From Wikipedia, the free encyclopedia
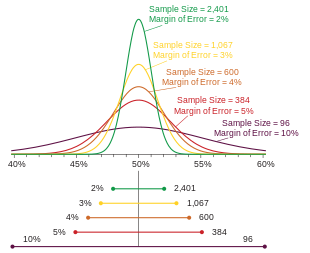
The margin of error is a statistic expressing the amount of random sampling error in the results of a survey. The larger the margin of error, the less confidence one should have that a poll result would reflect the result of a census of the entire population. The margin of error will be positive whenever a population is incompletely sampled and the outcome measure has positive variance, which is to say, whenever the measure varies.
The term margin of error is often used in non-survey contexts to indicate observational error in reporting measured quantities.
Concept[edit]
Consider a simple yes/no poll  as a sample of
as a sample of  respondents drawn from a population
respondents drawn from a population  reporting the percentage
reporting the percentage  of yes responses. We would like to know how close is to the true result of a survey of the entire population
of yes responses. We would like to know how close is to the true result of a survey of the entire population  , without having to conduct one. If, hypothetically, we were to conduct poll over subsequent samples of respondents (newly drawn from ), we would expect those subsequent results
, without having to conduct one. If, hypothetically, we were to conduct poll over subsequent samples of respondents (newly drawn from ), we would expect those subsequent results  to be normally distributed about
to be normally distributed about  , the true but unknown percentage of the population. The margin of error describes the distance within which a specified percentage of these results is expected to vary from .
, the true but unknown percentage of the population. The margin of error describes the distance within which a specified percentage of these results is expected to vary from .
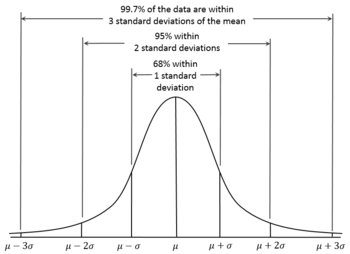
According to the 68-95-99.7 rule, we would expect that 95% of the results will fall within about two standard deviations ( ) either side of the true mean . This interval is called the confidence interval, and the radius (half the interval) is called the margin of error, corresponding to a 95% confidence level.
) either side of the true mean . This interval is called the confidence interval, and the radius (half the interval) is called the margin of error, corresponding to a 95% confidence level.
Generally, at a confidence level  , a sample sized of a population having expected standard deviation
, a sample sized of a population having expected standard deviation  has a margin of error
has a margin of error

where  denotes the quantile (also, commonly, a z-score), and
denotes the quantile (also, commonly, a z-score), and  is the standard error.
is the standard error.
Standard deviation and standard error[edit]
We would expect the average of normally distributed values to have a standard deviation which somehow varies with . The smaller , the wider the margin. This is called the standard error  .
.
For the single result from our survey, we assume that  , and that all subsequent results together would have a variance
, and that all subsequent results together would have a variance  .
.

Note that  corresponds to the variance of a Bernoulli distribution.
corresponds to the variance of a Bernoulli distribution.
Maximum margin of error at different confidence levels[edit]
For a confidence level , there is a corresponding confidence interval about the mean  , that is, the interval
, that is, the interval ![{\displaystyle [\mu -z_{\gamma }\sigma ,\mu +z_{\gamma }\sigma ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4568060e0cffbc8dfb793aa2ef4617c89cb9e94) within which values of should fall with probability . Precise values of are given by the quantile function of the normal distribution (which the 68-95-99.7 rule approximates).
within which values of should fall with probability . Precise values of are given by the quantile function of the normal distribution (which the 68-95-99.7 rule approximates).
Note that is undefined for  , that is,
, that is,  is undefined, as is
is undefined, as is  .
.
|
|
|
|
|
|
|---|---|---|---|---|
| 0.68 | 0.994457883210 | 0.999 | 3.290526731492 | |
| 0.90 | 1.644853626951 | 0.9999 | 3.890591886413 | |
| 0.95 | 1.959963984540 | 0.99999 | 4.417173413469 | |
| 0.98 | 2.326347874041 | 0.999999 | 4.891638475699 | |
| 0.99 | 2.575829303549 | 0.9999999 | 5.326723886384 | |
| 0.995 | 2.807033768344 | 0.99999999 | 5.730728868236 | |
| 0.997 | 2.967737925342 | 0.999999999 | 6.109410204869 |
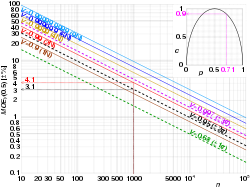
 vs sample size n and confidence level γ. The arrows show that the maximum margin error for a sample size of 1000 is ±3.1% at 95% confidence level, and ±4.1% at 99%.
vs sample size n and confidence level γ. The arrows show that the maximum margin error for a sample size of 1000 is ±3.1% at 95% confidence level, and ±4.1% at 99%.
The inset parabola  illustrates the relationship between
illustrates the relationship between  at
at  and
and  at
at  . In the example, MOE95(0.71) ≈ 0.9 × ±3.1% ≈ ±2.8%.
. In the example, MOE95(0.71) ≈ 0.9 × ±3.1% ≈ ±2.8%.
Since  at , we can arbitrarily set
at , we can arbitrarily set  , calculate
, calculate  , , and
, , and  to obtain the maximum margin of error for at a given confidence level and sample size , even before having actual results. With
to obtain the maximum margin of error for at a given confidence level and sample size , even before having actual results. With 


Also, usefully, for any reported 

Specific margins of error[edit]
If a poll has multiple percentage results (for example, a poll measuring a single multiple-choice preference), the result closest to 50% will have the highest margin of error. Typically, it is this number that is reported as the margin of error for the entire poll. Imagine poll reports  as
as 
 (as in the figure above)
(as in the figure above)



As a given percentage approaches the extremes of 0% or 100%, its margin of error approaches ±0%.
Comparing percentages[edit]
Imagine multiple-choice poll reports as  . As described above, the margin of error reported for the poll would typically be
. As described above, the margin of error reported for the poll would typically be  , as
, as  is closest to 50%. The popular notion of statistical tie or statistical dead heat, however, concerns itself not with the accuracy of the individual results, but with that of the ranking of the results. Which is in first?
is closest to 50%. The popular notion of statistical tie or statistical dead heat, however, concerns itself not with the accuracy of the individual results, but with that of the ranking of the results. Which is in first?
If, hypothetically, we were to conduct poll over subsequent samples of respondents (newly drawn from ), and report result  , we could use the standard error of difference to understand how
, we could use the standard error of difference to understand how  is expected to fall about
is expected to fall about  . For this, we need to apply the sum of variances to obtain a new variance,
. For this, we need to apply the sum of variances to obtain a new variance,  ,
,

where  is the covariance of
is the covariance of  and
and  .
.
Thus (after simplifying),



Note that this assumes that  is close to constant, that is, respondents choosing either A or B would almost never chose C (making and close to perfectly negatively correlated). With three or more choices in closer contention, choosing a correct formula for becomes more complicated.
is close to constant, that is, respondents choosing either A or B would almost never chose C (making and close to perfectly negatively correlated). With three or more choices in closer contention, choosing a correct formula for becomes more complicated.
Effect of finite population size[edit]
The formulae above for the margin of error assume that there is an infinitely large population and thus do not depend on the size of population , but only on the sample size . According to sampling theory, this assumption is reasonable when the sampling fraction is small. The margin of error for a particular sampling method is essentially the same regardless of whether the population of interest is the size of a school, city, state, or country, as long as the sampling fraction is small.
In cases where the sampling fraction is larger (in practice, greater than 5%), analysts might adjust the margin of error using a finite population correction to account for the added precision gained by sampling a much larger percentage of the population. FPC can be calculated using the formula[1]

…and so, if poll were conducted over 24% of, say, an electorate of 300,000 voters,


Intuitively, for appropriately large ,


In the former case, is so small as to require no correction. In the latter case, the poll effectively becomes a census and sampling error becomes moot.
See also[edit]
- Engineering tolerance
- Key relevance
- Measurement uncertainty
- Random error
References[edit]
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. Blackwell Publishing. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
Sources[edit]
- Sudman, Seymour and Bradburn, Norman (1982). Asking Questions: A Practical Guide to Questionnaire Design. San Francisco: Jossey Bass. ISBN 0-87589-546-8
- Wonnacott, T.H.; R.J. Wonnacott (1990). Introductory Statistics (5th ed.). Wiley. ISBN 0-471-61518-8.
External links[edit]
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Weisstein, Eric W. «Margin of Error». MathWorld.
Средняя и предельная ошибки выборки
Средняя ошибка выборкивсегда
присутствует в выборочных исследованиях
и появляется вследствие того, что
обследуются не все единицы статистической
совокупности, а лишь ее часть.
Средняя ошибка выборки превращается в
предельную ошибкуΔ
при умножении ее на коэффициент
доверияt, который задается
предварительно, исходя из требуемой
точности наблюдения. Предельная ошибка
позволяет судить об «истинном» размере
параметра в генеральной совокупности
с определенной степенью вероятности
|
|
При типическом и серийном
отборе, при расчете ошибки выборки
вместо общей дисперсии (σ2)
следует использовать
среднюю из внутригрупповых дисперсий
и межгрупповую дисперсию![]() ,
,
где![]() —
—
частная дисперсия i группы,![]() объем i группы
объем i группы
Формулы предельной ошибки случайной
выборки при определении средней
Для повторного отбора
|
|
где |
Для бесповторного отбора
|
|
Формулы предельной ошибки случайной
выборки при определении доли
Для повторного отбора
|
|
где |
Для бесповторного отбора
|
|
где |
Формулы численности случайной
выборки при определении средней величины
|
Для повторного |
Для |
|
|
|
Формулы численности случайной выборки при определении доли изучаемого признака
|
Для повторного |
Для |
|
|
|
Предельная разница между генеральной
и выборочной средней соответствует
величине предельной ошибки
|
для средней |
для доли: |
|
|
|
Значения вероятности и соответственно
tнаходятся по таблицам
распределения:
-
Лапласа
-
Стьюдента (в случае малой выборки)
Формулы случайной выборки подходят и
для механической выборки.
При необходимости округления, при
случайной выборке – округление в большую
сторону, при механической – в меньшую.
Малая выборка
Если численность выборочной совокупности
не более 30 единиц, то средняя ошибка
малой выборки при определении средней
величины рассчитывается по формуле:
|
при определении доли |
|
|
|
|
Для расчета ошибки малой выборки
применяется уточненная формула дисперсии
|
|
где n-1 — |
Типы задач выборочного наблюдения
-
определение ошибки выборки,
-
определение численности выборочной
совокупности n
, -
определение вероятности того, что
выборочная средняя (или доля) отклонится
от генеральной не более, чем на заданную
величину t=Δ/μ, -
оценка случайности расхождений
показателей выборочных наблюдений, -
перенос выборочных характеристик на
генеральную совокупность.
Проверка гипотез о средней и доле
Оценка случайности расхождений
показателей выборочных наблюдений
|
|
|
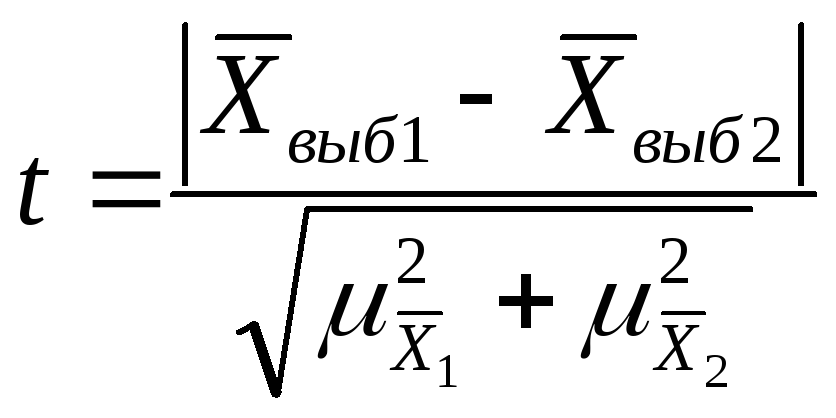
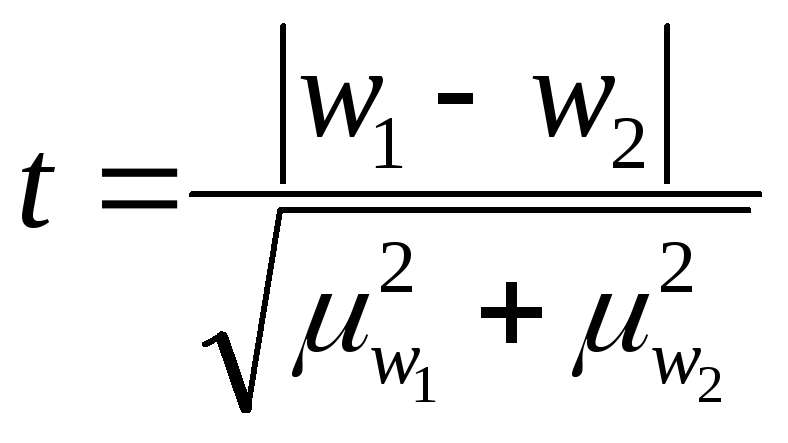
-
Если при n>30 коэффициент t<3, то делается
вывод о случайности расхождений. -
Если n≤ 30 , то полученное
значение t сравнивают с табличным,
определяемым по таблице распределения
Стьюдента -
Если
 ,
,
расхождение считается существенным. -
Если
,
расхождение считается случайным.
Методы переноса выборочных данных на
генеральную совокупность
-
метод взвешивания;
-
метод перевзвешивания;
-
метод заполнения случайным подбором
в классах замещения.
Предельная ошибка выборки
Предельная ошибка — максимально возможное расхождение средних или максимум ошибок при заданной вероятности ее появления.
1. Предельную ошибку выборки для средней при повторном отборе в контрольных по статистике в ВУЗах рассчитывают по формуле:

где t — нормированное отклонение — «коэффициент доверия», который зависит от вероятности, гарантирующей предельную ошибку выборки;
мю х — средняя ошибка выборки.
2. Предельная ошибка выборки для доли при повторном отборе определяется по формуле:

3. Предельная ошибка выборки для средней при бесповторном отборе:

4. Предельная ошибка выборки для доли при бесповторном отборе:

Предельная относительная ошибка выборки
Предельную относительную ошибку выборки определяют как процентное соотношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности. Она определяется таким образом:

Малая выборка
Теория малых выборок была разработана английским статистиком Стьюдентом в начале 20 века. В 1908 г. он выявил специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При n больше 100 дают такие же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 < n < 100 различия получаются незначительные. Поэтому на практике к малым выборкам относятся выборки объемом менее 30 единиц.

Средняя и предельная ошибки для малой выборки
В малой выборке средняя ошибка рассчитывается по формуле:

Предельная ошибка малой выборки рассчитывается по формуле:

где t — отношение Стьюдента
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.