Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
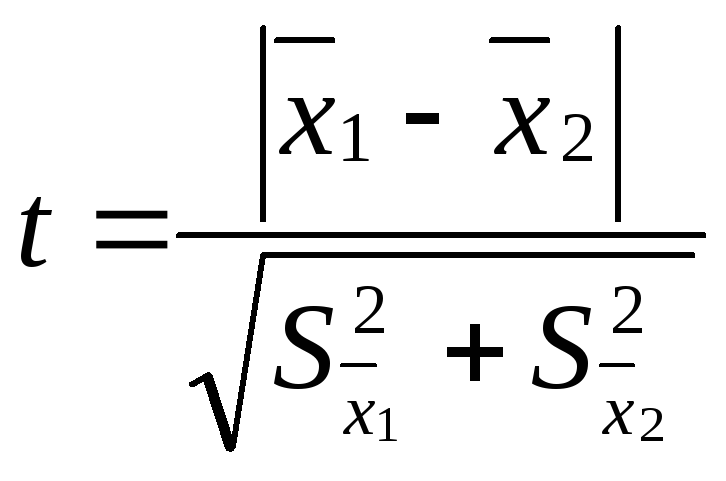 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.









Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
From Wikipedia, the free encyclopedia

The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of  observations
observations  is taken from a statistical population with a standard deviation of
is taken from a statistical population with a standard deviation of  . The mean value calculated from the sample,
. The mean value calculated from the sample,  , will have an associated standard error on the mean,
, will have an associated standard error on the mean,  , given by:[1]
, given by:[1]

Practically this tells us that when trying to estimate the value of a population mean, due to the factor  , reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
, reducing the error on the estimate by a factor of two requires acquiring four times as many observations in the sample; reducing it by a factor of ten requires a hundred times as many observations.
Estimate[edit]
The standard deviation of the population being sampled is seldom known. Therefore, the standard error of the mean is usually estimated by replacing with the sample standard deviation  instead:
instead:

As this is only an estimator for the true «standard error», it is common to see other notations here such as:

A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If is a sample of independent observations from a population with mean and standard deviation , then we can define the total

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements is simply given by

The variance of the mean is then

The standard error is, by definition, the standard deviation of which is simply the square root of the variance:

For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size  is a random variable whose variation adds to the variation of
is a random variable whose variation adds to the variation of  such that,
such that,

[6]
which follows from the law of total variance.
If has a Poisson distribution, then  with estimator
with estimator  . Hence the estimator of
. Hence the estimator of  becomes
becomes  , leading the following formula for standard error:
, leading the following formula for standard error:

(since the standard deviation is the square root of the variance).
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how  is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
is used is to make confidence intervals of the unknown population mean. If the sampling distribution is normally distributed, the sample mean, the standard error, and the quantiles of the normal distribution can be used to calculate confidence intervals for the true population mean. The following expressions can be used to calculate the upper and lower 95% confidence limits, where is equal to the sample mean, is equal to the standard error for the sample mean, and 1.96 is the approximate value of the 97.5 percentile point of the normal distribution:
In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
- Variance of the mean and predicted responses
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. Cambridge University Press. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R; Benjamin, C A (1970). Probability, Statistics, and Decisions for Civil Engineers. NY: McGraw-Hill. pp. 178–179. ISBN 0486796094.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
В практической и научно-практической работе
врачи обобщают результаты, полученные как правило на выборочных
совокупностях.
Для более широкого распространения и применения полученных при изучении
репрезентативной выборочной совокупности данных и выводов
надо уметь по части явления судить о явлении и его закономерностях в
целом.
Учитывая, что врачи, как правило, проводят исследования на
выборочных совокупностях, теория статистики позволяет с помощью
математического аппарата (формул) переносить данные с выборочного
исследования на генеральную совокупность. При этом врач должен
уметь не только воспользоваться математической формулой, но сделать
вывод, соответствующий каждому способу оценки достоверности
полученных данных. С этой целью врач должен знать способы оценки
достоверности.
Применяя метод оценки достоверности результатов исследования для изучения общественного здоровья и деятельности учреждений
здравоохранения, а также в своей научной деятельности, исследователь должен уметь правильно выбрать способ данного метода.
Среди методов оценки достоверности различают параметрические и непараметрические.
Параметрическими называют количественные методы статистической обработки данных, применение которых требует обязательного
знания закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Непараметрическими являются количественные методы статистической обработки данных, применение которых не требует знания
закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Как параметрические, так и непараметрические методы, используемые
для сравнения результатов исследований, т.е. для сравнения
выборочных совокупностей, заключаются в применении определенных формул и
расчете определенных показателей в соответствии с
предписанными алгоритмами. В конечном результате высчитывается
определенная числовая величина, которую сравнивают с табличными
пороговыми значениями. Критерием достоверности будет результат сравнения
полученной величины и табличного значения при данном числе
наблюдений (или степеней свободы) и при заданном уровне безошибочного
прогноза.
Таким образом, в статистической процедуре оценки основное
значение имеет полученный критерий достоверности, поэтому сам способ
оценки достоверности в целом иногда называют тем или иным критерием по
фамилии автора, предложившего его в качестве основы метода.
Применение параметрических методов
При проведении выборочных исследований полученный результат не обязательно совпадает с результатом, который мог бы быть получен
при исследовании всей генеральной совокупности. Между этими величинами существует определенная разница, называемая ошибкой
репрезентативности, т.е. это погрешность, обусловленная переносом результатов выборочного исследования на всю генеральную
совокупность.
Определение доверительных границ средних
и относительных величин
Формулы определения доверительных границ представлены следующим образом:
- для средних величин (М): Мген = Мвыб ± tm
- для относительных показателей (Р): Рген = Рвыб ± tm
где Мген и Рген — соответственно, значения средней величины и относительного показателя генеральной
совокупности;
Мвы6 и Рвы6 — значения средней величины и относительного показателя выборочной совокупности;
m — ошибка репрезентативности;
t — критерий достоверности (доверительный коэффициент).
Данный способ применяется в тех случаях, когда по результатам выборочной совокупности необходимо судить о размерах изучаемого
явления (или признака) в генеральной совокупности.
Обязательным условием для применения способа является репрезентативность выборочной совокупности. Для переноса результатов,
полученных при выборочных исследованиях, на генеральную совокупность необходима степень вероятности безошибочного прогноза (Р),
показывающая, в каком проценте случаев результаты выборочных исследований по изучаемому признаку (явлению) будут иметь место в
генеральной совокупности.
При определении доверительных границ средней величины или относительного показателя генеральной совокупности, исследователь сам
задает определенную (необходимую) степень вероятности безошибочного прогноза (Р).
Для большинства медико-биологических исследований считается
достаточной степень вероятности безошибочного прогноза, равная 95%,
а число случаев генеральной совокупности, в котором могут наблюдаться
отклонения от закономерностей, установленных при выборочном
исследовании, не будут превышать 5%. При ряде исследований, связанных,
например, с применением высокотоксичных веществ, вакцин,
оперативного лечения и т.п., в результате чего возможны тяжелые
заболевания, осложнения, летальные исходы, применяется степень
вероятности Р = 99,7%, т.е. не более чем у 1% случаев генеральной
совокупности возможны отклонения от закономерностей,
установленных в выборочной совокупности.
Заданной степени вероятности (Р) безошибочного прогноза соответствует определенное, подставляемое в формулу, значение критерия
t, зависящее также и от числа наблюдений.
При n>30 степени вероятности безошибочного прогноза Р = 99,7% — соответствует значение t = 3, а при Р = 95,5% — значение
t = 2.
При п<30 величина t при соответствующей степени вероятности безошибочного прогноза определяется по специальной таблице
(Н.А. Плохинского).
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген)
при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80
ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной
совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m):
m = σ / √n =
6 / √36 =
±1 удар в минуту - Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t,
определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2
удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р =
95%, что средняя частота пульса в генеральной совокупности,
т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в
аналогичных условиях будет находиться в пределах от 78 до 82
ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в
минуту возможна не более, чем у 5% случаев генеральной
совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности
(Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18%
случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя
генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя:
m = √P x q / n =
√18 x (100 — 18) / 164 =
± 3% - Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2).
Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у
детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
Оценка достоверности разности результатов исследования
Данный способ применяется в тех случаях, когда необходимо определить, случайны или достоверны (существенны), т.е. обусловлены
какой-то причиной, различия между двумя средними величинами или относительными показателями.
Обязательным условием для применения данного способа является репрезентативность выборочных совокупностей, а также наличие
причинно-следственной связи между сравниваемыми величинами (показателями) и факторами, влияющими на них.
Формулы определения достоверности разности представлены следующим образом:
Если вычисленный критерий t более или равен 2 (t ≥ 2), что соответствует вероятности безошибочного прогноза Р равном или
более 95% (Р ≥ 95%), то разность следует считать достоверной (существенной), т.е. обусловленной влиянием какого-то фактора, что
будет иметь место и в генеральной совокупности.
При t < 2, вероятность безошибочного прогноза Р < 95%, это означает, что разность недостоверна, случайна, т.е. не
обусловлена какой-то закономерностью (не обусловлена влиянием какого-то фактора).
Поэтому полученный критерий должен всегда оцениваться по отношению к конкретной цели исследования.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума
и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у водителей сельскохозяйственных
машин через 1 ч после начала работы составила 80 ударов в
минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы
водителей до начала работы равнялась 75 ударам в минуту;
m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч
работы.
Решение.
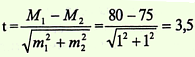
Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно
утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а
достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение
осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24%
(m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.
![]()
Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в
частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено
влиянием возраста детей.
Типичные ошибки, допускаемые исследователями при
применении способа оценки достоверности разности результатов исследования
- При оценке достоверности разности результатов исследования по критерию t часто делается вывод о достоверности (или
недостоверности) самих результатов исследования. В действительности же этот способ позволяет судить только о достоверности
(существенности) или случайности различий между результатами исследования. - При полученном значении критерия t<2 часто делается вывод о необходимости увеличения числа наблюдений. Если же
выборочные совокупности репрезентативны, то нельзя делать вывод о необходимости увеличения числа наблюдений, т.к. в данном
случае значение критерия t<2 свидетельствует о случайности, недостоверности различия между двумя сравниваемыми результатами
исследования.
Применение методов статистического анализа для изучения общественного здоровья и здравоохранения.
Под ред. чл.-корр. РАМН, проф. В.З.Кучеренко. М., «Гэотар-Медиа», 2007, учебное пособие для вузов
- Власов В.В. Эпидемиология. — М.: ГЭОТАР-МЕД, 2004. — 464 с.
- Лисицын Ю.П. Общественное здоровье и здравоохранение. Учебник для вузов. — М.: ГЭОТАР-МЕД, 2007. — 512 с.
- Медик В.А., Юрьев В.К. Курс лекций по общественному здоровью
и здравоохранению: Часть 1. Общественное здоровье. — М.: Медицина,
2003. — 368 с. - Миняев В.А., Вишняков Н.И. и др. Социальная медицина и организация здравоохранения (Руководство в 2 томах). — СПб, 1998. -528 с.
- Кучеренко В.З., Агарков Н.М. и др.Социальная гигиена и организация здравоохранения (Учебное пособие) — Москва, 2000. — 432 с.
- С. Гланц. Медико-биологическая статистика. Пер с англ. — М., Практика, 1998. — 459 с.