Выделение секций и шагов
Улучшаем код
В прошлом уроке мы написали тест на экран проверки доступности интернета, код тестового класса выглядел вот так:
package com.kaspersky.kaspresso.tutorial
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
WifiScreen {
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
}
}
}
И мы говорили о том, что одна из проблем этого кода заключается в том, что его сложно читать и поддерживать даже на данном этапе, а если функциональность экрана расширится и нам придется добавлять еще тесты, то код станет абсолютно нечитаемым.
На самом деле обычно любые тесты (в т.ч. ручные) выполняются по test-кейсам. То есть у тестировщика есть последовательность шагов, которые он выполняет для проверки работоспособности экрана. В нашем случае у нас есть эта последовательность шагов, но записана она сплошным текстом и непонятно, где завершается один шаг и начинается другой. Мы можем решить эту проблему при помощи комментариев.
Давайте скопируем этот класс WifiSampleTest и вставим в этот же пакет, но уже с другим названием WifiSampleWithStepsTest. Это нужно для того, чтобы вы потом смогли сравнить новую и старую реализации этого теста. Код WifiSampleTest мы сегодня менять не будем. Теперь в новом классе WifiSampleWithStepsTest мы добавляем комментарии к каждому шагу.
package com.kaspersky.kaspresso.tutorial
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
// Step 1. Open target screen
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
WifiScreen {
// Step 2. Check correct wifi status
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
// Step 3. Rotate device and check wifi status
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
}
}
}
Это немного улучшит читаемость кода, но всех проблем не решит. Например, у вас какой-то тест упадет, как вы узнаете, на каком шаге это произошло? Вам придется исследовать логи, пытаясь понять, что пошло не так. Было бы гораздо лучше, если бы в логах отображались записи вроде Step 1 started -> ... -> Step 1 succeed или Step 2 started -> ... -> Step 2 failed. Это позволит немедленно определить по записям в логе, на каком этапе возникла проблема.
Для этого мы можем сами добавить вывод в лог для каждого шага до и после его выполнения и обернуть это все в блок try catch, чтобы фиксировать падение теста в логах. В этом случае наш тест выглядел бы следующим образом:
package com.kaspersky.kaspresso.tutorial
import android.util.Log
import androidx.test.core.app.takeScreenshot
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
try {
Log.i("KASPRESSO", "Step 1. Open target screen -> started")
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
Log.i("KASPRESSO", "Step 1. Open target screen -> succeed")
} catch (e: Throwable) {
Log.i("KASPRESSO", "Step 1. Open target screen -> failed")
takeScreenshot()
}
WifiScreen {
try {
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> started")
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> succeed")
} catch (e: Throwable) {
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> failed")
}
try {
Log.i("KASPRESSO", "Step 3. Rotate device and check wifi status -> started")
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
Log.i("KASPRESSO", "Step 3. Rotate device and check wifi status -> succeed")
} catch (e: Throwable) {
Log.i("KASPRESSO", "Step 3. Rotate device and check wifi status -> failed")
takeScreenshot()
}
}
}
}
Давайте включим интернет на устройстве и проверим работу нашего теста.
Запускаем. Тест пройден успешно.
Теперь давайте посмотрим логи. Для этого откройте вкладку Logcat в нижней части Android Studio
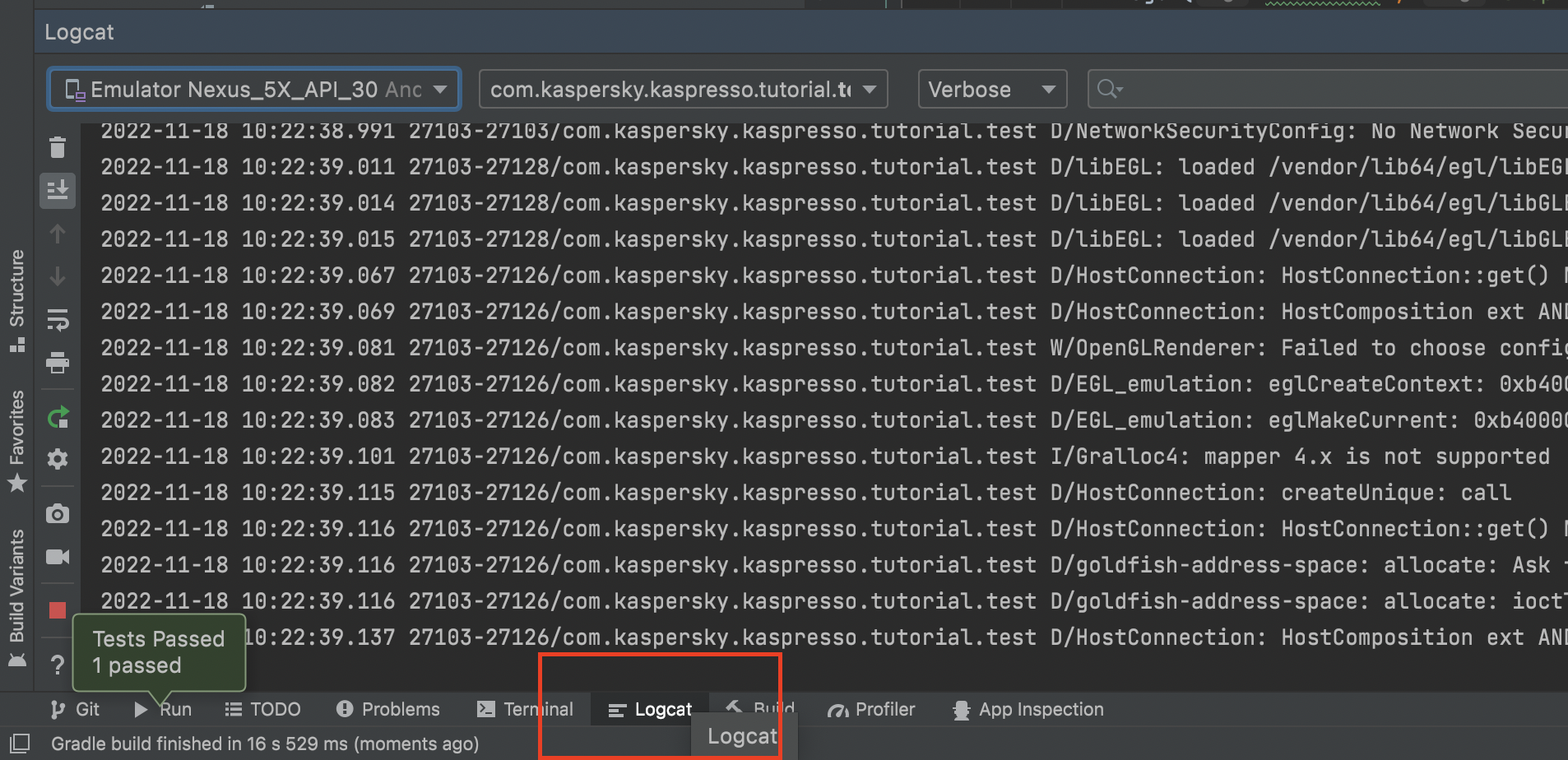
Здесь отображается множество логов и найти наши довольно сложно. Мы можем отфильтровать логи по тэгу, который указали («KASPRESSO»). Для этого кликните на стрелку в правой верхней части Logcat и выберите пункт Edit Configuration
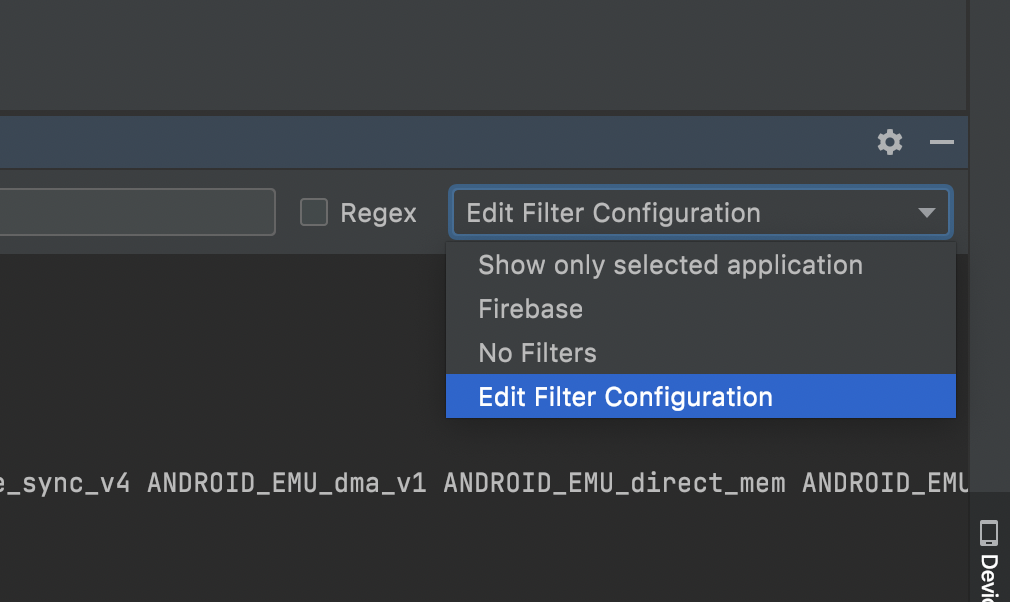
У вас откроется окно создания фильтра. Добавьте название фильтра, а также тэг, который нас интересует:
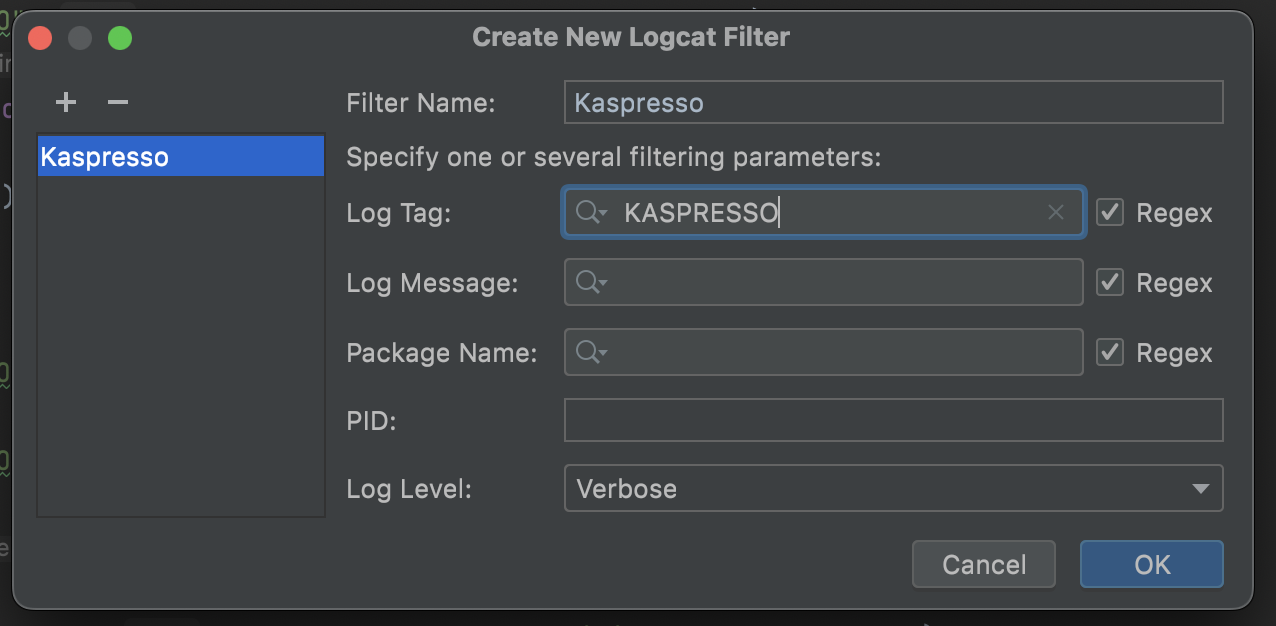
Теперь у нас отображается только полезная информация. Давайте очистим лог
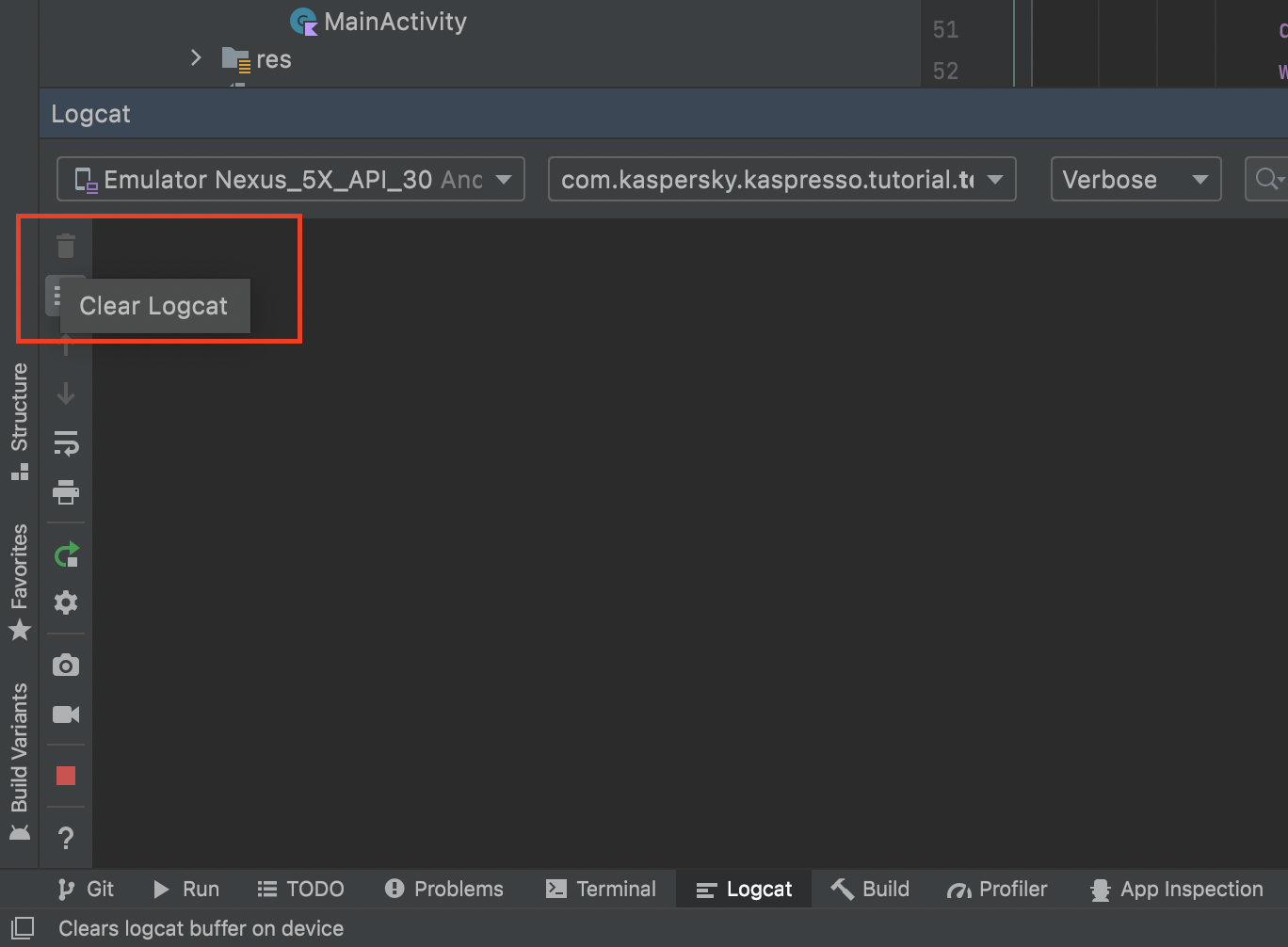
и запустим тест еще раз. Не забываем перед этим включать интернет на устройстве. Читаем логи:

Здесь идут логи, которые мы добавили — шаг 1 запущен, затем выполняются проверки, затем шаг 1 завершился успешно.
Смотрим дальше:
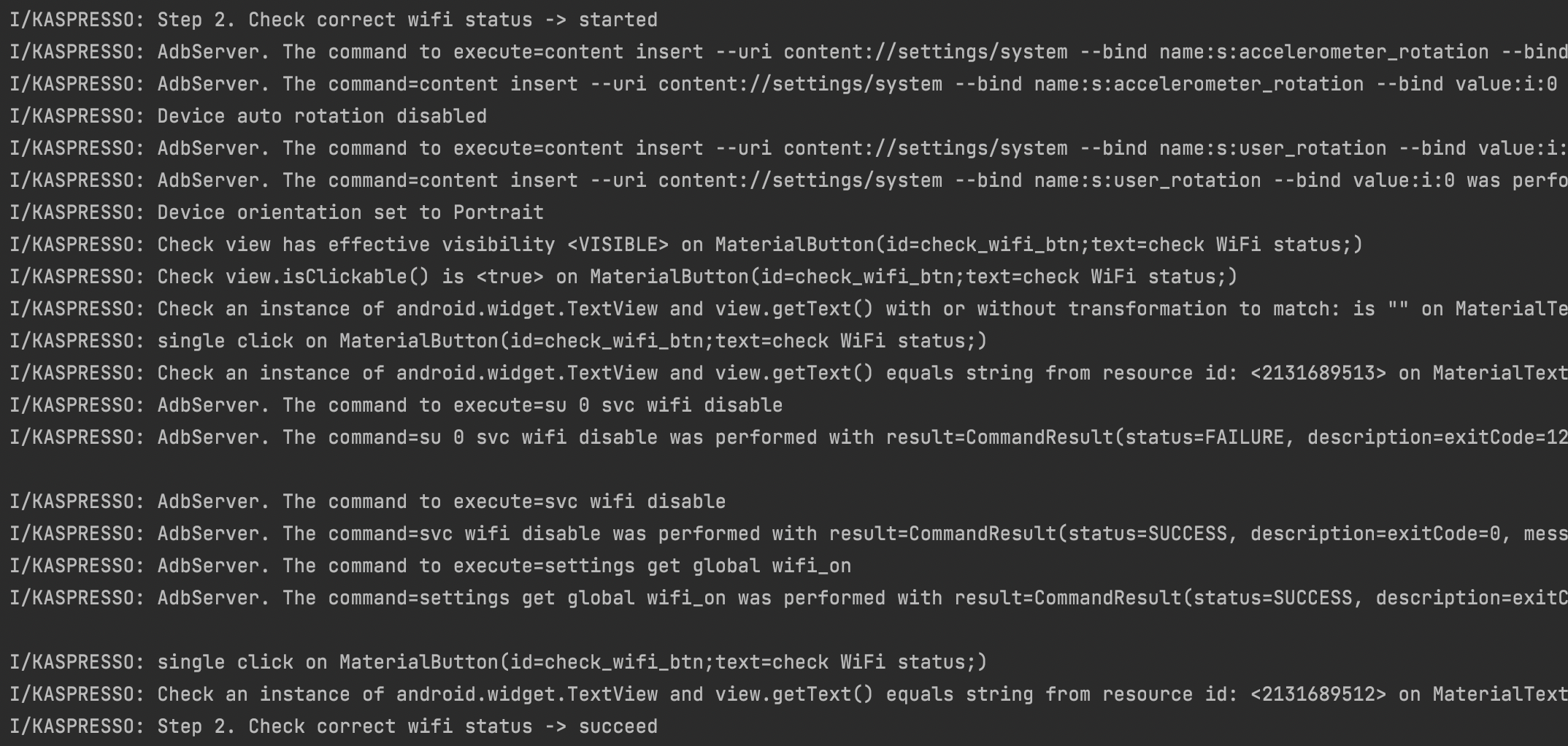
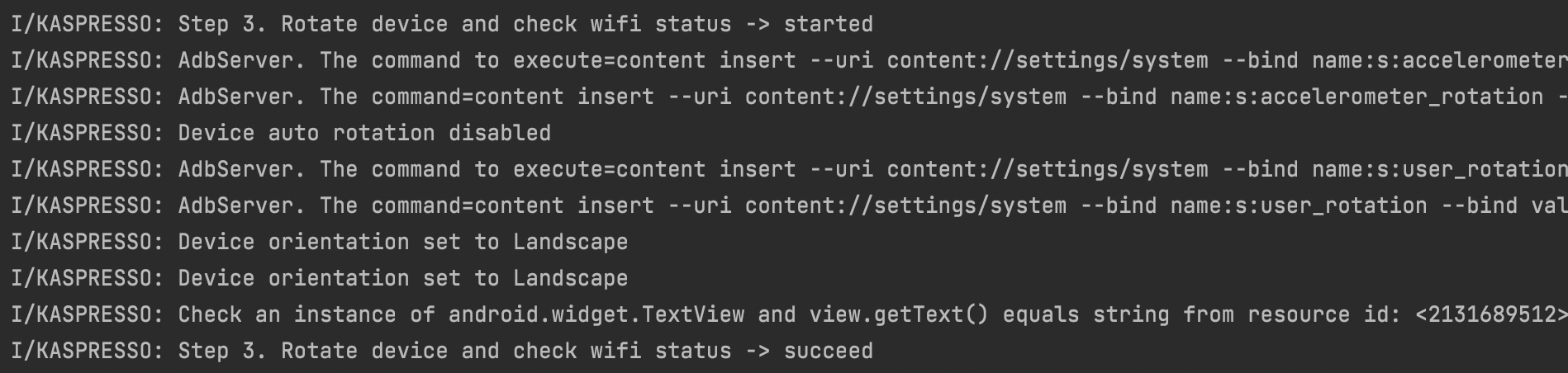
Со вторым и третьим шагами также все хорошо. Нам понятно, когда и какой шаг начинает выполнение, видны конкретные действия, которые в данный момент выполняет тест, и виден результат работы теста.
Теперь давайте выключим интернет и запустим тест еще раз. По нашей логике тест должен завершиться неудачно.
Несмотря на то, что тест должен был завершиться с ошибкой, все тесты зеленые. Смотрим в лог — сейчас нас интересует step 2, который должен был завершиться неудачно из-за того, что изначально интернет на устройстве выключен
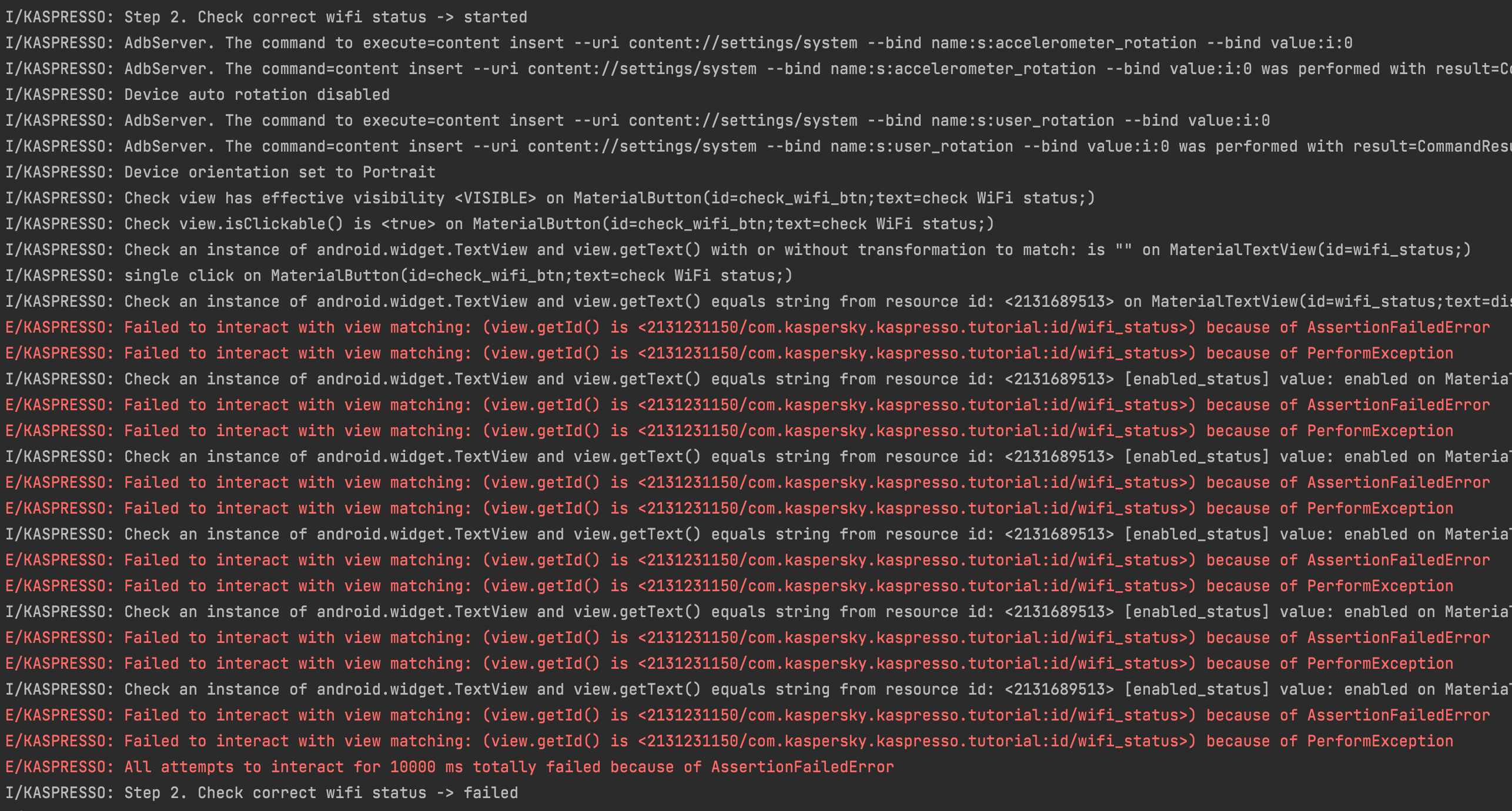
Судя по логам, step 2 действительно завершился неудачно. Был проверен статус заголовка, текст не совпал, программа осуществила еще несколько попыток проверить, что текст на заголовке содержит текст enabled, но все эти попытки не увенчались успехом и шаг завершился с ошибкой. Почему в этом случае тесты у нас зеленые?
Дело в том, что если тест завершается неудачно, то бросается исключение, и если это исключение никто не обработал в блоке try catch, то тесты будут красными. А мы в коде обрабатываем все исключения для того, чтобы сделать запись в лог о том, что тест завершился с ошибкой.
try {
...
} catch (e: Throwable) {
/**
* Мы обработали исключение и дальше оно проброшено не будет, поэтому такой
* тест считается выполненным успешно
*/
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> failed")
}
Для решения этой проблемы необходимо после вывода в лог сообщения об ошибке бросить это исключение дальше, чтобы тест упал. Делается это при помощи ключевого слова throw. Тогда код теста будет выглядеть следующим образом:
package com.kaspersky.kaspresso.tutorial
import android.util.Log
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
try {
Log.i("KASPRESSO", "Step 1. Open target screen -> started")
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
Log.i("KASPRESSO", "Step 1. Open target screen -> succeed")
} catch (e: Throwable) {
Log.i("KASPRESSO", "Step 1. Open target screen -> failed")
throw e
}
WifiScreen {
try {
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> started")
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> succeed")
} catch (e: Throwable) {
Log.i("KASPRESSO", "Step 2. Check correct wifi status -> failed")
throw e
}
try {
Log.i("KASPRESSO", "Step 3. Rotate device and check wifi status -> started")
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
Log.i("KASPRESSO", "Step 3. Rotate device and check wifi status -> succeed")
} catch (e: Throwable) {
Log.i("KASPRESSO", "Step 3. Rotate device and check wifi status -> failed")
throw e
}
}
}
}
Запускаем тест еще раз. Теперь он завершается с ошибкой и мы имеем понятные логи, где сразу видно, на каком шаге произошла ошибка. После step 2 в логах больше ничего нет.
Код, который мы написали, рабочий, но очень громоздкий, и нам приходится для каждого шага писать целое полотно одинакового кода (логи, блоки try catch и т.д).
Для того чтобы упростить написание тестов и сделать код более читаемым и расширяемым, в Kaspresso были добавлены step-ы. У них «под капотом» реализовано все то, что мы сейчас писали вручную.
Чтобы использовать step-ы, необходимо вызвать метод run {} и в фигурных скобках перечислить все шаги, которые будут выполнены во время теста. Каждый шаг нужно вызывать внутри функции step.
Давайте напишем это в коде. Для начала удаляем все лишнее — логи и блоки try catch.
package com.kaspersky.kaspresso.tutorial
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
WifiScreen {
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
}
}
}
Теперь в начале теста мы вызываем метод run, внутри которого для каждого шага вызываем функцию step. Этой функции в качестве параметра передаем название шага.
@Test
fun test() {
run {
step("Open target screen") {
...
}
step("Check correct wifi status") {
...
}
step("Rotate device and check wifi status") {
...
}
}
}
Внутри каждого step-а мы указываем действия, которые требуются на этом шаге. То же самое, что мы делали раньше. Тогда код теста будет выглядеть следующим образом:
package com.kaspersky.kaspresso.tutorial
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
run {
step("Open target screen") {
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
}
step("Check correct wifi status") {
WifiScreen {
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
}
}
step("Rotate device and check wifi status") {
WifiScreen {
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
}
}
}
}
}
Включаем интернет на устройстве и запускаем тест. Тест пройден успешно. Смотрим логи:
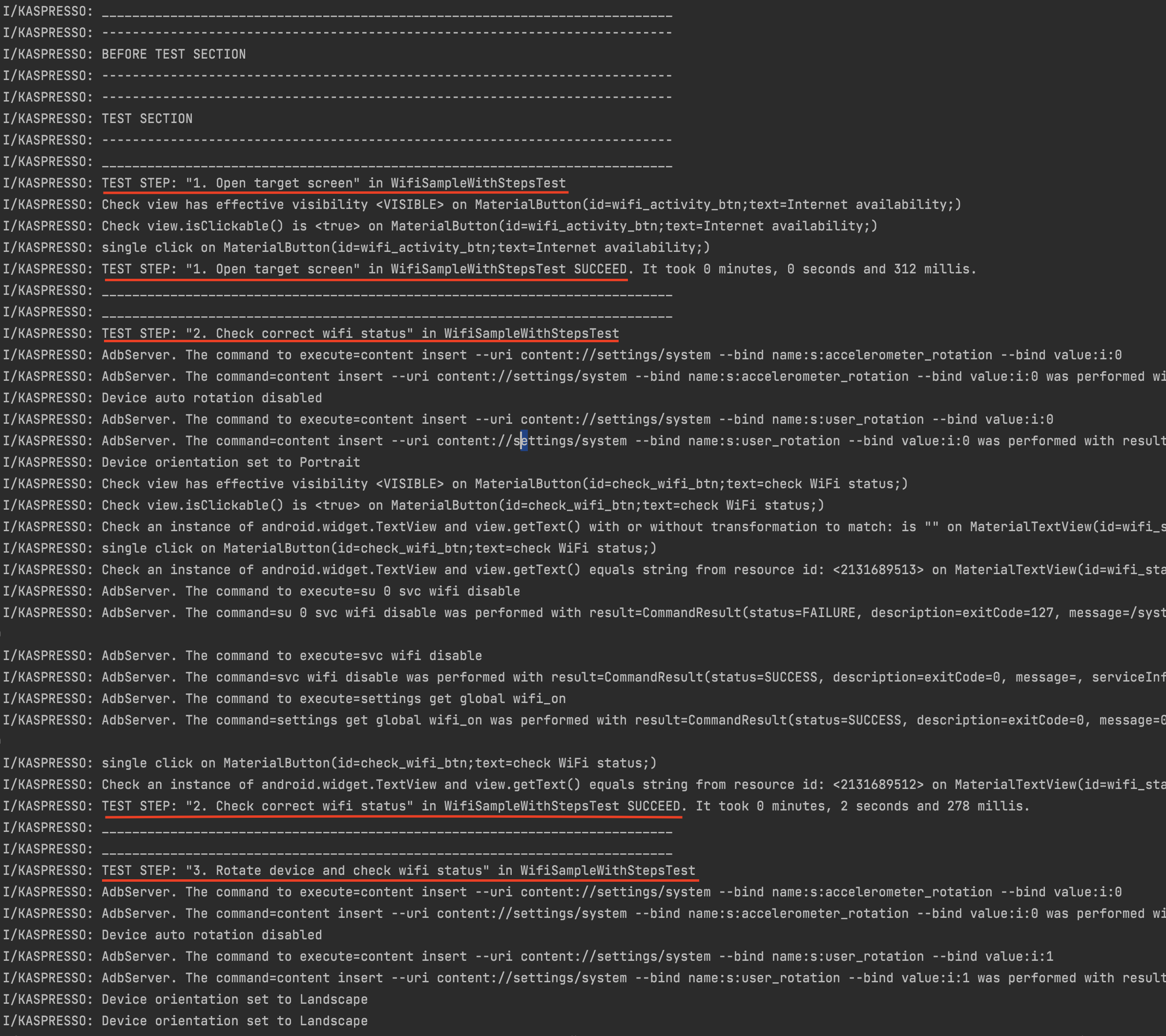
Таким образом, благодаря использованию step-ов, не только наш код стал более понятным и легким для восприятия, но также и логи имеют понятную структуру и позволяют быстро определить, какие этапы выполнялись и какой результат этих операций.
Давайте еще раз запустим этот тест теперь уже с выключенным интернетом. Тест падает. Смотрим логи.
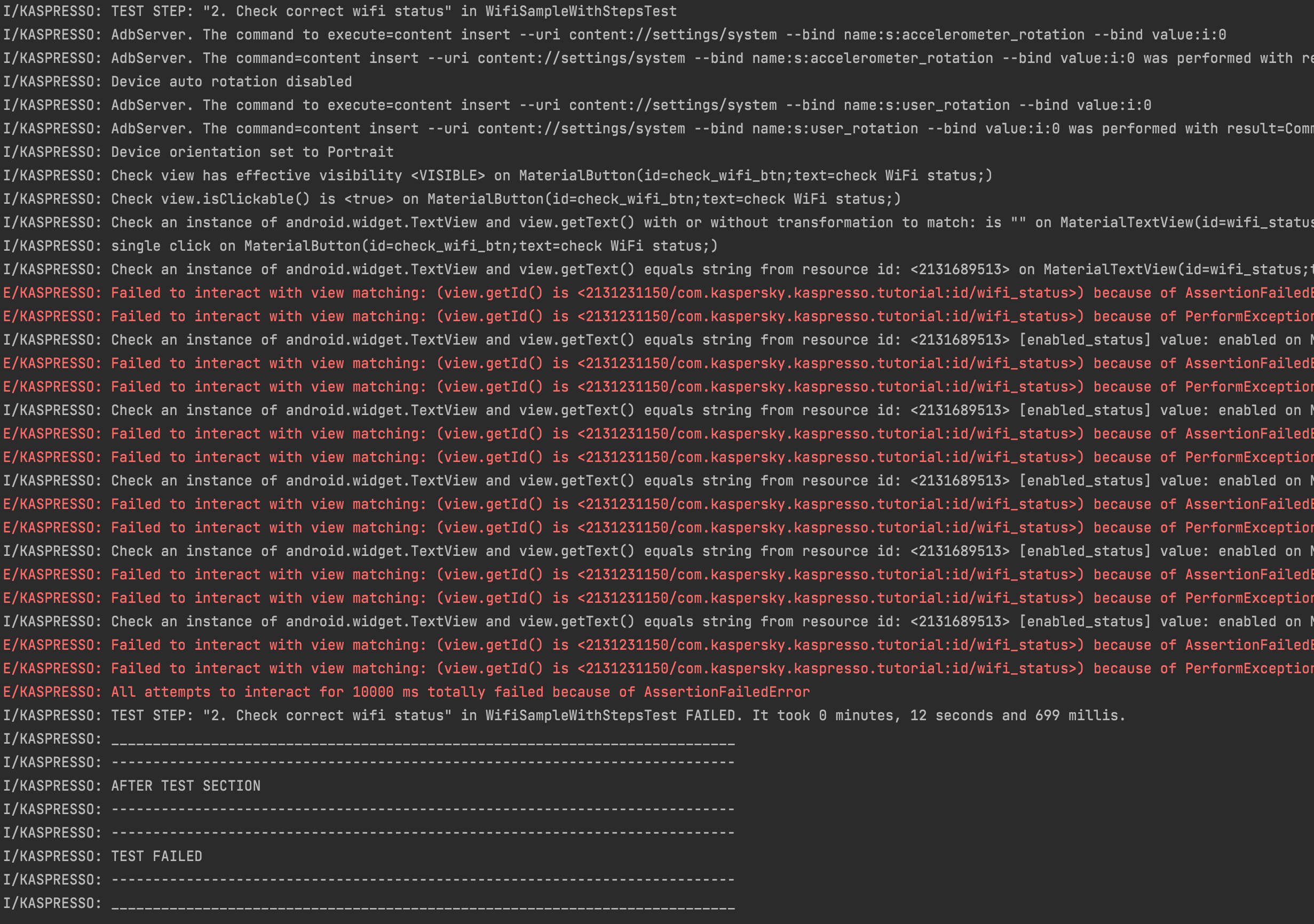
Теперь искать ошибку в тесте становится гораздо проще благодаря понятным логам.
Секции Before и After
Наш код стал гораздо лучше, но осталась одна важная проблема: необходимо, чтобы перед каждым тестом устройство приходило в дефолтное состояние — интернет должен быть включен и установлена книжная ориентация.
В Kaspresso есть возможность добавить блоки before и after. Код внутри блока before будет выполняться перед тестом — здесь мы можем установить настройки по умолчанию. Код внутри блока after будет выполнен после теста. Во время выполнения теста состояние телефона может меняться: мы можем выключить интернет, сменить ориентацию, но после теста нужно вернуть исходное состояние. Делать это мы будем внутри блока after.
Тогда код теста будет выглядеть следующим образом:
package com.kaspersky.kaspresso.tutorial
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
before {
/**
* Перед тестом устанавливаем книжную ориентацию и включаем Wifi
*/
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
device.network.toggleWiFi(true)
}.after {
/**
* После теста возвращаем исходное состояние
*/
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
device.network.toggleWiFi(true)
}.run {
step("Open target screen") {
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
}
step("Check correct wifi status") {
WifiScreen {
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
}
}
step("Rotate device and check wifi status") {
WifiScreen {
device.exploit.rotate()
wifiStatus.hasText(R.string.disabled_status)
}
}
}
}
}
Тест практически готов, можем добавить одно небольшое улучшение. Сейчас после переворота устройства мы проверяем, что текст остался прежним, но не проверяем, что ориентация действительно поменялась. Получается, что если метод device.expoit.rotate() по какой-то причине не сработал, то ориентация не поменяется и проверка на текст будет бесполезной. Давайте добавим проверку, что ориентация девайса стала альбомной.
Assert.assertTrue(device.context.resources.configuration.orientation == Configuration.ORIENTATION_LANDSCAPE)
Теперь полный код теста выглядит так:
package com.kaspersky.kaspresso.tutorial
import android.content.res.Configuration
import androidx.test.ext.junit.rules.activityScenarioRule
import com.kaspersky.kaspresso.device.exploit.Exploit
import com.kaspersky.kaspresso.testcases.api.testcase.TestCase
import com.kaspersky.kaspresso.tutorial.screen.MainScreen
import com.kaspersky.kaspresso.tutorial.screen.WifiScreen
import org.junit.Assert
import org.junit.Rule
import org.junit.Test
class WifiSampleWithStepsTest : TestCase() {
@get:Rule
val activityRule = activityScenarioRule<MainActivity>()
@Test
fun test() {
before {
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
device.network.toggleWiFi(true)
}.after {
device.exploit.setOrientation(Exploit.DeviceOrientation.Portrait)
device.network.toggleWiFi(true)
}.run {
step("Open target screen") {
MainScreen {
wifiActivityButton {
isVisible()
isClickable()
click()
}
}
}
step("Check correct wifi status") {
WifiScreen {
checkWifiButton.isVisible()
checkWifiButton.isClickable()
wifiStatus.hasEmptyText()
checkWifiButton.click()
wifiStatus.hasText(R.string.enabled_status)
device.network.toggleWiFi(false)
checkWifiButton.click()
wifiStatus.hasText(R.string.disabled_status)
}
}
step("Rotate device and check wifi status") {
WifiScreen {
device.exploit.rotate()
Assert.assertTrue(device.context.resources.configuration.orientation == Configuration.ORIENTATION_LANDSCAPE)
wifiStatus.hasText(R.string.disabled_status)
}
}
}
}
}
Итог
В этом уроке мы значительно улучшили наш код, он стал чище, понятнее, и его стало легче поддерживать. Это стало возможным благодаря таким функциям Kaspresso, как step, before и after. Также мы научились выводить сообщения в лог, а также читать логи, фильтровать их и анализировать.
Сообщения журнала могут быть очень полезны в различных сценариях. Они помогают изолировать, воспроизводить и разбираться во множестве проблем, которые возникают в неотладимых средах, таких как производственная среда.
Вы также можете использовать конвейер обработки журналов, такой как стек ELK (Elasticsearch, Logstash и Kibana) или CloudWatch Insights, для сбора полезной статистики, например времени ответа.
Как бэкэнд-разработчик, я нашел эти 5 журналов наиболее полезными.
Запрос и ответ обработчика

Довольно очевидные кандидаты на регистрацию — это объекты запроса и ответа. Теперь, когда вы видите исключение и вызвавший его запрос, гораздо проще воспроизвести проблему. Очень полезно, если вы выполняете микросервисы, но будьте предельно осторожны, чтобы не регистрировать конфиденциальные данные, такие как пароли пользователей или ключи доступа.
Запросы и ответы сторонних служб

Сторонние сервисы находятся вне вашего контроля. Регистрация запросов и ответов от них поможет вам обнаружить множество проблем. Регистрация запроса поможет вам воспроизвести проблему. Регистрация ответа поможет вам увидеть неожиданный код состояния или тело ответа, не похожее на то, что вы ожидаете, из-за того, что ваши учетные данные отозваны или изменились в условиях обслуживания.
Вы можете регистрировать их только тогда, когда происходит что-то неожиданное, чтобы не загромождать ваши журналы, особенно при работе с огромными коллекциями элементов. И не забудьте быть осторожными с учетными данными для ведения журнала и всеми другими видами конфиденциальных данных.
Работа над коллекциями: количество предметов, начало и конец работы над предметом

При работе со списком элементов вы хотите видеть, какой именно элемент вызвал ошибку. Если вы регистрируете начало и окончание обработки отдельных элементов, вы можете позже проанализировать этот журнал и построить статистику, такую как среднее и максимальное время обработки.
Обратной стороной регистрации каждого отдельного элемента является беспорядок, который вы создаете в журналах. Очень сложно найти что-то без использования таких утилит, как grep или процессоры журналов.
Однако регистрация количества элементов не загромождает журнал и поможет вам отлаживать и отслеживать различные сценарии.
Шаги обработки

Когда вы обрабатываете элементы по логическим шагам, целесообразно регистрировать начало и конец этих шагов. Это позволит вам узнать, на каком шаге произошла ошибка или взаимоблокировка, или какой шаг медленнее, чем другой. Просто не забывайте всегда добавлять отметки времени в свои журналы.
Различные ветви If-Else

Помимо вещей, которые уже упоминались, например, более простая отладка в этом конкретном сценарии с использованием процессора журналов, позволит нам извлекать статистику по коэффициенту попадания в кеш.
Правильный журнал ошибок

Вы видите, что не так в этом примере? Он скрывает исходную ошибку, которая может вводить в заблуждение и может занять несколько часов для отладки. Всегда записывайте исходную ошибку, особенно если вы разрабатываете библиотеку. Это значительно упростит отладку.

Отслеживание
Альтернативным решением для регистрации всего является использование системы отслеживания. Существует множество вариантов, включая решения для самостоятельного размещения, такие как Zipkin, и SaaS, например AWS X-Ray.

Интеграция системы отслеживания потребует некоторых изменений кода. Но у этого подхода есть много преимуществ, так как вы сможете быстро визуализировать сложные запросы на нескольких микросервисах, анализировать производительность различных частей и отслеживать ошибки до источника.
Использование системы отслеживания или конвейера обработки журналов позволит вам настраивать оповещения или сообщать об ошибках напрямую вашей команде.

Математика,
вопрос задал adele100110,
1 год назад
Добавить свой ответ
Ответы на вопрос
Ответил Chelovek773
44
Ответ:
шаг 4
Пошаговое объяснение:
нужно 5 * 2
Chelovek773:
а ок))
vikekarmiskuna:
Это правильный ответ?
dinaelevira:
ВЕРНО!!!!!!!!!!!!!!!!!!!!!!!!!!
dinaelevira:
спс
elenamakarenko40:
Спасибо
sabik000:
спс
qwerty6743:
спасибо
evgeniap889:
ГДЕ 5*2 СКАЖИ МНЕ
Добавить свой ответ
Предыдущий вопрос
Следующий вопрос
Новые вопросы
Русский язык,
4 месяца назад
анализ звукобуквеный слова имя и отчества…
Русский язык,
4 месяца назад
Корень в слове трактовать?
Физика,
1 год назад
ФИЗИКА СРОЧНООО Укажите верное утверждение 1. T1 > T2 2. T1 < T2 3. T1 = T2…
История,
1 год назад
Название Дата Участники Результат 30-летняя война 7-летняя война Война за «австрийское наследство» Северная война Война за «испанское наследство»…
Химия,
6 лет назад
Определите тип химической связи и запишите схему ее образования для веществ Li2O, S2,NH3…
Информатика,
6 лет назад
ПОМОЖІТЬ,ДАМ 50 БАЛІВ Допоможіть написати код з інформатики. потрібно написати код за допомогою функції StrReverse у VisualBasic,щоб задане слово прочитало навпаки (слово-оволс,школа-алокш)…

При установке демо-сайта Битрикс на хост столкнулась с несколькими ошибками:
Внимание! На данном шаге произошла ошибка установки продукта.
Текст ошибки:
Service Temporarily Unavailable You have made too many requests per second.
Повторите установку текущего шага. В случае повторения ошибки пропустите шаг.
а так же
4. установка решения
Внимание! На данном шаге произошла ошибка установки продукта.
Текст ошибки:
Connection error. Empty response.
Повторите установку текущего шага. В случае повторения ошибки пропустите шаг.
и тому подобное….
Внимание! На данном шаге произошла ошибка установки продукта.
Текст ошибки:
Fatal error: Allowed memory size of 16777216 bytes exhausted (tried to allocate 980604 bytes) in …/bitrix/modules/advertising/classes/mysql/advertising.php on line 2
Повторите установку текущего шага. В случае повторения ошибки пропустите шаг.

В общем см. скриншот.
Данная ошибка устранилась легко. Создаём файл .htaccess или редактируем его. Вставляем следующий текст:
php_value memory_limit 64M
Загружаем в корневую директорию сайта. Продолжаем установку.
Удачи!
Похожие записи:
битрикс · ошибки установки
Написать коммент
« Установка медиавики на локальный хост
1С Битрикс »
Оглавление
- Падение процесса расчета «Закрытия месяца» через сутки после запуска и расчет длительностью в 25 часов
- Кейс 1: Оптимизируем «Закрытие месяца» в 1С:ERP для нефтяной компании
- Особенности учета на предприятии
- Параметры нагрузочного тестирования и выявление ошибки на этапе расчета себестоимости
- Характеристики тестового стенда
- Ищем причины медленного выполнения этапа «Настройка распределения расходов»
- Настраиваем выполнение создание служебных документов «Распределение расходов» в несколько потоков
- Результат оптимизации этапа «Настройка распределения расходов»
- Ищем ошибку, прерывающую выполнение этапа «Расчет себестоимости»
- Устраняем прерывание процесса «Расчета себестоимости» и настраиваем параллелизм
- Финальная оптимизация «Расчета себестоимости»
- Дополнительная оптимизация времени выполнения «Закрытия месяца» на этапе «Регламентированный учет — отражение документов»
- Кейс 2: Ускоряем расчет себестоимости и закрытие месяца в 1С:ERP
- Характеристики серверов
- Применение подходов к повышению производительности, описанных выше, на другом проекте
- Оптимизируем этап «РаспределениеПартийНДСФИФОСкользящая»
- Оптимизируем этап «ЗаписатьСформированныеДвижения»
- Послесловие
Коротко напомним, что было в первой части статьи «От экспертов 1С‑Рарус».
Выявляем причины долгого «Закрытия месяца» в 1С:ERP и ускоряем выполнение операции. Часть I»:
- Мы разобрались с режимом отладки. Как его включить и что значит каждый настроечный параметр в этом режиме. Поговорили о том, почему и в каких случаях нужно обходиться с этими параметрами особенно осторожно.
- Разобрали три практических случая, и то, как мы сумели одержать победу в этих битвах за производительность.
- А также поделились советами, как можно смотреть на промежуточные результаты при отладке закрытия, когда речь об очень больших временных таблицах.
Прочитать первую часть статьи можно здесь.
Падение процесса расчета «Закрытия месяца» через сутки после запуска и расчет длительностью в 25 часов
В данной части статьи мы продолжим «медитировать» над практическими случаями, происходящими в процессе закрытия месяца.
А именно:
- Что делать, если на предприятии не могли закрыть месяц. После запуска расчета падал с нехваткой места на диске.
- На другом же предприятии закрытие завершалось успешно, но расчет шел 25 часов, что никак не было приемлемо для производственного цикла предприятия.
Итак, в путь!
Кейс 1: Оптимизируем «Закрытие месяца» в 1С:ERP для нефтяной компании
Вначале речь пойдет о крупном предприятии, входящем в список крупнейших российских нефтяных компаний. В составе предприятия развиваются нефтегазодобыча, нефтепереработка, нефтегазохимия, шинный комплекс, сеть АЗС, электроэнергетика, разработка и производство оборудования для нефтегазовой отрасли. В составе холдинга присутствует большое число сервисных структур и количество косвенных затрат для распределения не просто велико, а огромно.
Особенности учета на предприятии
Работа производится на 1С: ERP 2.5.5.82, то есть релиз достаточно свежий и много чего в нем оптимизировано. В ходе работ возникла задача присоединения большого количества обособленных подразделений к текущей системе, вследствие чего было принято решение смоделировать ситуацию для оценки влияния этого присоединения к процедуре закрытия месяца.
 Проверка потенциального влияния в виде проведения нагрузочного тестирования на предприятиях такого масштаба должно быть обязательной практикой. И если вам задают вопрос вида «Сколько понадобится прибавить в серверной мощности?», то правильнее всего занимать позицию эксперта, который даст ответ на этот вопрос только после эксперимента.
Проверка потенциального влияния в виде проведения нагрузочного тестирования на предприятиях такого масштаба должно быть обязательной практикой. И если вам задают вопрос вида «Сколько понадобится прибавить в серверной мощности?», то правильнее всего занимать позицию эксперта, который даст ответ на этот вопрос только после эксперимента.
Особенностью учета данного предприятия является то, что необходимо рассчитать себестоимость по каждому участку и виду деятельности, а себестоимость каждого процесса (вид деятельности, передел) в каждом участке состоит из определенного количества статей расходов. Поэтому аналитика участок * процесс выведена в справочник «Структура предприятия».
Параметры нагрузочного тестирования и выявление ошибки на этапе расчета себестоимости
В модельном примере ввели 1 000 участков и 4 технологических процесса, т. е. 4 000 подразделений (элементов справочника «Структура предприятия») и 30 статей расходов. После чего ввели первичные документы:
- На каждое подразделение документ «Отражение расходов» для всех статей расходов.
- Для каждого подразделения документ «Производство без заказа» (для подразделений промежуточных уровней направление списания — на расходы вышестоящего подразделения, для подразделений верхнего уровня направление выпуска — на склад).
Выбор документов обусловлен тем, что в ходе проекта для присоединяемых СП требовалось автоматизировать производственный процесс только в рамках регламентированного учета. Для простоты на первом этапе ограничились этими настройками и не усложняли их косвенными затратами, амортизацией, ОХР и т. д. Далее приступили к процедуре закрытия месяца.
Процесс работал более-менее в штатном режиме, пока не переходил к этапу «Настройка распределения расходов». На этом этапе производится распределение затрат на другие затраты и выпущенную продукцию, в ходе которого создаются служебные документы «Распределение прочих затрат» на некоторое сочетание аналитик Организация, Подразделение, Статья расходов, Аналитика расходов.
В нашем примере мы получали сочетание аналитик порядка 1000 * 4 * 30 = 120 000 документов. Быстрая оценка скорости текущего создания документов (2–3 документа в секунду) показала, что только этот этап закрытия месяца будет длиться более 13 часов.
Но, даже после ожидания окончания этого этапа, процесс, переходя к этапу расчета себестоимости, работал около 8 часов, пока не вылетал с ошибкой. Таким образом, можно было прождать почти сутки и все равно не дождаться результата.
Характеристики тестового стенда
- СУБД: MS SQL;
- Платформа 1С:Предприятие: 8.3.17;
- 1C:ERP: 2.5.5.82.
Сервер приложений:
- Оперативная память: 160 Гб;
- Процессор: 3.0 ГГц, 20 ядер.
Ищем причины медленного выполнения этапа «Настройка распределения расходов»
Отметим, что данный этап выполняется до начала этапа «Расчет себестоимости», а значит, нет возможности использовать методы анализа (отчет «Протокол расчета себестоимости», промежуточный протокол), которые мы описывали в первой статье. Поэтому будем анализировать общими способами, используемыми для расследования произвольных проблем производительности.
Предварительно мы уже описали назначение этапа и ход его работы — создание служебных документов «Распределение расходов» по всевозможным сочетаниям неких аналитик. То есть время этапа напрямую зависит от:
- длительности операции создания и записи одного документа;
- количества создаваемых документов.
Проанализируем длительность записи одного документа. Самый простой способ сделать это — снять замер производительности операции. Для этого во время выполнения этапа заглянем в журнал регистрации, чтобы убедиться, что система занята именно созданием документов «Распределений расходов». После чего можно установкой отладчика в процедуре модуля документа «ПередЗаписью» начать и завершить замер на следующей итерации создания документа.

Замер показал, на что тратится время (примерно по 0.5–0.6 секунд) создания одного документа. Львиную часть этого времени занимало выполнение запроса — небольшого и несложного, казалось бы.

Для сравнения выполнили этот запрос на сервере с другими настройками MS SQL. Запрос выполнялся моментально, буквально сотые доли секунды. Такая разница была вызвана преимущественно настройкой включенного параллелизма SQL (параметр max degree of parallelism).
Ниже приведена разница в получаемых планах запросов.

Итак, только настройкой maxdop мы значительно ускорили общее время выполнения этапа. Но, конечно, итоговое время операции все равно было слишком велико. При этом не было смысла рассматривать возможности улучшения именно этого запроса, ведь, как ни крути, даже если этот запрос стал бы выполняться 0 секунд, в пересчете на все количество создаваемых документов, время этапа было бы непозволительно большим.
Настраиваем выполнение создание служебных документов «Распределение расходов» в несколько потоков
Поэтому следующим шагом к ускорению этапа стало применение возможности выполнения операций создания документов несколькими фоновыми заданиями одновременно.
Следует с осторожностью и вдумчивостью подходить к применению возможности распараллеливания, так как необходимо исключить важные проблемы, например, возможное пересечение набора аналитик в разных фоновых заданиях, что может вызвать блокировки.
В нашем случае документы по наборам аналитик не пересекались, поскольку изначально данные собираются запросом по разным значениям аналитик и опасаться было нечего. В общем случае необходимо удостовериться, что документы и их движения, создаваемые разными фоновыми заданиями, не будут содержать одни и те же значения аналитик (измерений).
Для реализации вышенаписанного определим участок кода, в котором производится настройка распределения расходов и создание документов. Самый простой способ сделать это — понять, чем занимается система в момент выполнения этой операции. Способов для этого достаточно: заглянуть в журнал регистрации, подключить отладчик и выполнить его остановку, настроить сбор логов технологического журнала, включить трассировку на сервере СУБД… Выбор конкретного способа осуществляется исходя из возможностей — не всегда бывает включена серверная отладка, не всегда журнал регистрации покажет что-то существенное, не всегда есть доступ к серверу 1С (серверу СУБД).
Итак, запускаем процедуру закрытия месяца, дожидаемся начала выполнения нашей «долгой» операции, отслеживая ее начало по журналу регистрации. В нашем случае воспользуемся возможностью получения стека вызовов конфигуратором в момент остановки отладчика, из которого и определяем процедуру, которую будем модифицировать — процедура «СформироватьДокументы» модуля менеджера документа «РаспределениеПрочихЗатрат».

Алгоритм работает следующим образом:
- Вначале, анализируя данные регистров «Прочие расходы», «Себестоимость товаров» и «Материалы и работы в производстве», для статей расходов с установленным вариантом распределения расходов (на производственные затраты) определяются движения статей расходов с указанными выше аналитиками (Подразделение, Аналитика расходов, Направления деятельности и др.). Учитываются ранее сформированные документы «Распределения расходов» и в обработку берутся только те, по которым еще не было распределения (есть остаток распределения). Подобранные аналитики образуют массив настроек распределения.
- Далее производится обход массива циклом с вызовом функции «СформироватьДокумент» для каждого элемента массива.
Модифицируем процедуру следующим образом:
- Вначале определим количество фоновых заданий, исходя из параметра закрытия «МаксимальноеКоличествоФЗЗаписи» и общего количества настроек (создаваемых документов). Привязка именно к этому параметру несет исключительно рекомендуемый характер. Можно привязываться к другому параметру, подходящему вам по смыслу, либо добавлять свой собственный.
- Затем для каждого номера задания соберем те настройки, которые должно обрабатывать именно это задание и передадим их в виде параметров фонового задания. В теле процедуры самого фонового задания будет все та же типовая функция «СформироватьДокумент».
Ниже приведена возможная реализация распараллеливания операции создания документов «Распределение прочих затрат»:

В процедуре вызывается общая процедура, являющаяся частью механизма работы с потоками. Полный листинг механизма:
Функция МногопоточнаяОбработкаЗаданийРасчетаСС(Параметры)
МассивРезультатов = Новый Массив;
ПроцедураОбработки = Параметры.Процедура;
ПараметрыДанных = Параметры.Данные;
ПараметрыРасчета = Параметры.ПараметрыРасчета;
Потоки = Новый Массив;
КоличествоПотоков = ПараметрыРасчета.МаксимальноеКоличествоФЗЗаписи;
КоличествоОбъектовДляОбработки = ПараметрыДанных.ТаблицаДанных.Количество();
ОсталосьОбработать = КоличествоОбъектовДляОбработки;
КоличествоПотоковКЗапуску = Мин(КоличествоОбъектовДляОбработки, КоличествоПотоков);
ПоследнийЭлемент = -1;
Пока ОсталосьОбработать > 0 Цикл
РазмерПорции = Цел(КоличествоОбъектовДляОбработки / КоличествоПотоковКЗапуску);
МассивТаблиц = РазделитьТаблицуНаПорции(ПараметрыДанных.ТаблицаДанных, РазмерПорции, КоличествоПотоковКЗапуску);
Для Каждого ДанныеПотока Из МассивТаблиц Цикл
// инициализируем новый поток
Поток = НовоеОписаниеПотока(ПроцедураОбработки.Имя);
Поток.НаименованиеЗадания = ПроцедураОбработки.ПредставлениеЗадания;
// заполним его параметры
Поток.ПараметрыПроцедуры.Вставить("ДанныеКОбработке", ДанныеПотока);
Для Каждого Параметр Из ПараметрыДанных Цикл
Поток.ПараметрыПроцедуры.Вставить(Параметр.Ключ, Параметр.Значение);
КонецЦикла;
ЗапуститьОбработкуВФоне(Поток);
ОсталосьОбработать = ОсталосьОбработать - ДанныеПотока.Количество();
Потоки.Добавить(Поток);
КонецЦикла;
КонецЦикла;
ОжидатьЗавершениеВсехПотоков(Потоки, МассивРезультатов);
Возврат МассивРезультатов;
КонецФункции
Функция РазделитьТаблицуНаПорции(ТаблицаДанных, РазмерПорции, КоличествоТаблиц = Неопределено)
МассивПорций = Новый Массив;
КоличествоДанных = ТаблицаДанных.Количество();
КоличествоТаблиц = ?(КоличествоТаблиц = Неопределено, Цел(КоличествоДанных / РазмерПорции), КоличествоТаблиц);
ПоследнийЭлемент = -1;
Для НомерТаблицы = 1 По КоличествоТаблиц Цикл
ПервыйЭлемент = ПоследнийЭлемент + 1;
// определим последний обрабатываемый элемент потока - в зависимости от размера порции,
// либо последний элемент массива данных (если это последний поток)
Если НомерТаблицы = КоличествоТаблиц Тогда
ПоследнийЭлемент = КоличествоДанных - 1;
Иначе
ПоследнийЭлемент = НомерТаблицы*РазмерПорции - 1;
КонецЕсли;
ДанныеПорции = ДанныеДляОбработки(ТаблицаДанных, ПервыйЭлемент, ПоследнийЭлемент);
МассивПорций.Добавить(ДанныеПорции);
КонецЦикла;
Возврат МассивПорций;
КонецФункции
Функция ДанныеДляОбработки(ТаблицаДанных, ПервыйЭлемент, ПоследнийЭлемент)
ВозвращаемыеДанные = ТаблицаДанных.СкопироватьКолонки();
Для Сч = ПервыйЭлемент ПО ПоследнийЭлемент Цикл
НоваяСтр = ВозвращаемыеДанные.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтр, ТаблицаДанных[Сч])
КонецЦикла;
Возврат ВозвращаемыеДанные;
КонецФункции
#Область РаботаСПотоками
Функция НовоеОписаниеПотока(ИмяМетода)
Описание = Новый Структура;
Описание.Вставить("ИдентификаторЗадания", Неопределено);
Описание.Вставить("Процедура", ИмяМетода);
Описание.Вставить("АдресРезультата", "");
Описание.Вставить("НаименованиеЗадания", "");
Описание.Вставить("ПараметрыПроцедуры", Новый Структура);
Возврат Описание;
КонецФункции
Процедура ЗапуститьОбработкуВФоне(Поток)
ПараметрыВыполнения = ДлительныеОперации.ПараметрыВыполненияВФоне(Неопределено);
ПараметрыВыполнения.НаименованиеФоновогоЗадания = Поток.НаименованиеЗадания;
ПараметрыВыполнения.ОжидатьЗавершение = 0;
ПараметрыВыполнения.АдресРезультата = ПоместитьВоВременноеХранилище(Неопределено, Новый УникальныйИдентификатор);
РезультатЗапуска = ДлительныеОперации.ВыполнитьВФоне(Поток.Процедура, Поток.ПараметрыПроцедуры, ПараметрыВыполнения);
Поток.АдресРезультата = РезультатЗапуска.АдресРезультата;
Статус = РезультатЗапуска.Статус;
Если Статус = "Выполняется" Тогда
Поток.ИдентификаторЗадания = РезультатЗапуска.ИдентификаторЗадания;
ИначеЕсли Статус <> "Выполняется" И Статус <> "Выполнено" Тогда
ВызватьИсключение РезультатЗапуска.КраткоеПредставлениеОшибки;
КонецЕсли;
КонецПроцедуры
Процедура ОжидатьЗавершениеВсехПотоков(Потоки, МассивРезультатов)
Пока Потоки.Количество() > 0 Цикл
Если НЕ ЗавершитьПотокиВыполнившиеФЗ(Потоки, МассивРезультатов) Тогда
ОжидатьЗавершениеПотока(Потоки[0]);
КонецЕсли;
КонецЦикла;
КонецПроцедуры
Функция ЗавершитьПотокиВыполнившиеФЗ(Потоки, МассивРезультатов)
ЕстьЗавершенныеПотоки = Ложь;
Индекс = Потоки.Количество() - 1;
Пока Индекс >= 0 Цикл
Поток = Потоки[Индекс];
ИдентификаторЗадания = Поток.ИдентификаторЗадания;
Если ИдентификаторЗадания <> Неопределено Тогда
ЗаданиеВыполнено = ДлительныеОперации.ЗаданиеВыполнено(ИдентификаторЗадания);
КонецЕсли;
Если ИдентификаторЗадания = Неопределено ИЛИ ЗаданиеВыполнено Тогда
Если ЗначениеЗаполнено(Поток.АдресРезультата) Тогда
Результат = ПолучитьИзВременногоХранилища(Поток.АдресРезультата);
Если Результат <> Неопределено Тогда
МассивРезультатов.Добавить(Результат);
КонецЕсли;
УдалитьИзВременногоХранилища(Поток.АдресРезультата);
КонецЕсли;
Потоки.Удалить(Индекс);
ЕстьЗавершенныеПотоки = Истина;
КонецЕсли;
Индекс = Индекс - 1;
КонецЦикла;
Возврат ЕстьЗавершенныеПотоки;
КонецФункции
Функция ОжидатьЗавершениеПотока(Поток, Длительность = 1)
Если Поток <> Неопределено И Поток.ИдентификаторЗадания <> Неопределено Тогда
Задание = ФоновыеЗадания.НайтиПоУникальномуИдентификатору(Поток.ИдентификаторЗадания);
Если Задание <> Неопределено Тогда
Попытка
Задание.ОжидатьЗавершенияВыполнения(Длительность);
Возврат Истина;
Исключение
Возврат Ложь;
КонецПопытки;
КонецЕсли;
КонецЕсли;
Возврат Истина;
КонецФункции
#КонецОбласти
При этом в процедуру, которую будут вызывать фоновые задания, выведен алгоритм, который ранее выполнялся однопоточно (за исключением того, что теперь результаты потока помещаются во временное хранилище):

Количество фоновых заданий, создаваемых в процедуре, устанавливается из значения параметра операции закрытия месяца «Максимальное количество одновременно выполняемых заданий записи». В нашем случае это 10 потоков.
Результат оптимизации этапа «Настройка распределения расходов»
Общее время выполнения этапа после включения maxdop и параллельной записи документов — 1–1.5 часов.
Более того, сами документы можно создавать предварительно, не в процедуре закрытия месяца, а например отдельным регламентным заданием, выполняемым в течении месяца, что также позволяет выиграть время.
Ищем ошибку, прерывающую выполнение этапа «Расчет себестоимости»
Следующим долгим, и пожалуй самым важным этапом операции закрытия, стал этап расчета себестоимости. Напомним, что изначально этот этап вообще не завершался, после долгого времени ожидания процесс падал с ошибкой нехватки места на диске, где располагалась база tempDB.

Углубимся немного в теорию: одно из назначений служебной базы tempDB — хранение временных таблиц, создаваемых в запросах. Не каждая временная таблица будет создаваться в tempDB, в рядовых случаях они создаются в оперативной памяти сервера. Но в некоторых случаях, например, если получаемая таблица слишком велика, временная таблица может создаться в tempDB.
Ошибка, которая привела к прерыванию процесса расчета, наталкивает на мысль о том, что в данном этапе выполнялось большое количество тяжелых запросов с использованием большого количества временных таблиц. К тому же ситуацию может осложнить индексирование этих временных таблиц, ведь индексы тоже будут создаваться в tempDB, а также использование оператора SORT, что мы и видим в описании ошибки.
Теперь нам необходимо понять на каком шаге расчета себестоимости происходит эта ошибка и каким участком кода она вызвана.
Для того, чтобы узнать на каком шаге произошла ошибка, можно обратиться к журналу регистрации. В нем фиксируются все ключевые вехи этапов — начало, характеристики, инициализации и т. д. Найдем ближайшее событие расчета, возникшее перед ошибкой. В нем и содержится имя шага этапа.

В нашем случае ошибка возникла при прохождении этапа «РаспределитьДолиПроизводственныхРасходов».
Итак, мы знаем на каком шаге этапа есть проблема, найдем теперь процедуру, обрабатывающую данный шаг. Получить ее можно разными способами. Один из них — осуществить глобальный поиск по конфигурации по ключевому имени этапа — «РаспределитьДолиПроизводственныхРасходов». Так мы выйдем на процедуру
«РасчетСебестоимостиПостатейныеЗатраты.РаспределитьДолиПроизводственныхРасходов».
Теперь запустим расчет снова и в режиме отладки попробуем понять почему на нее уходит столько времени и в итоге процесс падает с ошибкой. Для вспомогательного анализа будем следить за текущей активностью MS SQL, также настроим сбор счетчиков монитора производительности MS SQL — Perfomance Monitor.
Алгоритм данного этапа программно формирует множество текстов запросов для дальнейшего пакетного выполнения в объекте конфигурации «СхемаЗапроса». При этом внутри этой схемы может быть очень большое число пакетов запросов, например, в нашем случае их около 8 000. Поэтому ее выполнение может быть очень длительным по времени в зависимости от ряда причин. Одна из них — неоптимальный код. В релизе 2.5.5.82 мы заметили, что происходит циклическое и избыточное заполнение служебных описаний групп при составлении отборов запроса:

Внутри цикла, выполняемого более 173 000 раз, выполняется функция «ОпределитьГруппу», внутри которой также происходит циклический обход таблицы значений более 6 000 раз. Далее по полученным описаниям групп составляется текст мегазапроса на выполнение. Результаты запросов схемы помещаются во временные таблицы для дальнейшей обработки, следующие элементы схемы используют результаты предыдущих элементов, в результате чего на одном из запросов выделенное место для tempDB заканчивается и процесс прерывается.
Наблюдая за счетчиком «Free Space in tempdb (KB)» («Свободное пространство в tempdb»), можно увидеть монотонное уменьшение показателя счетчика на протяжении нашей операции:
»")
Интенсивность процесса записи в базу можно увидеть с помощью счетчика «Page writes/sec» («Операций записей страниц в секунду»):

А выполняемые при этом планы показывали, что идет активная работа с временными таблицами и операциями над ними.

Теперь взглянем на счетчик «Page Life Expectancy» («Примерный срок хранения страницы»). Данный счетчик показывает сколько в среднем секунд страница хранится в буфере.

Видим, что наблюдаются просадки счетчика. Это говорит о том, что в эти моменты выполнялись запросы, читающие большое количество страниц с диска, которые замещали ранее прочитанные страницы в буфере. И скорее всего, запросы выполняли сканирование без использования поиска по индексу, так как местами значение счетчика близко к нулю.
Устраняем прерывание процесса «Расчета себестоимости» и настраиваем параллелизм
В нашем случае исправление этой ошибки было выполнено силами разработчиков 1С:ERP. Исправления значительно уменьшили объем читаемых и обрабатываемых данных, вследствие чего более не было нагрузки на tempDB.
Теперь рассмотрим более подробно влияние настроек СУБД на нашу операцию.
В предыдущей части статьи мы отметили, что процессам «Закрытия месяца» может помочь включение настройки параллелизма на сервере SQL. Мы проверили это влияние, установили следующие настройки MS SQL:
- max degree of parallelism = 4;
- cost threshold for parallelism = 100;
- legacy cardinality estimation = on.
Данные настройки были подобраны для нашего сервера индивидуально. Отметим, что нет универсальной «хорошей» настройки параллелизма, первичное назначение характеристик этих опций может осуществляться исходя из физических параметров сервера СУБД (количества ядер процессоров, поддержка Hyper-Threading и др.), а далее их следует подбирать, исходя из анализа и наблюдениями за ростом ожиданий, нагрузкой CPU и, конечно же, общей производительности работы пользователей.
Примечание:
В общем случае могут быть различные типы ожиданий, например такие как CXPACKET (ожидание завершения отстающих потоков главным потоком) , ожидания ввода-вывода (PageIOLatch_XX) и даже взаимоблокировки. Разговор об этом выходит за рамки данной статьи. Один из случаев страничных блокировок разобран в одной из наших предыдущих статей «Страничные блокировки в MS SQL Server при проведении документов».
Но заметим, что можно рассмотреть вариант установки данных параметров только на время процедуры закрытия месяца, если включение параллелизма для штатных операций вызывает замедления. В любом случае, не стоит пренебрегать данными возможностями SQL, когда они есть, зачастую они несут положительный эффект для различных операций.
После устранения ошибки неоптимального кода и установки настроек MS SQL этап наконец выполнился и время его работы составило 5.5 часа. Хотя время значительно улучшилось, оно не достигло целевых значений. Поэтому продолжаем расследование дальше.
Финальная оптимизация «Расчета себестоимости»
Для определения следующего узкого места обратимся к протоколу расчета. Это специального вида отчет, позволяющий увидеть ключевые характеристики прохождения конкретного расчета себестоимости. Подробно о том как его получить и читать мы рассматривали в первой части публикации «Выявляем причины долгого «Закрытия месяца» в 1С:ERP и ускоряем выполнение операции. Часть I».
Нас интересует топ самых длительных операций этапа «Расчет себестоимости».

Видим, что этапы №90 и №91 суммарно занимают более 4 часов, т. е. значительное время всей операции расчета себестоимости, а значит, именно ими следует заняться.
Для начала рассмотрим этап №90 — ЗаписатьСформированныеДвижения. Здесь записываются наборы записей регистров по ранее полученным таблицам движений. Типовой код записи предусматривает возможность параллельной записи несколькими фоновыми заданиями. Проанализируем процедуру записи движений «НачалоЗаписиДвижений» общего модуля «РасчетСебестоимостиПрикладныеАлгоритмы».

Общее количество движений документов делится на порции с учетом определенных условий (например, движения одного документа попадают строго в одну порцию). Далее, в проходе по количеству порций, отбираются движения только текущей порции и запускается фоновое задание записи движений:

Видим, что алгоритм производит разбиение на порции в зависимости от настроек блока «Управление многопоточностью» операции «Распределение затрат и расчет себестоимости». В зависимости от оборудования сервера, а также его конфигурации, эти параметры можно редактировать.
В нашем случае мы установили следующие значения параметров:

Теперь рассмотрим этап №91 — ЗарегистрироватьКОтражениюВРегламентированномУчете.
Найдем процедуру, содержащую алгоритм этапа способом, описанным выше — это процедура «ВернутьДокументыКОтражению» общего модуля «РеглУчетПроведениеСервер». Анализируя алгоритм, видим, что в процедуре определяются документы к отражению (с изменившимися движениями), затем происходит запись документов в служебный регистр сведений «ОтражениеДокументовВРеглУчете». В нашем случае документов к отражению — более 100 000.
Будем записывать этот регистр параллельно. Регистр подчинен регистратору, документы-регистраторы сгруппированы, а значит пересечений в измерениях не будет наблюдаться. Разбиение на порции осуществим аналогично приведенному выше примеру (как это сделано в типовой процедуре «НачалоЗаписиДвижений» общего модуля «РасчетСебестоимостиПрикладныеАлгоритмы»:

Определив максимальный номер порции (количество фоновых заданий), запускаем на выполнение задание со своим набором данных для обработки (код примера прохода цикла показан выше).
Для определения количества заданий в нашем случае был добавлен отдельный параметр закрытия — «КоличествоДвиженийВФЗЗаписиЭтапаОтраженияВРегУчете», но можно привязаться и к существующим, если они подходят под конкретные условия.
В результате ускорения этих этапов время выполнения расчета себестоимости сократилось до 3.5 часов, что полностью устроило заказчика.

Итак, мы рассмотрели способы расследования проблемы долгого расчета себестоимости как с помощью анализа протокола расчета (итогового, промежуточного), так и стандартными способами расследования проблем производительности, в случае, когда данных протокола недостаточно, либо их вообще нет.
Дополнительная оптимизация времени выполнения «Закрытия месяца» на этапе «Регламентированный учет — отражение документов»
Несмотря на то, что время расчета себестоимости достигло целевого результата, общее время закрытия все равно не устраивало Заказчика, а именно длительность одного из финальных этапов — отражения документов в регламентированном учете. Его время составляло в среднем 2–3 часа. Необходимо было ускорить этот этап хотя бы в два раза.
Сама процедура весьма проста — определяется набор документов, для которых необходимо произвести запись движений в различные регистры, и, собственно, производится запись. В самом алгоритме улучшить нечего. Долгая длительность этапа связана с большим количеством обрабатываемых документов. Поэтому попробуем решить задачу все тем же способом — разбиения документов на порции и обработкой этих порций отдельными фоновыми заданиями.
Итак, обратимся к процедуре «ОтразитьВсе» общего модуля «РеглУчетПроведениеСервер». Для каждого типа документов, для которого будет производиться запись в регистры рег. учета, вызывается процедура «ОтразитьДокументыПакетно». Доработаем ее для возможности разбиения на отдельные фоновые задания.
Обратим внимание, что после завершения работы всех заданий необходимо получить от каждого задания информацию о его прогрессе завершения: количество отраженных документов, количество документов с ошибками. В нашем примере код по работе с результатами выполнения заданий вынесен в отдельный модуль.

Логику работы перенесем в процедуру «СформироватьТаблицыОтбораДанныхФЗ» — аналог типовой процедуры «СформироватьТаблицыОтбораДанных» с разбиением данных для выполнения несколькими потоками.
Само разбиение снова выполним, назначая строкам временной таблицы данных разделитель (номер порции):

Модифицированный алгоритм показал отличные результаты — время этапа сократилось до 30–40 минут.
Итак, общее время закрытия (всех этапов) составило 4 с небольшим часа. По сравнению с начальным временем закрытия (напомним, 24 часа до момента падения процесса) — шестикратная разница.
Кейс 2: Ускоряем расчет себестоимости и закрытие месяца в 1С:ERP
Далее приведем пример оптимизации закрытия месяца на другом предприятии, которое только начинало свою работу в 1С:ERP, перейдя на него с другой системы учета. Особенностью являлось то, что проблемным оказалось первое закрытие в истории компании на ERP – только этап расчета себестоимости длился 29 часов.
Характеристики серверов
- СУБД: MS SQL;
- Платформа 1С:Предприятие: 8.3.17;
- 1C:ERP: 2.5.5.52.
Сервер приложений (3 рабочих сервера, 2 центральных):
- Оперативная память: 288 Гб;
- Процессор: 3.0 ГГц, 44 ядра.
Применение подходов к повышению производительности, описанных выше, на другом проекте
Ранее в статье мы рассмотрели оптимизацию нескольких этапов закрытия месяца. Применение подобных подходов возможно и на других медленных этапах, если их логика позволяет.
Проанализируем еще раз, из чего складывается такая большая длительность расчета себестоимости, по шагам, описанным выше:

Оптимизируем этап «РаспределениеПартийНДСФИФОСкользящая»
Видим, что в топе операций — этап «РаспределениеПартийНДСФИФОСкользящая». Простой глобальный поиск по конфигурации по имени этапа приводит нас к месту действия события — процедура «РасчетСебестоимостиНДС.ИнициализироватьТаблицыДляДокументовВводаОстатков».

Ее анализ показывает, что запросом выбираются документы Ввода начальных остатков за период расчета, затем последовательно в цикле происходит обработка — выполнение нового запроса по конкретному документу с последующим помещением данных во временную таблицу. Конечно, если в месяце закрытия нет документов Ввода остатков, то и не будет возникать этот этап.
В нашем случае проблема возникла при первом закрытии, т. е. в месяце закрытия было много документов Ввода начальных остатков. Последовательный обход большого количества документов с отдельной обработкой каждого привел к непозволительно длительному времени прохождения этапа.
И, так как после получения результатов закрытия постоянно вносились правки в документы, процедура проводилась снова и снова, поэтому не было никакой возможности смириться с длительностью этапа.
Снова понимаем, что для решения проблемы здесь отлично поможет метод разбиения множества документов на порции с последующей обработкой их разными сеансами. Реализация алгоритма схожа с реализацией из п. «Настройка распределения расходов» и использует тот же механизм работы с потоками. Поэтому приведем только кусочек кода доработанной процедуры «ИнициализироватьТаблицыДляДокументовВводаОстатков»:

Внутри процедуры, выполняемой каждым фоновым заданием, находится типовой код, который раньше выполнялся в цикле основной процедуры. Ранее, как было отмечено выше, на каждый документ собиралась временная таблица с данными, наша процедура делает то же самое. Но необходимо передать результаты этой процедуры в родительский сеанс — сделать это можно через временное хранилище (либо через запись в базу данных, если первый вариант по каким-то причинам не подходит). Отметим, что в данном случае возникает необходимость конвертации данных временной таблицы в иной формат (например, таблицу значений), так как менеджер временных таблиц не сериализуется.
Получив результаты всех дочерних сеансов, производится их объединение в единую временную таблицу. В зависимости от количества запускаемых потоков, можно добиться улучшения времени этапа в несколько раз, что и было сделано.
Оптимизируем этап «ЗаписатьСформированныеДвижения»
Второе место в топе операций занимает этап №89 — «ЗаписатьСформированныеДвижения», его оптимизация рассматривалась выше (в релизе 2.5.5 он шел под номером 90).
Улучшение производительности двух этапов расчета себестоимости позволило закрыть месяц за 5.5–6 часов, что значительно лучше исходных показателей.
Послесловие
Давайте подводить итоги нашей дилогии, которая дальше может вырасти и в трилогии и даже в некую сагу.
Во-первых, мы надеемся, что сумели показать, что расследования в области оптимизации закрытия месяца в 1С:ERP выходят за рамки штатной экспертизы по производительности, так как требуют от вас понимания архитектуры решения, математических принципов функционирования, методологии отладки закрытия.
Во-вторых, важно кейсы разделяются на два больших класса: там, где мы смогли получить протокол расчета и где не смогли.
В-третьих, для случаев, когда протокол расчета получен, надо научаться читать этот протокол. И хорошо ориентироваться в опциях настройки отладки закрытия. Потому что часть из них нельзя включать без нужды из-за риска ещё большего замедления процесса «Закрытия месяца».
Четвертый вывод состоит в том, что если закрытия не удалось дождаться, то не следует опускать руки. В этом случае в полной мере понадобятся ваши навыки эксперта по производительности.
Пятое — в ряде случаев мы способны оптимизировать код самостоятельно, а в некоторых разумнее открыть проект ЦКПТ и взаимодействовать с коллегами из 1С. Мы показали это в первом кейсе второй части статьи.
Надеемся, что данный цикл публикаций про оптимизацию производительности закрытия в ЕРП будет полезным для вас и до встречи в новом 2022 году.
Авторы статьи

Черанев Андрей