Методология управления, известная как Шесть Сигма стремится повысить эффективность и минимизировать дефекты в любом процессе. Один из методов, которые практикующие специалисты Six Sigma используют для определения эффективности процесса, — это измерение дефектов на миллион возможностей, или DPMO, Этот метод распознает, что для каждого компонента или действия в бизнес-процессе может возникать множество возможностей для дефектов. Метод DPMO позволяет более тщательно оценить бизнес-процессы.
Определение дефектов
Методология Шести Сигм определяет дефект как разница между желаемым и фактическим результатом любого бизнес-процесса. Каждый шаг в процессе может содержать множество возможностей для дефектов. Каждый дефект должен учитываться при расчете DPMO. Например, техник ввода данных может вводить ошибочные данные в три поля онлайн-формы. Каждое поле, содержащее ошибочные данные, может быть классифицировано как дефект в этой форме, поэтому одна форма содержит три дефекта.
Определение возможностей
возможность включает любой шаг в бизнес-процессе, во время которого может возникнуть дефект. Поскольку большинство бизнес-процессов связаны с множеством возможностей возникновения дефектов, метод Six Sigma использует количество возможностей, а не количество завершенных процессов, для определения эффективности, Используя приведенный выше пример, техник ввода данных должен правильно ввести данные в 20 полей, чтобы завершить процесс ввода данных. Каждое поле представляет возможность для дефекта, поэтому процесс заполнения формы содержит 20 возможностей.
Сам процесс расчета относительно прост. DPMO — это отношение количества дефектов к числу возможностей, умноженное на 1 миллион. Большинство предприятий используют образцы для определения полной степени DPMO. В приведенном выше примере форма ввода данных содержит 20 полей. Оценка 200 форм была оценена. Оценка обнаружила 500 полных дефектов в 200 формах. Расчет DPMO будет выглядеть так:
(500 дефектов) / (20 возможностей / форма) х (200 форм) х 1 000 000
= 500/4000 х 1 000 000
= 0,125 х 1 000 000
= 125 000 DPMO
Использует для DPMO
Эксперты Six Sigma используют DPMO, чтобы измерить, насколько эффективно бизнес осуществляет свои процессы. Каждая «Сигма» представляет собой шаг выше средней производительности. Оценка 6,0 сигма равна 3,4 DPMO, или 99,9997% бездефектного показателя. Подсчет DPMO, равный 125 000, из приведенного выше примера дает 87,5% бездефектных показателей и 2,65 сигма.
Какова формула для расчета DPMO?
Как вы рассчитываете DPMO? Это общее количество дефектов в выборке, деленного на размер выборки, тем, что количество возможных дефектов, которые вы можете иметь в элементе. Умножьте это на 1 000 000 , и вы получаете DPMO.
Как только можно рассчитать количество продуктов, дефектов и возможностей, как DPMO, так и уровня сигмы.
- Дефекты на возможность (dpo) = дефект/(продукт x возможностей). …
- Дефекты на миллион возможностей (DPMO) Шесть сигма определяется путем оценки DPMO, умножьте DPO на один миллион.
Как вы рассчитываете метрику DPMO?
dpmo = 4/500*1 000 000 или 8000.
Почему мы рассчитываем DPMO?
Это мера производительности процесса, используемая для оценки качества процесса – например, качества обслуживания или производства. Чем ниже значение DPMO, тем лучше, так как он связан с вероятностью наличия дефекта.
Каково значение dpmo?
Номер DPMO указывает на количество дефектов, наблюдаемых или ожидаемых в процессе, когда есть возможность (возможность) создало миллион дефектов . Это нормализованное число, так что легко сравнивать процессы, которые могут иметь разные возможности для ошибки (OFE) в каждой единице.
Что делает DPMO?
В усилиях по улучшению процессов, дефекты на миллион возможностей или DPMO (или несоответствия на миллион возможностей (NPMO)) – это мера эффективности процесса . Это определено как. Дефект может быть определен как несоответствие качественной характеристики (например, сила, ширина, время отклика) к ее спецификации.
Что такое хороший балл DPMO?
В Six Sigma показатель качества, который продукты должны соответствовать, составляет 3.4 на шкала DPMO. Это означает, что продукт или услуга считается высоким качеством в зависимости от стандарта Six Sigma, если он имеет максимум 3,4 дефекта на миллион возможностей.
.
Почему Six Sigma означает 3.4 дефекты?
Цель качества Six Sigma состоит в том, чтобы снизить изменение вывода процесса , так что на долгосрочной основе, который является совокупным опытом клиента с нашим процессом с течением времени, это приведет к не более 3,4 Дефектные части на миллион (ppm) возможностей (или 3,4 дефекта на миллион возможностей – DPMO).
Что такое формула CPK?
CPK – это индекс возможностей процесса, используемый для измерения того, что способен процесс. … формула для расчета CPK составляет cpk = min (usl – î¼, î¼ – lsl)/ (3ïƒ) , где USL и LSL являются пределами верхней и нижней спецификации, соответственно.
Что такое формула Six Sigma?
Наиболее важным уравнением Six Sigma является y = f (x) , где y является эффектом, а x – причины, поэтому, если вы удалите причины, вы удаляете следствие дефекта.
Что такое уровень сигмы dpmo?
Когда программа улучшения качества составляет шесть сигм, цель организации очевидна-достичь уровня сигмы в шесть или хорошо известной цели дефектов 3,4 на миллион возможностей ( DPMO). Организация, действующая на этом уровне, описывается шестью сторонниками Sigma как мировой класс.
Что такое сигма?
уровень Sigma-это статистический расчет, который получает краткосрочную информацию, касающуюся дефектов на миллион возможностей (DPMO) процесса, факторы, наклоненные процесса, сдвинувшись с течением времени, и дает оценку значения уровня, представляющую модифицированный DPMO с сдвигом в попытке помочь определить, есть ли …
Как вы рассчитываете общее время заказа?
А вот формула:
- Takt Time = Чистое время производства/спрос клиента.
- Время цикла = чистое время производства/количество сделанных единиц.
- Время выполнения (производство) = время предварительной обработки + время обработки + время после обработки.
- Время выполнения выполнения (управление цепочкой поставок) = Задержка поставок + задержка повторного заказа.
в чем разница между ppm и dpmo?
dpmo (дефекты на миллион возможностей) используются в качестве альтернативы PPM (части на миллион дефектных). Для клиентов дефектные предметы или не соответствующие результаты являются главной проблемой, и у них есть положения о штрафе, основанные на PPM. Компании иногда предпочитают использовать DPMO вместо PPM в качестве показателя производительности процесса.
Как рассчитывается DPPM?
Один DPPM означает один (дефект или событие) за миллион или 1/1 000 000 . Например, чтобы рассчитать, допустим, у вас было 25 штук дефектных в отправке 1000 штук. 25/1000 =. 025 или 2,5% дефектных.
Что такое хороший результат сигмы?
Процесс с 50% дефектами (DPMO = 500 000) будет иметь сигма -уровень 0. Обычно процесс с уровнем сигмы 6 или более обычно считается превосходным процессом. /p>
каковы 6 сигма?
Процесс Six Sigma имеет предел спецификации, который в 6 раз больше его сигмы (стандартного отклонения) от его среднего . Следовательно, точка данных процесса может быть 6 стандартными отклонениями от среднего и до сих пор приемлемой.
Что такое процесс 3 сигмы?
В бизнес-приложениях три сигма ссылаются на процессы, которые действуют эффективно и производят предметы самого высокого качества . Тримины с тремя сигмами используются для установки верхних и нижних ограничений управления в статистических диаграммах управления качеством.
Что такое 5 -сигма -результат?
В большинстве случаев результат из пяти сигма является считается золотым стандартом для значимости , что соответствует примерно один на один на один на миллион вероятности того, что результаты являются лишь результатом случайных вариаций; Six Sigma переводится на один шанс за полмиллиард, что результатом является случайная случайность.
Как уменьшить dpmo?
Уменьшите DPMO вашего бизнес -процесса за счет , определив, какие части процесса создали наиболее дефекты, и работая над улучшением этого компонента процесса . В производственных процессах это может идентифицировать машины, которую необходимо заменить или неэффективные методы работы.
Какое влияние на уровень сигмы DPMO?
Sigma – это мера изменчивости или распространения процесса. Чем выше уровень сигмы, тем меньше дефектов, которые создает процесс. Производительность Six Sigma – это долгосрочный (будущий) процесс, который создает уровень дефектов 3,4 на миллион возможностей (DPMO).
Каково использование dpmo?
Дефекты на миллион возможностей (DPMO) составляет количество дефектов в выборке, деленной на общее количество возможностей дефектов, умноженных на 1 миллион . DPMO стандартизирует количество дефектов на уровне возможностей и полезно, потому что вы можете сравнивать процессы с разными сложностями.

- Формула ДПМО
Формула DPMO (Содержание)
- формула
- Примеры
- Калькулятор
Формула ДПМО
DPMO обозначает дефекты на миллион возможностей. Эту концепцию мы привыкли слышать при производстве, и большую часть времени она используется производителями, которые участвуют в производственном процессе. DPMO — это один из полезных инструментов для определения вероятности появления дефектов в процессе производства, поэтому мы можем правильно использовать имеющиеся ресурсы и контролировать дефекты, возникающие в процессе производства. DPMO раньше знал количество возможностей для дефектов в процессе производства.
Формула для ДПМО —
DPMO = Total Number of Defects found in Sample / (Sample Size * Number of Defects Opportunities per Unit in the Sample) * 1000000
Примеры формулы DPMO (с шаблоном Excel)
Давайте рассмотрим пример, чтобы лучше понять расчет формулы DPMO.
Вы можете скачать этот шаблон DPMO Excel здесь — Шаблон DPMO Excel
Формула DPMO — Пример № 1
Форма содержит 20 полей информации, и только 10 форм проверяются и отбираются, и в выборке обнаружено 26 дефектов. Рассчитайте DPMO.
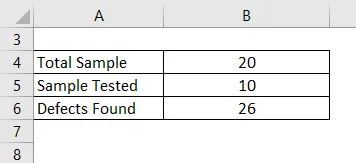
Решение:
DPMO рассчитывается по формуле, приведенной ниже
DPMO = общее количество дефектов, обнаруженных в образце / (размер образца * число возможностей дефектов на единицу в образце) * 1000000
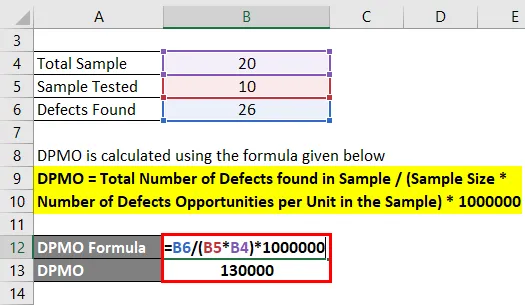
- DPMO = 26 / (10 * 20) * 1000000
- DPMO = 130000
Выше расчета мы ясно видим, что существует вероятность 130000 дефектов на миллион возможностей.
Формула DPMO — Пример № 2
Компания Voltas занимается кондиционированием воздуха, поэтому каждый месяц они производили кондиционеры в соответствии со спросом на рынке. Таким образом, они производят 50 кондиционеров, но они берут только 40 кондиционеров для оценки, и они обнаружили, что есть некоторые дефекты в некоторых кондиционерах, когда они передают этот кондиционер в отдел исследований и разработок, в ходе оценки они обнаружили, что есть 70 дефектов. Рассчитайте DPMO.
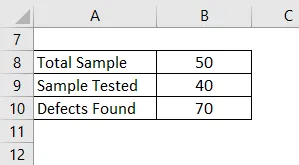
Решение:
DPMO рассчитывается по формуле, приведенной ниже
DPMO = общее количество дефектов, обнаруженных в образце / (размер образца * число возможностей дефектов на единицу в образце) * 1000000
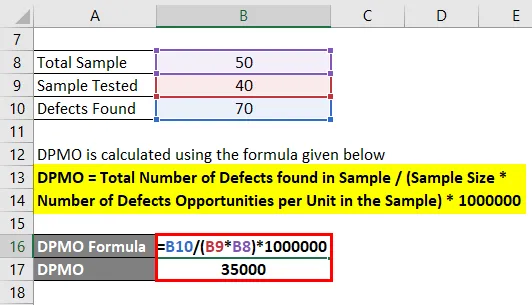
- DPMO = 70 / (40 * 50) * 1000000
- DPMO = 35000
Формула DPMO — Пример № 3
Компания A занимается производством и имеет собственный центр исследований и разработок для оценки качества. Они производят мобильные части и поставляют детали многим мобильным компаниям. Каждую неделю они производят 100 и вынимают только 80 для целей оценки, и на момент оценки они обнаруживают 156 дефектов в продуктах, рассчитывают DPMO.
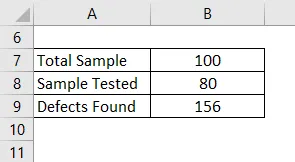
Решение:
DPMO рассчитывается по формуле, приведенной ниже
DPMO = общее количество дефектов, обнаруженных в образце / (размер образца * число возможностей дефектов на единицу в образце) * 1000000
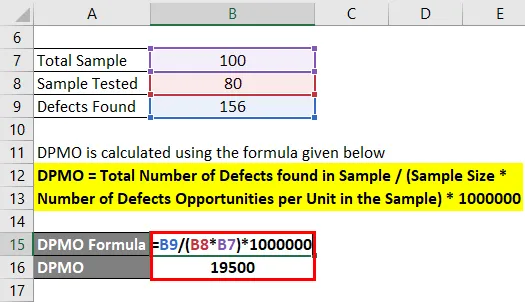
- DPMO = 156 / (80 * 100) * 1000000
- DPMO = 19500
Формула DPMO — Пример № 4
Tata Sponge занимается выплавкой железа и поставляет готовое железо металлургической компании. Они производят 520 железных прутков и предоставляют в отдел исследований и разработок только 500 стержней для оценки, а отдел исследований и разработок обнаружил, что в железном пруте имеется 635 дефектов. Рассчитайте DPMO.

Решение:
DPMO рассчитывается по формуле, приведенной ниже
DPMO = общее количество дефектов, обнаруженных в образце / (размер образца * число возможностей дефектов на единицу в образце) * 1000000
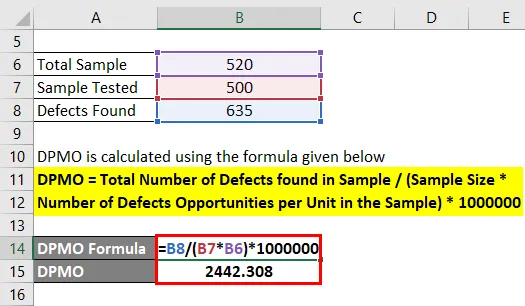
- DPMO = 635 / (500 * 520) * 1000000
- DPMO = 2442, 308
объяснение
DPMO = Общее количество дефектов, обнаруженных в образце / Общее количество возможных дефектов в образце * 100000
Таким образом, DPMO означает дефекты на миллион возможностей. DPMO является одним из показателей качества, который используется многими организациями и производственными компаниями для лучшего использования имеющихся, чтобы они могли предоставлять более качественные услуги. С помощью этого параметра мы можем узнать шансы или возможности для любых дефектов. Таким образом, общее число выборки учитывается в этой формуле и эта цифра делится на общее число возможных дефектов в выборке, и оно умножается на 1000000. Таким образом, с помощью одного из шести сигма-инструментов мы можем найти Мы исключаем вероятность появления дефектов в продукте, и мы стараемся исправить его, используя все ресурсы надлежащим образом.
Актуальность и использование формулы DPMO
DPMO мы привыкли слышать в области экономики и эксплуатации, и это актуально в эпоху современного мира, потому что оно помогает вам узнать о дефектах на миллион возможностей. Таким образом, он помогает многим производителям и оценивает вероятность появления дефектов на миллион. DPMO является одной из шести сигма-матриц, которая используется многими производителями и многими компаниями для проверки качества. DPMO может использоваться любой организацией для проверки качества, потому что качество является главной заботой во всех аспектах, поэтому очень важно обеспечить надлежащее и высокое качество для клиента, чтобы клиент был лояльным по отношению к продукту компании, Для проверки качества существует инструмент под названием «шесть сигм». В шести сигмах есть шесть инструментов, которые используются компаниями для проверки качества, но здесь мы говорим о DPMO, который является одним из наиболее важных шести сигма-инструментов. В DPMO мы можем найти дефекты на миллион возможностей в производственном процессе. Благодаря DPMO мы можем идентифицировать дефекты и принять корректирующие меры, чтобы избежать подобных дефектов в процессе производства.
DPMO Формула Калькулятор
Вы можете использовать следующий калькулятор DPMO
| Общее количество дефектов, найденных в образце | |
| Размер образца | |
| Количество возможностей дефектов на единицу в образце | |
| Формула DPMO = | |
| Формула DPMO = |
|
||||||||||
|
Рекомендуемые статьи
Это было руководство к формуле DPMO. Здесь мы обсудим, как рассчитать DPMO вместе с практическими примерами. Мы также предоставляем калькулятор DPMO с загружаемым шаблоном Excel. Вы также можете посмотреть следующие статьи, чтобы узнать больше —
- Формула Дохода от Продаж
- Руководство по формуле финансового рычага
- Расчет формулы текущих активов
- Как рассчитать собственный капитал?
Автор:
John Pratt
Дата создания:
13 Февраль 2021
Дата обновления:
20 Сентябрь 2023

Содержание
- Определение дефектов в бизнес-процессах
- Определение возможностей в бизнес-процессах
- Процесс расчета DPMO
- Использование для расчетов DPMO
Рецензент: Мишель Зайдель, бакалавр наук, бакалавр права, MBA
Методология управления, известная как Шесть Сигм стремится повысить эффективность и минимизировать дефекты в любом процессе. Один из методов, используемых практиками Шести сигм для определения эффективности процесса, — это измерение количества дефектов на миллион возможностей или ДПМО. DPMO означает дефектов на миллион возможностей.
Этот метод распознает, что для каждого компонента или действия в бизнес-процессе может возникнуть множество возможностей для дефектов. Метод DPMO позволяет более тщательно оценивать бизнес-процессы.
Определение дефектов в бизнес-процессах
Методология шести сигм определяет дефект как разница между желаемыми и фактическими результатами любого бизнес-процесса. Каждый этап процесса может содержать несколько возможностей для дефектов. Каждый дефект должен учитываться при расчете DPMO. Например, специалист по вводу данных может ввести ошибочные данные в три поля онлайн-формы. Каждое поле, содержащее ошибочные данные, может быть классифицировано как дефект в этой форме, поэтому одна форма содержит три дефекта.
Определение возможностей в бизнес-процессах
An возможность включает в себя любой этап бизнес-процесса, на котором может возникнуть дефект. Поскольку большинство бизнес-процессов подразумевают множество возможностей возникновения дефектов, метод шести сигм использует количество возможностей, а не количество завершенных процессов, для определения эффективности. Используя приведенный выше пример, специалист по вводу данных должен правильно ввести данные в 20 полей, чтобы завершить процесс ввода данных. Каждое поле представляет собой возможность для дефекта, поэтому процесс заполнения формы содержит 20 возможностей.
Процесс расчета DPMO
Сам процесс вычисления формулы DPMO относительно прост. DPMO — это отношение количества дефектов к количеству возможностей, умноженное на 1 миллион. Большинство предприятий используют образцы для определения полного объема DPMO.
Например, форма ввода данных содержит 20 полей. Была оценена выборка из 200 форм. Оценка выявила 500 дефектов в 200 формах. Расчет DPMO будет выглядеть так:
[(500 дефектов) / (20 возможностей / форма) x (200 форм)] x 1 000 000
= [500/4000] x 1 000 000
= [0,125] x 1 000 000
= 125 000 DPMO
Использование для расчетов DPMO
Эксперты «Шесть сигм» используют DPMO, чтобы измерить, насколько эффективно бизнес выполняет свои процессы. Каждая «сигма» представляет собой ступеньку выше средней производительности. Оценка 6.0 Sigma соответствует 3.4 DPMO, или 99,9997% бездефектности. Количество DPMO 125 000 из приведенного выше примера дает 87,5% бездефектности и 2,65 сигма.
Последствия и признаки появления ошибок в программе
Следствием
появления ошибки в программе является
ее отказ, заключающийся в отклонении
от выполнения программой заданных
функций. В зависимости от степени
серьезности последствий ошибок (отказов)
в программе эти отклонения можно
разделить следующим образом:
– полное прекращение
выполнения функций на длительное или
неопределенное время;
– кратковременное
нарушение хода вычислительного процесса.
Степень серьезности
последствий ошибок в программе может
быть оценена соотношением между
длительностью восстановительных работ,
которые необходимо произвести после
отказа в программе, и динамическими
характеристиками объектов, использующих
результаты работы программных средств.
К таким характеристикам объектов
относятся, например, инерционность
объектов, выступающих в качестве
источников и потребителей информации;
заданная частота решения задач обработки
информации; заданное время реакции
вычислительной системы на запросы
пользователей и др.
Наиболее типичными
симптомами появления ошибок в программе
являются:
-
преждевременное
(аварийное) окончание выполнения
программы; -
недопустимое
увеличение времени выполнения программы; -
зацикливание ЭВМ
на выполнении некоторой последовательности
команд одной из программ; -
полная потеря или
значительное искажение накопленных
данных, необходимых для успешного
выполнения решаемых задач; -
нарушение
последовательности вызова отдельных
программ, в результате чего происходит
пропуск необходимых программ либо
непредусмотренное обращение к программам; -
искажение отдельных
элементов данных (входных, выходных,
промежуточных) в результате обработки
искаженной исходной информации.
Аварийное завершение
прикладных программ, как правило, легко
идентифицируется, так как операционные
системы обеспечивают возможность выдачи
сообщений, содержащих соответствующий
аварийный код. Типичными причинами
появления кодов аварийного завершения
являются ошибки при выполнении
макрокоманды; неверное использование
методов доступа; нарушение защиты
памяти; нехватка ресурсов памяти;
неверное использование макрокоманды;
возникновение программных прерываний,
для которых не указан обработчик, и др.
При появлении
подобных ошибок после анализа аварийного
кода имеется принципиальная возможность
немедленного повторения запуска
прикладной программы. Для увеличения
эффективности восстановительных
процедур необходимо:
-
предусмотреть в
программах специальные средства
диагностики кодов аварийных завершений,
в том числе кодов, формируемых самими
пользователями; -
ввести в программы
контрольные точки; -
обеспечить
возможности рестарта программ с
контрольных точек.
Аналитические модели надежности программ
Аналитические
модели надежности дают возможность
исследовать закономерности проявления
ошибок в программах, а также прогнозировать
надежность при разработке и эксплуатации.
Модели надежности программ строятся
на предположении, что проявление ошибки
является случайным событием и поэтому
имеет вероятностный характер. Такие
модели предназначены для оценки
показателей надежности программ и
программных комплексов в процессе
тестирования: числа ошибок, оставшихся
не выявленными; времени, необходимого
для выявления очередной ошибки в процессе
эксплуатации программы; времени,
необходимого для выявления всех ошибок
с заданной вероятностью и т. д. Модели
дают возможность принять обоснованное
решение о времени прекращения отладочных
работ.
При построении
моделей используются следующие
характеристики надежности программы.
Функция
надежности
![]() ,
,
определяемая как вероятность того, что
ошибки программы не проявятся на
интервале времени от0
до
![]() ,
,
т. е. время ее безотказной работы будет
больше![]() .
.
Функция ненадежности
![]() – вероятность того, что в течение времени
– вероятность того, что в течение времени![]() произойдет отказ программы как результат
произойдет отказ программы как результат
проявления действия ошибки в программе.
Таким образом,
![]() .
.
Интенсивность
отказов
![]() – условная плотность вероятности
– условная плотность вероятности
времени до возникновения отказа программы
при условии, что до момента![]() отказа не было. Когда мы рассматривали
отказа не было. Когда мы рассматривали
потоки отказов и сбоев, мы показали
![]()
Средняя наработка
на отказ
![]() – математическое ожидание временного
– математическое ожидание временного
интервала между последовательными
отказами.
В настоящее время
основными типами применяемых моделей
надежности программ являются модели,
основанные на предположении о дискретном
изменении характеристик надежности
программ в моменты устранения ошибок,
и модели, основанные на экспоненциальном
характере изменения числа ошибок в
зависимости от времени тестирования и
функционирования программы.
Модель надежности
программ с дискретно-понижающейся
частотой (интенсивностью) проявления
ошибок.
В
этой модели предполагается, что
интенсивность обнаружения ошибок
описывается кусочно-постоянной функцией,
пропорциональной числу не устраненных
ошибок. Другими словами, предполагается,
что интенсивность отказов
![]() постоянна до обнаружения и исправления
постоянна до обнаружения и исправления
ошибки, после чего она опять становится
константой, но с другим, меньшим значением.
При этом предполагается, что между![]() и числом оставшихся в программе ошибок
и числом оставшихся в программе ошибок
существует прямая зависимость:
![]() ,
,
где
![]() – неизвестное первоначальное число
– неизвестное первоначальное число
ошибок;![]() – число обнаруженных ошибок, зависящее
– число обнаруженных ошибок, зависящее
от времени![]() ,
,![]() – некоторая константа (рис.2).
– некоторая константа (рис.2).

Рис.2 Зависимость
интенсивности отказов программы от
времени работы (модель с дискретно
понижающейся интенсивностью проявления
ошибок в программе)
Плотность
распределения времени обнаружения
![]() -й
-й
ошибки![]() задается соотношением
задается соотношением
![]() .
.
Значение неизвестных
параметров К
и М
может быть оценено на основании
последовательности наблюдений интервалов
между моментами обнаружения ошибок по
методу максимального правдоподобия.
При этом для нахождения оценок параметров
К
и М
необходимо решить следующие уравнения:
![]() ;
;
![]() ,
,
где
![]() ;
;![]() ;
;![]() ;
;![]() и
и![]()
– оценки
соответственно К
и М,
т
– число устраненных ошибок в момент
оценки надежности программ.
Рассмотренная
модель надежности программ является
достаточно грубой. На практике часто
не соблюдаются условия, на которых она
построена. Нередко при устранении ошибки
вносятся новые ошибки. Во многих случаях
не соблюдается также основное
предположение, что при всяком устранении
ошибки интенсивность отказов уменьшается
на одну и ту же величину К.
Не всегда удается определить и устранить
причину отказа, и программу часто
продолжают использовать, так как при
других исходных данных ошибка, вызвавшая
отказ, может себя и не проявить.
Модель надежности
программ с дискретным увеличением
времени наработки на отказ.
Данная модель
надежности программ построена на
предположении, что устранение ошибки
в программе приводит к увеличению
времени наработки на отказ на одну и ту
же случайную величину.
Предполагается,
что время между двумя последовательными
отказами
![]() является случайной величиной, которую
является случайной величиной, которую
можно представить в виде суммы двух
случайных величин:
![]() ,
,
где случайные
величины
![]() независимы и имеют одинаковые
независимы и имеют одинаковые
математические ожидания![]() и средние квадратические отклонения
и средние квадратические отклонения![]() .
.
Из выше приведенной
формулы следует, что т-й
отказ программы произойдет через время
 .
.
Предполагается
также, что
![]() .
.
Основанием для такого предположения
является то, что отказы программы в
начальном периоде эксплуатации возникают
часто. В этом случае можно считать, что
![]() .
.
При этих предположениях
средняя наработка между (![]() —1)-м
—1)-м
ит—м
отказами программы равна
![]() ,
,
а средняя наработка
до возникновения
![]() -го
-го
отказа определяется выражением
![]() .
.
Оценки величин
![]() ,
,![]() могут быть получены по данным об отказах
могут быть получены по данным об отказах
программы в течение периода наблюдения![]() следующим образом:
следующим образом:
![]() ;
;
![]() ,
,
где
![]() – число отказов программы за период
– число отказов программы за период![]() ;
;![]() – момент возникновения
– момент возникновения![]() -го
-го
отказа программы.
Функция надежности
определяется в зависимости от числа
возникших отказов
![]() ,
,
где Ф(х)
—функция
Лапласа.
Экспоненциальная
модель надежности программ.
Эта модель основана
на предположении об экспоненциальном
характере изменения во времени числа
ошибок в программе.
В этой модели
прогнозируется надежность программы
на основе данных, полученных во время
тестирования. В модели вводится суммарное
время функционирования
![]() ,
,
которое отсчитывается от момента начала
тестирования программы (с устранением
обнаруженных ошибок) до контрольного
момента, когда производится оценка
надежности.
Предполагается,
что все ошибки в программе независимы
и проявляются в случайные моменты
времени с постоянной средней интенсивностью
в течение всего времени выполнения
программы. Это означает, что число
ошибок, имеющихся в программе в данный
момент, имеет пуассоновское распределение,
а временной интервал между двумя отказами
распределен по экспоненциальному
закону, параметр которого изменяется
после исправления ошибки.
Следует отметить,
что характер закономерностей в этой
модели остается таким же, как и в
рассмотренных ранее, а именно интенсивность
отказов предполагается пропорциональной
числу оставшихся ошибок. Основное
отличие данной модели от предыдущих
состоит в том, что интенсивность отказов
предполагается непрерывной функцией.
Это упрощает математическое описание
модели, а модель приобретает дополнительную
гибкость.
Пусть М
– число
ошибок, имеющихся в программе перед
фазой тестирования (М
рассматривается как некоторая константа);
![]() – конечное число исправленных ошибок;
– конечное число исправленных ошибок;![]() – число оставшихся ошибок. Тогда
– число оставшихся ошибок. Тогда
![]() .
.
При принятых
предположениях интенсивность отказов
пропорциональна
![]() ,
,
т.е.
![]() ,
,
где С
–
коэффициент
пропорциональности, учитывающий реальное
быстродействие ЭВМ и число команд в
программе.
Введем дополнительное
предположение, что в процессе корректировки
новые ошибки не порождаются, т. е. что
интенсивность исправления ошибок
![]() будет равна интенсивности их обнаружения,
будет равна интенсивности их обнаружения,
т. е.
![]() .
.
Решая совместно
два последних уравнения, получаем
![]() .
.
Перед началом
работы ЭВМ
![]() ни одна ошибка исправлена не была
ни одна ошибка исправлена не была![]() ,
,
поэтому решением этого уравнения
является
![]() .
.
Будем характеризовать
надежность программы после тестирования
в течение времени
![]() средним временем наработки на отказ:
средним временем наработки на отказ:
![]() .
.
Следовательно,
![]() .
.
Введем
![]() – исходное значение среднего времени
– исходное значение среднего времени
наработки на отказ перед тестированием.
Тогда
![]() .
.
В результате имеем
![]()
Очевидно, что
среднее время наработки на отказ
увеличивается по мере выявления и
исправления ошибок.
Рассмотрим более
общий случай, когда в процессе корректировки
могут появляться новые ошибки. Пусть В
– коэффициент
уменьшения ошибок, определяемый как
отношение интенсивности уменьшения
ошибок к интенсивности их проявления,
т. е. к интенсивности отказов.
Пусть п—число
обнаруженных отказов, а
![]() – число отказов, которые должны произойти,
– число отказов, которые должны произойти,
чтобы можно было выявить и устранитьт
соответствующих ошибок, т. е.
![]()
![]() .
.
В этом случае
среднее время наработки на отказ
![]() и число обнаруженных отказовп
и число обнаруженных отказовп
определяются следующими соотношениями:
![]() ;
;
![]() .
.
Тогда для значения
среднего времени наработки на отказ
перед тестированием справедливо
![]() .
.
В результате
получаем
![]() ;
;
![]() .
.
Для практического
использования представляет интерес
число ошибок
![]() ,
,
которое должно быть обнаружено и
исправлено для того, чтобы добиться
увеличения среднего времени наработки
на отказ от![]() до
до![]() .
.
Этот показатель может быть получен из
следующих соотношений:
![]()
![]() .
.
Следовательно,
![]() .
.
Дополнительное
время работы, необходимое для обеспечения
увеличения среднего времени наработки
на отказ с
![]() до
до![]() ,
,
определяется как
![]() .
.
Рассмотрим, каким
образом можно оценить основные параметры
модели. Коэффициент В
может быть определен исходя из
статистических данных по числу ошибок,
порожденных во время обнаружения других
ошибок. Можно считать, что для систем
программного обеспечения общего
назначения В
изменяется в диапазоне 0,91—0,95.
Для оценки
![]() и
и![]() можно
можно
рассчитать среднюю интенсивность ошибок
(число ошибок на одну команду) в начале
различных фаз тестирования. По различным
оценкам в начале процесса тестирования
для программ, написанных на языке
ассемблера, число ошибок на 1000 команд
варьируется от 4 до 8. Рассмотренная
модель может применяться для определения
времени испытаний программ с целью
достижения заданного уровня надежности,
а также для оценки числа оставшихся в
программе ошибок.
Вторым существенным
составляющим стохастического
функционального тестирования является
проверка
правильности результатов вычислений
по генерированным случайным исходным
данным.
Проверка правильности
может осуществляться путем проверки
соответствия эталону; принадлежности
области; по времени выполнения; сравнения
с другими (соседними) значениями; через
достижения цели (в замкнутом контуре
управления).
Наиболее просто
проверка правильности осуществляется
через сравнение с эталоном. Эталоном
могут являться вычисления, выполняемые
по другой, эквивалентной программе или
другому алгоритму. Например, если
разработан улучшенный по быстродействию
вариант программы, то эталоном может
быть исходная программа.
Информационные
методы повышения
надежности
СВТ
Широко распространенным
методом повышения надежности СВТ
является обеспечение избыточности в
составе СВТ, в частности информационной
избыточности.
Применение
корректирующих кодов является одним
из наиболее удобных и гибких методов
введения избыточности в ЭВМ. В некоторых
условиях, например, при кратковременных
сеансах работы, когда ресурсы надежности
почти не расходуются, коррекция сбоев,
вызываемых различного рода помехами,
может иметь решающее значение для
обеспечения нормального функционирования.
Положительные качества корректирующих
кодов следующие:
1. корректирующие
коды обеспечивают исправление ошибок
без перерывов в работе ЭВМ;
2. способ кодирования
и применяемый код выбираются в зависимости
от алгоритма функционирования данного
вычислительного устройства, что дает
возможность согласования корректирующей
способности кода со статистическими
характеристиками потока ошибок устройства
и уменьшения избыточности, требуемой
для коррекции ошибок;
3. использование
корректирующих кодов позволяет учесть
необходимость устранения влияния ошибок
в устройстве последовательно на всех
этапах проектирования, начиная с
алгоритма функционирования.
Избыточность может
быть временной и пространственной.
Временная избыточность связана с
увеличением времени решения задачи (в
частном случае процесс решения задачи
может быть осуществлен дважды) и вводится
программным путем, являясь основой
программного способа обнаружения и
исправления ошибок.
Пространственная
избыточность заключается в удлинении
кодов чисел, в которые вводятся
дополнительные (контрольные) разряда.
Идея обнаружения и исправления ошибок
с использованием избыточности состоит
в следующем. Все множество
![]() выходных слов устройства разбивают на
выходных слов устройства разбивают на
подмножество разрешенных кодовых слов![]() ,
,
т.е. таких слов, которые могут появиться
в результате правильного выполнения
логических и арифметических операций,
и подмножество запрещенных кодовых
слов![]() ,
,
т.е. таких слов, которые могут появиться
только в результате ошибки.
Появившееся на
выходе устройства слово
![]() подвергают анализу. Если оно относится
подвергают анализу. Если оно относится
к подмножеству разрешенных слов, то оно
считается правильным и декодирующее
устройство переводит его в соответствующее
выходное слово![]() .
.
Если же слово![]() оказывается элементом подмножества
оказывается элементом подмножества
запрещенных слов, то это свидетельствует
о наличии ошибки.
Для исправления
обнаруженных ошибок запрещенные кодовые
слова разбиваются на группы. При этом
каждому разрешенному кодовому слову
соответствует одна такая группа. При
декодировании обнаруженное на выходе
устройства запрещенное кодовое слово
заменяется разрешенным словом, в группу
которого оно входит. Тем самым ошибка
исправляется. Однако работа декодирующего
устройства усложняется. Процесс
построения корректирующего кода состоит
из следующих этапов:
1 этап – выявление
наиболее вероятных ошибок для заданного
способа функционирования устройства
или наиболее опасных ошибок в условиях
использования этого устройства;
2 этап – формирование
избыточного множества выходных слов,
разделение этого множества на подмножества
разрешенных и запрещенных кодовых слов
и образование декодировочных групп;
3 этап – разработка
рационального способа декодирования
выходных слов, позволяющего реализовать
относительно несложными техническими
средствами обнаружение и исправление
ошибок;
4 этап – организация
множества входных так, чтобы заданное
преобразование, выполненное над любым
словом этого множества, дало на выходе
слово, принадлежащее к подмножеству
разрешенных кодовых слов.
При построении
ЭВМ, предназначенной для решения
определенного класса задач, важным
вопросом является рациональный выбор
уровня, на котором следует применять
корректирующий код.
Известно, что ЭВМ
слагается из отдельных устройств, в
каждом из которых информация претерпевает
определенные изменения. В то же время
составляющие части ЭВМ состоят из
отдельных блоков (сумматоров, регистров
и т.п.), которые в свою очередь набраны
из простейших логических элементов
(триггеров, схем И, ИЛИ, НЕ и т.п).
Корректирующие
коды применяют на любом из этих уровней
структуры ЭВМ. Однако результаты получают
различные. В ряде случаев корректировать
ошибки в работе логических схем
значительно труднее, чем например, в
работе сумматора в целом. Далее, если
контроль правильности и исправления
ошибок в работе отдельных блоков и
устройств осуществить сложно, то в
некоторых случаях прохождение всей
задачи легко контролируется применением
простейших принципов, например, путем
повторения счета.
Введение структурной
и информационной избыточности для
повышения надежности ЭВМ не дает желаемых
результатов, если при ее конструировании
будут нерационально решены компоновка
и конструктивное исполнение отдельных
узлов и блоков.
Для обеспечения
высокой надежности ЭВМ необходимо
стремиться максимально упростить
конструкцию, применять стандартные
элементы, обеспечивать возможность
проведения профилактики и контроля.