Методы исключения грубых ошибок
При
получении результата измерения, резко
отличающегося
от всех других результатов, естественно
возникает
подозрение, что допущена грубая ошибка.
В этом случае
необходимо сразу же проверить, не
нарушены ли основные
условия измерения.
Если
же такая проверка не была сделана
вовремя, то
вопрос о целесообразности браковки
одного «выскакивающего»
значения решается путем сравнения его
с
остальными результатами измерения. При
этом применяются различные критерии,
в зависимости от того, известна или нет
средняя квадратическая ошибка, а
измерений
(предполагается, что все измерения
производятся с
одной и той же точностью и независимо
друг от друга).
Метод
исключения при известной
![]() .
.
Обозначим
«выскакивающее»
значение через х*,
а
все остальные результаты
измерения через
![]() ,
,
![]() ……….
……….
![]() .
.
Подсчитаем
среднее арифметическое значение
![]()
и
сравним абсолютную величину
разности
![]() с величиной
с величиной![]() .
.
Дляполученного
отношения
![]()
подсчитаем
вероятность 1—2Ф(t)
(Приложение табл.2.)
Это даст вероятность того, что
рассматриваемое
отношение случайно примет значение,
не
меньшее чем t,
при
условии, что значение х*
не
содержит
грубой ошибки (что ошибка результата
х* только случайна). Если подсчитанная
указанным образом вероятность
окажется очень малой, то «выскакивающее»
значение
содержит грубую ошибку и его следует
исключить из
дальнейшей обработки результатов
измерений.
Какую
именно вероятность считать очень малой,
зависит
от конкретных условий решаемой задачи:
если назначить
слишком низкий уровень малых вероятностей,
то
грубые ошибки могут остаться, если
же взять этот уровень
неоправданно большим, то можно
исключить результаты
со случайными ошибками, необходимые
для правильной
обработки результатов измерения.
Обычно применяют
один из трех уровней малых вероятностей:
5%
уровень (исключаются ошибки, вероятность
появления
которых меньше 0,05);
1
%
уровень
(исключаются ошибки, вероятность
появления
которых меньше 0,01);
0,1%
уровень
(исключаются ошибки, вероятность
появления
которых меньше 0,001).
При
выбранном уровне
![]() малых вероятностей «выскакивающее»
малых вероятностей «выскакивающее»
значение х*
считают
содержащим грубую ошибку,
если для соответствующего отношения t
вероятность
1—2Ф(t)<![]() .
.
Чтобы подчеркнуть вероятностный
характер этого заключения, говорят, что
значение
х*
содержит
грубую ошибку с надежностью вывода
Р=1—![]() .
.
Значение t
= t(Р),
для
которого 1—2Ф(t)
=![]()
и,
значит, 2Ф(t)
=Р, называется критическим
значением
отношения
t
при надежности Р. Так, если
![]()
= 0,01 (1%
уровень),
то Р = 0,99, критическое значение t
= tР)
= 2,576,
и как только отношение t
превзойдет
это критическое значение, мы можем
браковать
«выскакивающее» значение х*
с
надежностью вывода
0,99.
Пример.
Пусть
среди 41 результата независимых измерений,
произведенных
со средней квадратической ошибкой
![]() =0,133,
=0,133,
обнаружено
одно «выскакивающее» значение x*=6,866,
в то время как среднее
из остальных 40 результатов составляет
![]() =6,500.
=6,500.
Можно ли считать,
что «выскакивающее» значение содержит
грубую ошибку, и исключить
его из дальнейшей обработки?
Решение.
Разность между «выскакивающим» значением
и средним составляет
![]() = 0,366, поэтому отношениеt
= 0,366, поэтому отношениеt
равно
![]()
По
табл.2 для t=2,72
оцениваем вероятность 1— 2Ф (t)=
0,0066 < 0,007. Следовательно, с надежностью
вывода Р
> 0,993
можно
считать, что значение x*
содержит
грубую ошибку, и исключить
это значение из дальнейшей обработки
результатов измерения.
Подчеркнем,
что указанный прием применяется только
тогда,
когда величина
![]() средней квадратической ошибкиточно
средней квадратической ошибкиточно
известна заранее.
Метод
исключения при
неизвестной
![]() .
.
Если
величина
![]()
заранее
неизвестна, то она оценивается приближенно
по результатам измерений, т. е. вместо
нее применяют эмпирический стандарт:
![]()
(1)
При
этом абсолютную величину разности
![]() между
между
«выскакивающим» значением х*
и
средним значением
![]()
остальных
(приемлемых) результатов делят на
эмпирический
стандарт и полученное отношение(2)
сравнивают с критическими значениями
![]() (Приложение табл. 3).
(Приложение табл. 3).
![]() (2)
(2)
Если
при данном числе п
приемлемых
результатов отношение (2) оказывается
между двумя
критическими значениями при надежностях
![]()
и
![]() (
(
![]() >
>![]() ),
),
то с надежностью вывода, большей
![]()
можно считать,
что «выскакивающее» значение содержит
грубую ошибку, и исключить его из
дальнейшей обработки результатов.
Заметим,
что если надежность вывода окажется
недостаточной,
то это свидетельствует не об отсутствии
грубой ошибки,
а лишь об отсутствии достаточных
оснований для
исключения «выскакивающего» значения.
Пример.
Пусть для n
результатов независимых равноточных
измерений
некоторой величины среднее значение
равно
![]() = 6,500,а
= 6,500,а
эмпирический стандарт s
=
0,133, и пусть (n
+ 1)-е измерение дало результат
х* = 6,866. Можно ли исключить этот результат
из дальнейшей
обработки?
Решение.
Здесь отношение (2) равно t
= 0,366/0,133 = 2,75. Если
число приемлемых результатов n
= 40, то полученное отношение превосходит
критическое значение 2,742 при надежности
P
= 0,99 и
значение х*
можно
исключить с надежностью вывода, большей
0,99. Если
же число приемлемых результатов n
= 6, то полученное отношение
меньше критического значения 2,78 даже
при надежности P=0,95
и значение x*
исключать не следует.
Грубые ошибки
возникают вследствие нарушения основных
условий измерения или в результате
недосмотра экспериментатора. Внешним
признаком результата, содержащего
грубую ошибку, является его резкое
отличие по величине от результатов
остальных измерений.
Выбор метода
зависит от того, известна ли
среднеквадратическая ошибка измерений
σ
(съёмка данных на конкретном элементарном
объекте измерений проводится с помощью
одного и того же устройства и в одних и
тех же условиях, поэтому можно считать,
что все измерения проводятся с одной и
той же точностью и, кроме того, независимо
друг от друга).
При известной
среднеквадратической ошибке измерений
применяют следующий метод:
Для каждого
экспериментального значения X*
находят выражение
![]() ,
,
(3)
где
![]() — среднее арифметическое всех значений
— среднее арифметическое всех значений
(кроме
X*),
n
– количество этих значений;
Ф(t)
– функция, возвращаемый результат
которой определяется с помощью массива
значений или с помощью формулы
![]() ,
,
(4)
где
![]() t
t
> 0,
ф( — t
) = — ф( t),
(5)
Если α
< А, значит
с вероятностью (1-
α)*100% можно
утверждать, что X*
— грубая ошибка.
Принято выбирать
А
из 0.05, 0.01,
0.001 для
вероятностей 95,
99, 99.9%
соответственно.
Отличительной
чертой исключения грубых ошибок при
неизвестной σ
является её замена в формуле (1) эмпирическим
стандартом
 ,
,
(6)
где i
– номер любого значения, кроме номера
исследуемого значения X*
.
После удаления
грубых ошибок из набора значений, можно
найти интервал, в котором будет находиться
действительное значение.
Xд
= Xcp
± sigma,
где sigma
= σ,
если известно среднеквадратическое
отклонение, или
![]() ,
,
если σ
неизвестно.
Но полученный
интервал можно будет считать верным,
только в определённом случае.
Все
доверительные оценки, как средних
значений, так и дисперсий основаны на
гипотезе нормальности закона распределения
случайных ошибок измерения
и поэтому могут применяться лишь до тех
пор,
пока результаты эксперимента не
противоречат этой гипотезе.
Если
результаты эксперимента вызывают
сомнение в
нормальности закона распределения
случайных ошибок, то
для решения вопроса о пригодности или
непригодности
нормального закона распределения надо
произвести достаточно
большое число измерений и применить
один из
описанных ниже критериев.
Критерий
соответствия
![]() 2
2
(«хи-квадрат»).
Результаты
измерений (разумеется, свободные от
систематических
ошибок) группируют по интервалам таким
образом,
чтобы эти интервалы покрывали всю ось
(-![]() ,
,
+![]() )
)
и чтобы количество данных в каждом
интервале былодостаточно
большим (во всяком случае не менее пяти,
лучше
десяти). Для каждого интервала (![]() )
)
подсчитывают
число
![]()
результатов
измерения, попавших в
этот интервал. Затем вычисляют вероятность
![]() попадания
попадания
в этот интервал при нормальном законе
распределения
вероятностей:
![]() (7)
(7)
где
![]() — среднее арифметическое значение
— среднее арифметическое значение
результатовизмерения,
s—эмпирический
стандарт (средняя квадратическая
ошибка), Ф — интеграл вероятностей,
представленный
таблицами 1 и 2(см. приложение).
Затем, вычисляют сумму
![]() (8)
(8)
где
L — число всех интервалов число всех
результатов измерений (-![]() ,
,![]() ),
),
(![]() ),…,(
),…,(![]() ),
),
n — число всех результатов измерений
(![]() ).
).
Если
сумма (8) окажется больше критического
значения
![]() по табл. 4 принекоторой
по табл. 4 принекоторой
доверительной вероятности P
и
числе степеней
свободы k
= L-3,
то
с надежностью P
можно
считать, что распределение вероятностей
случайных ошибок в
рассматриваемой серии измерений
отличается от нормального.
В противном случае для такого вывода
нет достаточных оснований.
При
отсутствии достаточных оснований для
того, чтобы отвергнуть
гипотезу о нормальном распределении
случайных
ошибок измерения, эта гипотеза
принимается, так как в обычных ситуациях
эта гипотеза часто может быть обоснована
теоретически. Однако следует иметь в
виду, что даже малая величина суммы (8)
не может служить доказательством
нормальности закона распределения.
Отметим
еще важное свойство критерия
![]() :
:
если
распределение
отлично от нормального, то при достаточно
большом числе измерений сумма (8) превысит
соответствующее
критическое значение
![]() .
.
Поэтому,
если при произведенном числе измерений
критерий
![]()
дал малую надежность,
но сомнение в нормальности распределения
осталось,
то следует увеличить число измерений
(в несколько
раз!).
Указанное
выше число степеней свободы k
= L-3
относится только к тому случаю, когда
оба параметра нормального закона
распределения определяются по результатам
измерений, т.е. когда вместо точных
значений а
и
![]() применяются
применяются
их эмпирические значения
![]()
и
s.
Если
значение а
точно
известно (например, при измерении
эталона), то число степеней свободы
равно k
= L-2,
если известны оба параметра а
и
![]() ,
,
то число степеней свободы равно k
= L-1.
На практике такая ситуация встречается
редко, и поэтому для получения числа
степеней свободы не менее пяти надо
брать число интервалов не менее
восьми.
В
заключение заметим, что эффективность
критерия
![]() повышается,
повышается,
если в каждый из выделенных интервалов
попадает примерно одинаковое количество
данных. Это следует
учитывать при группировке первичного
материала (если
возможно).
Пример.
Приведем пример расчета вероятностей
для применения
критерия
![]() .Возьмем
.Возьмем
интервальный ряд данных, значения
параметров нормального распределения
для которого были посчитаны:
![]() =8,63,
=8,63,
s
= 0,127. Для применения критерия
![]() 2
2
объединим крайние интервалы,
чтобы число данных в каждом интервале
стало не менее пяти.
Полученные данные представлены в первых
двух столбцах табл. 1. Крайние интервалы
взяты бесконечными. В третьем столбце
подсчитаны отношения
![]()
для
правых концов интервалов, например,
![]() = (8,425-8,63)/0,127 =-1,614.
= (8,425-8,63)/0,127 =-1,614.
В четвертом столбце приведены
соответствующие значения интеграла
вероятностей Ф (![]() )(Приложение
)(Приложение
табл. 1). При
этом произведена линейная интерполяция.
По значениям
Ф (![]() )-в
)-в
пятом столбце вычислены вероятности![]() —
—
как разностисоответствующих
значений Ф (t):
![]()
например,
р2
= -0,3888 — (-0,4467) = 0,0579. При вычислении
вероятности
![]() учтено, что Ф(-
учтено, что Ф(-![]() )
)
= -0,5. Последние столбцы таблицы
не нуждаются в пояснении. Сумма чисел
последнего столбца дает
нужное значение
![]() 2
2
=2,528. Сравнение этого значения с
критическими
значениями при числе степеней свободы
k
=10-3
= 7 показывает, что нет оснований
сомневаться в нормальности распределения
(основания для подобного сомнения могли
бы возникнуть, если
бы вычисленное значение
![]() 2
2
было бы по крайней мере раз в
5—6 больше).
Таблица
1
|
Интервалы |
|
|
|
|
|
|
|
|
||||||
|
(-
(8,425;
(8,475;
(8,525;
(8,575;
(8,625;
(8,675;
(8,725;
(8,775;
(8,825; |
7 5 8 10 18 17 12 9 7 7 |
-1,614 -1,220 -0,827 -0,433 -0,039 0,354 0,748 1,142 1,536
+ |
-0,4467 -0,3888 -0,2959 -0,1676 -0,0156 0,1383 0,2728 0,3733 0,4377 0,5000 |
0,0533 0,0579 0,0929 0,1283 0,1520 0,1539 0,1345 0,1005 0,0644 0,0623 |
1,67 -0,79 -1,29 -2,83 2,80 1,61 -1,45 -1,05 0,56 0,77 |
0,523 0,108 0,179 0,624 0,516 0,168 0,157 0,110 0,048 0,095 |
|
Суммы |
100=n |
— |
— |
1,0000 |
— |
2,528= |
Для
этого определяется критерий соответствия
χ2, который должен быть достаточно мал.
В этом случае с определённой достоверностью
можно будет говорить о нормальности
распределения набора значений, а как
следствие этого – право с определённой
вероятностью утверждать, что полученный
интервал верен.
Результаты
измерений, освобождённые от грубых
ошибок, группируют по интервалам таким
образом, чтобы они покрыли всю ось и
чтобы количество данных в каждом
интервале было достаточно большим.
Для
каждого интервала подсчитывают число
результатов измерения mi , попавших в
этот интервал.
Затем
вычисляется вероятность pi попадания в
этот интервал при нормальном законе
распределения вероятностей
![]() ,
,
где
Xi – правая граница i-го интервала.
Необходимо заметить,
что для первого интервала
![]() ,
,
Для последнего
интервала
![]()
В
качестве проверки правильности расчёта
значений pi можно использовать равенство
![]() .
.
Непосредственно
χ2 находится по формуле:
![]() ,
,
где
l – количество интервалов.
Если
полученное значение χ2 окажется больше
критического значения χ2кр
, при некоторой доверительной вероятности
Р и числе степеней свободы k = l – 3, то с
надёжностью Р можно считать, что
распределение вероятностей случайных
ошибок в рассматриваемой серии измерений
отличается от нормального. В противном
случае для такого вывода нет достаточных
оснований.
При
отсутствии достаточных оснований для
того, чтобы отвергнуть гипотезу о
нормальном распределении случайных
ошибок измерения, эта гипотеза
принимается, а следовательно интервал
Xд = Xcp ± sigma можно считать верным.
Разработанная автоматизированная
система позволяет оперативно проводить
оценку грубых ошибок эксперимента и
достоверность нормального распределения
результатов. Ввод данных осуществляется
автоматически с устройства либо из
предварительно подготовленного файла
данных.

Рис.1. Пример работы
автоматизированной системы оценки
статистических данных
В статье рассмотрены различные критерии отбрасывания грубых погрешностей измерений, применяемые в практической деятельности, на основе рекомендаций ведущих специалистов-метрологов, а также с учетом действующих в настоящий момент нормативных документов.
Приведен пример использования Excel при оценке грубых погрешностей по критериям Стьюдента и Романовского при обработке реальных результатов измерений.
Ключевые слова:
грубые погрешности, критерии согласия, сомнительные значения, уровень значимости, нормальное распределение, критерий согласия Стьюдента, критерий Романовского, выборка, отклонения, Excel.
Одним из важнейших условий правильного применения статистических оценок является отсутствие грубых ошибок при наблюдениях. Поэтому все грубые ошибки должны быть выявлены и исключены из рассмотрения в самом начале обработки наблюдений.
Единственным достаточно надежным способом выявления грубых ошибок является тщательный анализ условий самих испытаний. При этом наблюдения, проводившиеся в нарушенных условиях, должны отбрасываться, независимо от их результата. Например, если при проведении эксперимента, связанного с электричеством, в лаборатории на некоторое время был выключен ток, то весь эксперимент обязательно нужно проводить заново, хотя результат, быть может, не сильно отличается от предыдущих измерений. Точно так же отбрасываются результаты измерений на фотопластинках с поврежденной эмульсией и вообще на любых образцах с обнаруженным позднее дефектом.
На практике, однако, не всегда удается провести подобный анализ условий испытания. Чаще всего приходится иметь дело с окончательным цифровым материалом, в котором отдельные данные вызывают сомнение лишь своим значительным отклонением от остальных. При этом сама «значительность» отклонения во многом субъективна — зачастую приходится сталкиваться со случаями, когда исследователь отбрасывает наблюдения, которые ему не понравились, как ошибочные исключительно по той причине, что они нарушают уже созданную им в воображении картину изучаемого процесса.
Строгий научный анализ готового ряда наблюдений может быть проведен лишь статистическим путем, причем должен быть достаточно хорошо известен характер распределения наблюдаемой случайной величины. В большинстве случаев исследователи исходят из нормального распределения. Каждая грубая ошибка будет соответствовать нарушению этого распределения, изменению его параметров, иными словами, нарушится однородность испытаний (или, как говорят
,
однородность наблюдений), поэтому выявление грубых ошибок можно трактовать как проверку однородности наблюдений.
Промахи, или грубые погрешности, возникают при единичном измерении и обычно устраняются путем повторных измерений. Причиной их возникновения могут быть:
- Объективная реальность (наш реальный мир отличается от идеальной модели мира, которую мы принимаем в данной измерительной задаче);
- Внезапные кратковременные изменения условий измерения (могут быть вызваны неисправностью аппаратуры или источников питания);
- Ошибка оператора (неправильное снятие показаний, неправильная запись и т. п.).
В третьем случае, если оператор в процессе измерения обнаружит промах, он вправе отбросить этот результат и провести повторные измерения.
В настоящее время определение грубой погрешности приведено в ГОСТ Р 8.736–2011: «Грубая погрешность измерения: Погрешность измерения, существенно превышающая зависящие от объективных условий измерений значения систематической и случайной погрешностей» [1, с. 6].
Общие подходы к методам отсеивания грубых погрешностей, как это уже давно принято в практике измерений, заключаются в следующем.
Задаются вероятностью
Р
или уровнем значимости
α
(
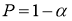
) того, что результат наблюдения содержит промах. Выявление сомнительного результата осуществляют с помощью специальных критериев. Операция отбрасывания удаленных от центра выборки сомнительных значений измеряемой величины называется «цензурированием выборки».
Проверяемая гипотеза состоит в утверждении, что результат наблюдения
x
i
не содержит грубой погрешности, т. е. является одним из значений случайной величины
x
с законом распределения Fx(x), статистические оценки параметров которого предварительно определены. Сомнительным может быть в первую очередь лишь наибольший x
max
или наименьший xmin из результатов наблюдений.
Предложим для практического использования наиболее простые методы отсева грубых погрешностей.
Если в распоряжении экспериментатора имеется выборка небольшого объема
n
≤ 25, то можно воспользоваться методом вычисления максимального относительного отклонения [2, с. 149]:
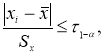
(1)
где
x
i
— крайний (наибольший или наименьший) элемент выборки, по которой подсчитывались оценки среднего значения
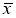
и среднеквадратичного отклонения
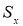
;
τ
1-
p
— табличное значение статистики
τ
, вычисленной при доверительной вероятности
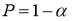
.
Таким образом, для выделения аномального значения вычисляют значение статистики,
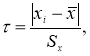
(2)
которое затем сравнивают с табличным значением
τ
1-α
:
τ
≤
τ
1-α
. Если неравенство
τ
≤
τ
1-α
соблюдается, то наблюдение не отсеивают, если не соблюдается, то наблюдение исключают. После исключения того или иного наблюдения или нескольких наблюдений характеристики эмпирического распределения должны быть пересчитаны по данным сокращенной выборки.
Квантили распределения статистики
τ
при уровнях значимости
α
= 0,10; 0,05; 0,025 и 0,01 или доверительной вероятности
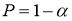
=
0,90; 0,95; 0,975 и 0,99 приведены в таблице 1. На практике очень часто используют уровень значимости
α
= 0,05 (результат получается с 95 %-й доверительной вероятностью).
Функции распределения статистики
τ
определяют методами теории вероятностей. По данным таблицы, приведенной в источниках [2, с. 283; 3, с. 184] при заданной доверительной вероятности
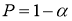
или уровне значимости
α
можно для чисел измерения п = 3–25 найти те наибольшие значения
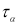
которые случайная величина
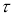
может еще принять по чисто случайным причинам.
Процедуру отсева можно повторить и для следующего по абсолютной величине максимального относительного отклонения, но предварительно необходимо пересчитать оценки среднего значения
и среднеквадратичного отклонения
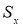
для выборки нового объема
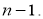
Таблица 1
Квантили распределения максимального относительного отклонения при отсеве грубых погрешностей [2, с. 283]
|
|
Уровень значимости |
|
Уровень значимости |
||||||
|
0,10 |
0,05 |
0,025 |
0,01 |
0,10 |
0,05 |
0,025 |
0,01 |
||
|
3 |
1,41 |
1,41 |
1,41 |
1,41 |
15 |
2,33 |
2,49 |
2,64 |
2,80 |
|
4 |
1,65 |
1,69 |
1,71 |
1,72 |
16 |
2,35 |
2,52 |
2,67 |
2,84 |
|
5 |
1,79 |
1,87 |
1,92 |
1,96 |
17 |
2,38 |
2,55 |
2,70 |
2,87 |
|
6 |
1,89 |
2,00 |
2,07 |
2,13 |
18 |
2,40 |
2,58 |
2,73 |
2,90 |
|
7 |
1,97 |
2,09 |
2,18 |
2,27 |
19 |
2,43 |
2,60 |
2,75 |
2,93 |
|
8 |
2,04 |
2,17 |
2,27 |
2,37 |
20 |
2,45 |
2,62 |
2,78 |
2,96 |
|
9 |
2,10 |
2,24 |
2,35 |
2,46 |
21 |
2,47 |
2,64 |
2,80 |
2,98 |
|
10 |
2,15 |
2,29 |
2,41 |
2,54 |
22 |
2,49 |
2,66 |
2,82 |
3,01 |
|
11 |
2,19 |
2,34 |
2,47 |
2,61 |
23 |
2,50 |
2,68 |
2,84 |
3,03 |
|
12 |
2,23 |
2,39 |
2,52 |
2,66 |
24 |
2,52 |
2,70 |
2,86 |
3,05 |
|
13 |
2,26 |
2,43 |
2,56 |
2,71 |
25 |
2,54 |
2,72 |
2,88 |
3,07 |
|
14 |
2,30 |
2,46 |
2,60 |
2,76 |
|||||
В литературе можно встретить большое количество методических рекомендаций для проведения отсева грубых погрешностей измерений, подробно рассмотренных в [4, с. 25]. Обратим внимание на некоторые из существующих критериев отсеивания грубых погрешностей.
-
Критерий «трех сигм» применяется для случая, когда измеряемая величина
x
распределена по нормальному закону. По этому критерию считается, что с вероятностью
Р
= 0,9973 и значимостью
α
= 0,0027 появление даже одной случайной погрешности, большей, чем
маловероятное событие и ее можно считать промахом, если

−
x
i
> 3
S
x
, где
S
x
—
оценка среднеквадратического отклонения (СКО) измерений. Величиныи
S
x
вычисляют без учета экстремальных значений
x
i
. Данный критерий надежен при числе измерений
n
≥ 20…50 и поэтому он широко применяется. Это правило обычно считается слишком жестким, поэтому рекомендуется назначать границу цензурирования в зависимости от объема выборки: при
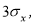
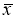
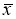
6 <
n
≤100 она равна 4
S
x
; при 100 <
n
≤1000 − 4,5
S
x
; при 1000 <
n
≤10000–5
Sx
. Данное правило также используется только при нормальном распределении.
Практические вычисления проводят следующим образом [5, с. 65]:
- Выявляют сомнительное значение измеряемой величины. Сомнительным значением может быть лишь наибольшее, либо наименьшее значение наблюдения измеряемой величины.
-
Вычисляют среднее арифметическое значение выборки

без учета сомнительного значения

измеряемой величины.
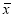
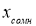
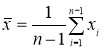
(3)
-
Вычисляют оценку СКО выборки

без учета сомнительного значения
измеряемой величины.
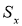
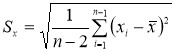
(4)
- Вычисляют разность среднеарифметического и сомнительного значения измеряемой величины и сравнивают.
Если
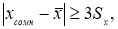
то сомнительное значение отбрасывают, как промах.
Если
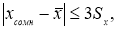
то сомнительное значение оставляют как равноправное в ряду наблюдений.
Данный метод «трех сигм» среди метрологов-практиков является самым популярным, достаточно надежным и удобным, так как при этом иметь под рукой какие-то таблицы нет необходимости.
-
Критерий В. И. Романовского применяется, если число измерений невелико,
n
≤ 20. При этом вычисляется соотношение
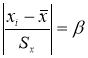
(5)
где
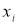
— результат, вызывающий сомнение,
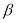
— коэффициент, предельное значение которого
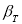
определяют по таблице 2. Если
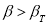
, сомнительное значение
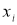
исключают («отбрасывают») как промах. Если

,
сомнительное значение оставляют как равноправное в ряду наблюдений [5, с. 65].
Таблица 2
Значение критерия Романовского
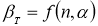
|
Уровень значимости, |
Число измерений, |
||||||
|
|
|
|
|
|
|
|
|
|
0,01 |
1,73 |
2,16 |
2,43 |
2,62 |
2,75 |
2,90 |
3,08 |
|
0,02 |
1,72 |
2,13 |
2,37 |
2,54 |
2,66 |
2,80 |
2,96 |
|
0,05 |
1,71 |
2,10 |
2,27 |
2,41 |
2,52 |
2,64 |
2,78 |
|
0,10 |
1,69 |
2,00 |
2,17 |
2,29 |
2,39 |
2,49 |
2,62 |
Несмотря на многообразие существующих и применяемых на практике методов отсеивания грубых погрешностей в настоящее время действует национальный стандарт ГОСТ Р 8.736–2011, который является основным нормативным документом в данной области. В новом стандарте для исключения грубых погрешностей применяется критерий Граббса.
- Статистический критерий Граббса (Смирнова) исключения грубых погрешностей основан на предположении о том, что группа результатов измерений принадлежит нормальному распределению [1, с. 8]. Для этого вычисляют критерии Граббса (Смирнова) G1 и G2, предполагая, что наибольший хmax или наименьший xmin результат измерений вызван грубыми погрешностями.
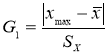
и
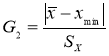
(6)
Сравнивают G1 и G2 с теоретическим значением GT критерия Граббса (Смирнова) при выбранном уровне значимости α. Таблица критических значений критерия Граббса (Смирнова) приведена в приложении к стандарту [1, с. 12]. Следует отметить, что критические значения критерия Граббса (Смирнова) GT отличаются от критических значений критериев
t
-статистик или значений критериев Стьюдента при одних и тех же величинах уровней значимости, что может вызывать некоторые трудности у пользователей при выборе конкретного метода отсеивания погрешностей, соответствующего нормативным документам.
Если G1>GТ, то хmax исключают как маловероятное значение. Если G2>GТ, то xmin исключают как маловероятное значение. Далее вновь вычисляют среднее арифметическое и среднее квадратическое отклонение ряда результатов измерений и процедуру проверки наличия грубых погрешностей повторяют.
Если G1
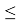
GТ, то хmax не считают промахом и его сохраняют в ряду результатов измерений. Если G2
GТ, то xmin не считают промахом и его сохраняют в ряду результатов измерений.
Отсев грубых погрешностей можно производить и для больших выборок (
n
= 50…100). Для практических целей лучше всего использовать таблицы распределения Стьюдента. Этот метод исключения аномальных значений для выборок большого объема отличается простотой, а таблицы распределения Стьюдента имеются практически в любой книге по математической статистике, кроме того, распределение Стьюдента реализовано в пакете Excel. Распределение Стьюдента относится к категории распределений, связанных с нормальным распределением. Подробно эти распределения рассмотрены в учебниках по математической статистике [3, с. 24].
Известно, что критическое значение
τ
p
(
p
— процентная точка нормирования выборочного отклонения) выражается через критическое значение распределения Стьюдента
t
α, n-2
[6, с. 26]:
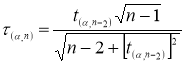
(7)
Учитывая это, можно предложить следующую процедуру отсева грубых погрешностей измерения для больших выборок (
n
= 100):
1) из таблицы наблюдений выбирают наблюдение имеющее наибольшее отклонение;
2)
по формуле
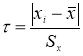
вычисляют значение статистики
τ
;
3)
по таблице (или в программе Excel) находят процентные точки
t
-распределения Стьюдента
t
(
α,
n
-2
)
:
t
(95
%, 98)
= 1,6602, и
t
(
99
%, 98)
= 3,1737;
По предыдущей формуле в программе Excel вычисляют соответствующие точки
t
(95
%, 100)
= 1,66023и
t
(99
%, 100)
=3,17374.
Сравнивают значение расчетной статистики с табличными критическими значениями и принимают решение по отсеву грубых погрешностей.
Рекомендуемый метод отсева грубых погрешностей удобен еще тем, что максимальные относительные отклонения могут быть разделены на три группы: 1)
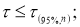
2)
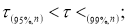
3)
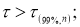
.
Наблюдения, попавшие в первую группу, нельзя отсеивать ни в коем случае. Наблюдения второй группы можно отсеять, если в пользу этой процедуры имеются еще и другие соображения экспериментатора (например, заключения, сделанные на основе изучения физических, химических и других свойств изучаемого явления). Наблюдения третьей группы, как правило, отсеивают всегда.
Рассмотрим далее пример с использованием средств программного пакета Excel, который позволяет снизить трудоемкость расчетов при осуществлении данной процедуры. К сожалению, в настоящее время средства Excel не позволяют автоматизировать расчеты по всем известным критериям отсеивания грубых погрешностей, поэтому проиллюстрируем рассмотренные методы с использованием доступных в Excel критериев Стьюдента.
Пример 1.
Имеется выборка из 100 шт. резисторов с номинальным сопротивлением
R
н
= (150,0 ± 5 %) кОм, которая используется для оценки качества партии резисторов (генеральная совокупность). Используя критерий Стьюдента, отсеем грубые погрешности (промахи) при измерениях.
- Заносим данные измерений в таблицу Excel в ячейки В2:В101
- Составляем вариационный ряд — располагаем данные в порядке возрастания с помощью функции «Сортировка по возрастанию» в ячейках С2:С101 (рис. 1)
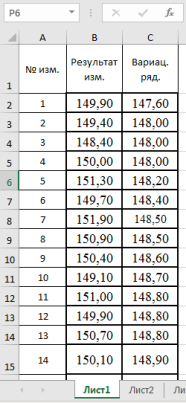
Рис. 1. Фрагмент диалогового окна с данными измерений и вариационного ряда
3. Находим среднее значение выборки с помощью мастера функций в категории «Статистические» и функции — СРЗНАЧ, результат в ячейке Н3 (рис. 2).
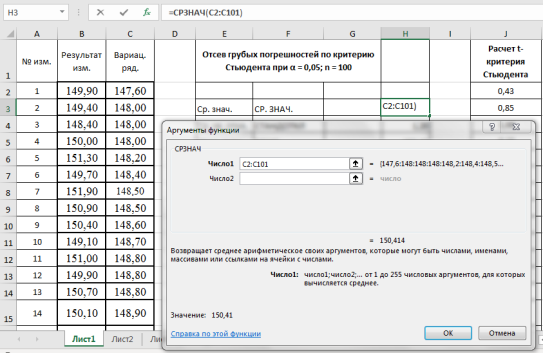
Рис. 2. Фрагмент диалогового окна при нахождении среднего значения выборки
-
Находим среднеквадратическое отклонение —
S
x
. Выделяем ячейку Н4, вызываем «Мастер функций», категория «Статистические», функция — СТАНДОТКЛОН, результат в ячейке Н4–1,20 (рис. 3).
Рис. 3. Фрагмент диалогового окна при нахождении среднего квадратического отклонения
-
Находим максимальное значение в выборке —
x
макс
. Выделяем ячейку Н5, в категории «Статистические», функция — МАКС, выделяем мышкой вариационный ряд C2:С101, результат в ячейке Н5–153,10 (рис. 4).
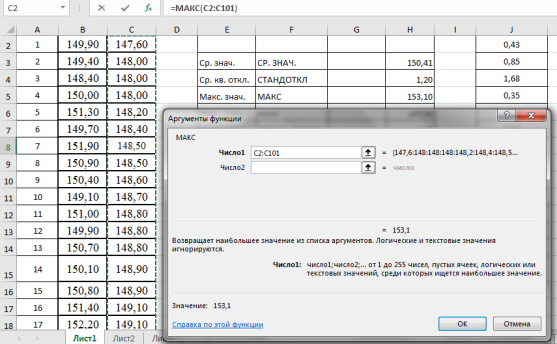
Рис. 4. Фрагмент диалогового окна при нахождении максимального значения
-
Находим минимальное значение в выборке —
x
мин
. Выделяем ячейку Н6, в категории «Статистические», функция — МИН, выделяем мышкой вариационный ряд C2:С101, результат в ячейке Н6–147,6 (рис. 5).
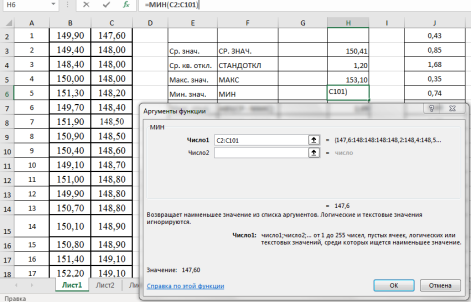
Рис. 5. Фрагмент диалогового окна при нахождении минимального значения
-
Находим максимальное и минимальное отклонения — Δ
макс
и Δ
мин
. Вводим в ячейки Н7 и Н8 формулы:
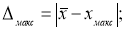
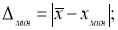
-
Находим теоретическое значение —
t
теор
. для максимального и минимального отклонений. Вводим в ячейки Н9 и Н12 формулу
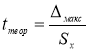
. и
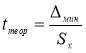
-
Находим табличное значение
t
табл.
Выделяем ячейку Н10, вызываем в категории «Статистические» функцию — СТЬЮДЕНТ.ОБР, «Вероятность» — 0,95, степени свободы (
n
-2) — 98, результат в ячейке Н10–1,66 (рис. 6).
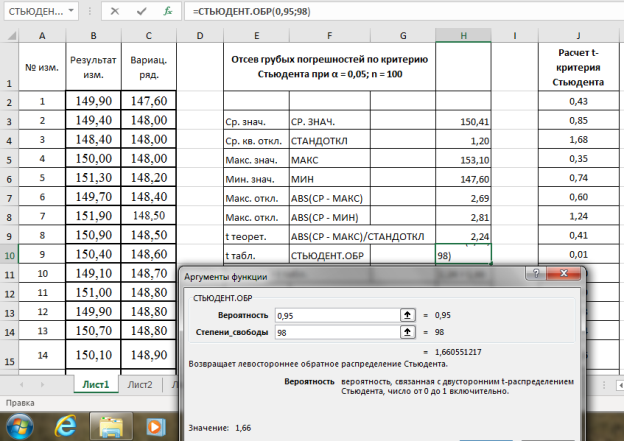
Рис. 6. Фрагмент диалогового окна при нахождении табличного значения критерия Стьюдента
-
Сравниваем теоретическое значение
t
теор
= 2,24 критерия Стьюдента для максимального значения — 153,1 кОм с табличным значением:
t
табл
.= 1,6605. - Аналогично п. 9 проверим на наличие грубой погрешности у минимального значения в выборке — 147,6 кОм. Результат в ячейке Н12–2,35 (рис. 7).
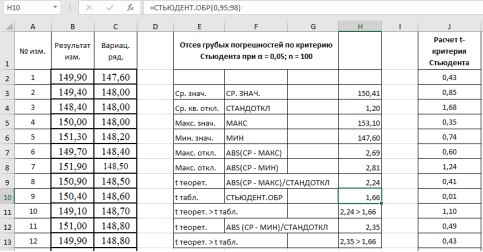
Рис. 7. Фрагмент диалогового окна при окончательном анализе данных
- Делаем вывод о наличии грубых ошибок в данных измерениях. Рассмотренная процедура подтвердила наши сомнения относительно достоверности максимального и минимального значений в данной выборке, т. е., указанные результаты могут быть отброшены из результатов измерений, и проверка может быть повторена снова без этих данных.
Пример расчета теоретического критерия Романовского по аналогичным формулам в Excel и диалоговое окно представлены на рис. 8, при условии α = 0,05, число измерений
n
= 20, β
табл
= 2,78 (из таблицы 2).

Рис. 8. Фрагмент диалогового окна при расчете критерия Романовского
Выводы
- Для использования различных критериев отбрасывания грубых погрешностей измерений необходимо учитывать требования действующих нормативных документов.
- Рассмотренный пример показал, что расчеты погрешностей по критерию Стьюдента с использованием таблиц и формул Excel значительно упрощаются, а процесс отбрасывания грубых погрешностей можно осуществить наиболее качественно и быстро.
Литература:
1. ГОСТ Р 8.736–2011 Государственная система обеспечения единства измерений. Измерения прямые многократные. Методы обработки результатов измерений. Основные положения. — М.: ФГУП Стандартинформ, 2013. — 24 с.
2. Пустыльник Е. И. Статистические методы анализа и обработки наблюдений. — М.: Наука, 1968. — 288 с.
3. Львовский Е. Н. Статистические методы построения эмпирических формул: Учеб. пособие. — М.: Высш. школа, 1982. — 224 с.
4. Фаюстов А. А. Ещё раз о критериях отсеивания грубых погрешностей. — Законодательная и прикладная метрология, 2016, № 5, с. 25–30.
5. Сергеев А. Г. Метрология: Учебник. — М.: Логос, 2005. — 272 с.
6. Большев Л. Н., Смирнов Н. В. Таблицы математической статистики. — М.: Наука, Главная редакция физико-математической литературы, 1983. — 416 с.
Основные термины (генерируются автоматически): диалоговое окно, сомнительное значение, уровень значимости, измеряемая величина, погрешность, критерий, нормальное распределение, ячейка, вариационный ряд, минимальное значение.
МЕТОДЫ ВЫЯВЛЕНИЯ ГРУБЫХ ОШИБОК В МАРКШЕЙДЕРСКИХ ИЗМЕРЕНИЯХ
Алексенко Анастасия Геннадьевна1, Гребенщикова Алена Николаевна2, Грибунина Ксения Антоновна3, Пучнина Алена Ивановна4
1Санкт-Петербургский горный университет, кандидат технических наук, ассистент кафедры маркшейдерского дела
2Санкт-Петербургский горный университет, студент кафедры маркшейдерского дела
3Санкт-Петербургский горный университет, студент кафедры маркшейдерского дела
4Санкт-Петербургский горный университет, студент кафедры маркшейдерского дела
Аннотация
Статья посвящена обзору методов выявления и исключения грубых ошибок в маркшейдерских измерениях. Данный вопрос является актуальным, поскольку напрямую влияет на точность полученных результатов. В ходе исследования способов контроля измерений по невязкам и по результатам уравнивания был сделан вывод о несовершенстве существующих методов выявления грубых ошибок.
Ключевые слова: анализ точности, грубые ошибки, маркшейдерские измерения, маркшейдерское обеспечение, точность измерений
Рубрика: 25.00.00 НАУКИ О ЗЕМЛЕ
Библиографическая ссылка на статью:
Алексенко А.Г., Гребенщикова А.Н., Грибунина К.А., Пучнина А.И. Методы выявления грубых ошибок в маркшейдерских измерениях // Современные научные исследования и инновации. 2017. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2017/05/82381 (дата обращения: 07.09.2023).
Ошибки, возникающие в процессе маркшейдерских и геодезических измерений, как правило, подразделяют на три вида [1]:
— систематические (постоянные, закономерные, могут быть исключены практически полностью в ходе анализа измерений);
— случайные (непредсказуемые по величине и знаку);
— грубые (также непредсказуемы, но при этом по величине значительно превосходят ожидаемые погрешности).
Одна из задач контроля и анализа точности маркшейдерских измерений – выявление и исключение грубых ошибок. Грубые искажения могут возникать по различным причинам, начиная от ошибок исполнителя во время съемки и при передаче данных, заканчивая неисправностью прибора.
Методы выявления грубых ошибок можно разделить на две основных категории: контроль по невязкам условных уравнений и контроль по поправкам, получаемым в ходе уравнивания съемочного построения.
В ходе проверки измерений по методам первой категории значения невязок всех возникающих условных уравнений связи сравнивают с допустимыми значениями, рассчитываемыми в общем виде по формуле:
![]() (1)
(1)
где t – коэффициент нормального распределения (2 или 2,5); ![]() — средняя квадратическая ошибка единицы веса (принимаемая до уравнивания);
— средняя квадратическая ошибка единицы веса (принимаемая до уравнивания); ![]() — диагональный элемент соответствующей строки нормальных уравнений коррелат.
— диагональный элемент соответствующей строки нормальных уравнений коррелат.
Превышение допуска говорит о наличии значительных по величине ошибок. В таком случае возникает необходимость локализовать эти ошибки, т.е. определить, в каких измерениях они могли быть допущены.
Достоинство данной категории методов выявления грубых ошибок в его оперативности. Но при этом некоторые авторы указывают на недостаточную эффективность такого способа исключения грубых промахов: не всегда выполнение условия допусков гарантирует отсутствие ошибок [2, 3, 4].
Более эффективными с точки зрения полноты выявления ошибок являются методы, связанные с результатами уравнивания, которые осуществляются на заключительном этапе обработки измерений.
Одним из наиболее распространенных методов в данной категории является проверка измерений по условию допустимости значений поправок в измерения, полученных в ходе параметрического уравнивания.
Некоторые исследователи отмечают основной недостаток подобных методов: поскольку в ходе параметрического уравнивания накладывается условие [pvv]=min, значения поправок не будут соответствовать реальным величинам ошибок в данном измерении [3, 5].
Использовать уравнение связи векторов поправок и ошибок измерений для выявления грубых промахов предложил В.А. Коугия [3]:
![]() (2)
(2)
где ![]() — вектор ошибок измерений, а
— вектор ошибок измерений, а ![]() — матрица линейных преобразований.
— матрица линейных преобразований.
В данной методике условием наличия грубого искажения является превышение значения вычисленной поправки ее допустимого значения, вычисляемого по формуле:
![]() (3)
(3)
где ![]() – параметр, принимаемый обычно равным 2,5;
– параметр, принимаемый обычно равным 2,5; ![]() – средняя квадратическая ошибка поправки – корень из i-го диагонального элемента корреляционной матрицы поправок
– средняя квадратическая ошибка поправки – корень из i-го диагонального элемента корреляционной матрицы поправок ![]() .
.
Предполагается, что измерению с грубой ошибкой будет соответствовать максимальное значение отношения поправки к её допуску. Тем не менее, автор методики отмечает, что при возникновении ряда условий (например, при равенстве значений отношений поправок к допускам нескольких измерений) локализация ошибок данным способом (как и аналогичными) будет невозможна [4].
Другим примером выявления грубых ошибок по результатам уравнивания является метод наложения условия «pV-максимума» [3, 6], предполагающий, что произведение веса измерения на его поправку в случае наличия в этом измерении грубой ошибки будет больше, чем данное произведение, рассчитанное для других измерений. Поскольку есть возможность наличия нескольких промахов в комплексе измерений, предполагается проводить несколько циклов их выявления и исключения. В этом случае ошибочные величины последовательно обнаруживаются и корректируются на примерную величину ошибки, вычисляемую по формуле:
![]() (4)
(4)
где ![]() — коэффициент влияния истинной ошибки i-го измерения на поправку в i-e измерение.
— коэффициент влияния истинной ошибки i-го измерения на поправку в i-e измерение.
Такой метод также имеет свои недостатки. Прежде всего, число избыточных измерений должно быть намного больше, чем ошибочных измерений (при этом зачастую в маркшейдерской практике используются съемочные построения с низкой избыточностью). Также исследователи отмечают, что этот метод не работает в случае схождения в одной точке трёх и более измерений, что также достаточно часто встречается в маркшейдерской практике. Помимо этого, результат не будет достоверным, если несколько измерений будут иметь близкие по величине погрешности.
Как видно из рассмотренных примеров, выбор метода выявления грубых ошибок напрямую может повлиять на качество результата данного этапа обработки измерений. Так, при определенной геометрии и избыточности построения локализация и исключение ошибок может представлять собой сложную и даже невыполнимую задачу.
При этом очевидно, что некачественное исключение грубых ошибок, вероятность возникновения которых не стоит недооценивать, напрямую повлияет на точность итоговых результатов съемки. В некоторых случаях даже при достоверном обнаружении промахов возникает необходимость дополнительных измерений, что недопустимо с точки зрения затрат времени и ресурсов.
Таким образом, следует внимательно относиться к выбору методов выявления и исключения грубых ошибок измерений. Также избежать проблем на данном этапе обработки измерений может помочь оценка внутренней и внешней надежности на этапе проектирования построения, поскольку параметры внутренней надежности характеризуют способность сети к выявлению грубых ошибок по результатам уравнивания, а параметры внешней надежности оценивают степень искажения результатов съемки возможными невыявленными ошибками [2, 7].
Библиографический список
- Гудков В.М., Хлебников А.В. Математическая обработка маркшейдерско-геодезических измерений / В.М. Гудков, А.В. Хлебников // М.: Недра, 1990. – 335 с.
- Алексенко А.Г. Разработка методики оценки и повышения внешней надежности маркшейдерских съемочных построений: дис. … канд. техн. наук: 25.00.16 / А.Г. Алексенко. – СПб, 2015. – 136 с.
- Зубов А.В. Автоматизированный контроль качества проектирования и обработки маркшейдерско-геодезических сетей: дис. … канд. техн. наук: 05.24.01 / А.В. Зубов. – СПб, 1996. – 160 с.
- Коугия В.А. Сравнение методов обнаружения и идентификации ошибок измерений / В.А. Коугия // Геодезия и картография. – 1998. – №5. – С. 23-27.
- Маркузе Ю.И. Основы метода наименьших квадратов и уравнительных вычислений: учебное пособие / Ю.И. Маркузе – М.: МИИГАиК, 2005. – 280 с.
- Дьяков Б.Н., Федорова Н.В. Пошаговый поиск грубых ошибок измерений / Б.Н. Дьяков, Н.В. Федорова // Геодезия и картография. – 2001. – №3. – с. 16-20.
- Алексенко А.Г., Зубов А.В. Проектирование маркшейдерско-геодезических сетей с учётом параметров надёжности // Маркшейдерский вестник.-2014.-№5. – с.31-32.
Количество просмотров публикации: Please wait
Все статьи автора «Алексенко Анастасия Геннадьевна»