Несмещенная оценка выборочной дисперсии
Краткая теория
Пусть из генеральной совокупности в результате
независимых наблюдений над количественным
признаком
извлечена повторная выборка объема
:
При этом
Требуется по данным выборки оценить (приближенно найти) неизвестную
генеральную дисперсию
.
Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то
эта оценка будет приводить в систематическим ошибкам, давая заниженное значение
генеральной дисперсии. Объясняется это тем, что, как можно доказать, выборочная
дисперсия является смещенной оценкой
,
другими словами, математическое ожидание выборочной дисперсии не равно
оцениваемой генеральной дисперсии, а равно:
Легко «исправить» выборочную дисперсию так, чтобы ее математическое
ожидание было равно генеральной дисперсии. Достаточно для этого умножить
на дробь
.
Сделав это, получим исправленную дисперсию, которую обычно обозначают через
:
Исправленная дисперсия является, конечно, несмещенной оценкой
генеральной дисперсии. Действительно:
Итак, в качестве оценки генеральной дисперсии принимают
исправленную дисперсию:
Для оценки среднего квадратического
отклонения генеральной совокупности используют исправленное среднее квадратическое отклонение, которое равно квадратному корню
из исправленной дисперсии:
При достаточно больших значениях
объема выборки выборочная и исправленная
дисперсия отличаются мало. На практике используются исправленной дисперсией,
если примерно
.
Пример решения задачи
Задача
Найти
несмещенную выборочную дисперсию на основании данного распределения выборки.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Выборочная дисперсия является смещенной оценкой генеральной дисперсии, поэтому в статистике применяют также исправленную выборочную дисперсию, которая является несмещенной оценкой генеральной дисперсии.
Сумма
частот:
Вычислим
среднюю:
Средняя квадратов:
Несмещенная
выборочная дисперсия:
Ответ:
Кроме этой задачи на другой странице сайта есть
пример расчета исправленной выборочной дисперсии и среднего квадратического отклонения для интервального вариационного ряда
Пусть
![]()
![]()
Поскольку
заменяются две величины (![]()
и
![]()
),
то это вызывает смещение оценки
![]()
:
![]()
. (1.22)
Покажем
это .
![]()
Известно
что
![]()
![]()
.
Пусть
Х1,
Х2,…,
Хi
,…,Xn
— независимые случайные величины, каждая
из которых имеет один и тот же закон
распределения с числовыми характеристиками:
![]()
и D(Xi)=D0.
Пусть
![]()
подставим в (*), тогда:
![]()
Найдем
E[Dв]:
![]()
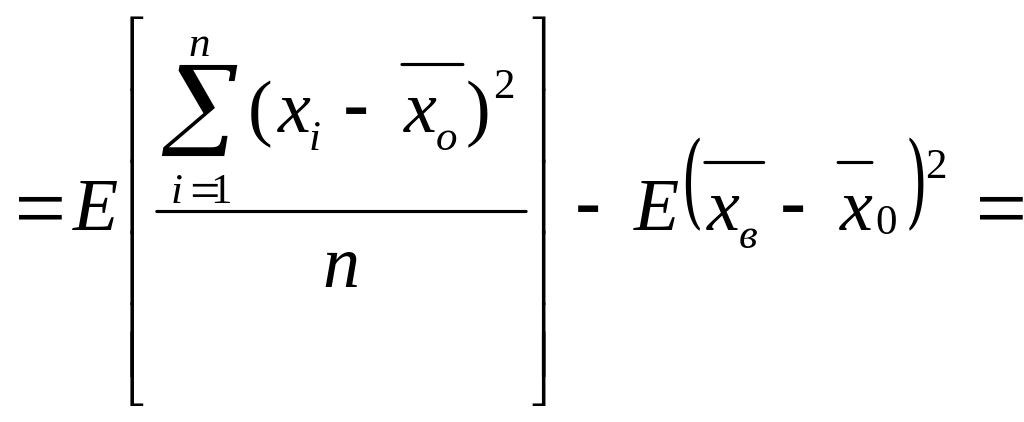
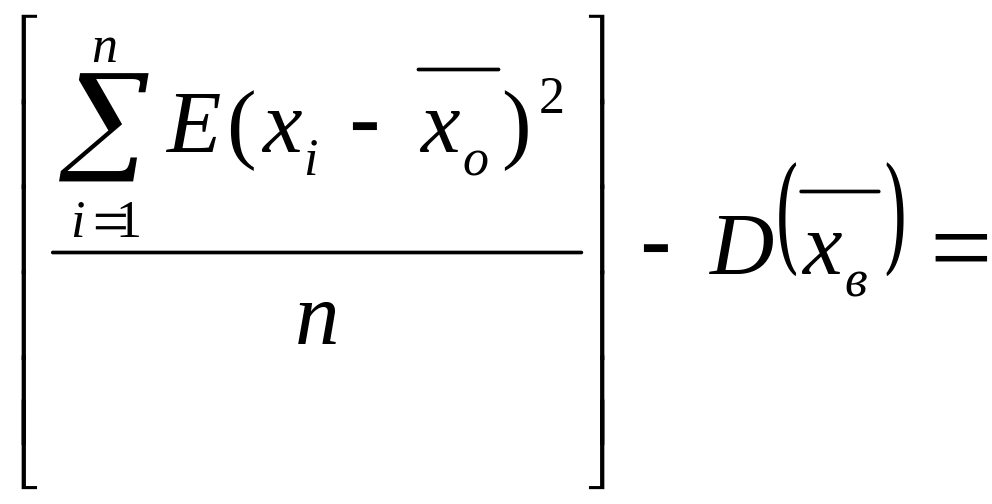
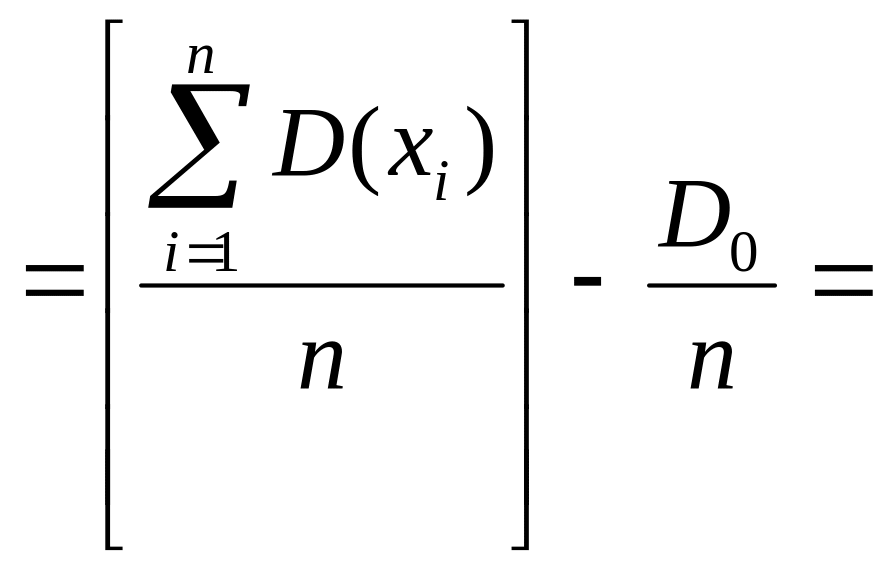
![]()
![]()
Итак
![]()
Что и требовалось доказать.
При
больших п
смещение невелико, им можно пренебречь,
но при малых выборках оно существенно.
Таким
образм,
![]()
есть несмещенная оценка дисперсии или
![]()
.
(1.23)
Тогда
исправленное среднее квадратическое
отклонение имеет вид:
![]()
.
(1.24)
Для
интервальной оценки используется
выражение
![]()
,
где
![]()
находится по формуле (1.24).
Замечание.
Однако для больших выборок можно считать,
что
![]()
.
В случае малых выборок (п
< 30) пользуются исправленной дисперсией
по формуле (1.24).
По
закону больших чисел
![]()
является состоятельной оценкой для
![]()
генеральной дисперсии. А так как множитель
![]()
при
![]()
,
то
![]()
также является состоятельной оценкой
для
.
Оценка
![]()
,
строго говоря, не является эффективной
оценкой для
,
однако при наличии нормального
распределения ее можно считать приближенно
эффективной.
Замечание.
Если известно точное значение
математического ожидания «![]()
»
для n
измерений, то E(Xi)
=
где хi
– отдельные измерения. Исправленная
(несмещённая) дисперсия находится по
формуле
![]()
(1.25)
Действительно.
![]()
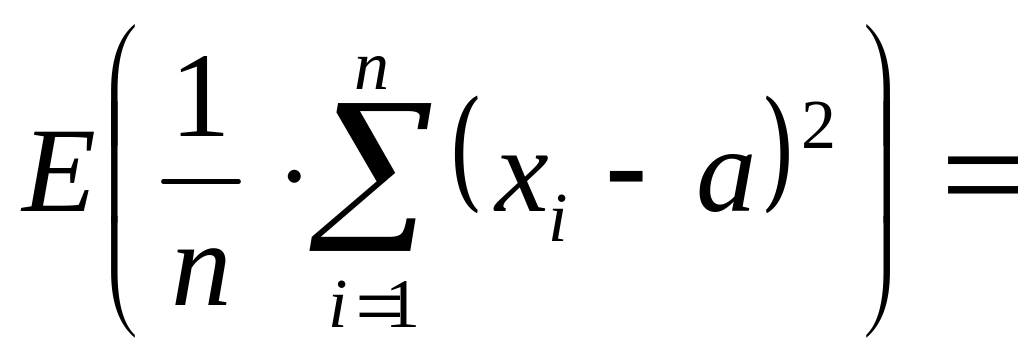
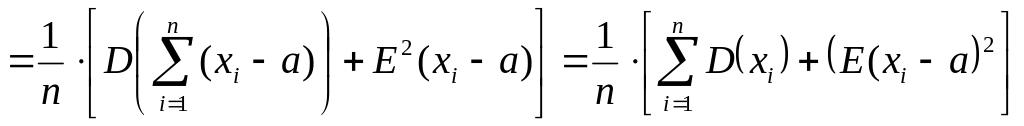
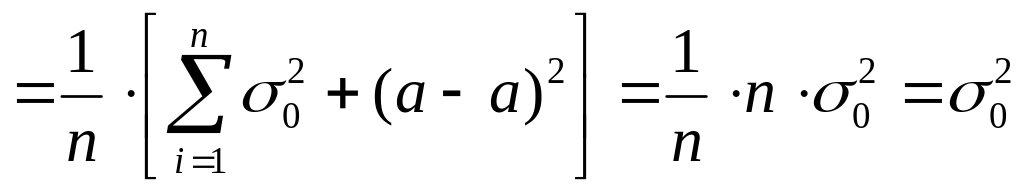
,
т.е. E(D*в)
= D0
.
Пример
1.19. В ящике содержатся стержни трех
размеров (N
= 3): 12 см, 14 см и 16 см с соответствующими
долями 0,1; 0,3; 0,6. Производится повторная
выборка двух стержней (n
= 2). Найти
все возможные выборочные распределения
и построить законы распределения для
![]()
![]()
и
![]()
.
Проверить на данном примере справедливость
равенств
![]()
.
Решение.
Определим
количество возможных выборок:
![]()
.
Закон
распределения генеральной совокупности
представлен в следующей в таблице
|
X |
12 |
14 |
16 |
|
P |
0,1 |
0,3 |
0,6 |
Вычислим
генеральные характеристики :
![]()
Все
выборочные законы представлены в
следующей таблице.
|
№ выборки |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
12 12 |
12 14 |
12 16 |
14 12 |
14 14 |
14 16 |
16 12 |
16 14 |
16 16 |
|
|
2 |
1 1 |
1 1 |
1 1 |
2 |
1 1 |
1 1 |
1 1 |
2 |
|
|
12 |
13 |
14 |
13 |
14 |
15 |
14 |
15 |
16 |
|
|
0 |
1 |
4 |
1 |
0 |
1 |
4 |
1 |
0 |
|
|
0,01 |
0,03 |
0,06 |
0,03 |
0,09 |
0,18 |
0,06 |
0,18 |
0,36 |
Проверим,
что
![]()
.
По
данным последней таблицы получим строим
законы распределения для
![]()
и Dв
и находим соответствующие характеристики.
|
|
12 |
13 |
14 |
15 |
16 |
|
|
P |
0,01 |
0,06 |
0,21 |
0,36 |
0,36 |
1 |
![]()
,![]()
|
|
0 |
1 |
4 |
|
|
|
0,46 |
0,42 |
0,12 |
1 |
E[Dв]=0,42+0,48=0.9/
Итак,
![]()
![]()
![]()
,
Откуда
следует:
![]()
и
![]()
при n
= 2.
Пример
1.20. Даны результаты 6 независимых
измерений одной и той же величины
прибором, не имеющим систематических
ошибок: 36; 37; 32; 43; 39; 41. Найдите несмещенную
оценку дисперсии ошибок измерений,
если истинная длина неизвестна.
Решение.
Представим исходные данные в виде
таблицы:
|
xi |
32 |
36 |
37 |
39 |
41 |
43 |
|
р |
1/6 |
1/6 |
1/6 |
1/6 |
1/6 |
1/6 |
Вычислим
последовательно
![]()
;
![]()
![]()
![]()
![]()
Отсюда
![]()
![]()
Пример
1.21.
В условиях предыдущей задачи найдите
несмещённую оценку дисперсии ошибок
измерений, если истинная величина
известна и равна 37,8.
Решение
В этом случае в формулу подставляется
не выборочное среднее, а истинная
величина:
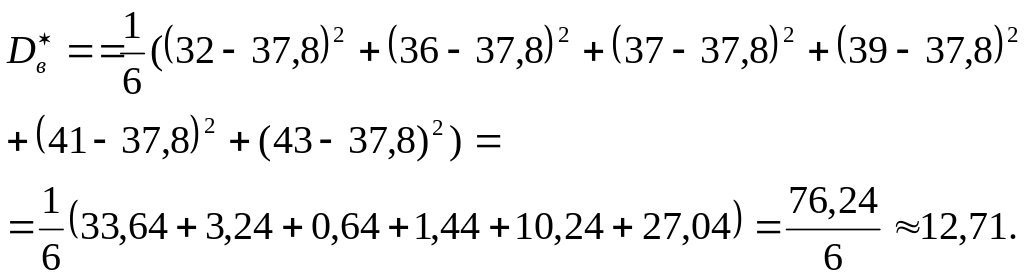
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
,
![]()
—
уравнение регрессии,
![]()
—
случайная ошибка (с ограничениями).
![]()
;
![]()
;
![]()
—
остатки регрессии. Надо различать
остатки и
ошибки регрессии.
Остатки в отличии от ошибок наблюдаемы.
Предположим,
что оценка σ2
связана с
суммой квадратов остатков регрессии

Вычислим:
![]()
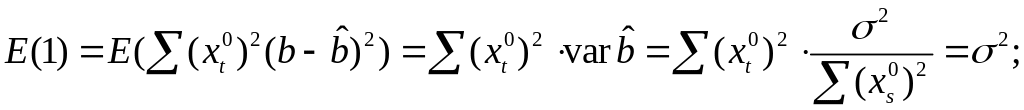
Используя,
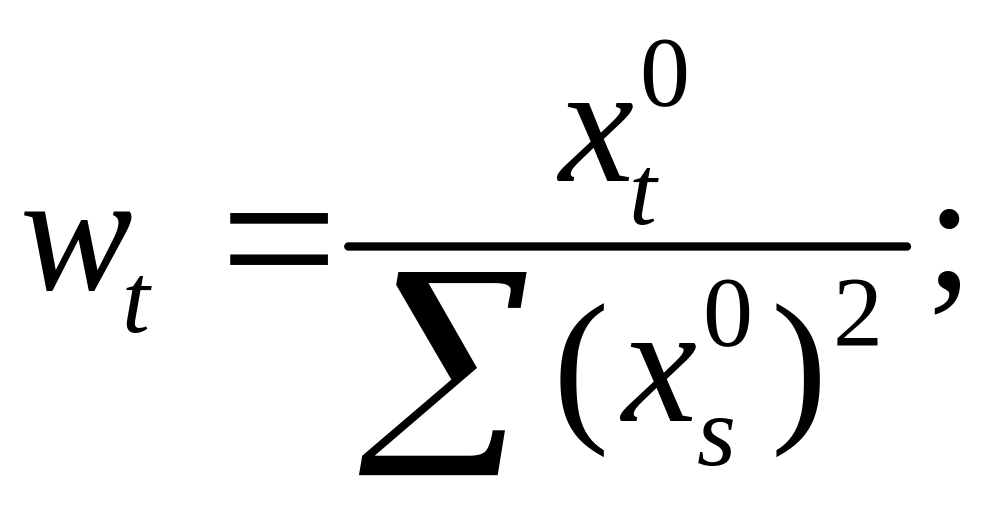
получим
![]()

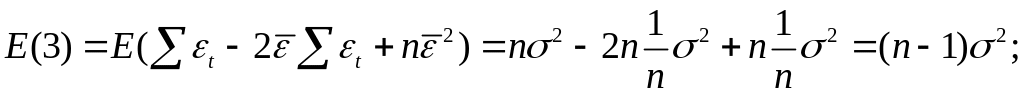
где
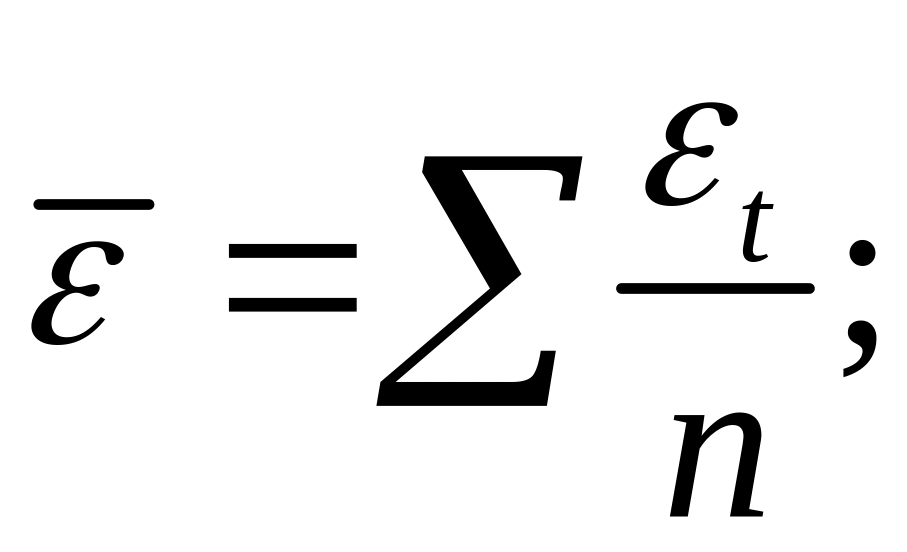
Таким образом
![]()
откуда следует,
что
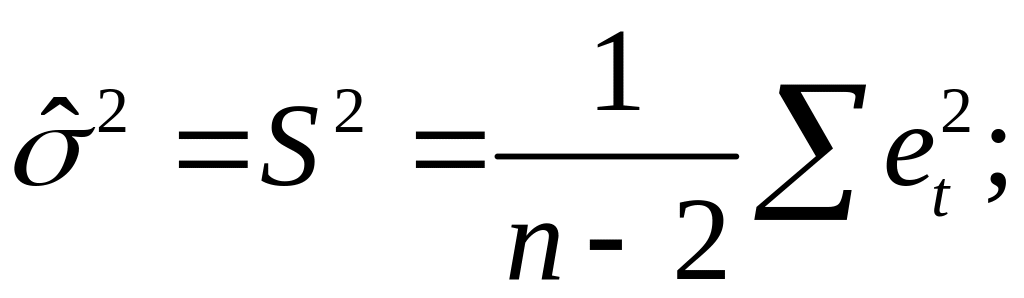
является
несмещенной оценкой дисперсии ошибок
σ2.
12. Оценка существенности параметров линейной регрессии и корреляции
Существенность
коэф-ов регрессии определяет можно ли
его заменить нулем. Если данный коэф-т
несуществ., то его можно заменить нулем.
При выполнении
дополнительного условия о совместном
нормальном распределении ошибок,
стандартная ошибка коэффициента
регрессии параметра Sb
рассчитывается
по формуле
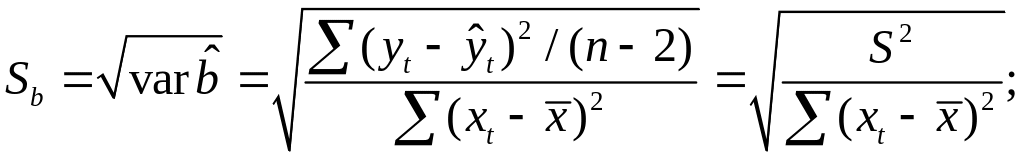
где S2
— остаточная
дисперсия на одну степень свободы.
Отношение коэф-та
регрессии к его стандартной ошибке дает
t-статистику,
кот. подчиняется статистике Стьюдента
при (n-2)
степенях свободы.
Эта статистика применяется для проверки
стат. значимости коэф-та
регрессии.
Для оценки значимости
коэф-та регрессии опр-ют фактическое
знач. t-критерия
Стьюдента: tb=b/Sb
, которое
затем сравнивают с табличным значением
при определенном уровне значимости
и числе степеней
свободы (n-2).
Если tb>tкр,
коэф-т b значим и
его нельзя заменить 0.
Доверительный
интервал для коэф-та регрессии опр-ся
как
![]()
.
Замечание: Т.к.
коэф-т регрессии b для эк. Исследований
имеет четкую интерпритацию доверит.
Интервалы не должны содержать
противоречивыхрезультатов, напр., от
«-10» до 20 , т.е. положит. и отрицат.
Значимость линейного
коэффициента корреляции r
проверяется на основе величины ошибки
коэффициента корреляции Sr=mr(заменить):
![]()
О![]()
тсюда
фактическое значение
Данная формула
свидетельствует, что в парной лин.
регрессии
tr2=F
=>tr2=
tb2
.
Таким образом,
проверка гипотез о значимости коэффициентов
регрессии и корреляции равносильна
проверке гипотезы о значимости линейного
уравнения регрессии.
13. Интервалы прогноза по линейному уравнению регрессии
Основное назначение
ур-ия регрессии — прогноз возможных
знач. результата при заданном значении
фактора.
Этот прогноз
осущ-ся путем подстановки знач. фактора
х=хk
в ур-ние
регрессии
![]()
.
Но данный
точечный прогноз не всегда реален. Он
должен дополняться интервальной
оценкой прогноза значения результата
y*.
Т.е.
![]()
,
где
![]()
—
стандартная ошибка оценки
![]()
.
Получим данную
оценку для лин. регрессии
![]()
.
Подставим это
выражение в ур-ие
![]()
![]()
.
Отсюда следует,
что стандартная ошибка
![]()
зависит от
ошибки
и ошибки
коэффициента b,
т.е.
![]()
.
В курсе мат. стат.
получено:
![]()
=S2/n,где
S2
– оценка дисперсии рез-ого признака.
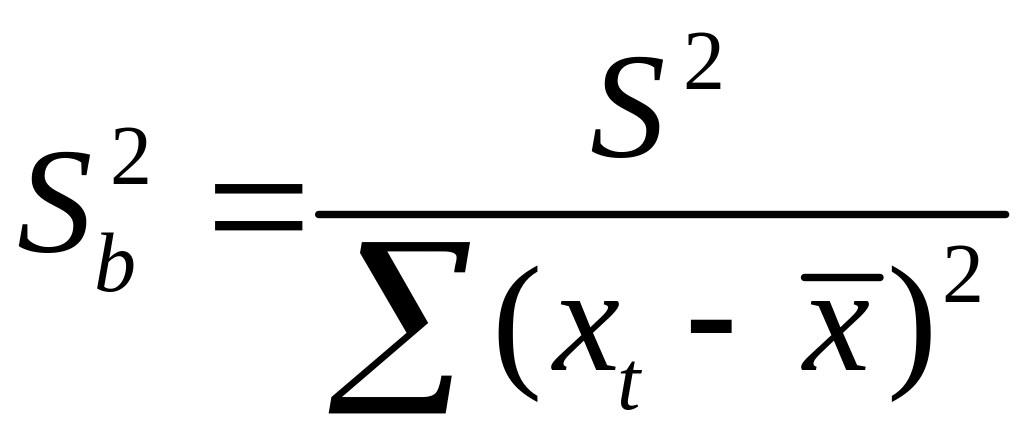
;Получим
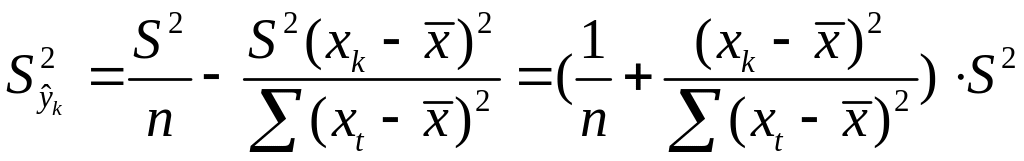
Откуд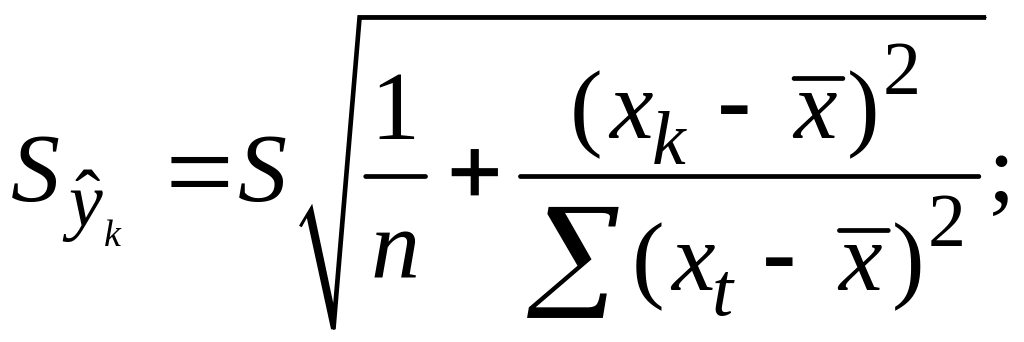
Где t=1,…n
– номера измерений, xk
не обязано совпадать с одним из xt.
Видно, что величина
стандартной ошибки xk
зависит от
![]()
.
Она достигает
мин. при xк=
и возрастает
по мере того, как «удаляется» от
в любом
направлении.
Т.е.
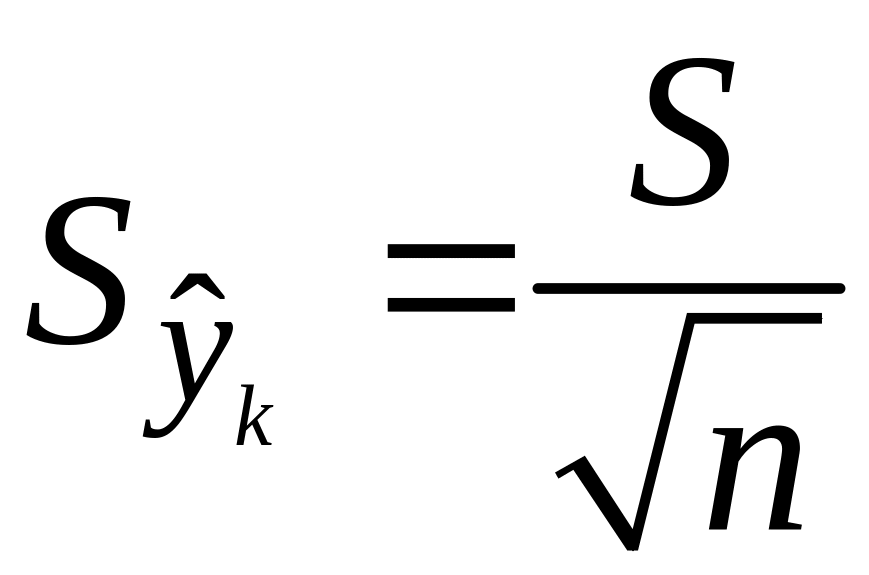
.
Можно строить
интервальные оценки рез-ого признака
при заданном xк
, которые
определяются как
![]()
,
где
![]()
—
критическое значение распределения
Стьюдента, при (n-2) степенями свободы.
На графике
доверительные границы для
![]()
представляют собой гиперболы,
расположенные по обе стороны от линии
регрессии.
Фактические знач.
yk
варьируют
около ср. знач.
на величину случ. ошибки ε, дисперсия
кот. оценивается как S2
, поэтому
ошибка предсказываемого индивид-ого
значения y
должно включать как станд.ошибку
![]()
так и случ.ошибку S.
Средняя ошибка
прогнозного индив.значения составит
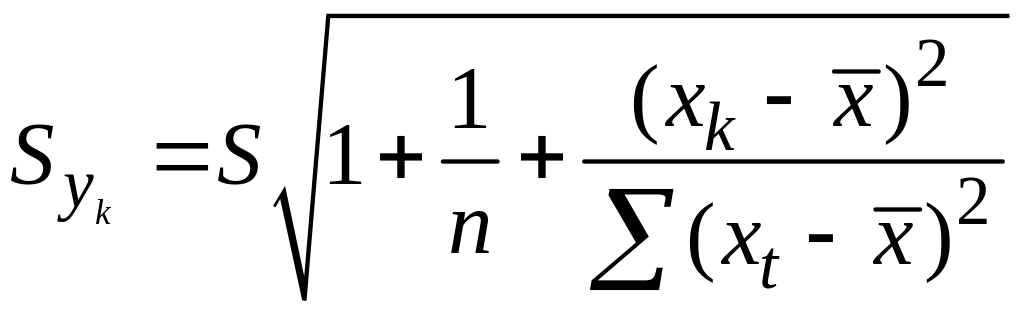
.
На основе этой оценки м.также строить
интервальные оценки, кот. б. содержать
заданные доверительной вероятностью,
измеряемые значения рез-ого признака.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Статистические оценки параметров генеральной совокупности
Определение статистической оценки. Точечные статистические оценки: смещенные и несмещенные, эффективные и состоятельные. Интервальные статистические оценки. Точность и надежность оценки; определение доверительного интервала; построение доверительных интервалов для средней при известном и неизвестном среднеквадратическом отклонении.
Определение статистической оценки
Пусть требуется изучить количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак. Возникает задача оценки параметров, которыми определяется это распределение. Например, если известно, что изучаемый признак распределен в генеральной совокупности по нормальному закону, то необходимо оценить математическое ожидание и среднеквадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение. Если имеются основания считать, что признак имеет распределение Пуассона, то необходимо оценить параметр , которым это распределение определяется. Обычно имеются лишь данные выборки, полученные в результате
наблюдений:
. Через эти данные и выражают оцениваемый параметр. Рассматривая
как значения независимых случайных величин
можно сказать, что найти статистическую оценку неизвестного параметра теоретического распределения означает найти функцию от наблюдаемых случайных величин, которая и дает приближенное значение оцениваемого параметра.
Точечные статистические оценки
Статистической оценкой неизвестного параметра теоретического распределения называют функцию от наблюдаемых случайных величин. Статистическая оценка неизвестного параметра генеральной совокупности одним числом называется точечной. Рассмотрим следующие точечные оценки: смещенные и несмещенные, эффективные и состоятельные.
Для того чтобы статистические оценки давали хорошие приближения оцениваемых параметров, они должны удовлетворять определенным требованиям. Укажем эти требования. Пусть есть статистическая оценка неизвестного параметра
теоретического распределения. Допустим, что по выборке объема
найдена оценка
. Повторим опыт, т. е. извлечем из генеральной совокупности другую выборку того же объема и по ее данным найдем оценку
и т. д. Получим числа
, которые будут различаться. Таким образом, оценку
можно рассматривать как случайную величину, а числа
— как возможные ее значения.
Если оценка дает приближенное значение
с избытком, то найденное по данным выборок число
будет больше истинного значения
. Следовательно, и математическое ожидание (среднее значение) случайной величины
будет превышать
, то есть
. Если
дает приближенное значение
с недостатком, то
.
Использование статистической оценки, математическое ожидание которой не равно оцениваемому параметру, приводит к систематическим ошибкам. Поэтому нужно потребовать, чтобы математическое ожидание оценки было равно оцениваемому параметру. Соблюдение требования
устраняет систематические ошибки.
Несмещенной называют статистическую оценку , математическое ожидание которой равно оцениваемому параметру
, то есть
.
Смещенной называют статистическую оценку , математическое ожидание которой не равно оцениваемому параметру.
Однако ошибочно считать, что несмещенная оценка всегда дает хорошее приближение оцениваемого параметра. Действительно, возможные значения могут быть сильно рассеяны вокруг своего среднего значения, т. е. дисперсия величины
может быть значительной. В этом случае найденная по данным одной выборки оценка, например
, может оказаться удаленной от своего среднего значения
, а значит, и от самого оцениваемого параметра
. Приняв
в качестве приближенного значения
, мы допустили бы ошибку. Если потребовать, чтобы дисперсия величины
была малой, то возможность допустить ошибку будет исключена. Поэтому к статистической оценке предъявляются требования эффективности.
Эффективной называют статистическую оценку, которая (при заданном объеме выборки ) имеет наименьшую возможную дисперсию. При рассмотрении выборок большого объема к статистическим оценкам предъявляется требование состоятельности.
Состоятельной называют статистическую оценку, которая при стремится по вероятности к оцениваемому параметру. Например, если дисперсия несмещенной оценки при
стремится к нулю, то такая оценка оказывается также состоятельной.
Рассмотрим вопрос о том, какие выборочные характеристики лучше всего в смысле несмещённости, эффективности и состоятельности оценивают генеральную среднюю и дисперсию.
Пусть изучается дискретная генеральная совокупность относительно количественного признака. Генеральной средней называется среднее арифметическое значений признака генеральной совокупности. Она вычисляется по формуле
или
где — значения признака генеральной совокупности объема
;
— соответствующие частоты, причем
Пусть из генеральной совокупности в результате независимых наблюдений над количественным признаком извлечена выборка объема со значениями признака
. Выборочной средней называется среднее арифметическое значений признака выборочной совокупности и вычисляется по формуле
или
где — значения, признака в выборочной совокупности объема
;
— соответствующие частоты, причем
Если генеральная средняя неизвестна и требуется оценить ее по данным выборки, то в качестве оценки генеральной средней принимают выборочную среднюю, которая является несмещенной и состоятельной оценкой. Отсюда следует, что если по нескольким выборкам достаточно большого объема из одной и той же генеральной совокупности будут найдены выборочные средние, то они будут приближенно равны между собой. В этом состоит свойство устойчивости выборочных средних.
Если дисперсии двух совокупностей одинаковы, то близость выборочных средних к генеральным не зависит от отношения объема выборки к объему генеральной совокупности. Она зависит- от объема выборки: чем больше объем выборки, тем меньше выборочная средняя отличается от генеральной.
Для того чтобы охарактеризовать рассеяние значений количественного признака генеральной совокупности вокруг своего среднего значения, вводят сводную характеристику — генеральную дисперсию. Генеральной дисперсией
называется среднее арифметическое квадратов отклонений значений признака генеральной совокупности от их среднего значения
, которое вычисляется по формуле
или
Для того чтобы охарактеризовать рассеяние наблюденных значений количественного признака выборки вокруг своего среднего значения хв, вводят сводную характеристику — выборочную дисперсию. Выборочной дисперсией называется среднее арифметическое квадратов отклонений наблюденных значений признака от их среднего значения
, которое вычисляется по формуле
или
Кроме дисперсии для характеристики рассеяния значений признака генеральной (выборочной) совокупности вокруг своего среднего значения используют сводную характеристику — среднее квадратическое отклонение. Генеральным средним квадратическим отклонением называют квадратный корень из генеральной дисперсии: . Выборочным средним квадратическим отклонением называют квадратный корень из выборочной дисперсии:
.
Пусть из генеральной совокупности в результате независимых наблюдений над количественным признаком
извлечена выборка объема
. Требуется по данным выборки оценить неизвестную генеральную дисперсию
. Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то эта оценка приведет к систематическим ошибкам, давая заниженное значение генеральной дисперсии. Объясняется это тем, что выборочная дисперсия является смещенной оценкой
. Другими словами, математическое ожидание выборочной дисперсии не равно оцениваемой генеральной дисперсии, а равно
.
Легко исправить выборочную дисперсию так, чтобы ее математическое ожидание было равно генеральной дисперсии. Для этого нужно умножить на дробь
. В результате получим исправленную дисперсию
, которая будет несмещенной оценкой генеральной дисперсии:
Интервальные оценки
Наряду с точечным оцениванием, статистическая теория оценивания параметров занимается вопросами интервального оценивания. Задачу интервального оценивания можно сформулировать так: по данным выборки построить числовой интервал, относительно которого с заранее выбранной вероятностью можно сказать, что внутри него находится оцениваемый параметр. Интервальное оценивание особенно необходимо при малом количестве наблюдений, когда точечная оценка малонадежна.
Доверительным интервалом для параметра
называется такой интервал, относительно которого с заранее выбранной вероятностью
, близкой к единице, можно утверждать, что он содержит неизвестное значение параметра
, то есть
. Чем меньше для выбранной вероятности число
, тем точнее оценка неизвестного параметра
. И, наоборот, если это число велико, то оценка, проведенная с помощью данного интервала, малопригодна для практики. Так как концы доверительного интервала зависят от элементов выборки, то значения
и
могут изменяться от выборки к выборке. Вероятность
принято называть доверительной (надежностью). Обычно надежность оценки задается наперед, причем в качестве
берут число, близкое к единице. Выбор доверительной вероятности не является математической задачей, а определяется конкретной решаемой проблемой. Наиболее часто задают надежность, равную 0,95; 0,99; 0,999.
Доверительный интервал для генеральной средней при известном значении среднего квадратического отклонения и при условии, что случайная величина (количественный признак ) распределена нормально, задается выражением
где — наперед заданное число, близкое к единице, а значения функции
приведены в таблице прил. 2.
Смысл этого соотношения заключается в следующем: с надежностью можно утверждать, что доверительный интервал
покрывает неизвестный параметр
, точность оценки
. Число
определяется из равенства
, или
. По прил. 2 находят аргумент
, которому соответствует значение функции Лапласа, равное
.
Пример 1. Случайная величина имеет нормальное распределение с известным средним квадратическим отклонением
. Найти доверительные интервалы для оценки неизвестной генеральной средней по выборочным средним, если объем выборок
и надежность оценки
.
Решение. Найдем . Из соотношения
получим, что
. По прил. 2 находим
. Найдем точность оценки
. Доверительные интервалы будут таковы:
. Например, если
, то доверительный интервал имеет следующие доверительные границы:
. Таким образом, значения неизвестного параметра
, согласующиеся с данными выборки, удовлетворяют неравенству
.
Доверительный интервал для генеральной средней нормального распределения признака при неизвестном значении среднего квадратического отклонения задается выражением
Отсюда следует, что с надежностью можно утверждать, что доверительный интервал
покрывает неизвестный параметр
.
Существуют таблицы (прил. 4), пользуясь которыми, по заданным и
находят вероятность
и, наоборот, по заданным
и
находят
.
Пример 2. Количественный признак генеральной совокупности распределен нормально. По выборке объема
найдены выборочная средняя
и исправленное среднеквадратическое отклонение
. Оценить неизвестную генеральную среднюю с помощью доверительного интервала с надежностью
.
Решение. Найдем . Пользуясь прил. 4 по
и
находим
. Найдем доверительные границы:
Итак, с надежностью неизвестный параметр
заключен в доверительном интервале
.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
15. Оценка дисперсии случайной ошибки модели регрессии
При проведении регрессионного анализа основная трудность заключается в том, что генеральная дисперсия случайной ошибки является неизвестной величиной, что вызывает необходимость в расчёте её несмещённой выборочной оценки.
Несмещённой оценкой дисперсии (или исправленной дисперсией) случайной ошибки линейной модели парной регрессии называется величина, рассчитываемая по формуле:
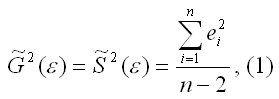
где n – это объём выборочной совокупности;
еi– остатки регрессионной модели:
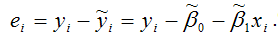
Для линейной модели множественной регрессии несмещённая оценка дисперсии случайной ошибки рассчитывается по формуле:
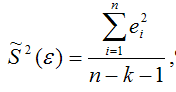
где k – число оцениваемых параметров модели регрессии.
Оценка матрицы ковариаций случайных ошибок Cov(?) будет являться оценочная матрица ковариаций:
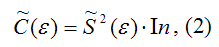
где In – единичная матрица.
Оценка дисперсии случайной ошибки модели регрессии распределена по ?2(хи-квадрат) закону распределения с (n-k-1) степенями свободы.
Для доказательства несмещённости оценки дисперсии случайной ошибки модели регрессии необходимо доказать справедливость равенства
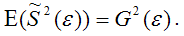
Доказательство. Примем без доказательства справедливость следующих равенств:
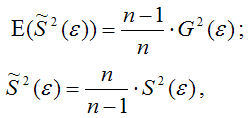
где G2(?) – генеральная дисперсия случайной ошибки;
S2(?) – выборочная дисперсия случайной ошибки;
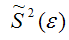
– выборочная оценка дисперсии случайной ошибки.
Тогда:
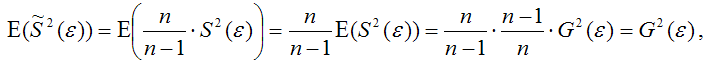
т. е.
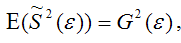
что и требовалось доказать.
Следовательно, выборочная оценка дисперсии случайной ошибки
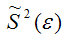
является несмещённой оценкой генеральной дисперсии случайной ошибки модели регрессии G2(?).
При условии извлечения из генеральной совокупности нескольких выборок одинакового объёма n и при одинаковых значениях объясняющих переменных х, наблюдаемые значения зависимой переменной у будут случайным образом колебаться за счёт случайного характера случайной компоненты ?. Отсюда можно сделать вывод, что будут варьироваться и зависеть от значений переменной у значения оценок коэффициентов регрессии и оценка дисперсии случайной ошибки модели регрессии.
Для иллюстрации данного утверждения докажем зависимость значения МНК-оценки
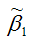
от величины случайной ошибки ?.
МНК-оценка коэффициента ?1 модели регрессии определяется по формуле:
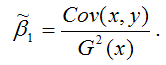
В связи с тем, что переменная у зависит от случайной компоненты ? (yi=?0+?1xi+?i), то ковариация между зависимой переменной у и независимой переменной х может быть представлена следующим образом:
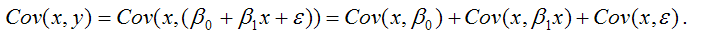
Для дальнейших преобразования используются свойства ковариации:
1) ковариация между переменной х и константой С равна нулю: Cov(x,C)=0, C=const;
2) ковариация переменной х с самой собой равна дисперсии этой переменной: Cov(x,x)=G2(x).
Исходя из указанных свойств ковариации, справедливы следующие равенства:
Cov(x,?0)=0 (?0=const);
Cov(x, ?1x)= ?1*Cov(x,x)= ?1*G2(x).
Следовательно, ковариация между зависимой и независимой переменными Cov(x,y) может быть записана как:
Cov(x,y)= ?1G2(x)+Cov(x,?).
В результате МНК-оценка коэффициента ?1 модели регрессии примет вид:
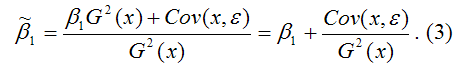
Таким образом, МНК-оценка
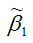
может быть представлена как сумма двух компонент:
1) константы ?1, т. е. истинного значения коэффициента;
2) случайной ошибки Cov(x,?), вызывающей вариацию коэффициента модели регрессии.
Однако на практике подобное разложение МНК-оценки невозможно, потому что истинные значения коэффициентов модели регрессии и значения случайной ошибки являются неизвестными. Теоретически данное разложение можно использовать при изучении статистических свойств МНК-оценок.
Аналогично доказывается, что МНК-оценка
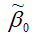
коэффициента модели регрессии и несмещённая оценка дисперсии случайной ошибки
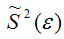
могут быть представлены как сумма постоянной составляющей (константы) и случайной компоненты, зависящей от ошибки модели регрессии ?.
Данный текст является ознакомительным фрагментом.
Читайте также
11. Критерии оценки неизвестных коэффициентов модели регрессии
11. Критерии оценки неизвестных коэффициентов модели регрессии
В ходе регрессионного анализа была подобрана форма связи, которая наилучшим образом отражает зависимость результативной переменной у от факторной переменной х:y=f(x).Необходимо оценить неизвестные
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
Помимо метода наименьших квадратов, с помощью которого в большинстве случаев определяются неизвестные параметры модели регрессии, в случае линейной модели парной регрессии
18. Характеристика качества модели регрессии
18. Характеристика качества модели регрессии
Качеством модели регрессии называется адекватность построенной модели исходным (наблюдаемым) данным.Для оценки качества модели регрессии используются специальные показатели.Качество линейной модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
Проверкой статистической гипотезы о значимости отдельных параметров модели называется проверка предположения о том, что данные параметры значимо отличаются от нуля.Необходимость проверки
25. Точечный и интервальный прогнозы для модели парной регрессии
25. Точечный и интервальный прогнозы для модели парной регрессии
Одна из задач эконометрического моделирования заключается в прогнозировании поведения исследуемого явления или процесса в будущем. В большинстве случаев данная задача решается на основе регрессионных
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
Помимо рекуррентных формул, которые используются для построения частных коэффициентов корреляции для
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Проверка значимости коэффициентов регрессии означает проверку основной гипотезы об их значимом отличии от нуля.Основная гипотеза состоит в предположении о незначимости
39. Модели регрессии, нелинейные по факторным переменным
39. Модели регрессии, нелинейные по факторным переменным
При исследовании социально-экономических явлений и процессов далеко не все зависимости можно описать с помощью линейной связи. Поэтому в эконометрическом моделировании широко используется класс нелинейных
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
Нелинейными по оцениваемым параметрам моделями регрессииназываются модели, в которых результативная переменная yi нелинейно зависит от коэффициентов модели ?0…?n.К моделям регрессии, нелинейными по
41. Модели регрессии с точками разрыва
41. Модели регрессии с точками разрыва
Определение. Моделями регрессии с точками разрыва называются модели, которые нельзя привести к линейной форме, т. е. внутренне нелинейные модели регрессии.Модели регрессии делятся на два класса:1) кусочно-линейные модели регрессии;2)
44. Методы нелинейного оценивания коэффициентов модели регрессии
44. Методы нелинейного оценивания коэффициентов модели регрессии
Функцией потерь или ошибок называется функционал вида
Также в качестве функции потерь может быть использована сумма модулей отклонений наблюдаемых значений результативного признака у от теоретических
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все
57. Гетероскедастичность остатков модели регрессии
57. Гетероскедастичность остатков модели регрессии
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:?i=yi–?0–?1x1i–…–?mxmiВ связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается
60. Устранение гетероскедастичности остатков модели регрессии
60. Устранение гетероскедастичности остатков модели регрессии
Существует множество методов устранения гетероскедастичности остатков модели регрессии. Рассмотрим некоторые из них.Наиболее простым методом устранения гетероскедастичности остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
В связи с тем, что наличие в модели регрессии автокорреляции между остатками модели может привести к негативным результатам всего процесса оценивания неизвестных коэффициентов модели, автокорреляция остатков
67. Модели регрессии с переменной структурой. Фиктивные переменные
67. Модели регрессии с переменной структурой. Фиктивные переменные
При построении модели регрессии может возникнуть ситуация, когда в неё необходимо включить не только количественные, но и качественные переменные (например, возраст, образование, пол, расовую