Когда мы подгоняем регрессионную модель к набору данных, нас часто интересует, насколько хорошо регрессионная модель «подходит» к набору данных. Две метрики, обычно используемые для измерения согласия, включают R -квадрат (R2) и стандартную ошибку регрессии , часто обозначаемую как S.
В этом руководстве объясняется, как интерпретировать стандартную ошибку регрессии (S), а также почему она может предоставить более полезную информацию, чем R 2 .
Стандартная ошибка по сравнению с R-квадратом в регрессии
Предположим, у нас есть простой набор данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их баллы за экзамен:

Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

R-квадрат — это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной. При этом 65,76% дисперсии экзаменационных баллов можно объяснить количеством часов, потраченных на учебу.
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом случае наблюдаемые значения отклоняются от линии регрессии в среднем на 4,89 единицы.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание, что некоторые наблюдения попадают очень близко к линии регрессии, в то время как другие не так близки. Но в среднем наблюдаемые значения отклоняются от линии регрессии на 4,19 единицы .
Стандартная ошибка регрессии особенно полезна, поскольку ее можно использовать для оценки точности прогнозов. Примерно 95% наблюдений должны находиться в пределах +/- двух стандартных ошибок регрессии, что является быстрым приближением к 95% интервалу прогнозирования.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Чтобы проиллюстрировать, почему стандартная ошибка регрессии может быть более полезной метрикой для оценки «соответствия» модели, рассмотрим другой пример набора данных, который показывает, сколько часов 12 студентов занимались в день в течение месяца, предшествующего важному экзамену, а также их экзаменационная оценка:

Обратите внимание, что это точно такой же набор данных, как и раньше, за исключением того, что все значения s сокращены вдвое.Таким образом, студенты из этого набора данных учились ровно в два раза дольше, чем студенты из предыдущего набора данных, и получили ровно половину экзаменационного балла.
Если мы подгоним простую модель линейной регрессии к этому набору данных в Excel, мы получим следующий результат:

Обратите внимание, что R-квадрат 65,76% точно такой же, как и в предыдущем примере.
Однако стандартная ошибка регрессии составляет 2,095 , что ровно вдвое меньше стандартной ошибки регрессии в предыдущем примере.
Если мы нанесем фактические точки данных вместе с линией регрессии, мы сможем увидеть это более четко:

Обратите внимание на то, что наблюдения располагаются гораздо плотнее вокруг линии регрессии. В среднем наблюдаемые значения отклоняются от линии регрессии на 2,095 единицы .
Таким образом, несмотря на то, что обе модели регрессии имеют R-квадрат 65,76% , мы знаем, что вторая модель будет давать более точные прогнозы, поскольку она имеет более низкую стандартную ошибку регрессии.
Преимущества использования стандартной ошибки
Стандартную ошибку регрессии (S) часто бывает полезнее знать, чем R-квадрат модели, потому что она дает нам фактические единицы измерения. Если мы заинтересованы в использовании регрессионной модели для получения прогнозов, S может очень легко сказать нам, достаточно ли точна модель для прогнозирования.
Например, предположим, что мы хотим создать 95-процентный интервал прогнозирования, в котором мы можем прогнозировать результаты экзаменов с точностью до 6 баллов от фактической оценки.
Наша первая модель имеет R-квадрат 65,76%, но это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. К счастью, мы также знаем, что у первой модели показатель S равен 4,19. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*4,19 = +/- 8,38 единиц, что слишком велико для нашего интервала прогнозирования.
Наша вторая модель также имеет R-квадрат 65,76%, но опять же это ничего не говорит нам о том, насколько точным будет наш интервал прогнозирования. Однако мы знаем, что вторая модель имеет S 2,095. Это означает, что 95-процентный интервал прогнозирования будет иметь ширину примерно 2*2,095= +/- 4,19 единиц, что меньше 6 и, следовательно, будет достаточно точным для использования для создания интервалов прогнозирования.
Дальнейшее чтение
Введение в простую линейную регрессию
Что такое хорошее значение R-квадрата?
Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
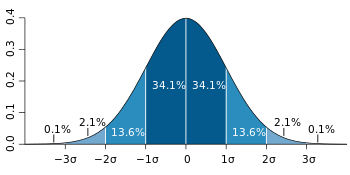
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {\displaystyle SE_{\bar {x}}\ ={\frac {s}{\sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
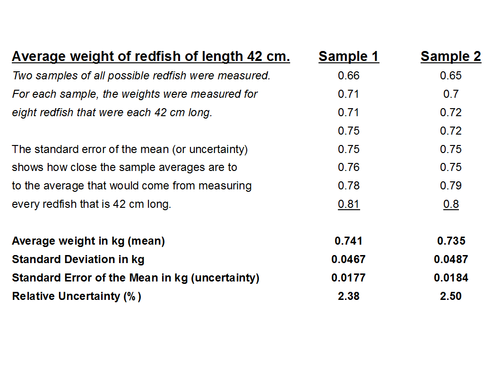
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Вопросы и ответы
В: Что такое стандартная ошибка?
О: Стандартная ошибка — это стандартное отклонение выборочного распределения статистики.
В: Можно ли использовать термин стандартная ошибка для оценки стандартного отклонения?
О: Да, термин стандартная ошибка может быть использован для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
В: Как можно оценить среднее значение для всей группы?
О: Среднее значение некоторой части группы (называемой выборкой) — это обычный способ оценки среднего значения для всей группы.
В: Почему трудно измерить всю группу?
О: Часто бывает слишком трудно или слишком дорого измерить всю группу.
В: Что такое стандартная ошибка среднего, и что она определяет?
О: Стандартная ошибка среднего — это способ узнать, насколько близко среднее значение выборки к среднему значению всей группы. Это способ узнать, насколько можно быть уверенным в среднем значении по выборке.
В: Известно ли обычно истинное значение стандартного отклонения среднего при реальных измерениях?
О: Нет, истинное значение стандартного отклонения среднего для всей группы обычно не известно в реальных измерениях.
В: Как количество измерений в выборке влияет на точность оценки?
О: Чем больше измерений в выборке, тем ближе предположение будет к истинному значению для всей группы.

Содержание
- Что такое стандартная ошибка?
- Стандартная ошибка
- Ключевые выводы
- Понимание стандартной ошибки
- Требования к стандартной ошибке
Что такое стандартная ошибка?
Стандартная ошибка (SE) статистики — это приблизительное стандартное отклонение статистической выборки. Стандартная ошибка — это статистический термин, который измеряет точность, с которой выборочное распределение представляет генеральную совокупность с помощью стандартного отклонения. В статистике выборочное среднее отклоняется от фактического среднего значения по генеральной совокупности — это отклонение является стандартной ошибкой среднего.
Стандартная ошибка
Ключевые выводы
- Стандартная ошибка — это приблизительное стандартное отклонение статистической выборки.
- Стандартная ошибка может включать вариацию между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное.
- Чем больше точек данных участвует в вычислении среднего, тем меньше стандартная ошибка.
Понимание стандартной ошибки
Термин «стандартная ошибка» используется для обозначения стандартного отклонения различных статистических данных выборки, таких как среднее или медианное значение. Например, «стандартная ошибка среднего» относится к стандартному отклонению распределения выборочных средних, взятых из генеральной совокупности. Чем меньше стандартная ошибка, тем более репрезентативной будет выборка для всей генеральной совокупности.
Связь между стандартной ошибкой и стандартным отклонением такова, что для данного размера выборки стандартная ошибка равна стандартному отклонению, деленному на квадратный корень из размера выборки. Стандартная ошибка также обратно пропорциональна размеру выборки; Чем больше размер выборки, тем меньше стандартная ошибка, поскольку статистика приближается к фактическому значению.
Стандартная ошибка считается частью описательной статистики. Он представляет собой стандартное отклонение среднего значения в наборе данных. Это служит мерой вариации случайных величин, обеспечивая измерение спреда. Чем меньше разброс, тем точнее набор данных.
Стандартная ошибка и стандартное отклонение — это меры изменчивости, в то время как меры центральной тенденции включают среднее значение, медианное значение и т. Д.
Требования к стандартной ошибке
Когда производится выборка из генеральной совокупности, обычно рассчитывается среднее или среднее значение. Стандартная ошибка может включать разброс между вычисленным средним для генеральной совокупности и тем, которое считается известным или принимаемым как точное. Это помогает компенсировать любые случайные неточности, связанные со сбором пробы.
В случаях, когда собирается несколько образцов, среднее значение каждой выборки может незначительно отличаться от других, создавая разброс между переменными. Этот разброс чаще всего измеряется как стандартная ошибка, учитывающая различия между средними значениями в наборах данных.
Чем больше точек данных участвует в вычислении среднего, тем меньше стандартная ошибка. Когда стандартная ошибка мала, данные считаются более репрезентативными для истинного среднего значения. В случаях, когда стандартная ошибка велика, данные могут иметь некоторые заметные отклонения.
Стандартное отклонение — это представление разброса каждой точки данных. Стандартное отклонение используется для определения достоверности данных на основе количества точек данных, отображаемых на каждом уровне стандартного отклонения. Стандартные ошибки больше служат способом определения точности образца или точности нескольких образцов путем анализа отклонения в пределах средних.
What Is the Standard Error?
The standard error (SE) of a statistic is the approximate standard deviation of a statistical sample population.
The standard error is a statistical term that measures the accuracy with which a sample distribution represents a population by using standard deviation. In statistics, a sample mean deviates from the actual mean of a population; this deviation is the standard error of the mean.
Key Takeaways
- The standard error (SE) is the approximate standard deviation of a statistical sample population.
- The standard error describes the variation between the calculated mean of the population and one which is considered known, or accepted as accurate.
- The more data points involved in the calculations of the mean, the smaller the standard error tends to be.
Investopedia / Joules Garcia
Understanding Standard Error
The term «standard error» is used to refer to the standard deviation of various sample statistics, such as the mean or median. For example, the «standard error of the mean» refers to the standard deviation of the distribution of sample means taken from a population. The smaller the standard error, the more representative the sample will be of the overall population.
The relationship between the standard error and the standard deviation is such that, for a given sample size, the standard error equals the standard deviation divided by the square root of the sample size. The standard error is also inversely proportional to the sample size; the larger the sample size, the smaller the standard error because the statistic will approach the actual value.
The standard error is considered part of inferential statistics—or, the conclusions drawn from the study. It represents the standard deviation of the mean within a dataset. This serves as a measure of variation for random variables, providing a measurement for the spread. The smaller the spread, the more accurate the dataset.
Standard error and standard deviation are measures of variability, while central tendency measures include mean, median, etc.
Formula and Calculation of Standard Error
Used in algorithmic trading, the standard error of an estimate can be calculated as the standard deviation divided by the square root of the sample size:
SE = σ / √n
where
- σ = the population standard deviation
- √n = the square root of the sample size
If the population standard deviation is not known, you can substitute the sample standard deviation, s, in the numerator to approximate the standard error.
Requirements for Standard Error
When a population is sampled, the mean, or average, is generally calculated. The standard error can include the variation between the calculated mean of the population and one which is considered known, or accepted as accurate. This helps compensate for any incidental inaccuracies related to the gathering of the sample.
In cases where multiple samples are collected, the mean of each sample may vary slightly from the others, creating a spread among the variables. This spread is most often measured as the standard error, accounting for the differences between the means across the datasets.
The more data points involved in the calculations of the mean, the smaller the standard error tends to be. When the standard error is small, the data is said to be more representative of the true mean. In cases where the standard error is large, the data may have some notable irregularities.
The standard deviation is a representation of the spread of each of the data points. The standard deviation is used to help determine the validity of the data based on the number of data points displayed at each level of standard deviation. Standard errors function more as a way to determine the accuracy of the sample or the accuracy of multiple samples by analyzing deviation within the means.
Standard Error vs. Standard Deviation
The standard error normalizes the standard deviation relative to the sample size used in an analysis. Standard deviation measures the amount of variance or dispersion of the data spread around the mean. The standard error can be thought of as the dispersion of the sample mean estimations around the true population mean. As the sample size becomes larger, the standard error will become smaller, indicating that the estimated sample mean value better approximates the population mean.
Example of Standard Error
Say that an analyst has looked at a random sample of 50 companies in the S&P 500 to understand the association between a stock’s P/E ratio and subsequent 12-month performance in the market. Assume that the resulting estimate is -0.20, indicating that for every 1.0 point in the P/E ratio, stocks return 0.2% poorer relative performance. In the sample of 50, the standard deviation was found to be 1.0.
The standard error is thus:
SE = 1.0/√50 = 1/7.07 = 0.141
Therefore, we would report the estimate as -0.20% ± 0.14, giving us a confidence interval of (-0.34 — -0.06). The true mean value of the association of the P/E on returns of the S&P 500 would therefore fall within that range with a high degree of probability.
Say now that we increase the sample of stocks to 100 and find that the estimate changes slightly from -0.20 to -0.25, and the standard deviation falls to 0.90. The new standard error would thus be:
SE = 0.90/√100 = 0.90/10 = 0.09.
The resulting confidence interval becomes -0.25 ± 0.09 = (-0.34 — -0.16), which is a tighter range of values.
What Is Meant by Standard Error?
Standard error is intuitively the standard deviation of the sampling distribution. In other words, it depicts how much disparity there is likely to be in a point estimate obtained from a sample relative to the true population mean.
What Is a Good Standard Error?
Standard error measures the amount of discrepancy that can be expected in a sample estimate compared to the true value in the population. Therefore, the smaller the standard error the better. In fact, a standard error of zero (or close to it) would indicate that the estimated value is exactly the true value.
How Do You Find the Standard Error?
The standard error takes the standard deviation and divides it by the square root of the sample size. Many statistical software packages automatically compute standard errors.
The Bottom Line
The standard error (SE) measures the dispersion of estimated values obtained from a sample around the true value to be found in the population. Statistical analysis and inference often involves drawing samples and running statistical tests to determine associations and correlations between variables. The standard error thus tells us with what degree of confidence we can expect the estimated value to approximate the population value.
Качество
подбора функции регрессии можно оценить
с помощью стандартных ошибок или
дисперсий остатков и оценок параметров
регрессии.
Стандартная
ошибка или дисперсия остатков. Стандартная
ошибка остатков называется также
стандартной ошибкой оценки регрессии
в связи с интерпретацией возмущающей
переменной и как результата ошибки
спецификации функции регрессии.
Возмущающая переменная и является
случайной с определенным распределением
вероятностей. Математическое ожидание
этой переменной равно нулю, а дисперсия
— ![]() .
.
Таким образом,![]() —
—
это дисперсия возмущения в генеральной
совокупности. Нам неизвестны значения
возмущающей переменной. Можно судить
о ней только по остаткам![]() .
.
Вычисленная по этим остаткам дисперсия![]() является оценкой дисперсии возмущающей
является оценкой дисперсии возмущающей
переменной. Несмещенной оценкой дисперсии
возмущающего воздействия![]() будет, следующее выражение:
будет, следующее выражение:
![]() (35)
(35)
В
знаменателе формулы (35) стоит число
степеней свободы ![]() ,
,
гдеn— объем выборки,
am— число объясняющих переменных.
Такое выражение числа степеней свободы
связано с тем, что остатки должны
удовлетворятьm + 1условиям. Кратко поясним это утверждение.
Параметры множественной регрессии
![]() (36)
(36)
вычисляют путем решения системы
нормальных уравнений, в матричной форме
записи имеющих вид
![]() (37)
(37)
Подставим
(36) в (37):
![]()
Раскрыв
скобки и сделав соответствующие выкладки,
получим
![]() (38)
(38)
Матричное
уравнение (38) содержит m
+ 1условий (уравнений), которые
накладываются на остатки, и это приводит
к уменьшению числа степеней свободы.
Приk = 0в силу того, чтох1
= 1для всехi,
![]() (39)
(39)
что
является следствием того, что математическое
ожидание возмущающей переменной равно
нулю. Из (38) при k = 1, … , m,
т также получим
![]() (40)
(40)
что
вытекает из следующего: переменные xk(k = 1, … , m) не
коррелируют со значениями возмущения,
т. е.xk(k = 1, … , m) являются
действительно объясняющими, а не
подлежащими объяснению переменными.
Следовательно, в регрессионном анализе
могут обсуждаться только односторонне
направленные зависимости. Поскольку
термин «степень свободы» используется
для обозначения независимой информации,
в данном случае число связей, налагаемых
наnнезависимых
случайных наблюдений, можно интерпретировать
какm + 1параметров
(b0, b1
…, bm),
которыми определяется функция регрессии.
В
связи с тем что вычисление числителя в
формуле (35) довольно затруднительно, мы
хотим, опустив вывод, привести более
простой способ его определения:
![]() (41)
(41)
или
в матричной форме записи:
![]()
Выражения
сумм в правой части (41) содержатся в
рабочей таблице для построения регрессии,
а оценки параметров уже получены. Если
снова обратиться к понятию коэффициента
детерминации, введенному в разделах 1
и 2, то станет ясным физический смысл
дисперсии (или стандартного отклонения)
остатков — это та доля общей дисперсии
![]() ,
,
которая не может быть объяснена
зависимостью переменной у от переменныхxk(k = 1, … , m).
Стандартные
ошибки или дисперсии оценок параметров
регрессии. При описании этих показателей
будем исходить из заданных значений
объясняющих переменных.
Оценки
параметров регрессии являются случайными
величинами, имеющими определенное
распределение вероятностей. Возможные
значения оценок рассеиваются вокруг
истинного значения параметра β. Определим
меру рассеяния оценки параметра.
Обозначим через ![]() матрицу дисперсий и ковариаций оценок
матрицу дисперсий и ковариаций оценок
параметров регрессии:
 (42)
(42)
Симметрическая
матрица (42) на главной диагонали содержит
дисперсии оценок параметров регрессии
βk,k = 0,1,…,m
![]() (43)
(43)
а
вне главной диагонали — их ковариации
![]() (44)
(44)
для
k≠lиk = 0,1,…,m, l
= 0,1,…,m.
Краткая
форма записи матрицы (42):
![]() (45)
(45)
Подставив
в (45) формулу (46)
![]() (46)
(46)
получим
![]()
или
![]() (47)
(47)
Далее,
в силу того, что
![]() (48)
(48)
имеем
![]() (49)
(49)
Так
как ![]() неизвестно, используем его оценку
неизвестно, используем его оценку![]() .
.
В результате получаем оценку матрицы
(49),
![]() (50)
(50)
элементами
главной диагонали которой являются
искомые оценки дисперсий. Матрицу ![]() легко определить, поскольку матрица
легко определить, поскольку матрица![]() известна (см. приложение Б), a
известна (см. приложение Б), a![]() вычисляется по (35).
вычисляется по (35).
Если
мы обозначим через ![]() элемент главной диагонали матрицы
элемент главной диагонали матрицы![]() ,
,
то оценка дисперсии параметра регрессии
bkбудет определяться
выражением
![]() (51)
(51)
т.
е. она равна произведению дисперсии
остатков на k-й элемент главной
диагонали обратной матрицы![]() ,.
,.
Таким образом, стандартная ошибка оценки
параметра регрессии bkопределяется как
![]() (52)
(52)
Найдем
дисперсию и стандартную ошибку оценок
параметров b0и b1простой
линейной регрессии. В случае простой
линейной регрессии имеем
![]() .
.
а
также
 .
.
Согласно
формуле (50) получим
 .
.
Умножая
![]() на первый элемент главной диагонали
на первый элемент главной диагонали
матрицы![]() ,
,
получим оценку дисперсии постоянной
уравнения регрессии b0:
![]() (53)
(53)
а
также ее стандартную ошибку:
![]() (54)
(54)
Умножив
![]() на второй элемент главной диагонали
на второй элемент главной диагонали
матрицы![]() ,
,
получим оценку дисперсии коэффициента
регрессии b1
![]() (55)
(55)
а
также стандартную ошибку этого
коэффициента:
![]() (56)
(56)
Рассмотрим
более обстоятельно стандартную ошибку
коэффициента b1, простой линейной
регрессии. Для этого сумму квадратов
отклонений в (56) заменим на выражение,
полученное путем преобразования формулы
(![]() ):
):
![]()
Формула
(56) приобретет вид
![]() (57)
(57)
Итак,
стандартная ошибка коэффициента
регрессии зависит:
от
рассеяния остатков. Чем больше доля
вариации значений переменной у,
необъясненной ее зависимостью отх,
найденной методом наименьших квадратов,
тем больше стандартная ошибка коэффициента
регрессии. Следовательно, чем сильнее
наблюдаемые значения переменнойуотклоняются от расчетных значений
регрессии, тем менее точной является
полученная оценка параметра регрессии;
от
рассеяния значений объясняющей переменной
х. Чем сильнее это рассеяние, тем
меньше стандартная ошибка коэффициента
регрессии. Отсюда следует, что при
вытянутом облаке точек на диаграмме
рассеяния получаем более надежную
оценку функции регрессии, чем при
небольшом скоплении точек, близко
расположенных друг к другу;
от
объема выборки. Чем больше объем выборки,
тем меньше стандартная ошибка коэффициента
регрессии. Здесь существует непосредственная
связь с таким свойством оценки параметра
регрессии, как асимптотическая
несмещенность.
Стандартная
ошибка оценки параметра регрессии
используется для оценки качества подбора
функции регрессии. Для этого вычисляется
относительный показатель рассеяния,
обычно выражаемый в процентах:
![]() (58)
(58)
Чем
больше относительная стандартная ошибка
оценки параметра, тем более оцененные
величины отличаются от наблюдаемых
значений зависимой переменной и тем
менее надежны оценки прогноза, основанные
на данной функции регрессии.
1
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #