С монетаристских
позиций, в условиях полной занятости
трудовые ресурсы не могут быть
задействованы на 100%. Отсюда возникло
понятие естественного уровня безработицы.
Подход монетаристов
(в частности М. Фридмана и Л. Лейдлера)
заключается в том, что постоянное наличие
некоторой безработицы объясняется
структурной и институциональной
негибкостью рынка труда, что ведет к
возникновению фрикционной и структурной
безработицы. Их сумма определяет
естественный уровень безработицы.
Структурные и
институциональные причины негибкости
рынка труда достаточно инертны и вполне
естественны. Полная занятость ресурсов,
которая соответствует потенциальному
ВВП, следовательно, означает отсутствие
только циклической безработицы.
-
Концепций адаптивных ожиданий.
Монетаристская
школа впервые предприняла попытку
теоретического анализа и моделирования
ожиданий в экономике. Ожидания
– это прогноз будущего со стороны
экономических субъектов.
Принципиально
новым положением монетаристской
концепции, связанной с именем М. Фридмана,
является его гипотеза: фирмы и домохозяйства
не являются достаточно пассивными
объектами экономической политики, как
это представлялось в кейнсианской
модели. В условиях стабильной и
предсказуемой экономики экономические
субъекты принимают решения, ориентируясь
на долгосрочный период времени, используя
прошлый опыт.
Конечно, роль
ожиданий прекрасно осознавал и Кейнс,
но проблема количественной оценки
ожиданий им решена не была. Кстати
говоря, удовлетворительных методов их
измерения нет до сих пор. Впервые, хотя
и в качестве паллиатива, попыткой решения
данной проблемы было введение Фридманом
в аппарат экономической теории концепции
адаптивных ожиданий.
Адаптивны ожидания
– ретроспективные ожидания, означающие,
что экономические субъекты прогнозируют
будущее значения экономических
показателей, основываясь исключительно
на их прошлых значениях.
-
Адаптивные
ожидания включают в себя корректировку
прошлых прогнозов. Так, если фактическое
значение параметров больше, чем
прогнозировалось, то его величина,
ожидаемая в следующем периоде,
корректируется в сторону увеличения,
если меньше – в сторону уменьшения.
Концепция адаптивных
ожиданий позволяет сделать вывод:
ожидаемое значение переменной является
взвешенным средним ее прошлых значений
с геометрически убывающими весами.
Разновидность
адаптивных ожиданий, когда ожидаемое
в следующем периоде значение показателя
Х равно его фактическому значению в
предыдущем периоде, называется
статическими
ожиданиями.
Тема 2: Монетаристская модель реального сектора: совокупное предложение.
-
Рынок труда: модель
ошибки наемных работников. -
Краткосрочная
кривая совокупного предложения. -
Долгосрочная
кривая совокупного предложения. -
Монетаристская
интерпретация кривой Филлипса. -
Акселерация
инфляции. Долгосрочная кривая Филлипса. -
Кривая Филлипса
и кривая совокупного предложения.
-
В монетаристской
модели выведение кривой совокупного
предложения, как и в неоклассической
модели, базируется на анализе рынка
труда.
Анализ рынка труда
(так называемая модель неверных
представлений, или ошибки наемных
работников) предполагает:
-
конкурентный
рынок труда, который уравновешивает
гибкая ставка заработной платы; -
отсутствие денежной
иллюзии у наемных работников и
предпринимателей, т. е. предложение
труда и спрос на труд представляют
собой функцию от реальной заработной
платы; -
адаптивный характер
ценовых ожиданий наемных работников
и предпринимателей, которые в целях
упрощения принимаются статическими,
т.. Рet
= P
t-1
. -
асимметричность
информации на рынке труда о фактическом
уровне цен.
Последняя предпосылка
означает, что предприниматели, принимающие
решения по установлению цен на товары
и услуги, имеют более точные представления
о фактическом уровне цен, чем наемные
работники. Поэтому величина спроса на
труд зависит от фактически
сложившегося уровня реальной заработной
платы.
Величина предложения
труда – от ее ожидаемого
значения. В
результате наемные работники (лишенные
денежной иллюзии) смешивают понятия
реальной и номинальной заработной
платы. Величина предложения труда
зависит как от ставки фактической
заработной платы в реальном выражении,
так и от правильности или ошибочности
представлений наемных работников об
уровне цен.

Рис. 1. Краткосрочная
реакция рынка труда на неожиданное
превышение фактического уровня цен над
ожидаемым
В состоянии
долгосрочного равновесия на рынке труда
(в точке А)
фактический уровень цен равен ожидаемому.
Уровень полной занятости, соответствует
уровню естественной безработицы.
Если в следующем
периоде уровень цен неожиданно возрастет,
то при статических ожиданиях фактический
уровень цен превысит уровень цен,
ожидаемый наемными работниками.
Фактическая реальная заработная плата
при неизменной ставке номинальной
заработной платы снизится.
Величина спроса
на труд, которая зависит от фактически
сложившегося уровня заработной платы,
возрастет.
Величина предложения
труда, которая зависит от ожидаемого
уровня заработной платы останется
неизменной.
На рынке труда
возникнет дефицит трудовых ресурсов.
Для того чтобы (в условиях полной
занятости) нанять дополнительный
персонал, фирмам приходится увеличивать
номинальную заработную плату, и
соответственно сокращать величину
спроса.
Поскольку при
статистических ожиданиях рост ставки
номинальной заработной платы будет
ошибочно восприниматься работниками
как увеличение реальной заработной
платы, то предложение труда возрастет.
Кривая предложения
труда переместится вниз. В точке
В установится
краткосрочное равновесие, которому
соответствуют новая ставка реальной
заработной платы, которая меньше прежней,
и возросший уровень занятости.
Ошибка наемных
работников предполагает другую
интерпретацию перехода к новому
равновесию на рынке труда. С их токи
зрения, увеличение реальной заработной
платы происходит в результате роста
спроса на труд со стороны фирм и
перемещения кривой спроса вверх.
Равновесие же, в соответствии с неверными
представлениями
работников, установится в точке
С. Ему
соответствует новая ставка реальной
заработной платы, которая больше прежней.
Таким образом, в
краткосрочном периоде неожиданное
повышение общего уровня цен приведет
к росту занятости в экономике. Очевидно,
что в случае неожиданного снижения
уровня цен события будут развиваться
в прямо противоположном направлении,
что приведет к росту безработицы.
-
Краткосрочная
кривая совокупного предложения.
Анализ рынка труда
позволяет построить график совокупного
предложения в монетаристской интерпретации.
Модель ошибки
наемных работников демонстрирует, что
благодаря асимметрии информации
изменение фактического уровня цен по
сравнению с ожидаемым приводит к
однонаправленному изменению уровня
занятости.

Рис. 2. Графический
вывод краткосрочной кривой совокупного
предложения монетаристской модели
Так, неожиданный
рост общего уровня цен приводит к
краткосрочному росту занятости. В
соответствии с производственной функцией
рост занятости будет сопровождаться
увеличением совокупного выпуска.
Если для упрощения
предположить, что функция совокупного
предложения является линейной и каждой
комбинации выпуска и занятости поставить
в соответствие характерные уровни цен,
а полученные точки А и В соединить прямой
линией, то таким образом будет построен
график совокупного предложения в
краткосрочном периоде.
Таким образом,
кривая совокупного предложения в
монетаристской модели имеет положительный
наклон относительно оси Y.
-
Долгосрочная
кривая совокупного предложения.
Долгосрочный
период у монетаристов – это промежуток
времени, который требуется наемным
работникам, чтобы приспособиться к
изменившейся рыночной конъюнктуре (в
рассматриваемой модели – к изменившемуся
уровню цен). Пока фактический уровень
цен не равен ожидаемому, экономика будет
находиться на краткосрочной кривой
совокупного предложения.
В долгосрочном
периоде наемные работники приспосабливаются
к сложившемуся уровню цен. Они добиваются
от предпринимателей такой ставки
номинальной заработной платы, которая
обеспечит им прежнюю покупательную
способность дохода. Другими словами,
за время адаптации реальная заработная
плата вернется к прежнему уровню.
Для рынка труда
это означает, что равновесие в долгосрочном
периоде установится на первоначальном
уровне, т. е. на уровне полной занятости.
В соответствии с производственной
функцией совокупный выпуск вернется
на потенциальный уровень.
Таким образом,
положительный эффект увеличения выпуска,
который возникает лишь тогда, когда
фактический уровень цен превосходит
ожидаемый, иссякает.

Рис.3. Графический
вывод долгосрочной кривой совокупного
предложения в монетаристской модели
Точка долговременного
совокупного предложения существует
только на уровне потенциального выпуска,
чему на рынке труда соответствует
одно-единственное значение нормы
безработицы, которая равна естественному
уровню.
-
Монетаристская
интерпретация кривой Филипса.
Модель Фридмана
— Фелпса.
Главная идея модели
Фридмана-Фелпса — введение в аппарат
кривой Филипса концепции адаптивных
инфляционных ожиданий.
Адаптивные
ожидания – прогноз будущей инфляции,
сформированный на основе ее предшествующих
значений (с учетом прошлых ошибок
прогнозирования).

Рис. 4. Кривая
Филипса, усиленная адаптивными
инфляционными ожиданиями
Пусть в периоде
t0
экономика находится в точке А0.
т. е. в ситуации полной занятости при
нулевом уровне инфляции. При этом, если
ожидания являются статичными, то и
ожидаемая инфляция равна нулю.
Следовательно,
государство должно проводить стимулирующую
политику, сделав ожидания наемных
работников ошибочными. Для этого мерами
экономической политики нужно неожиданно
увеличить существующий уровень цен,
увеличив совокупный спрос.
Тогда спрос на
продукцию фирм возрастет. В краткосрочном
периоде цены на товары повысятся, что
приведет к появлению положительной
экономической прибыли. У производителей
возникает стимул для расширения
производства и увеличения количества
труда.
Для этого
предпринимателям придется прибегнуть
к повышению номинальной заработной
платы. По кривой Филипса (РС0) экономическая
конъюнктура перемещается в точку В0.
Уровень безработицы в точке в этой точке
уменьшится, но при этом появляется
инфляция.
Монетаристы считают
экономику высококонкурентной. Поэтому
количество труда, которое нужно фирмам
определяется в соответствии с правилом:
МРL=w|P.
В результате
проведения стимулирующей политики
занятость растет. Однако при этом
предельный продукт труда уменьшается.
Его уменьшение, а также рост номинальной
заработной платы должны быть компенсированы
для предпринимателей соответствующим
ростом цен готовой продукции.
В отличие от
кейнсианской трактовки кривой Филлипса
монетаристы, во-первых, не считают
возросшую инфляцию в точке В0
платой за снизившуюся безработицу. Рост
занятости — результат расхождения
фактической и ожидаемой инфляции.
Во-вторых, положение в точке В0
по их мнению, не может являться устойчивым.
Наемные работники в периоде t2
пересмотрят
свои ожидания, естественно начнут
требовать повышения номинальной
заработной платы в соответствии с
возросшими инфляционными ожиданиями.
Здесь возможно два варианта дальнейшего
развития событий.
1 вариант –
государство больше не накачивает
совокупный спрос.
Соседние файлы в предмете [НА УДАЛЕНИЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Нет ни одного наёмного работника, который не хочет, чтобы ему платили больше. Что надо сделать или изменить для увеличения Вашей заработной платы? Как убедить Ваших начальников и работодателей в том, что Вы достойны гораздо большего вознаграждения? Как разрешить конфликт Ваших денежных интересов и финансовых целей Вашего работодателя?
Чтобы найти ответы на эти вопросы, надо определить причины того, почему Вам мало платят. Дело отнюдь не в скупости работодателей, хотя жадность тоже иногда встречается.
Работодатели – такие же люди как Вы. Они тоже обладают достоинствами и недостатками. У них, также как и у Вас, есть свои стереотипы и иллюзии. У них тоже есть провалы в знаниях. Они тоже ошибаются чаще, чем им кажется.
***
При найме на работу работодатели выступают покупателями Вашего времени, знаний, навыков и труда, которые являются Вашим личным товаром. А раз так, то Вам надо быть квалифицированным продавцом этого товара. Ваш товар надо «показать лицом» не только в тот момент, когда Вы устраиваетесь на работу. Вам необходимо поддерживать высокую степень удовлетворённости работодателя от совершённой покупки. То есть, свой товар Вы должны постоянно преподносить работодателю в лучшем виде. Иначе «покупатель» будет чувствовать себя обманутым, а это плохо скажется на Вашем доходе.
Слишком часто от наёмных работников можно услышать ошибочную фразу: «Как платят, так и работаем». Эта фраза ошибочна потому, что в ней нарушена причинно-следственная связь. На самом деле: как работаете, так Вам и платят. Почти все работодатели достойно вознаграждают по-настоящему хороший труд. Они очень не хотят, чтобы хорошие работники ушли к конкурентам за более высокой заработной платой. Они прекрасно знают, что хороших работников крайне мало. А Вы – хороший работник? Только ответьте на этот и следующие вопросы честно!
Все люди, покупая товары для себя или для предприятия, на котором работают, готовы заплатить больше за товар более высокого качества. А какого качества Ваш товар? Какова Ваша квалификация? Что Вы делаете для того, чтобы быть специалистом высокого уровня? Для того чтобы Ваш труд был высокопроизводительным? Для того чтобы результат Вашего труда был всегда высокого качества?
Увы, большинство наёмных работников, причём подавляющее большинство, порядка 90%, ничего не делают для этого. Больно смотреть на молодых людей, особенно на парней, не достигших ещё и тридцати лет, но уже «мёртвых» по своей сути. Нет. С физическим здоровьем у них пока всё в порядке. Они получили школьный аттестат, а многие даже диплом вуза. Они считают, что уже знают всё. У них осталось единственное желание, связанное с ростом. Это желание постоянно растущей «заработной платы».
Это они и такие же представители предыдущих поколений создают «болото» в трудовых коллективах. «Болото» требует того, чтобы не было «самых умных» и тех, кому больше всех надо. «Болоту» не нужно, чтобы кто-то гнал волну, которая заставит их шевелиться и что-то делать. «Болото» жёстко отстаивает свои интересы. Наёмным работникам трудно, а часто и небезопасно противостоять его засасывающей силе. Трудно, но не невозможно. А кто Вы? Гнилушка в «болоте» или хороший работник? Вы сделали свой выбор? С кем Вы? С работодателем или с таким «трудовым коллективом»? Кто оплачивает Ваш труд? Работодатель или «трудовой коллектив?»
Раз уж Вам платит работодатель, так и отдавайте ему сполна свой товар. Работодатель – Ваш клиент. Сделайте ему «красиво!»
***
Наверно, неоднократно совершая покупку, Вы получали маленький дешёвый подарок от продавца. Может быть, это был демонстративный перевес на рынке или какая-то полезная мелочь, или пробник какого-то товара. Вам было приятно? Скорее всего, да. И Вы снова и снова ходили к этому продавцу или много раз о нём вспоминали с тёплым чувством. Какое сладкое слово «Халява». А что Вы на халяву дали своему работодателю?
Вы, читатель, можете возразить, заявив, что делали «подарки» много раз и никогда ничего не получили взамен. Может быть, и так. Но, во-первых, подарок и не должен предполагать оплаты, а во-вторых, избавьтесь от иллюзии по поводу благодарности. Почти все люди так устроены, что чувство благодарности у них присутствует крайне непродолжительное время. Кстати, а испытываете ли Вы чувство благодарности своему работодателю за то, что он создал для Вас рабочее место? За то, что он предоставил Вам возможность получать постоянный доход? В том-то и дело: «Граждане, будьте взаимно вежливы!». Не считайте маленькие трудовые подарки работодателю бессмысленными!
***
Автору этой статьи в середине восьмидесятых годов прошлого века многократно доводилось наблюдать одну и ту же ситуацию. Это происходило в обычном советском проектном институте. Об окончании рабочего дня в нём извещал громкий и длительный звонок. Через миг после начала его звучания распахивались двери во всех помещениях, выходивших в длинный коридор. Из них выскакивали (слово «выходили» не подходит) люди, в глазах которых читались целеустремлённость и нерастраченная за рабочий день энергия, нацеленные на личные дела. Человек, оказавшийся в коридоре в тот момент, рисковал быть если не затоптанным, то унесённым бурным плотным людским потоком. Звонок звучал примерно десять секунд. Когда он умолкал, по коридору шли отдельные сотрудники, занявшие невыгодные позиции перед дверями.
Формально эти люди не нарушали трудовую дисциплину. Они имели несомненное право на личную жизнь и полноценный отдых. И если бы с такой же энергией и целеустремлённостью они работали, то эта ситуация не стоила бы упоминания. Но те, кто работал с полной отдачей, никогда не выскакивали из дверей по сигналу звонка. Эта категория людей с уважением относилась и к работодателю (государственному институту), и к себе. А как Вы и Ваши коллеги относитесь к работодателю?
***
У каждого работника есть круг должностных обязанностей. У кого-то он формализован должностной инструкцией, а у кого-то сложился «исторически». Наверно, у каждого работника хотя бы один раз был случай, когда начальник поручал ему выполнить работу, выходящую за круг его обязанностей. Отдавая такое поручение, начальники обычно слышат в ответ: «Это в мои обязанности не входит. Это должен делать тот-то. Мне за это не платят. Я это делать не буду». Вы, читатель, тоже много раз слышали подобные слова или даже сами их говорили.
Есть ли какие-то основания для таких слов? Нет таких оснований. Даже если у работника есть официальная должностная инструкция, в которой приведён список обязанностей, работник не имеет права на такие отговорки. Любой работник продал своё время работодателю. В это время работодатель и назначенные им начальники имеют право определять то, что должен сделать работник. Конечно, начальник должен учитывать квалификацию, знания и навыки, а если надо, то и физическое здоровье работника. И если работник может выполнить работу, выходящую за круг его обязанностей, то начальник вправе давать такие поручения. Начальник, а не работник решает, кто и что будет делать в рабочее время.
Вы можете возразить, сказав, что не целесообразно использовать высококвалифицированного сотрудника на работах, не требующих много знаний и редких навыков. Да. Работники, имеющие высокую квалификацию, должны использоваться на сложных и ответственных работах. Но если предприятию очень важно, чтобы относительно несложная работа была выполнена срочно, и в данный момент к ней можно привлечь только высококвалифицированных людей, то такие работники должны её выполнить без возражений и нытья. В рабочее время интересы предприятия выше интересов работников. Приоритеты в очерёдности выполнения работ расставляет начальник, а не работник.
Использование труда высокооплачиваемых людей на простых работах дорого для предприятий. Поэтому, если начальникам приходится прибегать к этой мере, значит, поиск других исполнителей обойдётся для работодателя дороже или займёт неприемлемо долгий срок. А для наёмных работников нет ничего зазорного в выполнении важной срочной работы, пусть и не требующей высокой квалификации.
А Вы, читатель, часто отгораживались кругом своих обязанностей от нежелательных для Вас работ? А, может быть, Вы использовали воображаемый круг своих обязанностей для торга за дополнительную оплату работы соответствующей Вам квалификации, но ранее не выполнявшейся Вами, или исполнявшейся кем-то другим? Если Вы так поступали, то корректно ли это по отношению к работодателю?
***
Причина того, что работники пытаются отгородиться от поручаемой им работы, не всегда состоит в нежелании делать что-то сверх обычных дел или в высокомерном отношении к неквалифицированному труду. Часто за приведёнными выше отговорками скрывается страх сотрудника из-за того, что ему придётся признаться в своей некомпетентности или в неумении выполнять другую работу. Особенно люди боятся признаться в том, что они лгали о себе в резюме или в разговорах с коллегами.
Обычно, знакомясь с резюме соискателей вакансий, работодатели читают о великих достижениях, об обширных знаниях и умениях, о прекрасной обучаемости кандидатов. Может быть, каждый соискатель рабочего места искренне считает, что всё написанное им в резюме соответствует действительности. Но у всех людей свои личные мерки и критерии оценки различных явлений. Например, кому-то трудовое достижение кажется выдающимся, а для кого-то оно кажется минимально необходимым, но недостаточным для выполнения такой работы.
Поэтому, скромная, по мнению работника, самооценка кажется непомерно завышенной с точки зрения работодателя. Ошибки, глупости и халтура со стороны исполнителей, которые видят и оценивают работодатели, работникам часто кажутся честным и достойным трудом. Эта разница обусловлена не тем, что работодатель хочет сэкономить на заработной плате, а огромным разрывом в оценках результатов труда.
Чтобы сблизить оценки Ваши и работодателя, прежде чем что-то делать, постарайтесь узнать как можно более подробно и точно какого результата ждёт от Вашей работы работодатель. Вы удивитесь тому, что ничего сверх естественного от Вас не требуется. Если уж Вы заявили о своей высокой квалификации, то не прячьтесь за отговорки о своём круге обязанностей. Подтяните свою квалификацию до заявленного Вами уровня!
Не пытайтесь обмануть работодателя! Ошибки, глупости, брак, недоработки с Вашей стороны «расскажут» всё сами. А Вы навсегда потеряете доверие и сами себе разрушите перспективы роста.
***
Во всём мире на предприятиях не утихает холодная война между работодателями и несунами. Слово «несун» придумано исходя из принципа «Не пойман – не вор». Какие только термины не приспособили для того, чтобы не называть кражу воровством. Откат, агентское или комиссионное вознаграждение, сдача. Но воровство остаётся воровством, как бы его не переименовывали.
Интересно, что получатели этих «вознаграждений» совершенно искренне не считают себя ворами. Они оправдывают себя тем, что, якобы, восстанавливают попранную справедливость. Они уверены, что их недооценили, что им недоплачивают, что им никогда не дождаться от работодателя адекватной оценки их труда. Поэтому они сами себя премируют, а не воруют.
Им наплевать, что они обворовывают своих коллег, на премии которым как раз и не хватает денег, украденных несунами, и денег, потраченных на борьбу с ними. Да что им их коллеги? Честных сотрудников они считают дураками. Им невдомёк, что работодатель и коллеги хорошо чувствуют тех, кто ворует. А не увольняют их только до тех пор, пока не поймают. Всё тот же принцип: «Не пойман, не – вор». Поэтому вся бравада и умничанье несунов живы до тех пор, пока они не пойманы.
А Вы кто – несун или «честный дурак?»
***
Кроме перечисленных выше, есть ещё множество причин, которые мешают работодателям платить высокую заработную плату работникам. Среди них – и экономические проблемы, и налоговые «тормоза». Но если работник нужен, полезен и эффективен, работодатель всегда находит возможность заплатить ему адекватную заработную плату. На предприятии, в котором работаете Вы, наверно, есть такие работники. Понаблюдайте за ними! Что особенное они делают для предприятия? Чем отличается их трудовой вклад от Вашего, в результате чего им платят высокое вознаграждение?
У Вас есть всё для того, чтобы Ваш труд был высоко оценён работодателем. Ваши знания, умения и навыки, Ваши лояльность и трудовая отдача, Ваши понимание потребностей работодателя и старание их полностью удовлетворить… Всё это у Вас есть. Осталось это красиво и постоянно преподносить в виде результатов труда. И любой вменяемый работодатель оценит Ваш труд по достоинству.
Только не ожидайте золотых гор! Ваш товар, с описания которого началась эта статья, как и все другие товары, имеет свою рыночную цену. Если Ваш товар относится к классу люкс, то он стоит на 20 — 50% дороже. Если Вы хотите ещё выше поднять свою рыночную стоимость, то Вам надо повышать свою квалификацию и чаще думать и искать решения задач увеличения эффективности предприятия, на котором Вы работаете.
Зарабатывайте больше! Вы знаете, как это сделать.
Как машинное обучение помогает проекту «ЗабастКом» анализировать новости и освещать трудовые конфликты
Уровень сложности
Средний
Время на прочтение
16 мин
Количество просмотров 5.8K

В посте расскажу о моем успешном взаимодействии с некоммерческим проектом ЗабастКом, который поддерживает наемных работников в отстаивании своих трудовых прав и интересов. Моя цель была реализовать что-то похожее на ML4SG проект, где волонтеры-специалисты по анализу данных направляют свою энергию на пользу обществу. Например, применяют алгоритмы искусственного интеллекта для спасения потерявшихся людей, для мониторинга качества воздуха или для анализа новостного потока.
Для Забасткома получилось улучшить систему автоматической обработки новостей с помощью алгоритмов машинного обучения. Это привело к увеличению охвата важных событий и уменьшению ручного труда редакторов. Добавлю, что работа с ребятами была похожа на мечту любого DS специалиста: «заказчик» легко шел на контакт; присутствовала заинтересованность и неплохое понимание ML алгоритмов; некоторая продакшн-система уже функционировала; данные для обучения алгоритмов легко собирались. А под катом — поделюсь подробностями и кодом.
О проекте

ЗабастКом — это содружество технических специалистов, которые неравнодушны к проблемам наемных работников и которые решили вместе освещать трудовые конфликты в России и странах ближнего зарубежья. Среди волонтеров этого проекта есть ребята из Yandex, VK, Tinkoff, OZON и других известных компаний. Трудовой конфликт – это когда ваш рабочий коллектив “нагрели” с зарплатой, обманули в процессе трудоустройства или как-то несправедливо поступили, а вы — организованно возмутились. Как показывает практика, чем громче и шире подобная новость разойдется в обществе, тем быстрее будет оказана помощь работникам, сглажена несправедливость и решена проблема. А Забастком как раз нацелен на максимальную огласку новости. Для этого у проекта есть свой новостной интернет-портал, база данных, мобильные приложения, telegram канал и др. соцсети, где оперативно публикуются отобранные редакторами новости. Отобранная информация может быть полезна другим активистам, которые оперативно оказывали бы бастующим юридическую и другую помощь. Все ПО Забасткома разработано и поддерживается добровольцами-активистами. Внутри проекта чувствуется атмосфера небольшой НКО или ИТ стартапа.
Подобной активностью занимаются и международные организации. Например, BHHRC следит за влиянием компаний на своих работников по всему миру. В своем октябрьском докладе и документе BHHRC приводит данные о систематическом нарушении прав трудящихся на предприятиях легкой промышленности в странах Азии. В документе приводятся причины возникающих забастовок и трудовых конфликтов между собственником предприятия и коллективом наемных работников:
- ухудшение условий труда;
- необоснованное снижение заработной платы;
- отмена оплаты сверхурочных работ;
- сокращения и увеличение нагрузки;
- экономия на защите жизни и здоровья;
- увеличение продолжительности рабочего дня;
- хищение заработной платы, выходных и др. пособий.
Негодование коллектива усиливается ввиду вышеперечисленного на фоне увеличения чистой прибыли их компании, подобно этой ситуации. Трудящиеся недовольны, когда прибыль возрастает за счет экономического наступления на их права. Часто выходит так, что профессия человека может быть применима только на одном предприятии его города, нет возможности сменить компанию. А еще единственное градообразующее предприятие могут пытаться закрыть или искусственно банкротить. Поэтому пикеты, забастовки и стачки являются ответной реакцией работников на действия руководства, если другие формы выражения коллективных требований (обращение, жалоба, протест) были проигнорированы. Акции рабочего протеста не направлены против потребителей производимого товара или пользователей.
API и база данных
У проекта ЗабастКом есть собственный API. Любой желающий может написать программный запрос и получить доступ к пополняющейся базе данных. База данных накоплена за 5 лет и содержит информацию об освещенных забастовках, пикетах, жалобах и результатах этих конфликтов. Использование API может осуществляться свободно и бесплатно, но без целей извлечения прибыли.
делюсь кодом для выгрузки данных из API
# python
import json
import requests
LINK = 'https://zabastcom.org/api/v2/all/events'
r = requests.get(LINK, params={'page':1,'perPage':10,'sort.field':'createdAt','sort.order':'desc'})
r = json.loads(r.text)
print('Events:', r['meta'])
# Events: {'total': 5671, 'currentPage': 1, 'perPage': 10, 'lastPage': 568}
print('Number of events on current page:', len(r['data']), '\n')
# Number of events on this page: 10
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(r['data'][0]){ 'conflict': { 'automanagingMainType': False,
'companyName': 'Алтайский краевой кардиологический '
'диспансер',
'conflictReasonId': 1,
'conflictResultId': 7,
'createdAt': 1672223749,
'dateFrom': 1672223670,
'dateTo': None,
'id': 3314,
'industryId': 10,
'latitude': 53.368935,
'longitude': 83.70607,
'mainTypeId': 9,
'parentEventId': None,
'titleDe': None,
'titleEn': None,
'titleEs': None,
'titleRu': 'Невыплата годовой премии медсестрам '
'барнаульского Кардиоцентра'},
'conflictId': 3314,
'contentDe': None,
'contentEn': None,
'contentEs': None,
'contentRu': 'В Барнауле прокуратура начала проверку после жалоб медсестер '
'Алтайского краевого кардиологического диспансера на '
'невыплату итоговой премии за год. Деньги пообещали дать '
'врачам и младшему медперсоналу, а вот средний медперсонал '
'финансовой помощи лишили.',
'createdAt': 1672223877,
'date': 1672223752,
'eventStatusId': 2,
'eventTypeId': 9,
'id': 5905,
'latitude': 53.368935,
'longitude': 83.70607,
'photoUrls': [ 'https://api.amic.ru/uploads/news/images/6A490C7E5FEE4C749EDF9DB8A6A3F324.png'],
'published': True,
'sourceLink': 'https://www.amic.ru/news/medicine/prokuratura-nachala-proverku-posle-zhaloby-medsester-barnaulskogo-kardiocentra-na-otmenu-godovoy-itogovoy-vyplaty',
'tags': [],
'titleDe': None,
'titleEn': None,
'titleEs': None,
'titleRu': 'Жалоба медсестёр барнаульского кардиоцентра',
'videos': [],
'views': 348}Если кто-то захочет «подписаться» на API, то он может использовать код ниже. Алгоритм следит за появлением всех новых трудовых конфликтов, которые редакторы добавляют в API, и пересылает их в выбранный tg бот.
делюсь кодом для мониторинга API
# zbs_api_monitoring.py
# pip install pyTelegramBotAPI
import telebot
import time
from datetime import datetime
import json
import requests
token = '...'
bot = telebot.TeleBot(token)
LINK = 'https://zabastcom.org/api/v2/all/events'
n_min = 30
@bot.message_handler(commands=['start'])
def start_message(message):
chat_id = message.chat.id
bot.send_message(chat_id, 'Алгоритм следит за API Забасткома.\n'+\
'Новые объекты будут пересылаться в этот tg бот.')
params = {'page':1,'perPage':5,
'sort.field':'createdAt',
'sort.order':'desc'}
r = requests.get(LINK,params=params)
r = json.loads(r.text)
n_prev = r['meta']['total']-1
while True:
r = requests.get(LINK,params=params)
r = json.loads(r.text)
n_now = r['meta']['total']
n_new = n_now-n_prev
if n_new>0:
print(f'{datetime.now().strftime("%H:%M")} появилось {n_new} новых объектов')
r = requests.get(LINK, params={'page':1,'perPage':n_new,
'sort.field':'createdAt',
'sort.order':'desc'})
r = json.loads(r.text)
for i in range(-1,-len(r['data'])-1,-1):
id_ = r['data'][i]['id']
title_ = r['data'][i]['titleRu']
content_ = r['data'][i]['contentRu']
link_ = r['data'][i]['sourceLink']
mess = f'{id_}\n{title_}\n\n{content_}\n{link_}'
bot.send_message(chat_id, mess)
n_prev = n_now
else:
print(f'{datetime.now().strftime("%H:%M")} новых объектов нет')
time.sleep(60*n_min)
bot.polling()Параметр n_min можно менять, в данном примере временной интервал равен 30 минутам:
Визуализируем данные
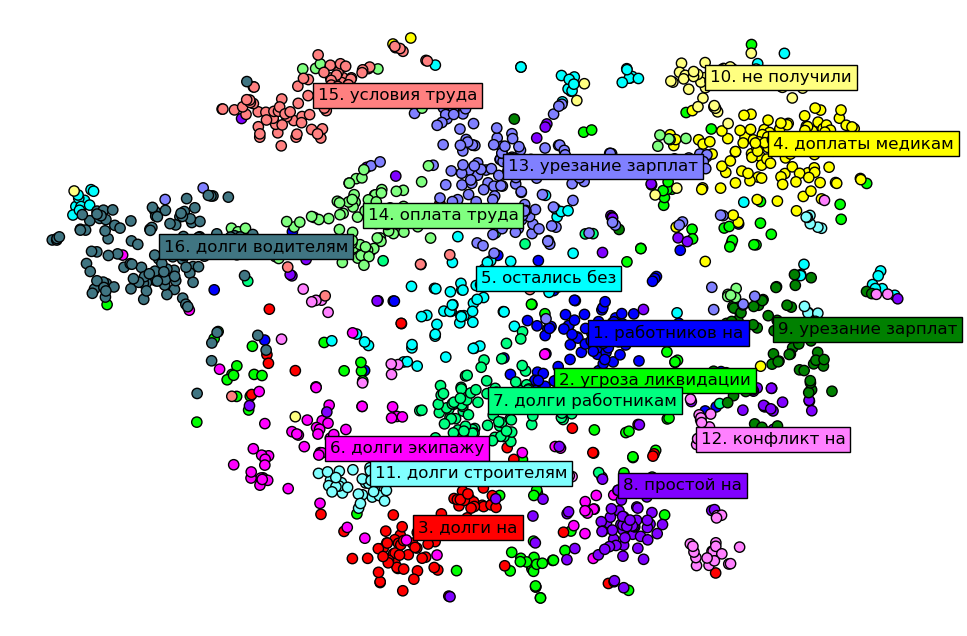
На визуализации показана кластеризация трудовых конфликтов на основе поля ‘titleRu’ для всех данных из API. Алгоритм кластеризации объединил схожие по смыслу тексты в группы. Для каждой группы на графике показано самое частое словосочетание. Оси графика не являются интерпретируемыми, однако похожие тексты лежат близко друг к другу, а менее похожие — дальше друг от друга. По рисунку видно, что проблемы работников в СНГ мало чем отличаются от проблем, описанных в докладе BHHRC, и от проблем зарубежных наемных работников в странах Азии, Европы или Америки.
делюсь кодом для кластеризации текстов
Для каждого текста был получен 312-размерный эмбеддинг помощью дистилированного берта. Для проектирования 312-размерных эмбеддингов на 2-размерное пространство использовал алгоритм t-SNE с метрикой косинусного расстояния. Для кластеризации выбрал K-Means с метрикой косинусного расстояния.
# python
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModel
from sklearn.metrics import pairwise_distances
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
def embed_bert_cls(text,model,tokenizer):
t = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**{k: v.to(model.device) for k, v in t.items()})
embeddings = model_output.last_hidden_state[:, 0, :]
embeddings = torch.nn.functional.normalize(embeddings)
return embeddings[0].cpu().numpy()
def get_bert_emb(list_of_texts):
# https://huggingface.co/cointegrated/rubert-tiny2
HF_model = "cointegrated/rubert-tiny2"
tokenizer = AutoTokenizer.from_pretrained(HF_model)
sent2vec = AutoModel.from_pretrained(HF_model)
embeddings = []
for i in range(len(list_of_texts)):
embeddings.append(embed_bert_cls(list_of_texts[i], sent2vec, tokenizer))
return np.array(embeddings)
def get_clusters(embeddings,n_clusters):
model = KMeans(n_clusters=n_clusters, random_state=42)
length = np.sqrt((embeddings**2).sum(axis=1))[:,None]
embeddings_ = embeddings/length
clusters = model.fit_predict(embeddings_)
idx_clusters = []
for x in np.unique(clusters):
idx_clusters.append(np.where(clusters==x)[0].tolist())
keywords_clusters = []
for i in range(n_clusters):
corpus_cluster = []
for j in range(len(list_of_texts)):
if clusters[j]==i:
corpus_cluster.append(list_of_texts[j].lower())
vectorizer = CountVectorizer(analyzer='word', ngram_range=(2, 2))
Y = vectorizer.fit_transform(corpus_cluster)
id_max = Y.toarray().sum(axis=0).argmax()
keywords_clusters.append(vectorizer.get_feature_names_out()[id_max])
return clusters,idx_clusters,keywords_clusters
def get_plot(embeddings,clusters,keywords_clusters,perplexity=30):
# get 2D projection of embeddings
distance_matrix = pairwise_distances(embeddings,embeddings,
metric='cosine',
n_jobs=-1)
model = TSNE(n_components=2,
perplexity=perplexity,
learning_rate='auto',
init='random',
metric="precomputed",
square_distances=True,
random_state = 42)
embeddings_2D = model.fit_transform(distance_matrix)
# visualize
colors = np.array([[0.,0.,1.],[0.,1.,0.],
[1.,0.,0.],[1.,1.,0.],
[0.,1.,1.],[1.,0.,1.],
[0.,1.,0.5],[0.5,0.,1.],
[0.,0.5,0.],[1.,1.,0.5],
[0.5,1.,1.],[1.,0.5,1.],
[0.5,0.5,1.],[0.5,1.,0.5],
[1.,0.5,0.5],[0.25,0.46,0.51]]*3)
fig, ax = plt.subplots(figsize=(12,8))
for i in np.unique(clusters):
ax.scatter(embeddings_2D[clusters==i][:, 0], embeddings_2D[clusters==i][:, 1],
c=np.array([colors[i]]*len(embeddings_2D[clusters==i])),
edgecolors='black', s=55, label=i)
ax.text(np.median(embeddings_2D[clusters==i][:, 0]),
np.median(embeddings_2D[clusters==i][:, 1]),
f'{i+1}. '+keywords_clusters[i], size=12,
bbox=dict(boxstyle="square",ec=(0., 0., 0.),fc=colors[i]))
# plt.legend(fontsize=10)
plt.axis('off')
plt.show()
#////////////////////////////////////////////////////////////////////////////
list_of_texts = ['Ковидные доплаты медикам', # 0
'Урезание зарплат работникам супермаркета', # 1
'Долги работникам организации утилизирующей отходы', # 2
'Снижения зарплат курьерам', # 3
'Долги работникам светотехнического предприятия', # 4
'Оплата и условия труда на месторождении', # 5
'Жалоба медиков', # 6
'Долги работникам строительной компании', # 7
'Нарушение условий соглашения с рабочими', # 8
'Урезание зарплат рабочим котельной', # 9
'Доплаты медикам медсанчасти', # 10
'Ухудшение условий труда медиков', # 11
'Задержка и урезание зарплат на заводе', # 12
'Отсутствие доплат медикам', # 13
'Долги работникам фабрики дверей'] # 14
embeddings = get_bert_emb(list_of_texts)
clusters,idx_clusters,keywords_clusters = get_clusters(embeddings,n_clusters=4)
print('Индексы текстов в группах: ',idx_clusters)
# Индексы текстов в группах: [[8, 11], [1, 3, 5, 9, 12], [0, 6, 10, 13], [2, 4, 7, 14]]
get_plot(embeddings,clusters,keywords_clusters,perplexity=2)Разрабатываем классификатор новостей

Ребятам нужно уметь оперативно выделять информацию о забастовках в огромном новостном потоке. За 5 лет существования проекта подходы к поиску интересующих новостей постоянно улучшались. В ноябре 2022 года процесс был настроен так: парсеры автоматически собирали тексты новостей из сотен источников; далее работали алгоритмы фильтрации на основе простых правил и ключевых слов; после – редакторы в ручном режиме проверяли каждую новость. Алгоритмы фильтрации работали, но могли пропускать важные новости о забастовках или, наоборот, могли выдавать много новостей на сторонние темы. Поэтому улучшение алгоритмов фильтрации с помощью ML-классификатора стало очень актуальной задачей. Без решения этой задачи было невозможно масштабирование проекта без привлечения значительных усилий.
пояснение для неподготовленных читателей
Для неподготовленных читателей посоветую прочитать ml ликбез и приведу простой пример классификации текста с помощью машинного обучения: в любой электронной почте есть детектор спама. Это алгоритм, который умеет отличать хорошее письмо от плохого письма-спама. Чтобы научить алгоритм решать эту задачу, нужно показать ему примеры решения этой задачи человеком. То есть нужно подготовить примеры спам-писем и хороших писем. Во время обучения алгоритм самостоятельно найдет, какие слова, словосочетания и группы символов часто присутствуют в спам письмах. После обучения он сможет оценивать текст каждого нового письма на принадлежность к спаму.
Про модели: Ребята уже задумывались о внедрении машинного обучения в процесс фильтрации и даже пробовали конструировать прототип. Им хотелось, чтобы ML-алгоритм мог относить каждый текст новости к одному из двух классов: класс 1 — если текст о трудовом коллективном конфликте и его стоит посмотреть редактору, класс 0 – если новость про что-то другое и на нее не нужно тратить время. Этот ML-алгоритм мог бы работать вместе с правилами фильтрации или вместо них. Поэтому после короткого обсуждения было решено взять побольше данных для обучения, сделать качественную предобработку текстов и обучить линейную модель для бинарной классификации с tf-idf векторизацией. Word2Vec/FastText, CNN/RNN сеточки, трансформерные эмбеддинги решили пока не применять, так как вычислительные ресурсы проекта пока слабы.
Обучающие данные собрать было легко: примеры новостей класса 1 взяли из базы данных проекта, выгрузив из API. Примеры новостей класса 0 запарсили за тот же временной промежуток. Класс 0 можно было бы дополнить известными датасетами новостей. В итоге получился такой баланс классов: класс 1 — около 5 тыс. примеров; класс 0 — около 300 тыс. примеров.
Про предобработку текстов: линейным моделям можно помочь — для этого нужно как можно сильнее уменьшить размер общего словаря слов в данных с помощью удаления неинформативных слов и лемматизации. А с помощью NER моделей из библиотеки natasha можно автоматически заменять группы слов на один и тот же токен:
- все ФИО заменяются на слово _пер
- все названия организаций заменяются на слово _орг
- все названия стран, городов, районов и тд заменяются на слово _лок
- все числа, написанные цифрами или буквами, заменяются на слово _чсл
- все названия месяцев, год и др. заменяются на слово _дат
делюсь кодом для предобработки новостей
# python
import re
from natasha import Segmenter,MorphVocab,NewsEmbedding,NewsMorphTagger,Doc
from navec import Navec
from slovnet import NER
rename_dict = {'ORG': ' _орг ',
'PER': ' _пер ',
'LOC': ' _лок '}
text_numbers = ['ноль', 'нуль', 'один', 'два', 'три','четыре','пять',
'шесть','семь','восемь','девять','десять',
'одиннадцать','двенадцать','тринадцать','четырнадцать',
'пятнадцать','шестнадцать','семнадцать','восемнадцать','девятнадцать',
'двадцать','тридцать','сорок','пятьдесят','шестьдесят',
'семьдесят','восемьдесят','девяносто',
'сто','двести','триста','четыреста','пятьсот',
'шестьсот','семьсот','восемьсот','девятьсот',
'тысяча','миллион','миллиард','триллион',
'полтысяча','полмиллиона','полмиллиард','полумиллиард','полмиллиарда',
'полутриллион','полтриллиона','млрд','млд','млн']
dats = ['декабрь','январь','февраль','март','апрель','май',
'июнь','июль','август','сентябрь','октябрь','ноябрь',
'понедельник','вторник','среда','четверг','пятница','суббота','воскресение']
stops = ['что','как','все','она','так','его','только','мне',
'было','меня','еще','нет','ему','теперь','когда','даже',
'вдруг','если','уже','или','быть','был','него','вас',
'нибудь','опять','вам','ведь','там','потом','себя','ничего',
'может','они','тут','где','есть','надо','ней','для',
'тебя','чем','была','сам','чтоб','без','будто','чего',
'раз','тоже','себе','под','будет','тогда','кто','этот',
'того','потому','этого','какой','совсем','ним','здесь','этом',
'один','почти','мой','тем','чтобы','нее','сейчас','были',
'куда','зачем','всех','никогда','можно','при','наконец','два',
'другой','хоть','после','над','больше','тот','через','эти',
'нас','про','всего','них','какая','много','разве','три',
'эту','моя','впрочем','хорошо','свою','этой','перед','иногда',
'лучше','чуть','том','нельзя','такой','более','всегда','конечно',
'всю','между','это','вовремя','вновь','вовсе']
class News_cleaner:
def __init__(self,path_navec_weights,path_ner_weights):
self.stops = set(stops)
self.ner = self.prepare_ner(path_navec_weights, path_ner_weights)
self.morph_vocab = MorphVocab()
self.segmenter = Segmenter()
self.morph_tagger = NewsMorphTagger(NewsEmbedding())
def prepare_ner(self,path_navec_weights,path_ner_weights):
navec = Navec.load(path_navec_weights)
ner = NER.load(path_ner_weights)
ner.navec(navec)
return ner
def clean_text(self,text):
ner_tokens = self.ner(text)
text = text.lower()
lemm_tokens = []
doc = Doc(text)
doc.segment(self.segmenter)
doc.tag_morph(self.morph_tagger)
for x in doc.tokens:
flag = False
for span in ner_tokens.spans:
if span.start<=x.start and span.stop>=x.stop:
flag = True
y = rename_dict[span.type]
lemm_tokens.append(y)
break
if flag==False:
x.lemmatize(self.morph_vocab)
y = x.lemma
lemm_tokens.append(y)
text = ' '.join(lemm_tokens)
text = re.sub(r'\d+',r' _чсл ',text)
for x in text_numbers:
text = text.replace(' '+x+' ',' _чсл ')
for x in dats:
text = text.replace(' '+x+' ',' _дат ')
text = re.sub(r'[^а-я_ ]',r' ',text)
text = re.sub(r' _ ',r' ', text)
text = ' '.join([w for w in text.split() if len(w)>2])
text = ' '.join([w for w in text.split() if w not in self.stops])
text = re.sub(r'(_орг )+',r'_орг ',text+' ')
text = re.sub(r'(_пер )+',r'_пер ',text+' ')
text = re.sub(r'(_лок )+',r'_лок ',text+' ')
text = re.sub(r'(_чсл )+',r'_чсл ',text+' ')
text = re.sub(r'(_дат )+',r'_дат ',text+' ')
return text.strip()
#//////////////////////////////////////////////////////////////////////////////////////
# weighs from github.com/natasha/navec and github.com/natasha/slovnet
path_navec_weights = './resources/navec_news_v1_1B_250K_300d_100q.tar'
path_ner_weights = './resources/slovnet_ner_news_v1.tar'
cleaner = News_cleaner(path_navec_weights,path_ner_weights)
text = 'В Лондоне курьеры ООО "Рога и копыта" во главе с Ивановым \
уже объявляли предупредительную забастовку на два дня в мае 2020 г.'
result = cleaner.clean_text(text)
print(result)
#_лок курьер _орг глава _пер объявлять предупредительный забастовка _чсл день _дат _чсл
Для оценки обученного классификатора можно посмотреть на самые сильные слова-триггеры, на которые модель обращает внимание при отнесении текста к классу 1. Метрика ROC AUC, равная 0.992 на валидации, выглядит неплохо, но в триггерах присутствуют слова, обозначающие профессии людей. Это можно считать небольшим переобучением, которое привело к нескольким забавным ситуациям, о которых напишу в результатах.

Для повышения универсальности модели слова-профессии можно заменить на какой-нибудь токен _прф в следующих экспериментах. Для этого, по хорошему, нужно применить NER модель. Но можно обойтись костылем на основе большого словаря профессий и синонимов, найденных с помощью word2vec.
Разрабатываем дедубликатор новостей

В новостном потоке появляется много дубликатов, когда несколько СМИ пишут про одно и то же событие. Иногда СМИ просто перепечатывает новость из другого источника с минимальными изменениями текста. Чтобы редакторы не тратили время на просмотр текстовых копий, нужна система, которая автоматически удаляет дубликаты. Для этого в NLP существует задача text similarity. При решении этой задачи каждый текст превращается в вектор чисел (BOW, tf-idf, doc2vec, взвешенная сумма эмбеддингов слов word2vec, эмбеддинг из sentence-трансформера) и полученные вектора сравниваются по некоторой метрике. Я реализовал через tf-idf векторизацию и косинусное расстояние с высоким порогом сходства.
делюсь кодом для поиска текстовых дубликатов
# python
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
class Dedublicator:
def __init__(self):
self.vectorizer = TfidfVectorizer()
def get_embeddings(self,list_of_texts):
#list_of_texts = clean_texts(list_of_texts)
embeddings = self.vectorizer.fit_transform(list_of_texts)
return embeddings
def find_duplicates(self,list_of_texts,sim=0.95):
sim = round(sim,2)
if not (-1<=sim<=1):
raise ValueError('sim-threshold have to be in [-1,1]')
embeddings = self.get_embeddings(list_of_texts)
clusters = np.array([-1]*len(list_of_texts))
for i in range(len(list_of_texts)):
if clusters[i]==-1:
tj = (clusters==-1)
cos_dist = embeddings[tj,:].dot(embeddings[i,:].T).T.toarray()[0]
cos_dist = np.round(cos_dist,2)>=sim
clusters[tj] += cos_dist.astype(np.int32)*(i+1)
idx_clusters = []
for x in np.unique(clusters):
idx_clusters.append(np.where(clusters == x)[0].tolist())
return idx_clusters
data = ['my text1', # i=0
'our text2', # i=1
'our text3', # i=2
'my text1', # i=3
'your text4'] # i=4
ded = Dedublicator()
print(ded.find_duplicates(data,0.9)) #[[0, 3], [1], [2], [4]]
print(ded.find_duplicates(data,0.3)) #[[0, 3], [1, 2], [4]]Результаты

За месяц работы с командой проекта удалось разработать и запустить в работу классификатор и дедубликатор новостей. Это привело к увеличению охвата важных событий и уменьшило количество ручного труда редакторов. Косвенно возросла оперативность реагирования на новость о конфликте, так как старые алгоритмы могли пропускать некоторые события и редакторам приходилось публиковать информацию намного позже — вечером, после дополнительной проверки. Теперь появилась возможность масштабировать решение на большее количество источников информации — в планах постепенное увеличение источников с 800 до 8-10 тысяч.
UPD: забавные случаи
Выше написал, что классификатор немного переобучился на названия некоторых профессий. Т.е. придал определенным словам огромный вес (например, токену «курьер»), проигнорировав контекст новостей. Для нас, человеков, ясно, что все слова-профессии являются синонимами с точки зрения труда. А с точки зрения математического алгоритма и статистики, различия есть в количестве примеров: алгоритм видел новости о курьерах и медиках очень много раз; а новости о малярах и сварщиках — мало раз. Поэтому для алгоритма, вес токена «курьер» будет чуть выше веса токена «маляр». Поэтому иногда алгоритм «радует» своей работой редакторов и присылает на проверку не совсем те новости:

А через несколько дней прислал развитие этого сюжета:
Если вы знаете, как сделать что-то круто/правильно/красиво с помощью вашей экспертизы в некоторой области — свяжитесь с проектом через tg bot или почту. Уверен, что ребята будут рады всем здравым предложениям для решения различных технических вызовов: от улучшения бэкенда до дизайна сайта и приложений. Есть интересные задачи и для Data Science специалиста:
- Настроить автоматическое создание документов-отчетов по шаблону, подобно годовым отчетам за 2021 и 2022 год.
- Сделать более глубокий анализ данных из API и дополнить им раздел сайта со статистикой.
- Автоматизировать поиск подобных новостей о травмах/трагедиях на работе.
- Обучить (или применить существующую) NER модель для автоматического выделения профессий и других важных слов.
- Улучшить текущий классификатор с помощью увеличенного количества данных, быстрого трансформера, разнообразных текстовых аугментаций.
- Автоматизировать заполнение большинства полей из API нужными словами, обрабатывая текст новости (сейчас все поля конфликта заполняются редактором): ‘titleRu’ — заголовок, ‘conflictReasonId’ — причина трудового конфликта, ‘conflictResultId’ — итог конфликта, ‘industryId’ — индустрия, ‘companyName’ — название предприятия и др.
- Настроить показ интерактивных дашбордов на сайте.
- Научиться определять необычные формулировки трудовых конфликтов (поиск текстовых аномалий).
Вместо заключения
ЗабастКом передает пламенный привет всем единомышленникам и призывает других технических специалистов быть неравнодушными к проблемам людей. Людей, которые лечат, учат, строят, готовят, доставляют, водят, делают уборку и многое необходимое другое. Благодаря разделению труда и профессиям, создающим все материальные блага для жизни, другие люди могут заниматься умственным трудом (программированием, наукой, искусством) и целенаправленно работать над улучшением жизни всех трудящихся масс.
Последнее время меня всё больше интересуют социально-экономические аспекты устройства общества. Возможно, поэтому тема поста оказалась на пересечении нескольких направлений. Во время работы с данными по этой теме увидел, как могут быть устроены отношения между рабочим коллективом и работодателем. Больнее всего видеть и чувствовать, какой несправедливости и издевательствам подвергают многих трудящихся эти «эффективные собственники». Несправедливость, в свою очередь, всегда вызывала, вызывает и будет вызывать наш коллективно-трудовой отпор. Еще вспоминается известная фраза: ничего личного, просто бизнес. Ее уже отлично переформулировали, когда речь идет о праве Человека на достойный труд: это не просто бизнес, это личное.
Оценка производительности работника, качества и эффективности его труда является одной из наиболее важных проблем менеджмента, поскольку мы не можем управлять тем, чего не можем оценить, и не можем улучшить то, чего не можем оценить. В прежнем мире работы, когда сотрудник увольнялся, компании теряли пару рук и ног. Когда сегодня люди уходят из организаций, они уносят с собой ценные знания и информацию — о бизнес-процессах, заказчиках, стратегиях и проектах фирмы. Компании, желающие преуспеть, не могут полагаться на технологии, которые меняются и совершенствуются постоянно. Они должны разработать систему выбора специалистов, которая позволит привлечь лучших и талантливых, сориентировать их в нужном направлении, поощрить за достигнутые результаты, научить терпимо относиться к переменам в организации и принимать их. Внутри компаний на смену старому «общественному договору», когда работодатели искали сотрудников, которые заполнят существующие вакансии и будут выполнять определенные функции, приходит новая концепция: работодатели вкладывают средства в сотрудников, которые увеличивают стоимость их бизнеса, что позволит стимулировать работников к достижению более высокого уровня эффективности работы. Вот почему так важен первоначальный отбор работников при их приеме в компанию.
Существуют различные модели оценки эффективности наемных работников. Мы рассматриваем те из них, которые основаны на предположении о том, что истинный уровень производительности работника оценить невозможно, поэтому единственным способом достоверной оценки является интерпретация сигналов в рамках разделяющего равновесия Байеса-Нэша. В соответствии с предпосылками о правдивости сигналов на рынке труда модели можно сгруппировать следующим образом:
модели exante, основанные на предпосылке о правдивости сигналов (модели Спенса, Шапиро и Стиглица, Райли, Ланга и Кроппа, Бедарда);
модели expost, основанные либо на предпосылке о том, что сигналы не являются правдивыми (модель конкуренции за талантливых работников Волдмана);
либо о том, что сигналы правдивы лишь наполовину (модель увольнений Гиббонса и Каца).
Спенс не ставил себе целью изучение рынка труда, взаимоотношений между работодателем и наемным работником, его исследования были посвящены теории сигналов и перераспределению информации на рынках, рынок труда использовался им лишь как показательный пример, таким образом, многие особенности и характерные черты взаимоотношений работодателей и работников были упущены. Тем не менее именно эти простейшие модели дали возможность сформировать теоретическую базу для анализа эффективности работы менеджмента. В модели Шапиро и Стиглица предполагается, что работодатель имеет возможность отследить, насколько эффективны его работники. Работника, пойманного на недобросовестном выполнении своих обязанностей, увольняют, и всю оставшуюся жизнь, независимо от того, устроится ли он на работу в другую фирму, или откроет собственное дело, он будет вынужден работать за резервную заработную плату, уровень которой ниже, чем он мог бы получать на своей прежней работе [Shapiro, Stiglitz, 1984]. Райли [Riley, 1979] сделал первую попытку эмпирически протестировать модель сигналов на рынке труда, предложенную Спенсом [Spence, 2001]. Его идея заключалась в том, что сигналы наиболее эффективны в тех отраслях, где трудно оценить качество труда. В таких отраслях заработная плата и образование должны иметь сильную взаимосвязь с карьерой, в то время как связь будет намного слабее в тех отраслях, где эффективность труда легче оценить. Со временем работодатели лучше узнают своих работников и даже в тех отраслях, где изначально было сложно отследить, насколько хорошо работники выполняют свои обязанности, связь между заработной платой, эффективностью труда, образованием и карьерой становится слабее. Позднее модель Спенса была протестирована Лангом, Кроппом [Lang, Kropp, 1986] и Бедардом [Bedard, 2001], и оба исследования подтвердили ее состоятельность.
Фарбер и Гиббонс [Farber, Gibbons, 1996] предложили дальнейший вариант развития модели Спенса, дав возможность работодателю получать информацию об эффективности труда работника, изучая его предыдущую карьеру. Их модель предполагает, что образование не влияет на уровень заработной платы (независимо от того, сколько времени человек является агентом рынка труда), а другие неизмеримые или трудно измеримые факторы, свидетельствующие об эффективности труда работника, со временем приводят к увеличению заработной платы.
Волдман [Waldman, 1984] рассматривал ситуацию, в которой фирмы конкурируют между собой за талантливых работников. В связи с тем что ни один работодатель не хочет потерять хорошего работника, он никогда не будет поручать этому работнику заданий, которые позволили бы тому в достаточной степени проявить себя как профессионала. Выполнение ответственных заданий будет рассматриваться как сигнал для конкурентов о том, что перед ними отличный специалист, в то время как в действительности эти задания будут выполняться вполне заурядными работниками, а настоящие «звезды» будут оставаться в тени. Такая стратегия может быть оптимальной для отдельной фирмы в условиях конкуренции за человеческие ресурсы, но итогом подобного поведения большого количества фирм, безусловно, является неэффективное и нерациональное использование человеческого капитала.
Бернар [Bernhardt, 1995] развивает эти идеи в собственном анализе продвижения по карьерной лестнице, объясняя, почему люди, имеющие более низкий уровень образования, чаще бывают рекомендованы на более высокие посты и почему они порой демонстрируют необыкновенную работоспособность. Работодатель, который хочет скрыть от своих конкурентов информацию о собственных работниках, имеет достаточно стимулов для того, чтобы не продвигать по службе специалистов, имеющих хорошее образование. Таким образом, для того, чтобы оправдать свой недостаточный уровень профессионализма и свое несправедливое повышение в должности, работник вынужден работать с гораздо большим усердием, чем его более профессиональный коллега. Мильгром и Остер [Milgrom, Oster, 1987] отмечают, что подобная дискриминация ведет к неэффективности социальных институтов: работники назначаются на те должности, которые не соответствуют их уровню образования и профессионализма, кроме того, работники не имеют достаточных стимулов к повышению квалификации и обучению.
В своем эмпирическом анализе увольнений на рынке труда с асимметричной информацией Гиббонс и Кац [Gibbons, Katz, 1991] тестировали значимость неблагоприятного отбора и сигналов. Если фирмы легко могут определить, кого из работников следует уволить, то другие агенты рынка труда будут считать увольнение сигналом о том, что это плохой работник («лимон»), что его производительность ниже среднего уровня. Работники, которые выглядят подобным же образом в свете оценки собственной трудоспособности, но лишились работы, например, по причине того, что закрылась их фирма, легче смогут найти себе новую работу с более высокой заработной платой. Основываясь на исследовании большой выборки уволенных работников, Гиббонс и Кац нашли подтверждение этой гипотезе.
Мы рассмотрели результаты различных исследований, показывающих, каким образом связаны между собой действия менеджмента корпораций и результаты сделок на рынке корпоративного контроля и то, насколько важно бывает порой для менеджмента избавиться от контроля владельцев бизнеса, а для собственников, наоборот, сделать этот контроль и оценку качества работы управляющих более эффективными. Точно так же и для самих топ-менеджеров необходимо иметь возможность максимально корректно оценить деятельность своих подчиненных.
Приведенные в статье примеры моделей оценки эффективности наемных работников позволяют сделать вывод о том, что выбор и качество управленческих решений зачастую обусловлены не только и не столько профессиональной подготовкой менеджмента компании, сколько комплексом мотиваций, на основе которых они принимаются. Далее мне хотелось бы более подробно остановиться на проблеме влияния действий советов директоров (как самого высокого уровня управляющих компанией) на благосостояние владельцев компаний, принимающих участие в сделке, при принятии решений о слияниях и поглощениях.