In statistics, we often use Forecasting Accuracy which denotes the closeness of a quantity to the actual value of that particular quantity. The actual value is also known as the true value. It basically denotes the degree of closeness or a verification process that is highly used by business professionals to keep track records of their sales and exchanges to maintain the demand and supply mapping every year. There are various methods to calculate Forecasting Accuracy.
So, one of the most common methods used to calculate the Forecasting Accuracy is MAPE which is abbreviated as Mean Absolute Percentage Error. It is an effective and more convenient method because it becomes easier to interpret the accuracy just by seeing the MAPE value.
In this article, we are going to see how to calculate Mean Absolute Percentage Error, MAPE in Excel.
The formula to calculate MAPE is :

The above formula can be interpreted as the average value of Absolute Percentage Error (APE) of all the observations in the data set.
Note: The actual value can’t be zero. We can observe from the above formula that if the Actual value becomes zero, it will be undefined.
Example:
Consider the dataset shown below :
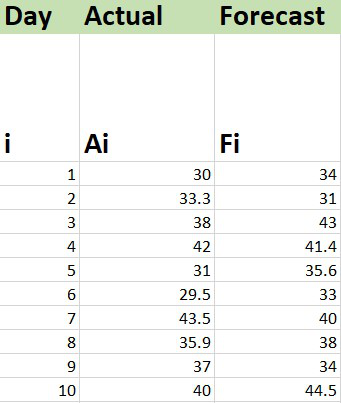
Calculation of MAPE in Excel:
The functions needed for formulas in Excel are-
ABS : To calculate the absolute value.
AVERAGE : To calculate the mean.
The steps are :
1. Insert the data set in the Excel sheet.
2. Calculate APE for each individual observation using Excel Formula. The formula will be :
=ABS(Cell_No_Act-Cell_No_Fore)/Cell_No_Act*100 where ABS : Used to calculate the absolute value Cell_No_Act : Cell number where Actual value is present Cell_No_Fore : Cell number where Forecast value is present
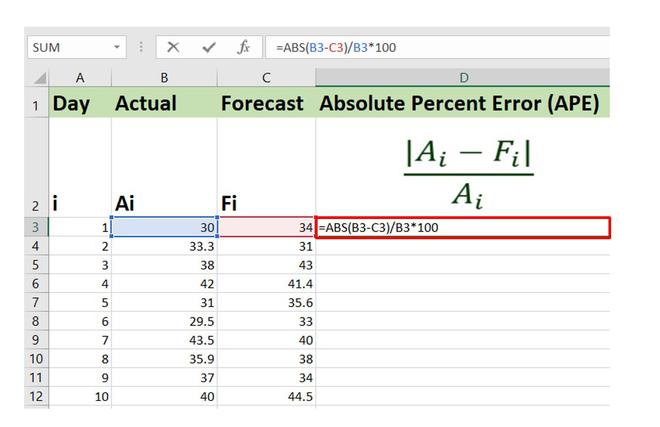
Similarly, you can write the formulas for the other entries and get the APE for all the records.
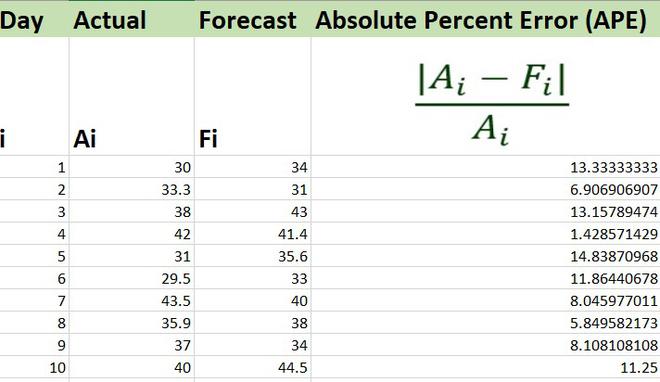
APE
3. Now, simply we need to find the average or the mean value for all these values in order to calculate MAPE.
The formula to find average value in Excel is :
=AVERAGE(Cell_Range)
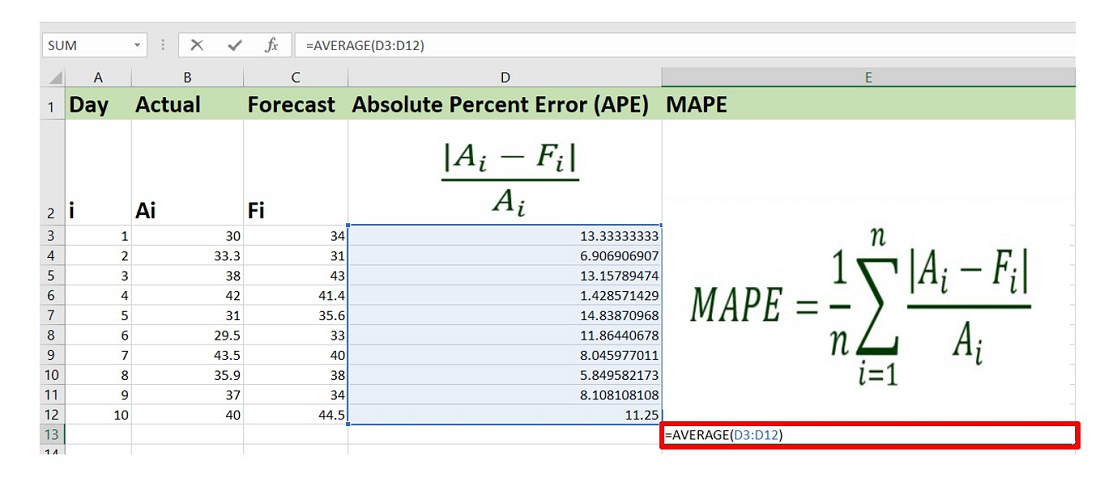
The value of MAPE for the given data set is 9.478% approximately. Therefore, we can say that the average difference between the actual value and forecasted value is 9.478%.

MAPE
Last Updated :
09 Jul, 2021
Like Article
Save Article
читать 2 мин
Одной из наиболее распространенных метрик, используемых для измерения точности прогнозирования модели, является MAPE , что означает среднюю абсолютную ошибку в процентах .
Формула для расчета MAPE выглядит следующим образом:
MAPE = (1/n) * Σ(|факт – прогноз| / |факт|) * 100
куда:
- Σ — причудливый символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
MAPE обычно используется, потому что его легко интерпретировать и легко объяснить. Например, значение MAPE, равное 11,5%, означает, что средняя разница между прогнозируемым значением и фактическим значением составляет 11,5%.
Чем ниже значение MAPE, тем лучше модель способна прогнозировать значения. Например, модель с MAPE 2% более точна, чем модель с MAPE 10%.
Как рассчитать MAPE в Excel
Чтобы рассчитать MAPE в Excel, мы можем выполнить следующие шаги:
Шаг 1: Введите фактические значения и прогнозируемые значения в два отдельных столбца.
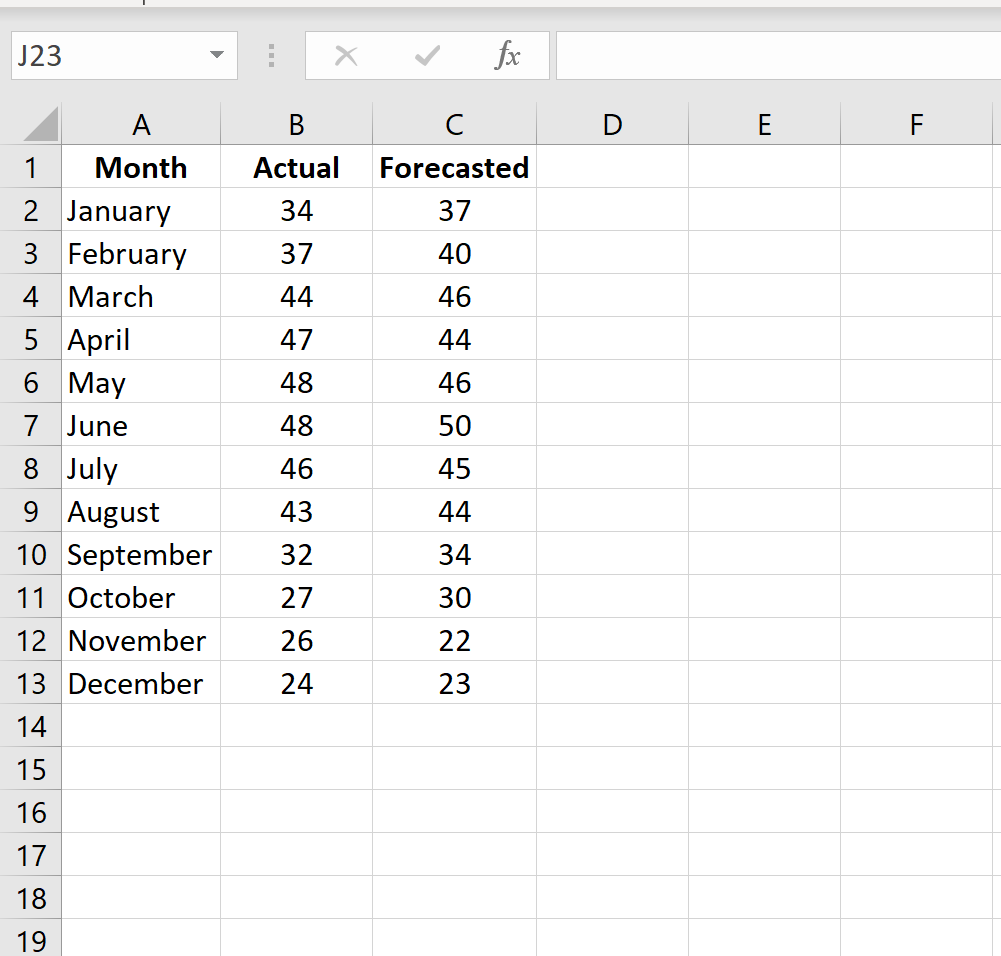
Шаг 2: Рассчитайте абсолютную процентную ошибку для каждой строки.
Напомним, что абсолютная процентная ошибка рассчитывается как: |фактический-прогноз| / |фактическое| * 100. Мы будем использовать эту формулу для расчета абсолютной процентной ошибки для каждой строки.
Столбец D отображает абсолютную процентную ошибку, а столбец E показывает формулу, которую мы использовали:
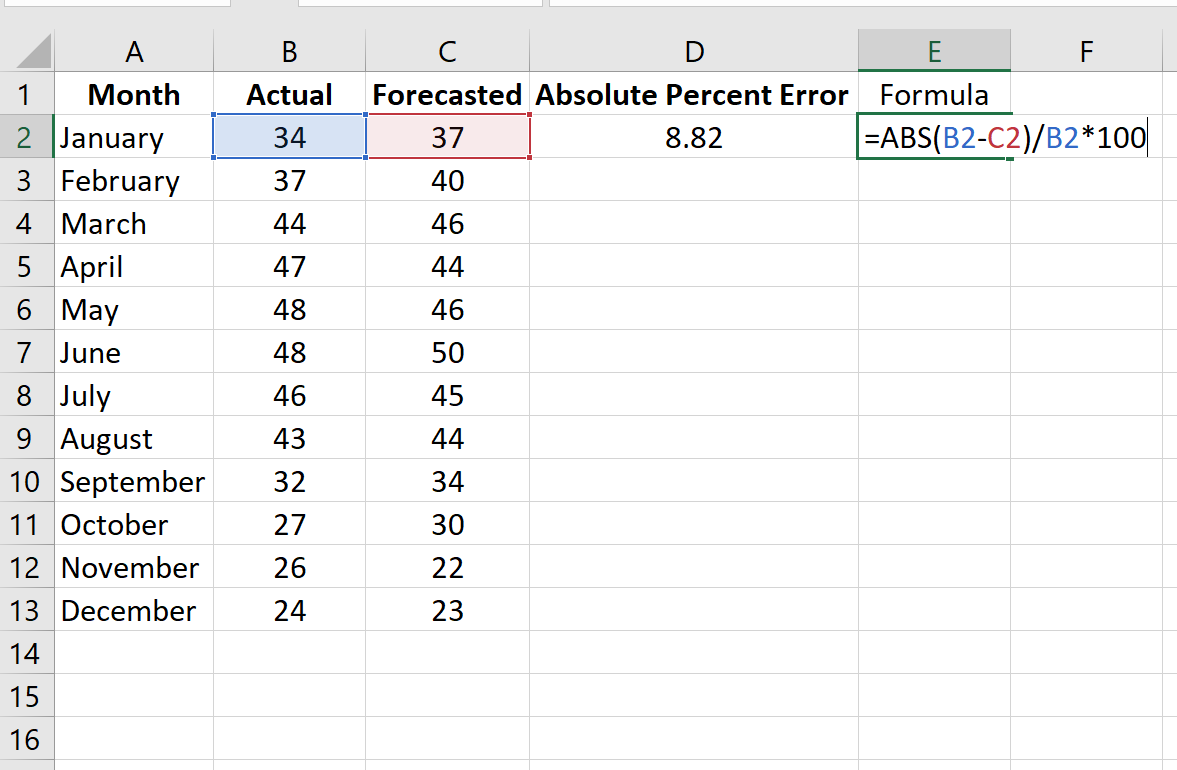
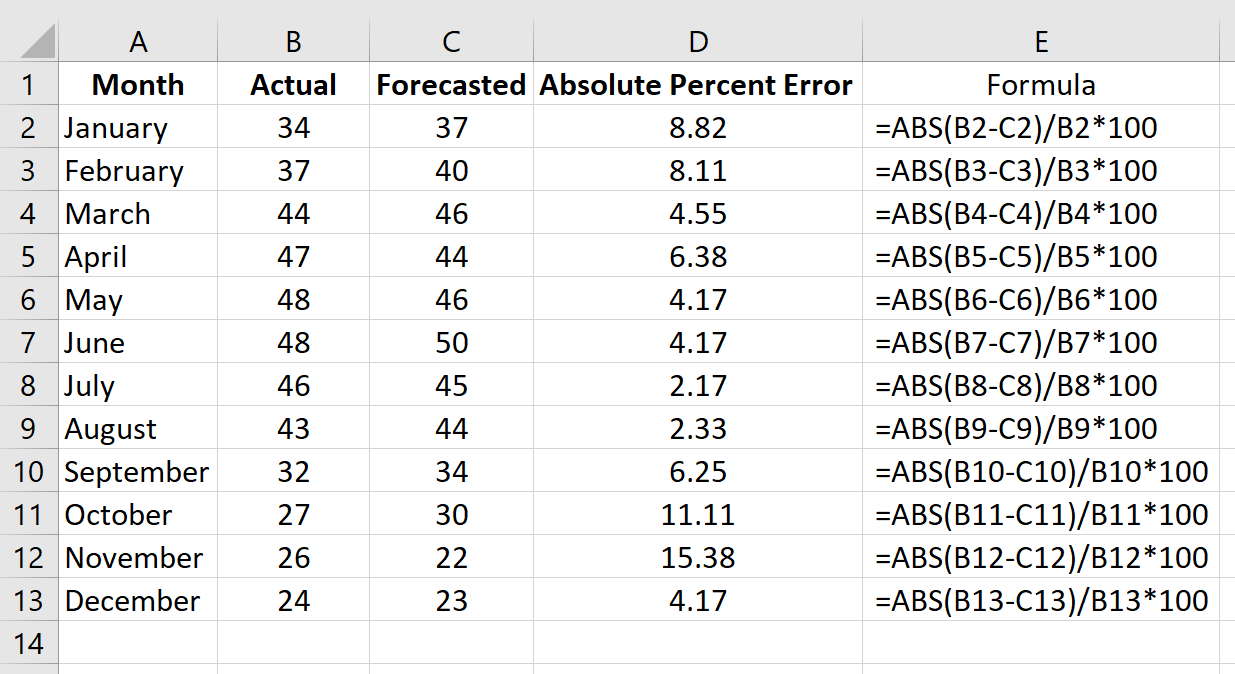
Повторим эту формулу для каждой строки:
Шаг 3: Рассчитайте среднюю абсолютную ошибку в процентах.
Рассчитайте MAPE, просто найдя среднее значение в столбце D:
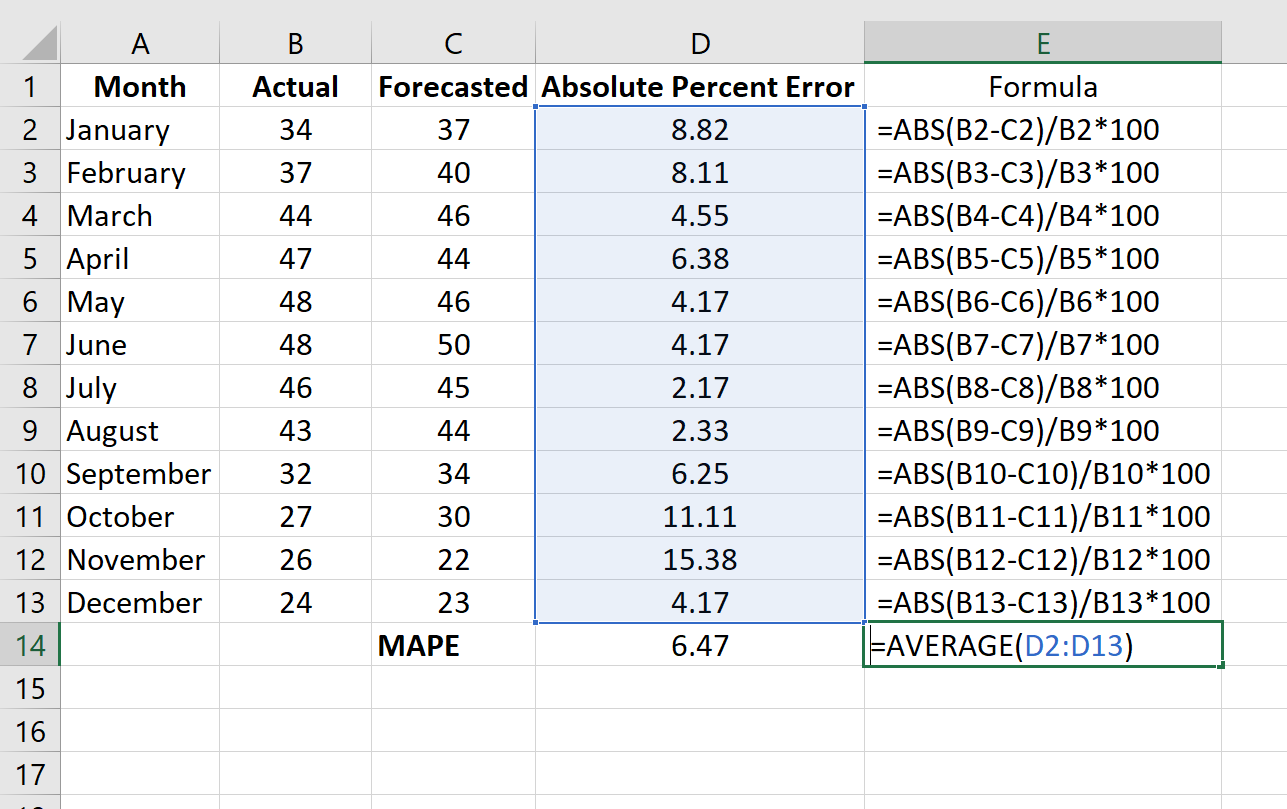
MAPE этой модели оказывается равным 6,47% .
Примечание по использованию MAPE
Хотя MAPE легко вычислить и легко интерпретировать, его использование имеет несколько потенциальных недостатков:
1. Поскольку формула для расчета абсолютной процентной ошибки |фактический-прогноз| / |фактическое| это означает, что он будет неопределенным, если какое-либо из фактических значений равно нулю.
2. MAPE не следует использовать с данными небольшого объема. Например, если фактический спрос на какой-либо товар равен 2, а прогноз равен 1, значение абсолютной процентной ошибки будет |2-1| / |2| = 50%, что создает впечатление, что ошибка прогноза довольно высока, несмотря на то, что прогноз отличается всего на одну единицу.
Другим распространенным способом измерения точности прогнозирования модели является MAD — среднее абсолютное отклонение. О том, как посчитать MAD в Excel, читайте здесь .
Дополнительные ресурсы
Что считается хорошей ценностью для MAPE?
Как рассчитать SMAPE в Excel
Как рассчитать MAE в Excel
 MAPE – средняя абсолютная ошибка в процентах используется:
MAPE – средняя абсолютная ошибка в процентах используется:
- Для оценки точности прогноза;
- Показывает на сколько велики ошибки в сравнении со значениями ряда;
- Хороша для сравнения 1-й модели для разных рядов;
- Используется для сравнения разных моделей для одного ряда;
- Оценки экономического эффекта, за счет повышения точности прогноза.
В данной статье мы рассмотрим, как рассчитать MAPE в Excel и как ее использовать.
Формула расчета MAPE:
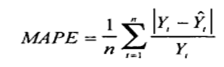
Где:
- Yt – фактический объем продаж за анализируемый период;
- Ŷt — значение прогнозной модели за аналазируемый период;
- n — количество периодов.
Для того, чтобы рассчитать среднюю абсолютную ошибку мы:
- Рассчитываем значение модели прогноза — Ŷt;
- Рассчитываем ошибку прогноза;
- Берем ошибку по модулю;
- Определяем абсолютную ошибку;
- Рассчитываем среднюю абсолютную ошибку в процентах — MAPE.
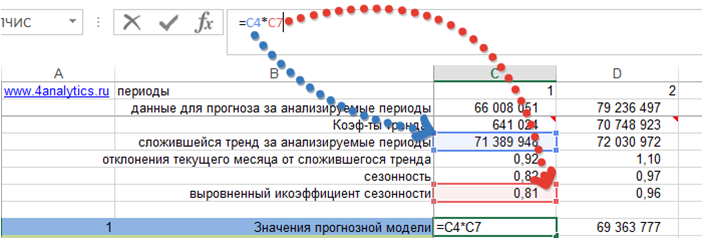
1. Рассчитаем значение модели прогноза — Ŷt
Возьмем модель с трендом и сезонностью. Рассчитаем значение модели для каждого периода, когда нам известны фактические продажи. Для этого сложившийся тренд за анализируемый период умножим на коэффициент сезонности для соответствующего месяца.
Получили значения прогнозной модели для каждого периода времени:
Подробнее о расчете прогноза с помощью тренда и сезонности читайте в статье «Расчет прогноза с помощью тренда и сезонности».
2. Рассчитаем значения ошибки прогноза.
В формуле расчета MAPE – это:
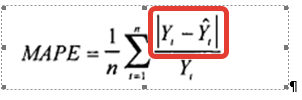
e — Ошибка прогноза — это разность между значениями временного ряда (фактом продаж) и моделью прогноза:
e= Yt — Ŷt
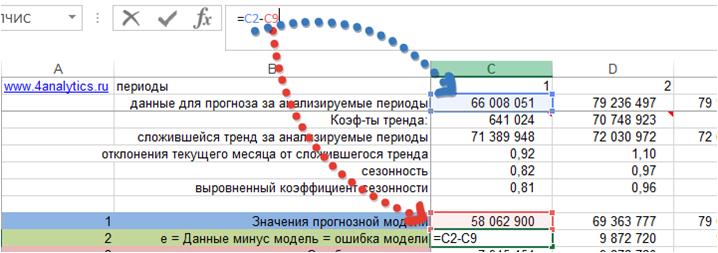
Получили значение ошибки прогноза для каждого момента времени за анализируемый период.
3. Рассчитаем ошибку по модулю.
Для этого воспользуемся функцией Excel =ABC()
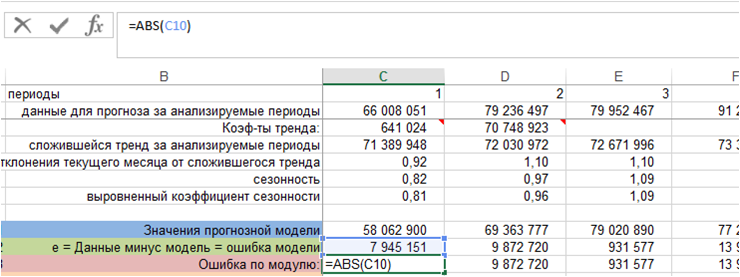
4. Определяем абсолютную ошибку.
Для каждого периода ошибку по модулю делим на фактические значения ряда, т.е. на фактический объем продаж:
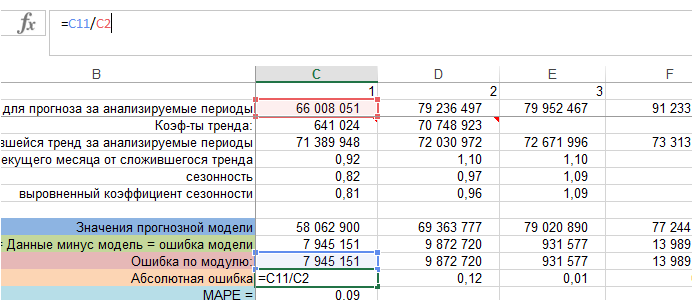
Получили абсолютную ошибку для каждого периода фактических продаж. В формуле MAPE — это:

5. Рассчитаем MAPE – среднюю абсолютную ошибку.
Для этого рассчитаем среднее значение абсолютной ошибки за все периоды:
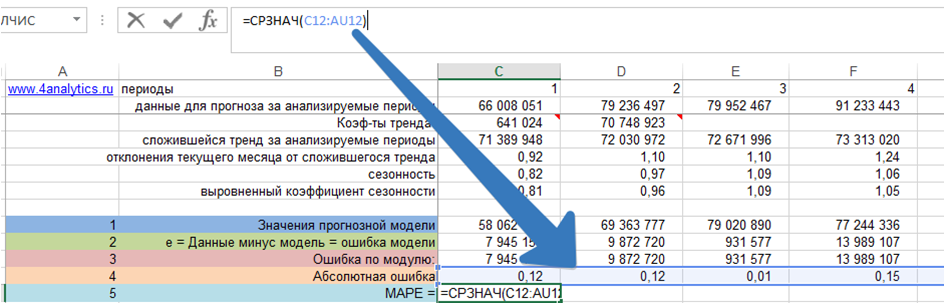
Скачать файл с примером расчета MAPE – средней абсолютной ошибки.
Как рассчитать показатель точность прогноза?
Показатель точность прогноза = 1 –MAPE:

С помощью MAPE вы можете сравнивать различные модели между собой, можете оценивать, как и на сколько модель делает точные прогнозы для разных временных рядов.
А также, что самое главное, можете оценить экономический эффект для компании за счет повышения точности прогноза.
Об этом подробнее можете почитать в нашей статье на сайте http://novoforecast.com/novo-forecast/instruktsiya/item/rost-tochnosti-prognoza-rost-pribyli.html
Если есть вопросы, пожалуйста, пишите в комментариях!
Forecast4AC PRO рассчитает MAPE для каждого временного ряда!
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
В статистике вы делаете прогнозы на основе имеющихся данных. К сожалению, прогнозы не всегда совпадают с фактическими значениями, сгенерированными данными. Знать разницу между прогнозами и фактическими значениями ваших данных полезно, поскольку это может помочь вам уточнить будущие прогнозы и сделать их более точными. Чтобы выяснить, насколько велика разница между вашими прогнозами и фактическим значением, вам необходимо вычислить среднюю абсолютную ошибку (также известную как MAE) данных.
Рассчитать SAE
Прежде чем вы сможете рассчитать MAE ваших данных, вам сначала необходимо рассчитать сумму абсолютных ошибок (SAE). Формула для SAE: Σ n i = 1 | x i — x t |, что может сначала показаться странным, если вы не привыкли к сигма-нотации. Однако фактическая процедура довольно проста.
-
Принять абсолютные значения
-
Повторите n раз
-
Добавить значения
Вычтите истинное значение (обозначенное как x t) из измеренного значения (обозначенное как x i), что может привести к отрицательному результату в зависимости от ваших точек данных. Возьмите абсолютное значение результата, чтобы сгенерировать положительное число. Например, если x i равно 5 и x t равно 7, 5-7 = -2. Абсолютное значение -2 (обозначенное как | -2 |) равно 2.
Повторите этот процесс для каждого набора измерений и прогнозов в ваших данных. Количество наборов обозначается в формуле n, где Σ n i = 1 указывая, что процесс начинается с первого набора (i = 1) и повторяется в общей сложности n раз. В предыдущем примере предположим, что предыдущие использованные точки были одной из 10 пар точек данных. В дополнение к 2, сгенерированным ранее, остальные наборы точек генерируют абсолютные значения 1, 4, 3, 4, 2, 6, 3, 2 и 9.
Добавьте абсолютные значения вместе, чтобы создать свой SAE. Например, это дает нам SAE = 2 + 1 + 4 + 3 + 4 + 2 + 6 + 3 + 2 + 9, что при суммировании дает нам SAE 36.
Рассчитать MAE
Как только вы вычислите SAE, вы должны найти среднее или среднее значение абсолютных ошибок. Используйте формулу MAE = SAE ÷ n, чтобы получить этот результат. Вы также можете увидеть две формулы, объединенные в одну, которая выглядит как MAE = (Σ n i = 1 | x i — x t |) ÷ n, но между ними нет функциональной разницы.
-
Разделить на n
-
Раунд по необходимости
Разделите ваш SAE на n, которое, как упоминалось выше, является общим количеством наборов баллов в ваших данных Продолжая предыдущий пример, получаем MAE = 36 ÷ 10 или 3, 6.
При необходимости округлите общее количество до заданного числа значащих цифр. В приведенном выше примере это не требуется, но для расчета, предусматривающего цифры, такие как MAE = 2.34678361, или повторяющиеся цифры, может потребоваться округление до чего-то более управляемого, например, MAE = 2.347. Количество используемых конечных цифр зависит от личных предпочтений и технических характеристик выполняемой вами работы.
Абсолютная и относительная погрешности (ошибки).
Пусть некоторая
величина x
измерена n
раз. В результате получен ряд значений
этой величины: x1,
x2,
x3,
…, xn
Величиной, наиболее
близкой к действительному значению,
является среднее арифметическое этих
результатов:
![]()
Отсюда следует,
что каждое физическое измерение должно
быть повторено несколько раз.
Разность между
средним значением
![]() измеряемой
измеряемой
величины и значением отдельного измерения
называется абсолютной
погрешностью отдельного измерения:
![]()
(13)
Абсолютная
погрешность может быть как положительной,
так и отрицательной и измеряется в тех
же единицах, что и измеряемая величина.
Средняя абсолютная
ошибка результата — это среднее
арифметическое значений абсолютных
погрешностей отдельных измерений,
взятых по абсолютной величине (модулю):
![]()
(14)
Отношения
![]()
называются относительными погрешностями
(ошибками) отдельных измерений.
Отношение средней
абсолютной погрешности результата
![]()
к среднему арифметическому значению
![]()
измеряемой величины называют относительной
ошибкой результата и выражают в процентах:
![]()
Относительная
ошибка характеризует точность измерения.
Законы распределения случайных величин.
Результат измерения
физической величины зависит от многих
факторов, влияние которых заранее учесть
невозможно. Поэтому значения, полученные
в результате прямых измерений какого
— либо параметра, являются случайными,
обычно не совпадающие между собой.
Следовательно, случайные
величины —
это такие величины, которые в зависимости
от обстоятельств могут принимать те
или иные значения. Если случайная
величина принимает только определенные
числовые значения, то она называется
дискретной.
Например,
количество заболеваний в данном регионе
за год, оценка, полученная студентом на
экзамене, энергия электрона в атоме и
т.д.
Непрерывная
случайная величина принимает любые
значения в данном интервале.
Например: температура
тела человека, мгновенные скорости
теплового движения молекул, содержание
кислорода в воздухе и т.д.
Под событием
понимается всякий результат или исход
испытания. В теории вероятностей
рассматриваются события, которые при
выполнение некоторых условий могут
произойти, а могут не произойти. Такие
события называются
случайными.
Например, событие, состоящее в появлении
цифры 1 при выполнении условия — бросания
игральной кости, может произойти, а
может не произойти.
Если событие
неизбежно происходит в результате
каждого испытания, то оно называется
достоверным.
Событие называется невозможным,
если оно вообще не происходит ни при
каких условиях.
Два события,
одновременное появление которых
невозможно, называются несовместными.
Пусть случайное
событие А в серии из n
независимых испытаний произошло m
раз, тогда отношение:
![]()
называется
относительной частотой события А. Для
каждой относительной частоты выполняется
неравенство:
![]()
При небольшом
числе опытов относительная частота
событий в значительной мере имеет
случайный характер и может заметно
изменяться от одной группы опытов к
другой. Однако при увеличении числа
опытов частота событий все более теряет
свой случайный характер и приближается
к некоторому постоянному положительному
числу, которое является количественной
мерой возможности реализации случайного
события А. Предел, к которому стремится
относительная частота событий при
неограниченном увеличении числа
испытаний, называется статистической
вероятностью события:
![]()
Например, при
многократном бросании монеты частота
выпадения герба будет лишь незначительно
отличаться от ½. Для достоверного события
вероятность Р(А) равна единице. Если
Р=0, то событие невозможно.
Математическим
ожиданием
дискретной случайной величины называется
сумма произведений всех ее возможных
значений хi
на вероятность этих значений рi:
![]()
Статистическим
аналогом математического ожидания
является среднее арифметическое значений
![]() :
:
![]() ,
,
где mi
— число дискретных случайных величин,
имеющих значение хi.
Для непрерывной
случайной величины математическим
ожиданием служит интеграл:
![]() ,
,
где р(х) — плотность
вероятности.
Отдельные значения
случайной величины группируются около
математического ожидания. Отклонение
случайной величины от ее математического
ожидания (среднего значения) характеризуется
дисперсией,
которая для дискретной случайной
величины определяется формулой:
![]()
(15)

(16)
Дисперсия имеет
размерность случайной величины. Для
того, чтобы оценивать рассеяние
(отклонение) случайной величины в
единицах той же размерности, введено
понятие среднего
квадратичного отклонения
σ(Х), которое
равно корню квадратному из дисперсии:
![]()
(17)
Вместо среднего
квадратичного отклонения иногда
используется термин «стандартное
отклонение».
Всякое отношение,
устанавливающее связь между всеми
возможными значениями случайной величины
и соответствующими им вероятностями,
называется законом
распределения случайной величины.
Формы задания закона распределения
могут быть разными:
а) ряд распределения
(для дискретных величин);
б) функция
распределения;
в) кривая распределения
(для непрерывных величин).
Существует
относительно много законов распределения
случайных величин.
Нормальный
закон распределения случайных
величин (закон
Гаусса).
Случайная величина
![]()
распределена по
нормальному закону, если ее плотность
вероятности f(x)
определяется формулой:

(18),
где <x>
— математическое ожидание (среднее
значение) случайной величины <x>
= M
(X);
![]() —
—
среднее квадратичное отклонение;
![]() —
—
основание натурального логарифма
(неперово число);
f
(x)
– плотность вероятности (функция
распределения вероятностей).
Многие случайные
величины (в том числе все случайные
погрешности) подчиняются нормальному
закону распределения (закону Гаусса).
Для этого распределения наиболее
вероятным значением
измеряемой
величины
является
её среднее
арифметическое
значение.
График нормального
закона распределения изображен на
рисунке (колоколообразная кривая).

Кривая симметрична
относительно прямой х=<x>=α,
следовательно, отклонения случайной
величины вправо и влево от <x>=α
равновероятны. При х=<x>±
кривая асимптотически приближается к
оси абсцисс. Если х=<x>,
то функция распределения вероятностей
f(x)
максимальна и принимает вид:
![]()
(19)
Таким образом,
максимальное значение функции fmax(x)
зависит от величины среднего квадратичного
отклонения. На рисунке изображены 3
кривые распределения. Для кривых 1 и 2
<x>
= α = 0 соответствующие значения среднего
квадратичного отклонения различны, при
этом 2>1.
(При увеличении
кривая распределения становится более
пологой, а при уменьшении
– вытягивается вверх). Для кривой 3 <x>
= α ≠ 0 и 3
= 2.
Закон
распределения
молекул в газах по скоростям называется
распределением
Максвелла.
Функция плотности вероятности попадания
скоростей молекул в определенный
интервал
![]()
теоретически была определена в 1860 году
английским физиком Максвеллом

. На рисунке
распределение Максвелла представлено
графически. Распределение движется
вправо или влево в зависимости от
температуры газа (на рисунке Т1
< Т2).
Закон распределения Максвелла определяется
формулой:
![]()
(20),
где mо
– масса молекулы, k
– постоянная Больцмана, Т – абсолютная
температура газа,
![]() —
—
скорость молекулы.
Распределение
концентрации молекул газа в атмосфере
Земли (т.е.
в силовом поле) в зависимости от высоты
было дано австрийским физиком Больцманом
и называется
распределением
Больцмана:

(21)
Где n(h)
– концентрация молекул газа на высоте
h,
n0
– концентрация у поверхности Земли, g
– ускорение свободного падения, m
– масса молекулы.

Распределение
Больцмана.
Совокупность всех
значений случайной величины называется
простым
статистическим рядом.
Так как простой статистический ряд
оказывается большим, то его преобразуют
в вариационный
статистический
ряд или интервальный
статистический ряд. По интервальному
статистическому ряду для оценки вида
функции распределения вероятностей по
экспериментальным данным строят
гистограмму
– столбчатую
диаграмму. (Гистограмма – от греческих
слов “histos”–
столб и “gramma”–
запись).
n

-
h
Гистограмма
распределения Больцмана.
Для построения
гистограммы интервал, содержащий
полученные значения случайной величины
делят на несколько интервалов xi
одинаковой ширины. Для каждого интервала
подсчитывают число mi
значений случайной величины, попавших
в этот интервал. После этого вычисляют
плотность частоты случайной величины
![]()
для каждого интервала xi
и среднее значение случайной величины
<xi
> в каждом интервале.
Затем по оси абсцисс
откладывают интервалы xi,
являющиеся основаниями прямоугольников,
высота которых равна
![]() (или
(или
высотой
![]()
– плотностью относительной частоты
![]() ).
).
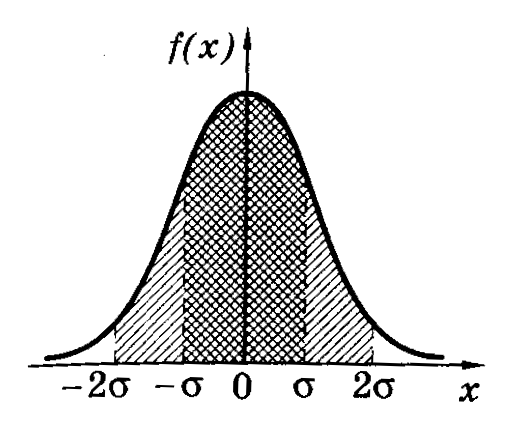
Расчетами показано,
что вероятность попадания нормально
распределенной случайной величины в
интервале значений от <x>–
до <x>+
в среднем равна 68%. В границах вдвое
более широких (<x>–2;
<x>+2)
размещается в среднем 95% всех значений
измерений, а в интервале (<x>–3;<x>+3)
– уже 99,7%. Таким образом, вероятность
того, что отклонение значений нормально
распределенной случайной величины
превысит 3
(
– среднее квадратичное отклонение)
чрезвычайно мала (~0,003). Такое событие
можно считать практически невозможным.
Поэтому границы <x>–3
и <x>+3
принимаются за границы практически
возможных значений нормально распределенной
случайной величины («правило трех
сигм»).
Если число измерений
(объем выборки) невелико (n<30),
дисперсия вычисляется по формуле:
![]()
(22)
Уточненное среднее
квадратичное отклонение отдельного
измерения вычисляется по формуле:

(23)
Напомним, что для
эмпирического распределения по выборке
аналогом математического ожидания
является среднее арифметическое значение
<x>
измеряемой величины.
Чтобы дать
представление о точности и надежности
оценки измеряемой величины, используют
понятия доверительного интервала и
доверительной вероятности.
Доверительным
интервалом
называется интервал (<x>–x,
<x>+x),
в который по определению попадает с
заданной вероятностью действительное
(истинное) значение измеряемой величины.
Доверительный интервал характеризует
точность полученного результата: чем
уже доверительный интервал, тем меньше
погрешность.
Доверительной
вероятностью
(надежностью)
результата серии измерений называется
вероятность того, что истинное значение
измеряемой величины попадает в данный
доверительный интервал (<x>±x).
Чем больше величина доверительного
интервала, т.е. чем больше x,
тем с большей надежностью величина <x>
попадает в этот интервал. Надежность
выбирается самим исследователем
самостоятельно, например, =0,95;
0,98. В медицинских и биологических
исследованиях, как правило, доверительную
вероятность (надежность) принимают
равной 0,95.
Если величина х
подчиняется нормальному закону
распределения Гаусса, а <x>
и <>
оцениваются по выборке (числу измерений)
и если объем выборки невелик (n<30),
то интервал (<x>
– t,n<>,
<x>
+ t,n<>)
будет доверительным интервалом для
известного параметра х с доверительной
вероятностью .
Коэффициент t,n
называется коэффициентом
Стьюдента
(этот коэффициент был предложен в 1908 г.
английским математиком и химиком В.С.
Госсетом, публиковавшим свои работы
под псевдонимом «Стьюдент» – студент).
Значении коэффициента
Стьюдента t,n
зависит от доверительной вероятности
и числа измерений n
(объема выборки). Некоторые значения
коэффициента Стьюдента приведены в
таблице 1.
Таблица 1
|
n |
|
||||||
|
0,6 |
0,7 |
0,8 |
0,9 |
0,95 |
0,98 |
0,99 |
|
|
2 |
1,38 |
2,0 |
3,1 |
6,3 |
12,7 |
31,8 |
63,7 |
|
3 |
1,06 |
1,3 |
1,9 |
2,9 |
4,3 |
7,0 |
9,9 |
|
4 |
0,98 |
1,3 |
1,6 |
2,4 |
3,2 |
4,5 |
5,8 |
|
5 |
0,94 |
1,2 |
1,5 |
2,1 |
2,8 |
3,7 |
4,6 |
|
6 |
0,92 |
1,2 |
1,5 |
2,0 |
2,6 |
3,4 |
4,0 |
|
7 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,1 |
3,7 |
|
8 |
0,90 |
1,1 |
1,4 |
1,9 |
2,4 |
3,0 |
3,5 |
|
9 |
0,90 |
1,1 |
1,4 |
1,9 |
2,3 |
2,9 |
3,4 |
|
10 |
0,88 |
1,1 |
1,4 |
1,9 |
2,3 |
2,8 |
3,3 |
В таблице 1 в верхней
строке заданы значения доверительной
вероятности
от 0,6 до 0,99, в левом столбце – значение
n.
Коэффициент Стьюдента следует искать
на пересечении соответствующих строки
и столбца.
Окончательный
результат измерений записывается в
виде:
![]()
(25)
Где
![]()
– полуширина доверительного интервала.
Результат серии
измерений оценивается относительной
погрешностью:

(26)
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #