Apologies for using my student number as my username, I have sent a request to Admin to change it to my name. Thank you for answers to my question.
Fernando:
the nature of the data is such that if there are values in PPE1 then there won’t be values in PPE2, PPE3, PPE4 & PPE5. There will only be a value in one of these (PPE1, PPE2, PPE3, PPE4 & PPE5) for each company and the other 4 will be missing values. I want a single set of results for presentation purposes. Apart from running 5 different regressions — is there any way to run the regression taking this into account?
Nick:
none of the variables are string — there are numerous missing values throughout the data.
2 questions:
1. For each company, there will only be one value for PPE1, PPE2, PPE3, PPE4 & PPE5 — the other four will be missing values. Is there any way to factor that in to the regression?
2. How do I take the panel structure into account with my regression?
. count if !missing(PRICE, BV, NI, PPE1, PPE2, PPE3, PPE4, PPE5)
0
Thanks again for the help.
When regression, time series analysis and panel data analysis are carried out in Stata, the problem of “no observations” often appears, as follows:
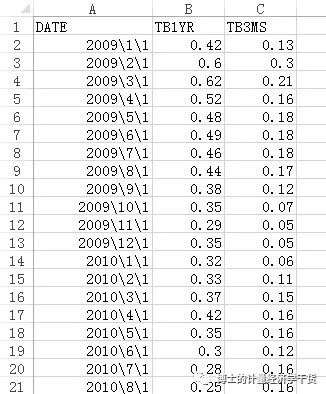
This is the excel format data of the relevant time series of US Treasury bond interest rates from January 2009 to December 2017
When we import the excel file through the file import Excel spreadsheet menu in Stata and name the first line as a variable, we import the excel file into Stata

At this point, when we test the unit root of tb1yr (first, we need tsset date to define the time variable), we will encounter the problem of “no observations”
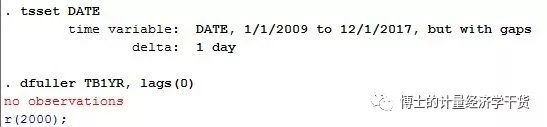
By querying the relevant websites and their information, we can find that the problem of “no observations” is not entirely due to the missing value of tb1yr or the character type value of the variable. The main reason is that although the date variable is an int or float variable, its data format is 1/1/2009, It does not conform to the traditional Stata data format about time and date
In order to solve this problem, many people on the Internet have put forward the method of dividing date, replacing, and converting date into “numerical variable”
![]()
DATE already numeric; No replace indicates that date is numeric and no conversion is needed
Many people on the Internet have adopted many methods, but they are not effective. What should we do to solve this problem
The author thinks that since the problem lies in date and the attribute of date can’t be changed by various means, it’s better to regenerate a variable t about date and endow it with numerical value to solve the problem
Because the date variable date or t does not participate in the actual regression or time series analysis process, but is a defined index variable. The solution process is as follows:

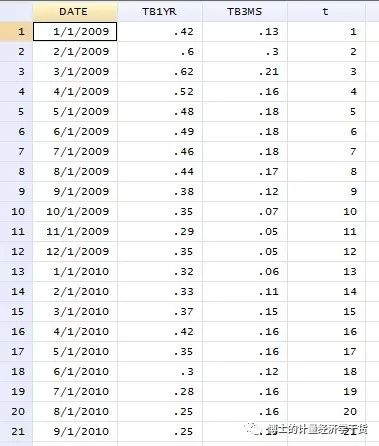
A completely numerical time variable is generated by Egen t = group (date), and then it is defined by tsset T. finally, the unit root test is carried out. It can be seen that the problem of “no observations” will not appear
In this case, the representation of T variable is as follows:
this article shares WeChat’s official account – Dr. PhD’s dry cargo (econometrics_ ABC)。
This article notes a technical problem that STATA noobs like myself may run into where it looks like STAT is failing to import certain variables or observations properly.
A big thanks to Joshua Ingber who solved this issue for me.
This article will solve a particular case of missing observations, not the general case. The general case could originate in a number of ways.
Problem description:
- Import delimited data into STAT
- STATA reports that it imported the variable, but when you enter “sum myvariablename”, STATA states that there are 0 observations.
- Use the toolbar at the top of the STATA GUI and open the data browser by clicking Data -> Data Editor -> Data Editor (Browse)
- Notice that the data appears in the browser even though it is not reported using “sum”
What’s really going on?
The issue is that your numerical data was interpreted by STATA as a string. We need to tell STATA that the variable is numerical by running the following:
“destring myVariableName, gen(myNewVariableName)”
Problem solved! Now sum works:

- 1
Stata is reading in my variables as string instead of numeric. If a variable is string, then typically Stata refuses to do calculations. You may even get the cryptic message no observations, which here means “no numeric values on which to do that”.
What is an observation in Stata?
As a program, Stata functions by manipulating variables. To refer to a particular observation in a variable, you type varname[n], where n is the observation number. For example, observation 7 in variable GDP could be called by typing GDP[7].
What are string variables in Stata?
String variables, simply speaking, are variables that contain not just numbers, but also other characters (possibly mixed with numbers). But actually a string variable may contain characters such as “\” or “-” or “:” and so on — anything a keyboard may produce.
Why does Stata drop observations in regression?
Note: regression analysis in Stata drops all observations that have a missing value for any one of the variables used in the model. To examine the differences between the two samples I ran model 3 once more and generated a new variable “in_model_3”.
What is no observation?
Non-observation in a survey occurs when measurements are not or cannot be made on some of the target population or the sample. Non-coverage and non- response can result in biased survey estimates when the part of the population or sample left out is different than the part that is observed.
How does Stata deal with missing data?
How Stata handles missing data in Stata procedures. As a general rule, Stata commands that perform computations of any type handle missing data by omitting the row with the missing values. However, the way that missing values are omitted is not always consistent across commands, so let’s take a look at some examples.
What is the Egen command in Stata?
The Stata command egen, which stands for extended generation, is used to create variables that require some additional function in order to be generated. Examples of these function include taking the mean, discretizing a continuous variable, and counting how many from a set of variables have missing values.
Why are strings called strings?
The text is a linearly ordered string of bits representing the rest of the information required in the loading and listing processes. In fact, it was through ALGOL in April of 1960 that string seems to have taken its modern-day shorthand form “string” (up until then people said string of [something]).
Why variables are omitted in Stata?
Dear Engy Ahmed Hassan , probably, stata omits these variables, because you have perfect multicollinearity, which means, that your independent variables can be presented as linear combinations of each other or they are identical.
How does Stata treat missing values in regression?
By default, Stata will handle the missing values using “listwise deletion”, meaning that it will remove any observation which is missing on the outcome variable or on any of the predictor variables. You do not need to do anything for Stata to do this, it does this automatically.
What does ” no observations ” mean in Stata?
Since there is no common ground for all, Stata assumes there are no observations (with common information) available to run a regression. The error code 2000 may mean that one or more of your variables is string when numeric variables are needed.
Why does Stata do not want to run a regression?
All my variables in the regression have between 40 and 75 observations, but if I include the Balance Budget variable then Stata refuses to perform the regression. I can’t figure out what is going on. The variable is a ratio between Government Budget/GDP for a 5 year period. Does anyone know why Stata does not want to run it in a regression? Thanks
When was no observations your 2000 error posted?
Juli 2009 08:02 An: [email protected] Betreff: st: no observations R 2000 error Hi I know this type of error has been posted before but i have followed some suggested solutions and i still cannot find a way to solve it.
When is an observation excluded from a regression?
What you need to confirm is that there are observations that have non-missing data for all variables in your regression. If there are observations with even one variable missing, the entire observation is excluded from the regression. It sounds like all of your observations are excluded for this reason.
Apologies for using my student number as my username, I have sent a request to Admin to change it to my name. Thank you for answers to my question.
Fernando:
the nature of the data is such that if there are values in PPE1 then there won’t be values in PPE2, PPE3, PPE4 & PPE5. There will only be a value in one of these (PPE1, PPE2, PPE3, PPE4 & PPE5) for each company and the other 4 will be missing values. I want a single set of results for presentation purposes. Apart from running 5 different regressions — is there any way to run the regression taking this into account?
Nick:
none of the variables are string — there are numerous missing values throughout the data.
2 questions:
1. For each company, there will only be one value for PPE1, PPE2, PPE3, PPE4 & PPE5 — the other four will be missing values. Is there any way to factor that in to the regression?
2. How do I take the panel structure into account with my regression?
. count if !missing(PRICE, BV, NI, PPE1, PPE2, PPE3, PPE4, PPE5)
0
Thanks again for the help.
You may go to use a data file in Stata and get the error…
no room to add more observations r(901);
Stata is probably telling you that Stata has not allocated enough
memory to read the data file. You can check to see how much memory is
allocated to hold your data using the memory command. I am running
Stata under Windows, and this is what the memory command told me.
memory
Total memory 1,024,000 bytes 100.00%
overhead (pointers) 0 0.00%
data 0 0.00%
------------
data + overhead 0 0.00%
programs, saved results, etc. 368 0.04%
------------
Total 368 0.04%
Free 1,023,632 99.96%
This tells me that I have a little bit under 1 megabyte free for reading in a
data file. I have a data file called bigfile.dta that I want to
read that is about 1.7 megabytes, so that is why I was getting the no room to
add more observations error. I will allocate 5 megabytes of memory with the
set
memory command below, and then try using my file.
set memory 5m (5120k) use bigfile
Now that I have allocated enough memory, I am able to read the file. If you
want to allocate 5m (five megabytes) every time I start Stata, you can type
set memory 5m, permanently
And then Stata will allocate this amount of memory every time you start
Stata.
If you routinely use very large datasets then you might want to consider setting the
memory allocated to Stata to be a much larger value, say…
set memory 100m, permanently
You can permanently set the memory to any value that you require and that your computer can
manage. It is also possible to set the permanent memory size from the Stata preferences page for
your system.
bertalob…@gmail.com
unread,
Dec 17, 2012, 8:24:58 PM12/17/12
to stata-us…@googlegroups.com
Hello,
I am having some problems when I trying to do the regression model tobit. I am insert the data and then, when I select statistics and choose the tobit model appears this error: no observations r(2000). Can you help me?
I send the print of the error.
Thank´s
Berta Pacheco
J
unread,
Dec 17, 2012, 9:05:52 PM12/17/12
to stata-us…@googlegroups.com
Berta,
It looks like all of your variables are strings rather than numeric values. You to convert the strings to numeric values. For example, look at the command destring.
Joseph
bertalob…@gmail.com
unread,
Dec 18, 2012, 2:06:00 AM12/18/12
to stata-us…@googlegroups.com
Joseph Cullen
unread,
Dec 18, 2012, 2:53:48 AM12/18/12
to stata-us…@googlegroups.com
You are generating all missing values. Read in the manual about missing values and the function «destring». «Real» is not the function you want to use.
On Monday, December 17, 2012 at 4:43 PM, bertalob…@gmail.com wrote:
Thank’s,
I generate the new variables and then I select to do the tobit model and the error «no observations» still appearing. I send the print of the error.
eric.a.booth
unread,
Mar 11, 2013, 11:36:29 PM3/11/13
to stata-us…@googlegroups.com
Berta — I realize this is an old thread, but (1) J’s advice is correct, you need to use -destring- on all your variables in the model and (2) your screenshot shows that you are using an illegal copy of Stata, you should consider purchasing a license.
— EAB
This article notes a technical problem that STATA noobs like myself may run into where it looks like STAT is failing to import certain variables or observations properly.
A big thanks to Joshua Ingber who solved this issue for me.
This article will solve a particular case of missing observations, not the general case. The general case could originate in a number of ways.
Problem description:
- Import delimited data into STAT
- STATA reports that it imported the variable, but when you enter “sum myvariablename”, STATA states that there are 0 observations.
- Use the toolbar at the top of the STATA GUI and open the data browser by clicking Data -> Data Editor -> Data Editor (Browse)
- Notice that the data appears in the browser even though it is not reported using “sum”
What’s really going on?
The issue is that your numerical data was interpreted by STATA as a string. We need to tell STATA that the variable is numerical by running the following:
“destring myVariableName, gen(myNewVariableName)”
Problem solved! Now sum works:
- 1
In some instance the standard option that STATA stops whenever an error occurs is a (minor) annoyance. In one of my projects I was running the same set of regressions over several groups with loops. However, whenever STATA found a group that could not run the regressions it would stop, stating the error no observations. Similar things can happen when you select (sub)groups to run commands like summarize, tabulate etc.
One solution is to “capture” the command, so that any error that is returned does not stop the do-file. My favourite example for capture is the following statement that can be found in almost all of my do-files…:
capture log close
log using mylog, replace
The capture log close before my log statement allows me to open a log, even if a log file has been open. It closes a running log-file. However, if no log-file is open, STATA would react with an error on the statement log close and exit. With a capture in front, this does not happen.
If you want to run the entire do-file without stopping, you could also state:
do my_do_file.do, nostop