Площадь под ROC-кривой – один из самых популярных функционалов качества в задачах бинарной классификации. На мой взгляд, простых и полных источников информации «что же это такое» нет. Как правило, объяснение начинают с введения разных терминов (FPR, TPR), которые нормальный человек тут же забывает. Также нет разборов каких-то конкретных задач по AUC ROC. В этом посте описано, как я объясняю эту тему студентам и своим сотрудникам…

Допустим, решается задача классификации с двумя классами {0, 1}. Алгоритм выдаёт некоторую оценку (может, но не обязательно, вероятность) принадлежности объекта к классу 1. Можно считать, что оценка принадлежит отрезку [0, 1].
Часто результат работы алгоритма на фиксированной тестовой выборке визуализируют с помощью ROC-кривой (ROC = receiver operating characteristic, иногда говорят «кривая ошибок»), а качество оценивают как площадь под этой кривой – AUC (AUC = area under the curve). Покажем на конкретном примере, как строится кривая.
Пусть алгоритм выдал оценки, как показано в табл. 1. Упорядочим строки табл. 1 по убыванию ответов алгоритма – получим табл. 2. Ясно, что в идеале её столбец «класс» тоже станет упорядочен (сначала идут 1, потом 0); в самом худшем случае – порядок будет обратный (сначала 0, потом 1); в случае «слепого угадывания» будет случайное распределение 0 и 1.
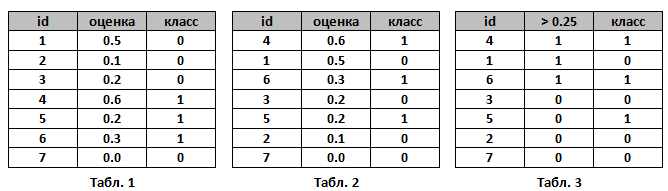
Чтобы нарисовать ROC-кривую, надо взять единичный квадрат на координатной плоскости, см. рис. 1, разбить его на m равных частей горизонтальными линиями и на n – вертикальными, где m – число 1 среди правильных меток теста (в нашем примере m=3), n – число нулей (n=4). В результате квадрат разбивается сеткой на m×n блоков.
Теперь будем просматривать строки табл. 2 сверху вниз и прорисовывать на сетке линии, переходя их одного узла в другой. Стартуем из точки (0, 0). Если значение метки класса в просматриваемой строке 1, то делаем шаг вверх; если 0, то делаем шаг вправо. Ясно, что в итоге мы попадём в точку (1, 1), т.к. сделаем в сумме m шагов вверх и n шагов вправо.

На рис. 1 (справа) показан путь для нашего примера – это и является ROC-кривой. Важный момент: если у нескольких объектов значения оценок равны, то мы делаем шаг в точку, которая на a блоков выше и b блоков правее, где a – число единиц в группе объектов с одним значением метки, b – число нулей в ней. В частности, если все объекты имеют одинаковую метку, то мы сразу шагаем из точки (0, 0) в точку (1, 1).
AUC ROC – площадь под ROC-кривой – часто используют для оценивания качества упорядочивания алгоритмом объектов двух классов. Ясно, что это значение лежит на отрезке [0, 1]. В нашем примере AUC ROC = 9.5 / 12 ~ 0.79.
Выше мы описали случаи идеального, наихудшего и случайного следования меток в упорядоченной таблице. Идеальному соответствует ROC-кривая, проходящая через точку (0, 1), площадь под ней равна 1. Наихудшему – ROC-кривая, проходящая через точку (1, 0), площадь под ней – 0. Случайному – что-то похожее на диагональ квадрата, площадь примерно равна 0.5.

Замечание. ROC-кривая считается неопределённой для тестовой выборки целиком состоящей из объектов только одного класса. Большинство современных реализаций выдают ошибку при попытки построить её в этом случае
Сетка на рис. 1 разбила квадрат на m×n блоков. Ровно столько же пар вида (объект класса 1, объект класса 0), составленных из объектов тестовой выборки. Каждый закрашенный блок на рис. 1 соответствует паре (объект класса 1, объект класса 0), для которой наш алгоритм правильно предсказал порядок (объект класса 1 получил оценку выше, чем объект класса 0), незакрашенный блок – паре, на которой ошибся.

Таким образом, AUC ROC равен доле пар объектов вида (объект класса 1, объект класса 0), которые алгоритм верно упорядочил, т.е. первый объект идёт в упорядоченном списке раньше. Численно это можно записать так:

Замечание. В формуле (*) все постоянно ошибаются, забывая случай равенства ответов алгоритма на нескольких объектах. Также эту формулу все постоянно переоткрывают. Она хороша тем, что легко обобщается и на другие задачи обучения с учителем.
Принятие решений на основе ROC-кривой
Пока наш алгоритм выдавал оценки принадлежности к классу 1. Ясно, что на практике нам часто надо будет решить: какие объекты отнести к классу 1, а какие к классу 0. Для этого нужно будет выбрать некоторый порог (объекты с оценками выше порога считаем принадлежащими классу 1, остальные – 0).
Выбору порога соответствует выбор точки на ROC-кривой. Например, для порога 0.25 и нашего примера – точка указана на рис. 4 (1/4, 2/3). см. табл. 3

Заметим, что 1/4 – это процент точек класса 0, которые неверно классифицированы нашим алгоритмом (это называется FPR = False Positive Rate), 2/3 – процент точек класса 1, которые верно классифицированы нашим алгоритмом (это называется TPR = True Positive Rate). Именно в этих координатах (FPR, TPR) построена ROC-кривая. Часто в литературе её определяют как кривую зависимости TPR от FPR при варьировании порога для бинаризации.
Кстати, для бинарных ответов алгоритма тоже можно вычислить AUC ROC, правда это практически никогда не делают, поскольку ROC-кривая состоит из трёх точек, соединёнными линиями: (0,0), (FPR, TPR), (1, 1), где FPR и TPR соответствуют любому порогу из интервала (0, 1). На рис. 4 (зелёным) показана ROC-кривая бинаризованного решения, заметим, что AUC после бинаризации уменьшился и стал равным 8.5/12 ~ 0.71.

В общем случае, как видно из рис. 5 AUC ROC для бинарного решения равна
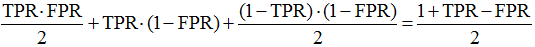
(как сумма площадей двух треугольников и квадрата). Это выражение имеет самостоятельную ценность и является «честной точностью» в задаче с дисбалансом классов (но об этом надо писать отдельный пост).
Задача
На ответах алгоритма a(x) объекты класса 0 распределены с плотностью p(a)=2-2a, а объекты класса 1 – с плотностью p(a)=2a, см. рис. 6. Интуитивно понятно, что алгоритм обладает некоторой разделяющей способностью (большинство объектов класса 0 имеют оценку меньше 0.5, а большинство объектов класса 1 – больше). Попробуйте угадать, чему здесь равен AUC ROC, а мы покажем как построить ROC-кривую и вычислить площадь под ней. Отметим, что здесь мы не работаем с конкретной тестовой выборкой, а считаем, что знаем распределения объектов всех классов. Такое может быть, например, в модельной задаче, когда объекты лежат в единичном квадрате, объекты выше одной из диагоналей принадлежат классу 0, ниже – классу 1, для решения используется логистическая регрессия (см. рис. 7). В случае, когда решение зависит только от одного признака (при втором коэффициент равен нулю), получаем как раз ситуацию, описанную в нашей задаче.


Значение TPR при выборе порога бинаризации равно площади, изображённой на рис. 6 (центр), а FPR – площади, изображённой на рис. 6 (справа), т.е.

Параметрическое уравнение для ROC-кривой получено, можно уже сразу вычислить площадь под ней:

Но если Вы не любите параметрическую запись, легко получить:

Заметим, что максимальная точность достигается при пороге бинаризации 0.5 (почему?), и она равна 3/4 = 0.75 (что не кажется очень большой). Это частая ситуация: AUC ROC существенно выше максимальной достижимой точности (accuracy)!
Кстати, AUC ROC бинаризованного решения (при пороге бинаризации 0.5) равна 0.75! Подумайте, почему это значение совпало с точностью?
В такой «непрерывной» постановке задачи (когда объекты двух классов описываются плотностями) AUC ROC имеет вероятностный смысл: это вероятность того, что случайно взятый объект класса 1 имеет оценку принадлежности к классу 1 выше, чем случайно взятый объект класса 0.

Для нашей модельной задачи можно провести несколько экспериментов: взять конечные выборки разной мощности с указанными распределениями. На рис. 8 показаны значения AUC ROC в таких экспериментах: все они распределены около теоретического значения 5/6, но разброс достаточно велик для небольших выборок. Запомните: для оценки AUC ROC выборка в несколько сотен объектов мала!

Также полезно посмотреть, как выглядят ROC-кривые в наших экспериментах. Естественно, при увеличении объёма выборок ROC-кривые, построенные по выборкам, будут сходиться к теоретической кривой (построенной для распределений).

Замечание
Интересно, что в рассмотренной задаче исходные данные линейны (например, плотности – линейные функции), а ответ (ROC-кривая) нелинейная (и даже неполиномиальная) функция!
Замечание
Почему-то многие считают, что ROC-кривая всегда является ступенчатой функцией – лишь при построении её для конечной выборки, в которой нет объектов с одинаковыми оценками. Полезно посмотреть на интерактивную визуализацию ROC-кривых для нормально распределённых классов.
Максимизация AUC ROC на практике
Оптимизировать AUC ROC напрямую затруднительно по нескольким причинам:
- эта функция недифференцируема по параметрам алгоритма,
- она в явном виде не разбивается на отдельные слагаемые, которые зависят от ответа только на одном объекте (как происходит в случае log_loss).
Есть несколько подходов к оптимизации
- замена в (*) индикаторной функции на похожую дифференцируемую функцию,
- использование смысла функционала (если это вероятность верного упорядочивания пары объектов, то можно перейти к новой выборке, состоящей из пар),
- ансамблирование нескольких алгоритмов с преобразованием их оценок в ранги (логика здесь простая: AUC ROC зависит только от порядка объектов, поэтому конкретные оценки не должны существенно влиять на ответ).
Замечания
- AUC ROC не зависит от строго возрастающего преобразования ответов алгоритма (например, возведения в квадрат), поскольку зависит не от самих ответов, а от меток классов объектов при упорядочивании по этим ответам.
- Часто используют критерий качества Gini, он принимает значение на отрезке [–1, +1] и линейно выражается через площадь под кривой ошибок:
Gini = 2 ×AUC_ROC – 1
- AUC ROC можно использовать для оценки качества признаков. Считаем, что значения признака — это ответы нашего алгоритма (не обязательно они должны быть нормированы на отрезок [0, 1], ведь нам важен порядок). Тогда выражение 2×|AUC_ROC — 0.5| вполне подойдёт для оценки качества признака: оно максимально, если по этому признаку 2 класса строго разделяются и минимально, если они «перемешаны».
- Практически во всех источниках приводится неверный алгоритм построения ROC-кривой и вычисления AUC ROC. По нашему описанию легко эти алгоритмы исправить…
- Часто утверждается, что AUC ROC не годится для задач с сильным дисбалансом классов. При этом приводятся совершенно некорректные обоснования этого. Рассмотрим одно из них. Пусть в задаче 1 000 000 объектов, при этом только 10 объектов из первого класса. Допустим, что объекты это сайты интернета, а первый класс – сайты, релевантные некоторому запросу. Рассмотрим алгоритм, ранжирующий все сайты в соответствии в эти запросом. Пусть он в начало списка поставил 100 объектов класса 0, потом 10 – класса 1, потом – все остальные класса 0. AUC ROC будет довольно высоким: 0.9999. При этом ответ алгоритма (если, например, это выдача поисковика) нельзя считать хорошей: в верхней части выдачи 100 нерелевантных сайтов. Разумеется, нам не хватит терпения пролистать выдачу и добраться до 10 тех самых релевантных.
В чём некорректность этого примера?! Главное: в том, что он никак не использует дисбаланс классов. С таким же успехом объектов класса 1 могло быть 500 000 – ровно половина, тогда AUC ROC чуть поменьше: 0.9998, но суть остаётся прежней. Таким образом, этот пример не показывает неприменимость AUC ROC в задачах с дисбалансом классов, а лишь в задачах поиска! Для таких задач есть другие функционалы качества, кроме того, есть специальные вариации AUC, например AUC@k. - В банковском скоринге AUC_ROC очень популярный функционал, хотя очевидно, что он также здесь не очень подходит. Банк может выдать ограниченное число кредитов, поэтому главное требование к алгоритму – чтобы среди объектов, которые получили наименьшие оценки были только представители класса 0 («вернёт кредит», если мы считаем, что класс 1 – «не вернёт» и алгоритм оценивает вероятность невозврата). Об этом можно судить по форме ROC-кривой (см. рис. 10).

П.С.
Если Вы дочитали до конца — можете попробовать пройти тест по AUC ROC (авторский, публикуется впервые). Задачи теста можно обсуждать в комментариях. Любые замечание по тексту — смело пишите!
Что можно ещё почитать…
- Wiki (и там есть хорошие ссылки!)
- Логистическая регрессия и ROC-анализ — математический аппарат
- Задачки про AUC (ROC)
Метрики в задачах машинного обучения
Время на прочтение
9 мин
Количество просмотров 555K
Привет, Хабр!

В задачах машинного обучения для оценки качества моделей и сравнения различных алгоритмов используются метрики, а их выбор и анализ — непременная часть работы датасатаниста.
В этой статье мы рассмотрим некоторые критерии качества в задачах классификации, обсудим, что является важным при выборе метрики и что может пойти не так.
Метрики в задачах классификации
Для демонстрации полезных функций sklearn и наглядного представления метрик мы будем использовать датасет по оттоку клиентов телеком-оператора.
Загрузим необходимые библиотеки и посмотрим на данные
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pylab import rc, plot
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import precision_recall_curve, classification_report
from sklearn.model_selection import train_test_split
df = pd.read_csv('../../data/telecom_churn.csv')
df.head(5)
Предобработка данных
# Сделаем маппинг бинарных колонок
# и закодируем dummy-кодированием штат (для простоты, лучше не делать так для деревянных моделей)
d = {'Yes' : 1, 'No' : 0}
df['International plan'] = df['International plan'].map(d)
df['Voice mail plan'] = df['Voice mail plan'].map(d)
df['Churn'] = df['Churn'].astype('int64')
le = LabelEncoder()
df['State'] = le.fit_transform(df['State'])
ohe = OneHotEncoder(sparse=False)
encoded_state = ohe.fit_transform(df['State'].values.reshape(-1, 1))
tmp = pd.DataFrame(encoded_state,
columns=['state ' + str(i) for i in range(encoded_state.shape[1])])
df = pd.concat([df, tmp], axis=1)Accuracy, precision и recall
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов, тогда матрица ошибок классификации будет выглядеть следующим образом:
 |
 |
|
|---|---|---|
 |
True Positive (TP) | False Positive (FP) |
 |
False Negative (FN) | True Negative (TN) |
Здесь  — это ответ алгоритма на объекте, а
— это ответ алгоритма на объекте, а  — истинная метка класса на этом объекте.
— истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
Обучение алгоритма и построение матрицы ошибок
X = df.drop('Churn', axis=1)
y = df['Churn']
# Делим выборку на train и test, все метрики будем оценивать на тестовом датасете
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.33, random_state=42)
# Обучаем ставшую родной логистическую регрессию
lr = LogisticRegression(random_state=42)
lr.fit(X_train, y_train)
# Воспользуемся функцией построения матрицы ошибок из документации sklearn
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
font = {'size' : 15}
plt.rc('font', **font)
cnf_matrix = confusion_matrix(y_test, lr.predict(X_test))
plt.figure(figsize=(10, 8))
plot_confusion_matrix(cnf_matrix, classes=['Non-churned', 'Churned'],
title='Confusion matrix')
plt.savefig("conf_matrix.png")
plt.show()

Accuracy
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:

Эта метрика бесполезна в задачах с неравными классами, и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:

Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую accuracy:

При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
Precision, recall и F-мера
Для оценки качества работы алгоритма на каждом из классов по отдельности введем метрики precision (точность) и recall (полнота).


Precision можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными, а recall показывает, какую долю объектов положительного класса из всех объектов положительного класса нашел алгоритм.

Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive. Recall демонстрирует способность алгоритма обнаруживать данный класс вообще, а precision — способность отличать этот класс от других классов.
Как мы отмечали ранее, ошибки классификации бывают двух видов: False Positive и False Negative. В статистике первый вид ошибок называют ошибкой I-го рода, а второй — ошибкой II-го рода. В нашей задаче по определению оттока абонентов, ошибкой первого рода будет принятие лояльного абонента за уходящего, так как наша нулевая гипотеза состоит в том, что никто из абонентов не уходит, а мы эту гипотезу отвергаем. Соответственно, ошибкой второго рода будет являться «пропуск» уходящего абонента и ошибочное принятие нулевой гипотезы.
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Классическим примером является задача определения оттока клиентов.
Очевидно, что мы не можем находить всех уходящих в отток клиентов и только их. Но, определив стратегию и ресурс для удержания клиентов, мы можем подобрать нужные пороги по precision и recall. Например, можно сосредоточиться на удержании только высокодоходных клиентов или тех, кто уйдет с большей вероятностью, так как мы ограничены в ресурсах колл-центра.
Обычно при оптимизации гиперпараметров алгоритма (например, в случае перебора по сетке GridSearchCV ) используется одна метрика, улучшение которой мы и ожидаем увидеть на тестовой выборке.
Существует несколько различных способов объединить precision и recall в агрегированный критерий качества. F-мера (в общем случае  ) — среднее гармоническое precision и recall :
) — среднее гармоническое precision и recall :

 в данном случае определяет вес точности в метрике, и при
в данном случае определяет вес точности в метрике, и при  это среднее гармоническое (с множителем 2, чтобы в случае precision = 1 и recall = 1 иметь
это среднее гармоническое (с множителем 2, чтобы в случае precision = 1 и recall = 1 иметь  )
)
F-мера достигает максимума при полноте и точности, равными единице, и близка к нулю, если один из аргументов близок к нулю.
В sklearn есть удобная функция _metrics.classificationreport, возвращающая recall, precision и F-меру для каждого из классов, а также количество экземпляров каждого класса.
report = classification_report(y_test, lr.predict(X_test), target_names=['Non-churned', 'Churned'])
print(report)
| class | precision | recall | f1-score | support |
|---|---|---|---|---|
| Non-churned | 0.88 | 0.97 | 0.93 | 941 |
| Churned | 0.60 | 0.25 | 0.35 | 159 |
| avg / total | 0.84 | 0.87 | 0.84 | 1100 |
Здесь необходимо отметить, что в случае задач с несбалансированными классами, которые превалируют в реальной практике, часто приходится прибегать к техникам искусственной модификации датасета для выравнивания соотношения классов. Их существует много, и мы не будем их касаться, здесь можно посмотреть некоторые методы и выбрать подходящий для вашей задачи.
AUC-ROC и AUC-PR
При конвертации вещественного ответа алгоритма (как правило, вероятности принадлежности к классу, отдельно см. SVM) в бинарную метку, мы должны выбрать какой-либо порог, при котором 0 становится 1. Естественным и близким кажется порог, равный 0.5, но он не всегда оказывается оптимальным, например, при вышеупомянутом отсутствии баланса классов.
Одним из способов оценить модель в целом, не привязываясь к конкретному порогу, является AUC-ROC (или ROC AUC) — площадь (Area Under Curve) под кривой ошибок (Receiver Operating Characteristic curve ). Данная кривая представляет из себя линию от (0,0) до (1,1) в координатах True Positive Rate (TPR) и False Positive Rate (FPR):


TPR нам уже известна, это полнота, а FPR показывает, какую долю из объектов negative класса алгоритм предсказал неверно. В идеальном случае, когда классификатор не делает ошибок (FPR = 0, TPR = 1) мы получим площадь под кривой, равную единице; в противном случае, когда классификатор случайно выдает вероятности классов, AUC-ROC будет стремиться к 0.5, так как классификатор будет выдавать одинаковое количество TP и FP.
Каждая точка на графике соответствует выбору некоторого порога. Площадь под кривой в данном случае показывает качество алгоритма (больше — лучше), кроме этого, важной является крутизна самой кривой — мы хотим максимизировать TPR, минимизируя FPR, а значит, наша кривая в идеале должна стремиться к точке (0,1).
Код отрисовки ROC-кривой
sns.set(font_scale=1.5)
sns.set_color_codes("muted")
plt.figure(figsize=(10, 8))
fpr, tpr, thresholds = roc_curve(y_test, lr.predict_proba(X_test)[:,1], pos_label=1)
lw = 2
plt.plot(fpr, tpr, lw=lw, label='ROC curve ')
plt.plot([0, 1], [0, 1])
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.savefig("ROC.png")
plt.show()
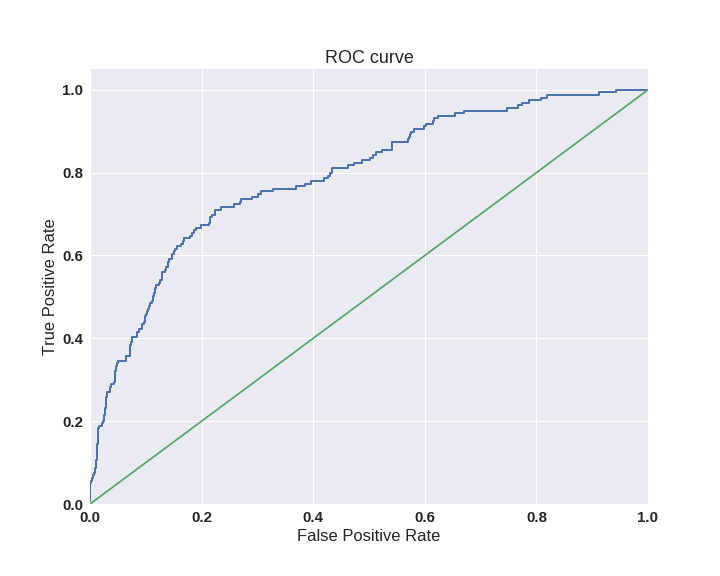
Критерий AUC-ROC устойчив к несбалансированным классам (спойлер: увы, не всё так однозначно) и может быть интерпретирован как вероятность того, что случайно выбранный positive объект будет проранжирован классификатором выше (будет иметь более высокую вероятность быть positive), чем случайно выбранный negative объект.
Рассмотрим следующую задачу: нам необходимо выбрать 100 релевантных документов из 1 миллиона документов. Мы намашинлернили два алгоритма:
- Алгоритм 1 возвращает 100 документов, 90 из которых релевантны. Таким образом,


- Алгоритм 2 возвращает 2000 документов, 90 из которых релевантны. Таким образом,

Скорее всего, мы бы выбрали первый алгоритм, который выдает очень мало False Positive на фоне своего конкурента. Но разница в False Positive Rate между этими двумя алгоритмами крайне мала — всего 0.0019. Это является следствием того, что AUC-ROC измеряет долю False Positive относительно True Negative и в задачах, где нам не так важен второй (больший) класс, может давать не совсем адекватную картину при сравнении алгоритмов.
Для того чтобы поправить положение, вернемся к полноте и точности :
- Алгоритм 1


- Алгоритм 2


Здесь уже заметна существенная разница между двумя алгоритмами — 0.855 в точности!
Precision и recall также используют для построения кривой и, аналогично AUC-ROC, находят площадь под ней.

Здесь можно отметить, что на маленьких датасетах площадь под PR-кривой может быть чересчур оптимистична, потому как вычисляется по методу трапеций, но обычно в таких задачах данных достаточно. За подробностями о взаимоотношениях AUC-ROC и AUC-PR можно обратиться сюда.
Logistic Loss
Особняком стоит логистическая функция потерь, определяемая как:

здесь — это ответ алгоритма на  -ом объекте, — истинная метка класса на -ом объекте, а
-ом объекте, — истинная метка класса на -ом объекте, а  размер выборки.
размер выборки.
Подробно про математическую интерпретацию логистической функции потерь уже написано в рамках поста про линейные модели.
Данная метрика нечасто выступает в бизнес-требованиях, но часто — в задачах на kaggle.
Интуитивно можно представить минимизацию logloss как задачу максимизации accuracy путем штрафа за неверные предсказания. Однако необходимо отметить, что logloss крайне сильно штрафует за уверенность классификатора в неверном ответе.
Рассмотрим пример:
def logloss_crutch(y_true, y_pred, eps=1e-15):
return - (y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
print('Logloss при неуверенной классификации %f' % logloss_crutch(1, 0.5))
>> Logloss при неуверенной классификации 0.693147
print('Logloss при уверенной классификации и верном ответе %f' % logloss_crutch(1, 0.9))
>> Logloss при уверенной классификации и верном ответе 0.105361
print('Logloss при уверенной классификации и НЕверном ответе %f' % logloss_crutch(1, 0.1))
>> Logloss при уверенной классификации и НЕверном ответе 2.302585Отметим, как драматически выросла logloss при неверном ответе и уверенной классификации!
Следовательно, ошибка на одном объекте может дать существенное ухудшение общей ошибки на выборке. Такие объекты часто бывают выбросами, которые нужно не забывать фильтровать или рассматривать отдельно.
Всё становится на свои места, если нарисовать график logloss:

Видно, что чем ближе к нулю ответ алгоритма при ground truth = 1, тем выше значение ошибки и круче растёт кривая.
Подытожим:
- В случае многоклассовой классификации нужно внимательно следить за метриками каждого из классов и следовать логике решения задачи, а не оптимизации метрики
- В случае неравных классов нужно подбирать баланс классов для обучения и метрику, которая будет корректно отражать качество классификации
- Выбор метрики нужно делать с фокусом на предметную область, предварительно обрабатывая данные и, возможно, сегментируя (как в случае с делением на богатых и бедных клиентов)
Полезные ссылки
- Курс Евгения Соколова: Семинар по выбору моделей (там есть информация по метрикам задач регрессии)
- Задачки на AUC-ROC от А.Г. Дьяконова
- Дополнительно о других метриках можно почитать на kaggle. К описанию каждой метрики добавлена ссылка на соревнования, где она использовалась
- Презентация Богдана Мельника aka ld86 про обучение на несбалансированных выборках
Благодарности
Спасибо mephistopheies и madrugado за помощь в подготовке статьи.
Классификация — одна из наиболее популярных технологий интеллектуального анализа данных. С необходимостью построения классификаторов рано или поздно сталкивается любой аналитик. Но даже построив модель, необходимо прежде всего убедиться в ее работоспособности. Для этого разработано большое количество мер качества. Наиболее популярные из них рассматриваются в данной статье.
Для классификационных моделей, как и для моделей регрессии, актуальна задача оценки их качества для определения работоспособности моделей и их сравнения. Однако решение этой задачи для моделей классификации вообще, и бинарной классификации в частности, сложнее, чем для регрессии. Связано это с тем, что целевая переменная (метка класса) является категориальным (дискретным) значением, и, следовательно, ошибка классификации не может быть выражена числовым значением.
Поэтому в основе оценки качества классификационных моделей лежит статистика результатов классификации обучающих примеров. С ее помощью вычисляются метрики качества — показатели, которые зависят от результатов классификации и не зависят от внутреннего состояния модели.
Среди наиболее популярных методов оценки качества классификаторов можно выделить следующие:
- Матрица ошибок (Сonfusion matrix).
- Меткость (Accuracy).
- Точность (Precision).
- Полнота (Recall).
- Специфичность (Specificity).
- F1-мера (F1-score).
- Метрика P4 .
- Площадь под ROC-кривой (Area under ROC-curve, AUC-ROC).
- Площадь под кривой полнота-точность (Area under precision-recall curve, AUC-PR).
- Коэффициент корреляции Мэтьюса (Matthews correlation coefficient, MCC).
- Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Матрица ошибок
Прежде чем переходить к описанию собственно метрик качества бинарных классификаторов, рассмотрим методику описания этих метрик в терминах ошибок классификации. Пусть заданы два класса y=\left \{ 0,1 \right \} и алгоритм, предсказывающий принадлежность каждого объекта одному из классов. Эта задача анализа известна как бинарная классификация.
Приведем пример. Пусть в страховой компании используется аналитическая платформа для поддержки принятия решений о целесообразности страхования того или иного объекта. Если риск наступления страхового события выше определенного порога, то такие объекты страховать нецелесообразно. Именно выявление таких объектов и является целью анализа. Тогда для объектов, страхование которых целесообразно, система должна установить класс 0, а объектам, в страховании которых отказано, — класс 1.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- класс 0 распознается классификатором как класс 1, что можно интерпретировать как «ложную тревогу»;
- класс 1 распознается как класс 0, что можно трактовать как «пропуск цели».
Очевидно, что приведенные ошибки неравноценны по связанным с ними издержкам классификации. В случае «ложной тревоги» компания потеряет только потенциальную страховую премию, т.е. будет иметь место всего лишь упущенная выгода. В случае «пропуска цели» возможна потеря значительной суммы из-за наступления страхового случая. Поэтому важнее не допустить «пропуск цели», чем «ложную тревогу».
Иными словами, важнее правильно определить объект, нежелательный для страхования из-за высокого риска, чем ошибиться в распознавании желательного. Будем называть соответствующий исход классификации положительным (объект не подлежит страхованию y=1), а противоположный — отрицательным (объект подлежит страхованию y=0). Тогда возможны следующие исходы классификации:
- Объект, нежелательный для страхования, классифицирован как нежелательный, т.е. «положительный» класс распознан как положительный. Такой исход классификации (а также пример, для которого он получен) называют истинноположительным.
- Объект, желательный для страхования, распознан как желательный, т.е. «отрицательный» класс распознан как отрицательный. Такой исход классификации называют истинноотрицательными.
- Объект, желаемый для страхования, классифицирован как не желаемый, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Данный исход классификации называют ложноположительным, а ошибка классификации называется ошибкой I рода.
- Нежелательный объект распознан как желательный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Такой исход классификации называется ложноотрицательным, а ошибка классификации — ошибкой II рода.
Таким образом, ошибка I рода, или ложноположительный исход классификации, имеет место, когда пример, с которым связано отрицательное событие распознан моделью как положительный. Ошибкой II рода, или ложноотрицательным исходом классификации, называют случай, когда пример, с которым связано положительное событие, распознан как отрицательный. Поясним это с помощью матрицы ошибок классификации, называемой также таблицей сопряженности:
| y=0 | y=1 | |
|---|---|---|
| \widehat{y}=0 | Истинноположительный (True Positive — TP) | Ложноположительный (False Positive — FP) |
| \widehat{y}=1 | Ложноотрицательный (False Negative — FN) | Истинноотрицательный (True Negative — TN) |
Здесь \widehat{y} — отклик модели, а y — фактическое значение. Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). В данном случае P означает, что классификатор определяет класс объекта как положительный, а N как — отрицательный. T значит, что класс предсказан правильно, соответственно, F — неправильно. Каждая строка в матрице ошибок представляет предсказанный класс, а каждый столбец — фактически наблюдаемый класс.
Идеальный классификатор, если бы он существовал, выдавал бы только истинноположительные и истинноотрицательные классификации, и его матрица ошибок содержала бы значения, отличные от нуля, только на главной диагонали.
Меткость
Представляет собой долю правильных классификаций модели:
ACC=\frac{TP+TN}{TP+TN+FP+FN}.
Несложно увидеть, что сумма в знаменателе формулы представляет собой общее число классифицируемых примеров. Графически это можно интерпретировать следующим образом:
Рисунок 1. Меткость
В английском языке этот термин обозначается как «accuracy», поэтому в интернете он часто упоминается как «аккуратность», хотя это слово и не передает смыслового значения данной величины.
Несмотря на то, что эта мера хорошо интерпретируется, на практике она используется достаточно редко, поскольку плохо работает в случае дисбаланса классов в обучающей выборке.
Поясним это на примере кредитного скоринга. Пусть требуется классифицировать заемщиков на добросовестных (не допустивших просрочку) и недобросовестных (допустивших просрочку). Целью является выявление недобросовестных заемщиков, поскольку связанные с ними издержки выше. Следовательно, классификация заемщика как недобросовестного является положительным событием, а как добросовестного — отрицательным.
Выборка содержит 1000 добросовестных заемщиков, 900 из которых классификатор предсказал правильно (TN=900, FP=100), и 100 недобросовестных, 50 из которых классификатор также определил верно (TP=50, FN=50).
Несложно вычислить, что:
ACC=\frac{50+900}{50+900+100+50}=0.866.
Однако, если построить «наивную» модель, которая просто будет классифицировать всех клиентов, как добросовестных (на основании того, что таковых большинство), то меткость такой модели окажется:
ACC=\frac{0+1000}{0+1000+0+100}=0.909.
Таким образом, оказалось, что меткость «бесполезной» модели, не имеющей предсказательной силы, выше, чем «рабочей» модели. Это противоречит здравому смыслу. Поэтому на практике стараются использовать альтернативные меры качества.
Точность
Точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение:
Pr=PPV=\frac{TP}{TP+FP}.
Поясним данное выражение с помощью рисунка:
Рисунок 2. Точность
Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту FP и уменьшению значения точности.
Полнота
Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений:
Re=TPR=\frac{TP}{TP+FN}.
Таким образом, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно проиллюстрировать с помощью рисунка:
Рисунок 3. Полнота
Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса.
PPV_{c}=\frac{A_{cc}}{\sum\limits_{i=1}^{n}A_{ci}},
TPR_{c}=\frac{A_{cc}}{\sum\limits_{i=1}^{n}A_{ic}},
где c — класс, n — число элементов столбца (равно числу классов), i — номер элемента в столбце, A — элемент матрицы ошибок.
Специфичность
Специфичность классификатора — это доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций:
Sp=TNR=\frac{TN}{TN+FP}.
TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Поясним это с помощью рисунка.
Рисунок 4. Специфичность
Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
F1-мера
Точность и полнота, в отличие от меткости, не зависят от соотношения классов и, следовательно, могут применяться в условиях несбалансированных выборок. На практике часто встречается задача поиска оптимального баланса между точностью и полнотой. Действительно, улучшая настройку модели на один класс, например, путем изменения дискриминационного порога, мы тем самым ухудшаем настройку на другой.
Чем выше точность и полнота, тем лучше модель. Но на практике их максимальные значения одновременно недостижимы, поэтому приходится искать баланс между ними. Для этого используется метрика, объединяющая в себе информацию о точности и полноте. Она называется F1-мера и вычисляется следующим образом:
F1=\frac{2\cdot PPV\cdot TPR}{PPV+TPR}=\frac{2\cdot TP}{2\cdot TP+FP+FN}.
В данном выражении точность PPV и полнота TPR имеют одинаковый вес, поэтому при их уменьшении F1-мера сокращается пропорционально.
Однако на практике чаще используется сбалансированная F1-мера, в которой точности и полноте присваиваются разные веса с целью найти оптимальный баланс между данными метриками. Для этого в формулу для F1-меры вводится дополнительный балансировочный параметр, обозначаемый β. Сбалансированная F1-мера вычисляется следующим образом:
F1=\frac{(1-\beta ^{2})\cdot PPV\cdot TPR}{\beta ^{2}\cdot PPV+TPR}.
Если параметр принимает значения из диапазона 0< \beta < 1, то приоритет имеет точность, а если \beta> 1, то полнота.
Еще одним источником критики F1-меры является отсутствие симметрии. Это означает, что она может изменить свое значение при инверсии положительного и отрицательного классов.
Метрика P4
Метрика P_{4} была разработана как расширение F1-меры, обладающее симметрией относительно инверсии классов. Вычисляется по формуле:
P_{4}=\frac{4\cdot TP\cdot TN}{4\cdot TP\cdot TN+(TP+TN)\cdot (FP+FN)}.
Метрика P_{4} изменяется в диапазоне от 0 до 1. Чем ближе значение метрики к 1, тем лучше работает модель. Очевидно, что значение меры стремится к 0, если хотя бы один из множителей в числителе становится равным нулю, т.е. когда модель теряет способность правильно распознавать положительные или отрицательные примеры.
AUC-ROC
ROC-кривая, или кривая рабочих характеристик приемника (Receiver Operating Characteristics curve), позволяет не только оценить качество работы классификатора, но и исследовать его поведение при различных значениях дискриминационного порога. Технология оценки качества моделей бинарной классификации с помощью ROC-кривых известна как ROC-анализ.
Рассмотрим совместно TPR и TNR классификатора. TPR показывает, насколько хорошо модель классифицирует положительные примеры. Очевидно, что если все положительные примеры классифицированы правильно (т.е. число ложноотрицательных случаев равно 0), то TPR=1. TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
Таким образом, по отдельности TPR и TNR характеризуют способность модели распознавать только один из классов. Но их совместное использование помогает создать метрику, которая позволяет выбирать значение дискриминационного порога, который оптимально балансирует модель между способностью распознавать положительные и отрицательные примеры. Именно эта задача и решается с помощью ROC-кривой.
Действительно, если изменять дискриминационный порог от 0 до 1 и наносить по оси абсцисс точки 1−TNR, а по оси ординат TPR, то полученный график и будет ROC-кривой. Величину 1−TNR называют долей ложноположительных классификаций (false positive rate) или показателем ложной тревоги. Она вычисляется следующим образом:
1-TNR=FPR=\frac{FP}{FP+TN}.
При пороге, равном 1, все примеры будут классифицированы как отрицательные (FPR=1, TPR=1), а при пороге, равном 0, — как положительные (FPR=0, TPR=0). Поэтому ROC-кривая всегда идет от точки (0,0) до точки (1,1).
Рисунок 5. ROC-кривая
Несложно увидеть, что для идеальной модели ROC-кривая превращается в ломаную, проходящую через точки (0,0), (0,1) и (1,1). При этом площадь под ROC-кривой (AUC — Area Under Curve) окажется равной 1. Площадь под кривой выделена на рисунке светло-серым цветом.
Точка (0,1) соответствует идеальному состоянию модели, в котором и TPR, и TNR одновременно равны 1. Т.е. модель одинаково хорошо «научилась» работать как с положительными, так и с отрицательными примерами при существующем в обучающей выборке балансе классов.
Идеальная модель является скорее гипотетической и на практике, как правило, недостижима. Поэтому обычно приходится иметь дело с ROC-кривыми, которые не проходят через точку (0,1), а приближаются к ней на определенное расстояние. Соответственно и AUC−ROC оказывается меньше 1.
Таким образом показатель AUC−ROC является удобной мерой качества классификатора относительно идеального. Принята следующая шкала оценки качества.
| AUC | Оценка |
|---|---|
| 0.9 — 1 | Отличное |
| 0.8 — 0.9 | Очень хорошее |
| 0.7 — 0.8 | Хорошее |
| 0.6 — 0.7 | Удовлетворительное |
| 0.5 — 0.7 | Плохое |
Если AUC-ROC=0.5, то ROC-кривая превращается в линию, проходящую через точки (0,0) и (1,1), которая соответствует бесполезному классификатору, работающему как случайный предсказатель. Если AUC-ROC< 0.5, то получается модель, которая работает хуже случайного предсказателя и от ее использования следует отказаться.
AUC-PR
PR-кривые определяются аналогично ROC-кривым, но только по оси абсцисс у них откладываются значения полноты, а по оси ординат — точности.
Точность и полнота — две наиболее важные метрики, на которые следует обращать внимание при оценке качества модели бинарной классификации в условиях несбалансированности классов. Они помогают увидеть, какая часть фактически положительных наблюдений была классифицирована правильно, и какие среди классифицированных как положительные, были истинноположительными.
Если точность равна 1, то ложноположительные классификации отсутствуют. Но это ничего не говорит о том, были ли распознаны все положительные примеры. Если полнота равна 1, то все положительные объекты были распознаны правильно, а ложноотрицательные классификации отсутствуют. При этом ничего не говорится о том, сколько было допущено ложноположительных классификаций.
Таким образом, точность и полнота не особенно полезны для оценки качества классификатора, если их использовать по отдельности. В задаче классификации оценка точности, равная 1 для класса C, означает, что каждый элемент, помеченный как принадлежащий классу C, действительно принадлежит к классу C, но ничего не говорит о количестве элементов из класса
C, которые не были правильно классифицированы. Тогда как полнота, равная 1, означает, что каждый элемент из класса C был помечен как принадлежащий к классу C, но ничего не говорит о том, сколько элементов из других классов были также неправильно классифицированы как принадлежащие к классу C.
Обычно показатели точности и полноты не используются по отдельности. Вместо этого либо значения одной меры сравниваются с фиксированным уровнем другой (например, точность на уровне полноты 0.75), либо обе меры объединяются в один показатель. Примерами такой комбинации и является F1-мера — взвешенное гармоническое среднее точности и полноты.
Еще одним способом комбинирования точности и полноты в задаче оценки качества классификации являются так называемые кривые полнота-точность, которые строятся в системе координат, где по оси абсцисс откладывается полнота, а по оси ординат — точность. Кривая точность-полнота показывает, как выбор порога влияет на точность классификатора, а также помогает выбрать лучшее значение дискриминационного порога для определенного баланса классов.
Рисунок 6. Кривая точность-полнота
Каждая точка PR-кривой представляет определенное значение дискриминационного порога, а ее расположение соответствует результирующей точности и полноте, когда этот порог выбран. Точка 1 на рисунке соответствует значению дискриминационного порога, равному 1, а точка 3 — значению порога 0. Точка 2 соответствует идеальному классификатору и совпадает с координатами (1,1), а точка 4 — оптимальному значению порога (точка кривой, наиболее близкая к идеальной точке (1,1)).
Преимущества PR-кривой по сравнению с ROC:
- ROC-кривая, как правило, дает чрезмерно оптимистичную картину в условиях несбалансированности классов.
- При изменении распределения классов ROC-кривая не меняется, а PR-кривая отражает изменение.
Аналогично ROC-кривой, площадь под PR-кривой (для отличия от ROC ее часто называют PR−AUC) отражает качество классификатора и позволяет сравнивать кривые, соответствующие различным балансам классов и значениям порога. Чем выше площадь, тем лучше работает модель.
Пунктирная линия внизу графика соответствует бесполезному классификатору (no-skill model — модель без навыков, или базовая модель), уровень которой изменяется при изменении баланса классов. Такая модель будет присваивать рейтинг 0.5 для любого примера.
На рисунке ниже представлена линия, соответствующая балансу классов, когда положительные примеры составляют 10% от обучающей выборки.
Рисунок 7. Кривая точность-полнота при фиксированном балансе классов
На рисунке точка 1 соответствует порогу 0.5, точка 2 соответствует порогу [0, 0.5). Для порогов (0.5, 1] точность не определена из-за деления на ноль. Можно увидеть, что точность здесь является константой, то есть PPV=0.1 (соответствует доле положительного класса), PR−AUC=0.1.
Таким образом, полнота базовой модели лежит в диапазоне (0.5, 1] независимо от дисбаланса классов, а точность равна доле положительного класса в обучающей выборке.
На следующем рисунке представлена PR-кривая для идеальной модели. На ней точка 1 соответствует порогу (0, 1], точка 2 соответствует порогу 0. Очевидно, что PR−AUC=1.
Рисунок 8. Кривая точность-полнота для идеальной модели
И, наконец, на рисунке ниже отображена PR-кривая (красная линия) для модели, которая работает хуже, чем базовая модель «без навыков» (синяя пунктирная линия). Она расположена ниже линии базовой модели.
Рисунок 9. Кривая точность-полнота для модели хуже бесполезной
Очевидный способ повысить качество «плохой» модели без каких-либо настроек — просто инвертировать классы (класс 0 изменить на класс 1). Это автоматически приведет к повышению точности по сравнению с базовой моделью.
Обычно «плохая» PR-кривая классификатора указывает на то, что в обучающих данных присутствуют проблемы: они содержат шум или классы в них плохо выражены (модель не может выявить закономерность, в соответствии с которой один класс отличается от другого). В этом случае PR−AUC не превышает доли положительных примеров обучающей выборке.
Возможен гибридный случай, когда «плохая» модель работает лучше, чем модель «без навыков», но для определенных пороговых значений.
Коэффициент корреляции Мэтьюса
Коэффициент используется в качестве показателя качества бинарных классификаторов. Он учитывает истинные и ложные классификации и обычно рассматривается как сбалансированная мера, которую можно использовать даже в условиях сильного дисбаланса классов.
MCC, по сути, коэффициент корреляции между фактическими и предсказанными моделью бинарными классификациями. Он изменяется в диапазоне от -1 до 1. MCC=1 указывает на идеальную классификацию, когда фактические и предсказанные классы совпадают для всех обучающих примеров (т.е. ложноположительные и ложноотрицательные классификации отсутствуют). Модель, для которой MCC=0, соответствует случайному предсказателю. MCC=−1 указывает на полное расхождение между фактом и предсказанием (т.е. вместо положительного класса модель всегда предсказывает отрицательный, и наоборот), следовательно, истинноположительные и истинноотрицательные классификации отсутствуют.
Формула для расчета MCC имеет вид:
MCC=\frac{TP\cdot TN-FP\cdot FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}.
Несложно увидеть, что если в этой формуле обнулить все ложные классификации, то MCC=1, что соответствует ранее сделанным заключениям. Если число истинных и ложных классификаций равны, то числитель формулы становится равным 0 и MCC=0. И, наконец, если число истинных классификаций равно нулю, то числитель становится отрицательным, и делает таковым результат формулы.
Если какая-либо из четырех сумм в знаменателе равна нулю, знаменатель можно произвольно установить равным единице, это приводит к нулевому коэффициенту корреляции Мэтьюса.
Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Функция потерь в задачах классификации показывает, какую «цену» придется заплатить за неточность предсказаний классификационной модели. Для логистической регрессии, решающей задачу бинарной классификации, она может быть вычислена следующим образом:
Log Loss=-\frac{1}{l}\sum\limits_{i=1}^{l}(y_{i}\cdot log(\widehat{y_{i}})+(1-y_{i})\cdot log(1-\widehat{y_{i}})),
где l — размер выборки, y_{i}=\left \{ 0,1 \right \} — бинарная метка класса, заданная в примере, \widehat{y_{i}} — предсказание модели.
Несложно увидеть, что функция потерь получается путем суммирования логарифма потерь на каждом примере. Потери на каждом примере определяются следующим образом: если предсказанный класс совпадает с фактическим, то потери равны 0, в противном случае потери равны 1. Очевидно, чем больше будет неправильных классификаций, тем больше будет значение LogLoss и тем хуже будет модель. Таким образом, чтобы получить лучшую модель, нужно минимизировать функцию потерь.
Преимуществом метрики LogLoss является устойчивость к выбросам и аномальным значениям в данных и простота вычисления. Недостатком — сложность интерпретации из-за нелинейного характера.
Сравнение метрик
Подведем итоги, кратко резюмируя преимущества и недостатки рассмотренных мер качества классификационных моделей.
| Мера | Преимущества | Недостатки |
|---|---|---|
| Меткость | Хорошо интерпретируется. | Чувствительна к дисбалансу классов. Неадекватно отражает точность классификации. |
| Точность | Не чувствительна к дисбалансу классов. | Отражает качество классификации только для положительного класса. |
| Полнота | Не чувствительна к дисбалансу классов. | Не учитывает отрицательные классификации. |
| Специфичность | Просто вычисляется и интерпретируется. | Характеризует способность модели распознавать только один класс. |
| F1-мера | Позволяет найти баланс между точностью и полнотой. | Чувствительность к дисбалансу, отсутствие симметрии. |
| P4 | Симметрична относительно инверсии классов. | Чувствительность к дисбалансу классов. |
| AUC-ROC | Наглядна, хорошо интерпретируется. | В условиях дисбаланса классов завышает качество модели. Не отражает изменения баланса классов. |
| AUC-PR | Наглядна, хорошо интерпретируется. | Не учитывает отрицательные классификации. |
| Коэффициент Мэтьюса | Более информативен, поскольку использует все типы результатов классификации. | Не может применяться, если один из множителей в знаменателе обращается в 0. |
| LogLoss | Устойчивость к выбросам в данных, простота вычисления. | Сложность интерпретации из-за нелинейного характера. |
В статье рассмотрены наиболее общие меры оценки качества моделей бинарной классификации, отмечены их преимущества и недостатки. Однако в литературе авторы предлагают и другие подходы, которые показали хорошие результаты при решении конкретных задач и не претендующие на универсальность.
Другие материалы по теме:
Метрики качества линейных регрессионных моделей
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Материал из MachineLearning.
(Перенаправлено с ROC-кривая)
Перейти к: навигация, поиск
Содержание
- 1 Задача классификации
- 2 TPR и FPR
- 3 ROC-кривая
- 4 Площадь под ROC-кривой AUC
- 5 Алгоритм построения ROC-кривой
- 6 Чувствительность и специфичность
- 7 История
- 8 См. также
- 9 Ссылки
Кривая ошибок или ROC-кривая – графичекая характеристика качества бинарного классификатора, зависимость доли верных положительных классификаций от доли ложных положительных классификаций при варьировании порога решающего правила. Преимуществом ROC-кривой является её инвариантность относительно отношения цены ошибки I и II рода.
Задача классификации
Рассмотрим задачу классификации в случае двух классов, называемых «положительным» и «отрицательным». Обозначим множество классов через  . Большинство известных классификаторов могут быть представлены в виде
. Большинство известных классификаторов могут быть представлены в виде
где
— произвольный объект,
— дискриминантная функция,
— вектор параметров, определяемый по обучающей выборке,
— порог.
Уравнение определяет разделяющую поверхность.
Примером является линейный классификатор, в котором дискриминантная функция имеет вид скалярного произведения вектора описания объекта на вектор параметров:
.
Пусть – цена ошибки (штраф за ошибку) на объекте класса .
Для байесовского классификатора при достаточно общих предположениях доказано, что оптимальное значение порога зависит только от соотношения цены ошибок:
тогда как оптимальное значение вектора параметров , наоборот, зависит от выборки и не зависит от цены ошибок.
Таким образом, варьирование порога для многих классификаторов эквивалентно варьированию отношения цены ошибок на отрицательных и положительных объектах.
На практике цены ошибок зависят от особенностей конкретной задачи (например, от различных экономических соображений или экспертных оценок) и могут многократно пересматриваться.
Заметим, что частным случаем линейного байесовского классификатора является логистическая регрессия.
ROC-кривая наглядно представляет, каким будет качество классификации при различных и фиксированном .
TPR и FPR
Пусть задана выборка объектов с соответствующими им верными ответами .
Тогда для классификатора можно определить две характеристики качества:
- Доля ложных положительных классификаций (False Positive Rate, FPR):
- Доля верных положительных классификаций (True Positive Rate, TPR):
ROC-кривая
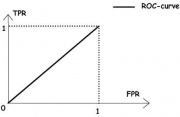
![]()
Рис.1. «Случайное гадание».
![]()
Рис.2. «Хороший» классификатор.
ROC-кривая показывает зависимость TPR от FPR при варьировании порога .
Она проходит из точки , соответствующей максимальному значению , в точку , соответствующую минимальному значению .
При все объекты классифицируются как отрицательные, и ошибки возникают на всех положительных объектах, , .
При все объекты классифицируются как положительные, и ошибки возникают на всех отрицательных объектах, , .
ROC-кривая монотонно не убывает.
Чем выше лежит кривая, тем лучше качество классификации.
На рисунке 1 приведена ROC-кривая, соответствующая худшему случаю — алгоритму «случайного гадания».
На рисунке 2 изображён общий случай.
Лучший случай — это кривая, проходящая через точки
ROC-кривая может быть вычислена по любой выборке. Однако ROC-кривая, вычисленная по обучающей выборке, является оптимистично смещённой влево-вверх вследствие переобучения. Величину этого смещения предсказать довольно трудно, поэтому на практике ROC-кривую всегда оценивают по независомой тестовой выборке.
Площадь под ROC-кривой AUC
Площадь под ROC-кривой AUC (Area Under Curve) является агрегированной характеристикой качества классификации, не зависящей от соотношения цен ошибок.
Чем больше значение AUC, тем «лучше» модель классификации.
Данный показатель часто используется для сравнительного анализа нескольких моделей классификации.
Алгоритм построения ROC-кривой
Следующий алгоритм строит ROC-кривую за обращений к дискриминантной функции.
Входные данные:
Результат:
1. вычислить количество представителей классов
Чувствительность и специфичность
Наряду с FPR и TPR используют также показатели чувствительности и специфичности, которые также изменяются в интервале :
Модель с высокой чувствительностью часто дает истинный результат при наличии положительного исхода (обнаруживает положительные примеры). Наоборот, модель с высокой специфичностью чаще дает истинный результат при наличии отрицательного исхода (обнаруживает отрицательные примеры). Если рассуждать в терминах медицинской диагностики, где модель классификации пациентов на больных и здоровых называется диагностическим тестом, то получится следующее:
- чувствительный диагностический тест проявляется в гипердиагностике – максимальном предотвращении пропуска больных;
- специфичный диагностический тест диагностирует только доподлинно больных. Это важно в случае, когда, например, лечение больного связано с серьезными побочными эффектами и гипердиагностика пациентов нежелательна.
История
Термин операционная характеристика приёмника (Receiver Operating Characteristic, ROC) пришёл из теории обработки сигналов.
Эту характеристику впервые ввели во время II мировой войны, после поражения американского военного флота в Пёрл Харборе в 1941 году, когда была осознана проблема повышения точности распознавания самолётов противника по радиолокационному сигналу. Позже нашлись и другие применения: медицинская диагностика, приёмочный контроль качества, кредитный скоринг, предсказание лояльности клиентов, и т.д.
См. также
- Линейный классификатор
- Логистическая регрессия
Ссылки
- Логистическая регрессия и ROC-анализ
- RoC-curve (english wikipedia)
Я думаю, что большинство людей слышали о ROC-кривой или о AUC (площади под кривой) раньше. Особенно те, кто интересуется наукой о данных. Однако, что такое ROC-кривая и почему площадь под этой кривой является хорошей метрикой для оценки модели классификации?
Полное название ROC — Receiver Operating Characteristic (рабочая характеристика приёмника). Впервые она была создана для использования радиолокационного обнаружения сигналов во время Второй мировой войны. США использовали ROC для повышения точности обнаружения японских самолетов с помощью радара. Поэтому ее называют рабочей характеристикой приемника.
AUC или area under curve — это просто площадь под кривой ROC. Прежде чем мы перейдем к тому, что такое ROC-кривая, нужно вспомнить, что такое матрица ошибок.
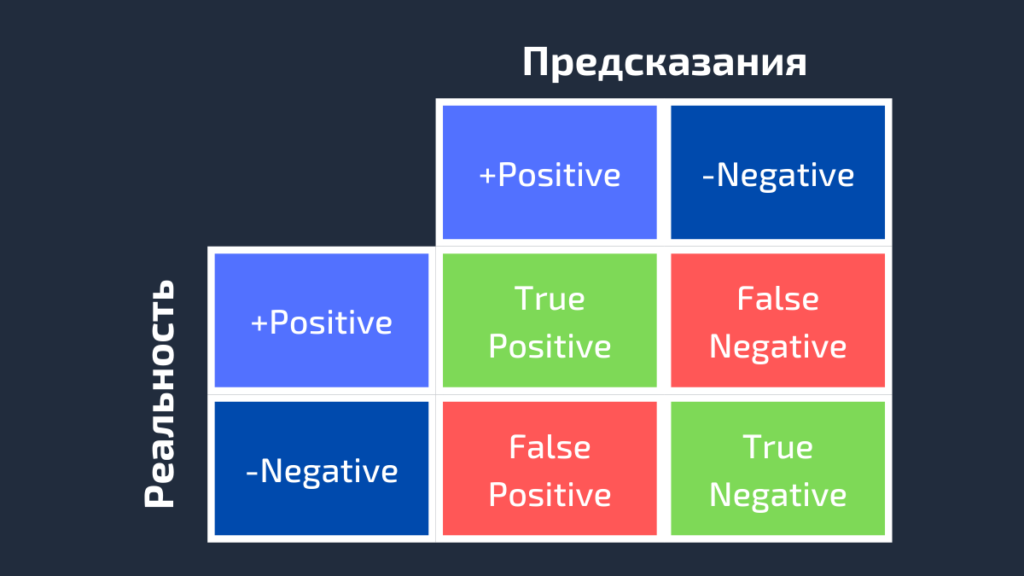
Как видно из рисунка выше, матрица ошибок — это комбинация вашего прогноза (1 или 0) и фактического значения (1 или 0). В зависимости от результата предсказания и того, корректна ли была проведена классификация, матрица разделена на 4 части. Например, true positive (истинно положительный) результат — это количество случаев, в которых вы правильно классифицируете семпл как положительный. А false positive (ложноположительный) — это число случаев, в которых вы ошибочно классифицируете семпл как положительный.
Матрица ошибок содержит только абсолютные числа. Однако, используя их, мы можем получить множество других метрик, основанных на процентных соотношениях. True Positive Rate (TPR) и False Positive Rate (FPR) — две из них.
True Positive Rate (TPR) показывает, какой процент среди всех positive верно предсказан моделью.
TPR = TP / (TP + FN).
False Positive Rate (FPR): какой процент среди всех negative неверно предсказан моделью.
FPR = FP / (FP + TN).
Хорошо, давайте теперь перейдем к кривой ROC!
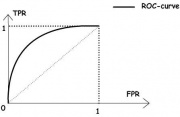
Что такое ROC-кривая?
Как вы можете видеть на графике, кривая ROC — это просто отношение TPR к FPR. Теперь вам все понятно, в заключение…
Поверили?
Если серьезно, вы можете прочитать намного больше информации из диаграммы. Первый вопрос, который я хочу здесь обсудить: у нас же есть только один набор TPR, FPR, посчитанный на основе сделанных моделью предсказаний. Так откуда взялось такое количество точек для построения целого графика?
Все следует из того, как работает модель классификации. Когда вы строите классификационную модель, такую как дерево решений, и хотите определить, будут ли акции расти в цене или падать на основе входных данных. Модель сначала рассчитает вероятность увеличения или уменьшения, используя предоставленные вами исторические данные. После этого, основываясь на пороговом значении, она решит, будет ли результат увеличиваться или уменьшаться.
Да, ключевое слово здесь — порог. Разные пороговые значения создают разные TPR и FPR. Они представляют те самые точки, что образуют кривую ROC. Вы можете выбрать «Увеличение» в качестве предсказания модели, если полученная на основе исторических данных вероятность роста акций больше 50%. Также можете изменить пороговое значение и отобразить «Увеличение», только если соответствующая вероятность больше 90%. Если вы установите 90% порог вместо 50%, вы будете более уверены в том, что выбранные для «Увеличения» акции действительно вырастут. Но так вы можете упустить некоторые потенциально выгодные варианты.
Что значит синяя пунктирная линия на графике?
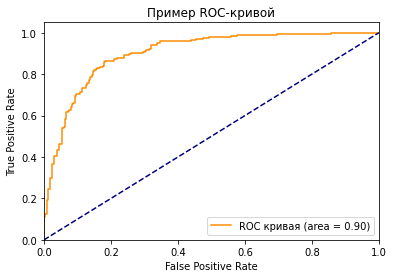
Как мы знаем, чем больше площадь под кривой (AUC), тем лучше классификация. Идеальная или наилучшая кривая — это вертикальная линия от (0,0) до (0,1), которая тянется до (1,1). Это означает: модель всегда может различить положительные и отрицательные случаи. Однако, если вы выбираете класс случайным образом для каждого семпла, TPR и FPR должны увеличиваться с одинаковой скоростью. Синяя пунктирная линия показывает кривую TPR и FPR при случайном определении positive или negative для каждого случая. Для этой диагональной линии площадь под кривой (AUC) составляет 0.5.
Что произойдет с TPR, FPR и ROC-кривой, если изменить пороговое значение?
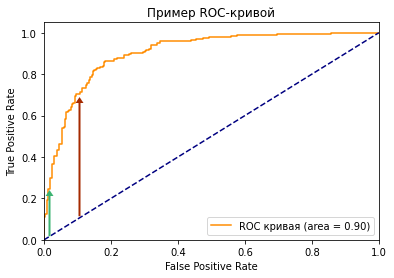
Посмотрите на две точки на ROC-кривой. Зеленая точка имеет очень высокий порог, это означает, что только если вы уверены на 99%, можете классифицировать случай как positive. Красная точка имеет относительно более низкий порог. Это означает, что вы можете классифицировать случай как positive, если вы уверены на 90%.
Как изменяются TPR и FPR при движении от зеленой точки к красной?
И TPR, и FPR увеличиваются. Когда вы уменьшаете порог, модель будет определять больше положительных случаев. Таким образом, TP увеличивается, как и TP/(TP + FN). С другой стороны, вы неизбежно ошибочно классифицируете некоторые отрицательные случаи как положительные из-за снижения порога, и поэтому FP и FP/(FP + TN) также увеличиваются.
Мы видим, что TPR и FPR положительно коррелируют. Вам нужно балансировать между максимальным охватом positive случаев и минимизацией неправильной классификации negative случаев.
Как выбрать оптимальную точку на кривой ROC?
Трудно определить оптимальную точку, потому что нужно выбрать наиболее подходящее пороговое значение, учитывая сферу применения модели. Однако общее правило — максимизировать разницу (TPR-FPR), которая на графике представлена вертикальным расстоянием между оранжевой и синей пунктирной линией.
Почему площадь под кривой ROC – хорошая метрика для оценки модели классификации?
Хорошая метрика модели машинного обучения должна отображать истинную и постоянную способность модели к прогнозированию. Это означает, что, если я изменю тестовый набор данных, он не должен давать другой результат.
ROC-кривая учитывает не только результаты классификации, но и вероятность предсказания всех классов. Например, если результат корректно классифицирован на основе 51% вероятности, то он, скорее всего, будет классифицирован неверно, если вы воспользуетесь другим тестовым датасетом. Кроме того, ROC-кривая также учитывает эффективность модели при различных пороговых значениях. Она является комплексной метрикой для оценки того, насколько хорошо разделяются случаи в разных группах.
Какое значение AUC является приемлемым для модели классификации?
Как я показал ранее, для задачи двоичной классификации при определении классов случайным образом, вы можете получить 0.5 AUC. Следовательно, если вы решаете задачу бинарной классификации, разумное значение AUC должно быть > 0.5. У хорошей модели классификации показатель AUC > 0.9, но это значение сильно зависит от сферы ее применения.
Как рассчитать AUC и построить ROC-кривую в Python?
Если вы просто хотите рассчитать AUC, вы можете воспользоваться пакетом metrics библиотеки sklearn (ссылка).
Если вы хотите построить ROC-кривую для результатов вашей модели, вам стоит перейти сюда.
Вот код для построения графика ROC, который я использовал в этой статье.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import roc_auc_score
from matplotlib import pyplot as plt
# генерируем датасет на 2 класса
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# разделяем его на 2 выборки
trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2)
# обучаем модель
model = LogisticRegression(solver='lbfgs')
model.fit(trainX, trainy)
# получаем предказания
lr_probs = model.predict_proba(testX)
# сохраняем вероятности только для положительного исхода
lr_probs = lr_probs[:, 1]
# рассчитываем ROC AUC
lr_auc = roc_auc_score(testy, lr_probs)
print('LogisticRegression: ROC AUC=%.3f' % (lr_auc))
# рассчитываем roc-кривую
fpr, tpr, treshold = roc_curve(testy, lr_probs)
roc_auc = auc(fpr, tpr)
# строим график
plt.plot(fpr, tpr, color='darkorange',
label='ROC кривая (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Пример ROC-кривой')
plt.legend(loc="lower right")
plt.show()
Вам нужны следующие входные данные: фактическое значение y и вероятность предсказания. Обратите внимание, что функция roc_curve требует только вероятность для положительного случая, а не для обоих классов. Если вам нужно решить задачу мультиклассовой классификации, вы также можете использовать этот пакет, и в приведенной выше ссылке есть пример того, как построить график.