Coverity: На 1000 строк исходного кода открытых программ насчитывается 1 дефект
Компания Coverity подготовила отчет о крупнейшем частно-государственном проекте — аудит исходных кодов открытого и проприетарного ПО.
Компания Coverity, которая специализируется на разработке и тестировании различных программных продуктов, опубликовала статистический отчет за 2011 год. При содействии Министерства внутренней безопасности США эксперты компании провели крупнейший частно-государственный аудит исходных кодов проприетарного и открытого ПО.
Исследователи провели автоматическую проверку на наличие ошибок и уязвимостей порядка 300 миллионов строк кода 41-го проприетарного программного продукта, название которых не разглашается, а также 37 миллионов строк кода 45-ти популярных программных продуктов с открытым исходным кодом.
Наиболее важные положения отчета:
· На 1000 строк кода в открытом ПО в исследователи насчитали в среднем 0,45 ошибки. Средний размер проекта с открытым исходным кодом составляет 832 000 строк кода.
· На 1000 строк кода в проприетарном ПО в исследователи обнаружили в среднем 0,64 ошибки. Средний размер такого проекта составляет 7,5 миллионов строк кода.
· Для обоих видов программных продуктов на 1000 строк кода приходится 1 ошибка.
· Наиболее качественный код, по мнению исследователей, содержится в PHP 5.3, PostgreSQL 9.1, а также Linux 2.6 с частотой ошибок 0,20, 0,21 и 0,62 соответственно.
«Качество нашего кода имеет решающее значение для успеха PHP, С помощью которого созданы некоторые из самых популярных сайтов в сети Интрнет, — прокомментировал один из разработчиков PHP Расмус Лердорф (Rasmus Lerdorf). — Наш код растет и становится все более сложным, сканирование становится еще более важным для нас, поскольку оно позволяет улучшить качество нашего продукта».
Более подробно ознакомиться с отчетом Coverity можно здесь .
Открой дверь в мир, где наука не имеет границ — подписывайся на наш канал!
Эта статья продемонстрирует, что при разработке крупных проектов статический анализ кода является не просто полезным, а совершенно необходимым элементом процесса разработки. Я начинаю цикл статей, посвященных возможности использования статического анализатора кода PVS-Studio для повышения качества и надежности операционной системы Tizen. Для начала я проверил небольшую часть операционной системы (3.3%) и выписал около 900 предупреждений, указывающих на настоящие ошибки. Если экстраполировать результаты, то получается, что наша команда способна выявить и устранить в Tizen около 27000 ошибок. По итогам проведённого исследования я подготовил презентацию, которая предназначалась для демонстрации представителям Samsung и была посвящена возможному сотрудничеству. Встреча перенесена на неопределённый срок, поэтому я решил не тратить время и трансформировать материал презентации в статью. Запасайтесь вкусняшками и напитками, нас ждёт длинный программистский триллер.
Начать, пожалуй, следует со ссылки на презентацию «Как команда PVS-Studio может улучшить код операционной системы Tizen», из которой и родилась эта статья: RU — pptx, slideshare; EN — pptx, slideshare. Впрочем, смотреть презентацию вовсе не обязательно, так как весь содержащийся в ней материал будет рассмотрен здесь, причём более подробно. Тема презентации пересекается с открытым письмом, в котором мы также рассказываем, что готовы поработать с проектом Tizen.
С разными воспоминаниями и ссылками я закончил и перехожу к сути дела. Первое, что стоит сделать, это напомнить читателю, что вообще из себя представляет операционная система Tizen.
Tizen
Tizen — открытая операционная система на базе ядра Linux, предназначенная для широкого круга устройств, включая смартфоны, интернет-планшеты, компьютеры, автомобильные информационно-развлекательные системы, «умные» телевизоры и цифровые камеры, разрабатываемая и управляемая такими корпорациями, как Intel и Samsung. Поддерживает аппаратные платформы на процессорах архитектур ARM и x86. Более подробная информация доступна на сайте Wikipedia.
Платформа Tizen показывает уверенный рост в течение нескольких последних лет, несмотря на насыщенность рынка операционных систем для мобильных и носимых устройств. Согласно отчёту Samsung, рост продаж мобильных телефонов с OC Tizen составил 100% в 2017 году.

Для нашей команды операционная система Tizen привлекательна тем, что компания Samsung заинтересована в её надёжности и прикладывает усилия для улучшения качества кода. Например, с целью улучшения качества кода, Samsung инвестировал разработку в ИСП РАН специализированного анализатора кода Svace. Инструмент Svace используется как основное средство для обеспечения безопасности системного и прикладного ПО платформы Tizen. Вот некоторые цитаты, взятые из заметки «Samsung have Invested $10 Million in Svace, Security Solution to Analyze Tizen Apps»:
As part of its security measures, Samsung are using the SVACE technology (Security Vulnerabilities and Critical Errors Detector) to detect potential vulnerabilities and errors that might exist in source code of applications created for the Tizen Operating System (OS). This technology was developed by ISP RAS (Institute for System Programming of the Russian Academy of Sciences), who are based in Moscow, Russia.
The solution is applied as part of the Tizen Static Analyzer tool that is included in the Tizen SDK and Studio. Using this tool you can perform Static security analysis of the Tizen apps native C / C ++ source code and discover any issues that they might have. The tool helps discover a wide range of issues at compilation time, such as the dereference of Null Pointers, Memory Leaks, Division by Zero, and Double Free etc.
Также стоит отметить новость «В России впервые создали защищенную операционную систему», опубликованную на сайте rbc.ru. Цитата:
О создании российской версии операционной системы (ОС) Tizen было объявлено 2 июня 2016. Tizen является независимой ОС, то есть она не привязана к облаку Apple или Google, и поэтому ее можно адаптировать под локальные рынки, рассказал президент ассоциации «Тайзен.ру» Андрей Тихонов. Основная особенность представленной ОС — в ее безопасности, уточнил Тихонов. Это первая и единственная в России сертифицированная в Федеральной службе по техническому и экспортному контролю (ФСТЭК) мобильная операционная система, уточнил представитель Samsung.
Команда PVS-Studio просто не могла пройти мимо такого интересного открытого проекта, не попробовав его проверить.
Анализ Tizen
Целью презентации, о которой я упоминал ранее, было продемонстрировать, что анализатор PVS-Studio находит очень много ошибок различного типа. Это своего рода резюме анализатора и нашей команды, которое мы хотим показать компании Samsung.
Читатель может засомневаться, стоит ли ему читать такую «статью-резюме». Да, стоит, здесь будет много интересного и полезного. Во-первых, лучше учиться на чужих ошибках, а не на своих. Во-вторых, статья отлично показывает, что методологию статического анализа просто необходимо применять в проектах большого размера. Если кто-то из коллег, занятых в большом проекте, уверяет вас, что они пишут код высокого качества и почти без ошибок, то покажите ему эту статью. Я не думаю, что создатели Tizen хотели, чтобы в проекте было много дефектов, но вот они — тысячи багов.
Как всегда, хочу напомнить, что статический анализ кода должен применяться регулярно. Разовая проверка Tizen или любого другого проекта, конечно, будет полезна, но малоэффективна. В основном будут найдены малозначительные ошибки, которые слабо оказывают влияние на работоспособность проекта. Все явные ошибки были выявлены другими методами, например, благодаря жалобам пользователей. Означает ли это, что толку от статического анализа мало? Конечно нет, просто, как я уже сказал, разовые проверки — это неэффективный способ использования анализаторов кода. Анализаторы должны использоваться регулярно и тогда многие, в том числе и критические, ошибки будут обнаруживаться на самом раннем этапе. Чем раньше ошибка выявлена, тем дешевле её исправить.
Я считаю, что:
- Сейчас анализатор PVS-Studio выявляет более 10% ошибок, которые присутствуют в коде проекта Tizen.
- В случае регулярного использования PVS-Studio в новом коде можно будет предотвратить около 20% ошибок.
- Я прогнозирую, что команда PVS-Studio может на данный момент выявить и исправить около 27000 ошибок в проекте Tizen.
Конечно, я могу ошибаться, но я не подгонял результаты исследования, чтобы показать возможности анализатора PVS-Studio в лучшем свете. Это просто не нужно. Анализатор PVS-Studio — мощный инструмент, который находит так много дефектов, что просто нет смысла фальсифицировать результаты. Далее я продемонстрирую, как получились все приведённые здесь числа.
Конечно, я не мог проверить весь проект Tizen. Вместе со сторонними библиотеками он насчитывает 72 500 000 строк C и C++ кода (без учёта комментариев). Поэтому я решил случайным образом проверить несколько десятков проектов, входящих в состав Tizen:Unified.
Выбирая проекты, я делил их на две группы. Первая группа — это проекты, написанные непосредственно сотрудниками компании Samsung. Я определял такие проекты по наличию в начале файлов комментариев, выглядящих вот так:
/*
* Copyright (c) 2015 Samsung Electronics Co., Ltd All Rights Reserved
....
*/Вторая группа — это сторонние проекты, используемые в проекте Tizen. Впрочем, многие проекты нельзя считать полностью сторонними, так как в них присутствуют различные патчи. Вот пример патча, сделанного в библиотеке efl-1.16.0:
//TIZEN_ONLY(20161121)
// Pre-rotation should be enabled only when direct
// rendering is set but client side rotation is not set
if ((sfc->direct_fb_opt) &&
(!sfc->client_side_rotation) &&
(evgl_engine->funcs->native_win_prerotation_set))
{
if (!evgl_engine->funcs->native_win_prerotation_set(eng_data))
ERR("Prerotation does not work");
}
//Так что деление получилось несколько условным, однако, точность для общей оценки и не требуется.
Выбранные случайным образом проекты были проверены, и я приступил к изучению отчётов анализатора и выбору предупреждений, которые заслуживают внимания. Конечно, многие ошибки достаточно безобидны или могут проявлять себя крайне редко. Например, следующий код будет давать сбой очень-очень редко:
m_ptr = (int *)realloc(m_ptr, newSize);
if (!m_ptr) return ERROR;Если не удастся выделить новый фрагмент памяти, то произойдёт утечка памяти. Подробнее этот тип ошибки будет рассмотрен далее. Да, вероятность утечки памяти крайне мала, но, на мой взгляд, это именно ошибка, которую следует исправить.
У меня ушло около недели на то, чтобы отобрать предупреждения, которые, по моему мнению, указывают на настоящие ошибки. Заодно я выписал большое количество примеров кода, которые я буду использовать для подготовки презентаций и статей.
Прошу внимания. Далее речь идёт именно о количестве ошибок, а не о количестве сообщений анализатора. Под ошибками я понимаю такие участки кода, которые, на мой взгляд, заслуживают того, чтобы их исправили.
Один из разработчиков, посмотрев презентацию и не разобравшись что к чему, написал комментарий вида «27000 предупреждений анализатора, тоже мне достижение, это даже мало». Поэтому ещё раз подчеркну, что речь идет именно об ошибках. В процессе исследования я считал и выписывал именно ошибки, а не просто все предупреждения анализатора без разбора.
Анализ проектов, разработанных специалистами компании Samsung
Для проверки я случайным образом выбрал следующие проекты: bluetooth-frwk-0.2.157, capi-appfw-application-0.5.5, capi-base-utils-3.0.0, capi-content-media-content-0.3.10, capi-maps-service-0.6.12, capi-media-audio-io-0.3.70, capi-media-codec-0.5.3, capi-media-image-util-0.1.15, capi-media-player-0.3.58, capi-media-screen-mirroring-0.1.78, capi-media-streamrecorder-0.0.10, capi-media-vision-0.3.24, capi-network-bluetooth-0.3.4, capi-network-http-0.0.23, cynara-0.14.10, e-mod-tizen-devicemgr-0.1.69, ise-engine-default-1.0.7, ise-engine-sunpinyin-1.0.10, ise-engine-tables-1.0.10, isf-3.0.186, org.tizen.app-selector-0.1.61, org.tizen.apps-0.3.1, org.tizen.bluetooth-0.1.2, org.tizen.browser-3.2.0, org.tizen.browser-profile_common-1.6.4, org.tizen.classic-watch-0.0.1, org.tizen.d2d-conv-setting-profile_mobile-1.0, org.tizen.d2d-conv-setting-profile_wearable-1.0, org.tizen.download-manager-0.3.21, org.tizen.download-manager-0.3.22, org.tizen.dpm-toolkit-0.1, org.tizen.elm-demo-tizen-common-0.1, org.tizen.indicator-0.2.53, org.tizen.inputdelegator-0.1.170518, org.tizen.menu-screen-1.2.5, org.tizen.myplace-1.0.1, org.tizen.privacy-setting-profile_mobile-1.0.0, org.tizen.privacy-setting-profile_wearable-1.0.0, org.tizen.quickpanel-0.8.0, org.tizen.screen-reader-0.0.8, org.tizen.service-plugin-sample-0.1.6, org.tizen.setting-1.0.1, org.tizen.settings-0.2, org.tizen.settings-adid-0.0.1, org.tizen.telephony-syspopup-0.1.6, org.tizen.voice-control-panel-0.1.1, org.tizen.voice-setting-0.0.1, org.tizen.volume-0.1.149, org.tizen.w-home-0.1.0, org.tizen.w-wifi-1.0.229, org.tizen.watch-setting-0.0.1, security-manager-1.2.17.
Проектов немало, но многие из них имеют совсем маленький размер. Давайте посмотрим, какие типы ошибок мне встретились.
Примечание. Помимо предупреждения PVS-Studio я буду стараться классифицировать найденные ошибки согласно CWE (Common Weakness Enumeration). Однако, я вовсе не делаю попытку найти какие-то уязвимости, а привожу CWE-ID исключительно для удобства тех читателей, которые привыкли именно к этой классификации дефектов. Моя основная цель — найти как можно больше ошибок, а определение того, насколько опасна ошибка с точки зрения безопасности, выходит за рамки моего исследования.
Это будет большой раздел, поэтому предлагаю заварить первую кружку чая или кофе. Вторая нам понадобится позже, так как мы только в самом начале статьи.

Опечатка в условии: слева и справа одно и то же (2 ошибки)
Классика. Даже так: классика самого высшего сорта!
Во-первых, эта ошибка выявляется с помощью диагностики V501. Диагностика выявляет опечатки и последствия неудачного Copy-Paste. Это невероятно популярный и распространенный тип ошибок. Посмотрите сами, какую замечательную коллекцию багов в открытых проектах мы собрали благодаря диагностике V501.
Во-вторых, эта ошибка находится в операторе меньше (<). Неправильное сравнение двух объектов — это тоже классическая ошибка, возникающая из-за того, что никто не проверяет такие простые функции. Недавно я написал интересную статью на эту тему «Зло живёт в функциях сравнения». Почитайте, это своего рода «Хребты безумия» для программистов.
Код, о котором идёт речь:
bool operator <(const TSegment& other) const {
if (m_start < other.m_start)
return true;
if (m_start == other.m_start)
return m_len < m_len; // <=
return false;
}Ошибка найдена благодаря предупреждению PVS-Studio: V501 There are identical sub-expressions to the left and to the right of the ‘<‘ operator: m_len < m_len segmentor.h 65
Software weaknesses type — CWE-570: Expression is Always False
Из-за этой ошибки объекты, которые отличаются только значением члена m_len, будут сравниваться некорректно. Правильный вариант сравнения:
return m_len < other.m_len;Аналогичная ошибка: V501 There are identical sub-expressions ‘0 == safeStrCmp(btn_str, setting_gettext(«IDS_ST_BUTTON_OK»))’ to the left and to the right of the ‘||’ operator. setting-common-general-func.c 919
Опечатка в условии: бессмысленное сравнение (2 ошибки)
static void __page_focus_changed_cb(void *data)
{
int i = 0;
int *focus_unit = (int *)data;
if (focus_unit == NULL || focus_unit < 0) { // <=
_E("focus page is wrong");
return ;
}
....
}Ошибка найдена благодаря предупреждению PVS-Studio: V503 This is a nonsensical comparison: pointer < 0. apps_view_circle_indicator.c 193
Software weaknesses type — CWE-697: Insufficient Comparison
Сравнение вида «pointer < 0» не имеет смысла и свидетельствует об опечатке в коде. Как я понимаю, пропущен оператор звездочка (*), который должен был разыменовать указатель. Корректный код:
if (focus_unit == NULL || *focus_unit < 0) {Этот код вместе с ошибкой скопировали, в результате чего точно такую же ошибку можно наблюдать в функции __page_count_changed_cb:
static void __page_count_changed_cb(void *data)
{
int i = 0;
int *page_cnt = (int *)data;
if (page_cnt == NULL || page_cnt < 0) {
_E("page count is wrong");
return ;
}
....
}Ох уж эта Copy-Paste технология. Для этого кода анализатор выдал предупреждение: V503 This is a nonsensical comparison: pointer < 0. apps_view_circle_indicator.c 219
Опасный способ использования функции alloca (1 ошибка)
Рассмотрим код, который хотя и плох, но на практике не приведёт к проблемам. Я не рассматривал эту ситуацию в презентации, так как она требует специального пояснения. Теперь же, в статье, я могу остановиться на данном примере и поделиться своими мыслями.
int audio_io_loopback_in_test()
{
....
while (1) {
char *buffer = alloca(size);
if ((ret = audio_in_read(input, (void *)buffer, size)) >
AUDIO_IO_ERROR_NONE)
{
fwrite(buffer, size, sizeof(char), fp);
printf("PASS, size=%d, ret=0x%x\n", size, ret);
} else {
printf("FAIL, size=%d, ret=0x%x\n", size, ret);
}
}
....
}Предупреждение PVS-Studio: V505 The ‘alloca’ function is used inside the loop. This can quickly overflow stack. audio_io_test.c 247
Software weaknesses type — CWE-770: Allocation of Resources Without Limits or Throttling
В цикле, который выполняется, пока не закончится аудио-поток, происходит выделение стековой памяти с помощью функции alloca. Такой код плох тем, что очень быстро может исчерпаться стековая память.
Однако я не могу сказать, что нашел серьезную ошибку. Дело в том, что этот код относится к тестам. Уверен, что звуковой поток в тестах короткий и никаких проблем при его обработке в тестах не возникает.
Таким образом, не совсем честно говорить, что это именно ошибка, ведь тесты работают.
Но я и не согласен с тем, чтобы назвать это предупреждение ложным. Ведь код действительно плох. Через некоторое время кто-то может захотеть выполнять тесты на данных чуть большего размера, и произойдёт сбой. При этом поток данных должен стать не таким уж и большим. Достаточно, чтобы обрабатывались данные размером, равным размеру свободного стека, а это, как правило, совсем не много.
Более того, код можно легко исправить, а значит — это надо сделать. Достаточно вынести выделение памяти из цикла. Это можно сделать, так как размер выделяемого буфера не изменяется.
Хороший код:
char *buffer = alloca(size);
while (1) {
if ((ret = audio_in_read(input, (void *)buffer, size)) >
AUDIO_IO_ERROR_NONE)
{
fwrite(buffer, size, sizeof(char), fp);
printf("PASS, size=%d, ret=0x%x\n", size, ret);
} else {
printf("FAIL, size=%d, ret=0x%x\n", size, ret);
}
}Используется уже несуществующий буфер (1 ошибка)
Следующий код также относится к тестам, но ошибка в нем гораздо серьезнее. Из-за ошибки возникает неопределённое поведение программы, поэтому доверять такому тесту совершенно нельзя. Другими словами — тест ничего не тестирует.
void extract_input_aacdec_m4a_test(
App * app, unsigned char **data, int *size, bool * have_frame)
{
....
unsigned char buffer[100000];
....
DONE:
*data = buffer;
*have_frame = TRUE;
if (read_size >= offset)
*size = offset;
else
*size = read_size;
}Ошибка найдена благодаря предупреждению PVS-Studio: V507 Pointer to local array ‘buffer’ is stored outside the scope of this array. Such a pointer will become invalid. media_codec_test.c 793
Software weaknesses type — CWE-562: Return of Stack Variable Address
Функция возвращает адрес массива, созданного на стеке. После завершения функции этот массив будет уничтожен, и возвращенный из функции адрес никак нельзя использовать.
Обрабатывается меньше или больше элементов массива, чем требуется (7 ошибок)
Для начала рассмотрим случай, когда обрабатывается меньше элементов, чем требуется.
typedef int gint;
typedef gint gboolean;
#define BT_REQUEST_ID_RANGE_MAX 245
static gboolean req_id_used[BT_REQUEST_ID_RANGE_MAX];
void _bt_init_request_id(void)
{
assigned_id = 0;
memset(req_id_used, 0x00, BT_REQUEST_ID_RANGE_MAX);
}Предупреждение PVS-Studio: V512 A call of the ‘memset’ function will lead to underflow of the buffer ‘req_id_used’. bt-service-util.c 38
Software weaknesses type — CWE-131: Incorrect Calculation of Buffer Size
Здесь программист забыл, что в качестве третьего аргумента функция memset принимает размер буфера в байтах, а не количество элементов массива. Не зря я в своё время назвал memset самой опасной функцией в мире программирования на C/C++. Эта функция продолжает сеять хаос в различных проектах.
Тип gboolean занимает не 1 байт, а 4. В результате будет обнулена только 1/4 часть массива, а остальные элементы останутся неинициализированными.
Правильный вариант кода:
memset(req_id_used, 0x00, BT_REQUEST_ID_RANGE_MAX * sizeof(gboolean));Или можно написать так:
memset(req_id_used, 0x00, sizeof(req_id_used));Теперь рассмотрим случай, когда может произойти выход за границу массива.
static void _on_atspi_event_cb(const AtspiEvent * event)
{
....
char buf[256] = "\0";
....
snprintf(buf, sizeof(buf), "%s, %s, ",
name, _("IDS_BR_BODY_IMAGE_T_TTS"));
....
snprintf(buf + strlen(buf), sizeof(buf),
"%s, ", _("IDS_ACCS_BODY_SELECTED_TTS"));
....
}Предупреждение PVS-Studio: V512 A call of the ‘snprintf’ function will lead to overflow of the buffer ‘buf + strlen(buf)’. app_tracker.c 450
Software weaknesses type — CWE-131: Incorrect Calculation of Buffer Size
Надежная операционная система… Эх…
Обратите внимание, что второй вызов snprintf должен добавить что-то к уже имеющейся строке. Поэтому адресом буфера является выражение buf + strlen(buf). При этом функция имеет право печатать символов меньше, чем размер буфера. Из размера буфера надо вычесть strlen(buf). Но про это забыли и может возникнуть ситуация, когда функция snprintf запишет данные за границу массива.
Корректный код:
snprintf(buf + strlen(buf), sizeof(buf) - strlen(buf),
"%s, ", _("IDS_ACCS_BODY_SELECTED_TTS"));Третий фрагмент кода демонстрирует ситуацию, когда выход за границу происходит всегда. Для начала рассмотрим некоторые структуры.
#define BT_ADDRESS_STRING_SIZE 18
typedef struct {
unsigned char addr[6];
} bluetooth_device_address_t;
typedef struct {
int count;
bluetooth_device_address_t addresses[20];
} bt_dpm_device_list_t;Здесь нам важно, что массив addr состоит из 6 элементов. Запомните этот размер, а также, что макрос BT_ADDRESS_STRING_SIZE раскрывается в константу 18.
Теперь собственно некорректный код:
dpm_result_t _bt_dpm_get_bluetooth_devices_from_whitelist(
GArray **out_param1)
{
dpm_result_t ret = DPM_RESULT_FAIL;
bt_dpm_device_list_t device_list;
....
for (; list; list = list->next, i++) {
memset(device_list.addresses[i].addr, 0, BT_ADDRESS_STRING_SIZE);
_bt_convert_addr_string_to_type(device_list.addresses[i].addr,
list->data);
}
....
}Предупреждение PVS-Studio: V512 A call of the ‘memset’ function will lead to overflow of the buffer ‘device_list.addresses[i].addr’. bt-service-dpm.c 226
Software weaknesses type — CWE-805: Buffer Access with Incorrect Length Value
Выделю самое главное:
memset(device_list.addresses[i].addr, 0, BT_ADDRESS_STRING_SIZE);Итак, как мы видели раньше, размер addr всего 6 байт. При этом функция memset обнуляет 18 байт и, как следствие, происходит выход за границу массива.
Ещё 4 найденные ошибки:
- V512 A call of the ‘memset’ function will lead to overflow of the buffer ‘device_list.addresses[i].addr’. bt-service-dpm.c 176
- V512 A call of the ‘memset’ function will lead to underflow of the buffer ‘formatted_number’. i18ninfo.c 544
- V512 A call of the ‘snprintf’ function will lead to overflow of the buffer ‘ret + strlen(ret)’. navigator.c 677
- V512 A call of the ‘snprintf’ function will lead to overflow of the buffer ‘trait + strlen(trait)’. navigator.c 514
Логическая ошибка в последовательностях if… else… if (4 ошибки)
char *voice_setting_language_conv_lang_to_id(const char* lang)
{
....
} else if (!strcmp(LANG_PT_PT, lang)) {
return "pt_PT";
} else if (!strcmp(LANG_ES_MX, lang)) { // <=
return "es_MX";
} else if (!strcmp(LANG_ES_US, lang)) { // <=
return "es_US";
} else if (!strcmp(LANG_EL_GR, lang)) {
return "el_GR";
....
}Предупреждение PVS-Studio: V517 The use of ‘if (A) {…} else if (A) {…}’ pattern was detected. There is a probability of logical error presence. Check lines: 144, 146. voice_setting_language.c 144
Software weaknesses type — CWE-570 Expression is Always False
Рассматривая этот код, нельзя понять, в чём же заключается ошибка. Всё дело в том, что LANG_ES_MX и LANG_ES_US — это идентичные строки. Вот они:
#define LANG_ES_MX "\x45\x73\x70\x61\xC3\xB1\x6f\x6c\x20\x28\" \
"x45\x73\x74\x61\x64\x6f\x73\x20\x55\x6e\x69\x64\x6f\x73\x29"
#define LANG_ES_US "\x45\x73\x70\x61\xC3\xB1\x6f\x6c\x20\x28\" \
"x45\x73\x74\x61\x64\x6f\x73\x20\x55\x6e\x69\x64\x6f\x73\x29"Как я понимаю, эти строки на самом деле должны отличаться. Но поскольку строки одинаковые, то второе условие всегда ложно и функция никогда не вернёт значение «es_US».
Примечание. ES_MX — это Spanish (Mexico), ES_US — это Spanish (United States).
Эту ошибку я нашел в проекте org.tizen.voice-setting-0.0.1. Что интересно, вновь подводит технология Copy-Paste, и точно такую же ошибку я встретил в проекте org.tizen.voice-control-panel-0.1.1.
Другие ошибки:
- V517 The use of ‘if (A) {…} else if (A) {…}’ pattern was detected. There is a probability of logical error presence. Check lines: 144, 146. voice_setting_language.c 144
- V517 The use of ‘if (A) {…} else if (A) {…}’ pattern was detected. There is a probability of logical error presence. Check lines: 792, 800. setting-common-general-func.c 792
- V517 The use of ‘if (A) {…} else if (A) {…}’ pattern was detected. There is a probability of logical error presence. Check lines: 801, 805. setting-common-general-func.c 801
Повторное присваивание (11 ошибок)
Рассмотрим ошибку в логике работы программы. Разработчик хотел обменять значения двух переменных, но запутался и у него получился следующий код:
void
isf_wsc_context_del (WSCContextISF *wsc_ctx)
{
....
WSCContextISF* old_focused = _focused_ic;
_focused_ic = context_scim;
_focused_ic = old_focused;
....
}Предупреждение PVS-Studio: V519 The ‘_focused_ic’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1260, 1261. wayland_panel_agent_module.cpp 1261
Software weaknesses type — CWE-563 Assignment to Variable without Use (‘Unused Variable’)
Переменной _focused_ic два раза подряд присваиваются разные значения. Правильный код должен быть таким:
WSCContextISF* old_focused = _focused_ic;
_focused_ic = context_scim;
context_scim = old_focused;Впрочем, в таких случаях лучше использовать функцию std::swap. Так намного меньше шансов ошибиться:
std::swap(_focused_ic, context_scim);Рассмотрим другой вариант ошибки, которая возникла при написании однотипного кода. Возможно, в её появлении виноват метод Copy-Paste.
void create_privacy_package_list_view(app_data_s* ad)
{
....
Elm_Genlist_Item_Class *ttc = elm_genlist_item_class_new();
Elm_Genlist_Item_Class *ptc = elm_genlist_item_class_new();
Elm_Genlist_Item_Class *mtc = elm_genlist_item_class_new();
....
ttc->item_style = "title";
ttc->func.text_get = gl_title_text_get_cb;
ttc->func.del = gl_del_cb; // <=
ptc->item_style = "padding";
ptc->func.del = gl_del_cb;
mtc->item_style = "multiline";
mtc->func.text_get = gl_multi_text_get_cb;
ttc->func.del = gl_del_cb; // <=
....
}Предупреждение PVS-Studio: V519 The ‘ttc->func.del’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 409, 416. privacy_package_list_view.c 416
Software weaknesses type — CWE-563 Assignment to Variable without Use (‘Unused Variable’)
Во втором случае значение должно было присваиваться переменной mtc->func.del.
Другие ошибки:
- V519 The ‘item’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1176, 1189. w-input-stt-voice.cpp 1189
- V519 The ‘ad->paired_item’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1614, 1617. bt-main-view.c 1617
- V519 The ‘ret’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 191, 194. main.c 194
- V519 The ‘ret’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 372, 375. setting-about-status.c 375
- V519 The ‘ret’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 91, 100. setting-applications-defaultapp.c 100
- V519 The ‘ret’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 52, 58. smartmanager-battery.c 58
- V519 The ‘ret’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 853, 872. setting-time-main.c 872
- V519 The ‘ret_str’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 2299, 2300. setting-password-sim.c 2300
- V519 The ‘display_status’ variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 110, 117. view_clock.c 117
При просмотре отчета анализатора я выделил только 11 мест, которые, на мой взгляд, следует исправить. Но на самом деле сообщений V519 было намного больше. Очень часто они относились к коду, когда в переменную много раз подряд сохранялся результат после вызова функций. Речь идёт о коде вида:
status = Foo(0);
status = Foo(1);
status = Foo(2);Такой код возникает, как правило, в двух случаях:
- Результат вызова функций не важен, но какой-то компилятор или анализатор выдал предупреждение, от которого избавились, записав результат в переменную. По-моему мнению, тогда было бы лучше написать (void)Foo(x);.
- Результат вызова функций не важен, но иногда может пригодиться для отладки. Намного проще отлаживать код, когда результат записывается в какую-то переменную.
Про этот момент я пишу, так как, возможно, не везде такой код безопасен, как кажется на первый взгляд. Вероятно, в некоторых местах результат, который вернули функции, зря обделён вниманием и не проверен. Я смотрел код быстро и не разбирался, как и что устроено. Думаю, если подойти к этим предупреждениям внимательнее, то можно будет обнаружить гораздо больше дефектов.
Разыменование (потенциально) нулевого указателя (всего ошибок 88)
Использование нулевых указателей выявляется с помощью диагностик V522 и V575. Предупреждение V522 выдаётся, кода происходит разыменование указателя, который может быть нулевым (*MyNullPtr = 2;). V575 — когда потенциально нулевой указатель передаётся в функцию, внутри которой он может быть разыменован (s = strlen(MyNullPtr);). На самом деле V575 выдаётся и для некоторых других случаев, когда используются некорректные аргументы, но на данный момент это нам не интересно. Сейчас, с точки зрения статьи, разницы между предупреждениями V522 и V575 нет, поэтому они будут рассмотрены в этой главе совместно.
Отдельно стоит поговорить о таких функциях, как malloc, realloc, strdup. Следует проверять, не вернули ли они NULL, если невозможно выделить блок памяти запрошенного размера. Впрочем, некоторые программисты придерживаются плохой практики и никогда сознательно не делают проверок. Их логика такова, раз нет памяти, то и не стоит дальше мучиться, пусть программа упадёт. Я считаю такой подход плохим, но он есть, и я не раз слышал доводы в его защиту.
К счастью, разработчики Tizen к упомянутой категории не относятся и обычно проверяют, удалось ли выделить память или нет. Иногда они это делают даже там, где не надо:
static FilterModule *__filter_modules = 0;
static void
__initialize_modules (const ConfigPointer &config)
{
....
__filter_modules = new FilterModule [__number_of_modules];
if (!__filter_modules) return;
....
}В такой проверке нет смысла, так как в случае неудачи выделения памяти оператор new сгенерирует исключение типа std::bad_alloc. Впрочем, это совсем другая история. Я привел этот код исключительно для того, чтобы показать, что в проекте Tizen принято проверять, удалось ли выделить память.
Так вот, анализатор PVS-Studio обнаруживает, что во многих местах проверок не хватает. Здесь я рассмотрю только один случай, так как в общем-то они все однотипны.
void QuickAccess::setButtonColor(Evas_Object* button,
int r, int g, int b, int a)
{
Edje_Message_Int_Set* msg =
(Edje_Message_Int_Set *)malloc(sizeof(*msg) + 3 * sizeof(int));
msg->count = 4;
msg->val[0] = r;
msg->val[1] = g;
msg->val[2] = b;
msg->val[3] = a;
edje_object_message_send(elm_layout_edje_get(button),
EDJE_MESSAGE_INT_SET, 0, msg);
free(msg);
}Предупреждение PVS-Studio: V522 There might be dereferencing of a potential null pointer ‘msg’. QuickAccess.cpp 743
Software weaknesses type — CWE-690: Unchecked Return Value to NULL Pointer Dereference
Нет гарантии, что функция malloc выделит память. Да, вероятность такого события крайне мала, но если проверки на равенство указателей NULL есть в других местах, то проверка должна быть и здесь. Поэтому я считаю, что этот код содержит настоящую ошибку, которую необходимо исправить.
Однако нулевые указатели могут возвращать не только функции, выделяющие память. Есть и другие ситуации, когда следует проверять указатель перед использованием. Рассмотрим пару таких примеров. Первый из них связан с небезопасным использованием оператора dynamic_cast.
int cpp_audio_in_peek(audio_in_h input, const void **buffer,
unsigned int *length) {
....
CAudioInput* inputHandle =
dynamic_cast<CAudioInput*>(handle->audioIoHandle);
assert(inputHandle);
inputHandle->peek(buffer, &_length);
....
}Предупреждение PVS-Studio: V522 There might be dereferencing of a potential null pointer ‘inputHandle’. cpp_audio_io.cpp 928
Software weaknesses type — CWE-690: Unchecked Return Value to NULL Pointer Dereference
Странный код. Если есть уверенность, что в handle->audioIoHandle хранится указатель на объект типа CAudioInput, то надо использовать static_cast. Если уверенности нет, то нужна проверка, так как макрос assert не поможет в release-версии.
Думаю, правильнее будет добавить вот такую проверку:
CAudioInput* inputHandle =
dynamic_cast<CAudioInput*>(handle->audioIoHandle);
if (inputHandle == nullptr) {
assert(false);
THROW_ERROR_MSG_FORMAT(
CAudioError::EError::ERROR_INVALID_HANDLE, "Handle is NULL");
}Кстати, именно подобным образом сделано в других функциях. Так что анализатор действительно нашел дефект в программе.
Следующий код, возможно, и не приводит к настоящей ошибке. Допустим, сейчас всегда обрабатываются такие строки, в которых обязательно присутствуют символы ‘-‘ и ‘.’. Однако, я надеюсь вы согласитесь, что код опасен и лучше подстраховаться. Выбрал я его, чтобы продемонстрировать разнообразие ситуаций, когда анализатор выдаёт предупреждения.
int main(int argc, char *argv[])
{
....
char *temp1 = strstr(dp->d_name, "-");
char *temp2 = strstr(dp->d_name, ".");
strncpy(temp_filename, dp->d_name,
strlen(dp->d_name) - strlen(temp1));
strncpy(file_format, temp2, strlen(temp2));
....
}Предупреждения PVS-Studio:
- V575 The potential null pointer is passed into ‘strlen’ function. Inspect the first argument. image_util_decode_encode_testsuite.c 207
- V575 The potential null pointer is passed into ‘strlen’ function. Inspect the first argument. image_util_decode_encode_testsuite.c 208
Software weaknesses type — CWE-690: Unchecked Return Value to NULL Pointer Dereference
Указатели temp1 и temp2 могут оказаться нулевыми, если в строке не обнаружатся символы ‘-‘ и ‘.’. В этом случае чуть позже произойдёт разыменование нулевого указателя.
Есть ещё 84 участка кода, где разыменовываются указатели, которые могут оказаться равны NULL. Рассматривать их в статье нет никакого смысла. Нет смысла даже приводить их просто списком, так как это все равно займёт много места. Поэтому я выписал эти предупреждения в отдельный файл: Tizen_V522_V575.txt.
Одинаковые действия (6 ошибок)
static void _content_resize(...., const char *signal)
{
....
if (strcmp(signal, "portrait") == 0) {
evas_object_size_hint_min_set(s_info.layout,
ELM_SCALE_SIZE(width), ELM_SCALE_SIZE(height));
} else {
evas_object_size_hint_min_set(s_info.layout,
ELM_SCALE_SIZE(width), ELM_SCALE_SIZE(height));
}
....
}Предупреждение PVS-Studio: V523 The ‘then’ statement is equivalent to the ‘else’ statement. page_setting_all.c 125
Software weaknesses type — не знаю как классифицировать, буду благодарен за подсказку.
Вне зависимости от условия, выполняются одни и те же действия. Как я понимаю, в одном из двух вызовов функции evas_object_size_hint_min_set следует поменять местами width и height.
Рассмотрим ещё одну ошибку этого типа:
static Eina_Bool _move_cb(void *data, int type, void *event)
{
Ecore_Event_Mouse_Move *move = event;
mouse_info.move_x = move->root.x;
mouse_info.move_y = move->root.y;
if (mouse_info.pressed == false) {
return ECORE_CALLBACK_RENEW; // <=
}
return ECORE_CALLBACK_RENEW; // <=
}Предупреждение PVS-Studio: V523 The ‘then’ statement is equivalent to the subsequent code fragment. mouse.c 143
Software weaknesses type — CWE-393 Return of Wrong Status Code
Очень странно, что функция выполняет какую-то проверку, но всё равно всегда возвращает значение ECORE_CALLBACK_RENEW. Думаю, возвращаемые значения должны различаться.
Другие ошибки этого типа:
- V523 The ‘then’ statement is equivalent to the ‘else’ statement. bt-httpproxy.c 383
- V523 The ‘then’ statement is equivalent to the ‘else’ statement. streamrecorder_test.c 342
- V523 The ‘then’ statement is equivalent to the ‘else’ statement. ise-stt-option.cpp 433
- V523 The ‘then’ statement is equivalent to the subsequent code fragment. dpm-toolkit-cli.c 87
Забыли разыменовать указатель (1 ошибка)
Очень красивая ошибка: пишем данные неизвестно куда.
int _read_request_body(http_transaction_h http_transaction,
char **body)
{
....
*body = realloc(*body, new_len + 1);
....
memcpy(*body + curr_len, ptr, body_size);
body[new_len] = '\0'; // <=
curr_len = new_len;
....
}Предупреждение PVS-Studio: V527 It is odd that the ‘\0’ value is assigned to ‘char’ type pointer. Probably meant: *body[new_len] = ‘\0’. http_request.c 370
Software weaknesses type — CWE-787: Out-of-bounds Write
Функция принимает указатель на указатель. Это позволяет при необходимости перевыделить память и вернуть адрес новой строки.
Ошибка кроется в строке:
body[new_len] = '\0';Получается, что указатель на указатель интерпретируется как массив указателей. Никакого массива, конечно, нет. Поэтому NULL (‘\0’ в данном случае воспринимается как нулевой указатель) будет записан совершенно непонятно куда. Происходит порча какого-то неизвестного блока памяти.

Помимо этого, возникает ещё одна ошибка. Строка не будет завершена терминальным нулём. В общем, всё плохо.
Правильный код:
(*body)[new_len] = '\0';Условие всегда true/false (9 ошибок)
Есть много причин, приводящих к ошибке, из-за которой условие всегда является истинным или ложным, но в статье для краткости я рассмотрю только 3 варианта возникновения ошибки.
Первый вариант.
unsigned m_candiPageFirst;
bool
CIMIClassicView::onKeyEvent(const CKeyEvent& key)
{
....
if (m_candiPageFirst > 0) {
m_candiPageFirst -= m_candiWindowSize;
if (m_candiPageFirst < 0) m_candiPageFirst = 0;
changeMasks |= CANDIDATE_MASK;
}
....
}Предупреждение PVS-Studio: V547 Expression ‘m_candiPageFirst < 0’ is always false. Unsigned type value is never < 0. imi_view_classic.cpp 201
Software weaknesses type — CWE-570: Expression is Always False
Переменная m_candiPageFirst имеет тип unsigned. Следовательно, значение этой переменной не может быть меньше нуля. Чтобы защититься от переполнения, следует переписать код так:
if (m_candiPageFirst > 0) {
if (m_candiPageFirst > m_candiWindowSize)
m_candiPageFirst -= m_candiWindowSize;
else
m_candiPageFirst = 0;
changeMasks |= CANDIDATE_MASK;
}Второй вариант.
void
QuickAccess::_grid_mostVisited_del(void *data, Evas_Object *)
{
BROWSER_LOGD("[%s:%d]", __PRETTY_FUNCTION__, __LINE__);
if (data) {
auto itemData = static_cast<HistoryItemData*>(data);
if (itemData)
delete itemData;
}
}Предупреждение PVS-Studio: V547 Expression ‘itemData’ is always true. QuickAccess.cpp 571
Software weaknesses type — CWE-571: Expression is Always True
Это очень подозрительный код. Если указатель data != nullptr, то и указатель itemData != nullptr. Следовательно, вторая проверка не имеет смысла. Здесь мы столкнулись с одной из двух ситуаций:
- Это ошибка. На самом деле вместо оператора static_cast следовало использовать оператор dynamic_cast, который может вернуть nullptr.
- Настоящей ошибки нет, это неаккуратный код. Вторая проверка просто лишняя и её следует удалить, чтобы она не сбивала с толку анализаторы кода и других программистов.
Сейчас мне сложно сказать, следует выбрать пункт 1 или 2, но в любом случае, этот код заслуживает внимания и его следует исправить.
Третий вариант.
typedef enum {
BT_HID_MOUSE_BUTTON_NONE = 0x00,
BT_HID_MOUSE_BUTTON_LEFT = 0x01,
BT_HID_MOUSE_BUTTON_RIGHT = 0x02,
BT_HID_MOUSE_BUTTON_MIDDLE = 0x04
} bt_hid_mouse_button_e;
int bt_hid_device_send_mouse_event(const char *remote_address,
const bt_hid_mouse_data_s *mouse_data)
{
....
if (mouse_data->buttons != BT_HID_MOUSE_BUTTON_LEFT ||
mouse_data->buttons != BT_HID_MOUSE_BUTTON_RIGHT ||
mouse_data->buttons != BT_HID_MOUSE_BUTTON_MIDDLE) {
return BT_ERROR_INVALID_PARAMETER;
}
....
}Предупреждение PVS-Studio: V547 Expression is always true. Probably the ‘&&’ operator should be used here. bluetooth-hid.c 229
Software weaknesses type — CWE-571: Expression is Always True
Чтобы было проще понять в чем ошибка, я подставлю значения констант и сокращу код:
if (buttons != 1 ||
buttons != 2 ||
buttons != 4) {Какое бы значение не хранилось в переменной, оно всегда будет не равно 1 или 2 или 4.
Другие ошибки:
- V547 Expression ‘ad->transfer_info’ is always true. bt-share-ui-popup.c 56
- V547 Expression ‘item_name’ is always true. SettingsUI.cpp 222
- V547 Expression ‘item_name’ is always true. SettingsUI.cpp 226
- V547 Expression ‘!urlPair’ is always false. GenlistManager.cpp 143
- V547 Expression ‘strlen(s_formatted) < 128’ is always true. clock.c 503
- V547 Expression ‘doc != ((void *) 0)’ is always true. setting-common-data-slp-setting.c 1450
Путаница с enum (18 ошибок)
В презентации этот вид ошибки я пропустил, так как примеры слишком длинные. Но в статье, я думаю, есть смысл вспомнить про них.
Есть два enum, в которых объявлены константы с похожими именами:
typedef enum {
WIFI_MANAGER_RSSI_LEVEL_0 = 0,
WIFI_MANAGER_RSSI_LEVEL_1 = 1,
WIFI_MANAGER_RSSI_LEVEL_2 = 2,
WIFI_MANAGER_RSSI_LEVEL_3 = 3,
WIFI_MANAGER_RSSI_LEVEL_4 = 4,
} wifi_manager_rssi_level_e;
typedef enum {
WIFI_RSSI_LEVEL_0 = 0,
WIFI_RSSI_LEVEL_1 = 1,
WIFI_RSSI_LEVEL_2 = 2,
WIFI_RSSI_LEVEL_3 = 3,
WIFI_RSSI_LEVEL_4 = 4,
} wifi_rssi_level_e;Неудивительно, что в именах можно запутаться и написать вот такой код:
static int
_rssi_level_to_strength(wifi_manager_rssi_level_e level)
{
switch (level) {
case WIFI_RSSI_LEVEL_0:
case WIFI_RSSI_LEVEL_1:
return LEVEL_WIFI_01;
case WIFI_RSSI_LEVEL_2:
return LEVEL_WIFI_02;
case WIFI_RSSI_LEVEL_3:
return LEVEL_WIFI_03;
case WIFI_RSSI_LEVEL_4:
return LEVEL_WIFI_04;
default:
return WIFI_RSSI_LEVEL_0;
}
}Переменная level имеет тип wifi_manager_rssi_level_e. Константы же имеют тип wifi_rssi_level_e. Получается, что есть сразу 5 неправильных сравнений, и поэтому анализатор выдаёт 5 предупреждений:
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. wifi.c 163
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. wifi.c 164
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. wifi.c 166
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. wifi.c 168
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. wifi.c 170
Software weaknesses type — CWE-697: Insufficient Comparison
Что забавно — этот код работает именно так, как задумывал программист. Благодаря везению, константа WIFI_MANAGER_RSSI_LEVEL_0 равна WIFI_RSSI_LEVEL_0 и так далее.
Несмотря на то, что сейчас код работает, это ошибка и её следует исправить. На это две причины:
- Этот код удивляет анализатор, а значит он будет удивлять и программистов, которые будут его сопровождать.
- Если хотя бы один из enum со временем изменится и значения констант перестанут совпадать, то программа начнет вести себя некорректно.
Другие неправильные сравнения:
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 885
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 889
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 892
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 895
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 898
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 901
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 904
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. e_devicemgr_video.c 907
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. myplace-placelist.c 239
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. myplace-placelist.c 253
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. myplace-placelist.c 264
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. telephony_syspopup_noti.c 82
- V556 The values of different enum types are compared: switch(ENUM_TYPE_A) { case ENUM_TYPE_B:… }. telephony_syspopup_noti.c 87
Часть условия всегда true/false (2 ошибки)
Я заметил всего 2 таких ошибки, но они обе интересные, поэтому давайте рассмотрим их.
int bytestream2nalunit(FILE * fd, unsigned char *nal)
{
unsigned char val, zero_count, i;
....
val = buffer[0];
while (!val) { // <=
if ((zero_count == 2 || zero_count == 3) && val == 1) // <=
break;
zero_count++;
result = fread(buffer, 1, read_size, fd);
if (result != read_size)
break;
val = buffer[0];
}
....
}Предупреждение PVS-Studio: V560 A part of conditional expression is always false: val == 1. player_es_push_test.c 284
Software weaknesses type — CWE-570: Expression is Always False
Цикл выполняется до тех пор, пока переменная val равна нулю. В начале тела цикла переменная val сравнивается со значением 1. Естественно, переменная val не может быть равна 1, иначе бы цикл уже остановился. Здесь явно какая-то логическая ошибка.
Теперь рассмотрим другую ошибку.
const int GT_SEARCH_NO_LONGER = 0,
GT_SEARCH_INCLUDE_LONGER = 1,
GT_SEARCH_ONLY_LONGER = 2;
bool GenericTableContent::search (const String &key,
int search_type) const
{
....
else if (nkeys.size () > 1 && GT_SEARCH_ONLY_LONGER) {
....
}Предупреждение PVS-Studio: V560 A part of conditional expression is always true: GT_SEARCH_ONLY_LONGER. scim_generic_table.cpp 1884
Software weaknesses type — CWE-571: Expression is Always True
Константа GT_SEARCH_ONLY_LONGER является частью условия. Это очень странно и у меня есть подозрение, что на самом деле условие должно выглядеть так:
if (nkeys.size () > 1 && search_type == GT_SEARCH_ONLY_LONGER)Путаница с типами создаваемых и уничтожаемых объектов (4 ошибки)
Объявлены три структуры, никак не связанные между собой:
struct sockaddr_un
{
sa_family_t sun_family;
char sun_path[108];
};
struct sockaddr_in
{
sa_family_t sin_family;
in_port_t sin_port;
struct in_addr sin_addr;
unsigned char sin_zero[sizeof (struct sockaddr) -
(sizeof (unsigned short int)) -
sizeof (in_port_t) -
sizeof (struct in_addr)];
};
struct sockaddr
{
sa_family_t sa_family;
char sa_data[14];
};Ошибка заключается в том, что создаются объекты одного типа, а уничтожаются они как объекты другого типа:
class SocketAddress::SocketAddressImpl
{
struct sockaddr *m_data;
....
SocketAddressImpl (const SocketAddressImpl &other)
{
....
case SCIM_SOCKET_LOCAL:
m_data = (struct sockaddr*) new struct sockaddr_un; // <=
len = sizeof (sockaddr_un);
break;
case SCIM_SOCKET_INET:
m_data = (struct sockaddr*) new struct sockaddr_in; // <=
len = sizeof (sockaddr_in);
break;
....
}
~SocketAddressImpl () {
if (m_data) delete m_data; // <=
}
};Предупреждения анализатора:
- V572 It is odd that the object which was created using ‘new’ operator is immediately cast to another type. scim_socket.cpp 136
- V572 It is odd that the object which was created using ‘new’ operator is immediately cast to another type. scim_socket.cpp 140
Software weaknesses type — CWE-762: Mismatched Memory Management Routines.
Создаются структуры типа sockaddr_un и sockaddr_in. При этом хранятся и уничтожаются они как структуры типа sockaddr. Типы всех трёх названных структур никак не связаны между собой. Это три разные структуры, имеющие разный размер. Сейчас код вполне может работать, так как структуры являются POD типами (не содержат деструкторы и т.д.) и вызов оператора delete превращается в простой вызов функции free. Однако формально код неверен. Нужно уничтожать объект точно такого же типа, который использовался при создании объекта.
Как я уже сказал, сейчас программа может работать, хотя формально и является неправильной. Надо понимать, что рассмотренный код очень опасен и достаточно, чтобы в одном из классов появился конструктор/деструктор или был добавлен член сложного типа (например std::string), как всё сразу сломается окончательно.
Другие ошибки:
- V572 It is odd that the object which was created using ‘new’ operator is immediately cast to another type. scim_socket.cpp 167
- V572 It is odd that the object which was created using ‘new’ operator is immediately cast to another type. scim_socket.cpp 171
Неправильная работа с printf-подобными функциями (4 ошибки)
static int _write_file(const char *file_name, void *data,
unsigned long long data_size)
{
FILE *fp = NULL;
if (!file_name || !data || data_size <= 0) {
fprintf(stderr,
"\tinvalid data %s %p size:%lld\n",
file_name, data, data_size);
return FALSE;
}
....
}Предупреждение PVS-Studio: V576 Incorrect format. Consider checking the third actual argument of the ‘fprintf’ function. Under certain conditions the pointer can be null. image_util_decode_encode_testsuite.c 124
Software weaknesses type — CWE-476: NULL Pointer Dereference
Возможна ситуация, когда указатель file_name будет содержать NULL. Как в таком случае поведёт себя функция printf, предсказать невозможно. На практике поведение будет зависеть от используемой реализации функции printf. См. дискуссию «What is the behavior of printing NULL with printf’s %s specifier?».
Рассмотрим ещё одну ошибку.
void subscribe_to_event()
{
....
int error = ....;
....
PRINT_E("Failed to destroy engine configuration for event trigger.",
error);
....
}Предупреждение PVS-Studio: V576 Incorrect format. A different number of actual arguments is expected while calling ‘printf’ function. Expected: 1. Present: 2. surveillance_test_suite.c 393
Software weaknesses type — не знаю как классифицировать, буду благодарен за подсказку.
Макрос PRINT_E раскрывается в printf. Как видите, переменная error никак не используется. Видимо номер ошибки забыли распечатать.
Другие ошибки:
- V576 Incorrect format. A different number of actual arguments is expected while calling ‘printf’ function. Expected: 1. Present: 2. surveillance_test_suite.c 410
- V576 Incorrect format. A different number of actual arguments is expected while calling ‘printf’ function. Expected: 1. Present: 2. surveillance_test_suite.c 417
Проверка указателя выполняется уже после его разыменования (5 ошибок)
static void _show(void *data)
{
SETTING_TRACE_BEGIN;
struct _priv *priv = (struct _priv *)data;
Eina_List *children = elm_box_children_get(priv->box); // <=
Evas_Object *first = eina_list_data_get(children);
Evas_Object *selected =
eina_list_nth(children, priv->item_selected_on_show); // <=
if (!priv) { // <=
_ERR("Invalid parameter.");
return;
}
....
}Предупреждение PVS-Studio: V595 The ‘priv’ pointer was utilized before it was verified against nullptr. Check lines: 110, 114. view_generic_popup.c 110
Software weaknesses type — CWE-476: NULL Pointer Dereference
Указатель priv дважды разыменовывается в выражениях:
- priv->box
- priv->item_selected_on_show
И только затем указатель проверяется на равенство нулю. Чтобы исправить код, проверку следует передвинуть выше:
static void _show(void *data)
{
SETTING_TRACE_BEGIN;
struct _priv *priv = (struct _priv *)data;
if (!priv) {
_ERR("Invalid parameter.");
return;
}
Eina_List *children = elm_box_children_get(priv->box);
Evas_Object *first = eina_list_data_get(children);
Evas_Object *selected =
eina_list_nth(children, priv->item_selected_on_show);
....
}Теперь рассмотрим более сложный случай.
Есть функция _ticker_window_create, в которой разыменовывается указатель, переданный функции в качестве аргумента.
static Evas_Object *_ticker_window_create(struct appdata *ad)
{
....
// нет проверки указателя 'ad'
....
evas_object_resize(win, ad->win.w, indicator_height_get());
....
}Важно отметить, что указатель разыменовывается без предварительной проверки на равенство NULL. Другими словами, в функцию _ticker_window_create можно передавать только ненулевые указатели. Теперь посмотрим, как эта функция используется на самом деле.
static int _ticker_view_create(void)
{
if (!ticker.win)
ticker.win = _ticker_window_create(ticker.ad); // <=
if (!ticker.layout)
ticker.layout = _ticker_layout_create(ticker.win);
if (!ticker.scroller)
ticker.scroller = _ticker_scroller_create(ticker.layout);
evas_object_show(ticker.layout);
evas_object_show(ticker.scroller);
evas_object_show(ticker.win);
if (ticker.ad) // <=
util_signal_emit_by_win(&ticker.ad->win,
"message.show.noeffect", "indicator.prog");
....
}Предупреждение PVS-Studio: V595 The ‘ticker.ad’ pointer was utilized before it was verified against nullptr. Check lines: 590, 600. ticker.c 590
Software weaknesses type — CWE-476: NULL Pointer Dereference
Указатель ticker.ad передаётся в функцию _ticker_window_create. Ниже есть проверка «if (ticket.ad)«, которая свидетельствует о том, что этот указатель может быть нулевым.
Другие ошибки:
- V595 The ‘core’ pointer was utilized before it was verified against nullptr. Check lines: 2252, 2254. media_codec_port_gst.c 2252
- V595 The ‘eyeCondition’ pointer was utilized before it was verified against nullptr. Check lines: 162, 168. FaceEyeCondition.cpp 162
- V595 The ‘dev->name’ pointer was utilized before it was verified against nullptr. Check lines: 122, 127. e_devicemgr_device.c 122
Не затираются приватные данные (1 ошибка)
static void SHA1Final(unsigned char digest[20],
SHA1_CTX* context)
{
u32 i;
unsigned char finalcount[8];
....
memset(context->count, 0, 8);
memset(finalcount, 0, 8);
}Предупреждение PVS-Studio: V597 The compiler could delete the ‘memset’ function call, which is used to flush ‘finalcount’ buffer. The memset_s() function should be used to erase the private data. wifi_generate_pin.c 185
Software weaknesses type — CWE-14: Compiler Removal of Code to Clear Buffers
Компилятор вправе удалить функцию memset, которая затирает приватные данные в буфере finalcount. С точки зрения языка C и C++, вызов функции можно удалить, так как далее этот буфер нигде не используется. Хочу обратить внимание, что это не теоретически возможное поведение компилятора, а самое что ни на есть обыденное. Компиляторы действительно удаляют такие функции (см. V597, CWE-14).
Путаница с выделением и освобождением памяти (2 ошибки)
Первая ошибка.
void
GenericTableContent::set_max_key_length (size_t max_key_length)
{
....
std::vector<uint32> *offsets;
std::vector<OffsetGroupAttr> *offsets_attrs;
offsets = new(std::nothrow) // <=
std::vector <uint32> [max_key_length];
if (!offsets) return;
offsets_attrs = new(std::nothrow)
std::vector <OffsetGroupAttr> [max_key_length];
if (!offsets_attrs) {
delete offsets; // <=
return;
}
....
}Предупреждение PVS-Studio: V611 The memory was allocated using ‘new T[]’ operator but was released using the ‘delete’ operator. Consider inspecting this code. It’s probably better to use ‘delete [] offsets;’. scim_generic_table.cpp 998
Software weaknesses type — CWE-762: Mismatched Memory Management Routines
В переменной offsets хранится указатель на массив объектов, созданных с помощью оператора new[]. Следовательно, разрушаться эти объекты должны с помощью оператора delete[].
Вторая ошибка.
static void __draw_remove_list(SettingRingtoneData *ad)
{
char *full_path = NULL;
....
full_path = (char *)alloca(PATH_MAX); // <=
....
if (!select_all_item) {
SETTING_TRACE_ERROR("select_all_item is NULL");
free(full_path); // <=
return;
}
....
}Предупреждение PVS-Studio: V611 The memory was allocated using ‘alloca’ function but was released using the ‘free’ function. Consider inspecting operation logics behind the ‘full_path’ variable. setting-ringtone-remove.c 88
Software weaknesses type — CWE-762: Mismatched Memory Management Routines
Память для буфера выделяется на стеке. Далее возможна ситуация, когда адрес этого буфера будет передан в качестве фактического аргумента в функцию free, что недопустимо.
Потенциально неинициализированная переменная (1 ошибка)
Тело функции _app_create, в которой находится ошибка, весьма длинное, поэтому я выделю только самую суть:
Eext_Circle_Surface *surface;
....
if (_WEARABLE)
surface = eext_circle_surface_conformant_add(conform);
....
app_data->circle_surface = surface;Предупреждение PVS-Studio: V614 Potentially uninitialized pointer ‘surface’ used. w-input-selector.cpp 896
Software weaknesses type — CWE-457: Use of Uninitialized Variable
Переменная surface инициализируется только в том случае, если выполняется условие «if (_WEARABLE)«.
Код не защищен от некорректных строк (6 ошибок)
Я не сразу обратил внимание на этот вид дефекта и, кажется, не выписал ряд предупреждений. Поэтому таких мест может быть не 6, а гораздо больше. Мне было неинтересно возвращаться к уже просмотренным отчётам анализатора, так что пусть будет только 6 дефектов.
void ise_show_stt_mode(Evas_Object *win)
{
....
snprintf(buf, BUF_LEN, gettext("IDS_ST_SK_CANCEL"));
....
}Предупреждение PVS-Studio: V618 It’s dangerous to call the ‘snprintf’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); ise-stt-mode.cpp 802
Software weaknesses type — CWE-134 Use of Externally-Controlled Format String
Код работает корректно, но он очень ненадёжен и опасен по двум причинам:
- Работа программы нарушится, если кто-то в дальнейшем в IDS_ST_SK_CANCEL использует символы спецификатора формата. Абстрактный пример: понадобится выводить сообщение «bla-bla %SystemDrive% bla-bla». Тогда %S будет воспринято как спецификатор формата, в результате чего будет напечатана абракадабра или возникнет access violation.
- Это слабое место может быть использовано для атаки. Если злоумышленнику удастся подменить строку, которая выводится на печать, он потенциально может использовать это для своей пользы.
В любом случае, в операционной системе, претендующей на звание надежной, такого кода быть не должно, тем более что ситуацию очень легко исправить. Достаточно написать так:
snprintf(buf, BUF_LEN, "%s", gettext("IDS_ST_SK_CANCEL"));Другие слабые места:
- V618 It’s dangerous to call the ‘snprintf’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); app_tracker.c 459
- V618 It’s dangerous to call the ‘snprintf’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); screen_reader_system.c 443
- V618 It’s dangerous to call the ‘snprintf’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); screen_reader_system.c 447
- V618 It’s dangerous to call the ‘snprintf’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); navigator.c 550
- V618 It’s dangerous to call the ‘snprintf’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); navigator.c 561
Самодельное объявление математических констант (2 ошибки)
#define PI 3.141592
void __apps_view_circle_get_pos(
int radius, double angle, int *x, int *y)
{
*x = radius * sin(angle * PI / 180);
*y = radius * cos(angle * PI / 180);
*x = *x + WINDOW_CENTER_X;
*y = WINDOW_CENTER_Y - *y;
}Предупреждения PVS-Studio:
- V624 The constant 3.141592 is being utilized. The resulting value could be inaccurate. Consider using the M_PI constant from <math.h>. apps_view_circle.c 306
- V624 The constant 3.141592 is being utilized. The resulting value could be inaccurate. Consider using the M_PI constant from <math.h>. apps_view_circle.c 307
Software weaknesses type — не знаю как классифицировать, буду благодарен за подсказку.
Признаю, что данную ситуацию можно признать ошибочной только с очень большой натяжкой. Точности константы 3.141592 более чем достаточно для любых практических расчётов.
Тем не менее, я считаю, что этот код надо модифицировать. Макрос PI — это лишняя сущность, которой просто не должно быть. Для таких случаев есть стандартный макрос M_PI, который вдобавок раскрывается в более точное значение.
Опасная арифметика (4 ошибки)
__extension__ typedef long int __time_t;
__extension__ typedef long int __suseconds_t;
struct timeval
{
__time_t tv_sec;
__suseconds_t tv_usec;
};
static struct timeval _t0 = {0, 0};
static struct timeval _t1;
void ISF_PROF_DEBUG_TIME (....)
{
float etime = 0.0;
....
etime = ((_t1.tv_sec * 1000000 + _t1.tv_usec) -
(_t0.tv_sec * 1000000 + _t0.tv_usec))/1000000.0;
....
}Предупреждение PVS-Studio: V636 The ‘_t1.tv_sec * 1000000’ expression was implicitly cast from ‘long’ type to ‘float’ type. Consider utilizing an explicit type cast to avoid overflow. An example: double A = (double)(X) * Y;. scim_utility.cpp 1492.
Software weaknesses type — CWE-681: Incorrect Conversion between Numeric Types
Здесь вычисляют количество секунд между двумя метками времени. Вычисления ведутся в микросекундах и для этого количество секунд умножается на миллион. Вычисления ведутся в типе long, который в 32-битной системе Tizen является 32-битным. Здесь очень легко может возникнуть переполнение. Чтобы этого избежать, для расчётов следует использовать тип long long или double.
Другие ошибки:
- V636 The ‘w / 2’ expression was implicitly cast from ‘int’ type to ‘float’ type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. poly_shape_hit_test.cpp 97
- V636 The ‘w / 2’ expression was implicitly cast from ‘int’ type to ‘float’ type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. poly_shape_hit_test.cpp 98
- V636 The ‘duration / 1000’ expression was implicitly cast from ‘int’ type to ‘double’ type. Consider utilizing an explicit type cast to avoid the loss of a fractional part. An example: double A = (double)(X) / Y;. e_devicemgr_device.c 648
Код выглядит не так, как работает (2 ошибки)
В первом случае, несмотря на ошибку, код работает правильно. Да, бывают такие счастливые совпадения.
int bt_tds_provider_send_activation_resp(
char *address, int result, bt_tds_provider_h provider)
{
....
if (error_code != BT_ERROR_NONE)
BT_ERR("%s(0x%08x)",
_bt_convert_error_to_string(error_code), error_code);
return error_code;
return error_code;
}Предупреждение PVS-Studio: V640 The code’s operational logic does not correspond with its formatting. The statement is indented to the right, but it is always executed. It is possible that curly brackets are missing. bluetooth-tds.c 313
Software weaknesses type — CWE-483: Incorrect Block Delimitation
Программисту повезло, так как независимо от условия следует вернуть одно и то же значение. Здесь забыты фигурные скобки. Корректный код должен был выглядеть так:
if (error_code != BT_ERROR_NONE)
{
BT_ERR("%s(0x%08x)",
_bt_convert_error_to_string(error_code), error_code);
return error_code;
}
return error_code;Или можно удалить один return и сделать код короче:
if (error_code != BT_ERROR_NONE)
BT_ERR("%s(0x%08x)",
_bt_convert_error_to_string(error_code), error_code);
return error_code;Теперь рассмотрим более интересный случай. Ошибка возникает из-за этого макроса:
#define MC_FREEIF(x) \
if (x) \
g_free(x); \
x = NULL;
Теперь посмотрим, как макрос используется:
static gboolean __mc_gst_init_gstreamer()
{
....
int i = 0;
....
for (i = 0; i < arg_count; i++)
MC_FREEIF(argv2[i]);
....
}Предупреждение PVS-Studio: V640 The code’s operational logic does not correspond with its formatting. The second statement will always be executed. It is possible that curly brackets are missing. media_codec_port_gst.c 1800
Software weaknesses type — CWE-483: Incorrect Block Delimitation, CWE-787: Out-of-bounds Write
Если раскрыть макрос, получится вот такой код:
for (i = 0; i < arg_count; i++)
if (argv2[i])
g_free(argv2[i]);
argv2[i] = NULL;Результат:
- Не будут обнулены указатели.
- NULL будет записан за границу массива.
Потеря старших бит (1 ошибка)
typedef unsigned char Eina_Bool;
static Eina_Bool _state_get(....)
{
....
if (!strcmp(part, STATE_BROWSER))
return !strcmp(id, APP_ID_BROWSER);
else if (!strcmp(part, STATE_NOT_BROWSER))
return strcmp(id, APP_ID_BROWSER);
....
}Предупреждение PVS-Studio: V642 Saving the ‘strcmp’ function result inside the ‘unsigned char’ type variable is inappropriate. The significant bits could be lost breaking the program’s logic. grid.c 137
Software weaknesses type — CWE-197: Numeric Truncation Error
Функция strcmp возвращает следующие значения типа int:
- < 0 — buf1 less than buf2;
- 0 — buf1 identical to buf2;
- > 0 — buf1 greater than buf2;
Обратите внимание. «Больше 0» означает любые числа, а вовсе не 1. Этими числами могут быть: 2, 3, 100, 256, 1024, 5555 и так далее. Аналогично дело обстоит и с «меньше 0». Отсюда следует, что результат нельзя поместить в переменную типа unsigned char, так как могут быть отброшены значащие биты. Это приведет к нарушению логики выполнения программы, например, число 256 превратится в 0.
Данная опасность может показаться надуманной. Однако, такая ошибка послужила причиной серьезной уязвимости в MySQL/MariaDB до версий 5.1.61, 5.2.11, 5.3.5, 5.5.22. Суть в том, что при подключении пользователя MySQL/MariaDB вычисляется токен (SHA от пароля и хэша), который сравнивается с ожидаемым значением функцией memcmp. На некоторых платформах возвращаемое значение может выпадать из диапазона [-128..127]. В итоге в 1 случае из 256 процедура сравнения хэша с ожидаемым значением всегда возвращает значение true, независимо от хэша. В результате простая команда на bash даёт злоумышленнику рутовый доступ к уязвимому серверу MySQL, даже если он не знает пароль. Причиной этому стал такой код в файле ‘sql/password.c’:
typedef char my_bool;
...
my_bool check(...) {
return memcmp(...);
}Более подробное описание этой проблемы приведено здесь: Security vulnerability in MySQL/MariaDB.
Вернемся к проекту Tizen. Мне кажется, в рассмотренном фрагменте кода пропустили оператор отрицания ‘!’. Тогда корректный код должен быть таким:
else if (!strcmp(part, STATE_NOT_BROWSER))
return !strcmp(id, APP_ID_BROWSER);Off-by-one Error (2 ошибки)
#define OP_MAX_URI_LEN 2048
char object_uri[OP_MAX_URI_LEN];
void op_libxml_characters_dd1(....)
{
....
strncat(dd_info->object_uri, ch_str,
OP_MAX_URI_LEN - strlen(dd_info->object_uri));
....
}Предупреждение PVS-Studio: V645 The ‘strncat’ function call could lead to the ‘dd_info->object_uri’ buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold. oma-parser-dd1.c 422
Software weaknesses type — CWE-193: Off-by-one Error
Программист не учёл, что третий аргумент функции strncat задаёт, сколько ещё символов можно добавить в строку, не учитывая терминальный ноль. Поясню эту ошибку на более простом примере:
char buf[5] = "ABCD";
strncat(buf, "E", 5 - strlen(buf));В буфере уже нет места для новых символов. В нём находятся 4 символа и терминальный ноль. Выражение 5 — strlen(buf) равно 1. Функция strncpy скопирует символ E в последний элемент массива. Терминальный 0 будет записан уже за пределами буфера.
Правильный вариант кода:
strncat(dd_info->object_uri, ch_str,
OP_MAX_URI_LEN - strlen(dd_info->object_uri) - 1);Ещё одна аналогичная ошибка: V645 The ‘strncat’ function call could lead to the ‘dd_info->name’ buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold. oma-parser-dd1.c 433
Коварный язык C. Используется необъявленная функция (1 ошибка)
void person_recognized_cb(
mv_surveillance_event_trigger_h handle,
mv_source_h source,
int video_stream_id,
mv_surveillance_result_h event_result,
void *user_data)
{
....
int *labels = malloc(sizeof(int) * number_of_persons);
....
}Предупреждение PVS-Studio: V647 The value of ‘int’ type is assigned to the pointer of ‘int’ type. surveillance_test_suite.c 928
Software weaknesses type — CWE-822: Untrusted Pointer Dereference
Здесь спрятана ловушка. Она «включится», когда код Tizen превратится в 64-битную операционную систему.
Дело в том, что не объявлена функция malloc, т.е. нигде нет #include <stdlib.h>. В этом можно убедиться, выполнив препроцессирование и заглянув внутрь i-файла. Раз функция не объявлена, то считается, что она возвращает тип int. Именно об этом и предупреждает анализатор, говоря, что значение типа int превращается в указатель.
В 32-битной системе всё хорошо, так как размер указателя совпадает с размером int. Ошибка может проявить себя в 64-битной программе, где будут отброшены старшие биты указателя. Подробнее суть этой ошибки рассматривается в статье «Коллекция примеров 64-битных ошибок в реальных программах» (см. Пример 7. Необъявленные функции в Си.)
Не учтено, что оператор new, в отличии от функции malloc, не возвращает NULL (54 ошибки)
Функция malloc, если не может выделить память, возвращает NULL. Оператор new при нехватке памяти генерирует исключение std::bad_alloc.
Если требуется, чтобы оператор new возвращал nullptr, следует использовать nothrow версию оператора:
P = new (std::nothrow) T;
Анализатор PVS-Studio знает про различия между двумя видами оператора new и выдаёт предупреждение только когда используется обыкновенный оператор new, генерирующий исключение.
Суть предупреждения анализатора PVS-Studio заключается в том, что нет смысла проверять, вернул оператор new нулевой указатель или нет.
Найденные ошибки можно разделить на безобидные и серьёзные. Начнем с безобидной ошибки.
template <class T> class vector {
private:
....
void push_back(const T &value)
{
T *clone = new T(value);
if (clone) {
g_array_append_val(parray, clone);
current_size++;
}
}
....
};Предупреждение PVS-Studio: V668 There is no sense in testing the ‘clone’ pointer against null, as the memory was allocated using the ‘new’ operator. The exception will be generated in the case of memory allocation error. maps_util.h 153
Software weaknesses type — CWE-697: Insufficient Comparison / CWE-571: Expression is Always True
Здесь проверка не несёт в себе никакой опасности и её можно просто удалить. Другими словами, ошибка заключается в избыточной проверке, которая только загромождает и усложняет код.
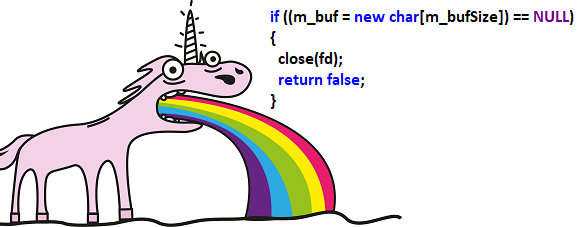
Теперь рассмотрим опасную ошибку.
bool CThreadSlm::load(const char* fname, bool MMap)
{
int fd = open(fname, O_RDONLY);
....
if ((m_buf = new char[m_bufSize]) == NULL) {
close(fd);
return false;
}
....
}Предупреждение PVS-Studio: V668 There is no sense in testing the ‘m_buf’ pointer against null, as the memory was allocated using the ‘new’ operator. The exception will be generated in the case of memory allocation error. slm.cpp 97
Software weaknesses type — даже не знаю как классифицировать. На мой взгляд, здесь сразу подходят три варианта:
- CWE-697: Insufficient Comparison
- CWE-570: Expression is Always False
- CWE-404: Improper Resource Shutdown or Release
Предполагается, что если не удастся выделить память для массива символов, то дескриптор файла будет закрыт и функция вернёт статус false. На самом деле, если память не будет выделена, то дескриптор закрыт не будет и возникнет утечка ресурса. Вдобавок вместо выхода из функции будет выброшено исключение, что нарушит ожидаемую последовательность работы программы.
Обычно такие ошибки появляются в процессе рефакторинга кода, когда вызов функции malloc заменяется на оператор new. Следующий фрагмент кода это очень хорошо демонстрирует:
void SettingsAFCreator::createNewAutoFillFormItem()
{
....
auto item_data = new AutoFillFormItemData;
if (!item_data) {
BROWSER_LOGE("Malloc failed to get item_data");
return;
}
....
}Предупреждение PVS-Studio: V668 There is no sense in testing the ‘item_data’ pointer against null, as the memory was allocated using the ‘new’ operator. The exception will be generated in the case of memory allocation error. SettingsAFCreator.cpp 112
Текст сообщения подсказывает нам, что когда-то давно здесь использовалась функция malloc.
Рекомендация. Замена malloc на new ради красоты ничего не даёт и может только спровоцировать появление ошибок. Поэтому старый код с malloc лучше оставить как он есть, а если вы решили изменить его, то отнеситесь к этому ответственно и внимательно.
Мы рассмотрели 3 ошибки. Осталась ещё 51 ошибка. Рассматривать их в статье нет никакого смысла, поэтому я просто приведу предупреждения анализатора в файле Tizen_V668.txt.
Путаница между integer и double (1 ошибка)
Код длинный, но я не буду его форматировать для статьи, т.к. хочется показать фрагмент программы таким, каков он есть. Поэтому я приведу картинку (можно нажать на картинку для её увеличения).
Предупреждение PVS-Studio: V674 The ‘0.5’ literal of the ‘double’ type is assigned to a variable of the ‘int’ type. Consider inspecting the ‘= 0.5’ expression. add-viewer.c 824
Software weaknesses type — CWE-681: Incorrect Conversion between Numeric Types
Был некий код, который вычислял значение delay, представленное в миллисекундах. Значение по умолчанию было 500 миллисекунд. Один из программистов по какой-то причине закомментировал этот код и решил, что всегда будет использоваться значение равное 500 миллисекунд. При этом он был невнимателен и использовал значение 0.5, которое по его замыслу означает пол секунды, т.е. как раз 500 миллисекунд. В результате переменная типа int инициализируется значением 0.5, которое превращается в 0.
Правильный вариант:
int delay = 500;Запись в readonly память (1 ошибка)
int test_batch_operations()
{
....
char *condition = "MEDIA_PATH LIKE \'";
strncat(condition,
tzplatform_mkpath(TZ_USER_CONTENT, "test/image%%jpg\'"),
17);
....
}Предупреждение PVS-Studio: V675 Calling the ‘strncat’ function will cause the writing into the read-only memory. Inspect the first argument. media-content_test.c 2952
Software weaknesses type — не знаю как классифицировать, буду благодарен за подсказку.
Везет, что этот код относится к тестам и не может причинить серьезного вреда. Тем не менее, это ошибка и она заслуживает внимания.
В переменной condition хранится адрес памяти, предназначенной только для чтения. Изменение этой памяти приведёт к неопределённому поведению программы. Скорее всего это неопределенное поведение программы будет представлять собой access violation.
Неправильные циклы do… while (2 ошибки)
enum nss_status _nss_securitymanager_initgroups_dyn(....)
{
....
do {
ret = TEMP_FAILURE_RETRY(getpwnam_r(....));
if (ret == ERANGE && buffer.size() < MEMORY_LIMIT) {
buffer.resize(buffer.size() << 1);
continue; // <=
}
} while (0);
....
}Предупреждение PVS-Studio: V696 The ‘continue’ operator will terminate ‘do {… } while (FALSE)’ loop because the condition is always false. Check lines: 73, 75. nss_securitymanager.cpp 73
Software weaknesses type — CWE-670: Always-Incorrect Control Flow Implementation
Легко забыть, что оператор continue в цикле do {… } while(0) остановит цикл, а не возобновит его. Оператор continue передаёт управление на условие проверки остановки цикла, а вовсе не на начало цикла. Так как условие всегда ложно, то continue останавливает цикл.
Код можно переписать следующим образом, чтобы исправить ошибку:
while (true) {
ret = TEMP_FAILURE_RETRY(getpwnam_r(....));
if (ret != ERANGE || buffer.size() >= MEMORY_LIMIT) {
break;
buffer.resize(buffer.size() << 1);
};Вторая ошибка находится в этом же файле чуть ниже: V696 The ‘continue’ operator will terminate ‘do {… } while (FALSE)’ loop because the condition is always false. Check lines: 120, 122. nss_securitymanager.cpp 120
Потенциальная утечка памяти при использовании realloc (11 ошибок)
Анализатор выдаёт предупреждения V701, когда встречает код вида:
P = (T *)realloc(P, n);
Если память не удастся выделить, то может произойти её утечка, так как в указатель P будет записано значение NULL. Произойдет утечка памяти или нет, зависит от того, хранится ли где-то ещё предыдущее значение указателя P и как оно используется. Анализатор не может разобраться в хитросплетениях логики работы программы, и поэтому часть предупреждений V701 являются ложными. Всего предупреждений было много, и я отобрал среди них только 11, которые показались мне наиболее достоверными. Возможно, я не прав, и ошибок этого типа может быть на самом деле как больше, так и меньше.
Рассмотрим одну из найденных ошибок.
static int _preference_get_key_filesys(
keynode_t *keynode, int* io_errno)
{
....
char *value = NULL;
....
case PREFERENCE_TYPE_STRING:
while (fgets(file_buf, sizeof(file_buf), fp)) {
if (value) {
value_size = value_size + strlen(file_buf);
value = (char *) realloc(value, value_size); // <=
if (value == NULL) {
func_ret = PREFERENCE_ERROR_OUT_OF_MEMORY;
break;
}
strncat(value, file_buf, strlen(file_buf));
} else {
....
}
}
....
if (value)
free(value);
break;
....
}Предупреждение PVS-Studio: V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘value’ is lost. Consider assigning realloc() to a temporary pointer. preference.c 951
Software weaknesses type — CWE-401: Improper Release of Memory Before Removing Last Reference (‘Memory Leak’)
В цикле из файла читаются данные и помещаются в буфер. Размер буфера увеличивается с помощью вызова функции realloc. В этом примере хорошо видно, что если функция realloc вернёт в какой-то момент значение NULL, то произойдёт утечка памяти.
Другие ошибки:
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘char_info->char_value’ is lost. Consider assigning realloc() to a temporary pointer. bt-gatt-service.c 2430
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘gif_data->frames’ is lost. Consider assigning realloc() to a temporary pointer. image_util.c 1709
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘gif_data->frames’ is lost. Consider assigning realloc() to a temporary pointer. image_util.c 1861
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘_handle->src_buffer’ is lost. Consider assigning realloc() to a temporary pointer. image_util.c 1911
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘gif_data->frames’ is lost. Consider assigning realloc() to a temporary pointer. image_util.c 1930
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘* body’ is lost. Consider assigning realloc() to a temporary pointer. http_request.c 362
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘header->rsp_header’ is lost. Consider assigning realloc() to a temporary pointer. http_transaction.c 82
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘name’ is lost. Consider assigning realloc() to a temporary pointer. popup.c 179
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘tmphstbuf’ is lost. Consider assigning realloc() to a temporary pointer. scim_socket.cpp 95
- V701 realloc() possible leak: when realloc() fails in allocating memory, original pointer ‘wsc_ctx->preedit_str’ is lost. Consider assigning realloc() to a temporary pointer. wayland_panel_agent_module.cpp 1745
Использование небезопасного источника данных (1 ошибка)
#define BUFFER_SIZE 128
int main(int argc, char *argv[])
{
....
char temp[BUFFER_SIZE] = {0,};
....
snprintf(temp, BUFFER_SIZE, "%s%s-%d%s",
argv[2], temp_filename, i, file_format);
....
}Предупреждение PVS-Studio: V755 A copy from unsafe data source to a buffer of fixed size. Buffer overflow is possible. image_util_decode_encode_testsuite.c 237
Software weaknesses type — CWE-121: Stack-based Buffer Overflow
Указатель на строку argv[2] является небезопасным источником данных, так как это аргумент командной строки. При формировании строки в буфере temp может произойти выход за границу массива.
Утечки памяти (3 ошибки)
В начале рассмотрим три используемые функции. Для нас важно, что все они возвращают указатель на выделенную память.
char *generate_role_trait(AtspiAccessible * obj) {
....
return strdup(ret);
}
char *generate_description_trait(AtspiAccessible * obj) {
....
return strdup(ret);
}
char *generate_state_trait(AtspiAccessible * obj) {
....
return strdup(ret);
}Теперь рассмотрим тело функции, содержащее 3 ошибки.
static char *generate_description_from_relation_object(....)
{
....
char *role_name = generate_role_trait(obj);
char *description_from_role = generate_description_trait(obj);
char *state_from_role = generate_state_trait(obj);
....
char *desc = atspi_accessible_get_description(obj, &err);
if (err)
{
g_error_free(err);
g_free(desc);
return strdup(trait);
}
....
}Предупреждения PVS-Studio:
- V773 The function was exited without releasing the ‘role_name’ pointer. A memory leak is possible. navigator.c 991
- V773 The function was exited without releasing the ‘description_from_role’ pointer. A memory leak is possible. navigator.c 991
- V773 The function was exited without releasing the ‘state_from_role’ pointer. A memory leak is possible. navigator.c 991
Software weaknesses type — CWE-401 Improper Release of Memory Before Removing Last Reference (‘Memory Leak’)
Если функция atspi_accessible_get_description отработает неудачно, то функция generate_description_from_relation_object должна прекратить свою работу. При этом освобождается память, указатель на которую хранится в переменной desc. Про переменные role_name, description_from_role и state_from_role автор забыл, и возникнет 3 утечки памяти.
Опечатка в однотипных блоках кода (1 ошибка)
BookmarkManagerUI::~BookmarkManagerUI()
{
BROWSER_LOGD("[%s:%d] ", __PRETTY_FUNCTION__, __LINE__);
if (m_modulesToolbar) {
evas_object_smart_callback_del(m_modulesToolbar,
"language,changed", _modules_toolbar_language_changed);
evas_object_del(m_modulesToolbar);
}
if (m_navigatorToolbar) {
evas_object_smart_callback_del(m_navigatorToolbar,
"language,changed", _navigation_toolbar_language_changed);
evas_object_del(m_modulesToolbar); // <=
}
....
}Предупреждение PVS-Studio: V778 Two similar code fragments were found. Perhaps, this is a typo and ‘m_navigatorToolbar’ variable should be used instead of ‘m_modulesToolbar’. BookmarkManagerUI.cpp 66
Software weaknesses type — CWE-675: Duplicate Operations on Resource
Код деструктора писался методом Copy-Paste. Случайно в одном месте забыли заменить имя m_modulesToolbar на m_navigatorToolbar.
Мёртвый код (8 ошибок)
Иногда, прежде чем сгенерировать исключение, в лог записывается информация, облегчающая отладку приложений. Вот как выглядит правильный код:
void Integrity::syncElement(....) {
....
if (ret < 0) {
int err = errno;
LOGE("'close' function error [%d] : <%s>",err,strerror(err));
throw UnexpectedErrorException(err, strerror(err));
}
}Теперь посмотрим на код, написанный с ошибкой:
void Integrity::createHardLink(....) {
int ret = link(oldName.c_str(), newName.c_str());
if (ret < 0) {
int err = errno;
throw UnexpectedErrorException(err, strerror(err));
LOGN("Trying to link to non-existent...", oldName.c_str());
}
}Предупреждение PVS-Studio: V779 Unreachable code detected. It is possible that an error is present. Integrity.cpp 233
Software weaknesses type — CWE-561: Dead Code
Думаю, очевидно, что нужно поменять две строчки местами, чтобы исключение генерировалось после записи в лог.
Рассмотрим ещё одну ошибку.
#define LS_FUNC_ENTER LS_LOGD("(%s) ENTER", __FUNCTION__);
#define LS_FUNC_EXIT LS_LOGD("(%s) EXIT", __FUNCTION__);
static bool __check_myplace_automation(void)
{
LS_FUNC_ENTER
bool myplace_automation_supported = false;
bool myplace_automation_consent = false;
....
return false;
LS_FUNC_EXIT
}Предупреждение PVS-Studio: V779 Unreachable code detected. It is possible that an error is present. myplace-suggest.c 68
Software weaknesses type — CWE-561: Dead Code
Макрос-эпилог не используется. Две последние строки в функции следует поменять местами.
Другие ошибки:
- V779 Unreachable code detected. It is possible that an error is present. bt-hdp.c 295
- V779 Unreachable code detected. It is possible that an error is present. media_codec_port_gst.c 2672
- V779 Unreachable code detected. It is possible that an error is present. myplace.c 197
- V779 Unreachable code detected. It is possible that an error is present. setting-common-view.c 124
- V779 Unreachable code detected. It is possible that an error is present. layout_network.c 1666
- V779 Unreachable code detected. It is possible that an error is present. ad-id.c 472
Неправильная инициализация объектов (2 ошибки)
Для начала рассмотрим объявление некоторых типов данных.
struct _VoiceData {
int voicefw_state;
....
std::vector<std::string> stt_results;
....
is::ui::MicEffector *effector;
};
typedef struct _VoiceData VoiceData;Обратите внимание, что один из членов класса VoiceData представляет собой массив строк. Теперь посмотрим, как экземпляр класса создаётся и уничтожается.
void show_voice_input(....)
{
....
my_voicedata = (VoiceData*)malloc(sizeof(VoiceData));
if (my_voicedata == NULL) {
LOGD("%d::::Heap Overflow, ......!", __LINE__);
return;
}
memset(my_voicedata, 0, sizeof(VoiceData));
....
}
void on_destroy(VoiceData *r_voicedata)
{
....
VoiceData *voicedata = (VoiceData *)r_voicedata;
....
free(voicedata);
}Предупреждение PVS-Studio: V780 The object ‘my_voicedata’ of a non-passive (non-PDS) type cannot be initialized using the memset function. ise-stt-mode.cpp 773
Software weaknesses type — CWE-762 Mismatched Memory Management Routines
Итак, объект создаётся с помощью функций malloc и memset, а уничтожается с помощью free. В результате:
- Не зовётся конструктор для объекта типа std::vector<std::string>. Использовать такой объект нельзя.
- Не зовётся деструктор. Как минимум будет утечка памяти.
Вообще, рассуждать, как будет работать этот код, не имеет смысла. Тут сплошные undefined behavior. Ужас.
Это был проект ise-default-1.3.34. Точно такую же ошибку мы встретим в проекте org.tizen.inputdelegator-0.1.170518. Ошибки размножаются почкованием (копирование кода): V780 The object ‘my_voicedata’ of a non-passive (non-PDS) type cannot be initialized using the memset function. w-input-stt-ise.cpp 51
Прочее (73 ошибки)
Есть ещё 73 ошибки, описание которых я опущу. Эти ошибки, на мой взгляд, неинтересные, или придётся приводить слишком много кода для их демонстрации, а я уже устал. Тем более, что и без них статья получается угрожающего размера, а я ведь хотел ещё немного поговорить об ошибках в сторонних библиотеках. Поэтому перечислю типы оставшихся ошибок общим списком.
- V524. It is odd that the body of ‘Foo_1’ function is fully equivalent to the body of ‘Foo_2’ function. (1 ошибка)
- V535. The variable ‘X’ is being used for this loop and for the outer loop. (4 ошибки)
- V571. Recurring check. This condition was already verified in previous line. (1 ошибка)
- V622. Consider inspecting the ‘switch’ statement. It’s possible that the first ‘case’ operator is missing. (1 ошибка)
- V646. Consider inspecting the application’s logic. It’s possible that ‘else’ keyword is missing. (2 ошибки)
- V686. A pattern was detected: A || (A && …). The expression is excessive or contains a logical error. (1 ошибка)
- V690. The class implements a copy constructor/operator=, but lacks the operator=/copy constructor. (7 ошибок)
- V692. An inappropriate attempt to append a null character to a string. To determine the length of a string by ‘strlen’ function correctly, a string ending with a null terminator should be used in the first place. (2 ошибки)
- V746. Type slicing. An exception should be caught by reference rather than by value. (32 ошибки)
- V759. Violated order of exception handlers. Exception caught by handler for base class. (9 ошибок)
- V762. Consider inspecting virtual function arguments. See NN argument of function ‘Foo’ in derived class and base class. (6 ошибок)
- V769. The pointer in the expression equals nullptr. The resulting value is meaningless and should not be used. (2 ошибки)
- V783. Dereferencing of invalid iterator ‘X’ might take place. (4 ошибки)
- V786. Assigning the value C to the X variable looks suspicious. The value range of the variable: [A, B]. (1 ошибка)
Сами предупреждения можно найти в файле Tizen_other_things.txt.
Промежуточные итоги
Я выявил 344 ошибки. В презентации я указывал число 345. Одну ошибку я решил исключить, так как, занимаясь написанием статьи, заметил, что одно из предупреждений на самом деле является ложным срабатыванием. Для статистики это несущественно, но я решил пояснить, почему число здесь и в презентации отличается.
Всего было проанализировано 1036000 строк кода, из которых 19.9% являются комментариями. Таким образом, «настоящих строк кода» (без комментариев): 830000.
Получается, что анализатор обнаруживает 0.41 ошибки на 1000 строк кода.
Много это или мало? Сложный вопрос. Чтобы на него ответить, надо знать среднюю плотность ошибок в коде Tizen, создаваемого в компании Samsung. У меня таких данных нет, давайте попробуем заняться экспертной оценкой. Да, тут можно сильно ошибиться, но всё равно интересно попробовать посчитать.
По данным исследователей университета Carnegie-Mellon на 1000 строк кода приходится от 5 до 15 ошибок. В свою очередь, ещё в 2011 году операционную систему Linux аналитики назвали одним из «эталонов качества» программного кода. Считается, что в Linux и его компонентах на 1000 строк кода приходится около 1 ошибки. Не могу найти, где я читал такую информацию, так что не гарантирую её достоверность, но выглядит она похожей на правду.
Операционная система Tizen основана на базе Linux, поэтому по идее также должна иметь высокое качество. Так сколько же ошибок на 1000 строк кода в Tizen? Давайте возьмем среднее между 1 и 5. Будем считать, что в среднем на 1000 строк кода присутствует 3 ошибки.
Если это так, то анализатор PVS-Studio поможет устранить более 10% ещё необнаруженных ошибок. Для нового непроверенного кода, который будет появляться, этот процент больше. Вполне можно говорить, что анализатор PVS-Studio сможет предотвращать около 20% ошибок.
Мы закончили разбор ошибок, которые я обнаружил в коде, написанном под копирайтом компании Samsung. Теперь нас ждут внешние библиотеки. Им я уделю меньше внимания, но всё равно до конца статьи ещё далеко, поэтому пришло время второй чашечки кофе/чая.

Анализ сторонних проектов, используемых в Tizen
Сторонними проектами я посчитал проекты, в которых не сказано явно, что они созданы компанией Samsung. Вот список этих проектов, также отобранных случайным образом: alsa-lib-1.0.28, aspell-0.60.6.1, augeas-1.3.0, bind-9.11.0, efl-1.16.0, enlightenment-0.20.0, ise-engine-anthy-1.0.9.
Проектов гораздо меньше по количеству, но зато они в несколько раз крупнее рассматриваемых ранее. Суммарный размер проектов, перечисленных здесь, по размеру больше, чем суммарный размер кода проектов, рассматриваемых в предыдущей главе.
Уверен, читатель понимает, что если я буду так же подробно рассматривать ошибки, то статья превратится в книгу. Поэтому я ограничусь рассмотрением совсем небольшого количества ошибок, которые мне показались наиболее заслуживающими внимания.
Опечатка в условии: слева и справа одно и то же (4 ошибки)
static void _edje_generate_source_state_map(....)
{
for (i = 0; i < pd->map.colors_count; ++i)
{
if ((pd->map.colors[i]->r != 255) ||
(pd->map.colors[i]->g != 255) ||
(pd->map.colors[i]->b != 255) ||
(pd->map.colors[i]->b != 255))
.....
}Предупреждение PVS-Studio: V501 There are identical sub-expressions ‘(pd->map.colors[i]->b != 255)’ to the left and to the right of the ‘||’ operator. edje_edit.c 14052
Software weaknesses type — CWE-570: Expression is Always False
Повторно проверили голубой компонент вместо альфа-канала. Данный пример в очередной раз демонстрирует, как здорово анализатор PVS-Studio умеет выявлять различные опечатки.
Другие ошибки:
- V501 There are identical sub-expressions to the left and to the right of the ‘&&’ operator: out_ && out_ != stdout && out_ != stdout checker_string.cpp 74
- V501 There are identical sub-expressions ‘(revoked_zsk[i] != 0)’ to the left and to the right of the ‘||’ operator. dnssectool.c 1832
- V501 There are identical sub-expressions to the left and to the right of the ‘>’ operator: ob->priv.last > ob->priv.last evas_outbuf.c 684
Разыменование (потенциально) нулевого указателя (всего ошибок 269)
В предыдущей главе мы обсуждали разыменование нулевых указателей. Но речь шла только о потенциально нулевых указателях, которые возвращали такие функции, как malloc, strdup и т.д. Другими словами, при везении программа могла работать корректно.
Теперь рассмотрим случай, когда разыменовывается указатель, который точно нулевой.
static isc_result_t
setup_style(dns_master_style_t **stylep) {
isc_result_t result;
dns_master_style_t *style = NULL;
REQUIRE(stylep != NULL || *stylep == NULL);
....
}Предупреждение PVS-Studio: V522 Dereferencing of the null pointer ‘stylep’ might take place. Check the logical condition. delv.c 500
Software weaknesses type — CWE-476: NULL Pointer Dereference
Проверка написана неправильно: если указатель нулевой, то он будет разыменован. Видимо программист планировал написать вот такую проверку:
REQUIRE(stylep != NULL && *stylep != NULL);Такой тип ошибки редок, так как ошибка быстро проявляет себя. В основном диагностики V522 и V575 выявляют указатели, которые будут нулевыми только при определённых условиях. Эти ситуации мы рассматривали ранее.
Оставшиеся предупреждения, указывающие на 268 ошибок, я собрал в файл Tizen_third_party_V522_V575.txt.
Функция возвращает случайное значение (3 ошибки)
Следующая ошибка интересна тем, что она находится в патче, который разработчики Tizen применяют к сторонним библиотекам, чтобы получать требуемую функциональность.
static Eina_Bool
_ipc_server_data(void *data, int type EINA_UNUSED, void *event)
{
....
//TIZEN_ONLY(170317): add skipping indicator buffer logic
if (indicator_buffer_skip)
return;
//END
....
}Предупреждение PVS-Studio: V591 Non-void function should return a value. ecore_evas_extn.c 1526
Software weaknesses type — CWE-393: Return of Wrong Status Code
Функция может возвращать некорректный статус (случайное значение) типа Eina_Bool.
Другие ошибки:
- V591 Non-void function should return a value. lsort.hpp 159
- V591 Non-void function should return a value. ecore_evas_extn.c 1617
Использование освобождённой памяти (5 ошибок)
static char *readline_path_generator(const char *text, int state) {
....
if (ctx != NULL) {
char *c = realloc(child, strlen(child)-strlen(ctx)+1); // <=
if (c == NULL)
return NULL;
int ctxidx = strlen(ctx);
if (child[ctxidx] == SEP) // <=
ctxidx++;
strcpy(c, &child[ctxidx]); // <=
child = c;
}
....
}Предупреждения анализатора:
- V774 The ‘child’ pointer was used after the memory was reallocated. augtool.c 151
- V774 The ‘child’ pointer was used after the memory was reallocated. augtool.c 153
Software weaknesses type — CWE-416: Use after free
Этот код совершенно неправильный, но иногда он может работать.
После успешного вызова функции realloc указатель child становится невалидным и его больше нельзя использовать.
Почему тогда я говорю, что временами это работает? Дело в том, что менеджер памяти может возвращать тот же адрес буфера, что и был раньше. То есть просто размер буфера увеличивается без изменения его адреса. Так менеджер памяти оптимизирует скорость, так как не требуется копировать данные из старого буфера в новый.
Другие ошибки:
- V774 The ‘res’ pointer was used after the memory was released. sample-request.c 225
- V774 The ‘res’ pointer was used after the memory was released. sample-update.c 193
- V774 The ‘res’ pointer was used after the memory was released. sample-update.c 217
Опечатка в однотипных блоках кода (1 ошибка)
void Config::del()
{
while (first_) {
Entry * tmp = first_->next;
delete first_;
first_ = tmp;
}
while (others_) {
Entry * tmp = others_->next;
delete first_;
others_ = tmp;
}
.....
}Предупреждение PVS-Studio: V778 Two similar code fragments were found. Perhaps, this is a typo and ‘others_’ variable should be used instead of ‘first_’. config.cpp 185
Software weaknesses type — CWE-401: Improper Release of Memory Before Removing Last Reference (‘Memory Leak’)
Красивая ошибка при использовании метода Copy-Paste. Скопировали блок текста, но в одном месте забыли изменить имя переменной.
После первого цикла переменная first_ имеет значение nullptr. Это значит, что во время выполнения второго цикла ничего удаляться не будет, и возникнут множественные утечки памяти.
Условие всегда true/false (9 ошибок)
StyleLineType StyleLine::get_type (void)
{
....
unsigned int spos, epos;
....
for (epos = m_line.length () - 1;
epos >= 0 && isspace (m_line[epos]);
epos--);
....
}Предупреждение PVS-Studio: V547 Expression ‘epos >= 0’ is always true. Unsigned type value is always >= 0. scim_anthy_style_file.cpp 103
Software weaknesses type — CWE-571 Expression is Always True
Бегло просматривая этот код, сложно заметить ошибку. Ошибка заключается в том, что epos является беззнаковой переменной. Это значит, что выражение epos >= 0 всегда истинно.
Из-за этой ошибки код не защищён от ситуации, когда строка m_line окажется пустой. Если строка пустая, то переменная epos будет равна UINT_MAX и, как следствие, доступ к массиву (m_line[epos]) приведёт к неприятным последствиям.
Другие ошибки:
- V547 Expression is always false. pcm_extplug.c 769
- V547 Expression is always false. pcm_extplug.c 791
- V547 Expression is always false. pcm_extplug.c 817
- V547 Expression is always false. pcm_extplug.c 839
- V547 Expression is always false. pcm_ioplug.c 1022
- V547 Expression is always false. pcm_ioplug.c 1046
- V547 Expression ‘pathPosEnd >= 0’ is always true. Unsigned type value is always >= 0. new_fmode.cpp 566
- V547 Expression ‘epos >= 0’ is always true. Unsigned type value is always >= 0. scim_anthy_style_file.cpp 137
Не затираются приватные данные (52 ошибки)
Сделал интересное наблюдение. Если в просмотренном коде, написанном в Samsung, я нашел только одну ошибку очистки приватных данных, то сторонние библиотеки просто кишат этими ошибками. Думаю, это серьезная недоработка, так как не важно, какая часть программы будет виновата, что приватные данные останутся болтаться где-то в памяти и потом этим кто-то воспользуется.
Рассмотрю в статье только два фрагмента кода, так как все эти баги выглядят однотипно.
void
isc_hmacsha1_sign(isc_hmacsha1_t *ctx,
unsigned char *digest, size_t len) {
unsigned char opad[ISC_SHA1_BLOCK_LENGTH];
unsigned char newdigest[ISC_SHA1_DIGESTLENGTH];
....
memset(newdigest, 0, sizeof(newdigest));
}Предупреждение PVS-Studio: V597 The compiler could delete the ‘memset’ function call, which is used to flush ‘newdigest’ buffer. The memset_s() function should be used to erase the private data. hmacsha.c 1140
Software weaknesses type — CWE-14: Compiler Removal of Code to Clear Buffers
Приватные данные, хранящиеся в буфере newdigest стёрты не будут.
Рассмотрим ещё одну функцию. Отличие от рассмотренного ранее случая заключается в том, что буфер создаётся не в стековой, а в динамической памяти.
static void
_e_icon_smart_del(Evas_Object *obj)
{
E_Smart_Data *sd;
if (!(sd = evas_object_smart_data_get(obj))) return;
evas_object_del(sd->obj);
evas_object_del(sd->eventarea);
....
evas_object_smart_data_set(obj, NULL);
memset(sd, 0, sizeof(*sd)); // <=
free(sd);
}Предупреждение PVS-Studio: V597 The compiler could delete the ‘memset’ function call, which is used to flush ‘sd’ object. The memset_s() function should be used to erase the private data. e_icon.c 838
Software weaknesses type — CWE-14: Compiler Removal of Code to Clear Buffers
Указатель sd после обнуления памяти ещё используется, так как он передаётся в функцию free. Однако это ничего не значит, и компилятор так же вправе удалить для оптимизации вызов функции memset.
С оставшимися 50 предупреждениями, указывающими на ошибки, вы можете ознакомиться в файле Tizen_third_party_V597.txt.
Прочее (227 ошибок)
Осталось ещё множество неописанных ошибок в коде, однако, я уверен, читатель согласится, что пора заканчивать. Я проделал кропотливую работу и представил её результаты в этой статье слоновьего размера. Да, что-то интересное осталось за кадром, но что делать.
Перечислю типы оставшихся ошибок общим списком:
- V502. Perhaps the ‘?:’ operator works in a different way than it was expected. The ‘?:’ operator has a lower priority than the ‘foo’ operator. (1 ошибка)
- V505. The ‘alloca’ function is used inside the loop. This can quickly overflow stack. (25 ошибок)
- V517. The use of ‘if (A) {…} else if (A) {…}’ pattern was detected. There is a probability of logical error presence. (4 ошибки)
- V519. The ‘x’ variable is assigned values twice successively. Perhaps this is a mistake. (3 ошибки)
- V523. The ‘then’ statement is equivalent to the ‘else’ statement. (2 ошибки)
- V528. It is odd that pointer is compared with the ‘zero’ value. Probably meant: *ptr != zero. (1 ошибка)
- V547. Expression is always true/false. (10 ошибок)
- V556. The values of different enum types are compared. (6 ошибок)
- V571. Recurring check. This condition was already verified in previous line. (1 ошибка)
- V576. Incorrect format. Consider checking the N actual argument of the ‘Foo’ function. (1 ошибка)
- V590. Consider inspecting this expression. The expression is excessive or contains a misprint. (3 ошибки)
- V593. Consider reviewing the expression of the ‘A = B == C’ kind. The expression is calculated as following: ‘A = (B == C)’. (1 ошибка)
- V595. The pointer was utilized before it was verified against nullptr. Check lines: N1, N2. (23 ошибки)
- V601. An odd implicit type casting. (1 ошибка)
- V609. Divide or mod by zero. (1 ошибка)
- V610. Undefined behavior. Check the shift operator. (2 ошибки)
- V636. The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid overflow or loss of a fractional part. (8 ошибок)
- V640. The code’s operational logic does not correspond with its formatting. (1 ошибка)
- V645. The function call could lead to the buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold. (4 ошибки)
- V646. Consider inspecting the application’s logic. It’s possible that ‘else’ keyword is missing. (2 ошибки)
- V649. There are two ‘if’ statements with identical conditional expressions. The first ‘if’ statement contains function return. This means that the second ‘if’ statement is senseless. (1 ошибка)
- V666. Consider inspecting NN argument of the function ‘Foo’. It is possible that the value does not correspond with the length of a string which was passed with the YY argument. (6 ошибок)
- V668. There is no sense in testing the pointer against null, as the memory was allocated using the ‘new’ operator. The exception will be generated in the case of memory allocation error. (1 ошибка)
- V686. There is no sense in testing the pointer against null, as the memory was allocated using the ‘new’ operator. The exception will be generated in the case of memory allocation error. (1 ошибка)
- V690. The class implements a copy constructor/operator=, but lacks the operator=/copy constructor. (1 ошибка)
- V694. The condition (ptr — const_value) is only false if the value of a pointer equals a magic constant. (2 ошибки)
- V701. realloc() possible leak: when realloc() fails in allocating memory, original pointer is lost. Consider assigning realloc() to a temporary pointer. (100 ошибок)
- V760. Two identical text blocks detected. The second block starts with NN string. (1 ошибка)
- V769. The pointer in the expression equals nullptr. The resulting value is meaningless and should not be used. (5 ошибок)
- V773. The function was exited without releasing the pointer/handle. A memory/resource leak is possible. (3 ошибки)
- V779. Unreachable code detected. It is possible that an error is present. (9 ошибок)
Сами предупреждения можно найти в файле Tizen_third_party_other_things.txt.
Промежуточные итоги
Найдено 570 ошибок. В презентации было указано 564, видимо раньше я что-то забыл посчитать. Проанализировано 1915000 строк кода. Из них комментариев — 17,6%.
PVS-Studio обнаруживает 0,36 ошибки на 1000 строк кода. Это означает, что предполагаемая плотность ошибок в сторонних библиотеках чуть-чуть ниже, чем плотность ошибок в коде самого Tizen (анализатор обнаружил 0.41 ошибки на 1000 строк кода).
Почему плотность ошибок в библиотеках немного ниже?
- Я мог изучать код библиотек менее внимательно и заметил не все ошибки.
- Некоторые библиотеки уже регулярно проверяются с помощью анализатора Coverity.
- Это погрешность, вызванная тем, что изучена только небольшая часть проектов.
Поэтому не стоит придавать большое значение этой разнице. Можно сказать, что плотность ошибок для двух рассмотренных групп проектов приблизительно равна.
Итоги
Программирование и статический анализ закончились! Пришло время статистики!
Для тех, кто пролистал статью не читая, повторю, что здесь речь идёт не о количестве предупреждений, выданных анализатором, а о настоящих ошибках. И когда я говорю, что в ходе исследования мной найдено 900 ошибок, это означает именно 900 ошибок, а не то, сколько предупреждений я увидел. Не верится? Тогда предлагаю прочитать всю статью с самого начала. 
Прошу извинения у читателя за то, что вынужден повторять некоторые вещи, но это очень важно. К сожалению, многие неправильно воспринимают данные в наших статьях и презентациях, путая количество предупреждений и количество ошибок.
Сводная таблица
Ещё раз перечислю все типы найденных ошибок и их количество:
| Диагностика | Сообщение | Ошибок |
|---|---|---|
| V501 | There are identical sub-expressions to the left and to the right of the ‘foo’ operator. | 6 |
| V502 | Perhaps the ‘?:’ operator works in a different way than it was expected. The ‘?:’ operator has a lower priority than the ‘foo’ operator. | 1 |
| V503 | This is a nonsensical comparison: pointer < 0. | 2 |
| V505 | The ‘alloca’ function is used inside the loop. This can quickly overflow stack. | 26 |
| V507 | Pointer to local array ‘X’ is stored outside the scope of this array. Such a pointer will become invalid. | 1 |
| V512 | A call of the ‘Foo’ function will lead to a buffer overflow or underflow. | 7 |
| V517 | The use of ‘if (A) {…} else if (A) {…}’ pattern was detected. There is a probability of logical error presence. | 8 |
| V519 | The ‘x’ variable is assigned values twice successively. Perhaps this is a mistake. | 14 |
| V522 | Dereferencing of the null pointer might take place. | 276 |
| V523 | The ‘then’ statement is equivalent to the ‘else’ statement. | 8 |
| V524 | It is odd that the body of ‘Foo_1’ function is fully equivalent to the body of ‘Foo_2’ function. | 1 |
| V527 | It is odd that the ‘zero’ value is assigned to pointer. Probably meant: *ptr = zero. | 1 |
| V528 | It is odd that pointer is compared with the ‘zero’ value. Probably meant: *ptr != zero. | 1 |
| V535 | The variable ‘X’ is being used for this loop and for the outer loop. | 4 |
| V547 | Expression is always true/false. | 18 |
| V556 | The values of different enum types are compared. | 24 |
| V560 | A part of conditional expression is always true/false. | 2 |
| V571 | Recurring check. This condition was already verified in previous line. | 2 |
| V572 | It is odd that the object which was created using ‘new’ operator is immediately cast to another type. | 4 |
| V575 | Function receives an odd argument. | 83 |
| V576 | Incorrect format. Consider checking the N actual argument of the ‘Foo’ function. | 5 |
| V590 | Consider inspecting this expression. The expression is excessive or contains a misprint. | 3 |
| V591 | Non-void function should return a value. | 3 |
| V593 | Consider reviewing the expression of the ‘A = B == C’ kind. The expression is calculated as following: ‘A = (B == C)’. | 1 |
| V595 | The pointer was utilized before it was verified against nullptr. Check lines: N1, N2. | 28 |
| V597 | The compiler could delete the ‘memset’ function call, which is used to flush ‘Foo’ buffer. The RtlSecureZeroMemory() function should be used to erase the private data. | 53 |
| V601 | An odd implicit type casting. | 1 |
| V609 | Divide or mod by zero. | 1 |
| V610 | Undefined behavior. Check the shift operator. | 2 |
| V611 | The memory allocation and deallocation methods are incompatible. | 2 |
| V614 | Uninitialized variable ‘Foo’ used. | 1 |
| V618 | It’s dangerous to call the ‘Foo’ function in such a manner, as the line being passed could contain format specification. The example of the safe code: printf(«%s», str); | 6 |
| V622 | Consider inspecting the ‘switch’ statement. It’s possible that the first ‘case’ operator is missing. | 1 |
| V624 | The constant NN is being utilized. The resulting value could be inaccurate. Consider using the M_NN constant from <math.h>. | 2 |
| V636 | The expression was implicitly cast from integer type to real type. Consider utilizing an explicit type cast to avoid overflow or loss of a fractional part. | 12 |
| V640 | The code’s operational logic does not correspond with its formatting. | 3 |
| V642 | Saving the function result inside the ‘byte’ type variable is inappropriate. The significant bits could be lost breaking the program’s logic. | 1 |
| V645 | The function call could lead to the buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold. | 6 |
| V646 | Consider inspecting the application’s logic. It’s possible that ‘else’ keyword is missing. | 4 |
| V647 | The value of ‘A’ type is assigned to the pointer of ‘B’ type. | 1 |
| V649 | There are two ‘if’ statements with identical conditional expressions. The first ‘if’ statement contains function return. This means that the second ‘if’ statement is senseless. | 1 |
| V666 | Consider inspecting NN argument of the function ‘Foo’. It is possible that the value does not correspond with the length of a string which was passed with the YY argument. | 6 |
| V668 | There is no sense in testing the pointer against null, as the memory was allocated using the ‘new’ operator. The exception will be generated in the case of memory allocation error. | 63 |
| V674 | The expression contains a suspicious mix of integer and real types. | 1 |
| V675 | Writing into the read-only memory. | 1 |
| V686 | A pattern was detected: A || (A && …). The expression is excessive or contains a logical error. | 2 |
| V690 | The class implements a copy constructor/operator=, but lacks the operator=/copy constructor. | 8 |
| V692 | An inappropriate attempt to append a null character to a string. To determine the length of a string by ‘strlen’ function correctly, a string ending with a null terminator should be used in the first place. | 2 |
| V694 | The condition (ptr — const_value) is only false if the value of a pointer equals a magic constant. | 2 |
| V696 | The ‘continue’ operator will terminate ‘do {… } while (FALSE)’ loop because the condition is always false. | 2 |
| V701 | realloc() possible leak: when realloc() fails in allocating memory, original pointer is lost. Consider assigning realloc() to a temporary pointer. | 113 |
| V746 | Type slicing. An exception should be caught by reference rather than by value. | 32 |
| V755 | Copying from unsafe data source. Buffer overflow is possible. | 1 |
| V759 | Violated order of exception handlers. Exception caught by handler for base class. | 9 |
| V760 | Two identical text blocks detected. The second block starts with NN string. | 1 |
| V762 | Consider inspecting virtual function arguments. See NN argument of function ‘Foo’ in derived class and base class. | 6 |
| V769 | The pointer in the expression equals nullptr. The resulting value is meaningless and should not be used. | 8 |
| V773 | The function was exited without releasing the pointer/handle. A memory/resource leak is possible. | 6 |
| V774 | The pointer was used after the memory was released. | 5 |
| V778 | Two similar code fragments were found. Perhaps, this is a typo and ‘X’ variable should be used instead of ‘Y’. | 2 |
| V779 | Unreachable code detected. It is possible that an error is present. | 16 |
| V780 | The object of non-passive (non-PDS) type cannot be used with the function. | 2 |
| V783 | Dereferencing of invalid iterator ‘X’ might take place. | 4 |
| V786 | Assigning the value C to the X variable looks suspicious. The value range of the variable: [A, B]. | 1 |
Таблица 1. Типы и количество ошибок, найденных в случайно выбранных проектах.
Всего я выявил 914 ошибок. Округлим для простоты до 900 ошибок.
Ложные срабатывания
Я не оценивал количество ложных срабатываний. Дело в том, что не производилась даже минимальная настройка анализатора, поэтому нет смысла пытаться считать процент ложных срабатываний. Это будет просто нечестно по отношению к анализатору. Большинство ложных срабатываний возникает из-за нескольких неудачных макросов. Настроив анализатор, чтобы не ругаться на них, можно в несколько раз сократить количество ложных срабатываний.
По личному ощущению, ложных срабатываний немного. Если бы это было не так, я бы не смог в одиночку так быстро провести такое обширное исследование.
Плюс отмечу, что количество ложных срабатываний вообще не имеет значения. Если мы начнем сотрудничество, ложные срабатывания будут в первую очередь головной болью нашей команды, а не разработчиков, трудящихся над Tizen.
27 000 ошибок
Настал момент, когда станет понятно, почему я заявил о 27000 ошибках.
Всего я проанализировал около 2 400 000 строк кода (без учёта комментариев).
Я обнаружил 900 ошибок.
Весь проект Tizen вместе со сторонними библиотеками насчитывает 72 500 000 строк C и C++ кода (без учёта комментариев).
Это значит, что было проверено только около 3.3% кода.
Прогноз:
(72500000*900/2400000=27187)
Используя анализатор PVS-Studio, мы можем обнаружить и исправить 27 000 ошибок.
Как видите, расчёты совершенно честные и прозрачные.
Заключение
Думаю, мне удалось вновь продемонстрировать возможности PVS-Studio по выявлению разнообразнейших видов ошибок. Да, получилось длинно, зато никто не сможет сказать, что я приукрашиваю PVS-Studio и фантазирую про 27000 ошибок. В статье представлены все данные и расчеты, которые каждый желающий может проверить самостоятельно.
Статический анализ просто необходим, когда речь заходит о больших проектах, таких как Tizen. Причем есть смысл использовать несколько инструментов, так как различные анализаторы дополняют друг друга.
Предлагаю скачать и попробовать анализатор PVS-Studio.
Поддерживаемые языки и компиляторы:
- Windows. Visual Studio 2017 C, C++, C++/CLI, C++/CX (WinRT), C#
- Windows. Visual Studio 2015 C, C++, C++/CLI, C++/CX (WinRT), C#
- Windows. Visual Studio 2013 C, C++, C++/CLI, C++/CX (WinRT), C#
- Windows. Visual Studio 2012 C, C++, C++/CLI, C++/CX (WinRT), C#
- Windows. Visual Studio 2010 C, C++, C++/CLI, C#
- Windows. MinGW C, C++
- Windows/Linux. Clang C, C++
- Linux. GCC C, C++
Всем спасибо за внимание. Приглашаю почитать про анализ других открытых проектов, а также подписывайтесь на мой твиттер @Code_Analysis. С уважением, Андрей Карпов.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. 27 000 errors in the Tizen operating system
Урок 32.
Предмет: Технология
разработки программных продуктов.
Тема: Метрики
измерения программного продукта.
Цели:
Образовательная
Ознакомление с метриками измерения ПО.
Развивающая:
Развивать умение слушать других, делать выводы и обобщать
полученные знания
Воспитательная:
Воспитывать чувство значимости предмета в профессиональной
деятельности, аккуратности в работе
Межпредметные связи:
—
Английский язык
—
Операционные системы
—
Информационные технологии
—
Основы алгоритмизации и программирования
Оборудование: доска, мел, письменные принадлежности,
проектор, ПК
Тип урока: комбинированный
Метод обучения: Объяснительно иллюстративный
Ход урока:
1.Организационный момент
— Проверка
готовности кабинета
— Объявление
темы
2. Постановка цели урока
3.Повторение пройденного материала
Эффективность и оптимизация
программ
Способы экономии памяти.
Способы уменьшения времени
выполнения.
Сопровождение программного продукта
Отладка программного продукта
4.Сообщение новых знаний
- Основные
понятия - Измерения,
меры и метрики. - Размерно-ориентированные
метрики - Функционально-ориентированные
метрики - Выполнение
оценки проекта на основе LOC- и FP-метрик - Метрики
объектно-ориентированных программных систем - Набор
метрик Чидамбера и Кемерера - Метрики
Лоренца и Кидда
5. Восприятие и осознание учащимися нового материала
6. Осмысление обобщение и систематизация знаний
7. Подведение итогов урока и
постановка домашнего задания
Выучить содержимое
темы
Орлов С.А. стр.189-209
Ответить на
вопросы:
1.Основные
понятия
Ме́трика програ́ммного
обеспе́чения (англ. software metric) — это мера,
позволяющая получить численное значение некоторого свойства программного обеспечения или его спецификаций.
Поскольку количественные методы хорошо зарекомендовали себя в
других областях, многие теоретики и практики информатики пытались перенести
данный подход и в разработку программного обеспечения.
Как сказал Том ДеМарко, «вы не можете контролировать
то, что не можете измерить».
Набор используемых метрик включает:
- порядок роста (имеется в виду анализ алгоритмов в терминах асимптотического анализа и O-нотации),
- количество строк кода,
- цикломатическая сложность,
- анализ
функциональных точек, - количество ошибок
на 1000 строк кода, - степень покрытия кода тестированием,
- покрытие требований,
- количество классов и интерфейсов,
- метрики
программного пакета от Роберта Сесиль Мартина, - связность.
Цикломати́ческая
сло́жность програ́ммы
(англ. Cyclomatic complexity of a program) — структурная (или топологическая) мера сложности программ, используемая для
измерения качества программного обеспечения, основанная на методах
статического анализа кода.
Покры́тие
ко́да — мера,
используемая при тестировании программного обеспечения.
Она показывает процент, насколько исходный код программы был протестирован.
Техника покрытия кода была одной из первых
методик, изобретённых для систематического тестирования ПО. Первое упоминание покрытия
кода в публикациях появилось в 1963 году.
Покрытие
требований — это метрика, используемая в тестировании программного обеспечения.
Покрытие требований позволяет оценить
степень полноты системы тестов по отношению к функциональности системы. В
сравнении с покрытием кода, покрытие требований позволяет выявить
нереализованные требования, но не позволяет оценить полноту по отношению к ее
программной реализации. Одна и та же функция может быть реализована при помощи
совершенно различных алгоритмов, требующих разного подхода к организации
тестирования.
Связность или сцепление (англ. cohesion) —
характеристика внутренней взаимосвязи между частями одного модуля (сравни со связанностью).
Потенциальные
недостатки подхода, на которые нацелена критика:
- Неэтичность: Утверждается, что неэтично сводить оценку работы
человека к нескольким числовым параметрам и по ним судить о
производительности. Менеджер может назначить наиболее талантливых
программистов на сложнейший участок работы; это означает, что разработка
этого участка займёт наибольшее время и породит наибольшее количество
ошибок, из-за сложности задачи. Не зная об этих трудностях, другой
менеджер по полученным показателям может решить, что программист сделал
свою работу плохо. - Замещение «управления людьми» на «управление цифрами»,
которое не учитывает опыт сотрудников и их другие качества - Искажение: Процесс измерения может быть искажён за счёт
того, что сотрудники знают об измеряемых показателях и стремятся
оптимизировать эти показатели, а не свою работу. Например, если количество
строк исходного кода является важным показателем, то программисты будут
стремиться писать как можно больше строк и не будут использовать способы
упрощения кода, сокращающие количество строк. - Неточность:
Нет метрик, которые были бы
одновременно и значимы и достаточно точны. Количество строк кода — это
просто количество строк, этот показатель не даёт представление о сложности
решаемой проблемы. Анализ функциональных точек был разработан с целью
лучшего измерения сложности кода и спецификации, но он использует личные
оценки измеряющего, поэтому разные люди получат разные результаты.
Сравнительно недавно появился ещё один аспект данной
проблемы — разница между программным кодом, написанным вручную, и
сгенерированным автоматически. Современные средства разработки
достаточно часто предоставляют возможность автоматически создавать большие
объёмы кода всего лишь несколькими кликами мыши. Наиболее ярким представителем данных
систем являются средства визуальной разработки графического пользовательского интерфейса.
Объём работы, затраченный при создании такого кода, никак не может сравниваться
с объёмом работы, например, по написанию драйвера устройства. С другой стороны, может оказаться, что на
написание вручную специализированного компонента пользовательского интерфейса со
сложным поведением времени может быть потрачено гораздо больше, чем на простой
драйвер.
Примеры
Размеры исходных кодов операционных систем семейства Microsoft
Windows NT
точно не известны, но согласно источнику [4]
они составляют:
|
Год |
Версия |
Cтрок кода |
|
1994 |
Windows NT 3.5 |
4 000 000 |
|
1996 |
Windows NT 4 |
16 500 000 |
|
2000 |
Windows 2000 |
20 000 000 |
|
2002 |
Windows XP |
40 000 000 |
Размеры исходных кодов ядра Linux вместе с включёнными туда драйверами устройств
можно посчитать точно:
|
Год |
Версия |
Cтрок кода |
|
1991 |
Ядро Linux 0.1 |
10 239 |
|
1994 |
Ядро Linux 1.0.0 |
176 250 |
|
1995 |
Ядро Linux 1.2.0 |
310 950 |
|
1996 |
Ядро Linux 2.0.0 |
777 956 |
|
1999 |
Ядро Linux 2.2.0 |
1 800 847 |
|
2001 |
Ядро Linux 2.4.0 |
3 377 902 |
|
2003 |
Ядро Linux 2.6.0 |
5 929 913 |
|
2009 |
Ядро Linux 2.6.32 |
12 606 910[5] |
Размеры других систем:
|
Год |
Версия |
Cтрок кода |
|
— |
PostgreSQL |
775 000 |
|
— |
1C |
3 000 000 |
|
2008 |
1С-Битрикс |
762 854 |
2. Измерения, меры и метрики. Размерно-ориентированные
метрики. Функционально-ориентированные метрики.
Измерения
помогают оценить как продукт, так и сам процесс его разработки. В результате
измерений определяется мера — количественная характеристика какого-либо
свойства объекта. Некоторые измерения позволяют сразу определить свойства
объекта. А остальные можно получить лишь за счет вычисления от значений опорных
характеристик. Результаты подобных вычислений называют метриками. Зачастую
понятие мера и метрика рассматривают как равноценные определения.
Измерения
при разработке ПО необходимы для того, чтобы:
—
определить или показать качество продукции;
—
оценить производительность труда персонала, занятого разработкой;
—
оценить выгоды (прибыль или доход), которые могут быть получены в результате
разработки новых программных средств;
—
сформировать основу (базовую линию) для последующих оценок;
—
получить данные для обоснования запросов на дополнительные средства, обучение и
т.п.
Измерения
бывают прямые и косвенные. Результаты прямых измерений процесса разработки и
сопровождения программного изделия: трудозатраты и стоимость, число строк кода
(LOC — lines-of-code), размер требуемой памяти, скорость выполнения программы,
число ошибок (дефектов), обнаруженных за определенный период времени. Косвенные
измерения дают оценку функциональных возможностей, показателей качества
программного продукта (надежность, эффективность, пригодность к сопровождению и
т.п.).
Существует
деление метрик на 3 группы: метрики производительности, метрики качества
продукции и технические характеристики продукта. Метрики производительности
фокусируются на выходе процессов разработки ПО. Метрики качества позволяют
судить о том, насколько близко соответствие программного изделия явным и
подразумеваемым требованиям пользователя, т.е. пригодности изделия к
использованию. Технические метрики в большей степени относятся к особенностям
программного изделия, а не к процессу его разработки (например, логическая
сложность изделия, модульность проекта и т.п.).
Вторая
классификация метрик — классификация по признаку их ориентации:
—
размеро-ориентированные метрики, использующиеся для сбора результатов прямых
измерений программного продукта и его качества, а также процесса разработки;
—
функционально-ориентированные метрики, которые являются косвенными мерами,
характеризующими функциональное назначение продукта и особенности его входных и
выходных данных;
—
человеко-ориентированные метрики, которые также являются косвенными мерами,
позволяющими судить об отношении персонала (разработчиков и пользователей), об
эффективности и качестве работы программного изделия, удобстве взаимодействия с
ним, простоте обучения и т.д.
3.Размерно-ориентированные метрики
Размерно-ориентированные
метрики прямо измеряют программный продукт и процесс его разработки.
Основываются такие метрики на LOC-оценках (Lines Of Code). LOC-оценка — это
количество строк в программном продукте. Принято регистрировать следующие
показатели:
—
общие затраты (в человеко-месяцах — чел.-мес);
—
объем программного изделия (в тысячах строк исходного кода -KLOC);
—
стоимость разработки (в тыс.рублей или в долларах $);
—
объем документации (в страницах документов -СД);
—
ошибки, обнаруженные в течение первого года эксплуатации (число ошибок — ЧО);
—
число людей, работавших над изделием (человек);
—
срок разработки (в календарных месяцах).
На
основе перечисленных показателей вычисляются размерно-ориентированные метрики
производительности и качества (для каждого проекта):
Достоинства
размерно-ориентированных метрик:
1)
широко распространены;
2)
просты и легко вычисляются.
Недостатки
размерно-ориентированных метрик:
1)
зависимы от языка программирования;
2)
требуют исходных данных, которые трудно получить на начальной стадии проекта;
3)
не приспособлены к непроцедурным языкам программирования.
4.Функционально-ориентированные метрики
Функционально-ориентированные
метрики косвенно измеряют программный продукт и процесс его разработки. Вместо
подсчета LOC-оценки при этом рассматривается не размер, а функциональность или
полезность продукта. Используется 5 информационных характеристик.
1.
Количество внешних вводов. Подсчитываются все вводы пользователя, по которым
поступают разные прикладные данные. Вводы должны быть отделены от запросов,
которые подсчитываются отдельно.
2.
Количество внешних выводов. Подсчитываются все выводы, по которым к
пользователю поступают результаты, вычисленные программным приложением. В этом
контексте выводы означают отчеты, экраны, распечатки, сообщения об ошибках.
Индивидуальные единицы данных внутри отчета отдельно не подсчитываются.
3.
Количество внешних запросов. Под запросом понимается диалоговый ввод, который
приводит к немедленному программному ответу в форме диалогового вывода. При
этом диалоговый ввод в приложении не сохраняется, а диалоговый вывод не требует
выполнения вычислений. Подсчитываются все запросы — каждый учитывается
отдельно.
4.
Количество внутренних логических файлов. Подсчитываются все логические файлы
(то есть логические группы данных, которые могут быть частью базы данных или
отдельным файлом).
5.
Количество внешних интерфейсных файлов. Подсчитываются все логические файлы из
других приложений, на которые ссылается данное приложение.
Количество
функциональных указателей вычисляется по формуле
После
вычисления FP на его основе формируются метрики производительности, качества и
т. д.:
Область
применения метода функциональных указателей — коммерческие информационные
системы. Для продуктов с высокой алгоритмической сложностью используются
метрики указателей свойств (Features Points). Они применимы к системному и
инженерному ПО. ПО реального времени и встроенному ПО. Для вычисления указателя
свойств добавляется одна характеристика — количество алгоритмов. Алгоритм здесь
определяется как ограниченная подпрограмма вычислений, которая включается в
общую компьютерную программу. Примеры алгоритмов: обработка прерываний,
инвертирование матрицы, расшифровка битовой строки. Для формирования указателя
свойств составляется табл. 6.
Достоинства
функционально-ориентированных метрик:
1.
Не зависят от языка программирования.
2.
Легко вычисляются на любой стадии проекта.
Недостаток
функционально-ориентированных метрик: результаты основаны на субъективных
данных, используются не прямые, а косвенные измерения.
FP-оценки
легко пересчитать в LOC-оценки. Результаты пересчета зависят от языка
программирования, используемого для реализации ПО.
5..
Выполнение оценки проекта на основе LOC- и FP-метрик
Цель
этой деятельности — сформировать предварительные оценки, которые позволят:
—
предъявить заказчику корректные требования по стоимости и затратам на
разработку программного продукта;
—
составить план программного проекта.
При
выполнении оценки возможны два варианта использования LOC- и FP-данных:
—
в качестве оценочных переменных, определяющих размер каждого элемента продукта;
—
в качестве метрик, собранных за прошлые проекты и входящих в метрический базис
фирмы.
Порядок
проведения процедуры оценки.
1.
Область назначения проектируемого продукта разбивается на ряд функций, каждую
из которых можно оценить индивидуально: f1 , f2 ,…, fn.
2.
Для каждой функции fi планировщик формирует лучшую LOCлучшi(FPлучшi), худшую
LOCхудшi(FPхудшi) и вероятную оценку LOCвер i(FPвер i). Используются опытные
данные (из метрического базиса) или интуиция. Диапазон значения оценок
соответствует степени предусмотренной неопределенности.
3.
Для каждой функции fi в соответствии с -распределением вычисляется ожидаемое
значение LOC- (или FP-) оценки:
4.
Определяется значение LOC- или FP-производительности разработки функции.
Используется один из трех подходов:
а)
для всех функции принимается одна и та же метрика средней производительности
ПРОИЗВср, взятая из метрического базиса;
б)
для i-й функции на основе метрики средней производительности вычисляется
настраиваемая величина производительности:
,где
LOCcp — средняя LOC-оценка, взятая из метрического базиса (соответствует
средней производительности);
в)
для i-й функции настраиваемая величина производительности вычисляется по
аналогу, взятому из метрического базиса: ,
Первый
подход обеспечивает минимальную точность (при максимальной простоте вычислений),
а третий подход — максимальную точность (при максимальной сложности
вычислений).
5.
Вычисляется общая оценка затрат на проект
6.Метрики объектно-ориентированных
программных систем
При конструировании объектно-ориентированных
программных систем значительная часть затрат приходится на создание визуальных
моделей. Очень важно корректно и всесторонне оценить качество этих моделей,
сопоставив качеству числовую оценку. Решение данной задачи требует введения
специального метрического аппарата. Такой аппарат развивает идеи классического
оценивания сложных программных систем, основанного на метриках сложности,
связности и сцепления. Вместе с тем он учитывает специфические особенности
объектно-ориентированных решений. В этой главе обсуждаются наиболее известные
объектно-ориентированные метрики, а также описывается методика их применения.
Метрические
особенности объектно-ориентированных программных систем
Объектно-ориентированные метрики вводятся с
целью:
q
улучшить понимание
качества продукта;
q
оценить эффективность
процесса конструирования;
q
улучшить качество
работы на этапе проектирования.
Все эти цели важны, но для программного
инженера главная цель — повышение качества продукта. Возникает вопрос — как
измерить качество объектно-ориентированной системы?
Для любого инженерного продукта метрики должны
ориентироваться на его уникальные характеристики. Например, для электропоезда
вряд ли полезна метрика «расход угля на километр пробега». С точки зрения
метрик выделяют пять характеристик объектно-ориентированных систем:
локализацию, инкапсуляцию, информационную закрытость, наследование и способы
абстрагирования объектов. Эти характеристики оказывают максимальное влияние на
объектно-ориентированные метрики.
Локализация
Локализация фиксирует способ группировки информации
в программе. В классических методах, где используется функциональная
декомпозиция, информация локализуется вокруг функций. Функции в них реализуются
как процедурные модули. В методах, управляемых данными, информация группируется
вокруг структур данных. В объектно-ориентированной среде информация
группируется внутри классов или объектов (инкапсуляцией как данных, так и
процессов).
Поскольку в классических методах основной
механизм локализации — функция, программные метрики ориентированы на внутреннюю
структуру или сложность функций (длина модуля, связность, цикломатическая
сложность) или на способ, которым функции связываются друг с другом (сцепление
модулей).
Так как в объектно-ориентированной системе
базовым элементом является класс, то локализация здесь основывается на
объектах. Поэтому метрики должны применяться к классу (объекту) как к
комплексной сущности. Кроме того, между операциями (функциями) и классами могут
быть отношения не только «один-к-одному». Поэтому метрики, отображающие способы
взаимодействия классов, должны быть приспособлены к отношениям
«один-ко-многим», «многие-ко-многим».
Инкапсуляция
Вспомним, что инкапсуляция — упаковка
(связывание) совокупности элементов. Для классических ПС примерами
низкоуровневой инкапсуляции являются записи и массивы. Механизмом инкапсуляции
среднего уровня являются подпрограммы (процедуры, функции).
В объектно-ориентированных системах
инкапсулируются обязанности класса, представляемые его свойствами (а для
агрегатов — и свойствами других классов), операциями и состояниями.
Для метрик учет инкапсуляции приводит к
смещению фокуса измерений с одного модуля на группу свойств и обрабатывающих
модулей (операций). Кроме того, инкапсуляция переводит измерения на более
высокий уровень абстракции (пример — метрика «количество операций на класс»).
Напротив, классические метрики ориентированы на низкий уровень — количество
булевых условий (цикломатическая сложность) и количество строк программы.
Информационная
закрытость
Информационная закрытость делает невидимыми операционные
детали программного компонента. Другим компонентам доступна только необходимая
информация.
Качественные объектно-ориентированные системы
поддерживают высокий уровень информационной закрытости. Таким образом, метрики,
измеряющие степень достигнутой закрытости, тем самым отображают качество
объектно-ориентированного проекта.
Наследование
Наследование — механизм, обеспечивающий
тиражирование обязанностей одного класса в другие классы. Наследование
распространяется через все уровни иерархии классов. Стандартные ПС не
поддерживают эту характеристику.
Поскольку наследование — основная
характеристика объектно-ориентированных систем, на ней фокусируются многие
объектно-ориентированные метрики (количество детей — потомков класса,
количество родителей, высота класса в иерархии наследования).
Абстракция
Абстракция — это механизм, который позволяет
проектировщику выделять главное в программном компоненте (как свойства, так и
операции) без учета второстепенных деталей. По мере перемещения на более
высокие уровни абстракции мы игнорируем все большее количество деталей,
обеспечивая все более общее представление понятия или элемента. По мере
перемещения на более низкие уровни абстракции мы вводим все большее количество
деталей, обеспечивая более удачное представление понятия или элемента.
Класс — это абстракция, которая может быть
представлена на различных уровнях детализации и различными способами (например,
как список операций, последовательность состояний, последовательности
взаимодействий). Поэтому объектно-ориентированные метрики должны представлять
абстракции в терминах измерений класса. Примеры: количество экземпляров класса
в приложении, количество родовых классов на приложение, отношение количества
родовых к количеству неродовых классов.
Эволюция
мер связи для объектно-ориентированных программных систем
В разделах «Связность модуля» и «Сцепление
модулей» главы 4 было показано, что классической мерой сложности внутренних
связей модуля является связность, а
классической мерой сложности внешних связей — сцепление. Рассмотрим развитие
этих мер применительно к объектно-ориентированным системам.
7.Набор метрик Чидамбера и Кемерера
В 1994 году С. Чидамбер и К. Кемерер (Chidamber и Кетегег) предложили шесть проектных метрик,
ориентированных на классы [24]. Класс — фундаментальный элемент
объектно-ориентированной (ОО) системы. Поэтому измерения и метрики для
отдельного класса, иерархии классов и сотрудничества классов бесценны для
программного инженера, который должен оценить качество проекта.
Набор Чидамбера-Кемерера наиболее часто
цитируется в программной индустрии и научных исследованиях. Рассмотрим каждую
из метрик набора.
Метрика 1: Взвешенные методы на класс WMC (Weighted Methods Per Class)
Допустим, что в классе С определены п методов со
сложностью с1…,c2,…, сn. Для оценки сложности
может быть выбрана любая метрика сложности (например, цикломатическая
сложность). Главное — нормализовать эту метрику так, чтобы номинальная
сложность для метода принимала значение 1. В этом случае
![]()
Количество методов и их сложность являются
индикатором затрат на реализацию и тестирование классов. Кроме того, чем больше
методов, тем сложнее дерево наследования (все подклассы наследуют методы их
родителей). С ростом количества методов в классе его применение становится все
более специфическим, тем самым ограничивается возможность многократного
использования. По этим причинам метрика WMC
должна иметь разумно низкое значение.
Очень часто применяют упрощенную версию
метрики. При этом полагают Сi= 1, и тогда
WMC — количество методов в классе.
Оказывается, что подсчитывать количество
методов в классе достаточно сложно. Возможны два противоположных варианта
учета.
1.
Подсчитываются только
методы текущего класса. Унаследованные методы игнорируются. Обоснование —
унаследованные методы уже подсчитаны в тех классах, где они определялись. Таким
образом, инкрементность класса — лучший показатель его функциональных
возможностей, который отражает его право на существование. Наиболее важным
источником информации для понимания того, что делает класс, являются его
собственные операции. Если класс не может отреагировать на сообщение (например,
в нем отсутствует собственный метод), тогда он пошлет сообщение родителю.
2.
Подсчитываются методы,
определенные в текущем классе, и все унаследованные методы. Этот подход
подчеркивает важность пространства состояний в понимании класса (а не
инкрементности класса).
Существует ряд промежуточных вариантов.
Например, подсчитываются текущие методы и методы, прямо унаследованные от
родителей. Аргумент в пользу данного подхода — на поведение дочернего класса
наиболее сильно влияет специализация родительских классов.
На практике приемлем любой из описанных
вариантов. Главное — не менять вариант учета от проекта к проекту. Только в
этом случае обеспечивается корректный сбор метрических данных.
Метрика WMC
дает относительную меру сложности класса. Если считать, что все методы имеют
одинаковую сложность, то это будет просто количество методов в классе.
Существуют рекомендации по сложности методов. Например, М. Лоренц считает, что
средняя длина метода должна ограничиваться 8 строками для Smalltalk и 24 строками для C++ [45]. Вообще, класс, имеющий
максимальное количество методов среди классов одного с ним уровня, является
наиболее сложным; скорее всего, он специфичен
для данного приложения и содержит наибольшее количество ошибок.
Метрика 2: Высота дерева наследования DIT (Depth of Inheritance
Tree)
DIT определяется как максимальная длина пути от листа до корня
дерева наследования классов. Для показанной на рис. 14.3 иерархии классов
метрика DIT равна 3.
Рис. 14.3. Дерево
наследования классов
Соответственно, для отдельного класса DIT, это длина максимального пути от данного класса до
корневого класса в иерархии классов.
По мере роста DIT
вероятно, что классы нижнего уровня будут наследовать много методов. Это
приводит к трудностям в предсказании поведения класса. Высокая иерархия классов
(большое значение DIT) приводит к большей сложности
проекта, так как означает привлечение большего количества методов и классов.
Вместе с тем, большое значение DIT подразумевает, что многие методы могут использоваться
многократно.
Метрика 3: Количество детей NOC (Number of children)
Подклассы, которые непосредственно подчинены
суперклассу, называются его детьми. Значение NOC
равно количеству детей, то есть количеству непосредственных наследников класса
в иерархии классов. На рис. 14.3 класс С2 имеет двух детей — подклассы С21 и С22.
С увеличением NOC
возрастает многократность использования, так как наследование — это форма
повторного использования.
Однако при возрастании NOC ослабляется абстракция родительского класса. Это означает,
что в действительности некоторые из детей уже не являются членами родительского
класса и могут быть неправильно использованы.
Кроме того, количество детей характеризует
потенциальное влияние класса на проект. По мере роста NOC
возрастает количество тестов, необходимых для проверки каждого ребенка.
Метрики DIT
и NOC — количественные характеристики формы и размера структуры
классов. Хорошо структурированная объектно-ориентированная система чаще бывает
организована как лес классов, чем как сверхвысокое дерево. По мнению Г. Буча,
следует строить сбалансированные по высоте и ширине структуры наследования:
обычно не выше, чем 7 ± 2 уровня, и не шире, чем 7 + 2 ветви [22].
Метрика 4: Сцепление между классами объектов СВО (Coupling between object classes)
СВО — это количество сотрудничеств, предусмотренных для класса,
то есть количество классов, с которыми он соединен. Соединение означает, что
методы данного класса используют методы или экземплярные переменные другого
класса.
Другое определение метрики имеет следующий
вид: СВО равно количеству сцеплений класса; сцепление образует вызов метода или
свойства в другом классе.
Данная метрика характеризует статическую
составляющую внешних связей классов.
С ростом СВО многократность использования
класса, вероятно, уменьшается. Очевидно, что чем больше независимость класса,
тем легче его повторно использовать в другом приложении.
Высокое значение СВО усложняет модификацию и
тестирование, которое следует за выполнением модификации. Понятно, что, чем
больше количество сцеплений, тем выше чувствительность всего проекта к
изменениям в отдельных его частях. Минимизация межобъектных сцеплений улучшает
модульность и содействует инкапсуляции проекта.
СВО для каждого класса должно иметь разумно низкое значение.
Это согласуется с рекомендациями по уменьшению сцепления стандартного
программного обеспечения.
Метрика 5: Отклик для класса RFC (Response For a Class)
Введем вспомогательное определение. Множество
отклика класса RS — это множество методов, которые
могут выполняться в ответ на прибытие сообщений в объект этого класса. Формула
для определения RS имеет вид
![]() ,
,
где {Ri} — множество методов, вызываемых методом г, {М} — множество всех методов в классе.
Метрика RFC
равна количеству методов во множестве отклика, то есть равна мощности этого
множества:
RFC – card{RS}.
Приведем другое определение метрики: RFC — это количество методов класса плюс количество методов
других классов, вызываемых из данного класса.
Метрика RFC
является мерой потенциального взаимодействия данного класса с другими классами,
позволяет судить о динамике поведения соответствующего объекта в системе.
Данная метрика характеризует динамическую составляющую внешних связей классов.
Если в ответ на сообщение может быть вызвано
большое количество методов, то усложняются тестирование и отладка класса, так
как от разработчика тестов требуется больший уровень понимания класса, растет
длина тестовой последовательности.
С ростом RFC
увеличивается сложность класса. Наихудшая величина отклика может использоваться
при определении времени тестирования.
Метрика 6: Недостаток связности в методах LСOM (Lack of Cohesion in Methods)
Каждый метод внутри класса обращается к одному
или нескольким свойствам (экземплярным переменным). Метрика LCOM показывает, насколько методы не связаны друг с другом через
свойства (переменные). Если все методы обращаются к одинаковым свойствам, то LCOM = 0.
Введем обозначения:
q
НЕ СВЯЗАНЫ —
количество пар методов без общих экземплярных переменных;
q
СВЯЗАНЫ — количество
пар методов с общими экземплярными переменными.
q
Ij— набор экземплярных переменных, используемых методом Мj
Очевидно, что
НЕ СВЯЗАНЫ = card {Iij | Ii ![]() Ij = 0},
Ij = 0},
СВЯЗАНЫ = card {Iij | Ii![]() Ij
Ij ![]() 0}.
0}.
Тогда формула для вычисления недостатка
связности в методах примет вид
![]()
Можно определить метрику по-другому: LCOM — это количество пар методов, не связанных по свойствам
класса, минус количество пар методов, имеющих такую связь.
Рассмотрим примеры применения метрики LCOM.
8.Метрики
Лоренца и Кидда
Коллекция метрик Лоренца и Кидда
— результат практического, промышленного подхода к оценке ОО-проектов [45].
Метрики,
ориентированные на классы
М. Лоренц и Д. Кидд подразделяют метрики,
ориентированные на классы, на четыре категории: метрики размера, метрики
наследования, внутренние и внешние метрики.
Размерно-ориентированные метрики основаны на
подсчете свойств и операций для отдельных классов, а также их средних значений
для всей ОО-системы. Метрики наследования акцентируют внимание на способе
повторного использования операций в иерархии
классов. Внутренние метрики классов рассматривают вопросы связности и
кодирования. Внешние метрики исследуют сцепление и повторное использование.
Метрика 1: Размер класса CS (Class Size)
Общий размер класса определяется с помощью
следующих измерений:
q
общее количество
операций (вместе с приватными и наследуемыми экземплярными операциями), которые
инкапсулируются внутри класса;
q
количество свойств
(вместе с приватными и наследуемыми экземплярными свойствами), которые
инкапсулируются классом.
Метрика WMC
Чидамбера и Кемерера также является взвешенной метрикой размера класса.
Большие значения CS
указывают, что класс имеет слишком много обязанностей. Они уменьшают
возможность повторного использования класса, усложняют его реализацию и
тестирование.
При определении размера класса унаследованным
(публичным) операциям и свойствам придают больший удельный вес. Причина —
приватные операции и свойства обеспечивают специализацию и более локализованы в
проекте.
Могут вычисляться средние количества свойств и
операций класса. Чем меньше среднее значение размера, тем больше вероятность
повторного использования класса.
Рекомендуемое значение CS ![]() 20 методов.
20 методов.
Метрика 2: Количество операций, переопределяемых
подклассом, NOO
(Number of Operations Overridden by
a Subclass)
Переопределением называют случай, когда подкласс
замещает операцию, унаследованную от суперкласса, своей собственной версией.
Большие значения NOO
обычно указывают на проблемы проектирования. Ясно, что подкласс должен
расширять операции суперкласса. Расширение проявляется в виде новых имен операций.
Если же NOО велико, то разработчик нарушает абстракцию суперкласса.
Это ослабляет иерархию классов, усложняет тестирование и модификацию
программного обеспечения.
Рекомендуемое значение NOO ![]() 3 методов.
3 методов.
Метрика 3: Количество операций, добавленных подклассом, NOA
(Number of Operations Added by a Subclass)
Подклассы специализируются добавлением
приватных операций и свойств. С ростом NOA
подкласс удаляется от абстракции суперкласса. Обычно при увеличении высоты
иерархии классов (увеличении DIT) должно
уменьшаться значение NOA на нижних уровнях иерархии.
Для рекомендуемых значений CS = 20 и DIT = 6 рекомендуемое
значение NOA ![]() 4 методов (для
4 методов (для
класса-листа).
Метрика 4: Индекс специализации SI (Specialization Index)
Обеспечивает грубую оценку степени
специализации каждого подкласса. Специализация достигается добавлением,
удалением или переопределением операций:
SI = (NOO x
уровень) /Mобщ,
где уровень
— номер уровня в иерархии, на котором находится подкласс, Мобщ — общее количество
методов класса.
Пример расчета индексов специализации приведен
на рис. 14.5.
Рис. 14.5. Расчет индексов
специализации классов
Чем выше значение SI,
тем больше вероятность того, что в иерархии классов есть классы, нарушающие
абстракцию суперкласса.
Рекомендуемое значение SI ![]() 0,15.
0,15.
Операционно-ориентированные метрики
Эта группа метрик ориентирована на оценку
операций в классах. Обычно методы имеют тенденцию быть небольшими как по
размеру, так и по логической сложности. Тем не менее реальные характеристики
операций могут быть полезны для глубокого понимания системы.
Метрика 5: Средний размер операции OSAVG (Average Operation Size)
В качестве индикатора размера может
использоваться количество строк программы, однако LOC-оценки
приводят к известным проблемам. Альтернативный вариант — «количество сообщений, посланных операцией».
Рост значения метрики означает, что
обязанности размещены в классе не очень удачно. Рекомендуемое значение OSAVG ![]() 9.
9.
Метрика 6: Сложность операции ОС (Operation Complexity
Сложность операции может вычисляться с помощью
стандартных метрик сложности, то есть с помощью LOC—
или FP-оценок, метрики цикломатической сложности, метрики
Холстеда.
М. Лоренц и Д. Кидд предлагают вычислять ОС
суммированием оценок с весовыми коэффициентами, приведенными в табл. 14.5.
Таблица
14.5. Весовые коэффициенты для метрики ОС
|
Параметр |
Вес |
|
Вызовы функций API |
5,0 |
|
Присваивания |
0,5 |
|
Арифметические операции |
2,0 |
|
Сообщения с параметрами |
3,0 |
|
Вложенные выражения |
0,5 |
|
Параметры |
0,3 |
|
Простые вызовы |
7,0 |
|
Временные переменные |
0,5 |
|
Сообщения без параметров |
1,0 |
Поскольку операция должна быть ограничена
конкретной обязанностью, желательно уменьшать ОС.
Рекомендуемое значение ОС ![]() 65 (для предложенного
65 (для предложенного
суммирования).
Метрика 7: Среднее количество параметров на операцию NPAVG
(Average Number of Parameters per
operation)
Чем больше параметров у операции, тем сложнее
сотрудничество между объектами. Поэтому значение NPAVG должно быть как можно меньшим.
Рекомендуемое значение NPAVG
= 0,7.
Метрики для ОО-проектов
Основными задачами менеджера проекта являются
планирование, координация, отслеживание работ и управление программным
проектом.
Одним из ключевых вопросов планирования является
оценка размера программного продукта. Прогноз размера продукта обеспечивают
следующие ОО-метрики.
Метрика 8: Количество описаний сценариев NSS (Number of Scenario Scripts)
Это количество прямо пропорционально
количеству классов, требуемых для реализации требований, количеству состояний
для каждого класса, а также количеству методов, свойств и сотрудничеств.
Метрика NSS — эффективный индикатор размера программы.
Рекомендуемое значение NSS — не менее одного сценария на публичный протокол
подсистемы, отражающий основные функциональные требования к подсистеме.
Метрика 9: Количество ключевых классов NKC (Number of Key Classes)
Ключевой класс прямо связан с коммерческой
проблемной областью, для которой предназначена система. Маловероятно, что
ключевой класс может появиться в результате повторного использования
существующего класса. Поэтому значение NKC
достоверно отражает предстоящий объем разработки. М. Лоренц и Д. Кидд
предполагают, что в типовой ОО-системе на долю ключевых классов приходится
20-40% от общего количества классов. Как правило, оставшиеся классы реализуют
общую инфраструктуру (GUI, коммуникации, базы данных).
Рекомендуемое значение: если NKC < 0,2 от общего количества классов системы, следует
углубить исследование проблемной области (для обнаружения важнейших абстракций,
которые нужно реализовать).
Метрика 10: Количество подсистем NSUB (NumberofSUBsystem)
Количество подсистем обеспечивает понимание
следующих вопросов: размещение ресурсов, планирование (с акцентом на
параллельную разработку), общие затраты на интеграцию.
Рекомендуемое значение: NSUB > 3.
Значения метрик NSS,
NKC, NSUB полезно накапливать как результат
каждого выполненного ОО-проекта. Так формируется метрический базис фирмы, в
который также включаются метрические значения по классами и операциям. Эти
исторические данные могут использоваться для вычисления метрик
производительности (среднее количество классов на разработчика или среднее
количество методов на человеко-месяц). Совместное применение метрик позволяет
оценивать затраты, продолжительность, персонал и другие характеристики текущего
проекта.
Однако при возрастании NOC ослабляется абстракция родительского класса. Это означает,
что в действительности некоторые из детей уже не являются членами родительского
класса и могут быть неправильно использованы.
Кроме того, количество детей характеризует
потенциальное влияние класса на проект. По мере роста NOC
возрастает количество тестов, необходимых для проверки каждого ребенка.
Метрики DIT
и NOC — количественные характеристики формы и размера структуры
классов. Хорошо структурированная объектно-ориентированная система чаще бывает
организована как лес классов, чем как сверхвысокое дерево. По мнению Г. Буча,
следует строить сбалансированные по высоте и ширине структуры наследования:
обычно не выше, чем 7 ± 2 уровня, и не шире, чем 7 + 2 ветви [22].
Метрика 4: Сцепление между классами объектов СВО (Coupling between object classes)
СВО — это количество сотрудничеств, предусмотренных для класса,
то есть количество классов, с которыми он соединен. Соединение означает, что
методы данного класса используют методы или экземплярные переменные другого
класса.
Другое определение метрики имеет следующий
вид: СВО равно количеству сцеплений класса; сцепление образует вызов метода или
свойства в другом классе.
Данная метрика характеризует статическую
составляющую внешних связей классов.
С ростом СВО многократность использования
класса, вероятно, уменьшается. Очевидно, что чем больше независимость класса,
тем легче его повторно использовать в другом приложении.
Высокое значение СВО усложняет модификацию и
тестирование, которое следует за выполнением модификации. Понятно, что, чем
больше количество сцеплений, тем выше чувствительность всего проекта к
изменениям в отдельных его частях. Минимизация межобъектных сцеплений улучшает
модульность и содействует инкапсуляции проекта.
СВО для каждого класса должно иметь разумно низкое значение.
Это согласуется с рекомендациями по уменьшению сцепления стандартного
программного обеспечения.
Введем вспомогательное определение. Множество
отклика класса RS — это множество методов, которые
могут выполняться в ответ на прибытие сообщений в объект этого класса. Формула
для определения RS имеет вид
где {Ri} — множество методов, вызываемых методом г, {М} — множество всех методов в классе.
Метрика RFC
равна количеству методов во множестве отклика, то есть равна мощности этого
множества:
RFC – card{RS}.
Приведем другое определение метрики: RFC — это количество методов класса плюс количество методов
других классов, вызываемых из данного класса.
Метрика RFC
является мерой потенциального взаимодействия данного класса с другими классами,
позволяет судить о динамике поведения соответствующего объекта в системе.
Данная метрика характеризует динамическую составляющую внешних связей классов.
Если в ответ на сообщение может быть вызвано
большое количество методов, то усложняются тестирование и отладка класса, так
как от разработчика тестов требуется больший уровень понимания класса, растет
длина тестовой последовательности.
С ростом RFC
увеличивается сложность класса. Наихудшая величина отклика может использоваться
при определении времени тестирования.
Каждый метод внутри класса обращается к одному
или нескольким свойствам (экземплярным переменным). Метрика LCOM показывает, насколько методы не связаны друг с другом через
свойства (переменные). Если все методы обращаются к одинаковым свойствам, то LCOM
Надёжность программного обеспечения | areliability.com блог инженера по надёжности

Статья обновлена 23.04.2020
Надёжность программного обеспечения. Введение
Надёжность программного обеспечения — загадочное и неуловимое нечто. Если вы попытаетесь найти что-то по этой теме в яндексе, вы увидите кучу теоретических статей, где написано множество умных слов и формул, но ни одна статья не содержит ни единого примера реального расчёта надёжности программы.
На предприятиях космической отрасли ситуация ещё лучше. Когда я спросил у специалистов одного уральского НПО, как они считают надёжность программного обеспечения, они сделали круглые глаза и сказали: «А чё там, за единицу берём да и всё. А надёжность обеспечиваем отработкой». Я согласен, что такой подход имеет право на жизнь, однако хотелось бы большего. Короче, я написал свою методику, прошу любить и жаловать. Внизу привожу калькулятор, на котором можно посчитать надёжность этого вашего ПО.
Проблема надёжности программного обеспечения приобретает все большее значение в связи с постоянным усложнением разрабатываемых систем, расширением круга задач, возлагаемых на них, а, следовательно, и значительным увеличением объемов и сложности ПО. Короче, мы дожили до того дня, когда железо стало надёжнее софта, и одна ошибка в программном коде может угробить космическую миссию ценой в миллиарды долларов.
По факту, пообщавшись с коллегами по надёжности и функциональной безопасности, мы коллективно пришли к выводу, что оценивать ВБР (вероятность безотказной работы) ПО не имеет смысла. ПО это тот объект, для которого малоприменимы хорошо отработанные методики оценки надёжности, используемые при оценке компонентов, агрегатов и систем.
Всё, что мы сейчас можем, это открыть неплохой ГОСТ Р 51904-2002 Программное обеспечение встроенных систем. Общие требования к разработке и документированию и выбрать уровень разработки нашего ПО. Самое высоконадёжное (и самое дорогое) ПО будет уровня А, затем B и так далее. Все, что написано ниже — моя творческая инициатива, позволяющая оценить ВБР ПО.
Надёжность программного обеспечения обуславливается наличием в программах разного рода ошибок, внесенных в неё, как правило, при разработке. Под надёжностью ПО будем понимать способность выполнять заданные функции, сохраняя во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующих заданным режимам и условиям исполнения. Под ошибкой понимают всякое невыполнение программой заданных функций. Проявление ошибки является отказом программы.
Показатели надёжности ПО
Наиболее распространенными показателями надёжности ПО являются следующие:
– начальное число ошибок N0 в ПО после сборки программы и перед её отладкой;
– число ошибок n в ПО, обнаруженных и оставшихся после каждого этапа отладки;
– наработка на отказ (MTBF), часов;
– вероятность безотказной работы (ВБР) ПО за заданное время работы P(t);
– интенсивность отказов ПО λ, 10-6 1/ч.
Упрощенная оценка надёжности ПО
Сперва рассмотрим методики, которые предлагаем нам отечественная нормативная база. Единственный нормативный документ по данной теме это ГОСТ 28195-99.
Оценка надежности ПО по ГОСТ 28195-99 рассчитывается по весьма упрощенной методике, констатирующей фактическую надёжность по опыту эксплуатации программного комплекса P(t) 1-n/N, где n – число отказов при испытаниях ПО; N – число экспериментов при испытаниях. Очевидно, что посчитать по этой методике ничего нельзя.
Статистическая оценка надёжности ПО
Куда больший интерес представляет описанная в [1] среднестатистическая оценка начального числа N0 ошибок в ПО после автономной отладки. Согласно данной оценке, количество ошибок на 1 К слов кода составляет 4,34 для языков низкого уровня (Ассемблер) и 1,44 для языков высокого уровня (С++). К сожалению, не совсем понятно, что имели в виду авторы под фразой «1 К слов кода». В англоязычной литературе принято использовать параметр тысяча строк кода (ТСК) (KLOC). Так, согласно [3] для операционной системы Windows 2000 плотность ошибок составляет 1,8-2,2 на ТСК. Учитывая, что Windows 2000 написан на языке программирования C и имеет близкую размерность числа ошибок, можно с высокой долей достоверности предположить, что отечественный авторы имели в виду именно параметр ТСК.
Отечественные авторы в [1] приводят статистические показатели интенсивности отказов ПО λ. Приведём их в таблице 1.1.
Таблица 1.1
К сожалению, для какого языка ПО это действительно, авторы не сказывают. Кроме того, вводятся поправочные коэффициенты:
Таблица 1.2

И коэффициент, отражающий влияние времени работы программы:
Таблица 1.3
Тогда интенсивность отказов ПО λ определяется с помощью таблиц 1.1-1.3 по выражению:
λ по = λ* Кр* Кк* Кз* Ки (1.1)
Пример расчёта 1.
Объем ПО составляет 1 Мб, например.
Тогда, согласно таблице 1.1 λ = 6
Используем усредненные поправочные коэффициенты. Пусть:
Кр = 2 (короткий срок использования ПО)
Кк = 0,25 (высокое качество ПО)
Кз = 0,25 (высокая частота изменений ПО)
Ки = 1 (уровень загруженности средний)
λ по = 0,1 * 10 -6 отказов/час
Далее, используя экспоненциальную модель надёжности (при использовании данной модели поток отказов считается постоянным), можно получить ВБР ПО по стандартной формуле надёжности:
P(t) = exp**(-λ*t) (1.2)
Данная статистическая модель оценки надёжности ПО обладает значительными достоинствами по сравнению с упрощенной, однако и обладает рядом серьезных недостатков, в частности, она не учитываем язык разработки ПО и имеет большие интервалы объема ПО. То есть нельзя, например, сказать, какая будет надёжность у программы объёмом 2 гига и которая должна работать 10 лет.
Кроме того, поправочные коэффициенты имеют субъективную оценку. С какого потолка они взяты — неизвестно.
Попыткой устранения данных недостатков является Количественная модель оценки надёжности ПО.
Количественная модель оценки надёжности ПО
В основе данной модели лежит моё предположение, что уровень надежности ПО зависит от объема ПО (в битах или тысячах строк кода). Это утверждение не противоречит классической теории надежности, согласно которой чем объект сложнее, тем ниже его надёжность. Логично же. Чем больше будет строк кода, тем больше в итоге будет ошибок и тем ниже будет вероятность безотказной работы программы.
Используем оценку количества ошибок в зависимости от языка разработки из статистической модели:
Таблица 1.4
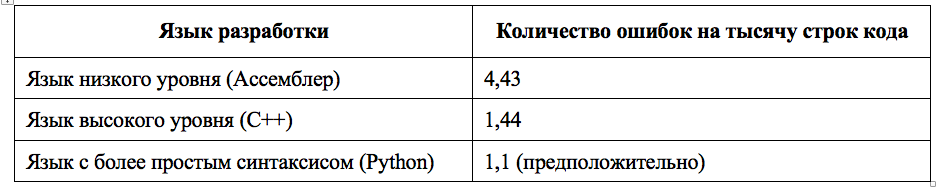
Далее, из [3] взята статистическая оценка связи количества строк кода и битов.
Для языка C, согласно [3] одна строка кода содержит 17 ± 3 байтов (146 битов) информации.
Зная V, объём кода ПО, в битах, мы можем получить число строк этого кода. Удобнее использовать параметр ТСК.
ТСК = V/146000 (1.3)
Используя данные таблицы 1.4 можно получить β, коэффициент количества ошибок на тысячу строк кода:
β = 1,44*ТСК/1000 (1.4)
Пример 2.
Объем ПО составляет 10 Мб. Язык разработки С++.
Тогда, согласно 1.3-1.4, β составит 0,08
Данный показатель очень близок к результату Примера 1.
Так появилась идея сопоставить параметр λ — интенсивности отказов ПО, получаемые статистической моделью и β, коэффициент количества ошибок ПО.
Сейчас внимание! Как видим, есть сильная корреляция результатов между интенсивностью отказов ПО с учётом поправочных коэффициентов и β — коэффициентом количества ошибок ПО. Использование других поправочных коэффициентов приводит к схожим результатам.
Можно сделать предположение, что введенный нами (придуманный мной) β по физическому смыслу близок к λ, интенсивности отказов. λ характеризует частоту отказов. β характеризует частоту ошибок в программе, а значит и отказов. Но! λ и β различаются. λ, единожды определённый для транзистора не изменяется от количества транзисторов. β — коэффициент динамический. Чем больше объём программы, тем больше β. Но это и логично. Чем больше программа, тем в ней больше ошибок. Кроме того, можно предположить, что авторы таблицы 1.1 написали её для ПО на языке С.
Очевидно, чем дольше работает программа, тем выше вероятность, что она откажет.
Используя экспоненциальную модель надёжности (при использовании данной модели поток отказов считается постоянным), можно получить ВБР ПО:
P(t) = exp**(-λ*t)
Резюмируя, для того чтобы оценить надёжность программного обеспечения, необходимо знать его язык разработки (высокий или низкий) и объём кода ПО.
[1] Надёжность авиационных приборов и измерительно-вычислительных комплексов, В.Ю. Чернов/ В.Г. Никитин; Иванов Ю.П. – М. 2004.
[2] Надёжность и эффективность в технике: Справочник., В.С. Авдуевский. 1988.
[3] Estimating source lines of code from object code, L. Hatton. 2005.
Попробуйте теперь что-нибудь посчитать. Например, найдите надёжность программного обеспечения, объём которого 100 Мб, и которое должно проработать 100 часов. Важно! Обратите внимание, что λ при изменении объёма ПО каждый раз пересчитывается под конкретный размер ПО.
KLOC, объём ПО в тысячах строк
β, к-т количества ошибок на тысячу строк кода для языка высокого уровня
β, к-т количества ошибок на тысячу строк кода для языка низкого уровня
λ, интенсивность отказов, язык высокого уровня
λ, интенсивность отказов, язык низкого уровня
t, время работы программы, часов
Вероятность безотказной работы, язык высокого уровня
Вероятность безотказной работы, язык низкого уровня
Валидация модели. Согласно этому сайту надёжность (вероятность безотказной работы) Windows 7 Home Premium составляет 0.98. Правда неизвестно, для какого времени работы сделан расчёт.
Давайте посчитаем по калькулятору. Windows 7 Home Premium после установки занимает около 15 гигабайт или 15360 мегабайт. Примем время работы — большой рабочий день = 12 часов. Тогда ВБР по калькулятору составит 0.984. Неплохо?
Продолжение. К вероятностной оценке надёжности программного обеспечения
Если вы хотите заказать у меня расчет надежности — нажмите на эту ссылку или на кнопку ниже.

Внимание! Если вас интересует корпоративное групповое обучение специалистов вашей компании, пожалуйста перейдите по ссылке ниже. Возможна адаптация учебной программы под ваши требования/пожелания/возможности как по объёму учёбы срокам обучения, формату обучения, так и по балансу теория/практика.


До встречи на обучении! С уважением, Алексей Глазачев. Инженер и преподаватель по надежности.
Качество программного обеспечения.
Проблемы разработки ПО
Наиболее распространёнными проблемами, возникающим в процессе разработки ПО, считают:
· Недостаток прозрачности. В любой момент времени сложно сказать, в каком состоянии находится проект и каков процент его завершения.
Данная проблема возникает при недостаточном планировании структуры (или архитектуры) будущего программного продукта, что чаще всего является следствием отсутствия достаточного финансирования проекта: программа нужна, сколько времени займёт разработка, каковы этапы, можно ли какие-то этапы исключить или сэкономить — следствием этого процесса является то, что этап проектирования сокращается.
· Недостаток контроля. Без точной оценки процесса разработки срываются графики выполнения работ и превышаются установленные бюджеты. Сложно оценить объем выполненной и оставшейся работы.
Данная проблема возникает на этапе, когда проект, завершённый более, чем на половину, продолжает разрабатываться после дополнительного финансирования без оценки степени завершённости проекта.
· Недостаток трассировки.
· Недостаток мониторинга. Невозможность наблюдать ход развития проекта не позволяет контролировать ход разработки в реальном времени. С помощью инструментальных средств менеджеры проектов принимают решения на основе данных, поступающих в реальном времени.
Данная проблема возникает в условиях, когда стоимость обучения менеджмента владению инструментальными средствами, сравнима со стоимостью разработки самой программы.
· Неконтролируемые изменения. У потребителей постоянно возникают новые идеи относительно разрабатываемого программного обеспечения. Влияние изменений может быть существенным для успеха проекта, поэтому важно оценивать предлагаемые изменения и реализовывать только одобренные, контролируя этот процесс с помощью программных средств.
Данная проблема возникает вследствие нежелания конечного потребителя использовать те или иные программные среды. Например, когда при создании клиент-серверной системы потребитель предъявляет требования не только к операционной системе на компьютерах-клиентах, но и на компьютере-сервере.
· Недостаточная надежность. Самый сложный процесс — поиск и исправление ошибок в программах на ЭВМ. Поскольку число ошибок в программах заранее неизвестно, то заранее неизвестна и продолжительность отладки программ и отсутствие гарантий отсутствия ошибок в программах. Следует отметить, что привлечение доказательного подхода к проектированию ПО позволяет обнаружить ошибки в программе до её выполнения. В этом направлении много работали Кнут, Дейкстра и Вирт. Профессор Вирт при разработке Паскаля и Оберона за счет строгости их синтаксиса добился математической доказуемости завершаемости и правильности программ, написанной на этих языках. Особенно крупный вклад в дисциплину программирования внёс Дональд Кнут. Его четырёхтомник «Искусство программирования» является необходимой для каждого серьезного программиста книгой.
Данная проблема возникает при неправильном выборе средств разработки. Например, при попытке создать программу, требующую средств высокого уровня, с помощью средств низкого уровня. Например, при попытке создать средства автоматизации с СУБД на ассемблере. В результате исходный код программы получается слишком сложным и плохо поддающимся структурированию.
· Отсутствие гарантий качества и надежности программ из-за отсутствия гарантий отсутствия ошибок в программах вплоть до формальной сдачи программ заказчикам.
Данная проблема не является проблемой, относящейся исключительно к разработке ПО. Гарантия качества — это проблема выбора поставщика товара (не продукта).
Качество программного обеспечения — характеристика программного обеспечения (ПО) как степени его соответствия требованиям. При этом требования могут трактоваться довольно широко, что порождает целый ряд независимых определений понятия. Чаще всего используется определение ISO 9001, согласно которому качество есть «степень соответствия присущих характеристик требованиям».
Качество исходного кода
Качество кода может определяться различными критериями. Некоторые из них имеют значение только с точки зрения человека. Например, то, как отформатирован текст программы, совершенно не важно для компьютера, но может иметь серьёзное значение для последующего сопровождения. Многие из имеющихся стандартов оформления кода, определяющих специфичные для используемого языка соглашения и задающие ряд правил, улучшающих читаемость кода, имеют своей целью облегчить будущее сопровождение ПО, включающее отладку и обновление. Существуют и другие критерии, определяющие, «хорошо» ли написан код, например, такие, как:
· Структурированность — степень логического разбиения кода на ряд управляемых блоков
· Читаемость кода
· Лёгкость поддержки, тестирования, отладки, исправления ошибок, изменения и портируемости
· Низкая сложность кода
· Низкое использование ресурсов: памяти и процессорного времени
· Корректная обработка исключительных ситуаций
· Низкое количество предупреждений при компиляции и линковке
· Вязкость — свойство программного проекта или среды разработки затруднять внесение изменений предусмотренными в них методами
Методы улучшения качества кода: рефакторинг.
Факторы качества
Фактор качества ПО — это нефункциональное требование к программе, которое обычно не описывается в договоре с заказчиком, но, тем не менее, является желательным требованием, повышающим качество программы.
Некоторые из факторов качества:
· понятность
Назначение ПО должно быть понятным, из самой программы и документации.
· полнота
Все необходимые части программы должны быть представлены и полностью реализованы.
· краткость
Отсутствие лишней, дублирующейся информации. Повторяющиеся части кода должны быть преобразованы в вызов общей процедуры. То же касается и документации.
· портируемость
Лёгкость в адаптации программы к другому окружению: другой архитектуре, платформе, операционной системе или её версии.
· согласованность
По всей программе и в документации должны использоваться одни и те же соглашения, форматы и обозначения.
· сопровождаемость
Насколько сложно изменить программу для удовлетворения новых требований. Это требование также указывает, что программа должна быть хорошо документирована, не слишком запутана, и иметь резерв роста по использованию ресурсов (память, процессор).
· тестируемость
Позволяет ли программа выполнить проверку реализованных в программе методов, классов, поддерживается ли возможность измерения производительности.
· удобство использования
Простота и удобство использования программы. Это требование относится прежде всего к интерфейсу пользователя.
· надёжность
отсутствие отказов и сбоев в работе программ, а также простота исправления дефектов и ошибок:
· структурированность
· эффективность
Насколько рационально программа относится к ресурсам (память, процессор) при выполнении своих задач.
· безопасность
С точки зрения пользователя
Помимо технического взгляда на качество ПО, существует и оценка качества с позиции пользователя. Для этого аспекта качества иногда используют термин «юзабилити» (англ. usability — дословно «возможность использования», «способность быть использованным», «полезность»). Довольно сложно получить оценку юзабилити для заданного программного продукта. Наиболее важные из вопросов, влияющих на оценку:
· Является ли пользовательский интерфейс интуитивно понятным?
· Насколько просто выполнять простые, частые операции?
· Насколько легко выполняются сложные операции?
· Выдаёт ли программа понятные сообщения об ошибках?
· Всегда ли программа ведёт себя так, как ожидается?
· Имеется ли документация и насколько она полна?
· Является ли интерфейс пользователя само-описательным/само-документирующим?
· Всегда ли задержки с ответом программы являются приемлемыми?
Методы улучшения качества кода: рефакторинг.
Рефакторинг — процесс изменения внутренней структуры программы, не затрагивающий её внешнего поведения и имеющий целью облегчить понимание её работы. В основе рефакторинга лежит последовательность небольших эквивалентных (то есть сохраняющих поведение) преобразований. Поскольку каждое преобразование маленькое, программисту легче проследить за его правильностью, и в то же время вся последовательность может привести к существенной перестройке программы и улучшению её согласованности и четкости. Рефакторинг позволяет разрабатывать архитектуру программы постепенно, откладывая проектные решения до тех пор, пока не станет более ясной их необходимость.
Цели рефакторинга
Цель рефакторинга — сделать код программы более легким для понимания; без этого рефакторинг нельзя считать успешным. Рефакторинг следует отличать от оптимизации производительности. Как и рефакторинг, оптимизация обычно не изменяет поведение программы, а только ускоряет ее работу. Но оптимизация часто затрудняет понимание кода, что противоположно рефакторингу. С другой стороны, нужно отличать рефакторинг от реинжиниринга, который осуществляется для расширения функциональности программного обеспечения. Как правило, крупные рефакторинги предваряют реинжиниринг.
Причины применения рефакторинга
Рефакторинг нужно применять постоянно при разработке кода. Основными стимулами его проведения являются следующие задачи:
· Необходимо добавить новую функцию, которая не достаточно укладывается в принятое архитектурное решение
· Необходимо исправить ошибку, причины возникновения которой сразу не ясны
· Трудности в командной разработке обусловлены сложной логикой программы
Какой код должен подвергаться рефакторингу
Во многом при рефакторинге лучше полагаться на интуицию, основанную на опыте. Но можно выделить наиболее очевидные причины, когда код нужно подвергнуть рефакторингу:
· Дублирование кода
· Длинный метод
· Большой класс
· Длинный список параметров
· «Завистливые» функции — это метод, который чрезмерно обращается к данным другого объекта
· Избыточные временные переменные
· Классы данных
· Несгруппированные данные
Рефакторинг кода
В программировании термин рефакторинг означает изменение исходного кода программы без изменения его внешнего поведения. В экстремальном программировании и других гибких методологиях рефакторинг является неотъемлемой частью цикла разработки ПО: разработчики попеременно то создают новые тесты и функциональность, то выполняют рефакторинг кода для улучшения его логичности и прозрачности. Автоматическое юнит-тестирование позволяет убедиться, что рефакторинг не разрушил существующую функциональность. Иногда под рефакторингом неправильно подразумевают коррекцию кода с заранее оговоренными правилами отступа, перевода строк, внесения комментариев и прочими визуально значимыми изменениями, которые никак не отражаются на процессе компиляции, с целью обеспечения лучшей читаемости кода.
Рефакторинг изначально не предназначен для исправления ошибок и добавления новой функциональности, он вообще не меняет поведение программного обеспечения. Но это помогает избежать ошибок и облегчить добавление функциональности. Он выполняется для улучшения понятности кода или изменения его структуры, для удаления «мёртвого кода» — всё это для того, чтобы в будущем код было легче поддерживать и развивать. В частности, добавление в программу нового поведения может оказаться сложным с существующей структурой — в этом случае разработчик может выполнить необходимый рефакторинг, а уже затем добавить новую функциональность.
Это может быть перемещение поля из одного класса в другой, вынесение фрагмента кода из метода и превращение его в самостоятельный метод или даже перемещение кода по иерархии классов. Каждый отдельный шаг может показаться элементарным, но совокупный эффект таких малых изменений в состоянии радикально улучшить проект или даже предотвратить распад плохо спроектированной программы.
Методы рефакторинга
Наиболее употребимые методы рефакторинга:
· Изменение сигнатуры метода (Change Method Signature)
· Инкапсуляция поля (Encapsulate Field)
· Выделение класса (Extract Class)
· Выделение интерфейса (Extract Interface)
· Выделение локальной переменной (Extract Local Variable)
· Выделение метода (Extract Method)
· Генерализация типа (Generalize Type)
· Встраивание (Inline)
· Введение фабрики (Introduce Factory)
· Введение параметра (Introduce Parameter)
· Подъём поля/метода (Pull Up)
· Спуск поля/метода (Push Down)
· Замена условного оператора полиморфизмом (Replace Conditional with Polymorphism)
Изменение сигнатуры метода (Change Method Signature)
Заключается в добавлении, изменении или удалении параметра метода. Изменив сигнатуру метода, необходимо скорректировать обращения к нему в коде всех клиентов. Это изменение может затронуть внешний интерфейс программы, кроме того, не всегда разработчику, изменяющему интерфейс, доступны все клиенты этого интерфейса, поэтому может потребоваться та или иная форма регистрации изменений интерфейса для последующей передачи их вместе с новой версией программы.
Инкапсуляция поля (Encapsulate field)
В случае, если у класса имеется открытое поле, необходимо сделать его закрытым и обеспечить методы доступа. После «Инкапсуляции поля» часто применяется «Перемещение метода».
Выделение метода (Extract Method)
Заключается в выделении из длинного и/или требующего комментариев кода отдельных фрагментов и преобразовании их в отдельные методы, с подстановкой подходящих вызовов в местах использования. В этом случае действует правило: если фрагмент кода требует комментария о том, что он делает, то он должен быть выделен в отдельный метод. Также правило: один метод не должен занимать более чем один экран (25-50 строк, в зависимости от условий редактирования), в противном случае некоторые его фрагменты имеют самостоятельную ценность и подлежат выделению. Из анализа связей выделяемого фрагмента с окружающим контекстом делается вывод о перечне параметров нового метода и его локальных переменных.
Перемещение метода (Move Method)
Применяется по отношению к методу, который чаще обращается к другому классу, чем к тому, в котором сам располагается.
Замена условного оператора полиморфизмом (Replace Conditional with Polymorphism)
Условный оператор с несколькими ветвями заменяется вызовом полиморфного метода некоторого базового класса, имеющего подклассы для каждой ветви исходного оператора. Выбор ветви осуществляется неявно, в зависимости от того, экземпляру какого из подклассов оказался адресован вызов.
Основные принципы:
1. вначале следует создать базовый класс и нужное число подклассов
2. в некоторых случаях следует провести оптимизацию условного оператора путем «Выделения метода»
3. возможно использование «Перемещения метода», чтобы поместить условный оператор в вершину иерархии наследования
4. выбрав один из подклассов, нужно конкретизировать в нём полиморфный метод базового класса и переместить в него тело соответствующей ветви условного оператора.
5. повторить предыдущее действие для каждой ветви условного оператора
6. заменить весь условный оператор вызовом полиморфного метода базового класса
Проблемы, возникающие при проведении рефакторинга
· проблемы, связанные с базами данных
· проблемы изменения интерфейсов
· трудности при изменении дизайна
Реинжиниринг программного обеспечения.
Реинжиниринг программного обеспечения — процесс создания новой функциональности или устранения ошибок, путём революционного изменения, но используя уже имеющееся в эксплуатации программное обеспечение. Процесс реинжиниринга описан Chikofsky и Кроссом в их труде 1990 года, как «The examination and alteration of a system to reconstitute it in a new form». Выражаясь менее формально, реинжиниринг является изменением системы программного обеспечения после проведения обратного инжиниринга.
Сложность реинжиниринга
Как правило, утверждается, что «легче разработать новый программный продукт». Это связано со следующими проблемами:
1. Обычному программисту сложно разобраться в чужом исходном коде
2. Реинжиниринг чаще всего дороже разработки нового программного обеспечения, т.к. требуется убрать ограничения предыдущих версий, но при этом оставить совместимость с предыдущими версиями
3. Реинжиниринг не может сделать программист низкой и средней квалификации. Даже профессионалы часто не могут качественно реализовать его. Поэтому требуется работа программистов с большим опытом переделки программ и знанием различных технологий.
В то же время, если изначально программа обладала строгой и ясной архитектурой, то провести реинжиниринг будет на порядок проще. Поэтому при проектировании как правило анализируется, что выгоднее провести реинжиниринг или разработать программный продукт «с нуля».
Тестирование программного обеспечения.
Тестирование программного обеспечения — процесс исследования программного обеспечения (ПО) с целью получения информации о качестве продукта.
Введение
Существующие на сегодняшний день методы тестирования ПО не позволяют однозначно и полностью выявить все дефекты и установить корректность функционирования анализируемой программы, поэтому все существующие методы тестирования действуют в рамках формального процесса проверки исследуемого или разрабатываемого ПО.
Такой процесс формальной проверки или верификации может доказать, что дефекты отсутствуют с точки зрения используемого метода. (То есть нет никакой возможности точно установить или гарантировать отсутствие дефектов в программном продукте с учётом человеческого фактора, присутствующего на всех этапах жизненного цикла ПО).
Существует множество подходов к решению задачи тестирования и верификации ПО, но эффективное тестирование сложных программных продуктов — это процесс в высшей степени творческий, не сводящийся к следованию строгим и чётким процедурам или созданию таковых.
С точки зрения ISO 9126, Качество (программных средств) можно определить как совокупную характеристику исследуемого ПО с учётом следующих составляющих:
· Надёжность
· Сопровождаемость
· Практичность
· Эффективность
· Мобильность
· Функциональность
Более полный список атрибутов и критериев можно найти в стандарте ISO 9126 Международной организации по стандартизации. Состав и содержание документации, сопутствующей процессу тестирования, определяется стандартом IEEE 829-1998 Standard for Software Test Documentation.
История развития тестирования программного обеспечения
Первые программные системы разрабатывались в рамках программ научных исследований или программ для нужд министерств обороны. Тестирование таких продуктов проводилось строго формализованно с записью всех тестовых процедур, тестовых данных, полученных результатов. Тестирование выделялось в отдельный процесс, который начинался после завершения кодирования, но при этом, как правило, выполнялось тем же персоналом.
В 1960-х много внимания уделялось «исчерпывающему» тестированию, которое должно проводиться с использованием всех путей в коде или всех возможных входных данных. Было отмечено, что в этих условиях полное тестирование ПО невозможно, потому что, во-первых, количество возможных входных данных очень велико, во-вторых, существует множество путей, в-третьих, сложно найти проблемы в архитектуре и спецификациях. По этим причинам «исчерпывающее» тестирование было отклонено и признано теоретически невозможным.
В начале 1970-х тестирование ПО обозначалось как «процесс, направленный на демонстрацию корректности продукта» или как «деятельность по подтверждению правильности работы ПО». В зарождавшейся программной инженерии верификация ПО значилась как «доказательство правильности». Хотя концепция была теоретически перспективной, на практике она требовала много времени и была недостаточно всеобъемлющей. Было решено, что доказательство правильности — неэффективный метод тестирования ПО. Однако, в некоторых случаях демонстрация правильной работы используется и в наши дни, например, приемо-сдаточные испытания. Во второй половине 1970-х тестирование представлялось как выполнение программы с намерением найти ошибки, а не доказать, что она работает. Успешный тест — это тест, который обнаруживает ранее неизвестные проблемы. Данный подход прямо противоположен предыдущему. Указанные два определения представляют собой «парадокс тестирования», в основе которого лежат два противоположных утверждения: с одной стороны, тестирование позволяет убедиться, что продукт работает хорошо, а с другой — выявляет ошибки в ПО, показывая, что продукт не работает. Вторая цель тестирования является более продуктивной с точки зрения улучшения качества, так как не позволяет игнорировать недостатки ПО.
В 1980-х тестирование расширилось таким понятием, как предупреждение дефектов. Проектирование тестов — наиболее эффективный из известных методов предупреждения ошибок. В это же время стали высказываться мысли, что необходима методология тестирования, в частности, что тестирование должно включать проверки на всем протяжении цикла разработки, и это должен быть управляемый процесс. В ходе тестирования надо проверить не только собранную программу, но и требования, код, архитектуру, сами тесты. «Традиционное» тестирование, существовавшее до начала 1980-х, относилось только к скомпилированной, готовой системе (сейчас это обычно называется системное тестирование), но в дальнейшем тестировщики стали вовлекаться во все аспекты жизненного цикла разработки. Это позволяло раньше находить проблемы в требованиях и архитектуре и тем самым сокращать сроки и бюджет разработки. В середине 1980-х появились первые инструменты для автоматизированного тестирования. Предполагалось, что компьютер сможет выполнить больше тестов, чем человек, и сделает это более надежно. Поначалу эти инструменты были крайне простыми и не имели возможности написания сценариев на скриптовых языках.
В начале 1990-х в понятие «тестирование» стали включать планирование, проектирование, создание, поддержку и выполнение тестов и тестовых окружений, и это означало переход от тестирования к обеспечению качества, охватывающего весь цикл разработки ПО. В это время начинают появляться различные программные инструменты для поддержки процесса тестирования: более продвинутые среды для автоматизации с возможностью создания скриптов и генерации отчетов, системы управления тестами, ПО для проведения нагрузочного тестирования. В середине 1990-х с развитием интернета и разработкой большого количества веб-приложений особую популярность стало получать «гибкое тестирование» (по аналогии с гибкими методологиями программирования).
В 2000-х появилось еще более широкое определение тестирования, когда в него было добавлено понятие «оптимизация бизнес-технологий» (en:business technology optimization, BTO). BTO направляет развитие информационных технологий в соответствии с целями бизнеса. Основной подход заключается в оценке и максимизации значимости всех этапов жизненного цикла разработки ПО для достижения необходимого уровня качества, производительности, доступности.
Тестирование программного обеспечения
Существует несколько признаков, по которым принято производить классификацию видов тестирования. Обычно выделяют следующие:
По объекту тестирования:
· Функциональное тестирование (functional testing)
· Нагрузочное тестирование
· Тестирование производительности (perfomance/stress testing)
· Тестирование стабильности (stability/load testing)
· Тестирование удобства использования (usability testing)
· Тестирование интерфейса пользователя (UI testing)
· Тестирование безопасности (security testing)
· Тестирование локализации (localization testing)
· Тестирование совместимости (compatibility testing)
По знанию системы:
· Тестирование чёрного ящика (black box)
· Тестирование белого ящика (white box)
· Тестирование серого ящика (gray box)
По степени автоматизированности:
· Ручное тестирование (manual testing)
· Автоматизированное тестирование (automated testing)
· Полуавтоматизированное тестирование (semiautomated testing)
По степени изолированности компонентов:
· Компонентное (модульное) тестирование (component/unit testing)
· Интеграционное тестирование (integration testing)
· Системное тестирование (system/end-to-end testing)
По времени проведения тестирования:
· Альфа тестирование (alpha testing)
· Тестирование при приёмке (smoke testing)
· Тестирование новых функциональностей (new feature testing)
· Регрессионное тестирование (regression testing)
· Тестирование при сдаче (acceptance testing)
· Бета тестирование (beta testing)
По признаку позитивности сценариев:
· Позитивное тестирование (positive testing)
· Негативное тестирование (negative testing)
По степени подготовленности к тестированию:
· Тестирование по документации (formal testing)
· Эд Хок (интуитивное) тестирование (ad hoc testing)
Уровни тестирования
Модульное тестирование (юнит-тестирование) — тестируется минимально возможный для тестирования компонент, например, отдельный класс или функция. Часто модульное тестирование осуществляется разработчиками ПО.
Интеграционное тестирование — тестируются интерфейсы между компонентами, подсистемами. При наличии резерва времени на данной стадии тестирование ведётся итерационно, с постепенным подключением последующих подсистем.
Системное тестирование — тестируется интегрированная система на её соответствие требованиям.
Альфа-тестирование — имитация реальной работы с системой штатными разработчиками, либо реальная работа с системой потенциальными пользователями/заказчиком. Чаще всего альфа-тестирование проводится на ранней стадии разработки продукта, но в некоторых случаях может применяться для законченного продукта в качестве внутреннего приёмочного тестирования. Иногда альфа-тестирование выполняется под отладчиком или с использованием окружения, которое помогает быстро выявлять найденные ошибки. Обнаруженные ошибки могут быть переданы тестировщикам для дополнительного исследования в окружении, подобном тому, в котором будет использоваться ПО.
Бета-тестирование — в некоторых случаях выполняется распространение версии с ограничениями (по функциональности или времени работы) для некоторой группы лиц, с тем чтобы убедиться, что продукт содержит достаточно мало ошибок. Иногда бета-тестирование выполняется для того, чтобы получить обратную связь о продукте от его будущих пользователей.
Часто для свободного/открытого ПО стадия Альфа-тестирования характеризует функциональное наполнение кода, а Бета тестирования — стадию исправления ошибок. При этом как правило на каждом этапе разработки промежуточные результаты работы доступны конечным пользователям.
Тестирование «белого ящика» и «чёрного ящика»
В терминологии профессионалов тестирования (программного и некоторого аппаратного обеспечения), фразы «тестирование белого ящика» и «тестирование чёрного ящика» относятся к тому, имеет ли разработчик тестов доступ к исходному коду тестируемого ПО, или же тестирование выполняется через пользовательский интерфейс либо прикладной программный интерфейс, предоставленный тестируемым модулем.
При тестировании белого ящика (англ. white-box testing, также говорят — прозрачного ящика), разработчик теста имеет доступ к исходному коду программ и может писать код, который связан с библиотеками тестируемого ПО. Это типично для юнит-тестирования (англ. unit testing), при котором тестируются только отдельные части системы. Оно обеспечивает то, что компоненты конструкции — работоспособны и устойчивы, до определённой степени. При тестировании белого ящика используются метрики покрытия кода.
При тестировании чёрного ящика, тестировщик имеет доступ к ПО только через те же интерфейсы, что и заказчик или пользователь, либо через внешние интерфейсы, позволяющие другому компьютеру либо другому процессу подключиться к системе для тестирования. Например, тестирующий модуль может виртуально нажимать клавиши или кнопки мыши в тестируемой программе с помощью механизма взаимодействия процессов, с уверенностью в том, все ли идёт правильно, что эти события вызывают тот же отклик, что и реальные нажатия клавиш и кнопок мыши. Как правило, тестирование чёрного ящика ведётся с использованием спецификаций или иных документов, описывающих требования к системе. Как правило, в данном виде тестирования критерий покрытия складывается из покрытия структуры входных данных, покрытия требований и покрытия модели (в тестировании на основе моделей).
Если «альфа-» и «бета-тестирование» относятся к стадиям до выпуска продукта (а также, неявно, к объёму тестирующего сообщества и ограничениям на методы тестирования), тестирование «белого ящика» и «чёрного ящика» имеет отношение к способам, которыми тестировщик достигает цели.
Бета-тестирование в целом ограничено техникой чёрного ящика (хотя постоянная часть тестировщиков обычно продолжает тестирование белого ящика параллельно бета-тестированию). Таким образом, термин «бета-тестирование» может указывать на состояние программы (ближе к выпуску чем «альфа»), или может указывать на некоторую группу тестировщиков и процесс, выполняемый этой группой. Итак, тестировщик может продолжать работу по тестированию белого ящика, хотя ПО уже «в бете» (стадия), но в этом случае он не является частью «бета-тестирования» (группы/процесса).
Статическое и динамическое тестирование
Описанные выше техники — тестирование белого ящика и тестирование чёрного ящика — предполагают, что код исполняется, и разница состоит лишь в той информации, которой владеет тестировщик. В обоих случаях это динамическое тестирование.
При статическом тестировании программный код не выполняется — анализ программы происходит на основе исходного кода, который вычитывается вручную, либо анализируется специальными инструментами. В некоторых случаях, анализируется не исходный, а промежуточный код (такой как байт-код или код на MSIL).
Также к статическому тестированию относят тестирование требований, спецификаций, документации.
Регрессионное тестирование
Регрессио́нное тести́рование (англ. regression testing, от лат. regressio — движение назад) — собирательное название для всех видов тестирования программного обеспечения, направленных на обнаружение ошибок в уже протестированных участках исходного кода. Такие ошибки — когда после внесения изменений в программу перестает работать то, что должно было продолжать работать, — называют регрессионными ошибками (англ. regression bugs).
Обычно используемые методы регрессионного тестирования включают повторные прогоны предыдущих тестов, а также проверки, не попали ли регрессионные ошибки в очередную версию в результате слияния кода.
Из опыта разработки ПО известно, что повторное появление одних и тех же ошибок — случай достаточно частый. Иногда это происходит из-за слабой техники управления версиями или по причине человеческой ошибки при работе с системой управления версиями. Но настолько же часто решение проблемы бывает «недолго живущим»: после следующего изменения в программе решение перестаёт работать. И наконец, при переписывании какой-либо части кода часто всплывают те же ошибки, что были в предыдущей реализации.
Поэтому считается хорошей практикой при исправлении ошибки создать тест на неё и регулярно прогонять его при последующих изменениях программы. Хотя регрессионное тестирование может быть выполнено и вручную, но чаще всего это делается с помощью специализированных программ, позволяющих выполнять все регрессионные тесты автоматически. В некоторых проектах даже используются инструменты для автоматического прогона регрессионных тестов через заданный интервал времени. Обычно это выполняется после каждой удачной компиляции (в небольших проектах) либо каждую ночь или каждую неделю.
Регрессионное тестирование является неотъемлемой частью экстремального программирования. В этой методологии проектная документация заменяется на расширяемое, повторяемое и автоматизированное тестирование всего программного пакета на каждой стадии цикла разработки программного обеспечения.
Регрессионное тестирование может быть использовано не только для проверки корректности программы, часто оно также используется для оценки качества полученного результата. Так, при разработке компилятора, при прогоне регрессионных тестов рассматривается размер получаемого кода, скорость его выполнения и время компиляции каждого из тестовых примеров.
Цитата
«Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20-50%) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, шаг назад».
Почему не удается устранять ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но если только структура не является очень ясной или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, ошибки обычно исправляет не автор программы, а зачастую младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное (регрессионное) тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.»
После внесения изменений в очередную версию программы, регрессионные тесты подтверждают, что сделанные изменения не повлияли на работоспособность остальной функциональности приложения. Регрессионное тестирование может выполняться как вручную, так и средствами автоматизации тестирования.
Тестовые скрипты
Тестировщики используют тестовые скрипты на разных уровнях: как в модульном, так и в интеграционном и системном тестировании. Тестовые скрипты, как правило, пишутся для проверки компонентов, в которых наиболее высока вероятность появления отказов или вовремя не найденная ошибка может быть дорогостоящей.
Покрытие кода
Покрытие кода — мера, используемая при тестировании программного обеспечения. Она показывает процент, насколько исходный код программы был протестирован. Техника покрытия кода была одной из первых методик, изобретённых для систематического тестирования ПО. Первое упоминание покрытия кода в публикациях появилось в 1963 году.
Критерии
Существует несколько различных способов измерения покрытия, основные из них:
· Покрытие операторов — каждая ли строка исходного кода была выполнена и протестирована?
· Покрытие условий — каждая ли точка решения (вычисления истинно ли или ложно выражение) была выполнена и протестирована?
· Покрытие путей — все ли возможные пути через заданную часть кода были выполнены и протестированы?
· Покрытие функций — каждая ли функция программы была выполнена
· Покрытие вход/выход — все ли вызовы функций и возвраты из них были выполнены
Для программ с особыми требованиями к безопасности часто требуется продемонстрировать, что тестами достигается 100 % покрытие для одного из критериев. Некоторые из приведённых критериев покрытия связаны между собой; например, покрытие путей включает в себя и покрытие условий и покрытие операторов. Покрытие операторов не включает покрытие условий, как показывает этот код на Си:
printf(«this is «);
if (bar < 1)
{
printf(«not «);
}
printf(«a positive integer»);
Если здесь bar = −1, то покрытие операторов будет полным, а покрытие условий — нет, так как случай несоблюдения условия в операторе if — не покрыт. Полное покрытие путей обычно невозможно. Фрагмент кода, имеющий n условий содержит 2n путей; конструкция цикла порождает бесконечное количество путей. Некоторые пути в программе могут быть не достигнуты из-за того, что в тестовых данных отсутствовали такие, которые могли привести к выполнению этих путей. Не существует универсального алгоритма, который решал бы проблему недостижимых путей (этот алгоритм можно было бы использовать для решения проблемы останова). На практике для достижения покрытия путей используется следующий подход: выделяются классы путей (например, к одному классу можно отнести пути отличающиеся только количеством итераций в одном и том же цикле), 100 % покрытие достигнуто, если покрыты все классы путей (класс считается покрытым, если покрыт хотя бы один путь из него).
Покрытие кода, по своей сути, является тестированием методом белого ящика. Тестируемое ПО собирается со специальными настройками или библиотеками и/или запускается в особом окружении, в результате чего для каждой используемой (выполняемой) функции программы определяется местонахождение этой функции в исходном коде. Этот процесс позволяет разработчикам и специалистам по обеспечению качества определить части системы, которые, при нормальной работе, используются очень редко или никогда не используются (такие как код обработки ошибок и т.п.). Это позволяет сориентировать тестировщиков на тестирование наиболее важных режимов.
Практическое применение
Обычно исходный код снабжается тестами, которые регулярно выполняются. Полученный отчёт анализируется с целью выявить невыполнявшиеся области кода, набор тестов обновляется, пишутся тесты для непокрытых областей. Цель состоит в том, чтобы получить набор тестов для регрессионного тестирования, тщательно проверяющих весь исходный код.
Степень покрытия кода обычно выражают в виде процента. Например, «мы протестировали 67 % кода». Смысл этой фразы зависит от того какой критерий был использован. Например, 67 % покрытия путей — это лучший результат чем 67 % покрытия операторов. Вопрос о связи значения покрытия кода и качеством тестового набора ещё до конца не решён.
Тестировщики могут использовать результаты теста покрытия кода для разработки тестов или тестовых данных, которые расширят покрытие кода на важные функции.
Как правило, инструменты и библиотеки, используемые для получения покрытия кода, требуют значительных затрат производительности и/или памяти, недопустимых при нормальном функционировании ПО. Поэтому они могут использоваться только в лабораторных условиях.
Метрика программного обеспечения
Метрика программного обеспечения (англ. software metric) — это мера, позволяющая получить численное значение некоторого свойства программного обеспечения или его спецификаций.
Поскольку количественные методы хорошо зарекомендовали себя в других областях, многие теоретики и практики информатики пытались перенести данный подход и в разработку программного обеспечения. Как сказал Том ДеМарко, «вы не можете контролировать то, что не можете измерить».
Метрики
Набор используемых метрик включает:
· порядок роста (имеется в виду анализ алгоритмов в терминах асимптотического анализа и O-нотации)
· количество строк кода
· цикломатическая сложность
· анализ функциональных точек
· количество ошибок на 1000 строк кода
· покрытие кода
· покрытие требований
· количество классов и интерфейсов
· метрики программного пакета от Роберта Сесиль Мартина
· связность
Критика
Потенциальные недостатки подхода, на которые нацелена критика:
Неэтичность: Утверждается, что неэтично сводить оценку работы человека к нескольким числовым параметрам и по ним судить о производительности. Менеджер может назначить наиболее талантливых программистов на сложнейший участок работы; это означает, что разработка этого участка займёт наибольшее время и породит наибольшее количество ошибок, из-за сложности задачи. Не зная об этих трудностях, другой менеджер по полученным показателям может решить, что программист сделал свою работу плохо.
Замещение «управления людьми» на «управление цифрами», которое не учитывает опыт сотрудников и их другие качества
Искажение: Процесс измерения может быть искажён за счёт того, что сотрудники знают об измеряемых показателях и стремятся оптимизировать эти показатели, а не свою работу. Например, если количество строк исходного кода является важным показателем, то программисты будут стремиться писать как можно больше строк и не будут использовать способы упрощения кода, сокращающие количество строк.
Неточность: Нет метрик, которые были бы одновременно и значимы и достаточно точны. Количество строк кода — это просто количество строк, этот показатель не даёт представление о сложности решаемой проблемы. Анализ функциональных точек был разработан с целью лучшего измерения сложности кода и спецификации, но он использует личные оценки измеряющего, поэтому разные люди получат разные результаты.
Обратная семантическая трассировка
Обратная семантическая трассировка (ОСТ) — метод контроля качества, который позволяет обнаруживать ошибки, утечку или искажение информации при создании проектных артефактов: документации, кода и т. д. Метод наиболее ценен на ранних стадиях разработки программного обеспечения, при создании требований и архитектуры будущей системы при отсутствии исполняемого кода для тестирования. ОСТ является частью P-Modeling Framework.
Вступление
Каждый этап процесса разработки программного обеспечения можно рассматривать как серию «переводов» с одного языка на другой. В самом начале проекта заказчик рассказывает команде свои требования к программе на естественном языке: русском, английском и т. д. Эти пожелания клиента иногда могут оказаться неполными, неясными или даже противоречащими друг другу. Первым шагом в цепочке «переводов» является определение и анализ пожеланий заказчика, их преобразование в формальный список требований для будущей системы. Затем требования становятся исходным материалом для архитектуры и проекта системы. Так шаг за шагом команда создает мегабайты кода, написанного на весьма формальном языке программирования. При переводе всегда существует риск ошибки, неправильного толкования или потери информации. Иногда это не имеет значения, но иногда даже небольшой дефект в спецификации требований может вызвать серьезные переделки системы на поздних стадиях проекта.
Чаще всего обратная семантическая трассировка применяется для:
· Проверки UML моделей;
· Проверки изменений в требованиях;
· Проверки исправлений ошибок в коде;
· Быстрой адаптации нового человека в команде (новому члену команды дают задание провести ОСТ сессию — он знакомится с программой, документацией, кодом и т. д. гораздо быстрее, так как ему необходимо не просто прочитать материал, но и проанализировать его).
·
Роли
Основными действующими лицами в процессе обратной семантической трассировки являются:
· авторы артефактов (как исходного, так и результирующего);
· реверс-инженеры;
· группа экспертов для оценки качества артефакта;
· менеджер проекта.
Процесс
Определить все артефакты проекта и их взаимосвязи
Обратная семантическая трассировка, как метод контроля качества, может быть применена к любому артефакту проекта, даже к любой части артефакта, вплоть до одной строки документа или кода. Однако очевидно, что выполнение такой процедуры для всех документов и изменений может создать ненужную нагрузку для проектной команды. Чтобы этого избежать, применение ОСТ должно быть обосновано. Какой объем ОСТ нужен для обеспечения качества — решает компания (в соответствие со стандартами качества и процессами, принятым в компании) и проджект менеджер (исходя из специфики конкретного проекта).
В общем случае, количество ОСТ сессий определяется важностью артефактов для проекта и уровнем контроля качества для этого артефакта (тестирование, верификация, рецензии и т. д.)
Количество ОСТ сессий определяется на этапе планирования проекта.
Прежде всего менеджер проекта создает список всех артефактов, которые будут созданы в процессе работы над проектом. Этот список может быть представлен в виде дерева, отображающего связи и отношения артефактов между собой. Артефакты могут быть представлены как в единственном экземпляре (например, документ описывающий ви́дение проекта), так и во многих экземплярах (например, задачи, дефекты или риски). Этот список может меняться в течение проекта, однако принцип принятия решения об ОСТ будет тем же.
Расставить приоритеты для артефактов
Следующий шаг — анализ важности артефактов и уровня контроля качества, который применяется по отношению к артефакту. Важность документа — это степень его влияния на успех проекта и качество финального продукта. Важность условно можно измерить по следующей шкале:
Очень высокая(1): качество артефакта очень важно для общего качества продукта и влияет на успех проекта в целом. Примеры таких артефактов: спецификация требований, архитектура системы, исправления критических ошибок в системе, риски с очень высокой вероятностью.
Высокая(2): артефакт имеет влияние на качество финального продукта. Например: тест кейсы, требования к интерфейсу и юзабилити, дефекты с высоким приоритетом, риски с высокой вероятностью.
Средняя(3): артефакт имеет среднее или косвенное влияние на качество конечного продукта. Например: план проекта, дефекты со средним приоритетом.
Низкая(4): артефакт имеет незначительное влияние на качество разрабатываемого программного продукта. Например: задачи программистов, косметические дефекты, риски с низкой вероятностью.
Уровень контроля качества для артефакта определяется в соответствии с объемом работ по обеспечению качества артефакта, вероятностью возникновения недоразумений и искажений информации в процессе его создания.
Низкий(1): Не предусмотрены тестирование или проверки (рецензии), недоразумения и потери информации очень вероятны, над артефактом работает распределенная команда, существует языковой барьер и т. д.
Средний(2): Рецензия не предусмотрена, над артефактом работает нераспределенная команда.
Достаточный(3): Предусмотрено рецензирование или парное программирование, над артефактом работает нераспределенная команда.
Отличный(4): Для артефакта предусмотрены парное программирование, верификация и\или тестирование, автоматическое или юнит тестирование. Есть инструменты для создания или тестирования артефактов.
Определить, кто будет проводить ОСТ
Успех ОСТ сессий во многом зависит от правильного выбора реверс-инженеров — они должны обладать достаточной компетенцией, чтобы суметь восстановить родительский артефакт. Но в то же время, реверс инженеры не должны знать деталей проекта, чтобы избежать предвзятости при восстановлении информации. В идеале, это должны быть инженеры из другого проекта, использующего сходные технологии или процессы.
Провести ОСТ
Процесс обратной семантической трассировки начинается, когда решение о ее необходимости принято и назначены ответственные инженеры для ее выполнения.
Менеджер проекта определяет какие документы будут являться входными для данной сессии ОСТ. Например, это может быть дополнительная информация, которая позволит реверс-инжерену восстановить родительский артефакт более полно. Рекомендуется также дать информацию о размере восстанавливаемого артефакта, чтобы помочь реверс-инженерам определить объем работы: это может быть одна-две строки или несколько страниц текста. И хотя восстановленный текст может не совпадать с исходным по количеству слов, эти величины должны быть соизмеримы.
После этого реверс-инженеры берут артефакт и восстанавливают из него исходный текст. ОСТ сессия сама по себе занимает около часа (для 1 страницы текста, примерно 750 слов)
Оценить качество артефактов
Чтобы завершить ОСТ сессию, необходимо сравнить исходный и восстановленный текст и оценить качество артефактов. Решение о переработке, доработке и исправлении артефактов делается на основании этой оценки.
Для оценки формируется группа экспертов. Эксперты должны иметь представление о предметной области проекта и иметь достаточно опыта, чтобы оценить качество артефакта. Например, аналитик может быть экспертом для сравнения и оценки документа описывающего видение проекта и видения, восстановленного из требований и сценариев.
Критерии оценки и шкала:
1. Восстановленный и оригинальный тексты имеют очень большие смысловые различия и потери критической информации.
2. Восстановленный и оригинальный тексты имеют смысловые различия, потерю или искажение важной информации.
3. Восстановленный и оригинальный тексты имеют смысловые различия, незначительную потерю или искажение информации.
4. Восстановленный и оригинальный тексты близки по смыслу, незначительное искажение информации.
5. Восстановленный и оригинальный тексты очень близки, информация не потеряна (искажена).
Каждый эксперт даёт свою оценку, затем вычисляется средняя оценка (среднее арифметическое). В зависимости от этой оценки, проджект менеджер принимает решение о исправлении артефактов, переделке их или доработке.
Если оценка ОСТ находится между 1 и 2 — качество артефакта очень низкое. Рекомендуется переработать не только тестируемый артефакт, но и родительский, для того чтобы внести однозначность в представленную там информацию. В этом случае может потребоваться несколько сессий ОСТ после доработки артефактов.
Для артефактов с оценкой от 2 до 3 требуется доработка оцениваемого артефакта и рекомендуется ревью родительского артефакта для того, чтобы понять, что привело к потере информации. Дополнительные ОСТ сессии не требуются.
Если средняя оценка от 3 до 4, требуется доработка тестируемого артефакта, чтобы исправить неточности.
Если оценка больше 4, это подразумевает что артефакт хорошего качества, доработка не предполагается.
Естественно, финальное решение принимает менеджер проекта, и оно должно учитывать причины расхождений в исходном и восстановленном текстах.