Среднеквадратическая ошибка (RMSE) и среднеквадратическая логарифмическая ошибка (RMSLE) — это методы, позволяющие определить разницу между значениями, предсказанными вашей моделью машинного обучения, и фактическими значениями.
Чтобы понять эти концепции и их различия, важно знать, что означает среднеквадратическая ошибка (MSE). MSE включает в себя как дисперсию, так и смещение предиктора. RMSE рассчитывается как квадратный корень из среднего квадрата разницы между прогнозируемыми и фактическими значениями. Он используется для оценки производительности регрессионной модели. Это мера того, насколько хорошо модель способна предсказывать целевую переменную, и она чувствительна к масштабу целевой переменной.
Примечание. Квадратный корень из дисперсии является стандартным отклонением.
RMSLE аналогичен RMSE, но рассчитывается с использованием логарифмической разницы между прогнозируемыми и фактическими значениями. Он используется для оценки производительности модели, когда целевая переменная искажена или имеет большой диапазон значений. Он менее чувствителен к масштабу целевой переменной по сравнению с RMSE. Итак, в основном, какие изменения вызывает дисперсия, которую вы измеряете? Я считаю, что RMSLE обычно используется, когда вы не хотите наказывать огромные различия в прогнозируемых и фактических значениях, когда и прогнозируемые, и истинные значения являются огромными числами.
- Если и предсказанные, и фактические значения малы: RMSE и RMSLE одинаковы.
- Если предсказанное или фактическое значение велико: RMSE > RMSLE
- Если и предсказанные, и фактические значения велики: RMSE > RMSLE (RMSLE становится практически незначительным)
Вот пример кода для вычисления RMSE и RMSLE в Python:
import numpy as np
def rmse(predictions, targets):
"""Calculate the root mean squared error between predictions and targets"""
return np.sqrt(np.mean((predictions - targets) ** 2))
def rmsle(predictions, targets):
"""Calculate the root mean squared logarithmic error between predictions and targets"""
return np.sqrt(np.mean((np.log(predictions + 1) - np.log(targets + 1)) ** 2))
Чтобы использовать эти функции, вы можете передать прогнозируемые значения и фактические значения в качестве аргументов. Например:
predictions = [10, 20, 30, 40]
targets = [9, 19, 29, 39]
rmse_error = rmse(predictions, targets)
print(f'RMSE: {rmse_error:.4f}')
rmsle_error = rmsle(predictions, targets)
print(f'RMSLE: {rmsle_error:.4f}')
Это выведет следующее:
RMSE: 1.4142 RMSLE: 0.0177
Вот пример кода для расчета RMSE и RMSLE в Python, а также визуализации результатов и сравнения производительности двух разных моделей:
import numpy as np
import matplotlib.pyplot as plt
def rmse(predictions, targets):
"""Calculate the root mean squared error between predictions and targets"""
return np.sqrt(np.mean((predictions - targets) ** 2))
def rmsle(predictions, targets):
"""Calculate the root mean squared logarithmic error between predictions and targets"""
return np.sqrt(np.mean((np.log(predictions + 1) - np.log(targets + 1)) ** 2))
# Generate some example data
predictions_1 = np.random.normal(100, 10, 1000)
targets = np.random.normal(100, 10, 1000)
predictions_2 = np.random.normal(100, 5, 1000)
# Calculate the RMSE and RMSLE for both models
rmse_1 = rmse(predictions_1, targets)
rmse_2 = rmse(predictions_2, targets)
rmsle_1 = rmsle(predictions_1, targets)
rmsle_2 = rmsle(predictions_2, targets)
# Visualize the results
x = np.arange(2)
errors = [rmse_1, rmse_2]
plt.bar(x, errors)
plt.xticks(x, ['Model 1', 'Model 2'])
plt.ylabel('RMSE')
plt.title('RMSE Comparison')
plt.show()
errors = [rmsle_1, rmsle_2]
plt.bar(x, errors)
plt.xticks(x, ['Model 1', 'Model 2'])
plt.ylabel('RMSLE')
plt.title('RMSLE Comparison')
plt.show()
Этот код создаст две гистограммы, одну для RMSE и одну для RMSLE, сравнивая производительность двух моделей. Более низкое значение по оси Y указывает на лучшую модель.


Другой пример регрессионных моделей:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# Generate some fake data for the plot
true = np.random.normal(loc=10, scale=2, size=100)
pred1 = true + np.random.normal(loc=0, scale=1, size=100)
pred2 = true + np.random.normal(loc=0, scale=3, size=100)
# Calculate the RMSE and RMSLE for each prediction
rmse1 = np.sqrt(np.mean((pred1 - true) ** 2))
rmsle1 = np.sqrt(np.mean((np.log(pred1 + 1) - np.log(true + 1)) ** 2))
rmse2 = np.sqrt(np.mean((pred2 - true) ** 2))
rmsle2 = np.sqrt(np.mean((np.log(pred2 + 1) - np.log(true + 1)) ** 2))
# Create a dataframe with the true values and the two predictions
df = pd.DataFrame({'true': true, 'pred1': pred1, 'pred2': pred2})
# Use seaborn to create a scatterplot with regression lines for each prediction
sns.lmplot(x='true', y='pred1', data=df, scatter_kws={'alpha': 0.5})
# Add text labels with the RMSE and RMSLE values for each prediction
plt.text(x=0, y=12, s='RMSE: {:.2f}\nRMSLE: {:.2f}'.format(rmse1, rmsle1), fontsize=12)
# Use seaborn to create a scatterplot with regression lines for each prediction
sns.lmplot(x='true', y='pred2', data=df, scatter_kws={'alpha': 0.5})
# Add text labels with the RMSE and RMSLE values for each prediction
plt.text(x=0, y=10, s='RMSE: {:.2f}\nRMSLE: {:.2f}'.format(rmse2, rmsle2), fontsize=12)
plt.show()


Этот код сгенерировал диаграмму рассеяния с двумя линиями регрессии, по одной для каждого прогноза. Значения RMSE и RMSLE для каждого прогноза отображаются в виде текстовых меток на графике.
Вы можете дополнительно настроить график, используя различные параметры, доступные в seaborn и matplotlib, такие как изменение цветов, маркеров и форматирование элементов графика.
Если вы найдете это полезным, не стесняйтесь поделиться им. Вы также можете оставить комментарий или связаться со мной по LinkedIn, если у вас есть какие-либо сомнения или вопросы.
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной \widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-\widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=\overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — \overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=\frac{1}{n}\sum\limits_{i=1}^{n}(y_{i}-\widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, \widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}(y_{i}-\widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
\frac{\partial RMSE}{\partial \widehat{y}_{i}}=\frac{1}{2\sqrt{MSE}}\frac{\partial MSE}{\partial \widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=\frac{100}{n}\sum\limits_{i=1}^{n}\left ( \frac{y_{i}-\widehat{y}_{i}}{y_{i}} \right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=\frac{1}{n}\sum\limits_{i=1}^{n}\left | y_{i}-\widehat{y}_{i} \right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=\frac{100}{n}\sum\limits_{i=1}^{n}\frac{\left | y_{i}-\widehat{y_{i}} \right |}{\left | y_{i} \right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=\frac{100}{n}\sum\limits_{i=1}^{n}\frac{\left | y_{i}-\widehat{y_{i}} \right |}{(\left | y_{i} \right |+\left | \widehat{y}_{i} \right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и \widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и \widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=\frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=\frac{1}{n}\sum\limits_{i=1}^{n}\frac{\left | y_{i}-\widehat{y}_{i}\right |}{\left | y_{i} \right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}(log(\widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-\frac{\sum\limits_{i=1}^{n}(\widehat{y}_{i}-y_{i})^{2}}{\sum\limits_{i=1}^{n}({\overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-\frac{\sum\limits_{i=1}^{n}(\widehat{y}_{i}-y_{i})^{2}/(n-k)}{\sum\limits_{i=1}^{n}({\overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Перевод
Ссылка на автора
В этой статье я буду обсуждать полезность каждой метрики регрессии в зависимости от цели и проблемы, которую мы пытаемся решить. Часть 1 представлены первые четыре метрики, как показано ниже, в то время как остальные представлены в этой статье. Вспомним сначала основные показатели регрессии:
- Средняя квадратическая ошибка (MSE)
- Среднеквадратическая ошибка (RMSE)
- Средняя абсолютная ошибка (MAE)
- R в квадрате (R²)
- Скорректированный R квадрат (R²)
- Средняя квадратная процентная ошибка (MSPE)
- Средняя абсолютная ошибка в процентах (MAPE)
- Среднеквадратичная логарифмическая ошибка (RMSLE)

Скорректированный R квадрат (R²)
R² показывает, насколько хорошо термины (точки данных) соответствуют кривой или линии. Скорректированный R2 также показывает, насколько хорошо термины соответствуют кривой или линии, но корректирует количество терминов в модели. Если вы добавляете больше и большебесполезный переменные для модели, скорректированный R в квадрате будет уменьшаться. Если вы добавите большеполезнымПеременные, скорректированные R в квадрате будут увеличиваться. Скорректированная R² всегда будет меньше или равна R².

где n — общее количество наблюдений, а k — количество независимых регрессоров, то есть количество переменных в вашей модели, исключая константу.
Основное различие между Скорректированным R² и R²
И R², и скорректированный R² дают вам представление о том, сколько точек данных попадает в линию уравнение регрессии, Однако R² предполагает, что каждая переменная объясняетизменение в зависимая переменная,Скорректированное R² говорит вам процент вариации, объясняемый только независимые переменные это на самом деле влияет на зависимую переменную.
В действительности, скорректированное R² накажет вас за добавление независимых переменных (K в уравнении), которые не соответствуют модели. Зачем? В регрессионный анализ может быть заманчиво добавить больше данных к данным, как вы о них думаете. Некоторые из этих переменных будут значимыми, но вы не можете быть уверены, что значение случайно. Скорректированное R² компенсирует это тем, что штрафует вас за эти дополнительные переменные.
Проблемы сr²которые исправлены с корректировкойr²
- R² увеличивается с каждым предиктором, добавленным в модель. Поскольку R² всегда увеличивается и никогда не уменьшается, может показаться, что он лучше подходит для большего количества терминов, которые вы добавляете в модель. Это может вводить в заблуждение.
- Аналогичным образом, если в вашей модели слишком много терминов и слишком много многочленов высокого порядка, вы можете столкнуться с проблемой чрезмерного соответствия данных. Когда вы перебираете данные, неверно высокое значение R² может привести к неверным прогнозам.
Все метрики, которые мы исследовали до этого момента, предполагают, что каждый прогноз предоставляет одинаково точную информацию об изменении ошибки. MSPE и MAPE не следуют этому предположению.
Среднеквадратичная ошибка в процентах (MSPE)
Давайте подумаем о следующей проблеме. Наша цель — предсказать, сколько ноутбуков продадут два магазина?
- Магазин 1: прогнозируемый 9, проданный 10, MSE = 1
- Магазин 2: предсказано 999, продано 1000, MSE = 1
Или даже,
- Магазин 1: прогнозируемый 9, проданный 10, MSE = 1
- Магазин 2: прогнозируемый 900, проданный 1000, MSE = 10000
MSE является одинаковым для обоих прогнозов магазинов, и, следовательно, согласно этим метрикам, эти отклонения от одной ошибки неразличимы. Это в основном потому, что MSE работает с абсолютными квадратами ошибок, в то время как относительная ошибка может быть более важной для нас.
Относительная ошибка предпочтения может быть выражена с помощью среднеквадратичной ошибки. Для каждого объекта абсолютная ошибка делится на целевое значение, давая относительную ошибку.

Итак, MSPE можно рассматривать как взвешенную версию MSE. Вес его образца обратно пропорционален целевому квадрату. Это означает, что стоимость, которую мы платим за фиксированную абсолютную ошибку, зависит от целевого значения, и когда цель увеличивается, мы платим меньше.
Поскольку MSPE считается взвешенной версией MSEоптимальные постоянные прогнозы для MSPEоказываетсясредневзвешенное значение целевых значений.
Средняя абсолютная ошибка в процентах (MAPE)
Предпочтение относительной ошибки также может быть выражено с помощью средней абсолютной ошибки процента, MAPE. Для каждого объекта абсолютная ошибка делится на целевое значение, что дает относительную ошибку. MAPE также можно рассматривать как взвешенную версию MAE.

Для MAPE вес ее выборки обратно пропорционален ее цели. Но так же, как и в MSPE, стоимость, которую мы платим за фиксированную абсолютную ошибку, зависит от целевого значения. И когда цель увеличивается, мы платим меньше.
Поскольку MAPE рассматривается как взвешенная версия MAEоптимальные постоянные прогнозы для MAPEоказываетсявзвешенная медиана целевых значений.
Обратите внимание, что если бы выброс имел очень и очень маленькое значение, MAPE был бы очень смещен к нему, так как этот выброс будет иметь наибольший вес

Среднеквадратичная логарифмическая ошибка (RMSLE)
Это просто RMSE, рассчитанная в логарифмическом масштабе. Фактически, чтобы вычислить его, мы берем логарифм наших прогнозов и целевых значений и вычисляем среднеквадратичное отклонение между ними. Цели обычно неотрицательны, но могут быть равны 0, а логарифм 0 не определен. Вот почему константа обычно добавляется к прогнозам и целям перед применением логарифмической операции. Эта константа также может быть выбрана, чтобы отличаться от одной в зависимости от проблемы.

Таким образом, этот показатель обычно используется в той же ситуации, что и MSPE и MAPE, поскольку он также несет в себе относительные ошибки в большей степени, чем абсолютные.

Заметкаасимметрия кривых ошибок. С точки зрения RMSLE, всегда лучше прогнозировать больше, чем та же сумма, меньше цели. Таким образом, мы заключаем, что RMSLE штрафует за заниженную оценку, превышающую завышенную оценку.
RMSLE может быть рассчитан без рут-операции, но более широко используется версия с правами root.
Теперь перейдем к вопросу о лучшей константе. (Вспомните связь между RMSLE и RMSE). Сначала мы находим лучшую константу для RMSE в лог-пространстве, которая будет средневзвешенным значением в лог-пространстве. И после этого нам нужно вернуться из лог-пространства к обычному с обратным преобразованием.
пример

Замечания:
- Оптимальная константа для RMSLE оказывается равной 9,1, что выше, чем константы для MAPE и MSPE.
- MSE весьма склонен к огромной ценности нашего набора данных, в то время как MAE гораздо менее предвзят.
- MSPE и MAPE смещены в сторону меньших целей, потому что они назначают больший вес объекту с маленькими целями.
- RMSLE часто считается лучшим показателем, чем MAPE, так как он менее смещен в сторону небольших целей, но работает с относительными ошибками.
Взять домой сообщение
Я настоятельно рекомендую вам подождать некоторое время, прежде чем начинать проект, и подумать о соответствующей метрике, это определенно вам очень поможет. Если вам понравилась эта статья, вы также можете прочитать Часть 1,

Спасибо за чтение, и я с нетерпением жду, чтобы услышать ваши вопросы 
Оставайтесь с нами и счастливого машинного обучения.
P.SЕсли вы хотите больше узнать о мире машинного обучения, вы также можете подписаться на меня в Instagram, напишите мне напрямую или найди меня на linkedin, Я хотел бы услышать от вас.
Средний квадрат логарифмической ошибки регрессионных потерь.
Подробнее читайте в Руководстве пользователя .
- Parameters
-
-
y_truearray-like of shape (n_samples,) or (n_samples, n_outputs) -
Основные (правильные)целевые значения.
-
y_predarray-like of shape (n_samples,) or (n_samples, n_outputs) -
Оценочные значения.
-
sample_weightarray-like of shape (n_samples,), default=None -
Sample weights.
-
multioutput{‘raw_values’, ‘uniform_average’} or array-like of shape (n_outputs,), default=’uniform_average’ -
Определяет агрегацию нескольких выходных значений.Массивное значение определяет веса,используемые для усреднения ошибок.
- ‘raw_values’ :
-
Возвращает полный набор ошибок,когда входной сигнал имеет многоканальный формат.
- ‘uniform_average’ :
-
Ошибки всех выходов усредняются равномерным весом.
-
- Returns
-
-
lossfloat or ndarray of floats -
Отрицательное значение с плавающей точкой (лучшее значение 0,0),или массив значений с плавающей точкой,по одному для каждой отдельной цели.
-
Examples
>>> from sklearn.metrics import mean_squared_log_error >>> y_true = [3, 5, 2.5, 7] >>> y_pred = [2.5, 5, 4, 8] >>> mean_squared_log_error(y_true, y_pred) 0.039... >>> y_true = [[0.5, 1], [1, 2], [7, 6]] >>> y_pred = [[0.5, 2], [1, 2.5], [8, 8]] >>> mean_squared_log_error(y_true, y_pred) 0.044... >>> mean_squared_log_error(y_true, y_pred, multioutput='raw_values') array([0.00462428, 0.08377444]) >>> mean_squared_log_error(y_true, y_pred, multioutput=[0.3, 0.7]) 0.060...
import matplotlib.pyplot as plt %matplotlib inline %config InlineBackend.figure_format = 'svg'
Существуют три вида лжи: ложь, наглая ложь и статистика.
— Затасканный афоризм
Если в споре не хватает аргументов, ссылайтесь на статистику — и 9 из 10 поверят.
— Народная мудрость
Как использовать данные для обмана

Обман №1: Ошибки выборки
Составление выборки — это очень важно. Выборка должна быть репрезентативна относительно генеральной совокупности.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
Ошибки выборки бывают систематичекие и случайные.
Случайные ошибки выборки
Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности. Случайную ошибку можно измерить методами математической статистики, если при формировании выборочной совокупности соблюдался принцип случайности, обеспечивающийся строго определенными правилами, которые составляют метод формирования выборочной совокупности, и устранить.
Систематические ошибки выборки
Систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что а) их невозможно оценить; б) они не уменьшается с увеличением выборки.
В результате систематической ошибки выборка легко может оказаться смещенной, так как при отборе каждой единицы допускается ошибка, всегда направленная в одну и ту же сторону. Особенность ошибки смещения состоит в том, что, являясь постоянной частью ошибки репрезентативности, она увеличивается с увеличением объема выборки.
Факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).


Самый известный случай предвзятой выборки — опрос Literary Digest в 1936 году. По его результатам на выборах президента США должен был победить Альфред Лэндон. Показательно то, что для исследования проводимого Литерари Дайджест было отобрано более 2 млн. респондентов. На самих же выборах победил Теодор Рузвельт, победу которого предсказывали Гэлап и Роупер на основе опроса всего 4000 человек.
В чём была ошибка Literary Digest?

Другой пример предвзятой выборки — армейская лотерея в США в конце 60-х годов. В США в 1969 году каждому из дней года в случайном порядке с помощью лототрона были присвоены номера от 1 до 366. Призыву в первую очередь подлежали молодые люди 1945-1950 годов рождения, родившиеся в дни, которым выпали наименьшие номера. Почему-то, вышло так, что раньше всех отправлялись служить родившиеся в ноябре-декабре.
Почему?
Ещё один пример предвзятой выборки — опрос выпускников университетов об их зарплатах. Почему эти данные оказывались завышенными?
Обман №2: Выбираем среднее «правильно»
— Какова средняя температура больных в энской больнице?
— 36,6 °С, включая морг!
Чиновники едят мясо, я — капусту. В среднем мы едим голубцы.
Меры средний тенденций
- Арифметическое среднее
- Среднее геометрическое
- Среднее гармоническое
- Винсоризованное среднее
- Усечённое среднее
- Медиана
- Мода
и др.
Обман №3: умалчиваем о нюансах
Нюанс №1 — слишком маленькая, а значит, статистически некорректная выборка, повторяемая много раз.
- Пример — испытать зубную пасту на десятке человек и зафиксировать улучшение, если оно есть, умолчать, если его нет. В какой-то момент удача улыбнётся.
- Пример: испытание противополиомиелитной вакцины. В некой местности были вакцинированы 450 детей, а 680 детей остались непривитыми (в качестве контрольной группы). Вскоре после этого в той местности случилась эпидемия полиомиелита. Ни у одного из вакцинированных детей не было выявлено полиомиелита, как не было его выявлено и у детей из контрольной группы. Что проглядели экспериментаторы (или просто не поняли), когда планировали свое испытание, так это редкость паралитического полиомиелита. В обычном случае в группе такой численности можно ожидать всего двух случаев заражения, так что испытание с самого начала было совершенно бессмысленным. Потребовалась бы группа численностью раз в пятнадцать, а то и в двадцать пять больше, чтобы получить сколько-нибудь значимый результат.
Нюанс №2, который часто предпочитают не указывать — размах исследуемого признака или
диапазон отклонения от указанного среднего. Не доверяйте особо среднестатистическим показателям, графикам и тенденциям, когда вам предъявляют их без тех важных цифр, что могли бы прояснить смысл.
- Пример: многое в американском жилом строительстве планировалось таким образом, чтобы соответствовать размеру среднестатистической семьи из 3,6 человека. В переводе на язык реальности это означает семью из трех или четырех человек, что, в свою очередь, предполагает необходимость в доме двух спален. А семья такого размера, какой бы «среднестатистической» она ни считалась, в Америке находится в меньшинстве.
- Пример: в книге «Нормы развития Гезелла» говорится, что ввозрасте стольких-то месяцев ребенку уже полагается сидеть. А поскольку примерно половина детей к указанному возрасту все еще не научилась сидеть, делает несчастными многих имногих родителей. Разумеется, говоря языком математики, их страдания уравновешиваются радостью другой половины родителей, обнаруживших, что у них вполне «развитые» дети. Зато большой вред могут причинить старания несчастных родителей подстегнуть развитие своего ребенка, чтобы он соответствовал норме и больше не считался недоразвитым.
Обман №4: много шума практически из ничего
Допустим, мы, выяснили, что у Питера коэффициент умственного развития (IQ) составил 98, а у Линды – 101, при этом в тесте на IQ коэффициент 100 принят за средний, то есть нормальный уровень. Значит ли это, что Линда у нас одареннее Питера, ее умственное развитие выше среднего, ау Питера – ниже среднего?
Конечно нет. Почему?
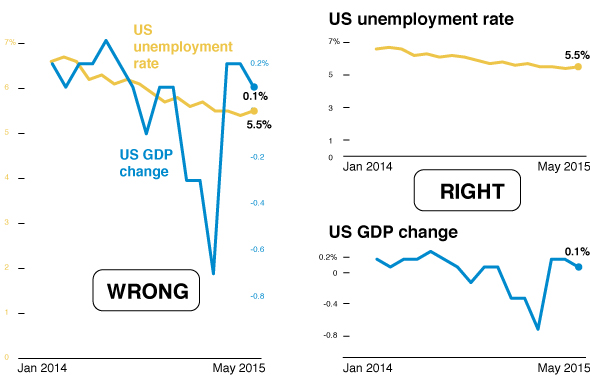
Обман №5: строим выгодные для себя графики
- A Quick Guide to Spotting Graphics That Lie
Начало координат не в 0
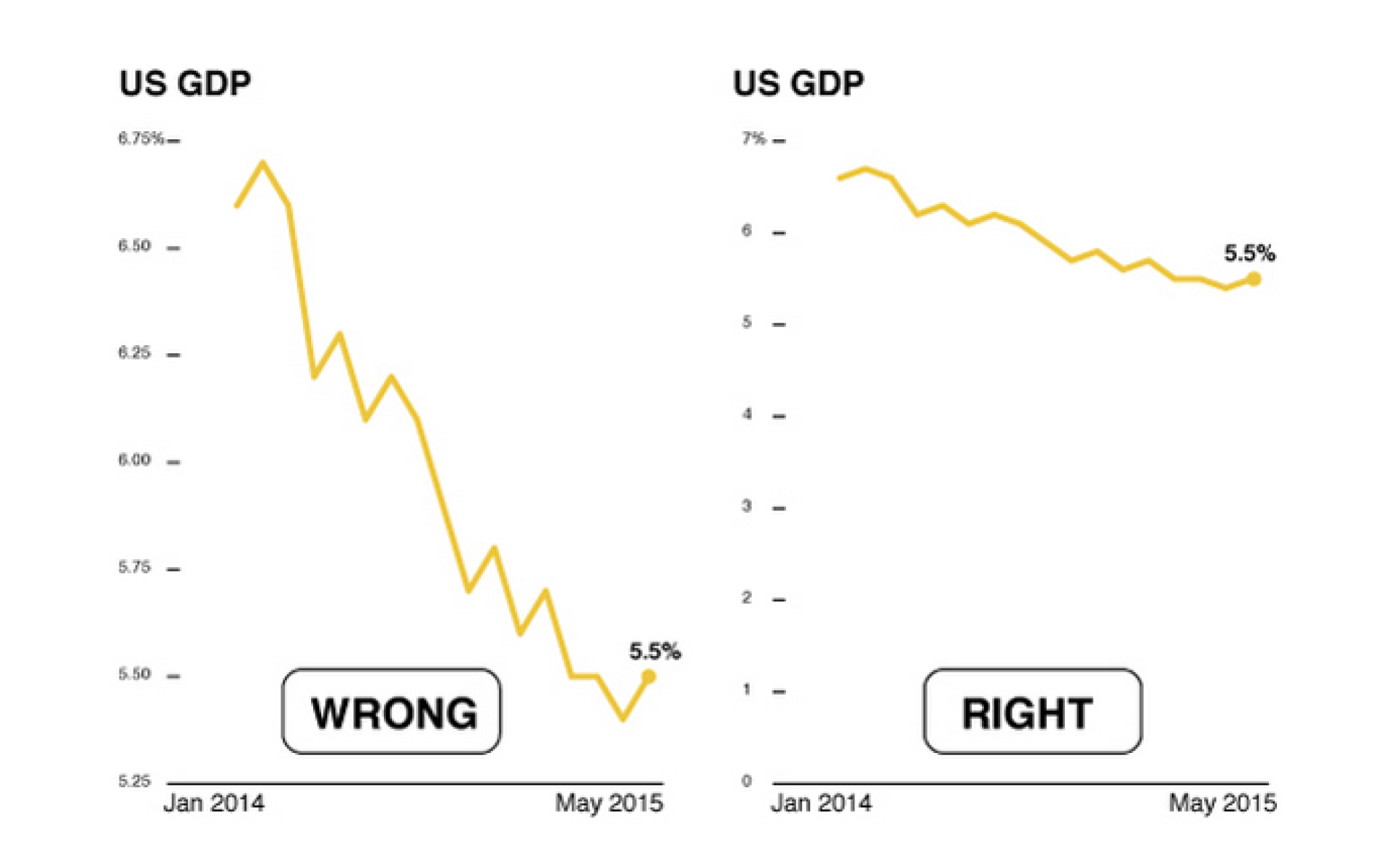
Разные шкалы на одном графике
Корреляция ≠ причинность

http://www.tylervigen.com/spurious-correlations
Не нормируем на размер популяции
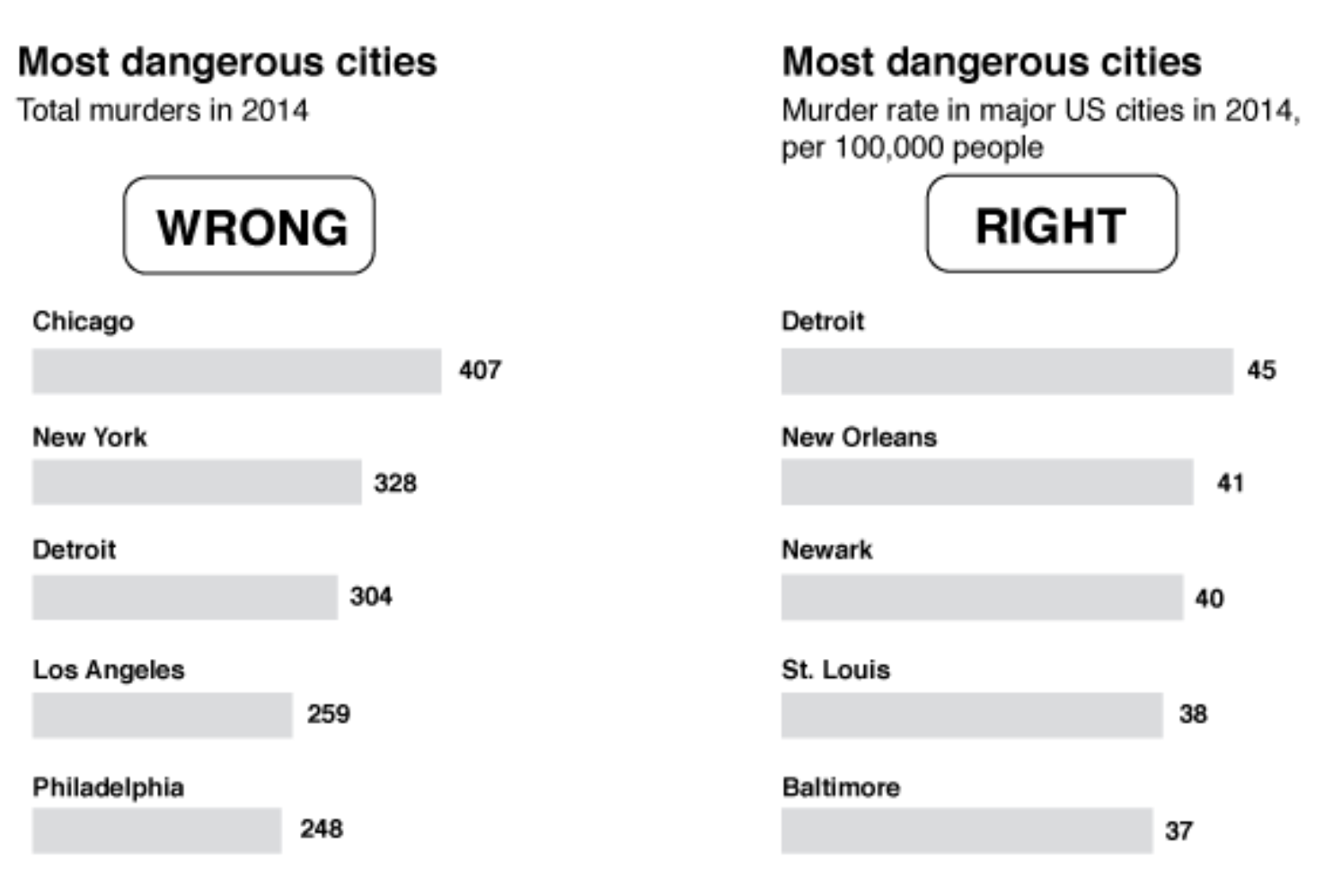
Излишне увлекаемся перспективой
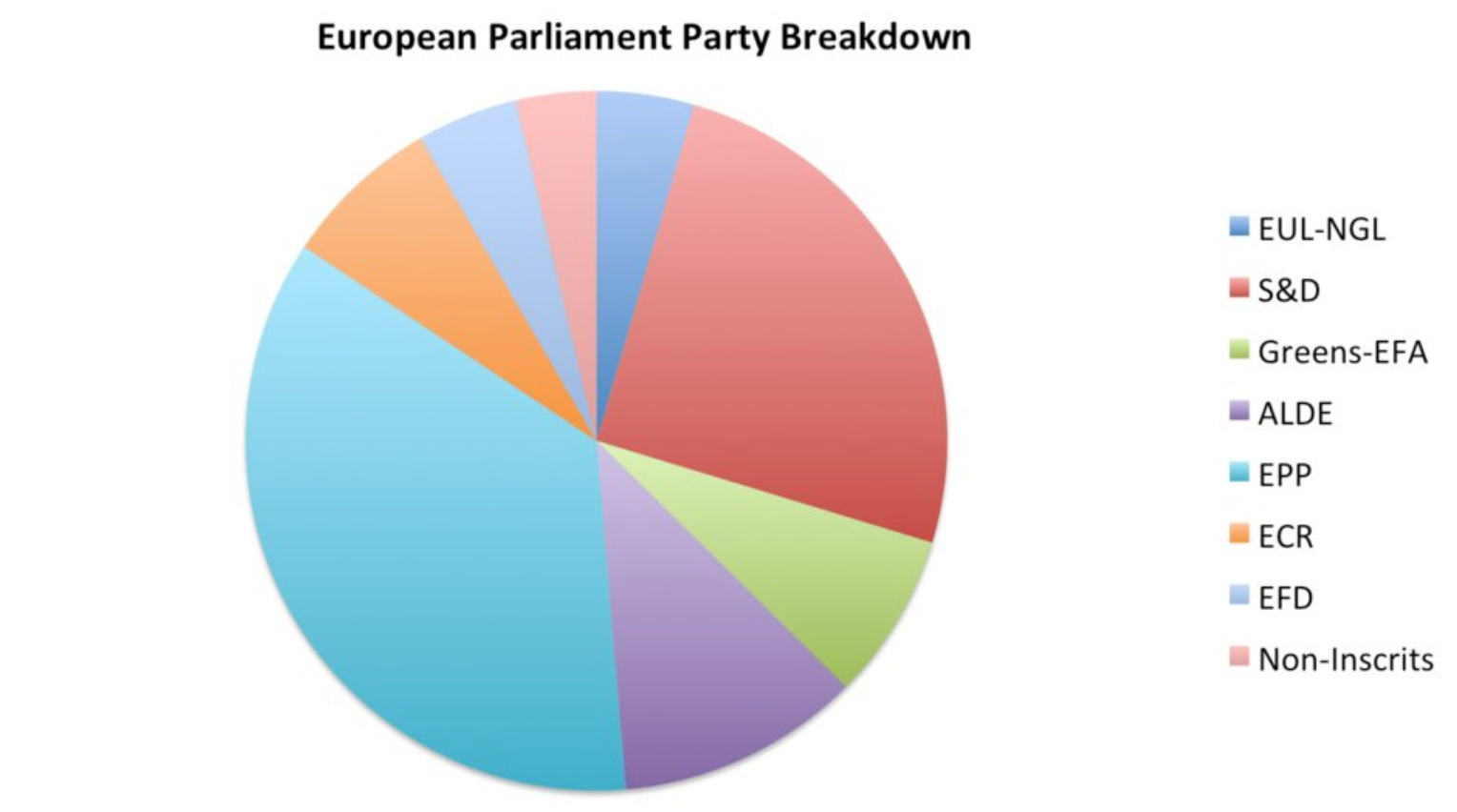
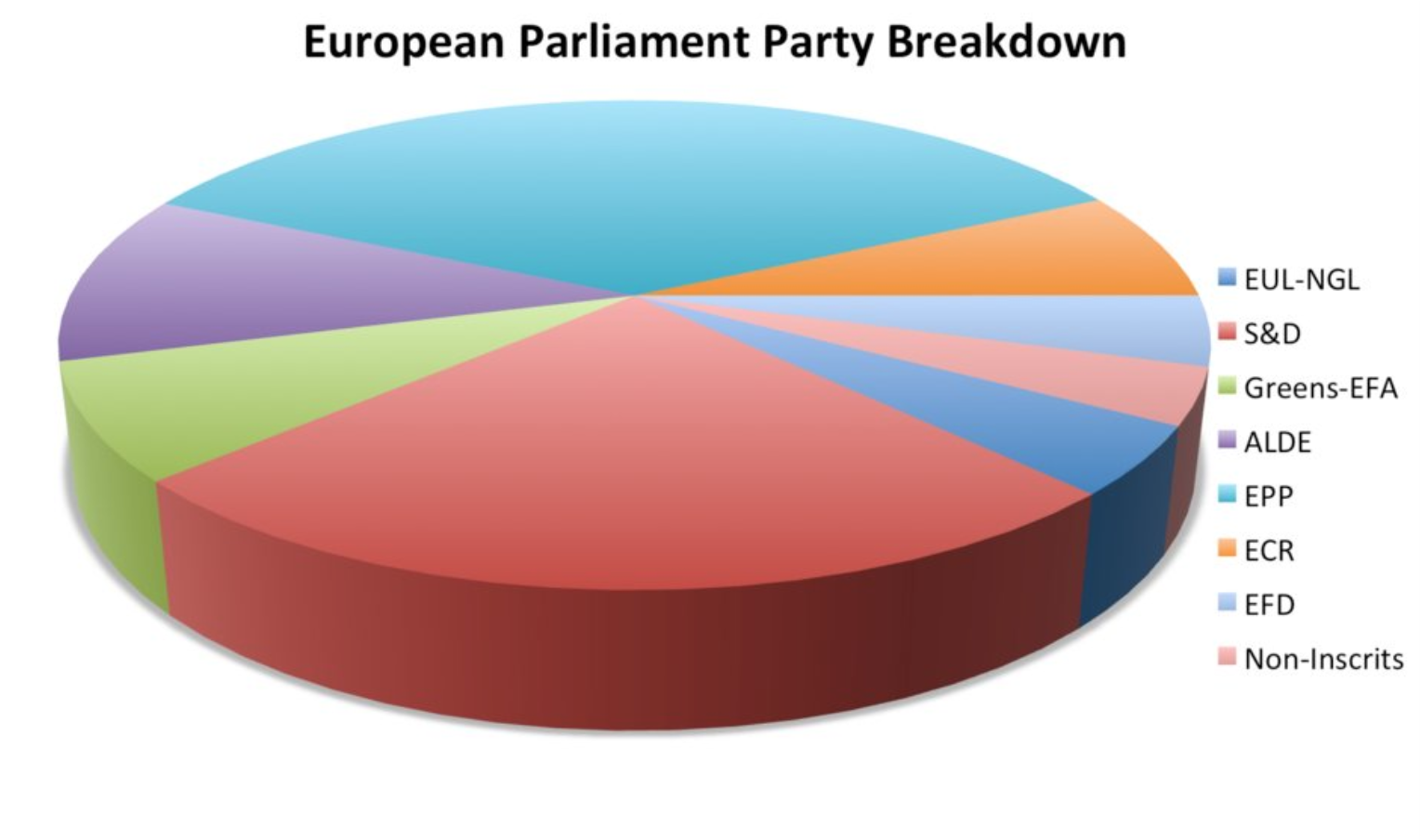
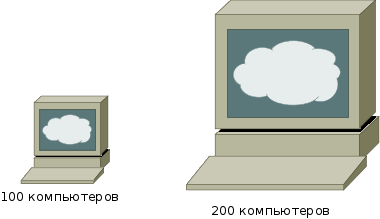
В инфографике забываем, что площадь фигуры = произведению её сторон
- False Visualizations: Sizing Circles in Infographics
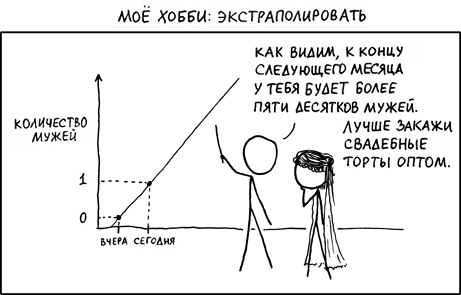
Увлекаемся экстраполяцией
Обман № 6: Используем псевдообоснованные данные
Любую количественную величину несложно выразить множеством разнообразных способов. Вы можете, например, представить один и тот же факт, называя его доходностью продаж в 1%, рентабельностью инвестиций в 15%, десятимиллионной прибылью, ростом прибылей на 40% (по
сравнению со средним показателем за 1935–1939 гг.) или сокращением на 60% по сравнению с предыдущим годом. Суть в том, чтобы выбрать формулировку, которая лучше всего подходит для текущих надобностей. А после остается уповать на то, что лишь единицы, читая эту информацию, сообразят, насколько она искажает реальное положение дел.
Уровень смертности в военно-морском флоте США в период Испано-Американской войны 1898 г. составлял девять человек на тысячу. За тот же период уровень смертности среди гражданского населения Нью-Йорка достигал шестнадцати человек на тысячу. Позже эти цифры использовали вербовщики, чтобы показать: служить в ВМС безопаснее, чем находиться за его пределами.
Допустим, что сами эти цифры точны. Что тут не так?
До и после занятия спортом. Что тут не так?
Данные против интуиции
Феномен Уилла Роджерса
Парадокс Симпсона
Парадокс инспекции
Почему при ожидании автобуса, который приходит в среднем каждые 10 минут, ваше среднее время ожидания будет около 10 минут (во всяком случае, точно больше 5)?
Парадокс дружбы
Парадокс Берксона
Метрики качества
При помощи метрик качества мы можем оценивать, насколько хорошо наши модели справляются с поставленной задачей. Метрики качества могут совпадать с функцией потерь, а могут и нет.
Функция потерь — функция, которая в теории статистических решений характеризует потери при неправильном принятии решений на основе наблюдаемых данных. Если решается задача оценки параметра сигнала на фоне помех, то функция потерь является мерой расхождения между истинным значением оцениваемого параметра и оценкой параметра.
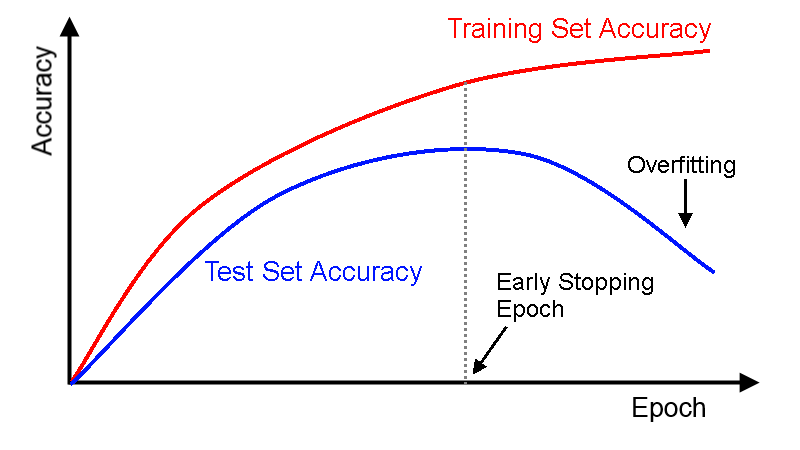
Early stopping
Accuracy не можнт выступать в качестве фукнции потерь, но может использоваться как метрика оценки качества. Показания метрики качества и функции потерь могут значительно расходиться. Для максимизации метрики качества придумана техника ранней остановки.
Метрики качества для регрессионных моделей
Итак, у нас имеет модель y^=f(x)=w0+∑i=1nwixi\hat{y}= f(x)=w_0+\sum_{i=1}^n w_i x_i

- Функции ошибок в задачах регрессии
- Regression metrics review
Среднеквадратическая ошибка (MSE).
Для вычисления среднеквадратической ошибки все отдельные остатки регрессии возводятся в квадрат, суммируются, сумма делится на общее число ошибок:
1N∑i=1N(yi−y^i)2\frac 1N\sum_{i=1}^N(y_i-\hat{y}_i)^2
y_true = np.array([4, 6, 9, 30]) def mse(y_true, y_pred): step1 = ((y_true - y_pred) ** 2) if isinstance(step1, (int, float)): return step1 else: return sum(step1) / len(y_true) print(mse(y_true, y_true-1), mse(y_true, y_true-5))
plt.figure(figsize=(10, 5)) for n in y_true.tolist(): x = [] y = [] for i in np.arange(-5, 5, .1).tolist(): x.append(n+i) y.append(mse(n, n + i)) plt.plot(x, y, label=f"true y = {n}") plt.legend() plt.title(label="Графики ошибок для каждого значения") plt.ylabel("MSE") plt.xlabel("y true")
Преимущества функции:
- дифференцируемость
Продифференцируйте функцию и найдите константу, которая обеспечит наилучшие предсказания.
plt.figure(figsize=(10, 5)) for n in y_true.tolist(): x = [] y = [] for i in np.arange(-15, 15, .1).tolist(): x.append(n+i) y.append(mse(n, n + i)) plt.plot(x, y, label=f"true y = {n}") x_const = [] y_const = [] for i in np.arange(-3, 35, .1).tolist(): x_const.append(i) y_const.append(mse(i, y_true.mean())) plt.plot(x_const, y_const, label=f"График производной при константном значении") plt.legend() plt.title(label="Графики ошибок для каждого значения") plt.ylabel("MSE") plt.xlabel("y true")
Особенности:
- использование квадратичной функции делает особый акцент на объектах с сильной ошибкой, поэтому метод обучения будет в первую очередь стараться уменьшить отклонения на таких объектах. Если же эти объекты являются выбросами (то есть значение целевой переменной на них либо ошибочно, либо относится к другому распределению и должно быть проигнорировано), то такая расстановка акцентов приведёт к плохому качеству модели.
Недостатки:
- функция не очень хорошо интерпретируется, поскольку не сохраняет единицы измерения. Если мы предсказываем цену в рублях, то MSE будет измеряться в квадратах рублей. Чтобы избежать этого, используют корень из среднеквадратичной ошибки.
- Самое по себе значение MSE мало о чем говорит т.к. оно не нормированно.
Корень из среднеквадратической ошибки (RMSE)
RMSE=1N∑i=1N(yi−y^i)2=MSERMSE = \sqrt{\frac 1N\sum_{i=1}^N(y_i-\hat{y}_i)^2} = \sqrt{MSE}
∂RMSE∂yi^=12MSE∂MSE∂yi^\frac{\partial RMSE}{\partial \hat{y_i}} = \frac{1}{2\sqrt{MSE}}\frac{\partial MSE}{\partial \hat{y_i}}
Производная от RMSE представляет собой то же самое, что производная по MSE, только с коэффициентом, зависящим от самой MSE.
Коэффициент детерминации R2R^2
Коэффициент детерминации измеряет долю дисперсии, объяснённую моделью, в общей дисперсии целевой переменной.
R2=1−∑i=1n(yi−y^<em>i)2∑</em>i=1n(yi−yˉ)2R^2=1 — \frac{\sum_{i=1}^n(y_i-\hat{y}<em>i)^2}{\sum</em>{i=1}^n(y_i-\bar y)^2}
Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Другими словами R2=SSRSST=сумма квадратов регрессииполная сумма квадратов=изменчивость, объяснимая линейной зависимостьюизменчивость, объяснимая линейной зависимостью и ошибкойR^2=\frac{SSR}{SST}=\frac{сумма \ квадратов \ регрессии}{полная \ сумма \ квадратов}=\frac{изменчивость, \ объяснимая \ линейной \ зависимостью}{изменчивость, \ объяснимая \ линейной \ зависимостью \ и \ ошибкой}
Средняя абсолютная ошибка (MAE)
1N∑i=1N∣yi−y^i∣\frac 1N\sum_{i=1}^N|y_i-\hat{y}_i|
Модуль отклонения не является дифференцируемым, но при этом менее чувствителен к выбросам, чем квадрат отклонения MSE.
Наилучший константный предиктор для MSE — медиана.
def mae(y_true, y_pred): step1 = abs(y_true - y_pred) if isinstance(step1, (int, float)): return step1 else: return sum(step1) / len(y_true)
plt.figure(figsize=(10, 5)) for n in y_true.tolist(): x = [] y = [] for i in np.arange(-5, 5, .1).tolist(): x.append(n+i) y.append(mae(n, n + i)) plt.plot(x, y, label=f"true y = {n}") x_const = [] y_const = [] for i in np.arange(0, 35, .1).tolist(): x_const.append(i) y_const.append(mae(i, np.median(y_true))) plt.plot(x_const, y_const, label=f"График производной при константном значении") plt.legend() plt.title(label="Графики ошибок для каждого значения") plt.ylabel("MAE") plt.xlabel("y true")
В чем разница с MSE и для каких случаев MAS подходит лучше?
Средняя квадратичная процентная ошибка (mean square percentage error, MSPE) и средняя абсолютная процентная ошибка (mean absolute percentage error, MAPE)**
1N∑i=1N(yi−y^<em>iyi)2\frac 1N\sum_{i=1}^N \Big( \frac{y_i-\hat{y}<em>i}{y_i} \Big)^2
1N∑</em>i=1N∣yi−y^iyi∣\frac 1N\sum</em>{i=1}^N \Bigl\lvert \frac{y_i-\hat{y}_i}{y_i} \Bigr\rvert
def mspe(y_true, y_pred): step1 = ((y_true - y_pred) ** 2) / y_true if isinstance(step1, (int, float)): return step1 else: return sum(step1) / len(y_true)
def mape(y_true, y_pred): step1 = abs(y_true - y_pred) / y_true if isinstance(step1, (int, float)): return step1 else: return sum(step1) / len(y_true)
fig, axes = plt.subplots(nrows=1, ncols=2) fig.set_size_inches(12, 5) kinds = [mspe, mape] for kind_num, kind in enumerate(kinds): for n in y_true.tolist(): x = [] y = [] for i in np.arange(-5, 5, .1).tolist(): x.append(n+i) y.append(kind(n, n + i)) axes[kind_num].plot(x, y, label=f"true y = {n}") axes[kind_num].set_title(f'График для {kind.__name__.upper()}') axes[kind_num].set_ylabel(f'{kind.__name__.upper()}')
Объясните, что мы видим на этих графиках.
Чем больше абсолютное значение наблюдения, тем меньше мы его штрафуем за единицу ошибки.
Среднеквадратичная логарифмическая ошибка (mean squared logarithmic error, MSLE)
MSLE=1N∑i=1N(log(yi+1)−log(y^i+1))2MSLE=\frac{1}{N}\sum_{i=1}^N(\log(y_i+1)-\log(\hat{y}_i+1))^2
За счёт логарифмирования ответов и прогнозов мы скорее штрафуем за отклонения в порядке величин, чем за отклонения в их значениях. Также следует помнить, что логарифм не является симметричной функцией, и поэтому данная функция потерь штрафует заниженные прогнозы сильнее, чем завышенные.
def msle(y_true, y_pred): step1 = (np.log(y_true + 1) - np.log(y_pred + 1)) ** 2 if isinstance(step1, (int, float)): return step1 else: return sum(step1) / len(y_true)
fig, axe = plt.subplots() fig.set_size_inches(12, 5) for n in y_true.tolist(): x = [] y = [] for i in np.arange(-3, 6, .1).tolist(): x.append(n+i) y.append(msle(n, n + i)) axe.plot(x, y, label=f"true y = {n}") axe.set_title('График для MSLE') axe.set_ylabel('MSLE')
В каких случаях лучше использовать MSLE?
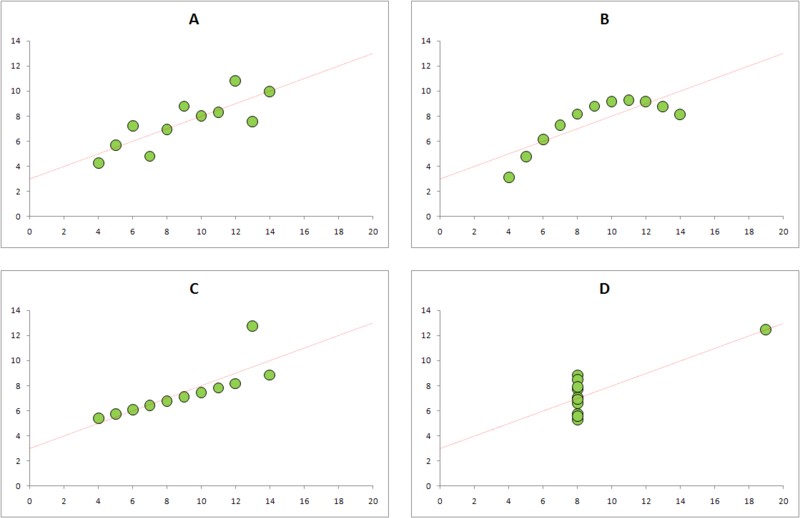
⚠️Осторожно!
Не всегда можно полагаться на цифры. Если это возможно, лучше также построить график зависимости yy от xx. Это позволит Вам избежать попадания в ловушку квадрата Энскомба. Основные числовые характеристики этих данных идентичны и все эти зависимости описываются формулой y=3+0.5xy = 3 + 0.5x, но, очевидно, выглядят они по-разному:
Метрики качества классификаторов
- В sklearn
- What’s WRONG with Metrics?
- Лекции Владимира Соколова
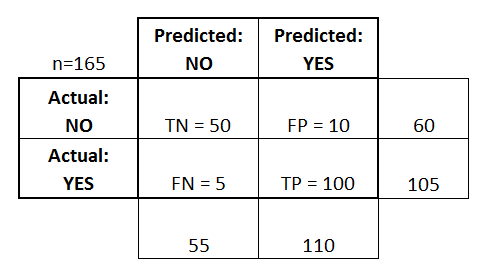
Матрица ошибок (Confusion matrix)
Матрица ошибок — это способ разбить объекты на четыре категории в зависимости от комбинации истинного ответа и ответа алгоритма.
Основные термины:
- TPTP — истино-положительное решение;
- TNTN — истино-отрицательное решение;
- FPFP — ложно-положительное решение (Ошибка первого рода);
- FNFN — ложно-отрицательное решение (Ошибка второго рода).
Интерактивная картинка с большим числом метрик
Accuracy
Наиболее очевидной мерой качества в задаче классификации является доля правильных ответов (accuracy). Например, если мы классифицируем картинки кошек, accuracy показывает долю правильных ответов.
Accuracy=TP+TNP+N=TP+TNTP+TN+FP+FN{\displaystyle \mathrm {Accuracy} ={\frac {\mathrm {TP} +\mathrm {TN} }{P+N}}={\frac {\mathrm {TP} +\mathrm {TN} }{\mathrm {TP} +\mathrm {TN} +\mathrm {FP} +\mathrm {FN} }}}
Первая проблема аккуратности в том, что её они недифференцируема.
В чём вторая проблема?

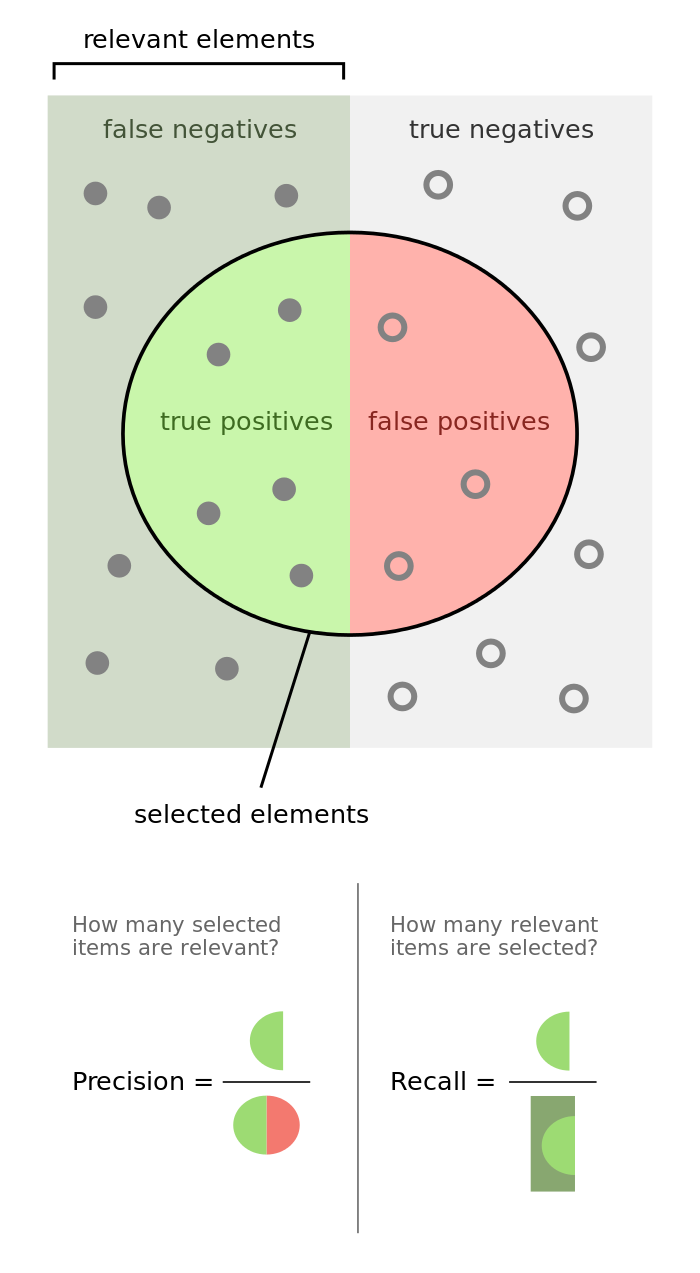
Точность (precision) и полнота (recall)
Более информативными критериями являются точность (precision) и полнота (recall). Они не зависят от соотношения размеров классов.
Точность показывает, какая доля объектов, выделенных классификатором как положительные, действительно является положительными:
Precision=TPTP+FPPrecision = \frac{TP}{TP+FP}
Полнота показывает, какая часть положительных объектов была выделена классификатором:
Recall=TPTP+FNRecall = \frac{TP}{TP+FN}
Какую метрику следует максимизировать в задаче классификации раковых клеток? Что будет, если выбрать другую метрику из этих двух?
F-мера, гармоническое среднее точности и полноты
F_\beta = (1 + \beta^2) \cdot \frac{\mathrm{precision} \cdot \mathrm{recall}}{(\beta^2 \cdot \mathrm{precision}) + \mathrm{recall}} = \frac {(1 + \beta^2) \cdot \mathrm{true\ positive} }{(1 + \beta^2) \cdot \mathrm{true\ positive} + \beta^2 \cdot \mathrm{false\ negative} + \mathrm{false\ positive}}
Среднее гармоническое обладает важным свойством — оно близко к нулю, если хотя бы один из аргументов близок к нулю. Именно поэтому оно является более предпочтительным, чем среднее арифметическое (если алгоритм будет относить все объекты к положительному классу, то он будет иметь recall = 1 и precision больше 0, а их среднее арифметическое будет больше 1/2, что недопустимо).
Чаще всего берут β=1\beta=1, хотя иногда встречаются и другие модификации. F2F_2 острее реагирует на recall (т. е. на долю ложноположительных ответов), а F0.5F_{0.5} чувствительнее к точности (ослабляет влияние ложноположительных ответов).
В sklearn есть удобная функция sklearn.metrics.classification_report, возвращающая recall, precision и F-меру для каждого из классов, а также количество экземпляров каждого класса.
AUC-ROC

Кривая ошибок или ROC-кривая – графичекая характеристика качества бинарного классификатора, зависимость доли верных положительных классификаций от доли ложных положительных классификаций при варьировании порога решающего правила.
Данная кривая представляет из себя линию от (0,0) до (1,1) в координатах True Positive Rate (TPR) и False Positive Rate (FPR):
TPR=TPTP+FN\large TPR = \frac{TP}{TP + FN}
FPR=FPFP+TN\large FPR = \frac{FP}{FP + TN}
True positive rate (TPR, sensitivity, recall, probability of detection) — показывает, какую долю из объектов positive класса алгоритм предсказал верно.
False positive rate (FPR) показывает, какую долю из объектов negative класса алгоритм предсказал неверно.
True negative rate (TNR, specificity) — показывает, какую долю из объектов negative класса алгоритм предсказал верно.
Критерий AUC-ROC более устойчив к несбалансированным классам и может быть интерпретирован как вероятность того, что случайно выбранный positive объект будет проранжирован классификатором выше (будет иметь более высокую вероятность быть positive), чем случайно выбранный negative объект.
Однако, баланс классов все равно важен. Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеет-ся 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм, идеально решающий задачу, то его TPR будет равен еди- нице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма. Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных.
В таким случаях можно использовать AUC-PR — площадь под кривой, простроенной в системе координат y=precisiony=precision и x=recallx=recall pdf.
Индекс Джини.
В задачах кредитного скоринга вместо AUC-ROC часто используется пропорциональная метрика, называемая индексом Джини (Gini index): Gini=2AUC−1.\large Gini = 2AUC − 1.
По сути это площадь между ROC-кривой и диагональю соединяющей точки (0,0) и (1, 1).
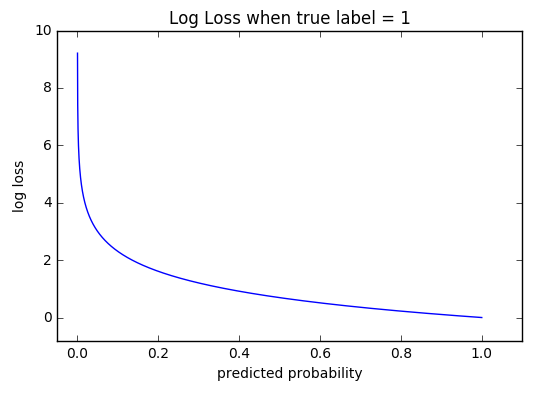
LogLoss
Для бинарной классификации:
−1N∑i=1N(yilog(yi^)+(1−yi)log(1−yi^))-\frac1N \sum_{i=1}^{N}(y_i\log(\hat{y_i}) + (1 — y_i)\log(1 — \hat{y_i}))
Для мультиклассовой классификации:
−1N∑i=1N∑l=1Lyillog(yil^)-\frac1N \sum_{i=1}^{N} \sum_{l=1}^{L} y_{il}\log(\hat{y_{il}})
Работает с вероятностными предсказаниями.
Улетает в бесконечность при очень больших ошибках.
Каппа Кохена
1−1−accuracy1−pe=1−errorbaseline error,1 — \frac{1 — accuracy}{1 — p_e} = 1 — \frac{error}{baseline \ error},
где pep_e — средняя аккуратность на подвыборках предсказаний.
- Landis, J.R.; Koch, G.G. (1977). “The measurement of observer agreement for categorical data”. Biometrics 33 (1): 159–174
- Видео с объяснением
Каппа Кохена может также быть взвешенной, т.е. штрафовать за ошибку разных классов по-разному. Формула от этого почти не меняется. Просто считаем взвешенные ошибки, вместо обычных. Эту модификацию удобно применять для классификации упорядоченных классов.
Вопрос 1
Предположим, что мы решаем задачу бинарной классификации, метрика качества — логлосс. Какие прогнозы более предпочтительны для этой метрики качества, если истинными метками являются [0, 0, 0, 0].
- [0, 0, 0, 1]
- [0.4, 0.5, 0.5, 0.6]
- [0.5, 0.5, 0.5, 0.5]
Вопрос 2
Предположим, что целевая метрика R-квадрат. Какие функции потерь нам следует использовать для наших моделей?
- RMSLE
- MAE
- RMSE
- AUC
- MSE
Вопрос 3
Подсчитайте AUC для таких предсказаний:
| true | predicted |
|---|---|
| 1 | 0.83 |
| 0 | 0.44 |
| 1 | 0.69 |
| 0 | 0.12 |
| 0 | 0.03 |
| 1 | 0.21 |
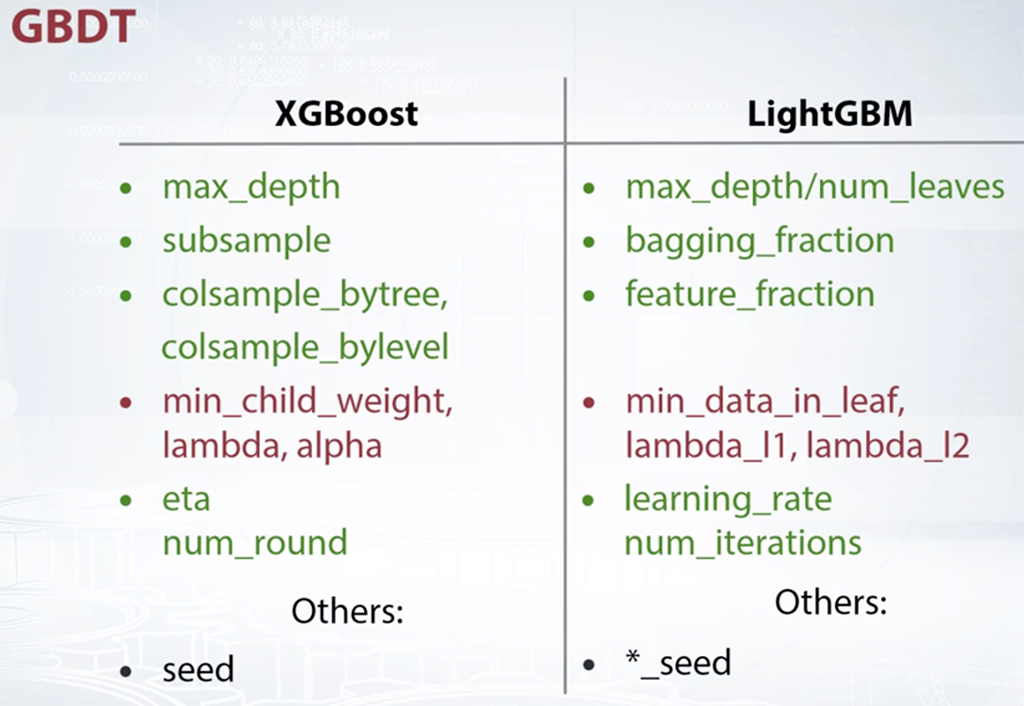
Выбор параметров модели
Главная задача обучаемых алгоритмов – их способность обобщаться, то есть хорошо работать на новых данных. Для того, чтобы алгоритм при обучении при обучении приобрёл наибольшую обобщающую способность нам необходимо подобрать значения гиперпараметров.
Вопрос с реального собеседования: что такое гиперпараметры? Привидите примеры.
Но тут над подстерегает опасность, под названием bias-variance tradeoff.

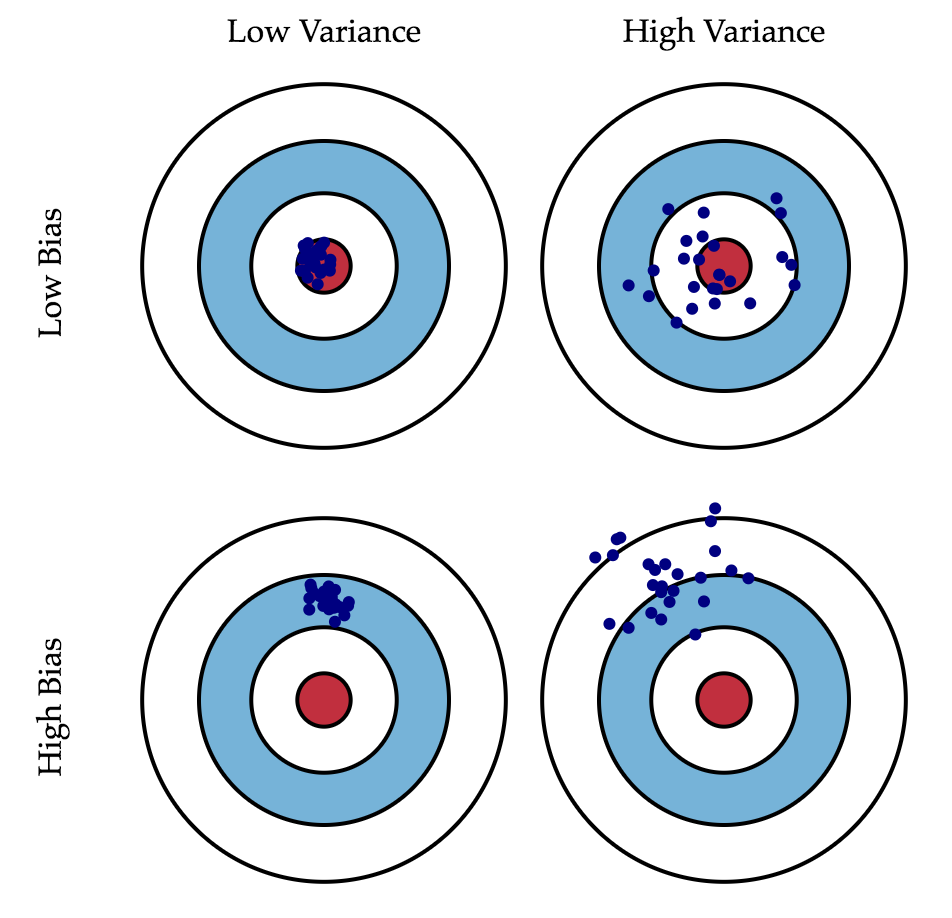
Смещение — это ошибка от ошибочных предположений в алгоритме обучения. Высокое смещение может привести к тому, что алгоритм упустит соответствующие отношения между функциями и целевыми выходами (underfitting).
Дисперсия — это ошибка от чувствительности к небольшим колебаниям в тренировочном наборе. Высокая дисперсия может привести к тому, что алгоритм моделирует случайный шум в данных обучения, а не предполагаемые выходы (overfitting).
Для борьбы с переобучением существуют множество методов:
- Собрать больше данных
- Кросс-валидация
- Регуляризация
- Удаление или снижение веса признаков
- Drop-out
- Ранняя остановка
- Ансамбли алгоритмов
- и др.
Кросс-валидация
Поскольку на новых данных мы сразу не можем проверить качество построенной модели (нам ведь надо для них сделать прогноз, то есть истинных значений целевого признака мы для них не знаем), то надо пожертвовать небольшой порцией данных, чтоб на ней проверить качество модели.

-
Проблема 1: Приходится слишком много объектов оставлять в контрольной подвыборке. Уменьшение длины обучающей подвыборки приводит к смещённой (пессимистически завышенной) оценке вероятности ошибки.
-
Проблема 2: Оценка существенно зависит от разбиения, тогда как желательно, чтобы она характеризовала только алгоритм обучения.
-
Проблема 3: Оценка имеет высокую дисперсию, которая может быть уменьшена путём усреднения по разбиениям.
Но это ещё не кросс валидация. При кросс-валидации имеющиеся в наличии данные разбиваются на k частей. Затем на k−1 частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется k раз; в итоге каждая из k частей данных используется для тестирования. В результате получается оценка эффективности выбранной модели с наиболее равномерным использованием имеющихся данных.
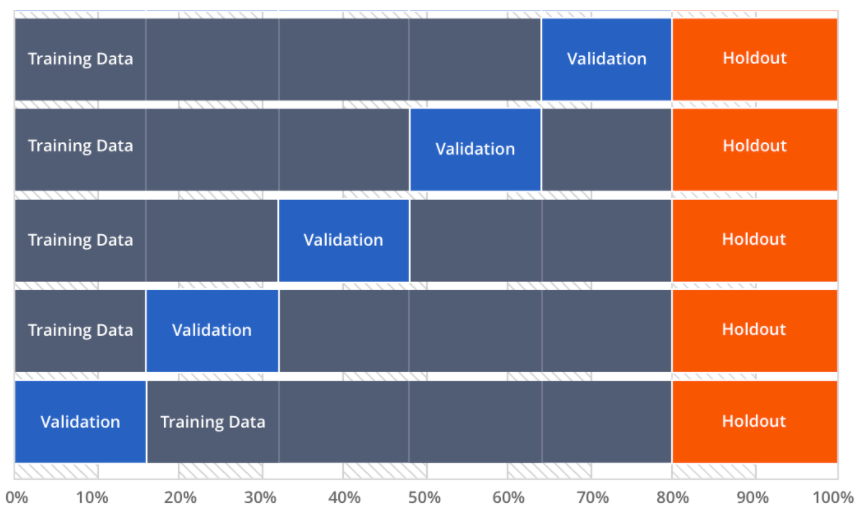
k можно выбирать от 2 до n (размера обучающей выборки).
Если k = n, подход называется leave-one-out CV (LOOCV), когда оценка ошибки происходит на одном наблюдении.
- Чем меньше k, тем меньше дисперсия ошибки
- Чем больше k, тем меньше смещение ошибки
- Чем больше k, тем больше моделей обучаем (дорого)
Подбор гиперпараметров модели по сетке

Суть подбора по сетке в том, что мы строим модель разными комбинациями параметров, после чего оцениваем качество модели на валидационных данных.
Самое важное здесь — знать, какие параметры и в каких моделях подбирать.
- Tuning the hyper-parameters of an estimator (sklearn)
- Optimizing hyperparameters with hyperopt
- Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
Из курса How to Win a Data Science Competition: Learn from Top Kagglers