Покажем
последовательность решения бизнес-задачи
сегментации абонентов с помощью подхода,
который основан на алгоритме Кохонена.
Решение состоит из двух шагов:
-
кластеризации
объектов алгоритмом Кохонена; -
построения и
интерпретации карты Кохонена.
В программе Deductor
сети и карты
Кохонена реализованы в обработчике
Карта Кохонена,
где содержатся сам алгоритм Кохонена
и специальный визуализатор Карта
Кохонена.
В Deductor
канонический
алгоритм Кохонена дополнен рядом
возможностей.
-
Алгоритм Кохонена
применяется к сети Кохонена, состоящей
из ячеек, упорядоченных на плоскости.
По умолчанию размер карты равен 16×12,
что соответствует 192 ячейкам. В выходном
наборе данных алгоритм Кохонена
формирует поля
Номер ячейки
и
Расстояние до центра ячейки. -
Ячейки карты с
помощью специальной дополнительной
процедуры объединяются в кластеры. Эта
процедура –
алгоритм k-means,
причем имеется
возможность автоматически определять
количество кластеров. В выходном наборе
данных алгоритм k-means
формирует
поля
Номер кластера
и
Расстояние до центра кластера. -
Каждый входной
признак может иметь весовой коэффициент
от 0 до 100%, который влияет на расчет
евклидова расстояния между векторами.
Импортируйте в
Deductor
набор данных
из файла mobile.txt.
Запустите
Мастер
обработки
и выберите узел
Карта Кохонена.
Установите все поля, кроме
Код, входными
(рис. 4.1).
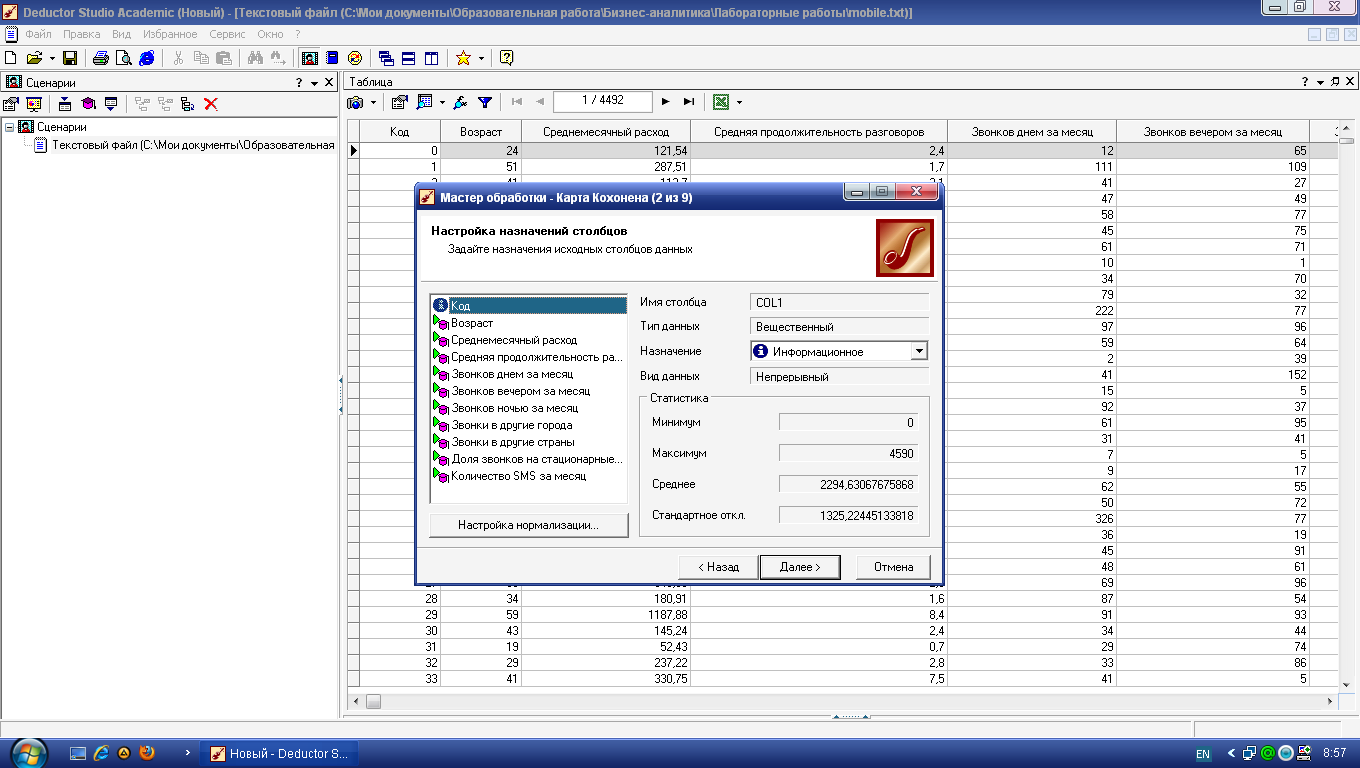
Рис.
4.1.
Установка входных полей в алгоритме
Кохонена
На этой же вкладке
при нажатии кнопки
Настройка нормализации
откроется окно, где можно задать
значимость каждого входного поля.
Оставьте значимость всех полей без
изменений.
Поскольку любой
метод кластеризации, в том числе алгоритм
Кохонена, субъективен, смысл в выделении
отдельного тестового множества, как
правило, отсутствует. Оставьте в обучающем
множестве 100% записей (рис. 4.2).
На третьей вкладке
задаются размер и форма карты Кохонена
(рис. 4.3). Увеличьте размер карты до 24×18
(соотношение рекомендуется делать
кратным 4:3).
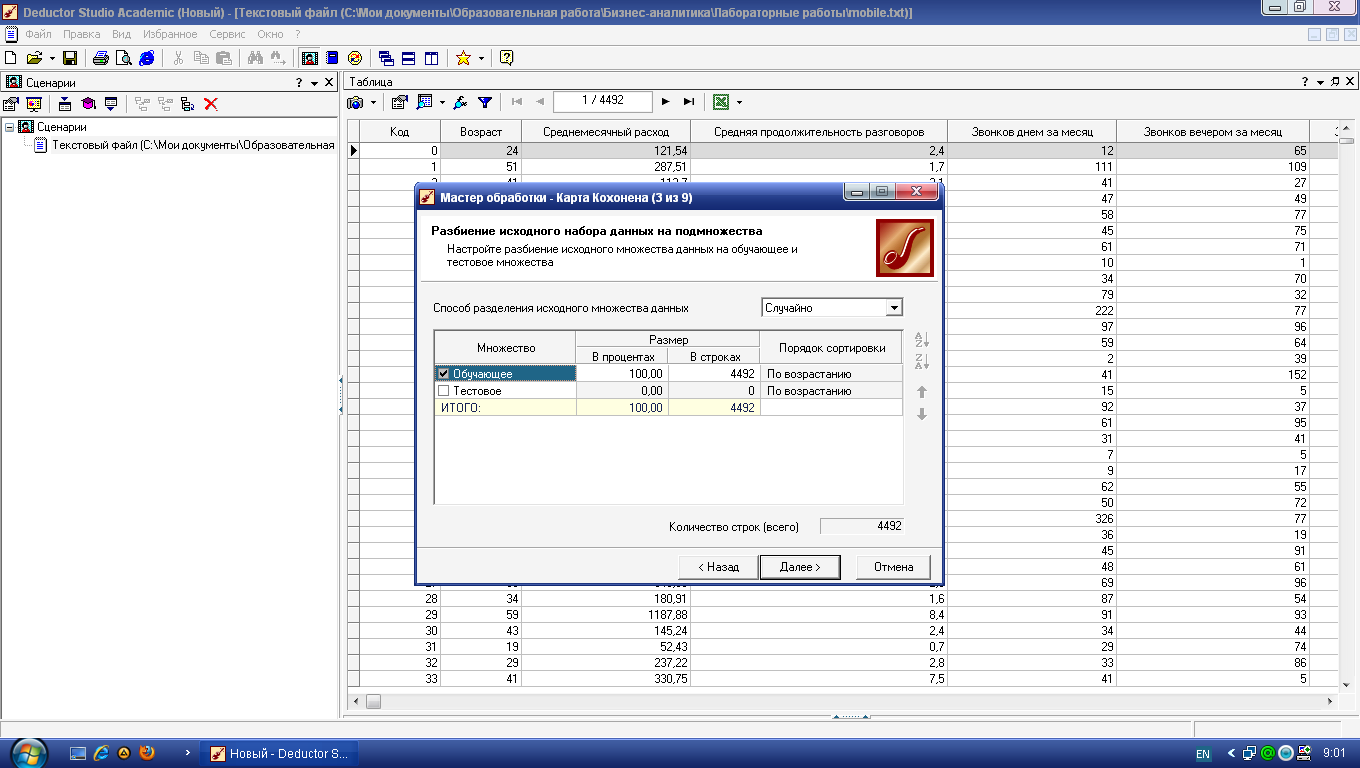
Рис.
4.2.
Разбиение набора данных на обучающее
и тестовое множества
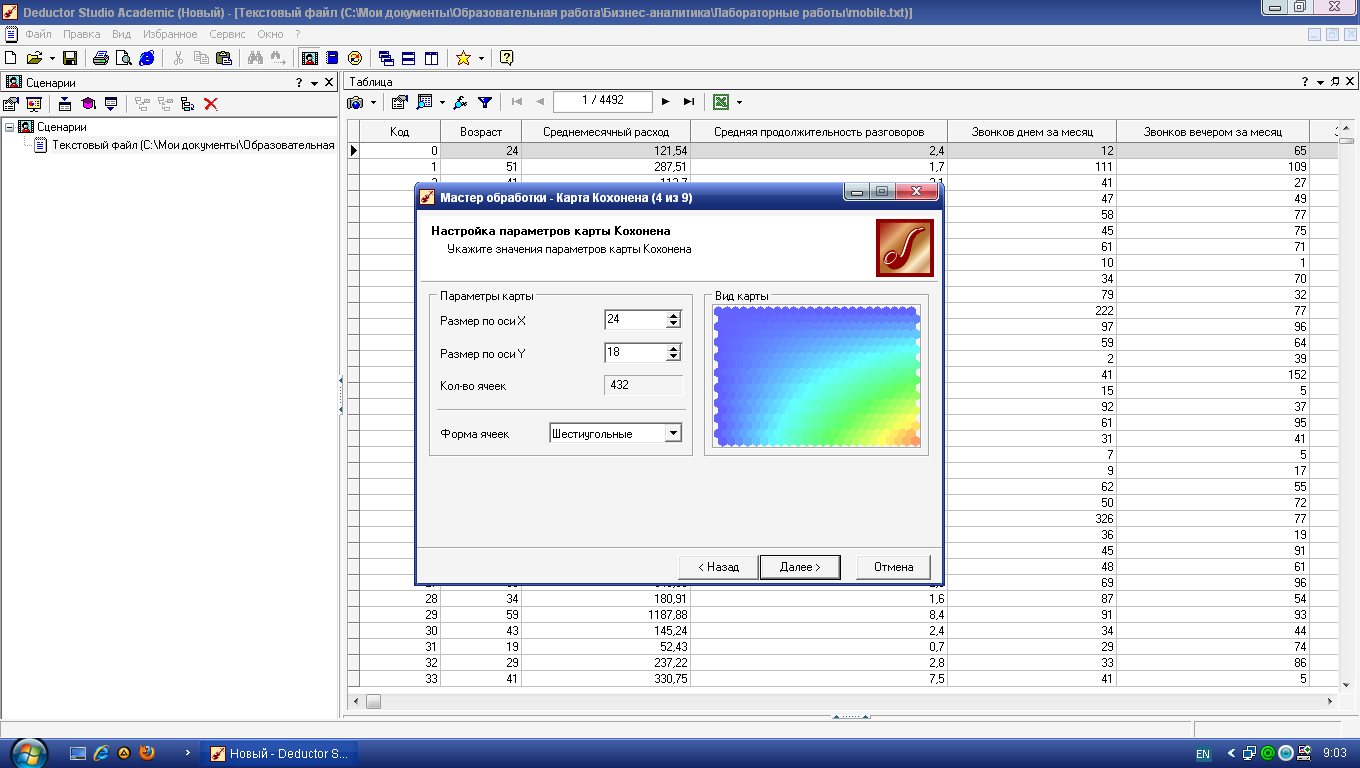
Рис.
4.3.
Параметры будущей карты Кохонена
На следующем шаге
оставьте все без изменений (рис. 4.4).
Наконец, на последнем
шаге, предшествующем обучению,
настраиваются параметры обучения
алгоритма Кохонена (рис. 4.5).
Здесь задаются
следующие опции.
Способ
начальной инициализации карты
определяет, как будут установлены
начальные веса нейронов карты. Удачно
выбранный способ инициализации может
существенно ускорить обучение и привести
к получению более качественных
результатов. Доступны три варианта.
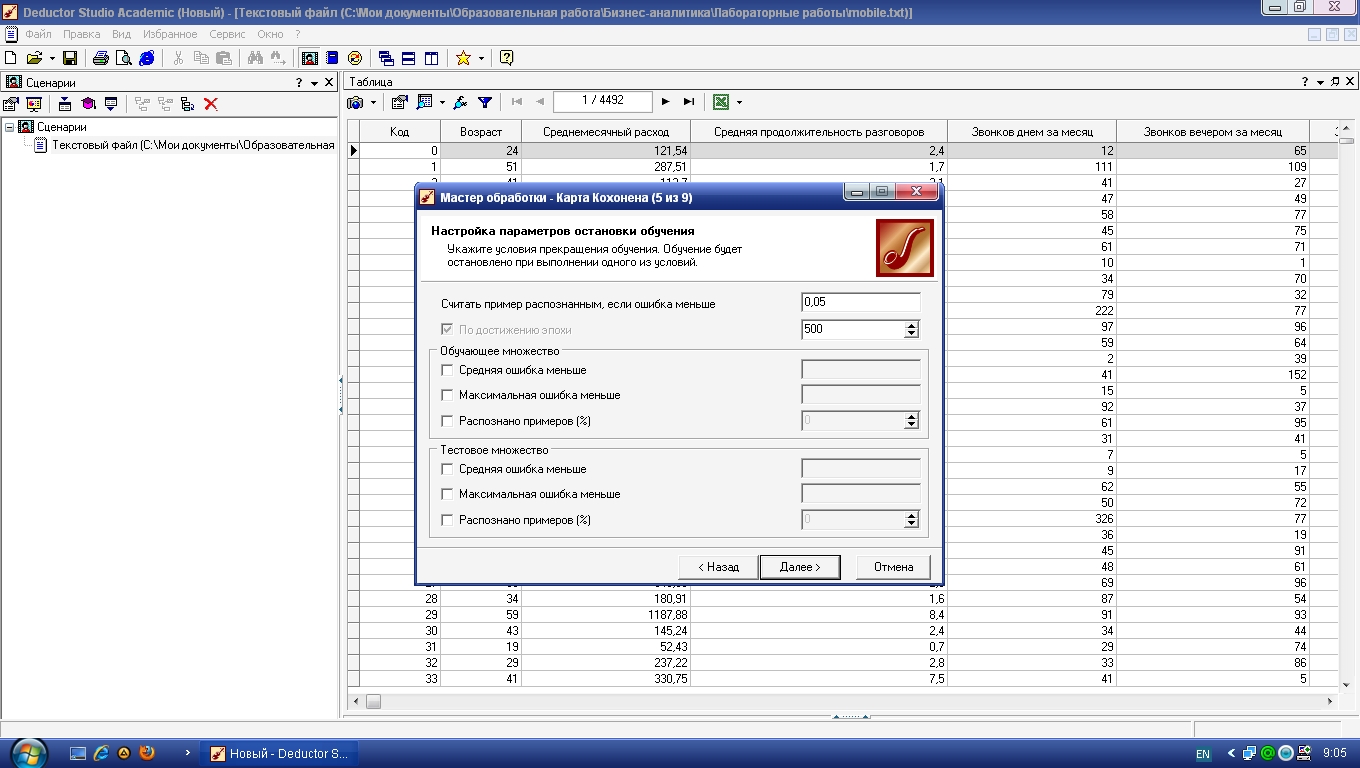
Рис.
4.4.
Параметры остановки алгоритма Кохонена
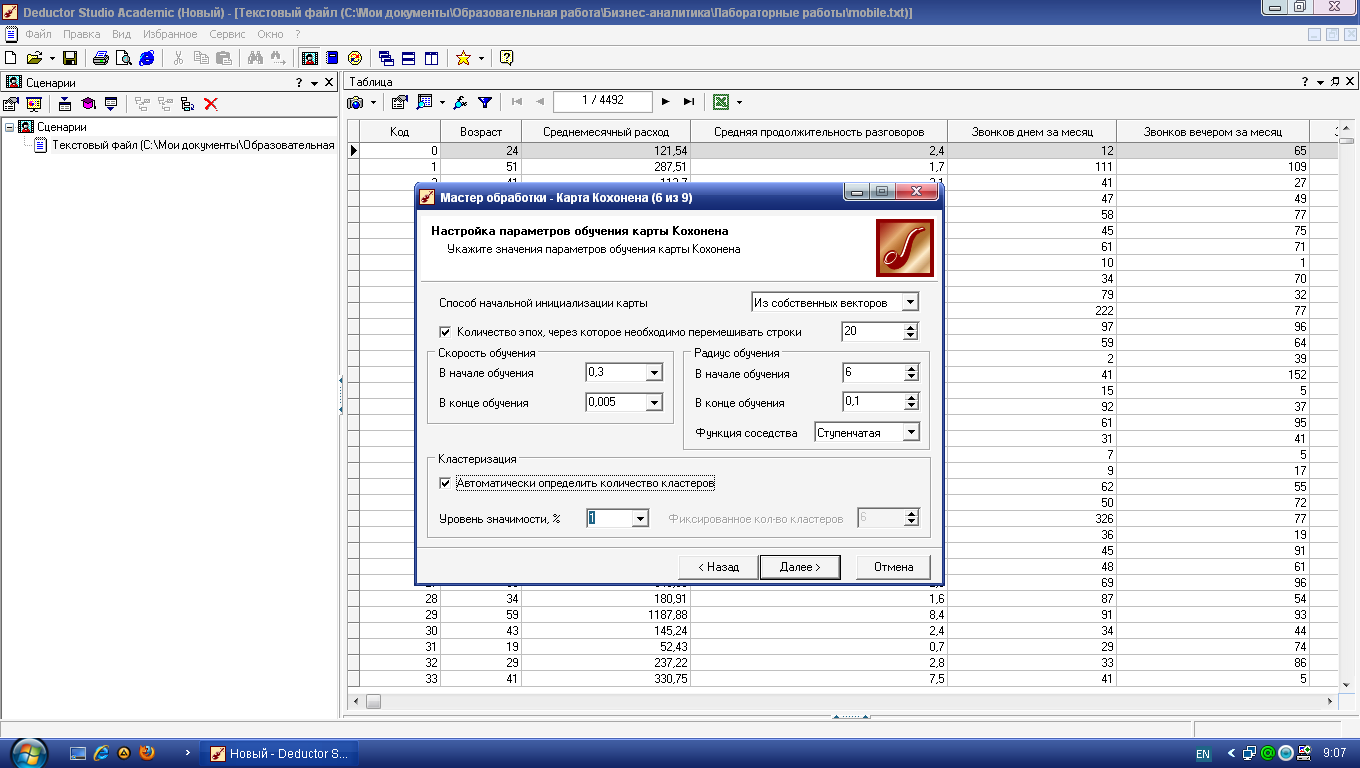
Рис.
4.5.
Параметры обучения сети Кохонена
-
Случайными
значениями
– начальные веса нейронов будут
инициированы случайными значениями. -
Из обучающего
множества –
в качестве начальных весов будут
использоваться случайные
примеры из обучающего множества. -
Из собственных
векторов –
начальные веса нейронов карты будут
проинициализированы значениями
подмножества гиперплоскости, через
которую проходят два главных собственных
вектора матрицы ковариации входных
значений обучающей выборки.
При выборе способа
начальной инициализации нужно
руководствоваться следующей информацией:
-
объемом обучающей
выборки; -
количеством эпох,
отведенных для обучения; -
размером карты.
Между указанными
параметрами и способом начальной
инициализации существует много
зависимостей. Выделим несколько главных.
-
Если объем обучающей
выборки значительно (в 100 раз и более)
превышает число ячеек карты и время
обучения не играет первоочередной
роли, то лучше выбрать инициализацию
случайными значениями. -
Если объем обучающей
выборки не очень велик, время обучения
ограниченно или если необходимо
уменьшить вероятность появления после
обучения пустых ячеек, в которые не
попало ни одного экземпляра обучающей
выборки, то следует использовать
инициализацию примерами из обучающего
множества. -
Инициализацию из
собственных векторов можно использовать
при любом стечении обстоятельств.
Именно этот способ лучше выбирать при
первом ознакомлении с данными.
Единственное замечание: вероятность
появления пустых ячеек после обучения
выше, чем при инициализации примерами
из обучающего множества.
Скорость
обучения
–
задается скорость обучения в начале и
в конце обучения сети Кохонена.
Рекомендуемые значения: 0,1-0,3 в начале
обучения и 0,05-0,005 в конце.
Радиус
обучения
–
задается радиус обучения в начале и в
конце обучения сети Кохонена, а также
тип функции соседства. Вначале радиус
обучения должен быть достаточно большим
–
примерно половина размера карты
(максимальное линейное расстояние от
любого нейрона до другого любого нейрона)
или меньше, а в конце –
достаточно малым, 1 или меньше. Начальный
радиус в Deductor
подбирается
автоматически в зависимости от размера
карты.
В этом же блоке
задается вид функции соседства: гауссова
или ступенчатая. Если функция соседства
ступенчатая, то «соседями» нейрона-победителя
будут считаться все нейроны, линейное
расстояние до которых не больше текущего
радиуса обучения. Если применяется
гауссова функция соседства, то «соседями»
нейрона-победителя будут считаться все
нейроны карты, но в разной степени. При
использовании гауссовой функции
соседства обучение проходит более
плавно и равномерно, так как одновременно
изменяются веса всех нейронов, что может
дать немного лучший результат, чем, если
бы использовалась ступенчатая функция.
Однако и времени на обучение требуется
больше, поскольку в каждой эпохе
корректируются все нейроны.
Кластеризация
–
в этой области указываются параметры
алгоритма k-means,
который
запускается после алгоритма Кохонена
для кластеризации ячеек карты.
Здесь нужно либо
позволить алгоритму автоматически
определить число кластеров, либо сразу
зафиксировать его. Следует знать, что
автоматически подбираемое число
кластеров не всегда приводит к желаемому
результату: оно может быть слишком
большим, поэтому рассчитывать на эту
опцию можно только на этапе исследования
данных.
Нажмите кнопку
Пуск
–
в следующем окне можно будет увидеть
динамику процесса обучения сети Кохонена
(рис. 4.6). По умолчанию алгоритм делает
500 итераций (эпох). Если предварительно
установить флажок
Рестарт,
то веса нейронов будут проинициализированы
согласно выбранному на предыдущем шаге
способу инициализации, иначе обучение
начнется с текущих весовых коэффициентов
(это справедливо только при повторной
настройке узла).
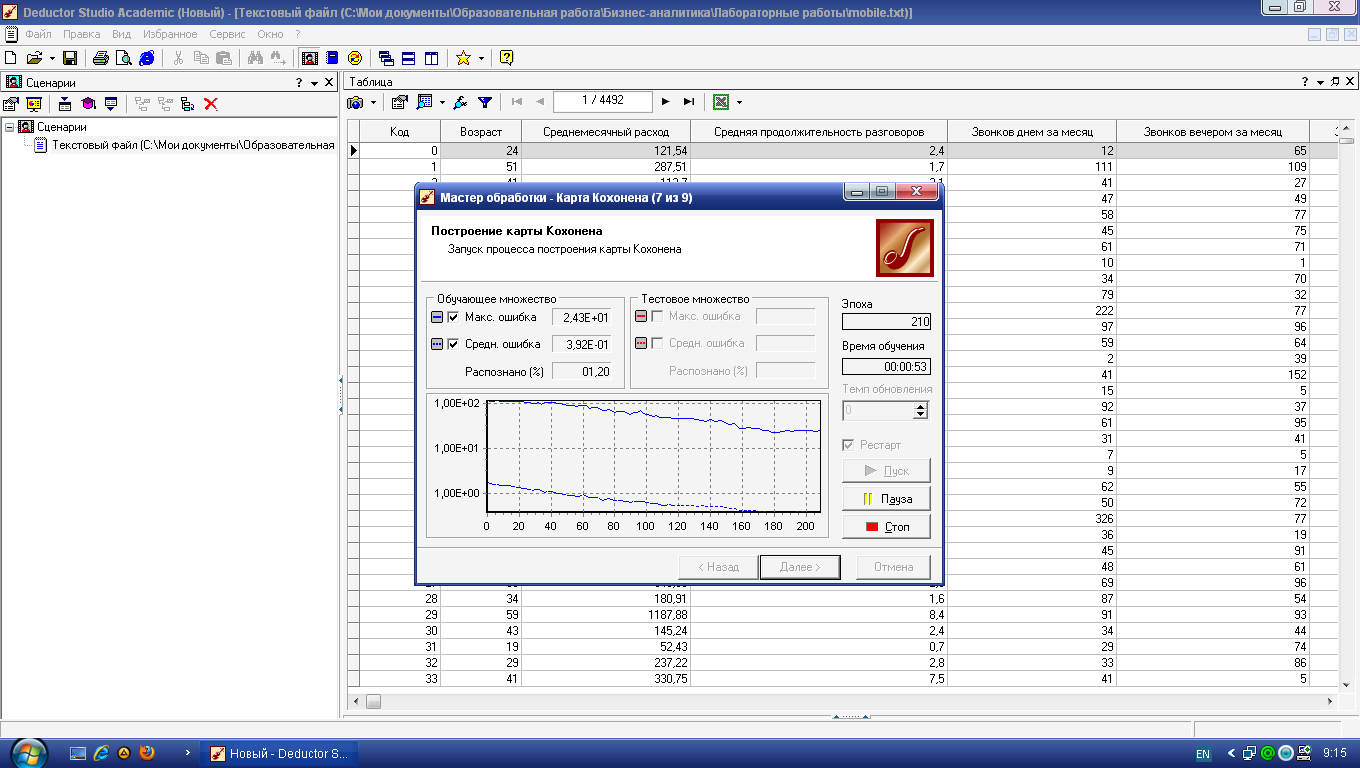
Рис. 4.6.
Обучение сети Кохонена
Для обученной сети
Кохонена предлагается специализированный
визуализатор –
Карта Кохонена.
Параметры ее отображения задаются на
одноименной вкладке мастера (рис. 4.7).
Область
Список допустимых отображений карты
содержит три группы –
Входные столбцы, Выходные столбцы
и
Специальные.
Последние не связаны с каким-либо полем
набора данных, а служат для анализа всей
карты.
-
Матрица
расстояний
применяется для визуализации структуры
кластеров, полученных в результате
обучения карты. Большое значение говорит
о том, что данный нейрон сильно отличается
от окружающих и относится к другому
классу. -
Матрица
ошибок квантования
отображает среднее расстояние от
расположения примеров до центра ячейки.
Расстояние считается как евклидово.
Матрица ошибок квантования показывает,
насколько хорошо обучена сеть Кохонена.
Чем меньше среднее расстояние до центра
ячейки, тем ближе к ней расположены
примеры и тем лучше модель.
Рис.
4.7.
Параметры карты Кохонена
Матрица
плотности попадания
отображает количество объектов, попавших
в ячейку.
Кластеры
–
ячейки карты Кохонена, объединенные в
кластеры алгоритмом k-means.
Проекция
Саммона –
матрица, являющаяся результатом
проецирования многомерных данных на
плоскость. При этом данные, расположенные
рядом в исходной многомерной выборке,
будут расположены рядом и на плоскости.
Дополнительно справа имеется еще ряд
настроек.
Способ
раскрашивания ячеек –
цветная палитра или градация серого.
Цветная палитра нагляднее, однако если
потребуется встраивать карту Кохонена
в отчет с последующей распечаткой на
бумажном носителе, то лучше выбрать
серую цветовую схему.
Сглаживание
цветов карты –
цвета на картах будут сглажены, то есть
будет обеспечен более плавный переход
цветов. Это поможет устранить случайные
выбросы.
Границы
ячеек –
установка данного флажка позволит
включить отображение границ ячеек на
карте.
Границы
кластеров –
установка данного флажка позволит
включить отображение границ кластеров
на всех картах. Этот режим удобен для
анализа структуры кластеров.
Размер
ячейки по умолчанию –
указывается размер ячейки на карте в
пикселях (по умолчанию 16).
Текущая ячейка
отображается на карте маленькой
окружностью черного цвета. Изменить
текущую ячейку просто: щелкнуть кнопкой
мыши на нужном участке карты. Внизу
каждой карты на градиентной шкале в
желтом прямоугольнике отображается
числовое значение признака, соответствующее
цвету ячейки.
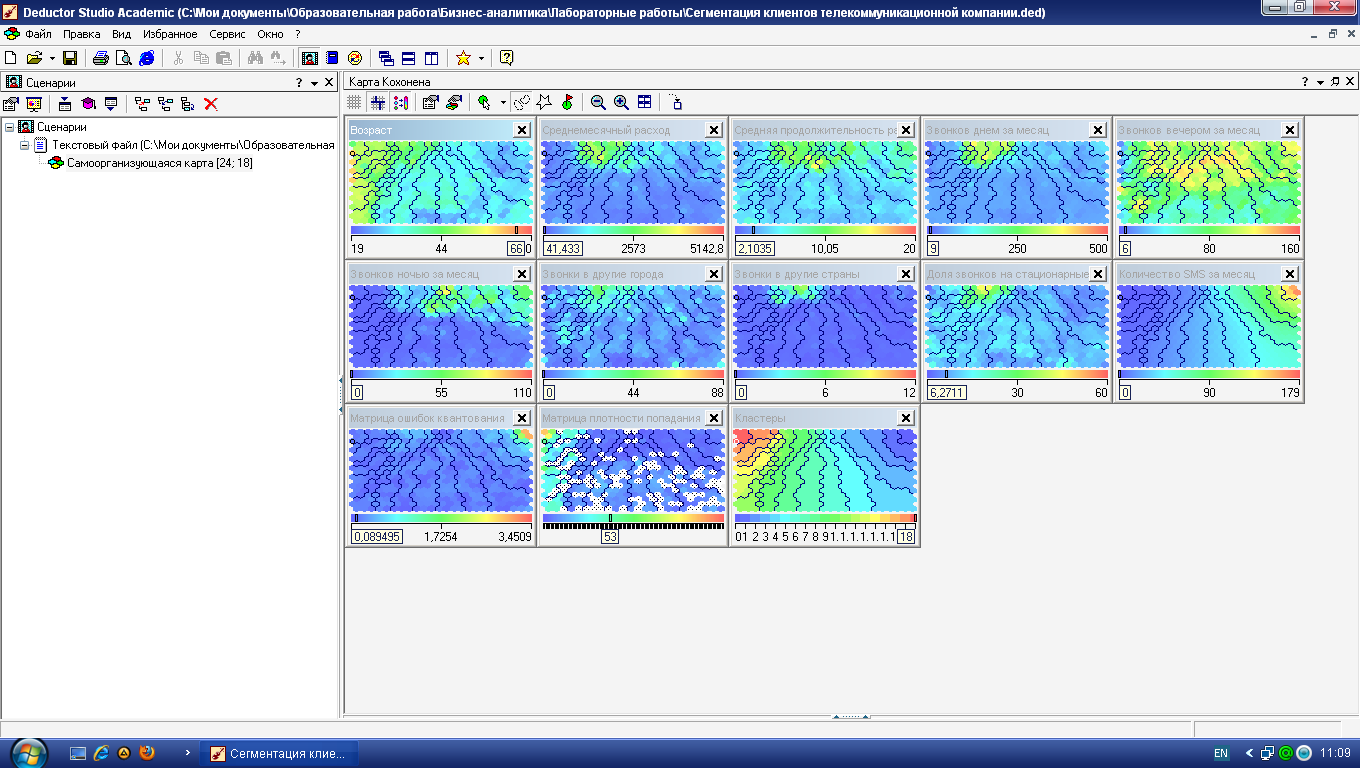
На рис. 4.8 приведены
получившиеся карты Кохонена. По матрице
плотности попадания видно, что в одной
ячейке сосредоточилось 259 объектов. Эта
ячейка выделяется белым цветом. Можно
приступать к интерпретации результатов
кластеризации.
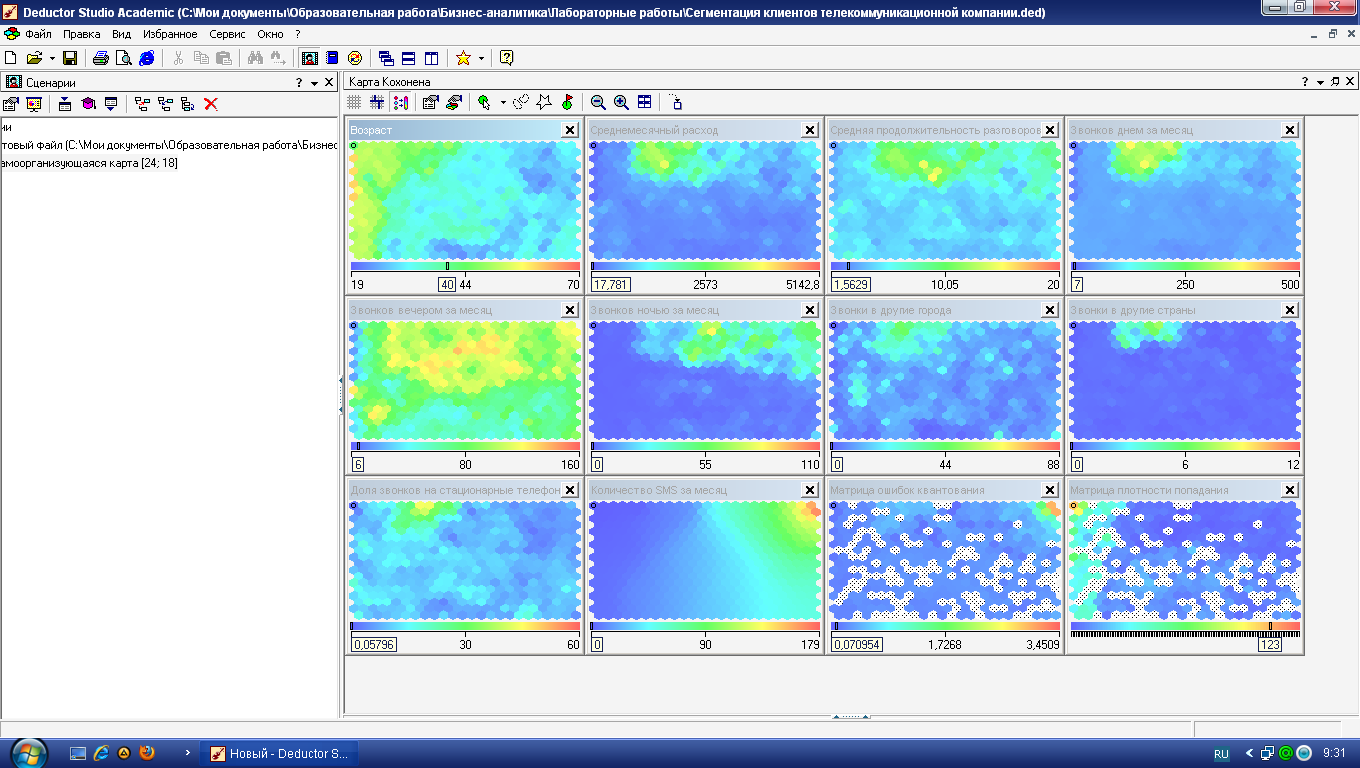
Рис.
4.8.
Карты Кохонена для сегментации абонентов
сети сотовой связи
Попробуем выделить
на карте изолированные области
самостоятельно (без использования
встроенного метода группировки ячеек
алгоритмом k-means).
Анализируя карту
Возраст
(рис. 4.8), видим, что четко выделяются три
возрастные группы: молодежь, люди
среднего возраста и люди старше 45 лет.
Остановимся
подробнее на молодежи. Она неоднородна
–
здесь можно выделить несколько кластеров.
Первый расположен в правом нижнем углу
(рис. 4.10). Абоненты этой условной зоны
активно и продолжительно разговаривают
по телефону вечером и ночью, отправляют
много SMS-сообщений,
соответственно, и тратят на разговоры
больше денег, чем другие представители
возрастной группы. Обратите внимание,
что в этот кластер попала львиная доля
тех, кто увлекается ночными разговорами.
Можно предположить, что это студенты и
молодежь, часто проводящие вечера вне
дома.
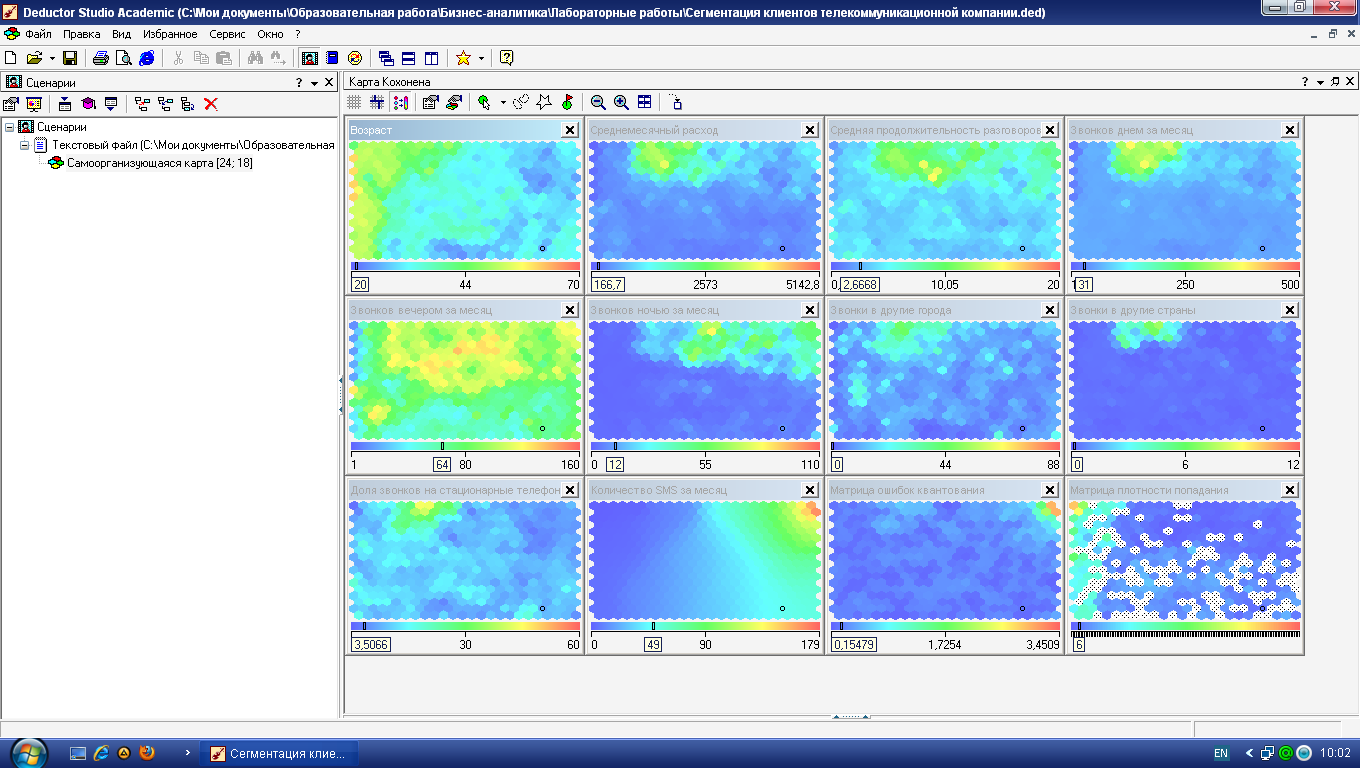
Рис.
4.10.
Кластер «Активная молодежь»
Вверху (рис. 4.11)
сосредоточилась небольшая по числу
ячеек группа молодежи, которая не
отличается активностью разговоров ни
днем, ни вечером, ни тем более ночью, и,
как следствие, ежемесячные расходы на
связь у представителей этого кластера
невелики.
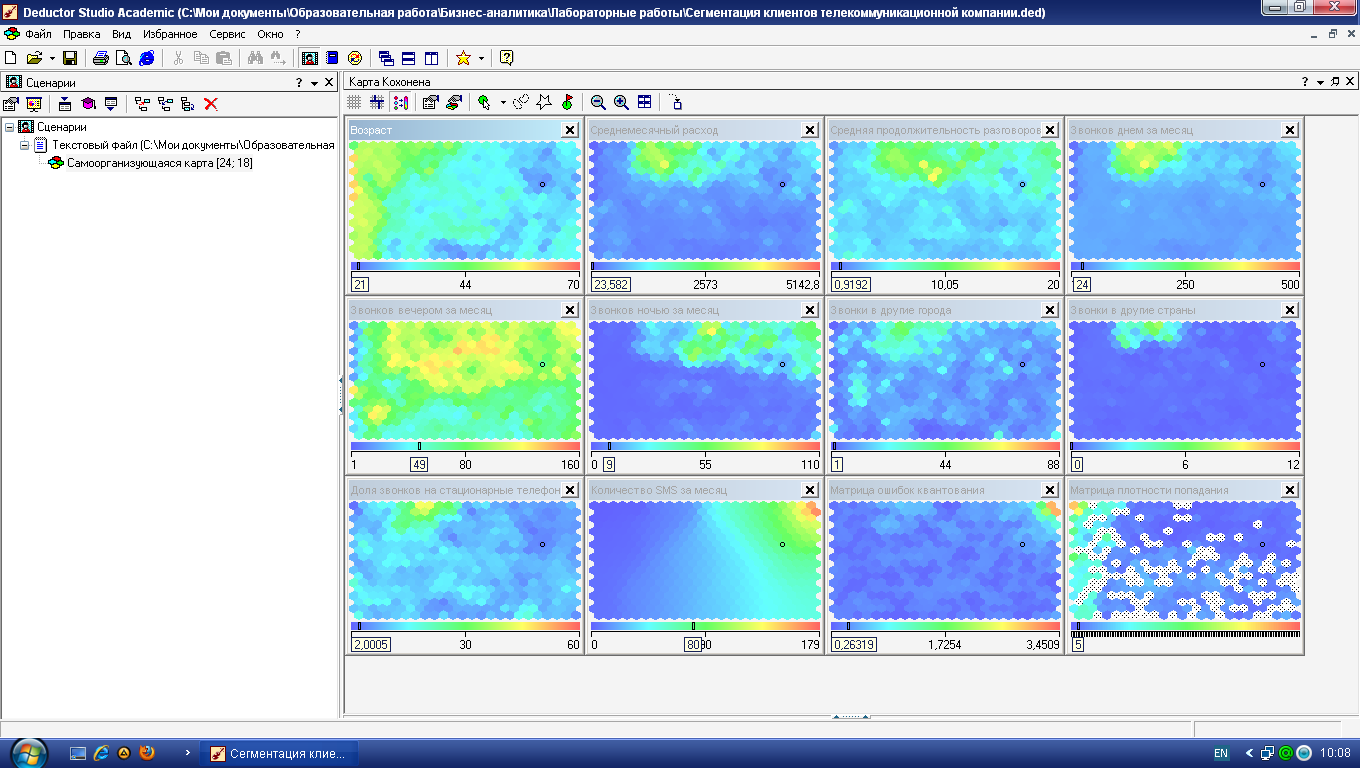
Рис.
4.11.
Кластер молодежи с пониженным потреблением
услуг связи
Остальные люди в
этой возрастной группе ничем особенным
не выделяются: умеренные расходы на
связь и преимущественно вечерние
разговоры. Можно предположить, что сюда
попала наибольшая часть молодежи. Таким
образом, в молодежной возрастной группе
мы обнаружили три кластера.
Продолжим
интерпретацию карты Кохонена и теперь
остановимся на людях зрелого и пенсионного
возраста. Обратим внимание на ярко
выраженный сгусток в верхней области,
в котором практически по всем признакам,
кроме SMS,
наблюдаются
высокие значения, в том числе по звонкам
в другие города и страны (рис. 4.12). Это
так называемые VIP-клиенты:
бизнесмены, руководители, топ-менеджеры.
Они преимущественно зрелого возраста,
очень много разговаривают днем и вечером
(скорее всего, по работе) и практически
не пользуются SMS-услугами.
Месячные расходы на связь у этой категории
абонентов самые высокие.

Рис.
4.12.
Кластер «VIP-клиенты»
Чуть выше в небольшом
кластере наблюдается противоположная
картина: люди практически не пользуются
услугами сотовой сети (рис. 4.13). Вероятнее
всего, это пенсионеры, которым мобильная
связь нужна преимущественно для приема
входящих звонков, сами же они почти не
звонят. Их расходы на связь самые низкие,
возможно, из-за того, что единственным
их доходом является пенсия.
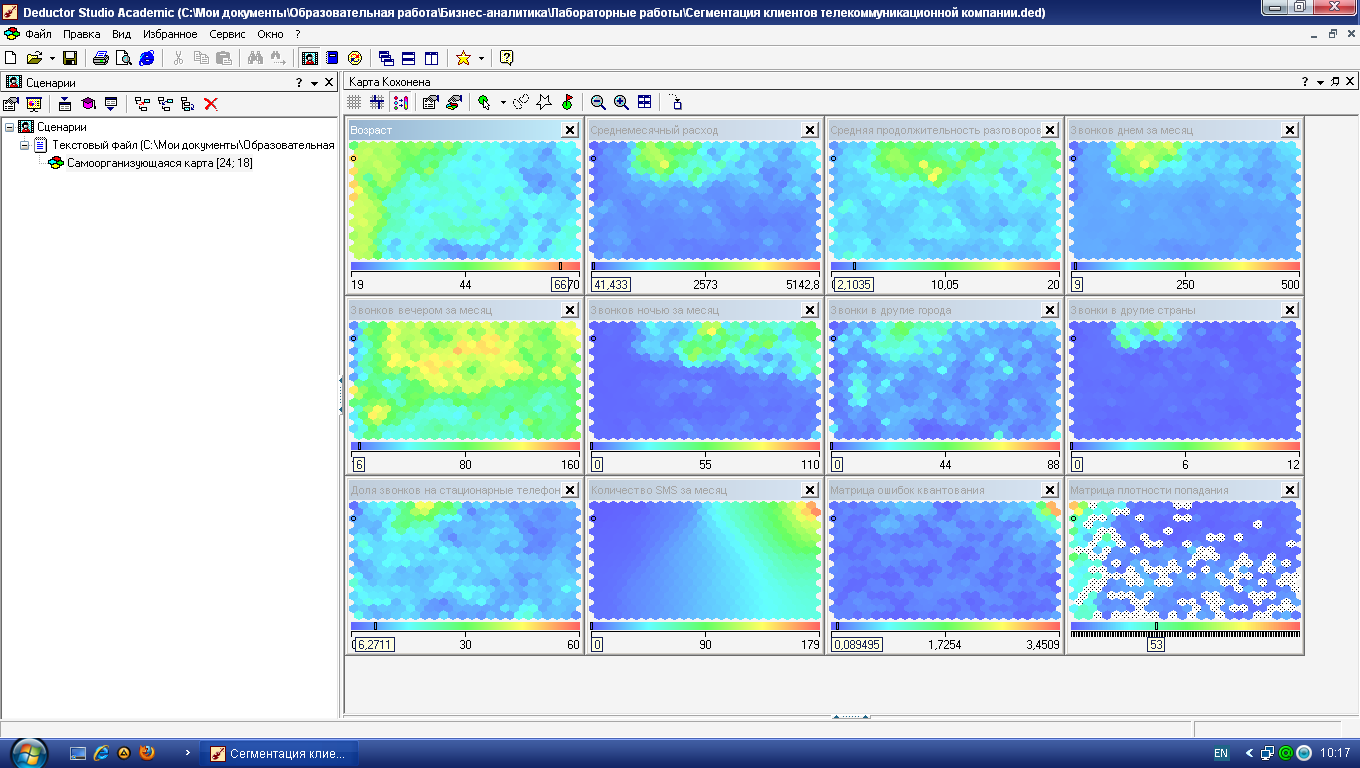
Рис.
4.13.
Пенсионеры, практически не делающие
исходящих звонков
Изучим статистические
характеристики этой группы людей.
Нажмите кнопку
Показать/скрыть
окно данных,
затем –
кнопку
Изменить
способ фильтрации
и установите
Фильтр
по выделенному.
Там же переключитесь в режим статистики
(кнопка
Способ
отображения).
Колонка
Среднее
даст следующие вычисленные значения
(табл. 4.2).
Таблица
4.2.
Статистические характеристики кластера
5
|
№ |
Признак |
Среднее |
|
1 |
Возраст |
65,7 |
|
2 |
Среднемесячный |
41,5 |
|
3 |
Средняя |
2,1 |
|
4 |
Звонков |
9,3 |
|
5 |
Звонков |
6,4 |
|
6 |
Звонков |
0,0 |
|
7 |
Звонки |
0 |
|
8 |
Звонки |
0 |
|
9 |
Доля |
6,3 |
|
10 |
Количество |
0 |
Остальных людей
в возрастной группе «Зрелый и пенсионный
возраст» объединяет то, что они в основном
звонят вечером и не используют SMS-сервис.
С большой долей вероятности можно
утверждать, что сюда входят работающие
пенсионеры, дачники, родители
совершеннолетних детей.
Осталась последняя,
средневозрастная группа. Это кластер
работающих людей. В нем можно отметить
группу тех, кто совершает мало звонков
вечером.
По площади, которую
занимают на карте Кохонена условно
выделенные кластеры, судить о мощности
каждого из них трудно: в разных ячейках
содержится различное число объектов.
Поэтому рекомендуется фиксировать
число объектов, попавших в каждый
кластер. Зная мощность кластера, можно
дополнительно оценить его прибыльность
–
сумму по признаку
Среднемесячный расход
(табл. 4.3).
Таблица
4.3.
Мощности кластеров
|
№ кластера |
Условное |
Мощность |
Прибыльность |
|
1 |
Активная |
||
|
2 |
Молодежь, |
||
|
3 |
Основная |
||
|
4 |
VIP-клиенты |
||
|
5 |
«Малоговорящие» |
569 |
23613,5 |
|
6 |
Активная |
||
|
7 |
Работающие |
Теперь включите
автоматическую группировку ячеек в
кластеры:
Настроить
отображения – Кластеры.
При установленном флажке
Автоматически
определить количество кластеров
(с уровнем значимости 1,00) получится
16
кластеров (рис. 4.14, а). Это очень много,
поэтому следует принудительно установить,
скажем, 6 кластеров (рис. 4.14, б).
а
б
Рис.
4.14.
Варианты автоматической группировки
ячеек алгоритмом k-means:
а – автоматическое число кластеров, б
– ручное задание числа кластеров, равное
6
Видно, что
автоматический алгоритм k-means
при 6 кластерах
выделил целиком кластер «Зрелый и
пенсионный возраст», раздробились
группы «Молодежь» и «Люди среднего
возраста». Не были явно выделены кластеры
2, 4 и 5 из табл. 4.3. Тем не менее, автоматическая
группировка ячеек в Deductor
имеет одно
важное преимущество: в наборе данных
появляется столбец
Кластер
с номером, который можно использовать
в дальнейшем, в частности «прогонять»
новые объекты и получать для них номер
кластера.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
dsp.ScalarQuantizerEncoder
(Removed) Associate input value with index value of quantization region
dsp.ScalarQuantizerEncoder has been removed.
Description
The dsp.ScalarQuantizerEncoder object encodes each input
value by associating that value with the index value of the quantization region. Then, the
object outputs the index of the associated region.
To encode an input value by associating it with an index value of the quantization
region:
-
Create the
dsp.ScalarQuantizerEncoderobject and set its properties. -
Call the object with arguments, as if it were a function.
To learn more about how System objects work, see What
Are System Objects?
Creation
Syntax
Description
example
sqenc = dsp.ScalarQuantizerEncoder
scalar quantizer encoder System object™, sqenc. This object maps each input value to a
quantization region by comparing the input value to the user-specified boundary
points.
sqenc = dsp.ScalarQuantizerEncoder(Name,Value)
returns a scalar quantizer encoder object, sqenc, with
each specified property set to the specified value.
Properties
expand all
Unless otherwise indicated, properties are nontunable, which means you cannot change their
values after calling the object. Objects lock when you call them, and the
release function unlocks them.
If a property is tunable, you can change its value at
any time.
For more information on changing property values, see
System Design in MATLAB Using System Objects.
BoundaryPointsSource — Source of boundary points
'Property' (default) | 'Input port'
Specify how to determine the boundary points and codebook values as
'Property' or 'Input port'.
Partitioning — Quantizer is bounded or unbounded
'Bounded' (default) | 'Unbounded'
Specify the quantizer as 'Bounded' or
'Unbounded'.
BoundaryPoints — Boundary points of quantizer regions
1:10 (default) | vector
Specify the boundary points of quantizer regions as a vector. The vector values must
be in ascending order. Let [p0 p1 p2 p3 ... pN] denote the boundary
points property in the quantizer. If the quantizer is bounded, the object uses this
property to specify [p0 p1 p2 p3 ... pN]. If the quantizer is
unbounded, the object uses this property to specify [p1 p2 p3 ... and sets
p(N-1)]p0 = -Inf and pN =.
+Inf
Tunable: Yes
Dependencies
This property applies when you set the BoundaryPointsSource
property to Property.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
SearchMethod — Find quantizer index by linear or binary search
'Linear' (default) | 'Binary'
Specify whether to find the appropriate quantizer index using a linear search or a
binary search as one of 'Linear' or 'Binary'. The
computational cost of the linear search method is of the order P and
the computational cost of the binary search method is of the order
where P is the number of boundary points.
TiebreakerRule — Behavior when input equals boundary point
'Choose the lower index' (default) | 'Choose the higher index'
Specify whether the input value is assigned to the lower indexed region or higher
indexed region when the input value equals boundary point by selecting 'Choose or
the lower index''Choose the higher index'.
CodewordOutputPort — Enable output of codeword value
false (default) | true
Set this property to true to output the codeword values that
correspond to each index value.
QuantizationErrorOutputPort — Enable output of quantization error
false (default) | true
Set this property to true to output the quantization error for
each input value. The quantization error is the difference between the input value and
the quantized output value.
Codebook — Codebook
1.5:9.5 (default) | vector
Specify the codebook as a vector of quantized output values that correspond to each
region. If the Partitioning property is
'Bounded' and the boundary points vector has length N, you must set
this property to a vector of length N-1. If the Partitioning property is 'Unbounded' and the boundary
points vector has length N, you must set this property to a vector of length N+1.
Tunable: Yes
Dependencies
This property applies when you set the BoundaryPointsSource
property to 'Property' and either the
CodewordOutputPort property or the
QuantizationErrorOutputPort property is
true.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
ClippingStatusOutputPort — Enable output of clipping status
false (default) | true
Set this property to true to output the clipping status. The
output is a 1 when an input value is outside the range defined by the
BoundaryPoints property. When the value is inside the range, the
exception output is a 0.
Dependencies
This property applies when you set the Partitioning property
to 'Bounded'.
OutputIndexDataType — Data type of the index output
int32 (default) | int8 | int16 | uint8 | uint16 | uint32
Specify the data type of the index output from the object as:
int8, uint8, int16,
uint16, int32, uint32.
Fixed-Point Properties
RoundingMethod — Rounding method for fixed-point operations
'Floor' (default) | 'Ceiling' | 'Convergent' | 'Nearest' | 'Round' | 'Simplest' | 'Zero'
Specify the rounding method.
OverflowAction — Overflow action for fixed-point operations
'Wrap' (default) | 'Saturate'
Specify the overflow action.
Usage
Syntax
Description
example
index = sqenc(input)
returns the index of the quantization region to which the
input belongs. The input data, boundary points, codebook values,
quantized output values, and the quantization error must have the same data type whenever
they are present.
[index] = sqenc(input,bpoints)
uses input bpoints as the boundary points when the
BoundaryPointsSource property is Input.
port
[index] = sqenc(input,bpoints,cBook)
uses input bpoints as the boundary points and input
cBook as the codebook when the BoundaryPointsSource property is 'Input port' and either
the CodewordOutputPort property or the QuantizationErrorOutputPort property is
true.
[index,codeword] = sqenc(___)
outputs the codeword values that corresponds to each index value when
the CodewordOutputPort property is
true.
[___,qerr] = sqenc(___)
outputs the quantization error qerr for each input value when the
QuantizationErrorOutputPort property is
true.
[___,cStatus] = sqenc(___)
also returns output cStatus as the clipping status output port for each
input value when the Partitioning property is
'Bounded' and the ClippingStatusOutputPort property is true. If an input
value is outside the range defined by the BoundaryPoints
property, cStatus is true. If an input value is
inside the range, cStatus is false.
Input Arguments
expand all
input — Input data
vector | matrix
Input data, specified as a vector or a matrix. If the input is fixed point, it
must be signed fixed point with power-of-two slope and zero bias.
Data Types: single | double | int8 | int16 | int32 | int64 | fi
bpoints — Boundary points
vector
Boundary points of the quantizer regions, specified as a vector. The vector values
must be in ascending order. Let [p0 p1 p2 p3 ... pN] denote the
boundary points in the quantizer. If the quantizer is bounded, the object uses this
input to specify [p0 p1 p2 p3 ... pN]. If the quantizer is
unbounded, the object uses this input to specify [p1 p2 p3 ... and sets
p(N-1)]p0 = -Inf and pN =.
+Inf
Dependencies
This input applies when you set the BoundaryPointsSource
property to Input port.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
cBook — Code book
vector
Codebook, specified as a vector of quantized output values that correspond to each
region. If the Partitioning property is
'Bounded' and the boundary points vector has length
N, this input must be a vector of length N-1.
If the Partitioning property is
'Unbounded' and the boundary points vector has length
N, this input must be a vector of length
N+1.
Dependencies
This input applies when you set the BoundaryPointsSource
property is 'Input port' and either the CodewordOutputPort property or the QuantizationErrorOutputPort property is true.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Output Arguments
expand all
index — Index of quantization region
vector | matrix
Index of the quantization region to which the input belongs,
returned as a vector or a matrix of the same size as the input.
Data Types: int32
codeword — Codeword values
vector | matrix
Codeword values that correspond to each index value, returned as a vector or a
matrix of the same size as the input.
Dependencies
This output is available when the CodewordOutputPort property is set to true.
Data Types: single | double | int8 | int16 | int32 | int64 | fi
qerr — Quantization error
vector | matrix
Quantization error for each input value, returned as a vector or a matrix of the
same size as the input.
Dependencies
This output is available when the
QuantizationErrorOutputPort property is set to
true.
Data Types: single | double | int8 | int16 | int32 | int64 | fi
cStatus — Clipping status
vector | matrix
Clipping status for each input value, returned as a vector or a matrix. If an
input value is outside the range defined by the BoundaryPoints property, cStatus is
true. If an input value is inside the range,
cStatus is false.
Dependencies
This output is available when the Partitioning
property is 'Bounded' and the ClippingStatusOutputPort property is set to
true.
Data Types: logical
Object Functions
To use an object function, specify the
System object as the first input argument. For
example, to release system resources of a System object named obj, use
this syntax:
expand all
Common to All System Objects
step |
Run System object algorithm |
release |
Release resources and allow changes to System object property values and input characteristics |
reset |
Reset internal states of System object |
Examples
collapse all
Quantize Varying Fractional Inputs
Quantize the varying fractional inputs between zero and five to the closest
integers, and then plot the results.
sqenc = dsp.ScalarQuantizerEncoder;
sqenc.BoundaryPoints = [-.001 .499 1.499 ...
2.499 3.499 4.499 5.001];
sqenc.CodewordOutputPort = true;
sqenc.Codebook = [0 1 2 3 4 5];
input = (0:0.02:5)';
[index, quantizedValue] = sqenc(input);
plot(1:length(input), [input quantizedValue]);
Algorithms
This object implements the algorithm, inputs, and outputs described on the Scalar
Quantizer Encoder block reference page. The object properties correspond to the
block parameters.
Extended Capabilities
Version History
Introduced in R2012a
expand all
R2023a: dsp.ScalarQuantizerEncoder
System object has been removed
The dsp.ScalarQuantizerEncoder
System object has been removed.
R2021b: dsp.ScalarQuantizerEncoder System object will be removed
dsp.ScalarQuantizerEncoder
System object will be removed in a future release.
Время на прочтение
4 мин
Количество просмотров 9.9K
Это продолжение статьи, в которой я больше расскажу о теории и практике кодирования видео с помощью Xvid, а также представлю улучшенную версию своей матрицы, в которой показатель «качество/размер» стал больше. Подробности под катом.
Недавно кодеку Xvid исполнилось 7 лет, а вообще данный принцип сжатия видео существует 15 лет, но в инете на русском языке путёвой информации по вопросам кодирования немного. Для затравки можете почитать это: сжатие видео, MPEG-4, Xvid.
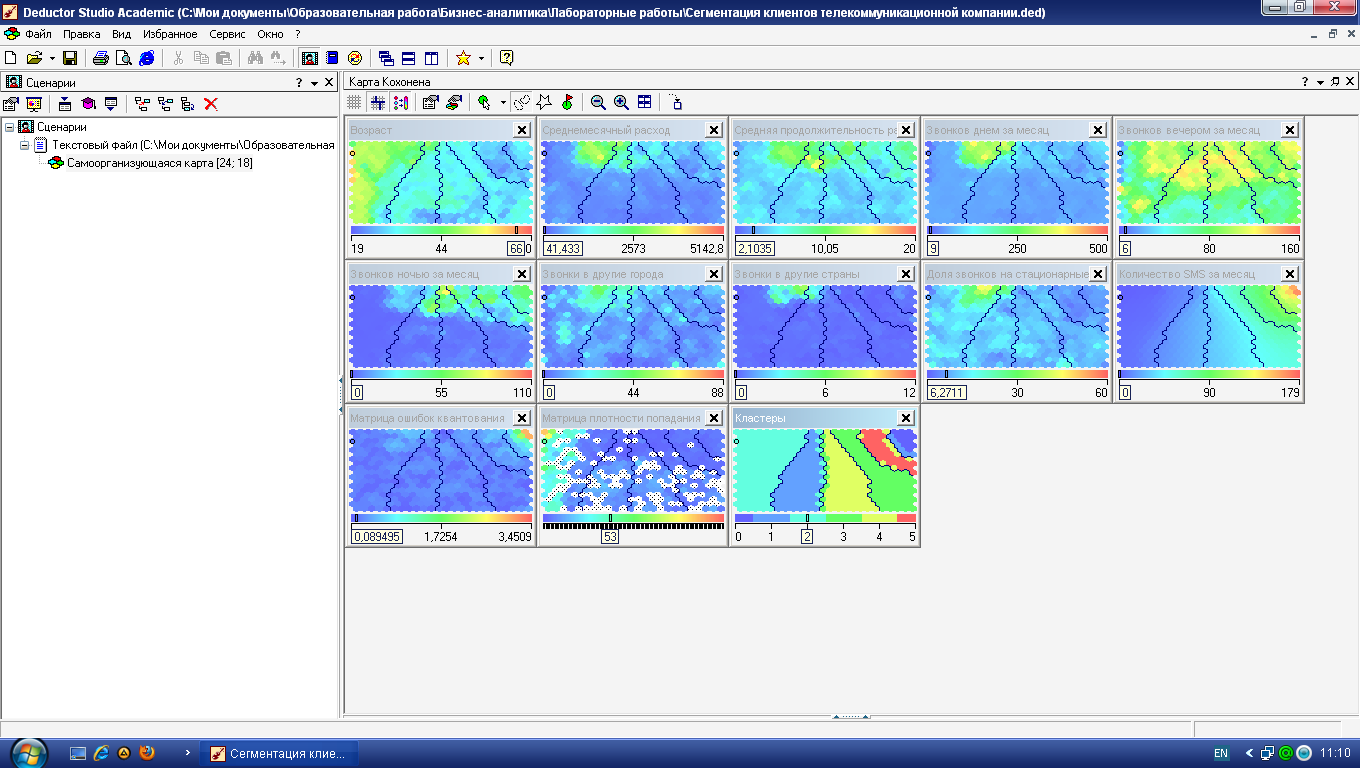
Я же только кратко коснусь теории (подробней, честно говоря, знаю не особо). Перед кодированием картинка разбивается на блоки 8х8, для каждого блока находятся средние значения яркости и цвета, а все пикселы преобразуются в математическую зависимость от средних величин. К полученной матрице применяется дискретно-косинусное преобразование с использованием матриц квантования. Матрица Intra для ключевых кадров, Inter для всех остальных. Левый верхний угол матриц используется для квантизации значений, которые мало отличаются от средней величины, соответственно правый нижний угол – для значений, которые сильно отличаются от средней величины. Чем больше коэффициент в матрице, тем больше огрубление значений яркости и цвета. Коэффициенты бывают в диапазоне 8-255. На этом квантизация не закончена, перед итоговой упаковкой все значения блока делятся на квантизатор, указанный в настройке кодека Xvid. На фото Target quantizer (выделен красным, фото после фото матрицы).
Квантизация – это огрубление сигнала. При кодировании значение сигнала делится на определённое число, а при декодировании умножается. Поскольку дробная часть отбрасывается, то при больших значениях квантизатора теряется много деталей и блоки 8х8 становятся слишком заметными. Но и размер файла при этом весьма мал. Поэтому задача кодирования сводится к тому, чтобы уменьшить квадратичность в файлах малого размера. И разработка собственной матрицы просто необходима.
Типы кадров. Проще говоря, кадры бывают ключевые и неключевые. Неключевые зависят от ключевых, они показывают изменение картинки (движение). На фото настроек Xvid показано стандартное значение интервала ключевых кадров 300, настройки вызываются нижней кнопкой «more» в основном окне настроек Xvid. Поскольку неключевой кадр занимает в 5 раз меньше места, чем ключевой, то малым размером файла мы обязаны именно ему. Значение больше 300 обычно не используется, ибо этого интервала хватает на 10-12 секунд просмотра. По объёму ключевые кадры при такой настройке займут 5-7 % вашего файла без учёта аудио.
На фотографиях ниже я покажу, как влияют коэффициенты матрицы квантования и квантизатор на качество картинки.
Для эксперимента я использовал следующую матрицу Intra:

Как видите, первые коэффициенты я сделал максимальными, чтобы увидеть, в каких местах будут наибольшие искажения.
Все фотки в масштабе 300%. Это картинка до сжатия:

Это сжатие с квантизатором 2:

Это сжатие с квантизатором 4:

Как видим, квантизатор 4 делает квадраты более заметными, а коэффициенты 255 в матрице огрубляют большую часть значений яркости и цвета, так что блок расплывается в квадратное пятно. Если бы блоки были круглыми, то это выглядело бы как боке – фон, который не в фокусе. А то, что детали картинки всё ещё видны, это потому, что мы остальные коэффициенты оставили минимальными. Квантизатор 1 использовать категорически не рекомендуется из-за особенностей кодека, а больше 4 я не использую, потому что при этом сильно искажаются блоки.
Теперь о моей матрице. Её новый вид таков:
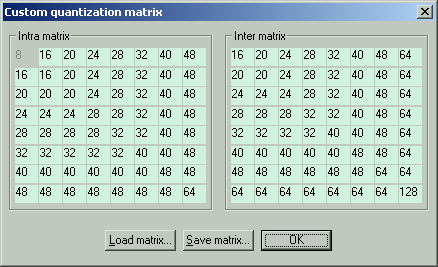
Она может применятся в трёх режимах. Настройки для всех режимов одинаковы, кроме одного параметра, основного квантизатора Target quantizer (выделен красным).
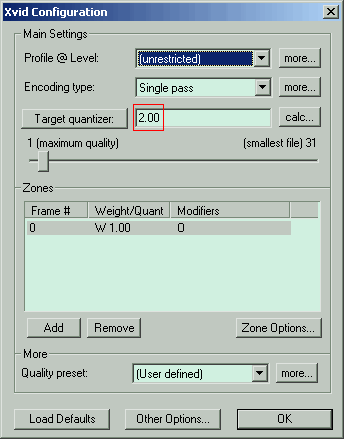
Важные настройки, выделенные красным, рекомендуется ставить как на фотке (подробно в первом посте).

1. Качественный. Target quantizer 2. Качество отличное, размер файла 80% (за 100% принимается размер файла при кодировании стандартной матрицей H263 с теми же настройками. От этого размера «пляшем» во всех режимах).
2. Компромисный. Target quantizer 3. Качество нормальное, размер 54%.
3. Сжатый. Target quantizer 4. Качество удовлетворительное, размер 40%.
Как видим, в третьем режиме имеем файл в 2 раза меньший, чем в первом (без аудио), но значительно жертвуем качеством. Хотя слово «значительно» имеет очень относительный смысл. Дело в том, что я сравнивал образцы, одновременно открытые в отдельных окнах VirtualDub’ом, покадрово в масштабах 200% и 300%. Если вы закодируете фильм с разрешением 1280х720 в третьем режиме и просто будете его просматривать в плеере, то может и не заметите разницу. Первый режим рекомендуется для видео с низким разрешением или для роликов, очень дорогих сердцу. Второй режим подходит для большинства фильмов, а третий для видео с большим разрешением или для роликов, где важно не качество, а сам материал.
Выбирая третий режим, не забудьте о качестве звука, ибо аудио в формате 5:1 384 Кбит занимает немало места (в фильме обычно 300 Мб). Для переноса аудио из любого формата в mp3 рекомендую Format Factory. Он бесплатен, кодирует видео и аудио. Ещё для информации: минимальный формат аудио mp3, при котором сохраняется нормальное звучание, это mono 48 Kbit 44 KHz. Не кодируйте в 22 KHz, ибо это значительно хуже на любом битрейте. Также не кодируйте в 48 KHz, если у вас исходник меньшей частоты или вы её не знаете. Изменение частоты обычно приводит к искажениям. 44 KHz – самая безопасная частота.
У многих возникнет вопрос: почему надо кодировать с постоянным квантизатором? Потому что в любом другом режиме (двухпроходный режим, постоянный битрейт) вы не контролируете квантизатор. А именно квантизатор в первую очередь отвечает за квадратичность (см. выше эксперимент). Также почитайте в первом посте о дополнительных настройках Xvid, без них использование моей матрицы не будет эффективным.
Кодируйте на здоровье!
Покажем
последовательность решения бизнес-задачи
сегментации абонентов с помощью подхода,
который основан на алгоритме Кохонена.
Решение состоит из двух шагов:
-
кластеризации
объектов алгоритмом Кохонена; -
построения и
интерпретации карты Кохонена.
В программе Deductor
сети и карты
Кохонена реализованы в обработчике
Карта Кохонена,
где содержатся сам алгоритм Кохонена
и специальный визуализатор Карта
Кохонена.
В Deductor
канонический
алгоритм Кохонена дополнен рядом
возможностей.
-
Алгоритм Кохонена
применяется к сети Кохонена, состоящей
из ячеек, упорядоченных на плоскости.
По умолчанию размер карты равен 16×12,
что соответствует 192 ячейкам. В выходном
наборе данных алгоритм Кохонена
формирует поля
Номер ячейки
и
Расстояние до центра ячейки. -
Ячейки карты с
помощью специальной дополнительной
процедуры объединяются в кластеры. Эта
процедура –
алгоритм k-means,
причем имеется
возможность автоматически определять
количество кластеров. В выходном наборе
данных алгоритм k-means
формирует
поля
Номер кластера
и
Расстояние до центра кластера. -
Каждый входной
признак может иметь весовой коэффициент
от 0 до 100%, который влияет на расчет
евклидова расстояния между векторами.
Импортируйте в
Deductor
набор данных
из файла mobile.txt.
Запустите
Мастер
обработки
и выберите узел
Карта Кохонена.
Установите все поля, кроме
Код, входными
(рис. 4.1).
Рис.
4.1.
Установка входных полей в алгоритме
Кохонена
На этой же вкладке
при нажатии кнопки
Настройка нормализации
откроется окно, где можно задать
значимость каждого входного поля.
Оставьте значимость всех полей без
изменений.
Поскольку любой
метод кластеризации, в том числе алгоритм
Кохонена, субъективен, смысл в выделении
отдельного тестового множества, как
правило, отсутствует. Оставьте в обучающем
множестве 100% записей (рис. 4.2).
На третьей вкладке
задаются размер и форма карты Кохонена
(рис. 4.3). Увеличьте размер карты до 24×18
(соотношение рекомендуется делать
кратным 4:3).
Рис.
4.2.
Разбиение набора данных на обучающее
и тестовое множества
Рис.
4.3.
Параметры будущей карты Кохонена
На следующем шаге
оставьте все без изменений (рис. 4.4).
Наконец, на последнем
шаге, предшествующем обучению,
настраиваются параметры обучения
алгоритма Кохонена (рис. 4.5).
Здесь задаются
следующие опции.
Способ
начальной инициализации карты
определяет, как будут установлены
начальные веса нейронов карты. Удачно
выбранный способ инициализации может
существенно ускорить обучение и привести
к получению более качественных
результатов. Доступны три варианта.
Рис.
4.4.
Параметры остановки алгоритма Кохонена
Рис.
4.5.
Параметры обучения сети Кохонена
-
Случайными
значениями
– начальные веса нейронов будут
инициированы случайными значениями. -
Из обучающего
множества –
в качестве начальных весов будут
использоваться случайные
примеры из обучающего множества. -
Из собственных
векторов –
начальные веса нейронов карты будут
проинициализированы значениями
подмножества гиперплоскости, через
которую проходят два главных собственных
вектора матрицы ковариации входных
значений обучающей выборки.
При выборе способа
начальной инициализации нужно
руководствоваться следующей информацией:
-
объемом обучающей
выборки; -
количеством эпох,
отведенных для обучения; -
размером карты.
Между указанными
параметрами и способом начальной
инициализации существует много
зависимостей. Выделим несколько главных.
-
Если объем обучающей
выборки значительно (в 100 раз и более)
превышает число ячеек карты и время
обучения не играет первоочередной
роли, то лучше выбрать инициализацию
случайными значениями. -
Если объем обучающей
выборки не очень велик, время обучения
ограниченно или если необходимо
уменьшить вероятность появления после
обучения пустых ячеек, в которые не
попало ни одного экземпляра обучающей
выборки, то следует использовать
инициализацию примерами из обучающего
множества. -
Инициализацию из
собственных векторов можно использовать
при любом стечении обстоятельств.
Именно этот способ лучше выбирать при
первом ознакомлении с данными.
Единственное замечание: вероятность
появления пустых ячеек после обучения
выше, чем при инициализации примерами
из обучающего множества.
Скорость
обучения
–
задается скорость обучения в начале и
в конце обучения сети Кохонена.
Рекомендуемые значения: 0,1-0,3 в начале
обучения и 0,05-0,005 в конце.
Радиус
обучения
–
задается радиус обучения в начале и в
конце обучения сети Кохонена, а также
тип функции соседства. Вначале радиус
обучения должен быть достаточно большим
–
примерно половина размера карты
(максимальное линейное расстояние от
любого нейрона до другого любого нейрона)
или меньше, а в конце –
достаточно малым, 1 или меньше. Начальный
радиус в Deductor
подбирается
автоматически в зависимости от размера
карты.
В этом же блоке
задается вид функции соседства: гауссова
или ступенчатая. Если функция соседства
ступенчатая, то «соседями» нейрона-победителя
будут считаться все нейроны, линейное
расстояние до которых не больше текущего
радиуса обучения. Если применяется
гауссова функция соседства, то «соседями»
нейрона-победителя будут считаться все
нейроны карты, но в разной степени. При
использовании гауссовой функции
соседства обучение проходит более
плавно и равномерно, так как одновременно
изменяются веса всех нейронов, что может
дать немного лучший результат, чем, если
бы использовалась ступенчатая функция.
Однако и времени на обучение требуется
больше, поскольку в каждой эпохе
корректируются все нейроны.
Кластеризация
–
в этой области указываются параметры
алгоритма k-means,
который
запускается после алгоритма Кохонена
для кластеризации ячеек карты.
Здесь нужно либо
позволить алгоритму автоматически
определить число кластеров, либо сразу
зафиксировать его. Следует знать, что
автоматически подбираемое число
кластеров не всегда приводит к желаемому
результату: оно может быть слишком
большим, поэтому рассчитывать на эту
опцию можно только на этапе исследования
данных.
Нажмите кнопку
Пуск
–
в следующем окне можно будет увидеть
динамику процесса обучения сети Кохонена
(рис. 4.6). По умолчанию алгоритм делает
500 итераций (эпох). Если предварительно
установить флажок
Рестарт,
то веса нейронов будут проинициализированы
согласно выбранному на предыдущем шаге
способу инициализации, иначе обучение
начнется с текущих весовых коэффициентов
(это справедливо только при повторной
настройке узла).
Рис. 4.6.
Обучение сети Кохонена
Для обученной сети
Кохонена предлагается специализированный
визуализатор –
Карта Кохонена.
Параметры ее отображения задаются на
одноименной вкладке мастера (рис. 4.7).
Область
Список допустимых отображений карты
содержит три группы –
Входные столбцы, Выходные столбцы
и
Специальные.
Последние не связаны с каким-либо полем
набора данных, а служат для анализа всей
карты.
-
Матрица
расстояний
применяется для визуализации структуры
кластеров, полученных в результате
обучения карты. Большое значение говорит
о том, что данный нейрон сильно отличается
от окружающих и относится к другому
классу. -
Матрица
ошибок квантования
отображает среднее расстояние от
расположения примеров до центра ячейки.
Расстояние считается как евклидово.
Матрица ошибок квантования показывает,
насколько хорошо обучена сеть Кохонена.
Чем меньше среднее расстояние до центра
ячейки, тем ближе к ней расположены
примеры и тем лучше модель.
Рис.
4.7.
Параметры карты Кохонена
Матрица
плотности попадания
отображает количество объектов, попавших
в ячейку.
Кластеры
–
ячейки карты Кохонена, объединенные в
кластеры алгоритмом k-means.
Проекция
Саммона –
матрица, являющаяся результатом
проецирования многомерных данных на
плоскость. При этом данные, расположенные
рядом в исходной многомерной выборке,
будут расположены рядом и на плоскости.
Дополнительно справа имеется еще ряд
настроек.
Способ
раскрашивания ячеек –
цветная палитра или градация серого.
Цветная палитра нагляднее, однако если
потребуется встраивать карту Кохонена
в отчет с последующей распечаткой на
бумажном носителе, то лучше выбрать
серую цветовую схему.
Сглаживание
цветов карты –
цвета на картах будут сглажены, то есть
будет обеспечен более плавный переход
цветов. Это поможет устранить случайные
выбросы.
Границы
ячеек –
установка данного флажка позволит
включить отображение границ ячеек на
карте.
Границы
кластеров –
установка данного флажка позволит
включить отображение границ кластеров
на всех картах. Этот режим удобен для
анализа структуры кластеров.
Размер
ячейки по умолчанию –
указывается размер ячейки на карте в
пикселях (по умолчанию 16).
Текущая ячейка
отображается на карте маленькой
окружностью черного цвета. Изменить
текущую ячейку просто: щелкнуть кнопкой
мыши на нужном участке карты. Внизу
каждой карты на градиентной шкале в
желтом прямоугольнике отображается
числовое значение признака, соответствующее
цвету ячейки.
На рис. 4.8 приведены
получившиеся карты Кохонена. По матрице
плотности попадания видно, что в одной
ячейке сосредоточилось 259 объектов. Эта
ячейка выделяется белым цветом. Можно
приступать к интерпретации результатов
кластеризации.
Рис.
4.8.
Карты Кохонена для сегментации абонентов
сети сотовой связи
Попробуем выделить
на карте изолированные области
самостоятельно (без использования
встроенного метода группировки ячеек
алгоритмом k-means).
Анализируя карту
Возраст
(рис. 4.8), видим, что четко выделяются три
возрастные группы: молодежь, люди
среднего возраста и люди старше 45 лет.
Остановимся
подробнее на молодежи. Она неоднородна
–
здесь можно выделить несколько кластеров.
Первый расположен в правом нижнем углу
(рис. 4.10). Абоненты этой условной зоны
активно и продолжительно разговаривают
по телефону вечером и ночью, отправляют
много SMS-сообщений,
соответственно, и тратят на разговоры
больше денег, чем другие представители
возрастной группы. Обратите внимание,
что в этот кластер попала львиная доля
тех, кто увлекается ночными разговорами.
Можно предположить, что это студенты и
молодежь, часто проводящие вечера вне
дома.
Рис.
4.10.
Кластер «Активная молодежь»
Вверху (рис. 4.11)
сосредоточилась небольшая по числу
ячеек группа молодежи, которая не
отличается активностью разговоров ни
днем, ни вечером, ни тем более ночью, и,
как следствие, ежемесячные расходы на
связь у представителей этого кластера
невелики.
Рис.
4.11.
Кластер молодежи с пониженным потреблением
услуг связи
Остальные люди в
этой возрастной группе ничем особенным
не выделяются: умеренные расходы на
связь и преимущественно вечерние
разговоры. Можно предположить, что сюда
попала наибольшая часть молодежи. Таким
образом, в молодежной возрастной группе
мы обнаружили три кластера.
Продолжим
интерпретацию карты Кохонена и теперь
остановимся на людях зрелого и пенсионного
возраста. Обратим внимание на ярко
выраженный сгусток в верхней области,
в котором практически по всем признакам,
кроме SMS,
наблюдаются
высокие значения, в том числе по звонкам
в другие города и страны (рис. 4.12). Это
так называемые VIP-клиенты:
бизнесмены, руководители, топ-менеджеры.
Они преимущественно зрелого возраста,
очень много разговаривают днем и вечером
(скорее всего, по работе) и практически
не пользуются SMS-услугами.
Месячные расходы на связь у этой категории
абонентов самые высокие.
Рис.
4.12.
Кластер «VIP-клиенты»
Чуть выше в небольшом
кластере наблюдается противоположная
картина: люди практически не пользуются
услугами сотовой сети (рис. 4.13). Вероятнее
всего, это пенсионеры, которым мобильная
связь нужна преимущественно для приема
входящих звонков, сами же они почти не
звонят. Их расходы на связь самые низкие,
возможно, из-за того, что единственным
их доходом является пенсия.
Рис.
4.13.
Пенсионеры, практически не делающие
исходящих звонков
Изучим статистические
характеристики этой группы людей.
Нажмите кнопку
Показать/скрыть
окно данных,
затем –
кнопку
Изменить
способ фильтрации
и установите
Фильтр
по выделенному.
Там же переключитесь в режим статистики
(кнопка
Способ
отображения).
Колонка
Среднее
даст следующие вычисленные значения
(табл. 4.2).
Таблица
4.2.
Статистические характеристики кластера
5
|
№ |
Признак |
Среднее |
|
1 |
Возраст |
65,7 |
|
2 |
Среднемесячный |
41,5 |
|
3 |
Средняя |
2,1 |
|
4 |
Звонков |
9,3 |
|
5 |
Звонков |
6,4 |
|
6 |
Звонков |
0,0 |
|
7 |
Звонки |
0 |
|
8 |
Звонки |
0 |
|
9 |
Доля |
6,3 |
|
10 |
Количество |
0 |
Остальных людей
в возрастной группе «Зрелый и пенсионный
возраст» объединяет то, что они в основном
звонят вечером и не используют SMS-сервис.
С большой долей вероятности можно
утверждать, что сюда входят работающие
пенсионеры, дачники, родители
совершеннолетних детей.
Осталась последняя,
средневозрастная группа. Это кластер
работающих людей. В нем можно отметить
группу тех, кто совершает мало звонков
вечером.
По площади, которую
занимают на карте Кохонена условно
выделенные кластеры, судить о мощности
каждого из них трудно: в разных ячейках
содержится различное число объектов.
Поэтому рекомендуется фиксировать
число объектов, попавших в каждый
кластер. Зная мощность кластера, можно
дополнительно оценить его прибыльность
–
сумму по признаку
Среднемесячный расход
(табл. 4.3).
Таблица
4.3.
Мощности кластеров
|
№ кластера |
Условное |
Мощность |
Прибыльность |
|
1 |
Активная |
||
|
2 |
Молодежь, |
||
|
3 |
Основная |
||
|
4 |
VIP-клиенты |
||
|
5 |
«Малоговорящие» |
569 |
23613,5 |
|
6 |
Активная |
||
|
7 |
Работающие |
Теперь включите
автоматическую группировку ячеек в
кластеры:
Настроить
отображения – Кластеры.
При установленном флажке
Автоматически
определить количество кластеров
(с уровнем значимости 1,00) получится
16
кластеров (рис. 4.14, а). Это очень много,
поэтому следует принудительно установить,
скажем, 6 кластеров (рис. 4.14, б).
а
б
Рис.
4.14.
Варианты автоматической группировки
ячеек алгоритмом k-means:
а – автоматическое число кластеров, б
– ручное задание числа кластеров, равное
6
Видно, что
автоматический алгоритм k-means
при 6 кластерах
выделил целиком кластер «Зрелый и
пенсионный возраст», раздробились
группы «Молодежь» и «Люди среднего
возраста». Не были явно выделены кластеры
2, 4 и 5 из табл. 4.3. Тем не менее, автоматическая
группировка ячеек в Deductor
имеет одно
важное преимущество: в наборе данных
появляется столбец
Кластер
с номером, который можно использовать
в дальнейшем, в частности «прогонять»
новые объекты и получать для них номер
кластера.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Подборка по базе: Курсовая Работа Максимов 19-КОП.odt, Практическая работа №1.docx, Самостоятельная работа к теме 2.1.2.docx, Практическая работа №1.docx, Практическая работа (11).docx, Практическая работа.doc, Контрольная работа по Базам данныхНазароваС.docx, Козлов В.А. Практическая работа №2..docx, Курсовая работа. Теоретические основы дошкольного образования (Д, Практическая работа 4.docx
Решение задачи
Откройте сценарий som. ded для изучения дальнейшего материала.
Покажем последовательность решения бизнес-задачи сегментации абонентов с помощью подхода, который основан на алгоритме Кохонена, которая состоит из двух шагов:
- кластеризация объектов алгоритмом Кохонена;
- построение и интерпретация карты Кохонена.
В Deductor Studio сети и карты Кохонена реализованы в обработчике Карта Кохонена, где содержатся сам алгоритм Кохонена и специальный визуализатор Карта Кохонена.
В Deductor канонический алгоритм Кохонена дополнен рядом возможностей, а именно:
- Алгоритм Кохонена применяется к сети Кохонена, состоящих из ячеек, упорядоченных на плоскости. По умолчанию размер карты равен 16 х 12, что соответствует 192 ячейкам. В выходном наборе данных алгоритм Кохонена формирует поля Номер ячейки и Расстояние до центра ячейки.
- Ячейки карты с помощью специальной дополнительной процедуры объединяются в кластеры. Эта процедура – алгоритм k-means, причем имеется возможность
автоматически определять количество кластеров. В выходном наборе данных алгоритм k- means формирует поля Номер кластера и Расстояние до центра кластера.
Каждый входной признак может иметь весовой коэффициент от 0 до 100%, последний влияет на расчет евклидового расстояния между векторами.
Для построения профилей клиентов воспользуется сетями и картами Кохонена. Импортируем в Deductor набор данных из файла mobile. txt . Запустим мастер обработки и выберем узел Карта Кохонена . Установим все поля, кроме Код, входными.
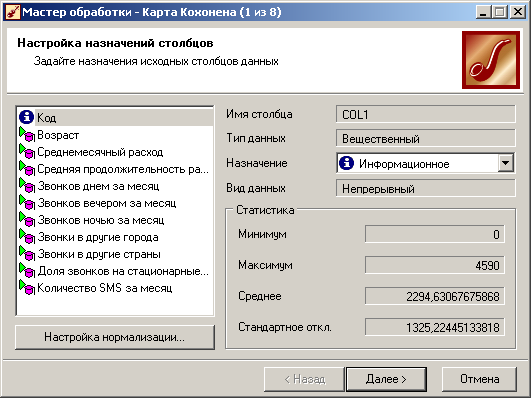
Рисунок 1 – Настройка назначений столбцов
На этой же вкладки при нажатии кнопки Настройка нормализации … откроется окно, где
можно задать значимость каждого входного поля. Оставим значимость одинаковой для всех полей без изменений.
Замечание

Поскольку любой метод кластеризации, в том числе и алгоритм Кохонена, субъективен, смысл в выделении отдельного, тестового множества, как правило, отсутствует. Оставим в обучающем 100
% записей (рисунок 2).
Рисунок 2 – Разбиение набора данных на обучающее и тестовое множества
На третьей вкладке задаются размер и форма карты Кохонена (рисунок 3). Пока что согласимся с настройками по умолчанию – шестиугольные ячейки, размер 16х12.
Рисунок 3 – Параметры будущей карты Кохонена
На следующем шаге также оставим все без изменений (рисунок 4).
Рисунок 4 – Параметры остановки алгоритма Кохонена
Наконец, на последнем шаге, предшествующем обучению, настраиваются параметры обучения алгоритма Кохонена (рисунок 5).
Здесь задаются следующие опции.
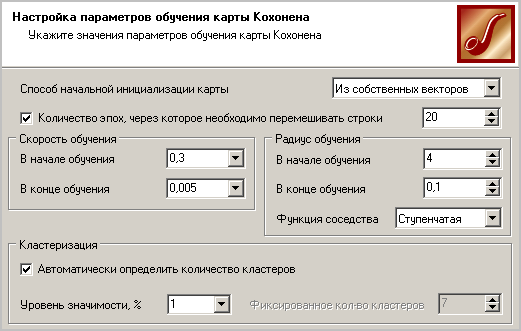
Рисунок 5 – Параметры обучения сети Кохонена
Способ начальной инициализации кар ты определяет, как будут установлены начальные веса нейронов карты. Удачно выбранный способ инициализации может существенно ускорить обучение и привести к получению более качественных результатов. Доступны три варианта:
Случайнымизначениями– начальные веса нейронов будут инициированы случайными значениями
- Изобучающегомножества– в качестве начальных весов будут использоваться случайные примеры из обучающего множества.
- Изсобственныхвекторов– начальные веса нейронов карты будут проинициализированы значениями подмножества гиперплоскости, через которую проходят два главных собственных вектора матрицы ковариации входных значений обучающей выборки.
При выборе способа начальной инициализации (рисунок 6)следует руководствоваться следующей информацией:
- объемом обучающей выборки;
- количеством эпох, отведенных для обучения;
- размером карты.
Между указанными параметрами и способом начальной инициализации существует много зависимостей. Выделим несколько главных.
- Если объем обучающей выборки значительно (в 100 и более) превышает число ячеек карты и время обучения не играет первоочередной роли, то лучше выбрать
инициализациюслучайнымизначениями, т.к. это даст меньшую вероятность попадания в локальный минимум ошибки кластеризации.
- Если объем обучающей выборки не очень велик, время обучения ограниченно или необходимо уменьшить вероятность появления после обучения пустых ячеек, в которые не попало ни одного экземпляра обучающей выборки, то следует использовать
инициализациюпримерамиизобучающегомножества.
- Инициализацию из собственных векторов можно использовать при любом стечении обстоятельств. Единственное замечание: вероятность появления пустых ячеек после обучения выше, чем при инициализации примерами из обучающего множества. Именно этот способ лучше выбирать при первом ознакомлении с данными.
Скорость обучения – задается скорость обучения в начале и в конце обучения сети Кохонена. Рекомендуемые значения: 0,1–0,3 в начале и 0,05–0,005 в конце обучения.
Радиус обучения – задается радиус обучения в начале и в конце обучения сети Кохонена. Радиус в начале должен быть достаточно большой – примерно половина или меньше размера карты (максимальное линейное расстояние от любого нейрона до другого любого нейрона). а в конце – достаточно малым, примерно 1 или меньше. Начальный радиус в Deductor подбирается автоматически в зависимости от размера карты.
В этом же блоке задается Функция соседства : Гауссова или Ступенчатая. Если функция соседства Ступенчатая, то «соседями» для нейрона-победителя будут считаться все нейроны, линейное расстояние до которых не больше текущего радиуса обучения. Если используется Гауссова функция соседства, то «соседями» для нейрона- победителя будут считаться все нейроны карты, но в разной степени полноты.
При использовании Гауссовой функции соседства обучение проходит более плавно и равномерно, так как одновременно изменяются веса всех нейронов, что может дать немного лучший результат, чем если бы использовалась ступенчатая функция. Однако время, необходимое на обучение, требуется немного большее, по причине того, что на каждой эпохе корректируются все нейроны.
Кластеризация – в этой области указываются параметры алгоритма k-means (G-means), который запускается после алгоритма Кохонена для группировки ячеек карты. Здесь нужно только определить, позволить алгоритму автоматически определить число кластеров (G-means), или сразу зафиксировать его (k-means). Следует знать, что автоматически подбираемое число кластеров не всегда приводит к желаемому результату – число кластеров может предлагаться слишком большим, поэтому рассчитывать на эту опцию можно только на этапе исследования данных.
В следующем окне, нажав кнопку Пуск, можно будет увидеть динамику процесса обучения сети Кохонена (рисунок 6). По умолчанию алгоритм делает 500 итераций (эпох). Если предварительно установить флаг Рестарт , то веса нейронов будут проинициализированы согласно выбранному на предыдущем шаге способу инициализации, иначе обучение начнется с текущих весовых коэффициентов (это справедливо только при повторной настройке узла).
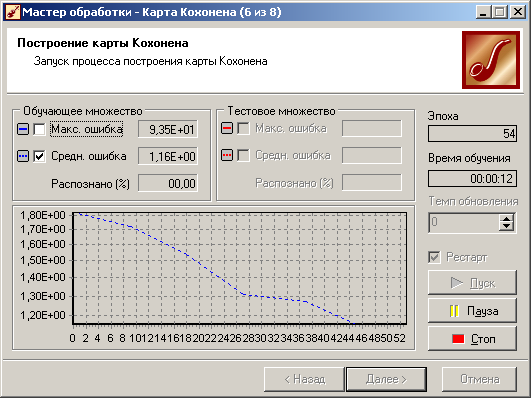
Рисунок 6 – Обучение сети Кохонена
К обученной сети Кохонена предлагается специализированный визуализатор – Карта
Кохонена . Параметры ее отображения задаются на специальной вкладке мастера (рисунок 7).
Список допустимых отображений карты содержит три группы – входные поля, выходные поля и специальные. Последние не связаны с каким-либо полем набора данных, а служат для анализа всей карты.
- Матрицарасстоянийприменяется для визуализации структуры кластеров, полученных в результате обучения карты. Большое значение говорит о том, что данный нейрон сильно отличается от окружающих и относится к другому классу.
- Матрицаошибокквантования– отображает среднее расстояние от расположения
примеров до центра ячейки. Расстояние считается как евклидово расстояние. Матрица ошибок квантования показывает, насколько хорошо обучена сеть Кохонена. Чем меньше среднее расстояние до центра ячейки, тем ближе к ней расположены примеры, и тем лучше модель.
- Матрицаплотностипопадания– отображает количество объектов, попавших в ячейку.
- Кластеры– ячейки карты Кохонена, объединенные в кластеры алгоритмом k-means.
Проекция Саммона – матрица, являющаяся результатом проецирования многомерных данных на плоскость. При этом данные, расположенные рядом в исходной многомерной выборке, будут расположены рядом и на плоскости
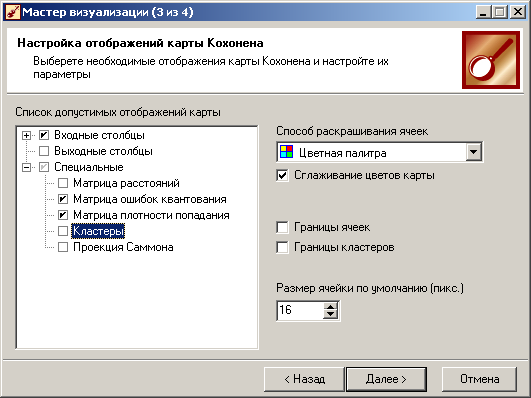
Рисунок 7 – Настройки визуализатора «Карта Кохонена»
Дополнительно справа имеется еще ряд настроек:
- Способраскрашиванияячеек–цветная палитра и или градация серого. Цветная палитра нагляднее, однако, если вам потребуется встраивать карту Кохонена в печатный отчет с последующей распечаткой на бумажный носитель, то лучше выбрать серую цветовую схему.
- Сглаживаниецветовкарты– цвета на картах будут сглажены, т.е. будет обеспечен более плавный переход цветов. Это поможет устранить случайные выбросы.
- Границыячеек– установка данного флажка позволяет включить отображение границ ячеек на карте.
- Границыкластеров– установка данного флага позволит включить отображение границ кластеров на всех картах. Этот режим удобен для анализа структуры кластеров.
- Размерячейки– указывается размер ячейки на карте в пикселях (по умолчанию 16).
Данное окно установки параметров карты можно будет в любой момент вызвать кнопкой ![]()
Настроить отображения… на панели инструментов визуализатора.
Посмотрим на получившуюся при настройках по умолчанию карту (рисунок 8 и файл som. ded ).
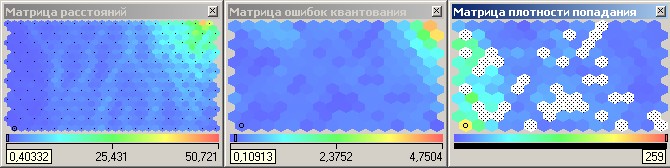
Рисунок 9 – Фрагмент карты Кохонена, построенной при стандартных настройках
Текущая ячейка отображается на карте маленькой окружностью черного цвета. Изменить текущую ячейку просто: щелкнуть мышью в нужный участок карты. Внизу каждого отображения на градиентной шкале в желтом прямоугольнике отображается числовое значение признака, соответствующее ее цвету.
При работе с картой доступны операции, выполняемые с помощью кнопок на панели инструментов визуализатора или контекстного меню, вызываемого правой кнопкой мыши в любом окне карты.
Ряд кнопок (![]() Границы ячеек ,
Границы ячеек , ![]() Границы кластеров ,
Границы кластеров , ![]() Настроить
Настроить
отображения… ) дублирует параметры, задаваемые в окне мастера настройки визуализатора (рисунок 7). Действия остальных кнопок описаны в таблице 2.
Таблица 2
| Команда | Описание | |
| Настроить кластеры… | Вызывается диалоговое окно Настройка кластеров , в котором можно изменять количество кластеров для уже
построенной карты. По сути, запускается алгоритм k- means для кластеризации ячеек карты с новым числом кластеров |
|
| Изменить режим работы | Устанавливает один из четырех режимов работы (простой, выделение, рисование контура, установка меток), который влияет на поведение при выделении ячейки. При открытии карты устанавливается простой режим | |
| Отображать выделенные ячейки | Показывать или скрывать выделенные ячейки на всех картах | |
| Отображать контур | Показывать или скрывать ломаную линию,
предназначенную для дополнительного выделения ячеек на картах |
|
| Отображать метки | Показывать или скрывать текстовые метки для ячеек | |
| Уменьшить/увеличить карты | Каждый щелчок по данной кнопке позволяет уменьшить/увеличить размер всех открытых окон
отображений карты одновременно. Аналогично изменению параметра Размер ячейки по умолчанию |
|
| Расположить встык | Расположить все открытые окна отображений карты рядом друг с другом | |
| Показать/скрыть окно данных | Показать/скрыть в нижней части окна визуализатора таблицу, в которой будут отображаться примеры обучающей выборки |
Замечание

Вернемся к сегментации заемщиков. По матрице плотности попадания видно (рис. 9), что в одной ячейке сосредоточилось 259 объектов. Эта ячейка выделяется желто-красным цветом. В
принципе, можно остановиться на этом варианте кластеризации и приступить к интерпретации карты. Забегая вперед, скажем, что карта с увеличенным масштабом оказалась лучше, так как позволила «разглядеть» кластер, который не удавалось обнаружить при размере карты 16х12. Поэтому здесь универсальных рецептов нет. Понять, лучше или хуже карта Кохонена, можно только сравнив ее с картами, построенными при других настройках, сравнив матрицы ошибок квантования и матрицы плотности попадания.
Поэтому построим еще одну карту Кохонена, увеличив ее размер в 1,5 раза до 24х18 и изменив способ инициализации («из обучающего множества») для снижения вероятности образования пустых ячеек. При размере карты 24х18 она имеет 432 ячейки, значит, на 1 ячейку приходится в среднем по 20 примеров. Полученная карта Кохонена изображена на рисунке 9 (см. также
som. ded ).
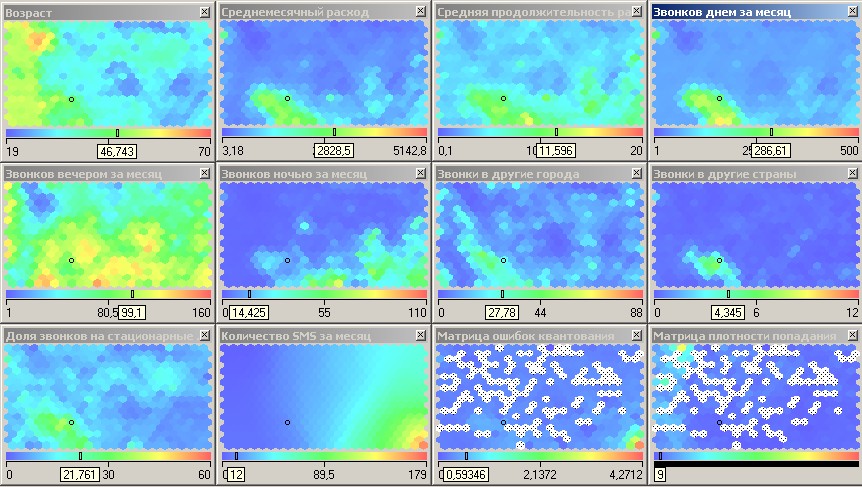
Рисунок 9 – Карты Кохонена масштаба 24х18 для сегментации абонентов сети сотовой связи
Попробуем выделить на карте изолированные области самостоятельно без использования встроенного метода группировки ячеек алгоритмом k-means.
Анализируя отображение карты Возраст (рисунок 10), видим, что четко выделяются три возрастные группы: молодежь, люди среднего возраста и люди старше 45 лет.
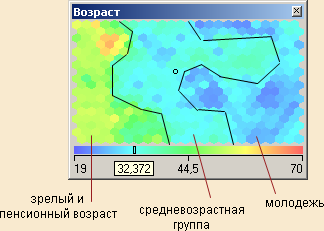
Рисунок 10 – Деление по возрастным группам
Остановимся подробнее на молодежи. Она не однородна, здесь можно выделить несколько кластеров. Первый расположился в правом нижнем углу (рисунок 11). Абоненты этой условной зоны на карте активно и продолжительно говорят вечером и ночью, отправляют много SMS- сообщений, соответственно, и тратят на разговоры больше денег, чем другая молодежь. Обратите внимание, что в этот кластер попала «львиная» доля людей, пользующихся ночными разговорами. Можно предположить, что это часть студентов и молодежи, часто проводящая вечера вне дома.
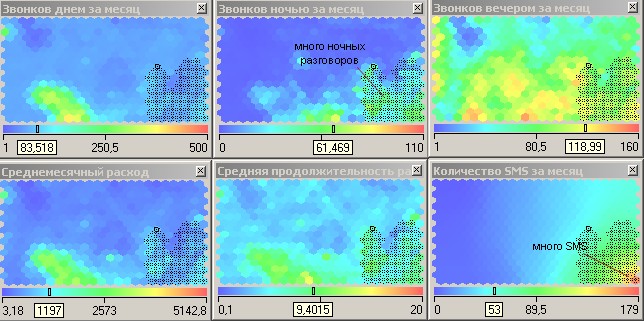
Рисунок 11 – Деление по возрастным группам
Вверху (рисунок 12) сосредоточилась небольшая по числу ячеек группа молодежи, которая не отличается активностью разговоров и SMS ни днем, ни вечером, ни, тем более, ночью, и, как следствие, их ежемесячные расходы на связь невелики
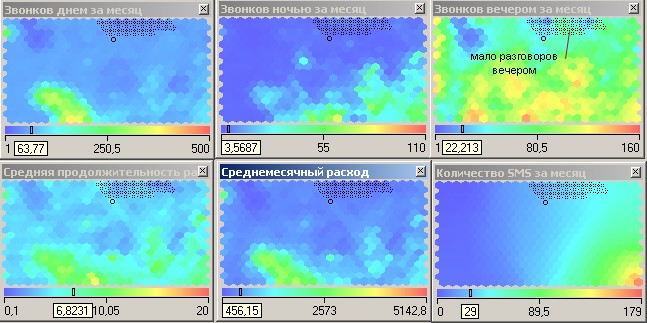
Рисунок 12 – Кластер молодежи с пониженным потреблением услуг связи
Остальные люди в возрастной группе молодежи ничем особенным не выделяются: умеренные расходы на связь и преимущественно вечерние разговоры. Можно предположить, что сюда попала наибольшая часть молодежи.
Таким образом, в молодой возрастной группе мы обнаружили три кластера. Продолжим интерпретацию карты Кохонена и возьмем людей зрелого и пенсионного возраста. Обратим внимание на ярко выраженный сгусток в нижней области, в котором практически по всем
признакам, кроме SMS, наблюдаются высокие значения, в том числе по звонкам в другие города и страны (рисунок 13). Это так называемые VIP-клиенты: бизнесмены, руководители, топ-
менеджеры. Они преимущественно зрелого возраста, очень много разговаривают днем и вечером (скорее всего по работе) и практически не пользуются SMS-услугами. Месячные расходы на связь этой категории абонентов самые высокие.
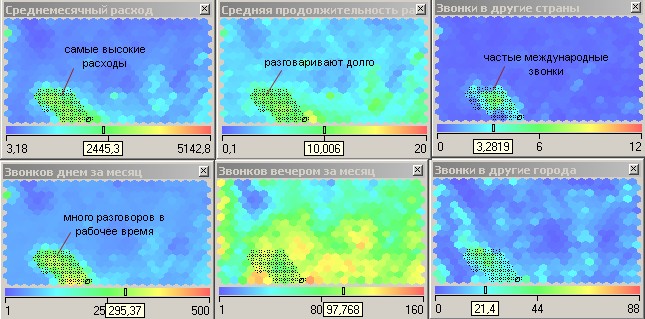
Рисунок 13 – Кластер «VIP-клиенты»
Чуть выше в небольшом кластере наблюдается противоположная картина – люди практически не пользуются услугами сотовой сети (рисунок 14). Вероятнее всего это пенсионеры, которые имеют мобильную связь преимущественно для приема входящих звонков, а сами практически не совершают звонков. Их расходы на связь самые низкие, возможно, из-за того, что единственным их доходом является пенсия.
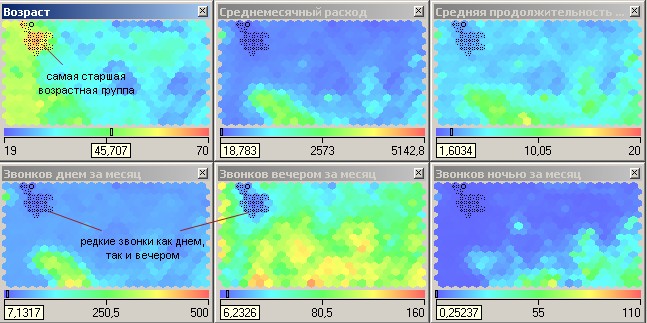
Рисунок 14 – Пенсионеры, практически не делающие исходящих звонков
Изучим статистические характеристики этой группы людей. Для этого нажмем на кнопку ![]()
Показать окно данных и установим ![]() Фильтр по выделенному , а потом
Фильтр по выделенному , а потом
переключимся в режим статистики. Колонка Среднее даст следующие вычисленные значения (таблица 3).
| N | Признак | Среднее значение |
| 1 | Возраст | 64,5 |
| 2 | Среднемесячный расход | 49,7 |
| 3 | Средняя продолжительность разговоров, мин. | 2,1 |
| 4 | Звонков днем за месяц | 13,4 |
| 5 | Звонков вечером за месяц | 7,4 |
| 6 | Звонков ночью за месяц | 0,3 |
| 7 | Звонки в другие города | 0,5 |
| 8 | Звонки в другие страны | 0,05 |
| 9 | Доля звонков на стационарные телефоны, % | 5,7 |
| 10 | Количество SMS в месяц | 1,6 |
Остальных людей в возрастной группе Зрелый и пенсионный возраст объединяет то, что они в основном звонят вечером и и не используют SMS-сервис. С большой долей вероятности можно утверждать, что сюда входят работающие пенсионеры, дачники, родители совершеннолетних детей.
Осталась последняя, средневозрастная группа. Это кластер работающих людей. В нем можно отметить группу тех, кто совершает мало звонков вечером.
По площади, которую занимают на карте Кохонена условно выделенные кластеры, судить о мощности каждого из них трудно: в разных ячейках содержится различное число объектов.
Поэтому рекомендуется фиксировать число объектов, попавших в каждый кластер. Зная мощность кластера, в нашей задаче можно дополнительно оценить его прибыльность – сумму по полю Среднемесячный расход (таблица 4).
Таблица 4
| N кластера | Условное название кластера | Мощность кластера | Прибыльность кластера |
| 1 | Активная молодежь | 370 (8%) | 281 413 (12%) |
| 2 | Молодежь, мало пользующаяся услугами | 157 (3,5%) | 49 863 (2,2%) |
| 3 | Основная молодежь | 890 (20%) | 458 763 (20%) |
| 4 | VIP-клиенты | 152 (3,4%) | 424 378 (18,7%) |
| 5 | «Малоговорящие» пенсионеры | 274 (6%) | 13 640 (0,6%) |
| 6 | Активная группа зрелого и пенсионного возраста | 1461 (33,1%) | 530 751 (33,8%) |
| 7 | Работающие люди среднего возраста | 1188 (26%) | 514 842 (22,7%) |
Теперь включим автоматическую группировку ячеек в кластеры: Настроить отображения ►
Кластеры . При установленном флаге Автоматически опр еделить количество
кластеров будет работать алгоритм G-means и получится 11 кластеров (рисунок 16а). Это очень много, поэтому принудительно установим, скажем, 6 кластеров (рисунок 16б).
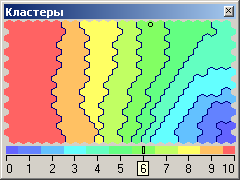
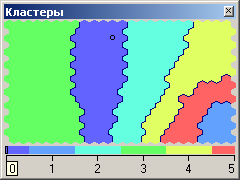
Рисунок 16 – Варианты автоматической группировки ячеек алгоритмом k-means, а – автоматическое число кластеров, б – ручное задание числа кластеров, равное 6
Видно, что автоматический алгоритм k-means при 6 кластерах выделил целиком кластер Зрелый и пенсионный возраст, раздробились группы Молодежь и Люди среднего возраста. Не были явно выделены кластеры №2, 4 и 5 из таблицы 3. Тем не менее, автоматическая группировка ячеек в Deductor имеет одно важное преимущество: в наборе данных появляется столбец Кластер с его номером, поэтому его можно использовать в дальнейшем, в частности, «прогонять» новые объекты и получать для них № кластера.
Кластеризация «новых» объектов
Наша карта Кохонена способна «прогонять» через себя новые объекты и относить их к той или иной ячейке, к тому или иному кластеру. Механизм этой операции прост: для нового объекта рассчитывается расстояние до всех центров ячеек и объект считается принадлежащим к том
ячейке, расстояние до которой минимально. А зная номер ячейки, определяется номер кластера.
В сценарии som. ded приведен пример «прогона» нового объекта (из файла
mobile 1 abonent. txt ) с использованием обработчика Скрипт .
Прогнозирование с помощью карт Кохонена
Ранее упоминалось, что опционально обработчик Карта Кохонена может иметь выходные поля. Как они будут использоваться? Представим, что в нашей задаче столбец Возраст не входной, а выходной. Он не будет использоваться при кластеризации. Однако после построения карты Кохонена появляется возможность для новых абонентов определять их возраст, зная остальные
параметры: число звонков, среднемесячный расход и т.д. Иначе говоря, с помощью кластеризации будет решаться задача регрессии или классификации.
Механизм работы этого следующий. Если выходное поле – дискретное, то выходом ячейки (по этому выходному полю) будет являться самое распространенное значение выходного поля тех строчек данных, которые «попали» в данную ячейку. Если же выходное поле – это непрерывное
поле, то выходом ячейки (по этому выходному полю) будет являться среднее значений выходного поля тех строчек данных, которые «попали» в данную ячейку.
Ограничения использования карт Кохонена в Deductor
В Deductor Studio алгоритм Кохонена ориентирован на работу преимущественно с числовыми типами данных, а также с упорядоченными (ординальными) типами. Обработка данных в полях, значения которых нельзя упорядочить будет приводить к некорректным результатам.
Упорядочивание ординальных типов осуществляется на вкладке Настройка нормализации…
Практическая работа:
- Изучите сценарий som. ded , прилагающийся к занятию. Выделите множества ячеек подобным образом, как это демонстрировалось на рисунках 10-13.
- Опишите, какими услугами и с какой частотой пользуются люди из средневозрастной группы.
- Проанализируйте людей, попавших в ячейку 48.
- Постройте карту Кохонена для сегментации абонентов, сделав поле Возраст выходным. Насколько сильно изменилась карта? Проведите эксперимент в визуализаторе Что-если: введите свои данные в поля Количество звонков, Среднемесячный расход и т.д. и
спрогнозируйте свой возраст.
- Превратите карту Кохонена в обычную сеть Кохонена с шестью выходными нейронами.
- Найдите в справке и самостоятельно изучите отображение Проекция Саммона.
Вопросы для проверки:
- Как выделить множество ячеек на карте и посмотреть объекты, попавшие в них?
- Как поставить текстовую метку на ячейке?
- Как проще всего посмотреть статистику по объектам, попавшим в ячейку?
- Какой кластер в приведенной бизнес-задаче, скорее всего, не удалось бы обнаружить при масштабе карты 16 х 12?
- В каких случаях следует задавать значимость входных полей?
- Как карта Кохонена может использоваться в задаче восстановления пропусков в данных? Опишите шаги, необходимые для этого.
- Почему при кластеризации в обработчике Карта Кохонена могут быть выходные поля? Каково их предназначение?
- В каком случае для карты Кохонена лучше установить цветовую палитру в серых тонах? Почему?
Мне всегда нравилась визуальная эстетика дизеринга (dithering, псевдотонирование, псевдосмешение цветов), но я не знал о том, как он применяется. Поэтому я провёл кое-какие изыскания. Эта статья может содержать отголоски ностальгии, но в ней не будет никаких следов Лены.

Как я сюда попал?
Я, конечно, припозднился, но, наконец, поиграл в «Return of the Obra Dinn», самую свежую игру Лукаса Поупа, создателя знаменитой «Papers Please». «Obra Dinn» — это история-головоломка, которую я могу только порекомендовать. Но я программист, и моё любопытство этот проект разжёг тем, что это — 3D-игра (созданная с использованием движка Unity), которая рендерится с использованием всего лишь двух цветов и с применением дизеринга. Видимо, это называется «дизерпанк», и мне это нравится.

Дизеринг, как я изначально его понимал, это техника, основанная на применении лишь небольшого количества цветов из некоей палитры. Цвета так хитро комбинируются, что мозгу зрителя кажется, что он видит множество цветов. Например, глядя на предыдущий рисунок, вам, возможно, покажется, что на нём представлено несколько уровней светлоты. А на самом деле их всего два — полностью белый цвет и полностью чёрный.
Тот факт, что я никогда не видел 3D-игру с дизерингом, подобным этому, возможно, объясняется тем, что цветовые палитры — это, в основном, достояние прошлого. Вы, может быть, помните работу в Windows 95 в 16-цветном режиме и игры вроде «Monkey Island».


Уже давно у нас имеется 8 бит на цветовой канал пикселя, что позволяет каждому пикселю на экране выводить один из 16 миллионов цветов. А учитывая то, что на горизонте виднеются технологии HDR и WCG, компьютерная графика уходит ещё дальше от ситуаций, в которых может хотя бы понадобиться какая-нибудь форма дизеринга. Но в «Obra Dinn», несмотря ни на что, дизеринг, всё же, используется. Эта игра вновь зажгла во мне давно забытую любовь. Я, после работы в Squoosh, кое-что знал о дизеринге. Поэтому был особенно впечатлён тем, как в этой игре дизеринг остаётся стабильным при перемещении и вращении камеры в трёхмерном пространстве. Мне хотелось разобраться с тем, как всё это работает.
Как оказалось, Лукас Поуп написал пост на форуме, в котором рассказал о том, какие техники дизеринга используются в игре, и о том, как они применяются в трёхмерном пространстве. Он проделал большую работу, чтобы сделать дизеринг стабильным при перемещениях камеры. После прочтения того поста я провалился в кроличью нору, а в этом материале я постараюсь рассказать о том, что там нашёл.
Дизеринг
Что такое дизеринг?
Из Википедии можно узнать о том, что дизеринг — это намеренное внесение в сигнал некоей разновидности шума, используемое для рандомизации ошибки квантования. Эта техника применима не только к изображениям. Она, до наших дней, используется и в звукозаписи. Но это — ещё одна кроличья нора, в которую можно будет провалиться как-нибудь в другой раз. Начнём с квантования.
Квантование
Квантование — это процесс отображения большого набора значений на меньший, обычно конечный, набор значений. В дальнейшем я, приводя примеры, буду использовать два следующих изображения.
: чёрно-белая фотография моста «Золотые ворота» в Сан-Франциско, уменьшенная до 400x267 пикселей")
: чёрно-белая фотография моста между Сан-Франциско и Оклендом, уменьшенная до 253x400 пикселей")
Обе чёрно-белые фотографии представлены в 256 оттенках серого. Если нужно будет использовать меньше цветов — например — только чёрный и белый, чтобы сделать изображения монохромными, придётся поменять цвет каждого пикселя, сделать каждый из них или полностью чёрным, или полностью белым. При таком сценарии чёрный и белый цвета называются «цветовой палитрой», а процесс изменения характеристик пикселей, которые не используют цвета из нашей палитры, называется «квантованием». Так как не все цвета из исходных изображений имеются в нашей цветовой палитре, это неизбежно приведёт к появлению ошибки, называемой «ошибкой квантования». Примитивное решение этой задачи заключается в том, чтобы квантовать каждый пиксель, приведя его цвет к цвету из палитры, наиболее близкому к исходному цвету пикселя.
Обратите внимание: определение того, какие цвета «близки друг к другу» — это вопрос, открытый для интерпретации. Ответ на него зависит от того, как измеряют расстояние между двумя цветами. Я исхожу из предположения о том, что мы, в идеале, измеряем расстояние между цветами с использованием психовизуальной модели. Но в большинстве найденных мной публикаций просто используется евклидово расстояние в RGB-кубе, вычисляемое по формуле ![]() .
.
Учитывая то, что наша палитра состоит лишь из чёрного и белого цветов, мы можем использовать светлоту пикселя для того чтобы решить, в какой цвет его квантовать. Светлота 0 — это чёрный цвет, светлота 1 — белый, а всё, что между ними, должно идеально коррелировать с человеческим восприятием. Таким образом, светлота 0.5 даст приятный средне-серый цвет. Для квантования заданного цвета нам лишь нужно сравнить его светлоту с 0.5, и, если светлота больше 0.5 — взять белый цвет, а если меньше — взять чёрный. Такое квантование вышеприведённых изображений приводит к… неудовлетворительным результатам.
grayscaleImage.mapSelf(brightness =>
brightness > 0.5
? 1.0
: 0.0
);Обратите внимание: здесь приведены примеры рабочего кода, созданного на базе вспомогательного класса GrayImageF32N0F8, который я написал для демонстрационного материала к этой статье. Он похож на интерфейс ImageData, но использует Float32Array, имеет лишь один цветовой канал, представляющий значения между 0.0 и 1.0, и содержит множество вспомогательных функций. Исходный код можно найти здесь.


Гамма-коррекция
Я завершил написание этой статьи и решил, так сказать, одним глазком глянуть на то, как будут выглядеть градиенты от чёрного к белому с использованием различных алгоритмов дизеринга. Результаты показали, что я не учёл того самого, что всегда становится проблемой при работе с изображениями. Речь идёт о цветовых пространствах. Я написал предложение «идеально коррелирует с человеческим восприятием», а сам не следовал этой идее.
Мои демонстрационные материалы созданы с использованием веб-технологий, и, самое главное, с помощью <canvas> и ImageData, а они, в момент написания статьи, предусматривали использование цветового пространства sRGB. Это — старая спецификация (от 1996 года), в которой сопоставление значений и цветов смоделировано для отражения поведения CRT-мониторов. Хотя в наши дни почти никто не пользуется такими мониторами, sRGB всё ещё считается «безопасным» цветовым пространством, которое правильно выводится любым дисплеем. В результате — это цветовое пространство, по умолчанию, применяемое на веб-платформе. Но цветовое пространство sRGB нелинейно, то есть — (0.5,0.5,0.5) в sRGB — это не тот цвет, который человек видит, когда смешивают 50% (0,0,0) и (1, 1, 1). Это — тот цвет, который получают, подав половину мощности, необходимой для вывода полностью белого цвета, на электронно-лучевую трубку.
![]()
Обратите внимание: я, при выводе большинства изображений в этой статье, применил свойство image-rendering: pixelated;. Это позволяет увеличивать страницу и реально видеть пиксели изображений. Но на устройствах с дробным значением devicePixelRatio это может привести к появлению артефактов. Если вы не уверены в том, что именно выводится на вашем экране — откройте изображение отдельно, в новой вкладке браузера.
На этом изображении видно, что градиент после дизеринга светлеет слишком быстро. Если нужно, чтобы 0.5 был бы цветом, находящимся между чёрным и белым цветами (как это воспринимается людьми), нужно преобразовать изображение из цветового пространства sRGB в RGB. Сделать это можно, прибегнув к процессу, называемому «гамма-коррекцией». В Википедии можно найти следующие формулы, предназначенные для преобразования между цветовым пространством sRGB и линейным RGB.

Применив эти преобразования, мы получаем (более) точный дизеринг градиента.
![]()
Дизеринг со случайным шумом (random noise)
Вспомним, что говорится о дизеринге в Википедии. Дизеринг — это намеренное внесение в сигнал некоей разновидности шума, используемое для рандомизации ошибки квантования. С квантованием мы разобрались, а теперь поговорим о шуме. О намеренном внесении шума в сигнал.
Вместо того чтобы квантовать каждый пиксель напрямую, мы добавляем к пикселям шум, значения которого находятся между -0.5 и 0.5. Идея тут в том, что некоторые пиксели теперь будут квантоваться к «неправильным» цветам, но то, как часто это происходит, зависит от изначальной светлоты пикселя. Чёрные пиксели всегда остаются чёрными, белые всегда остаются белыми, а средне-серые будут, примерно в 50% случаев, оказываться чёрными. Со статистической точки зрения общая ошибка квантования снижается, а наш мозг охотно сделает всё остальное и поможет нам увидеть, так сказать, общую картину.
grayscaleImage.mapSelf(brightness =>
brightness + (Math.random() - 0.5) > 0.5
? 1.0
: 0.0
);
![К каждому пикселю перед квантованием добавлен случайный шум [-0.5; 0.5]](https://habrastorage.org/getpro/habr/upload_files/e3c/5c7/ebb/e3c5c7ebb28469d03e33342b53d75046.png "К каждому пикселю перед квантованием добавлен случайный шум [-0.5; 0.5]")
Этот результат показался мне довольно-таки неожиданным! Не назову его «хорошим», видеоигры из 90-х показали нам, что такие картинки могут выглядеть куда лучше. Но перед нами — быстрый способ, не требующий особых усилий, позволяющий получить больше деталей на монохромном изображении. И если бы я понимал слово «дизеринг» буквально, то на этом я и окончил бы статью. Но это — далеко не всё.
Дизеринг с упорядоченным шумом (ordered dithering)
Вместо того чтобы говорить о том, какой именно шум добавить к изображению перед квантованием, можно изменить точку зрения и обсудить настройку порога квантования.
// Добавление шума
grayscaleImage.mapSelf(brightness =>
brightness + Math.random() - 0.5 > 0.5
? 1.0
: 0.0
);
// Настройка порога квантования
grayscaleImage.mapSelf(brightness =>
brightness > Math.random()
? 1.0
: 0.0
);В контексте монохромного дизеринга, где порог квантования равен 0.5, эти два подхода эквивалентны:
brightness+rand()-0.5 > 0.5
↔ brightness > 1.0-rand()
↔ brightness > rand()Положительный момент этого подхода в том, что мы можем говорить о «матрице пороговых значений». Матрицы пороговых значений можно визуализировать. Это облегчит обсуждение того, почему результирующее изображение выглядит так, как выглядит. Ещё их можно вычислять заранее и использовать многократно, что делает процесс дизеринга детерминистическим и поддающимся параллелизации на уровне каждого пикселя. В результате дизеринг можно выполнять на GPU в виде шейдера. Именно так сделано в «Return of the Obra Dinn»! Есть несколько различных подходов к генерированию матриц пороговых значений, но все они каким-то образом упорядочивают шум, который добавляют к изображению. Отсюда и название этого метода — «дизеринг с упорядоченным шумом», или «дизеринг с упорядоченным возбуждением».
Матрица пороговых значений для вышеприведённого примера дизеринга — это, в буквальном смысле, матрица, полная случайных пороговых значений, называемых ещё «белым шумом» (white noise). Это название пришло из сферы обработки сигналов, где каждая частота имеет одинаковую интенсивность, как, например, в белом свете.

Дизеринг Байера (Bayer dithering)
Дизеринг Байера использует в роли матрицы пороговых значений матрицу Байера. Эти сущности названы в честь Брюса Байера, создателя фильтра Байера, который до наших дней используется в цифровых фотоаппаратах. Каждый пиксель светочувствительной матрицы может регистрировать лишь яркость света. Но если перед отдельными пикселями по-умному разместить цветные фильтры, можно восстановить цветное изображение посредством алгоритма демозаизации. Шаблон для этих фильтров — это тот же шаблон, что используется в дизеринге Байера.
Матрицы Байера бывают разных размеров, которые я, в итоге, стал называть «уровнями». Матрица Байера уровня 0 — это матрица 2×2. Уровень 1 — это матрица 4×4. А матрица уровня ![]() — это матрица
— это матрица ![]() . Матрицу уровня n можно рекурсивно вычислить из матрицы уровня
. Матрицу уровня n можно рекурсивно вычислить из матрицы уровня ![]() (хотя в Википедии, кроме того, упомянут алгоритм, основанный на работе с отдельными ячейками). Если ваше изображение оказалось больше, чем матрица Байера, можно обработать его, расположив несколько матриц пороговых значений рядом друг с другом.
(хотя в Википедии, кроме того, упомянут алгоритм, основанный на работе с отдельными ячейками). Если ваше изображение оказалось больше, чем матрица Байера, можно обработать его, расположив несколько матриц пороговых значений рядом друг с другом.

Матрица Байера уровня n содержит числа от 0 до ![]() После того, как вы нормализуете матрицу Байера, то есть — разделите на
После того, как вы нормализуете матрицу Байера, то есть — разделите на ![]() , её можно использовать как матрицу пороговых значений:
, её можно использовать как матрицу пороговых значений:
const bayer = generateBayerLevel(level);
grayscaleImage.mapSelf((brightness, { x, y }) =>
brightness > bayer.valueAt(x, y, { wrap: true })
? 1.0
: 0.0
);Хочу отметить тут одну деталь: дизеринг Байера использующий матрицы, такие, которые определены выше, даст итоговое изображение, которые будет светлее исходного. Например — в области, где каждый пиксель имеет светлоту 1/255=0.4%, матрица Байера размера 2×2 сделает белым каждый из четырёх пикселей, что даст итоговую среднюю светлоту в 25%. Эта ошибка становится меньше при применении матриц Байера более высоких уровней, но фундаментальное отклонение от оригинала при этом остаётся таким же.

На нашем «тёмном» тестовом изображении небо не полностью чёрное, оно, при применении матрицы Байера уровня 0, оказывается значительно светлее. Хотя ситуация улучшается на более высоких уровнях, альтернативным решением может стать инвертирование отклонения, что приводит к получению изображений, которые темнее оригинала. Это делается путём обращения механизма использования матрицы Байера:
const bayer = generateBayerLevel(level);
grayscaleImage.mapSelf((brightness, { x, y }) =>
//Обратите внимание на “1 -” в следующей строке
brightness > 1 - bayer.valueAt(x, y, { wrap: true })
? 1.0
: 0.0
);Я использовал исходное определение матрицы Байера для «светлого» изображения и инвертированную версию для «тёмного» изображения. Лично мне больше всего нравятся результаты, полученные на уровнях 1 и 3.








Дизеринг с синим шумом (blue noise)
И у подхода к дизерингу, когда применяется белый шум, и у того, где используется матрица Байера, конечно, есть недостатки. Для дизеринга Байера, например, характерно наложение на изображение повторяющихся структур, которые, особенно, если увеличить изображение, оказываются заметными. Белый шум — это набор случайных значений, что неизбежно ведёт к появлению на матрице пороговых значений «кластеров» из светлых пикселей и «пустот» из тёмных пикселей. Эти факты можно сделать более очевидными, если наклонить, или, если это для вас слишком сложно, алгоритмически размыть матрицу пороговых значений. «Кластеры» и «пустоты» могут плохо подействовать на результаты дизеринга. Если тёмные области изображения придутся на один из «кластеров» — в соответствующей области выходного изображения будут потеряны детали (и, наоборот, для светлых областей изображения, пришедшихся на «пустоты»).
")
Существует разновидность шума, называемая «синим шумом», нацеленная на решение этой проблемы. Этот шум называют «синим» из-за того, что сигналы более высоких частот в нём имеют более высокие интенсивности, чем сигналы более низких частот (как в случае с синим светом). Убирая или заглушая низкие частоты, можно сделать так, что «кластеры» и «пустоты» оказываются менее выраженными. Дизеринг с синим шумом выполняется так же быстро, как и дизеринг с белым шумом — в итоге это просто матрица пороговых значений, но генерирование синего шума немного сложнее и ресурсозатратнее.
Наиболее распространённый алгоритм генерирования синего шума, похоже, это «метод пустот и кластеров» («void-and-cluster method») Роберта Улични. Вот публикация, где это описано. По-моему, описание алгоритма не отличается интуитивной понятностью, а теперь, когда я его реализовал, я убедился в том, что он описан в чрезмерно абстрактном стиле. Но алгоритм это весьма толковый!
Алгоритм основан на идее, в соответствии с которой можно найти пиксель, являющийся частью «кластера» или «пустоты», обработав изображение с помощью эффекта размытия по Гауссу и найдя самый светлый (или, соответственно, самый тёмный) пиксель на размытом изображении. После инициализации чёрного изображения с помощью нескольких случайно расположенных белых пикселей, алгоритм приступает к непрерывной замене пикселей «кластеров» и «пустот», стремясь как можно равномернее распределить по изображению белые пиксели. После этого каждому пикселю назначается номер между 0 и ![]() (где
(где ![]() — общее количество пикселей) в соответствии с их важностью для формирования «кластеров» и «пустот». Подробности об этом смотрите здесь.
— общее количество пикселей) в соответствии с их важностью для формирования «кластеров» и «пустот». Подробности об этом смотрите здесь.
Моя реализация этого алгоритма работает хорошо, но не очень быстро, так как я не тратил много времени на её оптимизацию. На моём MacBook 2018 года генерирование текстуры синего шума размером 64×64 занимает около минуты. Для наших целей этого достаточно. Если нужно что-то побыстрее — стоит обратить внимание на оптимизацию, касающуюся эффекта размытия по Гауссу, но не в пространственной области, а в частотной области.
Отступление: конечно, я, когда это узнал, увидел интересную задачу, которую просто не мог не решить. Перспективность этой оптимизации объясняется свёрткой (это — внутренний механизм размытия по Гауссу), которой приходится проходиться по каждому полю ядра размытия по Гауссу для каждого пикселя изображения. Но если перевести и изображение, и ядро размытия по Гауссу в частотную область (используя один из многих алгоритмов быстрого преобразования Фурье), свёртка превращается в поэлементное умножение. Так как размер целевой текстуры синего шума — это степень двойки — я мог реализовать хорошо исследованный in-place-вариант алгоритма быстрого преобразования Фурье Кули — Тьюки. После нескольких первоначальных неудач я смог уменьшить время генерирования текстуры синего шума на 50%. Код у меня получился довольно-таки посредственный, поэтому тут найдётся место и для дальнейших оптимизаций.
. Чётких структур на размытом варианте изображения не осталось")
Синий шум основан на размытии по Гауссу, которое вычисляется на тороидальной структуре (это — замысловатый способ сказать, что алгоритм на краях изображения «сворачивается»). В результате изображение можно бесшовно «замостить» текстурами синего шума. Поэтому можно воспользоваться текстурой размера 64×64 и покрыть её копиями всё изображение. Дизеринг с синим шумом даёт приятную, сбалансированную отрисовку деталей, не выдавая заметных повторяющихся паттернов. Итоговое изображение смотрится органично.


Дизеринг с рассеянием ошибки (error diffusion)
Все вышеописанные подходы к дизерингу основаны на том факте, что ошибки квантования статистически сглаживаются из-за того, что пороговые значения в соответствующей матрице распределены равномерно. Но есть и другой подход к квантованию, связанный с рассеянием ошибки. Вы, скорее всего, встречались с ним, если когда-нибудь интересовались дизерингом. Применяя этот подход, мы не просто выполняем квантование изображения, надеясь, что, в среднем, ошибка квантования останется незначительной. Вместо этого мы измеряем ошибку квантования и рассеиваем эту ошибку на соседние пиксели, влияя на то, как они будут квантоваться. Мы, по сути, в процессе работы меняем изображение, которое хотим подвергнуть дизерингу. Это делает процесс преобразования изображения, по сути, последовательным.
Предостережение: одним из больших плюсов алгоритмов рассеяния ошибки, о котором мы не говорим в этом материале, является тот факт, что эти алгоритмы способны работать с произвольными цветовыми палитрами. А дизеринг с упорядоченным шумом требует, чтобы цвета на цветовой палитре были бы расположены с равными интервалами. Подробнее об этом я расскажу как-нибудь в другой раз.
Почти все подходы к дизерингу с рассеиванием ошибки, которые я собираюсь рассмотреть, используют «матрицу рассеяния», которая определяет то, как ошибка квантования текущего пикселя распространяется по соседним пикселям. При работе с такими матрицами часто считается, что пиксели изображения просматриваются сверху вниз и слева направо — так же, как читают тексты жители Запада. Это важно, так как ошибка может быть рассеяна лишь на пиксели, которые ещё не подверглись квантованию. Если вы будете обходить изображения в порядке, не соответствующем тому, на который рассчитана матрица рассеяния, соответствующим образом отразите матрицу.
Дизеринг с «простым» двумерным рассеянием ошибки
Примитивный подход к дизерингу с рассеянием ошибки предусматривает распространение ошибки квантования на пиксель, который находится ниже текущего, и на пиксель, находящийся справа от него. Это можно описать следующей матрицей:

Алгоритм рассеяния ошибки посещает каждый пиксель изображения (в правильном порядке), квантует текущий пиксель и измеряет ошибку квантования. Обратите внимание на то, что значение ошибки квантования имеет знак, то есть — оно может быть отрицательным, если квантование делает пиксель светлее, чем исходный пиксель. Затем части ошибки добавляют к соседним пикселям в соответствии с матрицей. Потом этот процесс повторяется для следующего пикселя.
Пошаговая визуализация алгоритма рассеяния ошибки
Эта анимация предназначена для визуализации алгоритма, но она не способна показать то, как результаты дизеринга соотносятся с оригиналом изображения. Области размером 4×4 пикселя вряд ли достаточно для того, чтобы рассеять и усреднить ошибки квантования. Но тут можно видеть то, что если пиксель в ходе квантования делается светлее, то соседние пиксели, чтобы это скомпенсировать, делаются темнее (и наоборот).


Но простота матрицы рассеяния делает рассматриваемый подход к дизерингу подверженным появлению различимых паттернов, вроде паттернов в виде линий, которые можно видеть на вышеприведённых изображениях.
Дизеринг по алгоритму Флойда — Стейнберга (Floyd-Steinberg)
Алгоритм Флойда — Стейнберга — это, пожалуй, один из самых известных алгоритмов рассеяния ошибки, а, возможно, это — самый известный алгоритм, применяемый при дизеринге изображений. Он использует более сложную матрицу рассеяния ошибок, которая позволяет распределять ошибку на все непосещённые пиксели, являющиеся непосредственными соседями текущего пикселя. Числа в этой матрице тщательно подобраны для того чтобы как можно сильнее уменьшить возможность образования повторяющихся паттернов.

Применение алгоритма Флойда — Стейнберга — это большой шаг вперёд в нашем исследовании, так как это позволяет предотвращать возникновение множества паттернов. Но и при его применении большие пространства изображения с незначительным количеством деталей всё ещё могут выглядеть не очень хорошо.


Дизеринг по алгоритму Джарвиса — Джудиса — Нинке (Jarvis-Judice-Ninke)
В алгоритме Джарвиса — Джудиса — Нинке используется ещё большая матрица рассеяния ошибки. Ошибка распределяется на большее количество пикселей, а не только на те, которые находятся в непосредственной близости от текущего пикселя.

Использование такой матрицы рассеяния ошибки ведёт к дальнейшему снижению вероятности образования паттернов. И хотя на тестовых изображениях имеются паттерны в виде линий, теперь они не так сильно бросаются в глаза.


Дизеринг по алгоритму Аткинсона (Atkinson)
Алгоритм Аткинсона был разработан в компании Apple Биллом Аткинсоном и получил известность благодаря его использованию в ранних компьютерах Macintosh.

Стоит отметить, что матрица рассеяния ошибки Аткинсона состоит из шести единиц, но она нормализуется с использованием 1/8, то есть — она не переносит всю ошибку на соседние пиксели, увеличивая воспринимаемую контрастность изображения.


Дизеринг по алгоритму Римерсма (Riemersma)
Честно говоря, на алгоритм Римерсма я наткнулся случайно. Я, пока исследовал другие алгоритмы, нашёл одну обстоятельную статью, в которой было написано об этом алгоритме. Такое ощущение, что он не особенно широко известен, но он мне очень понравился. Понравились мне и те идеи, на которых он основан. Вместо того, чтобы, ряд за рядом, обходить изображение, он обходит изображение по кривой Гильберта. С технической точки зрения тут подошла бы любая кривая, заполняющая пространство. Но рекомендуется использовать именно кривую Гильберта. Этот алгоритм довольно просто реализовать с использованием генераторов. Благодаря этому алгоритм нацелен на то, чтобы взять лучшее из алгоритмов дизеринга с упорядоченным шумом и с рассеянием ошибки. Речь идёт об ограничении количества пикселей, на которые может подействовать один пиксель, а так же о приятном внешнем виде результата (и о скромных требованиях к памяти).

У кривой Гильберта есть свойство «локальности», которое выражается в том, что пиксели, находящиеся близко друг к другу на кривой, находятся близко друг к другу и на изображении. При таком подходе нам не нужно использовать матрицу рассеяния ошибки. Вместо этого достаточно применить последовательность рассеяния ошибки длиной n. Для квантования текущего пикселя к нему добавляются n последних ошибок квантования с весами, заданными в последовательности рассеяния ошибки. В вышеупомянутой статье для задания весов используется экспоненциальный спад. Ошибке квантования предыдущего пикселя назначается вес 1, самой старой ошибке квантования в списке назначается маленький, вычисляемый по особой формуле, вес ![]() . Для вычисления
. Для вычисления ![]() -го веса используется следующая формула:
-го веса используется следующая формула:
В статье рекомендуется использовать ![]() , а минимальный размер списка значений —
, а минимальный размер списка значений — ![]() , но, выполняя тесты, я обнаружил, что лучше всего выглядит изображение с
, но, выполняя тесты, я обнаружил, что лучше всего выглядит изображение с ![]() и
и ![]()


Результат выглядит чрезвычайно органично, почти так же приятно, как после дизеринга с синим шумом. И, в то же время, дизеринг по алгоритму Римерсма легче реализовать, чем оба предыдущих варианта. Это, правда, всё равно, алгоритм, основанный на рассеянии ошибки, то есть — он обрабатывает данные последовательно и не подходит для выполнения на GPU.
Я выбираю синий шум, дизеринг Байера и алгоритм Римерсма
«Return of the Obra Dinn» — это 3D-игра, поэтому в ней необходимо использовать дизеринг с упорядоченным шумом для того чтобы выполнять соответствующий код в виде шейдера. В ней используется и дизеринг Байера, и дизеринг с синим шумом. Я поддерживаю создателей игры в этом выборе и тоже считаю, что, с эстетической точки зрения, они дают наиболее приятные результаты. Дизеринг Байера даёт немного больше структуры, а изображения после дизеринга с синим шумом выглядят очень естественно и органично. Я, кроме того, хочу особо выделить дизеринг по алгоритму Римерсма, и мне хочется узнать о том, как он показывает себя на изображениях с многоцветной палитрой.
Большая часть окружения в «Obra Dinn» рендерится с применением дизеринга с синим шумом. Люди и другие интересные объекты обрабатываются с помощью дизеринга Байера. Это создаёт интересный визуальный контраст и выделяет их, не нарушая общую эстетику игры. Напомню, что подробности о том, почему в игре всё сделано именно так, и о том, как обрабатываются перемещения камеры, можно почитать в посте Лукаса Поупа.
Если вы хотите испытать разные алгоритмы дизеринга на своём изображении — взгляните на мою демо-страницу, использованную для создания всех примеров к этой статье. Учитывайте, что мои реализации алгоритмов дизеринга не относятся к разряду самых быстрых. Поэтому, если вы решите «скормить» моей программе 20-мегапиксельную JPEG-фотографию — её обработка займёт некоторое время.
Обратите внимание на то, что у меня такое ощущение, что в Safari я наткнулся на деоптимизацию. Так, в Chrome на работу моего генератора синего шума требуется примерно 30 секунд, а в Safari — более 20 минут. А вот в Safari Tech Preview генератор работает гораздо быстрее.
Уверен, что то, о чём я рассказал — это до крайности нишевая тема, но мне понравилось побывать в этой кроличьей норе. Если вам есть что сказать о дизеринге, если вы этим занимались — с радостью вас послушаю.
Благодарности и дополнительные материалы
Благодарю Лукаса Поупа за его игры и за источник визуального вдохновения.
Благодарю Кристофа Питерса за его замечательную статью о генерировании синего шума.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Присоединяйтесь к нашей команде.
Ошибки квантования
В реальных
устройствах цифровой обработки сигналов
необходимо учитывать
эффекты, обусловленные квантованием
входных сигналов
и конечной разрядностью всех регистров.
Источниками ошибок
в процессах обработки сигналов являются
округление (усечение)
результатов арифметических операций,
шум аналого-цифрового квантования
входных аналоговых сигналов, неточность
реализации характеристик цифровых
фильтров из-за округления их коэффициентов
(параметров). В дальнейшем с целью
упрощения анализа предполагается, что
вес источники ошибок независимы и не
коррелируют с входным сигналом (хотя
мы и рассмотрим явление предельных
циклов, обусловленных коррелированным
шумом округления).
Эффект квантования
приводят в конечном итоге к погрешностями выходных сигналах цифровых фильтров
(ЦФ), а в некоторыхслучаяхи к неустойчивым
режимам. Выходную ошибку ЦФ будем
рассчитыватькаксуперпозицию ошибок, обусловленных
каждым независимымисточником.
Квантование
чисел– нелинейная операция;m-разрядное
двоичное числоА
представляетсяb-разрядным
двоичнымчислом
B=F(A),
причем b
< m. В
результате квантования число А
представляется
с ошибкой
е
=B–А= F(А)
–А.
Шаг квантования
Q
=
2–b
определяется весом младшего
числовогоразряда.
При квантовании
используется усечение или округление.
Усечение
числаА
состоит в отбрасываниит
– b
младших разрядов числа, при этом
ошибка усечения
eус=
Fус(А) –А.
Оценим величину
ошибки в предположении m
» b.
Для положительных чисел при любом
способе кодирования –2–b
<еус
0. Для
отрицательных чисел при использовании
прямого и обратного кодов ошибка усечения
неотрицательна: 0еус
< 2–b,
а в дополнительном коде эта ошибка
неположительна: 0еус
> –2–b.
Таким образом, во всех случаях
абсолютное значение ошибки усечения
не превосходит шага квантования:maxeус
< 2–b
=Q.
Округление
m-разрядного
числаA
доb
разрядов (b «
m)b-й
разряд остается неизменным или
увеличивается на единицув
зависимости от соотношения (больше –
меньше) между отбрасываемой дробью
0,аb+1…ат
и величиной
![]() ,
,
гдеаi–i-й
разряд числаA;
i =
b+1,
…,m.
Округление можно практически выполнить
путемприбавления
единицы к (b+1)-му
разряду и усечения полученного числа
до b разрядов.
В таком случае ошибка округления еoк
=
fок(А)–
А
при всех способах кодирования лежит в
пределах
–2–(b+1)
<
еoк
< 2–(b+1)
(1.11)
и, следовательно,
max![]() <2–b
<2–b
= Q/2.
(1.12)
В задачах ЦОС
ошибки квантования чисел рассматриваются
как стационарный
шумоподобный процесс с равномерным
распределением
вероятности по диапазону распределения
ошибок квантования.
(nT)


x(nT)

e(nT)
Рис. 3. Линейная модель квантования
сигналов:
(nT) —дискретный
или m-разрядный
цифровой сигнал (m
> b);
x(nT) —квантованный
b-разрядный
цифровой сигнал;
e(nT)
= x(nT)
–f(nT)
— ошибка
квантования.
Квантование
дискретных сигналов состоит в
представлении отсчета
(выборки сигнала) числамиx(nT),
содержащими b
числовых разрядов. Квантование сигналов,
как и квантование
чисел – нелинейная операция. Однако
при анализе процессов в ЦФ целесообразно
использовать линейную модель квантования
сигналов – рис. 3.
Верхнее значение ошибки квантования
![]() определяетсясоотношением
определяетсясоотношением
(1.11) или (1.12).
Вероятностные
оценки ошибок квантования основаны на
предположениях о том, что
последовательностье(пТ)являетсястационарным
случайным процессом с равномерным
распределением вероятности по
диапазону ошибок квантования ие(пТ)
не коррелирован
с f(nT).
Математическое
ожидание (среднее значение) e
и дисперсия
![]() ошибки квантованияе
ошибки квантованияе
определяются
по формулам:
![]() =E(е)
=E(е)
=![]() ,
,
![]() =
=![]() =
=![]() =E(е2)
=E(е2)
–![]() ,
,
где ре
— плотность вероятности ошибки. По
этим формуламвычисляются
математическое ожидание и дисперсия
для ошибок
округления и усечения:
![]() =
=
![]() =
=
![]()
В логарифмическоммасштабе
![]() =
=![]()
Лекция 2
Вычислите ошибку квантования
В этом примере показано, как вычислить и сравнить статистику ошибки квантования сигнала при использовании различных методов округления.
Во-первых, случайный сигнал создается, который порождает линейную оболочку столбцов квантизатора.
Затем сигнал квантуется, соответственно, с округлением методов ‘фиксируют’, ‘ставят в тупик’, ‘перекрывают’, ‘самый близкий’, и ‘конвергентный’, и статистические данные сигнала оцениваются.
Теоретическая функция плотности вероятности ошибки квантования будет вычислена с ERRPDF, теоретическое среднее значение ошибки квантования будет вычислено с ERRMEAN, и теоретическое отклонение ошибки квантования будет вычислено с ERRVAR.
Равномерно распределенный случайный сигнал
Сначала мы создаем равномерно распределенный случайный сигнал, который охватывает область-1 к 1 из квантизаторов фиксированной точки, на которые мы посмотрим.
q = quantizer([8 7]);
r = realmax(q);
u = r*(2*rand(50000,1) - 1); % Uniformly distributed (-1,1)
xi=linspace(-2*eps(q),2*eps(q),256);
Фиксация: вокруг по направлению к нулю.
Заметьте, что с округлением ‘фиксации’, функция плотности вероятности вдвое более широка, чем другие. Поэтому отклонение в четыре раза больше чем это других.
q = quantizer('fix',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 3 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -46.8586 Theoretical error variance (dB) = -46.9154 Estimated mean = 7.788e-06 Theoretical mean = 0

Пол: вокруг к минус бесконечность.
Пол, округляющийся, часто называется усечением, когда используется с целыми числами и числами фиксированной точки, которые представлены в дополнении two. Это — наиболее распространенный режим округления процессоров DSP, потому что это требует, чтобы никакое оборудование не реализовало. Пол не производит квантованные значения, которые являются как близко к истинным значениям, когда ROUND будет, но это имеет то же отклонение, и маленькие сигналы, которые варьируются по знаку, будут обнаружены, тогда как в ROUND они будут потеряны.
q = quantizer('floor',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = -eps(q)/2 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = -0.0038956 Theoretical mean = -0.0039062

Потолок: вокруг к плюс бесконечность.
q = quantizer('ceil',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = eps(q)/2 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = 0.0039169 Theoretical mean = 0.0039062

Вокруг: вокруг к самому близкому. Вничью, вокруг к самой большой величине.
Вокруг более точно, чем пол, но все значения, меньшие, чем eps (q), округлены, чтобы обнулить и потеряны — также.
q = quantizer('nearest',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0

Конвергентный: вокруг к самому близкому. Вничью, вокруг к даже.
Конвергентное округление устраняет смещение, введенное обычным «раундом», вызванным, всегда округляя связь в том же направлении.
q = quantizer('convergent',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0

Сравнение самых близких по сравнению с конвергентным
Функция плотности вероятности появления ошибки для конвергентного округления затрудняет, чтобы различать от того из раунда-к-самому-близкому путем рассмотрения графика.
Ошибка p.d.f. из конвергентных
f(err) = 1/eps(q), for -eps(q)/2 <= err <= eps(q)/2, and 0 otherwise
в то время как ошибка p.d.f. из раунда
f(err) = 1/eps(q), for -eps(q)/2 < err <= eps(q)/2, and 0 otherwise
Обратите внимание на то, что ошибка p.d.f. из конвергентных симметрично, в то время как вокруг немного склоняется к положительному.
Единственной разницей является направление округления вничью.
x=(-3.5:3.5)'; [x convergent(x) nearest(x)]
ans =
-3.5000 -4.0000 -3.0000
-2.5000 -2.0000 -2.0000
-1.5000 -2.0000 -1.0000
-0.5000 0 0
0.5000 0 1.0000
1.5000 2.0000 2.0000
2.5000 2.0000 3.0000
3.5000 4.0000 4.0000
Постройте функцию помощника
Функция помощника, которая использовалась, чтобы сгенерировать графики в этом примере, описана ниже.
type(fullfile(matlabroot,'toolbox','fixedpoint','fidemos','+fidemo','qerrordemoplot.m')) %#ok<*NOPTS>
function qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
%QERRORDEMOPLOT Plot function for QERRORDEMO.
% QERRORDEMOPLOT(Q,F_T,XI,MU_T,V_T,ERR) produces the plot and display
% used by the example function QERRORDEMO, where Q is the quantizer
% whose attributes are being analyzed; F_T is the theoretical
% quantization error probability density function for quantizer Q
% computed by ERRPDF; XI is the domain of values being evaluated by
% ERRPDF; MU_T is the theoretical quantization error mean of quantizer Q
% computed by ERRMEAN; V_T is the theoretical quantization error
% variance of quantizer Q computed by ERRVAR; and ERR is the error
% generated by quantizing a random signal by quantizer Q.
%
% See QERRORDEMO for examples of use.
% Copyright 1999-2014 The MathWorks, Inc.
v=10*log10(var(err));
disp(['Estimated error variance (dB) = ',num2str(v)]);
disp(['Theoretical error variance (dB) = ',num2str(10*log10(v_t))]);
disp(['Estimated mean = ',num2str(mean(err))]);
disp(['Theoretical mean = ',num2str(mu_t)]);
[n,c]=hist(err);
figure(gcf)
bar(c,n/(length(err)*(c(2)-c(1))),'hist');
line(xi,f_t,'linewidth',2,'color','r');
% Set the ylim uniformly on all plots
set(gca,'ylim',[0 max(errpdf(quantizer(q.format,'nearest'),xi)*1.1)])
legend('Estimated','Theoretical')
xlabel('err'); ylabel('errpdf')
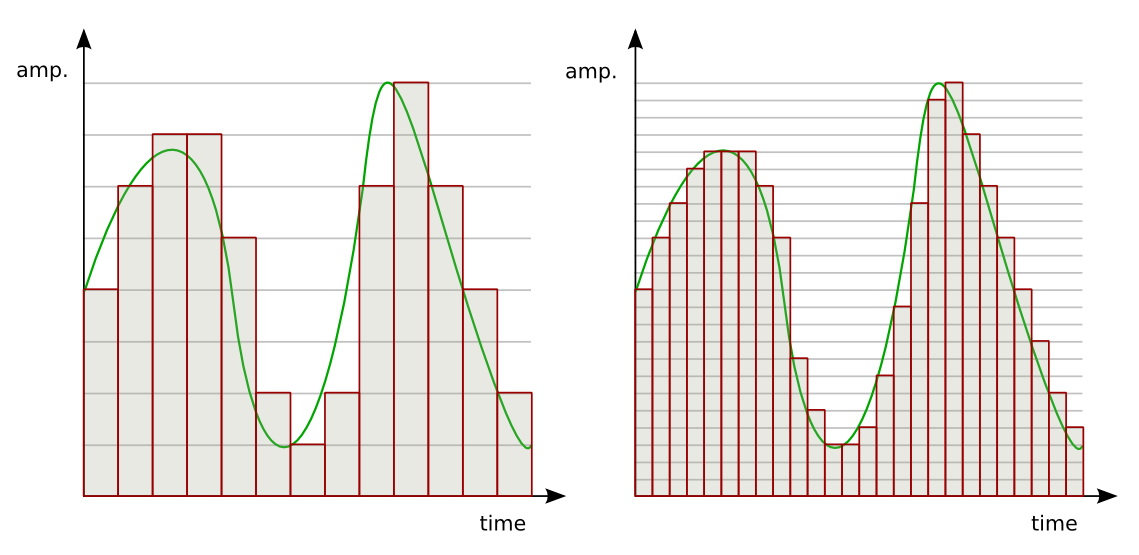
Дорогие читатели, меня зовут Феликс Арутюнян. Я студент, профессиональный скрипач. В этой статье хочу поделиться с Вами отрывком из моей презентации, которую я представил в университете музыки и театра Граца по предмету прикладная акустика.
Рассмотрим теоретические аспекты преобразования аналогового (аудио) сигнала в цифровой.
Статья не будет всеохватывающей, но в тексте будут гиперссылки для дальнейшего изучения темы.
Чем отличается цифровой аудиосигнал от аналогового?
Аналоговый (или континуальный) сигнал описывается непрерывной функцией времени, т.е. имеет непрерывную линию с непрерывным множеством возможных значений (рис. 1).
рис. 1
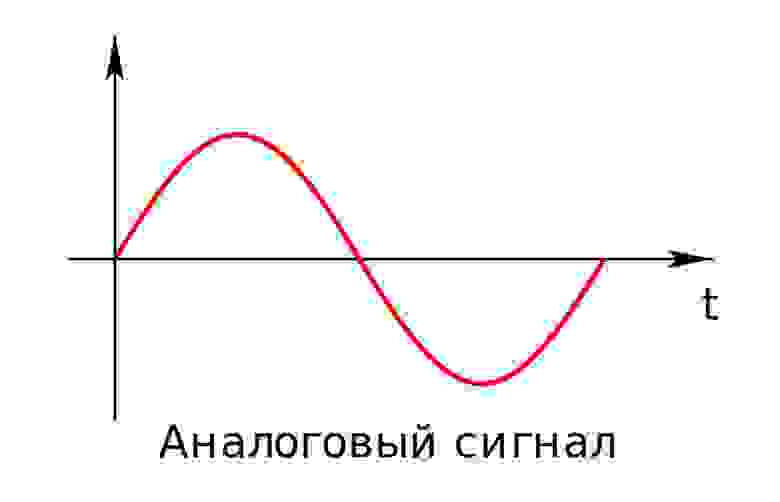
Цифровой сигнал — это сигнал, который можно представить как последовательность определенных цифровых значений. В любой момент времени он может принимать только одно определенное конечное значение (рис. 2).
рис. 2
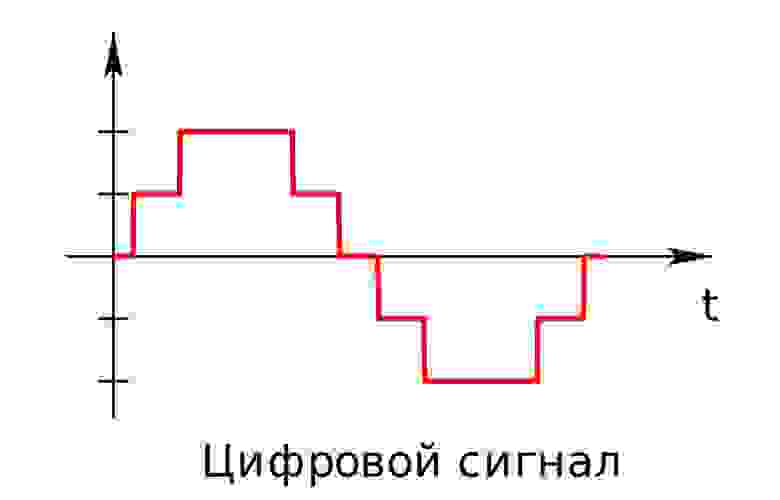
Аналоговый сигнал в динамическом диапазоне может принимать любые значения. Аналоговый сигнал преобразуется в цифровой с помощью двух процессов — дискретизация и квантование. Очередь процессов не важна.
Дискретизацией называется процесс регистрации (измерения) значения сигнала через определенные промежутки (обычно равные) времени (рис. 3).
рис. 3
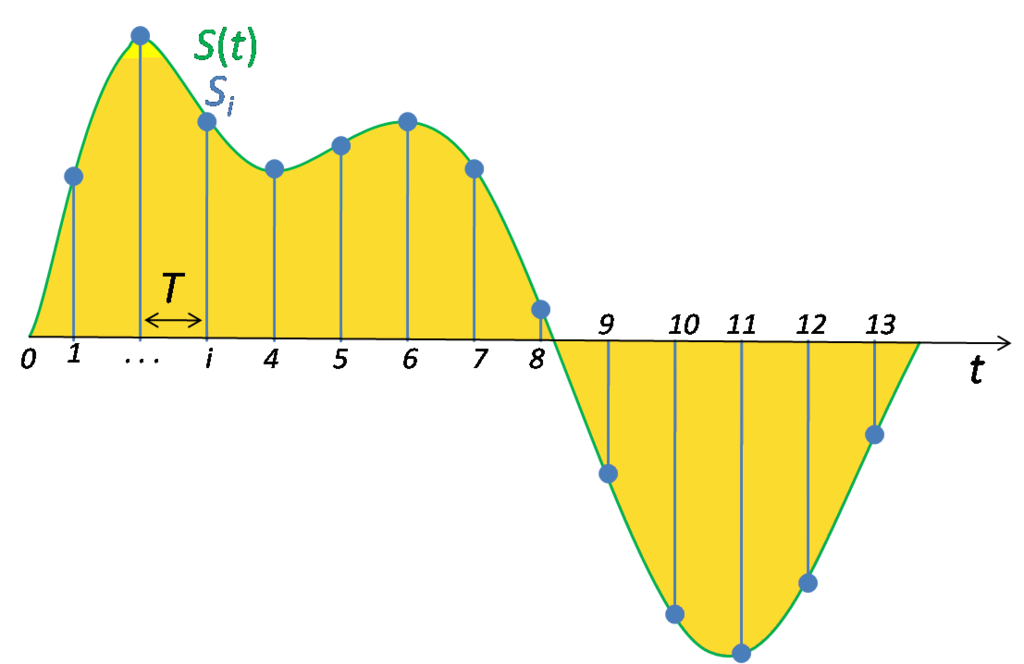
Квантование — это процесс разбиения диапазона амплитуды сигнала на определенное количество уровней и округление значений, измеренных во время дискретизации, до ближайшего уровня (рис. 4).
рис. 4
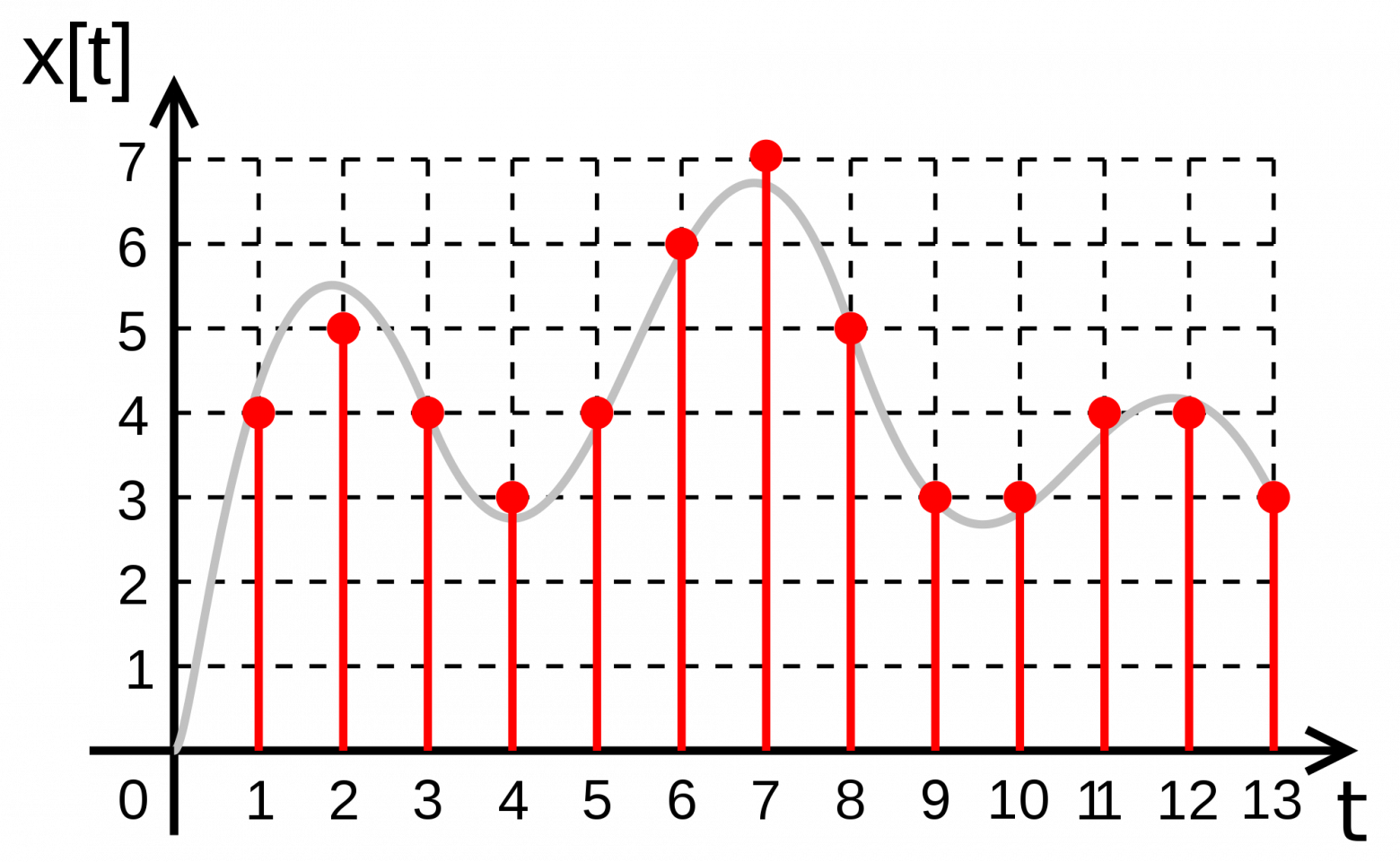
Дискретизация разбивает сигнал по временной составляющей (по вертикали, рис. 5, слева).
Квантование приводит сигнал к заданным значениям, то есть округляет сигнал до ближайших к нему уровней (по горизонтали, рис. 5, справа).
рис. 5
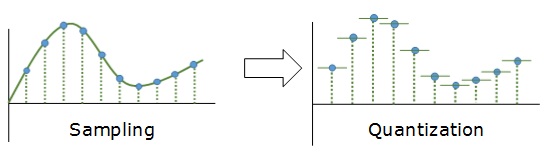
Эти два процесса создают как бы координатную систему, которая позволяет описывать аудиосигнал определенным значением в любой момент времени.
Цифровым называется сигнал, к которому применены дискретизация и квантование. Оцифровка происходит в аналого-цифровом преобразователе (АЦП). Чем больше число уровней квантования и чем выше частота дискретизации, тем точнее цифровой сигнал соответствует аналоговому (рис. 6).
рис. 6
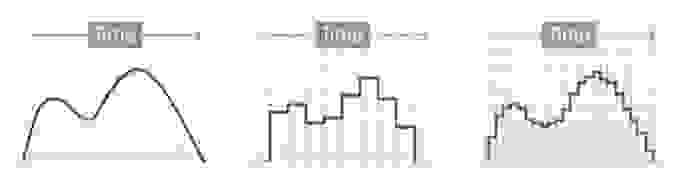
Уровни квантования нумеруются и каждому уровню присваивается двоичный код. (рис. 7)
рис. 7
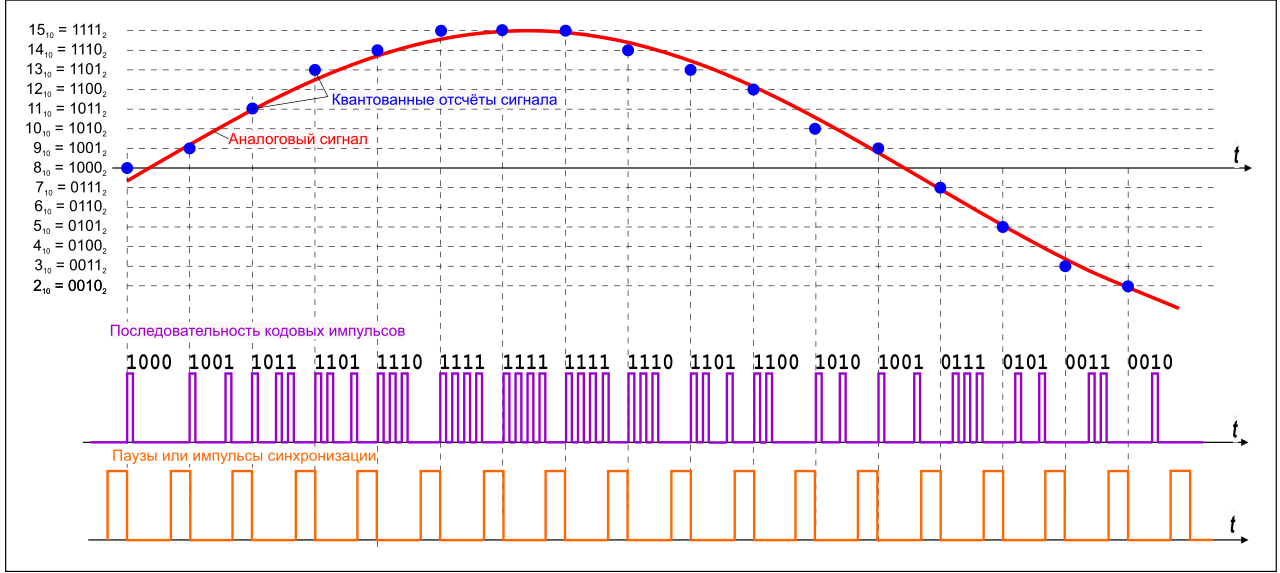
Количество битов, которые присваиваются каждому уровню квантования называют разрядностью или глубиной квантования (eng. bit depth). Чем выше разрядность, тем больше уровней можно представить двоичным кодом (рис. 8).
рис. 8.
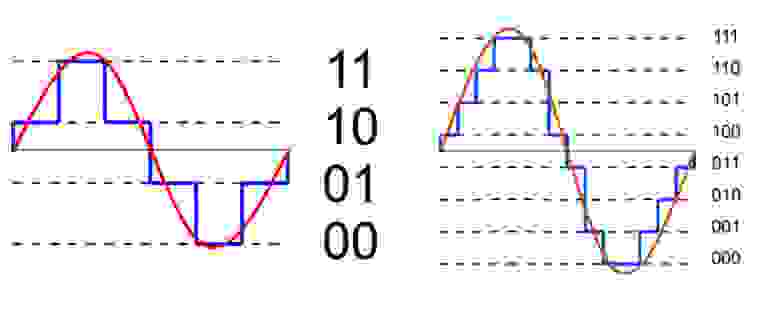
Данная формула позволяет вычислить количество уровней квантования:
Если N — количество уровней квантования,
n — разрядность, то

Обычно используют разрядности в 8, 12, 16 и 24 бит. Несложно вычислить, что при n=24 количество уровней N = 16,777,216.
При n = 1 аудиосигнал превратится в азбуку Морзе: либо есть «стук», либо нету. Существует также разрядность 32 бит с плавающей запятой. Обычный компактный Аудио-CD имеет разрядность 16 бит. Чем ниже разрядность, тем больше округляются значения и тем больше ошибка квантования.
Ошибкой квантований называют отклонение квантованного сигнала от аналогового, т.е. разница между входным значением  и квантованным значением
и квантованным значением  (
( )
)
Большие ошибки квантования приводят к сильным искажениям аудиосигнала (шум квантования).
Чем выше разрядность, тем незначительнее ошибки квантования и тем лучше отношение сигнал/шум (Signal-to-noise ratio, SNR), и наоборот: при низкой разрядности вырастает шум (рис. 9).
рис. 9
Разрядность также определяет динамический диапазон сигнала, то есть соотношение максимального и минимального значений. С каждым битом динамический диапазон вырастает примерно на 6dB (Децибел) (6dB это в 2 раза; то есть координатная сетка становиться плотнее, возрастает градация).
рис. 10. Интенсивность шумов при разрядности 6 бит и 8 бит
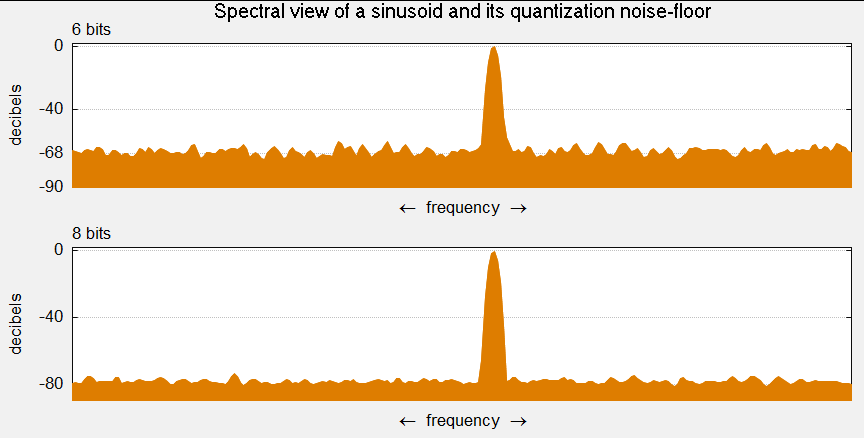
Ошибки квантования (округления) из-за недостаточного количество уровней не могут быть исправлены.
шум квантования
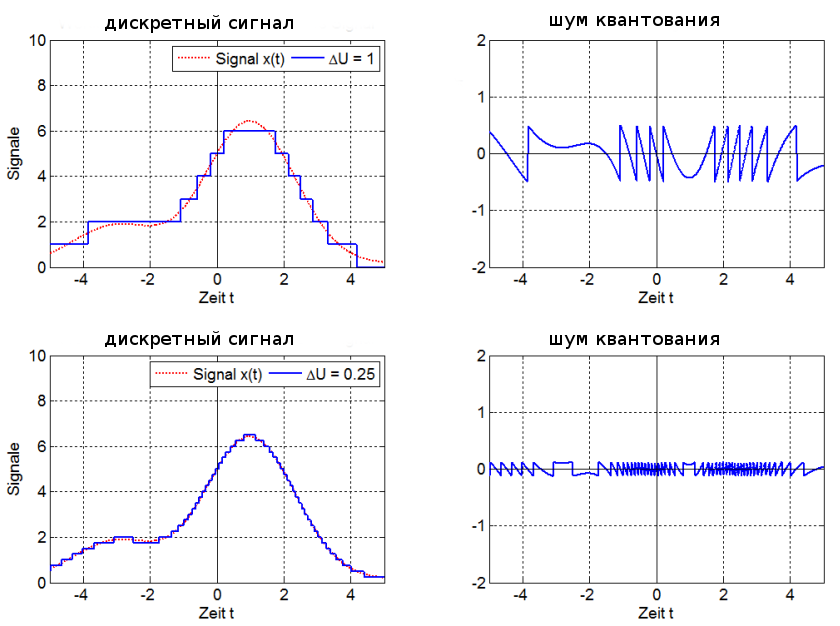
амплитуда сигнала при разрядности 1 бит (сверху) и 4 бит
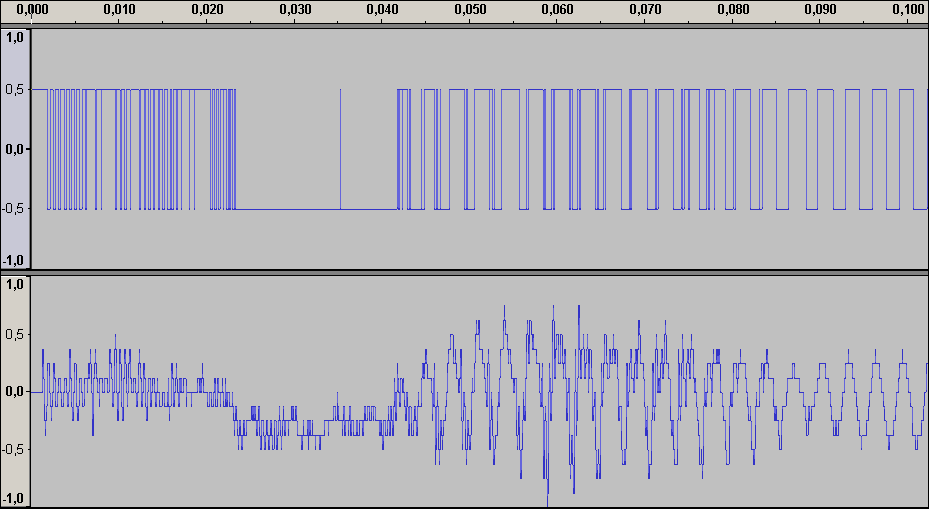
Аудиопример 1: 8bit/44.1kHz, ~50dB SNR
примечание: если аудиофайлы не воспроизводятся онлайн, пожалуйста, скачивайте их.
Аудиопример 1
Аудиопример 2: 4bit/48kHz, ~25dB SNR
Аудиопример 2
Аудиопример 3: 1bit/48kHz, ~8dB SNR
Аудиопример 3
Теперь о дискретизации.
Как уже говорили ранее, это разбиение сигнала по вертикали и измерение величины значения через определенный промежуток времени. Этот промежуток называется периодом дискретизации или интервалом выборок. Частотой выборок, или частотой дискретизации (всеми известный sample rate) называется величина, обратная периоду дискретизации и измеряется в герцах. Если
T — период дискретизации,
F — частота дискретизации, то

Чтобы аналоговый сигнал можно было преобразовать обратно из цифрового сигнала (точно реконструировать непрерывную и плавную функцию из дискретных, «точечных» значении), нужно следовать теореме Котельникова (теорема Найквиста — Шеннона).
Теорема Котельникова гласит:
Если аналоговый сигнал имеет финитный (ограниченной по ширине) спектр, то он может быть восстановлен однозначно и без потерь по своим дискретным отсчетам, взятым с частотой, строго большей удвоенной верхней частоты.
Вам знакомо число 44.1kHz? Это один из стандартов частоты дискретизации, и это число выбрали именно потому, что человеческое ухо слышит только сигналы до 20kHz. Число 44.1 более чем в два раза больше чем 20, поэтому все частоты в цифровом сигнале, доступные человеческому уху, могут быть преобразованы в аналоговом виде без искажении.
Но ведь 20*2=40, почему 44.1? Все дело в совместимости с стандартами PAL и NTSC. Но сегодня не будем рассматривать этот момент. Что будет, если не следовать теореме Котельникова?
Когда в аудиосигнале встречается частота, которая выше чем 1/2 частоты дискретизации, тогда возникает алиасинг — эффект, приводящий к наложению, неразличимости различных непрерывных сигналов при их дискретизации.
Алиасинг
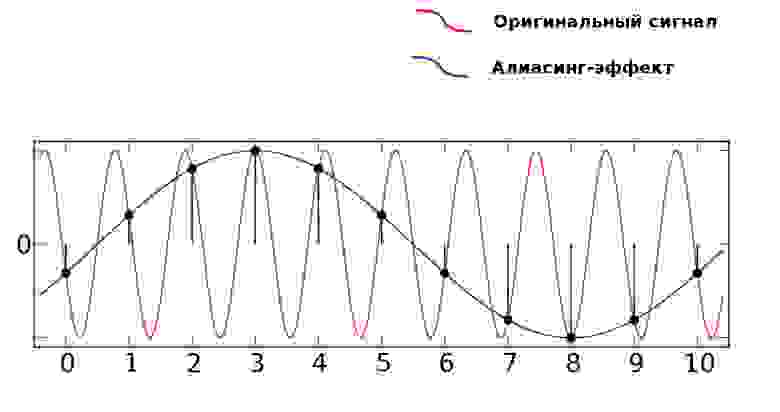
Как видно из предыдущей картинки, точки дискретизации расположены так далеко друг от друга, что при интерполировании (т.е. преобразовании дискретных точек обратно в аналоговый сигнал) по ошибке восстанавливается совершенно другая частота.
Аудиопример 4: Линейно возрастающая частота от ~100 до 8000Hz. Частота дискретизации — 16000Hz. Нет алиасинга.
Спектральный анализ
Аудиопример 5: Тот же файл. Частота дискретизации — 8000Hz. Присутствует алиасинг
Спектральный анализ
Пример:
Имеется аудиоматериал, где пиковая частота — 2500Hz. Значит, частоту дискретизации нужно выбрать как минимум 5000Hz.
Следующая характеристика цифрового аудио это битрейт. Битрейт (bitrate) — это объем данных, передаваемых в единицу времени. Битрейт обычно измеряют в битах в секунду (Bit/s или bps). Битрейт может быть переменным, постоянным или усреднённым.
Следующая формула позволяет вычислить битрейт (действительна только для несжатых потоков данных):
Битрейт = Частота дискретизации * Разрядность * Количество каналов
Например, битрейт Audio-CD можно рассчитать так:
44100 (частота дискретизации) * 16 (разрядность) * 2 (количество каналов, stereo)= 1411200 bps = 1411.2 kbit/s
При постоянном битрейте (constant bitrate, CBR) передача объема потока данных в единицу времени не изменяется на протяжении всей передачи. Главное преимущество — возможность довольно точно предсказать размер конечного файла. Из минусов — не оптимальное соотношение размер/качество, так как «плотность» аудиоматериала в течении музыкального произведения динамично изменяется.
При кодировании переменным битрейтом (VBR), кодек выбирает битрейт исходя из задаваемого желаемого качества. Как видно из названия, битрейт варьируется в течение кодируемого аудиофайла. Данный метод даёт наилучшее соотношение качество/размер выходного файла. Из минусов: точный размер конечного файла очень плохо предсказуем.
Усреднённый битрейт (ABR) является частным случаем VBR и занимает промежуточное место между постоянным и переменным битрейтом. Конкретный битрейт задаётся пользователем. Программа все же варьирует его в определенном диапазоне, но не выходит за заданную среднюю величину.
При заданном битрейте качество VBR обычно выше чем ABR. Качество ABR в свою очередь выше чем CBR: VBR > ABR > CBR.
ABR подходит для пользователей, которым нужны преимущества кодирования VBR, но с относительно предсказуемым размером файла. Для ABR обычно требуется кодирование в 2 прохода, так как на первом проходе кодек не знает какие части аудиоматериала должны кодироваться с максимальным битрейтом.
Существуют 3 метода хранения цифрового аудиоматериала:
- Несжатые («сырые») данные
- Данные, сжатые без потерь
- Данные, сжатые с потерями
Несжатый (RAW) формат данных
содержит просто последовательность бинарных значений.
Именно в таком формате хранится аудиоматериал в Аудио-CD. Несжатый аудиофайл можно открыть, например, в программе Audacity. Они имеют расширение .raw, .pcm, .sam, или же вообще не имеют расширения. RAW не содержит заголовка файла (метаданных).
Другой формат хранения несжатого аудиопотока это WAV. В отличие от RAW, WAV содержит заголовок файла.
Аудиоформаты с сжатием без потерь
Принцип сжатия схож с архиваторами (Winrar, Winzip и т.д.). Данные могут быть сжаты и снова распакованы любое количество раз без потери информации.
Как доказать, что при сжатии без потерь, информация действительно остаётся не тронутой? Это можно доказать методом деструктивной интерференции. Берем две аудиодорожки. В первой дорожке импортируем оригинальный, несжатый wav файл. Во второй дорожке импортируем тот же аудиофайл, сжатый без потерь. Инвертируем фазу одного из дорожек (зеркальное отображение). При проигрывании одновременно обеих дорожек выходной сигнал будет тишиной.
Это доказывает, что оба файла содержат абсолютно идентичные информации (рис. 11).
рис. 11
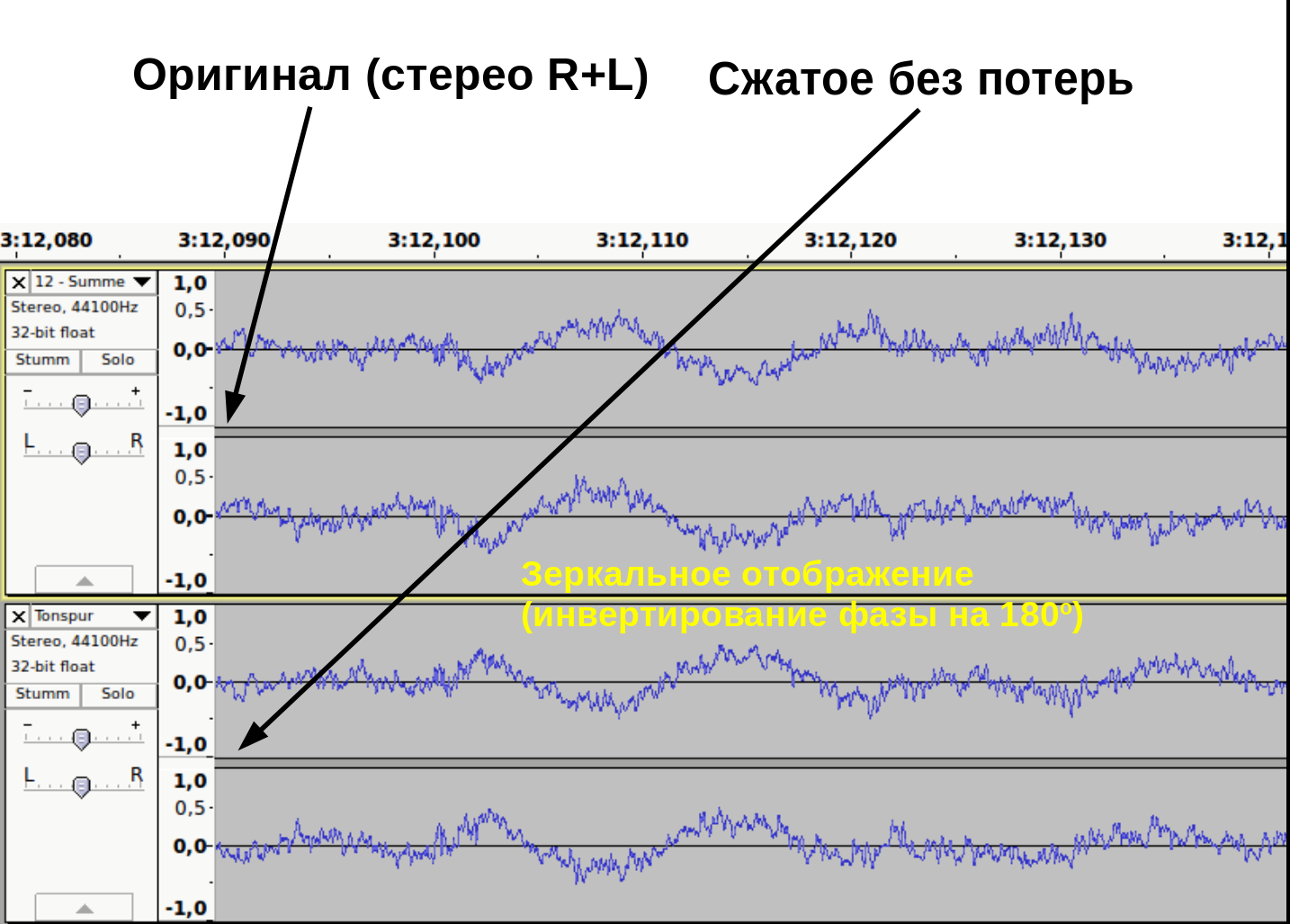
Кодеки сжатия без потерь: flac, WavPack, Monkey’s Audio…
При сжатии с потерями
акцент делается не на избежание потерь информации, а на спекуляцию с субъективными восприятиями (Психоакустика). Например, ухо взрослого человек обычно не воспринимает частоты выше 16kHz. Используя этот факт, кодек сжатия с потерями может просто жестко срезать все частоты выше 16kHz, так как «все равно никто не услышит разницу».
Другой пример — эффект маскировки. Слабые амплитуды, которые перекрываются сильными амплитудами, могут быть воспроизведены с меньшим качеством. При громких низких частотах тихие средние частоты не улавливаются ухом. Например, если присутствует звук в 1kHz с уровнем громкости в 80dB, то 2kHz-звук с громкостью 40dB больше не слышим.
Этим и пользуется кодек: 2kHz-звук можно убрать.
Спектральный анализ кодека mp3 с разными уровнями компрессии
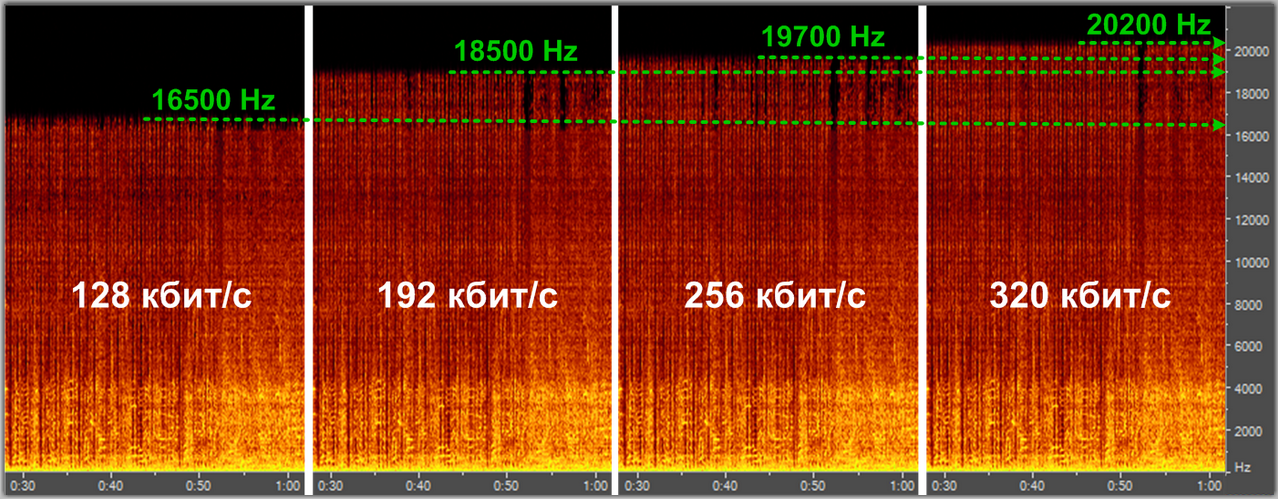
Кодеки сжатия с потерям: mp3, aac, ogg, wma, Musepack…
Спасибо за внимание.
UPD:
Если по каким-либо причинам аудиофайлы не загружаются, можете их скачать здесь: cloud.mail.ru/public/HbzU/YEsT34i4c