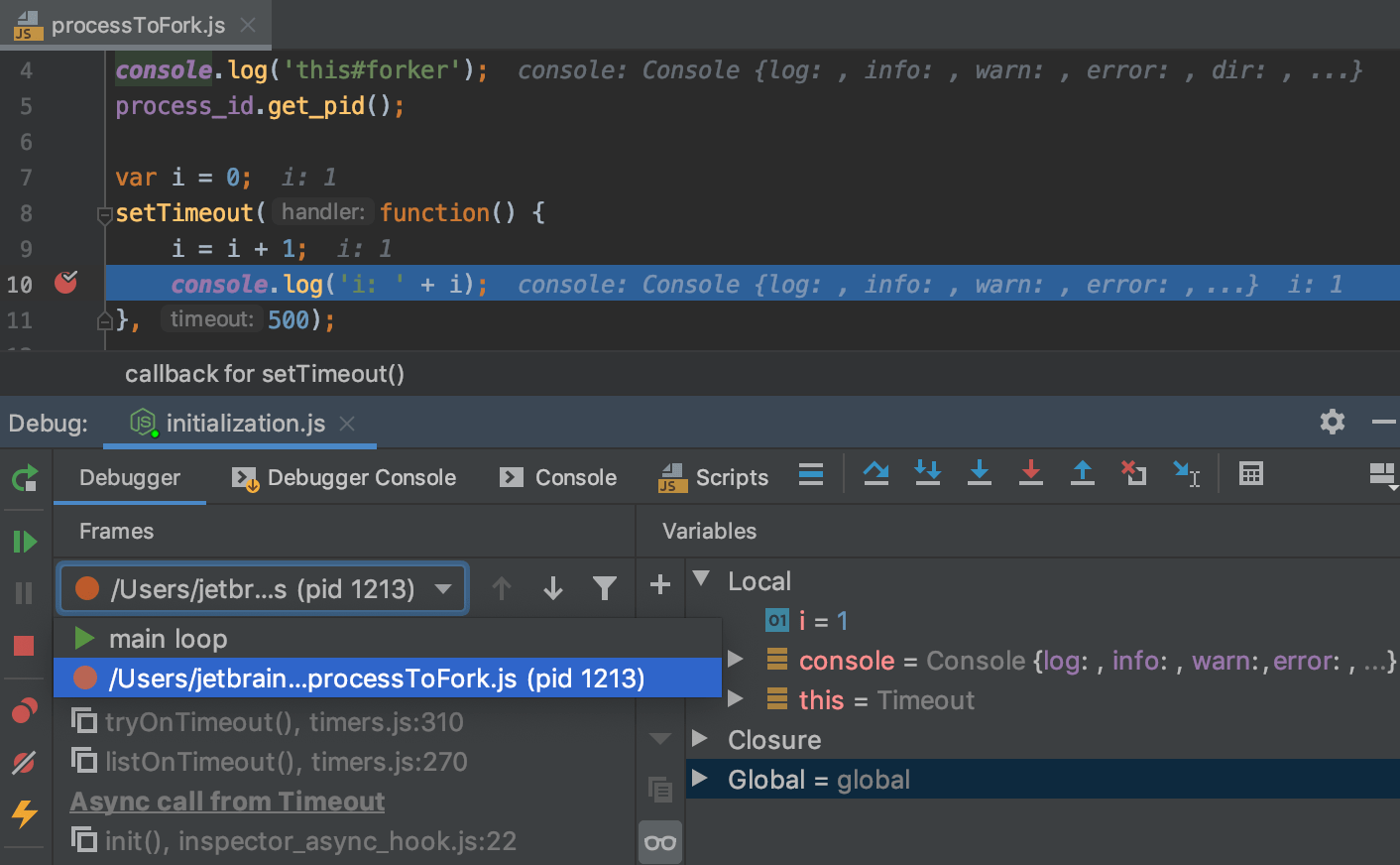
Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
- Сложность реальных приложений
- Логирование
- Уровни логирования
- Ротация логов
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
- DNS. Система трансляции имени сайта в ip-адрес сервера.
- Веб-сервер. Программа, обслуживающая входящие запросы, перенаправляет их в код приложения и забирает от приложения данные для пользователей.
- Физический сервер (или виртуальный) с его окружением. Включает в себя операционную систему, установленные и запущенные обслуживающие программы, например, мониторинг.
- База данных. Внешнее хранилище, с которым связывается код приложения и обменивается информацией.
- Само приложение. Помимо кода, который пишут программисты, приложение включает в себя сотни тысяч и миллионы строк кода сторонних библиотек. Кроме этого, код работает внутри фреймворка, у которого свои собственные правила обработки входящих запросов.
- Фронтенд часть. Код, который выполняется в браузере пользователя. И системы сборки для разработки, например, Webpack.
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает написанный нами код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
# Формат: ip-address / date / HTTP-method / uri / response code / body size
173.245.52.110 - [19/Jan/2021:01:54:20 +0000] "GET /my HTTP/1.1" 200 46018
108.162.219.13 - [19/Jan/2021:01:54:20 +0000] "GET /sockjs-node/244/gdt1vvwa/websocket HTTP/1.1" 0 0
162.158.62.12 - [19/Jan/2021:01:54:20 +0000] "GET /packs/css/application.css HTTP/1.1" 304 0
162.158.62.84 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/runtime-eb0a99abbe8cf813f110.js HTTP/1.1" 304 0
108.162.219.111 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/application-2cba5619945c4e5946f1.js HTTP/1.1" 304 0
108.162.219.21 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/0564a7b5d773bab52e53.js HTTP/1.1" 304 0
108.162.219.243 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/6fb7e908211839fac06e.js HTTP/1.1" 304 0
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
# Выведет 4 минуты логов за 31 марта 2020 года с 19:31 по 19:35
grep "31/Mar/2020:19:3[1-5]" access.log
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
- Ruby On Rails (Ruby)
- Django (Python)
- Laravel (PHP)
- Spring Boot (Java)
- Fastify (Node.js)
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
# Сюда же выводятся ошибки, если они были
「wds」: Project is running at http://hexletdev4.com/
「wds」: webpack output is served from /packs/
「wds」: Content not from webpack is served from /root/hexlet/public/packs
「wds」: 404s will fallback to /index.html
「wdm」: assets by chunk 10.8 MiB (auxiliary name: application) 115 assets
sets by path js/ 13.8 MiB
assets by path js/*.js 13.8 MiB 52 assets
assets by path js/pages/*.js 5.1 KiB
asset js/pages/da223d3affe56711f31f.js 2.6 KiB [emitted] [immutable] (name: pages/my_learning) 1 related asset
asset js/pages/04adacfdd660803b19f1.js 2.5 KiB [emitted] [immutable] (name: pages/referral) 1 related asset
sets by chunk 9.14 KiB (auxiliary id hint: vendors)
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
- debug
- info
- warning
- error
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
// Пример логирования внутри программы
// Логер: https://github.com/pinojs/pino
import buildLogger from 'pino';
const logger = buildLogger(/* возможная конфигурация */);
logger.info('тут что то полезное');
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
# https://github.com/fastify/fastify-cli#options
FASTIFY_LOG_LEVEL=debug fastify-server.js
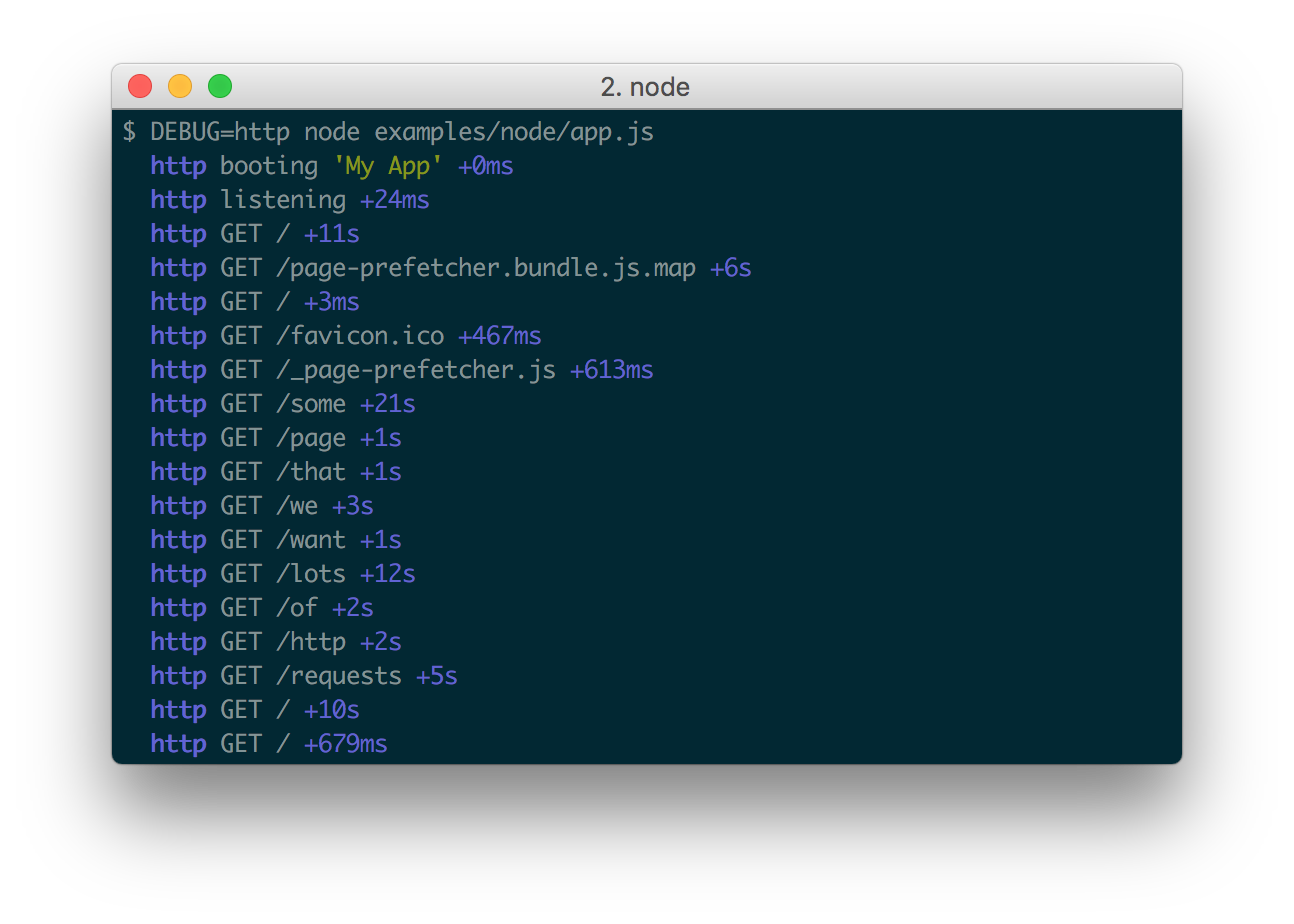
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
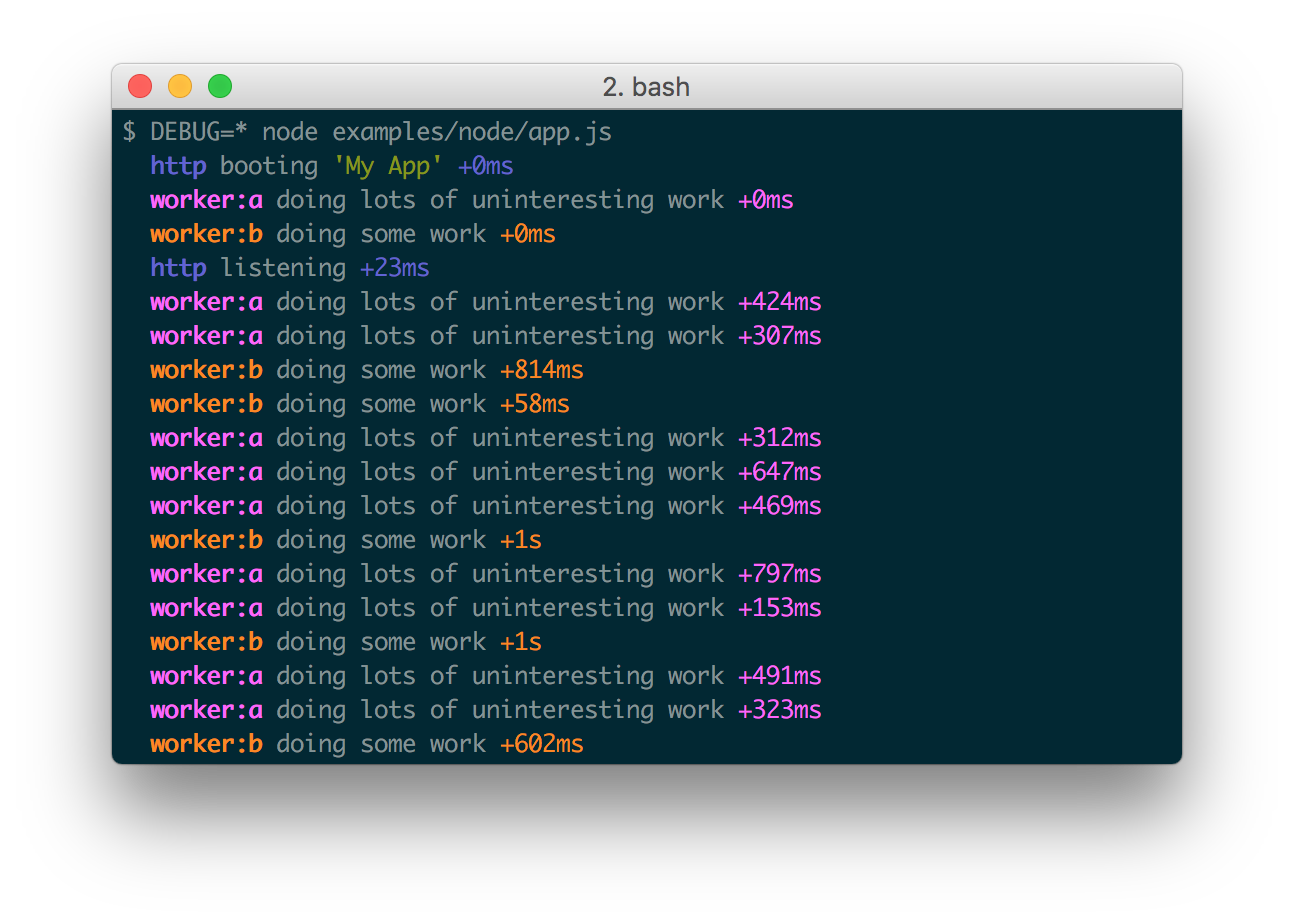
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
import debug from 'debug';
// Пространство имен http
const logHttp = debug('http');
const logSomethingElse = debug('another-namespace');
// Где-то в коде
logHttp(/* информация о http запросе */);
Запуск с нужным пространством:
DEBUG=http server.js
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системами созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack
О чём могут рассказать логи: важный инструмент в работе тестировщика
Уровень сложности
Средний
Время на прочтение
6 мин
Количество просмотров 8.3K
Привет, Хабр! Меня зовут Анфиса Одинцова, я — наставница в Яндекс Практикуме на курсе «Инженер по тестированию». Сейчас работаю в JoomPay, а раньше — в Яндекс Дзен и ВК. В этой статье расскажу о важном аспекте тестирования — работе с логами. Ведь в мире разработки программного обеспечения логирование играет ключевую роль в обеспечении качества и отладке приложений. Для тестировщиков логи — ценный инструмент, который помогает нам понять работу приложения, обнаружить потенциальные проблемы и сделать наше тестирование более эффективным.
Мы рассмотрим, зачем в работе могут понадобиться логи, какие виды логирования существуют и что внутри лога может быть нам полезным.
Что такое логи и когда в них смотреть
Логи — это записи событий и сообщений, создаваемые программой или системой во время ее работы. Они представляют собой источник информации о том, что происходит внутри приложения в определённый момент времени. Логи содержат различные данные, такие как сообщения об ошибках, предупреждения, информацию о выполнении определённых действий и многое другое.
Когда тестировщик смотрит в логи
В зависимости от вида проводимого тестирования тестировщик может воспользоваться информацией из логов.
-
При тестировании новой фичи. Стоит держать логи открытыми, они помогут отследить правильность выполнения определенных операций, последовательность событий и другие аспекты функциональности приложения.
К примеру, если упадет ошибка (ERROR) или предупреждение (WARN) — о них мы подробнее поговорим дальше, — мы всегда могли сообщить разработчику и быстро нейтрализовать проблему. -
При релизе приложения и проведении регрессионного тестирования нужно проверять логи, часто в командах это делают разработчики.
-
При проверке взаимодействия с внешними системами, такими как базы данных, API или другие службы. Логи могут содержать информацию о запросах и ответах, передаваемых данным, кодах состояния и других деталях взаимодействия.
-
Для более точного определения причины бага и отладки ошибки. В логах может содержаться необходимая информация для идентификации бага, логи могут содержать полезную информацию о возникших исключениях, трассировке стека, сообщениях об ошибках или недостаточных данных, которые могут помочь воспроизвести и понять причину ошибки. А чем больше информации мы принесём разработчику, тем быстрее он починит баг.
-
Для оценки производительности приложения. Логи могут содержать информацию о времени выполнения определенных операций, использовании ресурсов (например, процессора, памяти) и других показателях производительности. Тестировщик может использовать эти данные для определения узких мест в приложении и предложения улучшений.
-
При работе с событиями системы. Вас могут попросить разработчики или вам самим потребуется более детальная информация для понимания работы системы.
Типы и уровни логов
Для начала разберёмся в категориях логов. Логи бывают разных типов и уровней детализации и критичности.
Уровни логирования
Уровни логирования определяют, насколько важная информация будет записываться в лог-файлы или выводиться при выполнении программы. На верхнем уровне находятся самые важные сообщения. На них стоит обращать внимание в первую очередь. Чем ниже уровень логирования, тем менее критичная, но более подробная информация содержится в логе.
Тестировщику они нужны для понимания того, есть ли ошибка / насколько она серьёзная и нужно ли заводить баг и отнести баг-репорт.
Уровни логирования бывают:
-
FATAL: является наивысшим уровнем критичности логов и указывает на самые критические ошибки и проблемы, которые могут привести к немедленному завершению программы или системы. Логи с уровнем FATAL обычно означают серьезные сбои, которые требуют немедленного вмешательства и исправления.
-
ERROR: этот уровень используется для записи ошибок и проблем, которые могут привести к некорректной работе приложения. Логи с уровнем ERROR указывают на проблемы, которые требуют вмешательства и исправления.
-
WARN: уровень WARN указывает на предупреждения и потенциальные проблемы, которые не являются критическими ошибками. Логи с уровнем WARN могут включать сообщения о неправильном использовании приложения, некорректных данных или других ситуациях, требующих внимания.
-
INFO: этот уровень предоставляет информацию о ходе работы приложения и важных событиях. Логи с уровнем INFO содержат сообщения, которые помогают отслеживать основные операции и состояние приложения. Например, они могут сообщать о начале и окончании определенных операций, загрузке ресурсов, отправке и получении запросов, изменении состояния приложения и других событиях, которые могут быть полезны для отслеживания хода выполнения программы.
-
DEBUG: содержат подробности о ходе выполнения приложения, значимые переменные и другие данные, которые могут быть полезными при обнаружении и исправлении ошибок.
-
TRACE: это наиболее подробный уровень логирования. Логи с уровнем TRACE содержат очень подробную информацию о состоянии приложения, включая значения переменных, шаги выполнения и другие детали. Они обычно используются во время отладки и разработки для более глубокого анализа приложения.
Уровни детализации, с которыми чаще всего сталкивается тестировщик
Тестировщик чаще всего работает с ошибками (ERROR, реже FATAL) и c предупреждениями (WARN). Но для получения информации иногда, бывает, обращается к информационным логам (INFO).
Уровень логирования может быть настроен в зависимости от потребностей разработчика или тестировщика.
Обычно в продакшене уровень детализации не устанавливается на самый высокий, чтобы не перегружать логи большим объёмом информации. В то время как во время разработки или отладки можно использовать такие уровни детализации, как DEBUG или TRACE, для более глубокого анализа и отслеживания проблем.
Визуально уровни логирования можно представить таким образом:

Какие виды логов бывают и зачем их знать тестировщику
Существует несколько различных видов логов, которые широко используются в программировании и системном администрировании.
Зачем их знать тестировщику? Чтобы понимать, к какому типу логов обратиться для проверки и дебага сервера или клиента, например при тестировании бэкенда, нам скорее всего понадобятся логи сервера.
Тестировщик чаще всего работает с логами приложения, логами сервера и системными логами. Разберёмся, что значит каждый из видов:
-
Логи приложений (Application logs). Это логи, создаваемые самим приложением в процессе его работы. Это может быть веб, десктоп и мобильное приложение. Они содержат информацию о выполнении операций, событиях, ошибочных ситуациях, запросах, ответах и других событиях, внутри приложения.
-
Логи сервера (Server logs). Это логи, генерируемые серверами и веб-серверами. Они содержат информацию о работе сервера, запросах, ошибочных ситуациях, подключениях и других событиях, происходящих на сервере. Логи сервера помогают администраторам серверов и разработчикам отслеживать состояние сервера, обнаруживать проблемы с производительностью, безопасностью и настраивать серверное окружение.
Логи сервера часто делятся на два типа:
-
Error logs (это информация об ошибках)
-
Access Logs (общая информация о запросах и ответах к серверу)
-
Системные логи (System logs): Это логи, записываемые операционной системой. Они содержат информацию о работе операционной системы, событиях, ошибках, состоянии системы, процессах, сетевых подключениях и других системных событиях.
Это основные виды логов, с которыми обычно приходится сталкиваться тестировщику. Также существуют и другие виды, но чаще всего в работе тестировщик к ним не обращается.

Что хранится в логах
Разные виды и логи разной детализации содержат в себе информацию разного вида. Информация в логах также зависит от того, что туда решил положить разработчик, также от решения разработки зависит, какие уровни детализации и критичности логов будут использованы.
Большинство разработчиков стараются придерживаться общих правил написания логов. К примеру, практически любой лог имеет:
-
системную информацию (время и дата события, ID события и другая служебная информация);
-
уровень лога;
-
текст сообщения (например, сообщения об ошибке);
-
контекст (дополнительная информация).
Разберем, как это выглядит, на сообщении об ошибке:

Дата и время: 2023-05-18 10:23:45 — указывает точное время, когда произошла ошибка.
Уровень лога: [ERROR] — указывает на уровень ошибки.
Контекст: [Server] — указывает на компонент или модуль системы, в котором произошла ошибка.
Сообщение об ошибке: Exception occurred while processing request — описание самой ошибки.
Стек вызовов: Последующие строки показывают стек вызовов и указывают на классы и методы, в которых произошла ошибка. В данном примере указывается, что ошибка возникла в методе handleRequest класса MyController (строка 32), затем в методе processRequest класса Server (строка 87) и так далее.

Заключение
Обладая знаниями о логировании системы, тестировщик может легко понять, что происходит во время его работы с приложением, быстро отследить ошибки и лучше описывать ошибки внутри своих репортов. Это серьёзно ускорит процесс исправления бага, а значит, и скорость разработки новых фич и релиза.
13.04.2021
Дата обновления: 02.03.2022
Если в работе сервера, компьютера или программного обеспечения возникла неизвестная ошибка, в первую очередь смотрят логи. Лог — текстовый файл с информацией о действиях программного обеспечения или пользователей, который хранится на компьютере или сервере. Это хронология событий и их источников, ошибок и причин, по которым они произошли. Читать и анализировать логи можно с помощью специального ПО.
Логирование: что это и где применяется
Логированием называют запись логов. Оно позволяет ответить на вопросы, что происходило, когда и при каких обстоятельствах. Без логов сложно понять, из-за чего появляется ошибка, если она возникает периодически и только при определенных условиях. Чтобы облегчить задачу администраторам и программистам, в лог записывается информация не только об ошибках, но и о причинах их возникновения.
После перехода в продакшен, работу приложения нужно постоянно мониторить, чтобы предотвращать и быстро реагировать на потенциальные ЧП. Анализ логов — один из базовых инструментов в работе ИТ-специалистов. Он помогает обнаружить источники многих проблем, выявить конфликты в конфигурационных файлах, отследить события, связанные с ИБ. А главное, благодаря логам найденные ошибки можно быстро исправить. Поэтому логирование так важно при отладке программ, поиске источников проблем с прикладным программным обеспечением и базами данных.
Логи должны записываться во время работы каждого ИТ-компонента.
Вот несколько типичных случаев, в которых применяются логи:
- Администратор ищет причины возникновения технических проблем, сбоев в устройства или операционной системы и недоступности сайта.
- Разработчик проводит дебаг, то есть ищет, локализует и устраняет ошибки.
- Seo-специалисты собирают статистику посещаемости, оценивают качество целевого трафика.
- Администратор интернет-магазина отслеживает историю взаимодействия с платежными системами и данные об изменениях в заказах.
Типы логов
Существуют разные уровни и разные подробности логирования. Когда ошибку сложно воспроизвести, используют максимально подробные логи; если это не требуется, собирают только ключевую информацию. Для работы с логами и поиском информации в огромных текстовых данных используют специализированные инструменты.
Для удобной работы с логами их делят на типы. Это помогает быстрее находить нужные и выбирать правильные инструменты для работы с ними. Например, выделяют:
- системные логи, то есть те, которые связаны с системными событиями;
- серверные логи, регистрирующие обращения к серверу и возникшие при этом ошибки;
- логи баз данных, фиксирующие запросы к базам данных;
- почтовые логи, относящиеся к входящим/исходящим письмам и отслеживающие ошибки, из-за которых письма не были доставлены;
- логи авторизации;
- логи аутентификации;
- логи приложений, установленных на этих операционных системах.
Также логи можно типизировать по степени их важности:
- Fatal/critical error — то, что нужно срочно исправить.
- Not critical error — ошибки, которые не влияют на пользователя.
- Warning — предупреждения, то, на что нужно обратить внимание.
- Initial information — информация о вызовах API сервиса, запросах в БД, вызовах других сервисов.
Где ITGLOBAL.COM использует логирование
Специалисты ITGLOBAL.COM настраивают автоматический сбор, хранение и обработку логов в облачном хранилище. Облако позволяет воспроизвести события на целевой системе даже при ее полном отказе.
Поясним на примере. Допустим, файловая система одной из виртуальных машин повредилась и все данные на сервере были уничтожены. Инженеры получают уведомление об этом инциденте от системы мониторинга и восстанавливают работоспособность сервера через бэкапы. После этого они анализируют логи, которые сохранились благодаря удаленной системе хранения. Они похожи на черный ящик самолета, так как с их помощью специалисты восстанавливают последовательность событий при инциденте, делают выводы и вырабатывают решения, которые предотвратят появление таких инцидентов в будущем.
Также инженеры ITGLOBAL.COM используют логи для анализа действий пользователей. Они в любой момент могут восстановить, кто и когда совершал определенные действия внутри системы. Для этого специалисты используют инструменты, которые автоматически контролируют базовые события, касающиеся безопасности. Например, если в субботу ночью появится учетная запись с правами суперпользователя, система сразу зарегистрирует это событие и пришлет уведомление. Инженеры уточнят легитимность новой записи, чтобы предотвратить попытку несанкционированного доступа.
Инструменты
Сбор, хранение и анализ логов выполняется с помощью специальных инструментов. Расскажем, какие из них используют специалисты ITGLOBAL.COM.
Elasticsearch, Logstash и Kibana
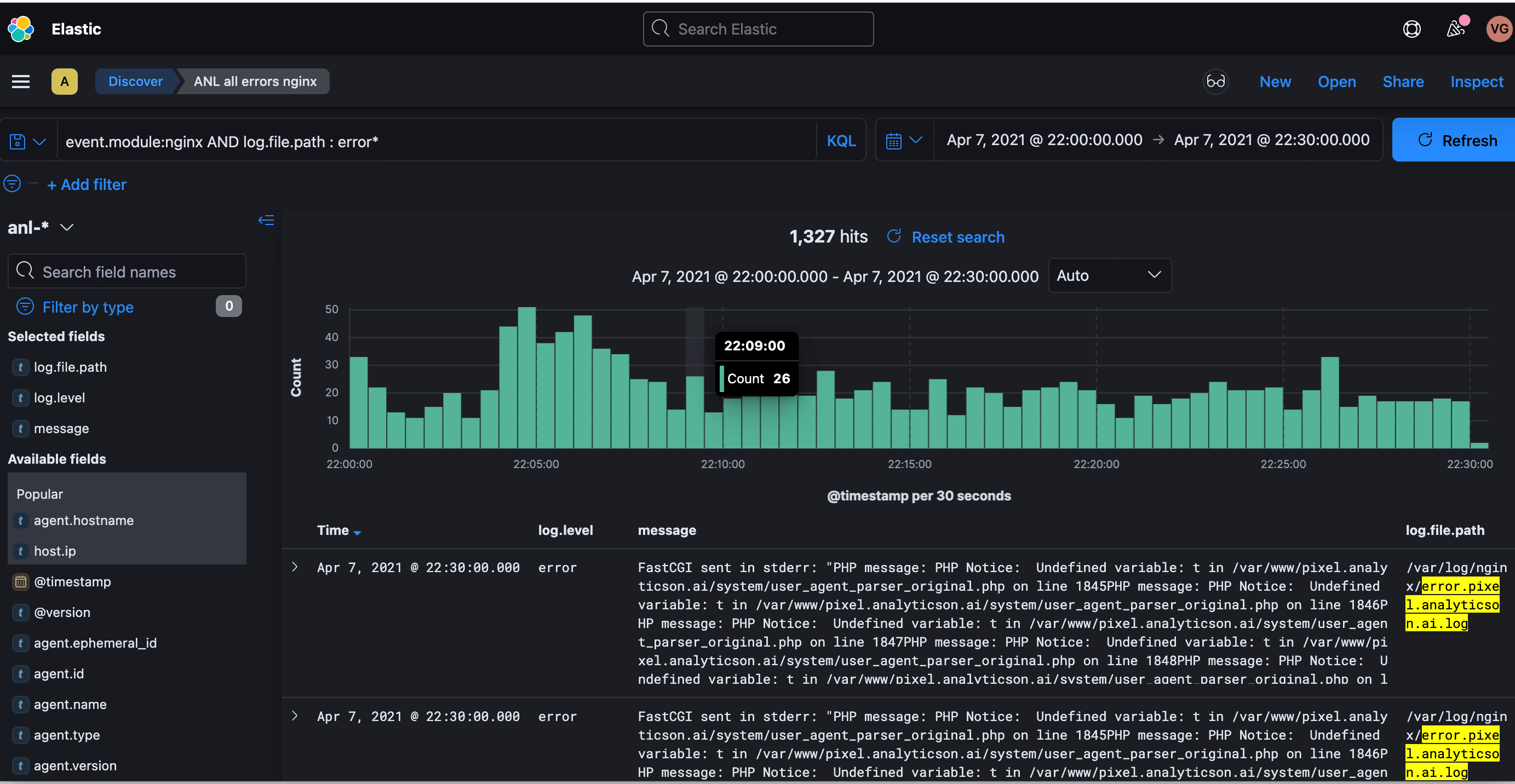
Логи всех информационных систем, подключенных к услуге Managed IT, хранятся в распределенном хранилище на базе решения ELK (Elasticsearch, Logstash и Kibana). Механизм сбора логов выглядит так: Logstash собирает логи и переносит их в хранилище, Elasticsearch помогает найти нужные строки в этих логах, а Kibana визуализирует их. Все три компонента разработаны на основе открытого кода, благодаря чему их можно модифицировать под потребности компании.
- Logstash — приложение для работы с большими объемами данных, собирает информацию из разных источников и переводит ее в удобный формат.
- Elasticsearch — система для поиска информации. Помогает быстро найти нужные строки в файлах хранения.
- Kibana — плагин визуализации данных и аналитики в Elasticsearch. Помогает обрабатывать информацию, находить в ней закономерности и слабые места.
Wazuh
Решение с открытым кодом для поиска логов, коррелирующих с моделями угроз информационной безопасности. С его помощью специалисты ITGLOBAL.COM мониторят целостность ИТ-систем и оперативно реагируют на инциденты.
Wazuh помогает:
- обнаружить скрытые процессы программ, которые используют уязвимости в ПО для обхода антивирусных систем;
- автоматически блокировать сетевую атаку, останавливать вредоносные процессы и файлы, зараженные вирусами.
Почему логирование нужно каждой компании
Логирование — еще один способ эффективно контролировать состояние инфраструктуры. В ITGLOBAL.COM оно входит в пакет услуг Managed IT. Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов. А главное, с помощью анализа логов можно предотвратить инциденты в будущем.
Компании, которые используют логирование в рамках услуги Managed IT, уменьшают общее количество инцидентов и получают принципиально другой уровень контроля над инфраструктурой.
Также сервис удобен для разработчиков, которые с помощью простых интерфейсов могут в режиме реального времени отслеживать работу своих приложений.
Логирование — это процесс формирования логов, сообщений программы разработчику о том, что происходит на том или ином этапе выполнения кода.
Организация полного и удобного логирования — важная составляющая разработки любой программы, поскольку это позволяет разработчикам отслеживать поведение своего кода и устранять неполадки.
В этой главе мы рассмотрим, какие способы выведения логов бывают в Dart и Flutter и как их эффективно использовать.
Первое использование
По умолчанию вы можете использовать функцию print, которая является встроенной функцией в Dart и выводит сообщения в консоль. Но хотя функция print может быть полезной для простых целей отладки, она плохо подходит для ситуаций, когда может быть нужно разделять логи на разные уровни, дополнять их понятным стек-трейсом и в целом удобно, а главное читаемо, форматировать.
Более того, логи, выводимые при помощи print, сохраняются в релизных сборках. Это не только неэффективно, но и небезопасно, поскольку порой в них может оказаться чувствительная информация, а стек-трейсы могут помочь злоумышленникам в реверс-инжиниринге программы.
Стек-трейс — цепочка вызовов функций и методов — позволяет постороннему получить представление, как именно устроена логика вашего приложения. Особенно если для методов используются человекочитаемые названия, что как раз наиболее распространено. Таким образом и осуществляется реверс-инжиниринг: получение данных об устройстве программы с помощью изучения в том числе логов.
Совсем отказываться от print не стоит — просто эта функция не даёт той тонкости настройки, которая делает отладку приложения более эффективной и безопасной. Какие инструменты вам в этом помогут — расскажем ниже.
Логирование по уровням
Наиболее частым примером организации логирования является разделение логов по уровням:
- verbose — малозначительные логи, условно «техническая» информация, требующаяся для глубокого погружения в то, что происходило до интересующего вас при дебаге момента;
- debug — чуть более важный уровень «технических» логов, часто выводящийся в консоль по умолчанию, в отличие от verbose;
- info — информационные сообщения, отражающие наступление каких-то существенных событий, но исключительно в рамках ожидаемого поведения;
- warning — что-то уже пошло не так, однако всё ещё не портит пользовательский опыт;
- error — произошла ошибка, которая сломала сценарий взаимодействия пользователя с программой;
- critical/fatal — критическая ошибка, разрушающая пользовательский опыт, например крэш.
В Flutter вы можете использовать функцию log из библиотеки dart:developer для логирования таких гранулярных сообщений. Эта функция принимает три параметра: сообщение, уровень критичности и имя. Имя используется для указания имени приложения или компонента, который выполняет логирование. Уровень критичности определяет тип сообщения, которое логируется.
Вот пример использования функции log во Flutter:
import 'dart:developer';
void main() {
log('This is a verbose message', name: 'MyApp', level: 200);
log('This is a debug message', name: 'MyApp', level: 300);
log('This is an info message', name: 'MyApp', level: 400);
log('This is a warning message', name: 'MyApp', level: 500);
log('This is an error message', name: 'MyApp', level: 1000);
log('This is a critical/fatal message', name: 'MyApp', level: 2000);
}
Здесь мы используем функцию log для логирования сообщений с различными уровнями критичности. Мы указываем название приложения в качестве параметра name.
При этом, если мы разрабатываем многомодульное приложение, разумным будет для каждого модуля указывать уникальный name, чтобы впоследствии легче отделять одни логи от других.
Чтобы увидеть логи в консоли Flutter, вы можете запустить ваше приложение в режиме debug и просмотреть вывод в консоли или открыть вкладку “Debug Console” в редакторе кода.
Вот так будет выглядеть вывод консоли:
V/MyApp(1234): This is a verbose message
D/MyApp(1234): This is a debug message
I/MyApp(1234): This is an info message
W/MyApp(1234): This is a warning message
E/MyApp(1234): This is an error message
F/MyApp(1234): This is a critical/fatal message
Есть ещё один способ вывода в консоль. Возможно, вы уже где-то видели функцию debugPrint. Она является обёрткой над функцией print и существует для того, чтобы обойти специфичную для Android проблему обрезания логов системой, которое может происходить в случаях, если сообщения слишком длинные. Важно помнить, что, несмотря на название, сообщения, выводимые debugPrint, также печатаются в релизных сборках. Таким образом, использовать debugPrint стоит аналогично обычному print и актуально оно, если выводимые сообщения содержат большой объём текста.
Логирование в вашем приложении
Хотя использование print/debugPrint и более продвинутого log позволяет успешно сообщать о происходящем в программе в консоль, это далеко не самые удобные инструменты.
print и debugPrint совсем примитивны. Над log вам потребуется написать собственную обёртку, чтобы не забывать, какое именно значение — 200, 300, 400 или 500 — соответствует искомому уровню критичности.
Что насчёт кастомизации стиля выводимых сообщений? А насчёт настройки отдельных хранилищ для сообщений на случай, если вы захотите дать пользователю возможность поделиться логом при отправке сообщения разработчикам или вовсе программно отправлять всю историю логов за последние X секунд при возникновении ошибки? Всё это невозможно из коробки реализовать при использовании log. Что же делать?
Например, использовать сторонние библиотеки. Это популярный подход к организации логирования. Мы рекомендуем две:
- logger — самая популярная библиотека;
- logging — чуть более простая, но от разработчиков Dart.
logger позволит вам выводить удобно отформатированные сообщения, включать в них стек-трейс, управлять многими другими параметрами итогового сообщения.
Пример организации логов с пакетом logger:
import 'package:logger/logger.dart';
void main() {
final logger = Logger();
logger.v('Verbose message');
logger.d('Debug message');
logger.i("Info message");
logger.w("Warning message");
logger.e("Error message");
logger.wtf("What a terrible failure message");
//...
}
Выводимые сообщения при этом будут выглядеть следующим образом:

И простой фильтр сообщений в консоли позволит быстро находить именно нужные вам логи.
Что следует помнить при организации системы логирования:
- Стоит сразу начинать использовать продвинутые инструменты логирования, а не откладывать на потом — это позволит сэкономить кучу времени, а также нервов при дебаге, который неизбежен в работе над любым приложением.
- Внимательно подходите к выбору уровня критичности сообщения — это позволит быстро ориентироваться в потоке сообщений и фильтровать только необходимые, игнорируя ненужные.
- Не логируйте персональные данные пользователей. Это неэтично и зачастую противозаконно.
- В случае работы с многомодульным проектом не пренебрегайте тегами или настройкой дерева логгеров, чтобы легко понимать, какой именно модуль залогировал что-то в консоль.
Обработка ошибок
Обработка ошибок — важный аспект любого приложения, и Flutter предоставляет несколько механизмов для работы с исключениями.
Блок try/catch
Один из распространённых способов обработки ошибок — использование try/catch блоков. Этот подход удобен, когда вы хотите перехватывать ошибки и обрабатывать их локально.
try {
// Код который может выбросить Exception (исключение)
} catch (error, stackTrace) {
// Обработка исключения
print('An error occurred: $error, stack trace: $stackTrace');
}
В этом примере код внутри try-блока может вызвать ошибку. Если возникает ошибка, запускается выполнение обработчика внутри блока catch. В нём мы можем работать как с ошибкой — первая объявленная переменная в скобках после ключевого слова catch, — так и со стек-трейсом возникшего исключения.
Объект ошибки обычно полезен для написания логики, связанной с обработкой конкретных типов ошибок. Ошибки наследуются от базового класса Error, и для доступа к свойствам специфичной ошибки, которую вы ожидаете в конкретном месте, можно использовать чуть более тонкий синтаксис. Рассмотрим на примере с DioException из популярной библиотеки для работы с сетевыми запросами Dio:
try {
final response = await dioClient.get(Constants.myEndpoint);
return response;
} on DioException catch (error, stackTrace) {
if (error.response?.statusCode == 401 {
print('User is not authorized. Full error: $error, stack trace: $stackTrace');
return MyCustomError.notAuthorized();
}
rethrow; // пробрасываем ошибку наружу
}
Стек-трейс позволяет отследить цепочку вызовов, что полезно, например, при логировании/репортинге исключений, происходящих в рантайме в пользовательских сессиях, в используемый вами сервис для сборки аналитических событий — к примеру, AppMetrica или Firebase.
Отдельно хочется рассмотреть работу try/catch в случае с асинхронными блоками кода:
Future<void> myAsyncMethod() async {
try {
await myThrowingMethod().then((res) => print(res));
} catch (error, stackTrace) {
print('An error occurred: $error, stack trace: $stackTrace');
}
}
Future<void> myThrowingMethod() {
throw Exception('oops!');
}
Ключевое слово await в вызове myThrowingMethod всё меняет: теперь catch остаётся в том же скоупе, что и вызов выбрасывающего ошибку метода myThrowingMethod, а вы увидите ожидаемый вызов print с деталями ошибки.
Если вы хотите обработать ошибку, которая выбрасывается асинхронным методом, и при этом не использовать try/catch, то следует использовать API класса Future: метод catchError. Рассмотрим пример с Dio:
dioClient.get(Constants.myEndpoint)
.then((response) {
return response;
})
.catchError((error) {
if (error.response?.statusCode == 401 {
print('User is not authorized. Full error: $error, stack trace: $stackTrace');
return MyCustomError.notAuthorized();
}
rethrow; // пробрасываем ошибку наружу
});
Ошибки, относящиеся к фреймворку Flutter
Для ошибок, которые возникают на уровне фреймворка Flutter, вы можете объявить глобальный обработчик:
void main() {
FlutterError.onError = (details) {
FlutterError.presentError(details); // отображение ошибки средствами фреймворка
// if (someLogic) someAction();
}
runApp(const MyApp());
}
Таким образом в одном месте можно обрабатывать все возникающие на уровне фреймворка ошибки.
Также вы можете столкнуться с ошибками на этапе построения виджетов — в build-phase. По умолчанию в debug-сессиях они вызывают показ красного экрана с логом и стак-трейсом ошибки, в release-сессиях просто выкрашивают «сломавшийся» виджет в серый цвет — совершенно непонятную и разочаровывающую пользователя картинку.
Для глобальной обработки подобных ошибок, а также для показа более «осмысленных» экранов, сообщающих о том, что что-то пошло не так, вы можете использовать MaterialApp.builder:
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
builder: (context, widget) {
// кастомный виджет, отображающий ошибку
Widget error = const Text('Произошла ошибка! :(');
if (widget is Scaffold || widget is Navigator) {
error = Scaffold(body: Center(child: error));
}
ErrorWidget.builder = (errorDetails) => error;
return widget!;
},
);
}
}
Ошибки, не отлавливаемые Flutter
Важно разделять ошибки, которые происходят на уровне Flutter, и ошибки, которые происходят на уровне Dart. Рассмотрим два примера.
@override
Widget build() {
return Column(
children: [
ListView(),
],
);
}
В примере выше ошибка происходит на уровне Flutter при отрисовке интерфейса: вьюпорт по вертикали имеет неограниченную высоту, что приводит к сбою отрисовки.
Future<void> main() async {
runApp(const MyApp());
await Future.delayed(Duration(seconds: 3), () {
throw Exception('delayed exception');
});
}
А в этом примере “delayed exception” является обыкновенным Exception на уровне асинхронного Dart-кода. Подобные ошибки не отлавливаются фреймворком Flutter, но могут обрабатываться try/catch либо централизованно через интерфейс PlatformDispatcher:
Future<void> main() async {
PlatformDispatcher.instance.onError = (error, st) {
print('Error, caught by PlatformDispatcher: $error');
return true;
};
runApp(const MyApp());
await Future.delayed(Duration(seconds: 3), () {
throw Exception('delayed exception');
});
}
Такие ошибки можно обрабатывать кастомно, отлавливать и отправлять в аналитику, на собственный бэкенд или куда угодно ещё по необходимости.
Важно помнить 2 вещи:
-
Обращения к синглтону через
PlatformDispatcher.instanceследует избегать, поскольку такой подход не позволяет подменять экземплярPlatformDispatcherфейками или моками в тестах. Вместо этого стоит использовать экземпляр, поставляемый синглтономWidgetsBinding, склеивающим слой UI и движка Flutter:WidgetsBinding.instance.platformDispatcher.Использовать синглтон
PlatformDispatcher.instanceстоит, только если обращение кPlatformDispatcherнеобходимо до вызоваrunAppилиWidgetsFlutterBinding.ensureInitialized(). Таким образом, пример выше будет правильно переписать, например, следующим образом:Future<void> main() async { WidgetsFlutterBinding.ensureInitialized(); WidgetsBinding.instance.platformDispatcher.onError = ((e, st) { print('FE: ${e.toString()}'); return true; } ); runApp(const MyApp()); await Future.delayed(Duration(seconds: 3), () { throw Exception('delayed exception'); }); } -
Колбэк, передаваемый в
onError, должен возвращатьtrue, если ошибка была обработана. В противном случае нужно возвращатьfalse, тогда сработает механизм-фоллбэк — например, вывод в ошибки в консоль. Конкретная механика фоллбэка определяется платформенным эмбеддером и может разниться от платформы к платформе.Кроме того, перехватывать ошибки можно в рамках конкретной
Zone— окружения, в контексте которого происходит выполнение вашего кода. По умолчанию весь код, вызывающийся из main.dart, выполняется в дефолтной Zone.root, однако мы можем обернуть его в кастомную зону. Тема зон заслуживает отдельного рассмотрения, поэтому пока что ограничимся конкретным примером с обработкой ошибок:Future<void> main() async { runZonedGuarded( () { runApp(const MyApp()); Future.delayed(Duration(seconds: 3), () { throw Exception('zone delayed exception'); }); }, (err, st) => print('Zone Catched: $err'), ); await Future.delayed(Duration(seconds: 3), () { throw Exception('main delayed exception'); }); }
Запустив приложение с подобным main.dart, мы увидим, что только Exception('zone delayed exception') будет перехвачен обработчиком onError, который мы реализовали в runZonedGuarded — методе, позволяющем выполнять Dart-код в отдельной зоне, в который мы передали наш runApp и Future.delayed с выбросом исключения.
При этом Exception('main delayed exception') выбрасывается как необработанное исключение, поскольку код, в котором оно происходит, выполняется за пределами зоны runZonedGuarded.
Таким образом, при помощи переопределения параметра onError в runZonedGuarded и при использовании других конструкторов для создания зоны и переопределении handleUncaughtError в ZoneSpecification мы можем реализовывать кастомную логику обработки ошибок в зонах.
При этом стоит помнить, что подобные способы обработки ошибок применимы далеко не всегда: хоть они и универсальны, но не получится удобно и понятно описать точечную логику для конкретных случаев, когда может произойти ошибка.
Из-за этого гораздо чаще вы увидите блоки try/catch и другие in-place обработчики ошибок вместо глобальных. И, скорее всего, решите сами их использовать.
Источники
- https://blog.logrocket.com/flutter-logging-best-practices/
- https://docs.flutter.dev/testing/errors

Из этой статьи вы получите полное представление о логировании в службах приложений. Она предназначена в первую очередь для начинающих разработчиков ПО и выпускников вузов.
Логирование играет важную роль в получении информации о поведении системы, помощи в отладке и эффективном решении проблем.
Метрики и логи
Метрики и логи обеспечивают наглядность состояния системы.
Метрики предоставляют агрегированные числовые данные, которые могут быть использованы для статистического анализа, анализа тенденций и мониторинга производительности. Они предлагают обзор более высокого уровня и могут быть полезны для создания визуализаций, дашбордов и автоматизированных отчетов.
Некоторые из распространенных примеров типов метрик, которые могут быть собраны, — это время отклика и количество ошибок.
Однако в некоторых сценариях одними метриками не обойтись.
Метрики помогают обнаружить неполадки в системе. Но, используя только их, трудно (хотя и не невозможно, если метрики достаточно точны) выяснить, что именно произошло.
В каких случаях одни метрики не помогут?
- Используя только метрики, нельзя отследить, что именно произошло с каждым отдельным запросом.
- Если возникает лишь незначительная аномалия (только для нескольких запросов), нам, как и системе мониторинга, будет сложно обнаружить ее.
Именно здесь на помощь приходят логи.
Логи обеспечивают прямой подход к пониманию поведения системы. Они позволяют эффективно отлаживать, отслеживать и воспроизводить проблемы.
Что логировать?
Чтобы логи были полезными для отладки, важно уделять особое внимание их содержанию. Логи должны давать четкое представление о том, что происходит внутри приложения или системы. Ниже приведены некоторые рекомендации по эффективному ведению логов.
- Избегайте как чрезмерного, так и недостаточного логирования. И то, и другое может обернуться проблемами. Избыточное логирование приводит к превышению расходов на производительность, увеличению затрат на сериализацию и требований к инфраструктуре. А недостаточное логирование может предоставить мало информации для эффективной диагностики проблем.
- Связывайте логи с идентификаторами запросов. Каждая запись лога должна быть связана с уникальным идентификатором запроса, таким как идентификатор транзакции, идентификатор заказа, идентификатор счета, идентификатор устройства или идентификатор трассировки (UUID). Такая взаимосвязь позволяет проследить путь конкретного запроса через систему.
- Придерживайтесь согласованного формата лога. Это особенно важно при наличии в организации различных приложений или служб. Такая согласованность облегчает анализ и корреляцию логов между различными компонентами.
- Стремитесь к ясности содержания лога. Записи должны быть понятны как вам, так и потребителям вашего лога. Он должен содержать информацию, которая поможет выявить и решить проблемы. Избегайте записи любой чувствительной информации, чтобы обеспечить конфиденциальность и безопасность данных.
Примеры плохих логов:
log.info("fetching from db");
log.error("error getting from db");
s.SharedHolder.Logger.Debugf("Processing search request");
Обратите особое внимание на вышеуказанные пункты, поскольку с логированием связано множество затрат:
- стоимость ввода-вывода;
- стоимость сериализации;
- стоимость Infra для обработки и сохранения лога (сохранение, а также запрос).
Стоимость ввода-вывода: накладные расходы на производительность, связанные с чтением с внешних устройств хранения, таких как жесткие диски и твердотельные накопители (SSD), и записью на них.
Каждая запись лога требует отдельной операции записи на устройство хранения. Частые операции ввода-вывода на диск могут привести к узким местам в производительности, особенно при работе с логами большого объема.
Для снижения затрат на ввод-вывод используются различные стратегии. Вот несколько примеров.
- Буферизация: накопление записей лога в памяти и запись их на диске партиями с сокращением количества отдельных операций ввода-вывода.
- Сжатие: перед записью на диск данные лога сжимаются, чтобы уменьшить объем данных, подлежащих логированию.
- Асинхронная запись: произведение операций логирования асинхронно позволяет приложению продолжать выполнение, не дожидаясь завершения операций логирования.
Стоимость сериализации — это накладные расходы, связанные с преобразованием структур данных в формат, пригодный для хранения и передачи. При логировании сериализация обычно требуется для преобразования сложных типов данных (таких как объекты и структуры) в формат, пригодный для логирования, например текстовый или двоичный.
Стоимость сериализации может зависеть от таких факторов, как сложность структуры данных и выбранный механизм сериализации.
Некоторые широко используемые форматы сериализации включают JSON, XML и Protocol Buffers. Каждый формат сериализации имеет свои компромиссы с точки зрения удобочитаемости, размера и накладных расходов на обработку.
Чтобы минимизировать затраты на сериализацию, воспользуйтесь следующими советами.
- Оптимизируйте структуры данных. Разрабатывайте структуры данных для эффективной сериализации. Избегайте ненужной вложенности и сложных иерархий объектов, которые требуют длительной обработки при сериализации.
- Выбирайте эффективные библиотеки сериализации. Различные библиотеки сериализации могут иметь разный уровень производительности. Используйте библиотеки и фреймворки, которые обеспечивают быструю и эффективную сериализацию.
- Используйте бинарные форматы. Бинарные форматы сериализации часто приводят к меньшему объему полезной нагрузки и более быстрой сериализации/десериализации по сравнению с текстовыми форматами, такими как JSON и XML.
Уровни логов
Уровни логов помогают добавить контекст ко всем логам и предоставляют возможность классифицировать и определять приоритеты сообщений лога на основе их серьезности или важности.
- Гранулированный контроль.
- Производственный мониторинг.
ERROR (ОШИБКА): указывает на критическую ошибку, которая нарушает работу системы и требует ручного вмешательства. Подобные ошибки чреваты неожиданными ситуациями, с которыми нельзя справиться.
WARN (ПРЕДУПРЕЖДЕНИЕ): указывает на состояние, которое может подлежать автокоррекции или требует внимания, но не является критическим. Означает неожиданные сценарии, предполагающие тщательную обработку.
INFO (ИНФОРМИРОВАНИЕ): предоставляет информацию о потоке системы. Как правило, не включается в процесс разработки, если того не требуют цели аудита.
DEBUG (ОТЛАДКА): включает подробные логи, необходимые для отладки проблем в производственной среде. Предполагает выборочную работу по устранению неполадок.
Если вы сомневаетесь в выборе уровня лога, выбирайте уровень с более высоким приоритетом.

Уровни логов: контрольные вопросы
Каждый вопрос имеет 4 возможных ответа: DEBUG, INFO, WARN и ERROR.
- Приложение запускается и инициализирует компоненты. Какой уровень лога вы бы использовали для индикации успешной инициализации каждого компонента?
- Во время выполнения функции возникло неожиданное, но устранимое состояние. Какой уровень лога следует использовать для получения информации об этом состоянии?
- Возникла ошибка, которая не позволяет приложению работать правильно. Какой уровень лога вы бы использовали, чтобы указать на эту критическую ошибку?
- Возникла исключительная ситуация, требующая немедленного внимания. Какой уровень лога вы бы использовали для указания этой серьезной ошибки?
- Приложение столкнулось с неожиданным вводом, но смогло восстановиться без какого-либо ущерба для функциональности. Какой уровень лога вы бы использовали для предоставления информации об этом инциденте?
- Был получен запрос на аутентификацию с неверными учетными данными. Какой уровень лога вы бы использовали, чтобы указать на этот сбой аутентификации?
- Не удалось установить соединение с базой данных. Какой уровень лога следует использовать, чтобы указать на этот сбой подключения?
- Пользователь выполнил действие, которое не рекомендуется, но не обязательно приводит к ошибке. Какой уровень лога следует использовать, чтобы предоставить информацию об этом действии?
- Во время выполнения критической функции было поймано неожиданное исключение. Какой уровень лога следует использовать для указания этого исключительного условия?
- Запланированное задание или работа успешно завершена. Какой уровень лога вы бы использовали для указания успешного завершения?
Ответы в конце статьи.
ELK-стек
ELK-стек (ELK — Elasticsearch, Logstash, Kibana — применение, установка, настройка) — это популярное решение для ведения логов и их анализа.
Filebeat
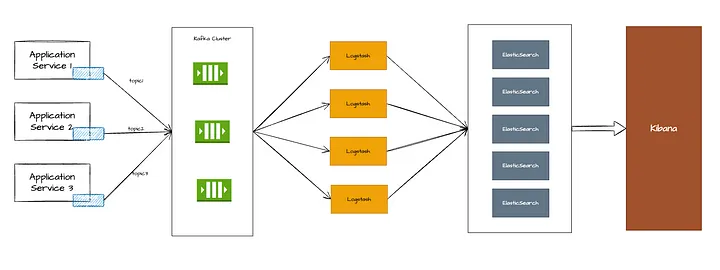
Filebeat — это легкий отправитель логов с открытым исходным кодом. Устанавливаемый на каждом сервисе агент filebeat следит за изменениями файлов в папке. В случае какого-либо изменения файла он отправляет сообщение в Kafka.
Необходимо настроить вводы filebeat для мониторинга нужной папки (папок) лога, а также тему, в которую нужно отправлять лог.
Рекомендуется использовать разные темы Kafka для каждого сервиса, чтобы справиться с разной скоростью генерации логов и предотвратить недостаток загрузки.
- Скорость генерации логов различна для каждого сервиса. Поэтому с помощью гранулирования по темам можно определить количество разделов, коэффициент репликации и т.д.
- Если по какой-либо причине один сервис начнет генерировать огромное количество логов, другие сервисы могут испытывать дефицит загрузки.
Пример конфигурации Filebeat:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/ubuntu/projects/**/logs/*.log
fields_under_root: false
tail_files: true
exclude_files: ['^*newrelic']
multiline.type: pattern
multiline.pattern: '(?i)^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:|^com\.|^net\.|^org\.|^io\.|^id\.'
multiline.negate: false
multiline.match: afteroutput.kafka:
hosts: [""]
topic: "logs-%{[fields.servicename]}"processors:
- script:
lang: javascript
source: >
function process(ev) {
var field;
field = ev.Get("log.file.path");
var serviceName = (field.split("/")[4] + "").toLowerCase();
ev.Put("fields.servicename", serviceName);
return ev;
};
Kafka
Kafka — это распределенная потоковая платформа, которая выступает в качестве брокера сообщений между Filebeat и Logstash.
Logstash
Logstash отвечает за прием, обработку и обогащение логов.
Logstash снабжен различными плагинами, которые позволяют ему передавать обработанные логи. Обычно в качестве части ELK выходной информацией является поисковой индекс Elastic, откуда ее может прочитать Kibana.
У нас есть несколько logstash-экземпляров, которые входят в одну группу потребителей, и каждый logstash-экземпляр прослушивает все темы Kafka. Это делается для того, чтобы все сообщения равномерно распределялись между потребителями и ни один logstash не оставался без дела.
- Все логи парсятся в logstash, чтобы узнать, можно ли получить какие-либо полезные поля, такие как уровень лога, threadId, traceId, className и т. д.
- Logstash использует фильтр Grok, чтобы определить, соответствует ли лог шаблону, и отфильтровать поля.
У Logstash есть 3 фазы.
- Ввод. Здесь настраиваем вводы для logstash. В нашем случае вводом является Kafka, поэтому нам нужно указать серверы загрузки Kafka и темы.
- Фильтр. На этом этапе выполняем операцию grok match (использование фильтра для определения, соответствует ли лог шаблону), добавляем/удаляем поля.
- Вывод. Здесь настраиваем вывод logstash, которым в нашем случае является Elasticsearch.
input {
kafka{
codec => json
bootstrap_servers => ""
topics_pattern => ".*"
decorate_events => true
consumer_threads => 128
}
}
filter {
grok {
match => [ "message", "\[%{LOGLEVEL:level}\] %{TIMESTAMP_ISO8601:logTime} \[%{DATA:threadId}\] %{JAVACLASS:className} "]
}
mutate {
add_field => {
"topic" => "%{[@metadata][kafka][topic]}"
}
add_field => {
"logpath" => "%{[log][file][path]}"
}
remove_field => ["input", "agent", "ecs", "log", "event", "uuid","tags"]
}uuid {
target => "uuid"
}
}
output {
elasticsearch {
hosts => []
index => "%{[topic]}-%{+YYYY.MM.dd}"
pool_max_per_route => 100
}
}
Имя индекса для Elasticsearch: topicName — YYYY.MM.dd.
Elasticsearch
Elasticsearch — это распределенный поисковый и аналитический механизм, который хранит и индексирует логи.
Kibana
Kibana — это пользовательский веб-интерфейс для визуализации и изучения логов. Рекомендации по конфигурации Kibana:
- Подключите Kibana к Elasticsearch, чтобы обеспечить визуализацию логов и выполнение запросов.
- Создавайте пользовательские дашборды и визуализации, чтобы получить представление о поведении системы.
- Настройте шаблоны индексов, чтобы определить, как Kibana интерпретирует поля данных лога.
Заключение
Ведение логов является неотъемлемой частью служб приложений и позволяет получить ценные сведения о поведении системы. Метрики и логи дополняют друг друга, а хорошо продуманная стратегия ведения логов обеспечивает эффективную отладку, решение проблем и мониторинг системы.
Следуя лучшим практикам и используя инструменты анализа логов, такие как ELK Stack, разработчики и операторы могут получить глубокое представление о своих системах и создать более надежные и производительные приложения.
Ответы на контрольные вопросы
INFO, WARNING, ERROR, ERROR, WARNING, WARNING, ERROR, WARNING, ERROR, INFO.
Читайте также:
- Профессиональный подход к ведению логов
- Всё, что вы хотели знать об отладке в IntelliJ IDEA
- Автоматизированные тесты - качественно и непременно эффективно!
Читайте нас в Telegram, VK и Дзен
Перевод статьи Aman Arora: Logging: The ‘Root’ of All Debugging Adventures