Знакомимся с методом обратного распространения ошибки
Время на прочтение
6 мин
Количество просмотров 50K
Всем привет! Новогодние праздники подошли к концу, а это значит, что мы вновь готовы делиться с вами полезным материалом. Перевод данной статьи подготовлен в преддверии запуска нового потока по курсу «Алгоритмы для разработчиков».
Поехали!

Метод обратного распространения ошибки – вероятно самая фундаментальная составляющая нейронной сети. Впервые он был описан в 1960-е и почти 30 лет спустя его популяризировали Румельхарт, Хинтон и Уильямс в статье под названием «Learning representations by back-propagating errors».
Метод используется для эффективного обучения нейронной сети с помощью так называемого цепного правила (правила дифференцирования сложной функции). Проще говоря, после каждого прохода по сети обратное распространение выполняет проход в обратную сторону и регулирует параметры модели (веса и смещения).
В этой статья я хотел бы подробно рассмотреть с точки зрения математики процесс обучения и оптимизации простой 4-х слойной нейронной сети. Я считаю, что это поможет читателю понять, как работает обратное распространение, а также осознать его значимость.
Определяем модель нейронной сети
Четырехслойная нейронная сеть состоит из четырех нейронов входного слоя, четырех нейронов на скрытых слоях и 1 нейрона на выходном слое.

Простое изображение четырехслойной нейронной сети.
Входной слой
На рисунке нейроны фиолетового цвета представляют собой входные данные. Они могут быть простыми скалярными величинами или более сложными – векторами или многомерными матрицами.

Уравнение, описывающее входы xi.
Первый набор активаций (а) равен входным значениям. «Активация» — это значение нейрона после применения функции активации. Подробнее смотрите ниже.
Скрытые слои
Конечные значения в скрытых нейронах (на рисунке зеленого цвета) вычисляются с использованием zl – взвешенных входов в слое I и aI активаций в слое L. Для слоев 2 и 3 уравнения будут следующими:
Для l = 2:

Для l = 3:

W2 и W3 – это веса на слоях 2 и 3, а b2 и b3 – смещения на этих слоях.
Активации a2 и a3 вычисляются с помощью функции активации f. Например, эта функция f является нелинейной (как сигмоид, ReLU и гиперболический тангенс) и позволяет сети изучать сложные паттерны в данных. Мы не будем подробно останавливаться на том, как работают функции активации, но, если вам интересно, я настоятельно рекомендую прочитать эту замечательную статью.
Присмотревшись внимательно, вы увидите, что все x, z2, a2, z3, a3, W1, W2, b1 и b2 не имеют нижних индексов, представленных на рисунке четырехслойной нейронной сети. Дело в том, что мы объединили все значения параметров в матрицы, сгруппированные по слоям. Это стандартный способ работы с нейронными сетями, и он довольно комфортный. Однако я пройдусь по уравнениям, чтобы не возникло путаницы.
Давайте возьмем слой 2 и его параметры в качестве примера. Те же самые операции можно применить к любому слою нейронной сети.
W1 – это матрица весов размерности (n, m), где n – это количество выходных нейронов (нейронов на следующем слое), а m – число входных нейронов (нейронов в предыдущем слое). В нашем случае n = 2 и m = 4.

Здесь первое число в нижнем индексе любого из весов соответствует индексу нейрона в следующем слое (в нашем случае – это второй скрытый слой), а второе число соответствует индексу нейрона в предыдущем слое (в нашем случае – это входной слой).
x – входной вектор размерностью (m, 1), где m – число входных нейронов. В нашем случае m = 4.

b1 – это вектор смещения размерности (n, 1), где n – число нейронов на текущем слое. В нашем случае n = 2.

Следуя уравнению для z2 мы можем использовать приведенные выше определения W1, x и b1 для получения уравнения z2:

Теперь внимательно посмотрите на иллюстрацию нейронной сети выше:

Как видите, z2 можно выразить через z12 и z22, где z12 и z22 – суммы произведений каждого входного значения xi на соответствующий вес Wij1.
Это приводит к тому же самому уравнению для z2 и доказывает, что матричные представления z2, a2, z3 и a3 – верны.
Выходной слой
Последняя часть нейронной сети – это выходной слой, который выдает прогнозируемое значение. В нашем простом примере он представлен в виде одного нейрона, окрашенного в синий цвет и рассчитываемого следующим образом:

И снова мы используем матричное представление для упрощения уравнения. Можно использовать вышеприведенные методы, чтобы понять лежащую в их основе логику.
Прямое распространение и оценка
Приведенные выше уравнения формируют прямое распространение по нейронной сети. Вот краткий обзор:

(1) – входной слой
(2) – значение нейрона на первом скрытом слое
(3) – значение активации на первом скрытом слое
(4) – значение нейрона на втором скрытом слое
(5) – значение активации на втором скрытом уровне
(6) – выходной слой
Заключительным шагом в прямом проходе является оценка прогнозируемого выходного значения s относительно ожидаемого выходного значения y.
Выходные данные y являются частью обучающего набора данных (x, y), где x – входные данные (как мы помним из предыдущего раздела).
Оценка между s и y происходит через функцию потерь. Она может быть простой как среднеквадратичная ошибка или более сложной как перекрестная энтропия.
Мы назовем эту функцию потерь С и обозначим ее следующим образом:

Где cost может равняться среднеквадратичной ошибке, перекрестной энтропии или любой другой функции потерь.
Основываясь на значении С, модель «знает», насколько нужно скорректировать ее параметры, чтобы приблизиться к ожидаемому выходному значению y. Это происходит с помощью метода обратного распространения ошибки.
Обратное распространение ошибки и вычисление градиентов
Опираясь на статью 1989 года, метод обратного распространения ошибки:
Постоянно настраивает веса соединений в сети, чтобы минимизировать меру разности между фактическим выходным вектором сети и желаемым выходным вектором.
и
…дает возможность создавать полезные новые функции, что отличает обратное распространение от более ранних и простых методов…
Другими словами, обратное распространение направлено на минимизацию функции потерь путем корректировки весов и смещений сети. Степень корректировки определяется градиентами функции потерь по отношению к этим параметрам.
Возникает один вопрос: Зачем вычислять градиенты?
Чтобы ответить на этот вопрос, нам сначала нужно пересмотреть некоторые понятия вычислений:
Градиентом функции С(x1, x2, …, xm) в точке x называется вектор частных производных С по x.

Производная функции С отражает чувствительность к изменению значения функции (выходного значения) относительно изменения ее аргумента х (входного значения). Другими словами, производная говорит нам в каком направлении движется С.
Градиент показывает, насколько необходимо изменить параметр x (в положительную или отрицательную сторону), чтобы минимизировать С.
Вычисление этих градиентов происходит с помощью метода, называемого цепным правилом.
Для одного веса (wjk)l градиент равен:

(1) Цепное правило
(2) По определению m – количество нейронов на l – 1 слое
(3) Вычисление производной
(4) Окончательное значение
Аналогичный набор уравнений можно применить к (bj)l:

(1) Цепное правило
(2) Вычисление производной
(3) Окончательное значение
Общая часть в обоих уравнениях часто называется «локальным градиентом» и выражается следующим образом:

«Локальный градиент» можно легко определить с помощью правила цепи. Этот процесс я не буду сейчас расписывать.
Градиенты позволяют оптимизировать параметры модели:
Пока не будет достигнут критерий остановки выполняется следующее:
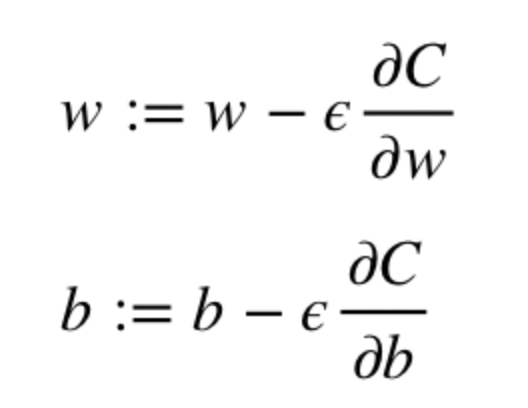
Алгоритм оптимизации весов и смещений (также называемый градиентным спуском)
- Начальные значения w и b выбираются случайным образом.
- Эпсилон (e) – это скорость обучения. Он определяет влияние градиента.
- w и b – матричные представления весов и смещений.
- Производная C по w или b может быть вычислена с использованием частных производных С по отдельным весам или смещениям.
- Условие завершение выполняется, как только функция потерь минимизируется.
Заключительную часть этого раздела я хочу посвятить простому примеру, в котором мы рассчитаем градиент С относительно одного веса (w22)2.
Давайте увеличим масштаб нижней части вышеупомянутой нейронной сети:

Визуальное представление обратного распространения в нейронной сети
Вес (w22)2 соединяет (a2)2 и (z2)2, поэтому вычисление градиента требует применения цепного правила на (z3)2 и (a3)2:

Вычисление конечного значения производной С по (a2)3 требует знания функции С. Поскольку С зависит от (a2)3, вычисление производной должно быть простым.
Я надеюсь, что этот пример сумел пролить немного света на математику, стоящую за вычислением градиентов. Если захотите узнать больше, я настоятельно рекомендую вам посмотреть Стэндфордскую серию статей по NLP, где Ричард Сочер дает 4 замечательных объяснения обратного распространения.
Заключительное замечание
В этой статье я подробно объяснил, как обратное распространение ошибки работает под капотом с помощью математических методов, таких как вычисление градиентов, цепное правило и т.д. Знание механизмов этого алгоритма укрепит ваши знания о нейронных сетях и позволит вам чувствовать себя комфортно при работе с более сложными моделями. Удачи вам в путешествии по глубокому обучению!
На этом все. Приглашаем всех на бесплатный вебинар по теме «Дерево отрезков: просто и быстро».
Нейронные сети обучаются с помощью тех или иных модификаций градиентного спуска, а чтобы применять его, нужно уметь эффективно вычислять градиенты функции потерь по всем обучающим параметрам. Казалось бы, для какого-нибудь запутанного вычислительного графа это может быть очень сложной задачей, но на помощь спешит метод обратного распространения ошибки.
Открытие метода обратного распространения ошибки стало одним из наиболее значимых событий в области искусственного интеллекта. В актуальном виде он был предложен в 1986 году Дэвидом Э. Румельхартом, Джеффри Э. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно красноярскими математиками С. И. Барцевым и В. А. Охониным. С тех пор для нахождения градиентов параметров нейронной сети используется метод вычисления производной сложной функции, и оценка градиентов параметров сети стала хоть сложной инженерной задачей, но уже не искусством. Несмотря на простоту используемого математического аппарата, появление этого метода привело к значительному скачку в развитии искусственных нейронных сетей.
Суть метода можно записать одной формулой, тривиально следующей из формулы производной сложной функции: если $f(x) = g_m(g_{m-1}(\ldots (g_1(x)) \ldots))$, то $\frac{\partial f}{\partial x} = \frac{\partial g_m}{\partial g_{m-1}}\frac{\partial g_{m-1}}{\partial g_{m-2}}\ldots \frac{\partial g_2}{\partial g_1}\frac{\partial g_1}{\partial x}$. Уже сейчас мы видим, что градиенты можно вычислять последовательно, в ходе одного обратного прохода, начиная с $\frac{\partial g_m}{\partial g_{m-1}}$ и умножая каждый раз на частные производные предыдущего слоя.
Backpropagation в одномерном случае
В одномерном случае всё выглядит особенно просто. Пусть $w_0$ — переменная, по которой мы хотим продифференцировать, причём сложная функция имеет вид
$$f(w_0) = g_m(g_{m-1}(\ldots g_1(w_0)\ldots)),$$
где все $g_i$ скалярные. Тогда
$$f'(w_0) = g_m'(g_{m-1}(\ldots g_1(w_0)\ldots))\cdot g’_{m-1}(g_{m-2}(\ldots g_1(w_0)\ldots))\cdot\ldots \cdot g’_1(w_0)$$
Суть этой формулы такова. Если мы уже совершили forward pass, то есть уже знаем
$$g_1(w_0), g_2(g_1(w_0)),\ldots,g_{m-1}(\ldots g_1(w_0)\ldots),$$
то мы действуем следующим образом:
-
берём производную $g_m$ в точке $g_{m-1}(\ldots g_1(w_0)\ldots)$;
-
умножаем на производную $g_{m-1}$ в точке $g_{m-2}(\ldots g_1(w_0)\ldots)$;
-
и так далее, пока не дойдём до производной $g_1$ в точке $w_0$.
Проиллюстрируем это на картинке, расписав по шагам дифференцирование по весам $w_i$ функции потерь логистической регрессии на одном объекте (то есть для батча размера 1):

Собирая все множители вместе, получаем:
$$\frac{\partial f}{\partial w_0} = (-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_1} = x_1\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
$$\frac{\partial f}{\partial w_2} = x_2\cdot(-y)\cdot e^{-y(w_0 + w_1x_1 + w_2x_2)}\cdot\frac{-1}{1 + e^{-y(w_0 + w_1x_1 + w_2x_2)}}$$
Таким образом, мы видим, что сперва совершается forward pass для вычисления всех промежуточных значений (и да, все промежуточные представления нужно будет хранить в памяти), а потом запускается backward pass, на котором в один проход вычисляются все градиенты.
Почему же нельзя просто пойти и начать везде вычислять производные?
В главе, посвящённой матричным дифференцированиям, мы поднимаем вопрос о том, что вычислять частные производные по отдельности — это зло, лучше пользоваться матричными вычислениями. Но есть и ещё одна причина: даже и с матричной производной в принципе не всегда хочется иметь дело. Рассмотрим простой пример. Допустим, что $X^r$ и $X^{r+1}$ — два последовательных промежуточных представления $N\times M$ и $N\times K$, связанных функцией $X^{r+1} = f^{r+1}(X^r)$. Предположим, что мы как-то посчитали производную $\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$ функции потерь $\mathcal{L}$, тогда
$$\frac{\partial\mathcal{L}}{\partial X^{r}_{st}} = \sum_{i,j}\frac{\partial f^{r+1}_{ij}}{\partial X^{r}_{st}}\frac{\partial\mathcal{L}}{\partial X^{r+1}_{ij}}$$
И мы видим, что, хотя оба градиента $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ и $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$ являются просто матрицами, в ходе вычислений возникает «четырёхмерный кубик» $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, даже хранить который весьма болезненно: уж больно много памяти он требует ($N^2MK$ по сравнению с безобидными $NM + NK$, требуемыми для хранения градиентов). Поэтому хочется промежуточные производные $\frac{\partial f^{r+1}}{\partial X^{r}}$ рассматривать не как вычисляемые объекты $\frac{\partial f_{ij}^{r+1}}{\partial X_{st}^{r}}$, а как преобразования, которые превращают $\frac{\partial\mathcal{L}}{\partial X_{ij}^{r+1}}$ в $\frac{\partial\mathcal{L}}{\partial X_{st}^{r}}$. Целью следующих глав будет именно это: понять, как преобразуется градиент в ходе error backpropagation при переходе через тот или иной слой.
Вы спросите себя: надо ли мне сейчас пойти и прочитать главу учебника про матричное дифференцирование?
Встречный вопрос. Найдите производную функции по вектору $x$:
$$f(x) = x^TAx,\ A\in Mat_{n}{\mathbb{R}}\text{ — матрица размера }n\times n$$
А как всё поменяется, если $A$ тоже зависит от $x$? Чему равен градиент функции, если $A$ является скаляром? Если вы готовы прямо сейчас взять ручку и бумагу и посчитать всё, то вам, вероятно, не надо читать про матричные дифференцирования. Но мы советуем всё-таки заглянуть в эту главу, если обозначения, которые мы будем дальше использовать, покажутся вам непонятными: единой нотации для матричных дифференцирований человечество пока, увы, не изобрело, и переводить с одной на другую не всегда легко.
Мы же сразу перейдём к интересующей нас вещи: к вычислению градиентов сложных функций.
Градиент сложной функции
Напомним, что формула производной сложной функции выглядит следующим образом:
$$\left[D_{x_0} (\color{#5002A7}{u} \circ \color{#4CB9C0}{v}) \right](h) = \color{#5002A7}{\left[D_{v(x_0)} u \right]} \left( \color{#4CB9C0}{\left[D_{x_0} v\right]} (h)\right)$$
Теперь разберёмся с градиентами. Пусть $f(x) = g(h(x))$ – скалярная функция. Тогда
$$\left[D_{x_0} f \right] (x-x_0) = \langle\nabla_{x_0} f, x-x_0\rangle.$$
С другой стороны,
$$\left[D_{h(x_0)} g \right] \left(\left[D_{x_0}h \right] (x-x_0)\right) = \langle\nabla_{h_{x_0}} g, \left[D_{x_0} h\right] (x-x_0)\rangle = \langle\left[D_{x_0} h\right]^* \nabla_{h(x_0)} g, x-x_0\rangle.$$
То есть $\color{#FFC100}{\nabla_{x_0} f} = \color{#348FEA}{\left[D_{x_0} h \right]}^* \color{#FFC100}{\nabla_{h(x_0)}}g$ — применение сопряжённого к $D_{x_0} h$ линейного отображения к вектору $\nabla_{h(x_0)} g$.
Эта формула — сердце механизма обратного распространения ошибки. Она говорит следующее: если мы каким-то образом получили градиент функции потерь по переменным из некоторого промежуточного представления $X^k$ нейронной сети и при этом знаем, как преобразуется градиент при проходе через слой $f^k$ между $X^{k-1}$ и $X^k$ (то есть как выглядит сопряжённое к дифференциалу слоя между ними отображение), то мы сразу же находим градиент и по переменным из $X^{k-1}$:

Таким образом слой за слоем мы посчитаем градиенты по всем $X^i$ вплоть до самых первых слоёв.
Далее мы разберёмся, как именно преобразуются градиенты при переходе через некоторые распространённые слои.
Градиенты для типичных слоёв
Рассмотрим несколько важных примеров.
Примеры
-
$f(x) = u(v(x))$, где $x$ — вектор, а $v(x)$ – поэлементное применение $v$:
$$v\begin{pmatrix}
x_1 \\
\vdots\\
x_N
\end{pmatrix}
= \begin{pmatrix}
v(x_1)\\
\vdots\\
v(x_N)
\end{pmatrix}$$Тогда, как мы знаем,
$$\left[D_{x_0} f\right] (h) = \langle\nabla_{x_0} f, h\rangle = \left[\nabla_{x_0} f\right]^T h.$$
Следовательно,
$$
\left[D_{v(x_0)} u\right] \left( \left[ D_{x_0} v\right] (h)\right) = \left[\nabla_{v(x_0)} u\right]^T \left(v'(x_0) \odot h\right) =\\
$$$$
= \sum\limits_i \left[\nabla_{v(x_0)} u\right]_i v'(x_{0i})h_i
= \langle\left[\nabla_{v(x_0)} u\right] \odot v'(x_0), h\rangle.
,$$где $\odot$ означает поэлементное перемножение. Окончательно получаем
$$\color{#348FEA}{\nabla_{x_0} f = \left[\nabla_{v(x_0)}u\right] \odot v'(x_0) = v'(x_0) \odot \left[\nabla_{v(x_0)} u\right]}$$
Отметим, что если $x$ и $h(x)$ — это просто векторы, то мы могли бы вычислять всё и по формуле $\frac{\partial f}{\partial x_i} = \sum_j\big(\frac{\partial z_j}{\partial x_i}\big)\cdot\big(\frac{\partial h}{\partial z_j}\big)$. В этом случае матрица $\big(\frac{\partial z_j}{\partial x_i}\big)$ была бы диагональной (так как $z_j$ зависит только от $x_j$: ведь $h$ берётся поэлементно), и матричное умножение приводило бы к тому же результату. Однако если $x$ и $h(x)$ — матрицы, то $\big(\frac{\partial z_j}{\partial x_i}\big)$ представлялась бы уже «четырёхмерным кубиком», и работать с ним было бы ужасно неудобно.
-
$f(X) = g(XW)$, где $X$ и $W$ — матрицы. Как мы знаем,
$$\left[D_{X_0} f \right] (X-X_0) = \text{tr}, \left(\left[\nabla_{X_0} f\right]^T (X-X_0)\right).$$
Тогда
$$
\left[ D_{X_0W} g \right] \left(\left[D_{X_0} \left( \ast W\right)\right] (H)\right) =
\left[ D_{X_0W} g \right] \left(HW\right)=\\
$$ $$
= \text{tr}\, \left( \left[\nabla_{X_0W} g \right]^T \cdot (H) W \right) =\\
$$ $$
=
\text{tr} \, \left(W \left[\nabla_{X_0W} (g) \right]^T \cdot (H)\right) = \text{tr} \, \left( \left[\left[\nabla_{X_0W} g\right] W^T\right]^T (H)\right)
$$Здесь через $\ast W$ мы обозначили отображение $Y \hookrightarrow YW$, а в предпоследнем переходе использовалось следующее свойство следа:
$$
\text{tr} , (A B C) = \text{tr} , (C A B),
$$где $A, B, C$ — произвольные матрицы подходящих размеров (то есть допускающие перемножение в обоих приведённых порядках). Следовательно, получаем
$$\color{#348FEA}{\nabla_{X_0} f = \left[\nabla_{X_0W} (g) \right] \cdot W^T}$$
-
$f(W) = g(XW)$, где $W$ и $X$ — матрицы. Для приращения $H = W — W_0$ имеем
$$
\left[D_{W_0} f \right] (H) = \text{tr} , \left( \left[\nabla_{W_0} f \right]^T (H)\right)
$$Тогда
$$
\left[D_{XW_0} g \right] \left( \left[D_{W_0} \left(X \ast\right) \right] (H)\right) = \left[D_{XW_0} g \right] \left( XH \right) = \
$$ $$
= \text{tr} , \left( \left[\nabla_{XW_0} g \right]^T \cdot X (H)\right) =
\text{tr}, \left(\left[X^T \left[\nabla_{XW_0} g \right] \right]^T (H)\right)
$$Здесь через $X \ast$ обозначено отображение $Y \hookrightarrow XY$. Значит,
$$\color{#348FEA}{\nabla_{X_0} f = X^T \cdot \left[\nabla_{XW_0} (g)\right]}$$
-
$f(X) = g(softmax(X))$, где $X$ — матрица $N\times K$, а $softmax$ — функция, которая вычисляется построчно, причём для каждой строки $x$
$$softmax(x) = \left(\frac{e^{x_1}}{\sum_te^{x_t}},\ldots,\frac{e^{x_K}}{\sum_te^{x_t}}\right)$$
В этом примере нам будет удобно воспользоваться формализмом с частными производными. Сначала вычислим $\frac{\partial s_l}{\partial x_j}$ для одной строки $x$, где через $s_l$ мы для краткости обозначим $softmax(x)_l = \frac{e^{x_l}} {\sum_te^{x_t}}$. Нетрудно проверить, что
$$\frac{\partial s_l}{\partial x_j} = \begin{cases}
s_j(1 — s_j),\ & j = l,\
-s_ls_j,\ & j\ne l
\end{cases}$$Так как softmax вычисляется независимо от каждой строчки, то
$$\frac{\partial s_{rl}}{\partial x_{ij}} = \begin{cases}
s_{ij}(1 — s_{ij}),\ & r=i, j = l,\
-s_{il}s_{ij},\ & r = i, j\ne l,\
0,\ & r\ne i
\end{cases},$$где через $s_{rl}$ мы обозначили для краткости $softmax(X)_{rl}$.
Теперь пусть $\nabla_{rl} = \nabla g = \frac{\partial\mathcal{L}}{\partial s_{rl}}$ (пришедший со следующего слоя, уже известный градиент). Тогда
$$\frac{\partial\mathcal{L}}{\partial x_{ij}} = \sum_{r,l}\frac{\partial s_{rl}}{\partial x_{ij}} \nabla_{rl}$$
Так как $\frac{\partial s_{rl}}{\partial x_{ij}} = 0$ при $r\ne i$, мы можем убрать суммирование по $r$:
$$\ldots = \sum_{l}\frac{\partial s_{il}}{\partial x_{ij}} \nabla_{il} = -s_{i1}s_{ij}\nabla_{i1} — \ldots + s_{ij}(1 — s_{ij})\nabla_{ij}-\ldots — s_{iK}s_{ij}\nabla_{iK} =$$
$$= -s_{ij}\sum_t s_{it}\nabla_{it} + s_{ij}\nabla_{ij}$$
Таким образом, если мы хотим продифференцировать $f$ в какой-то конкретной точке $X_0$, то, смешивая математические обозначения с нотацией Python, мы можем записать:
$$\begin{multline*}
\color{#348FEA}{\nabla_{X_0}f =}\\
\color{#348FEA}{= -softmax(X_0) \odot \text{sum}\left(
softmax(X_0)\odot\nabla_{softmax(X_0)}g, \text{ axis = 1}
\right) +}\\
\color{#348FEA}{softmax(X_0)\odot \nabla_{softmax(X_0)}g}
\end{multline*}
$$
Backpropagation в общем виде
Подытожим предыдущее обсуждение, описав алгоритм error backpropagation (алгоритм обратного распространения ошибки). Допустим, у нас есть текущие значения весов $W^i_0$ и мы хотим совершить шаг SGD по мини-батчу $X$. Мы должны сделать следующее:
- Совершить forward pass, вычислив и запомнив все промежуточные представления $X = X^0, X^1, \ldots, X^m = \widehat{y}$.
- Вычислить все градиенты с помощью backward pass.
- С помощью полученных градиентов совершить шаг SGD.
Проиллюстрируем алгоритм на примере двуслойной нейронной сети со скалярным output’ом. Для простоты опустим свободные члены в линейных слоях.
 Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
Обучаемые параметры – матрицы $U$ и $W$. Как найти градиенты по ним в точке $U_0, W_0$?
$$\nabla_{W_0}\mathcal{L} = \nabla_{W_0}{\left({\vphantom{\frac12}\mathcal{L}\circ h\circ\left[W\mapsto g(XU_0)W\right]}\right)}=$$
$$=g(XU_0)^T\nabla_{g(XU_0)W_0}(\mathcal{L}\circ h) = \underbrace{g(XU_0)^T}_{k\times N}\cdot
\left[\vphantom{\frac12}\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times 1}\odot
\underbrace{\nabla_{h\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}\mathcal{L}}_{N\times 1}\right]$$
Итого матрица $k\times 1$, как и $W_0$
$$\nabla_{U_0}\mathcal{L} = \nabla_{U_0}\left(\vphantom{\frac12}
\mathcal{L}\circ h\circ\left[Y\mapsto YW_0\right]\circ g\circ\left[ U\mapsto XU\right]
\right)=$$
$$=X^T\cdot\nabla_{XU^0}\left(\vphantom{\frac12}\mathcal{L}\circ h\circ [Y\mapsto YW_0]\circ g\right) =$$
$$=X^T\cdot\left(\vphantom{\frac12}g'(XU_0)\odot
\nabla_{g(XU_0)}\left[\vphantom{\in_0^1}\mathcal{L}\circ h\circ[Y\mapsto YW_0\right]
\right)$$
$$=\ldots = \underset{D\times N}{X^T}\cdot\left(\vphantom{\frac12}
\underbrace{g'(XU_0)}_{N\times K}\odot
\underbrace{\left[\vphantom{\int_0^1}\left(
\underbrace{h’\left(\vphantom{\int_0^1}g(XU_0)W_0\right)}_{N\times1}\odot\underbrace{\nabla_{h(\vphantom{\int_0^1}g\left(XU_0\right)W_0)}\mathcal{L}}_{N\times 1}
\right)\cdot \underbrace{W^T}_{1\times K}\right]}_{N\times K}
\right)$$
Итого $D\times K$, как и $U_0$
Схематически это можно представить следующим образом:

Backpropagation для двуслойной нейронной сети
Подробнее о предыдущих вычисленияхЕсли вы не уследили за вычислениями в предыдущем примере, давайте более подробно разберём его чуть более конкретную версию (для $g = h = \sigma$).
Рассмотрим двуслойную нейронную сеть для классификации. Мы уже встречали ее ранее при рассмотрении линейно неразделимой выборки. Предсказания получаются следующим образом:
$$
\widehat{y} = \sigma(X^1 W^2) = \sigma\Big(\big(\sigma(X^0 W^1 )\big) W^2 \Big).
$$
Пусть $W^1_0$ и $W^2_0$ — текущее приближение матриц весов. Мы хотим совершить шаг по градиенту функции потерь, и для этого мы должны вычислить её градиенты по $W^1$ и $W^2$ в точке $(W^1_0, W^2_0)$.
Прежде всего мы совершаем forward pass, в ходе которого мы должны запомнить все промежуточные представления: $X^1 = X^0 W^1_0$, $X^2 = \sigma(X^0 W^1_0)$, $X^3 = \sigma(X^0 W^1_0) W^2_0$, $X^4 = \sigma(\sigma(X^0 W^1_0) W^2_0) = \widehat{y}$. Они понадобятся нам дальше.
Для полученных предсказаний вычисляется значение функции потерь:
$$
l = \mathcal{L}(y, \widehat{y}) = y \log(\widehat{y}) + (1-y) \log(1-\widehat{y}).
$$
Дальше мы шаг за шагом будем находить производные по переменным из всё более глубоких слоёв.
-
Градиент $\mathcal{L}$ по предсказаниям имеет вид
$$
\nabla_{\widehat{y}}l = \frac{y}{\widehat{y}} — \frac{1 — y}{1 — \widehat{y}} = \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})},
$$где, напомним, $ \widehat{y} = \sigma(X^3) = \sigma\Big(\big(\sigma(X^0 W^1_0 )\big) W^2_0 \Big)$ (обратите внимание на то, что $W^1_0$ и $W^2_0$ тут именно те, из которых мы делаем градиентный шаг).
-
Следующий слой — поэлементное взятие $\sigma$. Как мы помним, при переходе через него градиент поэлементно умножается на производную $\sigma$, в которую подставлено предыдущее промежуточное представление:
$$
\nabla_{X^3}l = \sigma'(X^3)\odot\nabla_{\widehat{y}}l = \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \widehat{y}}{\widehat{y} (1 — \widehat{y})} =
$$$$
= \sigma(X^3)\left( 1 — \sigma(X^3) \right) \odot \frac{y — \sigma(X^3)}{\sigma(X^3) (1 — \sigma(X^3))} =
y — \sigma(X^3)
$$ -
Следующий слой — умножение на $W^2_0$. В этот момент мы найдём градиент как по $W^2$, так и по $X^2$. При переходе через умножение на матрицу градиент, как мы помним, умножается с той же стороны на транспонированную матрицу, а значит:
$$
\color{blue}{\nabla_{W^2_0}l} = (X^2)^T\cdot \nabla_{X^3}l = (X^2)^T\cdot(y — \sigma(X^3)) =
$$$$
= \color{blue}{\left( \sigma(X^0W^1_0) \right)^T \cdot (y — \sigma(\sigma(X^0W^1_0)W^2_0))}
$$Аналогичным образом
$$
\nabla_{X^2}l = \nabla_{X^3}l\cdot (W^2_0)^T = (y — \sigma(X^3))\cdot (W^2_0)^T =
$$$$
= (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T
$$ -
Следующий слой — снова взятие $\sigma$.
$$
\nabla_{X^1}l = \sigma'(X^1)\odot\nabla_{X^2}l = \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot \left( (y — \sigma(X^2W_0^2))\cdot (W^2_0)^T \right) =
$$$$
= \sigma(X^1)\left( 1 — \sigma(X^1) \right) \odot\left( (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T \right)
$$ -
Наконец, последний слой — это умножение $X^0$ на $W^1_0$. Тут мы дифференцируем только по $W^1$:
$$
\color{blue}{\nabla_{W^1_0}l} = (X^0)^T\cdot \nabla_{X^1}l = (X^0)^T\cdot \big( \sigma(X^1) \left( 1 — \sigma(X^1) \right) \odot (y — \sigma(\sigma(X^1)W_0^2))\cdot (W^2_0)^T\big) =
$$$$
= \color{blue}{(X^0)^T\cdot\big(\sigma(X^0W^1_0)\left( 1 — \sigma(X^0W^1_0) \right) \odot (y — \sigma(\sigma(X^0W^1_0)W_0^2))\cdot (W^2_0)^T\big) }
$$
Итоговые формулы для градиентов получились страшноватыми, но они были получены друг из друга итеративно с помощью очень простых операций: матричного и поэлементного умножения, в которые порой подставлялись значения заранее вычисленных промежуточных представлений.
Автоматизация и autograd
Итак, чтобы нейросеть обучалась, достаточно для любого слоя $f^k: X^{k-1}\mapsto X^k$ с параметрами $W^k$ уметь:
- превращать $\nabla_{X^k_0}\mathcal{L}$ в $\nabla_{X^{k-1}_0}\mathcal{L}$ (градиент по выходу в градиент по входу);
- считать градиент по его параметрам $\nabla_{W^k_0}\mathcal{L}$.
При этом слою совершенно не надо знать, что происходит вокруг. То есть слой действительно может быть запрограммирован как отдельная сущность, умеющая внутри себя делать forward pass и backward pass, после чего слои механически, как кубики в конструкторе, собираются в большую сеть, которая сможет работать как одно целое.
Более того, во многих случаях авторы библиотек для глубинного обучения уже о вас позаботились и создали средства для автоматического дифференцирования выражений (autograd). Поэтому, программируя нейросеть, вы почти всегда можете думать только о forward-проходе, прямом преобразовании данных, предоставив библиотеке дифференцировать всё самостоятельно. Это делает код нейросетей весьма понятным и выразительным (да, в реальности он тоже бывает большим и страшным, но сравните на досуге код какой-нибудь разухабистой нейросети и код градиентного бустинга на решающих деревьях и почувствуйте разницу).
Но это лишь начало
Метод обратного распространения ошибки позволяет удобно посчитать градиенты, но дальше с ними что-то надо делать, и старый добрый SGD едва ли справится с обучением современной сетки. Так что же делать? О некоторых приёмах мы расскажем в следующей главе.
Введение
- В последнее время, с ростом популярности этих двух методов появилось много библиотек на Matlab, R, Python, C ++ и т.д., которые получают на вход обучающий набор и автоматически создают соответствующую нейронную сеть для вашей задачи.
- Однако при использовании готовых библиотек бывает сложно понять, что именно происходит и как мы получаем оптимизированную сеть. А ведь знание основ решения важно для дальнейшего развития этих методов. Итак, в данной статье мы создадим очень простую структуру для алгоритма нейронной сети.
- Мы постараемся понять, как работает базовый тип нейронной сети — перцептрон с одним нейроном и многослойный перцептрон — замечательный алгоритм, который отвечает за обучение сети (градиентный спуск и обратное распространение). Эти сетевые модели будут основой для более сложных моделей, существующих на сегодняшний день.
Краткий обзор истории
- Первая нейронная сеть была задумана Уорренном Маккалоком и Уолтером Питтсом в 1943 году. Они написали великолепную статью о том, как должны работать нейроны, а затем построили модель на основе своих идей — создали простую нейронную сеть с электрическими цепями.
- Исследования в области искусственного интеллекта быстро развивались, и в 1980 году Кунихико Фукусима разработал первую настоящую многослойную нейронную сеть.
- Первоначальной целью нейронной сети было создание компьютерной системы, способной решать проблемы подобно тому, как это делает человеческий мозг. Однако, со временем исследователи сменили фокус и начали использовать нейронные сети для решения особенных задач. С тех пор нейронные сети выполняют самые разнообразные задачи, включая компьютерное зрение, распознавание голоса, машинный перевод, фильтрацию социальных сетей, настольные игры или видеоигры, медицинскую диагностику, прогноз погоды, прогнозирование временных рядов, распознавание (изображения, текста, голоса) и др.
Компьютерная модель нейрона: перцептрон
Перцептрон
Перцептрон вдохновлен идеей обработки информации единственной нервной клетки, называемой нейроном. Нейрон принимает на вход сигналы через свои дендриты, которые передают электрический сигнал телу клетки. Точно так же перцептрон получает входные сигналы из примеров обучающих данных, которые предварительно взвесили и объединили в линейное уравнение, называемое активацией.
- z = sum(weight_i * x_i) + bias
Где weight — это вес сети, X — это входное значение, i — индекс веса или входные данные, а смещение — это специальный вес, который не имеет множитель в виде входного значения (можем считать, что входные данные всегда равны 1.0).
Затем активация преобразуется в выходное (прогнозируемое) значение с помощью передаточной функции (функция активации).
- y = 1.0 если z >= 0.0, иначе 0.0
Таким образом, перцептрон представляет собой алгоритм классификации проблем с двумя классами (двоичный классификатор), где для разделения двух классов может использоваться линейное уравнение.
Это тесно связано с линейной регрессией и логистической регрессией, которые осуществляют прогнозы аналогичным образом (например, взвешенная сумма входов).
Алгоритм перцептрона — простейший вид искусственной нейронной сети. Это модель одного нейрона, которая может использоваться в задачах классификации двух классов и обеспечивает основу для дальнейшего развития гораздо более крупных сетей.
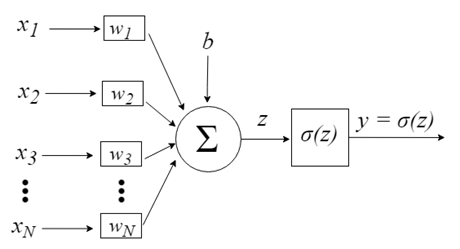
Входы нейронов представлены вектором x = [x1, x2, x3,…, xN], который может соответствовать, к примеру, ряду торговых цен актива, значениям технических индикаторов, числовой последовательности в пикселях изображения. Когда они попадают к нейрону, они умножаются на соответствующие синаптические веса, которые являются элементами вектора w = [w1, w2, w3, …, wN], и таким образом генерируют значение z, обычно называемое потенциалом активации, согласно выражению:
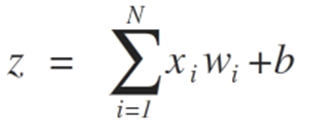
b обеспечивает более высокую степень свободы и не зависит от входа в это выражение, что обычно соответствует нейрону смещения (склонности). Затем z-значение проходит через функцию активации σ, которая отвечает за ограничение этого значения определенным интервалом (например, 0 — 1), что дает окончательное выходное значение и значение нейрона. Некоторые используемые триггерные функции: шаг, сигмоид, гиперболический тангенс, softmax и ReLU («rectified linear unit»).
Чтобы проиллюстрировать процесс, направленный на достижение предела разделимости классов, ниже мы показываем две ситуации, которые демонстрируют их сближение к стабилизации с учетом только двух входов {x1 и x2}
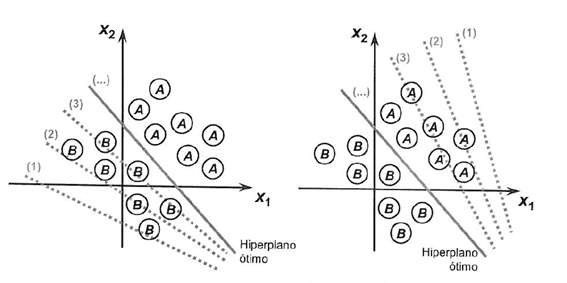
Веса алгоритма перцептрона следует оценивать на основе данных обучения с использованием стохастического градиентного спуска.
Стохастический градиент
Градиентный спуск — это процесс минимизации функции в направлении градиента функции стоимости.
Это подразумевает знание формулы стоимости, а также производной, чтобы с определенной точки мы могли узнать наклон и могли двигаться в этом направлении, например, вниз по направлению к минимальному значению.
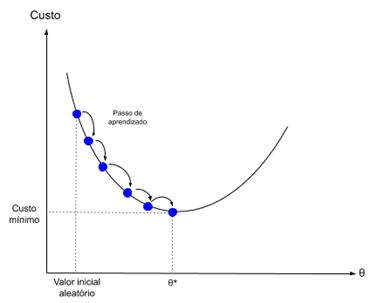
В машинном обучении мы можем использовать метод, который оценивает и обновляет веса для каждой итерации, называемый стохастическим градиентным спуском, чтобы минимизировать ошибку модели в наших обучающих данных.
Принцип работы этого алгоритма оптимизации заключается в том, что каждый обучающий экземпляр показывается модели по одному. Модель делает прогноз для обучающего экземпляра, вычисляет ошибку и обновляет модель, чтобы уменьшить ошибку для следующего прогноза.
Эту процедуру можно использовать для поиска набора весов в модели, который дает наименьшую ошибку для модели в обучающих данных.
Для алгоритма перцептрона на каждой итерации веса w обновляются с использованием уравнения:
- w = w + learning_rate * (expected — predicted) * x
Где w оптимизируется, learning_rate — это скорость обучения, которую мы должны установить (например, 0.1), (expected — predicted) — ошибка прогнозирования для модели в обучающих данных, относящихся к весу, а x — входное значение.
Для стохастического градиентного спуска требуются два параметра:
- Коэффициент обучения: используется для ограничения размера корректировки веса при каждом его обновлении.
- Эпохи — сколько раз обучающие данные должны выполняться при обновлении веса.
Они вместе с обучающими данными будут аргументами для функции.
Нам нужно выполнить 3 цикла в функции:
1. Цикл для каждой эпохи.
2. Цикл для каждой строки в обучающих данных для эпохи.
3. Цикл для каждого веса, который обновляется для одной строке в одной эпохи.
Веса обновляются в зависимости от ошибки, допущенной моделью. Ошибка рассчитывается как разница между фактическим значением и прогнозом, сделанным с помощью весов.
Для каждого входного атрибута есть свой вес, и они постоянно обновляются, например:
- w(t+1)= w(t) + learning_rate * (expected(t) — predicted(t)) * x(t)
Смещение обновляется аналогичным образом, только без входа, поскольку оно не связано с конкретным входным значением:
- bias(t+1) = bias(t) + learning_rate * (expected(t) — predicted(t)).
Применение модели нейрона:
Теперь перейдем к практическому применению.
Этот урок разделен на 2 части:
1. Делаем прогнозы
2. Оптимизация веса сети
Эти шаги обеспечат основу для реализации и применения алгоритма перцептрона к другим задачам классификации.
Нам нужно определить количество столбцов в нашем наборе X, для этого мы определяем константу
#define nINPUT 3
В MQL5 многомерный массив может быть статическим или динамическим только для первого измерения, а поскольку все остальные измерения будут статическими, при объявлении массива необходимо указать размер.
1. Делаем прогнозы
Первый шаг — разработать функцию, которая может делать прогнозы.
Это будет необходимо как при оценке значений весов кандидатов при стохастическом градиентном спуске, так и после завершения модели. Прогнозы надо делать и на тестовых данных, и на новых.
Ниже приведена функция predict, которая прогнозирует выходное значение для строки исходя от определенного набора весов.
Первый вес всегда является смещением, поскольку он автономен и не работает с конкретным входным значением.
template <typename Array> double predict(const Array &X[][nINPUT], const Array &weights[], const int row=0) { double z = weights[0]; for(int i=0; i<ArrayRange(X, 1)-1; i++) { z+=weights[i+1]*X[row][i]; } return activation(z); }
Перенос нейронов:
Как только нейрон активирован, нам нужно передать активацию, чтобы увидеть, каковы на самом деле выходные данные нейрона.
double activation(const double activation) { return activation>=0.0?1.0:0.0; }
Мы получаем в качестве аргумента в функции прогнозирования входной набор X, массив с весами (W) и строку, для которой прогнозируется входной набор X.
Мы можем придумать небольшой набор данных, чтобы проверить нашу функцию прогнозирования.
Мы также можем использовать заранее подготовленные веса, чтобы делать прогнозы для этого набора данных.
double weights[] = {-0.1, 0.20653640140000007, -0.23418117710000003};
После того, как мы собрали все это вместе, мы можем протестировать нашу функцию прогнозирования ниже.
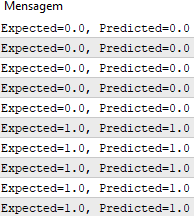
#define nINPUT 3 void OnStart() { random.seed(42); double dataset[][nINPUT] = { {2.7810836,2.550537003,0}, {1.465489372,2.362125076,0}, {3.396561688,4.400293529,0}, {1.38807019,1.850220317,0}, {3.06407232,3.005305973,0}, {7.627531214,2.759262235,1}, {5.332441248,2.088626775,1}, {6.922596716,1.77106367,1}, {8.675418651,-0.242068655,1}, {7.673756466,3.508563011,1} }; double weights[] = {-0.1, 0.20653640140000007, -0.23418117710000003}; for(int row=0; row<ArrayRange(dataset, 0); row++) { double predict = predict(dataset, weights, row); printf("Expected=%.1f, Predicted=%.1f", dataset[row][nINPUT-1], predict); } } template <typename Array> double predict(const Array &X[][nINPUT], const Array &weights[], const int row=0) { double z = weights[0]; for(int i=0; i<ArrayRange(X, 1)-1; i++) { z+=weights[i+1]*X[row][i]; } return activation(z); } double activation(const double activation) { return activation>=0.0?1.0:0.0; }
Есть два входных значения (X1 и X2) и три коэффициента веса (bias, w1 и w2). Уравнение активации, которое мы моделируем для данной проблемы, выглядит так:
activation = (w1 * X1) + (w2 * X2) + b
Или с конкретными значениями веса, мы вручную выбираем как:
activation = (0.206 * X1) + (-0.234 * X2) + -0.1
После завершения работы функции мы получаем прогнозы, которые соответствуют ожидаемым выходным значениям y.
Теперь можем реализовать стохастический градиентный спуск для оптимизации значений веса.
2. Оптимизируем веса сети
Веса для наших обучающих данных можно оценить, используя стохастический градиентный спуск, как было сказано ранее.
Ниже приведена функция train_weights(), которая вычисляет значения веса для набора обучающих данных с использованием стохастического градиентного спуска.
В MQL5 мы не можем получить возврат из этого массива с данными обученных весов, потому что, в отличие от переменных, массивы могут быть переданы в функцию только по ссылке. Это означает, что функция не создает собственный экземпляр массива, а вместо этого работает напрямую с переданным ей массивом. Таким образом, все изменения, осуществляемые в этом массиве внутри функции влияют на исходный массив.
template <typename Array> void train_weights(Array &weights[], const Array &X[][nINPUT], double l_rate=0.1, int n_epoch=5) { ArrayResize(weights, ArrayRange(X, 1)); for(int i=0; i<ArrayRange(X, 1); i++) { weights[i]=random.random(); } for(int epoch=0; epoch<n_epoch; epoch++) { double sum_error = 0.0; for(int row=0; row<ArrayRange(X, 0); row++) { double y = predict(X, weights, row); double error = X[row][nINPUT-1] - y; sum_error += pow(error, 2); weights[0] = weights[0] + l_rate * error; for(int i=0; i<ArrayRange(X, 1)-1; i++) { weights[i+1] = weights[i+1] + l_rate * error * X[row][i]; } } printf(">epoch=%d, lrate=%.3f, error=%.3f",epoch, l_rate, sum_error); } }
На каждой эпохе мы отслеживаем сумму квадратичной ошибки (положительное значение), чтобы отслеживать уменьшение ошибки. Это позволяет наблюдать как алгоритм минимизирует ошибку на каждой эпохе.
Давайте протестируем нашу функцию с одним и тем же набором данных, представленным выше.
#define nINPUT 3 void OnStart() { random.seed(42); double dataset[][nINPUT] = { {2.7810836,2.550537003,0}, {1.465489372,2.362125076,0}, {3.396561688,4.400293529,0}, {1.38807019,1.850220317,0}, {3.06407232,3.005305973,0}, {7.627531214,2.759262235,1}, {5.332441248,2.088626775,1}, {6.922596716,1.77106367,1}, {8.675418651,-0.242068655,1}, {7.673756466,3.508563011,1} }; double weights[]; train_weights(weights, dataset); ArrayPrint(weights, 20); for(int row=0; row<ArrayRange(dataset, 0); row++) { double predict = predict(dataset, weights, row); printf("Expected=%.1f, Predicted=%.1f", dataset[row][nINPUT-1], predict); } } template <typename Array> double predict(const Array &X[][nINPUT], const Array &weights[], const int row=0) { double z = weights[0]; for(int i=0; i<ArrayRange(X, 1)-1; i++) { z+=weights[i+1]*X[row][i]; } return activation(z); } double activation(const double activation) { return activation>=0.0?1.0:0.0; } template <typename Array> void train_weights(Array &weights[], const Array &X[][nINPUT], double l_rate=0.1, int n_epoch=5) { ArrayResize(weights, ArrayRange(X, 1)); ArrayInitialize(weights, 0); for(int epoch=0; epoch<n_epoch; epoch++) { double sum_error = 0.0; for(int row=0; row<ArrayRange(X, 0); row++) { double y = predict(X, weights, row); double error = X[row][nINPUT-1] - y; sum_error += pow(error, 2); weights[0] = weights[0] + l_rate * error; for(int i=0; i<ArrayRange(X, 1)-1; i++) { weights[i+1] = weights[i+1] + l_rate * error * X[row][i]; } } printf(">epoch=%d, lrate=%.3f, error=%.3f",epoch, l_rate, sum_error); } }
Мы используем скорость обучения 0,1 и обучаем модель только для 5 эпох или 5 показов весов для всего набора обучающих данных.
При выполнении примера для каждой эпохи печатается сообщение с суммой квадратичной ошибки для этой эпохи и окончательным набором весов.
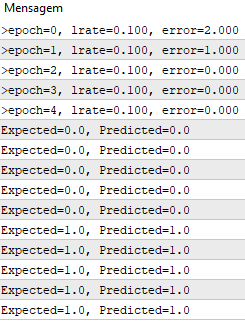
Мы видим, как быстро алгоритм выучивает проблему.
Этот тест можно найти в файле PerceptronScript.mq5.
Многослойный перцептрон
- Объединеняем нейроны в слои
С одним нейроном мало что можно сделать, но мы можем объединить их в многоуровневую структуру, каждый с разным количеством нейронов, и сформировать нейронную сеть, называемую многослойным перцептроном («multi layer perceptron, MLP»). Вектор входных значений X проходит через начальный слой, выходные значения которого связаны со входами следующего уровня, и так далее, пока сеть не предоставит выходные значения последнего слоя в качестве результата. Сеть может быть организована в несколько слоев, что делает ее глубокой и способной выучить все более сложные отношения.
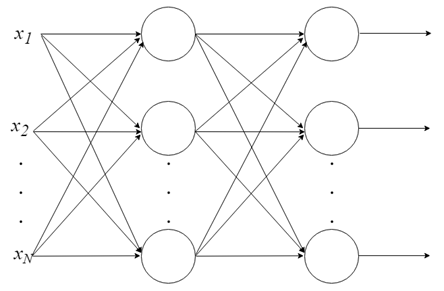
Обучение MLP
Для того, чтобы такая сеть работала, ее нужно обучать. Это как учить ребенка читать. Обучение MLP происходит в контексте машинного обучения с учителем, но как это работает?
Обучение с учителем:
- Нам дается набор отмеченных данных, для которых мы уже знаем какой именно является нашим правильным выходом, и он должен быть аналогичен набору, имея представление о том, что существует связь между входом и выходом.
- Задачи обучения с учителем подразделяются на задачи «регрессии» и «классификации». В задачах регрессии мы пытаемся предсказать результаты на непрерывном выходе, что означает, что мы пытаемся сопоставить входные переменные с некоторой непрерывной функцией. В задачах классификации мы стараемся предсказать результаты на дискретном выходе. Другими словами, мы пытаемся сопоставить входные переменные по разным категориям.
Пример 1:
- Учитывая набор данных о размерах домов на рынке недвижимости, попробуйте спрогнозировать их цену. Цена в зависимости от размера — это непрерывный результат, так что это проблема регрессии.
- Мы могли бы также превратить этот пример в задачу классификации, чтобы прогнозировать о том, «продастся ли дом дороже или дешевле, чем запрашиваемая цена». Здесь мы рассортируем дома по цене на две разные категории.
Обратное распространение
Обратное распространение, без сомнений, является самым важным алгоритмом в истории нейронных сетей — без (эффективного) обратного распространения, было бы невозможно обучить сети глубокого обучения так, как мы это делаем сегодня. Обратное распространение можно считать краеугольным камнем современных нейронных сетей и глубокого обучения.
Разве мы не учимся на ошибках?
Идея алгоритма обратного распространения ошибки состоит в том, чтобы на основе расчетной ошибки, полученной на выходном слое нейронной сети, пересчитать значение весов вектора W последнего слоя нейронов. Затем мы переходим к предыдущему слою и так далее, от конца к началу, то есть, он состоит из обновления всех весов W слоев, от последнего до достижения входного слоя сети путем обратного распространения ошибки, полученной сетью. Другими словами, ошибка вычисляется между тем, что предсказала сеть, и тем, что она была на самом деле (фактический 1, предсказанный 0; у нас есть ошибка!), поэтому мы пересчитываем значения всех весов, начиная с последнего слоя и переходя к первому, всегда обращая внимание на уменьшение этой ошибки.
Алгоритм обратного распространения ошибки состоит из двух этапов:
1. Прямой проход («forward pass»), при котором наши входы проходят через сеть и получают прогнозы выхода (этот шаг также известен как фаза распространения).
2. Обратный проход («backward pass»), при котором мы вычисляем градиент функции потерь на последнем слое (то есть слое прогнозирования) сети и используем этот градиент для рекурсивного применения цепного правила («chain rule») для обновления весов в нашей сети (также известного как стадия обновления веса или обратное распространение)
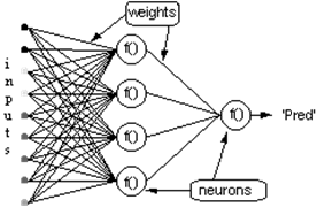
Рассмотрим сеть выше со слоем скрытых нейронов и выходным нейроном. Когда входной вектор распространяется по сети, для текущего набора весов существует выходной Pred(y). Цель обучения с учителем — настроить веса так, чтобы уменьшить разницу между Pred(y) сети и требуемым выходным Req(y). Для этого требуется алгоритм, который уменьшает абсолютную ошибку, что аналогично уменьшению квадратичной ошибки, где:
(1)
Сетевая ошибка = Pred — Req
= E
Алгоритм должен регулировать веса, чтобы минимизировать E². Обратное распространение — это алгоритм, который выполняет минимизацию градиентного спуска E². Чтобы минимизировать E², необходимо рассчитать его чувствительность к каждому весу. Другими словами, нам нужно знать, какое влияние будет иметь изменение каждого веса на E². Если нам будет известно, веса можно будет отрегулировать в направлении, уменьшающем абсолютную ошибку. Последующее описание правила обратного распространения основано на такой диаграмме:
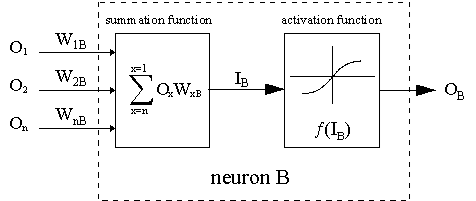
Пунктирная линия представляет нейрон B, который может быть скрытым или выходным нейроном. Выходы n нейронов (O 1 … O n) на предыдущем слое являются взодами для нейрона B. Если нейрон B находится в скрытом слое, он просто является входным вектором. Эти выходы умножаются на соответствующие веса (W1B … WnB), где WnB — вес, соединяющий нейрон n и нейрону B. Функция суммы складывает все эти произведения для получения входных данных, IB, который обрабатывается функцией триггера f(.) нейрона B. f (IB) это выход OB нейрона B. Рассмотрим пример. Назовем нейрон 1 нейроном A и рассмотрим вес WAB между двумя нейронами. Подход, используемый для изменения веса, определяется правилом дельты:
(2)
![]()
где ![]() — параметр скорости обучения, который определяет скорость обучения, а
— параметр скорости обучения, который определяет скорость обучения, а
![]()
является чувствительностью ошибки E² к весу WAB и определяет направление поиска в пространстве весов для нового веса WAB (новый), как изображено на рисунке ниже.
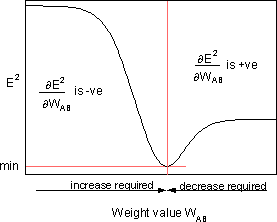
Чтобы минимизировать E², правило дельты обеспечивает необходимое направление изменения веса.
Ключевой концепцией приведенного выше уравнения является вычисление выражения ∂E² /∂WAB, которое состоит в вычислении частных производных функции ошибок E² по отношению к каждому весу вектора W.
Дифференцирование сложной функции:
(3)
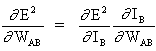
и
(4)
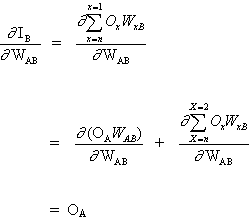
поскольку остальные входы нейрона B не зависят от веса WAB. Таким образом, исходя из уравнений (3) и (4), уравнение (2) становится
(5)
![]()
и изменение веса WAB зависит от чувствительности квадрата ошибки E² на входе IB, единицы B и входного сигнала OА.
Возможны две ситуации:
1. B — выходной нейрон;
2. B — скрытый нейрон.
Рассмотриваем первый случай:
Поскольку B является выходным нейроном, изменение квадрата ошибки из-за настроки WAB просто является изменением квадрата ошибки выходного сигнала B.
(6)
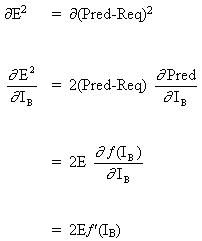
объединяя уравнение (5) и уравнение (6), получаем
(7)
![]()
Правило изменения весов, когда нейрон B является выходным нейроном, если выходная функция активации, f (.), является логистической функцией:
(8)
![]()
Дифференцируем уравнение (8) по аргументу x:
(9)
![]()
Но,
(10)
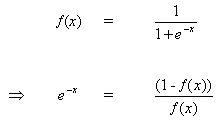
при вставке (10) в (9) получаем:
(11)
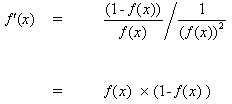
таким же образом для функции tanh
![]()
или для линейной функции (identity)
![]()
Так мы получаем:
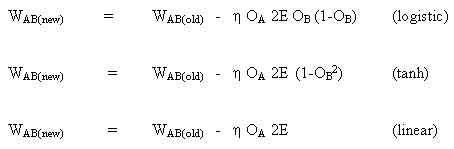
Рассматривая второй случай:
B это скрытый нейрон
(12)
![]()
где O представляет выходной нейрон
(13)
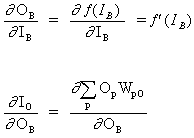
где p это индекс, который охватывает все нейроны, включая нейрон B, который обеспечивает входные сигналы для выходного нейрона. Расширяем правую часть уравнения (13),
(14)
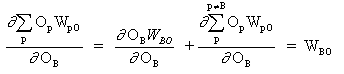
поскольку веса других нейронов WpO (p! = B) не имеют зависимости от OB.
При вставке (13) и (13) в (12):
(15)
![]()
Следовательно, ![]() теперь это выражается как функция от
теперь это выражается как функция от ![]() , вычисляемая, как описано в уравнении (6).
, вычисляемая, как описано в уравнении (6).
Полное правило изменения веса WAB между нейроном A, который посылает сигнал нейрону B, является таким:
(16)
![]()
где
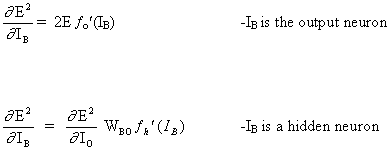
где fo (.) и fh (.) это скрытые функции активации и выхода соответственно.
Пример
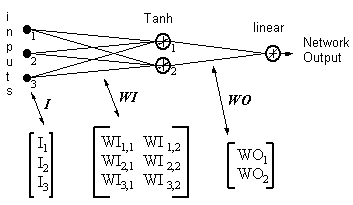
Выход из сети = [tanh(I T .WI)] . WO
HID = [Tanh(I T.WI)] T— выходы скрытых нейронов
ERROR = (выход из сети — нужный выход)
LR = коеффициент обучения
Обновления веса становятся
нейроном с линейным выходом
(17)
WO = WO — ( LR x ERROR x HID )
скрытым нейроном
(18)
WI = WI — { LR x [ERROR x WO x (1- HID 2)] . I T } T
Уравнения 17 и 18 показывают, что изменение веса — это входной сигнал, умноженный на локальный градиент. Это обеспечивает направление, величина которого также зависит от величины ошибки. Если берем направление без величины, все изменения будут одинакового размера, и это будет зависеть от темпа обучения. Вышеуказанный алгоритм является упрощенной версией, так как имеется только один выходной нейрон. В исходном алгоритме допускается более одного выхода, а уменьшение градиента минимизирует общую квадратную ошибку всех выходов. Есть много алгоритмов, которые произошли от исходного алгоритма для увеличения скорости обучения. Они кратко изложены в:
« Back Propagation family album» — Technical report C/TR96-05, Department of Computing, Macquarie University, NSW, Australia».
Обратное распространение — это элегантный и умелый алгоритм. Современные модели глубокого обучения, такие как сверточные нейронные сети, хотя и более совершенные, чем MLP, показали себя намного лучше в таких задачах, как классификация изображений и используют обратное распространение в качестве метода обучения, а также так называемые рекуррентные нейронные сети в условиях естественной языковой обработки, которые также используют этот алгоритм. Самое невероятное, что таким моделям удается находить ненаблюдаемые и непонятные закономерности для нас, людей, что удивляет и позволяет нам считать, что скоро мы получим помощь глубокого обучения для решения многих основных проблем, с которыми сталкивается человечество.
Применение модели MLP
Этот урок разделен на 5 частей:
1. Инициализация сети.
2. Прямое распространение (FeedForward).
3. Обратное распространение.
4. Обучение сети.
5. Прогноз.
Для нашей разработки мы реализуем применение на чистом MQL. Нам уже известно, что существуют библиотеки на других языках, которые уже являются гораздо более сложными, и настоятельно рекомендуется использовать их из практических соображений и соображений производительности, но, как уже было сказано в начале, важно понимать внутреннее устройство таких библиотек, чтобы иметь больший контроль над всем процессом. Мы также не использовали ООП в нашем тесте, поскольку это всего лишь алгоритм для иллюстрации предыдущих уравнений, в нем нет необходимости. Однако в реальных случаях гораздо практичнее использовать ООП, поскольку оно обеспечивает масштабируемость проекта.
1. Инициализация сети
У каждого нейрона есть набор весов, которые необходимо поддерживать. Вес для каждого входного соединения и дополнительный вес для смещения.
Рекомендуем инициализировать веса сети для небольших случайных чисел. В этом случае мы будем использовать случайные числа в диапазоне от 0 до 1. Для этого мы создали функцию для генерации случайных чисел.
double random(void) { return ((double)rand())/(double)SHORT_MAX; }
Ниже представлена функция под названием initialize_network(), которая создает веса нашей нейронной сети.
void forward_propagate(void) { int i = 0; for(i = 0; i<numHidden; i++) { hiddenVal[i] = 0.0; for(int j = 0; j<numInputs; j++) { hiddenVal[i] += (X[patNum][j] * weightsIH[j][i]); } hiddenVal[i] = tanh(hiddenVal[i]); } outPred = 0.0; for(i = 0; i<numHidden; i++) { outPred += hiddenVal[i] * weightsHO[i]; } errThisPat = outPred - y[patNum]; }
3. Обратное распространение
Алгоритм обратного распространения назван в честь способа обучения весов
Ошибка вычисляется между ожидаемыми выходами и выходными сигналами сети прямого распространения. Затем эти ошибки передаются обратно по сети от выходного слоя к скрытому слою, перекладывая ответственность за ошибку и обновляя веса по мере их поступления.
Математика ошибки обратного распространения была объяснена выше.
void backward_propagate_error(void) { for(int k = 0; k<numHidden; k++) { double weightChange = LR_HO * errThisPat * hiddenVal[k]; weightsHO[k] -= weightChange; regularisationWeights(weightsHO[k]); } for(int i = 0; i<numHidden; i++) { for(int k = 0; k<numInputs; k++) { double x = 1 - pow(hiddenVal[i],2); x = x * weightsHO[i] * errThisPat * LR_IH; x = x * X[patNum][k]; double weightChange = x; weightsIH[k][i] -= weightChange; } } }
метод regularizationWeights был создан только для регуляризации весов в диапазоне от -5 до 5.
void regularisationWeights(double &weight) { weight<-5?weight=-5:weight>5?weight=5:weight=weight; }
4. Обучение сети
Сеть обучается методом стохастического градиентного спуска.
Это включает в себя несколько итераций, раскрывающих набор обучающих данных в сети, и для каждой строки данных прямое распространение входных данных, обратное распространение ошибки и обновление весов сети.
//# Train a network for a fixed number of epochs void train(void) { for(int j = 0; j <= numEpochs; j++) { for(int i = 0; i<numPatterns; i++) { patNum = rand()%numPatterns; forward_propagate(); backward_propagate_error(); } calcOverallError(); printf("epoch = %d RMS Error = %f",j,RMSerror); } }
5. Прогноз
Делать прогнозы с помощью обученной нейронной сети довольно просто.
Мы уже видели, как распространить паттерн входа для получения выходных данных. Это все, что нам нужно сделать, чтобы осуществить прогноз. Мы можем использовать выходные значения напрямую как вероятность принадлежности паттерна к каждому выходному классу.
void predict(void) { for(int i = 0; i<numPatterns; i++) { patNum = i; forward_propagate(); printf("real = %d predict = %f",y[patNum],outPred); } }
Полный пример можно найти в файле MLP_Script.mq5.
Заключение
Мы занимались вычислениями, задействованными в процессе развития нейрона перцептрона, а также сети нейронов перцептрона, называемой «multi layer perceptron, MLP». В данном процессе мы поняли, как осуществляется обучение этого типа сетей с использованием обратного распространения ошибки и градиентного спуска.
Обратный анализ
Cтраница 1
Обратный анализ на этом завершен; однако уместны будут некоторые дополнительные замечания.
[1]
Обратный анализ позволяет оценить эквивалентные возмущения в исходных данных, которые при точном решении задачи повлияют на результат так же, как ошибки округления.
[2]
Цель обратного анализа ошибок состоит в том, чтобы оставить в стороне вопрос, получен ли точный ответ, поскольку это понятие для большинства реальных задач не является хорошо определенным. В действительности требуется найти ответ, который представляет собой истинное математическое решение задачи, лежащей в пределах области неопределенности исходной задачи. Любой результат, который удовлетворяет этому требованию, должен быть приемлем в качестве ответа к поставленной задаче, по крайней мере с позиции философии обратного анализа ошибок.
[3]
Идея обратного анализа ошибок может быть выражена в терминах неопределенных линейных систем.
[4]
Используется ли обратный анализ ошибок в терминах возмущения системы (36.1) при оценке точности ее решения вторым способом.
[5]
Развитием метода обратного анализа является метод эквивалентных возмущений. Вычисления по нек-рой расчетной схеме с округлениями рассматриваются как вычисления без округлений, но для уравнения с возмущенными коэффициентами. Сравнивая решение исходного уравнения с решением уравнения с невозмущенными коэффициентами, получают оценку погрешности.
[6]
Значительная часть обратного анализа ошибок в линейной алгебре выполняется по типичной схеме, которую можно показать на следующем примере.
[7]
Такой подход называется обратным анализом округлений, так как ошибки приписываются данным.
[8]
Полученные соотношения позволяют выполнить обратный анализ ошибок.
[9]
В наших исследованиях будет в основном использоваться обратный анализ ошибок, значительно реже — прямой анализ. В отдельных вспомогательных задачах может возникнуть необходимость в использовании обоих методик оценки суммарного влияния ошибок округления.
[10]
Этот последний способ учета ошибок округления называется обратным анализом, он был в большой степени разработан Дж. Говоря общо, такой подход характеризуется следующим вопросом: насколько малые изменения в исходных данных задачи необходимы для того, чтобы представить вычисленные результаты как точное решение возмущенной задачи.
[11]
Хотя оба метода полезны, важной особенностью точки зрения обратного анализа является то, что он позволяет анализировать ошибки округления больших матричных или полиномиальных задач, поскольку допускает использование ассоциативных операций, что часто очень затруднительно в прямом анализе ошибок.
[12]
Третий путь обоснования оптимальности аппроксимаций Ре-лея — Ритца соответствует обратному анализу ошибок ( см. гл. Так как & т не инвариантно относительно А, бессмысленно говорить о сужении А на SPm. Ут инвариантно относительно Р А, и поэтому имеет смысл говорить о сужении на Ут, а именно о матрице Р А, которая и является требуемой проекцией. Она тесно связана с матрицей Р & АР &, которая действует во всем, и также называется проекцией А. Такая двусмысленность не приносит вреда, поскольку действия двух проекторов на Ут одинаковы. Это и есть третья характеризация пар Ритца.
[13]
Прямой анализ ошибок ( оценка ошибки) не является побежденным соперником обратного анализа. В частности, пользователи заинтересованы главным образом в оценке точности своих выходных результатов. Соединение обратного анализа ( когда он может быть применен) и теории возмущений часто дает лучшие оценки, чем прямолинейные попытки проследить, как округления увеличивают промежуточную ошибку на каждом шаге.
[14]
На одном конце этого диапазона находится процесс, который можно назвать обратным анализом: каталогизируются результаты анализов структуры сети, а затем задача синтеза решается движением вспять.
[15]
Страницы:
1
2