|
0 / 0 / 0 Регистрация: 25.06.2014 Сообщений: 4 |
|
|
1 |
|
Страничные ошибки в мониторинге процессов25.06.2014, 06:51. Показов 1751. Ответов 7
Здравствуйте! Я пишу программу мониторинга процессов, в этом проекте мне нужно реализовать определенные столбцы (как в диспетчере задач) такие как: Имя процесса, PID, Кол-во страничных ошибок, используемое ОЗУ, загрузка ЦП, приоритет и.т.д. Вопрос звучит так: как мне реализовать столбец Кол-во страничных ошибок? Какими способами можно это сделать?
0 |

|
0 / 0 / 0 Регистрация: 25.06.2014 Сообщений: 4 |
|
|
26.06.2014, 20:00 [ТС] |
2 |
|
Да, извините забыл указать,пишу на C#.
0 |
|
0 / 0 / 0 Регистрация: 25.06.2014 Сообщений: 4 |
|
|
27.06.2014, 23:55 [ТС] |
4 |
|
Спасибо, конечно, но я не смог разобраться что нужно конкретно сделать в классе System.Management чтобы получить список страничных ошибок процессов
0 |
|
Master of Orion
6096 / 4952 / 905 Регистрация: 10.07.2011 Сообщений: 14,522 Записей в блоге: 5 |
|
|
28.06.2014, 00:25 |
5 |
|
chopski, а что конкретно не получилось разобрать?
0 |
|
0 / 0 / 0 Регистрация: 25.06.2014 Сообщений: 4 |
|
|
29.06.2014, 07:15 [ТС] |
6 |
|
Когда разбирал статью, попытался найти в ManegementClass метод связанный с страничными ошибками. Не нашел, вот и прошу о помощи у тех, кого опыта больше.
0 |
|
Ушел с форума
16467 / 7431 / 1186 Регистрация: 02.05.2013 Сообщений: 11,617 Записей в блоге: 1 |
|
|
29.06.2014, 12:29 |
7 |
|
Вопрос звучит так: как мне реализовать столбец Кол-во страничных ошибок? Какими способами можно это сделать? Один из способов: GetProcessMemoryInfo См. поле PageFaultCount структуры PROCESS_MEMORY_COUNTERS.
0 |

|
Master of Orion
6096 / 4952 / 905 Регистрация: 10.07.2011 Сообщений: 14,522 Записей в блоге: 5 |
|
|
29.06.2014, 15:27 |
8 |
|
chopski, если нужно добавить какой-то незнакомый класс, то
0 |
На главную -> MyLDP ->
Тематический каталог ->
Аппаратное обеспечение
Оригинал:
Memory part 7: Memory performance tools
Автор: Ulrich Drepper
Дата публикации: ноябрь 2007 г.
Перевод: М.Ульянов
Дата перевода: 5 мая 2010 г.
Инструменты для повышения производительности памяти
7.5 Оптимизация страничных ошибок
В операционных системах с замещением страниц по требованию (Linux — одна из таких систем) всё, что делает вызов mmap, — изменяет таблицы страниц. А именно — он гарантирует, что в случае обращения к страницам, связанным с файлами, соответствующие данные (файлы) будут доступны, а в случае обращения к анонимной памяти будут предоставлены страницы, инициализированные нулями. То есть, при вызове mmap в таких системах не происходит собственно выделения памяти. {Не согласны и хочется возразить? Погодите маленько, далее мы поговорим об исключениях.}
Память выделяется при первом обращении к странице, будь то запрос чтения или записи, либо при выполнении кода. В ответ на возникающую в таком случае страничную ошибку ядро берет на себя управление и определяет (с помощью дерева таблиц страниц), какие данные должна содержать страница. Такая обработка страничных ошибок недешево обходится, но тем не менее именно это происходит с каждой страницей, используемой процессом.
Для минимизации стоимости страничных ошибок (стоимость здесь и далее — в смысле «потери производительности») необходимо снижать общее число используемых страниц памяти. Этой цели может послужить соответствующая оптимизация исходного кода. Для уменьшения стоимости определенной области кода (например, кода инициализации), можно реорганизовать его в таком порядке, чтобы в данной области количество затрагиваемых страниц памяти было минимально. Но не так уж просто определить «правильный» порядок.
Автор данной работы написал утилиту на основе инструментария valgrind, позволяющую контролировать появление страничных ошибок. Но контролировать не количество, а причину их возникновения. Инструмент pagein выдает информацию о порядке и времени возникновения страничных ошибок. Выходные данные, записываемые в файл pagein.<PID>, выглядят как показано на рисунке 7.8.
0 0x3000000000 C 0 0x3000000B50: (within /lib64/ld-2.5.so) 1 0x 7FF000000 D 3320 0x3000000B53: (within /lib64/ld-2.5.so) 2 0x3000001000 C 58270 0x3000001080: _dl_start (in /lib64/ld-2.5.so) 3 0x3000219000 D 128020 0x30000010AE: _dl_start (in /lib64/ld-2.5.so) 4 0x300021A000 D 132170 0x30000010B5: _dl_start (in /lib64/ld-2.5.so) 5 0x3000008000 C 10489930 0x3000008B20: _dl_setup_hash (in /lib64/ld-2.5.so) 6 0x3000012000 C 13880830 0x3000012CC0: _dl_sysdep_start (in /lib64/ld-2.5.so) 7 0x3000013000 C 18091130 0x3000013440: brk (in /lib64/ld-2.5.so) 8 0x3000014000 C 19123850 0x3000014020: strlen (in /lib64/ld-2.5.so) 9 0x3000002000 C 23772480 0x3000002450: dl_main (in /lib64/ld-2.5.so)Рисунок 7.8: Выходные данные утилиты pagein
Второй столбец содержит адрес запрошенной страницы. Содержит она код или данные, указывается в третьем столбце, соответственно `C’ (Code) — код, `D’ (Data) — данные. Четвертый столбец содержит количество тактов, прошедших с момента первой страничной ошибки. Оставшаяся часть строки — попытка valgrind’а определить имя для адреса, вызвавшего данную страничную ошибку. Само значение адреса всегда верно, но с именем могут быть несоответствия, если нет доступа к информации отладки.
В примере, показанном на рисунке 7.8, выполнение начинается с адреса 0x3000000B50, который запрашивает страницу по адресу 0x3000000000. Вскоре запрашивается следующая за ней страница, на этот раз функцией под названием _dl_start. Код инициализации обращается к переменной на странице 0x7FF000000. Это происходит по прошествии всего 3,320 тактов после первой страничной ошибки и больше всего похоже на вторую инструкцию программы (от первой ее отделяют лишь три байта). Давайте взглянем на саму программу: видим нечто необычное относительно доступа к памяти. А именно, обращает на себя внимание инструкция call, которая вроде бы не загружает и не записывает никаких данных. Но она сохраняет адрес возврата в стек, что, собственно, мы и наблюдали в выходном отчете. Конечно, имеется в виду не официальный стек процесса, а внутренний стек приложения, используемый valgrind. Следовательно, при интерпретации результатов pagein важно помнить, что valgrind может внести некоторые искажения.
Выходные данные pagein можно использовать для определения, какие последовательности инструкций программы в идеале должны быть расположены рядом друг с другом. С первого же взгляда на код /lib64/ld-2.5.so видно, что первые команды сразу вызывают функцию _dl_start, и что два этих места расположены на разных страницах. Таким образом, реорганизация исходника путем перемещения кодовых последовательностей на одну и ту же страницу памяти может помочь избежать страничной ошибки — или хотя бы отсрочить её. Но пока что определение максимально эффективной организации кода — процесс обременительный. Поскольку повторные запросы страниц утилитой не записываются, то чтобы увидеть результаты изменений, приходится использовать метоб проб и ошибок. Путем анализа диаграммы вызовов можно предсказать возможные последовательности запросов, что поможет ускорить процесс сортировки функций и переменных.
На очень грубом, поверхностном уровне, последовательности запросов можно увидеть, изучая объектные файлы, из которых в итоге создается исполняемый модуль или DSO (Dynamic Shared Object = динамически разделяемый объект). Начиная с одной или нескольких отправных точек (например, имен функций), можно вычислять цепочки зависимостей. На уровне объектных файлов это неплохо работает даже без приложения особых усилий. На каждом проходе определяем, какие из объектных файлов содержат нужные нам функции и переменные. Начальный набор файлов необходимо определить однозначно. Затем выделяем все неопределенные ссылки в этих объектных файлах и добавляем их [ссылки] к набору нужных идентификаторов. И так повторяем, пока набор не станет стабилен.
Второй шаг — определение порядка. Объектные файлы необходимо скомпоновать друг с другом таким образом, чтобы «задеть» как можно меньше страниц памяти. Вдобавок, ни одна функция не должна пересекать границу страницы. Сложность в том, что для лучшего расположения объектных файлов необходимо знать, что дальше будет делать компоновщик. Тут важно, что компоновщик помещает объектные файлы в исполняемый модуль (или DSO) в том же порядке, в каком они расположены во входных файлах (например, архивах) и в командной строке. Это дает программисту значительные возможности.
Для тех, кто готов потратить немного больше времени: были успешные попытки реорганизации, сделанные с помощью автоматического отслеживания запросов через перехватчики (hooks) __cyg_profile_func_enter и __cyg_profile_func_exit, которые вставляет gcc при запуске с параметром -finstrument-functions [oooreorder]. Подробную информацию об интерфейсах __cyg_* можно найти в руководстве к gcc. Используя трассировку программы, программист может более точно определить цепочки запросов. Результаты, достигнутые в [oooreorder] — снижение стоимости инициализации на 5%, и это достигнуто всего лишь перестановкой функций. Основная польза — снижение числа страничных ошибок, но и кэш TLB тоже играет роль, и немалую, учитывая, что в виртуальных средах промахи TLB обходятся гораздо дороже.
Комбинируя анализ вывода утилиты pagein с информацией о последовательности запросов, можно оптимизировать определенные этапы работы программы (инициализация тому примером), минимизируя число страничных ошибок.
Ядро Linux предоставляет два дополнительных механизма для избежания страничных ошибок. Первый — флаг для mmap, заставляющий ядро не просто модифицировать таблицу страниц, но, по сути, заранее загрузить все страницы в отображаемой области. Это достигается просто — к четвертому параметру вызова mmap добавляется флаг MAP_POPULATE. В результате вызов mmap обойдется значительно дороже, но, если все страницы, выделенные по данному запросу, будут использованы в ближайшее время, преимущества могут оказаться огромными. Вместо обработки множества страничных ошибок, каждая из которых обходится довольно дорого в связи с требованиями синхронизации и пр., программе придется обработать всего один, хоть и дорогой, вызов mmap. Обратная сторона медали, т.е. этого флага, проявляется в случаях, когда большая часть выделенных страниц не используется в ближайшее время после вызова (или не используется вообще). Выделенные, но не используемые страницы — просто пустая трата времени и памяти. Страницы, выделенные, но не использованные сразу (в ближайшее время) после вызова, тоже засоряют систему. Память выделяется еще до того, когда это действительно нужно, что теоретически может привести к нехватке свободного места. С другой стороны, в худшем случае страница просто будет использована для других целей (ведь она еще не была изменена), что не так уж дорого обходится системе — хотя, с учетом выделения, чего-то тоже стоит.
В целом, механизму MAP_POPULATE недостает избирательности. А вторая проблема: это лишь оптимизация; даже если выделены все-все страницы — не беда. Если система слишком занята для выполнения операции, предварительное выделение может быть отменено. А когда страница будет реально нужна, опять же произойдет страничная ошибка; ничего страшного — по крайней мере, не страшнее искусственного создания нехватки ресурсов. Альтернатива — применение POSIX_MADV_WILLNEED с функцией posix_madvise. Это подсказка операционной системе, что в ближайшем будущем программе понадобится страница, описанная в запросе. Ядро может как проигнорировать эту подсказку, так и заранее выделить страницы. Преимущество этого механизма в том, что он более избирателен. Предварительно загружены могут быть как отдельные страницы, так и диапазоны страниц в любом отображенном адресном пространстве. В случае отображенного в память файла, содержащего множество не используемых при выполнении данных, этот метод имеет огромное преимущество перед MAP_POPULATE.
Помимо этих активных подходов к минимизации количества страничных ошибок, также можно применить более пассивный подход, популярный среди разработчиков оборудования. Динамически разделяемый объект (DSO) занимает смежные страницы в адресном пространстве, часть из них содержит код, другая часть — данные. Чем меньше размер страницы, тем больше страниц необходимо для одного объекта DSO. А это, в свою очередь, увеличивает число страничных ошибок. Но важно отметить, что верно и обратное. Чем больше размер страницы, тем меньше их нужно для отображения; а следовательно, уменьшается и число страничных ошибок.
Большинством архитектур поддерживаются страницы размером в 4 Кб. На IA-64 и PPC64 популярен размер страниц в 64 Кб. Это значит, что минимальный объем выделяемой памяти составляет 64 Кб. Данное значение необходимо указывать при компиляции ядра, и его нельзя изменить динамически, во время работы. По крайней мере, пока нельзя. Интерфейсы ABI архитектур, поддерживающих несколько размеров страниц, позволяют запускать приложения с любым из поддерживаемых размеров. Среда выполнения сама сделает необходимые настройки, а корректно написанная программа ничего не заметит. Увеличенные размеры страниц означают больше потерь в результате того, что страницы используются лишь частично, но в некоторых ситуациях это вполне допустимо.
Большинство архитектур также поддерживают очень большие размеры, от 1 Мб и больше. Такие страницы иногда бывают полезны, но выделять всю память такими огромными кусками — бессмысленно. Слишком велики будут потери физической памяти. Но огромные страницы имеют свои преимущества: если используются не менее огромные наборы данных, то хранение их в страницах по 2 Мб на х86-64 потребует на 511 страничных ошибок меньше (в расчете на каждую большую страницу), чем применение страничек по 4 Кб. Это может в корне всё изменить. Решение: избирательно выделять память таким образом, чтобы использовались большие страницы именно для указанного диапазона адресов, а для остальных отображений того же процесса оставить обычные размеры страниц.
Использование больших страниц имеет свою цену. Поскольку области физической памяти, используемые для больших страниц, должны быть непрерывны, то спустя какое-то время отображение таких страниц может стать невозможным вследствие фрагментации памяти. Не доводите до такого. Люди работают над проблемами дефрагментации памяти и способами избежания фрагментации, но это очень сложно. Для больших страниц размером, скажем, 2 Мб, необходимо найти 512 последовательных страничек, а это сложно сделать практически всегда, за исключением одного периода: загрузки системы. Вот поэтому-то сегодня для использования больших страниц применяется специальная файловая система, hugetlbfs. Эта псевдо-файловая система резервируется по требованию системного администратора с помощью записи количества страниц, которое необходимо зарезервировать, в
/proc/sys/vm/nr_hugepages
Данная операция не будет выполнена, если не будет найдено достаточно свободных, последовательно расположенных областей памяти. Становится еще интересней, если используется виртуализация. Виртуальная система, созданная с использованием модели VMM, не имеет прямого доступа к физической памяти и потому не может сама выделить hugetlbfs. Ей приходится полагаться на менеджер VMM, и не факт, что данная функциональность вообще поддерживается. Что касается модели KVM, ядро Linux, на котором запущен модуль KVM, может выполнить монтирование hugetlbfs и передать подмножество страниц для выделения на одном из гостевых доменов.
В дальнейшем, когда программе потребуется страница большого размера, будет несколько вариантов:
- программа может использовать разделяемую память System V, применив флаг
SHM_HUGETLB. - файловая система
hugetlbfsможет быть полностью смонтирована и затем программа может создавать файл уже внутри, и использоватьmmapдля отображения одной (или более) страниц в качестве анонимной памяти.
В первом случае hugetlbfs не требует монтирования. Код, запрашивающий одну или более страниц, будет выглядеть примерно так:
key_t k = ftok("/some/key/file", 42);
int id = shmget(k, LENGTH, SHM_HUGETLB|IPC_CREAT|SHM_R|SHM_W);
void *a = shmat(id, NULL, 0);
Критичные моменты данной кодовой последовательности — применение флага SHM_HUGETLB и выбор верного значения LENGTH, которое должно быть кратно размеру больших страниц системы. Для разных архитектур используются разные значения. Использование интерфейса разделяемой памяти System V неудобно, ибо завязано на ключевом аргументе для различия (разделения) отображений. Интерфейс ftok может легко привести к конфликтам, и поэтому лучше — если возможно — использовать другие механизмы.
Если требование обязательного монтирования системы hugetlbfs — не проблема, то лучше использовать именно этот вариант заместо разделяемой памяти System V. На деле может возникнуть пара затруднений с использованием специальной файловой системы — во-первых, ядро должно поддерживать ее, и во-вторых, пока нет стандартизированной точки монтирования. Когда файловая система смонтирована, к примеру, в /dev/hugetlb, программа легко может ее использовать:
int fd = open("/dev/hugetlb/file1", O_RDWR|O_CREAT, 0700);
void *a = mmap(NULL, LENGTH, PROT_READ|PROT_WRITE, fd, 0);
Используя одно и то же имя файла в запросе open, разные процессы могут совместно использовать одни и те же большие страницы и взаимодействовать. Также есть возможность сделать страницы исполняемыми, для чего нужно установить флаг PROT_EXEC в запросе mmap. Как и в примере с разделяемой памятью System V, значение LENGTH должно быть кратно размеру больших страниц.
Аккуратно написанные программы (а такими должны быть все программы) могут определять точку монтирования во время выполнения, используя функцию вроде этой:
char *hugetlbfs_mntpoint(void) {
char *result = NULL;
FILE *fp = setmntent(_PATH_MOUNTED, "r");
if (fp != NULL) {
struct mntent *m;
while ((m = getmntent(fp)) != NULL)
if (strcmp(m->mnt_fsname, "hugetlbfs") == 0) {
result = strdup(m->mnt_dir);
break;
}
endmntent(fp);
}
return result;
}
Больше информации об этих двух случаях можно найти в файле hugetlbpage.txt, являющемся частью дерева исходников ядра. Этот файл также описывает особый подход, требуемый в случае IA-64.
Рисунок 7.9: Выборка с применением больших страниц памяти, NPAD=0
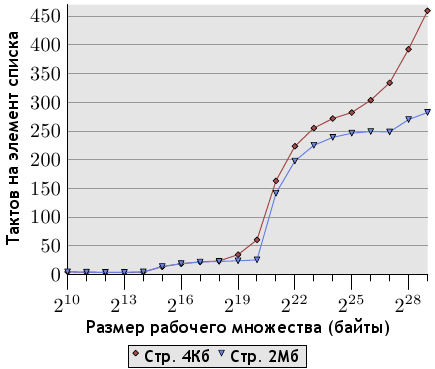
Чтоб продемонстрировать преимущества больших страниц, на рисунке 7.9 показаны результаты выполнения теста случайной выборки при NPAD=0. Это те же данные, что показаны на рисунке 3.15, но в этот раз мы используем также страницы памяти большого размера. Как видно — преимущество в производительности может быть огромно. Для 220 байт использование больших страниц дало прирост производительност в 57%. Это связано с тем, что данный размер всё еще полностью умещается в одну страницу размером 2 Мб, и потому не происходит никаких промахов DTLB.
Далее прирост поначалу не столь высок, но с повышением размера рабочего множества снова увеличивается. Для рабочего множества в 512 Мб использование больших страниц дает прирост производительности в 38%. Кривая теста с использованием больших страниц выравнивается на отметке в 250 тактов. Когда рабочие множества достигают размеров более 227 байт, цифры снова значительно вырастают. Причина выравнивания в том, что буфер TLB в 64 элемента для страниц в 2 Мб покрывает 227 байт.
Как показывают цифры, большую часть потерь при использовании больших рабочих множеств составляют потери TLB. Использование интерфейсов, описанных в этом разделе, дает большой выигрыш. Скорее всего, данные этого графика соответствуют идеальному варианту, но даже реально работающие программы демонстрируют значительное увеличение в скорости. Среди программ, использующих сегодня страницы больших размеров, находятся базы данных, поскольку они работают с большими объемами данных.
На данный момент нет способов использования больших страниц для отображения данных, связанных с файлами. Есть заинтересованность в реализации данной возможности, но все сделанные пока что предложения подразумевают использование исключительно больших страниц с помощью файловой системы hugetlbfs. Это неприемлемо: использование больших страниц в данном случае должно быть прозрачным. Ядро может легко определять, какие отображения достаточно велики, и может автоматически использовать страницы большого размера. Проблема в том, что ядро не всегда в курсе важных нюансов. Если память, отображаемая большими страницами, в дальнейшем потребуется разделить на маленькие, по 4 Кб (например, в случае частичного изменения защиты с применением mprotect), то будет потеряно очень много драгоценных ресурсов, в частности, последовательных областей физической памяти. Так что можно быть уверенным: пройдет еще какое-то время, прежде чем такой подход будет успешно реализован.
Замечания и предложения по переводу принимаются по адресу
michael@right-net.ru. М.Ульянов.
Если вам понравилась статья, поделитесь ею с друзьями:
Эксперимент. Наблюдение за ошибками страниц
Количество ошибок страниц, генерируемых процессом, можно наблюдать при помощи счетчика «Ошибок страницы». На рис. приведены графики поведения счетчиков «Ошибок страниц» и «Рабочее множество» для
процесса DempPageFaults. (см. программу, описанную выше)
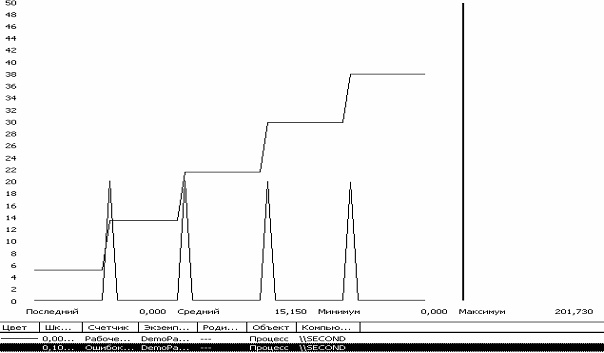
Рис.
10.6.
Наблюдение за размером рабочего набора процесса и количеством страничных ошибок
Графики, приведенные на
рис.
10.6, показывают, что увеличение рабочего набора коррелирует с интенсивностью процессов подкачки внешней памяти.
При помощи утилиты Pfmon.exe из ресурсов Windows можно не только «увидеть» общее количество страничных нарушений, но и определить виртуальные адреса, обращения к которым эти нарушения спровоцировали. На примере 10.1 приведен фрагмент результатов работы данной утилиты для процесса DemoPageFaults.
… SOFT: RtlFillMemoryUlong+0x10 : 0x00232000 SOFT: RtlFillMemoryUlong+0x10 : 0x00233000 SOFT: GetConsoleInputWaitHandle+0x11a : GetConsoleInputWaitHandle+0x119 SOFT: FindFirstFileExA+0x285 : FindFirstFileExA+0x285 SOFT: main+0xe4 : 0x00440000 SOFT: main+0xe4 : 0x00441000 SOFT: main+0xe4 : 0x00442000 SOFT: main+0xe4 : 0x00443000 SOFT: main+0xe4 : 0x00444000 SOFT: main+0xe4 : 0x00445000 SOFT: main+0xe4 : 0x00446000 SOFT: main+0xe4 : 0x00447000 SOFT: main+0xe4 : 0x00448000 SOFT: main+0xe4 : 0x00449000 SOFT: main+0xe4 : 0x0044a000 SOFT: main+0xe4 : 0x0044b000 SOFT: main+0xe4 : 0x0044c000 SOFT: main+0xe4 : 0x0044d000 SOFT: main+0xe4 : 0x0044e000 SOFT: main+0xe4 : 0x0044f000 SOFT: main+0xe4 : 0x00450000 SOFT: main+0xe4 : 0x00451000 SOFT: main+0xe4 : 0x00452000 SOFT: main+0xe4 : 0x00453000 SOFT: main+0xe4 : 0x00454000 SOFT: main+0xe4 : 0x00455000 …
Пример
10.3.
Часть результатов работы утилиты Pfmon.exe по отношению к процессу DemoPageFaults
Отдельные аспекты функционирования менеджера памяти
Корректная работа менеджера памяти помимо принципиальных вопросов, связанных с выбором абстрактной модели виртуальной памяти и ее аппаратной поддержкой, обеспечивается также множеством нюансов и мелких деталей.
Примером может служить локализация страниц в памяти, что означает временный запрет на выгрузку некоторых страниц, хранящих буферы ввода-вывода или другие важные данные и код, например, код и данные процессов реального времени.
Локализация страниц в памяти
По умолчанию, процессу разрешается блокировать максимум 30 страниц памяти. Если увеличить рабочее множество процесса при помощи функции SetProcessWorkingSetSize, то, согласно документации, максимальное число страниц, которое процесс может блокировать, равно минимальному размеру его рабочего набора за вычетом 8 страниц.
Локализация страниц в памяти осуществляется при помощи Win32 функции VirtualLock, а освобождение страниц — при помощи VirtualUnlock. Учет локализованных страниц ведется в страничной базе PFN.
Прогон программы, демонстрирующей блокировку страниц в памяти
Приведенный листинг является примером такой программы.
#include <windows.h>
#include <stdio.h>
void main(void)
{
PVOID pMem = NULL;
int nPageSize = 4096;
int nPages = 400;
int nPageLock = 100;
long SizeCommit = 0;
int i;
char * Ptr;
int nMinPages = 200, nMaxPages = 500;
long dwMinimumWorkingSetSize = 0, dwMaximumWorkingSetSize = 0;
HANDLE hProcess;
hProcess = GetCurrentProcess();
dwMinimumWorkingSetSize = nMinPages * nPageSize;
dwMaximumWorkingSetSize = nMaxPages * nPageSize;
i = SetProcessWorkingSetSize(hProcess, dwMinimumWorkingSetSize, dwMaximumWorkingSetSize);
if(i==0) printf("SetProcessWorkingSetSize Error\n");
SizeCommit = nPages * nPageSize;
pMem = VirtualAlloc(0, SizeCommit, MEM_RESERVE| MEM_COMMIT, PAGE_READWRITE);
if(pMem == NULL) printf("VirtualAlloc Error\n");
Ptr = (char *)pMem;
for(i=0; i<nPages; i++) Ptr[i*nPageSize] = '0';
i = VirtualLock(pMem, nPageLock * nPageSize);
if(i==0) printf("VirtualLock Error\n");
for(i=0; i<nPages; i++) Ptr[i*nPageSize] = '0';
VirtualUnlock(pMem, nPageLock * nPageSize);
VirtualFree(pMem, 0, MEM_RELEASE);
}
Копирование при записи
Другой нюанс в работе менеджера памяти, который можно проиллюстрировать на практике, связан с реализацией алгоритма отложенного выделения памяти — копирование при записи (copy-on-write). Это один из примеров алгоритма отложенной оценки (lazy evaluation), которые усложняют систему, но делают её более эффективной.
Рассмотрим ситуацию, когда некоторая приватная область памяти процесса является точной копией уже существующего в системе фрагмента памяти. Например, память дочернего процесса после вызова функции fork() в Unix является копией памяти родительского процесса. Другой пример — совместное использование динамической библиотеки, до тех пор, пока одна из программ не поменяла ее статические данные. В таких случаях разумно не выделять отдельную область памяти для процесса, а отображать в его адресное пространство уже существующую. Собственно выделение можно осуществить тогда, когда процесс приступит к изменению содержимого этой области. Эта техника называется копированием при записи.
Отложенное выделение памяти реализовано следующим образом. Отображаемые страницы помечаются флагом PAGE_WRITECOPY (доступные для чтения, но, в действительности, доступные для записи). Запись на такую страницу приводит к созданию ее приватной копии, которая и отображается на память. Теперь можно писать на эту страницу без риска изменить содержимое оригинальной страницы.
Прогон программы, иллюстрирующей отложенное выделение памяти
#include <windows.h>
#include <stdio.h>
void main(void)
{
HANDLE hMapFile;
LPVOID lpMapAddress;
HANDLE hFile;
char * String;
hFile = CreateFile("MyFile.txt",GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ| FILE_SHARE_WRITE, NULL, OPEN_ALWAYS,
FILE_ATTRIBUTE_NORMAL,NULL);
if (hFile == INVALID_HANDLE_VALUE) printf("Could not open file\n");
hMapFile = CreateFileMapping(hFile, NULL,
PAGE_WRITECOPY, // копирование при записи
0,0,"MyFileObject");
if (hMapFile == NULL) printf("Could not create file-mapping object.\n");
lpMapAddress = MapViewOfFile(hMapFile,
FILE_MAP_COPY, // копирование при записи
0,0,0);
if (lpMapAddress == NULL) printf("Could not map view of file.\n");
String = (char *)lpMapAddress;
getchar();
sprintf(String, "Hello, world");
printf("%s\n", String);
if (!UnmapViewOfFile(lpMapAddress)) printf("Could not unmap view of file.\n");
}
В приведенной программе часть страниц отображаемого файла помечена атрибутом PAGE_WRITECOPY. Запись текстовой строки в данный регион памяти осуществляется после нажатия клавиши «Enter». Рекомендуется осуществить прогон программы, наблюдая за счетчиком «запись копий страниц» при нажатии клавиши «Enter». Любопытно, что содержимое исходного файла при этом не меняется.
Контроль процессом памяти другого процесса
Изоляция адресных пространств различных процессов является базовой парадигмой современных ОС и обеспечивается путем прямой защиты памяти (атрибуты защиты) и косвенной защиты (механизм трансляции адреса). Вместе с тем, иногда возникают ситуации, когда доступ к памяти другого процесса все же необходим. В частности, эта возможность активно используется отладчиками.
Для доступа к памяти процесса нужно получить его описатель. Наиболее естественный способ получения описателя — получение описателя дочернего процесса путем извлечения его из параметра lProcessInformation функции CreateProcess.
Для создания регионов в памяти другого процесса можно использовать функцию VirtualAllocEx, которой нужно передать описатель этого процесса в качестве параметра. Для доступа к памяти другого процесса применяются функции ReadProcessMemory и WriteProcessMemory.
Написание, компиляция и выполнение программы, осуществляющей доступ к памяти дочернего процесса
Рекомендуется самостоятельно написать программу, которая создает регион памяти в адресном пространстве дочернего процесса и записывает в него текстовую строку. Задача дочернего процесса — вывести эту строку на экран.
Заключение
Базовой операцией менеджера памяти является трансляция виртуального адреса в физический с помощью таблицы страниц и ассоциативной (TLB) памяти. В ряде случаев, для реализации разделяемой памяти, интеграции с системой ввода-вывода и др., применяется прототипная таблица страниц, которая является промежуточным звеном между обычной таблицей страниц и физической памятью. Для описания страниц физической памяти поддерживается база данных PFN (page frame number). Локализацию страниц памяти, контроль процессом памяти другого процесса и технику копирования при записи можно отнести к интересным особенностям системы управления памятью ОС Windows.
Лабораторная
работа № 1
Цель работы
– практическое знакомство с методикой
использования функций Win32
API
для получения дополнительной информации
о процессах, потоках, модулях и драйверах
ОС Windows XP.
-
КРАТКИЕ ТЕОРЕТИЧЕСКИЕ
СВЕДЕНИЯ
-
Получение
дополнительной информации о процессах
и потоках
Задача получения
списка выполняющихся в системе процессов
и их базовых свойств является одной из
основных при выполнении мониторинга
ресурсов, как отдельного ПК, так и ЛВС
в целом. Для ее решения используются
базовые функции Win32
API
— CreateToolHelp32Snapshot(),
Process32First(),
Process32Next(),
Thread32First
(), Thread32Next(),
Module32First(),
Module32Next(),
Heap32ListFirst(),
Heap32ListNext(),
рассмотренные в первой части работы.
Для получения
дополнительной информации – о времени
работы процессов и их потоков, используемой
памяти и других ресурсов служат функции
Win32
API
GetProcessTimes(),
GetThreadTimes(),
GetProcessIoCounters(),
GetProcessHandleCount(),
GetProcessMemoryInfo(),
GetProcessWorkingSetSize(),
EnumDeviceDrivers(),
GetDeviceDriverBaseNameA(),
GetDeviceDriverFileNameA().
-
Получение
информации о времени выполнения
процессов и потоков
Функция
GetProcessTimes(Handle:
Thandle; CreateTime, ExitTime, KernelTime, UserTime: TFileTime)
используется для
получения времени запуска (создания),
времени завершения, времени работы
процесса в режиме ядра и пользователя.
Процесс задается описателем (Handle),
время возвращается ОС в переменных типа
TFileTime.
Время отсчитывается в 100 наносекундных
интервалах с 1.01.1601 по Гринвичу. Для
представления времени старта и завершения
в привычном формате используются функции
FileTimeToLocalFileTime(Tproc,
LocalFileTime : TFileTime)
FileTimeToSystemTime(fTime
: TFileTime ; SysT : TSystemTime)
Используя поля
структуры TSystemTime,
можно получить дату и время старта или
завершения процесса с точностью до
миллисекунды.
Функция
GetThreadTimes(Handle:
Thandle; CreateTime, ExitTime, KernelTime, UserTime: TFileTime)
используется для
получения времени запуска (создания),
времени завершения, времени работы
потока в режиме ядра и пользователя.
Поток задается описателем (Handle),
время возвращается ОС в переменных типа
TFileTime.
Время отсчитывается в 100 наносекундных
интервалах с 1.01.1601 по Гринвичу. Для
представления времени старта и завершения
в привычном формате используются функции
FileTimeToLocalFileTime(Tproc,
LocalFileTime : TFileTime)
FileTimeToSystemTime(fTime :
TFileTime ; SysT : TSystemTime)
Используя поля
структуры TSystemTime,
можно получить дату и время старта или
завершения потока.
Для получения
значений описателей процесса и потока
в общем случае следует использовать
функции OpenProcess()
см. часть 1 и OpenThread()
– ее аргументы аналогичны. Необходимые
значения идентификаторов процесса или
потока получаются с помощью функций,
рассмотренных в первой части работы.
В частном случае,
когда интерес представляет текущий
процесс (поток), описатель процесса
(потока) возвращается функциями
GetCurrentProcess()
и GetCurrentThread().
Эти функции не имеют аргументов.
-
Получение
информации счетчиков ввода-вывода и
количества описателей (дескрипторов)
Содержимое счетчиков
ввода-вывода – количество прочитанных
— записанных байт может быть получено
функцией
GetProcessIoCounters(Handle:
Thandle; pIOCounters : TProcessIOCounters
): bool;
Первый аргумент
определяет процесс, второй – указатель
на структуру
TProcessIOCounters
= record
ReadOperationCount
:
int64;
WriteOperationCount
: int64;
OtherOperationCount
: int64;
ReadTransferCount
:
int64;
WriteOTransferCount
: int64;
OtherOTransferCount
: int64;
end;
Данная
функция содержится в библиотеке
kernel32.dll.Поскольку
прототип данной функции в файле
windows.pas
отсутствует, для вызова данной функции
(как и всех описанных далее в этой работе
функций) используется неявный
вызов.
Для неявного вызова функции из библиотеки
динамической загрузки (DLL)
в программе должен быть создан прототип.
Пример прототипа
function
GetProcessIoCounters(Hprocess:
Thandle;
PIOCount
: TpprocessIOCounters):
BOOL;
stdcall
external
‘kernel32.dll’;
Прототипы
определенных таким образом функций
должны содержать:
-
имя
функции
(регистр учитывается); -
формальные
аргументы
и их типы; -
имя
содержащей функцию библиотеки.
Прототипы
записываются в разделе implementation.
Типы аргументов (не описанные в
windows.pas)
должны быть описаны в разделе type.
Для
рассматриваемого примера в раздел type
следует записать
TProcessIOCounters = record
ReadOperationCount : int64;
WriteOperationCount
: int64;
OtherOperationCount : int64;
ReadTransferCount : int64;
WriteOTransferCount : int64;
OtherOTransferCount : int64;
end;
TpprocessIOCounters =
^TprocessIOCounters;
а
в раздел implementation
вставить
описание прототипа
function
GetProcessIoCounters(Hprocess: Thandle; PIOCount :
TpprocessIOCounters): BOOL; stdcall external ‘kernel32.dll’;
Ошибка
в названии библиотеки приводит к
появлению на этапе выполнения сообщения
«библиотека не найдена», ошибка в
написании имени функции (РЕГИСТР
учитывается!) – к появлению сообщения
«функция XXX
не найдена в библиотеке YYY».
Ecли
имя функции и имя библиотеки заданы
правильно, описанную функцию можно
вызывать, указывая правильные типы
аргументов.
Функция
GetProcessHandleCount(Hprocess:
Thandle;
PHandCount
: TphandCount):
Bool
из
библиотекиkernel32.dllвозвращает
указатель на переменную типа Dword,
содержащую количество созданных
указанных процессом описателей
(дескрипторов). Для использования функции
необходимо создать прототип для ее
вызова из библиотеки, описать переменную
HandCount:Dwordи
указать вторым аргументом функции адрес
этой переменной, например
GetProcessHandleCount
(GetCurrentProcess,@HandCount);
-
Получение
информации об используемой процессом
памяти
Функция
GetProcessMemoryInfo(Hprocess:
Thandle; pmemcount : PPROCESS_MEMORY_COUNTERS)
: Bool
из библиотеки
Psapi.dll
содержит различную информацию об
используемой процессом памяти. Процесс
задается описателем (Handle),
структура, содержащая информацию об
использовании памяти
TProcess_Memory_Counters = record
size :
Dword; // размер структуры
PageFaultCount:
Dword; // количество страничных
ошибок
PeakWorkingSetSize:cardinal; // пиковый размер
используемой ОП
WorkingSetSize:cardinal; // используемый
объем ОП
QuotaPeakPagePoolUsage:cardinal;//максимальный
размер страничного пула памяти
QuotaPagePoolUsage
: cardinal; // размер страничного
пула памяти
QuotaPeakNonPagedPoolUsage
: cardinal;//макс размер
невыгружаемого пула
памяти
QuotaNonPagePollUsage
: cardinal; // размер невыгружаемого
пула памяти
PageFileUsage : cardinal;
PeakPageFileUsage
: cardinal;
PrivateUsage : cardinal;
end;
задается
указателем.
Для
использования функции необходимо
создать ее прототип для вызова из
библиотеки Psapi.dll.
Перед
вызовом функции необходимо в первое
поле структуры
Process_Memory_Countersзаписать
ее размер.
Функция
GetProcessWorkingSetSize(Hprocess:
Thandle;
Min,Max
: Cardinal
) возвращает
минимальный и максимальный размеры
рабочего множества страниц указанного
процесса (в байтах). Прототип функции
описан в файле windows.pas.
-
Получение
информации о загруженных драйверах
Для получения
информации о загруженных в память
драйверах и их адресах используются
функции EnumDeviceDrivers(),
GetDeviceDriverBaseNameA(),
GetDeviceDriverFileNameA(),
вызываемые из библиотеки Psapi.dll.
Прототипы функций имеют следующий вид:
function
EnumDeviceDrivers(lp : pointer; cb : DWORD ;
lpcbNeeded
: lpDWORD ): BOOL; stdcall external ‘psapi.dll’;
function
GetDeviceDriverBaseNameA(lp : pointer; lpBaseName : lpstr; nSize :
DWORD): BOOL; stdcall external ‘psapi.dll’;
function
GetDeviceDriverFileNameA( lp : pointer;
lpFilename
: LPTSTR; nSize :DWORD): DWORD ; stdcall external ‘psapi.dll’;
Функция
EnumDeviceDrivers ( lp : pointer; cb : DWORD ; lpcbNeeded :
lpDWORD ): BOOL; возвращает
массив
указателей
на
загруженные
в
ОП
драйверы.
Указатель
на массив задается первым аргументом
функции, второй аргумент (входной
параметр) задает размер массива, если
этот размер является недостаточным,
требуемый размер возвращается функцией
в третьем параметре.
Пример
вызова функции
var
pdriver :
array [1..138] of cardinal;
lpcbNeeded :
dword;
if EnumDeviceDrivers( @pdriver,
sizeof(pdriver), @lpcbNeeded )
then
label1.Caption:=inttostr(lpcbNeeded)
Для
получения списка имен драйверов служит
функция GetDeviceDriverBaseNameA(lp
: pointer;
lpBaseName
: lpstr;
nSize
: DWORD).
Она
получает адрес загруженного драйвера
(первый аргумент) и размер имени драйвера
(третий аргумент) и возвращает имя
драйвера.
Пример
вызова
функции
var
pdriver :
array [1..138] of cardinal;
lpcbNeeded :
dword;
i :
integer;
basename :
lpstr;
for I := 1 to lpcbneeded div 4 do
begin
getmem(basename,50);
GetDeviceDriverBaseNameA(pointer(pdriver[i]),
BaseName, 50);
Вопрос о размере файла подкачки довольно часто встречается на различных технических ресурсах, однако однозначных рекомендаций на этот счет нет. Попадаются как советы установить файл подкачки в 1.5-2 раза больше объема установленной памяти, так и полностью отключить его. И то и другое абсолютно бессмысленно с практической точки зрения. Поэтому сегодня речь пойдет о том, что такое файл подкачки (он же своп-файл, он же страничный файл) и как правильно выбрать и настроить его размер.
Чтобы понять, для чего нужен файл подкачки, стоит сначала разобраться в принципах работы памяти в Windows. Поэтому начнем с теории.
Виртуальная память
Как правило, говоря о памяти мы имеем в виду модули оперативной памяти, физически установленные на компьютере, или физическую память. Объем доступной физической памяти жестко ограничен и зависит от возможностей оборудования, разрядности операционной системы и условий лицензирования. Для того, чтобы обойти эти ограничения, в операционных системах Windows используется такой ресурс, как виртуальная память.
Операционная система Windows работает не с физической, а именно с виртуальной памятью. Технически виртуальная память состоит из физической памяти (ОЗУ) и специального файла(-ов) подкачки, объединенных в единое виртуальное адресное пространство. Для каждого запущенного процесса выделяется собственное, отдельное от других процессов адресное пространство в виртуальной памяти, в котором он выполняется и которым управляет. Для обращения к памяти используются указатели на адреса в виртуальном адресном пространстве, при этом сам процесс не в курсе 🙂 того, где именно хранятся его данные — в ОЗУ или в файле, это решает операционная система.
Максимально возможный объем доступной виртуальной памяти зависит от разрядности операционной системы. Так в 32-разрядной системе процесс может адресовать не более 4 гигабайт (232) памяти. Для 64-разрядного процесса теоретическое ограничение составляет 16 экзабайт (264), а практически в современных 64-разрядных версиях Windows поддерживается адресное пространство объемом до 16 терабайт.
Примечание. Некоторые 32-разрядные версии Windows Server используют технологию PAE, позволяющую адресовать до 64ГБ памяти. Подробнее о PAE можно узнать здесь.
В отличии от физической, виртуальная память имеет гораздо более гибкие ограничения. Это позволяет одновременно выполняться большому количеству процессов, которые не смогли бы поместиться в физической памяти. Таким образом, основная задача механизма виртуальной памяти — расширение доступной памяти компьютера.
Управление памятью происходит примерно так.
Виртуальное адресное пространство поделено на блоки равного размера, которые называют страницами (pages). Отсюда кстати и название pagefile — страничный файл. Физическая память также поделена на разделы, называемые страничными фреймами (page frames), которые используются для хранения страниц.
Каждому процессу при старте выделяется ″кусок″ адресного пространства в виртуальной памяти. Соответственно в каждый момент времени в памяти находятся страницы из виртуального адресного пространства каждого процесса. Страницы, находящиеся в физической памяти и доступные немедленно, называются действительными (valid pages), а страницы, которые в данный момент недоступны, например находящиеся на диске — недействительными (invalid pages).
При обращении процесса к странице памяти, помеченной как недействительная, происходит страничное прерывание (page fault). При возникновении прерывания диспетчер виртуальной памяти находит запрашиваемую страницу и загружает ее в свободный страничный фрейм физической памяти. Собственно этот процесс и называется подкачкой (paging).
При дефиците физической памяти диспетчер памяти выбирает фреймы, которые можно освободить и переносит их содержимое на диск, в файл подкачки. Принцип переноса такой: когда процесс использовал все выделенные ему фреймы, то при каждом страничном прерывании в этом процессе система удаляет из физической памяти одну из его страниц. Выбор страницы осуществляется по принципу первым пришел — первым ушел (first in, first out, FIFO), т.е. в файл подкачки переносится страница, дольше всех находившаяся в памяти.
У каждого процесса есть свой рабочий набор (working set) — набор страниц, находящихся в физической памяти. Рабочий набор определяет размер физической памяти, выделенной процессу, он имеет минимальный и максимальный размер. В момент запуска процессу назначается минимальный размер рабочего набора, т.е. минимальное количество страниц, которые гарантированно будут находится в оперативной памяти. При достаточном количестве свободной физической памяти процесс может увеличивать свой рабочий набор до размера, равного максимальному рабочему набору. Когда же начинается нехватка памяти, диспетчер виртуальной памяти начинает урезать рабочий набор всех процессов до минимального, удаляя лишние страницы из физической памяти.
После уменьшения рабочего набора процесса до минимума диспетчер памяти отслеживает страничные прерывания, генерируемые каждым процессом. При большом количестве прерываний диспетчер может увеличить размер рабочего набора процесса, при отсутствии — продолжает уменьшать рабочий набор до тех пор, пока не произойдет прерывание. Появление прерывания говорит о том, что достигнут минимальный размер памяти, необходимый процессу для работы. Таким образом достигается баланс между потреблением физической памяти и производительностью.
На самом деле это очень примерное описание работы виртуальной памяти, но для общего понимания его вполне хватит. Поэтому завязываем с теорией и переходим к практике.
Текущие настройки файла подкачки
Посмотреть текущий размер файла можно в оснастке Свойства системы (System Properties). Для этого надо нажать Win+R и выполнить команду sysdm.cpl. Затем перейти на вкладку «Advanced», в поле «Performance» нажать на кнопку «Settings» и в открывшемся окне перейти на вкладку «Advanced».
Здесь указан суммарный размер файла подкачки на всех дисках, а по кнопке «Change» можно перейти к его настройкам.

По умолчанию включено автоматическое управление размером файла подкачки. Это значит, что операционная система создает один файл подкачки pagefile.sys в корне системного диска и устанавливает его размер автоматически, исходя из своих потребностей.

Дамп памяти
Чтобы понять, чем руководствуется система при выборе размера файла подкачки, опять перейдем к теории и обратимся к такому понятию как дамп памяти (memory dump). Дело в том, что кроме расширения физической памяти файл подкачки имеет еще одно назначение — он используется при создании аварийных дампов памяти при сбоях системы. Происходит это следующим образом.
Во время загрузки операционная система создает карту секторов, занимаемых на диске файлом подкачки и сохраняет ее в памяти. При сбое системы проверяется целостность этой карты, драйвера диска и управляющей структуры дискового драйвера. Если целостность их не нарушена, то ядро системы вызывает специальные функции ввода\вывода, предназначенные для сохранения образа памяти после системного сбоя и записывает данные из памяти на диск, в файл подкачки, используя сохраненную карту секторов.
При следующей загрузке системы диспетчер сеанса (Session Manager Subsystem Service, SMSS) инициализирует файл подкачки и проверяет наличие в нем заголовка дампа. Если заголовок есть, то данные копируются из файла подкачки в файл аварийного дампа и делается соответствующая запись в системном журнале.
Соответственно при автоматическом управлении файлом подкачки система ориентируется на настройки создания аварийного дампа памяти, выбирая размер файла в соответствии с типом дампа:
• Полный дамп памяти (Complete memory dump) — в дамп записывается все содержимое оперативной памяти на момент сбоя, поэтому размер файла подкачки должен быть равен размеру физической памяти + 1Мб (для заголовка). Этот тип выбирается по умолчанию при количестве физической памяти меньше 4ГБ;
• Дамп памяти ядра (Kernel memory dump) — в дамп записывается только память, выделенная для ядра ОС, драйверов устройств и приложений, работающих в режиме ядра. Дамп ядра занимает гораздо меньше места, чем полный дамп, при этом его как правило достаточно для определения причин сбоя. Этот тип дампа выбирается по умолчанию для систем с объемом ОЗУ 4ГБ и более. Минимальный размер файла подкачки должен составлять примерно 1/3 от объема физической памяти;
• Малый дамп памяти (Small memory dump) — мини-дамп, в котором содержатся минимально необходимые данные: стоп-код и описание ошибки, список загруженных драйверов и информация о запущенных в момент сбоя процессах. Этот дамп требует файл подкачки не менее 2Мб;
• Автоматический дамп памяти (Automatic memory dump) — новый тип дампа, появившийся в Windows 8\Server 2012 и более новых. На самом деле это тот же дамп ядра, единственная разница в том, что он позволяет системе динамически управлять размером файла подкачки, выбирая наиболее оптимальный размер.
Настройки дампа памяти находятся в расширенных свойствах системы, в разделе Загрузка и восстановление (Startup and Recovery). Здесь можно один из четырех типов дампа либо совсем отключить его создание.

Даже зная настройки дампа и объем физической памяти, не получится точно сказать, какого размера файл подкачки создаст система. Поэтому я решил немного поэкспериментировать, для чего взял в качестве подопытных 2 системы — клиентскую Windows 8.1 (x64) и серверную Windows Server 2012 R2 и проверил, как размер файла подкачки зависит от объема физической памяти и настроек дампа. Вот что получилось:
| Windows 8.1 4Гб ОЗУ |
Windows 8.1 8Гб ОЗУ |
Windows Server 2012 R2 4Гб ОЗУ |
Windows Server 2012 R2 8Гб ОЗУ |
|
| Полный дамп | 4352 Мб | 8704 Мб | 4352 Мб | 8704 Мб |
| Дамп ядра | 4096 Мб | 8192 Мб | 4096 Мб | 8192 Мб |
| Автоматический дамп | 704 Мб | 1280 Мб | 1408 Мб | 1920 Мб |
| Малый дамп | 320 Мб | 512 Мб | 1408 Мб | 1920 Мб |
| Нет дампа | 320 Мб | 512 Мб | 1408 Мб | 1920 Мб |
Как видите, размер файла напрямую зависит не только от объема ОЗУ и настроек дампа, но и от типа операционной системы. Кроме того, отключение дампа не означает полное отсутствие файла подкачки.
Также стоит напомнить, что это начальные значения. При нехватке виртуальной в процессе работы памяти система может увеличивать файл подкачки вплоть до максимального значения, которое при автоматической настройке составляет 3 объема физической памяти.
Определение необходимого размера файла подкачки
Хотя размером файла подкачки и можно управлять через настройки дампа памяти, однако это не самый прямой способ. Гораздо правильней настроить размер файла вручную. Остается только выяснить, какой размер можно считать достаточным.
Однозначного ответа на этот вопрос нет. Единственный способ более-менее точно установить размер файла подкачки — это собрать в данной конкретной системе данные по потреблению памяти и использованию файла подкачки, выяснить, какой максимальный объем памяти может быть занят службами\приложениями и насколько реально используется файл подкачки. На основании полученных данных и следует выбирать размер файла.
Оперативно оценить текущее потребление виртуальной памяти можно в Task manager, в разделе Performance (производительность). В поле Commited показано отношение используемой виртуальной памяти к ее общему количеству. В моем примере на компьютере установлено 64Гб оперативной памяти и такого же объема файл подкачки. Текущий объем виртуальной памяти составляет 128Гб, занято 65Гб. Из них 62,4Гб приходятся на оперативную память и 2,6Гб на файл подкачки.

Также для сбора информации можно воспользоваться счетчиками производительности. Счетчики предоставляют больше информации, а также позволяют собрать статистику за определенное время, что позволит более точно определить потребности системы в виртуальной памяти. Нам потребуются следующие счетчики производительности:
Memory, Commited Bytes — этот счетчик показывает, какое количество байт в виртуальной памяти занято текущими процессами. Когда значение Commited Bytes превышает объем физической памяти, система начинает активно использовать файл подкачки;
Memory, Available Bytes — объем свободной физической памяти на компьютере. Этот параметр показывает загруженность оперативной памяти, а чем меньше физической памяти остается, тем активнее система использует файл подкачки.
Memory, Commit Limit — значение, равное сумме объема оперативной памяти и текущего размера файла подкачки. По другому — максимальное количество виртуальной памяти, которое может быть выделено всем процессам без увеличения размера файла подкачки.
Memory, %Commited Bytes In Use — показывает процент использования виртуальной памяти. Представляет из себя отношение Commited Bytes \Commit Limit.
Paging File, %Usage — процент использования файла подкачки, текущее значение.
Paging File, %Usage Peak — процент использования файла подкачки, пиковое значение.
Для более глубокого анализа потребления памяти можно дополнительно использовать такие счетчики:
Memory, Page Fault\sec — количество страничных ошибок (прерываний) в секунду при обращении к страницам памяти. Напомню, что страничное прерывание возникает при обращении к странице памяти, которая была выгружена на диск.
Memory, Pages\sec — показывает, сколько страниц в секунду было прочитано\записано в рамках страничного прерывания. Проще говоря, этот счетчик показывает интенсивность обмена данными между оперативной памятью и файлом подкачки. Представляет из себя сумму счетчиков Pages Input\sec и Pages Outpit\sec.
Process, Working Set — показывает текущее использование физической памяти активными процессами. Значение Total выдает суммарный объем по всем процессам, но можно вывести данные отдельно и по каждому конкретному процессу. Этот счетчик не имеет прямого отношения к файлу подкачки, но может помочь при диагностике проблем с производительностью.

Как видно на примере, 64-гигабайтный файл подкачки реально используется всего на 2-3%. То есть для нормальной работы с избытком хватит файла подкачки размером 4Гб. И это при том, что сервер очень прилично нагружен, для менее загруженного компьютера цифры будут еще меньше.
Отдельно стоит упомянуть о выборе размера файла подкачки для компьютеров с ролью Hyper-V. Дело в том, что в силу особенностей архитектуры гипервизор не использует файл подкачки для виртуальных машин даже в случае нехватки физической памяти. На серверах Hyper-V файл подкачки нужен исключительно для целей хостовой системы, в которой используется лишь небольшая часть ОЗУ (обычно не более 2-4ГБ). Поэтому создавать файл подкачки, исходя из общего объема физической памяти в данном случае абсолютно бессмысленно.
Настройка
Определив необходимый размер, переходим непосредственно о настройке. Для изменения размера файла подкачки открываем свойства виртуальной памяти и отключаем автоматический выбор размера. Затем в поле «Drive» выбираем логический диск, на котором будет располагаться файл, выбираем опцию «Custom size», указываем начальный и максимальный размер файла подкачки и жмем «Set». Для того, чтобы изменения вступили в силу, после настройки может потребоваться перезагрузка системы.
Для файла подкачки существуют некоторые ограничения:
• Максимальный размер файла может быть не более 16ТБ для 64-битной и не более 4ГБ для 32-битной системы;
• Можно создавать до 16 файлов подкачки, но каждый должен быть расположен на отдельном томе (логическом диске);
• Для возможности создания аварийного дампа памяти необходимо, чтобы файл подкачки (хотя бы один) находился на системном диске.

Для автоматизации процесса настройки можно использовать вот такой PowerShell скрипт (подставив свои значения):
# Disable automatic management for pagefile
$ComputerSystem = Get-WmiObject -Class Win32_ComputerSystem -EnableAllPrivileges
if ($ComputerSystem.AutomaticManagedPagefile) {
$ComputerSystem.AutomaticManagedPagefile = $false
$ComputerSystem.Put()
}
# Set manual size for pagefile
$PageFile = Get-WmiObject -Class Win32_PageFileSetting -EnableAllPrivileges
$PageFile.InitialSize = 4096
$PageFile.MaximumSize = 8192
$PageFile.Put()
Заключение
В заключение некоторые практические советы, которые могут помочь в настройке.
• При ручной настройке необходимо указать начальный и максимальный размер файла. В этом случае система создает файл начального размера, при необходимости увеличивая его до тех пор, пока он не достигнет максимального. При увеличении размера возможна фрагментация файла подкачки, что скажется на его быстродействии. Для борьбы с фрагментацией можно изначально указать начальный и максимальный размер одинаковыми. Тогда система сразу выделит под файл все необходимое место, а статический размер файла исключит возможную фрагментацию в дальнейшем.
• Для увеличения производительности системы файл подкачки можно перенести на другой раздел. Уточню, что переносить файл стоит только на раздел, находящийся на другом физическом диске. Размещение файла подкачки на дополнительном раздел одного и того же диска не приведет к повышению быстродействия. На практике имеет смысл перенос файла подкачки на отдельный SSD-диск, это может дать заметный прирост производительности.
• Еще один теоретический 🙂 способ повысить скорость работы с файлом подкачки — разместить его на отдельном, специально выделенном только под него разделе, для которого установить размер кластера 64Кб (вместо 4Кб по умолчанию). При работе с большими файлами (такими, как файл подкачки) большой размер кластера может повысить производительность файловой системы. Чем больше размер кластера, тем большими блоками читаются\пишутся данные, соответственно для одинакового объема данных при размере кластера 64Кб потребуется в 16 раз меньше операций чтения\записи, чем для 4Кб.
• Кое где встречаются советы полностью отключить файл подкачки. Действительно, в отдельных случаях это может дать некоторый прирост производительности, хотя лично я не вижу в этом большой пользы. Как можно убедиться с помощью счетчиков производительности, при наличии свободной физической памяти ОС и так использует файл подкачки по минимуму, поэтому прирост будет незначительный. Если же при отключенном файле подкачки в процессе работы закончится физическая память, то приложение, потребляющее память, будет остановлено, что чревато сбоем в работе и потерей данных. Кроме того, при отсутствии файла подкачки Windows не сможет сохранить дамп памяти в случае сбоя.
• И последнее. Манипуляции с файлом подкачки не особо сильно влияют на производительность системы в целом. Повторюсь, при достаточном количестве физической памяти файл подкачки используется по минимуму. Если же в системе постоянно не хватает памяти и она активно использует файл подкачки, то в первую очередь стоит подумать о расширении физической памяти.