Всякий раз при
обнаружении анализатором синтаксической
ошибки должно печататься соответствующее
сообщение. Например
SYNTAX
ERROR IN LINE 22.
Или
местоположение ошибки может описываться
полнее
LINE
22 SYMBOL 4.
В любом случае
пользователь может быть недоволен тем,
что сообщение не вполне ясное, так как
не указывается, в чем заключается ошибка
программиста. На практике фактическая
ошибка программирования могла произойти
гораздо раньше, анализатор же сообщает
об ошибке только тогда, когда ему
встречается недопустимый символ. Если
программист представляет анализатору
программу, имеющую синтаксическую
ошибку, компилятор, естественно, не
сможет решить, какую программу программист
должен был написать. Единственное, что
компилятор смог бы сделать, это принять
решение о «ремонте» на минимальном
расстоянии, т.е. о ремонте, требующем
минимальное число включений символов
в текст программы и исключений из него,
дающем синтаксически правильную
программу. Цель ремонта – обеспечить
анализатору условия для продолжения
анализа программы.
Хотя теоретически
ремонт на минимальном расстоянии кажется
привлекательным, его реализация
неэффективна, так как приходится часто
возвращаться назад по уже проанализированным
частям программы и отменять выполненные
компилятором ранее действия. Большинство
компиляторов не берется за такой ремонт.
Единственное исправление, которое они
осуществляют, — это вставка, исключение
или изменение символов в том месте,
где обнаружена ошибка. В этом случае
компилятор не может предоставить иной
информации, кроме точного указания о
том, где обнаружена ошибка. Компилятору
может быть известен еще и контекст, в
котором обнаружена ошибка; например,
она могла произойти в пределах присвоения,
в границах массива или в вызове процедуры.
Такая информация не всегда оказывается
полезной для пользователя, но она
показывает, какой тип конструкции
пытался распознать анализатор, когда
обнаружил ошибку, а это поможет найти
фактическую ошибку программирования.
Можно также сообщить пользователю,
какие символы допустимы при встрече
недопустимого символа. Если анализатор
способен сделать разумное предположение
о том, какая фактическая ошибка
программирования была допущена, он
может исправить программу для последующих
проходов.
Для исправления
программы (но не ремонта) необходимо
знать истинные намерения программиста.
В общем случае это невозможно, однако
для КС-языков многие типы ошибок можно
локализовать достаточно точно.
10.8. Контекстно-зависимые ошибки
Некоторые конструкции
типичных языков программирования нельзя
описать с помощью контекстно-свободной
грамматики. Следовательно, с точки
зрения таблицы разбора программы с
неописанными идентификаторами
синтаксически правильны. Такие
контекстно-зависимые ошибки могут быть
обнаружены действиями, включаемыми в
контекстно-свободную грамматику и
вызываемыми анализатором, который
запрашивает таблицу символов. Об ошибках
такого рода обычно выдаются четкие
сообщения при анализе таблицы
идентификаторов, например
Всякий раз при
обнаружении анализатором синтаксической
ошибки должно печататься соответствующее
сообщение. Например
SYNTAX
ERROR IN LINE 22.
Или
местоположение ошибки может описываться
полнее
LINE
22 SYMBOL 4.
В любом случае
пользователь может быть недоволен тем,
что сообщение не вполне ясное, так как
не указывается, в чем заключается ошибка
программиста. На практике фактическая
ошибка программирования могла произойти
гораздо раньше, анализатор же сообщает
об ошибке только тогда, когда ему
встречается недопустимый символ. Если
программист представляет анализатору
программу, имеющую синтаксическую
ошибку, компилятор, естественно, не
сможет решить, какую программу программист
должен был написать. Единственное, что
компилятор смог бы сделать, это принять
решение о «ремонте» на минимальном
расстоянии, т.е. о ремонте, требующем
минимальное число включений символов
в текст программы и исключений из него,
дающем синтаксически правильную
программу. Цель ремонта – обеспечить
анализатору условия для продолжения
анализа программы.
Хотя теоретически
ремонт на минимальном расстоянии кажется
привлекательным, его реализация
неэффективна, так как приходится часто
возвращаться назад по уже проанализированным
частям программы и отменять выполненные
компилятором ранее действия. Большинство
компиляторов не берется за такой ремонт.
Единственное исправление, которое они
осуществляют, — это вставка, исключение
или изменение символов в том месте,
где обнаружена ошибка. В этом случае
компилятор не может предоставить иной
информации, кроме точного указания о
том, где обнаружена ошибка. Компилятору
может быть известен еще и контекст, в
котором обнаружена ошибка; например,
она могла произойти в пределах присвоения,
в границах массива или в вызове процедуры.
Такая информация не всегда оказывается
полезной для пользователя, но она
показывает, какой тип конструкции
пытался распознать анализатор, когда
обнаружил ошибку, а это поможет найти
фактическую ошибку программирования.
Можно также сообщить пользователю,
какие символы допустимы при встрече
недопустимого символа. Если анализатор
способен сделать разумное предположение
о том, какая фактическая ошибка
программирования была допущена, он
может исправить программу для последующих
проходов.
Для исправления
программы (но не ремонта) необходимо
знать истинные намерения программиста.
В общем случае это невозможно, однако
для КС-языков многие типы ошибок можно
локализовать достаточно точно.
10.8. Контекстно-зависимые ошибки
Некоторые конструкции
типичных языков программирования нельзя
описать с помощью контекстно-свободной
грамматики. Следовательно, с точки
зрения таблицы разбора программы с
неописанными идентификаторами
синтаксически правильны. Такие
контекстно-зависимые ошибки могут быть
обнаружены действиями, включаемыми в
контекстно-свободную грамматику и
вызываемыми анализатором, который
запрашивает таблицу символов. Об ошибках
такого рода обычно выдаются четкие
сообщения при анализе таблицы
идентификаторов, например
Яндекс.Директ, Яндекс Маркет, Google Adwords, Google Merchant, Ремаркетинг

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Никто не может с первого раза выдавать достойный результат. Контекстной рекламе не учат в университетах. Рекомендаций, которые дает Яндекс, недостаточно. Без практики, без ошибок вы не научитесь вести рекламные кампании. Только личный опыт.
В этом материале мы собрали распространенные ошибки, которые встречаются в разных РК. Это чек-лист, по которому вы можете узнать, правильно ли настроили рекламу.
Начнем с распространенных ошибок новичков.
-
Ошибки новичков в контекстной рекламе
- Идеальная теоретическая подкованность
- Работать по шаблонам
- Делать идеальную РК
- Бросать рекламную кампанию на произвол
- Делать лишь по-своему
- Беспрекословно следовать за человеком из интернета
- Давать рекламодателю меньше, чем оговорено
- Бояться учиться новому
- Доверять справке Яндекс.Директа
-
Ошибки в конструкции объявления
- Не делать мобильную версию объявления
- Не использовать быстрые ссылки
- Не прописывать второй заголовок
- Не добавлять контактную информацию
- Нерелевантный заголовок или ссылка
- Не использовать дополнительные элементы
-
Ошибки в стратегии
- Забывать про ретаргетинг/ремаркетинг
- Не настроить связь со счетчиком Метрики
- Не отсеивать минус-слова
- Не разделять кампании
- Не настраивать географический таргетинг
- Не следить за модерацией
- Не оптимизировать кампанию под РСЯ
- Не настраивать отраслевые и региональные кампании
- Не проанализировать структуру рекламных кампаний
- При переходе по ссылке в рекламе сайт не открывается
- Запускать рекламу на товары без спроса
- Не анализировать конкурентов
- Искать максимальный охват при минимальных затратах
- Высокая стоимость кликов при неверных лимитах
-
Неверное семантическое ядро
- Использовать готовые списки минус-слов
- Не пользоваться системами автоматизации
- Пытаться занимать первую позицию в поиске
- Показывать рекламу только в рабочее время
- Заключение
Ошибки новичков в контекстной рекламе
Идеальная теоретическая подкованность
Никуда без матчасти. В этом пункте речь о тех специалистах, которые прочитали кучу книг, мониторят десятки порталов о контексте, слушали сотни вебинаров… И не применяли знания на практике.
Рекламщик знает, что ставки придется корректировать, знает, как это делать. Но в какой ситуации? Как именно?
Теория нужна. Но без практики вы ничего не добьетесь.
Работать по шаблонам
Новичок может найти свою схему, которая будет работать для нескольких рекламных кампаний и приносить успех.
Если слепо копировать стратегию той кампании, которая работает успешно, в новую — контекст превратится в лото. Либо повезет и схема сработает, либо бюджет сольется в никуда.
Каждый бизнес уникален. Даже два цветочных магазина могут функционировать по разным моделям. То, что сработало для одного, не обязательно сработает для другого. Поэтому нельзя слепо копировать схему, которая вдруг оказалась успешной.
Оцените, что именно дало положительный эффект в вашей кампании. Проанализируйте, какие составляющие сработали нужным образом. Выдвиньте гипотезу, протестируйте решение.
Делать идеальную РК
Есть поговорка: «Лучшее — враг хорошего».
Никто не может создать идеальную кампанию, которая будет отрабатывать на 100%, приносить вам клиентов и заявки. В погоне за заоблачным результатом возрастает риск все испортить.
Реклама работает с людьми — пользователями. Они определяют стоимость клика, частотность ключевых слов. Поэтому ситуация в контексте постоянно меняется.
Старайтесь минимизировать расходы и увеличивать показатель рентабельности, пробовать и тестировать новые методы. Но помните, что всегда можно что-то упустить, и в этом нет ничего зазорного.
Бросать рекламную кампанию на произвол
Интернет-маркетинг — динамическая сфера, в которой нет праздников и выходных. Мы ищем товары в интернете и вечером, и ночью, и в выходные. А значит, рекламная среда постоянно меняется.
Запустили РК? Отлично! Самое время проанализировать ее работу:
- оценить рентабельность;
- провести тестирование;
- убрать нецелевые ключи;
- защитить рекламу от конкурентов.
Рекламная кампания требует от специалиста постоянного внимания.
Делать лишь по-своему
В психологии есть эффект Даннинга-Крюгера. Это ситуация, когда новичок, лишь недавно начавший заниматься делом, уже думает, что он многое умеет. Как результат, начинающий специалист поддаются чувству собственного профессионализма и не прислушивается к сторонним советам.
С одной стороны, специалист труднее будет учиться новому. Он же уже научился! С другой — при разговоре с заказчиком могут возникнуть нереальные ожидания от рекламы. А при провале и спрос со специалиста будет соответствующий.
Беспрекословно следовать за человеком из интернета
Знаете, когда я начал работать в сфере интернет-маркетинга, в соцсетях меня завалила реклама обучающих курсов и вебинаров. Все объявления, как на подбор — «Работай, сколько хочешь», «Зарабатывай из любой точки мира». Какие-то посты сопровождались яркими картинками с Карибских островов.
Такие Аязы в интернет-рекламе.
Обучение — всегда полезно. Вы узнаете что-то новое, учитесь интересным методикам. Речь о том, что ничего не следует принимать на веру. Для любой фишки:
- постройте гипотезу — какие будут затраты, какие вы ждете результаты;
- проведите тестирование;
- проанализируйте.
Не бойтесь применять в работе новое. Но тестируйте все изменения, анализируйте ситуацию. Вы же маркетолог.
Давать рекламодателю меньше, чем оговорено
Вопрос этичности и профессионализма.
Многие начинающие специалисты грешат тем, что деньги взяли, но что-то забыли, где-то растянули сроки. Даже банально не подготовили отчет вовремя. В итоге подвели клиента.
В интернет-маркетинге высокая конкуренция. Поэтому работник, который подводит клиента, точно никогда не выйдет на должный уровень. Сарафанное радио тоже работает.
Бояться учиться новому
Выше мы уже сказали, что в интернете полно обучающих курсов, которые обещают сладкую жизнь и минимум усилий для достижения целей. Среди всех обучающих вебинаров, мастер-классов и платных курсов много обычных пересказов справки рекламных систем, которые доступны всем.
Однако всегда можно найти что-то новое и интересное. Не бойтесь пробовать советы, просто не забывайте о тестировании.
Доверять справке Яндекс.Директа
Справка — это краткое описание возможностей и функций. Поэтому доверяй, но проверяй.
Когда вы покупаете холодильник, к нему тоже полагается инструкция в комплекте. Вы узнаете, как его включать, как регулировать мощность, какие признаки говорят, что агрегат сломан. А чтобы его починить, наверняка вы обратитесь к мастерую
Справка — такая же инструкция. Она рассказывает основные моменты, но чему-то новому она вас не научит.
Ошибки в конструкции объявления
Не делать мобильную версию объявления
Смартфоны дают существенную долю трафика на сайт. Уже сейчас Google ввел Mobile-first indexing. Поэтому не забывайте адаптировать объявления под смартфоны.
Для этого есть отдельная галочка в Директе.
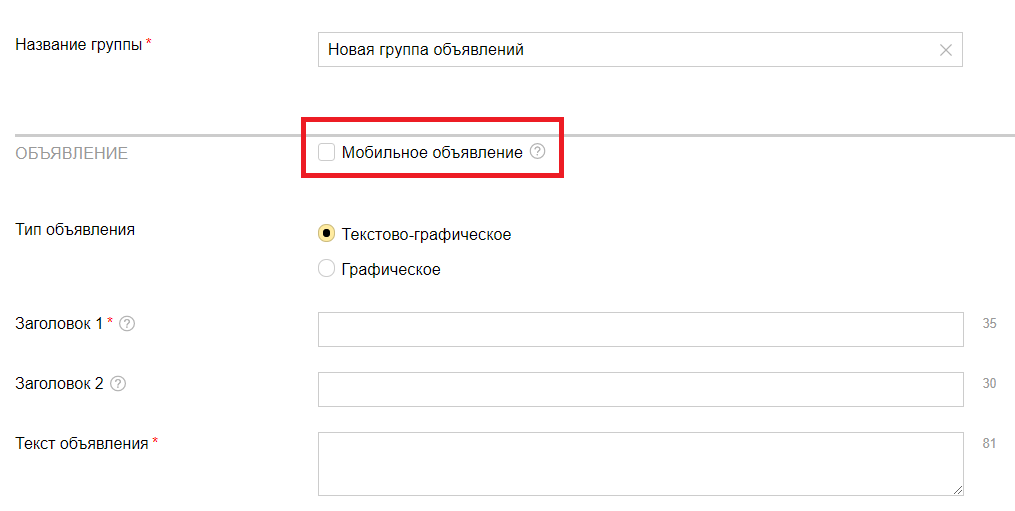
Экраны смартфонов меньше, чем у персональных компьютеров. Человек, который ищет информацию, хочет как можно быстрее получить ответ на свой вопрос. Придумайте короткий и яркий, релевантный заголовок для вашего товара.
Не забывайте и о том, что с телефона человеку проще вам позвонить. Добавьте в объявление номер. Кроме того, возможно потребуется изменить призыв к действию. Вы же хотите, чтобы человек позвонил вам.
Если ссылка ведет на сайт, то для смартфонов адресуйте пользователя на мобильную версию сайта.
Не использовать быстрые ссылки
Прежде всего, речь о быстрых ссылках. Они облегчают навигацию. Прямо из выдачи пользователь перейдет на тот раздел сайта, который ему интересен.
Например, вам нужна ветеринарная клиника. А здоровье питомца вы не согласны доверить первой строчке в Яндексе.
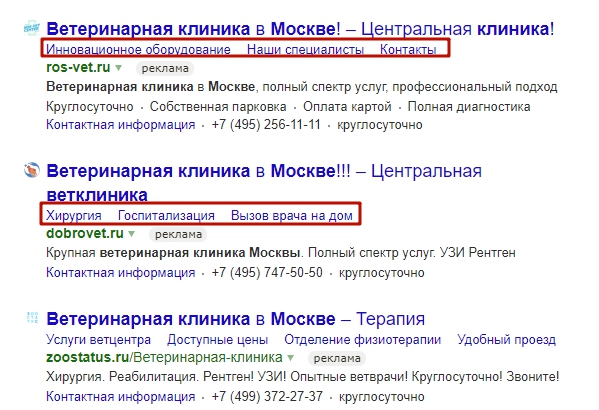
Быстрые ссылки помогут вам сразу перейти в раздел «О нас», где можно увидеть отзывы, или сразу ознакомиться с ценами. Яндекс позволяет добавить до 4 ссылок в объявление, Google — от 2.
Не прописывать второй заголовок
Второй заголовок дает дополнительные символы в тексте объявления.
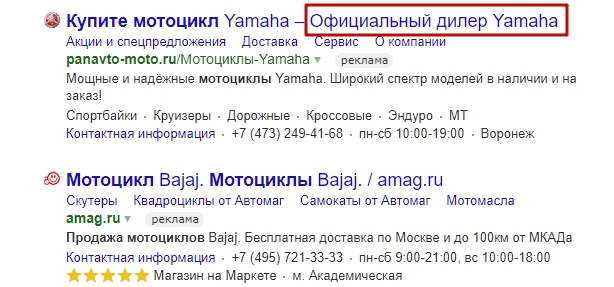
Он увеличит показатель кликабельности от 5 до 10%.
В дополнение к основному заголовку вы можете указать дополнительную информацию, которая склонит пользователя к покупке. Например, укажите название бренда, выгодные преимущества или действующие скидки.
Не добавлять контактную информацию
Чем больше каналов связи есть, тем вероятнее, что человек все же с вами свяжется.
Мы уже говорили про кампании для мобильных устройств. К десктопным кампаниям это тоже относится. Добавьте номера телефонов, электронный адрес — дайте возможность к вам обратиться.
Нерелевантный заголовок или ссылка
Маркетологи рекомендуют на один ключ запускать одно объявление. Вам будет удобнее анализировать эффект, следить за статистикой.
Кроме этого, вам легче написать детальный, яркий текст. Человек ищет черный мотоцикл-чоппер? Покажите ему соответствующее объявление. При общем тексте вы сможете привести пользователя только на список товаров, а не конкретно на ту позицию, которая ему интересна. Получите снижение конверсии.
Не использовать дополнительные элементы
Кроме текста, контактов и быстрых ссылок вы можете дополнить объявление другими элементами:
- уточнением;
- видеодополнением;
- изображением;
- визиткой.
Не использовать эти элементы значит упустить место в выдаче, которое сделает ссылку заметнее.
Ошибки в стратегии
Забывать про ретаргетинг/ремаркетинг
Ретаргетинг в Директе и ремаркетинг в AdWords — это показ объявлений пользователям, которые уже были на вашем сайте, в РСЯ или КМС.
По статистике, конверсия при повторном просмотре сайта может достигать 30%.
Не настроить связь со счетчиком Метрики
В 30% рекламных кампаний не настроена связь со счетчиком метрики. Поэтому система аналитики неправильно отслеживает достижения целей (даже если сами они настроены), у аналитика неверная информация о конверсии рекламы.
При этом, специалист не сможет воспользоваться настройками для автоматизации управления ставками, у него возникнут проблемы с ретаргетингом.
Когда все настроено верно, вы увидите дополнительную информацию по трафику — например, показатели отказов, конверсионные параметры.
Не отсеивать минус-слова
Минус-слова — это ключи, который не приводят к вам целевого пользователя.
Приведем пример. Вы продаете аквариумы, настраиваете рекламу. По слову «аквариум» вас увидят и рыбоводы, и поклонники Гребенщикова. Поэтому нужно составить список тех слов, которые отсекут нецелевую аудиторию.
Вы снизите стоимость рекламы, исключите нецелевые показы — сэкономите деньги.
Для рекламы на поиске минусовать слова обязательно, а при настройке РСЯ — будьте аккуратны и не исключите площадку с вашей аудиторией.
Ранее мы уже определились с вами, что кампанию нельзя просто бросать. В ходе анализа проверяйте ключи, по которым продвигаетесь и следите за списком минус-слов. Его тоже придется регулярно обновлять.
Не разделять кампании
Кампании на поиске — те, которые мы видим в поисковой выдаче. РСЯ — сеть партнерских сайтов Яндекса, пользователи которых также видят рекламные объявления.
Объявления отличаются друг от друга и в настройке, и в аудиториях, и в возможностях.
В поиске мы видим ту рекламу, которая соответствует введенному запросу. А значит, увидим то, что нам интересно прямо сейчас. РСЯ — это сайты. У них есть своя тематика, своя аудитория.
Более того, на партнерских сайтах к рекламному объявлению нужно привлекать внимание пользователя. Он же пришел за контентом, а не за рекламой.
Не настраивать географический таргетинг
Геотаргетинг — ориентированность ваших кампаний на жителей определенного города, региона, страны. Если ваш магазин работает только в Воронеже и не делает доставку в другие города, смысла показывать рекламу в Рязани нет никакого.
Вы можете как сузить зону показа рекламы, так и расширить ее, например, если хотите привлечь клиентов из других городов.
Не следить за модерацией
Все кампании по настройке проходят проверку.
Снова повторим: не бросайте свои кампании на произвол. Незамеченные вовремя отклоненные объявления — это упущенные конверсии и продажи.
Не оптимизировать кампанию под РСЯ
Реклама на поиске — объявления, которые идут перед основной выдачей. Они не требуют дополнительного внимания, пользователь их видит по умолчанию.
Реклама на РСЯ — отдельная история. Объявления пользователь видит, когда просматривает сайт-партнер, на который пришел за полезной информацией. Поэтому для рекламодателя, с одной стороны, нужно не раздражать посетителя сайта, а с другой — показать предложение.
Учтите:
- Вы можете (и должны!) добавлять картинки к рекламному объявлению в РСЯ.
- Поскольку ключевые слова для РСЯ не подсвечиваются, используйте всю фантазию для привлечения внимания.
- Тестируйте разные форматы.
Не настраивать отраслевые и региональные кампании

Вот пример, который я нашел на одном сайте о контекстной рекламе.
Для компании, которая занимается несколькими направлениями, целесообразно разделять кампании в соответствии с этими направлениями. Не сливайте все в одно ведро.
1 запрос — одно объявление.
Не проанализировать структуру рекламных кампаний
Без анализа структуры невозможно аналитика рекламных кампаний. Например, когда вы разобьете фразы на группы, вы не сможете сказать, какая из них самая результативная.
Например, если мы рекламируем автомобили, нам потребуются объявления:
- с именем бренда;
- с типом кузова;
- по моделям авто;
- с учетом географии автосалона.
При переходе по ссылке в рекламе сайт не открывается
Банально, но некоторые сайты могут не открываться у пользователя.
Если сайт не может обработать метку рекламной системы, то, скорее всего, пользователь не увидит на нем ничего. Поэтому вспоминаем советы выше: тестируем, проверяем и не оставляем кампании работать сами по себе.
Запускать рекламу на товары без спроса
Речь не о случае, когда вы выводите на рынок свой новый продукт или запускаете новую услугу.
Изучите спрос на ваш товар по ключевым словам.
Например, есть человек, который торгует сложными установками для сахарного завода. Его потенциальные клиенты — предприятия по производству сахара, который в стране всего 40.
В таком случае контекстная реклама не подойдет. Можно собрать семантику, которая косвенно будет описывать товар. Однако бюджет будет сливаться в никуда. Проще позвонить.
Не анализировать конкурентов
Оцените свое торговое предложение, сравнив его с конкурентскими.
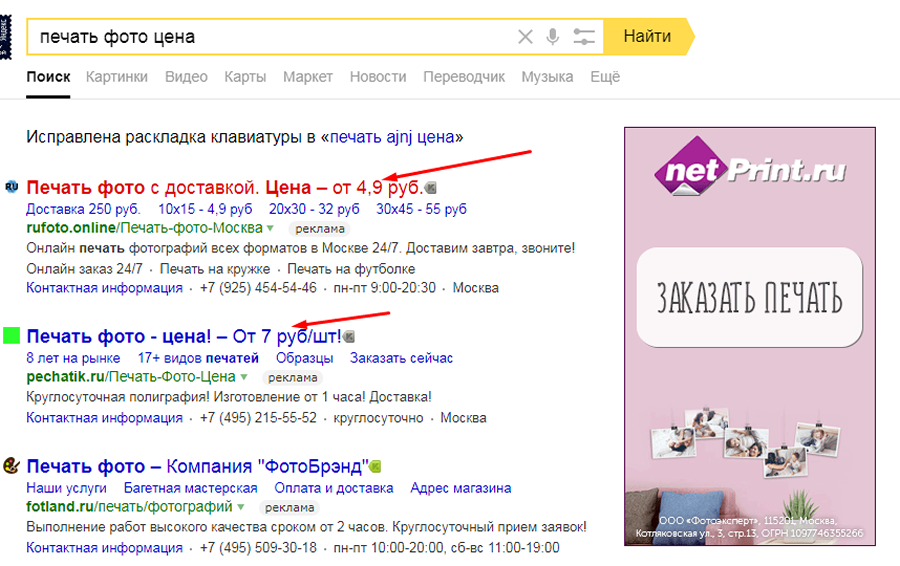
Как вы думаете, в примере выше по какой ссылке перейдет пользователь? Поэтому продумайте свое уникальное торговое предложение, которое покажет ваши преимущества перед конкурентами.
Вместе с этим не забывайте, что низкая цена и 100500 вариантов доставки все еще не завоюют сердце покупателя. Поэтому удобство и дизайн.
Искать максимальный охват при минимальных затратах
Контекстная реклама — постоянная работа. Чем больше людей вы хотите охватить, тем больший бюджет придется заложить.
Не получится рекламировать пиццу в Питере, когда вы хотите получить 100 заказов при бюджете 3 000 рублей.
Запаситесь средствами на клики. Запустите кампанию, дайте ей поработать. Затем соберите аналитику, прикиньте свои варианты. Со временем, обычно, цена клика снижается, если вы все настроите верно.
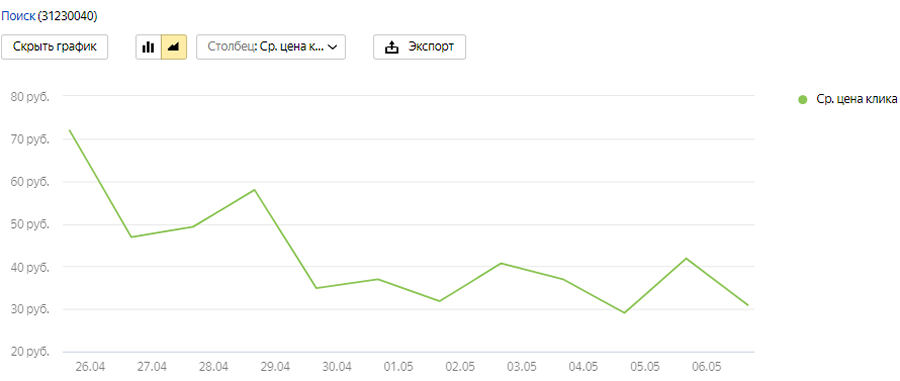
Высокая стоимость кликов при неверных лимитах
Это другая крайность ситуации из предыдущего пункта. Вы тратите огромную сумму на рекламу ежемесячно, но она не приносит результатов. Например, пользователь может просто заинтересоваться вашим сайтом, из любопытства зайти на него, но не сделать заказ.
Если у вас товар или услуга, которая нужна здесь и сейчас — например, экстренное открытие дверей, тогда разумно стараться оказаться выше конкурентов.
Для товара меньшей срочности можно попробовать сэкономить, установить дневной лимит на рекламу. Так у вас не уйдет весь бюджет за день. Вы постепенно будете накапливать информацию о РК, чтобы потом сделать выводы и скорректировать стратегию.
Неверное семантическое ядро
Не пытайтесь охватить все и сразу. Часто неэффективность кампании объясняется неверной семантикой. Я вспоминаю советы Константина Найчукова из eLama о том, что не стоит набивать кампанию over9000 ключами.
Настолько широкая семантика ничего не даст. Поэтому не начинайте рекламу с показа по высокочастотникам и околотематическим словам. Воспользуйтесь для начала максимально целевыми фразами.
Уделите внимание не количеству, а качеству фраз. А затем сможете добавить и конкурентные фразы, и более общие, чтобы привести дополнительную аудиторию. Следите за качеством трафика.
Использовать готовые списки минус-слов
Поскольку каждый бизнес уникален. Да, готовые списки минус-слов можно найти для большинства тематик.
Однако не используйте их бездумно. Можете исключить часть целевой аудитории и потерять клиентов.
Не пользоваться системами автоматизации
Системы автоматизации в контекстной рекламе позволяют вам установить стратегию управления ставками.
Вы можете выставить суточный лимит на рекламу, если бюджет ограничен. Можете настроить такое управление ставками, которое поможет существенно снизить стоимость клика. Можете настроить время показа — например, если привлекаете звонки, а менеджер работает только до 18:00.
Пытаться занимать первую позицию в поиске
Стратегия «Быть первым во всем» подходит далеко не для каждого типа бизнеса.
Вы оставите конкурента внизу, это здорово. Но не всегда стратегия принесет эффект. Обычно маркетологи строят воронку продаж и стараются моделировать ситуацию. Оцените свои показатели и решите, готовы ли вы платить по максимуму за первое место на поиске.
Показывать рекламу только в рабочее время
Конечно, для некоторых случаев (например, как в примере выше, вы не можете обрабатывать звонки в выходные) рекламу нецелесообразно показывать в нерабочее время.
Но если у вас рекламируются товары, которые человек может заказать в любое время — не пренебрегайте рекламой в выходные.
Заключение
Я постарался собрать для вас самые важные ошибки при запуске и ведении кампаний, при обучении контекстной рекламе. Наверняка, у вас есть собственные примеры.
Давайте вместе учиться на ошибках? Пишите в комментариях о личном опыте. Сделаем контекстную рекламу проще.
В платформе 1С сообщения об ошибках бывают достаточно запутаны, и без должных навыков разобраться в причинах достаточно сложно. Вот и сообщение об ошибке при вызове контекста может ввести в ступор начинающего разработчика. Однако в подавляющем большинстве случаев мы видим подобное сообщение, если разработчик допустил ошибку в своем коде. Причем речь зачастую идет не об орфографических ошибках, а о логических.
Исправляем ситуацию
Чтобы избавиться от этого неприятного сообщения об ошибке при вызове метода контекста, следует понимать, что контекстом называют методы платформы 1С. Значит в определенной строке кода воспользовались методом с неверными параметрами или вызвали его не от того владельца. Всегда внимательно и полностью читайте сообщения об ошибках – часто в них содержится указание на строку и метод, вызвавший ошибку. Это поможет сэкономить время на отладку и поиск проблемного места в коде.
Рассмотрим действия разработчика на примере со специально допущенной ошибкой. Мы запускаем на исполнение нижеприведенный кусок кода с запросом, в котором забыли дописать условие отбора. Компилятор 1С пропускает такую процедуру, так как орфографических ошибок в написании команд мы не допустили. Однако в режиме предприятия нас ждет такое сообщение об ошибке:
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Номенклатура.Ссылка КАК Ссылка,
| Номенклатура.ВерсияДанных КАК ВерсияДанных,
| Номенклатура.ПометкаУдаления КАК ПометкаУдаления,
| Номенклатура.Родитель КАК Родитель,
| Номенклатура.ЭтоГруппа КАК ЭтоГруппа,
| Номенклатура.Код КАК Код,
| Номенклатура.Наименование КАК Наименование,
| Номенклатура.Артикул КАК Артикул,
| Номенклатура.ЕдиницаИзмерения КАК ЕдиницаИзмерения,
| Номенклатура.ТипНоменклатуры КАК ТипНоменклатуры,
| Номенклатура.Предопределенный КАК Предопределенный,
| Номенклатура.ИмяПредопределенныхДанных КАК ИмяПредопределенныхДанных
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
|ГДЕ
| ";
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
Пока ВыборкаДетальныеЗаписи.Следующий() Цикл
КонецЦикла;
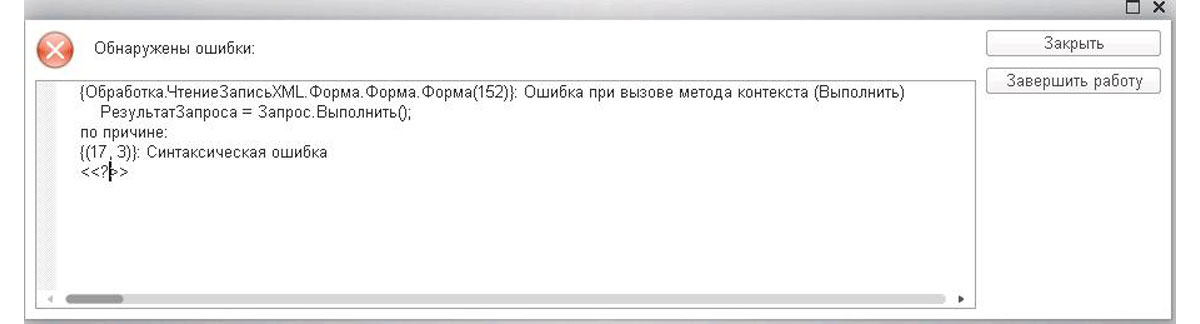
Приведенный текст ошибки программисту 1С скажет, что в модуле формы обработки «ЧтениеЗаписьXML на 152 строчке кода не может выполниться запрос. Причина в том, что на 17 строчке запроса нет чего-то, что ждал компилятор. Таким образом, чтобы убрать подобное сообщение, необходимо выяснить, что там должно быть и написать недостающий код.
Увидев вышеприведенный кусок кода, разработчик заметит, что в запросе есть служебное слово «ГДЕ», дающее сигнал 1С, что дальше будет условие. Но мы забыли дописать его и, естественно, система с помощью сообщения об ошибке спрашивает нас – «а где условие?». Чтобы исправить эту ситуацию необходимо либо убрать оператор «ГДЕ» из запроса, либо добавить условие.
Но ошибки могут быть не только в текстах запросов. Допустим, мы хотим выбрать всю номенклатуру и узнать, входит ли она в определенную группу. Проверка происходит с помощью метода «ПринадлежитЭлементу» и его параметра, который должен быть типа СправочникСсылка. Мы опять допускаем ошибку и вместо ссылки в параметр метода помещаем строку, содержащую имя переменной.
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Номенклатура.Ссылка КАК Ссылка,
| Номенклатура.ВерсияДанных КАК ВерсияДанных,
| Номенклатура.ПометкаУдаления КАК ПометкаУдаления,
| Номенклатура.Родитель КАК Родитель,
| Номенклатура.ЭтоГруппа КАК ЭтоГруппа,
| Номенклатура.Код КАК Код,
| Номенклатура.Наименование КАК Наименование,
| Номенклатура.Артикул КАК Артикул,
| Номенклатура.ЕдиницаИзмерения КАК ЕдиницаИзмерения,
| Номенклатура.ТипНоменклатуры КАК ТипНоменклатуры,
| Номенклатура.Предопределенный КАК Предопределенный,
| Номенклатура.ИмяПредопределенныхДанных КАК ИмяПредопределенныхДанных
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
|ГДЕ
| НЕ Номенклатура.ЭтоГруппа ";
НужнаяГруппаЭлементов = Справочники.Номенклатура.НайтиПоНаименованию("Мебель");
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
Пока ВыборкаДетальныеЗаписи.Следующий() Цикл
Сообщить(ВыборкаДетальныеЗаписи.Ссылка.ПринадлежитЭлементу("НужнаяГруппаЭлементов"));
КонецЦикла;
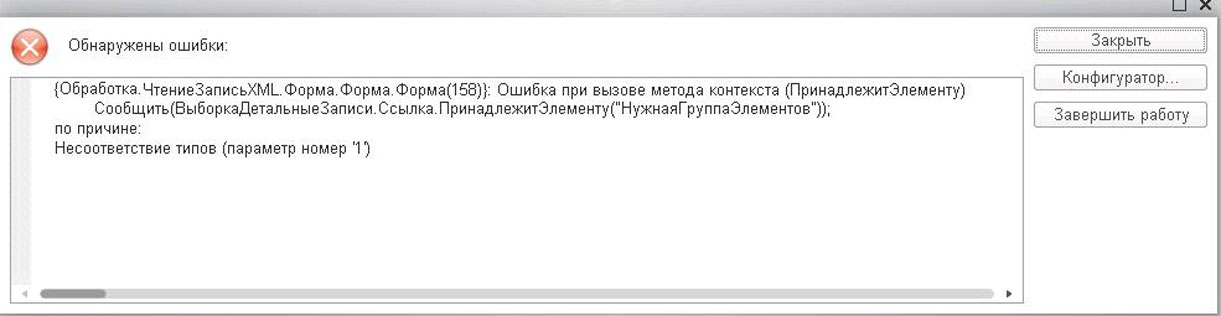
1С выдает настолько же информативное сообщение, из которого мы понимаем, что на 158 строке у 1 параметра неправильный тип. Но что же делать, если мы не знаем, какой тип должен быть? В этом нам поможет Синтакс-помощник, встроенный в платформу 1С.
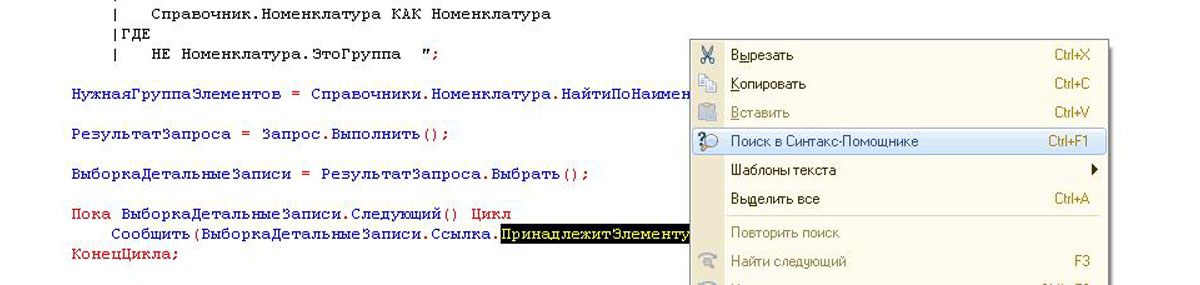
В конфигураторе находим строку и метод, на который указывало сообщение об ошибке, и нажимаем на него правой кнопкой мыши. Выбираем пункт «Поиск в синтакс-помощнике» и платформа самостоятельно ищет справочную информацию по выделенному методу. В справке мы видим не только подробное описание параметров и самого метода, но и пример. Сверив пример с нашим кодом, приходит понимание, что кавычки не нужны и без них все работает.
Чаще всего причиной подобных ошибок выступают следующие факторы:
- Невнимательность;
- Отсутствие опыта или знаний;
- Несогласованность действий разработчиков друг с другом;
- Изменения в методах контекста в новых версиях платформы.
Но ошибки при разработке ПО случаются постоянно, поскольку иногда ошибаются даже специалисты с многолетним опытом. Самое главное – уметь исправлять их и учиться на них. Постепенно вы будете видеть сообщения об ошибках все реже и научитесь замечать подобные «опечатки» еще до запуска 1С.
Больше семи лет мы помогаем бизнесу продвигать товары и услуги в интернете. К нам часто обращаются с одной и той же проблемой: запустили контекстную рекламу, потратили весь бюджет в Яндекс Директ или Google Реклама, но ни заявок, ни продаж не получили или получили совсем мало заявок по очень высокой стоимости.
Поэтому мы решили подробно описать популярные ошибки, из-за которых контекстная реклама может не работать.
Ошибка № 1. Не проводить комплексный аудит
Комплексный аудит – это проверка всей системы, которая помогает бизнесу привлекать клиентов. В эту систему входят:
- Качественный продукт.
- Удобный и стильный сайт.
- Конкурентное предложение для потребителей.
- Эффективная работа отдела продаж;
- Грамотная проработка стратегии продвижения.
- Корректно настроенная аналитика.
- Целевой трафик.
Это значит, что даже идеально настроенные рекламные кампании, работающие с устаревшим, медленным и неудобным сайтом, не принесут результата. И наоборот, идеальный сайт не будет эффективен, если плохо настроена реклама.
Решение: найти и устранить ошибки на всех уровнях системы: продукт — сайт — трафик — отдел продаж. После этого как правило удаётся значительно повысить эффективность продвижения и превратить контекстную рекламу в инструмент генерации заявок, поднять уровень продаж и увеличить прибыль компании.
Для начала предлагаем провести аудит контекстной рекламы, приведём наиболее частые ошибки при настройке Яндекс Директ и Google Реклама. Обратите внимание, что эти ошибки относятся в первую очередь к ситуации, когда контекстная реклама показала низкую эффективность сразу после запуска.
Ошибка № 2. Неверная стратегия продвижения
Неправильно составленная стратегия продвижения товара или услуги зачастую является причиной низкой эффективности контекстной рекламы.
Решение: прежде чем проводить настройку Яндекс директ или Google Реклама нужно:
- провести анализ рынка;
- провести маркетинговый анализ продукта или услуги;
- понять потребности целевой аудитории;
- оценить уровень спроса через различные сервисы;
- проанализировать предложения основных конкурентов.
На основе этих данных нужно составить стратегию продвижения в контекстной рекламе, которая ответит на несколько важных вопросов: какие инструменты подойдут лучше всего; какой рекламный бюджет будет оптимальным; на какой вид рекламы сделать упор — поисковая реклама или реклама сеть Яндекса (РСЯ); как работать со ставками за клик и др.
Ошибка № 3. Нецелевая или скудная семантика
Настройка контекстной рекламы начинается с формирования семантического ядра. Это список слов и фраз, по которым Яндекс Директ или Google Реклама показывают объявления пользователям. Если ключевые фразы подобраны неправильно и не соответствуют запросам вашей целевой аудитории, то эффективность контекстной рекламы будет низкой.
Решение: подбирать максимально целевые слова, коммерческие ключевые фразы и продающие добавки, которые сигнализируют о явном намерении людей купить ваш товар или воспользоваться вашими услугами. В контекстной рекламе термином «продающие добавки» обозначают «горячие» слова в ключевых фразах, по которым понятно, что клиент уже готов купить ваш товар или услугу.
Пример продающих добавок: купить, заказать, оптом, под ключ.
Пример коммерческой ключевой фразы: установка пластиковых окон под ключ.
В каждой нише свои продающие добавки, поэтому изучите, как именно ваши клиенты формулируют запросы и составьте подробный список. Например, люди, которые хотят купить санки-ватрушки, могут формулировать свои запросы по-разному: купить санки-ватрушки, заказать тюбинг недорого, надувные санки интернет-магазин и т.д.
Нужно проработать все возможные варианты ключевых слов, тогда вы сможете охватить всю целевую аудиторию. Использование около целевых ключевых слов или наличие нецелевых ключевых слов – это гарантированный «слив» рекламного бюджета. Также важно помнить, что не стоит использовать слишком «широкие» ключевые слова в поисковых кампаниях, не нужно охватывать все запросы сразу, ориентируйтесь только на свою целевую аудиторию.
Ошибка № 4. Отсутствуют или плохо проработаны минус-слова в поисковой рекламе
Минус-слова — это слова, помогающие ограничить показ рекламных материалов тем пользователям, которые не попадают в вашу целевую аудиторию. Без тщательного подбора минус-слов вы будете привлекать нецелевой трафик на свой сайт и неэффективно тратить рекламный бюджет.
Решение: тщательно прорабатывать и регулярно пополнять список минус-слов. Например, если вы продаёте товар только в розницу, то вам нужно добавить минус-слово «оптом», чтобы не показывать объявления по запросам с этим словом и не привлекать нецелевую для вас аудиторию.
Ошибка № 5. Не соблюдается принцип релевантности и последовательности
Эта ошибка допускается, когда рекламное объявление не отвечает на поисковый запрос пользователя.
Решение: всегда соблюдать этот принцип. Понять суть принципа поможет простой пример. Пользователь вводит поисковый запрос: «купить iphone 12 64gb красный». В ответ на свой поисковый запрос он должен увидеть рекламное объявление с заголовком, где написано «Красный iPhone 12 64GB». Далее, кликнув на это объявление, пользователь должен попасть на страницу с красным iPhone 12 на 64 ГБ. Ни на главную страницу, ни в каталог всех iPhone, а сразу на страницу конкретного, интересующего его товара.
Пользователь в объявлении получил точный ответ на свой поисковый запрос, а на сайте увидел именно тот товар, который искал, — это и есть принцип релевантности и последовательности. Контекстная реклама, настроенная по этому принципу, более эффективна.
Ошибка № 6. Несоответствие информации в объявлениях и на сайте
В объявлении вы обещаете грандиозные скидки, а на сайте нет об этом ни слова. Несоответствие информации в рекламе и на сайте вызывает у людей негатив по отношению к сайту и бренду и существенно снижает конверсию.
Решение: информация, которая указана в рекламных объявлениях, должна быть актуальной и полностью соответствовать данным на вашем сайте. Если в объявлении сказано о скидке 50% до конца недели, то и на сайте эта информация должна подтверждаться. Также внимательно нужно следить, чтобы цены в объявлениях и на сайте всегда совпадали.
Ошибка № 7. Неполные объявления
Часто можно встретить слишком короткие объявления, они не информативны и не кликабельны.
Решение: по максимуму заполнять рекламные объявления. Важно использовать все возможные дополнения и расширения: ссылки с описаниями, отображаемый URL, уточнения, контактную информацию, изображения, цены и т.д.
- Рекламное объявление, дающее пользователям полную информацию, более востребовано потребителями;
- Таким объявлениям присваивается высокий показатель качества, и они кликабельнее за счёт того, что более заметны, – это положительно влияет на стоимость клика;
- В Яндексе и в Google поисковая выдача подстраивается под каждого пользователя индивидуально, в зависимости от его поведенческих факторов. Одному пользователю может показаться один вариант выдачи или ещё его называют «трафарет», а второму — другой вариант. Поэтому полноценно информативное объявление имеет больше шансов показаться во всех рекламных «трафаретах» и охватить больше пользователей.
Сравните, как выглядят полное и неполное поисковое объявление в Яндекс Директе.
Ошибка № 8. Ссылки в объявлениях ведут на недоступные страницы
Бывает, что рекламные объявления по той или иной причине могут вести пользователей на недоступные страницы или страницы с ошибкой 404. В результате — впустую потраченный рекламный бюджет.
Решение: обращать особое внимание на этот момент перед запуском и периодически проверять это в процессе работы над рекламными кампаниями.
Ошибка № 9. Некорректные настройки геотаргетинга и временного таргетинга
Геотаргетинг позволяет распределять рекламные объявления по территориальному признаку, а временной таргетинг помогает настроить нужное время для показов. Многие пропускают эти настройки директ и объявления показываются впустую.
Решение: проверьте регионы показа рекламы и время, в которое ваши рекламные кампании активны. Регионы показа в настройках рекламных кампаний должны соответствовать тем регионам, в которых вы хотите продавать товары или оказывать услуги.
Если вы работаете в рамках только одного города, либо специфика вашего бизнеса не предусматривает, чтобы к вам обращались люди из других регионов, нужно в Яндекс Директ дополнительно отключить настройку «Расширенный географический таргетинг», а в Google Реклама выставить метод таргетинга: «Люди, находящиеся в целевых местоположениях или регулярно посещающие их».
Следующий этап в комплексном аудите — аудит сайта. Рассказываем, какие ошибки в разработке сайтов влияют на эффективность контекстной рекламы.
Ошибка № 10. Отсутствует или плохо свёрстана адаптивная версия сайта
Трафик с мобильных устройств давно превышает трафик с компьютеров и ноутбуков. Если ваш сайт не адаптирован и некорректно отображается на маленьких экранах смартфонов, то люди с большой долей вероятности сразу же закроют его, не выполнив целевого действия.
Решение: позаботиться о том, чтобы у вашего сайта была корректная и удобная адаптивная версия.
Ошибка № 11. Неудобная и нелогичная навигация по сайту
Если ваш сайт неудобный, нелогичный и запутанный, то вряд ли люди станут разбираться в его сложной структуре и просто-напросто уйдут.
Решение: сделать сайт удобным и интуитивно понятным для пользователей. Это касается и структуры сайта и навигации. Люди должны быстро и без усилий понимать, где они могут найти интересующую их информацию.
Ошибка № 12. Медленная загрузка сайта и технические неисправности
Если ваш сайт долго загружается, то люди не будут дожидаться его полной загрузки и закроют его, не совершив никаких целевых действий.
Решение: принять меры по увеличению скорости загрузки сайта.Оптимальное время полной загрузки сайта – 2-3 секунды. Можете проверить скорость загрузки своего сайта с помощью сервиса PageSpeed Insights.
Также, помимо скорости загрузки, сайт должен быть технически исправен: на нём не должно быть недоступных страниц, все его функции и кнопки должны корректно работать, а формы успешно отправляться. Изображения на сайте должны быть качественными, но при этом оптимизированными по размеру, иначе это существенно снизит скорость загрузки.
Ошибка № 13. Сложные формы и неверные призывы к действию
Люди не любят заполнять длинные и сложные формы. Формы заявок не должны быть перегружены большим количеством полей, тем более обязательных к заполнению.
Решение: постараться свести количество полей в ваших формах к минимуму. Идеально, если в форме будет всего два поля: Имя (необязательное поле) и Номер телефона (обязательное поле).
Рекомендуем с умом подойти к проработке призывов к действию на вашем сайте. Приведем простой пример: компания продаёт дорогостоящее оборудование для производства мебели. Стоимость самого дешевого станка составляет 1 500 000 рублей. В этом случае, учитывая высокую стоимость и отраслевую специфику, логично будет в заголовках, на кнопках и формах разместить призывы к действию «Получите консультацию», «Узнайте подробнее» и т.д. Призыв к действию «Купите» в данном случае будет не совсем уместен, так как может отпугнуть людей на пути к заявке.
Ошибка № 14. Мало удобных способов для связи с компанией
Если ваша контактная информация спрятана в нижнюю часть сайта или на странице «Контакты» и вы убеждены, что кому надо, те найдут, как связаться, то хотим вас огорчить: обычно людям проще найти другую компанию, с которой удобно связаться, чем искать в глубинах сайта контакты.
Решение: дать людям как можно больше вариантов для связи с вами. Кому-то из ваших клиентов удобнее позвонить, кому-то написать на почту или связаться с вами через мессенджер, кто-то привык оставлять заявки через форму. Подумайте, какие способы будут удобны для ваших клиентов, и разместите их на вашем сайте. Например, это можно сделать вот так:
Ошибка № 15. Сайт или бренд не вызывает доверия
В интернете люди покупают товары и заказывают услуги только у тех, кому доверяют. Низкое доверие к вашему сайту или вашей компании – это ещё одна причина, по которой люди к вам не обращаются.
Решение: разместите реальные отзывы ваших клиентов на сайте и в социальных сетях.Особенно хорошо работают видеоотзывы. Если это имеет значение в вашей нише, то рекомендуем разместить кейсы с описанием выполненных вами проектов, отраслевые сертификаты, награды, лицензии и т.д. Также доверие пользователей повышают статьи или видеоролики на вашем сайте, где вы можете показать людям свою экспертность в интересующих их вопросах.
Доверие пользователей снижается, если они видят на сайтах фотографии с фотостоков: замыленные картинки с рукопожатием или фото улыбающихся американцев, показывающих «палец вверх». Категорически не рекомендуем использовать такие фотографии на вашем сайте. Используйте только реальные фото своих товаров, помещений и сотрудников.
Ошибка № 16. На сайте нет информация о продукте, компании и о том, какие выгоды получит ваш клиент
Если люди не поймут в первые же минуты посещения сайта, что вы за компания, чем занимаетесь и какие у вас преимущества, то они не будут разбираться и уйдут с сайта, так и не оставив заявку.
Решение: важно сразу захватить внимание пользователя и быстро дать ему всю основную информацию на первой же странице. Также мы рекомендуем не скрывать цены на сайте: расчёт на то, что люди будут звонить, чтобы узнать стоимость, не оправдан. Если у вас такой бизнес, что назвать конкретную цену проблематично (например, вы делаете мебель на заказ), то указывайте цену в формате «от» или предложите людям расчёт примерной цены с помощью онлайн-калькулятора на сайте или квиза — опросника, в котором пользователю предлагается ответить на ряд вопросов, после чего система выдаст нужный расчет.
Далее переходим к описанию ошибок, которые обычно выявляются во время аудита систем учёта и аналитики
Ошибка № 17. Не настроены Яндекс Метрика и Google Аналитика
Системы аналитики позволяют оценивать эффективность вашей рекламной кампании, отслеживать, куда именно ушёл ваш бюджет и как реагируют пользователи на вашу рекламу. Если эти системы не настроены или настроены неправильно, то и эффективность оценить не получится.
Решение: ещё перед запуском рекламы нужно настроить и установить на все страницы сайта счётчики как минимум двух систем аналитики: Яндекс Метрика и Google Аналитика. Затем, чтобы в системы аналитики попадала вся детальная информация по вашим рекламным кампаниям, нужно настроить передачу данных из Яндекс.Директ в Яндекс Метрику и из Google Реклама в Google Аналитику.
Также крайне важно, чтобы в системах аналитики были правильно настроены цели. В этом случае у вас будет возможность отслеживать все важные события: заявки с форм, сообщения в онлайн-чат, входящие звонки, письма на почту и т.д. — и понимать, насколько эффективно работает контекстная реклама.
Ошибка № 18. Учитываются не все типы заявок
Бывает так, что учитывается только часть заявок, например, – заявки с формы, но при этом нет понимания, откуда приходят входящие звонки и письма на почту. По этой причине зачастую принимаются ошибочные решения о неэффективности контекстной рекламы.
Решение: отслеживать все типы заявок и понимать, откуда они приходят: заявки с форм, сообщения в онлайн-чат, заявки с виджетов, входящие звонки, письма на почту и т.д. Для отслеживания источника входящих звонков и писем на почту существуют специальные сервисы call-трекинга и email-трекинга: Calltracking.ru, Roistat, CoMagic, CallTouch, Callibri и др.
Всё, о чем мы рассказали выше, будет бессмысленно, если во время аудита продукта вы не сможете ответить на один простой вопрос: «почему клиент должен выбрать вас, а не вашего конкурента».
Ошибка № 19. Не оценить своих конкурентных преимуществ
У вас не будет заявок или их будет очень мало, если ваше предложение хуже, чем у ваших конкурентов, и не вызывает у людей интереса и желания купить у вас товар или обратиться к вам за услугой. Люди купят там, где им предложат выгоду.
Решение: позаботиться о том, чтобы ваше предложение было конкурентоспособным и интересным. При этом необязательно снижать цены или делать большую скидку. При рыночных или даже более высоких ценах вы можете склонить клиента на свою сторону с помощью других условий, например, бесплатная доставка товара до двери или бесплатная разработка нескольких вариантов дизайна.
Подумайте, как можно улучшить ваше предложение, чем вы можете отличаться от конкурентов, в чём ваши преимущества, какие ключевые выгоды вы можете предоставить своим клиентам, чтобы они обратились именно к вам, а не вышли на другие сайты.
Также крайне важно проводить аудит на уровне отдела продаж и отслеживать эффективность его работы.
Ошибка№ 20. Отдел продаж не получает, теряет, долго обрабатывает заявки
Часто встречаются ситуации, когда реклама настроена отлично и продумана до мелочей, выделен достаточный бюджет, разработан качественный продающий сайт, настроены коллтрекинг и системы аналитики, но менеджеры либо не берут трубку, либо демонстрируют неквалифицированную обработку звонков, либо вообще не видят заявки по причине технических неисправностей: не работает телефония, письма с заявками попадают в спам и т.д.
Решение: проверьте работу вашего отдела продаж. Необходимо проанализировать все ли заявки принимаются, насколько быстро они обрабатываются, пытаются ли менеджеры продать товар или услугу и проинформировать людей.
Вывод
Комплексный аудит — это довольно трудоёмкий, но крайне необходимый процесс, который позволяет в полной мере оценить все сильные и слабые стороны рекламной кампании, не «сливать» бюджет в пустую и с каждого клика приводить потенциального клиента.
В ситуации, когда контекстная реклама ранее работала и показывала стабильно хорошие результаты, но со временем показатели снизились, проблемы могут быть глубже и находиться за пределами того списка, который мы привели в этой статье.
В этом случае стандартным аудитом решить эти проблемы, скорее всего, не удастся, потому что добавление уточнений в объявления или минус-слов немного улучшит показатели, но кардинально ситуацию не изменит. Возможными причинами снижения эффективности могут быть:
- Активизация конкурентов или появление нового сильного конкурента.
- Отсутствие ведения и постоянной оптимизации рекламных кампаний.
- Изменение ситуации на рынке (например, как во время пандемии COVID-19)
Поэтому вместо стандартного аудита в данной ситуации нужно проводить более глубокий и гибкий «оптимизационный» аудит, привязанный не только к настройкам Яндекс Директ и рекламных кампаний в Google Реклама, но и к показателям рекламных кампаний и поиску закономерностей в их изменениях. И с этим лучше обратиться к специалистам, которые имеют большой опыт по работе с контекстной рекламой, например, к нам)

Советы
Почему контекстная реклама не конвертит. Разбор популярных ошибок
Меня зовут Павел Карпиков, я основатель диджитал-агентства Karboost. Каждый месяц мы проводим десятки аудитов для клиентов, которые пришли со словами «мне не нравится, как работает контекстная реклама». В большинстве случаев они правы — реклама действительно плохо конвертит. И на это есть свои причины.
В этой статье я расскажу про самые частые ошибки в настройке контекста и поделюсь чек-листом, с помощью которого вы сможете проверить настройки контекста самостоятельно.
Что влияет на эффективность контекстной рекламы
Прежде чем перейти к ошибкам, хочу отметить, что контекстная реклама работает не в вакууме. Ее результаты зависят от множества факторов. Среди них:
Емкость рынка. Сколько продуктов, аналогичных вашему, уже продают конкуренты; сможете ли вы своим продуктом удовлетворить незакрытые потребности пользователей; есть ли у людей возможность покупать ваш продукт.
Ниша. Нужно учитывать, есть ли законодательные ограничения на рекламу в нише и насколько часто покупатели ищут ваш товар. Если ваш тип товара не ищут в интернете, продавать будет сложно. Например, мы однажды столкнулись с тем, что не смогли помочь привлечь клиентов компании, которая занимается кабельными лотками. А оптовому поставщику спецодежды, напротив, за полтора года новые заявки принесли 63 млн рублей только на первичных заказах. С законодательными ограничениями не все так просто — есть сферы, в которых нельзя рекламировать продукт или услугу, но можно спокойно публиковать кейсы о продвижении в этих сферах или рекламировать оборудование и франшизы.
Развитость бренда. Чем известнее компания, тем проще покупателю отдать ей предпочтение.
Репутация. Если компания на хорошем счету у покупателей, контекст, действительно может помочь. Если же плохих отзывов больше, результаты по продажам будут неутешительными. Для контекста это действительно важно: 93% пользователей интернета ориентируются на отзывы (это относится и к B2B, и к B2C). А рейтинг организации в карточках Яндекса и Google подтягиваются к рекламным кампаниям. Высокий рейтинг психологически повышает доверие пользователя к объявлению, низкий — понижает.
Позиционирование на рынке. Чем точнее бизнес формулирует, что и для кого предлагает, тем выше шансы на хорошие результаты контекстной рекламы.
| Пример хорошего позиционирования | Пример плохого позиционирования |
| «Ветеринарная клиника с филиалами во всех районах города. Тщательная диагностика питомца перед лечением на экспертном оборудовании». | «Ветеринарная клиника» |
| В этом случае возможно точное сегментирование семантики по районам и улицам. Это позволяет занять весь охват по контексту в регионе. | В этом случае клиника не сможет сегментировать семантику и правильно настроить контекстную рекламу. |
Качество посадочной страницы. Кликнув по рекламе, человек должен найти ответы на все свои вопросы. У посадочной страницы должно быть понятное меню и хорошо сформулированный оффер.
Квалификация специалиста по контекстной рекламе. Чем лучше он разбирается в контексте, тем эффективнее будет рекламная кампания. Опытный специалист работал с разными проектами и бюджетами, у него глубокие знания в аналитике. Например, чтобы решить, отключать или нет кампанию РСЯ, он будет смотреть не только на заявки с прямых переходов с объявлений, но и на данные отчета многоканальных последовательностей. Кроме этого, опытные специалисты умеют экспериментировать, задавать вопросы «а что, если» и находить рабочие связки. Такой подход улучшает результаты в среднем на 15-50%.
Настройка контекста. От выбора ключевых слов до технических настроек и последующего ведения кампании.
Вовлеченность владельца бизнеса и маркетолога. Понимание ценности работ по подготовке, настройке и ведению контекстных рекламных кампаний. Это относится к любым вложениям в проект — временным, денежным и прочим. Кроме того, часто для эффективной работы контекста нужно доработать сайт, привлечь дизайнера, фотографа и переводчика. Если клиент понимает ценность этих этапов, вопросы «а почему так дорого» и «зачем это» отпадают сами собой.
Почему возникают ошибки при разработке рекламной кампании
Ошибки в настройке и ведении контекстной рекламы возникают по разным причинам. Самые распространенные из них:
Не построена воронка маркетинга и продаж или не настроена сквозная аналитика (колл-трекинг, емейл-трекинг и прочее). В этом случае сложно или почти невозможно проследить путь клиента от просмотра объявления до продажи и правильно оценить результаты контекстной рекламной кампании.
Нет понимания, как и в каких случаях контекстная реклама поможет бизнесу достичь целей по продажам. В этом случае контекст часто считают панацеей или путают с другими инструментами диджитал-маркетинга — SEO и таргетом. Контекстная реклама показывает хорошие результаты, если бизнес готов платить за качественную работу, внедрять нужные инструменты (например, коллтрекинг, сквозную аналитику, чат с консультантом на сайте), дорабатывать посадочную страницу и работать с отделом продаж, если лиды слабо конвертируются в продажи. Также важно быть готовыми подстраивать бизнес под ситуацию на рынке — придумывать привлекательные для покупателей офферы или снижать цены, если у конкурентов можно купить аналогичный продукт дешевле.
Нет желания повышать бюджет, чтобы по-прежнему получать хорошие результаты. Контекстная реклама по одним и тем же запросам — не безграничный источник заявок. Со временем приходится расширять семантическое ядро или и вовсе подключать другие инструменты — РСЯ, медийную рекламу, баннеры на поиске, видеорекламу (в том числе, в YouTube), ретаргетинг, торговые объявления и прочие. Эта ошибка обычно связана с первой — отсутствием воронки маркетинга и продаж. Отсюда вытекает непонимание, есть ли возврат инвестиций. Другая причина — ограничения в отделе продаж или на производстве, когда специалисты компании не успевают обрабатывать и выполнять заказы.
Убеждение, что если у одного предпринимателя контекст показывает отличные результаты, значит, так же будет и у других. Это не так. Расхождение всего в одном факторе из тех, что влияют на результат контекста, делает сравнение результатов разных компаний и, тем более, разных ниш бессмысленным.
Убеждение, что настройка контекста — это просто. На рынке онлайн-образования много курсов, которые учат настраивать контекст. Но мало кто учит вести рекламные кампании. Огромный пул работ начинается именно на этом этапе. К тому же, настройка контекста часто сопровождается изменениями на посадочных страницах, уточнением позиционирования и решением других задач.
Какие ошибки возникают чаще всего и как их избежать
На аудитах, которые мы проводим до начала сотрудничества с новыми клиентами, регулярно выявляем одни и те же ошибки. Сейчас я разберу каждую из них.
Реклама крутится на ощупь
По нашему опыту, мало какие компании настраивают сквозную аналитику. Это относится не только к очень маленькому бизнесу, но и к довольно крупному. Например, у одного из наших клиентов — федерального оптового поставщика средств индивидуальной защиты — до работы с нами была только хорошо настроенная CRM. Этого недостаточно, чтобы полноценно замерять эффективность контекстной рекламы.
В начале статьи я рассказал, что в большинстве аудитов мы обнаруживаем, что контекст не работает. У оставшихся результаты хорошие. Но это видят только предприниматели, которые настроили сквозную аналитику. Их единицы.
Без сквозной аналитики анализ результатов контекста сводится к количеству лидов и средней стоимости заявки. Со сквозной аналитикой вы можете проследить каждый шаг клиента по вашей воронке продаж, включая суммы первичных и повторных заказов. Например, для клиента, который занимается оптовой продажей спецодежды, мы подключили сервис Roistat. С его помощью мы видим весь рекламный трафик и реальные продажи. Например, в период с мая 2018 года по декабрь 2020 года первичные продажи с заявок, которые мы привели, принесли клиенту 63 177 122 рубля. Roistat помог нам отслеживать заявки и оплаты не только в моменте, но и на долгой дистанции (например, оставили заявку на спецодежду в январе, а оплатили в сентябре), определять эффективную географию продаж, тестировать гипотезы и проверять качество заявок в конкретное время.
Помимо полного отсутствия сквозной аналитики ошибкой так же будет и некорректная выгрузка результатов из Яндекс.Метрики или Google Analytics: кликов, показов, CTR, средней цены за клик, конверсий. Часто в выгрузках отсутствуют цели, UTM-метки и есть прочие недостатки со связкой аккаунта контекстной рекламы и сервиса сбора данных, из-за которых нельзя качественно оценить эффективность рекламы.
Плохо настроен сайт
С контекстного объявления пользователь переходит на посадочную страницу. Поэтому важно изначально уделить внимание настройке и оформлению сайта и с пониманием относиться к предложениям внести в них изменения. На что обращать внимание:
Релевантность посадочной страницы. Если у вас сайт-многостраничник, следите, чтобы контекстные объявления вели сразу на нужные страницы.
Наличие четко сформулированного предложения. Этот пункт напрямую связан с формулировкой позиционирования. Попав на страницу сайта, человек должен сразу понять:
- что вы предлагаете;
- кому;
- по какой цене (фиксированная стоимость или «от» и «до»);
- в каком городе/регионе/по всей стране;
- как он может получить продукт или услугу.
| Пример хорошего предложения | Пример плохого предложения |
| Решим любую задачу по 1С без предоплаты и прямого доступа к базе | Услуги 1С специалиста от 2000 р / час |
Использование инструментов привлечения и удержания посетителей в специфических нишах. Если у вас сложный продукт, по которому у клиентов часто возникают вопросы, используйте плагины и чаты для консультаций со специалистами. Это актуально, например, для клиник и онлайн-аптек.
Если вы работаете в B2B, обязательно дайте возможность быстро связаться с вами по электронной почте и подключите емейл-трекинг.
Не использован весь потенциал настройки рекламной кампании
К этому пункту относятся все технические моменты — от сбора семантического ядра до ведения кампании.
Используется некорректная семантика. Обратите внимание и на ключевые слова, и на их деление на логические группы. От этих шагов зависят формулировки офферов. Обычно ошибаются, когда неправильно сегментируют околосемантику.
Пример: компания продает только деревянные пазлы. Картонных, пластмассовых или поролоновых пазлов в торговой линейке нет.
| Целевой запрос | Не полностью целевой запрос |
| купить деревянные пазлы | купить пазлы |
Мы порекомендовали компании не запускать рекламу по этим запросам на одинаковые ставки или в одних и тех же группах объявлений. Гораздо эффективнее написать уникальные тексты объявлений для запроса «купить пазлы» и с их помощью пытаться убедить человека купить именно деревянные пазлы. Кроме этого, ставка таких объявлений должна быть ниже. Только так математика рекламной кампании сойдется.
Плохо сформулирован оффер. От оффера контекстного объявления зависит, кликнет по нему пользователь или нет. Из хорошего оффера ясно:
- какой продукт или услугу вы предлагаете;
- кто целевая аудитория;
- как и с помощью каких преимуществ вы закрываете потребности клиента.
| Примеры хороших офферов | Примеры плохих офферов |
|
Более 15000 довольных клиентов. Цены от <price> (если цена конкурентная). Скидка 15% на первый заказ. Бесплатная доставка по РФ. При заказе дивана — сборка бесплатно. |
Нам можно доверять. Квалицифированные специалисты. Лучший <tovar name> на рынке. Низкие цены. |
Крутятся объявления с нерелевантными заголовками. Заголовок объявления формулируется в зависимости от ключевых слов, которые вы используете в этом объявлении. Следовательно, для разной семантики нужно делать разные заголовки.
| Примеры хороших заголовков | Примеры плохих заголовков |
| Ключ: «усыпить собаку в омске». Заголовок: «Усыпление больных питомцев в Омске — Быстро и безболезненно». | Ключ: «усыпить собаку в омске». Заголовок: «Ветеринарные услуги в Омске» (более общий ключ). |
| Ключ: «перевести болгарский паспорт». Заголовок: «Перевести болгарский паспорт». | Ключ: «перевести болгарский паспорт». Заголовок: «Бюро переводов в Москве» (маленькое вхождение). |
Работа с рекламной кампанией заканчивается на этапе настройки
Эта ошибка популярна в двух случаях — когда контекст настраивает собственник бизнеса или маркетолог, который решает все вопросы по продвижению проекта, либо когда настройкой занимается фрилансер с низкой квалификацией. Это происходит, потому что большинство курсов по контекстной рекламе рассказывают только про настройку.
При этом настройка контекста — это лишь надводная часть айсберга и небольшая часть подводной. Огромный пласт работы лежит за ее пределами.
После настройки рекламные кампании нужно контролировать — первые пару недель ежедневно, затем пореже. Контроль кампании может показать, какие ключевые слова нужно убрать из семантического ядра, какие изменения внести на сайт, что убрать или добавить к настройкам. Только в этом случае контекстная реклама превращается в действительно эффективный инструмент интернет-маркетинга.
Например, когда мы вели проект по продвижению деревянных пазлов, добавили в семантическое ядро фразу «wooden puzzle» (дословный перевод запроса «деревянные пазлы» на английский). После запуска мы увидели, что по этой фразе появилось много нецелевых переходов. Выяснили, что это брендовый запрос конкурента, что вкупе с полным вхождением дало большое количество отказов по этой фразе.
Другой пример. У нас была гипотеза, что для клиента, который занимается оптовыми продажами спецодежды, семантика, связанная с ее пошивом, является целевой. Мы протестировали гипотезу и выяснили, что это не так — по этой семантике люди искали исключительно пошив на заказ по своим параметрам.
В обоих случаях отказ от контроля рекламной кампании привел бы к лишним расходам — реклама по этим запросам продолжала бы крутиться и приносить нецелевые переходы.
Чек-лист для самостоятельной проверки контекстных рекламных кампаний
В заключение объединю основную информацию в чек-лист. Мы в Karboost пользуемся расширенной версией. Вы можете скачать ее или проверить только основные пункты:
- Выгрузка результатов в систему сквозной аналитики настроена корректно.
- Сайт правильно оформлен: есть хорошо сформулированное позиционирование, ответы на вопросы, призывы к действию, при необходимости — плагины для общения с консультантами, возможность быстро отправить или оставить емейл.
- Семантическое ядро корректно собрано и разделено на логические группы.
- Оффер привлекает внимание целевой аудитории.
- Заголовки объявлений соответствуют семантике, которая в них используется.
- Вы регулярно проверяете настройки рекламной кампании и корректируете объявления или информацию на сайте в зависимости от результатов.
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Содержание
- Контекстная реклама. Частые ошибки и советы по базовой настройке
- Ошибка 1. Рекламное объявление без контактов
- Ошибка 2. Отсутствуют быстрые ссылки и фавикон
- Ошибка 3. Реклама не оптимизирована для рекламной сети Яндекса (РСЯ)
- Ошибка 4. Забыли настроить отраслевые и региональные кампании
- Ошибка 5. Не проработана структура рекламных кампаний
- Ошибка 6. Сайт не загружается при клике
- Базовый чек-лист по настройке контекстной рекламы
- Типичные ошибки при запуске рекламы в Яндекс.Директе: как сделать сразу правильно, чтобы не слить бюджет
- Вся контекстная реклама в eLama
- Часть 1. Ошибки при работе с семантикой
- Парсинг тысяч ключевых фраз
- Использование слишком общих высокочастотных фраз
- Отсутствие минус-слов
- Нет кросс-минусации в Поиске
- Ошибки в работе с семантикой в РСЯ
- Часть 2. Ошибки в настройках рекламной кампании
- Временной и географический таргетинг
- Использование дополнительных релевантных фраз и автотаргетинга на старте
- Яндекс.Директ не связан с Яндекс.Метрикой
- Часть 3. Типичные ошибки при создании объявлений
- Создание объявлений без анализа конкурентов
- Пренебрежение расширениями
- Объявления для РСЯ по образу и подобию поисковых
- Часть 4. Ошибки в управлении ставками
- Погоня за первым местом в Поиске
- Использование автостратегий Директа без достаточной статистики
- Выводы
Контекстная реклама. Частые ошибки и советы по базовой настройке
Считается, что контекстная реклама — это просто: ввели запросы, закинули деньги, запустили кампанию и ждем клиентов. На самом деле, контекстная реклама — огромная машина с сотнями настроек. Людей, которые знают все опции и математику аукциона, — очень немного.
Мы делаем аудиты контекстной рекламы и хотим показать вам ошибки, которые чаще всего находим у клиентов. Это базовые недочеты, по наличию или отсутствию которых можно оценить работу вашего специалиста по контекстной рекламе.
Также мы подготовили чек-лист с рекомендациями по улучшению контекстной рекламы, основанный на результатах нашей работы.
Ошибка 1. Рекламное объявление без контактов
Объявление без контактной информации (так называемой «Визитки») занимает меньше площади и проигрывает объявлениям конкурентов.

Кроме того, в объявлении на скриншоте стоит использовать релевантную отображаемую ссылку. Хороший пример — ссылки у конкурента выше, которые показывают, на какой раздел пользователя перенаправят при клике.
Ошибка 2. Отсутствуют быстрые ссылки и фавикон
Посмотрим на объявление в конкурентной нише — пластиковые окна. Компания разместилась на втором месте в спецразмещении. При этом у объявления отсутствуют быстрые ссылки и фавикон (иконка сайта), поэтому кликабельность меньше, чем у конкурентов. Эта ошибка ведет к тому, что вы будете недополучать трафик, CTR уменьшится, а значит — цены на ставки вырастут.

Ошибка 3. Реклама не оптимизирована для рекламной сети Яндекса (РСЯ)
Рекламная кампания в поисковике отличается от той, что показывают в РСЯ или контекстно-медийной сети Google. Если контекстолог этого не понимает и просто копирует кампанию на все системы размещения, получается плохо. Обрывки текстов и отсутствие картинок не помогают продавать предложение:

Это топорное ведение контекстной рекламы. Для компании это выливается в потерю тысяч и даже миллионов рублей.
Основные отличия кампаний на тематических площадках и в поиске:
- В поиске картинки не отображаются. В рекламу на тематических площадках их нужно добавлять обязательно
- В РСЯ не подсвечиваются ключевые слова
- Реклама на площадках может быть более креативной, чем в поиске. А в КМС много различных форматов, с которыми можно экспериментировать
Ошибка 4. Забыли настроить отраслевые и региональные кампании
Когда мы проводили очередной аудит контекстной рекламы у клиента, мы увидели неплохо настроенные кампании от известного агентства. Сначала клиент говорил, что не понимает, зачем вообще мы проводим аудит.
Но оказалось, что не продумана региональная стратегия контекстной рекламы по отраслям. Наше решение:

Ошибка 5. Не проработана структура рекламных кампаний
Структура кампаний в контекстной рекламе появляется не на пустом месте, а создается на основе интернет-спроса и анализа рынка клиента.
У крупного автодилера кампании не были разбиты по тем группам, которые нужны для автомобильной отрасли. Мы предложили такую структуру:
- Рекламная кампания (РК) на бренд компании
- РК под общие запросы
- РК в Москве
- РК по моделям автомобилей
- РК по цвету кузова
- РК по типу кузова, объему двигателя, типу КПП
- РК по станциям метро
- РК по районам
- РК с пробегом
- РК в кредит
- РК акции
- РК на конкурентов
После того, как структуру внедрили, клиент получил возможность отслеживать эффективность работы групп ключевых слов. Если к такой рекламе подключить простейшую аналитику, можно понять, какие ключевики лучше всего работают для выбранной ниши, и оптимизировать кампании.
Ошибка 6. Сайт не загружается при клике
Удивительно, но мы часто видим, что контекстная реклама запущена, но сервер не настроен, чтобы обрабатывать метки рекламных систем. Поэтому при клике на рекламу сайт может не загрузиться.
Базовый чек-лист по настройке контекстной рекламы
Полный чек-лист по настройке контекстной рекламы — это сотни пунктов. Здесь мы перечислим только минимальные требования, которые может реализовать каждая компания.
1. Разделение и кросс-минусовка B2B и B2C запросов. Это верхний уровень структуры. Чтобы ее улучшить, нужно детально изучить ваши сегменты аудитории.
2. Объявления оптимизировать под разные устройства. Рекламные кампании для мобильных собираем отдельно.
3. Пишите рекламное объявление правильно.

1 = Ключевые слова в заголовке
2 = Наличие уточняющих слов
3 = Ключевое слово в отображаемой ссылке
4 = Ключевое слово в описании
5 = Призыв к действию
6 = Наличие быстрых ссылок с ключевым словом
7 = Контактная информация
4. Используйте «Структурированые описания» и расширения объявлений: «Номера телефонов», «Адреса», «Цены» для повышения эффективности ваших объявлений в Google AdWords помимо быстрых ссылок и уточнений.
Пример расширения «Цены»:

Пример структурированного описания:

5. Придерживайтесь принципа 1 ключевое слово = 1 объявление для средне- и высокочастотников рекламные кампании должны строиться по принципу. Низкочастотники (когда показов 1–30) нужно группировать, а объявления для них — шаблонизировать с помощью решеток.

6. Сделайте кампании на околотематические ниши, например: сервис, лизинг, комплектующие.
7. Ограничивайте бюджет на неэффективные ключи, площадки, каналы.
8. Работайте с рекламной сетью Яндекса и контекстно-медийной сетью. Но фильтруйте площадки, чтобы к вам не шел мусорный трафик.
9. Запускайте новые инструменты. Это, в основном, касается AdWords: реклама в Gmail, объявление-звонок.
10. Следите за показателем качества ключевых слов. Это оценка того, насколько ваши объявление и сайт релевантны ключевым словам.
11. Используйте динамический ремаркетинг на незавершенные действия, брошенные корзины. Он позволяет обратиться к пользователям, с которыми вы уже контактировали на вашем сайте. Кейс по ретаргетингу для автомобильной отрасли.
12. Используйте многоканальность. Одна из схем работы: привести нового посетителя через контекст, вернуть его на сайт ремаркетингом в соцсети, привести к решению о звонке или заказе после третьего контакта через ретаргетинг MyTarget.
13. Помните: реклама может показываться не в нужное для вас время. Например, если ваше предложение из сферы B2B, не стоит тратить деньги на показы ночью или в выходные дни. В любом случае, обратите внимание на формирование ставок в это время и регулируйте их стоимость в зависимости от лидогенерации.
14. Заполните список минус-слов. Его часто забывают или составляют небрежно.
Каждого специалиста, в том числе и по контекстной рекламе, нужно контролировать. Многие пункты не выполняются просто потому, что никто не ожидает проверки. Проанализируйте контекстную рекламу по нашему чек-листу и распространенным ошибкам — и вы поймете квалификацию вашего подрядчика и сможете улучшить результаты в AdWords и Директе.
Источник
Типичные ошибки при запуске рекламы в Яндекс.Директе: как сделать сразу правильно, чтобы не слить бюджет

Контекстная реклама — уникальный канал привлечения целевой аудитории на сайт за счет возможности взаимодействовать с пользователями со сформированным спросом, которые ищут продукт «здесь и сейчас». Для этого используется поисковая реклама с таргетингом по ключевым фразам. Кроме того, контекст позволяет охватить аудиторию на самых разных стадиях принятия решения о покупке с помощью рекламы в партнерской сети (РСЯ).
Настройка рекламных кампаний может показаться несложной на первый взгляд, поэтому многие предприниматели решаются на самостоятельный запуск, что часто приводит к неэффективному расходованию маркетингового бюджета. За более чем семилетнюю практику я провел аудит огромного количества кампаний и в этой статье расскажу о типичных ошибках, которые совершают рекламодатели при создании и управлении кампаниями в Яндекс.Директ, чтобы вы могли их избежать.
Вся контекстная реклама в eLama
Один кабинет и кошелек для рекламы в Яндекс.Директе и Google Ads, инструменты для повышения эффективности, бесплатное обучение и помощь на всех этапах работы.
Часть 1. Ошибки при работе с семантикой
Парсинг тысяч ключевых фраз
Парсинг семантики «вглубь» для поисковых кампаний – это правильно. Благодаря использованию более низкочастотных и точных ключевиков можно точнее управлять ставками, перераспределять бюджет на самые эффективные фразы, создавать максимально релевантные объявления и посадочные страницы под конкретные запросы пользователей. Однако нет никакого смысла на первых этапах собирать и парсить «холодную семантику», околотематические фразы, запросы с единичной частотностью по Вордстату.
Например, если предприниматель занимается подбором подержанных автомобилей, его первая поисковая рекламная кампания должна состоять из целевых фраз: подбор авто, подобрать автомобиль, выездная диагностика машин и тд. Не стоит сразу запускать рекламу по фразам: бу авто, авто ру, купить авто. Да, эти ключевики, скорее всего, охватывают потенциальных клиентов предпринимателя, но вероятность того, что человек, который прямо сейчас ввел запрос «купить авто в москве», заинтересуется услугой подбора автомобиля, достаточно низкая.
Я не говорю, что по этим запросам не нужно запускать рекламу, просто стоит отложить их до того момента, когда вы протестируете наиболее целевой спрос. Еще позже можно дойти до запросов «какой автомобиль купить за 700 000», «надежные бу авто за 500 тысяч» и т.д. Реклама по ним может быть рентабельна и приносить прибыль, но воронка продаж должна быть другой. Подобрать наиболее целевые ключевые фразы для первой кампании вам помогут коммерческие добавки, такие как: купить, заказать, доставка, прайс, оптом и т.д. Иногда коммерческой добавки может не быть, как в примере с подбором авто. Главное понимать, на какой сегмент аудитории вы нацеливаетесь, в какой степени у этих пользователей сформирован спрос на ваш товар или услугу, и начинать с тех, кому надо было уже вчера.
Использование слишком общих высокочастотных фраз
Некоторые специалисты по контекстной рекламе используют при запуске кампаний следующий подход: добавляют в качестве ключевых фраз верхнеуровневые высокочастотные ключевые фразы, а потом вычленяют из отчета наиболее эффективные поисковые запросы, добавляя их в качестве ключевиков в новую кампанию. Этот метод имеет право на существование, но только в том случае, если у вас есть бюджеты, которые вы готовы слить на нецелевые клики.
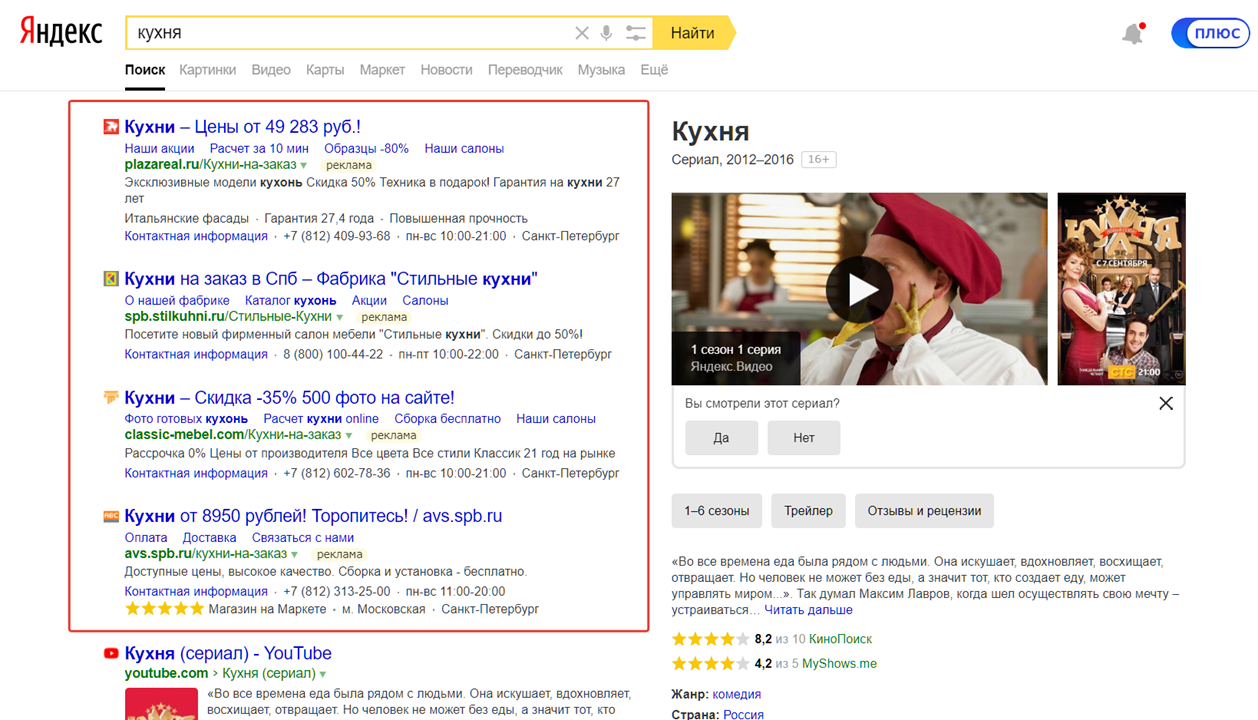
Например, компания занимается изготовлением кухонь на заказ. Не стоит использовать в качестве ключевой фразы слово «кухня», если вы не готовы тратить деньги на пользователей, которые искали сериал или передачу. Лучше подобрать более целевые запросы.
Отсутствие минус-слов
Минус-слова позволяют отсечь показы рекламных объявлений по нецелевым запросам. Такие слова нужно обязательно собирать на этапе парсинга семантики, а также при мониторинге отчета по поисковым запросам пользователей. Кстати, это довольно частое заблуждение: многие рекламодатели считают, что после создания и запуска кампании можно расслабиться, подкидывать деньги на рекламу и обрабатывать входящие заявки – всё само будет работать. На самом деле, после запуска работа над кампанией только начинается.
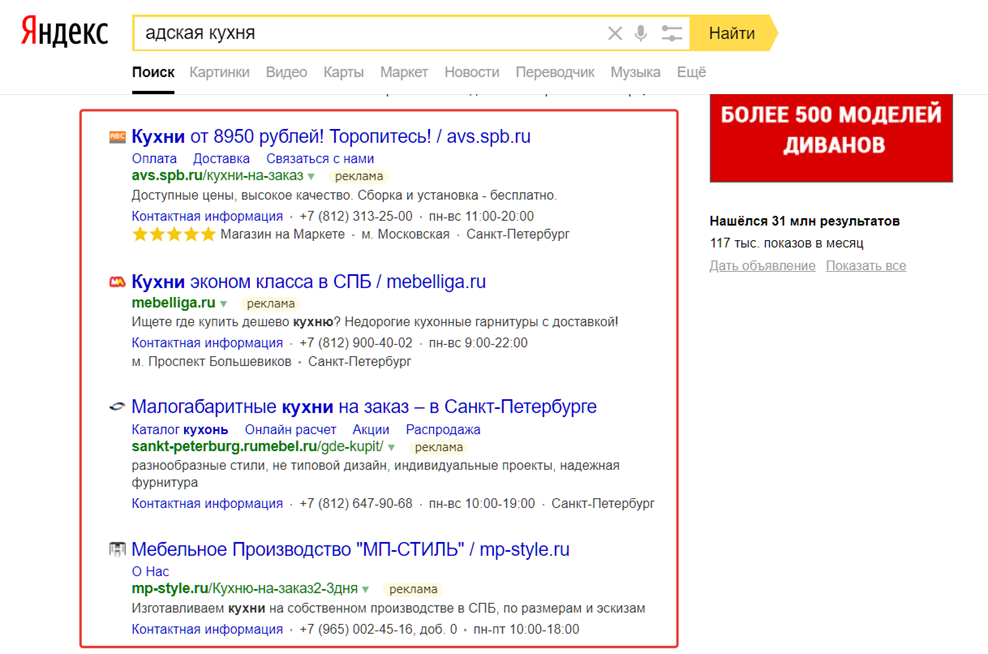
В примере выше рекламодатели не добавили минус-слово «адская», из-за чего я увидел их объявления по запросу, связанному с телепередачей. Бывает, что некоторые слова для исключения невозможно найти на этапе сбора семантики из-за того, что они крайне редко используются. В этом случае задача рекламодателя найти все нерелевантные запросы в отчете Яндекс.Директа и добавить минус-слова уже после запуска кампании.
Нет кросс-минусации в Поиске
Кросс-минусация позволяет убрать пересечения между ключевыми фразами в одной или нескольких кампаниях. В Яндекс.Директе сейчас кросс-минусовка происходит автоматически при создании кампании в веб-интерфейсе, но если вы ее загрузили из Excel или Коммандера, обязательно проверьте отсутствие пересечений. Это можно сделать за пару кликов в Директ Коммандере или сервисе eLama.
Кросс-минусовка нужна для того, чтобы по поисковым запросам пользователей отрабатывали правильные ключевые фразы и соответственно были показаны релевантные объявления с целевыми посадочными страницами. Например, будет правильно разводить пользователей по поисковым запросам «купить кухню» и «купить угловую кухню» на разные страницы сайта: по второму запросу желательно сразу показать информацию именно про угловые кухни.
На примере ниже первый рекламодатель добавил ключевую фразу в первый заголовок, благодаря чему он выделен полужирным, а также по клику приземляет посетителей сразу на страницу с заголовком «Угловые кухни по цене смартфона». Это верная стратегия, которая может давать отличные результаты.
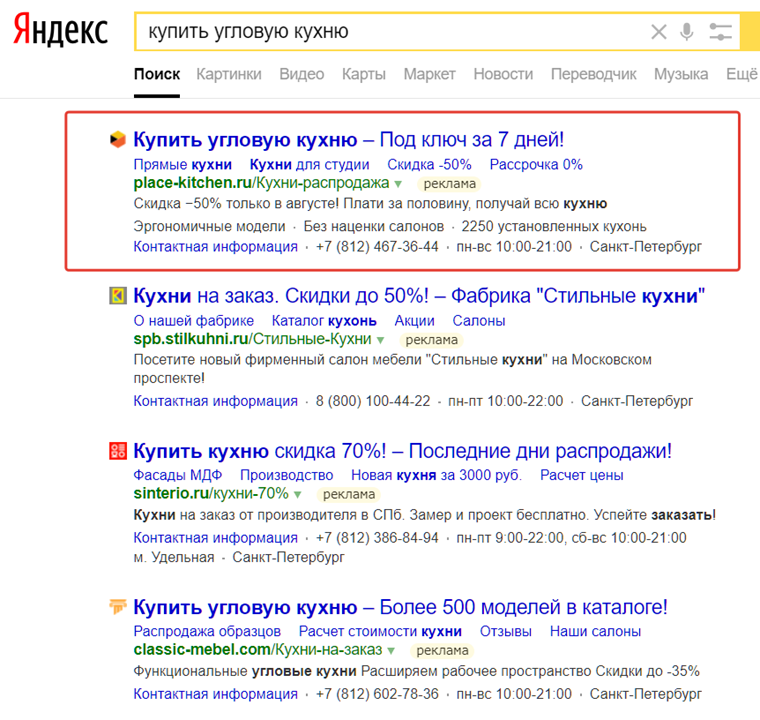
Сама кросс-минусация выглядит так:
купить кухню -угловая
купить угловую кухню
Часто в кампаниях рекламодателей я замечаю неправильную кросс-минусовку, которая может значительно снижать охват. Выглядит она таким образом:
купить кухню -угловая -спб
купить угловую кухню спб
Если в кампании нет промежуточных ключевых фраз «купить угловую кухню» и «купить кухню спб», то мы потеряем по ним показы, так как для более общей фразы «купить кухню» добавили минус-слова «угловая» и «спб».
Правило: кросс-минусация производится только между ключевыми фразами, отличающимися на 1 слово.
В примере выше для корректной минусовки стоит добавить еще два промежуточных ключевика:
Купить кухню –угловая -спб
Купить кухню угловую -спб
Купить кухню в спб -угловая
Купить кухню угловую в спб
Ошибки в работе с семантикой в РСЯ
Работа с семантикой в рекламной сети Яндекса отличается от работы с поисковыми кампаниями. Это связано с самим принципом работы РСЯ-кампаний: объявления показываются на сайтах-партнерах пользователям на основании тематики площадки или поведенческих характеристик (истории поиска и посещения различных сайтов). Следовательно, в РСЯ не нужно добавлять большое количество низкочастотных ключевых фраз с длинными хвостами, если уже добавлены базисы, от которых они образованы. Например, если вы добавили фразу «подбор автомобиля», нет смысла добавлять фразу «подбор автомобиля в москве недорого».
Кроме того, не стоит добавлять в РСЯ-кампании весь список минус-слов, который вы собрали для поиска, поскольку это снизит охват кампании. Достаточно использовать наиболее противоречивые минус-слова: работа, вакансии, реферат, контрольная, дипломная, смерть, трагедия. Делается это для того, чтобы отсечь показы на площадках с этим контентом.
Автоматическая кросс-минусовка фраз в РСЯ также не нужна. Хотя, если вы правильно подберете семантику, то, скорее всего, системе практически нечего будет минусовать. Однако, если вам необходимо показывать разным пользователям разные креативы, приземлять их на разные страницы сайта, имеет смысл делать перекрестную минусовку между группами объявлений. Например, в одну группу я добавлю фразы «купить угловую кухню», «заказать угловую кухню» и буду показывать информацию именно про угловые кухни. Тогда в другую группу я добавлю фразы «купить кухню», «заказать кухню» и минус-слово «угловая» на уровне группы.
Часть 2. Ошибки в настройках рекламной кампании
Временной и географический таргетинг
Первая частая ошибка — отключение показов ночью и в выходные или включение рекламы в какие-то определенные часы, например, с 9 до 18. Если у вас нет накопленной статистики, на основании которой вы делаете подобные настройки, обязательно протестируйте рекламу 24/7. Вполне возможно, что активность вашей целевой аудитории будет максимальной именно в те часы и дни, которые вы планировали отключить. Главное, реализуйте на сайте возможность оставить заявку в то время, когда вы не готовы отвечать на звонки.
Будьте аккуратны при настройке географического таргетинга, выбирайте только те регионы, где находится ваша целевая аудитория. Если вы планируете запускать поисковую рекламу по всей России, советую создать две дополнительные кампании с таргетингом на Москву и Санкт-Петербург, поскольку в этих городах высокий уровень конкуренции и могут быть завышены ставки/цены клика.
В настройках есть по умолчанию включенный чекбокс «расширенный геотаргетинг». Рекламодатели часто не обращают на него внимание. При включенной опции объявления могут быть показаны не только в выбранном регионе, но и в любом другом, если пользователь введет запрос с целевой геодобавкой. Например, геотаргетинг — Москва. Пользователь находится в Петербурге и вводит запрос «грумер мск». Директ может показать объявление московского рекламодателя. В некоторых тематиках эта функция будет приводить дополнительный целевой трафик, но не во всех. Решите, нужны ли вам показы в других городах. Если сомневаетесь, оставьте расширенный геотаргетинг включенным, а после накопления статистики, проверьте эффективность рекламы в срезе по местоположениям.
Использование дополнительных релевантных фраз и автотаргетинга на старте
Дополнительные релевантные фразы (ДРФ) включены по умолчанию в специальных настройках кампании. Причем задан расход в размере 40% от общего расхода всей кампании.
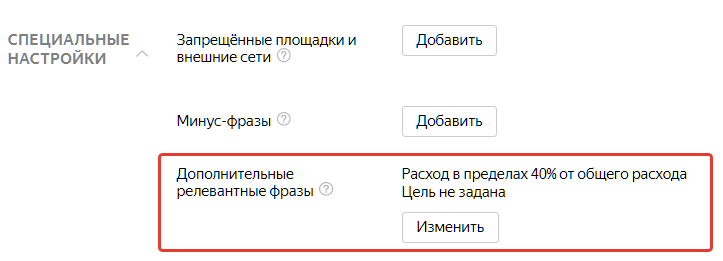
При включенной опции Яндекс.Директ подбирает дополнительные ключевые фразы и поисковые запросы на основе добавленных рекламодателем ключевиков. Иногда эффективность подобранных фраз не удовлетворяет заданным критериям. Поэтому, если вы хотите запускать первые кампании по максимально точной коммерческой семантике, которую подобрали самостоятельно, стоит отключить показы по дополнительным релевантным фразам. Если захотите протестировать возможности автоподбора фраз, включите ДРФ на 10% от общего расхода и обязательно укажите цели для оптимизации.
Автотаргетинг — это «бесфразный» таргетинг в Поиске и РСЯ. Система самостоятельно подбирает поисковые запросы (поиск) и аудиторию (РСЯ) на основе анализа ваших рекламных объявлений и посадочных страниц. По умолчанию автотаргетинг выключен. Включить его можно на уровне группы объявлений. Иногда рекламодатели включают эту опцию, чтобы избавиться от рутинной работы по сбору семантики.

Я рекомендую все же изначально запускать кампании по подобранной семантике, а автотаргетинг включить через пару месяцев в случае наличия свободного бюджета на эксперименты. Система может найти целевые запросы и пользователей, которые не были охвачены при настройке кампании, что даст вам дополнительный прирост конверсий за счет одного клика. Обычно в автотаргетинг попадает большое количество достаточно общих тематических запросов, которые рекламодатель не стал бы использовать в первой кампании.
Яндекс.Директ не связан с Яндекс.Метрикой
Очень часто при аудите рекламных кампаний я вижу, что рекламодатели не указывают счетчик Метрики в настройках. Кто-то вообще не настраивает веб-аналитику, кто-то использует для аналитики Google Analytics, проставляет UTM-метки и игнорирует Яндекс.Метрику. Это очень серьезная ошибка.
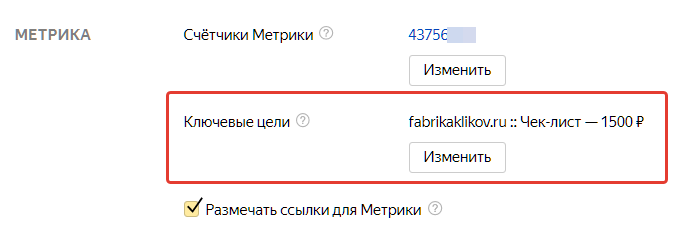
Указание счетчика Метрики в параметрах кампании позволяет передавать в полном объеме данные о кликах из Директа и данные о целях и сегментах из Метрики в Директ. Это означает, если Метрика не связана с Директом, вы не сможете оценивать эффективность рекламы в отчетах Директа, использовать автостратегии, основанные на конверсиях, настраивать ретаргетинг по целям и сегментам Метрики. Помимо прочего, рекламодатель не сможет указать ключевые цели, на основании которых система будет оптимизировать ставки в Поиске и сетях. Опция оптимизации неотключаемая, поэтому влиять на ее эффективность можно только через ключевые цели. Пожалуйста, не запускайте рекламные кампании без настроенной аналитики.
Часть 3. Типичные ошибки при создании объявлений
Создание объявлений без анализа конкурентов
Я не буду учить вас делать конкурентный анализ, но перед созданием объявлений обязательно посмотрите, что пишут в своих креативах конкуренты, и постарайтесь сделать более привлекательное предложение для потенциальных клиентов. В Поиске пользователи не всегда вчитываются в текст объявлений, но заголовки читают всегда. Первый заголовок должен быть максимально релевантным поисковому запросу, чтобы человек понял, что нашел именно то, что искал. Второй заголовок стоит использовать для привлечения внимания и создания желания кликнуть. Именно здесь стоит писать про акции, спецпредложения, уникальные условия, УТП, УЦП, призывы перейти на сайт и узнать подробнее и т.д. У вас есть всего несколько секунд на то, чтобы заинтересовать пользователя.
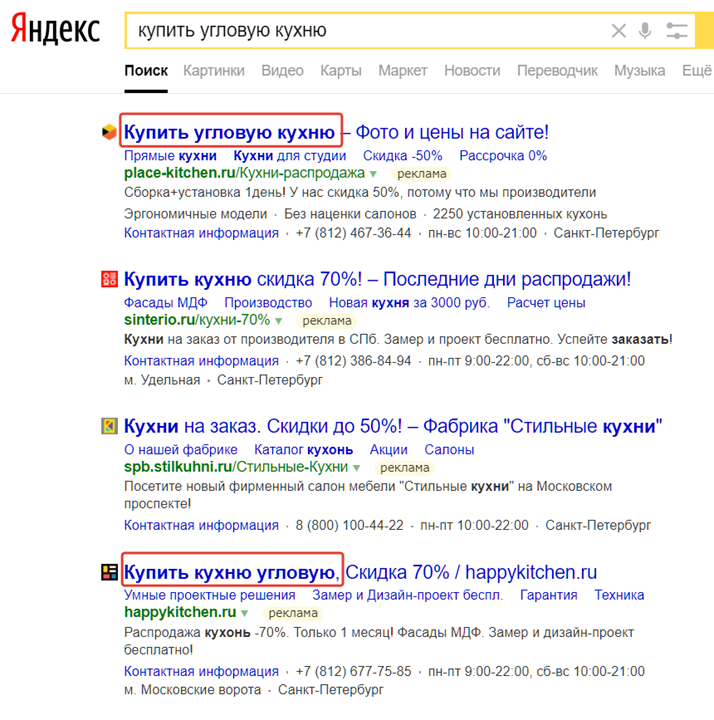
В примере выше можно заметить, что все рекламодатели используют в объявлениях предложение со скидкой 50 или 70%. Проценты скидки не всегда играют решающую роль, потенциальный клиент будет принимать решение по совокупности цены, условий оказания услуги, отзывов и других факторов. Но в рекламных объявлениях подобные триггеры работают хорошо. Самое главное — это связка объявление-посадочная страница. Если в объявлении написано «Скидка 70%», то это обязательно должно быть указано на посадочной странице, иначе пользователь решит, что его ввели в заблуждение. Сказать, что будет работать лучше всего в той или иной тематике и регионе нельзя – вам нужно поэкспериментировать с заголовками и текстами, чтобы найти оптимальный вариант.
Пренебрежение расширениями
Расширения или дополнения – это элементы, которые делают объявление более заметным и позволяют ему попадать во всевозможные варианты рекламной выдачи (трафареты). К дополнениям относятся быстрые ссылки с описаниями, уточнения, визитка, цена, отображаемая ссылка, диалоги, данные Яндекс.Маркета и справочника. Некоторые рекламодатели пренебрегают добавлением расширений из-за чего теряют часть показов и кликов. На картинке ниже выделены дополнения к объявлению о груминге. Представьте, как бы оно выглядело, если бы рекламодатель не заполнил все элементы. Не забывайте про это.
Объявления для РСЯ по образу и подобию поисковых
Это также одна из часто встречающихся ошибок. Например, когда в объявления для РСЯ добавляют ключевые фразы в заголовок или используют шаблон автоподстановки ключевиков. Главная задача объявления в РСЯ – это привлечь внимание пользователя и замотивировать его узнать подробнее о предложении на сайте. Привлечь внимание можно с помощью яркой, сочной картинки. А заголовок и текст используются для того, чтобы напомнить о том, что он недавно искал, и предложить оптимальное решение. Например, на картинке показать уютный светлый салон, где грумер сделал необычную, красивую стрижку пуделю, а в объявлении написать: «Хотите, чтобы ваш пудель выделялся? Наш грумер творит чудеса! Узнайте подробнее.» Остается только нацелить это объявление на владельцев пуделей. Кстати, сейчас я описал пример персонализации рекламных предложений для различных сегментов аудитории. Владелец пуделя скорее среагирует на картинку с пуделем, чем на что-то другое, используйте это.
Не ограничивайтесь одним объявлением в группе. Для поисковых кампаний создавайте минимум два, а в сетях примените весь ваш креатив и фантазию для создания шести-десяти разные вариантов объявлений на группу.
Часть 4. Ошибки в управлении ставками
В управлении ставками обычно встречается две основные ошибки: погоня за первой позицией в поиске и использование автостратегий Яндекса без нормально настроенной аналитики или без достаточного количества данных. Обе ошибки ведут к неэффективному расходованию бюджета.
Погоня за первым местом в Поиске
С этой проблемой сталкивались практически все специалисты по контекстной рекламе: запускаешь кампанию, а на следующий день клиент звонит и спрашивает, почему его объявление на третьей позиции, а не на первой. Дело в том, что управлять ставками нужно не от позиций, а от статистики. Часто бывает, что расчет искренней ставки не позволяет конкурировать за максимальный трафик, и это нормально. Нет никакого смысла завышать ставки с целью обогнать конкурентов, если это будет нерентабельно. Кроме того, аукцион в Яндекс.Директе устроен таким образом, что на позицию влияет не только ставка, но и коэффициент качества объявления и прогнозный CTR. Причем эти показатели не отображаются в интерфейсе и рассчитываются прямо в момент аукциона, когда конкретный пользователь ввел запрос. Поэтому совет прост: рассчитывайте выгодные цены клика и не работайте в минус. Поможет вам в этом калькулятор искренней ставки, разработанный специалистами eLama.
Использование автостратегий Директа без достаточной статистики
В Директе есть полностью автоматические стратегии, которые могут управлять ставками за рекламодателя. Нужно лишь указать KPI, на которые система должна ориентироваться. Для того, чтобы включить стратегию, нужно настроить счетчик Метрики, создать в нем цели и связать его с Яндекс Директом. Система позволяет подключать автостратегию без достаточного количества данных по целям, в этом случае вы увидите уведомление в интерфейсе, что целевых визитов мало.
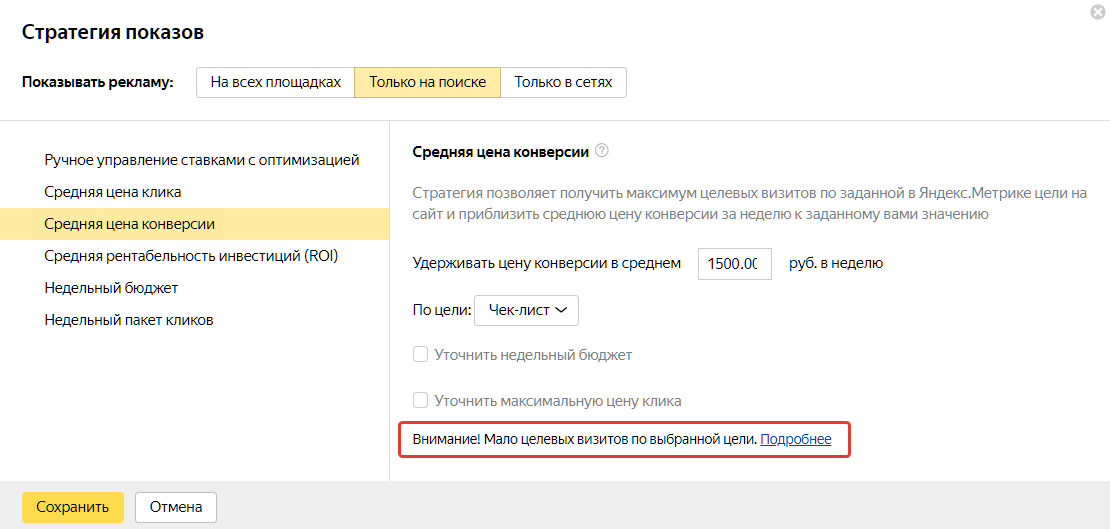
Подобное уведомление говорит о том, что алгоритму потребуется больше времени на обучение (несколько недель) и в этот период заданное условие по цене конверсии может не выдерживаться. На практике, если конверсий мало, система может никогда не прийти к заданному значению и расходовать бюджет неэффективно. В этом случае вы можете настроить дополнительные промежуточные микроцели в Яндекс Метрике, для того, чтобы данных для обучения было больше. Но у этого подхода есть минус: стоимость конкретного целевого действия на сайте определить несложно, а вот рассчитать единую цену конверсии по смешанному набору целей гораздо проблематичней. Поэтому зачастую рекламодателям с небольшими бюджетами, малым количеством переходов на сайт и конверсий, эффективнее использовать бид-менеджеры и оптимизаторы. Бид-менеджер eLama позволяет настроить автоматическое управление ставками с заданными лимитами по цене клика на всю кампанию или для каждой фразы. Это значит, что рекламодатель может самостоятельно рассчитать искренние ставки для разных фраз, исходя из их эффективности, и настроить шаблон, по которому биддер будет удерживать объявления на максимальных позициях, не превышая заданные пределы цены клика.
Автостратегии рекламных систем становятся умнее, но добиться максимальной эффективности могут далеко не всегда. Рекомендую протестировать ручное ставками с бид-менеджером в течение пары месяцев, набрать статистику по конверсиям, а затем переключить кампанию на автоматическую стратегию для теста возможностей системы.
Выводы
Яндекс.Директ может работать эффективно и приносить прибыль. Для этого необходимо выстраивать полноценную работу со всеми инструментами системы, настраивать веб-аналитику, анализировать статистику и не допускать типичных ошибок, о которых я рассказал в этой статье. У клиентов сервиса eLama, есть отличный инструмент, который позволяет в любой момент проверить новые или действующие рекламные кампании на ошибки и получить рекомендации по повышению эффективности кампаний. Вы можете воспользоваться этим инструментом бесплатно.
Источник
Считается, что контекстная реклама — это просто: ввели запросы, закинули деньги, запустили кампанию и ждем клиентов. На самом деле, контекстная реклама — огромная машина с сотнями настроек. Людей, которые знают все опции и математику аукциона, — очень немного.
Мы делаем аудиты контекстной рекламы и хотим показать вам ошибки, которые чаще всего находим у клиентов. Это базовые недочеты, по наличию или отсутствию которых можно оценить работу вашего специалиста по контекстной рекламе.
Также мы подготовили чек-лист с рекомендациями по улучшению контекстной рекламы, основанный на результатах нашей работы.
Ошибка 1. Рекламное объявление без контактов
Объявление без контактной информации (так называемой «Визитки») занимает меньше площади и проигрывает объявлениям конкурентов.
Кроме того, в объявлении на скриншоте стоит использовать релевантную отображаемую ссылку. Хороший пример — ссылки у конкурента выше, которые показывают, на какой раздел пользователя перенаправят при клике.
Ошибка 2. Отсутствуют быстрые ссылки и фавикон
Посмотрим на объявление в конкурентной нише — пластиковые окна. Компания разместилась на втором месте в спецразмещении. При этом у объявления отсутствуют быстрые ссылки и фавикон (иконка сайта), поэтому кликабельность меньше, чем у конкурентов. Эта ошибка ведет к тому, что вы будете недополучать трафик, CTR уменьшится, а значит — цены на ставки вырастут.
Ошибка 3. Реклама не оптимизирована для рекламной сети Яндекса (РСЯ)
Рекламная кампания в поисковике отличается от той, что показывают в РСЯ или контекстно-медийной сети Google. Если контекстолог этого не понимает и просто копирует кампанию на все системы размещения, получается плохо. Обрывки текстов и отсутствие картинок не помогают продавать предложение:
Это топорное ведение контекстной рекламы. Для компании это выливается в потерю тысяч и даже миллионов рублей.
Основные отличия кампаний на тематических площадках и в поиске:
- В поиске картинки не отображаются. В рекламу на тематических площадках их нужно добавлять обязательно
- В РСЯ не подсвечиваются ключевые слова
- Реклама на площадках может быть более креативной, чем в поиске. А в КМС много различных форматов, с которыми можно экспериментировать
Ошибка 4. Забыли настроить отраслевые и региональные кампании
Когда мы проводили очередной аудит контекстной рекламы у клиента, мы увидели неплохо настроенные кампании от известного агентства. Сначала клиент говорил, что не понимает, зачем вообще мы проводим аудит.
Но оказалось, что не продумана региональная стратегия контекстной рекламы по отраслям. Наше решение:
Ошибка 5. Не проработана структура рекламных кампаний
Структура кампаний в контекстной рекламе появляется не на пустом месте, а создается на основе интернет-спроса и анализа рынка клиента.
У крупного автодилера кампании не были разбиты по тем группам, которые нужны для автомобильной отрасли. Мы предложили такую структуру:
- Рекламная кампания (РК) на бренд компании
- РК под общие запросы
- РК в Москве
- РК по моделям автомобилей
- РК по цвету кузова
- РК по типу кузова, объему двигателя, типу КПП
- РК по станциям метро
- РК по районам
- РК с пробегом
- РК в кредит
- РК акции
- РК на конкурентов
После того, как структуру внедрили, клиент получил возможность отслеживать эффективность работы групп ключевых слов. Если к такой рекламе подключить простейшую аналитику, можно понять, какие ключевики лучше всего работают для выбранной ниши, и оптимизировать кампании.
Ошибка 6. Сайт не загружается при клике
Удивительно, но мы часто видим, что контекстная реклама запущена, но сервер не настроен, чтобы обрабатывать метки рекламных систем. Поэтому при клике на рекламу сайт может не загрузиться.
Базовый чек-лист по настройке контекстной рекламы
Полный чек-лист по настройке контекстной рекламы — это сотни пунктов. Здесь мы перечислим только минимальные требования, которые может реализовать каждая компания.
1. Разделение и кросс-минусовка B2B и B2C запросов. Это верхний уровень структуры. Чтобы ее улучшить, нужно детально изучить ваши сегменты аудитории.
2. Объявления оптимизировать под разные устройства. Рекламные кампании для мобильных собираем отдельно.
3. Пишите рекламное объявление правильно.
1 = Ключевые слова в заголовке
2 = Наличие уточняющих слов
3 = Ключевое слово в отображаемой ссылке
4 = Ключевое слово в описании
5 = Призыв к действию
6 = Наличие быстрых ссылок с ключевым словом
7 = Контактная информация
4. Используйте «Структурированые описания» и расширения объявлений: «Номера телефонов», «Адреса», «Цены» для повышения эффективности ваших объявлений в Google AdWords помимо быстрых ссылок и уточнений.
Пример расширения «Цены»:
Пример структурированного описания:
5. Придерживайтесь принципа 1 ключевое слово = 1 объявление для средне- и высокочастотников рекламные кампании должны строиться по принципу. Низкочастотники (когда показов 1–30) нужно группировать, а объявления для них — шаблонизировать с помощью решеток.
6. Сделайте кампании на околотематические ниши, например: сервис, лизинг, комплектующие.
7. Ограничивайте бюджет на неэффективные ключи, площадки, каналы.
8. Работайте с рекламной сетью Яндекса и контекстно-медийной сетью. Но фильтруйте площадки, чтобы к вам не шел мусорный трафик.
9. Запускайте новые инструменты. Это, в основном, касается AdWords: реклама в Gmail, объявление-звонок.
10. Следите за показателем качества ключевых слов. Это оценка того, насколько ваши объявление и сайт релевантны ключевым словам.
11. Используйте динамический ремаркетинг на незавершенные действия, брошенные корзины. Он позволяет обратиться к пользователям, с которыми вы уже контактировали на вашем сайте. Кейс по ретаргетингу для автомобильной отрасли.
12. Используйте многоканальность. Одна из схем работы: привести нового посетителя через контекст, вернуть его на сайт ремаркетингом в соцсети, привести к решению о звонке или заказе после третьего контакта через ретаргетинг MyTarget.
13. Помните: реклама может показываться не в нужное для вас время. Например, если ваше предложение из сферы B2B, не стоит тратить деньги на показы ночью или в выходные дни. В любом случае, обратите внимание на формирование ставок в это время и регулируйте их стоимость в зависимости от лидогенерации.
14. Заполните список минус-слов. Его часто забывают или составляют небрежно.
Каждого специалиста, в том числе и по контекстной рекламе, нужно контролировать. Многие пункты не выполняются просто потому, что никто не ожидает проверки. Проанализируйте контекстную рекламу по нашему чек-листу и распространенным ошибкам — и вы поймете квалификацию вашего подрядчика и сможете улучшить результаты в AdWords и Директе.
Хотите получить предложение от нас?
Смотрите также

(Visited 10 174 times, 26 visits today)
![]() Loading…
Loading…
Виктор Тимофеев, osa@pic24.ru (ноябрь, 2009)
Скачать в PDF-формате
Как писать программы без ошибок
Введение
Про ошибки
По профессии я занимаюсь поиском и исправлением ошибок в чужих программах. За время работы я набрал некоторую коллекцию всевозможных багов и попытался свести их в одну таблицу и классифицировать с тем, чтобы оформить некую брошюру по быстрому поиску и исправлению наиболее часто встречающихся ошибок. Однако произвести такую классификацию не удалось. Дело в том, что, выделив 5-6 основных ошибок, таких как: неправильное приведение типов, путаница со знаковыми и беззнаковыми выражениями, пренебрежение выполнением проверок аргументов функций и пр., — я увидел, что остальные ошибки слишком индивидуальны, чтобы их как-то обобщать. О приемах поиска и говорить нечего, т.к. их намного больше, чем самих ошибок.
Тем не менее, каждый раз, исправляя какую-либо ошибку, я для себя отмечал, что ее можно было и не совершить, если бы то-то, то-то. Со временем я уяснил, что большая часть ошибок совершается из-за неправильного подхода к процессу программирования. Поэтому идея написания брошюры «Локализация и исправление ошибок» перешла в идею написания брошюры «Как не совершать ошибки». И я считаю это правильным, потому что лучше учиться строить, а не восстанавливать плохо построенное. Большая часть советов, описываемых мной, довольно банальны и просты. Вроде как, все их знают, но почему-то многие не придерживаются.
О каких ошибках идет речь. Конечно же, не о тех, которые обнаруживает компилятор при трансляции программы. Пока мы не исправим эти ошибки, нам не удастся получить код, который мы сможем прошить в контроллер. Эти ошибки в большинстве своем означают, что текст не соответствует правилам языка программирования, и, по сути, являются помарками. Также в этом материале не хотелось бы касаться так называемых «запланированных» ошибок (обработка неправильных данных, пришедших извне, ошибочные действия пользователя и пр.). Мы будем говорить об ошибках реализации, т. е. о тех, которые будут проявляться в ходе выполнения программы. Эти ошибки являются следствием неправильно запрограммированного (или составленного) алгоритма, допуска условностей, невнимательности и неаккуратности.
Для кого это пособие
В этом пособии я изложил свой подход к программированию микроконтроллеров, привел свои правила, которыми руководствуюсь при написании программ, и обозначил те моменты, которым при написании программ уделяю особое внимание. Уверен, что моя точка зрения не единственная, а также, что где-то мне самому еще есть чему поучиться. Так что я буду рад, не только если пособие окажется кому-то полезным, но также если кто-то решит меня в чем-то поправить или дополнить.
Статья рассчитана на широкий круг программистов, поэтому я старался не затрагивать концепцию доказательного программирования, и вообще старался привести больше практических советов, чем теории (с которой сам на «Вы») и формалистики. Так же в этом пособии нет описания приемов повышения надежности программ (самодиагностика, троирование, перепроверка действий и пр.).
Не следует считать, что после прочтения данного пособия ваши программы автоматически станут безошибочными, и уж тем более, что в будущем ошибок не будет вовсе. Ошибки все равно будут, но процент их сильно сократится. Более того, на написание программ по правилам, изложенным в этом пособии, будет затрачено время в два, в три, в пять раз больше, чем без правил. Писать программы без ошибок — это труд, причем кропотливый. Просто в отличие от кропотливого труда по поиску и исправлению ошибок, этот вид труда поддается планированию и формализации, т.е. является предсказуемым. А применение описанных здесь правил в разы сократит время непредсказуемого процесса отладки, который, как показывает практика, зачастую отнимает намного больше времени, чем само кодирование.
Предполагается, что читатель знает, что такое контроллер, как он устроен, как включается, наконец, что такое электрический ток, потому что без этих знаний заниматься микроконтроллерами бесполезно. Так что, как говорилось в старом анекдоте: «Учите матчасть!»
![]()
«Учите матчасть!»
Это самая очевидная рекомендация. Про нее можно было и не говорить, но для полноты картины вскользь коснемся этой темы. Программист, пишущий для контроллеров должен знать схемотехнику, устройство самого контроллера, язык программирования, на котором пишет программу, и особенности используемого компилятора. Тот программист, который пренебрегает необходимостью иметь эти знания, теряет право жаловаться на то, что его программа не работает.
Схемотехника
Как минимум нужно знать:
-
основы электроники (и цифровой и аналоговой)
-
законы Ома и Кирхгофа
-
типовые схематические решения (RC-цепочки, транзисторные ключи)
Кроме того, нужно знать, что необходимо устанавливать диоды параллельно катушкам реле, что светодиоды включаются через токоограничивающий резистор, что у механических контактов есть такое явление как дребезг, и пр.
Контроллер
Нужно знать архитектуру контроллера, способы адресации, регистры и их назначения, периферийные модули и режимы их работы, диапазоны рабочих температур, частот, питаний и пр., нагрузочная способность портов и т.д.
Не нужно стесняться заглядывать в фирменные даташиты, там есть ответы на большинство вопросов. А то у кого-то не работает PORTA (в то время как не отключены аналоговые цепи), у кого-то не появляется «1» на выходе RA4, у кого-то прерывание по RB0 срабатывает только в половине случаев и т.д.
Язык
Конечно же, нужно знать сам применяемый язык программирования.
Для ассемблера это:
-
формат команд;
-
типы и количество операндов
Для языков высокого уровня это:
-
семантика операторов;
-
квалификаторы данных и функций;
-
типы данных;
-
преобразование типов;
-
приоритеты операций;
-
указатели (или указатели на указатели);
Компилятор
Разработчики компиляторов для микроконтроллеров, стремясь адаптировать компилятор под конкретную платформу, позволяют себе отходить от стандартов языка, одновременно не нарушая их. Каждый компилятор имеет свои особенности, незнание которых может привести к трудностям при портировании или при использовании чужих библиотек:
-
набор директив;
-
типы данных (размерность, знаковость);
-
квалификаторы (near, far, const, rom);
-
организация прерываний.
![]()
Этапы программирования
Когда ТЗ согласовано и задача формализована (переведена с проблемно ориентированных требований в технические: входные/выходные данные, режимы работы и пр.), начинается сам процесс программирования.
-
Планирование (включает в себя проектирование, составление плана действий, выявление требуемых ресурсов).
-
Кодирование (запись самой программы в машинном языке)
-
Отладка (локализация и устранение ошибок)
-
Тестирование (проверка работоспособности и соответствие спецификации)
-
Оформление проектной документации
-
Эксплуатация и сопровождение
Беда в том, что многие пренебрегают планированием, а также считают, что отладка появляется только в том случае, если была допущена какая-то ошибка при кодировании, а так как надеются с первого раза написать без ошибок, то и процесс отладки не учитывается. Однако же, в реальности отладка – это обязательный процесс, на который, вдобавок, приходится большая часть времени, сил и нервов. Закодировать даже самый сложный и запутанный алгоритм – это нетрудно, трудно заставить его работать, или, если они был написан правильно, убедиться в его работоспособности. Поэтому процессы отладки и тестирования самые длительные и самые трудоемкие. Однако, время отладки можно сократить, сделав процесс более предсказуемым и управляемым, а именно – спланировав программу.
![]()
Планирование программы
Почему-то часто планированием программы вообще пренебрегают. И в лучшем случае все планирование состоит из подсчета количества требуемых выводов входа/выхода. Напомню одну старую шутку: «Нетщательно спланированная работа отнимает в 3 раза больше предполагаемого времени, тщательно спланированная – только в два». Ее можно дополнить: «Неспланированная работа отнимает все время».
Кто-то может сказать: «Я пишу маленькие программы, что там планировать?». Тем не менее, практика показывает, что лучше для маленькой программы потратить 10-15 минут на планирование (просто расписать на листе бумаги), чем тратить 3-4 дня на поиск ошибки, рытье Интернета и отбивание от обвинений в ламерстве на форумах в сети.
Ниже приведены этапы планирования программы:
Рассмотрим каждый этап более подробно.
![]()
Расписать алгоритм
Алгоритм – это ДНК программы, вернее – ее генетический код. Если в нем ошибка, то программа будет вести себя неправильно. Часто еще при составлении алгоритма на бумаге всплывают некоторые ответвления, которые могут быть проигнорированы при написании программы «в лоб». Преимущество в том, что алгоритм составляется в абстрактных терминах, еще нет ни типов данных, ни переменных, поэтому есть возможность сосредоточиться на конкретных алгоритмических моментах, не думая пока о деталях реализации. В большинстве случаев требуется составить несколько алгоритмов: один общий для всей программы, описывающий режимы работы и порядок переключения между ними, и алгоритмы работы каждого режима в отдельности. Степень детальности алгоритма, конечно, зависит от сложности программы в целом и каждого узла в отдельности.
Алгоритм может быть представлен как в виде блок-схемы, так и в виде графа переходов, в виде графика эпюр сигналов и т.д. Не стоит забывать о требованиях к проектной документации; например, если в документации требуется привести алгоритм в виде блок-схемы, то не нужно его сначала рисовать в виде графа переходов, а затем переводить в блок-схему.
![]()
Продумать модули
Нам нужно заранее продумать, из каких модулей будет собираться наша программа, вернее, на какие модули она будет разбита. Преимущества модульности я поясню ниже, а здесь приведу рекомендации, как правильно разбить программу на модули.
Во-первых, разбиение должно быть произведено по функциональному признаку. Т.е. не нужно в один модуль заталкивать USART и вывод звука на пьезодинамик, даже если при конкретной реализации это и кажется целесообразным. Дело в том, что однажды написанный модуль можно будет переносить в другие проекты, избавляя себя от необходимости писать один и тот же код по много раз. Чем модуль будет функционально изолированнее, тем проще будет его перенос. Однако и здесь не следует бросаться в крайности и делать отдельно модули для передачи данных по USART, для приема данных по USART, для подсчета и сравнения контрольной суммы данных, принятых по USART, и т.п. Функционально модуль должен быть полным, но безысбыточным.
Также стоит отметить, что при разбиении своей будущей программы на модули нужно учитывать наличие уже готовых модулей (либо своих, либо чужих).
Большинство модулей можно разделить на два типа: системные (работают на уровне сигналов и железа) и алгоритмические (работают на уровне обработки данных и режимов). Хороший пример – работа ЖКИ. Предположим, нам требуется выводить информацию на ЖКИ HD44780. Крайне неудачным решением будет такое, при котором функции вывода конкретных данных на экран, вызываемые из головной программы, и функции работы с самим HD44780, вызываемые из функции вывода данных, будут помещены в один модуль. Тут получается, что модули обоих типов – алгоритмический и системный – смешаны в один, что сильно затруднит в дальнейшем, например, использование индикатора другого типа. Если же мы четко разделим системный функционал и алгоритмический, то в дальнейшем замена типа индикатора выльется для нас всего лишь в замену системного модуля.
![]()
Продумать данные
Также на этапе планирования мы определяем для себя, какими данными будет оперировать наша программа. Причем нужно обозначить не только назначение данных и требуемый их объем, но также заранее предусмотреть их размещение (ROM или RAM, конкретный банк RAM) и область видимости (например, нам нет смысла делать видимым во всей программе буфер выходных данных i2c).
![]()
Разделить периферию контроллера между процессами
Периферийные модули контроллера помогают упростить некоторые программные узлы, а иногда просто делают их возможными (например, без АЦП мы не сможем измерить аналоговый сигнал). Но зачастую бывает, что программных узлов, требующих использование встроенной периферии, больше, чем имеется на борту у контроллера. Поэтому периферийные модули приходится разделять между несколькими задачами (типичный пример – таймеры). При проектировании программы нужно заранее распределить периферийные модули между задачами, что поможет выбрать оптимальные параметры для каждого модуля.
(Видел программу, в которой неправильно распределенные ресурсы привели к тому, что пришлось мультиплексировать управление GSM-модулем и GPS-приемником на один USART. Программа начала сбоить и, насколько я знаю, ее так и не привели в рабочее состояние.)
![]()
Учесть физические свойства обвеса
Контроллер с нашей программой будет жить не сам по себе, его будут окружать какие-то внешние схематические узлы, специализированные микросхемы и пр. Проектируя программу, нужно заранее учесть особенности всех подключенных к контроллеру устройств, цепей и микросхем.
Например, если в устройстве будут кнопки, то нужно помнить, что механические контакты дребезжат и шуршат. Это сразу должно наталкивать на использование каких-то дополнительных счетчиков и/или таймеров для подавления этих эффектов.
Также стоит помнить про «холодный» старт внешней периферии. Например, у нас есть ЖКИ, которому после подачи питания требуется 10 мс для самоинициализации, во время которой он не будет слышать команд извне. Если этого не учесть, то может получиться так, что наш контроллер начинает инициализацию ЖКИ примерно в то же время, когда ЖКИ заканчивает свою внутреннюю инициализацию. В результате ЖКИ то будет успевать самоинициализирваться и начинать прием наших данных, то не будет. И когда мы поймем, в чем дело, и увеличим задержку перед инициализацией до 20 мс, мы с удивлением обнаружим, что теперь при включении питания, например, успевает туда-сюда сработать реле, т.к. с новой задержкой неинициализированное состояние управляющего им вывода держится достаточно для того, чтобы ток в катушке реле успел вырасти и привести к срабатыванию.
Если в нашем устройстве предполагается прием данных по радио, то мы должны учесть, что в радиоканале есть помехи, и что прием такого сигнала нельзя делать «в лоб» по фронтам, а нужно, как и в случае с обработкой сигналов от механических контактов, заводить дополнительные счетчики, таймеры и т.п.
Примеров про обвес можно придумать еще много: состязания на шине, емкостные нагрузки, внешние источники прерываний и т.д. Все это нужно учитывать еще до начала написания текста программы, заранее предусматривая порядок действий и резервируя дополнительные ресурсы (память и скорость).
![]()
Предусмотреть возможность расширения
При проектировании программы следует заранее убедиться, что в случае значительного разрастания в дальнейшем функционала (а значит и кода) будет возможность заменить выбранный контроллер более мощным с минимальными затратами. Если мы, например, решили использовать в нашей разработке контроллер из линейки PIC16, а на этапе планирования мы прикинули, что подойдет только 16F877, или 16F946, или 16F887 (короче говоря – с максимальным объемом памяти), значит, мы неправильно выбрали линейку. В этом случае нужно брать PIC18, потому что велика вероятность того, что программа в выбранный контроллер просто не влезет.
Часто встречаю на форумах крики души: «помогите оптимизировать программу, а то она не лезет в PIC18F67J60!» (прим.: контроллер из линейки PIC18, имеющий максимально возможный объем ROM = 128Кб). Это результат непродуманного выбора контроллера на этапе планирования, если этот этап вообще был проведен.
Так же надо учесть, что при отладке программы нам потребуются кое-какие ресурсы (об этом речь пойдет ниже).
![]()
Предусмотреть смену платформы или компилятора
Здесь речь, конечно, не о том, что нужно напичкать программу директивами условной компиляции, позволяющими максимально эффективно использовать возможности каждого компилятора, на который, возможно, придется переносить программу. Речь как раз о том, чтобы:
-
минимально использовать уникальные особенности конкретного компилятора, а те куски кода, которые все-таки так пишутся, блокировать условными директивами (бывает, что компилятор простую операцию развернет черт те во что, а – кровь из носа — хочется сделать кратко и красиво);
-
не использовать недокументированные особенности компилятора; некоторые операции могут быть реализованы различным способом, например, операция сдвига влево может после своего выполнения оставить флаг переноса, а может и изменит его, либо, выполнив оптимизацию, заменит инструкцию сдвига чем-нибудь, либо в качестве результата возьмет один из промежуточных результатов, получившихся при вычислении предыдущего выражения. В общем, нет гарантии, что флаг переноса будет установлен правильно.
-
переопределять типы данных. Стоит учитывать, что знаковость и размерность в стандарте языка определены для каждого типа довольно расплывчато (например, в HT-PICC18 тип char по умолчанию беззнаковый, в то время как в MPLAB C18 – знаковый; или в CCS тип int – 8-битный беззнаковый, а в остальных компиляторах – 16-битный знаковый). Поэтому в каждом проекте хорошо бы иметь h-файл с переопределениями типов
#if defined(__PICC__) || defined(__PICC18__) typedef signed char S08; typedef signed int S16; typedef signed long S32; typedef unsigned char U08; typedef unsigned int U16; typedef unsigned long U32; typedef bit BOOL; typedef signed char S_ALU_INT; typedef unsigned char U_ALU_INT; #endif
Обратим внимание на два типа: S_ALU_INT и U_ALU_INT – это знаковое и беззнаковое целые, имеющие размерность машинного слова для конкретного контроллера. Т.к. операции над операндами, имеющими размерность шины данных, производятся наиболее оптимально, иногда есть смысл пользоваться этими типами данных.
Примечание: далее в тексте для наглядности будут использоваться стандартные типы: char (8 бит), int (16 бит), long (32 бита).
![]()
Написание программы
При написании самого текста программы нужно руководствоваться двумя сводами правил:
Сами правила могут у каждого быть свои, но они должны по возможности исключать разночтения.
![]()
Кодирование
![]()
Соблюдать модульность
Мы уже говорили о разбиении программы на модули, еще раз приведу преимущества модульности:
-
Мобильность (легкий перенос модуля в другую программу)
-
Наглядность (легкий поиск определений конкретных функций)
-
Заменяемость (замена одного модуля другим при изменении условий работы, например, при смене внешнего оборудования)
Раз мы решили разбить программу на модули, то нужно следовать этому решению до конца и не совершать каких-либо действий, нарушающих модульность. Т.е. наши модули должны обладать следующими характеристиками:
-
Самобытность
Функции и переменные, относящиеся к одному модулю, определять именно внутри этого модуля. Понятно, что иначе перенос модуля в другую программу обернется тем, что в каждой новой программе придется переопределять недовнесенные переменные. -
Самодостаточность
Не использовать в модуле внешние переменные из верхних модулей. Опять же, причина в том, что при переносе модуля в другую программу придется в новой программе не только доопределять какие-то переменные, но и восстанавливать механизмы их работы с тем, чтобы модуль вел себя правильно. -
Гибкость в настройке
Например, если это модуль для работы по шине i2c, то при переносе в другой проект должна быть возможность выбирать (или задавать константами) адрес устройства, разрядность адреса данных, выводы, к которым подключено устройство i2c.
![]()
Избегать условностей
В программе следует избегать любых конструкций, которые при прочтении могут быть истолкованы двояко, или которые смогут при определенных условиях повести себя неправильно. Самые частые допуски, которые позволяют себе программисты, — это несоблюдение границ использованных типов, путаница со знаковыми и беззнаковыми переменными, пренебрежение приведением типов. Эти допуски рассмотрим в первую очередь.
Типы данных
Нужно определять переменные тем типом, который соответствует их назначению. Например, не следует переменную, которая будет использована как числовая, определять типом char. Число может быть либо signed char либо unsigned char. Сам же char определяет символьную переменную. Понятно, что для контроллера все эти переменные – одно и то же, но для компилятора, а также для человека, читающего текст программы, — это разные вещи.
Например, типичная ошибка:
Неправильно:
char Counter; Counter = 10; if (Counter >= 0) ...;
Это выражение будет правильно обрабатываться в MPLAB C18, в то время как в HT-PICC18 оно всегда будет возвращать true. Все из-за того, что в стандарте языка не оговаривается знаковость типа char, и каждый разработчик компиляторов вправе толковать его по-своему. В приведенном примере переменная должна быть определена так:
Правильно:
signed char Counter; Counter = 10; if (Counter >= 0) ...;
Приведение типов
Не стоит надеяться, что компилятор всегда сам сделает приведение типов в случае, когда в выражении участвуют разнотипные переменные и константы. Всегда следует выполнять приведение типов вручную, исключая разночтения выражения программистом и компилятором.
Неправильно:
int i; void *p; p = &i;
Правильно:
p = (void*)&i;
В конкретном примере мы, скорее всего, получим правильный результат и без приведения типов (хотя, возможны нюансы с однобайтовыми near-указателями для PIC18). Но бывает так, что программист, рассчитывая на автоматическое приведение типов, проморгает его отсутствие в более сложном выражении, например: выражение содержит подвыражения в скобках, в которых типы будут приведены только после выполнения подвыражения, т.е. тогда, когда, например, значимость будет уже потеряна (из-за переполнения).
То же самое относится к передаче параметров в функцию.
Побайтовое обращение к многобайтовой переменной
Пример неправильного обращения:
unsigned char lo, hi; unsigned int ui; ... lo = *((unsigned char*)&ui + 0); hi = *((unsigned char*)&ui + 1);
Дело в том, что стандартом языка не предусматривается порядок чередования байтов в многобайтовых объектах.
Правильное обращение:
lo = ui & 0xFF; hi = ui >> 8;
Определение функций
При определении функции следует указывать полностью входные и выходные типы. Если функция определена просто:
myfunc ()
, то компилятор по умолчанию будет считать, что она возвращает int, и не принимает параметров. Однако не следует оставлять такой неопределенности.
myfunc () // неправильно myfunc (void) // неправильно int myfunc () // неправильно int myfunc (void) // Правильно
Пустые операторы
Не следует в теле цикла while, а также в операторах if…else использовать пустой оператор:
while (!TRMT); // Ожидаем освобождение буфера TXREG = Data;
Нечаянно пропущенная ‘;’ обернется неправильным поведением программы. Лучше вместо пустого оператора ставить continue либо {}:
while (!TRMT) continue; // Ожидаем освобождение буфера TXREG = Data;
Про оператор switch
В операторе switch нужно:
-
Определять ветку
default -
В каждом
caseставитьbreak -
неиспользуемые
breakзакрывать комментариями
switch (...) { case 0x00: ... break; case 0x01: ... // break; // Поставив закомментированный break, мы даем себе понять, // что после обработки условия 0x01 мы хотим перейти к коду // обработки условия 0x02, а не пропустили break случайно case 0x02: ... break; default: // Обязательная ветка, даже если есть уверенность, что // выражение в switch всегда принимает одно из описанных // значений break; // Ветка default также должна заканчиваться break }
Неинициализированные переменные
Нельзя пользоваться неинициализированными переменными в расчете на то, что компилятор сам сгенерит код их инициализации (например, обнулит после сброса).
Скобки в сложных выражениях
В некоторых случаях в сложных выражениях есть смысл расставлять скобки даже тогда, когда есть уверенность в правильности приоритетов операций. Такие выражения легче анализировать, т.к. ошибка может быть не только в приоритетности операций, но и в самом выражении. Также это снижает вероятность внесения ошибки при модификации выражения.
«Такая ситуация никогда не случится!»
На эту тему можно вообще долго говорить. Вот интересный фрагмент определения типа из одной из присланных мне программ:
typedef struct { unsigned int seconds : 6; unsigned int minutes : 6; unsigned int hours : 4; // Неправильно задана размерность } T_CLOCK;
Обратите внимание на размерность полей данной структуры. Под минуты и под секунды выделено по 6 бит, чтобы охватить весь интервал 0..59. А под часы вместо 5 бит, выделено 4. Программист, написавший это, предположил, что т.к. программа будет работать только с 8 утра, то проще выделить 4 бита (покрывая интервал в оставшиеся 16 часов) с тем, чтобы вся структура влезла в два байта, а в самой программе к значению hours всегда прибавлять 8. Надо ли говорить, что сбой не заставил себя должго ждать?
Так что не стоит забывать о первом законе Мерфи: «Если неприятность может случиться, — она случается».
Мертвые циклы
Часто в программах встречаются участки кода, которые потенциально могут привести к зависанию. Самый распространенный пример – ожидание готовности или подтверждения при работе с внешней периферией:
Неправильно:
void lcd_wait_ready (void) { while (!PIN_LCD_READY) continue; }
Если произошла непредвиденная ситуация (обрыв линии, короткое замыкание, конденсат и пр.), то из этого цикла мы никогда не выйдем. (Разве что только WDT сработает). Поэтому нужно всегда предусматривать аварийный выход из таких циклов. Можно это делать с помощью таймера.
Правильно:
char lcd_wait_ready (void) { TMR0 = -100; // Готовим таймер для фиксации таймаута TMR0IF = 0; while (!PIN_LCD_READY) { if (TMR0IF) return 0; // Выходим с кодом ошибки } return 1; // Выходим OK }
Правда, целый таймер выделять для этого иногда накладно, и есть смысл работать с глобальной переменной, которая будет уменьшаться в прерывании по таймеру:
// Фрагмент обработчика прерывания if (TMR0IF && TMR0IE) { TMR0IF = 0; TMR0 -= TMR0_CONST; // Обновляем таймер if (!--g_WaitTimer) // Проверяем переполнение g_Timeout = 1; ... } ... char lcd_wait_ready (void) { g_WaitTimer = 10; // Готовим таймер для фиксации таймаута g_Timeout = 0; while (!PIN_LCD_READY) { if (g_Timeout) return 0;// Выходим с кодом ошибки } return 1; // Выходим OK }
Кстати, заметьте, что в обработчике прерывания проверяется не только флаг конкретного прерывания (TMR0IF), но и бит разрешения (TMR0IE). Дело в том, что в PIC-контроллерах младшего и среднего семейства несколько прерываний могут обрабатываются одним обработчиком. И если у нас прерывание по TMR0 отключено (TMR0IE = 0), а в обработчик мы попали от другого источника (например RCIF), то без проверки битов xxxIE мы обработаем все отключенные прерывания, у которых на момент входа в обработчик оказался установлен флаг xxxIF.
![]()
Не делать длинных и сложных выражений
Такие выражения не только трудно анализировать, но их также трудно тестировать и отлаживать.
Неправильно:
t = sqrt(p*r/(a+b*b+v))+sin(sqrt(b*b-4*a*c)/(1<<SHIFT_CONST));
Представьте, что программа делает вычисления неправильно и есть подозрения, что проблема в этом выражении. А это выражение даже в симуляторе не прогнать. Такие выражения желательно разбивать на несколько подвыражений:
Правильно:
A = p*r; B = a + b*b + v; C = b*b – 4*a*c; D = (1 << SHIFT_CONST); if (B == 0) ...; // Ошибка: «деление на 0» if (C < 0) ...; // Ошибка: «корень из отрицательного числа» E = A/B; If (E < 0) ...; // Ошибка: «корень из отрицательного числа» t = sqrt(E) + sin(sqrt(C)/D);
Теперь наше выражение не только легко читается, но и легко тестируется и отлаживается, а кроме того, – еще и имеет механизм защиты от неправильных входных данных (этот механизм можно было бы оставить и с длинным выражением, но тогда некоторые части выражения пришлось бы пересчитывать дважды).
![]()
Операторные скобки
При написании фрагментов программ, содержащих вложенные циклы или вложенные условные операторы, желательно расставлять операторные скобки даже для однострочных блоков.
Рассмотрим пример одной часто встречающейся ошибки:
Неправильно:
if (A == 1) if (B == 2) C = 3; else C = 4;
Замысел программиста был таков: если A равняется 1, то при B, равном 2, присвоить C значение 3, иначе присвоить C значение 4. Т.е. программист считал, что в C будет занесено значение 4, если A не равно 1. Однако на самом деле компилятор видит это по-другому: else применяется к ближайшему if, а не к тому, который выровнен с ним в тексте. В нашем случае else относится к условию if (b == 2).
Правильно это условие нужно было записать так:
if (A == 1) { if (B == 2) C = 3; } else C = 4;
![]()
Операторы break и continue во вложенных циклах
Часто встречающейся ошибкой является использование break или continue во вложенных циклах или операторе switch в расчете на то, что эти операторы сработают в рамках и внешнего цикла. Вот пример из реальной программы (он немного порезан для наглядности, и ошибка сразу бросается в глаза), который подсчитывал количество положительных и отрицательных единиц в массиве, причем нулевой элемент был признаком конца массива.
Неправильно:
Positive = Negative = 0; for (i = 0; i < MAX_ARRAY_SIZE; i++) { switch (array[i]) { case 0: break; // Выйти из цикла (ошибка, т.к. выйдем // только из switch) case 1: Positive++; break; case -1: Negative++; break; } }
Программист решил использовать для проверки конструкцию switch, в которой, среди прочего, при нахождении элемента со значением 0 счет должен был прерваться. Однако, очевидно, что break в ветке case 0 выведет программу из switch‘а, а не из цикла for.
Есть несколько способов решить эту проблему. Один из вариантов в данном случае – использовать дополнительный if:
Правильно:
Positive = Negative = 0; for (i = 0; i < MAX_ARRAY_SIZE; i++) { if (array[i] == 0) break; // Выйти из цикла switch (array[i]) { case 1: Positive++; break; case -1: Negative++; break; } }
Однако он не очень эффективный, т.к. приводит к повторному вычислению адреса элемента массива при косвенной адресации. Есть и другие варианты решения проблемы. Главное – помнить, что break/continue прерывает/продолжает только текущий цикл (или switch).
![]()
Точность вещественных чисел
Когда появляется необходимость работы с вещественными числами с плавающей запятой, нужно внимательнее изучить теорию об их структуре (мантисса, порядок, знаки). У некоторых программистов, которые с ней не знакомы, при виде диапазона +/- 1.7e38 появляется иллюзия всемогущества и универсальности этого типа данных. При этом из вида упускаются такие важные детали, как потеря значимости, нормирование, переполнение, относительная погрешность.
В одной программе я видел такой фрагмент:
long l; float f; f = 0.0; for (l = 0; l < 100000L; l++) { ...; f = f + 1.0; ...; }
(Примечание: в программе был использован вещественный тип размерностью 24-бита.)
На месте троеточий делались кое-какие вычисления, одним из параметров в которых была переменная f. В этом цикле первые две трети результатов оказывались правильными, а дальше появлялись отклонения, причем, чем дальше, тем сильнее.
А происходило следующее: когда переменная f досчитывала до значения 65536 (т.е. выходила за пределы 16-разрядной мантиссы), ее экспонента (порядок) увеличивалась на единицу. При этом вес младшего разряда мантиссы оказывался равным 2. При выполнении сложения двух вещественных чисел f и 1.0 сперва производится приведение их к общей экспоненте, в результате которого 1.0 превращается в 0, т.к. при сложении в обоих числах порядок выравнивается в большую сторону, т.е. вес младшего разряда мантиссы в обоих операндах будет равен 2, при этом происходит потеря значимости, и результат сложения 65536.0 + 1.0 будет равен 65536.0.
Также стоит отметить, что в общем случае для вещественных чисел нельзя проверять деление умножением.
![]()
Целочисленное деление
Округление
Часто встречается такой допуск при делении целых чисел, будто бы компилятор самостоятельно должен производить округление. Так вот: он этого не делает, это должен делать сам программист. Типичная ошибка, например, при расчете скорости USART’а:
Неправильно:
#define FOSC 200000000L #define BAUDRATE 115200L ... SPBRG = FOSC / (BAUDRATE*16) – 1;
При расчете на бумаге все выглядит красиво:
20000000/(115200*16) – 1 = 9.85
и округляется в большую сторону до 10. Ошибка скорости при этом составляет:
E = |10 - 9.85| / 9.85 * 100% = 1.5%
, что в допустимых пределах.
Однако, когда мы поручаем компилятору вычислить формулу в том виде, в котором мы ее привели, он округление произведет не по правилам математики (<0.5 – в меньшую сторону, >=0.5 – в большую), а просто откинет дробную часть. В результате ошибка будет уже:
E = |9 - 9.85| / 9.85 * 100% = 8.6%
, т.е. в 4 раза превышает допустимую.
Та же проблема всплывает при любых расчетах с целочисленными переменными и константами, где присутствует операция деления.
Для того чтобы округление производилось правильно, нужно к числителю прибавлять половину знаменателя:
Правильно:
SPBRG = (FOSC + BAUDRATE*8) / (BAUDRATE*16) – 1;
В общем случае формула “A = B / C” при использовании целых чисел в программе должна быть записана так:
| A = (B + C / 2) / C; |
|---|
Операцию деления на 2 (в выражении C/2) целесообразно заменять сдвигом вправо на один разряд. Обратите внимание, что деление на 2 – это то же самое целочисленное деление, но выражение записывается C/2 , а не (C+1)/2, т.е. к числителю не прибавляется половина знаменателя. Почему? Не вдаваясь в подробности насчет различия погрешностей при делении на разные значения (в нашем примере деление на 2 и деление на C), приведу тривиальный пример: «разделить 1 на 1». Результат деления должен быть равен 1:
(1 + 1 / 2) / 1 = (1 + 0) / 1 = 1
Если мы при делении на 2 в дроби 1/2 прибавим к числителю половину знаменателя, то получится:
(1 + (1 + 2/2) / 2) / 1 = (1 + 2 / 2) / 1 = (1+1) / 1 = 2
Последовательность делений и умножений
Дополню еще одной рекомендацией: если в выражении присутствуют операции как умножения так и деления, то формулу лучше переписать так, чтобы сперва выполнялись операции умножения, а затем деления:
Неправильно:
A = B / C * D;
Правильно:
A = B * D / C;
Причины очевидны: так как приоритет операций умножения и деления одинаков, то выражение будет вычисляться слева направо, причем округление будет выполняться после каждой операции. Таким образом, в первой формуле на D будет умножено не только отношение B/C, но еще и ошибка округления.
Рассмотрим пример: «2 / 3 * 3». Результат выражения должен быть равен 2. Сначала перепишем это выражение по правилам округления, как было описано выше (иначе 2/3 дадут результат 0, и результат всего выражения тоже будет нулевой):
(2 / 3) * 3 -> ((2 + 3/2) / 3) * 3 = ((2 + 1) / 3) * 3 = (3/3) * 3 = 1 * 3 = 3
Как видим, мы получили неправильный ответ. Почему? Потому что на 3 была умножена еще и ошибка округления отношения 2/3. Ошибка была равна 1/3, и, помножив ее на 3, мы получили лишнюю 1 (проблема произойдет также и при округлении вниз). Правильно было сначала произвести умножение, а потом деление, т.е. «2*3/3»:
(2 * 3) / 3 -> (2 * 3 + 3/2) / 3 = (6 + 1) / 3 = 7 / 3 = 2
Есть один тонкий момент – это переполнение, которое при перемножении нескольких чисел может возникнуть еще до того, как придет очередь до операторов деления. Но это можно предусмотреть на этапе разработки, взяв для вычислений числа большей разрядности.
![]()
Правила для констант
Не использовать числовые константы
Речь идет о неиспользовании числовых констант в оперативной части кода. Например, в программе предполагается использовать массив размерностью 25 элементов. Не следует по всему тексту программы явно указывать константу 25.
Пример неправильного подхода:
char String[25]; ... for (i = 0; i <= 24; i++) String[i] = ‘ ‘;
Правильно в одном месте программы определить константу, а потом в тексте оперировать только ее именем:
#define STRING_SIZE 25 ... char String[STRING_SIZE]; ... for (i = 0; i <= STRING_SIZE - 1; i++) String[i] = ‘ ‘;
Дело в том, что если по каким-то причинам придется изменить размерность массива, то придется и по всему тексту программы выискивать все относящиеся к размерности фрагменты и исправлять их. Пропустив всего один такой фрагмент, можно получить редко проявляющийся но довольно разрушительный баг. (Обратите внимание на то, что применен оператор «<= 24», а не «< 25»; я специально сделал для примера такой вариант, чтобы было понятно, что при изменении размерности массива простой поиск с заменой может не дать полноценного результата.)
Поэтому всем константам, не являющимся неоспоримыми (например, в минуте 60 секунд, в килобайте 1024 байта, при переводе в десятичную систему всегда число делим на 10 и т.д.), следует давать имена и в программе работать только с именованными константами.
Указывать тип константы
Неправильно:
#define FOSC 4000000 #define MAX_INTERATIONS 10000 #define MIDDLE_TEMPERATURE 25
Если с определением FOSC сомнений не возникает (компилятор однозначно поймет, что это 32-битная константа), то с MAX_ITERATIONS будут проблемы. Если где-нибудь в коде встретится выражение:
(MAX_ITERATIONS * 10)
, то результатом его будет не 100000, а… -31072. Почему? Потому что по умолчанию константа будет рассматриваться как знаковое 16-разрядное целое. Результат 100000 выходит за границы 16 разрядов, поэтому он будет обрезан до 0x86A0, что соответствует -31072.
То же самое касается констант, которые должны быть вещественными. Если в программе встретится выражение:
(MIDDLE_TEMPERATURE / 26)
, то результатом будет 0, а не предполагаемые 25/26 = 0,96.
Правильно:
#define FOSC 4000000L #define MAX_INTERATIONS 10000L #define MIDDLE_TEMPERATURE 25.0
Задавать константам осмысленные значения
Вот пример из реальной программы:
#define BAUDRATE 24 // 9600
В функции инициализации периферии была такая строчка:
SPBRG = BAUDRATE;
Программа должна была работать с тактовой частотой 4 МГц. А для такой тактовой частоты константа BAUDRATE должна иметь значение 25, а не 24. Таким образом, ошибка скорости составила 4%, что, в общем-то, почти на грани допустимого. В результате иногда принимались не те данные, которые ожидались. В разговоре с программистом выяснилось, что ранее программа работала по USART на скорости 19200 (константа BAUDRATE=12), но потом из-за смены внешнего оборудования пришлось изменить скорость на 9600, что программист и сделал, умножив константу на 2.
Но беда еще и в том, что даже с комментарием «9600» такое определение константы может заставлять задумываться. Ведь если при отладке выясняется, что что-то не так с приемом/передачей по USART, то эту константу придется проверять по формуле. Не говоря уже о том, что при выборе другой скорости или при смене тактовой частоты константу придется пересчитывать. И не надо забывать, что в программу может заглядывать не только автор, а для чужого человека заглядывание в подобный код равносильно написанию собственного.
Понятное дело, что в нашем примере программист просто ошибся с формулой (т.к. должен был сперва прибавить 1, потом умножить на 2, а затем отнять 1), но ошибки можно было бы избежать, если бы константа задавалась осмысленной:
#define FOSC 40000000L #define BAUDRATE 9600L
А уже при присваивании регистру SPBRG переводить эту константу в нужный вид с учетом тактовой частоты, также заданной в виде константы.
SPBRG = ((FOSC + BAUDRATE*8) / (BAUDRATE*16) – 1;
Итак, константы лучше задавать в том виде, в котором мы привыкли их видеть, т.е.:
-
время задавать в секундах, а не в тиках 65536 мкс;
-
давление – в паскалях (или в барах), а не в единицах АЦП;
-
Напряжение – в вольтах;
-
температуру – в градусах;
-
частоту – в герцах.
Это, во-первых, сделает программу более читабельной, а во-вторых, поможет избежать ошибок, которые будут являться следствием пересчетов из одной системы в другую. Правильнее один раз настроить формулу преобразования, чем каждый раз по ней же пересчитывать константы.
Два слова о проверке правильности задания констант
Задавая константу в понятном для нас виде, хотелось бы одновременно быть уверенным в том, что ее значения не выходят за рамки возможностей контроллера. Например, BAUDRATE из нашего примера должна обеспечивать точность скорости +/- 2%. Или давление, которое мы задаем в барах, должно быть таким, чтобы при переводе его в единицы АЦП получилось значение в пределах 1023. Поэтому в программе нужно блокировать неправильно заданные константы условными директивами и сообщениями об ошибке. Например:
// Задание параметров #define FOSC 4000000L #define BAUDRATE 9600L // Вычисление ошибки (в процентах) #define SPBRG_CONST ((FOSC + BAUDRATE*8) / (BAUDRATE*16) - 1) #define REAL_BAUDRATE ((FOSC + (SPBRG_CONST+1)*8)/((SPBRG_CONST + 1)*16)) #define BAUDRATE_ERROR ((100L * (BAUDRATE - REAL_BAUDRATE) + BAUDRATE/2) / (BAUDRATE)) // Проверка ошибки на диапазон -2%..+2% #if BAUDRATE_ERROR < -2 || BAUDRATE_ERROR > 2 #error "Неправильно задана константа BAUDRATE" #endif
Выглядит сложно, но сложность компенсируется тем, что эта формула должна быть проверена и отлажена один раз.
Примечание. В компиляторах HTPICC и HTPICC18 проверка константы BAUDRATE_ERROR директивой #if работать не будет (из-за ошибки компилятора). Проверку нужно делать либо в runtime’е, либо использовать другую формулу.
Соблюдать систему счисления
При задании константы нужно соблюдать ту систему счисления, которая подходит константе по сути. Бывает, делают так:
Неправильно:
TRISA = 21; // RA0,RA2,RA4 – вход, RA1, RA3 - выход TRISB = 65; // 65 = 0x41 = 0b01000001
В данном случае нужно задавать константу именно в бинарном виде (хотя, надо помнить, что бинарная запись числа не предусмотрена стандартом Си; тем не менее, почти все компиляторы для PIC’ов такую запись понимают). Каково будет программисту поменять один бит в такой записи?
Правильно:
#define TRISA_CONST 0b00010101 // RA0,RA2,RA4 – входы #define TRISB_CONST 0b01000001 // RB0, RB6 - входы ... TRISA = TRISA_CONST; TRISB = TRISB_CONST;
В этом случае четко видно, где единицы – там входы, нули выходы.
Также часто встречается довольно нелепая запись:
Неправильно:
TMR1H = 0xF0; TMR1L = 0xD8; // Отсчет 10000 тактов
Хорошо еще, если ее снабдят комментариями, хотя, как мы убедились на примере с BAURDATE, комментарий не гарантирует правильности константы. Опять же большие трудности возникают при пересчете констант. В данном случае нужно пользоваться именно макросом (тут есть тонкость для контроллеров PIC18: TMR1H – это буферный регистр, и нам важна последовательность присваивания: сначала старший, затем – младший; стандартом языка последовательность не предусмотрена).
Правильно:
#define TMR1_WRITE(timer) { TMR1H = timer >> 8; TMR1L = timer & 0xFF; } ... TMR1_WRITE(-10000);
![]()
Заключать константы и операнды макросов в круглые скобки
Типичная ошибка при определении числовых констант в виде выражения – не использование скобок.
Вот пример неправильного определения:
#define PIN_MASK_1 1 << 2 #define PIN_MASK_2 1 << 5 ... PORTB = PIN_MASK_1 + PIN_MASK_2;
Данное выражение развернется компилятором в такое:
PORTB = 1 << 2 + 1 << 5;
Вспомним, что приоритет операции «+» выше, чем приоритет сдвига, и получим выражение:
PORTB = 1 << (2 + 1) << 5 = 1 << 8
Т.е. совсем не то, что мы ожидали. Ошибки можно было бы избежать, взяв выражения при определении констант в скобки, т.е.
правильное определение:
#define PIN_MASK_1 (1 << 2) #define PIN_MASK_2 (1 << 5) ... PORTB = PIN_MASK_1 + PIN_MASK_2;
Транслируется в:
PORTB = (1 << 2) + (1 << 5);
Из этой же области часто совершаемая ошибка – не заключение в скобки операндов макросов. Например, имеем макрос:
Неправильно:
#define MUL_BY_3(a) a * 3
Выглядит просто и красиво, однако, попробуем вызвать макрос так:
i = MUL_BY_3(4 + 1);
И вместо предполагаемого результата 15 получим результат 7. Дело в том, что макрос развернется в следующее выражение:
i = 4 + 1 * 3
Ошибки можно было бы избежать, взяв аргумент макроса в скобки:
Правильно:
#define MUL_BY_3(a) (a) * 3
Тогда выражение примет вид:
i = (4 + 1) * 3;
![]()
Заключать тела макросов в фигурные скобки
Тематика схожа с предыдущей. Рассмотрим пример:
Неправильно:
#define I2C_CLOCK() NOP(); SCL = 1; NOP(); SCL = 0;
Т.е. выдерживаем паузу в один такт, затем формируем импульс длительностью два такта. Но такое определение может сыграть с нами злую шутку, если макрос будет использоваться внутри условного оператора:
if (...) I2C_CLOCK();
Компилятор развернет макрос следующим образом:
if (...) NOP(); SCL = 1; NOP(); SCL = 0;
Как видно, условием отрезается только один NOP(), а сам импульс все-таки формируется. Ошибки можно было бы избежать, взяв тело макроса в фигурные скобки:
Правильно:
#define I2C_CLOCK() do { NOP(); SCL = 1; NOP(); SCL = 0; } while (0)
Такие ошибки крайне трудно отслеживать, т.к. на вид все выглядит правильно, и ошибку будем искать перед условием, после условия, в выражении условия, но не в I2C_CLOCK().
Обратим внимание, что использована конструкция do {…} while (0). Если бы мы ее не использовали, то
постановка else в нашем условии:
if (...) I2C_CLOCK(); else return;
привела бы к сообщению компилятора об ошибке «inappropriate else». Все дело в том, что мы перед else и после ‘}’ ставим ‘;’, которая воспринимается компилятором как конец оператора if. Поэтому и использованы скобки в виде do {…} while.
![]()
Правила для функций
Объявлять прототипы для всех функций
Для любой функции, объявленной в модуле, нужно объявлять прототип в начале файла с тем, чтобы не задумываться при вызовах, где функция определена: выше вызова или ниже. Кроме того, при исследовании исходного текста программы это сразу дает общую картину: какие функции есть в модуле, какие параметры они принимают и какие значения возвращают. Вдобавок это позволяет сгруппировать наиболее значимые функции в начале файла, а все вспомогательные определить где-нибудь внизу, чтобы не мешались.
В заголовочный же файл нужно выносить прототипы только тех функций, которые будут вызываться из других модулей.
Проверять входные аргументы функций на правильность
Перед выполнением каких-либо операций с данными нужно убеждаться в их правильности:
-
Инициализированные указатели;
-
Попадают в область допустимых значений (например, номер элемента в массиве должен быть меньше размерности массива, чтобы не произошла запись в стороннюю ячейку); строка, содержащая имя, не может состоять из цифр.
-
Соответствуют реальности (например, счетчик битов в байте не может быть больше 8; температура в комнате не может быть -128 градусов Ц);
Часто область допустимых значений и соответствие реальности – это одно и то же. Однако, есть случаи, когда требуются дополнительные проверки. Например, если параметром является структура, то можно сначала определить, что значение каждого поля в отдельности попадает в область допустимых значений, а потом по совокупности проверять соответствие данных друг другу.
Возвращать функцией код ошибки
Желательно предусмотреть возможность любой функцией возвращать код ошибки. Например, при неправильных входных данных, при ошибке в вычислениях (деление на ноль, переполнение), при ошибке работы с внешними устройствами. Причем, учитывая, что сама ошибка может произойти на самом нижнем уровне вложенных функций, нужно предусмотреть возможность передачи значения ошибки наверх.
Для возврата кода ошибки иногда удобно пользоваться неиспользуемой результатом области значений. Но есть функции, возвращающие результат, который может принять любое значение из множества значений используемого типа. Например, функция перемножения двух чисел, или функция чтения байта из EEPROM. Также может вызвать трудности ситуация, когда вложенные функции возвращают результаты разных типов, что может помешать сквозной передаче кода ошибки. В таких случаях есть смысл пользоваться глобальной переменной. Однако, такой вариант затруднителен при использовании сторонних библиотек.
Все коды ошибок должны быть предопределены константами. Нежелательно пользоваться для их определения конструкцией enum с неинициализированными значениями, т.к. после первого релиза все будут снабжены спецификацией, где ошибки будут расписаны по номерам, а в следующей версии будет добавлен еще один код ошибки (втиснут куда-то в середину списка), из-за чего половина констант изменят свое состояние. Поэтому их нужно определять либо через #define, либо через инициализированный список перечислений:
enum ENUM_ERROR_CODES { // Математические ошибки ERROR_DIV_BY_ZERO = 0x100 ERROR_OVERFLOW, ERROR_UNDERFLOW, ... // Ошибки работы с EEPROM ERROR_EEPROM_READ = 0x110 ERROR_EEPROM_WRITE, ERROR_EEPROM_INIT, ... }
Следует отметить, что коды ошибок, генерируемые функциями, — это не те ошибки, которые можно показывать пользователю. Например «ДЕЛЕНИЕ НА НОЛЬ» на экране стиральной машины приведет хозяйку в панику, если внутри ее любимая блузка. Я уж не берусь предугадать действия суеверного человека, если ему вывести шестнадцатеричное представление числа 57005.
Не делать очень больших функций
Эта рекомендация схожа с рекомендацией «Не делать длинных выражений». Если функция получается длинной, то есть смысл разбить ее на несколько функций. Это даст нам следующие преимущества:
-
упростит внутреннюю логику функции;
-
сделает ее более читабельной;
-
упростит тестирование и отладку.
![]()
Использовать сторожевой таймер
Сторожевой таймер в контроллерах имеет три применения:
-
пробуждение контроллера из режима SLEEP с заданным инетервалом;
-
произведение аппаратного сброса при зависании программы.
-
Для PIC-контроллеров младшего семейства – выполнение программного сброса
Рассмотрим для начала второе применение, т.е. использование его в качестве дополнительного механизма защиты от зависания. Понятно, что лучше создавать правильные независающие алгоритмы и описывать их правильными независающими программами, но, к сожалению, часто даже в отлаженной и переотлаженной программе могут скрываться ошибки, которые при определенном стечении обстоятельств приведут к зависанию. Вдобавок можно сказать, что сложные программы с большим количеством состояний и параллельных процессов бывает сложно отладить и протестировать полностью. Полное тестирование таких программ может затянуться на время, превышающее экономически целесообразные сроки выпуска устройства. В таких случаях приходится идти на некий компромисс между полнотой теста и сроками выпуска, т.е. программа может выйти, грубо говоря, недоотлаженной. Это не значит, что она будет сбоить на каждом шагу и выдавать какие-то результаты, не соответствующие спецификации. Это значит, что при определенных условиях (чаще при совокупности внештатных ситуаций) возможно неадекватное поведение программы. И здесь нас может выручить сторожевой таймер, который не даст программе зависнуть наглухо. Конечно, он не является панацеей от неправильно составленного или неправильно запрограммированного алгоритма. Он всего лишь перезапустит программу, но не исправит допущенной ошибки. Тем не менее, с ним, по крайней мере, есть возможность восстановить работоспособность устройства.
Когда нужно обрабатывать WDT
Во многих программах вижу «интересный» прием программистов: в битах конфигурации включали WDT, а в самой программе сбрасывали его везде, где попало, лишь бы не произошло переполнение: и в главном цикле программы, и в прерывании, и в функции задержки. Сделают так – и радуются: «Ай, какую я надежную программу написал! С вочдогом!» Этот подход эквивалентен подходу без использования WDT с той разницей, что у программиста появляется еще одна иллюзия по поводу отказоустойчивости его программы.
Задача сброса WDT совсем нетривиальна, в каждой конкретной программе нужен свой алгоритм. В самом простом случае можно завести отдельную переменную, в которой каждая подпрограмма будет устанавливать свой бит, а отдельная подпрограмма обработки WDT будет проверять эту переменную, и только в том случае, когда все требуемые биты установлены, будет производиться очистка WDT. Но такой способ подойдет только для несложной программы с небольшим количеством состояний и с ограниченным временем пребывания в одной функции.
Для сложных программ требуются разработки индивидуальных алгоритмов, которые бы отслеживали не только факт выполнения каких-то функций, но также следили за тем, чтобы функции выполнялись в правильной последовательности, и чтобы время выполнения каждой функции было в пределах допустимого.
Здесь хотел бы пару слов сказать про третье применение WDT, т.е. программный сброс в контроллерах младших семейств, т.к. они не имеют отдельной инструкции, вроде RESET в PIC18. В системах с повышенными требованиями по надежности программа должна иметь механизмы контроля правильности работы. Т.е. следить за стеком, за порядком действий, временами выполнения отдельных узлов, настройками периферийных модулей и т.д. При обнаружении отклонений, которые не могут быть исправлены на лету (например, замечено, что в функцию попали не через вызов CALL, а каким-то другим путем), единственный выход – это сброс. Но если в контроллерах среднего и старшего семейств есть инструкции, выполняющие сброс, то в контроллерах младшего семейства единственный способ выполнить сброс программно – это дать WDT досчитать до конца.
Что делать, если произошел сброс по WDT
Порядок действий при сбросе контроллера (не только по WDT) — это отдельная тема (довольно большая). Здесь опишу только в двух словах.
Сделать нужно две вещи:
-
Восстановить работу (по возможности сделать это незаметным для пользователей)
-
Выяснить причину сброса.
С первым все понятно: все переменные, отвечающие за текущий режим работы, за состояние процессов, какие-то текущие рабочие данные и пр. должны быть определены в неинициализируемой части RAM, т.е. в той, в которую код стартапа ничего не пишет при сбросе. Для HT-PICC такие переменные должны быть определены с квалификатором persistent:
persistent unsigned char Mode; persistent unsigned int LastData[10];
Для MPLAB C18 они должны быть определены в секции udata, т.е. не инициализироваться при определении.
В самом начале функции main нужно проверять причины сброса (биты POR, BOR, TO, PO, RI и пр.), и в зависимости от их состояния принимать решение о том, восстанавливать ли прежний режим работы, начинать ли все с нуля, переходить ли в аварийный режим и т.д.
Теперь о выяснении причин сброса. Здесь многое зависит от стадии разработки устройства и его доступности. В зависимости от того, отлаживаем ли мы устройство, тестируем ли в реальных условиях или же устройство в эксплуатации, в зависимости от доступности самого устройства разработчику, от способности самого устройства известить о несанкционированном сбросе, от средств его связи с внешним миром и пр. факторов – средства выяснения причин могут быть различными. Мы не будем говорить о технике получения данных, которые нам смогут помочь установить причину сброса, из контроллера. Это может быть что угодно: сброс данных в отдельную страницу внешней EEPROM, передача их через какой-нибудь интерфейс для протоколирования, отображение на мониторе (или ЖКИ) и т.д. Я только укажу, какие данные могут быть полезными в общем случае:
-
Содержимое стека
-
Значения регистров указателей (FSR)
По этим данным зачастую можно сделать вывод о том, в каком месте произошел сбой. При использовании компиляторов от microchip для получения этих данных придется писать свой код startup, т.к. фирменная функция заранее предустанавливает регистры FSR (WREG14, WREG15 для MCC30). В каждом частном случае могут понадобиться дополнительные данные: текущий режим, какие-то индикаторы обработки критических участков кода и пр. Чем больше будет данных, тем проще будет анализировать причину сброса. Но нужно также искать некий компромисс, чтобы не загромождать дамп всякой ерундой, а еще, чтобы не дать пользователю запаниковать, если устройство уже в эксплуатации.
![]()
Два слова об операторе GOTO
Многие авторитетные источники строго не рекомендуют использовать оператор goto при написании программ на языках высокого уровня. Основными недостатками его применения называется сильное ухудшение читабельности текста программы и нарушение ее структурности. Да и вообще неизвестно, через что мы перепрыгиваем, выполняя goto (может быть через объявление переменной). Кроме того, часто упоминается то, что формально доказано, что любая программа, использующая goto, может быть переписана без его использования с полным сохранением функциональности. Доводы весьма убедительны, а небезызвестный Дейкстра свою статью «Доводы против оператора goto» вообще начинает с тезиса «… квалификация программистов – функция, обратно зависящая от частоты появления операторов goto в их программах».
Сам я не люблю использовать этот оператор и испытываю большие трудности с анализом чужого кода, где он применяется. Однако, применительно к микроконтроллерам с ограниченными ресурсами я бы оправдал использование goto в некоторых случаях.
Выход из вложенных циклов
Этот пример приводится чаще всех остальных. Действительно, использование оператора goto выглядит довольно простым (и наглядным) решением для выхода из циклов вида (удобны, например, при поиске вариантов решений в многомерных массивах):
for (i = 0; i < 10; i++) { for (j = 0; j < 15; j++) { if (...) goto BREAK_LOOP; } } BREAK_LOOP:
В принципе, при чтении такого кода не вызывает трудностей найти метку, т.к. по смыслу операции понятно, что она внизу, после закрывающей скобки верхнего цикла. Ярые противники goto приводят два варианта альтернативного кода, позволяющего избавиться от этого оператора.
Вариант 1 – переписать цикл в виде функции.
void loop_func (void) { int i, j; for (i = 0; i < 10; i++) { for (j = 0; j < 15; j++) { if (...) return ; } } }
Вариант 2 – использовать переменную-флаг.
bool StopLoop = false; for (i = 0; i < 10 && !StopLoop; i++) { for (j = 0; j < 15 && !StopLoop; j++) { if (...) { StopLoop = true; break; }; } }
(В принципе есть еще альтернативы, но они контекстно-зависимые и в общем случае применимы не во всех случаях)
Оба варианта полностью работоспособны, однако имеют свои небольшие недостатки, когда речь идет о работе с микроконтроллерами, имеющими дефицит ресурсов. Первый вариант не очень удачен, поскольку требует дополнительный свободный уровень стека (помним, что в PIC16 их всего 8, а в PIC18 — 32), что иногда может оказаться критичным. Второй вариант требует использования дополнительной переменной, что также существенно для контроллеров с малым ОЗУ. Т.е., применяя goto, мы имеем возможность сэкономить ресурсы контроллера. (Об экономии скорости я здесь не говорю, поскольку на фоне цикла из 10×15=150 итераций лишний вызов/возврат или две лишних проверки флага StopLoop будут несущественны).
«Стандартные» метки
Лично я позволяю себе использовать метки, которые могут считаться универсальными почти для любого случая. Таких меток немного. Типичный пример – выход из функции при обнаружении ошибки в ходе ее выполнении. Ошибку функция может обнаружить на любом этапе своего выполнения (как при проверке аргументов на правильность, так, например, и при работе с внешней периферией, и при проверке контрольных сумм и т.д.), а при выходе ей требуется освободить занимаемые ресурсы и установить флаг возникновения ошибки, так что обычный return нас может не устроить просто потому, что перед каждым return придется выполнять одну и ту же последовательность действий.
Главное для меня – местоположение таких меток всегда однозначно (например, понятно, что метка, куда переходит функция при обнаружении ошибки, находится в конце функции), их использование безопасно и с точки зрения экономии ресурсов целесообразно (не любой алгоритм удобно программировать приемами структурного программирования, есть случаи, когда такие приемы делают код менее читабельным и более ресурсоемким).
Оптимизация
Некоторые операции, такие как расчеты или работа с быстрыми сигналами, требуют оптимизации кода по скорости. В таких случаях я предпочитаю использовать операторы goto вместо if…else, break, continue и пр. из соображений экономии времени выполнения, даже в ущерб наглядности. Такие участки кода должны быть тщательно проверены и перепроверены и детально откомментированы.
![]()
Атомарный доступ
Часто причиной ошибки в программах может быть непредусмотренный механизм атомарного доступа к регистрам или переменным. Самый простой пример: на 8-битном контроллере имеем 16-битную переменную, которая обрабатывается как в основной программе, так и в обработчике прерывания. Конфликты при работе с ней могут возникнуть, если во время обращения к ней из основного тела программы возникает прерывание, обработчик которого также захочет с ней поработать. Это нестрашно, когда и там и там к переменной обращаются для чтения. А вот если в одном из кусков кода (или в обоих) производится запись, то могут возникнуть проблемы.
unsigned int ADCValue; // Результат чтения АЦП (производится в // прервании ... // Фрагмент обработчика прерывания If (ADIF && ADIE) { ADIF = 0; ADCValue = (ADRESH << 8) | ADRESL; // Читаем последнее измерение ADGO = 1; // Запускаем следующее } ... // Фрагмент основного тела программы Data[i] = ADCValue; // Примечание: Data[] – массив uint'ов
Я думаю, не нужно пояснять, что произойдет, если в момент чтения ADCValue в основной программе (а чтение произойдет в два этапа: сначала младший байт, затем старший), произойдет прерывание по завершению измерения ADC? В двух словах: на момент начала чтения переменная содержала значение 257 (0x101). Первым считается младший байт и скопируется в младший байт элемента массива Data[i]; далее произойдет прерывание, и в ADCValue запишется вновь измеренное значение напряжения, которое с момента последнего изменение стало, например, меньше на 3 единицы младшего разряда, т.е. 254 (0x0FE). Возвращаемся из прерывания и продолжаем копировать ADCValue в Data[i]; нам осталось скопировать старший байт, а он стал равным 0. Вот и получается, что в Data[i] окажется значение 0x001.
Часто встречал у людей недопонимание методов борьбы с этим явлением. Многие программисты считают, что их спасет квалификатор volatile, т.е. достаточно определить переменную, к которой есть доступ и в основном теле программ и в прерывании так:
volatile unsigned int ADCValue;
— и проблема будет решена автоматически на уровне компилятора. Однако, это не так. Квалификатор volatile всего лишь сообщает компилятору, что не нужно производить оптимизацию кода с участием этой переменной (подробнее о volatile читайте [9]). А это в свою очередь даст возможность программисту блокировать прерывания на время обращения к ней, но делать это надо вручную:
di(); Data[i] = ADCValue; ei();
Более детально про атомарный доступ рекомендую почитать [6].
![]()
Оформление
![]()
Удобный инструментарий
Очень важная составляющая успешного программирования – инструментарий. Применительно к написанию текста программы – это в первую очередь текстовый редактор. Если он удобный, функциональный и имеет интуитивно понятный интерфейс, то форматирование будет производиться легко и непринужденно. Помимо самого ввода текста, редактор может обеспечить нам:
-
автоматические отступы;
-
замену символа табуляции пробелами;
-
подсветку синтаксиса;
-
контекстную подстановку;
-
перекрестные ссылки внутри исходного текста или целого проекта;
-
вызов компилятора для сборки проекта из редактора
(Рекомендую SlickEdit).
![]()
Именование идентификаторов
Задавая имена переменным, функциям, константам, типам, перечислениям, макросам, файлам и пр., есть смысл следовать некоторым правилам:
-
Имя должно быть осмысленным (не i, а Counter)
-
Имя должно быть содержательным (не Counter, а BitsCounter)
И ниже приведем кое-какие отдельные правила именования различных объектов программы.
Именование функций
Имя функции внутри модуля, которую предполагается вызывать из других модулей, должно начинаться с префикса, обозначающего имя модуля. Зачем это нужно? Например, в одной программе вы используете память 24LC64, для которой определяете функцию write_byte(). Потом вы написали другую программу, которая работает с внутренней EEPROM контроллера, и для нее тоже определили функцию write_byte(). А потом понадобилось сделать проект, в котором будет использоваться и внешняя EEPROM, и внутренняя. Тут-то вы и столкнетесь с последствиями неправильного именования, потому что из-за одинаковых имен модули нельзя будет объединить в одной программе. Поэтому в самом начале нужно было предусмотреть префиксы имен функций (а запись байта – это операция универсальная, она есть в работе и с дисплеем, и с модемом и еще с чем угодно).
i2c_write_byte – для работы с памятью 24LC64;
eeprom_write_byte – для работы с внутренней EEPROM;
lcd_write_byte – для работы с LCD и т.д.
Кроме того, имя функции должно быть кратким и, по возможности, должно соответствовать системе именования: <модуль>_<действие>_<объект>[_<суффикс>] (могут быть в другом порядке, могут разделяться символом “_”), где:
<модуль>_<действие>_<объект>[_<суффикс>]
-
модуль – имя (или сокращенное имя) модуля, в котором определена функция;
-
действие – глагол, определяющий назначение функции (write, read, check, count и т.д.)
-
объект – существительное, определяющее параметрическую составляющую функции (byte, checksum, string, data и пр.)
-
суффикс – необязательное поле, отражающее какую-либо дополнительную характеристику функции (rom, timeout).
Конечно, все имена функций под одну гребенку подвести довольно трудно, и обязательно в любой системе именования будут исключения. Но не нужно называть функции так:
Неправильные имена функций:
CopyOneByteFromROMToRAM();
Check();
CompareAndGetMax();
В заключение надо сказать, что для некоторых функций можно оставить зарезервированные имена: atof(), init(), printf() и т.д.
Именование констант
-
Заглавными буквами
-
Слова разделяются символом ‘_’
-
Префикс в виде имени модуля или функционального назначения
// Определения параметров шины i2c #define I2C_DEV_ADDR 0xA0 #define I2C_ADDR_WIDTH 16 // Определения цветов RGB #define CL_RED 0xFF0000 #define CL_YELLOW 0xFFFF00 #define CL_GREEN 0x00FF00
Именование типов
-
Заглавными буквами
-
Слова разделяются символом ‘_’
-
Префикс в виде «T_», «TYPE_» и т.п.
typedef struct { unsigned long seconds : 6; unsigned long minutes : 6; unsigned long hours : 5; } T_CLOCK;
Именование переменных
-
Слова начинаются с заглавной буквы
-
Пишутся без разделителя
unsigned char BytesCounter; signed long XSize, YSize;
О «венгерской нотации»
Некоторые используют систему именования, в которой каждой переменной приписывается префикс, показывающий ее тип. Это часто может оказаться полезным при анализе чужого (а часто и собственного) кода. Например:
for (Counter = 0; Counter < 40000; Counter++) ...;
В данном примере мы не можем точно сказать, правильно ли у нас использована переменная в данном цикле или нет. Переменная Counter может быть, во-первых, 8-битной; во-вторых, она может быть знаковой (т.е. всегда будет меньше 40000). И для того, чтобы определить правильность использования переменной, нам нужно найти определение переменной в файле. Но если мы изначально предусмотрели в имени переменной ее тип, то это избавит нас от проделывания лишней работы:
for (wCounter = 0; wCounter < 40000; wCounter++) ...;
Теперь, глядя на эту запись, мы точно можем сказать, что здесь нет ошибки.
Также системой именований можно предусмотреть область видимости переменной.
Префиксы:
-
Префикс области видимости
-
Без префикса – локальная или параметр функции
-
s_— статическая -
m_— локальная для модуля -
g_— глобальная -
i_— Обрабатывается в прерывании
-
-
Префикс типа
-
uc– unsigned char -
sc– signed char -
ui– unsigned int (n) -
si– signed int (w)
-
И т.д.
Имя нашей переменной может выглядеть так:
static unsigned char s_ucRecCounter;
Встречая ее в любом месте функции, мы сразу понимаем, что:
-
Эта переменная предназначена для подсчета принятых байтов;
-
Эта переменная имеет тип unsigned char, т.е. может принимать значения 0..255;
-
Эта переменная статическая, т.е. сохраняет свое значение после выхода из функции.
Примечание. Можно для себя иметь некоторый набор зарезервированных имен для переменных общего назначения, которые встречаются наиболее часто. Например: i, j – signed int; a, b – char; f — float; и т.д. Но эти имена желательно согласовывать, во-первых, с применяемыми именами в литературе, а во-вторых, внутри собственной команды разработчиков, чтобы не было так, что у одного i – signed int, а у другого i – unsigned int.
Преимущества венгерской нотации:
-
Предотвращает ошибки использования типов
-
В большом коде помогает не запутаться в переменных
-
Упрощает чтение чужого кода
Недостатки венгерской нотации:
-
Ухудшают читабельность кода
-
Выражение из 3-4 переменных уже трудно читается
-
Префикс может получиться очень длинным
-
-
Изменение типа переменной влечет изменение ее имени во всех файлах
-
Префикс не дает гарантию правильности задания типа, из-за чего может получиться ложная уверенность в корректности применения переменной:
static signed char s_ucBytesCounter;
![]()
Форматирование текста
Очевидно, что форматирование нужно для того, чтобы программа была более наглядной. Рекомендую в качестве примера ознакомиться с документом an_2000_rus.pdf, где описаны правила форматирования текста программ, сформулированные для сотрудников компании micrium. Не обязательно точно следовать приведенным в нем правилам, но следует посмотреть, на чем сосредоточили внимание авторы документа, и принять это на вооружение:
-
Следовать одному стилю
-
При работе в команде следовать всей командой одним и тем же правилам
-
Не оправдывать отсутствие форматирования нехваткой времени
Я не буду пересказывать этот документ, а только вкратце приведу основные моменты:
Текст файла должен быть разбит на секции
Когда мы берем в руки книгу, мы знаем, что у нее помимо самой содержательной части есть титульные данные, оглавление, выпускные данные, а часто еще алфавитный указатель, список литературы. Кроме того, мы знаем, что каждый элементы каждой из перечисленных групп находится в одном месте, а не разбросаны по всем страницам. Все эти данные упрощают восприятие книги: на титуле в двух словах сказано, о чем (иногда – для кого) эта книга, по оглавлению можно быстро найти интересующую главу, по содержанию – понять содержание и т.д.
Для того чтобы текст программы легче читался, он также должен быть разбит на части (или секции), каждая из которых имеет свое назначение:
-
Заголовок файла (с информацией о назначении файла, авторе текста, используемом компиляторе, дате создания и пр.);
-
Хронологию изменений
-
Секция включаемых файлов
-
Секция определения констант
-
Секция определения макросов
-
Секция определения типов
-
Секция определения переменных (глобальные, затем локальные)
-
Секция прототипов функций (глобальные, затем локальные)
-
Секция описания функций.
Для секций есть свои правила:
-
Каждая секция должна содержать только те описания, которые ей соответствуют
-
Секции должны быть едины, а не разбросаны по всему файлу.
-
Каждой секции должен предшествовать хорошо заметный блок комментария с названием секции.
Горизонтальные отступы
Горизонтальные отступы служат для визуального подчеркивания структуры программы. Я каждый блок операторов делаю с отступом на 4 пробела вправо от верхнего блока.
Вертикальное выравнивание
При определении переменных: типы – под типами, квалификаторы – под квалификаторами, имена переменных – под именами, атрибуты – под атрибутами. В самой программе: при присваивании блока переменных желательно выравнивать знаки «=».
static unsigned char BytesCounter; static int Timer; double Price; char *p, c; ... { BytesCounter = 0; Timer = 0; Price = 1.12; }
Хочу отдельно внимание обратить на то, что ‘*’, показывающая, что переменная является указателем, ставится рядом с переменной, а не с типом. Сравните две записи:
char* p, c; и char *p, c;
Первая запись может быть ошибочно прочитана так: переменные p и c имеют тип char*. На самом же деле указателем будет только p. Во второй записи это наглядно отражено.
Не делать в строке больше символов, чем помещается на одном экране
Например, если функция содержит много параметров, то имеет смысл каждый параметр писать с новой строки. Длинные выражения можно также разбивать на строки.
int sendto ( SOCKET s, const char *buf, int len, int flags, const struct sockaddr *to, int tolen );
Обращу ваше внимание, что при определении функции в нескольких строках правилом вертикального выравнивания стоит пользоваться не в полной мере. Попробуйте переписать эту функцию, ставя квалификаторы под квалификаторами и т.д. Он станет выглядеть довольно безобразно и совершенно нечитабельно, так что в данном случае лучше все определения начинать с одного столбца.
Одна строка – одно действие
Разделять функциональные узлы или конструкции (for, if, …) пустыми строками
Пробелы между операндами и операциями
Ниже пример форматирования по трем последним правилам:
Неправильно:
for(i=0;i<10;i++)a[i]=0; if(j<k){a[0]=1;a[1]=2;}else{a[0]=3;a[1]=4;}
Правильно:
for (i = 0; i < 10; i++) a[i] = 0; if (j < k) { a[0] = 1; a[1] = 2; } else { a[0] = 3; a[1] = 4; }
![]()
Комментирование
Почему не пишут комментарии
-
«Время поджимает, писать некогда»
-
«Это временный код, его не нужно комментировать»
-
«Я и так все запомню»
-
«Моя программа понятна и без комментариев»
-
«В код, кроме меня, никто не заглядывает»
-
«Комментарии делают текст пестрым и затрудняют чтение самой программы»
-
«Я потом откомментирую»
Для кого пишутся комментарии
Комментарий программистом пишется в первую очередь для самого программиста. За отсутствие комментариев приходится платить временем. Чаще — своим, реже – чужим.
Содержание комментариев
Частенько в присланных мне программах вижу, что местами комментарий написан только для того, чтобы он там был. Такое ощущение, что человек знает, что комментарий написать надо, но не знает зачем.
Что должно быть в комментариях:
-
Спецификация функций:
-
что делает;
-
входные и выходные параметры (типы и краткое пояснение);
-
-
Назначение объявляемой переменной, определяемой константы, типа, макроса;
-
Краткое, емкое, безызбыточное описание действия или пояснение к нему;
-
Пометки об изменениях:
-
версия (или дата) и номер пометки.
-
Причины и описание изменения желательно держать в отдельном месте, т.к., во-первых, текст описания причин изменений и производимых действий может получиться громоздким и будет засорять основной текст программы, а во-вторых, одна причина может повлечь за собой изменения нескольких участков программы.
-
-
Указание отладочных узлов и временных конструкций
Пример спецификации функции:
/************************************************************* * * Function: rs_buf_delete * *------------------------------------------------------------ * * description: Удаляем N байт из буфера * * parameters: uchar N – количество удаляемых байтов * * on return: void * *************************************************************/ void rs_buf_delete (uchar N) { ...
Пример пометок об изменениях:
/**************************************************** * Список изменений * ... * Версия 1.6 (22.10.2009): * 1. ... * 2. ... * ... * 8. Иванов И.И., 17.09.2009: В функции * rs_buf_delete добавлена проверка * входного аргумента на 0 * ... ***************************************************/ ... void rs_buf_delete (signed char N) { // *1.6-8* if (N < 0) return; if (N <= 0) return; // *1.6-8* ...
Пример указания отладочного узла:
void rs_buf_delete (signed char N) { if (N <= 0) return; /*D*/ DebugCounter++; /*D*/ PIN_DEBUG = 1; /*D*/ delay_ms(5); /*D*/ PIN_DEBUG = 0; ...
Чего в комментариях быть не должно:
-
Эмоций
RB0 = 1; // Без этой хрени не работает.
-
Описания устаревших действий
if (BufSize > 0) // Буфер не пуст, флаг разрешения // вывода установлен
-
Дублирования действия
BufSize = 0; // Обнуляем переменную, показывающую // размер буфера
-
Бесполезной информации
if (N < 15) // Лучший вариант сравнения
-
Непонятных сокращений и жаргона:
A = X / Y + Z; // В (*1*), т.н.у., обход
-
Ложной или вводящей в заблуждение информации:
if (timer < 100 && V < 10) // Если за 100мс напряжение // стало выше 10 вольт
Расположение комментариев
Не следует мешать код и текст комментариев в одну кучу. Например, так:
Неправильный подход:
/* Инициализация портов*/ PIN_DATA = 0; PIN_CLC = 0; /* Очистка буфера */ for (i = 0; i < BUF_SIZE; i++) Buf[i] = 0; /*Ожидание данных */ while (ReadData()) { ...
Комментарии нужно писать так, чтобы они не сливались с кодом. Один из вариантов – выносить их на поля, выравнивая по вертикали.
Правильный подход:
PIN_DATA = 0; /* Инициализация портов */ PIN_CLC = 0; for (i = 0; i < BUF_SIZE; i++) Buf[i] = 0; /* Очистка буфера */ while (ReadData()) /* Ожидание данных */ { ...
Многострочные комментарии
При написании многострочного комментария (например, описывающего функцию), нужно, чтобы каждая строка начиналась с символа, обозначающего, что это комментарий.
Неправильный подход:
/* Эта функция считывает начальные установки из EEPROM, проверяя контрольную сумму. Если контрольная сумма не сошлась, то будут приняты установки по умолчанию. */ for (i = 0; i < BUF_SIZE; i++) ...;
Правильные подходы:
(не очень удобный вариант: из-за наличия правого ограничителя такой комментарий утомительно редактировать)
/* Эта функция считывает начальные установки из EEPROM, */ /* проверяя контрольную сумму. Если контрольная сумма не */ /* сошлась, то будут приняты установки по умолчанию. */ for (i = 0; i < BUF_SIZE; i++) ...;
(альтернативные варианты)
/* * Эта функция считывает начальные установки из EEPROM, * проверяя контрольную сумму. Если контрольная сумма не * сошлась, то будут приняты установки по умолчанию. */ for (i = 0; i < BUF_SIZE; i++) ...;
// Эта функция считывает начальные установки из EEPROM, // проверяя контрольную сумму. Если контрольная сумма не // сошлась, то будут приняты установки по умолчанию. for (i = 0; i < BUF_SIZE; i++) ...;
Часто удобно пользоваться горизонтальными разделителями для визуального отделения логически разных блоков в тексте программы:
//--------------------------------------------------
или
/**************************************************/
Содержательная часть комментария
Вспомним, что мы говорили про именование идентификаторов и использование именованных констант. Рассмотрим пример:
switch (result) // Проверяем состояние модема { case 0: // Модем выключен … break; case 1: // Модем готов к работе … break; case 2: // Модем производит дозвон … break; … }
Если бы использовали осмысленные имена (и переменной и констант), то сам фрагмент программы оказался бы понятным и без комментариев.
switch (ModemState) { case MODEM_OFF: … break; case MODEM_READY: … break; case MODEM_CALLING: … break; … }
Тем самым у нас появляется возможность комментарием пояснить какой-нибудь нюанс какой-то ситуации или какого-то действия.
Формулировка
Совет: формулируя комментарий, всегда представляйте, как будто комментарий читает другой человек. Это поможет сделать формулировку более четкой.
![]()
Отладка и тестирование
Отладка, как и тестирование, – неотъемлемая часть разработки. Я отвел для этих понятий один общий раздел, т.к. обычно, эти этапы производятся параллельно. Надо сказать, что эти два этапа дополняют друг друга.
Рассмотрим следующие моменты:
![]()
Инструменты
В арсенале программиста может быть довольно мощный инструментарий: симулятор, внутрисхемный отладчик, лог. анализатор, осциллограф и т.д. В целом, неизвестно, сколько ошибок нужно будет обнаружить и исправить, поэтому процесс отладки и тестирования может сильно затянуться. И здесь наличие хорошего инструментария и умение с ним работать поможет сэкономить массу времени и сделает сам процесс более легким. Поэтому не нужно скупиться на средства отладки.
![]()
Резерв по ресурсам
Желательно еще на этапе планирования предусмотреть возможность взять для отладки контроллер с запасом по ресурсам. Для чего они могут понадобиться? В процессе тестирования или отладки программы нам может понадобится контроль хода выполнения или каких-то внутренних переменных. Для этого нам понадобится запас:
-
периферийных возможностей
-
памяти для размещения отладочного кода
-
резерв по скорости
Запас по периферии
Внутренняя периферия контроллера
Здесь масса вариантов. Как минимум – иметь свободные выводы контроллера для возможности устанавливать на них логические уровни, соответствующие состоянию программы. Если в устройстве не планируется использовать модуль USART, то было бы удобно оставить свободными выводы контроллера, на которые этот модуль работает. Тогда отладочную информацию можно будет сливать, используя аппаратные возможности контроллера. Если использование USART все же планируется, а отладочную информацию все равно хочется слать через RS-232 в компьютер, то можно пожертвовать системным временем и сделать функцию вывода программно на любом свободном выводе контроллера (функция ввода нужна не так часто, а функция вывода реализуется довольно просто). Зачастую есть возможность скидывать отладочные данные в общем потоке данных (по UART, по радиоканалу).
Также для отладки и тестирования может понадобиться аппаратный таймер для определения скорости выполнения некоторых участков или времени реакции на событие. Так что, если есть возможность на этапе планирования зарезервировать один аппаратный таймер для нужд отладки, то лучше сделать это.
Внешняя периферия
Например, если используется LDC, то можно предусмотреть какой-то сегмент для вывода отладочной информации. В EEPROM можно выделить отдельную страницу, куда сохранять состояние контроллера после сброса, если при запуске выясняется, что сброс был аварийным (например, туда можно записать содержимое стека, пускай сам указатель и не сохранился).
Также можно на плате предусмотреть дополнительные кнопки, дополнительные светодиоды.
Память для размещения отладочного кода
Здесь все понятно: отладочный код занимает место в ROM и часто требует каких-то ячеек RAM-памяти. И будет очень обидно, если из-за отладочных функций и макросов не будет умещаться основная программа.
Резерв скорости
Естественно, подпрограммы вывода отладочной информации не выполняются мгновенно. Может получиться так, что из-за ее вывода программа будет просто не успевать отрабатывать свой алгоритм. Это нужно учитывать как при выборе тактовой частоты контроллера, так и при написании отладочных подпрограмм.
![]()
Заглушки и тестеры
Функции-заглушки
В процессе тестирования могут пригодиться так называемые заглушки – пустотелые функции, соответствующие спецификации, но подменяющие вычисления (или результаты какой-то другой операции) заведомо правильным результатом. Когда это может оказаться полезным:
-
Когда при отладке нужны результаты работы еще ненаписанных подпрограмм.
-
При тестировании в симуляторе, когда нет возможности работать с какими-то внешними устройствами (например, GPS);
-
При тестировании кода, содержащего долго выполняющиеся функции, не участвующие в тесте подпрограммы (типичный пример – задержки)
Функции-тестеры
Когда мы пишем новую функцию, мы хотим убедиться в ее работоспособности. Есть смысл писать небольшие функции, которые будут проводить тестирование новой, многократно запуская ее, передавая ей тестовые параметры. Дальнейший результат можно, в зависимости от назначения функции, наблюдать визуально или сравнивать с шаблоном. Такие функции могут формировать для нашей программы последовательность входных параметров, которая может возникнуть в реальной обстановке. Это также может оказаться особенно полезным, когда программа отлаживается или тестируется в симуляторе. Важно, чтобы при тестировании функция запускалась именно на рабочем контроллере или его аналоге (а не на Builder C++, Visual C++ и пр., на которых можно отлаживать только макет функции), т.к. каждый компилятор имеет свои особенности (типы данных, автоматическое преобразование типов, работа со стеком и пр.); каждый процессор – свои: архитектура (Гарвадрская и Неймоновская), объем доступной памяти и т.д.
Самое сложное место в этой схеме – шаблон. Ведь мы писали новую функцию именно для того, чтобы она нам этот результат вычисляла. Где брать шаблон для сравнения? Есть три пути:
-
В некоторых случаях есть возможность результат для сравнения формировать сторонней функцией. Например, известно, что функция printf из-за своей универсальности довольно громоздкая, и далеко не в каждом случае программист может позволить себе ее использовать, отняв у контроллера чуть ли не половину памяти и несколько тысяч тактов. Поэтому частое явление, когда программист пишет свою mini-printf, удовлетворяющую требованиям спецификации конкретной программы. Для проверки работоспособности своей функции он на этапе тестирования может пользоваться результатами работы встроенной функции printf. Причем эта функция может тестироваться в автоматическом режиме. Такой же способ подойдет для проверки математических функций.
-
Входные параметры и результат вбивать вручную. Довольно трудоемкий процесс, поэтому в первую очередь желательно тестировать граничные значения.
-
Третий вариант – брать данные извне (например, в автоматическом режиме с PC)
![]()
Предупреждения при компиляции
Серьезная ошибка, которую допускают программисты – это игнорирование предупреждений компилятора. Более того, к ним относятся как к назойливым мухам: «Ну, наконец-то собрал программу. Только своими дурацкими предупреждениями забил всю статистику, что ничего не прочтешь!» А между тем, компилятор ругается не просто так. Тут он нам не враг, а помощник. Он сообщает, что в программе есть двояко толкуемые конструкции, которые он транслировал на свое усмотрение. Дело в том, что ошибку можно совершить, даже написав все правильно с точки зрения языка. Например, в программе могут встретиться выражения вида:
if (a == b) ...; if (a = b) ...; // Warning: Assignment inside relational expression
В зависимости от того, что мы хотим сделать, мы можем применить первое или второе выражение в скобках оператора if. В первом выражении мы проверяем переменные a и b на равенство, в то время как во втором мы проверяем переменную a на 0 после присваивания ей значения из переменной b. В общем случае второй записью пользоваться не рекомендуется, т.к. гораздо нагляднее:
a = b; if (a) ...;
Потому-то компилятор и выдает нам предупреждение, что в выражении отношения имеется оператор присваивания, давая тем самым понять, что, возможно, мы имели в виду оператор отношения “==”. (Иногда, все же, есть смысл использовать вторую запись, когда, например, код критичен ко времени выполнения.)
Также частым следствием предупреждения компилятора является неаккуратное отношение к приведению типов. Например, в том же операторе сравнения:
signed int a; unsigned int b; … if (a > b) …; // Warning: signed and unsigned comparison
мы получим предупреждение, если одна переменная знаковая, а вторая – нет. Это предупреждение говорит не о том, что «осторожно! Может случиться коллизия», а о том, что программистом неправильно выбраны типы. Если же программист уверен в правильности, то он должен сделать приведение типов вручную:
signed int a; unsigned int b; ... if ((signed long) a > (signed long) b) ...;
Тем самым давая компилятору понять, что программист в курсе неправильно выбранных типов. Обратим внимание на то, что приведение типов производится к знаковому типу большей разрядности.
(Вообще же, повторюсь, с выражениями, где участвуют переменные различных типов, нужно быть осторожнее. Например, MPLAB C18 не выдаст предупреждения на наш пример, что в свою очередь приведет к неправильному поведению программы, если a будет иметь отрицательное значение.)
Что делать, если компилятор выдал предупреждение?
В первую очередь нужно определиться, почему он выдал предупреждение. Если его текст не понятен, то нужно обратиться к документации на компилятор и прочитать больше информации (часто в описании предупреждений приводятся наиболее частые причины их возникновения). Во вторую – привести код к однозначно интерпретируемому виду.
![]()
Вывод отладочной информации
При формировании отладочной информации нужно помнить, что информация об ошибках, выводимая для пользователя, и информация о поведении программы, выводимая для программиста, — это абсолютно разные вещи. Причем как по содержанию, так и по способу информирования.
Не нужно пользователя снабжать шестнадцатеричными кодами на дисплее, а по телефону потом разъяснять, что это «переменная режима работы приняла странное значение, сейчас подумаю, почему такое произошло». Также не нужно в конечном варианте программы оставлять всяческие вспыхивания светодиодов и взвизгивания пьезодинамика, которые при отладке говорили программисту о каком-то поведении программы или о ходе вычислений (а потом по телефону объяснять, что если лампочка мигнула 3 раза по 50 мс, то это не сошлась контрольная сумма). Т.е. вся отладочная информация, которая будет выводиться для программиста, должна быть скрыта от пользователя (запись в EEPROM, передача кода ошибки на центральный пульт, если такой есть).
![]()
Блокировка вывода отладочной информации
Нужно помнить, что возможность вывода отладочной информации, скорее всего, придется оставить в контроллере на всю жизнь. Иногда и отлаженные и переотлаженные программы могут содержать ошибки. Тем не менее, нужно иметь возможность отключать:
-
вывод отладочной информации (как всей скопом, так и отдельных узлов);
-
заглушки
-
тестеры (их полезно оставлять в тексте программы на случай проявлений ошибок в период эксплуатации)
Блокировать можно двумя способами:
-
на этапе компиляции, блокируя все отладочные узлы условными директивами компиляции:
#define DEBUG_ENABLE ... /*D*/ #ifdef DEBUG_ENABLE /*D*/ PIN_DEBUG = 1; /*D*/ #endif
(тогда, закомментировав определение DEBUG_ENABLE, мы удаляем из кода всю отладочную составляющую). Такой способ экономит ресурсы контроллера.
-
на программно-аппаратном уровне (например, контролируя состояние порта):
if (PIN_DEBUG_ENABLE) PIN_DEBUG = 1;
(тогда мы можем включать/отключать работу отладочных подпрограмм в ходе выполнения.) Такой способ требует ресурсы, но позволяет отлаживать устройство в реальных условиях.
То же самое касается блокировки функций-заглушек и функций-проверок. Например:
#define DUMMY_GPS_IN ... char * GetGPSData (void) { #ifdef DUMMY_GPS_IN char test_string[] = “$GPRMC,A,123456,…”; return test_string; #else /* Здесь код для работы с реальными данными от GPS */ #endif }
В последнем примере иногда можно обойтись и без #else, т.к. внутри этого блока окажется довольно большой код, что неудобно.
Разумеется, такие блоки в коде следует визуально выделять.
![]()
Резервное копирование
По ходу сопровождения (а иногда и разработки) программы нужно сохранять резервные копии, отмечая даты, номера версий, сделанные изменения и версию компилятора. Причем версию следует сохранять целиком, вместе с проектными файлами и HEX’ом. Бывает так, что незначительное изменение приводит к потере работоспособности кода, и, не имея резервных копий, зачастую трудно установить, какая именно из последних модификаций привела к таким последствиям.
Однако, сохранять целиком всю версию при каждой небольшой модификации довольно накладно (и по времени, и по трудоемкости). Поэтому для решения подобных задач удобно пользоваться специальными инструментами: системами контроля версий (VCS — version control systems).
Системы контроля версий обеспечивают два основных процесса:
-
взаимодействие группы разработчиков, работающих над одним проектом
-
сохранение текущих «срезов» проекта в базе данных.
Существуют различные реализации VCS: коммерческие и бесплатные, использующие центральный сервер и с распределенным хранением. Одна из самых распространенных — бесплатная система управления версий Subversion с открытым исходным кодом. Именно ее можно порекомендовать для начального ознакомления с VCS.
Subversion (или SVN) является клиент-серверной системой. База данных проекта или репозиторий хранится на сервере, а разработчик работает с локальной копией проекта, которую «отдает» ему приложение-клиент. Поработав с локальной копией, разработчик сохраняет на сервере изменения проекта — таким образом обеспечивается безопасная работа в группе и полный контроль над ходом работы. В любой момент можно извлечь один из «срезов» (в терминологии SVN — ревизий) проекта и посмотреть всю историю изменений, а также произвести сравнение различных версий.
Наиболее популярная программа клиент Subversion для Windows — TortoiseSVN.
![]()
Список литературы
-
Э. Йодан «Структурное проектирование и конструирование программ», М. Мир, 1979
-
Б. Керниган, Р. Пайк «Практика программирования»
-
А. Голуб «Веревка достаточной длины, чтобы… выстрелить себе в ногу»
-
С. Макконнелл «Совершенный код», Русская редакция, 2005
-
Ван Тассел Д. «Стиль, разработка, эффективность, отладка и испытание программ», М. «Мир», 1981
![]()
Виктор Тимофеев, ноябрь 2009
osa@pic24.ru
Обзор открытых решений для исправления опечаток
Время на прочтение
11 мин
Количество просмотров 15K
У каждого пользователя когда-либо были опечатки при написании поисковых запросов. Отсутствие механизмов, которые исправляют опечатки, приводит к выдаче нерелевантных результатов, а то и вовсе к их отсутствию. Поэтому, чтобы поисковая система была более ориентированной на пользователей, в неё встраивают механизмы исправления ошибок.

Задача исправления опечаток, на первый взгляд, кажется довольно несложной. Но если отталкиваться от разнообразия ошибок, реализация решения может оказаться трудной. В целом, исправление опечаток разделяется на контекстно-независимое и контекстно-зависимое (где учитывается словарное окружение). В первом случае ошибки исправляются для каждого слова в отдельности, во втором – с учетом контекста (например, для фразы «она пошле домой» в контекстно-независимом случае исправление происходит для каждого слова в отдельности, где мы можем получить «она пошел домой», а во втором случае правильное исправление выдаст «она пошла домой»).
В поисковых запросах русскоязычного пользователя можно выделить четыре основные группы ошибок только для контекстно-независимого исправления [1]:
1) ошибки в самих словах (пмрвет → привет), к этой категории относятся всевозможные пропуски, вставки и перестановки букв – 63,7%,
2) слитно-раздельное написание слов – 16,9%,
3) искаженная раскладка (ghbdtn → привет) – 9,7 %,
4) транслитерация (privet → привет) – 1,3%,
5) смешанные ошибки – 8,3%.
Пользователи совершают опечатки приблизительно в 10-15% случаях. При этом 83,6% запросов имеют одну ошибку, 11,7% –две, 4,8% – более трёх. Контекст важен в 26% случаев.
Эта статистика была составлена на основе случайной выборки из дневного лога Яндекса в далеком 2013 году на основе 10000 запросов. В открытом доступе есть гораздо более ранняя презентация от Яндекса за 2008 год, где показано похожее распределение статистики [2]. Отсюда можно сделать вывод, что распределение разновидностей ошибок для поисковых запросов, в среднем, с течением времени не изменяется.
В общем виде механизм исправления опечаток основывается на двух моделях: модель ошибок и языковая модель. Причем для контекстно-независимого исправления используется только модель ошибок, а в контекстно-зависимом – сразу две. В качестве модели ошибок обычно выступает либо редакционное расстояние (расстояние Левенштейна, Дамерау-Левенштейна, также сюда могут добавляться различные весовые коэффициенты, методы на подобие Soundex и т. д. – в таком случае расстояние называется взвешенным), либо модель Бриля-Мура, которая работает на вероятностях переходов одной строки в другую. Бриль и Мур позиционируют свою модель как более совершенную, однако на одном из последних соревнований SpellRuEval подход Дамерау-Левенштейна показал результат лучше [3], несмотря на тот факт, что расстояние Дамерау-Левенштейна (уточнение – невзвешенное) не использует априори информацию об опечаточной статистике. Это наблюдение особо показательно в том случае, если для разных реализаций автокорректоров в библиотеке DeepPavlov использовались одинаковые обучающие тексты.
Очевидно, что возможность контекстно-зависимого исправления усложняет построение автокорректора, т. к. дополнительно к модели ошибок добавляется необходимость в языковой модели. Но если обратить внимание на статистику опечаток, то ¾ всех неверно написанных поисковых запросов можно исправлять без контекста. Это говорит о том, что польза как минимум от контекстно-независимого автокорректора может быть весьма существенной.
Также контекстно-зависимое исправление для корректировки опечаток в запросах очень требовательно по ресурсам. Например, в одном из выступлений Яндекса список пар для исправления опечаток (биграмм) слов отличался в 10 раз по сравнению с количеством слов (униграмм), что тогда говорить про триграммы? Очевидно, что это существенно зависит от вариативности запросов. Немного странно выглядит, когда автокорректор занимает половину памяти от предлагаемого продукта компании, целевое назначение которого не ориентировано на решение проблемы правописания. Так что вопрос внедрения контекстно-зависимого исправления в поисковых системах программных продуктов может быть весьма спорным.
На первый взгляд, складывается впечатление, что существует много готовых решений под любой язык программирования, которые можно использовать без особого погружения в подробности работы алгоритмов, в том числе – в коммерческих системах. Но на практике продолжается разработка своих решений. Например, сравнительно недавно в Joom было сделано собственное решение по исправлению опечаток с использованием языковых моделей для поисковых запросов [4]. Действительно ли ситуация непроста с доступностью готовых решений? С этой целью был сделан, по возможности, широкий обзор существующих решений. Перед тем как приступить к обзору, определимся с тем, как проверяется качество работы автокорректора.
Проверка качества работы
Вопрос проверки качества работы автокорректора весьма неоднозначен. Один из простых подходов проверки — через точность (Precision) и полноту (Recall). В соответствии со стандартом ISO, точность и полнота дополняются правильностью (на англ. «corectness»).

Полнота (Recall) рассчитывается следующим образом: список из правильных слов подается автокорректору (Total_list_true), и, количество слов, которое автокорректор считает правильными (Spellchecker_true), разделенное на общее количество правильных слов (Total_list_true), будет считаться полнотой.

Для определения точности (Precision) на вход автокорректора подается список из неправильных слов (Total_list_false), и, количество слов, которое автокорректор считает неправильным (Spell_checker_false), разделенное на общее количество неправильных слов (Total_list_false), определяют как точность.

Насколько вообще эти метрики информативны и как могут быть полезны, каждый определяет самостоятельно. Ведь, фактически, суть данной проверки сводится к тому, что проверяется вхождение слова в обучающий словарь. Более наглядной метрикой можно считать correctness, согласно которой автокорректор для каждого слова из тестового множества неправильных слов формирует список кандидатов-замен, на которые можно исправить это неправильное слово (следует иметь в виду, что здесь могут оказаться слова, которые не содержатся в обучающем словаре). Допустим, размер такого списка кандидатов-замен равен 5. Исходя из того, что размер списка равен 5, будет сформировано 6 групп, в одну из которых мы будем помещать наше каждое исходное неправильное слово по следующему принципу: в 1-ую группу — если в списке кандидатов-замен предполагаемое нами правильное слово стоит 1-ым, во 2-ую если стоит 2-ым и т. д., а в последнюю группу — если предполагаемого правильного слова в списке кандидатов-замен не оказалось. Разумеется, чем больше слов попало в 1-ую группу и чем меньше в 6-ую, тем лучше работает автокорректор.
Рассмотренного выше подхода придерживались авторы в статье [5], в которой сравнивались контекстно-независимые автокорректоры с уклоном на стандарт ISO. Там же приведены ссылки на другие способы оценки качества.
С одной стороны, такой подход не базируется на опечаточной статистике, в основу которого может быть положена модель ошибок Бриля-Мура [6], либо модель ошибок взвешенного расстояния Дамерау-Левенштейна.
Для проверки качества работы контекстно-независимого автокорректора был создан собственный генератор опечаток, который генерировал опечатки неверной раскладки и орфографические опечатки исходя из статистики по опечаткам, представленной Яндексом. Для орфографических опечаток генерировались произвольные вставки, замены, удаления, перестановки, а количество ошибок так же варьировалось в соответствии с этой статистикой. Для ошибок искаженной раскладки, правильное слово посимвольно изменялось целиком в соответствии с таблицей перевода символов.
Далее была проведена серия экспериментов для всего списка слов обучающего словаря (слова обучающего словаря исправлялись на неправильные в соответствии с вероятностью возникновения той или иной опечатки). В среднем, автокорректор исправляет слова верно в 75% случаев. Вне всякого сомнения, это количество будет сокращаться при пополнении обучающего словаря близкими по редакционному расстоянию словами, большом многообразии словоформ. Эта проблема может решаться за счет дополнения языковыми моделями, но здесь следует учитывать, что количество требуемых ресурсов ощутимо возрастет.
Готовые решения

Рассмотрение готовых решений проводилось с уклоном на собственное использование, и приоритет отдавался автокорректорам, которые удовлетворяют трем критериям:
1) язык реализации,
2) тип лицензии,
3) обновляемость.
В продуктовой разработке язык Java считается одним из самых популярных, поэтому приоритет при поиске библиотек отдавался ему. Из лицензий актуальны: MIT, Public, Apache, BSD. Обновляемость — не более 2-х лет с последнего обновления. В ходе поиска фиксировалась дополнительная информация, например, о поддерживаемой платформе, требуемые дополнительные программы, особенности применения, возможные затруднения при первом использовании и т. д. Ссылки с основными и полезными ресурсами на источники приведены в конце статьи. В целом, если не ограничиваться вышеупомянутыми критериями, количество существующих решений велико. Давайте кратко рассмотрим основные, а более подробно уделим внимание лишь некоторым.
Исторически одним из самых старых автокорректоров является Ispell (International Spell), написан в 1971 на ассемблере, позднее перенесен на C и в качестве модели ошибок использует редакционное расстояние Дамерау-Левенштейна. Для него даже есть словарь на русском языке. В последующем ему на замену пришли два автокорректора HunSpell (ранее MySpell) и Aspell. Оба реализованы на на C++ и распространяются под GPL лицензиями. На HunSpell также распространяется GPL/MPL и его используют для исправления опечаток в OpenOffice, LibreOffice, Google Chrome и других инструментах.
Для Интернета и браузеров есть целое множество решений на JS (сюда можно отнести: nodehun-sentences, nspell, node-markdown-spellcheck, Proofreader, Spellcheck-API — группа решений, базирующаяся на автокорректоре Hunspell; grunt-spell — под NodeJS; yaspeller-ci — обертка для автокорректора Яндекс.Спеллер, распространяется под MIT; rousseau — Lightweight proofreader in JS — используется для проверки правописания).
В категорию платных решений входят: Spellex; Source Code Spell Checker — как десктопное приложение; для JS: nanospell; для Java: Keyoti RapidSpell Spellchecker, JSpell SDK, WinterTree (у WinterTree можно даже купить исходный код за $5000).
Широкой популярностью пользуется автокорректор Питера Норвига, программный код на Python которого находится в публичном доступе в статье «How to Write a Spelling Corrector» [7]. На основе этого простого решения были построены автокорректоры на других языках, например: Norvig-spell-check, scala-norvig-spell-check (на Scala), toy-spelling-corrector — Golang Spellcheck (на GO), pyspellchecker (на Python). Разумеется, здесь никакой речи не идет о языковых моделях и контекстно-зависимом исправлении.
Для текстовых редакторов, в частности для VIM сделаны vim-dialect, vim-ditto — распространяются под публичной лицензией; для Notepad++ разработан DspellCheck на C++, лицензия GPL; для Emacs сделан инструмент автоматического определения языка при печати, называется guess-language, распространяется под публичной лицензией.
Есть отдельные сервисы от поисковых гигантов: Яндекс.Спеллер — от Яндекса, про обертку к нему было сказано выше, google-api-spelling-java (соответственно, от Google).
Бесплатные библиотеки для Java: languagetool (лицензируется под LGPL), интегрируется с библиотекой текстового поиска Lucene и допускает использование языковых моделей, для работы необходима 8 версия Java; Jazzy (аналог Aspell) распространяется под лицензией LGPLv2 и не обновлялась с 2005 года, а в 2013 была перенесена на GitHub. По подобию этого автокорректора сделано отдельное решение [8]; Jortho (Java Orthography) распространяется под GPL и разрешает бесплатное использование исключительно в некоммерческих целях, в коммерческих — за дополнительную плату; Jaspell (лицензируется под BSD и не обновлялся с 2005 года); Open Source Java Suggester — не обновлялся с 2013 года, распространяется SoftCorporation LLC и разрешает коммерческое применение; LuceneSpellChecker — автокорректор библиотеки Lucene, написана на Java и распространяется под лицензией Apache.
На протяжении длительного времени вопросом исправления опечаток занимался Wolf Garbe, им были предложены алгоритмы SymSpell (под MIT лицензией) и LinSpell (под LGPL) с реализациями на C# [9], которые используют расстояние Дамерау-Левенштейна для модели ошибок. Особенность их реализации в том, что на этапе формирования возможных ошибок для входного слова, используются только удаления, вместо всевозможных удалений, вставок, замен и перестановок. По сравнению с реализацией автокорректора Питера Норвига оба алгоритма за счет этого работают быстрее, при этом прирост в скорости существенно увеличивается, если расстояние по Дамерау-Левенштейну становится больше двух. Также за счет того, что используются только удаления, сокращается время формирования словаря. Отличие между двумя алгоритмами в том, что LinSpell более экономичен по памяти и медленнее по скорости поиска, SymSpell — наоборот. В более поздней версии SymSpell исправляет ошибки слитно-раздельного написания. Языковые модели не используются.
К числу наиболее свежих и перспективных для пользования автокорректоров, работающих с языковыми моделями и исправляющих контекстно-зависимые опечатки относятся Яндекс.Спеллер, JamSpell [10], DeepPavlov [11]. Последние 2 распространяются свободно: JamSpell (MIT), DeepPavlov (под Apache).
Яндекс.Спеллер использует алгоритм CatBoost, работает с несколькими языками и исправляет всевозможные разновидности ошибок даже с учетом контекста. Единственное из найденных решение, которое исправляет ошибки неверной раскладки и транслитерацию. Решение обладает универсальностью, что делает его популярным. Его недостатком является то, что это удаленный сервис, а про ограничения и условия пользования можно прочитать здесь [12]. Сервис работает с ограниченным количеством языков, нельзя самостоятельно добавлять слова и управлять процессом исправления. В соответствии с ресурсом [3] по результатам соревнований RuSpellEval этот автокорректор показал самое высокое качество исправлений. JamSpell — самый быстрый из известных автокорректор (C++ реализация), здесь есть готовые биндинги под другие языки. Исправляет ошибки только в самих словах и работает с конкретным языком. Использовать решение на уровне униграмм и биграмм нельзя. Для получения приемлемого качества требуется большой обучающий текст.
Есть неплохие наработки у DeepPavlov, однако интеграция этих решений и последующая поддержка в собственном продукте может вызвать затруднения, т. к. при работе с ними требуется подключение виртуального окружения и использование более ранней версии Python 3.6. DeepPavlov предоставляет на выбор три готовых реализации автокорректоров, в двух из которых применены модели ошибок Бриля-Мура и в двух языковые модели. Исправляет только ошибки орфографии, а вариант с моделью ошибок на основе расстояния Дамерау-Левенштейна может исправлять ошибки слитного написания.
Упомяну ещё про один из современных подходов к исправлению опечаток, который основан на применении векторных представлений слов (Word Embeddings). Достоинством его является то, что на нем можно построить автокорректор для исправления слов с учетом контекста. Более подробно про этот подход можно прочитать здесь [13]. Но чтобы его использовать для исправления опечаток поисковых запросов вам потребуется накопить большой лог запросов. Кроме того, сама модель может оказаться довольно емкой по потребляемой памяти, что отразится на сложности интеграцию в продукт.
Выбор Naumen

Из готовых решений для Java был выбран автокорректор от Lucene (распространяется под лицензией от Apache). Позволяет исправлять опечатки в словах. Процесс обучения быстрый: например, формирование специальной структуры данных словаря – индекса для 3 млн. строк составило 30 секунд на процессоре Intel Core i5-8500 3.00GHz, 32 Gb RAM, Lucene 8.0.0. В более ранних версиях время может быть больше в 2 раза. Размер обучающего словаря – 3 млн. строк (~73 Mb txt-файл), структура индекса ~235 Mb. Для модели ошибок можно выбирать расстояние Джаро-Винклера, Левенштейна, Дамерау-Левенштейна, N-Gram, если нужно, то можно добавить свое. При необходимости есть возможность подключения языковой модели [14]. Модели известны с 2001 года, но их сравнение с известными современными решениями в открытом доступе не было обнаружено. Следующим этапом будет проверка их работы.
Полученное решение на основе Lucene исправляет только ошибки в самих словах. К любому подобному решению несложно добавить исправление искаженной раскладки клавиатуры путем соответствующей таблицы перевода, тем самым сократить возможность нерелевантной выдачи до 10% (в соответствии с опечаточной статистикой). Кроме того, несложно добавить раздельное написание слитых 2-х слов и транслитерацию.
В качестве основных недостатков решения можно выделить необходимость знания Java, отсутствие подробных кейсов использования и подробной документации, что отражается на снижении скорости разработки решения для Data-Science специалистов. Кроме того, не исправляются опечатки с расстоянием по Дамерау-Левенштейну более 2-х. Опять же, если отталкиваться от опечаточной статистики, более 2-х ошибок в слове возникает реже, чем в 5% случаев. Обоснована ли необходимость усложнения алгоритма, в частности, увеличение потребляемой памяти? Тут уже зависит от кейса заказчика. Если есть дополнительные ресурсы, то почему бы их не использовать?
Основные ресурсы по доступным автокорректорам:
- 30 best open source spellcheck project
- Evaluation of legal words in three Java open source spell checkers: Hunspell, Basic Suggester, and Jazzy
- spell checker: Java Glossary
- nlp — Looking for Java spell checker library
- Open source spell checking library for Java
Ссылки
- Панина М. Ф. Автоматическое исправление
опечаток в поисковых запросах
без учета контекста - Байтин А. Исправление поисковых запросов в Яндексе
- DeepPavlov. Таблица сравнения автокорректоров
- Joom. Исправляем опечатки в поисковых запросах
- Dall’Oglio P. Evaluation of legal words in three Java open source spell checkers: Hunspell, Basic Suggester, and Jazzy
- Eric B. and Robert M. An Improved Error Model for Noisy Channel Spelling Correction
- Norvig P. How to Write a Spelling Corrector
- Автокорректор на основе Jazzy
- Garbe W. SymSpell vs. BK-tree: 100x faster fuzzy string search & spell checking
- Jamspell. Исправляем опечатки с учётом контекста
- DeepPavlov. Automatic spelling correction pipelines
- Условия использования сервиса «API Яндекс.Спеллер»
- Singularis. Исправление опечаток, взгляд сбоку
- Apache Lucene. Языковые модели
From Wikipedia, the free encyclopedia
A context-sensitive grammar (CSG) is a formal grammar in which the left-hand sides and right-hand sides of any production rules may be surrounded by a context of terminal and nonterminal symbols. Context-sensitive grammars are more general than context-free grammars, in the sense that there are languages that can be described by a CSG but not by a context-free grammar. Context-sensitive grammars are less general (in the same sense) than unrestricted grammars. Thus, CSGs are positioned between context-free and unrestricted grammars in the Chomsky hierarchy.[1]
A formal language that can be described by a context-sensitive grammar, or, equivalently, by a noncontracting grammar or a linear bounded automaton, is called a context-sensitive language. Some textbooks actually define CSGs as non-contracting,[2][3][4][5] although this is not how Noam Chomsky defined them in 1959.[6][7] This choice of definition makes no difference in terms of the languages generated (i.e. the two definitions are weakly equivalent), but it does make a difference in terms of what grammars are structurally considered context-sensitive; the latter issue was analyzed by Chomsky in 1963.[8][9]
Chomsky introduced context-sensitive grammars as a way to describe the syntax of natural language where it is often the case that a word may or may not be appropriate in a certain place depending on the context. Walter Savitch has criticized the terminology «context-sensitive» as misleading and proposed «non-erasing» as better explaining the distinction between a CSG and an unrestricted grammar.[10]
Although it is well known that certain features of languages (e.g. cross-serial dependency) are not context-free, it is an open question how much of CSGs’ expressive power is needed to capture the context sensitivity found in natural languages. Subsequent research in this area has focused on the more computationally tractable mildly context-sensitive languages.[citation needed] The syntaxes of some visual programming languages can be described by context-sensitive graph grammars.[11]
Formal definition[edit]
Formal grammar[edit]
Let us notate a formal grammar as  , with
, with  a set of nonterminal symbols,
a set of nonterminal symbols,  a set of terminal symbols,
a set of terminal symbols,  a set of production rules, and
a set of production rules, and  the start symbol.
the start symbol.
A string  directly yields, or directly derives to, a string
directly yields, or directly derives to, a string  , denoted as
, denoted as  , if v can be obtained from u by an application of some production rule in P, that is, if
, if v can be obtained from u by an application of some production rule in P, that is, if  and
and  , where
, where  is a production rule, and
is a production rule, and  is the unaffected left and right part of the string, respectively.
is the unaffected left and right part of the string, respectively.
More generally, u is said to yield, or derive to, v, denoted as  , if v can be obtained from u by repeated application of production rules, that is, if
, if v can be obtained from u by repeated application of production rules, that is, if  for some n ≥ 0 and some strings
for some n ≥ 0 and some strings  . In other words, the relation
. In other words, the relation  is the reflexive transitive closure of the relation
is the reflexive transitive closure of the relation  .
.
The language of the grammar G is the set of all terminal-symbol strings derivable from its start symbol, formally:  .
.
Derivations that do not end in a string composed of terminal symbols only are possible, but do not contribute to L(G).
Context-sensitive grammar[edit]
A formal grammar is context-sensitive if each rule in P is either of the form  where
where  is the empty string, or of the form
is the empty string, or of the form
- αAβ → αγβ
with A ∈ N,[note 1]  ,[note 2] and
,[note 2] and  .[note 3]
.[note 3]
The name context-sensitive is explained by the α and β that form the context of A and determine whether A can be replaced with γ or not.
By contrast, in a context-free grammar, no context is present: the left hand side of every production rule is just a nonterminal.
The string γ is not allowed to be empty. Without this restriction, the resulting grammars become equal in power to unrestricted grammars.[10]
(Weakly) equivalent definitions[edit]
A noncontracting grammar is a grammar in which for any production rule, of the form u → v, the length of u is less than or equal to the length of v.
Every context-sensitive grammar is noncontracting, while every noncontracting grammar can be converted into an equivalent context-sensitive grammar; the two classes are weakly equivalent.[12]
Some authors use the term context-sensitive grammar to refer to noncontracting grammars in general.
The left-context— and right-context-sensitive grammars are defined by restricting the rules to just the form αA → αγ and to just Aβ → γβ, respectively. The languages generated by these grammars are also the full class of context-sensitive languages.[13] The equivalence was established by Penttonen normal form.[14]
Examples[edit]
anbncn[edit]
The following context-sensitive grammar, with start symbol S, generates the canonical non-context-free language { anbncn | n ≥ 1 } :[citation needed]
| 1. | S | → | a | B | C | ||
| 2. | S | → | a | S | B | C | |
| 3. | C | B | → | C | Z | ||
| 4. | C | Z | → | W | Z | ||
| 5. | W | Z | → | W | C | ||
| 6. | W | C | → | B | C | ||
| 7. | a | B | → | a | b | ||
| 8. | b | B | → | b | b | ||
| 9. | b | C | → | b | c | ||
| 10. | c | C | → | c | c |
Rules 1 and 2 allow for blowing-up S to anBC(BC)n−1; rules 3 to 6 allow for successively exchanging each CB to BC (four rules are needed for that since a rule CB → BC wouldn’t fit into the scheme αAβ → αγβ); rules 7–10 allow replacing a non-terminals B and C with its corresponding terminals b and c respectively, provided it is in the right place.
A generation chain for aaabbbccc is:
- S
- →2 aSBC
- →2 aaSBCBC
- →1 aaaBCBCBC
- →3 aaaBCZCBC
- →4 aaaBWZCBC
- →5 aaaBWCCBC
- →6 aaaBBCCBC
- →3 aaaBBCCZC
- →4 aaaBBCWZC
- →5 aaaBBCWCC
- →6 aaaBBCBCC
- →3 aaaBBCZCC
- →4 aaaBBWZCC
- →5 aaaBBWCCC
- →6 aaaBBBCCC
- →7 aaabBBCCC
- →8 aaabbBCCC
- →8 aaabbbCCC
- →9 aaabbbcCC
- →10 aaabbbccC
- →10 aaabbbccc
anbncndn, etc.[edit]
More complicated grammars can be used to parse { anbncndn | n ≥ 1 }, and other languages with even more letters. Here we show a simpler approach using non-contracting grammars:[citation needed]
Start with a kernel of regular productions generating the sentential forms
 and then include the non contracting productions
and then include the non contracting productions
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 .
.
ambncmdn[edit]
A non contracting grammar (for which there is an equivalent CSG) for the language  is defined by
is defined by
 ,
,- ,
- ,
- ,
- ,
- ,
- , and
- .








With these definitions, a derivation for  is:
is:
 .[citation needed]
.[citation needed]
a2i[edit]
A noncontracting grammar for the language { a2i | i ≥ 1 } is constructed in Example 9.5 (p. 224) of (Hopcroft, Ullman, 1979):[15]
![{\displaystyle S\rightarrow [ACaB]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/30e1325ff5cb595ef63a3000fa67f4be1624b29a)
![{\displaystyle {\begin{cases}\ [Ca]a\rightarrow aa[Ca]\\\ [Ca][aB]\rightarrow aa[CaB]\\\ [ACa]a\rightarrow [Aa]a[Ca]\\\ [ACa][aB]\rightarrow [Aa]a[CaB]\\\ [ACaB]\rightarrow [Aa][aCB]\\\ [CaB]\rightarrow a[aCB]\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b610fa908a8e0403fc0a7eb45e1ba5c76bab3499)
![{\displaystyle [aCB]\rightarrow [aDB]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e25ba01ca202a0593ae858b2335f6b3881b2cf0)
![{\displaystyle [aCB]\rightarrow [aE]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98f17ab26d272cb6566a18836d482b3c81572352)
![{\displaystyle {\begin{cases}\ a[Da]\rightarrow [Da]a\\\ [aDB]\rightarrow [DaB]\\\ [Aa][Da]\rightarrow [ADa]a\\\ a[DaB]\rightarrow [Da][aB]\\\ [Aa][DaB]\rightarrow [ADa][aB]\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a2fc2d6c3fc3f52b8311f08c191aba7aea9cbc40)
![{\displaystyle [ADa]\rightarrow [ACa]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/097b569ac1aa3d95e00d63c289ec763cda71aa0d)
![{\displaystyle {\begin{cases}\ a[Ea]\rightarrow [Ea]a\\\ [aE]\rightarrow [Ea]\\\ [Aa][Ea]\rightarrow [AEa]a\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c820f37471166abbed493f05c837857e8bd8918)
![{\displaystyle [AEa]\rightarrow a}](https://wikimedia.org/api/rest_v1/media/math/render/svg/979381ab73dede3da0427e33a316b592582cfcf0)
Kuroda normal form[edit]
Every context-sensitive grammar which does not generate the empty string can be transformed into a weakly equivalent one in Kuroda normal form. «Weakly equivalent» here means that the two grammars generate the same language. The normal form will not in general be context-sensitive, but will be a noncontracting grammar.[16][17]
The Kuroda normal form is an actual normal form for non-contracting grammars.
Properties and uses[edit]
Equivalence to linear bounded automaton[edit]
A formal language can be described by a context-sensitive grammar if and only if it is accepted by some linear bounded automaton (LBA).[18] In some textbooks this result is attributed solely to Landweber and Kuroda.[7] Others call it the Myhill–Landweber–Kuroda theorem.[19] (Myhill introduced the concept of deterministic LBA in 1960. Peter S. Landweber published in 1963 that the language accepted by a deterministic LBA is context sensitive. Kuroda introduced the notion of non-deterministic LBA and the equivalence between LBA and CSGs in 1964.[20][21])
As of 2010[needs update] it is still an open question whether every context-sensitive language can be accepted by a deterministic LBA.[22]
Closure properties[edit]
Context-sensitive languages are closed under complement. This 1988 result is known as the Immerman–Szelepcsényi theorem.[19]
Moreover, they are closed under union, intersection, concatenation, substitution,[note 4] inverse homomorphism, and Kleene plus.[23]
Every recursively enumerable language L can be written as h(L) for some context-sensitive language L and some string homomorphism h.[24]
Computational problems[edit]
The decision problem that asks whether a certain string s belongs to the language of a given context-sensitive grammar G, is PSPACE-complete. Moreover, there are context-sensitive grammars whose languages are PSPACE-complete. In other words, there is a context-sensitive grammar G such that deciding whether a certain string s belongs to the language of G is PSPACE-complete (so G is fixed and only s is part of the input of the problem).[25]
The emptiness problem for context-sensitive grammars (given a context-sensitive grammar G, is L(G)=∅ ?) is undecidable.[26][note 5]
As model of natural languages[edit]
Savitch has proven the following theoretical result, on which he bases his criticism of CSGs as basis for natural language: for any recursively enumerable set R, there exists a context-sensitive language/grammar G which can be used as a sort of proxy to test membership in R in the following way: given a string s, s is in R if and only if there exists a positive integer n for which scn is in G, where c is an arbitrary symbol not part of R.[10]
It has been shown that nearly all natural languages may in general be characterized by context-sensitive grammars, but the whole class of CSGs seems to be much bigger than natural languages.[citation needed] Worse yet, since the aforementioned decision problem for CSGs is PSPACE-complete, that makes them totally unworkable for practical use, as a polynomial-time algorithm for a PSPACE-complete problem would imply P=NP.
It was proven that some natural languages are not context-free, based on identifying so-called cross-serial dependencies and unbounded scrambling phenomena.[citation needed] However this does not necessarily imply that the class of CSGs is necessary to capture «context sensitivity» in the colloquial sense of these terms in natural languages. For example, linear context-free rewriting systems (LCFRSs) are strictly weaker than CSGs but can account for the phenomenon of cross-serial dependencies; one can write a LCFRS grammar for {anbncndn | n ≥ 1} for example.[27][28][29]
Ongoing research on computational linguistics has focused on formulating other classes of languages that are «mildly context-sensitive» whose decision problems are feasible, such as tree-adjoining grammars, combinatory categorial grammars, coupled context-free languages, and linear context-free rewriting systems. The languages generated by these formalisms properly lie between the context-free and context-sensitive languages.
More recently, the class PTIME has been identified with range concatenation grammars, which are now considered to be the most expressive of the mild-context sensitive language classes.[29]
See also[edit]
- Chomsky hierarchy
- Growing context-sensitive grammar
- Definite clause grammar#Non-context-free grammars
- List of parser generators for context-sensitive grammars
Notes[edit]
- ^ i.e., A a single nonterminal
- ^ i.e., α and β strings of nonterminals (except for the start symbol) and terminals
- ^ i.e., γ is a nonempty string of nonterminals (except for the start symbol) and terminals
- ^ more formally: if L ⊆ Σ* is a context-sensitive language and f maps each a∈Σ to a context-sensitive language f(a), the f(L) is again a context-sensitive language
- ^ This also follows from (1) context-free languages being also context-sensitive, (2) context-sensitive language being closed under intersection, but (3) disjointness of context-free languages being undecidable.
References[edit]
- ^ (Hopcroft, Ullman, 1979); Sect.9.4, p.227
- ^ Linz, Peter (2011). An Introduction to Formal Languages and Automata. Jones & Bartlett Publishers. p. 291. ISBN 978-1-4496-1552-9.
- ^ Meduna, Alexander (2000). Automata and Languages: Theory and Applications. Springer Science & Business Media. p. 730. ISBN 978-1-85233-074-3.
- ^ Davis, Martin; Sigal, Ron; Weyuker, Elaine J. (1994). Computability, Complexity, and Languages: Fundamentals of Theoretical Computer Science (2nd ed.). Morgan Kaufmann. p. 189. ISBN 978-0-08-050246-5.
- ^ Martin, John C. (2010). Introduction to Languages and the Theory of Computation (4th ed.). New York, NY: McGraw-Hill. p. 277. ISBN 9780073191461.
- ^ Levelt, Willem J. M. (2008). An Introduction to the Theory of Formal Languages and Automata. John Benjamins Publishing. p. 26. ISBN 978-90-272-3250-2.
- ^ a b Davis, Martin; Sigal, Ron; Weyuker, Elaine J. (1994). Computability, Complexity, and Languages: Fundamentals of Theoretical Computer Science (2nd ed.). Morgan Kaufmann. pp. 330–331. ISBN 978-0-08-050246-5.
- ^ Chomsky, N. (1963). «Formal properties of grammar». In Luce, R. D.; Bush, R. R.; Galanter, E. (eds.). Handbook of Mathematical Psychology. New York: Wiley. pp. 360–363.
- ^ Levelt, Willem J. M. (2008). An Introduction to the Theory of Formal Languages and Automata. John Benjamins Publishing. pp. 125–126. ISBN 978-90-272-3250-2.
- ^ a b c Carlos Martín Vide, ed. (1999). Issues in Mathematical Linguistics: Workshop on Mathematical Linguistics, State College, Pa., April 1998. John Benjamins Publishing. pp. 186–187. ISBN 90-272-1556-1.
- ^ Zhang, Da-Qian, Kang Zhang, and Jiannong Cao. «A context-sensitive graph grammar formalism for the specification of visual languages.» The Computer Journal 44.3 (2001): 186–200.
- ^ Hopcroft, John E.; Ullman, Jeffrey D. (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 9780201029888.; p. 223–224; Exercise 9, p. 230. In the 2003 edition, the chapter on CSGs has been omitted.
- ^ Hazewinkel, Michiel (1989). Encyclopaedia of Mathematics. Vol. 4. Springer Science & Business Media. p. 297. ISBN 978-1-55608-003-6. also at https://www.encyclopediaofmath.org/index.php/Grammar,_context-sensitive
- ^ Ito, Masami; Kobayashi, Yūji; Shoji, Kunitaka (2010). Automata, Formal Languages and Algebraic Systems: Proceedings of AFLAS 2008, Kyoto, Japan, 20–22 September 2008. World Scientific. p. 183. ISBN 978-981-4317-60-3. citing Penttonen, Martti (Aug 1974). «One-sided and two-sided context in formal grammars». Information and Control. 25 (4): 371–392. doi:10.1016/S0019-9958(74)91049-3.
- ^ They obtained the grammar by systematic transformation of an unrestricted grammar, given in Exm. 9.4, viz.:
- ,
- ,
- ,
- ,
- ,
- ,
- ,
- .
In the context-sensitive grammar, a string enclosed in square brackets, like
, is considered a single symbol (similar to e.g. <name-part>in Backus–Naur form). The symbol names are chosen to resemble the unrestricted grammar. Likewise, rule groups in the context-sensitive grammar are numbered by the unrestricted-grammar rule they originated from. - ^ Kuroda, Sige-Yuki (June 1964). «Classes of languages and linear-bounded automata». Information and Control. 7 (2): 207–223. doi:10.1016/s0019-9958(64)90120-2.
- ^ Mateescu, Alexandru; Salomaa, Arto (1997). «Chapter 4: Aspects of Classical Language Theory». In Rozenberg, Grzegorz; Salomaa, Arto (eds.). Handbook of Formal Languages. Volume I: Word, language, grammar. Springer-Verlag. pp. 175–252. ISBN 3-540-61486-9., Here: Theorem 2.2, p. 190
- ^ (Hopcroft, Ullman, 1979); Theorem 9.5, 9.6, p. 225–226
- ^ a b Sutner, Klaus (Spring 2016). «Context Sensitive Grammars» (PDF). Carnegie Mellon University. Archived from the original (PDF) on 2017-02-03. Retrieved 2019-08-29.
- ^ Meduna, Alexander (2000). Automata and Languages: Theory and Applications. Springer Science & Business Media. p. 755. ISBN 978-1-85233-074-3.
- ^ Levelt, Willem J. M. (2008). An Introduction to the Theory of Formal Languages and Automata. John Benjamins Publishing. pp. 126–127. ISBN 978-90-272-3250-2.
- ^ Martin, John C. (2010). Introduction to Languages and the Theory of Computation (4th ed.). New York, NY: McGraw-Hill. p. 283. ISBN 9780073191461.
- ^ (Hopcroft, Ullman, 1979); Exercise S9.10, p. 230–231
- ^ (Hopcroft, Ullman, 1979); Exercise S9.14, p. 230–232. h maps each symbol to itself or to the empty string.
- ^ An example of such a grammar, designed to solve the QSAT problem, is given in Lita, C. V. (2016-09-01). «On Complexity of the Detection Problem for Bounded Length Polymorphic Viruses». 2016 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC). pp. 371–378. doi:10.1109/SYNASC.2016.064. ISBN 978-1-5090-5707-8. S2CID 18067130.
- ^ (Hopcroft, Ullman, 1979); Exercise S9.13, p. 230–231
- ^ Kallmeyer, Laura (2011). «Mildly Context-Sensitive Grammar Formalisms: Natural Languages are not Context-Free» (PDF). Archived (PDF) from the original on 2014-08-19.
- ^ Kallmeyer, Laura (2011). «Mildly Context-Sensitive Grammar Formalisms: Linear Context-Free Rewriting Systems» (PDF). Archived (PDF) from the original on 2014-08-19.
- ^ a b Kallmeyer, Laura (2010). Parsing Beyond Context-Free Grammars. Springer Science & Business Media. pp. 1–5. ISBN 978-3-642-14846-0.








![{\displaystyle [ACaB]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ebc718787aa2b63d4df784709390e91dcdb0cef3)
Further reading[edit]
- Meduna, Alexander; Švec, Martin (2005). Grammars with Context Conditions and Their Applications. John Wiley & Sons. ISBN 978-0-471-73655-4.
External links[edit]
- Earley Parsing for Context-Sensitive Grammars