Решения задач на проверку статистических гипотез
Проверка статистических гипотез включает в себя большой пласт задач математической статистики. Зная некоторые характеристики выборки (или имея просто выборочные данные), мы можем проверять гипотезы о виде распределении случайной величины или ее параметрах.
В учебных задачах речь обычно идет о простой гипотезе $H_0$ (ее называют нулевой), однозначно определяющей закон распределения. Вместе с ней вводят альтернативную гипотезу $H_1$ (конкурирующую) и определяют уровень значимости $\alpha$, на котором будет сделан вывод о справедливости гипотезы.
Далее по выборочным данным вычисляется значение статистического критерия (формула зависит от конкретной гипотезы) и выясняется, попадает ли оно в критическую область (одностороннюю или двустороннюю). Если попадает — нулевую гипотезу следует отвергнуть. При проверке гипотез есть вероятность допустить ошибку: первого рода (верная гипотеза отклонена, $\alpha$) или второго рода (неверная гипотеза принята, $\beta$).
Ниже в примерах мы разберем основные учебные задачи на проверку гипотез о значении среднего, дисперсии, вероятности, о равенстве числовых характеристики. Задачи на проверку гипотез о виде распределения (с помощью критерия согласия Пирсона и других) ищите тут: Проверка гипотез о законе распределения.
Спасибо за ваши закладки и рекомендации
Примеры решений на проверку гипотез онлайн
Гипотеза о равенстве среднего значения числу
Пример 1. Утверждается, что шарики для подшипников, изготовленные автоматическим станком, имеют средний диаметр 10 мм. Используя односторонний критерий с α=0,05, проверить эту гипотезу, если в выборке из n шариков средний диаметр оказался равным 10,3 мм, а дисперсия известна и равна 1 мм.
Пример 2. Продавец утверждает, что средний вес пачки чая составляет 100 г. Из партии извлечена выборка и взвешена. Вес каждой пачки — см. таблицу вариантов. Не противоречит ли это утверждению продавца? Доверительная вероятность 99%. Вес пачек чая распределен нормально.
Гипотеза о равенстве дисперсии числу
Пример 3. По результатам $n=7$ независимых измерений найдено, что $\overline{x}=82,48$ мм, а $S=0,08$ мм. Допустив, что ошибки измерения имеют нормальное распределение проверить на уровне значимости $\alpha=0,05$ гипотезу $H_0: \sigma^2=0,01$ мм$^2$. против конкурирующей гипотезы $H_0: \sigma^2=0,005$ мм$^2$. В ответе записать разность между фактическим и табличным значениями выборочной характеристики.
Пример 4. Компания не осуществляет инвестиционных вложений в ценные бумаги с дисперсией годовой доходности более чем 0,04. Выборка из 52 наблюдений по активу А показала, что выборочная дисперсия ее доходности равна 0,045.Выяснить, допустимы ли для данной компании инвестиционные вложения в актив А на уровне значимости: а) 0,05; б) 0,01.
Гипотеза о равенстве вероятности числу
Пример 5. Фирма рассылает рекламные каталоги возможным заказчикам. Как показал опыт, вероятность того, что организация получившая каталог, закажет рекламируемое изделие, равна 0,08. Фирма разослала 1000 каталогов новой, улучшенной, формы и получила 100 заказов. На уровне значимости 0,05 выяснить, можно ли считать, что новая форма рекламы существенно лучше прежней.
Пример 6. Обычно применяемое лекарство снимает послеоперационные боли у 80% пациентов. Новое лекарство, применяемое для тех же целей, помогло 90 пациентам из первых 100 оперированных. Можно ли на уровне значимости а = 0,05 считать, что новое лекарство лучше? А на уровне а = 0,01?
Гипотеза о равенстве средних
Пример 7. Ожидается, что добавление специальных веществ уменьшит жесткость воды. По оценке жесткости воды до после добавления специальных веществ по 40-ка и 50-ти пробам соответственно получим средние значения жесткости (в стандартных единицах), равные 4,0 и 0,8. Дисперсия измерений в обоих случаях предполагается равно 0,25. Подтверждают ли эти результаты ожидаемый эффект? Принять $\alpha=0,05$. Контролируемая величина имеет нормальное распределение.
Пример 8. Производительность каждого из агрегатов А и В составила (в кг вещества за час работы)
Номер замера 1 2 3 4 5
Агрегат А 14,1 13,1 14,7 13,7 14,0
Агрегат В 14,0 14,5 13,7 12,7 14,1
Можно ли считать производительность агрегатов А и В одинаковой в предложении, что обе выборки получены из нормально распределенных генеральных совокупностей, при уровне значимости a = 0,1?
Гипотеза о равенстве дисперсий
Пример 9. До наладки станка была проверена точность изготовления 10 втулок и найдено значение оценки дисперсии диаметра $s_1^2=9,6$ мкм$^2$. После наладки подверглись контролю еще 15 втулок и получено новое значение оценки дисперсии $s_2^2=5,7$ мкм$^2$. Можно ли считать, что в результате наладки станка точность изготовления деталей увеличилась? Принять $\alpha=0,05$.
Пример 10. При уровне значимости $\alpha=0,1$ проверить гипотезу о равенстве дисперсий двух нормально распределенных случайных величин Х и Y на основе выборочных данных (табл. 4) при альтернативной гипотезе $H_1: \sigma_x^2 \ne \sigma_y^2$.
Гипотеза о равенстве вероятностей
Пример 11. Из 200 задач первого раздела курса математики, предложенных для решения, абитуриенты решили 130, а из 300 задач второго раздела абитуриенты решили 120. Можно ли при α=0,01 утверждать, что первый раздел школьного курса абитуриенты усвоили лучше, чем второй.
Пример 12. Выборочная проверка надежности материнских плат 2-х производителей дала следующие результаты: в течения месяца после продажи в 15 из 200 материнских плат производителя А обнаружены дефекты, тогда как среди 400 материнских плат производителя В 8% оказались дефектами. Существенны ли различия в надежности материнских плат производителей А и В? Уровень значимости принять равным 0,01.
Нужно решить задачи на проверку статистических гипотез?
Полезные ссылки
- Проверка гипотез о законе распределения по критерию Пирсона
- Что такое проверка статистической гипотезы?
- Решение задач на заказ
- Ссылки на учебники
- Решенные контрольные
Решебник по математической статистике
Ищете решенное задание на проверку статистических гипотез? Попробуйте тут:
-
Понятие статистической гипотезы. Общая постановка задачи проверки гипотез.
Проверка
статистических гипотез тесно связана
с теорией оценивания параметров. В
естествознании, технике экономике для
вычисления того или иного случайного
факта часто прибегают к высказыванию
гипотез, которые можно проверить
статистически (то есть, опираясь на
результаты наблюдений в случайной
выборке). Под статистическими
подразумевают такие гипотезы,
которые относятся или к виду, или к
отдельным параметрам распределения
случайной величины. Например, статистической
является гипотеза о том, что распределение
производительности труда рабочих,
выполняющих одинаковую работу в
одинаковых условиях, имеет нормальный
закон распределения. Статистической
будет также гипотеза о том, что средние
размеры деталей, производимых на
однотипных, параллельно работающих
станках, не различаются.
Статистическая
гипотеза называется простой,
если она однозначно определяет
распределение случайной величины
![]() ,
,
в противном случае гипотеза называется
сложной.
Например, простой гипотезой является
предположение о том, что случайная
величина
![]()
распределена по нормальному закону с
математическим ожиданием, равным нулю,
и дисперсией равной единице. Если
высказывается предположение, что
случайная величина
![]()
имеет нормальное распределение с
дисперсией, равной единице, а математическое
ожидание – число из отрезка
![]() ,
,
то это сложная гипотеза. Другим примером
сложной гипотезы является предположение
о том, что непрерывная случайная величина
![]()
с вероятностью
![]()
принимает значение из интервала
![]() ,
,
в этом случае распределение случайной
величины
![]()
может быть любым из класса непрерывных
распределений.
Часто распределение
величины
![]()
известно, и по выборке наблюдений
необходимо проверить предположения о
значении параметров этого распределения.
Такие гипотезы называются параметрическими.
Проверяемая
гипотеза называется нулевой
и обозначается
![]() .
.
Наряду с гипотезой
![]()
рассматривают одну из альтернативных
(конкурирующих) гипотез
![]() .
.
Например, если проверяется гипотеза о
равенстве параметра
![]()
некоторому заданному значению
![]() ,
,
то есть
![]() ,
,
то в качестве альтернативной гипотезы
можно рассматривать одну из следующих
гипотез:
![]() ,
,
где
![]()
– заданное значение, причём
![]() .
.
Выбор альтернативной
гипотезы определяется конкретной
формулировкой задачи.
Правило, по которому
принимается решение принять или отклонить
гипотезу
![]() ,
,
называется критерием
и обозначается
![]() .
.
Так как решение принимается на основе
выборки наблюдений случайной величины
![]() ,
,
необходимо выбрать подходящую статистику,
называемую в этом случае статистикой
![]()
критерия
![]() .
.
При проверке простой параметрической
гипотезы
![]()
в качестве статистики критерия выбирают
ту же статистику, что и для оценки
параметра
![]() .
.
Проверка
статистической гипотезы основывается
на принципе, в соответствии с которым
маловероятные события считаются
невозможными, а события, имеющие большую
вероятность,– достоверными. Этот принцип
можно реализовать следующим образом.
Перед анализом выборки фиксируется
некоторая малая вероятность
![]() ,
,
называемая уровнем
значимости.
Пусть
![]() –
–
множество значений статистики
![]() ,
,
а
![]()
– такое подмножество, что при условии
истинности гипотезы
![]()
вероятность попадания статистики
![]()
критерия в
![]()
равна
![]() ,
,
то есть
![]() .
.
Обозначим
![]()
выборочное значение статистики
![]() ,
,
вычисленное по выборке наблюдений.
Критерий формулируется так: отклонить
гипотезу
![]() ,
,
если
![]() ;
;
принять гипотезу
![]() ,
,
если
![]() .
.
Критерий, основанный на использовании
заранее заданного уровня значимости,
называется критерием
значимости.
Множество
![]()
всех значений статистики
![]()
критерия, при которых принимается
решение отклонить гипотезу
![]() ,
,
называется критической
областью;
область
![]()
называется областью
принятия гипотезы
![]() .
.



Уровень значимости
![]()
определяет размер критической области
![]() .
.
Положение критической области на
множестве значений статистики
![]()
зависит от формулировки альтернативной
гипотезы
![]() .
.
Например, если проверяется гипотеза
![]() ,
,
причём альтернативная гипотеза
формулируется как:
![]() ,
,
то критическая область размещается на
правом (левом) «хвосте» распределения
статистики
![]() ,
,
то есть имеет вид неравенства
![]() ,
,
где
![]() –
–
значения статистики
![]() ,
,
которые принимаются с вероятностями
![]()
и
![]()
при условии, что верна гипотеза
![]() .
.
В этом случае критерий называется
односторонним
(соответственно – правосторонним
и левосторонним).
Если альтернативная гипотеза формулируется
как
![]() ,
,
то критическая область размещается на
обеих «хвостах» распределения статистики
![]() ,
,
то есть определяется совокупностью
неравенств

В этом случае
критерий называется двусторонним.
Расположение
критической области
![]()
для различных альтернативных гипотез
показано рисунках, приведённых выше,
где
![]() –
–
плотность распределения статистики
![]()
критерия при условии, что верна гипотеза
![]() ,
,
![]() –
–
область принятия гипотезы,
![]() .
.
Проверку
параметрической статистической гипотезы
с помощью критерия значимости можно
разбить на этапы:
-
сформулировать
проверяемую ( )
)
и альтернативную ( )
)
гипотезы; -
назначить уровень
значимости
 ;
; -
выбрать статистику

критерия для проверки гипотезы
; -
определить
выборочное распределение статистики
при условии, что верна гипотеза
; -
в зависимости от
формулировки альтернативной гипотезы
определить критическую область

одним из неравенств

или совокупностью неравенств
 ;
; -
получить выборку
наблюдений и вычислить выборочные
значения

статистики критерия; -
принять статистическое
решение: если
 ,
,
то отклонить гипотезу
как не согласующуюся с результатами
наблюдений; если
 ,
,
то принять гипотезу
,
то есть считать, что гипотеза
не противоречит результатам наблюдений.1
ПРИМЕР 3.
По паспортным данным автомобильного
двигателя расход топлива на 100км пробега
составляет 10л. В результате изменения
конструкции двигателя ожидается, что
расход топлива уменьшится. Для проверки
проводятся испытания 25-и случайно
отобранных автомобилей с модернизированным
двигателем. Выборочное среднее расходов
топлива на 100км пробега по результатам
испытаний составило 9,3л. Предположим,
что выборка расходов топлива получена
из нормально распределённой генеральной
совокупности со средним2
![]()
и дисперсией
![]() .
.
Используя критерий значимости, проверить
гипотезу, утверждающую, что изменение
конструкции двигателя не повлияло на
расход топлива.
Решение.
Проверим гипотезу о среднем
![]()
нормально распределённой генеральной
совокупности. Проверку проведём по
этапам:
-
проверяемая
гипотеза
 ;
;
альтернативная гипотеза
 ;
; -
уровень значимости
 ;
; -
в качестве
статистики
критерия используем статистику
математического ожидания – выборочное
среднее
 ;
; -
так как выборка
получена из нормально распределённой
генеральной совокупности, выборочное
среднее также имеет нормальное
распределение с дисперсией
 .
.
При условии, что верна гипотеза
,
математическое ожидание этого
распределения равно 10. Нормированная
статистика

имеет нормальное распределение; -
альтернативная
гипотеза
предполагает уменьшение расхода
топлива, следовательно, нужно использовать
односторонний критерий. Критическая
область определяется неравенством
 .
.
По таблице (см. приложение) находим
 ;
; -
выборочное значение
нормированной статистики критерия

 ;
;
-
статистическое
решение: так как выборочное значение
статистики критерия принадлежит
критической области, гипотеза
отклоняется. Следует считать, что
изменение конструкции двигателя привело
к уменьшению расхода топлива. Границу

критической области для исходной
статистики
критерия можно получить из соотношения
 ,
,
откуда
 .
.
Таким образом, критическая область для
статистики
определяется неравенством
 .
.
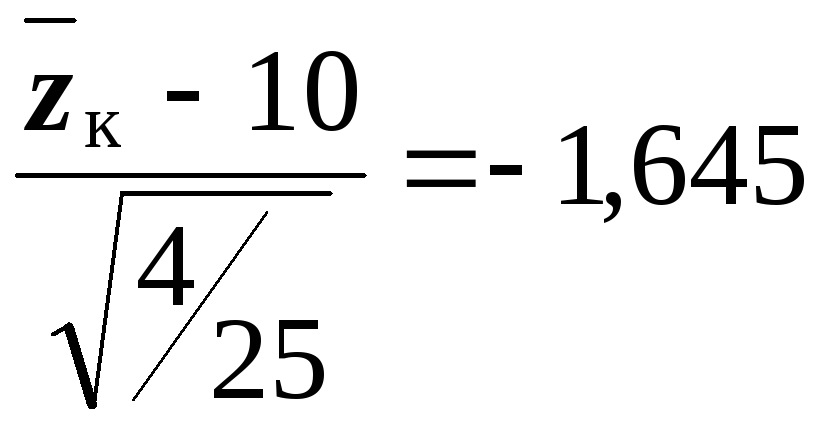 ,
,
Решение,
принимаемое на основе критерия значимости,
может быть ошибочным.
Пусть выборочное значение статистики
критерия попадает в критическую область,
и гипотеза
![]()
отклоняется в соответствии с критерием.
Если, тем не менее, гипотеза
![]()
верна, то принимаемое решение неверно.
Ошибка, совершаемая при отклонении
правильной гипотезы
![]() ,
,
называется ошибкой
первого рода.
Вероятность ошибки первого рода равна
вероятности попадания статистики
критерия в критическую область при
условии, что верна гипотеза
![]() ,
,
то есть равна уровню значимости
![]() :
:
![]() .
.
Ошибка второго
рода происходит
тогда, когда гипотеза
![]()
принимается, но в действительности
верна гипотеза
![]() .
.
Вероятность
![]()
ошибки второго рода вычисляется по
формуле:
![]() .
.
ПРИМЕР 4.
В условиях примера 3 предположим, что
наряду с гипотезой
![]()
рассматривается альтернативная гипотеза
![]() .
.
В качестве статистики критерия снова
возьмём выборочное среднее
![]() .
.
Предположим, что критическая область
задана неравенством
![]() .
.
Найти вероятность ошибок первого и
второго рода для критерия с такой
критической областью.
Решение.
Найдём вероятность ошибки первого рода.
Статистика
![]()
критерия при условии, что верна гипотеза
![]() ,
,
имеет нормальное распределение с
математическим ожиданием, равным 10, и
дисперсией, равной
![]() .
.
используя таблицу (см. приложение), по
формуле
![]()
находим:
 .
.
Это означает, что
принятый критерий классифицирует
примерно 8% автомобилей, имеющих расход
10л на 100км пробега, как автомобили,
имеющие меньший расход топлива.
При условии, что
верна гипотеза
![]() ,
,
статистика
![]()
имеет нормальное распределение с
математическим ожиданием, равным 9Б и
дисперсией, равной
![]() .
.
Нетрудно в этом случае найти вероятность
ошибки второго рода, воспользовавшись
формулой
![]() :
:
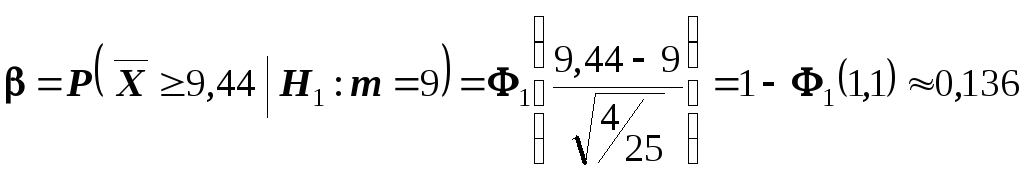 .
.
Следовательно, в
соответствии с принятым критерием 13,6%
автомобилей, имеющих расход топлива
9л на 100км пробега, классифицируются
как автомобили, имеющие расход топлива
10л.
Соседние файлы в папке Теор.вер. (лекции)
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Статистические гипотезы
Определение статистической гипотезы. Нулевая и альтернативная, простая и сложная гипотезы. Ошибки первого и второго рода. Статистический критерий, наблюдаемое значение критерия. Критическая область. Область принятия нулевой гипотезы; критическая точка. Общая методика построения право-, лево- и двухсторонней критических областей
Понятие и определение статистической гипотезы
Проверка статистических гипотез тесно связана с теорией оценивания параметров. В естествознании, технике, экономике для выяснения того или иного случайного факта часто прибегают к высказыванию гипотез, которые можно проверить статистически, т. е. опираясь на результаты наблюдений в случайной выборке. Под статистическими подразумеваются такие гипотезы, которые относятся или к виду, или к отдельным параметрам распределения случайной величины. Например, статистической является гипотеза о том, что распределение производительности труда рабочих, выполняющих одинаковую работу в одинаковых условиях, имеет нормальный закон распределения. Статистической будет также гипотеза о том, что средние размеры деталей, производимые на однотипных, параллельно работающих станках, не различаются.
Статистическая гипотеза называется простой, если она однозначно определяет распределение случайной величины , в противном случае гипотеза называется сложной. Например, простой гипотезой является предположение о том, что случайная величина
распределена по нормальному закону с математическим ожиданием, равным нулю, и дисперсией, равной единице. Если высказывается предположение, что случайная величина
имеет нормальное распределение с дисперсией, равной единице, а математическое ожидание — число из отрезка
, то это сложная гипотеза. Другим примером сложной гипотезы является предположение о том, что непрерывная случайная величина
с вероятностью
принимает значение из интервала
, в этом случае распределение случайной величины
может быть любым из класса непрерывных распределений.
Часто распределение величины известно, и по выборке наблюдений необходимо проверить предположения о значении параметров этого распределения. Такие гипотезы называются параметрическими.
Проверяемая гипотеза называется нулевой и обозначается . Наряду с гипотезой
рассматривают одну из альтернативных (конкурирующих) гипотез
. Например, если проверяется гипотеза о равенстве параметра
некоторому заданному значению
, то есть
, то в качестве альтернативной гипотезы можно рассмотреть одну из следующих гипотез:
где
— заданное значение,
. Выбор альтернативной гипотезы определяется конкретной формулировкой задачи.
Правило, по которому принимается решение принять или отклонить гипотезу , называется критерием
. Так как решение принимается на основе выборки наблюдений случайной величины
, необходимо выбрать подходящую статистику, называемую в этом случае статистикой
критерия
. При проверке простой параметрической гипотезы
в качестве статистики критерия выбирают ту же статистику, что и для оценки параметра
.
Проверка статистической гипотезы основывается на принципе, в соответствии с которым маловероятные события считаются невозможными, а события, имеющие большую вероятность, — достоверными; Этот принцип можно реализовать следующим образом. Перед анализом выборки фиксируется некоторая малая вероятность , называемая уровнем значимости. Пусть
— множество значений статистики
, а
— такое подмножество, что при условии истинности гипотезы
вероятность попадания статистики критерия в
равна
, то есть
.
Обозначим выборочное значение статистики
, вычисленное по выборке наблюдений. Критерий формулируется так: отклонить гипотезу
, если
; принять гипотезу
, если
. Критерий, основанный на использовании заранее заданного уровня значимости, называют критерием значимости. Множество
всех значений статистики критерия
, при которых принимается решение отклонить гипотезу
, называется критической областью; область
называется областью принятия гипотезы
.
Уровень значимости определяет размер критической области
. Положение критической области на множестве значений статистики
зависит от формулировки альтернативной гипотезы
. Например, если проверяется гипотеза
, а альтернативная гипотеза формулируется как
, то критическая область размещается на правом (левом) «хвосте» распределения статистики
, т. е. имеет вид неравенства
, где
— значения статистики
, которые принимаются с вероятностями соответственно
и
при условии, что верна гипотеза
. В этом случае критерий называется односторонним (соответственно правосторонним и левосторонним). Если альтернативная гипотеза формулируется как
, то критическая область размещается на обоих «хвостах» распределения
, то есть определяется совокупностью неравенств
и
в этом случае критерий называется двухсторонним.
Расположение критической области для различных альтернативных гипотез показано на рис. 30, где
— плотность распределения статистики
критерия при условии, что верна гипотеза
,
— область принятия гипотезы,
.
Проверку параметрической статистической гипотезы с помощью критерия значимости можно разбить на этапы:
1) сформулировать проверяемую и альтернативную
гипотезы;
2) назначить уровень значимости ;
3) выбрать статистику критерия для проверки гипотезы
;
4) определить выборочное распределение статистики при условии, что верна гипотеза
;
5) в зависимости от формулировки альтернативной гипотезы определить критическую область одним из неравенств
или совокупностью неравенств
и
;
6) получить выборку наблюдений и вычислить выборочные значения статистики критерия;
7) принять статистическое решение: если , то отклонить гипотезу
как не согласующуюся с результатами наблюдений; если
, то принять гипотезу
, т. е. считать, что гипотеза
не противоречит результатам наблюдений.
Обычно при выполнении пп. 4-7 используют статистику с нормальным распределением, статистику Стьюдента, Фишера.
Пример 3. По паспортным данным автомобильного двигателя расход топлива на 100 км пробега составляет 10 л. В результате изменения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки проводятся испытания 25 случайно отобранных автомобилей с модернизированным двигателем, причем выборочное среднее расходов топлива на 100 км пробега по результатам испытаний составило 9,3 л. Предположим, что выборка расходов топлива получена из нормально распределенной генеральной совокупности со средним и дисперсией
л². Используя критерий значимости, проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
Решение. Проверим гипотезу о среднем нормально распределенной генеральной совокупности. Проверку проведем по этапам:
1) проверяемая гипотеза ; альтернативная гипотеза
;
2) уровень значимости ;
3) в качестве статистики критерия используем статистику математического ожидания — выборочное среднее;
4) так как выборка получена из нормально распределенной генеральной совокупности, выборочное среднее также имеет нормальное распределение с дисперсией . При условии, что верна гипотеза
, математическое ожидание этого распределения равно 10. Нормированная статистика
имеет нормальное распределение;
5) альтернативная гипотеза предполагает уменьшение расхода топлива, следовательно, нужно использовать односторонний критерий. Критическая область определяется неравенством
. По прил. 5 находим
;
б) выборочное значение нормированной статистики критерия
7) статистическое решение: так как выборочное значение статистики критерия принадлежит критической области, гипотеза отклоняется: следует считать, что изменение конструкции двигателя привело к уменьшению расхода топлива. Границу
критической области для исходной статистики
критерия можно получить из соотношения
, откуда
, т. е. критическая область для статистики
определяется неравенством
.
Ошибки первого и второго рода
Решение, принимаемое на основе критерия значимости, может быть ошибочным. Пусть выборочное значение статистики критерия попадает в критическую область, и гипотеза , отклоняется в соответствии с критерием. Если, тем не менее, гипотеза
верна, то принимаемое решение неверно. Ошибка, совершаемая при отклонении правильной гипотезы if о, называется ошибкой первого рода. Вероятность ошибки первого рода равна вероятности попадания статистики критерия в критическую область при условии, что верна гипотеза
, т. е. равна уровню значимости
Ошибка второго рода происходит тогда, когда гипотеза принимается, но в действительности верна гипотеза
. Вероятность
ошибки второго рода вычисляется по формуле
Пример 4. В условиях примера 3 предположим, что наряду с гипотезой л рассматривается альтернативная гипотеза
л. В качестве статистики критерия снова возьмем выборочное среднее
. Предположим, что критическая область задана неравенством
л. Найти вероятности ошибок первого и второго рода для критерия с такой критической областью.
Решение. Найдем вероятность ошибки первого рода. Статистика критерия при условии, что верна гипотеза
л, имеет нормальное распределение с математическим ожиданием, равным 10, и дисперсией, равной
. Используя прил. 5, по формуле (11.1) находим
Это означает, что принятый критерий классифицирует примерно 8% автомобилей, имеющих расход 10 л на 100 км пробега, как автомобили, имеющие меньший расход топлива. При условии, что верна гипотеза л, статистика
имеет нормальное распределение с математическим ожиданием, равным 9, и дисперсией, равной
. Вероятность ошибки второго рода найдем по формуле (11.2):
Следовательно, в соответствии с принятым критерием 13,6% автомобилей, имеющих расход топлива 9 л на 100 км пробега, классифицируются как автомобили, имеющие расход топлива 10 л.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
![]() Пример 1
Пример 1
При исследовании качества выпускаемой предприятием продукции проведено обследование 100
случайно отобранных изделий. Оказалось, что 6 из них имеют брак. Пусть случайная величина X – число бракованных
изделий в партии из 1000 изделий, выпущенных тем же предприятием. Относительно случайной величины X могут быть
сформулированы, например, следующие предположения.
1)
Случайная величина X имеет биномиальное распределение B(1000; 0,06).
2)
Случайная величина X имеет биномиальное распределение B(1000, p), где 0,04 < p < 0,08.
3)
Математическое ожидание случайной величины X равно 70.
4)
Дисперсия случайной величины X не более 2,3.
5)
Вероятность того, что во всей партии будет более 80 бракованных изделий, не превосходит 90%.
6)
Вероятность того, что во всей партии будет равно 60 бракованных изделий, не менее 95%.
Определить, какие из сформулированных гипотез являются статистическими, какие
статистические гипотезы являются простыми, а какие сложными?
Решение
Запишем эти гипотезы формально.
1) ${{H}_{0}}:X\sim{\ }B(1000;0,6)$.
2) ${{H}_{0}}:X\sim{\ }B(1000;p),\ \ \ 0,04\le p\le 0,08$.
3) ${{H}_{0}}:{{m}_{X}}=70$.
4) ${{H}_{0}}:{{d}_{X}}\le 2,3$.
5) ${{H}_{0}}:P(X>80)\le 0,9$.
6) ${{H}_{0}}:P(X=60)\ge 0,95$.
Все приведённые гипотезы являются параметрическими, поскольку распределение случайной величины X известно априорно
из условий эксперимента, а все гипотезы связаны так или иначе с неизвестным параметром p биномиального распределения.
Гипотезы 1) и 3) являются простыми, поскольку содержат утверждения, однозначно определяющие значение оцениваемого
параметра.
![]() Пример 2
Пример 2
Исследуется качество производства элемента интегральной микросхемы на двух технологических линиях. Мерой качества
производства является дисперсия размера элементов. Результаты выборочного наблюдения размеров выпущенных
интегральных микросхем на двух технологических линиях приведены в
Примере 2*.
Пусть случайные величины X1 и X2 – размеры элементов микросхем на первой и второй линиях соответственно.
Относительно этих случайных величин могут быть сформулированы, например, следующие предположения.
1) Размер элементов микросхем, произведённых на первой линии, является нормально распределённой случайной величиной.
2) Размер элементов микросхем, произведённых на второй линии, распределён по закону N(0,25; 0,05).
3) Математические ожидания размеров элементов микросхем, произведённых на первой и второй линиях, равны.
4) Качество производства элементов микросхем на второй линии выше, чем на первой.
Определить, какие из сформулированных гипотез являются статистическими, какие
статистические гипотезы являются простыми, а какие сложными?
Решение
Запишем эти гипотезы формально.
1) ${{H}_{0}}:{{X}_{1}}\sim{\ }N({{m}_{1}},{{\sigma }_{1}})$.
2) ${{H}_{0}}:{{X}_{2}}\sim{\ }N(0,25;0,05)$.
3) ${{H}_{0}}:{{m}_{1}}={{m}_{2}}$.
4) ${{H}_{0}}:\sigma _{1}^{2}>\sigma _{2}^{2}$.
Здесь гипотезы 3) и 4) являются параметрическими, 1) и 2) – непараметрическими. Гипотезы 2) и 3) – простые, 1) и 4) – сложные.
![]() Пример 3
Пример 3
Наблюдаемый объект может быть либо своим, либо объектом противника. Система обнаружения
относит объект к одному из классов по результатам нескольких замеров определённых характеристик. Основная
гипотеза H0: объект свой; альтернативная гипотеза H’: объект чужой. В чём состоят ошибки
первого и второго рода?
Решение
Результат замера определённой характеристики объекта является случайной величиной
вследствие погрешности измерительного прибора, влияния на результат измерения внешних случайных факторов или вследствие
иных причин. Однако, вывод о том, является ли объект своим или чужим, должен проводиться на основе истинных значений этих
характеристик. Для этой цели выдвигается статистическая гипотеза.
Ошибка первого рода возникнет, если в результате проверки статистического критерия
будет принято решение о том, что характеристики объекта соответствуют своему объекту, в то время как на самом деле объект
является объектом противника («пропущен чужой»).
Ошибка второго рода возникнет, если в результате проверки статистического критерия будет
принято решение о том, что характеристики объекта соответствуют объекту противника, в то время как на самом деле объект
является своим («уничтожен свой»).
![]() Пример 4
Пример 4
Технология производства элемента интегральной микросхемы удовлетворяет производственным нормам,
если вероятность брака в элементе не более 0,01. Соответствие производственным нормам проводится на основе выборочного
наблюдения 1000 элементов. Если не более, чем 15 элементов, имеют брак, то считается, что производственные нормы соблюдены.
В противном случае делается вывод о несоответствии технологии производства нормам.
Пусть p – вероятность брака в элементе интегральной микросхемы.
Сформулируем основную и альтернативную гипотезы:
$H_0:p\le 0,01,$
$H’:p>0,01.$
Ответить на следующие вопросы.
1)
Какая статистика критерия используется в данной задаче, каковы её распределение и область значений?
2)
Какое решающее правило для проверки основной гипотезы используется в данной задаче. Какова область допустимых значений и критическая область?
3)
В чём состоят ошибки первого и второго рода?
Решение
По условию задачи статистическое решение принимается на основе значения случайной
величины Z – числа бракованных элементов в серии из 1000. Таким образом, случайная величина Z является
статистикой критерия. Очевидно, что $Z\sim{\ }B(1000,p)$. Возможные значения статистики Z: 0, 1, …, 1000.
Решающее правило: если z ≤ 15, то H0 принимается,
если z > 15, то H0 отвергается. Таким образом, область допустимых
значений ${{\Omega }_{0}}=\{0,…,15\}$, критическая область $\Omega ‘=\{16,…,1000\}$.
Ошибка первого рода возникнет, если число бракованных элементов в выборке из 1000 будет
более 15 (гипотеза H0 будет отвергнута), при этом вероятность брака в отдельном элементе p ≤ 0,01,
т.е. будет принято решение о несоответствии производственным нормам, в то время как на самом деле соответствие есть.
Ошибка второго рода возникнет, если число бракованных элементов в выборке из 1000 будет
не более 15 (гипотеза H0 будет принята), при этом вероятность брака в отдельном
элементе p > 0,01, т.е. будет принято решение о соответствии производственным нормам, в то время как на самом
деле соответствия нет.
![]() Пример 5
Пример 5
В условиях Примера 4 выдвигаются следующие основная и альтернативная гипотезы относительно
вероятности p брака в элементе интегральной микросхемы:
$ {{H}_{0}}:p=0,01, $
$H’:p>0,01.$
Построить функцию мощности статистического критерия: если выборочное значение z
статистики критерия Z – числа бракованных изделий из n = 1000 – не более 15, то H0 принимается,
если z > 15, то H0 отвергается.
Решение
Запишем выражение для вероятности β ошибки второго рода при условии, что
вероятность p = p1, где $p_1 \in (0;\infty)$:
$\beta ({{p}_{1}})=P(Z\in {{\Omega }_{0}}|p={{p}_{1}})$.
Статистика критерия Z при условии, что p = p1 имеет
биномиальное распределение B(1000, p1). Согласно теореме Муавра-Лапласа, при больших n
биномиальное распределение может быть аппроксимировано нормальным:
$Z\sim{\ }N({{m}_{Z}},{{\sigma }_{Z}})$,
где ${{m}_{Z}}({{p}_{1}})=n{{p}_{1}}$ и ${{\sigma }_{Z}}({{p}_{1}})=n{{p}_{1}}(1-{{p}_{1}})$.
Учитывая, что область допустимых значений статистики критерия ${{\Omega }_{0}}=\{0,…,15\}$,
запишем
$\beta ({{p}_{1}})=P(0\le Z\le 15|p={{p}_{1}})=P(0\le {{\sigma }_{Z}}({{p}_{1}})U+{{m}_{Z}}({{p}_{1}})\le 15)=P\left( -\frac{{{m}_{Z}}({{p}_{1}})}{{{\sigma }_{Z}}({{p}_{1}})}\le U\le \frac{15-{{m}_{Z}}({{p}_{1}})}{{{\sigma }_{Z}}({{p}_{1}})} \right)=P\left( -\frac{1}{1-{{p}_{1}}}\le U\le \frac{15-n{{p}_{1}}}{n{{p}_{1}}(1-{{p}_{1}})} \right)=\Phi \left( \frac{15-n{{p}_{1}}}{n{{p}_{1}}(1-{{p}_{1}})} \right)-\Phi \left( -\frac{1}{1-{{p}_{1}}} \right),$
где $ U \sim N(0,1)$ – стандартизованная нормально распределённая случайная величина, а Ф – функция Лапласа.
Вычисляя с помощью таблиц математической статистики вероятность β(p1) для нескольких
значений p1, строим функцию мощности критерия $\mu ({{p}_{1}})=1-\beta ({{p}_{1}})$ поточечно.
Вероятность ошибки первого рода: $ \alpha =P(Z\in \Omega ‘|{{H}_{0}})=P(Z>15|p=0,01)=1-\beta (0,01)=\mu (0,01)\approx 0,46.$
![]() Экспериментальное исследование
Экспериментальное исследование
Проверка гипотез
Постановка задачи
Статистической гипотезой
называется непротиворечивое утверждение, касающееся вида распределения имеющейся выборки.
Основная гипотеза, нуждающаяся в проверке называется нулевой или нуль-гипотезой. Любая
другая гипотеза, относительно которой проверяют нуль-гипотезу, называется альтернативой.
Например: пусть имеется выборка из распределения хи-квадрат с $N$ степенями свободы.
Нуль-гипотеза состоит в том, что –
$$H_0: N=2$$
альтернатива –
$$H_1: N>2$$
На практике альтернативу часто опускают, формулируя только нуль-гипотезу.
Гипотеза называется простой, если она однозначно определяет функцию распределения выборки.
В противном случае гипотеза называется сложной. В примере: $H_0$ – это простая гипотеза, а
$H_1$ – это сложная альтернатива.
Гипотезы бывают параметрическими, когда вид распределения известен заранее, с точностью
до численных значений его параметров – как в примере выше. Кроме того, гипотезы могут
быть непараметрическими.
Например: пусть имеется выборка из неизвестного распределения $F$. Нуль-гипотеза состоит
в том, что –
$H_0: F$ – это равномерное распределение.
Проверка гипотез
Метод проверки статистической гипотезы называется
статистическим критерием.
Он строится на основе имеющейся выборки $\mathbf{x}=(x_1,\dots,x_I)$ с помощью
измеримой функции $S(\mathbf{x})$, называемой статистикой критерия. В пространстве значений
статистики $S(\mathbf{x})$ выбирается область $C$, называемая критической. Если $S(\mathbf{x}) ∈ С$,
то гипотезу отклоняют (отвергают), в противном случае – принимают.
Статистика $S(\mathbf{x})$ должна быть устроена особым образом – так, чтобы ее
распределение не зависело от неизвестных параметров распределения выборки $\mathbf{x}$.
Кроме того функция распределения $S(\mathbf{x})$ должна быть табулирована заранее.
В большинстве практических приложений статистика $S(\mathbf{x})$ строится из
соображений нормальности.
Ошибки 1-го и 2-го родов
Проверка статистической гипотезы не дает ее логического подтверждения или опровержения.
Проверка только утверждает, что «имеющиеся данные (не) противоречат» выдвинутому предположению».
Поэтому при проверке статистической гипотезы возможны случайные ошибки, которые могут быть
двух родов.
Ошибка 1-го рода происходит тогда, когда нуль-гипотеза верна, но отвергается согласно критерию.
Ошибка 2-го рода происходит тогда, когда нуль-гипотеза не верна, но принимается согласно критерию.
Вероятность ошибки первого рода называется
[уровнем значимости]http://ru.wikipedia.org/wiki/Уровень_значимости и обозначается $\alpha$.
Обычно уровень значимости выбирается равным $0.01$, $0.05$, или $0.1$ и по этому значению
подбирают критическую область $C_α$.
Пример проверки гипотезы
Пусть имеется выборка $\mathbf{x}=(x_1,\dots,x_I)$ из нормального распределения –
$$x_i \sim N(\mu, \sigma^2)$$
с известной дисперсией $\sigma^2$ и неизвестным средним $\mu$.
Проверяется простая нуль-гипотеза:
$$H_0: \mu=0$$
Альтернативу мы сформулируем позже.
В качестве статистического критерия возьмем функцию
$$S(\mathbf{x}) = \sqrt{I} \frac{\bar{x}}{\sigma}$$
которая при $\mu=0$ подчиняется стандартному нормальному распределению –
$$S \sim N(0, 1)$$
При заданном уровне значимости α критическая область определяется условием –
$$\mathrm{Pr}\big\{ |S| > C_α \big\} = \alpha$$
Поэтому
$$C_α = \Phi^{–1}(1– \alpha/2)$$
Введем теперь альтернативную гипотезу –
$$H_1: \mu=a$$
и найдем величину ошибки 2-го рода. Ее величина
$$\beta = \mathrm{Pr} \big\{ |S|< C_α | \mu=a \big\}$$
рассчитывается при условии
$$S \sim N(а, 1)$$
Поэтому,
$$\beta = \Phi(C_α – a) – Φ(–C_α –a)$$
На листе Hypothesis приведены расчеты этого примера.

Критерий согласия хи-квадрат
Критерий согласия хи-квадрат
проверяет соответствие между теоретическими вероятностями $P_1, P_2, \dots$ и их эмпирическими
частотными оценками $I_1/I, I_2/I, \dots$.
Для примера рассмотрим выборку $\mathbf{x}=(x_1,\dots,x_I)$ из неизвестного распределения –
$$x_i \sim F(x)$$
Нуль гипотеза состоит в конкретизации этого распределения, т.е. в утверждении типа «$F$ – это
нормальное распределение с нулевым средним и дисперсией равной 2»
В соответствие с выбранным гипотетическим распределением, область изменения случайной
величины $X$, разбивается на $R$ классов (корзин) и рассчитываются теоретические вероятности
$P_1, P_2, \dots, P_R$ попадания в каждую из корзин. С другой стороны определяется, сколько
элементов выборки попало в каждую из этих корзин – $I_1, I_2, \dots, I_R$ и вычисляются
эмпирические вероятности $F_r=I_r/I$.
Статистикой критерия согласия служит случайная величина
$$S = \sum_{r=1}^R \frac{(I_r — IP_r)^2}{IP_r} = I \sum_{r=1}^R \frac{(F_r — P_r)^2}{P_r}$$
которая при $I \to \infty$ стремится к распределению хи-квадрат с $R–1$ степенями свободы.
Число и размеры корзин надо выбирать так, чтобы
$$IP_r > 6$$
Критическая область на уровне значимости α определяется условием –
$$S > \chi^{–2}(1–\alpha | R–1)$$
Критерий согласия хи-квадрат можно применять и в том случае, когда теоретическое
распределение $F(x | \mathbf{p})$ известно с точностью до неизвестных параметров
$\mathbf{p} = (p_1,\dots,p_M)$. Эти параметры предварительно оцениваются по той
же выборке $\mathbf{x}$ и подставляются в функцию $F(x|\mathbf{p})$. В этом случае
следует изменить число степеней свободы на $R–M–1$.
Для проверки согласия по критерию хи-квадрат в Excel применяется стандартная
функция CHITEST (ХИ2ТЕСТ):
CHITEST(actual_range, expected_range)
Вычисляет статистику $S$ приведеную выше используя actual_range=(I1, I2,...,IR)
и expected_range=(IP1, IP2,...,IPR). Возвращает вероятность $P= 1 – \chi^2(S|R–1)$.
Для принятия гипотезы на уровне значимости $\alpha$ необходимо, чтобы $P>1–\alpha$.

F-критерий
Этот критерий применяется для проверки нуль-гипотезы о равенстве дисперсий в двух
нормальных выборках: $\mathbf{x}=(x_1,\dots,x_I)$ и $\mathbf{y}=(y_1,\dots,y_J)$.
Пусть $s_x^2$, $s_y^2$ – суть оценки выборочных дисперсий.
Если $s_x^2 > s_y^2$, то обозначим:
$$s_1^2 = s_x^2, N_1 = I — 1$$
$$s_2^2 = s_y^2, N_2 = J — 1$$
Иначе:
$$s_1^2 = s_y^2, N_1 = J — 1$$
$$s_2^2 = s_x^2, N_2 = I — 1$$
Статистикой $F$-критерия служит случайная величина
$$S = \frac{s_1^2}{s_2^2} \sim F(N_1, N_2)$$
которая подчиняется распределению Фишера
с $N_1$, $N_2$ степенями свободы.
Критическая область на уровне значимости $\alpha$ определяется условием:
$$S > F^{–1}(1–\alpha | N_1, N_2)$$
$F$-критерий очень чувствителен к нарушению предположения о нормальности распределений
выборок, поэтому его не рекомендуется применять в практических приложениях.
Для проверки $F$-критерия в Excel применяется стандартная функция FTEST (ФТЕСТ):
FTEST(x, y)
Возвращает вероятность $P= 2[1 – F(S | N_1, N_2)]$. Для принятия гипотезы на уровне
значимости $\alpha$ необходимо, чтобы $P>2\alpha$.
