В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
- 1 Оценки качества классификации
- 1.1 Матрица ошибок (англ. Сonfusion matrix)
- 1.2 Аккуратность (англ. Accuracy)
- 1.3 Точность (англ. Precision)
- 1.4 Полнота (англ. Recall)
- 1.5 F-мера (англ. F-score)
- 1.6 ROC-кривая
- 1.7 Precison-recall кривая
- 2 Оценки качества регрессии
- 2.1 Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
- 2.2 Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
- 2.3 Коэффициент детерминации
- 2.4 Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
- 2.5 Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
- 2.6 Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
- 2.7 Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
- 3 Кросс-валидация
- 4 Примечания
- 5 См. также
- 6 Источники информации
Оценки качества классификации
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-

Рис.1 Сбалансированная F-мера,
-

Рис.2 F-мера c приоритетом точности,
-

Рис.3 F-мера c приоритетом полноты,
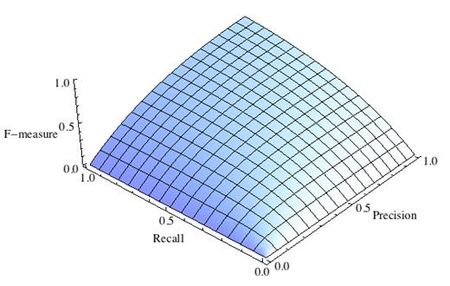
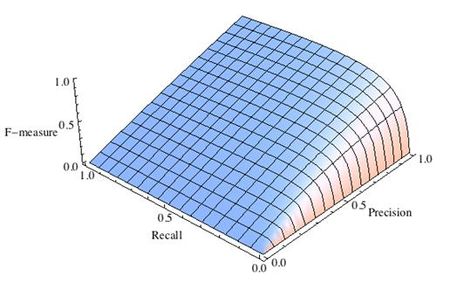
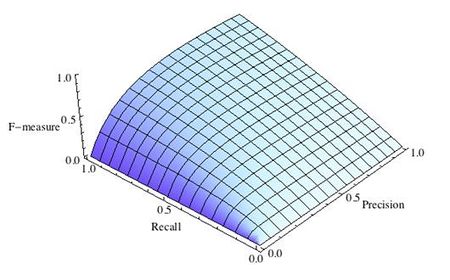
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
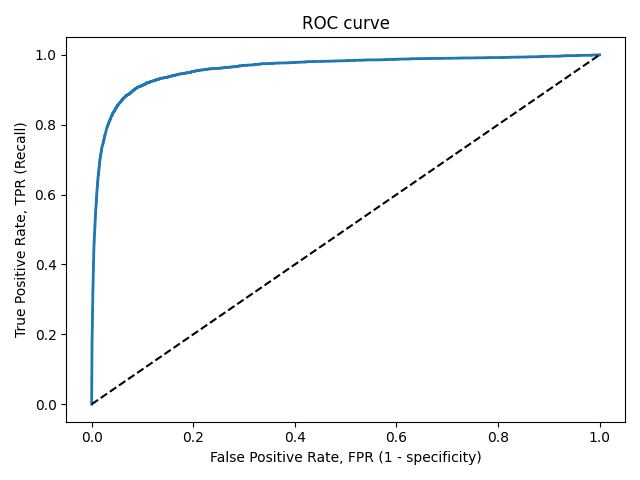
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
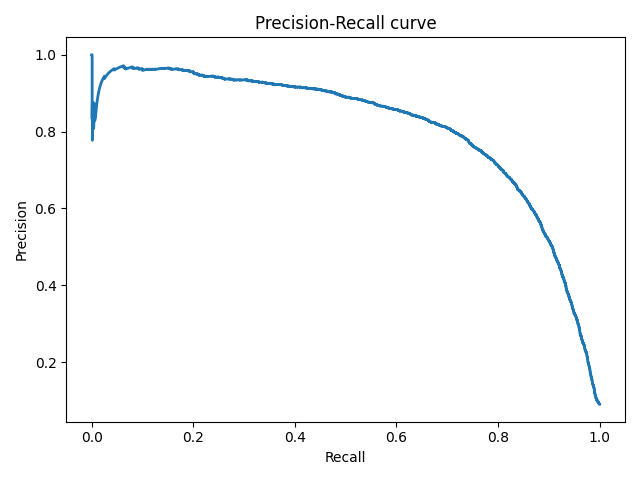
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Оценки качества регрессии
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Кросс-валидация
Хороший способ оценки модели предусматривает применение кросс-валидации (cкользящего контроля или перекрестной проверки).
В этом случае фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Примечания
- [1] Лекция «Оценивание качества» на www.coursera.org
- [2] Лекция на www.stepik.org о кросвалидации
- [3] Лекция на www.stepik.org о метриках качества, Precison и Recall
- [4] Лекция на www.stepik.org о метриках качества, F-мера
- [5] Лекция на www.stepik.org о метриках качества, примеры
См. также
- Оценка качества в задаче кластеризации
- Кросс-валидация
Источники информации
- [6] Соколов Е.А. Лекция линейная регрессия
- [7] — Дьяконов А. Функции ошибки / функционалы качества
- [8] — Оценка качества прогнозных моделей
- [9] — HeinzBr Ошибка прогнозирования: виды, формулы, примеры
- [10] — egor_labintcev Метрики в задачах машинного обучения
- [11] — grossu Методы оценки качества прогноза
- [12] — К.В.Воронцов, Классификация
- [13] — К.В.Воронцов, Скользящий контроль
Министерство связи и информатизации
Республики Беларусь
Учреждение образования
«ВЫСШИЙ ГОСУДАРСТВЕННЫЙ КОЛЛЕДЖ СВЯЗИ»
Факультет электросвязи
Кафедра телекоммуникационных систем
На тему «Критерии оценивания качества
воспроизведения речи и изображений»
по дисциплине
«Цифровая обработка
речи и изображений»
Выполнила: Проверил:
ст.
гр. ПО-041
_____
В.С. Карейша __ С.И. Киркоров
Минск2012
ВВЕДЕНИЕ
Одним из наиболее мощных программных
пакетов обработки мультимедийных данных
является MatLab. С его помощью может
осуществляться программное моделирование
процессов и систем передачи информации.
Основные достоинства применения MatLab
для программного моделирования состоят
в простоте программирования (синтаксис
команд интерпретатора MatLab аналогичен
синтаксису C-программ), в удобстве отладки
программ (отсутствует необходимость в
компиляции программы перед ее выполнением,
после выполнения программы доступна
информация о состояниях всех ее
переменных), в простоте и эффективности
визуализации результатов выполнения
программы (формирование одномерных,
двухмерных и трехмерных графических
объектов), в поддержке большинства
стандартных форматов представления и
хранения файлов данных, аудио- и видео-
информации (неподвижных и подвижных
изображений), в наличии развитой
библиотеки встроенных функций, реализующих
основные операции обработки (информационные
преобразования, фильтрация и т.д.) и
хорошей документированности встроенных
функций (поиск по функциям, описание
функций, теоретические сведения по
цифровой обработке сигналов, примеры
программ).
Цель работы:
Изучение критерий оценивания качества
воспроизведения речи и изображений.
Закрепление навыков полученных при
выполнении лабораторных заданий №1 и
№2.
Краткие теоретические сведения.
Изображение задается таблицей чисел
состоящей из M строк
и N столбцов (1024×1024).
Каждое число в данной таблице описывает
один пиксел, который представляется K
битами (8 бит). Во всех рассматриваемых
здесь критериях сравнения степень
близости изображений определяется
числом, которое некоторым образом
вычисляется по данным изображениям.
Пусть первое изображение описывается
таблицей чисел

,
а второе –

.
Для расчета оценок отличия изображений
можно использовать следующие выражения:
1. Пиковое отношение сигнал/шум psnr

где

– среднеквадратичная ошибка, К –
битовая глубина цвета, т.е. количество
бит требуемое для представления одного
пиксела. Обычно вычисляется в децибелах
[dB]. Данная мера отличий
изображений является классической и,
в некотором смысле, эталонной. Во всех
работах по сравнению изображений любой
нововведенный критерий сравнивается
с PSNR. Считается, что если
значения PSNR больше чем
37[dB], то различие изображений
практически незаметно, а если меньше
20[dB], то различие изображений
является существенным и весьма
значительным. Вместо PSNR
иногда используются похожие выражения.
Например, среднеквадратичная ошибка
MSE, которая записана выше,
максимальная среднеквадратичная
погрешность PMSE,

,
нормированная
среднеквадратичная погрешность NMSE

,
отношение
сигнал/шум SNR
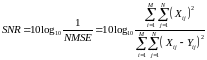
.
Все эти меры отличия изображений дают
результаты более или менее похожие с
PSNR. Поэтому их рассмотрение
не является целесообразным, при условии,
что используется PSNR.
2. Максимальная абсолютная ошибка
MAE

.
Классическая мера отличия изображений.
Если изображения идентичны, то MAE=0.
Эта
метрика хорошо отмечает даже самые
малые различия двух изображений.
3. Индекс структурной похожести (SSIM)
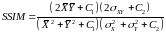
,
где

– среднее значение первого изображения,

– среднее значение первого изображения,

и

– выборочные дисперсии первого и второго
изображений соответственно,

– выборочный коэффициент корреляции.
Неотрицательные константы

и
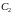
выбираются произвольно. Для расчета
констант я выбираю следующие значения

и
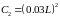
,
где

,
К – битовая глубина цвета. Индекс
структурной похожести может принимать
значения от -1 до 1. Причем SSIM = 1,
если изображения совпадают.
Результата
вычислений.
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
PSNR |
42,9198 |
41,6652 |
40,8894 |
43,7451 |
42,7284 |
41,8565 |
|
PMSE |
5,67*10-5 |
7,50*10-5 |
8,61*10-5 |
4,65*10-5 |
5,73*10-5 |
7,30*10-5 |
|
NMSE |
3,08*10-4 |
2,92*10-4 |
2,38*10-4 |
1,12*10-4 |
1,50*10-4 |
4,44*10-4 |
|
SNR |
35,1090 |
35,3461 |
36,2377 |
39,4999 |
38,2251 |
33,5305 |
|
MAE |
61 |
62 |
84 |
88 |
56 |
71 |
|
SSIM |
0,9991 |
0,9990 |
0,9988 |
0,9988 |
0,9993 |
0,9988 |







Рисунок
1 – График зависимости коэффициента
PSNR




Рисунок
2 – График зависимости коэффициента
МАЕ

Рисунок
3 – График зависимости коэффициента
SSIM
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ильичев Е.А. (ИБРАЭ РАН, Москва, Россия)
Содержание
- Введение
- 1. Расчетные средства моделирования и используемые подходы
- 2.Некоторые особенности результатов используемого подхода
- Заключение
- Список литературы
Введение
Оценка возможного радиологического воздействия на население при рассмотрении тяжелых запроектных аварий на АС для целей детерминистической поддержки ВАБ-2 предполагает проведение расчетов атмосферного переноса и доз облучения населения. Так как время начала выброса неизвестно, необходимо учесть все метеорологические условия, характерные для места расположения станции. Для решения этой задачи ранее использовались упрощенные подходы, основанные на применении гауссовых моделей и, как следствие, локальных метеорологических параметров, измеряемых на метеорологических станциях, расположенных на исследуемых площадках. На основе этих данных строились метеорологические ряды, для которых проводились расчеты возможных последствий и их статистический анализ. Недостатком этого подхода является невозможность учета информации по динамике выброса и учета изменения метеорологических параметров в течение выброса.
В настоящее время наиболее прогрессивным подходом, позволяющим снять эти ограничения, является применение моделей JRODOS [1], ARGOS[2], NOSTRADAMUS [3], FLEXPART-WRF [4] в связке с метеорологическими процессорами, учитывающими географические и климатические особенности расположения объекта при моделировании погоды, например, WRF [5] или CALMET [6]. Это в том числе связано с тем, что для тяжелых запроектных аварий по современным стандартам требуется рассматривать расстояния порядка 100 км [7], что превышает возможности даже самых современных версий гауссовых моделей. Еще одним фактором в пользу развития подходов проведения таких расчетов является совершенствование возможностей кодов по моделированию внутриреакторных процессов вплоть до выхода в атмосферу, которые позволяют получить динамические характеристики выброса с точностью порядка 1 часа, что открывает возможности для более точного моделирования последствий.
Применение моделирующих кодов для оценки возможных последствий в новом подходе предполагает предварительную подготовку трехмерных сеток метеорологических параметров, перекрывающих область интереса. Для этого, как и ранее, используются данные измерений со всех окрестных станций метеорологического мониторинга, при этом дополнительно используются данные повторного анализа, полученные за счет применения глобальных циркуляционных моделей, а также данные о характеристиках территории (орография, преобладающие ветра, осадки, наличие крупных водных объектов и др.).
Все эти данные объединяются в единый расчет в качестве начальных граничных условий с использованием метеопроцессоров высокого разрешения. При этом открытые базы данных позволяю получить такие параметры для широкого временного диапазона.
Таким образом, с практической точки зрения возникают две ключевые задачи: обеспечение расчетов метеорологическими данными и проведение многовариантных расчетов последствий тяжелых запроектных аварий. В ИБРАЭ РАН применяется модель WRF с ядром ARW для решения первой задачи и модель НОСТРАДАМУС для решения второй. В отличии от ранее использовавшихся подходов, где были исследованы и применялись варианты оптимизации вычислений, например, алгоритмы семплирования по погодной выборке [8,9], для подхода с применением трехмерных метеорологических полей в настоящее время таких законченных исследований нет, поэтому в настоящее время расчеты проводятся с использованием КВУ. Одновременно с этим исследуются схемы оптимизации вычислительной процедуры. В рамках данной работы рассматривается реализация ИБРАЭ РАН технологии проведения таких расчетов, а также предварительные результаты анализа получаемых величин с точки зрения построения дозовых функционалов, которые сопоставимы с критериями НРБ99/2009 [10] и ОНБ МАГАТЭ [11].
1. Расчетные средства моделирования и используемые подходы
1.1. Расчетные средства
Для расчетов атмосферного переноса использовалось ПС Нострадамус, предназначенное для моделирования поведения РВ в атмосфере, их осаждения на подстилающую поверхность и формирования параметров радиационной обстановки и доз облучения населения. В основе программного средства лежит Лагранжева стохастическая модель атмосферного переноса, дополненная моделями оценки доз облучения населения, реализована связка с кодами СОКРАТ и WRF-ARW для моделирования поведения продуктов деления до выхода в атмосферу и метеорологических параметров соответственно.
Входными данными для проведения расчетов являются данные об источнике выброса (положение, продолжительность и интенсивность выброса) и метеоданные (точечные или трехмерные). Метеоданные поступают в ПС Нострадамус из метеопроцессора WRF-ARW (Weather Research and Forecasting – Advanced Research WRF) с временным шагом 1 час (~8700 наборов метеоданных для одного года). Метеорологическая модель, реализованная в WRF, может применяться для широкого спектра метеорологических задач в масштабах от десятков метров до тысяч километров и позволяет выполнять моделирование на основе фактических атмосферных данных ( то есть из наблюдений и анализов).
Для уменьшения времени расчетов с метеоданными из WRF-ARW, в ПС Нострадамус реализована возможность выполнения вычислений на кластерной вычислительной установке.
1.2. Описание используемого подхода
Подход, применяемый в данной работе для расчета возможных последствий, представляет собой развитие подходов РОМ [12], VALMA[13] и JRODOS[1] и заключается в следующем: для выбранного объекта производится серия расчетов радиационной обстановки для одного сценария выброса РВ в атмосферу, полученного с использованием кода СОКРАТ для сценария тяжелой запроектной аварии. Выброс имеет конечную продолжительность и нелинейную динамику выхода активности (рис. 1).
В качестве входных метеорологических данных берутся трехмерные метеорологические поля, полученные с помощью метеопроцессоров за несколько лет рис. 2, 3. При расчетах в ПС Нострадамус использовались метеорологические ряды, построенные с помощью модели WRF-ARW по данным повторного анализа с задействованной процедурой ассимиляции данных метеорологического мониторинга (на базе открытых данных, из системы международного обмена). Производимые расчеты отличаются друг от друга сдвигом времени начала аварии по метеорологической шкале. Интервал смещения аварии при расчетах принимался равным двум часам, что позволяет учесть суточные изменения в атмосфере, например, смену направления бризовых ветров в прибрежной зоне. Данное обстоятельство отличает применяемый подход, от подхода в системе JRODOS, в которой проводятся расчеты для 365 различных времен начала выброса (один выброс в сутки в течение одного года). Время начала выброса выбирается случайным образом для каждого дня.

Рис. 1. Динамика поступления отдельных групп радионуклидов в атмосферу
Используемый в данной работе подход более ресурсоемкий, однако, снижение требований требует дополнительного анализа. Так же можно отметить отличия применяемого подхода от подхода, в финском коде VALMA, в котором входными метеорологическими данными служат воздушные траектории, основанные на численных прогнозах ECMWF. Общее количество траекторий для проведения расчетов составляет 878400 (100 траекторий в час за 2012 год).

Рис. 2. Наблюдаемая (желтая линия) и расчетная (зеленая линия) среднегодовая роза ветров (в процентах наблюдаемых случаев за год) за 2016 (а) и 2017 (б) гг.
Объединение расчетов для различных времен начала выброса предполагает, что в каждой точке расчетной области вычисляются значения целевых функций, например, доз облучения. Далее для каждого дозового функционала в каждой точке строится вариационный ряд (рис. 4, 5), состоящий из полученных значений за выбранный промежуток времени, например, 1 год. После этого, на основании полученного вариационного ряда, для каждой точки определяются прогнозируемые дозы с заданным уровнем доверия.


Следует отметить, что применяемый в данной работе подход является ресурсоемким. Для решения данной проблемы вычисления производятся с использованием кластерных вычислительных установок (КВУ). Время расчета радиационной обстановки для одного длительного сценария аварии (длительностью 300 часов и более) может достигать нескольких недель для расчетов с использованием 500 потоков.
Для статистической обработки полученного набора результатов на языке Python версии 2.7 была доработана и дополнена система модулей. Данная система позволяет в полном объеме обрабатывать, структурировать, извлекать необходимые данные, составлять из отдельных результатов величины, достаточные для сопоставления с дозовыми пределами, а также визуализировать результаты в виде графиков, карт, картинок и видеофайлов.
3. Результаты анализа демонстрационных расчетов
В качестве демонстрационного примера был выбран сценарий аварии на АС в результате потери охлаждающей жидкости. Расчет проводился для гипотетической АЭС, расположенной на побережье вблизи гор, выбранное расположение не совпадает ни с одной из существующих АЭС, но корреспондируется с расположением таких АЭС как АЭС Аккую и АЭС Бушер (расположена в сильно неоднородной, горной местности, на побережье, рис. 6). Длина метеорологического ряда составляла 1 год (от 1 января 2016 до 31 декабря 2016) со скважностью 1 час.
В результате расчетов были вычислены 206 функционалов для каждого из 4393 времени начала аварии, которые предназначены для сопоставления с российскими [10] и зарубежными [11] критериями для принятия решений в случае аварийной ситуации. В рамках данной работы рассматривалась прогнозируемая эффективная доза от выпадений на подстилающую поверхность и от проходящего облака за счет внешнего облучения и ингаляции за 7 суток, для ОБЭ-взвешенных доз, поглощенных доз закономерности аналогичны. На рис. 6 показана расчетная карта пространственного распределения эффективной дозы за 7 суток, полученная с уровнем доверия 95 %. Видно, что имеет место сильно неоднородная пространственная картина возможных последствий для населения, с наличием выделенных участков, вероятность загрязнения и, как следствие, вероятность получения более высоких доз для которых в случае аварий представляется более высокой. Такими участками являются ущелья гор и долина реки. На рисунках 7 и 8 показаны графики по оси следа для эффективной дозы за 7 суток.
Каждая точка графика соответствует максимальному значению эффективной дозы в зависимости от удаления от блока АЭС, построенной с уровнями доверия 95 % и 99,5 % [8,14]. Доверительный интервал 95 % означает, что приведенные значения могут быть превышены только в 5 % времен начала выброса, что для года составляет 438 часов [15]. Значения эффективной дозы нанесены пунктирной линией. Можно также отметить, что полученные значения прогнозируемой эффективной дозы для выбранных доверительных интервалов отличаются в 2–3 раза.

Полученные величины могут быть сопоставлены с критериями для определения размеров ЗПСМ, принятыми в работе [18]. Одним из таких критериев является не превышение прогнозируемой эффективной дозы за 7 дней значения 0,1 Зв. На графиках 7, 8 штрихпунктирной линией отмечен критерий 0,1 Зв. Исходя из полученных данных был сделан вывод, что получаемые результаты в новой постановке задачи корреспондируются с результатами, полученными с использованием классических подходов. Расстояния, полученные для рассматриваемой аварии, не превышают установленных МАГАТЭ расстояний ни для результатов, полученных с уровнем доверия 95 процентов (обычно используется для анализа последствий тяжелых запроектных аварий), ни для 99,5 (обычно используется для анализа проектных аварий). В тоже время учтены климатические и географические особенности местности, а также результаты моделирования глобальной циркуляционной моделью, что повышает достоверность проводимых расчетов. Дополнительно следует отметить, что в методологии МАГАТЭ рассматриваются остаточные дозы с учетом применяемых защитных мероприятий, что должно снизить прогнозируемые дозы как минимум в два раза.

2.Некоторые особенности результатов используемого подхода
Несмотря на очевидность перехода к рассматриваемому подходу, необходим дополнительный анализ результатов. Ниже рассмотрены следующие вопросы:
- оценка неопределенностей для различных длин метеорологических рядов;
- особенности формирования оси следа для одиночных расчетов;
- особенности формирования критических групп для одиночных расчетов.
2.1. Особенности статистической обработки полного набора расчетов атмосферного переноса с использованием трехмерных метеорологических полей
Обычно минимальная длина метеорологического ряда принимается равной одному году, что позволяет учесть сезонную сменяемость погодных условий [16,17], хотя есть и более жесткие требования по используемой длине выборки [7]. В целом метод представляет собой адаптацию подхода “Inner” Weather Loop method, где показано, что в статистическом плане результаты, рассчитанные с использованием годового метеорологического ряда, не будут сильно отличаться от результатов при выборе другого годового метеорологического ряда. Однако этот подход обычно использовался для средних величин, в тоже время для задач обоснования безопасности рассматриваются верхние перцентили распределения. С другой стороны требования регулятора [7] рассматривают 3 года как минимальную длину вариационного ряда для задач обоснования безопасности.
Поэтому еще одним исследованием, проведенным в рамках данной работы, была оценка отличий в результатах при выборе для расчетов метеорологического ряда за год и за два года, относительно результатов с трехлетними метеорологическими данными. В качестве основного результата для сравнения выбрана плотность поверхностных выпадений радионуклидов с доверительным интервалом 95 %, полученная с использованием метеорологических данных за 3 года. На рисунках 9, 10 приведены результаты на оси следа для плотности поверхностных выпадений с доверительным интервалом 95 %, для одно- и двухлетних метеорологических рядов соответственно.
Дополнительно на каждый из графиков нанесены результаты расчета, принимаемого за основной. Из графиков следует, что для оси следа различные длины метеорологических рядов могут давать как недооценку, так и переоценку прогнозируемой дозы относительно реперного расчета.


На рисунках 11, 12 нанесена разность в процентах между основным расчетом и расчетами с однолетним и двухлетним метеорологическим рядом в точках на оси следа плотности поверхностных выпадений. Из графиков следует, что разность в плотностях поверхностных выпадений, связанная с длиной метеорологического ряда, для расчетов с годовой метеорологией в подавляющем большинстве случаев будет менее 30 %, а для расчетов с двухлетней метеорологией менее 15 %.


Рис. 12. Разница в процентах для различных комбинаций времен двухгодового метеорологического ряда с уровнем доверия 95 % для плотности поверхностных выпадений
Ниже на рисунках 13 и 14 нанесена нормированная среднеквадратичная ошибка (NMSE) результатов относительно реперного расчета в зависимости от расстояния от источника выброса. Из графиков видно, что результаты с годовой метеорологией дают ошибку в среднем 0.1, когда для результатов с двухгодичной метеорологией в любых комбинациях ошибка составляет 0.03. Следовательно, варианты с двухгодичным метеорологическим рядом будут давать меньшие ошибки относительно реперного варианта, т.е. давать более точные оценки, чем варианты с годовой метеорологией. Так же отмечается тенденция, роста величины ошибки по мере удаления от источника выброса.


Рис. 14. Нормированная среднеквадратичная ошибка результатов с двухгодовой метеорологией относительно основного расчета
2.2. Особенности отдельных расчетов атмосферного переноса с использованием трехмерных метеорологических полей
Одним из традиционных способов представления результатов оценки возможного радиологического воздействия является использование так называемой оси радиоактивного следа. В случае применения гауссовых моделей в качестве оси следа рассматривается прямая, соответствующая максимумам целевых функций в зависимости от расстояния от источника. Для всех путей облучения она совпадает с направлением ветра в месте расположения источника. Так как в рамках используемого подхода скорость и направление ветра изменяются при удалении от источника, а так же с течением времени, ось следа строится по следующему принципу: выбирается набор окружностей с центром в точке выброса и далее для каждой окружности, происходит поиск положения точки с максимальным значением дозового функционала.
Исследование географического расположения точек, для которых значения функционалов соответствовали максимуму, показало, что, для разных целевых функций положение точек может существенно отличаться (рис. 15 и 16). Это связано с использованием лагранжевой модели переноса, которая учитывает поправки на скорость сухого осаждения в зависимости от типа подстилающей поверхности, трехмерные метеорологические поля, длительность выброса ( в рассматриваемой аварии длительность выброса составляла 8 часов, однако в обосновании безопасности также рассматриваются аварии длительностью до 15 суток). Данную особенность необходимо учитывать при составлении полной дозы облучения по нескольким путям облучения.

Еще одним нехарактерным результатом является распределение групп населения с максимальным значением прогнозируемой дозы. При оценках прогнозируемой дозы от ингаляции, рассматривались возрастные группы: до 1 года, от 1 года до 2 лет, от 2 до 7 лет, от 7 лет до 12, от 12 до 17 и от 17 лет и выше. Для отдельного расчета радиационной обстановки различия в дозах для рассматриваемых возрастных групп населения в разных точках могут достигать 300 % в любую сторону. Распределение групп населения в расчетной области представлено на рис. 17. Из рисунка следует, что в разных точках расчетной области, для одной и той же аварии, имеет место различное пространственное распределение категорий населения, подверженных наибольшему воздействию. Данный фактор представляется важным при определении критической группы населения или при составлении репрезентативного человека в новых терминах МАГАТЭ[18].

Рис. 17. Расчетное распределение групп населения с максимальными значениями прогнозируемой дозы для одного времени начала выброса
Заключение
В рамках настоящей работы был рассмотрен современный подход к расчетам последствий тяжелых аварий на АС, применяемый в ИБРАЭ РАН, заключающийся в использовании при расчетах трехмерных метеорологических полей за последние несколько лет и проведении расчетов атмосферного переноса со смещением времени начала действия источника по метеорологической шкале с последующей статистической обработкой. В отличии от классических подходов, он позволяет проводить расчеты на расстояниях от источника более 30 километров, что позволяет проводить анализ возможных последствий для населения от гипотетических аварий в соответствии с последними мировыми стандартами. Реализация выполнена на базе модели НОСТРАДАМУС и метеорологического процессора WRF-ARW с учетом современных исследований в этой области, выполненных в США, Финляндии, Турции и других странах.
Демонстрация подхода выполнена на базе серии расчетов эффективной дозы с уровнями доверия 95 % и 99.5 % для сценария развития гипотетической аварии, рассчитанной с помощью кода СОКРАТ. Рассмотренная территория моделируемой АС, расположенной в горной местности возле побережья, корреспондируется с расположением АЭС Аккую, однако географически не совпадает. Получено, что для рассматриваемого сценария интегральная картина возможных последствий представляет собой сложную структуру, которая вблизи источника выброса соответствует розе ветров, на дальних расстояниях эта закономерность нарушается. Также отмечены участки, вероятность загрязнения которых представляется более высокой.
Проведено сопоставление результатов с рекомендациями МАГАТЭ по установлению зон и расстояний планирования защитных мероприятий. Получено, что с уровнем доверия 95 % на основании эффективной дозы за 7 суток, установленной МАГАТЭ в качестве одного из критериев выбора зоны принятия срочных мер, расчетные значения превышения дозового предела для рассматриваемой аварии с запасом лежат внутри размеров 30 километровой зоны планирования срочных мер, предложенной в МАГАТЭ. Таким образом, подход не противоречит результатам МАГАТЭ, и расширяет возможности проведения расчетного анализа.
При анализе получаемых расчетных данных для отдельных расчетов атмосферного переноса с использованием трехмерных метеорологических полей было отмечено: имеет место различное положение оси следа для разных путей поступления дозы; отличие групп населения в разных точках расчетной области, для которых дозы будут максимальными, различия в дозах могут достигать 300 % и не могут быть отнесены к вычислительным ошибкам.
При статистической обработке всего комплекса расчетов показано, что уменьшение длины метеорологического ряда с трех лет до года в большинстве случаев приводит к различиям до 30 %, а при уменьшении до двух лет до 15 % для доверительного интервала 95 %. Оценка нормированной среднеквадратичной ошибки показывает, что выбор двухлетней метеорологии при расчетах так же приводит к меньшим (0,03) ошибкам, чем выбор годовой (0,1), относительно трехлетних метеорологических данных. Наблюдается тенденция, что использование любых двух лет для выполнения расчетов лучше, чем использование одного года, что корреспондируется с данными исследований Финляндии, Турции, США, а также подходам, заложенным в JRODOS.
Список литературы
- W. Raskob, D. Trybushnyi, I. Ievdin and M. Zheleznyak (2011) JRODOS: Platform for improved long term countermeasures modelling and management.
- Steen Hoe , Paul McGinnity , Tom Charnock , Florian Gering , Lars Henrik Schou Jacobsen, Jens Havskov Sørensen , Kasper Andersson, Poul Astrup; ARGOS Decision Support System for Emergency Management.
- Нострадамус. Компьютерная система прогнозирования и анализа радиационной обстановки на ранней стадииаварии на АЭС. Инструкция пользователя. ИБРАЭ РАН,инв. №3429. – М., 2001.
- Brioude, D. Arnold, A. Stohl, M. Cassiani, D. Morton, P. Seibert, W. Angevine, S. Evan, A. Dingwell, J. D. Fast, R. C. Easter, I. Pisso, J. Burkhart, and G. Wotawa (2013): The Lagrangian particle dispersion model FLEXPART-WRF version 3.1. Geoscientific Model Development, 6(6), 1889–1904, URL: http://www.geosci-model-dev.net/6/1889/. Citation as bibtex.
- WEATHER RESEARCH AND FORECASTING MODEL [Электронный ресурс] – Режим доступа: https://www.mmm.ucar.edu/weather-research-and-forecasting-model – свободный.
- Joseph S. Scire, Francoise R. Robe, Mark E. Fernau, Robert J. Yamartino (2000) A User’s Guide for the CALMET Meteorological Model
- Draft guidance document on atmospheric dispersion and dose calculations regarding releases in case of accidents that might take place in nuclear power plants (Руководство по расчету атмосферной дисперсии и дозы в результате выбросов радиоактивных веществ, в случае нарушений нормальной эксплуатации и аварий на атомной электростанции» (проект), TAEK, Анкара, версия 6, 2019).
- Nuclear Regulatory Commission (U.S.) (NRC). NUREG/CR-6613, “Code Manual forMACCS2: Volume 1, User’s Guide,” Washington D.C.: NRC, 1998.
- H-N Jow, J. L. Sprung, J. A. Rollstin, L. T. Ritchie, D. I. Chanin, (1990) MELCOR Accident Consequence Code System (MACCS)
- Нормы радиационной безопасности (НРБ-99/2009): Санитарно – эпидемиологические правила и нормативы. М.: Федеральный центр гигиены и эпидемиологии Роспотребнадзора, 2009. 100 с.
- INTERNATIONAL ATOMIC ENERGY AGENCY. Radiation protection and safety of radiation sources: International Basic Safety Standards. IAEA SAFETY STANDARDS SERIES. General Safety Requirements Part 3. IAEA, Vienna, 2014.
- Дзама Д.В., Семенов В.Н., Сороковикова О.С. Методология и программный код расчета радиационной обстановки при длительных аварийных выбросах в атмосферу с учетом реальных метеорологических стандартных данных с измерительной сети ВМО. Радиационная защита и радиационная безопасность в ядерных технологиях: Сборник тезисов докладов 10-й юбилейной Российской научной конференции г. Москва, г. Обнинск, 22–25 сентября 2015 г. – г. Обнинск: НОУ ДПО «ЦИПК Росатома»; 2015 –348c.
- Rossi J., Ilvoinen M. Dose estimates at long distances from severe accidents VTT-R-00589-16 VTT, 2016, pages 41.
- Jukka Rossi, Mikko Ilvonen, Dose estimates from severe accidents beyond emergency planning zone, RESEARCH REPORT :VTT-R-00432-15 VTT, 2015, pages 45.
- W. G. Snell, R. W. Jubach (1981) Technical Basis for Regulatory Guide 1.145, “Atmospheric Dispersion Models for Potential Accident Consequence Assessments at Nuclear Power Plants”
- SAFIR. The Finnish Research Programme on Nuclear Power Plant Safety 2003–2006. Executive Summary. Ed. by Eija Karita Puska. Espoo 2006.
- Baklanov A, J.H. SİŞrensen, A. Mahura, 2006: Long-Term Dispersion Modelling: Part I: Methodology for Probabilistic Atmospheric Studies. Journal of Computing Technologies, 11(1): 136–156.
- IAEA, 2013, Actions to Protect the Public in an Emergency due to Severe Conditions at a Light Water Reactor, EPR-NPP Public Protective Actions–2013, International Atomic Energy Agency, Vienna
Таблица 6

С целью предотвращения переобучения нейросетей ограничивается максимальное число итераций (эпох) по модификации синаптических весов — 1000. Байесовский ансамбль формируется из адекватных нейросетей. При этом нейросетевая модель признается адекватной при одновременном выполнении трех условий:
- нормированная среднеквадратическая ошибка (NMSE) не более 5%;
- коэффициент корреляции между эмпирическими и полученными в ходе нейромоделирования данными (r) превышает 0,975;
- частотный критерий качества (P*) не менее 80%. Такой показатель рассчитывается по следующей формуле [20]:
где N* — количество наблюдений выходного параметра, объясненных нейросетевой моделью с заданной точностью (в нашем случае с относительной погрешностью (), назначенной экспертно в размере 5 и 8%);
Ntest — объем тестирующей выборки.
Экспериментальным путем было установлено, что значение индекса социального развития субъектов Российской Федерации с заданной степенью точности аппроксимируется нелинейной функцией следующего вида:
где Х1агр и Х2агр — значения субиндексов, соответственно, уровень жизни населения, научные исследования и инновации;
xt — дополнительный входной фактор — время [19].
На основе ряда вычислительных экспериментов был сформирован адекватный байесовский ансамбль из пяти нейросетей. Их конфигурация и результаты оценки на адекватность представлены в табл. 6 и 7.
Варьировалось не только количество скрытых слоев, но и число нейронов в них. Число нейронов в скрытых слоях оптимизировалось с помощью специальных возможностей программного продукта Neuro Solutions for Excel.
Так, в программном продукте имеется возможность варьировать количество нейронов в одном из скрытых слоев с необходимым шагом при фиксированном их количестве в других скрытых слоях. При этом вид активационной функции в скрытых слоях и выходном слое оставался неизменным — соответственно гиперболический тангенс и линейная.
В нашем случае сформированный байесовский ансамбль нейросетей позволяет с высокой степенью точности аппроксимировать социальное развитие российских регионов, т.е. с 0,982 коэффициентом корреляции эмпирических и полученных в ходе моделирования данных, 4,1% нормализованной средней ошибкой, а также корректно распознавать порядка 86,75 и 98% наблюдений, соответственно при 5- и 8%-ной относительной погрешности.
Таблица 7
Далее осуществляется прогнозирование социального развития регионов — лидеров России, ПФО, а также РБ в среднесрочной перспективе (табл. 8).
Таблица 8

По причине малого (во временном разрезе) массива исходных данных прогнозирование значений входных параметров (двух субиндексов) производится на основе усредненных за 2011-2016 гг. темпов их роста. При этом сделано допущение о неизменности темпов роста таких показателей в 2017-2019 гг.
У региона — лидера РФ (г. Москва) в 20172019 гг. ожидается снижение индекса социального развития по сравнению с 2014-2016 гг. В другом регионе — лидере России — г. Санкт-Петербурге также в среднесрочной перспективе прогнозируется снижение индекса социального развития, но только по сравнению с 2016 г. Для регионов — лидеров ПФО (Республики Мордовия и Татарстан) в 2017-2019 гг., наоборот, ожидается социальное развитие по сравнению с 2014-2016 гг.
Таким образом, можно сделать вывод о необходимости актуализации положений социальной политики регионов — лидеров России. При этом драйвером социального развития субъектов РФ должно стать не только дополнительное бюджетное финансирование их социальной сферы, но и повышение эффективности использования соответствующих ресурсов.
В Республике Башкортостан ожидается, что индекс социального развития в среднесрочной перспективе снизится незначительно. Несмотря на это, прогнозируется сохранение существенного отставания республики в социальной сфере от регионов — лидеров РФ и ПФО. Это объясняется тем, что если по уровню жизни населения РБ является конкурентоспособным регионом страны, то в сфере научных исследований и инноваций наблюдается «разрыв» между республикой и регионами — лидерами РФ и ПФО. Отсюда, в современных условиях для Республики Башкортостан актуализируется вопрос повышения эффективности инновационной деятельности, что невозможно без увеличения господдержки инновационного бизнеса и усиления контроля целевого расходования бюджетных средств.
Зарождение социальной прогностики произошло в 20-30-е годы XX века, когда стала очевидна многозначность общественного развития. Основателями прогнозирования можно считать таких ученых, как Н. Винер, Г. Тейл, Б. де Жувенел, Д. Белл, Э. Янг, Ф. Полак.
Социальное прогнозирование имеет большое значение в современном обществе. Почти все политические решения сегодня основываются на прогнозах. Зная желаемый результат объекта управления, с помощью прогнозирования можно выявить наиболее эффективный комплекс действий, необходимых для достижения результата. С помощью социальных прогнозов разрабатываются наиболее эффективные варианты решения социальных проблем.
Социальное прогнозирование основано на научных методах познания социальных и экономических явлений. Основными методами социального прогнозирования являются: статистические методы; методы экспертных оценок (метод Делфи);логические методы и моделирование.
Результаты государственного прогнозирования социально-экономического развития Российской Федерации используются при принятии органами законодательной и исполнительной власти Российской Федерации конкретных решений в области социально-экономической политики государства. В Федеральном законе от 20 июля 1995 г. N 115-ФЗ «О государственном прогнозировании и программах социально-экономического развития Российской Федерации».В нем выделены этапы кратко-, средне- и долгосрочного планирования. Социальное прогнозирование осуществляется как на государственном, так и на муниципальном уровне.
На сегодняшний день исследования практики муниципального управления показывают, что в процессе планирования возникает много ведомственных рассогласований, особенно на стадии бюджетного планирования.
Опыт современного планирования на муниципальном уровне невелик, исключением являются те муниципалитеты, которые сформировали основные элементы системы бюджетного и социально-экономического планирования, а также те немногие города, которые традиционно уделяли системному управлению первостепенное внимание. Для обеспечения более высокого уровня жизни и осуществления более эффективной социальной политики необходимо уделять большее внимание разработке системы планирования на муниципальном уровне.
На основе комплексного подхода (сочетающего в себе черты различных известных подходов) авторы считают возможным уточнить понятие «социальный потенциал» следующим образом: система условий, возможностей и ресурсов, способствующих социально-экономическому прогрессу и интенсификации развития общества. Такая трактовка понятия носит универсальный характер (применима для межнационального, странового и регионального уровня). В свою очередь, под социальным развитием регионов страны понимается повышение степени реализации имеющегося у них социального потенциала. Для всесторонней и объективной оценки социального развития субъектов РФ предлагается использовать авторскую методику, практическое применение которой осуществляется в несколько последовательных этапов:
1. Формирование системы частных показателей, характеризующих уровень социального развития регионов страны. Такая система в нашем случае включает 14 ключевых индикаторов, объединенных в 5 групп: 1) население; 2) уровень жизни населения; 3) образование; 4) здравоохранение и 5) научные исследования и инновации.
2. Приведение в сопоставимый вид частных показателей путем нормализации их значений. Для этого используется метод «Паттерн», позволяющий объективно оценивать «глубину» межрегиональных «разрывов» в стране по всей системе социальных индикаторов.
3. При условии равнозначности частных показателей (также призвана обеспечивать объективность оценки) осуществляется расчет индекса социального развития субъектов РФ.
В настоящее время актуализировался вопрос повышения эффективности социальной политики на региональном уровне. А это предполагает не только увеличение финансирования социальной сферы субъектов РФ, но и обеспечение надлежащего контроля расходования бюджетных средств.
4. На основе нейросетевых технологий (самоорганизующихся карт Кохонена) проводится кластеризация регионов России по уровню социального развития.
По результатам оценки можно сделать вывод о наличии в условиях современной России существенных резервов социального развития у большинства ее регионов. На это указывает ряд обстоятельств. Так, в частности, в составе страны на протяжении последних трех лет превалировали регионы, имеющие либо низкий, либо ниже среднего уровень социального развития (порядка 60-70% от их общего числа). Также нельзя не отметить, что в стране отсутствовали субъекты с высоким уровнем социального развития.
Результаты прогнозирования (для этого используются нейросетевые технологии, а именно: формируется байесовский ансамбль динамических нейросетей различной конфигурации) на среднесрочную перспективу также нельзя признать оптимистичными. Так, в частности, у регионов — лидеров РФ (гг. Москва и Санкт-Петербург) в 2017-2019 гг. прогнозируется снижение уровня социального развития по сравнению, соответственно, с 2014-2016 гг. и только отчетным годом. Для РБ также прогнозируется в среднесрочной перспективе некоторое (пусть и незначительное) снижение уровня социального развития. При этом по-прежнему ожидается сохранение существенного «разрыва» между регионами — лидерами РФ (ПФО) и республикой в сфере социального развития. Такое «отставание» РБ объясняется не различием в уровне жизни населения, а «разрывом» в сфере инноваций.
Поэтому, на наш взгляд, в настоящее время актуализировался вопрос повышения эффективности социальной политики на региональном уровне. А это предполагает не только увеличение финансирования социальной сферы субъектов РФ, но и обеспечение надлежащего контроля расходования бюджетных средств.
Таким образом, государству необходимо перейти от экстенсивного к интенсивно-экстенсивному пути социального (и в его составе инновационного) развития регионов России.
- Федеральный закон от 20 июля 1995 г. N 115-ФЗ «О государственном прогнозировании и программах социально-экономического развития Российской Федерации»
- Белолипцев И. И., Горбатков С. А., Романов А. Н., Фархиева С. А. Моделирование управленческих решений в сфере экономики в условиях неопределенности. М.: Инфра-М; 2015. 299 с.
- Бокарева В. Б. Социальный потенциал российского малого бизнеса в условиях глобализации. Вестник Новосибирского государственного университета. Серия: Социально-экономические науки. 2001;11(3):196-204.
- Букаев Г. И., Бублик Н. Д., Горбатков С. А., Саттаров Р. Ф. Модернизация системы налогового контроля на основе нейросетевых информационных технологий. М.: Наука; 2001. 344 с
- Бурдье П. Формы капитала. Пер. с англ. Экономическая социология. 2002;3(5):60-74.
- Гагарина Г. Ю., Губарев Р. В., Дзюба Е. И., Файзуллин Ф. С. Прогнозирование социально-экономического развития российских регионов. Экономика региона. 2017;13(4):1080-1094. DOI: 10.17059/2017- 4-9
- Головко В. А. Нейронные сети: обучение, организация и применение. М.: ИПРЖР; 2001. 256 с.
- Дрегало А. А., Ульяновский В. И., Брызгалов В. В., Крикуненко В. И., Шехина Т. П. Социальный потенциал региона как фактор развития северных территорий. Архангельск: Изд-во СГМУ; 2008. 400 с.
- Корчагин Ю. А. Российский человеческий капитал: фактор развития или деградации? Воронеж: ЦИРЭ; 2005. 252 с.
- Коулман Дж. Капитал социальный и человеческий. Пер. с англ. Общественные науки и современность. 2001;(3):121-139.
- Лапшин В. А. Структурные компоненты человеческого потенциала. Знание. Понимание. Умение. 2013;(1):259-263.
- Михалкина Е. В., Косолапова Н. А., Сенькив О. Я. Модель оценки влияния факторов социально-экономического развития регионов России на формирование человеческого потенциала. Terra Economicus. 2015;13(2):57-72.
- Патнэм Р. Чтобы демократия сработала. Гражданские традиции в современной Италии. Пер. с англ. М.: Ad Marginem; 1996. 288 с.
- Подберезкин А. И. Национальный человеческий капиталъ. Т. III: Идеология русского социализма. Кн. 2: Идеология русского социализма и стратегия национального развития. М.: Изд. группа URSS; 2011. 621 с.
- Стратегия социально-экономического развития Тульской области до 2028 года.
- Сафронова В.М. Прогнозирование и моделирование в социальной работе: Учеб.пособие для студ. высш. учеб. заведений. — М.: Издательский центр «Академия», 2002
- Человеческий потенциал для инновационной экономики. Иванов С. А., ред. СПб.: ГУАП; 2011. 188 с.
- Файзуллин Ф. С., Шагиева Л. А. Социальный потенциал региона как объект социологического анализа. ВестникВЭГУ. 2016;(3):118-124.
- Шагиева Л. А. Методика измерения тенденций развития социального потенциала регионов. Вестник ВЭГУ. 2015;(6):185-192.
- Шафиков М. Т. Научно-образовательный потенциал региона: сущность, структура, состояние и динамика. Уфа: Гилем, 2002. 106 с.
- Эфендиева А. А., Темрокова А. Х. Разработка методики комплексного анализа и оценки социальноэкономического потенциала региона, основанного на применении метода балльных оценок. Terra Economicus. 2013;11(2-2):102-106.
- Rissanen J. Modeling by shortest data description. Automatica. 1978;14(5):465-471. DOI: 10.1016/0005- 1098(78)90005-5
- http://gks.ru
- http://ru.wikipedia.org
- http://www.economytula.ru
- http://www.programs-gov.ru
- http://gtmarket.ru
- http://www.bibliofond.ru
- NMSE
-
normalized mean-square error — нормализованная (нормированная) среднеквадратичная ошибка; приведенная среднеквадратичная ошибка
Англо-русский словарь технических аббревиатур.
2011.
Смотреть что такое «NMSE» в других словарях:
-
NMSE — normalized mean square error … Medical dictionary
-
NMSE — abbr. National Marine Service Expo … Dictionary of abbreviations
-
NMSE — • normalized mean square error … Dictionary of medical acronyms & abbreviations
-
Obsolete Scottish units of measurement — Scotland had a distinct system of measures and weights until at least the late 18th century, based on the ell as a unit of length, the stone as a unit of mass and the boll and the firlot as units of dry measure. This official system coexisted… … Wikipedia
-
William Beardmore & Co, Ltd — William Beardmore Co, Ltd William Beardmore Co, Ltd est une entreprise de construction mécanique écossaise disparue. Entre 1887 et 1967 elle a produit dans la région de Glasgow des navires, puis des locomotives, avant de s’intéresser à l’aviation … Wikipédia en Français
-
Аптекарский вес — Марка 1991 года в честь 750 летия основания аптекарской специальности Аптекарский вес (медицинский вес, нюрнбергский вес) историческая система мер массы, которая использовалась врачами и аптекарями при изготовлении лекарств, а также… … Википедия
-
RSE : Ecole de Montréal — Née en 2000 autour des travaux des membres de la Chaire de responsabilité sociale[1] de l UQAM, l Ecole de Montréal de la Responsabilité sociale des entreprises réunit des auteurs dont la réflexion se situe cheval entre le monde anglo saxon,… … Wikipédia en Français
-
William Beardmore and Company — est une entreprise de construction mécanique écossaise disparue. Entre 1887 et 1967 elle a produit dans la région de Glasgow des navires, puis des locomotives, avant de s’intéresser à l’aviation et enfin de produire des véhicules automobiles.… … Wikipédia en Français
-
приведённая среднеквадратичная ошибка — — [А.С.Гольдберг. Англо русский энергетический словарь. 2006 г.] Тематики энергетика в целом EN normalized mean square errorNMSE … Справочник технического переводчика