12.08.2019

Сегодня в статье рассмотрим, как в Linux проверить ваш HDD,SSD или USB флешку на битые сектора – Бэд-блоки.
Бэд-блок (англ. bad block) — испорченный кластер (единица хранения данных) дискового носителя информации, куда нельзя записать информацию.
Проверка HDD на бэд-блоки программой badblocks.
-
1.
Проверка HDD на бэд-блоки программой badblocks. -
2.
Проверка HDD на бэд-блоки на Linux с помощью smartmontools -
3.
Проверка HDD на бэд-блоки на Linux с помощью GParted -
4.
Safecopy
Badblocks — стандартная утилита Linux для проверки на битые секторы. Она устанавливается по-умолчанию практически в любой дистрибутив и с ее помощью можно проверить как жесткий диск, так и внешний накопитель.
Но для начала воспользуемся ещё одной стандартной утилитой для просмотра подключенных накопители к нашей системе — fdisk.
sudo fdisk -l- -l – показать список разделов и выйти.
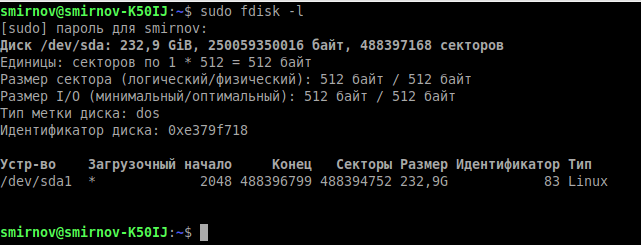
Теперь, когда мы знаем, какие разделы у нас есть, мы можем проверить их на битые секторы программой badblocks:
sudo badblocks -sv /dev/sda1 > ~/badblocks.txt- -v — вывод подробной информации о результатах проверки.
- -s — отображать в правильном порядке ход проверки блоков.
- /dev/sda1 — раздел, который мы хотим проверить на битые секторы.
- > ~/badblocks.txt — выводим результат выполнения команды в файл badblocks.txt расположенный в корневом каталоги пользователя.

Если же в результате были найдены битые секторы, то нам надо дать
указание операционной системе не записывать в них информацию в будущем.
Для этого нам понадобятся утилиты Linux для работы с файловыми
системами:
- e2fsck. Если мы будем исправлять раздел с файловыми система Linux ( ext2,ext3,ext4).
- fsck. Если мы будем исправлять файловую систему, отличную от ext.
Вводим следующие команды:
sudo e2fsck -l ~/badblocks.txt /dev/sda1Или, если у нас файловая система не ext:
sudo fsck -l ~/badblocks.txt /dev/sda1Если после ввода данных команд вы получаете что-то вроде этого:
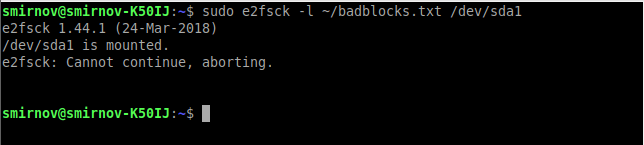
Значит данные операции надо выполнить в командной строке до загрузки операционной системы. Для этого выполним следующее:
sudo nano /etc/network/interfacesВ конце файла дописываем следующие строки:
pre-up e2fsck -l ~/badblocks.txt /dev/sda1Теперь перезагружаем ПК:
sudo rebootТеперь давайте рассмотрим более современный и надежный способ
проверить диск на битые секторы linux. Современные накопители ATA/SATA
,SCSI/SAS,SSD имеют встроенную систему самоконтроля S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology,
Технология самоконтроля, анализа и отчетности), которая производит
мониторинг параметров накопителя и поможет определить ухудшение
параметров работы накопителя на ранних стадиях. Для работы со S.M.A.R.T в
Linux есть утилита smartmontools.
Давайте сначала ее установим. Если ваш дистрибутив основан на Debian\Ubuntu, то вводите:
sudo apt install smartmontoolsЕсли же у Вас дистрибутив на основе RHEL\CentOS, то вводите:
sudo yum install smartmontoolsТеперь, когда мы установили smartmontools мы можем посмотреть страницу помощи, с помощью команды:
man smartctlили
smartctl -hДавайте перейдем к работе с утилитой. Вводим следующую команду с параметром -H,чтобы утилита показала нам информацию о состоянии накопителя:
sudo smartctl -H /dev/sda1
Как видим, проверка диска на битые секторы linux завершена и утилита говорит нам, что с накопителем все в порядке!
Ещё одна команда, если SMART поддерживается, то добавляем -s. Если он не поддерживается или уже включён, то этот аргумент можно убрать.
sudo smartctl -s on -a /dev/sdaДополнительно, можно указать следующие параметры -a или –all, чтобы получить еще больше информации о накопителе, или -x и –xall, чтобы просмотреть информацию в том числе и об остальных параметрах накопителя.
Проверка HDD на бэд-блоки на Linux с помощью GParted
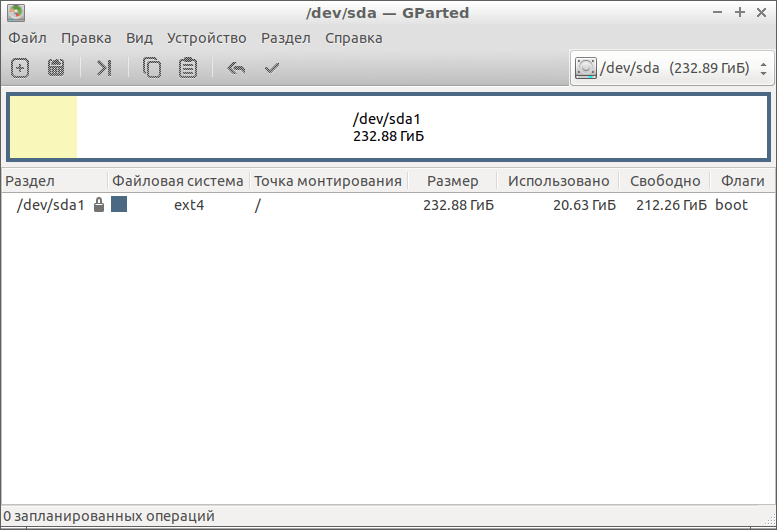
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Ubuntu и всех Debian-подобных системах. В их число входит и проверка диска на ошибки.
Для
начала нам нужно скачать и установить GParted. Вводим следующую
команду, чтобы выполнить загрузку из официальных репозиториев:
sudo apt install gparted- Открываем
приложение. На главном экране сразу же выводятся все носители. Если
какой-то из них помечен восклицательным знаком, значит, с ним уже что-то
не так. - Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Разделы», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может занять продолжительное время. После сканирования Вы будете оповещены о его результатах.
Safecopy
Это уже та программа,
которую впору использовать на тонущем судне. Если мы осведомлены, что с
нашим диском что-то не так, и нацелены спасти как можно больше выживших
файлов, то Safecopy придёт на помощь. Её задача как раз заключается в
копировании данных с повреждённых носителей. Причём она извлекает файлы
даже из битых блоков.
Устанавливаем Safecopy:
sudo apt install safecopyПереносим
файлы из одной директории в другую. Выбрать можно любую другую. В
данном случае мы переносим данные с диска sda в папку home.
sudo safecopy /dev/sda /home/Если есть вопросы, то пишем в комментариях.
Также можете вступить в Телеграм канал, ВКонтакте или подписаться на Twitter. Ссылки в шапке страницы.
Заранее всем спасибо!!!
RSS
Добавление RSS-ленты на главную страницу этого сайта не поддерживается, так как это может привести к зацикливанию, замедляющему работу вашего сайта. Попробуйте использовать другой блок, например блок Последние записи, для отображения записей сайта.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
5
4
голоса
Рейтинг статьи
Проверка и анализ состояния накопителей в Linux с помощью консольных утилит badblocks, smartmontools и графической программы GSmartControl
Типы накопителей:
- Встроенные жёсткие диски;
- Внешние жёсткие диски;
- USB-флеш-накопители (сленг. флешка);
- Карт памяти.
Проверка накопителей средствами badblocks
Утилита badblocks установлена по-умолчанию.
Для просмотра подключенных накопителей и разделов на них, введите команду:

Для проверки накопителя на битые сектора, выполнить команду:
sudo badblocks -v /dev/sdX > badblocks.txt.txt
-v – отображение подробной информации во время работы программы
/dev/sdX – имя устройства, которое необходимо проверить
> badblocks.txt – запись результатов проверки (сохраняется в домашней папке: /home/user)
![]()
При наличии битых секторов, можно воспользоваться утилитами: e2fsck (ext2, ext3, ext4), fsck (отличные от ext) для игнорирования системой битых секторов:
sudo e2fsck -l badblocks.txt /dev/sdX
sudo fsck -l badblocks.txt /dev/sdX
Проверка состояния накопителей при помощи S.M.A.R.T.
Установка:
sudo apt-get install smartmontools
Для проверки накопителя на битые сектора при помощи S.M.A.R.T., выполнить команду:
sudo smartctl -a /dev/sdX
/dev/sdX – имя устройства, которое необходимо проверить
Проверка состояния накопителей при помощи GSmartControl
Чтобы установить самую свежую стабильную версию GSmartControl в Ubuntu, можно воспользоваться PPA репозиторием. Для этого выполните последовательно в терминале команды:
sudo sh -c “echo ‘deb http://download.opensuse.org/repositories/home:/alex_sh/Ubuntu_16.04/ /’ > /etc/apt/sources.list.d/gsmartcontrol.list”
wget -nv http://download.opensuse.org/repositories/home:alex_sh/Ubuntu_16.04/Release.key -O Release.key sudo apt-key add – < Release.key sudo apt-get update
sudo apt-get update
sudo apt-get install gsmartcontrol
Установить через центр приложений
Работа с программой:
Выбираем диск и кликаем левой клавишей мыши 2 раза или выбираем диск, потом идём в меню, там жмём на Device, далее жмём View details, далее жмём на вкладку Attributes:
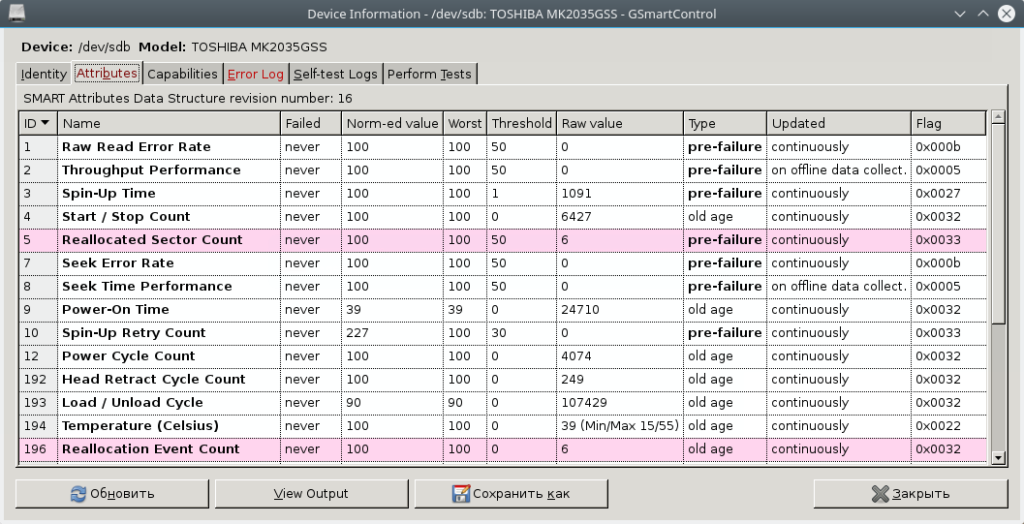
Анализ параметров, выводимых программой
Каждый атрибут имеет величину Value. Value Изменяется в диапазоне от 0 до 255 задается производителем). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Raw Value – это значение атрибута во внутреннем формате производителя значение малоинформативно для всех кроме сервисманов. Threshold – минимальное возможное значение атрибута, при котором гарантируется безотказная работа накопителя. SMART. Смотрим состояние жесткого диска. Если VALUE стало меньше THRESH – Атрибут считается failed и отображается в столбце WHEN_FAILED. При значении атрибута меньше Threshold очень вероятен сбой в работе или полный отказ. WORST- минимальное нормализованное значение. Это минимальное значение, которое достигалось с момента включения SMART на диске. Атрибуты бывают критически важными (Pre-fail) и некритически важными (Old_age). Выход критически важного параметра за пределы Threshold фактический означает выход диска из строя, выход за пределы допустимых значений не критически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность.
Критичные атрибуты
Raw Read Error Rate – частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time – время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся не максимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например просадка по вольтажу блока питания.
Spin Up Retry Count – число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно не максимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate – частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count – число операций переназначения секторов. SMART в современных дисках способен произвести анализ сектора на стабильность работы “на лету” и в случае признания его сбойным, произвести его переназначение.
Некритичные атрибуты:
Start/Stop Count – полное число запусков/остановов шпинделя. Гарантировано мотор диска способен перенести лишь определенное число включений/выключений. Это значение выбирается в качестве Treshold. Первые модели дисков со скоростью вращения 7200 оборотов/мин имели ненадежный двигатель, могли перенести лишь небольшое их число и быстро выходили из строя.
Power On Hours – число часов проведенных во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF). Обычно величина MTBF огромна, и маловероятно, что этот параметр достигнет критического порога. Но даже в этом случае выход из строя диска совершенно не обязателен.
Drive Power Cycle Count – количество полных циклов включения-выключения диска. По этому и предыдущему атрибуту можно оценить, например, сколько использовался диск до покупки.
Temperatue – Здесь хранятся показания встроенного термодатчика. Температура имеет огромное влияние на срок службы диска (даже если она находится в допустимых пределах). Вернее имеет влияние не на срок службы диска а на частоту возникновения некоторых типов ошибок, которые влияют на срок службы.
Current Pending Sector Count – Число секторов, являющихся кандидатами на замену. Они не были ещё определены как плохие, но считывание их отличается от чтения стабильного сектора, так называемые подозрительные или нестабильные сектора.
Uncorrectable Sector Count – число ошибок при обращении к сектору, которые не были скорректированы. Возможными причинами возникновения могут быть сбои механики или порча поверхности.
UDMA CRC Error Rate – число ошибок, возникающих при передаче данных по внешнему интерфейсу. Могут быть вызваны некачественными кабелями, нештатными режимами работы.
Write Error Rate – показывает частоту ошибок происходящих при записи на диск. Может служить показателем качества поверхности и механики накопителя.
Along the way to today, this thread raised some questions.
—How long will this take (implied by discussion of letting it run overnight).
I’m currently testing a USB 3.0 128G Sandisk using sudo badblocks -w -s -o, it is connected to my USB 3/USBC PCIe card in an older Athlon 64×2. So, USB3 into USB3 on PCIe should be quite fast.
Here is my console command line at 33% completion:
Testing with pattern 0xaa: 33.35% done, 49:47 elapsed. (0/0/0 errors)
and again later:
Testing with pattern 0xaa: 54.10% done, 1:17:04 elapsed. (0/0/0 errors)
Next came this segment:
Reading and comparing: 43.42% done, 2:23:44 elapsed. (0/0/0 errors)
This process repeats with oxaa, then 0x55, 0xff, and finally 0x00.
ArchLinux gave an unqualified statement:
For some devices this will take a couple of days to complete.
N.B.: The testing was started about 8:30 p.m., testing had completed before 8:45 a.m. the next day, completing in about 12 hours for my situation.
—Destructive testing isn’t the only method possible.
Wikipedia offered this statement:
badblocks -nvs /dev/sdb
This would check the drive "sdb" in non-destructive read-write mode and display progress by writing out the block numbers as they are checked.
My current distro man page confirms the -n is nondestructive.
-n Use non-destructive read-write mode. By default only a non-
destructive read-only test is done.
And finally that
it isn’t worth it. statement.
A summarizing statement, based on the situation of billions of memory sites in a flash chip, a failure is a cell that has already been written and erased tens of thousands of times, and is now failing. And when one test shows a cell has failed, remember that each file you added and erased is running up those cycles.
The idea here is that when 1 cell fails, many more cells are also reaching the same failure point. One cell failed today, but you use it normally for a while longer, then 3 more cells fail, then 24 more fail, then 183, and before you know it, the memory array is riddled with bad spots. There are only so many cells that can die before your usable capacity begins to fall, eventually falling rapidly. How will you know more cells are failing? So, posts here are guarding your data by saying once you have a bad cell, you are pretty much done in regards trustworthy storage. Your usage might still give you a few months.
It’s your data.
HTH
Throughout this answer I’ll assume, that a storage drive appears as a block device at the path /dev/sdc. To find the path of a storage drive in our current setup, use:
- Gnome Disks
 (formerly Gnome Disk Utility, a. k. a.
(formerly Gnome Disk Utility, a. k. a. palimpsest), if a GUI is available, or - on the terminal look at the output of
lsblkandls -l /dev/disk/by-idand try to find the right device by size, partitioning, manufacturer and model name.
Basic check
- only detects entirely unresponsive media
- almost instantaneous (unless medium is spun down or broken)
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
Sometimes a storage medium simply refuses to work at all. It still appears as a block device to the kernel and in the disk manager, but its first sector holding the partition table is not readable. This can be verified easily with:
sudo dd if=/dev/sdc of=/dev/null count=1
If this command results in a message about an “Input/output error”, our drive is broken or otherwise fails to interact with the Linux kernel as expected. In the a former case, with a bit of luck, a data recovery specialist with an appropriately equipped lab can salvage its content. In the latter case, a different operating system is worth a try. (I’ve come across USB drives that work on Windows without special drivers, but not on Linux or OS X.)
S.M.A.R.T. self-test
- adjustable thoroughness
- instantaneous to slow or slower (depends on thoroughness of the test)
- safe
- warns about likely failure in the near future
Devices that support it, can be queried about their health through S.M.A.R.T. or instructed to perform integrity self-tests of different thoroughness. This is generally the best option, but usually only available on (non-ancient) hard disk and solid state drives. Most removable flash media don’t support it.
Further resources and instructions:
- Answer about S.M.A.R.T. on this question
- How can I check the SMART status of a drive on Ubuntu 14.04 through 16.10?
Read-only check
- only detects some flash media errors
- quite reliable for hard disks
- slow
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
To test the read integrity of the whole device without writing to it, we can use badblocks(8) like this:
sudo badblocks -b 4096 -c 4096 -s /dev/sdc
This operation can take a lot of time, especially if the storage drive actually is damaged. If the error count rises above zero, we’ll know that there’s a bad block. We can safely abort the operation at any moment (even forcefully like during a power failure), if we’re not interested in the exact amount (and maybe location) of bad blocks. It’s possible to abort automatically on error with the option -e 1.
Note for advanced usage: if we want to reuse the output for e2fsck, we need to set the block size (-b) to that of the contained file system. We can also tweak the amount of data (-c, in blocks) tested at once to improve throughput; 16 MiB should be alright for most devices.
Non-destructive read-write check
- very thorough
- slowest
- quite safe (barring a power failure or intermittent kernel panic)
Sometimes – especially with flash media – an error only occurs when trying to write. (This will not reliably discover (flash) media, that advertise a larger size, than they actually have; use Fight Flash Fraud instead.)
-
NEVER use this on a drive with mounted file systems!
badblocksrefuses to operate on those anyway, unless you force it. -
Don’t interrupt this operation forcefully! Ctrl+C (SIGINT/SIGTERM) and waiting for graceful premature termination is ok, but
killall -9 badblocks(SIGKILL) isn’t. Upon forceful terminationbadblockscannot restore the original content of the currently tested block range and will leave it overwritten with junk data and possibly corrupt the file system.
To use non-destructive read-write checks, add the -n option to the above badblocks command.
Destructive read-write check
- very thorough
- slower
- ERASES ALL DATA ON THE DRIVE
As above, but without restoring the previous drive content after performing the write test, therefore it’s a little faster. Since data is erased anyway, forceful termination remains without (additional) negative consequence.
To use destructive read-write checks, add the -w option to the above badblocks command.
|
|
Duplicate Article |

See: SystemAdministration/Fsck and TestingStorageMedia
Introduction
Contents
- Introduction
-
Basic filesystem checks and repairs
- e2fsprogs — ext2, ext3, ext4 filesystems
- dosfstools — FAT12, FAT16 and FAT32 (vfat) filesystem
- ntfs-3g (previously also ntfsprogs) — NTFS filesystem
- reiserfstools — reiserfs
- xfsprogs — xfs
- Missing superblock
- Bad blocks
- Sources and further reading
This guide will help diagnose filesystem problems one may come across on a GNU/Linux system. New sections are still being added to this howto.
Basic filesystem checks and repairs
The most common method of checking filesystem’s health is by running what’s commonly known as the fsck utility. This tool should only be run against an unmounted filesystem to check for possible issues. Nearly all well established filesystem types have their fsck tool. e.g.: ext2/3/4 filesystems have the e2fsck tool. Most notable exception until very recently was btrfs. There are also filesystems that do not need a filesystem check tool i.e.: read-only filesystems like iso9660 and udf.
e2fsprogs — ext2, ext3, ext4 filesystems
Ext2/3/4 have the previously mentioned e2fsck tool for checking and repairing filesystem. This is a part of e2fsprogs package — the package needs to be installed to have the fsck tool available. Unless one removes it in aptitude during installation, it should already be installed.
There are 4 ways the fsck tool usually gets run (listed in order of frequency of occurrence):
- it runs automatically during computer bootup every X days or Y mounts (whichever comes first). This is determined during the creation of the filesystem and can later be adjusted using tune2fs.
- it runs automatically if a filesystem has not been cleanly unmounted (e.g.: powercut)
- user runs it against an unmounted filesystem
-
user makes it run at next bootup
case 1
When filesystem check is run automatically X days after the last check or after Y mounts, Ubuntu gives user the option to interrupt the check and continue bootup normally. It is recommended that user lets it finish the check.
case 2
If a filesystem has not been cleanly unmounted, the system detects a dirty bit on the filesystem during the next bootup and starts a check. It is strongly recommended that one lets it finish. It is almost certain there are errors on the filesystem that fsck will detect and attempt to fix. Nevertheless, one can still interrupt the check and let the system boot up on a possibly corrupted filesystem.
2 things can go wrong
-
fsck dies — If fsck dies for whatever reason, you have the option to press ^D (Ctrl + D) to continue with an unchecked filesystem or run fsck manually. See e2fsck cheatsheet for details how.
-
fsck fails to fix all errors with default settings — If fsck fails to fix all errors with default settings, it will ask to be run manually by the user. See e2fsck cheatsheet for details how.
case 3
User may run fsck against any filesystem that can be unmounted on a running system. e.g. if you can issue umount /dev/sda3 without an error, you can run fsck against /dev/sda3.
case 4
You can make your system run fsck by creating an empty ‘forcefsck’ file in the root of your root filesystem. i.e.: touch /forcefsck Filesystems that have 0 or nothing specified in the sixth column of your /etc/fstab, will not be checked
Till Ubuntu 6.06 you can also issue shutdown -rF now to reboot your filesystem and check all partitions with non-zero value in sixth column of your /etc/fstab. Later versions of Ubuntu use Upstart version of shutdown which does not support the -F option any more.
Refer to man fstab for what values are allowed.
e2fsck cheatsheet
e2fsck has softlinks in /sbin that one can use to keep the names of fsck tools more uniform. i.e. fsck.ext2, fsck.ext3 and fsck.ext4 (similarly, other filesystem types have e.g.: fsck.ntfs) This cheatsheet will make use of these softlinks and will use ext4 and /dev/sda1 as an example.
-
fsck.ext4 -p /dev/sda1 — will check filesystem on /dev/sda1 partition. It will also automatically fix all problems that can be fixed without human intervention. It will do nothing, if the partition is deemed clean (no dirty bit set).
-
fsck.ext4 -p -f /dev/sda1 — same as before, but fsck will ignore the fact that the filesystem is clean and check+fix it nevertheless.
-
fsck.ext4 -p -f -C0 /dev/sda1 — same as before, but with a progress bar.
-
fsck.ext4 -f -y /dev/sda1 — whereas previously fsck would ask for user input before fixing any nontrivial problems, -y means that it will simply assume you want to answer «YES» to all its suggestions, thus making the check completely non-interactive. This is potentially dangerous but sometimes unavoidable; especially when one has to go through thousands of errors. It is recommended that (if you can) you back up your partition before you have to run this kind of check. (see dd command for backing up filesystems/partitions/volumes)
-
fsck.ext4 -f -c -C0 /dev/sda1 — will attempt to find bad blocks on the device and make those blocks unusable by new files and directories.
-
fsck.ext4 -f -cc -C0 /dev/sda1 — a more thorough version of the bad blocks check.
-
fsck.ext4 -n -f -C0 /dev/sda1 — the -n option allows you to run fsck against a mounted filesystem in a read-only mode. This is almost completely pointless and will often result in false alarms. Do not use.
In order to create and check/repair these Microsoft(TM)’s filesystems, dosfstools package needs to be installed. Similarly to ext filesystems’ tools, dosfsck has softlinks too — fsck.msdos and fsck.vfat. Options, however, vary slightly.
dosfsck cheatsheet
These examples will use FAT32 and /dev/sdc1
-
fsck.vfat -n /dev/sdc1 — a simple non-interactive read-only check
-
fsck.vfat -a /dev/sdc1 — checks the file system and fixes non-interactively. Least destructive approach is always used.
-
fsck.vfat -r /dev/sdc1 — interactive repair. User is always prompted when there is more than a single approach to fixing a problem.
-
fsck.vfat -l -v -a -t /dev/sdc1 — a very verbose way of checking and repairing the filesystem non-interactively. The -t parameter will mark unreadable clusters as bad, thus making them unavailable to newly created files and directories.
Recovered data will be dumped in the root of the filesystem as fsck0000.rec, fsck0001.rec, etc. This is similar to CHK files created by scandisk and chkdisk on MS Windows.
ntfs-3g (previously also ntfsprogs) — NTFS filesystem
Due to the closed sourced nature of this filesystem and its complexity, there is no fsck.ntfs available on GNU/Linux (ntfsck isn’t being developed anymore). There is a simple tool called ntfsfix included in ntfs-3g package. Its focus isn’t on fixing NTFS volumes that have been seriously corrupted; its sole purpose seems to be making an NTFS volume mountable under GNU/Linux.
Normally, NTFS volumes are non-mountable if their dirty bit is set. ntfsfix can help with that by clearing trying to fix the most basic NTFS problems:
-
ntfsfix /dev/sda1 — will attempt to fix basic NTFS problems. e.g.: detects and fixes a Windows XP bug, leading to a corrupt MFT; clears bad cluster marks; fixes boot sector problems
-
ntfsfix -d /dev/sda1 — will clear the dirty bit on an NTFS volume.
-
ntfsfix -b /dev/sda1 — clears the list of bad sectors. This is useful after cloning an old disk with bad sectors to a new disk.
Windows 8 and GNU/Linux cohabitation problems This segment is taken from http://www.tuxera.com/community/ntfs-3g-advanced/ When Windows 8 is restarted using its fast restarting feature, part of the metadata of all mounted partitions are restored to the state they were at the previous closing down. As a consequence, changes made on Linux may be lost. This can happen on any partition of an internal disk when leaving Windows 8 by selecting “Shut down” or “Hibernate”. Leaving Windows 8 by selecting “Restart” is apparently safe.
To avoid any loss of data, be sure the fast restarting of Windows 8 is disabled. This can be achieved by issuing as an administrator the command : powercfg /h off
Install reiserfstools package to have reiserfsck and a softlink fsck.reiserfs available. Reiserfsck is a very talkative tool that will let you know what to do should it find errors.
-
fsck.reiserfs /dev/sda1 — a readonly check of the filesystem, no changes made (same as running with —check). This is what you should run before you include any other options.
-
fsck.reiserfs —fix-fixable /dev/sda1 — does basic fixes but will not rebuild filesystem tree
-
fsck.reiserfs —scan-whole-partition —rebuild-tree /dev/sda1 — if basic check recommends running with —rebuild-tree, run it with —scan-whole-partition and do NOT interrupt it! This will take a long time. On a non-empty 1TB partition, expect something in the range of 10-24 hours.
xfsprogs — xfs
If a check is necessary, it is performed automatically at mount time. Because of this, fsck.xfs is just a dummy shell script that does absolutely nothing. If you want to check the filesystem consistency and/or repair it, you can do so using the xfs_repair tool.
-
xfs_repair -n /dev/sda — will only scan the volume and report what fixes are needed. This is the no modify mode and you should run this first.
-
xfs_repair will exit with exit status 0 if it found no errors and with exit status 1 if it found some. (You can check exit status with echo $?)
-
-
xfs_repair /dev/sda — will scan the volume and perform all fixes necessary. Large volumes take long to process.
XFS filesystem has a feature called allocation groups (AG) that enable it to use more parallelism when allocating blocks and inodes. AGs are more or less self contained parts of the filesystem (separate free space and inode management). mkfs.xfs creates only a single AG by default.
xfs_repair checks and fixes your filesystems by going through 7 phases. Phase 3 (inode discovery and checks) and Phase 4 (extent discovery and checking) work sequentially through filesystem’s allocation groups (AG). With multiple AGs, this can be heavily parallelised. xfs_repair is clever enough to not process multiple AGs on same disks.
Do NOT bother with this if any of these is true for your system:
- you created your XFS filesystem with only a single AG.
-
your xfs_repair is older than version 2.9.4 or you will make the checks even slower on GNU/Linux. You can check your version with xfs_repair -V
- your filesystem does not span across multiple disks
otherwise:
-
xfs_repair -o ag_stride=8 -t 5 -v /dev/sda — same as previous example but reduces the check/fix time by utilising multiple threads, reports back on its progress every 5 minutes (default is 15) and its output is more verbose.
-
if your filesystem had 32 AGs, the -o ag_stride=8 would start 4 threads, one to process AGs 0-7, another for 8-15, etc… If ag_stride is not specified, it defaults to the number of AGs in the filesystem.
-
-
xfs_repair -o ag_stride=8 -t 5 -v -m 2048 /dev/sda — same as above but limits xfs_repair’s memory usage to a maximum of 2048 megabytes. By default, it would use up to 75% of available ram. Please note, -o bhash=xxx has been superseded by the -m option
== jfsutils — jfs == == btrfs ==
Missing superblock
Bad blocks
Sources and further reading
- man pages
-
<XFS user guide> — more details about XFS filesystem
Содержание
- Проверка HDD/SSD/USB flash на бэд-блоки на Linux.
- Проверка HDD на бэд-блоки программой badblocks.
- Проверка HDD на бэд-блоки на Linux с помощью smartmontools
- Проверка HDD на бэд-блоки на Linux с помощью GParted
- Safecopy
- Проверка диска на битые секторы в Linux
- Проверка диска на битые секторы Linux
- Выводы
- Проверка состояния накопителей в Linux
- Проверка накопителей средствами badblocks
- Проверка состояния накопителей при помощи S.M.A.R.T.
- Проверка состояния накопителей при помощи GSmartControl
Проверка HDD/SSD/USB flash на бэд-блоки на Linux.
Сегодня в статье рассмотрим, как в Linux проверить ваш HDD,SSD или USB флешку на битые сектора — Бэд-блоки.
Бэд-блок (англ. bad block) — испорченный кластер (единица хранения данных) дискового носителя информации, куда нельзя записать информацию.
Проверка HDD на бэд-блоки программой badblocks.
Badblocks — стандартная утилита Linux для проверки на битые секторы. Она устанавливается по-умолчанию практически в любой дистрибутив и с ее помощью можно проверить как жесткий диск, так и внешний накопитель.
Но для начала воспользуемся ещё одной стандартной утилитой для просмотра подключенных накопители к нашей системе — fdisk.
- -l — показать список разделов и выйти.
Теперь, когда мы знаем, какие разделы у нас есть, мы можем проверить их на битые секторы программой badblocks:
- -v — вывод подробной информации о результатах проверки.
- -s — отображать в правильном порядке ход проверки блоков.
- /dev/sda1 — раздел, который мы хотим проверить на битые секторы.
- >
/badblocks.txt — выводим результат выполнения команды в файл badblocks.txt расположенный в корневом каталоги пользователя.
Если же в результате были найдены битые секторы, то нам надо дать указание операционной системе не записывать в них информацию в будущем. Для этого нам понадобятся утилиты Linux для работы с файловыми системами:
- e2fsck. Если мы будем исправлять раздел с файловыми система Linux ( ext2,ext3,ext4).
- fsck. Если мы будем исправлять файловую систему, отличную от ext.
Вводим следующие команды:
Или, если у нас файловая система не ext:
Если после ввода данных команд вы получаете что-то вроде этого:
Значит данные операции надо выполнить в командной строке до загрузки операционной системы. Для этого выполним следующее:
В конце файла дописываем следующие строки:
Теперь перезагружаем ПК:
Проверка HDD на бэд-блоки на Linux с помощью smartmontools
Теперь давайте рассмотрим более современный и надежный способ проверить диск на битые секторы linux. Современные накопители ATA/SATA ,SCSI/SAS,SSD имеют встроенную систему самоконтроля S.M.A.R.T (Self-Monitoring, Analysis and Reporting Technology, Технология самоконтроля, анализа и отчетности), которая производит мониторинг параметров накопителя и поможет определить ухудшение параметров работы накопителя на ранних стадиях. Для работы со S.M.A.R.T в Linux есть утилита smartmontools.
Давайте сначала ее установим. Если ваш дистрибутив основан на DebianUbuntu, то вводите:
Если же у Вас дистрибутив на основе RHELCentOS, то вводите:
Теперь, когда мы установили smartmontools мы можем посмотреть страницу помощи, с помощью команды:
Давайте перейдем к работе с утилитой. Вводим следующую команду с параметром -H,чтобы утилита показала нам информацию о состоянии накопителя:
Как видим, проверка диска на битые секторы linux завершена и утилита говорит нам, что с накопителем все в порядке!
Ещё одна команда, если SMART поддерживается, то добавляем -s. Если он не поддерживается или уже включён, то этот аргумент можно убрать.
Дополнительно, можно указать следующие параметры -a или —all, чтобы получить еще больше информации о накопителе, или -x и —xall, чтобы просмотреть информацию в том числе и об остальных параметрах накопителя.
Проверка HDD на бэд-блоки на Linux с помощью GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Ubuntu и всех Debian-подобных системах. В их число входит и проверка диска на ошибки.
Для начала нам нужно скачать и установить GParted. Вводим следующую команду, чтобы выполнить загрузку из официальных репозиториев:
- Открываем приложение. На главном экране сразу же выводятся все носители. Если какой-то из них помечен восклицательным знаком, значит, с ним уже что-то не так.
- Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Разделы», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может занять продолжительное время. После сканирования Вы будете оповещены о его результатах.
Safecopy
Это уже та программа, которую впору использовать на тонущем судне. Если мы осведомлены, что с нашим диском что-то не так, и нацелены спасти как можно больше выживших файлов, то Safecopy придёт на помощь. Её задача как раз заключается в копировании данных с повреждённых носителей. Причём она извлекает файлы даже из битых блоков.
Переносим файлы из одной директории в другую. Выбрать можно любую другую. В данном случае мы переносим данные с диска sda в папку home.
Если есть вопросы, то пишем в комментариях.
Также можете вступить в Телеграм канал, ВКонтакте или подписаться на Twitter. Ссылки в шапке страницы.
Заранее всем спасибо.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
В этой статье поговорим о том как записать iso-образ какой либо операционной системы из терминала Linux дистрибутива. Для Linux на Читать
Что такое SSD, в чём его отличие от HDD, на что стоит обратить внимание при выборе SSD накопителя и как Читать
Уникальный идентификатор компьютера в сети, построенной на базе стека TCP/IP. Сетевые устройства взаимодействуют друг с другом, используя его. На данный момент применяется Читать
Как быстр ваш USB? Как быстр ваш SSD-накопитель? Это очень распространенный вопрос. Я собрал и скомпилировал несколько тестов, которые помогут Читать
Источник
Одно из самых важных устройств компьютера — это жесткий диск, именно на нём хранится операционная система и вся ваша информация. Единица хранения информации на жестком диске — сектор или блок. Это одна ячейка в которую записывается определённое количество информации, обычно это 512 или 1024 байт.
Битые сектора, это повреждённые ячейки, которые больше не работают по каким либо причинам. Но файловая система всё ещё может пытаться записать в них данные. Прочитать данные из таких секторов очень сложно, поэтому вы можете их потерять. Новые диски SSD уже не подвержены этой проблеме, потому что там существует специальный контроллер, следящий за работоспособностью ячеек и перемещающий данные из нерабочих в рабочие. Однако традиционные жесткие диски используются всё ещё очень часто. В этой статье мы рассмотрим как проверить диск на битые секторы Linux.
Проверка диска на битые секторы Linux
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:
sudo fdisk -l /dev/sda1
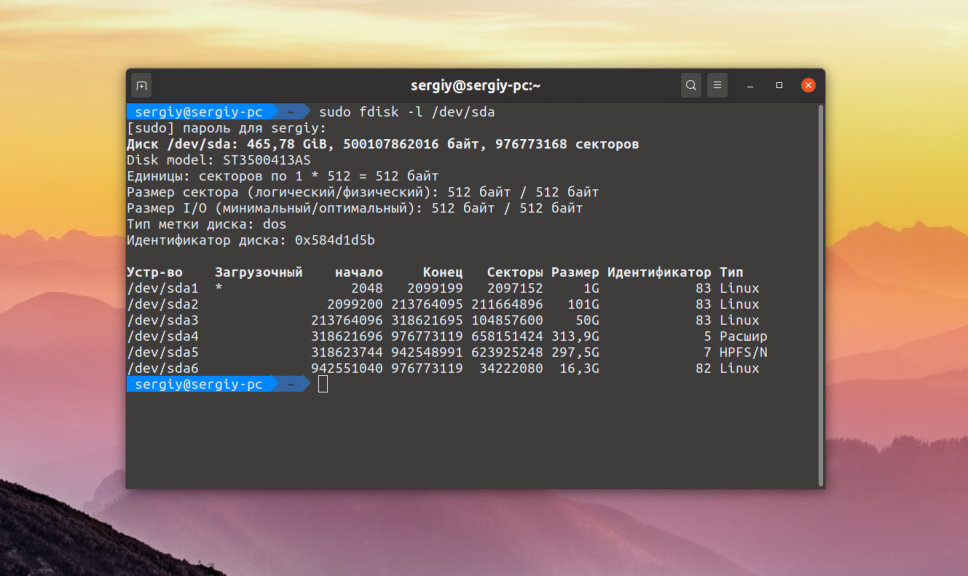
Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:
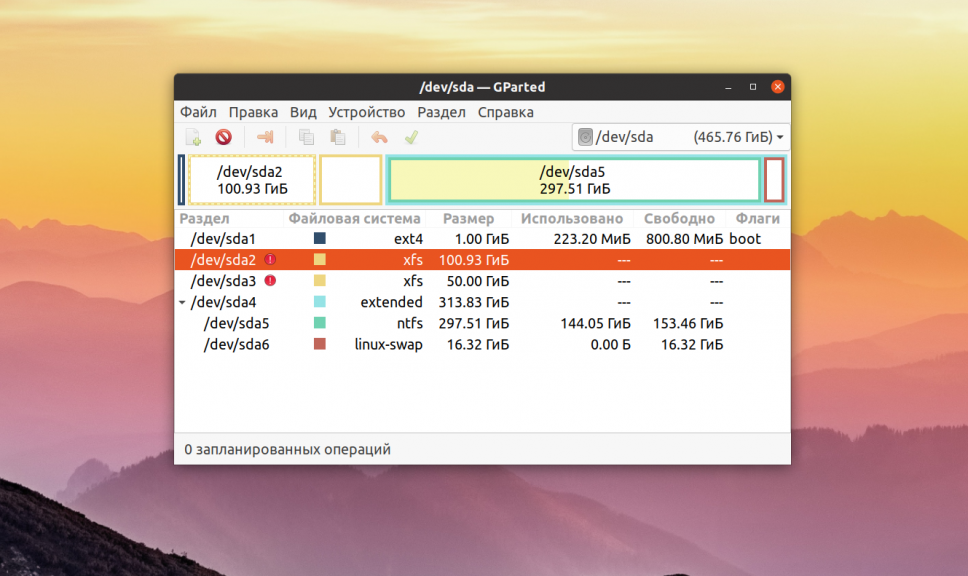
В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
- -e — позволяет указать количество битых блоков, после достижения которого дальше продолжать тест не надо;
- -f — по умолчанию утилита пропускает тест с помощью чтения/записи если файловая система смонтирована чтобы её не повредить, эта опция позволяет всё таки выполнять эти тесты даже для смонтированных систем;
- -i — позволяет передать список ранее найденных битых секторов, чтобы не проверять их снова;
- -n — использовать безопасный тест чтения и записи, во время этого теста данные не стираются;
- -o — записать обнаруженные битые блоки в указанный файл;
- -p — количество проверок, по умолчанию только одна;
- -s — показывать прогресс сканирования раздела;
- -v — максимально подробный режим;
- -w — позволяет выполнить тест с помощью записи, на каждый блок записывается определённая последовательность байт, что стирает данные, которые хранились там раньше.
Таким образом, для обычной проверки используйте такую команду:
sudo badblocks -v /dev/sda2 -o
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
sudo badblocks -vn /dev/sda2 -o
После завершения проверки, если были обнаружены битые блоки, надо сообщить о них файловой системе, чтобы она не пыталась писать туда данные. Для этого используйте утилиту fsck и опцию -l:
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
sudo e2fsck -cfpv /dev/sda1
Параметр -с позволяет искать битые блоки и добавлять их в список, -f — проверяет файловую систему, -p — восстанавливает повреждённые данные, а -v выводит всё максимально подробно.
Выводы
В этой статье мы рассмотрели как выполняется проверка диска на битые секторы Linux, чтобы вовремя предусмотреть возможные сбои и не потерять данные. Но на битых секторах проблемы с диском не заканчиваются. Там есть множество параметров стабильности работы, которые можно отслеживать с помощью таблицы SMART. Читайте об этом в статье Проверка диска в Linux.
Источник
Проверка состояния накопителей в Linux
Проверка и анализ состояния накопителей в Linux с помощью консольных утилит badblocks, smartmontools и графической программы GSmartControl
- Встроенные жёсткие диски;
- Внешние жёсткие диски;
- USB-флеш-накопители (сленг. флешка);
- Карт памяти.
Проверка накопителей средствами badblocks
Утилита badblocks установлена по-умолчанию.
Для просмотра подключенных накопителей и разделов на них, введите команду:
Для проверки накопителя на битые сектора, выполнить команду:
-v – отображение подробной информации во время работы программы
/dev/sdX – имя устройства, которое необходимо проверить
> badblocks.txt – запись результатов проверки (сохраняется в домашней папке: /home/user)
При наличии битых секторов, можно воспользоваться утилитами: e2fsck (ext2, ext3, ext4), fsck (отличные от ext) для игнорирования системой битых секторов:
Проверка состояния накопителей при помощи S.M.A.R.T.
Установка:
Для проверки накопителя на битые сектора при помощи S.M.A.R.T., выполнить команду:
/dev/sdX – имя устройства, которое необходимо проверить
Проверка состояния накопителей при помощи GSmartControl
Чтобы установить самую свежую стабильную версию GSmartControl в Ubuntu, можно воспользоваться PPA репозиторием. Для этого выполните последовательно в терминале команды:
sudo sh -c “echo ‘deb http://download.opensuse.org/repositories/home:/alex_sh/Ubuntu_16.04/ /’ > /etc/apt/sources.list.d/gsmartcontrol.list”
wget -nv http://download.opensuse.org/repositories/home:alex_sh/Ubuntu_16.04/Release.key -O Release.key sudo apt-key add – Работа с программой:
Выбираем диск и кликаем левой клавишей мыши 2 раза или выбираем диск, потом идём в меню, там жмём на Device, далее жмём View details, далее жмём на вкладку Attributes:
Анализ параметров, выводимых программой
Каждый атрибут имеет величину Value. Value Изменяется в диапазоне от 0 до 255 задается производителем). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Raw Value – это значение атрибута во внутреннем формате производителя значение малоинформативно для всех кроме сервисманов. Threshold – минимальное возможное значение атрибута, при котором гарантируется безотказная работа накопителя. SMART. Смотрим состояние жесткого диска. Если VALUE стало меньше THRESH – Атрибут считается failed и отображается в столбце WHEN_FAILED. При значении атрибута меньше Threshold очень вероятен сбой в работе или полный отказ. WORST- минимальное нормализованное значение. Это минимальное значение, которое достигалось с момента включения SMART на диске. Атрибуты бывают критически важными (Pre-fail) и некритически важными (Old_age). Выход критически важного параметра за пределы Threshold фактический означает выход диска из строя, выход за пределы допустимых значений не критически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность.
Критичные атрибуты
Raw Read Error Rate – частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time – время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся не максимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например просадка по вольтажу блока питания.
Spin Up Retry Count – число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно не максимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate – частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count – число операций переназначения секторов. SMART в современных дисках способен произвести анализ сектора на стабильность работы “на лету” и в случае признания его сбойным, произвести его переназначение.
Некритичные атрибуты:
Start/Stop Count – полное число запусков/остановов шпинделя. Гарантировано мотор диска способен перенести лишь определенное число включений/выключений. Это значение выбирается в качестве Treshold. Первые модели дисков со скоростью вращения 7200 оборотов/мин имели ненадежный двигатель, могли перенести лишь небольшое их число и быстро выходили из строя.
Power On Hours – число часов проведенных во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF). Обычно величина MTBF огромна, и маловероятно, что этот параметр достигнет критического порога. Но даже в этом случае выход из строя диска совершенно не обязателен.
Drive Power Cycle Count – количество полных циклов включения-выключения диска. По этому и предыдущему атрибуту можно оценить, например, сколько использовался диск до покупки.
Temperatue – Здесь хранятся показания встроенного термодатчика. Температура имеет огромное влияние на срок службы диска (даже если она находится в допустимых пределах). Вернее имеет влияние не на срок службы диска а на частоту возникновения некоторых типов ошибок, которые влияют на срок службы.
Current Pending Sector Count – Число секторов, являющихся кандидатами на замену. Они не были ещё определены как плохие, но считывание их отличается от чтения стабильного сектора, так называемые подозрительные или нестабильные сектора.
Uncorrectable Sector Count – число ошибок при обращении к сектору, которые не были скорректированы. Возможными причинами возникновения могут быть сбои механики или порча поверхности.
UDMA CRC Error Rate – число ошибок, возникающих при передаче данных по внешнему интерфейсу. Могут быть вызваны некачественными кабелями, нештатными режимами работы.
Write Error Rate – показывает частоту ошибок происходящих при записи на диск. Может служить показателем качества поверхности и механики накопителя.
Источник
![]()
How do I check the physical health of a USB stick in Linux operating systems? How do I check USB flash drive in Linux? Can you tell me Linux command to test and detect bad sector in USB flash memory or pen drives?
USB pen or stick is popular removable storage media. Like every other computer part, it will wear out with time. USB flash drive may develop bad sectors. Sometimes you buy a brand new pen drive and find out that it is not working. This page explains how to check the health status of a USB stick in Linux and obtain status so that you know if it is beyond repair or not.
Linux check USB stick or errors
The procedure to check the physical health of a USB pen drive in Linux:
- Open the terminal application.
- Insert your USB stick or pen drive into Linux system.
- To test and detect bad sector in USB flash memory or pen drive, run: badblocks -w -s -o error.log /dev/sdX
- To error check USB flash drive, you can use the f3write and f3read commands, which is an alternative to h2testw app from Windows operating systems.
Let us see all commands and examples in details.
Linux command to check the physical health of a USB stick
First, find out your USB stick or flash drive name under Linux, run:lsblk
The output indicated that I am using /dev/sda for USB and /dev/nvme0n1 for NVme pci ssd.
Warning: This will destroy any previously stored data on your USB pen/stick. Make sure you choose correct USB device name under Linux.
Once inserted the USB pen/stick, run the following command to search a device for bad blocks:sudo badblocks -w -s -o error.log /dev/sda
Where options are as follows:
- -w : Use write-mode test to scans for bad blocks by writing some patternson every block of the device, reading every block and comparing the contents.
- -s : Show the progress of the scan.
- -o error.log : Write the list of bad blocks to the error.log file in the current working directory.
Use the cat command to view error.log:cat error.log
Say hello to f3 tool
From the project home page:
f3 is a simple tool that tests flash cards capacity and performance to see if they live up to claimed specifications.
F3 stands for Fight Flash Fraud, or Fight Fake Flash.
How to install f3 tool on Linux
First, make sure you have compilers installed and running on Linux. If not, see the following tutorilas:
Download file using the wget command:wget https://github.com/AltraMayor/f3/archive/v7.2.tar.gz
Untar tar ball on Linux, run:tar xvf v7.2.tar.gz
Compile it:make
Install it:make install
Testing performance with f3read/f3write
Use the following two command. First, f3write will write large files to your mounted USB pen disk. For example, my /dev/sda is mounted at /mnt/:f3write /mnt/
Next, f3read will check if the flash disk contains exactly the written files:f3read /mnt/
Zero data lost indicate that my USB pen drive working fine.


Quick capacity tests with f3probe on Linux
If you believe you have bought a fake flash drive, try the following Linux commands. The f3probe command is the fastest drive test and suitable for large disks because it only writes what’s necessary to test the drive. It operates directly on the (unmounted) block device and needs to be run as a privileged user (be careful with device names again as --destructive option deletes all data):sudo ./f3probe --destructive --time-ops /dev/sdb
Sample outputs:
[sudo] password for vivek:
F3 probe 7.2
Copyright (C) 2010 Digirati Internet LTDA.
This is free software; see the source for copying conditions.
WARNING: Probing normally takes from a few seconds to 15 minutes, but
it can take longer. Please be patient.
Good news: The device `/dev/sdb' is the real thing
Device geometry:
*Usable* size: 15.24 GB (31969278 blocks)
Announced size: 15.24 GB (31969278 blocks)
Module: 16.00 GB (2^34 Bytes)
Approximate cache size: 0.00 Byte (0 blocks), need-reset=no
Physical block size: 512.00 Byte (2^9 Bytes)
Probe time: 5'16"
Operation: total time / count = avg time
Read: 1.95s / 4814 = 405us
Write: 5'11" / 4192321 = 74us
Reset: 1us / 1 = 1us
The outputs from the above indicate that I do not have fake usb drive.
Good news: The device `/dev/sdb’ is the real thing
How to correct capacity to actual size for my USB stick in Linux
Run f3fix command to creates a partition that fits the actual size of the fake drive. Only use to correct size for the fake drive. Use f3probe’s output to determine the parameters for i3fix:sudo ./f3fix --last-sec=16477878 /dev/sdb
Conclusion
You learned how to check the health status of a USB stick in Linux and further learned how to find out the actual size of a USB pen drive in case you got a faked USB pen drive.
The author is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a trainer for the Linux operating system/Unix shell scripting. Get the latest tutorials on SysAdmin, Linux/Unix and open source topics via RSS/XML feed or weekly email newsletter.