Коэффициент ошибок в словах ( WER ) — это общий показатель производительности системы распознавания речи или машинного перевода .
Общая сложность измерения производительности заключается в том, что распознанная последовательность слов может иметь длину, отличную от длины контрольной последовательности слов (предположительно правильной). WER происходит от расстояния Левенштейна и работает на уровне слов, а не на уровне фонем . WER — ценный инструмент для сравнения различных систем, а также для оценки улучшений в рамках одной системы. Этот вид измерения, однако, не дает подробных сведений о природе ошибок перевода, и поэтому требуется дальнейшая работа для определения основного источника (источников) ошибки и концентрации любых исследовательских усилий.
Эта проблема решается путем первого выравнивания распознанной последовательности слов с эталонной (произносимой) последовательностью слов с помощью динамического выравнивания строк. Рассмотрение этого вопроса осуществляется с помощью теории, называемой степенным законом, которая устанавливает корреляцию между недоумением и частотой ошибок в словах.
Затем коэффициент ошибок в словах можно рассчитать как:

где
- S — количество замен,
- D — количество удалений,
- I — количество прошивок,
- C — количество правильных слов,
- N — количество слов в справочнике (N = S + D + C)
Интуиция за «удалением» и «вставкой» заключается в том, как перейти от ссылки к гипотезе. Поэтому, если у нас есть ссылка «Это википедия» и гипотеза «Эта _ википедия», мы называем это удалением.
При сообщении о производительности системы распознавания речи иногда вместо этого используется точность слов (WAcc) :

Обратите внимание, что, поскольку N — это количество слов в ссылке, коэффициент ошибок по словам может быть больше 1,0, и, таким образом, точность слова может быть меньше 0,0.
Эксперименты
Обычно считается, что более низкая частота ошибок в словах показывает более высокую точность распознавания речи по сравнению с более высокой частотой ошибок в словах. Однако по крайней мере одно исследование показало, что это может быть неправдой. В ходе эксперимента Microsoft Research было показано, что, если бы люди были обучены принципу «что соответствует цели оптимизации для понимания» (Wang, Acero and Chelba, 2003), они бы показали более высокую точность понимания языка, чем другие люди, продемонстрировавшие меньшее количество ошибок в словах, что показывает, что истинное понимание разговорной речи зависит не только от высокой точности распознавания слов.
Прочие показатели
Однако одна проблема с использованием общей формулы, такой как приведенная выше, заключается в том, что не учитывается влияние, которое различные типы ошибок могут иметь на вероятность успешного результата, например, некоторые ошибки могут быть более разрушительными, чем другие, а некоторые могут исправляться легче, чем другие. Эти факторы, вероятно, будут специфичными для тестируемого синтаксиса . Еще одна проблема заключается в том, что даже при наилучшем выравнивании формула не может отличить ошибку замены от комбинированной ошибки удаления и вставки.
Хант (1990) предложил использовать взвешенную меру точности производительности, при которой ошибки подстановки взвешиваются на единицу, а ошибки удаления и вставки взвешиваются только на 0,5, таким образом:

Однако ведутся споры о том, можно ли правильно использовать формулу Ханта для оценки производительности отдельной системы, поскольку она была разработана как средство сравнения более справедливо конкурирующих систем-кандидатов. Еще одна сложность заключается в том, позволяет ли данный синтаксис исправлять ошибки и, если да, то насколько легко этот процесс для пользователя. Таким образом, есть некоторые достоинства аргумента в пользу того, что показатели производительности должны разрабатываться в соответствии с конкретной измеряемой системой.
Однако какая бы метрика ни использовалась, одна из основных теоретических проблем при оценке производительности системы состоит в том, чтобы решить, было ли слово «произнесено неправильно», то есть виноват пользователь или распознаватель. Это может быть особенно актуально в системе, которая предназначена для работы с людьми, для которых данный язык не является родным, или с сильными региональными акцентами.
Темп, с которым следует произносить слова в процессе измерения, также является источником различий между испытуемыми, так же как и потребность испытуемых в отдыхе или вдохе. Все эти факторы, возможно, необходимо каким-то образом контролировать.
Для текстового диктовки обычно считается, что точность производительности ниже 95% неприемлема, но это опять же может зависеть от синтаксиса и / или предметной области, например, есть ли у пользователей временное давление для выполнения задачи, есть ли альтернативные методы завершения и так далее.
Термин «частота ошибок одного слова» иногда называют процентом неправильных распознаваний для каждого отдельного слова в системном словаре.
Изменить расстояние
Коэффициент ошибок по словам также может называться нормализованным расстоянием редактирования по длине . Нормализованное расстояние редактирования между X и Y, d (X, Y) определяется как минимум W (P) / L (P), где P — это путь редактирования между X и Y, W (P) — это сумма веса элементарных операций редактирования P, а L (P) — количество этих операций (длина P).
Смотрите также
- BLEU
- F-мера
- МЕТЕОР
- NIST (метрическая система)
- ROUGE (метрическая система)
Ссылки
Ноты
- ^ Клаков, Дитрих; Йохен Петерс (сентябрь 2002 г.). «Проверка корреляции коэффициента ошибок по словам и недоумения». Речевое общение . 38 (1–2): 19–28. DOI : 10.1016 / S0167-6393 (01) 00041-3 . ISSN 0167-6393 .
- ^ Wang, Y .; Acero, A .; Челба, К. (2003). Является ли коэффициент ошибок в словах хорошим показателем точности понимания разговорной речи . Семинар IEEE по автоматическому распознаванию и пониманию речи. Сент-Томас, Виргинские острова США. CiteSeerX 10.1.1.89.424 .
- ^ Нейссендр. (2000)
- ^ Вычисление нормализованного расстояния редактирования и приложения: AndrCs Marzal и Enrique Vidal
Другие источники
- McCowan et al. 2005: Об использовании средств поиска информации для оценки распознавания речи
- Хант, М.Дж., 1990: Показатели качества для оценки распознавателей связанных слов (Речевая коммуникация, 9, 1990, стр. 239-336)
- Зехнер, К., Вайбель, А. Минимизация количества ошибок в словах в текстовых обзорах разговорной речи
A false positive error or false positive (false alarm) is a result that indicates a given condition exists when it doesn’t.
You can get the number of false positives from the confusion matrix. For a binary classification problem, it is described as follows:
| Predicted = 0 | Predicted = 1 | Total | |
|---|---|---|---|
| Actual = 0 | True Negative (TN) | False Positive(FP) | N |
| Actual = 1 | False Negative (FN) | True Positive (TP) | P |
| Total | N * | P * |
In statistical hypothesis testing, the false positive rate is equal to the significance level, (alpha), and (1 — alpha) is defined as the specificity of the test. Complementarily, the false negative rate is given by (beta).
The different measures for classification are:
| Name | Definition | Synonyms |
|---|---|---|
| False positive rate ((alpha)) | FP/N | Type I error, 1- specificity |
| True Positive rate ((1-beta)) | TP/P | 1 — Type II error, power, sensitivity, recall |
| Positive prediction value | TP/P* | Precision |
| Negative prediction value | TN/N* | |
| Overall accuracy | (TN + TP)/N | |
| Overall error rate | (FP + FN)/N |
Also, note that F-score is the harmonic mean of precision and recall.
[text{F1 score} = frac{2 * text{precision} * text{recall}}{text{precision} + text{recall}}]
For example, in cancer detection, sensitivity and specificity are the following:
- Sensitivity: Of all the people with cancer, how many were correctly diagnosed?
- Specificity: Of all the people without cancer, how many were correctly diagnosed?
And precision and recall are the following:
- Recall: Of all the people who have cancer, how many did we diagnose as having cancer?
- Precision: Of all the people we diagnosed with cancer, how many actually had cancer?
Often, we want to make binary prediction e.g. in predicting the quality of care of the patient in the hospital, whether the patient receive poor care or good care? We can do this using a threshold value (t).
- if (P(poor care = 1) geq t), predict poor quality
- if (P(poor care = 1 < t), predict good quality
Now, the question arises, what value of (t) we should consider.
- if (t) is large, the model will predict poor care rarely hence detect patients receiving the worst care.
- if (t) is small, the model will predict good care rarely hence detect all patients receiving poor care.
i.e.
- A model with a higher threshold will have a lower sensitivity and a higher specificity.
- A model with a lower threshold will have a higher sensitivity and a lower specificity.
Thus, the answer to the above question depends on what problem you are trying to solve. With no preference between the errors, we normally select (t = 0.5).
Area Under the ROC Curve gives the AUC score of a model.
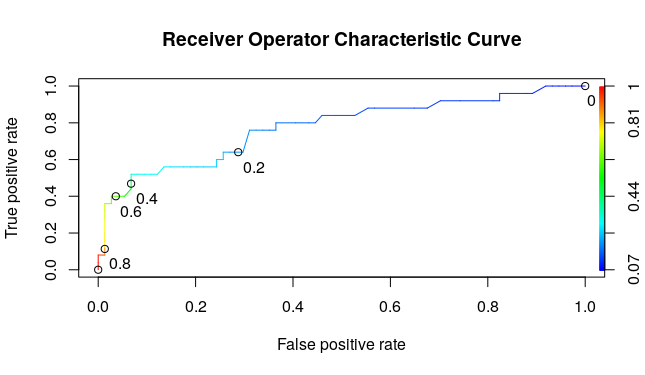
- The threshold of 1 means that the model will not catch any poor care cases, or have sensitivity of 0 but it’ll correctly label all the good care cases, meaning that you have a false positive rate of 0.
- The threshold of 0 means that the model will catch all of the poor care cases or have a sensitivity of 1, but it’ll label all of the good care cases as poor care cases too, meaning that you’ll have a false positive rate of 1.
Below is xkcd comic regarding the wrong interpretation of p-value and false positives.

Explanation of above comic on explain xkcd wiki.
References:
- An Introduction to Statistical Learning
- False positives and false negatives — Wikipedia
- Sensitivity and specificity — Wikipedia
- Precision and recall — Wikipedia
This page is open source. Improve its content!
Error Rate Calculation
Вычисляет вероятность битовых ошибок или вероятность символьных ошибок во входных данных
Библиотека
Связные получатели
Описание
Блок Error Rate Calculation сравнивает входные данные от передатчика с входными данными от приемника. Он вычисляет коэффициент ошибок как текущую статистику, деля общее количества неравных пар элементов данных на общее количество элементов входных данных от одного источника.
Используйте этот блок, чтобы вычислить вероятность символьных или битовых ошибок, поскольку он не учитывает величину разницы между элементами входных данных. Если входные параметры являются битами, то блок вычисляет вероятность битовой ошибки. Если входные параметры являются символами, то он вычисляет вероятность символьной ошибки.
Примечание
Когда вы устанавливаете параметр Output data на Workspace, блок не генерирует кода. Точно так же никакие данные не сохранены в рабочую область, если Simulation mode установлен в Accelerator или Rapid Accelerator. Если вы нуждаетесь в информации о коэффициенте ошибок в этих случаях, устанавливаете Output data на Port.
Входные данные
Этот блок имеет между двумя и четырьмя входными портами, в зависимости от того, как вы устанавливаете диалоговые параметры. Входные порты отметили Tx и Rx примите переданные и полученные сигналы, соответственно. Tx и Rx сигналы должны совместно использовать ту же частоту дискретизации.
Tx и Rx входные порты принимают сигналы вектор-столбца или скаляр. Для получения информации о типах данных, которые поддерживает каждый порт блока см. таблицу Supported Data Types на этой странице.
Если Tx скаляр и Rx вектор, или наоборот, затем блок сравнивает скаляр с каждым элементом вектора. В этом случае блок ведет себя, как будто вы предварительно обработали скалярный сигнал при помощи блока Repeat с набором параметров Rate options к Enforce single rate.
Если вы выбираете Reset port, то дополнительный входной порт появляется, пометил Rst. Rst введите принимает только скалярный сигнал (типа double или boolean) и должен иметь тот же шаг расчета порта как Tx и Rx порты. Когда Rst вход является ненулевым, блок очищает и затем повторно вычисляет статистику ошибок.
Если вы устанавливаете параметр Computation mode на Select samples from port, затем дополнительный входной порт появляется, пометил Sel. Sel введите указывает, какие элементы кадра важны для расчета. Sel введите может быть вектор-столбец типа double.
Инструкции ниже указывают, как необходимо сконфигурировать входные параметры и диалоговые параметры в зависимости от того, как вы хотите, чтобы этот блок интерпретировал ваш Tx и Rx данные.
-
Если оба сигнала данных являются скаляром, то этот блок сравнивает
Txскалярный сигнал сRxскалярный сигнал. Для этой настройки используйте значение по умолчанию параметра Computation mode,Entire frame. -
Если оба сигнала данных являются векторами, то этот блок сравнивает некоторых или весь
TxиRxданные:-
Если вы устанавливаете параметр Computation mode на
Entire frame, затем блок сравнивает весьTxструктурируйте со всемRxсистема координат. -
Если вы устанавливаете параметр Computation mode на
Select samples from mask, затем поле Selected samples from frame появляется в диалоговом окне. Это поле параметра принимает вектор, который перечисляет индексы тех элементовRxструктурируйте это, вы хотите, чтобы блок рассмотрел. Например, чтобы считать только первые и последние элементы длины шестью системами координат приемника, установите параметр Selected samples from frame на[1 6]. Если вектор Selected samples from frame включает нули, то блок игнорирует их. -
Если вы устанавливаете параметр Computation mode на
Select samples from port, затем дополнительный входной порт, пометилSel, появляется на значке блока. Данные в этом входном порту должны иметь тот же формат как тот из параметра Selected samples from frame, описанного выше.
-
-
Если один сигнал данных является скаляром, и другой вектор, то скаляр с каждой записью вектора. В этом случае, если
Rxскаляр, затем фраза “Rxструктурируйте” выше, относится к векторному расширениюRx.Примечание
Этот блок не поддерживает сигналы переменного размера. Если вы выбираете
Select samples from portопция и хочет, чтобы число элементов в подкадре варьировалось во время симуляции, затем необходимо заполнитьSelсигнал с нулями. Блок Error Rate Calculation игнорирует нули вSelсигнал.
Выходные данные
Этот блок производит вектор длины три, чьи записи соответствуют:
-
Коэффициент ошибок
-
Общее количество ошибок, то есть, количества экземпляров, что элемент Rx не совпадает с соответствующим элементом Tx
-
Общему количеству сравнений, которые сделал блок
Блок отправляет этому выходные данные в основной MATLAB® рабочая область или к выходному порту, в зависимости от того, как вы устанавливаете параметр Output data:
-
Если вы устанавливаете параметр Output data на
Workspaceи заполните параметр Variable name, затем та переменная в основном рабочем пространстве MATLAB содержит текущее значение, когда симуляция заканчивается. Приостановка симуляции не заставляет блок писать временные данные в переменную.Если вы планируете использовать этот блок наряду с Simulink® Программное обеспечение Coder™, затем вы не должны использовать
Workspaceопция. Вместо этого используйтеPortопция и подключение выходной порт с блоком Simulink To Workspace (Simulink). -
Если вы устанавливаете параметр Output data на
Port, затем выходной порт появляется. Этот выходной порт содержит рабочую статистику ошибок.
Задержки
Receive delay и параметры Computation delay реализуют два различных типов задержек этого блока. Одна задержка полезна, если вы хотите, чтобы этот блок компенсировал задержку полученного сигнала. Другой полезно, если вы хотите проигнорировать начальное переходное поведение обоих входных сигналов.
-
Параметр Receive delay представляет количество отсчетов, которым принятые данные отстают от передаваемых данных. Передаваемый сигнал неявно задерживается той же самой суммой, прежде чем блок сравнит его с принятыми данными. Это значение полезно, когда вы задерживаете передаваемый сигнал так, чтобы это выровнялось с полученным сигналом. Задержка приема сохраняется в течение симуляции.
-
Параметр Computation delay представляет количество отсчетов, которое блок игнорирует в начале сравнения.
Используйте блок Find Delay, чтобы определить задержку, и затем установить Receive delay на задержку, о которой сообщает блок Find Delay.
Если вы используете Select samples from mask или Select samples from port опция, затем каждый параметр задержки относится к количеству отсчетов, которое получает блок, игнорирует ли блок в конечном счете некоторых из них или нет.
При использовании порта Sel, чтобы вычислить ошибки на задержанный сигнал, задержка должна быть добавлена к индексам Sel. Для получения дополнительной информации смотрите, Вычисляют, Ошибки для Задержанного Выбрали Samples.
Остановка симуляции на основе статистики ошибок
Можно сконфигурировать этот блок так, чтобы его управление статистикой ошибок длительность симуляции. Это полезно для вычисления надежной установившейся статистики ошибок, не зная заранее, сколько времени переходные эффекты могут продлиться. Чтобы использовать этот режим, проверяйте Stop simulation. Блок пытается запустить симуляцию, пока это не обнаруживает количество ошибок, которые задает параметр Target number of errors. Однако остановки симуляции прежде, чем обнаружить достаточно ошибок, если время достигает установки Stop time модели (в диалоговом окне Configuration Parameters), если блок Error Rate Calculation делает сравнения Maximum number of symbols, или если другой блок в модели направляет симуляцию, чтобы остановиться.
Чтобы проигнорировать или этих двух критериев остановки в этом блоке, установите соответствующий параметр (Target number of errors или Maximum number of symbols) к Inf. Например, чтобы достигнуть целевого количества ошибок, не останавливая симуляцию рано, установите Maximum number of symbols на Inf и набор Stop time модели к Inf.
Настройка параметров в исполняемом файле RSim (программное обеспечение Simulink Coder)
Если вы используете Simulink Coder быстрая симуляция (RSim) цель, чтобы создать исполняемый файл RSim, то можно настроить Target number of errors и параметры Maximum number of symbols , не перекомпилировав модель. Это полезно для симуляций Монте-Карло, в которых вы запускаете симуляцию многократно (возможно, на нескольких компьютерах) с различными количествами шума.
Примеры
Вычисление ошибок целого кадра
Рисунок ниже показывает, как блок сравнивает пары элементов и считает количество ошибочных событий. Tx и Rx входные параметры являются вектор-столбцами.
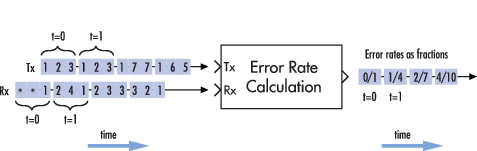
Этот пример предполагает, что шаг расчета каждого входного сигнала составляет 1 секунду и что параметры блока следующие:
-
Receive delay =
2 -
Computation delay =
0 -
Computation mode =
Entire frame
Оба входных сигнала являются вектор-столбцами длины три. Однако схематические расположения, каждый вектор-столбец горизонтально и выравнивает пары векторов, чтобы отразить задержку приема двух выборок. На каждом временном шаге блок сравнивает элементы Rx сигнал с теми из Tx сигнал, которые появляются непосредственно выше их в схематическом. Например, во время 1, блок выдерживает сравнение 2, 4, и 1 от Rx сигнал с 2, 3, и 1 от Tx сигнал.
Значения первых двух элементов Rx появитесь как звездочки, потому что они не влияют на выход. Точно так же 6 и 5 в Tx сигнал не влияет на выход до времени 3, хотя они влияли бы на выход во время 4.
В коэффициентах ошибок правой стороны рисунка каждый числитель во время t отражает количество ошибок при рассмотрении элементов Rx в течение времени t.
Подсчет ошибок целого кадра со сбросом
Если бы флажок Reset port блока был установлен, и сброс произошел во время = 3 секунды, то последний коэффициент ошибок будет 2/3 вместо 4/10. Это значение 2/3 отразило бы сравнение 3, 2, и 1 от Rx сигнал с 7, 7, и 1 от Tx сигнал. Рисунок ниже иллюстрирует этот сценарий. Tx и Rx входные параметры являются вектор-столбцами.

Подсчет ошибок на выборочных отсчетах в кадре
При использовании порта Sel, чтобы вычислить ошибки на задержанный сигнал, задержка должна быть добавлена к индексам Sel. Для получения дополнительной информации смотрите, Вычисляют, Ошибки для Задержанного Выбрали Samples.
Параметры
- Receive delay
-
Количество отсчетов, которым принятые данные отстают от передаваемых данных. (Если
TxилиRxвектор, затем каждая запись представляет выборку.) - Computation delay
-
Количество отсчетов, которые блок должен проигнорировать в начале сравнения.
- Computation mode
-
Любой
Entire frame,Select samples from mask, илиSelect samples from portВ зависимости от того, должен ли блок рассмотреть весь или только часть входных кадров. - Selected samples from frame
-
Вектор, который перечисляет индексы элементов
Rxструктурируйте вектор, который блок должен рассмотреть при создании сравнений. Это поле появляется, только если Computation mode установлен вSelect samples from mask. - Output data
-
Любой
WorkspaceилиPortВ зависимости от того, где вы хотите отправить выходные данные. - Variable name
-
Имя переменной для вектора выходных данных в основном рабочем пространстве MATLAB. Это поле появляется, только если Output data установлен в
Workspace. - Reset port
-
Если вы устанавливаете этот флажок, то дополнительный входной порт появляется, пометил
Rst. - Stop simulation
-
Если вы устанавливаете этот флажок, то симуляция запускается только, пока этот блок не обнаруживает конкретное количество ошибок или выполняет конкретное количество сравнений, какой бы ни на первом месте.
- Target number of errors
-
Остановки симуляции после обнаружения этого количества ошибок. Это поле активно, только если Stop simulation проверяется.
- Maximum number of symbols
-
Остановки симуляции после создания этого количества сравнений. Это поле активно, только если Stop simulation проверяется.
Поддерживаемые типы данных
| Порт | Поддерживаемые типы данных |
|---|---|
|
Tx |
|
|
Rx |
|
|
Sel |
|
|
Сброс |
|
Расширенные возможности
Генерация кода C/C++
Генерация кода C и C++ с помощью Simulink® Coder™.
Генерация HDL-кода
Сгенерируйте Verilog и код VHDL для FPGA и проекты ASIC с помощью HDL Coder™.
Этот блок может использоваться для видимости симуляции в подсистемах, которые генерируют HDL-код, но не включен в аппаратную реализацию.
Представлено до R2006a
From Wikipedia, the free encyclopedia
Word error rate (WER) is a common metric of the performance of a speech recognition or machine translation system.
The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the Levenshtein distance, working at the word level instead of the phoneme level. The WER is a valuable tool for comparing different systems as well as for evaluating improvements within one system. This kind of measurement, however, provides no details on the nature of translation errors and further work is therefore required to identify the main source(s) of error and to focus any research effort.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. Examination of this issue is seen through a theory called the power law that states the correlation between perplexity and word error rate.[1]
Word error rate can then be computed as:
where
- S is the number of substitutions,
- D is the number of deletions,
- I is the number of insertions,
- C is the number of correct words,
- N is the number of words in the reference (N=S+D+C)
The intuition behind ‘deletion’ and ‘insertion’ is how to get from the reference to the hypothesis. So if we have the reference «This is wikipedia» and hypothesis «This _ wikipedia», we call it a deletion.
When reporting the performance of a speech recognition system, sometimes word accuracy (WAcc) is used instead:
Note that since N is the number of words in the reference, the word error rate can be larger than 1.0, and thus, the word accuracy can be smaller than 0.0.
Experiments[edit]
It is commonly believed that a lower word error rate shows superior accuracy in recognition of speech, compared with a higher word error rate. However, at least one study has shown that this may not be true. In a Microsoft Research experiment, it was shown that, if people were trained under «that matches the optimization objective for understanding», (Wang, Acero and Chelba, 2003) they would show a higher accuracy in understanding of language than other people who demonstrated a lower word error rate, showing that true understanding of spoken language relies on more than just high word recognition accuracy.[2]
Other metrics[edit]
One problem with using a generic formula such as the one above, however, is that no account is taken of the effect that different types of error may have on the likelihood of successful outcome, e.g. some errors may be more disruptive than others and some may be corrected more easily than others. These factors are likely to be specific to the syntax being tested. A further problem is that, even with the best alignment, the formula cannot distinguish a substitution error from a combined deletion plus insertion error.
Hunt (1990) has proposed the use of a weighted measure of performance accuracy where errors of substitution are weighted at unity but errors of deletion and insertion are both weighted only at 0.5, thus:
There is some debate, however, as to whether Hunt’s formula may properly be used to assess the performance of a single system, as it was developed as a means of comparing more fairly competing candidate systems. A further complication is added by whether a given syntax allows for error correction and, if it does, how easy that process is for the user. There is thus some merit to the argument that performance metrics should be developed to suit the particular system being measured.
Whichever metric is used, however, one major theoretical problem in assessing the performance of a system is deciding whether a word has been “mis-pronounced,” i.e. does the fault lie with the user or with the recogniser. This may be particularly relevant in a system which is designed to cope with non-native speakers of a given language or with strong regional accents.
The pace at which words should be spoken during the measurement process is also a source of variability between subjects, as is the need for subjects to rest or take a breath. All such factors may need to be controlled in some way.
For text dictation it is generally agreed that performance accuracy at a rate below 95% is not acceptable, but this again may be syntax and/or domain specific, e.g. whether there is time pressure on users to complete the task, whether there are alternative methods of completion, and so on.
The term «Single Word Error Rate» is sometimes referred to as the percentage of incorrect recognitions for each different word in the system vocabulary.
Edit distance[edit]
The word error rate may also be referred to as the length normalized edit distance.[3] The normalized edit distance between X and Y, d( X, Y ) is defined as the minimum of W( P ) / L ( P ), where P is an editing path between X and Y, W ( P ) is the sum of the weights of the elementary edit operations of P, and L(P) is the number of these operations (length of P).[4]
See also[edit]
- BLEU
- F-Measure
- METEOR
- NIST (metric)
- ROUGE (metric)
References[edit]
Notes[edit]
- ^ Klakow, Dietrich; Jochen Peters (September 2002). «Testing the correlation of word error rate and perplexity». Speech Communication. 38 (1–2): 19–28. doi:10.1016/S0167-6393(01)00041-3. ISSN 0167-6393.
- ^ Wang, Y.; Acero, A.; Chelba, C. (2003). Is Word Error Rate a Good Indicator for Spoken Language Understanding Accuracy. IEEE Workshop on Automatic Speech Recognition and Understanding. St. Thomas, US Virgin Islands. CiteSeerX 10.1.1.89.424.
- ^ Nießen et al.(2000)
- ^ Computation of Normalized Edit Distance and Application:AndrCs Marzal and Enrique Vidal
Other sources[edit]
- McCowan et al. 2005: On the Use of Information Retrieval Measures for Speech Recognition Evaluation
- Hunt, M.J., 1990: Figures of Merit for Assessing Connected Word Recognisers (Speech Communication, 9, 1990, pp 239-336)
- Zechner, K., Waibel, A.Minimizing Word Error Rate in Textual Summaries of Spoken Language
From Wikipedia, the free encyclopedia
In digital transmission, the number of bit errors is the number of received bits of a data stream over a communication channel that have been altered due to noise, interference, distortion or bit synchronization errors.
The bit error rate (BER) is the number of bit errors per unit time. The bit error ratio (also BER) is the number of bit errors divided by the total number of transferred bits during a studied time interval. Bit error ratio is a unitless performance measure, often expressed as a percentage.[1]
The bit error probability pe is the expected value of the bit error ratio. The bit error ratio can be considered as an approximate estimate of the bit error probability. This estimate is accurate for a long time interval and a high number of bit errors.
Example[edit]
As an example, assume this transmitted bit sequence:
1 1 0 0 0 1 0 1 1
and the following received bit sequence:
0 1 0 1 0 1 0 0 1,
The number of bit errors (the underlined bits) is, in this case, 3. The BER is 3 incorrect bits divided by 9 transferred bits, resulting in a BER of 0.333 or 33.3%.
Packet error ratio[edit]
The packet error ratio (PER) is the number of incorrectly received data packets divided by the total number of received packets. A packet is declared incorrect if at least one bit is erroneous. The expectation value of the PER is denoted packet error probability pp, which for a data packet length of N bits can be expressed as
 ,
,

assuming that the bit errors are independent of each other. For small bit error probabilities and large data packets, this is approximately

Similar measurements can be carried out for the transmission of frames, blocks, or symbols.
The above expression can be rearranged to express the corresponding BER (pe) as a function of the PER (pp) and the data packet length N in bits:
![{displaystyle p_{e}=1-{sqrt[{N}]{(1-p_{p})}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f5d380e45b0451c45265e199221fae5bd5b84bf9)
Factors affecting the BER[edit]
In a communication system, the receiver side BER may be affected by transmission channel noise, interference, distortion, bit synchronization problems, attenuation, wireless multipath fading, etc.
The BER may be improved by choosing a strong signal strength (unless this causes cross-talk and more bit errors), by choosing a slow and robust modulation scheme or line coding scheme, and by applying channel coding schemes such as redundant forward error correction codes.
The transmission BER is the number of detected bits that are incorrect before error correction, divided by the total number of transferred bits (including redundant error codes). The information BER, approximately equal to the decoding error probability, is the number of decoded bits that remain incorrect after the error correction, divided by the total number of decoded bits (the useful information). Normally the transmission BER is larger than the information BER. The information BER is affected by the strength of the forward error correction code.
Analysis of the BER[edit]
The BER may be evaluated using stochastic (Monte Carlo) computer simulations. If a simple transmission channel model and data source model is assumed, the BER may also be calculated analytically. An example of such a data source model is the Bernoulli source.
Examples of simple channel models used in information theory are:
- Binary symmetric channel (used in analysis of decoding error probability in case of non-bursty bit errors on the transmission channel)
- Additive white Gaussian noise (AWGN) channel without fading.
A worst-case scenario is a completely random channel, where noise totally dominates over the useful signal. This results in a transmission BER of 50% (provided that a Bernoulli binary data source and a binary symmetrical channel are assumed, see below).
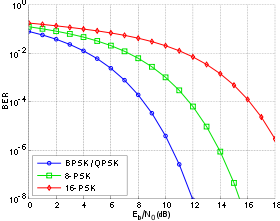
Bit-error rate curves for BPSK, QPSK, 8-PSK and 16-PSK, AWGN channel.

In a noisy channel, the BER is often expressed as a function of the normalized carrier-to-noise ratio measure denoted Eb/N0, (energy per bit to noise power spectral density ratio), or Es/N0 (energy per modulation symbol to noise spectral density).
For example, in the case of QPSK modulation and AWGN channel, the BER as function of the Eb/N0 is given by:
 .[2]
.[2]
People usually plot the BER curves to describe the performance of a digital communication system. In optical communication, BER(dB) vs. Received Power(dBm) is usually used; while in wireless communication, BER(dB) vs. SNR(dB) is used.
Measuring the bit error ratio helps people choose the appropriate forward error correction codes. Since most such codes correct only bit-flips, but not bit-insertions or bit-deletions, the Hamming distance metric is the appropriate way to measure the number of bit errors. Many FEC coders also continuously measure the current BER.
A more general way of measuring the number of bit errors is the Levenshtein distance.
The Levenshtein distance measurement is more appropriate for measuring raw channel performance before frame synchronization, and when using error correction codes designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.[3]
Mathematical draft[edit]
The BER is the likelihood of a bit misinterpretation due to electrical noise  . Considering a bipolar NRZ transmission, we have
. Considering a bipolar NRZ transmission, we have
 for a «1» and
for a «1» and  for a «0». Each of
for a «0». Each of  and
and  has a period of
has a period of  .
.
Knowing that the noise has a bilateral spectral density  ,
,
is 
and is  .
.
Returning to BER, we have the likelihood of a bit misinterpretation  .
.
 and
and 
where  is the threshold of decision, set to 0 when
is the threshold of decision, set to 0 when  .
.
We can use the average energy of the signal  to find the final expression :
to find the final expression :

±§
Bit error rate test[edit]
BERT or bit error rate test is a testing method for digital communication circuits that uses predetermined stress patterns consisting of a sequence of logical ones and zeros generated by a test pattern generator.
A BERT typically consists of a test pattern generator and a receiver that can be set to the same pattern. They can be used in pairs, with one at either end of a transmission link, or singularly at one end with a loopback at the remote end. BERTs are typically stand-alone specialised instruments, but can be personal computer–based. In use, the number of errors, if any, are counted and presented as a ratio such as 1 in 1,000,000, or 1 in 1e06.
Common types of BERT stress patterns[edit]
- PRBS (pseudorandom binary sequence) – A pseudorandom binary sequencer of N Bits. These pattern sequences are used to measure jitter and eye mask of TX-Data in electrical and optical data links.
- QRSS (quasi random signal source) – A pseudorandom binary sequencer which generates every combination of a 20-bit word, repeats every 1,048,575 words, and suppresses consecutive zeros to no more than 14. It contains high-density sequences, low-density sequences, and sequences that change from low to high and vice versa. This pattern is also the standard pattern used to measure jitter.
- 3 in 24 – Pattern contains the longest string of consecutive zeros (15) with the lowest ones density (12.5%). This pattern simultaneously stresses minimum ones density and the maximum number of consecutive zeros. The D4 frame format of 3 in 24 may cause a D4 yellow alarm for frame circuits depending on the alignment of one bits to a frame.
- 1:7 – Also referred to as 1 in 8. It has only a single one in an eight-bit repeating sequence. This pattern stresses the minimum ones density of 12.5% and should be used when testing facilities set for B8ZS coding as the 3 in 24 pattern increases to 29.5% when converted to B8ZS.
- Min/max – Pattern rapid sequence changes from low density to high density. Most useful when stressing the repeater’s ALBO feature.
- All ones (or mark) – A pattern composed of ones only. This pattern causes the repeater to consume the maximum amount of power. If DC to the repeater is regulated properly, the repeater will have no trouble transmitting the long ones sequence. This pattern should be used when measuring span power regulation. An unframed all ones pattern is used to indicate an AIS (also known as a blue alarm).
- All zeros – A pattern composed of zeros only. It is effective in finding equipment misoptioned for AMI, such as fiber/radio multiplex low-speed inputs.
- Alternating 0s and 1s — A pattern composed of alternating ones and zeroes.
- 2 in 8 – Pattern contains a maximum of four consecutive zeros. It will not invoke a B8ZS sequence because eight consecutive zeros are required to cause a B8ZS substitution. The pattern is effective in finding equipment misoptioned for B8ZS.
- Bridgetap — Bridge taps within a span can be detected by employing a number of test patterns with a variety of ones and zeros densities. This test generates 21 test patterns and runs for 15 minutes. If a signal error occurs, the span may have one or more bridge taps. This pattern is only effective for T1 spans that transmit the signal raw. Modulation used in HDSL spans negates the bridgetap patterns’ ability to uncover bridge taps.
- Multipat — This test generates five commonly used test patterns to allow DS1 span testing without having to select each test pattern individually. Patterns are: all ones, 1:7, 2 in 8, 3 in 24, and QRSS.
- T1-DALY and 55 OCTET — Each of these patterns contain fifty-five (55), eight bit octets of data in a sequence that changes rapidly between low and high density. These patterns are used primarily to stress the ALBO and equalizer circuitry but they will also stress timing recovery. 55 OCTET has fifteen (15) consecutive zeroes and can only be used unframed without violating one’s density requirements. For framed signals, the T1-DALY pattern should be used. Both patterns will force a B8ZS code in circuits optioned for B8ZS.
Bit error rate tester[edit]
A bit error rate tester (BERT), also known as a «bit error ratio tester»[4] or bit error rate test solution (BERTs) is electronic test equipment used to test the quality of signal transmission of single components or complete systems.
The main building blocks of a BERT are:
- Pattern generator, which transmits a defined test pattern to the DUT or test system
- Error detector connected to the DUT or test system, to count the errors generated by the DUT or test system
- Clock signal generator to synchronize the pattern generator and the error detector
- Digital communication analyser is optional to display the transmitted or received signal
- Electrical-optical converter and optical-electrical converter for testing optical communication signals
See also[edit]
- Burst error
- Error correction code
- Errored second
- Pseudo bit error ratio
- Viterbi Error Rate
References[edit]
- ^ Jit Lim (14 December 2010). «Is BER the bit error ratio or the bit error rate?». EDN. Retrieved 2015-02-16.
- ^
Digital Communications, John Proakis, Massoud Salehi, McGraw-Hill Education, Nov 6, 2007 - ^
«Keyboards and Covert Channels»
by Gaurav Shah, Andres Molina, and Matt Blaze (2006?) - ^ «Bit Error Rate Testing: BER Test BERT » Electronics Notes». www.electronics-notes.com. Retrieved 2020-04-11.
![]() This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
External links[edit]
- QPSK BER for AWGN channel – online experiment
Word Error Rate is a measure of how accurate an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, compared to a human transcription.
Broadly speaking, it’s important to measure the accuracy of any machine learning system. Whether it’s a self driving car, NLU system like Amazon Alexa, or an Automatic Speech Recognition system like the ones we develop at AssemblyAI, if you don’t know how accurate your machine learning system is, you’re flying blind!
In the field of Automatic Speech Recognition, the Word Error Rate has become the de facto standard for measuring how accurate a speech recognition model is. A common question we get from customers is “What’s your WER?”. In fact, when our company was accepted into Y Combinator back in 2017, one of the first questions the YC partners asked us was “What’s your WER?”
How To Calculate Word Error Rate (WER)
The actual math behind calculating a Word Error Rate is the following:
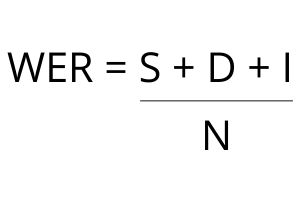
What we are doing here is combining the number of Substitutions (S), Deletions (D), and Insertions (N), divided by the Number of Words (N).
So for example, let’s say the following sentence is spoken:
"Hello there"If our Automatic Speech Recognition (ASR) is not very good, and predicts the following transcription:
"Hello bear"
Then our Word Error Rate (WER) would be 50%! That’s because there was 1 Substitution, “there” was substituted with “bear”. Let’s say our ASR system instead only predicted:
"Hello"And for some reason didn’t even predict a second word. In this case our Word Error Rate (WER) would also be 50%! That’s because there is a single Deletion — only 1 word was predicted by our ASR system when what was actually spoken was 2 words. The lower the Word Error Rate the better. You can think of word accuracy as 1 minus the Word Error Rate. So if your Word Error Rate is 20%, then your word accuracy, ie how accurate your transcription is, is 80%:
Is Word Error Rate a Good Measure of Speech Recognition Systems?
As with everything, it is not black and white. Overall, Word Error Rate can tell you how “different” the automatic transcription was compared to the human transcription, and generally, this is a reliable metric to determine how “good” an automatic transcription is.
For example, take the following:
Spoken text:
“Hi my name is Bob and I like cheese. Cheese is very good.”
Predicted text by model 1:
"Hi my frame is knob and I bike leafs. Cheese is berry wood"
WER: 46%
Predicted text by model 2:
"Hi my name is Bob and I bike cheese. Cheese is good."
WER: 15%As we can see, model 2 has a lower WER of 15%, and is obviously way more accurate to us as humans than the predicted text from model 1. This is why, in general, WER is a good metric for determining the accuracy of an Automatic Speech Recognition system.
However, take the following example:
Spoken:
"I like to bike around"
Model 1 prediction:
"I liked to bike around"
WER: 20%
Model 2 prediction:
"I like to bike pound"
WER: 20%In the above example, both Model 1 text and Model 2 text have a WER of 20%. But Model 1 clearly results in a more understandable transcription compared to Model 2. That’s because even with the error that Model 1 makes, it still results in a more legible and easy to understand transcription. This is compared to Model 2, which makes a mistake in the transcription that results in the transcription text being illegible (ie, “word soup”).
To further illustrate the downfalls of Word Error Rate, take the following example:
Spoken:
"My name is Paul and I am an engineer"
Model 1 prediction:
"My name is ball and I am an engineer"
WER: 11.11%
Model 2 prediction:
"My name is Paul and I'm an engineer"
WER: 22.22%In this example, Model 2 does a much better job producing an understandable transcription, but it has double (!!) the WER compared to Model 1. This difference in WER is especially pronounced in this example because the text contains so few words, but still, this illustrates some “gotchas” to be aware of when reviewing WER.
What these above examples illustrate is that the Word Error Calculation is not “smart”. It is literally just looking at the number of substitutions, deletions, and insertions that appear in the automatic transcription compared to the human transcription. This is why WER in the “real world” can be so problematic.
Take for example the simple mistake of not normalizing the casing in the human transcription and automatic transcription.
Human transcription:
"I live in New York"
Automatic transcription:
"i live in new york"
WER: 60%In this example, we see that the automatic transcription has a WER of 60% (!!) even though it perfectly transcribed what was spoken. Simply because we were comparing the human transcription with New York capitalized, compared to new york lowercase, the WER algorithm sees these as completely different words!
This is a major “gotcha” we see in the wild, and it’s why we internally always normalize our human transcriptions and automatic transcriptions when computing a WER, through things like:
- Lowercasing all text
- Removing all punctuation
- Changing all numbers to their written form («7» -> «seven»)
- Etc.
Alternatives to Word Error Rate
Unfortunately, Word Error Rate is the best metric we have today to determine the accuracy of an Automatic Speech Recognition system. There have been some alternatives proposed, but none have stuck in the research or commercial communities. A common technique used is to weight Substitutions, Insertions, and Deletions differently. So, for example, adding 0.5 for every Deletion versus 1.0.
However, unless the weights are standardized, it’s not really a “fair” way to compute WER. System 1 could be reporting a much lower WER because it used lower “weights” for Substitutions, for example, compared to System 2.
That’s why, for the time being, Word Error Rate is here to stay, but it’s important to keep the pitfalls we demonstrated in mind when calculating WER yourself!
A false positive error or false positive (false alarm) is a result that indicates a given condition exists when it doesn’t.
You can get the number of false positives from the confusion matrix. For a binary classification problem, it is described as follows:
| Predicted = 0 | Predicted = 1 | Total | |
|---|---|---|---|
| Actual = 0 | True Negative (TN) | False Positive(FP) | N |
| Actual = 1 | False Negative (FN) | True Positive (TP) | P |
| Total | N * | P * |
In statistical hypothesis testing, the false positive rate is equal to the significance level, \(\alpha\), and \(1 — \alpha\) is defined as the specificity of the test. Complementarily, the false negative rate is given by \(\beta\).
The different measures for classification are:
| Name | Definition | Synonyms |
|---|---|---|
| False positive rate (\(\alpha\)) | FP/N | Type I error, 1- specificity |
| True Positive rate (\(1-\beta\)) | TP/P | 1 — Type II error, power, sensitivity, recall |
| Positive prediction value | TP/P* | Precision |
| Negative prediction value | TN/N* | |
| Overall accuracy | (TN + TP)/N | |
| Overall error rate | (FP + FN)/N |
Also, note that F-score is the harmonic mean of precision and recall.
\[\text{F1 score} = \frac{2 * \text{precision} * \text{recall}}{\text{precision} + \text{recall}}\]
For example, in cancer detection, sensitivity and specificity are the following:
- Sensitivity: Of all the people with cancer, how many were correctly diagnosed?
- Specificity: Of all the people without cancer, how many were correctly diagnosed?
And precision and recall are the following:
- Recall: Of all the people who have cancer, how many did we diagnose as having cancer?
- Precision: Of all the people we diagnosed with cancer, how many actually had cancer?
Often, we want to make binary prediction e.g. in predicting the quality of care of the patient in the hospital, whether the patient receive poor care or good care? We can do this using a threshold value \(t\).
- if \(P(poor care = 1) \geq t\), predict poor quality
- if \(P(poor care = 1 < t\), predict good quality
Now, the question arises, what value of \(t\) we should consider.
- if \(t\) is large, the model will predict poor care rarely hence detect patients receiving the worst care.
- if \(t\) is small, the model will predict good care rarely hence detect all patients receiving poor care.
i.e.
- A model with a higher threshold will have a lower sensitivity and a higher specificity.
- A model with a lower threshold will have a higher sensitivity and a lower specificity.
Thus, the answer to the above question depends on what problem you are trying to solve. With no preference between the errors, we normally select \(t = 0.5\).
Area Under the ROC Curve gives the AUC score of a model.
- The threshold of 1 means that the model will not catch any poor care cases, or have sensitivity of 0 but it’ll correctly label all the good care cases, meaning that you have a false positive rate of 0.
- The threshold of 0 means that the model will catch all of the poor care cases or have a sensitivity of 1, but it’ll label all of the good care cases as poor care cases too, meaning that you’ll have a false positive rate of 1.
Below is xkcd comic regarding the wrong interpretation of p-value and false positives.
Explanation of above comic on explain xkcd wiki.
References:
- An Introduction to Statistical Learning
- False positives and false negatives — Wikipedia
- Sensitivity and specificity — Wikipedia
- Precision and recall — Wikipedia
This page is open source. Improve its content!
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
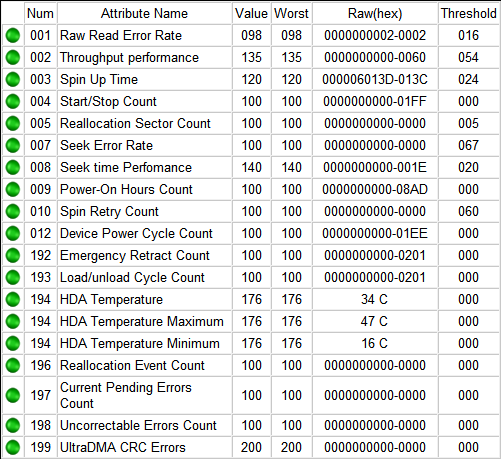
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
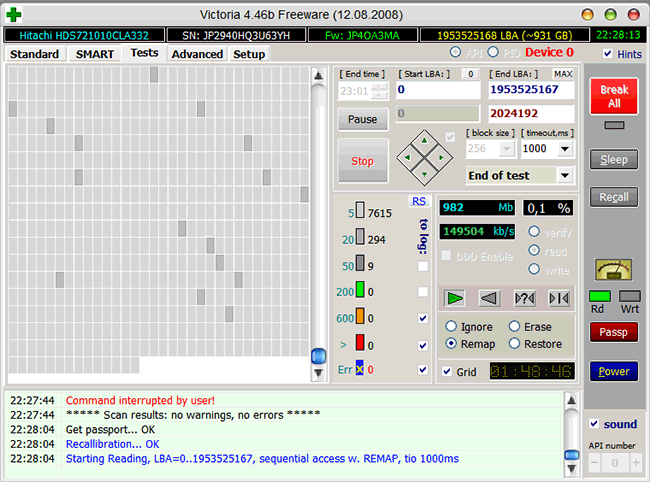
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
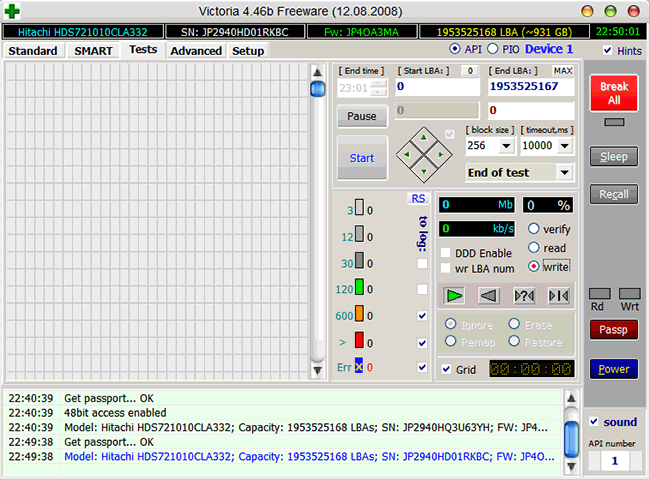
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
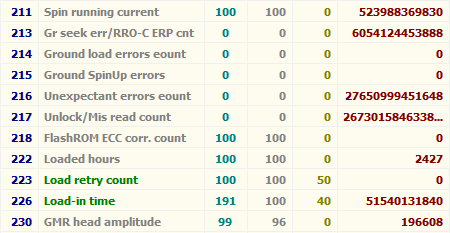
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Word Error Rate is a measure of how accurate an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, compared to a human transcription.
Broadly speaking, it’s important to measure the accuracy of any machine learning system. Whether it’s a self driving car, NLU system like Amazon Alexa, or an Automatic Speech Recognition system like the ones we develop at AssemblyAI, if you don’t know how accurate your machine learning system is, you’re flying blind!
In the field of Automatic Speech Recognition, the Word Error Rate has become the de facto standard for measuring how accurate a speech recognition model is. A common question we get from customers is “What’s your WER?”. In fact, when our company was accepted into Y Combinator back in 2017, one of the first questions the YC partners asked us was “What’s your WER?”
How To Calculate Word Error Rate (WER)
The actual math behind calculating a Word Error Rate is the following:
What we are doing here is combining the number of Substitutions (S), Deletions (D), and Insertions (N), divided by the Number of Words (N).
So for example, let’s say the following sentence is spoken:
"Hello there"If our Automatic Speech Recognition (ASR) is not very good, and predicts the following transcription:
"Hello bear"
Then our Word Error Rate (WER) would be 50%! That’s because there was 1 Substitution, “there” was substituted with “bear”. Let’s say our ASR system instead only predicted:
"Hello"And for some reason didn’t even predict a second word. In this case our Word Error Rate (WER) would also be 50%! That’s because there is a single Deletion — only 1 word was predicted by our ASR system when what was actually spoken was 2 words. The lower the Word Error Rate the better. You can think of word accuracy as 1 minus the Word Error Rate. So if your Word Error Rate is 20%, then your word accuracy, ie how accurate your transcription is, is 80%:
Is Word Error Rate a Good Measure of Speech Recognition Systems?
As with everything, it is not black and white. Overall, Word Error Rate can tell you how “different” the automatic transcription was compared to the human transcription, and generally, this is a reliable metric to determine how “good” an automatic transcription is.
For example, take the following:
Spoken text:
“Hi my name is Bob and I like cheese. Cheese is very good.”
Predicted text by model 1:
"Hi my frame is knob and I bike leafs. Cheese is berry wood"
WER: 46%
Predicted text by model 2:
"Hi my name is Bob and I bike cheese. Cheese is good."
WER: 15%As we can see, model 2 has a lower WER of 15%, and is obviously way more accurate to us as humans than the predicted text from model 1. This is why, in general, WER is a good metric for determining the accuracy of an Automatic Speech Recognition system.
However, take the following example:
Spoken:
"I like to bike around"
Model 1 prediction:
"I liked to bike around"
WER: 20%
Model 2 prediction:
"I like to bike pound"
WER: 20%In the above example, both Model 1 text and Model 2 text have a WER of 20%. But Model 1 clearly results in a more understandable transcription compared to Model 2. That’s because even with the error that Model 1 makes, it still results in a more legible and easy to understand transcription. This is compared to Model 2, which makes a mistake in the transcription that results in the transcription text being illegible (ie, “word soup”).
To further illustrate the downfalls of Word Error Rate, take the following example:
Spoken:
"My name is Paul and I am an engineer"
Model 1 prediction:
"My name is ball and I am an engineer"
WER: 11.11%
Model 2 prediction:
"My name is Paul and I'm an engineer"
WER: 22.22%In this example, Model 2 does a much better job producing an understandable transcription, but it has double (!!) the WER compared to Model 1. This difference in WER is especially pronounced in this example because the text contains so few words, but still, this illustrates some “gotchas” to be aware of when reviewing WER.
What these above examples illustrate is that the Word Error Calculation is not “smart”. It is literally just looking at the number of substitutions, deletions, and insertions that appear in the automatic transcription compared to the human transcription. This is why WER in the “real world” can be so problematic.
Take for example the simple mistake of not normalizing the casing in the human transcription and automatic transcription.
Human transcription:
"I live in New York"
Automatic transcription:
"i live in new york"
WER: 60%In this example, we see that the automatic transcription has a WER of 60% (!!) even though it perfectly transcribed what was spoken. Simply because we were comparing the human transcription with New York capitalized, compared to new york lowercase, the WER algorithm sees these as completely different words!
This is a major “gotcha” we see in the wild, and it’s why we internally always normalize our human transcriptions and automatic transcriptions when computing a WER, through things like:
- Lowercasing all text
- Removing all punctuation
- Changing all numbers to their written form («7» -> «seven»)
- Etc.
Alternatives to Word Error Rate
Unfortunately, Word Error Rate is the best metric we have today to determine the accuracy of an Automatic Speech Recognition system. There have been some alternatives proposed, but none have stuck in the research or commercial communities. A common technique used is to weight Substitutions, Insertions, and Deletions differently. So, for example, adding 0.5 for every Deletion versus 1.0.
However, unless the weights are standardized, it’s not really a “fair” way to compute WER. System 1 could be reporting a much lower WER because it used lower “weights” for Substitutions, for example, compared to System 2.
That’s why, for the time being, Word Error Rate is here to stay, but it’s important to keep the pitfalls we demonstrated in mind when calculating WER yourself!
Error Rate Calculation
Вычисляет вероятность битовых ошибок или вероятность символьных ошибок во входных данных
Библиотека
Связные получатели
Описание
Блок Error Rate Calculation сравнивает входные данные от передатчика с входными данными от приемника. Он вычисляет коэффициент ошибок как текущую статистику, деля общее количества неравных пар элементов данных на общее количество элементов входных данных от одного источника.
Используйте этот блок, чтобы вычислить вероятность символьных или битовых ошибок, поскольку он не учитывает величину разницы между элементами входных данных. Если входные параметры являются битами, то блок вычисляет вероятность битовой ошибки. Если входные параметры являются символами, то он вычисляет вероятность символьной ошибки.
Примечание
Когда вы устанавливаете параметр Output data на Workspace, блок не генерирует кода. Точно так же никакие данные не сохранены в рабочую область, если Simulation mode установлен в Accelerator или Rapid Accelerator. Если вы нуждаетесь в информации о коэффициенте ошибок в этих случаях, устанавливаете Output data на Port.
Входные данные
Этот блок имеет между двумя и четырьмя входными портами, в зависимости от того, как вы устанавливаете диалоговые параметры. Входные порты отметили Tx и Rx примите переданные и полученные сигналы, соответственно. Tx и Rx сигналы должны совместно использовать ту же частоту дискретизации.
Tx и Rx входные порты принимают сигналы вектор-столбца или скаляр. Для получения информации о типах данных, которые поддерживает каждый порт блока см. таблицу Supported Data Types на этой странице.
Если Tx скаляр и Rx вектор, или наоборот, затем блок сравнивает скаляр с каждым элементом вектора. В этом случае блок ведет себя, как будто вы предварительно обработали скалярный сигнал при помощи блока Repeat с набором параметров Rate options к Enforce single rate.
Если вы выбираете Reset port, то дополнительный входной порт появляется, пометил Rst. Rst введите принимает только скалярный сигнал (типа double или boolean) и должен иметь тот же шаг расчета порта как Tx и Rx порты. Когда Rst вход является ненулевым, блок очищает и затем повторно вычисляет статистику ошибок.
Если вы устанавливаете параметр Computation mode на Select samples from port, затем дополнительный входной порт появляется, пометил Sel. Sel введите указывает, какие элементы кадра важны для расчета. Sel введите может быть вектор-столбец типа double.
Инструкции ниже указывают, как необходимо сконфигурировать входные параметры и диалоговые параметры в зависимости от того, как вы хотите, чтобы этот блок интерпретировал ваш Tx и Rx данные.
-
Если оба сигнала данных являются скаляром, то этот блок сравнивает
Txскалярный сигнал сRxскалярный сигнал. Для этой настройки используйте значение по умолчанию параметра Computation mode,Entire frame. -
Если оба сигнала данных являются векторами, то этот блок сравнивает некоторых или весь
TxиRxданные:-
Если вы устанавливаете параметр Computation mode на
Entire frame, затем блок сравнивает весьTxструктурируйте со всемRxсистема координат. -
Если вы устанавливаете параметр Computation mode на
Select samples from mask, затем поле Selected samples from frame появляется в диалоговом окне. Это поле параметра принимает вектор, который перечисляет индексы тех элементовRxструктурируйте это, вы хотите, чтобы блок рассмотрел. Например, чтобы считать только первые и последние элементы длины шестью системами координат приемника, установите параметр Selected samples from frame на[1 6]. Если вектор Selected samples from frame включает нули, то блок игнорирует их. -
Если вы устанавливаете параметр Computation mode на
Select samples from port, затем дополнительный входной порт, пометилSel, появляется на значке блока. Данные в этом входном порту должны иметь тот же формат как тот из параметра Selected samples from frame, описанного выше.
-
-
Если один сигнал данных является скаляром, и другой вектор, то скаляр с каждой записью вектора. В этом случае, если
Rxскаляр, затем фраза “Rxструктурируйте” выше, относится к векторному расширениюRx.Примечание
Этот блок не поддерживает сигналы переменного размера. Если вы выбираете
Select samples from portопция и хочет, чтобы число элементов в подкадре варьировалось во время симуляции, затем необходимо заполнитьSelсигнал с нулями. Блок Error Rate Calculation игнорирует нули вSelсигнал.
Выходные данные
Этот блок производит вектор длины три, чьи записи соответствуют:
-
Коэффициент ошибок
-
Общее количество ошибок, то есть, количества экземпляров, что элемент Rx не совпадает с соответствующим элементом Tx
-
Общему количеству сравнений, которые сделал блок
Блок отправляет этому выходные данные в основной MATLAB® рабочая область или к выходному порту, в зависимости от того, как вы устанавливаете параметр Output data:
-
Если вы устанавливаете параметр Output data на
Workspaceи заполните параметр Variable name, затем та переменная в основном рабочем пространстве MATLAB содержит текущее значение, когда симуляция заканчивается. Приостановка симуляции не заставляет блок писать временные данные в переменную.Если вы планируете использовать этот блок наряду с Simulink® Программное обеспечение Coder™, затем вы не должны использовать
Workspaceопция. Вместо этого используйтеPortопция и подключение выходной порт с блоком Simulink To Workspace (Simulink). -
Если вы устанавливаете параметр Output data на
Port, затем выходной порт появляется. Этот выходной порт содержит рабочую статистику ошибок.
Задержки
Receive delay и параметры Computation delay реализуют два различных типов задержек этого блока. Одна задержка полезна, если вы хотите, чтобы этот блок компенсировал задержку полученного сигнала. Другой полезно, если вы хотите проигнорировать начальное переходное поведение обоих входных сигналов.
-
Параметр Receive delay представляет количество отсчетов, которым принятые данные отстают от передаваемых данных. Передаваемый сигнал неявно задерживается той же самой суммой, прежде чем блок сравнит его с принятыми данными. Это значение полезно, когда вы задерживаете передаваемый сигнал так, чтобы это выровнялось с полученным сигналом. Задержка приема сохраняется в течение симуляции.
-
Параметр Computation delay представляет количество отсчетов, которое блок игнорирует в начале сравнения.
Используйте блок Find Delay, чтобы определить задержку, и затем установить Receive delay на задержку, о которой сообщает блок Find Delay.
Если вы используете Select samples from mask или Select samples from port опция, затем каждый параметр задержки относится к количеству отсчетов, которое получает блок, игнорирует ли блок в конечном счете некоторых из них или нет.
При использовании порта Sel, чтобы вычислить ошибки на задержанный сигнал, задержка должна быть добавлена к индексам Sel. Для получения дополнительной информации смотрите, Вычисляют, Ошибки для Задержанного Выбрали Samples.
Остановка симуляции на основе статистики ошибок
Можно сконфигурировать этот блок так, чтобы его управление статистикой ошибок длительность симуляции. Это полезно для вычисления надежной установившейся статистики ошибок, не зная заранее, сколько времени переходные эффекты могут продлиться. Чтобы использовать этот режим, проверяйте Stop simulation. Блок пытается запустить симуляцию, пока это не обнаруживает количество ошибок, которые задает параметр Target number of errors. Однако остановки симуляции прежде, чем обнаружить достаточно ошибок, если время достигает установки Stop time модели (в диалоговом окне Configuration Parameters), если блок Error Rate Calculation делает сравнения Maximum number of symbols, или если другой блок в модели направляет симуляцию, чтобы остановиться.
Чтобы проигнорировать или этих двух критериев остановки в этом блоке, установите соответствующий параметр (Target number of errors или Maximum number of symbols) к Inf. Например, чтобы достигнуть целевого количества ошибок, не останавливая симуляцию рано, установите Maximum number of symbols на Inf и набор Stop time модели к Inf.
Настройка параметров в исполняемом файле RSim (программное обеспечение Simulink Coder)
Если вы используете Simulink Coder быстрая симуляция (RSim) цель, чтобы создать исполняемый файл RSim, то можно настроить Target number of errors и параметры Maximum number of symbols , не перекомпилировав модель. Это полезно для симуляций Монте-Карло, в которых вы запускаете симуляцию многократно (возможно, на нескольких компьютерах) с различными количествами шума.
Примеры
Вычисление ошибок целого кадра
Рисунок ниже показывает, как блок сравнивает пары элементов и считает количество ошибочных событий. Tx и Rx входные параметры являются вектор-столбцами.
Этот пример предполагает, что шаг расчета каждого входного сигнала составляет 1 секунду и что параметры блока следующие:
-
Receive delay =
2 -
Computation delay =
0 -
Computation mode =
Entire frame
Оба входных сигнала являются вектор-столбцами длины три. Однако схематические расположения, каждый вектор-столбец горизонтально и выравнивает пары векторов, чтобы отразить задержку приема двух выборок. На каждом временном шаге блок сравнивает элементы Rx сигнал с теми из Tx сигнал, которые появляются непосредственно выше их в схематическом. Например, во время 1, блок выдерживает сравнение 2, 4, и 1 от Rx сигнал с 2, 3, и 1 от Tx сигнал.
Значения первых двух элементов Rx появитесь как звездочки, потому что они не влияют на выход. Точно так же 6 и 5 в Tx сигнал не влияет на выход до времени 3, хотя они влияли бы на выход во время 4.
В коэффициентах ошибок правой стороны рисунка каждый числитель во время t отражает количество ошибок при рассмотрении элементов Rx в течение времени t.
Подсчет ошибок целого кадра со сбросом
Если бы флажок Reset port блока был установлен, и сброс произошел во время = 3 секунды, то последний коэффициент ошибок будет 2/3 вместо 4/10. Это значение 2/3 отразило бы сравнение 3, 2, и 1 от Rx сигнал с 7, 7, и 1 от Tx сигнал. Рисунок ниже иллюстрирует этот сценарий. Tx и Rx входные параметры являются вектор-столбцами.
Подсчет ошибок на выборочных отсчетах в кадре
При использовании порта Sel, чтобы вычислить ошибки на задержанный сигнал, задержка должна быть добавлена к индексам Sel. Для получения дополнительной информации смотрите, Вычисляют, Ошибки для Задержанного Выбрали Samples.
Параметры
- Receive delay
-
Количество отсчетов, которым принятые данные отстают от передаваемых данных. (Если
TxилиRxвектор, затем каждая запись представляет выборку.) - Computation delay
-
Количество отсчетов, которые блок должен проигнорировать в начале сравнения.
- Computation mode
-
Любой
Entire frame,Select samples from mask, илиSelect samples from portВ зависимости от того, должен ли блок рассмотреть весь или только часть входных кадров. - Selected samples from frame
-
Вектор, который перечисляет индексы элементов
Rxструктурируйте вектор, который блок должен рассмотреть при создании сравнений. Это поле появляется, только если Computation mode установлен вSelect samples from mask. - Output data
-
Любой
WorkspaceилиPortВ зависимости от того, где вы хотите отправить выходные данные. - Variable name
-
Имя переменной для вектора выходных данных в основном рабочем пространстве MATLAB. Это поле появляется, только если Output data установлен в
Workspace. - Reset port
-
Если вы устанавливаете этот флажок, то дополнительный входной порт появляется, пометил
Rst. - Stop simulation
-
Если вы устанавливаете этот флажок, то симуляция запускается только, пока этот блок не обнаруживает конкретное количество ошибок или выполняет конкретное количество сравнений, какой бы ни на первом месте.
- Target number of errors
-
Остановки симуляции после обнаружения этого количества ошибок. Это поле активно, только если Stop simulation проверяется.
- Maximum number of symbols
-
Остановки симуляции после создания этого количества сравнений. Это поле активно, только если Stop simulation проверяется.
Поддерживаемые типы данных
| Порт | Поддерживаемые типы данных |
|---|---|
|
Tx |
|
|
Rx |
|
|
Sel |
|
|
Сброс |
|
Расширенные возможности
Генерация кода C/C++
Генерация кода C и C++ с помощью Simulink® Coder™.
Генерация HDL-кода
Сгенерируйте Verilog и код VHDL для FPGA и проекты ASIC с помощью HDL Coder™.
Этот блок может использоваться для видимости симуляции в подсистемах, которые генерируют HDL-код, но не включен в аппаратную реализацию.
Представлено до R2006a
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
Описание
Блок Error Rate Calculation сравнивает входные данные от передатчика с входными данными от приемника. Он вычисляет коэффициент ошибок как текущую статистику, деля общее количества неравных пар элементов данных на общее количество элементов входных данных от одного источника.
Используйте этот блок, чтобы вычислить вероятность символьных или битовых ошибок, поскольку он не учитывает величину разницы между элементами входных данных. Если входные параметры являются битами, то блок вычисляет вероятность битовой ошибки. Если входные параметры являются символами, то он вычисляет вероятность символьной ошибки.
Примечание
Когда вы устанавливаете параметр Output data на Workspace, блок не генерирует кода. Точно так же никакие данные не сохранены в рабочую область, если Simulation mode установлен в Accelerator или Rapid Accelerator. Если вы нуждаетесь в информации о коэффициенте ошибок в этих случаях, устанавливаете Output data на Port.
Входные данные
Этот блок имеет между двумя и четырьмя входными портами, в зависимости от того, как вы устанавливаете диалоговые параметры. Входные порты отметили Tx и Rx примите переданные и полученные сигналы, соответственно. Tx и Rx сигналы должны совместно использовать ту же частоту дискретизации.
Tx и Rx входные порты принимают сигналы вектор-столбца или скаляр. Для получения информации о типах данных, которые поддерживает каждый порт блока см. таблицу Supported Data Types на этой странице.
Если Tx скаляр и Rx вектор, или наоборот, затем блок сравнивает скаляр с каждым элементом вектора. В этом случае блок ведет себя, как будто вы предварительно обработали скалярный сигнал при помощи блока Repeat с набором параметров Rate options к Enforce single rate.
Если вы выбираете Reset port, то дополнительный входной порт появляется, пометил Rst. Rst введите принимает только скалярный сигнал (типа double или boolean) и должен иметь тот же шаг расчета порта как Tx и Rx порты. Когда Rst вход является ненулевым, блок очищает и затем повторно вычисляет статистику ошибок.
Если вы устанавливаете параметр Computation mode на Select samples from port, затем дополнительный входной порт появляется, пометил Sel. Sel введите указывает, какие элементы кадра важны для расчета. Sel введите может быть вектор-столбец типа double.
Инструкции ниже указывают, как необходимо сконфигурировать входные параметры и диалоговые параметры в зависимости от того, как вы хотите, чтобы этот блок интерпретировал ваш Tx и Rx данные.
-
Если оба сигнала данных являются скаляром, то этот блок сравнивает
Txскалярный сигнал сRxскалярный сигнал. Для этой настройки используйте значение по умолчанию параметра Computation mode,Entire frame. -
Если оба сигнала данных являются векторами, то этот блок сравнивает некоторых или весь
TxиRxданные:-
Если вы устанавливаете параметр Computation mode на
Entire frame, затем блок сравнивает весьTxструктурируйте со всемRxсистема координат. -
Если вы устанавливаете параметр Computation mode на
Select samples from mask, затем поле Selected samples from frame появляется в диалоговом окне. Это поле параметра принимает вектор, который перечисляет индексы тех элементовRxструктурируйте это, вы хотите, чтобы блок рассмотрел. Например, чтобы считать только первые и последние элементы длины шестью системами координат приемника, установите параметр Selected samples from frame на[1 6]. Если вектор Selected samples from frame включает нули, то блок игнорирует их. -
Если вы устанавливаете параметр Computation mode на
Select samples from port, затем дополнительный входной порт, пометилSel, появляется на значке блока. Данные в этом входном порту должны иметь тот же формат как тот из параметра Selected samples from frame, описанного выше.
-
-
Если один сигнал данных является скаляром, и другой вектор, то скаляр с каждой записью вектора. В этом случае, если
Rxскаляр, затем фраза “Rxструктурируйте” выше, относится к векторному расширениюRx.Примечание
Этот блок не поддерживает сигналы переменного размера. Если вы выбираете
Select samples from portопция и хочет, чтобы число элементов в подкадре варьировалось во время симуляции, затем необходимо заполнитьSelсигнал с нулями. Блок Error Rate Calculation игнорирует нули вSelсигнал.
Выходные данные
Этот блок производит вектор длины три, чьи записи соответствуют:
-
Коэффициент ошибок
-
Общее количество ошибок, то есть, количества экземпляров, что элемент Rx не совпадает с соответствующим элементом Tx
-
Общему количеству сравнений, которые сделал блок
Блок отправляет этому выходные данные в основной MATLAB® рабочая область или к выходному порту, в зависимости от того, как вы устанавливаете параметр Output data:
-
Если вы устанавливаете параметр Output data на
Workspaceи заполните параметр Variable name, затем та переменная в основном рабочем пространстве MATLAB содержит текущее значение, когда симуляция заканчивается. Приостановка симуляции не заставляет блок писать временные данные в переменную.Если вы планируете использовать этот блок наряду с Simulink® Программное обеспечение Coder™, затем вы не должны использовать
Workspaceопция. Вместо этого используйтеPortопция и подключение выходной порт с блоком Simulink To Workspace (Simulink). -
Если вы устанавливаете параметр Output data на
Port, затем выходной порт появляется. Этот выходной порт содержит рабочую статистику ошибок.
Задержки
Receive delay и параметры Computation delay реализуют два различных типов задержек этого блока. Одна задержка полезна, если вы хотите, чтобы этот блок компенсировал задержку полученного сигнала. Другой полезно, если вы хотите проигнорировать начальное переходное поведение обоих входных сигналов.
-
Параметр Receive delay представляет количество отсчетов, которым принятые данные отстают от передаваемых данных. Передаваемый сигнал неявно задерживается той же самой суммой, прежде чем блок сравнит его с принятыми данными. Это значение полезно, когда вы задерживаете передаваемый сигнал так, чтобы это выровнялось с полученным сигналом. Задержка приема сохраняется в течение симуляции.
-
Параметр Computation delay представляет количество отсчетов, которое блок игнорирует в начале сравнения.
Используйте блок Find Delay, чтобы определить задержку, и затем установить Receive delay на задержку, о которой сообщает блок Find Delay.
Если вы используете Select samples from mask или Select samples from port опция, затем каждый параметр задержки относится к количеству отсчетов, которое получает блок, игнорирует ли блок в конечном счете некоторых из них или нет.
При использовании порта Sel, чтобы вычислить ошибки на задержанный сигнал, задержка должна быть добавлена к индексам Sel. Для получения дополнительной информации смотрите, Вычисляют, Ошибки для Задержанного Выбрали Samples.
Остановка симуляции на основе статистики ошибок
Можно сконфигурировать этот блок так, чтобы его управление статистикой ошибок длительность симуляции. Это полезно для вычисления надежной установившейся статистики ошибок, не зная заранее, сколько времени переходные эффекты могут продлиться. Чтобы использовать этот режим, проверяйте Stop simulation. Блок пытается запустить симуляцию, пока это не обнаруживает количество ошибок, которые задает параметр Target number of errors. Однако остановки симуляции прежде, чем обнаружить достаточно ошибок, если время достигает установки Stop time модели (в диалоговом окне Configuration Parameters), если блок Error Rate Calculation делает сравнения Maximum number of symbols, или если другой блок в модели направляет симуляцию, чтобы остановиться.
Чтобы проигнорировать или этих двух критериев остановки в этом блоке, установите соответствующий параметр (Target number of errors или Maximum number of symbols) к Inf. Например, чтобы достигнуть целевого количества ошибок, не останавливая симуляцию рано, установите Maximum number of symbols на Inf и набор Stop time модели к Inf.
Настройка параметров в исполняемом файле RSim (программное обеспечение Simulink Coder)
Если вы используете Simulink Coder быстрая симуляция (RSim) цель, чтобы создать исполняемый файл RSim, то можно настроить Target number of errors и параметры Maximum number of symbols , не перекомпилировав модель. Это полезно для симуляций Монте-Карло, в которых вы запускаете симуляцию многократно (возможно, на нескольких компьютерах) с различными количествами шума.
Примеры
Вычисление ошибок целого кадра
Рисунок ниже показывает, как блок сравнивает пары элементов и считает количество ошибочных событий. Tx и Rx входные параметры являются вектор-столбцами.
Этот пример предполагает, что шаг расчета каждого входного сигнала составляет 1 секунду и что параметры блока следующие:
-
Receive delay =
2 -
Computation delay =
0 -
Computation mode =
Entire frame
Оба входных сигнала являются вектор-столбцами длины три. Однако схематические расположения, каждый вектор-столбец горизонтально и выравнивает пары векторов, чтобы отразить задержку приема двух выборок. На каждом временном шаге блок сравнивает элементы Rx сигнал с теми из Tx сигнал, которые появляются непосредственно выше их в схематическом. Например, во время 1, блок выдерживает сравнение 2, 4, и 1 от Rx сигнал с 2, 3, и 1 от Tx сигнал.
Значения первых двух элементов Rx появитесь как звездочки, потому что они не влияют на выход. Точно так же 6 и 5 в Tx сигнал не влияет на выход до времени 3, хотя они влияли бы на выход во время 4.
В коэффициентах ошибок правой стороны рисунка каждый числитель во время t отражает количество ошибок при рассмотрении элементов Rx в течение времени t.
Подсчет ошибок целого кадра со сбросом
Если бы флажок Reset port блока был установлен, и сброс произошел во время = 3 секунды, то последний коэффициент ошибок будет 2/3 вместо 4/10. Это значение 2/3 отразило бы сравнение 3, 2, и 1 от Rx сигнал с 7, 7, и 1 от Tx сигнал. Рисунок ниже иллюстрирует этот сценарий. Tx и Rx входные параметры являются вектор-столбцами.
Подсчет ошибок на выборочных отсчетах в кадре
При использовании порта Sel, чтобы вычислить ошибки на задержанный сигнал, задержка должна быть добавлена к индексам Sel. Для получения дополнительной информации смотрите, Вычисляют, Ошибки для Задержанного Выбрали Samples.
Параметры
- Receive delay
-
Количество отсчетов, которым принятые данные отстают от передаваемых данных. (Если
TxилиRxвектор, затем каждая запись представляет выборку.) - Computation delay
-
Количество отсчетов, которые блок должен проигнорировать в начале сравнения.
- Computation mode
-
Любой
Entire frame,Select samples from mask, илиSelect samples from portВ зависимости от того, должен ли блок рассмотреть весь или только часть входных кадров. - Selected samples from frame
-
Вектор, который перечисляет индексы элементов
Rxструктурируйте вектор, который блок должен рассмотреть при создании сравнений. Это поле появляется, только если Computation mode установлен вSelect samples from mask. - Output data
-
Любой
WorkspaceилиPortВ зависимости от того, где вы хотите отправить выходные данные. - Variable name
-
Имя переменной для вектора выходных данных в основном рабочем пространстве MATLAB. Это поле появляется, только если Output data установлен в
Workspace. - Reset port
-
Если вы устанавливаете этот флажок, то дополнительный входной порт появляется, пометил
Rst. - Stop simulation
-
Если вы устанавливаете этот флажок, то симуляция запускается только, пока этот блок не обнаруживает конкретное количество ошибок или выполняет конкретное количество сравнений, какой бы ни на первом месте.
- Target number of errors
-
Остановки симуляции после обнаружения этого количества ошибок. Это поле активно, только если Stop simulation проверяется.
- Maximum number of symbols
-
Остановки симуляции после создания этого количества сравнений. Это поле активно, только если Stop simulation проверяется.
Поддерживаемые типы данных
| Порт | Поддерживаемые типы данных |
|---|---|
|
Tx |
|
|
Rx |
|
|
Sel |
|
|
Сброс |
|
Расширенные возможности
Генерация кода C/C++
Генерация кода C и C++ с помощью Simulink® Coder™.
Генерация HDL-кода
Сгенерируйте Verilog и код VHDL для FPGA и проекты ASIC с помощью HDL Coder™.
Этот блок может использоваться для видимости симуляции в подсистемах, которые генерируют HDL-код, но не включен в аппаратную реализацию.
Представлено до R2006a
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Word Error Rate is a measure of how accurate an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, compared to a human transcription.
Broadly speaking, it’s important to measure the accuracy of any machine learning system. Whether it’s a self driving car, NLU system like Amazon Alexa, or an Automatic Speech Recognition system like the ones we develop at AssemblyAI, if you don’t know how accurate your machine learning system is, you’re flying blind!
In the field of Automatic Speech Recognition, the Word Error Rate has become the de facto standard for measuring how accurate a speech recognition model is. A common question we get from customers is “What’s your WER?”. In fact, when our company was accepted into Y Combinator back in 2017, one of the first questions the YC partners asked us was “What’s your WER?”
How To Calculate Word Error Rate (WER)
The actual math behind calculating a Word Error Rate is the following:
What we are doing here is combining the number of Substitutions (S), Deletions (D), and Insertions (N), divided by the Number of Words (N).
So for example, let’s say the following sentence is spoken:
"Hello there"If our Automatic Speech Recognition (ASR) is not very good, and predicts the following transcription:
"Hello bear"
Then our Word Error Rate (WER) would be 50%! That’s because there was 1 Substitution, “there” was substituted with “bear”. Let’s say our ASR system instead only predicted:
"Hello"And for some reason didn’t even predict a second word. In this case our Word Error Rate (WER) would also be 50%! That’s because there is a single Deletion — only 1 word was predicted by our ASR system when what was actually spoken was 2 words. The lower the Word Error Rate the better. You can think of word accuracy as 1 minus the Word Error Rate. So if your Word Error Rate is 20%, then your word accuracy, ie how accurate your transcription is, is 80%:
Is Word Error Rate a Good Measure of Speech Recognition Systems?
As with everything, it is not black and white. Overall, Word Error Rate can tell you how “different” the automatic transcription was compared to the human transcription, and generally, this is a reliable metric to determine how “good” an automatic transcription is.
For example, take the following:
Spoken text:
“Hi my name is Bob and I like cheese. Cheese is very good.”
Predicted text by model 1:
"Hi my frame is knob and I bike leafs. Cheese is berry wood"
WER: 46%
Predicted text by model 2:
"Hi my name is Bob and I bike cheese. Cheese is good."
WER: 15%As we can see, model 2 has a lower WER of 15%, and is obviously way more accurate to us as humans than the predicted text from model 1. This is why, in general, WER is a good metric for determining the accuracy of an Automatic Speech Recognition system.
However, take the following example:
Spoken:
"I like to bike around"
Model 1 prediction:
"I liked to bike around"
WER: 20%
Model 2 prediction:
"I like to bike pound"
WER: 20%In the above example, both Model 1 text and Model 2 text have a WER of 20%. But Model 1 clearly results in a more understandable transcription compared to Model 2. That’s because even with the error that Model 1 makes, it still results in a more legible and easy to understand transcription. This is compared to Model 2, which makes a mistake in the transcription that results in the transcription text being illegible (ie, “word soup”).
To further illustrate the downfalls of Word Error Rate, take the following example:
Spoken:
"My name is Paul and I am an engineer"
Model 1 prediction:
"My name is ball and I am an engineer"
WER: 11.11%
Model 2 prediction:
"My name is Paul and I'm an engineer"
WER: 22.22%In this example, Model 2 does a much better job producing an understandable transcription, but it has double (!!) the WER compared to Model 1. This difference in WER is especially pronounced in this example because the text contains so few words, but still, this illustrates some “gotchas” to be aware of when reviewing WER.
What these above examples illustrate is that the Word Error Calculation is not “smart”. It is literally just looking at the number of substitutions, deletions, and insertions that appear in the automatic transcription compared to the human transcription. This is why WER in the “real world” can be so problematic.
Take for example the simple mistake of not normalizing the casing in the human transcription and automatic transcription.
Human transcription:
"I live in New York"
Automatic transcription:
"i live in new york"
WER: 60%In this example, we see that the automatic transcription has a WER of 60% (!!) even though it perfectly transcribed what was spoken. Simply because we were comparing the human transcription with New York capitalized, compared to new york lowercase, the WER algorithm sees these as completely different words!
This is a major “gotcha” we see in the wild, and it’s why we internally always normalize our human transcriptions and automatic transcriptions when computing a WER, through things like:
- Lowercasing all text
- Removing all punctuation
- Changing all numbers to their written form («7» -> «seven»)
- Etc.
Alternatives to Word Error Rate
Unfortunately, Word Error Rate is the best metric we have today to determine the accuracy of an Automatic Speech Recognition system. There have been some alternatives proposed, but none have stuck in the research or commercial communities. A common technique used is to weight Substitutions, Insertions, and Deletions differently. So, for example, adding 0.5 for every Deletion versus 1.0.
However, unless the weights are standardized, it’s not really a “fair” way to compute WER. System 1 could be reporting a much lower WER because it used lower “weights” for Substitutions, for example, compared to System 2.
That’s why, for the time being, Word Error Rate is here to stay, but it’s important to keep the pitfalls we demonstrated in mind when calculating WER yourself!
A false positive error or false positive (false alarm) is a result that indicates a given condition exists when it doesn’t.
You can get the number of false positives from the confusion matrix. For a binary classification problem, it is described as follows:
| Predicted = 0 | Predicted = 1 | Total | |
|---|---|---|---|
| Actual = 0 | True Negative (TN) | False Positive(FP) | N |
| Actual = 1 | False Negative (FN) | True Positive (TP) | P |
| Total | N * | P * |
In statistical hypothesis testing, the false positive rate is equal to the significance level, (alpha), and (1 — alpha) is defined as the specificity of the test. Complementarily, the false negative rate is given by (beta).
The different measures for classification are:
| Name | Definition | Synonyms |
|---|---|---|
| False positive rate ((alpha)) | FP/N | Type I error, 1- specificity |
| True Positive rate ((1-beta)) | TP/P | 1 — Type II error, power, sensitivity, recall |
| Positive prediction value | TP/P* | Precision |
| Negative prediction value | TN/N* | |
| Overall accuracy | (TN + TP)/N | |
| Overall error rate | (FP + FN)/N |
Also, note that F-score is the harmonic mean of precision and recall.
[text{F1 score} = frac{2 * text{precision} * text{recall}}{text{precision} + text{recall}}]
For example, in cancer detection, sensitivity and specificity are the following:
- Sensitivity: Of all the people with cancer, how many were correctly diagnosed?
- Specificity: Of all the people without cancer, how many were correctly diagnosed?
And precision and recall are the following:
- Recall: Of all the people who have cancer, how many did we diagnose as having cancer?
- Precision: Of all the people we diagnosed with cancer, how many actually had cancer?
Often, we want to make binary prediction e.g. in predicting the quality of care of the patient in the hospital, whether the patient receive poor care or good care? We can do this using a threshold value (t).
- if (P(poor care = 1) geq t), predict poor quality
- if (P(poor care = 1 < t), predict good quality
Now, the question arises, what value of (t) we should consider.
- if (t) is large, the model will predict poor care rarely hence detect patients receiving the worst care.
- if (t) is small, the model will predict good care rarely hence detect all patients receiving poor care.
i.e.
- A model with a higher threshold will have a lower sensitivity and a higher specificity.
- A model with a lower threshold will have a higher sensitivity and a lower specificity.
Thus, the answer to the above question depends on what problem you are trying to solve. With no preference between the errors, we normally select (t = 0.5).
Area Under the ROC Curve gives the AUC score of a model.
- The threshold of 1 means that the model will not catch any poor care cases, or have sensitivity of 0 but it’ll correctly label all the good care cases, meaning that you have a false positive rate of 0.
- The threshold of 0 means that the model will catch all of the poor care cases or have a sensitivity of 1, but it’ll label all of the good care cases as poor care cases too, meaning that you’ll have a false positive rate of 1.
Below is xkcd comic regarding the wrong interpretation of p-value and false positives.
Explanation of above comic on explain xkcd wiki.
References:
- An Introduction to Statistical Learning
- False positives and false negatives — Wikipedia
- Sensitivity and specificity — Wikipedia
- Precision and recall — Wikipedia
This page is open source. Improve its content!
Word Error Rate is a measure of how accurately an Automatic Speech Recognition (ASR) system performs. Quite literally, it calculates how many “errors” are in the transcription text produced by an ASR system, when compared to a human transcription.
Broadly speaking, it’s important to measure the accuracy of any machine learning system. Whether it’s a self-driving car, a Natural Language Understanding (NLU) system like Amazon Alexa, or an Automatic Speech Recognition system like the ones we develop at AssemblyAI, if you don’t know how accurate your machine learning system is, you’re flying blind.
In the field of Automatic Speech Recognition, the Word Error Rate has become the de facto standard for measuring how accurate a speech recognition model is. A common question we get from customers is “What’s your WER?” In fact, when our company was accepted into Y Combinator back in 2017, one of the first questions the YC partners asked us was “What’s your WER?”
However, WER is far from the only metric to use when analyzing the accuracy and utility of a speech recognition system.
In this blog post, we’ll go over how WER is calculated and how useful of a measurement this calculation is for comparing speech recognition systems. Then, we’ll also examine several other metrics and techniques in addition to WER and discuss the best holistic metrics and processes to consider during the evaluation process.
How To Calculate Word Error Rate (WER)
The actual math behind calculating a Word Error Rate is the following:
What we are doing here is combining the number of Substitutions (S), Deletions (D), and Insertions (N), divided by the Number of Words (N).
So for example, let’s say the following sentence is spoken:
"Hello there"If our Automatic Speech Recognition (ASR) is not very good, and predicts the following transcription:
"Hello bear"
Then our Word Error Rate (WER) would be 50%. That’s because there was 1 Substitution, “there” was substituted with “bear”. Let’s say our ASR system instead only predicted:
"Hello"And for some reason didn’t even predict a second word. In this case, our Word Error Rate (WER) would also be 50%. That’s because there is a single Deletion — only 1 word was predicted by our ASR system when what was actually spoken was 2 words.
The lower the Word Error Rate the better (all other things equal). You can think of word accuracy as 1 minus the Word Error Rate. So if your Word Error Rate is 20%, then your word accuracy, i.e. how accurate your transcription is, is 80%.
Is Word Error Rate useful?
Is Word Error Rate actually a good measurement of how well a speech recognition system performs?
As with everything, it is not black and white. Overall, Word Error Rate can tell you how “different” the automatic transcription was compared to the human transcription, and generally, this is a reliable metric to determine how “good” an automatic transcription is.
For example, take the following:
Spoken text:
“Hi my name is Bob and I like cheese. Cheese is very good.”
Predicted text by model 1:
"Hi my frame is knob and I bike leafs. Cheese is berry wood"
WER: 46%
Predicted text by model 2:
"Hi my name is Bob and I bike cheese. Cheese is good."
WER: 15%As we can see, model 2 has a lower WER of 15%, and is obviously way more accurate to us as humans than the predicted text from model 1. This is why, in general, WER is a good metric for determining the accuracy of an Automatic Speech Recognition system.
However, take the following example:
Spoken:
"I like to bike around"
Model 1 prediction:
"I liked to bike around"
WER: 20%
Model 2 prediction:
"I like to bike pound"
WER: 20%In the above example, both Model 1 text and Model 2 text have a WER of 20%. But Model 1 clearly results in a more understandable transcription compared to Model 2. That’s because even with the error that Model 1 makes, it still results in a more legible and easy-to-understand transcription. This is compared to Model 2, which makes a mistake in the transcription that results in the transcription text being illegible (i.e., “word soup”).
To further illustrate the downfalls of Word Error Rate, take the following example:
Spoken:
"My name is Paul and I am an engineer"
Model 1 prediction:
"My name is ball and I am an engineer"
WER: 11.11%
Model 2 prediction:
"My name is Paul and I'm an engineer"
WER: 22.22%In this example, Model 2 does a much better job producing an understandable transcription, but it has double the WER compared to Model 1. This difference in WER is especially pronounced in this example because the text contains so few words, but still, this illustrates some “gotchas” to be aware of when reviewing WER.
What these above examples illustrate is that the Word Error Calculation is not “smart”. It is literally just looking at the number of substitutions, deletions, and insertions that appear in the automatic transcription compared to the human transcription. This is why WER in the “real world” can be so problematic.
Take for example the simple mistake of not normalizing the casing in the human transcription and automatic transcription.
Human transcription:
"I live in New York"
Automatic transcription:
"i live in new york"
WER: 60%In this example, we see that the automatic transcription has a WER of 60% even though it perfectly transcribed what was spoken. Simply because we were comparing the human transcription with New York capitalized, compared to new york lowercase, the WER algorithm sees these as completely different words.
This is a major “gotcha” we see in the wild, and it’s why we internally always normalize our human transcriptions and automatic transcriptions when computing a WER, through things like:
- Lowercasing all text
- Removing all punctuation
- Changing all numbers to their written form («7» -> «seven»)
- Etc.
We discuss normalization in greater detail later in this article.
Are there any alternatives to Word Error Rate?
Word Error Rate is one of the best metrics we have today to determine the accuracy of an Automatic Speech Recognition system, considering the tradeoff between simplicity and human values. There have been some alternatives proposed, but none have stuck in the research or commercial communities. A common technique used is to weight Substitutions, Insertions, and Deletions differently. So, for example, adding 0.5 for every Deletion versus 1.0.
However, unless the weights are standardized, it’s not really a “fair” way to compute WER. System 1 could be reporting a much lower WER because it used lower “weights” for Substitutions, for example, compared to System 2.
While, for the time being, Word Error Rate is here to stay, there are some other important metrics and techniques to consider when comparing a speech recognition system that will provide a more holistic view.
Other metrics and techniques for comparing speech recognition systems
If you’re looking to truly compare and evaluate speech recognition systems, there are several other metrics you should consider in addition to WER. These metrics/techniques include:
- Proper noun evaluation
- Choosing the right dataset
- Normalizing
Proper noun evaluation helps evaluators better understand the model’s performance on proper nouns specifically, which are disproportionately important to the meaning of language.
The Jaro-Winkler distance allows a model to get ‘partial credit’ for transcribing proper nouns as different but similar words. For example, if the name ‘Sarah’ is transcribed as ‘Sara’, then Jaro-Winkler will count this as partially correct, whereas WER will count this as completely incorrect.
Choosing the right evaluation datasets is critically important to be confident in the evaluation results. It’s important to choose datasets that:
- Are relevant to the intended use case of the ASR model
- Simulate real-world datasets by already having, or by adding, noise to the audio file
Together, these considerations will ensure a more accurate comparison across models.
Finally, we should also consider the process of normalization when comparing ASR systems. A normalizer takes in a model’s output and then “normalizes” it to allow for a better, more fair comparison. For example, the normalizer may standardize spellings, remove disfluencies, or even ignore irrelevant discrepancies. A consistent normalizer helps evaluators be more confident in the results of their comparison.
This blog post goes into greater detail for each of the above metrics and techniques for those interested in using them during their comparison of speech recognition systems.
While WER is still an excellent starting point for comparison, the other metrics and techniques discussed in this article should always be considered in order to make a proper, fair evaluation of Automatic Speech Recognition systems.