Прогнозирование и планирование
1 2 3 4 5 6 7 8 9 10 11
 По учету прогнозного фона различают прогнозы:
По учету прогнозного фона различают прогнозы:
Некоторые ответы приведены ниже. Для гарантированной сдачи тестов можете заказать у нас полное прохождение тестов.
| Номер вопроса: | 2 | 5 | 6 |
| Ответ: | 1 | 3 | 1 |
Заказать прохождение тестов
Важным этапом прогнозирования
социально-экономических явлений
является оценка точности и надежности
прогнозов.
Эмпирической мерой точности прогноза,
служит величина его ошибки, которая
определяется как разность между
прогнозными (![]() )
)
и фактическими (уt)
значениями исследуемого показателя.
Данный подход возможен только в двух
случаях:
а) период упреждения известен, уже
закончился и исследователь располагает
необходимыми фактическими значениями
прогнозируемого показателя;
б) строится ретроспективный прогноз,
то есть рассчитываются прогнозные
значения показателя для периода времени
за который уже имеются фактические
значения. Это делается с целью проверки
разработанной методики прогнозирования.
В данном случае вся имеющаяся информация
делится на две части в соотношении 2/3
к 1/3. Одна часть информации (первые 2/3
от исходного временного ряда) служит
для оценивания параметров модели
прогноза. Вторая часть информации
(последняя 1/3 части исходного ряда)
служит для реализации оценок прогноза.
Полученные, таким образом, ретроспективно
ошибки прогноза в некоторой степени
характеризуют точность предлагаемой
и реализуемой методики прогнозирования.
Однако величина ошибки ретроспективного
прогноза не может в полной мере и
окончательно характеризовать используемый
метод прогнозирования, так как она
рассчитана только для 2/3 имеющихся
данных, а не по всему временному ряду.
В случае если, ретроспективное
прогнозирование осуществлять по связным
и многомерным динамическим рядам, то
точность прогноза, соответственно,
будет зависеть от точности определения
значений факторных признаков, включенных
в многофакторную динамическую модель,
на всем периоде упреждения. При этом,
возможны следующие подходы к
прогнозированию по связным временным
рядам: можно использовать как фактические,
так и прогнозные значения признаков.
Все показатели оценки точности
статистических прогнозов условно можно
разделить на три группы:
-
аналитические;
-
сравнительные;
-
качественные.
Аналитические показатели точности
прогноза позволяют количественно
определить величину ошибки прогноза.
К ним относятся следующие показатели
точности прогноза:
Абсолютная ошибка прогноза (D*)
определяется как разность между
эмпирическим и прогнозным значениями
признака и вычисляется по формуле:
![]() , (16.1)
, (16.1)
где уt– фактическое
значение признака;
![]() —
—
прогнозное значение признака.
Относительная ошибка прогноза (d*отн)
может быть определена как отношение
абсолютной ошибки прогноза (D*):
-
к
фактическому значению признака (уt):

(16.2)
— к прогнозному
значению признака (![]() )
)

(16.3)
Абсолютная и относительная ошибки
прогноза являются оценкой проверки
точности единичного прогноза, что
снижает их значимость в оценке точности
всей прогнозной модели, так как на
изучаемое социально-экономическое
явление подвержено влиянию различных
факторов внешнего и внутреннего
свойства. Единично удовлетворительный
прогноз может быть получен и на базе
реализации слабо обусловленной и
недостаточно адекватной прогнозной
модели и наоборот – можно получить
большую ошибку прогноза по достаточно
хорошо аппроксимирующей модели.
Поэтому на практике иногда определяют
не ошибку прогноза, а некоторый
коэффициент качества прогноза (Кк),
который показывает соотношение между
числом совпавших (с) и общим числом
совпавших (с) и несовпавших (н) прогнозов
и определяется по формуле:
![]() (16.4)
(16.4)
Значение Кк= 1 означает, что имеет
место полное совпадение значений
прогнозных и фактических значений и
модель на 100% описывает изучаемое
явление. Данный показатель оценивает
удовлетворительный вес совпавших
прогнозных значений в целом по временному
ряду и изменяющегося в пределах от 0 до
1.
Следовательно, оценку точности получаемых
прогнозных моделей целесообразно
проводить по совокупности сопоставлений
прогнозных и фактических значений
изучаемых признаков.
Средним показателем точности прогноза
является средняя абсолютная ошибка
прогноза (![]() ),
),
которая определяется как средняя
арифметическая простая из абсолютных
ошибок прогноза по формуле вида:
 , (16.5)
, (16.5)
де n– длина временного
ряда.
Средняя абсолютная ошибка прогноза
показывает обобщенную характеристику
степени отклонения фактических и
прогнозных значений признака и имеет
ту же размерность, что и размерность
изучаемого признака.
Для оценки точности прогноза используется
средняя квадратическая ошибка прогноза,
определяемая по формуле:
 (16.6)
(16.6)
Размерность средней квадратической
ошибки прогноза также соответствует
размерности изучаемого признака. Между
средней абсолютной и средней квадратической
ошибками прогноза существует следующее
примерное соотношение:
![]() (16.7)
(16.7)
Недостатками средней абсолютной и
средней квадратической ошибками
прогноза является их существенная
зависимость от масштаба измерения
уровней изучаемых социально-экономических
явлений.
Поэтому на практике в качестве
характеристики точности прогноза
определяют среднюю ошибку аппроксимации,
которая выражается в процентах
относительно фактических значений
признака, и определяется по формуле
вида:
![]() (16.8)
(16.8)
Данный показатель является относительным
показателем точности прогноза и не
отражает размерность изучаемых
признаков, выражается в процентах и на
практике используется для сравнения
точности прогнозов полученных как по
различным моделям, так и по различным
объектам. Интерпретация оценки точности
прогноза на основе данного показателя
представлена в следующей таблице:
-
 ,%
,%Интерпретация
точности< 10
10 – 20
20 – 50
> 50
Высокая
Хорошая
Удовлетворительная
Не удовлетворительная
В качестве сравнительного показателя
точности прогноза используется
коэффициент корреляции между прогнозными
и фактическими значениями признака,
который определяется по формуле:
 , (16.9)
, (16.9)
где
![]() —
—
средний уровень ряда динамики прогнозных
оценок.
Используя данный коэффициент в оценке
точности прогноза следует помнить, что
коэффициент парной корреляции в силу
своей сущности отражает линейное
соотношение коррелируемых величин и
характеризует лишь взаимосвязь между
временным рядом фактических значений
и рядом прогнозных значений признаков.
И даже если коэффициент корреляции R= 1, то это еще не предполагает полного
совпадения фактических и прогнозных
оценок, а свидетельствует лишь о наличии
линейной зависимости между временными
рядами прогнозных и фактических значений
признака.
Одним из показателей оценки точности
статистических прогнозов является
коэффициент несоответствия (КН), который
был предложен Г. Тейлом и может
рассчитываться в различных модификациях:
-
Коэффициент несоответствия (КН1),
определяемый как отношение средней
квадратической ошибки к квадрату
фактических значений признака:
 (16.10)
(16.10)
КН = о, если
 ,
,
то есть полное совпадение фактических
и прогнозных значений признака.
КН = 1, если при прогнозировании получают
среднюю квадратическую ошибку адекватную
по величине ошибке, полученной одним
из простейших методов экстраполяции
неизменности абсолютных цепных
приростов.
КН > 1, когда прогноз дает худшие
результаты, чем предположение о
неизменности исследуемого явления.
Верхней границы коэффициент несоответствия
не имеет.
2.Коэффициент несоответствия КН2определяется как отношение средней
квадратической ошибки прогноза к сумме
квадратов
отклонений
фактических значений признака от
среднего уровня исходного временного
ряда за весь рассматриваемый период:
 , (16.11)
, (16.11)
где ![]() — средний уровень исходного ряда
— средний уровень исходного ряда
динамики.
Если КН > 1, то прогноз на уровне среднего
значения признака дал бы лучший
результат, чем имеющийся прогноз.
3.Коэффициент несоответствия (КН3),
определяемый как отношение средней
квадратической ошибке прогноза к сумме
квадратов отклонений фактических
значений признака от теоретических,
выравненных по уравнению тренда:
 , (16.12)
, (16.12)
где ![]() — теоретические уровни временного ряда,
— теоретические уровни временного ряда,
полученные по
модели тренда.
Если КН > 1, то прогноз методом
экстраполяции тренда дает хороший
результат.
1. Статистика как наука изучает:
а) единичные явления;
б) массовые явления;
в) периодические события.
2. Термин «статистика» происходит от слова:
а) статика;
б) статный;
в) статус.
3. Статистика зародилась и оформилась как самостоятельная учебная дисциплина:
а) до новой эры, в Китае и Древнем Риме;
б) в 17-18 веках, в Европе;
в) в 20 веке, в России.
4. Статистика изучает явления и процессы посредством изучения:
а) определенной информации;
б) статистических показателей;
в) признаков различных явлений.
5. Статистическая совокупность – это:
а) множество изучаемых разнородных объектов;
б) множество единиц изучаемого явления;
в) группа зафиксированных случайных событий.
6. Основными задачами статистики на современном этапе являются:
а) исследование преобразований экономических и социальных процессов в обществе; б) анализ и прогнозирование тенденций развития экономики; в) регламентация и планирование хозяйственных процессов;
а) а, в
б) а, б
в) б, в
7. Статистический показатель дает оценку свойства изучаемого явления:
а) количественную;
б) качественную;
в) количественную и качественную.
8. Основные стадии экономико-статистического исследования включают: а) сбор первичных данных, б) статистическая сводка и группировка данных, в) контроль и управление объектами статистического изучения, г) анализ статистических данных
а) а, б, в
б) а, в, г
в) а ,б, г
г) б, в, г
9. Закон больших чисел утверждает, что:
а) чем больше единиц охвачено статистическим наблюдением,тем лучше проявляется общая закономерность;
б) чем больше единиц охвачено статистическим наблюдением, тем хуже проявляется общая закономерность;
в) чем меньше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность.
10. Современная организация статистики включает: а) в России — Росстат РФ и его территориальные органы, б) в СНГ — Статистический комитет СНГ, в) в ООН — Статистическая комиссия и статистическое бюро, г) научные исследования в области теории и методологии статистики
а) а, б, г
б) а, б, в
в) а, в, г
1. Статистическое наблюдение – это:
а) научная организация регистрации информации;
б) оценка и регистрация признаков изучаемой совокупности;
в) работа по сбору массовых первичных данных;
г) обширная программа статистических исследований.
2. Назовите основные организационные формы статистического наблюдения:
а) перепись и отчетность;
в) разовое наблюдение;
г) опрос.
3. Перечень показателей (вопросов) статистического наблюдения, цель, метод, вид, единица наблюдения, объект, период статистического наблюдения излагаются:
а) в инструкции по проведению статистического наблюдения;
б) в формуляре статистического наблюдения;
в) в программе статистического наблюдения.
4. Назовите виды статистического наблюдения по степени охвата единиц совокупности:
а) анкета;
б) непосредственное;
в) сплошное;
г) текущее.
5. Назовите виды статистического наблюдения по времени регистрации:
а) текущее, б) единовременное; в) выборочное; г) периодическое; д) сплошное
а) а, в, д
б) а, б, г
в) б, г, д
6. Назовите основные виды ошибок регистрации: а) случайные; б) систематические; в) ошибки репрезентативности; г) расчетные
а) а
б) а, б
в) а, б, в,
г) а, б, в, г
7. Несплошное статистическое наблюдение имеет виды: а) выборочное;
б) монографическое; в) метод основного массива; г) ведомственная отчетность
а) а, б, в
б) а, б, г
в) б, в, г
8. Организационный план статистического наблюдения регламентирует: а) время и сроки наблюдения; б) подготовительные мероприятия;
в) прием, сдачу и оформление результатов наблюдения; г) методы обработки данных
а) а, б, г
б) а, б, в
9. Является ли статистическим наблюдением наблюдения покупателя за качеством товаров или изменением цен на городских рынках?
а) да
б) нет
10. Ошибка репрезентативности относится к:
а) сплошному наблюдению;
б) не сплошному выборочному наблюдению.
1. Статистическая сводка — это:
а) систематизация и подсчет итогов зарегистрированных фактов и данных;
б) форма представления и развития изучаемых явлений;
в) анализ и прогноз зарегистрированных данных.
2. Статистическая группировка — это:
а) объединение данных в группы по времени регистрации;
б) расчленение изучаемой совокупности на группы по существенным признакам;
в) образование групп зарегистрированной информации по мере ее поступления.
3. Статистические группировки могут быть: а) типологическими; б) структурными; в) аналитическими; г) комбинированными
а) а
б) а, б
в) а, б, в
г) а, б, в, г
4. Группировочные признаки, которыми одни единицы совокупности обладают, а другие — нет, классифицируются как:
а) факторные;
б) атрибутивные;
в) альтернативные.
5. К каким группировочным признакам относятся: образование сотрудников, профессия бухгалтера, семейное положение:
а) к атрибутивным;
б) к количественны.
6. Ряд распределения — это:
а) упорядоченное расположение единиц изучаемой совокупности по группам;
б) ряд значений показателя, расположенных по каким-то правилам.
7. К каким группировочным признакам относятся: сумма издержек обращения, объем продаж, стоимость основных фондов
а) к дискретным;
б) к непрерывным.
8. Какие виды статистических таблиц встречаются:
а) простые и комбинационные;
б) линейные и нелинейные.
1. Статистический показатель — это
а) размер изучаемого явления в натуральных единицах измерения
б) количественная характеристика свойств в единстве с их качественной определенностью
в) результат измерения свойств изучаемого объекта
2. Статистические показатели могут характеризовать:
а) объемы изучаемых процессов
б) уровни развития изучаемых явлений
в) соотношение между элементами явлений
г) а, б, в
3. По способу выражения абсолютные статистические показатели подразделяются на: а) суммарные; б) индивидуальные; в) относительные; г) средние; д) структурные
а) а, д
б) б, в
в) в, г
г) а, б
4. В каких единицах выражаются абсолютные статистические показатели?
а) в коэффициентах
б) в натуральных
в) в трудовых
5. В каких единицах будет выражаться относительный показатель, если база сравнения принимается за единицу?
а) в процентах
б) в натуральных
в) в коэффициентах
6. Относительные показатели динамики с переменной базой сравнения подразделяются на:
а) цепные
б) базисные
7. Сумма всех удельных весов показателя структуры
а) строго равна 1
б) больше или равна 1
в) меньше или равна 1
8. Относительные показатели по своему познавательному значению подразделяются на показатели: а) выполнения и сравнения, б) структуры и динамики, в) интенсивности и координации, г) прогнозирования и экстраполяции
а) а, б, г
б) б, в, г
в) а, б, в
9. Статистические показатели по сущности изучаемых явлений могут быть:
а) качественными
б) объёмными
в) а, б
10. Статистические показатели в зависимости от характера изучаемых явлений могут быть:
а) интервальными
б) моментными
в) а, б
1. Исчисление средних величин — это
а) способ изучения структуры однородных элементов совокупности
б) прием обобщения индивидуальных значений показателя
в) метод анализа факторов
2. Требуется вычислить средний стаж деятельности работников фирмы: 6,5,4,6,3,1,4,5,4,5. Какую формулу Вы примените?
а) средняя арифметическая
б) средняя арифметическая взвешенная
в) средняя гармоническая
3. Средняя геометрическая — это:
а) корень из произведения индивидуальных показателей
б) произведение корней из индивидуальных показателей
4. По какой формуле производится вычисление средней величины в интервальном ряду?
а) средняя арифметическая взвешенная
б) средняя гармоническая взвешенная
5. Могут ли взвешенные и невзвешенные средние, рассчитанные по одним и тем же данным, совпадать?
а) да
б) нет
6. Как изменяется средняя арифметическая, если все веса уменьшить в А раз?
а) уменьшатся
б) увеличится
в) не изменится
7. Как изменится средняя арифметическая, если все значения определенного признака увеличить на число А?
а) уменьшится
б) увеличится
в) не изменится
8. Значения признака, повторяющиеся с наибольшей частотой, называется
а) модой
б) медианой
9. Средняя хронологическая исчисляется
а) в моментных рядах динамики с равными интервалами
б) в интервальных рядах динамики с равными интервалами
в) в интервальных рядах динамики с неравными интервалами
10. Медиана в ряду распределения с четным числом членов ряда равна
а) полусумме двух крайних членов
б) полусумме двух срединных членов
1. Что понимается в статистике под термином «вариация показателя»?
а) изменение величины показателя
б) изменение названия показателя
в) изменение размерности показателя
2. Укажите показатели вариации
а) мода и медиана
б) сигма и дисперсия
в) темп роста и прироста
3. Показатель дисперсии — это:
а) квадрат среднего отклонения
б) средний квадрат отклонений
в) отклонение среднего квадрата
4. Коэффициент вариации измеряет колеблемость признака
а) в относительном выражении
б) в абсолютном выражении
5. Среднеквадратическое отклонение характеризует
а) взаимосвязь данных
б) разброс данных
в) динамику данных
6. Размах вариации исчисляется как
а) разность между максимальным и минимальным значением показателя
б) разность между первым и последним членом ряда распределения
7. Показатели вариации могут быть
а) простыми и взвешенными
б) абсолютными и относительными
в) а) и б)
8. Закон сложения дисперсий характеризует
а) разброс сгруппированных данных
б) разброс неупорядоченных данных
9. Средне квадратическое отклонение исчисляется как
а) корень квадратный из медианы
б) корень квадратный из коэффициента вариации
в) корень квадратный из дисперсии
10. Кривая закона распределения характеризует
а) разброс данных в зависимости от уровня показателя
б) разброс данных в зависимости от времени
1. Выборочный метод в статистических исследованиях используется для:
а) экономии времени и снижения затрат на проведение статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2. Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3. Ошибка репрезентативности обусловлена:
а) самим методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
4. Коэффициент доверия в выборочном методе может принимать значения:
а) 1, 2, 3;
б) 4, 5, 6;
в) 7, 8, 9.
5. Выборка может быть: а) случайная, б) механическая, в) типическая, серийная, д) техническая
а) а, б, в, г,
б) а, б, в, д
в) б, в, г, д
6. Необходимая численность выборочной совокупности определяется:
а) колеблемостью признака;
б) условиями формирования выборочной совокупности;
7. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным объемом единиц непосредственного наблюдения;
в) разным числом зарегистрированных наблюдений.
8. Средняя ошибка выборки:
а) прямо пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
9. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная однажды единица наблюдения возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
10. Малая выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30 единиц изучаемой совокупности.
1. Ряд динамики характеризует: а) структуру совокупности по какому-то признаку; б) изменение характеристик совокупности во времени; в) определенное значение признака в совокупности; г) величину показателя на определенную дату или за определенный период
а) а, б
б) б, г
в) б, в
2. Ряд динамики может состоять: а) из абсолютных суммарных величин; б) из относительных и средних величин;
а) а
б) б
в) а, б
3. Ряд динамики, характеризующий уровень развития социально-экономического явления на определенные даты времени, называется:
а) интервальным;
б) моментным.
4. Средний уровень интервального ряда динамики определяется как:
а) средняя арифметическая;
б) средняя хронологическая.
5. Средний уровень моментного ряда динамики исчисляется как: а) средняя арифметическая взвешенная при равных интервалах между датами; б) при неравных интервалах между датами как средняя хронологическая, в) при равных интервалах между датами как средняя хронологическая;
а) а
б) б
в) б, в
6. Абсолютный прирост исчисляется как: а) отношение уровней ряда; б) разность уровней ряда. Темп роста исчисляется как: в) отношение уровней ряда; г) разность уровней ряда;
а) а, в
б) б, в
в) а, г
7. Для выявления основной тенденции развития используется: а) метод укрупнения интервалов; б) метод скользящей средней; в) метод аналитического выравнивания; г) метод наименьших квадратов;
а) а, г
б) б, г
в) а, б, г
г) а, б, в
8. Трендом ряда динамики называется:
а) основная тенденция;
б) устойчивый темп роста.
9. Прогнозирование в статистике ‑ это:
а) предсказание предполагаемого события в будущем;
б) оценка возможной меры изучаемого явления в будущем.
10. К наиболее простым методам прогнозирования относят:
а) индексный метод;
б) метод скользящей средней;
в) метод на основе среднего абсолютного прироста.
1. Статистический индекс — это:
а) критерий сравнения относительных величин;
б) сравнительная характеристика двух абсолютных величин;
в) относительная величина сравнения двух показателей.
2. Индексы позволяют соизмерить социально-экономические явления:
а) в пространстве;
б) во времени;
в) в пространстве и во времени.
3. В индексном методе анализа несуммарность цен на разнородные товары преодолевается:
а) переходом от абсолютных единиц измерения цен к относительной форме;
б) переходом к стоимостной форме измерения товарной массы.
4. Можно ли утверждать, что индивидуальные индексы по методологии исчисления адекватны темпам роста:
а) можно;
б) нельзя.
5. Сводные индексы позволяют получить обобщающую оценку изменения:
а) по товарной группе;
б) одного товара за несколько периодов.
6. Может ли в отдельных случаях средний гармонический индекс рассчитываться по средней гармонической невзвешенной:
а) может;
б) не может.
7. Индексы переменного состава рассчитываются:
а) по товарной группе;
б) по одному товару.
8. Может ли индекс переменного состава превышать индекс фиксированного состава:
а) может;
б) не может.
9. Первая индексная мультипликативная модель товарооборота – это:
а) произведение индекса цен на индекс физического объема товарооборота;
б) произведение индекса товарооборота в сопоставимых ценах на индекс средней цены постоянного состава;
в) а, б.
10. Вторая факторная индексная мультипликативная модель анализа – это:
а) произведение индекса постоянного состава на индекс структурных сдвигов;
б) частное от деления индекса переменного состава на индекс структурных сдвигов;
в) а, б.
1. Статистическая связь — это:
а) когда зависимость между факторным и результирующим
показателями неизвестна;
б) когда каждому факторному соответствует свой результирующий показатель;
в) когда каждому факторному соответствует несколько разных значений результирующего показателя.
2. Термин корреляция в статистике понимают как:
а) связь, зависимость;
б) отношение, соотношение;
в) функцию, уравнение.
3. По направлению связь классифицируется как:
а) линейная;
б) прямая;
в) обратная.
4. Анализ взаимосвязи в статистике исследует:
а) тесноту связи;
б) форму связи;
в) а, б
5. При каком значении коэффициента корреляции связь можно считать умеренной?
а) r = 0,43;
б) r = 0,71.
6. Термин регрессия в статистике понимают как: а) функцию связи, зависимости; б) направление развития явления вспять; в) функцию анализа случайных событий во времени; г) уравнение линии связи
а) а, б
б) в, г
в) а, г
7. Для определения тесноты связи двух альтернативных показателей применяют:
а) коэффициенты ассоциации и контингенции;
б) коэффициент Спирмена.
8. Дайте классификацию связей по аналитическому выражению:
а) обратная;
б) сильная;
в) прямая;
г) линейная.
9. Какой коэффициент корреляции характеризует связь между YиX:
а) линейный;
б) частный;
в) множественный.
10. При каком значении линейного коэффициента корреляции связь между YиXможно признать более существенной:
а) ryx = 0,25;
б) ryx = 0,14;
в) ryx = — 0,57.
Вопрос 1. Модель множественной регрессии с тремя объясняющими переменными без свободного коэффициента имеет вид: y =
- Ответ: b1x1 + b2x2 + b3x3
Вопрос 2. При автокорреляции оценка коэффициентов регрессии становится:
- Ответ: неэффективной
Вопрос 3. Cитуация, при которой нулевая гипотеза была отвергнута, хотя была истинной, носит название:
- Ответ: ошибки I рода
Вопрос 4. При использовании уровня значимости, равного 5%, истинная гипотеза отвергается в __________________ случаев.
- Ответ: 5%
Вопрос 5. Для идентификации АР и СС моделей сначала делают оценки
- Ответ: автокорреляционной функции
Вопрос 6. Значение статистики Дарбина-Уотсона находится между значениями
- Ответ: 0 и 4
Вопрос 7. Пересмотр оценок в методе Кокрана-Оркатта выполняется до тех пор, пока не будет __________________ оценок.
- Ответ: получена требуемая точность
Вопрос 8. Способ оценивания (estimator) — общее правило для получения __________________ какого-либо параметра по данным выборки.
- Ответ: приближенного численного значения
Вопрос 9. Явление, когда строгая линейная зависимость между переменными приводит к невозможности применения МНК, называется:
- Ответ: полной коллинеарностью
Вопрос 10. Выборочная дисперсия зависимой переменной регрессии равна __________________ объясненной дисперсии зависимой переменной и необъясненной дисперсии зависимой переменной.
- Ответ: сумме
Вопрос 11. Четвертое условие Гаусса-Маркова состоит в том, что для любого k cov (uk, хk) равна:
- Ответ: 0
Вопрос 12. Эластичность y по x рассчитывается __________________ величины относительного изменения y на величину относительного изменения x.
- Ответ: делением
Вопрос 13. Если выборка достаточно полно отражает изучаемые параметры генеральной совокупности, то ее называют:
- Ответ: репрезентативной
Вопрос 14. Целью эконометрики является получение количественных выводов о свойствах экономических явлений и процессов по данным
- Ответ: выборки
Вопрос 15. Если все наблюдения лежат на линии регрессии, то коэффициент детерминации R2 для модели парной регрессии равен:
- Ответ: единице
Вопрос 16. Если две переменные независимы, то их теоретическая ковариация равна:
- Ответ: 0
Вопрос 17. Обычно прогнозы, получаемые с помощью моделей Бокса-Дженкинса, оказываются на практике __________________ прогнозов, построенных по макроэкономическим моделям.
- Ответ: не хуже
Вопрос 18. Весовые коэффициенты в методе скользящего среднего
- Ответ: всегда больше нуля
Вопрос 19. Если вычисленное значение статистики Спирмена превысит некое критическое значение, то принимается решение о:
- Ответ: наличии гетероскедастичности
Вопрос 20. Отклонение еi в i-м наблюдении yi от регрессии с двумя объясняющими переменными:
- Ответ: ei = yi — a — b1x1 — b2x2
Вопрос 21. Положительная автокорреляция — ситуация, когда случайный член регрессии в следующем наблюдении ожидается:
- Ответ: того же знака, что и в настоящем наблюдении
Вопрос 22. При построении отдельных уравнений регрессии для каждого из 4-х кварталов сумма сезонных отклонений должна равняться:
- Ответ: 0
Вопрос 23. Коэффициент Тейла лежит в пределах
- Ответ: от 0 до 1
Вопрос 24. Множественный регрессионный анализ является __________________ парного регрессионного анализа.
- Ответ: развитием
Вопрос 25. При положительной автокорреляции DW
- Ответ:
Вопрос 26. Процесс Юла описывается моделью
- Ответ: АР (2)
Вопрос 27. Эконометрический инструментарий базируется на методах и моделях
- Ответ: математической статистики
Вопрос 28. Если из экономических соображений известно, что b >= b0, то нулевая гипотеза отвергается только при:
- Ответ: t > tкрит
Вопрос 29. При вычислении t-статистики применяется распределение
- Ответ: Стьюдента
Вопрос 30. Аналитические методы выделения неслучайной составляющей основаны на допущении, что …
- Ответ: известен общий вид неслучайной составляющей
Вопрос 31. Наблюдение зависимой переменной регрессии в предшествующий момент, используемое как объясняющая переменная, называется __________________ переменной.
- Ответ: лаговой
Вопрос 32. Явление, когда нестрогая линейная зависимость между объясняющими переменными в модели множественной регрессии приводит к получению ненадежных оценок регрессии, называют:
- Ответ: мультиколлинеарностью
Вопрос 33. Для модели парной регрессии оценки, полученные по МНК, являются несмещенными, эффективными, состоятельными, если …
- Ответ: выполнены условия Гаусса-Маркова
Вопрос 34. Если элементы набора данных не являются статистически независимыми, то речь идет о:
- Ответ: временном ряде
Вопрос 35. Метод наименьших квадратов — метод нахождения оценок параметров регрессии, основанный на минимизации __________________ квадратов остатков всех наблюдений.
- Ответ: суммы
Вопрос 36. Тест Бокса-Кокса (решетчатый поиск) — прямой компьютерный метод выбора наилучших значений __________________ модели в заданных исследователем пределах с заданным шагом (решеткой).
- Ответ: параметров нелинейной
Вопрос 37. Уравнение y = a + bx, где a и b — оценки параметров a и b, полученные в результате оценивания модели y = a + bx + u по данным выборки, называется уравнением
- Ответ: линейной регрессии
Вопрос 38. Фиктивную переменную для коэффициента наклона вводят как __________________ фиктивной переменной, отвечающей за исследуемую категорию, и интересующей нефиктивной переменной.
- Ответ: произведение
Вопрос 39. Ситуация, когда не отвергнута ложная гипотеза, называется:
- Ответ: ошибкой II рода
Вопрос 40. Доверительный интервал в 99% __________________ интервал в 95%.
- Ответ: шире, чем
Вопрос 41. В множественном регрессионном анализе коэффициент детерминации определяет ____________________________________ регрессией.
- Ответ: долю дисперсии y, объясненную
Вопрос 42. Гетероскедастичность заключается в том, что дисперсия случайного члена регрессии __________________ наблюдений.
- Ответ: зависит от номера
Вопрос 43. Третье условие Гаусса-Маркова состоит в том, что cov (ui, uj) = 0, если …
- Ответ: i ¹ j
Вопрос 44. В модели множественной регрессии всегда желательно присутствие хотя бы одной __________________ переменной для того, чтобы обеспечить надлежащий уровень достоверности оценок.
- Ответ: нефиктивной
Вопрос 45. Зависимая переменная может быть представлена как фиктивная в случае, если она
- Ответ: является качественной по своему характеру
Вопрос 46. Множество наблюдений, составляющих часть генеральной совокупности, называется:
- Ответ: выборкой
Вопрос 47. Сглаживание временного ряда означает устранение
- Ответ: случайных остатков
Вопрос 48. Если автокорреляция отсутствует, то DW»:
- Ответ: 2
Вопрос 49. В методе скользящего среднего веса определяется с помощью:
- Ответ: МНК
Вопрос 50. Отличие одностороннего теста от двустороннего заключается в том, что он имеет только
- Ответ: одно критическое значение
Вопрос 51. Сумма квадратов остатков всех наблюдений — __________________ сумма квадратов отклонений.
- Ответ: остаточная
Вопрос 52. F-статистика для __________________ является в точности квадратом t-статистики для rx, y.
- Ответ: коэффициента детерминации
Вопрос 53. Для уравнения регрессии у=4+2х и наблюденных данных х=4, у=14 остаток в наблюдении равен:
- Ответ: 2
Вопрос 54. Фиктивная переменная для коэффициента наклона предназначена для установление влияния категории на:
- Ответ: коэффициент при нефиктивной переменной
Вопрос 55. Для линейного регрессионного анализа требуется линейность
- Ответ: только по параметрам
Вопрос 56. Второе условие Гаусса-Маркова заключается в том, что …
- Ответ: s2 (ui) — не зависит от i
Вопрос 57. Любой набор категорий можно описать некоторой совокупностью __________________ переменных.
- Ответ: фиктивных
Вопрос 58. В экономике отрицательная автокорреляция встречается __________________ положительная.
- Ответ: гораздо реже, чем
Вопрос 59. Итерационные методы — компьютерные __________________ методы поиска наилучших значений параметров нелинейной модели.
- Ответ: сходящиеся
Вопрос 60. Коэффициент Тейла основан на расчете
- Ответ: среднеквадратичного значения ошибки прогноза приростов
Вопрос 61. Процесс СС (2) имеет автокорреляционную функцию, которая:
- Ответ: обращается в ноль после некоторой точки
Вопрос 62. Набор категорий представляет собой конечный набор __________________ событий.
- Ответ: взаимоисключающих
Вопрос 63. Авторегрессионная схема называется схемой первого порядка, если описываемое __________________ равно 1.
- Ответ: максимальное запаздывание
Вопрос 64. В модели АР (1) частная автокорреляционная функция случайных остатков, разделенных двумя тактами времени, равна:
- Ответ: 0
Вопрос 65. Для выполнения теста Чоу используется распределение
- Ответ: Фишера
Вопрос 66. Коэффициент детерминации равен __________________ выборочной корреляции между y и a + bx.
- Ответ: квадрату
Вопрос 67. Если в регрессионную модель включена лишняя переменная, то оценки коэффициентов оказываются, как правило, …
- Ответ: неэффективными
Вопрос 68. Для производственного процесса, описываемого функцией Кобба-Дугласа, увеличение капитала (К) и труда (i) в 4 раза приводит к увеличению объема выпуска (у):
- Ответ: в 4 раза
Вопрос 69. Коэффициент ранговой корреляции имеет дисперсию
- Ответ: 1/ (n — 1)
Вопрос 70. Коэффициент Тейла служит критерием
- Ответ: успешности сделанного прогноза
Вопрос 71. Метод скользящего среднего относятся к __________________ методам выделения неслучайной составляющей.
- Ответ: алгоритмическим
Вопрос 72. На первом этапе применения теста Голдфелда-Квандта в выборке все наблюдения
- Ответ: Упорядочиваются по возрастанию х
Вопрос 73. Регрессором в уравнении парной линейной регрессии называется:
- Ответ: объясняющая переменная
Вопрос 74. Число степеней свободы (верхнее и нижнее) для отношения RSS2 / RSS1 в тесте Голдфелда-Квандта равно:
- Ответ: n’ — k — 1
Вопрос 75. Доля объясненной дисперсии зависимой переменной в общей выборочной дисперсии y выражается коэффициентом
- Ответ: детерминации
Вопрос 76. Значение оценки является:
- Ответ: случайной величиной
Вопрос 77. Для регрессии второго порядка y = 12+7x1-3x2 отклонение от регрессии наблюдения (х1=2, х2=1, y=20) равно:
- Ответ: е=3
Вопрос 78. Критерий восходящих и нисходящих серий позволяет:
- Ответ: выявить неслучайную составляющую
Вопрос 79. На больших временах процесс формирования значений временного ряда находится под воздействием __________________ факторов.
- Ответ: долговременных и циклических
Вопрос 80. Критерий серий, основанный на медиане, позволяет:
- Ответ: выявить неслучайную составляющую
Вопрос 81. Близко к линии регрессии находится наблюдение, для которого теоретическое распределение случайного члена имеет
- Ответ: малое стандартное отклонение
Вопрос 82. Марковский процесс описывается моделью
- Ответ: АР (1)
Вопрос 83. Метод Кокрана-Оркатта — компьютерный итерационный метод устранения
- Ответ: автокорреляции
Вопрос 84. Второе условие Гаусса-Маркова предполагает, что дисперсия случайного члена __________________ в каждом наблюдении.
- Ответ: постоянна
Вопрос 85. Как правило в эталонной категории
- Ответ: все фиктивные переменные равны 0
Вопрос 86. Коэффициент наклона в уравнении линейной регрессии показывает __________________ изменяется y при увеличении x на одну единицу.
- Ответ: на сколько единиц
Вопрос 87. Оценка параметров в лаговой структуре Койка делается:
- Ответ: решетчатым методом
Вопрос 88. Эффективная оценка — несмещенная оценка, имеющая __________________ среди всех несмещенных оценок.
- Ответ: наименьшую дисперсию
Вопрос 89. В критерии серий, основанном на медиане, протяженность самой длинной серии временного ряда 5, 1, 4, 2 равна:
- Ответ: 1
Вопрос 90. Выборочная дисперсия расчетных значений величины y называется __________________ дисперсией зависимой переменной.
- Ответ: объясненной
Вопрос 91. Свойства коэффициентов регрессии как случайных величин зависят от свойств __________________ уравнения.
- Ответ: остаточного члена
Вопрос 92. Модель Бокса-Дженкинса — это модель …
- Ответ: АРПСС
Вопрос 93. Исследование соотношения между спросом на реальные денежные остатки и ожидаемым изменением уровня цен описывается моделью
- Ответ: Кейгана
Вопрос 94. Оценка ρ, полученная МНК для авторегрессионной схемы первого порядка рассчитывается по формуле __________________, ek — остатки в наблюдениях.
- Ответ: cov (ek-1, ek) / var (ek-1)
Вопрос 95. Фиктивные переменные включаются в модель множественной регрессии, если необходимо установить влияние каких-либо __________________ факторов.
- Ответ: дискретных
Вопрос 96. Для проверки нулевой гипотезы H0: b= b0 применяется тест
- Ответ: Стьюдента
Вопрос 97. Дисперсии оценок а и b __________________ дисперсии остаточного члена s2 (u).
- Ответ: прямо пропорциональны
Вопрос 98. Категория — это событие, которое определенно __________________ в каждом наблюдении.
- Ответ: либо происходит, либо нет
Вопрос 99. Область принятия гипотезы — множество значений __________________, при попадании в которое нулевая гипотеза не отвергается.
- Ответ: оценок параметра
Вопрос 100. Ловушка dummy trap приводит к:
- Ответ: полной коллинеарности
Вопрос 101. Модель Линтнера основывается на предположении, что желаемый объем дивидендов
- Ответ: пропорционален прибыли
Вопрос 102. Детерминированная переменная может рассматриваться как предельный вариант случайной переменной, принимающей свое единственное значение с вероятностью
- Ответ: 1
Вопрос 103. Показатель выборочной ковариации позволяет выразить связь между двумя переменными
- Ответ: единым числом
Вопрос 104. Эконометрика — часть экономической науки, занимающаяся разработкой и применением __________________ методов анализа экономических процессов.
- Ответ: математических
Вопрос 105. Статистика Дарбина-Уотсона проверяет нулевую гипотезу Но:
- Ответ: отсутствие автокорреляции
Вопрос 106. Зависимость объемов введенных основных фондов от капитальных вложений описывается:
- Ответ: регрессионной моделью с распределенными лагами
Вопрос 107. Для того, чтобы установить влияние категории на коэффициент регрессии при нефиктивной переменной, в модель включают:
- Ответ: фиктивную переменную для коэффициента наклона
Вопрос 108. При отрицательной автокорреляции DW
- Ответ: >2
Вопрос 109. На экзамене в группе из 15 студентов 4 человека получили отличную оценку, 8 человек — оценку хорошо, 3 человека — оценку удовлетворительно. Средний бал по группе равен:
- Ответ: 4,06
Вопрос 110. При использования обычного МНК наблюдению высокого качества придается вес __________________ наблюдению низкого качества.
- Ответ: такой же как
Вопрос 111. Фиктивная переменная взаимодействия — это __________________ фиктивных переменных.
- Ответ: произведение
Вопрос 112. При попадании оценки в критическое значение:
- Ответ: сохраняется неопределенность в отношении гипотезы
Вопрос 113. Модель Кейгана — модель, описывающая гиперинфляцию с помощью модели
- Ответ: адаптивных ожиданий
Вопрос 114. При проведении теста Голдфелда-Квандта из рассмотрения исключаются __________________ наблюдений.
- Ответ: средние (n — 2n’)
Вопрос 115. Фиктивные переменные, предназначены для обозначения различных лет, кварталов, месяцев и т.п. — это __________________ фиктивные переменные.
- Ответ: сезонные
Вопрос 116. Теоретическая ковариация двух случайных величин определяется как математическое ожидание __________________ отклонений этих величин от их средних значений.
- Ответ: произведения
Вопрос 117. В модели парной регрессии у* = 4 + 2х изменение х на 2 единицы вызывает изменение у на __________________ единиц.
- Ответ: 4
Вопрос 118. Вероятности, с которыми случайная величина принимает свои значения, называют __________________ случайной величины.
- Ответ: законом распределения
Вопрос 119. Мерой разброса значений случайной величины служит:
- Ответ: дисперсия
Вопрос 120. При снижении уровня значимости риск совершить ошибку I рода
- Ответ: уменьшается
Вопрос 121. Фиктивная переменная — переменная, принимающая в каждом наблюдении значения:
- Ответ: 0 или 1
Вопрос 122. На больших временах __________________ факторы описываются монотонной функцией.
- Ответ: долговременные
Вопрос 123. Необходимость применения специальных статистических методов для обработки экономической информации вызвана __________________ данных.
- Ответ: стохастической природой
Вопрос 124. При использовании метода Монте-Карло результаты наблюдения генерируются с помощью
- Ответ: датчика случайных чисел
Вопрос 125. Для отношения RSS2/RSS1 в рамках теста Голдфелда-Квандта проводят тест
- Ответ: Фишера
Вопрос 126. В парном регрессионном анализе коэффициент детерминации R2 равен:
- Ответ: rх;у2
Вопрос 127. Подбор порядка аппроксимирующего полинома производится при помощи
- Ответ: метода последовательных разностей
Вопрос 128. Функция цены — функция, где аргументом является __________________, а значением функции — цена ошибки.
- Ответ: род ошибки
Вопрос 129. Если нулевая гипотеза Н0: β = β0, то альтернативная гипотеза Н1 — это:
- Ответ: β≠β0
Вопрос 130. Невыполнение 2 и 3 условий Гаусса-Маркова, приводит к потере свойства __________________ оценок.
- Ответ: эффективности
Вопрос 131. Эксперимент по методу Монте-Карло — искусственный, контролируемый эксперимент, проводимый для проверки и сравнения эффективности различных
- Ответ: статистических методов
Вопрос 132. Нижний индекс переменной (t-s) означает, что она является:
- Ответ: лаговой
Вопрос 133. Автокорреляция первого порядка — ситуация, когда случайный член uк коррелирует с:
- Ответ: Uк-1
Вопрос 134. Для применения теста Зарембки необходимо
- Ответ: преобразование масштаба наблюдений у
Вопрос 135. Если элементы набора данных не являются одинаково распределенными, то речь идет о:
- Ответ: временном ряде
Вопрос 136. Нелинейная модель у = f (x), в которой возможна замена переменной z = g (x), приводящая получившуюся модель y = F (z) — к линейной, называется моделью, нелинейной по:
- Ответ: переменным
Вопрос 137. Гетероскедастичность приводит к __________________ оценок параметров регрессии по МНК.
- Ответ: неэффективности
Вопрос 138. Число степеней свободы для уравнения множественной (m-мерной) регрессии при достаточном числе наблюдений n составляет:
- Ответ: n — m — 1
Вопрос 139. В критерии восходящих и нисходящих серий, общее число серий временного ряда 5, 7, 6, 4, 3, 1 равно:
- Ответ: 2
Вопрос 140. Ловушка dummy trap — выбор совокупности фиктивных переменных, сумма которых
- Ответ: константа
Вопрос 141. Оценка параметра находится __________________ доверительного интервала.
- Ответ: в центре
Вопрос 142. Данные по определенному показателю, полученные для разных однотипных объектов, называются:
- Ответ: перекрестными
Вопрос 143. При увеличении размера выборки оценка математического ожидания
- Ответ: становится более точной
Вопрос 144. При стремлении размера выборки к бесконечности стандартное отклонение математического ожидания стремится к:
- Ответ: 0
Вопрос 145. Доля числа исходов, благоприятствующих данному событию, в общем числе равновероятных исходов называется __________________ этого события.
- Ответ: вероятностью
Вопрос 146. Нижнее число степеней свободы F-cтатистики в случае парной регрессии равно:
- Ответ: n-2
Вопрос 147. Автокорреляционная функция принимает значения в пределах
- Ответ: от -1 до 1
Вопрос 148. Фиктивная переменная взаимодействия — фиктивная переменная, предназначенная для установления влияния на регрессию __________________ событий.
- Ответ: одновременного наступления нескольких независимых
Вопрос 149. Метод Зарембки процедура выбора между линейной и __________________ моделями:
- Ответ: логарифмической
Вопрос 150. Функция спектральной плотности позволяет установить:
- Ответ: частоты колебаний
Вопрос 151. При проведении теста Голдфелда-Квандта предполагается, что стандартное отклонение остаточного члена регрессии растет с __________________ переменной.
- Ответ: ростом объясняющей
Вопрос 152. Ранг наблюдения переменной — номер наблюдения переменной в упорядоченной __________________ последовательности.
- Ответ: по возрастанию значений наблюдаемой величины
Вопрос 153. Коэффициенты при сезонных фиктивных переменных показывают __________________ при смене сезона.
- Ответ: численную величину изменения, происходящего
Вопрос 154. При высоком уровне значимости проблема заключается в высоком риске допущения
- Ответ: ошибки II рода
Вопрос 155. Тест ранговой корреляции Спирмена — тест на:
- Ответ: гетероскедастичность
Вопрос 156. Статистика для теста ранговой корреляции Спирмена имеет __________________ распределение.
- Ответ: нормальное
Вопрос 157. МНК дает __________________ для данной выборки значение коэффициента детерминации R2.
- Ответ: максимальное
Вопрос 158. Функция Кобба-Дугласа имеет вид Y =
- Ответ: AKa L1-a
Вопрос 159. Процесс АР (2) имеет автокорреляционную функцию, которая:
- Ответ: имеет бесконечную протяженность
Вопрос 160. Утверждение о том, что неизвестный параметр модели принадлежит другому заданному множеству В, АÇВ = Æ, называется:
- Ответ: альтернативной гипотезой
Вопрос 161. Эконометрика получает количественные зависимости для экономических соотношений, основываясь в первую очередь на:
- Ответ: данных
Вопрос 162. Строгая линейная зависимость между переменными — ситуация, когда __________________ двух переменных равна 1 или -1.
- Ответ: выборочная корреляция
Вопрос 163. При рассмотрении спектральной плотности ограничиваются значениями ω, лежащими в пределах
- Ответ: от 0 до π
Вопрос 164. Функция Кобба-Дугласа называется:
- Ответ: производственной функцией
Вопрос 165. Утверждение о том, что неизвестный параметр модели принадлежит заданному множеству А, называется:
- Ответ: нулевой гипотезой
Вопрос 166. Проверка гипотезы Н0: R2 = 0 происходит с помощью теста
- Ответ: Фишера
Вопрос 167. Спектральная плотность может принимать __________________ значения.
- Ответ: только положительные
Вопрос 168. В модели множественной регрессии за изменение __________________ регрессии отвечает несколько объясняющих переменных.
- Ответ: одной зависимой переменной
Вопрос 169. Функция потерь, используемая при выборе между несмещенной и эффективной оценкой, определяет стоимость неточности как функцию
- Ответ: размера ошибки
Вопрос 170. Для уравнения регрессии у = 3х — 2 прогнозное значение зависимой переменной, если объясняющая переменная равна 4, — это:
- Ответ: 10
Вопрос 171. Тест Глейзера устанавливает наличие __________________ связи между стандартным отклонением остаточного члена регрессии и объясняющей переменной.
- Ответ: нелинейной
Вопрос 172. Чем больше число наблюдений, тем __________________ зона неопределенности для критерия Дарбина-Уотсона.
- Ответ: уже
Вопрос 173. Остаток в i-ом наблюдении по модели парной регрессии y=a+bx равен:
- Ответ: yi — (a + bxi)
Вопрос 174. Модель парной регрессии — __________________ модель зависимости между двумя переменными.
- Ответ: линейная
Вопрос 175. Граничное значение области принятия гипотезы с p%-ной вероятностью совершить ошибку I рода определяется __________________ при p-процентном уровне значимости.
- Ответ: критическим значением теста
Вопрос 176. Спецификация запаздываний применительно к переменным в модели называется:
- Ответ: лаговой структурой
Вопрос 177. Если независимые переменные имеют ярко выраженный временной тренд, то они оказываются:
- Ответ: тесно коррелированными
Вопрос 178. Первое условие Гаусса-Маркова заключается в том, что __________________ для любого i.
- Ответ: М (ui) = 0
Вопрос 179. В критерии восходящих и нисходящих серий, длина самой длинной серии временного ряда 1, 5, 4, 1, 6 равна:
- Ответ: 2
Вопрос 180. Идентификация модели СС (2) сводится к решению системы двух __________________ уравнений.
- Ответ: нелинейных
Вопрос 181. Выборочная дисперсия как оценка теоретической дисперсии имеет __________________ смещение.
- Ответ: отрицательное
Вопрос 182. Функция спроса y = a xb pg n может быть линеаризована посредством
- Ответ: логарифмирования
Вопрос 183. Оценка стандартного отклонения случайной величины, полученная по данным выборки, называется стандартной __________________ случайной величины.
- Ответ: ошибкой
Вопрос 184. Оценивание каждого параметра в уравнении регрессии поглощает __________________ свободы в выборке.
- Ответ: одну степень
Вопрос 185. Выборочная корреляция является __________________ теоретической корреляции.
- Ответ: оценкой
Вопрос 186. Точность оценок по МНК улучшается, если увеличивается:
- Ответ: количество наблюдений
Вопрос 187. При добавлении объясняющей переменной в уравнение регрессии коэффициент детерминации
- Ответ: не уменьшается
Вопрос 188. В критерии серий, основанном на медиане, общее число серий временного ряда 1, 3, 5, 4, 2 равно:
- Ответ: 3
Вопрос 189. Для функции Кобба-Дугласа у=100к1/3*i2/3 эластичность выпуска продукции по капиталу равна:
- Ответ: 1/3
Вопрос 190. В процессе формирования значений всякого временного ряда всегда участвуют __________________ факторы.
- Ответ: случайные
Вопрос 191. Первый шаг метода Зарембки заключается в вычислении __________________ y по выборке.
- Ответ: среднего геометрического
Вопрос 192. Плоскость регрессии y = a + b1x1 + b2x2 — двумерная плоскость в __________________ пространстве.
- Ответ: трехмерном
Вопрос 193. Для функции y = 4x0,2, эластичность равна:
- Ответ: 0,2
Вопрос 194. Поправка Прайса-Уинстена — метод спасения __________________ в автокорреляционной схеме первого порядка.
- Ответ: первого наблюдения
Вопрос 195. В лаговой структуре Койка надо оценить только:
- Ответ: три параметра
Вопрос 196. Наилучший способ устранения автокорреляции — установление ответственного за нее фактора и включение соответствующей __________________ переменной в регрессию.
- Ответ: объясняющей
Вопрос 197. Автокорреляция представляет тем большую проблему, чем
- Ответ: меньше интервал между наблюдениями
Вопрос 198. Проблема, связанная со смещением оценки коэффициентов регрессии, в одном случае, или с утратой эффективности этих оценок в другом случае неправильной спецификации переменных, перестает существовать, если коэффициент парной корреляции между переменными равен:
- Ответ: 0
Вопрос 199. Выборочная дисперсия остатков в наблюдениях Var (y — (a + bx)) называется __________________ дисперсией зависимой переменной.
- Ответ: необъясненной
Вопрос 200. Тест ранговой корреляции Спирмена — тест, устанавливающий, имеет ли стандартное отклонение остаточного члена регрессии нестрогую линейную зависимость с __________________ переменной.
- Ответ: объясняющей
Вопрос 201. Если совокупность значений случайной величины представляет собой конечный или счетный набор возможных чисел, то случайная величина называется:
- Ответ: дискретной
Вопрос 202. Стандартные ошибки, вычисленные при гетероскедастичности
- Ответ: занижены по сравнению с истинными значениями
Вопрос 203. Логарифмическое преобразование позволяет осуществить переход от нелинейной модели y = 5x2u к модели
- Ответ: ln y = ln 5 + 2 ln x + ln u
Вопрос 204. Для одностороннего критерия нулевой гипотезы Н0: β =β0 альтернативная гипотеза Н1:
- Ответ: β > β
Вопрос 205. Для функции Кобба-Дугласа у=80К3/4*i1/4 эластичность выпуска продукции по труду равна:
- Ответ: 1/4
Вопрос 206. Если опущена переменная, которая должна входить в регрессионную модель, то оценки коэффициентов регрессии оказываются:
- Ответ: смещенными
Вопрос 207. Если между двумя переменными существует строгая положительная линейная зависимость, то коэффициент корреляции между ними принимает значение, равное:
- Ответ: единице
Вопрос 208. Процесс выбора необходимых для регрессии переменных и отбрасывание лишних переменных называется:
- Ответ: спецификацией переменных
Вопрос 209. Результаты проверки гипотезы H0: b = b0 представляются на __________________ значимости.
- Ответ: двух уровнях
Вопрос 210. Всю совокупность реализаций случайной величины называют __________________ совокупностью.
- Ответ: генеральной
Вопрос 211. Остатки значений log y __________________ остатков значений y.
- Ответ: значительно меньше
Вопрос 212. Общая (ТSS), объясненная (ESS) и необъясненная (RSS) суммы квадратов отклонений находятся в следующих соотношениях
- Ответ: TSS = RSS + ESS
Вопрос 213. Если F-статистика Фишера превысит критическое значение Fкрит, то регрессия считается:
- Ответ: значимой
Вопрос 214. Число степеней свободы для t-статистики равно числу наблюдений в выборке __________________ количество оцениваемых коэффициентов.
- Ответ: минус
Вопрос 215. Если коэффициент Тейла равен нулю, то …
- Ответ: прогноз сделан успешно
Вопрос 216. Верхнее число степеней свободы F-cтатистики в случае парной регрессии равно:
- Ответ: одному
Вопрос 217. Автокорреляция — нарушение __________________ условия Гаусса-Маркова.
- Ответ: третьего
Вопрос 218. Совокупность фиктивных переменных — некоторое количество фиктивных переменных, предназначенное для описания
- Ответ: набора категорий
Вопрос 219. Стандартное отклонение случайной величины характеризует среднее ожидаемое расстояние между наблюдениями этой случайной величины и ее:
- Ответ: математическим ожиданием
Вопрос 220. В авторегрессионной схеме первого порядка uкн = рuк + ek предполагается, что значение ek в каждом наблюдении:
- Ответ: не зависит от его значений во всех других наблюдениях
Вопрос 221. Цель регрессионного анализа состоит в объяснении поведения
- Ответ: зависимой переменной
Вопрос 222. Разность между математическим ожиданием оценки и истинным значением оцениваемого параметра называют:
- Ответ: смещением
Вопрос 223. В авторегрессионной схеме первого порядка зависимость между последовательными случайными членами описывается формулой uk+1 = __________________, где ρ — константа, ek+1 — новый случайный член.
- Ответ: ρuk + e k+1
Вопрос 224. В функции Кобба-Дугласа вида log Y = a + b1 log k + b2 log l (k — индекс затрат капитала, l — индекс затрат труда) роль замещающей переменной для показателя технического прогресса играет:
- Ответ: log k
Вопрос 225. Наиболее частая причина положительной автокорреляции заключается в постоянной направленности воздействия __________________ переменных.
- Ответ: не включенных в уравнение
Вопрос 226. Для линеаризации функции Кобба-Дугласа необходимо предварительно обе части уравнения
- Ответ: разделить на L
Вопрос 227. О наличии данной частоты в спектре временного ряда свидетельствует __________________ спектральной плотности.
- Ответ: пик на графике
Вопрос 228. При добавлении еще одной переменной в уравнение регрессии коэффициент детерминации:
- Ответ: не уменьшается
Вопрос 229. Стандартные отклонения коэффициентов регрессии обратно пропорциональны величине _________, где n – число наблюдений:
- Ответ: n
Вопрос 230. Зависимая переменная может быть представлена как фиктивная в случае если она:
- Ответ: трудноизмерима
Вопрос 231. Тест Фишера является:
- Ответ: односторонним
Вопрос 232. Выборочная корреляция является __________оценкой теоретической корреляции:
- Ответ: состоятельной
Вопрос 233. Определение отдельного вклада каждой из независимых переменных в объясненную дисперсию в случае их коррелированности является ___________ задачей:
- Ответ: невыполнимой
Вопрос 234. Условие гомоскедастичности означает, что вероятность того, что случайный член примет какое-либо конкретное значение _________ наблюдений:
- Ответ: одинакова для всех
Вопрос 235. Значения t-статистики для фиктивных переменных незначимо отличается от:
- Ответ: 0
Вопрос 236. Из перечисленных факторов: 1) число объясняющих переменных, 2) количество наблюдений в выборке, 3)конкретные значения переменных, критические значения статистики Дарбина-Уотсона зависят от:
- Ответ: 1, 2
Вопрос 237. Значение статистики DW находится между значениями:
- Ответ: 0 и 4
Вопрос 238. Наблюдение зависимой переменной регрессии в предшествующий момент, используемое как объясняющая переменная, называется:
- Ответ: лаговой
Вопрос 239. Чем больше число наблюдений, тем __________ зона неопределенности для критерия Дарбина-Уотсона:
- Ответ: уже
Вопрос 240. МНК автоматически дает ___________ для данной выборки значение коэффициента детерминации R2:
- Ответ: максимальное
Вопрос 241. В авторегрессионной схеме первого порядка предполагается, что значение в каждом наблюдении:
- Ответ: не зависит от его значения во всех других наблюдениях
Вопрос 242. Линия регрессии _______ через точку ( , ) :
- Ответ: всегда проходит
Вопрос 243. Если предположение о природе гетероскедастичности верно, то дисперсия случайного члена для первых наблюдений в упорядоченном ряду будет ________ для последних:
- Ответ: ниже, чем
Вопрос 244. Стандартные ошибки, вычисленные при гетероскедастичности:
- Ответ: занижены по сравнению с истинными значениями
Вопрос 245. Критерий Дарбина-Уотсона –метод обнаружения _________ с помощью статистики Дарбина-Уотсона:
- Ответ: автокорреляции
Вопрос 246. Параметры множественной регрессии ?1 , ?2 ,… ?м показывают _________ соответствующих экономических факторов:
- Ответ: степень влияния
Вопрос 247. Во множественном регрессионном анализе коэффициент детерминации определяет _______регрессией:
- Ответ: долю дисперсии y, объясненную
Вопрос 248. Сумма квадратов отклонений величины y от своего выборочного значения _____ сумма квадратов отклонений:
- Ответ: общая
Вопрос 249. Фиктивная переменная взаимодействия – фиктивная переменная, предназначенная для
- Ответ: одновременного наступления нескольких независимых
Вопрос 250. Автокорреляция первого порядка – ситуация, когда коррелируют случайные члены регрессии в __________ наблюдениях:
- Ответ: последовательных
Вопрос 251. Фиктивная переменная – переменная, принимающая в каждом наблюдении:
- Ответ: только два значения 0 или 1
Вопрос 252. Для того, чтобы установить влияние какого-либо события на коэффициент линейной регрессии при нефиктивной переменной, в модель включают:
- Ответ: фиктивную переменную для коэффициента наклона
Вопрос 253. Оценка параметра для модели множественной регрессии в случае двух независимых переменных вычисляется по формуле: а =
- Ответ: 1 1 2 2 y ? b x ? b x
Вопрос 254. Процесс выбора необходимых переменных для регрессии переменных и отбрасывание лишних переменных называется:
- Ответ: спецификацией переменных
Вопрос 255. Из перечисленного: 1) число объясняющих переменных, 2) количество наблюдений в выборке, 3) конкретные значения переменных критические значения статистики Дарбина-Уотсона зависят от:
- Ответ: 1, 2
Вопрос 256. Число степеней свободы для уравнения m-мерной регрессии при достаточном числе наблюдений n составляет:
- Ответ: n-m-1
Вопрос 257. Наилучший способ устранения автокорреляции – установление ответственного за нее фактора и включение соответствующей ___________ переменной в регрессию:
- Ответ: объясняющей
Вопрос 258. Строгая линейная зависимость между переменными – ситуация, когда ________ двух переменных равна 1 или -1:
- Ответ: выборочная корреляция
Вопрос 259. Значение статистики Дарбина-Уотсона находится между значениями:
- Ответ: 0 и 4
Важным этапом прогнозирования
социально-экономических явлений
является оценка точности и надежности
прогнозов.
Эмпирической мерой точности прогноза,
служит величина его ошибки, которая
определяется как разность между
прогнозными (![]() )
)
и фактическими (уt)
значениями исследуемого показателя.
Данный подход возможен только в двух
случаях:
а) период упреждения известен, уже
закончился и исследователь располагает
необходимыми фактическими значениями
прогнозируемого показателя;
б) строится ретроспективный прогноз,
то есть рассчитываются прогнозные
значения показателя для периода времени
за который уже имеются фактические
значения. Это делается с целью проверки
разработанной методики прогнозирования.
В данном случае вся имеющаяся информация
делится на две части в соотношении 2/3
к 1/3. Одна часть информации (первые 2/3
от исходного временного ряда) служит
для оценивания параметров модели
прогноза. Вторая часть информации
(последняя 1/3 части исходного ряда)
служит для реализации оценок прогноза.
Полученные, таким образом, ретроспективно
ошибки прогноза в некоторой степени
характеризуют точность предлагаемой
и реализуемой методики прогнозирования.
Однако величина ошибки ретроспективного
прогноза не может в полной мере и
окончательно характеризовать используемый
метод прогнозирования, так как она
рассчитана только для 2/3 имеющихся
данных, а не по всему временному ряду.
В случае если, ретроспективное
прогнозирование осуществлять по связным
и многомерным динамическим рядам, то
точность прогноза, соответственно,
будет зависеть от точности определения
значений факторных признаков, включенных
в многофакторную динамическую модель,
на всем периоде упреждения. При этом,
возможны следующие подходы к
прогнозированию по связным временным
рядам: можно использовать как фактические,
так и прогнозные значения признаков.
Все показатели оценки точности
статистических прогнозов условно можно
разделить на три группы:
-
аналитические;
-
сравнительные;
-
качественные.
Аналитические показатели точности
прогноза позволяют количественно
определить величину ошибки прогноза.
К ним относятся следующие показатели
точности прогноза:
Абсолютная ошибка прогноза (D*)
определяется как разность между
эмпирическим и прогнозным значениями
признака и вычисляется по формуле:
![]() , (16.1)
, (16.1)
где уt– фактическое
значение признака;
![]() —
—
прогнозное значение признака.
Относительная ошибка прогноза (d*отн)
может быть определена как отношение
абсолютной ошибки прогноза (D*):
-
к
фактическому значению признака (уt):
(16.2)
— к прогнозному
значению признака (![]() )
)
(16.3)
Абсолютная и относительная ошибки
прогноза являются оценкой проверки
точности единичного прогноза, что
снижает их значимость в оценке точности
всей прогнозной модели, так как на
изучаемое социально-экономическое
явление подвержено влиянию различных
факторов внешнего и внутреннего
свойства. Единично удовлетворительный
прогноз может быть получен и на базе
реализации слабо обусловленной и
недостаточно адекватной прогнозной
модели и наоборот – можно получить
большую ошибку прогноза по достаточно
хорошо аппроксимирующей модели.
Поэтому на практике иногда определяют
не ошибку прогноза, а некоторый
коэффициент качества прогноза (Кк),
который показывает соотношение между
числом совпавших (с) и общим числом
совпавших (с) и несовпавших (н) прогнозов
и определяется по формуле:
![]() (16.4)
(16.4)
Значение Кк= 1 означает, что имеет
место полное совпадение значений
прогнозных и фактических значений и
модель на 100% описывает изучаемое
явление. Данный показатель оценивает
удовлетворительный вес совпавших
прогнозных значений в целом по временному
ряду и изменяющегося в пределах от 0 до
1.
Следовательно, оценку точности получаемых
прогнозных моделей целесообразно
проводить по совокупности сопоставлений
прогнозных и фактических значений
изучаемых признаков.
Средним показателем точности прогноза
является средняя абсолютная ошибка
прогноза (![]() ),
),
которая определяется как средняя
арифметическая простая из абсолютных
ошибок прогноза по формуле вида:
, (16.5)
де n– длина временного
ряда.
Средняя абсолютная ошибка прогноза
показывает обобщенную характеристику
степени отклонения фактических и
прогнозных значений признака и имеет
ту же размерность, что и размерность
изучаемого признака.
Для оценки точности прогноза используется
средняя квадратическая ошибка прогноза,
определяемая по формуле:
(16.6)
Размерность средней квадратической
ошибки прогноза также соответствует
размерности изучаемого признака. Между
средней абсолютной и средней квадратической
ошибками прогноза существует следующее
примерное соотношение:
![]() (16.7)
(16.7)
Недостатками средней абсолютной и
средней квадратической ошибками
прогноза является их существенная
зависимость от масштаба измерения
уровней изучаемых социально-экономических
явлений.
Поэтому на практике в качестве
характеристики точности прогноза
определяют среднюю ошибку аппроксимации,
которая выражается в процентах
относительно фактических значений
признака, и определяется по формуле
вида:
![]() (16.8)
(16.8)
Данный показатель является относительным
показателем точности прогноза и не
отражает размерность изучаемых
признаков, выражается в процентах и на
практике используется для сравнения
точности прогнозов полученных как по
различным моделям, так и по различным
объектам. Интерпретация оценки точности
прогноза на основе данного показателя
представлена в следующей таблице:
-
,%
Интерпретация
точности< 10
10 – 20
20 – 50
> 50
Высокая
Хорошая
Удовлетворительная
Не удовлетворительная
В качестве сравнительного показателя
точности прогноза используется
коэффициент корреляции между прогнозными
и фактическими значениями признака,
который определяется по формуле:
, (16.9)
где
![]() —
—
средний уровень ряда динамики прогнозных
оценок.
Используя данный коэффициент в оценке
точности прогноза следует помнить, что
коэффициент парной корреляции в силу
своей сущности отражает линейное
соотношение коррелируемых величин и
характеризует лишь взаимосвязь между
временным рядом фактических значений
и рядом прогнозных значений признаков.
И даже если коэффициент корреляции R= 1, то это еще не предполагает полного
совпадения фактических и прогнозных
оценок, а свидетельствует лишь о наличии
линейной зависимости между временными
рядами прогнозных и фактических значений
признака.
Одним из показателей оценки точности
статистических прогнозов является
коэффициент несоответствия (КН), который
был предложен Г. Тейлом и может
рассчитываться в различных модификациях:
-
Коэффициент несоответствия (КН1),
определяемый как отношение средней
квадратической ошибки к квадрату
фактических значений признака:
(16.10)
КН = о, если
,
то есть полное совпадение фактических
и прогнозных значений признака.
КН = 1, если при прогнозировании получают
среднюю квадратическую ошибку адекватную
по величине ошибке, полученной одним
из простейших методов экстраполяции
неизменности абсолютных цепных
приростов.
КН > 1, когда прогноз дает худшие
результаты, чем предположение о
неизменности исследуемого явления.
Верхней границы коэффициент несоответствия
не имеет.
2.Коэффициент несоответствия КН2определяется как отношение средней
квадратической ошибки прогноза к сумме
квадратов
отклонений
фактических значений признака от
среднего уровня исходного временного
ряда за весь рассматриваемый период:
, (16.11)
где ![]() — средний уровень исходного ряда
— средний уровень исходного ряда
динамики.
Если КН > 1, то прогноз на уровне среднего
значения признака дал бы лучший
результат, чем имеющийся прогноз.
3.Коэффициент несоответствия (КН3),
определяемый как отношение средней
квадратической ошибке прогноза к сумме
квадратов отклонений фактических
значений признака от теоретических,
выравненных по уравнению тренда:
, (16.12)
где ![]() — теоретические уровни временного ряда,
— теоретические уровни временного ряда,
полученные по
модели тренда.
Если КН > 1, то прогноз методом
экстраполяции тренда дает хороший
результат.
1. Статистика как наука изучает:
а) единичные явления;
б) массовые явления;
в) периодические события.
2. Термин «статистика» происходит от слова:
а) статика;
б) статный;
в) статус.
3. Статистика зародилась и оформилась как самостоятельная учебная дисциплина:
а) до новой эры, в Китае и Древнем Риме;
б) в 17-18 веках, в Европе;
в) в 20 веке, в России.
4. Статистика изучает явления и процессы посредством изучения:
а) определенной информации;
б) статистических показателей;
в) признаков различных явлений.
5. Статистическая совокупность – это:
а) множество изучаемых разнородных объектов;
б) множество единиц изучаемого явления;
в) группа зафиксированных случайных событий.
6. Основными задачами статистики на современном этапе являются:
а) исследование преобразований экономических и социальных процессов в обществе; б) анализ и прогнозирование тенденций развития экономики; в) регламентация и планирование хозяйственных процессов;
а) а, в
б) а, б
в) б, в
7. Статистический показатель дает оценку свойства изучаемого явления:
а) количественную;
б) качественную;
в) количественную и качественную.
8. Основные стадии экономико-статистического исследования включают: а) сбор первичных данных, б) статистическая сводка и группировка данных, в) контроль и управление объектами статистического изучения, г) анализ статистических данных
а) а, б, в
б) а, в, г
в) а ,б, г
г) б, в, г
9. Закон больших чисел утверждает, что:
а) чем больше единиц охвачено статистическим наблюдением,тем лучше проявляется общая закономерность;
б) чем больше единиц охвачено статистическим наблюдением, тем хуже проявляется общая закономерность;
в) чем меньше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность.
10. Современная организация статистики включает: а) в России — Росстат РФ и его территориальные органы, б) в СНГ — Статистический комитет СНГ, в) в ООН — Статистическая комиссия и статистическое бюро, г) научные исследования в области теории и методологии статистики
а) а, б, г
б) а, б, в
в) а, в, г
1. Статистическое наблюдение – это:
а) научная организация регистрации информации;
б) оценка и регистрация признаков изучаемой совокупности;
в) работа по сбору массовых первичных данных;
г) обширная программа статистических исследований.
2. Назовите основные организационные формы статистического наблюдения:
а) перепись и отчетность;
в) разовое наблюдение;
г) опрос.
3. Перечень показателей (вопросов) статистического наблюдения, цель, метод, вид, единица наблюдения, объект, период статистического наблюдения излагаются:
а) в инструкции по проведению статистического наблюдения;
б) в формуляре статистического наблюдения;
в) в программе статистического наблюдения.
4. Назовите виды статистического наблюдения по степени охвата единиц совокупности:
а) анкета;
б) непосредственное;
в) сплошное;
г) текущее.
5. Назовите виды статистического наблюдения по времени регистрации:
а) текущее, б) единовременное; в) выборочное; г) периодическое; д) сплошное
а) а, в, д
б) а, б, г
в) б, г, д
6. Назовите основные виды ошибок регистрации: а) случайные; б) систематические; в) ошибки репрезентативности; г) расчетные
а) а
б) а, б
в) а, б, в,
г) а, б, в, г
7. Несплошное статистическое наблюдение имеет виды: а) выборочное;
б) монографическое; в) метод основного массива; г) ведомственная отчетность
а) а, б, в
б) а, б, г
в) б, в, г
8. Организационный план статистического наблюдения регламентирует: а) время и сроки наблюдения; б) подготовительные мероприятия;
в) прием, сдачу и оформление результатов наблюдения; г) методы обработки данных
а) а, б, г
б) а, б, в
9. Является ли статистическим наблюдением наблюдения покупателя за качеством товаров или изменением цен на городских рынках?
а) да
б) нет
10. Ошибка репрезентативности относится к:
а) сплошному наблюдению;
б) не сплошному выборочному наблюдению.
1. Статистическая сводка — это:
а) систематизация и подсчет итогов зарегистрированных фактов и данных;
б) форма представления и развития изучаемых явлений;
в) анализ и прогноз зарегистрированных данных.
2. Статистическая группировка — это:
а) объединение данных в группы по времени регистрации;
б) расчленение изучаемой совокупности на группы по существенным признакам;
в) образование групп зарегистрированной информации по мере ее поступления.
3. Статистические группировки могут быть: а) типологическими; б) структурными; в) аналитическими; г) комбинированными
а) а
б) а, б
в) а, б, в
г) а, б, в, г
4. Группировочные признаки, которыми одни единицы совокупности обладают, а другие — нет, классифицируются как:
а) факторные;
б) атрибутивные;
в) альтернативные.
5. К каким группировочным признакам относятся: образование сотрудников, профессия бухгалтера, семейное положение:
а) к атрибутивным;
б) к количественны.
6. Ряд распределения — это:
а) упорядоченное расположение единиц изучаемой совокупности по группам;
б) ряд значений показателя, расположенных по каким-то правилам.
7. К каким группировочным признакам относятся: сумма издержек обращения, объем продаж, стоимость основных фондов
а) к дискретным;
б) к непрерывным.
8. Какие виды статистических таблиц встречаются:
а) простые и комбинационные;
б) линейные и нелинейные.
1. Статистический показатель — это
а) размер изучаемого явления в натуральных единицах измерения
б) количественная характеристика свойств в единстве с их качественной определенностью
в) результат измерения свойств изучаемого объекта
2. Статистические показатели могут характеризовать:
а) объемы изучаемых процессов
б) уровни развития изучаемых явлений
в) соотношение между элементами явлений
г) а, б, в
3. По способу выражения абсолютные статистические показатели подразделяются на: а) суммарные; б) индивидуальные; в) относительные; г) средние; д) структурные
а) а, д
б) б, в
в) в, г
г) а, б
4. В каких единицах выражаются абсолютные статистические показатели?
а) в коэффициентах
б) в натуральных
в) в трудовых
5. В каких единицах будет выражаться относительный показатель, если база сравнения принимается за единицу?
а) в процентах
б) в натуральных
в) в коэффициентах
6. Относительные показатели динамики с переменной базой сравнения подразделяются на:
а) цепные
б) базисные
7. Сумма всех удельных весов показателя структуры
а) строго равна 1
б) больше или равна 1
в) меньше или равна 1
8. Относительные показатели по своему познавательному значению подразделяются на показатели: а) выполнения и сравнения, б) структуры и динамики, в) интенсивности и координации, г) прогнозирования и экстраполяции
а) а, б, г
б) б, в, г
в) а, б, в
9. Статистические показатели по сущности изучаемых явлений могут быть:
а) качественными
б) объёмными
в) а, б
10. Статистические показатели в зависимости от характера изучаемых явлений могут быть:
а) интервальными
б) моментными
в) а, б
1. Исчисление средних величин — это
а) способ изучения структуры однородных элементов совокупности
б) прием обобщения индивидуальных значений показателя
в) метод анализа факторов
2. Требуется вычислить средний стаж деятельности работников фирмы: 6,5,4,6,3,1,4,5,4,5. Какую формулу Вы примените?
а) средняя арифметическая
б) средняя арифметическая взвешенная
в) средняя гармоническая
3. Средняя геометрическая — это:
а) корень из произведения индивидуальных показателей
б) произведение корней из индивидуальных показателей
4. По какой формуле производится вычисление средней величины в интервальном ряду?
а) средняя арифметическая взвешенная
б) средняя гармоническая взвешенная
5. Могут ли взвешенные и невзвешенные средние, рассчитанные по одним и тем же данным, совпадать?
а) да
б) нет
6. Как изменяется средняя арифметическая, если все веса уменьшить в А раз?
а) уменьшатся
б) увеличится
в) не изменится
7. Как изменится средняя арифметическая, если все значения определенного признака увеличить на число А?
а) уменьшится
б) увеличится
в) не изменится
8. Значения признака, повторяющиеся с наибольшей частотой, называется
а) модой
б) медианой
9. Средняя хронологическая исчисляется
а) в моментных рядах динамики с равными интервалами
б) в интервальных рядах динамики с равными интервалами
в) в интервальных рядах динамики с неравными интервалами
10. Медиана в ряду распределения с четным числом членов ряда равна
а) полусумме двух крайних членов
б) полусумме двух срединных членов
1. Что понимается в статистике под термином «вариация показателя»?
а) изменение величины показателя
б) изменение названия показателя
в) изменение размерности показателя
2. Укажите показатели вариации
а) мода и медиана
б) сигма и дисперсия
в) темп роста и прироста
3. Показатель дисперсии — это:
а) квадрат среднего отклонения
б) средний квадрат отклонений
в) отклонение среднего квадрата
4. Коэффициент вариации измеряет колеблемость признака
а) в относительном выражении
б) в абсолютном выражении
5. Среднеквадратическое отклонение характеризует
а) взаимосвязь данных
б) разброс данных
в) динамику данных
6. Размах вариации исчисляется как
а) разность между максимальным и минимальным значением показателя
б) разность между первым и последним членом ряда распределения
7. Показатели вариации могут быть
а) простыми и взвешенными
б) абсолютными и относительными
в) а) и б)
8. Закон сложения дисперсий характеризует
а) разброс сгруппированных данных
б) разброс неупорядоченных данных
9. Средне квадратическое отклонение исчисляется как
а) корень квадратный из медианы
б) корень квадратный из коэффициента вариации
в) корень квадратный из дисперсии
10. Кривая закона распределения характеризует
а) разброс данных в зависимости от уровня показателя
б) разброс данных в зависимости от времени
1. Выборочный метод в статистических исследованиях используется для:
а) экономии времени и снижения затрат на проведение статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2. Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3. Ошибка репрезентативности обусловлена:
а) самим методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
4. Коэффициент доверия в выборочном методе может принимать значения:
а) 1, 2, 3;
б) 4, 5, 6;
в) 7, 8, 9.
5. Выборка может быть: а) случайная, б) механическая, в) типическая, серийная, д) техническая
а) а, б, в, г,
б) а, б, в, д
в) б, в, г, д
6. Необходимая численность выборочной совокупности определяется:
а) колеблемостью признака;
б) условиями формирования выборочной совокупности;
7. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным объемом единиц непосредственного наблюдения;
в) разным числом зарегистрированных наблюдений.
8. Средняя ошибка выборки:
а) прямо пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
9. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная однажды единица наблюдения возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
10. Малая выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30 единиц изучаемой совокупности.
1. Ряд динамики характеризует: а) структуру совокупности по какому-то признаку; б) изменение характеристик совокупности во времени; в) определенное значение признака в совокупности; г) величину показателя на определенную дату или за определенный период
а) а, б
б) б, г
в) б, в
2. Ряд динамики может состоять: а) из абсолютных суммарных величин; б) из относительных и средних величин;
а) а
б) б
в) а, б
3. Ряд динамики, характеризующий уровень развития социально-экономического явления на определенные даты времени, называется:
а) интервальным;
б) моментным.
4. Средний уровень интервального ряда динамики определяется как:
а) средняя арифметическая;
б) средняя хронологическая.
5. Средний уровень моментного ряда динамики исчисляется как: а) средняя арифметическая взвешенная при равных интервалах между датами; б) при неравных интервалах между датами как средняя хронологическая, в) при равных интервалах между датами как средняя хронологическая;
а) а
б) б
в) б, в
6. Абсолютный прирост исчисляется как: а) отношение уровней ряда; б) разность уровней ряда. Темп роста исчисляется как: в) отношение уровней ряда; г) разность уровней ряда;
а) а, в
б) б, в
в) а, г
7. Для выявления основной тенденции развития используется: а) метод укрупнения интервалов; б) метод скользящей средней; в) метод аналитического выравнивания; г) метод наименьших квадратов;
а) а, г
б) б, г
в) а, б, г
г) а, б, в
8. Трендом ряда динамики называется:
а) основная тенденция;
б) устойчивый темп роста.
9. Прогнозирование в статистике ‑ это:
а) предсказание предполагаемого события в будущем;
б) оценка возможной меры изучаемого явления в будущем.
10. К наиболее простым методам прогнозирования относят:
а) индексный метод;
б) метод скользящей средней;
в) метод на основе среднего абсолютного прироста.
1. Статистический индекс — это:
а) критерий сравнения относительных величин;
б) сравнительная характеристика двух абсолютных величин;
в) относительная величина сравнения двух показателей.
2. Индексы позволяют соизмерить социально-экономические явления:
а) в пространстве;
б) во времени;
в) в пространстве и во времени.
3. В индексном методе анализа несуммарность цен на разнородные товары преодолевается:
а) переходом от абсолютных единиц измерения цен к относительной форме;
б) переходом к стоимостной форме измерения товарной массы.
4. Можно ли утверждать, что индивидуальные индексы по методологии исчисления адекватны темпам роста:
а) можно;
б) нельзя.
5. Сводные индексы позволяют получить обобщающую оценку изменения:
а) по товарной группе;
б) одного товара за несколько периодов.
6. Может ли в отдельных случаях средний гармонический индекс рассчитываться по средней гармонической невзвешенной:
а) может;
б) не может.
7. Индексы переменного состава рассчитываются:
а) по товарной группе;
б) по одному товару.
8. Может ли индекс переменного состава превышать индекс фиксированного состава:
а) может;
б) не может.
9. Первая индексная мультипликативная модель товарооборота – это:
а) произведение индекса цен на индекс физического объема товарооборота;
б) произведение индекса товарооборота в сопоставимых ценах на индекс средней цены постоянного состава;
в) а, б.
10. Вторая факторная индексная мультипликативная модель анализа – это:
а) произведение индекса постоянного состава на индекс структурных сдвигов;
б) частное от деления индекса переменного состава на индекс структурных сдвигов;
в) а, б.
1. Статистическая связь — это:
а) когда зависимость между факторным и результирующим
показателями неизвестна;
б) когда каждому факторному соответствует свой результирующий показатель;
в) когда каждому факторному соответствует несколько разных значений результирующего показателя.
2. Термин корреляция в статистике понимают как:
а) связь, зависимость;
б) отношение, соотношение;
в) функцию, уравнение.
3. По направлению связь классифицируется как:
а) линейная;
б) прямая;
в) обратная.
4. Анализ взаимосвязи в статистике исследует:
а) тесноту связи;
б) форму связи;
в) а, б
5. При каком значении коэффициента корреляции связь можно считать умеренной?
а) r = 0,43;
б) r = 0,71.
6. Термин регрессия в статистике понимают как: а) функцию связи, зависимости; б) направление развития явления вспять; в) функцию анализа случайных событий во времени; г) уравнение линии связи
а) а, б
б) в, г
в) а, г
7. Для определения тесноты связи двух альтернативных показателей применяют:
а) коэффициенты ассоциации и контингенции;
б) коэффициент Спирмена.
8. Дайте классификацию связей по аналитическому выражению:
а) обратная;
б) сильная;
в) прямая;
г) линейная.
9. Какой коэффициент корреляции характеризует связь между YиX:
а) линейный;
б) частный;
в) множественный.
10. При каком значении линейного коэффициента корреляции связь между YиXможно признать более существенной:
а) ryx = 0,25;
б) ryx = 0,14;
в) ryx = — 0,57.
Вопрос 1. Модель множественной регрессии с тремя объясняющими переменными без свободного коэффициента имеет вид: y =
- Ответ: b1x1 + b2x2 + b3x3
Вопрос 2. При автокорреляции оценка коэффициентов регрессии становится:
- Ответ: неэффективной
Вопрос 3. Cитуация, при которой нулевая гипотеза была отвергнута, хотя была истинной, носит название:
- Ответ: ошибки I рода
Вопрос 4. При использовании уровня значимости, равного 5%, истинная гипотеза отвергается в __________________ случаев.
- Ответ: 5%
Вопрос 5. Для идентификации АР и СС моделей сначала делают оценки
- Ответ: автокорреляционной функции
Вопрос 6. Значение статистики Дарбина-Уотсона находится между значениями
- Ответ: 0 и 4
Вопрос 7. Пересмотр оценок в методе Кокрана-Оркатта выполняется до тех пор, пока не будет __________________ оценок.
- Ответ: получена требуемая точность
Вопрос 8. Способ оценивания (estimator) — общее правило для получения __________________ какого-либо параметра по данным выборки.
- Ответ: приближенного численного значения
Вопрос 9. Явление, когда строгая линейная зависимость между переменными приводит к невозможности применения МНК, называется:
- Ответ: полной коллинеарностью
Вопрос 10. Выборочная дисперсия зависимой переменной регрессии равна __________________ объясненной дисперсии зависимой переменной и необъясненной дисперсии зависимой переменной.
- Ответ: сумме
Вопрос 11. Четвертое условие Гаусса-Маркова состоит в том, что для любого k cov (uk, хk) равна:
- Ответ: 0
Вопрос 12. Эластичность y по x рассчитывается __________________ величины относительного изменения y на величину относительного изменения x.
- Ответ: делением
Вопрос 13. Если выборка достаточно полно отражает изучаемые параметры генеральной совокупности, то ее называют:
- Ответ: репрезентативной
Вопрос 14. Целью эконометрики является получение количественных выводов о свойствах экономических явлений и процессов по данным
- Ответ: выборки
Вопрос 15. Если все наблюдения лежат на линии регрессии, то коэффициент детерминации R2 для модели парной регрессии равен:
- Ответ: единице
Вопрос 16. Если две переменные независимы, то их теоретическая ковариация равна:
- Ответ: 0
Вопрос 17. Обычно прогнозы, получаемые с помощью моделей Бокса-Дженкинса, оказываются на практике __________________ прогнозов, построенных по макроэкономическим моделям.
- Ответ: не хуже
Вопрос 18. Весовые коэффициенты в методе скользящего среднего
- Ответ: всегда больше нуля
Вопрос 19. Если вычисленное значение статистики Спирмена превысит некое критическое значение, то принимается решение о:
- Ответ: наличии гетероскедастичности
Вопрос 20. Отклонение еi в i-м наблюдении yi от регрессии с двумя объясняющими переменными:
- Ответ: ei = yi — a — b1x1 — b2x2
Вопрос 21. Положительная автокорреляция — ситуация, когда случайный член регрессии в следующем наблюдении ожидается:
- Ответ: того же знака, что и в настоящем наблюдении
Вопрос 22. При построении отдельных уравнений регрессии для каждого из 4-х кварталов сумма сезонных отклонений должна равняться:
- Ответ: 0
Вопрос 23. Коэффициент Тейла лежит в пределах
- Ответ: от 0 до 1
Вопрос 24. Множественный регрессионный анализ является __________________ парного регрессионного анализа.
- Ответ: развитием
Вопрос 25. При положительной автокорреляции DW
- Ответ:
Вопрос 26. Процесс Юла описывается моделью
- Ответ: АР (2)
Вопрос 27. Эконометрический инструментарий базируется на методах и моделях
- Ответ: математической статистики
Вопрос 28. Если из экономических соображений известно, что b >= b0, то нулевая гипотеза отвергается только при:
- Ответ: t > tкрит
Вопрос 29. При вычислении t-статистики применяется распределение
- Ответ: Стьюдента
Вопрос 30. Аналитические методы выделения неслучайной составляющей основаны на допущении, что …
- Ответ: известен общий вид неслучайной составляющей
Вопрос 31. Наблюдение зависимой переменной регрессии в предшествующий момент, используемое как объясняющая переменная, называется __________________ переменной.
- Ответ: лаговой
Вопрос 32. Явление, когда нестрогая линейная зависимость между объясняющими переменными в модели множественной регрессии приводит к получению ненадежных оценок регрессии, называют:
- Ответ: мультиколлинеарностью
Вопрос 33. Для модели парной регрессии оценки, полученные по МНК, являются несмещенными, эффективными, состоятельными, если …
- Ответ: выполнены условия Гаусса-Маркова
Вопрос 34. Если элементы набора данных не являются статистически независимыми, то речь идет о:
- Ответ: временном ряде
Вопрос 35. Метод наименьших квадратов — метод нахождения оценок параметров регрессии, основанный на минимизации __________________ квадратов остатков всех наблюдений.
- Ответ: суммы
Вопрос 36. Тест Бокса-Кокса (решетчатый поиск) — прямой компьютерный метод выбора наилучших значений __________________ модели в заданных исследователем пределах с заданным шагом (решеткой).
- Ответ: параметров нелинейной
Вопрос 37. Уравнение y = a + bx, где a и b — оценки параметров a и b, полученные в результате оценивания модели y = a + bx + u по данным выборки, называется уравнением
- Ответ: линейной регрессии
Вопрос 38. Фиктивную переменную для коэффициента наклона вводят как __________________ фиктивной переменной, отвечающей за исследуемую категорию, и интересующей нефиктивной переменной.
- Ответ: произведение
Вопрос 39. Ситуация, когда не отвергнута ложная гипотеза, называется:
- Ответ: ошибкой II рода
Вопрос 40. Доверительный интервал в 99% __________________ интервал в 95%.
- Ответ: шире, чем
Вопрос 41. В множественном регрессионном анализе коэффициент детерминации определяет ____________________________________ регрессией.
- Ответ: долю дисперсии y, объясненную
Вопрос 42. Гетероскедастичность заключается в том, что дисперсия случайного члена регрессии __________________ наблюдений.
- Ответ: зависит от номера
Вопрос 43. Третье условие Гаусса-Маркова состоит в том, что cov (ui, uj) = 0, если …
- Ответ: i ¹ j
Вопрос 44. В модели множественной регрессии всегда желательно присутствие хотя бы одной __________________ переменной для того, чтобы обеспечить надлежащий уровень достоверности оценок.
- Ответ: нефиктивной
Вопрос 45. Зависимая переменная может быть представлена как фиктивная в случае, если она
- Ответ: является качественной по своему характеру
Вопрос 46. Множество наблюдений, составляющих часть генеральной совокупности, называется:
- Ответ: выборкой
Вопрос 47. Сглаживание временного ряда означает устранение
- Ответ: случайных остатков
Вопрос 48. Если автокорреляция отсутствует, то DW»:
- Ответ: 2
Вопрос 49. В методе скользящего среднего веса определяется с помощью:
- Ответ: МНК
Вопрос 50. Отличие одностороннего теста от двустороннего заключается в том, что он имеет только
- Ответ: одно критическое значение
Вопрос 51. Сумма квадратов остатков всех наблюдений — __________________ сумма квадратов отклонений.
- Ответ: остаточная
Вопрос 52. F-статистика для __________________ является в точности квадратом t-статистики для rx, y.
- Ответ: коэффициента детерминации
Вопрос 53. Для уравнения регрессии у=4+2х и наблюденных данных х=4, у=14 остаток в наблюдении равен:
- Ответ: 2
Вопрос 54. Фиктивная переменная для коэффициента наклона предназначена для установление влияния категории на:
- Ответ: коэффициент при нефиктивной переменной
Вопрос 55. Для линейного регрессионного анализа требуется линейность
- Ответ: только по параметрам
Вопрос 56. Второе условие Гаусса-Маркова заключается в том, что …
- Ответ: s2 (ui) — не зависит от i
Вопрос 57. Любой набор категорий можно описать некоторой совокупностью __________________ переменных.
- Ответ: фиктивных
Вопрос 58. В экономике отрицательная автокорреляция встречается __________________ положительная.
- Ответ: гораздо реже, чем
Вопрос 59. Итерационные методы — компьютерные __________________ методы поиска наилучших значений параметров нелинейной модели.
- Ответ: сходящиеся
Вопрос 60. Коэффициент Тейла основан на расчете
- Ответ: среднеквадратичного значения ошибки прогноза приростов
Вопрос 61. Процесс СС (2) имеет автокорреляционную функцию, которая:
- Ответ: обращается в ноль после некоторой точки
Вопрос 62. Набор категорий представляет собой конечный набор __________________ событий.
- Ответ: взаимоисключающих
Вопрос 63. Авторегрессионная схема называется схемой первого порядка, если описываемое __________________ равно 1.
- Ответ: максимальное запаздывание
Вопрос 64. В модели АР (1) частная автокорреляционная функция случайных остатков, разделенных двумя тактами времени, равна:
- Ответ: 0
Вопрос 65. Для выполнения теста Чоу используется распределение
- Ответ: Фишера
Вопрос 66. Коэффициент детерминации равен __________________ выборочной корреляции между y и a + bx.
- Ответ: квадрату
Вопрос 67. Если в регрессионную модель включена лишняя переменная, то оценки коэффициентов оказываются, как правило, …
- Ответ: неэффективными
Вопрос 68. Для производственного процесса, описываемого функцией Кобба-Дугласа, увеличение капитала (К) и труда (i) в 4 раза приводит к увеличению объема выпуска (у):
- Ответ: в 4 раза
Вопрос 69. Коэффициент ранговой корреляции имеет дисперсию
- Ответ: 1/ (n — 1)
Вопрос 70. Коэффициент Тейла служит критерием
- Ответ: успешности сделанного прогноза
Вопрос 71. Метод скользящего среднего относятся к __________________ методам выделения неслучайной составляющей.
- Ответ: алгоритмическим
Вопрос 72. На первом этапе применения теста Голдфелда-Квандта в выборке все наблюдения
- Ответ: Упорядочиваются по возрастанию х
Вопрос 73. Регрессором в уравнении парной линейной регрессии называется:
- Ответ: объясняющая переменная
Вопрос 74. Число степеней свободы (верхнее и нижнее) для отношения RSS2 / RSS1 в тесте Голдфелда-Квандта равно:
- Ответ: n’ — k — 1
Вопрос 75. Доля объясненной дисперсии зависимой переменной в общей выборочной дисперсии y выражается коэффициентом
- Ответ: детерминации
Вопрос 76. Значение оценки является:
- Ответ: случайной величиной
Вопрос 77. Для регрессии второго порядка y = 12+7x1-3x2 отклонение от регрессии наблюдения (х1=2, х2=1, y=20) равно:
- Ответ: е=3
Вопрос 78. Критерий восходящих и нисходящих серий позволяет:
- Ответ: выявить неслучайную составляющую
Вопрос 79. На больших временах процесс формирования значений временного ряда находится под воздействием __________________ факторов.
- Ответ: долговременных и циклических
Вопрос 80. Критерий серий, основанный на медиане, позволяет:
- Ответ: выявить неслучайную составляющую
Вопрос 81. Близко к линии регрессии находится наблюдение, для которого теоретическое распределение случайного члена имеет
- Ответ: малое стандартное отклонение
Вопрос 82. Марковский процесс описывается моделью
- Ответ: АР (1)
Вопрос 83. Метод Кокрана-Оркатта — компьютерный итерационный метод устранения
- Ответ: автокорреляции
Вопрос 84. Второе условие Гаусса-Маркова предполагает, что дисперсия случайного члена __________________ в каждом наблюдении.
- Ответ: постоянна
Вопрос 85. Как правило в эталонной категории
- Ответ: все фиктивные переменные равны 0
Вопрос 86. Коэффициент наклона в уравнении линейной регрессии показывает __________________ изменяется y при увеличении x на одну единицу.
- Ответ: на сколько единиц
Вопрос 87. Оценка параметров в лаговой структуре Койка делается:
- Ответ: решетчатым методом
Вопрос 88. Эффективная оценка — несмещенная оценка, имеющая __________________ среди всех несмещенных оценок.
- Ответ: наименьшую дисперсию
Вопрос 89. В критерии серий, основанном на медиане, протяженность самой длинной серии временного ряда 5, 1, 4, 2 равна:
- Ответ: 1
Вопрос 90. Выборочная дисперсия расчетных значений величины y называется __________________ дисперсией зависимой переменной.
- Ответ: объясненной
Вопрос 91. Свойства коэффициентов регрессии как случайных величин зависят от свойств __________________ уравнения.
- Ответ: остаточного члена
Вопрос 92. Модель Бокса-Дженкинса — это модель …
- Ответ: АРПСС
Вопрос 93. Исследование соотношения между спросом на реальные денежные остатки и ожидаемым изменением уровня цен описывается моделью
- Ответ: Кейгана
Вопрос 94. Оценка ρ, полученная МНК для авторегрессионной схемы первого порядка рассчитывается по формуле __________________, ek — остатки в наблюдениях.
- Ответ: cov (ek-1, ek) / var (ek-1)
Вопрос 95. Фиктивные переменные включаются в модель множественной регрессии, если необходимо установить влияние каких-либо __________________ факторов.
- Ответ: дискретных
Вопрос 96. Для проверки нулевой гипотезы H0: b= b0 применяется тест
- Ответ: Стьюдента
Вопрос 97. Дисперсии оценок а и b __________________ дисперсии остаточного члена s2 (u).
- Ответ: прямо пропорциональны
Вопрос 98. Категория — это событие, которое определенно __________________ в каждом наблюдении.
- Ответ: либо происходит, либо нет
Вопрос 99. Область принятия гипотезы — множество значений __________________, при попадании в которое нулевая гипотеза не отвергается.
- Ответ: оценок параметра
Вопрос 100. Ловушка dummy trap приводит к:
- Ответ: полной коллинеарности
Вопрос 101. Модель Линтнера основывается на предположении, что желаемый объем дивидендов
- Ответ: пропорционален прибыли
Вопрос 102. Детерминированная переменная может рассматриваться как предельный вариант случайной переменной, принимающей свое единственное значение с вероятностью
- Ответ: 1
Вопрос 103. Показатель выборочной ковариации позволяет выразить связь между двумя переменными
- Ответ: единым числом
Вопрос 104. Эконометрика — часть экономической науки, занимающаяся разработкой и применением __________________ методов анализа экономических процессов.
- Ответ: математических
Вопрос 105. Статистика Дарбина-Уотсона проверяет нулевую гипотезу Но:
- Ответ: отсутствие автокорреляции
Вопрос 106. Зависимость объемов введенных основных фондов от капитальных вложений описывается:
- Ответ: регрессионной моделью с распределенными лагами
Вопрос 107. Для того, чтобы установить влияние категории на коэффициент регрессии при нефиктивной переменной, в модель включают:
- Ответ: фиктивную переменную для коэффициента наклона
Вопрос 108. При отрицательной автокорреляции DW
- Ответ: >2
Вопрос 109. На экзамене в группе из 15 студентов 4 человека получили отличную оценку, 8 человек — оценку хорошо, 3 человека — оценку удовлетворительно. Средний бал по группе равен:
- Ответ: 4,06
Вопрос 110. При использования обычного МНК наблюдению высокого качества придается вес __________________ наблюдению низкого качества.
- Ответ: такой же как
Вопрос 111. Фиктивная переменная взаимодействия — это __________________ фиктивных переменных.
- Ответ: произведение
Вопрос 112. При попадании оценки в критическое значение:
- Ответ: сохраняется неопределенность в отношении гипотезы
Вопрос 113. Модель Кейгана — модель, описывающая гиперинфляцию с помощью модели
- Ответ: адаптивных ожиданий
Вопрос 114. При проведении теста Голдфелда-Квандта из рассмотрения исключаются __________________ наблюдений.
- Ответ: средние (n — 2n’)
Вопрос 115. Фиктивные переменные, предназначены для обозначения различных лет, кварталов, месяцев и т.п. — это __________________ фиктивные переменные.
- Ответ: сезонные
Вопрос 116. Теоретическая ковариация двух случайных величин определяется как математическое ожидание __________________ отклонений этих величин от их средних значений.
- Ответ: произведения
Вопрос 117. В модели парной регрессии у* = 4 + 2х изменение х на 2 единицы вызывает изменение у на __________________ единиц.
- Ответ: 4
Вопрос 118. Вероятности, с которыми случайная величина принимает свои значения, называют __________________ случайной величины.
- Ответ: законом распределения
Вопрос 119. Мерой разброса значений случайной величины служит:
- Ответ: дисперсия
Вопрос 120. При снижении уровня значимости риск совершить ошибку I рода
- Ответ: уменьшается
Вопрос 121. Фиктивная переменная — переменная, принимающая в каждом наблюдении значения:
- Ответ: 0 или 1
Вопрос 122. На больших временах __________________ факторы описываются монотонной функцией.
- Ответ: долговременные
Вопрос 123. Необходимость применения специальных статистических методов для обработки экономической информации вызвана __________________ данных.
- Ответ: стохастической природой
Вопрос 124. При использовании метода Монте-Карло результаты наблюдения генерируются с помощью
- Ответ: датчика случайных чисел
Вопрос 125. Для отношения RSS2/RSS1 в рамках теста Голдфелда-Квандта проводят тест
- Ответ: Фишера
Вопрос 126. В парном регрессионном анализе коэффициент детерминации R2 равен:
- Ответ: rх;у2
Вопрос 127. Подбор порядка аппроксимирующего полинома производится при помощи
- Ответ: метода последовательных разностей
Вопрос 128. Функция цены — функция, где аргументом является __________________, а значением функции — цена ошибки.
- Ответ: род ошибки
Вопрос 129. Если нулевая гипотеза Н0: β = β0, то альтернативная гипотеза Н1 — это:
- Ответ: β≠β0
Вопрос 130. Невыполнение 2 и 3 условий Гаусса-Маркова, приводит к потере свойства __________________ оценок.
- Ответ: эффективности
Вопрос 131. Эксперимент по методу Монте-Карло — искусственный, контролируемый эксперимент, проводимый для проверки и сравнения эффективности различных
- Ответ: статистических методов
Вопрос 132. Нижний индекс переменной (t-s) означает, что она является:
- Ответ: лаговой
Вопрос 133. Автокорреляция первого порядка — ситуация, когда случайный член uк коррелирует с:
- Ответ: Uк-1
Вопрос 134. Для применения теста Зарембки необходимо
- Ответ: преобразование масштаба наблюдений у
Вопрос 135. Если элементы набора данных не являются одинаково распределенными, то речь идет о:
- Ответ: временном ряде
Вопрос 136. Нелинейная модель у = f (x), в которой возможна замена переменной z = g (x), приводящая получившуюся модель y = F (z) — к линейной, называется моделью, нелинейной по:
- Ответ: переменным
Вопрос 137. Гетероскедастичность приводит к __________________ оценок параметров регрессии по МНК.
- Ответ: неэффективности
Вопрос 138. Число степеней свободы для уравнения множественной (m-мерной) регрессии при достаточном числе наблюдений n составляет:
- Ответ: n — m — 1
Вопрос 139. В критерии восходящих и нисходящих серий, общее число серий временного ряда 5, 7, 6, 4, 3, 1 равно:
- Ответ: 2
Вопрос 140. Ловушка dummy trap — выбор совокупности фиктивных переменных, сумма которых
- Ответ: константа
Вопрос 141. Оценка параметра находится __________________ доверительного интервала.
- Ответ: в центре
Вопрос 142. Данные по определенному показателю, полученные для разных однотипных объектов, называются:
- Ответ: перекрестными
Вопрос 143. При увеличении размера выборки оценка математического ожидания
- Ответ: становится более точной
Вопрос 144. При стремлении размера выборки к бесконечности стандартное отклонение математического ожидания стремится к:
- Ответ: 0
Вопрос 145. Доля числа исходов, благоприятствующих данному событию, в общем числе равновероятных исходов называется __________________ этого события.
- Ответ: вероятностью
Вопрос 146. Нижнее число степеней свободы F-cтатистики в случае парной регрессии равно:
- Ответ: n-2
Вопрос 147. Автокорреляционная функция принимает значения в пределах
- Ответ: от -1 до 1
Вопрос 148. Фиктивная переменная взаимодействия — фиктивная переменная, предназначенная для установления влияния на регрессию __________________ событий.
- Ответ: одновременного наступления нескольких независимых
Вопрос 149. Метод Зарембки процедура выбора между линейной и __________________ моделями:
- Ответ: логарифмической
Вопрос 150. Функция спектральной плотности позволяет установить:
- Ответ: частоты колебаний
Вопрос 151. При проведении теста Голдфелда-Квандта предполагается, что стандартное отклонение остаточного члена регрессии растет с __________________ переменной.
- Ответ: ростом объясняющей
Вопрос 152. Ранг наблюдения переменной — номер наблюдения переменной в упорядоченной __________________ последовательности.
- Ответ: по возрастанию значений наблюдаемой величины
Вопрос 153. Коэффициенты при сезонных фиктивных переменных показывают __________________ при смене сезона.
- Ответ: численную величину изменения, происходящего
Вопрос 154. При высоком уровне значимости проблема заключается в высоком риске допущения
- Ответ: ошибки II рода
Вопрос 155. Тест ранговой корреляции Спирмена — тест на:
- Ответ: гетероскедастичность
Вопрос 156. Статистика для теста ранговой корреляции Спирмена имеет __________________ распределение.
- Ответ: нормальное
Вопрос 157. МНК дает __________________ для данной выборки значение коэффициента детерминации R2.
- Ответ: максимальное
Вопрос 158. Функция Кобба-Дугласа имеет вид Y =
- Ответ: AKa L1-a
Вопрос 159. Процесс АР (2) имеет автокорреляционную функцию, которая:
- Ответ: имеет бесконечную протяженность
Вопрос 160. Утверждение о том, что неизвестный параметр модели принадлежит другому заданному множеству В, АÇВ = Æ, называется:
- Ответ: альтернативной гипотезой
Вопрос 161. Эконометрика получает количественные зависимости для экономических соотношений, основываясь в первую очередь на:
- Ответ: данных
Вопрос 162. Строгая линейная зависимость между переменными — ситуация, когда __________________ двух переменных равна 1 или -1.
- Ответ: выборочная корреляция
Вопрос 163. При рассмотрении спектральной плотности ограничиваются значениями ω, лежащими в пределах
- Ответ: от 0 до π
Вопрос 164. Функция Кобба-Дугласа называется:
- Ответ: производственной функцией
Вопрос 165. Утверждение о том, что неизвестный параметр модели принадлежит заданному множеству А, называется:
- Ответ: нулевой гипотезой
Вопрос 166. Проверка гипотезы Н0: R2 = 0 происходит с помощью теста
- Ответ: Фишера
Вопрос 167. Спектральная плотность может принимать __________________ значения.
- Ответ: только положительные
Вопрос 168. В модели множественной регрессии за изменение __________________ регрессии отвечает несколько объясняющих переменных.
- Ответ: одной зависимой переменной
Вопрос 169. Функция потерь, используемая при выборе между несмещенной и эффективной оценкой, определяет стоимость неточности как функцию
- Ответ: размера ошибки
Вопрос 170. Для уравнения регрессии у = 3х — 2 прогнозное значение зависимой переменной, если объясняющая переменная равна 4, — это:
- Ответ: 10
Вопрос 171. Тест Глейзера устанавливает наличие __________________ связи между стандартным отклонением остаточного члена регрессии и объясняющей переменной.
- Ответ: нелинейной
Вопрос 172. Чем больше число наблюдений, тем __________________ зона неопределенности для критерия Дарбина-Уотсона.
- Ответ: уже
Вопрос 173. Остаток в i-ом наблюдении по модели парной регрессии y=a+bx равен:
- Ответ: yi — (a + bxi)
Вопрос 174. Модель парной регрессии — __________________ модель зависимости между двумя переменными.
- Ответ: линейная
Вопрос 175. Граничное значение области принятия гипотезы с p%-ной вероятностью совершить ошибку I рода определяется __________________ при p-процентном уровне значимости.
- Ответ: критическим значением теста
Вопрос 176. Спецификация запаздываний применительно к переменным в модели называется:
- Ответ: лаговой структурой
Вопрос 177. Если независимые переменные имеют ярко выраженный временной тренд, то они оказываются:
- Ответ: тесно коррелированными
Вопрос 178. Первое условие Гаусса-Маркова заключается в том, что __________________ для любого i.
- Ответ: М (ui) = 0
Вопрос 179. В критерии восходящих и нисходящих серий, длина самой длинной серии временного ряда 1, 5, 4, 1, 6 равна:
- Ответ: 2
Вопрос 180. Идентификация модели СС (2) сводится к решению системы двух __________________ уравнений.
- Ответ: нелинейных
Вопрос 181. Выборочная дисперсия как оценка теоретической дисперсии имеет __________________ смещение.
- Ответ: отрицательное
Вопрос 182. Функция спроса y = a xb pg n может быть линеаризована посредством
- Ответ: логарифмирования
Вопрос 183. Оценка стандартного отклонения случайной величины, полученная по данным выборки, называется стандартной __________________ случайной величины.
- Ответ: ошибкой
Вопрос 184. Оценивание каждого параметра в уравнении регрессии поглощает __________________ свободы в выборке.
- Ответ: одну степень
Вопрос 185. Выборочная корреляция является __________________ теоретической корреляции.
- Ответ: оценкой
Вопрос 186. Точность оценок по МНК улучшается, если увеличивается:
- Ответ: количество наблюдений
Вопрос 187. При добавлении объясняющей переменной в уравнение регрессии коэффициент детерминации
- Ответ: не уменьшается
Вопрос 188. В критерии серий, основанном на медиане, общее число серий временного ряда 1, 3, 5, 4, 2 равно:
- Ответ: 3
Вопрос 189. Для функции Кобба-Дугласа у=100к1/3*i2/3 эластичность выпуска продукции по капиталу равна:
- Ответ: 1/3
Вопрос 190. В процессе формирования значений всякого временного ряда всегда участвуют __________________ факторы.
- Ответ: случайные
Вопрос 191. Первый шаг метода Зарембки заключается в вычислении __________________ y по выборке.
- Ответ: среднего геометрического
Вопрос 192. Плоскость регрессии y = a + b1x1 + b2x2 — двумерная плоскость в __________________ пространстве.
- Ответ: трехмерном
Вопрос 193. Для функции y = 4x0,2, эластичность равна:
- Ответ: 0,2
Вопрос 194. Поправка Прайса-Уинстена — метод спасения __________________ в автокорреляционной схеме первого порядка.
- Ответ: первого наблюдения
Вопрос 195. В лаговой структуре Койка надо оценить только:
- Ответ: три параметра
Вопрос 196. Наилучший способ устранения автокорреляции — установление ответственного за нее фактора и включение соответствующей __________________ переменной в регрессию.
- Ответ: объясняющей
Вопрос 197. Автокорреляция представляет тем большую проблему, чем
- Ответ: меньше интервал между наблюдениями
Вопрос 198. Проблема, связанная со смещением оценки коэффициентов регрессии, в одном случае, или с утратой эффективности этих оценок в другом случае неправильной спецификации переменных, перестает существовать, если коэффициент парной корреляции между переменными равен:
- Ответ: 0
Вопрос 199. Выборочная дисперсия остатков в наблюдениях Var (y — (a + bx)) называется __________________ дисперсией зависимой переменной.
- Ответ: необъясненной
Вопрос 200. Тест ранговой корреляции Спирмена — тест, устанавливающий, имеет ли стандартное отклонение остаточного члена регрессии нестрогую линейную зависимость с __________________ переменной.
- Ответ: объясняющей
Вопрос 201. Если совокупность значений случайной величины представляет собой конечный или счетный набор возможных чисел, то случайная величина называется:
- Ответ: дискретной
Вопрос 202. Стандартные ошибки, вычисленные при гетероскедастичности
- Ответ: занижены по сравнению с истинными значениями
Вопрос 203. Логарифмическое преобразование позволяет осуществить переход от нелинейной модели y = 5x2u к модели
- Ответ: ln y = ln 5 + 2 ln x + ln u
Вопрос 204. Для одностороннего критерия нулевой гипотезы Н0: β =β0 альтернативная гипотеза Н1:
- Ответ: β > β
Вопрос 205. Для функции Кобба-Дугласа у=80К3/4*i1/4 эластичность выпуска продукции по труду равна:
- Ответ: 1/4
Вопрос 206. Если опущена переменная, которая должна входить в регрессионную модель, то оценки коэффициентов регрессии оказываются:
- Ответ: смещенными
Вопрос 207. Если между двумя переменными существует строгая положительная линейная зависимость, то коэффициент корреляции между ними принимает значение, равное:
- Ответ: единице
Вопрос 208. Процесс выбора необходимых для регрессии переменных и отбрасывание лишних переменных называется:
- Ответ: спецификацией переменных
Вопрос 209. Результаты проверки гипотезы H0: b = b0 представляются на __________________ значимости.
- Ответ: двух уровнях
Вопрос 210. Всю совокупность реализаций случайной величины называют __________________ совокупностью.
- Ответ: генеральной
Вопрос 211. Остатки значений log y __________________ остатков значений y.
- Ответ: значительно меньше
Вопрос 212. Общая (ТSS), объясненная (ESS) и необъясненная (RSS) суммы квадратов отклонений находятся в следующих соотношениях
- Ответ: TSS = RSS + ESS
Вопрос 213. Если F-статистика Фишера превысит критическое значение Fкрит, то регрессия считается:
- Ответ: значимой
Вопрос 214. Число степеней свободы для t-статистики равно числу наблюдений в выборке __________________ количество оцениваемых коэффициентов.
- Ответ: минус
Вопрос 215. Если коэффициент Тейла равен нулю, то …
- Ответ: прогноз сделан успешно
Вопрос 216. Верхнее число степеней свободы F-cтатистики в случае парной регрессии равно:
- Ответ: одному
Вопрос 217. Автокорреляция — нарушение __________________ условия Гаусса-Маркова.
- Ответ: третьего
Вопрос 218. Совокупность фиктивных переменных — некоторое количество фиктивных переменных, предназначенное для описания
- Ответ: набора категорий
Вопрос 219. Стандартное отклонение случайной величины характеризует среднее ожидаемое расстояние между наблюдениями этой случайной величины и ее:
- Ответ: математическим ожиданием
Вопрос 220. В авторегрессионной схеме первого порядка uкн = рuк + ek предполагается, что значение ek в каждом наблюдении:
- Ответ: не зависит от его значений во всех других наблюдениях
Вопрос 221. Цель регрессионного анализа состоит в объяснении поведения
- Ответ: зависимой переменной
Вопрос 222. Разность между математическим ожиданием оценки и истинным значением оцениваемого параметра называют:
- Ответ: смещением
Вопрос 223. В авторегрессионной схеме первого порядка зависимость между последовательными случайными членами описывается формулой uk+1 = __________________, где ρ — константа, ek+1 — новый случайный член.
- Ответ: ρuk + e k+1
Вопрос 224. В функции Кобба-Дугласа вида log Y = a + b1 log k + b2 log l (k — индекс затрат капитала, l — индекс затрат труда) роль замещающей переменной для показателя технического прогресса играет:
- Ответ: log k
Вопрос 225. Наиболее частая причина положительной автокорреляции заключается в постоянной направленности воздействия __________________ переменных.
- Ответ: не включенных в уравнение
Вопрос 226. Для линеаризации функции Кобба-Дугласа необходимо предварительно обе части уравнения
- Ответ: разделить на L
Вопрос 227. О наличии данной частоты в спектре временного ряда свидетельствует __________________ спектральной плотности.
- Ответ: пик на графике
Вопрос 228. При добавлении еще одной переменной в уравнение регрессии коэффициент детерминации:
- Ответ: не уменьшается
Вопрос 229. Стандартные отклонения коэффициентов регрессии обратно пропорциональны величине _________, где n – число наблюдений:
- Ответ: n
Вопрос 230. Зависимая переменная может быть представлена как фиктивная в случае если она:
- Ответ: трудноизмерима
Вопрос 231. Тест Фишера является:
- Ответ: односторонним
Вопрос 232. Выборочная корреляция является __________оценкой теоретической корреляции:
- Ответ: состоятельной
Вопрос 233. Определение отдельного вклада каждой из независимых переменных в объясненную дисперсию в случае их коррелированности является ___________ задачей:
- Ответ: невыполнимой
Вопрос 234. Условие гомоскедастичности означает, что вероятность того, что случайный член примет какое-либо конкретное значение _________ наблюдений:
- Ответ: одинакова для всех
Вопрос 235. Значения t-статистики для фиктивных переменных незначимо отличается от:
- Ответ: 0
Вопрос 236. Из перечисленных факторов: 1) число объясняющих переменных, 2) количество наблюдений в выборке, 3)конкретные значения переменных, критические значения статистики Дарбина-Уотсона зависят от:
- Ответ: 1, 2
Вопрос 237. Значение статистики DW находится между значениями:
- Ответ: 0 и 4
Вопрос 238. Наблюдение зависимой переменной регрессии в предшествующий момент, используемое как объясняющая переменная, называется:
- Ответ: лаговой
Вопрос 239. Чем больше число наблюдений, тем __________ зона неопределенности для критерия Дарбина-Уотсона:
- Ответ: уже
Вопрос 240. МНК автоматически дает ___________ для данной выборки значение коэффициента детерминации R2:
- Ответ: максимальное
Вопрос 241. В авторегрессионной схеме первого порядка предполагается, что значение в каждом наблюдении:
- Ответ: не зависит от его значения во всех других наблюдениях
Вопрос 242. Линия регрессии _______ через точку ( , ) :
- Ответ: всегда проходит
Вопрос 243. Если предположение о природе гетероскедастичности верно, то дисперсия случайного члена для первых наблюдений в упорядоченном ряду будет ________ для последних:
- Ответ: ниже, чем
Вопрос 244. Стандартные ошибки, вычисленные при гетероскедастичности:
- Ответ: занижены по сравнению с истинными значениями
Вопрос 245. Критерий Дарбина-Уотсона –метод обнаружения _________ с помощью статистики Дарбина-Уотсона:
- Ответ: автокорреляции
Вопрос 246. Параметры множественной регрессии ?1 , ?2 ,… ?м показывают _________ соответствующих экономических факторов:
- Ответ: степень влияния
Вопрос 247. Во множественном регрессионном анализе коэффициент детерминации определяет _______регрессией:
- Ответ: долю дисперсии y, объясненную
Вопрос 248. Сумма квадратов отклонений величины y от своего выборочного значения _____ сумма квадратов отклонений:
- Ответ: общая
Вопрос 249. Фиктивная переменная взаимодействия – фиктивная переменная, предназначенная для
- Ответ: одновременного наступления нескольких независимых
Вопрос 250. Автокорреляция первого порядка – ситуация, когда коррелируют случайные члены регрессии в __________ наблюдениях:
- Ответ: последовательных
Вопрос 251. Фиктивная переменная – переменная, принимающая в каждом наблюдении:
- Ответ: только два значения 0 или 1
Вопрос 252. Для того, чтобы установить влияние какого-либо события на коэффициент линейной регрессии при нефиктивной переменной, в модель включают:
- Ответ: фиктивную переменную для коэффициента наклона
Вопрос 253. Оценка параметра для модели множественной регрессии в случае двух независимых переменных вычисляется по формуле: а =
- Ответ: 1 1 2 2 y ? b x ? b x
Вопрос 254. Процесс выбора необходимых переменных для регрессии переменных и отбрасывание лишних переменных называется:
- Ответ: спецификацией переменных
Вопрос 255. Из перечисленного: 1) число объясняющих переменных, 2) количество наблюдений в выборке, 3) конкретные значения переменных критические значения статистики Дарбина-Уотсона зависят от:
- Ответ: 1, 2
Вопрос 256. Число степеней свободы для уравнения m-мерной регрессии при достаточном числе наблюдений n составляет:
- Ответ: n-m-1
Вопрос 257. Наилучший способ устранения автокорреляции – установление ответственного за нее фактора и включение соответствующей ___________ переменной в регрессию:
- Ответ: объясняющей
Вопрос 258. Строгая линейная зависимость между переменными – ситуация, когда ________ двух переменных равна 1 или -1:
- Ответ: выборочная корреляция
Вопрос 259. Значение статистики Дарбина-Уотсона находится между значениями:
- Ответ: 0 и 4
ТЕСТЫ ПО ТЕМЕ №1
1. Статистика как наука изучает:
а) единичные явления;
б) массовые явления;
в) периодические события.
2. Термин «статистика» происходит от слова:
а) статика;
б) статный;
в) статус.
3. Статистика зародилась и оформилась как самостоятельная учебная
дисциплина:
а) до новой эры, в Китае и Древнем Риме;
б) в 17-18 веках, в Европе;
в) в 20 веке, в России.
4. Статистика изучает явления и процессы посредством изучения:
а) определенной информации;
б) статистических показателей;
в) признаков различных явлений.
5. Статистическая совокупность – это:
а) множество изучаемых разнородных объектов;
б) множество единиц изучаемого явления;
в) группа зафиксированных случайных событий.
6. Основными задачами статистики на современном этапе являются:
а) исследование преобразований экономических и социальных процессов в
обществе; б) анализ и прогнозирование тенденций развития экономики; в)
регламентация и планирование хозяйственных процессов;
а) а, в
б) а, б
в) б, в
7. Статистический показатель дает оценку свойства изучаемого явления:
а) количественную;
б) качественную;
в) количественную и качественную.
8. Основные стадии экономико-статистического исследования включают: а)
сбор первичных данных, б) статистическая сводка и группировка данных, в)
контроль и управление объектами статистического изучения, г) анализ
статистических данных
а) а, б, в
б) а, в, г
в) а ,б, г
г) б, в, г
9. Закон больших чисел утверждает, что:
а) чем больше единиц охвачено статистическим
наблюдением,
тем лучше проявляется общая закономерность;
б) чем больше единиц охвачено статистическим наблюдением, тем хуже
проявляется общая закономерность;
в) чем меньше единиц охвачено статистическим наблюдением, тем лучше
проявляется общая закономерность.
10. Современная организация статистики включает: а) в России — Росстат
РФ и его территориальные органы, б) в СНГ — Статистический комитет СНГ, в) в
ООН — Статистическая комиссия и статистическое бюро, г) научные исследования в области
теории и методологии статистики
а) а, б, г
б) а, б, в
в) а, в, г
ТЕСТЫ ПО ТЕМЕ №2
1. Статистическое наблюдение – это:
а) научная организация регистрации информации;
б) оценка и регистрация признаков изучаемой совокупности;
в) работа по сбору массовых первичных данных;
г) обширная программа статистических исследований.
2. Назовите основные организационные формы статистического наблюдения:
а) перепись и отчетность;
в) разовое наблюдение;
г) опрос.
3. Перечень показателей (вопросов) статистического наблюдения, цель,
метод, вид, единица наблюдения, объект, период статистического наблюдения
излагаются:
а) в инструкции по проведению статистического наблюдения;
б) в формуляре статистического наблюдения;
в) в программе статистического наблюдения.
4. Назовите виды статистического наблюдения по степени охвата единиц совокупности:
а) анкета;
б) непосредственное;
в) сплошное;
г) текущее.
5. Назовите виды статистического наблюдения по времени регистрации:
а) текущее, б) единовременное; в) выборочное; г) периодическое; д) сплошное
а) а, в, д
б) а, б, г
в) б, г, д
6. Назовите основные виды ошибок регистрации: а) случайные; б)
систематические; в) ошибки репрезентативности; г) расчетные
а) а
б) а, б
в) а, б, в,
г) а, б, в, г
7. Несплошное статистическое наблюдение имеет виды: а) выборочное;
б) монографическое; в) метод основного массива; г) ведомственная
отчетность
а) а, б, в
б) а, б, г
в) б, в, г
8. Организационный план статистического наблюдения регламентирует:
а) время и сроки наблюдения; б) подготовительные мероприятия;
в) прием, сдачу и оформление результатов наблюдения; г) методы
обработки данных
а) а, б, г
б) а, б, в
9. Является ли статистическим наблюдением наблюдения покупателя за качеством
товаров или изменением цен на городских рынках?
а) да
б) нет
10. Ошибка репрезентативности относится к:
а) сплошному наблюдению;
б) не сплошному выборочному
наблюдению.
ТЕСТЫ ПО ТЕМЕ №3
1. Статистическая сводка — это:
а) систематизация и подсчет итогов зарегистрированных
фактов и данных;
б) форма представления и развития изучаемых явлений;
в) анализ и прогноз зарегистрированных данных.
2. Статистическая группировка — это:
а) объединение данных в группы по времени регистрации;
б) расчленение изучаемой совокупности на группы по
существенным признакам;
в) образование групп зарегистрированной информации по мере ее
поступления.
3. Статистические группировки могут быть: а) типологическими; б)
структурными; в) аналитическими; г) комбинированными
а) а
б) а, б
в) а, б, в
г) а, б, в, г
4. Группировочные признаки, которыми одни единицы совокупности
обладают, а другие — нет, классифицируются как:
а) факторные;
б) атрибутивные;
в) альтернативные.
5. К каким группировочным признакам относятся: образование сотрудников,
профессия бухгалтера, семейное положение:
а) к атрибутивным;
б) к количественны.
6. Ряд распределения — это:
а) упорядоченное расположение единиц изучаемой
совокупности по группам;
б) ряд значений показателя, расположенных по каким-то правилам.
7. К каким группировочным признакам относятся: сумма издержек
обращения, объем продаж, стоимость основных фондов
а) к дискретным;
б) к непрерывным.
8. Охарактеризуйте вид ряда распределения продавцов магазина по уровню
образования
|
Квалификация продавцов |
Число продавцов |
Удельный вес продавцов (% к итогу) |
|
не имеют образования окончили ПТУ |
50 150 |
25 75 |
а) атрибутивный;
б) вариационный дискретный;
в) интервальный.
9. Охарактеризуйте вид ряда распределения коммерческих фирм по величине
уставного капитала
|
Группы фирм по величине уставного капитала, млн. руб. |
Число фирм |
Удельный вес фирм в %% к итогу |
|
До 9,0 9,0 -14,0 14,0-19,0 19,0-24,0 24,0 и более |
4 5 10 6 5 |
13,3 16,7 33,3 20,0 16,7 |
а) вариационный дискретный;
б) атрибутивный;
в) интервальный вариационный.
10. Какие виды статистических таблиц встречаются:
а) простые и комбинационные;
б) линейные и нелинейные.
ТЕСТЫ ПО ТЕМЕ №4
1. Статистический показатель — это
а) размер изучаемого явления в натуральных единицах измерения
б) количественная характеристика свойств в единстве с
их качественной определенностью
в) результат измерения свойств изучаемого объекта
2. Статистические показатели могут характеризовать:
а) объемы изучаемых процессов
б) уровни развития изучаемых явлений
в) соотношение между элементами явлений
г) а, б, в
3. По способу выражения абсолютные статистические показатели
подразделяются на: а) суммарные; б) индивидуальные; в) относительные; г)
средние; д) структурные
а) а, д
б) б, в
в) в, г
г) а, б
4. В каких единицах выражаются абсолютные статистические показатели?
а) в коэффициентах
б) в натуральных
в) в трудовых
5. В каких единицах будет выражаться относительный показатель, если
база сравнения принимается за единицу?
а) в процентах
б) в натуральных
в) в коэффициентах
6. Относительные показатели динамики с переменной базой сравнения
подразделяются на:
а) цепные
б) базисные
7. Сумма всех удельных весов показателя структуры
а) строго равна 1
б) больше или равна 1
в) меньше или равна 1
8. Относительные показатели по своему познавательному значению
подразделяются на показатели: а) выполнения и сравнения, б) структуры и
динамики, в) интенсивности и координации, г) прогнозирования и экстраполяции
а) а, б, г
б) б, в, г
в) а, б, в
9. Статистические показатели по сущности изучаемых явлений могут быть:
а) качественными
б) объёмными
в) а, б
10. Статистические показатели в зависимости от характера изучаемых
явлений могут быть:
а) интервальными
б) моментными
в) а, б
ТЕСТЫ ПО ТЕМЕ №5
1. Исчисление средних величин — это
а) способ изучения структуры однородных элементов
совокупности
б) прием обобщения индивидуальных значений показателя
в) метод анализа факторов
2. Требуется вычислить средний стаж деятельности работников фирмы:
6,5,4,6,3,1,4,5,4,5. Какую формулу Вы примените?
а) средняя арифметическая
б) средняя арифметическая взвешенная
в) средняя гармоническая
3. Средняя геометрическая — это:
а) корень из произведения индивидуальных показателей
б) произведение корней из индивидуальных показателей
4. По какой формуле производится вычисление средней величины в
интервальном ряду?
а) средняя арифметическая взвешенная
б) средняя гармоническая взвешенная
5. Могут ли взвешенные и невзвешенные средние, рассчитанные по одним и
тем же данным, совпадать?
а) да
б) нет
6. Как изменяется средняя арифметическая, если все веса уменьшить в А
раз?
а) уменьшатся
б) увеличится
в) не изменится
7. Как изменится средняя арифметическая, если все значения
определенного признака увеличить на число А?
а) уменьшится
б) увеличится
в) не изменится
8. Значения признака, повторяющиеся с наибольшей частотой, называется
а) модой
б) медианой
9.
Средняя хронологическая исчисляется
а) в моментных рядах динамики с
равными интервалами
б) в интервальных рядах динамики с равными
интервалами
в) в интервальных рядах динамики с неравными
интервалами
10.
Медиана в ряду
распределения с четным числом членов ряда равна
а) полусумме двух крайних членов
б) полусумме двух срединных членов
ТЕСТЫ ПО ТЕМЕ №6
1. Что понимается в статистике под термином
«вариация показателя»?
а) изменение величины показателя
б) изменение названия показателя
в) изменение размерности показателя
2. Укажите показатели вариации
а) мода и медиана
б) сигма и дисперсия
в) темп роста и прироста
3. Показатель дисперсии — это:
а) квадрат среднего отклонения
б) средний квадрат отклонений
в) отклонение среднего квадрата
4. Коэффициент вариации измеряет колеблемость признака
а) в относительном выражении
б) в абсолютном выражении
5. Среднеквадратическое отклонение характеризует
а) взаимосвязь данных
б) разброс данных
в) динамику данных
6. Размах вариации исчисляется как
а) разность между максимальным и минимальным
значением показателя
б) разность между первым и последним членом ряда распределения
7. Показатели вариации могут быть
а) простыми и взвешенными
б) абсолютными и относительными
в) а) и б)
8. Закон сложения дисперсий характеризует
а) разброс сгруппированных данных
б) разброс неупорядоченных данных
9. Средне квадратическое отклонение исчисляется как
а) корень квадратный из медианы
б) корень квадратный из коэффициента вариации
в) корень квадратный из дисперсии
10. Кривая закона распределения характеризует
а) разброс данных в зависимости от уровня показателя
б) разброс данных в зависимости от времени
ТЕСТЫ ПО ТЕМЕ №7
1. Выборочный метод в статистических исследованиях используется для:
а) экономии времени и снижения затрат на проведение
статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2. Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3. Ошибка репрезентативности обусловлена:
а) самим методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
4. Коэффициент доверия в выборочном методе может принимать значения:
а) 1, 2, 3;
б) 4, 5, 6;
в) 7, 8, 9.
5. Выборка может быть: а) случайная, б) механическая, в) типическая,
серийная, д) техническая
а) а, б, в, г,
б) а, б, в, д
в) б, в, г, д
6. Необходимая численность выборочной совокупности определяется:
а) колеблемостью признака;
б) условиями формирования выборочной совокупности;
7. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным объемом единиц непосредственного
наблюдения;
в) разным числом зарегистрированных наблюдений.
8. Средняя ошибка выборки:
а) прямо пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
9. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная однажды единица наблюдения
возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
10. Малая выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30 единиц изучаемой совокупности.
ТЕСТЫ ПО ТЕМЕ №8
1. Ряд динамики характеризует: а) структуру совокупности по какому-то
признаку; б) изменение характеристик совокупности во времени; в) определенное
значение признака в совокупности; г) величину показателя на определенную дату
или за определенный период
а) а, б
б) б, г
в) б, в
2. Ряд динамики может состоять: а) из абсолютных суммарных величин; б)
из относительных и средних величин;
а) а
б) б
в) а, б
3. Ряд динамики, характеризующий уровень развития
социально-экономического явления на определенные даты времени, называется:
а) интервальным;
б) моментным.
4. Средний уровень интервального ряда динамики определяется как:
а) средняя арифметическая;
б) средняя хронологическая.
5. Средний уровень моментного ряда динамики исчисляется как: а)
средняя арифметическая взвешенная при равных интервалах между датами; б) при
неравных интервалах между датами как средняя хронологическая, в) при равных
интервалах между датами как средняя хронологическая;
а) а
б) б
в) б, в
6. Абсолютный прирост исчисляется как: а) отношение уровней ряда; б)
разность уровней ряда. Темп роста исчисляется как: в) отношение уровней ряда;
г) разность уровней ряда;
а) а, в
б) б, в
в) а, г
7. Для выявления основной тенденции развития используется: а) метод
укрупнения интервалов; б) метод скользящей средней; в) метод аналитического
выравнивания; г) метод наименьших квадратов;
а) а, г
б) б, г
в) а, б, г
г) а, б, в
8. Трендом ряда динамики называется:
а) основная тенденция;
б) устойчивый темп роста.
9. Прогнозирование в статистике ‑ это:
а) предсказание предполагаемого события в
будущем;
б) оценка возможной меры изучаемого
явления в будущем.
10. К наиболее простым методам прогнозирования
относят:
а) индексный метод;
б) метод скользящей средней;
в) метод на основе среднего
абсолютного прироста.
ТЕСТЫ ПО ТЕМЕ №9
1. Статистический индекс — это:
а) критерий сравнения относительных величин;
б) сравнительная характеристика двух абсолютных величин;
в) относительная величина сравнения двух показателей.
2. Индексы позволяют соизмерить социально-экономические явления:
а) в пространстве;
б) во времени;
в) в пространстве и во времени.
3. В индексном методе анализа несуммарность цен на разнородные
товары преодолевается:
а) переходом от абсолютных единиц измерения цен к относительной
форме;
б) переходом к стоимостной форме измерения товарной
массы.
4. Можно ли утверждать, что индивидуальные индексы по методологии
исчисления адекватны темпам роста:
а) можно;
б) нельзя.
5. Сводные индексы позволяют получить обобщающую оценку изменения:
а) по товарной группе;
б) одного товара за несколько периодов.
6. Может ли в отдельных случаях средний гармонический индекс
рассчитываться по средней гармонической невзвешенной:
а) может;
б) не может.
7. Индексы переменного состава рассчитываются:
а) по товарной группе;
б) по одному товару.
8. Может ли индекс переменного состава превышать индекс фиксированного
состава:
а) может;
б) не может.
9. Первая индексная мультипликативная модель товарооборота – это:
а) произведение индекса цен на индекс физического
объема
товарооборота;
б) произведение индекса товарооборота в сопоставимых ценах на индекс
средней цены постоянного состава;
в) а, б.
10. Вторая факторная индексная мультипликативная модель анализа – это:
а) произведение индекса постоянного состава на индекс
структурных сдвигов;
б) частное от деления индекса переменного состава на индекс структурных
сдвигов;
в) а, б.
ТЕСТЫ ПО ТЕМЕ №10
1. Статистическая связь — это:
а) когда зависимость между факторным и результирующим
показателями неизвестна;
б) когда каждому факторному соответствует свой
результирующий
показатель;
в) когда каждому факторному соответствует несколько разных значений
результирующего показателя.
2. Термин корреляция в статистике понимают как:
а) связь, зависимость;
б) отношение, соотношение;
в) функцию, уравнение.
3. По направлению связь классифицируется как:
а) линейная;
б) прямая;
в) обратная.
4. Анализ взаимосвязи в статистике исследует:
а) тесноту связи; б) форму связи; в)
а, б
5. При каком значении коэффициента корреляции связь можно считать
умеренной?
а) r = 0,43;
б) r = 0,71.
6. Термин регрессия в статистике понимают как: а) функцию связи,
зависимости; б) направление развития явления вспять; в) функцию анализа
случайных событий во времени; г) уравнение линии связи
а) а, б
б) в, г
в) а, г
7. Для определения тесноты связи двух альтернативных показателей
применяют:
а) коэффициенты ассоциации и контингенции;
б) коэффициент Спирмена.
8. Дайте классификацию связей по аналитическому выражению:
а) обратная;
б) сильная;
в) прямая;
г) линейная.
9. Какой коэффициент корреляции характеризует связь между Y и X:
а) линейный;
б) частный;
в) множественный.
10. При каком значении линейного коэффициента корреляции связь между Y и X можно признать более существенной:
а) ryx = 0,25;
б) ryx = 0,14;
в) ryx = — 0,57.
Тема№11
Контрольные вопросы
1.
Что является
объектом изучения в социально-экономической статистике?
Социально-экономическая статистика, или
статистика, — это: 1) отрасль знаний — наука, представляющая собой сложную и
разветвленную систему научных дисциплин (разделов), обладающих определенной
спецификой и изучающих количественную сторону массовых явлений и процессов в
неразрывной связи с их качественной стороной; 2) отрасль практической
деятельности — сбор, обработка, анализ и публикация массовых данных о явлениях
и процессах общественной жизни; 3) совокупность цифровых сведений,
характеризующих состояние массовых явлений и процессов общественной жизни или
их совокупность; 4) отрасль статистики, использующая методы математической
статистики для изучения социально-экономических процессов и явлений
объектом изучения СЭС в широком смысле
является общество во всем его многообразии.
2.
Чем отличаются
теория статистики и прикладная (социально-экономическая) статистика?
Статистические методы анализа данных
применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо
получить и обосновать какие-либо суждения о группе (объектов или субъектов) с
некоторой внутренней неоднородностью. Целесообразно выделить три вида научной и
прикладной деятельности в области статистических методов анализа данных (по
степени специфичности методов, сопряженной с погруженностью в конкретные
проблемы):
а) разработка и исследование методов общего
назначения, без учета специфики области применения;
б) разработка и исследование статистических
моделей реальных явлений и процессов в соответствии с потребностями той или
иной области деятельности;
в) применение статистических методов и моделей
для статистического анализа конкретных данных.
Прикладная
статистика— это наука о том, как обрабатывать данные произвольной
природы, без учета их специфики. Математической основой прикладной статистики
и статистических методов анализа является теория вероятностей
и математическая
статистика. Описание вида данных и механизма их порождения—
начало любого статистического исследования. Для описания данных применяют как
детерминированные, так и вероятностные методы. С помощью детерминированных
методов можно проанализировать только те данные, которые имеются в распоряжении
исследователя. Например, с их помощью получены таблицы, рассчитанные органами
официальной государственной статистики на основе представленных предприятиями и
организациями статистических отчетов. Перенести полученные результаты на более
широкую совокупность, использовать их для предсказания и управления можно лишь
на основе вероятностно-статистического моделирования. Поэтому в математическую
статистику часто включают лишь методы, опирающиеся на теорию вероятностей.
3.
Какие методы
теории статистики применяются в СЭС?
СЭС изучает массовые процессы в производстве,
распределении и потреблении товаров и услуг, тенденции и закономерности их
развития, условия жизни людей. Таким образом, социально-экономическая
статистика является прикладной дисциплиной, изучающей использование методов
теории статистики для анализа массовых процессов в экономическом и социальном
развитии общества. Без такой статистики нельзя себе представить состояние и
развитие любого явления, невозможно организовать социальное и экономическое
планирование. Теоретической основой любой прикладной статистики является общая
теория статистики и общая экономическая теория. При этом методология включает
комплекс следующих методов: метод массового статистического наблюдения, метод
группировок, метод средних и обобщающих показателей, метод динамических рядов,
индексный метод и др.
4.
Какие процессы
изучает СЭС и с какой целью?
Социально-экономическая статистика изучает все
без исключения стороны общественной жизни. Поэтому всеобъемлющая система
показателей включает огромное количество блоков показателей по различным
признакам и направлениям анализа: по разделам статистики, по секторам и
отраслям экономики, по регионам, по временному признаку и т.д.
5.
Является ли
перечень изучаемых в данном курсе разделов СЭС исчерпывающим?
В данном учебном пособии (в курсе теории
статистики) изложены основные моменты в организации статистики в РФ, СНГ и ООН,
которые в полной мере относятся и к организации социально-экономической
статистики.
6.
Как
организована статистика в мире, в России, в Татарстане?
В Российской федерации функционирует
Федеральная служба государственной статистики (Росстат РФ). В республиках и
областях функционируют республиканские или областные подразделения ‑ органы
статистики с разветвленной сетью региональных отделов государственной
статистики (при местных органах власти). То есть в РФ статистика в основном
государственная. В Татарстане функционирует ‑ Татарстанстат.
7.
Для чего
необходимо упорядочивать информацию в статистике?
С целью создания единого информационного
пространства в стране, для систематизации и унификации
технико-экономической информации, для создания условий эффективной
автоматизированной обработки данных в статистике применяются так называемые
классификации и группировки. Их главная задача в том, чтобы обеспечить
однозначность и достоверность информации о каждом изучаемом объекте или
группе объектов или их элементах.
8.
Какие основные
классификации и группировки в СЭС Вы знаете?
С целью создания единого информационного
пространства в стране, для систематизации и унификации технико-экономической
информации, для создания условий эффективной автоматизированной обработки
данных в статистике применяются так называемые классификации и группировки. Их
главная задача в том, чтобы обеспечить однозначность и достоверность информации
о каждом изучаемом объекте или группе объектов или их элементах.
Классификация в статистике – это
систематизированное распределение явлений и объектов на определенные секции,
группы, классы на основании их сходства и развития.
Классификатор – это систематизированный
перечень объектов статистического наблюдения с присвоенным каждому их них
кодом. Код — это совокупность знаков для идентификации объекта.
Любой классификатор разбивается на группы по
определенным признакам. Объекты, объединенные в одну группу по какому-либо
классификационному признаку, образуют группировку. Для обозначения групп
применяются различные системы кодирования, главная задача которых шифровать
информацию о каждой классификационной группе или ее элементах. Существует
несколько систем кодирования – порядковая, позиционная, комбинированная и др.
Они изучаются в информатике.
Объектами статистического наблюдения,
требующими классификацию и кодирование в СЭС являются отрасли, регионы,
предприятия, продукция, основные фонды, категории населения, профессии и т.д. и
т.п. Например:
ОКП – Общероссийский классификатор (О/К)
продукции. Вся продукция разбивается по признакам: сырье, назначение, отрасль…
ОКДП – Общероссийский классификатор видов
деятельности. Объединяет около 55000 видов продукции и услуг.
ОКОГУ – Общероссийский классификатор органов
государственной власти и управления
ОКПО – О/К предприятий и объединений
ОКУД – О/К управленческой документации
ОКУН – О/К услуг населению и т.д.
9.
ЕГРПО ‑ что это
такое?
ЕГРПО ‑ единый государственный регистр
предприятий и организаций. В свою очередь, он разделен на два регистра: ЕГРЮЛ
(для юридических лиц) и ЕГРФЛ (для физических лиц). Они необходимы для единого
учета всех действующих субъектов рынка, для формирования нормативно-справочной
информации, единой базы данных. Эти регистры содержат по каждому субъекту рынка
– идентификаторы (шифры) объектов, отраслевую принадлежность, адреса,
экономические показатели, информацию о руководстве
10.
Какие разделы и
группы показателей изучаются в данном курсе?
в данном учебном курсе в соответствии с
программой выделяются для изучения только следующие основные разделы, каждому
из которых соответствует свой блок, группа, система показателей:
·
Статистика населения
(демографическая статистика)
·
Статистика рынка труда
(экономической активности, занятости, безработицы и трудовых ресурсов)
·
Статистика национального
богатства (в этом разделе, в основном, изучается только статистика основных и
оборотных фондов)
·
Статистика цен и
ценообразования
·
Статистика труда и его
оплаты (включая статистику производительности труда, рабочего времени,
движения кадров и др.)
·
Статистика уровня жизни
населения
·
Статистика финансов
предприятия
·
Система национальных
счетов
Тема№12
Контрольные вопросы
1.
Что является
объектом наблюдения в статистике населения?
Статистика изучает численность, состав,
размещение населения, распределение его по полу, возрасту, уровню образования,
семейному положению, миграции населения и по другим признакам. Важнейшая задача
статистики населения – определение общей численности населения страны.
2.
Что понимается
под «наличным» и «постоянным» населением?
Наличное население – это лица, которые на момент учета проживают в
данном населенном пункте независимо от того, живут ли они в нем постоянно или
временно.
Постоянное население – это лица, живущие обычно в данном населенном
пункте, включая те лица, которые в данный момент временно отсутствуют (т.е.
этот населенный пункт – место их постоянного жительства)
3.
Как
определяется среднегодовая численность населения за тот или иной период
времени?
По любой категории населения и в целом
исчисляется среднегодовая численность населения. Расчет этого показателя
зависит от имеющейся информации. Например, если заданы численности на начало и
конец года, то среднегодовая исчисляется как полусумма этих данных. Если
информация дана на несколько равноудаленных дат – то по средней хронологической
ряда динамики. Наиболее точным расчетом среднегодовой численности населения
является расчет по числу прожитых данным населением человеко-лет за изучаемый
период. Но таких данных, как правило, нет, поэтому используют упрощенные
методы.
Прирост населения (абсолютный) исчисляется как
разность численности на 1 января двух смежных годов. Прирост может быть
естественным (за счет смерти, рождения) и механическим (за счет миграции
населения).
Плотность размещения населения изучается показателем:
количество населения на 1 км2 той или иной территории региона или
страны в целом.
Состав населения по полу и возрасту изучают
методом группировок результатов переписи населения. При этом по возрасту
выделяются группы через каждые 5 лет: 0 ¸ 4 года,
5 ¸ 9 лет, 10 ¸ 14 лет, 15 ¸ 19
лет и т.д.
Кроме того, выделяются:
‑ группа населения экономически активного
возраста (15 ¸ 72 года)
‑ группа — лица трудоспособного возраста
(мужчины: 16 ¸ 59 лет; женщины: 16 ¸ 54 года)
‑ группа — лица старше трудоспособного
возраста (мужчины >60 лет; женщины > 55лет)
‑ группа — подростки, т.е. лица моложе
трудоспособного возраста (до 16 лет)
Перечисленные основные группировки статистики
населения при анализе
дополняются и другими возрастными группами:
1.
дети в возрасте до 1 года
2.
дети ясельного возраста –
до 3-х лет
3.
дошкольный контингент (от
3 до 7 лет)
4.
молодежь (от 16 до 29 лет
включительно) и др.
4.
Что понимают
под естественным движением населения?
Показателями естественного движения населения
является коэффициент рождаемости, смертности, жизненности (коэффициент
Покровского), а также коэффициенты, характеризующие вступление в брак,
расторжение брака.
5.
Какими
показателями характеризуется естественный прирост населения?
Показателями естественного прироста населения
является коэффициент рождаемости, жизненности (коэффициент Покровского), а
также коэффициенты, характеризующие вступление в брак, расторжение брака.
6.
Как
рассчитываются коэффициенты рождаемости и смертности?
Рождаемость – это отношение числа родившихся (N) за год к среднегодовой численности населения
за этот же год. Его называют коэффициентом рождаемости Крожд.
и рассчитывают на 1000 жителей населения.
![]() ;
;
Смертность – это отношение годового числа
умерших (М) к среднегодовой численности населения региона (S). Рассчитывают на 1000 жителей и называют
коэффициентом смертности
![]() .
.
7.
Что такое
миграция населения?
Миграция ‑ это такое передвижение людей из одних мест в
другие, при котором происходит перемена места жительства. Выезд из страны
называется эмиграцией. Прибытие в данную страну на жительство называется
иммиграцией.
8.
Назовите
основные показатели миграции?
Рассчитывают коэффициент интенсивности
миграции, а также коэффициент прибытия (П) и коэффициент выбытия (В):

![]()
![]()
Самостоятельными показателями передвижения населения
являются число прибывших и число выбывших лиц, а также прирост или снижение
населения вследствие миграции. Для анализа миграции широко используют
коэффициенты миграционного оборота и эффективности миграции. Они имеют вид:
![]() ;
; ![]()
9.
Как определяется
текущая и прогнозная численность населения?
Статистика исчисляет и текущую (оперативную) и
прогнозную (перспективную) численность населения
Текущая (оперативная) численность населения исчисляется по результатам переписи. Но так
как переписи проводятся один раз в десять лет, то точность текущих расчетов
определяется, во-первых, точностью результатов переписи, во-вторых,
достоверностью регистрации данных о движении населения.
Перспективная численность рассчитывается несколькими методами:
а) на основе показателя среднего абсолютного
прироста или
б) на основе показателя среднего темпа роста.
Для этого исчисляют средний абсолютный прирост
(D) _ или средний темп роста (К) за несколько лет, примыкающих к
началу прогнозируемого года.
Обозначим: S0 – исходная известная численность населения на
конец последнего периода, D ‑ средний
абсолютный прирост, К – средний темп роста,![]() St – искомая перспективная численность через t –
St – искомая перспективная численность через t –
лет, t – период учреждения (прогноза) (в годах).
Тогда:
![]() или
или ![]()
Более точным методом является повозрастной
метод оценки численности населения. Суть его в том, что используются данные
таблиц коэффициентов дожития (смертности) и получают численность каждой
возрастной группы умножением
![]()
![]()
Получаем численность населения следующего возраста, затем все
повозрастные суммы складываются.
Если определен коэффициент общего прироста
населения как
![]()
![]() ,
,
то перспективная численность населения
определяется:

Статистика определяет
перспективную численность по всем возрастным группам населения, по половому
признаку, по регионам и т.д. При прогнозировании численности еще может
использоваться и метод трендовой модели, если такая модель разработана на
уровне конкретных формул и аналитических зависимостей и найдены все параметры
модели. Например, если это линейная модель вида:
![]() , то
, то
при известных а0 и
а1, выполняется расчет численности на прогнозный
период (t+1).
10.
Какие методы
используются при прогнозировании численности населения?
Расчеты численности населения необходимы для
задач социального и экономического планирования. Поэтому статистика исчисляет и
текущую (оперативную) и прогнозную (перспективную) численность населения
Наиболее простой (оперативный) расчет
выполняется так: определяется общий прирост населения как сумма естественного и
механического прироста за определенный период времени, например, за год, и эта
величина прибавляется к численности на конец предыдущего года, известной по
переписи или предыдущему расчету.
Тема№13
Контрольные вопросы
1.
Что такое рынок
труда и в чем его суть?
Рынок труда ‑ это система экономических,
социальных и организационных отношений, определяющих использование рабочей силы
и ее распределение на основе свободы и добровольности.
2.
Что понимают
под экономически активным и неактивным населением?
Экономически активное население (Sэк.акт.) ‑ это часть населения, которая предполагает свой труд для производства
товаров и услуг. Сюда включаются все занятые (работающие) и безработные, в т.ч.
занятые в экономике, социальной сфере и в общественной жизни, военнослужащие,
культово-религиозные работники. К этой категории применяют термин рабочая
сила.
Экономически неактивное население ‑ это лица, не входящие в состав рабочей
силы, т.е. не работающие и не ищущие работу. Включает: учащихся, студентов
дневной формы обучения, домохозяек, пенсионеров по старости, инвалидов… (Sнеакт.). К этой категории могут относится лица всех
возрастов, если они не ищут работы. Особый интерес этой группы населения в том,
что она объединяет самые разные слои общества, например, бомжи и «новые»
русские (жены, родственники).
3.
Что понимают
под трудовыми ресурсами?
В отечественной статистике используется еще
одна категория населения ‑ так называемые трудовые ресурсы. В своей
основе это ‑ трудоспособное население в трудоспособном (рабочем) возрасте.
Население трудоспособного возраста ‑ это мужчины в возрасте 16-59 лет и женщины
в возрасте 16-54 года. Трудоспособное население ‑ это лица, способные к труду
по возрасту и состоянию здоровья.
трудовые ресурсы ‑ это совокупность лиц
трудоспособного населения, которые потенциально могли бы участвовать в
производстве товаров и услуг (во всех отраслях производственной и
непроизводственной сфер).
трудовые ресурсы ‑ это трудоспособное население в трудоспособном
(рабочем) возрасте. Население трудоспособного возраста ‑ это мужчины в возрасте
16-59 лет и женщины в возрасте 16-54 года. Трудоспособное население ‑ это лица,
способные к труду по возрасту и состоянию здоровья (подробнее см.п.3).
4.
Как исчисляются
коэффициенты экономической активности населения?
Экономическая активность населения измеряется
как абсолютными величинами (численностью), так и относительными величинами.
Коэффициент экономической активности имеет вид:
 .
.
где S ‑ численность населения на конкретную дату (в
регионе или в стране в целом).
5.
Как исчисляются
коэффициенты занятости населения?
Занятое население включает: работающих по
найму, работающих не по найму, служащих религиозных культов, военнослужащих.
Работающие по найму ‑ это лица, заключившие
договор об условиях труда и его оплаты с организацией или отдельным лицом
(контракт, соглашение).
Работающие не по найму ‑ это лица, занятые в
своем собственном деле (работодатели, члены семьи, члены производственных
кооперативов, лица, работающие за свой счет).
Занятость населения оценивается коэффициентом
занятости в нескольких вариантах расчета:
 ,
,
где Sзан. ‑
численность занятых на конкретную дату. Другой вариант расчета, когда в
знаменатель ставят численность всего населения (S),
а не только экономически активного.
При анализе занятости в определенной
возрастной группе в знаменатель ставят Sэк. акт в
данной группе населения.
Коэффициент занятости также рассчитывают по
отношению к населению трудоспособного возраста, т.е.:

Sзан. т/в и
Sт/в ‑ занятые и все население трудоспособного возраста.
Коэффициент занятости (по отношению к трудовым
ресурсам): 
Отношение занятого населения к общей
численности трудовых ресурсов (в %) показывает степень
использования трудовых ресурсов в стране, регионе
6.
Какая категория
людей относится к безработным?
К безработным относят лиц от 16 лет и
старше, не имеющих работу или занятия, приносящего доход, но которые искали
работу и готовы были приступить к ней незамедлительно (Sбезр). Поиск работы в этой группе населения
осуществляется или самостоятельно, или через службу занятости (биржу труда).
7.
Какими
показателями характеризуется уровень безработицы?
Безработица изучается с помощью коэффициента
безработицы, который
также исчисляется в нескольких вариантах
 ,
,
где Sбезр. ‑ общая численность безработных в регионе или в стране.
Если используются данные учета
зарегистрированных официальных безработных, то:

Продолжительность безработицы ‑ это промежуток времени, в течение которого
человек ищет работу, от начала поиска до трудоустройства. Исчисляется средняя
продолжительность поиска работы по региону, по группе населения или по
стране в целом.
8.
Что такое
естественный и механический прирост трудовых ресурсов и чем он отличается от
естественного и механического прироста населения?
Изменение численности населения происходит
под влиянием таких факторов, как естественный прирост и миграция. Естественный
прирост населения. Определяется превышением рождаемости над смертностью,
миграция показывает механическое движение или перемещение трудовых ресурсов по
экономическим регионам.
Абсолютный прирост трудовых
ресурсов в стране, регионе или отрасли определяется их разностью на начало и
конец планируемого периода с учетом динамики миграции населения. Темп прироста
трудовых ресурсов за отчетный или планируемый период характеризуется отношением
абсолютной величины их прироста к общей численности на начало или конец
соответствующего периода. Важной количественной характеристикой состояния
трудовых ресурсов и их динамики за тот или иной конкретный период служат
показатели рождаемости, смертности и естественного прироста населения,
исчисляемые в виде соотношения их соответствующих фактических значений к
среднегодовому количеству трудоспособных людей. Данные показатели обычно
устанавливают среднее количество рождений или смертей, а также разность между
ними в расчете на 1000 человек.
9.
Какие
показатели используются в статистике занятости и безработицы?
Показатели занятости и безработицы в
статистике используются такие как:
· коэффициент нагрузки на одного занятого:
Sнезан.
Кнагр. = ——-
Sзан.
где Sнезан ‑ численность незанятого населения, Sзан ‑
численность занятого населения всех возрастов.
· коэффициент трудоспособности всего населения:
Sтр. сп.
Ктр. сп. = ———-
S
· коэффициент пенсионной нагрузки (по отношению к
разным категориям населения). Например:
Sпенс.нагр.
Кпенс. нагр. = ————,
Sтр.сп.
где Sпенс. ‑ численность пенсионеров; Sтр сп. ‑ численность населения рабочих возрастов и
др.
10.
Как исчисляется
прогнозная численность трудовых ресурсов?
Численность потенциальных трудовых ресурсов,
т.е. на перспективу, исчисляется по таким же формулам, что и прогнозная
численность населения, только учитываются лица рабочих возрастов.
Источники статистической информации о трудовых
ресурсах: перепись населения; текущий учет миграции; выборочные обследования;
статистическая отчетность предприятий и др.
Тема№14
Контрольные вопросы
1.
В чем состоит
сущность цены?
Цена – важнейшая категория и показатель
рыночной экономики и сферы товарного обращения. И в рыночной, и в плановой, и в
переходной экономике цена в сфере обращения ‑ это сумма денег, уплачиваемая за
единицу товара, эквивалент обмена товара на деньги.
2.
Какова роль и
функция цены в рыночной экономике?
И в рыночной, и в плановой, и в переходной
экономике цена в сфере обращения ‑ это сумма денег, уплачиваемая за единицу
товара, эквивалент обмена товара на деньги
В связи с этим цена является одновременно:
— инструментом воздействия на баланс спроса и
предложения
— индикатором конъюнктуры рынка
— фактором покупательной способности населения
— единым соизмерителем разнородных
потребительских стоимостей.
Без статистического анализа цен невозможно
планирование и экономический анализ торговли и рынка товаров и услуг. Все
основные производственные и финансовые показатели деятельности и промышленных,
и торгово-коммерческих предприятий (ТКП), такие как товарооборот, издержки,
прибыль, рентабельность и другие, исчисляются только на основе ценовых показателей.
Конкретными задачами статистики цен являются:
·
регистрация рыночных цен;
·
изучение структуры и
динамики цен;
·
изучение сезонных
колебаний цен и товарооборота;
·
изучение процесса
ценообразования;
·
анализ соотношения цен на
товары в разнообразных сферах, областях и формах торговли;
·
изучение региональных цен.
3.
Какие группы
показателей используются при статистическом изучении цен?
Система показателей статистики цен включает
семь блоков показателей:
— показатели динамики цен (сюда относят индексы цен – групповые,
индивидуальные, средние);
— показатели уровня цен (индивидуальные,
средние, обобщающие);
— показатели структуры цен (доля в цене
различных наценок, скидки, издержки в цене и др.);
— показатели вариации цен (например, разброс
цен внутри товарной группы, сезонные колебания цен);
— показатели соотношения цен (например,
соотношение с базовыми ценами, соотношения цены и качества товара);
— показатели эластичности цены (коэффициенты
эластичности).
4.
С какими
проблемами сталкивается статистика цен при расчете средней цены?
Исчисление средних цен. Цена по своей природе
относится к часто изменяющимся величинам, особенно в рыночной экономике.
Поэтому необходимо уметь определять цены в пространстве, во времени, по видам
товаров и товарных групп. Например, если цена изменялась в течение месяца, то
надо уметь исчислять среднюю цену за месяц, учитывая сроки изменения цены, т.е.
на основе интервального ряда.
5.
Какие виды
индексов цен Вы знаете?
Индексы цен – это обобщающие показатели, характеризующие
относительное изменение или соотношение цен. Если сопоставляются цены во
времени, то это отношение цены товара в отчетном периоде к цене этого же товара
в базисном периоде. Если сопоставляются цены в пространстве, то сопоставляются
цены одного региона с ценами другого региона (т.е. это территориальные
индексы). Если сопоставляются цены в разных формах торговли, то это индексы
соотношения цен – например, цена товара в одной сфере торговли делится на цену
товара в другой.
Индивидуальные индексы (элементарные, однотоварные, простые) имеют
вид:
 ,
,
где p1 и p0 – цены товара отчетного и базисного периодов
соответственно.
Если дано изменение цены в виде
% прироста или снижения, то используется:

Индекс может иметь и коэффициентную, и
процентную форму.
Агрегатный (общий, групповой) индекс цены
используется для изучения динамики цен разнородных товаров. В числителе и
знаменателе берется одно и тоже количество товаров (или из отчетного периода –
индекс Пааше, или из базового периода – индекс Ласпейреса)
 (Пааше)
(Пааше)

(Ласпейреса),
где p1 и p0 — цены на товары в отчетном и базисном периодах, q1 и q0 – количество продаж в отчетном и
базисном периодах соответственно.
Эти индексы отвечают на вопрос – как в среднем
изменилась выручка за счет изменения цены отчетного периода по сравнению с
базисной на то постоянное количество товаров, которое продано или в отчетном
периоде (Паше) или в базисном периоде (Ласпейреса).
Территориальные индексы. Для анализа региональной колеблемости цен
используются пространственные индексы – территориальные
 ,
, 
где pА и pБ —
цены на i-ый товар регионов А и Б; ![]() –
–
среднероссийская цена i- го товара; Q—
продажа i— го
товара по всей стране.
Эти индексы показывают отклонения (разброс)
цен каждого региона (города) от среднего уровня цен по стране. Т.е., эти
показатели можно отнести к группе показателей вариации цен. Для сравнения
регионов применяют индекс:
![]()
Индексы соотношения цен. Для сравнения цен в разных формах торговли используются индексы
соотношения цен. Например:
 ,
,
где pрын., pгосторг – цены одного товара в свободной рыночной торговле и
в госторговле, qрын. – количество проданного товара в свободной рыночной торговле
(городской рынок).
Территориальные индексы и индексы соотношения
цен относятся к агрегатным (общим) индексам. К ним же относятся и индексы
средних цен.
Индексы цен исчисляются с различной
периодичностью (ежегодно, ежеквартально, ежемесячно и т.д.). В этих случаях
образуются ряды индексов как цепные, так и базисные. Это дает возможность
анализировать динамику цен.
Некоторые индексы цен имеют более конкретное
название в связи со своей спецификой или областью применения. Например: в
практике коммерческой деятельности определяют индекс сезонности цен. Его
условно можно считать одновременно и индексом среднего уровня цен и индексом
соотношения цен:
![]() ,
,
где ![]() – средняя
– средняя
арифметическая цена за каждый одноименный период (месяц) по совокупности лет, ![]() – среднегодовой уровень цены по всем
– среднегодовой уровень цены по всем
периодам (неизменная величина в течение длительного периода).
Индекс потребительских цен. Органами государственной статистики регулярно
исчисляется индекс потребительских цен (ИПЦ). Его часто называют индексом
стоимости жизни. Он необходим для оценки изменения цен на товары и услуги
непроизводственного потребления. Поэтому исчисляют его с разной периодичностью
в нескольких вариантах:
‑ Сводный индекс потребительских цен
‑ Оперативный индекс потребительских цен
‑ Индекс потребительских цен по минимальному
набору товарной корзины
Сводный индекс потребительских цен исчисляется
по группе продовольственных товаров (103 товара), по группе непродовольственных
товаров (222 товара) и по платным услугам (84 вида услуг) в 132- ух городах
России (всего 409 позиций) ‑ это сводный ИПЦ.
Исчисляется также оперативный индекс
потребительских цен по 122 видам товаров и услуг. В нашей стране индекс
исчисляется по формуле
Лайспереса и Пааше и используется в
статистике инфляции.
Индекс потребительских цен по набору
минимального потребительского бюджета, т.е. по прожиточному минимуму (т.е.
набор продовольственных и непродовольственных услуг по определенным нормативам
потребления). Как один из вариантов его исчисления используется индекс
потребительских цен по набору из 19 наименований продуктов, включая табачные
изделия, т.е. набор минимальной потребительской корзины.
Индекс покупательской способности рубля.
От уровня цен на товары и услуги зависит
покупательная способность рубля. Она показывает, как изменился объем
материальных благ и услуг, который можно получить на одинаковую сумму на один
рубль. Индекс покупательской способности рубля исчисляется как обратный индексу
цен на товары и индексу цен на услуги. Если:
 ,
,
Тогда индекс покупательной способности рубля
исчисляется:
 ,
,
где Q1 –
объем услуг за отчетный период; ру0 и ру1
– цены на услуги за базисный и отчетный периоды.
Индекс цен на потребительские товары
характеризует, кроме динамики самих цен, еще и реальную заработную плату (т.е.
зарплату с учетом цен.).
 ,
,
где ![]() ‑ cредняя
‑ cредняя
заработная плата (номинальная) за период. Тогда:
 ,
,
т.е. средняя реальная
заработная плата равна номинальной, деленной на сводный индекс потребительских
цен.
6.
Назовите
достоинства и недостатки индексов средних цен.
Исчисление средних цен. Цена по своей природе
относится к часто изменяющимся величинам, особенно в рыночной экономике.
Поэтому необходимо уметь осреднять цены в пространстве, во времени, по видам
товаров и товарных групп. Например, если цена изменялась в течение месяца, то
надо уметь исчислять среднюю цену за месяц, учитывая сроки изменения цены, т.е.
на основе интервального ряда. Наиболее часто используется средневзвешенная
арифметическая:
 ,
,
где рi
– цена i
– го ассортиментного вида
товара (региона, пояса, даты…);
qi –
количество i – го товара; n – число видов товаров.
Если учет ведется только в стоимости продаж
(количество не регистрируется), то средняя цена исчисляется по средневзвешенной
гармонической:
 .
.
7.
Дайте
определение понятию «эластичность цен». Что отражает коэффициент эластичности?
Эластичность (англ.
elasticity) численная характеристика
изменения одного показателя (например предложения
или спроса) показателю (например: цене, доходу) и показывающая, на
сколько процентов изменится первый показатель при изменении второго на
1 %.
Товары с эластичным спросом по
цене:
·
Предметы
роскоши (драгоценности, деликатесы)
·
Товары,
стоимость которых ощутима для семейного бюджета (мебель, бытовая техника)
·
Легкозаменяемые
товары (мясо, фрукты)
Товары с неэластичным спросом по
цене:
·
Предметы
первой необходимости (лекарства, обувь, электричество)
·
Товары,
стоимость которых незначительна для семейного бюджета (карандаши, зубные щётки)
·
Труднозаменяемые
товары (электрические лампочки, бензин)
Эластичными (по цене) считаются спрос или предложение,
когда изменение величины спроса (предложения) больше изменения цены (E>1).
Неэластичными считаются спрос или
предложение, когда изменение величины спроса (предложения) меньше изменения
цены (E<1).
Эластичность для участка 1—2: ![]() ;
;
Эластичность спроса по цене,
ценовая эластичность спроса (price elasticity of demand) относительное изменение объема
спроса при изменении цены на 1%.

Для измерения процентного
изменения величины спроса используется формула средней точки Аллена.
![]()
![]()
8.
В чем сущность
и назначение индекса потребительских цен? Как он исчисляется?
Индекс потребительских цен. Органами государственной статистики регулярно
исчисляется индекс потребительских цен (ИПЦ). Его часто называют индексом
стоимости жизни. Он необходим для оценки изменения цен на товары и услуги непроизводственного
потребления. Поэтому исчисляют его с разной периодичностью в нескольких
вариантах:
‑ Сводный индекс потребительских цен
‑ Оперативный индекс потребительских цен
‑ Индекс потребительских цен по минимальному
набору товарной корзины
Сводный индекс потребительских цен исчисляется
по группе продовольственных товаров (103 товара), по группе непродовольственных
товаров (222 товара) и по платным услугам (84 вида услуг) в 132- ух городах
России (всего 409 позиций) ‑ это сводный ИПЦ.
Исчисляется также оперативный индекс
потребительских цен по 122 видам товаров и услуг. В нашей стране индекс
исчисляется по формуле
Лайспереса и Пааше и используется в
статистике инфляции.
Индекс потребительских цен по набору
минимального потребительского бюджета, т.е. по прожиточному минимуму (т.е.
набор продовольственных и непродовольственных услуг по определенным нормативам
потребления). Как один из вариантов его исчисления используется индекс
потребительских цен по набору из 19 наименований продуктов, включая табачные
изделия, т.е. набор минимальной потребительской корзины.
9.
Как
определяется покупательная способность рубля и ее изменение?
От уровня цен на товары и услуги зависит
покупательная способность рубля. Она показывает, как изменился объем
материальных благ и услуг, который можно получить на одинаковую сумму на один
рубль. Индекс покупательской способности рубля исчисляется как обратный индексу
цен на товары и индексу цен на услуги. Если:

 ,
,
Тогда индекс покупательной способности рубля
исчисляется:
 ,
,
10.
Назовите
основные показатели динамики инфляции.
Инфляция – повышение общего уровня цен и обесценивание денег,
вызванное нарушением равновесия между денежной массой и товарным покрытием.
Уровень инфляции – это показатель роста общего уровня цен.
Уровень инфляции в мировой практике измеряется
двумя показателями:
1 Индекс потребительских цен (сводный ИПЦ) – оценивает
уровень инфляции только на потребительском рынке.
2 Дефлятор валового внутреннего продукта
(ДВВП) – оценивает степень инфляции по всей совокупности благ, производимых и
потребляемых в государстве (учитываются не только потребительские товары, но и
продукция производственного назначения, и инвестиции, и экспорт, и динамика
таможенных пошлин, и всевозможные услуги, и т.д.), в том числе и рост оптовых
цен.
ИПЦ рассчитывается по формуле
Ласпейреса:

ДВВП в большинстве стран
исчисляется по формуле Пааше:

Динамика инфляции измеряется
нормой инфляции, которая исчисляется:
 ,
,
где t и (t
– 1) – номера смежных
периодов.
Норма инфляции показывает: насколько процентов
изменился уровень инфляции за данный период. Если в месяц N » 1¸ 9 –
«ползучая» инфляция, 10 ¸ 49 %
«галопирующая» инфляция, 50% и более — гиперинфляция.
При статистическом анализе инфляции на уровне
отдельных фирм важно отделить в индексе цен на выпускаемую продукцию
инфляционную и неинфляционную составляющие:
![]() т.е.
т.е. ![]()
Эта группа индексов определяется или
экспертным путем, или дополнительными статистическими и экономическими
исследованиями, маркетингом и другими способами. В свою очередь,![]() статистически измеряется на макроуровне
статистически измеряется на макроуровне
соотношением товарной и денежной массы в стране. При этом динамика товарной
массы измеряется как динамика товарооборота товаров и услуг, а динамика
денежной массы – темпами роста денежной эмиссии и роста цен и доходов
населения.
Тема 15
Контрольные вопросы
1.
Что такое
национальное богатство и национальное имущество?
Национальное богатство – это собственный капитал страны,
определяется как разность между стоимостью всех активов и всех обязательств
страны. Другими словами, (по методическим положениям Росстата), национальное
богатство — это совокупность ресурсов страны, которая создает необходимые
условия для производства товаров и услуг и обеспечения условий жизни людей.
Национальное богатство – это запас материальных благ, которым
располагает общество в каждый достигнутый момент времени (т.е. это моментный
показатель) и который может быть использован для производства или потребления.
Доля национального имущества в национальном богатстве характеризует уровень
экономического развития страны.
Национальное имущество – это часть национального богатства –
накопленный собственный капитал у юридических и физических лиц, в отраслях,
секторах экономики и в регионах страны, а также личное имущество населения (это
понятие идет из другой концепции национального богатства для плановой
экономики), т.е. здесь не учитываются природные ресурсы.
2.
Что собой
представляют основные фонды и чем они отличаются от оборотных фондов?
Основные фонды – это материальная часть
основного капитала. Они переносят свою стоимость на изготовленные с их помощью
товары и услуги по частям, постепенно, по мере износа, в отличие от оборотных
фондов, которые принимают непосредственное участие в производстве товаров и
услуг, сразу перенося свою стоимость на изготовленный продукт.
Основные фонды могут быть материальными и
нематериальными. Вместе они образуют основной капитал. Материальная часть
основного капитала – это основные фонды, которые переносят свою стоимость на
изготовленные товары и услуги по частям, постепенно, по мере их износа,
долговременно.
К оборотным средствам относят запасы
материальных оборотных средств – производственные запасы, незавершенное
производство, готовая продукция, товары для перепродажи, государственные
материальные резервы. Их особенность в том, что они переносят свою стоимость на
изготовленный и реализуемый товар сразу, полностью, целиком за один
производственный цикл.
3.
Каковы состав и
структура основных фондов? Как классифицируются основные фонды?
Типовая классификация основных фондов, действующая
в Российской Федерации, выделяет 9 видов основных фондов: здания, сооружения,
жилища, машины и оборудование, транспортные средства, инструмент и
хозяйственный инвентарь, рабочий и продуктовый скот, многолетние насаждения,
прочие основные фонды (это музейные ценности, библиотечные фонды и т.д.).
Имеются и более детальные классификации основных фондов.
4.
Какие виды
оценки основных фондов используются в статистической практике?
виды оценки основных фондов:
‑ полная первоначальная стоимость основных
фондов (ППС)
‑ первоначальная стоимость основных фондов за
вычетом износа (ППС/)
‑ полная восстановительная стоимость (ПВС)
основных фондов.
‑ восстановительная стоимость основных фондов
за вычетом износа (остаточная, ПВС/)
5.
Что такое
«амортизация основных фондов» и как она исчисляется?
Амортизация – особая экономическая категория,
это денежное выражение стоимости основных фондов, перенесенной на продукцию,
включается в себестоимость продукции; это форма отчислений, включенных в
издержки производства и предназначенных для воспроизводства основных фондов и
поддержания их в работоспособном состоянии.
Амортизационные отчисления аккумулируются в
амортизационные фонды. Размеры амортизационные отчислений в фонды определяются
нормами амортизационных отчислений. При расчете норм амортизационных отчислений
учитывают первоначальную стоимость основных фондов, нормативные сроки их службы
(амортизационный период), затраты на капитальный ремонт и модернизацию, а также
ликвидационную стоимость основных фондов.
Норма амортизации основных фондов в стране в
среднем (общая) составляет » 7,5% (к
балансовой стоимости основных фондов). Годовая фактическая сумма амортизации
определяется по формуле:
![]()
где N = (Арасч. / ПВС) * 100 ‑ норма амортизации, ПВС ‑ средняя
стоимость основных фондов.
Полное представление о воспроизводстве
основных фондов можно получить на основе балансового метода. В практике составляются
балансы и по полным (ППС, ПВС) и по остаточным стоимостям (ППС/
и ПВС/).
Баланс по полным стоимостям ППС (ПВС):
ППСн + П = ППСк + В,
где ППСн и ППСк
– полная первоначальная стоимость на начало и конец периода; П –
поступление основных фондов за период; В – выбытие основных фондов за
период.
Баланс по остаточным стоимостям: ППС/н
+ П/ + К = ППС/к + В/ + А,
где ППС/н , ППС/к –
первоначальные стоимости основных фондов с учетом их износа на начало и конец
года соответственно; П/ ‑ поступление основных
фондов с учетом их износа; (П/ = П – если фонды новые, без
износа). В/ ‑ выбытие основных фондов с учетом их
износа; А – сумма амортизации за год. К ‑ затраты на капитальный
ремонт и модернизацию основных фондов за год.
Следует отметить, что ППС в условиях
инфляции является нереальной величиной, а условной оценкой основных фондов, она
искажает экономические расчеты. Поэтому переоценка основных фондов – очень
важное мероприятие, позволяет правильно исчислять налоги на имущество,
амортизационные отчисления, себестоимость продукции и другие показатели.
6.
Какие
показатели составляют основу баланса основных фондов по стоимости?
Основные фонды – это материальная часть
основного капитала. Они переносят свою стоимость на изготовленные с их помощью
товары и услуги по частям, постепенно, по мере износа,
БАЛАНС ОСНОВНЫХ ФОНДОВ представляет собой статистическую таблицу,
данные которой характеризуют объем, структуру, воспроизводство основных фондов
по экономике в целом, отраслям и формам собственности.
По данным этого баланса исчисляются показатели
износа, годности, обновления, выбытия, использования основных фондов. Данные о
наличии основных фондов используются для расчета показателей фондоемкости,
фондовооруженности, фондоотдачи и других важнейших экономических расчетов.
Баланс основных фондов, составленный по
балансовой стоимости, является исходным балансом, на базе которого могут быть
исчислены показатели в сопоставимых, среднегодовых и других ценах . Этот баланс
необходим для изучения объема, структуры и воспроизводства основных фондов в
реальных условиях и по реально складывающимся ценам.
Источниками информации о наличии и движении
основных фондов служит бухгалтерская и статистическая отчетность организаций,
данные выборочных обследований, в том числе основных фондов, принадлежащих
гражданам (физическим лицам).
7.
Какие
показатели рассчитываются по характеристикам состояния и движения основных
фондов?
При статистическом анализе состояния, движения
и эффективности использования основных фондов используется ряд показателей
Средний размер основных фондов за период (как правило ‑ это год,
полугодие, квартал). Необходимо отметить, что стоимость основных фондов – это
моментная величина, поэтому средняя стоимость основных фондов (Ф) за
любой период определяется по средней хронологической или как полусумма значений
основных фондов на начало и конец периода:
![]()
Коэффициент годности основных фондов – это есть отношение неизменной
остаточной стоимости основных фондов (т.е. с учетом их износа) к их полной
стоимости (как на начало, так и на конец года):

Коэффициент износа основных фондов – это есть отношение суммы износа (И)
основных фондов к их полной стоимости (как на начало, так и на конец года):
Кизн. = И /Ф (ППС) * 100
Коэффициент поступления основных фондов – это отношение стоимости
поступивших в течение отчетного периода основных фондов к их стоимости на конец
этого периода:
Кпост. (ввода) = Фпост. /
Фк
Коэффициент обновления основных фондов – это отношение стоимости
поступивших новых основных фондов к их стоимости на конец этого периода:
Кобн = Фнов / Фк
Коэффициент выбытия основных фондов – это отношение полной стоимости
выбывших в течение отчетного периода основных фондов к их полной стоимости на
начало отчетного периода:
Квыб. = Фв / Фн
Коэффициент ликвидации основных средств:
Кл = Фликв / Фн
Коэффициент замены основных фондов:
Кзам = Фликв / Фнов
8.
Что отражают
показатели фондоотдачи и фондоемкости и как они исчисляются?
Показатель фондоотдачи – отношение стоимости произведенной продукции
(Q) за
год к среднегодовой стоимости основных производственных фондов (коэффициент
фондоотдачи):
Кф/о = Q
/ Фср
Показатель фондоемкости – обратный показатель коэффициенту
фондоотдачи, называется ‑ коэффициент фондоемкости:
Кф/е = 1/ Кф/о
9.
Что такое
первоначальная и восстановительная стоимость основных фондов?
‑ полная первоначальная стоимость основных
фондов (ППС) – это фактическая стоимость основных фондов по ценам их
приобретения и ввода в их действие (включая все расходы по монтажу). По этой
стоимости основные фонды зачисляются на баланс предприятия. Она остается
постоянной всегда;
‑ первоначальная стоимость основных фондов за
вычетом износа (ППС/) – это часть стоимости основных фондов, которая
сохранилась после определенного периода их функционирования. Т.е. это
остаточная стоимость основных фондов, она равна полной первоначальной стоимости
минус сумма износа. Если основные фонды используются как лом (в силу их
ветхости), то их стоимость называется ликвидационной стоимостью основных фондов
(ЛС);
‑ полная восстановительная стоимость (ПВС)
основных фондов – это и есть стоимость их воспроизводства в новом виде, т.е. по
ценам на момент переоценки основных фондов;
‑ восстановительная стоимость основных фондов
за вычетом износа (остаточная, ПВС/) исчисляется как полная
восстановительная стоимость основных фондов минус стоимость износа; или умножением
ПВС на коэффициент износа. Определяется в момент переоценки основных фондов. В
системе национальных счетов основные фонды оцениваются только по
восстановительной стоимости.
10.Дайте характеристику состава
оборотных фондов, показателей размера оборотных фондов и эффективности их
использования?
Статистика оборотных фондов.
Для успешного функционирования промышленных и
торговых предприятий им необходимы кроме основных средств, и так называемые
оборотные средства. Их особенность в том, что они переносят свою стоимость на
изготовленный и реализуемый товар сразу, полностью, целиком за один
производственный цикл (оборот). К оборотным фондам относят
‑ производственные оборотные фонды;
‑ фонды обращения.
К производственным оборотным фондам относят
производственные запасы: сырье, материалы, топливо, энергию, упаковочные
материалы, а также незавершенное производство, запчасти, инструменты,
полуфабрикаты, малоценный и быстроизнашивающийся инвентарь и другое.
К фондам обращения относят запасы готовой
продукции у производителей (в промышленности) и товарные запасы для перепродажи
(в торговле). Кроме того, в торговле к фондам обращения относят затраты на
тару.
Задачами статистики оборотных средств (часто в
литературе их объединяют и называют оборотными фондами) являются:
1.
Определение объема,
структуры и динамики оборотных фондов.
2.
Анализ воспроизводства
оборотных фондов.
3.
Оценка оборачиваемости
оборотных средств.
4.
Анализ обеспеченности
производства оборотными средствами и эффективность их использования и др.
Денежные средства, уже вложенные в оборотные
фонды (в их оба вида) являются финансовым обеспечением предпринимательской
(торгово-экономической и производственной) деятельности и называется оборотным
капиталом. Это стоимостная категория призвана обеспечить непрерывность
воспроизводственного процесса и обслуживать процесс товарного обращения.
Элементом оборотных средств являются также
денежные средства в кассе и на расчетном счете предприятия, дебиторская
задолженность, расходы будущих периодов, краткосрочные финансовые вложения
(депозиты, займы, векселя и др.).
Формирование оборотных средств предприятия
происходит за счет:
·
формирование уставного
капитала (т.е. средств учредителей);
·
прибыли предприятия;
·
заемных и привлеченных
средств (в основном, это краткосрочные кредиты банка).
При анализе состояния оборотных средств
статистика использует следующие показатели:
‑ средняя величина (объем, остаток)
оборотного капитала по состоянию за период определяется в зависимости от
имеющихся данных: а) если заданы остатки оборотных средств на конец и начало
периода, то:
![]() ,
,
где Оср – средний остаток
оборотного капитала за период; Он и Ок —
остатки оборотного капитала на начало и конец периода;
б) если заданы остатки на конкретные даты
равноотстоящих периодов, то используется средняя хронологическая:
![]() ,
,
где О1, О2 —
остатки каждого периода на конкретные даты. (При неравных периодах используется
взвешенная средняя).
Для анализа процесса интенсивности
использования оборотных средств, т.е. процесса их оборачиваемости, применяются
следующие показатели (на примере торговли):
‑ Продолжительность (период) одного оборота
в днях:
 ,
,
где В ‑ продолжительность одного
оборота оборотного капитала в днях;
Оср – средние остатки оборотных средств; Q – объем
товарооборота; Д – число дней в анализируемом периоде.
Этот показатель характеризует периодичность
всех стадий кругооборота капитала на данном предприятии (в днях).
‑ Коэффициент оборачиваемости
оборотного капитала:

Этот коэффициент оборачиваемости оборотного
капитала характеризует количество оборотов за определенный период. Эти
показатели связаны между собой следующим образом:
В=Д / Кобор. и Кобор.=
Д / В
Они исчисляются как по всем оборотным
средствам, участвующим в обороте, так и по их отдельным элементам.
‑ Коэффициент закрепления или
относительный уровень запаса оборотного капитала – это обратный показатель
коэффициенту оборачиваемости:
 или
или 
Он характеризует объем оборотного капитала на
1 рубль товарооборота. Ускорение оборачиваемости высвобождает оборотные
средства, а замедление оборачиваемости замораживает их и ведет к образованию
сверхнормативных запасов товара.
К самостоятельной группе показателей
статистики оборотных средств относят производные показатели динамики:
абсолютный прирост, темпы роста и прироста, среднегодовые темпы роста и
прироста. При глубоком детальном анализе используются индексы средней
оборачиваемости и по числу оборотов, и по продолжительности одного оборота,
агрегатные индексы средних остатков оборотного капитала и товарооборота.
Использование этих индексов позволяет выявить влияние различных факторов на
процесс товарооборачиваемости.
Тема 16
Контрольные вопросы
1.
Перечислите
показатели состава и движения персонала фирм.
Движение рабочей силы – это изменение
списочной численности вследствие приема и увольнения работников. На фирмах
может быть составлен баланс рабочей силы:
Чн + П = Чк + В ,
где
Чн,, Чк ‑ численности на начало и конец периода,
П ‑ принятые за период,
В ‑ выбывшие за период
Применяются следующие показатели движения
рабочей силы на предприятиях:
1.
Коэффициент текучести
кадров – это отношение числа
уволенных по собственному желанию и за прогулы (Чс.ж.+Чпрог.)
к среднесписочной численности (Чср):
 .
.
Иногда используется в анализе коэффициент
стабильности кадров:
Kст. = 100 – Kтек (%)
2.
Коэффициент сменяемости
кадров – это отношение
разности числа выбывших и принятых за период к среднесписочной численности на
фирме:

3.
Коэффициент сменности
кадров – это отношение
среднесписочной численности к количеству занятых в наиболее заполненной смене.
Может измеряться и в человеко-днях отработанного времени.
 ,
,
где Чср.max – средняя
численность в максимально загруженной смене (при сменной работе предприятия).
4.
Коэффициент оборота (по приему) – это отношение принятых в отчетном
периоде (Чп) к среднесписочной численности:

5.
Коэффициент оборота (по выбытию) – это отношение числа выбывших
за отчетный период к среднесписочной численности:

6.
Коэффициент суммарного
(общего) оборота – это
отношение суммы принятых и выбывших за период к среднесписочной численности:

7.
Коэффициент
необходимого оборота – это
отношение разности общего числа выбывших и выбывших по собственному желанию и
за нарушение трудовой дисциплины к среднесписочной численности за один и тот же
период:

8.
Коэффициент численности
основных рабочих:

где Чср. в.р. –
численность вспомогательных рабочих. Этот показатель
исчисляется как для всех работников, так и
для работников основного и вспомогательного производства.
К показателям качественного состава кадров
относят:
1.
Коэффициент
обеспеченности кадрами:

где Чф – численность
фактически занятых на предприятии; Чшт. – число
должностей по штатному расписанию.
2.
Коэффициент
насыщенности специалистами:

где Чспец.в/о ‑ число
специалистов с высшим образованием на данной фирме, предприятии. Применяются и
другие показатели качественного состава персонала. Все они могут иметь как
процентную, так и коэффициентную форму.
2. Как рассчитывается
среднесписочная численность работников?
Среднесписочная численность (rср.,Чср.) – это сумма состоящих в списках предприятия
лиц за все календарные дни отчетного периода, включая выходные и праздничные,
деленная на число календарных дней периода. Другой способ расчета: как сумма
всех явок и неявок за все дни периода, включая выходные и праздничные дни,
деленная на число календарных дней периода:

3.
Назовите
абсолютные и относительные показатели оборота рабочей силы.
Движение рабочей силы – это изменение
списочной численности вследствие приема и увольнения работников. На фирмах
может быть составлен баланс рабочей силы:
Чн + П = Чк + В , где
Чн,, Чк ‑ численности на начало и конец периода, П
‑ принятые за период, В ‑ выбывшие за период
Применяются следующие показатели движения
рабочей силы на предприятиях:
Коэффициент текучести кадров – это отношение числа уволенных по
собственному желанию и за прогулы (Чс.ж.+Чпрог.) к
среднесписочной численности (Чср):
 .
.
Иногда используется в анализе коэффициент
стабильности кадров:
Kст. = 100 – Kтек (%)
Коэффициент сменяемости кадров – это отношение разности числа выбывших и
принятых за период к среднесписочной численности на фирме:

Коэффициент сменности кадров – это отношение среднесписочной численности к
количеству занятых в наиболее заполненной смене. Может измеряться и в
человеко-днях отработанного времени.
 ,
,
где Чср.max – средняя
численность в максимально загруженной смене (при сменной работе предприятия).
Коэффициент оборота (по приему) – это отношение принятых в отчетном
периоде (Чп) к среднесписочной численности:
Коэффициент оборота (по выбытию) – это отношение числа выбывших за
отчетный период к среднесписочной численности:

Коэффициент суммарного (общего) оборота – это отношение суммы принятых и выбывших за
период к среднесписочной численности:

Коэффициент необходимого оборота – это отношение разности общего числа
выбывших и выбывших по собственному желанию и за нарушение трудовой дисциплины
к среднесписочной численности за один и тот же период:

Коэффициент численности основных рабочих:

где Чср. в.р. –
численность вспомогательных рабочих. Этот показатель счисляется как для всех
работников, так и для работников основного вспомогательного производства.
4.
Что такое
рабочее время и что входит в его состав? Назовите единицы измерения рабочего
времени и какие фонды используются при его статистическом изучении?
Рабочее время – это часть календарного
времени, затрачиваемого на производство и реализацию продукции или выполнения
определенного объема работ и услуг (единица измерения: человеко-дни,
человеко-часы).
Рабочее время изучается следующими
показателями:
1.
Календарный фонд рабочего
времени – это произведение среднесписочной численности на календарное число
дней отчетного периода, т.е. это сумма отработанных и неотработанных дней
отчетного периода всем персоналом предприятия за календарную длительность
этого периода (КФРВ)
2.
Табельный фонд рабочего
времени – это календарный фонд рабочего времени за вычетом выходных и
праздничных дней (ТФРВ)
3.
Максимально возможный фонд
рабочего времени – это табельный фонд рабочего времени за вычетом очередных отпусков
всех работников (МФРВ).
4.
Явочный фонд рабочего
времени – это максимально возможный фонд рабочего времени за вычетом неявок на
работу (ЯФРВ).
5.
Фонд фактически рабочего
(отработанного) времени – это явочный фонд рабочего времени за вычетом
целодневных простоев (ФФРВ). Состоит из фактически отработанного и
неотработанного времени. В свою очередь, неотработанное время делится на
неотработанное по уважительным причинам (болезни, гособязанности и др.) и
неотработанное по неуважительным причинам (простои, прогулы и др.)
6.
Средняя фактическая
продолжительность рабочего периода – это общий фактический фонд отработанного
всеми работниками времени, деленный на среднесписочную численность предприятия
за год.
В статистике рабочего времени широко используются
показатели эффективности его использования. В этих коэффициентах в числитель
ставится или фактически отработанное время или тот или иной вид потерь
рабочего времени (по разным причинам), а в знаменатель ставится какой-либо
фонд рабочего времени (чаще всего это или календарный, или максимальный, или
какой-либо другой фонд).
5.
Что в
статистике понимается под производительностью труда и его видами?
Производительность труда в промышленности –
это характеристика результативности и эффективности производительного труда,
показывающая или количество продукции, произведенной за единицу времени, или
затраты труда на производство единицы продукции.
Различают производительность живого
труда – это или объем выпущенной продукции за единицу времени на конкретном
предприятии, или затраты времени на конкретном предприятии на производство
единицы продукции, и производительность общественного труда –
характеризуется затратами времени живого и прошлого труда, овеществленного в
сырье, материалах, энергии и др., потребленных в процессе производства
единицы продукции на всех стадиях ее изготовления.
6.
Какими
методами, показателями и как измеряются уровни производительности труда?
Производительность общественного труда по
экономике в целом в системе национального счетоводства исчисляют как отношение
валового внутреннего продукта (ВВП) к численности экономически активного
населения.
Производительность живого труда измеряется
двумя показателями, которые в общем виде можно представить так:
·
Выработка продукции в
единицу времени (w) :
![]()
·
Трудоемкость изготовления
единицы продукции (t):
 т.е.
т.е. ![]()
При этом в расчетах используются три метода
исчисления производительности труда и три различных вида единиц ее измерения:
·
Натуральный метод, т.е.
когда выпуск (Q) измеряется в натуральных единицах измерения (т.е. тонны, метры, штуки,
литры и т.д.). Используется в основном при выпуске однородной продукции.
Разновидность его – условно-натуральный метод. При его использовании
применяются такие условные единицы измерения готовой продукции или выполненных
работ, как сутко-комплекты, тонно-километры, машино-комплекты и др.
·
Трудовой метод измерения
(нормо-часы). То есть объемы выработки в натуральных единицах умножаются на
нормативы времени и результаты суммируются. Используется в тех производствах,
где часто изменяется ассортимент и номенклатура выпускаемой продукции.
·
Стоимостной метод
измерения производительности, т.е. все виды и объемы продукции, работ и услуг
умножаются на отпускные цены и переводятся в стоимостные показатели:

7.
Что
характеризует индексы производительности труда переменного состава, постоянного
состава и структурных сдвигов?
Для изучения динамики средней
производительности труда на предприятиях, где разные участки, смены,
технологии, оборудование с разными уровнями производительности труда, то
используются индексы среднего уровня (и для совокупности предприятий):
 ‑ индекс переменного состава;
‑ индекс переменного состава;
 ‑ индекс постоянного состава;
‑ индекс постоянного состава;
 ‑ индекс структурных сдвигов.
‑ индекс структурных сдвигов.
Связь между индексами, т.е. связь между относительными
характеристиками изменения производительности за счет факторов w и t:
Iv = Iw * Iс.с
Разность между числителем и знаменателем
каждого из этих индексов показывает абсолютное изменение производительности за
два периода за счет факторов w
(индивидуальной выработки) и Т (затраты труда на изготовление единицы
продукции).
Кроме этой модели связи, при анализе
производительности труда используется связь: IQ = Iv * IT , то есть

DQ
= S Q1 — S Q0 = (v1 — v0) ST1 + (S T1 — S T0)v0,
т.е. это аддитивный анализ общего изменения
выпуска продукции в абсолютном выражении по фактору изменения индивидуальной
выработки и по фактору изменения фактических затрат времени.
8.
Назовите
показатели заработной платы и дайте им характеристику.
показателям статистики оплаты труда относятся:
‑ средняя заработная плата одного работника,
исчисляется делением ФОТ на среднесписочную численность Чср.:
 или
или ![]()
где Т – фактически отработанное время в
человеко-часах за месяц, квартал, год. Среднемесячная заработная плата
исчисляется по предприятиям, по отраслям экономики, по регионам и по стране в
целом.
‑ статистика исчисляет номинальную и реальную
заработную плату. Номинальная – это начисленная денежная сумма каждому
работнику предприятия. Реальная – это характеристика объема товаров и услуг,
которые можно приобрести на начисленную (номинальную) заработную плату:
ƒ реал. = ƒ ном / ИПЦ
При изучении динамики заработной платы
используется соотношение:
 , так как
, так как  то
то
Iреал. = Iном. * Iп.с.р.
9.
Как исчисляется
реальная заработная плата и что она характеризует?
Статистика исчисляет номинальную и реальную
заработную плату.
Реальная – это характеристика объема товаров и
услуг, которые можно приобрести на начисленную (номинальную) заработную плату:
ƒ реал. = ƒ ном / ИПЦ
10.
С помощью каких
индексов изучается динамика уровней средней заработной платы?
При изучении динамики средней заработной платы
применяются индексы переменного состава, постоянного состава и структурных
сдвигов:
 ‑ индекс переменного состава
‑ индекс переменного состава
 ‑ индекс постоянного состава
‑ индекс постоянного состава
 ‑ индекс структурных сдвигов
‑ индекс структурных сдвигов
Тема№17
Контрольные вопросы
1.
Что такое
финансы, финансовые ресурсы и финансовые результаты?
Финансы — система денежных отношений, выражающих формирование
и использование денежных фондов в процессе их оборота
финансовые ресурсы – это денежные средства, привлеченные для
функционирования предприятия.
Финансовый результат— это итог хозяйственной деятельности предприятия за
отчетный период.
2.
Какие источники
финансовых ресурсов Вы знаете?
Показатели финансовых ресурсов и их источников
·
Абсолютный размер
уставного фонда (в него могут входить: величина акционерного капитала, паевые
взносы, кредиты, бюджетные средства и др.). Величина уставного капитала
характеризует размер основных и оборотных средств предприятий;
·
Прибыль от реализации
продукции;
·
Амортизационные отчисления;
·
Продажа акций, дивиденды и
проценты по ценным бумагам;
·
Венчурный капитал
(рисковые инвестиции);
·
Кредиты, займы, страховые
возмещения и др.;
·
Долевые участия других
предприятий.
3.
Какие
показатели финансового состояния предприятий Вы знаете?
Показатели финансового состояния фирм, т.е.
эффективности использования финансовых ресурсов.
·
Показатели ликвидности;
·
Показатели финансовой
устойчивости и платежеспособности фирм;
·
Показатели деловой
активности.
4.
Как исчисляются
показатели прибыльности?
Прибыль – это важнейшая экономическая
категория и в сфере производства, и в сфере обращения.
В сфере промышленного производства прибыль
разделяется на балансовую, прибыль от реализации, валовую, чистую прибыль.
Балансовая прибыль (Пб) (убыток) ‑ это сумма прибыли
от реализации (товаров, работ и услуг), от прочей реализации (продажи основных
фондов, имущества) и доходы от внереализационных операций:
Пб = Пр + Ппр
± Пвнер ,
где Пр – прибыль
от реализации; Ппр – прибыль от продажи основных
фондов, нематериальных активов, ценных бумаг и др.; Пвнер –
прибыль от внереализационных операций (аренда имущества, долевое участие в
других предприятиях).
Валовая прибыль‑ это расчетная величина для целей налогообложения, не
отражается в балансе. Представляет сумму прибыли балансовой, уменьшенной на
сумму расходов по внереализационным операциям.
Чистая прибыль – это разность между балансовой прибылью и суммой
всех налогов и платежей в бюджет из прибыли.
Прибыль от реализации – это разность между выручкой от реализации продукции
по оптовым ценам предприятия и затратами на производство и реализацию (т.е.
себестоимость продукции):
Пр = S рq ‑ S zq
,
где р – оптовая цена на товар; z ‑
затраты на единицу продукции; q – объем продукции.
5.
Как соотносятся
и исчисляются в торговле показатели прибыли и валового дохода?
в торговле прибыль – это экономическая
категория, также отражающая конечные результаты коммерческой деятельности
торговых предприятий. Она является составной частью валового дохода. А валовой
доход – это разность между товарооборотом (выручкой) и затратами на
приобретение товарной массы
ВД = О – П = S (т/н)i
где О – товарооборот; П –
затраты на приобретение товарной массы,
S (т/н)i ‑ сумма торговых наценок по всем i
‑ ым товарам. Тогда:
Пр = ВД – и/о,
где и/о – издержки обращения.
6.
Какими
основными абсолютными показателями характеризуется финансовый эффект
хозяйственной деятельности предприятия?
Показатели финансовых результатов деятельности
фирм;
Объем выручки от реализации (или валового
дохода);
Показатели прибыли;
Показатели рентабельности;
Показатели налогообложения (налоги, платежи и
сборы).
7.
Каковы
особенности методологии исчисления показателей рентабельности и их значение в
условиях рыночной экономики?
Показатели прибыли и рентабельности в сфере
обращения (т.е. в торговле) аналогичны перечисленным показателям, но имеют
некоторые особенности. Как и в промышленности, в торговле прибыль – это
экономическая категория, также отражающая конечные результаты коммерческой
деятельности торговых предприятий. Она является составной частью валового
дохода. А валовой доход – это разность между товарооборотом (выручкой) и
затратами на приобретение товарной массы
ВД = О – П = S (т/н)i ,
где О – товарооборот; П –
затраты на приобретение товарной массы,
S (т/н)i ‑ сумма торговых наценок по всем i ‑ ым
товарам. Тогда:
Пр = ВД – и/о,
где и/о – издержки обращения.
Прибыль в торговле бывает ‑ торговая (т.е.
прибыль от реализации), балансовая (общая), валовая и чистая.
Торговая прибыль (прибыль от реализации) – это превышение суммы
торговых надбавок (ВД) над величиной издержек обращения.
Балансовая прибыль – прибыль, полученная от всех видов деятельности
торгового предприятия, т.е. это прибыль от реализации + непланируемые доходы
(продажа имущества) за вычетом убытков и потерь от внереализационных операций.
Валовая прибыль – это балансовая прибыль, когда в составе
внереализационных доходов и убытков учитываются уплаченные штрафы и пени (до
уплаты налогов).
Чистая прибыль ‑ это прибыль, остающаяся в распоряжении предприятия
после уплаты налогов и других обязательных платежей в централизованные фонды и
вышестоящие организации.
При экономическом и статистическом анализе в
торговле также используются разнообразные показатели рентабельности (первые два
показателя основные):
‑ рентабельность как характеристика
эффективности основной деятельности в сфере товарного обращения:
![]()
т.е. отношение балансовой прибыли к
товарообороту.
Широко используется в хозяйственной практике и
рентабельность как характеристика эффективности использования затрат:

т.е. отношение торговой прибыли (прибыли от
реализации) к издержкам обращения.
‑ рентабельность как характеристика уровня
торговой прибыли на 1 рубль реализованного торгового наложения (ВД):

т.е. отношение прибыли от реализации к
валовому доходу.
‑ рентабельность как характеристика
эффективности использования
основных фондов – фондоотдача по прибыли
(фондорентабельность):

т.е. отношение торговой прибыли
к средней полной первоначальной стоимости основных фондов.
‑ рентабельность как характеристика
эффективности использования живого труда:

т.е. это отношение торговой прибыли к
среднесписочной численности персонала ‑ чср . Этот показатель
показывает прибыль на одного работника, иногда используется модификация этого
показателя:

т.е. это прибыль на 100 рублей фонда оплаты
труда.
‑ рентабельность как характеристика
эффективности использования капитала (вложенного, собственного, заемного или
общего):
![]()
К – капитал (собственный, акционерный)
Вложенный капитал – это сумма оборотных
средств и инвестиций. Общий капитал: основные средства + нематериальные активы
+ фонды обращения.
‑ рентабельность как характеристика
эффективности использования инвестиций:

где Какцион – размер
акционерного капитала (собственный); Ддолгоср – долгосрочные
обязательства предприятия. Или:

Таким образом, все показатели
рентабельности различаются тем, что используются разные основания
(знаменатели).
Анализ динамики прибыли с использованием показателя рентабельности
затрат:
![]() (показатель эффективности издержек),
(показатель эффективности издержек),
где И = у * О,у – уровень
издержкоемкости, О – товарооборот.
Тогда: Пр = у * О *
R и абсолютный прирост суммы прибыли за
два периода (отчетный и базисный) равен:
DПр = Пр1 – Пр0
= у1 * О1 * R1 – у0 * О0 * R0 ,
т.е. прирост прибыли определяется тремя факторами: издержкоемкостью
товарооборота (у), самим товарооборотом (О) и рентабельностью
использования издержек обращения (R):
DПр = DПр(о) + DПр(у) + Пр(R).
Методами аддитивного анализа
можно исчислить каждую долю прибыли в общем ее размере.
8.
Что понимают
под финансовой устойчивостью хозяйствующего субъекта?
Под финансовой
устойчивостью понимается способность хозяйствующего субъекта своевременно
из собственных средств покрывать затраты, вложенные в основной и оборотный
капитал, нематериальные активы, и расплачиваться по своим обязательствам, т.е.
быть платежеспособным. Для оценки изменения устойчивости хозяйствующего
субъекта применяются: коэффициент автономии; коэффициент соотношения
собственных и заемных средств; коэффициент маневренности; коэффициент
ликвидности и др.
Финансовое состояние хозяйствующего субъекта — это характеристика
его финансовой конкурентоспособности (т.е. платежеспособности,
кредитоспособности), использования финансовых ресурсов и капитала, выполнения
обязательств перед государством и другими хозяйствующими субъектами. Финансовое
состояние хозяйствующего субъекта включает анализ: доходности и рентабельности;
финансовой устойчивости; кредитоспособности; использования капитала; валютной
самоокупаемости
9.
Что такое
ликвидность и какие показатели ликвидности Вы знаете?
Ликвидность – это способность
предприятия погасить свои краткосрочные обязательства, т.е. характеризует
способность предприятия погасить свои долги или превратить имеющиеся ресурсы в
денежную форму. При анализе ликвидности используются понятия:
‑ текущие активы (ТА)
фирмы (Актив – это способ обозначения элементов собственного капитала
(ресурсов) субъектов рынка, т.е. на них устанавливаются индивидуальные или
коллективные права собственности, а владение или использование ими приносят
собственнику экономическую выгоду). К ним относят: ДС – денежные
средства, ЦБ – ценные бумаги, ДЗ – дебиторская задолженность, ЗП
– запасы товарно-материальных ценностей, КЗ – краткосрочная
задолженность.
1.
Общий коэффициент
ликвидности (он же индекс, текущий ликвидности, коэффициент покрытия):
Ко.л. = ТА : КЗ = (ДС + ЦБ + ДЗ +
ЗП) : КЗ ,
где ДС + ЦБ + ДЗ + ЗП – оборотный
капитал (норматив Ко.л. — 1¸3)
2.
Уточненный коэффициент
ликвидности (он же коэффициент критической ликвидности, промежуточный
коэффициент покрытия, индекс лакмусовой бумаги, быстрый индекс):
Кул = (ДС + ЦБ + ДЗ) : КЗ
Он характеризует способность
фирмы расплатиться с кредиторами в текущий момент. Норматив: 0,8 ¸ 1,0.
3.
Коэффициент абсолютной
ликвидности (он же коэффициент срочности):
Ка.л. = (ДС + ЦБ) : КЗ ,
т.е. здесь исключены запасы
товарно-материальных ценностей и долги других предприятий (т.к. они требуют
время для обмена их деньги).
Понятие финансовой устойчивости
и ликвидности – это идентичные понятия. Поэтому коэффициент ликвидности
характеризует и финансовую устойчивость и, в целом, процесс платежеспособности
фирм. Но в понятие финансовой устойчивости еще включают оценку независимости
финансового состояния фирм от заемных источников. И здесь используется
коэффициент автономии (независимости):

где Сс –
собственные средства; Sc — сумма всех источников финансовых ресурсов фирмы. Если Ка ³ 0,5 , то это означает, что реализация половины своего имущества дает
возможность погасить долги.
Другим показателем финансовой устойчивости
является непосредственно коэффициент финансовой стабильности:

где Дз.с. –
долгосрочные заемные средства. Т.е. если Дз.с. = 0
(нет кредитов),
то Кстаб.= Ка
Иногда в литературе используется
коэффициент устойчивости в другом виде:

где Кз – кредиторская
задолженность, но без кредитов банков и займов.
Коэффициент маневренности в оценке финансового
состояния предприятий характеризует долю собственных средств, вложенных в
наиболее мобильные активы:
![]()
где К – общий капитал и резервы
предприятия.
10.
Что
характеризуют показатели оборачиваемости оборотных средств?
Финансовое состояние фирм оценивается также
такими показателями, как показатель общей оборачиваемости капитала. Этот
показатель называют еще коэффициентом деловой активности:
![]()
где К – общий капитал = (основные фонды
+ оборотные фонды + нематериальные активы + фонды обращения).
Самостоятельной группой показателей
финансового состояния являются показатели анализа процесса интенсивности
использования оборотных средств, т.е. процесса их оборачиваемости. Здесь
применяются те же показатели, что и в статистике оборотных средств:
—
Продолжительность
(период) одного оборота в
днях:
 где
где
В ‑ продолжительность одного оборота оборотного капитала в днях; Оср
– средние остатки оборотных средств; Q – объем товарооборота; Д
– число дней в анализируемом периоде. Этот показатель характеризует
периодичность всех стадий кругооборота капитала на данном предприятии (в
днях).
—
Коэффициент
оборачиваемости оборотного
капитала:

Этот коэффициент оборачиваемости оборотного
капитала характеризует количество оборотов за определенный период.
Эти показатели связаны между собой следующим
образом:
В=Д / Кобор. и Кобор.= Д
/ В
Они исчисляются как по всем оборотным
средствам, участвующим в обороте, так и по их отдельным элементам.
‑ Коэффициент закрепления или
относительный уровень запаса оборотного капитала – это обратный показатель
коэффициенту оборачиваемости:
 или
или 
Он характеризует объем оборотного капитала на
1 рубль товарооборота. Ускорение оборачиваемости высвобождает оборотные
средства, а замедление оборачиваемости замораживает их и ведет к образованию сверхнормативных
запасов товара.
Тема№18
Контрольные вопросы
1.
Что такое рынок
товаров и услуг? Как Вы понимаете смысл термина «рыночная конъюнктура»? Какие
показатели рыночной конъюнктуры Вы знаете?
Рынок — многогранное и многоструктурное явление,
подчиняющееся в своем развитии закону спроса-предложения. Действие рыночного
механизма проявляется в сложных процессах, которые определяют состояние рынка,
темпы его развития и основные пропорции.
Рынок товаров (продуктов и услуг) — это система отношений купли — продажи между
экономически свободными продавцами и покупателями.
Рыночная конъюнктура — взаимозависимые колебания спроса и предложения
Конъюнктура рынка — это
совокупность условий, при которых в данный момент протекает деятельность на
рынке. Она характеризуется определенным соотношением спроса и предложения на
товары данного вида, а также уровнем и соотношением цен.
Изучение конъюнктуры рынков
включает в себя обработку, анализ и систематизацию количественных показателей и
качественной информации, характеризующей развитие рынка в данный период
времени. Выбор системы показателей определяется целями конкретного
исследования, например, анализ развития рынка, анализ ситуации на рынке за
определённый период времени, изменение технико-экономических характеристик
производства.
Количественное состояние
конъюнктуры может быть оценено с помощью следующих групп показателей :
— Измеряется объём и динамика
производства в целом, размер инвестиций, уровень занятости, размеры заработной
платы, данные о заказах. Это так называемые показатели сферы производства.
— Платёжеспособный спрос, размеры
реализации товаров в кредит, данные о розничной и оптовой торговле
-Перечисленное относится к показателям внутрирегиональной торговли.
— Объёмы, динамика, географическое
распределение межрегиональных связей, объёмы импорта и экспорта, объемы
грузоперевозок Данная группа показателей относится к группе межрегиональных и
внешнеэкономических связей.
— Кредитно-денежное обращение. К
этой группе оценки относятся курсы акций и других ценных бумаг, процентные
ставки, размеры банковских депозитов, валютные курсы.
2.
Какие виды
товарооборота Вы знаете?
Классификация видов товарооборота производится
по признакам:
По роли продавца ‑ следующие виды:
‑ товарооборот производителя ‑ Опроиз.
(характеризует сумму первых продаж, продавцом выступает производитель товара,
то есть отражает объем товарной массы, вовлекаемой в сферу товарного
обращения);
‑ торгово-посреднический товарооборот
или товарооборот торговых организаций ‑ Оторг.,Опосред.,Оторг.-посред.
(характеризует сумму проданных товаров торговыми предприятиями, то есть
отражает движение товарной массы внутри сферы обращения – продолжение процесса
обращения);
‑ сумма всех продаж на пути товара от
производителя до конечного потребителя дает валовой товарооборот
О вал= Опроиз+ Оторг
По роли покупателя ‑ другая классификация:
‑ оптовый товарооборот ‑ когда покупка
осуществляется для перепродажи, то есть купля–продажа товарной массы
осуществляется внутри сферы товарного обращения. Обозначается ‑ Оопт (кроме
того, это ‑ продажа крупными партиями массовому потребителю);
‑ розничный товарооборот ‑ (Орозн.),
когда покупателем является непосредственный, конечный потребитель (население).
Это – конец сферы товарного обращения;
‑ валовой товарооборот – это сумма
оптовых и розничных продаж. Таким образом, имеем:
Овал= Опроиз+ Оторг=
Оопт + Орозн.
В практике торгово-коммерческой деятельности
выделяют еще один вид товарооборота – мелкооптовый. Это – продажа товаров
массовым потребителям, торговым посредникам и отдельным лицам небольшими
партиями. Этот вид продаж занимает промежуточное положение между оптовым и
розничным товарооборотом.
3.
Что такое
коэффициент сбалансированности рынка товаров и услуг?
коэффициент
сбалансированности рынка как
отношение объема розничного товарооборота к объему покупательского спроса.
4.
Что такое
коэффициент эластичности спроса?
коэффициент эластичности спроса это — коэффициент, характеризующий степень
изменения спроса на товары в результате изменения цен. Рассчитывается как
отношение изменения спроса в количестве товара или услуги к изменению в цене в
процентах.
5.
Что относят к
товарным запасам и почему статистика их изучает?
Товарные запасы – это сфера, где
приходится мирится с неподвижностью товарной массы, где возникает
«омертвление» капитала, деньги и товары не оборачиваются, возникают убытки.
Поэтому возникает необходимость тщательного статистического изучения товарных
запасов.
Товарные запасы – это товары:
на складах готовой продукции в промышленности, на складах сферы товарного
обращения (в оптовой и розничной сети), в дороге, товары, сданные в
переработку и ожидающие момента своей продажи. Их существование обусловлено
временем транспортировки до места продажи, комплектацией, накоплением до
необходимого объема, временем разгрузки и погрузки, упаковки и др.
Товарные запасы, выраженные в
денежной форме, включаются в оборотный капитал (оборотные средства) торговли.
6.
Какие
показатели относят к товарным запасам?
Все показатели товарных запасов
разделяются на три группы:
‑ Показатели общего состояния
товарных запасов (характеризуют обеспеченность торговли товарными запасами).
‑ Показатели
товарооборачиваемости (характеризует процесс возобновления товарных запасов).
‑ Показатели динамики товарных
запасов.
К первой группе относят:
1. Показатель запасоемкости: Зе
= Зк / Очист., где Зк – товарный запас на
конец периода, Очист. – чистый товарооборот. Если
запас задан средней величиной, то в числителе ставят его. Для отдельных
предприятий торговли в знаменателе ставят соответствующий вид товарооборота:
валовый, розничный и др. Этот показатель показывает долю запаса в объеме
выручки.
2. Показатель
запасообеспеченности товарооборота: Зоi = Зкi / mi, где mi –
среднесуточный (однодневный) товарооборот: mi = Оi / t , где Оi
‑ товарооборот по i-ому товару, t ‑ число календарных
дней в периоде. Показатель измеряется в днях и показывает, на сколько дней
торговли хватит товарного запаса. В форме этого показателя задается норматив
товарного запаса.
3. Оптимальный размер товарного
запаса (т.е. наиболее экономически обоснованный размер) определяется по формуле
Уилсона:
______
З = √(2ОИ2)
/ И1,
где О ‑
спрос(товарооборот), И ‑ издержки на хранение(И2) и на
транспортировку(И1)
4. Средний размер товарного
запаса исчисляется в зависимости от исходных данных. Так как товарные запасы
подвижны и регистрируются на определенную дату, то формируется моментный ряд
динамики. Тогда средний запас рассчитывается или по средней хронологической,
или как полусумма запаса на начало и конец периода.
7.
Перечислите показатели
товарооборачиваемости
К товарооборачиваемости относят
скорость товарооборота и время обращения:
Скорость товарооборота: сi = Оi / ЗiЭтот
показатель измеряется в числе оборотов или в разах. Т.е. показывает – сколько
раз обновился товарный запас в отчетном периоде по i – му товару при его продаже в объеме – Оi
По множеству товаров исчисляется средняя скорость обращения товарной массы по
торговому предприятию в целом.
Время обращения: вi = Зi / mi То есть это ‑ средний товарный запас за
отчетный период, деленный на однодневный товарооборот – mi того же периода. Показывает – сколько дней прошло с
момента поступления товара до момента его реализации, т.е. за какой период
полностью обновился товарный запас, измеряется в днях. По множеству товаров
исчисляется среднее время обращения.
Между этими двумя показателями
имеется связь: сi вi = t , где t ‑ число календарных дней в
периоде.
8.
Как исчисляется
скорость товарооборота?
Скорость товарооборота: сi = Оi / Зi.Этот
показатель измеряется в числе оборотов или в разах. Т.е. показывает – сколько
раз обновился товарный запас в отчетном периоде по i – му товару при его продаже в объеме – Оi
. По множеству товаров исчисляется средняя скорость обращения товарной массы по
торговому предприятию в целом.
9.
Как исчисляется
время обращения?
Время обращения: вi = Зi / mi.То есть это ‑ средний товарный запас за
отчетный период, деленный на однодневный товарооборот – mi того же периода. Показывает – сколько дней прошло с
момента поступления товара до момента его реализации, т.е. за какой период
полностью обновился товарный запас, измеряется в днях. По множеству товаров
исчисляется среднее время обращения.
10.
Что такое
издержки обращения? Какие показатели относят к издержкам обращения?
Издержки обращения (торговли) –
это расходы, обеспечивающие процесс товарного обращения, т.е. это затраты
производителя или торгового предприятия, связанные со сбытом и реализацией
товаров. Это – текущие затраты доведения товара от производителя до
потребителя. Единовременные авансированные затраты в торговле (с целью прироста
основных фондов торгово-коммерческого предприятия ‑ инвестиции, капвложения) не
включаются в издержки обращения.
К издержкам обращения относят
транспортные расходы, оплату труда, амортизацию основных фондов, ремонт,
аренда, расходы на энергию, топливо, расходы на хранение, упаковку, рекламу и
др. Эти расходы классифицируются по многим признакам и подробно изучаются в
бухучете
Система показателей статистики
издержек торговли включает:
‑ абсолютная сумма издержек
обращения ‑ И, как сумма расходов по отдельным статьям (видам) затрат ‑ иi
И = Σ иi.
‑ структура издержек по статьям
(или видам) затрат
D = иi / Σ иi
Тема№19
Контрольные вопросы
1.
Что такое
«уровень жизни» и какой смысл вкладывается в это понятие?
Уровень жизни населения – это многогранная и
сложная категория, характеризующая реальные социально-экономические условия
жизни людей в сфере потребления. Это ‑ характеристика обеспеченности населения
необходимыми материальными благами и услугами, характеристика их потребления и
степени удовлетворения потребностей населения, т.е. это ‑ совокупность товаров
и услуг, которыми располагает отдельный человек, семья или социальная группа
населения. В широком смысле в понятие уровень жизни включают и условия жизни,
труда, занятости, быта, досуга, здоровья, образования, природную среду и др.
2.
Перечислите
группы показателей уровня жизни.
Выделяют следующие четыре уровня жизни
населения:
1)
достаток (уровень
пользования благами, обеспечивающий всестороннее развитие человека);
2)
нормальный уровень
(уровень рационального потребления благ, который обеспечивает восстановление
физических и интеллектуальных сил человека);
3)
бедность (потребление благ
на границе воспроизводства рабочей силы);
4)
нищета (потребление благ
на уровне поддержания жизнеспособности).
3.
Какие
показатели доходов населения применяются в статистическом анализе уровня жизни?
В статистике уровня жизни выделяются следующие
(основные) блоки показателей: показатели доходов населения, показатели расходов
и потребления населением материальных благ и услуг, показатели денежного
сбережения доходов населения, показатели накопления имущества и обеспеченности
жильем, показатели дифференциации уровня жизни, обобщающие оценки уровня жизни.
Кроме этих (основных) групп, уровень жизни
характеризуется множеством социальных показателей-индикаторов, косвенно
характеризующих другие стороны уровня жизни: культура и образование, здоровье
и охрана окружающей среды, структура потребления, комфорт жилья и многое другое.
4.
Какие
показатели дифференциации доходов Вы знаете?
К показателям дифференциации доходов
относятся: децильный коэффициент дифференциации; коэффициент фондов; кривая
Лоренца и коэффициент Джини; коэффициент контрастов, при их расчете
используются данные о доходах крайних (бедных и богатых) групп населения
(децильный коэффициент, коэффициент фондов, коэффициент контрастов) или
полностью распределение населения по доходам (кривая и коэффициент Лоренца и
коэффициент Джини).
Рассмотрим порядок изучения дифференциации
доходов населения, который включает:
расчет децильного коэффициента дифференциации;
проведение перегруппировки населения по
квинтильным группам;
расчет коэффициента Джини и построение кривой
Лоренца;
проведение перегруппировки населения по
покупательной способности;
построение коэффициента контрастов
5.
Что такое
модальный и медианный доход населения?
Для характеристики распределения населения по
доходу рассчитываются следующие показатели:
‑ Показатель модального дохода, т.е. уровень
дохода, наиболее часто
встречающийся среди населения.
‑ Показатели медианного дохода, т.е. уровень
дохода, находящийся в
середине упорядоченного ранжированного ряда
распределения населения по доходу. Половина населения имеет доход ниже
медианного, а вторая половина – выше.
6.
Чем по существу
различаются показатели доходов и расходов?
Показатели
дохода это ресурсы в денежном и натуральном выражении, которые могут быть
использованы на удовлетворение личных потребностей, налоговые и другие
обязательные и добровольные платежи, сбережения, составляют основу
материального благосостояния населения.
Показатель
расхода отражает количество использованных ресурсов растраченных на: удовлетворение личных
потребностей, налоговые и другие обязательные и добровольные платежи, в денежном
и натуральном выражении.
7.
Что такое
потребительская корзина и прожиточный минимум?
Потребительская корзина (или товарная корзина) ‑ это прожиточный
физиологический минимум, обозначающий стоимостную оценку минимального набора
товаров–представителей (продуктов, услуг) в заданных количествах с учетом
реальных цен. Используется при исчислении индексов цен, индексов стоимости
жизни, дефляторов, а также в международных сопоставлениях. При анализе уровня
жизни используются два вида потребительских корзин:
‑ набор из 19 продуктов питания;
‑ набор из 25 основных продуктов питания.
Первый набор используется для сопоставления
уровня цен на продовольственные товары. Второй – для расчета стоимости
прожиточного минимума (при этом включают дополнительно к 25 товарам еще и
услуги и непродовольственные товары).
Прожиточный минимум – это стоимостная оценка минимального набора продуктов
питания для сохранения здоровья и обеспечения нормальной жизнедеятельности
человека. Она выражает в натуральной и стоимостной формах минимальные
потребности человека в определенном наборе продовольственных и
непродовольственных товаров и услуг.
8.
Обобщенные
оценки уровня жизни ‑ что это такое?
Обобщающие показатели уровня жизни – это основные индикаторы состояния экономики страны
и уровня жизни населения. К ним относятся:
1.
Объем внутреннего валового
продукта (ВВП).
2.
Национальный доход (НД).
3.
Чистый национальный
располагаемый доход (ЧНРД).
4.
Индекс стоимости жизни.
5.
Индекс развития
человеческого потенциала (ИРЧП).
9.
Перечислите и
раскройте известные Вам показатели расходов и потребления?
Показатели расходов и потребления. Потребление – это использование произведенного
продукта для удовлетворения определенных потребностей (это широкое толкование).
Статистика разделяет промежуточное и конечное потребление. Промежуточное
потребление – это стоимость продуктов и услуг, потребленных с целью
производства других продуктов и услуг.
Конечное потребление – это расходы на
собственное потребление населением, т.е. это расходы хозяйственных единиц или
людей на произведенные продукты или услуги для непосредственного удовлетворения
индивидуальных или коллективных потребностей людей.
Показатели потребления следующие:
– уровень индивидуального потребления – это
средний размер потребления определенных товаров и услуг на душу населения.
Рассчитывается как отношение годового объема потребления товаров и услуг по
видам к среднегодовой численности (как в целом по стране, так и по отдельным
признакам ‑ пол, социальная группа, регион);
‑ средний уровень потребления на одно домохозяйство
(по ряду товаров длительного использования, таких как автомобиль, мебель,
сложная аппаратура и т.д.);
‑ по услугам используются показатели:
а) объем платных услуг на одного человека (или
домохозяйство);
б) объем бесплатных услуг на одного человека
(или домохозяйство).
‑ коэффициент удовлетворения потребностей в
i- ом товаре (применяется в отношении отдельных товаров и услуг)
 ,
,
где qср. i факт. ‑
фактическая потребность на душу населения, qср. i норм. –
нормативная потребность i – го товара на одного человека.
‑ при анализе потребления и расходов
населения часто используется коэффициент эластичности потребления при изменении
доходов населения на 1% :
 ,
,
где х – доходы (Dх – прирост доходов); у – потребление (Dу –
прирост потребления).
В статистике потребления существует понятие
«потребительский бюджет» (минимальный и рациональный) – как социальный
норматив.
Минимальный потребительский бюджет – это
минимальный уровень потребления товаров и услуг, обеспечивающий удовлетворение
потребностей человека (т.е. разработан некоторый стандарт допустимого
минимального потребления).
Рациональный потребительский бюджет – это
такой уровень потребления товаров и услуг, который обеспечивает домохозяйства
предметами культурно-бытового и хозяйственного назначения в соответствии с
научно-обоснованными нормами и нормативами удовлетворения рациональных
потребностей человека. Это тоже некий социальный норматив (например:
рациональная структура потребления: продовольственное питание ‑ 30%,
непродовольственные товары – 47%, мебель – 18%, услуги – 9% и т.д.).
Натурально-вещественный состав
потребительского бюджета представляется потребительской корзиной.
10.
Что показывает
кривая и коэффициент Лоренца?
При анализе неравенства населения по доходам
широко используется так называемая кривая Лоренца (см. рис.) и соответствующий
ей![]() коэффициент:
коэффициент:

1
‑ Линия равномерного распределения
доходов, т.е. абсолютное равенство групп населения по доходам.
2 ‑ Фактическая линия распределения доходов
(кривая Лоренца).
3 ‑ Линия абсолютного неравенства доходов.
(Закрашенная часть – это есть область
отклонений реальных доходов от их равномерного распределения).
Коэффициент исчисляется так:
![]() ,
,
где ![]() ‑ доля
‑ доля
доходов у ![]() — ой социальной группы
— ой социальной группы
населения, ![]() ‑ доля численности
‑ доля численности
населения в ![]() — ой социальной группе населения
— ой социальной группе населения
, ![]() ‑ число социальных групп населения.
‑ число социальных групп населения. ![]() 1 при полном неравенстве доходов.
1 при полном неравенстве доходов.
Коэффициент концентрации доходов Джинни (Кa) также характеризует
степень неравенства в распределении доходов
населения.
Рассчитывается по формуле:
Кa = S рi
* qi + 1 — S pi + 1 * qi,
где рi – доля населения с
доходом не выше чем его максимальный уровень в i—
ой группе населения, qi – доля доходов i—
ой группы населения в общей сумме доходов, исчисляется нарастающим итогом для
показателя денежного дохода.
Коэффициент Джинни изменяется от 0 до 1. Чем
ближе этот коэффициент к единице, тем неравномернее сконцентрированы доходы в
руках отдельных групп населения. Этот коэффициент тесно связан с кривой
Лоренца. В России рассчитывается с 1992 года и имеет общую тенденцию к росту.
Тема №20
Контрольные вопросы
1.
В чем
заключается суть и основное назначение СНС? Ее связь и отличие от
бухгалтерского учета.
В современной экономике предприятия выполняют
множество операций. Например, промышленная фирма закупает сырье, материалы,
топливо и др., производит разнообразные товары и услуги, продает их, при этом
берет деньги у других фирм, одновременно возвращает ранее взятые ссуды,
распределяет доходы, выплачивает заработную плату, инвестирует сама кого-то и
т.д. и т.п. При взгляде с макроуровня на все это множество операций, которые
одновременно выполняются тысячами и миллионами субъектов рынка (т.е.
юридическими и физическими лицами) возникает впечатление хаотического
нагромождения всевозможных потоков ресурсов и операций, разобраться в которых
невозможно. Так оно и есть, если учесть, что все процессы и условия
хозяйственной деятельности еще изменяются и во времени. Для того чтобы
разобраться во всем этом, подвергнуть общую экономическую ситуацию в стране
анализу, выявить общие тенденции и закономерности необходимо упорядочить всю
информацию о субъектах рынка, об операциях, о ресурсах и результатах, об
условиях деятельности и о динамике всей этой информации.
Общая идея и назначение СНС в том, чтобы
упорядочить абсолютно всю необходимую информацию и показать, насколько и за
счет чего изменилась стоимость экономических активов страны в целом (и по
отдельным секторам экономики) за исследуемый период. Достигается это путем построения
специальных счетов и балансовых таблиц, в которых отражается полный набор
экономических операций по воспроизводственному циклу: производство;
образование, распределение, использование доходов; инвестиции; финансы;
взаимоотношения с другими государствами. В СНС отражается сквозное движение
стоимости через все эти стадии. Полный набор экономических операций по
воспроизводственному циклу включает: производственные, распределительные,
обменные операции, а также операции потребления, сбережения, накопления.
2.
Какие основные
принципы построения СНС?
Общие принципы построения СНС:
‑ принцип двойной записи, т.е. каждая операция
записывается дважды: в разделе «использование» предыдущего счета, и в разделе
«ресурсы» последующего счета;
‑ принцип балансового равенства, т.е. увязки и
хозяйственного кругооборота ресурсов и результатов по замкнутой системе;
‑ принцип четкого отграничения границ
экономического производства, т.е. где производится ВВП и национальный доход
(охватывается практически все сферы производства товаров и услуг, за
исключением домашних услуг домохозяйками для собственного потребления внутри
семьи – приготовление пищи, воспитание детей…);
‑ принцип исчисления дохода, по концепции Дж.
Хикса, доход – это максимальная сумма денег, которую можно использовать
на потребление, не уменьшая своего накопленного богатства (капитала) и не
принимая на себя финансовых обязательств (долгов);
‑ принцип единых рыночных цен: т.е.
регистрация сделок и их учет в счетах СНС по единым ценам;
‑ принцип группировки всех хозяйствующих
субъектов рынка на секторы экономики, т.е. на так называемые институциональные
сектора – однородные группы предприятий (всего их пять):
·
нефинансовые корпорации
(производство и реализация товаров и услуг по ценам возмещения издержек
производства, т.е. промышленные фирмы);
·
финансовые корпорации (аккумулирующие
свободные денежные средства и инвестиции – банки, кредитные, страховые
учреждения…);
·
государственное управление
(основная функция: перераспределение национального дохода, бесплатные услуги –
оборона, управление, наука…);
·
сектор домохозяйств (производство,
продажа рабочей силы, приобретение товаров и услуг, собственники мелких
некорпорированных предприятий – фирмы, магазины. Производит товары и услуги
как на рынок, так и для собственного потребления). Финансовый результат –
смешанный доход, т.к. для домохозяйств трудно отделить прибыль и оплату труда,
доходы и расходы собственников и некорпорированных предприятий;
·
некоммерческие
организации, обслуживающие домохозяйства (общественные, политические,
религиозные); оказывают бесплатные услуги членам этих организаций.
3.
Перечислите
основные счета СНС.
СНС включает следующие счета:
·
консолидированные счета
для экономики в целом
·
секторные счета для групп
однородных единиц (например, финансовые корпорации, промышленные предприятия,
домашние хозяйства);
счета для отраслей экономики (показывают
отраслевую структуру ВВП), (сельское хозяйство, строительство, транспорт).
4.
Каким образом в
СНС обеспечивается учет хозяйственного кругооборота ресурсов и результатов
деятельности субъектов рынка?
Общая идея и назначение СНС в том, чтобы
упорядочить абсолютно всю необходимую информацию и показать, насколько и за
счет чего изменилась стоимость экономических активов страны в целом (и по
отдельным секторам экономики) за исследуемый период. Достигается это путем
построения специальных счетов и балансовых таблиц, в которых отражается полный
набор экономических операций по воспроизводственному циклу: производство;
образование, распределение, использование доходов; инвестиции; финансы;
взаимоотношения с другими государствами. В СНС отражается сквозное движение
стоимости через все эти стадии. Полный набор экономических операций по
воспроизводственному циклу включает: производственные, распределительные,
обменные операции, а также операции потребления, сбережения, накопления.
В национальных счетах получают количественную
характеристику все хозяйственные единицы – производители, финансовые
учреждения, страховые компании, органы государственного управления, домашние
хозяйства, частные некоммерческие организации СНС охватывает не только
материальное производство, но и услуги материального и нематериального
характера, финансовые потоки, движение ресурсов…
Таким образом, СНС – это всеобъемлющая система
взаимно согласованных показателей, которая охватывает и упорядочивает информацию
абсолютно по всем аспектам и фазам экономического процесса, все экономические
операции всех экономических субъектов, все активы и пассивы
5.
Назовите
сектора национальной экономики, используемые в СНС.
Современная СНС предполагает счета и
показатели не только для экономики в целом, но и для ее секторов:
§
нефинансовые
корпорации и предприятия;
§
финансовые
корпорации;
§
органы
государственного управления;
§
домашние
хозяйства;
§
частные некоммерческие
учреждения, обслуживающие домашние хозяйства.
6.
В чем сущность
ВДС? Методы ее исчисления?
ВАЛОВАЯ ДОБАВЛЕННАЯ СТОИМОСТЬ — разность между
выпуском товаров и промежуточным потреблением, обычно определяется в ценах
производителей.
Добавленная стоимость — в экономической
теории — стоимость проданного фирмой продукта минус стоимость материалов,
купленных и использованных фирмой для его производства. Добавленная стоимость
равна выручке, которая включает в себя эквиваленты заработной платы, арендной
платы, процентов и прибыли.
7.
Что
представляет собой ВВП и какими методами он исчисляется?
ВВП – основной показатель макроэкономического
анализа экономики и СНС – это рыночная стоимость всех товаров и услуг,
произведенных резидентами в рыночных ценах, т.е. стоимость конечных товаров и
услуг без стоимости промежуточных товаров и услуг, использованных при
производстве. ВВП применяется во всем мире для определения темпов развития
экономики, цикличных колебаний экономической активности, изучения структуры
производства, производительности труда и уровня жизни населения, а также для
международных сопоставлений разных стран. При исчислении ВВП используется три
метода:
1.
Производственный метод (на
стадии производства) – это сумма ВДС отраслей и секторов экономики:
ВВП = ∑ВДС + Н – С, где
Н – сумма всех налогов на продукты и импорт
С – сумма всех субсидий на продукты и импорт
или
ВВП = В – ПП + Н – С, где
В – выпуск товаров и услуг по экономике в
целом
ПП – промежуточное потребление.
2. Распределительный метод (на стадии
распределения) – это сумма первичных доходов, распределенных резидентами между
непосредственными участниками производственного процесса, т.е. оплата труда
наемных работников резидентов и нерезидентов, чистых налогов на производство и
на импорт, валовой прибыли:
ВВП = ОТ + ЧН + ЧНИ + ВП + ВСД, где
ОТ – оплата труда; ЧН – чистые налоги на
производство; ЧНИ – чистые налоги на импорт; ВП – валовая прибыль; ВСД –
валовые смешанные доходы
Метод используется для анализа распределения
ВДС, структуры доходов, доли первичных доходов в ВВП.
3. Метод конечного использования доходов (на
стадии конечного использования доходов). ВВП рассчитывается как сумма конечного
потребления товаров и услуг (КП) и валового накопления (ВН) с учетом сальдо
экспорта и импорта товаров и услуг (Э – И):
ВВП = КП + ВН + (Э – И), т.е.
это расчет суммы расходов на приобретение
товаров и услуг на конечное использование (потребление и накопление). Метод
используется для анализа пропорций в ВВП и доли национального богатства страны.
8.
Как измеряются
основные показатели СНС на валовой и чистой основе?
Главные показатели СНС. В
рамках системы СНС исчисляются следующие наиболее важные показатели:
валовой внутренний продукт (ВВП) – измеряет в
рыночных ценах стоимость конечных товаров и услуг, произведенных экономическими
единицами, т.е. предприятиями, финансовыми учреждениями, мелкими
некоммерческими организациями, органами государственного управления, частными
некоммерческими организациями и т.п., на экономической территории данной страны
в течение года и более. Формируется в счете производства как разность между
выпуском товаров и услуг и промежуточным потреблением, т.е. стоимостью
потребленных товаров, но с включением потребления основного капитала. Является
балансирующей статьей и называется валовой добавленной стоимостью (ВДС) в
секторальных счетах производства, в консолидированном счете производства – ВВП.
Может исчисляться как на валовой, так и на чистой основе (т.е. без учета
потребления основного капитала (ПОК)).
Валовая прибыль (ВП) – это часть ВДС, которая
остается у производителей после оплаты труда наемных работников и вычета чистых
налогов на производство и импорт (чистые – это значит без выплаченных субсидий;
субсидии – это отрицательные налоги – в основном из бюджета на производство
отдельных товаров – например, детское питание, жилье). Валовая прибыль
образуется как балансирующая статья счета образования доходов. У отдельных
секторов называется валовым смешанным доходом (сектор домохозяйств). ВСД на
чистой основе (т.е. за вычетом ПОК) – это чистая прибыль (ЧП) или чистый
смешанный доход (ЧСД).
Валовой национальный доход (ВНД) – это ВВП
плюс оплата труда наемных работников, доходы от собственности, чистые налоги на
производство (т.е. без субсидий) и минус доходы от собственности, выплаченные «остальному
миру», т.е. это все первичные доходы, полученные резидентами данной страны. ВНД
больше ВВП на сальдо первичных доходов, полученных резидентами от нерезидентов
ПД): т.е. ВНД = ВВП + ПД. Является балансирующей статьей счета распределения
первичных доходов. Называется – сальдо первичных доходов или ВНД. Исчисляется
также на чистой основе, т.е. без ПОК и называется чистый национальный доход
(ЧНД): ЧНД = ВНД – ПОК.
Валовой национальный располагаемый доход
(ВНРД) это есть сальдо первичных доходов, т.е. ВНД плюс разность между
выплаченными и полученными сектором и экономикой в целом трансфертами: текущие
налоги, отчисления на социальное страхование, социальные пособия, другие
трансферты (гуманитарная помощь, пожертвования и другое). ВНРД – это та сумма
доходов, которая может быть использованы институциональными единицами на
конечное потребление и накопление без изменения суммы накопленных активов. На
чистой основе – ЧНРД = ВНРД – ПОК. ВНРД является балансирующей статьей счета
вторичного распределения доходов и полностью переходит в раздел «ресурсы» счета
использования ВНРД.
Валовое национальное сбережение (ВНС) – это
часть располагаемого дохода, не израсходованная на конечное потребление товаров
и услуг, т.е. разность ВНРД и расходов на конечное потребление. Для отдельных
секторов называется валовым сбережением (ВС). На чистой основе ЧНС = ВНС – ПОК.
ВНС является балансирующей статьей счета использования ВНРД. В секторах – это у
домохозяйств, государственных учреждений, некоммерческих организаций. ВНС
переносится в раздел «ресурсы» счета операций с капиталом. Валовое сбережение
является источником валового накопления, которое выступает важным показателем
СНС, хотя и не является балансирующей статьей какого- либо счета.
Валовое накопление – это есть накопленный
основной капитал, изменение запасов оборотных средств и чистое приобретение
ценностей (ЧПЦ) (антиквариат, ювелирные изделия), т.е. это вложение резидентами
средств в объекты основного капитала для перспективы их использования в
производстве:
ВН = ВНОК + МОС + ЧПЦ.
Балансирующей статьей счета операций с
капиталом является ‑ чистое кредитование (+) чистое заимствование (-) –
показывает какая часть ВРНД не была истрачена ни на потребление, ни на
накопление, а осталась в виде финансовых активов. Отрицательная величина (заимствование
(-)) говорит о том, что субъект (сектор, институциональная единица, отрасль,
экономика в целом) взяли на себя новые финансовые обязательства. Эта
балансирующая статья полностью переходит в раздел «ресурсы» финансового счета.
Этот счет показывает в разделе «использование» конкретные виды финансовых активов
(деньги, золото, депозиты). Балансирующая статья этого счета та же самая
«чистое кредитование (+) / чистое заимствование (-)». Таким образом,
фактическое изменение финансовых активов (обязательств) сбалансируется с итогом
хозяйственной деятельности секторов, единиц отраслей и экономики в целом.
9.
В чем отличие
реального ВВП от номинального?
Номинальный ВВП – это ВВП, рассчитанный в текущих ценах, в ценах
данного года. На величину номинального ВВП оказывают влияние два фактора: 1)
изменение реального объема производства 2) изменение уровня цен. Чтобы измерить
реальный ВВП, необходимо «очистить» номинальный ВНП от воздействия на него
изменения уровня цен. Реальный ВВП – это ВВП, измеренный в сопоставимых
(неизменных) ценах, в ценах базового года. При этом, базовым годом может быть
выбран любой год, хронологически как раньше, так и позже текущего. Последнее
используется для исторических сравнений (например, для расчета реального ВВП
1980 года в ценах 1999 года. В этом случае 1999 год будет базовым, а 1980 год –
текущим).
10.
На основе,
каких методов изучается динамика ВВП?
Валовой внутренний продукт исчисляется тремя методами:
как сумма валовой добавленной стоимости (производственный метод)
как сумма компонентов конечного использования (метод конечного
использования)
как сумма первичных доходов (распределительный метод)
В основе расчёта ВВП производственным способом лежит такой
микроэкономический показатель, как валовой выпуск. Представляет собой стоимость
товаров и услуг, произведённых хозяйственными единицами — резидентами — за
определённый период. Сюда относят производство промышленной и
сельскохозяйственной продукции в стоимостном выражении, перевозку грузов,
стоимость строительно-монтажных работ, производство других отраслей. В
стоимость услуг включают услуги оптовой и розничной торговли, материально —
технического снабжения и заготовок, услуги связи, здравоохранение, культуры
науки, общественных организаций, услуги органов государственного управления,
обороны, финансовых учреждений, пенсионное обеспечение, услуги различных
организаций по обслуживанию предприятий и учреждений. В объём валового выпуска
также включается некоторые категории произведённых, но реализованных благ.
29 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
Важным этапом прогнозирования
социально-экономических явлений
является оценка точности и надежности
прогнозов.
Эмпирической мерой точности прогноза,
служит величина его ошибки, которая
определяется как разность между
прогнозными (![]() )
)
и фактическими (уt)
значениями исследуемого показателя.
Данный подход возможен только в двух
случаях:
а) период упреждения известен, уже
закончился и исследователь располагает
необходимыми фактическими значениями
прогнозируемого показателя;
б) строится ретроспективный прогноз,
то есть рассчитываются прогнозные
значения показателя для периода времени
за который уже имеются фактические
значения. Это делается с целью проверки
разработанной методики прогнозирования.
В данном случае вся имеющаяся информация
делится на две части в соотношении 2/3
к 1/3. Одна часть информации (первые 2/3
от исходного временного ряда) служит
для оценивания параметров модели
прогноза. Вторая часть информации
(последняя 1/3 части исходного ряда)
служит для реализации оценок прогноза.
Полученные, таким образом, ретроспективно
ошибки прогноза в некоторой степени
характеризуют точность предлагаемой
и реализуемой методики прогнозирования.
Однако величина ошибки ретроспективного
прогноза не может в полной мере и
окончательно характеризовать используемый
метод прогнозирования, так как она
рассчитана только для 2/3 имеющихся
данных, а не по всему временному ряду.
В случае если, ретроспективное
прогнозирование осуществлять по связным
и многомерным динамическим рядам, то
точность прогноза, соответственно,
будет зависеть от точности определения
значений факторных признаков, включенных
в многофакторную динамическую модель,
на всем периоде упреждения. При этом,
возможны следующие подходы к
прогнозированию по связным временным
рядам: можно использовать как фактические,
так и прогнозные значения признаков.
Все показатели оценки точности
статистических прогнозов условно можно
разделить на три группы:
-
аналитические;
-
сравнительные;
-
качественные.
Аналитические показатели точности
прогноза позволяют количественно
определить величину ошибки прогноза.
К ним относятся следующие показатели
точности прогноза:
Абсолютная ошибка прогноза (D*)
определяется как разность между
эмпирическим и прогнозным значениями
признака и вычисляется по формуле:
![]() , (16.1)
, (16.1)
где уt– фактическое
значение признака;
![]() —
—
прогнозное значение признака.
Относительная ошибка прогноза (d*отн)
может быть определена как отношение
абсолютной ошибки прогноза (D*):
-
к
фактическому значению признака (уt):
(16.2)
— к прогнозному
значению признака (![]() )
)
(16.3)
Абсолютная и относительная ошибки
прогноза являются оценкой проверки
точности единичного прогноза, что
снижает их значимость в оценке точности
всей прогнозной модели, так как на
изучаемое социально-экономическое
явление подвержено влиянию различных
факторов внешнего и внутреннего
свойства. Единично удовлетворительный
прогноз может быть получен и на базе
реализации слабо обусловленной и
недостаточно адекватной прогнозной
модели и наоборот – можно получить
большую ошибку прогноза по достаточно
хорошо аппроксимирующей модели.
Поэтому на практике иногда определяют
не ошибку прогноза, а некоторый
коэффициент качества прогноза (Кк),
который показывает соотношение между
числом совпавших (с) и общим числом
совпавших (с) и несовпавших (н) прогнозов
и определяется по формуле:
![]() (16.4)
(16.4)
Значение Кк= 1 означает, что имеет
место полное совпадение значений
прогнозных и фактических значений и
модель на 100% описывает изучаемое
явление. Данный показатель оценивает
удовлетворительный вес совпавших
прогнозных значений в целом по временному
ряду и изменяющегося в пределах от 0 до
1.
Следовательно, оценку точности получаемых
прогнозных моделей целесообразно
проводить по совокупности сопоставлений
прогнозных и фактических значений
изучаемых признаков.
Средним показателем точности прогноза
является средняя абсолютная ошибка
прогноза (![]() ),
),
которая определяется как средняя
арифметическая простая из абсолютных
ошибок прогноза по формуле вида:
, (16.5)
де n– длина временного
ряда.
Средняя абсолютная ошибка прогноза
показывает обобщенную характеристику
степени отклонения фактических и
прогнозных значений признака и имеет
ту же размерность, что и размерность
изучаемого признака.
Для оценки точности прогноза используется
средняя квадратическая ошибка прогноза,
определяемая по формуле:
(16.6)
Размерность средней квадратической
ошибки прогноза также соответствует
размерности изучаемого признака. Между
средней абсолютной и средней квадратической
ошибками прогноза существует следующее
примерное соотношение:
![]() (16.7)
(16.7)
Недостатками средней абсолютной и
средней квадратической ошибками
прогноза является их существенная
зависимость от масштаба измерения
уровней изучаемых социально-экономических
явлений.
Поэтому на практике в качестве
характеристики точности прогноза
определяют среднюю ошибку аппроксимации,
которая выражается в процентах
относительно фактических значений
признака, и определяется по формуле
вида:
![]() (16.8)
(16.8)
Данный показатель является относительным
показателем точности прогноза и не
отражает размерность изучаемых
признаков, выражается в процентах и на
практике используется для сравнения
точности прогнозов полученных как по
различным моделям, так и по различным
объектам. Интерпретация оценки точности
прогноза на основе данного показателя
представлена в следующей таблице:
-
,%
Интерпретация
точности< 10
10 – 20
20 – 50
> 50
Высокая
Хорошая
Удовлетворительная
Не удовлетворительная
В качестве сравнительного показателя
точности прогноза используется
коэффициент корреляции между прогнозными
и фактическими значениями признака,
который определяется по формуле:
, (16.9)
где
![]() —
—
средний уровень ряда динамики прогнозных
оценок.
Используя данный коэффициент в оценке
точности прогноза следует помнить, что
коэффициент парной корреляции в силу
своей сущности отражает линейное
соотношение коррелируемых величин и
характеризует лишь взаимосвязь между
временным рядом фактических значений
и рядом прогнозных значений признаков.
И даже если коэффициент корреляции R= 1, то это еще не предполагает полного
совпадения фактических и прогнозных
оценок, а свидетельствует лишь о наличии
линейной зависимости между временными
рядами прогнозных и фактических значений
признака.
Одним из показателей оценки точности
статистических прогнозов является
коэффициент несоответствия (КН), который
был предложен Г. Тейлом и может
рассчитываться в различных модификациях:
-
Коэффициент несоответствия (КН1),
определяемый как отношение средней
квадратической ошибки к квадрату
фактических значений признака:
(16.10)
КН = о, если
,
то есть полное совпадение фактических
и прогнозных значений признака.
КН = 1, если при прогнозировании получают
среднюю квадратическую ошибку адекватную
по величине ошибке, полученной одним
из простейших методов экстраполяции
неизменности абсолютных цепных
приростов.
КН > 1, когда прогноз дает худшие
результаты, чем предположение о
неизменности исследуемого явления.
Верхней границы коэффициент несоответствия
не имеет.
2.Коэффициент несоответствия КН2определяется как отношение средней
квадратической ошибки прогноза к сумме
квадратов
отклонений
фактических значений признака от
среднего уровня исходного временного
ряда за весь рассматриваемый период:
, (16.11)
где ![]() — средний уровень исходного ряда
— средний уровень исходного ряда
динамики.
Если КН > 1, то прогноз на уровне среднего
значения признака дал бы лучший
результат, чем имеющийся прогноз.
3.Коэффициент несоответствия (КН3),
определяемый как отношение средней
квадратической ошибке прогноза к сумме
квадратов отклонений фактических
значений признака от теоретических,
выравненных по уравнению тренда:
, (16.12)
где ![]() — теоретические уровни временного ряда,
— теоретические уровни временного ряда,
полученные по
модели тренда.
Если КН > 1, то прогноз методом
экстраполяции тренда дает хороший
результат.
1. Статистика как наука изучает:
а) единичные явления;
б) массовые явления;
в) периодические события.
2. Термин «статистика» происходит от слова:
а) статика;
б) статный;
в) статус.
3. Статистика зародилась и оформилась как самостоятельная учебная дисциплина:
а) до новой эры, в Китае и Древнем Риме;
б) в 17-18 веках, в Европе;
в) в 20 веке, в России.
4. Статистика изучает явления и процессы посредством изучения:
а) определенной информации;
б) статистических показателей;
в) признаков различных явлений.
5. Статистическая совокупность – это:
а) множество изучаемых разнородных объектов;
б) множество единиц изучаемого явления;
в) группа зафиксированных случайных событий.
6. Основными задачами статистики на современном этапе являются:
а) исследование преобразований экономических и социальных процессов в обществе; б) анализ и прогнозирование тенденций развития экономики; в) регламентация и планирование хозяйственных процессов;
а) а, в
б) а, б
в) б, в
7. Статистический показатель дает оценку свойства изучаемого явления:
а) количественную;
б) качественную;
в) количественную и качественную.
8. Основные стадии экономико-статистического исследования включают: а) сбор первичных данных, б) статистическая сводка и группировка данных, в) контроль и управление объектами статистического изучения, г) анализ статистических данных
а) а, б, в
б) а, в, г
в) а ,б, г
г) б, в, г
9. Закон больших чисел утверждает, что:
а) чем больше единиц охвачено статистическим наблюдением,тем лучше проявляется общая закономерность;
б) чем больше единиц охвачено статистическим наблюдением, тем хуже проявляется общая закономерность;
в) чем меньше единиц охвачено статистическим наблюдением, тем лучше проявляется общая закономерность.
10. Современная организация статистики включает: а) в России — Росстат РФ и его территориальные органы, б) в СНГ — Статистический комитет СНГ, в) в ООН — Статистическая комиссия и статистическое бюро, г) научные исследования в области теории и методологии статистики
а) а, б, г
б) а, б, в
в) а, в, г
1. Статистическое наблюдение – это:
а) научная организация регистрации информации;
б) оценка и регистрация признаков изучаемой совокупности;
в) работа по сбору массовых первичных данных;
г) обширная программа статистических исследований.
2. Назовите основные организационные формы статистического наблюдения:
а) перепись и отчетность;
в) разовое наблюдение;
г) опрос.
3. Перечень показателей (вопросов) статистического наблюдения, цель, метод, вид, единица наблюдения, объект, период статистического наблюдения излагаются:
а) в инструкции по проведению статистического наблюдения;
б) в формуляре статистического наблюдения;
в) в программе статистического наблюдения.
4. Назовите виды статистического наблюдения по степени охвата единиц совокупности:
а) анкета;
б) непосредственное;
в) сплошное;
г) текущее.
5. Назовите виды статистического наблюдения по времени регистрации:
а) текущее, б) единовременное; в) выборочное; г) периодическое; д) сплошное
а) а, в, д
б) а, б, г
в) б, г, д
6. Назовите основные виды ошибок регистрации: а) случайные; б) систематические; в) ошибки репрезентативности; г) расчетные
а) а
б) а, б
в) а, б, в,
г) а, б, в, г
7. Несплошное статистическое наблюдение имеет виды: а) выборочное;
б) монографическое; в) метод основного массива; г) ведомственная отчетность
а) а, б, в
б) а, б, г
в) б, в, г
8. Организационный план статистического наблюдения регламентирует: а) время и сроки наблюдения; б) подготовительные мероприятия;
в) прием, сдачу и оформление результатов наблюдения; г) методы обработки данных
а) а, б, г
б) а, б, в
9. Является ли статистическим наблюдением наблюдения покупателя за качеством товаров или изменением цен на городских рынках?
а) да
б) нет
10. Ошибка репрезентативности относится к:
а) сплошному наблюдению;
б) не сплошному выборочному наблюдению.
1. Статистическая сводка — это:
а) систематизация и подсчет итогов зарегистрированных фактов и данных;
б) форма представления и развития изучаемых явлений;
в) анализ и прогноз зарегистрированных данных.
2. Статистическая группировка — это:
а) объединение данных в группы по времени регистрации;
б) расчленение изучаемой совокупности на группы по существенным признакам;
в) образование групп зарегистрированной информации по мере ее поступления.
3. Статистические группировки могут быть: а) типологическими; б) структурными; в) аналитическими; г) комбинированными
а) а
б) а, б
в) а, б, в
г) а, б, в, г
4. Группировочные признаки, которыми одни единицы совокупности обладают, а другие — нет, классифицируются как:
а) факторные;
б) атрибутивные;
в) альтернативные.
5. К каким группировочным признакам относятся: образование сотрудников, профессия бухгалтера, семейное положение:
а) к атрибутивным;
б) к количественны.
6. Ряд распределения — это:
а) упорядоченное расположение единиц изучаемой совокупности по группам;
б) ряд значений показателя, расположенных по каким-то правилам.
7. К каким группировочным признакам относятся: сумма издержек обращения, объем продаж, стоимость основных фондов
а) к дискретным;
б) к непрерывным.
8. Какие виды статистических таблиц встречаются:
а) простые и комбинационные;
б) линейные и нелинейные.
1. Статистический показатель — это
а) размер изучаемого явления в натуральных единицах измерения
б) количественная характеристика свойств в единстве с их качественной определенностью
в) результат измерения свойств изучаемого объекта
2. Статистические показатели могут характеризовать:
а) объемы изучаемых процессов
б) уровни развития изучаемых явлений
в) соотношение между элементами явлений
г) а, б, в
3. По способу выражения абсолютные статистические показатели подразделяются на: а) суммарные; б) индивидуальные; в) относительные; г) средние; д) структурные
а) а, д
б) б, в
в) в, г
г) а, б
4. В каких единицах выражаются абсолютные статистические показатели?
а) в коэффициентах
б) в натуральных
в) в трудовых
5. В каких единицах будет выражаться относительный показатель, если база сравнения принимается за единицу?
а) в процентах
б) в натуральных
в) в коэффициентах
6. Относительные показатели динамики с переменной базой сравнения подразделяются на:
а) цепные
б) базисные
7. Сумма всех удельных весов показателя структуры
а) строго равна 1
б) больше или равна 1
в) меньше или равна 1
8. Относительные показатели по своему познавательному значению подразделяются на показатели: а) выполнения и сравнения, б) структуры и динамики, в) интенсивности и координации, г) прогнозирования и экстраполяции
а) а, б, г
б) б, в, г
в) а, б, в
9. Статистические показатели по сущности изучаемых явлений могут быть:
а) качественными
б) объёмными
в) а, б
10. Статистические показатели в зависимости от характера изучаемых явлений могут быть:
а) интервальными
б) моментными
в) а, б
1. Исчисление средних величин — это
а) способ изучения структуры однородных элементов совокупности
б) прием обобщения индивидуальных значений показателя
в) метод анализа факторов
2. Требуется вычислить средний стаж деятельности работников фирмы: 6,5,4,6,3,1,4,5,4,5. Какую формулу Вы примените?
а) средняя арифметическая
б) средняя арифметическая взвешенная
в) средняя гармоническая
3. Средняя геометрическая — это:
а) корень из произведения индивидуальных показателей
б) произведение корней из индивидуальных показателей
4. По какой формуле производится вычисление средней величины в интервальном ряду?
а) средняя арифметическая взвешенная
б) средняя гармоническая взвешенная
5. Могут ли взвешенные и невзвешенные средние, рассчитанные по одним и тем же данным, совпадать?
а) да
б) нет
6. Как изменяется средняя арифметическая, если все веса уменьшить в А раз?
а) уменьшатся
б) увеличится
в) не изменится
7. Как изменится средняя арифметическая, если все значения определенного признака увеличить на число А?
а) уменьшится
б) увеличится
в) не изменится
8. Значения признака, повторяющиеся с наибольшей частотой, называется
а) модой
б) медианой
9. Средняя хронологическая исчисляется
а) в моментных рядах динамики с равными интервалами
б) в интервальных рядах динамики с равными интервалами
в) в интервальных рядах динамики с неравными интервалами
10. Медиана в ряду распределения с четным числом членов ряда равна
а) полусумме двух крайних членов
б) полусумме двух срединных членов
1. Что понимается в статистике под термином «вариация показателя»?
а) изменение величины показателя
б) изменение названия показателя
в) изменение размерности показателя
2. Укажите показатели вариации
а) мода и медиана
б) сигма и дисперсия
в) темп роста и прироста
3. Показатель дисперсии — это:
а) квадрат среднего отклонения
б) средний квадрат отклонений
в) отклонение среднего квадрата
4. Коэффициент вариации измеряет колеблемость признака
а) в относительном выражении
б) в абсолютном выражении
5. Среднеквадратическое отклонение характеризует
а) взаимосвязь данных
б) разброс данных
в) динамику данных
6. Размах вариации исчисляется как
а) разность между максимальным и минимальным значением показателя
б) разность между первым и последним членом ряда распределения
7. Показатели вариации могут быть
а) простыми и взвешенными
б) абсолютными и относительными
в) а) и б)
8. Закон сложения дисперсий характеризует
а) разброс сгруппированных данных
б) разброс неупорядоченных данных
9. Средне квадратическое отклонение исчисляется как
а) корень квадратный из медианы
б) корень квадратный из коэффициента вариации
в) корень квадратный из дисперсии
10. Кривая закона распределения характеризует
а) разброс данных в зависимости от уровня показателя
б) разброс данных в зависимости от времени
1. Выборочный метод в статистических исследованиях используется для:
а) экономии времени и снижения затрат на проведение статистического исследования;
б) повышения точности прогноза;
в) анализа факторов взаимосвязи.
2. Выборочный метод в торговле используется:
а) при анализе ритмичности оптовых поставок;
б) при прогнозировании товарооборота;
в) при разрушающих методах контроля качества товаров.
3. Ошибка репрезентативности обусловлена:
а) самим методом выборочного исследования;
б) большой погрешностью зарегистрированных данных.
4. Коэффициент доверия в выборочном методе может принимать значения:
а) 1, 2, 3;
б) 4, 5, 6;
в) 7, 8, 9.
5. Выборка может быть: а) случайная, б) механическая, в) типическая, серийная, д) техническая
а) а, б, в, г,
б) а, б, в, д
в) б, в, г, д
6. Необходимая численность выборочной совокупности определяется:
а) колеблемостью признака;
б) условиями формирования выборочной совокупности;
7. Выборочная совокупность отличается от генеральной:
а) разными единицами измерения наблюдаемых объектов;
б) разным объемом единиц непосредственного наблюдения;
в) разным числом зарегистрированных наблюдений.
8. Средняя ошибка выборки:
а) прямо пропорциональна рассеяности данных;
б) обратно пропорциональна разбросу варьирующего признака;
в) никак не зависит от колеблемости данных;
9. Повторный отбор отличается от бесповторного тем, что:
а) отбор повторяется, если в процессе выборки произошел сбой;
б) отобранная однажды единица наблюдения возвращается в генеральную совокупность;
в) повторяется несколько раз расчет средней ошибки выборки.
10. Малая выборка — это выборка объемом:
а) 4-5 единиц изучаемой совокупности;
б) до 50 единиц изучаемой совокупности;
в) до 30 единиц изучаемой совокупности.
1. Ряд динамики характеризует: а) структуру совокупности по какому-то признаку; б) изменение характеристик совокупности во времени; в) определенное значение признака в совокупности; г) величину показателя на определенную дату или за определенный период
а) а, б
б) б, г
в) б, в
2. Ряд динамики может состоять: а) из абсолютных суммарных величин; б) из относительных и средних величин;
а) а
б) б
в) а, б
3. Ряд динамики, характеризующий уровень развития социально-экономического явления на определенные даты времени, называется:
а) интервальным;
б) моментным.
4. Средний уровень интервального ряда динамики определяется как:
а) средняя арифметическая;
б) средняя хронологическая.
5. Средний уровень моментного ряда динамики исчисляется как: а) средняя арифметическая взвешенная при равных интервалах между датами; б) при неравных интервалах между датами как средняя хронологическая, в) при равных интервалах между датами как средняя хронологическая;
а) а
б) б
в) б, в
6. Абсолютный прирост исчисляется как: а) отношение уровней ряда; б) разность уровней ряда. Темп роста исчисляется как: в) отношение уровней ряда; г) разность уровней ряда;
а) а, в
б) б, в
в) а, г
7. Для выявления основной тенденции развития используется: а) метод укрупнения интервалов; б) метод скользящей средней; в) метод аналитического выравнивания; г) метод наименьших квадратов;
а) а, г
б) б, г
в) а, б, г
г) а, б, в
8. Трендом ряда динамики называется:
а) основная тенденция;
б) устойчивый темп роста.
9. Прогнозирование в статистике ‑ это:
а) предсказание предполагаемого события в будущем;
б) оценка возможной меры изучаемого явления в будущем.
10. К наиболее простым методам прогнозирования относят:
а) индексный метод;
б) метод скользящей средней;
в) метод на основе среднего абсолютного прироста.
1. Статистический индекс — это:
а) критерий сравнения относительных величин;
б) сравнительная характеристика двух абсолютных величин;
в) относительная величина сравнения двух показателей.
2. Индексы позволяют соизмерить социально-экономические явления:
а) в пространстве;
б) во времени;
в) в пространстве и во времени.
3. В индексном методе анализа несуммарность цен на разнородные товары преодолевается:
а) переходом от абсолютных единиц измерения цен к относительной форме;
б) переходом к стоимостной форме измерения товарной массы.
4. Можно ли утверждать, что индивидуальные индексы по методологии исчисления адекватны темпам роста:
а) можно;
б) нельзя.
5. Сводные индексы позволяют получить обобщающую оценку изменения:
а) по товарной группе;
б) одного товара за несколько периодов.
6. Может ли в отдельных случаях средний гармонический индекс рассчитываться по средней гармонической невзвешенной:
а) может;
б) не может.
7. Индексы переменного состава рассчитываются:
а) по товарной группе;
б) по одному товару.
8. Может ли индекс переменного состава превышать индекс фиксированного состава:
а) может;
б) не может.
9. Первая индексная мультипликативная модель товарооборота – это:
а) произведение индекса цен на индекс физического объема товарооборота;
б) произведение индекса товарооборота в сопоставимых ценах на индекс средней цены постоянного состава;
в) а, б.
10. Вторая факторная индексная мультипликативная модель анализа – это:
а) произведение индекса постоянного состава на индекс структурных сдвигов;
б) частное от деления индекса переменного состава на индекс структурных сдвигов;
в) а, б.
1. Статистическая связь — это:
а) когда зависимость между факторным и результирующим
показателями неизвестна;
б) когда каждому факторному соответствует свой результирующий показатель;
в) когда каждому факторному соответствует несколько разных значений результирующего показателя.
2. Термин корреляция в статистике понимают как:
а) связь, зависимость;
б) отношение, соотношение;
в) функцию, уравнение.
3. По направлению связь классифицируется как:
а) линейная;
б) прямая;
в) обратная.
4. Анализ взаимосвязи в статистике исследует:
а) тесноту связи;
б) форму связи;
в) а, б
5. При каком значении коэффициента корреляции связь можно считать умеренной?
а) r = 0,43;
б) r = 0,71.
6. Термин регрессия в статистике понимают как: а) функцию связи, зависимости; б) направление развития явления вспять; в) функцию анализа случайных событий во времени; г) уравнение линии связи
а) а, б
б) в, г
в) а, г
7. Для определения тесноты связи двух альтернативных показателей применяют:
а) коэффициенты ассоциации и контингенции;
б) коэффициент Спирмена.
8. Дайте классификацию связей по аналитическому выражению:
а) обратная;
б) сильная;
в) прямая;
г) линейная.
9. Какой коэффициент корреляции характеризует связь между YиX:
а) линейный;
б) частный;
в) множественный.
10. При каком значении линейного коэффициента корреляции связь между YиXможно признать более существенной:
а) ryx = 0,25;
б) ryx = 0,14;
в) ryx = — 0,57.
Вопрос 1. Модель множественной регрессии с тремя объясняющими переменными без свободного коэффициента имеет вид: y =
- Ответ: b1x1 + b2x2 + b3x3
Вопрос 2. При автокорреляции оценка коэффициентов регрессии становится:
- Ответ: неэффективной
Вопрос 3. Cитуация, при которой нулевая гипотеза была отвергнута, хотя была истинной, носит название:
- Ответ: ошибки I рода
Вопрос 4. При использовании уровня значимости, равного 5%, истинная гипотеза отвергается в __________________ случаев.
- Ответ: 5%
Вопрос 5. Для идентификации АР и СС моделей сначала делают оценки
- Ответ: автокорреляционной функции
Вопрос 6. Значение статистики Дарбина-Уотсона находится между значениями
- Ответ: 0 и 4
Вопрос 7. Пересмотр оценок в методе Кокрана-Оркатта выполняется до тех пор, пока не будет __________________ оценок.
- Ответ: получена требуемая точность
Вопрос 8. Способ оценивания (estimator) — общее правило для получения __________________ какого-либо параметра по данным выборки.
- Ответ: приближенного численного значения
Вопрос 9. Явление, когда строгая линейная зависимость между переменными приводит к невозможности применения МНК, называется:
- Ответ: полной коллинеарностью
Вопрос 10. Выборочная дисперсия зависимой переменной регрессии равна __________________ объясненной дисперсии зависимой переменной и необъясненной дисперсии зависимой переменной.
- Ответ: сумме
Вопрос 11. Четвертое условие Гаусса-Маркова состоит в том, что для любого k cov (uk, хk) равна:
- Ответ: 0
Вопрос 12. Эластичность y по x рассчитывается __________________ величины относительного изменения y на величину относительного изменения x.
- Ответ: делением
Вопрос 13. Если выборка достаточно полно отражает изучаемые параметры генеральной совокупности, то ее называют:
- Ответ: репрезентативной
Вопрос 14. Целью эконометрики является получение количественных выводов о свойствах экономических явлений и процессов по данным
- Ответ: выборки
Вопрос 15. Если все наблюдения лежат на линии регрессии, то коэффициент детерминации R2 для модели парной регрессии равен:
- Ответ: единице
Вопрос 16. Если две переменные независимы, то их теоретическая ковариация равна:
- Ответ: 0
Вопрос 17. Обычно прогнозы, получаемые с помощью моделей Бокса-Дженкинса, оказываются на практике __________________ прогнозов, построенных по макроэкономическим моделям.
- Ответ: не хуже
Вопрос 18. Весовые коэффициенты в методе скользящего среднего
- Ответ: всегда больше нуля
Вопрос 19. Если вычисленное значение статистики Спирмена превысит некое критическое значение, то принимается решение о:
- Ответ: наличии гетероскедастичности
Вопрос 20. Отклонение еi в i-м наблюдении yi от регрессии с двумя объясняющими переменными:
- Ответ: ei = yi — a — b1x1 — b2x2
Вопрос 21. Положительная автокорреляция — ситуация, когда случайный член регрессии в следующем наблюдении ожидается:
- Ответ: того же знака, что и в настоящем наблюдении
Вопрос 22. При построении отдельных уравнений регрессии для каждого из 4-х кварталов сумма сезонных отклонений должна равняться:
- Ответ: 0
Вопрос 23. Коэффициент Тейла лежит в пределах
- Ответ: от 0 до 1
Вопрос 24. Множественный регрессионный анализ является __________________ парного регрессионного анализа.
- Ответ: развитием
Вопрос 25. При положительной автокорреляции DW
- Ответ:
Вопрос 26. Процесс Юла описывается моделью
- Ответ: АР (2)
Вопрос 27. Эконометрический инструментарий базируется на методах и моделях
- Ответ: математической статистики
Вопрос 28. Если из экономических соображений известно, что b >= b0, то нулевая гипотеза отвергается только при:
- Ответ: t > tкрит
Вопрос 29. При вычислении t-статистики применяется распределение
- Ответ: Стьюдента
Вопрос 30. Аналитические методы выделения неслучайной составляющей основаны на допущении, что …
- Ответ: известен общий вид неслучайной составляющей
Вопрос 31. Наблюдение зависимой переменной регрессии в предшествующий момент, используемое как объясняющая переменная, называется __________________ переменной.
- Ответ: лаговой
Вопрос 32. Явление, когда нестрогая линейная зависимость между объясняющими переменными в модели множественной регрессии приводит к получению ненадежных оценок регрессии, называют:
- Ответ: мультиколлинеарностью
Вопрос 33. Для модели парной регрессии оценки, полученные по МНК, являются несмещенными, эффективными, состоятельными, если …
- Ответ: выполнены условия Гаусса-Маркова
Вопрос 34. Если элементы набора данных не являются статистически независимыми, то речь идет о:
- Ответ: временном ряде
Вопрос 35. Метод наименьших квадратов — метод нахождения оценок параметров регрессии, основанный на минимизации __________________ квадратов остатков всех наблюдений.
- Ответ: суммы
Вопрос 36. Тест Бокса-Кокса (решетчатый поиск) — прямой компьютерный метод выбора наилучших значений __________________ модели в заданных исследователем пределах с заданным шагом (решеткой).
- Ответ: параметров нелинейной
Вопрос 37. Уравнение y = a + bx, где a и b — оценки параметров a и b, полученные в результате оценивания модели y = a + bx + u по данным выборки, называется уравнением
- Ответ: линейной регрессии
Вопрос 38. Фиктивную переменную для коэффициента наклона вводят как __________________ фиктивной переменной, отвечающей за исследуемую категорию, и интересующей нефиктивной переменной.
- Ответ: произведение
Вопрос 39. Ситуация, когда не отвергнута ложная гипотеза, называется:
- Ответ: ошибкой II рода
Вопрос 40. Доверительный интервал в 99% __________________ интервал в 95%.
- Ответ: шире, чем
Вопрос 41. В множественном регрессионном анализе коэффициент детерминации определяет ____________________________________ регрессией.
- Ответ: долю дисперсии y, объясненную
Вопрос 42. Гетероскедастичность заключается в том, что дисперсия случайного члена регрессии __________________ наблюдений.
- Ответ: зависит от номера
Вопрос 43. Третье условие Гаусса-Маркова состоит в том, что cov (ui, uj) = 0, если …
- Ответ: i ¹ j
Вопрос 44. В модели множественной регрессии всегда желательно присутствие хотя бы одной __________________ переменной для того, чтобы обеспечить надлежащий уровень достоверности оценок.
- Ответ: нефиктивной
Вопрос 45. Зависимая переменная может быть представлена как фиктивная в случае, если она
- Ответ: является качественной по своему характеру
Вопрос 46. Множество наблюдений, составляющих часть генеральной совокупности, называется:
- Ответ: выборкой
Вопрос 47. Сглаживание временного ряда означает устранение
- Ответ: случайных остатков
Вопрос 48. Если автокорреляция отсутствует, то DW»:
- Ответ: 2
Вопрос 49. В методе скользящего среднего веса определяется с помощью:
- Ответ: МНК
Вопрос 50. Отличие одностороннего теста от двустороннего заключается в том, что он имеет только
- Ответ: одно критическое значение
Вопрос 51. Сумма квадратов остатков всех наблюдений — __________________ сумма квадратов отклонений.
- Ответ: остаточная
Вопрос 52. F-статистика для __________________ является в точности квадратом t-статистики для rx, y.
- Ответ: коэффициента детерминации
Вопрос 53. Для уравнения регрессии у=4+2х и наблюденных данных х=4, у=14 остаток в наблюдении равен:
- Ответ: 2
Вопрос 54. Фиктивная переменная для коэффициента наклона предназначена для установление влияния категории на:
- Ответ: коэффициент при нефиктивной переменной
Вопрос 55. Для линейного регрессионного анализа требуется линейность
- Ответ: только по параметрам
Вопрос 56. Второе условие Гаусса-Маркова заключается в том, что …
- Ответ: s2 (ui) — не зависит от i
Вопрос 57. Любой набор категорий можно описать некоторой совокупностью __________________ переменных.
- Ответ: фиктивных
Вопрос 58. В экономике отрицательная автокорреляция встречается __________________ положительная.
- Ответ: гораздо реже, чем
Вопрос 59. Итерационные методы — компьютерные __________________ методы поиска наилучших значений параметров нелинейной модели.
- Ответ: сходящиеся
Вопрос 60. Коэффициент Тейла основан на расчете
- Ответ: среднеквадратичного значения ошибки прогноза приростов
Вопрос 61. Процесс СС (2) имеет автокорреляционную функцию, которая:
- Ответ: обращается в ноль после некоторой точки
Вопрос 62. Набор категорий представляет собой конечный набор __________________ событий.
- Ответ: взаимоисключающих
Вопрос 63. Авторегрессионная схема называется схемой первого порядка, если описываемое __________________ равно 1.
- Ответ: максимальное запаздывание
Вопрос 64. В модели АР (1) частная автокорреляционная функция случайных остатков, разделенных двумя тактами времени, равна:
- Ответ: 0
Вопрос 65. Для выполнения теста Чоу используется распределение
- Ответ: Фишера
Вопрос 66. Коэффициент детерминации равен __________________ выборочной корреляции между y и a + bx.
- Ответ: квадрату
Вопрос 67. Если в регрессионную модель включена лишняя переменная, то оценки коэффициентов оказываются, как правило, …
- Ответ: неэффективными
Вопрос 68. Для производственного процесса, описываемого функцией Кобба-Дугласа, увеличение капитала (К) и труда (i) в 4 раза приводит к увеличению объема выпуска (у):
- Ответ: в 4 раза
Вопрос 69. Коэффициент ранговой корреляции имеет дисперсию
- Ответ: 1/ (n — 1)
Вопрос 70. Коэффициент Тейла служит критерием
- Ответ: успешности сделанного прогноза
Вопрос 71. Метод скользящего среднего относятся к __________________ методам выделения неслучайной составляющей.
- Ответ: алгоритмическим
Вопрос 72. На первом этапе применения теста Голдфелда-Квандта в выборке все наблюдения
- Ответ: Упорядочиваются по возрастанию х
Вопрос 73. Регрессором в уравнении парной линейной регрессии называется:
- Ответ: объясняющая переменная
Вопрос 74. Число степеней свободы (верхнее и нижнее) для отношения RSS2 / RSS1 в тесте Голдфелда-Квандта равно:
- Ответ: n’ — k — 1
Вопрос 75. Доля объясненной дисперсии зависимой переменной в общей выборочной дисперсии y выражается коэффициентом
- Ответ: детерминации
Вопрос 76. Значение оценки является:
- Ответ: случайной величиной
Вопрос 77. Для регрессии второго порядка y = 12+7x1-3x2 отклонение от регрессии наблюдения (х1=2, х2=1, y=20) равно:
- Ответ: е=3
Вопрос 78. Критерий восходящих и нисходящих серий позволяет:
- Ответ: выявить неслучайную составляющую
Вопрос 79. На больших временах процесс формирования значений временного ряда находится под воздействием __________________ факторов.
- Ответ: долговременных и циклических
Вопрос 80. Критерий серий, основанный на медиане, позволяет:
- Ответ: выявить неслучайную составляющую
Вопрос 81. Близко к линии регрессии находится наблюдение, для которого теоретическое распределение случайного члена имеет
- Ответ: малое стандартное отклонение
Вопрос 82. Марковский процесс описывается моделью
- Ответ: АР (1)
Вопрос 83. Метод Кокрана-Оркатта — компьютерный итерационный метод устранения
- Ответ: автокорреляции
Вопрос 84. Второе условие Гаусса-Маркова предполагает, что дисперсия случайного члена __________________ в каждом наблюдении.
- Ответ: постоянна
Вопрос 85. Как правило в эталонной категории
- Ответ: все фиктивные переменные равны 0
Вопрос 86. Коэффициент наклона в уравнении линейной регрессии показывает __________________ изменяется y при увеличении x на одну единицу.
- Ответ: на сколько единиц
Вопрос 87. Оценка параметров в лаговой структуре Койка делается:
- Ответ: решетчатым методом
Вопрос 88. Эффективная оценка — несмещенная оценка, имеющая __________________ среди всех несмещенных оценок.
- Ответ: наименьшую дисперсию
Вопрос 89. В критерии серий, основанном на медиане, протяженность самой длинной серии временного ряда 5, 1, 4, 2 равна:
- Ответ: 1
Вопрос 90. Выборочная дисперсия расчетных значений величины y называется __________________ дисперсией зависимой переменной.
- Ответ: объясненной
Вопрос 91. Свойства коэффициентов регрессии как случайных величин зависят от свойств __________________ уравнения.
- Ответ: остаточного члена
Вопрос 92. Модель Бокса-Дженкинса — это модель …
- Ответ: АРПСС
Вопрос 93. Исследование соотношения между спросом на реальные денежные остатки и ожидаемым изменением уровня цен описывается моделью
- Ответ: Кейгана
Вопрос 94. Оценка ρ, полученная МНК для авторегрессионной схемы первого порядка рассчитывается по формуле __________________, ek — остатки в наблюдениях.
- Ответ: cov (ek-1, ek) / var (ek-1)
Вопрос 95. Фиктивные переменные включаются в модель множественной регрессии, если необходимо установить влияние каких-либо __________________ факторов.
- Ответ: дискретных
Вопрос 96. Для проверки нулевой гипотезы H0: b= b0 применяется тест
- Ответ: Стьюдента
Вопрос 97. Дисперсии оценок а и b __________________ дисперсии остаточного члена s2 (u).
- Ответ: прямо пропорциональны
Вопрос 98. Категория — это событие, которое определенно __________________ в каждом наблюдении.
- Ответ: либо происходит, либо нет
Вопрос 99. Область принятия гипотезы — множество значений __________________, при попадании в которое нулевая гипотеза не отвергается.
- Ответ: оценок параметра
Вопрос 100. Ловушка dummy trap приводит к:
- Ответ: полной коллинеарности
Вопрос 101. Модель Линтнера основывается на предположении, что желаемый объем дивидендов
- Ответ: пропорционален прибыли
Вопрос 102. Детерминированная переменная может рассматриваться как предельный вариант случайной переменной, принимающей свое единственное значение с вероятностью
- Ответ: 1
Вопрос 103. Показатель выборочной ковариации позволяет выразить связь между двумя переменными
- Ответ: единым числом
Вопрос 104. Эконометрика — часть экономической науки, занимающаяся разработкой и применением __________________ методов анализа экономических процессов.
- Ответ: математических
Вопрос 105. Статистика Дарбина-Уотсона проверяет нулевую гипотезу Но:
- Ответ: отсутствие автокорреляции
Вопрос 106. Зависимость объемов введенных основных фондов от капитальных вложений описывается:
- Ответ: регрессионной моделью с распределенными лагами
Вопрос 107. Для того, чтобы установить влияние категории на коэффициент регрессии при нефиктивной переменной, в модель включают:
- Ответ: фиктивную переменную для коэффициента наклона
Вопрос 108. При отрицательной автокорреляции DW
- Ответ: >2
Вопрос 109. На экзамене в группе из 15 студентов 4 человека получили отличную оценку, 8 человек — оценку хорошо, 3 человека — оценку удовлетворительно. Средний бал по группе равен:
- Ответ: 4,06
Вопрос 110. При использования обычного МНК наблюдению высокого качества придается вес __________________ наблюдению низкого качества.
- Ответ: такой же как
Вопрос 111. Фиктивная переменная взаимодействия — это __________________ фиктивных переменных.
- Ответ: произведение
Вопрос 112. При попадании оценки в критическое значение:
- Ответ: сохраняется неопределенность в отношении гипотезы
Вопрос 113. Модель Кейгана — модель, описывающая гиперинфляцию с помощью модели
- Ответ: адаптивных ожиданий
Вопрос 114. При проведении теста Голдфелда-Квандта из рассмотрения исключаются __________________ наблюдений.
- Ответ: средние (n — 2n’)
Вопрос 115. Фиктивные переменные, предназначены для обозначения различных лет, кварталов, месяцев и т.п. — это __________________ фиктивные переменные.
- Ответ: сезонные
Вопрос 116. Теоретическая ковариация двух случайных величин определяется как математическое ожидание __________________ отклонений этих величин от их средних значений.
- Ответ: произведения
Вопрос 117. В модели парной регрессии у* = 4 + 2х изменение х на 2 единицы вызывает изменение у на __________________ единиц.
- Ответ: 4
Вопрос 118. Вероятности, с которыми случайная величина принимает свои значения, называют __________________ случайной величины.
- Ответ: законом распределения
Вопрос 119. Мерой разброса значений случайной величины служит:
- Ответ: дисперсия
Вопрос 120. При снижении уровня значимости риск совершить ошибку I рода
- Ответ: уменьшается
Вопрос 121. Фиктивная переменная — переменная, принимающая в каждом наблюдении значения:
- Ответ: 0 или 1
Вопрос 122. На больших временах __________________ факторы описываются монотонной функцией.
- Ответ: долговременные
Вопрос 123. Необходимость применения специальных статистических методов для обработки экономической информации вызвана __________________ данных.
- Ответ: стохастической природой
Вопрос 124. При использовании метода Монте-Карло результаты наблюдения генерируются с помощью
- Ответ: датчика случайных чисел
Вопрос 125. Для отношения RSS2/RSS1 в рамках теста Голдфелда-Квандта проводят тест
- Ответ: Фишера
Вопрос 126. В парном регрессионном анализе коэффициент детерминации R2 равен:
- Ответ: rх;у2
Вопрос 127. Подбор порядка аппроксимирующего полинома производится при помощи
- Ответ: метода последовательных разностей
Вопрос 128. Функция цены — функция, где аргументом является __________________, а значением функции — цена ошибки.
- Ответ: род ошибки
Вопрос 129. Если нулевая гипотеза Н0: β = β0, то альтернативная гипотеза Н1 — это:
- Ответ: β≠β0
Вопрос 130. Невыполнение 2 и 3 условий Гаусса-Маркова, приводит к потере свойства __________________ оценок.
- Ответ: эффективности
Вопрос 131. Эксперимент по методу Монте-Карло — искусственный, контролируемый эксперимент, проводимый для проверки и сравнения эффективности различных
- Ответ: статистических методов
Вопрос 132. Нижний индекс переменной (t-s) означает, что она является:
- Ответ: лаговой
Вопрос 133. Автокорреляция первого порядка — ситуация, когда случайный член uк коррелирует с:
- Ответ: Uк-1
Вопрос 134. Для применения теста Зарембки необходимо
- Ответ: преобразование масштаба наблюдений у
Вопрос 135. Если элементы набора данных не являются одинаково распределенными, то речь идет о:
- Ответ: временном ряде
Вопрос 136. Нелинейная модель у = f (x), в которой возможна замена переменной z = g (x), приводящая получившуюся модель y = F (z) — к линейной, называется моделью, нелинейной по:
- Ответ: переменным
Вопрос 137. Гетероскедастичность приводит к __________________ оценок параметров регрессии по МНК.
- Ответ: неэффективности
Вопрос 138. Число степеней свободы для уравнения множественной (m-мерной) регрессии при достаточном числе наблюдений n составляет:
- Ответ: n — m — 1
Вопрос 139. В критерии восходящих и нисходящих серий, общее число серий временного ряда 5, 7, 6, 4, 3, 1 равно:
- Ответ: 2
Вопрос 140. Ловушка dummy trap — выбор совокупности фиктивных переменных, сумма которых
- Ответ: константа
Вопрос 141. Оценка параметра находится __________________ доверительного интервала.
- Ответ: в центре
Вопрос 142. Данные по определенному показателю, полученные для разных однотипных объектов, называются:
- Ответ: перекрестными
Вопрос 143. При увеличении размера выборки оценка математического ожидания
- Ответ: становится более точной
Вопрос 144. При стремлении размера выборки к бесконечности стандартное отклонение математического ожидания стремится к:
- Ответ: 0
Вопрос 145. Доля числа исходов, благоприятствующих данному событию, в общем числе равновероятных исходов называется __________________ этого события.
- Ответ: вероятностью
Вопрос 146. Нижнее число степеней свободы F-cтатистики в случае парной регрессии равно:
- Ответ: n-2
Вопрос 147. Автокорреляционная функция принимает значения в пределах
- Ответ: от -1 до 1
Вопрос 148. Фиктивная переменная взаимодействия — фиктивная переменная, предназначенная для установления влияния на регрессию __________________ событий.
- Ответ: одновременного наступления нескольких независимых
Вопрос 149. Метод Зарембки процедура выбора между линейной и __________________ моделями:
- Ответ: логарифмической
Вопрос 150. Функция спектральной плотности позволяет установить:
- Ответ: частоты колебаний
Вопрос 151. При проведении теста Голдфелда-Квандта предполагается, что стандартное отклонение остаточного члена регрессии растет с __________________ переменной.
- Ответ: ростом объясняющей
Вопрос 152. Ранг наблюдения переменной — номер наблюдения переменной в упорядоченной __________________ последовательности.
- Ответ: по возрастанию значений наблюдаемой величины
Вопрос 153. Коэффициенты при сезонных фиктивных переменных показывают __________________ при смене сезона.
- Ответ: численную величину изменения, происходящего
Вопрос 154. При высоком уровне значимости проблема заключается в высоком риске допущения
- Ответ: ошибки II рода
Вопрос 155. Тест ранговой корреляции Спирмена — тест на:
- Ответ: гетероскедастичность
Вопрос 156. Статистика для теста ранговой корреляции Спирмена имеет __________________ распределение.
- Ответ: нормальное
Вопрос 157. МНК дает __________________ для данной выборки значение коэффициента детерминации R2.
- Ответ: максимальное
Вопрос 158. Функция Кобба-Дугласа имеет вид Y =
- Ответ: AKa L1-a
Вопрос 159. Процесс АР (2) имеет автокорреляционную функцию, которая:
- Ответ: имеет бесконечную протяженность
Вопрос 160. Утверждение о том, что неизвестный параметр модели принадлежит другому заданному множеству В, АÇВ = Æ, называется:
- Ответ: альтернативной гипотезой
Вопрос 161. Эконометрика получает количественные зависимости для экономических соотношений, основываясь в первую очередь на:
- Ответ: данных
Вопрос 162. Строгая линейная зависимость между переменными — ситуация, когда __________________ двух переменных равна 1 или -1.
- Ответ: выборочная корреляция
Вопрос 163. При рассмотрении спектральной плотности ограничиваются значениями ω, лежащими в пределах
- Ответ: от 0 до π
Вопрос 164. Функция Кобба-Дугласа называется:
- Ответ: производственной функцией
Вопрос 165. Утверждение о том, что неизвестный параметр модели принадлежит заданному множеству А, называется:
- Ответ: нулевой гипотезой
Вопрос 166. Проверка гипотезы Н0: R2 = 0 происходит с помощью теста
- Ответ: Фишера
Вопрос 167. Спектральная плотность может принимать __________________ значения.
- Ответ: только положительные
Вопрос 168. В модели множественной регрессии за изменение __________________ регрессии отвечает несколько объясняющих переменных.
- Ответ: одной зависимой переменной
Вопрос 169. Функция потерь, используемая при выборе между несмещенной и эффективной оценкой, определяет стоимость неточности как функцию
- Ответ: размера ошибки
Вопрос 170. Для уравнения регрессии у = 3х — 2 прогнозное значение зависимой переменной, если объясняющая переменная равна 4, — это:
- Ответ: 10
Вопрос 171. Тест Глейзера устанавливает наличие __________________ связи между стандартным отклонением остаточного члена регрессии и объясняющей переменной.
- Ответ: нелинейной
Вопрос 172. Чем больше число наблюдений, тем __________________ зона неопределенности для критерия Дарбина-Уотсона.
- Ответ: уже
Вопрос 173. Остаток в i-ом наблюдении по модели парной регрессии y=a+bx равен:
- Ответ: yi — (a + bxi)
Вопрос 174. Модель парной регрессии — __________________ модель зависимости между двумя переменными.
- Ответ: линейная
Вопрос 175. Граничное значение области принятия гипотезы с p%-ной вероятностью совершить ошибку I рода определяется __________________ при p-процентном уровне значимости.
- Ответ: критическим значением теста
Вопрос 176. Спецификация запаздываний применительно к переменным в модели называется:
- Ответ: лаговой структурой
Вопрос 177. Если независимые переменные имеют ярко выраженный временной тренд, то они оказываются:
- Ответ: тесно коррелированными
Вопрос 178. Первое условие Гаусса-Маркова заключается в том, что __________________ для любого i.
- Ответ: М (ui) = 0
Вопрос 179. В критерии восходящих и нисходящих серий, длина самой длинной серии временного ряда 1, 5, 4, 1, 6 равна:
- Ответ: 2
Вопрос 180. Идентификация модели СС (2) сводится к решению системы двух __________________ уравнений.
- Ответ: нелинейных
Вопрос 181. Выборочная дисперсия как оценка теоретической дисперсии имеет __________________ смещение.
- Ответ: отрицательное
Вопрос 182. Функция спроса y = a xb pg n может быть линеаризована посредством
- Ответ: логарифмирования
Вопрос 183. Оценка стандартного отклонения случайной величины, полученная по данным выборки, называется стандартной __________________ случайной величины.
- Ответ: ошибкой
Вопрос 184. Оценивание каждого параметра в уравнении регрессии поглощает __________________ свободы в выборке.
- Ответ: одну степень
Вопрос 185. Выборочная корреляция является __________________ теоретической корреляции.
- Ответ: оценкой
Вопрос 186. Точность оценок по МНК улучшается, если увеличивается:
- Ответ: количество наблюдений
Вопрос 187. При добавлении объясняющей переменной в уравнение регрессии коэффициент детерминации
- Ответ: не уменьшается
Вопрос 188. В критерии серий, основанном на медиане, общее число серий временного ряда 1, 3, 5, 4, 2 равно:
- Ответ: 3
Вопрос 189. Для функции Кобба-Дугласа у=100к1/3*i2/3 эластичность выпуска продукции по капиталу равна:
- Ответ: 1/3
Вопрос 190. В процессе формирования значений всякого временного ряда всегда участвуют __________________ факторы.
- Ответ: случайные
Вопрос 191. Первый шаг метода Зарембки заключается в вычислении __________________ y по выборке.
- Ответ: среднего геометрического
Вопрос 192. Плоскость регрессии y = a + b1x1 + b2x2 — двумерная плоскость в __________________ пространстве.
- Ответ: трехмерном
Вопрос 193. Для функции y = 4x0,2, эластичность равна:
- Ответ: 0,2
Вопрос 194. Поправка Прайса-Уинстена — метод спасения __________________ в автокорреляционной схеме первого порядка.
- Ответ: первого наблюдения
Вопрос 195. В лаговой структуре Койка надо оценить только:
- Ответ: три параметра
Вопрос 196. Наилучший способ устранения автокорреляции — установление ответственного за нее фактора и включение соответствующей __________________ переменной в регрессию.
- Ответ: объясняющей
Вопрос 197. Автокорреляция представляет тем большую проблему, чем
- Ответ: меньше интервал между наблюдениями
Вопрос 198. Проблема, связанная со смещением оценки коэффициентов регрессии, в одном случае, или с утратой эффективности этих оценок в другом случае неправильной спецификации переменных, перестает существовать, если коэффициент парной корреляции между переменными равен:
- Ответ: 0
Вопрос 199. Выборочная дисперсия остатков в наблюдениях Var (y — (a + bx)) называется __________________ дисперсией зависимой переменной.
- Ответ: необъясненной
Вопрос 200. Тест ранговой корреляции Спирмена — тест, устанавливающий, имеет ли стандартное отклонение остаточного члена регрессии нестрогую линейную зависимость с __________________ переменной.
- Ответ: объясняющей
Вопрос 201. Если совокупность значений случайной величины представляет собой конечный или счетный набор возможных чисел, то случайная величина называется:
- Ответ: дискретной
Вопрос 202. Стандартные ошибки, вычисленные при гетероскедастичности
- Ответ: занижены по сравнению с истинными значениями
Вопрос 203. Логарифмическое преобразование позволяет осуществить переход от нелинейной модели y = 5x2u к модели
- Ответ: ln y = ln 5 + 2 ln x + ln u
Вопрос 204. Для одностороннего критерия нулевой гипотезы Н0: β =β0 альтернативная гипотеза Н1:
- Ответ: β > β
Вопрос 205. Для функции Кобба-Дугласа у=80К3/4*i1/4 эластичность выпуска продукции по труду равна:
- Ответ: 1/4
Вопрос 206. Если опущена переменная, которая должна входить в регрессионную модель, то оценки коэффициентов регрессии оказываются:
- Ответ: смещенными
Вопрос 207. Если между двумя переменными существует строгая положительная линейная зависимость, то коэффициент корреляции между ними принимает значение, равное:
- Ответ: единице
Вопрос 208. Процесс выбора необходимых для регрессии переменных и отбрасывание лишних переменных называется:
- Ответ: спецификацией переменных
Вопрос 209. Результаты проверки гипотезы H0: b = b0 представляются на __________________ значимости.
- Ответ: двух уровнях
Вопрос 210. Всю совокупность реализаций случайной величины называют __________________ совокупностью.
- Ответ: генеральной
Вопрос 211. Остатки значений log y __________________ остатков значений y.
- Ответ: значительно меньше
Вопрос 212. Общая (ТSS), объясненная (ESS) и необъясненная (RSS) суммы квадратов отклонений находятся в следующих соотношениях
- Ответ: TSS = RSS + ESS
Вопрос 213. Если F-статистика Фишера превысит критическое значение Fкрит, то регрессия считается:
- Ответ: значимой
Вопрос 214. Число степеней свободы для t-статистики равно числу наблюдений в выборке __________________ количество оцениваемых коэффициентов.
- Ответ: минус
Вопрос 215. Если коэффициент Тейла равен нулю, то …
- Ответ: прогноз сделан успешно
Вопрос 216. Верхнее число степеней свободы F-cтатистики в случае парной регрессии равно:
- Ответ: одному
Вопрос 217. Автокорреляция — нарушение __________________ условия Гаусса-Маркова.
- Ответ: третьего
Вопрос 218. Совокупность фиктивных переменных — некоторое количество фиктивных переменных, предназначенное для описания
- Ответ: набора категорий
Вопрос 219. Стандартное отклонение случайной величины характеризует среднее ожидаемое расстояние между наблюдениями этой случайной величины и ее:
- Ответ: математическим ожиданием
Вопрос 220. В авторегрессионной схеме первого порядка uкн = рuк + ek предполагается, что значение ek в каждом наблюдении:
- Ответ: не зависит от его значений во всех других наблюдениях
Вопрос 221. Цель регрессионного анализа состоит в объяснении поведения
- Ответ: зависимой переменной
Вопрос 222. Разность между математическим ожиданием оценки и истинным значением оцениваемого параметра называют:
- Ответ: смещением
Вопрос 223. В авторегрессионной схеме первого порядка зависимость между последовательными случайными членами описывается формулой uk+1 = __________________, где ρ — константа, ek+1 — новый случайный член.
- Ответ: ρuk + e k+1
Вопрос 224. В функции Кобба-Дугласа вида log Y = a + b1 log k + b2 log l (k — индекс затрат капитала, l — индекс затрат труда) роль замещающей переменной для показателя технического прогресса играет:
- Ответ: log k
Вопрос 225. Наиболее частая причина положительной автокорреляции заключается в постоянной направленности воздействия __________________ переменных.
- Ответ: не включенных в уравнение
Вопрос 226. Для линеаризации функции Кобба-Дугласа необходимо предварительно обе части уравнения
- Ответ: разделить на L
Вопрос 227. О наличии данной частоты в спектре временного ряда свидетельствует __________________ спектральной плотности.
- Ответ: пик на графике
Вопрос 228. При добавлении еще одной переменной в уравнение регрессии коэффициент детерминации:
- Ответ: не уменьшается
Вопрос 229. Стандартные отклонения коэффициентов регрессии обратно пропорциональны величине _________, где n – число наблюдений:
- Ответ: n
Вопрос 230. Зависимая переменная может быть представлена как фиктивная в случае если она:
- Ответ: трудноизмерима
Вопрос 231. Тест Фишера является:
- Ответ: односторонним
Вопрос 232. Выборочная корреляция является __________оценкой теоретической корреляции:
- Ответ: состоятельной
Вопрос 233. Определение отдельного вклада каждой из независимых переменных в объясненную дисперсию в случае их коррелированности является ___________ задачей:
- Ответ: невыполнимой
Вопрос 234. Условие гомоскедастичности означает, что вероятность того, что случайный член примет какое-либо конкретное значение _________ наблюдений:
- Ответ: одинакова для всех
Вопрос 235. Значения t-статистики для фиктивных переменных незначимо отличается от:
- Ответ: 0
Вопрос 236. Из перечисленных факторов: 1) число объясняющих переменных, 2) количество наблюдений в выборке, 3)конкретные значения переменных, критические значения статистики Дарбина-Уотсона зависят от:
- Ответ: 1, 2
Вопрос 237. Значение статистики DW находится между значениями:
- Ответ: 0 и 4
Вопрос 238. Наблюдение зависимой переменной регрессии в предшествующий момент, используемое как объясняющая переменная, называется:
- Ответ: лаговой
Вопрос 239. Чем больше число наблюдений, тем __________ зона неопределенности для критерия Дарбина-Уотсона:
- Ответ: уже
Вопрос 240. МНК автоматически дает ___________ для данной выборки значение коэффициента детерминации R2:
- Ответ: максимальное
Вопрос 241. В авторегрессионной схеме первого порядка предполагается, что значение в каждом наблюдении:
- Ответ: не зависит от его значения во всех других наблюдениях
Вопрос 242. Линия регрессии _______ через точку ( , ) :
- Ответ: всегда проходит
Вопрос 243. Если предположение о природе гетероскедастичности верно, то дисперсия случайного члена для первых наблюдений в упорядоченном ряду будет ________ для последних:
- Ответ: ниже, чем
Вопрос 244. Стандартные ошибки, вычисленные при гетероскедастичности:
- Ответ: занижены по сравнению с истинными значениями
Вопрос 245. Критерий Дарбина-Уотсона –метод обнаружения _________ с помощью статистики Дарбина-Уотсона:
- Ответ: автокорреляции
Вопрос 246. Параметры множественной регрессии ?1 , ?2 ,… ?м показывают _________ соответствующих экономических факторов:
- Ответ: степень влияния
Вопрос 247. Во множественном регрессионном анализе коэффициент детерминации определяет _______регрессией:
- Ответ: долю дисперсии y, объясненную
Вопрос 248. Сумма квадратов отклонений величины y от своего выборочного значения _____ сумма квадратов отклонений:
- Ответ: общая
Вопрос 249. Фиктивная переменная взаимодействия – фиктивная переменная, предназначенная для
- Ответ: одновременного наступления нескольких независимых
Вопрос 250. Автокорреляция первого порядка – ситуация, когда коррелируют случайные члены регрессии в __________ наблюдениях:
- Ответ: последовательных
Вопрос 251. Фиктивная переменная – переменная, принимающая в каждом наблюдении:
- Ответ: только два значения 0 или 1
Вопрос 252. Для того, чтобы установить влияние какого-либо события на коэффициент линейной регрессии при нефиктивной переменной, в модель включают:
- Ответ: фиктивную переменную для коэффициента наклона
Вопрос 253. Оценка параметра для модели множественной регрессии в случае двух независимых переменных вычисляется по формуле: а =
- Ответ: 1 1 2 2 y ? b x ? b x
Вопрос 254. Процесс выбора необходимых переменных для регрессии переменных и отбрасывание лишних переменных называется:
- Ответ: спецификацией переменных
Вопрос 255. Из перечисленного: 1) число объясняющих переменных, 2) количество наблюдений в выборке, 3) конкретные значения переменных критические значения статистики Дарбина-Уотсона зависят от:
- Ответ: 1, 2
Вопрос 256. Число степеней свободы для уравнения m-мерной регрессии при достаточном числе наблюдений n составляет:
- Ответ: n-m-1
Вопрос 257. Наилучший способ устранения автокорреляции – установление ответственного за нее фактора и включение соответствующей ___________ переменной в регрессию:
- Ответ: объясняющей
Вопрос 258. Строгая линейная зависимость между переменными – ситуация, когда ________ двух переменных равна 1 или -1:
- Ответ: выборочная корреляция
Вопрос 259. Значение статистики Дарбина-Уотсона находится между значениями:
- Ответ: 0 и 4
Есть 3 различных API для оценки качества прогнозов модели:
- Метод оценки оценщика : у оценщиков есть
scoreметод, обеспечивающий критерий оценки по умолчанию для проблемы, для решения которой они предназначены. Это обсуждается не на этой странице, а в документации каждого оценщика. - Параметр оценки: инструменты оценки модели с использованием перекрестной проверки (например,
model_selection.cross_val_scoreиmodel_selection.GridSearchCV) полагаются на внутреннюю стратегию оценки . Это обсуждается в разделе Параметр оценки: определение правил оценки модели . - Метрические функции : В
sklearn.metricsмодуле реализованы функции оценки ошибки прогноза для конкретных целей. Эти показатели подробно описаны в разделах по метрикам классификации , MultiLabel ранжирования показателей , показателей регрессии и показателей кластеризации .
Наконец, фиктивные оценки полезны для получения базового значения этих показателей для случайных прогнозов.
3.3.1. В scoring параметрах: определение правил оценки моделей
Выбор и оценка модели с использованием таких инструментов, как model_selection.GridSearchCV и model_selection.cross_val_score, принимают scoring параметр, который контролирует, какую метрику они применяют к оцениваемым оценщикам.
3.3.1.1. Общие случаи: предопределенные значения
Для наиболее распространенных случаев использования вы можете назначить объект подсчета с помощью scoring параметра; в таблице ниже показаны все возможные значения. Все объекты счетчика следуют соглашению о том, что более высокие возвращаемые значения лучше, чем более низкие возвращаемые значения . Таким образом, метрики, которые измеряют расстояние между моделью и данными, например metrics.mean_squared_error, доступны как neg_mean_squared_error, которые возвращают инвертированное значение метрики.
| Подсчет очков | Функция | Комментарий |
| Классификация | ||
| ‘accuracy’ | metrics.accuracy_score |
|
| ‘balanced_accuracy’ | metrics.balanced_accuracy_score |
|
| ‘top_k_accuracy’ | metrics.top_k_accuracy_score |
|
| ‘average_precision’ | metrics.average_precision_score |
|
| ‘neg_brier_score’ | metrics.brier_score_loss |
|
| ‘f1’ | metrics.f1_score |
для двоичных целей |
| ‘f1_micro’ | metrics.f1_score |
микро-усредненный |
| ‘f1_macro’ | metrics.f1_score |
микро-усредненный |
| ‘f1_weighted’ | metrics.f1_score |
средневзвешенное |
| ‘f1_samples’ | metrics.f1_score |
по многопозиционному образцу |
| ‘neg_log_loss’ | metrics.log_loss |
требуетсяpredict_probaподдержка |
| ‘precision’ etc. | metrics.precision_score |
суффиксы применяются как с ‘f1’ |
| ‘recall’ etc. | metrics.recall_score |
суффиксы применяются как с ‘f1’ |
| ‘jaccard’ etc. | metrics.jaccard_score |
суффиксы применяются как с ‘f1’ |
| ‘roc_auc’ | metrics.roc_auc_score |
|
| ‘roc_auc_ovr’ | metrics.roc_auc_score |
|
| ‘roc_auc_ovo’ | metrics.roc_auc_score |
|
| ‘roc_auc_ovr_weighted’ | metrics.roc_auc_score |
|
| ‘roc_auc_ovo_weighted’ | metrics.roc_auc_score |
|
| Кластеризация | ||
| ‘adjusted_mutual_info_score’ | metrics.adjusted_mutual_info_score |
|
| ‘adjusted_rand_score’ | metrics.adjusted_rand_score |
|
| ‘completeness_score’ | metrics.completeness_score |
|
| ‘fowlkes_mallows_score’ | metrics.fowlkes_mallows_score |
|
| ‘homogeneity_score’ | metrics.homogeneity_score |
|
| ‘mutual_info_score’ | metrics.mutual_info_score |
|
| ‘normalized_mutual_info_score’ | metrics.normalized_mutual_info_score |
|
| ‘rand_score’ | metrics.rand_score |
|
| ‘v_measure_score’ | metrics.v_measure_score |
|
| Регрессия | ||
| ‘explained_variance’ | metrics.explained_variance_score |
|
| ‘max_error’ | metrics.max_error |
|
| ‘neg_mean_absolute_error’ | metrics.mean_absolute_error |
|
| ‘neg_mean_squared_error’ | metrics.mean_squared_error |
|
| ‘neg_root_mean_squared_error’ | metrics.mean_squared_error |
|
| ‘neg_mean_squared_log_error’ | metrics.mean_squared_log_error |
|
| ‘neg_median_absolute_error’ | metrics.median_absolute_error |
|
| ‘r2’ | metrics.r2_score |
|
| ‘neg_mean_poisson_deviance’ | metrics.mean_poisson_deviance |
|
| ‘neg_mean_gamma_deviance’ | metrics.mean_gamma_deviance |
|
| ‘neg_mean_absolute_percentage_error’ | metrics.mean_absolute_percentage_error |
Примеры использования:
>>> from sklearn import svm, datasets >>> from sklearn.model_selection import cross_val_score >>> X, y = datasets.load_iris(return_X_y=True) >>> clf = svm.SVC(random_state=0) >>> cross_val_score(clf, X, y, cv=5, scoring='recall_macro') array([0.96..., 0.96..., 0.96..., 0.93..., 1. ]) >>> model = svm.SVC() >>> cross_val_score(model, X, y, cv=5, scoring='wrong_choice') Traceback (most recent call last): ValueError: 'wrong_choice' is not a valid scoring value. Use sorted(sklearn.metrics.SCORERS.keys()) to get valid options.
Примечание
Значения, перечисленные в виде ValueError исключения, соответствуют функциям измерения точности прогнозирования, описанным в следующих разделах. Объекты счетчика для этих функций хранятся в словаре sklearn.metrics.SCORERS.
3.3.1.2. Определение стратегии выигрыша от метрических функций
Модуль sklearn.metrics также предоставляет набор простых функций, измеряющих ошибку предсказания с учетом истинности и предсказания:
- функции, заканчивающиеся на,
_scoreвозвращают значение для максимизации, чем выше, тем лучше. - функции, заканчивающиеся на
_errorили_lossвозвращающие значение, которое нужно минимизировать, чем ниже, тем лучше. При преобразовании в объект счетчика с использованиемmake_scorerустановите дляgreater_is_betterпараметра значениеFalse(Trueпо умолчанию; см. Описание параметра ниже).
Метрики, доступные для различных задач машинного обучения, подробно описаны в разделах ниже.
Многим метрикам не даются имена для использования в качестве scoring значений, иногда потому, что они требуют дополнительных параметров, например fbeta_score. В таких случаях вам необходимо создать соответствующий объект оценки. Самый простой способ создать вызываемый объект для оценки — использовать make_scorer. Эта функция преобразует метрики в вызываемые объекты, которые можно использовать для оценки модели.
Один из типичных вариантов использования — обернуть существующую метрическую функцию из библиотеки значениями, отличными от значений по умолчанию для ее параметров, такими как beta параметр для fbeta_score функции:
>>> from sklearn.metrics import fbeta_score, make_scorer
>>> ftwo_scorer = make_scorer(fbeta_score, beta=2)
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.svm import LinearSVC
>>> grid = GridSearchCV(LinearSVC(), param_grid={'C': [1, 10]},
... scoring=ftwo_scorer, cv=5)
Второй вариант использования — создание полностью настраиваемого объекта скоринга из простой функции Python с использованием make_scorer, которая может принимать несколько параметров:
- функция Python, которую вы хотите использовать (
my_custom_loss_funcв примере ниже) - возвращает ли функция Python оценку (
greater_is_better=True, по умолчанию) или потерю (greater_is_better=False). В случае потери результат функции python аннулируется объектом скоринга в соответствии с соглашением о перекрестной проверке, согласно которому скоринтеры возвращают более высокие значения для лучших моделей. - только для показателей классификации: требуется ли для предоставленной вами функции Python постоянная уверенность в принятии решений (
needs_threshold=True). Значение по умолчанию неверно. - любые дополнительные параметры, такие как
betaилиlabelsвf1_score.
Вот пример создания пользовательских счетчиков очков и использования greater_is_better параметра:
>>> import numpy as np >>> def my_custom_loss_func(y_true, y_pred): ... diff = np.abs(y_true - y_pred).max() ... return np.log1p(diff) ... >>> # score will negate the return value of my_custom_loss_func, >>> # which will be np.log(2), 0.693, given the values for X >>> # and y defined below. >>> score = make_scorer(my_custom_loss_func, greater_is_better=False) >>> X = [[1], [1]] >>> y = [0, 1] >>> from sklearn.dummy import DummyClassifier >>> clf = DummyClassifier(strategy='most_frequent', random_state=0) >>> clf = clf.fit(X, y) >>> my_custom_loss_func(y, clf.predict(X)) 0.69... >>> score(clf, X, y) -0.69...
3.3.1.3. Реализация собственного скорингового объекта
Вы можете сгенерировать еще более гибкие модели скоринга, создав свой собственный скоринговый объект с нуля, без использования make_scorer фабрики. Чтобы вызываемый может быть бомбардиром, он должен соответствовать протоколу, указанному в следующих двух правилах:
- Его можно вызвать с параметрами (estimator, X, y), где estimator это модель, которая должна быть оценена, X это данные проверки и y основная истинная цель для (в контролируемом случае) или None (в неконтролируемом случае).
- Он возвращает число с плавающей запятой, которое количественно определяет
estimatorкачество прогнозированияXсо ссылкой наy. Опять же, по соглашению более высокие числа лучше, поэтому, если ваш секретарь сообщает о проигрыше, это значение следует отменить.
Примечание Использование пользовательских счетчиков в функциях, где n_jobs> 1
Хотя определение пользовательской функции оценки вместе с вызывающей функцией должно работать из коробки с бэкэндом joblib по умолчанию (loky), его импорт из другого модуля будет более надежным подходом и будет работать независимо от бэкэнда joblib.
Например, чтобы использовать n_jobsбольше 1 в примере ниже, custom_scoring_function функция сохраняется в созданном пользователем модуле ( custom_scorer_module.py) и импортируется:
>>> from custom_scorer_module import custom_scoring_function >>> cross_val_score(model, ... X_train, ... y_train, ... scoring=make_scorer(custom_scoring_function, greater_is_better=False), ... cv=5, ... n_jobs=-1)
3.3.1.4. Использование множественной метрической оценки
Scikit-learn также позволяет оценивать несколько показателей в GridSearchCV, RandomizedSearchCV и cross_validate.
Есть три способа указать несколько показателей оценки для scoring параметра:
- Как итерация строковых показателей:
>>> scoring = ['accuracy', 'precision']
- В качестве
dictсопоставления имени секретаря с функцией подсчета очков:
>>> from sklearn.metrics import accuracy_score
>>> from sklearn.metrics import make_scorer
>>> scoring = {'accuracy': make_scorer(accuracy_score),
... 'prec': 'precision'}
Обратите внимание, что значения dict могут быть либо функциями счетчика, либо одной из предварительно определенных строк показателей.
- Как вызываемый объект, возвращающий словарь оценок:
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import confusion_matrix
>>> # A sample toy binary classification dataset
>>> X, y = datasets.make_classification(n_classes=2, random_state=0)
>>> svm = LinearSVC(random_state=0)
>>> def confusion_matrix_scorer(clf, X, y):
... y_pred = clf.predict(X)
... cm = confusion_matrix(y, y_pred)
... return {'tn': cm[0, 0], 'fp': cm[0, 1],
... 'fn': cm[1, 0], 'tp': cm[1, 1]}
>>> cv_results = cross_validate(svm, X, y, cv=5,
... scoring=confusion_matrix_scorer)
>>> # Getting the test set true positive scores
>>> print(cv_results['test_tp'])
[10 9 8 7 8]
>>> # Getting the test set false negative scores
>>> print(cv_results['test_fn'])
[0 1 2 3 2]
3.3.2. Метрики классификации
В sklearn.metrics модуле реализованы несколько функций потерь, оценки и полезности для измерения эффективности классификации. Некоторые метрики могут потребовать оценок вероятности положительного класса, значений достоверности или значений двоичных решений. Большинство реализаций позволяют каждой выборке вносить взвешенный вклад в общую оценку с помощью sample_weight параметра.
Некоторые из них ограничены случаем двоичной классификации:
precision_recall_curve(y_true, probas_pred, *) |
Вычислите пары точности-отзыва для разных пороговых значений вероятности. |
roc_curve(y_true, y_score, *[, pos_label, …]) |
Вычислить рабочую характеристику приемника (ROC). |
det_curve(y_true, y_score[, pos_label, …]) |
Вычислите частоту ошибок для различных пороговых значений вероятности. |
Другие также работают в случае мультикласса:
balanced_accuracy_score(y_true, y_pred, *[, …]) |
Вычислите сбалансированную точность. |
cohen_kappa_score(y1, y2, *[, labels, …]) |
Каппа Коэна: статистика, измеряющая согласованность аннотаторов. |
confusion_matrix(y_true, y_pred, *[, …]) |
Вычислите матрицу неточностей, чтобы оценить точность классификации. |
hinge_loss(y_true, pred_decision, *[, …]) |
Средняя потеря петель (нерегулируемая). |
matthews_corrcoef(y_true, y_pred, *[, …]) |
Вычислите коэффициент корреляции Мэтьюза (MCC). |
roc_auc_score(y_true, y_score, *[, average, …]) |
Вычислить площадь под кривой рабочих характеристик приемника (ROC AUC) по оценкам прогнозов. |
top_k_accuracy_score(y_true, y_score, *[, …]) |
Top-k Рейтинг по классификации точности. |
Некоторые также работают в многоярусном регистре:
accuracy_score(y_true, y_pred, *[, …]) |
Классификационная оценка точности. |
classification_report(y_true, y_pred, *[, …]) |
Создайте текстовый отчет, показывающий основные показатели классификации. |
f1_score(y_true, y_pred, *[, labels, …]) |
Вычислите оценку F1, также известную как сбалансированная оценка F или F-мера. |
fbeta_score(y_true, y_pred, *, beta[, …]) |
Вычислите оценку F-beta. |
hamming_loss(y_true, y_pred, *[, sample_weight]) |
Вычислите среднюю потерю Хэмминга. |
jaccard_score(y_true, y_pred, *[, labels, …]) |
Оценка коэффициента сходства Жаккара. |
log_loss(y_true, y_pred, *[, eps, …]) |
Потеря журнала, также известная как потеря логистики или потеря кросс-энтропии. |
multilabel_confusion_matrix(y_true, y_pred, *) |
Вычислите матрицу неточностей для каждого класса или образца. |
precision_recall_fscore_support(y_true, …) |
Точность вычислений, отзыв, F-мера и поддержка для каждого класса. |
precision_score(y_true, y_pred, *[, labels, …]) |
Вычислите точность. |
recall_score(y_true, y_pred, *[, labels, …]) |
Вычислите отзыв. |
roc_auc_score(y_true, y_score, *[, average, …]) |
Вычислить площадь под кривой рабочих характеристик приемника (ROC AUC) по оценкам прогнозов. |
zero_one_loss(y_true, y_pred, *[, …]) |
Потеря классификации нулевая единица. |
А некоторые работают с двоичными и многозначными (но не мультиклассовыми) проблемами:
В следующих подразделах мы опишем каждую из этих функций, которым будут предшествовать некоторые примечания по общему API и определению показателей.
3.3.2.1. От бинарного до мультиклассового и многозначного
Некоторые метрики по существу определены для задач двоичной классификации (например f1_score, roc_auc_score). В этих случаях по умолчанию оценивается только положительная метка, предполагая по умолчанию, что положительный класс помечен 1 (хотя это можно настроить с помощью pos_label параметра).
При расширении двоичной метрики на задачи с несколькими классами или метками данные обрабатываются как набор двоичных задач, по одной для каждого класса. Затем есть несколько способов усреднить вычисления двоичных показателей по набору классов, каждый из которых может быть полезен в некотором сценарии. Если возможно, вы должны выбрать одно из них с помощью average параметра.
"macro"просто вычисляет среднее значение двоичных показателей, придавая каждому классу одинаковый вес. В задачах, где редкие занятия тем не менее важны, макро-усреднение может быть средством выделения их производительности. С другой стороны, предположение, что все классы одинаково важны, часто неверно, так что макро-усреднение будет чрезмерно подчеркивать обычно низкую производительность для нечастого класса."weighted"учитывает дисбаланс классов, вычисляя среднее значение двоичных показателей, в которых оценка каждого класса взвешивается по его присутствию в истинной выборке данных."micro"дает каждой паре выборка-класс равный вклад в общую метрику (за исключением результата взвешивания выборки). Вместо того, чтобы суммировать метрику для каждого класса, это суммирует дивиденды и делители, составляющие метрики для каждого класса, для расчета общего частного. Микро-усреднение может быть предпочтительным в настройках с несколькими ярлыками, включая многоклассовую классификацию, когда класс большинства следует игнорировать."samples"применяется только к задачам с несколькими ярлыками. Он не вычисляет меру для каждого класса, вместо этого вычисляет метрику по истинным и прогнозируемым классам для каждой выборки в данных оценки и возвращает их (sample_weight— взвешенное) среднее значение.- Выбор
average=Noneвернет массив с оценкой для каждого класса.
В то время как данные мультикласса предоставляются метрике, как двоичные цели, в виде массива меток классов, данные с несколькими метками указываются как индикаторная матрица, в которой ячейка [i, j] имеет значение 1, если у образца i есть метка j, и значение 0 в противном случае.
3.3.2.2. Оценка точности
Функция accuracy_score вычисляет точность , либо фракции ( по умолчанию) или количество (нормализует = False) правильных предсказаний.
В классификации с несколькими ярлыками функция возвращает точность подмножества. Если весь набор предсказанных меток для выборки строго соответствует истинному набору меток, то точность подмножества равна 1,0; в противном случае — 0, 0.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец и $y_i$ — соответствующее истинное значение, тогда доля правильных прогнозов по сравнению с $n_{samples}$ определяется как
$$texttt{accuracy}(y, hat{y}) = frac{1}{n_text{samples}} sum_{i=0}^{n_text{samples}-1} 1(hat{y}_i = y_i)$$
где $1(x)$- индикаторная функция .
>>> import numpy as np >>> from sklearn.metrics import accuracy_score >>> y_pred = [0, 2, 1, 3] >>> y_true = [0, 1, 2, 3] >>> accuracy_score(y_true, y_pred) 0.5 >>> accuracy_score(y_true, y_pred, normalize=False) 2
В многопозиционном корпусе с бинарными индикаторами меток:
>>> accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2))) 0.5
Пример:
- См. В разделе Проверка с перестановками значимости классификационной оценки пример использования показателя точности с использованием перестановок набора данных.
3.3.2.3. Рейтинг точности Top-k
Функция top_k_accuracy_score представляет собой обобщение accuracy_score. Разница в том, что прогноз считается правильным, если истинная метка связана с одним из kнаивысших прогнозируемых баллов. accuracy_score является частным случаем k = 1.
Функция охватывает случаи двоичной и многоклассовой классификации, но не случай многозначной классификации.
Если $hat{f}_{i,j}$ прогнозируемый класс для $i$-й образец, соответствующий $j$-й по величине прогнозируемый результат и $y_i$ — соответствующее истинное значение, тогда доля правильных прогнозов по сравнению с $n_{samples}$ определяется как
$$texttt{top-k accuracy}(y, hat{f}) = frac{1}{n_text{samples}} sum_{i=0}^{n_text{samples}-1} sum_{j=1}^{k} 1(hat{f}_{i,j} = y_i)$$
где k допустимое количество предположений и 1(x)- индикаторная функция.
>>> import numpy as np >>> from sklearn.metrics import top_k_accuracy_score >>> y_true = np.array([0, 1, 2, 2]) >>> y_score = np.array([[0.5, 0.2, 0.2], ... [0.3, 0.4, 0.2], ... [0.2, 0.4, 0.3], ... [0.7, 0.2, 0.1]]) >>> top_k_accuracy_score(y_true, y_score, k=2) 0.75 >>> # Not normalizing gives the number of "correctly" classified samples >>> top_k_accuracy_score(y_true, y_score, k=2, normalize=False) 3
3.3.2.4. Сбалансированный показатель точности
Функция balanced_accuracy_score вычисляет взвешенную точность , что позволяет избежать завышенных оценок производительности на несбалансированных данных. Это макросреднее количество оценок отзыва по классу или, что то же самое, грубая точность, где каждая выборка взвешивается в соответствии с обратной распространенностью ее истинного класса. Таким образом, для сбалансированных наборов данных оценка равна точности.
В двоичном случае сбалансированная точность равна среднему арифметическому чувствительности (истинно положительный показатель) и специфичности (истинно отрицательный показатель) или площади под кривой ROC с двоичными прогнозами, а не баллами:
$$texttt{balanced-accuracy} = frac{1}{2}left( frac{TP}{TP + FN} + frac{TN}{TN + FP}right )$$
Если классификатор одинаково хорошо работает в любом классе, этот термин сокращается до обычной точности (т. е. Количества правильных прогнозов, деленного на общее количество прогнозов).
Напротив, если обычная точность выше вероятности только потому, что классификатор использует несбалансированный набор тестов, тогда сбалансированная точность, при необходимости, упадет до $frac{1}{n_classes}$.
Оценка варьируется от 0 до 1 или, когда adjusted=True используется, масштабируется до диапазона $frac{1}{1 — n_classes}$ до 1 включительно, с произвольной оценкой 0.
Если yi истинная ценность $i$-й образец, и $w_i$ — соответствующий вес образца, затем мы настраиваем вес образца на:
$$hat{w}_i = frac{w_i}{sum_j{1(y_j = y_i) w_j}}$$
где $1(x)$- индикаторная функция . Учитывая предсказанный $hat{y}_i$ для образца $i$, сбалансированная точность определяется как:
$$texttt{balanced-accuracy}(y, hat{y}, w) = frac{1}{sum{hat{w}_i}} sum_i 1(hat{y}_i = y_i) hat{w}_i$$
С adjusted=True сбалансированной точностью сообщает об относительном увеличении от $texttt{balanced-accuracy}(y, mathbf{0}, w) =frac{1}{n_classes}$. В двоичном случае это также известно как * статистика Юдена * , или информированность .
Примечание
Определение мультикласса здесь кажется наиболее разумным расширением метрики, используемой в бинарной классификации, хотя в литературе нет определенного консенсуса:
- Наше определение: [Mosley2013] , [Kelleher2015] и [Guyon2015] , где [Guyon2015] принимает скорректированную версию, чтобы гарантировать, что случайные предсказания имеют оценку 0 а точные предсказания имеют оценку 1..
- Точность балансировки классов, как описано в [Mosley2013] : вычисляется минимум между точностью и отзывом для каждого класса. Затем эти значения усредняются по общему количеству классов для получения сбалансированной точности.
- Сбалансированная точность, как описано в [Urbanowicz2015] : среднее значение чувствительности и специфичности вычисляется для каждого класса, а затем усредняется по общему количеству классов.
Рекомендации:
- Гийон 2015 ( 1 , 2 ) И. Гайон, К. Беннет, Г. Коули, Х. Дж. Эскаланте, С. Эскалера, Т. К. Хо, Н. Масиа, Б. Рэй, М. Саид, А. Р. Статников, Э. Вьегас, Дизайн конкурса ChaLearn AutoML Challenge 2015 , IJCNN 2015 г.
- Мосли 2013 ( 1 , 2 ) Л. Мосли, Сбалансированный подход к проблеме мультиклассового дисбаланса , IJCV 2010.
- Kelleher2015 Джон. Д. Келлехер, Брайан Мак Нейме, Аойф Д’Арси, Основы машинного обучения для прогнозной аналитики данных: алгоритмы, рабочие примеры и тематические исследования , 2015.
- Урбанович2015 Urbanowicz RJ, Moore, JH ExSTraCS 2.0: описание и оценка масштабируемой системы классификаторов обучения , Evol. Intel. (2015) 8:89.
3.3.2.5. Каппа Коэна
Функция cohen_kappa_score вычисляет каппа-Коэна статистику. Эта мера предназначена для сравнения меток, сделанных разными людьми-аннотаторами, а не классификатором с достоверной информацией.
Показатель каппа (см. Строку документации) представляет собой число от -1 до 1. Баллы выше 0,8 обычно считаются хорошим совпадением; ноль или ниже означает отсутствие согласия (практически случайные метки).
Оценка Каппа может быть вычислена для двоичных или многоклассовых задач, но не для задач с несколькими метками (за исключением ручного вычисления оценки для каждой метки) и не более чем для двух аннотаторов.
>>> from sklearn.metrics import cohen_kappa_score >>> y_true = [2, 0, 2, 2, 0, 1] >>> y_pred = [0, 0, 2, 2, 0, 2] >>> cohen_kappa_score(y_true, y_pred) 0.4285714285714286
3.3.2.6. Матрица неточностей ¶
Точность функции confusion_matrix вычисляет классификацию пути вычисления матрицы путаницы с каждой строкой , соответствующей истинный классом (Википедия и другие ссылки могут использовать различные конвенции для осей).
По определению запись i,j в матрице неточностей — количество наблюдений в группе i, но предполагается, что он будет в группе j. Вот пример:
>>> from sklearn.metrics import confusion_matrix
>>> y_true = [2, 0, 2, 2, 0, 1]
>>> y_pred = [0, 0, 2, 2, 0, 2]
>>> confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
plot_confusion_matrix может использоваться для визуального представления матрицы неточностей, как показано в примере матрицы неточностей, который создает следующий рисунок:
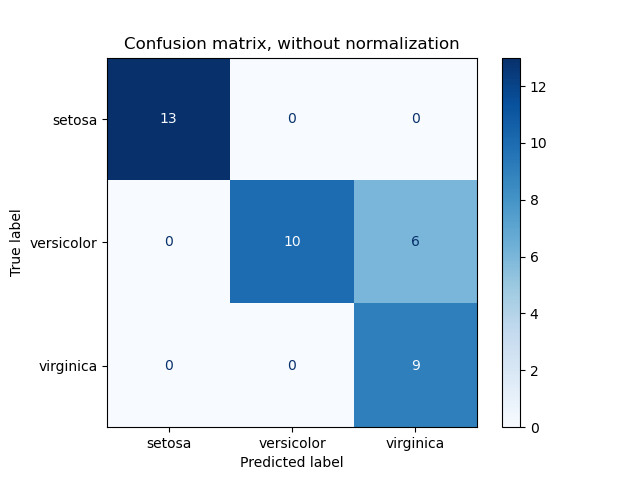
Параметр normalize позволяет сообщать коэффициенты вместо подсчетов. Матрица путаница может быть нормализована в 3 различными способами: 'pred', 'true'и 'all' которые будут делить счетчики на сумму каждого столбца, строки или всей матрицы, соответственно.
>>> y_true = [0, 0, 0, 1, 1, 1, 1, 1]
>>> y_pred = [0, 1, 0, 1, 0, 1, 0, 1]
>>> confusion_matrix(y_true, y_pred, normalize='all')
array([[0.25 , 0.125],
[0.25 , 0.375]])
Для двоичных задач мы можем получить подсчет истинно отрицательных, ложноположительных, ложноотрицательных и истинно положительных результатов следующим образом:
>>> y_true = [0, 0, 0, 1, 1, 1, 1, 1] >>> y_pred = [0, 1, 0, 1, 0, 1, 0, 1] >>> tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel() >>> tn, fp, fn, tp (2, 1, 2, 3)
Пример:
- См. В разделе Матрица неточностей пример использования матрицы неточностей для оценки качества выходных данных классификатора.
- См. В разделе Распознавание рукописных цифр пример использования матрицы неточностей для классификации рукописных цифр.
- См. Раздел Классификация текстовых документов с использованием разреженных функций для примера использования матрицы неточностей для классификации текстовых документов.
3.3.2.7. Отчет о классификации
Функция classification_report создает текстовый отчет , показывающий основные показатели классификации. Вот небольшой пример с настраиваемыми target_names и предполагаемыми ярлыками:
>>> from sklearn.metrics import classification_report
>>> y_true = [0, 1, 2, 2, 0]
>>> y_pred = [0, 0, 2, 1, 0]
>>> target_names = ['class 0', 'class 1', 'class 2']
>>> print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.67 1.00 0.80 2
class 1 0.00 0.00 0.00 1
class 2 1.00 0.50 0.67 2
accuracy 0.60 5
macro avg 0.56 0.50 0.49 5
weighted avg 0.67 0.60 0.59 5
Пример:
- См. В разделе Распознавание рукописных цифр пример использования отчета о классификации рукописных цифр.
- См. Раздел Классификация текстовых документов с использованием разреженных функций, где приведен пример использования отчета о классификации для текстовых документов.
- См. Раздел « Оценка параметров с использованием поиска по сетке с перекрестной проверкой», где приведен пример использования отчета о классификации для поиска по сетке с вложенной перекрестной проверкой.
3.3.2.8. Потеря Хэмминга
hamming_loss вычисляет среднюю потерю Хэмминга или расстояние Хемминга между двумя наборами образцов.
Если $hat{y}_j$ прогнозируемое значение для $j$-я этикетка данного образца, $y_j$ — соответствующее истинное значение, а $n_{labels}$ — количество классов или меток, то потеря Хэмминга $L_{Hamming}$ между двумя образцами определяется как:
$$L_{Hamming}(y, hat{y}) = frac{1}{n_text{labels}} sum_{j=0}^{n_text{labels} — 1} 1(hat{y}_j not= y_j)$$
где $1(x)$- индикаторная функция .
>>> from sklearn.metrics import hamming_loss >>> y_pred = [1, 2, 3, 4] >>> y_true = [2, 2, 3, 4] >>> hamming_loss(y_true, y_pred) 0.25
В многопозиционном корпусе с бинарными индикаторами меток:
>>> hamming_loss(np.array([[0, 1], [1, 1]]), np.zeros((2, 2))) 0.75
Примечание
В мультиклассовой классификации потери Хэмминга соответствуют расстоянию Хэмминга между y_true и, y_pred что аналогично функции потерь нуля или единицы . Однако, в то время как потеря нуля или единицы наказывает наборы предсказаний, которые не строго соответствуют истинным наборам, потеря Хэмминга наказывает отдельные метки. Таким образом, потеря Хэмминга, ограниченная сверху потерей нуля или единицы, всегда находится между нулем и единицей включительно; и прогнозирование надлежащего подмножества или надмножества истинных меток даст исключительную потерю Хэмминга от нуля до единицы.
3.3.2.9. Точность, отзыв и F-меры
Интуитивно, точность — это способность классификатора не маркировать как положительный образец, который является отрицательным, а отзыв — это способность классификатора находить все положительные образцы.
F-мера ($F_beta$ а также $F_1$ меры) можно интерпретировать как взвешенное гармоническое среднее значение точности и полноты. А $F_beta$ мера достигает своего лучшего значения на уровне 1 и худшего результата на уровне 0. С $beta = 1$, $F_beta$ а также $F_1$ эквивалентны, а отзыв и точность одинаково важны.
precision_recall_curve вычисляет кривую точности-отзыва на основе наземной метки истинности и оценки, полученной классификатором путем изменения порога принятия решения.
Функция average_precision_score вычисляет среднюю точность (AP) от оценки прогнозирования. Значение от 0 до 1 и выше — лучше. AP определяется как
$$text{AP} = sum_n (R_n — R_{n-1}) P_n$$
где $P_n$ а также $R_n$- точность и отзыв на n-м пороге. При случайных прогнозах AP — это доля положительных образцов.
Ссылки [Manning2008] и [Everingham2010] представляют альтернативные варианты AP, которые интерполируют кривую точности-отзыва. В настоящее время average_precision_score не реализован какой-либо вариант с интерполяцией. Ссылки [Davis2006] и [Flach2015] описывают, почему линейная интерполяция точек на кривой точности-отзыва обеспечивает чрезмерно оптимистичный показатель эффективности классификатора. Эта линейная интерполяция используется при вычислении площади под кривой с помощью правила трапеции в auc.
Несколько функций позволяют анализировать точность, отзыв и оценку F-мер:
average_precision_score(y_true, y_score, *) |
Вычислить среднюю точность (AP) из оценок прогнозов. |
f1_score(y_true, y_pred, *[, labels, …]) |
Вычислите оценку F1, также известную как сбалансированная оценка F или F-мера. |
fbeta_score(y_true, y_pred, *, beta[, …]) |
Вычислите оценку F-beta. |
precision_recall_curve(y_true, probas_pred, *) |
Вычислите пары точности-отзыва для разных пороговых значений вероятности. |
precision_recall_fscore_support(y_true, …) |
Точность вычислений, отзыв, F-мера и поддержка для каждого класса. |
precision_score(y_true, y_pred, *[, labels, …]) |
Вычислите точность. |
recall_score(y_true, y_pred, *[, labels, …]) |
Вычислите рекол. |
Обратите внимание, что функция precision_recall_curve ограничена двоичным регистром. Функция average_precision_score работает только в двоичном формате классификации и MultiLabel индикатора. В функции plot_precision_recall_curve графики точности вспомнить следующим образом .
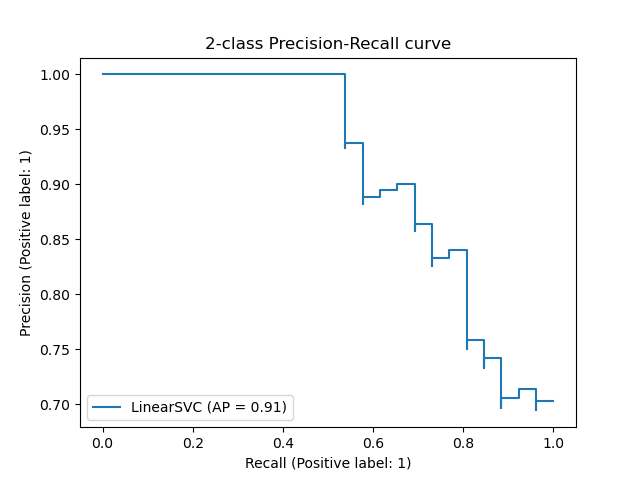
Примеры:
- См. Раздел Классификация текстовых документов с использованием разреженных функций для примера использования
f1_scoreдля классификации текстовых документов. - См. Раздел « Оценка параметров с использованием поиска по сетке с перекрестной проверкой», где приведен пример
precision_scoreиrecall_scoreиспользование для оценки параметров с помощью поиска по сетке с вложенной перекрестной проверкой. - См. В разделе Precision-Recall пример использования
precision_recall_curveдля оценки качества вывода классификатора.
Рекомендации:
- [Manning2008] г. CD Manning, P. Raghavan, H. Schütze, Introduction to Information Retrieval , 2008.
- [Everingham2010] М. Эверингем, Л. Ван Гул, CKI Уильямс, Дж. Винн, А. Зиссерман, Задача классов визуальных объектов Pascal (VOC) , IJCV 2010.
- [Davis2006] Дж. Дэвис, М. Гоадрич, Взаимосвязь между точным воспроизведением и кривыми ROC , ICML 2006.
- [Flach2015] П.А. Флэч, М. Кулл, Кривые точности-отзыва-выигрыша: PR-анализ выполнен правильно , NIPS 2015.
3.3.2.9.1. Бинарная классификация
В задаче бинарной классификации термины «положительный» и «отрицательный» относятся к предсказанию классификатора, а термины «истинный» и «ложный» относятся к тому, соответствует ли этот прогноз внешнему суждению ( иногда известное как «наблюдение»). Учитывая эти определения, мы можем сформулировать следующую таблицу:
| Фактический класс (наблюдение) | ||
| Прогнозируемый класс (ожидание) | tp (истинно положительный результат) Правильный результат | fp (ложное срабатывание) Неожиданный результат |
| Прогнозируемый класс (ожидание) | fn (ложноотрицательный) Отсутствует результат | tn (истинно отрицательное) Правильное отсутствие результата |
В этом контексте мы можем определить понятия точности, отзыва и F-меры:
$$text{precision} = frac{tp}{tp + fp},$$
$$text{recall} = frac{tp}{tp + fn},$$
$$F_beta = (1 + beta^2) frac{text{precision} times text{recall}}{beta^2 text{precision} + text{recall}}.$$
Вот несколько небольших примеров бинарной классификации:
>>> from sklearn import metrics >>> y_pred = [0, 1, 0, 0] >>> y_true = [0, 1, 0, 1] >>> metrics.precision_score(y_true, y_pred) 1.0 >>> metrics.recall_score(y_true, y_pred) 0.5 >>> metrics.f1_score(y_true, y_pred) 0.66... >>> metrics.fbeta_score(y_true, y_pred, beta=0.5) 0.83... >>> metrics.fbeta_score(y_true, y_pred, beta=1) 0.66... >>> metrics.fbeta_score(y_true, y_pred, beta=2) 0.55... >>> metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5) (array([0.66..., 1. ]), array([1. , 0.5]), array([0.71..., 0.83...]), array([2, 2])) >>> import numpy as np >>> from sklearn.metrics import precision_recall_curve >>> from sklearn.metrics import average_precision_score >>> y_true = np.array([0, 0, 1, 1]) >>> y_scores = np.array([0.1, 0.4, 0.35, 0.8]) >>> precision, recall, threshold = precision_recall_curve(y_true, y_scores) >>> precision array([0.66..., 0.5 , 1. , 1. ]) >>> recall array([1. , 0.5, 0.5, 0. ]) >>> threshold array([0.35, 0.4 , 0.8 ]) >>> average_precision_score(y_true, y_scores) 0.83...
3.3.2.9.2. Мультиклассовая и многозначная классификация
В задаче классификации по нескольким классам и меткам понятия точности, отзыва и F-меры могут применяться к каждой метке независимо. Есть несколько способов , чтобы объединить результаты по этикеткам, указанных в average аргументе к average_precision_score (MultiLabel только) f1_score, fbeta_score, precision_recall_fscore_support, precision_score и recall_score функция, как описано выше . Обратите внимание, что если включены все метки, «микро» -усреднение в настройке мультикласса обеспечит точность, отзыв и $F$ все они идентичны по точности. Также обратите внимание, что «взвешенное» усреднение может дать оценку F, которая не находится между точностью и отзывом.
Чтобы сделать это более явным, рассмотрим следующие обозначения:
- $y$ набор предсказанных ($sample$, $label$) пары
- $hat{y}$ набор истинных ($sample$, $label$) пары
- $L$ набор лейблов
- $S$ набор образцов
- $y_s$ подмножество $y$ с образцом $s$, т.е $y_s := left{(s’, l) in y | s’ = sright}$.
- $y_l$ подмножество $y$ с этикеткой $l$
- по аналогии, $hat{y}_s$ а также $hat{y}_l$ являются подмножествами $hat{y}$
- $P(A, B) := frac{left| A cap B right|}{left|Aright|}$ для некоторых наборов $A$ и $B$
- $R(A, B) := frac{left| A cap B right|}{left|Bright|}$ (Условные обозначения различаются в зависимости от обращения $B = emptyset$; эта реализация использует $R(A, B):=0$, и аналогичные для $P$.)
- $$F_beta(A, B) := left(1 + beta^2right) frac{P(A, B) times R(A, B)}{beta^2 P(A, B) + R(A, B)}$$
Тогда показатели определяются как:
| average | Точность | Отзывать | F_beta |
| «micro» | $P(y, hat{y})$ | $R(y, hat{y})$ | $F_beta(y, hat{y})$ |
| «samples» | $frac{1}{left|Sright|} sum_{s in S} P(y_s, hat{y}_s)$ | $frac{1}{left|Sright|} sum_{s in S} R(y_s, hat{y}_s)$ | $frac{1}{left|Sright|} sum_{s in S} F_beta(y_s, hat{y}_s)$ |
| «macro» | $frac{1}{left|Lright|} sum_{l in L} P(y_l, hat{y}_l)$ | $frac{1}{left|Lright|} sum_{l in L} R(y_l, hat{y}_l)$ | $frac{1}{left|Lright|} sum_{l in L} F_beta(y_l, hat{y}_l)$ |
| «weighted» | $frac{1}{sum_{l in L} left|hat{y}lright|} sum{l in L} left|hat{y}_lright| P(y_l, hat{y}_l)$ | $frac{1}{sum_{l in L} left|hat{y}lright|} sum{l in L} left|hat{y}_lright| R(y_l, hat{y}_l)$ | $frac{1}{sum_{l in L} left|hat{y}lright|} sum{l in L} left|hat{y}lright| Fbeta(y_l, hat{y}_l)$ |
| None | $langle P(y_l, hat{y}_l) | l in L rangle$ | $langle R(y_l, hat{y}_l) | l in L rangle$ | $langle F_beta(y_l, hat{y}_l) | l in L rangle$ |
>>> from sklearn import metrics >>> y_true = [0, 1, 2, 0, 1, 2] >>> y_pred = [0, 2, 1, 0, 0, 1] >>> metrics.precision_score(y_true, y_pred, average='macro') 0.22... >>> metrics.recall_score(y_true, y_pred, average='micro') 0.33... >>> metrics.f1_score(y_true, y_pred, average='weighted') 0.26... >>> metrics.fbeta_score(y_true, y_pred, average='macro', beta=0.5) 0.23... >>> metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5, average=None) (array([0.66..., 0. , 0. ]), array([1., 0., 0.]), array([0.71..., 0. , 0. ]), array([2, 2, 2]...))
Для мультиклассовой классификации с «отрицательным классом» можно исключить некоторые метки:
>>> metrics.recall_score(y_true, y_pred, labels=[1, 2], average='micro') ... # excluding 0, no labels were correctly recalled 0.0
Точно так же метки, отсутствующие в выборке данных, могут учитываться при макро-усреднении.
>>> metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro') 0.166...
3.3.2.10. Оценка коэффициента сходства Жаккара
Функция jaccard_score вычисляет среднее значение коэффициентов сходства Jaccard , также называемый индексом Jaccard, между парами множеств меток.
Коэффициент подобия Жаккара i-ые образцы, с набором меток наземной достоверности yi и прогнозируемый набор меток y^i, определяется как
$$J(y_i, hat{y}_i) = frac{|y_i cap hat{y}_i|}{|y_i cup hat{y}_i|}.$$
jaccard_score работает как precision_recall_fscore_support наивно установленная мера, применяемая изначально к бинарным целям, и расширена для применения к множественным меткам и мультиклассам за счет использования average(см. выше ).
В двоичном случае:
>>> import numpy as np >>> from sklearn.metrics import jaccard_score >>> y_true = np.array([[0, 1, 1], ... [1, 1, 0]]) >>> y_pred = np.array([[1, 1, 1], ... [1, 0, 0]]) >>> jaccard_score(y_true[0], y_pred[0]) 0.6666...
В многопозиционном корпусе с бинарными индикаторами меток:
>>> jaccard_score(y_true, y_pred, average='samples') 0.5833... >>> jaccard_score(y_true, y_pred, average='macro') 0.6666... >>> jaccard_score(y_true, y_pred, average=None) array([0.5, 0.5, 1. ])
Задачи с несколькими классами преобразуются в двоичную форму и обрабатываются как соответствующая задача с несколькими метками:
>>> y_pred = [0, 2, 1, 2] >>> y_true = [0, 1, 2, 2] >>> jaccard_score(y_true, y_pred, average=None) array([1. , 0. , 0.33...]) >>> jaccard_score(y_true, y_pred, average='macro') 0.44... >>> jaccard_score(y_true, y_pred, average='micro') 0.33...
3.3.2.11. Петля лосс
Функция hinge_loss вычисляет среднее расстояние между моделью и данными с использованием петля лосс, односторонний показателем , который учитывает только ошибки прогнозирования. (Потери на шарнирах используются в классификаторах максимальной маржи, таких как опорные векторные машины.)
Если метки закодированы с помощью +1 и -1, $y$: истинное значение, а $w$ — прогнозируемые решения на выходе decision_function, тогда потери на шарнирах определяются как:
$$L_text{Hinge}(y, w) = maxleft{1 — wy, 0right} = left|1 — wyright|_+$$
Если имеется более двух ярлыков, hinge_loss используется мультиклассовый вариант, разработанный Crammer & Singer. Вот статья, описывающая это.
Если $y_w$ прогнозируемое решение для истинного лейбла и $y_t$ — это максимум предсказанных решений для всех других меток, где предсказанные решения выводятся функцией принятия решений, тогда потеря шарнира в нескольких классах определяется следующим образом:
$$L_text{Hinge}(y_w, y_t) = maxleft{1 + y_t — y_w, 0right}$$
Вот небольшой пример, демонстрирующий использование hinge_loss функции с классификатором svm в задаче двоичного класса:
>>> from sklearn import svm >>> from sklearn.metrics import hinge_loss >>> X = [[0], [1]] >>> y = [-1, 1] >>> est = svm.LinearSVC(random_state=0) >>> est.fit(X, y) LinearSVC(random_state=0) >>> pred_decision = est.decision_function([[-2], [3], [0.5]]) >>> pred_decision array([-2.18..., 2.36..., 0.09...]) >>> hinge_loss([-1, 1, 1], pred_decision) 0.3...
Вот пример, демонстрирующий использование hinge_loss функции с классификатором svm в мультиклассовой задаче:
>>> X = np.array([[0], [1], [2], [3]]) >>> Y = np.array([0, 1, 2, 3]) >>> labels = np.array([0, 1, 2, 3]) >>> est = svm.LinearSVC() >>> est.fit(X, Y) LinearSVC() >>> pred_decision = est.decision_function([[-1], [2], [3]]) >>> y_true = [0, 2, 3] >>> hinge_loss(y_true, pred_decision, labels) 0.56...
3.3.2.12. Лог лосс
Лог лосс, также называемые потерями логистической регрессии или кросс-энтропийными потерями, определяются на основе оценок вероятности. Он обычно используется в (полиномиальной) логистической регрессии и нейронных сетях, а также в некоторых вариантах максимизации ожидания и может использоваться для оценки выходов вероятности ( predict_proba) классификатора вместо его дискретных прогнозов.
Для двоичной классификации с истинной меткой $y in {0,1}$ и оценка вероятности $p = operatorname{Pr}(y = 1)$, логарифмическая потеря на выборку представляет собой отрицательную логарифмическую вероятность классификатора с истинной меткой:
$$L_{log}(y, p) = -log operatorname{Pr}(y|p) = -(y log (p) + (1 — y) log (1 — p))$$
Это распространяется на случай мультикласса следующим образом. Пусть истинные метки для набора выборок будут закодированы размером 1 из K как двоичная индикаторная матрица $Y$, т.е. $y_{i,k}=1$ если образец $i$ есть ярлык $k$ взят из набора $K$ этикетки. Пусть $P$ — матрица оценок вероятностей, с $p_{i,k} = operatorname{Pr}(y_{i,k} = 1)$. Тогда потеря журнала всего набора равна
$$L_{log}(Y, P) = -log operatorname{Pr}(Y|P) = — frac{1}{N} sum_{i=0}^{N-1} sum_{k=0}^{K-1} y_{i,k} log p_{i,k}$$
Чтобы увидеть, как это обобщает приведенную выше потерю двоичного журнала, обратите внимание, что в двоичном случае $p_{i,0} = 1 — p_{i,1}$ и $y_{i,0} = 1 — y_{i,1}$, поэтому разложив внутреннюю сумму на $y_{i,k} in {0,1}$ дает двоичную потерю журнала.
В log_loss функции вычисляет журнал потеря дана список меток приземной истины и матриц вероятностей, возвращенный оценщик predict_proba методом.
>>> from sklearn.metrics import log_loss >>> y_true = [0, 0, 1, 1] >>> y_pred = [[.9, .1], [.8, .2], [.3, .7], [.01, .99]] >>> log_loss(y_true, y_pred) 0.1738...
Первое [.9, .1] в y_pred означает 90% вероятность того, что первая выборка будет иметь метку 0. Лог лос неотрицательны.
3.3.2.13. Коэффициент корреляции Мэтьюза
Функция matthews_corrcoef вычисляет коэффициент корреляции Матфея (MCC) для двоичных классов. Цитата из Википедии:
«Коэффициент корреляции Мэтьюза используется в машинном обучении как мера качества двоичных (двухклассных) классификаций. Он учитывает истинные и ложные положительные и отрицательные результаты и обычно рассматривается как сбалансированная мера, которую можно использовать, даже если классы очень разных размеров. MCC — это, по сути, значение коэффициента корреляции между -1 и +1. Коэффициент +1 представляет собой идеальное предсказание, 0 — среднее случайное предсказание и -1 — обратное предсказание. Статистика также известна как коэффициент фи ».
В бинарном (двухклассовом) случае $tp$, $tn$, $fp$ а также $fn$ являются соответственно количеством истинно положительных, истинно отрицательных, ложноположительных и ложноотрицательных результатов, MCC определяется как
$$MCC = frac{tp times tn — fp times fn}{sqrt{(tp + fp)(tp + fn)(tn + fp)(tn + fn)}}.$$
В случае мультикласса коэффициент корреляции Мэтьюза может быть определен в терминах confusion_matrix C для Kклассы. Чтобы упростить определение, рассмотрим следующие промежуточные переменные:
- $t_k=sum_{i}^{K} C_{ik}$ количество занятий k действительно произошло,
- $p_k=sum_{i}^{K} C_{ki}$ количество занятий k был предсказан,
- $c=sum_{k}^{K} C_{kk}$ общее количество правильно спрогнозированных образцов,
- $s=sum_{i}^{K} sum_{j}^{K} C_{ij}$ общее количество образцов.
Тогда мультиклассовый MCC определяется как:
$$MCC = frac{ c times s — sum_{k}^{K} p_k times t_k }{sqrt{ (s^2 — sum_{k}^{K} p_k^2) times (s^2 — sum_{k}^{K} t_k^2) }}$$
Когда имеется более двух меток, значение MCC больше не будет находиться в диапазоне от -1 до +1. Вместо этого минимальное значение будет где-то между -1 и 0 в зависимости от количества и распределения наземных истинных меток. Максимальное значение всегда +1.
Вот небольшой пример, иллюстрирующий использование matthews_corrcoef функции:
>>> from sklearn.metrics import matthews_corrcoef >>> y_true = [+1, +1, +1, -1] >>> y_pred = [+1, -1, +1, +1] >>> matthews_corrcoef(y_true, y_pred) -0.33...
3.3.2.14. Матрица путаницы с несколькими метками
Функция multilabel_confusion_matrix вычисляет класс-накрест ( по умолчанию) или samplewise (samplewise = True) MultiLabel матрицы спутанности для оценки точности классификации. Multilabel_confusion_matrix также обрабатывает данные мультикласса, как если бы они были многоклассовыми, поскольку это преобразование, обычно применяемое для оценки проблем мультикласса с метриками двоичной классификации (такими как точность, отзыв и т. д.).
При вычислении классовой матрицы путаницы с несколькими метками $C$, количество истинных негативов для класса i является $C_{i,0,0}$, ложноотрицательные $C_{i,1,0}$, истинные положительные стороны $C_{i,1,1}$ а ложные срабатывания $C_{i,0,1}$.
Вот пример, демонстрирующий использование multilabel_confusion_matrix функции с вводом многозначной индикаторной матрицы:
>>> import numpy as np
>>> from sklearn.metrics import multilabel_confusion_matrix
>>> y_true = np.array([[1, 0, 1],
... [0, 1, 0]])
>>> y_pred = np.array([[1, 0, 0],
... [0, 1, 1]])
>>> multilabel_confusion_matrix(y_true, y_pred)
array([[[1, 0],
[0, 1]],
[[1, 0],
[0, 1]],
[[0, 1],
[1, 0]]])
Или можно построить матрицу неточностей для каждой метки образца:
>>> multilabel_confusion_matrix(y_true, y_pred, samplewise=True)
array([[[1, 0],
[1, 1]],
[[1, 1],
[0, 1]]])
Вот пример, демонстрирующий использование multilabel_confusion_matrix функции с многоклассовым вводом:
>>> y_true = ["cat", "ant", "cat", "cat", "ant", "bird"]
>>> y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"]
>>> multilabel_confusion_matrix(y_true, y_pred,
... labels=["ant", "bird", "cat"])
array([[[3, 1],
[0, 2]],
[[5, 0],
[1, 0]],
[[2, 1],
[1, 2]]])
Вот несколько примеров, демонстрирующих использование multilabel_confusion_matrix функции для расчета отзыва (или чувствительности), специфичности, количества выпадений и пропусков для каждого класса в задаче с вводом многозначной индикаторной матрицы.
Расчет отзыва (также называемого истинно положительным коэффициентом или чувствительностью) для каждого класса:
>>> y_true = np.array([[0, 0, 1], ... [0, 1, 0], ... [1, 1, 0]]) >>> y_pred = np.array([[0, 1, 0], ... [0, 0, 1], ... [1, 1, 0]]) >>> mcm = multilabel_confusion_matrix(y_true, y_pred) >>> tn = mcm[:, 0, 0] >>> tp = mcm[:, 1, 1] >>> fn = mcm[:, 1, 0] >>> fp = mcm[:, 0, 1] >>> tp / (tp + fn) array([1. , 0.5, 0. ])
Расчет специфичности (также называемой истинно отрицательной ставкой) для каждого класса:
>>> tn / (tn + fp) array([1. , 0. , 0.5])
Расчет количества выпадений (также называемый частотой ложных срабатываний) для каждого класса:
>>> fp / (fp + tn) array([0. , 1. , 0.5])
Расчет процента промахов (также называемого ложноотрицательным показателем) для каждого класса:
>>> fn / (fn + tp) array([0. , 0.5, 1. ])
3.3.2.15. Рабочая характеристика приемника (ROC)
Функция roc_curve вычисляет рабочую характеристическую кривую приемника или кривую ROC . Цитата из Википедии:
«Рабочая характеристика приемника (ROC), или просто кривая ROC, представляет собой графический график, который иллюстрирует работу системы двоичного классификатора при изменении ее порога дискриминации. Он создается путем построения графика доли истинных положительных результатов из положительных (TPR = частота истинных положительных результатов) по сравнению с долей ложных положительных результатов из отрицательных (FPR = частота ложных положительных результатов) при различных настройках пороговых значений. TPR также известен как чувствительность, а FPR — это единица минус специфичность или истинно отрицательный показатель ».
Для этой функции требуется истинное двоичное значение и целевые баллы, которые могут быть либо оценками вероятности положительного класса, либо значениями достоверности, либо двоичными решениями. Вот небольшой пример использования roc_curve функции:
>>> import numpy as np >>> from sklearn.metrics import roc_curve >>> y = np.array([1, 1, 2, 2]) >>> scores = np.array([0.1, 0.4, 0.35, 0.8]) >>> fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2) >>> fpr array([0. , 0. , 0.5, 0.5, 1. ]) >>> tpr array([0. , 0.5, 0.5, 1. , 1. ]) >>> thresholds array([1.8 , 0.8 , 0.4 , 0.35, 0.1 ])
На этом рисунке показан пример такой кривой ROC:
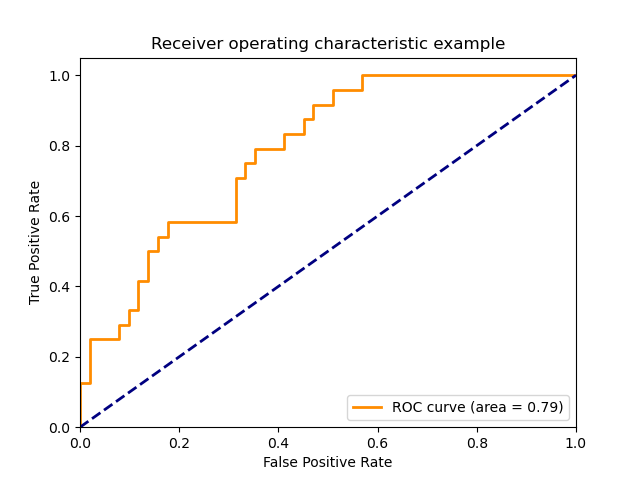
Функция roc_auc_score вычисляет площадь под операционной приемника характеристика (ROC) кривой, которая также обозначается через ППК или AUROC. При вычислении площади под кривой roc информация о кривой суммируется в одном номере. Для получения дополнительной информации см. Статью в Википедии о AUC.
По сравнению с такими показателями, как точность подмножества, потеря Хэмминга или оценка F1, ROC не требует оптимизации порога для каждой метки.
3.3.2.15.1. Двоичный регистр
В двоичном случае вы можете либо предоставить оценки вероятности, используя classifier.predict_proba() метод, либо значения решения без пороговых значений, заданные classifier.decision_function() методом. В случае предоставления оценок вероятности следует указать вероятность класса с «большей меткой». «Большая метка» соответствует classifier.classes_[1] и, следовательно classifier.predict_proba(X) [:, 1]. Следовательно, параметр y_score имеет размер (n_samples,).
>>> from sklearn.datasets import load_breast_cancer >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.metrics import roc_auc_score >>> X, y = load_breast_cancer(return_X_y=True) >>> clf = LogisticRegression(solver="liblinear").fit(X, y) >>> clf.classes_ array([0, 1])
Мы можем использовать оценки вероятностей, соответствующие clf.classes_[1].
>>> y_score = clf.predict_proba(X)[:, 1] >>> roc_auc_score(y, y_score) 0.99...
В противном случае мы можем использовать значения решения без порога.
>>> roc_auc_score(y, clf.decision_function(X)) 0.99...
3.3.2.15.2. Мультиклассовый кейс
Функция roc_auc_score также может быть использована в нескольких классах классификации . В настоящее время поддерживаются две стратегии усреднения: алгоритм «один против одного» вычисляет среднее попарных оценок AUC ROC, а алгоритм «один против остальных» вычисляет среднее значение оценок ROC AUC для каждого класса по сравнению со всеми другими классами. В обоих случаях предсказанные метки предоставляются в виде массива со значениями от 0 до n_classes, а оценки соответствуют оценкам вероятности того, что выборка принадлежит определенному классу. Алгоритмы OvO и OvR поддерживают равномерное взвешивание ( average='macro') и по распространенности ( average='weighted').
Алгоритм «один против одного» : вычисляет средний AUC всех возможных попарных комбинаций классов. [HT2001] определяет метрику AUC мультикласса, взвешенную равномерно:
$$frac{1}{c(c-1)}sum_{j=1}^{c}sum_{k > j}^c (text{AUC}(j | k) + text{AUC}(k | j))$$
где $c$ количество классов и $text{AUC}(j | k)$ AUC с классом $j$ как положительный класс и класс $k$ как отрицательный класс. В общем, $text{AUC}(j | k) neq text{AUC}(k | j))$ в случае мультикласса. Этот алгоритм используется, установив аргумент ключевого слова , multiclass чтобы 'ovo' и average в 'macro'.
[HT2001] мультиклассируют AUC метрика может быть расширена , чтобы быть взвешены по распространенности:
$$frac{1}{c(c-1)}sum_{j=1}^{c}sum_{k > j}^c p(j cup k)( text{AUC}(j | k) + text{AUC}(k | j))$$
где cколичество классов. Этот алгоритм используется, установив аргумент ключевого слова , multiclass чтобы 'ovo' и average в 'weighted'. В 'weighted' опции возвращает распространенность усредненные , как описано в [FC2009] .
Алгоритм «один против остальных» : вычисляет AUC каждого класса относительно остальных [PD2000] . Алгоритм функционально такой же, как и в случае с несколькими этикетками. Чтобы включить этот алгоритм, установите для аргумента ключевого слова multiclass значение 'ovr'. Как и OvO, OvR поддерживает два типа усреднения: 'macro' [F2006] и 'weighted' [F2001] .
В приложениях , где высокий процент ложных срабатываний не терпимый параметр max_fpr из roc_auc_score может быть использовано , чтобы суммировать кривую ROC до заданного предела.
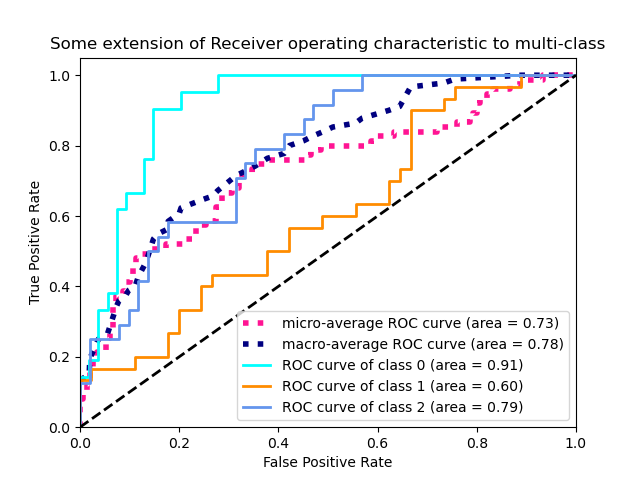
3.3.2.15.3. Кейс с несколькими метками
В классификации несколько меток, функция roc_auc_score распространяются путем усреднения меток , как выше . В этом случае вы должны указать y_score форму . Таким образом, при использовании оценок вероятности необходимо выбрать вероятность класса с большей меткой для каждого выхода.(n_samples, n_classes)
>>> from sklearn.datasets import make_multilabel_classification >>> from sklearn.multioutput import MultiOutputClassifier >>> X, y = make_multilabel_classification(random_state=0) >>> inner_clf = LogisticRegression(solver="liblinear", random_state=0) >>> clf = MultiOutputClassifier(inner_clf).fit(X, y) >>> y_score = np.transpose([y_pred[:, 1] for y_pred in clf.predict_proba(X)]) >>> roc_auc_score(y, y_score, average=None) array([0.82..., 0.86..., 0.94..., 0.85... , 0.94...])
И значения решений не требуют такой обработки.
>>> from sklearn.linear_model import RidgeClassifierCV >>> clf = RidgeClassifierCV().fit(X, y) >>> y_score = clf.decision_function(X) >>> roc_auc_score(y, y_score, average=None) array([0.81..., 0.84... , 0.93..., 0.87..., 0.94...])
Примеры:
- См. В разделе « Рабочие характеристики приемника» (ROC) пример использования ROC для оценки качества выходных данных классификатора.
- См. В разделе « Рабочие характеристики приемника» (ROC) с перекрестной проверкой пример использования ROC для оценки качества выходных данных классификатора с помощью перекрестной проверки.
- См. В разделе Моделирование распределения видов пример использования ROC для моделирования распределения видов.
- HT2001 ( 1 , 2 ) Рука, DJ и Тилль, RJ, (2001). Простое обобщение области под кривой ROC для задач классификации нескольких классов. Машинное обучение, 45 (2), стр. 171-186.
- FC2009 Ферри, Сезар и Эрнандес-Оралло, Хосе и Модройу, Р. (2009). Экспериментальное сравнение показателей эффективности для классификации. Письма о распознавании образов. 30. 27-38.
- PD2000 Провост Ф., Домингос П. (2000). Хорошо обученные ПЭТ: Улучшение деревьев оценки вероятностей (Раздел 6.2), Рабочий документ CeDER № IS-00-04, Школа бизнеса Стерна, Нью-Йоркский университет.
- F2006 Фосетт, Т., 2006. Введение в анализ ROC. Письма о распознавании образов, 27 (8), стр. 861-874.
- F2001Фосетт, Т., 2001. Использование наборов правил для максимизации производительности ROC в интеллектуальном анализе данных, 2001. Труды Международной конференции IEEE, стр. 131-138.
3.3.2.16. Компромисс при обнаружении ошибок (DET)
Функция det_curve вычисляет кривую компенсации ошибок обнаружения (DET) [WikipediaDET2017] . Цитата из Википедии:
«График компромисса ошибок обнаружения (DET) — это графическая диаграмма частоты ошибок для систем двоичной классификации, отображающая частоту ложных отклонений по сравнению с частотой ложных приемов. Оси x и y масштабируются нелинейно по их стандартным нормальным отклонениям (или просто с помощью логарифмического преобразования), в результате получаются более линейные кривые компромисса, чем кривые ROC, и большая часть области изображения используется для выделения важных различий в критический рабочий регион ».
Кривые DET представляют собой вариацию кривых рабочих характеристик приемника (ROC), где ложная отрицательная скорость нанесена на ось y вместо истинной положительной скорости. Кривые DET обычно строятся в масштабе нормального отклонения путем преобразования $phi^{-1}$ (с участием $phi$ — кумулятивная функция распределения). Полученные кривые производительности явно визуализируют компромисс типов ошибок для заданных алгоритмов классификации. См. [Martin1997], где приведены примеры и мотивация.
На этом рисунке сравниваются кривые ROC и DET двух примеров классификаторов для одной и той же задачи классификации:
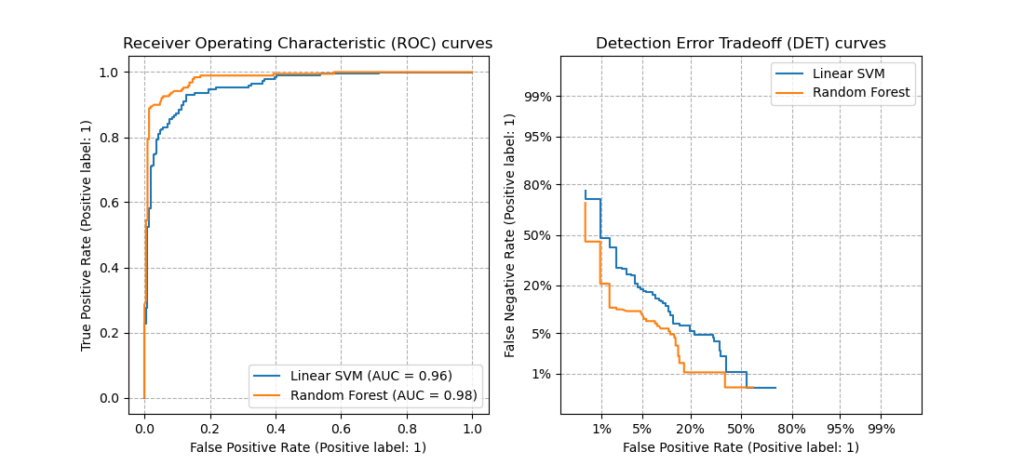
Характеристики:
- Кривые DET образуют линейную кривую по шкале нормального отклонения, если оценки обнаружения нормально (или близки к нормальному) распределены. В [Navratil2007] было показано, что обратное не обязательно верно, и даже более общие распределения могут давать линейные кривые DET.
- При обычном преобразовании масштаба с отклонением точки распределяются таким образом, что занимает сравнительно большее пространство графика. Следовательно, кривые с аналогичными характеристиками классификации легче различить на графике DET.
- С ложноотрицательной скоростью, «обратной» истинной положительной скорости, точкой совершенства для кривых DET является начало координат (в отличие от верхнего левого угла для кривых ROC).
Приложения и ограничения:
Кривые DET интуитивно понятны для чтения и, следовательно, позволяют быстро визуально оценить работу классификатора. Кроме того, кривые DET можно использовать для анализа пороговых значений и выбора рабочей точки. Это особенно полезно, если требуется сравнение типов ошибок.
С другой стороны, кривые DET не представляют свою метрику в виде единого числа. Поэтому для автоматической оценки или сравнения с другими задачами классификации лучше подходят такие показатели, как производная площадь под кривой ROC.
Примеры:
- См. Кривую компенсации ошибок обнаружения (DET) для примера сравнения кривых рабочих характеристик приемника (ROC) и кривых компенсации ошибок обнаружения (DET).
Рекомендации:
- ВикипедияDET2017 Авторы Википедии. Компромисс ошибки обнаружения. Википедия, свободная энциклопедия. 4 сентября 2017 г., 23:33 UTC. Доступно по адресу: https://en.wikipedia.org/w/index.php?title=Detection_error_tradeoff&oldid=798982054 . По состоянию на 19 февраля 2018 г.
- Мартин 1997 А. Мартин, Дж. Доддингтон, Т. Камм, М. Ордовски и М. Пшибоцки, Кривая DET в оценке эффективности задач обнаружения , NIST 1997.
- Навратил2007 Дж. Наврактил и Д. Клусачек, « О линейных DET », 2007 г. Международная конференция IEEE по акустике, обработке речи и сигналов — ICASSP ’07, Гонолулу, Гавайи, 2007 г., стр. IV-229-IV-232.
3.3.2.17. Нулевой проигрыш
Функция zero_one_loss вычисляет сумму или среднее значение потери 0-1 классификации ($L_{0−1}$) над $n_{samples}$. По умолчанию функция нормализуется по выборке. Чтобы получить сумму $L_{0−1}$, установите normalize значение False.
В классификации по zero_one_loss нескольким меткам подмножество оценивается как единое целое, если его метки строго соответствуют прогнозам, и как ноль, если есть какие-либо ошибки. По умолчанию функция возвращает процент неправильно спрогнозированных подмножеств. Чтобы вместо этого получить количество таких подмножеств, установите normalize значение False
Если $hat{y}_i$ прогнозируемое значение $i$-й образец и $y_i$ — соответствующее истинное значение, тогда потеря 0-1 $L_{0−1}$ определяется как:
$$L_{0-1}(y_i, hat{y}_i) = 1(hat{y}_i not= y_i)$$
где $1(x)$- индикаторная функция.
>>> from sklearn.metrics import zero_one_loss >>> y_pred = [1, 2, 3, 4] >>> y_true = [2, 2, 3, 4] >>> zero_one_loss(y_true, y_pred) 0.25 >>> zero_one_loss(y_true, y_pred, normalize=False) 1
В случае с несколькими метками с двоичными индикаторами меток, где первый набор меток [0,1] содержит ошибку:
>>> zero_one_loss(np.array([[0, 1], [1, 1]]), np.ones((2, 2))) 0.5 >>> zero_one_loss(np.array([[0, 1], [1, 1]]), np.ones((2, 2)), normalize=False) 1
Пример:
- См. В разделе « Рекурсивное исключение функции с перекрестной проверкой» пример использования нулевой потери для выполнения рекурсивного исключения функции с перекрестной проверкой.
3.3.2.18. Потеря очков по Брайеру
Функция brier_score_loss вычисляет оценку Шиповник для бинарных классов [Brier1950] . Цитата из Википедии:
«Оценка Бриера — это правильная функция оценки, которая измеряет точность вероятностных прогнозов. Это применимо к задачам, в которых прогнозы должны назначать вероятности набору взаимоисключающих дискретных результатов ».
Эта функция возвращает среднеквадратичную ошибку фактического результата. y∈{0,1} и прогнозируемая оценка вероятности $p=Pr(y=1)$ ( pred_proba ) как выведено :
$$BS = frac{1}{n_{text{samples}}} sum_{i=0}^{n_{text{samples}} — 1}(y_i — p_i)^2$$
Потеря по шкале Бриера также составляет от 0 до 1, и чем ниже значение (средняя квадратичная разница меньше), тем точнее прогноз.
Вот небольшой пример использования этой функции:
>>> import numpy as np >>> from sklearn.metrics import brier_score_loss >>> y_true = np.array([0, 1, 1, 0]) >>> y_true_categorical = np.array(["spam", "ham", "ham", "spam"]) >>> y_prob = np.array([0.1, 0.9, 0.8, 0.4]) >>> y_pred = np.array([0, 1, 1, 0]) >>> brier_score_loss(y_true, y_prob) 0.055 >>> brier_score_loss(y_true, 1 - y_prob, pos_label=0) 0.055 >>> brier_score_loss(y_true_categorical, y_prob, pos_label="ham") 0.055 >>> brier_score_loss(y_true, y_prob > 0.5) 0.0
Балл Бриера можно использовать для оценки того, насколько хорошо откалиброван классификатор. Однако меньшая потеря по шкале Бриера не всегда означает лучшую калибровку. Это связано с тем, что по аналогии с разложением среднеквадратичной ошибки на дисперсию смещения потеря оценки по Бриеру может быть разложена как сумма потерь калибровки и потерь при уточнении [Bella2012]. Потеря калибровки определяется как среднеквадратическое отклонение от эмпирических вероятностей, полученных из наклона ROC-сегментов. Потери при переработке можно определить как ожидаемые оптимальные потери, измеренные по площади под кривой оптимальных затрат. Потери при уточнении могут изменяться независимо от потерь при калибровке, таким образом, более низкие потери по шкале Бриера не обязательно означают более качественную калибровку модели. «Только когда потеря точности остается неизменной, более низкая потеря по шкале Бриера всегда означает лучшую калибровку» [Bella2012] , [Flach2008] .
Пример:
- См. Раздел « Калибровка вероятности классификаторов», где приведен пример использования потерь по шкале Бриера для выполнения калибровки вероятности классификаторов.
Рекомендации:
- Brier1950 Дж. Брайер, Проверка прогнозов, выраженных в терминах вероятности , Ежемесячный обзор погоды 78.1 (1950)
- Bella2012 ( 1 , 2 ) Белла, Ферри, Эрнандес-Оралло и Рамирес-Кинтана «Калибровка моделей машинного обучения» в Хосров-Пур, М. «Машинное обучение: концепции, методологии, инструменты и приложения». Херши, Пенсильвания: Справочник по информационным наукам (2012).
- Flach2008 Флак, Питер и Эдсон Мацубара. «О классификации, ранжировании и оценке вероятности». Дагштульский семинар. Schloss Dagstuhl-Leibniz-Zentrum от Informatik (2008).
3.3.3. Метрики ранжирования с несколькими ярлыками
В многоэлементном обучении с каждой выборкой может быть связано любое количество меток истинности. Цель состоит в том, чтобы дать высокие оценки и более высокий рейтинг наземным лейблам.
3.3.3.1. Ошибка покрытия
Функция coverage_error вычисляет среднее число меток , которые должны быть включены в окончательном предсказании таким образом, что все истинные метки предсказанные. Это полезно, если вы хотите знать, сколько меток с наивысшими баллами вам нужно предсказать в среднем, не пропуская ни одной истинной. Таким образом, наилучшее значение этого показателя — среднее количество истинных ярлыков.
Примечание
Оценка нашей реализации на 1 больше, чем оценка, приведенная в Tsoumakas et al., 2010. Это расширяет ее для обработки вырожденного случая, когда экземпляр имеет 0 истинных меток.
Формально, учитывая двоичную индикаторную матрицу наземных меток истинности $y in left{0, 1right}^{n_text{samples} times n_text{labels}}$ и оценка, связанная с каждой меткой $hat{f} in mathbb{R}^{n_text{samples} times n_text{labels}}$ покрытие определяется как
$$coverage(y, hat{f}) = frac{1}{n_{text{samples}}} sum_{i=0}^{n_{text{samples}} — 1} max_{j:y_{ij} = 1} text{rank}_{ij}$$
с участием $text{rank}{ij} = left|left{k: hat{f}{ik} geq hat{f}_{ij} right}right|$. Учитывая определение ранга, связи y_scores разрываются путем присвоения максимального ранга, который был бы присвоен всем связанным значениям.
Вот небольшой пример использования этой функции:
>>> import numpy as np >>> from sklearn.metrics import coverage_error >>> y_true = np.array([[1, 0, 0], [0, 0, 1]]) >>> y_score = np.array([[0.75, 0.5, 1], [1, 0.2, 0.1]]) >>> coverage_error(y_true, y_score) 2.5
3.3.3.2. Средняя точность ранжирования метки
В label_ranking_average_precision_score функции реализует маркировать ранжирование средней точности (LRAP). Этот показатель связан с average_precision_score функцией, но основан на понятии ранжирования меток, а не на точности и отзыве.
Средняя точность ранжирования меток (LRAP) усредняет по выборкам ответ на следующий вопрос: для каждой основной метки истинности какая доля меток с более высоким рейтингом была истинной? Этот показатель эффективности будет выше, если вы сможете лучше ранжировать метки, связанные с каждым образцом. Полученная оценка всегда строго больше 0, а наилучшее значение равно 1. Если имеется ровно одна релевантная метка для каждой выборки, средняя точность ранжирования меток эквивалентна среднему обратному рангу .
Формально, учитывая двоичную индикаторную матрицу наземных меток истинности $y in left{0, 1right}^{n_text{samples} times n_text{labels}}$ и оценка, связанная с каждой меткой $hat{f} in mathbb{R}^{n_text{samples} times n_text{labels}}$, средняя точность определяется как
$$LRAP(y, hat{f}) = frac{1}{n_{text{samples}}} sum_{i=0}^{n_{text{samples}} — 1} frac{1}{||y_i||0} sum{j:y_{ij} = 1} frac{|mathcal{L}{ij}|}{text{rank}{ij}}$$
где $mathcal{L}{ij} = left{k: y{ik} = 1, hat{f}{ik} geq hat{f}{ij} right}$, $text{rank}{ij} = left|left{k: hat{f}{ik} geq hat{f}_{ij} right}right|$, |cdot| вычисляет мощность набора (т. е. количество элементов в наборе), и $||cdot||_0$ это $ell_0$ «Norm» (который вычисляет количество ненулевых элементов в векторе).
Вот небольшой пример использования этой функции:
>>> import numpy as np >>> from sklearn.metrics import label_ranking_average_precision_score >>> y_true = np.array([[1, 0, 0], [0, 0, 1]]) >>> y_score = np.array([[0.75, 0.5, 1], [1, 0.2, 0.1]]) >>> label_ranking_average_precision_score(y_true, y_score) 0.416...
3.3.3.3. Потеря рейтинга
Функция label_ranking_loss вычисляет ранжирование потери , которые в среднем более образцы числа пар меток, которые неправильно упорядочены, т.е. истинные метки имеют более низкую оценку , чем ложные метки, взвешенную по обратной величине числа упорядоченных пар ложных и истинных меток. Наименьшая возможная потеря рейтинга равна нулю.
Формально, учитывая двоичную индикаторную матрицу наземных меток истинности $y in left{0, 1right}^{n_text{samples} times n_text{labels}}$ и оценка, связанная с каждой меткой $hat{f} in mathbb{R}^{n_text{samples} times n_text{labels}}$ потеря ранжирования определяется как
$$ranking_loss(y, hat{f}) = frac{1}{n_{text{samples}}} sum_{i=0}^{n_{text{samples}} — 1} frac{1}{||y_i||0(ntext{labels} — ||y_i||0)} left|left{(k, l): hat{f}{ik} leq hat{f}{il}, y{ik} = 1, y_{il} = 0 right}right|$$
где $|cdot|$ вычисляет мощность набора (т. е. количество элементов в наборе) и $||cdot||_0$ это $ell_0$ «Norm» (который вычисляет количество ненулевых элементов в векторе).
Вот небольшой пример использования этой функции:
>>> import numpy as np >>> from sklearn.metrics import label_ranking_loss >>> y_true = np.array([[1, 0, 0], [0, 0, 1]]) >>> y_score = np.array([[0.75, 0.5, 1], [1, 0.2, 0.1]]) >>> label_ranking_loss(y_true, y_score) 0.75... >>> # With the following prediction, we have perfect and minimal loss >>> y_score = np.array([[1.0, 0.1, 0.2], [0.1, 0.2, 0.9]]) >>> label_ranking_loss(y_true, y_score) 0.0
Рекомендации:
- Цумакас, Г., Катакис, И., и Влахавас, И. (2010). Майнинг данных с несколькими метками. В справочнике по интеллектуальному анализу данных и открытию знаний (стр. 667-685). Springer США.
3.3.3.4. Нормализованная дисконтированная совокупная прибыль
Дисконтированный совокупный выигрыш (DCG) и Нормализованный дисконтированный совокупный выигрыш (NDCG) — это показатели ранжирования, реализованные в dcg_score и ndcg_score; они сравнивают предсказанный порядок с оценками достоверности, такими как релевантность ответов на запрос.
Со страницы Википедии о дисконтированной совокупной прибыли:
«Дисконтированная совокупная прибыль (DCG) — это показатель качества ранжирования. При поиске информации он часто используется для измерения эффективности алгоритмов поисковой системы или связанных приложений. Используя шкалу градуированной релевантности документов в наборе результатов поисковой системы, DCG измеряет полезность или выгоду документа на основе его позиции в списке результатов. Прирост накапливается сверху вниз в списке результатов, причем прирост каждого результата дисконтируется на более низких уровнях »
DCG упорядочивает истинные цели (например, релевантность ответов на запросы) в предсказанном порядке, затем умножает их на логарифмическое убывание и суммирует результат. Сумма может быть усечена после первогоKрезультатов, и в этом случае мы называем это DCG @ K. NDCG или NDCG @ $K$ — это DCG, деленная на DCG, полученную с помощью точного прогноза, так что оно всегда находится между 0 и 1. Обычно NDCG предпочтительнее DCG.
По сравнению с потерей ранжирования, NDCG может принимать во внимание оценки релевантности, а не ранжирование на основе фактов. Таким образом, если основополагающая информация состоит только из упорядочивания, предпочтение следует отдавать потере ранжирования; если основополагающая информация состоит из фактических оценок полезности (например, 0 для нерелевантного, 1 для релевантного, 2 для очень актуального), можно использовать NDCG.
Для одного образца, учитывая вектор непрерывных значений истинности для каждой цели $y in R^M$, где $M$ это количество выходов, а прогноз $hat{y}$, что индуцирует функцию ранжирования $f$, оценка DCG составляет
$$sum_{r=1}^{min(K, M)}frac{y_{f(r)}}{log(1 + r)}$$
а оценка NDCG — это оценка DCG, деленная на оценку DCG, полученную для $y$.
Рекомендации:
- Запись в Википедии о дисконтированной совокупной прибыли
- Джарвелин, К., и Кекалайнен, Дж. (2002). Оценка IR методов на основе накопленного коэффициента усиления. Транзакции ACM в информационных системах (TOIS), 20 (4), 422-446.
- Ван, Ю., Ван, Л., Ли, Ю., Хе, Д., Чен, В., и Лю, Т. Ю. (2013, май). Теоретический анализ показателей рейтинга NDCG. В материалах 26-й ежегодной конференции по теории обучения (COLT 2013)
- МакШерри Ф. и Наджорк М. (2008, март). Эффективность вычислений при поиске информации измеряется эффективно при наличии связанных оценок. В Европейской конференции по поиску информации (стр. 414-421). Шпрингер, Берлин, Гейдельберг.
3.3.4. Метрики регрессии
В sklearn.metrics модуле реализованы несколько функций потерь, оценки и полезности для измерения эффективности регрессии. Некоторые из них были расширены , чтобы обработать случай multioutput: mean_squared_error, mean_absolute_error, explained_variance_score и r2_score.
У этих функций есть multioutput аргумент ключевого слова, который определяет способ усреднения результатов или проигрышей для каждой отдельной цели. По умолчанию используется значение 'uniform_average', которое определяет равномерно взвешенное среднее значение по выходным данным. Если передается ndarrayформа shape (n_outputs,), то ее записи интерпретируются как веса, и возвращается соответствующее средневзвешенное значение. Если multioutputесть 'raw_values'указан, то все неизменные индивидуальные баллы или потери будут возвращены в массиве формы (n_outputs,).
r2_score и explained_variance_score принять дополнительное значение 'variance_weighted' для multioutput параметра. Эта опция приводит к взвешиванию каждой индивидуальной оценки по дисперсии соответствующей целевой переменной. Этот параметр определяет количественно зафиксированную немасштабированную дисперсию на глобальном уровне. Если целевые переменные имеют разную шкалу, то этот балл придает большее значение хорошему объяснению переменных с более высокой дисперсией. multioutput='variance_weighted' — значение по умолчанию r2_score для обратной совместимости. В будущем это будет изменено на uniform_average.
3.3.4.1. Оценка объясненной дисперсии
explained_variance_score вычисляет объясненной дисперсии регрессии балл.
Если $hat{y}$ — расчетный целевой объем производства, y соответствующий (правильный) целевой результат, и $Var$- Дисперсия , квадрат стандартного отклонения, то объясненная дисперсия оценивается следующим образом:
$$explained_{}variance(y, hat{y}) = 1 — frac{Var{ y — hat{y}}}{Var{y}}$$
Наилучшая возможная оценка — 1.0, более низкие значения — хуже.
Вот небольшой пример использования explained_variance_score функции:
>>> from sklearn.metrics import explained_variance_score >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> explained_variance_score(y_true, y_pred) 0.957... >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> explained_variance_score(y_true, y_pred, multioutput='raw_values') array([0.967..., 1. ]) >>> explained_variance_score(y_true, y_pred, multioutput=[0.3, 0.7]) 0.990...
3.3.4.2. Максимальная ошибка
Функция max_error вычисляет максимальную остаточную ошибку , показатель , который фиксирует худшую ошибку случае между предсказанным значением и истинным значением. В идеально подобранной модели регрессии с одним выходом он max_error будет находиться 0 в обучающем наборе, и хотя это маловероятно в реальном мире, этот показатель показывает степень ошибки, которую имела модель при подборе.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец, и $y_i$ — соответствующее истинное значение, тогда максимальная ошибка определяется как
$$text{Max Error}(y, hat{y}) = max(| y_i — hat{y}_i |)$$
Вот небольшой пример использования функции max_error:
>>> from sklearn.metrics import max_error >>> y_true = [3, 2, 7, 1] >>> y_pred = [9, 2, 7, 1] >>> max_error(y_true, y_pred) 6
max_error не поддерживает multioutput.
3.3.4.3. Средняя абсолютная ошибка
Функция mean_absolute_error вычисляет среднюю абсолютную погрешность , риск метрики , соответствующей ожидаемого значение абсолютной потери или ошибок $l1$-нормальная потеря.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец, и $y_i$ — соответствующее истинное значение, тогда средняя абсолютная ошибка (MAE), оцененная за $n_{samples}$ определяется как
$$text{MAE}(y, hat{y}) = frac{1}{n_{text{samples}}} sum_{i=0}^{n_{text{samples}}-1} left| y_i — hat{y}_i right|.$$
Вот небольшой пример использования функции mean_absolute_error:
>>> from sklearn.metrics import mean_absolute_error >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> mean_absolute_error(y_true, y_pred) 0.5 >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> mean_absolute_error(y_true, y_pred) 0.75 >>> mean_absolute_error(y_true, y_pred, multioutput='raw_values') array([0.5, 1. ]) >>> mean_absolute_error(y_true, y_pred, multioutput=[0.3, 0.7]) 0.85...
3.3.4.4. Среднеквадратичная ошибка
Функция mean_squared_error вычисляет среднюю квадратическую ошибку , риск метрики , соответствующую ожидаемое значение квадрата (квадратичной) ошибки или потерю.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец, и $y_i$ — соответствующее истинное значение, тогда среднеквадратичная ошибка (MSE), оцененная на $n_{samples}$ определяется как
$$text{MSE}(y, hat{y}) = frac{1}{n_text{samples}} sum_{i=0}^{n_text{samples} — 1} (y_i — hat{y}_i)^2.$$
Вот небольшой пример использования функции mean_squared_error:
>>> from sklearn.metrics import mean_squared_error >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> mean_squared_error(y_true, y_pred) 0.375 >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> mean_squared_error(y_true, y_pred) 0.7083...
Примеры:
- См. В разделе Регрессия повышения градиента пример использования среднеквадратичной ошибки для оценки регрессии повышения градиента.
3.3.4.5. Среднеквадратичная логарифмическая ошибка
Функция mean_squared_log_error вычисляет риск метрики , соответствующий ожидаемому значению квадрата логарифмической (квадратичной) ошибки или потери.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец, и $y_i$ — соответствующее истинное значение, тогда среднеквадратичная логарифмическая ошибка (MSLE), оцененная на $n_{samples}$ определяется как
$$text{MSLE}(y, hat{y}) = frac{1}{n_text{samples}} sum_{i=0}^{n_text{samples} — 1} (log_e (1 + y_i) — log_e (1 + hat{y}_i) )^2.$$
Где $log_e (x)$ означает натуральный логарифм $x$. Эту метрику лучше всего использовать, когда цели имеют экспоненциальный рост, например, численность населения, средние продажи товара в течение нескольких лет и т. Д. Обратите внимание, что эта метрика штрафует за заниженную оценку больше, чем за завышенную оценку.
Вот небольшой пример использования функции mean_squared_log_error:
>>> from sklearn.metrics import mean_squared_log_error >>> y_true = [3, 5, 2.5, 7] >>> y_pred = [2.5, 5, 4, 8] >>> mean_squared_log_error(y_true, y_pred) 0.039... >>> y_true = [[0.5, 1], [1, 2], [7, 6]] >>> y_pred = [[0.5, 2], [1, 2.5], [8, 8]] >>> mean_squared_log_error(y_true, y_pred) 0.044...
3.3.4.6. Средняя абсолютная ошибка в процентах
mean_absolute_percentage_error (MAPE), также известный как среднее абсолютное отклонение в процентах (МАПД), является метрикой для оценки проблем регрессии. Идея этой метрики — быть чувствительной к относительным ошибкам. Например, он не изменяется глобальным масштабированием целевой переменной.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец и $y_i$ — соответствующее истинное значение, тогда средняя абсолютная процентная ошибка (MAPE), оцененная за $n_{samples}$ определяется как
$$text{MAPE}(y, hat{y}) = frac{1}{n_{text{samples}}} sum_{i=0}^{n_{text{samples}}-1} frac{{}left| y_i — hat{y}_i right|}{max(epsilon, left| y_i right|)}$$
где $epsilon$ — произвольное маленькое, но строго положительное число, чтобы избежать неопределенных результатов, когда y равно нулю.
В функции mean_absolute_percentage_error опоры multioutput.
Вот небольшой пример использования функции mean_absolute_percentage_error:
>>> from sklearn.metrics import mean_absolute_percentage_error >>> y_true = [1, 10, 1e6] >>> y_pred = [0.9, 15, 1.2e6] >>> mean_absolute_percentage_error(y_true, y_pred) 0.2666...
В приведенном выше примере, если бы мы использовали mean_absolute_error, он бы проигнорировал небольшие значения магнитуды и только отразил бы ошибку в предсказании максимального значения магнитуды. Но эта проблема решена в случае MAPE, потому что он вычисляет относительную процентную ошибку по отношению к фактическому выходу.
3.3.4.7. Средняя абсолютная ошибка
Это median_absolute_error особенно интересно, потому что оно устойчиво к выбросам. Убыток рассчитывается путем взятия медианы всех абсолютных различий между целью и прогнозом.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец и $y_i$ — соответствующее истинное значение, тогда средняя абсолютная ошибка (MedAE), оцененная на $n_{samples}$ определяется как
$$text{MedAE}(y, hat{y}) = text{median}(mid y_1 — hat{y}_1 mid, ldots, mid y_n — hat{y}_n mid).$$
median_absolute_error Не поддерживает multioutput.
Вот небольшой пример использования функции median_absolute_error:
>>> from sklearn.metrics import median_absolute_error >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> median_absolute_error(y_true, y_pred) 0.5
3.3.4.8. R² балл, коэффициент детерминации
Функция r2_score вычисляет коэффициент детерминации , как правило , обозначенный как R².
Он представляет собой долю дисперсии (y), которая была объяснена независимыми переменными в модели. Он обеспечивает показатель степени соответствия и, следовательно, меру того, насколько хорошо невидимые выборки могут быть предсказаны моделью через долю объясненной дисперсии.
Поскольку такая дисперсия зависит от набора данных, R² не может быть значимо сопоставимым для разных наборов данных. Наилучшая возможная оценка — 1,0, и она может быть отрицательной (потому что модель может быть произвольно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значение y, игнорируя входные характеристики, получит оценку R² 0,0.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец и $y_i$ соответствующее истинное значение для общего n образцов, расчетный R² определяется как:
$$R^2(y, hat{y}) = 1 — frac{sum_{i=1}^{n} (y_i — hat{y}i)^2}{sum{i=1}^{n} (y_i — bar{y})^2}$$
где $bar{y} = frac{1}{n} sum_{i=1}^{n} y_i$ и $sum_{i=1}^{n} (y_i — hat{y}i)^2 = sum{i=1}^{n} epsilon_i^2$.
Обратите внимание, что r2_score вычисляется нескорректированное R² без поправки на смещение выборочной дисперсии y.
Вот небольшой пример использования функции r2_score:
>>> from sklearn.metrics import r2_score >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> r2_score(y_true, y_pred) 0.948... >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> r2_score(y_true, y_pred, multioutput='variance_weighted') 0.938... >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> r2_score(y_true, y_pred, multioutput='uniform_average') 0.936... >>> r2_score(y_true, y_pred, multioutput='raw_values') array([0.965..., 0.908...]) >>> r2_score(y_true, y_pred, multioutput=[0.3, 0.7]) 0.925...
Пример:
- См. В разделе « Лассо и эластичная сеть для разреженных сигналов» приведен пример использования показателя R² для оценки лассо и эластичной сети для разреженных сигналов.
3.3.4.9. Средние отклонения Пуассона, Гаммы и Твиди
Функция mean_tweedie_deviance вычисляет среднюю ошибку Deviance Tweedie с powerпараметром ($p$). Это показатель, который выявляет прогнозируемые ожидаемые значения целей регрессии.
Существуют следующие особые случаи:
- когда
power=0это эквивалентноmean_squared_error. - когда
power=1это эквивалентноmean_poisson_deviance. - когда
power=2это эквивалентноmean_gamma_deviance.
Если $hat{y}_i$ прогнозируемое значение $i$-й образец и $y_i$ — соответствующее истинное значение, тогда средняя ошибка отклонения Твиди (D) для мощности $p$, оценивается более $n_{samples}$ определяется как
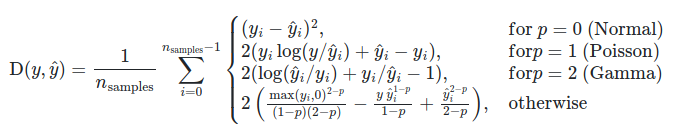
Отклонение от твиди — однородная функция степени 2-power. Таким образом, гамма-распределение power=2 означает, что одновременно масштабируется y_true и y_pred не влияет на отклонение. Для распределения Пуассона power=1 отклонение масштабируется линейно, а для нормального распределения ( power=0) — квадратично. В общем, чем выше, powerтем меньше веса придается крайним отклонениям между истинными и прогнозируемыми целевыми значениями.
Например, давайте сравним два прогноза 1.0 и 100, которые оба составляют 50% от их соответствующего истинного значения.
Среднеквадратичная ошибка ( power=0) очень чувствительна к разнице прогнозов второй точки:
>>> from sklearn.metrics import mean_tweedie_deviance >>> mean_tweedie_deviance([1.0], [1.5], power=0) 0.25 >>> mean_tweedie_deviance([100.], [150.], power=0) 2500.0
Если увеличить powerдо 1:
>>> mean_tweedie_deviance([1.0], [1.5], power=1) 0.18... >>> mean_tweedie_deviance([100.], [150.], power=1) 18.9...
разница в ошибках уменьшается. Наконец, установив power=2:
>>> mean_tweedie_deviance([1.0], [1.5], power=2) 0.14... >>> mean_tweedie_deviance([100.], [150.], power=2) 0.14...
мы получим идентичные ошибки. Таким образом, отклонение when power=2чувствительно только к относительным ошибкам.
3.3.5. Метрики кластеризации
В модуле sklearn.metrics реализованы несколько функций потерь, оценки и полезности. Для получения дополнительной информации см. Раздел « Оценка производительности кластеризации » для кластеризации экземпляров и « Оценка бикластеризации» для бикластеризации.
3.3.6. Фиктивные оценки
При обучении с учителем простая проверка работоспособности состоит из сравнения своей оценки с простыми практическими правилами. DummyClassifier реализует несколько таких простых стратегий классификации:
stratifiedгенерирует случайные прогнозы, соблюдая распределение классов обучающего набора.most_frequentвсегда предсказывает наиболее частую метку в обучающем наборе.priorвсегда предсказывает класс, который максимизирует предыдущий класс (какmost_frequent) иpredict_probaвозвращает предыдущий класс.uniformгенерирует предсказания равномерно в случайном порядке.constantвсегда предсказывает постоянную метку, предоставленную пользователем. Основная мотивация этого метода — оценка F1, когда положительный класс находится в меньшинстве.
Обратите внимание, что со всеми этими стратегиями predict метод полностью игнорирует входные данные!
Для иллюстрации DummyClassifier сначала создадим несбалансированный набор данных:
>>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import train_test_split >>> X, y = load_iris(return_X_y=True) >>> y[y != 1] = -1 >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
Далее сравним точность SVC и most_frequent:
>>> from sklearn.dummy import DummyClassifier >>> from sklearn.svm import SVC >>> clf = SVC(kernel='linear', C=1).fit(X_train, y_train) >>> clf.score(X_test, y_test) 0.63... >>> clf = DummyClassifier(strategy='most_frequent', random_state=0) >>> clf.fit(X_train, y_train) DummyClassifier(random_state=0, strategy='most_frequent') >>> clf.score(X_test, y_test) 0.57...
Мы видим, что SVC это не намного лучше, чем фиктивный классификатор. Теперь давайте изменим ядро:
>>> clf = SVC(kernel='rbf', C=1).fit(X_train, y_train) >>> clf.score(X_test, y_test) 0.94...
Мы видим, что точность увеличена почти до 100%. Для лучшей оценки точности рекомендуется стратегия перекрестной проверки, если она не требует слишком больших затрат на ЦП. Для получения дополнительной информации см. Раздел « Перекрестная проверка: оценка производительности оценщика ». Более того, если вы хотите оптимизировать пространство параметров, настоятельно рекомендуется использовать соответствующую методологию; подробности см. в разделе « Настройка гиперпараметров оценщика ».
В более общем плане, когда точность классификатора слишком близка к случайной, это, вероятно, означает, что что-то пошло не так: функции бесполезны, гиперпараметр настроен неправильно, классификатор страдает от дисбаланса классов и т. Д.
DummyRegressor также реализует четыре простых правила регрессии:
meanвсегда предсказывает среднее значение тренировочных целей.medianвсегда предсказывает медианное значение тренировочных целей.quantileвсегда предсказывает предоставленный пользователем квантиль учебных целей.constantвсегда предсказывает постоянное значение, предоставляемое пользователем.
Во всех этих стратегиях predict метод полностью игнорирует входные данные.