Соберу в одном месте список полезных команд для mdadm.
mdadm — утилита для управления программными RAID-массивами в Linux.
С помощью mdadm можно выполнять следующие операции:
- mdadm —create, C Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
- mdadm —assemble, -A Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
- mdadm —build, -B Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
- mdadm —manage Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
- mdadm —misc Действия, которые не относятся ни к одному из других режимов работы.
- mdadm —grow, G Расширение или уменьшение массива, включаются или удаляются новые диски.
- mdadm —incremental, I Добавление диска в массив.
- mdadm —monitor, —follow, -F Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
И другие: mdadm —help.
Формат вызова:
mdadm [mode] [array] [options]
Создание массива
Для создания массива нужно использовать не смонтированные разделы. Убедитесь в этом, при необходимости демонтируйте и уберите из fstab.
Пример создания RAID5 массива из трёх дисков:
- /dev/nvme0n1
- /dev/nvme1n1
- /dev/nvme2n1
Я использую NVMe диски, у вас названия дисков будут другие.
Желательно изменить тип разделов на FD (Linux RAID autodetect). Это можно сделать с помощью fdisk (t).
Занулить суперблоки дисков:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Стереть подпись и метаданные:
wipefs --all --force /dev/nvme0n1
wipefs --all --force /dev/nvme1n1
wipefs --all --force /dev/nvme2n1С помощью ключа —create создать RAID5 массив:
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1где:
- /dev/md0 — массив, который мы создаём;
- —level 5 — уровень RAID;
- —raid-devices=3 — количество дисков, из которых собирается массив;
- /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 — диски.
Для примера RAID1 из двух дисков /dev/sdb и /dev/sdc можно создать так:
mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sd{b,c}где:
- /dev/md2 — массив, который мы создаём;
- -l 5 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — диски sdb и sdc.
Состояние массива
Посмотреть инициализацию массива и текущее состояние можно с помощью команды:
cat /proc/mdstatПример 1:
root@ch01:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md127 : active raid1 nvme1n1[1] nvme0n1[0]
3750607192 blocks super 1.2 [2/2] [UU]
unused devices: <none>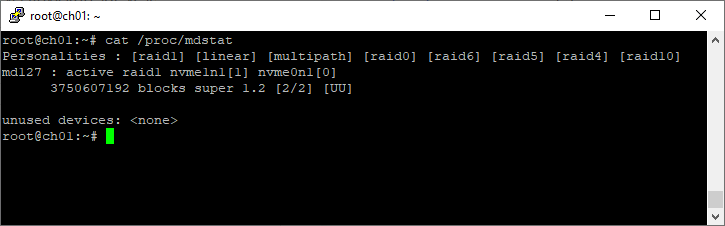
Пример 2:
[root@dbk00 ~]# cat /proc/mdstat
Personalities : [raid1] [raid0]
md10 : active raid0 sdb1[1] sda1[0]
70319335424 blocks super 1.2 512k chunks
md20 : active raid0 sdc1[0] sdd1[1]
70319335424 blocks super 1.2 512k chunks
md126 : active raid1 sde[1] sdf[0]
927881216 blocks super external:/md127/0 [2/2] [UU]
md127 : inactive sdf[1](S) sde[0](S)
10402 blocks super external:imsm
unused devices: <none>Подробный статус выбранного массива
mdadm --detail /dev/md2Пример:
root@ch01:~# mdadm --detail /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Wed May 6 16:39:32 2020
Raid Level : raid1
Array Size : 3750607192 (3576.86 GiB 3840.62 GB)
Used Dev Size : 3750607192 (3576.86 GiB 3840.62 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Fri Aug 14 17:09:47 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : VirtualDisk01
UUID : 1728ebed:ad0b0000:faad83b7:37070000
Events : 173
Number Major Minor RaidDevice State
0 259 0 0 active sync /dev/nvme0n1
1 259 1 1 active sync /dev/nvme1n1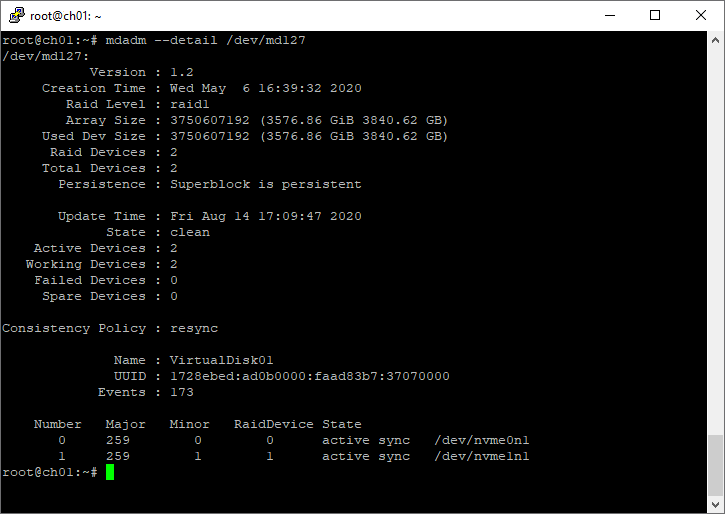
Список массивов
mdadm --detail --scan --verboseПример:
root@ch01:~# mdadm --detail --scan --verbose
ARRAY /dev/md/VirtualDisk01 level=raid1 num-devices=2 metadata=1.2 name=VirtualDisk01 UUID=1728ebed:ad0b0000:faad83b7:37070000
devices=/dev/nvme0n1,/dev/nvme1n1
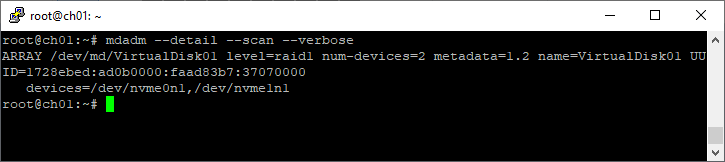
Создание файловой системы
Файловую систему в массиве можно создать с помощью mkfs, например:
mkfs.ext4 -m 0 /dev/md0Для лучшей производительности файловой системы имеет смысл указывать при её создании количество дисков в рейде и количество блоков файловой системы, которое может поместиться в один страйп (chunk), это касается массивов уровня RAID0, RAID5 ,RAID6 ,RAID10. Для RAID1 (mirror) это не имеет значения так как запись идет всегда на один device, a в других типах массивов данные записываются последовательно на разные диски порциями, соответствующими размеру stripe. Например, если мы используем RAID5 из 3 дисков с дефолтным размером страйпа в 64К и файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext3 так:
mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0stripe-width обычно рассчитывается как
stride * N
где N — это диски с данными в массиве, например, в RAID5 два диска с данными и один parity для контрольных сумм. Для файловой системы XFS нужно указывать не количество блоков файловой системы, соответствующих размеру stripe в массиве, а размер самого страйпа:
mkfs.xfs -d su=64k,sw=3 /dev/md0Создание mdadm.conf
Операционная система не запоминает какие RAID-массивы ей нужно создать и какие диски в них входят. Эта информация содержится в файле mdadm.conf.
mkdir /etc/mdadm
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.confВ интернете советуют применять команду mdadm —detail —scan —verbose, но я не рекомендую, т.к. она пишет в конфигурационный файл названия разделов, а они в некоторых случаях могут измениться, тогда RAID-массив не соберётся. А mdadm —detail —scan записывает UUID разделов, которые не изменятся.
Проверка целостности массива
echo 'check' >/sys/block/md0/md/sync_actionЕсть ли ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cntРабота с дисками
Диск в массиве можно условно сделать сбойным с помощью ключа —fail (-f):
mdadm /dev/md0 --fail /dev/nvme0n1
mdadm /dev/md0 -f /dev/nvme0n1Удалить из массива отказавший диск:
mdadm /dev/md0 --remove /dev/nvme0n1
mdadm /dev/md0 -r /dev/nvme0n1Добавить в массив заменённый диск:
mdadm /dev/md0 --add /dev/nvme0n1
mdadm /dev/md0 -a /dev/nvme0n1Сборка существующего массива
Собрать существующий массив можно с помощью mdadm —assemble:
mdadm --assemble /dev/md0 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1
mdadm --assemble --scanРасширение массива
Расширить массив можно с помощью ключа —grow (-G). Сначала добавляется диск, а потом массив расширяется:
mdadm /dev/md0 --add /dev/nvme3n1Проверяем, что диск добавился:
mdadm --detail /dev/md0
cat /proc/mdstatЕсли диск добавился, расширяем массив:
mdadm -G /dev/md0 --raid-devices=4Опция —raid-devices указывает новое количество дисков в массиве с учётом добавленного. Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например, добавить опцию:
--backup-file=/var/backup
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах:
- /proc/sys/dev/raid/speed_limit_min
- /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
cat /proc/mdstatНужно обновить конфигурационный файл с учётом сделанных изменений:
mdadm --detail --scan >> /etc/mdadm/mdadm.confВозобновление отложенной синхронизации resync=PENDING
Если синхронизации массива отложена, состояние массива resync=PENDING, то синхронизацию можно возобновить:
echo idle > /sys/block/md0/md/sync_actionили
mdadm --readwrite /dev/md0Переименовать массив
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Собираем массив с новым именем:
mdadm --assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 --update=nameИли для старых версий:
mdadm –assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 –update=super-minorУдаление массива
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Затем необходимо затереть superblock каждого из составляющих массива:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Или с помощью dd:
dd if=/dev/zero of=/dev/nvme0n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme1n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme2n1 bs=512 count=1Contents
- 1 Detecting, querying and testing
- 1.1 Detecting a drive failure
- 1.2 Querying the array status
- 1.3 Simulating a drive failure
- 1.3.1 Force-fail by hardware
- 1.3.2 Force-fail by software
- 1.4 Simulating data corruption
- 1.5 Monitoring RAID arrays
Detecting, querying and testing
This section is about life with a software RAID system, that’s
communicating with the arrays and tinkertoying them.
Note that when it comes to md devices manipulation, you should always
remember that you are working with entire filesystems. So, although
there could be some redundancy to keep your files alive, you must
proceed with caution.
Detecting a drive failure
Firstly: mdadm has an excellent ‘monitor’ mode which will send an email when a problem is detected in any array (more about that later).
Of course the standard log and stat files will record more details about a drive failure.
It’s always a must for /var/log/messages to fill screens with tons of
error messages, no matter what happened. But, when it’s about a disk
crash, huge lots of kernel errors are reported. Some nasty examples,
for the masochists,
kernel: scsi0 channel 0 : resetting for second half of retries.
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: Sending Bus Device Reset CCB #2666 to Target 0
kernel: scsi0: Bus Device Reset CCB #2666 to Target 0 Completed
kernel: scsi : aborting command due to timeout : pid 2649, scsi0, channel 0, id 0, lun 0 Write (6) 18 33 11 24 00
kernel: scsi0: Aborting CCB #2669 to Target 0
kernel: SCSI host 0 channel 0 reset (pid 2644) timed out - trying harder
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: CCB #2669 to Target 0 Aborted
kernel: scsi0: Resetting BusLogic BT-958 due to Target 0
kernel: scsi0: *** BusLogic BT-958 Initialized Successfully ***
Most often, disk failures look like these,
kernel: sidisk I/O error: dev 08:01, sector 1590410
kernel: SCSI disk error : host 0 channel 0 id 0 lun 0 return code = 28000002
or these
kernel: hde: read_intr: error=0x10 { SectorIdNotFound }, CHS=31563/14/35, sector=0
kernel: hde: read_intr: status=0x59 { DriveReady SeekComplete DataRequest Error }
And, as expected, the classic /proc/mdstat look will also reveal problems,
Personalities : [linear] [raid0] [raid1] [translucent]
read_ahead not set
md7 : active raid1 sdc9[0] sdd5[8] 32000 blocks [2/1] [U_]
Later on this section we will learn how to monitor RAID with mdadm so
we can receive alert reports about disk failures. Now it’s time to
learn more about /proc/mdstat interpretation.
Querying the array status
You can always take a look at the array status by doing cat /proc/mdstat
It won’t hurt. Take a look at the /proc/mdstat page to learn how to read the file.
Finally, remember that you can also use mdadm to check
the arrays out.
mdadm --detail /dev/mdx
These commands will show spare and failed disks loud and clear.
Simulating a drive failure
If you plan to use RAID to get fault-tolerance, you may also want to
test your setup, to see if it really works. Now, how does one
simulate a disk failure?
The short story is, that you can’t, except perhaps for putting a fire
axe thru the drive you want to «simulate» the fault on. You can never
know what will happen if a drive dies. It may electrically take the
bus it is attached to with it, rendering all drives on that bus
inaccessible. The drive may also just report a read/write fault
to the SCSI/IDE/SATA layer, which, if done properly, in turn makes the RAID layer handle this
situation gracefully. This is fortunately the way things often go.
Remember, that you must be running RAID-{1,4,5,6,10} for your array to be
able to survive a disk failure. Linear- or RAID-0 will fail
completely when a device is missing.
Force-fail by hardware
If you want to simulate a drive failure, you can just plug out the
drive. If your HW does not support disk hot-unplugging, you should do this with the power off (if you are interested in testing whether your data can survive with a disk less than the usual number, there is no point in being a hot-plug cowboy here. Take the system down, unplug the disk, and boot it up again)
Look in the syslog, and look at /proc/mdstat to see how the RAID is
doing. Did it work? Did you get an email from the mdadm monitor?
Faulty disks should appear marked with an (F) if you look at
/proc/mdstat. Also, users of mdadm should see the device state as
faulty.
When you’ve re-connected the disk again (with the power off, of
course, remember), you can add the «new» device to the RAID again,
with the mdadm —add’ command.
Force-fail by software
You can just simulate a drive failure without unplugging things.
Just running the command
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
should be enough to fail the disk /dev/sdc2 of the array /dev/md1.
Now things move up and fun appears. First, you should see something
like the first line of this on your system’s log. Something like the
second line will appear if you have spare disks configured.
kernel: raid1: Disk failure on sdc2, disabling device.
kernel: md1: resyncing spare disk sdb7 to replace failed disk
Checking /proc/mdstat out will show the degraded array. If there was a
spare disk available, reconstruction should have started.
Another useful command at this point is:
mdadm --detail /dev/md1
Enjoy the view.
Now you’ve seen how it goes when a device fails. Let’s fix things up.
First, we will remove the failed disk from the array. Run the command
mdadm /dev/md1 -r /dev/sdc2
Note that mdadm cannot pull a disk out of a running array.
For obvious reasons, only faulty disks can be hot-removed from an
array (even stopping and unmounting the device won’t help — if you ever want
to remove a ‘good’ disk, you have to tell the array to put it into the
‘failed’ state as above).
Now we have a /dev/md1 which has just lost a device. This could be a
degraded RAID or perhaps a system in the middle of a reconstruction
process. We wait until recovery ends before setting things back to
normal.
So the trip ends when we send /dev/sdc2 back home.
mdadm /dev/md1 -a /dev/sdc2
As the prodigal son returns to the array, we’ll see it becoming an
active member of /dev/md1 if necessary. If not, it will be marked as
a spare disk. That’s management made easy.
Simulating data corruption
RAID (be it hardware or software), assumes that if a write to a disk
doesn’t return an error, then the write was successful. Therefore, if
your disk corrupts data without returning an error, your data will
become corrupted. This is of course very unlikely to happen, but it
is possible, and it would result in a corrupt filesystem.
RAID cannot, and is not supposed to, guard against data corruption on
the media. Therefore, it doesn’t make any sense either, to purposely
corrupt data (using dd for example) on a disk to see how the RAID
system will handle that. It is most likely (unless you corrupt the
RAID superblock) that the RAID layer will never find out about the
corruption, but your filesystem on the RAID device will be corrupted.
This is the way things are supposed to work. RAID is not a guarantee
for data integrity, it just allows you to keep your data if a disk
dies (that is, with RAID levels above or equal one, of course).
Monitoring RAID arrays
You can run mdadm as a daemon by using the follow-monitor mode. If
needed, that will make mdadm send email alerts to the system
administrator when arrays encounter errors or fail. Also, follow mode
can be used to trigger contingency commands if a disk fails, like
giving a second chance to a failed disk by removing and reinserting
it, so a non-fatal failure could be automatically solved.
Let’s see a basic example. Running
mdadm --monitor --daemonise --mail=root@localhost --delay=1800 /dev/md2
should release a mdadm daemon to monitor /dev/md2. The —daemonise switch tells mdadm to run as a deamon. The delay parameter means that polling will be done in intervals of 1800 seconds.
Finally, critical events and fatal errors should be e-mailed to the
system manager. That’s RAID monitoring made easy.
Finally, the —program or —alert parameters specify the program to be
run whenever an event is detected.
Note that, when supplying the -f switch, the mdadm daemon will never exit once it decides that there
are arrays to monitor, so it should normally be run in the background.
Remember that your are running a daemon, not a shell command.
If mdadm is ran to monitor without the -f switch, it will behave as a normal shell command and wait for you to stop it.
Using mdadm to monitor a RAID array is simple and effective. However,
there are fundamental problems with that kind of monitoring — what
happens, for example, if the mdadm daemon stops? In order to overcome
this problem, one should look towards «real» monitoring solutions.
There are a number of free software, open source, and even commercial
solutions available which can be used for Software RAID monitoring on
Linux. A search on FreshMeat should return a good number of matches.
The point of RAID with redundancy is that it will keep going as long as it can, but obviously it will detect errors that put it into a degraded mode, such as a failing disk. You can show the current status of an array with mdadm --detail (abbreviated as mdadm -D):
# mdadm -D /dev/md0
<snip>
0 8 5 0 active sync /dev/sda5
1 8 23 1 active sync /dev/sdb7
Furthermore the return status of mdadm -D is nonzero if there is any problem such as a failed component (1 indicates an error that the RAID mode compensates for, and 2 indicates a complete failure).
You can also get a quick summary of all RAID device status by looking at /proc/mdstat. You can get information about a RAID device in /sys/class/block/md*/md/* as well; see admin-guide/md.html in the kernel documentation. Some /sys entries are writable as well; for example you can trigger a full check of md0 with echo check >/sys/class/block/md0/md/sync_action.
In addition to these spot checks, mdadm can notify you as soon as something bad happens. Make sure that you have MAILADDR root in /etc/mdadm.conf (some distributions (e.g. Debian) set this up automatically). Then you will receive an email notification as soon as an error (a degraded array) occurs.
Make sure that you do receive mail send to root on the local machine (some modern distributions omit this, because they consider that all email goes through external providers — but receiving local mail is necessary for any serious system administrator). Test this by sending root a mail: echo hello | mail -s test root@localhost. Usually, a proper email setup requires two things:
-
Run an MTA on your local machine. The MTA must be set up at least to allow local mail delivery. All distributions come with suitable MTAs, pick anything (but not nullmailer if you want the email to be delivered locally).
-
Redirect mail going to system accounts (at least
root) to an address that you read regularly. This can be your account on the local machine, or an external email address. With most MTAs, the address can be configured in/etc/aliases; you should have a line likeroot: djsmiley2kfor local delivery, or
root: djsmiley2k@mail-provider.example.comfor remote delivery. If you choose remote delivery, make sure that your MTA is configured for that. Depending on your MTA, you may need to run the
newaliasescommand after editing/etc/aliases.
Соберу в одном месте список полезных команд для mdadm.
mdadm — утилита для управления программными RAID-массивами в Linux.
С помощью mdadm можно выполнять следующие операции:
- mdadm —create, C Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
- mdadm —assemble, -A Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
- mdadm —build, -B Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
- mdadm —manage Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
- mdadm —misc Действия, которые не относятся ни к одному из других режимов работы.
- mdadm —grow, G Расширение или уменьшение массива, включаются или удаляются новые диски.
- mdadm —incremental, I Добавление диска в массив.
- mdadm —monitor, —follow, -F Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
И другие: mdadm —help.
Формат вызова:
mdadm [mode] [array] [options]
Создание массива
Для создания массива нужно использовать не смонтированные разделы. Убедитесь в этом, при необходимости демонтируйте и уберите из fstab.
Пример создания RAID5 массива из трёх дисков:
- /dev/nvme0n1
- /dev/nvme1n1
- /dev/nvme2n1
Я использую NVMe диски, у вас названия дисков будут другие.
Желательно изменить тип разделов на FD (Linux RAID autodetect). Это можно сделать с помощью fdisk (t).
Занулить суперблоки дисков:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Стереть подпись и метаданные:
wipefs --all --force /dev/nvme0n1
wipefs --all --force /dev/nvme1n1
wipefs --all --force /dev/nvme2n1С помощью ключа —create создать RAID5 массив:
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1где:
- /dev/md0 — массив, который мы создаём;
- —level 5 — уровень RAID;
- —raid-devices=3 — количество дисков, из которых собирается массив;
- /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 — диски.
Для примера RAID1 из двух дисков /dev/sdb и /dev/sdc можно создать так:
mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sd{b,c}где:
- /dev/md2 — массив, который мы создаём;
- -l 5 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — диски sdb и sdc.
Состояние массива
Посмотреть инициализацию массива и текущее состояние можно с помощью команды:
cat /proc/mdstatПример 1:
root@ch01:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md127 : active raid1 nvme1n1[1] nvme0n1[0]
3750607192 blocks super 1.2 [2/2] [UU]
unused devices: <none>
Пример 2:
[root@dbk00 ~]# cat /proc/mdstat
Personalities : [raid1] [raid0]
md10 : active raid0 sdb1[1] sda1[0]
70319335424 blocks super 1.2 512k chunks
md20 : active raid0 sdc1[0] sdd1[1]
70319335424 blocks super 1.2 512k chunks
md126 : active raid1 sde[1] sdf[0]
927881216 blocks super external:/md127/0 [2/2] [UU]
md127 : inactive sdf[1](S) sde[0](S)
10402 blocks super external:imsm
unused devices: <none>Подробный статус выбранного массива
mdadm --detail /dev/md2Пример:
root@ch01:~# mdadm --detail /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Wed May 6 16:39:32 2020
Raid Level : raid1
Array Size : 3750607192 (3576.86 GiB 3840.62 GB)
Used Dev Size : 3750607192 (3576.86 GiB 3840.62 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Fri Aug 14 17:09:47 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : VirtualDisk01
UUID : 1728ebed:ad0b0000:faad83b7:37070000
Events : 173
Number Major Minor RaidDevice State
0 259 0 0 active sync /dev/nvme0n1
1 259 1 1 active sync /dev/nvme1n1
Список массивов
mdadm --detail --scan --verboseПример:
root@ch01:~# mdadm --detail --scan --verbose
ARRAY /dev/md/VirtualDisk01 level=raid1 num-devices=2 metadata=1.2 name=VirtualDisk01 UUID=1728ebed:ad0b0000:faad83b7:37070000
devices=/dev/nvme0n1,/dev/nvme1n1
Создание файловой системы
Файловую систему в массиве можно создать с помощью mkfs, например:
mkfs.ext4 -m 0 /dev/md0Для лучшей производительности файловой системы имеет смысл указывать при её создании количество дисков в рейде и количество блоков файловой системы, которое может поместиться в один страйп (chunk), это касается массивов уровня RAID0, RAID5 ,RAID6 ,RAID10. Для RAID1 (mirror) это не имеет значения так как запись идет всегда на один device, a в других типах массивов данные записываются последовательно на разные диски порциями, соответствующими размеру stripe. Например, если мы используем RAID5 из 3 дисков с дефолтным размером страйпа в 64К и файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext3 так:
mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0stripe-width обычно рассчитывается как
stride * N
где N — это диски с данными в массиве, например, в RAID5 два диска с данными и один parity для контрольных сумм. Для файловой системы XFS нужно указывать не количество блоков файловой системы, соответствующих размеру stripe в массиве, а размер самого страйпа:
mkfs.xfs -d su=64k,sw=3 /dev/md0Создание mdadm.conf
Операционная система не запоминает какие RAID-массивы ей нужно создать и какие диски в них входят. Эта информация содержится в файле mdadm.conf.
mkdir /etc/mdadm
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.confВ интернете советуют применять команду mdadm —detail —scan —verbose, но я не рекомендую, т.к. она пишет в конфигурационный файл названия разделов, а они в некоторых случаях могут измениться, тогда RAID-массив не соберётся. А mdadm —detail —scan записывает UUID разделов, которые не изменятся.
Проверка целостности массива
echo 'check' >/sys/block/md0/md/sync_actionЕсть ли ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cntРабота с дисками
Диск в массиве можно условно сделать сбойным с помощью ключа —fail (-f):
mdadm /dev/md0 --fail /dev/nvme0n1
mdadm /dev/md0 -f /dev/nvme0n1Удалить из массива отказавший диск:
mdadm /dev/md0 --remove /dev/nvme0n1
mdadm /dev/md0 -r /dev/nvme0n1Добавить в массив заменённый диск:
mdadm /dev/md0 --add /dev/nvme0n1
mdadm /dev/md0 -a /dev/nvme0n1Сборка существующего массива
Собрать существующий массив можно с помощью mdadm —assemble:
mdadm --assemble /dev/md0 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1
mdadm --assemble --scanРасширение массива
Расширить массив можно с помощью ключа —grow (-G). Сначала добавляется диск, а потом массив расширяется:
mdadm /dev/md0 --add /dev/nvme3n1Проверяем, что диск добавился:
mdadm --detail /dev/md0
cat /proc/mdstatЕсли диск добавился, расширяем массив:
mdadm -G /dev/md0 --raid-devices=4Опция —raid-devices указывает новое количество дисков в массиве с учётом добавленного. Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например, добавить опцию:
--backup-file=/var/backup
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах:
- /proc/sys/dev/raid/speed_limit_min
- /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
cat /proc/mdstatНужно обновить конфигурационный файл с учётом сделанных изменений:
mdadm --detail --scan >> /etc/mdadm/mdadm.confВозобновление отложенной синхронизации resync=PENDING
Если синхронизации массива отложена, состояние массива resync=PENDING, то синхронизацию можно возобновить:
echo idle > /sys/block/md0/md/sync_actionили
mdadm --readwrite /dev/md0Переименовать массив
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Собираем массив с новым именем:
mdadm --assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 --update=nameИли для старых версий:
mdadm –assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 –update=super-minorУдаление массива
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Затем необходимо затереть superblock каждого из составляющих массива:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Или с помощью dd:
dd if=/dev/zero of=/dev/nvme0n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme1n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme2n1 bs=512 count=1Contents
- 1 Detecting, querying and testing
- 1.1 Detecting a drive failure
- 1.2 Querying the array status
- 1.3 Simulating a drive failure
- 1.3.1 Force-fail by hardware
- 1.3.2 Force-fail by software
- 1.4 Simulating data corruption
- 1.5 Monitoring RAID arrays
Detecting, querying and testing
This section is about life with a software RAID system, that’s
communicating with the arrays and tinkertoying them.
Note that when it comes to md devices manipulation, you should always
remember that you are working with entire filesystems. So, although
there could be some redundancy to keep your files alive, you must
proceed with caution.
Detecting a drive failure
Firstly: mdadm has an excellent ‘monitor’ mode which will send an email when a problem is detected in any array (more about that later).
Of course the standard log and stat files will record more details about a drive failure.
It’s always a must for /var/log/messages to fill screens with tons of
error messages, no matter what happened. But, when it’s about a disk
crash, huge lots of kernel errors are reported. Some nasty examples,
for the masochists,
kernel: scsi0 channel 0 : resetting for second half of retries.
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: Sending Bus Device Reset CCB #2666 to Target 0
kernel: scsi0: Bus Device Reset CCB #2666 to Target 0 Completed
kernel: scsi : aborting command due to timeout : pid 2649, scsi0, channel 0, id 0, lun 0 Write (6) 18 33 11 24 00
kernel: scsi0: Aborting CCB #2669 to Target 0
kernel: SCSI host 0 channel 0 reset (pid 2644) timed out - trying harder
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: CCB #2669 to Target 0 Aborted
kernel: scsi0: Resetting BusLogic BT-958 due to Target 0
kernel: scsi0: *** BusLogic BT-958 Initialized Successfully ***
Most often, disk failures look like these,
kernel: sidisk I/O error: dev 08:01, sector 1590410
kernel: SCSI disk error : host 0 channel 0 id 0 lun 0 return code = 28000002
or these
kernel: hde: read_intr: error=0x10 { SectorIdNotFound }, CHS=31563/14/35, sector=0
kernel: hde: read_intr: status=0x59 { DriveReady SeekComplete DataRequest Error }
And, as expected, the classic /proc/mdstat look will also reveal problems,
Personalities : [linear] [raid0] [raid1] [translucent]
read_ahead not set
md7 : active raid1 sdc9[0] sdd5[8] 32000 blocks [2/1] [U_]
Later on this section we will learn how to monitor RAID with mdadm so
we can receive alert reports about disk failures. Now it’s time to
learn more about /proc/mdstat interpretation.
Querying the array status
You can always take a look at the array status by doing cat /proc/mdstat
It won’t hurt. Take a look at the /proc/mdstat page to learn how to read the file.
Finally, remember that you can also use mdadm to check
the arrays out.
mdadm --detail /dev/mdx
These commands will show spare and failed disks loud and clear.
Simulating a drive failure
If you plan to use RAID to get fault-tolerance, you may also want to
test your setup, to see if it really works. Now, how does one
simulate a disk failure?
The short story is, that you can’t, except perhaps for putting a fire
axe thru the drive you want to «simulate» the fault on. You can never
know what will happen if a drive dies. It may electrically take the
bus it is attached to with it, rendering all drives on that bus
inaccessible. The drive may also just report a read/write fault
to the SCSI/IDE/SATA layer, which, if done properly, in turn makes the RAID layer handle this
situation gracefully. This is fortunately the way things often go.
Remember, that you must be running RAID-{1,4,5,6,10} for your array to be
able to survive a disk failure. Linear- or RAID-0 will fail
completely when a device is missing.
Force-fail by hardware
If you want to simulate a drive failure, you can just plug out the
drive. If your HW does not support disk hot-unplugging, you should do this with the power off (if you are interested in testing whether your data can survive with a disk less than the usual number, there is no point in being a hot-plug cowboy here. Take the system down, unplug the disk, and boot it up again)
Look in the syslog, and look at /proc/mdstat to see how the RAID is
doing. Did it work? Did you get an email from the mdadm monitor?
Faulty disks should appear marked with an (F) if you look at
/proc/mdstat. Also, users of mdadm should see the device state as
faulty.
When you’ve re-connected the disk again (with the power off, of
course, remember), you can add the «new» device to the RAID again,
with the mdadm —add’ command.
Force-fail by software
You can just simulate a drive failure without unplugging things.
Just running the command
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
should be enough to fail the disk /dev/sdc2 of the array /dev/md1.
Now things move up and fun appears. First, you should see something
like the first line of this on your system’s log. Something like the
second line will appear if you have spare disks configured.
kernel: raid1: Disk failure on sdc2, disabling device.
kernel: md1: resyncing spare disk sdb7 to replace failed disk
Checking /proc/mdstat out will show the degraded array. If there was a
spare disk available, reconstruction should have started.
Another useful command at this point is:
mdadm --detail /dev/md1
Enjoy the view.
Now you’ve seen how it goes when a device fails. Let’s fix things up.
First, we will remove the failed disk from the array. Run the command
mdadm /dev/md1 -r /dev/sdc2
Note that mdadm cannot pull a disk out of a running array.
For obvious reasons, only faulty disks can be hot-removed from an
array (even stopping and unmounting the device won’t help — if you ever want
to remove a ‘good’ disk, you have to tell the array to put it into the
‘failed’ state as above).
Now we have a /dev/md1 which has just lost a device. This could be a
degraded RAID or perhaps a system in the middle of a reconstruction
process. We wait until recovery ends before setting things back to
normal.
So the trip ends when we send /dev/sdc2 back home.
mdadm /dev/md1 -a /dev/sdc2
As the prodigal son returns to the array, we’ll see it becoming an
active member of /dev/md1 if necessary. If not, it will be marked as
a spare disk. That’s management made easy.
Simulating data corruption
RAID (be it hardware or software), assumes that if a write to a disk
doesn’t return an error, then the write was successful. Therefore, if
your disk corrupts data without returning an error, your data will
become corrupted. This is of course very unlikely to happen, but it
is possible, and it would result in a corrupt filesystem.
RAID cannot, and is not supposed to, guard against data corruption on
the media. Therefore, it doesn’t make any sense either, to purposely
corrupt data (using dd for example) on a disk to see how the RAID
system will handle that. It is most likely (unless you corrupt the
RAID superblock) that the RAID layer will never find out about the
corruption, but your filesystem on the RAID device will be corrupted.
This is the way things are supposed to work. RAID is not a guarantee
for data integrity, it just allows you to keep your data if a disk
dies (that is, with RAID levels above or equal one, of course).
Monitoring RAID arrays
You can run mdadm as a daemon by using the follow-monitor mode. If
needed, that will make mdadm send email alerts to the system
administrator when arrays encounter errors or fail. Also, follow mode
can be used to trigger contingency commands if a disk fails, like
giving a second chance to a failed disk by removing and reinserting
it, so a non-fatal failure could be automatically solved.
Let’s see a basic example. Running
mdadm --monitor --daemonise --mail=root@localhost --delay=1800 /dev/md2
should release a mdadm daemon to monitor /dev/md2. The —daemonise switch tells mdadm to run as a deamon. The delay parameter means that polling will be done in intervals of 1800 seconds.
Finally, critical events and fatal errors should be e-mailed to the
system manager. That’s RAID monitoring made easy.
Finally, the —program or —alert parameters specify the program to be
run whenever an event is detected.
Note that, when supplying the -f switch, the mdadm daemon will never exit once it decides that there
are arrays to monitor, so it should normally be run in the background.
Remember that your are running a daemon, not a shell command.
If mdadm is ran to monitor without the -f switch, it will behave as a normal shell command and wait for you to stop it.
Using mdadm to monitor a RAID array is simple and effective. However,
there are fundamental problems with that kind of monitoring — what
happens, for example, if the mdadm daemon stops? In order to overcome
this problem, one should look towards «real» monitoring solutions.
There are a number of free software, open source, and even commercial
solutions available which can be used for Software RAID monitoring on
Linux. A search on FreshMeat should return a good number of matches.
The point of RAID with redundancy is that it will keep going as long as it can, but obviously it will detect errors that put it into a degraded mode, such as a failing disk. You can show the current status of an array with mdadm --detail (abbreviated as mdadm -D):
# mdadm -D /dev/md0
<snip>
0 8 5 0 active sync /dev/sda5
1 8 23 1 active sync /dev/sdb7
Furthermore the return status of mdadm -D is nonzero if there is any problem such as a failed component (1 indicates an error that the RAID mode compensates for, and 2 indicates a complete failure).
You can also get a quick summary of all RAID device status by looking at /proc/mdstat. You can get information about a RAID device in /sys/class/block/md*/md/* as well; see Documentation/md.txt in the kernel documentation. Some /sys entries are writable as well; for example you can trigger a full check of md0 with echo check >/sys/class/block/md0/md/sync_action.
In addition to these spot checks, mdadm can notify you as soon as something bad happens. Make sure that you have MAILADDR root in /etc/mdadm.conf (some distributions (e.g. Debian) set this up automatically). Then you will receive an email notification as soon as an error (a degraded array) occurs.
Make sure that you do receive mail send to root on the local machine (some modern distributions omit this, because they consider that all email goes through external providers — but receiving local mail is necessary for any serious system administrator). Test this by sending root a mail: echo hello | mail -s test root@localhost. Usually, a proper email setup requires two things:
-
Run an MTA on your local machine. The MTA must be set up at least to allow local mail delivery. All distributions come with suitable MTAs, pick anything (but not nullmailer if you want the email to be delivered locally).
-
Redirect mail going to system accounts (at least
root) to an address that you read regularly. This can be your account on the local machine, or an external email address. With most MTAs, the address can be configured in/etc/aliases; you should have a line likeroot: djsmiley2kfor local delivery, or
root: djsmiley2k@mail-provider.example.comfor remote delivery. If you choose remote delivery, make sure that your MTA is configured for that. Depending on your MTA, you may need to run the
newaliasescommand after editing/etc/aliases.
Я начинаю собирать дома компьютеры, и для их поддержки у меня есть «серверная» Linux-система с RAID-массивом.
В настоящее время mdadm RAID-1, собирается, RAID-5когда у меня будет больше дисков (а потом RAID-6я надеюсь). Однако я слышал различные истории о повреждении данных на одном диске, и вы никогда не замечали это из-за использования другого диска, вплоть до того момента, когда первый диск вышел из строя, и вы обнаружили, что ваш второй диск также прикручен (и 3-й, 4-й , 5-й диск).
Очевидно, что резервные копии важны, и я тоже об этом позабочусь, однако я знаю, что ранее видел скрипты, которые утверждают, что помогают справиться с этой проблемой и позволяют вам проверять ваш RAID во время его работы. Однако, снова ища эти сценарии, мне трудно найти что-то похожее на то, что я запускал раньше, и я чувствую, что устарел и не понимаю, что изменилось.
Как бы вы проверили работающий RAID, чтобы убедиться, что все диски по-прежнему нормально работают?
Я отслеживаю SMART на всех дисках, а также mdadmнастроил отправку мне электронных писем в случае сбоя, но я хотел бы знать, что мои диски иногда тоже «проверяют» себя.
Ответы:
Смысл RAID с избыточностью заключается в том, что он будет продолжать работать так долго, как может, но, очевидно, он будет обнаруживать ошибки, которые переводят его в ухудшенный режим, например, выходящий из строя диск. Вы можете показать текущее состояние массива с помощью mdadm -D:
# mdadm -D /dev/md0
<snip>
0 8 5 0 active sync /dev/sda5
1 8 23 1 active sync /dev/sdb7
Кроме того, состояние возврата отлично от mdadm -Dнуля, если есть какая-либо проблема, например, неисправный компонент (1 указывает на ошибку, которую компенсирует режим RAID, а 2 указывает на полный сбой).
Вы также можете получить краткую информацию о состоянии всех устройств RAID, посмотрев на /proc/mdstat. Вы также можете получить информацию об устройстве RAID /sys/class/block/md*/md/*; смотрите Documentation/md.txtв документации ядра. Некоторые /sysзаписи также доступны для записи; например, вы можете запустить полную проверку md0с помощью echo check >/sys/class/block/md0/md/sync_action.
В дополнение к этим выборочным проверкам mdadm может уведомить вас, как только что-то случится. Убедитесь, что вы MAILADDR rootв /etc/mdadm.conf(некоторые дистрибутивы (например, Debian) настроили это автоматически). Затем вы получите уведомление по электронной почте, как только возникнет ошибка (ухудшенный массив) .
Убедитесь, что вы получаете отправку почты в корневой каталог на локальном компьютере (некоторые современные дистрибутивы пропускают это, потому что считают, что вся электронная почта проходит через внешних провайдеров, но получение локальной почты необходимо для любого серьезного системного администратора). Проверьте это, посылая корень почту: echo hello | mail -s test root@localhost. Обычно для правильной настройки электронной почты требуются две вещи:
- Запустите MTA на вашем локальном компьютере. MTA должен быть настроен как минимум для локальной доставки почты. Все дистрибутивы поставляются с подходящими MTA, выбирайте что угодно (но не nullmailer, если вы хотите, чтобы электронная почта доставлялась локально).
-
Перенаправляйте почту, поступающую в системные учетные записи (как минимум
root), на адрес, который вы регулярно читаете. Это может быть ваша учетная запись на локальном компьютере или внешний адрес электронной почты. В большинстве MTA адрес может быть настроен в/etc/aliases; у вас должна быть строчка вродеroot: djsmiley2kдля локальной доставки, или
root: djsmiley2k@mail-provider.example.comдля удаленной доставки. Если вы выбираете удаленную доставку, убедитесь, что ваш MTA настроен для этого. В зависимости от вашего MTA, вам может потребоваться запустить
newaliasesкоманду после редактирования/etc/aliases.
Вы можете принудительно проверить весь массив, пока он в сети. Например, чтобы проверить массив /dev/md0, запустите от имени пользователя root:
echo check > /sys/block/md0/md/sync_action
У меня также есть задание cron, которое запускает следующую команду раз в месяц:
tar c /dir/of/raid/filesystem > /dev/null
Это не тщательная проверка самого диска, но она вынуждает систему периодически проверять, что (почти) каждый файл может быть успешно прочитан с диска. Да, некоторые файлы будут считываться из кеша памяти, а не с диска. Но я полагаю, что если файл находится в кеше памяти, то он недавно был успешно прочитан с диска или готов к записи на диск, и любая из этих операций также обнаружит ошибки диска. Во всяком случае, выполнение этой работы проверяет самый важный критерий RAID-массива («Могу ли я успешно прочитать мои данные?»), И за три года работы моего массива один раз у меня вышел из строя диск, это было эта команда, которая обнаружила это.
Одно маленькое предупреждение: если ваша файловая система большая, эта команда займет много времени; моя система занимает около 6 часов / TiB. Я запускаю его ioniceтак, чтобы остальная часть системы не остановилась во время проверки диска:
ionice -c3 tar c /dir/of/raid/filesystem > /dev/null
пакет ‘mdadm’ Debian и Ubuntu содержит файл
/etc/cron.d/mdadm
который по очереди первое воскресенье каждого месяца будет запускать команду
/usr/share/mdadm/checkarray --cron --all --idle --quiet
это проверит все ваши массивы на согласованность (если вы не установите для AUTOCHECK значение false в / etc / default / mdadm ). Отчет будет отправлен пользователю root (убедитесь, что вы получаете такие письма).
Я использую эту простую функцию для проверки /proc/mdstat:
#Health of RAID array
raid() { awk '/^md/ {printf "%s: ", $1}; /blocks/ {print $NF}' /proc/mdstat; }
 Обновлено: 02.05.2023
Обновлено: 02.05.2023
Опубликовано: 08.03.2019
Тематические термины: RAID, Linux
mdadm — утилита для работы с программными RAID-массивами различных уровней. В данной инструкции рассмотрим примеры ее использования.
Установка утилиты mdadm
Создание RAID
Подготовка носителей
Сборка отказоустойчивого массива
Файл mdadm.conf
Создание файловой системы и монтирование
Получение информации о RAID
Проверка целостности массива
Восстановление RAID
Заменой диска
Пересборка массива
Использование Hot Spare
Добавление диска к массиву
Удаление массива
Утилита mdadm может быть установлена одной командой.
Если используем CentOS / Red Hat:
yum install mdadm
Если используем Ubuntu / Debian:
apt-get install mdadm
Сборка RAID
Перед сборкой, стоит подготовить наши носители. Затем можно приступать к созданию рейд-массива.
Подготовка носителей
Сначала необходимо занулить суперблоки на дисках, которые мы будем использовать для построения RAID (если диски ранее использовались, их суперблоки могут содержать служебную информацию о других RAID):
mdadm —zero-superblock —force /dev/sd{b,c}
* в данном примере мы зануляем суперблоки для дисков sdb и sdc.
Если мы получили ответ:
mdadm: Unrecognised md component device — /dev/sdb
mdadm: Unrecognised md component device — /dev/sdc
… то значит, что диски не использовались ранее для RAID. Просто продолжаем настройку.
Далее нужно удалить старые метаданные и подпись на дисках:
wipefs —all —force /dev/sd{b,c}
Создание рейда
Для сборки избыточного массива применяем следующую команду:
mdadm —create —verbose /dev/md0 -l 1 -n 2 /dev/sd{b,c}
* где:
- /dev/md0 — устройство RAID, которое появится после сборки;
- -l 1 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — сборка выполняется из дисков sdb и sdc.
Мы должны увидеть что-то на подобие:
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store ‘/boot’ on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
—metadata=0.90
mdadm: size set to 1046528K
Также система задаст контрольный вопрос, хотим ли мы продолжить и создать RAID — нужно ответить y:
Continue creating array? y
Мы увидим что-то на подобие:
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
Вводим команду:
lsblk
… и находим информацию о том, что у наших дисков sdb и sdc появился раздел md0, например:
…
sdb 8:16 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
sdc 8:32 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
…
* в примере мы видим собранный raid1 из дисков sdb и sdc.
Создание файла mdadm.conf
В файле mdadm.conf находится информация о RAID-массивах и компонентах, которые в них входят. Для его создания выполняем следующие команды:
mkdir /etc/mdadm
echo «DEVICE partitions» > /etc/mdadm/mdadm.conf
mdadm —detail —scan —verbose | awk ‘/ARRAY/ {print}’ >> /etc/mdadm/mdadm.conf
Пример содержимого:
DEVICE partitions
ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=proxy.dmosk.local:0 UUID=411f9848:0fae25f9:85736344:ff18e41d
* в данном примере хранится информация о массиве /dev/md0 — его уровень 1, он собирается из 2-х дисков.
Создание файловой системы и монтирование массива
Создание файловой системы для массива выполняется также, как для раздела, например:
mkfs.ext4 /dev/md0
* данной командой мы создаем на md0 файловую систему ext4.
или:
mkfs.xfs /dev/md0
* для файловой системы xfs.
Примонтировать раздел можно командой:
mount /dev/md0 /mnt
* в данном случае мы примонтировали наш массив в каталог /mnt.
Чтобы данный раздел также монтировался при загрузке системы, добавляем в fstab.
Сначала смотрим идентификатор раздела:
blkid
Мы увидим что-то на подобие:
/dev/md0: UUID=»ffa7c082-7613-4dbc-ae62-3f5508652cf6″ TYPE=»ext4″
* в моем примере мы будем использовать идентификатор ffa7c082-7613-4dbc-ae62-3f5508652cf6.
Открываем теперь fstab и добавляем строку:
vi /etc/fstab
UUID=»ffa7c082-7613-4dbc-ae62-3f5508652cf6″ /mnt ext4 defaults 0 0
Если ранее мы монтировали раздел в каталог /mnt, вводим:
umount /mnt
И после:
mount -a
Мы должны увидеть примонтированный раздел md, например:
df -h
/dev/md0 990M 2,6M 921M 1% /mnt
Информация о RAID
Посмотреть состояние всех RAID можно командой:
cat /proc/mdstat
В ответ мы получим что-то на подобие:
md0 : active raid1 sdc[1] sdb[0]
1046528 blocks super 1.2 [2/2] [UU]
* где md0 — имя RAID устройства; raid1 sdc[1] sdb[0] — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] [UU] — количество юнитов, которые на данный момент используются.
** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
mdadm -D /dev/md0
* где /dev/md0 — имя RAID устройства.
Пример ответа:
Version : 1.2
Creation Time : Wed Mar 6 09:41:06 2019
Raid Level : raid1
Array Size : 1046528 (1022.00 MiB 1071.64 MB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 6 09:41:26 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : proxy.dmosk.local:0 (local to host proxy.dmosk.local)
UUID : 304ad447:a04cda4a:90457d04:d9a4e884
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
* где:
- Version — версия метаданных.
- Creation Time — дата в время создания массива.
- Raid Level — уровень RAID.
- Array Size — объем дискового пространства для RAID.
- Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
- Raid Devices — количество используемых устройств для RAID.
- Total Devices — количество добавленных в RAID устройств.
- Update Time — дата и время последнего изменения массива.
- State — текущее состояние. clean — все в порядке.
- Active Devices — количество работающих в массиве устройств.
- Working Devices — количество добавленных в массив устройств в рабочем состоянии.
- Failed Devices — количество сбойных устройств.
- Spare Devices — количество запасных устройств.
- Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
- Name — имя компьютера.
- UUID — идентификатор для массива.
- Events — количество событий обновления.
- Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Подробнее про каждый параметр можно прочитать в мануале для mdadm:
man mdadm
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
fdisk -l /dev/md0
Проверка целостности
Для проверки целостности вводим:
echo ‘check’ > /sys/block/md0/md/sync_action
Результат проверки смотрим командой:
cat /sys/block/md0/md/mismatch_cnt
* если команда возвращает 0, то с массивом все в порядке.
Остановка проверки:
echo ‘idle’ > /sys/block/md0/md/sync_action
Восстановление RAID
Рассмотрим два варианта восстановлении массива.
Замена диска
В случае выхода из строя одного из дисков массива, команда cat /proc/mdstat покажет следующее:
cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0]
1046528 blocks super 1.2 [2/1] [U_]
* о наличии проблемы нам говорит нижнее подчеркивание вместо U — [U_] вместо [UU].
Или:
mdadm -D /dev/md0
…
Update Time : Thu Mar 7 20:20:40 2019
State : clean, degraded
…
* статус degraded говорит о проблемах с RAID.
Для восстановления, сначала удалим сбойный диск, например:
mdadm /dev/md0 —remove /dev/sdc
Теперь добавим новый:
mdadm /dev/md0 —add /dev/sde
Смотрим состояние массива:
mdadm -D /dev/md0
…
Update Time : Thu Mar 7 20:57:13 2019
State : clean, degraded, recovering
…
Rebuild Status : 40% complete
…
* recovering говорит, что RAID восстанавливается; Rebuild Status — текущее состояние восстановления массива (в данном примере он восстановлен на 40%).
Если синхронизация выполняется слишком медленно, можно увеличить ее скорость. Для изменения скорости синхронизации вводим:
echo ‘10000’ > /proc/sys/dev/raid/speed_limit_min
* по умолчанию скорость speed_limit_min = 1000 Кб, speed_limit_max — 200000 Кб. Для изменения скорости, можно поменять только минимальную.
Пересборка массива
Если нам нужно вернуть ранее разобранный или развалившийся массив из дисков, которые уже входили в состав RAID, вводим:
mdadm —assemble —scan
* данная команда сама найдет необходимую конфигурацию и восстановит RAID.
Также, мы можем указать, из каких дисков пересобрать массив:
mdadm —assemble /dev/md0 /dev/sdb /dev/sdc
Запасной диск (Hot Spare)
Если в массиве будет запасной диск для горячей замены, при выходе из строя одного из основных дисков, его место займет запасной.
Диском Hot Spare станет тот, который просто будет добавлен к массиву:
mdadm /dev/md0 —add /dev/sdd
Информация о массиве изменится, например:
mdadm -D /dev/md0
…
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
2 8 48 1 active sync /dev/sdc
3 8 32 — spare /dev/sdd
Проверить работоспособность резерва можно вручную, симулировав выход из строя одного из дисков:
mdadm /dev/md0 —fail /dev/sdb
И смотрим состояние:
mdadm -D /dev/md0
…
Rebuild Status : 37% complete
…
Number Major Minor RaidDevice State
3 8 32 0 spare rebuilding /dev/sdd
2 8 48 1 active sync /dev/sdc
0 8 16 — faulty /dev/sdb
…
* как видим, начинается ребилд. На замену вышедшему из строя sdb встал hot-spare sdd.
Добавить диск к массиву
В данном примере рассмотрим вариант добавления активного диска к RAID, который будет использоваться для работы, а не в качестве запасного.
Добавляем диск к массиву:
mdadm /dev/md0 —add /dev/sde
Новый диск мы увидим в качестве spare:
4 8 16 — spare /dev/sde
Теперь расширяем RAID:
mdadm -G /dev/md0 —raid-devices=3
* в данном примере подразумевается, что у нас RAID 1 и мы добавили к нему 3-й диск.
Удаление массива
При удалении массива внимателнее смотрите на имена массива и дисков и подставляйте свои значения.
Если нам нужно полностью разобрать RAID, сначала размонтируем и остановим его:
umount /mnt
* где /mnt — каталог монтирования нашего RAID.
Если мы получим ошибку umount: /mnt: target is busy, то смотрим пользовательские процессы, которые мешают отмонтировать раздел:
fuser -vm /mnt
И останавливаем их.
mdadm -S /dev/md0
* где /dev/md0 — массив, который мы хотим разобрать.
Если мы получим ошибку mdadm: fail to stop array /dev/md0: Device or resource busy, с помощью команды
lsof -f — /dev/md0
… смотрим процессы, которые используют раздел и останавливаем их.
Затем очищаем суперблоки на всех дисках, из которых он был собран:
mdadm —zero-superblock /dev/sdb
mdadm —zero-superblock /dev/sdc
mdadm —zero-superblock /dev/sdd
* где диски /dev/sdb, /dev/sdc, /dev/sdd были частью массива md0.
А также удаляем метаданные и подпись:
wipefs —all —force /dev/sd{b,c,d}
Сборка RAID¶
Сначала необходимо занулить суперблоки на дисках, которые мы будем использовать для построения RAID (если диски ранее использовались, их суперблоки могут содержать служебную информацию о других RAID):
sudo mdadm --zero-superblock --force /dev/sd{a,b}
- в данном примере мы зануляем суперблоки для дисков sda и sdb.
Если мы получили ответ:
mdadm: Unrecognised md component device - /dev/sda
mdadm: Unrecognised md component device - /dev/sdb
… то значит, что диски не использовались ранее для RAID. Просто продолжаем настройку.
Далее нужно удалить старые метаданные и подпись на дисках:
sudo wipefs —all —force /dev/sd{a,b}
/dev/sda: 8 bytes were erased at offset 0x00000200 (gpt): 45 46 49 20 50 41 52 54
/dev/sda: 8 bytes were erased at offset 0x1d1c1115e00 (gpt): 45 46 49 20 50 41 52 54
/dev/sda: 2 bytes were erased at offset 0x000001fe (PMBR): 55 aa
/dev/sdb: 8 bytes were erased at offset 0x00000200 (gpt): 45 46 49 20 50 41 52 54
/dev/sdb: 8 bytes were erased at offset 0x1d1c1115e00 (gpt): 45 46 49 20 50 41 52 54
/dev/sdb: 2 bytes were erased at offset 0x000001fe (PMBR): 55 aa
Создание рейда¶
Для сборки зеркального массива применяем следующую команду:
sudo mdadm --create --verbose /dev/md0 --level=mirror --raid-devices=2 /dev/sd{a,b}
-
где:
/dev/md0 — устройство RAID, которое появится после сборки; —level=mirror — уровень RAID; —raid-devices=2 — количество дисков, из которых собирается массив; /dev/sd{b,c} — сборка выполняется из дисков sda и sdb.
Мы должны увидеть что-то на подобие:
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 1953382464K
Также система задаст контрольный вопрос, хотим ли мы продолжить и создать RAID — нужно ответить y:
Continue creating array? y
Мы увидим что-то на подобие:
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
Создание файла mdadm.conf¶
В файле mdadm.conf находится информация о RAID-массивах и компонентах, которые в них входят. Для его создания выполняем следующие команды:
mdadm --detail --scan --verbose | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.conf
Пример содержимого:
ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=srv:0 UUID=4de6170a:b32ae0c8:dcba68e5:3a2e1623
* в данном примере хранится информация о массиве /dev/md0 — его уровень 1, он собирается из 2-х дисков.
Создание файловой системы и монтирование массива¶
Создание файловой системы для массива выполняется также, как для раздела, в данном случае будем использовать ext4:
sudo mkfs.ext4 /dev/md0
Примонтировать раздел можно командой:
sudo mount /dev/md0 /mnt/data
- в данном случае мы примонтировали наш массив в каталог /mnt/data.
Чтобы данный раздел также монтировался при загрузке системы, добавляем в fstab следующее:
sudo nano /etc/fstab
UUID="7bdf0a43-8c2d-40fb-b996-45c90131879b" /mnt/data ext4 relatime,noatime,nodiratime 0 0
UUID можно увидеть в выводе команды blkid
sudo blkid
...
/dev/md0: UUID="7bdf0a43-8c2d-40fb-b996-45c90131879b" BLOCK_SIZE="4096" TYPE="ext4"
...
Монтируем:
sudo mount -a
Мы должны увидеть примонтированный раздел md, например:
df -h
/dev/md0 1,8T 28K 1,7T 1% /mnt/data
Информация о RAID¶
Посмотреть состояние всех RAID можно командой:
cat /proc/mdstat
В ответ мы получим что-то на подобие:
md0 : active raid1 sdb[1] sda[0] 1046528 blocks super 1.2 [2/2] [UU]
- где md0 — имя RAID устройства; raid1 sdb[1] sda[0] — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] [UU] — количество юнитов, которые на данный момент используются. ** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
sudo mdadm -D /dev/md0
- где /dev/md0 — имя RAID устройства.
Пример ответа:
Version : 1.2
Creation Time : Mon May 30 08:11:42 2022
Raid Level : raid1
Array Size : 1953382464 (1862.89 GiB 2000.26 GB)
Used Dev Size : 1953382464 (1862.89 GiB 2000.26 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Mon May 30 08:25:30 2022
State : clean, resyncing
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : bitmap
Resync Status : 7% complete
Name : srv:0 (local to host srv)
UUID : 4de6170a:b32ae0c8:dcba68e5:3a2e1623
Events : 223
Number Major Minor RaidDevice State
0 8 0 0 active sync /dev/sda
1 8 16 1 active sync /dev/sdb
- где:
Version — версия метаданных.
Creation Time — дата в время создания массива.
Raid Level — уровень RAID.
Array Size — объем дискового пространства для RAID.
Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
Raid Devices — количество используемых устройств для RAID.
Total Devices — количество добавленных в RAID устройств.
Update Time — дата и время последнего изменения массива.
State — текущее состояние. clean — все в порядке.
Active Devices — количество работающих в массиве устройств.
Working Devices — количество добавленных в массив устройств в рабочем состоянии.
Failed Devices — количество сбойных устройств.
Spare Devices — количество запасных устройств.
Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
Name — имя компьютера.
UUID — идентификатор для массива.
Events — количество событий обновления.
Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
sudo fdisk -l /dev/md0
Проверка целостности¶
Для проверки целостности вводим:
echo 'check' > /sys/block/md0/md/sync_action
Результат проверки смотрим командой:
cat /sys/block/md0/md/mismatch_cnt
- если команда возвращает 0, то с массивом все в порядке.
Остановка проверки:
echo 'idle' > /sys/block/md0/md/sync_action
Замена вышедшего диска из строя mdadm¶
Помечаем диск как сбойный:
sudo mdadm /dev/md0 -f /dev/sde1
Удаляем диск из массива:
sudo mdadm /dev/md0 --remove /dev/sde1
Добавляем новый диск:
sudo mdadm /dev/md0 -a /dev/sde1
Идет ребилд, все ок:
/dev/md0:
Version : 1.2
Creation Time : Sun Apr 19 12:55:51 2015
Raid Level : raid5
Array Size : 6836404736 (6519.70 GiB 7000.48 GB)
Used Dev Size : 976629248 (931.39 GiB 1000.07 GB)
Raid Devices : 8
Total Devices : 8
Persistence : Superblock is persistent
Update Time : Sun Apr 19 20:46:21 2015
State : clean, degraded, recovering
Active Devices : 7
Working Devices : 8
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 0% complete
Name : srv:0 (local to host srv)
UUID : 5d022f24:5885cb2d:49c40425:39bb7bc1
Events : 81
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 49 1 active sync /dev/sdd1
8 8 65 2 spare rebuilding /dev/sde1
3 8 81 3 active sync /dev/sdf1
4 8 97 4 active sync /dev/sdg1
5 8 145 5 active sync /dev/sdj1
6 8 161 6 active sync /dev/sdk1
7 8 177 7 active sync /dev/sdl1
Если диск помечен как сбойный (F) - sdh1[8](F):
cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sdm1[7] sdi1[3] sdh1[8](F) sdj1[4] sdk1[5] sdl1[6] sdd1[1] sda1[0]
6836404736 blocks super 1.2 level 5, 512k chunk, algorithm 2 [8/7] [UU_UUUUU]
unused devices: <none>
Удаляем его
sudo mdadm --manage /dev/md0 --remove /dev/sdh1
Добавляем заново:
sudo mdadm /dev/md0 -a /dev/sdh1
Добавить диск к массиву¶
В данном примере рассмотрим вариант добавления активного диска к RAID, который будет использоваться для работы, а не в качестве запасного.
Добавляем диск к массиву:
sudo mdadm /dev/md0 --add /dev/sde
Новый диск мы увидим в качестве spare:
4 8 16 - spare /dev/sde
Теперь расширяем RAID:
sudo mdadm -G /dev/md0 --raid-devices=3
- в данном примере подразумевается, что у нас RAID 1 и мы добавили к нему 3-й диск.
Удаление массива¶
При удалении массива внимателнее смотрите на имена массива и дисков и подставляйте свои значения.
Если нам нужно полностью разобрать RAID, сначала размонтируем и остановим его:
sudo umount /mnt/data
- где /mnt/data — каталог монтирования нашего RAID.
sudo mdadm -S /dev/md0
- где /dev/md0 — массив, который мы хотим разобрать.
- если мы получим ошибку mdadm: fail to stop array /dev/md0: Device or resource busy, с помощью команды lsof -f — /dev/md0 смотрим процессы, которые используют раздел и останавливаем их.
Затем очищаем суперблоки на всех дисках, из которых он был собран:
sudo mdadm --zero-superblock /dev/sda
sudo mdadm --zero-superblock /dev/sdb
sudo mdadm --zero-superblock /dev/sdc
* где диски /dev/sda, /dev/sdb, /dev/sdc были частью массива md0.
А также удаляем метаданные и подпись:
sudo wipefs --all --force /dev/sd{a,b,c}
Запуск массива¶
Чтобы запустить все массивы, определенные в конфигурации или в /proc/mdstat, введите:
sudo mdadm --assemble --scan
Чтобы запустить конкретный массив, вы можете передать его в качестве аргумента в mdadm –assemble:
sudo mdadm --assemble /dev/md0
Это сработает, если массив определен в конфигурации. Если же в файле конфигурации нет правильного определения массива, его все равно можно запустить, передав компонентные устройства:
sudo mdadm --assemble /dev/md0 /dev/sda /dev/sdb /dev/sdc /dev/sdd
Собрав массив, его можно смонтировать как обычно:
sudo mount /dev/md0 /mnt/md0
Теперь массив доступен в точке монтирования.