Для малой выборки доверительный интервал
![]() ,
,
(2.3)
где
![]() — коэффициент Стьюдента, принимаемый
— коэффициент Стьюдента, принимаемый
потабл.1.2
в зависимости от
значения доверительной вероятности
![]() .
.
Зная
![]() ,
,
можно вычислить действительное значение
изучаемой величины для малой выборки
![]() .
.
(2.4)
Возможна и иная
постановка задачи.
По
![]() известных измерений малой выборки
известных измерений малой выборки
необходимо определить доверительную
вероятность![]() при условии, что погрешность среднего
при условии, что погрешность среднего
значения не выйдет за пределы![]() .
.
Задачу решают
в такой последовательности:
1.
Вначале вычисляется среднее значение
![]() ,
,
![]() и
и![]() .
.
2.
С помощью величины
![]() ,
,
известного![]() итабл.1.2
итабл.1.2
определяют доверительную вероятность.
В процессе
обработки экспериментальных данных
следует исключить грубые ошибки ряда.
Появление этих ошибок вполне вероятно,
а наличие их ощутимо влияет на результат
измерений. Однако прежде чем исключить
то или иное измерение, необходимо
убедиться, что это действительно грубая
ошибка, а не отклонение вследствие
статистического разброса.
Известно несколько
методов определения грубых ошибок
статистического ряда. Наиболее простым
способом исключения из ряда резко
выделяющегося измерения является
правило
«трех сигм»: разброс случайных
величин от среднего значения не должен
превышать
![]() .
.
(2.5)
Более достоверными
являются методы, базируемые на
использовании доверительного интервала.
Пусть имеется
статистический ряд малой выборки,
подчиняющийся закону нормального
распределения. При наличии грубых ошибок
критерии их появления вычисляются по
формулам
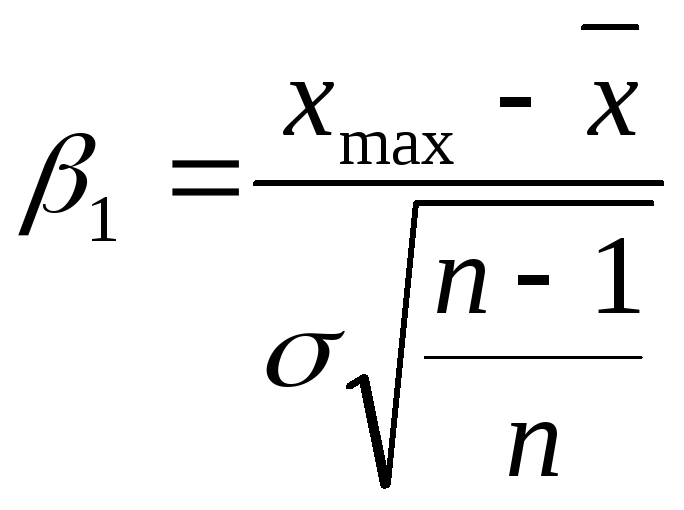 ;
;
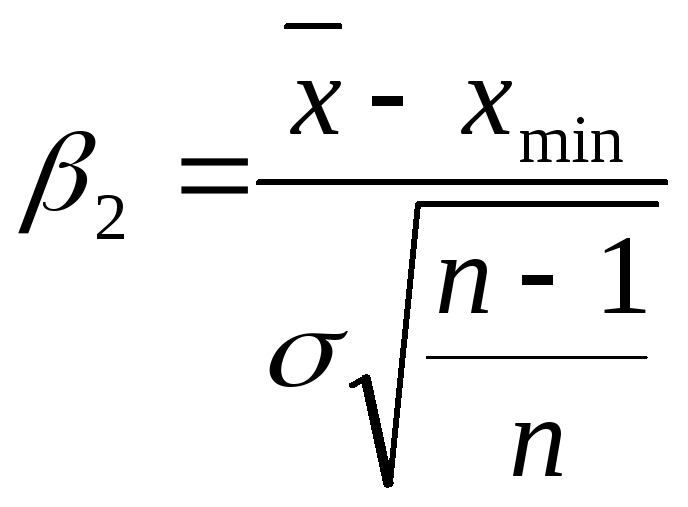 ,
,
(2.6)
где
![]() — наибольшее и наименьшее значения из
— наибольшее и наименьшее значения из![]() измерений.
измерений.
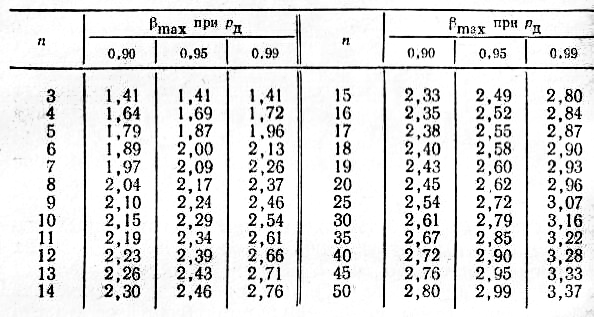
В табл.2.1
приведены максимальные значения
![]() ,
,
возникающие вследствие статистического
разброса, в зависимости от доверительной
вероятности.
Если
![]() ,
,
то значение![]() необходимо исключить из статистического
необходимо исключить из статистического
ряда как грубую погрешность.
Если
![]() исключается величина
исключается величина![]() .
.
После исключения
грубых ошибок определяют новые значения
![]() и
и![]() из
из![]() или
или![]() измерений.
измерений.
Таблица 2.1
Критерий появления грубых ошибок
Второй метод
установления грубых ошибок основан на
использовании критерия Романовского
В.И. и применим также для малой выборки.
Методика
выявления грубых ошибок сводится к
следующему.
1.
Задаются доверительной вероятностью
![]() и потабл.2.2
и потабл.2.2
в зависимости от
![]() находится коэффициент
находится коэффициент![]() .
.
2.
Вычисляют предельно допустимую абсолютную
ошибку отдельного измерения
![]() .
.
(2.7)
Если
![]() ,
,
то измерение![]() исключают из ряда наблюдений.
исключают из ряда наблюдений.
В случае более
глубокого анализа экспериментальных
данных рекомендуется такая
последовательность:
1.
После получения экспериментальных
данных в виде статистического ряда его
анализируют и исключают систематические
ошибки.
2.
Анализируют ряд в целях обнаружения
грубых ошибок и промахов:
устанавливают
подозрительные значения
![]() или
или![]() ;
;
определяют
среднеквадратичное отклонение
![]() ;
;
вычисляют
по (2.6) критерии
![]() и сопоставляют с
и сопоставляют с![]() ,
,
исключают при необходимости из
статистического ряда![]() или
или![]() и получают новый ряд из новых членов.
и получают новый ряд из новых членов.
3.
Вычисляют среднеарифметическое
![]() ,
,
погрешности отдельных измерений
![]() и среднеквадратичное очищенного ряда
и среднеквадратичное очищенного ряда![]() .
.
4.
Находят среднеквадратичное
![]() серии измерений, коэффициент вариации
серии измерений, коэффициент вариации![]() .
.
5.
При большой выборке задаются доверительной
вероятностью
![]() или уравнением значимости
или уравнением значимости![]() и потабл.1.1
и потабл.1.1
определяют
![]() .
.
6.
При малой выборке (![]() )
)
в зависимости от принятой
доверительной
вероятности
![]() и числа членов ряда
и числа членов ряда![]() принимают коэффициент Стьюдента
принимают коэффициент Стьюдента![]() ;
;
с помощью формулы (1.2) для большой выборки
или (2.3) для малой выборки определяют
доверительный интервал.
Таблица 2.2
Таблица 2.3

7.Устанавливают
по (2.4) действительное значение исследуемой
величины.
8.Оценивают
относительную погрешность (![]() )
)
результатов серии измерений при заданной
доверительной вероятности![]() :
:
![]() .
.
(2.8)
Если погрешность
серии измерений соизмерима с погрешностью
прибора
![]() ,
,
то границы доверительного интервала
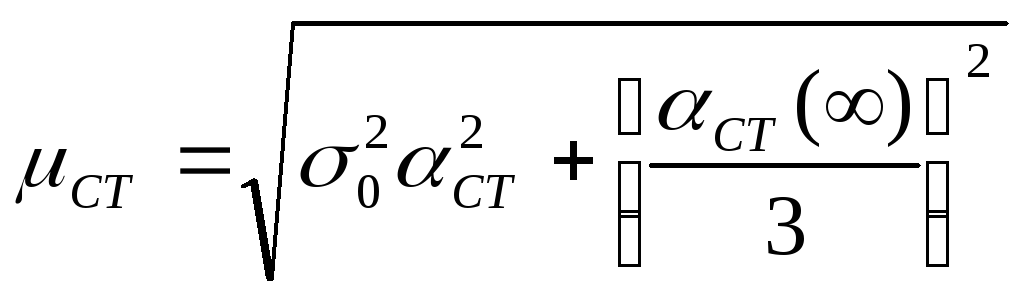 .
.
(2.9)
Формулой (2.9) следует
пользоваться при
![]() .
.
Если же
![]() ,
,
то доверительный интервал вычисляют с
помощью (1.1) или (2.4).
Пример
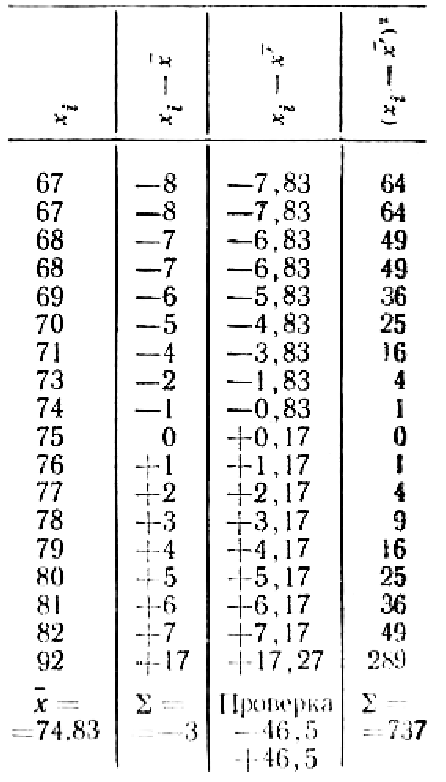
Пусть имеется
![]() измерений (табл.2.3).
измерений (табл.2.3).
Анализ средств и результатов измерений
показал, что систематических ошибок в
эксперименте не обнаружено. Необходимо
выяснить, не содержат ли измерения
грубых ошибок.
Если воспользоваться
первым
методом (критерий
![]() ),
),
то надо вычислить среднеарифметическое
![]() и отклонение
и отклонение![]() .
.
При этом удобно
пользоваться формулой
![]() ,
,
где
![]() — среднее произвольное число.
— среднее произвольное число.
Если принять
![]() то
то![]() .
.
В формуле (1.1)
значение
![]() можно найти упрощенным методом:
можно найти упрощенным методом:
![]() .
.
Используя (1.1),
получим
![]() ;
;
![]() .
.
Следовательно
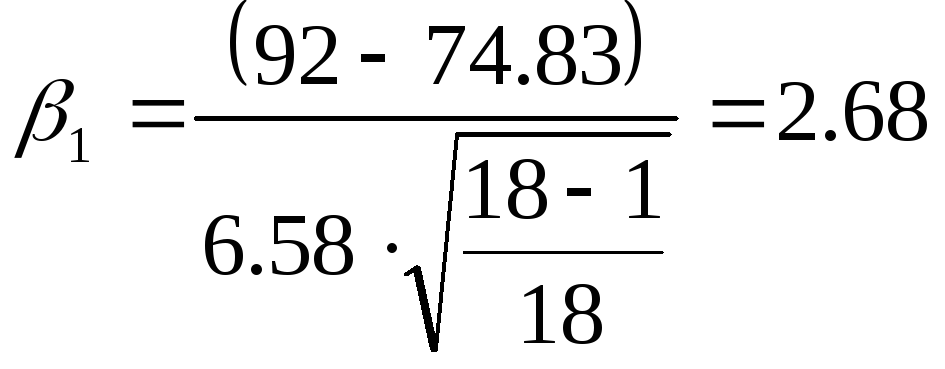 .
.
Как видно из
табл.2.1,
при доверительной вероятности
![]() и
и![]()
![]() .
.
Поскольку
![]() измерение
измерение![]() не является грубым промахом.
не является грубым промахом.
Если
![]() ,
,![]() то значение
то значение![]() следует исключить.
следует исключить.
Если применить
правило
![]() ,
,
то
![]()
т.е. измерение
![]() следует оставить.
следует оставить.
В случае, когда
измерение
![]() исключается,
исключается,
![]() ;
;
Среднеквадратичное
отклонение для всей серии измерений
![]() при
при
![]() .
.
При очищенном ряде
![]() .
.
Поскольку
![]() ,
,
ряд следует отнести к малой выборке, и
доверительный интервал вычисляется с
применением коэффициента Стьюдента![]() .
.
По табл.1.2
принимается доверительная вероятность
![]() и тогда
и тогда
![]() при
при
![]() ;
;
![]() при
при
![]() .
.
Доверительный
интервал
![]() при
при ![]() ;
;
![]() при
при ![]() .
.
Действительное
значение измеряемой величины:
![]() при
при ![]() ;
;
![]() при
при ![]() .
.
Относительная
погрешность результатов серии измерений:
![]() при
при ![]() ;
;
![]() при
при ![]() .
.
Таким образом,
если принять
![]() за грубый промах, то погрешность измерения
за грубый промах, то погрешность измерения
уменьшается с![]() до
до![]() т.е. на
т.е. на![]() .
.
Если необходимо
вычислить минимальное количество
измерений при заданной точности, проводят
серию опытов, вычисляют
![]() ,
,
затем с помощью формулы (2.2) определяют![]() .
.
В рассмотренном
случае
![]() .
.
Пусть задана
точность
![]() и
и![]() при доверительной вероятности
при доверительной вероятности![]() и
и![]() .
.
Тогда
![]() при
при
![]() ;
;
![]() при
при
![]() .
.
Таким образом,
требование повышения точности измерения
(но не выше точности прибора) приводит
к значительному увеличению повторяемости
опытов.
Выше были рассмотрены
общие методы проверки экспериментальных
измерений на точность и достоверность.
Ответственные
эксперименты должны быть проверены и
на воспроизводимость результатов, т.е.
на их повторяемость в определенных
пределах измерений с заданной|
доверительной достоверностью.
Суть такой
проверки сводится к следующему.
1.
Для каждой серии вычисляется
среднеарифметическое значение
![]() (
(![]() — число измерений одной серии, принимаемое
— число измерений одной серии, принимаемое
обычно равным![]() ).
).
2.
Далее вычисляют дисперсию
![]() .
.
3.
Чтобы оценить воспроизводимость,
рассчитывают критерий Кохрена (расчетный):
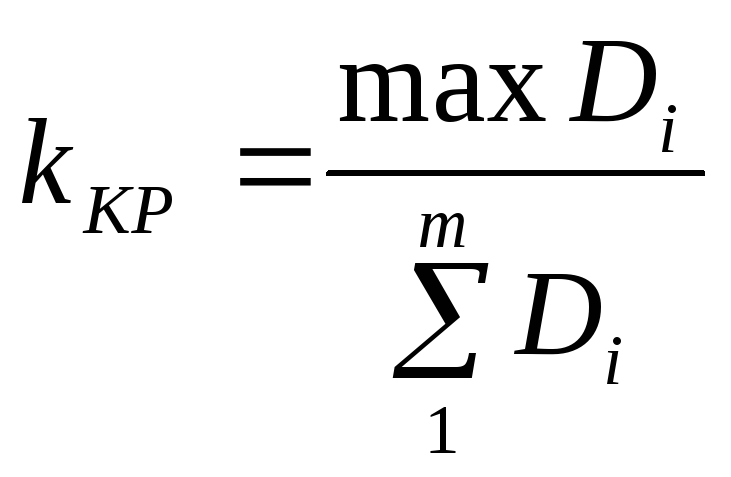 ,
,
![]() (2.10)
(2.10)
где
![]() — наибольшее значение дисперсий из числа
— наибольшее значение дисперсий из числа
рассматриваемых
параллельных серий
![]() ;
;
![]() — сумма дисперсий
— сумма дисперсий
![]() серий.
серий.
Опыты считаются
воспроизводимыми при
![]() ,
,
(2.11)
где
![]() — табличное значение критерия Кохрена
— табличное значение критерия Кохрена
(табл.2.4).
Таблица 2.4
Некоммерческое акционерное общество
Алматинский институт энергетики и связи
Кафедра электроснабжения промышленных
предприятий
ТЕОРИЯ И ПРАКТИКА
ТЕХНИЧЕСКОГО ЭКСПЕРИМЕНТА
В ЭЛЕКТРОЭНЕРГЕТИКЕ
Конспект лекций
для студентов всех
форм обучения специальности 6М0718 – Электроэнергетика
Алматы 2010
СОСТАВИТЕЛЬ: Фадеев В.Б. Теория и практика
технического эксперимента в электроэнергетике.
Конспект лекций для студентов всех форм
обучения специальности 6М0718 –
Электроэнергетика. — Алматы: АИЭС, 2010. – 52 с.
Конспект лекций содержит сведения по теории случайных
ошибок и обработке результатов измерений, рассматриваются вопросы анализа
экспериментальных данных, определения необходимого объема измерений, нахождения
грубых ошибок эксперимента, проверки данных на достоверность и воспроизводимость. Для
экспериментальных данных, имеющих стохастический характер, рассмотрено применение
статистических критериев, корреляционного и регрессионного анализа.
Особое внимание уделено применению встроенных
инструментов Excel для обработки и анализа результатов
эксперимента и нахождения эмпирических формул к опытным данным.
Содержание
|
1Классификация, |
4 |
|
2 Базовые понятия теории |
8 |
|
3. Статистическая обработка |
12 |
|
4 Основные статистические |
16 |
|
5 Теория ошибок. Обработка результатов измерений |
20 |
|
6 Методы определения грубых |
24 |
|
7 Исследование |
28 |
|
8 Применение статистических |
32 |
|
9 Применение |
36 |
|
10 Корреляционно – |
40 |
|
11Методы графической обработки экспериментальных |
44 |
|
12 Нахождение |
48 |
|
Литература |
51 |
1 Лекция. Классификация, характеристики, задачи и
организация эксперимента
Содержание лекции:
классификация,
типы и задачи эксперимента, организация
эксперимента, составление программы эксперимента.
Цель лекции:
знакомство с основными понятиями и терминологией дисциплины.
1.1. Классификация, характеристики и задачи
эксперимента
В
научном языке и
исследовательской работе термин «эксперимент» обычно используется в значении опыта и целенаправленного наблюдения. Основной целью эксперимента является изучение
свойств исследуемых объектов, проверка гипотез
и на этой основе более глубокое
изучение объекта исследования. Постановка
и организация эксперимента определяются
его назначением.
Эксперименты
могут быть классифицированы по различным признакам, в частности:
— по способу формирования условий,
(естественные и искусственные эксперименты);
— по организации проведения эксперимента (лабораторные,
натурные, производственные
и т.п.);
— по контролируемым величинам (пассивный и активный эксперимент);
— по числу варьируемых факторов
(однофакторный и многофакторный эксперимент).
1.2. Краткие характеристики экспериментов
Естественный
эксперимент проводится в
естественных условиях существования объекта исследования. Используется в
биологических, социальных, педагогических и психологических науках.
Искусственный
эксперимент проводится в
искусственных условиях, создаваемых с целью проверки выдвинутых гипотез. Широко
применяется в естественных и технических науках.
Лабораторный эксперимент проводится в лабораторных условиях. Чаще
всего в лабораторном эксперименте изучается не сам объект, а его модель или
образец. Этот эксперимент позволяет изучить влияние одних характеристик при
варьировании других, получить информацию с минимальными затратами времени и ресурсов.
Однако такой эксперимент не всегда полностью моделирует реальный ход
изучаемого процесса, поэтому возникает потребность в проведении натурного
эксперимента.
Натурный эксперимент
проводится в естественных условиях и на реальных объектах. Основная проблема
натурного эксперимента — обеспечить соответствие условий эксперимента реальной
ситуации, в которой будет работать впоследствии создаваемый объект.
Пассивный эксперимент
предусматривает измерение
и наблюдение за объектом без искусственного вмешательства в его функционирование.
Активный
эксперимент связан с
выбором специальных входных сигналов (факторов) и контролирует входные и
выходные сигналы исследуемой системы.
Однофакторный
эксперимент предполагает варьирование
исследуемого фактора и стабилизацию мешающих факторов.
Стратегия многофакторного
эксперимента состоит в том, что варьируются все переменные сразу и каждый
эффект оценивается по результатам всех опытов, проведенных в данной серии
экспериментов.
1.3. Организация эксперимента
Для организации
и проведения эксперимента необходимо:
— выдвинуть
гипотезу, подлежащую проверке;
— написать
методику и программу проведения экспериментальных работ;
— обеспечить
условия для выполнения экспериментальных работ;
— подготовить
журнал для фиксирования хода и результатов эксперимента.
Выбор
методики проведения эксперимента должен проводиться особенно тщательно. Необходимо убедиться
в том, что она соответствует современному
уровню науки и условиям, в которых выполняется
исследование.
1.4. Составление программы эксперимента
До начала проведения эксперимента составляется план (программа) выполнения
экспериментальных исследований, который включает в себя:
— цель
и задачи эксперимента;
— выбор
исследуемых факторов;
— обоснование
объема эксперимента (числа измерений и опытов);
— порядок
проведения опытов;
— обоснование
средств измерений;
— описание
проведения эксперимента;
-обоснование
способов обработки и анализа результатов эксперимента.
Важным
этапом подготовки к эксперименту является определение его целей и задач. Количество
задач для конкретного
эксперимента не должно быть слишком большим (3…4).
При экспериментальном исследовании одного и того же процесса (наблюдения
и измерения) повторные отсчеты на приборах, как правило, неодинаковы. Отклонения объясняются
различными причинами: неоднородностью свойств изучаемого тела, особенностями
изучаемого явления, качеством приборов, классом их точности, субъективными особенностями экспериментатора и проч.
Чем больше случайных факторов, влияющих на опыт, тем больше расхождения в
значениях, получаемых при измерениях, т. е. тем больше отклонения отдельных измерений от среднего значения.
Это требует повторных измерений, а,
следовательно, необходимо знать их минимальное количество. Под
необходимым минимальным количеством измерений понимают такое количество измерений, которое в данном опыте обеспечивает
устойчивое среднее значение измеряемой величины, удовлетворяющее заданной степени точности. Установление необходимого минимального
количества измерений имеет большое значение, поскольку обеспечивает получение
наиболее объективных результатов при минимальных затратах времени и средств.
При обработке экспериментальных данных особое внимание должно быть
уделено математическим
методам обработки и анализу опытных данных, например, нахождению эмпирических формул, применению
корреляционного и регрессионного анализа.
1.5. Порядок обработки результатов эксперимента
Все анализы,
определения и наблюдения необходимо записывать
в специальный журнал, форма которого должна
наилучшим образом соответствовать исследуемому процессу с максимальной фиксацией всех фактов и условий их
появления. При получении в одном статистическом
ряду результатов, резко отличающихся от соседних измерений, исполнитель должен, тем не менее, записать все данные
без искажений и указать обстоятельства, сопутствующие указанному
измерению. Это потом позволит установить
причины отклонений (искажений) и
соответствующим образом квалифицировать такие измерения. Если в
процессе измерения необходимы простейшие расчеты, то они должны быть внесены в
журнал или в отдельную тетрадь с указанием
дня или месяца проведения опыта,
номера и серии опытов.
Лабораторные журналы и тетради — важные документы. Поэтому они
должны содержаться в порядке и обеспечивать возможность легкой проверки. Нужно не
допускать исправлений, а в случае необходимости они должны делаться так, чтобы не
происходило
путаницы при расчетах. Каждое исправление должно сопровождаться подписью
экспериментатора и краткой справкой о причинах исправлений. Никаких записей
или пометок, не относящихся к делу, в лабораторных журналах и тетрадях
делать нельзя!
Важное
место в экспериментальных исследованиях занимают измерения. Теорией и практикой
измерения занимается метрология, являющаяся наукой об измерениях, методах и средствах
обеспечения их единства. Напомним некоторые основные понятия из курса
метрологии, которые понадобятся нам в дальнейшем.
1.6. Некоторые понятия из курса метрологии
Различают прямые и косвенные измерения. Наиболее
простым является прямое измерение, при котором искомое значение величины
находят непосредственно с помощью измерительного прибора. Например, длина
измеряется линейкой, напряжение – вольтметром, и т.п.
Если прямые измерения невозможны, используют косвенные
измерения. В них искомое значение величины находят на основании известной
зависимости этой величины от других, допускающих прямое измерение. Например,
среднюю плотность тела можно измерить по его массе и геометрическим размерам,
электрическое сопротивление резистора – по падению напряжения на нем и току
через него и т.п.
Измерительные приборы характеризуются величиной погрешности, стабильностью измерений
и чувствительностью.
Погрешности приборов бывают абсолютными и относительными.
Под абсолютной
погрешностью измерительного прибора понимается
величина
![]() ,
,
где ![]() —
—
показания
прибора;
![]() — действительное значение измеренной величины, полученное более точным методом.
— действительное значение измеренной величины, полученное более точным методом.
Однако абсолютная погрешность не отражает качества
измерений: например, абсолютная погрешность 1 мм при измерении размеров
помещения свидетельствует о высоком качестве измерения, та же погрешность
совершенно неприемлема при измерении диаметра тонкой проволоки.
Критерием качества измерения является отношение
абсолютной погрешности к окончательному результату измерения:
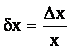 .
.
Это отношение безразмерно. Величину ![]() называют относительной
называют относительной
погрешностью. Высокой точности измерения соответствует малое значение
относительной погрешности.
Погрешности
измерения делятся на систематические погрешности и случайные.
Систематическая погрешность – это погрешность измерения, остающаяся
постоянной при повторных измерениях одной и той же величины. В дальнейшем под
систематической погрешностью мы будем понимать погрешность прибора.
Случайные погрешности обусловлены сочетаниями случайных факторов
– ошибками отсчета, свойствами исследуемого объекта, вариацией, параллаксом и
проч. Случайная погрешность при повторных измерениях изменяется случайным
образом, и результат измерения заранее предсказать невозможно.
Хотя исключить случайные погрешности отдельных измерений невозможно,
математическая теория, в основу которой положена теория вероятности и
математическая статистика, позволяет не только учесть, но и уменьшить влияние
случайных погрешностей на окончательный результат.
Поэтому изучение вопросов обработки результатов эксперимента мы начнем с
базовых понятий теории вероятности.
2 Лекция. Базовые понятия теории относительности
Содержание лекции:
случайные события, вероятность события, дискретные и непрерывные
случайные величины, математическое ожидание, дисперсия и моменты, законы
распределения вероятностей, нормальный закон распределения, стандартное
нормальное распределение, правило трех сигм.
Цель лекции:
знакомство с основными понятиями и терминологией теории вероятности,
являющейся теоретической базой методов обработки экспериментальных данных и
измерений.
2.1 Введение
Обработка данных, полученных при выполнении измерений или результатов
научных опытов и исследований, выполняется на основе методов математической
статистики, теоретической основой которой является теория вероятности.
2.2 Основы теории
вероятностей
В теории
вероятностей изучаются общие закономерности для случайных событий. Для
понимания предмета и методов теории вероятностей ознакомимся с некоторыми ее
базовыми понятиями.
2.3 Базовые понятия
теории вероятностей
Основополагающим
является понятие случайного события (или просто событие). Это такое
событие, которое может произойти, а может и не произойти в результате
эксперимента или измерения. Другими словами, наперед, до проведения опыта, нельзя
однозначно сказать, случится это событие или нет. В теории вероятностей каждое
такое событие принято характеризовать численной мерой степени объективной
возможности события. Эта численная мера называется вероятностью события,
или просто вероятностью. Вероятность — это число в диапазоне от 0 до 1.
Достоверным
является событие с вероятностью 1 (т.е. это такое событие, которое обязательно
произойдет). Если вероятность события равна нулю, то такое событие называется невозможным,
и оно никогда не произойдет. Кроме того, важным является понятие полной группы
событий. В результате проведения опыта в такой группе обязательно
произойдет хотя бы одно событие из этого набора. Если в качестве опыта
рассматривать процесс подбрасывания шестигранного кубика с цифрами от одного до
шести, то в качестве примеров полных групп событий могут быть приведены группа
из шести событий (выпадение числа 1, 2 и т.д. до 6) или группа из двух событий
(выпадение четного числа или выпадение нечетного числа).
С практической точки зрения
больший интерес представляет понятие случайной величины. Аналогично
случайному событию, это такая величина, значение которой до проведения опыта
нельзя предсказать абсолютно достоверно. Случайные величины бывают дискретными
и непрерывными. Возможными реализациями дискретной случайной
величины в процессе проведения опыта (измерения) являются отдельные числа, в то
время как непрерывная случайная величина может в процессе измерения принимать
непрерывный набор значений из какого-то интервала, который, в принципе, может
быть и неограниченным.
Важное место в
наборе числовых характеристик случайных величин занимает математическое
ожидание, которое для непрерывной случайной величины определяется как
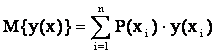 ,
,
а для дискретной величины,
как
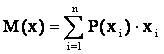 .
.
Кроме
математического ожидания, важной характеристикой является также и дисперсия.
Дисперсией случайной величины
называют ее числовую характеристику, которая определяется для непрерывной
случайной величины по формуле:
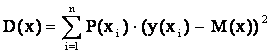 ,
,
а для дискретной случайной величины по
формуле: 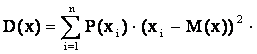 .
.![]()
2.4 Законы
распределения вероятностей
Зная
распределение вероятностей интересующих нас случайных величин можно делать
выводы о событиях, в которых участвуют эти величины. Конечно, эти выводы
также будут носить случайный характер.
Среди всех
вероятностных распределений есть такие, которые на практике используются особенно
часто. Эти распределения детально изучены, и свойства их хорошо известны.
Многие из этих распределений лежат в основе целых областей знания — таких как
теория массового обслуживания, теория надежности, теория измерений, теория игр
и т. п.
Большинство
применяемых на практике распределений являются дискретными или непрерывными.
Среди дискретных распределений наиболее важными являются биномиальное и пуассоновское
распределения, а среди непрерывных – нормальное распределение и
распределения, связанные с нормальным: Стьюдента, Фишера, хи-квадрат. Для нас
наибольший интерес представляет нормальное распределение, которое и рассмотрим.
Нормальный закон распределения
Большинство экспериментальных исследований в технике, в различных
областях естественных наук, биологии, медицине, и проч. связаны с
измерениями, результаты которых могут принимать практически любые значения в заданном
интервале, и описываются моделью непрерывных случайных величин. Одним из
важнейших непрерывных распределений является нормальное, или гауссово
распределение.
Нормальное распределение получило широкое распространение для приближенного
описания многих случайных явлений, в которых на результат воздействует большое количество
независимых случайных факторов, среди которых нет сильно выделяющихся.
Например, рассеяние снарядов при стрельбе. Кроме того, многие распределения,
связанные со случайной выборкой, при увеличении объема выборки переходят в
нормальное распределение. Однако следует иметь в виду, что в природе
встречаются экспериментальные распределения, для описания которых модель
нормального распределения может оказаться и не пригодной.
Плотность вероятностей нормально распределенной случайной величины
задается формулой Гаусса:
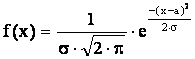 ,
, ![]() (2.1)
(2.1)
Здесь а и ![]() — параметры
— параметры
распределения.
График плотности (нормальная кривая) представлен на рисунке 2.1
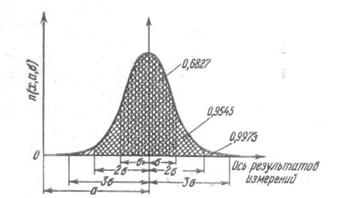
Рисунок 2.1 — Нормальная
кривая распределения
Площади под кривой на рисунке представляют
собой вероятности получения результатов измерений.
Площадь, отвечающая какому- либо интервалу оси
абсцисс, изображает вероятность попадания случайной величины в данный
интервал. В среднем доля (или процент) или, как еще говорят частость тех
измерений, которые попадают в рассматриваемый интервал, приближенно
соответствует величине вероятности, при том тем точнее, чем больше общее число
измерений. Из рисунка 2.1 видно, что основная масса получаемых результатов
будет группироваться около центрального или среднего значения а,
которому при отсутствии систематических, т.е. постоянно имеющих место
погрешностей отвечает неизвестная истинная величина измеряемого параметра. Параметр ![]() , называемый средним квадратическим
, называемый средним квадратическим
отклонением характеризует степень сжатия или растяжения (плотности) диаграммы.
Чем больше ![]() ,
,
тем «шире» кривая, а ее максимальная высота ниже. Кривая как бы растягивается в
стороны. В выделенный на рисунке 2.1 диапазон ![]() нормально распределенная случайная
нормально распределенная случайная
величина попадает с вероятностью 0,682. Следовательно, из 1000 измерений в
682 случаях полученное значение будет попадать в данный интервал. В диапазон
![]() случайная
случайная
величина попадает с вероятностью 0,954, а в диапазон ![]() — с вероятностью 0,997. В
— с вероятностью 0,997. В
последнем случае из тысячи испытаний только в трех из них полученное значение
будет находиться вне указанного интервала. Можно утверждать, что лишь
ничтожная часть результатов измерений будет находиться вне указанного предела. Последняя
закономерность трактуется как правило трех сигм или правило трех стандартов.
При
уменьшении параметра![]() ,
,
т.е. при повышении точности измерений (рисунок 2.2), результаты измерений
теснее группируются около центра, кривая (нанесена пунктиром) поднимается в
центре и круче спадает к оси абсцисс при удалении от него. С увеличением
параметра![]() ,
,
т.е. при снижении точности метода измерения рассеивание результатов измерений
увеличивается, и кривая приобретает более пологий вид.
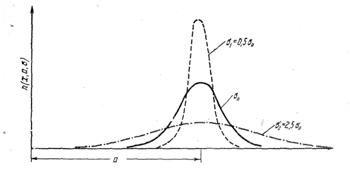
Рисунок 2.2 — Изменение формы нормальной кривой при
измерениях методами различной точности
3
Лекция. Статистическая обработка экспериментальных данных
Содержание лекции:
математическая
статистика, задачи и основные разделы математической статистики, генеральная и
выборочная совокупности, выборка, репрезентативность выборки, параметризация
выборки, применение встроенных инструментов Excel
для статистической обработки данных выборки.
Цель лекции:
знакомство
с предметом математической статистики и задачами, решаемыми с ее помощью.
При
выполнении эксперимента часто приходится сталкиваться с необходимостью
обработки и анализа экспериментальных данных, которые формируются под действием
множества факторов, многие из которых носят случайный характер. В качестве
примера можно привести электрическую нагрузку промышленных предприятий.
Можно сказать, что стохастическому характеру подвержены падение и колебания
напряжения сети, частота сети и другие электрические параметры в электрических
сетях промышленных предприятий и энергосистем.
Стохастическая
природа экспериментальных данных обусловливает необходимость применения
специальных статистических методов для их анализа и обработки, т.е. применения
математической статистики, основная задача которой заключается в получении по
данным выборки основных статистических характеристик изучаемого явления.
Приступая к
рассмотрению темы, необходимо вначале дать основные определения понятия
математической статистики и методов статистического исследования.
3.1. Основные понятия и определения
Математической
статистикой называется раздел математики, посвященный методам сбора, анализа и
обработки статистических данных для научных и практических целей.
Статистические данные представляют собой данные, полученные в
результате обследования большого числа объектов или явлений.
Математическая статистика подразделяется на две основные области:
1. Описательная статистика;
2. Аналитическая статистика.
Описательная
статистика охватывает методы описания статистических данных,
представления их в форме таблиц и распределений.
 Аналитическая статистика или теория статистических
Аналитическая статистика или теория статистических
выводов ориентирована на обработку данных, полученных в ходе эксперимента, с
целью формулировки выводов, имеющих практическое значение.
Пакет Excel оснащен средствами статистической обработки данных. И хотя
Excel существенно уступает специализированным статистическим пакетам обработки
данных, тем не менее, этот раздел математики представлен в Excel наиболее
полно.
В него включены основные, наиболее часто используемые статистические
процедуры: средства описательной статистики, критерии различия, корреляционные
и другие методы, позволяющие проводить необходимый статистический анализ
экспериментальных данных.
При рассмотрении применения методов обработки статистических данных мы
на практических занятиях ограничимся только простейшими и наиболее часто
используемыми методами, реализованными в пакете анализа Excel.
3.2. Выборочный метод
По охвату статистической совокупности исследование может быть сплошное
или не сплошное. При сплошном статистическом исследовании группа наблюдения
формируется путем полного охвата всех единиц изучаемого явления.
Множество всех единиц наблюдения, охватываемых таким сплошным
наблюдением, называется генеральной
совокупностью.
Если интересующая нас совокупность слишком многочисленна, либо ее
элементы малодоступны, а также, если имеются другие причины, не позволяющие
изучать сразу все ее элементы, прибегают к изучению какой-то части этой
совокупности. Эта выбранная для исследования группа элементов называется выборкой или выборочной
совокупностью.
Основным методом не сплошного наблюдения является выборочный метод.
Выборка — это
группа элементов, выбранная для исследования из всей совокупности элементов. Задача
выборочного метода состоит в том, чтобы сделать правильные выводы
относительно свойств генеральной совокупности. Так, например, пробуя пищу,
повар по одной ложке делает заключения о качестве приготавливаемой пищи во
всей кастрюле.
Конечной целью изучения выборочной совокупности всегда является получение
информации о генеральной совокупности. Поэтому естественно стремиться сделать
выборку так, чтобы она наилучшим образом представляла всю генеральную
совокупность, то есть была бы репрезентативной или представительной.
Для получения репрезентативной выборки необходимо четко определять,
что понимается под генеральной совокупностью. Ее состав и численность зависят
от объектов и целей проводимого исследования.
В тех случаях, когда генеральная совокупность недостаточно известна,
обычно не удается предложить лучшего способа получения представительной
выборки, чем случайный выбор. При этом случайная выборка формируется случайным
отбором — из генеральной совокупности с помощью генератора случайных чисел извлекается
по одному объекту.
3.3. Выборочная функция
распределения
В теории вероятности характеристики случайной величины опираются на
знание закона ее распределения. Для практических задач такое знание — редкость.
Здесь закон распределения обычно неизвестен.
Первая и основная задача математической статистики заключается в
получении по данным выборки наиболее рационально построенных статистических
характеристик распределения. Выяснение или оценка закона распределения по данным
выборки (так
называемая параметризация) и составляет существенную проблему математической
статистики: только зная закон распределения изучаемой величины, мы можем решать
возникающие на практике задачи по анализу, сравнению и предсказанию результатов исследуемого явления.
На практике во многих задачах вид или, иначе говоря, форма теоретического
распределения, с точностью до некоторых неизвестных параметров может считаться известной.
Так, например, при обработке деталей на металлорежущих станках по методу
автоматического получения размера (при устойчивом технологическом процессе) можно
считать, что распределение погрешностей деталей подчиняется нормальному
закону распределения.
Точно так же на практике очень часто исходят из того, что нормальному закону
следуют и погрешности измерений. Суммарную погрешность измерения можно рассматривать
как результат
действия большого числа независимых или слабо зависимых причин, и поэтому
наблюденную ошибку можно представлять как сумму «элементарных ошибок»; последние же
в свою очередь позволяют с высокой степенью приближения считать наблюдаемую ошибку нормально
распределенной.
Такое положение наблюдается всегда, когда рассматриваемый процесс может быть с
некоторым приближением подведен под теоретическую схему, анализируемую средствами
теории вероятностей.
Во всех этих случаях мы можем считать, что теоретический закон
распределения принадлежит к некоторому семейству, зависящему от одного или
нескольких параметров. Если бы точные значения параметров таких, как,
например, математическое ожидание и дисперсия при нормальном законе
распределения были известны, закон распределения для данного случая был бы
полностью определен. Иными словами, здесь задача нахождения закона
распределения изучаемой величины (или величин) сводится к нахождению
неизвестных значений параметров, т. е. к параметризации. Именно ради
определения этих параметров весьма часто и производится само статистическое
исследование. Так знание математического ожидания и дисперсии, параметров, связанных
с нормальным распределением дает возможность решать инженерные задачи из
области точности обработки и точности измерения. Как мы рассмотрим далее, для
их нахождения используются значения среднего арифметического и дисперсии
выборки, благодаря чему с некоторым приближением считается, что найдена и
теоретическая функция нормального распределения вероятностей данной задачи.
На практике сведения о законе распределения случайной величины получают
независимыми многократными повторениями опыта, в котором измеряются значения
интересующей исследователей случайной величины.
На основе информации из полученной выборки можно построить
приблизительные значения для функции распределения и другие характеристики
случайной величины.
По аналогии с теорией вероятностей на практике вводится понятие о статистической
вероятности.
По этому определению вероятность равна отношению числа испытаний (m), в
которых событие появилось, к общему количеству произведенных испытаний (n).
Такая вероятность называется еще статистической частотой.
Для построения выборочной функции распределения весь диапазон изменения
случайной величины X разбивают на ряд интервалов одинаковой ширины. Число
интервалов обычно выбирают не менее 5 и не более 15. Затем определяют число
значений случайной величины X, попавших в каждый интервал. Поделив это число на
общее количество наблюдений (n)., находят относительную частоту попадания
случайной величины X в заданные интервалы. По найденным относительным частотам
строят гистограммы выборочных функций распределения. Если соответствующие точки
относительных частот соединить ломаной линией, то полученная диаграмма будет
называться полигоном частот.
При увеличении размера выборки до бесконечности, как мы уже отмечали
ранее, эмпирическая частота приближается к вероятности, а выборочные функции
распределения превращаются в теоретические: гистограмма превращается в график
плотности распределения.
Как мы увидим далее совсем необязательно для получения данных о
характеристиках генеральной совокупности доводить размер выборки до очень
больших значений.
В Excel для построения выборочных функций распределения используются специальная
функция Частота и процедура пакета анализа Гистограмма. Работа с
ними изучается на практическом занятии.
4 Лекция. Основные
статистические характеристики выборочной совокупности
Содержание лекции:
мода, медиана, среднее значение, интервал, дисперсия
выборки, среднее квадратичное отклонение, стандартная ошибка, эксцесс,
асимметрия, инструменты Excel для
вычисления выборочных характеристик.
Цель лекции:
знакомство с основными характеристиками выборочной
совокупности и их определением с помощью формул и встроенных инструментов Excel.
4.1. Определение основных статистических характеристик
На предыдущей лекции мы познакомились с понятием
выборки или, иначе, выборочной совокупности. Выборка характеризуется вариационным
рядом, под которым в статистике понимают ряд, построенный по
количественному признаку. Любой вариационный ряд состоит из двух элементов —
вариантов и частот. Вариантами считаются отдельные значения признака,
т.е. конкретное значение варьирующего признака. Частоты – это числа,
показывающие, как часто встречаются варианты в ряду распределения. Сумма всех
частот определяет объем выборки. Частостями называются частоты,
выраженные в долях единицы или в процентах относительно объема выборки.
Замена теоретической функции распределения на ее
выборочный аналог в определении математического ожидания, дисперсии,
стандартного отклонения и других характеристик приводит нас к понятиям выборочного
среднего, выборочной дисперсии, выборочному стандартному отклонению и т.д.
Выборочные характеристики являются оценками соответствующих характеристик
генеральной совокупности, поэтому эти оценки должны удовлетворять определенным
требованиям, т.е. они должны быть:
— несмещенными, т.е. должны стремиться к истинному
значению характеристики генеральной совокупности при неограниченном увеличении
количества испытаний;
— состоятельными, т.е. с ростом размера выборки
оценка должна стремиться к соответствующему параметру генеральной совокупности
с вероятностью, приближающейся к 1;
— эффективными, т.е. для выборок равного объема
используемая оценка должна иметь минимальную дисперсию.
Среди
выборочных характеристик выделяют:
— показатели,
относящиеся к центру распределения;
— показатели
рассеяния;
— показатели,
характеризующие форму распределения.
К
показателям, характеризующим центр распределения, относятся: среднее
значение, мода и медиана.
Простейшим
показателем, характеризующим центр выборки, является мода.
Мода — это элемент
выборки с наиболее часто встречающимся значением (наиболее вероятная
величина).
Средним значением выборки называется
величина
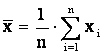
Иначе
говоря, среднее значение — это центр выборки, вокруг которого группируются элементы
выборки. При
увеличении числа наблюдений среднее выборки приближается к среднему
генеральной совокупности, т.е. к математическому ожиданию, поэтому среднее
значение генеральной совокупности часто обозначается, как и математическое
ожидание, буквой М.
Медиана – это число,
которое является серединой выборки.
Основными показателями
рассеяния вариант являются: интервал, дисперсия выборки, стандартное
отклонение и стандартная ошибка.
Интервал — это разница между максимальным и
минимальным значениями элементов выборки. Интервал является простейшей и
наименее надежной мерой вариации или рассеяния элементов в выборке.
Более точно отражают
рассеяние показатели, учитывающие не только крайние, но и все значения
элементов выборки. К таким показателям относится дисперсия. Дисперсией выборки
называется величина
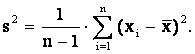
Дисперсия выборки — это параметр, характеризующий степень
разброса элементов выборки относительно среднего значения.
Чем больше дисперсия, тем
дальше отклоняются значения элементов выборки от среднего значения.
Выборочным стандартным отклонением или средним квадратичным отклонением
называется величина:
![]()
Это параметр, также
характеризующий степень разброса элементов выборки относительно среднего
значения. Чем больше среднее квадратичное отклонение, тем дальше отклоняются
значения элементов выборки от среднего значения. Параметр аналогичен
дисперсии и используется в тех случаях, когда необходимо, чтобы показатель
разброса случайной величины выражался в тех же единицах, что и среднее
значение этой случайной величины.
Стандартная ошибка
или ошибка среднего находится из выражения:
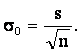
Стандартная ошибка — это
параметр, характеризующий степень возможного отклонения среднего значения
исследуемой выборки от истинного среднего значения генеральной совокупности
элементов. С помощью стандартной ошибки задается так называемый доверительный
интервал.
Например, 95%-ный
доверительный интервал, равный ![]() , обозначает диапазон, в который с
, обозначает диапазон, в который с
вероятностью р = 0,95 при условии достаточно большого числа наблюдений (n
> 30) попадает среднее значение генеральной совокупности.
В этом случае можно сказать,
что с вероятностью р = 0,95 из 100 случаев в 95 результат испытания будет
находиться в интервале ![]() и только в 5 случаях результат испытания
и только в 5 случаях результат испытания
будет за пределами интервала.
Показателями,
характеризующими форму распределения, являются эксцесс и асимметрия.
Эксцесс — это степень выраженности «хвостов»
распределения, то есть частоты появления величин удаленных от среднего
значения.
Асимметрия — величина, характеризующая
несимметричность распределения элементов выборки относительно среднего
значения. Принимает значения от -1 до 1. В случае симметричного распределения
асимметрия равна 0.
Часто значения асимметрии и
эксцесса используют для проверки гипотезы о том, что данная выборка
принадлежат к определенному теоретическому распределению, в частности, к нормальному
распределению. Для нормального распределения асимметрия равна нулю, а эксцесс —
трем.
Как
отмечалось выше, в результате наблюдений или эксперимента мы получаем наборы
данных, называемые выборками.
Для
проведения их анализа эти данные подвергаются статистической обработке.
Первое, что всегда делается при обработке данных, это вычисление элементарных
статистических характеристик выборок, как минимум: среднего,
среднеквадратичного отклонения, ошибки среднего по каждому исследуемому
параметру и по каждой группе. В Excel для вычисления статистических характеристик
выборки служит процедура Описательная статистика из пакета анализа,
работа с которой выполняется на практическом занятии.
4.2. Анализ однородности выборки
Одним из важных вопросов,
возникающих при анализе выборки, является вопрос: относится та или иная
варианта к данной статистической совокупности? Решение вопроса не представляет
сложности, если распределение в этой совокупности является нормальным. Для
этого достаточно использовать правило трех стандартов. Согласно этому правилу,
в пределах интервала ![]() находится 99,7% всех вариант. Поэтому,
находится 99,7% всех вариант. Поэтому,
если варианта попадает в этот интервал, то она считается принадлежащей к данной
совокупности. Если не попадает, то она может быть отброшена. Хотя этот метод и
предполагает нормальность исходного распределения, на практике он успешно
работает и может быть использован в большинстве случаев.
При числе элементов в выборке
n < 30 границы доверительного интервала определяют по формуле:
![]()
где
![]() — среднее значение выборки;
— среднее значение выборки;
![]() — табличное
— табличное
значение распределения Стьюдента с числом степеней свободы n и доверительной
вероятностью р.
В MS Excel для
вычисления границ доверительного интервала можно воспользоваться программой
«Описательная статистика» из пакета анализа Excel.
5 Лекция. Теория ошибок. Обработка результатов измерений
Содержание лекции:
основы теории случайных ошибок; методы оценки
случайных погрешностей в измерениях; доверительные интервалы и доверительная
вероятность; уровень значимости; определение минимального объема выборки.
Цель лекции:
изучение методов и приемов статистической обработки
результатов измерений.
5.1.Основы теории случайных ошибок и методов оценки случайных
погрешностей в измерениях
Анализ
случайных погрешностей основывается на теории случайных ошибок.
Теория случайных ошибок
дает возможность с определенной гарантией вычислить действительное значение измеренной величины и
оценить возможные ошибки при ее вычислении.
Основу
теории случайных ошибок составляют предположения о том, что при большом числе
измерений:
1. случайные погрешности
одинаковой величины, но разного знака встречаются одинаково часто;
2. большие
погрешности
встречаются реже, чем малые (вероятность появления погрешности уменьшается с ростом
ее величины);
3. при бесконечно большом числе измерений
истинное значение измеряемой величины равно
среднеарифметическому значению всех
результатов измерений,
4. появление
того или иного результата измерения как случайного события описывается
нормальным законом распределения.
В теории
ошибок различают генеральную и выборочную совокупность измерений.
Под генеральной совокупностью подразумевают
все множество возможных значений измерений ![]() или возможных значений погрешностей
или возможных значений погрешностей ![]() . Для выборочной
. Для выборочной
совокупности число измерений n ограничено, и в каждом конкретном случае строго
определяется. Обычно считают, если n >30, то среднее значение данной
совокупности измерений x достаточно приближается к его истинному значению.
Теория
случайных ошибок позволяет решать следующие задачи:
1. оценить
точность и надежность измерения при данном количестве замеров;
2.
определить минимальное количество замеров, гарантирующее требуемую (заданную) точность
и надежность измерений;
3. выявить и
исключить грубые ошибки, допущенные при проведении эксперимента;
4. определить
достоверность полученных данных.
5.2. Интервальная
оценка с помощью доверительной вероятности
Для большой выборки и нормального
закона распределения оценочными характеристиками выполненных измерений
являются среднее арифметическое выборки, стандартное отклонение и средняя
ошибка выборки:
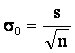
где
s – Среднеквадратичное отклонение (стандартное отклонение)
выборки;
n – Количество выполненных замеров.
Ошибка выборки для выборочной
относительной величины (доли) определяется по выражению:
![]() .
.
В теории ошибок достаточно
важными являются понятия доверительной вероятности и доверительного интервала.
Доверительной
вероятностью
(достоверностью) измерения называется вероятность того, что истинное значение
измеряемой величины попадает в интервал, называемый доверительным интервалом.
Доверительный
интервал определяет точность
измерения и называется предельной ошибкой выборки.
Предельная
ошибка выборки определяется
по формуле:
![]()
(5.1)
где
![]() — гарантийный коэффициент или
— гарантийный коэффициент или
нормированное отклонение.
Значения t и соответствующие им доверительные вероятности ![]() приведены
приведены
в справочной литературе.
При числе опытов n > 30 их значения определяются по таблице Лапласа, а при
n < 30 по таблице Стьюдента.
Для наиболее часто
встречающихся случаев, для n > 30 они
имеют следующие значения: для t =1 ![]() =0.683; t =2
=0.683; t =2 ![]() =0.95; t =3
=0.95; t =3 ![]() =0.997.
=0.997.
На практике наиболее часто
статистические расчеты производятся с доверительной вероятностью 0,95. Доверительный
интервал характеризует погрешность измерения, а доверительная вероятность —
достоверность (надежность) измерения.
Рассмотрим пример.
Пусть, например,
выполнено 30 измерений напряжения сети. Среднее напряжение сети 220В
среднеквадратическое отклонение ![]() =3,1 В.
=3,1 В.
Требуется
определить значение напряжения сети (среднее генеральной совокупности) с
доверительной вероятностью 0,95.
Решение:
Средняя ошибка
выборки
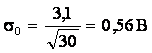
Предельная ошибка выборки
![]()
Зная предельную
ошибку, рассчитываем интервал, в котором с доверительной вероятностью 0,95
находится измеряемая величина – напряжение сети ![]() = 220±1,12, т.е. напряжение
= 220±1,12, т.е. напряжение
сети составляет не менее 219В и не более 221В.
Если нам заранее
задана предельная ошибка измерения, то по ней можно определить доверительную
вероятность попадания измеряемой величины в данный интервал.
Пусть, например,
задана предельная ошибка ![]() то для нахождения доверительного
то для нахождения доверительного
интервала по формуле (5.1) находим вначале нормированное отклонение ![]() . Для найденного
. Для найденного
значения t по таблице Лапласа находим ![]() . Это означает, что в заданный доверительный
. Это означает, что в заданный доверительный
интервал из 100 результатов измерений попадет 97, и только 3 результата из
100 будут вне найденного интервала.
Значение ![]() называют уровнем
называют уровнем
значимости.
Из него следует, что при
нормальном законе распределения погрешность, превышающая доверительный интервал, будет
встречаться один раз из ![]() измерений, где
измерений, где
![]() . (5.2)
. (5.2)
Или иначе приходится браковать одно из ![]() измерений.
измерений.
По данным
приведенного выше примера можно вычислить
количество измерений, из которых одно измерение превышает доверительный интервал.
По формуле (5.2) при рд=0,95 определяем ![]() = 0,95 /(1—0,95) = 19 измерений. При
= 0,95 /(1—0,95) = 19 измерений. При
доверительной вероятности ![]() , равной 0,997, это будет уже 332
, равной 0,997, это будет уже 332
измерения.
5.3. Определение минимального
количества измерений
Для проведения опытов с
заданной точностью и достоверностью необходимо знать то количество измерений, при
котором экспериментатор будет уверен в положительном исходе. В связи с этим
одной из первоочередных задач при статических методах оценки является
установление минимального, но достаточного числа измерений для данных условий.
Задача
сводится к установлению минимального объема выборки (числа измерений) ![]() , при заданных
, при заданных
значениях предельной ошибки выборки и заданной доверительной вероятности.
Предельная
ошибка выборки равна 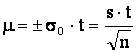
Из данного выражения можно
найти минимальный объем выборки, который при заданной доверительной
вероятности, определяемой гарантийным коэффициентом t, обеспечит требуемую точность результатов выборки ![]() .
.
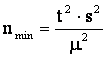 (5.3)
(5.3)
В исследованиях часто используется и
такая форма записи
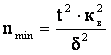
где
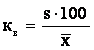 — коэффициент вариации, в %;
— коэффициент вариации, в %;
![]() — погрешность измерительного прибора, в
— погрешность измерительного прибора, в
%.
В зависимости от исходных
условий по формуле (5.3) могут решаться различные задачи, например:
1. Определение объема выборки,
необходимого для получения требуемой точности результатов с заданной
вероятностью (рассмотрено выше);
2. Определение возможного
предела ошибки репрезентативности, гарантированного с заданной вероятностью и
сравнение его с величиной допустимой погрешности;
3.Определение вероятности
того, что ошибка выборки не превысит допустимой погрешности.
6 Лекция. Методы определения грубых ошибок
экспериментального ряда
Содержание лекции:
кривые распределения Стьюдента, определение
доверительного интервала малой выборки, способы определения грубых ошибок
экспериментального ряда, округление результатов измерения.
Цель лекции:
продолжение изучения методов и приемов статистической
обработки результатов экспериментальных исследований.
6.1 Определение доверительного
интервала малой выборки. Кривая распределения Стьюдента
Как мы уже отмечали
ранее, при числе измерений n >30 нормированное отклонение t находится по таблице
Лапласа. Для
нахождения границы доверительного интервала при малых значениях применяют
метод, предложенный в 1808 г. английским математиком В.С. Госсетом (псевдоним
Стьюдент).
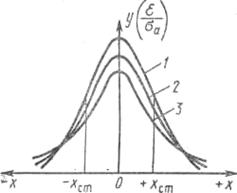
Кривые распределения Стьюдента в случае ![]()
(практически при n >20) переходят в кривые нормального
распределения (см. рисунок 6.1).
Для малой выборки
доверительный интервал определяется по формуле
![]() ,
,
где ![]() — коэффициент Стьюдента,
— коэффициент Стьюдента,
принимаемый по таблице Стьюдента в зависимости от числа измерений и принятого
значения доверительной вероятности ![]() .
.
Зная ![]() ,
,
можно вычислить действительное значение изучаемой величины для малой выборки ![]() .
.
 .
.
Рисунок 6.1 — Кривые распределения Стьюдента для различных
значений n: 1 — ![]() 2 — n = 10; 3 — n = 2
2 — n = 10; 3 — n = 2
Возможна и иная постановка задачи. По n известным значениям измерений малой
выборки необходимо определить доверительную вероятность ![]() при условии, чтобы погрешность среднего значения не выходила за пределы
при условии, чтобы погрешность среднего значения не выходила за пределы
предельной ошибки выборки ![]() .
.
Задачу решают в такой последовательности:
1) вначале вычисляется среднее значение![]() , средняя ошибка
, средняя ошибка![]() и
и
коэффициент Стьюдента 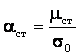 ;
;
2) далее на базе известных значений n и ![]() по таблице Стьюдента определяют доверительную
по таблице Стьюдента определяют доверительную
вероятность.
В процессе обработки экспериментальных данных следует исключать грубые
ошибки ряда. Появление этих ошибок вполне вероятно, а наличие их ощутимо влияет на результат
измерений. Однако прежде чем исключить то или иное измерение, необходимо убедиться,
что это действительно
грубая ошибка, а не отклонение вследствие статистического разброса.
6.2 Определение
грубых ошибок экспериментального ряда
Известно несколько методов определения грубых ошибок статистического ряда.
Наиболее простым способом исключения из ряда резко
выделяющегося измерения является
правило трех стандартов, согласно которому разброс случайных величин от среднего значения не должен превышать
![]() .
.
Более достоверными являются методы, базируемые на использовании критериев появления
грубых ошибок.
Пусть имеется статистический ряд малой выборки, подчиняющийся закону нормального распределения. При наличии грубых
ошибок критерии их появления вычисляются по формулам:
![]() ;
;
![]() .
.
где ![]() — наибольшее
— наибольшее
и наименьшее значения из n измерений.
По таблице «Критерии появления грубых ошибок»[1] в зависимости
от заданной доверительной вероятности находят максимальное значение ![]() , возникающее вследствие
, возникающее вследствие
статистического разброса. Если ![]() , то значение
, то значение ![]() необходимо исключить из статистического ряда
необходимо исключить из статистического ряда
как грубую погрешность. Если ![]() , исключается величина
, исключается величина![]() . После исключения грубых ошибок
. После исключения грубых ошибок
определяют новые значения ![]() и
и ![]() из (n — 1) или (n — 2) измерений.
из (n — 1) или (n — 2) измерений.
Второй
метод установления грубых ошибок основан на использовании критерия В. И. Романовского
и применим
также для малой выборки. Методика выявления грубых ошибок сводится к следующему. Задаются
доверительной
вероятностью![]() ,
,
и по таблице «Коэффициенты предельно допустимых ошибок измерения»
в зависимости от числа измерений n находят коэффициент q. Вычисляют предельно
допустимую
абсолютную ошибку отдельного измерения ![]() .
.
Если ![]() ,
,
то данное
измерение исключают из ряда наблюдений. Этот метод более
требователен к очистке ряда.
В настоящее время в связи с внедрением в практику обработки данных
статистических программ из пакета анализа Excel, нахождение грубых
ошибок экспериментального ряда (выпадающих вариант) может быть выполнено
следующим образом.
С помощью программы « Описательная статистика» определяются статистические
характеристики для исследуемого ряда данных, и вычисляется диапазон, в котором
с задаваемой доверительной вероятностью находится измеряемая величина по
формуле:
![]() .
.
Все данные, которые находятся вне найденного диапазона, считаются, с
точностью до заданной вероятности, ошибками.
6.3 Обработка
результатов прямых измерений
При обработке результатов прямых измерений
рекомендуется следующий порядок операций:
1. Выполнить
необходимые измерения и результаты занести в таблицу.
2. Найти
грубые ошибки, удалить их, вычислить среднее арифметическое.
3. Найти
погрешность отдельных измерений.
4. Вычислить
квадраты погрешностей отдельных измерений.
5. Вычислить
стандартную ошибку среднего арифметического.
6.Задаваясь
уровнем надежности, для проделанного числа измерений по таблице Стьюдента
найти коэффициент Стьюдента.
7.Вычислить доверительный
интервал нахождения случайной ошибки, т.е. погрешность измерения, обусловленную
случайными факторами.
Если
погрешность измерения, обусловленная случайными факторами, окажется сравнимой с
величиной погрешности прибора, то границы доверительного интервала находятся по
формуле:
![]() ,
,
где
![]() — половина
— половина
доверительного интервала для заданного уровня надежности;
![]() — погрешность
— погрешность
измерения, обусловленная случайными ошибками;
![]() — абсолютная
— абсолютная
погрешность прибора.
Если
одна из ошибок меньше другой в три и более раз, меньшую ошибку отбрасывают.
8.
Окончательный результат записывается в виде[2]:
![]() .
.
9.
Оценивается относительная погрешность измерения:
![]() .
.
6.4 Округление результатов измерения
Обработку
результатов измерений необходимо выполнять с учетом определенных
установленных правил. Рассмотрим эти правила.
Погрешность
измерения следует округлять до первой значащей цифры, всегда
увеличивая ее на единицу.
Значащими
называют цифры, кроме нулей, стоящих впереди числа. Например, 0,00807 – в этом
числе имеется три значащих цифры: 8, ноль между 8 и 7 и 7; первые три нуля
незначащие.
Примеры:
8.27
≈ 9;
0.237
≈ 0.3;
0.00035
≈ 0.0004;
0.0862
≈ 0.09;
857.3
≈ 900;
43.5
≈ 50.
Результаты измерения
округляют с точностью «до погрешности», т.е. последняя значащая цифра в
результате должна находиться в том же разряде, что и погрешность.
Примеры:
243.871 ± 0.026 ≈
243.87 ± 0.03;
243.871 ± 2.6 ≈ 244 ± 3;
1053 ± 47 ≈ 1050 ± 50.
7 Лекция. Исследование
экспериментального ряда на достоверность и воспроизводимость
Содержание лекции:
исследование
экспериментальных данных на достоверность и воспроизводимость результатов
измерений. Обработка данных косвенных измерений. Определение оптимальных
условий измерения. Обработка результатов экспериментальных данных при
однократном измерении.
Цель лекции:
продолжение изучения методов и приемов статистической
обработки результатов экспериментальных исследований.
7.1 Исследование экспериментальных
данных на достоверность
В исследованиях часто возникает вопрос о достоверности данных,
полученных в опытах. Решение такой задачи можно проиллюстрировать следующим примером.
Пусть установлена прочность контрольных образцов бетона до
виброперемешивания ![]() и прочность бетонных образцов после
и прочность бетонных образцов после
перемешивания ![]() .
.
Прирост прочности составляет 15%. Это упрочнение относительно небольшое и его
можно отнести за счет разброса опытных данных. В этом случае следует провести
проверку на достоверность экспериментальных данных по условию:
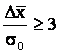 .
.
Разница средних
значений равна 23 – 20 = 3,0, а разница ошибок измерения равна ![]() 0,78, поэтому 3 /0,78
0,78, поэтому 3 /0,78
= 3,84 > 3.
Следовательно,
полученный прирост прочности бетона является достоверным, а не случайным.
7.2 Исследование экспериментальных данных на
воспроизводимость
Выше был
рассмотрен метод проверки экспериментальных измерений на достоверность.
Ответственные эксперименты должны быть проверены также и на воспроизводимость
результатов, т.е. на их повторяемость в определенных пределах измерений с
заданной доверительной достоверностью. Суть такой проверки сводится к
следующему. Имеется несколько параллельных опытов (серий). Для каждой серии
вычисляют среднеарифметическое значение ![]() . Далее вычисляют дисперсию
. Далее вычисляют дисперсию![]() . Чтобы оценить
. Чтобы оценить
воспроизводимость, рассчитывают критерий Кохрена:
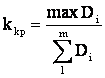
где max ![]() —
—
наибольшее значение дисперсии из числа рассматриваемых параллельных серий
опытов;
m – число серий опытов;
![]() — сумма дисперсий m серий.
— сумма дисперсий m серий.
Рекомендуется
принимать ![]() .
.
Опыты считают воспроизводимыми при
выполнении условия
![]()
где ![]() табличное значение
табличное значение
критерия Кохрена принимаемое в зависимости от доверительной вероятности ![]() и числа степеней
и числа степеней
свободы
q = n— 1.
В таблице m — число
серий опытов; n — число измерений в серии.
Пример:
Проведено 3 серии
опытов по 5 измерений в каждой серии.
По результатам
обработки полученных данных имеем наибольшее значение из дисперсий равное 3,7,
а суммарное значение всех дисперсий 3 серий опытов равно 6,7.Следовательно,
расчетный коэффициент Кохрена равен 3,7/6,7 = 0,55, а найденный по таблице для m =3 и
q=4 равен 0,74.
Так как 0,55 <
0.74 , то измерения в эксперименте следует считать воспроизводимыми. Если бы
было наоборот, то необходимо было бы увеличить число серий m
или число измерений n.
7.3 Обработка экспериментальных данных косвенных
измерений
Во многих
случаях в процессе экспериментальных исследований приходится иметь дело с
косвенными измерениями, когда искомая величина Z и ее погрешность определяется по результатам прямых измерений
других величин, связанных с Z определенной
зависимостью.
В общем случае решение этой
задачи оказывается весьма сложным. Однако есть несколько случаев, когда
оценить пределы погрешности результата косвенного измерения просто.
Случай № 1. Величины X и Y измерены с абсолютными погрешностями
∆Х и ∆Y, соответственно и определяется величина
Z, связанная зависимостью:
![]() .
.
В этом случае определяется абсолютная
погрешность Z как сумма абсолютных погрешностей величин X и Y без учета знака, а именно: ![]() .
.
Случай № 2. Величины X и Y измерены с абсолютными погрешностями
∆Х и ∆Y, соответственно и определяется величина
Z, связанная зависимостями: ![]() или
или ![]() .
.
В этом случае определяется относительная
погрешность Z, которая находится через составляющие
относительных погрешностей величин X и Y, которые суммируются без учета знака, а именно:
![]() .
.
Случай № 3.Величины X и Y измерены с абсолютными погрешностями
∆Х и ∆Y и определяется величина Z, связанная с X и Y функциональной зависимостью Z = F(X, Y). В этом случае для оценки предела абсолютной погрешности следует
использовать выражение:
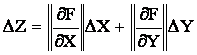
Легко
видеть, что предыдущие формулы для погрешностей следуют из последнего,
более общего, соотношения.
Приведенные
выше способы оценки предельной погрешности косвенных измерений могут дать завышенную
оценку значения результирующей погрешности. Однако с точки зрения достоверности
результата измерения и с учетом простоты описанного решения такой подход считается вполне
приемлемым.
7.4. Определение оптимальных условий
измерений
Одной из задач теории измерений является установление оптимальных, т. е. наиболее
выгодных, условий измерений. Оптимальные
условия измерений в данном эксперименте
имеют место при условии обеспечения минимальной относительной погрешности ![]() .
.
Методика
решения
этой задачи сводится к следующему. Если исследуется функция с одним неизвестным
переменным, то вначале следует взять первую производную по аргументу х, приравнять ее нулю и
определить ![]() . Если вторая
. Если вторая
производная по аргументу ![]() положительная, то функция y(x) в случае
положительная, то функция y(x) в случае ![]() имеет минимум.
имеет минимум.
При наличии нескольких переменных поступают
аналогичным образом, но берут производные по
всем переменным![]() .
.
В результате минимизации функций устанавливают оптимальную область измерений
(интервал температур, напряжений, силы тока, угла поворота стрелки на приборе и
т.д.) каждой
функции ![]() , при которой
, при которой
относительная ошибка
измерений минимальна, т. е. ![]() .
.
7.5 Обработка результатов экспериментальных данных при
однократном измерении
Выше были рассмотрены примеры обработки экспериментальных
данных, которые носят стохастический характер, вследствие чего для повышения
точности измерений приходится выполнять измерения с многократным повторением
опыта в одинаковых условиях с использованием одного и того же средства
измерения.
Однако на практике часто имеют дело с результатами,
полученными при однократном измерении.
Однократные измерения выполняются в тех случаях,
когда требуется лишь грубая оценка измеряемого параметра или когда
погрешность, обусловленная случайными факторами, мала, и ее можно не
учитывать.
При проведении однократных измерений эксперимент
стремятся организовать так, чтобы результирующая погрешность измерения
определялась главным образом погрешностью прибора[3].
В этом случае погрешность измерения оценивают исходя из точности прибора
измерения.
Пример 1.
Вольтметр имеет класс точности ![]() . Верхний предел измерения
. Верхний предел измерения ![]() . Прибор показывает
. Прибор показывает
значение 127В.
Определить чему равно измеряемое напряжение?
Решение:
Абсолютная погрешность вольтметра равна
![]() .
.
Значение измеряемого напряжения лежит в пределе от
126В до 128В.
Пример 2
Омметр класса точности 4,0 имеет неравномерную шкалу.
Прибор показывает 50Ом.
Чему равно измеряемое сопротивление?
Решение:
Абсолютная погрешность Омметра равна
![]() .
.
Истинное значение измеряемого сопротивления лежит в
пределах от 48Ом до 52 Ом.
8 Лекция.
Проверка статистических гипотез
Содержание лекции:
статистическая гипотеза, нулевая и альтернативная
гипотезы, вероятность ошибки и уровень значимости, проверка статистических
гипотез, проверка гипотезы о соответствии нормальному распределению, критерий
согласия хи – квадрат.
Цель лекции:
изучение вопросов, связанных с анализом
экспериментальных данных и проверкой на основе полученных выборок
статистических гипотез о параметрах и свойствах генеральной совокупности.
8.1 Применение аналитической статистики для анализа
экспериментальных данных
Помимо описательной статистики,
основные положения которой были рассмотрены на предыдущих занятиях, важное
место при обработке экспериментальных данных занимает также и аналитическая
статистика.
Аналитическая статистика или
теория статистических выводов ориентирована на обработку данных, полученных в
ходе эксперимента, с целью формулировки выводов, имеющих прикладное значение.
С помощью аналитической
статистики решается вопрос, отражают ли полученные данные объективно
существующую реальность.
Указанный вопрос решается
проверкой соответствующих статистических гипотез. При этом могут выявляться
достоверность различия между выборками, формы взаимосвязи между выборками,
влияющие факторы и т. п.
8.2 Принятие статистических решений
Статистическая гипотеза — это
предположение о виде или отдельных параметрах распределения вероятностей,
которое подлежит проверке на базе имеющихся данных. Проверка статистических
гипотез — это процесс формирования решения о возможности принять или
отвергнуть утверждение (гипотезу), основанный на информации, полученной из
анализа выборки. Методы проверки гипотез называются критериями. В
большинстве случаев рассматривают так называемую нулевую гипотезу
(нуль-гипотезу — Но), о том, что рассматриваемые события произошли
случайным образом и полученные данные носят стохастический характер.
Альтернативная гипотеза (H1)
состоит в том, что события случайным образом произойти не могли, и имело место
воздействие некого фактора.
Обычно нулевая гипотеза
формулируется таким образом, чтобы на основании эксперимента или наблюдений ее
можно было отвергнуть с заранее заданной вероятностью ошибки ![]() . Эта, заранее заданная
. Эта, заранее заданная
вероятность ошибки, называется уровнем значимости.
Уровень значимости — максимальное значение вероятности
появления события, которое считается практически невозможным. В статистике
наибольшее распространение получил уровень значимости, равный ![]() . Поэтому, если
. Поэтому, если
вероятность, с которой интересующее нас событие может произойти случайным образом
равно р < 0,05, то принято считать это событие маловероятным, но если оно
все же произошло, то это не было случайным.
В наиболее ответственных
случаях, когда требуется особая уверенность в достоверности полученных
результатов, надежности выводов уровень значимости принимают равным ![]() или даже
или даже ![]() .
.
Величину ![]() называют доверительной
называют доверительной
вероятностью (уровнем надежности), то есть вероятностью, признанной
достаточной для того, чтобы уверенно судить о принятом статистическом решении.
Соответственно, в качестве доверительных вероятностей выбирают значения 0,95,
0,99 и 0,999. Интервал, в котором с заданной доверительной вероятностью ![]() находится оцениваемый
находится оцениваемый
параметр, называется доверительным интервалом.
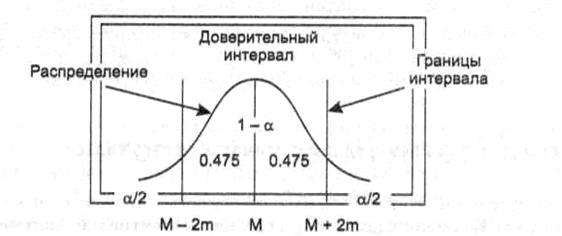
Рисунок 8.1 – 95%- доверительный
интервал для среднего значения
В соответствии с
доверительными вероятностями на практике используются 95%-, 99%-, 99,9%-ные
доверительные интервалы. Граничные точки доверительного интервала называют
доверительными пределами (см. рисунок 8.1).
Выбор того или иного уровня
значимости, выше которого результаты отвергаются как статистически не
подтвержденные, или, соответственно, выбор доверительной вероятности, в общем
случае является произвольным.
Окончательное решение зависит
от исследователя, традиций и накопленного практического опыта в данной области
исследований.
8.3 Проверка соответствия теоретическому распределению
Важной задачей, возникающей при анализе
экспериментальных данных, является оценка меры соответствия полученных данных
какому-либо теоретическому распределению. Это связано с тем, что в большинстве
случаев при решении реальных задач закон распределения и его параметры
неизвестны.
В то же время применяемые
статистические методы в качестве предпосылок часто требуют определенного закона
распределения.
Наиболее часто проверяется
предположение о нормальном распределении генеральной совокупности, поскольку
большинство статистических процедур ориентировано на выборки, полученные из
нормально распределенной генеральной совокупности.
Для оценки соответствия
имеющихся экспериментальных данных нормальному закону распределения обычно
используют:
— графический метод;
— выборочные параметры формы
распределения;
— критерии согласия.
Графический метод позволяет
дать ориентировочную оценку расхождения или совпадений распределений (см. рисунок
8.2).
При большом числе наблюдений
(n > 100) неплохие результаты дает использование выборочных параметров формы
распределения: эксцесса и асимметрии, которые определяются с помощью программы
описательной статистики. Принято говорить, что предположение о случайном
характере опытных данных справедливо, если асимметрия близка к нулю, то есть
лежит в диапазоне от -0,2 до 0,2, а эксцесс — от 2 до 4.
Наиболее убедительные
результаты дает использование критериев согласия. Критериями согласия
называют статистические критерии, предназначенные для проверки соответствия
опытных данных теоретической модели.
Здесь нулевая гипотеза Но
представляет собой утверждение о том, что распределение генеральной совокупности,
из которой получена выборка, не отличается от нормального, т.е. данные выборки
носят случайный характер.
Среди критериев согласия
большое распространение получил непараметрический критерий ![]() (хи-квадрат). Он основан на
(хи-квадрат). Он основан на
сравнении эмпирических частот с теоретическими частотами, рассчитанными по
формулам нормального распределения.
Принято считать, что
уверенно о нормальном характере распределения можно судить, если имеется не
менее 50 результатов наблюдений. В случаях меньшего числа данных можно
говорить только о том, что данные не противоречат нормальному закону, и в этом
случае обычно используют графические методы оценки соответствия. При большем
числе наблюдений целесообразно совместное использование графических и
статистических методов оценки, естественно дополняющих друг друга.
8.4 Использование критерия согласия хи-квадрат
Для применения критерия желательно,
чтобы объем выборки n > 50, выборочные данные были сгруппированы в
интервальный ряд с числом интервалов не менее 7, а в каждом интервале находилось
не менее 5 наблюдений (частот).
При этом, как и любой другой
статистический критерий, критерий хи-квадрат не доказывает справедливость
нулевой гипотезы, т.е. соответствия эмпирического распределения нормальному
закону, а только позволяет ее отвергнуть с определенной вероятностью (уровнем
значимости).
В MS Excel критерий
хи-квадрат реализован в функции ХИ2ТЕСТ. Функция ХИ2-ТЕСТ вычисляет вероятность
совпадения экспериментальных (фактических) значений и теоретических (гипотетических)
значений.
Если полученная вероятность
будет ниже уровня значимости (0,05), то нулевая гипотеза отвергается и
утверждается, что полученные данные не соответствуют нормальному закону
распределения.
Если же вычисленная
вероятность будет больше 0,05, а тем более близка к 1, то можно говорить о
высокой степени соответствия экспериментальных данных нормальному закону
распределения.
Рис. 8.2.- Сопоставление выборочного распределения веса студентов и
кривой нормального распределения
Проверка соответствия экспериментальных
данных нормальному закону распределения рассматривается на практических
занятиях.
9 Лекция 9. Применение
статистических критериев для анализа экспериментальных данных
Содержание лекции:
анализ двух выборок. Выявление
достоверности различий, параметрические критерии, критерий
Фишера, непараметрические критерии, критерий согласия Пирсона ![]() (хи – квадрат).
(хи – квадрат).
Цель лекции:
изучение вопросов, связанных с обработкой экспериментальных
данных с помощью критериев t — Стьюдента F — Фишера
и хи-квадрат Пирсона(![]() ).
).
9.1 Анализ двух выборок. Выявление достоверности
различий
Следующей задачей статистического анализа,
решаемой после определения основных выборочных характеристик и анализа одной
выборки, является совместный анализ нескольких выборок. Важнейшим вопросом,
возникающим при анализе двух выборок, является вопрос о наличии различий между
этими выборками. Обычно для этого проводят проверку статистических гипотез о
принадлежности обеих выборок одной генеральной совокупности или о равенстве
генеральных средних. Для решения задач такого типа используются так называемые
критерии различия.
Для проверки
одной и той же гипотезы могут быть использованы разные статистические
критерии. Правильный выбор критерия определяется как спецификой данных и
проверяемых гипотез, так и уровнем статистической подготовки исследователя.
Статистические критерии различия подразделяются на
параметрические и непараметрические критерии. Параметрические критерии
служат для проверки гипотез о параметрах определенных распределений
генеральной совокупности (чаще всего нормального распределения). Непараметрические
критерии для проверки гипотез не используют предположений о законе
распределения генеральной совокупности и не требуют знания параметров
распределения.
9.2 Параметрические критерии. Критерий Стьюдента
Параметрические
критерии служат для проверки гипотез о положении и рассеивании. Из
параметрических критериев наибольшей популярностью при проверке гипотез о
равенстве генеральных средних (математических ожиданий) пользуется t-критерий Стьюдента (t-критерий различия).
Критерий Стьюдента
(t) позволяет найти вероятность того, что средние двух выборок относятся к
одной и той же совокупности. Если эта вероятность р ниже уровня значимости (р
< 0,05), то принято считать, что выборки относятся к двум разным
совокупностям.
При использовании t
— критерия можно выделить два случая.
В первом случае
его применяют для проверки гипотезы о равенстве генеральных средних двух независимых,
несвязанных выборок (так называемый двухвыборочный t-критерий). В этом случае
есть контрольная и опытная группы, состоящие, например, из разных пациентов,
количество которых в группах может быть различно.
Во втором случае,
когда одна и та же группа объектов порождает числовой материал для проверки
гипотез о средних, используется так называемый парный t -критерий. Выборки при
этом называют зависимыми, связанными. Например, измеряется содержание
лейкоцитов у здоровых животных, а затем у тех же самых животных после облучения.
В обоих случаях в
принципе должно выполняться требование нормальности распределения исследуемого
признака в каждой из сравниваемых групп и равенстве дисперсий в сравниваемых
совокупностях. Однако на практике по большому счету корректное применение t
-критерия Стьюдента для двух групп часто бывает затруднительно, поскольку
достоверно проверить эти условия удается далеко не всегда.
Для оценки
достоверности отличий по критерию Стьюдента принимается нулевая гипотеза, что
средние выборок равны между собой. Затем вычисляется значение вероятности того,
что изучаемые события произошли случайным образом.
В MS Excel для
оценки достоверности отличий по критерию Стьюдента используется специальная
функция ТТЕСТ и процедуры пакета анализа.
Все перечисленные
инструменты вычисляют вероятность, соответствующую критерию Стьюдента, и
используются, чтобы определить, насколько вероятно, что две выборки взяты из
генеральных совокупностей, имеющих одно и то же среднее. Применение различных
типов критерия Стьюдента может приводить к различным результатам на основании
одних и тех же исходных данных. Предлагается следующий приблизительный способ
выбора типа критерия: если не ясно, какой тип критерия выбирать, выбирается тип
3; если очевидно, что выборки зависимы, связаны (например, это одни и те же
студенты), то следует выбирать тип 1.
9.3 Критерий Фишера
Критерий Фишера
используют для проверки гипотезы о принадлежности двух дисперсий одной
генеральной совокупности и, следовательно, их равенстве. При этом
предполагается, что данные независимы и распределены по нормальному закону.
Гипотеза о равенстве дисперсий принимается, если отношение большей дисперсии к
меньшей меньше критического значения распределения Фишера.
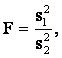
![]() ,
,
где ![]() зависит от уровня
зависит от уровня
значимости и числа степеней свободы для дисперсий в числителе и знаменателе.
В MS Excel для
расчета уровня вероятности выполнения гипотезы о равенстве дисперсий могут быть
использованы функция ФТЕСТ и процедура пакета анализа Двухвыборочный
F-тест для дисперсий.
Пример применения критерий
различия
Имеются данные о продажах
электрооборудования ТОО « Электросервис» до и после проведения этой фирмой
рекламной компании.
В результате применения
критерия Стьюдента к этим данным была получена вероятность р = 0,006.
Вывод: Поскольку полученная вероятность значительно
меньше 0.05, делается вывод, что сравниваемые данные существенно отличаются
друг от друга и это различие далеко не случайное, а имеется влияние некоего
фактора. В нашем случае это, по всей видимости, влияние проведенной рекламной
компании.
Аналогичный результат можно
получить и применяя критерий Фишера.
Если бы вероятность р была
бы больше 0,05, то вывод об эффективности рекламной компании делать нельзя:
различие в данных для принятого уровня значимости носит, по всей видимости,
случайный характер.
9.4 Непараметрические критерии
Непараметрические
критерии используются в тех случаях, когда закон распределения данных
отличается от нормального закона или неизвестен. Из большого числа
непараметрических критериев рассмотрим критерий Пирсона ![]() (хи- квадрат).
(хи- квадрат).
9.5 Критерий Пирсона
![]()
Бывают ситуации,
когда необходимо сравнить две относительные или выраженные в процентах
величины (доли). Примером может служить случай проверки успешности
трудоустройства молодых специалистов, когда известен процент трудоустроившихся
выпускников двух институтов. Для проверки достоверности различий здесь
критерий Стьюдента применить не удастся. В таких задачах обычно используют
критерий ![]() (хи-квадрат).
(хи-квадрат).
Критерий хи-квадрат относится к непараметрическим критериям.
Здесь, как и в
случае с критерием Стьюдента, принимается нулевая гипотеза о том, что выборки
принадлежат к одной генеральной совокупности. Кроме того, определяется
ожидаемое значение результата. Обычно это среднее значение между выборками
рассматриваемого показателя. Затем оценивается вероятность того, что ожидаемые
значения и наблюдаемые принадлежат к одной генеральной совокупности.
В MS Excel
критерий хи-квадрат реализован в функции ХИ2ТЕСТ. Функция ХИ2-ТЕСТ вычисляет
вероятность совпадения наблюдаемых (фактических) значений и теоретических
(гипотетических) значений. Если вычисленная вероятность ниже уровня значимости
(0,05), то нулевая гипотеза отвергается и утверждается, что наблюдаемые
значения не соответствуют теоретическим значениям.
Если полученная величина
вероятности будет меньше уровня значимости 0,05, то нулевая гипотеза
отвергается и делается вывод о не случайности различий между двумя выборками.
И, наоборот, если полученная вероятность будет больше 0,05, делается вывод,
что различие между выборками может носить случайный характер.
Рассмотрим пример.
Дано:
После окончания двух
институтов энергетического профиля трудоустроились по специальности из первого
института 90 человек, а из второго института 60 человек (обе группы молодых
специалистов включали по сто человек).
Вопрос — Случайны ли различия
в трудоустройстве выпускников этих вузов?
Решение:
Определяется ожидаемое
значение результата — среднее значение между двумя выборками – 75 человек. В
данном случае выдвигается гипотеза о том, что разницы между группами нет, и в
обоих случаях должно было трудоустроиться по 75 человек. С помощью функции
ХИ2ТЕСТ определяется значение вероятности. В нашем случае оно равно 0,01436.
Выводы:
Поскольку величина
вероятности меньше уровня значимости 0.05, то нулевая гипотеза отвергается.
Следовательно, различия между выборками не могут быть случайными и выборки
считаются достоверно отличающимися от друга.
Поэтому на основании
применения критерия хи- квадрат можно сделать вывод о том, что в двух группах
выпускников выявлены достоверные отличия по успешности трудоустройства, что
явилось, по всей видимости, результатом более высокой репутации выпускников
первого института.
![]()
![]()
![]() 10 Лекция. Корреляционно-регрессионный анализ
10 Лекция. Корреляционно-регрессионный анализ
экспериментальных данных
Содержание лекции:
корреляционный анализ, коэффициент корреляции,
корреляционная матрица, регрессионный анализ, уравнения регрессии, коэффициенты
регрессии, коэффициент детерминации.
Цель лекции:
изучение возможностей
применения корреляционного и регрессионного анализа для обработки
экспериментальных данных.
10.1 Корреляционный анализ
Важным разделом
статистического анализа экспериментальных данных является корреляционный
анализ, служащий для выявления взаимосвязей между данными выборок. Одна из
наиболее распространенных задач статистического исследования состоит в
изучении связи между исследуемыми переменными. Знание взаимозависимостей отдельных признаков дает возможность решать одну из кардинальных задач любого
научного исследования: возможность
предвидеть, прогнозировать развитие ситуации при изменении конкретных характеристик объекта исследования. Например,
основное содержание любой экономической
политики, в конечном счете, может быть сведено к регулированию экономических переменных, осуществляемому на базе
выявленной тем или иным образом
информации об их взаимовлиянии. Поэтому проблема изучения взаимосвязей
показателей различного рода является одной из важнейших в научном и статистическом
анализе. В общем случае взаимосвязь
между переменными носит не функциональный, а вероятностный, т.е. стохастический характер. В этом случае
нет строгой, однозначной зависимости
между величинами. Для изучения стохастических связей между переменными применяется
регрессионный и корреляционный анализ. С помощью регрессионного анализа
определяется форма (характер) зависимости
между случайной величиной Y и значениями одной или нескольких переменных
величин X.
С помощью корреляционного анализа определяют степень связи между двумя случайными
величинами X и Y. В качестве меры такой
связи используется коэффициент корреляции. Коэффициент корреляции оценивается по
выборке объема n связанных пар наблюдений ![]() из совместной генеральной
из совместной генеральной
совокупности X и Y.
Для оценки степени взаимосвязи большое распространение получил коэффициент
линейной корреляции (Пирсона), предполагающий нормальный закон распределения
экспериментальных данных.
Коэффициент корреляции (R, r) — параметр, характеризующий степень линейной взаимосвязи между
двумя выборками. Коэффициент корреляции изменяется от -1 (строгая
обратная линейная зависимость) до 1 (строгая прямая пропорциональная
зависимость). При значении 0 линейной зависимости между двумя выборками нет. Под
прямой зависимостью понимают зависимость, при которой увеличение или
уменьшение значения одного признака ведет, соответственно, к увеличению или
уменьшению второго. При обратной зависимости увеличение одного признака
приводит к уменьшению второго и наоборот. Выборочный коэффициент линейной корреляции
между двумя случайными величинами X и Y рассчитывается по
формуле:
Коэффициент корреляции является безразмерной величиной и его значение не
зависит от единиц измерения случайных величин X и Y.
На
практике коэффициент корреляции принимает некоторые промежуточные значения между 1 и -1
(рисунок 10.1). Для оценки степени взаимосвязи можно руководствоваться
следующими эмпирическими правилами. Если коэффициент корреляции (r) по абсолютной
величине (без учета знака) больше, чем 0,95, то принято считать, что между
параметрами существует практически линейная зависимость (прямая — при
положительном r и обратная -при отрицательном r).
Если
коэффициент корреляции r лежит в диапазоне от
0,8 до 0,95, говорят о сильной степени линейной связи между параметрами.
 Если
Если
0,6 < r < 0,8, говорят о наличии линейной связи между
параметрами. При r < 0,4 обычно считают, что линейную взаимосвязь
между параметрами выявить не удалось.
Рисунок 10.1- Примеры прямой (r = 0.7, а) и
обратной (r = — 0.8, б) корреляционной зависимости
В MS
Excel для вычисления парных коэффициентов линейной корреляции используется
специальная функция КОРРЕЛ. Параметрами функции являются КОРРЕЛ (массив1;
массив2), где: массив1 — это диапазон ячеек первой случайной величины; массив2
— это второй интервал ячеек со значениями второй случайной величины.
10.2 Корреляционная матрица
При большом числе наблюдений, когда коэффициенты корреляции необходимо последовательно вычислять из нескольких
рядов числовых данных, для удобства получаемые коэффициенты сводят в таблицы,
называемые корреляционными матрицами.
Корреляционная матрица — это квадратная (или прямоугольная) таблица, в
которой
на пересечении соответствующей строки и столбца находится коэффициент корреляции между
соответствующими параметрами. В MS Excel для вычисления
корреляционных матриц используется процедура Корреляция. Процедура позволяет
получить корреляционную матрицу, содержащую коэффициенты корреляции между различными
параметрами.
10.3 Регрессионный анализ
При
исследовании взаимосвязей между выборками помимо корреляции различают также и регрессию.
Регрессия используется для анализа воздействия на отдельную зависимую
переменную значений одной или более независимых переменных. Соответственно,
наряду с корреляционным анализом еще одним инструментом изучения стохастических
зависимостей является регрессионный анализ. С помощью регрессионного анализа устанавливается
форма зависимости между случайной величиной Y (зависимой) и
значениями одной или нескольких переменных величин (независимых),
причем значения последних считаются точно заданными. Такая зависимость обычно
определяется некоторой математической моделью (уравнением регрессии),
содержащей несколько неизвестных параметров. В ходе регрессионного анализа на
основании экспериментальных данных находят оценки этих параметров, определяются
статистические ошибки оценок или границы доверительных интервалов и
проверяется соответствие (адекватность) принятой математической модели
экспериментальным данным. В линейном регрессионном анализе связь между
случайными величинами предполагается линейной. В самом простом случае в линейной
регрессионной модели имеются
две переменные X и Y.
Требуется по n парам наблюдений ![]() построить
построить
(подобрать) прямую линию, называемую линией регрессии, которая «наилучшим образом» приближает наблюдаемые значения.
Уравнение этой линии ![]() является
является
регрессионным уравнением. С помощью регрессионного уравнения можно предсказать
ожидаемое значение зависимой величины ![]() , соответствующее заданному значению независимой
, соответствующее заданному значению независимой
переменной ![]() .
.
Таким
образом, можно сказать, что линейный регрессионный анализ заключается в подборе графика и
его уравнения для имеющихся экспериментальных данных. Мерой эффективности
регрессионной модели является коэффициент детерминации R2 (R-квадрат).
Коэффициент детерминации (R-квадрат) определяет, с какой степенью точности
полученное регрессионное уравнение описывает (аппроксимирует) исходные
данные. Например, R2=0,98 означает, что на 98% значение Y определяется
исследуемым фактором Х, а на 2 % — другими причинами.
В случае, когда рассматривается зависимость между одной зависимой
переменной ![]() и несколькими независимыми
и несколькими независимыми ![]() говорят о множественной линейной регрессии.
говорят о множественной линейной регрессии.
В этом случае регрессионное уравнение имеет вид
![]()
где
![]() — требующие определения
— требующие определения
коэффициенты при независимых переменных
![]() ;
;
![]() — константа.
— константа.
В регрессионном анализе все признаки (переменные), входящие в уравнение,
должны иметь непрерывную, а не дискретную природу.
Для выполнения регрессионного анализа и получения коэффициентов
регрессии используется процедура Регрессия из пакета анализа Excel.
Значимость регрессионной модели оценивается с помощью F -критерия Фишера. Если величина F-критерия значима (р
< 0,05), то и регрессионная модель является значимой.
Достоверность отличия коэффициентов ![]() от нуля проверяется с помощью критерия Стьюдента. В случаях, когда p > 0,05,
от нуля проверяется с помощью критерия Стьюдента. В случаях, когда p > 0,05,
коэффициент может считаться нулевым, а это означает, что влияние
соответствующей независимой переменной на зависимую переменную статистически недостоверно,
и эта независимая переменная может быть исключена из уравнения.
В MS Excel экспериментальные данные можно
аппроксимировать линейным уравнением до 16 порядка. Корреляционно-
регрессионный анализ экспериментальных данных с использованием инструментов Excel выполняется на
практических занятиях.
![]()
![]()
![]()
![]() 11 Лекция. Методы графической обработки экспериментальных данных.
11 Лекция. Методы графической обработки экспериментальных данных.
Интерполяция и аппроксимация данных
Содержание лекции:
методы
графической обработки экспериментальных данных, типы координатных систем и
координатных сеток; интерполяция и аппроксимация экспериментальных данных
Цель лекции:
рассмотрение основных
вопросов, связанных с графической обработкой экспериментальных данных,
применением современных возможностей ЭВМ для нахождения эмпирических формул к
полученным данным.
11.1 Методы графической обработки экспериментальных
данных
При обработке экспериментальных данных, т.е. результатов измерений или
наблюдений широко используются методы графического изображения, так как
результаты измерений, представленные в табличной форме, не позволяют достаточно наглядно характеризовать закономерности изучаемых процессов.
Графическое изображение дает наиболее наглядное представление о результатах
эксперимента, позволяет лучше понять
физическую сущность исследуемого процесса, выявить общий характер
функциональной зависимости изучаемых переменных величин, установить наличие максимума или минимума функции.
Для графического изображения результатов измерений (наблюдений), как
правило, применяют систему прямоугольных
координат.
Обычно
графики (смотри рисунок11.1) имеют плавный характер, поэтому резкое искривление графика чаще всего объясняется
погрешностями измерения. Если
эксперимент повторить с применением
средств измерений более высокой точности
и более тщательно, ломаная кривая
больше соответствует плавной кривой. Иногда
при построении графика некоторые точки могут резко удаляться от кривой. В
таких случаях вначале следует проанализировать физическую сущность явления, и,
если нет основания полагать наличие скачка функции, то такое резкое отклонение
можно объяснить грубой ошибкой или промахом. Это может возникнуть тогда, когда
данные измерений предварительно не исследовались на наличие грубых ошибок
измерений. В таких случаях необходимо повторить измерение в диапазоне резкого
отклонения данных замера. Если прежнее измерение оказалось ошибочным, то на
график наносят новую точку. Если же
повторные измерения дадут прежнее значение,
необходимо к этому интервалу кривой отнестись особенно внимательно и тщательно проанализировать физическую сущность
явления.
Рисунок 11.1 — Графическое изображение функции ![]()
а) — плавная зависимость: б) — при наличии скачка
1 — кривая по результатам непосредственных измерений; 2- плавная кривая
11.2 Типы координатных систем и координатных сеток
При графическом изображении
результатов экспериментов большую роль играет выбор системы координат или
координатой сетки. Координатные сетки бывают равномерными и неравномерными. У
равномерных координатных сеток ординаты и абсциссы имеют равномерную шкалу.
Например, в системе прямоугольных координат длина откладываемых единичных
отрезков на обеих осях одинаковая.
Из неравномерных координатных
сеток наиболее распространены
полулогарифмические, логарифмические и вероятностные.
Полулогарифмическая сетка имеют равномерную
ординату и логарифмическую абсциссу (рисунок11.2,а).
Логарифмическая координатная сеть имеет
обе оси логарифмические (рисунок 11.2,6), вероятностная — ординату обычно равномерную и по абсциссе — вероятностную шкалу (рисунок 11.2, в).
Неравномерные
сетки применяют для более наглядного изображения функций. Функция ![]() имеет различную форму при различных
имеет различную форму при различных
сетках. Так, многие криволинейные функции спрямляются на логарифмических сетках.
Рисунок 11.2.
Координатная сетка: а)- полулогарифмическая;
б) — логарифмическая;
в) — вероятностная сетка
Масштаб по
координатным осям обычно применяют различный.
От выбора
его зависит форма графика — он может быть узким или широким вдоль оси (рисунок
11.3). Узкие графики дают большую погрешность по оси у; широкие — по оси х. Из
рисунка видно, что правильно подобранный масштаб (нормальный график) позволяет
существенно повысить точность отсчетов. Расчетные графики, имеющие экстремум
функции или какой-либо сложный вид, особо тщательно необходимо проверять в
зонах изгиба. На таких участках количество экспериментальных точек для
построения графика должно быть значительно больше, чем на плавных участках.
Рисунок 11.3.-Форма графика в зависимости от масштаба
1- узкий; 2- широкий; 3-нормальная.
11.3 Интерполяция и аппроксимация экспериментальных
данных
К одной из важных задач, встречающихся при обработке
экспериментальных данных, относится задача нахождения по набору
экспериментальных значений функции ![]() в узловых точках
в узловых точках
аргумента ![]() аналитической
аналитической
зависимости ![]() или,
или,
как еще ее часто называют, эмпирической формулы. Обычно функция ![]() ищется в таком виде,
ищется в таком виде,
чтобы график, построенной на основании найденной функции, проходил бы через
все узловые точки (т.е. ![]() ).
).
Такая
задача называется задачей интерполяции, а сама функция — интерполяционной.
Достаточно
популярным для решения этой задачи является применение степенной функции, т.е.
полинома имеющего порядок степени равный количеству узловых точек минус
единица. При выполнении этого условия функция будет проходить через все узловые
точки. Если возможности (или необходимости) в том, чтобы функция проходила
через все узловые точки, нет, функцию выбирают из условия минимальности
отклонений от экспериментальных значений, исходя при этом из принимаемой
погрешности и практических потребностей.
Но в этом
случае говорят не о решении задачи интерполяции, а о решении задачи
аппроксимации. А найденную функцию называют аппроксимирующей функцией. Для
нахождения эмпирических формул достаточно популярным является применение
встроенных процедур и инструментов Excel.
Применение Excel для нахождения интерполирующих и
аппроксимирующих функций рассматриваются на практических занятиях.
12 Лекция.
Определение эмпирических формул
Содержание
лекции:
эмпирические
формулы, подбор формулы по виду графика экспериментальных данных, методы
оптимизации, метод наименьших квадратов, надстройка Excel « Поиск решения» и
ее применение для решения
задач оптимизации и определения эмпирических формул.
Цель
лекции:
в дополнении к лекции 11
дать дополнительные теоретические сведения по обработке экспериментальных
данных, подбору к полученным графикам эмпирических формул, применение для этой
цели задач оптимизации и встроенных инструментов Excel.
12.1 Методы подбора эмпирических формул
В процессе экспериментальных исследований
получается статистический ряд измерений двух величин, когда каждому значению
функции соответствует определенное значение аргумента.
На основе
экспериментальных данных можно подобрать алгебраические выражения функции ![]() , которые называют эмпирическими
, которые называют эмпирическими
формулами.
Такие формулы
подбираются лишь в пределах измеренных значений аргумента и имеют тем
большую ценность, чем больше соответствуют результатам эксперимента. Необходимость
в подборе эмпирических формул возникает во многих случаях. Так, если
аналитическое выражение сложное, требует громоздких вычислений, составления
программ для ЭВМ или вообще не имеет аналитического выражения, то эффективнее
пользоваться упрощенной приближенной эмпирической формулой. Эмпирические
формулы должны быть по возможности наиболее простыми и точно соответствовать
экспериментальным данным в пределах изменения аргумента. Таким образом,
эмпирические формулы являются приближенными выражениями аналитических формул.
Замену точных аналитических выражений приближенными называют
аппроксимацией, а функции – аппроксимирующими. При подборе эмпирических формул
можно воспользоваться практическими рекомендациями, связывающими форму графика,
построенного по экспериментальным данным, с рекомендуемой формулой для ее
аппроксимации.
Так,
например, если экспериментальный график имеет вид, показанный на рисунке 12.1а,
то рекомендуется применить формулу ![]() .
.
Если экспериментальный
график имеет вид, показанный на рисунке 12.1б, то целесообразно использовать
выражение ![]() .
.
Если экспериментальный график
имеет вид, представленный на рисунке 12.1в, то эмпирическая формула принимает вид ![]()
Рисунок 12.1 — Основные виды графиков
эмпирических формул
Если экспериментальный график имеет вид, показанный на рисунке 12.1г,
то нужно пользоваться формулой ![]() .
.
Если график имеет вид,
соответствующий кривым на рисунке 12.1д, то применяется выражение ![]() .
.
Если график имеет вид,
соответствующий кривым на рисунке 12.1е, то используют формулу ![]() .
.
Кроме приведенных выше выражений в качестве эмпирических формул широкое
применение нашли полиномы:
![]()
Ценность полинома определяется тем, что с его помощью можно
аппроксимировать любые результаты измерений, если они графически выражаются
непрерывными функциями.
На практических занятиях мы рассмотрели некоторые возможности Excel для нахождения
эмпирических формул, в частности применение для этой цели утилит: линия
тренда и регрессия.
На сегодняшнем занятии мы рассмотрим новые возможности Excel для решения
оптимизационных задач и для нахождения параметров эмпирических формул к
полученным экспериментальным данным.
12.2 Задачи оптимизации. Метод наименьших
квадратов
Очень
широкий класс задач составляют задачи оптимизации или, как их еще называют,
экстремальные задачи. В этой теме будут рассмотрены некоторые типы задач
оптимизации: задачи линейного программирования и метод наименьших квадратов.
В
задачах оптимизации требуется найти значения параметров ![]() , реализующих максимум или минимум
, реализующих максимум или минимум
некоторой зависящей от них, так называемой, целевой функции
![]() ,
,
На область нахождения
параметров могут быть наложены, при необходимости, дополнительные условия
— ограничения в виде равенств или неравенств:
![]() ( i =1,2…n).
( i =1,2…n).
В
случае, когда оптимизируемая целевая функция и ограничения линейны, задача
оптимизации решается методами линейного программирования и называется задачей
линейного программирования.
Во
многих инженерных и экономических задачах, например, желательно найти максимум
меры выполнения или минимум стоимости. В задачах электроэнергетике таким
задачам можно отнести задачи нахождения минимума потерь электроэнергии,
минимума приведенных затрат, максимума выработки электрической и тепловой
энергии и проч.
Другим
приложением задач оптимизации является нахождение параметров эмпирических
формул. Хорошие результаты при их определении
дает использование метода наименьших квадратов. Суть этого метода заключается в
том, что минимизируется сумма квадратов отклонений теоретических значений
функции, найденной по эмпирической формуле и значений, полученных из
эксперимента.
Максимум
и минимум функции объединяются общим названием экстремума функции. Для поиска
экстремумов существуют различные методы. Часто случается, что при отыскании
максимумов и минимумов функций многих переменных получают сложную систему
уравнений, в этих случаях экстремумы находятся численными методами, то есть при
помощи последовательного применения метода проб. При этом применение компьютера
является практически единственным способом решения задачи.
Инструментом решений задач оптимизации в
Excel служит надстройка «Поиск решения», внешний вид диалогового окна которой
приведен на рисунке 12.2
Рисунок12.2 – Диалоговое окно
Поиск решения
Применение данной надстройки для решения
оптимизационных задач и для нахождения параметров эмпирических формул
рассматривается на соответствующем практическом занятии.
Список литературы
Основная литература
1.
Дж. Тейлор Введение в теорию
ошибок. — М.,- Мир, 1985, 271с.
2.
Маркин Н.С. Основы теории
обработки результатов измерений,- М., Издательство стандартов, 1991, 176с.
3.
Агапьев Б.Д., Белов В.Н., Козловский В.В., Марков С.И.
Обработка экспериментальных данных: Учеб. пособие / СПбГТУ. СПб., 2001.
4.
Горелова Г.В. Теория вероятностей и математическая статистика в
примерах и задачах с применением Excel. – М.: Феникс, 2005. – 476 с.
5. Кассандрова О.Н., Лебедев В.В. Обработка результатов наблюдений.- М.:
Наука, 1970. 104 с.
Дополнительная литература
1.
Щеголев Б.М. Математическая
обработка наблюдений. — М.:Физматгиз, 1962.
2.
Козлов М.В. Прохоров Л.В. введение
в математическую статистику.- М., 1987, 264с.
3.
Кузнецов В.А. Якунина Е.В. Основы
метрологии.- М., Издательство стандартов, 1995, 279 с.
4.
Селиванов М.Н. Фридман А.Э.
Кудряшова Ж. Ф. Качество измерений. Метрологическая справочная книга.- Л.,
1987, 295с.
5.
Зайдель А.Н. Ошибки измерений
физических величин. -Л.: Наука, 1974. 101 с.
6.
Макарова Н.В., Трофимец В.Я.
Статистика в Excel. –М.: Финансы и статистика, 2002.
7.
Светозаров В.В. Основы
статистической обработки результатов измерений.- М.: Изд-во МИФИ, 1983.40 с.
8.
Линник Ю.В. Метод наименьших
квадратов и основы теории обработки наблюдений.- М.: Физматгиз, 1968. 390 с.
9.
Теория вероятностей и математическая статистика. Базовый курс
с примерами и задачами. – М.: Физматлит, 2002. – 223 с.
10.Решение математических задач средствами Excel:
Практикум /В.Я. Гельман.- СПб.: Питер, 2003.
[1] Все указанные в конспекте лекций таблицы приведены в
методических указаниях к соответствующим практическим занятиям.
[2]
В научных статьях, как правило,
приводят доверительный интервал «плюс-минус одна среднеквадратичная
ошибка»:
Этот интервал соответствует доверительной
вероятности р
= 0,68. Такой интервал называют стандартным и
при указании ошибки часто не приводят значение доверительной вероятности.
[3] Погрешность, обусловленная случайными факторами, может
быть сведена до •7необходимого минимума увеличением числа измерений.
Зарегистрируйтесь, чтобы просмотреть полный документ!
РЕГИСТРАЦИЯ

РОБАСТНОЕ СТАТИСТИЧЕСКОЕ ОЦЕНИВАНИЕ Грубые ошибки и методы их выявления в статистической совокупности данных n

n При исследовании статистических совокупностей часто приходится иметь дело с данными, отклоняющимися от основного массива, т. е. с ошибками, или выбросами.

1 2 3 4 5 6 7 8 9 10 15, 18, 47, 12, 16, 65, 17, 11, 12, 13, 2 4 3 1 0 3 2 4 0 9

n При выявлении подобных «выбросов» возникают серьезные вопросы: являются ли отклоняющиеся данные действительно ошибками (например, регистрации) или это реальные значения и как получить адекватные оценки для параметров изучаемой совокупности. Решением подобных вопросов занимается специальный раздел статистики — робастное (устойчивое) оценивание.

n Методы робастного оценивания — это статистические методы, которые позволяют получать достаточно надежные оценки статистической совокупности с учетом неявности закона ее распределения и наличия существенных отклонений в значениях данных. У истоков развития методов робастного оценивания стояли американский статистик Д. Тьюки и швейцарский математик П. Хубер.

При решении задач робастного оценивания выделяют два типа данных, засоряющих статистическую совокупность. n данные, несущественно отличающиеся от значений, которые наиболее часто встречаются в изучаемой совокупности. n резко выделяющиеся на фоне изучаемой совокупности, их называют «засорением» или «грубыми ошибками» , они оказывают сильное искажающее воздействие на аналитические результаты.

основные причины появления грубых ошибок: • Специфические особенности отдельных элементов изучаемой совокупности. Как правило, они приводят к появлению случайных, или «нормальных» ( «обычных» ) отклонений. • Неправильное причисление элементов к исследуемой совокупности, например, ошибки группировки, ошибки при организации наблюдения и т. п. • Грубые ошибки при регистрации и обработке данных.
 выделяют два основных подхода. n устранение из выборочной совокупности")
При обработке «грубых» ошибок (засорений) выделяют два основных подхода. n устранение из выборочной совокупности ошибок и оценку параметров по оставшимся «истинным» значениям n Усеченная выборка

Второй подход предполагает в каждом случае с грубой ошибкой выделение истинных значений признака и собственно ошибки n х=хист+ξ осуществляется модификация данных таким образом, чтобы искажающий элемент ξ получил нормальное распределение с нулевым математическим ожиданием
 распознавание ошибок в данных; 2) выбор")
Алгоритм обработки «засорений» включает последовательное выполнение шагов: 1) распознавание ошибок в данных; 2) выбор метода и проведение робастного оценивания данных; 3) критериальная или логическая проверка и интерпретация результатов устойчивого оценивания.

Простой формальный прием для обнаружения грубых ошибок основывается на расчете Ткритерия Граббса: n n где х — выборочная средняя. Ее оценка предпочтительна по истинным данным σ — выборочное среднеквадратическое отклонение случайной величины.

Наблюденные значения Т-критерия сравнивают с пороговыми, заданными соответствующим распределением. n Проверяемые признаковые значения относят к классу выбросов, если Тн >Ткр (Ткр=Тα, h). Если Тн<Ткр, то считается, что эти значения несущественно отличаются от других данных, и не будут давать сильного искажающего эффекта.

n Критерий Граббса прост и легко применим в анализе, но имеет существенные недостатки. В частности, исследователи обращают внимание на его недостаточную точность (часто дает весьма грубые оценки) и, кроме того, он «нечувствителен» к маскирующим эффектам, когда выбросы группируются достаточно близко друг от друга в отдаленности от основной массы наблюдений.

n Более точными по сравнению со статистикой Граббса оценками грубых ошибок признаются L- и Е-критерии, предложенные американскими статистиками Г. Титьеном и Г. Муром:

L-критерий исчисляется для выявления грубых ошибок в верхней части ранжированного ряда данных: число наблюдений с резко отклоняющимися значениями признака объем выборки средняя, которую рассчитывают по п — k наблюдениям, остающимися после отбрасывания k грубых ошибок «сверху» ранжированного ряда данных

L’-критерий применяется для выявления грубых ошибок в данных, расположенных в нижней части ранжированного ряда данных

E-критерий используется, когда в выборке имеются предположительно грубые ошибки с наибольшими и наименьшими значениями, т. е. расположенные в верхней и нижней частях ранжированного ряда данных

В нижней части ранжированного ряда данных – значит L’-критерий х1 х2 х3 х4 15, 4 13, 2 18, 3 47, 1 х9 х5 х10 х2 11 12 12, 9 13, 2 ранг 1 ранг 2 ранг 3 ранг 4 х5 х6 х7 х8 х9 х10 12 16, 3 65, 2 17, 4 11 12, 9 х1 х6 х8 х3 х4 х7 15, 4 16, 3 17, 4 18, 3 47, 1 65, 2 ранг 5 ранг 6 ранг 7 ранг 8 ранг 9 ранг 10

Усеченная выборка расчет Хк расчет Хср общая выборка х1 х2 х3 х4 15, 4 13, 2 18, 3 47, 1 х9 х5 х10 х2 11 12 12, 9 13, 2 ранг 1 ранг 2 ранг 3 ранг 4 х5 х6 х7 х8 х9 х10 12 16, 3 65, 2 17, 4 11 12, 9 х1 х6 х8 х3 х4 х7 15, 4 16, 3 17, 4 18, 3 47, 1 65, 2 ранг 5 ранг 6 ранг 7 ранг 8 ранг 9 ранг 10

n Все три критерия L, L’ и Е имеют табулированные критические значения для заданного уровня значимости α при известном объеме выборки п и предполагаемом числе ошибок k. Если наблюденные значения критериев оказываются меньше пороговых Са, k, то ошибки в данных, подвергаемые проверке, признаются грубыми, существенно отклоняющимися от основного массива данных. При L, L’, Е> Са, k данные гипотетически предполагаются типичными для изучаемой выборочной совокупности.

Графический метод

Выбросы либо исключаются либо модифицируются

Методы исчисления устойчивых статистических оценок: Пуанкаре, Винзора, Хубера n После обнаружения выбросов в данных решается задача оценивания параметров выборочной совокупности. При этом, как выше уже сказано, используются два основных подхода: экстремальные значения (грубые ошибки) отбрасываются либо модифицируются.

Американский статистик Пуанкаре n предложил следующую формулу для расчета средней по усеченной совокупности (урезанную среднюю): объем выборочной совокупности число грубых ошибок k≤ a∙n — целая часть от произведения a∙n, где п – объем выборочной совокупности, а α – некоторая функция величины засорения выборки ξ. Значения α находят по специальным таблицам. Обычно α колеблется в пределах от нуля до 0, 5.

Другой подход демонстрирует оценка Винзора она предполагает замену признаковых значений, засоряющих выборку, на модифицированные (винзорированные) значения с устраненными или уменьшенными ошибками. Средняя по Винзору определяется также с известным заранее уровнем а (0< α < 1/2) по формуле:
 и W(α), т. е. соответственно по усеченной")
n n По аналогии с оценками Т(α) и W(α), т. е. соответственно по усеченной совокупности, или винзорированным данным, могут быть найдены не только средние величины, но и другие оценки параметров статистической совокупности, например, вариации, моды, медианы и т. п. Приемы робастного оценивания Пуанкаре и Винзора дают хорошие результаты на выборках с симметричным распределением засорений, когда грубые ошибки группируются примерно на одном расстоянии от центра в нижней и верхней частях статистической совокупности.

n Наряду с уже названными методами робастного оценивания, широкое распространение имеет ставший классическим подход Хубера. Он напоминает процедуры для последовательного «улучшения» данных по Винзору. При этом используется некоторая исходная величина k, определяемая с учетом степени «засорения» статистической совокупности ξ; и определяющая шаг модификации резко отличающихся наблюдений (см. табл. 5. 6).

Оценка средней величины по методу Хубера производится по формуле: где – – численность группы наблюдений из совокупности, n 1 устойчивая оценка, определяется при помощи итеративных процедур; отличающихся наименьшими значениями: xi < Θ — k, или k — величина, которая допускается в качестве отклонения от значения в интервале (-∞; Θ — k); центра совокупности, принимает постоянные значения с учетом п 2 – численность группы наблюдений из совокупности, удельного веса грубых ошибок в совокупности данных ξ отличающихся наибольшими значениями: xi < Θ + k, или значения в интервале (Θ + k; ∞).

ВЫВОДЫ: При обнаружении «засорения» , или «грубых ошибок» , в совокупности данных, т. е. значений, резко отличающихся от медианных, используются принципы проверки статистических гипотез. Наиболее простыми и распространенными являются методы поиска ошибок Граббса, Титьена и Мура. Если в статистической совокупности действительно выявлены «грубые ошибки» , то для уменьшения их влияния на аналитические результаты рекомендуется применение специальных приемов обработки данных.

ВЫВОДЫ: Сущность этих приемов сводится к одному из двух решений: устранению из совокупности аномальных наблюдений, (усечению совокупности), или модификации резко отличающихся значений с целью уменьшения ошибок в данных. Первое решение представлено в подходе Пуанкаре, второе — в подходах Хубера и Винзора, Само изменение данных, направленное на минимизацию ошибки в них, принято называть как винзорирование.

ВЫВОДЫ: Проверка статистических гипотез и робастное оценивание часто используются как самостоятельные статистические приемы в решении задач оценки качества, оценки адекватности заданным условиям и т. п. n. Представленные методы в комплексе с другими статистическими методами позволяют предварительно анализировать наблюденные значения характерных признаков, выявить в них несоответствия и грубые ошибки, провести модификацию данных, повышающую гомогенность изучаемой совокупности. n
В статье рассмотрены различные критерии отбрасывания грубых погрешностей измерений, применяемые в практической деятельности, на основе рекомендаций ведущих специалистов-метрологов, а также с учетом действующих в настоящий момент нормативных документов.
Приведен пример использования Excel при оценке грубых погрешностей по критериям Стьюдента и Романовского при обработке реальных результатов измерений.
Ключевые слова:
грубые погрешности, критерии согласия, сомнительные значения, уровень значимости, нормальное распределение, критерий согласия Стьюдента, критерий Романовского, выборка, отклонения, Excel.
Одним из важнейших условий правильного применения статистических оценок является отсутствие грубых ошибок при наблюдениях. Поэтому все грубые ошибки должны быть выявлены и исключены из рассмотрения в самом начале обработки наблюдений.
Единственным достаточно надежным способом выявления грубых ошибок является тщательный анализ условий самих испытаний. При этом наблюдения, проводившиеся в нарушенных условиях, должны отбрасываться, независимо от их результата. Например, если при проведении эксперимента, связанного с электричеством, в лаборатории на некоторое время был выключен ток, то весь эксперимент обязательно нужно проводить заново, хотя результат, быть может, не сильно отличается от предыдущих измерений. Точно так же отбрасываются результаты измерений на фотопластинках с поврежденной эмульсией и вообще на любых образцах с обнаруженным позднее дефектом.
На практике, однако, не всегда удается провести подобный анализ условий испытания. Чаще всего приходится иметь дело с окончательным цифровым материалом, в котором отдельные данные вызывают сомнение лишь своим значительным отклонением от остальных. При этом сама «значительность» отклонения во многом субъективна — зачастую приходится сталкиваться со случаями, когда исследователь отбрасывает наблюдения, которые ему не понравились, как ошибочные исключительно по той причине, что они нарушают уже созданную им в воображении картину изучаемого процесса.
Строгий научный анализ готового ряда наблюдений может быть проведен лишь статистическим путем, причем должен быть достаточно хорошо известен характер распределения наблюдаемой случайной величины. В большинстве случаев исследователи исходят из нормального распределения. Каждая грубая ошибка будет соответствовать нарушению этого распределения, изменению его параметров, иными словами, нарушится однородность испытаний (или, как говорят
,
однородность наблюдений), поэтому выявление грубых ошибок можно трактовать как проверку однородности наблюдений.
Промахи, или грубые погрешности, возникают при единичном измерении и обычно устраняются путем повторных измерений. Причиной их возникновения могут быть:
- Объективная реальность (наш реальный мир отличается от идеальной модели мира, которую мы принимаем в данной измерительной задаче);
- Внезапные кратковременные изменения условий измерения (могут быть вызваны неисправностью аппаратуры или источников питания);
- Ошибка оператора (неправильное снятие показаний, неправильная запись и т. п.).
В третьем случае, если оператор в процессе измерения обнаружит промах, он вправе отбросить этот результат и провести повторные измерения.
В настоящее время определение грубой погрешности приведено в ГОСТ Р 8.736–2011: «Грубая погрешность измерения: Погрешность измерения, существенно превышающая зависящие от объективных условий измерений значения систематической и случайной погрешностей» [1, с. 6].
Общие подходы к методам отсеивания грубых погрешностей, как это уже давно принято в практике измерений, заключаются в следующем.
Задаются вероятностью
Р
или уровнем значимости
α
(
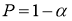
) того, что результат наблюдения содержит промах. Выявление сомнительного результата осуществляют с помощью специальных критериев. Операция отбрасывания удаленных от центра выборки сомнительных значений измеряемой величины называется «цензурированием выборки».
Проверяемая гипотеза состоит в утверждении, что результат наблюдения
x
i
не содержит грубой погрешности, т. е. является одним из значений случайной величины
x
с законом распределения Fx(x), статистические оценки параметров которого предварительно определены. Сомнительным может быть в первую очередь лишь наибольший x
max
или наименьший xmin из результатов наблюдений.
Предложим для практического использования наиболее простые методы отсева грубых погрешностей.
Если в распоряжении экспериментатора имеется выборка небольшого объема
n
≤ 25, то можно воспользоваться методом вычисления максимального относительного отклонения [2, с. 149]:
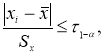
(1)
где
x
i
— крайний (наибольший или наименьший) элемент выборки, по которой подсчитывались оценки среднего значения
и среднеквадратичного отклонения
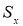
;
τ
1-
p
— табличное значение статистики
τ
, вычисленной при доверительной вероятности
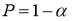
.
Таким образом, для выделения аномального значения вычисляют значение статистики,
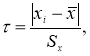
(2)
которое затем сравнивают с табличным значением
τ
1-α
:
τ
≤
τ
1-α
. Если неравенство
τ
≤
τ
1-α
соблюдается, то наблюдение не отсеивают, если не соблюдается, то наблюдение исключают. После исключения того или иного наблюдения или нескольких наблюдений характеристики эмпирического распределения должны быть пересчитаны по данным сокращенной выборки.
Квантили распределения статистики
τ
при уровнях значимости
α
= 0,10; 0,05; 0,025 и 0,01 или доверительной вероятности
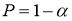
=
0,90; 0,95; 0,975 и 0,99 приведены в таблице 1. На практике очень часто используют уровень значимости
α
= 0,05 (результат получается с 95 %-й доверительной вероятностью).
Функции распределения статистики
τ
определяют методами теории вероятностей. По данным таблицы, приведенной в источниках [2, с. 283; 3, с. 184] при заданной доверительной вероятности
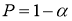
или уровне значимости
α
можно для чисел измерения п = 3–25 найти те наибольшие значения
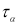
которые случайная величина
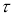
может еще принять по чисто случайным причинам.
Процедуру отсева можно повторить и для следующего по абсолютной величине максимального относительного отклонения, но предварительно необходимо пересчитать оценки среднего значения
и среднеквадратичного отклонения
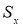
для выборки нового объема
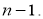
Таблица 1
Квантили распределения максимального относительного отклонения при отсеве грубых погрешностей [2, с. 283]
|
|
Уровень значимости |
|
Уровень значимости |
||||||
|
0,10 |
0,05 |
0,025 |
0,01 |
0,10 |
0,05 |
0,025 |
0,01 |
||
|
3 |
1,41 |
1,41 |
1,41 |
1,41 |
15 |
2,33 |
2,49 |
2,64 |
2,80 |
|
4 |
1,65 |
1,69 |
1,71 |
1,72 |
16 |
2,35 |
2,52 |
2,67 |
2,84 |
|
5 |
1,79 |
1,87 |
1,92 |
1,96 |
17 |
2,38 |
2,55 |
2,70 |
2,87 |
|
6 |
1,89 |
2,00 |
2,07 |
2,13 |
18 |
2,40 |
2,58 |
2,73 |
2,90 |
|
7 |
1,97 |
2,09 |
2,18 |
2,27 |
19 |
2,43 |
2,60 |
2,75 |
2,93 |
|
8 |
2,04 |
2,17 |
2,27 |
2,37 |
20 |
2,45 |
2,62 |
2,78 |
2,96 |
|
9 |
2,10 |
2,24 |
2,35 |
2,46 |
21 |
2,47 |
2,64 |
2,80 |
2,98 |
|
10 |
2,15 |
2,29 |
2,41 |
2,54 |
22 |
2,49 |
2,66 |
2,82 |
3,01 |
|
11 |
2,19 |
2,34 |
2,47 |
2,61 |
23 |
2,50 |
2,68 |
2,84 |
3,03 |
|
12 |
2,23 |
2,39 |
2,52 |
2,66 |
24 |
2,52 |
2,70 |
2,86 |
3,05 |
|
13 |
2,26 |
2,43 |
2,56 |
2,71 |
25 |
2,54 |
2,72 |
2,88 |
3,07 |
|
14 |
2,30 |
2,46 |
2,60 |
2,76 |
|||||
В литературе можно встретить большое количество методических рекомендаций для проведения отсева грубых погрешностей измерений, подробно рассмотренных в [4, с. 25]. Обратим внимание на некоторые из существующих критериев отсеивания грубых погрешностей.
-
Критерий «трех сигм» применяется для случая, когда измеряемая величина
x
распределена по нормальному закону. По этому критерию считается, что с вероятностью
Р
= 0,9973 и значимостью
α
= 0,0027 появление даже одной случайной погрешности, большей, чем
маловероятное событие и ее можно считать промахом, если

−
x
i
> 3
S
x
, где
S
x
—
оценка среднеквадратического отклонения (СКО) измерений. Величиныи
S
x
вычисляют без учета экстремальных значений
x
i
. Данный критерий надежен при числе измерений
n
≥ 20…50 и поэтому он широко применяется. Это правило обычно считается слишком жестким, поэтому рекомендуется назначать границу цензурирования в зависимости от объема выборки: при
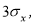
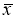
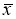
6 <
n
≤100 она равна 4
S
x
; при 100 <
n
≤1000 − 4,5
S
x
; при 1000 <
n
≤10000–5
Sx
. Данное правило также используется только при нормальном распределении.
Практические вычисления проводят следующим образом [5, с. 65]:
- Выявляют сомнительное значение измеряемой величины. Сомнительным значением может быть лишь наибольшее, либо наименьшее значение наблюдения измеряемой величины.
-
Вычисляют среднее арифметическое значение выборки

без учета сомнительного значения

измеряемой величины.
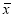
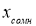
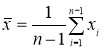
(3)
-
Вычисляют оценку СКО выборки

без учета сомнительного значения
измеряемой величины.
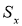
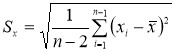
(4)
- Вычисляют разность среднеарифметического и сомнительного значения измеряемой величины и сравнивают.
Если
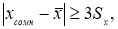
то сомнительное значение отбрасывают, как промах.
Если
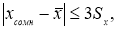
то сомнительное значение оставляют как равноправное в ряду наблюдений.
Данный метод «трех сигм» среди метрологов-практиков является самым популярным, достаточно надежным и удобным, так как при этом иметь под рукой какие-то таблицы нет необходимости.
-
Критерий В. И. Романовского применяется, если число измерений невелико,
n
≤ 20. При этом вычисляется соотношение
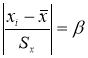
(5)
где
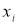
— результат, вызывающий сомнение,
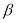
— коэффициент, предельное значение которого
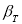
определяют по таблице 2. Если
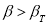
, сомнительное значение
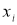
исключают («отбрасывают») как промах. Если

,
сомнительное значение оставляют как равноправное в ряду наблюдений [5, с. 65].
Таблица 2
Значение критерия Романовского
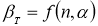
|
Уровень значимости, |
Число измерений, |
||||||
|
|
|
|
|
|
|
|
|
|
0,01 |
1,73 |
2,16 |
2,43 |
2,62 |
2,75 |
2,90 |
3,08 |
|
0,02 |
1,72 |
2,13 |
2,37 |
2,54 |
2,66 |
2,80 |
2,96 |
|
0,05 |
1,71 |
2,10 |
2,27 |
2,41 |
2,52 |
2,64 |
2,78 |
|
0,10 |
1,69 |
2,00 |
2,17 |
2,29 |
2,39 |
2,49 |
2,62 |
Несмотря на многообразие существующих и применяемых на практике методов отсеивания грубых погрешностей в настоящее время действует национальный стандарт ГОСТ Р 8.736–2011, который является основным нормативным документом в данной области. В новом стандарте для исключения грубых погрешностей применяется критерий Граббса.
- Статистический критерий Граббса (Смирнова) исключения грубых погрешностей основан на предположении о том, что группа результатов измерений принадлежит нормальному распределению [1, с. 8]. Для этого вычисляют критерии Граббса (Смирнова) G1 и G2, предполагая, что наибольший хmax или наименьший xmin результат измерений вызван грубыми погрешностями.
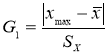
и
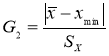
(6)
Сравнивают G1 и G2 с теоретическим значением GT критерия Граббса (Смирнова) при выбранном уровне значимости α. Таблица критических значений критерия Граббса (Смирнова) приведена в приложении к стандарту [1, с. 12]. Следует отметить, что критические значения критерия Граббса (Смирнова) GT отличаются от критических значений критериев
t
-статистик или значений критериев Стьюдента при одних и тех же величинах уровней значимости, что может вызывать некоторые трудности у пользователей при выборе конкретного метода отсеивания погрешностей, соответствующего нормативным документам.
Если G1>GТ, то хmax исключают как маловероятное значение. Если G2>GТ, то xmin исключают как маловероятное значение. Далее вновь вычисляют среднее арифметическое и среднее квадратическое отклонение ряда результатов измерений и процедуру проверки наличия грубых погрешностей повторяют.
Если G1
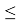
GТ, то хmax не считают промахом и его сохраняют в ряду результатов измерений. Если G2
GТ, то xmin не считают промахом и его сохраняют в ряду результатов измерений.
Отсев грубых погрешностей можно производить и для больших выборок (
n
= 50…100). Для практических целей лучше всего использовать таблицы распределения Стьюдента. Этот метод исключения аномальных значений для выборок большого объема отличается простотой, а таблицы распределения Стьюдента имеются практически в любой книге по математической статистике, кроме того, распределение Стьюдента реализовано в пакете Excel. Распределение Стьюдента относится к категории распределений, связанных с нормальным распределением. Подробно эти распределения рассмотрены в учебниках по математической статистике [3, с. 24].
Известно, что критическое значение
τ
p
(
p
— процентная точка нормирования выборочного отклонения) выражается через критическое значение распределения Стьюдента
t
α, n-2
[6, с. 26]:
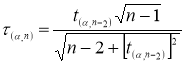
(7)
Учитывая это, можно предложить следующую процедуру отсева грубых погрешностей измерения для больших выборок (
n
= 100):
1) из таблицы наблюдений выбирают наблюдение имеющее наибольшее отклонение;
2)
по формуле
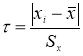
вычисляют значение статистики
τ
;
3)
по таблице (или в программе Excel) находят процентные точки
t
-распределения Стьюдента
t
(
α,
n
-2
)
:
t
(95
%, 98)
= 1,6602, и
t
(
99
%, 98)
= 3,1737;
По предыдущей формуле в программе Excel вычисляют соответствующие точки
t
(95
%, 100)
= 1,66023и
t
(99
%, 100)
=3,17374.
Сравнивают значение расчетной статистики с табличными критическими значениями и принимают решение по отсеву грубых погрешностей.
Рекомендуемый метод отсева грубых погрешностей удобен еще тем, что максимальные относительные отклонения могут быть разделены на три группы: 1)
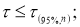
2)
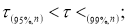
3)
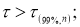
.
Наблюдения, попавшие в первую группу, нельзя отсеивать ни в коем случае. Наблюдения второй группы можно отсеять, если в пользу этой процедуры имеются еще и другие соображения экспериментатора (например, заключения, сделанные на основе изучения физических, химических и других свойств изучаемого явления). Наблюдения третьей группы, как правило, отсеивают всегда.
Рассмотрим далее пример с использованием средств программного пакета Excel, который позволяет снизить трудоемкость расчетов при осуществлении данной процедуры. К сожалению, в настоящее время средства Excel не позволяют автоматизировать расчеты по всем известным критериям отсеивания грубых погрешностей, поэтому проиллюстрируем рассмотренные методы с использованием доступных в Excel критериев Стьюдента.
Пример 1.
Имеется выборка из 100 шт. резисторов с номинальным сопротивлением
R
н
= (150,0 ± 5 %) кОм, которая используется для оценки качества партии резисторов (генеральная совокупность). Используя критерий Стьюдента, отсеем грубые погрешности (промахи) при измерениях.
- Заносим данные измерений в таблицу Excel в ячейки В2:В101
- Составляем вариационный ряд — располагаем данные в порядке возрастания с помощью функции «Сортировка по возрастанию» в ячейках С2:С101 (рис. 1)
Рис. 1. Фрагмент диалогового окна с данными измерений и вариационного ряда
3. Находим среднее значение выборки с помощью мастера функций в категории «Статистические» и функции — СРЗНАЧ, результат в ячейке Н3 (рис. 2).
Рис. 2. Фрагмент диалогового окна при нахождении среднего значения выборки
-
Находим среднеквадратическое отклонение —
S
x
. Выделяем ячейку Н4, вызываем «Мастер функций», категория «Статистические», функция — СТАНДОТКЛОН, результат в ячейке Н4–1,20 (рис. 3).
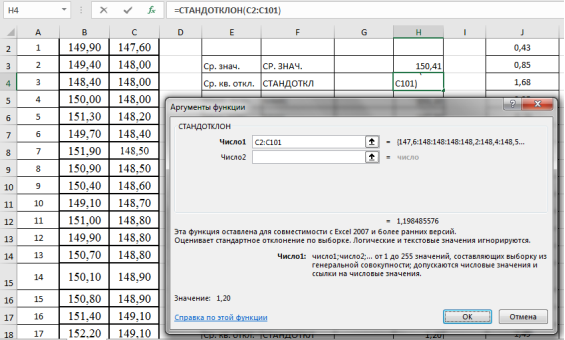
Рис. 3. Фрагмент диалогового окна при нахождении среднего квадратического отклонения
-
Находим максимальное значение в выборке —
x
макс
. Выделяем ячейку Н5, в категории «Статистические», функция — МАКС, выделяем мышкой вариационный ряд C2:С101, результат в ячейке Н5–153,10 (рис. 4).
Рис. 4. Фрагмент диалогового окна при нахождении максимального значения
-
Находим минимальное значение в выборке —
x
мин
. Выделяем ячейку Н6, в категории «Статистические», функция — МИН, выделяем мышкой вариационный ряд C2:С101, результат в ячейке Н6–147,6 (рис. 5).
Рис. 5. Фрагмент диалогового окна при нахождении минимального значения
-
Находим максимальное и минимальное отклонения — Δ
макс
и Δ
мин
. Вводим в ячейки Н7 и Н8 формулы:
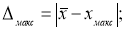
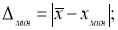
-
Находим теоретическое значение —
t
теор
. для максимального и минимального отклонений. Вводим в ячейки Н9 и Н12 формулу
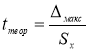
. и
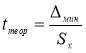
-
Находим табличное значение
t
табл.
Выделяем ячейку Н10, вызываем в категории «Статистические» функцию — СТЬЮДЕНТ.ОБР, «Вероятность» — 0,95, степени свободы (
n
-2) — 98, результат в ячейке Н10–1,66 (рис. 6).
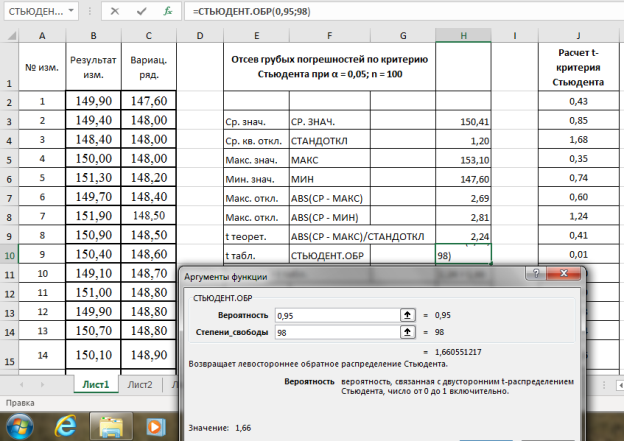
Рис. 6. Фрагмент диалогового окна при нахождении табличного значения критерия Стьюдента
-
Сравниваем теоретическое значение
t
теор
= 2,24 критерия Стьюдента для максимального значения — 153,1 кОм с табличным значением:
t
табл
.= 1,6605. - Аналогично п. 9 проверим на наличие грубой погрешности у минимального значения в выборке — 147,6 кОм. Результат в ячейке Н12–2,35 (рис. 7).
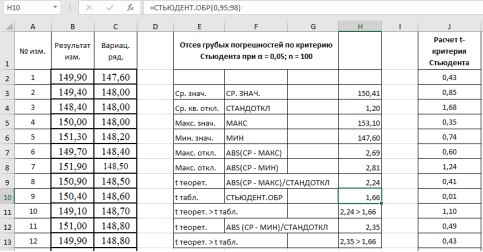
Рис. 7. Фрагмент диалогового окна при окончательном анализе данных
- Делаем вывод о наличии грубых ошибок в данных измерениях. Рассмотренная процедура подтвердила наши сомнения относительно достоверности максимального и минимального значений в данной выборке, т. е., указанные результаты могут быть отброшены из результатов измерений, и проверка может быть повторена снова без этих данных.
Пример расчета теоретического критерия Романовского по аналогичным формулам в Excel и диалоговое окно представлены на рис. 8, при условии α = 0,05, число измерений
n
= 20, β
табл
= 2,78 (из таблицы 2).

Рис. 8. Фрагмент диалогового окна при расчете критерия Романовского
Выводы
- Для использования различных критериев отбрасывания грубых погрешностей измерений необходимо учитывать требования действующих нормативных документов.
- Рассмотренный пример показал, что расчеты погрешностей по критерию Стьюдента с использованием таблиц и формул Excel значительно упрощаются, а процесс отбрасывания грубых погрешностей можно осуществить наиболее качественно и быстро.
Литература:
1. ГОСТ Р 8.736–2011 Государственная система обеспечения единства измерений. Измерения прямые многократные. Методы обработки результатов измерений. Основные положения. — М.: ФГУП Стандартинформ, 2013. — 24 с.
2. Пустыльник Е. И. Статистические методы анализа и обработки наблюдений. — М.: Наука, 1968. — 288 с.
3. Львовский Е. Н. Статистические методы построения эмпирических формул: Учеб. пособие. — М.: Высш. школа, 1982. — 224 с.
4. Фаюстов А. А. Ещё раз о критериях отсеивания грубых погрешностей. — Законодательная и прикладная метрология, 2016, № 5, с. 25–30.
5. Сергеев А. Г. Метрология: Учебник. — М.: Логос, 2005. — 272 с.
6. Большев Л. Н., Смирнов Н. В. Таблицы математической статистики. — М.: Наука, Главная редакция физико-математической литературы, 1983. — 416 с.
Основные термины (генерируются автоматически): диалоговое окно, сомнительное значение, уровень значимости, измеряемая величина, погрешность, критерий, нормальное распределение, ячейка, вариационный ряд, минимальное значение.
Обновлено: 21.09.2023
В начале главы уже было отмечено, что грубыми называют погрешности, явно превышающие по своему значению погрешности, оправданные условиями проведения эксперимента. Для их устранения желательно еще перед измерениями определить значение искомой величины приближенно, с тем чтобы в дальнейшем можно было сконцентрировать внимание лишь на уточнении предварительных данных. Если оператор в процессе измерений обнаруживает, что результат одного из наблюдений резко отличается от других, и находит причины этого, то он, конечно, вправе отбросить этот результат и провести повторные измерения. Но необдуманное отбрасывание резко отличающихся от других результатов может привести к существенному искажению характеристик рассеивания ряда измерений, поэтому повторные измерения лучше проводить не взамен сомнительных, а в дополнение к ним.
Особенно остро ставится вопрос об устранении грубых погрешностей при обработке уже имеющегося материала, когда невозможно учесть все обстоятельства, при которых проводили измерения. В этом случае приходится прибегать к чисто статистическим методам.
Вопрос о том, содержит ли данный результат наблюдений грубую погрешность, решается общими методами проверки статистических гипотез.
Проверяемая гипотеза состоит в утверждении, что результат наблюдения не содержит грубой погрешности, т.е. является одним из значений случайной величины Х с законом распределения , статистические оценки параметров которого предварительно определены. Сомнительным может быть в первую очередь лишь наибольший или наименьший из результатов наблюдений. Поэтому для проверки гипотезы следует воспользоваться распределениями величин
Функции их распределения определяют методами теории вероятностей [3]. Они совпадают между собой и для нормального распределения результатов наблюдений протабулированы и представлены в табл.П.7 приложения. По данным этой таблицы, при заданной доверительной вероятности или уровне значимости можно для количества измерения найти те наибольшие значения , которые случайная величина может еще принять по чисто случайным причинам.
Если вычисленное по опытным данным значение окажется меньше , то гипотеза принимается; в противном случае ее следует отвергнуть как противоречащую данным наблюдений. Тогда результат или соответственно приходится рассматривать как содержащий грубую погрешность и не принимать его во внимание при дальнейшей обработке результатов наблюдений.
Грубая погрешность, или промах, – это погрешность результата отдельного измерения, входящего в ряд измерений, которая для данных условий резко отличается от остальных результатов этого ряда. При однократных измерениях обнаружить промах невозможно. При многократных измерениях для обнаружения промахов используют статистические критерии, такие как критерий Романовского, критерий Шарлье, критерий Диксона.
Критерий Романовского
Критерий Романовского применяется, если число измерений n
где – проверяемое значение, – среднее арифметическое значение измеряемой величины, Sx – среднее квадратическое отклонение.
Далее расчетное значение bсравнивается с критерием bт, выбранным по табл. 10. Если b³bт, то результат xi считается промахом и отбрасывается.
Таблица № 10
Значения критерия Романовского b = f(n)
Пример решения
При шестикратном измерении расстояний между ориентирами осей здания получены следующие результаты: 25.155; 25,150; 25.165; 25.165; 25.160; 25.180 м. Последний результат вызывает сомнения. Производим проверку по критерию Романовского, не является ли он промахом.
Найдем среднее арифметическое значение
Определяем среднее квадратическое отклонение. Для удобства вычислений составим табл. 11.
Таблица № 11
Обработка результатов измерений
Вычисляем b для сомнительного результата
Критическое значение b при уровне значимости 0,05 и n = 6 составляет 2,1. Поскольку 1,58 20). Пользуясь данным критерием, отбрасывается результат, для значения которого выполняется неравенство
Пример решения
При измерении расстояний между колоннами были получены следующие результаты (см. табл. 12).
Таблица № 12
Обработка результатов измерений
Проверяем сомнительный результат измерения – 23,66. Для этого значения не выполняется неравенство ,
где Кш = 2,13 (см. табл. 13)
Таблица № 13
Значения критерия Шарлье
Таким образом, проверяемое значение 23,66 не является промахом и не отбрасывается.
Критерий Диксона
Практическое занятие №2
Пример.
Определить систематические погрешности и записать результат с учетом различных параметров.
Получен результат измерения длины стальной фермы xi = 24003 мм. Измерение выполнялось 3-метровой рулеткой из нержавеющей стали при t = -20 °С. При этом a1 = 20,5·10 -6 , a2 = 12,5·10 -6 , t1 = t2 = -20°С, = 3000 мм, = 3002 мм, h = 35 мм, P = 9 Н, Q = 1,2 Н.
Решение
1. Поправка на температуру окружающей среды
Действительную длину xi фермы с учетом поправки на температуру окружающей среды принимаем равной
= 24003 + 7,7 = 24010,7 мм.
2. Поправка на относительную скорость внешней среды
Действительную длину xi фермы с учетом поправки на относительную скорость внешней среды принимаем равной
= 24003 + 2,22 = 24002,22 мм.
3. Поправка на длину шкалы средства измерения
Действительную длину xi фермы с учетом поправки на длину шкалы средства измерения принимаем равной
= 24003 + 16,002 = 24019,002 мм.
4. Поправка на несовпадение направлений линии измерения и измеряемого размера
Действительную длину xi фермы с учетом поправки несовпадение направлений линии измерения и измеряемого размера принимаем равной
= 24003 + 0,025 = 24003,025 мм.
Действительную длину xi фермы с учетом всех поправок принимаем равной
= 24003 + 7,7 + 2,22 + 16,002 + 0,025 = 24028,9 мм.
Задание
Определить систематические погрешности и записать результат с учетом различных параметров.
Данные результатов измерений приведены в таблице №16
Таблица № 16
Задача 3
А) ПРЕДВАРИТЕЛЬНАЯ ОЦЕНКА ВИДА РАСПРЕДЕЛЕНИЯ РЕЗУЛЬТАТОВ ИЗМЕРЕНИЯ
Для предварительной оценки вида распределения по полученным данным строят гистограмму распределений или полигон распределения. В начале производится группирование – разделение данных от наименьшего xmin до наибольшего xmax на r интервалов. Для количества измерений от 30 до 100 рекомендуемое число интервалов – от 7 до 9. Ширину интервала выбирают постоянной для всего ряда данных, при этом следует иметь в виду, что ширина интервала должна быть больше погрешности округления при записи данных. Ширину интервала вычисляют по формуле
Вычисленное значение h обычно округляют. Например при h = 0,0187 это значение округляют до h = 0,02. Установив границы интервалов, подсчитывают число результатов измерений, попавших в каждый интервал. При построении гистограммы или полигона распределения масштаб этих графиков рекомендуется выбирать так, чтобы высота графика относилась к его основанию примерно как 3 к 5.
Пример
Построить гистограмму и полигон распределения по полученным экспериментальным данным, приведенным в табл. 17.
Таблица № 17
Результаты измерений
Определяем ширину интервала
Строим гистограмму распределений (рис. 1), подсчитав число экспериментальных данных, попавших в каждый интервал.
Рис.1. Гистограмма распределений результатов измерений
Далее, строим полигон распределения (рис. 2), который представляет собой кусочно-линейную аппроксимацию искомой функции плотности распределения результатов измерения.
Рис. 2. Полигон распределения результатов измерения
Б) ПРОВЕРКА ГИПОТЕЗЫ О НОРМАЛЬНОМ РАСПРЕДЕЛЕНИИ РЕЗУЛЬТАТОВ ИЗМЕРЕНИЙ
Нормальный закон распределения, называемый часто распределением Гаусса описывается зависимостью
где σ – параметр рассеивания распределения, равный среднему квадратическому отклонению.
Широкое использование нормального распределения на практике объясняется теоремой теории вероятностей, утверждающей, что распределение случайных погрешностей будет близко к нормальному всякий раз, когда результаты наблюдений формируются под действием большого числа независимо действующих факторов, каждый из которых оказывает лишь незначительное действие по сравнению с суммарным действием всех остальных.
При количестве измерений n * – смещенное СКО;
Гипотеза о нормальности подтверждается, если
где процентные точки распределения значений d, которые находятся по табл. 18.
Таблица № 18
Значения процентных точек q для распределения d
Критерий 2. Гипотеза о нормальности распределения результатов измерения подтверждается, если не более m разностей превзошли значения S×zp/2. Здесь zp/2 – верхняя 100 ∙ P/2 – процентная точка нормированной функции Лапласа
Значения доверительной вероятности P выбирают из табл. 19.
Таблица № 19
Значения доверительной вероятности Р
Пример
В табл. 19 приведены результаты измерения угла одним оператором, одним и тем же теодолитом, в одних и тех же условиях. Проверить, можно ли считать, что приведенные в табл. 20 данные принадлежат совокупности, распределенной нормально.
Таблица № 20
Результаты исследований
Оценка измеряемой величины равна
Средние квадратические отклонения S и S * найдем по формулам:
Оценка параметра d составит
Уровень значимости критерия 1 примем q = 2%. Из табл. 18 находим d1% = = 0,92 и d99% = 0,68. При определении d1% и d99% использовалась линейная интерполяция ввиду того, что значение n = 14 в таблице отсутствует. Критерий 1 выполняется, так как В нашем случае это – 0,68 2 м — радиус платформы;
r = (10,00 ± 0,05) 10 2 м — радиус верхнего диска подвеса;
l = (233,0 ± 0,2) 10 2 м — длина нитей подвеса;
m = (125,7 ±0,1) 10 3 кг — масса платформы;
T= (2,81 ± 0,01) с — период малых колебаний платформы;
g = 9,81 м с г — ускорение свободного падения;
Результаты приведены со средними квадратичными отклонениями.
Решение.
Подставляя в исходную формулу средние арифметические значения измеряемых прямыми способами величин и округленные значения постоянных, получим оценку истинного значения моментов инерции платформы.
так как результат должен быть округлен до трех значащих цифр.
Для оценки точности полученного результата вычислим частные производные и частные погрешности косвенных измерений:
Таким образом, среднее квадратичное отклонение косвенного измерения момента инерции платформы составит
Окончательно результат косвенного измерения записывается в виде I=(1,22 ±·0,01) 10 3 кг м 2 .
Задание
Определить предельное усилие при растяжении полос при сварке в стык по длинной полосе, по данным приведенным в таблице № 26
Таблица № 26
Продолжение таблица № 26
Практическое занятие №6
Пример
Определить в каком интервале находится измеренное значение, если при выполнении измерения прибором, имеющим на щитке обозначение , и полученный результат равен 200.
Решение
Определяем абсолютную погрешность измерения
И измеряемое значение будет находиться в интервале 200±1
Задание
Практическое занятие №7
ВЫБОР СРЕДСТВ ИЗМЕРЕНИЙ.
Расчет погрешности при выборе методов и средств измерения выполняют в соответствии с требованиями ГОСТ 26433.0-85.
Методы и средства измерений принимаем в соответствии с характером объекта и измеряемых параметров из условия.
где — расчетная суммарная погрешность принимаемого метода и средства измерения;
— предельная погрешность измерения.
Вычисляем расчетную погрешность измерения по одной из формул:
где — случайные составляющие погрешности;
— систематические составляющие погрешности;
— средние квадратические случайные составляющие погрешности;
— средние квадратические систематические составляющие погрешности;
— число случайных составляющих погрешностей;
— число систематических составляющих погрешностей;
— коэффициенты, учитывающие характер зависимости между суммарной и каждой из составляющих погрешностей измерения.
При расчете по указанным формулам принимаем, что составляющие погрешности независимы между собой или слабо коррелированны.
Предельную погрешность определяем из условия
где — допуск измеряемого геометрического параметра, установленный нормативно-технической документацией на объект измерения;
К — коэффициент, зависящий от цели измерений и характера объекта.
Для измерений, выполняемых в процессе и при контроле точности изготовления и установки элементов, а также при контроле точности разбивочных работ принимаем К = 0,2.
Для измерений, выполняемых в процессе производства разбивочных работ, К = 0,4.
Действительная погрешность выполненных измерений не должна превышать ее предельного значения.
Для случаев, когда процесс измерения состоит из большого числа отдельных операций, на основе принципа равных влияний определяем среднее значение составляющих погрешностей по формуле
где — число случайных составляющих погрешностей;
— число систематических составляющих погрешностей.
Выделяем те составляющие погрешности, которые легко могут быть уменьшены, увеличивая соответственно значения тех составляющих погрешностей, которые трудно обеспечить имеющимися методами и средствами.
Проверяем соблюдение условия (1) и в случае несоблюдения этого условия назначают более точные средства или принимают другой метод измерения.
Пример
Выбрать средство измерения для контроля длины изделия,
L = 3600 ± 2,0 мм ( = 4 мм, ГОСТ 21779-82).
Решение
1. Определяем предельную погрешность измерения
2. Для выполнения измерений применяем, например, 10-метровую металлическую рулетку 3-го класса точности ЗПК3-10АУТ/10 ГОСТ 7502-80.
3. В суммарную погрешность измерения длины изделия рулеткой входят составляющие погрешности: — поверки рулетки; — от погрешности измерения температуры окружающей среды; — от колебания силы натяжения рулетки; — снятия отсчетов по шкале рулетки на левом и правом краях изделия.
Определяем значения этих погрешностей.
3.1. Погрешность поверки рулетки в соответствии с ГОСТ 8.301-78 принимаем равной 0,2 мм.
3.2. Погрешность от изменения температуры окружающей среды термометром с ценой деления 1 °С (погрешность измерения равна 0,5 °С) составляет
3.3. Погрешность от колебания силы натяжения рулетки составляет
где = 10Н — погрешность натяжения рулетки вручную;
F = 2 мм 2 — площадь поперечного сечения рулетки;
E = 2·10 5 Н/мм — модуль упругости материала рулетки.
3.4. Экспериментально установлено, что погрешность снятия отсчета по шкале рулетки не превышает 0,3 мм, при этом погрешность снятия отсчетов на левом и правом краях изделия составит
4. Определяем расчетную суммарную погрешность измерения по формуле (2), учитывая, что — систематическая погрешность, а , и — случайные:
5. Данные метод и средство измерения могут быть приняты для выполнения измерений, так как расчетная суммарная погрешность измерения = 0,5 мм меньше предельной = 0,8 мм, что соответствует требованию.
Задание
По выше описанному алгоритму произвести выбор средства измерения с учетом погрешности, используя данные в таблице №6
Практическое занятие №8
Пример.
Произвести предварительную оценку точности измерений рулеткой длины изделий при контроле точности их изготовления.
Решение
Измерение длины каждого изделия в процессе контроля будут выполняться при числе наблюдений m = 2.
Выполняем многократные наблюдения длины одного изделия при числе наблюдений М = 10. Для уменьшения влияния систематической погрешности первые пять наблюдений выполняем в одном направлении каждый раз со сдвигом шкалы рулетки на 70 — 90 мм, а вторые пять наблюдений — в другом направлении с тем же сдвигом шкалы.
Результаты наблюдений и последовательность их обработки приведены в табл. 8 (приведены результаты 10 наблюдений, т.е. М = 10).
1. Определяем среднее арифметическое из результатов измерений:
Принимаем = 3205,0 мм. с ошибкой округления а = -0,2 мм.; х0 — наименьший результат из всех наблюдений, х0 =3200 мм..
2. Контроль правильности вычислений:
3. Среднее квадратическое отклонение результата измерений находим по формуле
4. Действительная погрешность измерения будет составлять.
5. Предельную погрешность измерения находим по формуле
При допуске на длину 16.5 мм по 16 квалитету
6. Проверяем соблюдение условия
Действительная погрешность измерения не соответствует требуемой, должны быть приняты другие средства измерений или увеличено количество наблюдений т. Принимаем т = 5, тогда
Вероятность того, что истинное значение измеряемой величины лежит внутри некоторого интервала, называется доверительной вероятностью, или коэффициентом надежности,а сам интервал — доверительным интервалом.
Каждой доверительной вероятности соответствует свой доверительный интервал. В частности, доверительной вероятности 0,67 соответствует доверительный интервал от до . Однако это утверждение справедливо только при достаточно большом числе измерений (более 10), да и вероятность 0,67 не представляется достаточно надежной — примерно в каждой из трех серий измерений y может оказаться за пределами доверительного интервала. Для получения большей уверенности в том, что значение измеряемой величины лежат внутри доверительного интервала, обычно задаются доверительной вероятностью 0,95 — 0,99. Доверительный интервал для заданной доверительной вероятности с учетом влияния числа измерений n можно найти, умножив стандартное отклонение среднего арифметического

.
на так называемый коэффициент Стьюдента. Коэффициенты Стьюдента для ряда значений и n приведены в таблице.

Таблица — Коэффициенты Стьюдента
| Число измерений n | Доверительная вероятность y | ||
| 0,67 | 0,90 | 0,95 | 0,99 |
| 2,0 | 6,3 | 12,7 | 63,7 |
| 1,3 | 2,4 | 3,2 | 5,8 |
| 1,2 | 2,1 | 2,8 | 4,6 |
| 1,2 | 2,0 | 2,6 | 4,0 |
| 1,1 | 1,8 | 2,3 | 3,3 |
| 1,0 | 1,7 | 2,0 | 2,6 |
Окончательно, для измеряемой величины y при заданной доверительной вероятности y и числе измерений n получается условие


Величину мы будем называть случайной погрешностьювеличины y.
Пример: см. лекцию №5 – ряд чисел.

При числе измерений – 45 и доверительной вероятности – 0,95 получим, что коэффициент Стьюдента приблизительно равен 2,15. Тогда доверительный интервал для данного ряда измерений равен 62,6.
Промахи(грубая погрешность) — грубые погрешности, связанные с ошибками оператора или неучтенными внешними воздействиями. Их обычно исключают из результатов измерений. Промахи, как правило, вызываются невнимательностью. Они могут возникать также вследствие неисправности прибора.
Источником грубых погрешностей нередко бывают резкие изменения условий измерения и ошибки, допущенные оператором:
— неправильный отсчет по шкале измерительного прибора, происходящий из-за неверного учета цены малых делений шкалы;
— неправильная запись результата наблюдений, значений отдельных мер использованного набора, например, гирь;
— хаотические изменения параметров напряжения, питающего средства измерения, например, его амплитуды или частоты.
Методы обнаружения и исключения грубых погрешностей

Проверяемая гипотеза состоит в утверждении, что результат наблюдения не содержит грубой погрешности, т.е. является одним из значений измеряемой величины. Пользуясь определенными статистическими критериями, пытаются опровергнуть выдвинутую гипотезу. Если это удается, то результат наблюдений рассматривают как содержащий грубую погрешность и его исключают.
Для выявления грубых погрешностей задаются вероятностью q (уровнем значимости) того, что сомнительный результат действительномог иметь место в данной совокупности результатов измерений.Обычно проверяют наибольшее и наименьшее значения результатовизмерений. Для проверки гипотез используются следующие критерии:
По этому критерию считается, что результат маловероятен и его можно считать промахом, если:


где – среднее арифметическое отдельных результатов измерений:

где n – число измерений;
– результат i-го измерения;

– среднее квадратичное отклонение (СКО):

Величины и вычисляют без учета экстремальных (вызывающих подозрение) значений
Выявляют сомнительное значение измеряемой величины. Сомнительным значением может быть лишь наибольшее либо наименьшее значение наблюдения измеряемой величины.
Вычисляют среднее арифметическое значение выборки без учета сомнительного значения измеряемой величины:

Вычисляют разность среднеарифметического и сомнительного значения измеряемой величины и сравнивают с СКО.

Если , то сомнительное значение отбрасывают, как промах.

Если , то сомнительное значение оставляют как равноправное в ряду наблюдений.
В литературе приведены различные методы оценки и исключения грубых погрешностей. Рассмотрим два наиболее простых для практического использования метода.
Исключение грубых промахов по Q-критерию

При малых выборках с числом измерений п Q (, пi)
Исключение грубых погрешностей методом вычисления максимального относительного отклонения. Статистический критерий обнаружения грубых погрешностей основан на предположении, что выборка взята из генеральной совокупности, распределенной нормально. Это позволяет использовать распределение наибольшего по абсолютному значению нормированного отклонения:

(4.12)
где tт – теоретическое значение квантиля распределения статистики.
Для уровней значимости р = >>0,10; 0,05; 0,01 или доверительной вероятности 1 – р = 0,90; 0,95; 0,99 и п ? 25 значения tт приведены в табл. 4.2. Уровень значимости р = (1 – Р) – максимальная вероятность того, что погрешность превзойдет некое предельное (критическое) значение ±?xkj, т.е. такое значение, что появление этой погрешности можно рассматривать как следствие значимой (неслучайной) причины. На практике обычно используют уровень значимости р = 0,05 (результат получается с 95 %-й доверительной вероятностью).
Для того, чтобы в группе из п наблюдений х1 х2, . хп отбросить результат хmax (или хmin), надо:

а) вычислить дробь
б) по табл. 4.2 найти теоретическое значение tт в зависимости от п и выбранного уровня значимости р;
Значения квантилей распределения максимального отклонения,
Читайте также:
- Методы воспитания в коррекционной школе
- Школа россии музыка тематическое планирование
- Методы семейного воспитания кратко
- Школьный семинар на тему
- Экологические проблемы кировской области 4 класс кратко