Привет, Хабр! Представляю вашему вниманию перевод статьи «Error and Transaction Handling in SQL Server. Part One – Jumpstart Error Handling» автора Erland Sommarskog.
1. Введение
Эта статья – первая в серии из трёх статей, посвященных обработке ошибок и транзакций в SQL Server. Её цель – дать вам быстрый старт в теме обработки ошибок, показав базовый пример, который подходит для большей части вашего кода. Эта часть написана в расчете на неопытного читателя, и по этой причине я намеренно умалчиваю о многих деталях. В данный момент задача состоит в том, чтобы рассказать как без упора на почему. Если вы принимаете мои слова на веру, вы можете прочесть только эту часть и отложить остальные две для дальнейших этапов в вашей карьере.
С другой стороны, если вы ставите под сомнение мои рекомендации, вам определенно необходимо прочитать две остальные части, где я погружаюсь в детали намного более глубоко, исследуя очень запутанный мир обработки ошибок и транзакций в SQL Server. Вторая и третья части, так же, как и три приложения, предназначены для читателей с более глубоким опытом. Первая статья — короткая, вторая и третья значительно длиннее.
Все статьи описывают обработку ошибок и транзакций в SQL Server для версии 2005 и более поздних версий.
1.1 Зачем нужна обработка ошибок?
Почему мы обрабатываем ошибки в нашем коде? На это есть много причин. Например, на формах в приложении мы проверяем введенные данные и информируем пользователей о допущенных при вводе ошибках. Ошибки пользователя – это предвиденные ошибки. Но нам также нужно обрабатывать непредвиденные ошибки. То есть, ошибки могут возникнуть из-за того, что мы что-то упустили при написании кода. Простой подход – это прервать выполнение или хотя бы вернуться на этап, в котором мы имеем полный контроль над происходящим. Недостаточно будет просто подчеркнуть, что совершенно непозволительно игнорировать непредвиденные ошибки. Это недостаток, который может вызвать губительные последствия: например, стать причиной того, что приложение будет предоставлять некорректную информацию пользователю или, что еще хуже, сохранять некорректные данные в базе. Также важно сообщать о возникновении ошибки с той целью, чтобы пользователь не думал о том, что операция прошла успешно, в то время как ваш код на самом деле ничего не выполнил.
Мы часто хотим, чтобы в базе данных изменения были атомарными. Например, задача по переводу денег с одного счета на другой. С этой целью мы должны изменить две записи в таблице CashHoldings и добавить две записи в таблицу Transactions. Абсолютно недопустимо, чтобы ошибки или сбой привели к тому, что деньги будут переведены на счет получателя, а со счета отправителя они не будут списаны. По этой причине обработка ошибок также касается и обработки транзакций. В приведенном примере нам нужно обернуть операцию в BEGIN TRANSACTION и COMMIT TRANSACTION, но не только это: в случае ошибки мы должны убедиться, что транзакция откачена.
2. Основные команды
Мы начнем с обзора наиболее важных команд, которые необходимы для обработки ошибок. Во второй части я опишу все команды, относящиеся к обработке ошибок и транзакций.
2.1 TRY-CATCH
Основным механизмом обработки ошибок является конструкция TRY-CATCH, очень напоминающая подобные конструкции в других языках. Структура такова:
BEGIN TRY
<обычный код>
END TRY
BEGIN CATCH
<обработка ошибок>
END CATCH
Если какая-либо ошибка появится в <обычный код>, выполнение будет переведено в блок CATCH, и будет выполнен код обработки ошибок.
Как правило, в CATCH откатывают любую открытую транзакцию и повторно вызывают ошибку. Таким образом, вызывающая клиентская программа понимает, что что-то пошло не так. Повторный вызов ошибки мы обсудим позже в этой статье.
Вот очень быстрый пример:
BEGIN TRY
DECLARE @x int
SELECT @x = 1/0
PRINT 'Not reached'
END TRY
BEGIN CATCH
PRINT 'This is the error: ' + error_message()
END CATCH
Результат выполнения: This is the error: Divide by zero error encountered.
Мы вернемся к функции error_message() позднее. Стоит отметить, что использование PRINT в обработчике CATCH приводится только в рамках экспериментов и не следует делать так в коде реального приложения.
Если <обычный код> вызывает хранимую процедуру или запускает триггеры, то любая ошибка, которая в них возникнет, передаст выполнение в блок CATCH. Если более точно, то, когда возникает ошибка, SQL Server раскручивает стек до тех пор, пока не найдёт обработчик CATCH. И если такого обработчика нет, SQL Server отправляет сообщение об ошибке напрямую клиенту.
Есть одно очень важное ограничение у конструкции TRY-CATCH, которое нужно знать: она не ловит ошибки компиляции, которые возникают в той же области видимости. Рассмотрим пример:
CREATE PROCEDURE inner_sp AS
BEGIN TRY
PRINT 'This prints'
SELECT * FROM NoSuchTable
PRINT 'This does not print'
END TRY
BEGIN CATCH
PRINT 'And nor does this print'
END CATCH
go
EXEC inner_spВыходные данные:
This prints
Msg 208, Level 16, State 1, Procedure inner_sp, Line 4
Invalid object name 'NoSuchTable'Как можно видеть, блок TRY присутствует, но при возникновении ошибки выполнение не передается блоку CATCH, как это ожидалось. Это применимо ко всем ошибкам компиляции, таким как пропуск колонок, некорректные псевдонимы и тому подобное, которые возникают во время выполнения. (Ошибки компиляции могут возникнуть в SQL Server во время выполнения из-за отложенного разрешения имен – особенность, благодаря которой SQL Server позволяет создать процедуру, которая обращается к несуществующим таблицам.)
Эти ошибки не являются полностью неуловимыми; вы не можете поймать их в области, в которой они возникают, но вы можете поймать их во внешней области. Добавим такой код к предыдущему примеру:
CREATE PROCEDURE outer_sp AS
BEGIN TRY
EXEC inner_sp
END TRY
BEGIN CATCH
PRINT 'The error message is: ' + error_message()
END CATCH
go
EXEC outer_spТеперь мы получим на выходе это:
This prints
The error message is: Invalid object name 'NoSuchTable'.На этот раз ошибка была перехвачена, потому что сработал внешний обработчик CATCH.
2.2 SET XACT_ABORT ON
В начало ваших хранимых процедур следует всегда добавлять это выражение:
SET XACT_ABORT, NOCOUNT ONОно активирует два параметра сессии, которые выключены по умолчанию в целях совместимости с предыдущими версиями, но опыт доказывает, что лучший подход – это иметь эти параметры всегда включенными. Поведение SQL Server по умолчанию в той ситуации, когда не используется TRY-CATCH, заключается в том, что некоторые ошибки прерывают выполнение и откатывают любые открытые транзакции, в то время как с другими ошибками выполнение последующих инструкций продолжается. Когда вы включаете XACT_ABORT ON, почти все ошибки начинают вызывать одинаковый эффект: любая открытая транзакция откатывается, и выполнение кода прерывается. Есть несколько исключений, среди которых наиболее заметным является выражение RAISERROR.
Параметр XACT_ABORT необходим для более надежной обработки ошибок и транзакций. В частности, при настройках по умолчанию есть несколько ситуаций, когда выполнение может быть прервано без какого-либо отката транзакции, даже если у вас есть TRY-CATCH. Мы видели такой пример в предыдущем разделе, где мы выяснили, что TRY-CATCH не перехватывает ошибки компиляции, возникшие в той же области. Открытая транзакция, которая не была откачена из-за ошибки, может вызвать серьезные проблемы, если приложение работает дальше без завершения транзакции или ее отката.
Для надежной обработки ошибок в SQL Server вам необходимы как TRY-CATCH, так и SET XACT_ABORT ON. Среди них инструкция SET XACT_ABORT ON наиболее важна. Если для кода на промышленной среде только на нее полагаться не стоит, то для быстрых и простых решений она вполне подходит.
Параметр NOCOUNT не имеет к обработке ошибок никакого отношения, но включение его в код является хорошей практикой. NOCOUNT подавляет сообщения вида (1 row(s) affected), которые вы можете видеть в панели Message в SQL Server Management Studio. В то время как эти сообщения могут быть полезны при работе c SSMS, они могут негативно повлиять на производительность в приложении, так как увеличивают сетевой трафик. Сообщение о количестве строк также может привести к ошибке в плохо написанных клиентских приложениях, которые могут подумать, что это данные, которые вернул запрос.
Выше я использовал синтаксис, который немного необычен. Большинство людей написали бы два отдельных выражения:
SET NOCOUNT ON
SET XACT_ABORT ONМежду ними нет никакого отличия. Я предпочитаю версию с SET и запятой, т.к. это снижает уровень шума в коде. Поскольку эти выражения должны появляться во всех ваших хранимых процедурах, они должны занимать как можно меньше места.
3. Основной пример обработки ошибок
После того, как мы посмотрели на TRY-CATCH и SET XACT_ABORT ON, давайте соединим их вместе в примере, который мы можем использовать во всех наших хранимых процедурах. Для начала я покажу пример, в котором ошибка генерируется в простой форме, а в следующем разделе я рассмотрю решения получше.
Для примера я буду использовать эту простую таблицу.
CREATE TABLE sometable(a int NOT NULL,
b int NOT NULL,
CONSTRAINT pk_sometable PRIMARY KEY(a, b))Вот хранимая процедура, которая демонстрирует, как вы должны работать с ошибками и транзакциями.
CREATE PROCEDURE insert_data @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
BEGIN TRANSACTION
INSERT sometable(a, b) VALUES (@a, @b)
INSERT sometable(a, b) VALUES (@b, @a)
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCHПервая строка в процедуре включает XACT_ABORT и NOCOUNT в одном выражении, как я показывал выше. Эта строка – единственная перед BEGIN TRY. Все остальное в процедуре должно располагаться после BEGIN TRY: объявление переменных, создание временных таблиц, табличных переменных, всё. Даже если у вас есть другие SET-команды в процедуре (хотя причины для этого встречаются редко), они должны идти после BEGIN TRY.
Причина, по которой я предпочитаю указывать SET XACT_ABORT и NOCOUNT перед BEGIN TRY, заключается в том, что я рассматриваю это как одну строку шума: она всегда должна быть там, но я не хочу, чтобы это мешало взгляду. Конечно же, это дело вкуса, и если вы предпочитаете ставить SET-команды после BEGIN TRY, ничего страшного. Важно то, что вам не следует ставить что-либо другое перед BEGIN TRY.
Часть между BEGIN TRY и END TRY является основной составляющей процедуры. Поскольку я хотел использовать транзакцию, определенную пользователем, я ввел довольно надуманное бизнес-правило, в котором говорится, что если вы вставляете пару, то обратная пара также должна быть вставлена. Два выражения INSERT находятся внутри BEGIN и COMMIT TRANSACTION. Во многих случаях у вас будет много строк кода между BEGIN TRY и BEGIN TRANSACTION. Иногда у вас также будет код между COMMIT TRANSACTION и END TRY, хотя обычно это только финальный SELECT, возвращающий данные или присваивающий значения выходным параметрам. Если ваша процедура не выполняет каких-либо изменений или имеет только одно выражение INSERT/UPDATE/DELETE/MERGE, то обычно вам вообще не нужно явно указывать транзакцию.
В то время как блок TRY будет выглядеть по-разному от процедуры к процедуре, блок CATCH должен быть более или менее результатом копирования и вставки. То есть вы делаете что-то короткое и простое и затем используете повсюду, не особо задумываясь. Обработчик CATCH, приведенный выше, выполняет три действия:
- Откатывает любые открытые транзакции.
- Повторно вызывает ошибку.
- Убеждается, что возвращаемое процедурой значение отлично от нуля.
Эти три действия должны всегда быть там. Мы можете возразить, что строка
IF @@trancount > 0 ROLLBACK TRANSACTIONне нужна, если нет явной транзакции в процедуре, но это абсолютно неверно. Возможно, вы вызываете хранимую процедуру, которая открывает транзакцию, но которая не может ее откатить из-за ограничений TRY-CATCH. Возможно, вы или кто-то другой добавите явную транзакцию через два года. Вспомните ли вы тогда о том, что нужно добавить строку с откатом? Не рассчитывайте на это. Я также слышу читателей, которые возражают, что если тот, кто вызывает процедуру, открыл транзакцию, мы не должны ее откатывать… Нет, мы должны, и если вы хотите знать почему, вам нужно прочитать вторую и третью части. Откат транзакции в обработчике CATCH – это категорический императив, у которого нет исключений.
Код повторной генерации ошибки включает такую строку:
DECLARE @msg nvarchar(2048) = error_message()Встроенная функция error_message() возвращает текст возникшей ошибки. В следующей строке ошибка повторно вызывается с помощью выражения RAISERROR. Это не самый простой способ вызова ошибки, но он работает. Другие способы мы рассмотрим в следующей главе.
Замечание: синтаксис для присвоения начального значения переменной в DECLARE был внедрен в SQL Server 2008. Если у вас SQL Server 2005, вам нужно разбить строку на DECLARE и выражение SELECT.
Финальное выражение RETURN – это страховка. RAISERROR никогда не прерывает выполнение, поэтому выполнение следующего выражения будет продолжено. Пока все процедуры используют TRY-CATCH, а также весь клиентский код обрабатывает исключения, нет повода для беспокойства. Но ваша процедура может быть вызвана из старого кода, написанного до SQL Server 2005 и до внедрения TRY-CATCH. В те времена лучшее, что мы могли делать, это смотреть на возвращаемые значения. То, что вы возвращаете с помощью RETURN, не имеет особого значения, если это не нулевое значение (ноль обычно обозначает успешное завершение работы).
Последнее выражение в процедуре – это END CATCH. Никогда не следует помещать какой-либо код после END CATCH. Кто-нибудь, читающий процедуру, может не увидеть этот кусок кода.
После прочтения теории давайте попробуем тестовый пример:
EXEC insert_data 9, NULLРезультат выполнения:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.Давайте добавим внешнюю процедуру для того, чтобы увидеть, что происходит при повторном вызове ошибки:
CREATE PROCEDURE outer_sp @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
EXEC insert_data @a, @b
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCH
go
EXEC outer_sp 8, 8Результат работы:
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Мы получили корректное сообщение об ошибке, но если вы посмотрите на заголовки этого сообщения и на предыдущее поближе, то можете заметить проблему:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9Сообщение об ошибке выводит информацию о расположении конечного выражения RAISERROR. В первом случае некорректен только номер строки. Во втором случае некорректно также имя процедуры. Для простых процедур, таких как наш тестовый пример, это не является большой проблемой. Но если у вас есть несколько уровней вложенных сложных процедур, то наличие сообщения об ошибке с отсутствием указания на место её возникновения сделает поиск и устранение ошибки намного более сложным делом. По этой причине желательно генерировать ошибку таким образом, чтобы можно было определить нахождение ошибочного фрагмента кода быстро, и это то, что мы рассмотрим в следующей главе.
4. Три способа генерации ошибки
4.1 Использование error_handler_sp
Мы рассмотрели функцию error_message(), которая возвращает текст сообщения об ошибке. Сообщение об ошибке состоит из нескольких компонентов, и существует своя функция error_xxx() для каждого из них. Мы можем использовать их для повторной генерации полного сообщения, которое содержит оригинальную информацию, хотя и в другом формате. Если делать это в каждом обработчике CATCH, это будет большой недостаток — дублирование кода. Вам не обязательно находиться в блоке CATCH для вызова error_message() и других подобных функций, и они вернут ту же самую информацию, если будут вызваны из хранимой процедуры, которую выполнит блок CATCH.
Позвольте представить вам error_handler_sp:
CREATE PROCEDURE error_handler_sp AS
DECLARE @errmsg nvarchar(2048),
@severity tinyint,
@state tinyint,
@errno int,
@proc sysname,
@lineno int
SELECT @errmsg = error_message(), @severity = error_severity(),
@state = error_state(), @errno = error_number(),
@proc = error_procedure(), @lineno = error_line()
IF @errmsg NOT LIKE '***%'
BEGIN
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsg
END
RAISERROR('%s', @severity, @state, @errmsg)Первое из того, что делает error_handler_sp – это сохраняет значение всех error_xxx() функций в локальные переменные. Я вернусь к выражению IF через секунду. Вместо него давайте посмотрим на выражение SELECT внутри IF:
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsgЦель этого SELECT заключается в форматировании сообщения об ошибке, которое передается в RAISERROR. Оно включает в себя всю информацию из оригинального сообщения об ошибке, которое мы не можем вставить напрямую в RAISERROR. Мы должны обработать имя процедуры, которое может быть NULL для ошибок в обычных скриптах или в динамическом SQL. Поэтому используется функция COALESCE. (Если вы не понимаете форму выражения RAISERROR, я рассказываю о нем более детально во второй части.)
Отформатированное сообщение об ошибке начинается с трех звездочек. Этим достигаются две цели: 1) Мы можем сразу видеть, что это сообщение вызвано из обработчика CATCH. 2) Это дает возможность для error_handler_sp отфильтровать ошибки, которые уже были сгенерированы один или более раз, с помощью условия NOT LIKE ‘***%’ для того, чтобы избежать изменения сообщения во второй раз.
Вот как обработчик CATCH должен выглядеть, когда вы используете error_handler_sp:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC error_handler_sp
RETURN 55555
END CATCHДавайте попробуем несколько тестовых сценариев.
EXEC insert_data 8, NULL
EXEC outer_sp 8, 8Результат выполнения:
Msg 50000, Level 16, State 2, Procedure error_handler_sp, Line 20
*** [insert_data], Line 5. Errno 515: Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure error_handler_sp, Line 20
*** [insert_data], Line 6. Errno 2627: Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Заголовки сообщений говорят о том, что ошибка возникла в процедуре error_handler_sp, но текст сообщений об ошибках дает нам настоящее местонахождение ошибки – как название процедуры, так и номер строки.
Я покажу еще два метода вызова ошибок. Однако error_handler_sp является моей главной рекомендацией для читателей, которые читают эту часть. Это — простой вариант, который работает на всех версиях SQL Server начиная с 2005. Существует только один недостаток: в некоторых случаях SQL Server генерирует два сообщения об ошибках, но функции error_xxx() возвращают только одну из них, и поэтому одно из сообщений теряется. Это может быть неудобно при работе с административными командами наподобие BACKUP\RESTORE, но проблема редко возникает в коде, предназначенном чисто для приложений.
4.2. Использование ;THROW
В SQL Server 2012 Microsoft представил выражение ;THROW для более легкой обработки ошибок. К сожалению, Microsoft сделал серьезную ошибку при проектировании этой команды и создал опасную ловушку.
С выражением ;THROW вам не нужно никаких хранимых процедур. Ваш обработчик CATCH становится таким же простым, как этот:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
;THROW
RETURN 55555
END CATCHДостоинство ;THROW в том, что сообщение об ошибке генерируется точно таким же, как и оригинальное сообщение. Если изначально было два сообщения об ошибках, оба сообщения воспроизводятся, что делает это выражение еще привлекательнее. Как и со всеми другими сообщениями об ошибках, ошибки, сгенерированные ;THROW, могут быть перехвачены внешним обработчиком CATCH и воспроизведены. Если обработчика CATCH нет, выполнение прерывается, поэтому оператор RETURN в данном случае оказывается не нужным. (Я все еще рекомендую оставлять его, на случай, если вы измените свое отношение к ;THROW позже).
Если у вас SQL Server 2012 или более поздняя версия, измените определение insert_data и outer_sp и попробуйте выполнить тесты еще раз. Результат в этот раз будет такой:
Msg 515, Level 16, State 2, Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 2627, Level 14, State 1, Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Имя процедуры и номер строки верны и нет никакого другого имени процедуры, которое может нас запутать. Также сохранены оригинальные номера ошибок.
В этом месте вы можете сказать себе: действительно ли Microsoft назвал команду ;THROW? Разве это не просто THROW? На самом деле, если вы посмотрите в Books Online, там не будет точки с запятой. Но точка с запятой должны быть. Официально они отделяют предыдущее выражение, но это опционально, и далеко не все используют точку с запятой в выражениях T-SQL. Более важно, что если вы пропустите точку с запятой перед THROW, то не будет никакой синтаксической ошибки. Но это повлияет на поведение при выполнении выражения, и это поведение будет непостижимым для непосвященных. При наличии активной транзакции вы получите сообщение об ошибке, которое будет полностью отличаться от оригинального. И еще хуже, что при отсутствии активной транзакции ошибка будет тихо выведена без обработки. Такая вещь, как пропуск точки с запятой, не должно иметь таких абсурдных последствий. Для уменьшения риска такого поведения, всегда думайте о команде как о ;THROW (с точкой с запятой).
Нельзя отрицать того, что ;THROW имеет свои преимущества, но точка с запятой не единственная ловушка этой команды. Если вы хотите использовать ее, я призываю вас прочитать по крайней мере вторую часть этой серии, где я раскрываю больше деталей о команде ;THROW. До этого момента, используйте error_handler_sp.
4.3. Использование SqlEventLog
Третий способ обработки ошибок – это использование SqlEventLog, который я описываю очень детально в третьей части. Здесь я лишь сделаю короткий обзор.
SqlEventLog предоставляет хранимую процедуру slog.catchhandler_sp, которая работает так же, как и error_handler_sp: она использует функции error_xxx() для сбора информации и выводит сообщение об ошибке, сохраняя всю информацию о ней. Вдобавок к этому, она логирует ошибку в таблицу splog.sqleventlog. В зависимости от типа приложения, которое у вас есть, эта таблица может быть очень ценным объектом.
Для использования SqlEventLog, ваш обработчик CATCH должен быть таким:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC slog.catchhandler_sp @@procid
RETURN 55555
END CATCH@@procid возвращает идентификатор объекта текущей хранимой процедуры. Это то, что SqlEventLog использует для логирования информации в таблицу. Используя те же тестовые сценарии, получим результат их работы с использованием catchhandler_sp:
Msg 50000, Level 16, State 2, Procedure catchhandler_sp, Line 125
{515} Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure catchhandler_sp, Line 125
{2627} Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Как вы видите, сообщение об ошибке отформатировано немного не так, как это делает error_handler_sp, но основная идея такая же. Вот образец того, что было записано в таблицу slog.sqleventlog:
| logid | logdate | errno | severity | logproc | linenum | msgtext |
| 1 | 2015-01-25 22:40:24.393 | 515 | 16 | insert_data | 5 | Cannot insert … |
| 2 | 2015-01-25 22:40:24.395 | 2627 | 14 | insert_data | 6 | Violation of … |
Если вы хотите попробовать SqlEventLog, вы можете загрузить файл sqleventlog.zip. Инструкция по установке находится в третьей части, раздел Установка SqlEventLog.
5. Финальные замечания
Вы изучили основной образец для обработки ошибок и транзакций в хранимых процедурах. Он не идеален, но он должен работать в 90-95% вашего кода. Есть несколько ограничений, на которые стоит обратить внимание:
- Как мы видели, ошибки компиляции не могут быть перехвачены в той же процедуре, в которой они возникли, а только во внешней процедуре.
- Пример не работает с пользовательскими функциями, так как ни TRY-CATCH, ни RAISERROR нельзя в них использовать.
- Когда хранимая процедура на Linked Server вызывает ошибку, эта ошибка может миновать обработчик в хранимой процедуре на локальном сервере и отправиться напрямую клиенту.
- Когда процедура вызвана как INSERT-EXEC, вы получите неприятную ошибку, потому что ROLLBACK TRANSACTION не допускается в данном случае.
- Как упомянуто выше, если вы используете error_handler_sp или SqlEventLog, мы потеряете одно сообщение, когда SQL Server выдаст два сообщения для одной ошибки. При использовании ;THROW такой проблемы нет.
Я рассказываю об этих ситуациях более подробно в других статьях этой серии.
Перед тем как закончить, я хочу кратко коснуться триггеров и клиентского кода.
Триггеры
Пример для обработки ошибок в триггерах не сильно отличается от того, что используется в хранимых процедурах, за исключением одной маленькой детали: вы не должны использовать выражение RETURN (потому что RETURN не допускается использовать в триггерах).
С триггерами важно понимать, что они являются частью команды, которая запустила триггер, и в триггере вы находитесь внутри транзакции, даже если не используете BEGIN TRANSACTION.
Иногда я вижу на форумах людей, которые спрашивают, могут ли они написать триггер, который не откатывает в случае падения запустившую его команду. Ответ таков: нет способа сделать это надежно, поэтому не стоит даже пытаться. Если в этом есть необходимость, по возможности не следует использовать триггер вообще, а найти другое решение. Во второй и третьей частях я рассматриваю обработку ошибок в триггерах более подробно.
Клиентский код
У вас должна быть обработка ошибок в коде клиента, если он имеет доступ к базе. То есть вы должны всегда предполагать, что при любом вызове что-то может пойти не так. Как именно внедрить обработку ошибок, зависит от конкретной среды.
Здесь я только обращу внимание на важную вещь: реакцией на ошибку, возвращенную SQL Server, должно быть завершение запроса во избежание открытых бесхозных транзакций:
IF @@trancount > 0 ROLLBACK TRANSACTIONЭто также применимо к знаменитому сообщению Timeout expired (которое является не сообщением от SQL Server, а от API).
6. Конец первой части
Это конец первой из трех частей серии. Если вы хотели изучить вопрос обработки ошибок быстро, вы можете закончить чтение здесь. Если вы настроены идти дальше, вам следует прочитать вторую часть, где наше путешествие по запутанным джунглям обработки ошибок и транзакций в SQL Server начинается по-настоящему.
… и не забывайте добавлять эту строку в начало ваших хранимых процедур:
SET XACT_ABORT, NOCOUNT ONSearch code, repositories, users, issues, pull requests…
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
Error handling overview
Error handling in SQL Server gives us control over the Transact-SQL code. For example, when things go wrong, we get a chance to do something about it and possibly make it right again. SQL Server error handling can be as simple as just logging that something happened, or it could be us trying to fix an error. It can even be translating the error in SQL language because we all know how technical SQL Server error messages could get making no sense and hard to understand. Luckily, we have a chance to translate those messages into something more meaningful to pass on to the users, developers, etc.
In this article, we’ll take a closer look at the TRY… CATCH statement: the syntax, how it looks, how it works and what can be done when an error occurs. Furthermore, the method will be explained in a SQL Server case using a group of T-SQL statements/blocks, which is basically SQL Server way of handling errors. This is a very simple yet structured way of doing it and once you get the hang of it, it can be quite helpful in many cases.
On top of that, there is a RAISERROR function that can be used to generate our own custom error messages which is a great way to translate confusing error messages into something a little bit more meaningful that people would understand.
Handling errors using TRY…CATCH
Here’s how the syntax looks like. It’s pretty simple to get the hang of. We have two blocks of code:
|
BEGIN TRY —code to try END TRY BEGIN CATCH —code to run if an error occurs —is generated in try END CATCH |
Anything between the BEGIN TRY and END TRY is the code that we want to monitor for an error. So, if an error would have happened inside this TRY statement, the control would have immediately get transferred to the CATCH statement and then it would have started executing code line by line.
Now, inside the CATCH statement, we can try to fix the error, report the error or even log the error, so we know when it happened, who did it by logging the username, all the useful stuff. We even have access to some special data only available inside the CATCH statement:
- ERROR_NUMBER – Returns the internal number of the error
- ERROR_STATE – Returns the information about the source
- ERROR_SEVERITY – Returns the information about anything from informational errors to errors user of DBA can fix, etc.
- ERROR_LINE – Returns the line number at which an error happened on
- ERROR_PROCEDURE – Returns the name of the stored procedure or function
- ERROR_MESSAGE – Returns the most essential information and that is the message text of the error
That’s all that is needed when it comes to SQL Server error handling. Everything can be done with a simple TRY and CATCH statement and the only part when it can be tricky is when we’re dealing with transactions. Why? Because if there’s a BEGIN TRANSACTION, it always must end with a COMMIT or ROLLBACK transaction. The problem is if an error occurs after we begin but before we commit or rollback. In this particular case, there is a special function that can be used in the CATCH statement that allows checking whether a transaction is in a committable state or not, which then allows us to make a decision to rollback or to commit it.
Let’s head over to SQL Server Management Studio (SSMS) and start with basics of how to handle SQL Server errors. The AdventureWorks 2014 sample database is used throughout the article. The script below is as simple as it gets:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
USE AdventureWorks2014 GO — Basic example of TRY…CATCH BEGIN TRY — Generate a divide-by-zero error SELECT 1 / 0 AS Error; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_STATE() AS ErrorState, ERROR_SEVERITY() AS ErrorSeverity, ERROR_PROCEDURE() AS ErrorProcedure, ERROR_LINE() AS ErrorLine, ERROR_MESSAGE() AS ErrorMessage; END CATCH; GO |
This is an example of how it looks and how it works. The only thing we’re doing in the BEGIN TRY is dividing 1 by 0, which, of course, will cause an error. So, as soon as that block of code is hit, it’s going to transfer control into the CATCH block and then it’s going to select all of the properties using the built-in functions that we mentioned earlier. If we execute the script from above, this is what we get:
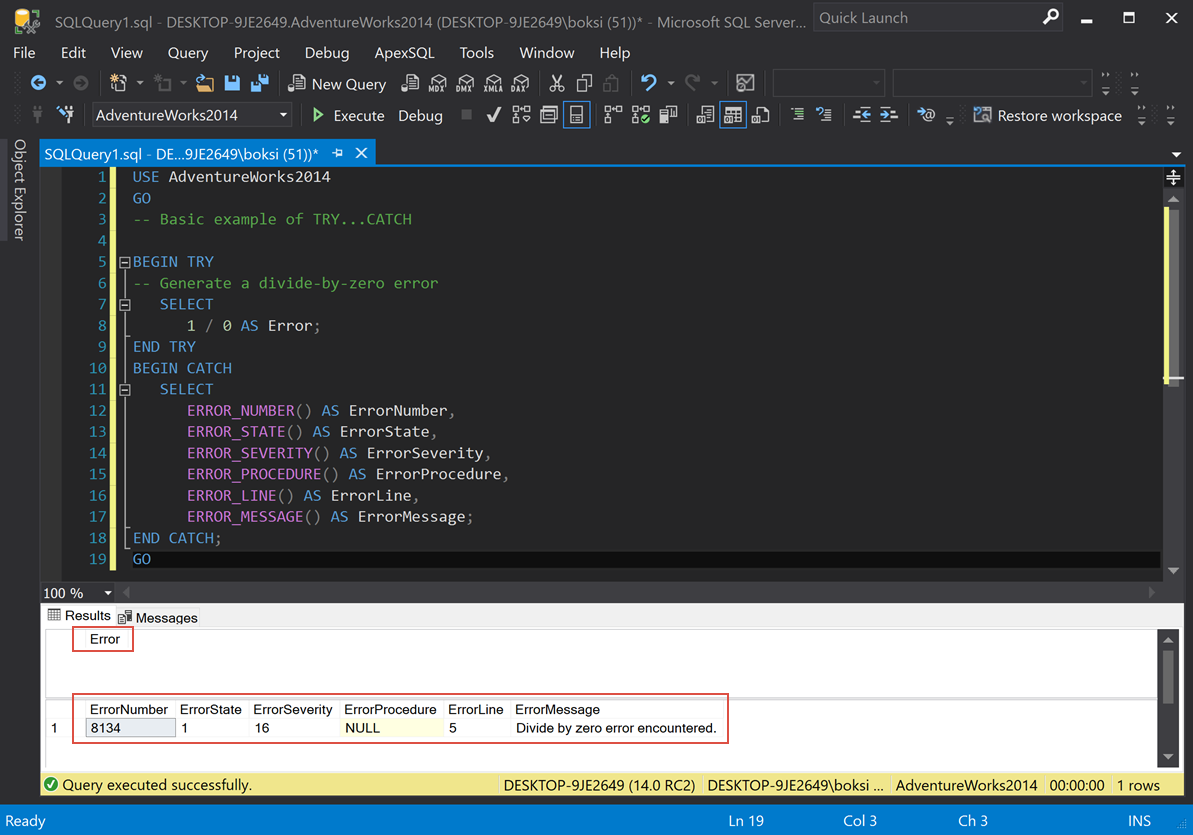
We got two result grids because of two SELECT statements: the first one is 1 divided by 0, which causes the error and the second one is the transferred control that actually gave us some results. From left to right, we got ErrorNumber, ErrorState, ErrorSeverity; there is no procedure in this case (NULL), ErrorLine, and ErrorMessage.
Now, let’s do something a little more meaningful. It’s a clever idea to track these errors. Things that are error-prone should be captured anyway and, at the very least, logged. You can also put triggers on these logged tables and even set up an email account and get a bit creative in the way of notifying people when an error occurs.
If you’re unfamiliar with database email, check out this article for more information on the emailing system: How to configure database mail in SQL Server
The script below creates a table called DB_Errors, which can be used to store tracking data:
|
— Table to record errors CREATE TABLE DB_Errors (ErrorID INT IDENTITY(1, 1), UserName VARCHAR(100), ErrorNumber INT, ErrorState INT, ErrorSeverity INT, ErrorLine INT, ErrorProcedure VARCHAR(MAX), ErrorMessage VARCHAR(MAX), ErrorDateTime DATETIME) GO |
Here we have a simple identity column, followed by username, so we know who generated the error and the rest is simply the exact information from the built-in functions we listed earlier.
Now, let’s modify a custom stored procedure from the database and put an error handler in there:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
ALTER PROCEDURE dbo.AddSale @employeeid INT, @productid INT, @quantity SMALLINT, @saleid UNIQUEIDENTIFIER OUTPUT AS SET @saleid = NEWID() BEGIN TRY INSERT INTO Sales.Sales SELECT @saleid, @productid, @employeeid, @quantity END TRY BEGIN CATCH INSERT INTO dbo.DB_Errors VALUES (SUSER_SNAME(), ERROR_NUMBER(), ERROR_STATE(), ERROR_SEVERITY(), ERROR_LINE(), ERROR_PROCEDURE(), ERROR_MESSAGE(), GETDATE()); END CATCH GO |
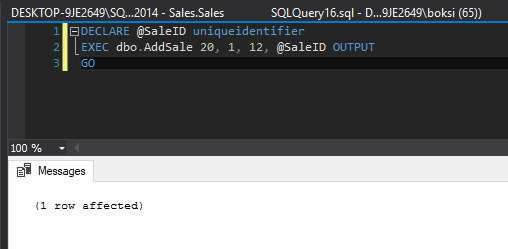
Altering this stored procedure simply wraps error handling in this case around the only statement inside the stored procedure. If we call this stored procedure and pass some valid data, here’s what happens:
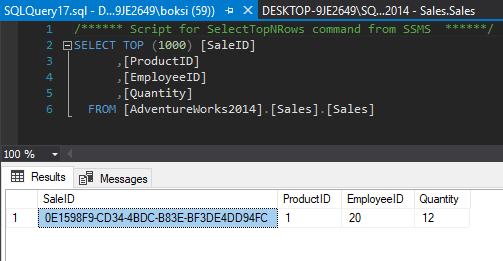
A quick Select statement indicates that the record has been successfully inserted:
However, if we call the above-stored procedure one more time, passing the same parameters, the results grid will be populated differently:
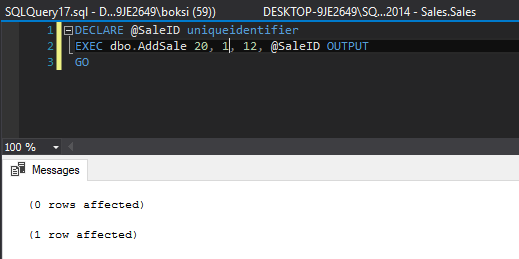
This time, we got two indicators in the results grid:
0 rows affected – this line indicated that nothing actually went into the Sales table
1 row affected – this line indicates that something went into our newly created logging table
So, what we can do here is look at the errors table and see what happened. A simple Select statement will do the job:
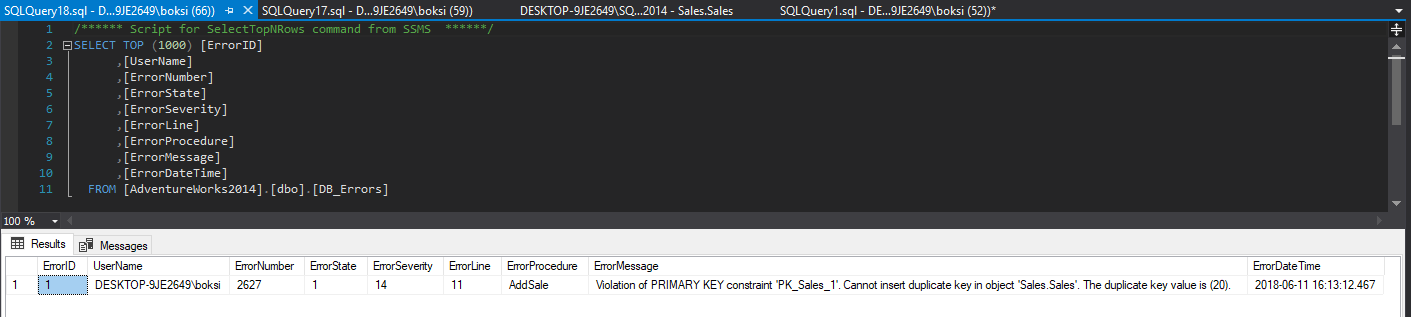
Here we have all the information we set previously to be logged, only this time we also got the procedure field filled out and of course the SQL Server “friendly” technical message that we have a violation:
Violation of PRIMARY KEY constraint ‘PK_Sales_1′. Cannot insert duplicate key in object’ Sales.Sales’. The duplicate key value is (20).
How this was a very artificial example, but the point is that in the real world, passing an invalid date is very common. For example, passing an employee ID that doesn’t exist in a case when we have a foreign key set up between the Sales table and the Employee table, meaning the Employee must exist in order to create a new record in the Sales table. This use case will cause a foreign key constraint violation.
The general idea behind this is not to get the error fizzled out. We at least want to report to an individual that something went wrong and then also log it under the hood. In the real world, if there was an application relying on a stored procedure, developers would probably have SQL Server error handling coded somewhere as well because they would have known when an error occurred. This is also where it would be a clever idea to raise an error back to the user/application. This can be done by adding the RAISERROR function so we can throw our own version of the error.
For example, if we know that entering an employee ID that doesn’t exist is more likely to occur, then we can do a lookup. This lookup can check if the employee ID exists and if it doesn’t, then throw the exact error that occurred. Or in the worst-case scenario, if we had an unexpected error that we had no idea what it was, then we can just pass back what it was.
Advanced SQL error handling
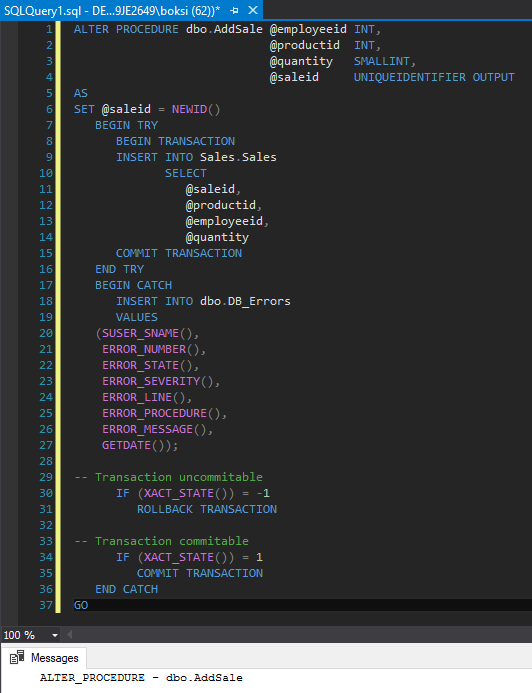
We only briefly mentioned tricky part with transactions, so here’s a simple example of how to deal with them. We can use the same procedure as before, only this time let’s wrap a transaction around the Insert statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
ALTER PROCEDURE dbo.AddSale @employeeid INT, @productid INT, @quantity SMALLINT, @saleid UNIQUEIDENTIFIER OUTPUT AS SET @saleid = NEWID() BEGIN TRY BEGIN TRANSACTION INSERT INTO Sales.Sales SELECT @saleid, @productid, @employeeid, @quantity COMMIT TRANSACTION END TRY BEGIN CATCH INSERT INTO dbo.DB_Errors VALUES (SUSER_SNAME(), ERROR_NUMBER(), ERROR_STATE(), ERROR_SEVERITY(), ERROR_LINE(), ERROR_PROCEDURE(), ERROR_MESSAGE(), GETDATE()); — Transaction uncommittable IF (XACT_STATE()) = —1 ROLLBACK TRANSACTION — Transaction committable IF (XACT_STATE()) = 1 COMMIT TRANSACTION END CATCH GO |
So, if everything executes successfully inside the Begin transaction, it will insert a record into Sales, and then it will commit it. But if something goes wrong before the commit takes place and it transfers control down to our Catch – the question is: How do we know if we commit or rollback the whole thing?
If the error isn’t serious, and it is in the committable state, we can still commit the transaction. But if something went wrong and is in an uncommittable state, then we can roll back the transaction. This can be done by simply running and analyzing the XACT_STATE function that reports transaction state.
This function returns one of the following three values:
1 – the transaction is committable
-1 – the transaction is uncommittable and should be rolled back
0 – there are no pending transactions
The only catch here is to remember to actually do this inside the catch statement because you don’t want to start transactions and then not commit or roll them back:
How, if we execute the same stored procedure providing e.g. invalid EmployeeID we’ll get the same errors as before generated inside out table:
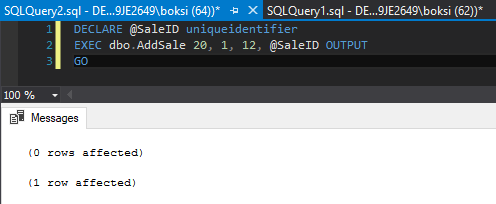
The way we can tell that this wasn’t inserted is by executing a simple Select query, selecting everything from the Sales table where EmployeeID is 20:
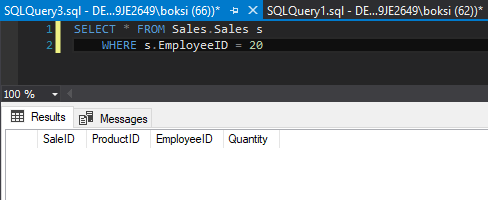
Generating custom raise error SQL message
Let’s wrap things up by looking at how we can create our own custom error messages. These are good when we know that there’s a possible situation that might occur. As we mentioned earlier, it’s possible that someone will pass an invalid employee ID. In this particular case, we can do a check before then and sure enough, when this happens, we can raise our own custom message like saying employee ID does not exist. This can be easily done by altering our stored procedure one more time and adding the lookup in our TRY block:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
ALTER PROCEDURE dbo.AddSale @employeeid INT, @productid INT, @quantity SMALLINT, @saleid UNIQUEIDENTIFIER OUTPUT AS SET @saleid = NEWID() BEGIN TRY IF (SELECT COUNT(*) FROM HumanResources.Employee e WHERE employeeid = @employeeid) = 0 RAISEERROR (‘EmployeeID does not exist.’, 11, 1) INSERT INTO Sales.Sales SELECT @saleid, @productid, @employeeid, @quantity END TRY BEGIN CATCH INSERT INTO dbo.DB_Errors VALUES (SUSER_SNAME(), ERROR_NUMBER(), ERROR_STATE(), ERROR_SEVERITY(), ERROR_LINE(), ERROR_PROCEDURE(), ERROR_MESSAGE(), GETDATE()); DECLARE @Message varchar(MAX) = ERROR_MESSAGE(), @Severity int = ERROR_SEVERITY(), @State smallint = ERROR_STATE() RAISEERROR (@Message, @Severity, @State) END CATCH GO |
If this count comes back as zero, that means the employee with that ID doesn’t exist. Then we can call the RAISERROR where we define a user-defined message, and furthermore our custom severity and state. So, that would be a lot easier for someone using this stored procedure to understand what the problem is rather than seeing the very technical error message that SQL throws, in this case, about the foreign key validation.
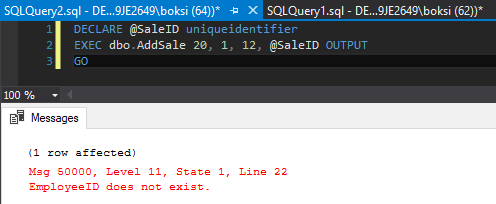
With the last changes in our store procedure, there also another RAISERROR in the Catch block. If another error occurred, rather than having it slip under, we can again call the RAISERROR and pass back exactly what happened. That’s why we have declared all the variables and the results of all the functions. This way, it will not only get logged but also report back to the application or user.
And now if we execute the same code from before, it will both get logged and it will also indicate that the employee ID does not exist:
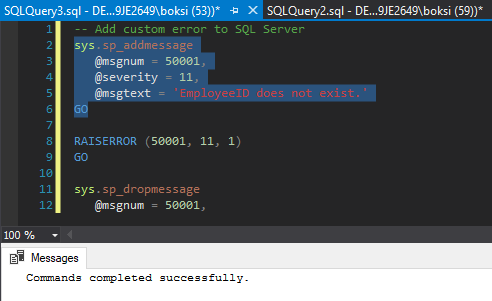
Another thing worth mentioning is that we can actually predefine this error message code, severity, and state. There is a stored procedure called sp_addmessage that is used to add our own error messages. This is useful when we need to call the message on multiple places; we can just use RAISERROR and pass the message number rather than retyping the stuff all over again. By executing the selected code from below, we then added this error into SQL Server:
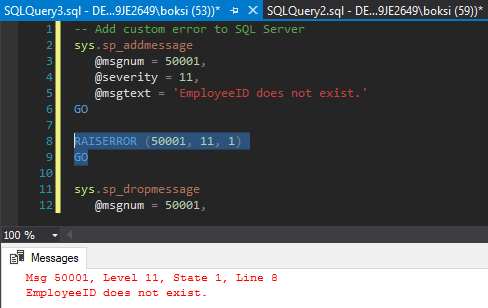
This means that now rather than doing it the way we did previously, we can just call the RAISERROR and pass in the error number and here’s what it looks like:
The sp_dropmessage is, of course, used to drop a specified user-defined error message. We can also view all the messages in SQL Server by executing the query from below:
|
SELECT * FROM master.dbo.sysmessages |
There’s a lot of them and you can see our custom raise error SQL message at the very top.
I hope this article has been informative for you and I thank you for reading.
References
- TRY…CATCH (Transact-SQL)
- RAISERROR (Transact-SQL)
- System Functions (Transact-SQL)
- Author
- Recent Posts

Bojan aka “Boksi”, an AP graduate in IT Technology focused on Networks and electronic technology from the Copenhagen School of Design and Technology, is a software analyst with experience in quality assurance, software support, product evangelism, and user engagement.
He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
See more about Bojan at LinkedIn
View all posts by Bojan Petrovic
Summary: in this tutorial, you will learn how to use the SQL Server TRY CATCH construct to handle exceptions in stored procedures.
SQL Server TRY CATCH overview
The TRY CATCH construct allows you to gracefully handle exceptions in SQL Server. To use the TRY CATCH construct, you first place a group of Transact-SQL statements that could cause an exception in a BEGIN TRY...END TRY block as follows:
BEGIN TRY
-- statements that may cause exceptions
END TRY
Code language: SQL (Structured Query Language) (sql)Then you use a BEGIN CATCH...END CATCH block immediately after the TRY block:
BEGIN CATCH
-- statements that handle exception
END CATCH
Code language: SQL (Structured Query Language) (sql)The following illustrates a complete TRY CATCH construct:
BEGIN TRY
-- statements that may cause exceptions
END TRY
BEGIN CATCH
-- statements that handle exception
END CATCH
Code language: SQL (Structured Query Language) (sql)If the statements between the TRY block complete without an error, the statements between the CATCH block will not execute. However, if any statement inside the TRY block causes an exception, the control transfers to the statements in the CATCH block.
The CATCH block functions
Inside the CATCH block, you can use the following functions to get the detailed information on the error that occurred:
ERROR_LINE()returns the line number on which the exception occurred.ERROR_MESSAGE()returns the complete text of the generated error message.ERROR_PROCEDURE()returns the name of the stored procedure or trigger where the error occurred.ERROR_NUMBER()returns the number of the error that occurred.ERROR_SEVERITY()returns the severity level of the error that occurred.ERROR_STATE()returns the state number of the error that occurred.
Note that you only use these functions in the CATCH block. If you use them outside of the CATCH block, all of these functions will return NULL.
Nested TRY CATCH constructs
You can nest TRY CATCH construct inside another TRY CATCH construct. However, either a TRY block or a CATCH block can contain a nested TRY CATCH, for example:
BEGIN TRY
--- statements that may cause exceptions
END TRY
BEGIN CATCH
-- statements to handle exception
BEGIN TRY
--- nested TRY block
END TRY
BEGIN CATCH
--- nested CATCH block
END CATCH
END CATCH
Code language: SQL (Structured Query Language) (sql)SQL Server TRY CATCH examples
First, create a stored procedure named usp_divide that divides two numbers:
CREATE PROC usp_divide(
@a decimal,
@b decimal,
@c decimal output
) AS
BEGIN
BEGIN TRY
SET @c = @a / @b;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber
,ERROR_SEVERITY() AS ErrorSeverity
,ERROR_STATE() AS ErrorState
,ERROR_PROCEDURE() AS ErrorProcedure
,ERROR_LINE() AS ErrorLine
,ERROR_MESSAGE() AS ErrorMessage;
END CATCH
END;
GO
Code language: SQL (Structured Query Language) (sql)In this stored procedure, we placed the formula inside the TRY block and called the CATCH block functions ERROR_* inside the CATCH block.
Second, call the usp_divide stored procedure to divide 10 by 2:
DECLARE @r decimal;
EXEC usp_divide 10, 2, @r output;
PRINT @r;
Code language: SQL (Structured Query Language) (sql)Here is the output
5
Code language: SQL (Structured Query Language) (sql)Because no exception occurred in the TRY block, the stored procedure completed at the TRY block.
Third, attempt to divide 20 by zero by calling the usp_divide stored procedure:
DECLARE @r2 decimal;
EXEC usp_divide 10, 0, @r2 output;
PRINT @r2;
Code language: SQL (Structured Query Language) (sql)The following picture shows the output:
![]()
Because of division by zero error which was caused by the formula, the control was passed to the statement inside the CATCH block which returned the error’s detailed information.
SQL Serer TRY CATCH with transactions
Inside a CATCH block, you can test the state of transactions by using the XACT_STATE() function.
- If the
XACT_STATE()function returns -1, it means that an uncommittable transaction is pending, you should issue aROLLBACK TRANSACTIONstatement. - In case the
XACT_STATE()function returns 1, it means that a committable transaction is pending. You can issue aCOMMIT TRANSACTIONstatement in this case. - If the
XACT_STATE()function return 0, it means no transaction is pending, therefore, you don’t need to take any action.
It is a good practice to test your transaction state before issuing a COMMIT TRANSACTION or ROLLBACK TRANSACTION statement in a CATCH block to ensure consistency.
Using TRY CATCH with transactions example
First, set up two new tables sales.persons and sales.deals for demonstration:
CREATE TABLE sales.persons
(
person_id INT
PRIMARY KEY IDENTITY,
first_name NVARCHAR(100) NOT NULL,
last_name NVARCHAR(100) NOT NULL
);
CREATE TABLE sales.deals
(
deal_id INT
PRIMARY KEY IDENTITY,
person_id INT NOT NULL,
deal_note NVARCHAR(100),
FOREIGN KEY(person_id) REFERENCES sales.persons(
person_id)
);
insert into
sales.persons(first_name, last_name)
values
('John','Doe'),
('Jane','Doe');
insert into
sales.deals(person_id, deal_note)
values
(1,'Deal for John Doe');
Code language: SQL (Structured Query Language) (sql)Next, create a new stored procedure named usp_report_error that will be used in a CATCH block to report the detailed information of an error:
CREATE PROC usp_report_error
AS
SELECT
ERROR_NUMBER() AS ErrorNumber
,ERROR_SEVERITY() AS ErrorSeverity
,ERROR_STATE() AS ErrorState
,ERROR_LINE () AS ErrorLine
,ERROR_PROCEDURE() AS ErrorProcedure
,ERROR_MESSAGE() AS ErrorMessage;
GO
Code language: SQL (Structured Query Language) (sql)Then, develop a new stored procedure that deletes a row from the sales.persons table:
CREATE PROC usp_delete_person(
@person_id INT
) AS
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
-- delete the person
DELETE FROM sales.persons
WHERE person_id = @person_id;
-- if DELETE succeeds, commit the transaction
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- report exception
EXEC usp_report_error;
-- Test if the transaction is uncommittable.
IF (XACT_STATE()) = -1
BEGIN
PRINT N'The transaction is in an uncommittable state.' +
'Rolling back transaction.'
ROLLBACK TRANSACTION;
END;
-- Test if the transaction is committable.
IF (XACT_STATE()) = 1
BEGIN
PRINT N'The transaction is committable.' +
'Committing transaction.'
COMMIT TRANSACTION;
END;
END CATCH
END;
GO
Code language: SQL (Structured Query Language) (sql)In this stored procedure, we used the XACT_STATE() function to check the state of the transaction before performing COMMIT TRANSACTION or ROLLBACK TRANSACTION inside the CATCH block.
After that, call the usp_delete_person stored procedure to delete the person id 2:
EXEC usp_delete_person 2;
Code language: SQL (Structured Query Language) (sql)There was no exception occurred.
Finally, call the stored procedure usp_delete_person to delete person id 1:
EXEC usp_delete_person 1;
Code language: SQL (Structured Query Language) (sql)The following error occurred:
![]()
In this tutorial, you have learned how to use the SQL Server TRY CATCH construct to handle exceptions in stored procedures.
Обработка ошибок
Последнее обновление: 14.08.2017
Для обработки ошибок в T-SQL применяется конструкция TRY…CATCH. Она имеет следующий формальный синтаксис:
BEGIN TRY инструкции END TRY BEGIN CATCH инструкции END CATCH
Между выражениями BEGIN TRY и END TRY помещаются инструкции, которые потенциально могут вызвать ошибку, например,
какой-нибудь запрос. И если в этом блоке TRY возникнет ошибка, то управление передается в блок CATCH, где можно обработать ошибку.
В блоке CATCH для обаботки ошибки мы можем использовать ряд функций:
-
ERROR_NUMBER(): возвращает номер ошибки
-
ERROR_MESSAGE(): возвращает сообщение об ошибке
-
ERROR_SEVERITY(): возвращает степень серьезности ошибки. Степень серьезности представляет числовое значение. И если оно равно 10 и меньше, то
такая ошибка рассматривается как предупреждение и не обрабатывается конструкцией TRY…CATCH. Если же это значение равно 20 и выше, то
такая ошибка приводит к закрытию подключения к базе данных, если она не обрабатывается конструкцией TRY…CATCH. -
ERROR_STATE(): возвращает состояние ошибки
Например, добавим в таблицу данные, которые не соответствуют ограничениям столбцов:
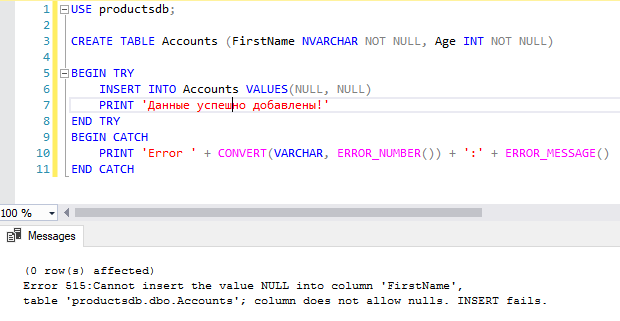
CREATE TABLE Accounts (FirstName NVARCHAR NOT NULL, Age INT NOT NULL) BEGIN TRY INSERT INTO Accounts VALUES(NULL, NULL) PRINT 'Данные успешно добавлены!' END TRY BEGIN CATCH PRINT 'Error ' + CONVERT(VARCHAR, ERROR_NUMBER()) + ':' + ERROR_MESSAGE() END CATCH
В данном случае для столбцов таблицы вставляются недопустимые данные — значения NULL, поэтому обработка программы перейдет к блоку CATCH: