| Binary Hamming codes | |
|---|---|
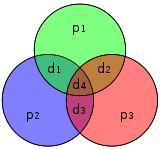
The Hamming(7,4) code (with r = 3) |
|
| Named after | Richard W. Hamming |
| Classification | |
| Type | Linear block code |
| Block length | 2r − 1 where r ≥ 2 |
| Message length | 2r − r − 1 |
| Rate | 1 − r/(2r − 1) |
| Distance | 3 |
| Alphabet size | 2 |
| Notation | [2r − 1, 2r − r − 1, 3]2-code |
| Properties | |
| perfect code | |
|
In computer science and telecommunication, Hamming codes are a family of linear error-correcting codes. Hamming codes can detect one-bit and two-bit errors, or correct one-bit errors without detection of uncorrected errors. By contrast, the simple parity code cannot correct errors, and can detect only an odd number of bits in error. Hamming codes are perfect codes, that is, they achieve the highest possible rate for codes with their block length and minimum distance of three.[1]
Richard W. Hamming invented Hamming codes in 1950 as a way of automatically correcting errors introduced by punched card readers. In his original paper, Hamming elaborated his general idea, but specifically focused on the Hamming(7,4) code which adds three parity bits to four bits of data.[2]
In mathematical terms, Hamming codes are a class of binary linear code. For each integer r ≥ 2 there is a code-word with block length n = 2r − 1 and message length k = 2r − r − 1. Hence the rate of Hamming codes is R = k / n = 1 − r / (2r − 1), which is the highest possible for codes with minimum distance of three (i.e., the minimal number of bit changes needed to go from any code word to any other code word is three) and block length 2r − 1. The parity-check matrix of a Hamming code is constructed by listing all columns of length r that are non-zero, which means that the dual code of the Hamming code is the shortened Hadamard code, also known as a Simplex code. The parity-check matrix has the property that any two columns are pairwise linearly independent.
Due to the limited redundancy that Hamming codes add to the data, they can only detect and correct errors when the error rate is low. This is the case in computer memory (usually RAM), where bit errors are extremely rare and Hamming codes are widely used, and a RAM with this correction system is a ECC RAM (ECC memory). In this context, an extended Hamming code having one extra parity bit is often used. Extended Hamming codes achieve a Hamming distance of four, which allows the decoder to distinguish between when at most one one-bit error occurs and when any two-bit errors occur. In this sense, extended Hamming codes are single-error correcting and double-error detecting, abbreviated as SECDED.
History[edit]
Richard Hamming, the inventor of Hamming codes, worked at Bell Labs in the late 1940s on the Bell Model V computer, an electromechanical relay-based machine with cycle times in seconds. Input was fed in on punched paper tape, seven-eighths of an inch wide, which had up to six holes per row. During weekdays, when errors in the relays were detected, the machine would stop and flash lights so that the operators could correct the problem. During after-hours periods and on weekends, when there were no operators, the machine simply moved on to the next job.
Hamming worked on weekends, and grew increasingly frustrated with having to restart his programs from scratch due to detected errors. In a taped interview, Hamming said, «And so I said, ‘Damn it, if the machine can detect an error, why can’t it locate the position of the error and correct it?'».[3] Over the next few years, he worked on the problem of error-correction, developing an increasingly powerful array of algorithms. In 1950, he published what is now known as Hamming code, which remains in use today in applications such as ECC memory.
Codes predating Hamming[edit]
A number of simple error-detecting codes were used before Hamming codes, but none were as effective as Hamming codes in the same overhead of space.
Parity[edit]
Parity adds a single bit that indicates whether the number of ones (bit-positions with values of one) in the preceding data was even or odd. If an odd number of bits is changed in transmission, the message will change parity and the error can be detected at this point; however, the bit that changed may have been the parity bit itself. The most common convention is that a parity value of one indicates that there is an odd number of ones in the data, and a parity value of zero indicates that there is an even number of ones. If the number of bits changed is even, the check bit will be valid and the error will not be detected.
Moreover, parity does not indicate which bit contained the error, even when it can detect it. The data must be discarded entirely and re-transmitted from scratch. On a noisy transmission medium, a successful transmission could take a long time or may never occur. However, while the quality of parity checking is poor, since it uses only a single bit, this method results in the least overhead.
Two-out-of-five code[edit]
A two-out-of-five code is an encoding scheme which uses five bits consisting of exactly three 0s and two 1s. This provides ten possible combinations, enough to represent the digits 0–9. This scheme can detect all single bit-errors, all odd numbered bit-errors and some even numbered bit-errors (for example the flipping of both 1-bits). However it still cannot correct any of these errors.
Repetition[edit]
Another code in use at the time repeated every data bit multiple times in order to ensure that it was sent correctly. For instance, if the data bit to be sent is a 1, an n = 3 repetition code will send 111. If the three bits received are not identical, an error occurred during transmission. If the channel is clean enough, most of the time only one bit will change in each triple. Therefore, 001, 010, and 100 each correspond to a 0 bit, while 110, 101, and 011 correspond to a 1 bit, with the greater quantity of digits that are the same (‘0’ or a ‘1’) indicating what the data bit should be. A code with this ability to reconstruct the original message in the presence of errors is known as an error-correcting code. This triple repetition code is a Hamming code with m = 2, since there are two parity bits, and 22 − 2 − 1 = 1 data bit.
Such codes cannot correctly repair all errors, however. In our example, if the channel flips two bits and the receiver gets 001, the system will detect the error, but conclude that the original bit is 0, which is incorrect. If we increase the size of the bit string to four, we can detect all two-bit errors but cannot correct them (the quantity of parity bits is even); at five bits, we can both detect and correct all two-bit errors, but not all three-bit errors.
Moreover, increasing the size of the parity bit string is inefficient, reducing throughput by three times in our original case, and the efficiency drops drastically as we increase the number of times each bit is duplicated in order to detect and correct more errors.
Description[edit]
If more error-correcting bits are included with a message, and if those bits can be arranged such that different incorrect bits produce different error results, then bad bits could be identified. In a seven-bit message, there are seven possible single bit errors, so three error control bits could potentially specify not only that an error occurred but also which bit caused the error.
Hamming studied the existing coding schemes, including two-of-five, and generalized their concepts. To start with, he developed a nomenclature to describe the system, including the number of data bits and error-correction bits in a block. For instance, parity includes a single bit for any data word, so assuming ASCII words with seven bits, Hamming described this as an (8,7) code, with eight bits in total, of which seven are data. The repetition example would be (3,1), following the same logic. The code rate is the second number divided by the first, for our repetition example, 1/3.
Hamming also noticed the problems with flipping two or more bits, and described this as the «distance» (it is now called the Hamming distance, after him). Parity has a distance of 2, so one bit flip can be detected but not corrected, and any two bit flips will be invisible. The (3,1) repetition has a distance of 3, as three bits need to be flipped in the same triple to obtain another code word with no visible errors. It can correct one-bit errors or it can detect — but not correct — two-bit errors. A (4,1) repetition (each bit is repeated four times) has a distance of 4, so flipping three bits can be detected, but not corrected. When three bits flip in the same group there can be situations where attempting to correct will produce the wrong code word. In general, a code with distance k can detect but not correct k − 1 errors.
Hamming was interested in two problems at once: increasing the distance as much as possible, while at the same time increasing the code rate as much as possible. During the 1940s he developed several encoding schemes that were dramatic improvements on existing codes. The key to all of his systems was to have the parity bits overlap, such that they managed to check each other as well as the data.
General algorithm[edit]
The following general algorithm generates a single-error correcting (SEC) code for any number of bits. The main idea is to choose the error-correcting bits such that the index-XOR (the XOR of all the bit positions containing a 1) is 0. We use positions 1, 10, 100, etc. (in binary) as the error-correcting bits, which guarantees it is possible to set the error-correcting bits so that the index-XOR of the whole message is 0. If the receiver receives a string with index-XOR 0, they can conclude there were no corruptions, and otherwise, the index-XOR indicates the index of the corrupted bit.
An algorithm can be deduced from the following description:
- Number the bits starting from 1: bit 1, 2, 3, 4, 5, 6, 7, etc.
- Write the bit numbers in binary: 1, 10, 11, 100, 101, 110, 111, etc.
- All bit positions that are powers of two (have a single 1 bit in the binary form of their position) are parity bits: 1, 2, 4, 8, etc. (1, 10, 100, 1000)
- All other bit positions, with two or more 1 bits in the binary form of their position, are data bits.
- Each data bit is included in a unique set of 2 or more parity bits, as determined by the binary form of its bit position.
- Parity bit 1 covers all bit positions which have the least significant bit set: bit 1 (the parity bit itself), 3, 5, 7, 9, etc.
- Parity bit 2 covers all bit positions which have the second least significant bit set: bits 2-3, 6-7, 10-11, etc.
- Parity bit 4 covers all bit positions which have the third least significant bit set: bits 4–7, 12–15, 20–23, etc.
- Parity bit 8 covers all bit positions which have the fourth least significant bit set: bits 8–15, 24–31, 40–47, etc.
- In general each parity bit covers all bits where the bitwise AND of the parity position and the bit position is non-zero.
If a byte of data to be encoded is 10011010, then the data word (using _ to represent the parity bits) would be __1_001_1010, and the code word is 011100101010.
The choice of the parity, even or odd, is irrelevant but the same choice must be used for both encoding and decoding.
This general rule can be shown visually:
-
Bit position 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 … Encoded data bits p1 p2 d1 p4 d2 d3 d4 p8 d5 d6 d7 d8 d9 d10 d11 p16 d12 d13 d14 d15 Parity
bit
coveragep1 
p2 p4
p8 p16
Shown are only 20 encoded bits (5 parity, 15 data) but the pattern continues indefinitely. The key thing about Hamming Codes that can be seen from visual inspection is that any given bit is included in a unique set of parity bits. To check for errors, check all of the parity bits. The pattern of errors, called the error syndrome, identifies the bit in error. If all parity bits are correct, there is no error. Otherwise, the sum of the positions of the erroneous parity bits identifies the erroneous bit. For example, if the parity bits in positions 1, 2 and 8 indicate an error, then bit 1+2+8=11 is in error. If only one parity bit indicates an error, the parity bit itself is in error.
With m parity bits, bits from 1 up to  can be covered. After discounting the parity bits,
can be covered. After discounting the parity bits,  bits remain for use as data. As m varies, we get all the possible Hamming codes:
bits remain for use as data. As m varies, we get all the possible Hamming codes:
| Parity bits | Total bits | Data bits | Name | Rate |
|---|---|---|---|---|
| 2 | 3 | 1 | Hamming(3,1) (Triple repetition code) |
1/3 ≈ 0.333 |
| 3 | 7 | 4 | Hamming(7,4) | 4/7 ≈ 0.571 |
| 4 | 15 | 11 | Hamming(15,11) | 11/15 ≈ 0.733 |
| 5 | 31 | 26 | Hamming(31,26) | 26/31 ≈ 0.839 |
| 6 | 63 | 57 | Hamming(63,57) | 57/63 ≈ 0.905 |
| 7 | 127 | 120 | Hamming(127,120) | 120/127 ≈ 0.945 |
| 8 | 255 | 247 | Hamming(255,247) | 247/255 ≈ 0.969 |
| 9 | 511 | 502 | Hamming(511,502) | 502/511 ≈ 0.982 |
| … | ||||
| m | 
|

|
Hamming
|

|
Hamming codes with additional parity (SECDED)[edit]
Hamming codes have a minimum distance of 3, which means that the decoder can detect and correct a single error, but it cannot distinguish a double bit error of some codeword from a single bit error of a different codeword. Thus, some double-bit errors will be incorrectly decoded as if they were single bit errors and therefore go undetected, unless no correction is attempted.
To remedy this shortcoming, Hamming codes can be extended by an extra parity bit. This way, it is possible to increase the minimum distance of the Hamming code to 4, which allows the decoder to distinguish between single bit errors and two-bit errors. Thus the decoder can detect and correct a single error and at the same time detect (but not correct) a double error.
If the decoder does not attempt to correct errors, it can reliably detect triple bit errors. If the decoder does correct errors, some triple errors will be mistaken for single errors and «corrected» to the wrong value. Error correction is therefore a trade-off between certainty (the ability to reliably detect triple bit errors) and resiliency (the ability to keep functioning in the face of single bit errors).
This extended Hamming code was popular in computer memory systems, starting with IBM 7030 Stretch in 1961,[4] where it is known as SECDED (or SEC-DED, abbreviated from single error correction, double error detection).[5] Server computers in 21st century, while typically keeping the SECDED level of protection, no longer use the Hamming’s method, relying instead on the designs with longer codewords (128 to 256 bits of data) and modified balanced parity-check trees.[4] The (72,64) Hamming code is still popular in some hardware designs, including Xilinx FPGA families.[4]
[7,4] Hamming code[edit]

In 1950, Hamming introduced the [7,4] Hamming code. It encodes four data bits into seven bits by adding three parity bits. As explained earlier, it can either detect and correct single-bit errors or it can detect (but not correct) both single and double-bit errors.
With the addition of an overall parity bit, it becomes the [8,4] extended Hamming code which is SECDED and can both detect and correct single-bit errors and detect (but not correct) double-bit errors.
Construction of G and H[edit]
The matrix
 is called a (canonical) generator matrix of a linear (n,k) code,
is called a (canonical) generator matrix of a linear (n,k) code,
and  is called a parity-check matrix.
is called a parity-check matrix.
This is the construction of G and H in standard (or systematic) form. Regardless of form, G and H for linear block codes must satisfy
 , an all-zeros matrix.[6]
, an all-zeros matrix.[6]
Since [7, 4, 3] = [n, k, d] = [2m − 1, 2m − 1 − m, 3]. The parity-check matrix H of a Hamming code is constructed by listing all columns of length m that are pair-wise independent.
Thus H is a matrix whose left side is all of the nonzero n-tuples where order of the n-tuples in the columns of matrix does not matter. The right hand side is just the (n − k)-identity matrix.
So G can be obtained from H by taking the transpose of the left hand side of H with the identity k-identity matrix on the left hand side of G.
The code generator matrix  and the parity-check matrix
and the parity-check matrix  are:
are:

and

Finally, these matrices can be mutated into equivalent non-systematic codes by the following operations:[6]
- Column permutations (swapping columns)
- Elementary row operations (replacing a row with a linear combination of rows)
Encoding[edit]
- Example
From the above matrix we have 2k = 24 = 16 codewords.
Let  be a row vector of binary data bits,
be a row vector of binary data bits, ![{\displaystyle {\vec {a}}=[a_{1},a_{2},a_{3},a_{4}],\quad a_{i}\in \{0,1\}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/898ddf319567d4af0acecf5c7fd450f5f466e28b) . The codeword
. The codeword  for any of the 16 possible data vectors is given by the standard matrix product
for any of the 16 possible data vectors is given by the standard matrix product  where the summing operation is done modulo-2.
where the summing operation is done modulo-2.
For example, let ![{\displaystyle {\vec {a}}=[1,0,1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e838e2ec81e9fe6223596b61f747b195d3d338fb) . Using the generator matrix
. Using the generator matrix  from above, we have (after applying modulo 2, to the sum),
from above, we have (after applying modulo 2, to the sum),

[8,4] Hamming code with an additional parity bit[edit]

The [7,4] Hamming code can easily be extended to an [8,4] code by adding an extra parity bit on top of the (7,4) encoded word (see Hamming(7,4)).
This can be summed up with the revised matrices:

and

Note that H is not in standard form. To obtain G, elementary row operations can be used to obtain an equivalent matrix to H in systematic form:

For example, the first row in this matrix is the sum of the second and third rows of H in non-systematic form. Using the systematic construction for Hamming codes from above, the matrix A is apparent and the systematic form of G is written as

The non-systematic form of G can be row reduced (using elementary row operations) to match this matrix.
The addition of the fourth row effectively computes the sum of all the codeword bits (data and parity) as the fourth parity bit.
For example, 1011 is encoded (using the non-systematic form of G at the start of this section) into 01100110 where blue digits are data; red digits are parity bits from the [7,4] Hamming code; and the green digit is the parity bit added by the [8,4] code.
The green digit makes the parity of the [7,4] codewords even.
Finally, it can be shown that the minimum distance has increased from 3, in the [7,4] code, to 4 in the [8,4] code. Therefore, the code can be defined as [8,4] Hamming code.
To decode the [8,4] Hamming code, first check the parity bit. If the parity bit indicates an error, single error correction (the [7,4] Hamming code) will indicate the error location, with «no error» indicating the parity bit. If the parity bit is correct, then single error correction will indicate the (bitwise) exclusive-or of two error locations. If the locations are equal («no error») then a double bit error either has not occurred, or has cancelled itself out. Otherwise, a double bit error has occurred.
See also[edit]
- Coding theory
- Golay code
- Reed–Muller code
- Reed–Solomon error correction
- Turbo code
- Low-density parity-check code
- Hamming bound
- Hamming distance
Notes[edit]
- ^ See Lemma 12 of
- ^ Hamming (1950), pp. 153–154.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), Mathematical Association of America, pp. 16–17, ISBN 0-88385-023-0
- ^ a b c Kythe & Kythe 2017, p. 115.
- ^ Kythe & Kythe 2017, p. 95.
- ^ a b Moon T. Error correction coding: Mathematical Methods and
Algorithms. John Wiley and Sons, 2005.(Cap. 3) ISBN 978-0-471-64800-0
References[edit]
- Hamming, Richard Wesley (1950). «Error detecting and error correcting codes» (PDF). Bell System Technical Journal. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773. Archived (PDF) from the original on 2022-10-09.
- Moon, Todd K. (2005). Error Correction Coding. New Jersey: John Wiley & Sons. ISBN 978-0-471-64800-0.
- MacKay, David J.C. (September 2003). Information Theory, Inference and Learning Algorithms. Cambridge: Cambridge University Press. ISBN 0-521-64298-1.
- D.K. Bhattacharryya, S. Nandi. «An efficient class of SEC-DED-AUED codes». 1997 International Symposium on Parallel Architectures, Algorithms and Networks (ISPAN ’97). pp. 410–415. doi:10.1109/ISPAN.1997.645128.
- «Mathematical Challenge April 2013 Error-correcting codes» (PDF). swissQuant Group Leadership Team. April 2013. Archived (PDF) from the original on 2017-09-12.
- Kythe, Dave K.; Kythe, Prem K. (28 July 2017). «Extended Hamming Codes». Algebraic and Stochastic Coding Theory. CRC Press. pp. 95–116. ISBN 978-1-351-83245-8.
External links[edit]
- Visual Explanation of Hamming Codes
- CGI script for calculating Hamming distances (from R. Tervo, UNB, Canada)
- Tool for calculating Hamming code
Развитие
принципа контроля по четности приводит
к корректирующему коду Хэмминга, который
позволяет не только обнаруживать, но
и исправлять одинарную ошибку в
передаваемых по каналу связи или
хранимых в ЗУ данных. Р. Хэмминг –
сотрудник фирмы Bell
Telephone
Laboratories
в 1948 г. разработал метод обнаружения и
исправления одиночных ошибок в
передаваемых кодовых словах. В его
честь используемый код был назван
кодом Хэмминга.
В
коде Хэмминга из n
позиций (разрядов) слова m
используются в качестве информационных,
а
k
разрядов в качестве контрольных (n=m+k).
Все
информационные разряды разбиваются
на k
групп. За каждой группой закрепляется
один контрольный разряд. Перед передачей
информации в канал связи или записи её
в ЗУ в контрольные разряды заносится
символ 0 и 1 таким образом, чтобы сумма
единиц в группе, включая контрольный
разряд, стала четной. При этом контрольные
символы располагают в разрядах кодового
слова, номера которых равны целой
степени основания 2, т.е. в первом, втором,
четвертом и т.д.
Контрольная
аппаратура (декодер) на выходе из канала
производит k
проверок
на четность всех k
групп. После каждой проверке в специальный
k
–
разрядный регистр, именуемый регистром
синдрома ошибки,
записывается 0, если результат
соответствующей проверки свидетельствует
об отсутствии ошибки в разрядах
проверяемой группы, и 1, если проверка
выявила ошибку. Таким образом, каждая
проверка заканчивается записью в
соответствующие разряды регистра
синдрома ошибки 0 или 1. Полученная
последовательность нулей и единиц
(синдром ошибки) указывает номер позиции
(разряд слова) с искаженным символом.
Требуемое
число контрольных разрядов и,
следовательно, контрольных групп, на
которое разбивают слово, определяется
из следующих соображений.
Синдром
ошибки должен описывать (задавать)
состояния, соответствующие появлению
ошибки в любом разряде n
–
разрядного кодового слова, а также
состояние, соответствующее отсутствию
ошибки.
Следовательно,
должно соблюдаться соотношение:
![]() .
.
(2.19)
Неравенство
(2.19) дает возможность определить
минимальное значение k
для заданного m
и, следовательно, разрядность кодового
слова – n.
В
табл.2.8 приведены значения k
и n,
определенные в соответствии с (2.19) для
некоторых заданных значений m.
Таблица
2.8.
|
m |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
k |
2 |
3 |
3 |
3 |
4 |
4 |
4 |
4 |
4 |
4 |
4 |
5 |
|
n |
3 |
5 |
6 |
7 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
17 |
Способ
разбивки информационных разрядов на
контрольные группы и определения
номеров позиций контрольных разрядов
следуют непосредственно из структуры
ряда чисел, представленных в двоичной
форме.
Рассмотрим
это на следующем примере.
Предположим,
что предназначенное для передачи по
линии связи (или записи в память)
информационное слово содержит четыре
разряда, т.е.
![]() .
.
Из таблицы 2.8 видно, что корректирующий
код для этого случая должен содержать
7 разрядов (n=7),
т.е. к 4 информационным должно быть
добавлено 3 контрольных разряда:
![]()
и
![]()
(рис. 2.6).
Информационное
слово Кодовое слово
|
|
|
|
|

|
|
|
|
|
|
|
|
 7
7
6 5 4 3 2 1
№ разряда
Рис. 2.6. Преобразование информационного
слова в кодовое, представленного в
коде
Хэмминга (7,4)
Разбивка
разрядов слова на контрольные группы
производится следующим образом (рис.
2.7). В группу с номером i
входят
те разряды кодового слова, в двоичном
номере которых в i—й
позиции стоит единица. Так, в первую
группу включены те разряды кодового
слова, номер которых в двоичной системе
счисления имеет единицу в первом разряде
(1, 3, 5, 7). Вторая группа включает разряды,
номера которых имеют единицу во втором
разряде (2, 3, 6,7) и т.д.
Разряды
1, 2 и 4, каждый из которых принадлежит
только одной контрольной группе,
используется в качестве контрольных.

Рис.
2.7. Структура кодового слова и контрольных
групп кода Хэмминга (7,4)
Процедуру
коррекции одинарной ошибки проиллюстрируем
следующим примером.
Пример
2.7.
Положим, что информационное слово,
подлежащее передаче или хранению, имеет
вид
![]() =1100.
=1100.
Значения проверочных символов
![]()
и
![]() ,
,
обеспечивающие четность каждой из
контрольных групп, найдем из уравнений
кодирования:

(2.20)
Следовательно,
в канал поступит семиразрядное кодовое
слово
![]() =1100001.
=1100001.
Схема кодера, реализующего уравнения
(2.20), изображена на рис. 2.8.
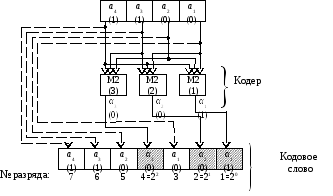
Рис.
2.8. Кодер кода Хэмминга (7, 4)
Допустим,
что в канале исказился один из разрядов
этого слова, например, третий, т.е. a1.
В результате на выходе из канала получим
искаженное слово
![]() 11001100
11001100
(искаженный символ подчеркнут, а на
рис. 2.9 – заштрихован).

Рис.
2.9. Кодовое слово и контрольные группы
при искажении символа a1
![]()
поступает
на декодер (рис. 2.10), который в первую
очередь проверяет сохранность четности
в пределах контрольных групп.
Другими
словами, декодер определяет значения
разрядов синдрома S=s3s2s1
по
уравнениям проверок:

(2.21)
Неравенство
синдрома S
нулю
свидетельствует об искажении кодового
слова, а его значение указывает на номер
искаженного разряда – S=0112=310.
Для
восстановления (коррекции) слова
значение искаженного разряда нужно
проинвертировать. Достигается это
следующим образом. Синдром ошибки
подают на дешифратор, активный выход
которого возбуждает управляемый
инвертор (двухвходовый элемент
М2)
в том разряде, в котором произошла
ошибка. Если искажение кодового слова
при его передаче не произошло, то все
разряды синдрома ошибки будут нулями,
о чем сигнализирует возбужденный
нулевой выход дешифратора. Управляемые
инверторы при этом пропускают принятое
слово без изменений.

Рис.
2.10. Декодер кода Хэмминга
В
тех случаях, когда принятые из канала
слова дальше передаваться не будут и
необходимость в контрольных разрядах
отпадает, можно ограничиться исправлением
разрядов только информационного слова
и, следовательно, сократить число
управляемых инверторов до четырех.
Избыточность
рассмотренного варианта кода Хэмминга
достаточна лишь для исправления в
кодовых словах одинарных ошибок.
Действительно, значение минимального
кодового расстояния кода Хэмминга
Dmin=3
и, следовательно, согласно (2.13) код
позволяет исправлять только одинарные
ошибки. Если же в кодовом слове возникают
две ошибки (или более), то с помощью кода
Хэмминга исправить их не удается. Более
того, вместо исправления двух уже
возникших в канале ошибок декодером
кода Хэмминга будет привнесена третья.
Проиллюстрируем
сказанное на примере (рис. 2.11).
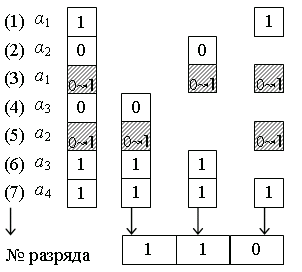
Рис.
2.11. Кодовое слово и контрольные группы
при искажении символов a1
и
a2
Предположим,
что в кодовом слове
![]() =1100001
=1100001
исказились два разряда, например, третий
и пятый, т.е. ошибки пришлись на символы
а1
и а2.
В результате на выходе из канала получим
искаженное слово
![]() =1110101(искаженные
=1110101(искаженные
разряды подчеркнуты, а на рис. 2.11 –
заштрихованы). Декодер проведет коррекцию
по тем же формальным правилам – определив
значение синдрома ошибки S=1102=610,
он «исправит» (проинвертирует) шестой
разряд (а3)
– фактически не искаженный, и тем самым
к двум имеющимся ошибкам добавиться
третья. При этом формально обеспечивается
условие отсутствия ошибок – восстановлена
четность в пределах каждой группы и,
следовательно, равенство нулю синдрома
ошибки S.
От
этого нежелательного эффекта можно
избавиться, если использовать удлиненный
код Хэмминга, способный исправлять
одинарные и обнаруживать двойные
ошибки, т.е. с Dmin=4.
Удлиненный код строится из уже
рассмотренного кода Хэмминга добавлением
к нему еще одного проверочного разряда
![]() ,
,
значение которого образуется таким
образом, чтобы была обеспечена четность
всего (n+1)-разрядного
кодового слова, т.е.
![]()
(2.22)
При
декодировании кодовых слов, представленных
в удлиненном коде Хэмминга, к проверкам
четности контрольных групп добавляется
проверка четности кодового слова в
целом, т.е.
![]()
(2.23)
Если
предположить, что кратность ошибок в
кодовых словах не превышает двух, т.е.
![]() ,
,
то возможны следующие ситуации:
d=0,
тогда S=0
и
P=0
(ошибок
нет),
d=1,
тогда S![]() 0
0
и
P=1(ошибка
исправима),
d=2,
тогда
S![]() 0
0
и P=0
(ошибки
не исправимы).
Хотя
удлиненный код Хэмминга и не исправляет
двойные ошибки, он все же дает возможность
верно интерпретировать ситуацию и не
наносить ещё большего ущерба.
В
рассмотренных примерах предполагалось,
что ошибки произошли в информационных
разрядах кодового слова. Все выше
изложенное в равной степени справедливо
и для случаев, когда искаженные
контрольные (проверочные) разряды
слова.
Код Хэмминга – это надежный и эффективный способ обнаружения и исправления ошибок в передаче данных, широко применяемый в теле- и радиосвязи, компьютерных сетях и других областях.
О чем статья
Введение
В данной лекции мы рассмотрим код Хэмминга – один из наиболее известных и широко используемых кодов для обнаружения и исправления ошибок в передаче данных. Код Хэмминга является блочным кодом, который позволяет обнаруживать и исправлять одиночные ошибки в передаваемой информации. В этой лекции мы изучим структуру кода Хэмминга, его принцип работы, а также рассмотрим его применение, преимущества и недостатки.
Нужна помощь в написании работы?
![]()
Мы — биржа профессиональных авторов (преподавателей и доцентов вузов). Наша система гарантирует сдачу работы к сроку без плагиата. Правки вносим бесплатно.
Заказать работу
Определение кода Хэмминга
Код Хэмминга – это способ исправления ошибок в передаче данных, который используется в цифровых системах связи и хранения информации. Он был разработан Ричардом Хэммингом в 1950-х годах и получил широкое применение благодаря своей простоте и эффективности.
Основная идея кода Хэмминга заключается в добавлении дополнительных битов (контрольных битов) к передаваемым данным, которые позволяют обнаруживать и исправлять ошибки. Код Хэмминга использует битовую позицию для кодирования информации и проверки наличия ошибок.
Код Хэмминга обладает свойством исправления одиночных ошибок и обнаружения двойных ошибок. Он основан на принципе проверки четности, где контрольные биты используются для обнаружения и исправления ошибок в передаваемых данных.
Код Хэмминга широко применяется в различных областях, включая цифровую связь, компьютерные сети, хранение данных на жестких дисках и памяти компьютеров. Он позволяет повысить надежность передачи данных и уменьшить вероятность ошибок.
Структура кода Хэмминга
Код Хэмминга представляет собой способ кодирования данных, который добавляет дополнительные биты к исходным данным для обнаружения и исправления ошибок. Он основан на использовании контрольных битов, которые добавляются к исходным данным.
Структура кода Хэмминга включает в себя следующие элементы:
Исходные данные
Исходные данные представляют собой биты, которые нужно закодировать. Обычно они представлены в виде последовательности 0 и 1.
Контрольные биты
Контрольные биты добавляются к исходным данным для обнаружения и исправления ошибок. Количество контрольных битов зависит от размера исходных данных и выбранного типа кода Хэмминга.
Позиции контрольных битов
Контрольные биты размещаются на определенных позициях в коде Хэмминга. Позиции контрольных битов выбираются таким образом, чтобы каждый контрольный бит проверял определенное подмножество битов исходных данных.
Значение контрольных битов
Значение каждого контрольного бита определяется путем подсчета четности битов, которые он проверяет. Если количество единиц в проверяемом подмножестве битов нечетное, то значение контрольного бита будет 1, в противном случае – 0.
Кодированные данные
Кодированные данные представляют собой исходные данные, к которым добавлены контрольные биты. Они представлены в виде последовательности битов, где контрольные биты занимают определенные позиции.
Таким образом, структура кода Хэмминга включает исходные данные, контрольные биты, позиции контрольных битов, значения контрольных битов и кодированные данные. Эта структура позволяет обнаруживать и исправлять ошибки в передаваемых данных.
Принцип работы кода Хэмминга
Код Хэмминга – это метод обнаружения и исправления ошибок в передаваемых данных. Он основан на добавлении дополнительных контрольных битов к исходным данным.
Принцип работы кода Хэмминга заключается в следующих шагах:
Расположение контрольных битов
Перед кодированием данных необходимо определить позиции контрольных битов. Количество контрольных битов зависит от размера исходных данных и выбранного типа кода Хэмминга.
Контрольные биты размещаются на позициях, которые являются степенями двойки (1, 2, 4, 8 и т.д.). Например, для кода Хэмминга с 7-битными данными, контрольные биты занимают позиции 1, 2 и 4.
Вычисление значений контрольных битов
Значения контрольных битов вычисляются на основе исходных данных. Каждый контрольный бит отвечает за определенную позицию исходных данных и проверяет четность битов на этой позиции.
Для вычисления значения контрольного бита, необходимо просуммировать все биты данных, которые контрольный бит должен проверять. Если сумма битов на этой позиции четная, то значение контрольного бита будет 0, в противном случае – 1.
Добавление контрольных битов
После вычисления значений контрольных битов, они добавляются к исходным данным. Контрольные биты занимают свои позиции в кодированных данных.
Передача и прием данных
Кодированные данные передаются по каналу связи. В процессе передачи могут возникать ошибки, которые могут изменить значения битов данных.
Обнаружение и исправление ошибок
При приеме данных, происходит проверка контрольных битов. Если контрольные биты не соответствуют значениям исходных данных, то произошла ошибка.
Код Хэмминга позволяет обнаружить ошибку, так как контрольные биты проверяют четность битов на определенных позициях. Если обнаружена ошибка, то можно определить позицию ошибочного бита и исправить его.
Исправление ошибок осуществляется путем изменения значения бита на противоположное в позиции, которая соответствует ошибочному контрольному биту.
Таким образом, принцип работы кода Хэмминга заключается в добавлении контрольных битов к исходным данным, вычислении значений контрольных битов, передаче и приеме данных, а также обнаружении и исправлении ошибок.
Свойства кода Хэмминга
Код Хэмминга обладает несколькими важными свойствами, которые делают его эффективным и надежным для обнаружения и исправления ошибок:
Обнаружение ошибок
Код Хэмминга способен обнаружить и указать на наличие ошибок в переданных данных. Контрольные биты, добавленные к исходным данным, позволяют выявить ошибки, возникшие в процессе передачи или хранения информации.
Исправление одиночных ошибок
Код Хэмминга может исправить одиночные ошибки, то есть ошибки, которые затрагивают только один бит. Благодаря контрольным битам, код Хэмминга может определить позицию ошибочного бита и изменить его значение на противоположное.
Определение позиции ошибки
Если в переданных данных обнаружена ошибка, код Хэмминга может определить позицию ошибочного бита. Контрольные биты расположены на определенных позициях, которые соответствуют степеням двойки (1, 2, 4, 8 и т.д.). Используя значения контрольных битов, можно вычислить позицию ошибки.
Минимальное количество контрольных битов
Код Хэмминга использует минимальное количество контрольных битов для обнаружения и исправления ошибок. Количество контрольных битов зависит от длины передаваемых данных и определяется формулой 2^r ≥ m + r + 1, где r – количество контрольных битов, m – количество битов данных.
Простота реализации
Код Хэмминга относительно прост в реализации и может быть реализован с помощью простых логических операций, таких как XOR (исключающее ИЛИ) и AND (логическое И).
Все эти свойства делают код Хэмминга популярным и широко используемым методом для обнаружения и исправления ошибок в передаваемых данных.
Применение кода Хэмминга
Код Хэмминга широко применяется в различных областях, где требуется обнаружение и исправление ошибок в передаваемых данных. Вот некоторые из основных областей применения кода Хэмминга:
Цифровая связь
В цифровых коммуникационных системах, таких как сети передачи данных, код Хэмминга используется для обнаружения и исправления ошибок, которые могут возникнуть в процессе передачи данных по каналу связи. Это позволяет повысить надежность передачи данных и уменьшить вероятность искажения информации.
Хранение данных
Код Хэмминга также применяется для обеспечения надежности хранения данных на различных носителях, таких как жесткие диски, флэш-память и оптические диски. Он позволяет обнаруживать и исправлять ошибки, которые могут возникнуть при чтении или записи данных на этих носителях.
Память компьютера
Код Хэмминга используется для обнаружения и исправления ошибок в памяти компьютера. Это особенно важно в системах, где надежность хранения данных критически важна, например, в серверах или системах безопасности.
Коррекция ошибок в процессорах
Код Хэмминга может быть использован для обнаружения и исправления ошибок, которые могут возникнуть в процессорах компьютера. Это позволяет повысить надежность работы процессора и предотвратить возможные сбои или неправильные результаты вычислений.
Кодирование аудио и видео
В сфере аудио и видео кодирования, код Хэмминга может быть использован для обнаружения и исправления ошибок, которые могут возникнуть при передаче или хранении аудио- и видеоданных. Это позволяет улучшить качество воспроизведения и предотвратить возможные искажения или потери информации.
В целом, код Хэмминга является важным инструментом для обеспечения надежности передачи и хранения данных в различных областях, где ошибки могут возникнуть. Он позволяет обнаруживать и исправлять ошибки, что способствует повышению надежности и качества работы систем и устройств.
Преимущества кода Хэмминга:
1. Обнаружение и исправление ошибок: Одним из основных преимуществ кода Хэмминга является его способность обнаруживать и исправлять ошибки в передаваемых данных. Код Хэмминга использует дополнительные биты, называемые проверочными битами, которые позволяют определить наличие ошибок и восстановить исходные данные.
2. Простота реализации: Код Хэмминга относительно прост в реализации и может быть использован в различных системах и устройствах. Он основан на простых логических операциях, таких как XOR (исключающее ИЛИ), что делает его доступным для широкого круга разработчиков и инженеров.
3. Эффективность использования ресурсов: Код Хэмминга позволяет достичь высокой степени обнаружения и исправления ошибок при относительно небольшом использовании дополнительных битов. Это позволяет снизить нагрузку на систему и уменьшить объем передаваемых данных.
Недостатки кода Хэмминга:
1. Дополнительные затраты на передачу данных: Использование кода Хэмминга требует передачи дополнительных битов, что увеличивает объем передаваемых данных. Это может быть нежелательным в случаях, когда пропускная способность канала передачи ограничена или стоимость передачи данных высока.
2. Ограниченная способность исправления ошибок: Хотя код Хэмминга способен обнаруживать и исправлять ошибки, его способность исправления ограничена. Он может исправить только одиночные ошибки и обнаруживать двойные ошибки. Если количество ошибок превышает возможности кода Хэмминга, то он не сможет восстановить исходные данные.
3. Дополнительная задержка: Использование кода Хэмминга влечет за собой некоторую задержку в передаче данных. Это связано с необходимостью вычисления и проверки проверочных битов. В некоторых приложениях, где требуется минимальная задержка, это может быть нежелательным.
Таблица сравнения кода Хэмминга
| Свойство | Код Хэмминга | Обычный код |
|---|---|---|
| Обнаружение ошибок | Может обнаружить и исправить одну ошибку | Не может обнаружить ошибки |
| Исправление ошибок | Может исправить одну ошибку | Не может исправить ошибки |
| Избыточность | Требует дополнительных битов для проверки и исправления ошибок | Не требует дополнительных битов |
| Применение | Часто используется в системах передачи данных и памяти компьютеров | Не используется в системах передачи данных и памяти компьютеров |
| Сложность | Требует дополнительных вычислений для проверки и исправления ошибок | Не требует дополнительных вычислений |
Заключение
Код Хэмминга – это метод исправления ошибок, который используется для обнаружения и исправления одиночных битовых ошибок в передаваемых данных. Он основан на добавлении дополнительных битов к исходным данным, которые позволяют определить и исправить ошибки.
Код Хэмминга. Пример работы алгоритма
Время на прочтение
4 мин
Количество просмотров 525K
Вступление.
Прежде всего стоит сказать, что такое Код Хэмминга и для чего он, собственно, нужен. На Википедии даётся следующее определение:
Коды Хэмминга — наиболее известные и, вероятно, первые из самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Другими словами, это алгоритм, который позволяет закодировать какое-либо информационное сообщение определённым образом и после передачи (например по сети) определить появилась ли какая-то ошибка в этом сообщении (к примеру из-за помех) и, при возможности, восстановить это сообщение. Сегодня, я опишу самый простой алгоритм Хемминга, который может исправлять лишь одну ошибку.
Также стоит отметить, что существуют более совершенные модификации данного алгоритма, которые позволяют обнаруживать (и если возможно исправлять) большее количество ошибок.
Сразу стоит сказать, что Код Хэмминга состоит из двух частей. Первая часть кодирует исходное сообщение, вставляя в него в определённых местах контрольные биты (вычисленные особым образом). Вторая часть получает входящее сообщение и заново вычисляет контрольные биты (по тому же алгоритму, что и первая часть). Если все вновь вычисленные контрольные биты совпадают с полученными, то сообщение получено без ошибок. В противном случае, выводится сообщение об ошибке и при возможности ошибка исправляется.
Как это работает.
Для того, чтобы понять работу данного алгоритма, рассмотрим пример.
Подготовка
Допустим, у нас есть сообщение «habr», которое необходимо передать без ошибок. Для этого сначала нужно наше сообщение закодировать при помощи Кода Хэмминга. Нам необходимо представить его в бинарном виде.

На этом этапе стоит определиться с, так называемой, длиной информационного слова, то есть длиной строки из нулей и единиц, которые мы будем кодировать. Допустим, у нас длина слова будет равна 16. Таким образом, нам необходимо разделить наше исходное сообщение («habr») на блоки по 16 бит, которые мы будем потом кодировать отдельно друг от друга. Так как один символ занимает в памяти 8 бит, то в одно кодируемое слово помещается ровно два ASCII символа. Итак, мы получили две бинарные строки по 16 бит:
 и
и 
После этого процесс кодирования распараллеливается, и две части сообщения («ha» и «br») кодируются независимо друг от друга. Рассмотрим, как это делается на примере первой части.
Прежде всего, необходимо вставить контрольные биты. Они вставляются в строго определённых местах — это позиции с номерами, равными степеням двойки. В нашем случае (при длине информационного слова в 16 бит) это будут позиции 1, 2, 4, 8, 16. Соответственно, у нас получилось 5 контрольных бит (выделены красным цветом):
Было:
Стало:

Таким образом, длина всего сообщения увеличилась на 5 бит. До вычисления самих контрольных бит, мы присвоили им значение «0».
Вычисление контрольных бит.
Теперь необходимо вычислить значение каждого контрольного бита. Значение каждого контрольного бита зависит от значений информационных бит (как неожиданно), но не от всех, а только от тех, которые этот контрольных бит контролирует. Для того, чтобы понять, за какие биты отвечает каждых контрольный бит необходимо понять очень простую закономерность: контрольный бит с номером N контролирует все последующие N бит через каждые N бит, начиная с позиции N. Не очень понятно, но по картинке, думаю, станет яснее:
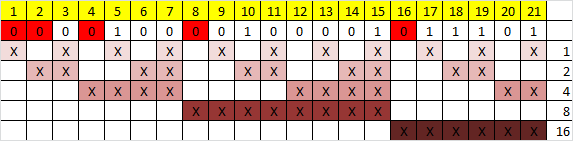
Здесь знаком «X» обозначены те биты, которые контролирует контрольный бит, номер которого справа. То есть, к примеру, бит номер 12 контролируется битами с номерами 4 и 8. Ясно, что чтобы узнать какими битами контролируется бит с номером N надо просто разложить N по степеням двойки.
Но как же вычислить значение каждого контрольного бита? Делается это очень просто: берём каждый контрольный бит и смотрим сколько среди контролируемых им битов единиц, получаем некоторое целое число и, если оно чётное, то ставим ноль, в противном случае ставим единицу. Вот и всё! Можно конечно и наоборот, если число чётное, то ставим единицу, в противном случае, ставим 0. Главное, чтобы в «кодирующей» и «декодирующей» частях алгоритм был одинаков. (Мы будем применять первый вариант).
Высчитав контрольные биты для нашего информационного слова получаем следующее:

и для второй части:

Вот и всё! Первая часть алгоритма завершена.
Декодирование и исправление ошибок.
Теперь, допустим, мы получили закодированное первой частью алгоритма сообщение, но оно пришло к нас с ошибкой. К примеру мы получили такое (11-ый бит передался неправильно):

Вся вторая часть алгоритма заключается в том, что необходимо заново вычислить все контрольные биты (так же как и в первой части) и сравнить их с контрольными битами, которые мы получили. Так, посчитав контрольные биты с неправильным 11-ым битом мы получим такую картину:

Как мы видим, контрольные биты под номерами: 1, 2, 8 не совпадают с такими же контрольными битами, которые мы получили. Теперь просто сложив номера позиций неправильных контрольных бит (1 + 2 + 8 = 11) мы получаем позицию ошибочного бита. Теперь просто инвертировав его и отбросив контрольные биты, мы получим исходное сообщение в первозданном виде! Абсолютно аналогично поступаем со второй частью сообщения.
Заключение.
В данном примере, я взял длину информационного сообщения именно 16 бит, так как мне кажется, что она наиболее оптимальная для рассмотрения примера (не слишком длинная и не слишком короткая), но конечно же длину можно взять любую. Только стоит учитывать, что в данной простой версии алгоритма на одно информационное слово можно исправить только одну ошибку.
Примечание.
На написание этого топика меня подвигло то, что в поиске я не нашёл на Хабре статей на эту тему (чему я был крайне удивлён). Поэтому я решил отчасти исправить эту ситуацию и максимально подробно показать как этот алгоритм работает. Я намеренно не приводил ни одной формулы, дабы попытаться своими словами донести процесс работы алгоритма на примере.
Источники.
1. Википедия
2. Calculating the Hamming Code
Коды Хэмминга — вероятно, наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Построены они применительно к двоичной системе счисления.
Содержание
- 1 История
- 2 Систематические коды
- 3 Самоконтролирующиеся коды
- 4 Самокорректирующиеся коды
- 5 Код Хемминга
- 6 Алгоритм кодирования
- 7 Алгоритм декодирования
- 8 Литература
- 9 Применение
- 10 См. также
История[править | править вики-текст]
В середине 1940-х годов Ричард Хэмминг работал в знаменитых лабораториях фирмы Белл (Bell Labs) на счётной машине Bell Model V. Это была электромеханическая машина, использующая релейные блоки, скорость которых была очень низка: один оборот за несколько секунд. Данные вводились в машину с помощью перфокарт, поэтому в процессе чтения часто происходили ошибки. В рабочие дни использовались специальные коды, чтобы обнаруживать и исправлять найденные ошибки, при этом оператор узнавал об ошибке по свечению лампочек, исправлял и снова запускал машину. В выходные дни, когда не было операторов, при возникновении ошибки машина автоматически выходила из программы и запускала другую.
Хэмминг часто работал в выходные дни, и все больше и больше раздражался, потому что часто должен был перезагружать свою программу из-за ненадежности перфокарт. На протяжении нескольких лет он проводил много времени над построением эффективных алгоритмов исправления ошибок. В 1950 году он опубликовал способ, который известен как код Хэмминга.
Систематические коды[править | править вики-текст]
Систематические коды образуют большую группу из блочных, разделимых кодов (в которых все символы можно разделить на проверочные и информационные). Особенностью систематических кодов является то, что проверочные символы образуются в результате линейных операций над информационными символами. Кроме того, любая разрешенная кодовая комбинация может быть получена в результате линейных операций над набором линейно независимых кодовых комбинаций.
Самоконтролирующиеся коды[править | править вики-текст]
Коды Хэмминга являются самоконтролирующимися кодами, то есть кодами, позволяющими автоматически обнаруживать ошибки при передаче данных. Для их построения достаточно приписать к каждому слову один добавочный (контрольный) двоичный разряд и выбрать цифру этого разряда так, чтобы общее количество единиц в изображении любого числа было, например, нечетным. Одиночная ошибка в каком-либо разряде передаваемого слова (в том числе, может быть, и в контрольном разряде) изменит четность общего количества единиц. Счетчики по модулю 2, подсчитывающие количество единиц, которые содержатся среди двоичных цифр числа, могут давать сигнал о наличии ошибок.
При этом невозможно узнать, в каком именно разряде произошла ошибка, и, следовательно, нет возможности исправить её. Остаются незамеченными также ошибки, возникающие одновременно в двух, четырёх, и т.д. — в четном количестве разрядов. Впрочем, двойные, а тем более четырёхкратные ошибки полагаются маловероятными.
Самокорректирующиеся коды[править | править вики-текст]
Коды, в которых возможно автоматическое исправление ошибок, называются самокорректирующимися. Для построения самокорректирующегося кода, рассчитанного на исправление одиночных ошибок, одного контрольного разряда недостаточно. Как видно из дальнейшего, количество контрольных разрядов k должно быть выбрано так, чтобы удовлетворялось неравенство  или
или  , где m — количество основных двоичных разрядов кодового слова. Минимальные значения k при заданных значениях m, найденные в соответствии с этим неравенством, приведены в таблице.
, где m — количество основных двоичных разрядов кодового слова. Минимальные значения k при заданных значениях m, найденные в соответствии с этим неравенством, приведены в таблице.
| Диапазон m | kmin |
|---|---|
| 1 | 2 |
| 2-4 | 3 |
| 5-11 | 4 |
| 12-26 | 5 |
| 27-57 | 6 |
В настоящее время наибольший интерес представляют двоичные блочные корректирующие коды. При использовании таких кодов информация передаётся в виде блоков одинаковой длины и каждый блок кодируется и декодируется независимо друг от друга. Почти во всех блочных кодах символы можно разделить на информационные и проверочные. Таким образом, все комбинации кодов разделяются на разрешенные (для которых соотношение информационных и проверочных символов возможно) и запрещенные.
Основными характеристиками самокорректирующихся кодов являются:
- Число разрешенных и запрещенных комбинаций. Если n — число символов в блоке, r — число проверочных символов в блоке, k — число информационных символов, то
 — число возможных кодовых комбинаций, — число разрешенных кодовых комбинаций, — число запрещенных комбинаций.
— число возможных кодовых комбинаций, — число разрешенных кодовых комбинаций, — число запрещенных комбинаций. - Избыточность кода. Величину называют избыточностью корректирующего кода.
- Минимальное кодовое расстояние. Минимальным кодовым расстоянием d называется минимальное число искаженных символов, необходимое для перехода одной разрешенной комбинации в другую.
- Число обнаруживаемых и исправляемых ошибок. Если g — количество ошибок, которое код способен исправить, то необходимо и достаточно, чтобы
- Корректирующие возможности кодов.
 — число возможных кодовых комбинаций,
— число возможных кодовых комбинаций,  — число разрешенных кодовых комбинаций,
— число разрешенных кодовых комбинаций,  — число запрещенных комбинаций.
— число запрещенных комбинаций. называют избыточностью корректирующего кода.
называют избыточностью корректирующего кода.
Граница Плоткина даёт верхнюю границу кодового расстояния  или
или  при
при 
Граница Хемминга устанавливает максимально возможное число разрешенных кодовых комбинаций  где
где  — число сочетаний из n элементов по i элементам. Отсюда можно получить выражение для оценки числа проверочных символов:
— число сочетаний из n элементов по i элементам. Отсюда можно получить выражение для оценки числа проверочных символов:  Для значений
Для значений  разница между границей Хемминга и границей Плоткина невелика.
разница между границей Хемминга и границей Плоткина невелика.
Граница Варшамова-Гильберта для больших n определяет нижнюю границу числа проверочных символов  Все вышеперечисленные оценки дают представление о верхней границе d при фиксированных n и k или оценку снизу числа проверочных символов
Все вышеперечисленные оценки дают представление о верхней границе d при фиксированных n и k или оценку снизу числа проверочных символов
Код Хемминга[править | править вики-текст]
Построение кодов Хемминга основано на принципе проверки на четность числа единичных символов: к последовательности добавляется такой элемент, чтобы число единичных символов в получившейся последовательности было четным.  знак
знак  здесь означает сложение по модулю 2
здесь означает сложение по модулю 2
 .
.  — ошибки нет,
— ошибки нет,  однократная ошибка. Такой код называется
однократная ошибка. Такой код называется  или
или  . Первое число — количество элементов последовательности, второе — количество информационных символов. Для каждого числа проверочных символов
. Первое число — количество элементов последовательности, второе — количество информационных символов. Для каждого числа проверочных символов  существует классический код Хемминга с маркировкой
существует классический код Хемминга с маркировкой  т.е. —
т.е. —  . При иных значениях k получается так называемый усеченный код, например международный телеграфный код МТК-2, у которого
. При иных значениях k получается так называемый усеченный код, например международный телеграфный код МТК-2, у которого  . Для него необходим код Хемминга
. Для него необходим код Хемминга  , который является усеченным от классического
, который является усеченным от классического  . Для Примера рассмотрим классический код Хемминга
. Для Примера рассмотрим классический код Хемминга  . Сгруппируем проверочные символы следующим образом:
. Сгруппируем проверочные символы следующим образом:



знак  здесь означает сложение по модулю 2.
здесь означает сложение по модулю 2.
- Получение кодового слова выглядит следующим образом:
- =

 =
= На вход декодера поступает кодовое слово  где штрихом помечены символы, которые могут исказиться в результате помехи. В декодере в режиме исправления ошибок строится последовательность синдромов:
где штрихом помечены символы, которые могут исказиться в результате помехи. В декодере в режиме исправления ошибок строится последовательность синдромов:



 называется синдромом последовательности.
называется синдромом последовательности.
- Получение синдрома выглядит следующим образом:

 =
= 
Кодовые слова кода Хемминга
 |
 |
 |
 |
 |
 |
 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 0 | 0 | 1 | 1 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| 0 | 1 | 1 | 1 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Синдром  указывает на то, что в последовательности нет искажений. Каждому ненулевому синдрому соответствует определенная конфигурация ошибок, которая исправляется на этапе декодирования. Для кода в таблице указаны ненулевые синдромы и соответствующие им конфигурации ошибок (для вида: ).
указывает на то, что в последовательности нет искажений. Каждому ненулевому синдрому соответствует определенная конфигурация ошибок, которая исправляется на этапе декодирования. Для кода в таблице указаны ненулевые синдромы и соответствующие им конфигурации ошибок (для вида: ).
| Синдром | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| Конфигурация ошибок | 0000001 | 0000010 | 0001000 | 0000100 | 1000000 | 0010000 | 0100000 |
| Ошибка в символе | |
|
|
|
|
|
|


Алгоритм кодирования[править | править вики-текст]
Предположим, что нужно сгенерировать код Хемминга для некоторого информационного кодового слова. В качестве примера возьмём 15-битовое кодовое слово x1…x15, хотя алгоритм пригоден для кодовых слов любой длины. В приведённой ниже таблице в первой строке даны номера позиций в кодовом слове, во второй — условное обозначение битов, в третьей — значения битов.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | x12 | x13 | x14 | x15 |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
Вставим в информационное слово контрольные биты r0…r4 таким образом, чтобы номера их позиций представляли собой целые степени двойки: 1, 2, 4, 8, 16… Получим 20-разрядное слово с 15 информационными и 5 контрольными битами. Первоначально контрольные биты устанавливаем равными нулю. На рисунке контрольные биты выделены розовым цветом.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
В общем случае количество контрольных бит в кодовом слове равно двоичному логарифму числа бит кодового слова (включая контрольные биты), округлённому в большую сторону до ближайшего целого. Например, информационное слово длиной 1 или 2 бита требует двух контрольных разрядов, 3- или 4-битовое информационное слово — трёх, 5…11-битовое — четырёх, 12…26-битовое — пяти и т.д.
Добавим к таблице 5 строк (по количеству контрольных битов), в которые поместим матрицу преобразования. Каждая строка будет соответствовать одному контрольному биту (нулевой контрольный бит — верхняя строка, четвёртый — нижняя), каждый столбец — одному биту кодируемого слова. В каждом столбце матрицы преобразования поместим двоичный номер этого столбца, причём порядок следования битов будет обратный — младший бит расположим в верхней строке, старший — в нижней. Например, в третьем столбце матрицы будут стоять числа 11000, что соответствует двоичной записи числа три: 00011.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 | ||
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | r0 | |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | r1 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | r2 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | r3 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | r4 |
В правой части таблицы мы оставили пустым один столбец, в который поместим результаты вычислений контрольных битов. Вычисление контрольных битов производим следующим образом. Берём одну из строк матрицы преобразования (например, r0) и находим её скалярное произведение с кодовым словом, то есть перемножаем соответствующие биты обеих строк и находим сумму произведений. Если произведение получилось больше единицы, находим остаток от его деления на 2. Иными словами, мы подсчитываем сколько раз в кодовом слове и соответствующей строке матрицы в одинаковых позициях стоят единицы и берём это число по модулю 2.
Если описывать этот процесс в терминах матричной алгебры, то операция представляет собой перемножение матрицы преобразования на матрицу-столбец кодового слова, в результате чего получается матрица-столбец контрольных разрядов, которые нужно взять по модулю 2.
Например, для строки r0:
r0 = (1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·1+0·1+1·1+0·0+1·0+0·0+1·0+0·1) mod 2 = 5 mod 2 = 1.
Полученные контрольные биты вставляем в кодовое слово вместо стоявших там ранее нулей. Кодирование по Хэммингу завершено. Полученное кодовое слово — 11110010001011110001.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 | ||
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | r0 | 1 |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | r1 | 1 |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | r2 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | r3 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | r4 | 1 |
Алгоритм декодирования[править | править вики-текст]
Алгоритм декодирования по Хэммингу абсолютно идентичен алгоритму кодирования. Матрица преобразования соответствующей размерности умножается на матрицу-столбец кодового слова и каждый элемент полученной матрицы-столбца берётся по модулю 2. Полученная матрица-столбец получила название «матрица синдромов». Легко проверить, что кодовое слово, сформированное в соответствии с алгоритмом, описанным в предыдущем разделе, всегда даёт нулевую матрицу синдромов.
Матрица синдромов становится ненулевой, если в результате ошибки (например, при передаче слова по линии связи с шумами) один из битов исходного слова изменил своё значение. Предположим для примера, что в кодовом слове, полученном в предыдущем разделе, шестой бит изменил своё значение с нуля на единицу (на рисунке обозначено красным цветом). Тогда получим следующую матрицу синдромов.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r0 | r1 | x1 | r2 | x2 | x3 | x4 | r3 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | r4 | x12 | x13 | x14 | x15 | ||
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | ||
| 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | s0 | 0 |
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | s1 | 1 |
| 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | s2 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | s3 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | s4 | 0 |
Заметим, что при однократной ошибке матрица синдромов всегда представляет собой двоичную запись (младший разряд в верхней строке) номера позиции, в которой произошла ошибка. В приведённом примере матрица синдромов (01100) соответствует двоичному числу 00110 или десятичному 6, откуда следует, что ошибка произошла в шестом бите.
Литература[править | править вики-текст]
- Питерсон У., Уэлдон Э. Коды, исправляющие ошибки: Пер. с англ. М.: Мир, 1976, 600 c.
- Пенин П.Е.,Филиппов Л.Н. Радиотехнические системы передачи информации. М.: Радио и Связь, 1984, 256 с.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. Пер. с англ. М.: Мир, 1986, 576 с.
Применение[править | править вики-текст]
Код Хэмминга используется в некоторых прикладных программах в области хранения данных, особенно в RAID 2; кроме того, метод Хэмминга давно применяется в памяти типа ECC и позволяет «на лету» исправлять однократные и обнаруживать двукратные ошибки.
См. также[править | править вики-текст]
- Бит чётности