200
Ugh… (309, 400, 403, 409, 415, 422)… a lot of answers trying to guess, argue and standardize what is the best return code for a successful HTTP request but a failed REST call.
It is wrong to mix HTTP status codes and REST status codes.
However, I saw many implementations mixing them, and many developers may not agree with me.
HTTP return codes are related to the HTTP Request itself. A REST call is done using a Hypertext Transfer Protocol request and it works at a lower level than invoked REST method itself. REST is a concept/approach, and its output is a business/logical result, while HTTP result code is a transport one.
For example, returning «404 Not found» when you call /users/ is confuse, because it may mean:
- URI is wrong (HTTP)
- No users are found (REST)
«403 Forbidden/Access Denied» may mean:
- Special permission needed. Browsers can handle it by asking the user/password. (HTTP)
- Wrong access permissions configured on the server. (HTTP)
- You need to be authenticated (REST)
And the list may continue with ‘500 Server error» (an Apache/Nginx HTTP thrown error or a business constraint error in REST) or other HTTP errors etc…
From the code, it’s hard to understand what was the failure reason, a HTTP (transport) failure or a REST (logical) failure.
If the HTTP request physically was performed successfully it should always return 200 code, regardless is the record(s) found or not. Because URI resource is found and was handled by the HTTP server. Yes, it may return an empty set. Is it possible to receive an empty web-page with 200 as HTTP result, right?
Instead of this you may return 200 HTTP code with some options:
- «error» object in JSON result if something goes wrong
- Empty JSON array/object if no record found
- A bool result/success flag in combination with previous options for a better handling.
Also, some internet providers may intercept your requests and return you a 404 HTTP code. This does not means that your data are not found, but it’s something wrong at transport level.
From Wiki:
In July 2004, the UK telecom provider BT Group deployed the Cleanfeed
content blocking system, which returns a 404 error to any request for
content identified as potentially illegal by the Internet Watch
Foundation. Other ISPs return a HTTP 403 «forbidden» error in the same
circumstances. The practice of employing fake 404 errors as a means to
conceal censorship has also been reported in Thailand and Tunisia. In
Tunisia, where censorship was severe before the 2011 revolution,
people became aware of the nature of the fake 404 errors and created
an imaginary character named «Ammar 404» who represents «the invisible
censor».
Why not simply answer with something like this?
{
"result": false,
"error": {"code": 102, "message": "Validation failed: Wrong NAME."}
}
Google always returns 200 as status code in their Geocoding API, even if the request logically fails: https://developers.google.com/maps/documentation/geocoding/intro#StatusCodes
Facebook always return 200 for successful HTTP requests, even if REST request fails: https://developers.facebook.com/docs/graph-api/using-graph-api/error-handling
It’s simple, HTTP status codes are for HTTP requests. REST API is Your, define Your status codes.
Уровень сложности
Сложный
Время на прочтение
12 мин
Количество просмотров 4.4K
Это главы 39 и 40 раздела «HTTP API & REST» моей книги «API». Второе издание книги будет содержать три новых раздела: «Паттерны API», «HTTP API и REST», «SDK и UI‑библиотеки». Если эта работа была для вас полезна, пожалуйста, оцените книгу на GitHub, Amazon или GoodReads. English version on Substack.
Глава 39. Работа с ошибками в HTTP API
Рассмотренные в предыдущих главах примеры организации API согласно стандарту HTTP и принципам REST покрывают т.н. «happy path», т.е. стандартный процесс работы с API в отсутствие ошибок. Конечно, нам не менее интересен и обратный кейс — каким образом HTTP API следует работать с ошибками, и чем стандарт и архитектурные принципы могут нам в этом помочь. Пусть какой-то агент в системе (неважно, клиент или гейтвей) пытается создать новый заказ:
POST /v1/orders?user_id=<user_id> HTTP/1.1
Authorization: Bearer <token>
If-Match: <ревизия>
{ /* параметры заказа */ }Какие потенциальные неприятности могут ожидать нас при выполнении этого запроса? Навскидку, это:
-
Запрос не может быть прочитан (недопустимые символы, нарушение синтаксиса).
-
Токен авторизации отсутствует.
-
Токен авторизации невалиден.
-
Токен валиден, но пользователь не обладает правами создавать новый заказ.
-
Пользователь удалён или деактивирован.
-
Идентификатор пользователя неверен (не существует).
-
Ревизия не передана.
-
Ревизия не совпадает с последней актуальной.
-
В теле запроса отсутствуют обязательные поля.
-
Какое-то из полей запроса имеет недопустимое значение.
-
Превышены лимиты на допустимое количество запросов.
-
Сервер перегружен и не может ответить в настоящий момент.
-
Неизвестная серверная ошибка (т.е. сервер сломан настолько, что диагностика ошибки невозможна).
Исходя из общих соображений, соблазнительной кажется идея назначить каждой из ошибок свой статус-код. Скажем, для ошибки (4) напрашивается код 403, а для ошибки (11) — 429. Не будем, однако, торопиться, и прежде зададим себе вопрос с какой целью мы хотим назначить тот или иной код ошибки.
В нашей системе в общем случае присутствуют три агента: пользователь приложения, само приложение (клиент) и сервер. Каждому из этих акторов необходимо понимать ответ на три вопроса относительно ошибки (причём для каждого из акторов ответ может быть разным):
-
Кто допустил ошибку (конечный пользователь, разработчик клиента, разработчик сервера или какой-то промежуточный агент, например, программист сетевого стека).
-
Не забудем учесть тот факт, что и конечный пользователь, и разработчик клиента могут допустить ошибку намеренно, например, пытаясь перебором подобрать пароль к чужому аккаунту.
-
-
Можно ли исправить ошибку, просто повторив запрос.
-
Если да, то через какое время.
-
-
Если повтором запроса ошибку исправить нельзя, то можно ли её исправить, переформулировав запрос.
-
Если ошибку вообще нельзя исправить, то что с этим делать.
На один из этих вопрос в рамках стандарта HTTP ответить достаточно легко: регулировать желаемое время повтора запроса можно через параметры кэширования ответа и заголовок Retry-After. Также HTTP частично помогает с первым вопросом: для определения, на чьей стороне произошла ошибка, используется первая цифра статус-кода (см. ниже).
Со всеми остальными вопросами, увы, ситуация сильно сложнее.
Клиентские ошибки
Статус-коды, начинающиеся с цифры 4, индицируют, что ошибка допущена пользователем или клиентом (или, по крайней мере, сервер так считает). Обычно, полученную 4xx повторять бессмысленно — если не предпринять дополнительных действий по изменению состояния сервиса, этот запрос не будет выполнен успешно никогда. Однако из этого правила есть исключения, самые важные из которых — 429 Too Many Requests и 404 Not Found. Последняя по стандарту имеет смысл «состояния неопределённости»: сервер имеет право использовать её, если не желает раскрывать причины ошибки. После получения ошибки 404, можно сделать повторный запрос, и он вполне может отработать успешно. Для индикации персистентной ошибки «ресурс не найден» используется отдельный статус 410 Gone.
Более интересный вопрос — а что всё-таки клиент может (или должен) сделать, получив такую ошибку. Как мы указывали в главе «Разграничение областей ответственности», если ошибка может быть исправлена программно, необходимо в машиночитаемом виде индицировать это клиенту; если ошибка не может быть исправлена, необходимо включить человекочитаемые сообщения для пользователя (даже просто «попробуйте начать сначала / перезагрузить приложение» лучше с точки зрения UX, чем «неизвестная ошибка») и для разработчика, который будет разбираться с проблемой.
С восстановимыми ошибками в HTTP, к сожалению, ситуация достаточно сложная. С одной стороны, протокол включает в себя множество специальных кодов, которые индицируют проблемы с использованием самого протокола — такие как 405 Method Not Allowed (данный глагол неприменим к указанному ресурсу), 406 Not Acceptable (сервер не может вернуть ответ согласно Accept-заголовкам запроса), 411 Length Required, 414 URI Too Long и так далее. Код клиента может обработать данные ошибки и даже, возможно, предпринять какие-то действия по их устранению (например, добавить заголовок Content-Length в запрос после получения ошибки 411), но все они очень плохо применимы к ошибкам в бизнес-логике. Например, мы можем вернуть 429 Too Many Requests при превышении лимитов запросов, но у нас нет никакого стандартного способа указать, какой именно лимит был превышен.
Частично проблему отсутствия стандартных подходов к возврату ошибок компенсируют использованием различных близких по смыслу статус-кодов для индикации разных состояний (либо и вовсе выбор произвольного кода ошибки и придания ему нового смысла в рамках конкретного API). В частности, сегодня де-факто стандартом является возврат кода 401 Unauthorized при отсутствии заголовков авторизации или невалидном токене (получение этого кода, таким образом, является сигналом для приложения предложить пользователю залогиниться в системе), что противоречит стандарту (который требует при возврате 401 обязательно указать заголовок WWW-Authenticate с описанием способа аутентификации пользователя; нам неизвестны реальные API, которые выполняют это требованием).
Однако таких кодов, которые могут отражать нюансы одной и той же проблемы, в стандарте очень мало. Фактически, мы приходим к тому, что множество различных ошибок в логике приложения приходится возвращать под очень небольшим набором статус-кодов:
-
400 Bad Requestдля всех ошибок валидации запроса (некоторые пуристы утверждают, что, вообще говоря,400соответствует нарушению формата запроса — невалидному JSON, например — а для логических ошибок следует использовать код422 Unprocessable Content; в постановке задачи это мало что меняет); -
403 Forbiddenдля любых проблем, связанных с авторизацией действий клиента; -
404 Not Foundв случае, если какие-то из указанных в запросе сущностей не найдены либо раскрытие причин ошибки нежелательно; -
409 Conflictпри нарушении целостности данных; -
410 Goneесли ресурс был удалён; -
429 Too Many Requestsпри превышении лимитов.
Разработчики стандарта HTTP об этой проблеме вполне осведомлены, и отдельно отмечают, что для решения бизнес-сценариев необходимо передавать в метаданных либо теле ответа дополнительные данные для описания возникшей ситуации («the server SHOULD send a representation containing an explanation of the error situation, and whether it is a temporary or permanent condition»), что (как и введение новых специальных кодов ошибок) противоречит самой идее унифицированного машиночитаемого формата ошибок. (Отметим, что отсутствие стандартов описания ошибок в бизнес-логике — одна из основных причин, по которым мы считаем разработку REST API как его описал Филдинг в манифесте 2008 года невозможной; клиент должен обладать априорным знанием о том, как работать с метаинформацией об ошибке, иначе он сможет восстанавливать своё состояние после ошибки только перезагрузкой.)
Дополнительно, у проблемы есть и третье измерение в виде серверного ПО мониторинга состояния системы, которое часто полагается на статус-коды ответов при построении графиков и уведомлений. Между тем, ошибки, скрывающиеся под одним статус кодом — например ввод неправильного пароля и истёкший срок жизни токена — могут быть очень разными по смыслу; повышенный фон первой ошибки может говорить о потенциальной попытке взлома путём перебора паролей, а второй — о потенциальных ошибках в новой версии приложения, которая может неверно кэшировать токены авторизации.
Всё это естественным образом подводит нас к следующему выводу: если мы хотим использовать ошибки для диагностики и (возможно) восстановления состояния клиента, нам необходимо добавить машиночитаемую метаинформацию о подвиде ошибки и, возможно, тело ошибки с указанием подробной информации о проблемах — например, как мы предлагали в главе «Описание конечных интерфейсов»:
POST /v1/coffee-machines/search HTTP/1.1
{
"recipes": ["lngo"],
"position": {
"latitude": 110,
"longitude": 55
}
}
→
HTTP/1.1 400 Bad Request
X-OurCoffeeAPI-Error-Kind:⮠
wrong_parameter_value
{
"reason": "wrong_parameter_value",
"localized_message":
"Что-то пошло не так.⮠
Обратитесь к разработчику приложения.",
"details": {
"checks_failed": [{
"field": "recipe",
"error_type": "wrong_value",
"message":
"Value 'lngo' unknown.⮠
Did you mean 'lungo'?"
}, {
"field": "position.latitude",
"error_type": "constraint_violation",
"constraints": {
"min": -90,
"max": 90
},
"message":
"'position.latitude' value⮠
must fall within⮠
the [-90, 90] interval"
}]
}
}Также напомним, что любые неизвестные 4xx-статус-коды клиент должен трактовать как ошибку 400 Bad Request, следовательно, формат (мета)данных ошибки 400 должен быть максимально общим.
Серверные ошибки
Ошибки 5xx индицируют, что клиент, со своей стороны, выполнил запрос правильно, и проблема заключается в сервере. Для клиента, по большому счёту, важно только то, имеет ли смысл повторять запрос и, если да, то через какое время. Если учесть, что в любых публично доступных API причины серверных ошибок, как правило, не раскрывают — в абсолютном большинстве кодов 500 Internal Server Error и 503 Service Unavailable достаточно для индикации серверных ошибок (второй код указывает, что отказ в обслуживании имеет разовый характер и есть смысл автоматически повторить запрос), или можно вовсе ограничиться одним из них с опциональным заголовком Retry-After.
Для внутренних систем, вообще говоря, такое рассуждение неверно. Для построения правильных мониторингов и системы оповещений необходимо, чтобы серверные ошибки, точно так же, как и клиентские, содержали подтип ошибки в машиночитаемом виде. Здесь по-прежнему применимы те же подходы — использование широкой номенклатуры кодов и/или передача типа ошибки заголовком — однако эта информация должна быть вырезана гейтвеем на границе внешней и внутренней систем, и заменена на общую информацию для разработчика и для конечного пользователя системы с описанием действий, которые необходимо выполнить при получении ошибки.
POST /v1/orders/?user_id=<user id> HTTP/1.1
If-Match: <ревизия>
{ parameters }
→
// Ответ, полученный гейтвеем
// от сервиса обработки заказов,
// метаданные которого будут
// использованы для мониторинга
HTTP/1.1 500 Internal Server Error
// Тип ошибки: получен таймаут от БД
X-OurCoffeAPI-Error-Kind: db_timeout
{ /* Дополнительные данные, например,
какой хост ответил таймаутом */ }// Ответ, передаваемый клиенту.
// Детали серверной ошибки удалены
// и заменены на инструкцию клиенту.
// Поскольку гейтвей не знает, был
// ли в действительности сделан заказ,
// клиенту рекомендуется попробовать
// повторить запрос и/или попытаться
// получить актуальное состояние
HTTP/1.1 500 Internal Server Error
Retry-After: 5
{
"reason": "internal_server_error",
"localized_message": "Не удалось⮠
получить ответ от сервера.⮠
Попробуйте повторить операцию
или обновить страницу.",
"details": {
"can_be_retried": true,
"is_operation_failed": "unknown"
}
}
Вот здесь мы, однако, вступаем на очень скользкую территорию. Современная практика реализации HTTP-клиентов такова, что безусловно повторяются только немодифицирующие (GET, HEAD, OPTIONS) запросы. В случае модифицирующих запросов разработчик должен написать код, который повторит запрос — и для этого разработчику нужно очень внимательно прочитать документацию к API, чтобы убедиться, что это поведение допустимо и не приведёт к побочным эффектам.
Теоретически идемпотентные методы PUT и DELETE можно вызывать повторно. Практически, однако, ввиду того, что многие разработчики упускают требование идемпотентности этих методов, фреймворки работы с HTTP API по умолчанию перезапросов модифицирующих методов, как правило, не делают, но некоторую выгоду из следования стандарту мы всё же можем извлечь — по крайней мере, сама сигнатура индицирует, что запрос можно повторять.
Что касается более сложных ситуаций, когда мы хотим указать разработчику, что он может безопасно повторить потенциально неидемпотентную операцию, то мы могли бы предложить формат описания доступных действий в теле ошибки… но практически никто не ожидает найти такое описание в самой ошибке. Возможно, потому, что с ошибками 5xx, в отличие от 4xx, программисты практически не сталкиваются при написании клиентского кода, и мало какие тестовые среды позволяют такие ошибки эмулировать. Так или иначе, описывать необходимые действия при получении серверной ошибки вам придётся в документации. (Имейте в виду, что эти инструкции с большой долей вероятности будут проигнорированы. Таков путь.)
Организация системы ошибок в HTTP API на практике
Как понятно из вышесказанного, фактически есть три способа работать с ошибками HTTP API:
-
Расширительно трактовать номенклатуру статус-кодов и использовать новый код каждый раз, когда требуется индицировать новый вид ошибки. (Автор этой книги неоднократно встречал ситуации, когда при разработке API просто выбирался «похоже выглядящий» статус безо всякой оглядки на его описание в стандарте.)
-
Полностью отказаться от использования статус-кодов и вкладывать описание ошибки в тело и/или метаданные ответа с кодом
200. Этим путём идут почти все RPC-фреймворки.-
2а. Вариантом этой стратегии можно считать использование всего двух статус-кодов ошибок (
400для любой клиентской ошибки,500для любой серверной), опционально трёх (те же плюс404для статуса неопределённости).
-
-
Применить смешанный подход, то есть использовать статус-код согласно его семантике для индикации рода ошибки и вложенные (мета)данные в специально разработанном формате для детализации (подобно фрагментам кода, предложенным нами в настоящей главе).
Как нетрудно заметить, считать соответствующим стандарту можно только подход (3). Будем честны и скажем, что выгоды следования ему, особенно по сравнению с вариантом (2а), не очень велики и состоят в основном в чуть лучшей читабельности логов и большей прозрачности для промежуточных прокси.
Глава 40. Заключительные положения и общие рекомендации
Подведём итог описанному в предыдущих главах. Чтобы разработать качественный HTTP API, необходимо:
-
Описать happy path, т.е. составить диаграмму вызовов для стандартного цикла работы клиентского приложения.
-
Определить каждый вызов как операцию над некоторым ресурсом и, таким образом, составить номенклатуру URL и применимых методов.
-
Понять, какие ошибки возможны при выполнении операций и каким образом клиент должен восстанавливаться из какого состояния.
-
Решить, какая функциональность будет передана на уровень протокола HTTP [какие стандартные возможности протокола будут использованы в сопряжении с какими инструментами разработки] и в каком объёме.
-
Опираясь на решения 1-4, разработать конкретную спецификацию.
-
Проверить себя: пройти по пунктам 1-3, написать псевдокод бизнес-логики приложения согласно разработанной спецификации, и оценить, насколько удобным, понятным и читабельным оказался результирующий API.
Позволим себе так же дать несколько советов по code style:
-
Не различайте пути с
/на конце и без него и примите какую-то рекомендацию по умолчанию (мы рекомендуем все пути заканчивать на/— по простой причине, это позволяет разумно описать обращение к корню домена какГЛАГОЛ /). Если вы решили запретить один из вариантов (скажем, пути без слэша в конце), при обращении по второму варианту должен быть или редирект или однозначно читаемая ошибка. -
Включайте в ответы стандартные заголовки —
Date,Content-Type,Content-Encoding,Content-Length,Cache-Control,Retry-After— и вообще старайтесь не полагаться на то, что клиент правильно догадывается о параметрах протокола по умолчанию. -
Поддержите метод
OPTIONSи протокол CORS на случай, если ваш API захотят использовать из браузеров. -
Определитесь с правилами выбора кейсинга параметров (и преобразований кейсинга при перемещении параметра между различными частями запроса) и придерживайтесь их.
-
Всегда оставляйте себе возможность обратно-совместимого расширения операции API. В частности, всегда возвращайте корневой JSON-объект в ответах эндпойтов — потому что приписать новые поля к объекту вы можете, а к массивам и примитивам — нет.
-
Отметим также, что пустая строка не является валидным JSON, поэтому корректнее возвращать пустой объект
{}там, где ответа не подразумевается (или статус204 No Contentс пустым телом, но тогда эндпойнт нельзя будет расширить в будущем).
-
-
Для всех
GET-запросов указывайте политику кэширования (иначе всегда есть шанс, что клиент или промежуточный агент придумает её за вас). -
Не эксплуатируйте известные возможности оперировать запросами в нарушение стандарта и не изобретайте свои решения для «серых зон» протокола. В частности:
-
не размещайте модифицирующие операции за методом
GETи неидемпотентные операции заPUT/DELETE; -
соблюдайте симметрию
GET/PUT/DELETEметодов; -
не позволяйте
GET/HEAD/DELETE-запросам иметь тело, не возвращайте тело в ответе методаHEADили совместно со статус-кодом204 No Content; -
не придумывайте свой стандарт для передачи массивов и вложенных объектов в query — лучше воспользоваться HTTP-глаголом, позволяющим запросу иметь тело, или, в крайнем случае, передать параметры в виде Base64-кодированного JSON-поля;
-
не размещайте в пути и домене URL параметры, по формату требующие эскейпинга (т.е. могущие содержать символы, отличные от цифр и букв латинского алфавита); для этой цели лучше воспользоваться query-параметрами или телом запроса.
-
-
Ознакомьтесь хотя бы с основными видами уязвимостей в типичных имплементациях HTTP API, которыми могут воспользоваться злоумышленники:
-
CSFR
-
SSRF
-
HTTP Response Splitting
-
Unvalidated Redirects and Forwards
и заложите защиту от этих векторов атак на уровне вашего серверного ПО. Организация OWASP предоставляет хороший обзор лучших security-практик для HTTP API.
-
В заключение хотелось бы сказать следующее: HTTP API — это способ организовать ваше API так, чтобы полагаться на понимание семантики операций как разнообразным программным обеспечением, от клиентских фреймворков до серверных гейтвеев, так и разработчиком, который читает спецификацию. В этом смысле экосистема HTTP предоставляет пожалуй что наиболее широкий (и в плане глубины, и в плане распространённости) по сравнению с другими технологиями словарь для описания самых разнообразных ситуаций, возникающих во время работы клиент-серверных приложений. Разумеется, эта технология не лишена своих недостатков, но для разработчика публичного API она является выбором по умолчанию — на сегодняшний день скорее надо обосновывать отказ от HTTP API чем выбор в его пользу.
![]()
From Wikipedia, the free encyclopedia
This is a list of Hypertext Transfer Protocol (HTTP) response status codes. Status codes are issued by a server in response to a client’s request made to the server. It includes codes from IETF Request for Comments (RFCs), other specifications, and some additional codes used in some common applications of the HTTP. The first digit of the status code specifies one of five standard classes of responses. The optional message phrases shown are typical, but any human-readable alternative may be provided, or none at all.
Unless otherwise stated, the status code is part of the HTTP standard (RFC 9110).
The Internet Assigned Numbers Authority (IANA) maintains the official registry of HTTP status codes.[1]
All HTTP response status codes are separated into five classes or categories. The first digit of the status code defines the class of response, while the last two digits do not have any classifying or categorization role. There are five classes defined by the standard:
- 1xx informational response – the request was received, continuing process
- 2xx successful – the request was successfully received, understood, and accepted
- 3xx redirection – further action needs to be taken in order to complete the request
- 4xx client error – the request contains bad syntax or cannot be fulfilled
- 5xx server error – the server failed to fulfil an apparently valid request
1xx informational response
An informational response indicates that the request was received and understood. It is issued on a provisional basis while request processing continues. It alerts the client to wait for a final response. The message consists only of the status line and optional header fields, and is terminated by an empty line. As the HTTP/1.0 standard did not define any 1xx status codes, servers must not[note 1] send a 1xx response to an HTTP/1.0 compliant client except under experimental conditions.
- 100 Continue
- The server has received the request headers and the client should proceed to send the request body (in the case of a request for which a body needs to be sent; for example, a POST request). Sending a large request body to a server after a request has been rejected for inappropriate headers would be inefficient. To have a server check the request’s headers, a client must send
Expect: 100-continueas a header in its initial request and receive a100 Continuestatus code in response before sending the body. If the client receives an error code such as 403 (Forbidden) or 405 (Method Not Allowed) then it should not send the request’s body. The response417 Expectation Failedindicates that the request should be repeated without theExpectheader as it indicates that the server does not support expectations (this is the case, for example, of HTTP/1.0 servers).[2] - 101 Switching Protocols
- The requester has asked the server to switch protocols and the server has agreed to do so.
- 102 Processing (WebDAV; RFC 2518)
- A WebDAV request may contain many sub-requests involving file operations, requiring a long time to complete the request. This code indicates that the server has received and is processing the request, but no response is available yet.[3] This prevents the client from timing out and assuming the request was lost. The status code is deprecated.[4]
- 103 Early Hints (RFC 8297)
- Used to return some response headers before final HTTP message.[5]
2xx success
This class of status codes indicates the action requested by the client was received, understood, and accepted.[1]
- 200 OK
- Standard response for successful HTTP requests. The actual response will depend on the request method used. In a GET request, the response will contain an entity corresponding to the requested resource. In a POST request, the response will contain an entity describing or containing the result of the action.
- 201 Created
- The request has been fulfilled, resulting in the creation of a new resource.[6]
- 202 Accepted
- The request has been accepted for processing, but the processing has not been completed. The request might or might not be eventually acted upon, and may be disallowed when processing occurs.
- 203 Non-Authoritative Information (since HTTP/1.1)
- The server is a transforming proxy (e.g. a Web accelerator) that received a 200 OK from its origin, but is returning a modified version of the origin’s response.[7][8]
- 204 No Content
- The server successfully processed the request, and is not returning any content.
- 205 Reset Content
- The server successfully processed the request, asks that the requester reset its document view, and is not returning any content.
- 206 Partial Content
- The server is delivering only part of the resource (byte serving) due to a range header sent by the client. The range header is used by HTTP clients to enable resuming of interrupted downloads, or split a download into multiple simultaneous streams.
- 207 Multi-Status (WebDAV; RFC 4918)
- The message body that follows is by default an XML message and can contain a number of separate response codes, depending on how many sub-requests were made.[9]
- 208 Already Reported (WebDAV; RFC 5842)
- The members of a DAV binding have already been enumerated in a preceding part of the (multistatus) response, and are not being included again.
- 226 IM Used (RFC 3229)
- The server has fulfilled a request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.[10]
3xx redirection
This class of status code indicates the client must take additional action to complete the request. Many of these status codes are used in URL redirection.[1]
A user agent may carry out the additional action with no user interaction only if the method used in the second request is GET or HEAD. A user agent may automatically redirect a request. A user agent should detect and intervene to prevent cyclical redirects.[11]
- 300 Multiple Choices
- Indicates multiple options for the resource from which the client may choose (via agent-driven content negotiation). For example, this code could be used to present multiple video format options, to list files with different filename extensions, or to suggest word-sense disambiguation.
- 301 Moved Permanently
- This and all future requests should be directed to the given URI.
- 302 Found (Previously «Moved temporarily»)
- Tells the client to look at (browse to) another URL. The HTTP/1.0 specification (RFC 1945) required the client to perform a temporary redirect with the same method (the original describing phrase was «Moved Temporarily»),[12] but popular browsers implemented 302 redirects by changing the method to GET. Therefore, HTTP/1.1 added status codes 303 and 307 to distinguish between the two behaviours.[11]
- 303 See Other (since HTTP/1.1)
- The response to the request can be found under another URI using the GET method. When received in response to a POST (or PUT/DELETE), the client should presume that the server has received the data and should issue a new GET request to the given URI.
- 304 Not Modified
- Indicates that the resource has not been modified since the version specified by the request headers If-Modified-Since or If-None-Match. In such case, there is no need to retransmit the resource since the client still has a previously-downloaded copy.
- 305 Use Proxy (since HTTP/1.1)
- The requested resource is available only through a proxy, the address for which is provided in the response. For security reasons, many HTTP clients (such as Mozilla Firefox and Internet Explorer) do not obey this status code.
- 306 Switch Proxy
- No longer used. Originally meant «Subsequent requests should use the specified proxy.»
- 307 Temporary Redirect (since HTTP/1.1)
- In this case, the request should be repeated with another URI; however, future requests should still use the original URI. In contrast to how 302 was historically implemented, the request method is not allowed to be changed when reissuing the original request. For example, a POST request should be repeated using another POST request.
- 308 Permanent Redirect
- This and all future requests should be directed to the given URI. 308 parallel the behaviour of 301, but does not allow the HTTP method to change. So, for example, submitting a form to a permanently redirected resource may continue smoothly.
4xx client errors
This class of status code is intended for situations in which the error seems to have been caused by the client. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and whether it is a temporary or permanent condition. These status codes are applicable to any request method. User agents should display any included entity to the user.
- 400 Bad Request
- The server cannot or will not process the request due to an apparent client error (e.g., malformed request syntax, size too large, invalid request message framing, or deceptive request routing).
- 401 Unauthorized
- Similar to 403 Forbidden, but specifically for use when authentication is required and has failed or has not yet been provided. The response must include a WWW-Authenticate header field containing a challenge applicable to the requested resource. See Basic access authentication and Digest access authentication. 401 semantically means «unauthorised», the user does not have valid authentication credentials for the target resource.
- Some sites incorrectly issue HTTP 401 when an IP address is banned from the website (usually the website domain) and that specific address is refused permission to access a website.[citation needed]
- 402 Payment Required
- Reserved for future use. The original intention was that this code might be used as part of some form of digital cash or micropayment scheme, as proposed, for example, by GNU Taler,[14] but that has not yet happened, and this code is not widely used. Google Developers API uses this status if a particular developer has exceeded the daily limit on requests.[15] Sipgate uses this code if an account does not have sufficient funds to start a call.[16] Shopify uses this code when the store has not paid their fees and is temporarily disabled.[17] Stripe uses this code for failed payments where parameters were correct, for example blocked fraudulent payments.[18]
- 403 Forbidden
- The request contained valid data and was understood by the server, but the server is refusing action. This may be due to the user not having the necessary permissions for a resource or needing an account of some sort, or attempting a prohibited action (e.g. creating a duplicate record where only one is allowed). This code is also typically used if the request provided authentication by answering the WWW-Authenticate header field challenge, but the server did not accept that authentication. The request should not be repeated.
- 404 Not Found
- The requested resource could not be found but may be available in the future. Subsequent requests by the client are permissible.
- 405 Method Not Allowed
- A request method is not supported for the requested resource; for example, a GET request on a form that requires data to be presented via POST, or a PUT request on a read-only resource.
- 406 Not Acceptable
- The requested resource is capable of generating only content not acceptable according to the Accept headers sent in the request. See Content negotiation.
- 407 Proxy Authentication Required
- The client must first authenticate itself with the proxy.
- 408 Request Timeout
- The server timed out waiting for the request. According to HTTP specifications: «The client did not produce a request within the time that the server was prepared to wait. The client MAY repeat the request without modifications at any later time.»
- 409 Conflict
- Indicates that the request could not be processed because of conflict in the current state of the resource, such as an edit conflict between multiple simultaneous updates.
- 410 Gone
- Indicates that the resource requested was previously in use but is no longer available and will not be available again. This should be used when a resource has been intentionally removed and the resource should be purged. Upon receiving a 410 status code, the client should not request the resource in the future. Clients such as search engines should remove the resource from their indices. Most use cases do not require clients and search engines to purge the resource, and a «404 Not Found» may be used instead.
- 411 Length Required
- The request did not specify the length of its content, which is required by the requested resource.
- 412 Precondition Failed
- The server does not meet one of the preconditions that the requester put on the request header fields.
- 413 Payload Too Large
- The request is larger than the server is willing or able to process. Previously called «Request Entity Too Large» in RFC 2616.[19]
- 414 URI Too Long
- The URI provided was too long for the server to process. Often the result of too much data being encoded as a query-string of a GET request, in which case it should be converted to a POST request. Called «Request-URI Too Long» previously in RFC 2616.[20]
- 415 Unsupported Media Type
- The request entity has a media type which the server or resource does not support. For example, the client uploads an image as image/svg+xml, but the server requires that images use a different format.
- 416 Range Not Satisfiable
- The client has asked for a portion of the file (byte serving), but the server cannot supply that portion. For example, if the client asked for a part of the file that lies beyond the end of the file. Called «Requested Range Not Satisfiable» previously RFC 2616.[21]
- 417 Expectation Failed
- The server cannot meet the requirements of the Expect request-header field.[22]
- 418 I’m a teapot (RFC 2324, RFC 7168)
- This code was defined in 1998 as one of the traditional IETF April Fools’ jokes, in RFC 2324, Hyper Text Coffee Pot Control Protocol, and is not expected to be implemented by actual HTTP servers. The RFC specifies this code should be returned by teapots requested to brew coffee.[23] This HTTP status is used as an Easter egg in some websites, such as Google.com’s «I’m a teapot» easter egg.[24][25][26] Sometimes, this status code is also used as a response to a blocked request, instead of the more appropriate 403 Forbidden.[27][28]
- 421 Misdirected Request
- The request was directed at a server that is not able to produce a response (for example because of connection reuse).
- 422 Unprocessable Entity
- The request was well-formed but was unable to be followed due to semantic errors.[9]
- 423 Locked (WebDAV; RFC 4918)
- The resource that is being accessed is locked.[9]
- 424 Failed Dependency (WebDAV; RFC 4918)
- The request failed because it depended on another request and that request failed (e.g., a PROPPATCH).[9]
- 425 Too Early (RFC 8470)
- Indicates that the server is unwilling to risk processing a request that might be replayed.
- 426 Upgrade Required
- The client should switch to a different protocol such as TLS/1.3, given in the Upgrade header field.
- 428 Precondition Required (RFC 6585)
- The origin server requires the request to be conditional. Intended to prevent the ‘lost update’ problem, where a client GETs a resource’s state, modifies it, and PUTs it back to the server, when meanwhile a third party has modified the state on the server, leading to a conflict.[29]
- 429 Too Many Requests (RFC 6585)
- The user has sent too many requests in a given amount of time. Intended for use with rate-limiting schemes.[29]
- 431 Request Header Fields Too Large (RFC 6585)
- The server is unwilling to process the request because either an individual header field, or all the header fields collectively, are too large.[29]
- 451 Unavailable For Legal Reasons (RFC 7725)
- A server operator has received a legal demand to deny access to a resource or to a set of resources that includes the requested resource.[30] The code 451 was chosen as a reference to the novel Fahrenheit 451 (see the Acknowledgements in the RFC).
5xx server errors
The server failed to fulfil a request.
Response status codes beginning with the digit «5» indicate cases in which the server is aware that it has encountered an error or is otherwise incapable of performing the request. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and indicate whether it is a temporary or permanent condition. Likewise, user agents should display any included entity to the user. These response codes are applicable to any request method.
- 500 Internal Server Error
- A generic error message, given when an unexpected condition was encountered and no more specific message is suitable.
- 501 Not Implemented
- The server either does not recognize the request method, or it lacks the ability to fulfil the request. Usually this implies future availability (e.g., a new feature of a web-service API).
- 502 Bad Gateway
- The server was acting as a gateway or proxy and received an invalid response from the upstream server.
- 503 Service Unavailable
- The server cannot handle the request (because it is overloaded or down for maintenance). Generally, this is a temporary state.[31]
- 504 Gateway Timeout
- The server was acting as a gateway or proxy and did not receive a timely response from the upstream server.
- 505 HTTP Version Not Supported
- The server does not support the HTTP version used in the request.
- 506 Variant Also Negotiates (RFC 2295)
- Transparent content negotiation for the request results in a circular reference.[32]
- 507 Insufficient Storage (WebDAV; RFC 4918)
- The server is unable to store the representation needed to complete the request.[9]
- 508 Loop Detected (WebDAV; RFC 5842)
- The server detected an infinite loop while processing the request (sent instead of 208 Already Reported).
- 510 Not Extended (RFC 2774)
- Further extensions to the request are required for the server to fulfil it.[33]
- 511 Network Authentication Required (RFC 6585)
- The client needs to authenticate to gain network access. Intended for use by intercepting proxies used to control access to the network (e.g., «captive portals» used to require agreement to Terms of Service before granting full Internet access via a Wi-Fi hotspot).[29]
Unofficial codes
The following codes are not specified by any standard.
- 218 This is fine (Apache HTTP Server)
- Used by Apache servers. A catch-all error condition allowing the passage of message bodies through the server when the
ProxyErrorOverridesetting is enabled. It is displayed in this situation instead of a 4xx or 5xx error message.[34] - 419 Page Expired (Laravel Framework)
- Used by the Laravel Framework when a CSRF Token is missing or expired.[citation needed]
- 420 Method Failure (Spring Framework)
- A deprecated response used by the Spring Framework when a method has failed.[35]
- 420 Enhance Your Calm (Twitter)
- Returned by version 1 of the Twitter Search and Trends API when the client is being rate limited; versions 1.1 and later use the 429 Too Many Requests response code instead.[36] The phrase «Enhance your calm» comes from the 1993 movie Demolition Man, and its association with this number is likely a reference to cannabis.[citation needed]
- 430 Request Header Fields Too Large (Shopify)
- Used by Shopify, instead of the 429 Too Many Requests response code, when too many URLs are requested within a certain time frame.[37]
- 450 Blocked by Windows Parental Controls (Microsoft)
- The Microsoft extension code indicated when Windows Parental Controls are turned on and are blocking access to the requested webpage.[38]
- 498 Invalid Token (Esri)
- Returned by ArcGIS for Server. Code 498 indicates an expired or otherwise invalid token.[39]
- 499 Token Required (Esri)
- Returned by ArcGIS for Server. Code 499 indicates that a token is required but was not submitted.[39]
- 509 Bandwidth Limit Exceeded (Apache Web Server/cPanel)
- The server has exceeded the bandwidth specified by the server administrator; this is often used by shared hosting providers to limit the bandwidth of customers.[40]
- 529 Site is overloaded
- Used by Qualys in the SSLLabs server testing API to signal that the site can’t process the request.[41]
- 530 Site is frozen
- Used by the Pantheon Systems web platform to indicate a site that has been frozen due to inactivity.[42]
- 598 (Informal convention) Network read timeout error
- Used by some HTTP proxies to signal a network read timeout behind the proxy to a client in front of the proxy.[43]
- 599 Network Connect Timeout Error
- An error used by some HTTP proxies to signal a network connect timeout behind the proxy to a client in front of the proxy.
Internet Information Services
Microsoft’s Internet Information Services (IIS) web server expands the 4xx error space to signal errors with the client’s request.
- 440 Login Time-out
- The client’s session has expired and must log in again.[44]
- 449 Retry With
- The server cannot honour the request because the user has not provided the required information.[45]
- 451 Redirect
- Used in Exchange ActiveSync when either a more efficient server is available or the server cannot access the users’ mailbox.[46] The client is expected to re-run the HTTP AutoDiscover operation to find a more appropriate server.[47]
IIS sometimes uses additional decimal sub-codes for more specific information,[48] however these sub-codes only appear in the response payload and in documentation, not in the place of an actual HTTP status code.
nginx
The nginx web server software expands the 4xx error space to signal issues with the client’s request.[49][50]
- 444 No Response
- Used internally[51] to instruct the server to return no information to the client and close the connection immediately.
- 494 Request header too large
- Client sent too large request or too long header line.
- 495 SSL Certificate Error
- An expansion of the 400 Bad Request response code, used when the client has provided an invalid client certificate.
- 496 SSL Certificate Required
- An expansion of the 400 Bad Request response code, used when a client certificate is required but not provided.
- 497 HTTP Request Sent to HTTPS Port
- An expansion of the 400 Bad Request response code, used when the client has made a HTTP request to a port listening for HTTPS requests.
- 499 Client Closed Request
- Used when the client has closed the request before the server could send a response.
Cloudflare
Cloudflare’s reverse proxy service expands the 5xx series of errors space to signal issues with the origin server.[52]
- 520 Web Server Returned an Unknown Error
- The origin server returned an empty, unknown, or unexpected response to Cloudflare.[53]
- 521 Web Server Is Down
- The origin server refused connections from Cloudflare. Security solutions at the origin may be blocking legitimate connections from certain Cloudflare IP addresses.
- 522 Connection Timed Out
- Cloudflare timed out contacting the origin server.
- 523 Origin Is Unreachable
- Cloudflare could not reach the origin server; for example, if the DNS records for the origin server are incorrect or missing.
- 524 A Timeout Occurred
- Cloudflare was able to complete a TCP connection to the origin server, but did not receive a timely HTTP response.
- 525 SSL Handshake Failed
- Cloudflare could not negotiate a SSL/TLS handshake with the origin server.
- 526 Invalid SSL Certificate
- Cloudflare could not validate the SSL certificate on the origin web server. Also used by Cloud Foundry’s gorouter.
- 527 Railgun Error
- Error 527 indicates an interrupted connection between Cloudflare and the origin server’s Railgun server.[54]
- 530
- Error 530 is returned along with a 1xxx error.[55]
AWS Elastic Load Balancing
Amazon Web Services’ Elastic Load Balancing adds a few custom return codes to signal issues either with the client request or with the origin server.[56]
- 460
- Client closed the connection with the load balancer before the idle timeout period elapsed. Typically when client timeout is sooner than the Elastic Load Balancer’s timeout.[56]
- 463
- The load balancer received an X-Forwarded-For request header with more than 30 IP addresses.[56]
- 464
- Incompatible protocol versions between Client and Origin server.[56]
- 561 Unauthorized
- An error around authentication returned by a server registered with a load balancer. You configured a listener rule to authenticate users, but the identity provider (IdP) returned an error code when authenticating the user.[56]
Caching warning codes (obsoleted)
The following caching related warning codes were specified under RFC 7234. Unlike the other status codes above, these were not sent as the response status in the HTTP protocol, but as part of the «Warning» HTTP header.[57][58]
Since this «Warning» header is often neither sent by servers nor acknowledged by clients, this header and its codes were obsoleted by the HTTP Working Group in 2022 with RFC 9111.[59]
- 110 Response is Stale
- The response provided by a cache is stale (the content’s age exceeds a maximum age set by a Cache-Control header or heuristically chosen lifetime).
- 111 Revalidation Failed
- The cache was unable to validate the response, due to an inability to reach the origin server.
- 112 Disconnected Operation
- The cache is intentionally disconnected from the rest of the network.
- 113 Heuristic Expiration
- The cache heuristically chose a freshness lifetime greater than 24 hours and the response’s age is greater than 24 hours.
- 199 Miscellaneous Warning
- Arbitrary, non-specific warning. The warning text may be logged or presented to the user.
- 214 Transformation Applied
- Added by a proxy if it applies any transformation to the representation, such as changing the content encoding, media type or the like.
- 299 Miscellaneous Persistent Warning
- Same as 199, but indicating a persistent warning.
See also
- Custom error pages
- List of FTP server return codes
- List of HTTP header fields
- List of SMTP server return codes
- Common Log Format
Explanatory notes
- ^ Emphasised words and phrases such as must and should represent interpretation guidelines as given by RFC 2119
References
- ^ a b c «Hypertext Transfer Protocol (HTTP) Status Code Registry». Iana.org. Archived from the original on December 11, 2011. Retrieved January 8, 2015.
- ^ Fielding, Roy T. «RFC 9110: HTTP Semantics and Content, Section 10.1.1 «Expect»«.
- ^ Goland, Yaronn; Whitehead, Jim; Faizi, Asad; Carter, Steve R.; Jensen, Del (February 1999). HTTP Extensions for Distributed Authoring – WEBDAV. IETF. doi:10.17487/RFC2518. RFC 2518. Retrieved October 24, 2009.
- ^ «102 Processing — HTTP MDN». 102 status code is deprecated
- ^ Oku, Kazuho (December 2017). An HTTP Status Code for Indicating Hints. IETF. doi:10.17487/RFC8297. RFC 8297. Retrieved December 20, 2017.
- ^ Stewart, Mark; djna. «Create request with POST, which response codes 200 or 201 and content». Stack Overflow. Archived from the original on October 11, 2016. Retrieved October 16, 2015.
- ^ «RFC 9110: HTTP Semantics and Content, Section 15.3.4».
- ^ «RFC 9110: HTTP Semantics and Content, Section 7.7».
- ^ a b c d e Dusseault, Lisa, ed. (June 2007). HTTP Extensions for Web Distributed Authoring and Versioning (WebDAV). IETF. doi:10.17487/RFC4918. RFC 4918. Retrieved October 24, 2009.
- ^ Delta encoding in HTTP. IETF. January 2002. doi:10.17487/RFC3229. RFC 3229. Retrieved February 25, 2011.
- ^ a b «RFC 9110: HTTP Semantics and Content, Section 15.4 «Redirection 3xx»«.
- ^ Berners-Lee, Tim; Fielding, Roy T.; Nielsen, Henrik Frystyk (May 1996). Hypertext Transfer Protocol – HTTP/1.0. IETF. doi:10.17487/RFC1945. RFC 1945. Retrieved October 24, 2009.
- ^ «The GNU Taler tutorial for PHP Web shop developers 0.4.0». docs.taler.net. Archived from the original on November 8, 2017. Retrieved October 29, 2017.
- ^ «Google API Standard Error Responses». 2016. Archived from the original on May 25, 2017. Retrieved June 21, 2017.
- ^ «Sipgate API Documentation». Archived from the original on July 10, 2018. Retrieved July 10, 2018.
- ^ «Shopify Documentation». Archived from the original on July 25, 2018. Retrieved July 25, 2018.
- ^ «Stripe API Reference – Errors». stripe.com. Retrieved October 28, 2019.
- ^ «RFC2616 on status 413». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ «RFC2616 on status 414». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ «RFC2616 on status 416». Tools.ietf.org. Archived from the original on March 7, 2011. Retrieved November 11, 2015.
- ^ TheDeadLike. «HTTP/1.1 Status Codes 400 and 417, cannot choose which». serverFault. Archived from the original on October 10, 2015. Retrieved October 16, 2015.
- ^ Larry Masinter (April 1, 1998). Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0). doi:10.17487/RFC2324. RFC 2324.
Any attempt to brew coffee with a teapot should result in the error code «418 I’m a teapot». The resulting entity body MAY be short and stout.
- ^ I’m a teapot
- ^ Barry Schwartz (August 26, 2014). «New Google Easter Egg For SEO Geeks: Server Status 418, I’m A Teapot». Search Engine Land. Archived from the original on November 15, 2015. Retrieved November 4, 2015.
- ^ «Google’s Teapot». Retrieved October 23, 2017.[dead link]
- ^ «Enable extra web security on a website». DreamHost. Retrieved December 18, 2022.
- ^ «I Went to a Russian Website and All I Got Was This Lousy Teapot». PCMag. Retrieved December 18, 2022.
- ^ a b c d Nottingham, M.; Fielding, R. (April 2012). «RFC 6585 – Additional HTTP Status Codes». Request for Comments. Internet Engineering Task Force. Archived from the original on May 4, 2012. Retrieved May 1, 2012.
- ^ Bray, T. (February 2016). «An HTTP Status Code to Report Legal Obstacles». ietf.org. Archived from the original on March 4, 2016. Retrieved March 7, 2015.
- ^ alex. «What is the correct HTTP status code to send when a site is down for maintenance?». Stack Overflow. Archived from the original on October 11, 2016. Retrieved October 16, 2015.
- ^ Holtman, Koen; Mutz, Andrew H. (March 1998). Transparent Content Negotiation in HTTP. IETF. doi:10.17487/RFC2295. RFC 2295. Retrieved October 24, 2009.
- ^ Nielsen, Henrik Frystyk; Leach, Paul; Lawrence, Scott (February 2000). An HTTP Extension Framework. IETF. doi:10.17487/RFC2774. RFC 2774. Retrieved October 24, 2009.
- ^ «218 This is fine — HTTP status code explained». HTTP.dev. Retrieved July 25, 2023.
{{cite web}}: CS1 maint: url-status (link) - ^ «Enum HttpStatus». Spring Framework. org.springframework.http. Archived from the original on October 25, 2015. Retrieved October 16, 2015.
- ^ «Twitter Error Codes & Responses». Twitter. 2014. Archived from the original on September 27, 2017. Retrieved January 20, 2014.
- ^ «HTTP Status Codes and SEO: what you need to know». ContentKing. Retrieved August 9, 2019.
- ^ «Screenshot of error page». Archived from the original (bmp) on May 11, 2013. Retrieved October 11, 2009.
- ^ a b «Using token-based authentication». ArcGIS Server SOAP SDK. Archived from the original on September 26, 2014. Retrieved September 8, 2014.
- ^ «HTTP Error Codes and Quick Fixes». Docs.cpanel.net. Archived from the original on November 23, 2015. Retrieved October 15, 2015.
- ^ «SSL Labs API v3 Documentation». github.com.
- ^ «Platform Considerations | Pantheon Docs». pantheon.io. Archived from the original on January 6, 2017. Retrieved January 5, 2017.
- ^ «HTTP status codes — ascii-code.com». www.ascii-code.com. Archived from the original on January 7, 2017. Retrieved December 23, 2016.
- ^
«Error message when you try to log on to Exchange 2007 by using Outlook Web Access: «440 Login Time-out»«. Microsoft. 2010. Retrieved November 13, 2013. - ^ «2.2.6 449 Retry With Status Code». Microsoft. 2009. Archived from the original on October 5, 2009. Retrieved October 26, 2009.
- ^ «MS-ASCMD, Section 3.1.5.2.2». Msdn.microsoft.com. Archived from the original on March 26, 2015. Retrieved January 8, 2015.
- ^ «Ms-oxdisco». Msdn.microsoft.com. Archived from the original on July 31, 2014. Retrieved January 8, 2015.
- ^ «The HTTP status codes in IIS 7.0». Microsoft. July 14, 2009. Archived from the original on April 9, 2009. Retrieved April 1, 2009.
- ^ «ngx_http_request.h». nginx 1.9.5 source code. nginx inc. Archived from the original on September 19, 2017. Retrieved January 9, 2016.
- ^ «ngx_http_special_response.c». nginx 1.9.5 source code. nginx inc. Archived from the original on May 8, 2018. Retrieved January 9, 2016.
- ^ «return» directive Archived March 1, 2018, at the Wayback Machine (http_rewrite module) documentation.
- ^ «Troubleshooting: Error Pages». Cloudflare. Archived from the original on March 4, 2016. Retrieved January 9, 2016.
- ^ «Error 520: web server returns an unknown error». Cloudflare.
- ^ «527 Error: Railgun Listener to origin error». Cloudflare. Archived from the original on October 13, 2016. Retrieved October 12, 2016.
- ^ «Error 530». Cloudflare. Retrieved November 1, 2019.
- ^ a b c d e «Troubleshoot Your Application Load Balancers – Elastic Load Balancing». docs.aws.amazon.com. Retrieved May 17, 2023.
- ^ «Hypertext Transfer Protocol (HTTP/1.1): Caching». datatracker.ietf.org. Retrieved September 25, 2021.
- ^ «Warning — HTTP | MDN». developer.mozilla.org. Retrieved August 15, 2021.
 Some text was copied from this source, which is available under a Creative Commons Attribution-ShareAlike 2.5 Generic (CC BY-SA 2.5) license.
Some text was copied from this source, which is available under a Creative Commons Attribution-ShareAlike 2.5 Generic (CC BY-SA 2.5) license.
- ^ «RFC 9111: HTTP Caching, Section 5.5 «Warning»«. June 2022.
External links
- «RFC 9110: HTTP Semantics and Content, Section 15 «Status Codes»«.
- Hypertext Transfer Protocol (HTTP) Status Code Registry at the Internet Assigned Numbers Authority
- HTTP status codes at http-statuscode.com
- MDN status code reference at mozilla.org
# Коды ответов и ошибки
HTTP-коды ответов REST API ноды представлены в таблице.
| Значение | Описание |
|---|---|
| 200 OK | Успешный запрос и ответ |
| 400 Bad Request | Неверные параметры запроса |
| 403 Forbidden | Отсутствует или указан неверный API-ключ при вызове приватного метода |
| 404 Not Found | Запрошенный объект (блок, транзакция, алиас, ключ записи в хранилище данных) не найден |
| 429 Too Many Requests | Размер очереди запросов превысил ограничение, установленное для публичных нод |
| 500 Internal Server Error | Ошибка сервера |
| 501 Not Implemented | Неподдерживаемый тип транзакции |
| 503 Service Unavailable | API недоступен, или нода не успела обработать запрос в отведенное время (см. раздел Медленные запросы), или превышено количество одновременных соединений, установленное для публичных нод |
В случае ошибки 4xx или 501 возвращается следующая структура:
Пример:
| Код ошибки | Текст сообщения | Комментарий, возможные причины |
|---|---|---|
| 0 | Error is unknown | |
| 1 | failed to parse json message | • Невалидный JSON • Отсутствует обязательное поле • Невалидное значение поля |
| 2 | Provided API key is not correct | Отсутствует или указан неверный API-ключ при вызове приватного метода |
| 10 | Too big sequences requested | Количество данных больше установленного лимита: • Запрошено транзакций больше, чем указано в настройке waves.rest-api.transactions-by-address-limit• Запрошено больше 100 блоков • Превышены ограничения для транзакции данных • Превышена длина поля attachment для транзакции перевода или массового перевода |
| 101 | Invalid signature | |
| 102 | Invalid address | |
| 108 | Invalid public key | |
| 110 | Invalid message | Не удалось декодировать сообщение, подпись или ключ в /addresses/verify/{address} or /addresses/verifyText/{address} |
| 113 | Overflow error | Сумма fee+amount или итоговая сумма в транзакции массового перевода больше максимального значения Long |
| 116 | Request contains invalid IDs. id1, id2, … | Невалидные base58 в списке ID транзакций |
| 199 | … | Прочие ошибки валидации |
| 301 | Block does not exist | |
| 302 | • alias ‘…’ doesn’t exist • alias for address ‘…’ doesn’t exist |
|
| 303 | • Transaction timestamp … is more than … ms in the future relative to block timestamp … • Transaction timestamp … is more than … ms in the past relative to previous block timestamp … |
|
| 304 | no data for this key | Запрашиваемый ключ отсутствует в хранилище данных аккаунта |
| 305 | … | Ошибка компиляции скрипта |
| 306 | Error while executing (token|account)-script: … | Ошибка при выполнении скрипта ассета или аккаунта |
| 307 | Transaction is not allowed by account-script | |
| 308 | Transaction is not allowed by token-script | |
| 311 | transactions does not exist | • Не найден ассет по ID • Не найдена транзакция по ID |
| 312 | transaction type not supported | |
| 400 | Transaction … is already in the state on a height of … | Повторная отправка транзакции |
| 402 | Accounts balance errors | • У отправителя транзакции недостаточно средств для уплаты комиссии или для перевода • У dApp недостаточно средств для выполнения действий ( ScriptTransfer или Burn) |
| 403 | Order validation error: … | • Указанное в ордере количество уже исполнено • Недостаточная комиссия |
| 404 | Wrong chain-id. Expected — …, provided — … | |
| 405 | • Too many proofs (…), only … allowed • Too large proof (…), must be max … bytes |
|
| 4001 | • Transaction ID was not specified • Wrong char • … has invalid length …. Length can either be … or … |
ID транзакции отсутствует, невалидный или имеет недопустимую длину |
| 4002 | • Wrong char • … has invalid length …. Length can either be … or … |
ID блока невалидный или имеет недопустимую длину |
| 4007 | Invalid asset id |
Просмотров 14.4к. Опубликовано
Обновлено
Каждый сайт, который создает компания, должен отвечать принятым стандартам. В первую очередь затем, чтобы он попадал в поисковую выдачу и был удобен для пользователей. Если код страниц содержит ошибки, неточности, он становится “невалидным”, то есть не соответствующим требованиям. В результате интернет-ресурс не увидят пользователи или информация на нем будет отображаться некорректно.
В этой статье рассмотрим, что такое валидность, какие могут быть ошибки в HTML-разметке и как их устранить.
Содержание
- Что такое HTML-ошибка валидации и зачем она нужна
- Чем опасны ошибки в разметке
- Как проверить ошибки валидации
- Предупреждения
- Ошибки
- Пример прохождения валидации для страницы сайта
- Как исправить ошибку валидации
- Плагины для браузеров, которые помогут найти ошибки в коде
- Коротко о главном
Что такое HTML-ошибка валидации и зачем она нужна
Под понятием “валидация” подразумевается процесс онлайн-проверки HTML-кода страницы на соответствие стандартам w3c. Эти стандарты были разработаны Организацией всемирной паутины и стандартов качества разметки. Сама организация продвигает идею унификации сайтов по HTML-коду — чтобы каждому пользователю, вне зависимости от браузера или устройства, было удобно использовать ресурс.
Если код отвечает стандартам, то его называют валидным. Браузеры могут его прочитать, загрузить страницы, а поисковые системы легко находят страницу по соответствующему запросу.
Чем опасны ошибки в разметке
Ошибки валидации могут разными — видимыми для глаза простого пользователя или такими, которые можно засечь только с помощью специальных программ. В первом случае кроме технических проблем, ошибки в разметке приводят к негативному пользовательскому опыту.
К наиболее распространённым последствиям ошибок в коде HTML-разметки также относят сбои в нормальной работе сайта и помехи в продвижении ресурса в поисковых системах.
Рассмотрим несколько примеров, как ошибки могут проявляться при работе:
- Медленно подгружается страница
Согласно исследованию Unbounce, более четверти пользователей покидают страницу, если её загрузка занимает более 3 секунд, ещё треть уходит после 6 секунд;
- Не видна часть текстовых, фото и видео-блоков
Эта проблема делает контент для пользователей неинформативным, поэтому они в большинстве случаев уходят со страницы, не досмотрев её до конца;
- Страница может остаться не проиндексированной
Если поисковый робот распознает недочёт в разметке, он может пропустить страницу и прервать её размещение в поисковых системах;
- Разное отображение страниц на разных устройствах
Например, на компьютере или ноутбуке страница будет выглядеть хорошо, а на мобильных гаджетах половина кнопок и изображений будет попросту не видна.
Из-за этих ошибок пользователь не сможет нормально работать с ресурсом. Единственное решение для него — закрыть вкладку и найти нужную информацию на другом сайте. Так количество посетителей сайта постепенно уменьшается, он перестает попадать в поисковую выдачу — в результате ресурс становится бесполезным и пропадает в пучине Интернета.
Как проверить ошибки валидации
Владельцы ресурсов используют 2 способа онлайн-проверки сайтов на наличие ошибок — технический аудит или использование валидаторов.
Первый случай подходит для серьёзных проблем и масштабных сайтов. Валидаторами же пользуются ежедневно. Наиболее популярный — сервис The W3C Markup Validation Service. Он сканирует сайт и сравнивает код на соответствие стандартам W3C. Валидатор выдаёт 2 типа несоответствий разметки стандартам W3C: предупреждения и ошибки.
Давайте рассмотрим каждый из типов чуть подробнее.
Предупреждения
Предупреждения отмечают незначительные проблемы, которые не влияют на работу ресурса. Они появляются из-за расхождений написания разметки со стандартами W3C.
Тем не менее, предупреждения всё равно нужно устранять, так как из-за них сайт может работать медленнее — например, по сравнению с конкурентами с такими же сайтами.
Примером предупреждения может быть указание на отсутствие тега alt у изображения.
Ошибки
Ошибки — это те проблемы, которые требуют обязательного устранения.
Они представляют угрозу для корректной работы сайта: например, из-за них могут скрываться разные блоки — текстовые, фото, видео. А в некоторых более запущенных случаях содержимое страницы может вовсе не отображаться, и сам ресурс не будет загружаться. Поэтому после проверки уделять внимание ошибкам с красными отметками нужно в первую очередь.
Распространённым примером ошибки может быть отсутствие тега <!DOCTYPE html> в начале страницы, который помогает информации преобразоваться в разметку.
Пример прохождения валидации для страницы сайта
Рассмотрим процесс валидации на примере сайта avavax.ru, который создали на WordPress.
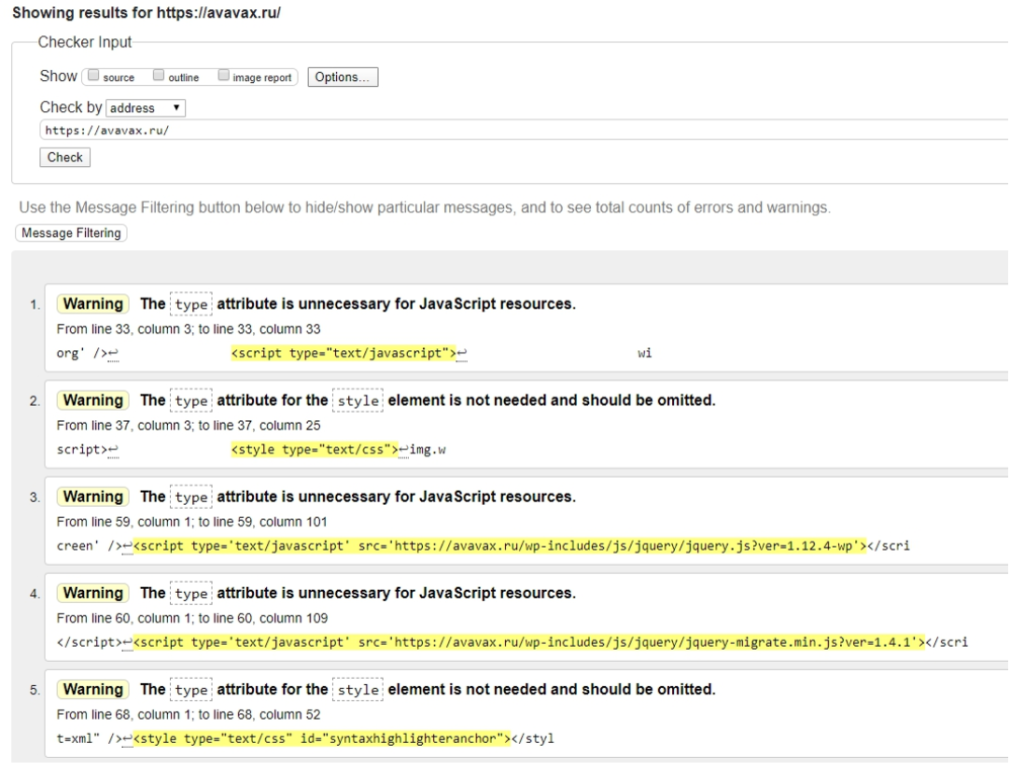
В результате проверки валидатор выдал 17 замечаний. После анализа отчета их можно свести к 3 основным:
- атрибут ‘text/javascript’ не требуется при подключении скрипта;
- атрибут ‘text/css’ не требуется при подключении стиля;
- у одного из элементов section нет внутри заголовка h1-h6.
Первое и второе замечания генерирует сам движок WordPress, поэтому разработчикам не нужно их убирать. Третье же замечание предполагает, что каждый блок текста должен иметь заголовок, даже если это не всегда необходимо или видно для читателя.
Решить проблемы с предупреждениями для стилей и скриптов можно через добавление кода в файл темы function.php.
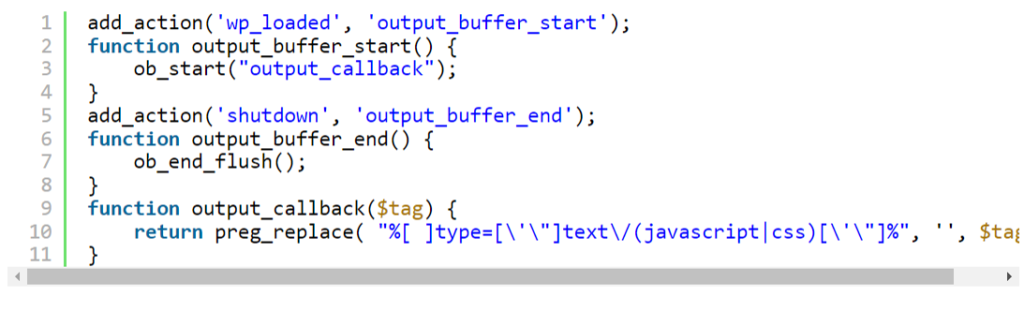
Для этого на хук wp_loaded нужно повесить функцию output_buffer_start(), которая загрузит весь генерируемый код html в буфер. При выводе в буфер вызывается функция output_callback($tag), которая просматривает все теги, находит нежелательные атрибуты с помощью регулярных выражений и заменяет их пробелами. Затем на хук ‘shutdown вешается функция output_buffer_end(), которая возвращает обработанное содержимое буфера.
Для исправления семантики на сайте нужно использовать заголовки. Валидатор выдаёт предупреждение на секцию about, которая содержит фото и краткий текст. Валидатор требует, чтобы в каждой секции был заголовок. Для исправления предупреждения нужно добавить заголовок, но сделать это так, чтобы его не было видно пользователям:
- Добавить заголовок в код: <h3>Обо мне</h3>
Отключить отображение заголовка:
1 #about h3 {
2 display: none;
3 }
После этой части заголовок будет в коде, но валидатор его увидит, а посетитель — нет.
За 3 действия удалось убрать все предупреждения, чтобы качество кода устроило валидатор. Это подтверждается зелёной строкой с надписью: “Document checking completed. No errors or warnings to show”.
Как исправить ошибку валидации
Всё зависит от того, какими техническими знаниями обладает владелец ресурса. Он может сделать это сам, вручную. Делать это нужно постепенно, разбирая ошибку за ошибкой. Но нужно понимать, что если при проверке валидатором было выявлено 100 проблем — все 100 нужно обязательно решить.
Поэтому если навыков и знаний не хватает, лучше привлечь сторонних специалистов для улучшения качества разметки. Это могут быть как фрилансеры, так и профессиональные веб-агентства. При выборе хорошего специалиста, результат будет гарантироваться в любом случае, но лучше, чтобы в договоре оказания услуг будут чётко прописаны цели проведения аудита и гарантии решения проблем с сайтом.
Если объём работ большой, выгоднее заказать профессиональный аудит сайта. С его помощью можно обнаружить разные виды ошибок, улучшить внешний вид и привлекательность интернет-ресурса для поисковых ботов, обычных пользователей, а также повысить скорость загрузки страниц, сделать качественную верстку и избавиться от переспама.
Плагины для браузеров, которые помогут найти ошибки в коде
Для поиска ошибок валидации можно использовать и встроенные в браузеры плагины. Они помогут быстро находить неточности еще на этапе создания кода.
Для каждого браузера есть свой адаптивный плагин:
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- HTML5 Editor для Opera.
С помощью этих инструментов можно не допускать проблем, которые помешают нормальному запуску сайта. Плагины помогут оценить качество внешней и внутренней оптимизации, контента и другие характеристики.
Коротко о главном
Валидация — процесс выявления проблем с HTML-разметкой сайта и ее соответствия стандартам W3C. Это унифицированные правила, с помощью которых сайт может нормально работать и отображаться и для поисковых роботов, и для пользователей.
Проверку ресурса можно проводить тремя путями: валидаторами, специалистам полномасштабного аудита и плагинами в браузере. В большинстве случаев валидатор — самое удобное и быстрое решение для поиска проблем. С его помощью можно выявить 2 типа проблем с разметкой — предупреждения и ошибки.
Работать необходимо сразу с двумя типами ошибок. Даже если предупреждение не приведет к неисправности сайта, оставлять без внимания проблемные блоки нельзя, так как это снизит привлекательность ресурса в глазах пользователя. Ошибки же могут привести к невозможности отображения блоков на сайте, понижению сайта в поисковой выдаче или полному игнорированию ресурса со стороны поискового бота.
Даже у крупных сайтов с миллионной аудиторией, например, Яндекс.Дзен или ВКонтакте, есть проблемы с кодом. Но комплексный подход к решению проблем помогает устранять серьёзные моменты своевременно. Нужно развивать сайт всесторонне, чтобы получить результат от его существования и поддержки. Если самостоятельно разобраться с проблемами не получается, не стоит “доламывать” — лучше обратиться за помощью к профессионалам, например, агентствам по веб-аудиту.