The tasks of the Error Handling process are to detect each error, report it to the user, and then make some recovery strategy and implement them to handle the error. During this whole process processing time of the program should not be slow.
Functions of Error Handler:
- Error Detection
- Error Report
- Error Recovery
Error handler=Error Detection+Error Report+Error Recovery.
An Error is the blank entries in the symbol table.
Errors in the program should be detected and reported by the parser. Whenever an error occurs, the parser can handle it and continue to parse the rest of the input. Although the parser is mostly responsible for checking for errors, errors may occur at various stages of the compilation process.
So, there are many types of errors and some of these are:
Types or Sources of Error – There are three types of error: logic, run-time and compile-time error:
- Logic errors occur when programs operate incorrectly but do not terminate abnormally (or crash). Unexpected or undesired outputs or other behaviour may result from a logic error, even if it is not immediately recognized as such.
- A run-time error is an error that takes place during the execution of a program and usually happens because of adverse system parameters or invalid input data. The lack of sufficient memory to run an application or a memory conflict with another program and logical error is an example of this. Logic errors occur when executed code does not produce the expected result. Logic errors are best handled by meticulous program debugging.
- Compile-time errors rise at compile-time, before the execution of the program. Syntax error or missing file reference that prevents the program from successfully compiling is an example of this.
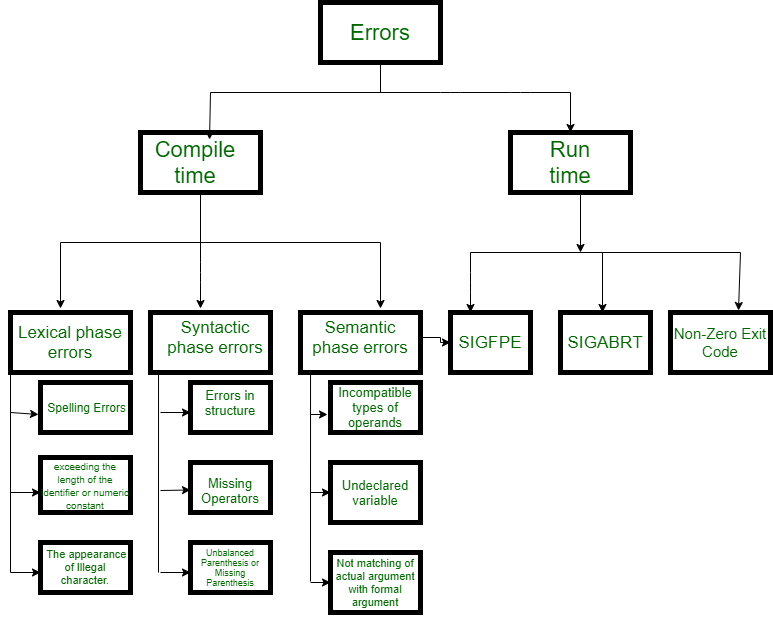
Classification of Compile-time error –
- Lexical : This includes misspellings of identifiers, keywords or operators
- Syntactical : a missing semicolon or unbalanced parenthesis
- Semantical : incompatible value assignment or type mismatches between operator and operand
- Logical : code not reachable, infinite loop.
Finding error or reporting an error – Viable-prefix is the property of a parser that allows early detection of syntax errors.
- Goal detection of an error as soon as possible without further consuming unnecessary input
- How: detect an error as soon as the prefix of the input does not match a prefix of any string in the language.
Example: for(;), this will report an error as for having two semicolons inside braces.
Error Recovery –
The basic requirement for the compiler is to simply stop and issue a message, and cease compilation. There are some common recovery methods that are as follows.
We already discuss the errors. Now, let’s try to understand the recovery of errors in every phase of the compiler.
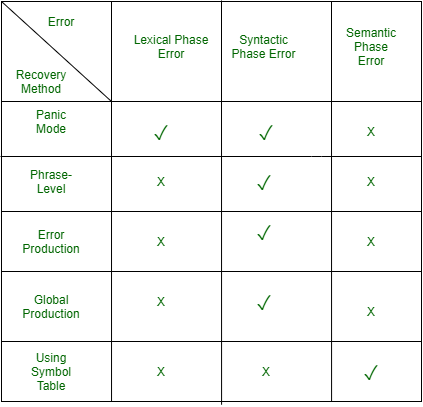
1. Panic mode recovery :
This is the easiest way of error-recovery and also, it prevents the parser from developing infinite loops while recovering error. The parser discards the input symbol one at a time until one of the designated (like end, semicolon) set of synchronizing tokens (are typically the statement or expression terminators) is found. This is adequate when the presence of multiple errors in the same statement is rare. Example: Consider the erroneous expression- (1 + + 2) + 3. Panic-mode recovery: Skip ahead to the next integer and then continue. Bison: use the special terminal error to describe how much input to skip.
E->int|E+E|(E)|error int|(error)
2. Phase level recovery :
When an error is discovered, the parser performs local correction on the remaining input. If a parser encounters an error, it makes the necessary corrections on the remaining input so that the parser can continue to parse the rest of the statement. You can correct the error by deleting extra semicolons, replacing commas with semicolons, or reintroducing missing semicolons. To prevent going in an infinite loop during the correction, utmost care should be taken. Whenever any prefix is found in the remaining input, it is replaced with some string. In this way, the parser can continue to operate on its execution.
3. Error productions :
The use of the error production method can be incorporated if the user is aware of common mistakes that are encountered in grammar in conjunction with errors that produce erroneous constructs. When this is used, error messages can be generated during the parsing process, and the parsing can continue. Example: write 5x instead of 5*x
4. Global correction :
In order to recover from erroneous input, the parser analyzes the whole program and tries to find the closest match for it, which is error-free. The closest match is one that does not do many insertions, deletions, and changes of tokens. This method is not practical due to its high time and space complexity.
Advantages of Error Handling in Compiler Design:
1.Robustness: Mistake dealing with improves the strength of the compiler by permitting it to deal with and recuperate from different sorts of blunders smoothly. This guarantees that even within the sight of blunders, the compiler can keep handling the information program and give significant mistake messages.
2.Error location: By consolidating blunder taking care of components, a compiler can distinguish and recognize mistakes in the source code. This incorporates syntactic mistakes, semantic blunders, type blunders, and other potential issues that might make the program act startlingly or produce erroneous result.
3.Error revealing: Compiler mistake taking care of works with viable blunder answering to the client or software engineer. It creates engaging blunder messages that assist developers with understanding the nature and area of the mistake, empowering them to effectively fix the issues. Clear and exact mistake messages save designers significant time in the troubleshooting system.
4.Error recuperation: Mistake dealing with permits the compiler to recuperate from blunders and proceed with the aggregation cycle whenever the situation allows. This is accomplished through different methods like blunder adjustment, mistake synchronization, and resynchronization. The compiler endeavors to redress the blunders and continues with assemblage, keeping the whole interaction from being ended unexpectedly.
5.Incremental gathering: Mistake taking care of empowers gradual aggregation, where a compiler can order and execute right partitions of the program regardless of whether different segments contain blunders. This element is especially helpful for enormous scope projects, as it permits engineers to test and investigate explicit modules without recompiling the whole codebase.
6.Productivity improvement: With legitimate mistake taking care of, the compiler diminishes the time and exertion spent on troubleshooting and blunder fixing. By giving exact mistake messages and supporting blunder recuperation, it assists programmers with rapidly recognizing and resolve issues, prompting further developed efficiency and quicker advancement cycles.
7.Language turn of events: Mistake taking care of is a fundamental part of language plan and advancement. By consolidating mistake dealing with systems in the compiler, language fashioners can characterize the normal blunder conduct and authorize explicit standards and imperatives. This adds to the general dependability and consistency of the language, guaranteeing that developers stick to the expected utilization designs.
Disadvantages of error handling in compiler design:
Increased complexity: Error handling in compiler design can significantly increase the complexity of the compiler. This can make the compiler more challenging to develop, test, and maintain. The more complex the error handling mechanism is, the more difficult it becomes to ensure that it is working correctly and to find and fix errors.
Reduced performance: Error handling in compiler design can also impact the performance of the compiler. This is especially true if the error handling mechanism is time-consuming and computationally intensive. As a result, the compiler may take longer to compile programs and may require more resources to operate.
Increased development time: Developing an effective error handling mechanism can be a time-consuming process. This is because it requires significant testing and debugging to ensure that it works as intended. This can slow down the development process and result in longer development times.
Difficulty in error detection: While error handling is designed to identify and handle errors in the source code, it can also make it more difficult to detect errors. This is because the error handling mechanism may mask some errors, making it harder to identify them. Additionally, if the error handling mechanism is not working correctly, it may fail to detect errors altogether.
Next related article – Error detection and Recovery in Compiler
Обработка ошибок и проектирование компилятора
Перевод статьи Error Handling in Compiler Designopen in new window.
Задача по обработке ошибок (Error Handling) включает в себя: обнаружение ошибок, сообщения об ошибках пользователю, создание стратегии восстановления и реализации обработки ошибок. Кроме того система обработки ошибок должна работать быстро.
Типы источников ошибок
Источники ошибок делятся на два типа: ошибки времени выполнения (run-time error) и ошибки времени компиляции (compile-time error).
Ошибки времени выполнения возникают когда программа запущена. Обычно они связаны с неверными входными данными. Примеры таких ошибок: недостаток памяти, конфликт с другим приложением, логические ошибки. Логическая ошибка означает что запуск программы не приводит к ожидаемому результату. Логические ошибки лучше всего обрабатывать тщательным тестированием и отладкой программы.
Ошибки времени компиляции возникают во время компиляции, до запуска программы. Примеры таких ошибок: синтаксическая ошибка или отсутствие файла с кодом на который есть ссылка.
Типы ошибок времени компиляции
Ошибки компиляции разделяются на:
- Лексические (Lexical): включают в себя опечатки идентификаторов, ключевых слов и операторов
- Синтаксические (Syntactical): пропущенная точка с запятой или незакрытая скобка
- Семантические (Semantical): несовместимое значение при присвоении или несовпадение типов между оператором и операндом
- Логические (Logical): недостижимый код, бесконечный цикл
Парсер, обрабатывая текст, пытается как можно раньше обнаружить ошибку. В современных средах разработки синтаксические ошибки отображаются прямо в редакторе кода, предотвращая последующий неверный ввод. Обнажение ошибки происходит когда введённый префикс не совпадает с префиксами строк верными в выбранном языке программирования. Например префикс for(;) может привести к сообщению об ошибке, так как обычно внутри for должно быть две точки с запятой.
Восстановление после ошибок
Базовое требование к компилятору — прервать компиляцию и выдать сообщение при появлении ошибки. Кроме этого есть несколько методов восстановления после ошибки.
Panic mode recovery
Это самый простой способ восстановления после ошибок и он предотвращает бесконечные циклы в компиляторе при попытках исправить ошибку. Парсер отклоняет следующие за ошибкой символы до того как будет обнаружен специальный символ (например, разделитель команд, точка с запятой). Такой подход адекватен если низкая вероятность нескольких ошибок в одной конструкции.
Пример: рассмотрим выражение с ошибкой (1 + + 2) + 3. При обнаружении второго + пропускаются все символы до следующего числа.
Phase level recovery
Производится локальное изменение входного потока чтобы исправить ошибку.
Error productions
Разработчики компиляторов знают часто встречаемые ошибки. При появлении таких ошибок могут применяться расширения грамматики для их обработки. Например: написание 5x вместо 5*x.
Global correction
Производится как можно меньше изменений чтобы преобразовать код с ошибкой в корректный код. Эту стратегию дорого реализовывать.
Время на прочтение
8 мин
Количество просмотров 24K
О чём тут не будет: напоминания базовых конструкций языка и основных моментов о том, как с ними работать; подробного разбора, как работают исключения (писали тут и тут); как грамотно спроектировать ваш класс/программу, чтобы не наломать дров в будущем с гарантией исключений (разве что совсем чуть-чуть, хотя я сам и не очень-то тук-тук).
О чём будет: разные способы обработки ошибок в C++, несколько советов от сообщества и немного заметок о различных жизненных (и не очень) ситуациях.
Текущее состояние дел
Перед тем, как посмотреть, что же есть в C++, давайте вспомним, как с ошибками жили C-программисты. Тут есть несколько опций:
-
возвращать код ошибки. Например заранее определить enum с возможными кодами ошибок:
enum err { OK = 0, UNEXPECTED };
err func(int x, int** result);-
использовать thread-local значения вроде
errno(для windowsGetLastError):
-
передавать отдельную переменную для ошибки:
int* func(int x, err* errcode);-
использовать setjmp/longjmp. В C++ стоит об этом категорически забыть (деструкторы и всё такое).
Почему этого недостаточно? Код возврата/параметр очень легко проигнорировать. Как часто вы проверяли, что вернули scanf/printf? Установку errno ещё легче.
Из-за этих (и ряда других) причин в С++ появились исключения. Их преимущества:
-
код не замусоривается обработкой кодов ошибок. Обработка исключений более менее отделена от логики приложения (если не говнокодить) + на каждый код возврата у вас нет лишнего бранча, который иногда может быть не очень просто предсказать;
-
исключения сложно игнорировать.
И недостатки:
-
flow кода может быть непредсказуем;
-
некоторый оверхед на поддержку исключений. Причём он есть, даже если вы исключения не используете (и не сделали что-то для того, чтобы его не было).
Кроме исключений ещё есть продвинутые коды возвратов. Тут не только значения, но и категории значений, чтобы можно было проверять, относится ли код к какой-то группе (прям как ловить базовый класс исключения вместо конкретных наследников):
std::error_code ec { MY_ERRC, std::errc::not_enough_memory};
...
if (ec == std::errc::not_enough_memory) {…}Спорить о том, что же удобнее и эффективнее, – не самое продуктивное занятие. В языке есть оба инструмента, которые нужно применять исходя из ваших нужд и требований (даже Bjarne Stroustrup писал, что исключения не замена другим возможным техникам обработки). Самый простой пример – исполнение в constexpr-контексте. При выполнении кода с бросанием исключений в constexpr-контексте вы получите ошибку компиляции (это даже как чит используется). Однако вы можете захотеть уметь в compile time обрабатывать ошибки. Тут вам и помогут коды возвратов. Только не std::error_code: эти ребята в constexpr не умеют.
Ещё, грубо говоря, std::optional тоже своего рода механизм обработки ошибок, но семантически его часто используют не для исключительных ситуаций, а для приемлемых ситуаций. Так что well yes but actually no.
Светлое будущее
Следующим шагом для стандартного C++ является пропозал по введению std::expected<T, E> (аналог Result<T, E> из Rust). Здесь возвращается либо результат, либо сконструированное исключение (или std::error_code, int, MyErrorClass и что угодно ещё). Есть хороший доклад Andrei Alexandrescu на CppCon2018 про это. Можно посмотреть вариант базовой реализации.
Всё новое хорошо забытое старое…
Вообще подобные штуки можно было делать и раньше, например с помощью std::exception_ptr, std::current_exception и std::rethrow_exception. Ловите ваше исключение и работаете с ним, как объектом, пока не нужно бросить его дальше. Но идея std::expected это всё-таки уровень повыше: у вас всегда пара значений, в которой есть только что-то одно.
Мне нравятся варианты с корутинами, если не обращать внимания на неприятные глазу приставки co_ к половине операторов. Например такой, где они совмещаются со std::expected и всё это варится в виде монад, что позволяет напрямую не обрабатывать ошибки без необходимости:
struct error {
int code;
};
expected<int, error> f1() { return 7; }
expected<double, error> f2(int x) { return 2.0 * x; }
expected<int, error> f3(int x, double y) { return error{42}; }
auto test_expected_coroutine() {
return []() -> expected<int, error> {
auto x = co_await f1();
auto y = co_await f2(x);
auto z = co_await f3(x, y);
co_return z;
}();
}Или вот замечательный доклад про подобное в другом виде. Хотя конечно на практике такое не очень используется, потому что могут быть проблемы с производительностью.
Рядом с пропозалом о std::expected ещё есть пропозал об operator try() (что-то вроде operator ? из Rust), который помогает писать меньше кода. Автор предлагает ввести понятную конструкцию, чтобы не приходилось абузить корутины для достижения таких же результатов. Правда она в перспективе не дойдёт до стандарта до C++29.
Самой конфетой является предложение Herb Sutter про использование статических исключений. Пример из пропозала:
string f() throws {
if (flip_a_coin()) throw arithmetic_error::something;
return “xyzzy”s + “plover”; // any dynamic exception is translated to error
}
string g() throws { return f() + “plugh”; } // any dynamic exception is translated to error
int main() {
try {
auto result = g();
cout << “success, result is: ” << result;
}
catch(error err) { // catch by value is fine
cout << “failed, error is: ” << err.error();
}
}
Появляется новое ключевое слово throws, которое означает, что функция возвращает на самом деле (грубо говоря) std::expected<T, error_code>, а все throw в функции — на самом деле return, который возвращает код ошибки. И теперь можно будет писать всегда либо throws, либо noexcept. Ещё тут предлагается расширить кейсы использования ключевого слова try: использовать вместе с/вместо return, при инициализации, использовать при передаче аргументов функций. Немного синтаксического сахара при использовании catch. А ещё предлагаемая модель является real-time safe (это когда время работы инструмента/механизма ограничено сверху известной величиной) в отличие от текущей реализации исключений. Однако работа над этим пропозалом не велась с 2019, и что с ним и как непонятно.
Как альтернатива есть статья James Renwick о другой реализации такого же механизма, как у Herb Sutter, но она подразумевает слом ABI, что почти наверняка в ближайшие годы не случится.
Набросы
Часто считается плохой практикой бросать что-то не унаследованное от стандартных ошибок. И тут (как и со своими типами) стоит быть аккуратным:
struct e1 : std::exception {};
struct e2 : std::exception {};
struct e3 : ex1, ex2 {};
int main() {
try { throw_e3(); }
catch(std::exception& e) {}
catch(...) {}
}Т.к. у e3 несколько предков std::exception => компилятор не сможет понять, к какому именно std::exception нужно привести объект e3, потому это исключение будет отловлено в catch(...). При виртуальном наследовании e1, e2 от std::exception всё работает как ожидается.
Знатные маслины можно ловить при бросании исключений откуда не надо. Например, у стандартной библиотеки есть некоторые инварианты, без которых написание кода стало бы ужасной мукой (а может и вовсе невозможным). Одним из них является предположение, что деструкторы, операции удаления и swap не бросают исключений, потому хорошо бы помечать их noexcept. Если по каким-то причинам внутри что-то может вылететь, на месте (прям до выхода из функции/методов) ловите исключения и пытайтесь исправить ситуацию, чтобы состояние программы осталось валидным. По-хорошему ещё и move-операции должны быть небросающими, т.к. это открывает путь к более эффективному коду (классический пример это использование std::move_if_noexcept в std::vector).
Собственно с деструкторами и начинается самый флекс: если исключение вылетает при раскрутке стека, вы сразу ловите std::terminate. Бороться с такими проблемами можно разными способами. Самый хороший – не бросать исключения из деструкторов. Если очень хочется, юзайте noexcept(false), но лучше отбросьте эти богохульные мысли и идите спать. Чуть больше про это можно почитать вот тут.
Интересные штуки ещё можно делать со статическими переменными. Во-первых, их инициализация происходит атомарно. Во-вторых, только один раз. Т.е. если вы хотите выполнить какой-то единожды, вы можете сделать следующее:
[[maybe_unused]] static bool unused = [] {
std::cout << "printed once" << std::endl;
return true;
}();А что, если хочется выполнить какой-то код ровно n раз? Тут можно воспользоваться фактом, что, если при инициализации вылетает исключение, переменная не инициализируется и попытается инициализироваться в следующий раз:
struct Throwed {};
constexpr int n = 3;
void init() {
try {
[[maybe_unused]] static bool unused = [] {
static int called = 0;
std::cout << "123" << std::endl;
if (++called < n) {
throw Throwed{};
}
return true;
}();
} catch (Throwed) {}
}Но это тоже говнокод ¯\_(ツ)_/¯.
Какие-то рекомендации
Набросы из личного опыта и советов из интернетов, которые, к сожалению, получилось прочувствовать на себе:
-
Исключения задумывались в мире, где существуют деструкторы, а значит и RAII. Используйте эту идиому максимально, если речь идёт об освобождении ресурсов.
Если для ситуации RAII подходит недостаточно (нужно совершить не очистку ресурсов, а просто набор действий), сообразите что-то вроде gsl::finally.
-
Используйте исключения, если в конструкторе объекта становится понятно, что объект создать невозможно (раз, два). Тут так-то других вариантов особо и нет: возвращаемое значение у конструкторов не предусмотрено. Можно конечно завести условный метод
IsValidи обмазаться конструкциями сif, но имхо не оч удобно. -
Можно использовать исключения для проверки пред-/постусловий.
-
В силу непредсказуемости flow выполнения вашего кода из-за исключений, можно с ними знатные приколы мутить. Встречались кейсы, когда исключения использовались для выхода из глубокой рекурсии, нескольких циклов сразу или, внезапно, даже возврата значения из функции. Не делайте так. Исключения они на то и исключения, чтобы детектить ошибки. Exceptions are for exceptional.
-
Но не переусердствуйте с ловлей исключений. Хорошо, когда вы ожидаете какую-то конкретную ошибку и ловите именно её. Думаю, вы тоже видели код с конструкциями вида
catch (...) {}, потому что “ну там какие-то исключения вылетают, а падать не хочется”. Разберитесь с этим и контролируйте (может у вас есть действительно хорошие примеры, где это наилучшее решение; тогда расскажите в комментариях). -
Если не можете обработать исключение, делайте аборт (
std::abort/std::terminate/std::exit/std::quick_exit). -
Старайтесь ловить исключения так, чтобы они копировались минимальное количество раз (с помощью ссылок/указателей/
exception_ptr). В идеале ноль.
Ещё немного набросов
В некоторых проектах исключения вообще стараются не использовать, т.к. это не очень эффективно (размотка стека и проблемы с некоторыми оптимизациями). В таких случаях применяются другие подходы обработки ошибок (например падение). Тут же есть практики постоянно писать noexcept. Это хорошая практика, но всё же стоит быть осторожным, т.к. это часть интерфейса. Короче пользуйтесь с умом.
Если вы точно не хотите использовать исключения, можно компилировать ваш проект с -fno-exceptions, что позволяет не поддерживать исключения при компиляции -> открыть возможности для новых оптимизаций (будьте готовы к разным неожиданным эффектам; например стандартная библиотека станет падать там, где раньше вылетали исключения).
Вы можете использовать function-try-block для ловли исключений из всей функции/конструкторов со списками инициализации:
struct S {
MyClass x;
S(MyClass& x) try : x(x) {
} catch (MyClassInitializationException& ex) {...}
};Но имейте в виду некоторые возможные проблемы.
Мне нравится как принято работать с ошибками в Golang: вы словили её, добавили к сообщению какую-то информацию и бросили дальше, чтобы в итоге сообщение у ошибки получилось примерно такое: “topFunc: secondFunc: firstFunc: some error text”. Довольно удобно (по крайней мере в Go), если у вас похожая парадигма работы с ошибками и нет stacktrace рядом с исключениями. Однако в C++ стоит быть осторожным, потому что есть механизм std::throw_with_nested, который совсем о другом. Концептуально тут всё просто: у исключений может быть вложенное исключение, которое можно достать из родительского исключения. Получается, можно сделать дерево в виде цепочки из исключений (прямо как в Java есть cause у исключений, но там этот механизм чуть шире и делать так принято). Имхо если вы такое используете, у вас какие-то архитектурные проблемы, так что перед написанием новых велосипедов, задумайтесь, всё ли в порядке.
Бесполезный (но забавный) факт. Вот такой код вполне себе корректен: throw nothrow.
Несмешная нешутка.
*шутка про то, что C++ – ошибка, которую не сумели правильно обработать*
Реклама.
Можете подписаться на канал о C++ и программировании в целом в тг: t.me/thisnotes.
Обработка ошибок
Каждая фаза компиляции может обнаружить ошибки в транслируемой программе. После обнаружения ошибки фаза должна каким-то образом справиться с возникшей ситуацией. Иными словами, процесс компиляции должен быть продолжен, причем так, чтобы была возможность поиска следующих ошибок в исходной программе. Компилятор, который останавливается после обнаружения первой ошибки, не может быть признан достаточно хорошим. Впрочем, в некоторых ситуациях это вполне приемлемо. Такие ситуации возникают, например, если разрабатывается диалоговый транслятор, который будет использоваться в учебных целях, поскольку начинающему программисту, с одной стороны, вполне достаточно получать информацию об одной ошибке, с другой стороны, получение информации сразу о большом количестве ошибках может его дезориентировать. Одно из основных требований, предъявляемых промышленным трансляторам, заключается в том, чтобы пользователь получил как можно больше корректных ошибок за одну трансляцию. Мы не зря использовали прилагательное «корректные», говоря об ошибках, которые обнаруживает компилятор. Дело в том, что иногда трансляторы выдают информацию о так называемых «наведенных» ошибках. Наведенные ошибки, т.е. такие, которых в программе на самом деле нет, могут возникнуть в результате не совсем корректной работы транслятора после обнаружения какой-нибудь ошибки.
Наибольшая доля ошибок приходится, как правило, на две фазы: синтаксический анализ и фазу контроля типов. Лексический анализатор может обнаружить только те ошибки, которые связаны, например, с использованием неверных литер, или если выделенная лексема не принадлежит ни одному из лексических классов языка. Количество типов ошибок, которые может обнаружить фаза лексического анализа, весьма незначительно, поскольку лексический анализатор «видит» только небольшой, локальный, участок программы. Например, лексический анализатор не сможет обнаружить ошибку в следующем контексте:
Ошибки, связанные с нарушением синтаксической структуры исходной программы, определяются на фазе синтаксического анализа. Ошибки, возникающие на фазе контроля типов, связаны с неверным использованием идентификаторов, с некорректной передачей фактических параметров процедурам и т.п.
Обычно, фазы оптимизации и генерации не обнаруживают ошибки, хотя и здесь бывают исключения. Например, представим себе, что в реализуемом языке определено присваивание одной структуры другой по именам полей. Это означает, что если у нас есть две структуры, то присваивание одной структуры другой будет иметь эффект в том случае, если обе из этих структур имеют по крайней мере одну пару одинаковых выделителей полей. При таком определении присваивания структур, компилятор, должен проверить, возможно ли такое присваивание, и если все выделители полей структур различны, должен выдать сообщение об ошибке. Понятно, что ситуация такого рода станет ясна только после контроля типов. Кроме того, поскольку компилятор должен выполнить так называемую «расклейку» присваивания (т.е. преобразовать исходное присваивание в одно или несколько присваиваний соответствующих полей), то такого рода действия можно считать оптимизирующими и, соответственно, сообщение об ошибке в случае, если все имена полей структуры-получателя и структуры-источника различны, будет выдавать фаза оптимизации.
Информация, необходимая для выдачи сообщения об ошибке
В однопросмотровом компиляторе все фазы выполняются параллельно. Если возникает ошибка в исходной программе, то текущая позиция лексического анализатора является приемлемой аппроксимацией позиции исходной программы, содержащей ошибку. В таком компиляторе лексический анализатор сохраняет текущую позицию в глобальной переменной. Процедура, предназначенная для выдачи сообщений об ошибках, печатает сообщение об ошибке и значение переменной, содержащей текущую позицию.
Компиляторы, состоящие более чем из одного просмотра, часто выполняют синтаксический анализ и типовой анализ на разных просмотрах. Естественно, это облегчает жизнь в различных аспектах, но существенно усложняет выдачу сообщений о типовых ошибках. Лексический анализатор достигает конца исходной программы раньше, чем начнет выполняться фаза контроля типов. Контроль типов осуществляется во время обхода синтаксического дерева, поэтому невозможно использовать текущую позицию в исходной программе, которую поддерживает лексический анализатор, для выдачи информации об ошибке. Поэтому каждый узел синтаксического дерева должен содержать позицию соответствующей ему конструкции в исходном файле, т.е. структура, определяющая узел дерева, должна содержать поле pos, предназначенное для этой цели. Это поле pos само является структурой из двух полей: номера строки исходной программы и номера позиции в строке. Понятно, что текущая позиция первоначально определяется лексическим анализатором (оно является одним из полей структуры Lexeme ), а затем передается синтаксическому анализатору, который и помещает это значение в поле pos узла синтаксического дерева. Для более точного определения позиции в исходном файле каждый узел синтаксического дерева обычно содержит два поля, определяющих положение конструкции, а именно, позицию начала конструкции и позицию ее конца ( beg_pos и end_pos соответственно).
В C++ различают ошибки времени компиляции и ошибки времени выполнения. Ошибки первого типа обнаруживает компилятор до запуска программы. К ним относятся, например, синтаксические ошибки в коде. Ошибки второго типа проявляются при запуске программы. Примеры ошибок времени выполнения: ввод некорректных данных, некорректная работа с памятью, недостаток места на диске и т. д. Часто такие ошибки могут привести к неопределённому поведению программы.
Некоторые ошибки времени выполнения можно обнаружить заранее с помощью проверок в коде. Например, такими могут быть ошибки, нарушающие инвариант класса в конструкторе. Обычно, если ошибка обнаружена, то дальнейшее выполение функции не имеет смысла, и нужно сообщить об ошибке в то место кода, откуда эта функция была вызвана. Для этого предназначен механизм исключений.
Коды возврата и исключения
Рассмотрим функцию, которая считывает со стандартного потока возраст и возвращает его вызывающей стороне. Добавим в функцию проверку корректности возраста: он должен находиться в диапазоне от 0 до 128 лет. Предположим, что повторный ввод возраста в случае ошибки не предусмотрен.
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
// Что вернуть в этом случае?
}
return age;
}
Что вернуть в случае некорректного возраста? Можно было бы, например, договориться, что в этом случае функция возвращает ноль. Но тогда похожая проверка должна быть и в месте вызова функции:
int main() {
if (int age = ReadAge(); age == 0) {
// Произошла ошибка
} else {
// Работаем с возрастом age
}
}
Такая проверка неудобна. Более того, нет никакой гарантии, что в вызывающей функции программист вообще её напишет. Фактически мы тут выбрали некоторое значение функции (ноль), обозначающее ошибку. Это пример подхода к обработке ошибок через коды возврата. Другим примером такого подхода является хорошо знакомая нам функция main. Только она должна возвращать ноль при успешном завершении и что-либо ненулевое в случае ошибки.
Другим способом сообщить об обнаруженной ошибке являются исключения. С каждым сгенерированным исключением связан некоторый объект, который как-то описывает ошибку. Таким объектом может быть что угодно — даже целое число или строка. Но обычно для описания ошибки заводят специальный класс и генерируют объект этого класса:
#include <iostream>
struct WrongAgeException {
int age;
};
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Здесь в случае ошибки оператор throw генерирует исключение, которое представлено временным объектом типа WrongAgeException. В этом объекте сохранён для контекста текущий неправильный возраст age. Функция досрочно завершает работу: у неё нет возможности обработать эту ошибку, и она должна сообщить о ней наружу. Поток управления возвращается в то место, откуда функция была вызвана. Там исключение может быть перехвачено и обработано.
Перехват исключения
Мы вызывали нашу функцию ReadAge из функции main. Обработать ошибку в месте вызова можно с помощью блока try/catch:
int main() {
try {
age = ReadAge(); // может сгенерировать исключение
// Работаем с возрастом age
} catch (const WrongAgeException& ex) { // ловим объект исключения
std::cerr << "Age is not correct: " << ex.age << "\n";
return 1; // выходим из функции main с ненулевым кодом возврата
}
// ...
}
Мы знаем заранее, что функция ReadAge может сгенерировать исключение типа WrongAgeException. Поэтому мы оборачиваем вызов этой функции в блок try. Если происходит исключение, для него подбирается подходящий catch-обработчик. Таких обработчиков может быть несколько. Можно смотреть на них как на набор перегруженных функций от одного аргумента — объекта исключения. Выбирается первый подходящий по типу обработчик и выполняется его код. Если же ни один обработчик не подходит по типу, то исключение считается необработанным. В этом случае оно пробрасывается дальше по стеку — туда, откуда была вызвана текущая функция. А если обработчик не найдётся даже в функции main, то программа аварийно завершается.
Усложним немного наш пример, чтобы из функции ReadAge могли вылетать исключения разных типов. Сейчас мы проверяем только значение возраста, считая, что на вход поступило число. Но предположим, что поток ввода досрочно оборвался, или на входе была строка вместо числа. В таком случае конструкция std::cin >> age никак не изменит переменную age, а лишь возведёт специальный флаг ошибки в объекте std::cin. Наша переменная age останется непроинициализированной: в ней будет лежать неопределённый мусор. Можно было бы явно проверить этот флаг в объекте std::cin, но мы вместо этого включим режим генерации исключений при таких ошибках ввода:
int ReadAge() {
std::cin.exceptions(std::istream::failbit);
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Теперь ошибка чтения в операторе >> у потока ввода будет приводить к исключению типа std::istream::failure. Функция ReadAge его не обрабатывает. Поэтому такое исключение покинет пределы этой функции. Поймаем его в функции main:
int main() {
try {
age = ReadAge(); // может сгенерировать исключения разных типов
// Работаем с возрастом age
} catch (const WrongAgeException& ex) {
std::cerr << "Age is not correct: " << ex.age << "\n";
return 1;
} catch (const std::istream::failure& ex) {
std::cerr << "Failed to read age: " << ex.what() << "\n";
return 1;
} catch (...) {
std::cerr << "Some other exception\n";
return 1;
}
// ...
}
При обработке мы воспользовались функцией ex.what у исключения типа std::istream::failure. Такие функции есть у всех исключений стандартной библиотеки: они возвращают текстовое описание ошибки.
Обратите внимание на третий catch с многоточием. Такой блок, если он присутствует, будет перехватывать любые исключения, не перехваченные ранее.
Исключения стандартной библиотеки
Функции и классы стандартной библиотеки в некоторых ситуациях генерируют исключения особых типов. Все такие типы выстроены в иерархию наследования от базового класса std::exception. Иерархия классов позволяет писать обработчик catch сразу на группу ошибок, которые представлены базовым классом: std::logic_error, std::runtime_error и т. д.
Вот несколько примеров:
-
Функция
atу контейнеровstd::array,std::vectorиstd::dequeгенерирует исключениеstd::out_of_rangeпри некорректном индексе. -
Аналогично, функция
atуstd::map,std::unordered_mapи у соответствующих мультиконтейнеров генерирует исключениеstd::out_of_rangeпри отсутствующем ключе. -
Обращение к значению у пустого объекта
std::optionalприводит к исключениюstd::bad_optional_access. -
Потоки ввода-вывода могут генерировать исключение
std::ios_base::failure.
Исключения в конструкторах
В параграфе 3.1 мы написали класс Time. Этот класс должен был соблюдать инвариант на значение часов, минут и секунд: они должны были быть корректными. Если на вход конструктору класса Time передавались некорректные значения, мы приводили их к корректным, используя деление с остатком.
Более правильным было бы сгенерировать в конструкторе исключение. Таким образом мы бы явно передали сообщение об ошибке во внешнюю функцию, которая пыталась создать объект.
class Time {
private:
int hours, minutes, seconds;
public:
// Заведём класс для исключения и поместим его внутрь класса Time как в пространство имён
class IncorrectTimeException {
};
Time::Time(int h, int m, int s) {
if (s < 0 || s > 59 || m < 0 || m > 59 || h < 0 || h > 23) {
throw IncorrectTimeException();
}
hours = h;
minutes = m;
seconds = s;
}
// ...
};
Генерировать исключения в конструкторах — совершенно нормальная практика. Однако не следует допускать, чтобы исключения покидали пределы деструкторов. Чтобы понять причины, посмотрим подробнее, что происходит при генерации исключения.
Свёртка стека
Вспомним класс Logger из предыдущего параграфа. Посмотрим, как он ведёт себя при возникновении исключения. Воспользуемся в этом примере стандартным базовым классом std::exception, чтобы не писать свой класс исключения.
#include <exception>
#include <iostream>
void f() {
std::cout << "Welcome to f()!\n";
Logger x;
// ...
throw std::exception(); // в какой-то момент происходит исключение
}
int main() {
try {
Logger y;
f();
} catch (const std::exception&) {
std::cout << "Something happened...\n";
return 1;
}
}
Мы увидим такой вывод:
Logger(): 1 Welcome to f()! Logger(): 2 ~Logger(): 2 ~Logger(): 1 Something happened...
Сначала создаётся объект y в блоке try. Затем мы входим в функцию f. В ней создаётся объект x. После этого происходит исключение. Мы должны досрочно покинуть функцию. В этот момент начинается свёртка стека (stack unwinding): вызываются деструкторы для всех созданных объектов в самой функции и в блоке try, как если бы они вышли из своей области видимости. Поэтому перед обработчиком исключения мы видим вызов деструктора объекта x, а затем — объекта y.
Аналогично, свёртка стека происходит и при генерации исключения в конструкторе. Напишем класс с полем Logger и сгенерируем нарочно исключение в его конструкторе:
#include <exception>
#include <iostream>
class C {
private:
Logger x;
public:
C() {
std::cout << "C()\n";
Logger y;
// ...
throw std::exception();
}
~C() {
std::cout << "~C()\n";
}
};
int main() {
try {
C c;
} catch (const std::exception&) {
std::cout << "Something happened...\n";
}
}
Вывод программы:
Logger(): 1 // конструктор поля x C() Logger(): 2 // конструктор локальной переменной y ~Logger(): 2 // свёртка стека: деструктор y ~Logger(): 1 // свёртка стека: деструктор поля x Something happened...
Заметим, что деструктор самого класса C не вызывается, так как объект в конструкторе не был создан.
Механизм свёртки стека гарантирует, что деструкторы для всех созданных автоматических объектов или полей класса в любом случае будут вызваны. Однако он полагается на важное свойство: деструкторы самих классов не должны генерировать исключений. Если исключение в деструкторе произойдёт в момент свёртки стека при обработке другого исключения, то программа аварийно завершится.
Пример с динамической памятью
Подчеркнём, что свёртка стека работает только с автоматическими объектами. В этом нет ничего удивительного: ведь за временем жизни объектов, созданных в динамической памяти, программист должен следить самостоятельно. Исключения вносят дополнительные сложности в ручное управление динамическими объектами:
void f() {
Logger* ptr = new Logger(); // конструируем объект класса Logger в динамической памяти
// ...
g(); // вызываем какую-то функцию
// ...
delete ptr; // вызываем деструктор и очищаем динамическую память
}
На первый взгляд кажется, что в этом коде нет ничего опасного: delete вызывается в конце функции. Однако функция g может сгенерировать исключение. Мы не перехватываем его в нашей функции f. Механизм свёртки уберёт со стека лишь сам указатель ptr, который является автоматической переменной примитивного типа. Однако он ничего не сможет сделать с объектом в памяти, на которую ссылается этот указатель. В логе мы увидим только вызов конструктора класса Logger, но не увидим вызова деструктора. Нам придётся обработать исключение вручную:
void f() {
Logger* ptr = new Logger();
// ...
try {
g();
} catch (...) { // ловим любое исключение
delete ptr; // вручную удаляем объект
throw; // перекидываем объект исключения дальше
}
// ...
delete ptr;
}
Здесь мы перехватываем любое исключение и частично обрабатываем его, удаляя объект в динамической памяти. Затем мы прокидываем текущий объект исключения дальше с помощью оператора throw без аргументов.
Согласитесь, этот код очень далёк от совершенства. При непосредственной работе с объектами в динамической памяти нам приходится оборачивать в try/catch любую конструкцию, из которой может вылететь исключение. Понятно, что такой код чреват ошибками. В параграфе 3.6 мы узнаем, как с точки зрения C++ следует работать с такими ресурсами, как память.
Гарантии безопасности исключений
Предположим, что мы пишем свой класс-контейнер, похожий на двусвязный список. Наш контейнер позволяет добавлять элементы в хранилище и отдельно хранит количество элементов в некотором поле elementsCount. Один из инвариантов этого класса такой: значение elementsCount равно реальному числу элементов в хранилище.
Не вдаваясь в детали, давайте посмотрим, как могла бы выглядеть функция добавления элемента.
template <typename T>
class List {
private:
struct Node { // узел двусвязного списка
T element;
Node* prev = nullptr; // предыдущий узел
Node* next = nullptr; // следующий узел
};
Node* first = nullptr; // первый узел списка
Node* last = nullptr; // последний узел списка
int elementsCount = 0;
public:
// ...
size_t Size() const {
return elementsCount;
}
void PushBack(const T& elem) {
++elementsCount;
// Конструируем в динамической памяти новой узел списка
Node* node = new Node(elem, last, nullptr);
// Связываем новый узел с остальными узлами
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
}
};
Не будем здесь рассматривать другие функции класса — конструкторы, деструктор, оператор присваивания… Рассмотрим функцию PushBack. В ней могут произойти такие исключения:
-
Выражение
newможет сгенерировать исключениеstd::bad_allocиз-за нехватки памяти. -
Конструктор копирования класса
Tможет сгенерировать произвольное исключение. Этот конструктор вызывается при инициализации поляelementсоздаваемого узла в конструкторе классаNode. В этом случаеnewведёт себя как транзакция: выделенная перед этим динамическая память корректно вернётся системе.
Эти исключения не перехватываются в функции PushBack. Их может перехватить код, из которого PushBack вызывался:
#include <iostream>
class C; // какой-то класс
int main() {
List<C> data;
C element;
try {
data.PushBack(element);
} catch (...) { // не получилось добавить элемент
std::cout << data.Size() << "\n"; // внезапно 1, а не 0
}
// работаем дальше с data
}
Наша функция PushBack сначала увеличивает счётчик элементов, а затем выполняет опасные операции. Если происходит исключение, то в классе List нарушается инвариант: значение счётчика elementsCount перестаёт соответствовать реальности. Можно сказать, что функция PushBack не даёт гарантий безопасности.
Всего выделяют четыре уровня гарантий безопасности исключений (exception safety guarantees):
-
Гарантия отсутствия сбоев. Функции с такими гарантиями вообще не выбрасывают исключений. Примерами могут служить правильно написанные деструктор и конструктор перемещения, а также константные функции вида
Size. -
Строгая гарантия безопасности. Исключение может возникнуть, но от этого объект нашего класса не поменяет состояние: количество элементов останется прежним, итераторы и ссылки не будут инвалидированы и т. д.
-
Базовая гарантия безопасности. При исключении состояние объекта может поменяться, но оно останется внутренне согласованным, то есть, инварианты будут соблюдаться.
-
Отсутствие гарантий. Это довольно опасная категория: при возникновении исключений могут нарушаться инварианты.
Всегда стоит разрабатывать классы, обеспечивающие хотя бы базовую гарантию безопасности. При этом не всегда возможно эффективно обеспечить строгую гарантию.
Переместим в нашей функции PushBack изменение счётчика в конец:
void PushBack(const T& elem) {
Node* node = new Node(elem, last, nullptr);
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
++elementsCount; // выполнится только если раньше не было исключений
}
Теперь такая функция соответствует строгой гарантии безопасности.
В документации функций из классов стандартной библиотеки обычно указано, какой уровень гарантии они обеспечивают. Рассмотрим, например, гарантии безопасности класса std::vector.
-
Деструктор, функции
empty,size,capacity, а такжеclearпредоставляют гарантию отсутствия сбоев. -
Функции
push_backиresizeпредоставляют строгую гарантию. -
Функция
insertпредоставляет лишь базовую гарантию. Можно было бы сделать так, чтобы она предоставляла строгую гарантию, но за это пришлось бы заплатить её эффективностью: при вставке в середину вектора пришлось бы делать реаллокацию.
Функции класса, которые гарантируют отсутствие сбоев, следует помечать ключевым словом noexcept:
class C {
public:
void f() noexcept {
// ...
}
};
С одной стороны, эта подсказка позволяет компилятору генерировать более эффективный код. С другой — эффективно обрабатывать объекты таких классов в стандартных контейнерах. Например, std::vector<C> при реаллокации будет использовать конструктор перемещения класса C, если он помечен как noexcept. В противном случае будет использован конструктор копирования, который может быть менее эффективен, но зато позволит обеспечить строгую гарантию безопасности при реаллокации.