From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of  predictions is generated from a sample of data points on all variables, and
predictions is generated from a sample of data points on all variables, and  is the vector of observed values of the variable being predicted, with
is the vector of observed values of the variable being predicted, with  being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as
being the predicted values (e.g. as from a least-squares fit), then the within-sample MSE of the predictor is computed as

In other words, the MSE is the mean  of the squares of the errors
of the squares of the errors  . This is an easily computable quantity for a particular sample (and hence is sample-dependent).
. This is an easily computable quantity for a particular sample (and hence is sample-dependent).
In matrix notation,

where  is
is  and
and  is a
is a  column vector.
column vector.
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as cross-validation, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator  with respect to an unknown parameter
with respect to an unknown parameter  is defined as[1]
is defined as[1]
![{\displaystyle \operatorname {MSE} ({\hat {\theta }})=\operatorname {E} _{\theta }\left[({\hat {\theta }}-\theta )^{2}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator is derived as a sample statistic and is used to estimate some population parameter, then the expectation is with respect to the sampling distribution of the sample statistic.
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{\displaystyle {\begin{aligned}\operatorname {MSE} ({\hat {\theta }})&=\operatorname {E} _{\theta }\left[({\hat {\theta }}-\theta )^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]+\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}+2\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+\operatorname {E} _{\theta }\left[2\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\right]+\operatorname {E} _{\theta }\left[\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\right]\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+2\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\operatorname {E} _{\theta }\left[{\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right]+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}&&\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta ={\text{const.}}\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+2\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}&&\operatorname {E} _{\theta }[{\hat {\theta }}]={\text{const.}}\\&=\operatorname {E} _{\theta }\left[\left({\hat {\theta }}-\operatorname {E} _{\theta }[{\hat {\theta }}]\right)^{2}\right]+\left(\operatorname {E} _{\theta }[{\hat {\theta }}]-\theta \right)^{2}\\&=\operatorname {Var} _{\theta }({\hat {\theta }})+\operatorname {Bias} _{\theta }({\hat {\theta }},\theta )^{2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable  ,
,  . By substituting with,
. By substituting with,  , we have
, we have
![{\displaystyle {\begin{aligned}\operatorname {MSE} ({\hat {\theta }})&=\mathbb {E} [({\hat {\theta }}-\theta )^{2}]\\&=\operatorname {Var} ({\hat {\theta }}-\theta )+(\mathbb {E} [{\hat {\theta }}-\theta ])^{2}\\&=\operatorname {Var} ({\hat {\theta }})+\operatorname {Bias} ^{2}({\hat {\theta }},\theta )\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a89b110dd50aaf64585bb22b53b45f92d39adbf9)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
In the context of gradient descent algorithms, it is common to introduce a factor of  to the MSE for ease of computation after taking the derivative. So a value which is technically half the mean of squared errors may be called the MSE.
to the MSE for ease of computation after taking the derivative. So a value which is technically half the mean of squared errors may be called the MSE.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size from a population,  . Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the
. Suppose the sample units were chosen with replacement. That is, the units are selected one at a time, and previously selected units are still eligible for selection for all draws. The usual estimator for the  is the sample average
is the sample average

which has an expected value equal to the true mean (so it is unbiased) and a mean squared error of
![{\displaystyle \operatorname {MSE} \left({\overline {X}}\right)=\operatorname {E} \left[\left({\overline {X}}-\mu \right)^{2}\right]=\left({\frac {\sigma }{\sqrt {n}}}\right)^{2}={\frac {\sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where  is the population variance.
is the population variance.
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is ), hence also called the unbiased sample variance, and its MSE is[8]

where  is the fourth central moment of the distribution or population, and
is the fourth central moment of the distribution or population, and  is the excess kurtosis.
is the excess kurtosis.
However, one can use other estimators for which are proportional to  , and an appropriate choice can always give a lower mean squared error. If we define
, and an appropriate choice can always give a lower mean squared error. If we define

then we calculate:
![{\displaystyle {\begin{aligned}\operatorname {MSE} (S_{a}^{2})&=\operatorname {E} \left[\left({\frac {n-1}{a}}S_{n-1}^{2}-\sigma ^{2}\right)^{2}\right]\\&=\operatorname {E} \left[{\frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2\left({\frac {n-1}{a}}S_{n-1}^{2}\right)\sigma ^{2}+\sigma ^{4}\right]\\&={\frac {(n-1)^{2}}{a^{2}}}\operatorname {E} \left[S_{n-1}^{4}\right]-2\left({\frac {n-1}{a}}\right)\operatorname {E} \left[S_{n-1}^{2}\right]\sigma ^{2}+\sigma ^{4}\\&={\frac {(n-1)^{2}}{a^{2}}}\operatorname {E} \left[S_{n-1}^{4}\right]-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}&&\operatorname {E} \left[S_{n-1}^{2}\right]=\sigma ^{2}\\&={\frac {(n-1)^{2}}{a^{2}}}\left({\frac {\gamma _{2}}{n}}+{\frac {n+1}{n-1}}\right)\sigma ^{4}-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}&&\operatorname {E} \left[S_{n-1}^{4}\right]=\operatorname {MSE} (S_{n-1}^{2})+\sigma ^{4}\\&={\frac {n-1}{na^{2}}}\left((n-1)\gamma _{2}+n^{2}+n\right)\sigma ^{4}-2\left({\frac {n-1}{a}}\right)\sigma ^{4}+\sigma ^{4}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where  , this means that the MSE is minimized when dividing the sum by
, this means that the MSE is minimized when dividing the sum by  . The minimum excess kurtosis is
. The minimum excess kurtosis is  ,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for
,[a] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for  Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Hence regardless of the kurtosis, we get a «better» estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one «shrinks» the estimator towards zero (scales down the unbiased estimator).
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is ideal (but typically not possible).
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной \widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-\widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=\overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — \overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=\frac{1}{n}\sum\limits_{i=1}^{n}(y_{i}-\widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, \widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}(y_{i}-\widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
\frac{\partial RMSE}{\partial \widehat{y}_{i}}=\frac{1}{2\sqrt{MSE}}\frac{\partial MSE}{\partial \widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=\frac{100}{n}\sum\limits_{i=1}^{n}\left ( \frac{y_{i}-\widehat{y}_{i}}{y_{i}} \right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=\frac{1}{n}\sum\limits_{i=1}^{n}\left | y_{i}-\widehat{y}_{i} \right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=\frac{100}{n}\sum\limits_{i=1}^{n}\frac{\left | y_{i}-\widehat{y_{i}} \right |}{\left | y_{i} \right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=\frac{100}{n}\sum\limits_{i=1}^{n}\frac{\left | y_{i}-\widehat{y_{i}} \right |}{(\left | y_{i} \right |+\left | \widehat{y}_{i} \right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и \widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и \widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=\frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=\frac{1}{n}\sum\limits_{i=1}^{n}\frac{\left | y_{i}-\widehat{y}_{i}\right |}{\left | y_{i} \right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}(log(\widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-\frac{\sum\limits_{i=1}^{n}(\widehat{y}_{i}-y_{i})^{2}}{\sum\limits_{i=1}^{n}({\overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-\frac{\sum\limits_{i=1}^{n}(\widehat{y}_{i}-y_{i})^{2}/(n-k)}{\sum\limits_{i=1}^{n}({\overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Среднеквадратичная ошибка (Mean Squared Error) – Среднее арифметическое (Mean) квадратов разностей между предсказанными и реальными значениями Модели (Model) Машинного обучения (ML):

Рассчитывается с помощью формулы, которая будет пояснена в примере ниже:
$$MSE = \frac{1}{n} × \sum_{i=1}^n (y_i — \widetilde{y}_i)^2$$
$$MSE\space{}{–}\space{Среднеквадратическая}\space{ошибка,}$$
$$n\space{}{–}\space{количество}\space{наблюдений,}$$
$$y_i\space{}{–}\space{фактическая}\space{координата}\space{наблюдения,}$$
$$\widetilde{y}_i\space{}{–}\space{предсказанная}\space{координата}\space{наблюдения,}$$
MSE практически никогда не равен нулю, и происходит это из-за элемента случайности в данных или неучитывания Оценочной функцией (Estimator) всех факторов, которые могли бы улучшить предсказательную способность.
Пример. Исследуем линейную регрессию, изображенную на графике выше, и установим величину среднеквадратической Ошибки (Error). Фактические координаты точек-Наблюдений (Observation) выглядят следующим образом:

Мы имеем дело с Линейной регрессией (Linear Regression), потому уравнение, предсказывающее положение записей, можно представить с помощью формулы:
$$y = M * x + b$$
$$y\space{–}\space{значение}\space{координаты}\space{оси}\space{y,}$$
$$M\space{–}\space{уклон}\space{прямой}$$
$$x\space{–}\space{значение}\space{координаты}\space{оси}\space{x,}$$
$$b\space{–}\space{смещение}\space{прямой}\space{относительно}\space{начала}\space{координат}$$
Параметры M и b уравнения нам, к счастью, известны в данном обучающем примере, и потому уравнение выглядит следующим образом:
$$y = 0,5252 * x + 17,306$$
Зная координаты реальных записей и уравнение линейной регрессии, мы можем восстановить полные координаты предсказанных наблюдений, обозначенных серыми точками на графике выше. Простой подстановкой значения координаты x в уравнение мы рассчитаем значение координаты ỹ:

Рассчитаем квадрат разницы между Y и Ỹ:

Сумма таких квадратов равна 4 445. Осталось только разделить это число на количество наблюдений (9):
$$MSE = \frac{1}{9} × 4445 = 493$$
Само по себе число в такой ситуации становится показательным, когда Дата-сайентист (Data Scientist) предпринимает попытки улучшить предсказательную способность модели и сравнивает MSE каждой итерации, выбирая такое уравнение, что сгенерирует наименьшую погрешность в предсказаниях.
MSE и Scikit-learn
Среднеквадратическую ошибку можно вычислить с помощью SkLearn. Для начала импортируем функцию:
import sklearn
from sklearn.metrics import mean_squared_errorИнициализируем крошечные списки, содержащие реальные и предсказанные координаты y:
y_true = [5, 41, 70, 77, 134, 68, 138, 101, 131]
y_pred = [23, 35, 55, 90, 93, 103, 118, 121, 129]Инициируем функцию mean_squared_error(), которая рассчитает MSE тем же способом, что и формула выше:
mean_squared_error(y_true, y_pred)
Интересно, что конечный результат на 3 отличается от расчетов с помощью Apple Numbers:
496.0Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: @mmoshikoo
Фото: @tobyelliott
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
- 1 Оценки качества классификации
- 1.1 Матрица ошибок (англ. Сonfusion matrix)
- 1.2 Аккуратность (англ. Accuracy)
- 1.3 Точность (англ. Precision)
- 1.4 Полнота (англ. Recall)
- 1.5 F-мера (англ. F-score)
- 1.6 ROC-кривая
- 1.7 Precison-recall кривая
- 2 Оценки качества регрессии
- 2.1 Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
- 2.2 Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
- 2.3 Коэффициент детерминации
- 2.4 Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
- 2.5 Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
- 2.6 Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
- 2.7 Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
- 3 Кросс-валидация
- 4 Примечания
- 5 См. также
- 6 Источники информации
Оценки качества классификации
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-

Рис.1 Сбалансированная F-мера,
-

Рис.2 F-мера c приоритетом точности,
-

Рис.3 F-мера c приоритетом полноты,
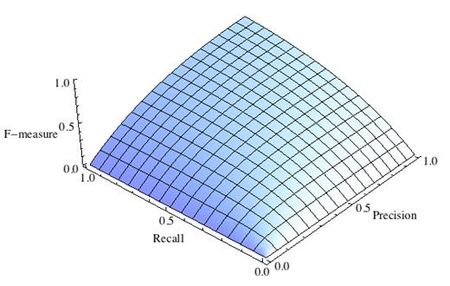
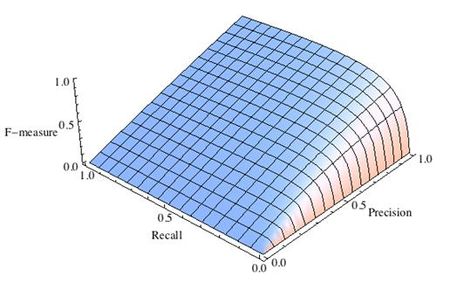
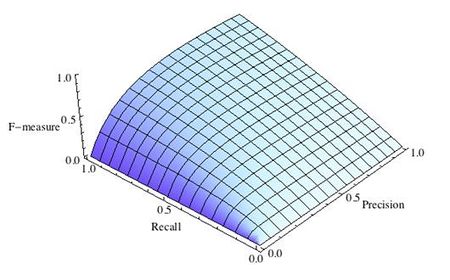
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
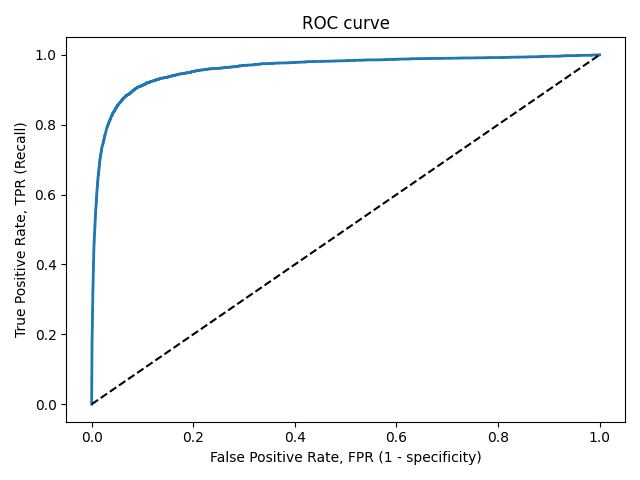
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
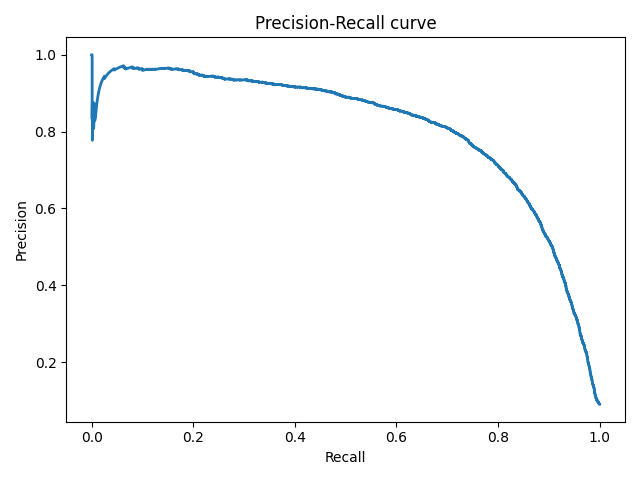
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Оценки качества регрессии
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Кросс-валидация
Хороший способ оценки модели предусматривает применение кросс-валидации (cкользящего контроля или перекрестной проверки).
В этом случае фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Примечания
- [1] Лекция «Оценивание качества» на www.coursera.org
- [2] Лекция на www.stepik.org о кросвалидации
- [3] Лекция на www.stepik.org о метриках качества, Precison и Recall
- [4] Лекция на www.stepik.org о метриках качества, F-мера
- [5] Лекция на www.stepik.org о метриках качества, примеры
См. также
- Оценка качества в задаче кластеризации
- Кросс-валидация
Источники информации
- [6] Соколов Е.А. Лекция линейная регрессия
- [7] — Дьяконов А. Функции ошибки / функционалы качества
- [8] — Оценка качества прогнозных моделей
- [9] — HeinzBr Ошибка прогнозирования: виды, формулы, примеры
- [10] — egor_labintcev Метрики в задачах машинного обучения
- [11] — grossu Методы оценки качества прогноза
- [12] — К.В.Воронцов, Классификация
- [13] — К.В.Воронцов, Скользящий контроль
Оценка ошибки прогнозирования временного ряда
Работая с научными публикациями, сталкиваюсь с различными показателями ошибок прогнозирования временных рядов. Среди всех встречающихся оценок ошибки прогнозирования стоит отметить две, которые в настоящее время, являются самыми популярными: MAE и MAPE.
Пусть ошибка есть разность:
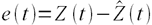 ,
,
где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Тогда формулы для оценок ошибки прогнозирования временных рядов для N отчетов можно записать в следующем виде.
MAPE – средняя абсолютная ошибка в процентах
 .
.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
ME – средняя ошибка
 .
.
SD – стандартное отклонение
 , где ME – есть средняя ошибка, определенная по формуле выше.
, где ME – есть средняя ошибка, определенная по формуле выше.
Связь точности и ошибки прогнозирования
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE
Величину точности оценивать не принято, говоря о прогнозировании всегда оценивают, то есть определяют значение именно ошибки прогноза, то есть величину MAPE и/или MAE. Однако нужно понимать, что если MAPE = 5%, то точность прогнозирования = 95%. Говоря о высокой точности, мы всегда говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности.
При этом величина MAPE является количественной оценкой именно ошибки, и эта величина нам ясно говорит и о точности прогнозирования, исходя из приведенной выше простой формулы. Таким образом, оценивая ошибку, мы всегда оцениваем точность прогнозирования.