Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5
Санкт-Петербургский
Государственный Политехнический
Университет
Доклад на тему:
“Коды
исправляющие ошибки”
Выполнил
студент гр. 5091/1 (подпись)
А.Э. Кузнецов
Руководитель
(подпись)
Д. В. Дикий
«_____»
июнь 2014г.
Санкт
– Петербург,
2014г.
Содержание:
-
Введение…………………………………………………………………..3
-
Коды
с обнаружением и исправлением
ошибок………..…………….4 -
Коды
с обнаружением ошибок……………………………..…………10 -
Непомехозащищенные
коды………………………………………….15 -
Список
литературы…………………………………………………….18
Введение
Обнаружение
ошибок в
технике связи —
действие, направленное на контроль
целостности данных при
записи/воспроизведении информации или
при её передаче по линиям связи. Исправление
ошибок (коррекция
ошибок) —
процедура восстановления информации
после чтения её из устройства хранения
или канала связи.
Для
обнаружения ошибок используют коды
обнаружения ошибок,
для исправления — корректирующие
коды (коды,
исправляющие ошибки, коды
с коррекцией ошибок, помехоустойчивые
коды)
Способы
борьбы с ошибками
В
процессе хранения данных и передачи
информации по сетям связи неизбежно
возникают ошибки. Контроль целостности
данных и исправление ошибок — важные
задачи на многих уровнях работы с
информацией (в
частности, физическом, канальном, транспортном уровнях сетевой
модели OSI).
В
системах связи возможны несколько
стратегий борьбы с ошибками:
обнаружение
ошибок в блоках данных и автоматический
запрос повторной передачи повреждённых
блоков — этот подход применяется, в
основном, на канальном и транспортном
уровнях; обнаружение ошибок в блоках
данных и отбрасывание повреждённых
блоков — такой подход иногда
применяется в системах потокового
мультимедиа, где важна задержка передачи
и нет времени на повторную передачу;
исправление ошибок (англ. forward
error correction) применяется на физическом
уровне.
Если
кодовые комбинации составлены так, что
они отличаются друг от друга на кодовое
расстояние d ≥3,
то они образуют корректирующий код,
который позволяет по имеющейся в кодовой
комбинации избыточности обнаруживать
и исправлять ошибки.
Корректирующие
коды делятся на систематические и
несистематические.
Систематическим
или линейным, кодом называется код,
имеющий постоянную длину и четкое
деление всех кодовых элементов на
информационные k и
контрольные m элементы,
занимающие определенные места в
комбинациях.
Составление
корректирующих кодов производится
примерно по следующему правилу. Сначала
определяется количество контрольных
символов m, которое следует добавить к
данной кодовой комбинации, состоящей
из k
информационных
символов. Далее устанавливается место,
где эти контрольные символы должны быть
расставлены в комбинации, и их состав,
то есть является ли данный контрольный
символ 1 или 0. На приеме обычно применяется
проверка на четность определенной части
разрядов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Содержание
- 1 Способы борьбы с ошибками
- 2 Коды обнаружения и исправления ошибок
- 2.1 Блоковые коды
- 2.1.1 Линейные коды общего вида
- 2.1.1.1 Минимальное расстояние и корректирующая способность
- 2.1.1.2 Коды Хемминга
- 2.1.1.3 Общий метод декодирования линейных кодов
- 2.1.2 Линейные циклические коды
- 2.1.2.1 Порождающий (генераторный) полином
- 2.1.2.2 Коды CRC
- 2.1.2.3 Коды БЧХ
- 2.1.2.4 Коды коррекции ошибок Рида — Соломона
- 2.1.3 Преимущества и недостатки блоковых кодов
- 2.1.1 Линейные коды общего вида
- 2.2 Свёрточные коды
- 2.2.1 Преимущества и недостатки свёрточных кодов
- 2.3 Каскадное кодирование. Итеративное декодирование
- 2.4 Сетевое кодирование
- 2.5 Оценка эффективности кодов
- 2.5.1 Граница Хемминга и совершенные коды
- 2.5.2 Энергетический выигрыш
- 2.6 Применение кодов, исправляющих ошибки
- 2.1 Блоковые коды
- 3 Автоматический запрос повторной передачи
- 3.1 Запрос ARQ с остановками (stop-and-wait ARQ)
- 3.2 Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
- 3.3 Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
- 4 См. также
- 5 Литература
- 6 Ссылки
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется, в основном, на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (англ. forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки, делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной  бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной  бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число  называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет  проверочных, такой код называется систематическим, иначе — несистематическим.
проверочных, такой код называется систематическим, иначе — несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако хороший код должен удовлетворять как минимум следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его  ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу  , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а  — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и  называется количество отличных бит на соответствующих позициях:
называется количество отличных бит на соответствующих позициях:
 .
.

Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
- .

Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кодового слова
) можно гарантированно исправить. То есть вокруг каждого кодового слова  имеем
имеем  -окрестность
-окрестность  , которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом, получив искажённую кодовую комбинацию из , декодер принимает решение, что исходной была кодовая комбинация , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и, в частности, к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и, в частности, к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.


Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному  . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC
Коды CRC (англ. cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путём деления  на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| Название кода | Степень | Полином |
|---|---|---|
| CRC-12 | 12 | 
|
| CRC-16 | 16 | 
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды

Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Сетевое кодирование
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
Пусть имеется двоичный блоковый  код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также
- Цифровая связь
- Код ответа (Код причины завершения)
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / пер. с англ. В. Б. Афанасьева. — М.: Техносфера, 2006. — 320 с. — (Мир связи). — 2000 экз. — ISBN 5-94836-035-0.
Ссылки
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006. Архивировано 25 августа 2011 года.
- Коды Рида-Соломона. Простой пример. Просто, доступно, на конкретных числах. Для начинающих.
Реферат: Коды с обнаружением и исправлением ошибок
Компьютер при передаче данных между устройствами и при выполнении вычислений может делать ошибки из-за сбоев и отказов аппаратуры. Если компьютер не оснащен средствами для обнаружения и исправления ошибок, то необнаруженные ошибки приводят к сколь угодно серьезным искажениям результатов вычислений, и компьютер становится источником дезинформации пользователей. В связи с этим большинство компьютеров оснащаются средствами, обеспечивающими контроль работоспособности аппаратуры компьютеров за счет увеличения длины байтов, слов и сегментов данных на некоторое число битов, с помощью которых обеспечивается возможность обнаружения и исправления ошибок в передаваемых и обрабатываемых данных, т.е. за счет использования специальным образом представленных данных – кодированных байтов, слов и сегментов.
Наиболее простой способ кодирования данных – присоединение к данным одного бита четности. Например, байт данных представляется двоичной последовательностью
10110011.
Бит четности формируется за счет присоединения к байту одного бита, формируемого следующим образом: если число единиц в байте четно, то бит четности равен 0, если число единиц в байте нечетно, то бит четности равен 1. Таким образом, указанный байт с битом четности имеет следующую структуру:
10110011 1 ,
Байт Бит
четности
где бит имеет значение 1. Ясно, что при указанном правиле вычисления значения бита четности, число битов в кодированном байте всегда четно, в результате чего всякая одиночная ошибка в кодированном байте будет обнаружена. Впрочем, будут обнаружены и 3-, 5-, 7- и 9-кратные ошибки, но не поддаются обнаружению 2-, 4- и 8- кратные ошибки. Бит четности формируется аппаратурой компьютера крайне просто и обеспечивает защиту от многих ошибок.
Для обнаружения и исправления ошибок теория информации предлагает значительное число различных методов. Ясно, что с увеличением длины данных, определяемой длиной битов в данных, должно увеличиваться число контрольных разрядов, присоединяемых к данным для обнаружения и исправления ошибок. Число контрольных разрядов, необходимое для кода, способного обнаруживать и исправлять ошибки по методу Хэмминга, представлено в табл. 3.1.
Таблица 3.1.Число контрольных разрядов кода, способного обнаруживать и исправлять ошибки
| Длина данных, бит | Количество контрольных разрядов, бит | Общая длина данных, бит | Увеличение длины данных, % |
Из таблицы видно, что для обнаружения и исправления одиночной ошибки к байту данных необходимо добавить четыре контрольных разряда, в результате чего длина кодирование сегмента данных будет равна 12 разрядам при увеличении длины кодирования сегмента на 50%. Из последующих строк таблицы видно, что при увеличении длины сегмента в 2 раза, количество контрольных разрядов увеличивается только на единицу, в результате чего процент увеличения длины данных уменьшается. При длине данных 1024 битов для исправления одиночных ошибок необходимо всего 11 разрядов, что приводит к увеличению длины контрольного сегмента всего на 1%. Естественно, что затраты оборудования для обнаружения и исправления единственной ошибки по методу Хэмминга значительно больше затрат оборудования при использовании бита четности. Однако при этом достигается существенный эффект – возможность исправления одной ошибки в работе компьютера.
Наряду с кодами Хэмминга, обеспечивающими обнаружение и исправление одной, двух и более ошибок в кодированных словах, широкое применение получили циклические коды, имеющие широкие возможности обнаружения и исправления при сложной картине многократных помех и достаточно простых способах построения систем контроля кодированных слов. Кодированные слова используются и для контроля арифметических и логических операций, выполняемых процессором. Таким образом, существует широкая гамма методов защиты устройств компьютеров от всякого рода искажений обрабатываемых и передаваемых данных, но любые системы защиты не дают 100% гарантии в результативности методов защиты.
Обновлено: 21.09.2023
1. Код с проверкой на четность.
Такой код образуется путем добавления к передаваемой комбинации, состоящей из k информационных символов, одного контрольного символа (0 или 1), так, чтобы общее число единиц в передаваемой комбинации было четным.
Пример 5.1 . Построим коды для проверки на четность, где k — исходные комбинации, r — контрольные символы.
Определим, каковы обнаруживающие свойства этого кода. Вероятность Poo обнаружения ошибок будет равна
Так как вероятность ошибок является весьма малой величиной, то можно ограничится
Вероятность появления всевозможных ошибок, как обнаруживаемых так и не обнаруживаемых, равна , где — вероятность отсутствия искажений в кодовой комбинации. Тогда .
При передаче большого количества кодовых комбинаций Nk , число кодовых комбинаций, в которых ошибки обнаруживаются, равно:
Общее количество комбинаций с обнаруживаемыми и не обнаруживаемыми ошибками равно
Тогда коэффициент обнаружения K обн для кода с четной защитой будет равен
Например, для кода с k =5 и вероятностью ошибки коэффициент обнаружения составит . То есть 90% ошибок обнаруживаем, при этом избыточность будет составлять или 17%.
2. Код с постоянным весом.
Этот код содержит постоянное число единиц и нулей. Число кодовых комбинаций составит
Пример 5.2. Коды с двумя единицами из пяти и тремя единицами из семи.
Этот код позволяет обнаруживать любые одиночные ошибки и часть многократных ошибок. Не обнаруживаются этим кодом только ошибки смещения, когда одновременно одна единица переходит в ноль и один ноль переходит в единицу, два ноля и две единицы меняются на обратные символы и т.д.
Рассмотрим код с тремя единицами из семи. Для этого кода возможны смещения трех типов.
Вероятность появления не обнаруживаемых ошибок смещения
Вероятность появления всевозможных ошибок как обнаруживаемых, так и не обнаруживаемых будет составлять
Вероятность обнаруживаемых ошибок . Тогда коэффициент обнаружения будет равен
Например, код при коэффициент обнаружения составит , избыточность L =27%.
3. Корреляционный код (Код с удвоением). Элементы данного кода заменяются двумя символами, единица ‘1’ преобразуется в 10, а ноль ‘0’ в 01.
Вместо комбинации 1010011 передается 10011001011010. Ошибка обнаруживается в том случае, если в парных элементах будут одинаковые символы 00 или 11 (вместо 01 и 10).
Например, при k =5, n =10 и вероятности ошибки , . Но при этом избыточность будет составлять 50%.
4. Инверсный код. К исходной комбинации добавляется такая же комбинация по длине. В линию посылается удвоенное число символов. Если в исходной комбинации четное число единиц, то добавляемая комбинация повторяет исходную комбинацию, если нечетное, то добавляемая комбинация является инверсной по отношению к исходной.
Прием инверсного кода осуществляется в два этапа. На первом этапе суммируются единицы в первой основной группе символов. Если число единиц четное, то контрольные символы принимаются без изменения, если нечетное, то контрольные символы инвертируются. На втором этапе контрольные символы суммируются с информационными символами по модулю два. Нулевая сумма говорит об отсутствии ошибок. При ненулевой сумме, принятая комбинация бракуется. Покажем суммирование для принятых комбинаций без ошибок (1,3) и с ошибками (2,4).
Обнаруживающие способности данного кода достаточно велики. Данный код обнаруживает практически любые ошибки, кроме редких ошибок смещения, которые одновременно происходят как среди информационных символов, так и среди соответствующих контрольных. Например, при k =5, n =10 и . Коэффициент обнаружения будет составлять .
5. Код Грея. Код Грея используется для преобразования угла поворота тела вращения в код. Принцип работы можно представить по рис.5.2. На пластине, которая вращается на валу, сделаны отверстия, через которые может проходить свет. Причём, диск разбит на сектора, в которых и сделаны эти отверстия. При вращении, свет проходит через них, что приводит к срабатыванию фотоприёмников. При снятии информации в виде двоичных кодов может произойти существенная ошибка. Например, возьмем две соседние цифры 7 и 8. Двоичные коды этих цифр отличаются во всех разрядах.
Если ошибка произойдет в старшем разряде, то это приведет к максимальной ошибке, на 360 0 . А код Грея, это такой код в котором все соседние комбинации отличаются только одним символом, поэтому при переходе от изображения одного числа к изображению соседнего происходит изменение только на единицу младшего разряда. Ошибка будет минимальной.
Задача кодирования заключается в формировании по информационным словам a(x) кодовых слов (x) циклического (n,k)-кода, который по своей структуре может быть несистематическим и систематическим.
Формирование кодовых слов несистематического кода заключается в умножении многочлена a(x), отображающего информационную последовательность длины k, на порождающий многочлен, т.е. (x)=a(x)(g(x). Формирование кодовых слов систематического кода заключается в преобразовании информационной последовательности a(x) в соответствии с выражением (x)=a(x)x r +r(x).
Проверочная последовательность r(x) определяется двумя способами:
при использовании «классического» способа кодирования ;
при использовании способа кодирования, рекомендованного МККТТ ,
где x(1) r-1 — единичный многочлен степени (r-1).
Указанные выше математические операции выполняют кодеры несистематического и систематического кодов.
Способы декодирования с обнаружением ошибок
Процедура декодирования циклического кода с обнаружением ошибок, по аналогии с процессом кодирования, использует два способа:
— при кодировании «классическим» способом декодирование основано на использовании свойства делимости без остатка кодового многочлена (x) циклического (n,k)-кода на порождающий многочлен g(x). Поэтому алгоритм декодирования включает в себя деление принятого кодового слова, описываемого многочленом на g(x), вычисление и анализ остатка r(x). Если r(x)=0, то принятое кодовое слово считается неискаженным. Если r(x)0, то принятое кодовое слово стирается и формируется сигнал «ошибка».
— при кодировании способом МККТТ декодирование основано на свойстве получения определенного контрольного остатка R0 (x) при делении принятого кодового многочлена (x) на порождающий многочлен. Поэтому, если полученный при делении остаток , то принятое кодовое слово считается неискаженным. Если остаток , то принятое кодовое слово стирается и формируется сигнал «ошибка». Значение контрольного остатка определяется из выражения .
Способы декодирования с исправлением ошибок и схемная реализация декодирующих устройств
Декодирование циклического кода в режиме исправления ошибок можно осуществлять различными способами. Ниже излагаются два способа, являющиеся наиболее простыми.
В основу первого способа положено использование таблицы синдромов (декодирования), в которой каждому многочлену или образцу ошибок ei (x), соответствует определенный синдром Si (x), представляющий остаток от деления принятого кодового слова и соответствующего ему ei (x) на g(x). Процедура декодирования следующая. Принятое кодовое слово делится на g(x), определяется Si (x) и соответствующий ему многочлен ei (x), а затем суммируется с ei (x). В результате получаем исправленное кодовое слово, т.е. .
В состав декодера входят: вычислитель синдрома (ВС), два регистра сдвига RG1 и RG2, постоянное запоминающее устройство (ПЗУ), которое содержит слова длины n, соответствующие многочленам ошибок ei (x).
Принятое кодовое слово поступает на вход вычислителя синдрома, где осуществляется деление его на g(x) и формирование Si (x), и одновременно — на вход RG2, где накапливается. Синдром Si (x) используется в качестве адреса, по которому из ПЗУ в регистр RG1 записывается ei (x), соответствующий синдрому Si (x). Перечисленные операции завершаются за n тактов. В течение последующих n тактов происходит поэлементное суммирование содержимого RG2 и RG1, т.е. операция , и исправление. ошибок.
В основе второго способа исправления ошибок, позволяющего значительно сократить объем используемых табличных синдромов и существенно упростить схему декодера, лежат следующие положения:
1. Синдром Si (x), соответствующий принятому кодовому слову равен остатку от деления на g(x), а также остатку от деления соответствующего многочлена ошибок ei(x) на g(x), т.е. .
2. Если Si (x) соответствует и ei (x), то x( Si (x) является синдромом, который соответствует и или .
3. При исправлении ошибок используются синдромы образцов ошибок только с ненулевым коэффициентом в старшем разряде.
Поэтому при реализации этого способа множество всех образцов ошибок разбивается на классы эквивалентности. Каждый класс представляет циклический сдвиг одного образца ошибок, а синдром этого класса соответствует образцу ошибок с ненулевым старшим разрядом. Если вычисленный синдром принадлежит одному из классов эквивалентности образцов исправляемых ошибок, то старший символ кодового слова исправляется. Затем принятое слово и синдром циклически сдвигается, а процесс нахождения в предыдущей по старшинству позиции повторяется.
Для исправления ошибок, принадлежащих данному классу эквивалентности, нужно произвести n циклических сдвигов.

Простейшим является декодер Меггитта. В состав декодера входят: вычислитель синдрома, осуществляющий деление кодового слова на g(x) и формирование соответствующего синдрома; блок декодеров (ДК), который настроен на синдромы всех образцов исправляемых ошибок с ненулевыми старшими разрядами; регистр сдвига RG.
При поступлении на вход схемы кодового слова его символы заполняют регистр RG, а в вычислителе формируется соответствующий синдром Si (x). Вычисленный синдром сравнивается со всеми табличными синдромами, заложенными в схему блока ДК, и в случае совпадения с одним из них на его выходе формируется сигнал, который исправляет ошибочный символ, находящийся в старшем разряде регистра. После этого содержимое вычислителя и RG циклически сдвигается на один шаг. Этот сдвиг реализует операции и . Если новый синдром совпадает с одним из табличных синдромов, то это означает, что произошла ошибка во втором по старшинству символе кодового слова, который, перейдя в старший разряд RG, исправляется. Затем производится новый циклический сдвиг на одну позицию и новая проверка на совпадение синдромов. После повторения этого процесса n раз в RG будет сформировано исправленное кодовое слово. Введение обратной связи для RG не обязательно, так как в процессе исправления ошибок символы кодового слова поступают на выход декодера.
Пример. Рассмотрим схему и работу декодера Меггитта циклического (15,7)-кода, обеспечивающего исправление одиночных и двойных ошибок, с g(x)=x 8 + x 7 + x 6 + x 4 +1 (см. рисунок 1).



Блок декодеров настраивается на 15 синдромов, которые представлены в таблице 1 и соответствуют классам эквивалентности с образцами ошибок в старшем разряде.
| Таблица 1 | |||||
| № | |||||
| е(х) | S(x) | № | е(х) | S(x) | |
| 1 | x 14 | x 7 + x 6 +x 5 + x 3 | 9 | x 14 + x 6 | |
| 2 | x 14 + x 13 | x 7 + x 4 +x 3 + x 2 | 10 | x 14 + x 5 | x 7 + x 6 +x 3 |
| 3 | x 14 + x 12 | x 7 + x 6 +x 4 + x | 11 | x 14 + x 4 | x 7 + x 6 +x 5 + x 4 +x 3 |
| 4 | x 14 + x 11 | 12 | x 14 + x 3 | x 7 + x 6 +x 5 | |
| 5 | x 14 + x 10 | 13 | x 14 + x 2 | x 7 + x 6 +x 5 + x 3 +x 2 | |
| 6 | x 14 + x 9 | 14 | x 14 + x 1 | x 7 + x 6 +x 5 + x 3 +x | |
| 7 | x 14 + x 8 | 15 | x 14 + x 0 | x 7 + x 6 +x 5 + x 3 +0 | |
| 8 | x 14 + x 7 |
Допустим, что ошибки в 3 и 5 разрядах, т.е. им соответствует многочлен ошибки e(x)=x 12 +x 10 .

При поступлении на вход декодера искаженного кодового слова он заполняет регистр и в вычислителе формируется синдром .
Блок декодеров не реагирует на этот синдром.

Затем происходит сдвиг кодового слова в RG, а в BC формируется новый синдром .
Блок декодеров и в этом случае не срабатывает.

При следующем сдвиге кодового слова в RG первый искаженный разряд занимает старшую позицию в RG, а в BC формируется синдром , от которого срабатывает БДК. В результате исправляется первая ошибка.

Следующим сдвиг приводит к формированию синдрома .
Этот синдром соответствует многочлену ошибки e(x)=x 13 +x 0 , т.к. первый искаженный разряд по обратной связи должен занять младшую позицию RG.
На синдром S(13,0) блок декодеров не реагирует.

При следующем сдвиге кодового слова в RG второй искаженный разряд занимает старшую позицию в RG, а в BC формируется синдром , от которого срабатывает БДК. В результате исправляется вторая ошибка в кодовом слове.
Коды Рида-Соломона (РС)
Коды РС являются недвоичными циклическими кодами, символы кодовых слов которых берутся из конечного поля GF(q). Здесь q степень некоторого простого числа, например q=2 m .
Допустим, что РС-код построен над GF(8), которое является расширением поля GF(2) по модулю примитивного многочлена f(z)=z 3 +z+1. В этом случае символы кодовых слов кода будут иметь значения, представленные в таблице 2.
| Таблица 2 | |||||
| 000 | 0 | 0 | 011 | z+1 | 3 |
| 001 | 1 | 0 | 110 | z 2 +z | 4 |
| 010 | z | 1 | 111 | z 2 +z+1 | 5 |
| 100 | z 2 | 2 | 101 | z 2 +1 | 6 |

Кодовые слова РС-кода отображаются в виде многочленов
,
где N — длина кода; Vi — q-ичные коэффициенты (символы кодовых слов), которые могут принимать любое значение из GF(q).

Эти коэффициенты как это следует из таблицы, также отображаются многочленами с двоичными коэффициентами . Коды РС являются максимальными, т.к. при длине кода N и информационной последовательности k они обладают наибольшим кодовым расстоянием d=N-k+1.
Порождающим многочленом g(x) РС-кода является делитель двучлена x N +1 степени меньшей N с коэффициентами из GF(q) при условии, что элементы этого поля являются корнями g(x). Здесь — примитивный элемент GF(q).

На основе этого определения, а также теоремы Безу, выражение для порождающего многочлена РС-кода будет иметь вид .
Степень g(x) равна d-1=N-k=R.

В РС-кодах принадлежность кодовых слов данному коду определяется выполнением d-1 уравнений в соответствии с выражением (*), где Vi — символы-коэффициенты из GF(q); z0 , z1 . zN-1 — ненулевые элементы GF(q).
Элементы z0 , z1 . zN-1 называются локаторами, т.е. указывающими на номер позиции символа кодового слова.
Например, указателем i — позиции является локатор zi или элемент i GF(q).
Так как все локаторы должны быть различны и причем ненулевыми, то их число в GF(q) равно q-1. Следовательно, такое количество символов должно быть в кодовых словах кода.Поэтому обычно длина РС-кода определяется из выражения N=q-1.

Пример. Допустим, что длина РС-кода равна N, кодовое расстояние d=3, то в соответствии с (*) проверочными уравнениями будут
1. Циклический сдвиг кодовых слов, символы которых принимают значение из GF(q), порождает новые кодовые слова этого же кода.
2. Сумма по mod2 двух и более кодовых слов дает кодовое слово, принадлежащее этому же коду.
3. Кодовое расстояние РС-кода определяется не по двоичным элементам, а по q-ичным символам.

4. В РС-коде, исправляющем tu ошибок порождающий многочлен определяется из выражения . Обычно m0 принимают равным 1. Однако, с помощью разумного выбора значения m0 , иногда можно упростить схему кодера.

5. Корректирующие способности РС-кода определяются его кодовым расстоянием.
где T0 и Tu — длина пакетов, в которых обнаруживаются и исправляются ошибки.
Обнаружение ошибок в кодовых словах состоит в проверке условий ((), т.е. определении синдрома , элементы которого определяются из выражения .
Пример. Требуется сформировать кодовое слово РС-кода над GF(2 3 ), соответствующее двоичной информационной последовательности a(1,0)=000000011100101.
Так как m=3, то каждый q-ичный символ кода состоит из трех двоичных элементов. Поэтому с учетом таблицы 6 a(x)= 3 x 2 + 2 x+ 6 .

Определяем параметры кода. N=q-1=7; k=5; R=2; d=N-k+1=3;
.
Кодовое слово формируется в соответствии с выражением. ,
где .

В результате или в двоичной форме V(1,0)=000.000.011.100.101.101.101.
2. Метрология и радиоизмерения в телекоммуникационных системах. Учебник для ВУЗов. / В.И.Нефедов, В.И.Халкин, Е.В.Федоров и др. – М.: Высшая школа, 2001 г. – 383с.
3. Цапенко М.П. Измерительные информационные системы. — . – М.: Энергоатом издат, 2005. — 440с.
4. Зюко А.Г. , Кловский Д.Д., Назаров М.В., Финк Л.М. Теория передачи сигналов. М: Радио и связь, 2001 г. –368 с.
История кодирования, контролирующего ошибки, началась в 1948 г. публикацией знаменитой статьи Клода Шеннона. Шеннон показал, что с каждым каналом связано измеряемое в битах в секунду и называемое пропускной способностью канала число С, имеющее следующее значение. Если требуемая от системы связи скорость передачи информации R (измеряемая в битах в секунду) меньше С, то, используя коды, контролирующие ошибки, для данного канала можно построить такую систему связи, что вероятность ошибки на выходе будет сколь угодно мала.
В самом деле, из шенноновской теории информации следует тот важный вывод, что построение слишком хороших каналов является расточительством; экономически выгоднее использовать кодирование.
Содержание работы
Введение. 3
1. Обнаружение ошибок. 4
2. Коррекция ошибок. 6
3. Циклические коды. 11
4. Линейные блочные коды. 15
Заключение 18
Литература. 19
Файлы: 1 файл
РЕФЕРАТ Обнаружение и коррекция ошибок при передаче информации..docx
1. Обнаружение ошибок. 4
2. Коррекция ошибок. 6
3. Циклические коды. 11
4. Линейные блочные коды. 15
Введение.
История кодирования, контролирующего ошибки, началась в 1948 г. публикацией знаменитой статьи Клода Шеннона. Шеннон показал, что с каждым каналом связано измеряемое в битах в секунду и называемое пропускной способностью канала число С, имеющее следующее значение. Если требуемая от системы связи скорость передачи информации R (измеряемая в битах в секунду) меньше С, то, используя коды, контролирующие ошибки, для данного канала можно построить такую систему связи, что вероятность ошибки на выходе будет сколь угодно мала.
В самом деле, из шенноновской теории информации следует тот важный вывод, что построение слишком хороших каналов является расточительством; экономически выгоднее использовать кодирование. В следующем десятилетии решению этой увлекательной задачи уделялось меньше внимания; вместо этого исследователи кодов предприняли длительную атаку по двум основным направлениям.
Первое направление носило чисто алгебраический характер и преимущественно рассматривало блоковые коды. Первые блоковые коды были введены в 1950 г., когда Хэмминг описал класс блоковых кодов, исправляющих одиночные ошибки.
Второе направление исследований по кодированию носило скорее вероятностный характер. Ранние исследования были связаны с оценками вероятностей ошибки для лучших семейств блоковых кодов, несмотря на то, что эти лучшие коды не были известны.
Так как развитие кодов, контролирующих ошибки, первоначально стимулировалось задачами связи, терминология теории кодирования проистекает из теории связи. Построенные коды, однако, имеют много других приложений. Коды используются для защиты данных в памяти вычислительных устройств и на цифровых лентах и дисках, а также для защиты от неправильного функционирования или шумов в цифровых логических цепях.
1. Обнаружение ошибок.
Каналы передачи данных ненадежны, да и само оборудование обработки информации работает со сбоями. По этой причине важную роль приобретают механизмы детектирования ошибок. Ведь если ошибка обнаружена, можно осуществить повторную передачу данных и решить проблему. Если исходный код по своей длине равен полученному коду, обнаружить ошибку передачи не предоставляется возможным.
Простейшим способом обнаружения ошибок является контроль по четности. Обычно контролируется передача блока данных (М бит). Этому блоку ставится в соответствие кодовое слово длиной N бит, причем N>M. Избыточность кода характеризуется величиной 1–M/N. Вероятность обнаружения ошибки определяется отношением M/N (чем меньше это отношение, тем выше вероятность обнаружения ошибки, но и выше избыточность).
При передаче информации она кодируется таким образом, чтобы с одной стороны характеризовать ее минимальным числом символов, а с другой – минимизировать вероятность ошибки при декодировании получателем. Для выбора типа кодирования важную роль играет так называемое расстояние Хэмминга.
Пусть А и Б две двоичные кодовые последовательности равной длины. Расстояние Хэмминга между двумя этими кодовыми последовательностями равно числу символов, которыми они отличаются. Например, расстояние Хэмминга между кодами 00111 и 10101 равно 2.
Можно показать, что для детектирования ошибок в n битах, схема кодирования требует применения кодовых слов с расстоянием Хэмминга не менее N+1. Можно также показать, что для исправления ошибок в N битах необходима схема кодирования с расстоянием Хэмминга между кодами не менее 2N+1. Таким образом, конструируя код, мы пытаемся обеспечить расстояние Хэмминга между возможными кодовыми последовательностями больше, чем оно может возникнуть из-за ошибок.
Широко распространены коды с одиночным битом четности. В этих кодах к каждым М бит добавляется 1 бит, значение которого определяется четностью (или нечетностью) суммы этих М бит. Так, например, для двухбитовых кодов 00, 01, 10, 11 кодами с контролем четности будут 000, 011, 101 и 110. Если в процессе передачи один бит будет передан неверно, четность кода из М+1 бита изменится.
Предположим, что частота ошибок (BER) равна р=10 -4 . В этом случае вероятность передачи 8 бит с ошибкой составит: 1–(1–p) 8 =7,9∙10 -4 .
Добавление бита четности позволяет детектировать любую ошибку в одном из переданных битах. Здесь вероятность ошибки в одном из 9 бит равна 9p(1–p) 8 . Вероятность же реализации необнаруженной ошибки составит: 1– (1– p) 9 – 9p(1– p) 8 = 3,6∙10 -7 .
Таким образом, добавление бита четности уменьшает вероятность необнаруженной ошибки почти в 1000 раз. Использование одного бита четности типично для асинхронного метода передачи. В синхронных каналах чаще используется вычисление и передача битов четности как для строк, так и для столбцов передаваемого массива данных. Такая схема позволяет не только регистрировать но и исправлять ошибки в одном из битов переданного блока.
Контроль по четности достаточно эффективен для выявления одиночных и множественных ошибок в условиях, когда они являются независимыми. При возникновении ошибок в кластерах бит метод контроля четности неэффективен и тогда предпочтительнее метод вычисления циклических сумм (CRC).
2. Коррекция ошибок.
Но существуют и более простые методы коррекции ошибок. Например, передача блока данных, содержащего N строк и M столбцов, снабженных битами четности для каждой строки и столбца. Обнаружение ошибки четности в строке i и столбце j указывает на бит, который должен быть инвертирован. Может показаться, что в случае, когда неверны два бита, находящиеся в разных строках и столбцах, они также могут быть исправлены. Но это не так. Ведь нельзя разделить варианты i1,j1 — i2,j2 и i1,j2 — i2,j1. Этот метод может быть развит путем формирования блока данных с N строками, M столбцами и K слоями. Здесь биты четности формируются для всех строк и столбцов каждого из слоев, а также битов, имеющих одинаковые номера строк и столбцов i,j. Полное число битов четности в этом случае равно (N+M+1)×K +(N+1)×(M+1). Если M=N=K=8, число бит данных составит 512, а число бит четности — 217. Нетрудно видеть, что в этом случае число исправляемых ошибок будет больше 1. (Рис. 1).
Рис. 1. Метод коррекции более одной ошибки в блоке данных
(битам данных соответствуют окрашенные квадраты)
Коды Хэмминга наиболее известные и, вероятно, первые из самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Для того, чтобы понять работу данного алгоритма, рассмотрим пример.
Прежде всего, необходимо вставить контрольные биты. Они вставляются в строго определённых местах — это позиции с номерами, равными степеням двойки. В нашем случае (при длине информационного слова в 16 бит) это будут позиции 1, 2, 4, 8, 16. Соответственно, у нас получилось 5 контрольных бит (выделенные):
Вычисление контрольных бит.
Теперь необходимо вычислить значение каждого контрольного бита. Значение каждого контрольного бита зависит от значений информационных бит, но не от всех, а только от тех, которые этот контрольных бит контролирует. Для того, чтобы понять, за какие биты отвечает каждых контрольный бит необходимо понять очень простую закономерность: контрольный бит с номером N контролирует все последующие N бит через каждые N бит, начиная с позиции N.
Но как же вычислить значение каждого контрольного бита? Делается это очень просто: берём каждый контрольный бит и смотрим, сколько среди контролируемых им битов единиц, получаем некоторое целое число и, если оно чётное, то ставим ноль, в противном случае ставим единицу.
Высчитав контрольные биты для нашего информационного слова получаем следующее:
и для второй части:
Декодирование и исправление ошибок.
Вся вторая часть алгоритма заключается в том, что необходимо заново вычислить все контрольные биты (так же как и в первой части) и сравнить их с контрольными битами, которые мы получили. Так, посчитав контрольные биты с неправильным 11-ым битом мы получим такую картину:
Метод коррекции ошибок FEC.
Для FEC(Forward Error Correction)-кодирования иногда используется метод сверки, который впервые был применен в 1955 году. Главной особенностью этого метода является сильная зависимость кодирования от предыдущих информационных битов и высокие требования к объему памяти. FEC-код обычно просматривает при декодировании 2-8 бит десятки или даже сотни бит.
В 1967 году Эндрю Витерби (Andrew Viterbi) разработал технику декодирования, которая стала стандартной для кодов свертки. Эта методика требовала меньше памяти. Метод свертки более эффективен, когда ошибки распределены случайным образом, а не группируются в кластеры. Работа же с кластерами ошибок более эффективна при использовании алгебраического кодирования.
Одним из широко используемых разновидностей коррекции ошибок является турбо кодирование, разработанное американской аэрокосмической корпорацией. В этой схеме комбинируется два или более относительно простых кодов свертки. В FEC, также как и в других методах коррекции ошибок (коды Хэмминга, алгоритм Рида-Соломона и др.), блоки данных из k бит снабжаются кодами четности, которые пересылаются вместе с данными, и обеспечивают не только детектирование, но и исправление ошибок. Каждый дополнительный (избыточный) бит является сложной функцией многих исходных информационных бит. Исходная информация может содержаться в выходном передаваемом коде, тогда такой код называется систематическим, а может и не содержаться.
Аннотация: Контроль по четности, CRC, алгоритм Хэмминга. Введение в коды Рида-Соломона: принципы, архитектура и реализация. Метод коррекции ошибок FEC (Forward Error Correction).
Каналы передачи данных ненадежны ( шумы , наводки и т.д.), да и само оборудование обработки информации работает со сбоями. По этой причине важную роль приобретают механизмы детектирования ошибок. Ведь если ошибка обнаружена, можно осуществить повторную передачу данных и решить проблему. Если исходный код по своей длине равен полученному коду, обнаружить ошибку передачи не предоставляется возможным. Можно, конечно, передать код дважды и сравнить, но это уже двойная избыточность .
Простейшим способом обнаружения ошибок является контроль по четности . Обычно контролируется передача блока данных ( М бит ). Этому блоку ставится в соответствие кодовое слово длиной N бит , причем N>M . Избыточность кода характеризуется величиной 1-M/N . Вероятность обнаружения ошибки определяется отношением M/N (чем меньше это отношение , тем выше вероятность обнаружения ошибки, но и выше избыточность ).
При передаче информации она кодируется таким образом, чтобы с одной стороны характеризовать ее минимальным числом символов, а с другой – минимизировать вероятность ошибки при декодировании получателем. Для выбора типа кодирования важную роль играет так называемое расстояние Хэмминга .
Пусть А и Б — две двоичные кодовые последовательности равной длины. Расстояние Хэмминга между двумя этими кодовыми последовательностями равно числу символов, которыми они отличаются. Например, расстояние Хэмминга между кодами 00111 и 10101 равно 2.
Можно показать, что для детектирования ошибок в n битах схема кодирования требует применения кодовых слов с расстоянием Хэмминга не менее N + 1 . Можно также показать, что для исправления ошибок в N битах необходима схема кодирования с расстоянием Хэмминга между кодами не менее 2N + 1 . Таким образом, конструируя код, мы пытаемся обеспечить расстояние Хэмминга между возможными кодовыми последовательностями большее, чем оно может возникнуть из-за ошибок.
Широко распространены коды с одиночным битом четности . В этих кодах к каждым М бит добавляется 1 бит , значение которого определяется четностью (или нечетностью) суммы этих М бит . Так, например, для двухбитовых кодов 00 , 01 , 10 , 11 кодами с контролем четности будут 000 , 011 , 101 и 110 . Если в процессе передачи один бит будет передан неверно, четность кода из М+1 бита изменится.
Предположим, что частота ошибок ( BER – Bit Error Rate ) равна р = 10 -4 . В этом случае вероятность передачи 8 бит с ошибкой составит 1 – (1 – p) 8 = 7,9 х 10 -4 . Добавление бита четности позволяет детектировать любую ошибку в одном из переданных битах. Здесь вероятность ошибки в одном из 9 битов равна 9p(1 – p) 8 . Вероятность же реализации необнаруженной ошибки составит 1 – (1 – p) 9 – 9p(1 – p) 8 = 3,6 x 10 -7 . Таким образом, добавление бита четности уменьшает вероятность необнаруженной ошибки почти в 1000 раз. Использование одного бита четности типично для асинхронного метода передачи. В синхронных каналах чаще используется вычисление и передача битов четности как для строк, так и для столбцов передаваемого массива данных. Такая схема позволяет не только регистрировать, но и исправлять ошибки в одном из битов переданного блока.
Контроль по четности достаточно эффективен для выявления одиночных и множественных ошибок в условиях, когда они являются независимыми. При возникновении ошибок в кластерах бит метод контроля четности неэффективен, и тогда предпочтительнее метод вычисления циклических сумм ( CRC — Cyclic Redundancy Check ). В этом методе передаваемый кадр делится на специально подобранный образующий полином . Дополнение остатка от деления и является контрольной суммой.
В Ethernet вычисление CRC производится аппаратно. На рис. 4.1 показан пример реализации аппаратного расчета CRC для образующего полинома R(x) = 1 + x 2 + x 3 + x 5 + x 7 . В этой схеме входной код приходит слева.
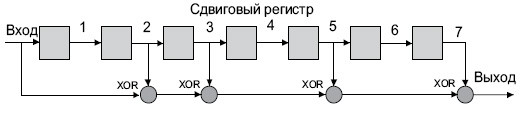
Эффективность CRC для обнаружения ошибок на многие порядки выше простого контроля четности . В настоящее время стандартизовано несколько типов образующих полиномов . Для оценочных целей можно считать, что вероятность невыявления ошибки в случае использования CRC , если ошибка на самом деле имеет место , равна (1/2) r , где r — степень образующего полинома .
4.1. Алгоритмы коррекции ошибок
Читайте также:
- Интеракционистский подход к поведению личности реферат
- Систематизация законодательства понятие виды значение и функции реферат
- Компенсация морального вреда в россии и в странах западной европы реферат
- Реферат на тему красноухая черепаха
- Рефераты по философии права магистратура