тельских интерфейсов и созданию четкой концепции качества ПС. Появляются языки программирования (например, Ада), учитывающие требования технологии программирования. Развиваются методы и языки спецификации ПС. Начинается бурный процесс стандартизации технологических процессов и, прежде всего, документации, создаваемой в этих процессах. Выходит на передовые позиции объектный подход к разработке ПС. Создаются различные инструментальные среды разработки и сопровождения ПС. Развивается концепция компьютерных сетей.
90-е годы знаменательны широким охватом всего человеческого общества международной компьютерной сетью, персональные компьютеры стали подключаться к ней как терминалы. Это поставило ряд проблем (как технологического, так и юридического и этического характера) регулирования доступа к информации компьютерных сетей. Остро встала проблема защиты компьютерной информации и передаваемых по сети сообщений. Стали бурно развиваться компьютерная технология (CASEтехнология) разработки ПС и связанные с ней формальные методы спецификации программ. Начался решающий этап полной информатизации и компьютеризации общества.
Интеллектуальные возможности человека, используемые при разработке программных систем. Понятия о простых и сложных системах, о малых и больших системах. Неправильный перевод информации из одного представления в другое — основная причина ошибок при разработке программных средств. Модель перевода и источники ошибок
2.1 Интеллектуальные возможности человека
Дейкстра выделяет три интеллектуальные возможности человека, используемые при разработке ПС:
•способность к перебору,
•способность к абстракции,
15
• способность к математической индукции.
Способность человека к перебору связана с возможностью последовательного переключения внимания с одного предмета на другой, позволяя узнавать искомый предмет. Эта способность весьма ограничена — в среднем человек может уверенно (не сбиваясь) перебирать в пределах 1000 предметов (элементов). Человек должен научиться действовать с учетом этой своей ограниченности. Средством преодоления этой ограниченности является его способность к абстракции, благодаря которой человек может объединять разные предметы или экземпляры в одно понятие, заменять множество элементов одним элементом (другого рода). Способность человека к математической индукции позволяет ему справляться с бесконечными последовательностями.
При разработке ПС человек имеет дело с системами. Под системой будем понимать совокупность взаимодействующих (находящихся в отношениях) друг с другом элементов. ПС можно рассматривать как пример системы. Логически связанный набор программ является другим примером системы. Любая отдельная
программа также является системой. Понять систему − значит осмысленно перебрать все пути взаимодействия между ее элементами. В силу ограниченности человека к перебору будем различать простые и сложные системы. Под простой будем понимать такую систему, в которой человек может уверенно перебирать все пути взаимодействия между ее элементами, а под сложной будем понимать такую систему, в которой он этого делать не в состоянии. Между простыми и сложными системами нет четкой границы, поэтому можно говорить и о промежуточном классе систем: к таким системам относятся программы, о которых программистский фольклор утверждает, что «в каждой отлаженной программе имеется хотя бы одна ошибка».
При разработке ПС мы не всегда можем уверенно знать о всех связях между ее элементами из-за возможных ошибок. Поэтому полезно уметь оценивать сложность системы по числу ее элементов: числом потенциальных путей взаимодействия между
ее элементами, т.е. n!, где n − число ее элементов. Систему назовем малой, если n < 7 (6! = 7 20 < 1000), систему назовем большой, если n > 7. При n=7 имеем промежуточный класс систем.
16
Малая система всегда проста, а большая может быть как простой,
так и сложной. Задача технологии программирования − научиться делать большие системы простыми.
Полученная оценка простых систем по числу элементов широко используется на практике. Так, для руководителя коллектива весьма желательно, чтобы в нем не было больше шести взаимодействующих между собой подчиненных. Весьма важно также следовать правилу: «все, что может быть сказано, должно быть сказано в шести пунктах или меньше». Этому правилу мы будем стараться следовать в настоящем пособии: всякие перечисления взаимосвязанных утверждений (набор рекомендаций, список требований и т.п.) будут соответствующим образом группироваться и обобщаться. Полезно ему следовать и при разработке ПС.
2.2 Неправильный перевод как причина ошибок в программных средствах
При разработке и использовании ПС мы многократно имеем дело с преобразованием (переводом) информации из одной формы в другую (рис.2.1). Заказчик формулирует свои потребности в ПС в виде некоторых требований. Исходя из этих требований, разработчик создает внешнее описание ПС, используя при этом спецификацию (описание) заданной аппаратуры и, возможно, спецификацию базового программного обеспечения. На основании внешнего описания и спецификации языка программирования создаются тексты программ ПС на этом языке. По внешнему описанию ПС разрабатывается также и пользовательская документация. Текст каждой программы является исходной информацией при любом ее преобразовании, в частности, при исправлении в ней ошибки. Пользователь на основании документации выполняет ряд действий для применения ПС и осуществляет интерпретацию получаемых результатов. Везде здесь, а также в ряде других процессах разработки ПС, имеет место указанный перевод информации.
17

|
ТРЕБОВАНИЯ К ПС |
|
|
СПЕЦИФИКАЦИЯ |
|
|
АППАРАТУРЫ |
|
|
ВНЕШНЕЕ |
РУКОВОДСТВО |
|
ОПИСАНИЕ |
ПО |
|
ПС |
ПРИМЕНЕНИЮ |
|
СПЕЦИФИКАЦИЯ |
ПС |
|
БАЗОВОГО |
|
|
ПРОГРАММНОГО |
|
|
ОБЕСПЕЧЕНИЯ |
|
|
ТЕКСТЫ |
|
|
ПРОГРАММ |
|
|
ПС |
СПЕЦИФИКАЦИЯ
ЯЗЫКА
ПРОГРАММИРОВАРИЯ
Рис. 2.1. Грубая схема разработки и применения ПС
На каждом из этих этапов перевод информации может быть осуществлен неправильно, например, из-за неправильного понимания исходного представления информации. Возникнув на одном из этапов разработки ПС, ошибка в представлении информации преобразуется в новые ошибки результатов, полученных на последующих этапах разработки, и, в конечном счете, окажется в ПС.
18
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Человеку свойственно ошибаться.
Сенека
Лекция 2.
ИСТОЧНИКИ ОШИБОК В ПРОГРАММНЫХ СРЕДСТВАХ
Интеллектуальные возможности человека, используемые при разработке программных систем. Понятия о простых и сложных системах, о малых и больших системах. Неправильный перевод информации из одного представления в другое — основная причина ошибок при разработке программных средств. Модель перевода и источники ошибок.
· Интеллектуальные возможности человека.
Дейкстра [2.1] выделяет три интеллектуальные возможности человека, используемые при разработке ПС:
Рекомендуемые материалы
способность к перебору,
способность к абстракции,
способность к математической индукции.
Способность человека к перебору связана с возможностью последовательного переключения внимания с одного предмета на другой, позволяя узнавать искомый предмет. Эта способность весьма ограничена — в среднем человек может уверенно (не сбиваясь) перебирать в пределах 1000 предметов (элементов). Человек должен научиться действовать с учетом этой своей ограниченности. Средством преодоления этой ограниченности является его способность к абстракции, благодаря которой человек может объединять разные предметы или экземпляры в одно понятие, заменять множество элементов одним элементом (другого рода). Способность человека к математической индукции позволяет ему справляться с бесконечными последовательностями.
При разработке ПС человек имеет дело с системами. Под системой будем понимать совокупность взаимодействующих (находящихся в отношениях) друг с другом элементов. ПС можно рассматривать как пример системы. Логически связанный набор программ является другим примером системы. Любая отдельная программа также является системой. Понять систему — значит осмысленно перебрать все пути взаимодействия между ее элементами. В силу ограниченности человека к перебору будем различать простые и сложные системы [2.2]. Под простой будем понимать такую систему, в которой человек может уверенно перебирать все пути взаимодействия между ее элементами, а под сложной будем понимать такую систему, в которой он этого делать не в состоянии. Между простыми и сложными системами нет четкой границы, поэтому можно говорить и о промежуточном классе систем: к таким системам относятся программы, о которых программистский фольклор утверждает, что «в каждой отлаженной программе имеется хотя бы одна ошибка».
При разработке ПС мы не всегда можем уверенно знать о всех связях между ее элементами из-за возможных ошибок. Поэтому полезно уметь оценивать сложность системы по числу ее элементов: числом потенциальных путей взаимодействия между ее элементами, т.е. n! , где n — число ее элементов. Систему назовем малой, если n < 7 (6! = 720 < 1000), систему назовем большой, если n > 7. При n=7 имеем промежуточный класс систем. Малая система всегда проста, а большая может быть как простой, так и сложной. Задача технологии программирования — научиться делать большие системы простыми.
Полученная оценка простых систем по числу элементов широко используется на практике. Так, для руководителя коллектива весьма желательно, чтобы в нем не было больше шести взаимодействующих между собой подчиненных. Весьма важно также следовать правилу: «все, что может быть сказано, должно быть сказано в шести пунктах или меньше». Этому правилу мы будем стараться следовать в настоящем пособии: всякие перечисления взаимосвязанных утверждений (набор рекомендаций, список требований и т.п.) будут соответствующим образом группироваться и обобщаться. Полезно ему следовать и при разработке ПС.
Неправильный перевод как причина ошибок в программных средствах.
При разработке и использовании ПС мы многократно имеем дело [2.3, стр. 22-28] с преобразованием (переводом) информации из одной формы в другую (см. рис.2.1). Заказчик формулирует свои потребности в ПС в виде некоторых требований. Исходя из этих требований, разработчик создает внешнее описание ПС, используя при этом спецификацию (описание) заданной аппаратуры и, возможно, спецификацию базового программного обеспечения. На основании внешнего описания и спецификации языка программирования создаются тексты программ ПС на этом языке. По внешнему описанию ПС разрабатывается также и пользовательская документация. Текст каждой программы является исходной информацией при любом ее преобразовании, в частности, при исправлении в ней ошибки. Пользователь на основании документации выполняет ряд действий для применения ПС и осуществляет интерпретацию получаемых результатов. Везде здесь, а также в ряде других процессах разработки ПС, имеет место указанный перевод информации.

Рис. 2.1. Грубая схема разработки и применения ПС.
На каждом из этих этапов перевод информации может быть осуществлен неправильно, например, из-за неправильного понимания исходного представления информации. Возникнув на одном из этапов разработки ПС, ошибка в представлении информации преобразуется в новые ошибки результатов, полученных на последующих этапах разработки, и, в конечном счете, окажется в ПС.
1. Модель перевода.
Чтобы понять природу ошибок при переводе рассмотрим модель [2.3, стр. 22-28], изображенную на рис.2.2. На ней человек осуществляет перевод информации из представления A в представление B. При этом он совершает четыре основных шага перевода:

Рис.2.2. Модель перевода.
· он получает информацию, содержащуюся в представлении A, с помощью своего читающего механизма R;
· он запоминает полученную информацию в своей памяти M;
· он выбирает из своей памяти преобразуемую информацию и информацию, описывающую процесс преобразования, выполняет перевод и посылает результат своему пишущему механизму W;
· с помощью этого механизма он фиксирует представление B.
На каждом из этих шагов человек может совершить ошибку разной природы. На первом шаге способность человека «читать между строк» (способность, которая часто оказывается полезной, позволяя ему понимать текст, содержащий неточности или даже ошибки) может стать причиной ошибки в ПС. Ошибка возникает в том случае, когда при чтении документа A человек, пытаясь восстановить недостающую информацию, видит то, что он ожидает, а не то, что имел в виду автор документа A. В этом случае лучше было бы обратиться к автору документа за разъяснениями. При запоминании информации человек осуществляет ее осмысливание (здесь важен его уровень подготовки и знание предметной области, к которой относится документ A). И, если он поверхностно или неправильно поймет, то информация будет запомнена в искаженном виде. На третьем этапе забывчивость человека может привести к тому, что он может выбрать из своей памяти не всю преобразуемую информацию или не все правила перевода, в результате чего перевод будет осуществлен неверно. Это обычно происходит при большом объеме плохо организованной информации. И, наконец, на последнем этапе стремление человека быстрее зафиксировать информацию часто приводит к тому, что представление этой информации оказывается неточным, создавая ситуацию для последующей неоднозначной ее интерпретации.
2.4. Основные пути борьбы с ошибками.
Учитывая рассмотренные особенности действий человека при переводе можно указать следующие пути борьбы с ошибками:
сужение пространства перебора (упрощение создаваемых систем),
обеспечение требуемого уровня подготовки разработчика (это функции менеджеров коллектива разработчиков),
обеспечение однозначности интерпретации представления информации,
контроль правильности перевода (включая и контроль однозначности интерпретации).
Упражнения к лекции 2.
Вместе с этой лекцией читают «Часть 1».
2.1. Что такое простая и сложная системы?
2.2. Что такое малая и большая системы?
Литература к лекции 2.
2.1. Э. Дейкстра. Заметки по структурному программированию / У. Дал, Э. Дейкстра, К. Хоор. Структурное программирование. — М.: Мир, 1975. — С. 7-19.
2.2. Е.А. Жоголев. Технологические основы модульного программирования. // Программирование, 1980, #2. — С. 44-49.
1. Г. Майерс. Надежность программного обеспечения. — М.: Мир, 1980.
План занятия №___. Понятие об ошибке программного обеспечения. Источники ошибок
Учебная дисциплина: МДК 01.01 Системное программирование
Тема занятия: Понятие об ошибке программного обеспечения. Источники ошибок.
Цели занятия:
Образовательные:
— изучить виды ошибок программного обеспечения, некоторые источники ошибок;
Воспитательные:
— развитие усидчивости;
Развивающие:
— развитие внимательности, логического мышления при нахождении ошибок во фрагментах программ.
Оснащение: план занятия, презентация.
Ход занятия:
1. Организационный момент. (2 мин).
Отметить присутствующих.
2. Актуализация опорных знаний
Хотелось бы сказать, что задача программиста — устранить все ошибки. Разумеется, это было бы прекрасно, но часто этот идеал оказывается недостижимым. На самом деле для реальных программ трудно сказать, что подразумевается под выражением «все ошибки». Например, если во время выполнения своей программы мы выдернем электрический шнур из розетки, то следует ли это рассматривать как ошибку и предусмотреть ее обработку? Во многих случаях совершенно очевидно, что ответ будет отрицательным, но в программе медицинского мониторинга или в программе, управляющей телефонными переключениями, это уже не так. В этих ситуациях пользователь вполне обоснованно может потребовать, чтобы система, частью которой является ваша программа, продолжала выполнять осмысленные действия, даже если исчезло энергопитание компьютера или космические лучи повредили его память. Основной вопрос заключается в следующем: должна ли программа сама обнаруживать ошибки?
3. Изучение нового материала.
(Страуструп, Бьярне, Программирование: принципы и практика использования C++. : Пер. с англ. — М. : ООО «И.Д. Вильяме», 2011. — 1248 с.: ил. — Парал. тит. англ., стр.161)
При разработке программ ошибки просто неизбежны, хотя окончательный вариант программы должен быть безошибочным или, по крайней мере, не содержать неприемлемых ошибок. Существует множество способов классификации ошибок. Рассмотрим пример.
Классификация ошибок:
-
Ошибки во время компиляции. Это ошибки, обнаруженные компилятором. Их можно подразделить на категории в зависимости от того, какие правила языка он нарушают:
• синтаксические ошибки;
• ошибки, связанные с типами.
-
Ошибки во время редактирования связей. Это ошибки, обнаруженные редактором связей при попытке объединить объектные файлы в выполняемый модуль.
-
Ошибки во время выполнения. Это ошибки, обнаруженные в ходе контрольных проверок выполняемого модуля. Эти ошибки подразделяются на следующие категории:
• ошибки, обнаруженные компьютером (аппаратным обеспечением и/или операционной системой);
• ошибки, обнаруженные с помощью библиотеки (например, стандартной);
• ошибки, обнаруженные с помощью программы пользователя.
-
Логические ошибки. Это ошибки, найденные программистом в поисках причины неправильных результатов.
Ошибки периода компиляции – ошибки, связанные с нарушением синтаксиса программирования или неверным набором текста программы.
Ошибки периода выполнения – связаны, в основном, с неверной формулировкой алгоритма решения задачи, либо с неправильной его записью на алгоритмическом языке.
Если не указано явно, будем предполагать, что ваша программа удовлетворяет следующим условиям.
1. Должна вычислять желаемые результаты при всех допустимых входных данных.
2. Должна выдавать осмысленные сообщения обо всех неправильных входных
данных.
3. Не обязана обрабатывать ошибки аппаратного обеспечения.
4. Не обязана обрабатывать ошибки программного обеспечения.
5. Должна завершать работу после обнаружения ошибки.
Предположения 1 и 2 являются частью основных профессиональных требований, а профессионализм— это именно то, к чему мы стремимся. Даже если мы не всегда соответствуем идеалу на 100%, он должен существовать.
При создании программы ошибки естественны и неизбежны. Вопрос лишь в том, как с ними справиться. По нашему мнению, при разработке серьезного программного обеспечения попытки обойти, найти и исправить ошибки занимают более 90% времени. Для программ, безопасность работы которых является первоочередной задачей, эти усилия займут еще больше времени. В маленьких программах легко избежать ошибок, но в больших вероятность ошибок возрастает.
Мы предлагаем три подхода к разработке приемлемого программного обеспечения.
• Организовать программное обеспечение так, чтобы минимизировать количество ошибок.
• Исключить большинство ошибок в ходе отладки и тестирования.
• Убедиться, что оставшиеся ошибки не серьезны.
Источники ошибок
Перечислим несколько источников ошибок.
• Плохая спецификация. Если мы слабо представляем себе, что должна делать программа, то вряд ли сможем адекватно проверить все ее «темные углы» и убедиться, что все варианты обрабатываются правильно (т.е. что при любом входном наборе данных мы получим либо правильный ответ, либо осмысленное сообщение об ошибке).
• Неполные программы. В ходе разработки неизбежно возникают варианты, которые мы не предусмотрели. Наша цель — убедиться, что все варианты обработаны правильно.
• Непредусмотренные аргументы. Функции принимают аргументы. Если функция принимает аргумент, который не был предусмотрен, то возникнет проблема, как, например, при вызове стандартной библиотечной функции извлечения корня из -1,2: sqrt(-1.2). Поскольку функция sqrt() получает положительную переменную типа double, в этом случае она не сможет вернуть правильный результат.
• Непредусмотренные входные данные. Обычно программы считывают данные (с клавиатуры, из файлов, из средств графического пользовательского интерфейса, из сетевых соединений и т.д.). Как правило, программы выдвигают к входным данным много требований, например, чтобы пользователь ввел число. А что, если пользователь введет не ожидаемое целое число, а строку
• Неожиданное состояние. Большинство программ хранит большое количество данных («состояний»), предназначенных для разных частей системы. К их числу относятся списки адресов, каталоги телефонов и данные о температуре, записанные в объекты типа vector. Что произойдет, если эти данные окажутся
неполными или неправильными? В этом случае разные части программы должны сохранять управляемость.
• Логические ошибки. Эти ошибки приводят к тому, что программа просто делает не то, что от нее ожидается; мы должны найти и исправить эти ошибки.
Ошибки во время компиляции
Когда вы пишете программы, на первой линии защиты от ошибок находится компилятор. Перед тем как приступить к генерации кода, компилятор анализирует его в поисках синтаксических ошибок и опечаток. Только если компилятор убедится, что программа полностью соответствует спецификациям языка, он разрешит ее дальнейшую обработку. Многие ошибки, которые обнаруживает компилятор, относятся к категории «грубых ошибок», представляющих собой ошибки, связанные с типами, или результат неполного редактирования кода. Другие ошибки являются результатом плохого понимания взаимодействия частей нашей программы. Новичкам компилятор часто кажется маловажным, но по мере изучения свойств языка — и особенно его системы типов — вы по достоинству оцените способности компилятора выявлять проблемы, которые в противном случае заставили бы вас часами ломать голову.
Пример: вызов функции
int area(int length, int width); // вычисление площади прямоугольника
Синтаксические ошибки
Что произойдет, если мы вызовем функцию area () следующим образом:
int si = area(7,2; // ошибка: пропущена скобка )
int si = area(7,2) // ошибка: пропущена точка с запятой ;
Int s3 = агеа(7,2); // ошибка: Int — это не тип
int s4 = area(‘7,2); // ошибка: добавлен апостроф
Каждая из этих строк содержит синтаксическую ошибку; иначе говоря, они не соответствуют грамматике языка C++, поэтому компилятор их отклоняет. К сожалению, синтаксические ошибки не всегда можно описать так, чтобы программист легко понял, в чем дело. Это объясняется тем, что компилятор должен проанализировать немного более крупный фрагмент текста, чтобы понять, действительно ли он обнаружил ошибку. В результате даже самые простые синтаксические ошибки (в которые даже невозможно поверить) часто описываются довольно запутанно, и при этом компилятор ссылается на строку, которая расположена в программе немного дальше, чем сама ошибка. Итак, если вы не видите ничего неправильного в строке, на которую ссылается компилятор, проверьте предшествующие строки программы.
Обратите внимание на то, что компилятор не знает, что именно вы пытаетесь сделать, поэтому формулирует сообщения об ошибках с учетом того, что вы на самом деле сделали, а не того, что намеревались сделать. Например, обнаружив ошибочное объявление переменной sЗ, компилятор вряд ли напишет что-то вроде следующей фразы:
«Вы неправильно написали слово Int; не следует употреблять прописную букву I.»
Скорее, он выразится так:
«Синтаксическая ошибка: пропущена «;» перед идентификатором “s3”
«У переменной s3 пропущен идентификатор класса или типа»
«Неправильный идентификатор класса или типа “int”
Такие сообщения выглядят туманными, пока вы не научитесь их понимать и использовать. Разные компиляторы могут выдавать разные сообщения, анализируя один и тот же код. В общем, все эти сообщения можно перевести так:
«Перед переменной s3 сделана синтаксическая ошибка, и надо что-то сделать либо с типом int, либо с переменной s3″
Поняв это, уже нетрудно решить проблему.
Ошибки, связанные с типами
После того как вы устраните синтаксические ошибки, компилятор начнет выдавать сообщения об ошибках, связанных с типами; иначе говоря, он сообщит о несоответствиях между объявленными типами (или о типах, которые вы забыли объявить) ваших переменных, функций и так далее и типами значений и выражений, которые вы им присваиваете, передаете в качестве аргументов и т.д.
int x0 = arena(7,2); // ошибка: необъявленная функция
int xl = area(7); // ошибка: неправильное количество аргументов
int x2 = area(«seven«,2) ; // ошибка: первый аргумент
// имеет неправильный тип
Не ошибки
Работая с компилятором, вы в какой-то момент захотите, чтобы он угадывал ваши намерения; иначе говоря, захотите, чтобы некоторые ошибки он не считал таковыми. Это естественно. Однако удивительно то, что по мере накопления опыта вы захотите, чтобы компилятор был более придирчивым и браковал больше, а не меньше выражений. Рассмотрим пример.
1) int х4 = аrеа(10,-7); // ОК: но что представляет собой прямоугольник,
// у которого ширина равна минус 7?
2) int х5 = area(10.7,9.3); // ОК: но на самом деле вызывается аrеа(10,9)
3) char х6 = area (100, 9999); // ОК: но результат будет усечен
1) Компилятор не выдаст никаких сообщений о переменной х4. С его точки зрения вызов area(10,-7) является правильным: функция агеа() запрашивает два целых числа, и вы их ей передаете; никто не говорил, что они должны быть положительными.
2) Относительно переменной х5 хороший компилятор должен был бы предупредить, что значения типа double, равные 10.7 и 9.3, будут преобразованы в значения типа int, равные 10 и 9. Однако (устаревшие) правила языка утверждают, что вы можете неявно преобразовать переменную типа double в переменную типа int, поэтому у компилятора нет никаких оснований отвергать вызов area(10.7,9.3).
3) Инициализация переменной х6 представляет собой вариант той же проблемы, что и вызов area(10.7,9.3). Значение типа int, возвращенное после вызова аrеа( 100,9999), вероятно, равное 9999, будет присвоено переменной типа char. В итоге, скорее всего, в переменную х6 будет записано «усеченное» значение -36. И опять-таки хороший компилятор должен выдать предупреждение, даже если устаревшие правила языка позволяют ему не делать этого.
Предотвратить ошибку при вызове функции area (x, у) в модуле main() относительно просто:
if (x<=0) error(«неположительное х»);
if (у<=0) error(«неположительное у»);
int area_1 = area(x,у);
Ошибки во время редактирования связей
Любая программа состоит из нескольких отдельно компилируемых частей, которые называют единицами трансляции (translation units). Каждая функция в программе должна быть объявлена с теми же самыми типами, которые указаны во всех единицах трансляции, откуда она вызывается. Для этого используются заголовочные файлы. Кроме того, каждая функция должна быть объявлена в программе только один раз. Если хотя бы одно из этих правил нарушено, то редактор связей выдаст ошибку. Способы исправления ошибок во время редактирования связей рассматриваются в разделе 8.3. А пока рассмотрим пример программы, которая порождает типичную ошибку на этапе редактирования связей.
int area(int length, int width); // вычисляет площадь прямоугольника
int main()
{
int x = area(2,3);
}
Если функция area () не объявлена в другом исходном файле и не связана с нашим файлом с помощью редактора связей, то он сообщит об отсутствии объявления функции area ().
Ошибки во время выполнения программы
Если программа не содержит ошибок, которые можно обнаружить на этапах компиляции и редактирования связей, то она выполняется. Здесь-то и начинаются настоящие приключения. При написании программы можно выявить и устранить ошибки, но исправить ошибку, обнаруженную на этапе выполнения программы, не так легко.
Сообщения об ошибках
Рассмотрим немного иной вопрос: что делать, если вы проверили набор аргументов и обнаружили ошибку? Иногда можно вернуть сообщение «Неправильное значение». Рассмотрим пример.
// Попросим пользователя ввести да или нет;
// Символ ‘b‘ означает неверный ответ (т.е. ни да ни нет)
char ask_user(string question)
{
cout << question « “? (да или нет)\n”;
string answer = “ ”;
сin >> answer;
if (answer ==»y» || answer== «yes») return ‘y’;
if (answer ==”n” jj answer==»no») return ‘n’;
return ‘b’; // ‘b‘, если «ответ неверный»
}
// Вычисляет площадь прямоугольника;
// возвращает -1, если аргумент неправильный
int area(int length, int width)
if (length<=0 || width <=0) return -1;
return length*width;
}
Существует другой способ решить описанную проблему: использовать исключения (exceptions)
4. Закрепление нового материала.
Типичные ошибки при записи условного оператора.
1.4.3 Типичные ошибки
if(x==1) // правильно!
{
y=x+3;
z=y*5;
}
if(x=1) // неправильно!
// выполняется всегда!
{
y=x+3;
z=y*5;
}
ошибочное употребление операции присваивания = вместо операции равенства ==
if(x==1); // неправильно!
// выполняется всегда!
{
y=x+3;
z=y*5;
}
эквивалентно коду:
if(x==1)
{
[пустой оператор];
}
y=x+3;
z=y*5;
if(x==1) // неправильно!
y=x+3;
z=y*5;
отсутствуют фигурные скобки, хотя в условии задумано больше одного оператора
эквивалентно коду:
if(x==1)
{
y=x+3;
}
z=y*5;
5. Самостоятельная работа. (Можно решить на следующем занятии)
Выполнение заданий: найти и исправить ошибки во фрагментах программы.
Обработка ошибок
1 вариант
1. Назовите некоторые советы по отладке программы: что необходимо выполнять при написании кода программы, чтобы было легко понять назначение фрагментов кода.
2. Найдите ошибки в следующих кодах программы и напишите верный вариант.
-
cout << «Привет, << name << “\n”;
-
for (int i=0; i<=25; i++)
{
if (a>0) { /* операторы 1*/ }
else { /* операторы 2*/
}
-
if (b<=0 y = abs(b);
-
if (b<=0 && b>-25 y = abs(b;
-
int b=15.6;
double a=7.8;
z:=a+b*10;
-
coUt>> “Введите название книги: ”;
-
int mas[3];
mas[0]=15;
mas[3]=23;
-
cout << «Enter two integers: «;
cin >> x;
cin>>у;
int x, у;
cout << «The sum of » << x << » and » << у << » is » << x + у << ‘\n’;
-
if (age >= 65); cout<<«Age is greater than or equal to 65\n»); else cout<<«Age is less than 65\n»);
-
int ch;
ch1=35;
-
х = sqrT(y+10)+2
z = х+3;
-
for (int k = 0; k<=max; ++l)
cout << “k=» << k << “\n”;
-
Int s3;
s3=15*5-2;
-
int pr(int a, int b, int c); // периметр треугольника
int main()
{
…
int x2 = pr(2,3.3,4.5);
int x1 = pr(2,3,3);
cout>>”perimetr3=”<
cout>>pr(“2”,“3”,“3.5”);
…
}
Обработка ошибок
2 вариант
1. Назовите некоторые виды ошибок и коротко опишите их: где и когда возникают.
2. Найдите ошибки в следующих кодах программы и напишите верный вариант.
-
cout << «New word is << str << \n”;
-
for (k=-5; k<=15; k++)
{
if (m==0) { /* операторы 1*/ }
else /* операторы 2*/}
}
-
if (a>0 z = pow(a,5);
-
if (a>0 || b>0 z = b+pow(a,5;
-
double x=3.8;
int y=5,6;
w:=x-5*y;
-
int kolich;
ciN<< kolich;
-
int massiv[5];
massiv[0]=10;
massiv[5]=35;
-
cout << «Vvedite cenu i kolichestvo monitorov: «;
cin >> c;
cin>>k;
double c;
int k ;
cout << «Obschaya cena» << » ravna » << x * у << ‘\n’;
-
if (rost < 185); cout<<«Height is less than 185\n»); else cout<<«Height is greater than 185\n»);
-
double kol;
koll=21;
-
х = Sin(y+10)+2
z = х+3;
-
for (int n = 0; n>min; ++m) cout << “n=» << n << “\n”;
-
Double a1;
a1=21*4/9;
-
int pr(int a, int b, int c); // периметр треугольника
int main()
{
…
int x2 = pr(2,3.3,4.5);
int x1 = pr(2,3,3);
cout>>”perimetr3=”<
cout>>pr(“2”,“3”,“3.5”);
…
}
Подведение итогов занятия: выводы, оценки за ответы на вопросы, за решение заданий.
7. Д/з: Выучить основные источники ошибок , СР №25: написать примеры возможных ошибок для нескольких операторов
Подпись преподавателя ________
![]()
Содержание:

Введение
Программное обеспечение, согласно ГОСТ 19781-90, – совокупность программ системы обработки информации и программных документов, необходимых для их эксплуатации.
Существует и другое, более простое определение, согласно которому программное обеспечение представляет собой совокупность компьютерных инструкций. Оно охватывает программы, подпрограммы (разделы программы) и данные. Таким образом, программное обеспечение указывает компьютеру, что делать, как, когда, в какой последовательности и как часто. Нередко программное обеспечение называют просто программой.
Проблема надежности программного обеспечения относится, похоже, к категории «вечных». В посвященной ей монографии Г.Майерса, выпущенной в 1980 году (американское издание — в 1976), отмечается, что, хотя этот вопрос рассматривался еще на заре применения вычислительных машин, в 1952 году, он не потерял актуальности до настоящего времени. Отношение к проблеме довольно выразительно сформулировано в книге Р.Гласса: «Надежность программного обеспечения — беспризорное дитя вычислительной техники». Следует далее отметить, что сама проблема надежности программного обеспечения имеет, по крайней мере, два аспекта: обеспечение и оценка (измерение) надежности. Практически вся имеющаяся литература на эту тему, включая упомянутые выше монографии, посвящена первому аспекту, а вопрос оценки надежности компьютерных программ оказывается еще более «беспризорным». Вместе с тем очевидно, что надежность программы гораздо важнее таких традиционных ее характеристик, как время исполнения или требуемый объем оперативной памяти, однако никакой общепринятой количественной меры надежности программ до сих пор не существует.
Для обеспечения надежности программ предложено множество подходов, включая организационные методы разработки, различные технологии и технологические программные средства, что требует, очевидно, привлечения значительных ресурсов. Однако отсутствие общепризнанных критериев надежности не позволяет ответить на вопрос, насколько надежнее становится программное обеспечение при соблюдении данных процедур и технологий и в какой степени оправданы расходы. Получается, что таким образом, приоритет задачи оценки надежности должен быть выше приоритета задачи ее обеспечения, чего на самом деле не наблюдается.
Цель данной работы – рассмотреть классификацию ошибок программного обеспечения для обеспечения его надежности.
Надежность программного обеспечения
Показатели качества программного обеспечения
Оценка качества программного обеспечения могут проводиться с двух позиций: с позиции положительной эффективности и непосредственной адекватности их характеристик назначению, целям создания и применения, а также с негативной позиции, возможного при этом ущерба – риска от пользования ПС или системы. Показатели качества преимущественно отражают положительный эффект от применения программного обеспечения и основная задача разработчиков проекта состоит в обеспечении высоких значений качества. Риски характеризуют возможные негативные последствия проявившихся в ходе эксплуатации ошибок или ущерб для пользователя при применении и функционировании программного обеспечения.
Согласно ГОСТ 9126[2], качество программного обеспечения – это весь объем признаков и характеристик программного обеспечения, который относится к ее способности удовлетворять установленным или предполагаемым потребностям.
Качество программного обеспечения оценивается следующими характеристиками:
- Функциональные возможности (Functionality). Набор атрибутов, относящихся к сути набора функций и их конкретным свойствам. Функциями являются те, которые реализуют установленные или предполагаемые потребности.
- Надежность (Reliability). Набор атрибутов относящихся к способности программного обеспечения сохранять свой уровень качества функционирования при установленных условиях за установленный период времени.
- Практичность (Usability). Набор атрибутов, относящихся к объему работ, требуемых для использования и индивидуальной оценки такого использования определенным и предполагаемым кругом пользователей.
- Эффективность (Efficiencies). Набор атрибутов, относящихся к соотношению между уровнем качества функционирования программного обеспечения и объемом используемых ресурсов при установленных условиях.
- Сопровождаемость (Maintainability). Набор атрибутов, относящихся к объему работ, требуемых для проведения конкретных изменений (модификаций).
- Мобильность (Portability). Набор атрибутов, относящихся к способности программного обеспечения быть перенесенным из одного окружения в другое.
В общем случае под ошибкой подразумевается неправильность, погрешность или неумышленное искажение объекта или процесса, что может быть причиной ущерба – риска при функционировании или применении программы. При этом предполагается, что известно правильное, эталонное состояние объекта или процесса по отношению к которому может быть определено наличие отклонения. Исходным эталоном для любого программного обеспечения являются спецификации требований заказчика или потенциального пользователя, предъявляемых к программам и ожидаемый пользователем или заказчиком эффект от использования программного обеспечения. Важной особенностью при этом является отсутствие полностью определенной программы – эталона, которой должны соответствовать текст и результаты функционирования разрабатываемой программы. Поэтому определить качество программного обеспечения и наличие ошибок в нем путем сравнения разрабатываемой программы с эталонной программой невозможно.
Риски проявляются как негативные последствия проявления ошибок в программном обеспечении в ходе его пользования и функционирования, которые могут нанести ущерб системе, в которой используется это программное обеспечение, внешней среде или пользователям этой системы в результате отклонения характеристик программного обеспечения заданных или ожидаемых пользователем или заказчиком.
Исходя из определения ошибки в программном обеспечении, приведенном выше, можно сделать вывод, что ошибки, возникающие в ходе использования программного обеспечения, могут изменять некоторые или все показатели качества. В работе рассматриваются ошибки, изменения которых влияют на надежность использования программного обеспечения.
По правилу, установленному в [2], надежность – свойство объекта осуществлять заданные функции, храня во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующим заданным режимам и условиям использования, ремонта, технического обслуживания, хранения, транспортирования.

Рис. 1. Надежность по ГОСТ 27.002 – 89
При этом надежность является комплексным свойством, которое в зависимости от функции объекта и условий его использования может включать безотказность, ремонтопригодность, долговечность, сохраняемость или некоторые сочетания данных свойств (рис. 1). Так как программное обеспечение в процессе эксплуатации не изнашивается, его поломка и ремонт в общепринятом смысле не делается, то надежность программного обеспечения имеет смысл характеризовать только с точки зрения безотказности его функционирования и возможности исправления функционирования после отказов по вызванных проявлениями ошибок.
В [3] надежность программного обеспечения предлагается характеризовать с помощью следующих характеристик (рис. 2): стабильность, устойчивость и восстанавливаемость.

Рис. 2. Надежность программного обеспечения
В этом случае стабильность и устойчивость характеризуют безотказность программного обеспечения, а восстанавливаемость – возможность восстановления функционирования программного обеспечения после его отказа. Для количественной оценки надежности программного обеспечения необходимо определить показатели надежности для каждого свойства и методику их определения (оценки).
Для оценки стабильности программного обеспечения возможно использование показателей характеризующих безотказность технических устройств [2] (рис. 3).

Рис. 3. Показатели безотказности
В большинстве случаев поток программных ошибок может быть описан негомогенным процессом Пуассона [4]. Это означает, что программные ошибки происходят в статистически независимые моменты времени, наработки подчиняются экспоненциальному распределению, а интенсивность проявления ошибок изменяется во времени. Обычно используют убывающую интенсивность проявления ошибок. Это означает, что ошибки, как только они выявлены, эффективно устраняются без введения новых ошибок. Главная цель анализа надежности программного обеспечения заключается в том, чтобы определить форму функции интенсивности проявления ошибок и оценить ее параметры по наблюдаемым данным. Как только функция интенсивности проявления ошибок определена, могут быть найдены такие показатели надежности как:
- общее количество ошибок;
- количество остающихся ошибок;
- время до проявления следующей ошибки;
- вероятность безошибочной работы;
- интенсивность проявления ошибок;
- остаточное время испытаний (до принятия решения);
- максимальное количество ошибок (относительно срока службы).
При этом следует различать понятия ошибка и отказ. Применительно к надежности программного обеспечения ошибка это погрешность или искажение кода программы, неумышленно внесенные в нее в процессе разработки, которые в ходе функционирования этой программы могут вызвать отказ или снижение эффективности функционирования. Под отказом в общем случае понимают событие, заключающееся в нарушении работоспособности объекта [2]. Состояние объекта, при котором значения всех параметров характеризующих способность выполнять заданные функции, соответствуют требованиям нормативно – технической и (или) конструкторской (проектной) документации – называется работоспособным. При этом критерии отказов, как признаки или совокупность признаков нарушения работоспособного состояния программного обеспечения, должны определяться исходя из его предназначения в нормативно – технической и (или) конструкторской (проектной) документации.
В общем случае отказ программного обеспечения можно определить как:
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время превышающее заданный порог;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время не превышающее заданный порог, но с потерей всех или части обрабатываемых данных;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) потребовавшее перезагрузки ЭВМ, на которой функционирует программное обеспечение.
При этом исходя из [2], все отказы в программном обеспечении следует трактовать как сбои (самоустраняющиеся отказы или однократные отказы, устраняемые незначительным вмешательством оператора), поскольку восстановление работоспособного состояния программного обеспечения может произойти без вмешательства оператора (перезагрузка ЭВМ не требуется), либо при участии оператора или эксплуатирующего персонала (перезагрузка ЭВМ необходима).
Приведенные выше критерии отказов приводят к необходимости анализа временных характеристик функционирования программы и динамических характеристик потребителей данных, полученных в ходе функционирования программного обеспечения. Временная зона перерыва нормальной выдачи информации и потери работоспособности, которую следует рассматривать как зону сбоя (отказа), тем шире, чем более инертный объект находится под воздействием данных, полученным в ходе работы программы. Пороговое время восстановления работоспособного состояния системы, при превышении которого следует соответствующему потребителю (абоненту).
Для любого потребителя данных существует допустимое время отсутствия данных от программы, при котором его характеристики находятся в допустимых пределах. Исходя из этого времени, можно установить границы временной зоны, которая разделяет работоспособное и неработоспособное состояние программного обеспечения и позволяет использовать данные критерии отказов.
Из приведенного выше определения программной ошибки с точки зрения надежности, можно сделать вывод о том, что ошибки, при их проявлении, не всегда вызывают отказ программного обеспечения и каждую ошибку можно характеризовать условной вероятностью возникновения отказа при проявлении этой ошибки. Следует также отметить, что само по себе наличие ошибки в исходном коде не определяет надежность программы до тех пор, пока не произойдет проявления этой ошибки, поэтому пользоваться для оценки надежности программного обеспечения только показателями характеризующие общее количество ошибок в программе, количество оставшихся ошибок и максимального количества ошибок нельзя.
В [5] стабильность предлагается оценивать вероятностью безотказной работы, которая оценивается исходя из модели относительной частоты, при этом применение ее ограничено периодом эксплуатации программного обеспечения, что не всегда приемлемо, поскольку надежность объекта, как правило, необходимо оценивать не только в процессе его эксплуатации, но и до начала эксплуатации этого объекта. Ограничение модели относительной частоты вызвано тем, что в этой модели не учитываются процессы тестирования и отладки, а конкретно то, что при возникновении отказа программного обеспечения, ошибка, вызвавшая этот отказ, исправляется.
Наиболее приемлемыми показателями характеризующими стабильность (безотказность) программного обеспечения представляются показатели сходные с показателями безотказности технических систем: вероятность безотказной работы, интенсивность отказов, и среднее время наработки на отказ. Эти показатели взаимосвязаны и, зная один из них, можно определить другие [2]. При определении этих показателей в большинстве случаев можно исходить из модели надежности, предполагающей, что интенсивность проявления ошибок убывает по мере исправления этих ошибок, время между проявлениями ошибок распределено экспоненциально, а интенсивность проявления ошибок постоянна между двумя соседними проявлениями ошибок. Применение такой модели надежности программного обеспечения позволит оценить надежность программного обеспечения во время тестирования и отладки.
Устойчивость, как свойство или совокупность свойств программного обеспечения, характеризующие его возможность поддерживать приемлемый уровень функционирования при проявлениях ошибок в нем, можно оценивать условной вероятностью безотказной работы при проявлении ошибки. Согласно [5] устойчивость оценивается с помощью трех метрик, включающих двадцать оценочных элементов (рис. 4). Результаты оценки каждой метрики определяются результатами оценки определяющих ее оценочных элементов, а результат оценки устойчивости определяются результатами соответствующих ему метрик. Программное обеспечение по каждому из оценочных элементов оценивается группой экспертов – специалистов, компетентных в решении данной задачи, на базе их опыта и интуиции. Для оценочных элементов принимается единая шкала оценки от 0 до 1.
Недостатком такого подхода является одинаковая оценка устойчивости для всех возможных ошибок. Поскольку вероятность возникновения отказа при проявлении разных ошибок может быть разной, возникает необходимость разделения ошибок на несколько категорий. Признаком, по которому в этом случае можно относить ошибки к той или иной категории, можно считать тяжесть ошибки. Под тяжестью ошибки в этом случае следует понимать количественную или качественную оценку вероятного ущерба при проявлении этой ошибки [6], а если говорить о надежности, то оценку вероятности возникновения отказа при проявлении ошибки. При этом категорией тяжести последствий ошибки будет являться классификационная группа ошибок по тяжести их последствий, характеризуемая определенным сочетанием качественных и/или количественных учитываемых составляющих ожидаемого (вероятного) отказа или нанесенного отказом ущерба.
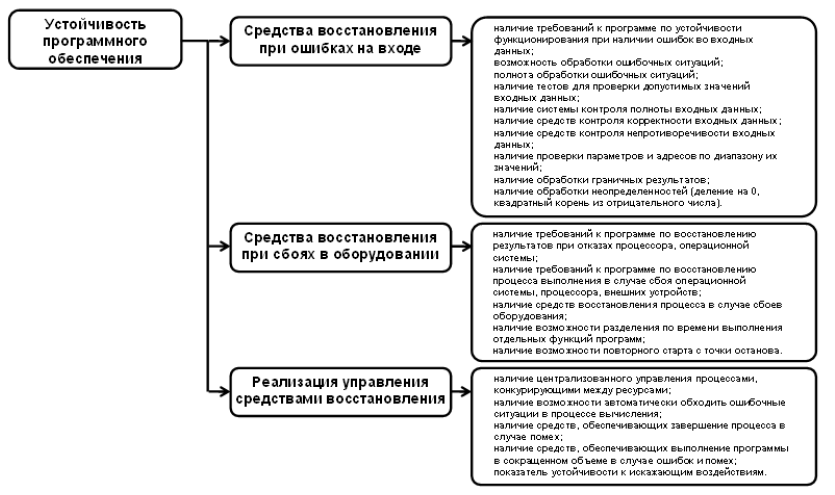
Рис. 4. Метрики и оценочные элементы устойчивости программного обеспечения по ГОСТ 28195 – 89
В качестве показателя степени тяжести ошибки, позволяющего дать количественную оценку тяжести проявления последствий ошибки целесообразно использовать условную вероятность отказа и его возможных последствий при проявлении ошибок разных категорий. Для программного обеспечения, создаваемого для систем управления, потеря работоспособности которых может повлечь за собой катастрофические последствия, возможные категории тяжести ошибок приведены в таблице 1.
Таблица 1. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого могут привести к катастрофическим последствиям
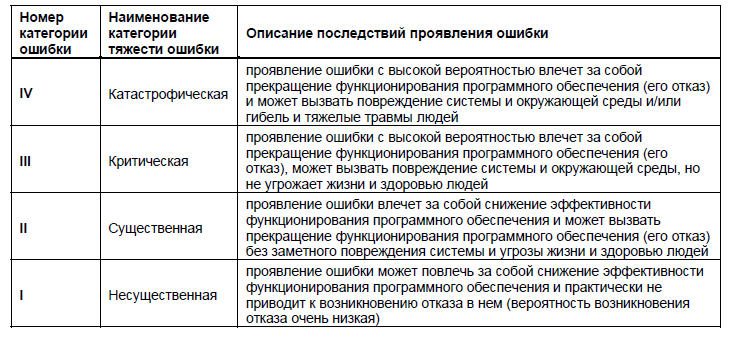
Для программного обеспечения общего применения или программного обеспечения систем, нарушение работоспособности которых не представляет угрозы жизни людей и не приводит к разрушению самой системы, возможные категории тяжести приведены в таблице 2.
Таблица 2. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого не приводят к катастрофическим последствиям

Оценку степени тяжести ошибки как условной вероятности возникновения отказа (последствий этого отказа), можно производить согласно [5], используя метрики и оценочные элементы, характеризующие устойчивость программного обеспечения. При этом оценка производится для каждой ошибки в отдельности, а не для всего программного обеспечения. Далее исходя из проведенных оценок возможно определение устойчивости программного обеспечения к проявлениям ошибок каждой из категорий.
Восстанавливаемость программного обеспечения, как свойство или совокупность свойств характеризующих способность программного обеспечения восстановления своего уровня пригодности и восстановления данных, непосредственно поврежденных вследствии проявлении ошибки (отказа), характеризуется полнотой и длительностью восстановления функционирования программ в процессе перезапуска или перезагрузки ЭВМ. В [5] восстанавливаемость предлагается оценивать по среднему времени восстановления. При этом следует учитывать, что время восстановления функционирования программного обеспечения складывается не только из времени потребного для перезагрузки ЭВМ и загрузки самого программного обеспечения, но и из времени необходимого для восстановления данных и это время в ряде случаев может значительно превышать время перезагрузки.
Показатели надежности программного обеспечения в значительной степени адекватны аналогичным характеристикам, принятых для других технических систем. Наиболее широко используется показатель наработки на отказ. Наработка на отказ – это отношение суммарной наработки объекта к математическому ожиданию числа его отказов в течении этой наработки. Для программного обеспечения использование данного показателя затруднено, в силу особенностей тестирования и отладки программного обеспечения (ошибка вызвавшая отказ, как правило, исправляется и больше не повторяется). Поэтому целесообразно использовать показатель средней наработки до отказа – математического ожидания времени функционирования программного обеспечения до отказа. При использовании модели надежности программного обеспечения предполагающей экспоненциальное распределение времени между отказами, среднее время наработки до отказа равно величине обратной интенсивности отказов. Интенсивность отказов можно оценить исходя из оценок стабильности и устойчивости программного обеспечения. Обобщение характеристик отказов и восстановлений производится в показателе коэффициент готовности [2]. Коэффициент готовности программного обеспечения это вероятность того, что программное обеспечение окажется в работоспособном состоянии в произвольный момент времени. Значение коэффициента готовности соответствует доле времени полезной работы программного обеспечения на достаточно большом интервале времени, содержащем отказы и восстановления.
Источники ошибок программного обеспечения
Источниками ошибок в программном обеспечении являются специалисты – конкретные люди с их индивидуальными особенностями, квалификацией, талантом и опытом. Вследствие этого плотность потоков ошибок и размеры необходимых корректировок в модулях и компонентах при разработке и сопровождении программного обеспечения могут различаться в десятки раз. Однако в крупных комплексах программ статистика и распределение ошибок и типов выполняемых изменений, необходимых для их исправления, для коллективов разных специалистов нивелируются и проявляются общие закономерности, которые могут использоваться как ориентиры при выявлении ошибок и их систематизации. Этому могут помогать оценки типовых ошибок, модификаций и корректировок путем их накопления и обобщения по опыту создания определенных классов программного обеспечения.
Основными причинами ошибок программного обеспечения являются:
- Большая сложность программного обеспечения, например, по сравнению с аппаратурой ЭВМ.
- Неправильный перевод информации из одного представления в другое на макро и микро уровнях. На макро уровне, уровне проекта, осуществляется передача и преобразование различных видов информации между организациями, подразделениями и конкретными исполнителями на всех этапах жизненного цикла ПО. На микро уровне, уровне исполнителя, производится преобразование информации по схеме: получить информацию, запомнить, выбрать из памяти, воспроизвести информацию.
Источниками ошибок программного обеспечения являются:
Внутренние: ошибки проектирования, ошибки алгоритмизации, ошибки программирования, недостаточное качество средств защиты, ошибки в документации.
Внешние: ошибки пользователей, сбои и отказы аппаратуры ЭВМ, искажение информации в каналах связи, изменения конфигурации системы.
- Признаками выявления ошибок являются:
- Преждевременное окончание программы.
- Увеличение времени выполнения программы.
- Нарушение последовательности вызова отдельных подпрограмм.
Ошибки выхода информации, поступающей от внешних источников, между входной информацией возникает не соответствие из-за: искажение данных на первичных носителях, сбои и отказы в аппаратуре, шумы и сбои в каналах связи, ошибки в документации.
Ошибки, скрытые в самой программе: ошибка вычислений, ошибка ввода-вывода, логические ошибки, ошибка манипулирования данными, ошибка совместимости, ошибка сопряжения.
Искажения входной информации, подлежащей обработке: искажения данных на первичных носителях информации; сбои и отказы в аппаратуре ввода данных с первичных носителей информации; шумы и сбои в каналах связи при передачи сообщений по линиям связи; сбои и отказы в аппаратуре передачи или приема информации; потери или искажения сообщений в буферных накопителях вычислительных систем; ошибки в документировании; используемой для подготовки ввода данных; ошибки пользователей при подготовки исходной информации.
Неверные действия пользователя:
- Неправильная интерпретация сообщений.
- Неправильные действия пользователя в процессе диалога с программным обеспечением.
- Неверные действия пользователя или по-другому, их можно назвать ошибками пользователя, которые возникают вследствие некачественной программной документации: неверные описания возможности программ; неверные описания режимов работы; неверные описания форматов входной и выходной информации; неверные описания диагностических сообщений.
Неисправности аппаратуры установки: приводят к нарушениям нормального хода вычислительного процесса; приводят к искажениям данных и текстов программ в основной и внешней памяти.
Итак, при рассмотрении основных причин возникновения отказа и сбоев программного обеспечения можно сказать, что эти знания позволяют своевременно принимать необходимые меры по недопущению отказов и сбоев программного обеспечения.
Виды ошибок программного обеспечения
Характеристика основных видов ошибок программного обеспечения
Рассмотрим классификацию ошибок по месту их возникновения, которая рассмотрена в книге С. Канера «Тестирование программного обеспечения». Фундаментальные концепции менеджмента бизнес-приложений. Главным критерием программы должно быть ее качество, которое трактуется как отсутствие в ней недостатков, а также сбоев и явных ошибок. Недостатки программы зависят от субъективной оценкой ее качества потенциальным пользователем. При этом авторы скептически относятся к спецификации и утверждают, что даже при ее наличии, выявленные на конечном этапе недостатки говорят о ее низком качестве. При таком подходе преодоление недостатков программы, особенно на заключительном этапе проектирования, может приводить к снижению надежности. Очевидно, что для разработки ответственного и безопасного программного обеспечения (ПО) такой подход не годится, однако проблемы наличия ошибок в спецификациях, субъективного оценивания пользователем качества программы существуют и не могут быть проигнорированы. Должна быть разработана система некоторых ограничений, которая бы учитывала эти факторы при разработке и сертификации такого рода ПО. Для обычных программ все проблемы, связанные с субъективным оцениванием их качества и наличием ошибок, скорее всего неизбежны.
В краткой классификации выделяются следующие ошибки.
- ошибки пользовательского интерфейса.
- ошибки вычислений.
- ошибки управления потоком.
- ошибки передачи или интерпретации данных.
- перегрузки.
- контроль версий.
- ошибка выявлена и забыта.
- ошибки тестирования.
1. Ошибки пользовательского интерфейса.
Многие из них субъективны, т.к. часто они являются скорее неудобствами, чем «чистыми» логическими ошибками. Однако они могут провоцировать ошибки пользователя программы или же замедлять время его работы до неприемлемой величины. В результате чего мы будем иметь ошибки информационной системы (ИС) в целом. Основным источником таких ошибок является сложный компромисс между функциональностью программы и простотой обучения и работы пользователя с этой программой. Проблему надо начинать решать при проектировании системы на уровне ее декомпозиции на отдельные модули, исходя из того, что вряд ли удастся спроектировать простой и удобный пользовательский интерфейс для модуля, перегруженного различными функциями. Кроме того, необходимо учитывать рекомендации по проектированию пользовательских интерфейсов. На этапе тестирования ПО полезно предусмотреть встроенные средства тестирования, которые бы запоминали последовательности действий пользователя, время совершения отдельных операций, расстояния перемещения курсора мыши. Кроме этого возможно применение гораздо более сложных средств психо-физического тестирования на этапе тестирования интерфейса пользователя, которые позволят оценить скорость реакции пользователя, частоту этих реакций, утомляемость и т.п. Необходимо отметить, что такие ошибки очень критичны с точки зрения коммерческого успеха разрабатываемого ПО, т.к. они будут в первую очередь оцениваться потенциальным заказчиком.
2.Ошибки вычислений.
Выделяют следующие причины возникновения таких ошибок:
- неверная логика (может быть следствием, как ошибок проектирования, так и кодирования);
- неправильно выполняются арифметические операции (как правило — это ошибки кодирования);
- неточные вычисления (могут быть следствием, как ошибок проектирования, так и кодирования). Очень сложная тема, надо выработать свое отношение к ней с точки зрения разработки безопасного ПО.
Выделяются подпункты: устаревшие константы; ошибки вычислений; неверно расставленные скобки; неправильный порядок операторов; неверно работает базовая функция; переполнение и потеря значащих разрядов; ошибки отсечения и округления; путаница с представлением данных; неправильное преобразование данных из одного формата в другой; неверная формула; неправильное приближение.
3.Ошибки управления потоком.
В этот раздел относится все то, что связано с последовательностью и обстоятельствами выполнения операторов программы.
Выделяются подпункты:
- очевидно неверное поведение программы;
- переход по GOTO;
- логика, основанная на определении вызывающей подпрограммы;
- использование таблиц переходов;
- выполнение данных (вместо команд). Ситуация возможна из-за ошибок работы с указателями, отсутствия проверок границ массивов, ошибок перехода, вызванных, например, ошибкой в таблице адресов перехода, ошибок сегментирования памяти.
4.Ошибки обработки или интерпретации данных.
Выделяются подпункты:
- проблемы при передаче данных между подпрограммами (сюда включены несколько видов ошибок: параметры указаны не в том порядке или пропущены, несоответствие типов данных, псевдонимы и различная интерпретация содержимого одной и той же области памяти, неправильная интерпретация данных, неадекватная информация об ошибке, перед аварийным выходом из подпрограммы не восстановлено правильное состояние данных, устаревшие копии данных, связанные переменные не синхронизированы, локальная установка глобальных данных (имеется в виду путаница локальных и глобальных переменных), глобальное использование локальных переменных, неверная маска битового поля, неверное значение из таблицы);
- границы расположения данных (сюда включены несколько видов ошибок: не обозначен конец нуль-терминированной строки, неожиданный конец строки, запись/чтение за границами структуры данных или ее элемента, чтение за пределами буфера сообщения, чтение за пределами буфера сообщения, дополнение переменных до полного слова, переполнение и выход за нижнюю границу стека данных, затирание кода или данных другого процесса);
- проблемы с обменом сообщений (сюда включены несколько видов ошибок: отправка сообщения не тому процессу или не в тот порт, ошибка распознавания полученного сообщения, недостающие или несинхронизированные сообщения, сообщение передано только N процессам из N+1, порча данных, хранящихся на внешнем устройстве, потеря изменений, не сохранены введенные данные, объем данных слишком велик для процесса-получателя, неудачная попытка отмены записи данных).
5.Повышенные нагрузки.
При повышенных нагрузках или нехватке ресурсов могут возникнуть дополнительные ошибки. Выделяются подпункты: требуемый ресурс недоступен; не освобожден ресурс; нет сигнала об освобождении устройства; старый файл не удален с накопителя; системе не возвращена неиспользуемая память; лишние затраты компьютерного времени; нет свободного блока памяти достаточного размера; недостаточный размер буфера ввода или очереди; не очищен элемент очереди, буфера или стека; потерянные сообщения; снижение производительности; повышение вероятности ситуационных гонок; при повышенной нагрузке объем необязательных данных не сокращается; не распознается сокращенный вывод другого процесса при повышенной загрузке; не приостанавливаются задания с низким приоритетом.
7.Ошибки тестирования.
Являются ошибками сотрудников группы тестирования, а не программы. Выделяются подпункты:
- пропущенные ошибки в программе;
- не замечена проблема (отмечаются следующие причины этого: тестировщик не знает, каким должен быть правильный результат, ошибка затерялась в большом объеме выходных данных, тестировщик не ожидал такого результата теста, тестировщик устал и невнимателен, ему скучно, механизм выполнения теста настолько сложен, что тестировщик уделяет ему больше внимания, чем результатам);
- пропуск ошибок на экране;
- не документирована проблема (отмечаются следующие причины этого: тестировщик неаккуратно ведет записи, тестировщик не уверен в том, что данные действия программы являются ошибочными, ошибка показалась слишком незначительной, тестировщик считает, что ошибку не будет исправлена, тестировщика просили не документировать больше подобные ошибки).
8.Ошибка выявлена и забыта.
Описываются ошибки использования результатов тестирования. По-моему, раздел следует объединить с предыдущим. Выделяются подпункты: не составлен итоговый отчет; серьезная проблема не документирована повторно; не проверено исправление; перед выпуском продукта не проанализирован список нерешенных проблем.
Необходимо заметить, что изложенные в 2-х последних разделах ошибки тестирования требуют для устранения средств автоматизации тестирования и составления отчетов. В идеальном случае, эти средства должны быть проинтегрированы со средствами и технологиями проектирования ПО. Они должны стать важными инструментальными средствами создания высококачественного ПО. При разработке средств автоматизированного тестирования следует избегать ошибок, которые присущи любому ПО, поэтому нужно потребовать, чтобы такие средства обладали более высокими характеристиками надежности, чем проверяемое с их помощью ПО.
Меры по повышению надежности программного обеспечения
Лучшим и самым оптимальным способом (если не брать во внимание научно-технический прогресс и постоянное развитие IT-технологий, которые способствуют повышению качества характеристик программ) повышения надёжности программного обеспечения является строжайший контроль продукции на выходе с предприятия.
В последние годы сформировалась комплексная система управления качеством продукции TQM (Totaly Quality Management), которая концептуально близка к предшествующей более общей системе на основе стандартов ИСО серии 9000. Система ориентирована на удовлетворение требований потребителя, на постоянное улучшение процессов производства или проектирования, на управление процессами со стороны руководства предприятия на основе фактического состояния проекта. Основные достижения TQM состоят в углублении и дифференциации требований потребителей по реализации процессов, их взаимодействию и обеспечению качества продукции. Системный подход поддержан рядом специализированных инструментальных средств, ориентированных на управление производством продукции. Поэтому эта система пока не находит применения в области обеспечения качества жизненного цикла программных средств.
Применение этого комплекса может служить основой для систем обеспечения качества программных средств, однако требуется корректировка, адаптация или исключение некоторых положений стандартов применительно к принципиальным особенностям технологий и характеристик этого вида продукции. Кроме того, при реализации систем качества необходимо привлечение ряда стандартов, формально не относящихся к этой серии и регламентирующих показатели качества, жизненный цикл, верификацию и тестирование, испытания, документирование и другие особенности комплексов программ.
Активные методы повышения надежности ПС совершенствуются за счет развития средств автоматизации тестирования программ. Сложность ПС и высокие требования по их надежности требуют выработки принципов структурного построения сложных программных средств, обеспечивающих гибкость модификации ПС и эффективность их отладки. К таким принципам в работе относят:
- модульность и строгую иерархию в структурном построении программ;
- унификацию правил проектирования, структурного построения и взаимодействия компонент ПС;
- унификацию правил организации межмодульного интерфейса;
- поэтапный контроль полноты и качества решения функциональных задач.
Заключение
Несмотря на очевидную актуальность, вопрос надежности программного обеспечения не привлекает должного внимания. Вместе с тем, даже поверхностный анализ проблемы с теоретико-вероятностной точки зрения позволяет выявить некоторые закономерности.
В заключение можно подвести итог:
- В программном обеспечении имеется ошибка, если оно не выполняет того, что пользователю разумно от него ожидать;
- Отказ программного обеспечения — это появление в нем ошибки;
- Надежность программного обеспечения — есть вероятность его работы без отказов в течении определенного периода времени, рассчитанного с учетом стоимости для пользователя каждого отказа.
Из данных определений можно сделать важные выводы:
- Надежность программного обеспечения является не только внутренним свойством программы;
- Надежность программного обеспечения — это функция как самого ПО, так и ожиданий (действий) его пользователей.
Основными причинами ошибок программного обеспечения являются:
- большая сложность ПО, например, по сравнению с аппаратурой ЭВМ;
- неправильный перевод информации из одного представления в другое.
Список использованной литературы
- ГОСТ 27.002 – 89. Надежность в технике. Основные понятия. Термины и определения. // М.: Издательство стандартов, 1990.
- ГОСТ Р ИСО/МЭК 9126 – 93. Информационная технология. Оценка программной продукции. Характеристики качества и руководства по их применению. // М.: Издательство стандартов, 1994.
- ГОСТ 51901.5 – 2005. Менеджмент риска. Руководство по применению методов анализа надежности. // М.: Издательство стандартов, 2007.
- ГОСТ 28195 – 89. Оценка качества программных средств. Общие положения. // М.: Издательство стандартов, 1989.
- ГОСТ 27.310 – 95. Надежность в технике. Анализ видов, последствий и критичности отказов. // М.: Издательство стандартов, 1995.
- ГОСТ 51901.12 – 2007. Менеджмент риска. Метод анализа видов и последствий отказов. // М.: Издательство стандартов, 2007.
- Братчиков И.Л. «Синтаксис языков программирования» Наука, М.:Инси, 2005. — 344 с.
- Дейкстра Э. Заметки по структурному программированию.- М.:Дрофа, 2006, — 455 с.
- Ершов А.П. Введение в теоретическое программирование.- М.:РОСТО, 2008, — 288 с.
- Кнут Д. Искусство программирования для ЭВМ, т.1. М.: 2006, 735 с.
- Коган Д.И., Бабкина Т.С. «Основы теории конечных автоматов и регулярных языков. Учебное пособие» Издательство ННГУ, 2002. — 97 с.
- Липаев В. В. / Программная инженерия. Методологические основы. // М.: ТЕИС, 2006.
- Майерс Г. Надежность программного обеспечения.- М.:Дрофа, 2008, — 360 с.
- Рудаков А. В. Технология разработки программных продуктов. М.:Издательский центр «Академия», 2006. — 306 с.
- Тыугу, Э.Х. Концептуальное программирование. — М.: Наука, 2001, — 256 с.
- Хьюз Дж., Мичтом Дж. Структурный подход к программированию.-М.:Мир, 2000, — 278 с.

- Разработка клиент-серверного приложения по работе с базой данных «Локомотивное депо «
- Анализ особенности управления мотивацией сотрудников на предприятиях гостиничного и ресторанного бизнеса на примере АО ТГК «Вега»
- СУЩНОСТЬ И СОДЕРЖАНИЕ БАНКОВСКОГО МАРКЕТИНГА
- Оформление и ведение учета операций с сомнительными, неплатежеспособными и имеющими признаки подделки денежными знаками
- Виды, понятия, задачи оплаты труда на предприятии
- ценообразование на услуги фитнес-клубов (Российский рынок фитнес-услуг)
- Место и роль спортивной индустрии в экономике России (Теоретические аспекты индустрии спорта)
- Влияние кадровой стратегии на работу службы персонала. (СОДЕРЖАНИЕ И СУЩНОСТЬ КАДРОВОЙ СТРАТЕГИИ)
- Эффективный лидер и его команда (Виды лидерства)
- Межфирменная научно-техническая кооперация
- Прогнозирование эффективности реальных инвестиций коммерческого банка. Анализ инвестиционной деятельности ПАО «Сбербанк»
- Страхование и его государственное регулирование в РФ
A software bug is an error, flaw or fault in the design, development, or operation of computer software that causes it to produce an incorrect or unexpected result, or to behave in unintended ways. The process of finding and correcting bugs is termed «debugging» and often uses formal techniques or tools to pinpoint bugs. Since the 1950s, some computer systems have been designed to deter, detect or auto-correct various computer bugs during operations.
Bugs in software can arise from mistakes and errors made in interpreting and extracting users’ requirements, planning a program’s design, writing its source code, and from interaction with humans, hardware and programs, such as operating systems or libraries. A program with many, or serious, bugs is often described as buggy. Bugs can trigger errors that may have ripple effects. The effects of bugs may be subtle, such as unintended text formatting, through to more obvious effects such as causing a program to crash, freezing the computer, or causing damage to hardware. Other bugs qualify as security bugs and might, for example, enable a malicious user to bypass access controls in order to obtain unauthorized privileges.[1]
Some software bugs have been linked to disasters. Bugs in code that controlled the Therac-25 radiation therapy machine were directly responsible for patient deaths in the 1980s. In 1996, the European Space Agency’s US$1 billion prototype Ariane 5 rocket was destroyed less than a minute after launch due to a bug in the on-board guidance computer program.[2] In 1994, an RAF Chinook helicopter crashed, killing 29; this was initially blamed on pilot error, but was later thought to have been caused by a software bug in the engine-control computer.[3] Buggy software caused the early 21st century British Post Office scandal, the most widespread miscarriage of justice in British legal history.[4]
In 2002, a study commissioned by the US Department of Commerce’s National Institute of Standards and Technology concluded that «software bugs, or errors, are so prevalent and so detrimental that they cost the US economy an estimated $59 billion annually, or about 0.6 percent of the gross domestic product».[5]
History[edit]
The Middle English word bugge is the basis for the terms «bugbear» and «bugaboo» as terms used for a monster.[6]
The term «bug» to describe defects has been a part of engineering jargon since the 1870s[7] and predates electronics and computers; it may have originally been used in hardware engineering to describe mechanical malfunctions. For instance, Thomas Edison wrote in a letter to an associate in 1878:[8]
… difficulties arise—this thing gives out and [it is] then that «Bugs»—as such little faults and difficulties are called—show themselves[9]
Baffle Ball, the first mechanical pinball game, was advertised as being «free of bugs» in 1931.[10] Problems with military gear during World War II were referred to as bugs (or glitches).[11] In a book published in 1942, Louise Dickinson Rich, speaking of a powered ice cutting machine, said, «Ice sawing was suspended until the creator could be brought in to take the bugs out of his darling.»[12]
Isaac Asimov used the term «bug» to relate to issues with a robot in his short story «Catch That Rabbit», published in 1944.

The term «bug» was used in an account by computer pioneer Grace Hopper, who publicized the cause of a malfunction in an early electromechanical computer.[13] A typical version of the story is:
In 1946, when Hopper was released from active duty, she joined the Harvard Faculty at the Computation Laboratory where she continued her work on the Mark II and Mark III. Operators traced an error in the Mark II to a moth trapped in a relay, coining the term bug. This bug was carefully removed and taped to the log book. Stemming from the first bug, today we call errors or glitches in a program a bug.[14]
Hopper was not present when the bug was found, but it became one of her favorite stories.[15] The date in the log book was September 9, 1947.[16][17][18] The operators who found it, including William «Bill» Burke, later of the Naval Weapons Laboratory, Dahlgren, Virginia,[19] were familiar with the engineering term and amusedly kept the insect with the notation «First actual case of bug being found.» This log book, complete with attached moth, is part of the collection of the Smithsonian National Museum of American History.[17]
The related term «debug» also appears to predate its usage in computing: the Oxford English Dictionary‘s etymology of the word contains an attestation from 1945, in the context of aircraft engines.[20]
The concept that software might contain errors dates back to Ada Lovelace’s 1843 notes on the analytical engine, in which she speaks of the possibility of program «cards» for Charles Babbage’s analytical engine being erroneous:
… an analysing process must equally have been performed in order to furnish the Analytical Engine with the necessary operative data; and that herein may also lie a possible source of error. Granted that the actual mechanism is unerring in its processes, the cards may give it wrong orders.
Terminology[edit]
While the use of the term «bug» to describe software errors is common, many have suggested that it should be abandoned. One argument is that the word «bug» is divorced from a sense that a human being caused the problem, and instead implies that the defect arose on its own, leading to a push to abandon the term «bug» in favor of terms such as «defect», with limited success.[21]
The term «bug» may also be used to cover up an intentional design decision. In 2011, after receiving scrutiny from US Senator Al Franken for recording and storing users’ locations in unencrypted files,[22] Apple called the behavior a bug. However, Justin Brookman of the Center for Democracy and Technology directly challenged that portrayal, stating «I’m glad that they are fixing what they call bugs, but I take exception with their strong denial that they track users.»[23]
In software engineering, mistake metamorphism (from Greek meta = «change», morph = «form») refers to the evolution of a defect in the final stage of software deployment. Transformation of a «mistake» committed by an analyst in the early stages of the software development lifecycle, which leads to a «defect» in the final stage of the cycle has been called ‘mistake metamorphism’.[24]
Different stages of a «mistake» in the entire cycle may be described as «mistakes», «anomalies», «faults», «failures», «errors», «exceptions», «crashes», «glitches», «bugs», «defects», «incidents», or «side effects».[24]
Prevention[edit]

The software industry has put much effort into reducing bug counts.[25][26] These include:
Typographical errors[edit]
Bugs usually appear when the programmer makes a logic error. Various innovations in programming style and defensive programming are designed to make these bugs less likely, or easier to spot. Some typos, especially of symbols or logical/mathematical operators, allow the program to operate incorrectly, while others such as a missing symbol or misspelled name may prevent the program from operating. Compiled languages can reveal some typos when the source code is compiled.
Development methodologies[edit]
Several schemes assist managing programmer activity so that fewer bugs are produced. Software engineering (which addresses software design issues as well) applies many techniques to prevent defects. For example, formal program specifications state the exact behavior of programs so that design bugs may be eliminated. Unfortunately, formal specifications are impractical for anything but the shortest programs, because of problems of combinatorial explosion and indeterminacy.
Unit testing involves writing a test for every function (unit) that a program is to perform.
In test-driven development unit tests are written before the code and the code is not considered complete until all tests complete successfully.
Agile software development involves frequent software releases with relatively small changes. Defects are revealed by user feedback.
Open source development allows anyone to examine source code. A school of thought popularized by Eric S. Raymond as Linus’s law says that popular open-source software has more chance of having few or no bugs than other software, because «given enough eyeballs, all bugs are shallow».[27] This assertion has been disputed, however: computer security specialist Elias Levy wrote that «it is easy to hide vulnerabilities in complex, little understood and undocumented source code,» because, «even if people are reviewing the code, that doesn’t mean they’re qualified to do so.»[28] An example of an open-source software bug was the 2008 OpenSSL vulnerability in Debian.
Programming language support[edit]
Programming languages include features to help prevent bugs, such as static type systems, restricted namespaces and modular programming. For example, when a programmer writes (pseudocode) LET REAL_VALUE PI = "THREE AND A BIT", although this may be syntactically correct, the code fails a type check. Compiled languages catch this without having to run the program. Interpreted languages catch such errors at runtime. Some languages deliberately exclude features that easily lead to bugs, at the expense of slower performance: the general principle being that, it is almost always better to write simpler, slower code than inscrutable code that runs slightly faster, especially considering that maintenance cost is substantial. For example, the Java programming language does not support pointer arithmetic; implementations of some languages such as Pascal and scripting languages often have runtime bounds checking of arrays, at least in a debugging build.
Code analysis[edit]
Tools for code analysis help developers by inspecting the program text beyond the compiler’s capabilities to spot potential problems. Although in general the problem of finding all programming errors given a specification is not solvable (see halting problem), these tools exploit the fact that human programmers tend to make certain kinds of simple mistakes often when writing software.
Instrumentation[edit]
Tools to monitor the performance of the software as it is running, either specifically to find problems such as bottlenecks or to give assurance as to correct working, may be embedded in the code explicitly (perhaps as simple as a statement saying PRINT "I AM HERE"), or provided as tools. It is often a surprise to find where most of the time is taken by a piece of code, and this removal of assumptions might cause the code to be rewritten.
Testing[edit]
Software testers are people whose primary task is to find bugs, or write code to support testing. On some efforts, more resources may be spent on testing than in developing the program.
Measurements during testing can provide an estimate of the number of likely bugs remaining; this becomes more reliable the longer a product is tested and developed.[citation needed]
Debugging[edit]
Finding and fixing bugs, or debugging, is a major part of computer programming. Maurice Wilkes, an early computing pioneer, described his realization in the late 1940s that much of the rest of his life would be spent finding mistakes in his own programs.[29]
Usually, the most difficult part of debugging is finding the bug. Once it is found, correcting it is usually relatively easy. Programs known as debuggers help programmers locate bugs by executing code line by line, watching variable values, and other features to observe program behavior. Without a debugger, code may be added so that messages or values may be written to a console or to a window or log file to trace program execution or show values.
However, even with the aid of a debugger, locating bugs is something of an art. It is not uncommon for a bug in one section of a program to cause failures in a completely different section,[citation needed] thus making it especially difficult to track (for example, an error in a graphics rendering routine causing a file I/O routine to fail), in an apparently unrelated part of the system.
Sometimes, a bug is not an isolated flaw, but represents an error of thinking or planning on the part of the programmer. Such logic errors require a section of the program to be overhauled or rewritten. As a part of code review, stepping through the code and imagining or transcribing the execution process may often find errors without ever reproducing the bug as such.
More typically, the first step in locating a bug is to reproduce it reliably. Once the bug is reproducible, the programmer may use a debugger or other tool while reproducing the error to find the point at which the program went astray.
Some bugs are revealed by inputs that may be difficult for the programmer to re-create. One cause of the Therac-25 radiation machine deaths was a bug (specifically, a race condition) that occurred only when the machine operator very rapidly entered a treatment plan; it took days of practice to become able to do this, so the bug did not manifest in testing or when the manufacturer attempted to duplicate it. Other bugs may stop occurring whenever the setup is augmented to help find the bug, such as running the program with a debugger; these are called heisenbugs (humorously named after the Heisenberg uncertainty principle).
Since the 1990s, particularly following the Ariane 5 Flight 501 disaster, interest in automated aids to debugging rose, such as static code analysis by abstract interpretation.[30]
Some classes of bugs have nothing to do with the code. Faulty documentation or hardware may lead to problems in system use, even though the code matches the documentation. In some cases, changes to the code eliminate the problem even though the code then no longer matches the documentation. Embedded systems frequently work around hardware bugs, since to make a new version of a ROM is much cheaper than remanufacturing the hardware, especially if they are commodity items.
Benchmark of bugs[edit]
To facilitate reproducible research on testing and debugging, researchers use curated benchmarks of bugs:
- the Siemens benchmark
- ManyBugs[31] is a benchmark of 185 C bugs in nine open-source programs.
- Defects4J[32] is a benchmark of 341 Java bugs from 5 open-source projects. It contains the corresponding patches, which cover a variety of patch type.
Bug management[edit]
Bug management includes the process of documenting, categorizing, assigning, reproducing, correcting and releasing the corrected code. Proposed changes to software – bugs as well as enhancement requests and even entire releases – are commonly tracked and managed using bug tracking systems or issue tracking systems.[33] The items added may be called defects, tickets, issues, or, following the agile development paradigm, stories and epics. Categories may be objective, subjective or a combination, such as version number, area of the software, severity and priority, as well as what type of issue it is, such as a feature request or a bug.
A bug triage reviews bugs and decides whether and when to fix them. The decision is based on the bug’s priority, and factors such as development schedules. The triage is not meant to investigate the cause of bugs, but rather the cost of fixing them. The triage happens regularly, and goes through bugs opened or reopened since the previous meeting. The attendees of the triage process typically are the project manager, development manager, test manager, build manager, and technical experts.[34][35]
Severity[edit]
Severity is the intensity of the impact the bug has on system operation.[36] This impact may be data loss, financial, loss of goodwill and wasted effort. Severity levels are not standardized. Impacts differ across industry. A crash in a video game has a totally different impact than a crash in a web browser, or real time monitoring system. For example, bug severity levels might be «crash or hang», «no workaround» (meaning there is no way the customer can accomplish a given task), «has workaround» (meaning the user can still accomplish the task), «visual defect» (for example, a missing image or displaced button or form element), or «documentation error». Some software publishers use more qualified severities such as «critical», «high», «low», «blocker» or «trivial».[37] The severity of a bug may be a separate category to its priority for fixing, and the two may be quantified and managed separately.
Priority[edit]
Priority controls where a bug falls on the list of planned changes. The priority is decided by each software producer. Priorities may be numerical, such as 1 through 5, or named, such as «critical», «high», «low», or «deferred». These rating scales may be similar or even identical to severity ratings, but are evaluated as a combination of the bug’s severity with its estimated effort to fix; a bug with low severity but easy to fix may get a higher priority than a bug with moderate severity that requires excessive effort to fix. Priority ratings may be aligned with product releases, such as «critical» priority indicating all the bugs that must be fixed before the next software release.
A bug severe enough to delay or halt the release of the product is called a «show stopper»[38] or «showstopper bug».[39] It is named so because it «stops the show» – causes unacceptable product failure.[39]
Software releases[edit]
It is common practice to release software with known, low-priority bugs. Bugs of sufficiently high priority may warrant a special release of part of the code containing only modules with those fixes. These are known as patches. Most releases include a mixture of behavior changes and multiple bug fixes. Releases that emphasize bug fixes are known as maintenance releases, to differentiate it from major releases that emphasize feature additions or changes.
Reasons that a software publisher opts not to patch or even fix a particular bug include:
- A deadline must be met and resources are insufficient to fix all bugs by the deadline.[40]
- The bug is already fixed in an upcoming release, and it is not of high priority.
- The changes required to fix the bug are too costly or affect too many other components, requiring a major testing activity.
- It may be suspected, or known, that some users are relying on the existing buggy behavior; a proposed fix may introduce a breaking change.
- The problem is in an area that will be obsolete with an upcoming release; fixing it is unnecessary.
- «It’s not a bug, it’s a feature».[41] A misunderstanding has arisen between expected and perceived behavior or undocumented feature.
Types[edit]
In software development, a mistake or error may be introduced at any stage. Bugs arise from oversight or misunderstanding by a software team during specification, design, coding, configuration, data entry or documentation. For example, a relatively simple program to alphabetize a list of words, the design might fail to consider what should happen when a word contains a hyphen. Or when converting an abstract design into code, the coder might inadvertently create an off-by-one error which can be a «<» where «<=» was intended, and fail to sort the last word in a list.
Another category of bug is called a race condition that may occur when programs have multiple components executing at the same time. If the components interact in a different order than the developer intended, they could interfere with each other and stop the program from completing its tasks. These bugs may be difficult to detect or anticipate, since they may not occur during every execution of a program.
Conceptual errors are a developer’s misunderstanding of what the software must do. The resulting software may perform according to the developer’s understanding, but not what is really needed. Other types:
Arithmetic[edit]
In operations on numerical values, problems can arise that result in unexpected output, slowing of a process, or crashing.[42] These can be from a lack of awareness of the qualities of the data storage such as a loss of precision due to rounding, numerically unstable algorithms, arithmetic overflow and underflow, or from lack of awareness of how calculations are handled by different software coding languages such as division by zero which in some languages may throw an exception, and in others may return a special value such as NaN or infinity.
Control flow[edit]
Control flow bugs are those found in processes with valid logic, but that lead to unintended results, such as infinite loops and infinite recursion, incorrect comparisons for conditional statements such as using the incorrect comparison operator, and off-by-one errors (counting one too many or one too few iterations when looping).
Interfacing[edit]
- Incorrect API usage.
- Incorrect protocol implementation.
- Incorrect hardware handling.
- Incorrect assumptions of a particular platform.
- Incompatible systems. A new API or communications protocol may seem to work when two systems use different versions, but errors may occur when a function or feature implemented in one version is changed or missing in another. In production systems which must run continually, shutting down the entire system for a major update may not be possible, such as in the telecommunication industry[43] or the internet.[44][45][46] In this case, smaller segments of a large system are upgraded individually, to minimize disruption to a large network. However, some sections could be overlooked and not upgraded, and cause compatibility errors which may be difficult to find and repair.
- Incorrect code annotations.
Concurrency[edit]
- Deadlock, where task A cannot continue until task B finishes, but at the same time, task B cannot continue until task A finishes.
- Race condition, where the computer does not perform tasks in the order the programmer intended.
- Concurrency errors in critical sections, mutual exclusions and other features of concurrent processing. Time-of-check-to-time-of-use (TOCTOU) is a form of unprotected critical section.
Resourcing[edit]
- Null pointer dereference.
- Using an uninitialized variable.
- Using an otherwise valid instruction on the wrong data type (see packed decimal/binary-coded decimal).
- Access violations.
- Resource leaks, where a finite system resource (such as memory or file handles) become exhausted by repeated allocation without release.
- Buffer overflow, in which a program tries to store data past the end of allocated storage. This may or may not lead to an access violation or storage violation. These are frequently security bugs.
- Excessive recursion which—though logically valid—causes stack overflow.
- Use-after-free error, where a pointer is used after the system has freed the memory it references.
- Double free error.
Syntax[edit]
- Use of the wrong token, such as performing assignment instead of equality test. For example, in some languages x=5 will set the value of x to 5 while x==5 will check whether x is currently 5 or some other number. Interpreted languages allow such code to fail. Compiled languages can catch such errors before testing begins.
Teamwork[edit]
- Unpropagated updates; e.g. programmer changes «myAdd» but forgets to change «mySubtract», which uses the same algorithm. These errors are mitigated by the Don’t Repeat Yourself philosophy.
- Comments out of date or incorrect: many programmers assume the comments accurately describe the code.
- Differences between documentation and product.
Implications[edit]
The amount and type of damage a software bug may cause naturally affects decision-making, processes and policy regarding software quality. In applications such as human spaceflight, aviation, nuclear power, health care, public transport or automotive safety, since software flaws have the potential to cause human injury or even death, such software will have far more scrutiny and quality control than, for example, an online shopping website. In applications such as banking, where software flaws have the potential to cause serious financial damage to a bank or its customers, quality control is also more important than, say, a photo editing application.
Other than the damage caused by bugs, some of their cost is due to the effort invested in fixing them. In 1978, Lientz et al. showed that the median of projects invest 17 percent of the development effort in bug fixing.[47] In 2020, research on GitHub repositories showed the median is 20%.[48]
Residual bugs in delivered product[edit]
In 1994, NASA’s Goddard Space Flight Center managed to reduce their average number of errors from 4.5 per 1000 lines of code (SLOC) down to 1 per 1000 SLOC.[49]
Another study in 1990 reported that exceptionally good software development processes can achieve deployment failure rates as low as 0.1 per 1000 SLOC.[50] This figure is iterated in literature such as Code Complete by Steve McConnell,[51] and the NASA study on Flight Software Complexity.[52] Some projects even attained zero defects: the firmware in the IBM Wheelwriter typewriter which consists of 63,000 SLOC, and the Space Shuttle software with 500,000 SLOC.[50]
Well-known bugs[edit]
A number of software bugs have become well-known, usually due to their severity: examples include various space and military aircraft crashes. Possibly the most famous bug is the Year 2000 problem or Y2K bug, which caused many programs written long before the transition from 19xx to 20xx dates to malfunction, for example treating a date such as «25 Dec 04» as being in 1904, displaying «19100» instead of «2000», and so on. A huge effort at the end of the 20th century resolved the most severe problems, and there were no major consequences.
The 2012 stock trading disruption involved one such incompatibility between the old API and a new API.
In politics[edit]
«Bugs in the System» report[edit]
The Open Technology Institute, run by the group, New America,[53] released a report «Bugs in the System» in August 2016 stating that U.S. policymakers should make reforms to help researchers identify and address software bugs. The report «highlights the need for reform in the field of software vulnerability discovery and disclosure.»[54] One of the report’s authors said that Congress has not done enough to address cyber software vulnerability, even though Congress has passed a number of bills to combat the larger issue of cyber security.[54]
Government researchers, companies, and cyber security experts are the people who typically discover software flaws. The report calls for reforming computer crime and copyright laws.[54]
The Computer Fraud and Abuse Act, the Digital Millennium Copyright Act and the Electronic Communications Privacy Act criminalize and create civil penalties for actions that security researchers routinely engage in while conducting legitimate security research, the report said.[54]
In popular culture[edit]
- In video gaming, the term «glitch» is sometimes used to refer to a software bug. An example is the glitch and unofficial Pokémon species MissingNo..
- In both the 1968 novel 2001: A Space Odyssey and the corresponding 1968 film 2001: A Space Odyssey, a spaceship’s onboard computer, HAL 9000, attempts to kill all its crew members. In the follow-up 1982 novel, 2010: Odyssey Two, and the accompanying 1984 film, 2010, it is revealed that this action was caused by the computer having been programmed with two conflicting objectives: to fully disclose all its information, and to keep the true purpose of the flight secret from the crew; this conflict caused HAL to become paranoid and eventually homicidal.
- In the English version of the Nena 1983 song 99 Luftballons (99 Red Balloons) as a result of «bugs in the software», a release of a group of 99 red balloons are mistaken for an enemy nuclear missile launch, requiring an equivalent launch response, resulting in catastrophe.
- In the 1999 American comedy Office Space, three employees attempt (unsuccessfully) to exploit their company’s preoccupation with the Y2K computer bug using a computer virus that sends rounded-off fractions of a penny to their bank account—a long-known technique described as salami slicing.
- The 2004 novel The Bug, by Ellen Ullman, is about a programmer’s attempt to find an elusive bug in a database application.[55]
- The 2008 Canadian film Control Alt Delete is about a computer programmer at the end of 1999 struggling to fix bugs at his company related to the year 2000 problem.
See also[edit]
- Anti-pattern
- Bug bounty program
- Glitch removal
- Hardware bug
- ISO/IEC 9126, which classifies a bug as either a defect or a nonconformity
- Orthogonal Defect Classification
- Racetrack problem
- RISKS Digest
- Software defect indicator
- Software regression
- Software rot
- Automatic bug fixing
References[edit]
- ^ Mittal, Varun; Aditya, Shivam (January 1, 2015). «Recent Developments in the Field of Bug Fixing». Procedia Computer Science. International Conference on Computer, Communication and Convergence (ICCC 2015). 48: 288–297. doi:10.1016/j.procs.2015.04.184. ISSN 1877-0509.
- ^ «Ariane 501 – Presentation of Inquiry Board report». www.esa.int. Retrieved January 29, 2022.
- ^ Prof. Simon Rogerson. «The Chinook Helicopter Disaster». Ccsr.cse.dmu.ac.uk. Archived from the original on July 17, 2012. Retrieved September 24, 2012.
- ^ «Post Office scandal ruined lives, inquiry hears». BBC News. February 14, 2022.
- ^ «Software bugs cost US economy dear». June 10, 2009. Archived from the original on June 10, 2009. Retrieved September 24, 2012.
{{cite web}}: CS1 maint: unfit URL (link) - ^ Computerworld staff (September 3, 2011). «Moth in the machine: Debugging the origins of ‘bug’«. Computerworld. Archived from the original on August 25, 2015.
- ^ «bug». Oxford English Dictionary (Online ed.). Oxford University Press. (Subscription or participating institution membership required.) 5a
- ^ «Did You Know? Edison Coined the Term «Bug»«. August 1, 2013. Retrieved July 19, 2019.
- ^ Edison to Puskas, 13 November 1878, Edison papers, Edison National Laboratory, U.S. National Park Service, West Orange, N.J., cited in Hughes, Thomas Parke (1989). American Genesis: A Century of Invention and Technological Enthusiasm, 1870–1970. Penguin Books. p. 75. ISBN 978-0-14-009741-2.
- ^ «Baffle Ball». Internet Pinball Database.
(See image of advertisement in reference entry)
- ^ «Modern Aircraft Carriers are Result of 20 Years of Smart Experimentation». Life. June 29, 1942. p. 25. Archived from the original on June 4, 2013. Retrieved November 17, 2011.
- ^ Dickinson Rich, Louise (1942), We Took to the Woods, JB Lippincott Co, p. 93, LCCN 42024308, OCLC 405243, archived from the original on March 16, 2017.
- ^ FCAT NRT Test, Harcourt, March 18, 2008
- ^ «Danis, Sharron Ann: «Rear Admiral Grace Murray Hopper»«. ei.cs.vt.edu. February 16, 1997. Retrieved January 31, 2010.
- ^ James S. Huggins. «First Computer Bug». Jamesshuggins.com. Archived from the original on August 16, 2000. Retrieved September 24, 2012.
- ^ «Bug Archived March 23, 2017, at the Wayback Machine», The Jargon File, ver. 4.4.7. Retrieved June 3, 2010.
- ^ a b «Log Book With Computer Bug Archived March 23, 2017, at the Wayback Machine», National Museum of American History, Smithsonian Institution.
- ^ «The First «Computer Bug», Naval Historical Center. But note the Harvard Mark II computer was not complete until the summer of 1947.
- ^ IEEE Annals of the History of Computing, Vol 22 Issue 1, 2000
- ^ Journal of the Royal Aeronautical Society. 49, 183/2, 1945 «It ranged … through the stage of type test and flight test and ‘debugging’ …»
- ^ «News at SEI 1999 Archive». cmu.edu. Archived from the original on May 26, 2013.
- ^ «Apple faces questions from Congress about iPhone tracking». Computerworld. April 21, 2011. Archived from the original on July 20, 2019.
- ^ «Apple denies tracking iPhone users, but promises changes». Computerworld. April 27, 2011. Archived from the original on March 29, 2023.
- ^ a b «Testing experience : te : the magazine for professional testers». Testing Experience. Germany: testingexperience: 42. March 2012. ISSN 1866-5705. (subscription required)
- ^ Huizinga, Dorota; Kolawa, Adam (2007). Automated Defect Prevention: Best Practices in Software Management. Wiley-IEEE Computer Society Press. p. 426. ISBN 978-0-470-04212-0. Archived from the original on April 25, 2012.
- ^ McDonald, Marc; Musson, Robert; Smith, Ross (2007). The Practical Guide to Defect Prevention. Microsoft Press. p. 480. ISBN 978-0-7356-2253-1.
- ^ «Release Early, Release Often» Archived May 14, 2011, at the Wayback Machine, Eric S. Raymond, The Cathedral and the Bazaar
- ^ «Wide Open Source» Archived September 29, 2007, at the Wayback Machine, Elias Levy, SecurityFocus, April 17, 2000
- ^ Maurice Wilkes Quotes
- ^ «PolySpace Technologies history». christele.faure.pagesperso-orange.fr. Retrieved August 1, 2019.
- ^ Le Goues, Claire; Holtschulte, Neal; Smith, Edward K.; Brun, Yuriy; Devanbu, Premkumar; Forrest, Stephanie; Weimer, Westley (2015). «The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs». IEEE Transactions on Software Engineering. 41 (12): 1236–1256. doi:10.1109/TSE.2015.2454513. ISSN 0098-5589.
- ^ Just, René; Jalali, Darioush; Ernst, Michael D. (2014). «Defects4J: a database of existing faults to enable controlled testing studies for Java programs». Proceedings of the 2014 International Symposium on Software Testing and Analysis – ISSTA 2014. pp. 437–440. CiteSeerX 10.1.1.646.3086. doi:10.1145/2610384.2628055. ISBN 9781450326452. S2CID 12796895.
- ^ Allen, Mitch (May–June 2002). «Bug Tracking Basics: A beginner’s guide to reporting and tracking defects». Software Testing & Quality Engineering Magazine. Vol. 4, no. 3. pp. 20–24. Retrieved December 19, 2017.
- ^ Rex Black (2002). Managing The Testing Process (2nd ed.). Wiley India Pvt. Limited. p. 139. ISBN 978-8126503131. Retrieved June 19, 2021.
- ^ Chris Vander Mey (2012). Shipping Greatness — Practical Lessons on Building and Launching Outstanding Software, Learned on the Job at Google and Amazon. O’Reilly Media. pp. 79–81. ISBN 978-1449336608.
- ^ Soleimani Neysiani, Behzad; Babamir, Seyed Morteza; Aritsugi, Masayoshi (October 1, 2020). «Efficient feature extraction model for validation performance improvement of duplicate bug report detection in software bug triage systems». Information and Software Technology. 126: 106344. doi:10.1016/j.infsof.2020.106344. S2CID 219733047.
- ^ «5.3. Anatomy of a Bug». bugzilla.org. Archived from the original on May 23, 2013.
- ^ Jones, Wilbur D. Jr., ed. (1989). «Show stopper». Glossary: defense acquisition acronyms and terms (4 ed.). Fort Belvoir, Virginia: Department of Defense, Defense Systems Management College. p. 123. hdl:2027/mdp.39015061290758 – via Hathitrust.
- ^ a b Zachary, G. Pascal (1994). Show-stopper!: the breakneck race to create Windows NT and the next generation at Microsoft. New York: The Free Press. p. 158. ISBN 0029356717 – via archive.org.
- ^ «The Next Generation 1996 Lexicon A to Z: Slipstream Release». Next Generation. No. 15. March 1996. p. 41.
- ^ Carr, Nicholas (2018). «‘It’s Not a Bug, It’s a Feature.’ Trite – or Just Right?». wired.com.
- ^ Di Franco, Anthony; Guo, Hui; Cindy, Rubio-González. «A Comprehensive Study of Real-World Numerical Bug Characteristics» (PDF). Archived (PDF) from the original on October 9, 2022.
- ^ Kimbler, K. (1998). Feature Interactions in Telecommunications and Software Systems V. IOS Press. p. 8. ISBN 978-90-5199-431-5.
- ^ Syed, Mahbubur Rahman (2001). Multimedia Networking: Technology, Management and Applications: Technology, Management and Applications. Idea Group Inc (IGI). p. 398. ISBN 978-1-59140-005-9.
- ^ Wu, Chwan-Hwa (John); Irwin, J. David (2016). Introduction to Computer Networks and Cybersecurity. CRC Press. p. 500. ISBN 978-1-4665-7214-0.
- ^ RFC 1263: «TCP Extensions Considered Harmful» quote: «the time to distribute the new version of the protocol to all hosts can be quite long (forever in fact). … If there is the slightest incompatibly between old and new versions, chaos can result.»
- ^ Lientz, B. P.; Swanson, E. B.; Tompkins, G. E. (1978). «Characteristics of Application Software Maintenance». Communications of the ACM. 21 (6): 466–471. doi:10.1145/359511.359522. S2CID 14950091.
- ^ Amit, Idan; Feitelson, Dror G. (2020). «The Corrective Commit Probability Code Quality Metric». arXiv:2007.10912 [cs.SE].
- ^ An overview of the Software Engineering Laboratory (PDF) (Report). Maryland: Goddard Space Flight Center, NASA. December 1, 1994. pp 41–42 Figure 18; pp 43–44 Figure 21. CR-189410; SEL-94-005. Archived (PDF) from the original on November 22, 2022. Retrieved November 22, 2022. (bibliography: An overview of the Software Engineering Laboratory)
- ^ a b Cobb, Richard H.; Mills, Harlan D. (1990). «Engineering software under statistical quality control». IEEE Software. 7 (6): 46. doi:10.1109/52.60601. ISSN 1937-4194. S2CID 538311 – via University of Tennessee – Harlan D. Mills Collection.
- ^ McConnell, Steven C. (1993). Code Complete. Redmond, Washington: Microsoft Press. p. 611. ISBN 978-1556154843 – via archive.org.
(Cobb and Mills 1990)
- ^ Holzmann, Gerard (March 6, 2009). «Appendix D – Software Complexity» (PDF). In Dvorak, Daniel L. (ed.). NASA Study on Flight Software Complexity (Report). NASA. pdf frame 109/264. Appendix D p.2. Archived (PDF) from the original on March 8, 2022. Retrieved November 22, 2022. (under NASA Office of the Chief Engineer Technical Excellence Initiative)
- ^ Wilson, Andi; Schulman, Ross; Bankston, Kevin; Herr, Trey. «Bugs in the System» (PDF). Open Policy Institute. Archived (PDF) from the original on September 21, 2016. Retrieved August 22, 2016.
- ^ a b c d Rozens, Tracy (August 12, 2016). «Cyber reforms needed to strengthen software bug discovery and disclosure: New America report – Homeland Preparedness News». Retrieved August 23, 2016.
- ^ Ullman, Ellen (2004). The Bug. Picador. ISBN 978-1-250-00249-5.
External links[edit]
- «Common Weakness Enumeration» – an expert webpage focus on bugs, at NIST.gov
- BUG type of Jim Gray – another Bug type
- Picture of the «first computer bug» at the Wayback Machine (archived January 12, 2015)
- «The First Computer Bug!» – an email from 1981 about Adm. Hopper’s bug
- «Toward Understanding Compiler Bugs in GCC and LLVM». A 2016 study of bugs in compilers