1. Совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
Выборка
Генеральная совокупность
Панель
Простая совокупность
2. Свойства выборки, которые позволяют ей выступать моделью (представителем) генеральной совокупности с точки зрения ее характеристик, которые изучаются при проведении исследования, – это … выборки.
устойчивость
достоверность
надежность
репрезентативность
3. Метод вероятностной выборки, предусматривающий расчет шага (интервала) отбора выборки
Метод жребия
Метод построения таблиц случайных чисел
Метод систематической (механической) выборки
Гнездовая выборка
4. Объем выборки влияет на ее репрезентативность.
Да
Нет
5. Чем больше различий внутри генеральной совокупности, тем больше величина возможной ошибки выборки.
Да
Нет
6. Объем выборки влияет на ее ошибку.
Да
Нет
7. Параллельное использование нескольких методов формирования выборки, основанное на поэтапном отборе ее объектов, – это … выборка.
пропорциональная
стратифицированная
квотированная
многоступенчатая
8. Основное условие осуществления вероятностной выборки – наличие …
полного списка всех элементов генеральной совокупности
согласия респондентов на участие в опросе
списка участников опроса
9. Под контуром выборки в маркетинговых исследованиях подразумевается …
список всех единиц генеральной совокупности
совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
определенная часть генеральной совокупности, которая призвана отражать все ее базовые характеристики
10. В маркетинговых исследованиях под ошибкой выборки подразумеваются отклонения (различия) между данными …
полученными от выборки и истинными данным
существующего и предыдущего исследования
вероятностной и невероятностной выборки
11. Метод выборки, предусматривающий отбор единиц выборки (респондентов), способных дать наиболее точные сведения
выборка по доступности
метод снежного кома
квотированная выборка
выборка по усмотрению
12. Когда исследователь использует случайную выборку, основанную на информации о числовых характеристиках генеральной совокупности, то …
наиболее корректный подход к определению объема выборки основан на расчете доверительных интервалов и среднего квадратического отклонения
невозможно точно рассчитать ошибку выборки и указать уровень ее надежности
13. Метод выборки, используемый в том случае, если генеральная совокупность разделяется на страты, а затем для каждой из них производится расчет простой случайной выборки – метод …
зональной выборки
многоступенчатой выборки
стратифицированной выборки
типичных представителей
14. Ключевая характеристика вероятностной (случайной) выборки заключается в том, что …
принцип отбора единиц выборки отличен от случайного
все единицы выборки имеют известную вероятность (шанс) попасть в выборку
невозможно рассчитать ошибку выборки
Формирование выборки
Характерными
особенностями количественных исследований
является четко определенный формат
собираемых данных и источники их
получения, а обработка собранных данных
осуществляется с помощью упорядоченных
процедур, в основном количественных по
своей природе. Результаты количественных
исследований дают ответы на вопросы:
Кто?, Что?, Где?, Когда?, Сколько?
Если
исследование охватывает весь изучаемый
массив, оно будет сплошным,
т.
е. в таком исследовании каждый элемент
генеральной совокупности служит единицей
сбора информации. В тех случаях, когда
объект исследования насчитывает более
500 человек, единственно правильным
признается применение выборочного
метода.
§ 1. Формирование выборки исследования
Совокупность
всех возможных социальных объектов,
которые подлежат изучению в пределах
программы исследования, называется
генеральной
совокупностью.
Выборочная
совокупность (выборка)
— часть
объектов генеральной совокупности,
отобранная с помощью специальных приемов
для получения информации о всей
совокупности. Репрезентативность
— свойство
выборочной совокупности воспроизводить
параметры и значимые элементы структуры
генеральной совокупности.
Преимущества
выборочного исследования по отношению
к сплошному
состоят
в том, что оно:
-
позволяет
сократить затраты на сбор и обработку
информации; -
позволяет
добиться большей оперативности; -
имеет
более широкую область применения; -
в
ряде случаев позволяет получить более
достоверные сведения.
Процесс
выборки основан на двух моментах:
во-первых,
на взаимосвязи и
взаимообусловленности
качественных характеристик и признаков
социальных объектов; во-вторых,
на правомерности выводов о целом на
основании изучения его части при условии,
что по своей структуре эта часть является
микромоделью целого.
Единицы
отбора
—
элемент или набор элементов, предназначенный
для отбора на определенной ступени
выборки.
Единицы
анализа
—
элементы выборочной совокупности
(респонденты), подлежащие изучению.
Переменная
—
множество отдельных значений характеристик
элементов совокупности. Параметр
—
суммарное описание переменной в
генеральной совокупности. Статистика
—
суммарное описание переменной в
выборочной совокупности.
Основная
цель выборочного метода
— выбор элементов из совокупности таким
образом, чтобы распределение этих
элементов в выборке повторяло их
распределение в совокупности. Достижению
этой цели служит вероятностная выборка.
Модель
вероятностной (случайной) выборки
связана с понятием статистической
вероятности,
изучаемой
в социальных науках (вероятность
некоторого ожидаемого события есть
отношение числа ожидаемых событий к
числу всех возможных).
Случайная
выборка носит наиболее распространенный
характер.
Самый легкий путь получения случайной
выборки — присвоить каждому элементу
свой номер, а затем с помощью компьютера
рассчитать случайные числа, из которых
и берется выборка (например, каждый
десятый номер в каждой случайной цепи).
Можно выбирать из генеральной совокупности
по какому-то принципу (каждая тысячная
фамилия из списка абонентов телефонной
сети, каждый третий дом на определенной
улице, студенты, родившиеся в сентябре,
и т. д.)
Преимущества
случайной выборки:
-
объективность
и точность отбора респондентов; -
не
требуется детальное знание изучаемой
совокупности; -
использование
методов математической вероятности.
Недостатки
случайной выборки:
-
сложность
процедуры отбора; -
затратность
ресурсов.
На
практике часто применяется метод
гнездовой выборки.
Он
предполагает отбор в качестве единиц
анализа не отдельных людей, а групп
(семьи, студенческие группы, бригады и
т. д.), с последующим сплошным опросом в
отобранных группах. Гнездовая выборка
будет репрезентативна в том случае,
если состав групп в максимальной степени
близок по основным демографическим
признакам респондентов.
В
некоторых случаях невозможно использование
вероятностных схем отбора, описанных
выше. Тогда используется целенаправленная
выборка,
к
которой неприменимы правила теории
вероятности. Она осуществляется с
помощью следующих
методов:
стихийной
выборки,
метода
квот и метода основного массива.
В
случае
стихийной
выборки
невозможно
предопределить структуру массива
респондентов и соответственно трудно
определить репрезентативность. Существует
несколько разновидностей
стихийного отбора:
так
называемый отбор «первого встречного».
Встречается в практике обследований,
проводимых средствами массовой
информации. Исследователь проводит
опрос лиц, которые встретились ему в
месте опроса (например, на улице);
отбор
«себе подобных».
Исследователь подбирает для опроса или
наблюдения респондентов из своего
окружения (знакомые, коллеги);
отбор
«желающих участвовать».
Примером может служить почтовый опрос
читателей газеты или журнала. При таких
опросах решение о включении в выборку
принимает сам респондент.
Метод
квотной выборки
— распространенный способ отбора
респондентов при массовых опросах
общественного мнения. Его используют
в том случае, если до начала исследования
имеются статистические данные о
контрольных признаках элементов
генеральной совокупности. Все данные
о том или ином контрольном признаке
выступают в качестве квоты. Респонденты
отбираются целенаправленно, с соблюдением
параметров квот.
Число характеристик, данные о которых
выбираются в качестве квот, как правило,
не превышает четырех.
Главная
задача для интервьюера
заключается
в том, чтобы создать условия, близкие к
случайному отбору, с равными шансами
для каждого элемента генеральной
совокупности попасть в выборку.
Метод
квот позволяет существенно сократить
время и средства,
затрачиваемые на опросы. К преимуществам
квотной выборки относятся также
оперативность и малая трудоемкость.
Недостатки
квотной выборки:
-
требуется
детальное знание изучаемой совокупности; -
субъективизм
интервьюера при отборе респондентов; -
ограниченное
время посещения респондентов; -
уклонение
респондентов от опроса;1 -
не
позволяет использовать методы
математической вероятности.
Метод
основного массива
применяется в разведывательных
исследованиях
для
уточнения какого-нибудь контрольного
вопроса. В таких случаях опрашивается
50-60% потенциальных респондентов.
Все
рассмотренные методы представляют
собой пример одноступенчатой выборки.
Многоступенчатые
выборки
осуществляются
в несколько ступеней: на
первой ступени
обычно реализуется гнездовая выборка,
а потом
проводится случайный отбор респондентов
в гнездах.
Многоступенчатая
выборка используется в крупномасштабных
исследованиях, когда в генеральной
совокупности насчитываются тысячи и
миллионы единиц, размещенных на
значительной территории. При построении
многоступенчатой выборки используются
несколько способов отбора элементов
выборочной совокупности.
Районированный
отбор (типический)
производится
на основе распределения заданного числа
отбираемых единиц измерения, т. е. объема
выборки, между так называемыми районами,
типами — группами элементов генеральной
совокупности, выделяемыми в соответствии
со значениями изучаемого в исследовании
заданного «базового признака». Выделяемые
таким образом слои будут внутренне
однородными, но отличными друг от друга
и взятые вместе исчерпывать всю
совокупность.
В
крупномасштабных многоступенчатых
выборках требования к точности оценок
смещаются на второй план,
уступая место вопросам снижения стоимости
исследования благодаря выбору минимально
допустимого числа единиц опроса.
Объем
выборки определяется аналитическими
задачами исследования,
ее
репрезентативность
— целевой
установкой программы.
Объем
выборки влияет на ошибки репрезентации:
чем больше величина выборки, тем меньше
возможная ошибка. Для
увеличения точности в два раза необходимо
увеличить выборку в четыре раза.
Ошибка
репрезентации
—
это различие между характеристиками
генеральной и выборочной совокупности.
Количество респондентов, включенных в
выборочную совокупность, должно
составлять 10% от генеральной совокупности,
но не превышать 2000—2500 человек (если
величина генеральной совокупности 5000
человек и более).
Для
пробных опросов достаточна выборочная
совокупность объемом 100-250 человек. При
массовых опросах, если величина
генеральной совокупности составляет
менее 5000 человек, достаточный объем
выборочной совокупности, гарантирующий
достоверные результаты исследования,
составляет 500 человек.
Оценка
надежности результатов выборочного
обследования проводится следующим
образом:
-
ошибка
выборки до 3% — повышенная надежность; -
ошибка
выборки 3-10% — обыкновенная; -
ошибка
выборки от 10 до 20% — приближенная; -
ошибка
выборки от 20 до 40% — ориентировочная; -
более
40% — прикидочная надежность.
В
аналитических и экспериментальных
исследованиях проблема репрезентативности
выборки является второстепенной в
сравнении с необходимостью обеспечить
качественное представительство изучаемых
объектов.
Качество
выборки зависит:
а) от
меры однородности социальных объектов
по наиболее существенным характеристикам
(чем более они однородны, тем меньшая
численность может обеспечить статистически
достоверные выводы);
б) от
степени дробности группировок анализа,
планируемых по задачам исследования;
в) от
целесообразного уровня надежности
выводов из предпринимаемого исследования.
Традиционно
выделяют следующие виды ошибок:
-
случайные
отклонения выборочных значений
параметров; -
систематические
ошибки (ошибки смещения); -
погрешности
вычислений.
Погрешности
вычислений
возникают
при математико-статистической обработке
результатов измерений. О погрешности
вычислений необходимо помнить при
оценке точности и надежности выборочных
данных и при интерпретации результатов.
Случайные
ошибки
бывают
следствием большого числа разнообразных
факторов, и учесть действие каждого из
них невозможно. Ошибка выборки считается
случайной, а выборочная совокупность
репрезентативной, если отклонение не
превышает в среднем 5%.
Наиболее
опасный вид ошибок — систематические
ошибки
(или
ошибки смещения). Такие ошибки являются
результатом действий в одном направлении
определенной группы причин, которую
возможно выявить.
Источники
систематических ошибок:
а) неверные
статистические данные о параметрах
контрольных признаков генеральной
совокупности;
б) ошибочная
модель выборки;
в) неправильное
формирование выборочной совокупности;
г) несовершенство
инструментария и ошибки в организации
сбора данных;
д) неправильная
интерпретация результатов первичных
измерений и неправильная последующая
обработка и анализ информации.
На
правильность результатов исследования
в наибольшей степени влияют
ошибки смещения, вызванные неправильной
реализацией модели выборки, несовершенством
инструментария и организации сбора
данных. Систематические ошибки могут
появиться на любом этапе исследования.
Необходимо стремиться к тому, чтобы по
возможности исключить ситуации,
способствующие возникновению ошибок,
критически анализировать полученные
результаты, природу расхождений
выборочных и генеральных совокупностей.
При
конструировании модели выборки
целесообразно консультироваться со
специалистами по математической
статистике.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет

Любая научная работа (особенно в психологии, медицине) предполагает проведение некоего эксперимента для сбора доказательств и оценки реальной ситуации. Притом чем больше факторов учитывает автор, тем точнее результаты исследования и возможности их использования в дальнейшем.
В любом эксперименте важно определить оптимальный объем выборки, который бы позволили получить достоверный результат. В этой статье Вы узнаете, какое число испытуемых считается достаточным, и как грамотно подобрать объем выборки для собственного исследования.
Влияет ли объем выборки на результаты исследования?
Результаты исследования зависят от множества факторов: объем и достоверность первоначальных данных, цель (достижимая и реалистичная или не поддающаяся измерению и достижению), качество материалов (достоверные, актуальные и пр.) и т.д. Если научное изыскание предполагает проведение практических мероприятий, то одним из важнейших моментов являются определение объема выборки.

Объем выборки представляет собой число испытуемых, которое будет принимать участие в эксперименте и подлежать оценке. Количество респондентов, их действия напрямую отражаются на результатах исследования. Если в эксперименте будет участвовать малая часть испытуемых, то не всегда будет возможно получить репрезентативные результаты.
Большое число участников же в значительной степени усложняет ход исследования, но позволяет получить более точные результаты при условии, если исследователь внимательно следит за ходом событий и учитывает все факторы, погрешности и отклонения и пр.
Таким образом, объем выборки влияет не только на точность измерений, но и качество исследования.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

Больше – лучше, или наоборот?
Казалось бы, чем больше число испытуемых, тем точнее результаты. На самом деле, здесь палка о двух концах.
С одной стороны, большое число испытуемых позволяет получить более точные результаты исследования, определить динамику или тенденции развития событий. В то же время внушительное количество респондентов требует более пристального внимания со стороны автора: моментальное фиксирование результатов, контроль за каждым индивидом, оценка всех действий и достижений/итогов и пр. Сможет ли автор в одиночку уследить за 100-200 и более испытуемыми.
Во-вторых, большой объем выборки провоцирует рождение более высоких затрат на организацию и проведение эксперимента: привлечение сторонних экспертов для контроля за ходом исследования, подготовка дополнительных материалов для испытуемых (анкеты или опросники, задания, создание специальных условий (например, для проживания и пр.)) и т.д.
Небольшой объем выборки – самый оптимальный в плане затратности, но он дает менее точные результаты. Если в эксперименте принимает участие всего 2-4 человека, то это не значит, что выборка будет репрезентативной. В данной ситуации автор оценит лишь частный случай, но не данные генеральной совокупности.
Поэтому чтобы результаты исследования были пригодными для более широкой аудитории, важно, чтобы выборка оказалась репрезентативной, а для этого необходимо подобрать оптимальное число испытуемых.
Какой объем выборки считается оптимальным?
Объем выборки зависит не только от вида исследования, но и его масштабов. Например, в социологических опросах принято проводить соответствующие мероприятия (например, задать вопросы всем подряд или конкретной группе) с целью определения общественного мнения. Как правило, в таких проектах принимает участие свыше 1000 человек.

В психологических и медицинских экспериментах и исследованиях количество испытуемых гораздо меньше, так как обработка данных здесь может занять более длительное время, а информация обладает таким свойством как актуальность, которая может быть утрачена из-за медлительности. Оптимальным числом для таких научных изысканий считается 10-30 человек, притом все испытуемые подлежат строгой классификации по конкретному признаку.
Оптимальный объем выборки – это то количество изучаемых объектов и явлений, которое позволяет получить достоверный и максимально точный (приближенный) результат с минимальными погрешностями, который можно «репрезентовать» на более широкий круг лиц. В случае нерепрезентативности выборки исследователь получит «частный эксперимент» с субъективной оценкой происходящего.
Как определить оптимальный объем выборки для научного исследования?
Каждый исследователь самостоятельно определяет, какой объем выборки для него оптимальный. Данный параметр зависит от ряда условий:
- Сколько авторов и компетентных ученых принимает участие в организации и проведении научного изыскания?
- За сколькими испытуемыми автор сможет следить самостоятельно?
- Какое количество объектов посильно для каждого «контролера»?
- Возможность оперативной фиксации получаемых результатов?
- Объем факторов, которые должны быть учтены в ходе испытания?
- Шкала для оценки полученных итогов?
- Наличие определенных знаний навыков, образования или опыта работы в конкретной области для проведения научного изыскания?
- Методы исследования?
- Требования к испытуемым?
- Продолжительность исследования?
- Точность результатов, допустимые погрешности и пр.?
Оптимальный объем выборки предполагает подбор стольких испытуемых, за которыми посильно проследить и оценить их результаты без лишних затрат времени, материальных и иных ресурсов с учетом располагаемых сил.
Если исследование предполагает оценку конкретной ситуации в определенной отрасли, то достаточно подобрать 10-30 участников, соответствующих конкретных условиям и требованиям.
Если же научное изыскание носит глобальный масштаб, то необходимо подобрать опытную и сильную команду, грамотно распределить обязанности, а затем, исходя из общих возможностей команды, определить объем выборки: до 100 участников, от 101 до 500, более 500 и пр.
В идеале на каждого «контролера» должно приходиться не более 10-20 испытуемых, чтобы качество получаемых данных было высоким, а жизнь контролера проходила не только в стенах «лаборатории». Поэтому объему выборки необходимо уделять особое внимание, так как именно этот критерий позволяет получить более качественные результаты научных и иных изысканий.
Вопрос 1. Метод вероятностной выборки, предусматривающий расчет шага (интервала) отбора выборки
- Ответ: Метод систематической (механической) выборки
Вопрос 2. Основное преимущество панельного метода исследования, состоит в …
- Ответ: возможности регулярного изучения поведения потребителей
Вопрос 3. Тип вопроса в анкете, предусматривающий возможность выбора нескольких вариантов ответов
- Ответ: Альтернативный
Вопрос 4. Цель пилотажа анкет
- Ответ: Определение реакции респондентов на содержание анкеты
Вопрос 5. Такое требование к маркетинговой информации как актуальность подразумевает …
- Ответ: представление реальных сведений в нужный момент времени
Вопрос 6. В анкете нужны вопросы-фильтры для того, чтобы …
- Ответ: проконтролировать правильность ответов респондентов
Вопрос 7. Вид маркетинговых исследований, к которому относятся исследования деятельности посредников, называется …
- Ответ: изучение каналов распределения
Вопрос 8. Под контуром выборки в маркетинговых исследованиях подразумевается …
- Ответ: список всех единиц генеральной совокупности
Вопрос 9. Анализ, в основе которого лежит использование статистических процедур (например, проверка гипотез) с целью обобщения полученных результатов на всю совокупность, называется …
- Ответ: выводным анализом
Вопрос 10. Система, которая в ответ на вопрос типа: «что если?» дает немедленные ответы, используемые при принятии маркетинговых решений
- Ответ: Маркетинговая информационная система (МИС)
Вопрос 11. Такой критерий оценки отчета о маркетинговом исследовании, как ясность предполагает …
- Ответ: внятность и четкость фразеологии отчета
Вопрос 12. Перед внедрением нового товара на рынок проводят его рыночные испытания. Если исследователи предлагают специально отобранной группе потребителей посетить «виртуальный магазин» (с использованием программного продукта «Simul-Shop») и сделать покупки с целью проверки реакции на новые товары, то используется …
- Ответ: процедура моделируемого пробного маркетинга
Вопрос 13. Метод сбора информации, предусматривающий групповую дискуссию, которая направляется модератором
- Ответ: Фокус-группа
Вопрос 14. Вид тестирования эффективности рекламы, используемый в случае, если группе потребителей (читателям определенного журнала, зрителям определенного телевизионного канала и т.п.) задают следующий вопрос: «Какую из реклам они помнят, и какие ее части могут воспроизвести/пересказать?»
- Ответ: Тест на узнавание
Вопрос 15. Документ, в котором сформулированы основные требования к содержанию стандартного отчета о маркетинговом исследовании
- Ответ: Международный кодекс ЕSОМАR и МТП по практике маркетинговых и социальных исследований
Вопрос 16. Результаты обследования фокус-групп можно считать репрезентативными.
- Ответ: Нет
Вопрос 17. Основное отличие рекомендаций, данных в отчете, от заключений
- Ответ: В том, что они интерпретируют полученную информацию с точки зрения того, что она может означать для дальнейшего развития бизнеса
Вопрос 18. Вид маркетинговых исследований, к которому относятся исследования отношения к марке товара, называется …
- Ответ: изучение потребителей
Вопрос 19. Основное условие осуществления вероятностной выборки – наличие …
- Ответ: полного списка всех элементов генеральной совокупности
Вопрос 20. Вид маркетинговых исследований, к которому относятся мотивационные исследования
- Ответ: Изучение потребителей
Вопрос 21. Виды маркетинговой информации по источнику ее получения
- Ответ: первичная и вторичная
Вопрос 22. Ошибка, допущенная при формулировке следующего вопроса анкеты: «Какое количество банок майонеза Вы приобрели за последние полгода? – меньше 20 банок – около 20 банок – больше 20 банок»
- Ответ: Превышение возможностей памяти респондента
Вопрос 23. Использование таких статистических мер, как средняя величина (средняя), мода, среднее квадратическое отклонение, размах вариации лежит в основе …
- Ответ: дескриптивного анализа
Вопрос 24. Под гипотезой маркетингового исследования подразумевается …
- Ответ: вероятностное суждение о возможных путях решения поставленных проблем
Вопрос 25. Совокупность процедур, методов, персонала, оборудования, предназначенных для регулярного сбора, анализа, распределения достоверной информации для подготовки и принятия маркетинговых решений
- Ответ: Маркетинговая информационная система (МИС)
Вопрос 26. Алгоритм, с помощью которого осуществляется измерение в том случае, если исследователь стремиться отобразить изучаемые явления количественно
- Ответ: шкала измерения
Вопрос 27. Суть метода логико-смыслового моделирования проблем исследования заключается в …
- Ответ: формировании каталога проблем, их структуризации и ранжировании по степени приоритетности
Вопрос 28. Возможно использование индивидуальных экспертных оценок.
- Ответ: Да
Вопрос 29. В основной части типового отчета о маркетинговом исследовании содержится(атся) …
- Ответ: описание методологии исследования, его основные результаты и ограничения
Вопрос 30. Результаты … исследований можно переносить на группы большего размера.
- Ответ: количественных
Вопрос 31. Последовательность этапов процесса маркетинговых исследований
- Ответ: 1-определение проблемы
- Ответ: 2-отбор источников информации
- Ответ: 3-сбор информации
- Ответ: 4-обработка и анализ информации
- Ответ: 5-представление выводов и рекомендаций
Вопрос 32. Простая табуляция полученных в результате исследования данных подразумевает подсчет количества событий, которые попадают в …
- Ответ: каждую категорию анализа, когда категории базируются на одной переменной
Вопрос 33. Ошибка, допущенная при формулировке следующего вопроса анкеты: «Часто ли Ваше внимание привлекает реклама моющих средств?» – в газетах – по радио – по телевидению»
- Ответ: Несоответствие между смыслом вопроса и характером предлагаемых ответов
Вопрос 34. Более емкое понятие
- Ответ: Маркетинговое исследование
Вопрос 35. Ошибка, допущенная при формулировке следующего вопроса анкеты: «На самом ли деле реклама заставляет Вас покупать тот или иной товар?»
- Ответ: Подталкивание респондента к нужному ответу
Вопрос 36. Объем выборки влияет на ее репрезентативность.
- Ответ: Нет
Вопрос 37. Вид маркетинговых исследований, к которому относятся мотивационные исследования, называется …
- Ответ: изучение потребителей
Вопрос 38. Проекционные методы относятся к … исследованиям.
- Ответ: качественным
Вопрос 39. Если Вы стремитесь к высокому проценту возврата ответов, хотите сэкономить средства на проведение исследования, и у Вас ограничено время. Влияние исследователя на респондента Вас не беспокоит. Вы предпочтете …
- Ответ: опрос по телефону
Вопрос 40. В маркетинговых исследованиях под ошибкой выборки подразумеваются отклонения (различия) между данными …
- Ответ: полученными от выборки и истинными данным
Вопрос 41. Статистический способ моделирования зависимости результативного признака от факторного признака/признаков – это … анализ.
- Ответ: регрессионный
Вопрос 42. Тип исследований, который помогает выдвинуть возможные гипотезы исследования, это …исследования.
- Ответ: качественные
Вопрос 43. Тип вопроса, не содержащий никаких подсказок и дающий возможность респонденту выразить свое мнение
- Ответ: Открытый
Вопрос 44. Точность измерений по отношению к тому, что существует в реальности, – это … измерения.
- Ответ: достоверность
Вопрос 45. Информация, извлекаемая из публикаций в специализированной печати, относится к … информации.
- Ответ: вторичной
Вопрос 46. Максимальный размер рынка при наибольшей активности маркетинговых усилий всех компаний, входящих в отраслевой сектор, при определенном состоянии окружающей маркетинговой среды – это …
- Ответ: рыночный потенциал
Вопрос 47. Под таким принципом проведения маркетингового исследования, как объективность подразумевается …
- Ответ: учет возможных погрешностей при измерении того или иного явления
Вопрос 48. Тип вопроса, который следует использовать в том случае, если от респондента требуется выразить критическое отношение к себе
- Ответ: Косвенный
Вопрос 49. Свойства выборки, которые позволяют ей выступать моделью (представителем) генеральной совокупности с точки зрения ее характеристик, которые изучаются при проведении исследования, – это … выборки.
- Ответ: репрезентативность
Вопрос 50. Число случаев появления каждого значения измеренной характеристики (признака) в каждом выбранном диапазоне ее значений, можно определить с помощью …
- Ответ: распределения частот
Вопрос 51. Техника шкалирования, использованная при формулировке следующего вопроса анкеты: «Согласны ли Вы с утверждением, что крупные фирмы обычно выпускают товары лучшего качества, чем мелкие?» – совсем не согласен – не согласен – частично согласен – согласен – полностью согласен
- Ответ: шкала Лайкерта
Вопрос 52. Экспертный опрос, проводимый в несколько туров с целью последовательного уточнения оценок экспертов без непосредственного контакта между ними
- Ответ: Метод Дельфи
Вопрос 53. Тип вопроса в анкете, предусматривающий наличие набора всех возможных вариантов ответов
- Ответ: Закрытый
Вопрос 54. Присвоение численной оценки объектам, которые обладают некоторыми качественными характеристиками
- Ответ: измерение
Вопрос 55. Параллельное использование нескольких методов формирования выборки, основанное на поэтапном отборе ее объектов, – это … выборка.
- Ответ: многоступенчатая
Вопрос 56. Основное преимущество опроса состоит в …
- Ответ: возможности табулирования полученных данных и проведения статистического анализа результатов
Вопрос 57. Если тестируемой группе потребителей предлагают набор альтернативных рекламных роликов и просят дать их оценку по вербальной шкале с точки зрения привлекательности, убедительности и поведенческой ценности, то используется …
- Ответ: прямая оценка
Вопрос 58. Когда исследователь использует случайную выборку, основанную на информации о числовых характеристиках генеральной совокупности, то …
- Ответ: наиболее корректный подход к определению объема выборки основан на расчете доверительных интервалов и среднего квадратического отклонения
Вопрос 59. Чем больше различий внутри генеральной совокупности, тем больше величина возможной ошибки выборки.
- Ответ: Да
Вопрос 60. Взаимосвязанный набор систем данных, инструментов и методик, поддерживаемый программным обеспечением, с помощью которого фирма собирает и интерпретирует информацию для принятия маркетинговых действий, называется
- Ответ: Система собственных маркетинговых исследований
Вопрос 61. Упорядоченный и постоянно обновляемый массив данных о потенциальных потребителях и клиентах фирмы
- Ответ: Маркетинговая база данных (БДМ)
Вопрос 62. Необходимость в проведении маркетингового исследования возникает, когда …
- Ответ: обнаруживается, что комплекс маркетинга не соответствует условиям рынка
Вопрос 63. Основные функции анкет заключаются в …
- Ответ: возможности обратиться к определенной совокупности респондентов и систематизировать данные, извлекаемых их ответов
Вопрос 64. Предпочтительный метод сбора данных в том случае, если результат исследования складывается под влиянием нескольких переменных
- Ответ: Эксперимент
Вопрос 65. Статистический показатель, характеризующий степень несхожести респондентов или их ответов
- Ответ: Размах вариации
Вопрос 66. Цель поискового исследования заключается в …
- Ответ: сборе предварительной информации, предназначенной для более точного определения проблемы
Вопрос 67. Основная цель маркетинговых исследований
- Ответ: Создать информационно-аналитическую базу для принятия маркетинговых решений
Вопрос 68. Фирмы, специализирующиеся на продаже стандартизированной маркетинговой информации относятся к фирмам, специализирующимся на …
- Ответ: сборе синдикативной (подходящей сразу для нескольких заказчиков) информации
Вопрос 69. Метод сбора данных, предусматривающий использование ассоциативных тестов
- Ответ: Проекционный
Вопрос 70. Структурные части анкеты
- Ответ: Введение, основная часть, реквизитная часть
Вопрос 71. Существует единый типовой образец плана маркетингового исследования.
- Ответ: Нет
Вопрос 72. Существует единый типовой образец МИС.
- Ответ: Нет
Вопрос 73. Быстро определить удельный вес той доли совокупности, которая находиться выше или ниже некоторой заданной величины значения переменной можно с помощью …
- Ответ: кумулятивного (накопленного) распределения частот
Вопрос 74. Показатель, обладающий большей степенью информативности для исследователя – это …
- Ответ: средняя величина
Вопрос 75. Ключевая характеристика вероятностной (случайной) выборки заключается в том, что …
- Ответ: все единицы выборки имеют известную вероятность (шанс) попасть в выборку
Вопрос 76. Юридические и физические лица, обладающие нужными фирме сведениями и занимающиеся определенной рыночной деятельностью – это … информации.
- Ответ: носитель
Вопрос 77. Анализ степени согласия или несогласия потребителей с набором утверждений подобного рода: – Мне нравится пробовать новые и разнообразные вещи. – Я всегда стараюсь одеваться согласно тенденциям моды. – Если мои дети больны, я бросаю все, чтобы заняться ими. – Политика – это дело мужчин, а не женщин. – Загрязнение окружающей среды – крупнейшая проблема нашей эпохи. – Мы часто принимаем гостей.
- Ответ: лежит в основе исследования стиля жизни и социально-культурной сегментации потребителей
Вопрос 78. Ключевая характеристика дескриптивного исследования
- Ответ: Описание тех или иных аспектов реальной маркетинговой ситуации
Вопрос 79. Возможно ли использование индивидуальных экспертных оценок.
- Ответ: Да
Вопрос 80. Метод экспертного опроса, направленный на получение большого количества идей, высказанных в ходе свободной дискуссии
- Ответ: Метод мозгового штурма
Вопрос 81. Под таким принципом проведения маркетингового исследования, как достоверность подразумевается …
- Ответ: получение адекватных данных за счет обеспечения научных принципов их сбора и проведения
Вопрос 82. Если Вы стремитесь к высокому проценту возврата ответов, у Вас достаточно средств, ограничено время, а влияние исследователя на респондента Вас не беспокоит, то Вы предпочтете …
- Ответ: личное интервью
Вопрос 83. Единодушие большинства экспертов является критерием достоверности данных ими оценок тех или иных явлений или прогнозов их развития в будущем.
- Ответ: Не всегда
Вопрос 84. Средняя характеристика из высказанных группой компетентных специалистов мнений о каком-либо явлении или процессе, при условии, что удалось достичь согласованности их взглядов, называется …
- Ответ: Экспертная оценка
Вопрос 85. Школа неформального подхода к проведению маркетингового исследования подразумевает …
- Ответ: использование качественных оценок, отказ от использования математического аппарата
Вопрос 86. Отличие качественных исследований от количественных исследований состоит в том, что они направлены на …
- Ответ: объяснение наблюдаемых явлений и помогают выдвинуть гипотезы исследования
Вопрос 87. Аналитический процесс, включающий определение проблемы, сбор, обработку и анализ информации, а также выработку рекомендаций по решению проблемы
- Ответ: Маркетинговые исследования
Вопрос 88. На первом этапе экспертного опроса, проводимого методом Дельфи, осуществляется …
- Ответ: анонимное заполнение экспертами заранее разработанных анкет
Вопрос 89. Экспертный опрос, проводимый в несколько туров с целью последовательного уточнения оценок экспертов без непосредственного контакта между ними, называется …
- Ответ: Метод Дельфи
Вопрос 90. Фундаментальный критерий, по которому оцениваются все отчеты об исследованиях
- Ответ: обеспечение связи (эффективной коммуникации) исследователя с заказчиком исследования
Вопрос 91. Исследования, проводимые с помощью омнибусных панелей это … исследования.
- Ответ: мультиспонсируемые
Вопрос 92. Заранее подготовленный бланк с перечнем вопросов, на которые должен ответить респондент
- Ответ: анкета
Вопрос 93. Вид маркетинговых исследований, к которому относятся исследования деятельности посредников
- Ответ: Изучение каналов распределения
Вопрос 94. Представляя отчет заказчику – менеджеру специализированного спортивного магазина, исследователь заявил следующее: «Были проанализированы данные по признанной удовлетворительной выборке, объемом 15 магазинов. Результаты показали, что 95% доверительный интервал для среднегодового объема продаж в генеральной совокупности спортивных магазинов составляет 1000000 + 150000 млн. руб.» Правильно ли исследователь сформулировал данный вывод с точки зрения возможности его понимания слушателями?
- Ответ: Вывод сформулирован правильно, но большей части аудитории он будет непонятен
Вопрос 95. Более емкое понятие, это …
- Ответ: Маркетинговое исследование
Вопрос 96. Величина признака, появляющаяся наиболее часто по сравнению с другими величинами данного признака, называется …
- Ответ: модой
Вопрос 97. Статистическая модель, выражающая в математической форме динамические закономерности развития изучаемого явления или процесса
- Ответ: Трендовая модель
Вопрос 98. Упорядоченная совокупность источников информации и процедур их получения, используемая для воссоздания текущей картины, происходящих в рыночной среде перемен – это система …
- Ответ: сбора внешней информации (маркетинговой разведки)
Вопрос 99. Основное преимущество наблюдения, как метода сбора данных заключается в …
- Ответ: отсутствии влияния на изучаемые явления со стороны исследователя
Вопрос 100. Основной недостаток экспериментов заключается в …
- Ответ: высокой стоимости и длительности проведения
Вопрос 101. Источники внешней вторичной информации
- Ответ: официальные отчеты фирм, специальные издания, Интернет, данные государственной статистики
Вопрос 102. Аналитический процесс, включающий определение проблемы, сбор, обработку и анализ информации, а также выработку рекомендаций по решению проблемы, называется …
- Ответ: маркетинговые исследования
Вопрос 103. Цель казуального исследования заключается в …
- Ответ: обосновании гипотез, определяющих содержание выявленных причинно-следственных связей
Вопрос 104. Ключевая характеристика метода экспертных оценок – он основан …
- Ответ: на использовании интуиции, опыта и воображения людей
Вопрос 105. Метод выборки, предусматривающий отбор единиц выборки (респондентов), способных дать наиболее точные сведения
- Ответ: выборка по усмотрению
Вопрос 106. Методы сбора первичных данных, используемые при проведении маркетингового исследования
- Ответ: Наблюдение, эксперимент, опрос
Вопрос 107. Основные преимущества синдикативной маркетинговой информации
- Ответ: Долевая стоимость
- Ответ: Высокое качество
Вопрос 108. При изучении перспектив и факторов успеха нового товара проводятся разнообразные исследования. Если группе потенциальных потребителей предлагают описание нового товара и просят ответить на следующие вопросы теста: – Ясен ли Вам замысел товара: насколько легко он воспринимается? – Видите ли Вы у этого товара достоинства по сравнению с товарами-конкурентами? – Верите ли Вы в реальность этих достоинств? – Предпочтете ли Вы этот товар товарам-конкурентам? – Отвечает ли этот товар Вашим реальным потребностям? – Готовы ли Вы купить этот товар? то при этом осуществляется:
- Ответ: Проверка концепции товара
Вопрос 109. Основное отличие вторичной маркетинговой информации от первичной заключается в том, что она …
- Ответ: собрана ранее, для других целей
Вопрос 110. Метод экспертного опроса, направленный на получение большого количества идей, высказанных в ходе свободной дискуссии, называется …
- Ответ: Метод мозгового штурма
Вопрос 111. Магазинные тесты, направленные на тестирование альтернативных концепций упаковки товара относятся к … экспериментам.
- Ответ: полевым
Вопрос 112. Ключевая характеристика метода экспертных оценок
- Ответ: Он основан на использовании интуиции, опыта и воображения людей
Вопрос 113. Тип наблюдения, предусматривающий использование заранее разработанной схемы и стандартного листа наблюдений
- Ответ: Структурированное
Вопрос 114. Совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
- Ответ: Генеральная совокупность
Вопрос 115. Вид маркетинговых исследований, к которому относятся исследования отношения к марке товара
- Ответ: Изучение потребителей
Вопрос 116. Объем выборки влияет на ее ошибку.
- Ответ: Да
Вопрос 117. Цели исследования с помощью фокус-групп
- Ответ: Выдвижение гипотез исследования, изучение мотивов покупки товаров, реакции на новые товары, отношения к рекламе
Вопрос 118. Маркетинговая информационная система (МИС) компании позволяет получать информацию, …
- Ответ: на основе которой можно принимать управленческие решения
Вопрос 119. Блок Маркетинговой Информационной Системы, в котором содержатся данные о заказах, продажах, ценах, товарных запасах предприятия
- Ответ: данных, полученных в результате собственных маркетинговых исследований
Вопрос 120. Методы, относящиеся к методам обработки маркетинговой информации
- Ответ: определения средних величин
- Ответ: регрессионный
- Ответ: корреляционный анализ
Вопрос 121. Предсказательный анализ направлен на
- Ответ: прогнозирование развития событий в будущем (например, путем анализа временных рядов)
Вопрос 122. Элемент Маркетинговой Информационной Системы, для которого используются такие источники информации, как торговый персонал фирмы, конкуренты, дистрибьюторы, розничные торговцы – это система …
- Ответ: сбора внешней информации (маркетинговой разведки)
Вопрос 123. Данные, полученные по заказу конкретных фирм и недоступные для широкой публики – это … информация.
- Ответ: синдикативная
Вопрос 124. Основные преимущества вторичной маркетинговой информации
- Ответ: экономия времени и денег
Вопрос 125. Пробный маркетинг относится к …
- Ответ: эксперименту
Вопрос 126. Рассмотрите следующую последовательность: 68, 45, 72, 50, 56, 50, 45, 45, 50, 56, 45, 68, 45, 68, 45, 72, 45. Какое из следующих утверждений является верным
- Ответ: Мода равна 45
Вопрос 127. Выявление смысловых единиц текста, количество которых характеризует общую направленность анализируемого документа, называется …
- Ответ: контент-анализ
Вопрос 128. Классификация панелей по характеру изучаемых единиц
- Ответ: Потребительские, торговые, промышленные
Вопрос 129. Фирмы, специализирующиеся на продаже стандартизированной маркетинговой информации относятся к фирмам, …
- Ответ: специализирующимся на сборе синдикативной (подходящей сразу для нескольких заказчиков) информации
Вопрос 130. Методы сбора данных, используемые при проведении количественных исследований
- Ответ: Фокус-группы, наблюдения, эксперименты
Вопрос 131. Средняя характеристика из высказанных группой компетентных специалистов мнений о каком-либо явлении или процессе, при условии, что удалось достичь согласованности их взглядов
- Ответ: Экспертная оценка
Вопрос 132. Тип шкалы измерений, использованный при формулировке следующего вопроса анкеты: «Какой безалкогольный напиток из приведенного списка Вам нравится больше всего? – Coca-cola – Pepsi – Sprite – Seven Up
- Ответ: номинальная
Вопрос 133. Статистический показатель, характеризующий значение признака, занимающего срединное место в упорядоченном ряду значений данного признака
- Ответ: Медиана
Вопрос 134. Такое требование к маркетинговой информации как релевантность подразумевает …
- Ответ: соответствие информации целям и задачам исследования
Вопрос 135. Метод выборки, используемый в том случае, если генеральная совокупность разделяется на страты, а затем для каждой из них производится расчет простой случайной выборки – метод …
- Ответ: стратифицированной выборки
14 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
|
Исходные данные |
Таблица 16 |
|||||||
|
Профессия |
Число |
Месячная заработная плата каждого рабочего за март, |
||||||
|
рабочих |
руб. |
|||||||
|
Токари |
4 |
3252; |
3548; |
3600; |
3400; |
|||
|
Слесари |
6 |
3450; |
3380; |
3260; |
3700; |
3250; |
3372 |
Проверить правило сложения дисперсий и указать, велико ли влияние профессии на различие в уровне заработной платы.
6.Средняя величина в совокупности равна 12, среднее квадратическое отклонение равно 7. Чему равен средний квадрат индивидуальных значений этого признака?
7.Средняя величина признака в совокупности равна 18, а средний квадрат индивидуальных значений этого признака равен 328. Определить коэффициент вариации.
8.Дисперсия признака равна 250 000, коэффициент вариации равен 50%. Чему равна средняя величина признака?
9.Дисперсия признака равна 25, средний квадрат индивидуальных значений равен 250. Чему равна средняя?
10.Средняя величина признака равна 2600 единицам, а коэффициент вариации равен 30%. Определить дисперсию признака.
11.Общая дисперсия равна 8,4. Средняя величина признака для всей совокупности равна 13. Средние по группам равны соответственно 10, 15 и 12. Численность единиц в каждой группе составляет 32, 53 и 45. Определить среднюю внутригрупповую дисперсию.
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ ПО ТЕМЕ «ВЫБОРОЧНОЕ НАБЛЮДЕНИЕ»
Главной целью практического занятие является повторение, закрепление знаний и получений умений и навыков решения конкретных задач. В этих целях студентам перед занятием необходимо повторить, изучить лекции по теме «Выборочное наблюдение».
В начале занятия студентам нужно ответит на следующие вопросы:
1. Что такое выборочное наблюдение, и в каких случаях к нему прибе-
гают?
17
3.Какие существуют способы отбора (виды выборки)?
4.Что такое повторная и бесповторная выборка?
5.Как определяется объем собственно-случайной бесповторной выборки?
6.В чем отличие средней и предельной ошибок выборки?
7.Решение каких вопросов зависит от объема выборки? Как влияет объем выборки на ее ошибке?
Далее студенты совместно с преподавателем решаю следующие задания:
1.Выборочное обследование цен на вторичном рынке жилья позволило получить следующие данные (табл. 17).
|
Исходные данные |
Таблица 17 |
|||
|
Тип жилого помещения |
Количество |
Средняя |
Среднее квадра- |
|
|
жилых по- |
цена 1 кв. |
тическое откло- |
||
|
мещений |
м, тыс. |
нение цены, |
||
|
руб. |
тыс., руб. |
|||
|
Комната в коммуналь- |
||||
|
ной квартире |
25 |
12,2 |
0,8 |
|
|
1-комнатная квартира |
34 |
14,5 |
0,6 |
|
|
2-комнатная квартира |
46 |
13,1 |
0,5 |
|
|
3-комнатная квартира |
62 |
11,6 |
0,3 |
|
|
Многокомнатная квар- |
11 |
15,0 |
1,1 |
|
|
тира |
Предполагая, что в ходе обследования применялась повторная выборка, пропорциональная объему выделяемых типических групп, определите границы средней цены 1 кв. м жилья в данном городе.
2. В результате выборочного обследования покупателей супермаркета (собственно-случайная повторная выборка) получено следующее распределение по размеру сделанных покупок (табл. 18).
Таблица 18
Данные собственно-случайной повторной выборки
|
Стоимость покупки, |
до 100 |
100 — 200 |
200 — 300 |
300 и более |
|
руб. |
||||
|
Число покупателей |
17 |
58 |
89 |
43 |
С вероятностью P(t)=0,997 определите:
а) границы среднего размера покупки в генеральной совокупности; б) границы удельного веса покупок на сумму до 100 руб. в генеральной
совокупности.
3. Определите, сколько клиентов автосервиса, отобранных на основе алгоритмов собственно-случайной выборки, необходимо опросить для определе-
18
ния доли лиц, неудовлетворенных качеством обслуживания. При этом предельная ошибка не должна превышать 2,5% при уровне вероятности 0,683. Из аналогичных обследований известно, что дисперсия данного альтернативного признака (удовлетворенность качеством обслуживания) не превышает 0,21.
4.В результате опроса каждого пятого учащегося выпускных классов школ района было выяснено, что среднее время, затрачиваемое ежедневно на подготовку к занятиям, составляет 86 мин. при коэффициенте вариации 29,4%. При этом выборочная совокупность составила 128 чел. С вероятностью 0,997 определите границы средних затрат времени на подготовку к занятиям в целом по всем учащимся выпускных классов школ района.
5.На основе 3%-ного выборочного обследования (собственно-случайная бесповторная выборка) получены следующие данные о расходах населения на оплату жилищно-коммунальных услуг (табл. 19).
|
Исходные данные |
Таблица 19 |
||||||||
|
Расходы на оплату жи- |
до 100 |
100-200 |
200-300 |
300-400 |
400-500 |
500 и |
|||
|
лищно-коммунальных |
более |
||||||||
|
услуг, руб. |
|||||||||
|
Число домохозяйств |
93 |
190 |
555 |
335 |
84 |
18 |
С какой вероятностью можно утверждать, что удельный вес домохозяйств, расходующих на оплату жилищно-коммунальный услуг более 400 руб. в месяц, в целом по данному региону не превышает 9,5%?
6.Как изменится необходимый объем собственно-случайной повторной выборки, если уровень вероятности, с которым требуется получить результат,
увеличить с 0,683 до 0,954; с 0,954 до 0,997?
7.Определите, каким должен быть интервал отбора при организации выборочного наблюдения на основе механической выборки, чтобы процент отбо-
ра составил 20%; 5%; 2,5%; 2%?
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ ПО ТЕМЕ «СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА КОРРЕЛЯЦИОННЫХ СВЯЗЕЙ»
Главной целью практического занятие является повторение, закрепление знаний и получений умений и навыков решения конкретных задач. В этих целях студентам перед занятием необходимо повторить, изучить лекции по теме «Статистические методы анализа корреляционных связей».
В начале занятия студентам нужно ответит на следующие вопросы:
1.В чем различие между функциональной и корреляционной зависимо-
19
стью?
2.В чем смысл коэффициента парной корреляции, каковы границы его значений?
3.Как определяется значимость коэффициента корреляции, рассчитанного по выборочным данным?
4.Как определяются параметры линейного уравнения регрессии?
5.Как определяется значимость уравнения регрессии?
6.Как использовать уравнение регрессии для прогноза?
7.Какие вы знаете показатели измерения тесноты зависимости?
Далее студенты совместно с преподавателем решаю следующие задания: 1. Установите направление и характер связи между четырьмя показателями, характеризующими экспорт технологий и услуг технического характе-
ра, по 10 областям РФ в 2003 г. (табл. 20).
|
Исходные данные (млн. руб.) |
Таблица 20 |
||||
|
Номер |
Число |
Стоимость |
Чистая стоимость |
Поступления |
|
|
области |
соглашений |
предмета |
предмета соглаше- |
по соглашени- |
|
|
соглашения |
ния |
ям |
|||
|
1 |
9 |
0,49 |
0,49 |
0,42 |
|
|
2 |
7 |
4,19 |
4,18 |
0,19 |
|
|
1 |
3 |
0,11 |
0,11 |
0,11 |
|
|
4 |
20 |
3,69 |
3,69 |
2,38 |
|
|
5 |
8 |
0,51 |
0,51 |
0,51 |
|
|
6 |
11 |
5,10 |
5,05 |
2,04 |
|
|
7 |
6 |
0,52 |
0,52 |
0,52 |
|
|
8 |
13 |
1,75 |
1,74 |
0,28 |
|
|
9 |
18 |
4,28 |
4,22 |
3,30 |
|
|
10 |
16 |
2,49 |
2,48 |
0,30 |
2. Взаимосвязь между стоимостью активной части основных фондов и затратами на производство работ по 35 строительным фирмам представлена в табл. 21.
20
![]()
Таблица 21
Исходные данные
|
Затраты на производство строитель- |
Стоимость активной части основ- |
Всего |
||||
|
но-монтажных работ, % к стоимости |
ных фондов, млн. руб. |
фирм |
||||
|
активной части основных фондов |
||||||
|
50-100 |
100-150 |
150-200 |
200-250 |
|||
|
1-5 |
2 |
4 |
6 |
|||
|
5-9 |
2 |
6 |
4 |
12 |
||
|
9-13 |
5 |
3 |
8 |
|||
|
3-17 |
2 |
2 |
4 |
|||
|
17-21 |
5 |
5 |
||||
|
Итого |
7 |
9 |
11 |
8 |
35 |
Постройте поле корреляции и эмпирическую линию регрессии.
3. Зависимость между объемом произведенной продукции и балансовой прибылью по 10 предприятиям одной из отраслей промышленности характеризуется следующими данными (табл. 22).
Таблица 22
|
Исходные данные |
|||
|
Номер |
Объем реализован- |
Балансовая при- |
|
|
предпри- |
ной |
продукции, |
быль, млрд. руб. |
|
ятия |
млрд. руб. |
||
|
1 |
491,8 |
133,8 |
|
|
2 |
483,0 |
124,1 |
|
|
3 |
481,7 |
62,4 |
|
|
4 |
478,7 |
62,9 |
|
|
5 |
476,9 |
51,4 |
|
|
6 |
475,2 |
72,4 |
|
|
7 |
474,4 |
99,3 |
|
|
8 |
459,5 |
40,9 |
|
|
9 |
452,9 |
104,0 |
|
|
10 |
446,5 |
116,1 |
Определите вид корреляционной зависимости, постройте уравнение регрессии, рассчитайте параметры уравнения, вычислите тесноту связи. Объясните полученные статистические характеристики.
4.Для оценки степени тесноты связи между уровнем выработки рабочих
истажем их непрерывной работы была рассчитана величина корреляционного отношения, оказавшаяся равной 0,9 (объем выборки был равен 100). Опреде-
21
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Запуск рекламной кампании в маркетинге предполагает А/В-тестирование, однако не каждый проведенный тест будет показательным, а его результаты – значимыми для статистики. Одна из распространенных ошибок при проведении исследований – неправильное определение нормального размера выборки. Как следствие – запуск рекламы, которая не даст результатов, и зря потраченные деньги.
Что такое объем выборки
Объем выборки – это количество людей из общего числа целевой аудитории (ЦА) продукта или бренда, участвовавших в исследовании, или количество заполненных анкет, которые были учтены при подсчете результатов.
![]()
![]()

Термин «выборка» говорит о том, что из всей совокупности участников опроса проводится оценка лишь части ответов.
В зависимости от параметров проекта, которые были указаны изначально, выборка может быть разной. Например, при случайной выборке респонденты выбираются из целевой совокупности случайным образом.
Зачем необходимо рассчитывать
Объем выборки определяют перед запуском количественных исследований в маркетинге (например, контент-анализа), чтобы узнать, какое число представителей ЦА должно поучаствовать в тестировании, и получить достоверные результаты. Если данных о объеме выборки нет, это может стать причиной того, что исследователь получит некорректные результаты.
Для качественных исследований объем выборки не определяют. Также он неактуален, если речь идет о проведении пилотных, т. е. предварительных исследований.
Основные понятия определения
В определении размера выборки участвуют различные параметры:
- генеральная совокупность;
- выборочная совокупность;
- достоверность измерений;
- репрезентативность выборки;
- нулевая и альтернативная гипотезы;
- доверительная вероятность;
- уровень значимости;
- мощность;
- клинически важный размер эффекта;
- односторонний / двусторонний тест значимости;
- доверительный интервал;
- погрешность измерения;
- процент ответов.
Разберем, что означают основные из них.
Генеральная совокупность
Генеральной совокупностью называется общее количество объектов наблюдения, которые обладают определенными общими признаками (возраст, пол, оборот, численность, доход и пр.) и о которых будут сделаны заявления после обработки результатов исследования.
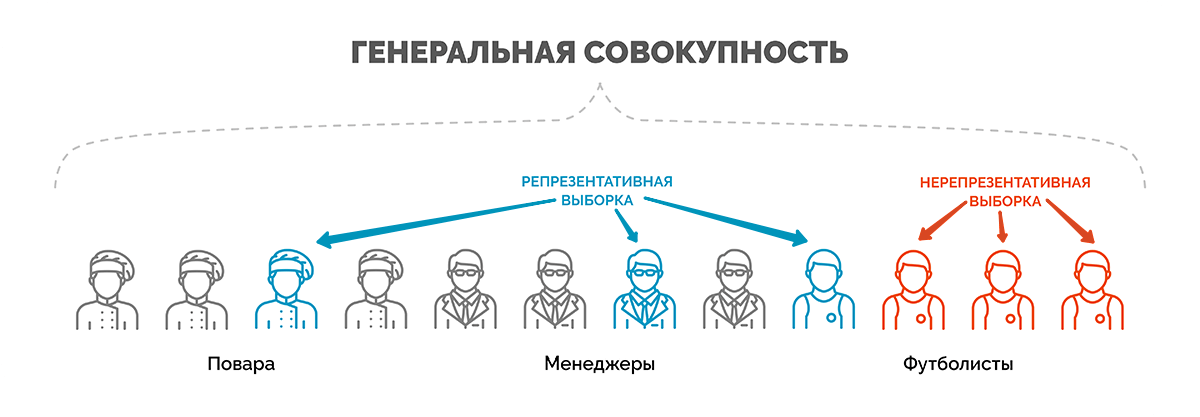
Объектами наблюдения могут быть люди, предприятия, домохозяйства, населенные пункты, отдельные малые социальные группы и т. д.
Если известно, что результаты опроса касаются всех жителей Москвы, то генеральная совокупность будет равна общей численности населения города, т. е. 13 млн человек (по данным 2021 года).
Оценивать свойства генеральный совокупностей, основываясь на выборочных методах, позволяет кривая нормального распределения.
Выборочная совокупность
Выборка или выборочная совокупность – это некоторая часть объектов из числа генеральной совокупности, отобранная для участия в исследовании с целью оценить распределение мнений и сделать итоговое заключение, которое будет распространяться на всю генеральную совокупность.
Характеристики выборочной совокупности должны корректно отражать параметры генеральной совокупности, т. е. обладать свойством репрезентативности. Только в данном случае заключение, сделанное исходя из результатов анализа выборки, будет с одинаковой вероятностью распространяться на представителей всей генеральной совокупности.
Выборка, состоящая из работников московских предприятий, не будет репрезентировать население города трудоспособного возраста и особенно все население столицы, т. к. не включает неработающих людей, женщин в декрете, удаленных сотрудников и т. д. Даже если мы будем увеличивать количество опрошенных работников столичных компаний, выборка все равно не сможет отразить характеристики генеральной совокупности, т. е. всего трудоспособного населения Москвы.
Погрешность измерений
Допустимая погрешность измерений – это процент возможной ошибки или отклонения результатов исследования, т. е. то значение, на которое истинный показатель может откланяться от значения, полученного в результате исследования.
Чем меньше погрешность, тем больше должна быть выборка.
Результаты опроса показали, что 60% опрощенных предпочитают делать покупки в сетевых магазинах. Предел погрешности 5% говорит о том, что в генеральной совокупности доля сторонников сетевых точек продаж может увеличиться или уменьшиться на 5% относительно уровня полученных 60%. Т. е. фактическое значение будет лежать в пределах значений от 55 до 65%.
Достоверность измерений
Уровень достоверности (надежности) измерений – это вероятность того, что полученные в результате исследования истинные результаты выбранного параметра генеральной совокупности находятся в пределах ее доверительного интервала (в примере выше это интервал 55-65%). Простыми словами, это степень уверенности в репрезентативности результатов.
Чем меньше доверительный интервал и выше заданный уровень достоверности, тем больше должна быть выборочная совокупность.
Если взять приведенный выше в статье пример с погрешностью в 5%, вы можете быть уверены в следующем: вероятность того факта, что от 55 до 65% людей предпочитают совершать покупки в сетевых магазинах, составляет не менее 95%.
Репрезентативность выборки
Под репрезентативностью понимают степень соответствия характеристик выборочной совокупности характеристикам генеральной совокупности, которые можно экстраполировать на всю популяцию.
- выборка, состоящая на 100% из автомобилистов Санкт-Петербурга, не репрезентирует всех жителей Санкт-Петербурга;
- выборка, состоящая только из российских фирм B2B с количеством сотрудников до 200 человек, не репрезентирует все компании страны, работающих в этом сегменте.
Исследование должно быть репрезентативным, если стоит задача по результатам количественного исследования сформировать представление о популяции в целом и правильно оценить ее. Если же исследование качественное или люди опрашиваются ради сбора мнений, предложений, идей, в этом случае репрезентативная выборка практически не играет роли.
Что влияет на результаты
Результаты тестирования могут изменяться под влиянием ряда факторов:
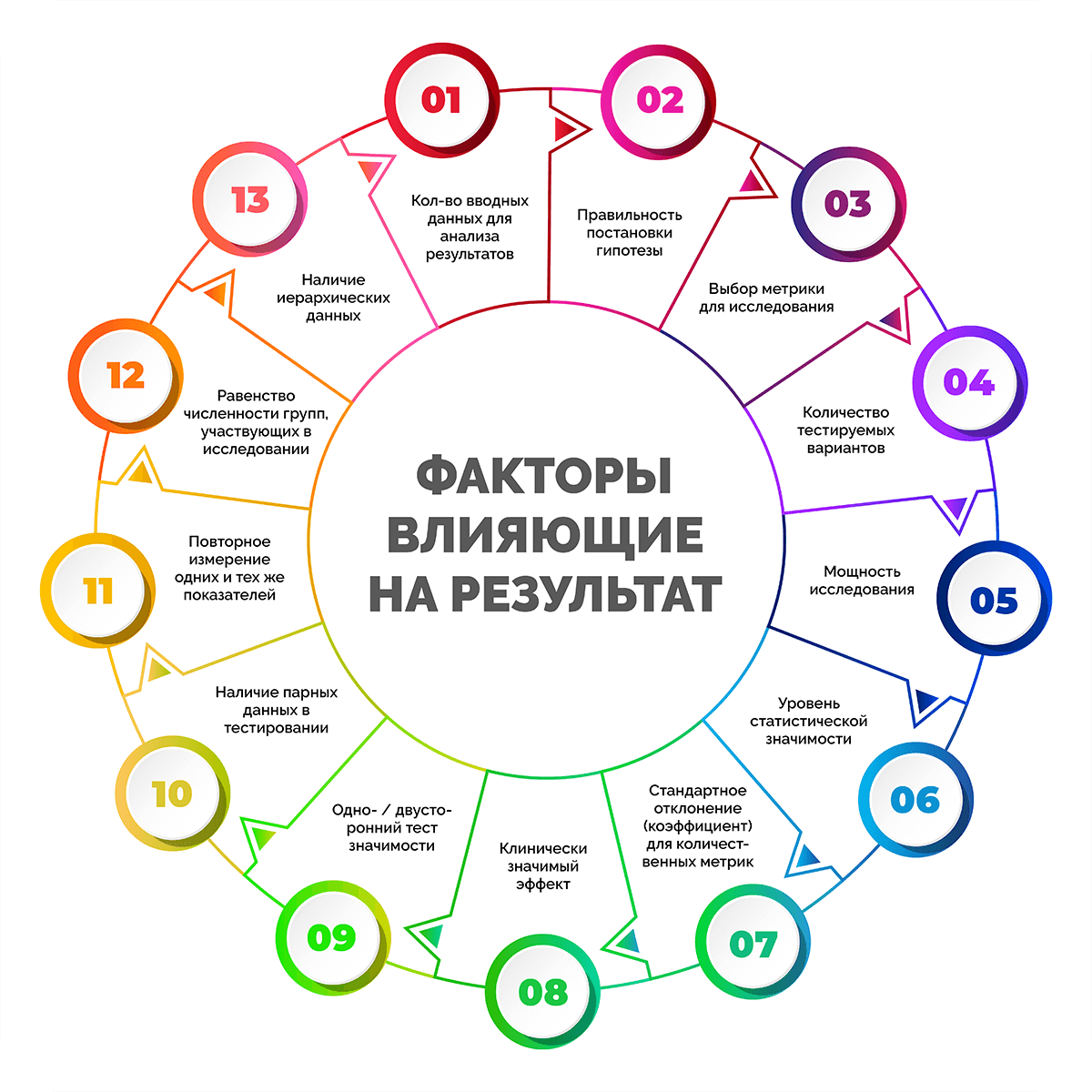
- количество вводных данных для анализа результатов;
- правильность постановки гипотезы;
- выбор той или иной метрики (показателя, переменных) для исследования;
- количество тестируемых вариантов;
- мощность исследования;
- уровень статистической значимости;
- стандартное отклонение (коэффициент) для количественных метрик;
- клинически значимый эффект;
- одно- / двусторонний тест значимости;
- наличие парных данных в тестировании;
- повторное измерение одних и тех же показателей;
- равенство численности групп, участвующих в исследовании;
- наличие иерархических данных.
Также расчет размера выборки может давать разные результаты, если анализ является:
- рандомизированным и контролируемым;
- рандомизированным и кластерным;
- нерандомизированным экспериментом вмешательства;
- исследованием эквивалентности;
- исследованием распространенности;
- обсервационным;
- изучением специфичности и чувствительности теста.
Нерандомизированные тестирования взаимосвязей или различий предполагают задействования в маркетинговых исследованиях выборки гораздо большего размера, чтобы при анализе было не сложно учесть влияние третьих факторов.
Типы выборок
Различают два типа выборок: вероятностные и невероятностные или детерминированные. Каждая группа включает в себя виды. Разберем, какие из них входят в каждый тип.
Вероятностные выборки:
- Случайная или простой случайный отбор – предполагает полный список элементов (отбираются при помощи таблицы случайных чисел), равную вероятность доступности всех из них и однородную генеральную совокупность;
- Механическая или систематическая – выступает в качестве разновидности случайной выборки, при этом упорядочивание происходит по тому или иному признаку, причем первый элемент отбирается случайно, затем с шагом n отбирается каждый последующий элемент;
- Стратифицированная или районированная – выборка используется при неоднородной генеральной совокупности, которая разделяется на страты (группы), в каждой из которых выполняется случайный отбор пропорционально их доле в генеральной совокупности;
- Серийная или кластерная, или гнездовая – единицами отбора выступают целые группы (гнезда или кластеры), которые могут попасть в выборку случайным образом, а все объекты внутри них подлежат сплошному исследованию.
Невероятностные (детерминированные) выборки:
- Квотная выборка – формируется несколько групп объектов, в каждой из которых зачастую пропорционально доле в генеральной совокупности задается определенное число объектов, которые нужно исследовать;
- Метод снежного кома – для формирования выборки каждый участник опроса предоставляет контакты своих знакомых; применяется для исследования труднодоступных групп респондентов;
- Стихийная выборка или выборка «первого встречного» – ее состав и размер заранее неизвестен и зависит от активности людей, опрос проводится среди самых доступных респондентов (интернет-опросы, опросы в журналах и газетах, анкеты на самозаполнение и т. д.);
- Выборка типичных случаев – для исследования отбираются отдельные представители генеральной совокупности, которым присуще среднее значение исследуемого признака.
Отбор в детерминированных выборках происходит не случайно, а по субъективным критериям: типичности, доступности, равного представительства каждой стороны и пр.
Расчет объема выборки
Расчет объема выборки – своего рода компромисс между требуемой мощностью исследования и возможностью реализовать его на практике с учетом имеющихся ресурсов и фокус-группы. При этом выбор метода расчета во многом определяется знаниями о параметрах и характеристиках изучаемых параметров.
Определить объем выборки можно двумя способами: по таблицам и с помощью формулы. Разберем эти методы.
По таблицам
Когда никаких данных о предстоящем исследовании нет, а сам эксперимент является инновационным, никто ранее ничего подобного не проводил и не предлагал решения, для определения объема выборки лучше выбрать табличный метод.
Ниже представлены различные методики. Выбор той или иной из них определяется имеющимися исходными данными или пожеланиями исследователя.
Таблица А. Определение объема выборки по методике К. А. Отдельновой
|
Уровень значимости |
Уровень точности |
||
|
Ориентировочное знакомство |
Исследование средней точности |
Исследование высокой точности |
|
|
0,01 |
100 |
225 |
900 |
|
0,05 |
44 |
100 |
400 |
Объем выборки указан в абсолютных значениях.
Таблица Б. Методика определения размера выборки В. И. Паниотто
|
Размер генеральной совокупности |
500 |
1000 |
2000 |
3000 |
4000 |
5000 |
10000 |
100000 |
∞ |
|
Объем выборки |
222 |
286 |
333 |
350 |
360 |
370 |
385 |
398 |
400 |
Данные указаны в единицах.
Таблица В. Методика N. Fox для определения объема выборки
|
Процент допускаемой ошибки |
Объем выборки в единицах |
|
10 |
88 |
|
5 |
350 |
|
3 |
971 |
|
2 |
2188 |
|
1 |
8750 |
Таблица Г. Определение размера согласно способу K. Mitra, S. Das, M. Mandal
|
Величина различий между основной и контрольной группами |
Уровень значимости |
Мощность |
Объем выборки |
|
0,2 |
0,5 |
80 |
586 |
|
0,2 |
0,1 |
80 |
773 |
|
0,2 |
0,5 |
90 |
746 |
|
0,4 |
0,5 |
80 |
146 |
|
0,4 |
0,1 |
80 |
193 |
|
0,4 |
0,5 |
90 |
186 |
|
0,6 |
0,5 |
80 |
65 |
|
0,6 |
0,1 |
80 |
86 |
|
0,6 |
0,5 |
90 |
83 |
По формулам
Объем выборки, достаточный для проведения новых исследований, определяется следующими параметрами:
- изменчивость признака;
- уровень доверия;
- размер эффекта.
Объем выборки всегда зависит от предполагаемой строгости эксперимента и изменчивости исследуемого признака.
Формула для оценки среднего значения размера выборки:
n = (z × σ / H)2, где:
n – размер выборки;
z – доверительный уровень (при р = 0,05 z = 1,96);
σ – стандартное отклонение;
Н – допустимая ошибка в натуральных величинах.
Формула для оценки доли выборки:

Где:
n – размер выборки;
z – доверительный уровень (при р = 0,05 z = 1,96);
p – доля признака (наибольшее значение достигается при р = 0,5);
H – допустимая ошибка в процентах.
Еще одна формула расчета объема выборки (чаще всего калькулятор размера выборки использует именно ее):

Где:
n – размер выборки;
z – нормированное отклонение;
p – вариация для выборки;
q = 1 – р;
е – допустимая ошибка.
Нормированное отклонение (z) определяется по таблице, зная основные значения доверительной вероятности (α).
|
α, % |
60 |
70 |
80 |
85 |
90 |
95 |
97 |
99 |
99,7 |
|
z |
0,84 |
1,03 |
1,29 |
1,44 |
1,65 |
1,96 |
2,18 |
2,58 |
3,0 |
Последняя формула расчета имеет особенности.
- Начинать считать размер выборки следует с проведения качественного анализа генеральной совокупности, чтобы выяснить степень схожести и близости исследуемых единиц совокупности относительно их географических, демографических, социальных и других характеристик.
- Рекомендуется предварительно выполнить пилотное исследование с целью определения приблизительного значения р.
- Если максимальная вариация р = 50%, то и значение q = 50%, что является наиболее худшим вариантом.
Пример расчета размера выборки
Маркетолог проводит исследование с целью определить, нужны ли компании визитки. Для этого промоутеру предстоит опросить потенциальных клиентов и задавать только один вопрос: «Вы пользуетесь визитками?». На что человек должен будет ответить «Да» или «Нет».
В таком случае размер выборки будет рассчитываться так. Принимаем, что уровень доверительности равен 95% (стандартное значение). При этом нормированное отклонение z составит 1,96. После предварительного анализа предположим, что 80% представителей генеральной совокупности дадут положительный ответ, а значит, р = 0,8. Соответственно, q = 1 – 0,8 = 0,2. Вероятность допустимой ошибки примем за 10%, т. е. e = 0,1. Теперь можно выполнить расчет.

Округлив значение, получаем размер выборки n = 62 человека. Соответственно, в опросе с заданными параметрами нужно задействовать 62 человека из числа целевой аудитории компании.
Подходы к определению размера выборки
Выделяют несколько подходов, которые позволяют установить объем выборки для проведения статистического исследования.
- Арбитражный подход. Объем выборки составляет определенный процент от генеральной совокупности. Например, 10% от общего количество потребителей.
- Традиционный подход. Выборка составляется на основе определенных норм, которые были выработаны в процессе проведенных ранее исследований. Подход игнорирует обстоятельства и условия, строгая логика отсутствует.
- Затратный подход. Объем выборки определяется в зависимости от стоимости сбора информации и возможных затрат на материалы для проведения исследования.
- Подход на основе использования доверительных интервалов. Размер выборки в этом случае рассчитывается по формуле, что обеспечивает высокую точность результата:
n = (p × q) / s2, где:
n – размер выборки;
p – вероятность того, что нужное событие наступит, %;
q = 100% – p;
s – стандартное отклонение, которое соответствует доверительному уровню.
Ошибки выборки
Объем выборки при массовом исследовании определяется двумя факторами:
- Точностью полученных данных или статистической погрешностью.
- Размером и количеством подгрупп, на которые будет разбита выборка при проведении анализа.
При любом исследовании, которое предполагает выборочный опрос респондентов из генеральной совокупности, может присутствовать погрешность данных или ошибка выборки. Выделяют два ее типа:
- случайная – обусловлена действием статистических законов, поэтому очень легко рассчитывается по формулам теории вероятности и математической статистики;
- систематическая – является следствием неточностей при проектировании выборки, определить ее степень смещения, направление и размер практически невозможно.
При расчете размера выборки важно так собрать данные, чтобы вероятность систематической ошибки в результате работы была минимальной.
Расчет случайной ошибки выборки зависит от объема последней, а также от степени однородности данных (дисперсии). Принцип такой: чем меньше дисперсия, тем меньше ошибка. Для расчета чаще всего используют онлайн калькуляторы.
Также выделяют:
- Ошибки первого рода – альфа-ошибка, при которой делается вывод о достоверности гипотезы, которая на самом деле неверна. Величина выбирается произвольно в диапазоне от 0 до 1, чаще всего это значение 0,05 или 0,01.
- Ошибки второго рода – бета-ошибка, при которой тот факт, что гипотеза неверна, остается не выявленным. Значение, как правило, устанавливается на уровне 0,2.
Расчет доверительного интервала
Для расчета доверительного интервала применяются достаточно простые формулы, выбор которых зависит от доли выборки в составе генеральной совокупности.
Если выборка значительно меньше генеральной совокупности:

Если выборка и генеральная совокупность сопоставимы:

В обеих формулах:
Δ – предельная ошибка выборки в процентах;
z – нормированное отклонение или z-фактор;
p – доля респондентов с наличием признака, который исследуется;
q – доля респондентов без исследуемого признака;
n – размер выборки;
N – объем генеральной совокупности (сколько всего респондентов).
Доверительный интервал удобно рассчитывать с помощью онлайн-калькулятора, который использует те же формулы, что мы привели выше. Просто введите необходимые переменные, и система рассчитает результат.
Расчет статистической значимости
Определить этот показатель проще всего с помощью онлайн-сервиса. Калькулятор позволяет проверить, существует ли статистически значимая разница между долями признака, которые были получены из независимых выборок.

Рассчитывать статистическую значимость можно только в том случае, если произведения (n × p) и (n × (1 – р)) превышают значение 5. При этом n – объем выборки, р – доля признака.
Часто задаваемые вопросы
Обычно размер выборки и ее статистическая значимость прямо пропорциональны, т. е. с ростом выборки получение случайных результатов сводится к минимуму. Важность статистической значимости зависит от определенной ситуации. Вот некоторые из них.
|
Ситуация |
Важность статистической значимости |
|
Опросы сотрудников |
Важна, т. к. повышает всесторонность выводов по итогам опроса. |
|
Опросы клиентов об уровне их удовлетворенности |
Не имеет значения, т. к. важен каждый ответ независимо от того, положительный он или отрицательный. |
|
Исследование рынка |
Имеет решающее значение, т. к. помогает сделать вывод о целевом рынке. |
|
Опросы об образовании |
Важна, если нужно использовать результаты исследования при внесении изменений в учебном заведении. |
|
Здравоохранение |
Помогает выявлять серьезные проблемы, делать выводы в исследованиях. Если же опрос проводится ради оценки удовлетворенности пациентов, то не имеет значения. |
|
Опросы для развлечения |
Не важна. |
Заданный размер выборки нужен для получения оценок с желаемым уровнем точности, если речь идет об исследовании распространенности в популяции конкретной характеристики.
- Мало просмотров.
- Узкая тематика.
- Низкий бюджет.
- Высокий бюджет.
Чтобы правильно рассчитать размер выборки и провести показательное исследование с учетом выдвинутых требований:
- наберитесь терпения и дождитесь, пока соберется требуемое количество респондентов;
- будьте последовательны и показывайте рекламу только ЦА в определенное время;
- устанавливайте высокий уровень достоверности при расчете выборки.
При определении объема выборки основную роль играет переменная исхода конкретного исследования. Если в расчет добавляются дополнительные важные переменные, то размер выборки должен позволять адекватно проанализировать их.
Это такое количество объектов исследования, которое позволит получить максимально точный и достоверный результат с предельно небольшой погрешностью. При этом его можно репрезентовать на более широкую аудиторию, в т. ч. по отношению к генеральной совокупности.
Заключение
Объем выборки – важный показатель, без которого невозможно провести адекватное исследование и сделать объективные выводы. Он отражает количество представителей целевой аудитории, которое будет принимать непосредственное участие в эксперименте, и требуется во всех случаях, когда стоит задача сделать определенные заключения по результатам опроса.
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
|
Исходные данные |
Таблица 16 |
|||||||
|
Профессия |
Число |
Месячная заработная плата каждого рабочего за март, |
||||||
|
рабочих |
руб. |
|||||||
|
Токари |
4 |
3252; |
3548; |
3600; |
3400; |
|||
|
Слесари |
6 |
3450; |
3380; |
3260; |
3700; |
3250; |
3372 |
Проверить правило сложения дисперсий и указать, велико ли влияние профессии на различие в уровне заработной платы.
6.Средняя величина в совокупности равна 12, среднее квадратическое отклонение равно 7. Чему равен средний квадрат индивидуальных значений этого признака?
7.Средняя величина признака в совокупности равна 18, а средний квадрат индивидуальных значений этого признака равен 328. Определить коэффициент вариации.
8.Дисперсия признака равна 250 000, коэффициент вариации равен 50%. Чему равна средняя величина признака?
9.Дисперсия признака равна 25, средний квадрат индивидуальных значений равен 250. Чему равна средняя?
10.Средняя величина признака равна 2600 единицам, а коэффициент вариации равен 30%. Определить дисперсию признака.
11.Общая дисперсия равна 8,4. Средняя величина признака для всей совокупности равна 13. Средние по группам равны соответственно 10, 15 и 12. Численность единиц в каждой группе составляет 32, 53 и 45. Определить среднюю внутригрупповую дисперсию.
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ ПО ТЕМЕ «ВЫБОРОЧНОЕ НАБЛЮДЕНИЕ»
Главной целью практического занятие является повторение, закрепление знаний и получений умений и навыков решения конкретных задач. В этих целях студентам перед занятием необходимо повторить, изучить лекции по теме «Выборочное наблюдение».
В начале занятия студентам нужно ответит на следующие вопросы:
1. Что такое выборочное наблюдение, и в каких случаях к нему прибе-
гают?
17
3.Какие существуют способы отбора (виды выборки)?
4.Что такое повторная и бесповторная выборка?
5.Как определяется объем собственно-случайной бесповторной выборки?
6.В чем отличие средней и предельной ошибок выборки?
7.Решение каких вопросов зависит от объема выборки? Как влияет объем выборки на ее ошибке?
Далее студенты совместно с преподавателем решаю следующие задания:
1.Выборочное обследование цен на вторичном рынке жилья позволило получить следующие данные (табл. 17).
|
Исходные данные |
Таблица 17 |
|||
|
Тип жилого помещения |
Количество |
Средняя |
Среднее квадра- |
|
|
жилых по- |
цена 1 кв. |
тическое откло- |
||
|
мещений |
м, тыс. |
нение цены, |
||
|
руб. |
тыс., руб. |
|||
|
Комната в коммуналь- |
||||
|
ной квартире |
25 |
12,2 |
0,8 |
|
|
1-комнатная квартира |
34 |
14,5 |
0,6 |
|
|
2-комнатная квартира |
46 |
13,1 |
0,5 |
|
|
3-комнатная квартира |
62 |
11,6 |
0,3 |
|
|
Многокомнатная квар- |
11 |
15,0 |
1,1 |
|
|
тира |
Предполагая, что в ходе обследования применялась повторная выборка, пропорциональная объему выделяемых типических групп, определите границы средней цены 1 кв. м жилья в данном городе.
2. В результате выборочного обследования покупателей супермаркета (собственно-случайная повторная выборка) получено следующее распределение по размеру сделанных покупок (табл. 18).
Таблица 18
Данные собственно-случайной повторной выборки
|
Стоимость покупки, |
до 100 |
100 — 200 |
200 — 300 |
300 и более |
|
руб. |
||||
|
Число покупателей |
17 |
58 |
89 |
43 |
С вероятностью P(t)=0,997 определите:
а) границы среднего размера покупки в генеральной совокупности; б) границы удельного веса покупок на сумму до 100 руб. в генеральной
совокупности.
3. Определите, сколько клиентов автосервиса, отобранных на основе алгоритмов собственно-случайной выборки, необходимо опросить для определе-
18
ния доли лиц, неудовлетворенных качеством обслуживания. При этом предельная ошибка не должна превышать 2,5% при уровне вероятности 0,683. Из аналогичных обследований известно, что дисперсия данного альтернативного признака (удовлетворенность качеством обслуживания) не превышает 0,21.
4.В результате опроса каждого пятого учащегося выпускных классов школ района было выяснено, что среднее время, затрачиваемое ежедневно на подготовку к занятиям, составляет 86 мин. при коэффициенте вариации 29,4%. При этом выборочная совокупность составила 128 чел. С вероятностью 0,997 определите границы средних затрат времени на подготовку к занятиям в целом по всем учащимся выпускных классов школ района.
5.На основе 3%-ного выборочного обследования (собственно-случайная бесповторная выборка) получены следующие данные о расходах населения на оплату жилищно-коммунальных услуг (табл. 19).
|
Исходные данные |
Таблица 19 |
||||||||
|
Расходы на оплату жи- |
до 100 |
100-200 |
200-300 |
300-400 |
400-500 |
500 и |
|||
|
лищно-коммунальных |
более |
||||||||
|
услуг, руб. |
|||||||||
|
Число домохозяйств |
93 |
190 |
555 |
335 |
84 |
18 |
С какой вероятностью можно утверждать, что удельный вес домохозяйств, расходующих на оплату жилищно-коммунальный услуг более 400 руб. в месяц, в целом по данному региону не превышает 9,5%?
6.Как изменится необходимый объем собственно-случайной повторной выборки, если уровень вероятности, с которым требуется получить результат,
увеличить с 0,683 до 0,954; с 0,954 до 0,997?
7.Определите, каким должен быть интервал отбора при организации выборочного наблюдения на основе механической выборки, чтобы процент отбо-
ра составил 20%; 5%; 2,5%; 2%?
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ ПО ТЕМЕ «СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА КОРРЕЛЯЦИОННЫХ СВЯЗЕЙ»
Главной целью практического занятие является повторение, закрепление знаний и получений умений и навыков решения конкретных задач. В этих целях студентам перед занятием необходимо повторить, изучить лекции по теме «Статистические методы анализа корреляционных связей».
В начале занятия студентам нужно ответит на следующие вопросы:
1.В чем различие между функциональной и корреляционной зависимо-
19
стью?
2.В чем смысл коэффициента парной корреляции, каковы границы его значений?
3.Как определяется значимость коэффициента корреляции, рассчитанного по выборочным данным?
4.Как определяются параметры линейного уравнения регрессии?
5.Как определяется значимость уравнения регрессии?
6.Как использовать уравнение регрессии для прогноза?
7.Какие вы знаете показатели измерения тесноты зависимости?
Далее студенты совместно с преподавателем решаю следующие задания: 1. Установите направление и характер связи между четырьмя показателями, характеризующими экспорт технологий и услуг технического характе-
ра, по 10 областям РФ в 2003 г. (табл. 20).
|
Исходные данные (млн. руб.) |
Таблица 20 |
||||
|
Номер |
Число |
Стоимость |
Чистая стоимость |
Поступления |
|
|
области |
соглашений |
предмета |
предмета соглаше- |
по соглашени- |
|
|
соглашения |
ния |
ям |
|||
|
1 |
9 |
0,49 |
0,49 |
0,42 |
|
|
2 |
7 |
4,19 |
4,18 |
0,19 |
|
|
1 |
3 |
0,11 |
0,11 |
0,11 |
|
|
4 |
20 |
3,69 |
3,69 |
2,38 |
|
|
5 |
8 |
0,51 |
0,51 |
0,51 |
|
|
6 |
11 |
5,10 |
5,05 |
2,04 |
|
|
7 |
6 |
0,52 |
0,52 |
0,52 |
|
|
8 |
13 |
1,75 |
1,74 |
0,28 |
|
|
9 |
18 |
4,28 |
4,22 |
3,30 |
|
|
10 |
16 |
2,49 |
2,48 |
0,30 |
2. Взаимосвязь между стоимостью активной части основных фондов и затратами на производство работ по 35 строительным фирмам представлена в табл. 21.
20
![]()
Таблица 21
Исходные данные
|
Затраты на производство строитель- |
Стоимость активной части основ- |
Всего |
||||
|
но-монтажных работ, % к стоимости |
ных фондов, млн. руб. |
фирм |
||||
|
активной части основных фондов |
||||||
|
50-100 |
100-150 |
150-200 |
200-250 |
|||
|
1-5 |
2 |
4 |
6 |
|||
|
5-9 |
2 |
6 |
4 |
12 |
||
|
9-13 |
5 |
3 |
8 |
|||
|
3-17 |
2 |
2 |
4 |
|||
|
17-21 |
5 |
5 |
||||
|
Итого |
7 |
9 |
11 |
8 |
35 |
Постройте поле корреляции и эмпирическую линию регрессии.
3. Зависимость между объемом произведенной продукции и балансовой прибылью по 10 предприятиям одной из отраслей промышленности характеризуется следующими данными (табл. 22).
Таблица 22
|
Исходные данные |
|||
|
Номер |
Объем реализован- |
Балансовая при- |
|
|
предпри- |
ной |
продукции, |
быль, млрд. руб. |
|
ятия |
млрд. руб. |
||
|
1 |
491,8 |
133,8 |
|
|
2 |
483,0 |
124,1 |
|
|
3 |
481,7 |
62,4 |
|
|
4 |
478,7 |
62,9 |
|
|
5 |
476,9 |
51,4 |
|
|
6 |
475,2 |
72,4 |
|
|
7 |
474,4 |
99,3 |
|
|
8 |
459,5 |
40,9 |
|
|
9 |
452,9 |
104,0 |
|
|
10 |
446,5 |
116,1 |
Определите вид корреляционной зависимости, постройте уравнение регрессии, рассчитайте параметры уравнения, вычислите тесноту связи. Объясните полученные статистические характеристики.
4.Для оценки степени тесноты связи между уровнем выработки рабочих
истажем их непрерывной работы была рассчитана величина корреляционного отношения, оказавшаяся равной 0,9 (объем выборки был равен 100). Опреде-
21
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
14 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
Ошибка выборки – это распространенное явление в статистике и обработке данных, которое возникает в результате неправильного или непредставительного выбора элементов для анализа или исследования. Ошибка выборки может внести серьезные искажения в получаемые результаты и привести к неверным выводам.
Причины ошибки выборки могут быть разнообразными. Одной из основных причин является неправильное методологическое планирование исследования, включая непредставительность выборки, отсутствие случайного отбора или избирательность включения или исключения определенных элементов.
Способы исправления ошибки выборки включают в себя несколько подходов. Во-первых, можно увеличить объем выборки, чтобы уменьшить возможное влияние ошибки. Во-вторых, следует строго придерживаться правил случайного отбора, исключая возможность манипуляции в выборе элементов. Кроме того, необходимо учитывать различные факторы, которые могут влиять на получаемые результаты, и включать их в анализ.
Ошибка выборки – это серьезное явление, требующее внимательного исследования и постоянного контроля. Только правильное понимание причин и методов исправления ошибки позволит проводить достоверные и надежные исследования и получать точные результаты.
Содержание
- Что такое ошибка выборки?
- Определение и сущность
- Причины возникновения ошибки выборки
- Неправильное определение целевой аудитории
- Недостаточный объем выборки
- Неслучайная выборка
- Последствия ошибки выборки
- Неверные выводы и решения на основе ошибочной выборки
- Вопрос-ответ
- Что такое ошибка выборки?
- Какие причины могут быть у ошибки выборки?
- Как исправить ошибку выборки?
Что такое ошибка выборки?
Ошибка выборки – это один из типов ошибок, возникающих при проведении исследований или статистического анализа данных. Ошибка выборки происходит, когда результаты исследования или анализа основаны не на полной генеральной совокупности, а только на ее части – выборке.
Ошибку выборки можно объяснить следующим образом: вся генеральная совокупность – это некоторая группа людей, объектов или явлений, а выборка – это просто небольшая часть этой генеральной совокупности, которая выбирается для исследования. Идеальная выборка должна быть репрезентативной, то есть отражать все разнообразие и особенности генеральной совокупности, чтобы результаты исследования можно было обобщить на всю генеральную совокупность.
Ошибки выборки могут возникать по разным причинам. Наиболее распространенные причины – неправильная процедура выборки, недостаточный размер выборки, неучтение всех специфических характеристик генеральной совокупности при выборе выборки и другие.
Ошибка выборки может иметь серьезные последствия и сильно исказить результаты исследования или анализа данных. Поэтому очень важно проводить выборку и анализ данных с учетом всех необходимых требований и правил, чтобы минимизировать возможные ошибки и получить достоверные результаты.
Определение и сущность
Ошибка выборки является одной из наиболее распространенных проблем, с которой сталкиваются исследователи и аналитики при работе с данными. Она возникает, когда выборка (набор данных, используемый для анализа) не является репрезентативной для всей популяции (группы, класса объектов, которую мы хотим изучить).
Сущность ошибки выборки заключается в том, что полученные результаты и выводы, основанные на нерепрезентативной выборке, не могут быть обобщены на всю популяцию с высокой степенью уверенности и достоверности.
Ошибка выборки может возникнуть по разным причинам, таким как:
- Недостаточный размер выборки: выборка может быть слишком мала, чтобы достаточно точно представлять всю популяцию, что приводит к искажению результатов и неверным выводам.
- Неслучайная выборка: при использовании неслучайной выборки вместо случайной, можно получить искаженные результаты, так как возникает возможность систематического искажения данных в сторону определенного направления.
- Искажение выборки: при определенных условиях, таких как самоотбор или выбытие из выборки, данные могут стать неслучайными, что приведет к ошибочным результатам.
Для уменьшения ошибки выборки и обеспечения более точных и достоверных результатов необходимо применять соответствующие методы и стратегии выборки, анализировать и учитывать возможные источники искажений и принимать меры по их устранению. Только тогда мы сможем быть уверены в надежности и правильности полученных научных исследований и практических рекомендаций.
Причины возникновения ошибки выборки
Ошибка выборки – это ошибка, которая возникает при обработке данных в процессе выполнения выборки из базы данных. Она может быть вызвана разными причинами, и важно уметь их распознавать и исправлять.
Основными причинами возникновения ошибки выборки являются:
- Неправильный синтаксис запроса: ошибка может возникнуть, если запрос на выборку данных сформулирован некорректно, содержит синтаксические ошибки или несовместимые операторы. Например, неправильно указаны имена таблиц или полей, отсутствуют запятые или кавычки.
- Несуществующие данные или таблицы: возникает, когда в запросе указаны неправильные или несуществующие имена таблиц или полей. Убедитесь, что все используемые имена корректны и существуют в базе данных.
- Несоответствие типов данных: при выборке данных важно учитывать типы полей, с которыми работаете. Если тип данных, указанный в запросе, не соответствует типу данных в таблице, может возникнуть ошибка выборки.
- Проблемы с подключением к базе данных: ошибки выборки могут возникать из-за проблем с подключением к базе данных. Проверьте правильность настроек подключения, доступность сервера базы данных и наличие необходимых прав доступа.
- Дублирование данных: ошибка выборки может возникнуть, если в таблице есть дублирующиеся записи или если две или более записи имеют одинаковые значения ключевого поля.
Важно проводить тщательный анализ и отладку запросов на выборку данных, чтобы найти и исправить возможные ошибки. Также рекомендуется использовать средства и методы защиты от ошибок выборки, такие как проверка входных данных, использование подготовленных выражений и санитизация запросов.
Неправильное определение целевой аудитории
Ошибки выборки могут возникать по разным причинам. Одной из них является неправильное определение целевой аудитории.
При разработке маркетинговых стратегий и создании продуктов или услуг необходимо четко определить свою целевую аудиторию. Целевая аудитория — это группа людей, которым предназначен продукт или услуга, и к которой будет направлено все маркетинговое воздействие.
Однако, неправильное определение целевой аудитории может стать серьезной ошибкой, которая может привести к неэффективным результатам и потере ресурсов. Вот несколько примеров неправильного определения целевой аудитории:
- Неправильное определение демографических характеристик: Важно учитывать возраст, пол, доходы и другие критерии при определении целевой аудитории. Неправильная оценка этих характеристик может привести к неправильной ориентации маркетинговых усилий.
- Игнорирование психографических факторов: Кроме демографических характеристик, важно учитывать и психологический профиль вашей целевой аудитории. Игнорирование таких факторов может привести к тому, что ваш продукт или услуга не будут соответствовать потребностям и предпочтениям ваших клиентов.
- Недостаточное исследование рынка: Несмотря на то, что неправильное определение целевой аудитории может происходить из-за недооценки факторов, также существует опасность переоценки и неправильного понимания ваших потенциальных клиентов. Недостаточное исследование рынка может привести к неправильному определению целевой аудитории и, следовательно, к неправильному маркетинговому воздействию.
Чтобы избежать ошибок при определении целевой аудитории, рекомендуется провести тщательное исследование рынка, а также использовать различные методы сбора и анализа данных. Например, провести опросы, фокус-группы, анализировать поведенческие данные и т.д.
Недостаточный объем выборки
Недостаточный объем выборки является одной из наиболее распространенных причин ошибки выборки при проведении исследований. Эта ошибка возникает, когда выборка, которая используется для анализа, слишком мала, чтобы представлять всю популяцию.
Ошибки, связанные с недостаточным объемом выборки, могут иметь серьезные последствия и привести к искажению результатов исследования. Например, если выборка слишком мала, то она может не улавливать все значимые различия в популяции, что приведет к неправильным выводам.
Если выборка слишком мала, то результаты исследования не будут иметь статистической значимости и не смогут быть обобщены на всю популяцию. Кроме того, слишком маленькая выборка может привести к возникновению смещений, таких как смещение выборки или смещение в сторону особой подгруппы популяции.
Чтобы исправить недостаточный объем выборки, исследователи могут принять следующие меры:
- Увеличить размер выборки: чем больше выборка, тем более надежные будут результаты исследования. Однако увеличение объема выборки может быть связано с дополнительными затратами и усилиями.
- Использовать случайную выборку: случайная выборка помогает уменьшить возможные смещения и представляет популяцию более точно.
- Разбить популяцию на подгруппы: для увеличения достоверности результатов исследования, исследователи могут провести анализ в каждой подгруппе популяции отдельно. Это позволит получить более полную картину.
- Провести дополнительное исследование: если объем выборки все еще является проблемой, исследователи могут провести дополнительное исследование, чтобы увеличить общий объем данных и повысить достоверность результатов.
В целом, недостаточный объем выборки может привести к серьезным ошибкам и искажениям результатов исследования. Поэтому особое внимание следует уделять размеру выборки и применять стратегии, направленные на увеличение ее достоверности в соответствии с целями исследования.
Неслучайная выборка
Неслучайная выборка — это ошибка выборки, которая возникает в результате неправильного способа отбора выборки из генеральной совокупности или неправильного представления самих данных. Она может привести к некорректным или искаженным результатам и выводам и значительно исказить общую картину.
При неслучайной выборке может быть несколько причин:
- Смещение выборки: В результате смещения выборки отбираются определенные группы или характеристики, что исключает другие группы или характеристики. В итоге, полученная выборка не является представительной для всей генеральной совокупности.
- Выборочный метод: Применение определенного метода для отбора выборки может привести к неслучайной выборке. Например, использование удобных субъектов для исследования или отсутствие четкого алгоритма отбора.
- Отсутствие случайности: Если не было использовано случайное или рандомизированное отборочное процедура, то выборка может быть неслучайной.
Следующие стратегии могут быть использованы для исправления ошибки неслучайной выборки:
- Случайный отбор: Использование случайного отбора поможет устранить смещение и получить максимально представительную выборку.
- Проверка метода: Важно проверить метод отбора выборки на соответствие целям исследования и наличию систематических ошибок.
- Учет всех групп и характеристик: Необходимо обеспечить представительность всех групп и характеристик генеральной совокупности.
Исправление ошибки неслучайной выборки требует тщательного анализа данных, грамотного подхода к отбору выборки и строгого следования установленным методикам и принципам исследования и статистики.
Последствия ошибки выборки
Ошибка выборки – это ситуация, когда изучаемая выборка данных не является репрезентативной для всей генеральной совокупности. То есть, данные, полученные из выборки, не могут дать достоверную картину о всей группе или явлений, которые изучаются. Это может привести к ошибочным выводам и неверным решениям.
Последствия ошибки выборки могут быть крайне серьезными и затрагивать различные аспекты жизни и деятельности человека. Ниже приведены некоторые из них:
- Незначительность результата исследования: Если выборка нерепрезентативна, то результаты исследования могут быть несущественными и не иметь практической ценности. Например, исследование эффективности нового лекарства может показать положительные результаты на маленькой выборке пациентов, но когда оно будет применено на практике, оказаться неэффективным.
- Потеря ресурсов: Ошибочные выводы, основанные на нерепрезентативной выборке, могут привести к ненужным затратам – как времени, денег, так и других ресурсов. Например, компания может разработать новый продукт на основе исследования маленькой выборки, но когда продукт будет запущен на рынок, обнаружится его низкая востребованность.
- Неправильные решения: Ошибка выборки может привести к принятию неправильных решений в различных сферах – от бизнеса до политики. Например, политический кандидат может опираться на результаты исследования, проведенного на незначительной выборке, и базируясь на этом, строить свою предвыборную программу, которая может оказаться неэффективной или даже непопулярной среди избирателей.
Чтобы избежать последствий ошибки выборки, необходимо при исследованиях и аналитической работе тщательно подбирать выборку и стараться, чтобы она была максимально репрезентативной для интересующей нас генеральной совокупности. Также важно применять различные методы статистического анализа, которые помогут оценить достоверность полученных результатов.
Неверные выводы и решения на основе ошибочной выборки
Одной из основных проблем, связанных с ошибкой выборки, является возможность сделать неверные выводы и принять неправильные решения на основе полученных данных.
Когда проводится исследование или опрос, важно, чтобы выборка была репрезентативной, то есть достаточно представительной для всей генеральной совокупности. Если выборка содержит только определенную категорию людей или объектов, полученные результаты могут быть искажены и не могут быть обобщены на всю генеральную совокупность.
Например, если проводится исследование о вкусовых предпочтениях населения в отношении газированных напитков, а выборка включает только людей молодого возраста, это может привести к неверному выводу о предпочтениях всех возрастных групп.
Кроме того, ошибочная выборка может привести к неадекватным или неправильным решениям. Представим ситуацию, когда на основе опроса о вреде социальных сетей для здоровья была проведена кампания по запрету их использования. Однако, если выборка состояла только из людей старшего поколения, которые мало пользуются интернетом, такое решение может оказаться необоснованным и непродуманным.
Исправить ошибку выборки можно с помощью следующих методов:
- Увеличение выборки: Повышение размера выборки может помочь снизить вероятность ошибки выборки. Чем больше объектов в выборке, тем более репрезентативной она будет.
- Случайная выборка: Использование случайной выборки помогает уменьшить искусственные искажения и сделать выборку более репрезентативной.
- Стратифицированная выборка: Разделение генеральной совокупности на страты и проведение выборки в каждой страте помогает обеспечить более точные и репрезентативные результаты.
В целом, важно понимать, что ошибочная выборка может привести к неверным выводам и неправильным решениям. Поэтому необходимо проводить исследования и опросы с помощью корректных и надежных методов выборки, чтобы получить достоверные и репрезентативные данные.
Вопрос-ответ
Что такое ошибка выборки?
Ошибка выборки — это разница между реальными значениями в генеральной совокупности и значениями, полученными при проведении выборки. Она может возникнуть из-за случайной ошибки в процессе выборки или из-за систематической ошибки в методологии выборки.
Какие причины могут быть у ошибки выборки?
Ошибки выборки могут быть вызваны различными факторами. Например, неправильный выбор метода выборки, недостаточный размер выборки, отклонение от случайной выборки, неправильная оценка параметров генеральной совокупности, систематические ошибки в сборе данных и другие факторы.
Как исправить ошибку выборки?
Существует несколько способов исправить ошибку выборки. Во-первых, можно увеличить размер выборки, чтобы уменьшить случайную ошибку. Во-вторых, можно использовать более точные методы выборки, такие как стратифицированная выборка или кластеризованная выборка. Также можно заново оценить параметры генеральной совокупности и учесть систематические ошибки, если они имеются. Важно также проводить анализ результатов выборки, чтобы определить искажения и принять меры по их исправлению.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
1. Свойства выборки, которые позволяют ей выступать моделью (представителем) генеральной совокупности с точки зрения ее характеристик, которые изучаются при проведении исследования, – это … выборки.
устойчивость
достоверность
надежность
репрезентативность
2. Метод выборки, используемый в том случае, если генеральная совокупность разделяется на страты, а затем для каждой из них производится расчет простой случайной выборки – метод …
зональной выборки
многоступенчатой выборки
стратифицированной выборки
типичных представителей
3. Чем больше различий внутри генеральной совокупности, тем больше величина возможной ошибки выборки.
Да
Нет
4. Метод вероятностной выборки, предусматривающий расчет шага (интервала) отбора выборки
Метод жребия
Метод построения таблиц случайных чисел
Метод систематической (механической) выборки
Гнездовая выборка
5. Совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
Выборка
Генеральная совокупность
Панель
Простая совокупность
6. Объем выборки влияет на ее ошибку.
Да
Нет
7. Метод выборки, предусматривающий отбор единиц выборки (респондентов), способных дать наиболее точные сведения
выборка по доступности
метод снежного кома
квотированная выборка
выборка по усмотрению
8. Под контуром выборки в маркетинговых исследованиях подразумевается …
список всех единиц генеральной совокупности
совокупность элементов, из которых производиться отбор единиц выборки и которая отвечает некоторым заданным параметрам
определенная часть генеральной совокупности, которая призвана отражать все ее базовые характеристики
9. Когда исследователь использует случайную выборку, основанную на информации о числовых характеристиках генеральной совокупности, то …
наиболее корректный подход к определению объема выборки основан на расчете доверительных интервалов и среднего квадратического отклонения
невозможно точно рассчитать ошибку выборки и указать уровень ее надежности
10. Ключевая характеристика вероятностной (случайной) выборки заключается в том, что …
принцип отбора единиц выборки отличен от случайного
все единицы выборки имеют известную вероятность (шанс) попасть в выборку
невозможно рассчитать ошибку выборки
11. В маркетинговых исследованиях под ошибкой выборки подразумеваются отклонения (различия) между данными …
полученными от выборки и истинными данным
существующего и предыдущего исследования
вероятностной и невероятностной выборки
12. Основное условие осуществления вероятностной выборки – наличие …
полного списка всех элементов генеральной совокупности
согласия респондентов на участие в опросе
списка участников опроса
13. Объем выборки влияет на ее репрезентативность.
Да
Нет
14. Параллельное использование нескольких методов формирования выборки, основанное на поэтапном отборе ее объектов, – это … выборка.
пропорциональная
стратифицированная
квотированная
многоступенчатая
Размер
выборки
– это количество элементов, которые
необходимо отобрать из генеральной
совокупности для проведения выборочного
исследования.
Определение
размера выборки для вероятностного
метода отбора представляет собой сложный
процесс, включающий ряд этапов: 1) оценка
факторов, влияющих на объем выборки; 2)
выбор метода расчета размера выборки;
3) расчет размера выборки; 4) оценка
стандартного отклонения среднего в
выборочной совокупности; 5) расчет
предельной ошибки выборки; 6) оценка
среднего значения признака в генеральной
совокупности (см. рис. 4.8).
В
случае применения детерминированного
метода отбора используются только
приблизительные методы расчета размера
выборки и оценить объективно точность
результатов исследования не представляется
возможным.
1.
Оценка факторов, влияющих на размер
выборки.
К наиболее важным факторам, определяющим
объем выборки, относятся следующие:
важность принимаемого решения, характер
исследования, бюджет исследования,
стоимость сбора информации, число групп
и подгрупп в генеральной совокупности,
коэффициенты охвата и завершенности,
размер генеральной совокупности и
требуемая точность исследования (см.
рис. 4.9). На размер ошибки выборки и,
соответственно, точность результатов
исследования влияют применяемая
процедура отбора и степень вариации
признака в совокупности.
Как
правило, для
принятия важных решений
необходима детальная, максимально
точная информация. Ее получение
предусматривает создание больших
выборок, но при увеличении объема выборки
возрастает и стоимость каждой
дополнительной единицы информации.
На
величину объема выборки влияет также
характер
исследования.
В поисковых исследованиях, изучающих
качественные характеристики, объем
выборки, как правило, невелик. Для
исследований, предусматривающих
статистическое заключение, таких как
дескриптивные, необходим больший объем
выборки. Кроме того, большие выборки
нужны, когда информация собирается
с учетом большого количества переменных.
Большой объем выборки позволяет снизить
общий эффект от ошибок выборки по всем
переменным.
Принимая
решения об объеме выборки, нужно учитывать
фактор ограниченности ресурсов или
располагаемый
бюджет исследования.
В любом исследовательском проекте
существуют временные и финансовые
ограничения. При жестких бюджетных
ограничениях исследователь будет стоять
перед выбором: использовать более
дешевые методы сбора информации или
ограничить размер выборки, допуская
снижение точности результатов.
Р
исунок
4.8.
Этапы расчета необходимого размера
выборки и оценки значения признака в
генеральной совокупности
Р
исунок
4.9.
Факторы, учитываемые при определении
размера выборки и взаимосвязи между
ними
Чем
больше размер выборки
(чем
он ближе к размерам генеральной
совокупности в целом), тем надежнее и
достовернее полученные данные, однако
стоимость
сбора информации
(включающая в себя расходы на размножение
инструментария, оплату труда интервьюеров,
супервайзеров и операторов компьютерного
набора данных) при этом значительно
возрастает;
При
проведении углубленного анализа данных
с использованием разнообразных
методов многомерного статистического
анализа необходим большой объем выборки.
Это же касается данных, которые
анализируются с особой точностью. Таким
образом, для
анализа данных на уровне группы или
подгруппы
потребуется больший объем выборки, чем
для анализа общей или генеральной
совокупности.
К примеру, мы хотим
исследовать потребительское поведение
населения города. Перед нами – структура
генеральной совокупности, которая
представляет распределение в целом
населения города и по трем квотным
признакам: район города, пол, возраст.
Совершенно очевидно, что если в
исследовании ставится задача изучить
мнения населения города в целом — это
одна ситуация; если в том числе и по
возрастным группам – это другая (здесь
мы имеем 3 группы); если необходимо
выявить распределения мнений по
возрастным и половым группам — это третья
ситуация (здесь мы имеем уже шесть
групп); наконец, если в исследовании нас
интересует распределение информации
по возрастным, половым группам и районам
города (к примеру, мы хотим определить,
как к покупкам того или иного товара
относятся молодые женщины, проживающие
во Фрунзенском районе г. Минска), то
здесь мы имеем дело уже с четвертой
ситуацией (54 группы). Для получения
репрезентативной информации в последним
случае необходимо обеспечить
представительство в минимальной из
этих пятидесяти четырех групп 25-30 чел.
Следовательно, минимальный объем
выборочной совокупности здесь будет
находиться в пределах 1600 чел.
Статистически
определенный объем выборки представляет
собой конечный, или чистый объем выборки,
который необходимо получить, чтобы
обеспечить расчет параметров с желательной
степенью точности и заданным уровнем
достоверности. При проведении опросов
он выражается в количестве завершенных
интервью. Для получения конечного объема
выборки необходимо связаться с большим
количеством потенциальных респондентов.
Другими словами, начальный объем выборки
должен намного превышать конечный,
поскольку коэффициенты охвата и
завершенности обычно составляют меньше
100%.
Коэффициентом
охвата
называется степень наличия или процент
людей, подходящих для участия в
исследовании. Коэффициент охвата
определяет, какое количество контактов
с людьми необходимо осуществить, чтобы
в итоге получить объем выборки,
соответствующий заданным критериям.
Предположим,
что для исследования характеристик
моющих средств необходимо создать
выборку из женщин – глав семьи в возрасте
от 25 до 55 лет. Приблизительно 75% женщин
в возрасте от 20 до 60 лет, к которым можно
обратиться, – это женщины – главы семьи
в возрасте от 25 до 55 лет. Это означает,
что, в среднем, необходимо обратиться
к 1,33 женщин, чтобы получить одного
подходящего респондента. Дополнительные
критерии для отбора респондентов
(например, каким образом использовался
продукт) увеличивают необходимое
количество контактов. Предположим, что
дополнительным критерием является
использование женщиной моющего средства
для пола в течение последних двух
месяцев. Предполагается, что 60% женщин,
к которым обратятся исследователи,
будут соответствовать этому критерию.
Тогда коэффициент охвата составит 0,75
х 0,60 = 0,45. Таким образом, конечный объем
выборки следует увеличить на 2,22 (1/0,45).
Точно
так же при определении объема выборки
необходимо учитывать ожидаемые отказы
людей, соответствующих критериям
исследования. Коэффициент
завершенности
указывает на процент респондентов,
соответствующих критериям отбора,
которые полностью прошли интервью.
Например, если исследователь предполагает,
что коэффициент завершенности интервью
составит 80% от числа подходящих
респондентов, необходимое количество
контактов следует умножить на коэффициент
1,25. Применение коэффициентов охвата и
завершенности означает, что число
контактов с потенциальными респондентами,
т.е. начальный объем выборки, должно
быть в 2,22 х 1,25 (или 2,77) раз больше
необходимого объема выборки.
Заранее
заданная точность
результатов исследования или допустимая
ошибка выборки
позволяют рассчитать необходимый размер
выборочной совокупности, используя
статистические методы, которые будут
рассмотрены далее.
Ошибкой
выборочного исследования
называется
любая ошибка, возникающая в результате
опроса или наблюдения и являющаяся
следствием использования выборки, а не
всей генеральной совокупности. Ошибки
выборочного исследования обусловлены
процедурой формирования выборки и
объемом выборки. Крупные выборки
порождают меньшую ошибку выборочного
исследования, чем малые.
Чтобы
извлечь выборку, как уже отмечалось в
предыдущем параграфе, сначала необходимо
определит: основу
выборки,
представляющую собой сводный список
все членов генеральной совокупности.
Как известно, списки не всегда полно
представляют генеральную совокупность,
поскольку в ней постоянно происходят
изменения: одни члены появляются, другие
– уходят. Кроме того, списки не застрахованы
от ошибок и опечаток. Таким образом,
ошибка
основы выборки
выражается
в неправильном описании всей генеральной
совокупности. Независимо от способа
формирования выборки, исследователь
должен учитывать ошибку основы. Иногда
в распоряжении исследователя оказывается
основа, лишь приблизительно описывающая
всю генеральную совокупность, однако,
если альтернативы нет, приходится
использовать и такие списки. Исследователь
должен тщательно выбирать основу
выборки, стремясь минимизировать
ошибки. Кроме того, исследователь должен
предупредить клиента о том, что
используемая основа выборки может
содержать ошибки.
Далее
будет идти речь только о случайных
ошибках выборочного
исследования, которые не связанны с
основой выборки и могут быть оценены
статистически. Иначе говоря, будем
предполагать, что основа выборки является
достаточно качественной и обеспечивает
низкий уровень ошибок, так что мы можем
извлечь из нее репрезентативную выборку.
Ошибка
выборки
зависит
не
только от ее величины, но и от
степени различий между отдельными
единицами внутри данной генеральной
совокупности.
Например, если нужно узнать, средний
размер потребления пива молодежью г.
Минска в возрасте 18-25 лет, то обнаружится,
что внутри имеющейся генеральной
совокупности нормы потребления у
различных людей существенно различны
(гетерогенная
генеральная
совокупность). Если же необходимо узнать
размер потребления хлеба в той же
генеральной совокупности, то он будет
различаться значительно меньше
(гомогенная
генеральная
совокупность). Чем больше различия
(гетерогенность) внутри генеральной
совокупности, тем больше возможная
ошибка выборки.
Некоторые
методы выборочного исследования
минимизируют ошибку выборки, другие –
никак на нее не влияют.
Например, использование стратифицированного
отбора может дать выигрыш в точности
при оценивании характеристик всей
совокупности. Часто неоднородную
совокупность удается расслоить на
подсовокупности (страты), каждая из
которых внутренне однородна. Если каждая
страта однородна в том смысле, что
результаты измерений в ней мало изменяются
от единицы к единице, то можно получить
точную оценку среднего значения для
любой страты по небольшой выборке в
этой страте. Затем эти оценки можно
объединить в одну точную оценку для
всей совокупности.
2. Выбор метода
расчета размера выборки.
Если специалист из опыта знает, какой
размер выборки следует использовать,
или же существуют различные ограничения
(например, связанные с бюджетом),
используют приблизительные
методы расчета размера выборки,
к которым относятся следующие:
— произвольный
метод расчета.
В этом случае объем выборки определяется
на уровне 5-10 % от генеральной совокупности.
— по
эмпирическим правилам.
Рекомендуется
выбирать размер выборки таким образом,
чтобы при ее разделении на группы в
каждой группе было не меньше 100 элементов.
Кроме сопоставления основных групп
анализ часто может потребовать
использования подгрупп. Размеры таких
подгрупп должны составлять от 20 до 50
человек. Это основано на том, что для
подгрупп требуется меньшая точность.
Если
одна из групп или подгрупп составляет
сравнительно небольшой процент
совокупности, то будет разумно использовать
непропорциональную выборку. Допустим,
что только 10% совокупности смотрит
образовательные телепередачи, и мнения
представителей этой группы требуется
сопоставить с мнениями других членов
совокупности. Если используются
телефонные интервью, контакты с жителями
могут устанавливаться случайно до тех
пор, пока не будут набраны 100 человек,
которые не смотрят образовательные
телепередачи. Далее опрос продолжается,
однако уже опрашиваются лишь те
респонденты, кто образовательные
телепередачи смотрит. В результате
будет получена выборка из 200 человек,
половина из которых смотрят образовательные
телепередачи.
— традиционный
метод расчета
связан с проведением периодических
ежегодных исследований, охватывающих,
например, 500, 1000 или 1500 респондентов.
— на
основе опыта сопоставимых исследований.
Таблица
4.7 дает представление об объемах выборок,
используемых в различных маркетинговых
исследованиях. Эти величины установлены
опытным путем и могут использоваться
в качестве ориентировочных данных,
особенно при детерминированных методах
формирования выборки.
— затратный
метод основан
на размере расходов, которые допустимо
затратить на проведение исследования.
Статистический
метод определения объема выборки
основан на традиционном статистическом
заключении. В соответствии с этим методом
заранее определяется уровень (степень)
точности.
Рассмотрение
данного метода начнем с краткой
характеристики базовых
понятий математической статистики.
Наиболее
важным понятием, позволяющим делать
заключения о свойствах генеральной
совокупности на основе выборочных
методов является кривая нормального
распределения.
Таблица
4.7.
Объемы выборок, используемых в
маркетинговых исследованиях
|
Вид исследования |
Минимальный объем |
Обычный диапазон |
|
Исследование, цель которого |
500 |
1000-2500 |
|
Исследование, цель которого |
200 |
300-500 |
|
Тестирование товара |
200 |
300-500 |
|
Пробный маркетинг |
200 |
300-500 |
|
Теле- радио- и печатная |
150 |
200-300 |
|
Аудит на пробном рынке |
10 магазинов |
10-20 магазинов |
|
Фокус-группы |
2 группы |
10-15 групп |
Кривая нормального
распределения
– это теоретическая модель, представляющая
собой абсолютно симметричный и гладкий
вид полигона частот. Она имеет форму
колокола и одну вершину, а ее концы
уходят в бесконечность в обоих
направлениях. Важнейшим свойством,
которым обладает кривая нормального
распределения, является то, что расстояние
по абсциссе (горизонтальная ось)
распределения, измеренное в единицах
стандартного отклонения от среднего
арифметического распределения, всегда
дает одинаковую общую площадь под
кривой: между ±1 стандартным отклонением
находится 68,3% площади; между ±2 стандартными
отклонениями – 95,4% площади; между ±3
стандартными отклонениями – 99,7% площади
(см. рис. 4.10).


Рисунок
4.10. Области
под теоретической кривой нормального
распределения
C
понятием кривой нормального распределения
связана центральная
предельная теорема, которая
гласит:
«Если
из генеральной совокупности, имеющей
любое распределение со средним μ
и
стандартным отклонением σ,
многократно извлекать случайные выборки
объема n,
то
при большом n
распределение всех возможных выборочных
средних будет стремиться к нормальному
распределению со средним μ
и
стандартным
отклонением σ
/![]()
».
Таким
образом, центральная предельная теорема
позволяет распространять данные,
полученные в результате выборочного
исследования на всю генеральную
совокупность с определенной степенью
допущения при условии достаточно
большого объема выборки.
Конечно,
остается вопрос о том, что же такое
большой объем выборки. Полезное
эмпирическое правило гласит: если объем
выборки (n)
равен
100 или более, то применима центральная
предельная теорема и вы можете принять
допущение о нормальности распределения
всех возможных выборочных средних. Если
же n
меньше
100, то вы должны иметь веские доказательства
нормальности распределения генеральной
совокупности, и только после этого вы
можете полагать, что распределение,
которому подчиняются выборочные
статистики, является нормальным.
Следовательно, нормальность распределения
выборочных статистик гарантируется
путем использования довольно больших
выборок.
3.
Выбор требуемой степени точности и
достоверности результатов исследования.
При проведении любого выборочного
опроса или наблюдения перед исследователем
ставится задача оценить, каково истинное
значение во всей генеральной совокупности
либо среднего
значения
абсолютного
признака (доход
потребителей, размер потребления
конкретного товара), либо доли
единиц в совокупности, обладающих
каким-либо
признаком
(доля постоянных потребителей конкретного
товара; доля потребителей, удовлетворенных
уровнем обслуживания). Точность
выборки
в первом случае будет представлена в
виде абсолютной величины со знаком ±
(например, ±100 тыс. руб.; ±1 кг), или в виде
процента, во втором случае – только в
виде процента с тем же знаком (например,
±1% или ±5%).
Интерпретация
точности выборки подчиняется следующей
логике: если объем выборки обеспечивает
точность ±5%, то результаты опроса или
наблюдения, полученные с помощью выборки,
отличаются от результатов полной
переписи не более чем на 5%.
Еще одним фактором,
влияющим на объем выборки является
заданная исследователем степень
достоверности
(надежности)
оценки,
то есть степень
уверенности в том, что оценка близка к
истинному значению.
Для выборки
фиксированного объема степень точности
и степень достоверности являются
связанными величинами. На деле определение
объема выборки предполагает достижение
известного баланса между двумя этими
принципами.
Зависимость
точности выборки от ее объема для 95,4% и
99,7% уровня надежности представлена на
рисунке 4.11. Объем выборок на графике
колеблется от 50 до 2000. График демонстрирует,
что при увеличении объема выборки
ее ошибка уменьшается. Однако, как видим,
зависимость ошибки выборки от ее объема
не является прямолинейной. Иначе говоря,
удвоение объема выборки, не приводит к
существенному уменьшению ошибки.
Р
исунок
4.11. Зависимость
точности и достоверности от объема
выборки
Если
объем выборки превышает 500, ошибка
выборки для 95,4% надежности падает ниже
±4% и продолжает очень медленно снижаться.
С другой стороны, анализ графика в
области малых выборок показывает, что
относительно небольшое изменение объема
выборки позволяет значительно повысить
их точность. Например, если объем выборки
равен 50, то ее уровень точности равен
±13,9%, а увеличение их объема до 250 позволяет
уменьшить ошибку выборки до ±6,2%. Иными
словами, точность выборки, объем которой
равен 25 примерно вдвое выше, чем точность
выборки, объем которой равен 50. Однако
в области крупных выборок это правило
не выполняется.
4. Определение
t
параметра, связанного с уровнем
надежности.
Определить значение t,
связанное с уровнем надежности можно
воспользовавшись таблицей 1 приложения.
Как видно по данным таблицы, при объеме
выборки больше 100 для 95,4% надежности
t≈2,
для 99,7% надежности t≈3.
5. Поиск информации
об уровне стандартного отклонения
среднего значения признака в генеральной
совокупности.
Здесь возможны
две различные ситуации: 1) стандартное
отклонение среднего значения признака
(σ)
в генеральной совокупности известно и
2) стандартное отклонение среднего
значения признака в генеральной
совокупности неизвестно.
В
первом случае можно приступить к расчету
объема
выборки с помощью формулы стандартной
ошибки выборки.
6.
Определение
объема выборки с помощью формулы
стандартной ошибки с учетом корректировки
на охват и завершенность.
Принято различать
среднюю и предельную ошибки выборки.
Предельная ошибка выборки определяется
следующим образом:
![]()
где
∆
— предельная ошибка выборки;
t
– параметр, связанный с уровнем
надежности;
μ
– средняя ошибка выборки.
Формулы расчета
средней ошибки
выборки для средней и для доли с учетом
способа отбора приведены в таблице 4.8.
Доверительные
интервалы для генеральной средней
можно установить на основе соотношений
![]()
Доверительные
интервалы для генеральной доли
устанавливаются на основе соотношений
![]()
Далее
для вычисления объема выборки применяется
формула
вычисление объема выборки по заданному
доверительному интервалу.
Формулы
расчета численности выборки
для определения средней и доли с учетом
способа отбора приведены в таблице 4.9.
Например,
для обследования, преследующего цель
выявить мнение потребителей о новом
товаре, в регионе, насчитывающем 10 тыс.
семей, необходимо провести анкетирование.
Условно принимается, что в каждой
квартире проживает одна семья и на нее
будет выделена одна анкета. Предварительные
исследования установили, что дисперсия
среднего размера покупки составляет
24 тыс. руб.; σ2
= 2; предельная ошибка не должна превышать
0,5 тыс. руб. Отсюда численность выборки
(п)
составит:
![]()
Эта
величина округляется до 400 семей
(квартир), т.е. установлена 4%-я выборка.
Однако практика показывает, что некоторая
часть анкет не возвращается (предположим
каждая пятая), поэтому увеличиваем число
анкет до 500. Следовательно, необходимо
включить в выборку каждую 20-ю квартиру
(10000 : 500).
Все
вышеприведенные формулы применимы для
большой выборки.
Кроме большой выборки используются так
называемые малые
выборки (n
< 30), которые могут иметь место в случаях
нецелесообразности использования
больших выборок.
При
расчете ошибок малой
выборки
необходимо учесть два момента:
1) формула средней
ошибки имеет вид
![]()
2)
при определении доверительных интервалов
исследуемого показателя в генеральной
совокупности или при нахождении
вероятности допуска той или иной ошибки
необходимо использовать таблицы
вероятности Стьюдента. При этом
вероятность
определяется
в зависимости от объема выборки и t
(см. табл.
прил. 1).
Таблица 4.8.
Формулы определения стандартной ошибки
выборки при различных способах отбора
|
Виды выборки Способы отбора |
Повторная выборка |
Бесповторная выборка |
|
Для средней |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
|
|
Для доли |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
— |
В
таблице используются следующие условные
обозначения:
N
– объем генеральной совокупности;
п
– объем выборочной совокупности;
![]()
– средняя в
генеральной совокупности;
![]()
–
средняя в выборочной
совокупности;
р
– доля единиц в генеральной совокупности;
w
– доля единиц в выборочной совокупности;
![]()
– генеральная
дисперсия (заменяется на выборочную
(S2) в случае, если она
не известна);
![]()
– межсерийная
дисперсия
![]()
;
r
— число отобранных серий;
R—
число серий в генеральной совокупности.
Таблица 4.9.
Формулы определения численности выборки
(n)
при различных способах отбора
|
Виды выборки Способы отбора |
Повторная выборка |
Бесповторная выборка |
|
Для средней |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
|
|
Для доли |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
— |

Например, для
разработки бизнес-плана нового ресторана,
который открывается в центральной части
г. Минска необходимо узнать ожидаемый
диапазон расходов одного посетителя в
вечернее время. Удалось получить
информацию о том, что стандартное
отклонение расходов посетителей близкого
по уровню и месту расположения ресторана
составляет 30$. Существует возможность
опросить около 26 посетителей ресторана.
С какой достоверностью можно получить
результат при заданной точности ±10$?
Рассчитаем среднюю
ошибку выборки:
![]()
Тогда
![]()
Из
таблицы приложения 1 для n=26
и t=1,66
можно определить, что при допуске ошибки
±10$ достоверность
результатов составит менее 90%. Более
точное значение достоверности для тех
же параметров можно получить, например,
при помощи функции СТЬЮДРАСП в Microsoft
Excel
— 89,2%.
С 95,4% надежностью
будет обеспечена меньшая точность:
![]()
7. Отбор
произвольной пробной выборки.
В случае если стандартное
отклонение среднего значения признака
в генеральной совокупности неизвестно,
необходимо сформировать произвольную
пробную выборку.
8. Расчет
стандартного отклонения средней в
выборочной совокупности.
На основе полученных данных рассчитывается
стандартное отклонение признака в
выборочной совокупности и, затем –
необходимый размер выборки по приведенным
выше формулам.
9. Расчет точности
полученных результатов по формуле
предельной ошибки выборки.По
данным, собранным в ходе проведенного
выборочного исследования, рассчитывается
точность результатов. Если полученная
точность не устраивает исследователя,
может возникнуть необходимость увеличить
размер выборки с учетом рассчитанного
стандартного отклонения и коэффициентов
отклика и завершенности.
Предположим, что
в предыдущем примере не было возможности
узнать стандартное отклонение расходов
посетителей ресторана. По данным опроса
30 случайно отобранных респондентов
получены следующие данные: 25$ – 2 чел.;
30$ – 3 чел.; 45$ – 7 чел.; 55$ – 6 чел.; 70$ – 3
чел.; 85$ – 5 чел.; 110$ – 2 чел.; 150$ – 2 чел.
Определяем среднее
значение по формуле средней взвешенной:

Далее
рассчитываем дисперсию (квадрат
стандартного отклонения) расходов
посетителей ресторана по выборочной
совокупности.

Тогда
точность полученных результатов с
достоверностью 95,4%:
![]()
Для
того, чтобы обеспечить заданную точность
(±10$) рассчитываем
необходимый размер выборки:
![]()
В
целом, для принятия взвешенного решения
по размеру выборки наряду со статистическими
методами расчета следует применить
рассмотренные ранее приблизительные
методы и сравнить полученные результаты.
10. Оценка значения
признака в генеральной совокупности.
Основными
методами распространения выборочного
наблюдения на генеральную совокупность
являются прямой пересчет и способ
коэффициентов.
Прямой
пересчет есть
произведение среднего значения признака
на объем генеральной совокупности.
Однако большое число факторов не
позволяет в полной мере использовать
точечную оценку прямого пересчета при
распространении результатов выборки
на генеральную совокупность. На практике
чаще пользуются интервальной оценкой,
которая дает возможность учитывать
размер предельной ошибки выборки,
которая рассчитана для средней или для
доли признака.
Оценка
среднего по совокупности при использовании
стратифицированной выборки является
взвешенным средним средних значений
по каждой страте выборки.
Например,
производителю пива для оценки емкости
внутреннего рынка в частности необходимо
определить долю потребителей пива в
общей численности населения региона в
возрасте от 20 до 60 лет с точностью ±5%.
Можно предположить, что данный показатель
будет варьировать по полу и возрасту.
В таблице 4.10 представлена информация
о численности и структуре населения
региона в возрасте от 20 до 60 лет.
Таблица
4.10. Численность
населения региона в возрасте от 20 до 60
лет
|
Возрастные категории населения |
Всего, тыс. чел. |
В том числе |
|
|
мужчины |
женщины |
||
|
20-29 |
1576,0 |
802,0 |
774,0 |
|
30-39 |
1357,3 |
671,4 |
685,9 |
|
40-49 |
1559,6 |
751,9 |
807,7 |
|
50-59 |
1276,1 |
582,7 |
693,4 |
|
Всего |
5769,0 |
2807,9 |
2961,1 |
Ранее
проведенный опрос 200 респондентов в
возрасте от 20 до 60 лет показал, что доля
потребителей пива в общей численности
населения региона составляет 83%. По
имеющейся информации был рассчитан
необходимый объем выборки:
![]()
С
учетом необходимости обеспечить
необходимый минимальный размер подгрупп
округляем полученный результат до 300
человек и рассчитываем объем выборки
для каждой из страт по полу и возрасту
пропорционально соответствующей
численности населения. Результаты
расчета представлены в таблице 4.11.
Таблица
4.11. Структура
населения региона в возрасте от 20 до 60
лет и численность выборки.
|
Возрастные категории населения |
В % к общей численности населения |
Численность выборки |
|||
|
всего |
мужчины |
женщины |
мужчины |
женщины |
|
|
20-29 |
27,3 |
13,9 |
13,4 |
42 |
40 |
|
30-39 |
23,6 |
11,7 |
11,9 |
35 |
36 |
|
40-49 |
27,0 |
13,0 |
14,0 |
39 |
42 |
|
50-59 |
22,1 |
10,1 |
12,0 |
30 |
36 |
|
Всего |
100,0 |
48,7 |
51,3 |
146 |
154 |
В
результате опроса получены данные,
представленные в таблице 4.12.
Таблица
4.12. Доля
потребителей пива в общей численности
населения в разрезе возрастных категорий
по данным выборочного опроса.
|
Возрастные категории населения |
Доля потребителей пива |
|
|
мужчины |
женщины |
|
|
20-29 |
0,812 |
0,795 |
|
30-39 |
0,855 |
0,743 |
|
40-49 |
0,848 |
0,683 |
|
50-59 |
0,867 |
0,542 |
Определяем долю
потребителей пива по формуле средней
взвешенной:
![]()
Средняя
ошибка выборки:
![]()
Предельная ошибка
выборки для 95,4% надежности составит:
![]()
Таким
образом, с 95,4% надежностью можно
утверждать, что доля потребителей пива
в общей численности населения региона
в возрасте от 20 до 60 лет находится в
интервале от 71,8% (76,6% — 4,8%) до 81,4% (76,6% +
4,8%).
Опрос
обычно не ограничивается одним вопросом
–
иногда их сотни. Поэтому повторять
подобный процесс для каждого вопроса
смысла не имеет. Разумный подход –
выбрать несколько репрезентативных
вопросов и по ним определить размер. В
этот набор следует включить наиболее
критичные вопросы с максимальным уровнем
ожидаемой дисперсии.
В таком случае
может оказаться полезным подход
к расчету объема выборки, основанный
на сценарии максимально возможной
вариации признака в совокупности. Как
видно на рисунке 6, вариант,
когда w=
0,5 (50%) является наиболее консервативным,
поскольку он порождает максимальный
размер ошибки и, соответственно,
максимальный объем выборки. Следовательно,
его следует выбирать, когда изменчивость
не известна. Тогда формула размера
выборки упрощается:
![]()
Для 95% уровня
надежности и 5% уровня точности:
![]()
Р
исунок
4.12.
График
![]()
Использование
номограмм для
расчета
объема выборки. Стремление
упростить процедуру расчета объема
выборки приводит к созданию таблиц,
шкал или программ, которые ориентированы
на обеспечение статистической
надежности информации, но при этом не
обременяют пользователя знаниями
специальных формул из области статистики.
Например, существует калькулятор выборки
(www.
shortway.
to/few/calculator,
htm).
Номограмма является
графическим способом определения
размера выборки. Номограмма включает
три шкалы (рис. 7). На шкале слева
устанавливается разметка показателя
среднеквадратического отклонения
или распределения доли признака. На
правой шкале наносится разметка точности
измерения в виде допустимой ошибки при
заданной доверительной вероятности
95,4% или 99,7%. На средней шкале делается
разметка, соответствующая требуемому
объему выборки. На правой и левой
шкалах делаются отметки на уровне
желаемых значений показателей (доли
признака и допустимой ошибки). Линейкой
эти две отметки соединяются, на пересечении
линейки со средней шкалой делается
отметка, соответствующая тому объему
выборки, который отвечает пожеланиям
исследователя.
Добреньков В.И., Кравченко А.И. Фундаментальная социология. Методика и техника исследования — файл n1.doc
приобрести
Добреньков В.И., Кравченко А.И. Фундаментальная социология. Методика и техника исследования
скачать (9759 kb.)
Доступные файлы (1):
- Смотрите также:
- Добреньков В.И., Кравченко А.И. Фундаментальная социология. Социальная структура (Документ)
- Добреньков В.И., Кравченко А.И. Социология. Учебник (Документ)
- Добреньков В.И., Кравченко А.И. Методология и методика социологического исследования (Документ)
- Добреньков В.И., Кравченко А.И. Методология и методика социологического исследования (Документ)
- Добреньков В.И., Кравченко А.И. Методы социологического исследования (Документ)
- Добреньков В.И., Кравченко А.И. Методология и методика социологического исследования (Документ)
- Добреньков В.И., Кравченко А.И. Социология. Том 2: Социальная стратификация и мобильность (Документ)
- Добреньков В.И., Кравченко А.И. Социология в трех томах (Документ)
- Кравченко А.И., Тюрина И.О. Социология управления. Фундаментальный курс (Документ)
- Методика и техника социологического исследования (Документ)
- Шпаргалки — Методика и техника социологических исследований (Шпаргалка)
- Юсупов А.В. Лекции по курсу Социология (Документ)
n1.doc
ПРОБЛЕМА ВЫБОРКИ И РЕПРЕЗЕНТАТИВНОСТИ
Маркетологу приходится уделять значительное внимание построению выборки. Для маркетинговых исследований весьма типично подвергать опросу лишь очень небольшую часть той группы людей (генеральной совокупности), которая представляет интерес для исследователей. Она обычно составляет несколько сотен, иногда тысячу респондентов. Поэтому исходным пунктом расчета выборки становится вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов: стоимости сбора информации и стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь. Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость выборки (включающая в себя оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое, вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400
Кудяков В.А. Анкетирование в системе маркетинговых исследований //
http://www.bma.ru/lib/lib
10.htm
364
человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли любое маркетинговое исследование испытывает нужду в 100%-ной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает его марку, а не пиво конкурента, — 60 или 40%, то на его планы никак не повлияет разница между 57, 60 или 63%.
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей10.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность).В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно (гомогенная генеральная совокупность). Чем больше различия (или гетерогенности) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Собственно, указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «чис-
Врезка
Выборка репрезентативна?
Некоторые маркетинговые фирмы вместо указания величины выборки часто озвучивают лозунг: «Информация достоверна, поскольку выборка репрезентативна». В подтверждение приводится пример: по контрольному показателю, т.е. по полу, получили количество мужчин, равное 46% плюс-минус 1,2%. Значит, выборка репрезентативна, и данные очень высокого качества. Но основная информация, полученная в результате исследования, вовсе не соответствует уровню 46%, 50 или 70% от опрошенных. Иногда она характеризуется уровнем 5-10%. А на этом уровне очень велика взаимосвязь между величиной выборки и точностью получаемых результатов. Для того чтобы определить долю мужчин в популяции, достаточно опросить 100 человек. А вот чтобы определить, сколько мужчин носят усы и сотовый телефон — уже понадобится опросить 1000, 2000 или даже 3000 человек. Поэтому такие горе-исследователи иногда вводят заказчика в заблуждение, ручаясь за точность данных, полученных на недостаточном количестве опрошенных. Мы всегда пользуемся таблицей доверительных интервалов, отражающей числовые промежутки, в пределах которых с 95%-ной вероятностью
находятся истинные значения результатов. Когда речь идет о маленьких долях, т.е. о дробле нии выборки на множество категорий в зависи мости от полученных ответов, например, npi> составлении различных рейтингов, то первук тройку-пятерку лидеров получить просто. Ест

же нужны данные о второй, третьей десятке, т< следует делать выборку гораздо больше. Ина че погрешность превысит само значение, flpi составлении проекта каждого исследования пс этой таблице определяется необходимая вели чина выборки в зависимости от поставленны задач. В одних случаях — наиболее простых -достаточно опроса 100 компаний, в других, бо лее сложных, их требуется 500 или 1000, а то i больше.
Источник: Как проводятся маркетинговые исследо вания //
http://www.ci.ru/inform6_98/toy_opin.htm
Паниотто В.И., Максименко B.C. Количественные методы в социологических исследованиях. Киег 1982. С. 81.
365
ленность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы»».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки12 (табл. 7):
Таблица 7 Расчеты репрезентативной выборки
| Объем генеральной совокупности | 500 | 1000 | 2000 | 3000 | 4000 | 5000 | 10000 | 100 000 |
| Объем выборки | 222 | 286 | 333 | 350 | 360 | 370 | 385 | 358 |
Это означает следующее. Если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной13 вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33(±5)% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки (табл. 8):
Таблица 8 Отношение между размером выборки и ошибкой выборки по Гэллапу
| Размер выборки | Интервал доверия, % |
| 4000 | +2 |
| 1500 | ±3 |
| 1000 | ±4 |
| 600 | +5 |
| 400 | ±6 |
| 200 | ±8 |
| 100 | ±11 |
Следует выделить наиболее существенные ошибки, которые допускают маркетологи при сборе первичных данных:
? при планировании маркетингового исследования нечетко сформулированы цели и задачи, вследствие чего получено большое количество несущественной информации, затрудняющей принятие правильного маркетингового решения;
Ядов В.А. Социологическое исследование. С. 72. 12 Паниотто В.И., Максименко B.C. Количественные методы в социологических исследованиях. Киев, 1982. С. 81.
Уровень уверенности в 95% — это условие, используемое социологами: оно показывает 95% уверенности в том, что параметр популяции попадает в пределы допуска ошибки выборочной статистики.
366
- в период подготовки исследования ошиблись в выборе метода (телефон ный опрос, анкетирование и т.д.). Такого рода ошибка может привести i тому, что потенциальные потребители ответят на ограниченный круг воп росов, у них не будет возможности высказаться по другим, не менее важным с их точки зрения, вопросам;
- маркетологи ошиблись в выборе объекта исследования. Фирма, котора; планирует реализацию своей продукции непосредственно потребителю, оп росила менеджеров оптовых фирм, чьи взгляды могут значительно отличать ся от мнения покупателей. Таким образом, при экономии средств, выражаю щейся в меньшем количестве интервьюируемых оптовиков, фирма може—понести потери, серьезно превышающие затраты, необходимые на организа цию опроса значительно большего количества рядовых потребителей;
- ошибка при составлении выборки (круга опрашиваемых), на основа нии которой выбиралась стратегия продаж. Например, недостаточная репрезентативность выборки (по регионам, сегментам рынка и т.д.), ее мальп объем (некорректно делать выводы о рейтинге предпочтений потребителе]; на всем рынке на основании 10—20 анкет);
- вопросы, предложенные респондентам, были либо некорректны, либс сложны для понимания; в этом случае возможно снижение интереса к анке те и повышение вероятности сбора поверхностной информации;
- на этапе анализа данных были сделаны ошибки в ходе их интерпретации, а следовательно, и при формировании дальнейшей стратегии фирмы|4
Врезка _____
Ошибки, совершаемые заказчиком
При проведении маркетинговых исследований множество ошибок совершается не только учеными, но и заказчиком. Вот лишь две из них. Ошибка первая: неправильная мотивация. Очень часто исследования заказываются ради самих исследований. Например, для того чтобы сказать с умным видом на каком-нибудь форуме: «Основываясь на результатах исследования, которое заказала наша компания и которое обошлось нам в триста, или нет, в пятьсот тысяч, я могу точно сказать, что наши автомобили покупают люди с доходами выше среднего уровня». Или еще пример из той же серии. Около года назад один наш потенциальный заказчик так обозначил цели исследования: «Вообще-то, мне всего этого не надо, я и сам все знаю. Но вот мой заграничный инвестор заставляет какие-то там исследования провести. Или, говорит, денег тебе не дам».
Ошибка вторая: неправильное взаимодействие заказчика с исследователем. Здесь тоже можно встретиться с двумя крайностями: заказчик либо вообще не общается с исследователем, либо, что
еще хуже, общается слишком активно. Это ког да телефонная «долбежка» начинается на второь день исследования и продолжается, кажется бесконечно. Доходит до абсурда: некоторые ком пании-заказчики настаивают на том, чтобы и: представители сами контролировали работу ин

тервьюеров. Например, полтора года назад ор,т наш заказчик назначил человека, который произвел стопроцентный контроль поля, то есть повторно опросил всех респондентов. Информация с веб-сайта ООО «Социс»:
http:// subscribe.ru/archive/ad.sresearch/200106/
17121513.html
14 Кддонь В. Типичные ошибки маркетологов //
http://www.bma.ru/lib/libl9.htm
; Голубков Е.П. Основы маркетинга. М.: Финпресс, 1999; Черчилль Г.А. Маркетинговые исследования. СПб.: Питер 2000; Burns Alvin С, Bush Ronald F. Marketing Research. New Jersey: Prentice Hall, 1995; Kotler Philip Marketing Management: Analysis, Planning, Implementation, and Control: 9th ed. Prentice Hall, 1997.
367
Наряду с традиционными вопросами — закрытыми, открытыми, вопросами-меню и др. — в опросный лист могут входить фирменные товарные знаки и каталоги товаров, как изготовленные типографским способом, так и с изображениями товаров, снятыми с фотографий при помощи сканера и отпечатанными на цветном принтере. Опросный лист может служить одновременно бланком для заполнения, но могут использоваться и специальные бланки для ответов.
Вопросы делятся на несколько групп:
- социальный и гражданский статус потребителя (пол, возраст, образование, состоит ли в браке, сколько имеет детей, форма занятости, если работает, то руководитель он или исполнитель, и т.п.);
- уровень достатка в семье потребителя;
- товары, реально приобретенные потребителем за последнее время;
- товары, которые потребитель приобрел бы, если бы у него была финансовая возможность;
- частота приобретения товаров по их видам;
- какие потребительские и стоимостные характеристики товаров привлекают потребителя и какие его не устраивают;
- где потребитель реально приобретает товары: у частных лиц, в магазинах (каких), на рынках (каких);
- какие места приобретения товаров потребитель знает: наименования магазинов и рынков;
- какую роль в выборе товара играет сервис и способ обслуживания в магазине или на рынке.
В результате проведения маркетингового исследования выявляются потребительские предпочтения различных групп населения в определенном секторе рынка. Выясняется, «что, где, когда», кем и по каким причинам приобретается.
Например, выясняется, что данная категория населения приобретает такие-то виды товаров в таких-то местах, а приобрела бы и такие, но если бы цена на них была более приемлемая.
На основе этой информации может быть разработан план закупок или производства товаров, определена потенциальная емкость рынка на данный момент и перспективу, а также спрогнозирована его динамика, товар может поставляться адресно в те торговые точки, которые пользуются популярностью у конкретных категорий потребителей.
? ? ?
Подводя краткие итоги рассмотрения методов, этапов и принципов организации маркетингового исследования, приведем общую схему основных стадий такого исследования в подаче специалистов фирмы «Гортис»:
- Постановка задачи, разработка методики исследования (формирование и согласование технического задания).
- Разработка и согласование с заказчиком основных методов сбора информации, в том числе анкет, бланков регистрации и принципов формирования выборок.
- Реализация комплекса мероприятий по сбору информации (опросы, запросы, перлюстрация и т.п.).
- Мероприятия по контролю качества работ по сбору первичной информации (анкетирования, интервью).
368
- Обработка результатов опросов, интервью, фокус-групп.
- Анализ и структурирование всего комплекса информации по проблеме (предметной области), в том числе «внутренней» информации заказчика.
- Формулирование выводов, прогнозов, рекомендаций.
- Подготовка печатного отчета, содержащего необходимую текстовук информацию, таблицы и графики.
- Презентация результатов исследования. Передача заказчику всех первичных материалов, аудио- и видеозаписей, если таковые планировались.
10. Консультационная поддержка по результатам исследования.Таким образом, несмотря на огромное многообразие исследовательски)
методик и техник, общая схема мероприятий, реализуемых в рамках маркетинговых исследований, достаточно проста и понятна. Она приближается ъ программе традиционного социологического исследования, правда, с определенными коррективами.
ТРУДНОСТИ В ОБЩЕНИИ ЗАКАЗЧИКА И ИССЛЕДОВАТЕЛЯ
Взаимоотношения между заказчиками и исполнителями научного иссле дования никогда не были безоблачными. Они и в принципе не должны бып таковыми, поскольку это поле столкновения различных, а иногда и проти

воположных интересов. Как в совет ские, так и в постсоветские времена со циологи жаловались на недопонимание их стараний и заслуг со стороны дирек торского корпуса, равнодушие к науке конъюнктурное использование инфор мации (для парадных отчетов, лично! выгоды) либо ее полное игнорирована (положить «под сунко»). Времена изме нились. Но изменились ли проблемы, которые возникают в ходе непростой диалога клиента и маркетолога?
Приведем краткий перечень проблем, составленный нами на основе ана лиза многочисленной литературы.
- Иногда бывает трудно объяснить заказчику результаты, полученньп сложными методами. Поэтому на первый план выходят простые методы, по зволяющие наглядно представить результаты исследования.
- Очень часто заказчики и маркетологи по-разному смотрят на одни и т же маркетинговые проблемы. Поэтому в последние годы все чаще проводятс: совместные встречи-обсуждения заказчиков и исследователей.
- Неразвитость российского рынка позволяет западным компаниям на вязывать свои стандарты в маркетинговых исследованиях, не всегда отража ющие национальную специфику страны.
- Неразвитость рыночного менталитета у заказчика — у большинства рос сийских предпринимателей средства на маркетинговые исследования про ходят по статье «затраты», в то время как на Западе — это стратегические ин вестиции.
369
- Устаревшая стратегия маркетинга: для россиян он — все еще жестокая борьба с конкурентом, в которой выживает сильнейший, для Запада — игра по соответствующим правилам, где надо не уничтожить соперника, а переиграть его.
- Преобладание устаревших технологий маркетинга: в России хорошо освоена только ценовая конкуренция, а более современные методы маркетинга, как, например, брэндинг, не прижились.
- Острый дефицит опытных кадров и неравномерность их распределения: лучшие кадры оседают в: а) иностранных компаниях; б) столичных городах.
- Расхождение ориентации исследователей и заказчиков: предприниматели, некогда добившиеся значительного успеха, считают, что и в будущем они будут жить хорошо; от маркетологов они требуют таких технологий, которые позволят увеличить прибыль на 50,70 и даже 100%. На самом деле условия на рынке постоянно меняются, а исторический этап первоначального накопления, характеризовавшийся непомерными заработками, прошел или подходит к концу.
- Сохраняется недоверие к маркетинговым исследованиям со стороны руководителей бизнеса, которым ученые не могут дать четких гарантий. Исследовательские компании, которые предлагают свои услуги, вполне резонно отвечают, что если бы в бизнесе существовали гарантии, то они сами бы им занялись.
- В стране очень мало квалифицированных маркетологов, а те, которые все умеют, понимают свою исключительность и берут за исследования огром -ные деньги; малому бизнесу такие консультанты недоступны, а крупный обходится без них.
- Несоответствие ожиданий заказчика и предоставляемых услуг: бизнесмен, приглашающий маркетолога, ожидает от него решения всех своих проблем, но часто получает развернутый научный отчет, непонятные формулы и множество таблиц.
- Сотрудники отдела маркетинга иногда не могут поставить адекватные вопросы и выдвинуть гипотезы; работая в своей компании, в своей отрасли, они зачастую имеют искаженные представления о рынке вообще, поскольку знают о нем гораздо больше потенциальных потребителей.
- Маркетингом на фирмах занимаются иногда довольно случайные люди. Хотя по своей сути отдел маркетинга должен быть одним из основных подразделений компании, чаще всего он влачит жалкое существование либо потому, что его сотрудники некомпетентны, либо потому, что для руководства наличие отдела маркетинга — всего лишь дань моде.
- Необходимость проводить исследования за короткий срок, оставаясь при этом в рамках определенного бюджета.
Опрос 1690 компаний Великобритании выявил, что 36% из них пользуются услугами маркетинговых агентств, а 64% — не пользуются. Основные причины, из-за которых фирмы не обращаются в агентства, — это неуверенность в достоверности исследований и желание сохранить конфиденциальность полученных данных, что, как полагают в фирмах, может быть достигнуто только при проведении исследования силами собственных отделов маркетинга. Если говорить об общих трудностях, с которыми сталкиваются сегодня западные маркетологи в исследовательских фирмах, то можно выделить три основные проблемы:
? Нежелание потребителей, чтобы вторгались в их личную жизнь, и какследствие отказ отвечать на вопросы интервьюеров.
370
- Этические трудности формирования тех или иных вопросов при проведении исследования, касающегося интимных сторон жизни респондента
- Глобализация маркетинга — необходимость учитывать мировые тенденции при изучении того или иного рынка.
Но немало трудностей создают и сами маркетологи. Первая среди них -добросовестность исполнителя. При массовом опросе, когда фирма набирает случайных людей, например желающих подзаработать студентов, часто ан -кеты заполняют сами анкетеры, а не респонденты. Однако и при найме более взрослых анкетеров, постоянно сотрудничающих с исследовательской фирмой, риска не избежать. Некоторые из них, желая заработать легкие деньги, что называется, рисуют ответы, не отходя от кассы.
Много проблем возникает при отборе участников фокус-групп. Нередкс одни и те же лица кочуют из одной фокус-группы в другую, представляясь то владельцем мобильного телефона, то иномарки, то курильщиком «Мальборо» и т.д. Здесь несколько причин: а) стремление респондента заработать если за участие в исследовании сулят подарок или денежное вознаграждение б) желание рекрутеров заработать — рекрутируют одних и тех же респондентов (как правило, своих знакомых), в) нерегулярный или плохо организованный контроль поля (качества заполнения анкет).
Среди затруднений, создаваемых себе маркетологами, нужно назвать также несовершенство инструментария, в частности чрезмерно длинные списки закрытий к анкетным вопросам. Когда респонденту предлагают выбрать
Врезка
Как провести маркетинговое исследование
На первом этапе отдел маркетинга компании-заказчика призван собрать данные о потребности в информации со всех остальных отделов и четко поставить задачи маркетинговой компании, т.е. нам. Затем мы готовим проект исследования, анкету, определяем фильтрующие вопросы, выбираем методику сбора информации и обсуждаем все это в отделе маркетинга и с другими заинтересованными отделами заказчика. Вносятся необходимые изменения. В процессе совместного обсуждения заказчик получает четкое представление о том, какого рода информацию он получит и в каком виде. После проведения исследования на основании нашего отчета отдел маркетинга выдает рекомендации, например, отделу продаж, рекламному отделу и далее.
Исходя из опыта питерской компании ТОЙ-ОПИ-НИОН, можно сказать, что даже если компания уже созрела для проведения маркетинговых исследований, то в первый раз ей иногда все-таки бывает сложно поставить перед нами четкую цель и определить конкретные задачи. Но если компания обращается к нам второй-третий раз, то проблем, как правило, не возникает. Мы уже понимаем друг друга с полуслова.
Хотелось бы отметить, что серьезные маркетин говые исследования требуют большого количе ства сотрудников, разработанных методик опро сов и оценок, техники. Некоторые фирмы самь проводят маркетинговые исследования для сво их собственных нужд и не обращаются к услу

гам маркетинговых компаний. Но если фирм; проводит 3—4 исследования в год, то экономи чески неоправданно содержать специалистов технику, отвлекать свой персонал от работы дл! проведения опросов. Целесообразней обра щаться к специалистам в маркетинговые фир мы, в которых такая работа поставлена на по ток. Ведь ничего хорошего не получится, есгн будет «сапоги тачать пирожник». Источник: Как проводятся маркетинговые исследо вания //
http://www.ci.ru/inform6_98/toy_opin.htm
371
один вид упаковки товара из десяти альтернативных, то ему очень трудно оценить достоинства каждой, если различия между ними невелики. Человек, оценивая пятый вариант, теряет чувствительность.
Анализируя особенности национального парка социологических технологий, профессиональное мастерство специалистов, а также непредсказу-мость поведения заказчиков, российские маркетологи говорят так: «Маркетинговые исследования это — бизнес в Соединенных Штатах, это — индустрия в Великобритании, это — наука в Германии, и это — искусство в России» (А.Демидов).
БРИФ И БРИФИНГ
Бриф можно сравнить с техническим заданием. Невозможно построить дом, если у вас нет чертежа, а также представления о материалах и их примерной стоимости. Все это необходимо иметь прежде, чем приглашать строителей или самому браться за лопату.
Как мы уже выяснили, общение заказчика и исполнителя, преследующих каждый свою цель, редко представляет идиллическую картину, напоминающую дружеские сценки античных бесед Сократа с учениками. Если противоречия и не выплескиваются наружу, то внутренняя напряженность чувствуется в каждом жесте, слове, движении. Стороны нередко поглядывают друг на друга с опаской, не зная, какого еще подвоха стоит ожидать.
Первым шагом, легитимизирующим их сотрудничество, выступает заключение договора о проведении исследования и обязанностях сторон. Договор может снять напряженность у тех агентств, которые пострадали от недобросовестных клиентов, а также значительно облегчает взаимопонимание сторон. Он может подтверждать обязательство агентства не разглашать предоставленную ему информацию, являющуюся коммерческой тайной клиента. Клиент же обязуется не разглашать и не использовать без специального разрешения предложения, идеи и концепции агентства.
Договору предшествует написание технического задания, отвечающего вполне определенным формальным нормам (бриф). Бриф (от англ. Brief— кратко, сжато) — документ, в котором кратко и четко формулируются задачи, которые ставит клиент перед агентством, и содержится дополнительная информация, необходимая агентству для их достижения. Бриф представляется нескольким агентствам для проведения конкурса на лучший проект маркетингового исследования. Нормальный срок проведения конкурса (если речь идет о комплексном обслуживании и объемном предложении) — 1—2 месяца’5.
Инфо-брифами называют информационные подборки по наиболее актуальным политическим, социальным и экономическим вопросам. Такие брифы один раз в месяц выпускает, в частности, Центр Информационных ресурсов Генерального консульства США в Санкт-Петербурге. Кроме того, регулярные «Брифы Центральная Азия» издаются Агентством БРИФ (г. Алматы, Казахстан). Они представляют собой дайджест свежей информации по маркетингу и рекламе, в том числе информации о проведенных в разных странах эмпирических исследованиях. В отличие от этих, издательских брифов, исследовательские брифы
15 Федоров А. Технология эффективного выбора //
http://tender.org.ua/additional/full
.html?8&10
372
(research brief) создают под конкретные научно-поисковые цели специалисть (менеджеры) отделов рекламы или маркетинга компании.
Первое совещание между заказчиком и исполнителем маркетингового ис следования на профессиональном языке называется исследовательским бри фингом. Оно представляет собой достаточно сложный ритуал опробование сил исполнителя, знакомства с его возможностями, их правильную и точнук оценку, торг вокруг цены будущего исследования. «Процедура брифинга по зволяет заказчику пообщаться с одним или несколькими исследовательски ми агентствами на основе брифа, проконсультировать их по предстоящем1 проекту и представить все необходимые элементы информации таким обра зом, чтобы компания-исследователь смогла глубже проникнуть и осознат: маркетинговый контекст ситуации и управленческой проблемы заказчика узнать о рамках и практических ограничениях исследования, а следователь но, занять такую позицию, в которой оказалась бы возможной подготовк релевантного предложения, полностью адаптированного к проблеме заказ чика. Чем точнее бриф заказчика — тем действеннее подход исследователей Чем больше информированы исследователи о размерах риска (или выигры ша) заказчика в случае плохого (или хорошего) решения, тем более реалис тичным и соразмерным по цене будет предлагаемый бюджет исследования»»
У брифа нет стандартной формы, но его содержание предполагает нали чие некоторой обязательной информации. К обязательным элементам бри фа относят:
- описание маркетингового контекста;
- определение управленческой проблемы;
- информирование о практических ограничениях.
Хороший бриф требует точного научного мышления, ведущего к: а) пра вильной постановке проблемы исследования; б) выявлению всех гипоте: которые следует проверить, а также типов информации, которые будут сл> жить подтверждением каждой гипотезы.
Итак, бриф — ознакомительный документ, заявка на будущее сотруднн чество, брифинг — ознакомительная встреча клиента и исследователей.
Технология проведения брифинга в маркетинговом исследовании, пос ледовательность и логика его этапов, согласно Иву Марбу17, выглядит еле дующим образом (рис. 19).
Брифинг предоставляет возможность сформировать взаимоотношения kon пании заказчика с компанией исследователя. Это особенно важно, если зака: чик еще никогда не работал с данной исследовательской компанией. Иссл< довательский брифинг устанавливает будущее пространство кооперации межг компаниями заказчика и исследователей. Первое правило —- конфиденциал1 ность. Агентство не должно открывать каким-либо конкурентам заказчиь информацию, полученную на брифинге. Исследователь должен точно выпет нять то, что описано в предложении, до тех пор, пока клиент не попросит сд< лать иначе. Оплата должна производиться в согласованное время. Обычн агентство предъявляет счет на предоплату 50% от общей стоимости договор что идет на оплату полевой работы. Предпочтительно, чтобы на брифинге ил
Марбу И. Маркетинговое исследование начинается с грамотного брифинга//
http://marketing.spb
.г lib-research/b riefing.htm 17 Там же.
373
вскоре после него заказчик проинформировал агентство о желаемых параметрах обслуживания. Ему следует сообщить, какой тип отчета он ожидает, какую структуру должен иметь отчет, вся ли компьютерная обработка должна быть выполнена или выборочная, какой стиль презентации ему нужен18.

Рис. 19. Определение проблемы в исследовательском процессе
18 Марбу И. Маркетинговое исследование начинается с грамотного брифинга //
http://marketing.spb.ru/
lib-research/briefing.htm
![]()
ПРОБЛЕМА ВЫБОРКИ И РЕПРЕЗЕНТАТИВНОСТИ
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!
Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:
где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).
Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:
Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)
где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.
Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).
Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.
Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.
При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет