В
статистике выделяют два основных метода
исследования — сплошной и выборочный.
При проведении выборочного исследования
обязательным является соблюдение
следующих требований: репрезентативность
выборочной совокупности и достаточное
число единиц наблюдений. При выборе
единиц наблюдения возможны ошибки
смещения,
т.е. такие события, появление которых
не может быть точно предсказуемым. Эти
ошибки являются объективными и
закономерными. При определении степени
точности выборочного исследования
оценивается величина ошибки, которая
может произойти в процессе выборки
— случайная
ошибка репрезентативности (m)
— является
фактической разностью между средними
или относительными величинами, полученными
при проведении выборочного исследования
и аналогичными величинами, которые были
бы получены при проведении исследования
на генеральной совокупности.
Оценка
достоверности результатов исследования
предусматривает определение:
1.
ошибки репрезентативности
2.
доверительных границ средних (или
относительных) величин в генеральной
совокупности
3.
достоверности разности средних (или
относительных) величин (по критерию t)
Расчет
ошибки репрезентативности
(mм)
средней арифметической величины
(М):
![]()
![]() ,
,
где σ
— среднее квадратическое отклонение; n
— численность выборки (>30).
Расчет
ошибки репрезентативности (mР)
относительной величины (Р):
![]() ,
,
где Р — соответствующая относительная
величина (рассчитанная, например, в %);
q
=100 — Ρ%
— величина, обратная Р; n
— численность выборки (n>30)
В
клинических и экспериментальных работах
довольно часто приходится использовать
малую
выборку, когда
число наблюдений меньше или равно 30.
При малой выборке для расчета ошибок
репрезентативности, как средних, так
и относительных величин,
число
наблюдений уменьшается на единицу,
т.е.
![]() ;
;
![]() .
.
Величина
ошибки репрезентативности зависит от
объема выборки: чем больше число
наблюдений, тем меньше ошибка. Для оценки
достоверности выборочного показателя
принят следующий подход: показатель
(или средняя величина) должен в 3 раза
превышать свою ошибку, в этом случае он
считается достоверным.
83. Определение доверительных границ средних и относительных величин.
Знание
величины ошибки недостаточно для того,
чтобы быть уверенным в результатах
выборочного исследования, так как
конкретная ошибка выборочного
исследования может быть значительно
больше (или меньше) величины средней
ошибки репрезентативности. Для
определения точности, с которой
исследователь желает получить результат,
в статистике используется такое понятие,
как вероятность безошибочного
прогноза, которая является характеристикой
надежности результатов выборочных
медико-биологических статистических
исследований. Обычно, при проведении
медико-биологических статистических
исследований используют вероятность
безошибочного прогноза 95% или 99%. В
наиболее ответственных случаях, когда
необходимо сделать особенно важные
выводы в теоретическом или практическом
отношении, используют вероятность
безошибочного прогноза 99,7%
Определенной
степени вероятности безошибочного
прогноза соответствует определенная
величина предельной
ошибки случайной выборки (Δ
— дельта),
которая определяется по формуле:
Δ=t
* m
, где t
— доверительный коэффициент, который
при большой выборке при вероятности
безошибочного прогноза 95% равен 2,6;
при вероятности безошибочного
прогноза 99% — 3,0; при вероятности
безошибочного прогноза 99,7% — 3,3, а при
малой выборке определяется по специальной
таблице значений t
Стьюдента.
Используя
предельную ошибку выборки (Δ),
можно определить доверительные
границы,
в которых с определенной вероятностью
безошибочного прогноза заключено
действительное значение статистической
величины,
характеризующей
всю генеральную совокупность (средней
или относительной).
Для
определения доверительных границ
используются следующие формулы:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В практической и научно-практической работе
врачи обобщают результаты, полученные как правило на выборочных
совокупностях.
Для более широкого распространения и применения полученных при изучении
репрезентативной выборочной совокупности данных и выводов
надо уметь по части явления судить о явлении и его закономерностях в
целом.
Учитывая, что врачи, как правило, проводят исследования на
выборочных совокупностях, теория статистики позволяет с помощью
математического аппарата (формул) переносить данные с выборочного
исследования на генеральную совокупность. При этом врач должен
уметь не только воспользоваться математической формулой, но сделать
вывод, соответствующий каждому способу оценки достоверности
полученных данных. С этой целью врач должен знать способы оценки
достоверности.
Применяя метод оценки достоверности результатов исследования для изучения общественного здоровья и деятельности учреждений
здравоохранения, а также в своей научной деятельности, исследователь должен уметь правильно выбрать способ данного метода.
Среди методов оценки достоверности различают параметрические и непараметрические.
Параметрическими называют количественные методы статистической обработки данных, применение которых требует обязательного
знания закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Непараметрическими являются количественные методы статистической обработки данных, применение которых не требует знания
закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Как параметрические, так и непараметрические методы, используемые
для сравнения результатов исследований, т.е. для сравнения
выборочных совокупностей, заключаются в применении определенных формул и
расчете определенных показателей в соответствии с
предписанными алгоритмами. В конечном результате высчитывается
определенная числовая величина, которую сравнивают с табличными
пороговыми значениями. Критерием достоверности будет результат сравнения
полученной величины и табличного значения при данном числе
наблюдений (или степеней свободы) и при заданном уровне безошибочного
прогноза.
Таким образом, в статистической процедуре оценки основное
значение имеет полученный критерий достоверности, поэтому сам способ
оценки достоверности в целом иногда называют тем или иным критерием по
фамилии автора, предложившего его в качестве основы метода.
Применение параметрических методов
При проведении выборочных исследований полученный результат не обязательно совпадает с результатом, который мог бы быть получен
при исследовании всей генеральной совокупности. Между этими величинами существует определенная разница, называемая ошибкой
репрезентативности, т.е. это погрешность, обусловленная переносом результатов выборочного исследования на всю генеральную
совокупность.
Определение доверительных границ средних
и относительных величин
Формулы определения доверительных границ представлены следующим образом:
- для средних величин (М): Мген = Мвыб ± tm
- для относительных показателей (Р): Рген = Рвыб ± tm
где Мген и Рген — соответственно, значения средней величины и относительного показателя генеральной
совокупности;
Мвы6 и Рвы6 — значения средней величины и относительного показателя выборочной совокупности;
m — ошибка репрезентативности;
t — критерий достоверности (доверительный коэффициент).
Данный способ применяется в тех случаях, когда по результатам выборочной совокупности необходимо судить о размерах изучаемого
явления (или признака) в генеральной совокупности.
Обязательным условием для применения способа является репрезентативность выборочной совокупности. Для переноса результатов,
полученных при выборочных исследованиях, на генеральную совокупность необходима степень вероятности безошибочного прогноза (Р),
показывающая, в каком проценте случаев результаты выборочных исследований по изучаемому признаку (явлению) будут иметь место в
генеральной совокупности.
При определении доверительных границ средней величины или относительного показателя генеральной совокупности, исследователь сам
задает определенную (необходимую) степень вероятности безошибочного прогноза (Р).
Для большинства медико-биологических исследований считается
достаточной степень вероятности безошибочного прогноза, равная 95%,
а число случаев генеральной совокупности, в котором могут наблюдаться
отклонения от закономерностей, установленных при выборочном
исследовании, не будут превышать 5%. При ряде исследований, связанных,
например, с применением высокотоксичных веществ, вакцин,
оперативного лечения и т.п., в результате чего возможны тяжелые
заболевания, осложнения, летальные исходы, применяется степень
вероятности Р = 99,7%, т.е. не более чем у 1% случаев генеральной
совокупности возможны отклонения от закономерностей,
установленных в выборочной совокупности.
Заданной степени вероятности (Р) безошибочного прогноза соответствует определенное, подставляемое в формулу, значение критерия
t, зависящее также и от числа наблюдений.
При n>30 степени вероятности безошибочного прогноза Р = 99,7% — соответствует значение t = 3, а при Р = 95,5% — значение
t = 2.
При п<30 величина t при соответствующей степени вероятности безошибочного прогноза определяется по специальной таблице
(Н.А. Плохинского).
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген)
при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80
ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной
совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m):
m = σ / √n =
6 / √36 =
±1 удар в минуту - Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t,
определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2
удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р =
95%, что средняя частота пульса в генеральной совокупности,
т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в
аналогичных условиях будет находиться в пределах от 78 до 82
ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в
минуту возможна не более, чем у 5% случаев генеральной
совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности
(Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18%
случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя
генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя:
m = √P x q / n =
√18 x (100 — 18) / 164 =
± 3% - Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2).
Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у
детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
Оценка достоверности разности результатов исследования
Данный способ применяется в тех случаях, когда необходимо определить, случайны или достоверны (существенны), т.е. обусловлены
какой-то причиной, различия между двумя средними величинами или относительными показателями.
Обязательным условием для применения данного способа является репрезентативность выборочных совокупностей, а также наличие
причинно-следственной связи между сравниваемыми величинами (показателями) и факторами, влияющими на них.
Формулы определения достоверности разности представлены следующим образом:
Если вычисленный критерий t более или равен 2 (t ≥ 2), что соответствует вероятности безошибочного прогноза Р равном или
более 95% (Р ≥ 95%), то разность следует считать достоверной (существенной), т.е. обусловленной влиянием какого-то фактора, что
будет иметь место и в генеральной совокупности.
При t < 2, вероятность безошибочного прогноза Р < 95%, это означает, что разность недостоверна, случайна, т.е. не
обусловлена какой-то закономерностью (не обусловлена влиянием какого-то фактора).
Поэтому полученный критерий должен всегда оцениваться по отношению к конкретной цели исследования.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума
и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у водителей сельскохозяйственных
машин через 1 ч после начала работы составила 80 ударов в
минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы
водителей до начала работы равнялась 75 ударам в минуту;
m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч
работы.
Решение.
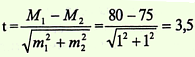
Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно
утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а
достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение
осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24%
(m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.
![]()
Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в
частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено
влиянием возраста детей.
Типичные ошибки, допускаемые исследователями при
применении способа оценки достоверности разности результатов исследования
- При оценке достоверности разности результатов исследования по критерию t часто делается вывод о достоверности (или
недостоверности) самих результатов исследования. В действительности же этот способ позволяет судить только о достоверности
(существенности) или случайности различий между результатами исследования. - При полученном значении критерия t<2 часто делается вывод о необходимости увеличения числа наблюдений. Если же
выборочные совокупности репрезентативны, то нельзя делать вывод о необходимости увеличения числа наблюдений, т.к. в данном
случае значение критерия t<2 свидетельствует о случайности, недостоверности различия между двумя сравниваемыми результатами
исследования.
Применение методов статистического анализа для изучения общественного здоровья и здравоохранения.
Под ред. чл.-корр. РАМН, проф. В.З.Кучеренко. М., «Гэотар-Медиа», 2007, учебное пособие для вузов
- Власов В.В. Эпидемиология. — М.: ГЭОТАР-МЕД, 2004. — 464 с.
- Лисицын Ю.П. Общественное здоровье и здравоохранение. Учебник для вузов. — М.: ГЭОТАР-МЕД, 2007. — 512 с.
- Медик В.А., Юрьев В.К. Курс лекций по общественному здоровью
и здравоохранению: Часть 1. Общественное здоровье. — М.: Медицина,
2003. — 368 с. - Миняев В.А., Вишняков Н.И. и др. Социальная медицина и организация здравоохранения (Руководство в 2 томах). — СПб, 1998. -528 с.
- Кучеренко В.З., Агарков Н.М. и др.Социальная гигиена и организация здравоохранения (Учебное пособие) — Москва, 2000. — 432 с.
- С. Гланц. Медико-биологическая статистика. Пер с англ. — М., Практика, 1998. — 459 с.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
Понятие репрезентативности часто встречается в статистических отчетностях и при подготовке выступлений и докладов. Пожалуй, без нее трудно представить себе какой-либо из видов подачи информации на обозрение.
Репрезентативность — что это?
Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.

Также репрезентативность информации определяют как способность выборочных данных представить параметры и свойства совокупности, важные с точки зрения проводимого исследования.
Репрезентативная выборка
Принцип формирования выборки заключается в избрании наиболее важных и точно отображающих свойства общей совокупности данных. Для этого используются различные методы, которые позволяют получать точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качества всех данных.
Таким образом, нет необходимости изучать весь материал, а достаточно рассмотреть выборочную репрезентативность. Что это? Это выборка отдельных данных для того, чтобы иметь понятие об общей массе информации.

Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.

Вероятностные выборки
Для вероятностных выборок исчисляется ряд параметров, которым объекты в выборке будут соответствовать, и среди них разными способами могут избираться именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Такими способами вычисления нужных данных могут быть:
- Простая случайная выборка. Заключается в том, что среди выбранного сегмента совершенно случайным методом лотереи выбирается необходимое количество данных, которые будут являться репрезентативной выборкой.
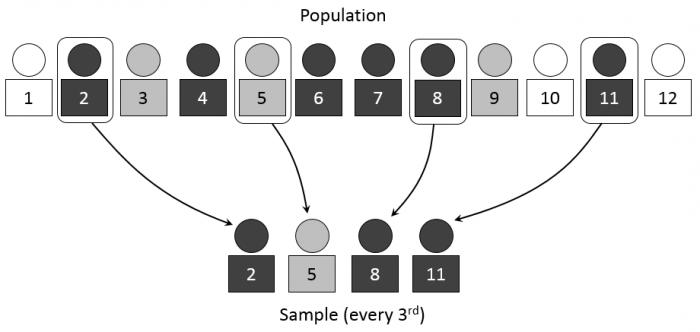
- Систематическая и случайная выборка дает возможность составить систему вычисления необходимых данных на основе случайно выбранного сегмента. Таким образом, если первое случайное число, которое указывает на порядковый номер данных, выбранных из общей совокупности, будет 5, то последующими данными, которые будут выбраны, могут стать, например, 15, 25, 35 и так далее. Этот пример наглядно объясняет, что даже случайный выбор может основываться на систематических вычислениях необходимых исходных данных.
Выборка потребителей
Осмысленная выборка – это способ, который заключается в рассмотрении каждого отдельного сегмента, и на основании его оценки составляется совокупность, отражающая характеристики и свойства общей базы данных. Таким образом набирается большее количество данных, соответствующих требованиям репрезентативной выборки. Можно легко отобрать некоторое количество вариантов, которые не войдут в общее число, не потеряв при этом качество отобранных данных, представляющих общую совокупность. Таким способом определяется репрезентативность результатов исследования.
Размер выборки
Не последний вопрос, который необходимо решить, – это размер выборки для репрезентативного представления генеральной совокупности. Размер выборки не всегда зависит от количества исходников в генеральной совокупности. Однако репрезентативность выборочной совокупности напрямую зависит от того, на сколько сегментов должен быть в итоге разделён результат. Чем больше таких сегментов, тем больше данных попадает в результативную выборку. Если результаты требуют общего обозначения и не требуют конкретики, тогда, соответственно, выборка становится меньше, поскольку, не вдаваясь в детали, информация излагается более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.

Средняя ошибка – это разница между усредненными значениями выборки и основной совокупностью. Она не зависит от количества единиц в выборке. Она обратно пропорциональна объему выборки. Тогда чем больше объем, тем меньше значение средней ошибки.
Предельная ошибка – это наибольшая возможная разница между усредненными значениями сделанной выборки и общей совокупностью. Такая ошибка охарактеризовывается как максимум вероятных ошибок при заданных условиях их появления.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки смещения данных бывают преднамеренными и непреднамеренными.
Тогда причинами появления преднамеренных ошибок является подход к подбору данных по методу определения тенденций. Непреднамеренные ошибки возникают еще на стадии подготовки выборочного наблюдения, формирования репрезентативной выборки. Для недопущения подобных ошибок необходимо создать хорошую основу для выборки, составляющей списки единиц отбора. Она должна полностью соответствовать целям проведения выборки, быть достоверной, охватывающей все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок
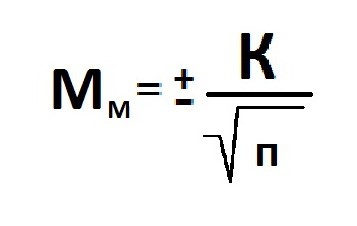
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
Репрезентативные системы
Не только в процессе оценки подачи информации используется репрезентативная выборка, но и сам человек, получающий информацию, использует репрезентативные системы. Таким образом, мозг обрабатывает некоторое количество информации, создавая репрезентативную выборку из всего потока информации, чтобы качественно и быстро оценить подаваемые данные и понять суть вопроса. Ответить на вопрос: «Репрезентативность — что это?» — в масштабах человеческого сознания довольно просто. Для этого мозг использует все подвластные органы чувств, в зависимости от того, какую именно информацию необходимо вычленить из общего потока. Таким образом, различают:
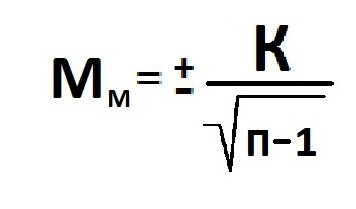
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
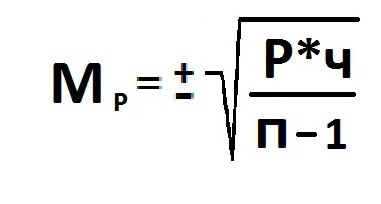
- Дигитальная репрезентативная система используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и осмысление полученных данных.

Итак, репрезентативность — что это? Простая выборка из множества или неотъемлемая процедура при обработке информации? Однозначно можно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая вычленить из него наиболее веские и значимые.