Статья давно не обновлялась, поэтому информация могла устареть.
Содержание
- 1 Как выявить аппаратную проблему с сервером?
- 2 Сервер не отвечает на запросы
- 3 Проверка состояния жестких дисков
- 4 SATA/SAS
- 5 SSD
- 6 Правила подачи запроса в службу поддержки
- 6.1 Информация, необходимая для подачи запроса:
- 6.2 Пример запроса
- 7 Возможности по диагностированию оперативной памяти
- 8 Заключение
Как выявить аппаратную проблему с сервером?
В данной статье мы рассмотрим выявление и диагностирование сбойных винчестеров, возможности для проверки оперативной памяти, так же рассмотрим подачу заявки в службу технической поддержки.
Анализируя запросы в службу поддержки, связанные с аппаратными проблемами на выделенных серверах, можно резюмировать следующее: большинство клиентов просто не умеют правильно идентифицировать проблему, возникшую на сервере, а так же составить четкий запрос специалистам компании.
Помочь клиентам в этом вопросе и будет являться целью данной статьи. Во множестве заявок клиент не указывает всей необходимой информации о сервере, выяснение которой затягивает решение вопросов.
Сервер, являясь электронным прибором, может рано или поздно выйти из строя. Любой современный электронный прибор, и сервер в частности, построен на модульном принципе, что имеет множество преимуществ: взаимозаменяемость, быстрая замена и диагностика без применения специального оборудования. При выходе сервера из эксплуатации, эти преимущества играют огромную роль.
Сервер не отвечает на запросы
Наиболее типичной является ситуация, когда сервер перестает отвечать на запросы. Перед тем, как написать запрос в службу технической поддержки, следует провести следующие диагностические мероприятия:
Для начала необходимо перезагрузить сервер, используя панель управления DCImanager, «Перезагрузить».
Если сервер не загрузился, по прошествии некоторого времени, следует запросить IP-KVM для того, чтобы иметь доступ к консоли сервера и видеть вывод ошибок.
Возможно, идет проверка файловой системы, при худшем раскладе – на консоли ошибки “kernel panic”, ошибки “disk boot failure, insert system disk and press enter”, темный экран. В первом случае вам просто следует подождать, сервер «поднимется». Во втором случае желательно обратиться к техническим специалистам компании.
После загрузки сервера, необходимо проверить состояние винчестеров.
Проверка состояния жестких дисков
В этом поможет технология SMART, встроенная в современные диски. Она позволяет оценить состояние и предсказать выход диска из стоя. Доступ к данным, предоставляемым технологией SMART, осуществляется различными утилитами. В ОС семейства FreeBSD и Linux это – smartctl входящая в пакет утилит smartmontools, адрес официального сайта: http://sourceforge.net/apps/trac/smartmontools/.
Чтобы установить пакет воспользуйтесь командой для вашего дистрибутива ОС:
* для Centos/Redhat: yum install -y smartmontools * для Debian/Ubuntu: apt-get install -y smartmontools * для FreeBSD: make -C /usr/ports/sysutils/smartmontools/ install clean
Проверяем диск так:
# smartctl -a /dev/sda
Имя диска может отличаться и быть одним из следующих:
- /dev/ada0
- /dev/sda
- /dev/sdb
Виртуальный сервер на виртуализации KVM имеет диски /dev/vda
smartctl -a /dev/УСТРОЙСТВО
Например, для FreeBSD команда может выглядеть так:
smartctl -a /dev/ad1
а для Linux так:
smartctl -a /dev/sda
Детальное описание можно посмотреть на официальном сайте проекта smartmontools , описание атрибутов на русском языке на Википедии.
Получив данные SMART с диска, следует обратить внимание на следующие показатели:
SATA/SAS
Reallocated Sectors Count — Показывает количество переназначенных секторов (remaping). Большое число свидетельствует о проблемах с поверхностью дисков. Можно считать ключевым параметром при оценке состояния диска, особенно при постоянном увеличении данного параметра.
Current Pending Sector Count — Текущее количество нестабильных секторов. Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает претендентами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка претендентов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped). Постоянно ненулевое значение raw value этого атрибута говорит о низком качестве (отдельной зоны) поверхности диска.
Uncorrectable Sector Count — Количество нескорректированных ошибок. Атрибут показывает общее количество ошибок, возникших при чтении/записи сектора и которые не удалось скорректировать. Рост значения в поле raw value этого атрибута указывает на явные дефекты поверхности и/или проблемы в работе механики накопителя.
Рассмотрение остальных параметров имеет менее важное значение и не входит в рамки данной статьи. Более детальное описание есть на ресурсе, указанном выше.
В качестве примера рассмотрим вывод утилиты smartctl
В данном случае наблюдается большое значение параметра “Reallocated Sectors Count” указывающее на возможное наличие сбойных секторов(bad blocks) и “Seek_Error_Rate” – ошибки позиционирования считывающих головок диска. В данном примере диск можно считать сбойным и в ближайшее время, возможен выход его из строя.
Как показывает наш опыт в случае если значения Uncorrectable Sector Count, Current Pending Sector Count, UDMA_CRC_Error_Count больше нуля, то жесткий диск требует срочной замены.
Так же будет полезно провести тест диска:
smartctl --test=short /dev/sda
Следить за процессом и посмотреть результат можно командой:
smartctl -a /dev/sda | grep -A1 "Test_Description"
Если нужной информации не отобразилось, то просмотрите полный вывод команды:
smartctl -a /dev/sda
SSD
Основной показатель здоровья диска:
233 Media_Wearout_Indicator
Media Wearout Indicator — эта переменная напрямую указывает на износ диска. Счётчик имеет ненулевое значение в начале (100), и уменьшается со временем. При достижении некоего определённого производителем порогового значения, диск признается изношенным и переходит в read-only режим.
Если его значение упало ниже 10, значит пора диск менять.
Так же стоит обращать внимание на:
5 Reallocated_Sector_Ct
При оценке состояния жестких дисков очень важно делать проверку не при возникновении проблем, а с достаточной для оперативной реакции периодичностью. Поможет в этом демон мониторинга жестких дисков smatrd. Его настройка не составит больших трудностей, т.к. он очень хорошо документирован на официальном сайте проекта (см. http://smartmontools.sourceforge.net/man/smartd.8.html и http://smartmontools.sourceforge.net/man/smartd.conf.5.html). Процедура не займет много времени, но при этом позволит всегда знать в каком состоянии находятся жесткие диски ваших серверов, а при появлении ошибок позволит вовремя принять меры и предотвратить потерю данных.
Получив и проанализировав показатели SMART, необходимо написать запрос в службу технической поддержки. Правильно составленный запрос облегчает работу специалистов и уменьшает время реакции.
Правила подачи запроса в службу поддержки
Информация, необходимая для подачи запроса:
- Идентификационные данные сбойного диска, при невозможности извлечения, данные о целом диске. Информация будет передана техническим сотрудникам в ДЦ, которые будут заниматься заменой сбойного диска.
- Результат выполнения команды smartctl -a на проблемном жестком диске.
- Данные доступа на сервер, для подтверждения состояния дисков сотрудниками компании.
Сообщения, не содержащие данной информации не могут быть приняты к рассмотрению.
Работа утилиты smartctl. Для определения данных о сбойном диске необходим следующий блок информации:
=== START OF INFORMATION SECTION === Model Family: Seagate Momentus 5400.3 series Device Model: ST9120822AS Serial Number: 5LZ71TKQ Firmware Version: 3.ALC User Capacity: 120 034 123 776 bytes Device is: In smartctl database [for details use: -P show] ATA Version is: 7 ATA Standard is: Exact ATA specification draft version not indicated Local Time is: Mon Oct 15 06:52:24 2012 IRKT SMART support is: Available - device has SMART capability. SMART support is: Enabled
Пример запроса
Рассмотрим небольшой пример переписки воображаемого клиента К с сотрудником технической поддержки С:
К: У меня вышел из строя диск.В приложении файл с результатом работы команды smartctl -a. Можете произвести замену? С: Да, мы можем заменить ваш диск. Для этого нам необходимы данные целого диска(серийный номер) или доступ на сервер. К: Вот номер целого – 000000000, доступ к серверу — root:PASSWORD С: Работы выполнены, диск заменен.
Данный диалог можно сократить до запроса о замене диска и ответа о выполнении работ:
Прошу заменить сбойный диск Serial Number: 5LZ71TKQ, Device Model: ST9120822AS. В приложении файл с результатом работы команды smartctl -a Доступ к серверу — root:PASSWORD
Такой запрос будет выполнен сотрудниками технической поддержки без дополнительных уточняющих вопросов, что сокращает время выполнения заявки и экономит рабочее время сотрудников технической поддержки.
Возможности по диагностированию оперативной памяти
Данная проблема может проявляться неявно и решение проблемы затянется. Примером могут быть случаи с выходом из строя отдельных ячеек памяти. Сбои в работе сервера будут происходить не часто или проявляться как ошибки чтения/записи по адресу памяти без выхода из строя сервера.
Диагностика данной проблемы проводится тестом Memtest, официальный сайт проекта — http://www.memtest.org/. Идея данного теста проста — проверка ячеек памяти чтением/записью значений, от простого к сложному. Запуск теста можно сделать, заказав IP-KVM и подключение образа с Memtes’ом в техподдержке (нужно будет загрузиться с этого образа). При наличии проблем с памятью, вероятнее всего, тест пройден не будет, что будет отображено на экране (в какой ячейке и при записи какого значения произошел сбой).
Примечание: Тестирование идет в цикле и его завершение производится вручную. Нужно, чтобы было проведено минимум 3-4 круга тестирования (определяется значением параметра Pass - между Test и Errors).
После выявления проблемы с памятью пишем запрос в службу технической поддержки. В запросе необходимо приложить снимок экрана с ошибкой. Сообщения, не содержащие данной информации не могут быть приняты к рассмотрению. Если ваш провайдер не предоставляет доступ в панель DCImanager, то вам следует сразу написать обращение в службу поддержки с просьбой провести данный тест. При подтверждении ошибки, память будет заменена.
Заключение
Вместо заключения хотелось бы сказать следующее: проблемы выхода винчестеров из строя — явление прогнозируемое и в этом может помочь сервис мониторинга состояния диска smartd, так же включенный в пакет smartmontools . Его настройка и использование неоднократно рассматривались в интернете и не входит в рамки данной статьи. Использование клиентами этого средства мониторинга может спасти от нежелательной потери данных.
Проблемы оперативной памяти — явление непредсказуемое и спонтанное. Выход её из строя не грозит потерей информации, однако вызывает простои в эксплуатации.
И последнее — желаем вам, чтобы ваши сервера не ломались, а обращений в службу технической поддержки по данной тематике было меньше.
Время на прочтение
8 мин
Количество просмотров 7.4K

Привет, Хабр! Меня зовут Данил, я системный инженер, работаю с серверами и клиентским оборудованием в дата-центре Selectel в Дубровке (Ленобласть). Бывают ситуации, когда диски в серверах работают некорректно. В таком случае нужно быстро определить причину, понять, на чьей она стороне, и исправить проблему.
Под катом расскажу, с какими дисками и как мы работаем в Selectel, а также поделюсь советами, как ускорить решение проблем с накопителем.
Небольшой дисклеймер. В тексте мы говорим о работе с дисками в выделенных серверах Selectel — всех, кроме линейки Chipcore.
Какие диски мы используем в Selectel и их особенности работы в дата-центре
Для начала я коротко расскажу о том, какие виды дисков мы используем в выделенных серверах.
HDD SATA (жесткий диск) — запоминающее устройство, работающее на принципе магнитной записи. Самый распространенный вид носителя и дешевый относительно стоимости за 1 ГБ. Существенно проигрывает по скорости записи и чтения данных твердотельным накопителям. Используется интерфейс SATA.
Когда-то в Selectel были доступны HDD-диски с интерфейсом SAS, но сейчас их уже не заказать. Но у нас еще остались клиенты, которые используют такие диски, и мы продолжаем обслуживать серверы с ними.
HDD SAS — жесткие диски с интерфейсом подключения SAS. Как и в случае NVMe U.2, такие диски подключаются в специальный корпус с поддержкой SAS. SAS-интерфейс обратно совместим с SATA, что дает подключать в такой корпус SATA-диски.
SSD SATA — твердотельный накопитель, в котором нет движущихся частей. В основном использует флеш-память. Имеют гораздо большую скорость производимых операций, но в то же время меньшую износоустойчивость, чем HDD.
SSD NVMe PCIe подключаются напрямую в матплату через интерфейс PCI Express x4. Из-за этого таких дисков можно подключить меньше, чем тех же NVMe U.2. Также для данных дисков нет возможности подключения к RAID-контроллеру.
SSD NVMe U.2 — твердотельный накопитель форм-фактора 2.5” с разъемом для подключения U.2. На вид данный диск очень похож на обычный SSD SATA, но имеет другой порт подключения, не совместимый с SATA. При этом SATA-диск можно подключить к разъему U.2. Обладает гораздо большей скоростью записи/чтения по сравнению с SSD SATA.
Преимущества SSD NVMe U.2 перед NVMe PCIe в том, что есть возможность выполнения горячей замены и подключение большого количества дисков, не занимая при этом слоты PCIe на материнской плате. Также такие диски можно подключить к RAID-контроллеру. Если вы хотите добавить SSD NVMe U.2 к в уже имеющийся сервер произвольной конфигурации, необходимо уточнить, если ли в наличии корпус с разъемами U.2 и поддерживает ли материнская плата подключение данных накопителей.

Дисковые корзины
Накопители HDD SATA, SSD SATA и SSD NVMe U.2 подключаются к серверам через дисковые корзины.
Дисковая корзина — это модуль, который используется для подключения определенного количества дисков к серверу. Корзины позволяют легко выполнить подключение или отключение диска в работающем сервере без отключения, вскрытия корпуса и снятия из стойки. То есть выполнить «горячую» замену без даунтайма.

Корзина для диска, форм-фактор 3.5”.
Каждый производитель корпусов использует свои корзины, которые не совместимы с корпусами конкурентов.

Переходник для диска 2.5”.

HDD-диск, прикрученный к корзине.

SSD-диск, прикрученный к корзине.
Другая ситуация с SSD NVMe PCIe. Этот диск подключается напрямую в матплату, поэтому его без отключения сервера, снятия из стойки и вскрытия корпуса не заменить. К слову, эти диски используются довольно редко, и экстренно менять их на практике мне не доводилось. Единственный раз был связан с плановым апгрейдом сервера клиента и согласованным даунтаймом.
Проблемы в работе диска. Что делать?
При обнаружении проблем с накопителем стоит выполнить первичную диагностику и сообщить результаты в тикет-систему. В случае выявления аппаратной неисправности инженеры дата-центра подготовят накопитель и согласуют этапы проведения замены.
Первичную диагностику можно выполнить средствами ОС или через Rescue.
Rescue — образ LiveCD, основанный на Arch Linux c набором утилит для диагностики, который загружается в оперативную память. Более подробно о Rescue можно прочитать по ссылке.
Если накопитель не инициализируется в ОС, то по обратной связи инженер дата-центра выполняет переподключение диска. Далее принимается решение о неисправности накопителя.
Существует несколько способов выявить неисправность накопителя:
- проверить SMART показатели,
- оценить заявленную производительность модели накопителя с текущей,
- проанализировать ошибки в журналах событий.
С первыми двумя пунктами ознакомимся более подробно.
Проверка диска SMART
Основным методом оценки неисправности диска является значения атрибутов SMART — технологии оценки состояния жесткого диска встроенной аппаратурой самодиагностики. Более подробно с атрибутами можно ознакомиться по ссылке.
Для просмотра показателей SMART конкретного накопителя потребуется пакет smartmontools. Для ОС Windows его можно найти по ссылке.
Рассмотрим, как вывести информацию о диске на практике.
Для вывода модели с серийным номером и списка атрибутов достаточно ввести следующую команду:
smartctl -iA /dev/sdX, где X — идентификатор накопителяПример вывода команды
=== START OF INFORMATION SECTION ===
Model Family: <Model Family>
Device Model: <Device Model>
Serial Number: <Serial Number>
LU WWN Device Id: 5 0014ee 058ae9c5c
Firmware Version: 01.01S02
User Capacity: 500 107 862 016 bytes [500 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Device is: In smartctl database 7.3/5254
ATA Version is: ATA8-ACS (minor revision not indicated)
SATA Version is: SATA 3.0, 3.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Fri Sep 23 11:49:58 2022 RTZ
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 3
3 Spin_Up_Time 0x0027 141 140 021 Pre-fail Always - 3950
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 24
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 065 065 000 Old_age Always - 26190
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 22
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 20
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 3
194 Temperature_Celsius 0x0022 117 107 000 Old_age Always - 26
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
При наличии RAID-контроллера команда может быть следующего вида:
smartctl -iA -d megaraid,2 /dev/sdaПодробнее в manual smartctl.
Также с помощью данной утилиты можно выполнить тестирование или произвести полный вывод с журналом событий о ошибках. Например:
smartctl --test=long /dev/sda — команда запуска теста
smartctl -l selftest /dev/sda — команда вывода результатов тестаПример вывода команды
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 26190
smartctl -x /dev/sda — полный вывод информации о дискеПри принятии решения о замене мы ориентируемся на базовые атрибуты и атрибуты конкретной модели накопителя. Также необходимо отметить, что значения определяются по параметрам RAW_VALUE или VALUE в зависимости от атрибута.
Базовые атрибуты для HDD-дисков
*при превышении этого значения диск не становится неисправным — цифра установлена Selectel. После 5 лет эксплуатации требуется замена диска согласно внутренним регламентам.
При росте значений параметров 199 UltraDMA CRC Error Count и 200 Multi_Zone_Error_Rate проявляются проблемы на уровне интерфейса. В данном случае проверяем корректность подключения дисков SATA.
Базовые атрибуты для SSD-дисков
Также существуют атрибуты модели, которые можно узнать на официальном сайте конкретного производителя.
Проверка скорости чтения
Еще один немаловажный параметр — это скорость работы диска.
Заявленную скорость можно посмотреть на официальном сайте производителя. Учитывайте, что реальная скорость может отличаться от заявленной производителем. Чтобы быстро проверить скорость чтения, можно воспользоваться утилитой hdparm (для Linux):
hdparm -Tt /dev/sdaТакже можно произвести полноценное нагрузочное тестирование с помощью утилиты fio, оценив показатели IOPS. Подробнее можно почитать здесь.
Как правильно составить обращение к провайдеру
Корректная формулировка тикета позволит быстрее решить проблему.
Сотрудникам техподдержки не придется задавать дополнительные вопросы, а значит, инженер скорее получит нужную информацию и приступит к решению проблемы.
В заголовке тикета укажите суть проблемы (в нашем случае — неисправен диск) и ID сервера.
В теле тикета необходимо добавить следующую информацию:
- Название и ID сервера.
- Буквенное обозначение (идентификатор в ОС) и серийный номер неисправного диска. Если диск перестал определяться в системе, то необходимо написать S/N всех “здоровых” накопителей.
- Приложить показатели SMART, выводы скорости записи/чтения, описать другие ошибки, связанные с диском.

Пример тикета
Тикет у инженера
Анализ информации
После получения данных инженер их анализирует.
Для проверки SMART мы в Selectel используем самописного бота в Telegram. Боту отправляется полный вывод команды smartctl. Он, в свою очередь, в зависимости от типа диска и вендора проверяет определенные атрибуты и выносит «приговор» — подлежит ли данный диск замене. Именно поэтому мы всегда рекомендуем отправлять вывод SMART текстом, а не скрином :).

Телеграм-бот для проверки SMART
Подготовка диска
Если неисправность диска подтверждается, то инженер приступает к подготовке носителя для замены. Для быстрого решения проблемы такие диски находятся на складе в определенном месте — они уже проверены и готовы к добавлению в сервер. Инженеру остается накрутить нужную корзину и согласовать с клиентом время замены.
Идентификация проблемного диска
Перед заменой клиенту необходимо вывести диск из RAID-массива (если массив используется) и «подсветить».
Существует несколько способов подсветки диска в Linux:
- Самый простой способ — воспользоваться встроенной утилитой dd:
dd if=/dev/sdX of=/dev/null bs=4M, где Х — идентификатор диска - Вариант с использованием libstoragemgmt:
Включить fault led ячейки —
ledon /dev/sdX
Выключить fault led ячейки —ledoff /dev/sdX - Утилита ledctl:
Включить —
ledctl locate=/dev/sdX
Выключить —ledctl locate_off=/dev/sdX
Если диски подключены к RAID-контроллеру, подсветка включается через утилиты вендора — например arcconf, storcli.
После этого необходимо сообщить в тикете о включении индикации. Инженер Selectel со своей стороны смотрит индикацию на дисках, определяет нужный диск и просит клиента остановить действие подсветки. Так он убеждается, что неисправный диск определен верно.
Далее инженер выполняет замену диска и сообщает об этом клиенту, чтобы тот проверил, определился ли новый диск в ОС.
Бывают случаи, что индикация не срабатывает на корзине. В такой ситуации замену диска можно выполнить только с отключением сервера, то есть даунтаймом.
Мы заменили диск. Что дальше?
Самая сложная часть позади. Клиент может продолжать пользоваться своим сервером.
Неисправный диск инженер передает в отдел сборки. Там его полностью очищают от данных с помощью специальных программ.
Далее может произойти два варианта развития событий:
- Если на диск еще действует гарантия, он будет отправлен поставщику.
- Диск можно будет вылечить с помощью специального ПО.
Если первые два варианта не подошли — например, носитель не записывает информацию и не подлежит ремонту, он будет ждать утилизации. Неисправные диски из Аттестованного ЦОД уничтожаются с помощью специального устройства.

Устройство для уничтожения дисков
Если вам понравился этот текст, советуем также почитать:
→ Как Selectel подходит к утилизации техники
→ Как собираются кастомные серверы
→ Что такое серверы Chipcore и зачем десктопное железо в дата-центрах
Параметры fsck
Пример проверки диска на ошибки с помощью fsck
Запуск автоматической проверки и исправления найденных ошибок
Ручное добавление параметров в меню GRUB при загрузке ОС
Добавление параметров в меню GRUB с помощью утилиты grubby
Создание файла /forcefsck
Запуск проверки в ручном режиме
Использование загрузочного диска/flash для проверки файловой системы на ошибки
Проверка LVM-разделов с помощью утилиты fsck
В определенных случаях (в результате сбоя или некорректного завершения работы) на файловой системе могут накапливаться ошибки. В РЕД ОС для проверки файловой системы и исправления ошибок имеется утилита fsck («file system consistency check»).
Инструмент fsck обладает следующим функционалом:
-
проверка файловой системы при возникновении проблем (не загружается система/поврежденные файлы) или в качестве профилактического обслуживания;
-
диагностика состояния внешних накопителей, таких как SD-карты или USB-накопители.
Базовый синтаксис соответствует следующему шаблону:
fsck <опции> <файловая_система>
В качестве файловой системы может быть устройство, точка монтирования или раздел, в том числе LVM.
На нашем Youtube-канале вы можете подробнее ознакомиться с возможностями проверки файловой системы на наличие ошибок, просмотрев видео Проверка файловой системы на наличие ошибок, а также найти много другой полезной информации.
Параметры fsck
fsck –p – утилита автоматически исправит найденные ошибки.
Вывод аналогичен простой проверке.
fsck –с – проверка файловой системы на поврежденные сектора.

Для получения списка команд наберите fsck ––help или fsck –h.
| Опция | Описание |
| -a | Устаревшая опция. Указывает исправлять все найденные ошибки без одобрения пользователя. |
| -r | Применяется для файловых систем ext. Указывает fsck спрашивать пользователя перед исправлением каждой ошибки |
| -n | Выполняет только проверку ФС, без исправления ошибок. Используется также для получения информации о ФС |
| -c | Применяется для файловых систем ext3/4. Помечает все повреждённые блоки для исключения последующей записи в них |
| -f | Принудительно проверяет ФС, даже если ФС исправна |
| -y | Автоматически подтверждает запросы к пользователю |
| -b | Задаёт адрес суперблока |
| -p | Автоматически исправлять найденные ошибки. Заменяет устаревшую опцию -a |
| -A | Проверяет все ФС |
| -С [<fd>] | Показывает статус выполнения. Здесь fd – дескриптор файла при отображении через графический интерфейс |
| -l | Блокирует устройство для исключительного доступа |
| -M | Запрещает проверять примонтированные ФС |
| -N | Показывает имитацию выполнения, без запуска реальной проверки |
| -P | Проверять вместе с корневой ФС |
| -R | Пропускает проверку корневой ФС. Может использоваться только совместно с опцией -A |
| -r [<fd>] | Выводит статистику для каждого проверенного устройства |
| -T | Не показывать заголовок при запуске |
| -t <тип> | Задаёт ФС для проверки. Можно задавать несколько ФС, перечисляя через запятую |
| -V | Выводит подробное описание выполняемых действий |
Пример проверки диска на ошибки с помощью fsck
Запуск автоматической проверки и исправления найденных ошибок
Существует несколько способов запуска автоматической проверки на ошибки:
1. Ручное добавление параметров в меню GRUB при загрузке ОС.
2. Добавление параметров в меню GRUB с помощью утилиты grubby.
3. Создание файла /forcefsck.
1. Ручное добавление параметров в меню GRUB при загрузке ОС
Первый вариант проверки и исправления ошибок на разделах жесткого диска.
В меню GRUB перейдите в режим редактирования загрузочной строки, нажав при этом клавишу e. Добавьте параметры:
fsck.mode=force fsck.repair=yes
в конец предпоследней строки.
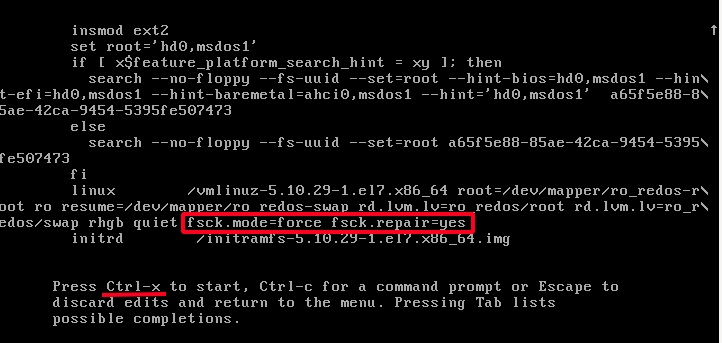
Нажмите Ctrl+Х для запуска ОС с этими параметрами, во время запуска будет произведена проверка разделов диска, и при наличии ошибок произведено их исправление.
2. Добавление параметров в меню GRUB с помощью утилиты grubby
Существует еще один способ добавления параметров ядра для принудительной проверки файловой системы на ошибки и их исправления. Добавить параметры можно командой:
grubby --update-kernel /boot/vmlinuz-$(uname -r) --args="fsck.mode=force fsck.repair=yes"
Удалить установленные параметры можно следующей командой:
grubby --update-kernel /boot/vmlinuz-$(uname -r) --remove-args="fsck.mode=force fsck.repair=yes"
3. Создание файла /forcefsck
Бывают ситуации, когда систему необходимо проверить на наличие ошибок в незапланированный момент. Для этого можно принудительно запустить утилиту fsck для проверки при следующей перезагрузке. Запуск осуществляется командой:
sudo touch /forcefsck
Команда sudo (после ввода пароля) предоставит права для создания с помощью touch пустого файла в корне диска /forcefsck, который послужит сигналом (флагом) для fsck, что нужно проверить диски.
Останется только перезагрузить компьютер и fsck начнет проверять все жесткие диски, указанные в /etc/fstab.
Запуск проверки в ручном режиме
Следующий метод относится к проверке диска, когда операционная система загружена в режиме single mode.
1. Запустим ОС в single mode, для этого пропишите в меню загрузки grub параметр init=/bin/bash в конце строки, которая начинается на linux16, см. рисунок.
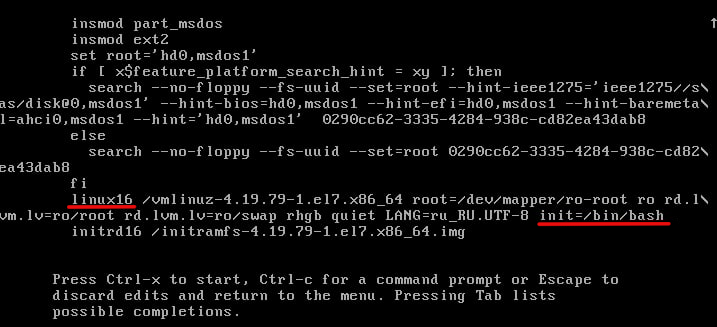
Также данная строка может начинаться с linuxefi, этот параметр характерен для систем с загрузкой в UEFI. Нажмите «ctrl+x» для запуска с этим параметром(init=/bin/bash).
2. Запустите проверку выполнив команду:
/usr/sbin/fsck -ACVfyv
Во время проверки на экране появится отчет о выполненных операциях, если отчет длинный, то можно его можно пролистать вверх сочетанием клавиш shift+PageUp. После проверки дисков перезагрузите компьютер, нажав на кнопку на системном блоке.
Наглядное видео примера проверки диска на ошибки:
Использование загрузочного диска/flash для проверки файловой системы на ошибки.
Загрузившись в режим восстановления операционной системы РЕД ОС с помощью загрузочного диска или съемного накопителя с установленным образом операционной системы РЕД ОС. Выберите пункт: «Решение проблем» -> «Исправить установленную RED OS».

Система перезагрузится в режим восстановления. Введите «2» и нажмите 2 раза Enter. Так вы смонтируете операционную систему в режим «Только для чтения»
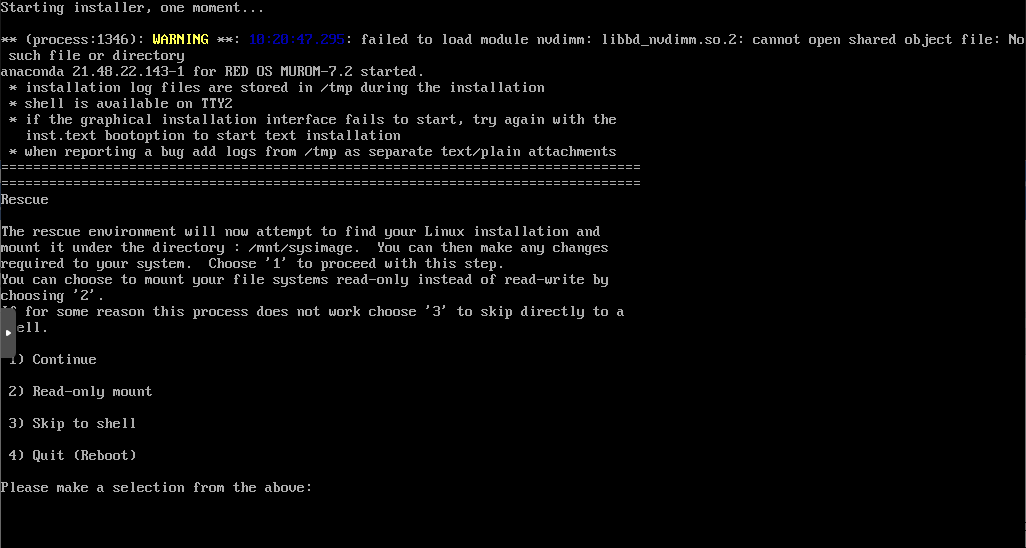
Для корректного отображения в терминале кириллических символов введите команду:
setfont cyr-sun16
Потом введите команду:
# сhroot /mnt/sysimage
После этого можете вводить fsck:
# fsck -ACVfyv
Если проверка завершится с такой ошибкой:
[путь_к_файловой_системе] is mounted
Введите:
umount [путь_к_файловой_системе]
И еще раз запустите утилиту fsck:
# fsck -ACVfyv fsck from util-linux 2.30.2 …
Если система не выявит ошибок, то получится такой вывод:
[путь_к_файловой_системе] clean …
Чтобы выйти из режима восстановления, вы должны смонтировать все разделы, которые были отмонтированы командой umount, с помощью команды mount, нажать сочетание клавиш сtrl+d, а затем ввести команду reboot, которая перезапустит вашу операционную систему.
# reboot
По умолчанию, утилита fsck при проверке будет использовать разделы, указанные в /etc/fstab/, сформированные при установке операционной системы РЕД ОС.
Проверка LVM-разделов с помощью утилиты fsck
Перед проведением проверки необходимо найти устройство и размонтировать его.
Для просмотра всех подключенных устройств и проверки расположения диска выполните команду:
lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─ro_redos-root 253:0 0 17G 0 lvm / └─ro_redos-swap 253:1 0 2G 0 lvm [SWAP] sr0 11:0 1 4,3G 0 rom /run/media/user/redos-MUROM-7.3.1 x86_64
При попытке запустить проверку на смонтированном диске или разделе в консоли появляется предупреждение о том, что невозможно продолжить проверку, так как диск смонтирован.
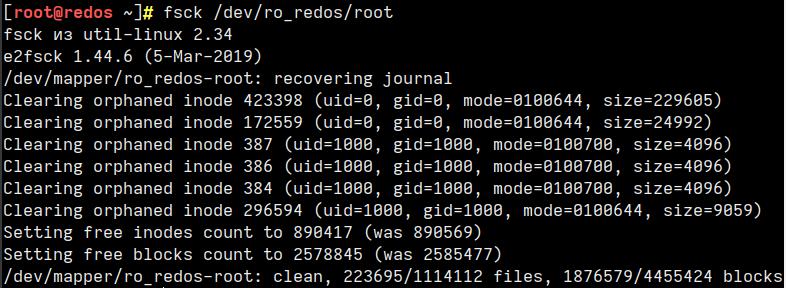
fsck -nf /dev/ro_redos/root fsck из util-linux 2.37.3 e2fsck 1.44.6 (5-Mar-2019) Warning! /dev/mapper/ro_redos-root is mounted.
Для того чтобы размонтировать диск, следует использовать команду:
umount <файловая_система>
Однако попытка выполнить данную процедуру на работающей ОС ни к чему не приведет.
umount /dev/ro_redos/root umount: /: target is busy.
Также проблемой при попытке проверить LVM-разделы может быть и то, что они являются не активными. Для проверки следует использовать команду:
lvscan ACTIVE '/dev/ro_redos/swap' [2,00 GiB] inherit ACTIVE '/dev/ro_redos/root' [<17,00 GiB] inherit
Для активации раздела служит команда:
vgchange –ay <раздел>
Таким образом, можно сделать вывод, что проверка LVM-разделов через консоль с использованием утилиты fsck невозможна. Но это не значит, что LVM-разделы совсем не подлежат проверке. Существует как минимум два способа, позволяющие провести диагностику LVM-разделов.
Первым способом является проведение проверки через консоль загрузчика операционной системы GRUB.
А вторым — запуск утилиты fsck в live-сессии системы.
Очевидным плюсом при проверке дисковых пространств, в том числе LVM-разделов, через live-сессию является то, что разделы там по умолчанию являются не смонтированными. Поэтому проверка LVM-раздела будет выполнена с первого раза.
Дата последнего изменения: 18.01.2023
Если вы нашли ошибку, пожалуйста, выделите текст и нажмите Ctrl+Enter.
Если и есть то, с чем вы очень не хотите столкнуться в вашей операционной системе, то это неожиданный выход из строя жестких дисков. С помощью резервного копирования и технологии хранения RAID вы можете очень быстро вернуть все данные на место, но потеря аппаратного устройства может очень сильно сказаться на бюджете, особенно если вы такого не планировали.
Чтобы избежать таких проблем можно использовать пакет smartmontools. Это программный пакет для управления и мониторинга устройств хранения данных с помощью технологии Self-Monitoring Analysis and Reporting Technology или просто SMART.
Большинство современных ATA/SATA/SCSI/SAS накопителей информации предоставляют интерфейс SMART. Цель SMART — мониторинг надежности жесткого диска, для выявления различных ошибок и своевременного реагирования на их появление. Пакет smartmontools состоит из двух утилит — smartctl и smartd. Вместе они представляют мощную систему мониторинга и предупреждения о возможных поломках HDD в Linux. Дальше будет подробно рассмотрена проверка жесткого диска linux.
Установка Smartmontools
Пакет smartmontools есть в официальных репозиториях большинства дистрибутивов Linux, поэтому установка сводится к выполнению одной команды. В Debian и основанных на нем системах выполните:
sudo apt install smartmontools
А для RedHat:
sudo yum install smartmontools
Во время установки надо выбрать способ настройки почтового сервера. Можно его вовсе не настраивать, если вы не собираетесь отправлять уведомления о проблемах с диском на почту.
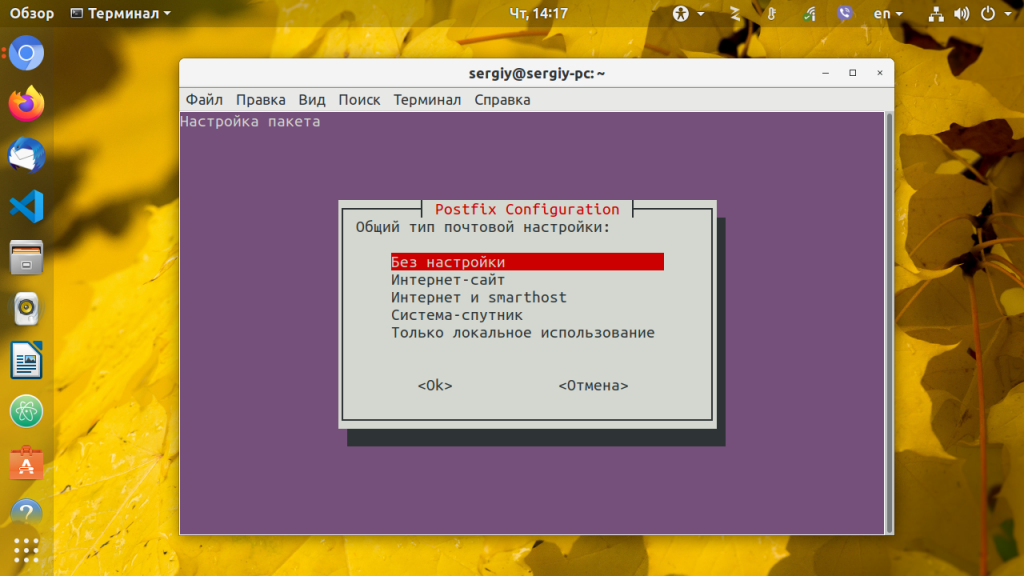
Отправлять почту получится только на веб-сервере, к которому привязан домен, на локальной машине можно выбрать пункт только для локального использования и тогда почта будет складываться в локальную папку и её можно будет посмотреть утилитой mail. Теперь можно переходить к диагностике жесткого диска Linux.
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
ls -l /dev | grep -E 'sd|hd'
В выводе будет что-то подобное:
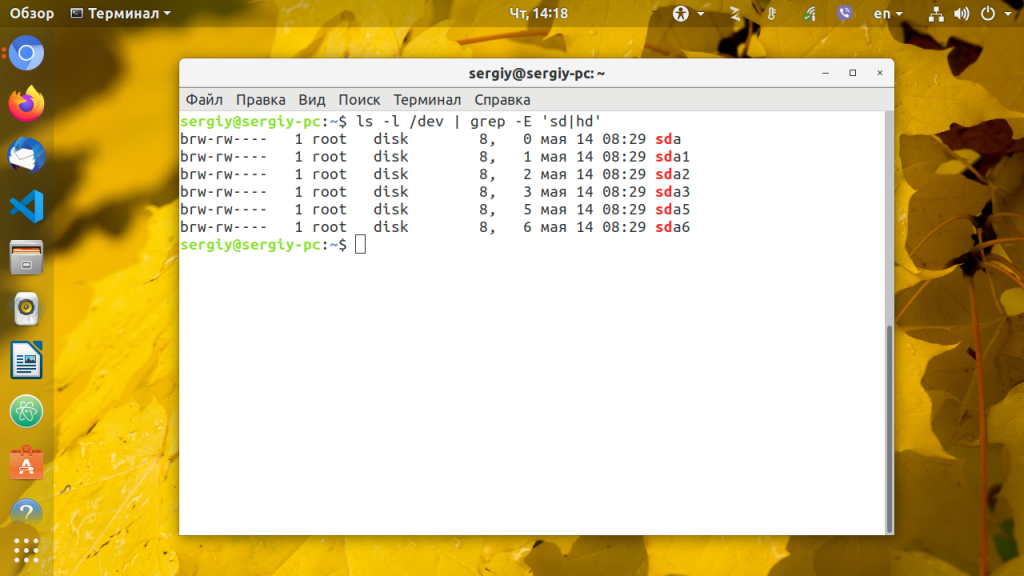
Здесь sdX это имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:
smartctl --info /dev/sda
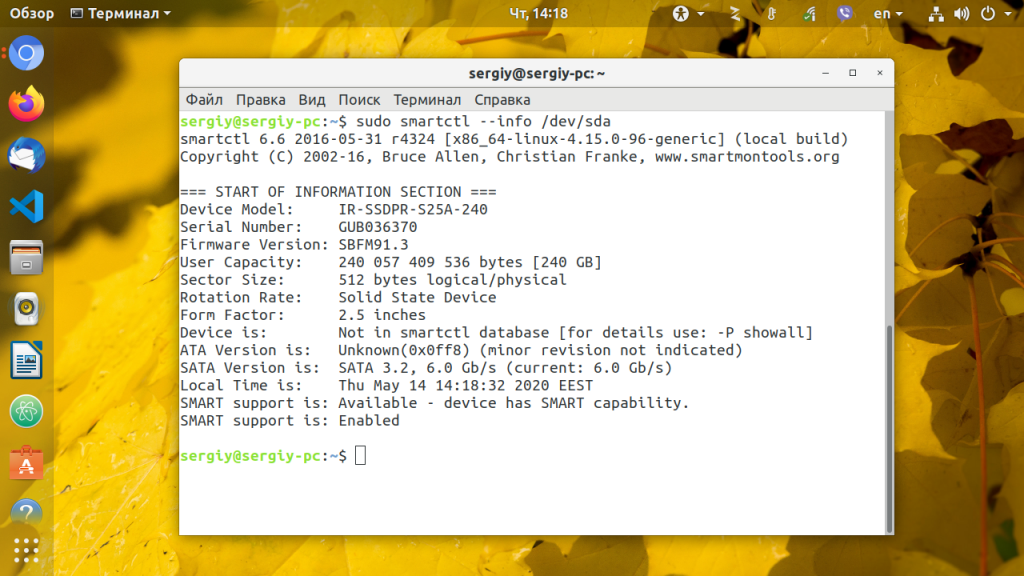
Хотя вы можете и не обратить внимания на версию SATA или ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими. Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты. В данном случае для замены лучше всего выбрать жесткий диск SATA 3.2.
Запустить проверку жесткого диска ubuntu можно командой:
smartctl -s on -a /dev/sda
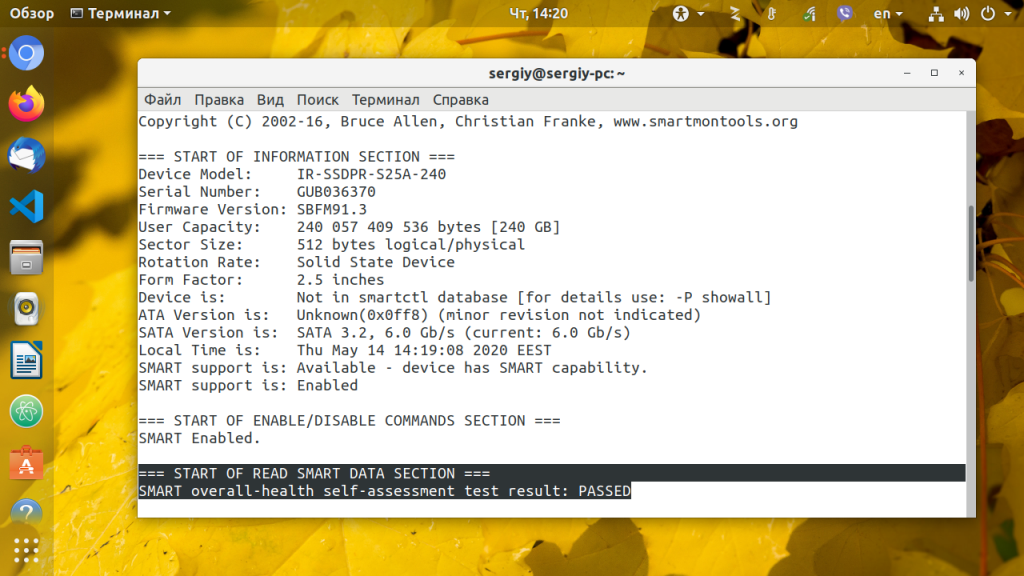
Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment rest result: PASSED
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда выполняется диагностика HDD в linux, это таблица SMART атрибутов.
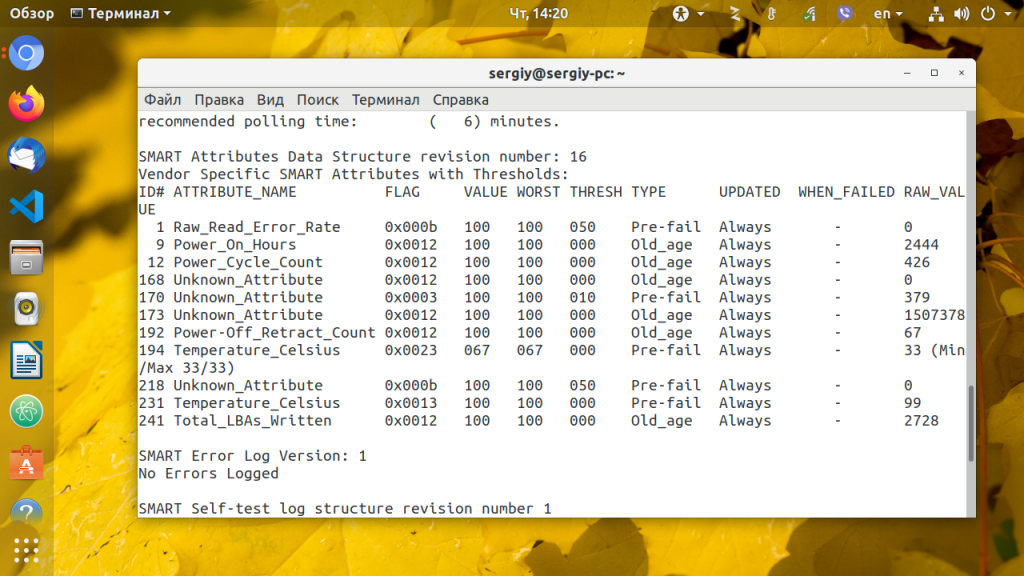
В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
- ID # — идентификатор атрибута, как правило, десятичное число между 1 и 255;
- ATTRIBUTE_NAME — название атрибута;
- FLAG — флаг обработки атрибута;
- VALUE — это поле представляет нормальное значение для состояния данного атрибута в диапазоне от 1 до 253, 253 — лучшее состояние, 1 — худшее. В зависимости от свойств, начальное значение может быть от 100 до 200;
- WORST — худшее значение value за все время;
- THRESH — самое низкое значение value, после перехода за которое нужно сообщить что диск непригоден для эксплуатации;
- TYPE — тип атрибута, может быть Pre-fail или Old_age. Все атрибуты по умолчанию считаются критическими, то-есть если диск не прошел проверку по одному из атрибутов, то он уже считается не пригодным (FAILED) но атрибуты old_age не критичны;
- UPDATED — показывает частоту обновления атрибута;
- WHEN_FAILED — будет установлено в FAILING_NOW если значение атрибута меньше или равно THRESH, или в «—» если выше. В случае FAILING_NOW, лучше как можно скорее выполнить резервное копирование, особенно если тип атрибута pre-fail.
- RAW_VALUE — значение, определенное производителем.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
Автоматическая диагностика в smartd
Автоматическая диагностика HDD в Linux настраивается очень просто. Сначала отредактируйте файл конфигурации smartd — /etc/smartd.conf. Добавьте следующую строку:
nano /etc/smartd.conf
/dev/sda -m myemail@mydomain.com -M test
Здесь:
- -m <email адрес> — адрес электронной почты для отправки результатов проверки. Это может быть адрес локального пользователя, суперпользователя или внешний адрес, если настроен сервер для отправки электронной почты;
- -M — частота отправки писем. once — отправлять только одно сообщение о проблемах с диском. daily — отправлять сообщения каждый день если была обнаружена проблема. diminishing — отправлять сообщения через день если была обнаружена проблема. test — отправлять тестовое сообщение при запуске smartd. exec — выполняет указанную программу в место отправки почты.
Сохраните изменения и перезапустите smartd:
sudo systemctl restart smartd
Вы должны получить на электронную почту письмо о том, что программа была запущена успешно. Это будет работать только если на компьютере настроен почтовый сервер.
Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа T/MM/ДД/ДН/ЧЧ, где:
Здесь T — тип теста:
- L — длинный тест;
- S — короткий тест;
- C — тест перемещения (ATA);
- O — оффлайн тест.
Остальные символы определяют дату и время теста:
- ММ — месяц в году;
- ДД — день месяца;
- ЧЧ — час дня;
- ДН — день недели (от 1 — понедельник 7 — воскресенье;
- MM, ДД и ЧЧ — указываются с двух десятичных цифр.
Точка означает все возможные значения, выражение в скобках (A|B|C) — означает один из трех вариантов, выражение в квадратных скобках [1-5] означает диапазон (от 1 до 5).
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте опцию -s в строчку конфигурации вашего устройства:
/dev/sda -m myemail@mydomain.com -M once -s (L /../../[1-5]/13)
Если вы хотите чтобы утилита сканировала и проверяла все устройства, которые есть в системе используйте вместо имени устройства директиву DEVICESCAN:
DEVICESCAN -m myemail@mydomain.com -M once -s (L /../../[1-5]/13)
Проверка диска на ошибки в GUI
В графическом интерфейсе тоже можно посмотреть информацию из SMART. Для этого можно воспользоваться приложением Gnome Диски, откройте его из главного меню, выберите нужный диск, а затем кликните по пункту Данные самодиагностики и SMART в контекстном меню:
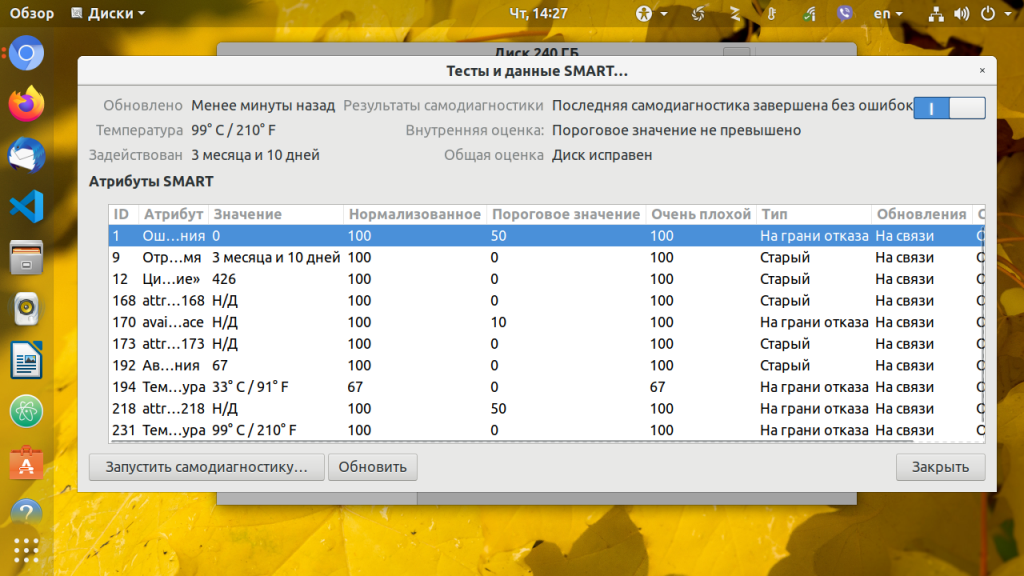
В открывшемся окне вы увидите те же данные диагностики SMART, а также все атрибуты SMART и их состояние:
Выводы
Если вы хотите быстро проверить механическую работу жесткого диска, посмотреть его физическое состояние или выполнить более-менее полное сканирование поверхности диска используйте smartmontools. Не забывайте выполнять регулярное сканирование, потом будете себя благодарить. Вы уже делали это раньше? Будете делать? Или используете другие методы? Напишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Неисправный жёсткий диск — одно из самых неприятных явлений в работе компьютера. Мало того что мы легко можем потерять очень много важной информации и файлов, так и замена HDD неслабо бьёт по бюджету. Прибавим к этому потраченное время и нервы, которые, как известно, не восстанавливаются. Чтобы не дать проблеме застать нас врасплох и заранее диагностировать её, стоит знать, как проверить жёсткий диск на ошибки в ОС Ubuntu. Программных средств, предоставляющих такие услуги, предостаточно.

Как в Ubuntu протестировать жесткий диск на ошибки.
Проверка с помощью встроенного ПО
Совсем необязательно качать программы, чтобы выполнить проверку диска в Ubuntu. Операционная система уже обладает утилитой, которая предназначена для этой задачи. Называется она badblocks, управляется через терминал.
Открываем терминал и вводим:
sudo fdisk -l
Эта команда отображает информацию о всех HDD, которые используются системой.
После этого вводим:
sudo badblocks -sv /dev/sda
Команда служит уже для поиска повреждённых секторов. Вместо /dev/sda вводим имя своего накопителя. Ключи -s и -v служат для того, чтобы отображать в правильном порядке ход проверки блоков (s) и чтобы выдавать отчёт обо всех действиях (v).

Нажатием клавиш Ctrl + C мы останавливаем проверку жёсткого диска.
Для контроля за файловой системой можно также использовать две другие команды.
Для того чтобы размонтировать файловую систему, вводим:
umount /dev/sda
Для проверки и исправления ошибок:
sudo fsck -f -c /dev/sda
- «-f» делает процесс принудительным, то есть проводит его, даже если HDD помечен как работоспособный;
- «-c» находит и помечает бэд-блоки;
- «-y» — дополнительный вводимый аргумент, который сразу же отвечает Yes на все вопросы системы. Вместо него можно ввести «-p», он проведёт проверку в автоматическом режиме.
Программы
Дополнительное программное обеспечение также отлично справляется с этой функцией. А иногда даже лучше. Тем более что некоторым пользователям проще работать с графическим интерфейсом.
GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Убунту. В их число входит и проверка диска на ошибки.

Для начала нам нужно скачать и установить GParted. Вводим следующую команду, чтобы выполнить загрузку из официальных репозиториев:
sudo apt-get install gparted
Установить программу легко и при помощи Центра загрузки приложений.
- Открываем приложение. На главном экране сразу же выводятся все носители. Если какой-то из них помечен восклицательным знаком, значит, с ним уже что-то не так.
- Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Раздел», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может идти дольше или меньше. После сканирования мы будем оповещены о его результатах.
Smartmontools
Это уже более сложная утилита, которая выполняет более серьёзную проверку HDD по различным параметрам. Как следствие, управлять ей тоже сложнее. Графический интерфейс в Smartmontools не предусмотрен.

Качаем программу:
aptitude install smartmontools
Смотрим, какие накопители подключены к нашей системе. Обращать внимание нужно на строчки, оканчивающиеся буквой, а не цифрой. Именно в этих строках содержится информация о дисках.
ls -l /dev | grep -E ‘sd|hd’
Вбиваем команду для выведения подробной информации о носителе. Стоит посмотреть на параметр ATA. Дело в том, что при замене родного диска, лучше ставить устройство с тем же либо большим ATA. Так можно максимально раскрыть его возможности. А также посмотрите и запомните параметры SMART.
smartctl —info /dev/sde
Запускаем проверку. Если SMART поддерживается, то добавляем «-s». Если он не поддерживается или уже включён, то этот аргумент можно убрать.
smartctl -s on -a /dev/sde
После этого смотрим информацию под READ SMART DATA. Результат может принимать два значения: PASSED или FAILED. Если выпало последнее, можно начинать делать резервные копии и искать замену винчестеру.
Этим возможности программы не исчерпываются. Но для однократной проверки HDD этого будет вполне достаточно.
Safecopy
Это уже та программа, которую впору использовать на тонущем судне. Если мы осведомлены, что с нашим диском что-то не так, и нацелены спасти как можно больше выживших файлов, то Safecopy придёт на помощь. Её задача как раз заключается в копировании данных с повреждённых носителей. Причём она извлекает файлы даже из битых блоков.
Устанавливаем Safecopy:
sudo apt install safecopy
Переносим файлы из одной директории в другую. Выбрать можно любую другую. В данном случае мы переносим данные с диска sda в папку home.
sudo safecopy /dev/sda /home/
Бэд-блоки
У некоторых могут возникнуть вопросы: «что такое эти битые блоки и откуда они, вообще, взялись на моём HDD, если я его ни разу не трогал?» Bad blocks, или бэд-секторы — разделы HDD, которые больше не читаются. Во всяком случае так они по объективным причинам были помечены файловой системой. И скорее всего, с диском в этих местах действительно что-то не так. «Бэды» встречаются как на старых винчестерах, так и на самых современных, поскольку работают они практически по тем же самым технологиям.

Появляются же сбойные секторы по разным причинам.
- Прерывание записи из-за отключения питания. Вся информация, поступающая на жёсткий диск, разбивается в виде единиц и нулей на самые разные его части. Сбить этот процесс — значит сильно запутать винчестер. После такого сбоя может нарушиться загрузочный сектор и тогда система вообще не запускается.
- Некачественная сборка. Тут и говорить нечего. У дешёвого китайского устройства полететь может что угодно.
Теперь вы знаете, как сканировать HDD на ошибки. Проверка диска как на Ubuntu, так и на других системах довольно важная операция, которую стоит проводить хотя бы раз в год.
|
|
Duplicate Article |

See: SystemAdministration/Fsck and TestingStorageMedia
Introduction
Contents
- Introduction
-
Basic filesystem checks and repairs
- e2fsprogs — ext2, ext3, ext4 filesystems
- dosfstools — FAT12, FAT16 and FAT32 (vfat) filesystem
- ntfs-3g (previously also ntfsprogs) — NTFS filesystem
- reiserfstools — reiserfs
- xfsprogs — xfs
- Missing superblock
- Bad blocks
- Sources and further reading
This guide will help diagnose filesystem problems one may come across on a GNU/Linux system. New sections are still being added to this howto.
Basic filesystem checks and repairs
The most common method of checking filesystem’s health is by running what’s commonly known as the fsck utility. This tool should only be run against an unmounted filesystem to check for possible issues. Nearly all well established filesystem types have their fsck tool. e.g.: ext2/3/4 filesystems have the e2fsck tool. Most notable exception until very recently was btrfs. There are also filesystems that do not need a filesystem check tool i.e.: read-only filesystems like iso9660 and udf.
e2fsprogs — ext2, ext3, ext4 filesystems
Ext2/3/4 have the previously mentioned e2fsck tool for checking and repairing filesystem. This is a part of e2fsprogs package — the package needs to be installed to have the fsck tool available. Unless one removes it in aptitude during installation, it should already be installed.
There are 4 ways the fsck tool usually gets run (listed in order of frequency of occurrence):
- it runs automatically during computer bootup every X days or Y mounts (whichever comes first). This is determined during the creation of the filesystem and can later be adjusted using tune2fs.
- it runs automatically if a filesystem has not been cleanly unmounted (e.g.: powercut)
- user runs it against an unmounted filesystem
-
user makes it run at next bootup
case 1
When filesystem check is run automatically X days after the last check or after Y mounts, Ubuntu gives user the option to interrupt the check and continue bootup normally. It is recommended that user lets it finish the check.
case 2
If a filesystem has not been cleanly unmounted, the system detects a dirty bit on the filesystem during the next bootup and starts a check. It is strongly recommended that one lets it finish. It is almost certain there are errors on the filesystem that fsck will detect and attempt to fix. Nevertheless, one can still interrupt the check and let the system boot up on a possibly corrupted filesystem.
2 things can go wrong
-
fsck dies — If fsck dies for whatever reason, you have the option to press ^D (Ctrl + D) to continue with an unchecked filesystem or run fsck manually. See e2fsck cheatsheet for details how.
-
fsck fails to fix all errors with default settings — If fsck fails to fix all errors with default settings, it will ask to be run manually by the user. See e2fsck cheatsheet for details how.
case 3
User may run fsck against any filesystem that can be unmounted on a running system. e.g. if you can issue umount /dev/sda3 without an error, you can run fsck against /dev/sda3.
case 4
You can make your system run fsck by creating an empty ‘forcefsck’ file in the root of your root filesystem. i.e.: touch /forcefsck Filesystems that have 0 or nothing specified in the sixth column of your /etc/fstab, will not be checked
Till Ubuntu 6.06 you can also issue shutdown -rF now to reboot your filesystem and check all partitions with non-zero value in sixth column of your /etc/fstab. Later versions of Ubuntu use Upstart version of shutdown which does not support the -F option any more.
Refer to man fstab for what values are allowed.
e2fsck cheatsheet
e2fsck has softlinks in /sbin that one can use to keep the names of fsck tools more uniform. i.e. fsck.ext2, fsck.ext3 and fsck.ext4 (similarly, other filesystem types have e.g.: fsck.ntfs) This cheatsheet will make use of these softlinks and will use ext4 and /dev/sda1 as an example.
-
fsck.ext4 -p /dev/sda1 — will check filesystem on /dev/sda1 partition. It will also automatically fix all problems that can be fixed without human intervention. It will do nothing, if the partition is deemed clean (no dirty bit set).
-
fsck.ext4 -p -f /dev/sda1 — same as before, but fsck will ignore the fact that the filesystem is clean and check+fix it nevertheless.
-
fsck.ext4 -p -f -C0 /dev/sda1 — same as before, but with a progress bar.
-
fsck.ext4 -f -y /dev/sda1 — whereas previously fsck would ask for user input before fixing any nontrivial problems, -y means that it will simply assume you want to answer «YES» to all its suggestions, thus making the check completely non-interactive. This is potentially dangerous but sometimes unavoidable; especially when one has to go through thousands of errors. It is recommended that (if you can) you back up your partition before you have to run this kind of check. (see dd command for backing up filesystems/partitions/volumes)
-
fsck.ext4 -f -c -C0 /dev/sda1 — will attempt to find bad blocks on the device and make those blocks unusable by new files and directories.
-
fsck.ext4 -f -cc -C0 /dev/sda1 — a more thorough version of the bad blocks check.
-
fsck.ext4 -n -f -C0 /dev/sda1 — the -n option allows you to run fsck against a mounted filesystem in a read-only mode. This is almost completely pointless and will often result in false alarms. Do not use.
In order to create and check/repair these Microsoft(TM)’s filesystems, dosfstools package needs to be installed. Similarly to ext filesystems’ tools, dosfsck has softlinks too — fsck.msdos and fsck.vfat. Options, however, vary slightly.
dosfsck cheatsheet
These examples will use FAT32 and /dev/sdc1
-
fsck.vfat -n /dev/sdc1 — a simple non-interactive read-only check
-
fsck.vfat -a /dev/sdc1 — checks the file system and fixes non-interactively. Least destructive approach is always used.
-
fsck.vfat -r /dev/sdc1 — interactive repair. User is always prompted when there is more than a single approach to fixing a problem.
-
fsck.vfat -l -v -a -t /dev/sdc1 — a very verbose way of checking and repairing the filesystem non-interactively. The -t parameter will mark unreadable clusters as bad, thus making them unavailable to newly created files and directories.
Recovered data will be dumped in the root of the filesystem as fsck0000.rec, fsck0001.rec, etc. This is similar to CHK files created by scandisk and chkdisk on MS Windows.
ntfs-3g (previously also ntfsprogs) — NTFS filesystem
Due to the closed sourced nature of this filesystem and its complexity, there is no fsck.ntfs available on GNU/Linux (ntfsck isn’t being developed anymore). There is a simple tool called ntfsfix included in ntfs-3g package. Its focus isn’t on fixing NTFS volumes that have been seriously corrupted; its sole purpose seems to be making an NTFS volume mountable under GNU/Linux.
Normally, NTFS volumes are non-mountable if their dirty bit is set. ntfsfix can help with that by clearing trying to fix the most basic NTFS problems:
-
ntfsfix /dev/sda1 — will attempt to fix basic NTFS problems. e.g.: detects and fixes a Windows XP bug, leading to a corrupt MFT; clears bad cluster marks; fixes boot sector problems
-
ntfsfix -d /dev/sda1 — will clear the dirty bit on an NTFS volume.
-
ntfsfix -b /dev/sda1 — clears the list of bad sectors. This is useful after cloning an old disk with bad sectors to a new disk.
Windows 8 and GNU/Linux cohabitation problems This segment is taken from http://www.tuxera.com/community/ntfs-3g-advanced/ When Windows 8 is restarted using its fast restarting feature, part of the metadata of all mounted partitions are restored to the state they were at the previous closing down. As a consequence, changes made on Linux may be lost. This can happen on any partition of an internal disk when leaving Windows 8 by selecting “Shut down” or “Hibernate”. Leaving Windows 8 by selecting “Restart” is apparently safe.
To avoid any loss of data, be sure the fast restarting of Windows 8 is disabled. This can be achieved by issuing as an administrator the command : powercfg /h off
Install reiserfstools package to have reiserfsck and a softlink fsck.reiserfs available. Reiserfsck is a very talkative tool that will let you know what to do should it find errors.
-
fsck.reiserfs /dev/sda1 — a readonly check of the filesystem, no changes made (same as running with —check). This is what you should run before you include any other options.
-
fsck.reiserfs —fix-fixable /dev/sda1 — does basic fixes but will not rebuild filesystem tree
-
fsck.reiserfs —scan-whole-partition —rebuild-tree /dev/sda1 — if basic check recommends running with —rebuild-tree, run it with —scan-whole-partition and do NOT interrupt it! This will take a long time. On a non-empty 1TB partition, expect something in the range of 10-24 hours.
xfsprogs — xfs
If a check is necessary, it is performed automatically at mount time. Because of this, fsck.xfs is just a dummy shell script that does absolutely nothing. If you want to check the filesystem consistency and/or repair it, you can do so using the xfs_repair tool.
-
xfs_repair -n /dev/sda — will only scan the volume and report what fixes are needed. This is the no modify mode and you should run this first.
-
xfs_repair will exit with exit status 0 if it found no errors and with exit status 1 if it found some. (You can check exit status with echo $?)
-
-
xfs_repair /dev/sda — will scan the volume and perform all fixes necessary. Large volumes take long to process.
XFS filesystem has a feature called allocation groups (AG) that enable it to use more parallelism when allocating blocks and inodes. AGs are more or less self contained parts of the filesystem (separate free space and inode management). mkfs.xfs creates only a single AG by default.
xfs_repair checks and fixes your filesystems by going through 7 phases. Phase 3 (inode discovery and checks) and Phase 4 (extent discovery and checking) work sequentially through filesystem’s allocation groups (AG). With multiple AGs, this can be heavily parallelised. xfs_repair is clever enough to not process multiple AGs on same disks.
Do NOT bother with this if any of these is true for your system:
- you created your XFS filesystem with only a single AG.
-
your xfs_repair is older than version 2.9.4 or you will make the checks even slower on GNU/Linux. You can check your version with xfs_repair -V
- your filesystem does not span across multiple disks
otherwise:
-
xfs_repair -o ag_stride=8 -t 5 -v /dev/sda — same as previous example but reduces the check/fix time by utilising multiple threads, reports back on its progress every 5 minutes (default is 15) and its output is more verbose.
-
if your filesystem had 32 AGs, the -o ag_stride=8 would start 4 threads, one to process AGs 0-7, another for 8-15, etc… If ag_stride is not specified, it defaults to the number of AGs in the filesystem.
-
-
xfs_repair -o ag_stride=8 -t 5 -v -m 2048 /dev/sda — same as above but limits xfs_repair’s memory usage to a maximum of 2048 megabytes. By default, it would use up to 75% of available ram. Please note, -o bhash=xxx has been superseded by the -m option
== jfsutils — jfs == == btrfs ==
Missing superblock
Bad blocks
Sources and further reading
- man pages
-
<XFS user guide> — more details about XFS filesystem
Содержание
- 12 методов проверки разделов жесткого диска и сам жесткий диск в Linux
- Это можно проверить с помощью следующих 12 методов.
- Как проверить раздел жесткого диска в Linux с помощью команды fdisk?
- Как проверить разделы жесткого диска Linux с помощью команды sfdisk?
- Как проверить разделы жесткого диска Linux с помощью команды cfdisk?
- Как проверить разделы жесткого диска в Linux с помощью команды parted?
- Как проверить разделы жесткого диска в Linux с помощью команды lsblk?
- Как проверить разделы жесткого диска в Linux с помощью команды blkid?
- Как проверить разделы жесткого диска в Linux с помощью команды hwinfo?
- Как проверить разделы жесткого диска в Linux с помощью команды lshw?
- Как проверить разделы жесткого диска в Linux с помощью команды inxi?
- Как проверить разделы жесткого диска в Linux с помощью команды lsscsi?
- Как проверить разделы жесткого диска в Linux с помощью ProcFS?
- Как проверить разделы жесткого диска в Linux, используя путь /dev/disk?
- База знаний wiki
- Содержание
- Проверка состояния жестких дисков в Linux
- Задача:
- Решение:
- Проверка жесткого диска в Linux
- Установка Smartmontools
- Проверка жесткого диска в smartctl
- Автоматическая диагностика в smartd
- Проверка диска на ошибки в GUI
- Выводы
- Оцените статью:
- Об авторе
- 9 комментариев
- Проверка исправности работы диска в Ubuntu
- Проверка с помощью встроенного ПО
- Программы
- GParted
- Smartmontools
- Safecopy
- Бэд-блоки
- Проверка диска на битые секторы в Linux
- Проверка диска на битые секторы Linux
- Выводы
12 методов проверки разделов жесткого диска и сам жесткий диск в Linux

Обычно администраторы Linux проверяют доступный жесткий диск и его разделы, когда хотят добавить новые диски или дополнительный раздел в систему.
Мы использовали для проверки таблицы разделов нашего жесткого диска, чтобы просмотреть разделы диска.
Это поможет вам увидеть, сколько разделов уже было создано на диске.
Кроме того, это позволяет нам проверить, есть ли у нас свободное место или нет.
Обычно жесткие диски можно разделить на один или несколько логических дисков, называемых разделами.
Каждый раздел может использоваться как отдельный диск со своей файловой системой, а информация о разделе хранится в таблице разделов.
Это 64-байтовая структура данных.
Таблица разделов является частью основной загрузочной записи (MBR), которая представляет собой небольшую программу, которая выполняется при загрузке компьютера.
Информация о разделе сохраняется в 0 секторе диска.
Запишите, все разделы должны быть отформатированы с соответствующей файловой системой, прежде чем файлы могут быть записаны в него.
Это можно проверить с помощью следующих 12 методов.
Как проверить раздел жесткого диска в Linux с помощью команды fdisk?
fdisk обозначает фиксированный диск или формат диска.
Это утилита cli, которая позволяет пользователям выполнять следующие действия с дисками.
Это позволяет нам просматривать, создавать, изменять размер, удалять, перемещать и копировать разделы.
Как проверить разделы жесткого диска Linux с помощью команды sfdisk?
sfdisk – это скрипт-ориентированный инструмент для разделения любого блочного устройства.
sfdisk поддерживает метки дисков MBR (DOS), GPT, SUN и SGI, но больше не предоставляет никаких функций для адресации CHS (головка цилиндра)
Как проверить разделы жесткого диска Linux с помощью команды cfdisk?
cfdisk – это программа на основе curses для разделения любого блочного устройства.
Устройство по умолчанию – /dev/sda.
Он обеспечивает базовую функциональность разделения с удобным интерфейсом.
Как проверить разделы жесткого диска в Linux с помощью команды parted?
parted – это программа для работы с разделами диска.
Он поддерживает несколько форматов таблиц разделов, включая MS-DOS и GPT.
Он полезен для создания пространства для новых операционных систем, реорганизации использования диска и копирования данных на новые жесткие диски.
Как проверить разделы жесткого диска в Linux с помощью команды lsblk?
lsblk выводит информацию обо всех доступных или указанных блочных устройствах.
Команда lsblk читает файловую систему sysfs и базу данных udev для сбора информации.
Если база данных udev недоступна или lsblk скомпилирован без поддержки udev, он пытается прочитать метки LABEL, UUID и типы файловых систем с блочного устройства.
В этом случае необходимы права суперпользователя.
По умолчанию команда выводит все блочные устройства (кроме дисков RAM) в древовидном формате.
Как проверить разделы жесткого диска в Linux с помощью команды blkid?
blkid – это утилита командной строки для поиска / вывода атрибутов блочных устройств.
Она использует библиотеку libblkid для получения UUID раздела диска в системе Linux.
Как проверить разделы жесткого диска в Linux с помощью команды hwinfo?
hwinfo расшифровывается как инструмент информации об оборудовании.
Это еще одна замечательная утилита, которая используется для поиска оборудования, присутствующего в системе, и отображения подробной информации о различных компонентах оборудования в удобочитаемом формате.
Как проверить разделы жесткого диска в Linux с помощью команды lshw?
lshw (расшифровывается как Hardware Lister) – это небольшой изящный инструмент, который генерирует подробные отчеты о различных аппаратных компонентах на машине, таких как конфигурация памяти, версия прошивки, конфигурация материнской платы, версия и скорость процессора, конфигурация кеша, usb, сетевая карта, графические карты, мультимедиа, принтеры, скорость шины и т. д.
Как проверить разделы жесткого диска в Linux с помощью команды inxi?
Inxi – это отличный инструмент для проверки информации об оборудовании в Linux и предлагает широкий спектр возможностей для получения всей информации об оборудовании в системе Linux, которую я никогда не нашел ни в одной другой утилите, доступной в Linux.
Как проверить разделы жесткого диска в Linux с помощью команды lsscsi?
Использует информацию в sysfs (ядро Linux серии 2.6 и новее) для просмотра списка устройств (или хостов) SCSI, которые в данный момент подключены к системе.
Параметры могут использоваться для контроля количества и формы информации, предоставляемой для каждого устройства.
По умолчанию в этой утилите имена узлов устройства (например, «/dev/sda» или «/dev/root_disk») получаются, отмечая старшие и младшие номера для перечисленного устройства, полученные из sysfs.
Как проверить разделы жесткого диска в Linux с помощью ProcFS?
Файловая система proc (procfs) – это специальная файловая система в Unix-подобных операционных системах, которая предоставляет информацию о процессах и другую системную информацию.
Иногда ее называют псевдофайловой системой с информацией о процессе.
Она содержит не «реальные» файлы, а системную информацию времени выполнения (например, системную память, подключенные устройства, конфигурацию оборудования и т. д.).
Как проверить разделы жесткого диска в Linux, используя путь /dev/disk?
Этот каталог содержит четыре каталога, это by-id, byuuid, by-path и by-partuuid.
Каждый каталог содержит некоторую полезную информацию, и он связан с реальными файлами блочных устройств.
Источник
База знаний wiki
Продукты
Статьи
Содержание
Проверка состояния жестких дисков в Linux
Слова для поиска: проверка дисков, hdparm, badblocks, smart, smartctl, iostat, mdstat
Задача:
Проверить состояние жестких дисков на выделенном сервере, наличие сбойных блоков на HDD, анализ S.M.A.R.T
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
Чтобы получить список подключенных HDD в систему, выполнить:
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
Если мы используем софтовый RAID, его состояние мы можем проверить следующей командой:
Если всё в порядке, то мы увидим что-то подобное:
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1[0] sdc1[1]), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] [UU])
Смотрим скорость чтения с накопителя
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat Ставим:
Теперь смотрим вывод iostat по всем дискам в системе:
С интервалом 10 секунд:
Или по определённому накопителю:
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
Для того, чтобы записать сбойные блоки, выполняем:
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
Источник
Проверка жесткого диска в Linux
Если и есть то, с чем вы очень не хотите столкнуться в вашей операционной системе, то это неожиданный выход из строя жестких дисков. С помощью резервного копирования и технологии хранения RAID вы можете очень быстро вернуть все данные на место, но потеря аппаратного устройства может очень сильно сказаться на бюджете, особенно если вы такого не планировали.
Чтобы избежать таких проблем можно использовать пакет smartmontools. Это программный пакет для управления и мониторинга устройств хранения данных с помощью технологии Self-Monitoring Analysis and Reporting Technology или просто SMART.
Пакет smartmontools есть в официальных репозиториях большинства дистрибутивов Linux, поэтому установка сводится к выполнению одной команды. В Debian и основанных на нем системах выполните:
sudo apt install smartmontools
sudo yum install smartmontools
Во время установки надо выбрать способ настройки почтового сервера. Можно его вовсе не настраивать, если вы не собираетесь отправлять уведомления о проблемах с диском на почту.

Отправлять почту получится только на веб-сервере, к которому привязан домен, на локальной машине можно выбрать пункт только для локального использования и тогда почта будет складываться в локальную папку и её можно будет посмотреть утилитой mail. Теперь можно переходить к диагностике жесткого диска Linux.
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
В выводе будет что-то подобное:

Здесь sdX это имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:

Хотя вы можете и не обратить внимания на версию SATA или ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими. Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты. В данном случае для замены лучше всего выбрать жесткий диск SATA 3.2.
Запустить проверку жесткого диска ubuntu можно командой:

Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment rest result: PASSED
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда выполняется диагностика HDD в linux, это таблица SMART атрибутов.

В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
Автоматическая диагностика в smartd
Сохраните изменения и перезапустите smartd:
sudo systemctl restart smartd
Вы должны получить на электронную почту письмо о том, что программа была запущена успешно. Это будет работать только если на компьютере настроен почтовый сервер.

Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа T/MM/ДД/ДН/ЧЧ, где:
Остальные символы определяют дату и время теста:
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте опцию -s в строчку конфигурации вашего устройства:
Если вы хотите чтобы утилита сканировала и проверяла все устройства, которые есть в системе используйте вместо имени устройства директиву DEVICESCAN:
Проверка диска на ошибки в GUI
В графическом интерфейсе тоже можно посмотреть информацию из SMART. Для этого можно воспользоваться приложением Gnome Диски, откройте его из главного меню, выберите нужный диск, а затем кликните по пункту Данные самодиагностики и SMART в контекстном меню:

В открывшемся окне вы увидите те же данные диагностики SMART, а также все атрибуты SMART и их состояние:

Выводы
Если вы хотите быстро проверить механическую работу жесткого диска, посмотреть его физическое состояние или выполнить более-менее полное сканирование поверхности диска используйте smartmontools. Не забывайте выполнять регулярное сканирование, потом будете себя благодарить. Вы уже делали это раньше? Будете делать? Или используете другие методы? Напишите в комментариях!




Оцените статью:
Об авторе
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
9 комментариев
Подскажите пожалуйста, можно ли получить карту диска, наподобие таковой в виктории, программой под линукс?
whdd наверное хорошо, только deb пакетов нет, а из исходников не собирается.
Здравствуйте!
У меня получается непонятка.
По smart характеристикам диск хороший,
но после запуска самотестирования выдает ошибки чтения в одних и тех же секторах
Что это значит?
в то же время внутренний лог говорит о фиксации 79 ошибок:
SMART Error Log Version: 1
ATA Error Count: 79 (device log contains only the most recent five errors)
а вот результаты самотестирования, которые я запускал:
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 516606384 1953525160 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
из них видно куча bad секторов, а смарт атрибуты(выше) говорят что все ок.
Что это означает, не подскажете?
Источник
Неисправный жёсткий диск — одно из самых неприятных явлений в работе компьютера. Мало того что мы легко можем потерять очень много важной информации и файлов, так и замена HDD неслабо бьёт по бюджету. Прибавим к этому потраченное время и нервы, которые, как известно, не восстанавливаются. Чтобы не дать проблеме застать нас врасплох и заранее диагностировать её, стоит знать, как проверить жёсткий диск на ошибки в ОС Ubuntu. Программных средств, предоставляющих такие услуги, предостаточно.
Как в Ubuntu протестировать жесткий диск на ошибки.
Проверка с помощью встроенного ПО
Совсем необязательно качать программы, чтобы выполнить проверку диска в Ubuntu. Операционная система уже обладает утилитой, которая предназначена для этой задачи. Называется она badblocks, управляется через терминал.
Открываем терминал и вводим:
Эта команда отображает информацию о всех HDD, которые используются системой.
После этого вводим:
Нажатием клавиш Ctrl + C мы останавливаем проверку жёсткого диска.
Для контроля за файловой системой можно также использовать две другие команды.
Для того чтобы размонтировать файловую систему, вводим:
Для проверки и исправления ошибок:
Программы
Дополнительное программное обеспечение также отлично справляется с этой функцией. А иногда даже лучше. Тем более что некоторым пользователям проще работать с графическим интерфейсом.
GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Убунту. В их число входит и проверка диска на ошибки.
Для начала нам нужно скачать и установить GParted. Вводим следующую команду, чтобы выполнить загрузку из официальных репозиториев:
Установить программу легко и при помощи Центра загрузки приложений.
Программа отсканирует диск. В зависимости от его объёма процесс может идти дольше или меньше. После сканирования мы будем оповещены о его результатах.
Smartmontools
Это уже более сложная утилита, которая выполняет более серьёзную проверку HDD по различным параметрам. Как следствие, управлять ей тоже сложнее. Графический интерфейс в Smartmontools не предусмотрен.
aptitude install smartmontools
Смотрим, какие накопители подключены к нашей системе. Обращать внимание нужно на строчки, оканчивающиеся буквой, а не цифрой. Именно в этих строках содержится информация о дисках.
Вбиваем команду для выведения подробной информации о носителе. Стоит посмотреть на параметр ATA. Дело в том, что при замене родного диска, лучше ставить устройство с тем же либо большим ATA. Так можно максимально раскрыть его возможности. А также посмотрите и запомните параметры SMART.
Запускаем проверку. Если SMART поддерживается, то добавляем «-s». Если он не поддерживается или уже включён, то этот аргумент можно убрать.
После этого смотрим информацию под READ SMART DATA. Результат может принимать два значения: PASSED или FAILED. Если выпало последнее, можно начинать делать резервные копии и искать замену винчестеру.
Этим возможности программы не исчерпываются. Но для однократной проверки HDD этого будет вполне достаточно.
Safecopy
Это уже та программа, которую впору использовать на тонущем судне. Если мы осведомлены, что с нашим диском что-то не так, и нацелены спасти как можно больше выживших файлов, то Safecopy придёт на помощь. Её задача как раз заключается в копировании данных с повреждённых носителей. Причём она извлекает файлы даже из битых блоков.
Переносим файлы из одной директории в другую. Выбрать можно любую другую. В данном случае мы переносим данные с диска sda в папку home.
Бэд-блоки
У некоторых могут возникнуть вопросы: «что такое эти битые блоки и откуда они, вообще, взялись на моём HDD, если я его ни разу не трогал?» Bad blocks, или бэд-секторы — разделы HDD, которые больше не читаются. Во всяком случае так они по объективным причинам были помечены файловой системой. И скорее всего, с диском в этих местах действительно что-то не так. «Бэды» встречаются как на старых винчестерах, так и на самых современных, поскольку работают они практически по тем же самым технологиям.
Появляются же сбойные секторы по разным причинам.
Теперь вы знаете, как сканировать HDD на ошибки. Проверка диска как на Ubuntu, так и на других системах довольно важная операция, которую стоит проводить хотя бы раз в год.
Источник
Проверка диска на битые секторы в Linux
Битые сектора, это повреждённые ячейки, которые больше не работают по каким либо причинам. Но файловая система всё ещё может пытаться записать в них данные. Прочитать данные из таких секторов очень сложно, поэтому вы можете их потерять. Новые диски SSD уже не подвержены этой проблеме, потому что там существует специальный контроллер, следящий за работоспособностью ячеек и перемещающий данные из нерабочих в рабочие. Однако традиционные жесткие диски используются всё ещё очень часто. В этой статье мы рассмотрим как проверить диск на битые секторы Linux.
Проверка диска на битые секторы Linux
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:

Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:

В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
Таким образом, для обычной проверки используйте такую команду:
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
Выводы
В этой статье мы рассмотрели как выполняется проверка диска на битые секторы Linux, чтобы вовремя предусмотреть возможные сбои и не потерять данные. Но на битых секторах проблемы с диском не заканчиваются. Там есть множество параметров стабильности работы, которые можно отслеживать с помощью таблицы SMART. Читайте об этом в статье Проверка диска в Linux.
Источник
Компьютер представляет собой устройство, работа которого основана на взаимодействии множества компонентов. Со временем они могут вызывать сбои в работе. Одной из частых причин неполноценной работы машины становятся битые сектора на диске, поэтому периодически его нужно тестировать. Linux предоставляет для этого все возможности.
Что такое битые блоки и почему они появляются
Блок (сектор) – это маленькая ячейка диска, на которой в виде битов (0 и 1) хранится информация. Когда системе не удается записать очередной бит в ячейку, говорят о битом секторе. Причин возникновения таких блоков может быть несколько:
- брак при производстве;
- отключение питания в процессе записи информации;
- физический износ диска.
Изначально практически на всех носителях имеются нарушения. Со временем их количество может увеличиваться, что говорит о скором выходе устройства из строя. В Linux тестировать диск на ошибки возможно несколькими способами.

Проверка диска Linux
На ядре Linux работает несколько ОС, среди которых Ubuntu и Debian. Процедура проверки диска универсальная и подходит для каждой из них. О том, что носитель пора тестировать, стоит задуматься, когда на дисковую систему оказывается большая нагрузка, скорость работы с носителем (запись/чтение) значительно уменьшилась, либо эти процедуры и вовсе вызывают ошибки.
Многие знакомы с программой на Windows – Victoria HDD. Разработчики позаботились о написании ее аналогов для Linux.
Badblocks
Badblocks – дисковая утилита, имеющаяся в Ubuntu и других дистрибутивах Linux по умолчанию. Программа позволяет тестировать как жесткий диск, так и внешние накопители.
Важно! Все приведенные в статье терминальные команды начинаются с параметра sudo, так как для выполнения требуются права суперпользователя.
Перед тем, как тестировать диск в Linux следует проверить, какие накопители подключены к системе, с помощью утилиты fdisk-l. Она также покажет имеющиеся на них разделы.

Теперь можно приступать к непосредственному тестированию на битые сектора. Работа Badblocks организовывается следующим образом:
badblocks -v /dev/sdk1 > bsector.txt
В записи используются следующие команды и операнды:·
- -v – выводит подробный отчет о проведенной проверке;·
- /dev/sdk1 – проверяемый раздел;·
- bsector.txt – запись результатов в текстовый файл.

Если при проверке диска нашлись битые блоки, нужно запустить утилиту fsck, либо e2fsck, в зависимости от используемой файловой системы. Они ограничат запись информации в нерабочие сектора. В случае файловых систем ext2, ext3 или ext4 выполняется следующая команда:
fsck -l bsector.txt /dev/sdk1
В противном случае:
fsck -l bsector.txt /dev/sdk1
Параметр -l указывает программе, что битые блоки перечислены в файле bsector.txt, и исключать нужно именно их.
GParted
Утилита проверяет файловую систему Linux, не прибегая к текстовому интерфейсу.
Инструмент изначально не содержится в дистрибутивах операционной системы, поэтому ее необходимо установить, выполнив команду:
apt-get install gparted
В главном окне приложения отображаются доступные диски. О том, что носитель пора тестировать, понятно по восклицательному знаку, расположенному рядом с его именем. Запуск проверки производится путем щелчка по пункту «Проверка на ошибки» в подменю «Раздел», расположенном на панели сверху. Предварительно выбирается нужный диск. По завершении сканирования утилита выведет результат.

Проверка HDD и других запоминающих устройств приложением GParted доступна для пользователей ОС Ubuntu, FreeBSD, Centos, Debian и других и других дистрибутивов, работающих на ядре Linux.
Smartmontools
Инструмент позволяет тестировать файловую систему с большей надежностью. В современных жестких дисках имеется встроенный модуль самоконтроля S. M. A. R. T., который анализирует данные накопителя и помогает определить неисправность на первоначальной стадии. Smartmontools предназначен для работы с этим модулем.
Запуск установки производится через терминал:
- apt install smartmontools – для Ubuntu/Debian;
- yum install smartmontools – для CentOS.
Для просмотра информации о состоянии жесткого диска, вводится строка:
smartctl –H /dev/sdk1

Проверка на ошибки занимает различное время, в зависимости от объема диска. По окончании программа выведет результат о наличии битых секторов, либо их отсутствии.
Утилита имеет и другие параметры: -a, —all, -x, —xall. Для получения дополнительной информации вызывается справка:
man smartctl –h

Safecopy
Когда возникает потребность тестировать винчестер в Linux, стоит быть готовым к любому результату.
Приложение Safecopy копирует данные с поврежденного устройства на рабочее. Источником могут быть как жесткие диски, так и съемные носители. Этот инструмент игнорирует ошибки ввода/вывода, чтения, битые блоки, продолжая беспрерывно работать. Скорость выполнения максимально возможная, которую обеспечивает компьютер.

Для установки Safecopy на Linux в терминал вводится строка:
apt install safecopy
Сканирование запускается командой:
safecopy /dev/sdk1 /home/files/
Здесь первый путь обозначает поврежденный диск, второй – директорию, куда сохранятся файлы.
Программа способна создать образ файловой системы нестабильно работающего запоминающего устройства.
Установка нового программного обеспечения или изменения системных настроек могут вызвать сообщение «Обнаружена ошибка в системной программе». Многие его игнорируют, так как на общей работе оно не отражается.

С проблемой обычно сталкиваются пользователи Ubuntu версии 16.04. Тестировать HDD в этом случае нет необходимости, так как проблема скорее заключается именно в программном сбое. Сообщение оповещает о непредвиденном завершении работы программы и предлагает отправить отчет разработчикам. При согласии откроется окно браузера, где требуется заполнить форму из 4 шагов. Такой вариант вызывает сложности и не гарантирует исчезновения ошибки.
Второй способ поможет избежать появления сообщения лишь в том случае, если оно вызывается одной и той же программой. Для этого при очередном оповещении нужно установить галку на опцию «Не показывать больше для этой программы».
Третий метод – отключить утилиту Apport, которая отвечает в Linux за сбор информации и отправку отчетов. Такой подход полностью исключит всплывание окон с ошибками. Возможно отключение только показа уведомлений, оставляя службу сбора в рабочем состоянии. Для этого необходимо выполнить:
gsettings set com.ubuntu.update-notifier show-apport-crashes false

Данные продолжат собираться в папке /var/crash. Их периодически необходимо чистить, чтобы они не заполняли дисковое пространство:
rm /var/crash
Для полного отключения служб Apport, в терминал вводится запись:
gksu gedit /etc/default/apport
В появившемся тексте значение поля enable меняется с 1 на 0. В дальнейшем, чтобы снова включить службу, возвращаются настройки по умолчанию.
Заключение
Для предотвращения потери файлов жесткий диск и съемные носители рекомендуется периодически тестировать. Linux предлагает несколько подходов к решению задачи. На выбор предоставляется перечень утилит, которые выявляют поврежденные сектора и обеспечивают перенос информации на нормально функционирующее устройство.