В этой статье мы расскажем о том, что делает QA-специалист, когда он находит тот или иной баг. Также рассмотрим, какие бывают дефекты и с чем их «едят».
Основные термины:
Дефект (или баг) — изъян в компоненте или системе, который может привести компонент или систему к невозможности выполнить требуемую функцию. Дефект, обнаруженный во время выполнения, может привести к отказам компонента или системы. Например: невозможно сохранить данные после заполнения анкеты.
Ошибка — действие человека, которое может привести к неправильному результату. Например: ввод букв в поле для ввода даты (должны приниматься только цифры) с последующим сохранением данных.
Отказ (failure) — отклонение компонента или системы от ожидаемого результата, выполнения, эксплуатации. Например: при переходе на следующую страницу анкеты данные предыдущей страницы затираются.
Классификация багов
- Функциональные дефекты — в этом случае приложение функционально работает не так, как задумано. Например:
— не сохраняются изменения данных в профиле;
— не работает добавление комментария;
— не работает удаление товара из корзины;
— не работает поиск.
- Визуальные дефекты — в этом случае приложение выглядит не так, как задумано.
— текст вылезает за границы поля;
— элемент управления сайтом наслаивается на нижестоящий элемент;
— не отображается картинка.
- Логические дефекты — в этом случае приложение работает неправильно с точки зрения логики.
— можно поставить дату рождения «из будущего», а также несуществующие даты — 31 февраля, 32 декабря и т.п.;
— можно сделать заказ, не указав адрес доставки;
— логика поиска работает неправильно.
- Дефекты контента
— орфографические и пунктуационные ошибки;
— картинка товара не соответствует карточке товара;
— конвертация валют идет по неправильному курсу (калькулятор считает правильно, но при программировании указан неверный курс).
- Дефекты удобства использования — в этом случае приложение неудобно в использовании.
— отсутствие подсветки или уведомления об ошибке при некорректно заполненных полях формы;
— сброс всех данных при ошибке заполнения регистрационной формы;
— перегруженный интерфейс.
- Дефекты безопасности — в этом случае могут быть затронуты пользовательские данные, есть риск падения системы и т.п.
— можно получить логин, пароль в результате использования SQL-инъекций;
— неограниченное время жизни сессии после авторизации.
Итак, мы рассмотрели типы и виды дефектов. Теперь расскажем о том, как их документировать.

Документирование ошибок
Отчет об ошибке (Bug Report) — это документ, описывающий ситуацию или последовательность действий, приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
«Следующий этап заключается в документировании ошибок», — могли бы подумать вы, но оказались бы неправы.
Нельзя просто взять и задокументировать найденный дефект. Прежде всего, важно выполнить локализацию.
Например, если дефект может затрагивать другие части системы, то это обязательно нужно отобразить в баг-репорте, предварительно проверив эту гипотезу. Также необходимо очень подробно описать все условия и шаги, чтобы разработчик смог этот баг проверить и в него поверить.
Как же искать ошибки в системе таким образом, чтобы разработчикам было предельно понятно, откуда эти дефекты взялись и как их исправлять? Следует придерживаться определенного плана действий, который мы опишем далее.
Перепроверка дефекта
Нужно проверить себя еще раз: воспроизвести баг снова при тех же условиях. Если ошибка не повторилась при очередном тестировании, то нужно разобраться, точно ли были соблюдены все действия и шаги воспроизведения, приведшие к этому результату. Возможно, дефект появляется только при первоначальной загрузке системы (при первом использовании). Для того, чтобы более точно определить условия воспроизведения ошибки, необходимо эту ошибку локализовать.
Локализация дефекта
Чтобы локализовать баг, необходимо собрать максимальное количество информации о его воспроизведении:
- Выявить причины возникновения дефекта
Например, не проходит восстановление пароля. Необходимо выявить, откуда приходит запрос на сервер в неверном формате — от backend либо frontend.
- Проанализировать возможность влияния найденного дефекта на другие области
Например, в одной из форм, которую редко используют, возникает ошибка при нажатии на кнопку «Редактировать». Если в качестве временного варианта решения проблемы скрыть кнопку, это может повлиять на аналогичную форму в другом окне/вкладке, к которой пользователи обращаются чаще. Для качественного анализа необходимо знать, как работает приложение и какие зависимости могут быть между его частями.
- Отклонение от ожидаемого результата
Нужно проверить, соответствует ли результат тестирования ожидаемому результату. Справиться с этой задачей помогает техническое задание (в частности, требования к продукту), где должна быть задокументирована информация о тестируемом ПО и его функционировании. Пропускать этот шаг при тестировании не следует: если специалист недостаточно опытен, не зная требований, он может ошибаться и неправильно понимать, что относится к багам, а что нет. Внимательное изучение документации позволяет избежать таких ошибок.
- Исследовать окружение
Необходимо воспроизвести баг в разных операционных системах (iOS, Android, Windows и т.д.) и браузерах (Google Chrome, Mozilla, Internet Explorer и др.). При этом нужно проверить требования к продукту, чтобы выяснить, какие системы должны поддерживаться. Некоторые приложения работают только в определенных ОС или браузерах, поэтому проверять другие варианты не нужно.
- Проверить на разных устройствах
Например, desktop-приложение предназначено для использования на компьютерах, поэтому зачастую нет необходимости тестировать его на мобильных устройствах. Для смартфонов в идеале должна быть разработана отдельная мобильная версия, которую, в свою очередь, нет смысла тестировать на компьютерах. Кроме того, есть web-приложения, которые могут работать и на компьютерах, и на мобильных устройствах, а тестировать их нужно на всех типах устройств. Для тестирования можно использовать эмулятор той или иной среды, но в рамках статьи мы не будем затрагивать этот вопрос.
Мобильную версию приложения нужно тестировать на нескольких устройствах с разной диагональю экрана. При этом можно руководствоваться требованиями к ПО, в которых должно быть указано, с какими устройствами это ПО совместимо.
- Проверить в разных версиях ПО
Для того, чтобы не запутаться в реализованных задачах, в разработке используют версионность ПО. Иногда тот или иной баг воспроизводится в одной версии продукта, но не воспроизводится в другой. Этот атрибут обязательно необходимо указывать в баг-репорте, чтобы программист понимал, в какой ветке нужно искать проблему.
- Проанализировать ресурсы системы
Возможно, дефект был найден при нехватке внутренней или оперативной памяти устройства. В таком случае баг может воспроизводиться на идентичных устройствах по-разному.
Для того, чтобы оптимизировать сроки тестирования, мы рекомендуем использовать техники тест-дизайна.
Фиксирование доказательств
Доказательства воспроизведения бага нужно фиксировать при помощи логов, скринов или записи экрана.
- Логи (лог-файлы или журнал) — это файлы, содержащие системную информацию работы сервера или компьютера, в них хранят информацию об определенных действиях пользователя или программы. Опытному разработчику бывает достаточно посмотреть в логи, чтобы понять, в чем заключается ошибка. Обычно логи прикрепляют к баг-репорту в виде .txt-файла.
Live-логирование – это снятие системных логов в режиме реального времени. Для этого можно использовать следующие программы: Fiddler, Visual Studio для Windows, iTools, Xcode для iOS, Android Debug Monitor, Android Studio для Android и др.
- Скрин (снимок) экрана. При ошибках в интерфейсе снимок помогает быстрее разобраться в проблеме. Программ для снятия скриншотов очень много, каждый QA-специалист может использовать те, которые ему наиболее удобны: Jing, ShareX, Lightshot и др.
- Скринкаст (англ. screen – экран, broadcasting – трансляция) – это запись видеоизображения с экрана компьютера или другого цифрового устройства. Это один из самых эффективных способов поделиться тем, что происходит на экране монитора. Таким способом QA-специалисту легко наглядно показать ошибки в работе любого программного продукта. Сделать запись с экрана помогут незаменимые инструменты любого QA-специалиста: Snagit, Monosnap, Movavi Screen Capture, Jing, Reflector, ADB Shell Screenrecord, AZ Screen Recorder и др.
- Рекордер действий. Программные средства дают возможность воспроизвести все записанные движения мышки и действия, производимые на клавиатуре компьютера. Примеры программ – Advanced Key and Mouse Recorder для desktop-платформ.

Оформление баг-репорта
Все найденные дефекты обязательно нужно документировать, чтобы каждый задействованный на проекте специалист мог получить инструкции по воспроизведению обнаруженного дефекта и понять, насколько это критично. Если в команде принято устно передавать разработчику информацию о найденных дефектах, есть риск упустить что-то из вида.
Дефект, который не задокументирован – не найден!
Когда вся необходимая информация собрана, а баг локализован, можно приступать к оформлению баг-репорта в таск-трекере. Чем точнее описание бага, тем меньше времени нужно для его исправления. Список атрибутов для каждого проекта индивидуален, но некоторые из них – например, шаги воспроизведения, ожидаемый результат, фактический результат – присутствуют практически всегда.
Атрибуты баг-репорта:
1. Название
Баг должен быть описан кратко и ёмко, иметь понятное название. Это поможет разработчику разобраться в сути ошибки и в том, может ли он взять этот случай в работу, если занимается соответствующим разделом системы. Также это позволяет упростить подключение новых специалистов на проект, особенно если разработка ведется много лет подряд, а запоминать баги и отслеживать их в таск-трекере становится все сложнее. Название проекта можно составлять по принципу «Где? Что? Когда?» или «Что? Где? Когда?», в зависимости от внутренних правил команды.
Например:
Где происходит? — В карточке клиента (в каком разделе системы).
Что именно происходит? — Не сохраняются данные.
Когда происходит? — При сохранении изменений.
2. Проект (название проекта)
3. Компонент приложения
В какой части функциональности тестируемого продукта найден баг.
4. Номер версии
Версия продукта, ветка разработки, в которой воспроизводится ошибка.
5. Критичность
Этот атрибут показывает влияние дефекта на функциональность системы, например:
· Blocker — дефект, блокирующий использование системы.
· Critical — ошибка, которая нарушает основную бизнес-логику работы системы.
· Major — ошибка, которая нарушает работу определенной функции, но не всей системы.
· Minor — незначительная ошибка, не нарушающая бизнес-логику приложения, например, ошибка пользовательского интерфейса.
· Trivial — малозаметная, неочевидная ошибка. Это может быть опечатка, неправильная иконка и т.п.
6. Приоритет
Приоритет определяет, насколько срочно нужно исправить ошибку. Обычно выделяют следующие виды приоритетов:
High — ошибка должна быть исправлена как можно скорее, является критичной для проекта.
Medium — ошибка должна быть исправлена, но её наличие не является критичным для проекта.
Low — ошибка должна быть исправлена, но не требует срочного решения.
7. Статус
Статус указывает стадию жизненного цикла бага, взят он в работу или уже решен. Примеры: to do, in progress, in testing (on QA), done. В зависимости от особенностей проекта возможны дополнительные статусы (например, аналитика).
8. Автор баг-репорта
9. На кого назначен
Баг-репорт отправляют тимлиду проекта или разработчику, который будет заниматься исправлением дефекта, в зависимости от принятых в команде договоренностей.
10. Окружение
Где найден баг: операционная система, наименование и версия браузера.
11. Предусловие (если необходимо)
Необходимо для описания действий, которые предшествовали воспроизведению бага. Например, клиент авторизован в системе, создана заявка с параметрами ABC и т.д. Баг-репорт может не содержать предусловие, но иногда оно бывает необходимо для того, чтобы проще описать шаги воспроизведения.
12. Шаги воспроизведения
Один из самых важных атрибутов — описание шагов, которые привели к нахождению бага. Оптимально использовать 5-7 понятных и кратких шагов для описания бага, например:
1. Открыть (…)
2. Кликнуть (…)
3. Ввести в поле А значение N1
4. Ввести в поле B значение N2
5. Кликнуть кнопку «Calculate»
13. Фактический результат
Что произошло после воспроизведения указанных выше шагов.
14. Ожидаемый результат
Что должно произойти после воспроизведения шагов тестирования, согласно требованиям.
15. Прикрепленный файл
Логи, скриншоты, видеозапись экрана — всё, что поможет разработчику понять суть ошибки и исправить ее.
После составления баг-репорта обязательно нужно проверить его, чтобы избежать ошибок или опечаток.
Локализация и оформление багов — необходимые составляющие работы QA-специалиста с программным продуктом. Приглашаем подробнее ознакомиться с услугами тестирования и обеспечения качества в SimbirSoft.
7.1. Способы локализации
После
того, как с помощью контрольных тестов
(или каким либо другим путем) установлено,
что в программе или в конкретном ее
блоке имеется ошибка, возникает задача
ее локализации, то есть установления
точного места в программе, где находится
ошибка.
Процесс
локализации ошибок состоит из следующих
трех компонент:
1.
Получение на машине тестовых результатов.
2.
Анализ тестовых результатов и сверка
их с эталонными.
3.
Выявление ошибки или формулировка
предположения о характере и месте ошибки
в программе.
По
принципам работы средства локализации
разделяются на 4 типа :
1.
Аварийная печать.
2.
Печать в узлах.
3.
Слежение.
4.
Прокрутка.
АВАРИЙНАЯ
ПЕЧАТЬ
осуществляется один раз при работе
отлаживаемой программы, в момент
возникновения аварийной ситуации в
программе, препятствующей ее нормальному
выполнению. Тем самым, конкретное место
включения в работу аварийной печати
определяется автоматически без
использования информации от программиста,
который должен только определить список
выдаваемых на печать переменных.
ПЕЧАТЬ
В УЗЛАХ
включается в работу в выбранных
программистом местах программы; после
осуществления печати значений данных
переменных продолжается выполнение
отлаживаемой программы.
СЛЕЖЕНИЕ
производится или по всей программе, или
на заданном программистом участке.
Причем слежение может осуществляться
как за переменными (арифметическое
слежение), так и за операторами (логическое
слежение). Если обнаруживается, что
происходит присваивание заданной
переменной или выполнение оператора с
заданной меткой, то производится печать
имени переменной или метки и выполнение
программы продолжается. Отличием от
печати в узлах является то, что место
печати может точно и не определяться
программистом (для арифметического
слежения); отличается также и содержание
печати.
ПРОКРУТКА
производится на заданных участках
программы, и после выполнения каждого
оператора заданного типа (например,
присваивания или помеченного) происходит
отладочная печать.
По
типам печатаемых значений (числовые и
текстовые или меточные) средства
разделяются на арифметические и
логические.
7.2. Классификация средств локализации ошибок
Ниже
дана классификация средств локализации.
ТИПЫ
СРЕДСТВ ЛОКАЛИЗАЦИИ ОШИБОК :
1.
Языковые.
1.1.
Обычные.
1.2.
Специальные.
2.
Системные.
(3.
Пакетные)
СРЕДСТВА
ЛОКАЛИЗАЦИИ:
1.
Аварийная печать (арифметическая).
1.1.
Специальные средства языка.
1.2.
Системные средства.
2.
Печать в узлах (арифметическая).
2.1.
Обычные средства языка.
2.2.
Специальные средства языка.
3.
Слежение (специальные средства).
3.1.
Арифметическое.
3.2.
Логическое.
4.
Прокрутка (специальные средства).
4.1.
Арифметическая.
4.2.
Логическая.
8. Технология отладки программы автоматизации учета движения товаров на складе малого предприятия
При
отладке программы использовались
следующие методы контроля и локализации
ошибок (обзор методов см. в теоретической
части раздела) :
1.
Просмотр текста программы и прокрутка
с целью обнаружения явных синтаксических
и логических ошибок.
2.
Трансляция программы (транслятор выдает
сообщения об обнаруженных им ошибках
в тексте программы).
3.
Тестирование.
Тестирование
проводилось посредством ввода исходных
данных, с дальнейшей их обработкой,
выводом результатов на печать и экран.
Результаты работы программы сравнивались
заданными в техническом задании.
4.
При локализации ошибок преимущественно
использовалась печать в узлах, которыми
являлись в основном глобальные переменные,
переменные, используемые при обмене
данными основной программы с подпрограммами.
Отладка
программы производилась по следующему
алгоритму :
1.
Прогонка программы с набором тестовых
входных данных и выявление наличия
ошибок.
2.
Выделение области программы, в которой
может находиться ошибка. Просмотр
листинга программы с целью возможного
визуального обнаружения ошибок. В
противном случае — установка контрольной
точки примерно в середине выделенной
области.
3.
Новая прогонка программы. Если работа
программы прервалась до обработки
контрольной точки, значит, ошибка
произошла раньше. Контрольная точка
переносится, и процесс отладки возвращается
к шагу 2.
4.
Если контрольная точка программы была
обработана, то далее следует изучение
значений регистров, переменных и
параметров программы с тем, чтобы
убедиться в их правильности. При появлении
ошибки — новый перенос контрольной точки
и возврат к шагу 2.
5.
В случае не обнаружения ошибки продолжение
выполнения программы покомандно, с
контролем правильности выполнения
переходов и содержимого регистров и
памяти в контрольных точках. При
локализации ошибки она исправляется и
процесс возвращается к шагу 1.
В
качестве тестовых входных данных
использовалась последовательность
частотных выборок, генерируемых
имитатором в режиме 1. (Каждому интервалу
соответствует фиксированное значение
выборок.)
Соседние файлы в папке 4Diplom
- #
16.04.201332.77 Кб9A4.vsd
- #
- #
- #
- #
- #
Что общего между локализацией багов и расследованием преступления?
Время на прочтение
4 мин
Количество просмотров 5.5K
Всем привет! Меня зовут Иван, я QA-инженер релизной команды в inDriver. В этой статье хочу вольно порассуждать о схожести моделей когнитивной деятельности в тестировании ПО и расследовании уголовных дел. Мне кажется, у этих сфер много общего — например, оба процесса представляют из себя исследование результатов неправильного поведения, причин и следствий такого поведения и документирование результатов.
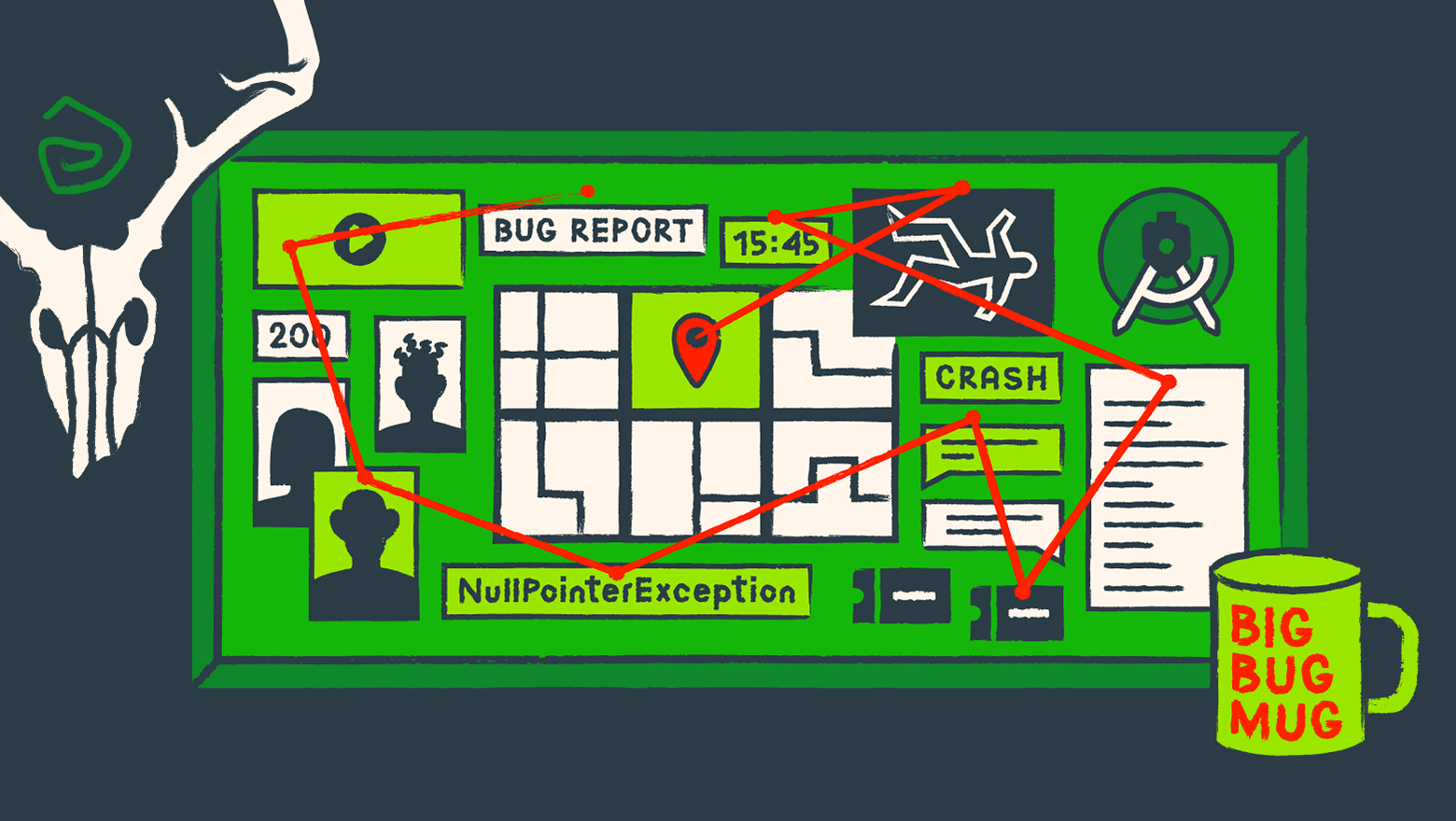
Год назад я получил оффер на должность QA Manual Engineer в inDriver. Но до этого я семь лет расследовал уголовные дела в разных подразделениях правоохранительных органов. За время службы я работал со значительным спектром преступлений: от тяжких против жизни и здоровья до экономических межрегионального характера. На последнем месте работы моя должность звучала так: «Старший следователь СЧ по РОПД СУ МВД по РС (Я)». Если опустить два первых слова, выглядит как ребус.
Сейчас я занимаюсь организацией регрессионного тестирования, написанием мобильных UI-автотестов, а также многим другим, что связано с ускорением доставки новых фич пользователям без потери в качестве продукта.
Начинаем расследование
Как расследование уголовного дела начинается с осмотра места происшествия, так и баг-репорт начинается с описания окружения, в котором был обнаружен дефект. Так мы получаем какие-то безусловные данные. А на их основе, применяя дедукцию, знания об окружающем мире или о продукте, можно сузить область исследования, начать планировать дальнейшие действия и строить гипотезы.

Составляем план действий
Когда мы получаем исходные данные, возникает ситуация информационного разнообразия. Теперь важно составить план действий. Время является нашим главным ресурсом. Вряд ли проверка всех значений от -2147483648 до 2147483647 в поле ввода имени — хорошая идея, чтобы найти дефект. Следователь также не имеет возможности допросить всех жителей города или отправить всю домашнюю утварь на молекулярно-генетическую экспертизу.

Для решения этой проблемы QA применяет техники тест-дизайна — граничные значения, классы эквивалентности, pairwise. Следователь же применяет тактические приемы и комбинации, позволяющие спланировать свои дальнейшие действия максимально эффективно.

Выдвигаем первые гипотезы
Предположим, нам поступило сообщение об убийстве о краше в нашем приложении. Исходя из опыта следователя я знаю, что почти в 90% случаев убийцы тем или иным образом связаны с жертвой (мужья, жены, родственники, друзья, соседи). Так и в приложении — мы руководствуемся знаниями о продукте: скажем, достаем сниффер, проверяем исходящие запросы и получаемые ответы. Пока ничего интересного — у всех членов семьи алиби, а в ответе с сервера «200». Похоже, тут все в порядке.

Также мы знаем, что психически здоровый человек не пойдет на убийство, не имея на то причин. Исходя из этого мы от неограниченного круга лиц можем перейти к тем, с кем у потерпевшего были финансовые, рабочие или иные связи. Так и в приложении мы можем выяснить версию, с которой начинает воспроизводиться дефект, и построить гипотезы о том, какие изменения кода могли повлечь его появление.
Снимаем логи
Далее мы пытаемся установить все события, предшествовавшие преступлению, чтобы обнаружить какие-нибудь следы:
-
Смотрим записи видеокамер.
-
Опрашиваем соседей: слышали ли они звуки борьбы, видели ли подозрительных лиц.
-
Устанавливаем, с кем созванивался потерпевший незадолго до совершения преступления.
В случае с дефектом мы также собираем следы:
-
Снимаем логи в Android Studio или XCode.
-
Проверяем логи сервера.
В ходе этого обнаруживаем, что незадолго до совершения преступления в квартиру вошел NullPointerException мужчина. Соседи опознали его как ранее осужденного местного хулигана, который регулярно выпивал и держал в страхе весь дом.

Проверяем показания на месте
Предположим, после предъявления доказательств мужчина сознается в совершении преступления. Но расследование на этом не заканчивается. Мы должны убедиться, что именно он совершил данное преступление, а признание вины вызвано раскаянием, а не страхом испортить настроение следователя.
Для этого проводится «проверка показаний на месте», в ходе которой обвиняемый досконально воспроизводит детали преступления и рассказывает об обстоятельствах, которые не могут быть известны непричастному к совершению преступления лицу. Так, найдя стабильный сценарий воспроизведения дефекта, мы убедились, что нашли именно того, кого искали.

Законченное уголовное дело = баг-репорт
Установив все обстоятельства преступления, следователь не занимается устранением этого дефекта. Он оформляет полученные сведения в материалы уголовного дела, составляет обвинительное заключение и передает их в суд. Решение о мере наказания, способе устранения дефекта, либо о признании бага невиновной фичей принимается уже за пределами процесса тестирования.

Устанавливаем причины преступления
С целью профилактики совершения в будущем похожих преступлений, следователь обязан установить обстоятельства, которые поспособствовали его совершению и принять меры. Например, разобраться, почему никто ранее не реагировал на сообщения о хулигане или почему принятые в отношении него меры не помогли предотвратить преступление.
Также и в случае с тестированием — при обнаружении бага на проде не помешает установить факторы, способствовавшие этому:
-
Недостаточное тестовое покрытие.
-
Мердж без тестов.
-
Плохая постановка задачи.
-
Недоработанные требования.
-
Непроверенные QA-специалистом corner-кейсы.
-
Небольшое количество времени, выделенное на тестирование и разработку.
-
Низкая квалификация команды разработки.
-
Часто меняющиеся требования.
Заключение
Очевидно, профессии следователя и тестировщика отличаются друг от друга. Даже при наличии схожих моментов, различий все же значительно больше. Но если у вас по какой-либо причине появилось желание кардинально сменить ремесло, то вы можете найти подходящие курсы у нашего партнера это возможно. Даже в абсолютно чуждой сфере можно найти деятельность со схожим майндсетом — и тогда добиться поставленной цели будет немного проще.
Отладка мобильных приложений: локализация дефектов и создание отчетов об ошибках
20 декабря 2022 г.
В этой статье я опишу, что делает QA-специалист, обнаружив конкретную ошибку мобильного приложения.
Основные термины:
* Ошибка — это недостаток компонента или системы, из-за которого мобильное приложение не может выполнять требуемую функцию. Ошибка, обнаруженная во время выполнения, может привести к сбою мобильного приложения. Например, человек не может сохранить данные после заполнения анкеты.
* Ошибка — это человеческая деятельность, которая может привести к неверному результату. Например: ввод букв в поле даты (допустимы только цифры) и последующее сохранение данных.
* Сбой — это отклонение компонента или системы от ожидаемого результата, производительности или операции. Например: когда человек переходит на следующую страницу анкеты, данные с предыдущей страницы перезаписываются.
Начнем.
Классификация ошибок мобильных приложений

Функциональные ошибки мобильного приложения — мобильное приложение функционально не работает должным образом. Например:
* изменения данных в профиле не сохраняются
* добавление комментария не работает
* удаление товаров из корзины не работает
* поиск не работает
Визуальные ошибки мобильного приложения: мобильное приложение выглядит не так, как должно. Например:
* текст выходит за пределы полей
* элемент управления располагается поверх основного элемента
* картинка не отображается
Логические ошибки мобильного приложения — мобильное приложение работает некорректно с точки зрения логики. Например:
* пользователь может поставить дату рождения «из будущего», а также несуществующие даты — 31 февраля, 32 декабря и т.д.
* возможно оформление заказа без указания адреса доставки
* логика поиска работает некорректно
Ошибки безопасности мобильного приложения — могут быть затронуты пользовательские данные, существует риск сбоя системы и т. д. Например:
* возможно получить логин и пароль в результате SQL инъекции
* неограниченное время жизни сессии после авторизации
Итак, мы рассмотрели виды багов мобильных приложений. Теперь давайте поговорим о том, как их задокументировать.
Документация по ошибкам в мобильных приложениях

Отчет об ошибке мобильного приложения — это документ, описывающий ситуацию или последовательность действий, приведших к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
Возможно, вы думаете, что «следующим шагом будет документирование ошибок мобильного приложения», но вы ошибаетесь.
Вы не можете просто пойти и задокументировать найденную ошибку мобильного приложения. В первую очередь важно выполнить локализацию.
Например, если ошибка мобильного приложения может повлиять на другие части системы, она должна быть представлена в отчете об ошибке, и эта гипотеза должна быть проверена заранее. Также необходимо очень подробно описать все условия и шаги, чтобы разработчик мог проверить этот баг мобильного приложения.
Но как искать баги в мобильных приложениях, чтобы разработчикам было понятно, откуда берутся эти дефекты и как их исправить? Было бы полезно, если бы вы придерживались определенного плана действий, который я опишу ниже.
Повторно проверьте ошибку мобильного приложения
Вам нужно еще раз проверить себя: воспроизвести ошибку мобильного приложения в тех же условиях. Если при следующем тесте ошибка не возникает, нужно убедиться, что все действия и этапы повтора, приведшие к такому результату, были соблюдены точно. Возможно, ошибка мобильного приложения появляется только при начальной загрузке системы (при первом использовании). Для более точного определения условий, при которых воспроизводилась ошибка, ее необходимо локализовать.
Локализация ошибки мобильного приложения
Для локализации бага мобильного приложения необходимо собрать как можно больше информации о его воспроизведении:
* Определите причины ошибки
Например, не удается восстановить пароль. Вы должны определить источник неправильного запроса к серверу: внутренний или внешний интерфейс.
* Анализ возможного влияния ошибки на другие области
Например, в одной из форм, которая редко используется, есть ошибка при нажатии кнопки «Редактировать». Если кнопка скрыта в качестве временного решения проблемы, это может повлиять на аналогичную форму в другом окне/вкладке, к которой пользователи обращаются чаще. Для качественного анализа нужно знать, как работает мобильное приложение и зависимости между его частями.
*Отклонение от ожидаемого результата
Вам необходимо проверить, соответствует ли результат теста ожидаемому результату. Решить эту задачу помогает техническое задание, в котором должна быть задокументирована информация о тестируемом мобильном приложении и его функционировании. Вы не должны пропускать этот шаг при тестировании. Если специалист недостаточно опытен и не знает требований, он может ошибаться и неправильно понимать, что относится к багам, а что нет. Внимательное изучение документации позволяет избежать подобных ошибок.
* Исследуйте окружающую среду
Необходимо воспроизвести ошибку в разных операционных системах (iOS, Android, Windows и т. д.) или браузерах (Google Chrome, Mozilla, Internet Explorer и т. д.). Вы должны проверить требования к продукту, чтобы определить, какие системы должны поддерживаться. Некоторые мобильные приложения работают только в определенных операционных системах или браузерах, поэтому вам не нужно проверять другие параметры.
* Проверяйте на разных устройствах
Например, настольное приложение предназначено для использования на компьютере, поэтому нет необходимости тестировать его на мобильных устройствах. Для смартфонов в идеале должна быть отдельная мобильная версия, которую, в свою очередь, нет смысла тестировать на компьютерах. Кроме того, некоторые PWA могут работать как на компьютерах, так и на мобильных устройствах, и их необходимо тестировать на всех типах устройств. Вы можете использовать эмулятор той или иной среды для тестирования.
Мобильное приложение необходимо протестировать на нескольких устройствах с разными диагоналями экрана. При этом можно руководствоваться требованиями к ПО, в которых должно быть указано, с какими устройствами ПО совместимо.
* Протестируйте разные версии мобильных приложений
Чтобы не путать реализуемые задачи, при разработке используется версионность программного обеспечения. Иногда ошибка воспроизводится в одной версии мобильного приложения, но не воспроизводится в другой. Этот атрибут нужно обязательно указать в баг-репорте, чтобы программист понял, в какой ветке искать проблему.
* Анализ системных ресурсов
Возможно, ошибка мобильного приложения была обнаружена при нехватке внутренней памяти устройства или оперативной памяти. В этом случае ошибка может воспроизводиться по-разному на одинаковых устройствах.
Исправление ошибок в мобильном приложении
Доказательства ошибки мобильного приложения должны быть зарегистрированы в журналах, снимках экрана или в записях с экрана:
* Журналы — это файлы, содержащие системную информацию сервера или устройства, в них содержится информация об определенных действиях пользователя или программы. Опытный разработчик должен просмотреть лог-файлы, чтобы понять ошибку. Обычно журналы прикрепляются к отчету об ошибке в виде файла .txt.
* Живое ведение журнала — это запись системных журналов в реальном времени. Для этого можно использовать Sentry.
* Скриншот. При наличии ошибок в интерфейсе скриншот помогает быстрее разобраться в проблеме. Программ для снятия скриншотов очень много, каждый QA специалист может использовать наиболее удобные для себя: Jing, ShareX, Lightshot и т.д.
* Скринкаст — видеозапись экрана устройства. Таким образом, QA-специалист может легко показать ошибки в работе любого программного продукта. Незаменимыми инструментами любого эксперта по обеспечению качества являются Reflector, ADB Shell Screenrecord, AZ Screen Recorder и т. д.
Формат отчета об ошибках мобильного приложения
Все обнаруженные ошибки должны быть задокументированы, чтобы все участники проекта могли получить инструкции о том, как воспроизвести найденную ошибку и понять, насколько она критична. Если в команде принято устно передавать информацию о найденных багах разработчику, есть риск что-то упустить из виду.
Незадокументированная ошибка мобильного приложения Ошибка не обнаружена!
Когда вся необходимая информация собрана и ошибка локализована, вы можете выпустить отчет об ошибке в мобильном приложении. Чем точнее описание ошибки, тем меньше времени уходит на ее исправление. Список атрибутов разный для каждого проекта, но некоторые из них, такие как шаги воспроизведения, ожидаемые результаты и фактические результаты, присутствуют почти всегда.
Атрибуты отчета об ошибке мобильного приложения

* Имя
Ошибка мобильного приложения должна быть описана кратко и лаконично и иметь понятное название. Это поможет разработчику понять природу ошибки мобильного приложения и сможет ли он принять ее в работу. Это также облегчает подключение к проекту новых специалистов, особенно если разработка ведется много лет, и запомнить баги и отследить их становится все труднее. Название проекта можно составить по принципу «Где? Что? Когда?» или «Что? Где? Когда?» в зависимости от внутренних правил команды.
Например:
Где это происходит? — В карточке клиента (в каком разделе системы).
Что именно происходит? — Данные не сохраняются.
Когда это происходит? — При сохранении изменений.
* Компонент мобильного приложения
В какой части функционала обнаружена ошибка?
* Номер версии мобильного приложения
Версия продукта, в которой воспроизводится ошибка.
* Критичность
Этот атрибут показывает влияние ошибки на функциональность системы, например:
Блокировщик — ошибка, которая блокирует использование системы
Критическая — ошибка, нарушающая базовую бизнес-логику системы
Серьезная ошибка – ошибка, которая нарушает работу определенной функции, но не всей системы.
Незначительная — незначительная ошибка, не нарушающая бизнес-логику приложения, например, ошибка пользовательского интерфейса
Trivial — незаметная, неочевидная ошибка
* Приоритет
Приоритет определяет, насколько срочно ошибка должна быть исправлена. Обычно выделяют следующие виды приоритетов:
Высокий — ошибка должна быть исправлена как можно быстрее, она критична для проекта
Средний — ошибка должна быть исправлена, но ее наличие не критично для проекта
Низкий — ошибка подлежит исправлению, но не требует срочного решения
* Статус
Статус ошибки указывает на стадию жизненного цикла ошибки, независимо от того, находится ли ошибка в процессе или была устранена. Примеры: делать, в процессе, в тестировании, готово. Возможны дополнительные статусы в зависимости от особенностей проекта (например, аналитический).
* Назначено
Отчет об ошибке отправляется руководителю группы проекта или разработчику, который будет нести ответственность за исправление ошибки, в зависимости от соглашений, принятых командой.
* Предисловие (при необходимости)
Необходимо описать действия, предшествовавшие воспроизведению ошибки. Например, клиент авторизуется в приложении, создается запрос с параметрами ABC и т. д. Отчеты об ошибках могут не содержать предисловия, но иногда необходимо более простое описание шагов повтора.
* Повторить шаги
Одним из наиболее важных атрибутов является описание шагов, которые привели к обнаружению ошибки. Для описания бага оптимально использовать 5-7 четких и кратких шагов, например:
- Открыть (…)
- Нажмите (…)
- Введите значение N1 в поле A.
- Введите в поле B значение N2.
- Нажмите кнопку «Рассчитать».
* Фактический результат и ожидаемый результат
Что произошло после воспроизведения описанных выше шагов и что должно произойти после воспроизведения тестовых шагов в соответствии с требованиями?
* Прикрепленные файлы
Логи, скриншоты, записи экрана — все, что поможет разработчику понять и исправить ошибку мобильного приложения.
После создания отчета об ошибке вы должны проверить его, чтобы избежать ошибок или опечаток.
Я также рекомендую вам прочитать:
* Жизнь и времена Adobe Flash Player Gaming
* Обречены ли облачные игры из-за физики?
* Почему важна безопасность веб-сайтов и веб-приложений
* Самый странный нераскрытый телевизионный взлом Америки и его история
* Почему сетевая безопасность является неотъемлемой частью любого интернет- Подключенный бизнес
Оригинал
В этой статье мы расскажем о том, что делает QA-специалист, когда он находит тот или иной баг. Также рассмотрим, какие бывают дефекты и с чем их «едят».
Основные термины:
Дефект (или баг) — изъян в компоненте или системе, который может привести компонент или систему к невозможности выполнить требуемую функцию. Дефект, обнаруженный во время выполнения, может привести к отказам компонента или системы. Например: невозможно сохранить данные после заполнения анкеты.
Ошибка — действие человека, которое может привести к неправильному результату. Например: ввод букв в поле для ввода даты (должны приниматься только цифры) с последующим сохранением данных.
Отказ (failure) — отклонение компонента или системы от ожидаемого результата, выполнения, эксплуатации. Например: при переходе на следующую страницу анкеты данные предыдущей страницы затираются.
Классификация багов
- Функциональные дефекты — в этом случае приложение функционально работает не так, как задумано. Например:
— не сохраняются изменения данных в профиле;
— не работает добавление комментария;
— не работает удаление товара из корзины;
— не работает поиск.
- Визуальные дефекты — в этом случае приложение выглядит не так, как задумано.
— текст вылезает за границы поля;
— элемент управления сайтом наслаивается на нижестоящий элемент;
— не отображается картинка.
- Логические дефекты — в этом случае приложение работает неправильно с точки зрения логики.
— можно поставить дату рождения «из будущего», а также несуществующие даты — 31 февраля, 32 декабря и т.п.;
— можно сделать заказ, не указав адрес доставки;
— логика поиска работает неправильно.
- Дефекты контента
— орфографические и пунктуационные ошибки;
— картинка товара не соответствует карточке товара;
— конвертация валют идет по неправильному курсу (калькулятор считает правильно, но при программировании указан неверный курс).
- Дефекты удобства использования — в этом случае приложение неудобно в использовании.
— отсутствие подсветки или уведомления об ошибке при некорректно заполненных полях формы;
— сброс всех данных при ошибке заполнения регистрационной формы;
— перегруженный интерфейс.
- Дефекты безопасности — в этом случае могут быть затронуты пользовательские данные, есть риск падения системы и т.п.
— можно получить логин, пароль в результате использования SQL-инъекций;
— неограниченное время жизни сессии после авторизации.
Итак, мы рассмотрели типы и виды дефектов. Теперь расскажем о том, как их документировать.
Документирование ошибок
Отчет об ошибке (Bug Report) — это документ, описывающий ситуацию или последовательность действий, приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
«Следующий этап заключается в документировании ошибок», — могли бы подумать вы, но оказались бы неправы.
Нельзя просто взять и задокументировать найденный дефект. Прежде всего, важно выполнить локализацию.
Например, если дефект может затрагивать другие части системы, то это обязательно нужно отобразить в баг-репорте, предварительно проверив эту гипотезу. Также необходимо очень подробно описать все условия и шаги, чтобы разработчик смог этот баг проверить и в него поверить.
Как же искать ошибки в системе таким образом, чтобы разработчикам было предельно понятно, откуда эти дефекты взялись и как их исправлять? Следует придерживаться определенного плана действий, который мы опишем далее.
Перепроверка дефекта
Нужно проверить себя еще раз: воспроизвести баг снова при тех же условиях. Если ошибка не повторилась при очередном тестировании, то нужно разобраться, точно ли были соблюдены все действия и шаги воспроизведения, приведшие к этому результату. Возможно, дефект появляется только при первоначальной загрузке системы (при первом использовании). Для того, чтобы более точно определить условия воспроизведения ошибки, необходимо эту ошибку локализовать.
Локализация дефекта
Чтобы локализовать баг, необходимо собрать максимальное количество информации о его воспроизведении:
- Выявить причины возникновения дефекта
Например, не проходит восстановление пароля. Необходимо выявить, откуда приходит запрос на сервер в неверном формате — от backend либо frontend.
- Проанализировать возможность влияния найденного дефекта на другие области
Например, в одной из форм, которую редко используют, возникает ошибка при нажатии на кнопку «Редактировать». Если в качестве временного варианта решения проблемы скрыть кнопку, это может повлиять на аналогичную форму в другом окне/вкладке, к которой пользователи обращаются чаще. Для качественного анализа необходимо знать, как работает приложение и какие зависимости могут быть между его частями.
- Отклонение от ожидаемого результата
Нужно проверить, соответствует ли результат тестирования ожидаемому результату. Справиться с этой задачей помогает техническое задание (в частности, требования к продукту), где должна быть задокументирована информация о тестируемом ПО и его функционировании. Пропускать этот шаг при тестировании не следует: если специалист недостаточно опытен, не зная требований, он может ошибаться и неправильно понимать, что относится к багам, а что нет. Внимательное изучение документации позволяет избежать таких ошибок.
- Исследовать окружение
Необходимо воспроизвести баг в разных операционных системах (iOS, Android, Windows и т.д.) и браузерах (Google Chrome, Mozilla, Internet Explorer и др.). При этом нужно проверить требования к продукту, чтобы выяснить, какие системы должны поддерживаться. Некоторые приложения работают только в определенных ОС или браузерах, поэтому проверять другие варианты не нужно.
- Проверить на разных устройствах
Например, desktop-приложение предназначено для использования на компьютерах, поэтому зачастую нет необходимости тестировать его на мобильных устройствах. Для смартфонов в идеале должна быть разработана отдельная мобильная версия, которую, в свою очередь, нет смысла тестировать на компьютерах. Кроме того, есть web-приложения, которые могут работать и на компьютерах, и на мобильных устройствах, а тестировать их нужно на всех типах устройств. Для тестирования можно использовать эмулятор той или иной среды, но в рамках статьи мы не будем затрагивать этот вопрос.
Мобильную версию приложения нужно тестировать на нескольких устройствах с разной диагональю экрана. При этом можно руководствоваться требованиями к ПО, в которых должно быть указано, с какими устройствами это ПО совместимо.
- Проверить в разных версиях ПО
Для того, чтобы не запутаться в реализованных задачах, в разработке используют версионность ПО. Иногда тот или иной баг воспроизводится в одной версии продукта, но не воспроизводится в другой. Этот атрибут обязательно необходимо указывать в баг-репорте, чтобы программист понимал, в какой ветке нужно искать проблему.
- Проанализировать ресурсы системы
Возможно, дефект был найден при нехватке внутренней или оперативной памяти устройства. В таком случае баг может воспроизводиться на идентичных устройствах по-разному.
Для того, чтобы оптимизировать сроки тестирования, мы рекомендуем использовать техники тест-дизайна.
Фиксирование доказательств
Доказательства воспроизведения бага нужно фиксировать при помощи логов, скринов или записи экрана.
- Логи (лог-файлы или журнал) — это файлы, содержащие системную информацию работы сервера или компьютера, в них хранят информацию об определенных действиях пользователя или программы. Опытному разработчику бывает достаточно посмотреть в логи, чтобы понять, в чем заключается ошибка. Обычно логи прикрепляют к баг-репорту в виде .txt-файла.
Live-логирование – это снятие системных логов в режиме реального времени. Для этого можно использовать следующие программы: Fiddler, Visual Studio для Windows, iTools, Xcode для iOS, Android Debug Monitor, Android Studio для Android и др.
- Скрин (снимок) экрана. При ошибках в интерфейсе снимок помогает быстрее разобраться в проблеме. Программ для снятия скриншотов очень много, каждый QA-специалист может использовать те, которые ему наиболее удобны: Jing, ShareX, Lightshot и др.
- Скринкаст (англ. screen – экран, broadcasting – трансляция) – это запись видеоизображения с экрана компьютера или другого цифрового устройства. Это один из самых эффективных способов поделиться тем, что происходит на экране монитора. Таким способом QA-специалисту легко наглядно показать ошибки в работе любого программного продукта. Сделать запись с экрана помогут незаменимые инструменты любого QA-специалиста: Snagit, Monosnap, Movavi Screen Capture, Jing, Reflector, ADB Shell Screenrecord, AZ Screen Recorder и др.
- Рекордер действий. Программные средства дают возможность воспроизвести все записанные движения мышки и действия, производимые на клавиатуре компьютера. Примеры программ – Advanced Key and Mouse Recorder для desktop-платформ.
Оформление баг-репорта
Все найденные дефекты обязательно нужно документировать, чтобы каждый задействованный на проекте специалист мог получить инструкции по воспроизведению обнаруженного дефекта и понять, насколько это критично. Если в команде принято устно передавать разработчику информацию о найденных дефектах, есть риск упустить что-то из вида.
Дефект, который не задокументирован – не найден!
Когда вся необходимая информация собрана, а баг локализован, можно приступать к оформлению баг-репорта в таск-трекере. Чем точнее описание бага, тем меньше времени нужно для его исправления. Список атрибутов для каждого проекта индивидуален, но некоторые из них – например, шаги воспроизведения, ожидаемый результат, фактический результат – присутствуют практически всегда.
Атрибуты баг-репорта:
1. Название
Баг должен быть описан кратко и ёмко, иметь понятное название. Это поможет разработчику разобраться в сути ошибки и в том, может ли он взять этот случай в работу, если занимается соответствующим разделом системы. Также это позволяет упростить подключение новых специалистов на проект, особенно если разработка ведется много лет подряд, а запоминать баги и отслеживать их в таск-трекере становится все сложнее. Название проекта можно составлять по принципу «Где? Что? Когда?» или «Что? Где? Когда?», в зависимости от внутренних правил команды.
Например:
Где происходит? — В карточке клиента (в каком разделе системы).
Что именно происходит? — Не сохраняются данные.
Когда происходит? — При сохранении изменений.
2. Проект (название проекта)
3. Компонент приложения
В какой части функциональности тестируемого продукта найден баг.
4. Номер версии
Версия продукта, ветка разработки, в которой воспроизводится ошибка.
5. Критичность
Этот атрибут показывает влияние дефекта на функциональность системы, например:
· Blocker — дефект, блокирующий использование системы.
· Critical — ошибка, которая нарушает основную бизнес-логику работы системы.
· Major — ошибка, которая нарушает работу определенной функции, но не всей системы.
· Minor — незначительная ошибка, не нарушающая бизнес-логику приложения, например, ошибка пользовательского интерфейса.
· Trivial — малозаметная, неочевидная ошибка. Это может быть опечатка, неправильная иконка и т.п.
6. Приоритет
Приоритет определяет, насколько срочно нужно исправить ошибку. Обычно выделяют следующие виды приоритетов:
High — ошибка должна быть исправлена как можно скорее, является критичной для проекта.
Medium — ошибка должна быть исправлена, но её наличие не является критичным для проекта.
Low — ошибка должна быть исправлена, но не требует срочного решения.
7. Статус
Статус указывает стадию жизненного цикла бага, взят он в работу или уже решен. Примеры: to do, in progress, in testing (on QA), done. В зависимости от особенностей проекта возможны дополнительные статусы (например, аналитика).
8. Автор баг-репорта
9. На кого назначен
Баг-репорт отправляют тимлиду проекта или разработчику, который будет заниматься исправлением дефекта, в зависимости от принятых в команде договоренностей.
10. Окружение
Где найден баг: операционная система, наименование и версия браузера.
11. Предусловие (если необходимо)
Необходимо для описания действий, которые предшествовали воспроизведению бага. Например, клиент авторизован в системе, создана заявка с параметрами ABC и т.д. Баг-репорт может не содержать предусловие, но иногда оно бывает необходимо для того, чтобы проще описать шаги воспроизведения.
12. Шаги воспроизведения
Один из самых важных атрибутов — описание шагов, которые привели к нахождению бага. Оптимально использовать 5-7 понятных и кратких шагов для описания бага, например:
1. Открыть (…)
2. Кликнуть (…)
3. Ввести в поле А значение N1
4. Ввести в поле B значение N2
5. Кликнуть кнопку «Calculate»
13. Фактический результат
Что произошло после воспроизведения указанных выше шагов.
14. Ожидаемый результат
Что должно произойти после воспроизведения шагов тестирования, согласно требованиям.
15. Прикрепленный файл
Логи, скриншоты, видеозапись экрана — всё, что поможет разработчику понять суть ошибки и исправить ее.
После составления баг-репорта обязательно нужно проверить его, чтобы избежать ошибок или опечаток.
Локализация и оформление багов — необходимые составляющие работы QA-специалиста с программным продуктом. Приглашаем подробнее ознакомиться с услугами тестирования и обеспечения качества в SimbirSoft.
7.1. Способы локализации
После
того, как с помощью контрольных тестов
(или каким либо другим путем) установлено,
что в программе или в конкретном ее
блоке имеется ошибка, возникает задача
ее локализации, то есть установления
точного места в программе, где находится
ошибка.
Процесс
локализации ошибок состоит из следующих
трех компонент:
1.
Получение на машине тестовых результатов.
2.
Анализ тестовых результатов и сверка
их с эталонными.
3.
Выявление ошибки или формулировка
предположения о характере и месте ошибки
в программе.
По
принципам работы средства локализации
разделяются на 4 типа :
1.
Аварийная печать.
2.
Печать в узлах.
3.
Слежение.
4.
Прокрутка.
АВАРИЙНАЯ
ПЕЧАТЬ
осуществляется один раз при работе
отлаживаемой программы, в момент
возникновения аварийной ситуации в
программе, препятствующей ее нормальному
выполнению. Тем самым, конкретное место
включения в работу аварийной печати
определяется автоматически без
использования информации от программиста,
который должен только определить список
выдаваемых на печать переменных.
ПЕЧАТЬ
В УЗЛАХ
включается в работу в выбранных
программистом местах программы; после
осуществления печати значений данных
переменных продолжается выполнение
отлаживаемой программы.
СЛЕЖЕНИЕ
производится или по всей программе, или
на заданном программистом участке.
Причем слежение может осуществляться
как за переменными (арифметическое
слежение), так и за операторами (логическое
слежение). Если обнаруживается, что
происходит присваивание заданной
переменной или выполнение оператора с
заданной меткой, то производится печать
имени переменной или метки и выполнение
программы продолжается. Отличием от
печати в узлах является то, что место
печати может точно и не определяться
программистом (для арифметического
слежения); отличается также и содержание
печати.
ПРОКРУТКА
производится на заданных участках
программы, и после выполнения каждого
оператора заданного типа (например,
присваивания или помеченного) происходит
отладочная печать.
По
типам печатаемых значений (числовые и
текстовые или меточные) средства
разделяются на арифметические и
логические.
7.2. Классификация средств локализации ошибок
Ниже
дана классификация средств локализации.
ТИПЫ
СРЕДСТВ ЛОКАЛИЗАЦИИ ОШИБОК :
1.
Языковые.
1.1.
Обычные.
1.2.
Специальные.
2.
Системные.
(3.
Пакетные)
СРЕДСТВА
ЛОКАЛИЗАЦИИ:
1.
Аварийная печать (арифметическая).
1.1.
Специальные средства языка.
1.2.
Системные средства.
2.
Печать в узлах (арифметическая).
2.1.
Обычные средства языка.
2.2.
Специальные средства языка.
3.
Слежение (специальные средства).
3.1.
Арифметическое.
3.2.
Логическое.
4.
Прокрутка (специальные средства).
4.1.
Арифметическая.
4.2.
Логическая.
8. Технология отладки программы автоматизации учета движения товаров на складе малого предприятия
При
отладке программы использовались
следующие методы контроля и локализации
ошибок (обзор методов см. в теоретической
части раздела) :
1.
Просмотр текста программы и прокрутка
с целью обнаружения явных синтаксических
и логических ошибок.
2.
Трансляция программы (транслятор выдает
сообщения об обнаруженных им ошибках
в тексте программы).
3.
Тестирование.
Тестирование
проводилось посредством ввода исходных
данных, с дальнейшей их обработкой,
выводом результатов на печать и экран.
Результаты работы программы сравнивались
заданными в техническом задании.
4.
При локализации ошибок преимущественно
использовалась печать в узлах, которыми
являлись в основном глобальные переменные,
переменные, используемые при обмене
данными основной программы с подпрограммами.
Отладка
программы производилась по следующему
алгоритму :
1.
Прогонка программы с набором тестовых
входных данных и выявление наличия
ошибок.
2.
Выделение области программы, в которой
может находиться ошибка. Просмотр
листинга программы с целью возможного
визуального обнаружения ошибок. В
противном случае — установка контрольной
точки примерно в середине выделенной
области.
3.
Новая прогонка программы. Если работа
программы прервалась до обработки
контрольной точки, значит, ошибка
произошла раньше. Контрольная точка
переносится, и процесс отладки возвращается
к шагу 2.
4.
Если контрольная точка программы была
обработана, то далее следует изучение
значений регистров, переменных и
параметров программы с тем, чтобы
убедиться в их правильности. При появлении
ошибки — новый перенос контрольной точки
и возврат к шагу 2.
5.
В случае не обнаружения ошибки продолжение
выполнения программы покомандно, с
контролем правильности выполнения
переходов и содержимого регистров и
памяти в контрольных точках. При
локализации ошибки она исправляется и
процесс возвращается к шагу 1.
В
качестве тестовых входных данных
использовалась последовательность
частотных выборок, генерируемых
имитатором в режиме 1. (Каждому интервалу
соответствует фиксированное значение
выборок.)
Соседние файлы в папке 4Diplom
- #
16.04.201332.77 Кб9A4.vsd
- #
- #
- #
- #
- #
#1
![]()
single player
-

- Members
-
- 11 сообщений
Новый участник


Отправлено 21 сентября 2006 — 17:34
найти ошибку недостаточно. нужно ее качественно локализовать. делимся опытом:)
я себе представляю процесс поиска возможных причин примерно так:
Рассматривается классическая схема:
на входе есть некий набор данных, некая последовательность шагов, скрытый от Вас черный ящик, в котором происходит, что-то неизвестное и набор выходных данных.
В процессе тестирования Вы получаете не тот результат, который ожидали увидеть. После того как Вы убедитесь, что в таком
нехорошем положении вещей виновата именно тестируемая программа, можно считать, что в программе найдена очередная ошибка.
Следующий шаг — добиться четкого повторения ошибки. Обычно это удается сделать по памяти. Если память Вас подводит, то
полезно иметь тетрадку по записям из которой можно воспроизвести багу еще раз. Многие программы записывают логи.
Исследование логов также может позволить Вам воспроизвести ошибку.
Отступление:
сложнее обстоит дело с «плавающими ошибками»…(не будем здесь про них).
Вы добились четкого повторения ошибки. Настало время заняться анализом набора входных данных и имеющейся
последовательности шагов.
Здесь основной принцип — чем проще, тем лучше. Т. е. наша задача повторить эту же ошибку за минимальное кол-во шагов и на
наиболее простом наборе входных данных(под наиболее простым понимается тот набор, на котором программа должна работать с
высокой степенью вероятности).
Следующий шаг — анализ выходных данных. Сравнивая разницу между наблюдаемым и ожидаемым выходом, нужно постараться понять
из-за чего эта разница могла возникнуть.
После этого нужно попытаться найти наиболее простой путь(несколько путей), с помощью которого можно обойти найденную
ошибку и получить требуемый результат. Возможно, это поможет программисту в исправлении ошибки, ну а в крайнем случае у Вас
будут рекомендации для отдела тех. поддержки:)
Далее обобщаем результаты исследований, оставляем нужное, отсекаем лишнее и заносим новый баг в базу данных ошибок.
Тоже самое коротко:
-действительно ошибка?
-анализ и упрощение входа.
-анализ выхода
-поиск обходных путей
-оформление в базу данных ошибок.
-
0
- Наверх
#2
![]()
serega
Отправлено 22 сентября 2006 — 06:13
Слов много, а по сути…. 
найти ошибку недостаточно. нужно ее качественно локализовать. делимся опытом:)
Тоже самое коротко:
-действительно ошибка?

Попробуйте занести программисту несколько раз минимую ошибку баг трекинг -моментально научитесь проверять
-анализ и упрощение входа.
Никто с вами и разговаривать не будет, если вы будете описывать баги нечетко — баг будет возвращаться на уточнение, пока не научитесь
-анализ выхода
-поиск обходных путей
У Вас всегда есть на это время?
Если вы знаете внутреннюю логику программы, то можно потратить 5 мин, иначе какой смысл
-оформление в базу данных ошибок.
А какой еще результат нужен от тестирования?
С моей точки зрения локализация ошибки — это способ сузить облась её поиска раработчиком, т.е. постараться максимально отсечь все лишнее в описании.
Для этого надо обладать достаточными знаниями о внутренней логике программы и уметь анализировать код. Даже в этом случае Вы не всегда сможете точно указать проблемное место, тока рекомендации.
-
0
- Наверх
#3
![]()
Rost
Rost
- ФИО:Rostyslav Boruk
- Город:Украина, Киев
Отправлено 22 сентября 2006 — 07:03
Тоже самое коротко:
-действительно ошибка?
-анализ и упрощение входа.
-анализ выхода
-поиск обходных путей
-оформление в базу данных ошибок.
Я согласен с serega в том, что на
«-анализ и упрощение входа.
-анализ выхода
-поиск обходных путей»
чаще всего нет времени. На самом деле это довольно редко надо делать. Вы нашли ошибку, воспроизвели ее и подробно описали. Можете двигаться дальше.
С моей точки зрения локализация ошибки — это способ сузить облась её поиска раработчиком, т.е. постараться максимально отсечь все лишнее в описании.
Для этого надо обладать достаточными знаниями о внутренней логике программы и уметь анализировать код. Даже в этом случае Вы не всегда сможете точно указать проблемное место, тока рекомендации.
Согласен с максимальным отсечением. Не согласен, в данном контексте, с анализом кода. Предлагался черный ящик.
Рассматривается классическая схема:
на входе есть некий набор данных, некая последовательность шагов, скрытый от Вас черный ящик, в котором происходит, что-то неизвестное и набор выходных данных.
Так что грамотного детального описания (в разумных пределах) достаточно.
-
0
Ростислав Борук,
Консультант по процессам тестирования
- Наверх
#4
![]()
Clauster
Clauster
- ФИО:Худобородов Валерий
- Город:Espoo
Отправлено 22 сентября 2006 — 08:14
Это краткий пересказ какой-то книжки по тестированию или что?
-
0
- Наверх
#5
![]()
Rost
Rost
- ФИО:Rostyslav Boruk
- Город:Украина, Киев
Отправлено 22 сентября 2006 — 08:18
Это краткий пересказ какой-то книжки по тестированию или что?
Очень похоже на обсуждение содержания краткого пересказа основной идеи локализации и описания ошибки. 
-
0
Ростислав Борук,
Консультант по процессам тестирования
- Наверх
#6
![]()
single player
single player
-
- Members
-
- 11 сообщений
Новый участник
Отправлено 22 сентября 2006 — 15:13
«Это краткий пересказ какой-то книжки по тестированию или что?»
— я же написал, что основано на своем опыте, получилось книжно, потому что хотелось рассказать самое основное.
(статья была написана по просьбе руководства для начинающих тестировщиков. после каждого пункта запланирован небольшой пример непосредственно из тестирования боевых программ).
«Слов много, а по сути….»
поэтому и хотелось что бы народ поделился своим опытом.
«Попробуйте занести программисту несколько раз минимую ошибку баг трекинг -моментально научитесь проверять»
— а зачем пробовать? не лучше ли сразу научиться проверять?
«Никто с вами и разговаривать не будет, если вы будете описывать баги нечетко — баг будет возвращаться на уточнение, пока не научитесь»
— про четкое описание бага нужно говорить отдельно (если коротко, то в описании должны быть 3 вещи: последовательность шагов, наблюдаемое поведение, ожидаемое поведение). описание ошибкилокализация ошибки — это разные понятия, ИМХО.
«А какой еще результат нужен от тестирования?»
— Вы считаете, что единственным результатом тестирования, является запись об ошибке в базе?
-
0
- Наверх
#7
![]()
serega
Отправлено 25 сентября 2006 — 12:05
«Попробуйте занести программисту несколько раз минимую ошибку баг трекинг -моментально научитесь проверять»
— а зачем пробовать? не лучше ли сразу научиться проверять?
меня смущает словосочетание «научиться проверять» — мне кажется, невелика наука делать все адекватно
«Никто с вами и разговаривать не будет, если вы будете описывать баги нечетко — баг будет возвращаться на уточнение, пока не научитесь»
— про четкое описание бага нужно говорить отдельно (если коротко, то в описании должны быть 3 вещи: последовательность шагов, наблюдаемое поведение, ожидаемое поведение). описание ошибкилокализация ошибки — это разные понятия, ИМХО.
Вы забыли: название, версия, в которой найден, требования, ответсвенного, важность….и т.д.
Тоже будем учить? или заведем баг-трекинг?
«А какой еще результат нужен от тестирования?»
— Вы считаете, что единственным результатом тестирования, является запись об ошибке в базе?
Не стоит выдергивать вопрос из контекста.
Найти и зафиксировать ошибку в базу — основная задача тестирования. Кому то надо доказывать, что найденную ошбику необходимо зарегистрировать?
-
0
- Наверх
#8
![]()
Imbecile
Отправлено 25 сентября 2006 — 12:26
Следующий шаг — анализ выходных данных. Сравнивая разницу между наблюдаемым и ожидаемым выходом, нужно постараться понять
из-за чего эта разница могла возникнуть.
Так недолго и до того, что: «Открыл исходники и пофиксил». Понять из-за чего возникла ошибка может (в первую очередь) только программист.
-
0
In Test we trust.
- Наверх
#9
![]()
Imbecile
Отправлено 25 сентября 2006 — 12:32
Не стоит выдергивать вопрос из контекста.
Найти и зафиксировать ошибку в базу — основная задача тестирования. Кому то надо доказывать, что найденную ошбику необходимо зарегистрировать?
По поводу основной задачи тестирования:
ИМХО: Процесс тестирования является неотъемлемой частью процесса обеспечения качества (в данном случае программного продукта). Никому не нужно тестирование, если в результате этого процесса качество не изменится (улучшится). Следовательно, при процессе тестирование важно не нахождение ошибки, как таковой, а нахождение ошибок, нахождение (простите за тавтологию) которых, повлечёт изменение качества продукта (в лучшую сторону).
-
0
In Test we trust.
- Наверх
#10
![]()
ea_rx
ea_rx
-
- Members
-
- 10 сообщений
Новый участник

- ФИО:Evgeny Bartashevich
Отправлено 25 сентября 2006 — 14:16
найти ошибку недостаточно. нужно ее качественно локализовать. делимся опытом:)
я себе представляю процесс поиска возможных причин примерно так:
[..]
Следующий шаг — добиться четкого повторения ошибки. Обычно это удается сделать по памяти. Если память Вас подводит, то
полезно иметь тетрадку по записям из которой можно воспроизвести багу еще раз. Многие программы записывают логи.
Исследование логов также может позволить Вам воспроизвести ошибку.
для того, чтобы не воспроизводить по памяти (а если ошибка из-за данных, введенных 20 шагов назад?), можно записывать видео с производимыми действиями.
-
0
- Наверх
#11
![]()
single player
single player
-
- Members
-
- 11 сообщений
Новый участник
Отправлено 25 сентября 2006 — 14:45
«Так недолго и до того, что: «Открыл исходники и пофиксил». Понять из-за чего возникла ошибка может (в первую очередь) только программист.»
понять может только программист. мы можем только высказать свои предположения.
собственно что имелось в виду: допустим есть конечное состояние «A»(успешное выполнение) и конечное состояние «B»(ошибка). Далее представим себе, что «A» является успешным при выполнении более простых a1, a2, a3. А «B» является ошибкой, т.к. например вместо a2 мы получили х. Непосредственно проверить функцию, влиюящую на a2, мы не можем (у нас есть только доступ к функции, которая результатом которой является все «A» ), но предположить, что сбой произошел из-за того, что некорректно отработала функция, ответственная за a2, мы можем.
«ИМХО: … а нахождение ошибок, нахождение (простите за тавтологию) которых, повлечёт изменение качества продукта (в лучшую сторону).»
угу. тоже ИМХО: более качественным продукт делает нахождение ошибок и их исправление. соответственно быстрому исправлению ошибки должна помочь хорошо выполненная локализация.
2serega:
не хочется спорить и ругаться  . мне не интересно как заносить ошибки в базу — интересно как их локализовывать.
. мне не интересно как заносить ошибки в базу — интересно как их локализовывать.
-
0
- Наверх
#12
![]()
Rost
Rost
- ФИО:Rostyslav Boruk
- Город:Украина, Киев
Отправлено 25 сентября 2006 — 15:53
угу. тоже ИМХО: более качественным продукт делает нахождение ошибок и их исправление. соответственно быстрому исправлению ошибки должна помочь хорошо выполненная локализация.
Все правильно если Вы не тратите на локализацию пол дня. 
Если Вы тратите на локализацию больше времени чем можно просто, подробно описать ошибку, это совсем не БЫСТРОЕ исправление. Исправление в себе содержит нахождение и изменение, а не только изменение.
-
0
Ростислав Борук,
Консультант по процессам тестирования
- Наверх
#13
![]()
single player
single player
-
- Members
-
- 11 сообщений
Новый участник
Отправлено 25 сентября 2006 — 16:04
«Все правильно если Вы не тратите на локализацию пол дня.»
угу  во всем нужно чувство меры.
во всем нужно чувство меры.
offtopic:
для меня в работе всегда было интересно сначала поломать что-нить, а потом уже разобраться из-за чего же оно сломалось. если же тупо тестировать по сценариям, то и самому отупеть не долго
-
0
- Наверх
#14
![]()
Imbecile
Отправлено 26 сентября 2006 — 07:48
«ИМХО: … а нахождение ошибок, нахождение (простите за тавтологию) которых, повлечёт изменение качества продукта (в лучшую сторону).»
угу. тоже ИМХО: более качественным продукт делает нахождение ошибок и их исправление. соответственно быстрому исправлению ошибки должна помочь хорошо выполненная локализация.
А это уже зависит от специфики продукта. Я не спорю, что выявление дефектов и их справление — это важный процесс в достижении качества продукта, но далеко не единственный.
-
0
In Test we trust.
- Наверх
#15
![]()
Imbecile
Отправлено 26 сентября 2006 — 07:51
offtopic:
для меня в работе всегда было интересно сначала поломать что-нить, а потом уже разобраться из-за чего же оно сломалось. если же тупо тестировать по сценариям, то и самому отупеть не долго
Открою страшную тайну, т-с-с-с, никому не говорите: чтобы люди не сидели и тупо не тестировали по тестовым сценариям и, следовательно, не тупели, придумали автоматизацию тестирования. Во как.
-
0
In Test we trust.
- Наверх
#16
![]()
Clauster
Clauster
- ФИО:Худобородов Валерий
- Город:Espoo
Отправлено 26 сентября 2006 — 08:14
offtopic:
для меня в работе всегда было интересно сначала поломать что-нить, а потом уже разобраться из-за чего же оно сломалось. если же тупо тестировать по сценариям, то и самому отупеть не долго
Открою страшную тайну, т-с-с-с, никому не говорите: чтобы люди не сидели и тупо не тестировали по тестовым сценариям и, следовательно, не тупели, придумали автоматизацию тестирования. Во как.
В ответ открываю ещё более страшную тайну: далеко не во все проекты имеет смысл внедрять автоматизацию. 
-
0
- Наверх
#17
![]()
serega
Отправлено 26 сентября 2006 — 08:40
По поводу основной задачи тестирования:
ИМХО: Процесс тестирования является неотъемлемой частью процесса обеспечения качества (в данном случае программного продукта). Никому не нужно тестирование, если в результате этого процесса качество не изменится (улучшится). Следовательно, при процессе тестирование важно не нахождение ошибки, как таковой, а нахождение ошибок, нахождение (простите за тавтологию) которых, повлечёт изменение качества продукта (в лучшую сторону).
Очень толково. Только обясните мне, чем отличаются ошибки, которые влекут изменение качества продукта, от остальных ошибок?
Вы правильно заметили, что тестирование — неотъемлимая часть процесса управления качеством, в который помимо тестирования входят еще куча дисциплин.
Поэтому я считаю ошибочным вывод «Никому не нужно тестирование, если в результате этого процесса качество не изменится (улучшится).»
Тестирование может обеспечивать выполнение своих задач, но при этом хромать остальные дисциплины, начиная от управления проектов и заканчивая Help Desk
-
0
- Наверх
#18
![]()
serega
Отправлено 26 сентября 2006 — 08:46
2serega:
не хочется спорить и ругаться
Как локализовавать ошибки — слишком общий вопрос.
Учите преметную область и овладевайте широкими познаниями в области IT.
Пример из личного опыта. Разрабатывалась система электронной передачи документов с локальных мест в общую базу при помощи почтового сервиса.
Система состояла из 4-х модулей: локальный клиент, почтовый клиент, дешифратор со стороны сервера, парсер на центральном сервере.
Появляется ошибка — письмо не приходит, вот и локализуешь на каком сегменте произошел сбой, без знания логики всех сегментов никуда:(
-
0
- Наверх
#19
![]()
Rost
Rost
- ФИО:Rostyslav Boruk
- Город:Украина, Киев
Отправлено 26 сентября 2006 — 09:09
Поэтому я считаю ошибочным вывод «Никому не нужно тестирование, если в результате этого процесса качество не изменится (улучшится).»
Тестирование может обеспечивать выполнение своих задач, но при этом хромать остальные дисциплины, начиная от управления проектов и заканчивая Help Desk
А зачем тратить ресурсы на то, что не приносит никаких изменений? Просто потому что в цепочке разработки ПО обязано быть тестирование?
-
0
Ростислав Борук,
Консультант по процессам тестирования
- Наверх
#20
![]()
serega
Отправлено 26 сентября 2006 — 10:37
Поэтому я считаю ошибочным вывод «Никому не нужно тестирование, если в результате этого процесса качество не изменится (улучшится).»
Тестирование может обеспечивать выполнение своих задач, но при этом хромать остальные дисциплины, начиная от управления проектов и заканчивая Help Desk
А зачем тратить ресурсы на то, что не приносит никаких изменений? Просто потому что в цепочке разработки ПО обязано быть тестирование?
ага, и виновато тестирование.. под нож
будем строить дом, монтажные чертежи опустим — так дешевле 
-
0
- Наверх
Регистрация на курс
Плавающий баг?
Ох уж эти мистические «плавающие ошибки». Сколько вокруг них мифов! Но, когда причина найдена, всегда оказывается, что нет плавающих багов, а есть недолокализованные.
Поэтому мы будем учиться локализовывать баги, которые «не воспроизводятся». Учиться искать причину проблемы без помощи разработчика. Учиться смотреть в код и искать причину снаружи. Делить бисекционно и читать логи. В общем, всё, что нужно для воспроизведения!
Воспроизведение ошибки
Если вы не можете вопроизвести ошибку, то:
- Прочитайте логи — если есть доступ к логам, всегда в первую очередь смотрим туда! Если у нас веб-приложение, проверьте, что ушло с клиента на сервер.
- Проверьте граничные значения — баги часто тусят на границах.
- Попробуйте пойти «от обратного» — подумать, как получить саму проблему. Этот метод хорошо работает для багов с кэшом
- Составьте таблицу отличий — у вас то все работает. Что отличает ваш кейс от падающего?
Что записывать в таблицу отличий:
- Состояние объекта.
- Действия, которые с ним выполняли.
- Устройство, на котором воспроизводится.
- Время выполнения действия (какой релиз?).
- Способ воспроизведения (GUI, API).
- Количество открытых вкладок в браузере.
В отлове багов помогает понимание того, где копятся баги и какого рода: как влияет на работу системы concurrency, миграция данных, перетипизация переменной внутри кода… Зная последствия, вы будете понимать, что именно записать в таблицу отличий.
Локализация ошибки
Если вы можете воспроизвести баг, но не можете локализовать (слишком много шагов воспроизведения / слишком большой файл, внутри которого есть ошибка), то:
- Посмотрите код — возможно, это будет самым быстрым решением.
- Используйте бисекционное деление.
- Придумайте теорию (на баг влияет то и то) — подтвердите ее, а потом попробуйте опровергнуть.
- Выкиньте лишнее из шагов — возможно, именно это сбивает вас с толку
На курсе мы будем рассматривать каждую из техник. Вы сможете сразу применить ее на практике на специально подобранных домашних заданиях, которые показывают именно данную технику или конкретную проблему (миграции данных, стыка интеграции и т.д.)
О курсе
Это практический курс: теории минимум. Типичная лекция — на 10-15 минут. Короткая лекция «как это применять» и тут же практика! Конечно, есть и сложные лекции (на 30 минут). Есть и короткие, на 7 минут. Нет жесткой привязки ко времени лекции. Сколько надо дать теории, столько и говорю, а дальше уже практикуйтесь.
Для локализации багов мы будем применять техники:
- Черного ящика — как понять, что происходит, если нет доступа в код.
- Белого ящика — куда можно посмотреть в коде? Смотреть будем на примере приложения folks с открытым исходным java-кодом. Разумеется, у вас на проекте код будет выглядеть по-другому, но зато вы получите представление, где там могут вылезти баги. Баги, которые мы будем рассматривать на курсе, не были внесены в приложение нарочно — так что все приближено к реальности.
Лекции идут в моем фирменном стиле, с картинками. Посмотрите примеры видео на моем youtube-канале, чтобы понять, подходит ли вам такой стиль изложения.
Если вы переживаете, что не сможете что-то сделать (например, задания на просмотр кода), вот вам задача для самопроверки — соберите проект folks и запустите тесты. Инструкция есть, есть даже видео-инструкция по установке java, maven на Windows, Если справитесь, то и все остальное будет вам по плечу!
Программа курса
0. Введение
Что такое локализация и зачем она вообще нужна тестировщику.
Как умение локализовывать задачи экономит время команды и убирает панику.
Как знание о типовых проблемах помогает воспроизводить баги, которые «не воспроизводятся».
1. Уточнение устройств, на которых есть баг
На что обращать внимание при багах «поехала верстка», «текст вылезает за пределы экрана».
Как понять, в какой момент едет верстка? Какие инструменты использовать:
— как замерить размер окна;
— какие есть линейки;
— как посмотреть размер окна в консоли.
2. Исследование состояний
Изучим разные состояния объекта. Если проблема при сохранении — а кого мы вообще сохраняем?
— свежесозданную карточку
— отредактированную
— удаленную
…
Если у нас есть пользователь, то какой он? А как регистрировался? Как это может повлиять на воспроизведение бага?
3. Использование классов эквивалентности и граничных значений
Что такое классы эквивалентности.
Почему на границах встречаются баги.
Зачем тестировать ноль и как его найти, если у нас не строка ввода?
4. Опровержение своих теорий
Как опровергать свои теории и зачем это нужно.
— таблица отличий;
— метод «найди 5 отличий»;
— принцип минимализма (отсеивание лишнего).
5. Метод бисекционного деления
Что такое бисекционное деление.
Как его использовать тестировщику для локализации бага.
Как оно используется в разработке и к каким проблемам может привести.
6. Чтение логов
Что такое логи. Что в них записывается?
Как читать логи. Как читать стектрейс ошибки.
Логи на сервере и на клиенте.
7. Просмотр запросов с клиента на сервер
На клиенте помимо JS-логов можно смотреть, что вообще ушло на сервер.
Это помогает понять, где произошла ошибка и кто виноват: клиент или сервер. Учимся это делать.
8. Воспроизведение «от обратного»
Техника расследования закрытой комнаты. Наиболее актуальна для багов с кэшом.
Вот есть баг, из кэша достаются неправильные данные. Как воспроизвести? Идем от обратного, пытаемся получить “плохие данные” разными путями.
9. Проверка по коду
Как читать код, при условии, что разработчики идут вам на встречу и разделяют потроха логики и описание объектов.
Читаем java-объект и схему создания БД. Выверяем их на соответствие друг другу.
Внимание: у вас на проекте может быть не java, но принцип все тот же. На примере домашнего задания вы увидите, как можно найти баг, исследуя код
10. Проверка соответствия типов данных
Если поле встречается в коде несколько раз:
— в объектной модели;
— в схеме создания БД;
— где-то еще
Важно проверять соответствие типов. Смотрим, какие встречаются баги на несоответствие типов.
11. Проверка стыка интеграции
Какая бывает интеграция между системами.
Какие бывают баги на стыке интеграции.
Куда смотреть в первую очередь.
12. Проверка данных после миграции
Зачем тестировщику нужна как чистая база, так и база, живущая веками?
Примеры ошибок, вылезающих после миграции и почему они не ловятся на свежей тестовой БД.
13. Проверка concurrency
Типичная ошибка — выполнение CRUD над одним пользователем. Тестировщик может найти баги, переключаясь между вкладками интерфейса. Но это про поиск багов, а не про локализацию, казалось бы, да?
Но о concurrency важно знать, так как параллельная работа может быть и на другом уровне:
- Идет забор данных из базы по 1000 записей за раз. Что, если в этой 1000 встретились 2 одинаковых клиента? Строка базы заблокирована первым изменением — второе разваливается.
- Интеграция по SOAP REST. Если запросов много, там тоже можно влететь на изменение одного и того же клиента.
И в этом случае к вам придут “у меня тут ошибка”, а вы понять не можете, откуда она взялась, так как текст невразумительный. Надо помнить про параллельную работу, чтобы локализовать причину.
14. Заключение
Подводим итоги.
Вопросы и ответы
1. Можно ли проходить курс на Linux или Mac?
Да, он не зависит от вашей OS
2. Какие знания нужны для курса?
Общие знания о тестировании — что это вообще такое, как составлять тесты, что такое классы эквивалентности.
Если будете делать ДЗ с просмотром кода (необязательные), то:
- Базовое понимание языка программирования (любого) — вы не должны падать в обморок от слов string или «тип данных». Но все, что будет нужно для ДЗ, я объясню.
- Умение устанавливать новые программы — мы будем смотреть в код, а для этого нужно будет установить java, mercurial, maven. Вот инструкция, соберите проект перед записью на курс.
3. Будет ли мне интересно, если я проходил другие ваши курсы?
Если вы прошли «Школу для начинающих тестировщиков» в группе, то встречались с багами в коде folks — но эти задания на курсе необязательные! Так что сильно не влияют на интерес.
Если вы прошли «Логи как инструмент тестировщика», то уже сделали пару обязательных заданий. Но всё равно будет много нового и полезного
4. А скидку то дадут мне за эти ДЗ?
Да, покажите ваш сертификат и получите скидку:
- Логи как инструмент тестировщика → 20%
- Школа для начинающих, пройденная в группе → 10%
Как записаться
Напишите на trainings@software-testing.ru: свое ФИО и желаемый курс («курс про техники отлова ошибок»).
.
Способы оплаты
Регистрация и дата ближайшего запуска
Сколько раз мы всматривались в этот код:
do {
try writeEverythingToDisk()
} catch let error {
// ???
}или в этот:
switch result {
case .failure(let error):
// ???
}и задавали себе вопрос: “Как же мне выудить из этой ошибки информацию?”
Проблема в том, что ошибка, вероятно, содержит много информации, которая могла бы нам помочь. Но получение этой информации часто дело не простое.
Чтобы понять причину этого, давайте рассмотрим имеющиеся в нашем распоряжении способы прикрепления информации к ошибкам.
Новое: LocalizedError
В языке Swift мы передаем ошибки в соответствии с протоколом Error. Протокол LocalizedError его наследует, расширяя его некоторыми полезными свойствами:
- errorDescription
- failureReason
- recoverySuggestion
Соответствие протоколу LocalizedError вместо протокола Error (и обеспечение реализации этих новых свойств), позволяет нам дополнить нашу ошибку множеством полезной информации, которая может быть передана во время исполнения программы (интернет-журнал NSHipster рассматривает этот вопрос более подробно):
enum MyError: LocalizedError {
case badReference
var errorDescription: String? {
switch self {
case .badReference:
return "The reference was bad."
}
}
var failureReason: String? {
switch self {
case .badReference:
return "Bad Reference"
}
}
var recoverySuggestion: String? {
switch self {
case .badReference:
return "Try using a good one."
}
}
}Старое: userInfo
Хорошо знакомый класс NSError содержит свойство — словарь userInfo, который мы можем заполнить всем, чем захотим. Но также, этот словарь содержит несколько заранее определённых ключей:
- NSLocalizedDescriptionKey
- NSLocalizedFailureReasonErrorKey
- NSLocalizedRecoverySuggestionErrorKey
Можно заметить, что их названия очень похожи на свойства LocalizedError. И, фактически, они играют аналогичную роль:
let info = [
NSLocalizedDescriptionKey:
"The reference was bad.",
NSLocalizedFailureReasonErrorKey:
"Bad Reference",
NSLocalizedRecoverySuggestionErrorKey:
"Try using a good one."
]
let badReferenceNSError = NSError(
domain: "ReferenceDomain",
code: 42,
userInfo: info
)Это выглядит, как будто LocalizedError и NSError должны быть в основном равнозначны, верно? Что ж, в этом-то и заключается основная проблема.
Старое встречается с новым
Дело в том, что класс NSError соответствует протоколу Error, но не протоколу LocalizedError. Иными словами:
badReferenceNSError is NSError //> true
badReferenceNSError is Error //> true
badReferenceNSError is LocalizedError //> falseЭто значит, что если мы попытаемся извлечь информацию из любой произвольной ошибки привычным способом, то это сработает должным образом только для Error и LocalizedError, но для NSError будет отражено только значение свойства localizedDescription:
// The obvious way that doesn’t work:
func log(error: Error) {
print(error.localizedDescription)
if let localized = error as? LocalizedError {
print(localized.failureReason)
print(localized.recoverySuggestion)
}
}
log(error: MyError.badReference)
//> The reference was bad.
//> Bad Reference
//> Try using a good one.
log(error: badReferenceNSError)
//> The reference was bad.Это довольно неприятно, потому как известно, что наш объект класса NSError содержит в себе информацию о причине сбоя и предложение по исправлению ошибки, прописанные в его словаре userInfo. И это, по какой-то причине, не отображается через соответствие LocalizedError.
Новое становится старым
В этом месте мы можем впасть в отчаяние, мысленно представляя себе множество операторов switch, пытающихся отсортировать по типам и по наличию различные свойства словаря userInfo. Но не бойтесь! Есть несложное решение. Просто оно не совсем очевидно.
Обратите внимание, что в классе NSError определены удобные методы для извлечения локализованного описания, причины сбоя и предложения по восстановлению в свойстве userInfo:
badReferenceNSError.localizedDescription
//> "The reference was bad."
badReferenceNSError.localizedFailureReason
//> "Bad Reference"
badReferenceNSError.localizedRecoverySuggestion
//> "Try using a good one."Они отлично подходят для обработки NSError, но не помогают нам извлечь эти значения из LocalizedError… или это так?
Оказывается, протокол языка Swift Error соединён компилятором с классом NSError. Это означает, что мы можем превратить Error в NSError с помощью простого приведения типа:
let bridgedError: NSError
bridgedError = MyError.badReference as NSErrorНо ещё больше впечатляет то, что когда мы производим приведение LocalizedError этим способом, то мост срабатывает правильно и подключает localizedDescription, localizedFailureReason и localizedRecoverySuggestion, указывая на соответствующие значения!
Поэтому, если мы хотим, чтобы согласованный интерфейс извлекал локализованную информацию из Error, LocalizedError и NSError, нам просто нужно не долго думая привести всё к NSError:
func log(error: Error) {
let bridge = error as NSError
print(bridge.localizedDescription)
print(bridge.localizedFailureReason)
print(bridge.localizedRecoverySuggestion)
}
log(error: MyError.badReference)
//> The reference was bad.
//> Bad Reference
//> Try using a good one.
log(error: badReferenceNSError)
//> The reference was bad.
//> Bad Reference
//> Try using a good one.Готово!
Оригинал статьи
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
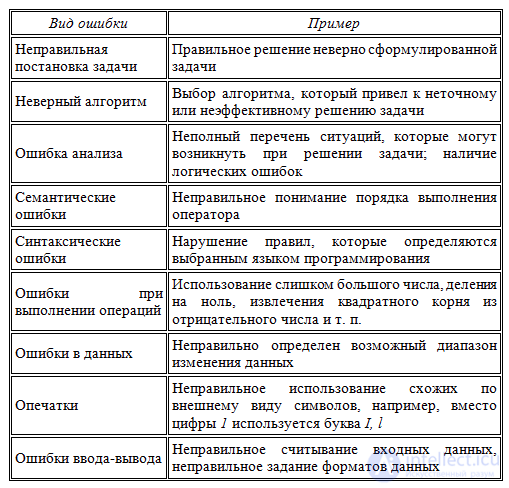
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
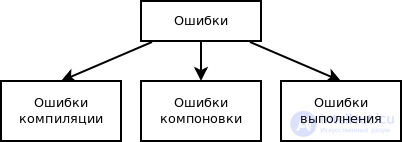
Классификация ошибок по этапу обработки программы
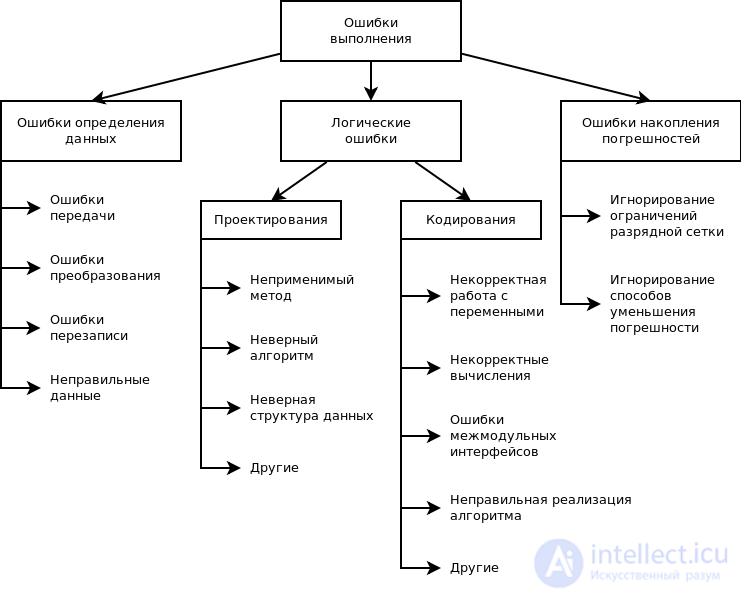
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.