+’ ON ‘+ sc.name+’.’+ t.name+
CASE
WHEN st.avg_fragmentation_in_percent > 30 THEN ‘ REBUILD WITH (ONLINE=OFF) END TRY BEGIN CATCH ALTER INDEX ‘+idx.name+’ ON ‘+ sc.name+’.’+ t.name+ ‘ REBUILD WITH (ONLINE=OFF) END CATCH;’
ELSE ‘ REORGANIZE END TRY BEGIN CATCH END CATCH;’
END as query
from sys.dm_db_index_physical_stats( DB_ID(),NULL,NULL,NULL,NULL) st
join sys.tables t on (st.object_id=t.object_id)
join sys.schemas sc on (sc.schema_id=t.schema_id)
join sys.indexes idx on (t.object_id=idx.object_id and st.index_id=idx.index_id)
join sys.partitions p on (p.index_id=idx.index_id and p.object_id=idx.object_id)
where p.rows > @minRows and st.avg_fragmentation_in_percent > 30
order by st.avg_fragmentation_in_percent desc
FOR XML PATH(»), TYPE
) as nvarchar(max))
,'</query>’,’;
‘),'<query>’,»)
print @reindexQuery
exec (@reindexQuery)
null
MS SQL error 1073548784 access to path … denied
Ошибка с кодом -1073548784
ms sql error 1073548784 access to path ... denied
при выполнении планов обслуживания (maintenance plan) в ms sql server.
Несмотря на пользователей от которых работают сервисы, необходимо дать разрешения на уровне файловой системы для пользователя NT ServiceMSSQLSERVER на уровне rw или full controll
Hi,
I am having a Microsoft SQL Server 2012 Standard version 11.0.6020.0 installation where all our SharePoint databases are placed.
select @@version returns:
Microsoft SQL Server 2012 (SP3) (KB3072779) — 11.0.6020.0 (X64) Oct 20 2015 15:36:27 Copyright (c) Microsoft Corporation Standard Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
We are having a rather large SharePoint environment (6 SharePoint servers) and we have over 70 SharePoint related databases (more than 6 TB data).
During the last couple of months, we have upgraded our SharePoint environment to SharePoint SP1 and SharePoint CU september 2015 edition and upgraded the SQL server to MSSQL SP3.
After all these upgrades, we now experience that our nightly «Rebuild index tasks» jobs fails every night.
Alle the databases are placed in 4 different Rebuild index tasks, and each job is configurated like this:
«Object:» Tables and Views
«Free space options»:
x Default free space per page
«Advanced options»
x Sort results in tempdb
x Keep index online while reindexing
x Rebuild indexes offline
But now they fail with the following error:
Failed:(-1073548784) Executing the query «ALTER INDEX [UserInfo_Mobile] ON [dbo].[UserInfo] …» Failed with the following error: «Transaction (Process ID 1468) was deadlocked on lock resources with another process and has been chosen as the
deadlock victim. Rerun the transaction.». Possible failure reasons: Problems with the qurey, «Resultset» property not set correctly, parameters not set correctly, or connection not established correctly.
Each job used to run between 2 or 3 hours before completing succesfuld, and now they run for around 2 hours before failing with the deadlock error above.
I have tried to change the running schedule to different times during the night where the user workload on the SharePoint environment not should be so large, and no other SQL jobs are running (diffential backup or update statistics).
The only SQL job that are running, is the transaction log backup every 3 hours 24/7.
If I just create a job with just one of the databases and run it, it also fails after running for 13 minuts (the database is one of the smaller (~20 GB — but it is active in the SharePoint environment).
My weekly «Update statistics job» and «Integrity check job» runs succesfull without errors (The integrity check is performed on all online databases and include indexes).
Low diskspace is not an issue, there is plenty availiable on each disk and the transaction log drive also have plenty.
There is not errors or warnings in SharePoint about this issue.
Do you have any suggestions to what I can try to get the rebuild index tasks to run succesfully again?
Kind regards,
Carl-Marius
Hi,
I am having a Microsoft SQL Server 2012 Standard version 11.0.6020.0 installation where all our SharePoint databases are placed.
select @@version returns:
Microsoft SQL Server 2012 (SP3) (KB3072779) — 11.0.6020.0 (X64) Oct 20 2015 15:36:27 Copyright (c) Microsoft Corporation Standard Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
We are having a rather large SharePoint environment (6 SharePoint servers) and we have over 70 SharePoint related databases (more than 6 TB data).
During the last couple of months, we have upgraded our SharePoint environment to SharePoint SP1 and SharePoint CU september 2015 edition and upgraded the SQL server to MSSQL SP3.
After all these upgrades, we now experience that our nightly «Rebuild index tasks» jobs fails every night.
Alle the databases are placed in 4 different Rebuild index tasks, and each job is configurated like this:
«Object:» Tables and Views
«Free space options»:
x Default free space per page
«Advanced options»
x Sort results in tempdb
x Keep index online while reindexing
x Rebuild indexes offline
But now they fail with the following error:
Failed:(-1073548784) Executing the query «ALTER INDEX [UserInfo_Mobile] ON [dbo].[UserInfo] …» Failed with the following error: «Transaction (Process ID 1468) was deadlocked on lock resources with another process and has been chosen as the
deadlock victim. Rerun the transaction.». Possible failure reasons: Problems with the qurey, «Resultset» property not set correctly, parameters not set correctly, or connection not established correctly.
Each job used to run between 2 or 3 hours before completing succesfuld, and now they run for around 2 hours before failing with the deadlock error above.
I have tried to change the running schedule to different times during the night where the user workload on the SharePoint environment not should be so large, and no other SQL jobs are running (diffential backup or update statistics).
The only SQL job that are running, is the transaction log backup every 3 hours 24/7.
If I just create a job with just one of the databases and run it, it also fails after running for 13 minuts (the database is one of the smaller (~20 GB — but it is active in the SharePoint environment).
My weekly «Update statistics job» and «Integrity check job» runs succesfull without errors (The integrity check is performed on all online databases and include indexes).
Low diskspace is not an issue, there is plenty availiable on each disk and the transaction log drive also have plenty.
There is not errors or warnings in SharePoint about this issue.
Do you have any suggestions to what I can try to get the rebuild index tasks to run succesfully again?
Kind regards,
Carl-Marius
- Remove From My Forums
-
Question
-
I scheduled a maint plan to rebuild index. All table’s indexes are successfully built except for one table. The error message I got:
Failed:(-1073548784) Executing the query «ALTER INDEX [Index_name] ON [dbo].[table] REBUILD WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = ON )
» failed with the following error: «Online index operations can only be performed in Enterprise edition of SQL Server.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.Can someone tell me what the problem is and how to fix it? Thanks.
Answers
- Remove From My Forums
-
Question
-
Hi everyone,
We’ve a problem when we want to do a reorganization of indexes, it give us the following error:
Error Number: -1073548784
Error message:
Executing the query «ALTER INDEX [ARFCRDATA~0] ON [qas].[ARFCRDATA] REORGANIZE WITH ( LOB_COMPACTION = ON )
» failed with the following error: «The index «ARFCRDATA~0» (partition 1) on table «ARFCRDATA» cannot be reorganized because page level locking is disabled.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.We’re using SQL Server 2005 with SAP ECC 6.0.
Have you any idea to solve this??
I’m created the plan with the wizard, and manually, and the same error occurs.Thanks in advance
Answers
-
Talk to the SAP people, or do rebuild instead of reorganize.
Tibor Karaszi, SQL Server MVP
http://www.karaszi.com/sqlserver/default.asp
http://sqlblog.com/blogs/tibor_karaszi
- Proposed as answer by
Monday, November 30, 2009 2:33 AM
- Marked as answer by
Alex Feng (SQL)
Friday, December 4, 2009 3:24 AM
- Proposed as answer by
-
Its better to get a recommendation from SAP regarding rebuilding / reorganising SQL indexes.
Thanks,
Leks- Proposed as answer by
Alex Feng (SQL)
Monday, November 30, 2009 2:33 AM - Marked as answer by
Alex Feng (SQL)
Friday, December 4, 2009 3:24 AM
- Proposed as answer by
- Remove From My Forums
-
Question
-
Hi everyone,
We’ve a problem when we want to do a reorganization of indexes, it give us the following error:
Error Number: -1073548784
Error message:
Executing the query «ALTER INDEX [ARFCRDATA~0] ON [qas].[ARFCRDATA] REORGANIZE WITH ( LOB_COMPACTION = ON )
» failed with the following error: «The index «ARFCRDATA~0» (partition 1) on table «ARFCRDATA» cannot be reorganized because page level locking is disabled.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.We’re using SQL Server 2005 with SAP ECC 6.0.
Have you any idea to solve this??
I’m created the plan with the wizard, and manually, and the same error occurs.Thanks in advance
Answers
-
Talk to the SAP people, or do rebuild instead of reorganize.
Tibor Karaszi, SQL Server MVP
http://www.karaszi.com/sqlserver/default.asp
http://sqlblog.com/blogs/tibor_karaszi
- Proposed as answer by
Monday, November 30, 2009 2:33 AM
- Marked as answer by
Alex Feng (SQL)
Friday, December 4, 2009 3:24 AM
- Proposed as answer by
-
Its better to get a recommendation from SAP regarding rebuilding / reorganising SQL indexes.
Thanks,
Leks- Proposed as answer by
Alex Feng (SQL)
Monday, November 30, 2009 2:33 AM - Marked as answer by
Alex Feng (SQL)
Friday, December 4, 2009 3:24 AM
- Proposed as answer by
ночной регламент, через раз возникает ошибка Сбой выполнения запроса «ALTER INDEX [_InfoRg8163_ByDims8181_RRNR] ON [dbo]…» со следующей ошибкой: «Транзакция (идентификатор процесса 51) вызвала взаимоблокировку ресурсов блокировка с другим процессом и стала жертвой взаимоблокировки. Запустите транзакцию повторно.». Возможные причины сбоя: проблемы с этим запросом, свойство «ResultSet» установлено неправильно, параметры установлены неправильно или соединение было установлено неправильно. Как лечить?
а 1с то причем? это ошибка при работе плана обслуживания для скуля
Так ты обслуживание в один поток запускай… И всех пользователей, включая регламенты, выгоняй…
ну пользователи ночью спят, а вот регламенты возможно, хотя тяжелые точно не запускаются, спасибо посмотрю, но раньше такого не было
Если на секунду отвлечься от вопроса — ALTER INDEX в ночное обслуживание? Это что за задание такое интересное?
alter index rebuild или alter index REORGANIZE нормальное задание.
Тэги:
Комментарии доступны только авторизированным пользователям
- Remove From My Forums
-
Question
-
Any assistance with this issue would be greatly appreciated. TIA!
Server: DBServer-1
Task Detail: Reorganize index on Local server connection
Databases: dbA,dbB,dbC,dbD,dbE,master,model,msdb
Object: Tables and views
Compact large objects
Error No: -1073548784
Error Message: Executing the query «ALTER INDEX [PK_Residential] ON [dbo].[Residential] REORGANIZE WITH ( LOB_COMPACTION = ON )» failed with the following error: «A severe error occurred on the current command. The results, if any, should be discarded.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.
Windows Server 2003 Standard Edition w/ SP2
SQL Server 2005 Standard Edition (9.0.3054)
Answers
-
-
Proposed as answer by
Wednesday, April 24, 2013 12:50 PM
-
Marked as answer by
Ed Price — MSFTMicrosoft employee
Tuesday, April 30, 2013 3:51 AM
-
Proposed as answer by
Hi,
I am having a Microsoft SQL Server 2012 Standard version 11.0.6020.0 installation where all our SharePoint databases are placed.
select @@version returns:
Microsoft SQL Server 2012 (SP3) (KB3072779) — 11.0.6020.0 (X64) Oct 20 2015 15:36:27 Copyright (c) Microsoft Corporation Standard Edition (64-bit) on Windows NT 6.1 <X64> (Build 7601: Service Pack 1)
We are having a rather large SharePoint environment (6 SharePoint servers) and we have over 70 SharePoint related databases (more than 6 TB data).
During the last couple of months, we have upgraded our SharePoint environment to SharePoint SP1 and SharePoint CU september 2015 edition and upgraded the SQL server to MSSQL SP3.
After all these upgrades, we now experience that our nightly «Rebuild index tasks» jobs fails every night.
Alle the databases are placed in 4 different Rebuild index tasks, and each job is configurated like this:
«Object:» Tables and Views
«Free space options»:
x Default free space per page
«Advanced options»
x Sort results in tempdb
x Keep index online while reindexing
x Rebuild indexes offline
But now they fail with the following error:
Failed:(-1073548784) Executing the query «ALTER INDEX [UserInfo_Mobile] ON [dbo].[UserInfo] …» Failed with the following error: «Transaction (Process ID 1468) was deadlocked on lock resources with another process and has been chosen as the
deadlock victim. Rerun the transaction.». Possible failure reasons: Problems with the qurey, «Resultset» property not set correctly, parameters not set correctly, or connection not established correctly.
Each job used to run between 2 or 3 hours before completing succesfuld, and now they run for around 2 hours before failing with the deadlock error above.
I have tried to change the running schedule to different times during the night where the user workload on the SharePoint environment not should be so large, and no other SQL jobs are running (diffential backup or update statistics).
The only SQL job that are running, is the transaction log backup every 3 hours 24/7.
If I just create a job with just one of the databases and run it, it also fails after running for 13 minuts (the database is one of the smaller (~20 GB — but it is active in the SharePoint environment).
My weekly «Update statistics job» and «Integrity check job» runs succesfull without errors (The integrity check is performed on all online databases and include indexes).
Low diskspace is not an issue, there is plenty availiable on each disk and the transaction log drive also have plenty.
There is not errors or warnings in SharePoint about this issue.
Do you have any suggestions to what I can try to get the rebuild index tasks to run succesfully again?
Kind regards,
Carl-Marius
- Remove From My Forums
-
Question
-
I scheduled a maint plan to rebuild index. All table’s indexes are successfully built except for one table. The error message I got:
Failed:(-1073548784) Executing the query «ALTER INDEX [Index_name] ON [dbo].[table] REBUILD WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = ON )
» failed with the following error: «Online index operations can only be performed in Enterprise edition of SQL Server.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.Can someone tell me what the problem is and how to fix it? Thanks.
Answers
- Remove From My Forums
-
Вопрос
-
I am getting the following error on Rebuild Index Maintenance Task.
«Executing the query «ALTER INDEX [PK_cartrige] ON [dbo…» failed with the following error: «A severe error occurred on the current command. The results, if any, should be discarded.
A severe error occurred on the current command. The results, if any, should be discarded.». Possible failure reasons: Problems with the query, «ResultSet» property not set correctly, parameters not set correctly, or connection not established correctly.»Where can i find more details on troubleshooting this error and find more details on the error. It seems to be a persistant problem since sql server 2005.
Details:
- -Maintenance Plan has been working well for months.
- -Std Edition Sql Server 2008
- -Db Integrity check successfull
- -sort result in tempdb is off
- -keep index online while reindexing is off
- -local server connection works for all other jobs prior to the task
Ответы
-
Your absolutly right, the db was on full recovery mode and that was causing the logs to grow.
for now i had to babysit the backup and issued a checkpoint, and the rebuild was successfull. I’m looking into it and will add details. However, the logs should have grown without any problem as there was enough space. I am suspecting the authogrowth
factor was not appropriate for the task.Thanks Josh
Possible solutions in this senario:
-turn to simple recovery model (if appropriate)
-checkpoint
-in my case, on full recovery model, increase freq of log backups esp during large rebuilds as the logs grow pretty rapidly. Here is a link that may help.
http://support.microsoft.com/kb/317375#3
-
Помечено в качестве ответа
24 октября 2010 г. 22:09
-
Помечено в качестве ответа
SQL Server 2014 Developer — duplicate (do not use) SQL Server 2014 Enterprise — duplicate (do not use) SQL Server 2014 Standard — duplicate (do not use) Еще…Меньше
Проблемы
Рассмотрим следующий сценарий.
-
Функция групп доступности AlwaysOn используется в Microsoft SQL Server 2014.
-
У вас есть группа доступности, для параметра резервного копирования которой задано значение «предпочитать вспомогательный» или «только вторичный».
-
Вы создаете план обслуживания, использующий задачу резервного копирования базы данных для создания резервной копии базы данных, а база данных входит в группу доступности.
-
Вы выбираете параметр «проверять целостность резервных копий», а затем очищаете параметр «для баз данных доступности, не учитывать приоритеты реплики для резервного копирования и резервного копирования на основных параметрах задачи» резервная копия базы данных «.
-
Вы выполняете план обслуживания.
В этом случае появляется следующее сообщение об ошибке:
Номер ошибки:-1073548784Error сообщение: выполнение запроса «<инструкции запроса>» завершилось сбоем со следующей ошибкой: «не удается открыть устройство резервного копирования <путь к файлу резервной копии>». Ошибка операционной системы 2 (системе не удается найти указанный файл). Убедитесь, что база данных аварийно завершает работу. Возможные причины сбоя: проблемы с запросом, свойство «ResultSet» задано неправильно, параметры заданы неправильно или соединение установлено неправильно.
Решение
Эта проблема впервые устранена в следующих накопительных обновлениях SQL Server:
-
Накопительное обновление 2 для SQL Server 2014 с пакетом обновления 1 (SP1)
-
Накопительное обновление 9 для SQL Server 2014
Статус
Корпорация Майкрософт подтверждает наличие этой проблемы в своих продуктах, которые перечислены в разделе «Применяется к».
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.