Предельные ошибки и необходимый объем выборки (Повторный и бесповторный отбор)
Для
определения необходимого объема выборки
![]() необходимо задать надежность (доверительную
необходимо задать надежность (доверительную
вероятность)![]() оценки и точность (предельную ошибку
оценки и точность (предельную ошибку
выборки)![]() .
.
В этом случае необходимый объем выборки
для оценки генеральной средней![]() для повторного отбора находим по формуле:
для повторного отбора находим по формуле:
![]() ,
,
и для бесповторного
отбора:
 .
.
Необходимый
объем выборки для оценки генеральной
доли
![]() для повторного отбора находим:
для повторного отбора находим:
![]() ,
,
И для бесповторного
отбора:
![]() .
.
Лекция №12. Проверка статистических гипотез.
Статистической
гипотезой называется
любое предположение о виде или параметрах
генеральной совокупности, проверяемое
по выборке.
Различают
простую
и сложную
статистические гипотезы. Простая
гипотеза, в отличие от сложной, полностью
определяет теоретическую функцию
распределения наблюдаемой случайной
величины.
Проверяемую
гипотезу обычно называют нулевой
![]() .Наряду с
.Наряду с
нулевой гипотезой
![]() рассматривают
рассматривают
альтернативную,
или
конкурирующую,
гипотезу
![]() ,
,
являющуюся логическим отрицанием
![]() .
.
Правило,
по которому принимается или отвергается
![]() ,называется
,называется
статистическим
критерием.
Суть
проверки статистической гипотезы
заключается в том, что используется
специальная составленная выборочная
характеристика (критерий)
![]() ,
,
полученная по выборке![]() ,
,
точный или приближенный закон распределения
которой при выдвинутой гипотезе![]() известно.
известно.
По этому распределению определяется
критическое значение критерия
![]() из
из
условия, что вероятность![]() мала. Так что в соответствие с принципом
мала. Так что в соответствие с принципом
практической уверенности в условиях
данного исследования при правильности
гипотезы
![]()
событие![]() практически
практически
невозможно. Таким образом, множества
значений критерия![]() разбивается
разбивается
значением![]() на два непересекающихся подмножества:
на два непересекающихся подмножества:
При таком подходе
возможны четыре случая (см. табл.):
|
Гипотеза |
Принимается |
Отвергается |
|
Верна |
Правильное |
Ошибка |
|
Неверна |
Ошибка |
Правильное |
Таким
образом, вероятность
![]() ,
,
называемаяуровнем
значимости критерия,
есть вероятность допущения ошибки
1-ого рода.
Вероятность
допустить ошибку 2-ого рода обозначают
![]() .
.
Вероятность недопущения ошибки 2-ого
рода![]() называетсямощностью
называетсямощностью
критерия.
При
фиксированном объеме выборке невозможно
одновременное уменьшение ошибок 1-ого
и 2-ого рода. Критическая область
![]() следует
следует
выбирать так, чтобы при заданном уроне
значимости![]() мощность критерия
мощность критерия![]() была максимальной. Вид критической
была максимальной. Вид критической
области зависит от конкурирующей
гипотезы![]() и
и
бывает трех видом:
-
Правосторонняя,
выбирается из соотношения:
 ;
; -
Левосторонняя:
; -
Двухсторонняя:
 .
.
Критерии проверки
гипотез называю параметрическими, если
известен закон распределения генеральной
совокупности, что задает определенное
распределение критерия. При неизвестном
законе распределения генеральной
совокупности, то критерии называют
непараметрическими.
По своему прикладному
содержанию. Статистические гипотезы
подразделяются на несколько основных
типов:
-
О
равенстве числовых характеристики
генеральных совокупностей; -
О
числовых значениях параметров; -
О
законе распределения; -
Об
однородности выборок (т.е. о принадлежности
их одной и той же генеральной совокупности).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| |
Верная гипотеза | ||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
Скачать материал

Скачать материал
Рабочие листы
к вашим урокам
Скачать
Описание презентации по отдельным слайдам:
-

1 слайд
Основы теории проверки статистических гипотез.
Доцент Аймаханова А.Ш.
-
2 слайд
План лекции:
1. Статистические гипотезы в медико-
биологических исследованиях.
2. Параметрические критерии различий.
3. Непараметрические критерии.
4. Критерии согласия. -
3 слайд
Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотез.
Задачи статистической проверки гипотез:
Относительно некоторой генеральной совокупности высказывается та или иная гипотеза Н0.
Из этой генеральной совокупности извлекается выборка.
Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу Н0 или принять ее. -
4 слайд
Статистическая гипотеза- это предположение о виде распределения или о величинах неизвестных параметров генеральной совокупности, которая может быть проверена на основании выборочных показателей.
Примеры статистических гипотез:
Генеральная совокупность распределена по нормальному закону Гаусса.
Дисперсии двух нормальных совокупностей равны между собой. -
5 слайд
Статистические гипотезы
Параметрические Непараметрические
-
6 слайд
Нулевой гипотезой Н0 называется основная гипотеза, которая проверяется.
Альтернативной гипотезой Н1, называется гипотеза, конкурирующая с нулевой, то есть противоречащая ей.
Простой называют гипотезу, содержащую только одно предположение. a=a0
Сложной называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез.
Статистическим критерием проверки гипотезы Н0 называется правило, по которому принимается решение принять или отклонить гипотезу Н0. -
7 слайд
Основной принцип проверки гипотез
Проверку гипотез осуществляют на основании результатов выборки X1,X2,…,Xn , из которых формируют функцию выборки Tn=T(X1,X2,…,Xn ), называемой статистикой критерия.Tn=T(X1,X2,…,Xn )
критическая область S область принятия гипотезы
-
8 слайд
Возможные ошибки при проверке гипотез
Первого рода Второго рода
-
9 слайд
Уровнем значимости критерия () называется вероятность допустить ошибку 1-го рода.
Вероятность ошибки 2-го рода обозначается через β.
Мощностью критерия называется вероятность недопущения ошибки 2-го рода (1- β).
Р(отвергнуть Н0/Н0 верна) или Р(Н1/Н0)
βР(принять Н0/Н0 неверна) или βР(Н0 /Н1)
1-βР(принять Н1/Н1 верна)
Чем больше мощность критерия, тем вероятность ошибки 2-го рода меньше.
Разумное соотношение между и β находят, исходя из тяжести последствий каждой из ошибок. -
10 слайд
Методика проверки гипотез:
1. Формирование нулевой Н0 и альтернативной Н1 гипотез исходя из выборки X1,X2,…,Xn .
2. Подбор статистики критерия Tn=T(X1,X2,…,Xn )
3. По статистике критерия Tn и уровню значимости определяют критическую точку tкр, то есть границу, отделяющую область от S.
4. Для полученной реализации выборки Х=(X1,X2,…,Xn ) подсчитывают значение критерия, то есть Tнабл=T(X1,X2,…,Xn )t
5. Если tS (например, t> tкр для правосторонней области S), то нулевую гипотезу Н0 отвергают; если же t (t <tкр), то нет оснований, чтобы отвергнуть гипотезу Н0. -
11 слайд
t-критерий Стьюдента:
Общий вид: -
12 слайд
Случай независимых выборок.
df= n1+n2-2
n1=n2=n
df=n-1
n1≠n2 -
13 слайд
Случай зависимых выборок.
df=n-1
-
14 слайд
Вывод:
Критерий Стьюдента может быть использован для проверки гипотезы о различии средних только для двух групп.
Критерий Стьюдента применяется в случае малых выборок, что характерно для медико- биологических экспериментов.
Если схема эксперимента предполагает большее число групп, воспользуйтесь дисперсионным анализом.
Если критерий Стьюдента был использован для проверки различий между несколькими группами, то истинный уровень значимости можно получить, умножив уровень значимости, на число возможных сравнений. -
15 слайд
F- критерий Фишера:
1>2
df1=n1-1, df2=n2-1 -
16 слайд
Критерии различия называют непараметрическими, если он не базируется на предположении о типе распределения генеральной совокупности и не использует параметры этой совокупности.
Применение непараметрических методов целесообразно:
на этапе разведочного анализа;
при малом числе наблюдений (до 30);
когда нет уверенности в соответствии данных закону нормального распределения. -
17 слайд
Непараметрические критерии представлены основными группами:
критерии различия между группами
независимых выборок;
критерии различия между группами
зависимых выборок. -
18 слайд
Различия между независимыми группами
U критерий Манна-Уитни
двухвыборочный критерий
Колмогорова – Смирнова. -
19 слайд
Различия между зависимыми группами
z – критерий знаков
Т – критерий Уилкоксона парных
сравнений -
20 слайд
Критерии согласия:
Критерием согласия называют статистический критерий проверки гипотезы о предполагаемом законе неизвестного распределения.Пирсона (Хи-квадрат),
Колмогорова,
Фишера,
Смирнова. -
21 слайд
Критерий согласия χ2 (хи-квадрат) Пирсона.
Н0: «между эмперическим распределением и теоретической моделью нет никакого различия».Если эмпирические частоты (ni) сильно отличаются от теоретических (npi) ,то проверяемую гипотезу Но следует отвергнуть; в противном случае-принять.
-
22 слайд
Критерий согласия χ2 (хи-квадрат) Пирсона.
n-объем выборки
k-число интервалов разбиения выборки
ni-число значений выборки, попавших в і-й интервал
npi — теоретическая частота попадания значений случайной величины Х в і-й интервал. -
23 слайд
Критерий согласия χ2 (хи-квадрат) Пирсона.
илиО-фактически наблюдаемое число
Е- теоретически ожидаемое число -
24 слайд
Поправка Йейтса
Для распределения признаков, которые принимают всего 2 значения.
-
25 слайд
Правило применения критерия χ2.
*По формуле вычисляют — выборочное
значение статистики критерия.
*выбрав уровень значимости α критерия,
по таблице -распределения находим критическую точку*Если ≤ , то гипотеза Н0 не противоречит опытным данным;
если > , то гипотеза Н0 отвергается.
Неоходимым условием применения критерия Пирсона является наличие в каждом из интервалов не менее 5 наблюдений -
26 слайд
ЛИТЕРАТУРА:
Медик В.А.,Токмачев М.С.,Фишман Б.Б.Статистика в медицине и биологии. М.: Медицина, 2000.
Лукьянова Е.А. Медицинская статистика.- М.: Изд. РУДН, 2002.
Рокицкий П.Ф. Биологическая статистика.- Высшая школа, 1973.
И.В. Павлушков и др. Основы высшей математики и математической статистики.
(учебник для медицинских и фармацевтических вузов) М., «ГЭОТАР — МЕД»; 2003 -

 с выборочными...")





 называется вероятность допустить ошибку 1-...")











 Пирсона.Н0: «между эмперическим распределен...")
 Пирсона.
n-объем выборки
k-число интервал...")
 Пирсона. или
О-фактически наблюдаемое чи...")




Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 363 318 материалов в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 20.12.2020
- 232
- 2
- 06.12.2020
- 248
- 2
- 19.11.2020
- 403
- 8
- 12.11.2020
- 640
- 9
- 23.10.2020
- 230
- 1
- 15.10.2020
- 672
- 3
- 22.09.2020
- 264
- 4
- 14.09.2020
- 121
- 0
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Педагогическая риторика в условиях реализации ФГОС»
-
Курс повышения квалификации «Основы управления проектами в условиях реализации ФГОС»
-
Курс профессиональной переподготовки «Организация логистической деятельности на транспорте»
-
Курс профессиональной переподготовки «Логистика: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Финансы: управление структурой капитала»
-
Курс профессиональной переподготовки «Разработка эффективной стратегии развития современного вуза»
-
Курс профессиональной переподготовки «Управление информационной средой на основе инноваций»
-
Курс профессиональной переподготовки «Риск-менеджмент организации: организация эффективной работы системы управления рисками»
-
Курс профессиональной переподготовки «Организация деятельности специалиста оценщика-эксперта по оценке имущества»
-
Курс профессиональной переподготовки «Методика организации, руководства и координации музейной деятельности»
-
Курс профессиональной переподготовки «Организация и управление службой рекламы и PR»
-
Настоящий материал опубликован пользователем Трушанова Елена Сергеевна. Инфоурок является
информационным посредником и предоставляет пользователям возможность размещать на сайте
методические материалы. Всю ответственность за опубликованные материалы, содержащиеся в них
сведения, а также за соблюдение авторских прав несут пользователи, загрузившие материал на сайтЕсли Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с
сайта, Вы можете оставить жалобу на материал.Удалить материал
-

- На сайте: 2 года и 8 месяцев
- Подписчики: 0
- Всего просмотров: 62659
-
Всего материалов:
223
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Компьютеры
- 4.1.1 Компьютерная безопасность
- 4.1.2 Фильтрация спама
- 4.1.3 Вредоносное программное обеспечение
- 4.1.4 Поиск в компьютерных базах данных
- 4.1.5 Оптическое распознавание текстов (OCR)
- 4.1.6 Досмотр пассажиров и багажа
- 4.1.7 Биометрия
- 4.2 Массовая медицинская диагностика (скрининг)
- 4.3 Медицинское тестирование
- 4.4 Исследования сверхъестественных явлений
- 4.1 Компьютеры
- 5 См. также
- 6 Примечания
Определения
Пусть дана выборка 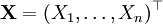 из неизвестного совместного распределения
из неизвестного совместного распределения 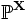 , и поставлена бинарная задача проверки статистических гипотез:
, и поставлена бинарная задача проверки статистических гипотез:
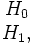
где H0 — нулевая гипотеза, а H1 — альтернативная гипотеза. Предположим, что задан статистический критерий
 ,
,
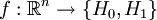 ,
,сопоставляющий каждой реализации выборки 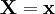 одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе H0, и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе H0, но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе H1, и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе H1, но она неверно отвергнута статистическим критерием, то есть .
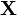 соответствует гипотезе
соответствует гипотезе 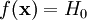 .
.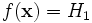 .
.Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно.
| Верная гипотеза | |||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
О смысле ошибок первого и второго рода
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы H0 и H1, то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза H0 соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследумый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза H1 обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня.
Соответственно, ошибку второго рода иногда называют пропуском события — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Ниже, в разделе Примеры использования, подробно рассматривается применение понятий ошибок первого и второго рода в различных областях.
Вероятности ошибок (уровень значимости и мощность)
Для проверки статистических гипотез используют так называемые критерии согласия. Для них вероятности ошибок первого и второго рода играют значительную роль.
Вероятность ошибки первого рода при проверке статистических гипотез назывют уровнем значимости и обычно обозначают греческой буквой α (отсюда название α-errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой β (отсюда β-errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле (1 − β). Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода)
- когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода)
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «анти-спам» алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда анти-спам система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности анти-спам алгоритма.
Вредоносное программное обеспечение
Понятие ошибки первого рода также ипользуется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с анти-троянскими и анти-
Поиск в компьютерных базах данных
При поиске в базе данных, к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако, это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в комьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т. п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как террориста) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т. д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т. п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[1]
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые в основном применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[2]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15 %, это самый высокий показатель в мире.[3] Самый низкий уровень наблюдается в Нидерландах, 1 %.[4]
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70 %, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[5]
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиа-свидетельство» (изображение, видеозапись, аудиозапись и т. д.), которое имеет обычное объяснение.[6]
См. также
- Ложное срабатывание (ошибка первого рода)
- Статистическая значимость
Примечания
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95 % женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research).
Wikimedia Foundation.
2010.
Тема 3.5.
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ
План лекции:
-
Понятие гипотезы.
-
Схема статистической
проверки гипотезы.
Список литературы:
-
Вентцель, Е.С.
Теория вероятностей [Текст] / Е.С.
Вентцель. – М.: Высшая школа, 2006. – 575 с. -
Гмурман, В.Е. Теория
вероятностей и математическая статистика
[Текст] / В.Е. Гмурман. — М.: Высшая школа,
2007. — 480 с. -
Кремер, Н.Ш. Теория
вероятностей и математическая статистика
[Текст] / Н.Ш.
Кремер — М: ЮНИТИ, 2002. – 543 с.
п.1. Понятие
гипотезы.
Одна
из
часто
встречающихся на практике задач,
связанных с применением статистических
методов, состоит в решении вопроса о
том, должно ли на основании данной
выборки быть принято или, напротив,
отвергнуто некоторое предположение
(гипотеза) относительно генеральной
совокупности (случайной величины).
Например,
новое
лекарство испытано на определенном
числе людей. Можно ли сделать по
данным результатам лечения обоснованный
вывод о том, что новое лекарство более
эффективно, чем применявшиеся ранее
методы лечения? Аналогичный вопрос
логично задать, говоря о новом правиле
поступления в вуз, о новом методе
обучения, о пользе быстрой ходьбы, о
преимуществах новой модели автомобиля
или технологического процесса и т.
д.
Процедура
сопоставления высказанного предположения
(гипотезы) с выборочными данными
называется проверкой
гипотез.
Задачи
статистической проверки гипотез ставятся
в следующем виде: относительно некоторой
генеральной совокупности высказывается
та или иная гипотеза Н.
Из
этой генеральной совокупности извлекается
выборка. Требуется указать правило, при
помощи которого можно было бы по выборке
решить вопрос о том, следует ли
отклонить
гипотезу Н
или
принять
ее.
Следует
отметить, что статистическими методами
гипотезу можно
только опровергнуть или не опровергнуть,
но
не доказать. Например,
для
проверки утверждения (гипотеза Н)
автора,
что «в рукописи нет ошибок», рецензент
прочел (изучил)
несколько страниц рукописи.
Если
он обнаружил хотя бы одну ошибку, то
гипотеза Н
отвергается,
в противном случае — не отвергается,
говорят, что «результат проверки с
гипотезой согласуется».
Выдвинутая
гипотеза может быть правильной или
неправильной, поэтому возникает
необходимость ее проверки.
Под
статистической
гипотезой (или
просто гипотезой)
понимают
всякое высказывание (предположение) о
генеральной совокупности, проверяемое
по
выборке.
Статистические
гипотезы делятся на гипотезы о параметрах
распределения известного вида (это
так называемые параметрические
гипотезы)
и гипотезы о виде неизвестного
распределения (непараметрические
гипотезы).
Например,
статистическими являются гипотезы:
-
генеральная
совокупность распределена по закону
Пуассона; -
дисперсии
двух нормальных совокупностей равны
между собой.
В
первой гипотезе сделано предположение
о виде неизвестного распределения, во
второй – о параметрах двух известных
распределений.
Гипотеза
«на Марсе есть жизнь» не является
статистической, т.к. в ней не идёт речь
ни о виде, ни о параметрах распределения.
Наряду
с выдвинутой гипотезой рассматривают
и противоречащую ей гипотезу. Если
выдвинутая гипотеза будет отвергнута,
то имеет место противоречащая гипотеза.
Таким
образом, одну из гипотез выделяют в
качестве основной
(или
нулевой)
и
обозначают Но,
а другую, являющуюся логическим отрицанием
Н0,
т. е. противоположную Но
—
в качестве конкурирующей
(или
альтернативной)
гипотезы
и обозначают Н1.
Гипотезу,
однозначно фиксирующую распределение
наблюдений, называют простой
(в
ней идет речь об одном значении параметра),
в противном случае — сложной.
Например,
гипотеза Но,
состоящая
в том что математическое ожидание
случайной
величины
X
равно ао,
т.е. М(Х)=ао
является
простой. В качестве альтернативной
гипотезы можно рассматривать гипотезу
Н1:
М(Х)≠
ао
(сложная
гипотеза).
Имея
две гипотезы Но
и
Н1,
надо
на основе выборки Х1,…
,Хп
принять
либо основную гипотезу Н0,
либо
конкурирующую Н1.
Правило,
по которому принимается решение принять
или отклонить гипотезу Но
(соответственно,
отклонить или принять Н1),
называется
статистическим
критерием К (или
просто критерием)
проверки
гипотезы Но.
Проверку
гипотез осуществляют на основании
результатов выборки Х1,
Х2,…,
Хп,
из
которых формируют функцию выборки Кп
=К(Х1,
Х2,…,
Хn),
называемой статистикой
критерия.
Основной
принцип проверки гипотез состоит
в следующем. Множество возможных
значений статистики критерия Кп
разбивается
на два непересекающихся подмножества:
критическую
область S,
т.
е. область отклонения гипотезы Но
и
область
![]()
принятия
этой
гипотезы. Если фактически наблюдаемое
значение статистики критерия (т. е.
значение критерия, вычисленное по
выборке: Кнабл
=К(х1,х2,…,
хп))
попадает
в критическую область S,
то
основная гипотеза Но
отклоняется
и принимается альтернативная гипотеза
Н1;
если
же Кнабл
попадает
в
![]() ,
,
то
принимается Но,
а
Н1
отклоняется.
При
проверке гипотезы может быть принято
неправильное решение, т.
е. могут быть допущены ошибки двух родов:
Ошибка
первого рода состоит
в том, что отвергается нулевая гипотеза
Но,
когда
на самом деле она верна.
Ошибка
второго рода состоит
в том, что отвергается альтернативная
гипотеза Н1,
когда
она на самом деле верна.
Рассматриваемые
случаи наглядно иллюстрирует следующая
таблица.
|
Гипотеза |
Отвергается |
Принимается |
|
верна |
ошибка |
правильное |
|
неверна |
правильное |
ошибка |
Вероятность
ошибки 1-го рода (обозначается через α)
называется
уровнем
значимости критерия.
Очевидно,
α
= P(Н1Но).
Чем
меньше α,
тем
меньше вероятность отклонить верную
гипотезу. Допустимую ошибку 1-го рода
обычно задают заранее.
В
одних случаях считается возможным
пренебречь событиями, вероятность
которых меньше 0,05 (α=
0,05
означает, что в среднем в 5 случаях из
100 испытаний верная гипотеза будет
отвергнута), в других случаях, когда
речь идет, например, о разрушении
сооружений, гибели судна и т. п., нельзя
пренебречь обстоятельствами, которые
могут появиться с вероятностью,
равной
0,001.
Обычно
для α
используются
стандартные значения: α
= 0,05;
0,01; 0,005; 0,001.
Вероятность
ошибки 2-го рода обозначается через β,
т.е.
β
= Р(Н0Н1).
Величину
1- β,
т.
е. вероятность недопущения ошибки 2-го
рода (отвергнуть неверную гипотезу
принять верную Н1),
называется
мощностью
критерия.
Чем
больше мощность критерия, тем вероятность
ошибки 2-го рода меньше, что, конечно,
желательно (как и уменьшение α).
Последствия
ошибок 1-го, 2-го рода могут быть совершенно
различными: в одних случаях надо
минимизировать α,
в
другом — β.
Так,
применительно к производству, к торговле
можно сказать, что α
—
риск поставщика (т.е. забраковка по
выборке всей партии изделий, удовлетворяющих
стандарту), β — риск потребителя (т.е.
прием по выборке всей партии изделий,
не удовлетворяющей стандарту);
применительно к судебной системе, ошибка
1-го рода приводит к оправданию виновного,
ошибка 2-го рода — осуждению невиновного.
Или, например, если отвергнуто правильное
решение «продолжить строительство
жилого дома», то эта ошибка первого рода
повлечёт материальный ущерб; если же
принято неправильное решение «продолжать
строительство», несмотря на опасность
обвала стройки, то эта ошибка второго
рода может повлечь гибель людей.
Отметим,
что одновременное
уменьшение ошибок 1-го
и 2-го рода возможно лишь при увеличении
объема выборок. Поэтому
обычно при заданном уровне значимости
α
отыскивается
критерий с наибольшей мощностью.
п.2. Схема
статистической проверки гипотезы.
Методика
проверки гипотез сводится к следующему:
-
Располагая
выборкой Х1,
Х2,…,Хп,
формируют
нулевую гипотезу Но
и
альтернативную Н1. -
В
каждом конкретном случае подбирают
статистику критерия Кп=К(Х1,Х2,…,
Хп). -
По
статистике критерия Кп
и
уровню значимости а
определяют
критическую область S
(и ).
).
Для
ее отыскания достаточно найти критическую
точку kкр,
т.е. границу (или квантиль), отделяющую
область S
от.
Границы
областей определяются, соответственно,
из соотношений: Р(Kп
>
kкр)
= а,
для
правосторонней критической области S;
Р(Kп
<kкр)
= а,
для
левосторонней критической области
S;
Р(Kп
<
![]() )
)
= Р(Kп
>
![]() )
)
=![]() ,
,
для двусторонней критической области
S.
Для
каждого критерия имеются соответствующие
таблицы, по которым и находят
критическую точку, удовлетворяющую
приведенным выше соотношениям.
-
Для
полученной реализации выборки

подсчитывают значение критерия, т.е.
Кнабл
=К(х1,х2,…,
хп)=
k. -
Если

(например,

для правосторонней области S),
то нулевую гипотезу Н0
отвергают, если же
(),
то нет оснований, чтобы отвергнуть
гипотезу Но.
Во
многих случаях закон распределения
изучаемой случайно величины неизвестен,
но есть основания предположить, что он
имеет вполне определенный вид: нормальный,
биномиальный или какой-либо другой.
Пусть
необходимо проверить гипотезу Но
о
том, что случайная
величина
X
подчиняется
определенному закону распределения,
заданному функцией распределения Fо(х),
т.
е. Но:
Fх(х)=Fо(х).
Под
альтернативной гипотезой Н1
будем
понимать в данном случае то, что просто
не выполнена основная (т.е. Н1:
Fх(х)≠
Fо(х)).
Для
проверки гипотезы о распределении
случайной величины X
проведем
выборку, которую оформим в виде
статистического ряда:
|
xi |
x1 |
x2 |
… |
Xm |
|
ni |
n1 |
n2 |
… |
nm |
где
![]()
—
объем выборки.
Требуется
сделать заключение: согласуются ли
результаты наблюдений с высказанным
предположением. Для этого используем
специально подобранную величину —
критерий согласия.
Критерием
согласия называют
статистический критерий проверки
гипотезы о предполагаемом законе
неизвестного распределения. (Он
используется для проверки согласия
предполагаемого вида распределения
с опытными данными на основании выборки.)
Существуют
различные критерии согласия: Пирсона,
Колмогорова, Фишера, Смирнова и др.
Критерий согласия Пирсона — наиболее
часто употребляемый критерий для
проверки простой гипотезы о законе
распределения.
Рассмотрим
применение критерия согласия Пирсона
для проверки гипотезы о нормальном
распределении исследуемой случайной
величины X.
По
результатам выборки подсчитывают:
![]()
— эмпирическую абсолютную частоту для
каждого варианта;
![]() —
—
оценку математического ожидания;
![]()
— несмещённую оценку среднего
квардатического отклонения; числа
![]()
в предположении нормальности случайной
величины X
с параметрами
![]() ,
,
![]() ;
;
числа
![]()
— теоретические частоты, где n
– объем выборки.
В
качестве критерия проверки нулевой
гипотезы примем случайную величину
![]() .
.
Доказано, что при
![]()
закон распределения этой случайной
величины, независимо от закона
распределения изучаемой величины X,
стремиться к известному закону
![]()
с f
степенями
свободы. Число f
находят из равенства
![]() ,
,
где i
– число частичных интервалов, r
– число параметров предполагаемого
распределения. В случае нормального
закона r=2.
Построим
правостороннюю критическую область,
исходя из требования, что вероятность
попадания критерия в эту область, в
предположении справедливости нулевой
гипотезы, была равна принятому уровню
значимости α:
![]() .
.
Точка
![]()
по данным f
и α находится по таблице критических
точек распределения
![]() .
.
На основании выборки вычисляем
![]() .
.
Если
![]() ,
,
то нулевую гипотезу отвергают, в противном
случае её можно принять.
5
Скачать материал
Скачать материал




- Сейчас обучается 395 человек из 63 регионов




Описание презентации по отдельным слайдам:
-
1 слайд
Основы теории проверки статистических гипотез.
Доцент Аймаханова А.Ш.
-
2 слайд
План лекции:
1. Статистические гипотезы в медико-
биологических исследованиях.
2. Параметрические критерии различий.
3. Непараметрические критерии.
4. Критерии согласия. -
3 слайд
Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотез.
Задачи статистической проверки гипотез:
Относительно некоторой генеральной совокупности высказывается та или иная гипотеза Н0.
Из этой генеральной совокупности извлекается выборка.
Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу Н0 или принять ее. -
4 слайд
Статистическая гипотеза- это предположение о виде распределения или о величинах неизвестных параметров генеральной совокупности, которая может быть проверена на основании выборочных показателей.
Примеры статистических гипотез:
Генеральная совокупность распределена по нормальному закону Гаусса.
Дисперсии двух нормальных совокупностей равны между собой. -
5 слайд
Статистические гипотезы
Параметрические Непараметрические
-
6 слайд
Нулевой гипотезой Н0 называется основная гипотеза, которая проверяется.
Альтернативной гипотезой Н1, называется гипотеза, конкурирующая с нулевой, то есть противоречащая ей.
Простой называют гипотезу, содержащую только одно предположение. a=a0
Сложной называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез.
Статистическим критерием проверки гипотезы Н0 называется правило, по которому принимается решение принять или отклонить гипотезу Н0. -
7 слайд
Основной принцип проверки гипотез
Проверку гипотез осуществляют на основании результатов выборки X1,X2,…,Xn , из которых формируют функцию выборки Tn=T(X1,X2,…,Xn ), называемой статистикой критерия.Tn=T(X1,X2,…,Xn )
критическая область S область принятия гипотезы
-
8 слайд
Возможные ошибки при проверке гипотез
Первого рода Второго рода
-
9 слайд
Уровнем значимости критерия () называется вероятность допустить ошибку 1-го рода.
Вероятность ошибки 2-го рода обозначается через β.
Мощностью критерия называется вероятность недопущения ошибки 2-го рода (1- β).
Р(отвергнуть Н0/Н0 верна) или Р(Н1/Н0)
βР(принять Н0/Н0 неверна) или βР(Н0 /Н1)
1-βР(принять Н1/Н1 верна)
Чем больше мощность критерия, тем вероятность ошибки 2-го рода меньше.
Разумное соотношение между и β находят, исходя из тяжести последствий каждой из ошибок. -
10 слайд
Методика проверки гипотез:
1. Формирование нулевой Н0 и альтернативной Н1 гипотез исходя из выборки X1,X2,…,Xn .
2. Подбор статистики критерия Tn=T(X1,X2,…,Xn )
3. По статистике критерия Tn и уровню значимости определяют критическую точку tкр, то есть границу, отделяющую область от S.
4. Для полученной реализации выборки Х=(X1,X2,…,Xn ) подсчитывают значение критерия, то есть Tнабл=T(X1,X2,…,Xn )t
5. Если tS (например, t> tкр для правосторонней области S), то нулевую гипотезу Н0 отвергают; если же t (t <tкр), то нет оснований, чтобы отвергнуть гипотезу Н0. -
11 слайд
t-критерий Стьюдента:
Общий вид: -
12 слайд
Случай независимых выборок.
df= n1+n2-2
n1=n2=n
df=n-1
n1≠n2 -
13 слайд
Случай зависимых выборок.
df=n-1
-
14 слайд
Вывод:
Критерий Стьюдента может быть использован для проверки гипотезы о различии средних только для двух групп.
Критерий Стьюдента применяется в случае малых выборок, что характерно для медико- биологических экспериментов.
Если схема эксперимента предполагает большее число групп, воспользуйтесь дисперсионным анализом.
Если критерий Стьюдента был использован для проверки различий между несколькими группами, то истинный уровень значимости можно получить, умножив уровень значимости, на число возможных сравнений. -
15 слайд
F- критерий Фишера:
1>2
df1=n1-1, df2=n2-1 -
16 слайд
Критерии различия называют непараметрическими, если он не базируется на предположении о типе распределения генеральной совокупности и не использует параметры этой совокупности.
Применение непараметрических методов целесообразно:
на этапе разведочного анализа;
при малом числе наблюдений (до 30);
когда нет уверенности в соответствии данных закону нормального распределения. -
17 слайд
Непараметрические критерии представлены основными группами:
критерии различия между группами
независимых выборок;
критерии различия между группами
зависимых выборок. -
18 слайд
Различия между независимыми группами
U критерий Манна-Уитни
двухвыборочный критерий
Колмогорова – Смирнова. -
19 слайд
Различия между зависимыми группами
z – критерий знаков
Т – критерий Уилкоксона парных
сравнений -
20 слайд
Критерии согласия:
Критерием согласия называют статистический критерий проверки гипотезы о предполагаемом законе неизвестного распределения.Пирсона (Хи-квадрат),
Колмогорова,
Фишера,
Смирнова. -
21 слайд
Критерий согласия χ2 (хи-квадрат) Пирсона.
Н0: «между эмперическим распределением и теоретической моделью нет никакого различия».Если эмпирические частоты (ni) сильно отличаются от теоретических (npi) ,то проверяемую гипотезу Но следует отвергнуть; в противном случае-принять.
-
22 слайд
Критерий согласия χ2 (хи-квадрат) Пирсона.
n-объем выборки
k-число интервалов разбиения выборки
ni-число значений выборки, попавших в і-й интервал
npi — теоретическая частота попадания значений случайной величины Х в і-й интервал. -
23 слайд
Критерий согласия χ2 (хи-квадрат) Пирсона.
илиО-фактически наблюдаемое число
Е- теоретически ожидаемое число -
24 слайд
Поправка Йейтса
Для распределения признаков, которые принимают всего 2 значения.
-
25 слайд
Правило применения критерия χ2.
*По формуле вычисляют — выборочное
значение статистики критерия.
*выбрав уровень значимости α критерия,
по таблице -распределения находим критическую точку*Если ≤ , то гипотеза Н0 не противоречит опытным данным;
если > , то гипотеза Н0 отвергается.
Неоходимым условием применения критерия Пирсона является наличие в каждом из интервалов не менее 5 наблюдений -
26 слайд
ЛИТЕРАТУРА:
Медик В.А.,Токмачев М.С.,Фишман Б.Б.Статистика в медицине и биологии. М.: Медицина, 2000.
Лукьянова Е.А. Медицинская статистика.- М.: Изд. РУДН, 2002.
Рокицкий П.Ф. Биологическая статистика.- Высшая школа, 1973.
И.В. Павлушков и др. Основы высшей математики и математической статистики.
(учебник для медицинских и фармацевтических вузов) М., «ГЭОТАР — МЕД»; 2003 -
Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 204 015 материалов в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 20.12.2020
- 214
- 2
- 06.12.2020
- 217
- 2
- 19.11.2020
- 360
- 6
- 12.11.2020
- 504
- 9
- 23.10.2020
- 197
- 0
- 15.10.2020
- 548
- 2
- 22.09.2020
- 206
- 4
- 14.09.2020
- 112
- 0
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Педагогическая риторика в условиях реализации ФГОС»
-
Курс повышения квалификации «Основы управления проектами в условиях реализации ФГОС»
-
Курс профессиональной переподготовки «Организация логистической деятельности на транспорте»
-
Курс профессиональной переподготовки «Логистика: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Финансы: управление структурой капитала»
-
Курс профессиональной переподготовки «Разработка эффективной стратегии развития современного вуза»
-
Курс профессиональной переподготовки «Управление информационной средой на основе инноваций»
-
Курс профессиональной переподготовки «Риск-менеджмент организации: организация эффективной работы системы управления рисками»
-
Курс профессиональной переподготовки «Организация деятельности специалиста оценщика-эксперта по оценке имущества»
-
Курс профессиональной переподготовки «Методика организации, руководства и координации музейной деятельности»
-
Курс профессиональной переподготовки «Организация и управление службой рекламы и PR»
Презентация на тему «Основы теории проверки статистических гипотез»
-
Скачать презентацию (0.18 Мб)
-
48 загрузок -
5.0 оценка
Ваша оценка презентации
Оцените презентацию по шкале от 1 до 5 баллов
- 1
- 2
- 3
- 4
- 5
Комментарии
Добавить свой комментарий
Аннотация к презентации
Презентация powerpoint для студентов на тему «Основы теории проверки статистических гипотез». Содержит 27 слайдов. Скачать файл 0.18 Мб. Самая большая база качественных презентаций. Смотрите онлайн с анимацией или скачивайте на компьютер. Средняя оценка: 5.0 балла из 5.
-
Формат
pptx (powerpoint)
-
Количество слайдов
27
-
Слова
-
Конспект
Отсутствует
Содержание
-
Слайд 1
Основы теории проверки статистических гипотез.
Доцент Аймаханова А.Ш.
-
Слайд 2
План лекции:
1. Статистические гипотезы в медико-
биологических исследованиях.
2. Параметрические критерии различий.
3. Непараметрические критерии.
4. Критерии согласия. -
Слайд 3
Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотез.
Задачи статистической проверки гипотез:
Относительно некоторой генеральной совокупности высказывается та или иная гипотеза Н0.
Из этой генеральной совокупности извлекается выборка.
Требуется указать правило, при помощи которого можно было бы по выборке решить вопрос о том, следует ли отклонить гипотезу Н0 или принять ее. -
Слайд 4
Статистическая гипотеза- это предположение о виде распределения или о величинах неизвестных параметров генеральной совокупности, которая может быть проверена на основании выборочных показателей.
Примеры статистических гипотез:
Генеральная совокупность распределена по нормальному закону Гаусса.
Дисперсии двух нормальных совокупностей равны между собой. -
Слайд 5
Статистические гипотезы
Параметрические Непараметрические
-
Слайд 6
Нулевой гипотезой Н0 называется основная гипотеза, которая проверяется.
Альтернативной гипотезой Н1, называется гипотеза, конкурирующая с нулевой, то есть противоречащая ей.
Простойназывают гипотезу, содержащую только одно предположение. a=a0
Сложной называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез.
Статистическим критерием проверки гипотезы Н0 называется правило, по которому принимается решение принять или отклонить гипотезу Н0. -
Слайд 7
Основной принцип проверки гипотез
Проверку гипотез осуществляют на основании результатов выборки X1,X2,…,Xn , из которых формируют функцию выборки Tn=T(X1,X2,…,Xn ), называемой статистикой критерия.
Tn=T(X1,X2,…,Xn )
критическая область S область принятия гипотезы
-
Слайд 8
Возможные ошибки при проверке гипотез
Первого рода Второго рода
-
Слайд 9
Уровнем значимости критерия ()называется вероятность допустить ошибку 1-го рода.
Вероятность ошибки 2-го рода обозначается через β.
Мощностью критерия называется вероятность недопущения ошибки 2-го рода (1- β).
Р(отвергнуть Н0/Н0 верна) или Р(Н1/Н0)
βР(принять Н0/Н0 неверна) или βР(Н0 /Н1)
1-βР(принять Н1/Н1 верна)
Чем больше мощность критерия, тем вероятность ошибки 2-го рода меньше.
Разумное соотношение между и β находят, исходя из тяжести последствий каждой из ошибок. -
Слайд 10
Методика проверки гипотез:
1. Формирование нулевой Н0 и альтернативной Н1 гипотез исходя из выборки X1,X2,…,Xn .
2. Подбор статистики критерия Tn=T(X1,X2,…,Xn )
3. По статистике критерия Tn и уровню значимости определяют критическую точку tкр, то есть границу, отделяющую область от S.
4. Для полученной реализации выборки Х=(X1,X2,…,Xn ) подсчитывают значение критерия, то есть Tнабл=T(X1,X2,…,Xn )t
5. Если tS (например, t> tкр дляправосторонней области S), то нулевую гипотезу Н0 отвергают; если же t (t -
Слайд 11
t-критерий Стьюдента:
Общий вид:
-
Слайд 12
Случай независимых выборок.
df= n1+n2-2
n1=n2=n
df=n-1
n1≠n2
-
Слайд 13
Случай зависимых выборок.
df=n-1
-
Слайд 14
Вывод:
Критерий Стьюдента может быть использован для проверки гипотезы о различии средних только для двух групп.
Критерий Стьюдента применяется в случае малых выборок, что характерно для медико- биологических экспериментов.
Если схема эксперимента предполагает большее число групп, воспользуйтесь дисперсионным анализом.
Если критерий Стьюдента был использован для проверки различий между несколькими группами, то истинный уровень значимости можно получить, умножив уровень значимости, на число возможных сравнений. -
Слайд 15
F- критерий Фишера:
1>2
df1=n1-1, df2=n2-1 -
Слайд 16
Критерии различия называют непараметрическими, если он не базируется на предположении о типе распределения генеральной совокупности и не использует параметры этой совокупности.
Применение непараметрических методовцелесообразно:
на этапе разведочного анализа;
при малом числе наблюдений (до 30);
когда нет уверенности в соответствии данных закону нормального распределения. -
Слайд 17
Непараметрические критерии представленыосновными группами:
критерии различия между группами
независимых выборок;
критерии различия между группами
зависимых выборок. -
Слайд 18
Различия между независимыми группами
U критерий Манна-Уитни
двухвыборочный критерий
Колмогорова – Смирнова. -
Слайд 19
Различия между зависимыми группами
z – критерий знаков
Т – критерий Уилкоксона парных
сравнений -
Слайд 20
Критерии согласия:
Критерием согласияназывают статистический критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Пирсона (Хи-квадрат),
Колмогорова,
Фишера,
Смирнова. -
Слайд 21
Критерий согласия χ2 (хи-квадрат) Пирсона.
Н0: «между эмперическим распределением и теоретической моделью нет никакого различия».
Если эмпирические частоты (ni) сильно отличаются от теоретических (npi) ,то проверяемую гипотезу Но следует отвергнуть; в противном случае-принять.
-
Слайд 22
n-объем выборки
k-число интервалов разбиения выборки
ni-число значений выборки, попавших в і-й интервал
npi — теоретическая частота попадания значений случайной величины Х в і-й интервал. -
Слайд 23
или
О-фактически наблюдаемое число
Е- теоретически ожидаемое число -
Слайд 24
Поправка Йейтса
Для распределения признаков, которые принимают всего 2 значения.
-
Слайд 25
Правило применения критерия χ2.
*По формуле вычисляют — выборочное
значение статистики критерия.
*выбрав уровень значимости α критерия,
по таблице -распределения находим критическую точку*Если ≤ , то гипотеза Н0 не противоречит опытным данным;
если > , то гипотеза Н0 отвергается.
Неоходимым условием применения критерия Пирсонаявляется наличие в каждом из интервалов не менее 5 наблюдений -
Слайд 26
ЛИТЕРАТУРА:
Медик В.А.,Токмачев М.С.,Фишман Б.Б.Статистика в медицине и биологии. М.: Медицина, 2000.
Лукьянова Е.А. Медицинская статистика.- М.: Изд. РУДН, 2002.
Рокицкий П.Ф. Биологическая статистика.- Высшая школа, 1973.
И.В. Павлушков и др. Основы высшей математики и математической статистики.
(учебник для медицинских и фармацевтических вузов) М., «ГЭОТАР — МЕД»; 2003 -
Слайд 27
СПАСИБО ЗА ВНИМАНИЕ.



























Посмотреть все слайды
Сообщить об ошибке
Похожие презентации












Спасибо, что оценили презентацию.
Мы будем благодарны если вы поможете сделать сайт лучше и оставите отзыв или предложение по улучшению.
Добавить отзыв о сайте
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Компьютеры
- 4.1.1 Компьютерная безопасность
- 4.1.2 Фильтрация спама
- 4.1.3 Вредоносное программное обеспечение
- 4.1.4 Поиск в компьютерных базах данных
- 4.1.5 Оптическое распознавание текстов (OCR)
- 4.1.6 Досмотр пассажиров и багажа
- 4.1.7 Биометрия
- 4.2 Массовая медицинская диагностика (скрининг)
- 4.3 Медицинское тестирование
- 4.4 Исследования сверхъестественных явлений
- 4.1 Компьютеры
- 5 См. также
- 6 Примечания
Определения
Пусть дана выборка из неизвестного совместного распределения , и поставлена бинарная задача проверки статистических гипотез:
где H0 — нулевая гипотеза, а H1 — альтернативная гипотеза. Предположим, что задан статистический критерий
- ,
сопоставляющий каждой реализации выборки одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе H0, и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе H0, но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе H1, и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе H1, но она неверно отвергнута статистическим критерием, то есть .
Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно.
| Верная гипотеза | |||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
О смысле ошибок первого и второго рода
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы H0 и H1, то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза H0 соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследумый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза H1 обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня.
Соответственно, ошибку второго рода иногда называют пропуском события — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Ниже, в разделе Примеры использования, подробно рассматривается применение понятий ошибок первого и второго рода в различных областях.
Вероятности ошибок (уровень значимости и мощность)
Для проверки статистических гипотез используют так называемые критерии согласия. Для них вероятности ошибок первого и второго рода играют значительную роль.
Вероятность ошибки первого рода при проверке статистических гипотез назывют уровнем значимости и обычно обозначают греческой буквой α (отсюда название α-errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой β (отсюда β-errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле (1 − β). Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода)
- когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода)
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «анти-спам» алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда анти-спам система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности анти-спам алгоритма.
Вредоносное программное обеспечение
Понятие ошибки первого рода также ипользуется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с анти-троянскими и анти-
Поиск в компьютерных базах данных
При поиске в базе данных, к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако, это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в комьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т. п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как террориста) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т. д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т. п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[1]
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые в основном применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[2]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15 %, это самый высокий показатель в мире.[3] Самый низкий уровень наблюдается в Нидерландах, 1 %.[4]
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70 %, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[5]
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиа-свидетельство» (изображение, видеозапись, аудиозапись и т. д.), которое имеет обычное объяснение.[6]
См. также
- Ложное срабатывание (ошибка первого рода)
- Статистическая значимость
Примечания
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95 % женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research).
Wikimedia Foundation.
2010.