Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU
Изучение
всех влияющих на исследуемый объект
факторов одновременно провести
невозможно, поэтому в эксперименте
рассматривается их ограниченное число.
Остальные активные факторы стабилизируются,
т.е. устанавливаются на каких-то одинаковых
для всех опытов уровнях.
Некоторые
факторы не могут быть обеспечены
системами стабилизации (например,
погодные условия, самочувствие оператора
и т.д.), другие же стабилизируются с
какой-то погрешностью (например,
содержание какого-либо компонента в
среде зависит от ошибки при взятии
навески и приготовления раствора).
Учитывая также, что измерение параметра
у
осуществляется
прибором, обладающим какой-то погрешностью,
зависящей от класса точности прибора,
можно прийти к выводу, что результаты
повторностей одного и того же опыта ук
будут
приближенными и должны отличаться один
от другого и от истинного значения
выхода процесса. Неконтролируемое,
случайное изменение и множества других
влияющих на процесс факторов вызывает
случайные
отклонения
измеряемой величины ук
от
ее истинного значения – ошибку опыта.
Каждый
эксперимент содержит элемент
неопределенности вследствие ограниченности
экспериментального материала. Постановка
повторных (или параллельных) опытов не
дает полностью совпадающих результатов,
потому что всегда существует ошибка
опыта (ошибка воспроизводимости). Эту
ошибку и нужно оценить по параллельным
опытам. Для этого опыт воспроизводится
по возможности в одинаковых условиях
несколько раз и затем берется среднее
арифметическое всех результатов. Среднее
арифметическое у равно сумме всех n
отдельных результатов, деленной на
количество параллельных опытов n:

Отклонение
результата любого опыта от среднего
арифметического можно представить как
разность yq–
![]()
,
где yq
– результат отдельного опыта. Наличие
отклонения свидетельствует об
изменчивости, вариации значений повторных
опытов. Для измерения этой изменчивости
чаще всего используют дисперсию.
Дисперсией
называется среднее значение квадрата
отклонений величины от ее среднего
значения. Дисперсия обозначается s2
и выражается формулой:

где
(n-1)
– число степеней свободы, равное
количеству опытов минус единица. Одна
степень свободы использована для
вычисления среднего.
Корень
квадратный из дисперсии, взятый с
положительным знаком, называется средним
квадратическим отклонением, стандартом
или квадратичной ошибкой:
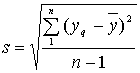
Ошибка
опыта является суммарной величиной,
результатом многих ошибок: ошибок
измерений факторов, ошибок измерений
параметра оптимизации и др. Каждую из
этих ошибок можно, в свою очередь,
разделить на составляющие.
Все
ошибки принято разделять на два класса:
систематические и случайные (рисунок
1).
Систематические
ошибки порождаются причинами, действующими
регулярно, в определенном направлении.
Чаще всего эти ошибки можно изучить и
определить количественно. Систематическая
ошибка –
это ошибка, которая остаётся постоянно
или закономерно изменяется при повторных
измерениях одной и той же величины. Эти
ошибки появляются вследствие неисправности
приборов, неточности метода измерения,
какого либо упущения экспериментатора,
либо использования для вычисления
неточных данных. Обнаружить систематические
ошибки, а также устранить их во многих
случаях нелегко. Требуется тщательный
разбор методов анализа, строгая проверка
всех измерительных приборов и безусловное
выполнение выработанных практикой
правил экспериментальных работ. Если
систематические ошибки вызваны известными
причинами, то их можно определить.
Подобные погрешности можно устранить
введением поправок.
Систематические
ошибки находят, калибруя измерительные
приборы и сопоставляя опытные данные
с изменяющимися внешними условиями
(например, при градуировке термопары
по реперным точкам, при сравнении с
эталонным прибором). Если систематические
ошибки вызываются внешними условиями
(переменной температуры, сырья и т.д.),
следует компенсировать их влияние.
Случайными
ошибками называются те, которые появляются
нерегулярно, причины, возникновения
которых неизвестны и которые невозможно
учесть заранее. Случайные ошибки
вызываются и объективными причинами и
субъективными. Например, несовершенством
приборов, их освещением, расположением,
изменением температуры в процессе
измерений, загрязнением реактивов,
изменением электрического тока в цепи.
Когда случайная ошибка больше величины
погрешности прибора, необходимо
многократно повторить одно и тоже
измерение. Это позволяет сделать
случайную ошибку сравнимой с погрешностью
вносимой прибором. Если же она меньше
погрешности прибора, то уменьшать её
нет смысла. Такие ошибки имеют значение,
которое отличается в отдельных измерениях.
Т.е. их значения могут быть неодинаковыми
для измерений сделанных даже в одинаковых
условиях. Поскольку причины, приводящие
к случайным ошибкам неодинаковы в каждом
эксперименте, и не могут быть учтены,
поэтому исключить случайные ошибки
нельзя, можно лишь оценить их значения.
При многократном определении какого-либо
показателя могут встречаться результаты,
которые значительно отличаются от
других результатов той же серии. Они
могут быть следствием грубой ошибки,
которая вызвана невнимательностью
экспериментатора.
Систематические
и случайные ошибки состоят из множества
элементарных ошибок. Для того чтобы
исключать инструментальные ошибки,
следует проверять приборы перед опытом,
иногда в течение опыта и обязательно
после опыта. Ошибки при проведении
самого опыта возникают вследствие
неравномерного нагрева реакционной
среды, разного способа перемешивания
и т.п.
При
повторении опытов такие ошибки могут
вызвать большой разброс экспериментальных
результатов.
Очень
важно исключить из экспериментальных
данных грубые ошибки, так называемый
брак при повторных опытах. Грубые
ошибки легко
обнаружить. Для выявления ошибок
необходимо произвести измерения в
других условиях или повторить измерения
через некоторое время. Для предотвращения
грубых ошибок нужно соблюдать аккуратность
в записях, тщательность в работе и записи
результатов эксперимента. Грубая ошибка
должна быть исключена из экспериментальных
данных. Для отброса ошибочных данных
существуют определённые правила.
Например,
используют критерий Стьюдента t
(Р; f):
Опыт считается бракованным, если
экспериментальное значение критерия
t по модулю больше табличного значения
t
(Р; f).
Если
в распоряжении исследователя имеется
экспериментальная оценка дисперсии
S2(yk)
с небольшим конечным числом степеней
свободы, то доверительные ошибки
рассчитываются с помощью критерий
Стьюдента t
(Р; f):
ε(![]()
)
= t (Р;
f)* S(yk)/![]()
=
t (Р;
f)* S(
)
ε(yk)
= t
(Р; f)*
S(yk)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
«Начиная»
Меры погрешностей прогнозов: их понимание с помощью экспериментов
Измерение — это первый шаг, ведущий к контролю и, в конечном итоге, к улучшению.
Х. Джеймс Харрингтон
Во многих бизнес-приложениях способность планировать наперед имеет первостепенное значение, и в большинстве таких сценариев мы используем прогнозы, чтобы помочь нам планировать наперед. Например, если у меня розничный магазин , сколько коробок этого шампуня я должен заказать сегодня? Посмотрите прогноз. Достигну ли я своих финансовых планов к концу года? Давайте спрогнозируем и при необходимости внесем корректировки. Если я управляю фирмой по прокату велосипедов, сколько велосипедов мне нужно оставить на станции метро завтра в 16:00?
Если для всех этих сценариев мы принимаем меры на основе прогноза, мы также должны иметь представление о том, насколько хороши эти прогнозы. В классической статистике или машинном обучении у нас есть несколько общих функций потерь, таких как квадрат ошибки или абсолютная ошибка. Но из-за того, как эволюционировало прогнозирование временных рядов, существует гораздо больше способов оценить вашу эффективность.
В этом сообщении блога давайте рассмотрим различные способы измерения ошибок прогноза с помощью экспериментов и поймем недостатки и преимущества каждого из них.
Метрики в прогнозировании временных рядов
Есть несколько ключевых моментов, которые отличают метрики прогнозирования временных рядов от обычных показателей машинного обучения.
1. Временная релевантность
Как следует из названия, прогнозирование временных рядов имеет встроенный временной аспект, и есть такие показатели, как совокупная ошибка прогноза или смещение прогноза, которые также принимают этот временной аспект.
2. Сводные показатели
В большинстве случаев использования в бизнесе мы прогнозируем не один временной ряд, а набор временных рядов, связанных или несвязанных друг с другом. И высшее руководство не захочет рассматривать каждый из этих временных рядов по отдельности, а скорее представляет собой совокупную меру, которая указывает им, насколько хорошо мы выполняем работу по прогнозированию. Этот совокупный показатель помогает даже практикам получить общее представление о прогрессе, которого они достигли в моделировании.
3. Завышение или занижение прогноза
Еще один ключевой аспект прогнозирования — это концепция чрезмерного и недостаточного прогнозирования. Мы не хотели бы, чтобы модель прогнозирования имела структурные отклонения, которые всегда превышали или занижали прогнозы. И чтобы бороться с этим, нам нужны показатели, которые не одобряют ни завышенного, ни заниженного прогноза.
4. Интерпретируемость
Последний аспект — интерпретируемость. Поскольку эти показатели также используются бизнес-функциями, не связанными с аналитикой, их необходимо интерпретировать.
Из-за этих различных вариантов использования в этом пространстве используется множество показателей, и здесь мы пытаемся объединить их в рамках некоторой структуры, а также критически их исследовать.
Таксономия прогнозных показателей

Мы можем классифицировать различные метрики прогноза. в широком смысле. на два сегмента — Внутренний и Внешний. Внутренние меры — это меры, которые просто используют сгенерированный прогноз и основную информацию для вычисления метрики. Внешние меры — это меры, которые используют внешний эталонный прогноз также в дополнение к сгенерированному прогнозу и достоверным данным для вычисления метрики.
Давайте пока остановимся на внутренних показателях (внешние требуют совершенно другого подхода к этим показателям). Существует четыре основных способа вычисления ошибок — абсолютная ошибка, квадратичная ошибка, процентная ошибка и симметричная ошибка. Все показатели, которые подпадают под эти категории, представляют собой всего лишь различные агрегаты этих фундаментальных ошибок. Итак, без потери общности, мы можем обсудить эти широкие разделы, и они также будут применяться ко всем показателям под этими заголовками.
Абсолютная ошибка
Эта группа ошибок измерения использует абсолютное значение ошибки в качестве основы.

Квадратная ошибка
Вместо того чтобы брать абсолютные значения, мы возводим ошибки в квадрат, чтобы сделать их положительными, и это является основой для этих показателей.

Процент ошибки
В этой группе измерений ошибок мы масштабируем абсолютную ошибку на основе истинного значения, чтобы преобразовать ее в процентное выражение.

Симметричная ошибка
Симметричная ошибка была предложена в качестве альтернативы процентной ошибке, в которой мы берем среднее значение прогноза и достоверности в качестве основы для масштабирования абсолютной ошибки.

Эксперименты
Вместо того, чтобы просто говорить, что это недостатки и преимущества тех или иных показателей, давайте проведем несколько экспериментов и сами посмотрим, каковы эти преимущества и недостатки.
Масштабная зависимость
В этом эксперименте мы пытаемся выяснить влияние масштаба таймсерий в агрегированных показателях. Для этого эксперимента мы
- Сгенерируйте 10000 синтетических временных рядов в разных масштабах, но с той же ошибкой.
- Разделите эти серии на 10 бинов гистограммы.
- Размер выборки = 5000; Перебрать каждую корзину
- Выборка 50% из текущего бина и равномерного распределения из других бункеров.
- Рассчитайте агрегированные показатели по этому набору временных рядов.
- Запись по нижнему краю бункера
- Нанесите совокупные меры по краям бункера.
Симметричность
Мера ошибки должна быть симметричной входным данным, то есть прогнозу и достоверности. Если мы поменяем местами прогноз и фактические данные, в идеале показатель ошибки должен возвращать то же значение.
Чтобы проверить это, давайте создадим сетку от 0 до 10 как для фактических данных, так и для прогноза и вычислим метрики ошибок в этой сетке.
Дополнительные пары
В этом эксперименте мы берем дополнительные пары основных истин и прогнозов, которые в сумме составляют постоянное количество, и измеряем производительность в каждой точке. В частности, мы используем ту же настройку, что и в эксперименте с симметричностью, и вычисляем точки вдоль поперечной диагонали, где истинность + прогноз всегда дает в сумме 10.
Кривые потерь
Наши метрики зависят от двух сущностей — прогноза и фактов. Мы можем исправить одну и изменить другую, используя симметричный диапазон ошибок ((например, от -10 до 10), тогда мы ожидаем, что метрика будет вести себя одинаково по обе стороны от этого диапазона. В нашем эксперименте мы решили зафиксируйте Основную Истину, потому что на самом деле это фиксированная величина, и мы сравниваем прогноз с наземной истиной.
Эксперимент с завышением и занижением прогнозов
В этом эксперименте мы генерируем 4 случайных временных ряда — достоверные данные, базовый прогноз, низкий прогноз и высокий прогноз. Это просто случайные числа, сгенерированные в определенном диапазоне. Наземная истина и базовый прогноз — это случайные числа, сгенерированные между 2 и 4. Низкий прогноз — это случайное число, сгенерированное между 0 и 3, а высокий прогноз — это случайное число, сгенерированное между 3 и 6. В этой настройке базовый прогноз должен действовать как базовый уровень. для нас низкий прогноз — это прогноз, в котором мы постоянно занижаем, а высокий прогноз — это прогноз, в котором мы постоянно завышаем. А теперь давайте рассчитаем MAPE для этих трех прогнозов и повторим эксперимент 1000 раз.

Влияние выброса
Чтобы проверить влияние на выбросы, мы настроили эксперимент ниже.
Мы хотим проверить относительное влияние выбросов по двум осям — количеству выбросов, шкале выбросов. Итак, мы определяем сетку — количество выбросов [0% -40%] и шкалу выбросов [от 0 до 2]. Затем мы случайным образом выбрали синтетический временной ряд и итеративно вводили выбросы в соответствии с параметрами сетки, которые мы определили ранее, и записали меры ошибок.
Результаты и обсуждение
Абсолютная ошибка
Симметричность

Это красивая симметричная тепловая карта. Мы видим нулевые ошибки по диагонали и более высокие ошибки на удалении от нее в красивом симметричном узоре.
Кривые потерь

Опять симметричный. MAE меняется одинаково, если мы идем по обе стороны кривой.
Дополнительные пары

И снова хорошие новости. Если мы изменяем прогноз, сохраняя постоянные фактические данные, и наоборот, изменение показателя также будет симметричным.
Завышенный и заниженный прогноз

Как и ожидалось, завышение или занижение прогноза не имеет большого значения для MAE. Оба наказываются одинаково.
Масштабная зависимость

Это ахиллесова пята МАЭ. здесь, когда мы увеличиваем базовый уровень временного ряда, мы можем видеть, что MAE увеличивается линейно. Это означает, что когда мы сравниваем характеристики по таймсериям, это не та мера, которую вы хотите использовать. Например, при сравнении двух таймсерий, один с уровнем 5, а другой с уровнем 100, использование MAE всегда будет назначать более высокую ошибку таймсериям с уровнем 100. Другой пример — когда вы хотите сравнить разные подсекции вашего набора временных рядов, чтобы увидеть, где ошибка выше (например, для разных категорий продуктов и т. д.), то при использовании MAE вы всегда будете знать, что подсекция с более высокими средними продажами также будет иметь более высокий MAE, но это не означает, что этот подраздел не очень хорошо работает.
Квадратная ошибка
Симметричность

Squared Error также показывает симметрию, которую мы ищем. Но еще один момент, который мы можем здесь увидеть, заключается в том, что ошибки смещены в сторону более высоких ошибок. Распределение цвета по диагонали не так равномерно, как мы видели в Absolute Error. Это связано с тем, что квадратичная ошибка (из-за квадратного члена) приписывает большее влияние более высоким ошибкам, чем меньшим ошибкам. По этой же причине ошибки в квадрате, как правило, более подвержены искажениям из-за выбросов.
Дополнительное примечание: Поскольку квадрат ошибки и абсолютная ошибка также используются в качестве функций потерь во многих алгоритмах машинного обучения, это также влияет на обучение таких алгоритмов. Если мы выберем квадратичную потерю ошибок, мы будем менее чувствительны к меньшим ошибкам и больше — к большим. И если мы выбираем абсолютную ошибку, мы наказываем более высокие и более низкие ошибки одинаково, и, следовательно, один выброс не будет так сильно влиять на общие потери.
Кривые потерь

Здесь мы видим ту же закономерность. Он симметричен относительно начала координат, но из-за квадратичной формы более высокие ошибки имеют непропорционально большую ошибку по сравнению с более низкими.
Дополнительные пары

Завышенный и заниженный прогноз

Подобно MAE, из-за симметрии, Over и Under Forecasting имеют примерно одинаковое влияние.
Масштабная зависимость

Подобно MAE, RMSE также имеет проблему зависимости от масштаба, что означает, что все недостатки, которые мы обсуждали для MAE, применимы и здесь, но хуже. Мы видим, что RMSE масштабируется квадратично, когда мы увеличиваем масштаб.
Процент ошибки
Процент ошибки — это самый популярный показатель ошибок, используемый в отрасли. Вот несколько причин, по которым он так популярен:
- Независимость от масштаба — как мы видели ранее на графиках зависимости от масштаба, линия MAPE является плоской, поскольку мы увеличиваем масштаб временных рядов.
- Интерпретируемость — поскольку ошибка представлена в виде процентного показателя, который довольно популярен и поддается интерпретации, показатель ошибки также мгновенно становится интерпретируемым. Если мы говорим, что RMSE составляет 32, это ничего не значит изолированно. Но с другой стороны, если мы говорим, что MAPE составляет 20%, мы сразу узнаем, хороший или плохой прогноз.
Симметричность

Теперь это выглядит не так, не так ли? Самый популярный из них, Percent Error, вообще не выглядит симметричным. Фактически, мы можем видеть, что пик ошибок достигается, когда фактические значения близки к нулю, и стремятся к бесконечности, когда фактические значения равны нулю (бесцветная полоса внизу — это место, где ошибка равна бесконечности из-за деления на ноль).
Здесь мы видим два недостатка процентной ошибки:
- Не определено, когда основная истина равна нулю (из-за деления на ноль)
- Он присваивает более высокую ошибку, когда значение истинности ниже (верхний правый угол)
Давайте посмотрим на графики кривых потерь и дополнительных пар, чтобы понять больше.
Кривые потерь

Внезапно асимметрии, которую мы наблюдаем, больше нет. Если мы сохраним основную истину фиксированной, процент ошибки будет симметричным относительно начала координат.
Дополнительные пары

Но когда мы смотрим на дополнительные пары, мы видим асимметрию, которую мы видели ранее на тепловой карте. Когда фактические значения низкие, у той же ошибки процент ошибки намного выше, чем у той же ошибки, когда прогноз был низким.
Все это из-за базы, которую мы берем для ее масштабирования. Даже если у нас будет такая же величина ошибки, если истинное значение будет низким, процент ошибки будет высоким, и наоборот. Например, рассмотрим два случая:
- F = 8, A = 2 — ›Абсолютная ошибка в процентах = (8–2) / 2 = 3
- F = 2, A = 8 — ›Абсолютная погрешность в процентах = (8–2) / 8 = 0,75
Существует бесчисленное количество статей и блогов, в которых асимметрия процентной ошибки нарушает условия сделки. Популярное утверждение состоит в том, что абсолютный процент ошибки больше наказывает завышение прогноза, чем занижение, или, другими словами, стимулирует занижение прогнозов.
Один аргумент против этой точки зрения состоит в том, что эта асимметрия существует только потому, что мы меняем основную истину. Ошибка 6 для временного ряда, который имеет ожидаемое значение 2, намного серьезнее, чем ошибка 2 для временного ряда, имеющего ожидаемое значение 6. Итак, согласно этой интуиции, процентная ошибка делает то, что есть должен делать, не так ли?
Завышенный и заниженный прогноз

Не совсем. На некоторых уровнях критика процентной ошибки вполне оправдана. Здесь мы видим, что прогноз, в котором мы занижали прогноз, имеет постоянно более низкую MAPE, чем прогнозы, в которых мы прогнозировали завышение. Распространение низкого MAPE также значительно ниже, чем у других. Но означает ли это, что прогноз, который всегда дает более низкую оценку, является лучшим прогнозом для бизнеса? Точно нет. В цепочке поставок это приводит к дефициту товаров, чего вы не хотите, если хотите оставаться конкурентоспособными на рынке.
Симметричная ошибка
Симметричная ошибка была предложена как лучшая альтернатива процентной ошибке. У Percent Error было два основных недостатка: Undefined, если истинное значение равно нулю, и Asymmetry. И для решения симметричной ошибки предлагается использовать как среднее истинное значение, так и прогноз в качестве основы, по которой мы вычисляем процент ошибки.
Симметричность

Сразу видно, что это симметрично относительно диагонали, почти аналогично абсолютной ошибке в случае симметрии. И нижняя полоса, которая была пустой, теперь имеет цвета (что означает, что они не являются неопределенными). Но при более внимательном рассмотрении открывается нечто большее. Он не симметричен относительно второй диагонали. Мы видим, что ошибки выше, когда и фактические данные, и прогноз низкие.
Кривые потерь

Это дополнительно видно на кривых потерь. Мы можем видеть асимметрию по мере увеличения ошибок по обе стороны от начала координат. И вопреки названию, симметричная ошибка наказывает за недооценку прогноза больше, чем за переоценку.
Дополнительные пары

Но если мы посмотрим на дополнительные пары, то увидим, что они абсолютно симметричны. Вероятно, это из-за базы, которую мы сохраняем постоянной.
Завышенный и заниженный прогноз

Мы видим то же самое и здесь. Ряд завышенного прогноза имеет стабильно более низкую ошибку по сравнению с рядом заниженного прогноза. Таким образом, в попытке нормализовать предвзятость в сторону заниженного прогнозирования процентной ошибки, симметричная ошибка направлена в другую сторону и склоняется в сторону завышенного прогноза.
Влияние выброса
В дополнение к вышеупомянутым экспериментам мы также провели эксперимент, чтобы проверить влияние выбросов (единичные прогнозы, которые сильно ошибаются) на совокупные показатели.

При переходе к выбросам все четыре меры ошибки ведут себя одинаково. Количество выбросов оказывает гораздо большее влияние, чем их масштаб.
Среди этих четырех RMSE оказывает наибольшее влияние на выбросы. Мы можем видеть, что контурные линии далеко разнесены, показывая, что скорость изменения высока, когда мы вводим выбросы. На другом конце спектра у нас есть sMAPE, который имеет наименьшее влияние на выбросы. Это видно по ровным и близко расположенным контурным линиям. MAE и MAPE ведут себя почти одинаково, возможно, MAPE немного лучше.
Резюме

В заключение, не существует единой метрики, которая удовлетворяла бы всем желаемым критериям измерения ошибок. И в зависимости от варианта использования нам нужно выбирать. Из четырех внутренних мер (и всех их агрегатов, таких как MAPE, MAE и т. Д.), Если нас не интересуют интерпретируемость и зависимость от масштаба, мы должны выбрать меры абсолютной ошибки. А когда мы ищем меры, не зависящие от масштаба, процент ошибки — лучшее, что у нас есть (даже со всеми его недостатками). Измерения внешних ошибок, такие как Scaled Error, предлагают гораздо лучшую альтернативу в таких случаях (возможно, в другом сообщении блога я также расскажу о них).
Код для воссоздания экспериментов
Ознакомьтесь с остальными статьями этой серии
- Меры погрешностей прогнозов: их понимание посредством экспериментов
- Меры погрешности прогноза: масштабные, относительные и другие погрешности
- Меры погрешности прогноза: прерывистый спрос
Дополнительная информация
- Щербаков и др. 2013, Обзор показателей погрешности прогнозов
- Гудвин и Лоутон, 1999, Об асимметрии симметричного MAPE
Отредактировано (29–09–2020): исправлена ошибка с неправильной маркировкой на контурной карте.
Первоначально опубликовано на http://deep-and-shallow.com 26 сентября 2020 г.
From Wikipedia, the free encyclopedia
In statistics, a forecast error is the difference between the actual or real and the predicted or forecast value of a time series or any other phenomenon of interest. Since the forecast error is derived from the same scale of data, comparisons between the forecast errors of different series can only be made when the series are on the same scale.[1]
In simple cases, a forecast is compared with an outcome at a single time-point and a summary of forecast errors is constructed over a collection of such time-points. Here the forecast may be assessed using the difference or using a proportional error. By convention, the error is defined using the value of the outcome minus the value of the forecast.
In other cases, a forecast may consist of predicted values over a number of lead-times; in this case an assessment of forecast error may need to consider more general ways of assessing the match between the time-profiles of the forecast and the outcome. If a main application of the forecast is to predict when certain thresholds will be crossed, one possible way of assessing the forecast is to use the timing-error—the difference in time between when the outcome crosses the threshold and when the forecast does so. When there is interest in the maximum value being reached, assessment of forecasts can be done using any of:
- the difference of times of the peaks;
- the difference in the peak values in the forecast and outcome;
- the difference between the peak value of the outcome and the value forecast for that time point.
Forecast error can be a calendar forecast error or a cross-sectional forecast error, when we want to summarize the forecast error over a group of units. If we observe the average forecast error for a time-series of forecasts for the same product or phenomenon, then we call this a calendar forecast error or time-series forecast error. If we observe this for multiple products for the same period, then this is a cross-sectional performance error. Reference class forecasting has been developed to reduce forecast error. Combining forecasts has also been shown to reduce forecast error.[2][3]
Calculating forecast error[edit]
The forecast error is the difference between the observed value and its forecast based on all previous observations. If the error is denoted as  then the forecast error can be written as:
then the forecast error can be written as:

where,
 = observation
= observation
 = denote the forecast of based on all previous observations
= denote the forecast of based on all previous observations
Forecast errors can be evaluated using a variety of methods namely mean percentage error, root mean squared error, mean absolute percentage error, mean squared error. Other methods include tracking signal and forecast bias.
For forecast errors on training data
denotes the observation and is the forecast
For forecast errors on test data
 denotes the actual value of the h-step observation and the forecast is denoted as
denotes the actual value of the h-step observation and the forecast is denoted as 
Academic literature[edit]
Dreman and Berry in 1995 «Financial Analysts Journal», argued that securities analysts’ forecasts are too optimistic, and that the investment community relies too heavily on their forecasts. However, this was countered by Lawrence D. Brown in 1996 and then again in 1997 who argued that the analysts are generally more accurate than those of «naive or sophisticated time-series models» nor have the errors been increasing over time.[4][5]
Hiromichi Tamura in 2002 argued that herd-to-consensus analysts not only submit their earnings estimates that end up being close to the consensus but that their personalities strongly affect these estimates.[6]
Examples of forecasting errors[edit]
Michael Fish — A few hours before the Great Storm of 1987 broke, on 15 October 1987, he said during a forecast: «Earlier on today, apparently, a woman rang the BBC and said she heard there was a hurricane on the way. Well, if you’re watching, don’t worry, there isn’t!». The storm was the worst to hit South East England for three centuries, causing record damage and killing 19 people.[7]
Great Recession — The financial and economic «Great Recession» that erupted in 2007—arguably the worst since the Great Depression of the 1930s—was not foreseen by most forecasters, though a number of analysts had been predicting it for some time (for example, Brooksley Born, Dean Baker, Marc Faber, Fred Harrison, Raghuram Rajan, Stephen Roach, Nouriel Roubini, Peter Schiff, Gary Shilling, Robert Shiller, William White, and Meredith Whitney).[8][9][10][11] The UK’s Queen Elizabeth herself asked why had “nobody” noticed that the credit crunch was on its way, and a group of economists—experts from business, the City, its regulators, academia, and government—tried to explain in a letter.[12]
It was not just forecasting the Great Recession, but also its impact where it was clear that economists struggled. For example, in Singapore, Citi argued the country would experience «the most severe recession in Singapore’s history». The economy grew in 2009 by 3.1%, and in 2010 the nation saw a 15.2% growth rate.[13][14]
Similarly, Nouriel Roubini predicted in January 2009 that oil prices would stay below $40 for all of 2009. By the end of 2009, however, oil prices were at $80.[15][16] In March 2009, he predicted the S&P 500 would fall below 600 that year, and possibly plummet to 200.[17] It closed at over 1,115 however, up 24%, the largest single-year gain since 2003. CNBC’s Jim Cramer wrote that Roubini was «intoxicated» with his own «prescience and vision,» and should realize that things are better than he predicted; Roubini called Cramer a «buffoon,» and told him to «just shut up».[15][18] Although in April 2009, Roubini prophesied that the United States economy would decline in the final two quarters of 2009, and that the US economy would increase just 0.5% to 1% in 2010, in fact the U.S. economy in each of those six quarters increased at a 2.5% average annual rate.[19] Then in June 2009 he predicted that what he called a «perfect storm» was just around the corner, but no such perfect storm ever appeared.[20][19] In 2009 he also predicted that the US government would take over and nationalize a number of large banks; it did not happen.[21] In October 2009 he predicted that the price of gold «can go above $1,000, but it can’t move up 20-30%”; he was wrong, as the price of gold rose over the next 18 months, breaking through the $1,000 barrier to over $1,400.[22]
2020 Global Growth — At the end of 2019 the International Monetary Fund estimated global growth in 2020 to reach 3.4%, but as a result of the coronavirus pandemic, the IMF have revised its estimate in November 2020 to expect the global economy to shrink by 4.4%.[23][24]
See also[edit]
- Calculating demand forecast accuracy
- Errors and residuals in statistics
- Forecasting
- Forecasting accuracy
- Mean squared prediction error
- Optimism bias
- Reference class forecasting
References[edit]
- ^ 2.5 Evaluating forecast accuracy | OTexts. Retrieved 2016-05-12.
- ^ J. Scott Armstrong (2001). «Combining Forecasts». Principles of Forecasting: A Handbook for Researchers and Practitioners (PDF). Kluwer Academic Publishers.
- ^ J. Andreas Graefe; Scott Armstrong; Randall J. Jones, Jr.; Alfred G. Cuzán (2010). «Combining forecasts for predicting U.S. Presidential Election outcomes» (PDF).
- ^ Brown, Lawrence D. (1996). «Analyst Forecasting Errors and Their Implications for Security Analysis: An Alternative Perspective». Financial Analysts Journal. 52 (1): 40–47. doi:10.2469/faj.v52.n1.1965. ISSN 0015-198X. JSTOR 4479895. S2CID 153329250.
- ^ Brown, Lawrence D. (1997). «Analyst Forecasting Errors: Additional Evidence». Financial Analysts Journal. 53 (6): 81–88. doi:10.2469/faj.v53.n6.2133. ISSN 0015-198X. JSTOR 4480043. S2CID 153810721.
- ^ Tamura, Hiromichi (2002). «Individual-Analyst Characteristics and Forecast Error». Financial Analysts Journal. 58 (4): 28–35. doi:10.2469/faj.v58.n4.2452. ISSN 0015-198X. JSTOR 4480404. S2CID 154943363.
- ^ «Michael Fish revisits 1987’s Great Storm». BBC. 16 October 2017. Retrieved 16 October 2017.
- ^ Helaine Olen (March 30, 2009). «The Prime of Mr. Nouriel Roubini», Entrepreneur.
- ^ Jerry H. Tempelman (July 30, 2014). «Austrian Business Cycle Theory and the Global Financial Crisis: Confessions of a Mainstream Economist,» The Quarterly Journal of Austrian Economics]
- ^ «The Economic Crisis and the Crisis in Economics». www.eatonak.org.
- ^ Bezemer, Dirk J, 16 June 2009. «“No One Saw This Coming”: Understanding Financial Crisis Through Accounting Models»
- ^ British Academy-The Global Financial Crisis Why Didn’t Anybody Notice?-Retrieved July 27, 2015 Archived July 7, 2015, at the Wayback Machine
- ^ Chen, Xiaoping; Shao, Yuchen (2017-09-11). «Trade policies for a small open economy: The case of Singapore». The World Economy. doi:10.1111/twec.12555. ISSN 0378-5920. S2CID 158182047.
- ^ Subler, Jason (2009-01-02). «Factories slash output, jobs around world». Reuters. Retrieved 2020-09-20.
- ^ a b Joe Keohane (January 9, 2011). «That guy who called the big one? Don’t listen to him.» The Boston Globe.
- ^ Eric Tyson (2018). Personal Finance For Dummies
- ^ Maneet Ahuja (2014). The Alpha Masters; Unlocking the Genius of the World’s Top Hedge Funds
- ^ «Roubini to Cramer: ‘Just shut up’», The Los Angeles Times, April 8, 2009.
- ^ a b Daniel Altman (October 8, 2012). «Nouriel Roubini; He may not be perfect, but there’s never been a better time to be in the prophet of doom business,» Foreign Policy Magazine.
- ^ Nouriel Roubini (June 16, 2009). «Financial Gain, Economic Pain,» Project Syndicate.
- ^ Joseph Lazzaro (March 26, 2009). «‘Dr. Doom’ predicts some big banks will be nationalized,» AOL.com.
- ^ Alice Guy (January 16, 2023). «Seven times the experts got it very wrong on the economy,» Interactive Investor.
- ^ «IMF warns world growth slowest since financial crisis». BBC News. 2019-10-15. Retrieved 2020-11-22.
- ^ «IMF: Economy ‘losing momentum’ amid virus second wave». BBC News. 2020-11-19. Retrieved 2020-11-22.
Что такое ошибка прогноза в статистике? (Определение и примеры)
читать 2 мин
В статистике ошибка прогнозирования относится к разнице между прогнозируемыми значениями, сделанными некоторой моделью, и фактическими значениями.
Ошибка прогноза часто используется в двух случаях:
1. Линейная регрессия: используется для прогнозирования значения некоторой переменной непрерывного отклика.
Обычно мы измеряем ошибку прогноза модели линейной регрессии с помощью метрики, известной как RMSE , что означает среднеквадратичную ошибку.
Он рассчитывается как:
СКО = √ Σ(ŷ i – y i ) 2 / n
куда:
- Σ — это символ, который означает «сумма»
- ŷ i — прогнозируемое значение для i -го наблюдения
- y i — наблюдаемое значение для i -го наблюдения
- n — размер выборки
2. Логистическая регрессия: используется для прогнозирования значения некоторой бинарной переменной отклика.
Одним из распространенных способов измерения ошибки прогнозирования модели логистической регрессии является метрика, известная как общий коэффициент ошибочной классификации.
Он рассчитывается как:
Общий коэффициент ошибочной классификации = (# неверных прогнозов / # всего прогнозов)
Чем ниже значение коэффициента ошибочной классификации, тем лучше модель способна предсказать результаты переменной отклика.
В следующих примерах показано, как на практике рассчитать ошибку прогнозирования как для модели линейной регрессии, так и для модели логистической регрессии.
Пример 1: Расчет ошибки прогноза в линейной регрессии
Предположим, мы используем регрессионную модель, чтобы предсказать количество очков, которое 10 игроков наберут в баскетбольном матче.
В следующей таблице показаны прогнозируемые очки по модели и фактические очки, набранные игроками:

Мы рассчитали бы среднеквадратичную ошибку (RMSE) как:
- СКО = √ Σ(ŷ i – y i ) 2 / n
- СКО = √(((14-12) 2 +(15-15) 2 +(18-20) 2 +(19-16) 2 +(25-20) 2 +(18-19) 2 +(12- 16) 2 +(12-20) 2 +(15-16) 2 +(22-16) 2 ) / 10)
- СКО = 4
Среднеквадратическая ошибка равна 4. Это говорит нам о том, что среднее отклонение между прогнозируемыми набранными баллами и фактическими набранными баллами равно 4.
Связанный: Что считается хорошим значением RMSE?
Пример 2: Расчет ошибки прогноза в логистической регрессии
Предположим, мы используем модель логистической регрессии, чтобы предсказать, попадут ли 10 баскетболистов из колледжа в НБА.
В следующей таблице показан прогнозируемый результат для каждого игрока по сравнению с фактическим результатом (1 = выбран на драфте, 0 = не выбран на драфте):

Мы рассчитали бы общий коэффициент ошибочной классификации как:
- Общий коэффициент ошибочной классификации = (# неверных прогнозов / # всего прогнозов)
- Общий коэффициент ошибочной классификации = 4/10
- Общий коэффициент ошибочной классификации = 40%
Общий уровень ошибочной классификации составляет 40% .
Это значение довольно велико, что указывает на то, что модель не очень хорошо предсказывает, будет ли игрок выбран на драфте.
Дополнительные ресурсы
Следующие руководства содержат введение в различные типы методов регрессии:
Введение в простую линейную регрессию
Введение в множественную линейную регрессию
Введение в логистическую регрессию